Delete 4.人工智能 directory
This commit is contained in:
@@ -1,64 +0,0 @@
|
||||
# 科研论文写作
|
||||
|
||||
> author:晓宇
|
||||
|
||||
序言:写作,一门需要反馈才能学习的科目,无论一个人有多么厉害,第一篇论文的写作,总是那么不尽人意。
|
||||
|
||||
其原因在于,首先学术性写作是一门需要刻意训练的科目,其次学术写作训练的反馈成本是巨大的,很难落实到每一个人身上,这并不是一门看看网课就能学会的技能。
|
||||
|
||||
所以开设本栏目分享一些感悟与资料。
|
||||
|
||||
论文写作方法论简述:
|
||||
|
||||
我分为两大块:先想清楚你干了什么,在训练好你表达的规范性
|
||||
|
||||
<font color=green>大白话 -》提取后的逻辑链条</font> -》<font color=red>科研写作 -》英文翻译</font>
|
||||
|
||||
<strong>干了什么:</strong>
|
||||
|
||||
1. 如果没有想清楚要做的是什么,要写什么,可以先用大白话,在草稿上写,有利于理清思路,抽丝剥茧
|
||||
|
||||
失败案例:一上来直接英文【】‘’写作,一会 we want ,一会 80 个词语的长难句,思路英语都不清晰
|
||||
|
||||
2. 先列出 Outline 每一个科研 section 你打算做什么,尝试去回答问题
|
||||
|
||||
::: warning 📌
|
||||
Introduction(Longer version of theAbstract,i.e.of the entire paper):
|
||||
|
||||
X: What are we trying to do and why is it relevant?
|
||||
|
||||
Y: Why is this hard?
|
||||
|
||||
Z: How do we solve it (i.e. ourcontribution!)
|
||||
|
||||
1: How do we verify that we solved it:
|
||||
|
||||
1a) Experimental results1b)
|
||||
|
||||
TheoryExtra space? Future work!Extra points for havingFigure 1
|
||||
|
||||
on the first page
|
||||
|
||||
:::
|
||||
|
||||
之所以要用大白话是因为基础的不足,如果有一定功底的人,可能先天写出来文字自带规范性,所以仅供大家参考)
|
||||
|
||||
<strong>表达规范性:</strong>
|
||||
|
||||
此处的方法论为一句话,则是从模仿到超越的浑然天成。
|
||||
|
||||
1. 但凡是写作,原理无非是学习表达各种逻辑的常用性词语,要表达转折,对比,强调要是用什么词,使用什么句式,在学习的过程中,先是看优秀论文一句话表达的逻辑,然后抽丝剥茧,去掉他的主要内容填入自己的即可。
|
||||
|
||||
2. 迭代式写作,尝试多次更改写作的内容,优秀的作品都是改出来的,在把一部分的意思表达清晰知识
|
||||
|
||||
|
||||
上述内容是写作的怎么去写,而下面则是内容层面,什么样的文章算是一篇好的文章
|
||||
|
||||
::: warning 📌
|
||||
C 会文章与 A 会文章的区别认知:
|
||||
|
||||
(1).C 是对于相关工作一个是罗列,A 是整理相关工作的脉络和方法类别,以及方法缺陷。
|
||||
|
||||
(2).对于设计的方法,C会只是说明我们比另外几个模型好,并不能从原理层面深入分析为什么比别人好,而A会则是能够说明每一部设计对模型的增量效果,以及为什么要做这一步。
|
||||
|
||||
:::
|
||||
@@ -1,985 +0,0 @@
|
||||
# 从 AI 到 智能系统 —— 从 LLMs 到 Agents
|
||||
|
||||
author:廖总
|
||||
|
||||
<em>Last revised 2023/04/18</em>
|
||||
|
||||
先声夺人:AI 时代最大的陷阱,就是盲目考察 AI 能为我们做什么,而不去考虑我们能为 AI 提供什么
|
||||
|
||||
### <em>免责声明</em>
|
||||
|
||||
本文纯文本量达 16k(我也不知道字数统计的 28k 是怎么来的),在这 游离散乱的主线 和 支离破碎的文字 中挣扎,可能浪费您生命中宝贵的十数分钟。
|
||||
|
||||
但如果您坚持尝试阅读,可能看到如下内容(假设没在其中绕晕的话 ):
|
||||
|
||||
- 对大语言模型本质 以及 AI 时代人们生产创作本位 的讨论
|
||||
- 对大语言模型 上下文学习(In-Context Learning,ICL)和 思维链(Chain of Thought,COT)能力的几种通识性认知
|
||||
- 围绕 Prompt Decomposition 对使用大语言模型构建复杂应用的基础讨论
|
||||
- 对当前热门大模型 Agent 化框架(如 Generative Agents (即斯坦福 25 人小镇)、AutoGPT)其本质的讨论
|
||||
- 对使用大语言模型构建智能系统(基于全局工作空间意识理论)的初步讨论
|
||||
- 对使用大语言模型构建符合当今生产需求的智能系统的方法论讨论
|
||||
|
||||
(顺便,如果这篇的阅读体验有点一路偏题,请不要见怪,因为我也被这两周的新工作一路被带着跑)
|
||||
|
||||
(而这也导致了很多从最开始就埋好想说的东西最后懒得挖了,一路开摆)
|
||||
|
||||
(所以唯一有参考价值的思路主干就是下面这条总结)
|
||||
|
||||
该文章主要分为几个部分:
|
||||
|
||||
- 引言:讨论当前基于 AI 构建工程的背景痛点,连带着讨论 AI 智能如何区别于人类,人类仍应在生产中发挥的智能在何处。
|
||||
- LLMs 能力考察:讨论了大语言模型涌现的一系列基本能力,并讨论基于这些基本能力和工程化,大模型能做到哪一步
|
||||
- Decomp 方法论:将大语言模型微分化使用的方法论,以此展开对大语言模型的新认知
|
||||
- AI 作为智能系统:结合 Generative Agents、AutoGPT 两项工作讨论大语言模型本身的局限性,围绕人类认知模型的启发,讨论通过构建复杂系统使得 LLMs Agent 化的可能性
|
||||
- 予智能以信息:讨论基于 LLMs 构建能够充分帮助我们提升生产力的 AI 剩余的一切痛点。借以回到主题 —— 在 AI 时代,我们要打造什么样的生产和信息管理新范式 (有一说,还是空口无凭)
|
||||
|
||||
总体而言,本文包括对 LLM 领域近一个月的最新几项工作(TaskMatrix、HuggingGPT、Generative Agents、AutoGPT)的讨论,并基于此考察一个真正可用的 AI 会以什么样的形态出现在我们面前。
|
||||
|
||||
而本文的核心观点如下:
|
||||
|
||||
- 大语言模型的实质是一个拥有智能计算能力的语言计算器
|
||||
- 我们不该将其当作独立的智能体看待,但能在其基础上通过构建系统创建智能 Agent
|
||||
- 为此,我们需要通过构建信息工程,让 AI 能够真正感知和改造世界,从而改变我们的生产进程
|
||||
|
||||
仅作展望。
|
||||
|
||||
# 引言
|
||||
|
||||
在开启正式讨论之前,我们希望从两个角度分别对 AI 进行讨论,从而夹逼出我们 从 AI 到 智能系统 的主题
|
||||
|
||||
- 形而上:我们尝试讨论 AI 智能的形态,进而发现 人类智能 的亮点
|
||||
- 形而下:我们尝试给出 AI 使用的样例,进而发掘 人工智能 的痛点
|
||||
|
||||
结合二者,我们待解释一种通过人类智能引领人工智能跨越痛点的可能性
|
||||
|
||||
> 形而上者谓之道,形而下者谓之器;<br/>化而裁之谓之变,推而行之谓之通,<br/>举而措之天下之民,谓之事业。
|
||||
|
||||
以前只知前边两句,现在才知精髓全在后者
|
||||
|
||||
## 形而下者器:LLMs + DB 的使用样例
|
||||
|
||||
(为了不让话题一开场就显得那么无聊,我们先来谈点有意思的例子)
|
||||
|
||||
前些时日,简单尝试构建了一个原型应用,通过 LLM 的文本信息整合能力和推理能力,实现文本到情感表现的映射,并依此实现了游戏对话生成流水线中动作配置的自动生成。
|
||||
|
||||
该应用的工程步骤分为以下几步:
|
||||
|
||||
- 基于现有任务演出动作库和动作采用样例,构建一个使用情感表达向量化索引动作的数据库
|
||||
- 向 LLMs 构建请求,通过向对话文本中添加情感动作标签丰富对话表现
|
||||
- 召回填充完毕后的对话样本,正则化收集对话情感标签,并对数据库进行索引
|
||||
- 召回数据库索引,逐句完成情感动作选择,并反解析至配档文件
|
||||
|
||||
这还是一个极简的工程原型,甚至 LLMs 在其中智能能力的发挥程度依旧存疑,但我主要还是希望其起到一个提醒作用:这彰显了所谓“信息”在实际开发、以及在后续将 AI 引入开发过程中的重要性。
|
||||
|
||||
我们要如何将原本储存于大脑的跨模态开发数据知识外化到一个可读的模态上并有效收集起来,同时要如何尽一切可能让 AI 能帮助我们挖掘数据中蕴含的价值,这是最核心的出发点。
|
||||
|
||||
而上面这一步,才是应对 LLM 的到来,在未来可期层面上最值得展开讨论的内容。
|
||||
|
||||
(后面会给出更多关联的讨论,这里就先不赘叙了)
|
||||
|
||||
## 形而上者道:对 LLM 既有智能能力及其局限性的讨论
|
||||
|
||||
这一节中,想讨论一下人工智能与人类智能的碰撞()
|
||||
|
||||
从 Plugins 到 AI 解决问题的能力
|
||||
|
||||
此相关的讨论是在 ChatGPT Plugins 出现后展开的:
|
||||
|
||||
ChatGPT Plugins 在两篇论文两个角度的基础上,对 LLMs 的能力的能力进行延拓
|
||||
|
||||
- ToolFormer:让 AI 具有使用工具的能力
|
||||
- Decomp:让 AI 能逐层分解并完成任务
|
||||
|
||||
此相关的能力,其实在微软最新的一篇论文 TaskMatrix.AI 中被进一步阐述,其通过工程构建了一个 AI 能 自由取用 API 解决问题 的环境。
|
||||
|
||||
上述能力,在实质上进一步将 AI 解决问题的能力与人类进行了对齐:人们通过问题的拆解,将任务转化为自己能处理的多个步骤;并通过工具借自己所不能及之力,将问题最终解决。此二者无疑是人类解决问题最核心的步骤,即确定“做什么”和“怎么做”
|
||||
|
||||
而这也基本奠定了后续面向 AI 的工作流,其基本展开形态:
|
||||
|
||||
- 为 AI 提供接口,为 AI 拓展能力
|
||||
- 建模自身问题,促进有效生成
|
||||
|
||||
### 从人工智能到人类智能
|
||||
|
||||
在上面的论断中,我们看似已经能将绝大多数智能能力出让予 AI 了,但我还想从另一角度对 AI 与人类的能力进行展开讨论:
|
||||
|
||||
即讨论一下人工智能的模型基础与其历程
|
||||
|
||||
- 人工智能:AI 的元智能能力
|
||||
- “人工”智能:辅佐 AI 实现的智能
|
||||
- 人类智能:于人类独一无二的东西
|
||||
|
||||
### AI 智能的形态
|
||||
|
||||
大语言模型的原始目的是制造一个“压缩器”,设计者们希望他能有效地学习世界上所有信息,并对其进行通用的压缩。
|
||||
|
||||
在压缩的过程中,我们希望 AI 丢掉信息表征,并掌握知识背后的智能能力与推理能力,从而使得该“压缩器”能在所有的域上通用。
|
||||
|
||||
该说法是略显抽象的,但我们可以给出一个简单的现实例子对其进行描摹:
|
||||
|
||||
> “人总是要死的,苏格拉底也是人,所以苏格拉底是要死的”<br/>这是一个经典苏格拉底式的三段论,其中蕴含着人类对于演绎推理能力的智慧。<br/>假设上面的样本是 LLM 既有学习的,而这时来了一个新的样本:<br/>“人不吃饭会被饿死,我是人,所以我也是要恰饭的嘛”<br/>那么对于一个理想的智能压缩器而言,其可能发现新句与旧句之间的关联,并有效学习到了句子的表征形式及其背后的逻辑
|
||||
|
||||
$$
|
||||
S1=<(人,苏格拉底,死),三段式推理>
|
||||
$$
|
||||
|
||||
$$
|
||||
S2=<(人,我,恰饭),三段式推理>
|
||||
$$
|
||||
|
||||
> 而随后,压缩器会倾向于储存三段式推理这一智能结构,并在一定程度上丢弃后来的(人,我,恰饭)这一实体关系组,仅简单建模其间联系,并在生成时按需调整预测权重。
|
||||
|
||||
换言之,对 LLMs 而言,其对“智能”的敏感性要远高于“信息”
|
||||
|
||||
而这也带来了大语言模型训练的一些要点,通常对 LLM 而言,越是底层的训练越容易混入并给予 LLM“信息表征”,而越是高层的训练,越倾向于让 LLM 掌握新的“智能模式”
|
||||
|
||||
基于这一点,我们能对 LLM 的智能能力出发点进行简要推断:
|
||||
|
||||
LLM 的实质上还是通过“语言结构”对“外显人类智能”进行掌握,也正是相应的,引入了一系列问题
|
||||
|
||||
- AI 偏好学习智能,却不能很好的学习“信息型知识”
|
||||
- AI 只能掌握基于语言模态等可外显表征模态下的智能
|
||||
|
||||
进一步的,受限于自回归解码器结构的限制,AI 只能线性地回归文本序列,而无法构建自反馈。
|
||||
|
||||
而也正是这些固有缺陷,为人类的自我定位和进一步利用 AI 找到了立足点。
|
||||
|
||||
### 赋能 AI 实现智能
|
||||
|
||||
作为上面一点的衍生,我们可以从大体两个角度去辅助 AI 智能的实现:
|
||||
|
||||
- 补全 AI 的智能能力
|
||||
|
||||
- 通过 Prompt Engineering 激发 AI 既有的能力
|
||||
- 通过启发方法构建 AI 的智能链条
|
||||
|
||||
- 内隐启发:通过复杂 Prompt 指导 AI 理解并完成任务
|
||||
ICL / COT Prompt
|
||||
- 外显启发:通过程序规范化 LLMs 完成任务所需流程
|
||||
ChatGPT Plugins / LangChain
|
||||
- 结构启发:通过构建工程结构支持 AI 自迭代分解并解决问题
|
||||
Decomp / TaskMatrix.AI / Hugging GPT
|
||||
- 附加 AI 的信息能力
|
||||
|
||||
- 通过知识工程和迭代调用等方法,为 AI 构造“记忆宫殿”
|
||||
|
||||
### 反思人类智能
|
||||
|
||||
作为人类而言,我们所拥有的智能能力显然也不是能被 AI 所覆盖的
|
||||
|
||||
首先,我们是“能动”与“体验”功能都脱离于我们狭义的智能而存在,而正是这些要素赋予了我们“主体性”
|
||||
|
||||
其次,也正是这些成分脱离于语言和表达而存在,使他们成为无法被显式学习的要素
|
||||
|
||||
- AI 不具备深层动机,它有的只是被语言所描述的目标
|
||||
- AI 不具备体验能力,因此它的创作是无反馈无迭代的
|
||||
|
||||
但是,相应的,不涉及上述内容的工作流程,在可预见的将来,会由 AI 全面参与。
|
||||
|
||||
而我们为了不被时代淘汰,要更加积极主动地将 AI 引进来。
|
||||
|
||||
### 化而裁之,推而行之:回到我们的主题
|
||||
|
||||
回顾一下上文,我们从应用和概念两个角度简要讨论了 AI 当前的使用情况,以及这些应用依托于什么
|
||||
|
||||
- 应用
|
||||
|
||||
- 通过 AI 实现了高度智能化的工作
|
||||
- 通过整理开发信息使得链路通顺
|
||||
- 概念
|
||||
|
||||
- 我们能通过外力引导赋予 AI 更强的解决问题的能力
|
||||
- AI 的核心能力是通用智能能力,对工作情境已高度可用
|
||||
- 人类能力的核心是能动和体验,而非浅显的智能
|
||||
- 展望
|
||||
|
||||
- 如何更好的赋能 AI
|
||||
- 如何更好的驾驭 AI
|
||||
|
||||
在唠嗑了这么多之后,我们终于能引入今天的主题了。
|
||||
|
||||
简而言之,我希望能追随着 AI 的发展,讨论是否能构建这样一个通用的 AI 框架,并将其引入工作生产的方方面面。希望能讨论及如何对生产信息进行有效的管理,也包括如何让我们更好调用 AI,如何让 AI 满足我们的生产需要。
|
||||
|
||||
# LLMs:生成原理及能力考察
|
||||
|
||||
相信无论是否专业,各位对 LLMs 的生成原理都有着一定的认知
|
||||
|
||||
简单来说,这就是一个单字接龙游戏,通过自回归地预测“下一个字”。在这个过程的训练中,LLMs 学习到了知识结构,乃至一系列更复杂的底层关联,成为了一种人类无法理解的智能体。
|
||||
|
||||
## In-Context Learning / Chain of Thought
|
||||
|
||||
经过人们对模型背后能力的不懈考察,发现了一系列亮点,其中最瞩目的还是两点:
|
||||
|
||||
ICL(In-Context Learning,上下文学习)和 COT(Chain of Thought,思维链)
|
||||
|
||||
可以说,绝大部分对于使用 LLMs 的启发,都源自这两个特性,简单说明此二者的表现
|
||||
|
||||
- ICL:上下文学习使得模型能从上下文中提供的样例/信息中学习,有效影响输出
|
||||
- COT:当模型在输出过程中写出思维过程时,能大幅提升输出效果
|
||||
|
||||
虽然学界对此没有太大的共识,但其原理无非在于给予 LLMs 更翔实的上下文,让输出与输入有着更紧密的关联与惯性。(从某种意义上来说,也可以将其认为是一种图灵机式的编程)
|
||||
|
||||
> ICL:<br/>
|
||||
|
||||
ICL 为输出增加惯性
|
||||
|
||||
> 可以简单认为,通过 ICL Prompt,能强化人类输入到机器输出的连贯性,借以提升输出的确定性。<br/>在经过“回答”的 finetune 之前,大模型的原始能力就是基于给定文本进行接龙,而 ICL 的引入则在“回答”这一前提条件下,降低了机器开始接龙这一步骤中的语义跨度,从而使得输出更加可控。<br/>
|
||||
|
||||
COT:<br/>
|
||||
|
||||
COT 为输出增加关联
|
||||
|
||||
> 同样可以简单认为,在引入 COT 后,AI 能将一次完整的输出看作两次分离的输出。<br/>对这两次输出而言,输入输出之间均有更高的关联度,避免了长程的抽象推理。对应短程推理的误差相对较小,最终使得积累误差也要更小。
|
||||
|
||||
进一步的,ICL 的发现,让 LLMs 能避免过多的传统 Finetune,轻易将能力运用在当前的情景中;COT 的发现,使得通过 LLMs 解决复杂问题成为可能。此二者的组合,为 LLMs 的通用能力打下了基础。
|
||||
|
||||
|
||||
## TaskMatrix.AI
|
||||
|
||||
微软对 [TaskMatrix.AI](https://arxiv.org/abs/2303.16434) 这一项目的研究,很大程度上展示了 LLMs 基于 ICL 和 COT 所能展现的能力
|
||||
|
||||
(需要注意的是,TaskMatrix.AI 更大程度上是一个愿景向的调研案例,尚未正式落地生态)
|
||||
|
||||

|
||||
|
||||
TaskMatrix 的生态愿景
|
||||
|
||||
该文展现了一个生态愿景,即将 LLMs 作为终端,整合诸多 API 的能力,让 AI 运用在生活中的方方面面。
|
||||
|
||||
简单介绍的话,该框架主要分为四个模块
|
||||
|
||||
- Multimodal Conversational Foundation Model:通过与用户对话了解问题情景,并按需组装 API 实现操作,帮助用户解决问题
|
||||
- API Platform:构建统一的 API 制式,储存和管理平台内上所有 API 及其关联文档
|
||||
- API Selector:根据 MCFM 对用户问题的理解,向 MCFM 选择并推荐可用 API
|
||||
- API Executor:代替 MCFM 执行 API 脚本,并返回执行结果或中间信息
|
||||
|
||||
基于这一框架,微软于论文中实现了诸如图像编辑(基于我们摸不到的 GPT4)、论文写作、PPT 制作等工作。不难想象,微软即将推出的 Office 365 Copilot 也是基于相关技术及更深层的 API 定制实现的。
|
||||
|
||||
而与此相关的工作还可以关注 [HuggingGPT](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2303.17580),也是微软同期发布的论文,让 AI 能自主调用 Hugging Face 上的通用模型接口解决 AI 问题,从而实现一种“AGI”性能。
|
||||
|
||||
毫无疑问,我们通常会认为这种通过构造框架来大幅增强 LLMs 能力的可能性,是构建在既有 ICL 和 COT 的能力之上的,而我会围绕此二者重新进行简单展开
|
||||
|
||||
(当然,硬要说的话,对 ICL 和 COT 两种能力都有一个狭义与广义之争,但这不重要,因为我喜欢广义)
|
||||
|
||||
### ICL for TaskMatrix
|
||||
|
||||
> 狭义的 ICL:从输入的既有样例中学习分布和规范<br/>广义的 ICL:有效的将输入内容有效运用到输出中
|
||||
|
||||
以 TaskMatrix 为例,在 API 组装阶段,其为 MCFM 提供的 ICL 内容即为 API 的文档
|
||||
|
||||
以论文为例,其提供的每个 API 文档分为如下部分
|
||||
|
||||
- API Name:用于描述该 API 名,亦即函数的调用名
|
||||
- Parameter List:用于描述 API 中的参数列表,介绍每个参数的特性及输入输出内容
|
||||
- API Description:API 描述,用于描述 API 功能,查找 API 时的核心依据
|
||||
- Usage Example:API 的调用方法样例
|
||||
- Composition Instruction:API 的使用贴士,如应该与其它什么 API 组合使用,是否需要手动释放等
|
||||
|
||||
> 样例:打开文件 API<br/>
|
||||
|
||||
基于此类文档内容和 ICL 的能力,LLMs 能从输入中习得调用 API 的方法,依此快速拓展了其横向能力
|
||||
|
||||
COT for TaskMatrix
|
||||
|
||||
> 狭义的 COT:通过 Lets Think Step by Step 诱导 LLMs 生成有效的解答中间步骤,辅助输出<br/>广义的 COT:通过 LLMs 的固有能力对问题进行拆解,构建解决问题的链条
|
||||
|
||||
通过此种模式,能极好的将问题分解至可被执行的原子形态
|
||||
|
||||
在 TaskMatirx 中,通过该模式,让 MCFM 将任务转化为待办大纲,并最终围绕大纲检索并组合 API,完成整体工作
|
||||
|
||||
> 样例:写论文<br/>构建完成工作大纲<br/>
|
||||
|
||||
TaskMatrix 自动围绕目标拆解任务
|
||||
|
||||
> 自动调用插件和组件<br/>
|
||||
|
||||
TaskMatrix 自动为任务创建 API 调用链
|
||||
|
||||
## 初步考察
|
||||
|
||||
基于上述的简单介绍,我们已经初步认识了 AI 在实际情景中的高度可用性
|
||||
|
||||
而接下来,我们继续从工程的角度揭示这种可用性的根源 —— 其源自一项通用的 Prompt 技术
|
||||
|
||||
# Prompt Decomposition:方法论
|
||||
|
||||
我们可以认为,TaskMatirx 的能力极大程度上依托于 Prompt Decomposition 的方法
|
||||
|
||||
而这实质上也是串联 LLM 能力与实际工程需求的必经之路
|
||||
|
||||
[[2210.02406] Decomposed Prompting: A Modular Approach for Solving Complex Tasks (](https://arxiv.org/abs/2210.02406)[arxiv.org](https://arxiv.org/abs/2210.02406)[)](https://arxiv.org/abs/2210.02406)
|
||||
|
||||
## 原始 Decomp
|
||||
|
||||
Decomp 的核心思想为将复杂问题通过 Prompt 技巧,将一个复杂的问题由 LLMs 自主划分为多个子任务。随后,我们通过 LLMs 完成多个任务,并将过程信息最终组合并输出理想的效果
|
||||
|
||||

|
||||
|
||||
几种 Prompt 方法图示
|
||||
|
||||
参考原始论文中阐述的方案,Decomp 方法区别于传统 Prompt 方法就在于,Decomp 会根据实际问题的需要,将原始问题拆解为不同形式的 Sub-Task,并在 Sub-Task 中组合使用多种符合情景的 Prompt 方法。
|
||||
|
||||
而对于 Decomp 过程,则又是由一个原始的 Decomp Prompt 驱动
|
||||
|
||||

|
||||
|
||||
Decomp 方法执行样例
|
||||
|
||||
在实际运行中,Decomp 过程由一个任务分解器,和一组程序解析器组成
|
||||
|
||||
其中分解器作为语言中枢,需要被授予如何分解复杂任务 —— 其将根据一个问题 Q 构建一个完整的提示程序 P ,这个程序包含一系列简单的子问题 Q_i,以及用于处理该子问题的专用函数 f_i(可以通过特定小型 LLM 或专用程序,也可以以更小的提示程序 P_i 形式呈现)。
|
||||
|
||||
模型将通过递归运行完整的提示程序,来获得理想的答案。
|
||||
|
||||
在构建 Decomp 流程的初期,其主要是为了解决 LLMs 无法直接解决的具有严密逻辑的工作(比方说基于文本位置的文字游戏,比方说检索一首藏头诗的头是啥(当然这个太简单了),大模型的位置编码系统和概率系统让其很难长程处理相关工作),我们希望通过 Decomp 方法,将复杂问题逐步归约回 LLMs 能处理的范畴。
|
||||
|
||||
我们也可以认为,在每个子任务中,我们通过 Prompt 将 LLMs 的能力进行了劣化,从而让其成为一个专职的功能零件。而这种对单个 LLMs 能力迷信的削减,正延伸出了后续的发展趋势。
|
||||
|
||||
## Decomp 衍生
|
||||
|
||||
Decomp 的原始功能实际上并不值得太过关注,但我们急需考虑,该方法还能用于处理些什么问题。
|
||||
|
||||
### 递归调用
|
||||
|
||||
我们可以构建规则,让 Decomp 方法中的分解器递归调用自身,从而使得一个可能困难的问题无限细分,并最终得以解决
|
||||
|
||||
### 外部调用
|
||||
|
||||
通过问题的分解和通过“专用函数”的执行,我们可以轻易让 LLMs 实现自身无法做到的调用 API 工作,例如主动从外部检索获取回答问题所需要的知识。
|
||||
|
||||

|
||||
|
||||
Decomp 方法调用外部接口样例
|
||||
|
||||
如上图为 LLMs 利用 ElasticSearch 在回答问题过程中进行检索
|
||||
|
||||
基于此,我们还希望进一步研究基于这些机制能整出什么花活儿,并能讨论如何进一步利用 LLMs 的能力
|
||||
|
||||
## 回顾:HuggingGPT 对 Decomp 方法的使用
|
||||
|
||||
[HuggingGPT](https://arxiv.org/abs/2303.17580) 一文也许并未直接参考 Decomp 方法,而是用一些更规范的手法完成该任务,但其充分流水线化的 Prompt 工程无疑是 Decomp 方法在落地实践上的最佳注脚
|
||||
|
||||

|
||||
|
||||
HuggingGPT
|
||||
|
||||
如图所示,在实际工程中,对于这个调用 HuggingFace API 的“通用人工智能”而言,其所需的任务并不复杂,仅仅分为三步(获取并运行缝在一起了)
|
||||
|
||||
- 理解并规划解决问题所需步骤
|
||||
- 选择并运行解决问题所需模型
|
||||
- 基于子问题输出结果总结反馈
|
||||
|
||||
同样的,TaskMatrix.AI 也使用了相似的方法和步骤来完成任务,最新的进展高度明晰了该框架的可用性,并为我们如何有效使用 AI 来完成专用任务提供了有效的指导。
|
||||
|
||||
接下来,我们会讨论一个很新的,在为 Agent 模拟任务构建框架上,把 Decomp 和 Prompting 技术用到登峰造极的样例。
|
||||
|
||||
# Generative Agents:社群模拟实验
|
||||
|
||||
[[2304.03442] Generative Agents: Interactive Simulacra of Human Behavior (](https://arxiv.org/abs/2304.03442)[arxiv.org](https://arxiv.org/abs/2304.03442)[)](https://arxiv.org/abs/2304.03442)
|
||||
|
||||
Generative Agents 一文通过的自然语言框架 AI 构建出了一个模拟社群,一方面我们震撼于以 AI 为基础的社群复杂系统也能涌现出如此真实可信的表现,另一方面则需要关注他们通过 Prompt 技巧和工程设计,为 AI 构建的 感知、记忆、交互 大框架。
|
||||
|
||||
其在极大程度上能为我们想建立的其它基于 AI 的工程提供参考。
|
||||
|
||||
因为,其本质是一个信息管理框架的实验。
|
||||
|
||||
## 简要介绍
|
||||
|
||||
简单介绍该项目构建的框架:
|
||||
|
||||
我们可以认为该工程由三个核心部分构成
|
||||
|
||||
- 世界信息管理
|
||||
- 角色信息管理
|
||||
- 时间驱动机制
|
||||
|
||||
我们可以从宏观到微观渐进讨论该课题:
|
||||
|
||||
Generative Agents 构建了一套框架,让 NPC 可以感知被模块化的世界信息。同时,对于全游戏的每个时间步,该框架驱动 NPC 自主感知世界环境的信息与自身信息,并依此决策自己想要执行的行为。
|
||||
|
||||
根据 NPC 的决策,NPC 能反向更新自身所使用的记忆数据库,并提炼总结出高层记忆供后续使用。
|
||||
|
||||
## 世界沙盒的构建
|
||||
|
||||
相比角色信息的构建是重头戏,世界沙盒的构建使用的方法要相对朴素一些
|
||||
|
||||
世界沙盒的核心是一个树状 Json 数据,其依据层次储存游戏场景中所有的信息:
|
||||
|
||||
- 一方面,其包含场景中既有对象,包括建筑和摆件等的基础层级信息
|
||||
|
||||

|
||||
|
||||
Generative Agents 的场景信息管理
|
||||
|
||||
- 另一方面,其储存了沙盒世界中每个代理的信息,包括其位置、当前动作描述、以及他们正在交互的沙盒对象
|
||||
|
||||
对于每个时间步,服务器将解析场景的状态,例如对于 Agent 使用咖啡机的情景,会自动将咖啡机转换为正在使用中的状态。
|
||||
|
||||
而相对更有趣的设计是,场景中的所有信息会依靠认知过滤(即 NPC 是否能感知其感知范围外的环境变化)进行筛选,并最终呈现成 NPC 可感知/有印象的子集。
|
||||
|
||||
同时,空间信息会被自动组成自然语言 Prompt,用于帮助 Agent 更好地理解外部信息。甚至当 Agent 希望获取空间信息时,其能主动递归调用世界信息,从而让 NPC 能准确找到其希望抵达的叶子节点。
|
||||
|
||||
## Agent 构建
|
||||
|
||||
模型中的 Agent 由 数据库 + LLMs 构建
|
||||
|
||||
对于一个初始化的 Agent,会将角色的初始设定和角色关联设定作为高优先级的“种子”储存在“记忆”中,在记忆种子的基础上,得以构建角色的基本特征和社交关系,用于展开后续关联
|
||||
|
||||
一个 Agent 核心的能力是 —— 将当前环境和过去经验作为输入,并将生成行为作为输出
|
||||
|
||||
对于当前环境,在构建世界沙盒模块对方法论进行了简要的介绍。
|
||||
|
||||
而对于过去经验的输入,则是文章的一大亮点
|
||||
|
||||
## 记忆模式
|
||||
|
||||
对于 Agent 的记忆,依托于一个储存信息流的数据库
|
||||
|
||||
数据库中核心储存三类关键记忆信息 memory, planning and reflection
|
||||
|
||||
### Memory
|
||||
|
||||
对于 Agent 每个时间步观测到的事件,会被顺序标记时间戳储存进记忆数据库中
|
||||
|
||||
而对于储存进数据库的信息,记忆管理器通过三个标准对其进行评估和管理
|
||||
|
||||
- Recency:时效性,记忆在数据库中会随着时间推移降低时效性,数据库储存记忆的最后访问时间,并由此与当前时间对比,计算时效性评分
|
||||
- Importance:重要性,当记忆储存时,会使用特定 Prompt 让 Agent 自主评估当前记忆的重要性,并依据该评分调整该记忆的权重(例如扫地和做咖啡可能就是无关紧要的记忆)
|
||||
- Relevance:关联性,该指标被隐式地储存,表现为一个嵌入索引,当调取记忆时,会将调取记忆的关键词嵌入与索引相匹配,以取得关联性的评分
|
||||
|
||||
对于对记忆数据库进行索引的情况,会实时评估上述三个指标,并组合权重,返回对记忆索引内容的排序
|
||||
|
||||
### Reflection
|
||||
|
||||
反思机制用于定期整理当前的 memory 数据库,让 npc 构建对世界和自身的高层认知
|
||||
|
||||
反思机制依靠一个自动的过程,反思-提问-解答
|
||||
|
||||
在这个过程中,Agent 需要复盘自身所接受的记忆,并基于记忆对自己进行追问:
|
||||
|
||||
“根据上述信息,我们能问出哪些最高优先级(有趣)的问题”
|
||||
|
||||
依据由 Agent 的好奇自主产生的问题,我们重新索引数据库,并围绕相关的记忆产生更高层的洞察
|
||||
|
||||
> What 5 high-level insights can you infer from the above statements?<br/>(example format: insight (because of 1, 5, 3))
|
||||
|
||||
进一步的,我们将这些洞察以相同的形式重新储存至记忆库中,由此模拟人类的记忆认知过程
|
||||
|
||||
### Planning
|
||||
|
||||
Planning 的核心在于鼓励 Agent 为未来做出一定的规划,使得后续行动变得可信
|
||||
|
||||
计划由 Agent 自行生成,并存入记忆流中,用于在一定程度上影响 Agent 的当前行为
|
||||
|
||||
对于每天 Agent 都会构建粗略的计划,并在实际执行中完善细节
|
||||
|
||||
在此基础上,Agent 也需要对环境做出反应而调整自己的计划表(例如自身判断外界交互的优先级比当前计划更高。
|
||||
|
||||
## 交互构建
|
||||
|
||||
基于上述记忆框架,进一步实时让 Agent 自行感知并选择与其它 Agent 构建交互
|
||||
|
||||
并最终使得复杂的社群在交互中涌现
|
||||
|
||||
## 启发
|
||||
|
||||
Generative Agent 框架主要带来了一些启发,不止于 AI-NPC 的构建,其操作的诸多细节都是能进一步为我们在实际的工程中所延拓的。
|
||||
|
||||
例如:
|
||||
|
||||
> 感知,围绕目标递归对地图搜索,带来了递归检索数据库的可能性,以及要如何有效构建数据库之间的关联(不止于树<br/>记忆,将 AI 的 Reflection 等表现储存进数据库中,用于实现高层观点的构建,比方说自动构建对复杂对象,如代码库的高层理解<br/>交互,通过地图要素的拆分和可读化构建的交互框架,如何基于该思路构建大世界地图关卡数据的数据库,如何把它拓展到更复杂的游戏中
|
||||
|
||||
我们可以认为,Generative Agents 一文的核心亮点在于,其构建了一套充分有效的信息管理机制以支撑世界运行的需要,并未我们提供了一系列启发性的数据管理观点
|
||||
|
||||
- 层次管理数据:通过对数据进行分层的管理和访问,降低运算开销,并通过系统级递归实现访问
|
||||
- 层次管理信息:通过语言模型的能力为信息构建高层的 Insight,对碎片信息的信息量进行聚合
|
||||
- 数据价值评估:通过实际需求对信息进行评估,构建多样化的信息评估指标,实现信息的有效获取
|
||||
- AI x 信息自动化系统的构建:基于 AI + 软件系统而非基于人工对数据进行收集和管理
|
||||
- etc...
|
||||
|
||||
# AutoGPT:自动化的智能软件系统
|
||||
|
||||
[Torantulino/Auto-GPT: An experimental open-source attempt to make GPT-4 fully autonomous. (](https://github.com/Torantulino/Auto-GPT)[github.com](https://github.com/Torantulino/Auto-GPT)[)](https://github.com/Torantulino/Auto-GPT)[github.com/Torantulino/Auto-GPT](https://github.com/Torantulino/Auto-GPT)
|
||||
|
||||
同为近期,一个名为 AutoGPT 的软件系统在 Github 上被开源,其通过构建软件系统支持,让 AI 能围绕预设定的目标反复迭代,并自主获取外界的反馈,从而形成一个能自动化满足需求的自动机。
|
||||
|
||||
特别的,其可以被视为前文中 Generative Agent 中由系统自驱动单个 Agent 的拓展,通过构建内置和外置的不同目标驱动 GPT 作为 Agent 持续运行
|
||||
|
||||
AutoGPT 主要特性如下:
|
||||
|
||||
- 使用 GPT-4 实例进行文本生成
|
||||
- ️ 使用 GPT-3.5 进行文件存储和摘要
|
||||
- 接入互联网获取信息
|
||||
- 长期和短期内存管理
|
||||
|
||||
考虑到工程细节,该项目实际上没有特别大的落地案例,但毫无疑问这是面向未来的 GPT 使用方式
|
||||
|
||||
其核心机制在于,通过 LLMs 和 记忆/目标管理模块 的符合,构建出了一个复杂的 Agent 系统
|
||||
|
||||
我们通常不再将该系统认为是一个完整的 GPT 线程:
|
||||
|
||||
这是一个通过工程、通过系统化、通过反馈构建的自动机,就像人一样。
|
||||
|
||||
(我们需要放下通过 LLMs 来模拟智能体的执念,我们作为智能体的实质是一个输入输出的系统,而我们所自认为的自由意志也只是大脑的一个解释模块而已,也许与智能系统中调用的单个 LLMs 线程异曲同工)
|
||||
|
||||
当前,AutoGPT 的能力主要反应在主动通过 Google API 联网,寻找并记忆自己需要使用到的知识,包括某些软件的接口和其它 API,也包括自己完成某些分析所需要的知识。
|
||||
|
||||
(已经有人尝试通过其快速构建软件工程,或者完成其它某些自动化操作。)
|
||||
|
||||
(虽然感觉依旧不甚理想)
|
||||
|
||||
(如下是 AutoGPT 的基础 Prompt)
|
||||
|
||||
```
|
||||
[
|
||||
{
|
||||
'content': 'You are Eliza, an AI designed to write code according to my requirements.\n'
|
||||
'Your decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and pursue simple strategies with no legal complications.\n\n'
|
||||
|
||||
'GOALS:\n\n'
|
||||
'1. \n\n\n'
|
||||
|
||||
'Constraints:\n'
|
||||
'1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files.\n'
|
||||
'2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.\n'
|
||||
'3. No user assistance\n'
|
||||
'4. Exclusively use the commands listed in double quotes e.g. "command name"\n\n'
|
||||
|
||||
'Commands:\n'
|
||||
'1. Google Search: "google", args: "input": "<search>"\n'
|
||||
'2. Browse Website: "browse_website", args: "url": "<url>", "question": "<what_you_want_to_find_on_website>"\n'
|
||||
'3. Start GPT Agent: "start_agent", args: "name": "<name>", "task": "<short_task_desc>", "prompt": "<prompt>"\n'
|
||||
'4. Message GPT Agent: "message_agent", args: "key": "<key>", "message": "<message>"\n'
|
||||
'5. List GPT Agents: "list_agents", args: \n'
|
||||
'6. Delete GPT Agent: "delete_agent", args: "key": "<key>"\n'
|
||||
'7. Write to file: "write_to_file", args: "file": "<file>", "text": "<text>"\n'
|
||||
'8. Read file: "read_file", args: "file": "<file>"\n'
|
||||
'9. Append to file: "append_to_file", args: "file": "<file>", "text": "<text>"\n'
|
||||
'10. Delete file: "delete_file", args: "file": "<file>"\n'
|
||||
'11. Search Files: "search_files", args: "directory": "<directory>"\n'
|
||||
'12. Evaluate Code: "evaluate_code", args: "code": "<full_code_string>"\n'
|
||||
'13. Get Improved Code: "improve_code", args: "suggestions": "<list_of_suggestions>", "code": "<full_code_string>"\n'
|
||||
'14. Write Tests: "write_tests", args: "code": "<full_code_string>", "focus": "<list_of_focus_areas>"\n'
|
||||
'15. Execute Python File: "execute_python_file", args: "file": "<file>"\n'
|
||||
'16. Execute Shell Command, non-interactive commands only: "execute_shell", args: "command_line": "<command_line>"\n'
|
||||
'17. Task Complete (Shutdown): "task_complete", args: "reason": "<reason>"\n'
|
||||
'18. Generate Image: "generate_image", args: "prompt": "<prompt>"\n'
|
||||
'19. Do Nothing: "do_nothing", args: \n\n'
|
||||
|
||||
'Resources:\n'
|
||||
'1. Internet access for searches and information gathering.\n'
|
||||
'2. Long Term memory management.\n'
|
||||
'3. GPT-3.5 powered Agents for delegation of simple tasks.\n'
|
||||
'4. File output.\n\n'
|
||||
|
||||
'Performance Evaluation:\n'
|
||||
'1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n'
|
||||
'2. Constructively self-criticize your big-picture behavior constantly.\n'
|
||||
'3. Reflect on past decisions and strategies to refine your approach.\n'
|
||||
'4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.\n\n'
|
||||
|
||||
'You should only respond in JSON format as described below \n'
|
||||
'Response Format: \n'
|
||||
'{\n'
|
||||
' "thoughts": {\n'
|
||||
' "text": "thought",\n'
|
||||
' "reasoning": "reasoning",\n'
|
||||
' "plan": "- short bulleted\\n- list that conveys\\n- long-term plan",\n'
|
||||
' "criticism": "constructive self-criticism",\n'
|
||||
' "speak": "thoughts summary to say to user"\n'
|
||||
' },\n'
|
||||
' "command": {\n'
|
||||
' "name": "command name",\n'
|
||||
' "args": {\n'
|
||||
' "arg name": "value"\n'
|
||||
' }\n'
|
||||
' }\n'
|
||||
'} \n'
|
||||
'Ensure the response can be parsed by Python json.loads',
|
||||
'role': 'system'
|
||||
},
|
||||
{
|
||||
'content': 'The current time and date is Fri Apr 14 18:47:50 2023',
|
||||
'role': 'system'
|
||||
},
|
||||
{
|
||||
'content': 'This reminds you of these events from your past:\n\n\n',
|
||||
'role': 'system'
|
||||
},
|
||||
{
|
||||
'content': 'Determine which next command to use, and respond using the format specified above:',
|
||||
'role': 'user'
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
# 回归正题:AI 作为智能系统
|
||||
|
||||
作为正题的回归,我们需要重新考虑什么是一个 AI,一个能帮助我们的 AI 应当处于什么样的现实形态?
|
||||
|
||||
<em>我们需要的 </em><em>AI</em><em> 仅仅是大语言模型吗?如果是,它能帮我们做什么呢?如果不是,那 AI 的实质是什么呢?</em>
|
||||
|
||||
我首先武断地认为,我们需要的 AI,并不是一个语言模型实体,而是一个复杂智能系统
|
||||
|
||||
而上述围绕 GPT 展开的实验,实质都是上述观点的佐证。
|
||||
|
||||
接下来,我们会围绕此进行展开
|
||||
|
||||
## 意识理论之于 AI:全局工作空间理论
|
||||
|
||||
全局工作空间理论(英语:Global workspace theory,GWT)是美国心理学家伯纳德·巴尔斯提出的[意识](https://zh.wikipedia.org/wiki/%E6%84%8F%E8%AF%86)模型。该理论假设意识与一个全局的“广播系统”相关联,这个系统会在整个大脑中广播资讯。大脑中专属的智能处理器会按照惯常的方式自动处理资讯,这个时候不会形成[意识](https://zh.wikipedia.org/wiki/%E6%84%8F%E8%AF%86)。当人面对新的或者是与习惯性刺激不同的事物时,各种专属智能处理器会透过合作或竞争的方式,在全局工作空间中对新事物进行分析以获得最佳结果,而意识正是在这个过程中得以产生。
|
||||
|
||||
这通常被认为是 神经科学家接受度最高的哲学理论
|
||||
|
||||
从某种意义上来说,该理论将“系统”摆在了主体的位置,而把纯粹的语言或“意识”转变成了系统运动的现象,表现为系统特殊运作情况的外显形式。
|
||||
|
||||
其提醒我们,就连我们的意识主体性,也只是陈述自我的一个表述器而已。我们是否应当反思对语言能力的过度迷信,从而相信我们能通过训练模型构建 All in One 的智能实体?
|
||||
|
||||

|
||||
|
||||
全局工作空间理论
|
||||
|
||||
如图所示,在全局工作空间理论的建模中,全局工作空间作为系统,有五个主要的模块负责输入和输出
|
||||
|
||||
其分别是:
|
||||
|
||||
- 长时记忆(过去)
|
||||
- 评估系统(价值)
|
||||
- 注意系统(关注)
|
||||
- 知觉系统(现在)
|
||||
- 运动系统(未来)
|
||||
|
||||
### 例子:意识系统 For Generative Agent
|
||||
|
||||
单独解释的话,或许会比较麻烦,毕竟我对认知科学并不专业
|
||||
|
||||
我们可以简单对比 Generative Agents 其框架,结合意识模型讨论 Agent 是如何被有效构建的
|
||||
|
||||
回顾前文,我们核心对照 Agent 的记忆模块构建:
|
||||
|
||||
(不想手写,让 GPT4 来进行代笔)
|
||||
|
||||
> 从全局工作空间理论(GWT)的角度来看,Generative Agent 的设计确实与之有相似之处。GWT 提出了一个全局工作空间,负责整合来自不同认知子系统的信息。在 Generative Agent 的框架中,这些认知子系统可以看作是上述提到的几个模块。
|
||||
|
||||
- 首先,我们可以将长时记忆(过去)与 Generative Agent 的 memory 模块进行类比。memory 模块中存储了 Agent 在过去时间步观察到的事件,这与长时记忆中存储的过去信息相对应。
|
||||
- 其次,评估系统(价值)可以与 Generative Agent 的 Importance 和 Relevance 进行对应。Importance 可以理解为对记忆的重要性评估,而 Relevance 则评估了记忆与当前情境的关联性。这两者与全局工作空间理论中对不同认知子系统信息的竞争和广播过程相呼应。
|
||||
- 注意系统(关注)可以与 Generative Agent 的 Recency 相关联。Recency 衡量了记忆的时效性,这类似于在全局工作空间中,我们需要关注当前环境中的新信息,以便及时做出反应。
|
||||
- 知觉系统(现在)在 Generative Agent 中可以对应于当前环境的输入,这与全局工作空间理论中的感知子系统相一致。
|
||||
- 运动系统(未来)可以与 Generative Agent 的 planning 和 reflection 模块相关联。planning 模块让 Agent 为未来做出规划,而 reflection 模块则允许 Agent 对过去的记忆进行整理,构建高层认知,进而影响未来的行为。这两个模块与全局工作空间理论中的行动子系统相呼应。
|
||||
|
||||
> 综上所述,Generative Agent 的设计确实与全局工作空间理论有相似之处,通过将这些模块整合到一个统一的框架中,Agent 能够模拟人类在虚拟世界中扮演角色进行交互。这种整合有助于理解大脑如何处理和整合来自不同认知来源的信息,从而实现更接近人类的智能行为。
|
||||
|
||||
当然,我个人对该问题的认知与 GPT4 并非完全相同,包括注意系统与运动系统的部分。但其实我并不一定需要将所有东西全都呈现出来,因为在框架上它已然如此。
|
||||
|
||||
记忆、评估、反思这几块的设计通过 Prompt 把 LLMs 劣化成专用的智能处理器单元, 并系统性实现信息的整合与输出。从整体的观点上来看,Generative Agents 中的 Agent,其主体性并不在于 LLM,而是在于这个完整的系统。(相应的,LLMs 只是这个系统的运算工具和陈述工具)
|
||||
|
||||
### 例子:AutoGPT 的考察
|
||||
|
||||
我们再从相同的角度考察 AutoGPT 这一项目:
|
||||
|
||||
- 内存管理:全局工作空间理论强调了长时记忆、短时记忆和注意力机制之间的互动。AutoGPT 中的长期和短期内存管理与此类似,需要智能体在执行任务时权衡信息的重要性、时效性和关联性,以便有效地组织和存储信息。
|
||||
- 信息获取:全局工作空间理论的知觉系统负责处理来自外部的信息。AutoGPT 通过搜索和浏览网站等功能,获取外部信息,这与知觉系统的作用相符。
|
||||
- 生成与执行:全局工作空间理论中的运动系统负责生成和执行行为。AutoGPT 通过多种命令实现了文本生成、代码执行等功能,体现了运动系统的特点。
|
||||
|
||||
同时,其也具有对应的缺陷:
|
||||
|
||||
- AutoGPT 的长期记忆存在较大漏洞,并没有较强的注意力能力
|
||||
- AutoGPT 不能围绕记忆擢升更高层的认知,从而进一步指导未来的行为
|
||||
- AutoGPT 的运动系统,即执行能力受限于 Prompt 提供的接口,无法自适应完成更多任务
|
||||
- AutoGPT 对自身既往行为认知较差,短期记忆依赖于 4000 字 Context 窗口,并被系统输入占据大半
|
||||
|
||||
这也对应 AutoGPT 虽然看似有着极强的能力,但实际智能效果又不足为外人道也
|
||||
|
||||
## 构建一个什么样的智能系统
|
||||
|
||||
再次回归正题,Generative Agents 和 AutoGPT 这两个知名项目共同将 AI 研究从大模型能力研究导向了智能系统能力研究。而我们也不能驻足不前,我们应当更积极地考虑我们对于一个 AI 智能体有着什么样的需求,也对应我们需要构建、要怎么构建一个基于 LLMs 语言能力的可信可用的智能系统。
|
||||
|
||||
我们需要从两个角度展开考虑,从我们需要什么展开,并围绕框架进行延拓
|
||||
|
||||
当前,ChatGPT 虽然成了炙手可热的明珠,但却依然存在一些微妙的问题
|
||||
|
||||
> 来自 即刻网友 马丁的面包屑<br/>观察到一些现象:<br/>1. 除了最早期,最成熟的 Jasper 这样围绕短文本生成领域的应用,还没有看到太颠覆性的大模型应用<br/>2. 从 GPT-4 发布后的狂欢,其实是应用上的狂欢,无论 HuggingGPT、AutoGPT、Generative Agent 本质上是一种“玩法”的挖掘。<br/>3. 这种 Demo 级的产品展现了创意,但是我们知道 Demo 离最终落地还有非常多要解决的问题,这些问题哪些是可控的只需要堆时间,哪些是不可控的需要基座模型升级目前还看不清楚。<br/>4. 另外我在尝试将他融入我的工作流,帮助有限。我让一些程序员朋友测试 Github Copilot,评价上也比较有限
|
||||
|
||||
该讨论中所展现的问题,其核心在于,如何真正将 GPT 沉入“场景”中去。
|
||||
|
||||
而这才是真正一直悬而未决的 —— 作为一个打工人,你真正需要帮助的那些场景,GPT 都是缺席的。
|
||||
|
||||
同时,这样的场景,他是一个活场景抑或死场景?在这样的场景上,我们是否需要一个全知的神为我们提供信息?还是说,我们想要的是一个能像我们一样在场景中获取信息,并辅助我们决策/工作的个体?
|
||||
|
||||
这些问题都在指导、质问我们究竟需要一个怎样的智能系统。
|
||||
|
||||
# 予智能以信息:难题与展望
|
||||
|
||||
回到最开始的话题,我们构建一个可用智能系统的基底,依旧是信息系统
|
||||
|
||||
我们大胆假设,如果我们希望构建一个足以帮助我们的智能系统,其需要拥有以下几个如 全局工作空间理论 [1](http://127.0.0.1:6125/#footnotes-def-1) 所述的基本模块
|
||||
|
||||
- 知觉系统(现在)
|
||||
- 工作记忆(中继)
|
||||
|
||||
- 长时记忆(过去)
|
||||
- 评估系统(价值)
|
||||
- 注意系统(关注)
|
||||
- 运动系统(未来)
|
||||
|
||||
而接下来,我们希望对其进行逐一评估,讨论他们各自将作用的形式,讨论他们需要做到哪一步,又能做到哪一步。
|
||||
|
||||
## 知觉系统:构建 AI 可读的结构化环境
|
||||
|
||||
知觉系统负责让智能体实现信息的感知,其中也包括对复杂输入信息的解析
|
||||
|
||||
举两个简单的例子,并由此引出该课题中存在的难题
|
||||
|
||||
AutoGPT 的知觉设计:结构性难题
|
||||
|
||||
AutoGPT 所使用的 Commands 接口中,就有很大一部分接口用于实现知觉
|
||||
|
||||
典型的包含 Google Search & Browse Website & Read file
|
||||
|
||||
- Google Search: "google",
|
||||
|
||||
- args: "input": `"<search>"`
|
||||
- 返回网页关键信息与网址的匹配列表
|
||||
- Browse Website: "browse_website",
|
||||
|
||||
- args:
|
||||
|
||||
- "url": `"<url>"`,
|
||||
- "question": `"<what_you_want_to_find_on_website>"`
|
||||
- 返回网址中与 question 相关的匹配文段(通过 embedding 搜索)
|
||||
- Read file: "read_file",
|
||||
|
||||
- args: "file": `"<file>"`
|
||||
- 读取文件并解析文本数据
|
||||
|
||||
这些访问接口由程序集暴露给 GPT ,将知觉系统中实际使用的微观处理器隐藏在了系统框架之下
|
||||
|
||||
AutoGPT 所实际感知的信息为纯文本的格式,得益于以开放性 Web 为基础的网络世界环境,AutoGPT 能较方便地通过搜索(依赖于搜索引擎 API)和解析 html 文件(依赖于软件辅助,GPT 难以自行裁剪 html 中过于冗杂的格式信息),从而有效阅读绝大多数互联网信息。
|
||||
|
||||
但显然的,Read file 接口能真正有效读取的就只有纯文本文件此类了。
|
||||
|
||||
由此,这带来了知觉系统设计的第一个难题:我们要如何面对生产环境中的一系列非结构化信息?如何对其进行规范和整理?如何设计“处理器”使得 GPT 能有效对其进行读取?
|
||||
|
||||
围绕这一难题,我们简单例举几个例子来进行讨论,用作抛砖引玉:
|
||||
|
||||
- 我们以 Excel 或 Word 等格式编写排版的策划文档,要如何让 GPT 读取和索引?
|
||||
- 如果我们希望让 GPT 掌握游戏中的关卡信息,其要如何对关卡编辑器进行理解?
|
||||
- 如果我们有一个数千行的代码文件,如何让 GPT 能掌握其结构信息,充分理解模功能,而非因为草率输入爆掉上下文限制?
|
||||
- 如果我们希望让 GPT 帮助我们通过点击 UI 要素自动测试游戏,我们要如何向其传达当前界面 UI 结构?如何向其展示测试进程和玩家状态?
|
||||
- etc...
|
||||
|
||||
综上所述,第一个难题就是,我们要如何为所有期待由 AI 帮忙解决的问题,构造 AI 能理解的语境,如何把所有抽象信息规范化、结构化地储存(不止步于文本,而是把更多东西文本化(顺便这里的文本化是可读化的意思,在 GPT4 完全公开后,图像也将成为索引信息,因此这段话的本意还是将更多东西 token 化))
|
||||
|
||||
Generative Agents 的知觉设计:关联性难题
|
||||
|
||||
区别于接受互联网环境信息的 AutoGPT,Generative Agents 的知觉系统仅在人工赋予 Agent 的有限环境中生效,因此也显得愈发可控。
|
||||
|
||||
也正是因为如此,对于场景中可知觉的信息,在 GA 的框架下能得到更有效的管理
|
||||
|
||||
> [Agent's Summary Description]<br/>Eddy Lin is currently in The Lin family's house: (Eddy Lin's bedroom: desk) that has Mei and John Lin's bedroom, Eddy Lin's bedroom, common room, kitchen, bathroom, and garden.<br/>Eddy Lin knows of the following areas:<br/>The Lin family's house, Johnson Park, Harvey Oak Supply Store, The Willows Market and Pharmacy, Hobbs Cafe, The Rose and Crown Pub.<br/>* Prefer to stay in the current area if the activity can be done there.<br/>Eddy Lin is planning to take a short walk around his workspace. Which area should Eddy Lin go to?
|
||||
|
||||
如上述 Prompt 所示,由于 Generative Agents 预定义了空间的树状层级关系,这使得当其作为知觉系统时,可通过对树的层级遍历和自然语言拼装实现知觉系统的有效传达。
|
||||
|
||||
同时,基于树状结构,这允许了 Agent 基于自身需求在树上进行深度搜索。
|
||||
|
||||
该样例作为补充,讨论了数据结构设计中关联性和结构化的价值。以搜索引擎为例,仅通过关键词关联进行检索的联系是偏弱的,且不能体现层次信息,以及层次信息中蕴含的知识。
|
||||
|
||||
> 对于上面这点,我们举一个简单的例子:<br/>迪娜泽黛是一个因身患魔鳞病深居简出的 Agent,她的家在须弥城,有一天她突发奇想希望能在病逝之前看一看海。她通过搜索引擎关联搜索,并找到了推荐度最高的大海聚香海岸,为此她不远万里来到了沙漠,但差点在路上噶掉。她的好朋友迪希娅追上来给了她梆梆两拳,跟她说你去隔壁奥摩斯港看海她不香吗?
|
||||
|
||||
对于绝大部分的信息,我们所需的并不只是信息本身,更包含其中的潜在结构和关联。而对于游戏中的复杂数据更是如此。
|
||||
|
||||
这为我们知觉系统设计带来了第二个难题:我们要如何建模我们语境空间中零散的信息?我们要怎么通过最结构化最易读的方式有效对其索引?我们要如何建模并用工程辅助 GPT 的索引过程?
|
||||
|
||||
我们依旧简单举几个例子来进行讨论:
|
||||
|
||||
- 如果 GPT 能够读取我们的设计文档,它要如何整合多个文档之间的关联?如何构建索引?
|
||||
- 如果 GPT 要阅读我们的代码库,其要怎么快速跳转并逐层理解模块、功能、接口?
|
||||
- 如果我们希望 GPT 作为 Agent 来进行游戏,GPT 要如何经过 UI 步骤准确进入系统层级?
|
||||
|
||||
由此,除了数据本身的结构化(指高度可读),数据库的结构化(指关联构建)也是为知觉系统服务的一个重要课题。
|
||||
|
||||
知觉系统及开发数据环境的构建
|
||||
|
||||
该议题显然还只是一个开放性的讨论,知觉系统的设计并不仅仅包括设计智能体依赖什么接口进行知觉,更要求知觉系统与环境的匹配,以及工作目的与环境的匹配。
|
||||
|
||||
仅就这方面而言,作为一个方向性的倡议,对知觉系统的开发可能分为以下步骤
|
||||
|
||||
### <em>数据处理/管理</em>
|
||||
|
||||
- 对 办公文件/数据 构建通用读取接口
|
||||
- 以同类信息为单位,设计通用的字段(由人设计和管理,AI 能力尚不至此)
|
||||
|
||||
- 以程序 API 接口为例:可能包含以下字段
|
||||
|
||||
- API 接口名
|
||||
- API 调用参数
|
||||
- 所属命名空间
|
||||
- 所属父类
|
||||
- API 接口描述
|
||||
- API 接口描述向量(可能用于语义索引)
|
||||
- 源文件索引(用于监听和更新)
|
||||
- 源信息(源文本 or)
|
||||
- etc...
|
||||
- 围绕既定的通用字段,以对象为单位,依靠 GPT 的文本能力自底向上进行总结和编码
|
||||
|
||||
- 我们尝试给定规范让 GPT 自动阅读代码段并总结接口,转化为 bson 文件
|
||||
- 构建对象索引数据库
|
||||
|
||||
- 如储存进 mongoDB
|
||||
- (设计孪生数据的自动更新机制)
|
||||
|
||||
### <em>知觉系统驱动</em>
|
||||
|
||||
- 基于上述索引数据库,以视图为单位进行访问,并设计 视图 2 Prompt 的转化格式
|
||||
|
||||
- 依旧以 API 接口为例,我们将 AutoGPT 的 Command 信息表现为以数据库形式储存
|
||||
|
||||
对于如上数据库信息,我们对于以视图为单位进行整理,将其转化为 prompt 输入
|
||||
|
||||
'Commands:\n'
|
||||
'1. Google Search: "google", args: "input": `"<search>"`\n'
|
||||
'2. Browse Website: "browse_website", args: "url": `"<url>"`, "question": `"<what_you_want_to_find_on_website>"`\n'
|
||||
'3. Start GPT Agent: "start_agent", args: "name": `"<name>"`, "task": `"<short_task_desc>"`, "prompt": `"<prompt>"`\n'
|
||||
'4. Message GPT Agent: "message_agent", args: "key": `"<key>"`, "message": `"<message>"`\n'
|
||||
'5. List GPT Agents: "list_agents", args: \n'
|
||||
|
||||
- 对于对数据库进行感知的任务,我们需要进一步设计 Pormpt 驱动 Agent 的行为
|
||||
|
||||
- 对于 Agent 开启的指定任务线程(区分于主线程的感知模块),其起始 Prompt 可能呈这样的形式
|
||||
|
||||
> <br/>如上是你的目标,为了实现这个目标,你可能需要获取一系列的信息,为了帮助你获得信息,我会为你提供一系列的索引访问接口,请你通过如下格式输出语句让我为你返回信息。<br/>注:如果你请求错误,请你阅读返回的报错信息以自我纠正<br/>例:<br/>< 通过接口名称检索("接口名称")><br/>< 通过接口功能检索("访问网页")><br/>< 通过父级名称检索("父级名称")>
|
||||
|
||||
- 为 GPT 设计自动化指令解析与执行模块
|
||||
|
||||
- 如对上述数据访问接口,仍需匹配一套自动解析访问指令并进行数据库检索,返回指定视图格式转换后的 Prompt(当然也可以是对应视图的 bson 转 json 文件,不使用源数据以过滤系统信息)
|
||||
|
||||
可以预见的,基于上述知觉框架,我们能让 Agent 一定程度上在语境中自动化实现基于任务的信息收集。
|
||||
|
||||
非工程化的试验样例
|
||||
|
||||
(使用了我先前写过的卡牌游戏,基于指定任务让其主动收集信息并编写新的技能脚本)
|
||||
|
||||
> TBD:号被 OpenAI 噶了,我也很绝望啊
|
||||
|
||||
## 工作记忆:组织 AI 记忆系统
|
||||
|
||||
记忆系统的构成其实相较知觉系统等更为抽象,它用于管理 AI 运行时作为背景的长期记忆,以及定义决定了 AI 当前任务及目标的短期记忆。
|
||||
|
||||
从某种意义上来说,其极度依赖工程实践中的迭代,因此我现在空手无凭,相比也说不出什么好东西。
|
||||
|
||||
但我们依旧能从前人的工作中获得一定的参考。
|
||||
|
||||
### AutoGPT 的记忆设计:粗放但有效
|
||||
|
||||
在 长时记忆(过去)、评估系统(价值)、注意系统(关注) 这三个要素中,AutoGPT 做得比较好的无疑只有第一个。
|
||||
|
||||
AutoGPT 的核心记忆设计依赖于预包装的 Prompt 本体,这一包装包含如下部分:
|
||||
|
||||
- Content:用于定义 AI 当前的状态
|
||||
- Goals:用于储存用户定义的 AI 任务
|
||||
- Constraints:用于告诉 AI 约束和部分行为指引
|
||||
|
||||
- 让 AI 通过“thought”调用长期记忆就是在这里约束好的
|
||||
- 同时鼓励 AI 把当前的输入尽快存入长期记忆数据库
|
||||
- Commands:用于告诉 AI 其可执行的行为
|
||||
- Resources:告诉 AI 它主要能做什么(没啥用)
|
||||
- Performance Evaluation:用于提醒 AI 自我反思
|
||||
- Response Format:用于确保 AI 输出可解析
|
||||
|
||||
而在这个预定义本体信息之上,进一步拼贴了如下要素
|
||||
|
||||
- 当前时间戳
|
||||
- 过去几步行为记录
|
||||
- 依据“thought”从长期记忆数据库中抽取的记忆片段
|
||||
- 用于驱动执行下一步的 Prompt
|
||||
|
||||
如上形式,AutoGPT 的记忆设计相对粗放,其依赖于 GPT 对数据库的写入,并将索引记忆的工作完全交予了基于关联的向量数据库索引。
|
||||
|
||||
也正是因为这个,在实际使用中,不乏能遇到 AutoGPT 在运行中发生记忆紊乱,开始重复进行了既往的劳动、或钻牛角尖做些无用功的情景。
|
||||
|
||||
但从另一角度,其“自主将收集到的信息写入记忆”这一功能作为一个 以完成任务为目标 的 Agent 而言无疑是非常合适的架构设计。
|
||||
|
||||
### Generative Agents 的记忆设计:精心构建的金字塔
|
||||
|
||||
区别于 AutoGPT 主动写入的记忆,Generative Agents 的记忆源自被动的无限感知和记录,因此显得更加没有目的性。也正因如此,其需要一种更妥善的管理形式。
|
||||
|
||||
Generative Agent 通过自动化评估记忆的价值,并构建遗忘系统、关注系统等用于精准从自己繁杂的记忆中检索对于当前情景有用的信息。
|
||||
|
||||

|
||||
|
||||
Generative Agents :基于 Reflection 构建记忆金字塔
|
||||
|
||||
进一步的,其通过反思机制强化了记忆的价值,使得高层洞察从既有记忆的连结中涌现,这一机制通常被用于将 信息转化为知识,并构建出了有效记忆的金字塔。
|
||||
|
||||
而毫无疑问,相关的洞见对于“完成任务”而言也是极具价值的。
|
||||
|
||||
相关的更有效的记忆管理无疑很快就会被更新的项目学习。
|
||||
|
||||
### 记忆系统的构建讨论(放飞大脑)
|
||||
|
||||
但从某种意义上来说,对于一个我们希望其帮助我们工作的智能体而言,像 Generative Agent 这般的巨大数据库也许并未有充分的价值,何况我们所输入的内容原始层级就较高(这一层可能在前面的知觉系统中,就让一定程度上的高层洞见自主产生了),不易于进一步的堆叠。
|
||||
|
||||
也许,我们更该关注的是 Agent 对自身短期记忆的管理,即让 Agent 锚定自身的状态,并自主抽象出凝练的短期记忆和关注方向。
|
||||
|
||||
在 AutoGPT 的框架下,我们能构建一个专用的短期记忆文本文件,供 GPT 自身编辑,对于每次会话开始时,该文本文件都会自动嵌入 Prompt 中,从而永续保存在 GPT 的上下文窗口内。
|
||||
|
||||
该短期记忆主要用于记录当前目标执行进度,以及 GPT 对目标的实际分解形式。
|
||||
|
||||
相应的,GPT 的行为记录也能被下放至长期记忆中,构成行为与储存资料的数据对,使得记忆管理更加规范。易于在记忆向量检索时取得期望的效果。
|
||||
|
||||
(我本该写得更靠谱一点,但我写到这里已经快累死了,让我开摆罢)
|
||||
|
||||
不过显然,这部分设计需要在工程中得到迭代
|
||||
|
||||
(可以遇见的,以 AutoGPT 的热度,半个月内就会有人为其设计相应的 mod)
|
||||
|
||||
## 运动系统:让 AI 可及一切
|
||||
|
||||
基于知觉系统和记忆系统,已经能构建一个使用语言解决问题的智能体了。但最为关键的改造世界部分则依旧缺席。
|
||||
|
||||
虽然这么说也不准确,其实运动系统的部分在知觉系统的讨论中就以提及了:对外界的主动交互并感知,就是一种“运动”。
|
||||
|
||||
我们最终总会不满足于让 AI 帮助我们思考问题,我们想让 AI 帮我们走完最后一步。由此,我们需要让 AI 能与世界进一步地互动。
|
||||
|
||||
- 我们大胆假设未来游戏中的 Agent 能通过 API 驱动自身在场景中无拘无束(拼装行为树
|
||||
- 再大胆假设他们能使用 API 实时把需求的内容转化为发布给玩家的任务(拼装任务节点
|
||||
- 继续大胆假设, AI 根据我的需求把今天要配的啥比表直接配完,当场下班(笑
|
||||
|
||||
(而这一切,都是可能,且近在眼前的)
|
||||
|
||||
而这最终又回到了原始的问题 —— 我们能给 AI 什么
|
||||
|
||||
AI 能做的一切都基于我们的赋予,包括语言能力,包括思维能力,包括对话能力,更包括前面那些知觉和记忆的能力。运动也无外乎如是,其落实到了两个问题上:
|
||||
|
||||
- 如何为 AI 构造充分实用的工具(高度开放的 API 设计
|
||||
- 如何让 AI 找到足够趁手的工具(易于检索的 API 平台
|
||||
- 如果让 AI 能够正确地使用工具(高鲁棒的 API 执行器
|
||||
|
||||
而这其中,进一步要求让 API 可读和可索引,由此回到我们在知觉系统中的课题,也不必过多赘述了。
|
||||
|
||||
在结尾处重新梳理一下本文核心讨论的观点
|
||||
|
||||
- 大语言模型的实质是一个拥有智能能力的语言计算器
|
||||
- 我们不该将其当作独立的智能体看待,但能在其基础上通过构建系统创建智能 Agent
|
||||
- 为此,我们需要通过信息工程,让 AI 能够真正感知和改造世界,从而改变我们的生产进程
|
||||
|
||||
# 寄予厚望
|
||||
|
||||
感谢有人忍受了我阴间的行文和一路跑偏的思路,真能看到这里
|
||||
|
||||
红豆泥私密马赛西塔!!!
|
||||
|
||||
从某种意义上,本文实际上并没有讨论什么实质性的东西,但作为一个近期思路变化的总结,和对 AI 未来发展的展望,乃至对未来生产力发展的展望。我希望它有一定的参考价值。
|
||||
|
||||
可以预见的,AI 对于生产的作用显然并不止于我们上面所讨论的这些,我们不仅希望人要为 AI“赋能”,更希望 AI 能进一步地为人赋能:
|
||||
|
||||
- 通过 AI、以及对信息的管理,我们能极大程度上降低复杂团队内部的沟通成本和信息获取成本
|
||||
- 通过更智能的 AI,能更好地辅助内容创作,让创作者把有限的生产力放在抓住更亮眼的 Sparks 上
|
||||
- 通过基于 AI 的高度自动化流程,也许我们真的能看到每个人都能将自己的空想所具现化的未来
|
||||
|
||||
为 AI 开放一切,为 AI 提供信息,这两个“为”才是走向 AIGC 的唯一明路。是让 AI 真正走入生产,解放生产力的唯一正路。
|
||||
|
||||
- 作为 AI 研究者,我愿意拭目以待
|
||||
- 作为游戏开发者,我希望积极地将其运用到我的生产过程中
|
||||
- 作为团队成员,我期盼生产革命能从我的身边掀起
|
||||
- 作为马克思主义者,我必将推动着它解放世人们的生产力
|
||||
@@ -1,63 +0,0 @@
|
||||
# 本章节内容的局限性
|
||||
|
||||
作为一个本科生和部分研究生为主书写的教程,必须承认的是,我们在本章节内容,存在非常多的局限性,而本节内容,就是对目前存在的局限性和为什么还没有立马改进做的一定解释。
|
||||
|
||||
## 缺少一些前沿的内容
|
||||
|
||||
让我们时时刻刻都跟进最前沿的内容并且进行输出是相当困难的,当然我们也欢迎各位得贡献
|
||||
|
||||
## 少有机器学习的一些算法
|
||||
|
||||
机器学习领域有非常庞大的知识体系和一代人十几年的积累。
|
||||
|
||||
无数伟大的科学家究其一生的研究和探索它,但是你发现本章内容少有相关内容,还是以深度学习为主?为什么?
|
||||
|
||||
## 原因一:时代的浪潮
|
||||
|
||||
近乎全民深度学习的浪潮下,机器学习的知识被科研界一而再再而三的抛掷脑后,大家争先恐后的刷点,并使用深度学习的解决问题,因此深度学习领域的知识材料得到了井喷式的增长,而少有人愿意投入非常长的时间去研究机器学习的每一条数学公式的背后机理。
|
||||
|
||||
也正因如此,诸位花费自己的大学四年时光去钻研几条算法兴许是有意义的,但是对你拓展视野增长知识面的帮助没那么大,也没有办法帮助你引导到一些实操项目的工作中去,因此除了真正热爱的那一批人以外,过多的投入时间去学机器学习知识可能会让你感觉患得患失最后半途而废。
|
||||
|
||||
## 原因二:算法的性质
|
||||
|
||||
算法的性质就是严谨,一丝不苟的推导。因此,他涉及了大量的数学方程以及严谨的一步一步的推导过程。在学习的过程中,没有捷径,也没有更快的方法,你只能踏踏实实一步一步的进行积累。
|
||||
|
||||
而本教程的性质更偏向于导学,当你决心在机器学习算法深耕的时候,你已经脱离了需要导学的范畴更偏向于领域内容钻研,这是一项伟大的但是在当今时代略有吃力不讨好的工作,我真心祝愿你能乐在其中~感受到学习的快乐。
|
||||
|
||||
## 原因三:缺乏应用空间
|
||||
|
||||
ZZM 曾经尝试过投入大量时间去钻研数学以及机器学习相关的算法,但是发现了一个很残酷的现实就是,我们欠缺的积累和知识不是靠猛然突击可以弥补的,自己学都很吃力了,写出来不是误人子弟么 hhhh。
|
||||
|
||||
同时,尽管知识的内容让人很快乐,但是如果你不经常使用,或者实打实的拿一张白纸从头到尾推演一遍的话,你忘记的速度是非常快的,因此我们写下他,你们看一遍甚至说认真的阅览一遍,也不会留下太多内容。
|
||||
|
||||
## 如果真的感兴趣这方面内容呢
|
||||
|
||||
如果你阅览了本章节的数学相关知识和内容以及拓展感觉非常感兴趣并且毫无压力的话,我推荐你尝试去啃一啃大家公认的困难的书籍,比如说著名的花书,互联网上,社区内也有大量的辅助材料来帮助你更进一步的入门
|
||||
|
||||
# 科研导向明显
|
||||
|
||||
整篇教程大范围的在教怎么从科研角度去理解一些知识,感觉和工业上的逻有不符之处。
|
||||
|
||||
确实如此,工业界的逻辑和科研界的逻辑是截然不同的。
|
||||
|
||||
工业界的逻辑更偏向于低成本,高产出。而科研更偏向于你在一个好故事的背景下做了如何优雅的提升。
|
||||
|
||||
粗鲁地说就是工业更注重你这个项目,如果现在有一百万人用,能不能把百分之九十正确率的这个东西用好,科研更偏向于九十五到九十九。
|
||||
|
||||
我们自身并没有接触过太多的工业项目,也无法深入大厂去揭示他的算法,自然就算写东西写出来也不具备任何说服力。
|
||||
|
||||
因此如果你对这方面感兴趣,可能你需要别的途径去获取更多的思考和资源了。
|
||||
|
||||
# 繁杂的知识内容
|
||||
|
||||
这点非常抱歉,AI 领域的知识本身就是网状的,复杂的,甚至是互相引用的,这点会导致不可避免的内容变得冗长。
|
||||
|
||||
可能需要你花费大量的时间建立自己的知识框架和逻辑体系
|
||||
|
||||
而不是别人强行灌输给你的
|
||||
|
||||
# 还有更多???
|
||||
|
||||
联系 ZZM,我努力改
|
||||
|
||||

|
||||
@@ -1,91 +0,0 @@
|
||||
# 对AI大致方向的概述
|
||||
|
||||
|
||||
# 前言
|
||||
|
||||
在这个时代,相关内容是非常泛滥的,我们在本章内容中,大致的写一些目前比较有名的方向以及它的简介(也许会比wiki和百度有趣一点?)
|
||||
|
||||
# 深度学习 的大致方向分类
|
||||
|
||||
本模块会粗略地介绍目前审读学习的研究与应用领域,在这里提前说明:笔者也只是一名普通的杭电学生,视野与认知有限,某些领域我们了解较多就会介绍地更加详细,某些领域了解较少或笔者中无人从事相关研究,就难免会简略介绍甚至有所偏颇,欢迎大家的指正。
|
||||
|
||||
## CV(计算机视觉)
|
||||
|
||||
计算机视觉旨在<strong>用计算机模拟人类处理图片信息的能力</strong>,就比如这里有一张图片——手写数字 9
|
||||
|
||||

|
||||
|
||||
对我们人类而言,能够很轻松地知道这张图片中包含的信息(数字 9),而对计算机来说这只是一堆像素。计算机视觉的任务就是让计算机能够从这堆像素中得到‘数字 9’这个信息。
|
||||
|
||||
相信你通过上面简单的介绍应该能够了解到计算机视觉是在干嘛了,接下来我会举几个相对复杂的例子来让大家了解一下目前的 cv 是在做怎样的研究:
|
||||
|
||||
<strong>图像分割</strong>是在图片中对物体分类,并且把它们所对应的位置标示出来。下图就是把人的五官,面部皮肤和头发分割出来,效(小)果(丑)图如下:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
<strong>图像生成</strong>相信大家一定不陌生,NovalAI 在 2022 年火的一塌糊涂,我觉得不需要我过多赘述,对它(Diffusion model)的改进工作也是层出不穷,这里就放一张由可控姿势网络(ControlNet)生成的图片吧:
|
||||
|
||||

|
||||
|
||||
<strong>三维重建</strong>也是很多研究者关注的方向,指的是传入对同一物体不同视角的照片,来生成 3D 建模的任务。这方面比图像处理更加前沿并且难度更大。具体见[4.6.5.4神经辐射场(NeRF)](4.6.5.4%E7%A5%9E%E7%BB%8F%E8%BE%90%E5%B0%84%E5%9C%BA(NeRF).md) 章节。
|
||||
|
||||
如果对计算机视觉有兴趣,可以通过以下路线进行学习:深度学习快速入门—> 经典网络。本块内容的主要撰写者之一<strong>SRT 社团</strong>多数成员主要从事 CV 方向研究,欢迎与我们交流。
|
||||
|
||||
## NLP(自然语言处理)
|
||||
|
||||
这就更好理解了,让计算机能够像人类一样,理解文本中的“真正含义”。在计算机眼中,文本就是单纯的字符串,NLP 的工作就是把字符转换为计算机可理解的数据。举个例子,ChatGPT(或者 New Bing)都是 NLP 的成果。在过去,NLP 领域被细分为了多个小任务,比如文本情感分析、关键段落提取等。而 ChatGPT 的出现可以说是集几乎所有小任务于大成,接下来 NLP 方向的工作会向 ChatGPT 的方向靠近。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## 多模态(跨越模态的处理)
|
||||
|
||||
模态,可以简单理解为数据形式,比如图片是一种模态,文本是一种模态,声音是一种模态,等等……
|
||||
|
||||
而多模态就是让计算机能够将不同模态的信息相对应,一种常用的方法就是让计算机把图片的内容和文本的内容理解为相同的语义(在这个领域一般用一个较长的向量来表示语义)。
|
||||
|
||||
也就是说我<strong>传入一张狗子的照片经过模型得到的向量</strong>与<strong>DOG 这个单词经过模型得到的向量</strong>相近。
|
||||
|
||||
具体的任务比如说<strong>图片问答</strong>,传入一张图片,问 AI 这张图片里面有几只猫猫,它们是什么颜色,它告诉我有一只猫猫,是橙色的:
|
||||
|
||||

|
||||
|
||||
## 对比学习
|
||||
|
||||
因为传统 AI 训练一般都需要数据集标注,比如说图片分割数据集需要人工在数万张图片上抠出具体位置,才能进行训练,这样的人力成本是巨大的,而且难以得到更多数据。因此,对比学习应运而生,这是一种不需要进行标注或者只需要少量标注的训练方式,具体可见[4.6.8对比学习](4.6.8%E5%AF%B9%E6%AF%94%E5%AD%A6%E4%B9%A0.md) 。
|
||||
|
||||
## 强化学习
|
||||
|
||||
强调模型如何依据环境(比如扫地机器人在学习家里的陈设,这时陈设就是环境)的变化而改进,以取得最大的收益(比如游戏得到最高分)。
|
||||
|
||||
强化学习是除了监督学习和非监督学习之外的第三种基本的机器学习方法。与监督学习不同的是,强化学习不需要带标签的输入输出对,同时也无需对非最优解的精确地纠正。其关注点在于寻找探索(对未知领域的)和利用(对已有知识的)的平衡。 -------wiki
|
||||
|
||||
强化学习主要理论来源于心理学中的动物学习和最优控制的控制理论。说的通俗点,强化学习就是操控智能体与环境交互、去不断试错,在这个过程中进行学习。因此,强化学习被普遍地应用于游戏、资源优化分配、机器人等领域。强化学习本身已经是个老东西了,但是和深度学习结合之后焕发出了第二春——深度强化学习(DRL)。
|
||||
|
||||
深度强化学习最初来源是2013年谷歌DeepMind团队发表的《Playing Atari with Deep Reinforcement Learning》一文,正式提出Deep Q-network(DQN)算法。在这篇论文中,DeepMind团队训练智能体Agent玩雅达利游戏,并取得了惊人的成绩。事实上,深度强化学习最为人熟知的成就是AlphaGO Zero,它没有使用任何人类棋谱进行训练,训练了三天的成就就已经超过了人类几千年的经验积累<del>导致柯洁道心破碎</del>。
|
||||
|
||||
# 交叉学科&经典机器学习算法
|
||||
|
||||
交叉学科巨大的难度在于你往往需要掌握多个学科以及其相对应的知识。
|
||||
|
||||
举个例子:如果你想要做出一个可以识别病人是否得了某种疾病,现在你得到了一批数据,你首先得自己可以标注出或者找到这个数据中,哪些是有问题的,并且可以指明问题在哪,如果你想分出更具体的,比如具体哪里有问题,那你可能甚至需要熟悉他并且把他标注出来。
|
||||
|
||||
目前其实全学科都有向着AI走的趋势,例如量化金融,医疗,生物科学(nature的那篇有关氨基酸的重大发现真的很cool)。他们很多都在用非常传统的机器学习算法,甚至有的大公司的算法岗在处理某些数据的时候,可能会先考虑用最简单的决策树试一试
|
||||
|
||||
当然,在大语言模型出现的趋势下,很多学科的应用会被融合会被简化会被大一统(科研人的崇高理想),但是不得不提的是,传统的机器学习算法和模型仍然希望你能去了解甚至更进一步学习。
|
||||
|
||||
除了能让你了解所谓前人的智慧,还可以给你带来更进一步的在数学思维,算法思维上的提高。
|
||||
|
||||
# And more?
|
||||
|
||||
我们对AI的定义如果仅仅只有这些内容,我认为还是太过于狭隘了,我们可以把知识规划,知识表征等等东西都可以将他划入AI的定义中去,当然这些还期待着你的进一步探索和思考~
|
||||
|
||||
|
||||
# 特别致谢
|
||||
|
||||
非常荣幸能在本章中得到 IIPL智能信息处理实验室 http://iipl.net.cn 的宝贵贡献,衷心感谢他们的无私支持与帮助!
|
||||
@@ -1,454 +0,0 @@
|
||||
# 机器学习(AI)快速入门(quick start)
|
||||
|
||||
本章内容需要你掌握一定的 python 基础知识。
|
||||
|
||||
如果你想要快速了解机器学习,并且动手尝试去实践他,你可以先阅览本部分内容。
|
||||
|
||||
里面包含 python 内容的一点点基本语法包括 if,for 等语句,函数等概念即可,你可以遇到了再去学。
|
||||
|
||||
就算没有编程基础也基本能看懂,选择着跳过吧
|
||||
|
||||
当然我需要承认一点,为了让大家都可以看懂,我做了很多抽象,具有了很多例子,某些内容不太准确,这是必然的,最为准确的往往是课本上精确到少一个字都不行的概念,这是难以理解的。
|
||||
|
||||
本篇内容只适合新手理解使用,所以不免会损失一些精度。
|
||||
|
||||
# 什么是机器学习
|
||||
|
||||
这个概念其实不需要那么多杂七杂八的概念去解释。
|
||||
|
||||
首先你要认识到他是人工智能的一部分,不需要写任何与问题有关的特定代码。你把数据输入相关的算法里面,他给你总结相应的规律。
|
||||
|
||||
我举个例子,你现在把他当成一个黑盒,不需要知道里面有什么,但是你知道他会回答你的问题。你想知道房价会怎么变动来决定现在买不买房。然后你给了他十年的房价数据,他发现每年都在涨,所以给你预测了一个数值。
|
||||
|
||||
然后你给了他更多信息,比如说国家给出了某些条例,他分析这个条例一出,房价就会降低,他给你了个新的数据。
|
||||
|
||||
因此我们得出一个结论:机器学习 = 泛型算法。
|
||||
|
||||
甚至深度学习,也只是机器学习的一部分,不过使用了更多技巧和方法,增大了计算能力罢了。
|
||||
|
||||

|
||||
|
||||
# 两种机器学习算法
|
||||
|
||||
你可以把机器学习算法分为两大类:监督式学习(supervised Learning)和非监督式学习(unsupervised Learning)。要区分两者很简单,但也非常重要。
|
||||
|
||||
## 监督式学习
|
||||
|
||||
你是卖方的,你公司很大,因此你雇了一批新员工来帮忙。
|
||||
|
||||
但是问题来了——虽然你可以一眼估算出房子的价格,但新员工却不像你这样经验丰富,他们不知道如何给房子估价。
|
||||
|
||||
为了帮助你的新员工,你决定写一个可以根据房屋大小、地段以及同类房屋成交价等因素来评估一间房屋的价格的小软件。
|
||||
|
||||
近三个月来,每当你的城市里有人卖了房子,你都记录了下面的细节——卧室数量、房屋大小、地段等等。但最重要的是,你写下了最终的成交价:
|
||||
|
||||

|
||||
|
||||
然后你让新人根据着你的成交价来估计新的数量
|
||||
|
||||

|
||||
|
||||
这就是监督学习,你有一个参照物可以帮你决策。
|
||||
|
||||
## 无监督学习
|
||||
|
||||
没有答案怎么办?
|
||||
|
||||
你可以把类似的分出来啊!
|
||||
|
||||
我举个例子,比如说警察叔叔要查晚上的现金流,看看有没有谁干了不好的事情,于是把数据拎出来。
|
||||
|
||||
发现晚上十点到十二点间,多数的现金交易是几十块几百块。有十几个是交易几千块的。
|
||||
|
||||
然后再把交易给私人账户的和公司账户的分开,发现只有一个是给个人账户的,发现他还是在酒店交易的!
|
||||
|
||||
这下糟糕了,警察叔叔去那个酒店一查,果然发现了有人在干不好的事情。
|
||||
|
||||
这其实就是一种经典的聚类算法
|
||||
|
||||

|
||||
|
||||
可以把特征不一样的数据分开,有非常多的操作,你感兴趣可以选择性的去了解一下。
|
||||
|
||||
## 太酷炫了,但这也叫 AI?这也叫学习?
|
||||
|
||||
作为人类的一员,你的大脑可以应付绝大多数情况,并且在没有任何明确指令时也能够学习如何处理这些情况。而目前的机器学习就是在帮助我们机器建立起解决问题的能力。
|
||||
|
||||
但是目前的机器学习算法还没有那么强大——它们只能在非常特定的、有限的问题上有效。也许在这种情况下,「学习」更贴切的定义是「在少量样本数据的基础上找出一个公式来解决特定的问题」。
|
||||
|
||||
但是「机器在少量样本数据的基础上找出一个公式来解决特定的问题」不是个好名字。所以最后我们用「机器学习」取而代之。而深度学习,则是机器在数据的基础上通过很深的网络(很多的公式)找一个及解决方案来解决问题。
|
||||
|
||||
# 看看 Code
|
||||
|
||||
如果你完全不懂机器学习知识,你可能会用一堆 if else 条件判断语句来判断比如说房价
|
||||
|
||||
```python
|
||||
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
|
||||
price = 0 # In my area, the average house costs $200 per sqft
|
||||
price_per_sqft = 200
|
||||
if neighborhood == "hipsterton":
|
||||
# but some areas cost a bit more
|
||||
price_per_sqft = 400
|
||||
elif neighborhood == "skid row":
|
||||
# and some areas cost less
|
||||
price_per_sqft = 100 # start with a base price estimate based on how big the place is
|
||||
price = price_per_sqft * sqft # now adjust our estimate based on the number of bedrooms
|
||||
if num_of_bedrooms == 0:
|
||||
# Studio apartments are cheap
|
||||
price = price - 20000
|
||||
else:
|
||||
# places with more bedrooms are usually
|
||||
# more valuable
|
||||
price = price + (num_of_bedrooms * 1000)
|
||||
return price
|
||||
```
|
||||
|
||||
假如你像这样瞎忙几个小时,最后也许会得到一些像模像样的东西。但是永远感觉差点东西。
|
||||
|
||||
并且,你维护起来非常吃力,你只能不断地加 if else。
|
||||
|
||||
现在看起来还好,但是如果有一万行 if else 呢?
|
||||
|
||||
所以你最好考虑换一种方法:如果能让计算机找出实现上述函数功能的办法,岂不更好?只要返回的房价数字正确,谁会在乎函数具体干了些什么呢?
|
||||
|
||||
```python
|
||||
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
|
||||
price = <电脑电脑快显灵>
|
||||
return price
|
||||
```
|
||||
|
||||
如果你可以找到这么一个公式:
|
||||
|
||||
Y(房价)=W(参数)*X1(卧室数量)+W*X2(面积)+W*X3(地段)
|
||||
|
||||
你是不是会舒服很多,可以把他想象成,你要做菜,然后那些参数就是佐料的配比
|
||||
|
||||
有一种笨办法去求每一个参数的值:
|
||||
|
||||
第一步:将所有参数都设置为 1
|
||||
|
||||
```python
|
||||
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
|
||||
price = 0 # a little pinch of this
|
||||
price += num_of_bedrooms *1.0 # and a big pinch of that
|
||||
price += sqft * 1.0 # maybe a handful of this
|
||||
price += neighborhood * 1.0 # and finally, just a little extra salt for good measure
|
||||
price += 1.0
|
||||
return price
|
||||
```
|
||||
|
||||
第二步把每个数值都带入进行运算。
|
||||
|
||||

|
||||
|
||||
比如说,如果第一套房产实际成交价为 25 万美元,你的函数估价为 17.8 万美元,这一套房产你就差了 7.2 万。
|
||||
|
||||
现在,将你的数据集中的每套房产估价偏离值平方后求和。假设你的数据集中交易了 500 套房产,估价偏离值平方求和总计为 86,123,373 美元。这个数字就是你的函数现在的「错误」程度。
|
||||
|
||||
现在,将总和除以 500,得到每套房产的估价偏差的平均值。将这个平均误差值称为你函数的代价(cost)。
|
||||
|
||||
如果你能通过调整权重,使得这个代价变为 0,你的函数就完美了。它意味着,根据输入的数据,你的程序对每一笔房产交易的估价都是分毫不差。所以这就是我们的目标——通过尝试不同的权重值,使代价尽可能的低。
|
||||
|
||||
第三步:
|
||||
|
||||
通过尝试所有可能的权重值组合,不断重复第二步。哪一个权重组合的代价最接近于 0,你就使用哪个。当你找到了合适的权重值,你就解决了问题!
|
||||
|
||||
兴奋的时刻到了!
|
||||
|
||||
挺简单的,对吧?想一想刚才你做了些什么。你拿到了一些数据,将它们输入至三个泛型的、简单的步骤中,最后你得到了一个可以对你所在区域任何房屋进行估价的函数。房价网站们,你们要小心了!
|
||||
|
||||
但是下面的一些事实可能会让你更兴奋:
|
||||
|
||||
1. 过去 40 年来,很多领域(如语言学、翻译学)的研究表明,这种「搅拌数字汤」(我编的词)的泛型学习算法已经超过了那些真人尝试明确规则的方法。机器学习的「笨」办法终于打败了人类专家。
|
||||
2. 你最后写出的程序是很笨的,它甚至不知道什么是「面积」和「卧室数量」。它知道的只是搅拌,改变数字来得到正确的答案。
|
||||
3. 你可能会对「为何一组特殊的权重值会有效」一无所知。你只是写出了一个你实际上并不理解却能证明有效的函数。
|
||||
4. 试想,如果你的预测函数输入的参数不是「面积」和「卧室数量」,而是一列数字,每个数字代表了你车顶安装的摄像头捕捉的画面中的一个像素。然后,假设预测的输出不是「价格」而是「方向盘转动角度」,这样你就得到了一个程序可以自动操纵你的汽车了!
|
||||
|
||||
这可行吗?瞎尝试这不得尝试到海枯石烂?
|
||||
|
||||
为了避免这种情况,数学家们找到了很多种[聪明的办法](https://link.zhihu.com/?target=http%3A//en.wikipedia.org/wiki/Gradient_descent)来快速找到优秀的权重值。下面是一种:
|
||||
|
||||

|
||||
|
||||
这就是被称为 loss 函数的东西。
|
||||
|
||||
这是个专业属于,你可以选择性忽略他,我们将它改写一下
|
||||
|
||||

|
||||
|
||||
<em>θ 表示当前的权重值。 J(θ) 表示「当前权重的代价」。</em>
|
||||
|
||||
这个等式表示,在当前权重值下,我们估价程序的偏离程度。
|
||||
|
||||
如果我们为这个等式中所有卧室数和面积的可能权重值作图的话,我们会得到类似下图的图表:
|
||||
|
||||

|
||||
|
||||
因此,我们需要做的只是调整我们的权重,使得我们在图上朝着最低点「走下坡路」。如果我们不断微调权重,一直向最低点移动,那么我们最终不用尝试太多权重就可以到达那里。
|
||||
|
||||
如果你还记得一点微积分的话,你也许记得如果你对一个函数求导,它会告诉你函数任意一点切线的斜率。换句话说,对于图上任意给定的一点,求导能告诉我们哪条是下坡路。我们可以利用这个知识不断走向最低点。
|
||||
|
||||
所以,如果我们对代价函数关于每一个权重求偏导,那么我们就可以从每一个权重中减去该值。这样可以让我们更加接近山底。一直这样做,最终我们将到达底部,得到权重的最优值。(读不懂?不用担心,继续往下读)。
|
||||
|
||||
这种为函数找出最佳权重的方法叫做批量梯度下降(Batch Gradient Descent)。
|
||||
|
||||
当你使用一个机器学习算法库来解决实际问题时,这些都已经为你准备好了。但清楚背后的原理依然是有用的。
|
||||
|
||||

|
||||
|
||||
枚举法
|
||||
|
||||
上面我描述的三步算法被称为多元线性回归(multivariate linear regression)。你在估算一个能够拟合所有房价数据点的直线表达式。然后,你再根据房子可能在你的直线上出现的位置,利用这个等式来估算你从未见过的房屋的价格。这是一个十分强大的想法,你可以用它来解决「实际」问题。
|
||||
|
||||
但是,尽管我展示给你的这种方法可能在简单的情况下有效,它却不能应用于所有情况。原因之一,就是因为房价不会是简简单单一条连续的直线。
|
||||
|
||||
不过幸运的是,有很多办法来处理这种情况。有许多机器学习算法可以处理非线性数据。除此之外,灵活使用线性回归也能拟合更复杂的线条。在所有的情况下,寻找最优权重这一基本思路依然适用。
|
||||
|
||||
<strong>如果你还是无法理解,你可以将 cost 类比为你出错误的程度,而数学科学家找到各种方法来降低这种程度,当程度降到最低时,我们就可以知道我们要求的数值了</strong>
|
||||
|
||||
另外,我忽略了过拟合(overfitting)的概念。得到一组能完美预测原始数据集中房价的权重组很简单,但用这组权重组来预测原始数据集之外的任何新房屋其实都不怎么准确。这也是有许多解决办法的(如[正则化](https://link.zhihu.com/?target=http%3A//en.wikipedia.org/wiki/Regularization_%2528mathematics%2529%23Regularization_in_statistics_and_machine_learning)以及使用[交叉验证](https://link.zhihu.com/?target=http%3A//en.wikipedia.org/wiki/Cross-validation_%2528statistics%2529)的数据集)。学习如何应对这一问题,是学习如何成功应用机器学习技术的重点之一。
|
||||
|
||||
换言之,尽管基本概念非常简单,要通过机器学习得到有用的结果还是需要一些技巧和经验的。但是,这是每个开发者都能学会的技巧。
|
||||
|
||||
# 更为智能的预测
|
||||
|
||||
我们通过上一次的函数假设已经得到了一些值。
|
||||
|
||||
```python
|
||||
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
|
||||
price = 0# a little pinch of this
|
||||
price += num_of_bedrooms * 0.123# and a big pinch of that
|
||||
price += sqft * 0.41# maybe a handful of this
|
||||
price += neighborhood * 0.57
|
||||
return price
|
||||
```
|
||||
|
||||
我们换一个好看的形式给他展示
|
||||
|
||||

|
||||
|
||||
<em>箭头头表示了函数中的权重。</em>
|
||||
|
||||
然而,这个算法仅仅能用于处理一些简单的问题,就是那些输入和输出有着线性关系的问题。但如果真实价格和决定因素的关系并不是如此简单,那我们该怎么办? 比如说,地段对于大户型和小户型的房屋有很大影响,然而对中等户型的房屋并没有太大影响。那我们该怎么在我们的模型中收集这种复杂的信息呢?
|
||||
|
||||
所以为了更加的智能化,我们可以利用不同的权重来多次运行这个算法,收集各种不同情况下的估价。
|
||||
|
||||

|
||||
|
||||
然后我们把四种整合到一起,就得到一个超级答案
|
||||
|
||||

|
||||
|
||||
这样我们相当于得到了更为准确的答案
|
||||
|
||||
# 神经网络是什么
|
||||
|
||||

|
||||
|
||||
我们把四个超级网络的结合图整体画出来,其实这就是个超级简单的神经网络,虽然我们省略了很多的内容,但是他仍然有了一定的拟合能力
|
||||
|
||||
最重要的是下面的这些内容:
|
||||
|
||||
我们制造了一个权重 × 因素的简单函数,我们把这个函数叫做神经元。
|
||||
|
||||
通过连接许许多多的简单神经元,我们能模拟那些不能被一个神经元所模拟的函数。
|
||||
|
||||
通过对这些神经元的有效拼接,我们可以得到我们想要的结果。
|
||||
|
||||
当我用 pytorch 写对一个函数拟合时
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
x_data =torch.Tensor ([[1.0],[2.0], [3.0]])
|
||||
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
|
||||
|
||||
class LinearModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super(LinearModel,self).__init__()
|
||||
self.linear=torch.nn.Linear(1,1)
|
||||
|
||||
def forward(self,x):
|
||||
y_pred=self.linear(x)
|
||||
return y_pred
|
||||
'''
|
||||
线性模型所必须的前馈传播,即wx+b
|
||||
'''
|
||||
|
||||
model=LinearModel()
|
||||
#对于对象的直接使用
|
||||
criterion=torch.nn.MSELoss()
|
||||
#损失函数的计算
|
||||
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
|
||||
#优化器
|
||||
for epoch in range(100):
|
||||
y_pred=model(x_data)
|
||||
loss=criterion(y_pred,y_data)
|
||||
print(epoch,loss)
|
||||
|
||||
optimizer.zero_grad()
|
||||
loss.backward()
|
||||
#反向传播
|
||||
optimizer.step()
|
||||
#数值更新
|
||||
print('w=',model.linear.weight.item())
|
||||
print('b=',model.linear.bias.item())
|
||||
|
||||
x_test=torch.Tensor([[4.0]])
|
||||
y_test=model(x_test)
|
||||
print('y_pred=',y_test.data)
|
||||
```
|
||||
|
||||
# 由浅入深(不会涉及代码)
|
||||
|
||||
# 为什么不教我写代码?
|
||||
|
||||
因为你可能看这些基础知识感觉很轻松毫无压力,但是倘若附上很多代码,会一瞬间拉高这里的难度,虽然仅仅只是调包。
|
||||
|
||||
但是我还是会在上面贴上一点代码,但不会有很详细的讲解,因为很多都是调包,没什么好说的,如果你完全零基础,忽略这部分内容即可
|
||||
|
||||
我们尝试做一个神奇的工作,那就是用神经网络来识别一下手写数字,听上去非常不可思议,但是我要提前说的一点是,图像也不过是数据的组合,每一张图片有不同程度的像素值,如果我们把每一个像素值都当成神经网络的输入值,然后经过一个黑盒,让他识别出一个他认为可能的数字,然后进行纠正即可。
|
||||
|
||||
机器学习只有在你拥有数据(最好是大量数据)的情况下,才能有效。所以,我们需要有大量的手写「8」来开始我们的尝试。幸运的是,恰好有研究人员建立了 [MNIST 手写数字数据库](https://link.zhihu.com/?target=http%3A//yann.lecun.com/exdb/mnist/),它能助我们一臂之力。MNIST 提供了 60,000 张手写数字的图片,每张图片分辨率为 18×18。即有这么多的数据。
|
||||
|
||||
```python
|
||||
(X_train, y_train), (X_test, y_test) = mnist.load_data()
|
||||
#这段是导入minist的方法,但是你看不到,如果你想看到的话需要其他操作
|
||||
```
|
||||
|
||||
我们试着只识别一个数字 8
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
我们把一幅 18×18 像素的图片当成一串含有 324 个数字的数组,就可以把它输入到我们的神经网络里面了:
|
||||
|
||||

|
||||
|
||||
为了更好地操控我们的输入数据,我们把神经网络的输入节点扩大到 324 个:
|
||||
|
||||

|
||||
|
||||
请注意,我们的神经网络现在有了两个输出(而不仅仅是一个房子的价格)。第一个输出会预测图片是「8」的概率,而第二个则输出不是「8」的概率。概括地说,我们就可以依靠多种不同的输出,利用神经网络把要识别的物品进行分组。
|
||||
|
||||
```python
|
||||
model = Sequential([Dense(32, input_shape=(784,)),
|
||||
Activation('relu'),Dense(10),Activation('softmax')])
|
||||
# 你也可以通过 .add() 方法简单地添加层:
|
||||
model = Sequential()
|
||||
model.add(Dense(32, input_dim=784))
|
||||
model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东西可以让他效果更好
|
||||
```
|
||||
|
||||
虽然我们的神经网络要比上次大得多(这次有 324 个输入,上次只有 3 个!),但是现在的计算机一眨眼的功夫就能够对这几百个节点进行运算。当然,你的手机也可以做到。
|
||||
|
||||
现在唯一要做的就是用各种「8」和非「8」的图片来训练我们的神经网络了。当我们喂给神经网络一个「8」的时候,我们会告诉它是「8」的概率是 100% ,而不是「8」的概率是 0%,反之亦然。
|
||||
|
||||
# 仅此而已吗
|
||||
|
||||
当数字并不是正好在图片中央的时候,我们的识别器就完全不工作了。一点点的位移我们的识别器就掀桌子不干了
|
||||
|
||||

|
||||
|
||||
这是因为我们的网络只学习到了正中央的「8」。它并不知道那些偏离中心的「8」长什么样子。它仅仅知道中间是「8」的图片规律。
|
||||
|
||||
在真实世界中,这种识别器好像并没什么卵用。真实世界的问题永远不会如此轻松简单。所以,我们需要知道,当「8」不在图片正中时,怎么才能让我们的神经网络识别它。
|
||||
|
||||
## 暴力方法:更多的数据和更深的网络
|
||||
|
||||
他不能识别靠左靠右的数据?我们都给他!给他任何位置的图片!
|
||||
|
||||
或者说,我们可以用一些库把图片进行一定的裁剪,翻转,甚至添加一些随机噪声。
|
||||
|
||||
如果这些都识别一遍,那不是都懂了吗?
|
||||
|
||||
当然,你同时也需要更强的拟合能力和更深的网络。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
一层一层堆叠起来,这种方法很早就出现了。
|
||||
|
||||
## 更好的方法?
|
||||
|
||||
你可以通过卷积神经网络进行进一步的处理
|
||||
|
||||
作为人类,你能够直观地感知到图片中存在某种层级(hierarchy)或者是概念结构(conceptual structure)。比如说,你在看
|
||||
|
||||

|
||||
|
||||
你会快速的辨认出一匹马,一个人。
|
||||
|
||||
当这些东西换个地方出现的时候,他该是马还是马该是人还是人。
|
||||
|
||||
但是现在,我们的神经网络做不到这些。它认为「8」出现在图片的不同位置,就是不一样的东西。它不能理解「物体出现在图片的不同位置还是同一个物体」这个概念。这意味着在每种可能出现的位置上,它必须重新学习识别各种物体。
|
||||
|
||||
有人对此做过研究,人的眼睛可能会逐步判断一个物体的信息,比如说你看到一张图片,你会先看颜色,然后看纹理然后再看整体,那么我们需要一种操作来模拟这个过程,我们管这种操作叫卷积操作。
|
||||
|
||||

|
||||
|
||||
## 卷积是如何工作的
|
||||
|
||||
之前我们提到过,我们可以把一整张图片当做一串数字输入到神经网络里面。不同的是,这次我们会利用<strong>平移不变性</strong>的概念来把这件事做得更智能。
|
||||
|
||||
当然也有最新研究说卷积不具备平移不变性,但是我这里使用这个概念是为了大伙更好的理解,举个例子:你将 8 无论放在左上角还是左下角都改变不了他是 8 的事实
|
||||
|
||||

|
||||
|
||||
我们将一张图像分成这么多个小块,然后输入神经网络中的是一个小块。<em>每次判断一张小图块。</em>
|
||||
|
||||
然而,有一个非常重要的不同:对于每个小图块,我们会使用同样的神经网络权重。换一句话来说,我们平等对待每一个小图块。如果哪个小图块有任何异常出现,我们就认为这个图块是「异常」
|
||||
|
||||

|
||||
|
||||
换一句话来说,我们从一整张图片开始,最后得到一个稍小一点的数组,里面存储着我们图片中的哪一部分有异常。
|
||||
|
||||
## 池化层
|
||||
|
||||
图像可能特别大。比如说 1024*1024 再来个颜色 RGB
|
||||
|
||||
那就有 1024*1024*3 这么多的数据,这对计算机来说去处理是不可想象的占用计算资源,所以我们需要用一种方式来降低他的计算量并且尽可能地保证丢失的数据不多。
|
||||
|
||||
让我们先来看每个 2×2 的方阵数组,并且留下最大的数:
|
||||
|
||||

|
||||
|
||||
每一波我们只保留一个数,这样就大大减少了图片的计算量了。
|
||||
|
||||
当然你也可以不选最大的,池化有很多种方式。
|
||||
|
||||
这损失也太大了吧!
|
||||
|
||||
这样子搞不会很糟糕么?确实,他会损失大量的数据,也正因如此,我们需要往里面塞大量的数据,有的数据集大的超乎你的想象,你可以自行查阅 imagenet 这种大型数据集。
|
||||
|
||||
当然,还有一些未公开的商用数据集,它们的数量更为庞大,运算起来更为复杂。
|
||||
|
||||
尽管如此,我们依然要感谢先驱,他们让一件事从能变成了不能
|
||||
|
||||
我们也要感谢显卡,这项技术早就出现了但是一直算不了,有了显卡让这件事成为了可能。
|
||||
|
||||
## 作出预测
|
||||
|
||||
到现在为止,我们已经把一个很大的图片缩减到了一个相对较小的数组。
|
||||
|
||||
你猜怎么着?数组就是一串数字而已,所以我们我们可以把这个数组输入到另外一个神经网络里面去。最后的这个神经网络会决定这个图片是否匹配。为了区分它和卷积的不同,我们把它称作「全连接」网络
|
||||
|
||||

|
||||
|
||||
我们的图片处理管道是一系列的步骤:卷积、最大池化,还有最后的「全连接」网络。
|
||||
|
||||
你可以把这些步骤任意组合、堆叠多次,来解决真实世界中的问题!你可以有两层、三层甚至十层卷积层。当你想要缩小你的数据大小时,你也随时可以调用最大池化函数。
|
||||
|
||||
我们解决问题的基本方法,就是从一整个图片开始,一步一步逐渐地分解它,直到你找到了一个单一的结论。你的卷积层越多,你的网络就越能识别出复杂的特征。
|
||||
|
||||
比如说,第一个卷积的步骤可能就是尝试去识别尖锐的东西,而第二个卷积步骤则是通过找到的尖锐物体来找鸟类的喙,最后一步是通过鸟喙来识别整只鸟,以此类推。
|
||||
|
||||
# 结语
|
||||
|
||||
这篇文章仅仅只是粗略的讲述了一些机器学习的一些基本操作,如果你要更深一步学习的话你可能还需要更多的探索。
|
||||
|
||||
# 参考资料
|
||||
|
||||
[machine-learning-for-software-engineers/README-zh-CN.md at master · ZuzooVn/machine-learning-for-sof](https://github.com/ZuzooVn/machine-learning-for-software-engineers/blob/master/README-zh-CN.md#%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%A6%82%E8%AE%BA)
|
||||
@@ -1,210 +0,0 @@
|
||||
# 程序示例——maze 迷宫解搜索
|
||||
::: warning 😋
|
||||
阅读程序中涉及搜索算法的部分,然后运行程序,享受机器自动帮你寻找路径的快乐!
|
||||
完成习题
|
||||
:::
|
||||
|
||||
::: tip 📥
|
||||
本节附件下载 <Download url="https://pic-hdu-cs-wiki-1307923872.cos.ap-shanghai.myqcloud.com/code/1-Lecture.zip"/>
|
||||
:::
|
||||
|
||||
/4.人工智能/code/MAZE.zip
|
||||
|
||||
# Node
|
||||
|
||||
```python
|
||||
# 节点类 Node
|
||||
class Node:
|
||||
def __init__(self, state, parent, action):
|
||||
self.state = state # 存储该结点的迷宫状态(即位置)
|
||||
self.parent = parent # 存储父结点
|
||||
self.action = action # 存储采取的行动
|
||||
```
|
||||
|
||||
## 节点复习:
|
||||
|
||||
- 节点是一种包含以下数据的数据结构:
|
||||
- 状态——state
|
||||
- 其父节点,通过该父节点生成当前节点——parent node
|
||||
- 应用于父级状态以获取当前节点的操作——action
|
||||
- 从初始状态到该节点的路径成本——path cost
|
||||
|
||||
# 堆栈边域——DFS
|
||||
|
||||
```python
|
||||
class StackFrontier: # 堆栈边域
|
||||
def __init__(self):
|
||||
self.frontier = [] # 边域
|
||||
def add(self, node): # 堆栈添加结点
|
||||
self.frontier.append(node)
|
||||
def contains_state(self, state):
|
||||
return any(node.state == state for node in self.frontier)
|
||||
def empty(self): # 判断边域为空
|
||||
return len(self.frontier) == 0
|
||||
def remove(self): # 移除结点
|
||||
if self.empty():
|
||||
raise Exception("empty frontier")
|
||||
else:
|
||||
node = self.frontier[-1]
|
||||
self.frontier = self.frontier[:-1]
|
||||
return node
|
||||
```
|
||||
|
||||
## 深度优先搜索复习:
|
||||
|
||||
- 深度优先搜索算法在尝试另一个方向之前耗尽每个方向。在这些情况下,边域作为堆栈数据结构进行管理。这里需要记住的流行语是“后进先出”。在将节点添加到边域后,第一个要删除和考虑的节点是最后一个要添加的节点。这导致了一种搜索算法,该算法在第一个方向上尽可能深入,直到尽头,同时将所有其他方向留到后面。“不撞南墙不回头”
|
||||
|
||||
# 队列边域——BFS
|
||||
|
||||
```python
|
||||
class QueueFrontier(StackFrontier): # 队列边域
|
||||
def remove(self):
|
||||
if self.empty():
|
||||
raise Exception("empty frontier")
|
||||
else:
|
||||
node = self.frontier[0]
|
||||
self.frontier = self.frontier[1:]
|
||||
return node
|
||||
```
|
||||
|
||||
## 广度优先搜索复习:
|
||||
|
||||
- 广度优先搜索算法将同时遵循多个方向,在每个可能的方向上迈出一步,然后在每个方向上迈出第二步。在这种情况下,边域作为队列数据结构进行管理。这里需要记住的流行语是“先进先出”。在这种情况下,所有新节点都会排成一行,并根据先添加的节点来考虑节点(先到先得!)。这导致搜索算法在任何一个方向上迈出第二步之前,在每个可能的方向上迈出一步。
|
||||
|
||||
# 迷宫解——Maze_solution
|
||||
|
||||
```python
|
||||
class Maze:
|
||||
def __init__(self, filename): # 读入迷宫图
|
||||
# 读入文件,设置迷宫大小
|
||||
with open(filename) as f:
|
||||
contents = f.read()
|
||||
# 验证起点和目标
|
||||
if contents.count("A") != 1:
|
||||
raise Exception("maze must have exactly one start point")
|
||||
if contents.count("B") != 1:
|
||||
raise Exception("maze must have exactly one goal")
|
||||
# 绘制迷宫大小
|
||||
contents = contents.splitlines()
|
||||
self.height = len(contents)
|
||||
self.width = max(len(line) for line in contents)
|
||||
# 绘制迷宫墙,起点,终点
|
||||
self.walls = []
|
||||
for i in range(self.height):
|
||||
row = []
|
||||
for j in range(self.width):
|
||||
try:
|
||||
if contents[i][j] == "A": # 设置起点
|
||||
self.start = (i, j)
|
||||
row.append(False)
|
||||
elif contents[i][j] == "B":
|
||||
self.goal = (i, j) # 设置终点
|
||||
row.append(False)
|
||||
elif contents[i][j] == " ":
|
||||
row.append(False) # 设置墙体
|
||||
else:
|
||||
row.append(True) # 可移动的点为 True
|
||||
except IndexError:
|
||||
row.append(False)
|
||||
self.walls.append(row)
|
||||
self.solution = None
|
||||
# 打印结果
|
||||
def print(self):
|
||||
...
|
||||
# 寻找邻结点,返回元组(动作,坐标(x,y))
|
||||
def neighbors(self, state):
|
||||
row, col = state
|
||||
candidates = [
|
||||
("up", (row - 1, col)),
|
||||
("down", (row + 1, col)),
|
||||
("left", (row, col - 1)),
|
||||
("right", (row, col + 1))
|
||||
]
|
||||
result = []
|
||||
for action, (r, c) in candidates:
|
||||
if 0 <= r < self.height and 0 <= c < self.width and not self.walls[r][c]:
|
||||
result.append((action, (r, c)))
|
||||
return result
|
||||
def solve(self):
|
||||
# 搜索迷宫解
|
||||
self.num_explored = 0 # 已搜索的路径长度
|
||||
# 将边界初始化为起始位置
|
||||
start = Node(state=self.start, parent=None, action=None)
|
||||
frontier = StackFrontier() # 采用DFS
|
||||
# frontier = QueueFrontier() # 采用BFS
|
||||
frontier.add(start)
|
||||
# 初始化一个空的探索集
|
||||
self.explored = set() # 存储已搜索的结点
|
||||
# 保持循环直到找到解决方案
|
||||
while True:
|
||||
# 无解情况
|
||||
if frontier.empty():
|
||||
raise Exception("no solution")
|
||||
# 从边界中选择一个节点
|
||||
node = frontier.remove()
|
||||
self.num_explored += 1
|
||||
# 得到解决路径
|
||||
if node.state == self.goal:
|
||||
actions = []
|
||||
cells = []
|
||||
while node.parent is not None: # 遍历父节点得到路径动作
|
||||
actions.append(node.action)
|
||||
cells.append(node.state)
|
||||
node = node.parent
|
||||
actions.reverse()
|
||||
cells.reverse()
|
||||
self.solution = (actions, cells)
|
||||
return
|
||||
# 将节点标记为已探索
|
||||
self.explored.add(node.state)
|
||||
# 将邻居添加到边界(展开节点)
|
||||
for action, state in self.neighbors(node.state):
|
||||
if not frontier.contains_state(state) and state not in self.explored:
|
||||
child = Node(state=state, parent=node, action=action)
|
||||
frontier.add(child)
|
||||
def output_image(self, filename, show_solution=True, show_explored=False):
|
||||
...
|
||||
```
|
||||
|
||||
# Quiz
|
||||
|
||||
1. 在深度优先搜索(DFS)和广度优先搜索(BFS)之间,哪一个会在迷宫中找到更短的路径?
|
||||
1. DFS 将始终找到比 BFS 更短的路径
|
||||
2. BFS 将始终找到比 DFS 更短的路径
|
||||
3. DFS 有时(但并非总是)会找到比 BFS 更短的路径
|
||||
4. BFS 有时(但并非总是)会找到比 DFS 更短的路径
|
||||
5. 两种算法总是能找到相同长度的路径
|
||||
2. 下面的问题将问你关于下面迷宫的问题。灰色单元格表示墙壁。在这个迷宫上运行了一个搜索算法,找到了从 A 点到 B 点的黄色突出显示的路径。在这样做的过程中,红色突出显示的细胞是探索的状态,但并没有达到目标。
|
||||
|
||||

|
||||
|
||||
在讲座中讨论的四种搜索算法中——深度优先搜索、广度优先搜索、曼哈顿距离启发式贪婪最佳优先搜索和曼哈顿距离启发式$A^*$
|
||||
|
||||
搜索——可以使用哪一种(或多种,如果可能的话)?
|
||||
1. 只能是$A^*$
|
||||
2. 只能是贪婪最佳优先搜索
|
||||
3. 只能是 DFS
|
||||
4. 只能是 BFS
|
||||
5. 可能是$A^*$或贪婪最佳优先搜索
|
||||
6. 可以是 DFS 或 BFS
|
||||
7. 可能是四种算法中的任何一种
|
||||
8. 不可能是四种算法中的任何一种
|
||||
3. 为什么有深度限制的极大极小算法有时比没有深度限制的极大极小更可取?
|
||||
1. 深度受限的极大极小算法可以更快地做出决定,因为它探索的状态更少
|
||||
2. 深度受限的极大极小算法将在没有深度限制的情况下实现与极大极小算法相同的输出,但有时会使用较少的内存
|
||||
3. 深度受限的极大极小算法可以通过不探索已知的次优状态来做出更优化的决策
|
||||
4. 深度限制的极小极大值永远不会比没有深度限制的极大极小值更可取
|
||||
4. 下面的问题将询问您关于下面的 Minimax 树,其中绿色向上箭头表示 MAX 玩家,红色向下箭头表示 MIN 玩家。每个叶节点都标有其值。
|
||||
|
||||

|
||||
|
||||
根节点的值是多少?
|
||||
|
||||
- 2
|
||||
- 3
|
||||
- 4
|
||||
- 5
|
||||
- 6
|
||||
- 7
|
||||
- 8
|
||||
- 9
|
||||
@@ -1,62 +0,0 @@
|
||||
# 项目:Tic-Tac-Toe 井字棋
|
||||
|
||||
我们为你提供了一个简单有趣的项目,帮助你进行知识巩固,请认真阅读文档内容。
|
||||
|
||||
如果你卡住了,请记得回来阅读文档,或请求身边人的帮助。
|
||||
|
||||
::: tip 📥
|
||||
本节附件下载 <Download url="https://pic-hdu-cs-wiki-1307923872.cos.ap-shanghai.myqcloud.com/code/1-Projects.zip"/>
|
||||
:::
|
||||
|
||||
`pip3 install -r requirements.txt`
|
||||
|
||||
# 理解
|
||||
|
||||
- 这个项目有两个主要文件:`runner.py` 和 `tictactoe.py`。`tictactoe.py` 包含了玩游戏和做出最佳动作的所有逻辑。`runner.py` 已经为你实现,它包含了运行游戏图形界面的所有代码。一旦你完成了 `tictactoe.py` 中所有必需的功能,你就可以运行 `python runner.py` 来对抗你的人工智能了!
|
||||
- 让我们打开 `tictactoe.py` 来了解所提供的内容。首先,我们定义了三个变量:X、O 和 EMPTY,以表示游戏的可能移动。
|
||||
- 函数 `initial_state` 返回游戏的启动状态。对于这个问题,我们选择将游戏状态表示为三个列表的列表(表示棋盘的三行),其中每个内部列表包含三个值,即 X、O 或 EMPTY。以下是我们留给你实现的功能!
|
||||
|
||||
# 说明
|
||||
|
||||
- 实现 `player`, `actions`, `result`, `winner`, `terminal`, `utility`, 以及 `minimax`.
|
||||
|
||||
- `player` 函数应该以棋盘状态作为输入,并返回轮到哪个玩家(X 或 O)。
|
||||
|
||||
- 在初始游戏状态下,X 获得第一步。随后,玩家交替进行每一个动作。
|
||||
- 如果提供结束棋盘状态作为输入(即游戏已经结束),则任何返回值都是可接受的。
|
||||
- `actions` 函数应该返回一组在给定的棋盘状态上可以采取的所有可能的操作。
|
||||
|
||||
- 每个动作都应该表示为元组 `(i,j)`,其中 `i` 对应于移动的行(0、1 或 2),`j` 对应于行中的哪个单元格对应于移动(也是 0、1、或 2)。
|
||||
- 可能的移动是棋盘上任何没有 X 或 O 的单元格。
|
||||
- 如果提供结束棋盘状态作为输入,则任何返回值都是可接受的。
|
||||
- `result` 函数以一个棋盘状态和一个动作作为输入,并且应该返回一个新的棋盘状态,而不修改原始棋盘。
|
||||
|
||||
- 如果 `action` 函数接受了一个无效的动作,你的程序应该<u>raise an exception</u>.
|
||||
- 返回的棋盘状态应该是从原始输入棋盘,并让轮到它的玩家在输入动作指示的单元格处移动所产生的棋盘。
|
||||
- 重要的是,原始棋盘应该保持不变:因为 Minimax 最终需要在计算过程中考虑许多不同的棋盘状态。这意味着简单地更新棋盘上的单元格本身并不是 `result` 函数的正确实现。在做出任何更改之前,你可能需要先对棋盘状态进行<u>deep copy</u>。
|
||||
- `winner` 函数应该接受一个棋盘作为输入,如果游戏结束,则返回游戏的获胜者。
|
||||
|
||||
- 如果 X 玩家赢得了游戏,函数应该返回 X。如果 O 玩家赢得了比赛,函数应该返回 O。
|
||||
- 一个人可以通过水平、垂直或对角连续三次移动赢得比赛。
|
||||
- 你可以认为最多会有一个赢家(也就是说,没有一个棋盘会同时有两个玩家连着三个,因为这将是一个无效的棋盘状态)。
|
||||
- 如果游戏没有赢家(要么是因为游戏正在进行,要么是因为比赛以平局结束),函数应该返回 `None`。
|
||||
- `terminal` 函数应该接受一个棋盘作为输入,并返回一个布尔值,指示游戏是否结束。
|
||||
|
||||
- 如果游戏结束,要么是因为有人赢得了游戏,要么是由于所有单元格都已填充而没有人获胜,则函数应返回 `True`。
|
||||
- 否则,如果游戏仍在进行中,则函数应返回 `False`。
|
||||
- `utility` 函数应接受结束棋盘状态作为输入,并输出该棋盘的分数。
|
||||
|
||||
- 如果 X 赢得了比赛,则分数为 1。如果 O 赢得了比赛,则分数为-1。如果比赛以平局结束,则分数为 0。
|
||||
- 你可以假设只有当 `terminal(board)` 为 True 时,才会在棋盘上调用 `utility`。
|
||||
- `minimax` 函数应该以一个棋盘作为输入,并返回玩家在该棋盘上移动的最佳移动。
|
||||
|
||||
- 返回的移动应该是最佳动作 `(i,j)`,这是棋盘上允许的动作之一。如果多次移动都是同样最佳的,那么这些移动中的任何一次都是可以接受的。
|
||||
- 如果该棋盘是结束棋盘状态,则 `minimax` 函数应返回 `None`。
|
||||
- 对于所有接受棋盘作为输入的函数,你可以假设它是一个有效的棋盘(即,它是包含三行的列表,每行都有三个值 X、O 或 EMPTY)。你不应该修改所提供的函数声明(每个函数的参数的顺序或数量)。、
|
||||
- 一旦所有功能都得到了正确的实现,你就应该能够运行 `python runner.py` 并与你的人工智能进行比赛。而且,由于井字棋是双方最佳比赛的平局,你永远不应该能够击败人工智能(尽管如果你打得不好,它可能会打败你!)
|
||||
|
||||
# 提示
|
||||
|
||||
- 如果你想在不同的 Python 文件中测试你的函数,你可以用类似于 `from tictactoe import initial_state` 的代码来导入它们。
|
||||
- 欢迎在 `tictactoe.py` 中添加其他辅助函数,前提是它们的名称不会与模块中已有的函数或变量名称冲突。
|
||||
- alpha-beta 剪枝是可选的,这可能会让你的人工智能运行更高效!
|
||||
@@ -1,319 +0,0 @@
|
||||
# 搜索
|
||||
|
||||
在我们日常生活中,其实有非常多的地方使用了所谓的 AI 算法,只是我们通常没有察觉。
|
||||
|
||||
比如美团的外卖程序里面,可以看到外卖员到达你所在的位置的路线,它是如何规划出相关路线的呢?
|
||||
|
||||
在我们和电脑下围棋下五子棋的时候,他是如何“思考”的呢?希望你在阅读完本章内容之后,可以有一个最基本的理解。并且,我们还会给你留下一个井字棋的小任务,可以让你的电脑和你下井字棋,是不是很 cool
|
||||
|
||||
让我们现在开始吧!
|
||||
|
||||
# 基本定义
|
||||
|
||||
也许第一次看会觉得云里雾里,没有必要全部记住所有的概念。可以先大致浏览一遍之后,再后续的代码中与概念进行结合,相信你会有更深入的理解
|
||||
|
||||
> 即检索存储在某个[数据结构](https://zh.wikipedia.org/wiki/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84)中的信息,或者在问题域的搜索空间中计算的信息。 --wiki
|
||||
|
||||
从本质上来说,你将搜索问题理解为一个函数,那么它的输入将会是你用计算机的数据结构或计算机数据所构成的初始状态以及你期望他达成的目标状态,搜索问题将尝试从中得到解决方案。
|
||||
|
||||
导航是使用搜索算法的一个典型的搜索,它接收您的当前位置和目的地作为输入,并根据搜索算法返回建议的路径。
|
||||
|
||||

|
||||
|
||||
在计算机科学中,还有许多其他形式的搜索问题,比如谜题或迷宫。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
# 举个例子
|
||||
|
||||
要找到一个数字华容道谜题的解决方案,需要使用搜索算法。
|
||||
|
||||
- 智能主体(Agent)
|
||||
|
||||
- 感知其环境并对该环境采取行动的实体。
|
||||
- 例如,在导航应用程序中,智能主体将是一辆汽车的代表,它需要决定采取哪些行动才能到达目的地。
|
||||
- 状态(State)
|
||||
|
||||
- 智能主体在其环境中的配置。
|
||||
- 例如,在一个数字华容道谜题中,一个状态是所有数字排列在棋盘上的任何一种方式。
|
||||
- 初始状态(Initial State)
|
||||
|
||||
- 搜索算法开始的状态。在导航应用程序中,这将是当前位置。
|
||||
|
||||

|
||||
|
||||
- 动作(Action)
|
||||
|
||||
- 一个状态可以做出的选择。更确切地说,动作可以定义为一个函数。当接收到状态$s$作为输入时,$Actions(s)$将返回可在状态$s$ 中执行的一组操作作为输出。
|
||||
- 例如,在一个数字华容道中,给定状态的操作是您可以在当前配置中滑动方块的方式。
|
||||
|
||||

|
||||
|
||||
- 过渡模型(Transition Model)
|
||||
|
||||
- 对在任何状态下执行任何适用操作所产生的状态的描述。
|
||||
- 更确切地说,过渡模型可以定义为一个函数。
|
||||
- 在接收到状态$s$和动作$a$作为输入时,$Results(s,a)$返回在状态$s$中执行动作$a$ 所产生的状态。
|
||||
- 例如,给定数字华容道的特定配置(状态$s$),在任何方向上移动正方形(动作$a$)将导致谜题的新配置(新状态)。
|
||||
|
||||

|
||||
|
||||
- 状态空间(State Space)
|
||||
|
||||
- 通过一系列的操作目标从初始状态可达到的所有状态的集合。
|
||||
- 例如,在一个数字华容道谜题中,状态空间由所有$\frac{16!}{2}$种配置,可以从任何初始状态达到。状态空间可以可视化为有向图,其中状态表示为节点,动作表示为节点之间的箭头。
|
||||
|
||||

|
||||
|
||||
- 目标测试(Goal Test)
|
||||
|
||||
- 确定给定状态是否为目标状态的条件。例如,在导航应用程序中,目标测试将是智能主体的当前位置是否在目的地。如果是,问题解决了。如果不是,我们将继续搜索。
|
||||
- 路径成本(Path Cost)
|
||||
|
||||
- 完成给定路径相关的代价。例如,导航应用程序并不是简单地让你达到目标;它这样做的同时最大限度地减少了路径成本,为您找到了达到目标状态的最快方法。
|
||||
|
||||
# 解决搜索问题
|
||||
|
||||
- 解(solution)
|
||||
|
||||
- 从初始状态到目标状态的一系列动作。
|
||||
- 最优解(Optimal Solution)
|
||||
|
||||
- 在所有解决方案中路径成本最低的解决方案。
|
||||
- 在搜索过程中,数据通常存储在<strong>节点(Node)</strong> 中,节点是一种包含以下数据的数据结构:
|
||||
|
||||
- 状态——state
|
||||
- 其父节点,通过该父节点生成当前节点——parent node
|
||||
- 应用于父级状态以获取当前节点的操作——action
|
||||
- 从初始状态到该节点的路径成本——path cost
|
||||
- 节点包含的信息使它们对于搜索算法非常有用。
|
||||
|
||||
它们包含一个状态,可以使用目标测试来检查该状态是否为最终状态。
|
||||
|
||||
如果是,则可以将节点的路径成本与其他节点的路径代价进行比较,从而可以选择最佳解决方案。
|
||||
|
||||
一旦选择了节点,通过存储父节点和从父节点到当前节点的动作,就可以追溯从初始状态到该节点的每一步,而这一系列动作就是解决方案。
|
||||
|
||||
- 然而,节点只是一个数据结构——它们不搜索,而是保存信息。为了实际搜索,我们使用了边域(frontier),即“管理”节点的机制。边域首先包含一个初始状态和一组空的已探索项目(探索集),然后重复以下操作,直到找到解决方案:
|
||||
|
||||
- 重复
|
||||
|
||||
- 如果边域为空
|
||||
|
||||
- 停止,搜索问题无解
|
||||
- 从边域中删除一个节点。这是将要考虑的节点。
|
||||
- 如果节点包含目标状态
|
||||
|
||||
- 返回解决方案,停止
|
||||
- 否则
|
||||
|
||||
- 展开节点(找到可以从该节点到达的所有新节点),并将生成的节点添加到边域。
|
||||
- 将当前节点添加到探索集。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
边域从节点 A 初始化开始
|
||||
|
||||
a. 取出边域中的节点 A,展开节点 A,将节点 B 添加到边域。
|
||||
b. 取出节点 B,展开,添加......
|
||||
c. 到达目标节点,停止,返回解决方案
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
会出现什么问题?节点 A-> 节点 B-> 节点 A->......-> 节点 A。我们需要一个探索集,记录已搜索的节点!
|
||||
|
||||
## 不知情搜索(Uninformed Search)
|
||||
|
||||
- 在之前对边域的描述中,有一件事没有被提及。在上面伪代码的第 1 阶段,应该删除哪个节点?这种选择对解决方案的质量和实现速度有影响。关于应该首先考虑哪些节点的问题,有多种方法,其中两种可以用堆栈(深度优先搜索)和队列(广度优先搜索)的数据结构来表示。
|
||||
- 深度优先搜索(Depth-First Search)
|
||||
|
||||
- 深度优先搜索算法在尝试另一个方向之前耗尽每个方向。在这些情况下,边域作为堆栈数据结构进行管理。这里需要记住的流行语是“后进先出”。在将节点添加到边域后,第一个要删除和考虑的节点是最后一个要添加的节点。这导致了一种搜索算法,该算法在第一个方向上尽可能深入,直到尽头,同时将所有其他方向留到后面。“不撞南墙不回头”
|
||||
- (一个例子:以你正在寻找钥匙的情况为例。在深度优先搜索方法中,如果你选择从裤子里搜索开始,你会先仔细检查每一个口袋,清空每个口袋,仔细检查里面的东西。只有当你完全筋疲力尽时,你才会停止在裤子里搜索,开始在其他地方搜索。)
|
||||
- 优点
|
||||
|
||||
- 在最好的情况下,这个算法是最快的。如果它“运气好”,并且总是(偶然)选择正确的解决方案路径,那么深度优先搜索需要尽可能少的时间来找到解决方案。
|
||||
- 缺点
|
||||
|
||||
- 所找到的解决方案可能不是最优的。
|
||||
- 在最坏的情况下,该算法将在找到解决方案之前探索每一条可能的路径,从而在到达解决方案之前花费尽可能长的时间。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
- 代码实现
|
||||
|
||||
```python
|
||||
def remove(self):
|
||||
if self.empty():
|
||||
raise Exception("empty frontier")
|
||||
else:
|
||||
node = self.frontier[-1]
|
||||
self.frontier = self.frontier[:-1]
|
||||
return node
|
||||
```
|
||||
|
||||
- 广度优先搜索(Breadth-First Search)
|
||||
|
||||
- 广度优先搜索算法将同时遵循多个方向,在每个可能的方向上迈出一步,然后在每个方向上迈出第二步。在这种情况下,边域作为队列数据结构进行管理。这里需要记住的流行语是“先进先出”。在这种情况下,所有新节点都会排成一行,并根据先添加的节点来考虑节点(先到先得!)。这导致搜索算法在任何一个方向上迈出第二步之前,在每个可能的方向上迈出一步。
|
||||
- (一个例子:假设你正在寻找钥匙。在这种情况下,如果你从裤子开始,你会看你的右口袋。之后,你会在一个抽屉里看一眼,而不是看你的左口袋。然后在桌子上。以此类推,在你能想到的每个地方。只有在你用完所有位置后,你才会回到你的裤子上,在下一个口袋里找。)
|
||||
- 优点
|
||||
|
||||
- 该算法可以保证找到最优解。
|
||||
- 缺点
|
||||
|
||||
- 几乎可以保证该算法的运行时间会比最短时间更长。
|
||||
- 在最坏的情况下,这种算法需要尽可能长的时间才能运行。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
- 代码实现
|
||||
|
||||
```python
|
||||
def remove(self):
|
||||
if self.empty():
|
||||
raise Exception("empty frontier")
|
||||
else:
|
||||
node = self.frontier[0]
|
||||
self.frontier = self.frontier[1:]
|
||||
return node
|
||||
```
|
||||
|
||||
## 知情搜索(Informed Search)
|
||||
|
||||
- 广度优先和深度优先都是不知情的搜索算法。也就是说,这些算法没有利用他们没有通过自己的探索获得的关于问题的任何知识。然而,大多数情况下,关于这个问题的一些知识实际上是可用的。例如,当人类进入一个路口时,人类可以看到哪条路沿着解决方案的大致方向前进,哪条路没有。人工智能也可以这样做。一种考虑额外知识以试图提高性能的算法被称为知情搜索算法。
|
||||
- 贪婪最佳优先搜索(Greedy Best-First Search)
|
||||
|
||||
- 贪婪最佳优先搜索扩展最接近目标的节点,如启发式函数$h(n)$所确定的。顾名思义,该函数估计下一个节点离目标有多近,但可能会出错。贪婪最佳优先算法的效率取决于启发式函数的好坏。例如,在迷宫中,算法可以使用启发式函数,该函数依赖于可能节点和迷宫末端之间的曼哈顿距离。曼哈顿距离忽略了墙壁,并计算了从一个位置到目标位置需要向上、向下或向两侧走多少步。这是一个简单的估计,可以基于当前位置和目标位置的$(x,y)$坐标导出。
|
||||
|
||||

|
||||
|
||||
- 然而,重要的是要强调,与任何启发式算法一样,它可能会出错,并导致算法走上比其他情况下更慢的道路。不知情的搜索算法有可能更快地提供一个更好的解决方案,但它比知情算法更不可能这样。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
- $A^*$搜索
|
||||
|
||||
- 作为贪婪最佳优先算法的一种发展,$A^*$搜索不仅考虑了从当前位置到目标的估计成本$h(n)$,还考虑了直到当前位置为止累积的成本$g(n)$。通过组合这两个值,该算法可以更准确地确定解决方案的成本并在旅途中优化其选择。该算法跟踪(到目前为止的路径成本+到目标的估计成本,$g(n)+h(n)$),一旦它超过了之前某个选项的估计成本,该算法将放弃当前路径并返回到之前的选项,从而防止自己沿着$h(n)$错误地标记为最佳的却长而低效的路径前进。
|
||||
|
||||
- 然而,由于这种算法也依赖于启发式,所以它依赖它所使用的启发式。在某些情况下,它可能比贪婪的最佳第一搜索甚至不知情的算法效率更低。对于最佳的$A^*$搜索,启发式函数$h(n)$应该:
|
||||
|
||||
- 可接受,从未高估真实成本。
|
||||
|
||||
- 一致性,这意味着从新节点到目标的估计路径成本加上从先前节点转换到该新节点的成本应该大于或等于先前节点到目标的估计路径成本。用方程的形式表示,$h(n)$是一致的,如果对于每个节点n$和后续节点n'$,从n$到$n'$的步长为c$,满足$h(n)≤h(n')+c$。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
# 对抗性搜索
|
||||
|
||||
尽管之前我们讨论过需要找到问题答案的算法,但在对抗性搜索中,算法面对的是试图实现相反目标的对手。通常,在游戏中会遇到使用对抗性搜索的人工智能,比如井字游戏。
|
||||
|
||||
- 极大极小算法(Minimax)
|
||||
|
||||
- 作为对抗性搜索中的一种算法,Minimax 将获胜条件表示为$(-1)$表示为一方,$(+1)$表示为另一方。进一步的行动将受到这些条件的驱动,最小化的一方试图获得最低分数,而最大化的一方则试图获得最高分数。
|
||||
|
||||

|
||||
|
||||
- 井字棋 AI 为例
|
||||
|
||||
- $s_0$: 初始状态(在我们的情况下,是一个空的3X3棋盘)
|
||||
|
||||

|
||||
|
||||
- $Players(s)$: 一个函数,在给定状态$$s$$的情况下,返回轮到哪个玩家(X或O)。
|
||||
|
||||

|
||||
|
||||
- $Actions(s)$: 一个函数,在给定状态$$s$$的情况下,返回该状态下的所有合法动作(棋盘上哪些位置是空的)。
|
||||
|
||||

|
||||
|
||||
- $Result(s, a)$: 一个函数,在给定状态$$s$$和操作$$a$$的情况下,返回一个新状态。这是在状态$$s$$上执行动作$$a$$(在游戏中移动)所产生的棋盘。
|
||||
|
||||

|
||||
|
||||
- $Terminal(s)$: 一个函数,在给定状态$$s$$的情况下,检查这是否是游戏的最后一步,即是否有人赢了或打成平手。如果游戏已结束,则返回True,否则返回False。
|
||||
|
||||

|
||||
|
||||
- $Utility(s)$: 一个函数,在给定终端状态s的情况下,返回状态的效用值:$$-1、0或1$$。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
- 算法的工作原理:
|
||||
|
||||
- 该算法递归地模拟从当前状态开始直到达到终端状态为止可能发生的所有游戏状态。每个终端状态的值为$(-1)$、$0$或$(+1)$。
|
||||
|
||||

|
||||
|
||||
- 根据轮到谁的状态,算法可以知道当前玩家在最佳游戏时是否会选择导致状态值更低或更高的动作。
|
||||
|
||||
通过这种方式,在最小化和最大化之间交替,算法为每个可能的动作产生的状态创建值。举一个更具体的例子,我们可以想象,最大化的玩家在每一个回合都会问:“如果我采取这个行动,就会产生一个新的状态。如果最小化的玩家发挥得最好,那么该玩家可以采取什么行动来达到最低值?”
|
||||
|
||||
然而,为了回答这个问题,最大化玩家必须问:“要想知道最小化玩家会做什么,我需要在最小化者的脑海中模拟同样的过程:最小化玩家会试图问:‘如果我采取这个动作,最大化玩家可以采取什么动作来达到最高值?’”
|
||||
|
||||
这是一个递归过程,你可能很难理解它;看看下面的伪代码会有所帮助。最终,通过这个递归推理过程,最大化玩家为每个状态生成值,这些值可能是当前状态下所有可能的操作所产生的。
|
||||
|
||||
在得到这些值之后,最大化的玩家会选择最高的一个。
|
||||
|
||||

|
||||
|
||||
- 具体算法:
|
||||
|
||||
- 给定状态 $s$
|
||||
|
||||
- 最大化玩家在$Actions(s)$中选择动作$a$,该动作产生$Min-value(Result(s,a))$ 的最高值。
|
||||
- 最小化玩家在$Actions(s)$中选择动作$a$,该动作产生$Max-value(Result(s,a))$ 的最小值。
|
||||
|
||||
- Function Max-Value(state):
|
||||
- $$v=-\infty$$
|
||||
- if $Terminal(state)$:
|
||||
- return $Utility(state)$
|
||||
- for $action$ in $Actions(state)$:
|
||||
- $$v = Max(v, Min-Value(Result(state, action)))$$
|
||||
- return $v$
|
||||
- Function Min-Value(state):
|
||||
- $$v=\infty$$
|
||||
- if $Terminal(state)$:
|
||||
- return $Utility(state)$
|
||||
- for $action$ in $Actions(state)$:
|
||||
- $$v = Min(v, Max-Value(Result(state, action)))$$
|
||||
- return $v$
|
||||
|
||||
不会理解递归?也许你需要看看这个:[阶段二:递归操作](../3.%E7%BC%96%E7%A8%8B%E6%80%9D%E7%BB%B4%E4%BD%93%E7%B3%BB%E6%9E%84%E5%BB%BA/3.6.4.2%E9%98%B6%E6%AE%B5%E4%BA%8C%EF%BC%9A%E9%80%92%E5%BD%92%E6%93%8D%E4%BD%9C.md)
|
||||
|
||||
- $\alpha$-$\beta$剪枝(Alpha-Beta Pruning)
|
||||
|
||||
- 作为一种优化Minimax的方法,Alpha-Beta剪枝跳过了一些明显不利的递归计算。在确定了一个动作的价值后,如果有初步证据表明接下来的动作可以让对手获得比已经确定的动作更好的分数,那么就没有必要进一步调查这个动作,因为它肯定比之前确定的动作不利。
|
||||
|
||||
- 这一点最容易用一个例子来说明:最大化的玩家知道,在下一步,最小化的玩家将试图获得最低分数。假设最大化玩家有三个可能的动作,第一个动作的值为4。然后玩家开始为下一个动作生成值。要做到这一点,如果当前玩家做出这个动作,玩家会生成最小化者动作的值,并且知道最小化者会选择最低的一个。然而,在完成最小化器所有可能动作的计算之前,玩家会看到其中一个选项的值为3。这意味着没有理由继续探索最小化玩家的其他可能行动。尚未赋值的动作的值无关紧要,无论是10还是(-10)。如果该值为10,则最小化器将选择最低选项3,该选项已经比预先设定的4差。如果尚未估价的行动结果是(-10),那么最小化者将选择(-10)这一选项,这对最大化者来说更加不利。因此,在这一点上为最小化者计算额外的可能动作与最大化者无关,因为最大化玩家已经有了一个明确的更好的选择,其值为4。
|
||||
|
||||

|
||||
|
||||
- 深度限制的极大极小算法(Depth-Limited Minimax)
|
||||
|
||||
- 总共有$255168$个可能的井字棋游戏,以及有$10^{29000}$个可能的国际象棋中游戏。到目前为止,最小最大算法需要生成从某个点到<strong>终端条件</strong>的所有假设游戏状态。虽然计算所有的井字棋游戏状态对现代计算机来说并不是一个挑战,但目前用来计算国际象棋是不可能的。
|
||||
|
||||
- 深度限制的 Minimax 算法在停止之前只考虑预先定义的移动次数,而从未达到终端状态。然而,这不允许获得每个动作的精确值,因为假设的游戏还没有结束。为了解决这个问题,深度限制 Minimax 依赖于一个评估函数,该函数从给定状态估计游戏的预期效用,或者换句话说,为状态赋值。例如,在国际象棋游戏中,效用函数会将棋盘的当前配置作为输入,尝试评估其预期效用(基于每个玩家拥有的棋子及其在棋盘上的位置),然后返回一个正值或负值,表示棋盘对一个玩家对另一个玩家的有利程度。这些值可以用来决定正确的操作,并且评估函数越好,依赖它的 Minimax 算法就越好。
|
||||
@@ -1,415 +0,0 @@
|
||||
# 程序示例——命题逻辑与模型检测
|
||||
::: warning 😋
|
||||
阅读程序中涉及命题逻辑的部分,然后“玩一玩”程序!
|
||||
|
||||
完成习题
|
||||
:::
|
||||
|
||||
::: tip 📥
|
||||
本节附件下载 <Download url="https://pic-hdu-cs-wiki-1307923872.cos.ap-shanghai.myqcloud.com/code/2-Lecture.zip"/>
|
||||
:::
|
||||
# Sentence——父类
|
||||
|
||||
```python
|
||||
class Sentence(): # 父类
|
||||
def evaluate(self, model):
|
||||
"""计算逻辑表达式的值"""
|
||||
raise Exception("nothing to evaluate")
|
||||
def formula(self):
|
||||
"""返回表示逻辑表达式的字符串形式。"""
|
||||
return ""
|
||||
def symbols(self):
|
||||
"""返回逻辑表达式中所有命题符号的集合。"""
|
||||
return set()
|
||||
@classmethod # @classmethod装饰器 使得类方法可以在类上被调用 Sentence.validate(...)
|
||||
def validate(cls, sentence):
|
||||
"""验证操作数是否是Sentence或其子类"""
|
||||
if not isinstance(sentence, Sentence):
|
||||
raise TypeError("must be a logical sentence")
|
||||
@classmethod # @classmethod装饰器 使得类方法可以在类上被调用 Sentence.parenthesize(...)
|
||||
def parenthesize(cls, s):
|
||||
"""如果表达式尚未加圆括号,则加圆括号。"""
|
||||
def balanced(s):
|
||||
"""检查字符串是否有配对的括号。"""
|
||||
count = 0
|
||||
for c in s:
|
||||
if c == "(":
|
||||
count += 1
|
||||
elif c == ")":
|
||||
if count <= 0:
|
||||
return False
|
||||
count -= 1
|
||||
return count == 0
|
||||
if not len(s) or s.isalpha() or (s[0] == "(" and s[-1] == ")" and balanced(s[1:-1])):
|
||||
return s
|
||||
else:
|
||||
return f"({s})"
|
||||
```
|
||||
|
||||
# Symbol——命题符号类
|
||||
|
||||
```python
|
||||
class Symbol(Sentence):
|
||||
def __init__(self, name):
|
||||
"""初始化命题符号"""
|
||||
self.name = name
|
||||
def __eq__(self, other):
|
||||
"""定义命题符号的相等"""
|
||||
return isinstance(other, Symbol) and self.name == other.name
|
||||
...
|
||||
def evaluate(self, model):
|
||||
"""命题符号在模型中赋值"""
|
||||
try:
|
||||
return bool(model[self.name])
|
||||
except KeyError:
|
||||
raise EvaluationException(f"variable {self.name} not in model")
|
||||
def formula(self):
|
||||
"""返回表示命题符号的字符串形式。"""
|
||||
return self.name
|
||||
def symbols(self):
|
||||
"""返回命题符号的集合。"""
|
||||
return {self.name}
|
||||
```
|
||||
|
||||
# Not——逻辑非类
|
||||
|
||||
```python
|
||||
class Not(Sentence):
|
||||
def __init__(self, operand):
|
||||
"""验证操作数是否是Sentence或其子类"""
|
||||
Sentence.validate(operand)
|
||||
self.operand = operand
|
||||
def __eq__(self, other):
|
||||
"""定义相等"""
|
||||
return isinstance(other, Not) and self.operand == other.operand
|
||||
...
|
||||
def evaluate(self, model):
|
||||
"""逻辑非在模型中的赋值"""
|
||||
return not self.operand.evaluate(model)
|
||||
def formula(self):
|
||||
"""返回表示逻辑非的字符串形式"""
|
||||
return "¬" + Sentence.parenthesize(self.operand.formula())
|
||||
def symbols(self):
|
||||
"""返回逻辑非中的命题符号的集合"""
|
||||
return self.operand.symbols()
|
||||
```
|
||||
|
||||
# And——逻辑乘类
|
||||
|
||||
```python
|
||||
class And(Sentence):
|
||||
def __init__(self, *conjuncts):
|
||||
for conjunct in conjuncts:
|
||||
"""验证操作数是否是Sentence或其子类"""
|
||||
Sentence.validate(conjunct)
|
||||
self.conjuncts = list(conjuncts)
|
||||
def __eq__(self, other):
|
||||
"""定义相等"""
|
||||
return isinstance(other, And) and self.conjuncts == other.conjuncts
|
||||
def add(self, conjunct):
|
||||
"""添加命题"""
|
||||
Sentence.validate(conjunct)
|
||||
self.conjuncts.append(conjunct)
|
||||
def evaluate(self, model):
|
||||
"""逻辑乘在模型中的赋值"""
|
||||
return all(conjunct.evaluate(model) for conjunct in self.conjuncts)
|
||||
def formula(self):
|
||||
"""返回表示逻辑乘的字符串形式"""
|
||||
if len(self.conjuncts) == 1:
|
||||
return self.conjuncts[0].formula()
|
||||
return " ∧ ".join([Sentence.parenthesize(conjunct.formula())
|
||||
for conjunct in self.conjuncts])
|
||||
def symbols(self):
|
||||
""""返回逻辑乘中的所有命题符号的集合"""
|
||||
return set.union(*[conjunct.symbols() for conjunct in self.conjuncts])
|
||||
```
|
||||
|
||||
# Or——逻辑和类
|
||||
|
||||
```python
|
||||
class Or(Sentence):
|
||||
def __init__(self, *disjuncts):
|
||||
for disjunct in disjuncts:
|
||||
"""验证操作数是否是Sentence或其子类"""
|
||||
Sentence.validate(disjunct)
|
||||
self.disjuncts = list(disjuncts)
|
||||
def __eq__(self, other):
|
||||
"""定义相等"""
|
||||
return isinstance(other, Or) and self.disjuncts == other.disjuncts
|
||||
...
|
||||
def evaluate(self, model):
|
||||
"""逻辑和在模型中的赋值"""
|
||||
return any(disjunct.evaluate(model) for disjunct in self.disjuncts)
|
||||
def formula(self):
|
||||
"""返回表示逻辑和的字符串形式"""
|
||||
if len(self.disjuncts) == 1:
|
||||
return self.disjuncts[0].formula()
|
||||
return " ∨ ".join([Sentence.parenthesize(disjunct.formula())
|
||||
for disjunct in self.disjuncts])
|
||||
def symbols(self):
|
||||
""""返回逻辑乘中的所有命题符号的集合"""
|
||||
return set.union(*[disjunct.symbols() for disjunct in self.disjuncts])
|
||||
```
|
||||
|
||||
# Implication——逻辑蕴含类
|
||||
|
||||
```python
|
||||
class Implication(Sentence):
|
||||
def __init__(self, antecedent, consequent):
|
||||
"""验证操作数是否是Sentence或其子类"""
|
||||
Sentence.validate(antecedent)
|
||||
Sentence.validate(consequent)
|
||||
"""前件"""
|
||||
self.antecedent = antecedent
|
||||
"""后件"""
|
||||
self.consequent = consequent
|
||||
def __eq__(self, other):
|
||||
"""定义相等"""
|
||||
return (isinstance(other, Implication)
|
||||
and self.antecedent == other.antecedent
|
||||
and self.consequent == other.consequent)
|
||||
...
|
||||
def evaluate(self, model):
|
||||
"""逻辑蕴含在模型中的赋值"""
|
||||
return ((not self.antecedent.evaluate(model))
|
||||
or self.consequent.evaluate(model))
|
||||
def formula(self):
|
||||
"""返回表示逻辑蕴含的字符串形式"""
|
||||
antecedent = Sentence.parenthesize(self.antecedent.formula())
|
||||
consequent = Sentence.parenthesize(self.consequent.formula())
|
||||
return f"{antecedent} => {consequent}"
|
||||
def symbols(self):
|
||||
""""返回逻辑蕴含中的所有命题符号的集合"""
|
||||
return set.union(self.antecedent.symbols(), self.consequent.symbols())
|
||||
```
|
||||
|
||||
# Biconditional——逻辑等值类
|
||||
|
||||
```python
|
||||
class Biconditional(Sentence):
|
||||
def __init__(self, left, right):
|
||||
"""验证操作数是否是Sentence或其子类"""
|
||||
Sentence.validate(left)
|
||||
Sentence.validate(right)
|
||||
self.left = left
|
||||
self.right = right
|
||||
def __eq__(self, other):
|
||||
"""定义相等"""
|
||||
return (isinstance(other, Biconditional)
|
||||
and self.left == other.left
|
||||
and self.right == other.right)
|
||||
...
|
||||
def evaluate(self, model):
|
||||
"""逻辑等值在模型中的赋值"""
|
||||
return ((self.left.evaluate(model)
|
||||
and self.right.evaluate(model))
|
||||
or (not self.left.evaluate(model)
|
||||
and not self.right.evaluate(model)))
|
||||
def formula(self):
|
||||
"""返回表示逻辑等值的字符串形式"""
|
||||
left = Sentence.parenthesize(str(self.left))
|
||||
right = Sentence.parenthesize(str(self.right))
|
||||
return f"{left} <=> {right}"
|
||||
def symbols(self):
|
||||
""""返回逻辑等值中的所有命题符号的集合"""
|
||||
return set.union(self.left.symbols(), self.right.symbols())
|
||||
```
|
||||
|
||||
# Model_check()——模型检测算法
|
||||
|
||||
```python
|
||||
def model_check(knowledge, query):
|
||||
"""
|
||||
检查知识库是否推理蕴含查询结论。
|
||||
>>> p = Symbol("p")
|
||||
>>> q = Symbol("q")
|
||||
>>> r = Symbol("r")
|
||||
>>> knowledge = And(p, q, Implication(And(p, q), r))
|
||||
>>> knowledge.formula()
|
||||
'p ∧ q ∧ ((p ∧ q) => r)'
|
||||
>>> query = r
|
||||
>>> model_check(knowledge,query)
|
||||
True
|
||||
"""
|
||||
def check_all(knowledge, query, symbols, model):
|
||||
"""检查给定特定模型的知识库是否推理蕴含查询结论。"""
|
||||
# 如果模型已经为所有的命题符号赋值
|
||||
if not symbols: # symbols为空即所有 symbols都在模型中被赋值
|
||||
# 若模型中的知识库为真,则查询结论也必须为真
|
||||
if knowledge.evaluate(model):
|
||||
return query.evaluate(model)
|
||||
return True
|
||||
else:
|
||||
# 递归生成并检测所有模型
|
||||
# 选择其余未使用的命题符号之一
|
||||
remaining = symbols.copy()
|
||||
p = remaining.pop()
|
||||
# 创建一个命题符号为true的模型
|
||||
model_true = model.copy()
|
||||
model_true[p] = True
|
||||
# 创建一个命题符号为false的模型
|
||||
model_false = model.copy()
|
||||
model_false[p] = False
|
||||
# 确保在两种模型中都进行蕴含推理
|
||||
return (check_all(knowledge, query, remaining, model_true) and
|
||||
check_all(knowledge, query, remaining, model_false))
|
||||
# 获取知识库和查询结论中的所有命题符号
|
||||
symbols = set.union(knowledge.symbols(), query.symbols())
|
||||
# 进行模型检测
|
||||
return check_all(knowledge, query, symbols, dict())
|
||||
```
|
||||
|
||||
# 线索游戏
|
||||
|
||||
在游戏中,一个人在某个地点使用工具实施了谋杀。人、工具和地点用卡片表示。每个类别的一张卡片被随机挑选出来,放在一个信封里,由参与者来揭开真相。参与者通过揭开卡片并从这些线索中推断出信封里必须有什么来做到这一点。我们将使用之前的模型检查算法来揭开这个谜团。在我们的模型中,我们将已知与谋杀有关的项目标记为 True,否则标记为 False。
|
||||
|
||||
```python
|
||||
import termcolor
|
||||
from logic import *
|
||||
mustard = Symbol("ColMustard")
|
||||
plum = Symbol("ProfPlum")
|
||||
scarlet = Symbol("MsScarlet")
|
||||
characters = [mustard, plum, scarlet]
|
||||
|
||||
ballroom = Symbol("ballroom")
|
||||
kitchen = Symbol("kitchen")
|
||||
library = Symbol("library")
|
||||
rooms = [ballroom, kitchen, library]
|
||||
|
||||
knife = Symbol("knife")
|
||||
revolver = Symbol("revolver")
|
||||
wrench = Symbol("wrench")
|
||||
weapons = [knife, revolver, wrench]
|
||||
|
||||
symbols = characters + rooms + weapons
|
||||
def check_knowledge(knowledge):
|
||||
for symbol in symbols:
|
||||
if model_check(knowledge, symbol):
|
||||
termcolor.cprint(f"{symbol}: YES", "green")
|
||||
elif not model_check(knowledge, Not(symbol)):
|
||||
# 模型检测无法确定知识库可以得出 Not(symbol) 即 symbol是可能的
|
||||
print(f"{symbol}: MAYBE")
|
||||
else:
|
||||
termcolor.cprint(f"{symbol}: No", "red")
|
||||
# 必须有人、房间和武器。
|
||||
knowledge = And(
|
||||
Or(mustard, plum, scarlet),
|
||||
Or(ballroom, kitchen, library),
|
||||
Or(knife, revolver, wrench)
|
||||
)
|
||||
# 初始卡牌
|
||||
knowledge.add(And(
|
||||
Not(mustard), Not(kitchen), Not(revolver)
|
||||
))
|
||||
# 未知卡牌
|
||||
knowledge.add(Or(
|
||||
Not(scarlet), Not(library), Not(wrench)
|
||||
))
|
||||
# 已知卡牌
|
||||
knowledge.add(Not(plum))
|
||||
knowledge.add(Not(ballroom))
|
||||
check_knowledge(knowledge)
|
||||
```
|
||||
|
||||
# Mastermind 游戏
|
||||
|
||||
在这个游戏中,玩家一按照一定的顺序排列颜色,然后玩家二必须猜测这个顺序。每一轮,玩家二进行猜测,玩家一返回一个数字,指示玩家二正确选择了多少颜色。让我们用四种颜色模拟一个游戏。假设玩家二猜测以下顺序:
|
||||
|
||||

|
||||
|
||||
玩家一回答“二”。因此,我们知道其中一些两种颜色位于正确的位置,而另两种颜色则位于错误的位置。根据这些信息,玩家二试图切换两种颜色的位置。
|
||||
|
||||

|
||||
|
||||
现在玩家一回答“零”。因此,玩家二知道切换后的颜色最初位于正确的位置,这意味着未被切换的两种颜色位于错误的位置。玩家二切换它们。
|
||||
|
||||

|
||||
|
||||
在命题逻辑中表示这一点需要我们有(颜色的数量)$^2$个原子命题。所以,在四种颜色的情况下,我们会有命题 red0,red1,red2,red3,blue0…代表颜色和位置。下一步是用命题逻辑表示游戏规则(每个位置只有一种颜色,没有颜色重复),并将它们添加到知识库中。最后一步是将我们所拥有的所有线索添加到知识库中。在我们的案例中,我们会补充说,在第一次猜测中,两个位置是错误的,两个是正确的,而在第二次猜测中没有一个是对的。利用这些知识,模型检查算法可以为我们提供难题的解决方案。
|
||||
|
||||
```python
|
||||
from logic import *
|
||||
colors = ["red", "blue", "green", "yellow"]
|
||||
symbols = []
|
||||
for i in range(4):
|
||||
for color in colors:
|
||||
symbols.append(Symbol(f"{color}{i}"))
|
||||
knowledge = And()
|
||||
# 每种颜色都有一个位置。
|
||||
for color in colors:
|
||||
knowledge.add(Or(
|
||||
Symbol(f"{color}0"),
|
||||
Symbol(f"{color}1"),
|
||||
Symbol(f"{color}2"),
|
||||
Symbol(f"{color}3")
|
||||
))
|
||||
# 每种颜色只有一个位置。
|
||||
for color in colors:
|
||||
for i in range(4):
|
||||
for j in range(4):
|
||||
if i != j:
|
||||
knowledge.add(Implication(
|
||||
Symbol(f"{color}{i}"), Not(Symbol(f"{color}{j}"))
|
||||
))
|
||||
# 每个位置只有一种颜色。
|
||||
for i in range(4):
|
||||
for c1 in colors:
|
||||
for c2 in colors:
|
||||
if c1 != c2:
|
||||
knowledge.add(Implication(
|
||||
Symbol(f"{c1}{i}"), Not(Symbol(f"{c2}{i}"))
|
||||
))
|
||||
knowledge.add(Or(
|
||||
And(Symbol("red0"), Symbol("blue1"), Not(Symbol("green2")), Not(Symbol("yellow3"))),
|
||||
And(Symbol("red0"), Symbol("green2"), Not(Symbol("blue1")), Not(Symbol("yellow3"))),
|
||||
And(Symbol("red0"), Symbol("yellow3"), Not(Symbol("blue1")), Not(Symbol("green2"))),
|
||||
And(Symbol("blue1"), Symbol("green2"), Not(Symbol("red0")), Not(Symbol("yellow3"))),
|
||||
And(Symbol("blue1"), Symbol("yellow3"), Not(Symbol("red0")), Not(Symbol("green2"))),
|
||||
And(Symbol("green2"), Symbol("yellow3"), Not(Symbol("red0")), Not(Symbol("blue1")))
|
||||
))
|
||||
knowledge.add(And(
|
||||
Not(Symbol("blue0")),
|
||||
Not(Symbol("red1")),
|
||||
Not(Symbol("green2")),
|
||||
Not(Symbol("yellow3"))
|
||||
))
|
||||
print(knowledge.formula())
|
||||
for symbol in symbols:
|
||||
if model_check(knowledge, symbol):
|
||||
print(symbol)
|
||||
```
|
||||
|
||||
# Quiz
|
||||
|
||||
1. 下面的问题将问你关于以下逻辑句子的问题。 1.如果 Hermione 在图书馆,那么 Harry 在图书馆。 2.Hermione 在图书馆里。 3.Ron 在图书馆,Ron 不在图书馆。 4.Harry 在图书馆。 5.Harry 不在图书馆,或者 Hermione 在图书馆。 6.Rom 在图书馆,或者 Hermione 在图书馆。
|
||||
|
||||
以下哪一个逻辑蕴含推理是正确的?
|
||||
|
||||
1. $1\vDash 4$
|
||||
2. $5\vDash 6$
|
||||
3. $1\vDash 2$
|
||||
4. $6\vDash 2$
|
||||
5. $2\vDash 5$
|
||||
6. $6\vDash 3$
|
||||
|
||||
2. 除了讲义上讨论的连接词之外,还有其他的逻辑连接词。其中最常见的是“异或”(用符号$\oplus$表示)。表达式$A\oplus B$表示句子“A 或 B,但不是两者都有。”以下哪一个在逻辑上等同于$A\oplus B$?
|
||||
1. $(A ∨ B) ∧ ¬ (A ∨ B)$
|
||||
2. $(A ∨ B) ∧ (A ∧ B)$
|
||||
3. $(A ∨ B) ∧ ¬ (A ∧ B)$
|
||||
4. $(A ∧ B) ∨ ¬ (A ∨ B)$
|
||||
|
||||
3. 设命题变量$R$为“今天下雨”,变量$C$为“今天多云”,变量$S$ 为“今天晴”。下面哪一个是“如果今天下雨,那么今天多云但不是晴天”这句话的命题逻辑表示?
|
||||
|
||||
1. $(R → C) ∧ ¬S$
|
||||
2. $R → C → ¬S$
|
||||
3. $R ∧ C ∧ ¬S$
|
||||
4. $R → (C ∧ ¬S)$
|
||||
5. $(C ∨ ¬S) → R$
|
||||
|
||||
4. 在一阶逻辑中,考虑以下谓词符号。$Student(x)$表示“x 是学生”的谓词。$Course(x)$代表“x 是课程”的谓词,$Enrolled(x,y)$表示“x 注册了 y”的谓词以下哪一项是“有一门课程是 Harry 和 Hermione 都注册的”这句话的一阶逻辑翻译?
|
||||
1. $∀x(Course(x)∧Enrolled(Harry, x) ∧ Enrolled(Hermione, x))$
|
||||
2. $∀x(Enrolled(Harry, x) ∨ Enrolled(Hermione, x))$
|
||||
3. $∀x(Enrolled(Harry, x) ∧ ∀y Enrolled(Hermione, y))$
|
||||
4. $∃xEnrolled(Harry, x) ∧ ∃y Enrolled(Hermione, y)$
|
||||
5. $∃x(Course(x) ∧ Enrolled(Harry, x) ∧ Enrolled(Hermione, x))$
|
||||
6. $∃x(Enrolled(Harry, x) ∨ Enrolled(Hermione, x))$
|
||||
@@ -1,206 +0,0 @@
|
||||
# 项目:扫雷,骑士与流氓问题
|
||||
|
||||
我们为你提供了两个简单有趣的项目,帮助你进行知识巩固,请认真阅读文档内容。
|
||||
|
||||
如果你卡住了,请记得回来阅读文档,或请求身边人的帮助。
|
||||
|
||||
::: tip 📥
|
||||
本节附件下载 <Download url="https://pic-hdu-cs-wiki-1307923872.cos.ap-shanghai.myqcloud.com/code/2-Projects.zip"/>
|
||||
:::
|
||||
|
||||
`pip3 install -r requirements.txt`
|
||||
|
||||
# 骑士与流氓问题
|
||||
|
||||
## 背景
|
||||
|
||||
- 在 1978 年,逻辑学家雷蒙德·斯穆里安(Raymond Smullyan)出版了《这本书叫什么名字?》,这是一本逻辑难题的书。在书中的谜题中,有一类谜题被斯穆里安称为“骑士与流氓”谜题。
|
||||
- 在骑士与流氓谜题中,给出了以下信息:每个角色要么是骑士,要么是流氓。骑士总是会说实话:如果骑士陈述了一句话,那么这句话就是真的。相反,流氓总是说谎:如果流氓陈述了一个句子,那么这个句子就是假的。
|
||||
- 谜题的目标是,给出每个角色说的一组句子,确定每个角色是骑士还是流氓。
|
||||
- 比如,这里有一个简单的谜题只有一个名为 A 的角色。A 说:“我既是骑士又是流氓。”
|
||||
- 从逻辑上讲,我们可以推断,如果 A 是骑士,那么这句话一定是真的。但我们知道这句话不可能是真的,因为 A 不可能既是骑士又是流氓——我们知道每个角色要么是骑士,要么是流氓,不会出现是流氓的骑士或是骑士的流氓。所以,我们可以得出结论,A 一定是流氓。
|
||||
- 那个谜题比较简单。随着更多的字符和更多的句子,谜题可以变得更加棘手!你在这个问题中的任务是确定如何使用命题逻辑来表示这些谜题,这样一个运行模型检查算法的人工智能可以为我们解决这些谜题。
|
||||
|
||||
## 理解
|
||||
|
||||
- 看一下 `logic.py`,你可能还记得讲义的内容。无需了解此文件中的所有内容,但请注意,此文件为不同类型的逻辑连接词定义了多个类。这些类可以相互组合,所以表达式 `And(Not(A), Or(B, C))` 代表逻辑语句:命题 A 是不正确的,同时,命题 B 或者命题 C 是正确的。(这里的“或”是同或,不是异或)
|
||||
- 回想一下 `logic.py`,它还包含一个 函数 `model_check` 。`model_check` 输入知识库和查询结论。知识库是一个逻辑命题:如果知道多个逻辑语句,则可以将它们连接在一个表达式中。 递归考虑所有可能的模型,如果知识库推理蕴含查询结论,则返回 `True`,否则返回 `False`。
|
||||
- 现在,看看 `puzzle.py`,在顶部,我们定义了六个命题符号。例如,`AKnight` 表示“A 是骑士”的命题,`AKnave` 而表示“A 是流氓”的句子。我们也为字符 B 和 C 定义了类似的命题符号。
|
||||
- 接下来是四个不同的知识库 `knowledge0`, `knowledge1`, `knowledge2`, and `knowledge3`,它们将分别包含推断即将到来的谜题 0、1、2 和 3 的解决方案所需的知识。请注意,目前,这些知识库中的每一个都是空的。这就是你进来的地方!
|
||||
- 这个 `puzzle.py` 的 `main` 函数在所有谜题上循环,并使用模型检查来计算,给定谜题的知识,无论每个角色是骑士还是无赖,打印出模型检查算法能够得出的任何结论。
|
||||
|
||||
## 明确
|
||||
|
||||
- 将知识添加到知识库 `knowledge0`, `knowledge1`, `knowledge2`, 和 `knowledge3` 中,以解决以下难题。
|
||||
|
||||
- 谜题 0 是背景中的谜题。它只包含一个简单的角色 A
|
||||
|
||||
A 说:“我既是骑士又是流氓。”
|
||||
|
||||
- 谜题 1 有两个角色:A 和 B
|
||||
|
||||
A 说:“我们都是流氓。”
|
||||
|
||||
B 什么都没说。
|
||||
|
||||
- 谜题 2 有两个角色:A 和 B
|
||||
|
||||
A 说:“我们是同一种身份。”
|
||||
|
||||
B 说:“我们不是同一种身份。”
|
||||
|
||||
- 谜题 3 有三个角色:A,B 和 C
|
||||
|
||||
A 说:“我是骑士”或者 A 说:“我是流氓”(这里“或”是异或,不是同或),但你不知道 A 说的是哪句话。
|
||||
|
||||
B 说:“A 说过‘我是流氓’。”
|
||||
|
||||
B 又说:“C 是流氓。”
|
||||
|
||||
C 说:“A 是骑士。”
|
||||
|
||||
- 上述每个谜题中,每个角色要么是骑士,要么是流氓。骑士说的每一句话都是真的,流氓说的每一句话都是假的。
|
||||
- 一旦你完成了一个问题的知识库,你应该能够运行 `python puzzle.py` 来查看谜题的解决方案。
|
||||
|
||||
## 提示
|
||||
|
||||
- 对于每个知识库,你可能想要编码两种不同类型的信息:(1)关于问题本身结构的信息(即骑士与流氓谜题定义中给出的信息),以及(2)关于角色实际说了什么的信息。
|
||||
- 考虑一下,如果一个句子是由一个角色说出的,这意味着什么。在什么条件下这句话是真的?在什么条件下这个句子是假的?你如何将其表达为一个合乎逻辑的句子?
|
||||
- 每个谜题都有多个可能的知识库,可以计算出正确的结果。你应该尝试选择一个能对谜题中的信息进行最直接的知识库,而不是自己进行逻辑推理。你还应该考虑谜题中信息最简洁的表达方式是什么。
|
||||
|
||||
- 例如,对于谜题 0,设置 `knowledge0=AKnave` 将产生正确的输出,因为通过我们自己的推理,我们知道 A 一定是一个无赖。但这样做违背了这个问题的精神:目标是让你的人工智能为你做推理。
|
||||
- 您不需要(也不应该)修改 `logic.py` 来完成这个问题。
|
||||
|
||||
# 扫雷
|
||||
|
||||
写一个 AI 来玩扫雷游戏。
|
||||
|
||||

|
||||
|
||||
## 背景
|
||||
|
||||
### 扫雷
|
||||
|
||||
- 扫雷器是一款益智游戏,由一个单元格网格组成,其中一些单元格包含隐藏的“地雷”。点击包含地雷的单元格会引爆地雷,导致用户输掉游戏。单击“安全”单元格(即不包含地雷的单元格)会显示一个数字,指示有多少相邻单元格包含地雷,其中相邻单元格是指从给定单元格向左、向右、向上、向下或对角线一个正方形的单元格。
|
||||
- 例如,在这个 3x3 扫雷游戏中,三个 1 值表示这些单元格中的每个单元格都有一个相邻的单元格,该单元格是地雷。四个 0 值表示这些单元中的每一个都没有相邻的地雷。
|
||||
|
||||

|
||||
|
||||
- 给定这些信息,玩家根据逻辑可以得出结论,右下角单元格中一定有地雷,左上角单元格中没有地雷,因为只有在这种情况下,其他单元格上的数字标签才会准确。
|
||||
- 游戏的目标是标记(即识别)每个地雷。在游戏的许多实现中,包括本项目中的实现中,玩家可以通过右键单击单元格(或左键双击,具体取决于计算机)来标记地雷。
|
||||
|
||||
### 命题逻辑
|
||||
|
||||
- 你在这个项目中的目标是建立一个可以玩扫雷游戏的人工智能。回想一下,基于知识的智能主体通过考虑他们的知识库来做出决策,并根据这些知识做出推断。
|
||||
- 我们可以表示人工智能关于扫雷游戏的知识的一种方法是,使每个单元格成为命题变量,如果单元格包含地雷,则为真,否则为假。
|
||||
|
||||

|
||||
|
||||
- 我们现在掌握了什么信息?我们现在知道八个相邻的单元格中有一个是地雷。因此,我们可以写一个逻辑表达式,如下所示,表示其中一个相邻的单元格是地雷。
|
||||
- `Or(A,B,C,D,E,F,G,H)`
|
||||
- 但事实上,我们知道的比这个表达所说的要多。上面的逻辑命题表达了这样一种观点,即这八个变量中至少有一个是真的。但我们可以做一个更有力的陈述:我们知道八个变量中有一个是真的。这给了我们一个命题逻辑命题,如下所示。
|
||||
|
||||
```
|
||||
Or(
|
||||
And(A, Not(B), Not(C), Not(D), Not(E), Not(F), Not(G), Not(H)),
|
||||
And(Not(A), B, Not(C), Not(D), Not(E), Not(F), Not(G), Not(H)),
|
||||
And(Not(A), Not(B), C, Not(D), Not(E), Not(F), Not(G), Not(H)),
|
||||
And(Not(A), Not(B), Not(C), D, Not(E), Not(F), Not(G), Not(H)),
|
||||
And(Not(A), Not(B), Not(C), Not(D), E, Not(F), Not(G), Not(H)),
|
||||
And(Not(A), Not(B), Not(C), Not(D), Not(E), F, Not(G), Not(H)),
|
||||
And(Not(A), Not(B), Not(C), Not(D), Not(E), Not(F), G, Not(H)),
|
||||
And(Not(A), Not(B), Not(C), Not(D), Not(E), Not(F), Not(G), H)
|
||||
)
|
||||
```
|
||||
|
||||
- 这是一个相当复杂的表达!这只是为了表达一个单元格中有 1 意味着什么。如果一个单元格有 2、3 或其他值,这个表达式可能会更长。
|
||||
- 试图对这类问题进行模型检查也会很快变得棘手:在 8x8 网格(微软初级游戏模式使用的大小)上,我们有 64 个变量,因此需要检查
|
||||
$$
|
||||
2^64
|
||||
$$
|
||||
|
||||
个可能的模型——太多了,计算机无法在任何合理的时间内计算。对于这个问题,我们需要更好地表达知识。
|
||||
|
||||
### 知识表示
|
||||
|
||||
- 相反,我们将像下面这样表示人工智能知识的每一句话。
|
||||
- `{A, B, C, D, E, F, G, H} = 1`
|
||||
- 这种表示法中的每个逻辑命题都有两个部分:一个是网格中与提示数字有关的一组单元格 `cell`,另一个是数字计数 `count`,表示这些单元格中有多少是地雷。上面的逻辑命题说,在单元格 A、B、C、D、E、F、G 和 H 中,正好有 1 个是地雷。
|
||||
- 为什么这是一个有用的表示?在某种程度上,它很适合某些类型的推理。考虑下面的游戏。
|
||||
|
||||

|
||||
|
||||
- 利用左下数的知识,我们可以构造命题 `{D,E,G}=0`,意思是在 D、E 和 G 单元中,正好有 0 个是地雷。凭直觉,我们可以从这句话中推断出所有的单元格都必须是安全的。通过推理,每当我们有一个 `count` 为 0 的命题时,我们就知道该命题的所有 `cell` 都必须是安全的。
|
||||
- 同样,考虑下面的游戏。
|
||||
|
||||

|
||||
|
||||
- 我们的人工智能会构建命题 `{E,F,H}=3`。凭直觉,我们可以推断出所有的 E、F 和 H 都是地雷。更一般地说,任何时候 `cell` 的数量等于 `count`,我们都知道这个命题的所有单元格都必须是地雷。
|
||||
- 一般来说,我们只希望我们的命题是关于那些还不知道是安全的还是地雷的 `cell`。这意味着,一旦我们知道一个单元格是否是地雷,我们就可以更新我们的知识库来简化它们,并可能得出新的结论。
|
||||
- 例如,如果我们的人工智能知道命题 `{A,B,C}=2`,那么我们还没有足够的信息来得出任何结论。但如果我们被告知 C 是安全的,我们可以将 C 从命题中完全删除,留下命题 `{A,B}=2`(顺便说一句,这确实让我们得出了一些新的结论)
|
||||
- 同样,如果我们的人工智能知道命题 `{A,B,C}=2`,并且我们被告知 C 是一颗地雷,我们可以从命题中删除 C,并减少计数的值(因为 C 是导致该计数的地雷),从而得到命题 `{A、B}=1`。这是合乎逻辑的:如果 A、B 和 C 中有两个是地雷,并且我们知道 C 是地雷,那么 A 和 B 中一定有一个是地雷。
|
||||
- 如果我们更聪明,我们可以做最后一种推理。
|
||||
|
||||

|
||||
|
||||
- 考虑一下我们的人工智能根据中间顶部单元格和中间底部单元格会知道的两个命题。从中上角的单元格中,我们得到 `{A,B,C}=1`。从底部中间单元格中,我们得到 `{A,B,C,D,E}=2`。从逻辑上讲,我们可以推断出一个新的知识,即 `{D,E}=1`。毕竟,如果 A、B、C、D 和 E 中有两个是地雷,而 A、B 和 C 中只有一个是地雷的话,那么 D 和 E 必须是另一个地雷。
|
||||
- 更一般地说,任何时候我们有两个命题满足 `set1=count1` 和 `set2=count2`,其中 `set1` 是 `set2` 的子集,那么我们可以构造新的命题 `set2-set1=count2-count1`。考虑上面的例子,以确保你理解为什么这是真的。
|
||||
- 因此,使用这种表示知识的方法,我们可以编写一个人工智能智能主体,它可以收集有关扫雷的知识,并希望选择它知道安全的单元格!
|
||||
|
||||
## 理解
|
||||
|
||||
- 这个项目有两个主要文件:`runner.py` 和 `minesweeper.py`。`minesweeper.py` 包含游戏本身和 AI 玩游戏的所有逻辑。`runner.py` 已经为你实现,它包含了运行游戏图形界面的所有代码。一旦你完成了 `minesweeper.py` 中所有必需的功能,你就可以运行 `python runner.py` 来玩扫雷了(或者让你的 AI 为你玩)!
|
||||
- 让我们打开 `minesweeper.py` 来了解提供了什么。这个文件中定义了三个类,`Minesweeper`,负责处理游戏;`Sentence`,表示一个既包含一组 `cell` 又包含一个 `count` 的逻辑命题;以及 `MinesweeperAI`,它处理根据知识做出的推断。
|
||||
- `Minesweeper` 类已经完全实现了。请注意,每个单元格都是一对 `(i,j)`,其中 `i` 是行号(范围从 `0` 到 `height-1`),`j` 是列号(范围从 `0` 到 `width-1`)。
|
||||
- `Sentence` 类将用于表示背景中描述的形式的逻辑命题。每个命题中都有一组 `cell`,以及 `count` 表示其中有多少单元格是地雷。该类还包含函数 `known_mines` 和 `known_safes`,用于确定命题中的任何单元格是已知的地雷还是已知的安全单元格。它还包含函数 `mark_mine` 和 `mark_safe`,用于响应有关单元格的新信息来更新命题。
|
||||
- 最后,`MinesweeperAI` 类将实现一个可以玩扫雷的 AI。AI 类跟踪许多值。`self.moves_made` 包含一组已经点击过的所有单元格,因此人工智能知道不要再选择这些单元格。`self.mines` 包含一组已知为地雷的所有单元格。`self.safes` 包含一组已知安全的所有单元格。而 `self.knowledge` 包含了人工智能知道是真的所有命题的列表。
|
||||
- `mark_mine` 函数为 `self.mines` 添加了一个单元格,因此 AI 知道这是一个地雷。它还循环遍历人工智能知识中的所有命题,并通知每个命题该单元格是地雷,这样,如果命题包含有关地雷的信息,它就可以相应地更新自己。`mark_safe` 函数也做同样的事情,只是针对安全单元格。
|
||||
- 剩下的函数 `add_knowledge`、`make_safe_move` 和 `make_random_move` 由你完成!
|
||||
|
||||
## 明确
|
||||
|
||||
- 完成 `minesweeper.py` 中的 `Sentence` 类和 `MinesweeperAI` 类的实现。
|
||||
- 在 `Sentence` 类中,完成 `known_mines`、`known_safes`、`mark_mine` 和 `mark_safe` 的实现。
|
||||
|
||||
- `known_mines` 函数应该返回 `self.cells` 中已知为地雷的所有单元格的集合。
|
||||
- `known_safes` 函数应该返回 `self.cells` 中已知安全的所有单元格的集合。
|
||||
- `mark_mine` 函数应该首先检查单元格是否是命题中包含的单元格之一。
|
||||
|
||||
- 如果 `cell` 在命题中,函数应该更新命题,使单元格不再在命题中但仍然表示一个逻辑正确的命题,因为该 `cell` 已知是地雷。
|
||||
- 如果命题中没有 `cell`,则不需要采取任何行动。
|
||||
- `mark_safe` 函数应该首先检查单元格是否是命题中包含的单元格之一。
|
||||
|
||||
- 如果 `cell` 在命题中,则函数应更新命题,使单元格不再在命题中但仍然表示一个逻辑正确的命题,因为该 `cell` 已知是安全的。
|
||||
- 如果命题中没有 `cell`,则不需要采取任何行动。
|
||||
- 在 `MinesweeperAI` 类中,完成 `add_knowledge`、`make_safe_move` 和 `make_random_move` 的实现。
|
||||
|
||||
- `add_knowledge` 应该接受一个单元格(表示为元组 `(i,j)`)及其相应的 `count`,并使用 AI 可以推断的任何新信息更新 `self.mines`、`self.safes`、`self.moves_made` 和 `self.knowledge`,因为该单元格是已知的安全单元格,其附近有计数地雷。
|
||||
|
||||
- 该函数应将该 `cell` 标记为游戏中的一个动作。
|
||||
- 函数应该将 `cell` 标记为安全单元格,同时更新包含该单元格的任何命题。
|
||||
- 该函数应该根据 `cell` 和 `count` 的值,在人工智能的知识库中添加一个新命题,以表明 `cell` 的邻居有 `count` 是地雷。请确保在命题中只包含状态尚未确定的单元格。
|
||||
- 如果根据 `self.knowledge` 中的任何一个命题,新的单元格可以被标记为安全的或地雷,那么函数应该这样做。
|
||||
- 如果根据 `self.knowledge` 中的任何一个命题,可以推断出新的命题(使用背景技术中描述的子集方法),那么这些命题也应该添加到知识库中。
|
||||
- 请注意,每当你对人工智能的知识做出任何改变时,都有可能得出以前不可能的新推论。如果可能的话,请确保将这些新的推断添加到知识库中。
|
||||
- `make_safe_move` 应该返回一个已知安全的选择 `(i,j)`。
|
||||
|
||||
- 必须知道返回的动作是安全的,而不是已经做出的动作。
|
||||
- 如果无法保证安全移动,则函数应返回 `None`。
|
||||
- 该函数不应修改 `self.moves_made`、`self.mines`、`self.safes` 或 `self.knowledge`。
|
||||
- `make_random_move` 应该返回一个随机选择 `(i,j)`。
|
||||
|
||||
- 如果无法安全移动,将调用此功能:如果人工智能不知道移动到哪里,它将选择随机移动。
|
||||
- 此举不得是已经采取的行动。
|
||||
- 此举决不能是已知的地雷行动。
|
||||
- 如果无法进行此类移动,则函数应返回 `None`。
|
||||
|
||||
## 提示
|
||||
|
||||
- 确保你已经彻底阅读了背景部分,以了解知识在这个人工智能中是如何表现的,以及人工智能是如何进行推理的。
|
||||
- 如果对面向对象编程感觉不太舒服,你可能会发现<u>python 关于类</u>的文档很有帮助。
|
||||
- 你可以在<u>python 关于集合</u>的文档中找到一些常见的集合操作。
|
||||
- 在 `Sentence` 类中实现 `known_mines` 和 `known_safes` 时,请考虑:在什么情况下,你确信命题的单元格是安全的?在什么情况下,你确定一个命题的单元格是地雷?
|
||||
- `add_knowledge` 做了很多工作,可能是迄今为止你为该项目编写的最长的函数。一步一步地实现此函数的行为可能会有所帮助。
|
||||
- 如果愿意,欢迎您向任何类添加新方法,但不应修改任何现有函数的定义或参数。
|
||||
- 当你运行你的人工智能(如点击“AI Move”)时,请注意它并不总是获胜!在某些情况下,人工智能必须进行猜测,因为它缺乏足够的信息来进行安全行动。这是意料之中的事。`runner.py` 将打印人工智能是否正在进行其认为安全的移动,或者是否正在进行随机移动。
|
||||
- 在对集合进行迭代时,请注意不要修改它。这样做可能会导致错误!
|
||||
@@ -1,322 +0,0 @@
|
||||
# 知识推理
|
||||
|
||||
人类根据现有的知识进行推理并得出结论。表示知识并从中得出结论的概念也被用于人工智能中,在本章中我们将探讨如何实现这种行为。
|
||||
::: warning 😱
|
||||
# 说好的 AI 呢?怎么感觉越来越偏了?
|
||||
|
||||
如果有这样的疑问的同学,可能存在一定的误区,认为人工智能就是局限在深度学习的算法或者说机器学习的部分算法上,其实这是对这个领域一个巨大的误解。
|
||||
|
||||
在 AI 的发展历程上,曾经存在一次符号主义(Symbolic)与联结主义(Connectionism)之争。
|
||||
|
||||
联结主义的中心原则是使用,简单且经常一致的单元互联网络,来描述各种现象,即简单的复杂叠加。在目前的深度学习网络中有着最为广泛的应用。
|
||||
|
||||
符号主义则相信,智能的许多特征可以透过[符号](https://zh.wikipedia.org/wiki/%E7%89%A9%E7%90%86%E7%AC%A6%E8%99%9F%E7%B3%BB%E7%B5%B1)处理来实现。最为显著的应用即是早期的专家系统。
|
||||
|
||||
从本质上来说,二者都存在用机器可以理解的语言表征知识,随后让机器依照人为制定的理论或数据依照概率或推理得到人所期望获得的的知识或结果。
|
||||
|
||||
而在本章的内容中,知识推理目标是让机器存储相应的知识,并且能够按照某种规则推理演绎得到新的知识,与 AI 的主体逻辑是相融洽的。目前的主流 AI 领域,知识图谱的重要组成部分,便包括了知识推理这个步骤,即从已知到未知。
|
||||
|
||||
那么如何构建让计算机可以理解的知识体系呢?如何让机器从已告知他的逻辑延伸到未告知他逻辑呢?数学家和计算机科学家甚至为此构建了相较而言非常完善的理论体系,包括但不限于离散数学,计算理论甚至是抽象数学,我在最后补充三本阅读材料,各位如果想要深入了解,可以进行进一步的阅读和理解。
|
||||
|
||||
较为基础的知识各位可以看以下的内容。
|
||||
:::
|
||||
# 基础知识
|
||||
|
||||
- 基于知识的智能主体(Knowledge-Based Agents)
|
||||
- 智能主体通过对内部的知识表征进行操作来推理得出结论。
|
||||
- “根据知识推理得出结论”是什么意思?
|
||||
- 让我们开始用哈利波特的例子来回答这个问题。 考虑以下句子:
|
||||
1. 如果没有下雨,哈利今天会去拜访海格。
|
||||
2. 哈利今天拜访了海格或邓布利多,但没有同时拜访他们。
|
||||
3. 哈利今天拜访了邓布利多。
|
||||
- 基于这三个句子,我们可以回答“今天下雨了吗?”这个问题,尽管没有一个单独的句子告诉我们今天是否下雨,根据推理我们可以得出结论“今天下雨了”。
|
||||
- 陈述句(Sentence)
|
||||
- 陈述句是知识表示语言中关于世界的断言。 陈述句是人工智能存储知识并使用它来推断新信息的方式。
|
||||
|
||||
# 命题逻辑(Propositional Logic)
|
||||
|
||||
命题逻辑基于命题。命题是关于世界的陈述,可以是真也可以是假,正如上面例子中的句子。
|
||||
|
||||
- 命题符号(Propositional Symbols)
|
||||
- 命题符号通常是用于表示命题的字母$P、Q、R$
|
||||
- 逻辑连接词(Logical Connectives)
|
||||
- 逻辑连接词是连接命题符号的逻辑符号,以便以更复杂的方式对世界进行推理。
|
||||
- <strong>Not</strong><strong> </strong><strong>(</strong>$\lnot$<strong>)</strong> 逻辑非: 命题真值的反转。 例如,如果 $P$:“正在下雨”,那么 $¬P$:“没有下雨”。
|
||||
- 真值表用于将所有可能的真值赋值与命题进行比较。 该工具将帮助我们更好地理解与不同逻辑连接词相关联的命题的真值。 例如,下面是我们的第一个真值表:
|
||||
|
||||
| $P$ | $\lnot P$ |
|
||||
| -------- | --------- |
|
||||
| false(0) | true(1) |
|
||||
| true(1) | false(0) |
|
||||
|
||||
- <strong>And(</strong>$\land$<strong>)</strong> 逻辑乘(合取): 连接两个不同的命题。 当这两个命题$P$和$Q$用$∧$连接时,得到的命题$P∧Q$只有在$P$和$Q$都为真的情况下才为真。
|
||||
|
||||
| $P$ | $Q$ | $P\land Q$ |
|
||||
| --- | --- | ---------- |
|
||||
| 0 | 0 | 0 |
|
||||
| 0 | 1 | 0 |
|
||||
| 1 | 0 | 0 |
|
||||
| 1 | 1 | 1 |
|
||||
|
||||
- <strong>Or(</strong>$\lor$<strong>)</strong> 逻辑和(析取): 只要它的任何一个参数为真,它就为真。 这意味着要使 $P ∨ Q$为真,$P$ 或 $Q$ 中至少有一个必须为真。
|
||||
|
||||
| $P$ | $Q$ | $P\lor Q$ |
|
||||
| --- | --- | --------- |
|
||||
| 0 | 0 | 0 |
|
||||
| 0 | 1 | 1 |
|
||||
| 1 | 0 | 1 |
|
||||
| 1 | 1 | 1 |
|
||||
|
||||
|
||||
- 值得一提的是,Or有两种类型:同或Or和异或Or。在异或中,如果$P\lor Q$为真,则$P∧Q$为假。也就是说,一个异或要求它只有一个论点为真,而不要求两者都为真。如果$P、Q$或$P∧Q$中的任何一个为真,则包含或为真。在Or($\lor$)的情况下,意图是一个包含的Or。
|
||||
|
||||
- <strong>Implication (→)</strong> 逻辑蕴含: 表示“如果$P$,则$Q$的结构。例如,如果$P$:“正在下雨”,$Q$:“我在室内”,则$P→ Q$的意思是“如果下雨,那么我在室内。”在$P$的情况下,意味着$Q$,$P$被称为前件,$Q$ 被称为后件。
|
||||
|
||||
- 当前件为真时,在后件为真的情况下,整个蕴含逻辑为真(这是有道理的:如果下雨,我在室内,那么“如果下雨,那么我在室内”这句话是真的)。当前件为真时,如果后件为假,则蕴含逻辑为假(如果下雨时我在外面,那么“如果下雨,那么我在室内”这句话是假的)。然而,当前件为假时,无论后件如何,蕴含逻辑总是真的。这有时可能是一个令人困惑的概念。从逻辑上讲,我们不能从蕴含中学到任何东西$(P→ Q)$如果前件($P$)为假。看一下我们的例子,如果没有下雨,这个蕴含逻辑并没有说我是否在室内的问题。我可能是一个室内型的人,即使不下雨也不在外面走,或者我可能是一个室外型的人,不下雨的时候一直在外面。当前件是假的,我们说蕴含逻辑是真的。
|
||||
|
||||
| $P$ | $Q$ | $P\to Q$ |
|
||||
| --- | --- | -------- |
|
||||
| 0 | 0 | 1 |
|
||||
| 0 | 1 | 1 |
|
||||
| 1 | 0 | 0 |
|
||||
| 1 | 1 | 1 |
|
||||
|
||||
- <strong>Biconditional (</strong>$\leftrightarrow$<strong>)</strong> :是一个双向的蕴含。你可以把它读成“如果且仅当”$P↔ Q$等同$P→ Q$和$Q→ P$合在一起。例如,如果$P$:“正在下雨”,$Q$:“我在室内”,那么$P↔ Q$的意思是“如果下雨,那么我在室内”,“如果我在室内,那么就在下雨。”这意味着我们可以推断出比简单蕴含更多的东西。如果$P$为假,那么$Q$ 也为假;如果不下雨,我们知道我也不在室内。
|
||||
|
||||
| $P$ | $Q$ | $P\leftrightarrow Q$ |
|
||||
| --- | --- | -------------------- |
|
||||
| 0 | 0 | 1 |
|
||||
| 0 | 1 | 0 |
|
||||
| 1 | 0 | 0 |
|
||||
| 1 | 1 | 1 |
|
||||
|
||||
- 模型(Model)
|
||||
- 模型是对每个命题的真值赋值。 重申一下,命题是关于世界的陈述,可以是真也可以是假。 然而,关于世界的知识体现在这些命题的真值中。 模型是提供有关世界的信息的真值赋值。
|
||||
- 例如,如果 $P$:“正在下雨。” 和 $Q$:“今天是星期二。”,模型可以是以下真值赋值:$\set{P = True, Q = False}$。 此模型表示正在下雨,但不是星期二。 然而,在这种情况下有更多可能的模型(例如,$\set{P = True, Q = True}$,星期二并且下雨)。 事实上,可能模型的数量是命题数量的 2 次方。 在这种情况下,我们有 2 个命题,所以 $2^2=4$ 个可能的模型。
|
||||
- 知识库(Knowledge Base (KB))
|
||||
- 知识库是基于知识的智能主题已知的一组陈述句。 这是关于人工智能以命题逻辑语句的形式提供的关于世界的知识,可用于对世界进行额外的推理。
|
||||
- 蕴含推理(Entailment ($\vDash$))
|
||||
- 如果 $α ⊨ β$($α$蕴含推理出 $β$),那么在任何 $α$为真的世界中,$β$也为真。
|
||||
- 例如,如果 $α$:“今天是一月的星期二”和 $β$:“今天是星期二”,那么我们知道 $α ⊨ β$。 如果确实是一月的星期二,我们也知道这是星期二。 蕴含推理不同于逻辑蕴含。 逻辑蕴涵是两个命题之间的逻辑连接。 另一方面,推理蕴含关系是指如果 $α$中的所有信息都为真,则 $β$中的所有信息都为真。
|
||||
|
||||
# 推理(Inference)
|
||||
|
||||
推理是从原有命题推导出新命题的过程。
|
||||
|
||||
- 模型检查算法(Model Checking algorithm)
|
||||
- 确定是否$KB ⊨ α$(换句话说,回答问题:“我们能否根据我们的知识库得出结论 $α$为真?”)
|
||||
- 枚举所有可能的模型。
|
||||
- 如果在 $KB$为真的每个模型中,$α$也为真,则 $KB ⊨ α$。
|
||||
- 一个例子
|
||||
- $P$: 今天是星期四,$Q$: 今天下雨,$R$: 我将出门跑步$
|
||||
- $KB$: 如果今天是星期四并且不下雨,那我将出门跑步;今天是星期四;今天不下雨。$(P\land\lnot Q)\to R,P,\lnot Q$
|
||||
- 查询结论(query): $R$
|
||||
|
||||

|
||||
|
||||
- 接下来,让我们看看如何将知识和逻辑表示为代码。
|
||||
|
||||
```python
|
||||
from logic import * # 创建新类,每个类都有一个名称或一个符号,代表每个命题。
|
||||
rain = Symbol("rain") # 今天下雨
|
||||
hagrid = Symbol("hagrid") # 哈利拜访了海格
|
||||
dumbledore = Symbol("dumbledore") # 哈利拜访了邓布利多
|
||||
# 知识库中的陈述句
|
||||
knowledge = And( # 从“和”逻辑连接词开始,因为每个命题都代表我们知道是真实的知识。
|
||||
Implication(Not(rain), hagrid), # ¬(今天下雨) → (哈利拜访了海格)
|
||||
Or(hagrid, dumbledore), # (哈利拜访了海格) ∨ (哈利拜访了邓布利多).
|
||||
Not(And(hagrid, dumbledore)), # ¬(哈利拜访了邓布利多 ∧ 哈利拜访了海格) i.e. 哈利没有同时去拜访海格和邓布利多。
|
||||
dumbledore # 哈利拜访了邓布利多。请注意,虽然之前的命题包含多个带有连接符的符号,但这是一个由一个符号组成的命题。 这意味着我们将在这个 KB 中,Harry 拜访了 Dumbledore 作为事实。
|
||||
)
|
||||
```
|
||||
|
||||
- 要运行模型检查算法,需要以下信息:
|
||||
|
||||
- 知识库(KB),将用于得出推论
|
||||
- 一个查询结论(query),或者我们感兴趣的命题是否被$KB$包含
|
||||
- 命题符号,所有使用的符号(或原子命题)的列表(在我们的例子中,这些是 rain、hagrid 和 dumbledore)
|
||||
- 模型,将真值和假值分配给命题
|
||||
- 模型检查算法如下所示:
|
||||
|
||||
```python
|
||||
def check_all(knowledge, query, symbols, model):# 如果模型对每个符号都有一个赋值
|
||||
# (下面的逻辑可能有点混乱:我们从命题符号列表开始。该函数是递归的,每次调用自身时,它都会从命题符号列表中弹出一个命题符号并从中生成模型。 因此,当命题符号列表为空时,我们知道我们已经完成生成模型,其中包含每个可能的命题真值分配。)
|
||||
if not symbols:
|
||||
# 如果知识库在模型中为真,则查询结论也必须为真
|
||||
if knowledge.evaluate(model):
|
||||
return query.evaluate(model)
|
||||
return True
|
||||
else:
|
||||
# 选择剩余未使用的符号之一
|
||||
remaining = symbols.copy()
|
||||
p = remaining.pop()
|
||||
# 创建一个模型,其中命题符号为真
|
||||
model_true = model.copy()
|
||||
model_true[p] = True
|
||||
# 创建一个模型,其中命题符号为假
|
||||
model_false = model.copy()
|
||||
model_false[p] = False
|
||||
# 确保两种模型都进行蕴含推理
|
||||
return(check_all(knowledge, query, remaining, model_true) and check_all(knowledge, query, remaining, model_false))
|
||||
```
|
||||
|
||||
- 请注意,我们只对$KB$为真的模型感兴趣。 如果$KB$为假,那么我们知道真实的条件并没有出现在这些模型中,使它们与我们的案例无关。
|
||||
|
||||
> 另一个例子:假设 $P$:Harry 扮演找球手,$Q$:Oliver 扮演守门员,$R$:Gryffindor获胜。 我们的$KB$指定$P$, $Q$, $(P ∧ Q) \to R$。换句话说,我们知道$P$为真,即Harry扮演找球手,$Q$为真,即Oliver扮演守门员,并且如果$P$和$Q$都为真, 那么$R$也为真,这意味着Gryffindor赢得了比赛。 现在想象一个模型,其中Harry扮演击球手而不是找球手(因此,Harry没有扮演找球手,$¬P$)。 嗯,在这种情况下,我们不关心Gryffindor是否赢了(无论$R$是否为真),因为我们的$KB$中有信息表明Harry扮演的是找球手而不是击球手。 我们只对$P$和$Q$ 为真的模型感兴趣。)
|
||||
|
||||
- 此外,`check_all` 函数的工作方式是递归的。 也就是说,它选择一个命题符号,创建两个模型,其中一个符号为真,另一个为假,然后再次调用自己,现在有两个模型因该命题符号的真值分配不同而不同。 该函数将继续这样做,直到所有符号都已在模型中分配了真值,使 `symbol` 符号为空。 一旦它为空(由 `if not symbols` 行标识),在函数的每个实例中(其中每个实例都包含不同的模型),函数检查$KB$是否为给定的有效模型。 如果$KB$在此模型中为真,函数将检查查询结论是否为真,如前所述。
|
||||
|
||||
# 知识工程(Knowledge Engineering)
|
||||
|
||||
知识工程是弄清楚如何在 AI 中表示命题和逻辑的工程。
|
||||
|
||||
## 推理规则(Inference Rules)
|
||||
|
||||
- 模型检查不是一种有效的算法,因为它必须在给出答案之前考虑每个可能的模型(提醒:如果在$KB$为真的所有模型(真值分配)下,查询结论$R$为真,则$R$ 也为真)。 推理规则允许我们根据现有知识生成新信息,而无需考虑所有可能的模型。
|
||||
- 推理规则通常使用将顶部部分(前提)与底部部分(结论)分开的水平条表示。 前提是我们有什么知识,结论是根据这个前提可以产生什么知识。
|
||||
|
||||

|
||||
|
||||
- 肯定前件(Modus Ponens)
|
||||
|
||||
- 如果我们知道一个蕴涵及其前件为真,那么后件也为真。
|
||||
|
||||

|
||||
|
||||
- 合取消除(And Elimination)
|
||||
|
||||
- 如果 And 命题为真,则其中的任何一个原子命题也为真。 例如,如果我们知道哈利与罗恩和赫敏是朋友,我们就可以得出结论,哈利与赫敏是朋友。
|
||||
|
||||

|
||||
|
||||
- 双重否定消除(Double Negation Elimination)
|
||||
|
||||
- 被两次否定的命题为真。 例如,考虑命题“哈利没有通过考试是不正确的”。 这两个否定相互抵消,将命题“哈利通过考试”标记为真。
|
||||
|
||||

|
||||
|
||||
- 蕴含消除(Implication Elimination)
|
||||
|
||||
- 蕴涵等价于被否定的前件和后件之间的 Or 关系。 例如,命题“如果正在下雨,哈利在室内”等同于命题“(没有下雨)或(哈利在室内)”。
|
||||
|
||||

|
||||
|
||||
| $P$ | $Q$ | $P\to Q$ | $\lnot P\lor Q$ |
|
||||
| --- | --- | -------- | --------------- |
|
||||
| 0 | 0 | 1 | 1 |
|
||||
| 0 | 1 | 1 | 1 |
|
||||
| 1 | 0 | 0 | 0 |
|
||||
| 1 | 1 | 1 | 1 |
|
||||
|
||||
- 等值消除(Biconditional Elimination)
|
||||
|
||||
- 等值命题等价于蕴涵及其逆命题的 And 关系。 例如,“当且仅当 Harry 在室内时才下雨”等同于(“如果正在下雨,Harry 在室内”和“如果 Harry 在室内,则正在下雨”)。
|
||||
|
||||

|
||||
|
||||
- 德摩根律(De Morgan’s Law)
|
||||
|
||||
- 可以将 And 连接词变成 Or 连接词。考虑以下命题:“哈利和罗恩都通过了考试是不正确的。” 由此,可以得出“哈利通过考试不是真的”或者“罗恩不是真的通过考试”的结论。 也就是说,要使前面的 And 命题为真,Or 命题中至少有一个命题必须为真。
|
||||
|
||||

|
||||
|
||||
- 同样,可以得出相反的结论。考虑这个命题“哈利或罗恩通过考试是不正确的”。 这可以改写为“哈利没有通过考试”和“罗恩没有通过考试”。
|
||||
|
||||

|
||||
|
||||
- 分配律(Distributive Property)
|
||||
|
||||
- 具有两个用 And 或 Or 连接词分组的命题可以分解为由 And 和 Or 组成的更小单元。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## 知识和搜索问题
|
||||
|
||||
- 推理可以被视为具有以下属性的搜索问题:
|
||||
|
||||
- 初始状态:知识库
|
||||
- 动作:推理规则
|
||||
- 过渡模型:推理后的新知识库
|
||||
- 目标测试:检查我们要证明的语句是否在知识库中
|
||||
- 路径成本:证明中的步骤数
|
||||
- 这显示了搜索算法的通用性,使我们能够使用推理规则根据现有知识推导出新信息。
|
||||
|
||||
# 归结(Resolution)
|
||||
|
||||
- 归结是一个强大的推理规则,它规定如果 Or 命题中的两个原子命题之一为假,则另一个必须为真。 例如,给定命题“Ron 在礼堂”或“Hermione 在图书馆”,除了命题“Ron 不在礼堂”之外,我们还可以得出“Hermione 在图书馆”的结论。 更正式地说,我们可以通过以下方式定义归结:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
- 归结依赖于互补文字,两个相同的原子命题,其中一个被否定而另一个不被否定,例如$P$和$¬P$。
|
||||
- 归结可以进一步推广。 假设除了“Rom 在礼堂”或“Hermione 在图书馆”的命题外,我们还知道“Rom 不在礼堂”或“Harry 在睡觉”。 我们可以从中推断出“Hermione 在图书馆”或“Harry 在睡觉”。 正式地说:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
- 互补文字使我们能够通过解析推理生成新句子。 因此,推理算法定位互补文字以生成新知识。
|
||||
- 从句(Clause)是多个原子命题的析取式(命题符号或命题符号的否定,例如$P$, $¬P$)。 析取式由Or逻辑连接词 ($P ∨ Q ∨ R$) 相连的命题组成。 另一方面,连接词由And逻辑连接词 ($P ∧ Q ∧ R$) 相连的命题组成。 从句允许我们将任何逻辑语句转换为合取范式 (CNF),它是从句的合取,例如:$(A ∨ B ∨ C) ∧ (D ∨ ¬E) ∧ (F ∨ G)$。
|
||||
- 命题转换为合取范式的步骤、
|
||||
|
||||
- 等值消除
|
||||
|
||||
- 将$(α↔ β)$转化为$(α→ β)∧ (β → α)$
|
||||
- 蕴含消除
|
||||
|
||||
- 将$(α→ β)$转化为$\lnotα∧β$
|
||||
- 使用德摩根定律,将否定向内移动,直到只有原子命题被否定(而不是从句)
|
||||
|
||||
- 将$\lnot(\alpha∧β)$转换为$\lnotα\lor\lnotβ$
|
||||
- 下面是一个转换$(P∧Q)\to R$
|
||||
|
||||
到合取范式的例子:
|
||||
|
||||
- $(P ∨ Q) → R$
|
||||
- $\lnot(P\lor Q)\lor R$蕴含消除
|
||||
- $(\lnot P\land\lnot Q)\lor R$德摩根律
|
||||
- $(\lnot P\lor R)\land(\lnot Q\lor R)$分配律
|
||||
- 归结命题及其否定,即$\lnot P$和$P$,得到空从句$()$。空从句总是假的,这是有道理的,因为$P$和$\lnot P$ 不可能都是真的。归结算法使用了这个事实。
|
||||
|
||||
- 确定是否$KB⊨α$:
|
||||
|
||||
- 检查:$(KB∧\lnotα)$是矛盾的吗?
|
||||
|
||||
- 如果是这样,那么$KB⊨α$。
|
||||
- 否则,$KB$无法蕴含推理出$\alpha$。
|
||||
- 矛盾证明是计算机科学中经常使用的一种工具。如果我们的知识库是真的,并且它与$\lnot α$相矛盾,那就意味着$\lnot\alpha$是假的,因此$α$必须是真的。从技术上讲,该算法将执行以下操作:
|
||||
|
||||
- 确定是否$KB⊨α$:
|
||||
- 将$(KB∧\lnotα)$转换为合取范式。
|
||||
- 继续检查,看看我们是否可以使用归结来生成一个新的从句。
|
||||
- 如果我们生成了空从句(相当于 False),那么恭喜你!我们得出了一个矛盾,从而证明了$KB⊨α$。
|
||||
- 然而,如果没有实现矛盾,并且不能推断出更多的从句,那么就没有蕴含性。
|
||||
- 以下是一个示例,说明了该算法的工作原理:
|
||||
- $(A ∨ B) ∧ (¬B ∨ C) ∧ (¬C)\vDash A?$
|
||||
- $(A ∨ B) ∧ (¬B ∨ C) ∧ (¬C) ∧ (¬A)$
|
||||
- $(\lnot B\lor C)\land\lnot C\vDash\lnot B\implies(A ∨ B) ∧ (¬B ∨ C) ∧ (¬C) ∧ (¬A)\land (\lnot B)$
|
||||
- $(A\lor B)\land\lnot B\vDash A\implies(A ∨ B) ∧ (¬B ∨ C) ∧ (¬C) ∧ (¬A)\land (\lnot B)\land(A)$
|
||||
- $(\lnot A\land A)\vDash ()\implies(A ∨ B) ∧ (¬B ∨ C) ∧ (¬C) ∧ (¬A)\land (\lnot B)\land(A)\land ()\implies False$
|
||||
|
||||
# 一阶逻辑(First Order Logic)
|
||||
|
||||
- 一阶逻辑是另一种类型的逻辑,它使我们能够比命题逻辑更简洁地表达更复杂的想法。一阶逻辑使用两种类型的符号:常量符号和谓词符号。常量符号表示对象,而谓词符号类似于接受参数并返回 true 或 false 值的关系或函数。
|
||||
- 例如,我们回到霍格沃茨不同的人和家庭作业的逻辑谜题。常量符号是指人或房子,如 Minerva、Pomona、Gryffindor、Hufflepuff 等。谓语符号是一些常量符号的真或虚的属性。例如,我们可以使用句子 `person(Minerva)` 来表达 Minerva 是一个人的想法。同样,我们可以用 `house(Gryffindor)` 这个句子来表达 Gryffindor 是一所房子的想法。所有的逻辑连接词都以与以前相同的方式在一阶逻辑中工作。例如,$\lnot$`House(Minerva)` 表达了 Minerva 不是房子的想法。谓词符号也可以接受两个或多个自变量,并表达它们之间的关系。例如,BelongsTo 表达了两个论点之间的关系,即人和人所属的房子。因此,Minerva 拥有 Gryffindor 的想法可以表达为 `BelongsTo(Minerva,Gryffindor)`。一阶逻辑允许每个人一个符号,每个房子一个符号。这比命题逻辑更简洁,因为命题逻辑中每个人的房屋分配都需要不同的符号。
|
||||
- 全称量化(Universal Quantification)
|
||||
|
||||
- 量化是一种可以在一阶逻辑中使用的工具,可以在不使用特定常量符号的情况下表示句子。全称量化使用符号$∀$来表示“所有”。例如,$\forall x(BelongsTo(x, Gryffindor) → ¬BelongsTo(x, Hufflepuff))$表达了这样一种观点,即对于每个符号来说,如果这个符号属于 Gryffindor,那么它就不属于 Hufflepuff。
|
||||
- 存在量化(Existential Quantification)
|
||||
|
||||
- 存在量化是一个与全称量化平行的概念。然而,虽然全称量化用于创建对所有$x$都成立的句子,但存在量化用于创建至少对一个$x$成立的句子。它使用符号$∃$表示。例如,$∃x(House(x) ∧ BelongsTo(Minerva, x))$ 意味着至少有一个符号既是房子,又是属于 Minerva。换句话说,这表达了Minerva 拥有房子的想法。
|
||||
- 存在量化和全称量化可以用在同一个句子中。例如,$∀x(Person(x) → (∃y(House(y) ∧ BelongsTo(x, y))))$表达了这样一种观点,即如果$x$是一个人,那么这个人至少拥有一个房子$y$。换句话说,这句话的意思是每个人都拥有一所房子。
|
||||
|
||||
还有其他类型的逻辑,它们之间的共同点是,它们都是为了表示信息而存在的。这些是我们用来在人工智能中表示知识的系统。
|
||||
|
||||
# 补充材料
|
||||
|
||||
Introduction to the Theory of Computation, Third International Edition (Michael Sipser)
|
||||
|
||||
具体数学:计算机科学基础.第 2 版
|
||||
@@ -1,58 +0,0 @@
|
||||
# 程序示例
|
||||
::: tip
|
||||
阅读程序,然后“玩一玩”程序!
|
||||
|
||||
完成习题
|
||||
:::
|
||||
|
||||
|
||||
::: tip 📥
|
||||
本节附件下载 <Download url="https://pic-hdu-cs-wiki-1307923872.cos.ap-shanghai.myqcloud.com/code/3-Lecture.zip"/>
|
||||
:::
|
||||
|
||||
本节代码不做额外梳理,[不确定性问题](./4.3.3%E4%B8%8D%E7%A1%AE%E5%AE%9A%E6%80%A7%E9%97%AE%E9%A2%98.md) 中已有解释。
|
||||
|
||||
## Quiz
|
||||
|
||||
1. 考虑一副标准的 52 张牌,在四种花色(梅花、方块、红心、黑桃)中各有 13 种牌值(A、K、Q、J 和 2-10)。如果随机抽出一张牌,它是黑桃或 2 的概率是多少?
|
||||
1. About 0.019
|
||||
2. About 0.077
|
||||
3. About 0.17
|
||||
4. About 0.25
|
||||
5. About 0.308
|
||||
6. About 0.327
|
||||
7. About 0.5
|
||||
8. None of the above
|
||||
2. 想象一下,抛出两枚硬币,每枚硬币都有正面和反面,50% 的时间出现正面,50% 的时间出现反面。抛出这两枚硬币后,其中一枚是正面,另一枚是反面的概率是多少?
|
||||
1. 0
|
||||
2. 0.125
|
||||
3. 0.25
|
||||
4. 0.375
|
||||
5. 0.5
|
||||
6. 0.625
|
||||
7. 0.75
|
||||
8. 0.875
|
||||
9. 1
|
||||
3. 回答关于贝叶斯网络的问题,问题如下:
|
||||
|
||||

|
||||
|
||||
以下哪句话是真的?
|
||||
|
||||
1. 假设我们知道有轨道维护,那么是否有雨并不影响列车准时到达的概率。
|
||||
2. 假设我们知道有雨,那么是否有轨道维修并不影响列车准时到达的概率。
|
||||
3. 假设我们知道火车是准时的,是否有雨会影响到赴约的概率。
|
||||
4. 假设我们知道火车是准时的,那么是否有轨道维修并不影响赴约的概率。
|
||||
5. 假设我们知道有轨道维护,那么是否有雨并不影响参加约会的概率。
|
||||
4. 两家工厂--A 厂和 B 厂--设计用于手机的电池。A 厂生产 60% 的电池,B 厂生产另外 40%。A 厂 2% 的电池有缺陷,B 厂 4% 的电池有缺陷。一个电池既由 A 厂生产又有缺陷的概率是多少?
|
||||
1. 0.008
|
||||
2. 0.012
|
||||
3. 0.024
|
||||
4. 0.028
|
||||
5. 0.02
|
||||
6. 0.06
|
||||
7. 0.12
|
||||
8. 0.2
|
||||
9. 0.429
|
||||
10. 0.6
|
||||
11. None of the above
|
||||
@@ -1,98 +0,0 @@
|
||||
# 项目:遗传
|
||||
|
||||
::: tip
|
||||
我们为你提供了一个简单有趣的项目,帮助你进行知识巩固,请认真阅读文档内容。
|
||||
|
||||
如果你卡住了,请记得回来阅读文档,或请求身边人的帮助。
|
||||
:::
|
||||
|
||||
::: tip 📥
|
||||
本节附件下载 <Download url="https://pic-hdu-cs-wiki-1307923872.cos.ap-shanghai.myqcloud.com/code/3-Projects.zip"/>
|
||||
:::
|
||||
|
||||
## 背景
|
||||
|
||||
- GJB2 基因的突变版本是导致新生儿听力障碍的主要原因之一。每个人都携带两个版本的基因,因此每个人都有可能拥有 0、1 或 2 个听力障碍版本的 GJB2 基因。不过,除非一个人接受基因测试,否则要知道一个人拥有多少个变异的 GJB2 基因并不那么容易。这是一些 "隐藏状态":具有我们可以观察到的影响(听力损伤)的信息,但我们不一定直接知道。毕竟,有些人可能有 1 或 2 个突变的 GJB2 基因,但没有表现出听力障碍,而其他人可能没有突变的 GJB2 基因,但仍然表现出听力障碍。
|
||||
- 每个孩子都会从他们的父母那里继承一个 GJB2 基因。如果父母有两个变异基因,那么他们会将变异基因传给孩子;如果父母没有变异基因,那么他们不会将变异基因传给孩子;如果父母有一个变异基因,那么该基因传给孩子的概率为 0.5。不过,在基因被传递后,它有一定的概率发生额外的突变:从导致听力障碍的基因版本转变为不导致听力障碍的版本,或者反过来。
|
||||
- 我们可以尝试通过对所有相关变量形成一个贝叶斯网络来模拟所有这些关系,就像下面这个网络一样,它考虑了一个由两个父母和一个孩子组成的家庭。
|
||||
|
||||

|
||||
|
||||
- 家庭中的每个人都有一个 `Gene` 随机变量,代表一个人有多少个特定基因(例如,GJB2 的听力障碍版本):一个 0、1 或 2 的值。家族中的每个人也有一个 `Trait` 随机变量,它是 `yes` 或 `no`,取决于该人是否表达基于该基因的性状(例如,听力障碍)。从每个人的 `Gene` 变量到他们的 `Trait` 变量之间有一个箭头,以编码一个人的基因影响他们具有特定性状的概率的想法。同时,也有一个箭头从母亲和父亲的 `Gene` 随机变量到他们孩子的 `Gene` 随机变量:孩子的基因取决于他们父母的基因。
|
||||
- 你在这个项目中的任务是使用这个模型对人群进行推断。给出人们的信息,他们的父母是谁,以及他们是否具有由特定基因引起的特定可观察特征(如听力损失),你的人工智能将推断出每个人的基因的概率分布,以及任何一个人是否会表现出有关特征的概率分布。
|
||||
|
||||
## 理解
|
||||
|
||||
- 打开 `data/family0.csv`,看看数据目录中的一个样本数据集(你可以在文本编辑器中打开,或者在 Google Sheets、Excel 或 Apple Numbers 等电子表格应用程序中打开)。注意,第一行定义了这个 CSV 文件的列:`name`, `mother`, `father`, 和 `trait`。下一行表明 Harry 的母亲是 Lily,父亲是 James,而 `Trait` 的空单元格意味着我们不知道 Harry 是否有这种性状。同时,James 在我们的数据集中没有列出父母(如母亲和父亲的空单元格所示),但确实表现出了性状(如 `Trait` 单元格中的 1 所示)。另一方面,Lily 在数据集中也没有列出父母,但没有表现出这种性状(如 `Trait` 单元格中的 0 表示)。
|
||||
- 打开 `heredity.py`,首先看一下 `PROBS` 的定义。`PROBS` 是一个包含若干常数的字典,代表各种不同事件的概率。所有这些事件都与一个人拥有多少个特定的突变基因,以及一个人是否基于该基因表现出特定的性状有关。这里的数据松散地基于 GJB2 基因的听力障碍版本和听力障碍性状的概率,但通过改变这些值,你也可以用你的人工智能来推断其他的基因和性状!
|
||||
- 首先,`PROBS["gene"]` 代表了该基因的无条件概率分布(即如果我们对该人的父母一无所知的概率)。根据分布代码中的数据,在人群中,有 1% 的机会拥有该基因的 2 个副本,3% 的机会拥有该基因的 1 个副本,96% 的机会拥有该基因的零副本。
|
||||
- 接下来,`PROBS["trait"]` 表示一个人表现出某种性状(如听力障碍)的条件概率。这实际上是三个不同的概率分布:基因的每个可能值都有一个。因此,`PROBS["trait"][2]` 是一个人在有两个突变基因的情况下具有该特征的概率分布:在这种情况下,他们有 65% 的机会表现出该特征,而有 35% 的机会不表现出该特征。同时,如果一个人有 0 个变异基因,他们有 1% 的机会表现出该性状,99% 的机会不表现出该性状。
|
||||
- 最后,`PROBS["mutation"]` 是一个基因从作为相关基因突变为不是该基因的概率,反之亦然。例如,如果一个母亲有两个变异基因,并因此将其中一个传给她的孩子,就有 1% 的机会突变为不再是变异基因。相反,如果一个母亲没有任何变异基因,因此没有把变异基因传给她的孩子,但仍有 1% 的机会突变为变异基因。因此,即使父母双方都没有变异基因,他们的孩子也可能有 1 个甚至 2 个变异基因。
|
||||
- 最终,你计算的概率将以 `PROBS` 中的这些数值为基础。
|
||||
- 现在,看一下 `main` 函数。该函数首先将数据从一个文件加载到一个字典 `people` 中。`people` 将每个人的名字映射到另一个包含他们信息的字典中:包括他们的名字,他们的母亲(如果数据集中有一个母亲),他们的父亲(如果数据集中有一个父亲),以及他们是否被观察到有相关的特征(如果有则为 `True`,没有则为 `False`,如果我们不知道则为 `None`)。
|
||||
- 接下来,`main` 中定义了一个字典 `probabilities`,所有的概率最初都设置为 0。这就是你的项目最终要计算的内容:对于每个人,你的人工智能将计算他们有多少个变异基因的概率分布,以及他们是否具有该性状。例如,`probabilities["Harry"]["gene"][1]` 将是 Harry 有 1 个变异基因的概率,而 `probabilities["Lily"]["trait"][False]` 将是 Lily 没有表现出该性状的概率。
|
||||
- 如果不熟悉的话,这个 `probabilities` 字典是用 [python 字典](https://www.python.org/dev/peps/pep-0274/)创建的,在这种情况下,它为我们的 `people` 中的每个 `person` 创建一个键/值对。
|
||||
- 最终,我们希望根据一些证据来计算这些概率:鉴于我们知道某些人有或没有这种特征,我们想确定这些概率。你在这个项目中的任务是实现三个函数来做到这一点: `joint_probability` 计算一个联合概率,`update` 将新计算的联合概率添加到现有的概率分布中,然后 `normalize` 以确保所有概率分布最后和为 1。
|
||||
|
||||
## 明确
|
||||
|
||||
- 完成 `joint_probability`、`update` 和 `normalize` 的实现。
|
||||
- `joint_probability` 函数应该接受一个 `people` 的字典作为输入,以及关于谁拥有多少个变异基因,以及谁表现出该特征的数据。该函数应该返回所有这些事件发生的联合概率。
|
||||
|
||||
- 该函数接受四个数值作为输入:`people`, `one_gene`, `two_genes`, 和 `have_trait`。
|
||||
|
||||
- `people` 是一个在 "理解"一节中描述的人的字典。键代表名字,值是包含 `mother` 和 `father` 键的字典。你可以假设 `mother` 和 `father` 都是空白的(数据集中没有父母的信息),或者 `mother` 和 `father` 都会指代 `people` 字典中的其他人物。
|
||||
- `one_gene` 是一个集合,我们想计算所有集合元素有一个变异基因的概率。
|
||||
- `two_genes` 是一个集合,我们想计算所有集合元素有两个变异基因的概率。
|
||||
- `have_trait` 是一个集合,我们想计算所有集合元素拥有该性状的概率。
|
||||
- 对于不在 `one_gene` 或 t `wo_genes` 中的人,我们想计算他们没有变异基因的概率;对于不在 `have_trait` 中的人,我们想计算他们没有该性状的概率。
|
||||
|
||||
- 例如,如果这个家庭由 Harry、James 和 Lily 组成,那么在 `one_gene = {"Harry"}`、`two_genes = {"James"}` 和 `trait = {"Harry"、"James"}` 的情况下调用这个函数,应该计算出 Lily 没有变异基因、Harry 拥有一个变异基因、James 拥有两个变异基因、Harry 表现出该性状、James 表现出该性状和 Lily 没有表现出该性状的联合概率。
|
||||
- 对于数据集中没有列出父母的人,使用概率分布 `PROBS["gene"]` 来确定他们有特定数量基因的概率。
|
||||
- 对于数据集中有父母的人来说,每个父母都会把他们的两个基因中的一个随机地传给他们的孩子,而且有一个 `PROBS["mutation"]` 的机会,即它会发生突变(从变异基因变成正常基因,或者相反)。
|
||||
- 使用概率分布 `PROBS["trait"]` 来计算一个人具有或不具有形状的概率。
|
||||
- `update` 函数将一个新的联合分布概率添加到 `probabilities` 中的现有概率分布中。
|
||||
|
||||
- 该函数接受五个值作为输入:`probabilities`, `one_gene`, `two_genes`, `have_trait`, 和 `p`。
|
||||
|
||||
- `probabilities` 是一个在 "理解 "部分提到的字典。每个人都被映射到一个 `"gene"` 分布和一个 `"trait"` 分布。
|
||||
- `one_gene` 是一个集合,我们想计算所有集合元素有一个变异基因的概率。
|
||||
- `two_genes` 是一个集合,我们想计算所有集合元素有两个变异基因的概率。
|
||||
- `have_trait` 是一个集合,我们想计算所有集合元素拥有该性状的概率。
|
||||
- `p` 是联合分布的概率。
|
||||
- 对于概率中的每个人,该函数应该更新 `probabilities[person]["gene"]` 分布和 `probabilities[person]["trait"]` 分布,在每个分布中的适当数值上加上 `p`。所有其他数值应保持不变。
|
||||
- 例如,如果"Harry"同时出现在 `two_genes` 和 `have_trait` 中,那么 `p` 将被添加到 `probabilities["Harry"]["gene"][2]` 和 `probabilities["Harry"]["trait"][True]`。
|
||||
- 该函数不应返回任何值:它只需要更新 `probabilities` 字典。
|
||||
- `normalize` 函数更新 `probabilities` 字典,使每个概率分布被归一化(即和为 1,相对比例相同)。
|
||||
|
||||
- 该函数接受一个单一的值:`probabilities`。
|
||||
|
||||
- `probabilities` 是一个在"理解"部分提到的字典。每个人都被映射到一个 `"gene"` 分布和一个 `"trait"` 分布。
|
||||
- 对于 `probabilities` 中每个人的两个分布,这个函数应该将该分布归一化,使分布中的数值之和为 1,分布中的相对数值是相同的。
|
||||
- 例如,如果 `probabilities["Harry"]["trait"][True]` 等于 `0.1`,概率 `probabilities["Harry"]["trait"][False]` 等于 `0.3`,那么你的函数应该将前一个值更新为 `0.25`,后一个值更新为 `0.75`: 现在数字之和为 1,而且后一个值仍然比前一个值大三倍。
|
||||
- 该函数不应返回任何值:它只需要更新 `probabilities` 字典。
|
||||
- 除了规范中要求你实现的三个函数外,你不应该修改 `heredity.py` 中的任何其他东西,尽管你可以编写额外的函数和/或导入其他 Python 标准库模块。如果熟悉的话,你也可以导入 `numpy` 或 `pandas`,但是你不应该使用任何其他第三方 Python 模块。
|
||||
|
||||
## 一个联合概率例子
|
||||
|
||||
- 为了帮助你思考如何计算联合概率,我们在下面附上一个例子。
|
||||
- 请考虑以下 `people` 的值:
|
||||
|
||||
```python
|
||||
{
|
||||
'Harry': {'name': 'Harry', 'mother': 'Lily', 'father': 'James', 'trait': None},
|
||||
'James': {'name': 'James', 'mother': None, 'father': None, 'trait': True},
|
||||
'Lily': {'name': 'Lily', 'mother': None, 'father': None, 'trait': False}
|
||||
}
|
||||
```
|
||||
|
||||
- 这里我们将展示 `joint_probability(people, {"Harry"}, {"James"}, {"James"})` 的计算。根据参数,`one_gene` 是 `{"Harry"}`,`two_genes` 是 `{"James"}`,而 `has_trait` 是 `{"James"}`。因此,这代表了以下的概率:Lily 没有变异基因,不具有该性状;Harry 有一个变异基因,不具有该性状;James 有 2 个变异基因,具有该性状。
|
||||
- 我们从 Lily 开始(我们考虑人的顺序并不重要,只要我们把正确的数值乘在一起,因为乘法是可交换的)。Lily 没有变异基因,概率为 `0.96`(这就是 `PROBS["gene"][0]`)。鉴于她没有变异基因,她没有这个性状的概率为 `0.99`(这是 `PROBS["trait"][0][False]`)。因此,她没有变异基因且没有该性状的概率是 `0.96*0.99=0.9504`。
|
||||
- 接下来,我们考虑 James。James 有 2 个变异基因,概率为 `0.01`(这是 `PROBS["gene"][2]`)。鉴于他有 2 个变异基因,他确实具有该性状的概率为 `0.65`。因此,他有 2 个变异基因并且他确实具有该性状的概率是 `0.01*0.65=0.0065`。
|
||||
- 最后,我们考虑 Harry。Harry 有 1 个变异基因的概率是多少?有两种情况可以发生。要么他从母亲那里得到这个基因,而不是从父亲那里,要么他从父亲那里得到这个基因,而不是从母亲那里。他的母亲 Lily 没有变异基因,所以 Harry 会以 `0.01` 的概率从他母亲那里得到这个基因(这是 `PROBS["mutation"]`),因为从他母亲那里得到这个基因的唯一途径是基因突变;相反,Harry 不会从他母亲那里得到这个基因,概率是 `0.99`。他的父亲 James 有 2 个变异基因,所以 Harry 会以 `0.99` 的概率从他父亲那里得到这个基因(这是 `1-PROBS["mutation"]`),但会以 `0.01` 的概率从他母亲那里得到这个基因(突变的概率)。这两种情况加在一起可以得到 `0.99*0.99+0.01*0.01=0.9802`,即 Harry 有 1 个变异基因的概率。
|
||||
- 考虑到 Harry 有 1 个变异基因,他没有该性状的概率是 `0.44`(这是 `PROBS["trait"][1][false]`)。因此,哈利有 1 个变异基因而没有该性状的概率是 `0.9802 * 0.44 = 0.431288`。
|
||||
- 因此,整个联合概率是三个人中每个人的所有这些数值相乘的结果: `0.9504 * 0.0065 * 0.431288 = 0.0026643247488`。
|
||||
|
||||
## 提示
|
||||
|
||||
- 回顾一下,要计算多个事件的联合概率,你可以通过将这些概率相乘来实现。但请记住,对于任何孩子来说,他们拥有一定数量的基因的概率是以他们的父母拥有什么基因为条件的。
|
||||
@@ -1,465 +0,0 @@
|
||||
# 不确定性问题
|
||||
|
||||
- 上一讲中,我们讨论了人工智能如何表示和推导新知识。然而,在现实中,人工智能往往对世界只有部分了解,这给不确定性留下了空间。尽管如此,我们还是希望我们的人工智能在这些情况下做出尽可能好的决定。例如,在预测天气时,人工智能掌握了今天的天气信息,但无法 100% 准确地预测明天的天气。尽管如此,我们可以做得比偶然更好,今天的讲座是关于我们如何创造人工智能,在有限的信息和不确定性的情况下做出最佳决策。
|
||||
|
||||
## 概率(Probability)
|
||||
|
||||
- 不确定性可以表示为多个事件以及每一个事件发生的可能性或概率。
|
||||
|
||||
### 概率世界
|
||||
|
||||
- 每一种可能的情况都可以被视为一个世界,由小写的希腊字母$ω$表示。例如,掷骰子可以产生六个可能的世界:骰子出现 1 的世界,骰子出现 2 的世界,依此类推。为了表示某个世界的概率,我们写$P(ω)$。
|
||||
|
||||
### 概率公理
|
||||
|
||||
- $0<P(ω)<1$ :表示概率的每个值必须在0和1之间。
|
||||
- 0是一个不可能发生的事件,就像掷一个标准骰子并出现7一样。
|
||||
- 1是肯定会发生的事件,比如掷标准骰子,得到的值小于10。
|
||||
- 一般来说,值越高,事件发生的可能性就越大。
|
||||
- 每一个可能发生的事件的概率加在一起等于 1。
|
||||
|
||||
$
|
||||
\sum_{\omega\in\Omega}P(\omega)=1
|
||||
$
|
||||
|
||||
- 用标准骰子掷出数字 R 的概率可以表示为 $P(R)$ 。在我们的例子中,$P(R)=1/6$ ,因为有六个可能的世界(从 1 到 6 的任何数字),并且每个世界有相同的可能性发生。现在,考虑掷两个骰子的事件。现在,有 36 个可能的事件,同样有相同的可能性发生。
|
||||
|
||||

|
||||
|
||||
- 然而,如果我们试图预测两个骰子的总和,会发生什么?在这种情况下,我们只有 11 个可能的值(总和必须在 2 到 12 之间),而且它们的出现频率并不相同。
|
||||
|
||||

|
||||
|
||||
- 为了得到事件发生的概率,我们将事件发生的世界数量除以可能发生的世界总数。例如,当掷两个骰子时,有 36 个可能的世界。只有在其中一个世界中,当两个骰子都得到 6 时,我们才能得到 12 的总和。因此,$P(12)=\frac{1}{36}$,或者,换句话说,掷两个骰子并得到两个和为 12 的数字的概率是$\frac{1}{36}$。$P(7)$是多少?我们数了数,发现和 7 出现在 6 个世界中。因此,$P(7)=\frac{6}{36}=\frac{1}{6}$。
|
||||
|
||||
### 无条件概率(Unconditional Probability)
|
||||
|
||||
- 无条件概率是指在没有任何其他证据的情况下对命题发生的概率。到目前为止,我们所问的所有问题都是无条件概率的问题,因为掷骰子的结果并不取决于之前的事件。
|
||||
|
||||
## 条件概率(Conditional Probability)
|
||||
|
||||
- 条件概率是在给定一些已经揭示的证据的情况下,命题发生的概率。正如引言中所讨论的,人工智能可以利用部分信息对未来进行有根据的猜测。为了使用这些影响事件在未来发生概率的信息,我们需要依赖条件概率。
|
||||
- 条件概率用以下符号表示:$P(a|b)$,意思是“如果我们知道事件$b$已经发生,事件$a$发生的概率”,或者更简洁地说,“给定$b$的概率”。现在我们可以问一些问题,比如如果昨天下雨,今天下雨的概率是多少$P(今天下雨 | 昨天下雨)$,或者给定患者的测试结果,患者患有该疾病的概率 $P(疾病 | 测试结果)$ 是多少。
|
||||
- 在数学上,为了计算给定$b$的条件概率,我们使用公式:$P(a|b)=\frac{P(a\land b)}{P(b)}$
|
||||
- 换句话说,给定$b$为真的概率等于$a$并且$b$为真,除以$b$的概率。对此进行推理的一种直观方式是认为“我们对$a$并且$b$都为真的事件(分子)感兴趣,但只对我们知道$b$为真(分母)的世界感兴趣。“除以 $b$ 将可能的世界限制在 $b$ 为真的世界。以下是上述公式的代数等价形式:
|
||||
|
||||
$P(a\land b)=P(b)P(a|b)$
|
||||
|
||||
$P(a\land b)=P(a)P(b|a)$
|
||||
|
||||
- 例如,考虑$P(总和为12|在一个骰子上掷出6)$,或者掷两个骰子假设我们已经掷了一个骰子并获得了六,得到十二的概率。为了计算这一点,我们首先将我们的世界限制在第一个骰子的值为六的世界:
|
||||
|
||||

|
||||
|
||||
- 现在我们问,在我们将问题限制在(除以$P(6)$,或第一个骰子产生 6 的概率)的世界中,事件 a(和为 12)发生了多少次?
|
||||
|
||||

|
||||
|
||||
## 随机变量(Random Variables)
|
||||
|
||||
- 随机变量是概率论中的一个变量,它有一个可能取值的域。例如,为了表示掷骰子时的可能结果,我们可以定义一个随机变量 Roll,它可以取值$\set{0,1,2,3,4,5,6}$。为了表示航班的状态,我们可以定义一个变量 flight,它采用$\set{准时、延迟、取消}$的值。
|
||||
- 通常,我们对每个值发生的概率感兴趣。我们用概率分布来表示这一点。例如:
|
||||
|
||||
$P(Flight=准时)=0.6$
|
||||
|
||||
$P(Flight=延迟)=0.3$
|
||||
|
||||
$P(Flight=取消)=0.1$
|
||||
|
||||
- 用文字来解释概率分布,这意味着航班准时的可能性为 60%,延误的可能性为 30%,取消的可能性为 10%。注意,如前所述,所有可能结果的概率之和为 1。
|
||||
- 概率分布可以更简洁地表示为向量。例如,$P(Flight)=<0.6,0.3,0.1>$。为了便于解释,这些值有一个固定的顺序(在我们的情况下,准时、延迟、取消)。
|
||||
|
||||
### 独立性(Independence)
|
||||
|
||||
- 独立性是指一个事件的发生不会影响另一个事件发生的概率。例如,当掷两个骰子时,每个骰子的结果与另一个骰子的结果是独立的。用第一个骰子掷出 4 不会影响我们掷出的第二个骰子的值。这与依赖事件相反,比如早上的云和下午的雨。如果早上多云,下午更有可能下雨,所以这些事件是有依赖性的。
|
||||
- 独立性可以用数学定义:事件$a$和$b$是独立的,当且仅当$a$并且$b$的概率等于$a$的概率乘以$b$的概率:$P(a∧b)=P(a)P(b)$。
|
||||
|
||||
## 贝叶斯规则(Bayes’ Rule)
|
||||
|
||||
- 贝叶斯规则在概率论中常用来计算条件概率。换句话说,贝叶斯规则说,给定$b$条件下$a$的概率等于给定$a$的条件下$b$概率,乘以$b$的概率除以$a$ 的概率。
|
||||
- $P(b|a)=\frac{P(a|b)P(b)}{P(a)}$
|
||||
- 例如,如果早上有云,我们想计算下午下雨的概率,或者$P(雨|云)$。我们从以下信息开始:
|
||||
|
||||
- 80% 的雨天下午开始于多云的早晨,或$P(云|雨)$。
|
||||
- 40% 的日子早晨多云,或$P(云)$。
|
||||
- 10% 的日子有下雨的下午,或$P(雨)$。
|
||||
- 应用贝叶斯规则,我们计算$\frac{0.8*0.1}{0.4}=0.2$。也就是说,考虑到早上多云,下午下雨的可能性是 20%。
|
||||
- 除了$P(a)$和$P(b)$之外,知道$P(a|b)$还允许我们计算$P(b|a)$。这是有帮助的,因为知道给定未知原因的可见效应的条件概率$P(可见效应|未知原因)$,可以让我们计算给定可见效应的未知原因的概率$P(未知原因|可见效应)$。例如,我们可以通过医学试验来学习$P(医学测试结果|疾病)$,在医学试验中,我们对患有该疾病的人进行测试,并观察测试结果发生的频率。知道了这一点,我们就可以计算出$P(疾病|医学检测结果)$,这是有价值的诊断信息。
|
||||
|
||||
## 联合概率(Joint Probability)
|
||||
|
||||
- 联合概率是指多个事件全部发生的可能性。
|
||||
- 让我们考虑下面的例子,关于早上有云,下午有雨的概率。
|
||||
|
||||
| C=云 | C=$\lnot$云 |
|
||||
| ---- | ----------- |
|
||||
| 0.4 | 0.6 |
|
||||
|
||||
| R=雨 | R=$\lnot$雨 |
|
||||
| ---- | ----------- |
|
||||
| 0.1 | 0.9 |
|
||||
|
||||
- 从这些数据来看,我们无法判断早上的云是否与下午下雨的可能性有关。为了做到这一点,我们需要看看这两个变量所有可能结果的联合概率。我们可以将其表示在下表中:
|
||||
|
||||
| | R=雨 | R=$\lnot$ 雨 |
|
||||
| ----------- | ---- | ------------ |
|
||||
| C=云 | 0.08 | 0.32 |
|
||||
| C=$\lnot$云 | 0.02 | 0.58 |
|
||||
|
||||
- 现在我们可以知道有关这些事件同时发生的信息了。例如,我们知道某一天早上有云,下午有雨的概率是 0.08。早上没有云,下午没有雨的概率是 0.58。
|
||||
- 使用联合概率,我们可以推导出条件概率。例如,如果我们感兴趣的是在下午下雨的情况下,早上云层的概率分布。$P(C|雨)=\frac{P(C,雨)}{P(雨)}$旁注:在概率上,逗号和$∧$可以互换使用。因此,$P(C,雨)=P(C\land 雨)$。换句话说,我们将降雨和云层的联合概率除以降雨的概率。
|
||||
- 在最后一个方程中,可以将$P(雨)$视为$P(C,雨)$乘以的某个常数$\alpha=\frac{1}{P(雨)}$。因此,我们可以重写$P(C|雨)=\frac{P(C,雨)}{P(雨)}=αP(C,雨)$,或$α<0.08,0.02>=<0.8,0.2>$。考虑到下午有雨,将$α$分解后,我们可以得到 C 的可能值的概率比例。也就是说,如果下午有雨,那么早上有云和早上没有云的概率的比例是$0.08:0.02$。请注意,0.08 和 0.02 的总和不等于 1;然而,由于这是随机变量 C 的概率分布,我们知道它们应该加起来为 1。因此,我们需要通过算$α$来归一化这些值,使得$α0.08+α0.02=1$。最后,我们可以说$P(C|雨)=<0.8,0.2>$。
|
||||
|
||||
## 概率规则(Probability Rules)
|
||||
|
||||
- 否定(Negation): $P(\lnot a)=1-P(a)$。这源于这样一个事实,即所有可能世界的概率之和为 1,互补事件$\lnot a$和 $a$ 包括所有可能世界。
|
||||
- 包含-排除 Inclusion-Exclusion:$P(a\lor b)=P(a)+P(b)-P(a\land b)$。这可以用以下方式解释:$a$或$b$为真的世界等于$a$为真的所有世界,加上$b$为真的所有世界。然而,在这种情况下,有些世界被计算两次(a和$b$都为真的世界)。为了消除这种重叠,我们将$a$和$b$ 都为真的世界减去一次(因为它们被计算了两次)。
|
||||
|
||||
> 下面是一个例子,可以说明这一点。假设我 80% 的时间吃冰淇淋,70% 的时间吃饼干。如果我们计算今天我吃冰淇淋或饼干的概率,不减去$P(冰淇淋∧饼干)$,我们错误地得出 0.7+0.8=1.5。这与概率在 0 和 1 之间的公理相矛盾。为了纠正我同时吃冰淇淋和饼干的天数计算两次的错误,我们需要减去$P(冰淇淋∧饼干)$一次。
|
||||
|
||||
- 边缘化(Marginalization):$P(a)=P(a,b)+P(a,\lnot b)$。这里的观点是,$b$和$\lnot b$是独立的概率。也就是说,$b$和$\lnot b$同时发生的概率为0。我们也知道$b$和$\lnot b$的总和为1。因此,当$a$发生时,$b$可以发生也可以不发生。当我们把$a$和$b$发生的概率加上$a$和$\lnot b$的概率时,我们得到的只是$a$ 的概率。
|
||||
- 随机变量的边缘化可以用:$P(X=x_i)=\sum_jP(X=x_i,Y=y_j)$表示
|
||||
- 方程的左侧表示“随机变量$X$具有$x_i$值的概率” 例如,对于我们前面提到的变量C,两个可能的值是早上有云和早上没有云。等式的正确部分是边缘化的概念。$P(X=x_i)$等于$x_i$以及随机变量$Y$的每一个值的所有联合概率之和。例如,$P(C=云)=P(C=云,R=雨)+P(C=云,R=\lnot 雨)=0.08+0.32=0.4$。
|
||||
|
||||
- 条件边缘化: $P(a)=P(a|b)P(b)+P(a|\lnot b)P(\lnot b)$。这是一个类似于边缘化的想法。事件$a$发生的概率等于给定$b$的概率乘以$b$的概率,再加上给定$\lnot b$的概率乘以$\lnot b$ 的概率。
|
||||
- $P(X=x_i)=\sum_jP(X=x_i|Y=y_i)P(Y=y_i)$
|
||||
- 在这个公式中,随机变量$X$取$x_i$值概率等于$x_i$以及随机变量$Y$的每个值的联合概率乘以变量$Y$取该值的概率之和。如果我们还记得$P(a|b)=\frac{P(a,b)}{P(b)}$,就可以理解这个公式。如果我们将这个表达式乘以$P(b)$,我们得到$P(a,b)$,从这里开始,我们做的与边缘化相同。
|
||||
|
||||
## 贝叶斯网络(Bayesian Networks)
|
||||
|
||||
- 贝叶斯网络是一种表示随机变量之间相关性的数据结构。贝叶斯网络具有以下属性:
|
||||
|
||||
- 它们是有向图。
|
||||
- 图上的每个节点表示一个随机变量。
|
||||
- 从 X 到 Y 的箭头表示 X 是 Y 的父对象。也就是说,Y 的概率分布取决于 X 的值。
|
||||
- 每个节点 X 具有概率分布$P(X|Parents(X))$。
|
||||
- 让我们考虑一个贝叶斯网络的例子,该网络包含影响我们是否按时赴约的随机变量。
|
||||
|
||||

|
||||
|
||||
- 让我们从上到下描述这个贝叶斯网络:
|
||||
|
||||
- rain 是这个网络的根节点。这意味着它的概率分布不依赖于任何先前的事件。在我们的例子中,Rain 是一个随机变量,可以采用以下概率分布的值$\set{none,light,heavy}$:
|
||||
|
||||
| none | light | heavy |
|
||||
| ---- | ----- | ----- |
|
||||
| 0.7 | 0.2 | 0.1 |
|
||||
|
||||
|
||||
- Maintenance对是否有列车轨道维护进行编码,取值为$\set{yes,no}$。Rain是Maintenance的父节点,这意味着Maintenance概率分布受到Rain的影响。
|
||||
|
||||
|
||||
| R | yes | no |
|
||||
| ----- | --- | --- |
|
||||
| none | 0.4 | 0.6 |
|
||||
| light | 0.2 | 0.8 |
|
||||
| heavy | 0.1 | 0.9 |
|
||||
|
||||
|
||||
- Train是一个变量,用于编码列车是准时还是晚点,取值为$\set{on\ time,delayed}$。请注意,列车上被“Maintenance”和“rain”指向。这意味着两者都是Train的父对象,它们的值会影响Train的概率分布。
|
||||
|
||||
|
||||
| R | M | On time | Delayed |
|
||||
| ------ | --- | ------- | ------- |
|
||||
| none | yes | 0.8 | 0.2 |
|
||||
| none | no | 0.9 | 0.1 |
|
||||
| light | yes | 0.6 | 0.4 |
|
||||
| light | no | 0.7 | 0.3 |
|
||||
| heavry | yes | 0.4 | 0.6 |
|
||||
| heavy | no | 0.5 | 0.5 |
|
||||
|
||||
|
||||
- Appointment 是一个随机变量,表示我们是否参加约会,取值为$\set{attend, miss}$。请注意,它唯一的父级是Train。关于贝叶斯网络的这一点值得注意:父子只包括直接关系。的确,Maintenance会影响Train是否准时,而Train是否准时会影响我们是否赴约。然而,最终,直接影响我们赴约机会的是Train是否准时,这就是贝叶斯网络所代表的。例如,如果火车准时到达,可能会有大雨和轨道维护,但这对我们是否赴约没有影响。
|
||||
|
||||
|
||||
| T | attend | miss |
|
||||
| ------- | ------ | ---- |
|
||||
| on time | 0.9 | 0.1 |
|
||||
| delayed | 0.6 | 0.4 |
|
||||
|
||||
|
||||
- 例如,如果我们想找出在没有维护和小雨的一天火车晚点时错过约会的概率,或者$P(light,no,delayed,miss)$,我们将计算如下:$P(light)P(no|light)P(delayed|light,no)P(miss|delayed)$。每个单独概率的值可以在上面的概率分布中找到,然后将这些值相乘以产生$P(light,no,delayed,miss)$。
|
||||
|
||||
|
||||
### 推理(Inference)
|
||||
|
||||
- 在知识推理,我们通过蕴含来看待推理。这意味着我们可以在现有信息的基础上得出新的信息。我们也可以根据概率推断出新的信息。虽然这不能让我们确切地知道新的信息,但它可以让我们计算出一些值的概率分布。推理具有多个属性。
|
||||
- Query 查询变量 $X$:我们要计算概率分布的变量。
|
||||
- Evidence variables 证据变量$E$: 一个或多个观测到事件$e$ 的变量。例如,我们可能观测到有小雨,这一观测有助于我们计算火车延误的概率。
|
||||
- Hidden variables 隐藏变量 $H$: 不是查询结论的变量,也没有被观测到。例如,站在火车站,我们可以观察是否下雨,但我们不知道道路后面的轨道是否有维修。因此,在这种情况下,Maintenance 将是一个隐藏的变量。
|
||||
- The goal 目标: 计算$P(X|e)$。例如,根据我们知道有小雨的证据 $e$ 计算 Train 变量(查询)的概率分布。
|
||||
- 举一个例子。考虑到有小雨和没有轨道维护的证据,我们想计算 Appointment 变量的概率分布。也就是说,我们知道有小雨,没有轨道维护,我们想弄清楚我们参加约会和错过约会的概率是多少,$P(Appointment|light,no)$。从联合概率部分中,我们知道我们可以将约会随机变量的可能值表示为一个比例,将$P(Appointment|light,no)$重写为$αP(Appointment,light,no)$。如果 Appointment 的父节点仅为 Train 变量,而不是 Rain 或 Maintenance,我们如何计算约会的概率分布?在这里,我们将使用边缘化。$P(Appointment,light,no)$的值等于$α[P(Appointment,light,no,delay)+P(Appointment,light,no,on\ time)]$。
|
||||
|
||||
### 枚举推理
|
||||
|
||||
- 枚举推理是在给定观测证据$e$和一些隐藏变量$Y$的情况下,找到变量$X$ 的概率分布的过程。
|
||||
- $P(X|e)=\alpha P(X,e)=\alpha \sum_yP(X,e,y)$
|
||||
- 在这个方程中,$X$代表查询变量,$e$代表观察到的证据,$y$代表隐藏变量的所有值,$α$归一化结果,使我们最终得到的概率加起来为1。用文字来解释这个方程,即给定$e$的$X$的概率分布等于$X$和$e$的归一化概率分布。为了得到这个分布,我们对$X、e$和$y$的归一化概率求和,其中$y$每次取隐藏变量$Y$ 的不同值。
|
||||
- Python 中存在多个库,以简化概率推理过程。我们将查看库 `pomegranate`,看看如何在代码中表示上述数据。
|
||||
|
||||
```python
|
||||
from pomegranate import *
|
||||
'''创建节点,并为每个节点提供概率分布'''
|
||||
# Rain节点没有父节点
|
||||
rain = Node(DiscreteDistribution({
|
||||
"none": 0.7,
|
||||
"light": 0.2,
|
||||
"heavy": 0.1
|
||||
}), name="rain")
|
||||
# Track maintenance节点以rain为条件
|
||||
maintenance = Node(ConditionalProbabilityTable([
|
||||
["none", "yes", 0.4],
|
||||
["none", "no", 0.6],
|
||||
["light", "yes", 0.2],
|
||||
["light", "no", 0.8],
|
||||
["heavy", "yes", 0.1],
|
||||
["heavy", "no", 0.9]
|
||||
], [rain.distribution]), name="maintenance")
|
||||
# Train node节点以rain和maintenance为条件
|
||||
train = Node(ConditionalProbabilityTable([
|
||||
["none", "yes", "on time", 0.8],
|
||||
["none", "yes", "delayed", 0.2],
|
||||
["none", "no", "on time", 0.9],
|
||||
["none", "no", "delayed", 0.1],
|
||||
["light", "yes", "on time", 0.6],
|
||||
["light", "yes", "delayed", 0.4],
|
||||
["light", "no", "on time", 0.7],
|
||||
["light", "no", "delayed", 0.3],
|
||||
["heavy", "yes", "on time", 0.4],
|
||||
["heavy", "yes", "delayed", 0.6],
|
||||
["heavy", "no", "on time", 0.5],
|
||||
["heavy", "no", "delayed", 0.5],
|
||||
], [rain.distribution, maintenance.distribution]), name="train")
|
||||
# Appointment节点以列车为条件
|
||||
appointment = Node(ConditionalProbabilityTable([
|
||||
["on time", "attend", 0.9],
|
||||
["on time", "miss", 0.1],
|
||||
["delayed", "attend", 0.6],
|
||||
["delayed", "miss", 0.4]
|
||||
], [train.distribution]), name="appointment")
|
||||
'''我们通过添加所有节点来创建模型,然后通过在节点之间添加边来描述哪个节点是另一个节点的父节点(回想一下,贝叶斯网络是一个有向图,节点之间由箭头组成)。'''
|
||||
# 创建贝叶斯网络并添加状态
|
||||
model = BayesianNetwork()
|
||||
model.add_states(rain, maintenance, train, appointment)
|
||||
# 添加连接节点的边
|
||||
model.add_edge(rain, maintenance)
|
||||
model.add_edge(rain, train)
|
||||
model.add_edge(maintenance, train)
|
||||
model.add_edge(train, appointment)
|
||||
# 最终确定模型
|
||||
model.bake()
|
||||
'''模型可以计算特定条件下的概率'''
|
||||
# 计算给定观测的概率
|
||||
probability = model.probability([["none", "no", "on time", "attend"]])
|
||||
print(probability)
|
||||
'''我们可以使用该模型为所有变量提供概率分布,给出一些观测到的证据。在以下情况下,我们知道火车晚点了。给定这些信息,我们计算并打印变量Rain、Maintenance和Appointment的概率分布。'''
|
||||
# 根据火车晚点的证据计算预测
|
||||
predictions = model.predict_proba({
|
||||
"train": "delayed"
|
||||
})
|
||||
# 打印每个节点的预测
|
||||
for node, prediction in zip(model.states, predictions):
|
||||
# 预测已确定时返回字符串
|
||||
if isinstance(prediction, str):
|
||||
print(f"{node.name}: {prediction}")
|
||||
else:
|
||||
# 预测不确定时返回概率分布
|
||||
print(f"{node.name}")
|
||||
for value, probability in prediction.parameters[0].items():
|
||||
print(f" {value}: {probability:.4f}")
|
||||
```
|
||||
|
||||
- 上面的代码使用了枚举推理。然而,这种计算概率的方法效率很低,尤其是当模型中有很多变量时。另一种方法是放弃精确推理,转而采用近似推理。这样做,我们在生成的概率中会失去一些精度,但这种不精确性通常可以忽略不计。相反,我们获得了一种可扩展的概率计算方法。
|
||||
|
||||
### 采样(Sampling)
|
||||
|
||||
- 采样是一种近似推理技术。在采样中,根据每个变量的概率分布对其值进行采样。
|
||||
|
||||
> 要使用骰子采样生成分布,我们可以多次掷骰子,并记录每次获得的值。假设我们把骰子掷了 600 次。我们计算得到 1 的次数,应该大约是 100,然后对其余的值 2-6 重复采样。然后,我们将每个计数除以投掷的总数。这将生成掷骰子的值的近似分布:一方面,我们不太可能得到每个值发生概率为 1/6 的结果(这是确切的概率),但我们会得到一个接近它的值。
|
||||
|
||||
- 如果我们从对 Rain 变量进行采样开始,则生成的值 none 的概率为 0.7,生成的值 light 的概率为 0.2,而生成的值 heavy 的概率则为 0.1。假设我们的采样值为 none。当我们得到 Maintenance 变量时,我们也会对其进行采样,但只能从 Rain 等于 none 的概率分布中进行采样,因为这是一个已经采样的结果。我们将通过所有节点继续这样做。现在我们有一个样本,多次重复这个过程会生成一个分布。现在,如果我们想回答一个问题,比如什么是$P(Train=on\ time)$,我们可以计算变量 Train 具有准时值的样本数量,并将结果除以样本总数。通过这种方式,我们刚刚生成了$P(Train=on\ {time})$的近似概率。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
- 我们也可以回答涉及条件概率的问题,例如$P(rain=light|train=on\ {time})$。在这种情况下,我们忽略 Train 值为 delay 的所有样本,然后照常进行。我们计算在$Train=\text{on time}$的样本中有多少样本具有变量$Rain=light$,然后除以$Train=\text{on time}$的样本总数。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
去除$T= on time$的样本
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
选择$R=light$的样本
|
||||
|
||||
- 在代码中,采样函数可以是 `generate_sample`:
|
||||
|
||||
```python
|
||||
'''如果你对pomegrante库不熟悉,没有关系,考虑generate_sample为一个黑盒,或者你可以在python解释器中查看model.states, state.distribution的值以了解model在该库中的实现方式'''
|
||||
import pomegranate
|
||||
from collections import Counter
|
||||
def generate_sample():
|
||||
# 随机变量与生成的样本之间的映射
|
||||
sample = {}
|
||||
# 概率分布与样本的映射
|
||||
parents = {}
|
||||
# 为所有状态节点采样
|
||||
for state in model.states:
|
||||
# 如果我们有一个非根节点,则以父节点为条件进行采样
|
||||
if isinstance(state.distribution, pomegranate.ConditionalProbabilityTable):
|
||||
sample[state.name] = state.distribution.sample(parent_values=parents)
|
||||
# 否则,只根据节点的概率分布单独取样
|
||||
else:
|
||||
sample[state.name] = state.distribution.sample()
|
||||
# 追踪映射中的采样值
|
||||
parents[state.distribution] = sample[state.name]
|
||||
# 返回生成的样本
|
||||
return sample
|
||||
# 采样
|
||||
# 观测到train=delay,计算appointment分布
|
||||
N = 10000
|
||||
data = []
|
||||
# 重复采样10000次
|
||||
for i in range(N):
|
||||
# 根据我们之前定义的函数生成一个样本
|
||||
sample = generate_sample()
|
||||
# 如果在该样本中,Train的变量的值为delay,则保存样本。由于我们对给定train=delay的appointment概率分布感兴趣,我们丢弃了train=on time的采样样本。
|
||||
if sample["train"] == "delayed":
|
||||
data.append(sample["appointment"])
|
||||
# 计算变量的每个值出现的次数。我们可以稍后通过将结果除以保存的样本总数来进行归一化,以获得变量的近似概率,该概率加起来为1。
|
||||
print(Counter(data))
|
||||
```
|
||||
|
||||
### 似然加权
|
||||
|
||||
- 在上面的采样示例中,我们丢弃了与我们所掌握的证据不匹配的样本。这是低效的。解决这一问题的一种方法是使用似然加权,使用以下步骤:
|
||||
|
||||
- 首先固定证据变量的值。
|
||||
- 使用贝叶斯网络中的条件概率对非证据变量进行采样。
|
||||
- 根据其可能性对每个样本进行加权: 所有证据出现的概率。
|
||||
- 例如,如果我们观察到$Train=\text{on time}$,我们将像之前一样开始采样。我们对给定概率分布的 Rain 值进行采样,然后对 Maintenance 进行采样,但当我们到达 Train 时,我们总是按照观测值取值。然后,我们继续进行,并在给定$Train=\text{on time}$的情况下,根据其概率分布对 Appointment 进行采样。既然这个样本存在,我们就根据观察到的变量在给定其采样父变量的情况下的条件概率对其进行加权。也就是说,如果我们采样了 Rain 并得到了 light,然后我们采样了 Maintenance 并得到了 yes,那么我们将用$P(Train=\text{on time}|light,yes)$来加权这个样本。
|
||||
|
||||
## 马尔科夫模型(Markov Models)
|
||||
|
||||
- 到目前为止,我们已经研究了概率问题,给出了我们观察到的一些信息。在这种范式中,时间的维度没有以任何方式表示。然而,许多任务确实依赖于时间维度,例如预测。为了表示时间变量,我们将创建一个新的变量$X$,并根据感兴趣的事件对其进行更改,使$X_t$ 是当前事件,$X_{t+1}$ 是下一个事件,依此类推。为了能够预测未来的事件,我们将使用马尔可夫模型。
|
||||
|
||||
### 马尔科夫假设(<strong>The Markov Assumption</strong>)
|
||||
|
||||
- 马尔科夫假设是一个假设,即当前状态只取决于有限的固定数量的先前状态。想想预测天气的任务。在理论上,我们可以使用过去一年的所有数据来预测明天的天气。然而,这是不可行的,一方面是因为这需要计算能力,另一方面是因为可能没有关于基于 365 天前天气的明天天气的条件概率的信息。使用马尔科夫假设,我们限制了我们以前的状态(例如,在预测明天的天气时,我们要考虑多少个以前的日子),从而使这个任务变得可控。这意味着我们可能会得到感兴趣的概率的一个更粗略的近似值,但这往往足以满足我们的需要。此外,我们可以根据最后一个事件的信息来使用马尔可夫模型(例如,根据今天的天气来预测明天的天气)。
|
||||
|
||||
### 马尔科夫链(<strong>Markov Chain</strong>)
|
||||
|
||||
- 马尔科夫链是一个随机变量的序列,每个变量的分布都遵循马尔科夫假设。也就是说,链中的每个事件的发生都是基于之前事件的概率。
|
||||
- 为了构建马尔可夫链,我们需要一个过渡模型,该模型将根据当前事件的可能值来指定下一个事件的概率分布。
|
||||
|
||||

|
||||
|
||||
- 在这个例子中,基于今天是晴天,明天是晴天的概率是 0.8。这是合理的,因为晴天之后更可能是晴天。然而,如果今天是雨天,明天下雨的概率是 0.7,因为雨天更有可能相继出现。使用这个过渡模型,可以对马尔可夫链进行采样。从一天是雨天或晴天开始,然后根据今天的天气,对第二天的晴天或雨天的概率进行采样。然后,根据明天的情况对后天的概率进行采样,以此类推,形成马尔科夫链:
|
||||
|
||||

|
||||
|
||||
- 给定这个马尔可夫链,我们现在可以回答诸如“连续四个雨天的概率是多少?”这样的问题。下面是一个如何在代码中实现马尔可夫链的例子:
|
||||
|
||||
```python
|
||||
from pomegranate import *
|
||||
# 定义起始概率
|
||||
start = DiscreteDistribution({
|
||||
"sun": 0.5,
|
||||
"rain": 0.5
|
||||
})
|
||||
# 定义过渡模型
|
||||
transitions = ConditionalProbabilityTable([
|
||||
["sun", "sun", 0.8],
|
||||
["sun", "rain", 0.2],
|
||||
["rain", "sun", 0.3],
|
||||
["rain", "rain", 0.7]
|
||||
], [start])
|
||||
# 创造马尔科夫链
|
||||
model = MarkovChain([start, transitions])
|
||||
# 采样50次
|
||||
print(model.sample(50))
|
||||
```
|
||||
|
||||
## 隐马尔科夫模型(Hidden Markov Models)
|
||||
|
||||
- 隐马尔科夫模型是一种具有隐藏状态的系统的马尔科夫模型,它产生了一些观察到的事件。这意味着,有时候,人工智能对世界有一些测量,但无法获得世界的精确状态。在这些情况下,世界的状态被称为隐藏状态,而人工智能能够获得的任何数据都是观察结果。下面是一些这方面的例子:
|
||||
|
||||
- 对于一个探索未知领域的机器人来说,隐藏状态是它的位置,而观察是机器人的传感器所记录的数据。
|
||||
- 在语音识别中,隐藏状态是所讲的话语,而观察是音频波形。
|
||||
- 在衡量网站的用户参与度时,隐藏的状态是用户的参与程度,而观察是网站或应用程序的分析。
|
||||
- 举个例子。我们的人工智能想要推断天气(隐藏状态),但它只能接触到一个室内摄像头,记录有多少人带了雨伞。这里是我们的传感器模型(sensor model),表示了这些概率:
|
||||
|
||||

|
||||
|
||||
- 在这个模型中,如果是晴天,人们很可能不会带伞到大楼。如果是雨天,那么人们就很有可能带伞到大楼来。通过对人们是否带伞的观察,我们可以合理地预测外面的天气情况。
|
||||
|
||||
### 传感器马尔科夫假设
|
||||
|
||||
- 假设证据变量只取决于相应的状态。例如,对于我们的模型,我们假设人们是否带雨伞去办公室只取决于天气。这不一定反映了完整的事实,因为,比如说,比较自觉的、不喜欢下雨的人可能即使在阳光明媚的时候也会到处带伞,如果我们知道每个人的个性,会给模型增加更多的数据。然而,传感器马尔科夫假设忽略了这些数据,假设只有隐藏状态会影响观察。
|
||||
- 隐马尔科夫模型可以用一个有两层的马尔科夫链来表示。上层,变量$X$,代表隐藏状态。底层,变量$E$,代表证据,即我们所拥有的观察。
|
||||
|
||||

|
||||
|
||||
- 基于隐马尔科夫模型,可以实现多种任务:
|
||||
|
||||
- 筛选 Filtering: 给定从开始到现在的观察结果,计算出<strong>当前</strong>状态的概率分布。例如,给从从特定时间开始到今天人们带伞的信息,我们产生一个今天是否下雨的概率分布。
|
||||
- 预测 Prediction: 给定从开始到现在的观察,计算<strong>未来</strong>状态的概率分布。
|
||||
- 平滑化 Smoothing: 给定从开始到现在的观察,计算<strong>过去</strong>状态的概率分布。例如,鉴于今天人们带了雨伞,计算昨天下雨的概率。
|
||||
- 最可能的解释 Most likely explanation: 鉴于从开始到现在的观察,计算最可能的事件顺序。
|
||||
- 最可能的解释任务可用于语音识别等过程,根据多个波形,人工智能推断出给这些波形带来的最有可能的单词或音节的序列。接下来是一个隐马尔科夫模型的 Python 实现,我们将用于最可能的解释任务:
|
||||
|
||||
```python
|
||||
from pomegranate import *
|
||||
# 每个状态的观测模型
|
||||
sun = DiscreteDistribution({
|
||||
"umbrella": 0.2,
|
||||
"no umbrella": 0.8
|
||||
})
|
||||
rain = DiscreteDistribution({
|
||||
"umbrella": 0.9,
|
||||
"no umbrella": 0.1
|
||||
})
|
||||
states = [sun, rain]
|
||||
# 过渡模型
|
||||
transitions = numpy.array(
|
||||
[[0.8, 0.2], # Tomorrow's predictions if today = sun
|
||||
[0.3, 0.7]] # Tomorrow's predictions if today = rain
|
||||
)
|
||||
# 起始概率
|
||||
starts = numpy.array([0.5, 0.5])
|
||||
# 建立模型
|
||||
model = HiddenMarkovModel.from_matrix(
|
||||
transitions, states, starts,
|
||||
state_names=["sun", "rain"]
|
||||
)
|
||||
model.bake()
|
||||
```
|
||||
|
||||
- 请注意,我们的模型同时具有传感器模型和过渡模型。对于隐马尔可夫模型,我们需要这两个模型。在下面的代码片段中,我们看到了人们是否带伞到大楼的观察序列,根据这个序列,我们将运行模型,它将生成并打印出最可能的解释(即最可能带来这种观察模式的天气序列):
|
||||
|
||||
```python
|
||||
from model import model
|
||||
# 观测到的数据
|
||||
observations = [
|
||||
"umbrella",
|
||||
"umbrella",
|
||||
"no umbrella",
|
||||
"umbrella",
|
||||
"umbrella",
|
||||
"umbrella",
|
||||
"umbrella",
|
||||
"no umbrella",
|
||||
"no umbrella"
|
||||
]
|
||||
# 预测隐藏状态
|
||||
predictions = model.predict(observations)
|
||||
for prediction in predictions:
|
||||
print(model.states[prediction].name)
|
||||
```
|
||||
|
||||
- 在这种情况下,程序的输出将是 rain,rain,sun,rain,rain,rain,rain,sun,sun。根据我们对人们带伞或不带伞到大楼的观察,这一输出代表了最有可能的天气模式。
|
||||
@@ -1,19 +0,0 @@
|
||||
# 人工智能导论及机器学习入门
|
||||
|
||||
人工智能(Artificial Intelligence, AI)是机器,特别是计算机系统对人类智能过程的模拟。人工智能是一个愿景,目标就是让机器像我们人类一样思考与行动,能够代替我们人类去做各种各样的工作。人工智能研究的范围非常广,包括演绎、推理和解决问题、知识表示、学习、运动和控制、数据挖掘等众多领域。
|
||||
|
||||
# 人工智能、机器学习与深度学习关系
|
||||
|
||||
人工智能是一个宏大的愿景,目标是让机器像我们人类一样思考和行动,既包括增强我们人类脑力也包括增强我们体力的研究领域。而学习只是实现人工智能的手段之一,并且,只是增强我们人类脑力的方法之一。所以,人工智能包含机器学习。机器学习又包含了深度学习,他们三者之间的关系见下图。
|
||||
|
||||

|
||||
|
||||
# 如何学习本节内容
|
||||
|
||||
作者深知学习人工智能时面临许多繁碎数学知识,复杂数学公式的痛苦,因此,本节内容重在讲解核心概念和算法,略去了复杂的数学推导,尽可能以直觉的方式去理解,本文的数学知识,高中生足以掌握。阅读本节内容不需要人工智能基础,你可以直接从本节入门 AI。本节内容的算法、项目实现将使用 python 实现,需要掌握一定的 python 基础语法。当然如果你急于了解 AI,却又不会 python,没有关系,你可以选择跳过其中的编程部分,着眼于其中的概念、算法,程序语言是算法实现的工具,并非学习算法的必须品。
|
||||
|
||||
# 学习建议
|
||||
|
||||
本节内容是作者根据[哈佛的 CS50AI 导论](https://cs50.harvard.edu/ai/2020/)以及 [Andrew Ng 的机器学习专项课程](https://www.coursera.org/specializations/machine-learning-introduction)简化编写,当然你可以直接学习这两门课程。本节内容的总学习时间应该是二到三个月,如果你在某个知识点上卡住了,你也许需要反复阅读讲义,必要时向身边人求助。
|
||||
|
||||
# 目录
|
||||
@@ -1,60 +0,0 @@
|
||||
# FAQ:常见问题
|
||||
|
||||
## 我是非计算机专业的,感觉AI很火,可以看这篇内容吗
|
||||
|
||||
如果你不打算做相关研究的话,我觉得你最先应该考虑的是熟练掌握使用AI工具,本章内容更偏向于完善AI方面的知识体系架构
|
||||
|
||||
## 我对AI/CV/NLP/blabla研究方向很感兴趣可以看这篇内容吗?
|
||||
|
||||
目前的本章节的内容的定位仍在引导大家有更广阔的视野,在引导的同时给大家正确的学习/思考模式。
|
||||
|
||||
因此如果你想学某个知识体系,可以参考本章内容的路线,但是若你有足够强大的能力可以直接应对国外课程体系的困难,那么我非常推荐你去直接看英文内容
|
||||
|
||||
因为我们在降低门槛的时候也一定程度上让各位损失了一定的训练,在概括的过程中,信息量被稀释了,抽象地描述也许更能让你get到一些思想性的内容
|
||||
|
||||
## 我数学不好可以学吗
|
||||
|
||||
可以。我将在教程的脉络中引入数学的相关内容,帮助你正确认识数学和 AI 技术的相关性。
|
||||
|
||||
并且我希望你阅读这些文章
|
||||
|
||||
- [数学不好可以学机器学习吗](https://machinelearningmastery.com/what-if-im-not-good-at-mathematics/)
|
||||
- [没有数学专业背景和理解机器学习算法的 5 种技巧](http://machinelearningmastery.com/techniques-to-understand-machine-learning-algorithms-without-the-background-in-mathematics/)
|
||||
- [我是如何学习机器学习的?](https://www.quora.com/Machine-Learning/How-do-I-learn-machine-learning-1)
|
||||
|
||||
## 很多东西学校都没学
|
||||
|
||||
如果你完全依赖学校的进度,你可能一直都会有认为学校应该教但你没学到的东西
|
||||
|
||||
同时,这是一门前沿学科,学校学习的多数内容并不能达到掌握相关知识的要求。
|
||||
|
||||
你应该更多地依赖自己而不是学校
|
||||
|
||||
|
||||
|
||||
# [如果不是相关领域可以找到这个领域工作吗](https://www.quora.com/How-do-I-get-a-job-in-Machine-Learning-as-a-software-programmer-who-self-studies-Machine-Learning-but-never-has-a-chance-to-use-it-at-work)
|
||||
|
||||
> “我正在为团队招聘专家,但你的 MOOC 并没有给你带来工作学习机会。我大部分机器学习方向的硕士也并不会得到机会,因为他们(与大多数工作)上过 MOOC 的人一样)并没有深入地去理解。他们都无法帮助我的团队解决问题。” Ross C. Taylor
|
||||
|
||||
## 人工智能,深度学习,机器学习,数据分析,我该如何区分
|
||||
|
||||
人工智能包括机器学习
|
||||
|
||||
机器学习包括深度学习
|
||||
|
||||

|
||||
|
||||
[同时向你推荐这个 Data Analytics,Data Analysis,数据挖掘,数据科学,机器学习,大数据的区别是什么?](https://www.quora.com/What-is-the-difference-between-Data-Analytics-Data-Analysis-Data-Mining-Data-Science-Machine-Learning-and-Big-Data-1)
|
||||
|
||||

|
||||
|
||||
## 我没有任何相关概念
|
||||
|
||||
尝试阅读以下内容
|
||||
|
||||
- [形象的机器学习简介](http://www.r2d3.us/visual-intro-to-machine-learning-part-1/)
|
||||
- [为开发者准备的机器学习简介](http://blog.algorithmia.com/introduction-machine-learning-developers/)
|
||||
- [菜鸟的机器学习基础](https://www.analyticsvidhya.com/blog/2015/06/machine-learning-basics/)
|
||||
- [你如何向非计算机专业的人来解释机器学习与数据挖掘?](https://www.quora.com/How-do-you-explain-Machine-Learning-and-Data-Mining-to-non-Computer-Science-people)
|
||||
- [在罩子下的机器学习,博文简单明了地介绍了机器学习的原理](https://georgemdallas.wordpress.com/2013/06/11/big-data-data-mining-and-machine-learning-under-the-hood/)
|
||||
- [机器学习是什么?它是如何工作的呢?](https://www.youtube.com/watch?v=elojMnjn4kk&list=PL5-da3qGB5ICeMbQuqbbCOQWcS6OYBr5A&index=1)
|
||||
@@ -1,240 +0,0 @@
|
||||
# 工欲善其事,必先利其器
|
||||
|
||||
> 有一个英语词汇叫做 Handy,讲的是便利的,易使用的,当你有一个良好的环境配置时候,编程将变得 handy,随手打开即可编程,一点都不复杂,所以配置好的环境,是未来学习快速进步的必要保障。
|
||||
|
||||
首先来了解一下深度学习框架
|
||||
|
||||
## 深度学习框架
|
||||
|
||||

|
||||
|
||||
### 1、深度学习框架是什么
|
||||
|
||||
在深度学习初始阶段,每个深度学习研究者都需要写大量的重复代码。
|
||||
|
||||
为了提高工作效率,他们就将这些代码写成了框架放到网上让所有研究者一起使用。
|
||||
|
||||
作一个简单的比喻,一套深度学习框架就是一套积木,各个组件就是某个模型或算法的一部分,你可
|
||||
|
||||
以自己设计如何使用积木去堆砌符合你数据集的积木。
|
||||
|
||||
#### 思考题
|
||||
|
||||
自行了解张量和基于张量的各种操作。
|
||||
|
||||
### 2、为什么需要深度学习框架
|
||||
|
||||
显然是为了降低使用门槛。 深度学习对硬件环境的依赖很高,对于开发者有较高的门槛,深度学习计
|
||||
|
||||
算框架的出现,屏蔽了大量硬件环境层面的开发代价,使研究者和开发人员可以专注于算法的实现,
|
||||
|
||||
快速迭代。
|
||||
|
||||
## TensorFlow 和 pytorch
|
||||
|
||||
这么多的框架,我们应该如何选择呢(好吧直接就 TensorFlow 和 pytorch 了)
|
||||
|
||||
### 1. TensorFlow
|
||||
|
||||
#### 开发语言
|
||||
|
||||
基于 python 编写,通过 C/C++ 引擎加速,是 Google 开源的第二代深度学习框架。
|
||||
|
||||
#### 编程语言
|
||||
|
||||
Python 是处理 TensorFlow 的最方便的客户端语言。不过,JavaScript、C++、Java、Go、C#和 Julia 也提供了实验性的交互界面。
|
||||
|
||||
#### 优点
|
||||
|
||||
(不讲人话的版本)
|
||||
|
||||
处理循环神经网 RNN 非常友好。其用途不止于深度学习,还可以支持增强学习和其他算法。
|
||||
|
||||
内部实现使用了向量运算的符号图方法,使用图 graph 来表示计算任务,使新网络的指定变得相当容易,支持快速开发。TF 使用静态计算图进行操作。也就是说,我们首先定义图,然后运行计算,如果需要对架构进行更改,我们将重新训练模型。TF 选择这种方法是为了提高效率,但是许多现代神经网络工具能够在不显著降低学习速度的情况下,同时兼顾到在学习过程中进行改进。在这方面,TensorFlow 的主要竞争对手是 Pythorch。
|
||||
|
||||
(讲人话啊喂!!)
|
||||
|
||||
- 谷歌爸爸一撑腰,研究代码两丰收
|
||||
- 新版 TensorFlow API(STFW) 较简洁
|
||||
- 天生和谷歌云兼容
|
||||
- 有良好的推断支持
|
||||
- 功能十分强大!
|
||||
|
||||
#### 缺点
|
||||
|
||||
(不讲人话的版本)
|
||||
|
||||
目前 TensorFlow 还不支持“内联(inline)”矩阵运算,必须要复制矩阵才能对其进行运算,复制庞大的矩阵会导致系统运行效率降低,并占用部分内存。
|
||||
|
||||
TensorFlow 不提供商业支持,仅为研究者提供的一种新工具,因此公司如果要商业化需要考虑开源协议问题。
|
||||
|
||||
(讲人话!!)
|
||||
|
||||
- API 不稳定
|
||||
- 学习成本高
|
||||
- 开发成本高
|
||||
- 会出现前面版本存在的功能后面版本直接没了
|
||||
|
||||
### 2.pytorch
|
||||
|
||||
#### 开发语言
|
||||
|
||||
Facebook 用 Lua 编写的开源计算框架,支持机器学习算法。Tensorflow 之后深入学习的主要软件工具是 PyTorch。
|
||||
|
||||
Facebook 于 2017 年 1 月开放了 Torch 的 Python API ― PyTorch 源代码。
|
||||
|
||||
#### 编程语言
|
||||
|
||||
PyTorch 完全基于 Python。
|
||||
|
||||
(直接说人话吧)
|
||||
|
||||
#### 优点
|
||||
|
||||
- 上手容易
|
||||
- 代码简洁
|
||||
- 有较好的灵活性和速度
|
||||
- 发展快速,现在已经支持 TPU
|
||||
- API 相对稳定
|
||||
- 里面附带许多开源模型代码可以直接调用
|
||||
- 非常建议使用 pytorch,tensorflow 版本更迭会导致很多代码失效,前期不建议使用。
|
||||
|
||||
#### 缺点
|
||||
|
||||
-
|
||||
|
||||
没有 Keras API 那么简洁
|
||||
|
||||
- 一些功能难以实现
|
||||
|
||||
## 安装
|
||||
|
||||
### Pytorch
|
||||
|
||||
官网如下
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
选择 Conda 或者 Pip 安装皆可
|
||||
|
||||
有独立显卡请下载 CUDA,没有的话请下载 CPU
|
||||
|
||||
最后选择 CUDA 版本或者 CPU 版本运行指令就好了
|
||||
|
||||
### Tip:conda 换源
|
||||
|
||||
如果你使用 conda 安装 pytorch 太慢或者失败,不妨换个下载源试试
|
||||
|
||||
在 cmd 命令行中,输入添加以下命令:
|
||||
|
||||
```bash
|
||||
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
|
||||
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
|
||||
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
|
||||
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
|
||||
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
|
||||
conda config --set show_channel_urls yes
|
||||
```
|
||||
|
||||
### TensorFlow
|
||||
|
||||

|
||||
|
||||
#### 教程
|
||||
|
||||
[在 Windows 上配置 pytorch!(CPU 和 GPU 版)](https://www.bilibili.com/video/BV1YY4y1B7cA)
|
||||
|
||||
<Bilibili bvid='BV1YY4y1B7cA'/>
|
||||
|
||||
[Windows 下 PyTorch 入门深度学习环境安装与配置 CPU GPU 版](https://www.bilibili.com/video/BV1S5411X7FY)
|
||||
|
||||
<Bilibili bvid='BV1S5411X7FY'/>
|
||||
|
||||
[最新 TensorFlow 2.8 极简安装教程](https://www.bilibili.com/video/BV1i34y1r7dv)
|
||||
|
||||
<Bilibili bvid='BV1i34y1r7dv'/>
|
||||
|
||||
#### 思考题:为什么需要 CUDA 版本???
|
||||
|
||||
cuda 版本需要额外配置,我们将这个任务留给聪明的你!!!
|
||||
|
||||
### Tips:Windows 和 Linux 如何查看显卡信息
|
||||
|
||||
#### windows
|
||||
|
||||
同时按下键盘的 win+r 键,打开 cmd,键入 `dxdiag` 然后回车
|
||||
系统、显卡、声卡以及其他输入设备的信息都在这里了。(给出我的界面)
|
||||
|
||||

|
||||
|
||||
cuda 版本查看
|
||||
|
||||
桌面空白位置摁下右键
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
#### linux
|
||||
|
||||
打开 bash 键入
|
||||
|
||||
```bash
|
||||
nvidia-smi
|
||||
```
|
||||
|
||||
## 很多人会混淆的东西(非常重要)
|
||||
|
||||
### cuda driver version / cuda runtime version
|
||||
|
||||
通常大家所指的 cuda 是位于/usr/local 下的 cuda
|
||||
|
||||

|
||||
|
||||
当然可以看到 cuda 是 cuda-11.6 所指向的软链接(类似 windows 的快捷方式),所以我们如果要切换 cuda 版本只需要改变软链接的指向即可。
|
||||
|
||||

|
||||
|
||||
cuda driver version 是 cuda 的驱动版本。
|
||||
|
||||
cuda runtimer version 是我们实际很多时候我们实际调用的版本。
|
||||
|
||||
二者的版本是可以不一致的。如下图所示:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
一般来讲 cuda driver 是向下兼容的。所以 cuda driver version >= cuda runtime version 就不会太大问题。
|
||||
|
||||
如果我们用 C++ 写 CUDA,具体的说就是编写以.cu 为后缀的文件。就是用 nvcc(cuda 编译器)去编译的,nvcc 是 cuda runtime api 的一部分。cuda runtime 只知道自身构建时的版本,并不知道是否 GPU driver 的版本,甚至不知道是否安装了 GPU driver。
|
||||
|
||||
### Pytorch/tensorflow 使用的 cuda 版本
|
||||
|
||||
以 pytorch 为例,可以看到在安装过程中我们选择的 cuda 版本是 10.2
|
||||
|
||||

|
||||
|
||||
那么这个 cudatookit10.2 和 nvidia-smi 的 11.7 以及 nvcc -V 的 11.4 三者有什么区别呢?
|
||||
|
||||
pytorch 实际只需要 cuda 的链接文件,即.so 文件,这些链接文件就都包含的 cudatookkit 里面。并不需要 cuda 的头文件等其他东西,如下所示
|
||||
|
||||

|
||||
|
||||
所以我们如果想让使用 pytorch-cuda 版本,我们实际上不需要/usr/local/cuda。只需要在安装驱动的前提下,在 python 里面安装 cudatookit 即可。
|
||||
|
||||
但是有一种情况例外,就是你要用 C++ CUDA 编写核函数给 pytorch 当做插件。这种情况下就需要/usr/local/cuda 以及 nvcc,cudatookit,而且后面两个版本很多时候需要保持严格一致。
|
||||
|
||||
### Cudnn
|
||||
|
||||
Cudnn 是一些链接文件,你可以理解成是为了给 cuda 计算加速的东西。同样的我们也可以用以下命令查看/usr/local/cuda 的 cudnn:
|
||||
|
||||

|
||||
|
||||
以及 pytorch 的 cuda 环境的 cudnn
|
||||
|
||||

|
||||
@@ -1,47 +0,0 @@
|
||||
# 你可能会需要的术语介绍
|
||||
|
||||
众所周知,一个领域的黑话对新人来说是比较不友好的,为此我从知乎上找了一篇黑话大赏(bushi)做了点改良放在这里。如果遇到看不懂的词了可以来这找找。<strong>在系统学习之前可以先无视这篇文章,遇到问题再来找找</strong><u>。</u>
|
||||
|
||||
> 作者:Young<br/>链接:[https://www.zhihu.com/question/469612040/answer/2008770105](https://www.zhihu.com/question/469612040/answer/2008770105)<br/>来源:知乎
|
||||
|
||||
- feature:一个向量
|
||||
- representation:还是一个向量
|
||||
- embedding:把输入映射成向量,有时作为名词=feature
|
||||
- 提高泛化性:在各种东西上预测更准了
|
||||
- 过拟合:训练过头了
|
||||
- attention:加权提取特征,越重要的 feature 权重越高
|
||||
- adaptive:还是加权
|
||||
- few-shot learning:看了几个样本就学会了
|
||||
- zero-shot learning:一个没看就开始用自带的知识瞎蒙
|
||||
- self-supervised:自学(自监督)
|
||||
- semi-supervised:教一点自学一点(半监督)
|
||||
- unsupervised:没人教了,跟谁学?(无监督)
|
||||
- end-to-end:一套操作,行云流水搞到底(输入是图像,输出也是图像就算)
|
||||
- multi-stage:发现不行,还得一步一步来
|
||||
- domain:我圈起来一堆样本,就管他叫一个<u>domain</u>
|
||||
- transfer:我非得在这一堆样本上训练,用在另一堆样本上,就是不直接训练,就是玩 ~
|
||||
- adversarial:我加了一部分就是让 loss 增大
|
||||
- robust:很稳我不会让 loss 变大的(但也不容易变小了)
|
||||
- state of the art(sota):我(吹 nb)第一
|
||||
- outperform:我虽然没第一,但是我比 baseline 强
|
||||
- baseline:(故意)选出来的方法,让我能够看起来比它强
|
||||
- empirically:我做实验了,但不知道为啥 work
|
||||
- theoretically:我以为我知道为啥 work,但没做实验,或者只做了个 toy model
|
||||
- multi 开头词组
|
||||
- multi-task:把几个不同任务的 loss 加一起,完事
|
||||
- multi-domain:把几堆儿样本混一块训练,完事
|
||||
- multi-modality:把视频语音文字图像 graph 点云 xxx 混一块训练,完事
|
||||
- multi-domain multi-modal multi-media model:mua~mua~mua~mua……
|
||||
- 消融实验:删掉某模块做对比实验
|
||||
- 长尾数据:出现频率低的类别很多
|
||||
- ... Is all you need:骗你的,就是把你骗进来。除了...你还要一堆 trick
|
||||
- 体素:我把世界变成 MC 了,世界是一堆方块,他们在不同视角下有各自的颜色和透明度
|
||||
- 点云:我每采样一次得到一个点,由这些点去表示我要的物体,不太直观,来张图
|
||||
|
||||
这是我用照片重建的独角兽<strong>稀疏</strong>点云,红色的不用管,是照相机视角(图不够多,巨糊)
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
先这些,后续想起来了可能会补充。
|
||||
@@ -1,114 +0,0 @@
|
||||
# 深度学习快速入门
|
||||
|
||||
## <strong>刘二大人(Pytorch)</strong>
|
||||
|
||||
## 速成课:人工智能
|
||||
[【速成课:人工智能】Ai - [21 集全/中英双语] - Artificial Intelligence_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1P7411r7Dw)
|
||||
|
||||
<Bilibili bvid='BV1P7411r7Dw'/>
|
||||
|
||||
Crash course 的课程,可以基本了解pytorch的内容,但是当然有很多内容已经有些过时
|
||||
|
||||
# 这是啥?
|
||||
|
||||
这是一个快速入门深度学习的途径。
|
||||
|
||||
# 课程大概讲了啥?
|
||||
|
||||
刘二大人的深度学习是用来给小白快速上手用的。其中介绍了大概的深度学习框架,基本的几种损失函数,激活函数,网络。
|
||||
|
||||
课程中用到了 3 个数据集:糖尿病数据集,泰坦尼克号数据集,和最经典的 MINIST 数据集。其中我们只需要用到 MINIST 数据集,其他两个如果有兴趣可以去尝试。我们最快可以在 1 个星期内训练出我们的第一个模型用来识别手写数字,初窥人工智能的门槛。
|
||||
|
||||
这个课程最主要的是着重讲解了大致的框架,深度学习的代码就像搭积木一样,当大致的框架有了,剩下的就只剩下往里面塞东西就好了。当我们学习了刘二大人的课程之后,一些基本的任务都可以用这些基本的网络简单解决。
|
||||
|
||||
# 学习这系列视频需要哪些前置条件?
|
||||
|
||||
## python
|
||||
|
||||
基本的一些 python 知识,你可以在本讲义中的 [3.6python 模块](../3.%E7%BC%96%E7%A8%8B%E6%80%9D%E7%BB%B4%E4%BD%93%E7%B3%BB%E6%9E%84%E5%BB%BA/3.6Python%EF%BC%88%E7%81%B5%E5%B7%A7%E7%9A%84%E8%83%B6%E6%B0%B4%EF%BC%89.md)中进行简单的学习。解决其中的题目大致就可以了,之后遇到不会的只要去 Google 一下,或者去问问 ChatGPT,问问 New Bing。
|
||||
|
||||
## pycharm,pytorch,anaconda 等环境配置
|
||||
|
||||
你可以在本讲义中的 [Pytorch 安装](../4.%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/4.6.4Pytorch%E5%AE%89%E8%A3%85.md)中找到怎么配置 pytorch,你可以在这里安装 [Pycharm](https://www.jetbrains.com/zh-cn/pycharm/)。
|
||||
|
||||
你可以在本讲义中的 [python 安装](../3.%E7%BC%96%E7%A8%8B%E6%80%9D%E7%BB%B4%E4%BD%93%E7%B3%BB%E6%9E%84%E5%BB%BA/3.6.3%E5%AE%89%E8%A3%85python.md)中找到 Pycharm 和 anaconda 的安装教学视频
|
||||
|
||||
## 一个找乐子的心
|
||||
|
||||
如果觉得它好玩的话,就去学吧。
|
||||
|
||||
## 前置知识?
|
||||
|
||||
要啥前置知识,这就是给你入门用的。如果你不打无准备的仗,你可以简单看看[机器学习快速入门](4.2%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88AI%EF%BC%89%E5%BF%AB%E9%80%9F%E5%85%A5%E9%97%A8%EF%BC%88quick%20start%EF%BC%89.md)。
|
||||
|
||||
# 学完课程之后可能出现的问题
|
||||
|
||||
通过这个课程虽然我们可以进行快速入门,但经过我个人的入门实践表明,视频中没有告诉你完整的数学推导,也懒得进行公式推导,所以在观看这门教程之后虽然已经会基本的 coding 能力了但是基础并不扎实。
|
||||
|
||||
我们不知道每一个给你封装好的函数具体在干什么,不知道经过这个线性层,经过这个卷积操作出来的特征大致对应着什么,它们对我们来说确实变成了一个黑盒。我们只知道:欸,我就这么一写,in_feature 和 out_feature 写对了,程序成功运行了,正确率有 80% 多欸,我已经会深度学习了。
|
||||
|
||||
所以在这门课程结束之后建议手写其中的一些封装好的函数,比如一些基础的线性层。尝试画个图,像课程中刘二讲给我们的那样,看看大致的流程,每一层出来的特征大致代表着什么。
|
||||
|
||||
# 你还有疑惑?
|
||||
|
||||
你可以通过以下方式解决你对于此课程的疑惑:
|
||||
|
||||
|
||||
## 基础知识的疑惑
|
||||
|
||||
如果你对于课程中的一些基本知识比如说梯度下降算法等感到疑惑,你可以移步[机器学习快速入门](4.2%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88AI%EF%BC%89%E5%BF%AB%E9%80%9F%E5%85%A5%E9%97%A8%EF%BC%88quick%20start%EF%BC%89.md)
|
||||
|
||||
当然,在这里我会简单的为你讲解一下最基础最关键的算法:梯度下降算法。和怎么快速理解计算机为什么能识别手写数字。
|
||||
|
||||
## torch 我还不会呢!
|
||||
|
||||
学会一个<strong>庞大并且高度封装</strong>的包并不是一蹴而就的,我们建议从实践开始,比如说自己搭建一个神经网络来实现 MNIST 的分类。在使用这些函数和类的过程中你能更快地掌握它们的方法。
|
||||
|
||||
# 关于梯度下降算法:
|
||||
|
||||
### 损失
|
||||
|
||||

|
||||
|
||||
首先我们需要有一个损失函数$F(x),x=true-predict$
|
||||
|
||||
|
||||
这样通过一个函数我们就得到了一个具体的数值,这个数值的意义是:现在的输入数据经过一个拟合函数处理后得到的结果和真实结果的差距,梯度下降算法就是根据这个为基础进行对拟合函数中参数的优化。
|
||||
|
||||
### 梯度下降
|
||||
|
||||

|
||||
|
||||
假设损失函数为$y=x^2$,梯度下降的目的是快速找到导数为 0 的位置(附近)
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
以此类推,我们最后的 w 在 0 的附近反复横跳,最后最接近目标函数的权重 w 就是 0。
|
||||
|
||||
### 简单理解
|
||||
|
||||
你可以简单这样理解:游戏中你在靶场练狙击枪,你用 4-8 倍镜瞄了 400 米的靶子,真实值就是靶心。你开了一枪后发现落在靶心上方,于是你根据距离靶心的远近,你的大脑开始计算优化下次瞄的位置,如果你往上面偏了很多,你就会将瞄点往下移动很多,如果往上偏了一点点,你就会将瞄点往下移动一点点。
|
||||
|
||||
移动的途中可能出现移动的过多的情况,从上偏变成下偏了,这就是如果学习率过大会出现的问题。
|
||||
|
||||
总而言之,你打狙击枪脑子怎么分析的,梯度下降算法就是怎么算的。当然由于它是电脑没有灵活的机动性,他的权重只能逐渐改变。
|
||||
|
||||
# 关于 MINIST
|
||||
|
||||

|
||||
|
||||
这个数据集可以说是最最经典的数据集了,里面有 0-9 这 10 个数字的手写图片和标注,正确率最高已经到了 99.7%.
|
||||
|
||||
# 接下来干什么?
|
||||
|
||||
- <strong>我想学 CV !!!!!!</strong>
|
||||
|
||||
你可以在 CV 模块中找到[4.6.5.3CV中的经典网络](4.6.5.3CV%E4%B8%AD%E7%9A%84%E7%BB%8F%E5%85%B8%E7%BD%91%E7%BB%9C.md) ,这里是一些最最经典的论文,我们推荐你阅读它们的原文并且复现它们的代码,这可以同时锻炼你的<strong>coding 能力和论文阅读能力</strong>,在阅读前,请参见[如何读论文](../1.%E6%9D%AD%E7%94%B5%E7%94%9F%E5%AD%98%E6%8C%87%E5%8D%97/1.10%E5%A6%82%E4%BD%95%E8%AF%BB%E8%AE%BA%E6%96%87.md) 。本模块的撰写者<strong>SRT 社团</strong>主要从事 CV 方向的研究,遇到问题欢迎与我们交流。(你都完成这些了不至于找不到我们的联系方式吧~)<strong>如果你读完了经典网络模块,你可以在它的最后找到接下来的学习路线~</strong>
|
||||
|
||||
- <strong>我想做</strong><strong>NLP</strong><strong> !!!!!!</strong>
|
||||
|
||||
NLP 研究方向庞大且复杂,若直接从 GPT 系列开始不免有些过于困难。我们建议你从了解 NLP 的任务开始,在有足够的基础后开始学习 RNN,LSTM 基准方法后向 [4.6.7Transformer](4.6.7Transformer.md) 进发 ,这个方法广泛运用在几乎所有深度学习领域,尤其是 NLP 的前沿研究已经无法离开 Transformer 了 hhhh。这个模块中我们也加入了一些 Transformer 的改进工作,包括 NLP,CV,和多模态
|
||||
|
||||
- <strong>如果你想做多模态,对比学习等</strong>,请同时了解 CV 和 NLP 模块。这将是你后续知识的基础。多模态我们没有完善的讲义推出,对比学习可以参见[4.6.8对比学习](4.6.8%E5%AF%B9%E6%AF%94%E5%AD%A6%E4%B9%A0.md) 。这是撰写者之一的论文阅读笔记,不保证准确性与理解是否准确,可以作为论文阅读路线图来参考~
|
||||
@@ -1,63 +0,0 @@
|
||||
# Pytorch 安装
|
||||
|
||||
官网如下:
|
||||
|
||||
进入官网后选择 Install,在下面表格中按照你的配置进行选择:
|
||||
|
||||

|
||||
|
||||
其中 Package 部分选择安装的途径,这里主要介绍 Pip 和 Conda 两种途径。
|
||||
|
||||
# 通过 Pip 安装
|
||||
|
||||
Pip 在通过 python 官网下载 python 并安装时可以选择同时安装 pip,不需要额外安装 Anaconda,比较方便。
|
||||
|
||||
1. 根据你的系统、CUDA 版本等配置在表中选择,最后复制表格最下面生成的指令。
|
||||
2. Win+R 唤出 cmd 命令行窗口,将指令粘贴并运行,然后会生成下载计划并在最后附上[y/n],输入 y 并等待下载完成即可。完整的环境大概有 2.9G 且从官网下载,如果没有挂梯子需要等待较长时间。也可以配置镜像源,方法按照接下来的步骤。
|
||||
3. 对于 Windows 用户,在 C:\Users\xx\pip 目录下(没有 pip 目录就新建)创建一个 pip.ini 文件,并将下面代码块中内容复制进去:
|
||||
4. 对于 Linux 用户,同样在~/.pip/pip.conf 进行配置。如果没有.pip 目录就新建,然后将下面代码块中内容复制进去:
|
||||
|
||||
```
|
||||
[global]
|
||||
index-url = http://pypi.douban.com/simple
|
||||
extra-index-url = https://pypi.mirrors.ustc.edu.cn/simple/
|
||||
https://mirrors.aliyun.com/pypi/simple/
|
||||
https://pypi.tuna.tsinghua.edu.cn/simple/
|
||||
https://pypi.org/simple/
|
||||
trusted-host = pypi.mirrors.ustc.edu.cn
|
||||
mirrors.aliyun.com
|
||||
pypi.tuna.tsinghua.edu.cn
|
||||
pypi.org
|
||||
pypi.douban.com
|
||||
```
|
||||
|
||||
# 通过 Conda 安装
|
||||
|
||||
因为 Conda 可以配置并切换虚拟环境,较为方便的下载各种库,这里更推荐使用 Conda 配环境。
|
||||
|
||||
1. 以管理员身份打开 Anaconda Prompt。这是一个操作 conda 的命令行窗口。不给管理员权限最后可能下载完成后无法安装。
|
||||
2. 按照你的配置在官网选择,记得把 Package 改为 conda,复制命令到 Anaconda Prompt 运行。
|
||||
3. 接下来 conda 会开始 solving environment,这个过程需要较长时间,并且 conda 会自动尝试多次,笔者在重配环境时平均每次 solving environment 需要 15min 左右,这一过程结束后才开始获取并生成下载计划,最后显示[y/n]询问是否开始下载。输入 y 回车开始下载。过程中请保证网络稳定!!!否则会下载失败终止进程,需要重新输入命令开始下载并等待再次 solving environment,相当折磨。
|
||||
4. 如果需要加快下载速度,可以在 Anaconda 中添加新的 channel 来换源加快下载速度,方法主要有两种:一是通过 Anaconda Navigaiton,在左边选择 Environments,在上方选择 Channels,Add,最后记得 Update Channels 即可(某些 channel 通过这种方式添加好像会显示 invalid,但是通过下一种方法却可以成功添加,原理未知);或者在 Anaconda Prompt 执行以下指令:
|
||||
|
||||
```bash
|
||||
conda config --set show_channel_urls yes
|
||||
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
|
||||
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
|
||||
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
|
||||
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
|
||||
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
|
||||
conda config --show channels
|
||||
```
|
||||
|
||||
# Tips:关于如何查看自己设备信息
|
||||
|
||||
## Windows
|
||||
|
||||
同时按下 Win+R,运行 cmd,输入 `dxdiag` 并回车。系统、显卡、声卡以及其他设备信息都会显示。
|
||||
|
||||

|
||||
|
||||
cuda 版本查看
|
||||
|
||||

|
||||
@@ -1,61 +0,0 @@
|
||||
# CV 领域任务(研究目标)
|
||||
|
||||
### CV 领域的大任务
|
||||
|
||||

|
||||
|
||||
#### (a)Image classification <strong>图像分类</strong>
|
||||
|
||||
- 识别这个图片整体所属的类别,解决的是"what"问题,给这个图片打上相应的标签,在 a 图内标签是 `bottle,cup,cube`,其他类型的图片也都有它们自己的标签,然后把这些打上标签的图片带进网络结构里作为训练集训练。
|
||||
|
||||
#### (b)Object localization <strong>目标检测</strong>(对象定位)
|
||||
|
||||
- 识别图片中各个物体所在的位置,解决的是"where"问题,此处还细分两个问题:
|
||||
|
||||
- 定位:检测出图片中的物体位置,一般只需要进行画框。
|
||||
- 检测:不仅想要知道这些物体所属的类别,还想知道他们所在的具体位置,比如这张图片有 `bottle,cup,cube`,我们不仅要检测出这些物体所在的位置,还要检测处在这个位置的物体所属的类别,这就是目标检测。
|
||||
- 再看一个目标检测的例子(此处为 [Roboflow-数据集标注工具](https://roboflow.com/)的示例)
|
||||
|
||||
- 这张图我们需要标注两个类别 `head(头)、helmet(头盔)`
|
||||
|
||||

|
||||
|
||||
#### (c)Semantic segmentation <strong>语义分割</strong>
|
||||
|
||||
- 语义分割需要进一步判断图像中哪些像素属于哪个目标(进阶目标检测)。
|
||||
- 看图右下角两个 `cube` 是连在一块的 并没有分出哪一部分是哪一个的 `cube`
|
||||
|
||||
#### (d)Instance segmentation <strong>实例分割</strong>
|
||||
|
||||
- 实例分割需要区分出哪些像素属于第一个物体、哪些像素属于第二个物体,即目标检测 + 语义分割。
|
||||
- 看图右下角两个 `cube` 是分开的
|
||||
|
||||
#### (e)Key Point 人体关键点检测
|
||||
|
||||

|
||||
|
||||
通过人体关键节点的组合和追踪来识别人的运动和行为,对于描述人体姿态,预测人体行为至关重要。
|
||||
|
||||
#### (f)Scene Text Recognition(STR)场景文字识别
|
||||
|
||||

|
||||
|
||||
很多照片中都有一些文字信息,这对理解图像有重要的作用。
|
||||
|
||||
场景文字识别是在图像背景复杂、分辨率低下、字体多样、分布随意等情况下,将图像信息转化为文字序列的过程。
|
||||
|
||||
#### (g)Pattern Generation 图像生成
|
||||
|
||||
利用两张图片或者其他信息生成一张新的图片
|
||||
|
||||

|
||||
|
||||
利用左边两张小图生成右边的图片
|
||||
|
||||
#### (h)Super Resolution 超分辨率
|
||||
|
||||
将输入图片分辨率增加
|
||||
|
||||

|
||||
|
||||
当然还有一些新兴领域我们没有写入~
|
||||
@@ -1,194 +0,0 @@
|
||||
# 数据读取
|
||||
|
||||
Torchvision 中默认使用的图像加载器是 PIL,因此为了确保 Torchvision 正常运行,我们还需要安装一个 Python 的第三方图像处理库——Pillow 库。Pillow 提供了广泛的文件格式支持,强大的图像处理能力,主要包括图像储存、图像显示、格式转换以及基本的图像处理操作等。
|
||||
|
||||
我们先介绍 Torchvision 的常用数据集及其读取方法。
|
||||
|
||||
PyTorch 为我们提供了一种十分方便的数据读取机制,即使用 Dataset 类与 DataLoader 类的组合,来得到数据迭代器。在训练或预测时,数据迭代器能够输出每一批次所需的数据,并且对数据进行相应的预处理与数据增强操作。
|
||||
|
||||
下面我们分别来看下 Dataset 类与 DataLoader 类。
|
||||
|
||||
# Dataset 类
|
||||
|
||||
PyTorch 中的 Dataset 类是一个抽象类,它可以用来表示数据集。我们通过继承 Dataset 类来自定义数据集的格式、大小和其它属性,后面就可以供 DataLoader 类直接使用。
|
||||
|
||||
其实这就表示,无论使用自定义的数据集,还是官方为我们封装好的数据集,其本质都是继承了 Dataset 类。而在继承 Dataset 类时,至少需要重写以下几个方法:
|
||||
|
||||
- __init__():构造函数,可自定义数据读取方法以及进行数据预处理;
|
||||
- __len__():返回数据集大小;
|
||||
- __getitem__():索引数据集中的某一个数据。
|
||||
|
||||
下面我们来编写一个简单的例子,看下如何使用 Dataset 类定义一个 Tensor 类型的数据集。
|
||||
|
||||
```
|
||||
import torch
|
||||
from torch.utils.data import Dataset
|
||||
|
||||
class MyDataset(Dataset):
|
||||
# 构造函数
|
||||
def __init__(self, data_tensor, target_tensor):
|
||||
self.data_tensor = data_tensor
|
||||
self.target_tensor = target_tensor
|
||||
# 返回数据集大小
|
||||
def __len__(self):
|
||||
return self.data_tensor.size(0)
|
||||
# 返回索引的数据与标签
|
||||
def __getitem__(self, index):
|
||||
return self.data_tensor[index], self.target_tensor[index]
|
||||
'''
|
||||
我们定义了一个名字为 MyDataset 的数据集,在构造函数中,传入 Tensor 类型的数据与标签;
|
||||
在 __len__ 函数中,直接返回 Tensor 的大小;在 __getitem__ 函数中返回索引的数据与标签。
|
||||
'''
|
||||
```
|
||||
|
||||
然后我们来看一下如何调用刚才定义的数据集。首先随机生成一个 10*3 维的数据 Tensor,然后生成 10 维的标签 Tensor,与数据 Tensor 相对应。利用这两个 Tensor,生成一个 MyDataset 的对象。查看数据集的大小可以直接用 len() 函数,索引调用数据可以直接使用下标。
|
||||
|
||||
```
|
||||
# 生成数据
|
||||
data_tensor = torch.randn(10, 3)
|
||||
target_tensor = torch.randint(2, (10,)) # 标签是0或1
|
||||
# 生成10个随机数,随机数的范围只能是0或者1
|
||||
|
||||
# 将数据封装成Dataset
|
||||
my_dataset = MyDataset(data_tensor, target_tensor)
|
||||
|
||||
# 查看数据集大小
|
||||
print('Dataset size:', len(my_dataset))
|
||||
|
||||
# 使用索引调用数据
|
||||
print('tensor_data[0]: ', my_dataset[0])
|
||||
```
|
||||
|
||||
# DataLoader 类
|
||||
|
||||
在实际项目中,如果数据量很大,考虑到内存有限、I/O 速度等问题,在训练过程中不可能一次性的将所有数据全部加载到内存中,也不能只用一个进程去加载,所以就需要多进程、迭代加载,而 DataLoader 就是基于这些需要被设计出来的。
|
||||
|
||||
DataLoader 是一个迭代器,最基本的使用方法就是传入一个 Dataset 对象,它会根据参数 batch_size 的值生成一个 batch 的数据,节省内存的同时,它还可以实现多进程、数据打乱等处理。
|
||||
|
||||
DataLoader 类的调用方式如下:
|
||||
|
||||
```
|
||||
from torch.utils.data import DataLoader
|
||||
tensor_dataloader = DataLoader(dataset=my_dataset, # 传入的数据集, 必须参数
|
||||
batch_size=2, # 输出的batch大小
|
||||
shuffle=True, # 数据是否打乱
|
||||
num_workers=0) # 进程数, 0表示只有主进程
|
||||
|
||||
# 以循环形式输出
|
||||
for data, target in tensor_dataloader:
|
||||
print(data, target)
|
||||
'''
|
||||
输出:
|
||||
tensor([[-0.1781, -1.1019, -0.1507],
|
||||
[-0.6170, 0.2366, 0.1006]]) tensor([0, 0])
|
||||
tensor([[ 0.9451, -0.4923, -1.8178],
|
||||
[-0.4046, -0.5436, -1.7911]]) tensor([0, 0])
|
||||
tensor([[-0.4561, -1.2480, -0.3051],
|
||||
[-0.9738, 0.9465, 0.4812]]) tensor([1, 0])
|
||||
tensor([[ 0.0260, 1.5276, 0.1687],
|
||||
[ 1.3692, -0.0170, -1.6831]]) tensor([1, 0])
|
||||
tensor([[ 0.0515, -0.8892, -0.1699],
|
||||
[ 0.4931, -0.0697, 0.4171]]) tensor([1, 0])
|
||||
'''
|
||||
|
||||
# 输出一个batch(用iter()强制类型转换成迭代器的对象,next()是输出迭代器下一个元素)
|
||||
print('One batch tensor data: ', iter(tensor_dataloader).next())
|
||||
'''
|
||||
输出:
|
||||
One batch tensor data: [tensor([[ 0.9451, -0.4923, -1.8178],
|
||||
[-0.4046, -0.5436, -1.7911]]), tensor([0, 0])]
|
||||
'''
|
||||
```
|
||||
|
||||
结合代码,我们梳理一下 DataLoader 中的几个参数,它们分别表示:
|
||||
|
||||
- dataset:Dataset 类型,输入的数据集,必须参数;
|
||||
- batch_size:int 类型,每个 batch 有多少个样本;
|
||||
- shuffle:bool 类型,在每个 epoch 开始的时候,是否对数据进行重新打乱;
|
||||
- num_workers:int 类型,加载数据的进程数,0 意味着所有的数据都会被加载进主进程,默认为 0。
|
||||
|
||||
<strong>思考题</strong>
|
||||
|
||||
按照上述代码,One batch tensor data 的输出是否正确,若不正确,为什么?
|
||||
|
||||
# 利用 Torchvision 读取数据
|
||||
|
||||
Torchvision 库中的 torchvision.datasets 包中提供了丰富的图像数据集的接口。常用的图像数据集,例如 MNIST、COCO 等,这个模块都为我们做了相应的封装。
|
||||
|
||||
下表中列出了 torchvision.datasets 包所有支持的数据集。各个数据集的说明与接口,详见链接 [https://pytorch.org/vision/stable/datasets.html](https://pytorch.org/vision/stable/datasets.html)。
|
||||
|
||||

|
||||
|
||||
注意,torchvision.datasets 这个包本身并不包含数据集的文件本身,它的工作方式是先从网络上把数据集下载到用户指定目录,然后再用它的加载器把数据集加载到内存中。最后,把这个加载后的数据集作为对象返回给用户。
|
||||
|
||||
为了让你进一步加深对知识的理解,我们以 MNIST 数据集为例,来说明一下这个模块具体的使用方法。
|
||||
|
||||
# MNIST 数据集简介
|
||||
|
||||
MNIST 数据集是一个著名的手写数字数据集,因为上手简单,在深度学习领域,手写数字识别是一个很经典的学习入门样例。
|
||||
|
||||
MNIST 数据集是 NIST 数据集的一个子集,MNIST 数据集你可以通过[这里](http://yann.lecun.com/exdb/mnist/)下载。它包含了四个部分。
|
||||
|
||||

|
||||
|
||||
MNIST 数据集是 ubyte 格式存储,我们先将“训练集图片”解析成图片格式,来直观地看一看数据集具体是什么样子的。具体怎么解析,我们在后面数据预览再展开。
|
||||
|
||||

|
||||
|
||||
接下来,我们看一下如何使用 Torchvision 来读取 MNIST 数据集。
|
||||
|
||||
对于 torchvision.datasets 所支持的所有数据集,它都内置了相应的数据集接口。例如刚才介绍的 MNIST 数据集,torchvision.datasets 就有一个 MNIST 的接口,接口内封装了从下载、解压缩、读取数据、解析数据等全部过程。
|
||||
|
||||
这些接口的工作方式差不多,都是先从网络上把数据集下载到指定目录,然后再用加载器把数据集加载到内存中,最后将加载后的数据集作为对象返回给用户。
|
||||
|
||||
以 MNIST 为例,我们可以用如下方式调用:
|
||||
|
||||
```
|
||||
# 以MNIST为例
|
||||
import torchvision
|
||||
mnist_dataset = torchvision.datasets.MNIST(root='./data',
|
||||
train=True,
|
||||
transform=None,
|
||||
target_transform=None,
|
||||
download=True)
|
||||
```
|
||||
|
||||
torchvision.datasets.MNIST 是一个类,对它进行实例化,即可返回一个 MNIST 数据集对象。构造函数包括包含 5 个参数:
|
||||
|
||||
- root:是一个字符串,用于指定你想要保存 MNIST 数据集的位置。如果 download 是 Flase,则会从目标位置读取数据集;
|
||||
- download:布尔类型,表示是否下载数据集。如果为 True,则会自动从网上下载这个数据集,存储到 root 指定的位置。如果指定位置已经存在数据集文件,则不会重复下载;
|
||||
- train:布尔类型,表示是否加载训练集数据。如果为 True,则只加载训练数据。如果为 False,则只加载测试数据集。这里需要注意,并不是所有的数据集都做了训练集和测试集的划分,这个参数并不一定是有效参数,具体需要参考官方接口说明文档;
|
||||
- transform:用于对图像进行预处理操作,例如数据增强、归一化、旋转或缩放等。这些操作我们会在下节课展开讲解;
|
||||
- target_transform:用于对图像标签进行预处理操作。
|
||||
|
||||
运行上述的代码后,程序会首先去指定的网址下载了 MNIST 数据集,然后进行了解压缩等操作。如果你再次运行相同的代码,则不会再有下载的过程。
|
||||
|
||||
如果你用 type 函数查看一下 mnist_dataset 的类型,就可以得到 torchvision.datasets.mnist.MNIST ,而这个类是之前我们介绍过的 Dataset 类的派生类。相当于 torchvision.datasets ,它已经帮我们写好了对 Dataset 类的继承,完成了对数据集的封装,我们直接使用即可。
|
||||
|
||||
这里我们主要以 MNIST 为例,进行了说明。其它的数据集使用方法类似,调用的时候你只要需要将类名“MNIST”换成其它数据集名字即可。
|
||||
|
||||
# 数据预览
|
||||
|
||||
完成了数据读取工作,我们得到的是对应的 mnist_dataset,刚才已经讲过了,这是一个封装了的数据集。
|
||||
|
||||
如果想要查看 mnist_dataset 中的具体内容,我们需要把它转化为列表。(如果 IOPub data rate 超限,可以只加载测试集数据,令 train=False)
|
||||
|
||||
```
|
||||
mnist_dataset_list = list(mnist_dataset)
|
||||
print(mnist_dataset_list)
|
||||
```
|
||||
|
||||
转换后的数据集对象变成了一个元组列表,每个元组有两个元素,第一个元素是图像数据,第二个元素是图像的标签。
|
||||
|
||||
这里图像数据是 PIL.Image.Image 类型的,这种类型可以直接在 Jupyter 中显示出来。显示一条数据的代码如下。
|
||||
|
||||
```
|
||||
display(mnist_dataset_list[0][0])
|
||||
print("Image label is:", mnist_dataset_list[0][1])
|
||||
```
|
||||
|
||||
上面介绍了两种读取数据的方法,也就是自定义和读取常用图像数据集。最通用的数据读取方法,就是自己定义一个 Dataset 的派生类。而读取常用的图像数据集,就可以利用 PyTorch 提供的视觉包 Torchvision。
|
||||
|
||||
极客时间版权所有: [https://time.geekbang.org/column/article/429826](https://time.geekbang.org/column/article/429826)
|
||||
|
||||
(有删改)
|
||||
@@ -1,340 +0,0 @@
|
||||
# 数据增强
|
||||
|
||||
仅仅将数据集中的图片读取出来是不够的,在训练的过程中,神经网络模型接收的数据类型是 Tensor,而不是 PIL 对象,因此我们还需要对数据进行预处理操作,比如图像格式的转换。
|
||||
|
||||
我们对一张数据进行裁剪,很明显裁剪前后我们都可以辨认图片中的物体,但是我们的神经网络却没有这个能力。所以我们在训练前可能还需要对图像数据进行一系列图像变换与增强操作,例如裁切边框、调整图像比例和大小、标准化等,对同一张图片进行多种处理并送入神经网络进行训练,以便模型能够更好地学习到数据的特征。而这些操作都可以使用 torchvision.transforms 工具完成。
|
||||
|
||||
# Torchvision.transforms
|
||||
|
||||
Torchvision 库中的 torchvision.transforms 包中提供了常用的图像操作,包括对 Tensor 及 PIL Image 对象的操作,例如随机切割、旋转、数据类型转换等等。
|
||||
|
||||
按照 torchvision.transforms 的功能,大致分为以下几类:数据类型转换、对 PIL.Image 和 Tensor 进行变化和变换的组合。
|
||||
|
||||
## 数据类型转换
|
||||
|
||||
读取数据集中的图片,读取到的数据是 PIL.Image 的对象。而在模型训练阶段,需要传入 Tensor 类型的数据,神经网络才能进行运算。
|
||||
|
||||
那么如何将 PIL.Image 或 Numpy.ndarray 格式的数据转化为 Tensor 格式呢?这需要用到 transforms.ToTensor() 类。
|
||||
|
||||
而反之,将 Tensor 或 Numpy.ndarray 格式的数据转化为 PIL.Image 格式,则使用 transforms.ToPILImage(mode=None) 类。它则是 ToTensor 的一个逆操作,它能把 Tensor 或 Numpy 的数组转换成 PIL.Image 对象。
|
||||
|
||||
其中,参数 mode 代表 PIL.Image 的模式,如果 mode 为 None(默认值),则根据输入数据的维度进行推断:
|
||||
|
||||
- 输入为 3 通道:mode 为’RGB’;
|
||||
- 输入为 4 通道:mode 为’RGBA’;
|
||||
- 输入为 2 通道:mode 为’LA’;
|
||||
- 输入为单通道:mode 根据输入数据的类型确定具体模式。
|
||||
|
||||
我们来看一个具体的例子加深理解。将图片进行一下数据类型的相互转换。具体代码如下:
|
||||
|
||||
```
|
||||
from PIL import Image
|
||||
from torchvision import transforms
|
||||
|
||||
|
||||
|
||||
img = Image.open('tupian.jpg')
|
||||
display(img)
|
||||
print(type(img)) # PIL.Image.Image是PIL.JpegImagePlugin.JpegImageFile的基类
|
||||
'''
|
||||
输出:
|
||||
<class 'PIL.JpegImagePlugin.JpegImageFile'>
|
||||
'''
|
||||
|
||||
# PIL.Image转换为Tensor
|
||||
img1 = transforms.ToTensor()(img)
|
||||
print(type(img1))
|
||||
'''
|
||||
输出:
|
||||
<class 'torch.Tensor'>
|
||||
'''
|
||||
|
||||
# Tensor转换为PIL.Image
|
||||
img2 = transforms.ToPILImage()(img1) #PIL.Image.Image
|
||||
print(type(img2))
|
||||
'''
|
||||
输出:
|
||||
<class 'PIL.Image.Image'>
|
||||
'''
|
||||
```
|
||||
|
||||
首先用读取图片,查看一下图片的类型为 PIL.JpegImagePlugin.JpegImageFile,这里需要注意,<strong>PIL.JpegImagePlugin.JpegImageFile 类是 PIL.Image.Image 类的子类</strong>。然后,用 transforms.ToTensor() 将 PIL.Image 转换为 Tensor。最后,再将 Tensor 转换回 PIL.Image。
|
||||
|
||||
## 对 PIL.Image 和 Tensor 进行变换
|
||||
|
||||
torchvision.transforms 提供了丰富的图像变换方法,例如:改变尺寸、剪裁、翻转等。并且这些图像变换操作可以接收多种数据格式,不仅可以直接对 PIL 格式的图像进行变换,也可以对 Tensor 进行变换,无需我们再去做额外的数据类型转换。
|
||||
|
||||
### Resize
|
||||
|
||||
将输入的 PIL Image 或 Tensor 尺寸调整为给定的尺寸,具体定义为:
|
||||
|
||||
```
|
||||
torchvision.transforms.Resize(size, interpolation=2)
|
||||
```
|
||||
|
||||
- size:期望输出的尺寸。如果 size 是一个像 (h, w) 这样的元组,则图像输出尺寸将与之匹配。如果 size 是一个 int 类型的整数,图像较小的边将被匹配到该整数,另一条边按比例缩放。
|
||||
- interpolation:插值算法,我们在这里使其接收一个 int 类型 2,表示 PIL.Image.BILINEAR(双线性插值,感兴趣可以自己单独了解,这个算法的应用比较广泛),但是需要注意的是当该参数接受 int 类型时会出现 warning,这个无需担心,也可以正常使用。
|
||||
|
||||
有关 Size 中是 tuple 还是 int 这一点请你一定要注意。
|
||||
|
||||
让我说明一下,在我们训练时,通常要把图片 resize 到一定的大小,比如说 128x128,256x256 这样的。如果直接给定 resize 后的高与宽,是没有问题的。但如果设定的是一个 int 型,较长的边就会按比例缩放。
|
||||
|
||||
在 resize 之后呢,一般会接一个 crop 操作,crop 到指定的大小。对于高与宽接近的图片来说,这么做问题不大,但是高与宽的差距较大时,就会 crop 掉很多有用的信息。关于这一点,我们在后续的图像分类部分还会遇到,到时我在详细展开。
|
||||
|
||||
```
|
||||
from PIL import Image
|
||||
from torchvision import transforms
|
||||
|
||||
# 定义一个Resize操作
|
||||
resize_img_oper = transforms.Resize((200,200), interpolation=2)
|
||||
|
||||
# 原图
|
||||
orig_img = Image.open('tupian.jpg')
|
||||
display(orig_img)
|
||||
|
||||
# Resize操作后的图
|
||||
img = resize_img_oper(orig_img)
|
||||
display(img)
|
||||
```
|
||||
|
||||
首先定义一个 Resize 操作,设置好变换后的尺寸为 (200, 200),然后对图片进行 Resize 变换。
|
||||
|
||||
### 裁剪
|
||||
|
||||
torchvision.transforms 提供了多种剪裁方法,例如中心剪裁、随机剪裁、四角和中心剪裁等。我们依次来看下它们的定义。
|
||||
|
||||
先说中心剪裁,在中心裁剪指定的 PIL Image 或 Tensor,其定义如下:
|
||||
|
||||
```
|
||||
torchvision.transforms.CenterCrop(size)
|
||||
```
|
||||
|
||||
其中,size 表示期望输出的剪裁尺寸。如果 size 是一个像 (h, w) 这样的元组,则剪裁后的图像尺寸将与之匹配。如果 size 是 int 类型的整数,剪裁出来的图像是 (size, size) 的正方形。
|
||||
|
||||
然后是随机剪裁,在一个随机位置剪裁指定的 PIL Image 或 Tensor,定义如下:
|
||||
|
||||
```
|
||||
torchvision.transforms.RandomCrop(size, padding=None)
|
||||
```
|
||||
|
||||
其中,size 代表期望输出的剪裁尺寸,用法同上。而 padding 表示图像的每个边框上的可选填充。默认值是 None,即没有填充。通常来说,不会用 padding 这个参数,至少对于我来说至今没用过。
|
||||
|
||||
最后要说的是 FiveCrop,我们将给定的 PIL Image 或 Tensor ,分别从四角和中心进行剪裁,共剪裁成五块,定义如下:
|
||||
|
||||
```
|
||||
torchvision.transforms.FiveCrop(size)
|
||||
```
|
||||
|
||||
size 可以是 int 或 tuple,用法同上。掌握了各种剪裁的定义和参数用法以后,我们来看一下这些剪裁操作具体如何调用,代码如下:
|
||||
|
||||
```
|
||||
from PIL import Image
|
||||
from torchvision import transforms
|
||||
|
||||
# 定义剪裁操作
|
||||
center_crop_oper = transforms.CenterCrop((60,70))
|
||||
random_crop_oper = transforms.RandomCrop((80,80))
|
||||
five_crop_oper = transforms.FiveCrop((60,70))
|
||||
|
||||
# 原图
|
||||
orig_img = Image.open('tupian.jpg')
|
||||
display(orig_img)
|
||||
|
||||
# 中心剪裁
|
||||
img1 = center_crop_oper(orig_img)
|
||||
display(img1)
|
||||
# 随机剪裁
|
||||
img2 = random_crop_oper(orig_img)
|
||||
display(img2)
|
||||
# 四角和中心剪裁
|
||||
imgs = five_crop_oper(orig_img)
|
||||
for img in imgs:
|
||||
display(img)
|
||||
```
|
||||
|
||||
### 翻转
|
||||
|
||||
接下来,我们来看一看翻转操作。torchvision.transforms 提供了两种翻转操作,分别是:以某一概率随机水平翻转图像和以某一概率随机垂直翻转图像。我们分别来看它们的定义。
|
||||
|
||||
以概率 p 随机水平翻转图像,定义如下:
|
||||
|
||||
```
|
||||
torchvision.transforms.RandomHorizontalFlip(p=0.5)
|
||||
```
|
||||
|
||||
以概率 p 随机垂直翻转图像,定义如下:
|
||||
|
||||
```
|
||||
torchvision.transforms.RandomVerticalFlip(p=0.5)
|
||||
```
|
||||
|
||||
其中,p 表示随机翻转的概率值,默认为 0.5
|
||||
|
||||
这里的随机翻转,是为数据增强提供方便。如果想要必须执行翻转操作的话,将 p 设置为 1 即可。图片翻转代码如下:
|
||||
|
||||
```
|
||||
from PIL import Image
|
||||
from torchvision import transforms
|
||||
|
||||
# 定义翻转操作
|
||||
h_flip_oper = transforms.RandomHorizontalFlip(p=1)
|
||||
v_flip_oper = transforms.RandomVerticalFlip(p=1)
|
||||
|
||||
# 原图
|
||||
orig_img = Image.open('tupian.jpg')
|
||||
display(orig_img)
|
||||
|
||||
# 水平翻转
|
||||
img1 = h_flip_oper(orig_img)
|
||||
display(img1)
|
||||
# 垂直翻转
|
||||
img2 = v_flip_oper(orig_img)
|
||||
display(img2)
|
||||
```
|
||||
|
||||
### 只对 Tensor 进行变换
|
||||
|
||||
目前版本的 Torchvision(v0.10.0)对各种图像变换操作已经基本同时支持 PIL Image 和 Tensor 类型了,因此只针对 Tensor 的变换操作很少,只有 4 个,分别是 LinearTransformation(线性变换)、Normalize(标准化)、RandomErasing(随机擦除)、ConvertImageDtype(格式转换)。
|
||||
|
||||
这里我们重点来看最常用的一个操作:标准化,其他 3 个你可以查阅官方文档。
|
||||
|
||||
### 标准化
|
||||
|
||||
标准化是指每一个数据点减去所在通道的平均值,再除以所在通道的标准差,数学的计算公式:output=(input−mean)/std
|
||||
|
||||
而对图像进行标准化,就是对图像的每个通道利用均值和标准差进行正则化。这样做的目的,是<strong>为了保证数据集中所有的图像分布都相似,这样在训练的时候更容易收敛,既加快了训练速度,也提高了训练效果</strong>。
|
||||
|
||||
让我来解释一下:首先,标准化是一个常规做法,可以理解为无脑进行标准化后再训练的效果,大概率要好于不进行标准化。
|
||||
|
||||
如果我们把一张图片上的每个像素点都减去某一数值得到一张新的图片,但在我们眼里他们还是内容一样的两张图片,只是颜色有一些不同。但卷积神经网络是通过图像的像素进行提取特征的,两张图片像素的数值都一样,如何让神经网络认为是一张图片?
|
||||
|
||||
而标准化后的数据就会避免这一问题,标准化后会将数据映射到同一区间中,一个类别的图片虽说有的像素值可能有差异,但是它们分布都是类似的分布。
|
||||
|
||||
torchvision.transforms 提供了对 Tensor 进行标准化的函数,定义如下:
|
||||
|
||||
```
|
||||
torchvision.transforms.Normalize(mean, std, inplace=False)
|
||||
```
|
||||
|
||||
其中,每个参数的含义如下所示:
|
||||
|
||||
- mean:表示各通道的均值;
|
||||
- std:表示各通道的标准差;
|
||||
- inplace:表示是否原地操作,默认为否。
|
||||
|
||||
我们来看看以 (R, G, B) 均值和标准差均为 (0.5, 0.5, 0.5) 来标准化图片后,是什么效果:
|
||||
|
||||
```
|
||||
from PIL import Image
|
||||
from torchvision import transforms
|
||||
|
||||
# 定义标准化操作
|
||||
norm_oper = transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
|
||||
|
||||
# 原图
|
||||
orig_img = Image.open('tupian.jpg')
|
||||
display(orig_img)
|
||||
|
||||
# 图像转化为Tensor
|
||||
img_tensor = transforms.ToTensor()(orig_img)
|
||||
|
||||
# 标准化
|
||||
tensor_norm = norm_oper(img_tensor)
|
||||
|
||||
# Tensor转化为图像
|
||||
img_norm = transforms.ToPILImage()(tensor_norm)
|
||||
display(img_norm)
|
||||
```
|
||||
|
||||
我们首先定义了均值和标准差均为 (0.5, 0.5, 0.5) 的标准化操作,然后将原图转化为 Tensor,接着对 Tensor 进行标准化,最后再将 Tensor 转化为图像输出。
|
||||
|
||||
### 变换的组合
|
||||
|
||||
其实前面介绍过的所有操作都可以用 Compose 类组合起来,进行连续操作。
|
||||
|
||||
Compose 类是将多个变换组合到一起,它的定义如下:
|
||||
|
||||
```
|
||||
torchvision.transforms.Compose(transforms)
|
||||
```
|
||||
|
||||
其中,transforms 是一个 Transform 对象的列表,表示要组合的变换列表。
|
||||
|
||||
我们还是结合例子动手试试,如果我们想要将图片变为 200*200 像素大小,并且随机裁切成 80 像素的正方形。那么我们可以组合 Resize 和 RandomCrop 变换,具体代码如下所示:
|
||||
|
||||
```
|
||||
from PIL import Image
|
||||
from IPython.display import display
|
||||
from torchvision import transforms
|
||||
|
||||
# 原图
|
||||
orig_img = Image.open('tupian.jpg')
|
||||
display(orig_img)
|
||||
|
||||
# 定义组合操作
|
||||
composed = transforms.Compose([transforms.Resize((200, 200)),
|
||||
transforms.RandomCrop(80)])
|
||||
|
||||
# 组合操作后的图
|
||||
img = composed(orig_img)
|
||||
display(img)
|
||||
```
|
||||
|
||||
### 结合 datasets 使用
|
||||
|
||||
Compose 类是未来我们在实际项目中经常要使用到的类,结合 torchvision.datasets 包,就可以在读取数据集的时候做图像变换与数据增强操作。
|
||||
|
||||
在利用 torchvision.datasets 读取 MNIST 数据集时,有一个参数“transform”,它就是用于对图像进行预处理操作的,例如数据增强、归一化、旋转或缩放等。这里的“transform”就可以接收一个 torchvision.transforms 操作或者由 Compose 类所定义的操作组合。
|
||||
|
||||
我们在读取 MNIST 数据集时,直接读取出来的图像数据是 PIL.Image.Image 类型的。但是遇到要训练手写数字识别模型这类的情况,模型接收的数据类型是 Tensor,而不是 PIL 对象。这时候,我们就可以利用“transform”参数,使数据在读取的同时做类型转换,这样读取出的数据直接就可以是 Tensor 类型了。
|
||||
|
||||
不只是数据类型的转换,我们还可以增加归一化等数据增强的操作,只需要使用上面介绍过的 Compose 类进行组合即可。这样,在读取数据的同时,我们也就完成了数据预处理、数据增强等一系列操作。
|
||||
|
||||
我们还是以读取 MNIST 数据集为例,看下如何在读取数据的同时,完成数据预处理等操作。具体代码如下:
|
||||
|
||||
```
|
||||
from torchvision import transforms
|
||||
from torchvision import datasets
|
||||
|
||||
# 定义一个transform
|
||||
my_transform = transforms.Compose([transforms.ToTensor(),
|
||||
transforms.Normalize((0.5), (0.5))
|
||||
])
|
||||
# 读取MNIST数据集 同时做数据变换
|
||||
mnist_dataset = datasets.MNIST(root='./data',
|
||||
train=False,
|
||||
transform=my_transform,
|
||||
target_transform=None,
|
||||
download=True)
|
||||
|
||||
# 查看变换后的数据类型
|
||||
item = mnist_dataset.__getitem__(0)
|
||||
print(type(item[0]))
|
||||
'''
|
||||
输出:
|
||||
<class 'torch.Tensor'>
|
||||
'''
|
||||
```
|
||||
|
||||
当然,MNIST 数据集非常简单,根本不进行任何处理直接读入的话,效果也非常好,但是它确实适合学习来使用,你可以在利用它进行各种尝试。
|
||||
|
||||
我们下面先来看看,在图像分类实战中使用的 transform,可以感受一下实际使用的 transforms 是什么样子:
|
||||
|
||||
```
|
||||
transform = transforms.Compose([
|
||||
transforms.RandomResizedCrop(dest_image_size),
|
||||
transforms.RandomHorizontalFlip(),
|
||||
transforms.ToTensor(),
|
||||
transforms.Normalize(mean=[0.485, 0.456, 0.406],
|
||||
std=[0.229, 0.224, 0.225])])
|
||||
```
|
||||
|
||||
常用的图像处理操作包括数据类型转换、图像尺寸变化、剪裁、翻转、标准化等等。Compose 类还可以将多个变换操作组合成一个 Transform 对象的列表。
|
||||
|
||||
torchvision.transforms 与 torchvision.datasets 结合使用,可以在数据加载的同时进行一系列图像变换与数据增强操作,不仅能够直接将数据送入模型训练,还可以加快模型收敛速度,让模型更好地学习到数据特征。
|
||||
|
||||
当然,我们在实际的项目中会有自己的数据,而不会使用 torchvision.datasets 中提供的公开数据集,我们今天讲的 torchvision.transforms 同样可以在我们自定义的数据集中使用,这里不再详细讲述。
|
||||
|
||||
极客时间版权所有: [https://time.geekbang.org/column/article/429826](https://time.geekbang.org/column/article/429826)
|
||||
|
||||
(有删改)
|
||||
@@ -1,17 +0,0 @@
|
||||
# 数据预处理(torchvision)
|
||||
|
||||
不管我们的网络设计的有多复杂,选择什么样的优化器和损失函数,我们在训练模型时首先需要面对的是如何处理我们的数据。最简单的一个问题,我们需要怎么把数据拿过来送进我们的网络中呢(数据读取)。还有,我们把数据送进去之前还需要对其进行一些什么操作呢。
|
||||
|
||||
PyTorch 为我们提供了丰富的 API 以供我们方便的进行学习。
|
||||
|
||||
torchvision 是 pytorch 的一个图形库,其中还提供一些常用的数据集和几个已经搭建好的经典网络模型,以及一些图像数据处理方面的工具,主要供数据预处理阶段使用。它服务于 PyTorch 深度学习框架,主要用来构建计算机视觉模型。以下是 torchvision 的构成:
|
||||
|
||||
torchvision.datasets: 一些加载数据的函数及常用的数据集接口;
|
||||
|
||||
torchvision.models: 包含常用的模型结构(含预训练模型),例如 AlexNet、VGG、ResNet 等;
|
||||
|
||||
torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;
|
||||
|
||||
torchvision.utils: 其他的一些有用的方法。
|
||||
|
||||
这部分是讲解如何读取数据集和处理数据集,如果你不是想真正上手写深度学习的代码,可以无视这块。
|
||||
@@ -1,61 +0,0 @@
|
||||
# AlexNet
|
||||
|
||||
所谓“深度”学习的开山之作。
|
||||
|
||||
AlexNet 有 6 千万个参数和 650,000 个神经元。
|
||||
|
||||
虽然一些理念和方式已经略有过时,但仍然是入门非常有必要读的一篇论文
|
||||
|
||||
[知乎](https://zhuanlan.zhihu.com/p/42914388)
|
||||
|
||||
[论文](http://www.cs.toronto.edu/~fritz/absps/imagenet.pdf)
|
||||
|
||||
### <strong>网络框架图</strong>
|
||||
|
||||

|
||||
|
||||
### <strong>使用 ReLU 激活函数代替 tanh</strong>
|
||||
|
||||
在当时,标准的神经元激活函数是 tanh()函数,这种饱和的非线性函数在梯度下降的时候要比非饱和的非线性函数慢得多,因此,在 AlexNet 中使用 ReLU 函数作为激活函数。
|
||||
|
||||

|
||||
|
||||
### <strong>采用 Dropout 防止过拟合</strong>
|
||||
|
||||
dropout 方法会遍历网络的每一层,并设置消除神经网络中节点的概率。假设网络中的每一层,每个节点都以抛硬币的方式设置概率,每个节点得以保留和消除的概率都是 0.5,设置完节点概率,我们会消除一些节点,然后删除掉从该节点进出的连线,最后得到一个节点更少,规模更小的网络(如下图所示),然后再用反向传播方法进行训练。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
###
|
||||
|
||||
###
|
||||
|
||||
### <strong>视频讲解</strong>
|
||||
|
||||
# 思考
|
||||
|
||||
### 思考 1
|
||||
|
||||
AlexNet 中有着卷积和 MLP 两种不同的网络结构,那两者之间有着何种区别和联系呢?(可以从两者的权值矩阵去思考)
|
||||
|
||||
### <strong>思考 2</strong>
|
||||
|
||||
卷积中有一个叫感受野的概念,是什么意思呢?不同的感受野对网络有什么影响?
|
||||
|
||||
### 思考 3
|
||||
|
||||
CNN 的平移不变性是什么意思?
|
||||
|
||||
### 思考 4
|
||||
|
||||
分成两块来训练是一个历史遗留问题,后面接线性层也是历史问题,可以思考一下为什么并且你会在下一章中得到一定的答案。
|
||||
|
||||
### 思考 5
|
||||
|
||||
这里面提出了 relu 激活函数,你在这章知道 relu 是怎么样的函数,那么它是怎么样实现线性与非线性的转化呢
|
||||
|
||||
### 思考 6
|
||||
|
||||
前面学习中你已经掌握了卷积,那卷积是怎样实现特征提取的呢。
|
||||
@@ -1,51 +0,0 @@
|
||||
# FCN
|
||||
|
||||
图像分割领域的开山之作。
|
||||
|
||||
首次将<strong>End-to-End</strong>的思想应用在了 CV 领域。
|
||||
|
||||
[知乎](https://zhuanlan.zhihu.com/p/30195134)
|
||||
|
||||
[论文](https://arxiv.org/pdf/1411.4038.pdf)
|
||||
|
||||
### 框架图
|
||||
|
||||

|
||||
|
||||
### 同 CNN 的对比
|
||||
|
||||
通常 CNN 网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。以 AlexNet 为代表的经典 CNN 结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的一个数值描述,比如 AlexNet 的 ImageNet 模型输出一个 1000 维的向量表示输入图像属于每一类的概率。
|
||||
|
||||
FCN 对图像进行像素级的分类,从而解决了语义级别的图像分割问题。与经典的 CNN 在卷积层之后使用全连接层得到固定长度的特征向量进行分类不同,FCN 可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的 feature map 进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
|
||||
|
||||
<strong>简单的来说,FCN 与 CNN 的区域在把于 CNN 最后的全连接层换成卷积层,输出的是一张已经 Label 好的图片。</strong>
|
||||
|
||||
### 反卷积
|
||||
|
||||
这里提到的反卷积,FCN 作者称为 backwards convolution,有人称 Deconvolution layer is a very unfortunate name and should rather be called a transposed convolutional layer. 我们可以知道,在 CNN 中有 con layer 与 pool layer,con layer 进行对图像卷积提取特征,pool layer 对图像缩小一半筛选重要特征,对于经典的图像识别 CNN 网络,如 IMAGENET,最后输出结果是 1X1X1000,1000 是类别种类,1x1 得到的是。FCN 作者,或者后来对 end to end 研究的人员,就是对最终 1x1 的结果使用反卷积(事实上 FCN 作者最后的输出不是 1X1,是图片大小的 32 分之一,但不影响反卷积的使用)。
|
||||
|
||||
这里图像的反卷积使用了这一种反卷积手段使得图像可以变大,FCN 作者使用的方法是这里所说反卷积的一种变体,这样就可以获得相应的像素值,图像可以实现 end to end。
|
||||
|
||||

|
||||
|
||||
### 视频
|
||||
|
||||
# 思考
|
||||
|
||||
## 思考 1
|
||||
|
||||
什么是端到端(End-to-End)?
|
||||
|
||||
端到端的网络有什么优点?
|
||||
|
||||
## 思考 2
|
||||
|
||||
关于反卷积,你理解了吗?
|
||||
|
||||
## 思考 3
|
||||
|
||||
FCN 的任务和上一篇论文 AlexNet 有什么区别,从对图像的最终预测延伸到数学上是哪两种模型?
|
||||
|
||||
## 思考 4
|
||||
|
||||
在该文中提到的语义分割是什么意思呢?语义又代表什么?
|
||||
@@ -1,211 +0,0 @@
|
||||
# ResNet
|
||||
::: warning 🕶
|
||||
残差神经网络(ResNet)是由微软研究院的何恺明大神团队提出的一个经典网络模型,一经现世就成为了沿用至今的超级 Backbone。
|
||||
:::
|
||||
[知乎](https://zhuanlan.zhihu.com/p/101332297)
|
||||
|
||||
[论文](https://arxiv.org/pdf/1512.03385.pdf)
|
||||
|
||||
## WHY residual?
|
||||
::: warning 🎨
|
||||
在 ResNet 提出之前,所有的神经网络都是通过卷积层和池化层的叠加组成的。
|
||||
人们认为卷积层和池化层的层数越多,获取到的图片特征信息越全,学习效果也就越好。但是在实际的试验中发现,随着卷积层和池化层的叠加,不但没有出现学习效果越来越好的情况,反而出现两种问题:
|
||||
|
||||
- 梯度消失和梯度爆炸
|
||||
|
||||
梯度消失:若每一层的梯度误差小于 1,反向传播时,网络越深,梯度越趋近于 0
|
||||
|
||||
梯度爆炸:若每一层的梯度误差大于 1,反向传播时,网络越深,梯度越趋近于无穷大
|
||||
|
||||
- 退化现象
|
||||
|
||||
如图所示,随着层数越来越深,预测的效果反而越来越差(error 越大)
|
||||
:::
|
||||

|
||||
|
||||
## 网络模型
|
||||
|
||||

|
||||
|
||||
::: warning 😺
|
||||
我们可以看到,ResNet 的网络依旧非常深,这是因为研究团队不仅发现了退化现象,还采用出一个可以将网络继续加深的 trick:shortcut,亦即我们所说的 residual。
|
||||
|
||||
- 为了解决梯度消失或梯度爆炸问题,ResNet 论文提出通过数据的预处理以及在网络中使用 BN(Batch Normalization)层来解决。
|
||||
- 为了解决深层网络中的退化问题,可以人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为 残差网络 (ResNets)。ResNet 论文提出了 residual 结构(残差结构)来减轻退化问题。
|
||||
:::
|
||||
### residual 结构
|
||||
|
||||

|
||||
|
||||
## 网络代码
|
||||
|
||||
```python
|
||||
import torch.nn as nn
|
||||
import torch
|
||||
|
||||
|
||||
# ResNet18/34的残差结构,用的是2个3x3的卷积
|
||||
class BasicBlock(nn.Module):
|
||||
expansion = 1 # 残差结构中,主分支的卷积核个数是否发生变化,不变则为1
|
||||
|
||||
def __init__(self, in_channel, out_channel, stride=1, downsample=None): # downsample对应虚线残差结构
|
||||
super(BasicBlock, self).__init__()
|
||||
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
|
||||
kernel_size=3, stride=stride, padding=1, bias=False)
|
||||
self.bn1 = nn.BatchNorm2d(out_channel)
|
||||
self.relu = nn.ReLU()
|
||||
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
|
||||
kernel_size=3, stride=1, padding=1, bias=False)
|
||||
self.bn2 = nn.BatchNorm2d(out_channel)
|
||||
self.downsample = downsample
|
||||
|
||||
def forward(self, x):
|
||||
identity = x
|
||||
if self.downsample is not None: # 虚线残差结构,需要下采样
|
||||
identity = self.downsample(x) # 捷径分支 short cut
|
||||
|
||||
out = self.conv1(x)
|
||||
out = self.bn1(out)
|
||||
out = self.relu(out)
|
||||
|
||||
out = self.conv2(out)
|
||||
out = self.bn2(out)
|
||||
|
||||
out += identity
|
||||
out = self.relu(out)
|
||||
|
||||
return out
|
||||
|
||||
# ResNet50/101/152的残差结构,用的是1x1+3x3+1x1的卷积
|
||||
class Bottleneck(nn.Module):
|
||||
expansion = 4 # 残差结构中第三层卷积核个数是第一/二层卷积核个数的4倍
|
||||
|
||||
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
|
||||
super(Bottleneck, self).__init__()
|
||||
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
|
||||
kernel_size=1, stride=1, bias=False) # squeeze channels
|
||||
self.bn1 = nn.BatchNorm2d(out_channel)
|
||||
# -----------------------------------------
|
||||
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
|
||||
kernel_size=3, stride=stride, bias=False, padding=1)
|
||||
self.bn2 = nn.BatchNorm2d(out_channel)
|
||||
# -----------------------------------------
|
||||
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel * self.expansion,
|
||||
kernel_size=1, stride=1, bias=False) # unsqueeze channels
|
||||
self.bn3 = nn.BatchNorm2d(out_channel * self.expansion)
|
||||
self.relu = nn.ReLU(inplace=True)
|
||||
self.downsample = downsample
|
||||
|
||||
def forward(self, x):
|
||||
identity = x
|
||||
if self.downsample is not None:
|
||||
identity = self.downsample(x) # 捷径分支 short cut
|
||||
|
||||
out = self.conv1(x)
|
||||
out = self.bn1(out)
|
||||
out = self.relu(out)
|
||||
|
||||
out = self.conv2(out)
|
||||
out = self.bn2(out)
|
||||
out = self.relu(out)
|
||||
|
||||
out = self.conv3(out)
|
||||
out = self.bn3(out)
|
||||
|
||||
out += identity
|
||||
out = self.relu(out)
|
||||
|
||||
return out
|
||||
|
||||
|
||||
class ResNet(nn.Module):
|
||||
# block = BasicBlock or Bottleneck
|
||||
# block_num为残差结构中conv2_x~conv5_x中残差块个数,是一个列表
|
||||
def __init__(self, block, blocks_num, num_classes=1000, include_top=True):
|
||||
super(ResNet, self).__init__()
|
||||
self.include_top = include_top
|
||||
self.in_channel = 64
|
||||
|
||||
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
|
||||
padding=3, bias=False)
|
||||
self.bn1 = nn.BatchNorm2d(self.in_channel)
|
||||
self.relu = nn.ReLU(inplace=True)
|
||||
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
|
||||
self.layer1 = self._make_layer(block, 64, blocks_num[0]) # conv2_x
|
||||
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2) # conv3_x
|
||||
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2) # conv4_x
|
||||
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2) # conv5_x
|
||||
if self.include_top:
|
||||
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
|
||||
self.fc = nn.Linear(512 * block.expansion, num_classes)
|
||||
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
|
||||
|
||||
# channel为残差结构中第一层卷积核个数
|
||||
def _make_layer(self, block, channel, block_num, stride=1):
|
||||
downsample = None
|
||||
|
||||
# ResNet50/101/152的残差结构,block.expansion=4
|
||||
if stride != 1 or self.in_channel != channel * block.expansion:
|
||||
downsample = nn.Sequential(
|
||||
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
|
||||
nn.BatchNorm2d(channel * block.expansion))
|
||||
|
||||
layers = []
|
||||
layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride))
|
||||
self.in_channel = channel * block.expansion
|
||||
|
||||
for _ in range(1, block_num):
|
||||
layers.append(block(self.in_channel, channel))
|
||||
|
||||
return nn.Sequential(*layers)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.conv1(x)
|
||||
x = self.bn1(x)
|
||||
x = self.relu(x)
|
||||
x = self.maxpool(x)
|
||||
|
||||
x = self.layer1(x)
|
||||
x = self.layer2(x)
|
||||
x = self.layer3(x)
|
||||
x = self.layer4(x)
|
||||
|
||||
if self.include_top:
|
||||
x = self.avgpool(x)
|
||||
x = torch.flatten(x, 1)
|
||||
x = self.fc(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
def resnet34(num_classes=1000, include_top=True):
|
||||
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
|
||||
|
||||
|
||||
def resnet101(num_classes=1000, include_top=True):
|
||||
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
|
||||
|
||||
|
||||
'''
|
||||
我们希望你能够去将论文下载下来以后跟一些讲解视频尝试将论文与代码结合起来理解
|
||||
看论文的源码是我们必须要做的一个中重要的工作
|
||||
'''
|
||||
```
|
||||
|
||||
## 视频
|
||||
|
||||
<Bilibili bvid='BV1P3411y7nn'/>
|
||||
|
||||
## 思考
|
||||
|
||||
### 思考 1
|
||||
::: warning 🤔
|
||||
请你自行了解网络结构中的 BN(Batch Normalization)层,这是很重要的一个 normalization 操作,如果感兴趣还可以继续了解 LN (Layer Normalization)
|
||||
:::
|
||||
### 思考 2
|
||||
::: warning 🤔
|
||||
你觉得论文中提出用 residual 这一解决方法来解决网络的退化现象的依据是什么,如果可以,请你进一步尝试用数学角度思考这一问题
|
||||
:::
|
||||
@@ -1,64 +0,0 @@
|
||||
# UNet
|
||||
|
||||
[论文](https://arxiv.org/pdf/1505.04597.pdf)
|
||||
|
||||
[博客](https://blog.csdn.net/Formlsl/article/details/80373200)
|
||||
|
||||
[博客 2](https://blog.csdn.net/BreakingDawn0/article/details/103435768?spm=1001.2101.3001.6650.16&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-16-103435768-blog-87979765.t5_layer_targeting_s&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-16-103435768-blog-87979765.t5_layer_targeting_s&utm_relevant_index=19)
|
||||
|
||||
## 网络框架
|
||||
|
||||

|
||||
|
||||
|
||||
::: warning 😺
|
||||
|
||||
2015 年,OlafRonneberger 等人提出了 U-net 网络结构,U-net 网络是基于 FCN 的一种语义分割网络,适用于做医学图像的分割
|
||||
|
||||
U-net 网络结构与 FCN 网络结构相似,也是分为下采样阶段和上采样阶段,网络结构中只有卷积层和池化层,没有全连接层,网络中较浅的高分辨率层用来解决像素定位的问题,较深的层用来解决像素分类的问题,从而可以实现图像语义级别的分割,与 FCN 网络不同的是,U-net 的上采样阶段与下采样阶段采用了相同数量层次的卷积操作,且使用 skip connection 结构将下采样层与上采样层相连,使得下采样层提取道的特征可以直接传递到上采样层,这使得 U-net 网络的像素定位更加准确,分割精度更高。此外在训练过程中,U-net 只需要一次训练,FCN 为达到较精确的 FCN-8s 结构需要三次训练,故 U-net 网络的训练效率也高于 FCN 网络。
|
||||
|
||||
U-net 网络的结构如图所示,蓝色箭头代表卷积和激活函数,灰色箭头代表复制剪切操作,红色箭头代表下采样,绿色箭头代表反卷积,conv1X1 代表卷积核为 1X1 的卷积操作。U-net 网络没有全连接层,只有卷积和下采样。U-net 可以对像素进行端到端的分割,即输入是一幅图像,输出也是一幅图像。
|
||||
|
||||
:::
|
||||
|
||||
### 下采样(编码)
|
||||
|
||||
::: warning 😽
|
||||
|
||||
编码层由 N 个结构相同的卷积层 L(i)级联组成,L(i)包含两个 3x3 卷积层和一个 2x2 最大池化层,经过 L(i)后图像通道数加倍。
|
||||
|
||||
其中卷积和池化的 padding 都是‘valid’(不补 0),即只对图像的有效部分进行窄卷积,得到图像的有效特征,因此得到的输出图像会比输入图像小。解决这个问题的方法是根据输出图像的大小应该等于原图像大小(out_size=img_size),沿着网络逆向计算出输入图像的大小 in_size,对原图像沿着四条边进行镜像扩大,作为输入图像。图中,输出分割图像的黄框与输入图像的黄框对应,输入图像中蓝框的边缘部分由于窄卷积丢失,最后的到输出图像中的黄框,因此输出的分割图像对应输入图像中原图 img 的位置。
|
||||
|
||||
:::
|
||||
|
||||
### 上采样(解码)
|
||||
|
||||
::: warning 😻
|
||||
|
||||
解码层由 N 个结构相同的反卷积层 L(i)级联组成,L(i)包含一个 2x2 反卷积层和两个 3x3 卷积层,经过 L(i)后图像通道减半。
|
||||
|
||||
每层解码层会将反卷积恢复的特征,与同层编码层提取的特征连接(concatenate),再进行卷积,实现了编码层和解码层的特征融合,有助于特征恢复过程中保留图像的更多细节,使得到的分割图像轮廓更清晰。如图,在训练左心室内外膜分割的 UNet 网络时,c 得到的特征比 b 更接近标签。
|
||||
|
||||
最后,解码层连接一个 1x1 全卷积网络,逐像素二分类,得到 2 个通道的输出图像。
|
||||
|
||||
:::
|
||||
|
||||
## 视频
|
||||
|
||||
<Bilibili bvid='BV1Vq4y127fB'/>
|
||||
|
||||
## 思考 1
|
||||
::: warning 🤔
|
||||
UNet 的跳连接结构好在哪?跟 Resnet 相比有什么异同?
|
||||
:::
|
||||
## 思考 2
|
||||
|
||||
::: warning 🐒
|
||||
有很多的论文是基于 Unet 的改进,包括但不限于
|
||||
|
||||
Unet++
|
||||
|
||||
U2net
|
||||
|
||||
甚至其结构也被视为 EN-DE 结构的一个经典案例,你能否通过这些论文感受一下神经网络整体的发展脉络。
|
||||
:::
|
||||
@@ -1,24 +0,0 @@
|
||||
# GAN
|
||||
|
||||
这篇论文画风都和前面的几篇完全不一样,因为他的任务是生成,本篇文章将作为可选的拓展阅读。
|
||||
|
||||
比如说生成一些虚拟的 vtuber 他也是完全办得到的,首先留下经典的文章
|
||||
|
||||
[Generative Adversarial Networks](https://arxiv.org/abs/1406.2661)
|
||||
|
||||
GAN 的基本原理其实非常简单,这里以生成图片为例进行说明。假设我们有两个网络,G(Generator)和 D(Discriminator)。正如它的名字所暗示的那样,它们的功能分别是:
|
||||
|
||||
- G 是一个生成图片的网络,它接收一个随机的噪声 z,通过这个噪声生成图片,记做 G(z)。
|
||||
- D 是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是 x,x 代表一张图片,输出 D(x)代表 x 为真实图片的概率,如果为 1,就代表 100% 是真实的图片,而输出为 0,就代表不可能是真实的图片。
|
||||
|
||||
在训练过程中,生成网络 G 的目标就是尽量生成真实的图片去欺骗判别网络 D。而 D 的目标就是尽量把 G 生成的图片和真实的图片分别开来。这样,G 和 D 构成了一个动态的“博弈过程”。
|
||||
|
||||
最后博弈的结果是什么?在最理想的状态下,G 可以生成足以“以假乱真”的图片 G(z)。对于 D 来说,它难以判定 G 生成的图片究竟是不是真实的,因此 D(G(z)) = 0.5。
|
||||
|
||||
其实就是一个骗一个验证。
|
||||
|
||||
提到他我就想提到另一个算法叫 VAE,你可以对比一下两者的相同点和不同点
|
||||
|
||||
同时,数学推导要从极大似然估计考虑起!
|
||||
|
||||
[https://zhuanlan.zhihu.com/p/266677860](https://zhuanlan.zhihu.com/p/266677860)
|
||||
@@ -1,53 +0,0 @@
|
||||
# 思考题参考
|
||||
|
||||
思考并无绝对的对错,此处仅供参考,希望大家能在自己的思考的基础上再来这里解决思考的疑惑。
|
||||
|
||||
##
|
||||
|
||||
## 思考 1
|
||||
|
||||
### 1.1
|
||||
|
||||
[CNN 与 MLP 之间的关系,优缺点](https://www.editcode.net/archive/detail/89781)
|
||||
|
||||
### 1.2
|
||||
|
||||
[深度理解感受野](https://blog.csdn.net/weixin_40756000/article/details/117264194)
|
||||
|
||||
### 1.3
|
||||
|
||||
[卷积神经网络中的平移不变性](https://zhuanlan.zhihu.com/p/382926269)
|
||||
|
||||
### 1.5
|
||||
|
||||
[你真的看懂 Relu 了吗?大家都说是非线性,为什么我怎么看都是线性啊?](https://zhuanlan.zhihu.com/p/405068757)
|
||||
|
||||
### 1.6
|
||||
|
||||
[什么是深度学习中的卷积?](https://zhuanlan.zhihu.com/p/140550547)
|
||||
|
||||
## 思考 2
|
||||
|
||||
### 2.1
|
||||
|
||||
[深度学习端到端的理解](https://blog.csdn.net/Bulldozer_GD/article/details/95071826)
|
||||
|
||||
### 2.2
|
||||
|
||||
[反卷积详解](https://blog.csdn.net/bestrivern/article/details/89553513)
|
||||
|
||||
### 2.3
|
||||
|
||||
### 2.4
|
||||
|
||||
[语义分割概念及应用介绍](https://zhuanlan.zhihu.com/p/46200875)
|
||||
|
||||
## 思考 3
|
||||
|
||||
### 3.1
|
||||
|
||||
[Batch Normalization(BN 层)详解](https://www.jianshu.com/p/b05282e9ca57)
|
||||
|
||||
### 3.2
|
||||
|
||||
[ResNet 残差、退化等细节解读](https://blog.csdn.net/a8039974/article/details/122380735)
|
||||
@@ -1,19 +0,0 @@
|
||||
# 还要学更多?
|
||||
|
||||
# Try it yourself!
|
||||
|
||||
你已经基本了解现代 CV 的理论架构了,你可以尝试写一些自己的网络来锻炼你的 coding 能力并且切身体会这些技术的效果
|
||||
|
||||
- 你可以先行尝试一下怎么把在 MNIST 上训练的网络真正投入应用,比如识别一张你自己用黑笔写的数字~
|
||||
|
||||

|
||||
|
||||
- 比如你可以尝试训练一个网络来实现人体五官分割(笔者之前就玩过这个)数据集采用 [helen 数据集](https://pages.cs.wisc.edu/~lizhang/projects/face-parsing/),关于数据集的架构你可以搜一搜,自己设计一个 Dataloader 和 YourModle 来实现前言中的五官分割效果(真的很有乐子 hhh)
|
||||
|
||||

|
||||
|
||||
- 当然你也可以尝试一些自己感兴趣的小任务来锻炼工程能力~
|
||||
|
||||
# Reading more!
|
||||
|
||||
阅读更多的经典论文!当然如果你有更为具体的方向,你可以从该论文的开山之作慢慢学习
|
||||
@@ -1,5 +0,0 @@
|
||||
# 经典网络
|
||||
|
||||
这篇文章罗列了对领域造成较大影响的一些经典的论文,要么他们开辟了一个先河,要么他们的方法广为流传。
|
||||
|
||||
通过熟悉与掌握这些网络,可以帮助你真的
|
||||
@@ -1,95 +0,0 @@
|
||||
# NeRF
|
||||
|
||||
最原始的 NeRF 在 2020 年被提出,这还是一个比较新的领域。NeRF 的主要目标是在密集采样的图片中对这个图片中的物体进行三维重建。
|
||||
|
||||
NeRF 想做这样一件事,不需要中间三维重建的过程,仅根据位姿内参和图像,直接合成新视角下的图像。
|
||||
|
||||
在生成建模前,我们需要对被建模物体进行密集的采样,如下图是一个示例的训练集,它含有 100 张图片以及保存了每一张图片相机参数(表示拍摄位置,拍摄角度,焦距的矩阵)的 json 文件。
|
||||
|
||||

|
||||
|
||||
你可以看到,这 100 张图片是对一个乐高推土机的多角度拍摄结果。我们需要的是一个可<strong>以获取这个推土机在任意角度下拍摄的图片</strong>的模型。如图所示:
|
||||
|
||||

|
||||
|
||||
现在来看 NeRF 网络:
|
||||
|
||||
在 NeRF 中,我们把空间<strong>认为是一个个的小方块叠成的空间</strong>(可以理解为 MC)每一个方块有以下属性:
|
||||
|
||||
- 3 个位置坐标(x,y,z)
|
||||
- 透明度$\sigma$
|
||||
- 注意:因为每个角度观察的颜色并不相同(光线原因),颜色属于一个会根据观察角度变化的隐藏属性。
|
||||
|
||||
# 用 NeRF 如何建模?(思路部分)
|
||||
|
||||
## 得到模型
|
||||
|
||||
我们需要的是每个视角下的图片,可以理解为从一个视角发射<strong>光线</strong>,<u>一根光线对应一个像素点</u>。这些光线穿透路径上的所有方块,把这些方块上的属性信息以某种方式累计,就能得到这个像素的颜色。这是 一个已有的公式,只要我们获得每个小方块的颜色信息和不透明度,我们就能知道这个角度下的视图。(这个我们后面介绍)
|
||||
|
||||
现在的难点在于:我们不知道<strong>每个小方块的颜色信息</strong>(因为颜色会随着观察角度变化)。众所周知,算法解决不了的问题就扔给神经网络试试啦~
|
||||
|
||||
<strong>为了获取根据角度变化而变化的颜色信息,我们选择了神经网络。</strong>
|
||||
|
||||
<strong>这个网络的输入是:</strong>
|
||||
|
||||
- 小方块的位置坐标(x,y,z)
|
||||
- 观察角度(以二维坐标表示两个偏转角)
|
||||
|
||||
<strong>这个网络的输出是:</strong>
|
||||
|
||||
- 对应的小方块的 RGB 信息
|
||||
- 不透明度
|
||||
|
||||

|
||||
|
||||
在这里,作者选择了最简单的 MLP,因此,<strong>这是一个输入为 5 维,输出为 4 维向量</strong>($R,G,B,\sigma$)的简单网络,值得注意的是,不透明度与观察角度无关,这里在网络中进行了特殊处理,让这个值与后两维无关。
|
||||
|
||||
<strong>现在我们能够输入坐标和视角信息得到小方块的颜色和不透明度,我们就可以对光线穿过的小方块进行计算了。</strong>
|
||||
|
||||
## 进行渲染
|
||||
|
||||
(渲染就是得到三维建模的某视角下图片)
|
||||
|
||||
得到每条光线上的方块信息后,我们对其进行计算(这里开始介绍上面略过的公式)
|
||||
|
||||
这个公式对光线上的所有小方块的颜色进行加权求和,权重是关于不透明度$\sigma$的一个函数$T(\sigma)$,不透明度在[0,1]之间,越不透明这个值越大。也就是越不透明,占的颜色比重越高,比如空气的$\sigma$就接近于 0,乐高本身就接近 1。而求和的结果就是这个光线对应像素的颜色。
|
||||
|
||||
这里展开说一下$T(\sigma)$,我们把不透明度理解为光线在这个小方块被阻止的概率,越不透明,越容易阻挡光线,而光线一旦被阻挡,就不用计算后面的小方块颜色了。因此,我们的$T(\sigma)$就表示<strong>光线能够行进到这个小方块的概率</strong>,也就是这点之前所有小方块的$(1-\sigma)$的乘积。
|
||||
|
||||
这段要仔细看和推导,第一遍不容易直接懂。顺带一提,我们的<strong>小方块</strong>学名叫<strong>体素</strong>,<del>为了显得我们更专业一点以后就叫它体素罢</del>
|
||||
|
||||

|
||||
|
||||
上面所说的公式具体如下:t 是我们的$\sigma$,$t_f,t_n$分别是离发射点最远的体素和最近的体素。这个公式求得是像素的颜色。
|
||||
|
||||

|
||||
|
||||
思路总体如上,这里放一张找来的渲染过程示意图(<del>不知道为什么有点包浆</del>)
|
||||
|
||||

|
||||
|
||||
# 算法细节部分
|
||||
|
||||
上述只是 NeRF 的思路,也是后续改进工作的核心,具体实现使用了很多 trick,下面进行列举介绍:
|
||||
|
||||
## 采样方法
|
||||
|
||||
因为上述计算使用了积分,而计算机只能处理非连续的信息,因此我们先把光线分为数个小段,在每个小段中使用蒙特卡罗采样(就是随机抽),得到积分的近似值。
|
||||
|
||||
我们也可以配合另一种更巧妙的方法实现采样,就在下面啦。
|
||||
|
||||
## 粗网络和精细网络
|
||||
|
||||
如上述采样方法所说,因为是均匀采样,我们对空气和实体的体素关注度都是差不多的,但是这并无必要,空气上采样点少了也不会怎么样,而实体上如果采样点增多,图片就会更加清晰,因此我们设计了以下算法来进行优化。
|
||||
|
||||
我们使用了两个网络:粗网络和精细网络。
|
||||
|
||||
粗网络就是上述采样方法用的普通网络,而<strong>粗网络输出的不透明度值会被作为一个概率分布函数</strong>,精细网络根据这个概率分布在光线上进行采样,不透明度越大的点,它的邻域被采样的概率越大,也就实现了我们要求的在实体上多采样,空气中少采样。最后精细网络输出作为结果,因此粗网络可以只求不透明度,无视颜色信息。
|
||||
|
||||

|
||||
|
||||
## 位置编码
|
||||
|
||||
学过 cv 的大家想必对这个东西耳熟能详了吧~,这里的位置编码是对输入的两个位置和一个方向进行的(体素位置,相机位置和方向),使用的是类似 transformer 的三角函数类编码如下。位置编码存在的意义是放大原本的 5 维输入对网络的影响程度,把原本的 5D 输入变为 90 维向量;并且加入了与其他体素的相对位置信息。
|
||||
|
||||

|
||||
@@ -1,172 +0,0 @@
|
||||
# NeRF 的改进方向
|
||||
|
||||
这里只列出论文的名字或者模型简称,以及一些概括,没看的先留白,这里写的会很随意,当作备忘录了。
|
||||
|
||||
适合作为学习索引或者备忘录,忘了就来这里找找。(更新中)
|
||||
|
||||
# 1.泛化性
|
||||
|
||||
## 1)减少输入图像类
|
||||
|
||||
### 1.Pixel-nerf
|
||||
|
||||
<strong>Pixel-nerf</strong><strong> </strong>对输入图像使用卷积进行特征提取再执行 nerf,若有多个输入,对每个视角都执行 CNN,在计算光线时,取每一个已有视角下该坐标的特征,经过 mlp 后算平均。可以在少量视角下重建视图,需要进行预训练才能使用,有一定自动补全能力(有限)
|
||||
|
||||

|
||||
|
||||
### 2.IBRnet
|
||||
|
||||
<strong>IBRnet</strong><strong> </strong>是 pixel-nerf 的改进版,取消了 CNN,并且在 mlp 后接入了 transformer 结构处理体密度(不透明度),对这条光线上所有的采样点进行一个 transformer。同时,在获取某个体素的颜色和密度时,作者用了本视角相邻的两个视角,获取对应体素在这两张图片中的像素,以图片像素颜色,视角,图片特征作为 mlp 的输入。
|
||||
|
||||

|
||||
|
||||
### 3.MVSnerf
|
||||
|
||||
<strong>MVSnerf</strong><strong> </strong>它用 MVS 的方法构建代价体然后在后面接了一个 nerf,MVS 是使用<strong>多视角立体匹配</strong>构建一个代价体,用 3D 卷积网络进行优化,这里对代价体进行 nerf 采样,可以得到可泛化网络。它需要 15min 的微调才能在新数据上使用。<strong>多视角立体匹配是一种传统算法,通过光线,几何等信息计算图像中小块的相似度,得出两个相机视角之间的位置关系。这个算法也被广泛使用在得到我们自己采样的数据的相机变换矩阵上(我就是这么干的)</strong>
|
||||
|
||||

|
||||
|
||||
此处涉及较多图形学,使用了平面扫描算法,其中有单应性变换这个角度变换算法,推导与讲解如下:
|
||||
|
||||
[MVSNet 单应性变换推导_朽一的博客-CSDN 博客_可微单应性变换](https://blog.csdn.net/qq_43027065/article/details/116946686)
|
||||
|
||||
简单来说就是把 A 视角下的图像转换到 B 视角
|
||||
|
||||
平面扫描就是把 A 视角中的某一像素点(如图中红色区域)的相邻的几个像素提取出来,用单应性变换转换到 B 视角中,这时候用的深度是假设的深度,遍历所有假设的深度,计算通过每一个假设深度经过单应性变换得到的像素小块和 B 视角中对应位置的差值(loss),取最小的 loss 处的深度作为该像素的深度。
|
||||
|
||||

|
||||
|
||||
构建代价体:
|
||||
|
||||
构建三维代价体的主要步骤:
|
||||
1)假设离散的深度平面。
|
||||
2)将每个视图提取的特征图变换到假设平面上,构造特征体;
|
||||
3)将不同视角的特征体融合在一起,形成三维代价体。
|
||||
|
||||
## 2)可以 zero-shot 或者 fine-tune 类
|
||||
|
||||
<strong>MVSnerf</strong><strong>,上面已经说了。</strong>
|
||||
|
||||
# 2.速度提升
|
||||
|
||||
### 1.instan-ngp
|
||||
|
||||
使用了<strong>哈希表</strong>结构的<strong>instant-ngp</strong>,渲染完美只需要几分钟(采样正常的情况下)这块的速度已经到极致了。
|
||||
|
||||
展开说说:其实这也是神经网络发展的一个方向,以前的深层网络倾向于把所有东西用网络参数表示,这样推理速度就会慢,这里使用哈希表的快速查找能力存储一些数据信息,instant-ngp 就是把要表达的模型数据特征按照不同的精细度存在哈希表中,使用时通过哈希表调用或插值调用。
|
||||
|
||||

|
||||
|
||||
# 3.可编辑(指比如人体运动等做修改工作的)
|
||||
|
||||
### 1.Human-nerf
|
||||
|
||||
<strong>Human-nerf</strong><strong> </strong>生成可编辑的人体运动视频建模,输入是一段人随便动动的视频。输出的动作可以编辑修改,并且对衣物折叠等有一定优化。使用的模型并非全隐式的,并且对头发和衣物单独使用变换模型。使用了逆线性蒙皮模型提取人物骨骼(可学习的模型),上面那个蓝色的就是姿态矫正模块,这个模块赋予骨骼之间运动关系的权重(因为使用的是插值处理同一运动时不同骨骼的平移旋转矩阵,一块骨骼动会牵动其他骨骼)图中的 Ω 就是权重的集合,它通过 mlp 学习得到。然后得到显式表达的人物骨骼以及传入视频中得到的对应骨骼的 mesh,skeletal motion 就是做游戏人物动作用的编辑器这种,后面残差链接了一个 non-rigid-motion(非刚性动作),这个是专门处理衣物和毛发的,主要通过学习得到,然后粗暴的加起来就能得到模型,再经过传统的 nerf 渲染出图像。
|
||||
|
||||

|
||||
|
||||
### 2.Neural Body
|
||||
|
||||
<strong>Neural Body</strong> 通过下面这种<strong>单视角视频</strong>或稀<strong>疏视角照片</strong>来生成人体建模。
|
||||
|
||||
因为生成的是人体建模,作者使用了他们以前的工作 EasyMocap 得到<strong>SMPL 模型(就是人体的结构)然后在 SMPL 表面生成一些 latent code(包含颜色,不透明度和位置),也就是下左中的那些点。</strong>
|
||||
|
||||
[EasyMocap 的代码](https://link.zhihu.com/?target=https%3A//github.com/zju3dv/EasyMocap)
|
||||
|
||||
EasyMocap 是通过多视角视频生成骨架以及 SMPL 模型的一个工作,演示视频右下。
|
||||
|
||||

|
||||
|
||||
这是 EasyMocap 的演示。
|
||||
|
||||
这里作者对 nerf 进行了修改,让 nerf 通过 latent code 渲染图片。流程是先用 latent code 构建三维网格,在这个网络中用空间插值得到具体某个点的值。这一步通过 3D 卷积实现,把原先存在空间中的离散的点整合到一个 latent code volume 中,在这个空间中进行 nerf 的渲染。省掉了 mlp,把整个建模储存在 3D 网格中而非 MLP 中,加快计算速度。
|
||||
|
||||
作者把每一帧提取到的骨架用 latent codes 进行蒙皮,使得人体变成对应的姿势,就可以进行逐帧渲染。
|
||||
|
||||
个人感觉这个模型不能很好处理光影效果,还有待改进。
|
||||
|
||||
是个预训练模型,<strong>训练的模块就是这个 3D 卷积神经网络</strong>。
|
||||
|
||||

|
||||
|
||||
### 3.wild-nerf
|
||||
|
||||
<strong>wild-nerf</strong> 思路很简单,就是加入了新的输入参数来调整白天黑夜等等一些简单的变化,并且把行人车辆之类的在采样过程中<strong>不固定的物品</strong>作为<strong>随机项</strong>,在渲染时按照概率加入。
|
||||
|
||||
### 4.D-nerf
|
||||
|
||||
<strong>D-nerf</strong> 是一种动态编辑的 nerf,输入为:x,y,z,相机位置,相机角度,<strong>时间 t。</strong>
|
||||
|
||||
把整个网络分为两块,一块是正常的 nerf 渲染,另一块是下面这个,输入时间与现在的位置坐标,输出<strong>这个位置坐标中的物体现在的位置</strong>与 t=0 时的<strong>位置的差</strong>。再用 t=0 时物体的点信息进行渲染。
|
||||
|
||||
在此网络的单个输出上貌似是不监督的,因为没办法进行人为标注。这点我不是很确定,以后如果发现了会来修改的。
|
||||
|
||||

|
||||
|
||||
渲染经过形变的物体时,光线其实是在 t=0 时刻进行渲染的,因为推土机的铲子放下去了,所以<strong>光线是弯曲的</strong>。
|
||||
|
||||

|
||||
|
||||
# 4.用于辅助传统图像处理
|
||||
|
||||
还没涉猎,待补全
|
||||
|
||||
# 5.与对比学习结合
|
||||
|
||||
### 1.clip-nerf
|
||||
|
||||
<strong>clip-nerf</strong><strong> 太贵了玩不起,没仔细研究,应该是文本跟 3D 建模关联,跟 clip 一样。</strong>
|
||||
|
||||
# 6.生成类(指加入新物体或者额外生成新场景)
|
||||
|
||||
### 1.GRAF
|
||||
|
||||
<strong>GRAF</strong><strong> </strong>把 GAN 与 nerf 结合,增加了两个输入,分别是<strong>外观/形状编码 z</strong>和<strong>2D 采样编码 v</strong>,z 用来改变渲染出来东西的特征,比如把生成的车变色或者变牌子,suv 变老爷车之类的。v(s,u)用来改变下图 2 中训练时选择光线的标准。这里训练时不是拿 G 生成的整张图扔进 D 网络,而是根据 v 的参数选择一些光线组成的 batch 扔进 D 进行辨别
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 2.GIRAFFE
|
||||
|
||||
<strong>GIRAFFE</strong> 是 GRAF 的改进工作,可以把图片中的物品,背景一个个解耦出来单独进行改变或者移动和旋转,也可以增加新的物品或者减少物品,下图中蓝色是不可训练的模块,橙色可训练。以我的理解好像要设置你要解耦多少个(N)物品再训练,网络根据类似 k 近邻法的方法在特征空间上对物品进行分割解耦,然后分为 N 个渲染 mlp 进行训练,训练前加入外观/形状编码 z。最后还是要扔进 D 训练。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 3.OSF
|
||||
|
||||
<strong>OSF</strong>Object-Centric Neural Scene Rendering,可以给移动的物体生成合理的阴影和光照效果。加入了新的坐标信息:光源位置,与相机坐标等一起输入。对每个小物件构建一个单独的小 nerf,计算这个小 nerf 的体素时要先经过光源照射处理(训练出来的)然后在每个小物件之间也要计算反射这样的光线影响,最后进行正常的渲染。<del>这篇文章没人写 review,有点冷门,这些都是我自己读完感觉的,不一定对。</del>
|
||||
|
||||

|
||||
|
||||
### 4.Hyper-nerf-gan
|
||||
|
||||
使用了超网络与 nerf-gan 结合,这篇比较新没有 review,是我自己理解的,可能有出入。
|
||||
|
||||
作者用了几个我比较陌生的技术,比如超网络 hypernet,还有超网络与 gan 结合的 INR-Gan。
|
||||
|
||||
<strong>hypernet</strong>:把随机初始化和直接梯度回传更新的网络参数用另一个神经网络来更新,就是我们要同时训练两个网络,一个是本体,一个是调整参数用的超网络。
|
||||
|
||||
<strong>INR-Gan</strong>:把超网络技术与 Gan 结合,并且用了 INR 技术,这个技术类似 nerf,不过是处理图片用到的,是构建一个坐标(x,y)->RGB 的网络,可以让图片达到更高分辨率,也就是把离散的像素变成连续的。
|
||||
|
||||
左边是常规卷积网络生成图像,右边是用 INR 生成图像。
|
||||
|
||||

|
||||
|
||||
这种方法存在两个问题:
|
||||
|
||||
1.因为 INR 其实是一种超网络,也就是说我们要训练两个网络,但是只存在一个监督。使得网络训练更难。
|
||||
|
||||
2.因为使用神经网路去表示图片,占用内存更大。
|
||||
|
||||
因此,作者设计了<strong>FMM</strong>去应对这两个问题,这也是 Hyper-nerf-gan 借鉴的主要部分。
|
||||
|
||||
FMM 主要是把要学习的矩阵转化为两个低秩矩阵,去先生成他们俩再相乘,减少网络计算量。
|
||||
|
||||

|
||||
|
||||
现在开始讲 Hyper-nerf-gan 本身,它看上去其实就是 nerf 接在 gan 上。不过有一些变化,比如输入不再包含视角信息,我<strong>很怀疑它不能很好表达反光效果</strong>。而且抛弃了粗网络细网络的设计,只使用粗网络减少计算量。这里的 generator 完全就是 INR-Gan 的形状,生成权重,然后再经过 nerf 的 mlp 层生成,没啥别的了,就这样吧。
|
||||
|
||||

|
||||
@@ -1,64 +0,0 @@
|
||||
# 自制数据集的工具 COLMAP <Badge type="danger">由于作者换方向了,所以如下关于NERF的内容待完善</Badge>
|
||||
|
||||
如何使用和怎么下载就不讲了,直接搜就有,它可以把多个拍摄同一物体的图片转换为它们对应视角的相机矩阵和拍摄角度,可以实现自制数据集做 nerf。它的流程(SFM 算法)可以概括如下:
|
||||
|
||||

|
||||
|
||||
这里主要是记录一下它的原理:
|
||||
首先是一个经典关键点匹配技术:<strong>SIFT</strong>
|
||||
|
||||
# SIFT 特征点匹配
|
||||
|
||||
## DOG 金字塔
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
下面是原理方法:
|
||||
|
||||
首先是<strong>高斯金字塔</strong>,它是把原图先放大两倍,然后使用高斯滤波(高斯卷积)对图像进行模糊化数次,取出倒数第三层缩小一半继续进行这个过程,也就是说它是由一组一组的小金字塔组成的。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
然后是基于高斯金字塔的 DOG 金字塔,也叫差分金字塔,它是把相邻的高斯金字塔层做减法得到的,因为经过高斯模糊,物体的轮廓(或者说不变特征)被模糊化,也就是被改变。通过相减可以得到这些被改变的点。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## 空间极值点检测
|
||||
|
||||
为了找到变化的最大的几个点来作为特征点,我们需要找到变化的极值点,因此需要进行比较,这里是在整个金字塔中进行对比,我们提取某个点周边 3*3*3 的像素点进行比较,找到最大或最小的局部极值点。
|
||||
|
||||

|
||||
|
||||
同时我们也对关键点分配方向,也就是这个点在图片空间中的梯度方向
|
||||
|
||||
梯度为:
|
||||
|
||||

|
||||
|
||||
梯度方向为:
|
||||
|
||||

|
||||
|
||||
我们计算以关键点为中心的邻域内所有点的梯度方向,然后把这些 360 度范围内的方向分配到 36 个每个 10 度的方向中,并构建方向直方图,这里的示例使用了 8 个方向,几个随你其实:
|
||||
|
||||

|
||||
|
||||
取其中最大的为主方向,若有一个方向超过主方向的 80%,那么把它作为辅方向。
|
||||
|
||||
操作可以优化为下图,先把关键点周围的像素分成 4 块,每块求一次上面的操作,以这个 4 个梯度直方图作为关键点的方向描述。也就是一个 2*2*8(方向数量)的矩阵作为这个点的方向特征。
|
||||
|
||||

|
||||
|
||||
实验表明,使用 4*4*8=122 的描述更加可靠。
|
||||
|
||||

|
||||
|
||||
特征点的匹配是通过计算两组特征点的 128 维的关键点的欧式距离实现的。欧式距离越小,则相似度越高,当欧式距离小于设定的阈值时,可以判定为匹配成功。
|
||||
|
||||
以上是 colmap 的第一步,SIFT
|
||||
@@ -1,11 +0,0 @@
|
||||
# 神经辐射场(NeRF)
|
||||
|
||||
> Author:康可均
|
||||
|
||||
NeRF 是一项用于三维重建的技术,使用深度学习对图片中的物体进行重建。
|
||||
|
||||
严格来讲,它属于计算机视觉的分支。
|
||||
|
||||
因为网络上能够找到的教程较少且不连贯,本文不会像 CV 和 NLP 那样简单介绍,而是像对比学习的介绍方式一样,介绍发展历程以及改进工作。
|
||||
|
||||
不建议直接通过 nerf 了解深度学习,学习之前希望你已有 CV 的基础。
|
||||
@@ -1,17 +0,0 @@
|
||||
# 行人重识别(ReID)
|
||||
|
||||
> Author:陈维文
|
||||
|
||||
行人重识别(ReID)是一项纯粹的计算机视觉(CV)任务,其主要目标是在不同的监控摄像头中识别出不同的人物或车辆,并确定它们是否是同一个人或车辆。
|
||||
|
||||
监控视频通常难以捕捉高质量的人脸,并且经常会遇到刻意回避或遮盖的情况。为了解决这些问题,ReID技术应运而生。它可以通过对身体外貌特征和行为模式的分析,对监控视频中的个体进行识别和跟踪。
|
||||
|
||||
该任务目前在学术上是检索出不同摄像头下的相同行人图片,同时数据集中只有人的全身照,如下图所示。
|
||||
|
||||

|
||||
|
||||
但是实际上在实际应用中的时候会和检测结合,简单来说先框出目标后分类,如下图所示。
|
||||
|
||||

|
||||
|
||||
这个方向做的比较的奇怪,该模块只做整体性介绍,同时希望学习该模块的你对经典网络有所了解。
|
||||
@@ -1 +0,0 @@
|
||||
# 计算机视觉(CV)
|
||||
@@ -1,29 +0,0 @@
|
||||
# NLP 领域任务(研究目标)
|
||||
|
||||
下面给出了 NLP 的四大常见的应用。由于预训练的模型是在连续的文本序列上训练的,所以需要进行一些修改才能将其应用于不同的这些 NLP 任务。
|
||||
|
||||
<strong>分类 (text classification):</strong> 给一句话或者一段文本,判断一个标签。
|
||||
|
||||

|
||||
|
||||
图 2:分类 (text classification)
|
||||
|
||||
<strong>蕴含 (textual entailment):</strong> 给一段话,和一个假设,看看前面这段话有没有蕴含后面的假设。
|
||||
|
||||

|
||||
|
||||
图 3:蕴含 (textual entailment)
|
||||
|
||||
<strong>相似 (Similarity):</strong> 判断两段文字是否相似。
|
||||
|
||||

|
||||
|
||||
图 4:相似 (Similarity)
|
||||
|
||||
<strong>多选题 (Multiple Choice):</strong> 给个问题,从 N 个答案中选出正确答案。
|
||||
|
||||

|
||||
|
||||
图 5:多选题 (Multiple Choice)
|
||||
|
||||
可以看出,随着任务类型的变化,就需要构造不同的输入形式,把不同的子任务统一成相同的输入形式。但是,不变的是 Transformer 模型的结构。所有转换都包括添加随机初始化的开始 (Start) 和结束 (Extract) tokens,有的包括分隔符 Delimiter tokens (Delim)。
|
||||
@@ -1,180 +0,0 @@
|
||||
# 推荐系统经典模型综述
|
||||
|
||||
Author: 周东霖
|
||||
|
||||
# 概论
|
||||
|
||||
## 1.1 摘要
|
||||
|
||||
推荐系统技术最早起源于上世纪末和本世纪初,最早是数据挖掘领域最为经典的应用之一。2012 年至 2015 年,机器学习技术进入推荐系统领域,使得这项古老的应用再次发光发热。 2016 年以来,随着深度学习的发展,大规模算力、大数据的应用的逐渐普及,基于深度学习的推荐系统研究再次成为行业热点,在工业界和学术界都占据极其重要之地。
|
||||
|
||||
本文旨在回顾经典的推荐系统经典模型和研究思路,但并不提供具体的推导方案,并讨论它们各自的优缺点。希望能够为后来入坑者提供一些思路。由于是个人观点陈述,未免存在遗漏和评价不当之嫌,望请见谅。
|
||||
|
||||
## 1.2 关键术语:
|
||||
|
||||
Recommender Systems(RS) : 推荐系统
|
||||
|
||||
Information overlaod: 信息过载
|
||||
|
||||
user:用户
|
||||
|
||||
item:物品
|
||||
|
||||
feedback:用户反馈
|
||||
|
||||
explicit feedback:显式反馈,例如用户评分
|
||||
|
||||
implicit feedback:隐式反馈,浏览、点击、购买等行为
|
||||
|
||||
## 1.3 主要任务
|
||||
|
||||
推荐系统的主要任务包括两方面:
|
||||
|
||||
评分预测(rating prediction)
|
||||
|
||||
物品推荐(item recommendation)
|
||||
|
||||
## 1.4 评价方式和评价指标
|
||||
|
||||
学术界通常采用离线方式进行评估,一般进行 N 折交叉验证。
|
||||
|
||||
优点:依赖数据集、容易验证和评估;
|
||||
|
||||
缺点:无法直接反映商业需求。
|
||||
|
||||
工业界常采用在线测试,比如 A/B test。
|
||||
|
||||
优点:和商业需求紧密挂钩。
|
||||
|
||||
缺点:成本高、风险大。
|
||||
|
||||
对于评分预测任务,常用评价指标包括:
|
||||
|
||||
Root Mean Squared Error (RMSE)
|
||||
Mean Absolute Error (MAE)
|
||||
|
||||
对于物品推荐任务,常用评价指标包括:
|
||||
|
||||
Precision、Recall、F-measure、Hit Ratio(HR)
|
||||
Average Precision (AP)、Mean Average Precision(MAP)
|
||||
Area Under the ROC Curve (AUC)、Mean Reciprocal Rank (MRR)
|
||||
|
||||
Normalized Discounted Cumulative Gain (NDCG)
|
||||
|
||||
通常情况下,常用 @N 表示推荐前 N 个物品的性能,即 Top-N 推荐。近几年的论文常常采用 HR、NDCG 作为评价指标。
|
||||
|
||||
# 经典 SOTA
|
||||
|
||||
## 2.1 协同过滤(collaborative filtering, CF)
|
||||
|
||||
协同过滤是最早的一种推荐系统技术,最早用于电影推荐系统。最早开启这项研究的是明尼苏达大学的研究小组(GroupLens),随后,亚马逊研发了基于物品的协同过滤算法,并开始将 RS 部署上线,正式推向工业界。
|
||||
|
||||
协同过滤的方法主要包括两大类:
|
||||
|
||||
- User-based CF:基于用户的协同过滤[1]
|
||||
- Item-based CF:基于物品的协同过滤[2,3]
|
||||
|
||||
## 2.2 分解模型(Factorization model)
|
||||
|
||||
最早的推荐系统采用的是邻域模型(neighborhood),本质上是计算物品和用户的相似度进行推荐。但是这种方法存在两个致命缺点:
|
||||
|
||||
- 稀疏性(sparsity):实际应用(例如大型电商平台)中,数据非常稀疏,两个用户购买物品存在交集的情况非常少。
|
||||
- 维度灾难:用户向量维度高、物品向量维度高,导致计算成本高,且无法保证准确度。
|
||||
|
||||
由此,分解模型横空出世。最为经典的分解模型就是矩阵分解(Matirx Factorization, MF)[4]。它的理论基础来源于奇异值分解 SVD(Singular Value Decomposition)。 基于 SVD 理论,评分矩阵可被分解成用户和物品的潜在因子,潜在因子的维度 k 远小于用户数量 m 和物品数量 n,由此可以大大降低计算量。(可以看作是后来的 embedding 技术的一个简化版)
|
||||
|
||||
Koren 等人提出 MF 以后,开始在最基础的矩阵分解模型上加入各种辅助信息,并衍生出分解模型的高阶版本,比如 SVD++,TimeSVD++,WRMF,BPR,SLIM 等等。
|
||||
|
||||
其中,特别推荐几个经典模型,它们的一些思想直到今天仍然未过时,也是学习分解模型的必备。
|
||||
|
||||
- SVD++[4]:加入了邻域信息之后的矩阵分解
|
||||
- BPR[5]:采用贝叶斯概率思想,引入隐式反馈优化
|
||||
|
||||
## 2.3 高阶分解模型(high order factorization model)
|
||||
|
||||
矩阵分解模型包括用户和物品两类因子,在处理额外信息比如时间、标签时存在局限。处理额外信息的另一种直接做法是使用张量分解,主要的经典模型包括基于马尔可夫的分解模型 FPMC(Factorizing Personalized Markov Chains)。但是高阶张量分解开销十分巨大,各阶的交互方式不灵活。
|
||||
|
||||
提到高阶分解模型,不得不提推荐系统领域的元老级人物——Rendle。他提出的因子分解机模型——Factorization machines,几乎杀遍所有数据挖掘竞赛,霸榜 SOTA 数年,引领数年风骚[6]。FM——因子分解机,可以将多种信息进行高阶交互(二阶、三阶等等),但是一般到二阶以后,训练将变得异常困难,计算量也急剧增加。
|
||||
|
||||
当然,高阶分解的另一个相似模型,就是学术界明星-华人陈天奇在上海交大读研时提出的 SVDFeature 模型[7]。在原始论文中,FM 模型称 SVDFeature 模型仅仅是高阶 FM 的一个泛化。
|
||||
|
||||
后来陈天奇赴美留学,将梯度树的性能提升到极致,也就是经典 XGBoost 模型[8],也霸榜 SOTA 数年,一时风光无两。SVDFeature 库是上海交大实验室采用 C++ 编写,XGBoost 开源版本很多,建议可以阅读前人开源代码,增加代码能力。同时,在机器学习时代,原版论文涉及很多数学推导和梯度计算,阅读这些论文,也是增进个人内功的很好法门。
|
||||
|
||||
## 2.4 深度模型(deep-learning models)
|
||||
|
||||
深度模型进入推荐系统领域大概是 16 年左右,最早将深度模型应用于推荐领域的应用主要是在评论文本挖掘领域。
|
||||
|
||||
评论信息中包含用户偏好、评价等反馈信息。研究者将 CNN 引入推荐系统领域,将文本映射成 word vector,并采用卷积网络训练,将 CNN 和传统的矩阵分解结合,并套上一个概率的外壳进行解释。这方面的工作主要包括 ConvMF[9]、DeepCoNN[10]。
|
||||
|
||||
基于 CNN 的模型主要是应用于评论文本挖掘和可解释性推荐方面,但是这种方法的计算量非常大,并且准确率不高,难以训练。个人认为这种方法仅仅是新奇,并不具备特别大的商业价值。对于推荐这种时效性非常强的应用,训练一个几百亿数量级的文本挖掘模型,却非用于自然语言领域,产生的价值和消耗的资源不成正比。
|
||||
|
||||
何向南在 2017 年提出 NCF,将神经网络结合协同过滤——深度协同过滤,霸榜 SOTA[11]。从此,推荐系统几乎被深度学习攻陷,各种方法层出不穷。他在中科大的团队同时开发了 NeuRec 开源框架——一个基于 Tensorflow 的推荐框架,适合新手入门。
|
||||
|
||||
在工业界方面,最早将深度学习应用于推荐系统领域的是 YouTobe,它的大规模推荐系统分成两步——排序和召回。排序阶段是初排,将百万级别数量级的物品进行排序,选出几百个候选物品;召回阶段是精排,根据物品特征和用户偏好对几百个物品进行细粒度排序。
|
||||
|
||||
## 2.5 序列推荐(sequential recommender)
|
||||
|
||||
前面介绍了机器学习时代的几种经典模型,接下来介绍深度序列推荐。Session based SRs 是会话推荐,Sequential recommender 是序列推荐。前者是指一个用户在一个 session 当中的点击序列,而后者更关注于物品序列顺序本身,而与用户无关。但是两者之间有着非常相似而密切的联系。
|
||||
|
||||
最早开始将深度引入会话推荐的模型是 GRU4Rec[12],它直接将 RNNs 用于会话推荐系统,并采用 zero-padding 补齐序列长度不一致的问题。实际上,Padding 是常见的序列补齐技术,但是值得注意的是,有些开源代码采用的是左补齐(在序列的左边补齐,如 RecBole),有些采用的是右补齐(如 GRU4Rec,SASRec)。
|
||||
|
||||
2018 年的 ICDM 顶会上,加州大学圣地亚哥分校的 McAuley 团队(推荐系统领域的又一个大牛)提出的 SASRec[13],直接将注意力机制用于序列推荐,完成 SOTA。原论文的实验部分设置十分精彩,值得论文初写者模仿和借鉴。
|
||||
|
||||
从此以后,基于 attention-based 的模型开始百花齐放,比如加入物品序列和物品特征序列的双路注意力 FDSA[14]、使用双向注意力机制的 BERT4Rec[15]等等。
|
||||
|
||||
20 年以来,由于图神经的方法渐渐成为研究热点。基于图网络的推荐系统也引起了学术界的兴趣。SR-GNN[16]是最近将 GNN 的方法用于会话推荐系统。随后,各种图方法开始爆发,目前主流的图神经网络方法包括清华大学和快手联合推出的 SURGE[17]。
|
||||
|
||||
# 主要会议和期刊
|
||||
|
||||
- ACM Conference on Recommender System (RecSys): 推荐系统顶会
|
||||
- ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. KDD 竞赛,数据挖掘顶会
|
||||
- IEEE International Conference on Data Mining : ICDM,数据挖掘顶会
|
||||
- International Joint Conference on Artificial Intelligence: IJCAI
|
||||
- **ACM the Web Conference**: 3W
|
||||
- **ACM International Conference on Web Search and Data Mining**:WSDM
|
||||
- **ACM International Conference on Informaiton and Knowledge Management**:CIKM
|
||||
|
||||
# 国内外大牛 Follow
|
||||
|
||||
- Koren: 矩阵分解模型提出者,2009 年 Netflix prize 获得者
|
||||
- Steffen Rendle: FM 系列提出者,工业界推荐系统大牛
|
||||
- 何向南:中科大教授,NUS 博士,百万青橙奖得主,国内学术界推荐大牛,开源 NeuRec
|
||||
- McAuley:加州大学圣地亚哥分校教授,北美推荐系统领域大牛,SASRec 模型
|
||||
- 赵鑫:中国人民大学教授,联合开发 Recbole 开源库
|
||||
|
||||
# 参考文献
|
||||
|
||||
[1]Breese et al. 1998. Empirical analysis of predictive algorithms for collaborative filtering. In Proceedings of the Fourteenth conference on Uncertainty in artificial intelligence (UAI'98), 43–52.
|
||||
|
||||
[2]G. Linden J. Jacobi and E. Benson, Collaborative Recommendations Using Item-to Item Similarity Mappings, US Patent 6,266,649 (to Amazon.com), Patent and Trademark Office, Washington, D.C., 2001
|
||||
|
||||
[3]Sarwar et al., Item-based collaborative filtering recommendation algorithms, Proceedings of the 10th international conference on World Wide Web, p.285-295,
|
||||
May 01-05, 2001, Hong Kong
|
||||
|
||||
[4] Koren, Y. 2008. Factorization meets the neighborhood: A multifaceted collaborative filtering model [C]. Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. KDD ’08. Las Vegas, Nevada, USA: ACM, 426–434
|
||||
|
||||
[5] Rendle, S., Freudenthaler, C., Gantner, Z., and Schmidt-Thieme, L. 2009b. Bpr: Bayesian personalized ranking from implicit feedback [C]. Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence. UAI ’09. Montreal, Quebec, Canada, 452–461.
|
||||
|
||||
[6] Rendle, S. 2013. Scaling factorization machines to relational data [C]. Proceedings of the 39th International Conference on Very Large Data Bases. volume 6 of Proc. VLDB Endow. Riva del Garda, Trento, Italy: VLDB Endowment, 337–348.
|
||||
|
||||
[7] Chen, T., Zhang, W., Lu, Q., Chen, K., Zheng, Z., and Yu, Y. 2012c. Svdfeature: a toolkit for feature-based collaborative filtering [J]. The Journal of Machine Learning Research, 13(1):3585–3588
|
||||
|
||||
[8] Chen, Tianqi, and Carlos Guestrin. "Xgboost: A scalable tree boosting system." Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 2016.
|
||||
|
||||
[9]Kim, Donghyun, et al. "Convolutional matrix factorization for document context-aware recommendation." Proceedings of the 10th ACM conference on recommender systems. 2016.
|
||||
|
||||
[10]Zheng, Lei, Vahid Noroozi, and Philip S. Yu. "Joint deep modeling of users and items using reviews for recommendation." Proceedings of the tenth ACM international conference on web search and data mining. 2017.
|
||||
|
||||
[11]He, Xiangnan, et al. "Neural collaborative filtering." Proceedings of the 26th international conference on world wide web. 2017.
|
||||
|
||||
[12] Hidasi, Balázs, et al. "Session-based recommendations with recurrent neural networks." arXiv preprint arXiv:1511.06939 (2015)
|
||||
|
||||
[13] Kang, Wang-Cheng, and Julian McAuley. "Self-attentive sequential recommendation." 2018 IEEE International Conference on Data Mining (ICDM). IEEE, 2018.
|
||||
|
||||
[14] Tingting Zhang, Pengpeng Zhao et al. Feature-level Deeper Self-Attention Network for Sequential Recommendation.2019.
|
||||
|
||||
[15]Fei Sun, Jun Liu et al. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer.2019.
|
||||
|
||||
[16]Shu Wu, Yuyuan Tang, Yanqiao Zhu, Liang Wang, Xing Xie, Tieniu Tan. Session-based Recommendation with Graph Neural Networks. 2019.
|
||||
|
||||
[17]Jianxin et al., Sequential Recommendation with Graph Neural Networks. SIGIR 2021.
|
||||
@@ -1,9 +0,0 @@
|
||||
# 《推荐系统实践》读后的一些想法
|
||||
|
||||
- 说在前头的话:
|
||||
在对这本书进行阅读之前,我对于大模块知识的学习方式一无所知,所以就想借由学习推荐系统的知识,来构建属于自己的大模块知识学习方式。我把这个方向上的学习,更倾向于一种对于学习本身的探索,而不强求自己真正能掌握多少知识。出于以上的原因,我将要记录的东西更偏向于一种阅读完之后的自己的理解,相当于把别人的东西吃进去,嚼两口再吐出来。其中所产生的信息缺失或信息差错,还望读者体谅,对于一些存疑的地方,翻阅原著是最佳的方式,若是有自己的思考,敬请斧正。
|
||||
- 所以说,如果想对这方面有所了解的话,那我推荐您阅读原著,然后把文档中内容当成是复习或者是对照学习的资料,文档中的内容缺少了原文中生动形象的例子,对于刚接触者来说可能难以理解
|
||||
- 小人不才,在专业知识匮乏和自身水平较低的情况下,擅自对这书的内容下一个定义。全书所围绕的主题重点在于从数据的角度出发,进行推荐系统的构造,重点着墨于包括:基于用户的行为数据,基于标签数据,基于上下文信息,给予社交网络数据,这些一早就写在目录中的数据。
|
||||
- 书中的讲述深入浅出,如果愿意用心阅读作者的描述的话,很多的晦涩概念都被作者准确的描述了出来,再辅以一些实际例子,让整本书的阅读难度甚至降低到了兴趣者能读懂的程度。足以见到作者高超的笔力和深厚的理解。
|
||||
- 当然书中并没有一个完整推荐系统的代码,这方面的空缺建议辅佐另一本《深度学习推荐系统》和 fun-rec 开源社区中的代码进行学习。
|
||||
- 对于有想法了解推荐系统的人来说,这本书可以是一本合适的入门作品,书中对于推荐系统的定义和描述,足以让有想法的人对于这个领域有一个大概的了解。
|
||||
@@ -1,63 +0,0 @@
|
||||
# 推荐系统概念解释 and 一个好的推荐系统
|
||||
|
||||
- <strong>用户满意度</strong>
|
||||
|
||||
- 用户满意度是推荐系统测评的重要指标,但是实际上,用户满意度数据获得的方式十分有限,因为这是一种用户的主观情感。
|
||||
- 设计合适的方式对于用户的满意度进行回收分析,是改进推荐系统的一个很好的方式。这样的的方式包括但不限于,设计合适的调查问卷,在物品的购买结束后附上一份满意度调查。
|
||||
- 满意度在一些程度上可以细分为更加具体的信息。例如点击率,用户停留时间,转化率,完播率,或者是哔站视频点赞,三连的比例。
|
||||
- <strong>预测准确度</strong>
|
||||
|
||||
- <strong>召回率(Recall)</strong>
|
||||
|
||||
$$
|
||||
Recall =\frac{\sum_{u\in U}{\vert R(u)\cap T(u) \vert}}{\sum_{u\in U \vert T(u)\vert}}
|
||||
$$
|
||||
|
||||
|
||||
- 其中 $R(u)$ 是根据用户在训练集上的行为给用户做出的推荐列表, $T(u)$ 是用户在测试集上的行为列表。
|
||||
|
||||
- 召回率的意义?可以参考机器学习中留下的定义进行理解
|
||||
|
||||
|
||||
- <strong>精确率</strong>
|
||||
|
||||
$$
|
||||
Precision =\frac{\sum_{u\in U}{\vert R(u)\cap T(u)\vert}}{\sum_{u\in U}{\vert R(u) \vert}}
|
||||
$$
|
||||
|
||||
|
||||
- 其中 $R(u)$ 是根据用户在训练集上的行为给用户做出的推荐列表, $T(u)$ 是用户在测试集上的行为列表。
|
||||
|
||||
- 精确率的意义?
|
||||
|
||||
|
||||
- <strong>覆盖率</strong>
|
||||
|
||||
- 描述了一个系统对于物品长尾的发掘能力。
|
||||
- 覆盖率的一个定义可以是:
|
||||
$$
|
||||
Coverage = \frac{\vert \bigcup_{u\in U}{R(u)}\vert}{\vert I \vert}
|
||||
$$
|
||||
- 其中,用户集合为 $U$ ,系统为每位用户推荐一个长度为 $N$ 的物品列表 $R(u)$
|
||||
- 覆盖率的意义:覆盖率越高,以为这系统中被推荐给用户的物品,占所有物品的比例越大,对于一个好的推荐系统,不仅需要有较高的用户满意度,还需要有较高的覆盖率。
|
||||
- 当然对于覆盖率的定义,不止以上的这一种,甚至说,在实际使用上,上述简单的覆盖率不足以支撑大规模复杂系统的覆盖率计算,所以如何对于覆盖率进行修正和更新?信息熵与基尼系数!
|
||||
- 推荐了解,马太效应,一个强者更强,弱者更弱的效应,在推荐系统中也同样存在。
|
||||
- <strong>多样性</strong>
|
||||
|
||||
- 假设,$s(i,j)$ 定义了物品 i 和 j 之间的相似度,给用户 $u$ 的推荐列表 $R(u)$的多样性定义:
|
||||
$$
|
||||
Diversity = 1- \frac{\sum_{i,j\in R(u),i\ne j}{s(i,j)}}{\frac{1}{2}\vert R(u)\vert (\vert R(u)-1\vert)}
|
||||
$$
|
||||
- 推荐系统整体的多样性可以定义为,用户推荐列表多样性的平均值:
|
||||
$$
|
||||
Diversity = \frac{1}{\vert U\vert}\sum_{u\in U}{Diversity(R(u))}
|
||||
$$
|
||||
- <strong>信任度</strong>
|
||||
|
||||
- 用户对于该系统的信任程度
|
||||
- <strong>实时性</strong>
|
||||
|
||||
- 系统对于数据更新的时效性
|
||||
- <strong>健壮性</strong>
|
||||
|
||||
- 系统对于外来攻击的防护性
|
||||
@@ -1,80 +0,0 @@
|
||||
# 推荐系统的外围架构
|
||||
|
||||

|
||||
|
||||
<center>推荐系统外围架构图</center>
|
||||
|
||||
在外围结构中,我们有以下部分:
|
||||
|
||||
- **UI界面**:负责与用户进行交互,并收集用户的各种行为数据记录至日志系统。
|
||||
|
||||
- **日志系统**:通过日志系统,将用户的行为数据存储至用户日志存储系统。
|
||||
|
||||
- **用户日志存储系统**:可能存储在内存缓存中,数据库中或者文件系统中。
|
||||
|
||||
- **推荐系统**:分析行为数据,生成推荐列表,展示至UI界面供用户选择。
|
||||
|
||||
# 推荐系统的架构
|
||||
推荐系统的任务集中于:根据提供的数据,生成用户的推荐列表。这个任务可以抽象为一个从用户通过各种各样的特征最终走到不同物品的过程。而这个过程又可以拆解成两个部分:一是如何生成用户的特征,二是如何根据特征找到物品。
|
||||
|
||||
而基于之前学习的各种知识,我们可以对于这两个部分找到对应的方法。生成特征可以看成是在庞大的数据集中找到一个适合的分类规则,例如:通过基于上下文信息分类,通过标签信息,利用行为信息等,而根据特征找到物品可以看成是基于不同特征下的计算用户对于物品的兴趣度。(待斟酌)
|
||||
|
||||
若是将推荐系统的任务细分,可以结合现实实际情况:将最新加入的物品推荐给用户;商业上需要宣传的物品推荐给用户;为用户推荐不同种类的物品。
|
||||
**复杂的特征和情况不同的任务**会让推荐系统变得非常复杂,所以推荐系统的架构为了方便考虑,采用多个不同的推荐引擎组成,每个推荐引擎专门负责某一类特征和一种任务,而推荐系统再将推荐引擎的结果按照一定的优先级合并,排序并返回给UI系统。
|
||||
|
||||

|
||||
|
||||
<center>推荐系统的架构</center>
|
||||
如上图所示。
|
||||
|
||||
这样做能够灵活的更换推荐引擎,以适应不同用户或不同场景下的推荐需求。
|
||||
|
||||
# 推荐引擎的架构
|
||||
推荐引擎的架构主要包括三个部分:
|
||||
|
||||
- 特征向量生成部分(特征向量输出部分)
|
||||
|
||||
- 初始推荐物品列表生成部分
|
||||
|
||||
- 推荐列表筛选、过滤、重排列部分
|
||||
|
||||

|
||||
|
||||
以上为推荐引擎的架构图。
|
||||
|
||||
## 特征向量生成部分
|
||||
特征向量生成时,若用户的人口统计学特征等信息直接缓存在内存中,则推荐是直接拿到用户的特征数据进行特征向量生成。
|
||||
|
||||
而另一种情况中,系统缺少人口统计学特征或是无法直接调用,则需要从用户的行为信息中生成特征向量。此时,就需要将用户行为的一些特征素纳入考虑,并将这些特征赋予适合的权重进行计算。
|
||||
|
||||
## 初始推荐物品列表生成
|
||||
由得到的特征向量,进行特征-物品迁移,从而生成初始的推荐物品列表
|
||||
|
||||
## 推荐列表筛选、过滤、重排列
|
||||
|
||||
**筛选过滤模块**
|
||||
|
||||
得到了初始化的推荐列表之后,此时是不能直接将其展示给用户的,因为在这个列表中仍然存在包括:**用户已产生过行为**、**候选物品外的物品**、**某些质量很差的物品**,等不符合推荐原则的物品,所以需要进行第一步筛选过滤。
|
||||
|
||||
**排名模块**
|
||||
|
||||
再经历了筛选过滤之后的推荐列表,已经具有只是给用户的能力了,但若是能将排名进一步更新则会提高用户的满意度。对于排名进行更新有以下几种思路:
|
||||
|
||||
**新颖性排名**
|
||||
|
||||
为了提高列表的新颖性,可以对列表中的热门物品进行适当的降权处理
|
||||
|
||||
**多样性排名**
|
||||
|
||||
思路有:按照物品的内容分类后,从分类中选择排名最高的物品组合推荐;控制不同推荐理由出现的次数。
|
||||
|
||||
**时间多样性**
|
||||
|
||||
为了避免用户每次使用系统时得到的推荐列表没有任何变化
|
||||
|
||||
**用户反馈**
|
||||
|
||||
对于用户反馈的信息在排名加权计算中进行反馈,从而生成对应的推荐列表
|
||||
|
||||
|
||||
|
||||
@@ -1,230 +0,0 @@
|
||||
# 利用用户行为数据
|
||||
## 用户行为数据介绍
|
||||
### 什么是用户行为数据?
|
||||
顾名思义,用户行为数据是指一些能表示用户行为的数据,最简单的存在形式就是网站上的日志,包括用户在网站上的点击被记录至点击日志,完成一次网站相应被记录至会话日志等。
|
||||
### 用户行为数据分类
|
||||
- 显性反馈数据:显形反馈包括用户明确表示对物品喜好的行为,例如对于一个视频的顶或者踩,更进一步是对于这个视频写下的评价、打上的标签等。
|
||||
|
||||
- 隐形反馈数据:隐形反馈包括用户的页面浏览行为等不能明确反映用户兴趣的行为,包括一个视频的完播率,页面的停留时间等数据。
|
||||
|
||||
若是按照反馈的划分,数据又可以被分为正反馈和负反馈,正反馈指用户的行为倾向于用户喜欢该物品,而负反馈则相反。
|
||||
|
||||
## 用户行为数据分析
|
||||
### 用户活跃度和物品流行度的关系
|
||||
|
||||
**长尾分布** 互联网中很多数据都遵循长尾分布:$f(x)=\alpha x^k$ ,用户行为数据同样蕴含长尾分布的规律。
|
||||
|
||||
令 $f_{u}(k)$ 为对 $k$ 个物品产生过行为的用户数,$f_i(k)$ 为对 $k$ 个用户产生过行为的物品数。那么有以下的规律存在
|
||||
$f_i(k)=\alpha_ik^{\beta_i},f_u(k)=\alpha_uk^{\beta_u}$
|
||||
|
||||
|
||||
## 协同过滤算法
|
||||
仅对用户行为数据所设计的推荐系统算法被称为协同过滤算法。协同过滤算法中包含多种算法:基于邻域的方法、隐语义模型、基于图的随机游走算法。
|
||||
### 基于邻域的算法
|
||||
推荐系统中最基本的算法,可以分为基于用户的协同过滤盒基于物品的协同过滤。
|
||||
|
||||
#### 基于用户的协同过滤
|
||||
|
||||
算法简介:当你想要出去玩时,你会询问身边和自己游玩兴趣相似的朋友的意见,并从他们的推荐中选择你自己的出行方案,而且一般你制定的出行方案中大部分是自己为听说过或去玩过的景点,这就是一种生活中的基于用户的协同过滤。
|
||||
|
||||
特点分析:可以从上面的例子看出,此类协同过滤主要包含两个步骤:
|
||||
|
||||
**(1)找到和目标用户相似的用户集合** ,我们称这个被找到的用户为,被寻用户以方便下文讲解
|
||||
|
||||
**(2)从被寻用户的兴趣集合中,找到目标用户喜欢的且目标用户未听说过的物品**
|
||||
|
||||
以上就是,基于用户的协同过滤最基本的思想,让我们分步对这个算法进行分析。
|
||||
|
||||
#### 如何找到和目标用户相似的被寻用户?
|
||||
|
||||
关键就是计算用户与用户之间的相似度,计算相似度有两种不同的方法,我们给定用户 $u$ 和用户 $v$ ,$N(u)$ 为用户 $u$ 有过正反馈的物品集合,$N(v)$ 为用户 $v$ 有过正反馈的物品集合。
|
||||
|
||||
**Jaccard 相似度** 公式为:$w_{uv} = \frac{\vert N(u)\cap N(v)\vert}{\vert N(u)\cup N(v)\vert}$
|
||||
|
||||
**余弦相似度** 公式为:$w_{uv} = \frac{\vert N(u)\cap N(v)\vert}{\sqrt{\vert N(u)\vert \vert N(v)\vert}}$
|
||||
|
||||
这就是一种计算相似度的方法,但是不可避免的,这样的相似度计算方法需要遍历整个用户信息表,时间开销极大,而且存在很多无效查询,所以考虑进行改进。**倒排表改法?**
|
||||
|
||||
用户相似度在遭遇热门物品时,会导致严重的误差,例如:如果两人同时购买了《新华字典》,可能并不是因为两人都对它有兴趣,而是因为它是一本基本工具书,所以不能通过这个过热门物品确定二人的兴趣相似。**改进公式惩罚热门物品?**
|
||||
|
||||
#### 如何为目标用户推荐物品?
|
||||
|
||||
关键是计算出目标用户对于各个物品的兴趣,设 $S(u,K)$ 包含和用户 $u$ 最接近的 $K$ 个用户,$N(i)$ 是对物品 $i$ 有过行为的物品集合,$w_{uv}$ 表示用户 $u 和 v$ 的兴趣相似度,$r_{vi}$ 表示用户 $u对i$ 的兴趣,这个变量的值仅有01取值。
|
||||
|
||||
所以用户$u对于物品i的相似度$ 可表示为:$p(u,i)=\sum_{v\in S(u,K)\cap N(i)}{w_{uv}r_{vi}}$
|
||||
|
||||
其中会对这个推荐结果产生较大影响的外部变量,$K$。如何确定一个合适的K值是?
|
||||
|
||||
#### 基于物品的协同过滤算法
|
||||
|
||||
算法简介:例如你以前购买过《算法导论》,而系统判断《算法导论》与《数据结构》具有较高的相似度,那么系统就会将《数据结构》推荐给你,需要注意的是,系统对于物品之间相似度的判定,来源与用户对于物品的行为信息,而不是根据物品与物品之间内容的相关性。
|
||||
|
||||
特点分析:**较高的解释性**,系统在进行推荐时,可以利用用户的历史行为给推荐结果提供解释;**较低的时间复杂度**,相较于基于用户协同过滤的和用户数量成平方的时间复杂度,基于物品协同过滤的时间复杂度较低。
|
||||
|
||||
该算法与用户协同过滤类似,分成两步:
|
||||
|
||||
**计算物品之间的相似度**,定义$N(i)$ 是喜欢物品 i 的用户数, $N(i)\cap N(j)$ 为喜欢物品 i 和 j 的用户数,因此物品相似度可定义为如下公式
|
||||
|
||||
<center>
|
||||
|
||||
$w_{ij}=\frac{\vert N(i)\cap N(j)\vert}{\vert N(i) \vert}$
|
||||
|
||||
</center>
|
||||
|
||||
同样的,该公式也存在热门物品造成误差的问题,因为如果多数人都喜欢 j ,那么 $w_{ij}$ 就会无限趋近于1,导致系统中任何物品对于物品j都具有很大的物品相似度,影响了推荐系统的覆盖率,所以考虑对于公式进行修正为
|
||||
|
||||
<center>
|
||||
|
||||
$w_{ij}=\frac{\vert N(i)\cap N(j) \vert}{\vert N(i)\vert \vert N(j)\vert}$
|
||||
|
||||
</center>
|
||||
|
||||
**用户活跃度对于相似度的影响?** 如果一个批发商大肆购买物品,那么他对于这大量物品的相似度的实际贡献,是不如一个只购买了十几本书的兴趣爱好者的。那么,**如何对这种行为进行惩罚?**
|
||||
|
||||
更进一步,**归一化?**,将相似度矩阵按最大值归一化,可以有效提升推荐系统的性能。
|
||||
|
||||
#### 得到用户对于物品i的兴趣
|
||||
|
||||
同样通过相似度对于兴趣进行推测,$N(u)$ 表示用户喜欢的物品集合,$S(j,K)$ 是和物品 j 最相似的 K 个物品集合,$w_{ij}$ 是物品 i 和物品 j 的相似度,$r_{ui}$ 是用户 u 对于物品 i 的兴趣(根据隐反馈数据集,若用户对于物品有过行为,则值为1),所以公式为
|
||||
<center>
|
||||
|
||||
$P_{uj}=\sum_{i\in N(u)\cap S(j,K)}{w_{ji}r_{ui}}$
|
||||
|
||||
</center>
|
||||
|
||||
|
||||
## 隐语义模型
|
||||
隐语义模型的基本思想是,通过隐含特征联系用户兴趣和物品,进行进一步解释即为:以物品的内容进行分类,根据用户的行为对用户进行兴趣判断,从对应符合用户兴趣的物品类别中推荐物品。
|
||||
|
||||
基于上述理解,需要解决的问题分别有:
|
||||
|
||||
(1)如何对于物品进行分类;
|
||||
|
||||
(2)如何确定用户的兴趣方向,以及用户对于不同兴趣方向的感兴趣程度;
|
||||
|
||||
(3)对于一个兴趣方向,如何挑选给定分类中的物品给用户,如何确定该物品在分类中的权重。
|
||||
|
||||
为了解决上述问题,以及上述问题牵扯出的一系列问题(思考这一系列问题中有哪些?是个很好的锻炼思维方式)。考虑采用隐含语义分析技术,因为**隐含语义分析技术**采取基于用户行为统计的自动聚类,具有对于以上问题较好的适应性。
|
||||
|
||||
类似于itemCF的思想,若两件物品同时被很多用户标记,则这两件物品可能属于统一分类
|
||||
|
||||
隐语义能够指定最终的分类数量,从而控制分类的粒度,当分类数量较大时,粒度则较小,分类数量较小时,粒度较大
|
||||
|
||||
隐语义会计算出单个物品不同内容的所占权重,所以不会出现一个物品只在一个分类中
|
||||
|
||||
隐语义所给出的分类是基于用户共同兴趣的,所以给出的分类有更大可能会给予不同维度
|
||||
|
||||
隐语义通过统计用户的行为来确定物品在当前分类的权重
|
||||
|
||||
#### LFM模型
|
||||
|
||||
###### 建立数据集
|
||||
|
||||
用户所产生的行为分为正反馈与负反馈,LFM模型在显性反馈数据集上解决评分预测问题有很好的精度,但是若是在隐性反馈数据集上,样本只存在正样本而没有负样本,如何解决这个问题,**生成令人满意的负样本?**
|
||||
|
||||
生成负样本有如下的几种思路
|
||||
|
||||
定义用户未有过行为的物品、定义未有过行为中随机采样出的物品、定义未有过行为中随机采样出的物品,且这些物品数量与正样本数量相当、定义未有过行为的物品,且着重挑选一些不热门的物品。
|
||||
|
||||
在实际实验的过程中,上述四种思路各有胜负,最终通过一场2011年的推荐算法比赛,得出了负样本采样应遵循的原则
|
||||
|
||||
- 负样本采样应保证正负样本平衡
|
||||
|
||||
- 采取负样本时,应遵循冷门物品有限的原则
|
||||
|
||||
#### 通过随机梯度下降法优化参数
|
||||
|
||||
通过建立的数据集 $K=\{(u,i)\}$ ,其中如果 $(u,i)$ 是正样本,则有 $r_{ui}=1$ 否则为0。然后通过优化如下的损失函数来找到合适的参数 $p,q$
|
||||
|
||||
$$C=sum_{(u,i)\in K}{(r_{ui}\hat r_{ui})^2}=\sum_{(u,i)\in K}{(r_{ui}\sum^K_{k=1}{p_{u,k} q_{i,k} })^2}+\lambda\Vert p_u\Vert^2+\lambda\Vert q_i\Vert^2$$
|
||||
|
||||
其中,$\lambda\Vert p_u\Vert^2+\lambda\Vert q_i\Vert^2$ 是用来防止过拟合的正则项,$\lambda$ 可通过实验获得。
|
||||
|
||||
使用随机梯度下降法优化以上的损失函数,递推公式如下:
|
||||
|
||||
$p_{uk}=p_{uk}+\alpha(q_{ik}\lambda p_{uk})$
|
||||
|
||||
$q_{ik}=q_{ik}+\alpha(p_{uk}\lambda q_{ik})$
|
||||
|
||||
重要参数共四个:
|
||||
|
||||
- 隐特征数量F
|
||||
|
||||
- 学习速率$\alpha$
|
||||
|
||||
- 正则化参数$\lambda$
|
||||
|
||||
- 负样本与正样本的比例ratio
|
||||
|
||||
将得到的参数代入Preference公式中
|
||||
|
||||
LFM定义了 $p_{u,k}$ 和 $q_{i,k}$ 作为模型的参数,其中,$p_{u,k}$ 度量了用户 u 的兴趣和第 k 个隐类的关系,而$q_{i,k}$ 度量了第 k 个隐类和物品 i 之间的关系,所以可以有公式计算兴趣度
|
||||
|
||||
<center>
|
||||
|
||||
$$Preference(u,i)=r_{ui}=p^T_uq_i=\sum^F_{f=1}{p_{u,k}q_{i,k}}$$
|
||||
|
||||
</center>
|
||||
|
||||
得到用户对于物品的兴趣度之后,就能进行排名再生成推荐列表。
|
||||
|
||||
#### LFM局限性
|
||||
|
||||
对于参数的训练的要再数据集上进行多次迭代,在一般的实际应用中每天只能训练一次并且得出结果,所以很难满足根据用户的实时行为对用户进行推荐,即实时性较弱。
|
||||
|
||||
## 基于图的模型
|
||||
|
||||
可以想到用户与物品之间的相互关系可以由二分图进行表示,所以在推荐算法中引入图模型
|
||||
### 用户数据的二分图表示
|
||||
|
||||
在研究图模型之前,需要用已有的数据生成一个图,设二元组 $(u,i)$ 表示用u对于物品 i 产生过行为。令 $G(V,E)$ 表示用户物品二分图,其中$V=V_U\cup V_I$ 由用户顶点集合和物品顶点集合组成,$E$ 是边的集合。对于数据集中的二元组 $(u,i)$ 图中都会有对应的边 $e(v_u,v_i)\in E$ 如下图所示。
|
||||
|
||||

|
||||
|
||||
### 基于图的推荐算法
|
||||
|
||||
将数据集转换为图模型之后,原来的给用户u推荐物品的任务就可以等效于计算与用户u没有边直接相连的物品集合中,计算用户与物品的相关性,相关性越高则它在推荐列表中的权限就越高。
|
||||
|
||||
#### 相关性计算
|
||||
|
||||
相关性的计算主要依赖于一下三个因素
|
||||
|
||||
1. 两个顶点间的路径数
|
||||
|
||||
2. 两个顶点之间的路径距离
|
||||
|
||||
3. 两个顶点之间的路径经过的顶点
|
||||
|
||||
相关性高的两个顶点,通常具有以下的特征
|
||||
|
||||
1. 两个顶点之间有很多路径相连
|
||||
|
||||
2. 连接两个顶点间的路径很短(相似度高)
|
||||
|
||||
3. 连接两个顶点之间的路径不会出现出度过大的顶点(热门物品少)
|
||||
|
||||
**PersonalRank算法**
|
||||
|
||||
基于上述相关性计算的因素,有多种多样不同侧重的图算法,下面将介绍一种基于随机游走的PersonalRank算法
|
||||
|
||||
PersonalRank算法的基本思想是,假设要给用户u进行个性化推荐,可以从用户节点 $v_u$ 开始在用户物品二分图上开始随机游走。当游走到一个节点是,首先按照概率$\alpha$ 决定是继续游走,还是停止游走并直接返回 $v_u$ 重新开始游走。如果决定继续游走,那么就从当前节点所指向的节点按照均匀分布随机选取一个节点作为下次游走的目标。这样,经过多轮游走之后,每个物品节点被访问到的概率会收敛到一个数。最终推荐列表的权重就是这个点的访问概率。
|
||||
|
||||
可表示为公式
|
||||
$$
|
||||
PR(v)=\begin{cases}\alpha \sum_{v'\in in(v)}\frac{PR(v')}{\vert out(v')\vert},&v\ne v_u\\(1\alpha)+\alpha \sum_{v'\in in(v)}\frac{PR(v')}{\vert out(v')\vert},&v=v_u\end{cases}
|
||||
$$
|
||||
|
||||
与上面几种算法一样,PersonalRank算法需要在全图迭代,所耗费的时间是难以接受的,如何改进算法?
|
||||
|
||||
1. **减少迭代次数**
|
||||
|
||||
2. **通过矩阵论重新设计算法**
|
||||
|
||||
## 总结
|
||||
在本节内容中,我们主要立足于用户的行为数据,介绍用户行为数据是什么?用户行为数据有哪些分类?用户行为数据的特点。并且通过用户对于物品产生行为数据这一活动,我们设计了一系列算法包括,基于邻域算法、隐特征模型、基于图的模型。
|
||||
|
||||
但是用户对于物品产生数据这一行为,在当今互联网上算是最为简单的一种交互,无法满足用户日益刁钻的推荐需求。反过来思考,一旦当系统是一个新上线的系统,还没有大量的数据信息进行训练参数时,如何进行推荐。这就是后面我们主要解决的两个问题
|
||||
|
||||
如何解决冷启动问题?
|
||||
|
||||
如何增加推荐因素以满足用户增长的推荐需求?
|
||||
@@ -1 +0,0 @@
|
||||
# 推荐系统冷启动 <badge type="warning">待补充 by:buwyi</badge>
|
||||
@@ -1 +0,0 @@
|
||||
# 利用标签信息 <badge type="warning">待补充 by:buwyi</badge>
|
||||
@@ -1,253 +0,0 @@
|
||||
# 利用上下文信息
|
||||
|
||||
## 概述
|
||||
|
||||
- 在对用户进行推荐时,用户所处的空间与时间会对用户的喜好产生影响。例如,最经典的例子,如果当前季节是冬天,推荐系统不应该给用户推荐短袖。这就是一个很经典的时间上下文。同样能被成为上下文信息的包括但不限于,心情,地点等能描述用户当前状态的信息。利用这些上下文信息,我们能将推荐系统的推荐更加精确。
|
||||
|
||||
- 将重点讨论基于时间上下文信息的推荐系统
|
||||
|
||||
## 时间上下文
|
||||
|
||||
### 时间信息效应
|
||||
|
||||
- 时间信息对于用户的的影响可以主要分为以下几项:
|
||||
|
||||
- <strong>用户的兴趣是变化的</strong>
|
||||
对于一个用户,其幼年时期和青年时期喜欢的动画片是不一样的;晴天和雨天想要的物品是不一样的;一个人开始工作前和开始工作后的需求也是不同的。
|
||||
所以应该关注用户的近期行为,确定他的兴趣,最后给予用户推荐。
|
||||
- <strong>物品具有生命周期</strong>
|
||||
流行物品会随着热度持续火爆一段时间,但最终会无人问津;生活必需品无论在什么时候都有稳定的需求量。
|
||||
- <strong>季节效应</strong>
|
||||
正如概述中列出的冬衣与夏衣的区别,应该在合适的季节给用户推荐合适的物品。
|
||||
|
||||
### 系统时间特性分析
|
||||
|
||||
- 当系统由之前的静态系统变成随时间变化的时变系统后,需要关注特性也会发生变化,则需要重新观测一些数据,以推断系统的关于时间变化的特性。
|
||||
下面是一些可以用来观测的数据:
|
||||
|
||||
- <strong>确定系统的用户增长数</strong>,以判断系统的增长情况或是衰退情况。
|
||||
- <strong>物品的平均在线天数</strong>,即将满足用户物品互动次数的物品标记为在线,测算物品的平均在线天数以标量物品的生命周期。
|
||||
- 系统的时效性,判断<strong>相隔一段时间的物品流行度向量的相似度</strong>,若是相隔一段时间的相似度仍然较大,说明经过一段时间后,该物品还是被大众喜欢,则说明这件物品具有持久流行性。而对于系统来说,若是系统中大量物品的相似度变化都不大,则说明这个系统是一个推荐热度较持久物品的系统,说明系统的时效性较弱。
|
||||
- 系统对于用户的黏着性,统计<strong>用户的平均活跃天数</strong>,或者计算<strong>相隔一段时间的用户活跃度</strong>,以此判断系统对于用户的留存力或者说黏着性。
|
||||
|
||||
### 推荐系统的实时性
|
||||
|
||||
- 当引入了时间上下文信息后,推荐系统就可以进行实时性推荐,就类似于观看完一个视频后,立马弹出一系列的相关推荐列表“猜你想看”,存在这样特性的推荐系统有如下的特征:
|
||||
|
||||
- 实时推荐系统能根据用户的行为,实时计算推荐列表,而不是像之前所说的离线计算推荐列表。
|
||||
- 推荐系统需要平衡用户短期行为和长期行为,用户的推荐列表需要体现其短期的兴趣变化,但是推荐列表的又不能完全受用户近期行为影响,需要保证推荐列表预测的延续性。
|
||||
|
||||
### 推荐算法的时间多样性
|
||||
|
||||
- 想象这样一种情况,现在有 ABC 三个系统,A 系统为您推荐您最感兴趣的十样物品,但是不会更新。B 系统为您推荐一百样物品中的十样物品,推荐间隔一周,一周之后的榜单有七件不会是这周的物品。C 系统随机为您推荐一百样物品中的十样物品。
|
||||
|
||||
用推荐系统的思想分析上述三个系统:A 系统缺乏了随时间变化的推荐多样性,所以用户对于其满意度会随着时间推移而下降;B 系统兼顾了时间变化和推荐精度,会得到用户较高的好评;C 系统则是过于随机导致推荐精度下降。
|
||||
|
||||
综上,时间多样性会提高用户的满意度,所以如何在确保精度的条件下提高系统的时间多样性呢?
|
||||
|
||||
- <strong>需要用户在有新行为时,更新推荐列表</strong>
|
||||
传统的离线更新的推荐系统无法满足需求,所以需要使用实时推荐系统。
|
||||
- <strong>需要用户在没有新行为的时候,经常变化推荐列表</strong>
|
||||
通常采取以下三种方法:
|
||||
|
||||
- 生成推荐列表时加入一定的随机性。
|
||||
- 记录用户每天得到的推荐列表,在一段时间后,降低列表中用户未出现过行为的物品的权重。
|
||||
- 每次给用户使用不同的推荐算法。
|
||||
|
||||
当然,对于推荐系统来说,推荐准度的重要性要大于时间多样性,所以应该在尽量保证准度的基础上强化实践多样性,而这个强化的程度,则需要对推荐系统进行多次实验得到。
|
||||
|
||||
### 时间上下文推荐算法
|
||||
|
||||
- <strong>最近最热门</strong>
|
||||
一种最朴素的思想, 在系统引入了时间信息之后,最简单的非个性化推荐算法就是给用户推荐最近最热门的物品。
|
||||
|
||||
给定时间 T,物品 i 在最近的流行度可定义为:
|
||||
|
||||
$$
|
||||
n_i(T)= \sum_{(u,i,t) \in Train ,t<T} \frac{1}{1+\alpha(T-t)}
|
||||
$$
|
||||
|
||||
- <strong>时间上下文相关的 itemCF 算法</strong>
|
||||
itemCF 算法所依赖的核心部分,在引入时间信息后可以进行进一步更新
|
||||
|
||||
- <strong>物品相似度</strong> 利用用户行为,计算物品间的相似度,用户在相隔很短的时间内喜欢的物品通常具有更高的相似度,所以可以在相似度计算公式中引入时间信息,使得相似度计算更加准确。
|
||||
原本的相似度公式为:
|
||||
|
||||
$$
|
||||
sim(i,j)=\frac{\sum_{u\in N(i) \cap N(i)}{1}}{\sqrt{\vert N(i)\vert \vert N(j) \vert}}
|
||||
$$
|
||||
|
||||
|
||||
引入时间信息后,可更新为:
|
||||
|
||||
$$
|
||||
sim(i,j)=\frac{\sum_{u\in N(i) \cap N(i)}{f(\vert t_{ui} - t_{uj}\vert)}}{\sqrt{\vert N(i)\vert \vert N(j) \vert}}$$
|
||||
|
||||
|
||||
其中$f(\vert t_{ui}-t_{uj} \vert)$ 为时间衰减项,其中$t_{ui}$为用户u对物品i产生行为的时间,$f()$ 函数的作用是,用户对i与j的作用时间相距越远,对应函数值越小,相当于对输入因子$\vert t_{ui}-t_{uj} \vert$ 进行一个反比操作。可以找到在数学中许多的衰减函数,例如:
|
||||
|
||||
$$f(\vert t_{ui}-t_{uj} \vert)=\frac{1}{1+\alpha(\vert t_{ui}-t_{uj}\vert)}$$
|
||||
|
||||
|
||||
其中$\alpha$ 是时间衰减参数,它的取值与系统的对于自身定义有关系。收到用户兴趣变化的额外影响。
|
||||
|
||||
- <strong>在线推荐</strong> 用户近期行为相比用户很久之前的行为,更能体现用户目前的兴趣,所以在进行预测时,应当加重用户近期行为的权重,但不应该偏离用户长期行为的行为基调。
|
||||
原本的用户u对于物品i的兴趣$p(u,i)$ 可通过如下公式计算:
|
||||
|
||||
$$p(u,i)=\sum_{j\in N(u)}{sim(i,j)}$$
|
||||
|
||||
|
||||
引入时间信息可更新为:
|
||||
|
||||
$$
|
||||
p(u,i)=\sum_{j\in N(u)\cap S(i,k)}{sim(i,j)\frac{1}{1+\beta \vert t_0-t_{uj}\vert}}
|
||||
$$
|
||||
|
||||
|
||||
在上面的更新后公式中,$t_0$ 表示当前时间,该公式表明,当 $t_{uj}$ 与 $t_0$ 越靠近,和物品j相似的物品就会在用户u的推荐列表中获得更高的排名。其中的$\beta$和上文的 $\alpha$ 是一样的,需要根据系统的情况选择合适的值。
|
||||
|
||||
- <strong>时间上下文相关的userCF算法</strong>
|
||||
|
||||
与itemCF算法类似,userCF在引入时间信息后也可以进行更新
|
||||
|
||||
- <strong>用户兴趣相似度</strong> 用户相似度在引入时间信息后,会将用户相同的逆时序选择相似度降低。简单来说,就是A一月BF1长时间在线,二月BF5长时间在线,而B一月BF5长时间在线,二月BF1长时间在线;C行为信息与A相同。如果不引入时间信息,那么AB的相似度与AC的相似度是一样的,而实际上,AC的相似度会大于AB的相似度。
|
||||
|
||||
userCF的用户uv间相似度的基本公式为:
|
||||
|
||||
$$
|
||||
w_{uv}=\frac{\vert N(u)\cap N(v)\vert}{\sqrt{\vert N(u)\cap N(v)\vert}}
|
||||
$$
|
||||
|
||||
|
||||
其中,$N(u)$ 是用户u喜欢的物品的合集,$N(v)$ 是用户v喜欢的物品的合集。
|
||||
|
||||
引入时间信息后,公式可更新为:
|
||||
|
||||
$$
|
||||
w_{uv}=\frac{\sum_{i \in N(u)\cap N(i)}{\frac{1}{1+\alpha \vert t_{ui}-t_{vi}\vert}}}{\sqrt{\vert N(u)\cap N(v)\vert}}
|
||||
$$
|
||||
|
||||
|
||||
同样增加了一个时间衰减因子,用户uv对于i的作用时间差距越大,那么两人的相似度会相应降低。
|
||||
|
||||
- <strong>相似兴趣用户的最近行为</strong> 对于用户u来说,存在最近行为与用户u相似的用户v,那么用户v的最近行为,将会比用户u很久之前的行为更具有参考价值。
|
||||
|
||||
userCF中用户u对于物品i兴趣的基础公式为:
|
||||
|
||||
$$
|
||||
p(u,i)=\sum_{v\in S(u,k)}{w_{ui}r_{vi}}
|
||||
$$
|
||||
|
||||
|
||||
其中,$S(u,k)$ 包含了与用户 u 相似度最高的 k 名用户。而对应的$r_{ui}$ ,若用户产生过对i的行为,则其值为1 ,否则为0 。
|
||||
引入时间信息更新公式:
|
||||
|
||||
$$
|
||||
p(u,i)=\sum_{v\in S(u,k)}{w_{ui}r_{vi}} \frac{1}{1+\alpha(\vert t_0-t_{vi}\vert)}
|
||||
$$
|
||||
|
||||
- <strong>时间段图模型</strong>
|
||||
同样是一个基于图的推荐系统模型,引入时间信息,建立一个二分图时间段图模型:
|
||||
|
||||
$$
|
||||
(U,S_U,I,S_I,,E,w,\sigma)
|
||||
$$
|
||||
|
||||
|
||||
其中,$U$ 是用户节点集合,$S_U$ 表示用户时间段节点集合,一个用户时间段节点$v_{ut}\in S_U$ 会和用户 $u$ 在时刻 $t$ 喜欢的的物品通过边相连。$I$ 是物品集合,$S_I$ 是物品时间段节点集合,一个物品时间段节点 $v_{it}\in S_I$ 会和所有在时间$t$ 喜欢物品 $i$ 的用户节点相连。
|
||||
|
||||
|
||||
$E$ 是边集合,包含两大类边
|
||||
|
||||
第一种:若用户 $u$ 对于物品 $i$ 有行为,则会存在边 $e(u,i)\in E$ ;第二种,若用户 $u$ 对于物品 $i$ 在时间 $t$ 有行为,那么将存在对应的两条边,$e(v_{ut},v_i),e(v_u,v_{it})\in E$ 。
|
||||
|
||||
|
||||
而 $w(e)$ 定义了边的权重,$\sigma(e)$ 定义了顶点的权重。具体示例:
|
||||
|
||||
|
||||
|
||||
在构建了引入时间信息的图结构后,最简单的思想就是利用PersonalRank算法给用进行个性化推荐。但由于其复杂度较高,所以引入路径融合算法。
|
||||
一般来说,图上两个点的相关度强有以下的特征:
|
||||
|
||||
- <strong>两个顶点间有很多路径</strong>
|
||||
|
||||
- <strong>两个顶点间路径比较短</strong>
|
||||
|
||||
- <strong>两点间不经过出度大的点</strong> ,即不经过与很多其他点相连的节点,在推荐系统思维中等效于不与过热门物品关系紧密。
|
||||
|
||||
#### 路径融合算法
|
||||
|
||||
- 首先提取两个节点之间,长度小于一个给定值的所有路径。然后根据每条路径经过的不同节点,给予路径不同的权重。最后将所有路径的权重之和,作为两点的相关度。
|
||||
设 $P=\lbrace v_1,v_2,...,v_n\rbrace$ 是链接顶点 $v_1$ 到 $v_n$ 的一条路径,这条路径的权重 $\Gamma(P)$ 取决于这条路径所经过的所有顶点和边。
|
||||
|
||||
$$
|
||||
\Gamma(P)=\sigma(v_n)\prod_{i=1}^{n-1}{\frac{\sigma(v_i)\cdot w(v_i,v_{i+1})}{\vert out(v_i)\vert ^{\rho}}}
|
||||
$$
|
||||
|
||||
|
||||
其中,$out(v)$ 是顶点 $v$ 指向的顶点的集合,$\vert out(v) \vert$ 是顶点 $v$ 的出度,$\sigma(v_i)\in(0,1]$ 定义了顶点的权重,$w(v_i,v_{i+1})\in (0,1]$ 定义了边 $e(v_i,v_{i+1})$ 的权重。
|
||||
|
||||
定义了一条边的权重之后,就可以定义顶点之间的相关度。
|
||||
|
||||
对于顶点$v_1,v_n$ ,令$p(v_1,v_n,K)$ 为这两个顶点间距离小于K的所有路径,那么这两个顶点的相关度就可以表示为:
|
||||
|
||||
$$d(v_1,v_n)=\sum_{P\in P(v_1,v_n,K)}{\Gamma(P)}$$
|
||||
|
||||
而关于路径融合算法的算法实现,可以使用基于图上的广度优先搜索算法实现。
|
||||
|
||||
## 地点上下文
|
||||
|
||||
### 地点信息效应
|
||||
|
||||
- <strong>基于用户当前位置的推荐</strong>:对于用户当前位置,为其推荐距离更近的餐馆,娱乐场所或消费场所。
|
||||
|
||||
- <strong>基于用户活跃位置的推荐</strong>:对于用户长期活跃的区域,降低该区域内物品的权重,提高范围外物品的权重,以提高系统的新鲜度。
|
||||
|
||||
### 基于位置的推荐算法
|
||||
|
||||
- 明尼苏达大学的LARS推荐系统(Location Aware Recommender System,位置感知推荐系统)。
|
||||
|
||||
- <strong>对于数据的预处理</strong>
|
||||
|
||||
|
||||
将物品分为两类:(1)有空间属性的物品,餐馆,商店,旅游景点。(2)没有空间属性的物品,图书电影等。
|
||||
|
||||
将用户分为两类:(1)有空间属性的用户,(2)另一类用户没有空间属性。
|
||||
|
||||
基于上述的分类,将数据集整理成三个部分:
|
||||
|
||||
(用户,用户位置,物品,评分):记录了某一地点的用户,对于一个物品的评分。
|
||||
|
||||
(用户,物品,物品位置,评分):记录了用户对于某一地点的物品的评分。
|
||||
|
||||
(用户,用户位置,物品,物品位置,评分):记录了某个位置的用户,对于某个地点的物品的评分。
|
||||
|
||||
|
||||
- <strong>研究前两组数据</strong>:发现两种特征:(1)兴趣本地化,不同位置的用户存在较大的兴趣差异,不同国家和不同地区的差异。(2)活动本地化,一个用户往往在附近的地区活动。
|
||||
|
||||
- <strong>对于不同数据的处理</strong>
|
||||
|
||||
- 第一种数据:LARS的基本思想是,采用树状结构来进行数据集划分。
|
||||
|
||||
(1)例如:将所有用户作为根节点,将国家作为第一级子节点,省作为第二级,依次往下。
|
||||
|
||||
(2)对于某一个具有位置信息的用户,我们就可以将他分配到一个子节点下,而该子节点包含了与当前用户具有相同位置信息的全体用户的行为数据。
|
||||
|
||||
(3)LARS通过该节点的行为数据,利用基本推荐算法进行为用户进行推荐。
|
||||
|
||||
但是,对于上述过程,若是树的深度较大,则划分到每个节点的用户数据将较少,难以训练出一个令人满意的模型。所以有改进方法如下:
|
||||
从根节点出发,利用每个中间节点的数据训练出一个模型,而最终的推荐结果,是这一些列推荐模型所产出的推荐结果的加权结果。这个模型也被称为“<strong>金字塔模型</strong>”,其中<strong>深度</strong>是影响这个模型性能的重要参数,选取合适的深度对于该算法十分重要。
|
||||
|
||||
- 第二种数据:对于物品i在用户u推荐列表中的权重公式进行修正
|
||||
(1)首先忽略物品的位置信息,利用itemCF算法计算用户u对物品i的兴趣。
|
||||
|
||||
(2)计算物品i对于用户u的代价 $TravelPenalty(u,i)$ ,对于物品i与用户u之前评分的所有物品的位置距离计算平均值,度量方式通常采用交通网络数据。
|
||||
|
||||
(3) 利用公式
|
||||
|
||||
$$RecScore(u,i)=P(u,i)-TravelPenalty(u,i)$$
|
||||
|
||||
|
||||
计算最终的权重。
|
||||
|
||||
- 第三种数据:LARS的处理方法相当于在第二种数据中引入了用户当前位置的信息。
|
||||
@@ -1,9 +0,0 @@
|
||||
# 基于数据的角度,看待推荐系统的构造 <badge type="warning">待补充 by:buwyi</badge>
|
||||
|
||||
推荐系统诞生的二十年以来,各种各样的推荐算法层出不穷。若是将他们进行一个粗略的分类,可以按照数据的形式和算法的形式分类。
|
||||
|
||||
按照数据的分类中:协同过滤,内容过滤,社会化过滤等
|
||||
|
||||
按照算法的分类中:基于领域的算法、基于图的算法、基于矩阵分解的算法等
|
||||
|
||||
接下来的这部分内容,主要遵循项亮老师在《推荐系统实践》中的思路,进行基于数据的角度的推荐系统构建介绍。
|
||||
@@ -1,14 +0,0 @@
|
||||
# 序列化推荐
|
||||
|
||||
# 什么是序列化推荐?
|
||||
|
||||
在现实世界中,用户的前后行为都存在强烈的关联性与因果性,将用户过去的这一系列交互行为视作用户行为序列 u={$i_1$,$i_2$,……,$i_n$}并通过构建模型对其建模,来预测下一时刻用户最感兴趣的内容$i_{n+1}$,这就是序列化推荐(Sequential Recommendation)的核心思想。目前序列化推荐的常用模型包括RNN、CNN、GNN以及Transformer。
|
||||
|
||||
|
||||
|
||||
> 传统的推荐系统,例如基于内容和协同过滤的推荐系统,以一种静态的方式建模用户和商品的交互并且只可以捕获用户广义的喜好。
|
||||
<br/><br/>
|
||||
而SRSs则是将用户和商品的交互建模为一个动态的序列并且利用序列的依赖性来活捉当前和最近用户的喜好。
|
||||
|
||||

|
||||
|
||||
@@ -1,17 +0,0 @@
|
||||
# 推荐系统
|
||||
|
||||
许多人把推荐系统视为一种神秘的存在,推荐系统似乎知道我们的想法是什么。
|
||||
|
||||
如下图是阿里巴巴著名的“千人千面”推荐系统
|
||||
|
||||

|
||||
|
||||
还有短视频应用用户数量的急剧增长,这背后,视频推荐引擎发挥着不可替代的作用
|
||||
|
||||
个性化资讯应用更是以摧枯拉朽之势击败了传统的门户网站和新闻类应用
|
||||
|
||||
可以说,推荐系统几乎成了驱动互联网所有应用领域的核心技术系统,成为当今助推互联网增长的强劲引擎。
|
||||
|
||||
> 对于信息消费者,需要从大量信息中找到自己感兴趣的信息,而在信息过载时代,用户难以从大量信息中获取自己感兴趣、或者对自己有价值的信息。<br/>对于信息生产者,需要让自己生产的信息脱颖而出,受到广大用户的关注。从物品的角度出发,推荐系统可以更好的发掘物品的长尾。
|
||||
|
||||
请大家自行了解什么是长尾效应。
|
||||
@@ -1,44 +0,0 @@
|
||||
# 知识图谱
|
||||
|
||||
## 谷歌的新概念
|
||||
|
||||
2012 年,谷歌工程师阿米特·辛格尔(Amit Singhal)在自己的 official blog 发表了一篇名叫《Introduce the Knowledge Graph》的文章,初次提出了知识图谱的概念,并将知识图谱运用于 Google 搜索中,文中介绍到,结合了知识图谱的 Google 搜索有了更强的能力:
|
||||
|
||||
- Find the right thing :如果碰到要找的事物有同名时,你可以在相关推荐中看到
|
||||
- Get the best Summary:你能得到相关领域的一个很好概述
|
||||
- Go deeper and broader:除了你要找的知识外,你可能可以意外获得新领域的事物
|
||||
|
||||
原文:
|
||||
|
||||
- https://www.blog.google/products/search/introducing-knowledge-graph-things-not/
|
||||
|
||||
## 发展脉络
|
||||
|
||||
不过知识图谱并非是一种新的技术和研究方向,更准确来说是一个新壶装老酒的概念包装,它的核心已有非常悠久的发展历史,甚至最早可以追溯到二十世纪五六年代,人工智能刚作为一个学科成立的时候,其中三大学派之一——符号主义。
|
||||
|
||||
具体其发展历程参考:
|
||||
|
||||
- [https://mp.weixin.qq.com/s/Mcikp99bsVgxAaykctmcAw](https://mp.weixin.qq.com/s/Mcikp99bsVgxAaykctmcAw) 知识图谱的前世今生
|
||||
|
||||
在大致了解知识图谱的历史发展脉络后,我们或许对它有了一个初步的认知——一个由抽象符号构成的知识库,目的是为了让计算机理解人类的语义信息,打个不太恰当的比方,就是个计算机理解人类世界的大脑。
|
||||
|
||||
从中我们可以也窥探到当年符号主义学派学者们的野心,不过很显然,这条道路发展并不顺利,如今知识图谱还无法完全担任“大脑”这种重要的角色,绝大多时候,都是作为一个辅助位的角色,不过这个方向的潜力无疑是巨大的,并且它所能勾连的方向是非常宽广繁多的(不仅仅局限于 NLP 里),这导致了其复杂程度很高,但也衬托出其上限也可以很高。
|
||||
|
||||
不过这些都是题外话,继续深入,我们可能会从这个认知上延申出两个问题,一是如何存储这个知识库,而是形成这个知识库后又如何让计算机理解,毕竟计算机只懂 01。这两个问题也是知识图谱的发展方向。
|
||||
|
||||
## 构建
|
||||
|
||||
在了解了抽象的概念后,我们将视角移到具体实现上,如何来存储这个知识库?于是,现在就需要寻找一种较为简单方便的,并且能够表达语义关系的数据结构,然后图(Graph)就被拉来了。了解过图的都知道,图由节点和边构成。所以如果当我们将节点看作实体,即一个个具体的事物或概念(例如小明,小红,人),再由边代表实体之间的关系(朋友关系,种族),虽然可能存在一定程度上语义表达的不完备性,但面对生活中的大多数事物,这种简单的三元组(RDF)关系都可以进行表示,不够就多来几组。
|
||||
|
||||
于是这种由 head(头实体),relation(关系),tail(尾实体)所构成的有向图的数据结构,就变成了如今知识图谱的大致构成方式。不过它的整个构建流程是有一套更加详细且具体的流程的,从知识抽取到实体消歧到知识推理。
|
||||
|
||||
更具体的可参考:
|
||||
|
||||
- [https://www.woshipm.com/pmd/5328539.html](https://www.woshipm.com/pmd/5328539.html) 产品视角下的知识图谱构建
|
||||
|
||||
## 让计算机理解
|
||||
|
||||
在成功搭建起知识图谱这个数据库后,接下来就是最重要的一步了,让计算机理解——表示学习。目前这个方向,最重要的就是向量化,将节点和关系全部向量化,一方面有向量的平移不变性的好处,另一方面也方便计算,在从中穿插点图论的相关知识,例如将知识图谱看成特大号异构图进行处理。不过这方面方向太多,难以一一列举。
|
||||
|
||||
- [https://www.cnblogs.com/fengwenying/default.html?page=5](https://www.cnblogs.com/fengwenying/default.html?page=5) 胡萝不青菜的博客
|
||||
- [up主 骰子 AI](https://space.bilibili.com/497998686?spm_id_from=333.337.0.0) up 主 骰子 AI,知识图谱在推荐系统上的利用
|
||||
@@ -1,7 +0,0 @@
|
||||
# 自然语言处理(NLP)
|
||||
|
||||
Natural Language Processing(NLP)
|
||||
|
||||
当你看到这篇文章时,这一个领域已经被 GPT 等大语言模型干爆了。
|
||||
|
||||
[https://github.com/HarderThenHarder/transformers_tasks](https://github.com/HarderThenHarder/transformers_tasks)
|
||||
@@ -1,73 +0,0 @@
|
||||
# VIT
|
||||
|
||||
## 前言
|
||||
|
||||
VIT前Transformer模型被大量应用在NLP自然语言处理当中,而在CV领域,Transformer的注意力机制attention也被广泛应用,比如Se模块,CBAM模块等等注意力模块,这些注意力模块能够帮助提升网络性能。
|
||||
|
||||
而<strong>VIT的工作展示了不需要依赖CNN的结构,也可以在图像分类任务上达到很好的效果</strong>。
|
||||
|
||||
同时VIT也影响了近2年的CV领域,改变了自2012年AlexNet提出以来卷积神经网络在CV领域的绝对统治地位。
|
||||
|
||||
|
||||
在本节内容中我们会带你了解这一框架。
|
||||
|
||||
## 论文
|
||||
|
||||
[知乎](https://zhuanlan.zhihu.com/p/356155277)
|
||||
[论文](https://arxiv.org/abs/2010.11929)
|
||||
|
||||
## 模型详解
|
||||
|
||||

|
||||
|
||||
### 模型主题结构
|
||||
|
||||
结构上,VIT 采取的是原始 Transformer 模型,方便开箱即用,即在 encoder-decoder 结构上与 NLP 的 Transform 模型并无差别。
|
||||
|
||||
主要做出的贡献在于<strong>数据处理和分类头</strong>
|
||||
|
||||
### Patch embedding
|
||||
|
||||
#### 从 Word embedding 到 Patch embedding
|
||||
|
||||
##### Word embedding
|
||||
|
||||
简单来说就是用特殊的向量来表示一个句子中的某个词
|
||||
|
||||
即例如
|
||||
|
||||
> 今天天气不错,我要去看电影
|
||||
|
||||
其中<strong>我</strong>则编码为[0.5,0.6,0.6]
|
||||
|
||||
而具体来说 Word embedding 分为以下两步
|
||||
|
||||
1. 对 context 进行分词操作。
|
||||
2. 对分好的词进行 one-hot 编码,根据学习相应的权重对 one-hot 编码进行 N(embedded_dim)维空间的映射.
|
||||
|
||||
##### Patch embedding
|
||||
|
||||
简单来说 用一个特殊的向量来表示一张图片中某块图
|
||||
|
||||
例如
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
其中该张图片的编码为[0.5,0.6,0.3,....]
|
||||
|
||||
具体来说
|
||||
|
||||
1. 先对图片作分块
|
||||
1. 假设原始输入的图片数据是 H * W * C,
|
||||
2. 假设每个块的长宽为(P, P),那么分块的数目为 N=H ∗ W / (P ∗ P)
|
||||
3. 其中 vit 的分块是定下每一块的大小然后块的数量为计算结果
|
||||
2. 然后对每个图片块展平成一维向量
|
||||
1. 每个向量大小为 P * P * C
|
||||
3. 接着对每个向量都做一个线性变换(即全连接层),得到 patch embedding
|
||||
|
||||
|
||||
## 视频
|
||||
|
||||
<Bilibili bvid='BV15P4y137jb'/>
|
||||
@@ -1,81 +0,0 @@
|
||||
# BERT
|
||||
|
||||
如果你想深入了解自然语言处理相关知识,本文只能让你在基础上了解 BERT 的架构和理念,细节就不能保证了。
|
||||
|
||||
但如果你看 BERT 的目的是了解 BERT 的创新点以了解把 BERT 拓展到 cv 领域的工作(如 MAE),本文可以让你快速理解 BERT 的理念。
|
||||
|
||||
# 前言
|
||||
|
||||
BERT 是一种基于 transformer 架构的自然语言处理模型,它把在 cv 领域广为应用的<strong>预训练(pre-trainning)</strong>和<strong>微调(fine-tune)</strong>的结构成功引入了 NLP 领域。
|
||||
|
||||
简单来说,BERT 就是一种<strong>认识几乎所有词的</strong>,<strong>训练好</strong>的网络,当你要做一些下游任务时,可以在 BERT 预训练模型的基础上进行一些微调,以进行你的任务。也就是 backbone 模型,输出的是文本特征。
|
||||
|
||||
举个例子,我要做一个文本情感分析任务,也就是把文本对情感进行分类,那我只需要在 BERT 的基础上加一个 mlp 作为分类头,在我的小规模数据上进行继续训练即可(也就是微调)。
|
||||
|
||||
mlp 的重点和创新并非它的模型结构,而是它的训练方式,前面没看懂的话可以先看看训练方式。
|
||||
|
||||
# 模型简单讲解
|
||||
|
||||
## 输入与输出
|
||||
|
||||
因为 BERT 是一个“backbone”模型,所以它的任务是从文本中抽取特征(feature,embedding...叫法很多,其实就是个向量)因此,它的输入是文本,输出是向量。
|
||||
|
||||
### 文本输入前的处理
|
||||
|
||||
在文本被输入模型之前,我们要对它进行一些处理:
|
||||
|
||||
1. <strong>词向量</strong>(wordpiece embedding):单词本身的向量表示。每个词(或者进行时过去时后缀之类的)会被记录为一个向量。它们被储存在一个字典里,这一步其实就是在字典中查找这个词对应的向量。
|
||||
2. <strong>位置向量</strong>(position embedding):将单词的位置信息编码成特征向量。构建 position embedding 有两种方法:BERT 是初始化一个 position embedding,<strong>然后通过训练将其学出来</strong>;而 Transformer 是通过<strong>制定规则</strong>来构建一个 position embedding。
|
||||
3. <strong>句子向量</strong>(segment embedding):用于区分两个句子的向量表示。这个在问答等非对称句子中是用于区别的。(这个主要是因为可能会用到对句子的分析中)
|
||||
|
||||
BERT 模型的输入就是上面三者的和,如图所示:
|
||||
|
||||

|
||||
|
||||
## 模型结构
|
||||
|
||||
简单来说,BERT 是 transformer<strong>编码器</strong>的叠加,<strong>也就是下图左边部分</strong>。这算一个 block。
|
||||
|
||||

|
||||
|
||||
说白了就是一个 多头自注意力=>layer-norm=> 接 feed forward(其实就是 mlp)=>layer-norm,没有什么创新点在这里。因为是一个 backbone 模型,它没有具体的分类头之类的东西。输出就是最后一层 block 的输出。
|
||||
|
||||
# 训练方式
|
||||
|
||||
BERT 训练方式跟 cv 里的很多 backbone 模型一样,是先用几个具体任务训练模型,最后把分类头之类的去掉即可。
|
||||
|
||||
它用了以下两种具体任务进行训练:
|
||||
|
||||
## 随机掩码(完形填空 MLM)
|
||||
|
||||
跟以往的 nlp 模型不同,BERT 的掩码并非 transformer 那样,给前面不给后面,而是在句子中随机把单词替换为 mask,让模型去猜,也就是完形填空。下面给个例子:
|
||||
|
||||
<strong>划掉的单词是被 mask 的</strong>
|
||||
|
||||
正常的掩码:I am a <del>little cat</del>
|
||||
|
||||
BERT 的随机掩码:I <del>am</del> a little <del>cat</del>
|
||||
|
||||
#### 一些技术细节:
|
||||
|
||||
mask 方法是先抽取 15% 的单词,这些单词中 10% 不做变化,10% 替换为随机单词(让模型适应错别字用的),剩下 80% 替换为 mask。
|
||||
|
||||
## 前后句判别(NSP)
|
||||
|
||||
这个很简单,从一篇文章中抽出两句,让模型判断它们是否是相邻的两个句子。
|
||||
|
||||
## 意义
|
||||
|
||||
BERT 的训练方式完全是无监督或者说自监督的。无论是 MLM 还是 NSP 都不需要进行人工标注,只要它是一个通顺的句子,就可以拿来进行训练,这大大降低了训练成本并且加大了数据使用量,这也是 BERT 最大的贡献点所在。
|
||||
|
||||
### 局限
|
||||
|
||||
BERT 因为是以完型填空训练的,因此不能用于文本生成任务,但是在分类等任务上效果显著并且广为适用。
|
||||
|
||||
# 相关资料:
|
||||
|
||||
李沐的【BERT 论文逐段精读【论文精读】】https://www.bilibili.com/video/BV1PL411M7eQ
|
||||
|
||||
<Bilibili bvid='BV1PL411M7eQ'/>
|
||||
|
||||
原论文:[https://arxiv.org/pdf/1810.04805v2](https://arxiv.org/pdf/1810.04805v2)
|
||||
@@ -1,51 +0,0 @@
|
||||
# MAE
|
||||
|
||||
看本文前,请确保你已了解 BERT 的相关知识
|
||||
|
||||
# 前言
|
||||
|
||||
MAE 是一个把 BERT 的随机掩码结构拓展应用到 cv 领域的模型
|
||||
|
||||
目的是通过自监督训练一个通用的 cv 的 backbone 模型
|
||||
|
||||
## MAE 想解决的问题
|
||||
|
||||
cv 领域,其实预训练模型早已推广,一般是在 imagenet 上进行预训练,但是 imagenet 的图片是有局限性的,比如物体一般是在图片中间等等。并且指标也越来越难刷上去。于是作者想通过像 BERT 一样进行无监督学习来引入更多数据并降低训练成本。
|
||||
|
||||
那么问题来了,既然我们要学习 BERT 的随机掩码,那么我们应该对什么做 mask 呢?
|
||||
|
||||
因为图片不像文本,有单词这一基础单位。图片的基础单位像素在被单独拿出来的时候包含的语义信息是完全不如单词的。因为像素的语义信息与<strong>上下左右的连续关系</strong>很密切。于是作者采用了像 VIT 那样把图片分成好几个 patch,对 patch 做随机掩码。
|
||||
|
||||
# 模型结构与训练方式
|
||||
|
||||
看了上面的解释,相信你也有些思路了,其实这个模型很简单,只要拿随便一个抽取特征用的 backbone 模型,比如 VIT,CNN 之类的做编码器,再接一个生成图像的解码器就 ok 啦。下面讲一下作者用的模型结构:
|
||||
|
||||
## 具体模型结构
|
||||
|
||||
为了方便比较起见,作者用了 VIT-large 做编码器,多层堆叠的 transformer 做解码器,其他貌似也没什么特殊的了。
|
||||
|
||||
## 模型输入
|
||||
|
||||
在这里,作者为了加大任务的难度,扩大了被 mask 掉的比例,避免模型只学到双线性插值去修补缺的图像。作者把 75% 的 patch 进行 mask,然后放入模型训练。从下图可以看出,被 mask 的块是不进行编码的,这样也可以降低计算量,减少成本。
|
||||
|
||||

|
||||
|
||||
在被保留的块通过编码器后,我们再在原先位置插入只包含位置信息的 mask 块,一起放入解码器。
|
||||
|
||||
## 训练方式
|
||||
|
||||
在通过 VIT 编码抽取特征和多层 transformer 生成图片后,我们对生成的图片做简单的 MSE 损失(就是平方损失),在训练完成后,去掉多层 transformer,留下训练好的 VIT 做 backbone,进行微调就可以处理下游任务了。这个在 BERT 里讲了,这里不再赘述。
|
||||
|
||||
下面是原论文给的训练结果,可以看到效果是很惊人的。(有些图我脑补都补不出来)
|
||||
|
||||

|
||||
|
||||
# 相关资料
|
||||
|
||||
更具体的比如模型性能对比最好还是去看原论文或者李沐老师的讲解
|
||||
|
||||
李沐【MAE 论文逐段精读【论文精读】】 https://www.bilibili.com/video/BV1sq4y1q77t
|
||||
|
||||
<Bilibili bvid='BV1sq4y1q77t'/>
|
||||
|
||||
原论文:[https://arxiv.org/pdf/2111.06377v2.pdf](https://arxiv.org/pdf/2111.06377v2.pdf)
|
||||
@@ -1,61 +0,0 @@
|
||||
# Transformer
|
||||
|
||||
# 简介
|
||||
|
||||
看到这个,不知道你是否会感到奇怪,为什么要单独把一个奇怪的英文单词提出来单独放到一章内容里面来?或者说这个词可以翻译成变形金刚,变形金刚和深度学习有什么联系吗?
|
||||
|
||||
这一切要从 2017 年一篇命名都很清奇的文章说起:[Attention Is All You Need](https://arxiv.org/abs/1706.03762?context=cs)
|
||||
|
||||
他本来是用于机器翻译的文章,属于 NLP 领域,但是他所提出的框架 transformer 一时声名鹊起,首先是在 NLP 领域,Bert 及其无数改进席卷了整个领域,大规模的预训练模型广泛地被应用于各个任务内。
|
||||
|
||||
随后在 CV 领域中,VIT 的横空出世标志着 transformer 几乎一统了深度学习的多数领域,直到现在,一篇文章十有八九会用但 transformer 的相关内容。
|
||||
|
||||
并且,不少人也尝试去验证他的可解释性,目前为止给我印象最深的就是新加坡的一位教授发的文章,他把其中一个重要模块换成了 POOLING 层,依然有还不错的效果。
|
||||
|
||||
在本章节中我会尝试带你走进这个神奇的算法框架,但是在这之前,有几点是需要声明的:
|
||||
|
||||
1. 鉴于我们视野的局限性,我无法很好的阐述清楚 NLP 领域的知识,但是有些内容是必要的,因此我会留下一下重要的教程供你参考。如果有机会我会进行补充
|
||||
2. 并不是你接触 NLP 或者了解一些任务,你就必须得把 RNN,LSTM 这些经典网络弄得烂熟于心,完全没必要,你可以让你对他们保持一个大体上的理解,希望这可以帮助你节约更多的时间。
|
||||
3. 该算法耗费的算力资源非常大,有时候想跑起来一个模型可能需要更大的显存
|
||||
|
||||
# 必要知识
|
||||
|
||||
## Sequence to Sequence
|
||||
|
||||
序列到序列学习,一个有趣的概念
|
||||
|
||||
[A ten-minute introduction to sequence-to-sequence learning in Keras](https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html)
|
||||
|
||||
你可以实操一下,它是调包 LSTM 的。你也可以借此了解一下他的概念,不用太精通。
|
||||
|
||||
## 注意力机制
|
||||
|
||||
大家不需要觉得它非常神秘,因为他其实本身就是矩阵运算的一种操作罢了,取了个好听的名字,我在很早的目标检测文章上看到过类似的机制,不过那时候没有这个名字罢了。
|
||||
|
||||
他很重要的一点在于处理序列数据上的优越性,在这里附上一个视频帮助大家学习
|
||||
|
||||
但是在 transformer 内,他使用的是名为 self attention 的东西,这点需要你额外进行学习
|
||||
|
||||
论文的优秀讲解
|
||||
|
||||
[Transformer 中 Self-Attention 以及 Multi-Head Attention 详解_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV15v411W78M)
|
||||
|
||||
<Bilibili bvid='BV15v411W78M'/>
|
||||
|
||||
除此之外就是相关代码,不要求你可以完全自己复现,但是要保证非常重要的知识都懂
|
||||
|
||||
再贴上一个难度稍高的教程
|
||||
|
||||
[Vision Transformer 超详细解读 (原理分析 + 代码解读) (一)](https://zhuanlan.zhihu.com/p/340149804)
|
||||
|
||||
# 思考题
|
||||
|
||||
我在这里留下一些思考题希望对你有启发
|
||||
|
||||
在 Multi-head Self-attention 中所谓 Q,K,V 到底指代的是什么?他们怎么产生的?
|
||||
|
||||
位置编码有没有更好的形式产生?
|
||||
|
||||
为什么用的是 LN 层?为什么不用 BN 层?
|
||||
|
||||
你能不能阅读一下 transformer 的代码并且能明确说出哪些维度变换所对应的操作呢?
|
||||
@@ -1,30 +0,0 @@
|
||||
# 总结
|
||||
|
||||
对比学习综述讲到这里也就基本结束了
|
||||
|
||||
来回顾一下对比学习的发展历程和一些要点吧!
|
||||
|
||||
# 发展历程
|
||||
|
||||
| 论文名称 | 贡献 | 网络类型 | 用的代理任务 | 延续了哪篇工作 |
|
||||
| -------------------------------------------------- | ------------------------------------------------------------------------------------------ | ---------------------------- | ------------------------------------- | -------------- |
|
||||
| Inst Disc | 奠基作,引入 Memory Bank 大字典的概念,提出个体判别任务。 | 判别式网络 | 个体判别任务 | 无 |
|
||||
| 定义正负样本的方式(因为不止一篇论文就不放名字了) | 引入生成式网络的概念,提出多视角作为不同正样本 | 前者是生成,后者是判别 | 时序预测任务<br/>多视角判别任务 | 无 |
|
||||
| MoCo | 使用队列储存字典,提出动量编码器,提出 infoNCEloss | 判别式网络 | 个体判别任务 | Inst Disc |
|
||||
| SimCLR | 提出 projection head,提出把一张图片做不同的数据增强进行对比,并且分析了各种数据增强的贡献 | 判别式网络 | 个体判别任务 | Inst Disc |
|
||||
| SwAV | 使用聚类中心矩阵,提出新的聚类任务 | 聚类式网络(或许也算判别式) | 聚类 | SimCLR |
|
||||
| BYOL | 提出无负样本学习,提出预测头 predictor | 判别式网络 | 或许算预测?<br/>但也有个体判别的感觉 | SimCLR |
|
||||
| SimSiam | 在 BYOL 基础上做了改进,总结了前面的工作,提出了对称式的孪生网络 | 判别式网络 | 同上 | BYOL |
|
||||
| MoCo v3 | 缝合了 MoCo 和 SimSiam,引入了 VIT,提出小 trick 解决训练不稳定 | 判别式网络 | 同上 | MoCo |
|
||||
|
||||
# 要点提问
|
||||
|
||||
1.什么是 memory bank?
|
||||
|
||||
2.个体判别任务的局限
|
||||
|
||||
3.什么是 NCEloss,infoNCEloss 呢?
|
||||
|
||||
4.能画出每个网络的结构图吗?
|
||||
|
||||
5.能列出提到过的所有小 trick 吗?
|
||||
@@ -1,41 +0,0 @@
|
||||
# 前言
|
||||
|
||||
> 作者:可可
|
||||
|
||||
对比学习是近来比较热门的一个方向,它属于无监督学习的一种,在阅读本文前,请确保已经掌握 cv 和 nlp 的基础知识并且了解 transformer。本文致力于把论文本身讲的故事通俗的概括出来,以便大家理解发展路程。
|
||||
|
||||
|
||||
打个比方,一个梨很甜,用数学的语言可以表述为糖分含量90%,但只有亲自咬一口,你才能真正感觉到这个梨有多甜,也才能真正理解数学上的90%的糖分究竟是怎么样的。
|
||||
|
||||
如果对比学习是个梨,本文的目的就是带领大家咬一口。
|
||||
|
||||
|
||||
这类方法训练需要消耗巨大的算力(微调改进那种另说),我也没有能力去训练这类模型(好贵!
|
||||
|
||||
# 何为对比
|
||||
|
||||
对比学习,故名思意,是对比着来学习。而我们拿来对比的东西就是在模型眼里的语义,也就是我们叫做特征的向量。
|
||||
|
||||
在具体讲对比之前,我们先看看传统的<strong>监督学习</strong>是怎么学特征的:
|
||||
|
||||
数据 + 模型=> 特征,特征对人工标注进行学习,也就是说我们要把模型抽取的特征尽可能的靠近人工标注
|
||||
|
||||
而在无监督学习中,我们不希望有人工标注的出现,那么一种方法就是让同类的特征进可能相近,也就是我们说的聚类。
|
||||
|
||||
直观来讲,我们把特征的向量进行一下归一化,它们就分布在一个超球面上。简单起见,我们先看 3 维向量
|
||||
|
||||

|
||||
|
||||
我们通过<strong>正样本</strong>(跟拿到的特征<strong>应当相近</strong>的另一个特征)与<strong>负样本</strong>(反之)的对比,使得
|
||||
|
||||
越相近的物体,它们的特征就在超球面上越靠近,越不像的物体离的越远,去学习图片更本质的特征
|
||||
|
||||
那么具体的对比学习方法我在后面结合一些论文一起讲吧~
|
||||
|
||||
这部分内容更像一个综述,讲述对比学习这几年的发展路程,所以我会尽可能的描述作者在论文里讲的<strong>故事</strong>,来方便大家弄清为什么要这么做。
|
||||
|
||||
<strong>可能会有很多我的主观理解在此</strong>,并且<strong>不会</strong>深入细节。可以算是一个总结和分享,我会在这里带着读者过一遍近期对比学习的工作来给大家一个对比学习方向的直观感性理解。
|
||||
|
||||
同时因为笔者水平,视野,精力有限,不可能包含所有的算法,也不可能保证完全正确。因此仅作为笔记分享使用。若有错误,请多多指正。
|
||||
|
||||
> 若对文章内容有任何疑惑或者批评指正,可以联系我
|
||||
@@ -1,63 +0,0 @@
|
||||
# Inst Disc
|
||||
|
||||
这篇论文是对比学习的一篇开山之作,后续很多论文都参考了它的方法,这里不止讲了论文本身,还有一些扩展补充
|
||||
|
||||
## 提出的背景
|
||||
|
||||
作者团队发现,当把一张豹子的图片喂给以前的有监督训练的模型。得分最高的都是跟豹子很像的动物,比如雪豹,猎豹,而分数最低的几个都是跟豹子一点都不像的东西比如救生艇,书架。
|
||||
|
||||
作者团队认为,让这些猎豹,雪豹的标签相互接近(指互相在判别时都排名靠前)的原因并不是它们有相似的标签,而是它们有相似的图像特征。
|
||||
|
||||

|
||||
|
||||
## 个体判别任务
|
||||
|
||||
既然有了上面这个发现,那么作者想我能不能把分类任务推到极致呢?
|
||||
|
||||
于是他们<strong>把每一个图片当作一个类别</strong>,去跟其他的图片做对比,具体模型如下
|
||||
|
||||

|
||||
|
||||
先介绍一下模型结构:
|
||||
|
||||
1.CNN 用的是经典的 RES50,没什么特殊。
|
||||
|
||||
2.后面接了一个 Non-param Softmax(非参数 softmax),其实就是一个不被训练的,把所有特征投射到超球面上的一个分类头(把所有特征模长变为 1)。
|
||||
|
||||
3.后面的<strong>Memory Bank</strong>是这篇文章的<strong>重点</strong>,它是一个<strong>动态字典</strong>。我们把每一个图片抽取出来的特征存入 memory bank,每次计算时抽取其中部分作为一个 batch 进行对比学习,把更新后的模型得到的特征替换 memory bank 里原先的特征。
|
||||
|
||||
4.具体损失函数用的是一个叫 NCEloss 的损失,它把多分类问题分为<strong>若干个二分类问题</strong>,<strong>是</strong>与<strong>不是</strong>,每个 batch 中只有一个的 ground truth 是’yes‘,其余都是’no‘
|
||||
|
||||
在训练的时候,相当于是有一组以前的编码器抽取的特征 A,B,C,D...,一组当前编码器抽取的特征 a,b,c,d...,对它们进行对比学习。对 a 来说,A 是正样本,其他都是负样本,同理类推。
|
||||
|
||||
## 一些小 trick 和小细节
|
||||
|
||||
上面这些就是这篇文章的主体,后面是一些对后续工作有贡献的小 trick 和细节:
|
||||
|
||||
### 动量更新
|
||||
|
||||
用动量更新的方法去更新 memory bank 中的特征
|
||||
|
||||
也就是让特征的变化<strong>不那么剧烈</strong>
|
||||
|
||||
原因:如果一直保持更新,<strong>特征总体的变化就会比较大</strong>,而我们在大数据集上训练的时候,等第二次调用一个特征时,它跟现在的特征分布已经大相径庭,那就不好训练了,也就是<strong>特征缺乏一致性</strong>。因此我们引入动量更新来确保特征进行平稳的改变,而非突变。
|
||||
|
||||
#### 关于动量的小拓展
|
||||
|
||||
大家在使用诸如 SGD,Adam 等优化器的时候一定见过动量这个概念了,这里给不了解这个概念的读者简单讲解一下动量这个概念:
|
||||
|
||||
A 是起始点,B 是第一次更新后的点,C 是第二次更新后的点
|
||||
|
||||

|
||||
|
||||
而在我们刚刚提到的动量更新里,它的公式可以概括为:
|
||||
|
||||

|
||||
|
||||
m 表示动量,k 是新的特征,q 是上一个特征,只要设置小的动量就可以使改变放缓。
|
||||
|
||||
# 总结
|
||||
|
||||
总体来说,Inst Disc 把对比学习成功引入了 CV 领域,核心思想是构建动态字典进行对比学习
|
||||
|
||||
<strong>PS:若无特殊说明,最后保留下来去做下游任务的模型只有编码器,其他都删除了。</strong>
|
||||
@@ -1,27 +0,0 @@
|
||||
# 定义正负样本的方式
|
||||
|
||||
因为涉及多篇论文,就不具体一个个讲了,在这里总结一下一些定义正负样本的方式,这两种方式虽然本身并不突出,但是都对后续一些重要工作有一些铺垫作用。
|
||||
|
||||
# 1.时序性定义(生成式模型)
|
||||
|
||||

|
||||
|
||||
这是处理音频的一个例子,<strong>给模型 t 时刻以前的信息,让它抽取特征并对后文进行预测,真正的后文作为正样本,负样本当然是随便选取就好啦。</strong>
|
||||
|
||||
不同于之前说的个体判别,这个是<strong>生成式模型</strong>,这个模型不止可以处理音频,还可以处理图片(每一个块换成一个词)或者处理图片(以 patch 为单位)。
|
||||
|
||||
是不是有点眼熟?这跟我前面写的 BERT 和 MAE 其实异曲同工,不过这两位是随机 mask,而非时序性的 mask。
|
||||
|
||||
# 2.以物体不同角度或者感官作为正样本
|
||||
|
||||
一只狗可以被我们用不同感官所感受到,比如看见狗,听见狗叫声,摸到狗,得到文字描述等等。如果我们能统一这些模态的信息,这未尝不是一种特征提取。
|
||||
|
||||
这里就用了几个不同感官下的数据进行训练,不过可能是找配对的音频比较困难,作者用的是
|
||||
|
||||
原始图片,深度图,swav ace normal,分割图片这四个视角作为正样本,其他不相关图片作为负样本。
|
||||
|
||||
这种多视角的特征提取也引出了后面 CLIP 这篇论文,它做到了文本和图像特征的统一,我们后续再讲
|
||||
|
||||
(这篇论文我准备开个新坑放着了,因为说实话不算对比学习,算多模态)
|
||||
|
||||

|
||||
@@ -1,75 +0,0 @@
|
||||
# MoCo
|
||||
|
||||
# 提出背景
|
||||
|
||||
MoCo 是 Inst Disc 的改进工作,那我们自然要先看一下 Inst Disc 有什么不足
|
||||
|
||||
## 1.Memory Bank 过大,不能应用在更大的数据集上
|
||||
|
||||
因为其字典的数据类型,导致计算开销会加大
|
||||
|
||||
## 2.动量更新并不能完全解决特征一致性差的问题
|
||||
|
||||
即使使用了动量更新的方式,同一个特征前后被调用的跨度也还是很长,一致性依旧不够
|
||||
|
||||
## 3.NCEloss 负样本分类不合理的问题
|
||||
|
||||
NCE 把<strong>所有负样本都视作一样的</strong>,但实际上负样本<strong>并不能被完全归为一类</strong>
|
||||
|
||||
举个例子:我现在的正样本是<strong>猫猫</strong>,然后有两个负样本是<strong>狗勾</strong>和<strong>汽车</strong>,那<strong>猫猫</strong>肯定跟<strong>狗勾</strong>更相近,跟<strong>汽车</strong>更不相似,也就是说<strong>狗</strong>的得分虽然低于<strong>猫</strong>,但是一定要高于<strong>汽车</strong>,<strong>而不是像 NCE 那样把狗和车打成一类</strong>,这样不利于模型学习。
|
||||
|
||||
并且它也不是很灵活,下文细讲
|
||||
|
||||
### 虽然大家应该都懂了(应该吧?),但还是贴一下模型总览图。
|
||||
|
||||
右边就是 memory bank 啦
|
||||
|
||||

|
||||
|
||||
# MoCo 做出的改进
|
||||
|
||||
## 1.针对 Memory Bank 过大
|
||||
|
||||
作者使用队列的数据结构去储存这个大字典,因为是先进先出,所以好处是新进来的特征可以把最老的特征替换掉。每次不用把整个字典全部载入,而是用队列形式即可。很简单地解决了这个问题。
|
||||
|
||||
## 2.针对动量更新不能完全解决特征一致性差的问题
|
||||
|
||||
作者提出了一个新的<strong>动量编码器</strong>来替代动量更新。
|
||||
|
||||
动量编码器是独立于原编码器的一个编码器,它的参数是根据原编码器动量更新的,k 和 q 就是指代全部参数了
|
||||
|
||||

|
||||
|
||||
这样的话就是解码器在缓慢更新,比对特征使用动量更新要更有连续性。
|
||||
|
||||
## 3.负样本分类不合理的问题通过替换 infoNCEloss 解决
|
||||
|
||||
下面是 infoNCE loss 的公式,它是 NCE 和交叉熵损失的结合体,长得就很像交叉熵,只是多了个 T。
|
||||
|
||||
[(什么?你看到这了还不会交叉熵?戳这里)](https://zhuanlan.zhihu.com/p/149186719)
|
||||
|
||||

|
||||
|
||||
q·k 其实就是各个特征(因为那时候用的都是 transformer 了,这里就是 trnasformer 里的 k 和 q)
|
||||
|
||||
这里分母级数上的<strong>k 是代表负样本的个数,也就是 k=batchsize-1(总样本-正样本)</strong>。其实就是<strong>对一个 batch 做 k+1 分类</strong>,并且引入了一个<strong>超参数 T</strong>。它的名字叫做<strong>温度参数</strong>,控制的是 softmax 后得分分布的平滑程度(直观理解,不是很严谨)
|
||||
|
||||
T 越大,损失函数就越对所有负样本<strong>一视同仁</strong>,退化为二分类的 NCEloss;T 越小,损失函数就<strong>越关注一些难分类的特征</strong>,但有时候会出现两张其实都是猫猫的图片,你硬要让模型说猫猫跟猫猫不一样,这也不太好,这个参数要根据数据集情况适中调整。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
上面那张是 T 较大的情况,下面是 T 较小的情况(x 轴是各个类别,y 轴是分类得分)
|
||||
|
||||
所谓的灵活性就是指:infoNCE loss 引入了温度参数,这个参数可以帮我们调整训练的难度,T 越大,模型越关注类似的特征,训练也就越难,总之就是非常灵活。
|
||||
|
||||
# 总结
|
||||
|
||||
总而言之,MoCo 就是基于 Inst Disc 主要做了如上三点改进,模型和参数都是完全不变的。它的核心在于动量编码器和活动大字典。
|
||||
|
||||
能在 imagenet 上达到媲美甚至超越有监督学习的模型的结果,并且可以作为 backbone 很好的拓展应用到多个下游任务上。
|
||||
|
||||
# 另外
|
||||
|
||||
其实 MoCo 有两篇后续工作,MoCo v2 和 MoCo v3,v2 其实就是缝合了后面讲的 SimCLR 的方法,不展开了,V3 留到以后讲。
|
||||
@@ -1,29 +0,0 @@
|
||||
# SimCLR
|
||||
|
||||
顾名思义,以‘SIMPLE’为主,这个模型主打的就是简单。
|
||||
|
||||
# 模型结构
|
||||
|
||||
x 是输入的图片,它经过两种不同的数据增强得到 xi 和 xj 两个正样本,而同一个 mini-batch 里的所有其他样本都作为负样本。<del>说白了还是个体判别任务</del>
|
||||
|
||||

|
||||
|
||||
左右的<strong>f 都是编码器</strong>,并且是<strong>完全一致共享权重</strong>的,可以说是同一个。
|
||||
|
||||
而 g 是一层 mlp 结构,只在训练中使用,<strong>应用到下游任务时用的仅仅是 f</strong>(与前面几篇一样都是 RES50),很神奇的是,就仅仅多了这么一层 mlp,它在 imagenet 上的正确率直接加了十个点。
|
||||
|
||||
关于这点也很奇怪,作者做了很多实验但是也没有很合理的解释。
|
||||
|
||||
最后的对比学习是对 zi 和 zj 做的。
|
||||
|
||||
下面这个是更加具体的流程图
|
||||
|
||||

|
||||
|
||||
# 总结
|
||||
|
||||
因为这个真的很简单,没有太多可讲的,它就是单纯的简单且效果拔群,想具体了解数据增强相关或者具体效果对比的可以去看一下[原论文](https://arxiv.org/pdf/2002.05709v3)。
|
||||
|
||||
# 另外
|
||||
|
||||
SimCLR 也有 v2,缝合了 MoCo 的方法,同样不展开了。
|
||||
@@ -1,71 +0,0 @@
|
||||
# SwAV
|
||||
|
||||
# 前言
|
||||
|
||||
与前面的一些工作不同,SwAV<strong>不再进行个体判别任务</strong>,而是提出了新的任务————<strong>聚类</strong>
|
||||
|
||||
并在训练的模型结构上也做了相应改动,而非只调整训练方法。
|
||||
|
||||
这里因为涉及到了聚类,具体数学推导难度较大,有兴趣可以跟着我后面贴的视频走一遍
|
||||
|
||||
# 提出的背景
|
||||
|
||||
## 个体判别任务的局限性
|
||||
|
||||
1.进行个体判别任务时,我们有可能选到与正样本属于一个类的特征作为负样本,比如两张不同狗的图片等等,这会影响学习的效率。
|
||||
|
||||
2.个体判别任务把类别分的过细,不能很好地抽取特征,过多的类也增大了计算压力和字典储存压力。作者认为这过于原始和暴力。
|
||||
|
||||
# 模型结构
|
||||
|
||||
下图左边是常规的对比学习(比如 SimCLR)的结构,右图是 SWAV 的结构,不难看出多了一个叫 prototypes 的东西。这个东西其实是聚类中心向量所构成的矩阵。
|
||||
|
||||

|
||||
|
||||
下面的内容可能有些理解上的难度(反正我第一次听讲解的时候就云里雾里的),我会尽可能直白地描述这个过程。
|
||||
|
||||
## 聚类中心?
|
||||
|
||||
首先我们有个新的东西<strong>prototypes</strong>,它是<strong>聚类中心的集合</strong>,也就是许多作为聚类中心的向量构成的矩阵。
|
||||
|
||||
这些聚类中心是我设定在超球面上的,离散的一些点,我希望让不同的特征向它们靠拢以进行区分(也就是所谓聚类)。
|
||||
|
||||
更直白地讲,我在地上撒了一把面包屑,地上本来散乱的蚂蚁会向面包屑聚集,形成一个个<strong>小团体</strong>。蚂蚁就是<strong>不同图像的特征</strong>,面包屑就是<strong>我设定的聚类中心</strong>
|
||||
|
||||
## 聚类中心我知道了,然后呢?
|
||||
|
||||
先说我拿他干了什么,再一步步讲为什么要这么做吧。
|
||||
|
||||
首先我们手里有抽取出来的特征<strong>z1</strong>,<strong>z2</strong>,以及一个我随机初始化的<strong>聚类中心矩阵 c</strong>。我分别求这个<strong>矩阵</strong>和<strong>z1</strong>,<strong>z2</strong>的内积,并<strong>进行一些变换</strong>得到 Q1,Q2。当 z1,z2 都是正样本时,我希望<strong>Q1 与 z2 相近</strong>,<strong>Q2 与 z1 相近</strong>。如果有一个是负样本则尽可能远离。也就是拿 Q 当 ground-truth 做训练。最后这步前面已经讲过 NCEloss 等损失函数了,用它们就可以达成这个任务。
|
||||
|
||||
而我们的优化要采用 [K-means](https://zhuanlan.zhihu.com/p/78798251)(不懂可以看这里)的类似做法,先对聚类中心进行优化,再对特征进行优化。
|
||||
|
||||

|
||||
|
||||
so,why?相信你现在肯定是一脸懵,不过别急,希望我能为你讲懂。
|
||||
|
||||
## 首先是第一步,为什么要求内积?
|
||||
|
||||
如果你有好好了解线性代数的几何性质,应当了解<strong>两个向量的内积就是一个向量在另一个向量上的投影</strong>,而一个向量与一个矩阵的内积,<strong>就是把这个向量投影到这个矩阵代表的基空间中</strong>。
|
||||
|
||||
我做的第一步就是把<strong>抽出来的特征 z 用聚类中心的向量表示,这样更加方便对比聚类成功与否</strong>。
|
||||
|
||||
## 然后是第二步,我说的变换是什么呢?
|
||||
|
||||
我们现在求内积是为了把特征投影到聚类中心空间,为了避免模型训练坍塌(就是网络把特征全部聚到同一个点,<del>开摆~</del>)我要保证每个聚类中心被<strong>"使用"</strong>的次数,所以我们请出了<strong>Sinkhorn-Knopp 算法。</strong>这个算法比较硬核,我在这里不展开了,大家知道它是干啥的就行,具体的推导可以看我后面贴的视频,那里面有讲。
|
||||
|
||||
## 第三步应该不用怎么讲了吧?
|
||||
|
||||
就是普通的对比学习,也没啥特殊的了。正样本是自身通过数据增强和上面两步处理得到的特征,负样本则是同一 batch 中的其他特征。
|
||||
|
||||
# 数据增强的小 trick:multi-crop
|
||||
|
||||
其实就是一个工程经验,一般我们数据增强是取 2 个 224*224 的块,这里换成了面积基本不变的 2 大 2 小的 4 个块,事实证明效果不错。想了解这个的话可以看看原论文的实验
|
||||
|
||||
# 总结
|
||||
|
||||
主要贡献是上面我说的三步聚类算法以及后面的小 trick,<strong>Sinkhorn-Knopp 算法难度较高,大家有兴趣的话自行观看后面这个视频理解哈~</strong>
|
||||
|
||||
# 相关资料
|
||||
|
||||
【[论文简析]SwAV: Swapping Assignments between multiple Views[2006.09882]】
|
||||
@@ -1,71 +0,0 @@
|
||||
# BYOL
|
||||
|
||||
# 前言
|
||||
|
||||
这篇论文的主要特点是<strong>它的训练不需要负样本</strong>,并且能保证<strong>模型不坍塌</strong>。
|
||||
|
||||
当一个普通的对比学习模型没有负样本时,它的损失函数就<strong>只有正样本之间的差距</strong>,这样模型只会学到一个<strong>捷径解</strong>————你给我什么输入我都输出同一个值,这样 loss 就永远=0 了(<del>开摆</del>)
|
||||
|
||||
而<strong>BYOL</strong>就解决了这一问题,使得训练不再需要负样本。
|
||||
|
||||
# 模型结构
|
||||
|
||||
前半部分很普通,跟 SimCLR 是基本一致的,一个图片经过两种不同的数据增强,进入两个编码器,得到两个不同的特征。
|
||||
|
||||
值得一提的是,这里下面的这个粉色的编码器用的是<strong>动量编码器</strong>的更新方式。也就是说它是紫色那个编码器的动量编码器。
|
||||
|
||||
而提取特征之后,经过两个 `SimCLR` 中提出的额外的 mlp 层 z,在此之后,它们给紫色的那支加了一个新的模块,<strong>predictor</strong>。
|
||||
|
||||
<strong>predictor</strong>的模型结构就是跟 z 一样的<strong>mlp 层</strong>。它的任务是<strong>通过紫色的特征去预测粉色的特征</strong>。也就是说它的代理任务换成了<strong>生成式</strong>。
|
||||
|
||||

|
||||
|
||||
而具体的损失只有预测特征和真实特征的损失,用的是<strong>MSEloss</strong>。
|
||||
|
||||
下面的粉色分支最后一步是不进行梯度回传的。它的更新完全依赖紫色的那个编码器。
|
||||
|
||||
# 所以为什么不用负样本能左脚踩右脚螺旋升天呢?
|
||||
|
||||
在原文中,作者也没有说出个所以然来,不过后面有篇博客发现了问题所在。
|
||||
|
||||
其实这是 BN 的锅,蓝色的那个是一般的对比学习使用的,而紫色的是 BYOL 使用的。很明显发现它多了一个 BN。
|
||||
|
||||
### 有篇博客在复现 BYOL 时,不小心没加这个 BN 层,导致模型直接摆烂。那么 BN 到底藏着什么呢?
|
||||
|
||||

|
||||
|
||||
我们得先来回顾一下 BN 做了什么。
|
||||
|
||||
BN 根据批次的均值和方差进行归一化
|
||||
|
||||
训练时,均值、方差分别是该批次内数据相应维度的均值与方差;
|
||||
|
||||
推理时,均值、方差是基于所有批次的期望计算所得。
|
||||
|
||||
因此,博客作者认为,虽然我们只用了正样本进行训练,但是这个正样本包含了<strong>本批次所有样本的信息</strong>(均值,方差),所以<strong>实际上并不是真正的无负样本。</strong>
|
||||
|
||||
而这个 batch 的均值,即平均图片,可以看作 `SawAV` 里的聚类中心,是所有历史样本的聚类中心。(<del>很玄学</del>)
|
||||
|
||||
### 作者看到这个博客就急了
|
||||
|
||||
如果真是这样的话,<strong>BYOL 就还是没有逃脱出对比学习的范畴</strong>,它还是找了一个东西去做对比,其创新性就大大降低了。所以作者赶紧做实验,看看能不能找到 BYOL 模型不坍塌的另外一种解释。最终又写了一篇论文进行回应。
|
||||
|
||||
这篇论文叫 BYOL works even without batch statistics,即在没有 BN 的时候 BYOL 照样能工作,详细的消融实验结果如下表所示 :
|
||||
|
||||

|
||||
|
||||
<strong>BN 非常关键</strong>:只要是 `projector`(SimCLR 提出的 mlp)中没有 BN 的地方,SimCLR 性稍微下降;但是 BYOL 全都模型坍塌了。
|
||||
|
||||
<strong>有 BN 也会坍塌</strong>:作者找到了特例(红色框),即使当 `projector` 有 BN 的时候,BYOL 还是训练失败了 。如果 BN 真的很关键,它真的提供了隐式负样本的对比学习的话,训练就不应该失败
|
||||
|
||||
<strong>完全没有 BN,SimCLR 也坍塌</strong>(最后三列的结果。要注意 SimCLR 只有一层 projector)。这表明完全不用归一化,SimCLR 这种使用负样本进行对比学习的方式也无法训练。
|
||||
|
||||
最终结论:BN 跟它原来的设计初衷一样,主要作用就是提高模型训练时的稳定性,从而不会导致模型坍塌 。作者进一步延伸,如果一开始就能让模型初始化的比较好,后面的训练即使离开了 BN 也没有问题。
|
||||
|
||||
作者为此又设计了一个实验,使用 `group norm`+`weight standardization` (前者也是一种归一化方式,后者是一种卷积权重标准化方式,但都没有对 batch 中的数据进行融合),BYOL 的 top-准确率可以达到 74.1%,和原来精度可以认为是一样了(74.3%)。
|
||||
|
||||
<strong>至今其实这个问题也没有一个很合理能服众的解释。</strong>
|
||||
|
||||
# 总结
|
||||
|
||||
主要的贡献在于无需负样本的学习。但是没有合理的解释。
|
||||
@@ -1,59 +0,0 @@
|
||||
# SimSiam
|
||||
|
||||
# 前言
|
||||
|
||||
## 提出背景
|
||||
|
||||
BYOL 之后,大家都发现对比学习是靠许许多多的小 trick 和技术堆叠起来的,每个技术都有贡献,但是不算很多,前沿的网络往往采用了众多的技术得到很好的效果。
|
||||
|
||||
这时候,作者团队希望能够化繁为简,探索一下哪些真正有用,哪些贡献不大。
|
||||
|
||||
## 于是就有了 SimSiam
|
||||
|
||||
是对前面几乎所有工作的总结,它提出了一个非常简单的网络,但是达到了很高的性能,并在其上追加了前面工作的一些细节,来展示每个小技术的真正贡献如何。
|
||||
|
||||
它不需要动量编码器,不需要负样本,不需要 memory bank,就是非常简单。
|
||||
|
||||
# 模型结构
|
||||
|
||||
模型的结构是一个 `“孪生网络”`,其实于 BYOL 的结构很像,不过没有用动量编码器,左右两个编码器都是一样的,因此叫 `孪生网络`。
|
||||
|
||||
虽然看起来只有左边预测右边,其实右边也有一个 predictor 去预测左边的特征,两边是对称的,左右的优化有先后顺序。
|
||||
|
||||

|
||||
|
||||
结构其实没什么特殊的地方,主要讲讲思想。
|
||||
|
||||
# SimSiam 主要回答的是两个问题
|
||||
|
||||
# 1.为什么不用负样本模型不会坍塌?
|
||||
|
||||
原论文中提出的解释并不是最完美的。而且这个问题的解释涉及了动力学等知识,我也没有足够的知识储备去讲解这个问题,这里只能讲一些与解答相关的信息,如果有兴趣可以看下面链接中的解释:
|
||||
|
||||
这里要涉及到一个机器学习的经典算法,<strong>EM 算法</strong>,它也是<strong>k-means</strong>的核心思想之一。
|
||||
|
||||
因为本文的主旨原因,我不会在这里细讲这个算法,但是大家了解这是个什么东西即可。
|
||||
|
||||
<strong>EM 算法</strong>用于优化带有未知参数的模型,`k-means` 的聚类中心就可以看作一个未知参数,我们要同时优化模型本体和聚类中心。所以我们先对其中一个目标 A 做<strong>随机初始化</strong>,然后<strong>先优化</strong>另一个目标 B,再反过来用另一个目标 B 优化后<strong>的结果优化被随机初始化的目标 A</strong>,这就是一次迭代,只要不断循环这个迭代,EM 算法往往能找到最优解。
|
||||
|
||||
这里可以把<strong>经过 predictor 预测头的特征</strong>作为 `k-means` 里的特征,而另一个作为<strong>目标的特征</strong>作为<strong>聚类中心</strong>,经过预测头的特征直接反向传播进行优化,作为目标的特征则是通过上面说的对称的操作经过预测头进行优化。
|
||||
|
||||
最最直白地解读结论的话,可以说是,这种先后优化的 EM 算法,使得模型“来不及“去把权重全部更新为 0。(模型坍塌)具体的推导需要动力学的知识,这里不做展开。
|
||||
|
||||
# 2.对前人工作的总结
|
||||
|
||||
这是作者总结的所有”孪生网络“的模型结构,很精炼。
|
||||
|
||||

|
||||
|
||||
下面是这些网络训练结果的对比,也列出了它们分别有哪些 trick(用的是分类任务)
|
||||
|
||||
```
|
||||
负样本 动量编码器 训练轮数
|
||||
```
|
||||
|
||||

|
||||
|
||||
具体结果还是图片比较直观(
|
||||
|
||||

|
||||
@@ -1,29 +0,0 @@
|
||||
# MoCo v3
|
||||
|
||||
# 前言
|
||||
|
||||
在 VIT 出来之后,大家也都想着把对比学习的 backbone 换成 VIT。于是新的缝合怪自然而然地诞生了
|
||||
|
||||
MoCo v3,它缝合了 MoCo 和 SimSiam,以及新的骨干网络 VIT。
|
||||
|
||||
# 模型架构
|
||||
|
||||
可能因为和前面的工作太像了,作者就没有给模型总览图,我们借 MoCo 的总览图来讲
|
||||
|
||||

|
||||
|
||||
总体架构其实没有太多变化,还是 memory bank 的结构,右边也还是动量编码器,不过加入了 SimCLR 提出的 projection head(就是额外的那层 mlp),并且在对比上用了 SimSiam 的预测头对称学习方式。具体也不展开了,都是老东西缝合在一起。
|
||||
|
||||
# 讲这篇文章主要是冲着 VIT 来的
|
||||
|
||||
作者在用 VIT 做骨干网络训练的时候,发现如下问题:
|
||||
|
||||

|
||||
|
||||
在使用 VIT 训练的时候,batchsize 不算太大时训练很平滑,但是一旦 batchsize 变大,训练的图像就会出现如上图这样的<strong>波动</strong>。于是作者去查看了每一层的梯度,发现问题出在<strong>VIT 的第一层线性变换</strong>上。也就是下图中的粉色那个层,<strong>把图片打成 patch 后展平做的线性变换</strong>。
|
||||
|
||||

|
||||
|
||||
在这一层中,梯度会出现波峰,而正确率则会突然下跌。
|
||||
|
||||
作者就想,既然你训练不好,我就把你冻住,不让它训练,然后就能成功运用了。而且这个 trick 对几乎所有的对比学习模型都有效果。
|
||||
@@ -1,7 +0,0 @@
|
||||
# 对比学习
|
||||
|
||||
这里不再区分 nlp 和 cv,因为对比学习有些时候跟多模态挂钩,两个领域都有涉及,读者均需一定的了解。
|
||||
|
||||
这里因为笔者知识储备的原因,主要讲的是 CV 方面的对比学习。
|
||||
|
||||
还会涉及一些传统机器学习的算法,读者需一定的理论基础或者边看边学。
|
||||
@@ -1,21 +0,0 @@
|
||||
# 前言
|
||||
强化学习已经是一门很老的内容了,这从它被列为和监督学习与无监督学习并列的三大基本机器学习算法就可以看出来。但是在和深度学习结合后,强化学习焕发出了属于它的第二春。
|
||||
|
||||
虽然如此,但笔者还是必须提醒各位读者,强化学习相较于CV/NLP来说,仍然是一个非常冷门的方向,这不是没有原因的。总结原因如下:
|
||||
|
||||
1. 强化学习概念繁多芜杂,并且没有办法绕开:作为一个研究强化学习的人,你得理解整个交互过程,绕不开的概念包括但不限于:智能体(agent)、环境(environment)、状态(state)、动作(action)、奖励(reward)、动作价值函数(Action-Value Function)、状态价值函数(State-Value Function)等。这足以使一个初学者头大。
|
||||
|
||||
2. 强化学习涉及的数学知识较为高深,需要奠定较好的数理基础才能理解公式以及概念。马尔可夫过程作为强化学习最基本的模型,所需的前置知识包括以下内容:
|
||||
1. 概率论与数理统计,用于描述MDP模型。
|
||||
2. 线性代数,用向量来描述状态与动作。
|
||||
3. 统计学理论,众多算法都是基于统计学推导出来的。
|
||||
4. 最优化理论,众多算法都属于优化算法的范畴。
|
||||
5. 微积分,这是所有机器学习的内容都需要掌握的知识。
|
||||
|
||||
如果你不喜欢推导公式,那么强化学习对你来说可能并不是那么适合。
|
||||
|
||||
3. 强化学习应用范围以及未来就业市场较为单一。研究强化学习的方向倒是很多,博弈论、资源分配优化、游戏、推荐等领域都能见到强化学习的身影。但是根据笔者的观察,强化学习将来的就业岗位较为单一,一般只有游戏公司招收强化学习相关的岗位。
|
||||
|
||||
4. 强化学习固有的弊端,包括但不限于采样效率令人堪忧、奖励函数的设计过于玄学、学术领域的严重灌水以及源码的难以复现等。这对初学者造成了极大的困扰。
|
||||
|
||||
综上所述,强化学习是一个“有坑”的领域,入坑需谨慎!!!当然了,如果只是喜欢训练智能体“打游戏”,那么平台上存在着众多的源代码项目可供参考,祝你玩得愉快!
|
||||
@@ -1,34 +0,0 @@
|
||||
# 深度强化学习基础资料推荐
|
||||
1. 书籍:周志华《机器学习》(西瓜书)关于强化学习的部分,作为概念引导和初步理解。
|
||||
|
||||
2. 书籍:Sutton《Reinforcement Learning》,强化学习圣经,推荐作为参考书查阅而不是硬啃。
|
||||
|
||||
3. 网课:王树森《Deep Reinforcement Learning》,课件是英文的授课是中文的,概念讲的非常清楚而且形象,强推。
|
||||
|
||||
Github课件链接:<https://github.com/wangshusen/DRL>
|
||||
|
||||
网课链接:[深度强化学习-王树森(Youtube)](https://www.youtube.com/watch?v=vmkRMvhCW5c&list=PLvOO0btloRnsiqM72G4Uid0UWljikENlU)。
|
||||
|
||||
4. 网课:CS285,无论是csdiy还是主流资料推荐的网课,但是笔者的英语听力不怎么能跟上老师上课的语速,也没有找到有中文字幕的版本,推荐作为进阶资料使用。
|
||||
|
||||
项目链接:[CS285:Deep Reinforcement Learning](http://rail.eecs.berkeley.edu/deeprlcourse/)
|
||||
|
||||
5. 书籍+网课+实操:张伟楠《Hands On RL》(动手学强化学习),有书+有代码+有网课,不错的整合。但是配套网课质量只能说还可以,代码可以看看。
|
||||
|
||||
Github主页:<https://github.com/boyu-ai/Hands-on-RL>
|
||||
|
||||
电子书版:[动手学强化学习](https://hrl.boyuai.com/chapter/intro)
|
||||
|
||||
网课链接:[伯禹学习平台](https://www.boyuai.com/elites/course/xVqhU42F5IDky94x/lesson/O1N8hUTUb4HZuchPSedea)
|
||||
|
||||
6. 项目:OpenAI Spinning up,强推,动手做项目以及体会强化学习的快乐才是真谛所在。
|
||||
|
||||
项目主页:[OpenAI Spinning up](https://spinningup.openai.com/en/latest/index.html)
|
||||
|
||||
7. 资源:机器之心 SOTA!模型资源站,一站式查看原理+概论+代码+论文原文。
|
||||
|
||||
网站主页:[机器之心 SOTA!](https://www.jiqizhixin.com/columns/sotaai)
|
||||
|
||||
8. 论坛:RLChina,讲课的确实都是大牛,但是感觉略有枯燥。有时间表安排,适合希望自律、有规划地学习的同学。
|
||||
|
||||
论坛主页:[RLChina](http://rlchina.org/)
|
||||
@@ -1,149 +0,0 @@
|
||||
# 基本概念介绍
|
||||
前面已经介绍过,强化学习难入坑的的原因之一就在于概念繁多。下面将进行基本概念的介绍,本章节最好能够理解,不理解也没有关系,但是建议作为参考章节常看常新。后续章节不理解某个概念时,便回来看看,相信一定能够做到常看常新、从而加深你对于概念的理解。下面将进行四个部分的介绍,分别为强化学习的基本过程、强化学习的基本组成内容、强化学习的基本概念以及强化学习的目标。
|
||||
|
||||
|
||||
## 强化学习的基本过程
|
||||
前面已经介绍过强化学习的核心过程,在于智能体与环境进行交互,通过给出的奖励反馈作为信号学习的过程。简单地用图片表示如下:
|
||||

|
||||
正是在这个与环境的交互过程中,智能体不断得到反馈,目标就是尽可能地让环境反馈的奖励足够大。
|
||||
|
||||
## 强化学习过程的基本组成内容
|
||||
为了便于理解,我们引入任天堂经典游戏——[新超级马里奥兄弟U](https://www.nintendoswitch.com.cn/new_super_mario_bros_u_deluxe/pc/index.html),作为辅助理解的帮手。作为一个2D横向的闯关游戏,它的状态空间和动作空间无疑是简单的。
|
||||
|
||||

|
||||
|
||||
1.智能体(Agent):它与环境交互,可以观察到环境并且做出决策,然后反馈给环境。在马里奥游戏中,能操控的这个马里奥本体就是智能体。
|
||||
|
||||
2.环境(Environment):智能体存在并且与其交互的世界。新超级马里奥兄弟U本身,就是一个环境。
|
||||
|
||||
3.状态(State):对环境当前所处环境的全部描述,记为 $S$。在马里奥游戏中,上面的这张图片就是在本时刻的状态。
|
||||
|
||||
4.动作(Action):智能体可以采取的行为,记为 $a$。在马里奥游戏中,马里奥能采取的动作只有:上、左、右三个。这属于**离散动作**,动作数量是有限的。而在机器人控制中,机器人能采取的动作是无限的,这属于**连续动作**。
|
||||
|
||||
5.策略(Policy):智能体采取动作的规则,分为**确定性策略**与**随机性策略**。确定性策略代表在相同的状态下,智能体所输出的动作是唯一的。而随机性策略哪怕是在相同的状态下,输出的动作也有可能不一样。这么说有点过于抽象了,那么请思考这个问题:在下面这张图的环境中,如果执行确定性策略会发生什么?(提示:着重关注两个灰色的格子)
|
||||
|
||||

|
||||
|
||||
因此,在强化学习中我们一般使用随机性策略。随机性策略通过引入一定的随机性,使环境能够被更好地探索。同时,如果策略固定——你的对手很容易能预测你的下一步动作并予以反击,这在博弈中是致命的。
|
||||
随机性策略$\pi$定义如下:
|
||||
|
||||
<center>
|
||||
|
||||
$\pi(\mathrm{a} \mid \mathrm{s})=P(A=a \mid S=s)$
|
||||
|
||||
</center>
|
||||
|
||||
这代表着在给定状态s下,作出动作$a$的概率密度。举个例子,在马里奥游戏中,定义动作 $a_{1}$="left",$a_{2}$="right",$a_{3}$="down",动作空间 $a$={$a_{1}$,$a_{2}$,$a_{3}$}。<br>
|
||||
其中,假设$\pi(\mathrm{a_{1}} \mid \mathrm{s})=0.7$,$\pi(\mathrm{a_{2}} \mid \mathrm{s})=0.2$,$\pi(\mathrm{a_{3}} \mid \mathrm{s})=0.1$。这就代表着,在给定状态s下,执行动作$a_{1}$的概率为0.7,执行动作$a_{2}$的概率为0.2,执行动作$a_{3}$的概率为0.1,智能体随机抽样,依据概率执行动作。也就是说,马里奥左、右、上三个动作都有可能被执行,无非是执行几率大不大的问题。很显然,在知道策略$\pi$的情况下,就可以指导智能体“打游戏”了,学习策略$\pi$是强化学习的最终目标之一,这种方法被称为**基于策略的强化学习**。
|
||||
|
||||
6.奖励(Reward):这是一种反馈信号,用于表现智能体与环境交互后"表现"如何。在不同的环境中,我们需要设置不同的奖励。比如,在围棋游戏中,最后赢得游戏才会获得一个奖励。比如在量化交易中,可以直接拿收益亏损作为奖励。拿我们的马里奥游戏举例,吃到金币可以获得较小的奖励,最终通关游戏会获得一个极大的奖励,这样使得智能体以通关为目标、以吃金币为锦上添花。当然了,如果碰到怪物或者是死亡,需要设置一个极大的负奖励,因为这将直接导致游戏结束。
|
||||
|
||||
我们可以得出一个结论:每一个奖励 $R_{i}$,都与当时刻的状态 $S_{i}$ 与动作 $A_{i}$ 有关。拿马里奥游戏举例,在当前状态下,是否采取什么样的动作就会决定获得什么样的奖励?马里奥如果采取"向上",就可以获得金币奖励。如果采取"向右",碰到小怪会死掉,会获得一个很大的负奖励。如果采取"向左",那么可能什么事情都不会发生。
|
||||
|
||||
7.状态转移(State transition):环境可不会在原地等你。在你操控马里奥执行一个动作后,比如"left",那屏幕上显示的画面肯定会改变,这就发生了一个状态转移。状态转移函数记作
|
||||
|
||||
<center>
|
||||
|
||||
$p\left(s^{\prime} \mid s, a\right)=P\left(S^{\prime}=s^{\prime} \mid S=s, A=a\right)$
|
||||
|
||||
</center>
|
||||
|
||||
状态转移可以是固定的,也可以是随机的,我们通常讨论的是随机的情况。从公式的形式上也可以看出来,这还是一个概率密度函数。这代表着在观测到当前的状态$s$以及动作$a$后,状态转移函数输出新状态$s'$的概率,这个转移函数是只有环境、也就是游戏本身才知道的。比如在超级马里奥兄弟中,操控马里奥执行动作"left"后,敌人"板栗仔"可能向左也可能向右,比如说向左概率为0.8,向右概率为0.2,但是要注意这个概率只有游戏程序本身才知道。敌人动作的不确定性也就导致了环境的不确定性。
|
||||
|
||||
知道了上述几个概念,构建强化学习的基本过程就尽在掌握之中了。我们可以构建一个(state,action,reward)轨迹,即:<br>
|
||||
i.观察到状态$s_{1}$<br>
|
||||
ii.执行动作$a_{1}$,发生状态转移<br>
|
||||
iii.观察新状态$s_{2}$与得到奖励$r_{1}$<br>
|
||||
iv.执行动作$a_{2}$,发生状态转移<br>
|
||||
v.不断迭代......
|
||||
|
||||
该序列轨迹写作:$\langle s_{1},a_{1},r_{1},s_{2},a_{2},r_{2},\ldots,s_{T},a_{T},r_{T} \rangle$
|
||||
|
||||
## 强化学习的基本概念
|
||||
在阅读了前两个小节后,你可能对于强化学习的基本过程以及基本组成内容有了初步的了解。下面将进行强化学习基本概念的介绍,本章节与"基本组成内容"小节是继承关系,请一起阅读。(注:标题真难取,其实上一章就是强化学习的基本元素,这一章为基础元素推导出的基础概念)
|
||||
|
||||
1.回报(Retrun),需要与奖励区分开来。回报又称为"未来的累计奖励"(Cumulative future reward),这可以在其定义中窥见端倪:
|
||||
|
||||
<center>
|
||||
|
||||
$U_{\mathrm{t}}=R_{t}+R_{t+1}+R_{t+2}+R_{t+3}+\ldots . R_{t+n}$
|
||||
|
||||
</center>
|
||||
|
||||
但是这个定义有一个很明显的问题,未来时刻的奖励和现在的一样重要吗?如果我承诺未来给你100块钱,这份**承诺**在你心里的分量和现在就给你100块钱能够等价吗?很明显不能。因此我们引入折扣因子 $\gamma$ ,用以对未来的奖励做出一个折扣。定义折扣回报(Cumulative Discounted future reward)如下:
|
||||
|
||||
<center>
|
||||
|
||||
$U_{t}=R_{t}+\gamma R_{t+1}+\gamma^{2} R_{t+2}+\ldots \gamma^{n} R_{t+n}$
|
||||
|
||||
</center>
|
||||
|
||||
这是我们在强化学习中经常使用的概念。其中,折扣率是一个超参数,会对强化学习的结果造成一定的影响。
|
||||
|
||||
**注意格式**:如果游戏结束,每一个时刻的奖励都被观测到了——即站在任意时刻,一直到游戏结束的奖励都是可被观测的状态,那么奖励使用小写字母 $r$ 表示。如果游戏还没有结束,未来的奖励还是一个随机变量,那么我们使用大写字母 $R$ 来表示奖励。由于回报是由奖励组成的,那么我们也理所当然地用大写字母 $U_{t}$ 来表示回报。
|
||||
|
||||
*Fix:真的理所当然吗?*<br>
|
||||
让我们回顾一下,之前讲述"奖励"的定义时,我们得出过一个结论:每一个奖励 $R_{i}$,都与当时刻的状态 $S_{i}$ 与动作 $A_{i}$ 有关。我们又知道,状态 $S_{i}$ 与动作 $A_{i}$ 在某种意义上都是随机变量,不要忘了:<br>
|
||||
i.状态$S_{i}$是由状态转移函数,随机抽样得到的<br>
|
||||
ii.动作$A_{i}$是由策略 $\pi$ ,以状态$S_{i}$作为输入后随机抽样输出的
|
||||
|
||||
因此,$U_{t}$ 就跟 $t$ 时刻开始未来所有的状态和动作都有关,$U_{t}$的随机性也因此和未来所有的状态和动作有关。
|
||||
|
||||
2.动作价值函数(Action-Value Function)
|
||||
|
||||
$U_{t}$ 在强化学习过程中的重要性不言而喻,这就代表着总体奖励——可以用于衡量智能体总的表现水平,并且智能体的目标就是让这个回报越大越好。但是由于我们前面说过的原因,回报 $U_{t}$ 受制于状态与动作,是一个随机变量。也就是说,在 $t$ 时刻,我们无法得知 $U_{t}$ 究竟是什么。有没有一种办法,能够消除掉随机性?很自然的,我们想起了《概率论与数理统计》中的期望。从数学上来说,对 $U_{t}$ 在策略函数 $\pi$ 下求期望,就可以消掉里边所有的随机性。因此,我们得到动作价值函数 $Q_\pi$ 的定义如下:
|
||||
|
||||
<center>
|
||||
|
||||
$Q_\pi=E\left(U_t \mid S_t=s_t, A_t=a_t\right)$
|
||||
|
||||
</center>
|
||||
|
||||
动作价值函数 $Q_\pi$ 消除了不确定的未来的动作和状态,转而把已观测到的状态 $s_{t}$ 和动作 $a_{t} $ 作为被观测的变量而非随机变量来对待。动作价值函数带来的意义就在于,能够在策略 $\pi$ 下,对于当前状态 $s$ 下所有动作 $a$ 进行打分,基于分数我们就可以知道哪个动作好、哪个动作不好。
|
||||
|
||||
3.最优动作价值函数(Optimal action-value function)
|
||||
|
||||
动作价值函数对于回报 $U_{t}$ 关于策略 $\pi$ 求取了期望,成功地消去了状态以及动作的随机性。但是需要注意的是,使用不同的策略 $\pi$ 就会得到不同的动作价值函数 $Q_\pi$ ——其实质上受到三个参数影响,即($\pi$,$s$,$a$)。我们应该使用"效果最好"的那种函数,也就是能让 $Q_\pi$ 最大化的那个 $\pi$ ,基于此我们可以得到最优动作价值函数:
|
||||
|
||||
<center>
|
||||
|
||||
$Q^*\left(s_t, a_t\right)= \underset{\pi}{max} Q_\pi\left(s_t, a_t\right)$
|
||||
|
||||
</center>
|
||||
|
||||
我们跨出了历史性的一步。
|
||||
|
||||
如果有了 $Q^*$ 函数,意味着可以评价动作的好坏了。我们的价值函数不再和策略有关,在观测的状态 $s$ 下,$Q^*$函数成为指挥智能体动作的“指挥官”——哪个动作的分数最高,智能体就应该执行哪个动作。学习 $Q^*$ 函数也是强化学习的最终目标之一,我们可以维护一张价值表用于选择收益最大的动作。学习 $Q^*$ 函数的过程被称为**基于价值的学习**。
|
||||
|
||||
4.状态价值函数(State-value function)
|
||||
|
||||
在动作价值函数中,$Q^*$ 函数将未来的随机变量消去,留下 $s_{t}$ 和 $a_{t}$ 作为观测变量。如果把动作作为随机变量,然后对于动作求期望,求得的新函数将仅与策略 $\pi$ 和状态 $s$ 有关,这就得到了状态价值函数 $V_\pi\left(s_t\right)$ 。下面是状态价值函数的定义:
|
||||
|
||||
<center>
|
||||
|
||||
$\begin{aligned} & V_\pi\left(s_t\right)=E_A\left[Q_\pi\left(s_t, A\right)\right] \\ & A \sim \pi\left(\cdot \mid s_t\right)\end{aligned}$
|
||||
|
||||
</center>
|
||||
|
||||
状态价值函数消去了动作 $a$,留下了策略 $\pi$ 与状态 $s$。这就意味着,在策略$\pi$下,目前状态的好坏可以根据状态价值函数的值来判断。如果策略是固定的,那么 $V_\pi$ 的值越大代表当前形势越好、对自己越有利。同样,策略价值函数也能用于评价策略的好坏,策略越好,$V_\pi\left(s_t\right)$ 的平均值就会越大。
|
||||
|
||||
## 强化学习的基本目标
|
||||
|
||||
看完上述内容的你,心里想必有十万个为什么:我是谁?我在哪?我要做什么?
|
||||
|
||||
明明最初说好的要训练智能体打游戏,我才耐着性子看下去的!看了这么久了,我光学到了一大堆似是而非的概念,推导并尝试理解了一大堆可能之前都没有接触到过的数学公式,抑或是翻开了尘封已久的《概率论与数理统计》才勉强跟上公式推导及其步骤,却连强化学习怎么训练智能体都不知道!这是诈骗!~~日内瓦,退钱!~~
|
||||
|
||||
这也是我在学习过程中的心路历程。理解/半懂不懂的带过了一堆概念,却连强化学习最基本的任务都不明白。我要干什么,才能训练智能体打游戏?
|
||||
|
||||
还记得我们前面提到过的**基于价值的学习**和**基于策略的学习**吗?没错,强化学习的最终目标就是通过两者完成的,下面将给出具体阐述。
|
||||
|
||||
1.**基于价值的学习**。说人话,就是学习 $Q^*$ 函数。我们之前已经推导过 $Q^*$ 函数在学习过程中的重要性了,它就好像一个"指挥官",智能体只需要按照它输出的动作照着执行就够了。试想:在现实世界里如果有这样一位人,他一直在指导你炒股,并且证明了他的选择永远是收益最高的,你还管什么原理,跟着大哥梭哈就完事了!在基于价值的学习中,我们通过使用最优值函数来选择最优的动作以最大化长期奖励的方式来间接地学习最优策略。基于价值的学习使用值函数来指导行为,直接体现就是维护了一个价值表格或价值函数,并通过这个价值表格或价值函数来选取价值最大的动作。
|
||||
|
||||
2.**基于策略的学习**。说人话,就是学习 $\pi$ 函数。我们复习一下策略 $\pi$ 的定义,是指智能体采取动作的规则。试想:在现实世界里,由于少年你骨骼清朗,兼有大机缘大智慧大定力,捡到了一本炒股秘籍。这本秘籍想必是心思慎密的高人前辈所留,无论是在何种状态下都有规则匹配当前状态告诉你应该怎么操作——并且你操作之后收益永远是最大化的,这本指导手册就是策略。基于策略的学习在每个状态下选择最优的动作,以最大化长期奖励。这种方法的目标是直接优化策略本身,因此它通常需要在策略空间中进行搜索,并且在每个策略上评估其长期累积奖励。
|
||||
|
||||
通常情况下,学到 $Q^*$ 函数和 $\pi$ 函数之一,就可以操控智能体打游戏了。但是也有方法结合了价值学习和策略学习,这就是演员-批评家网络(Actor-Critic)。不必太过担心,我们会在后续章节详细阐述该框架。
|
||||
|
||||
## 总结与展望
|
||||
在本章节里,我们了解了强化学习的基本过程、组成要素、基本概念以及最终目标,无论你是否真正搞懂每一个知识点,想必已经对强化学习有一个初步的了解了。接下来,我拟从 Q-learning、SARSA 算法等传统强化学习算法开始,推到结合了深度学习的 Deep Q-learning(DQN) ,以及其改进版本Double DQN(DDQN)、Dueling DQN 等算法,以完成基于价值学习侧的算法介绍。然后,我将从 Reinforce 这一最基础的强化学习算法引入基于策略学习侧的基本理念,然后介绍结合基于策略学习和基于价值学习的演员-批评家网络(Actor-Critic)架构,并且引出PPO、DDPG等算法。
|
||||
|
||||
为了不让你的大脑继续过载,下一章节将讲述强化学习基本环境的搭建。
|
||||
@@ -1,11 +0,0 @@
|
||||
# 深度强化学习
|
||||
前面已经介绍过强化学习(RL)的基本概念了,这里着重介绍深度强化学习(DRL)。
|
||||
|
||||
在笔者浅薄的理解里,深度强化学习的本质还是一个强化学习的问题,只不过引入了深度学习里的深度神经网络用于拟合函数。在传统的强化学习中,我们有一张表格用于存储状态以及动作的值函数。
|
||||
|
||||
很显然,在状态和动作空间较少的情况下,无论是存储这张表格还是查找这张表格都是轻而易举的。但是在复杂的环境下,继续使用这种方法会出现维度灾难,我们不得不使用函数逼近的办法来估计值函数。
|
||||
|
||||
这时候深度学习便加入进来与强化学习相结合,可以利用深度学习能处理高维、非线性数据与具有强大的学习能力这两个特点来逼近这个值函数并且提取特征,从而处理复杂状态下的问题。
|
||||
|
||||
也正是基于此,笔者在后续不会刻意区分强化学习与深度强化学习,因为他们的目标是一致的。这也是为什么本内容会放在深度学习的大模块下,而不是另外单独起一个强化学习模块的原因。
|
||||
|
||||
@@ -1,2 +0,0 @@
|
||||
# 深度学习
|
||||
|
||||
@@ -1,269 +0,0 @@
|
||||
# 图网络略述(intro&GCN)
|
||||
|
||||
> author:廖总
|
||||
|
||||
其实开始冲图神经网络也已经有一段时间了,从半年前阅览《Relational inductive biases, deep learning, and graph networks》一文,对图网络有了一定的了解,到现在已经过去半年了。然而这半年中我一直在摸鱼,就算偶尔复习图神经网络的方法,也一直在复习相同的工作。如今有幸受实验室隔座的兄弟邀请参与一个科研项目。比较尴尬的是,我除了自诩知晓图网络以外,对实际的操作与应用一无所知。我遂写下这篇文章,来昭示自己正式开始图网络的学习,并且尝试记录和融汇已知的知识点,不在浪费时间于重复的工作上。
|
||||
|
||||
首先,图网络是为什么产生的呢,通常,我们简略的称之为,方便表达结构化的知识,处理结构化的数据。这里的结构其实跟数据库及数据结构中描述的结构是相似的,即一种信息之间关联的结构,以及知识之间关联的结构。图拥有这样的特点,能通过节点来对实体进行描述,并用边描述实体之间的关系,与此同时还有着隐含信息的储存和全局信息的存在,于是构成了一个新颖且复杂的神经网络结构。
|
||||
|
||||
在周志华的机器学习一书半监督学习章节中,有对基本的图学习策略进行基本的描述,详见我为了应付课程考试整理的[图半监督学习](http://blog.cyasylum.top/index.php/2020/07/05/%E5%9B%BE%E5%8D%8A%E7%9B%91%E7%9D%A3%E5%AD%A6%E4%B9%A0/)。其基本思路是这样的,通过”样本距离度量“刻画获取样本之间的联系,将样本嵌入到“图”,即样本即其关系的集合中。后通过图将半监督学习中有标记样本的标签对未标记样本进行传递,从而获取未标记样本的属性,进行学习。
|
||||
|
||||
如此,便定下来图网络的基本思路,即通过<em>信息在图上的传递</em>,迭代学习知识。有了这样的基础,我们便可以开始对图网络进行讨论了。
|
||||
|
||||
接下来,我们从最基础的部分来讲讲,信息是如何在图上进行传播的。
|
||||
|
||||
## 消息传递
|
||||
|
||||
那么,消息是什么呢?在大多数时候,我们将消息理解为节点(但其实在特定场合,边或者全局信息都是可以或者需要考虑的),即“实体”包含的,要传递的信息。对于一个结构相对复杂的节点而言,假设其拥有 n 个属性,我们便用一个 n 维的向量(或是其他什么)$\mathbf{x}$表示节点中储存的信息。然后,节点上的信息要怎么传递呢?
|
||||
|
||||
答案必然是通过节点之间的连接。
|
||||
|
||||
在离散数学中,我们使用邻接矩阵来刻画图上所有节点之间的联系,即 Adjacency Matrix,记作$\mathbf{A}$。在不考虑边权重的情况下,我们将存在节点$x_{i},x_{j}$之间的联系表示为$A_{ij}=1$,在存在权重的情况下,我们将$A_{ij}$的值记作两节点之间边的权重。值得注意的是,$\mathbf{A}$对角线上的值,即节点之间自连接的系数,在不做考虑自连接时都被记作 $0$ 。
|
||||
|
||||
另外,我们特殊定义节点的度为该点所有连接权重之和,即$D_i=\sum_{j=0}^n A_{ij} $,使用对角矩阵$\mathbf{D}=diag(D_1,D_2,\cdots,D_n)$进行统一描述。
|
||||
|
||||
如此,我们便通过了两个矩阵刻画了一张图上所有节点之间的传递关系。为了方便计算,以及因为种种特性,一张图最终的传递特性,被描述成了拉普拉斯矩阵$\mathbf{L}=\mathbf{D}-\mathbf{A}$。
|
||||
|
||||
我们通过拉普拉斯矩阵 $L$ 来考虑图上的消息传递特性。
|
||||
|
||||
同时,我们可以理解为,拉普拉斯矩阵描述了图的结构。
|
||||
|
||||
## 归一化拉普拉斯矩阵
|
||||
|
||||
为了方便拉普拉斯矩阵在机器学习等众多需要迭代求解问题中的实际使用,我们要求对拉普拉斯矩阵进行归一化操作,从而避免在多次传递后导致的梯度爆炸和梯度消失。我们需要令其对角线上元素统一等于 1。
|
||||
|
||||
我们已知的是,主对角线上的元素只会同
|
||||
$D$矩阵有关,因此,我们引入了
|
||||
$\mathbf{D}^{-\tfrac{1}{2}}$ 作为归一化算子,令归一化拉普拉斯矩阵为
|
||||
|
||||
$$
|
||||
\mathbf{L}^{sym}
|
||||
=\mathbf{D}^{-\frac{1}{2}}
|
||||
\mathbf{L}\mathbf{D}^{-\frac{1}{2}}
|
||||
=\mathbf{I}-\mathbf{D}^{-\frac{1}{2}}
|
||||
\mathbf{A}\mathbf{D}^{-\frac{1}{2}}
|
||||
$$
|
||||
|
||||
$$
|
||||
L_{ij}^{sym}=
|
||||
\begin{cases}
|
||||
1 \quad\quad\quad\quad\quad\quad\quad\enspace\thinspace \left ( i=j\right ) \cup \left ( deg(v_i)\ne0 \right ) \\
|
||||
-\frac{1}{\sqrt{deg(v_i)deg(v_j)}} \qquad \left ( i\ne j \right ) \cup \left ( v_i adj v_j \right ) \\
|
||||
0 \quad\quad\quad\quad\quad\quad\quad\;\;\; else.
|
||||
\end{cases}
|
||||
$$
|
||||
|
||||
现在,我们可以尝试用$\mathbf{L}$对图进行表示了。
|
||||
|
||||
另外还有个<em>随机游走归一化拉普拉斯矩阵</em>
|
||||
$$
|
||||
\mathbf{L}^{sym}=\mathbf{D}^{-1}\mathbf{L}=\mathbf{I}-\mathbf{D}^{-1}\mathbf{A}
|
||||
$$
|
||||
|
||||
,不过我还不熟,暂时不管了。
|
||||
|
||||
## 图的频域表示
|
||||
|
||||
其实挺意外的,早在去年的这个时候,我也考虑过这个问题。对图像的矩阵进行奇异值分解,通过切除部分奇异值,我们可以对图像中的低频和高频信息进行定量的剪切,使得减少储存信息的同时不丢失大部分画质。这样的特性是不是同信号的频域分析,即傅里叶变换有着相似之处。当时的我寻遍了全网,并没有得到什么结果。而如今,我在做图的谱分析。
|
||||
|
||||
为了直观地对描述信号传播的图进行直观的“卷积滤波(需要注意的是,这里的卷积就不是图像意义上的卷积了,而是信号意义的卷积。但是在实际运用中图的卷积表示的也是信号在相邻图节点上的传播,这又与图像的卷积有着异曲同工之妙,那么新的问题来了,信号卷积和图像卷积是否也存在着什么物理层面上的联系?)”我们通过特征分解,获取图的“频谱”,从这边开始,便是 Spectral Graph Convolution 的思想了。
|
||||
|
||||
我们将 L 矩阵进行特征分解,有$\mathbf{L}=\mathbf{U}\boldsymbol{\Lambda}\mathbf{U}^\mathsf{T}$,其中特征值描述的是图像的频谱强度,而特征向量描述了分解的基底,即频率,对应频谱分析中的$e^{-j\omega t}$。
|
||||
|
||||
于是,我们考虑滤波和滤波器,我们设计$g\theta=diag(\theta)$,有滤波器改变了基底上信号的强度,即有$g\theta(\Lambda)$为特征值的函数。我们有$g\theta$在图$\mathbf{L}$上对输入信号$x$的卷积等于$g\theta$、$x$在频域相乘:
|
||||
$g\theta\star
|
||||
x=\mathbf{U}g\theta\mathbf{U}^\mathsf{T}x
|
||||
$
|
||||
|
||||
如此,我们完成了在图神经网络上进行分析的基础。
|
||||
|
||||
但是在实际问题下,这样的图是极难计算的,当我们的节点规模较大时,对 N^2^ 规模的图进行矩阵分解,并且进行多次矩阵乘法需要消耗极大的资源,这使得图网络很难运行。因此纵使图网络有着其特殊的性质,其热度一直不是很高。
|
||||
|
||||
## ChebNet 及其思考
|
||||
|
||||
ChebNet 的引入是当今神经网络大热门的开端,也是图卷积网络的基础。其思路为,使用切比雪夫多项式对卷积过程 K 阶拟合([参考](https://zhuanlan.zhihu.com/p/138420723))
|
||||
|
||||
ChebNet 假设$g\theta$对$\Lambda$的滤波结果是原始特征值多项式函数,而网络的目的是抛弃原本通过矩阵相乘来对卷积结果进行求解,而通过参数学习来对结果进行表示,给出下式
|
||||
|
||||
$$
|
||||
g\theta(\Lambda)=\sum_{k=0}^K \beta_kT_k(\hat{\Lambda})=\begin{pmatrix}
|
||||
\begin{matrix}\sum_{k=1}^K \beta_kT_k(\hat{\lambda_1})\end{matrix}\\
|
||||
&\cdots\\
|
||||
&&\begin{matrix} \sum_{k=1}^K \beta_kT_k(\hat{\lambda_n})\end{matrix}
|
||||
\end{pmatrix}
|
||||
$$
|
||||
|
||||
其中有切比雪夫多项式在矩阵上的表示,具体数学背景可以详细查看
|
||||
|
||||
$$
|
||||
T_0(L) = I\ T_1(L)=L\ T_{n+1}(L)=2LT_n(L) - T_{n-1}(L)
|
||||
$$
|
||||
|
||||
有$\beta_k$为网络的待学习参数
|
||||
|
||||
我们将原式
|
||||
$$
|
||||
g\theta\star
|
||||
x=\mathbf{U}g\theta\mathbf{U}^\mathsf{T}x
|
||||
$$
|
||||
|
||||
表示为拟合形式
|
||||
$$
|
||||
\mathbf{U}
|
||||
\begin{matrix} \sum_{k=0}^K \beta_kT_k(\hat{\Lambda})
|
||||
\mathbf{U}^\mathsf{T}x
|
||||
\end{matrix}
|
||||
$$
|
||||
|
||||
,并对其中无关输入信号 $x$ 的部分进行改写
|
||||
|
||||
|
||||
$$
|
||||
\mathbf{U}\begin{matrix}\sum_{k=0}^K
|
||||
\beta_kT_k(\hat{\Lambda})
|
||||
\mathbf{U}^\mathsf{T}
|
||||
\end{matrix}
|
||||
$$
|
||||
|
||||
$$
|
||||
=\begin{matrix} \sum_{k=0}^K
|
||||
\mathbf{U}\beta_k(\begin{matrix}\sum_{c=0}^k\alpha_{kc}\hat{\Lambda^k}
|
||||
\end{matrix}\mathbf{U}^\mathsf{T})
|
||||
\end{matrix}
|
||||
$$
|
||||
$$
|
||||
=\begin{matrix} \sum_{k=0}^K\beta_k(\begin{matrix}\sum_{c=0}^k\alpha_{kc}(\mathbf{U}\hat{\Lambda}
|
||||
\mathbf{U}^\mathsf{T})^k
|
||||
\end{matrix})
|
||||
\end{matrix}
|
||||
$$
|
||||
$$
|
||||
=\begin{matrix} \sum_{k=0}^K\beta_kT_k(\mathbf{U}\hat{\Lambda}
|
||||
\mathbf{U}^\mathsf{T})
|
||||
\end{matrix}
|
||||
$$
|
||||
$$
|
||||
=\begin{matrix} \sum_{k=0}^K\beta_kT_k(\hat{\mathbf{L}})
|
||||
\end{matrix}
|
||||
$$
|
||||
|
||||
其中
|
||||
$$
|
||||
\hat{\mathbf{L}}=\frac{2}{\lambda_{max}}\mathbf{L}-\mathbf{I}_N
|
||||
$$
|
||||
|
||||
于是我们获得了
|
||||
$$
|
||||
g\theta\star
|
||||
x
|
||||
=\mathbf{U}g\theta\mathbf{U}^\mathsf{T}x
|
||||
=\begin{matrix}
|
||||
\sum_{k=0}^K\beta_kT_k
|
||||
(\hat{\mathbf{L}})x
|
||||
\end{matrix}
|
||||
$$
|
||||
|
||||
|
||||
作为 ChebNet 的卷积结构
|
||||
|
||||
其中值得注意的一点是,ChebNet 的 K 值限制了卷积核的多项式次数,但是这里的多项式次数描述了什么呢?其实就是卷积的“范围”,即单次卷积内最高可获得的 K 阶相邻节点信息。在 K=n 的时候,我们从理论上可以通过单次卷积,获取一张连通图上所有结点的信息,而这也是原方法难以计算的根本原因。
|
||||
|
||||
到这里为止,我介绍了 2018 年 GCN 出现之前图网络的基本使用,并给出了对图网络的基本认知,于是,我们拥有了相对充分的工具去认识图网络近期的发展,以及更深层次的使用。
|
||||
|
||||
## Graph Convolutional Networks
|
||||
|
||||
前面谈论的都是基于图传播的方法以及理论基础,之后才是图神经网络(GNN)相关的内容,即我们需要将一个抽象的图的概念存入实际的数据结构,并考虑其在实际数据上的应用,好吧换句话来说就是开始抄论文。
|
||||
|
||||
## 设计思考
|
||||
|
||||
GCN 是典型的依靠消息传递进行迭代的网络,并通过对图卷积谱的线性逼近,其实就是只考虑相邻元素的线性组合,从而达到单层参数的最小化,使得 GCN 的深度构建成为可能。同时,一阶的拟合表示图卷积神经网络在单次卷积迭代中,仅考虑邻域的信息,这使得 GCN 在物理直觉上产生了与 CNN 的相似之处。我们可以发现,GCN 中的 Convolutional 是图的频谱卷积和图的邻域卷积的融合。即表现出了多种层面的滤波特性。也许正是如此,使得 GCN 有着如此好的表现。
|
||||
|
||||
## 数学表示
|
||||
|
||||
### 卷积层
|
||||
|
||||
### 原典
|
||||
|
||||
之前我们引入的是图传播特性的建模,而现在我们需要考虑一次实际的迭代如何在图上进行。
|
||||
|
||||
我们通常考虑输入的参数与节点的隐含状态,作为网络的隐含层,即 ℎ,我们需要在每一轮迭代中对每个节点的状态进行更新,从而达到端对端训练的可能性。因此我们要确定隐含状态的更新模式,如下展示:
|
||||
|
||||
$$
|
||||
\mathbf{h}_i^{l+1}=\sigma(\mathbf{W}_0^{(l)\mathsf{T}}\mathbf{h}_i^{(l)}+
|
||||
\begin{matrix}
|
||||
\sum_{j\in\mathcal{N}_i}c_{ij}\mathbf{W}_1^{(l)\mathsf{T}}\mathbf{h}_j^{l}+\mathbf{b}_0^{(l)}
|
||||
\end{matrix}
|
||||
)
|
||||
$$
|
||||
|
||||
### 归一化单参数
|
||||
|
||||
在实际场景中,减少了网络的参数,并对传播进行了重新的归一化
|
||||
|
||||
$$
|
||||
\mathbf{H}^{(l+1)}=\sigma(\tilde{\mathbf{D}}^{-\frac{1}{2}}\tilde{\mathbf{A}}\tilde{\mathbf{D}}^{-\frac{1}{2}}\mathbf{H}^{(l)}\mathbf{W}^{(l)})
|
||||
$$
|
||||
|
||||
其中
|
||||
$$
|
||||
\tilde{\mathbf{A}}=\mathbf{A}+\mathbf{I}_N,\tilde{D}_i
|
||||
=\begin{matrix}
|
||||
\sum_j\tilde{A}_{ij}
|
||||
\end{matrix}
|
||||
$$
|
||||
|
||||
作为传播的预处理部分,由此得到了 GCN 的完整数学表示。
|
||||
|
||||
### 损失函数
|
||||
|
||||
文中针对半监督节点分类问题设计了一下目标函数,仅对有监督部分设计交叉熵损失,有:
|
||||
|
||||
$$
|
||||
\mathcal{L}_{sup}
|
||||
=-\begin{matrix}
|
||||
\sum_{l\in\mathcal{y}_L}
|
||||
\end{matrix}
|
||||
\begin{matrix}
|
||||
\sum_{\mathcal{f}=1}^{d_{out}}\gamma_{l,f}\ln
|
||||
Z_{l,f}
|
||||
\end{matrix}
|
||||
$$
|
||||
|
||||
其中 γ 为指示变量,表示蒸馏分类正确类的交叉熵损失。
|
||||
$$
|
||||
\mathbf{Z}=f(\mathbf{X},\mathbf{A})
|
||||
$$
|
||||
|
||||
为预测结果。即我们希望正确分类下类可能性的最大化。
|
||||
|
||||
## 代码实现
|
||||
|
||||
归一化步骤
|
||||
|
||||
```python
|
||||
def norm(A):
|
||||
A = A + torch.eye(A.size(0))
|
||||
d = torch.sum(A, dim=1)
|
||||
D = torch.diag(d)
|
||||
|
||||
return torch.pow(D,-0.5).mm(A).mm(torch.pow(D,-0.5))
|
||||
```
|
||||
|
||||
GCN 本体
|
||||
|
||||
```python
|
||||
class GCN(nn.Module):
|
||||
def __init__(self, A, din, hidden, dout):
|
||||
super(GCN, self).__init__()
|
||||
self.A = norm(A)
|
||||
self.gcn1 = nn.Linear(din, hidden, bias=True)
|
||||
self.gcn2 = nn.Linear(hidden, dout, bias=True)
|
||||
def forward(self, X):
|
||||
X = F.relu(self.gcn1(self.A.mm(X)))
|
||||
X = self.gcn2(self.A.mm(X))
|
||||
return X
|
||||
```
|
||||
|
||||
### 测试方法
|
||||
|
||||
参考 dgl 的[使用教程](https://docs.dgl.ai/tutorials/basics/1_first.html)
|
||||
@@ -1,227 +0,0 @@
|
||||
# 数据科学
|
||||
author:zzm
|
||||
# 本章内容会从一个小故事开始
|
||||
|
||||
讲讲某个人在大一的悲惨经历来为大家串起来一个精简的数据科学工作包括了哪些步骤,同时给各位介绍一些优质的教程
|
||||
|
||||
同时,这章内容将详细阐述[与人合作的生死疲劳](../1.杭电生存指南/1.5小组作业避雷指南.md)
|
||||
|
||||
# 悲惨世界
|
||||
|
||||
::: danger 若有雷同,纯属瞎编~~根据真实事件改编
|
||||
|
||||
后人哀之而不鉴之,亦使后人而复哀后人也!
|
||||
|
||||
请欣赏小故事的同时,根据自己的需求选择自己想学的教程
|
||||
|
||||
:::
|
||||
## Day1
|
||||
|
||||
你是一个可怜的大一学生,学校的短学期的第一天,你的心情非常好,因为要放寒假了,只要再坚持过这个短学期,你的快乐假期要来了!什么是短学期?不知道啊,也没听学长说过,好像是新研究出来的一个课程,去试试看吧。
|
||||
|
||||
当你快乐的走进教室,老师告诉你:“你们看看PPT上的任务,自由选择啊!”
|
||||
|
||||
你看到PPT上赫然印着
|
||||
::: tip 任务目标
|
||||
基础系统:
|
||||
1. 淘宝客户价值分析系统,实现爬取数据,数据处理,数据分析。
|
||||
2. 二手房数据分析预测系统,实现爬取数据,数据分析,绘制图表。
|
||||
3. 智能停车场运营分析系统,实现爬取数据,数据分析,绘制图表。
|
||||
4. 影视作品分析系统,实现爬取数据,数据分析,绘制图表。
|
||||
升级系统:
|
||||
1. 利用爬虫理论,实现 12306 抢票小助手系统。
|
||||
2. 利用数据分析方法,实现淘宝商品排行分析。
|
||||
3. 利用爬虫原理,爬 Google 搜索引擎分析。”
|
||||
要求实现三项以上的功能模块或三种以上的特征分析或提取。
|
||||
:::
|
||||
|
||||
心中一惊,暗道不妙,这都什么玩意,怎么还有爬谷歌,淘宝和抢12306的票啊,这tm不是犯法的么!这我要能做出来我还上什么大一的学啊!🥺🥺🥺🥺
|
||||
|
||||
老师紧接着补充“十个人一组啊!一周内做完,数据自己想办法,第三天就要检查你们的进度了!”
|
||||
|
||||
这是你倒是暗暗松了一口气,好像十个人一起干也没有那么复杂!😎(这时正是愚昧之峰,错误的认为工作总量就是工作量除以十)迅速的组好队之后,你问了问大伙的进度,what?大伙都没有python基础,只有我有?幸好学了hdu-wiki和datawhale的[聪明方法学python](https://github.com/datawhalechina/learn-python-the-smart-way)
|
||||
|
||||
那就把教程分给大伙吧,我们选一个最简单的,二手房数据的分析系统好了!
|
||||
|
||||
第一天选好题了,又是大下午的,摆了摆了,你开心的打开电脑,打开了steam,开摆!
|
||||
|
||||
day 1 End!🤣
|
||||
|
||||
## Day 2
|
||||
|
||||
昨天真是美滋滋的一天,玩了一晚上的你有点头昏脑涨,今天就开始干活好了,反正一周时间呢,比期末复习周可长太多了,就做这么个玩意我还能做不出来吗?
|
||||
|
||||
虽然你没有学过爬虫,但是你很幸运的找到了github上一个现成的爬虫代码,虽然费了一翻力气,但是仍然躲过了某房价网站的爬虫,他成功爬下来了,我们就把他存在哪里呢?~~(爬虫待补充)
|
||||
|
||||
先试试excel好了,毕竟这是大家最耳熟能详的存表格的方法,但是你貌似没有深入了解过他,打开了datawhale的[free-excel](https://github.com/datawhalechina/free-excel),你才惊讶的发现,wow,原来他有这么多牛逼的功能啊!它除了可以将房价统计,找到它的平均价格,算出他的最高价格之类以外,竟然也可以把他可视化!甚至它还可以对房价进行多元分析!根据房屋数量面积地段等等因素帮你预测房价,甚至可以自动帮你检索和去除重复数据,实在是太好用啦!
|
||||
|
||||
当然,这只是一个理想状态,残酷的现实很快给你当头一棒!当你试着多爬点不同城市数据的时候,他崩了!这么脆弱的吗?!干点活就喊累的吗?!😨
|
||||
|
||||
当然你想起了有一个备用方案,好像你可以用数据库去存储他!
|
||||
|
||||
之前好像看到有一个教程叫做[wonderful-sql](https://github.com/datawhalechina/wonderful-sql?from=from_parent_mindnote)
|
||||
|
||||
他提到“随着社会的快速发展,各类企业数字化转型迫在眉睫,SQL 应用能力日趋重要。 在诸多领域中 SQL 应用广泛,数据分析、开发、测试、维护、产品经理等都有可能会用到SQL,而在学校里系统性讲授 SQL 的课程较少,但是面试及日常工作中却经常会涉及到 SQL。”
|
||||
|
||||
确实学校没有教过,但是幸好你有教程,折腾了一翻之后,你发现你对数据库有了更深的理解,他帮助了我们在容纳大量的多种不同的数据形式的时候不用专门去考虑怎么设计一个数据结构而是规划了一定的存储方法后全部塞给他,完全不用考虑具体的物理性的以及性能问题存储模式,并且他很多高级的功能可以帮助你便捷的把数据组织成一般情况下难以到达的形式,他的底层设计被严格的包装起来让你在进行数据增删改查的时候都又快又好。
|
||||
|
||||
并且它可以非常方便的存一些excel不好存的所谓的非结构化的数据,比如说图像等等,并且他不会动不动就喊累!处理几十万条也是一下子!
|
||||
|
||||
当然同时你也了解到,你所用的是关系型数据库,是老东西了,目前还有很多较为前沿的非关系型数据库,例如MongoDB(这玩意什么都能存,比如说地图),Neo4j(像一张蜘蛛网一样的结构,图)等等,他们不用固定的表来存储,可以用图存或者键值对进行存储,听起来好像非常的高级,不过你暂时用不到,数据搞都搞下来了,量也够了,是时候看看队友做到哪了?说不定后面你都不用做了,已经做的够多够累的了!
|
||||
|
||||
什么?!刚开始学python?!woc!完蛋,你逐渐来到了绝望之谷,唉!明天继续做吧!看来休息不了了。
|
||||
day 2 End 😔!
|
||||
|
||||
## Day 3
|
||||
|
||||
God!No!昨天已经够累的了,今天老师还要讲课,还要早起!你期待着老师可以降低要求,可是当老师托起长音,讲起了他知道了学生的累,所以今天决定开始讲课了!(现在讲有毛用啊,你明天就要验收我们的进度了!)
|
||||
|
||||
而他却慢悠悠的开始讲python的历史,把这点内容讲了足足两节课,你终于绷不住了,本来时间就不够,他竟然又浪费了你足足一早上的时间!这也太该死了!🤬
|
||||
|
||||
你回到了寝室,准备今天争取数据分析完就直接交上去好了!
|
||||
|
||||
可是你发现了一个让你震惊的噩耗!你找到的数据,是混乱的!😱
|
||||
|
||||
这个野鸡房价网站每个城市的排版不一样,你爬虫爬取的完全是按照顺序标的,也就是说你爬取的所有房价信息处于混沌状态!完全就相当于给每个房子爬了一段句子的描述!
|
||||
|
||||
没有办法了,看来今天有的折腾了,你找到了一个叫pandas(熊猫?)的东西,找到了这个教程[Joyful-Pandas](https://github.com/datawhalechina/joyful-pandas),开始了一天的学习!
|
||||
|
||||
你了解到pandas是一个开源的Python数据处理库,提供了高性能、易用、灵活和丰富的数据结构,可以帮助用户轻松地完成数据处理、清洗、分析和建模等任务。你使用了DataFrame来装载二维表格对象。
|
||||
|
||||
用一些关键词来提取数据中隐藏的信息,例如提取“平米”前面的数字放到‘area'列,提取房价到'price’列,提取位置到'locate'里面,当然你也遇到了可怕的bug,提取所有“室”和“厅”前面的数字,他总是告诉你有bug,全部输出之后才发现你提取到了“地下室”结果他没法识别到数字所以炸了!
|
||||
|
||||
将数据勉强弄得有序之后,你提取了平均数填充到缺失数据的房屋里面,将一些处理不了的删掉。
|
||||
|
||||
当然,你也额外了解到pandas这只可爱的小熊猫还有非常多强大的功能,例如数据可视化,例如分类数据,甚至可以让房屋按照时序排列,但是你实在不想动了!
|
||||
|
||||
不论怎么说,你勉强有了一份看得过去的数据,你看了看表,已经晚上十一点半了,今天实在是身心俱疲!
|
||||
|
||||
问问队友吧,什么,他们怎么还是在python语法?!你就像进了米奇不妙屋~队友在想你说“嘿~你呀瞅什么呢~是我!你爹~”
|
||||
|
||||
此时你像一头挨了锤的老驴,曾经的你有好多奢望,你想要GPA,想要老师的认同,甚至想要摸一摸水里忽明忽暗的🐟,可是一切都随着你的hadworking变成了泡影。
|
||||
|
||||
可是步步逼近的截止日期不允许你有太多的emo期,说好的七天时间,最后一天就剩下展示了!也就是说实际上只有6天的开发时间,也就是说你必须得挑起大梁了
|
||||
|
||||
> 世界上只有一种真正的英雄主义,那就是看清生活的真相之后,依然热爱生活
|
||||
|
||||
好的,你真不愧是一个真正的英雄!
|
||||
|
||||
day 3 end!👿 👹 👺 🤡
|
||||
|
||||
## Day 4
|
||||
|
||||
老师在验收的时候认为你什么工作也没做,他认为一份数据实在是太单薄了,特别是被你疯狂结构优化后的数据已经没几个特征了,让你去做点看得到的东西,不然就要让你不及格了,你的心里很难过,你想到也许你需要一些更好看的东西。数据可视化你在昨天的pandas看到过,可是你并没有详细了解,你觉得pandas已经在昨天把你狠狠的暴捶一顿了,并且老师想要更好看的图。
|
||||
|
||||
于是你考虑pandas配合Matplotlib画一些简单的图(Matplotlib的缺点是它的绘图语法比较繁琐,需要编写较多的代码才能得到漂亮的图形。)
|
||||
|
||||
加上Plotly绘制一些复杂的图,让你的图有着更漂亮的交互效果,然后加上看起来很牛逼的英语描述
|
||||
|
||||
|
||||
你找到了下面的教程
|
||||
[matplotlib奇遇记文字教程](https://github.com/datawhalechina/fantastic-matplotlib)
|
||||
|
||||
[极好的Plotly文字教程:](https://github.com/datawhalechina/wow-plotly)
|
||||
[视频教程](https://www.bilibili.com/video/BV1Df4y1A7aR)
|
||||
|
||||
🤗
|
||||
你绘制了柱状图,散点图,箱线图,甚至花了点钱找了外包去做了一个前端的热力图,虽然你爬的城市和数据不够覆盖全国,但是可以数据不够前端来凑啊!把城市的热量铺洒在全国。
|
||||
|
||||
这时你认为你的任务已经完成了!于是早早就心满意足的早早睡着了🍻 🥂。最近真的太累了,天天一两点睡,早上惊醒,做梦都是在爬数据分析数据!太可怕了!
|
||||
|
||||
在梦里,你好像看到了美好的假期时光。 😪
|
||||
|
||||
day 4 end!~🤤
|
||||
|
||||
## Day 5
|
||||
|
||||
你睡得很死,因为你已经你做完了所有的东西,第二天只要美美的验收结束,买了机票就可以回家了,可是老师仍然制止了你,跟你说如果你今晚走了就给你挂科,因为你没有用机器学习来分析他!
|
||||
|
||||
可是机票今晚就要起飞了啊!😰你已经要气疯了,想和老师据理力争,但是又害怕这么一个课被打上不及格的分数,这实在是太难受了!
|
||||
|
||||
终归你还是在老师的逼迫下,改签了机票,好吧,多少得加点功能了!呜呜呜~🤢 🤮
|
||||
|
||||
可是你并不完全会机器学习的算法,可怜的大一本科生的你没有学信息论也没有学最优化理论,很多算法你完全不懂其理论知识!听说西瓜书很好,可是你在图书馆借到了西瓜书之后根本看不懂!
|
||||
|
||||
于是你找到了吃瓜教程,也就是所谓市面上的南瓜书的[文字教程](https://github.com/datawhalechina/pumpkin-book)
|
||||
|
||||
你也找到了西瓜书的代码实践[文字教程](https://github.com/datawhalechina/machine-learning-toy-code)
|
||||
|
||||
你对着他啃了半天,觉得很多东西你都能看懂了,你脑子里已经有了很多思路,你想按使用高级的机器学习的算法!
|
||||
|
||||
但是!时间还是太紧张了!你没有办法从头开始实现了!
|
||||
|
||||
你想尝试[pytorch文字教程](https://github.com/datawhalechina/thorough-pytorch),但是时间也不够让你去重整数据去训练了。你随便塞在线性层里的数据梯度直接爆炸,你这时候还不知道归一化的重要性,紧张之下把几万几十万的房价往里面塞,结果结果烂成💩了,并且你没有波如蝉翼的基础知识并不够让你去解决这些个bug,只能疯狂的瞎挑参数,可是结果往往不如人意~
|
||||
|
||||
时间来到了晚上八点,明天就要最后验收了,走投无路的你把目光看向了远在几十千米外已经入职了的大哥,晚上跟他打电话哭诉你最近的遭遇,你实在搞不懂,为什么十二生肖大伙都属虎,就你属驴。
|
||||
|
||||
大哥嘎嘎猛,连夜打车过来,我在因疫情封校的最后两个小时赶出了学校,和大哥一起租了个酒店,通宵奋战,他采取了更多更为优雅的特征工程和模型调参的方式,让模型优雅的收敛到了一定程度,再用春秋笔法进行汇总,在半夜两点半,终于将内容搞定了
|
||||
|
||||
终于你可以睡个好觉了~
|
||||
|
||||
day 5 end!😍 🥰 😘
|
||||
|
||||
## Day 6
|
||||
|
||||
验收日,老师端坐在底下,宛如一尊大佛,提出了一系列无关紧要的问题,比如问我们能不能拿这个程序给老年人查资料???
|
||||
|
||||
等等问题和技术一点关系都没有!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
|
||||
|
||||
😣 😖 😫 😩
|
||||
|
||||
极度悲愤之下,当天晚上,你火速提着行李,离开了这伤心之地~~~~~~~~~~~~~~~~~
|
||||
|
||||
The End~~~~~~~~~~
|
||||
|
||||
# 事后总结
|
||||
|
||||
你在那个暑假详细了解和学习一下数据科学竞赛,发现他的含金量在职场领域有时候相当高,并且对提升自身的实力也有相当大的帮助!
|
||||
|
||||
[数据竞赛Baseline & Topline分享](https://github.com/datawhalechina/competition-baseline)
|
||||
|
||||
你还发现了之前从来没有注意到的kaggle平台以及一些很棒的综合实践项目!
|
||||
|
||||
例如[根据贷款申请人的数据信息预测其是否有违约的可能](https://github.com/datawhalechina/team-learning-data-mining/tree/master/FinancialRiskControl)
|
||||
|
||||
[根据汽车类型等信息预测二手汽车的交易价格](https://github.com/datawhalechina/team-learning-data-mining/tree/master/SecondHandCarPriceForecast)
|
||||
|
||||
例如:[使用公开的arXiv论文完成对应的数据分析操作](https://github.com/datawhalechina/team-learning-data-mining/tree/master/AcademicTrends)
|
||||
|
||||
|
||||
想到如果你早做准备,没有荒废大一的时光,也许你不但能圆满的通过这次课程,也可以开辟更为广阔的新世界了吧~
|
||||
|
||||
同时,你也初窥了数学+机器学习世界的瑰丽传奇,你想更为深入的对其有一个了解,并且做出点东西,希望对你日后的学习生活有个见证~~
|
||||
|
||||
少年将去开启新的传奇~~~~~
|
||||
|
||||
::: danger 再次警告,本章内容有很多瞎编的内容,不要全信
|
||||
|
||||
比如说一天学完pandas,一天学完sql之类的都是很不现实的!希望大家注意!
|
||||
|
||||
当然你也可以在需要用的时候再研究,也来得及,就是很累
|
||||
|
||||
不要打击到大家的自信心!
|
||||
:::
|
||||
|
||||
# 补充内容:下个定义
|
||||
|
||||
数据分析是独立于开发和算法岗的另一个方向,它主要是通过<strong>应用</strong>机器学习和深度学习的<strong>已有算法</strong>来分析现实问题的一个方向
|
||||
|
||||
我们常说:数据是客观的,但是解读数据的人是主观的。
|
||||
|
||||
数据这门科学就像中西医混合的一门医学,既要有西医的理论、分析模型以及实验,又需要有中医的望闻问切这些个人经验。
|
||||
|
||||
|
||||
> 这世界缺的真不是算法和技术,而是能用算法、技术解决实际问题的人
|
||||
|
||||
|
||||
# 什么是数据科学
|
||||
|
||||
数据科学是当今计算机和互联网领域最热门的话题之一。直到今天,人们已经从应用程序和系统中收集了相当大量的数据,现在是分析它们的时候了。从数据中产生建议并创建对未来的预测。[在这个网站中](https://www.quora.com/Data-Science/What-is-data-science),您可以找到对于数据科学的更为精确的定义。
|
||||
|
||||
同时,我向各位推荐一个非常有趣的科普视频想你讲解数据分析师到底在做什么:[怎么会有这么性感的职业吶?](https://www.bilibili.com/video/BV1ZW4y1x7UU)
|
||||
|
||||
<Bilibili bvid='BV1ZW4y1x7UU'/>
|
||||
|
||||
# Datawhale的生态体系
|
||||
|
||||
在与Datawhale开源委员会的负责人文睿进行一翻畅谈之后。zzm受震惊于其理念以及已经构建的较为完善的体系架构,毅然决然的删除了本章和其广泛的体系比起来相形见绌的内容。为了更大伙更好的阅读以及学习体验,我们决定在本章内容引入了[datawhale人工智能培养方案数据分析体系](https://datawhale.feishu.cn/docs/doccn0AOicI3LJ8RwhY0cuDPSOc#),希望各位站在巨人的肩膀上,争取更进一步的去完善它。
|
||||
@@ -1,153 +0,0 @@
|
||||
# 如何做研究
|
||||
|
||||
# 0. 讲在前面
|
||||
|
||||
Author: 任浩帆
|
||||
|
||||
Email: yqykrhf@163.com
|
||||
|
||||
术语介绍的补充:Spy
|
||||
|
||||
仅供参考,如有不足,不吝赐教。
|
||||
|
||||
# 术语的介绍
|
||||
|
||||
<strong>Benchmark:</strong>评测的基准。通常会是一些公开的数据集。
|
||||
|
||||
<strong>Baseline:</strong> 基准,一般指的是一个现有的工作。
|
||||
|
||||
<strong>SOTA </strong>(state-of-art): 截止目前,指标最好。
|
||||
|
||||
举个例子:
|
||||
|
||||
我们选取 XXX-Net 作为我们的 Baseline,在加入我们设计的注意力机制的模块,在 KITTI 这个 Benchmark 上性能达到了 SOTA。
|
||||
|
||||
<strong>Backbone:</strong>
|
||||
|
||||
这个单词原意指的是人的脊梁骨,后来引申为支柱,核心的意思。
|
||||
|
||||
在神经网络中,尤其是 CV 领域,一般先对图像进行特征提取(常见的有 vggnet,resnet,谷歌的 inception),这一部分是整个 CV 任务的根基,因为后续的下游任务都是基于提取出来的图像特征去做文章(比如分类,生成等等)。
|
||||
|
||||
所以将这一部分网络结构称为 backbone 十分形象,仿佛是一个人站起来的支柱。
|
||||
|
||||
<strong>Solid</strong>
|
||||
|
||||
一般是描述这个工作非常扎实。
|
||||
|
||||
这个工作很 solid。 每一步都 make sense(合理)。没有特意为了刷 benchmark 上的指标,用一些 fancy trick(奇技淫巧)。
|
||||
|
||||
<strong>Robust</strong>
|
||||
|
||||
鲁棒性,是描述一个系统受到外界的干扰情况下,仍然能保持较好的性能。
|
||||
|
||||
举个例子:
|
||||
|
||||
我们的系统的图片加入大量的噪声,已经旋转平移缩放以后,仍然能正确的分类,这表明了我们的工作具有一定的鲁棒性。
|
||||
|
||||
# 坐而论道
|
||||
|
||||
## 2.1 研究是什么
|
||||
|
||||
从实际的几个例子讲起:
|
||||
|
||||
1. 某学生,被老师分配了一个课题的名字:《语义分割》。之后开始看相关的论文,了解到有实时语义分割,视频语义分割,跨模态语义分割等等子任务或者交叉任务,然后跟导师开始汇报自己的一些感想,最后在老师的建议之下拟定了具体的课题,开始思考解决方案。
|
||||
2. 某学生,被老师分配了一个课题的名字:《存在遮挡情况下的单目人体重建》 。之后这个学生对这个问题提出了有效的解决方案。
|
||||
3. 某同学在 waymo(Google 自动驾驶子公司)实习,发现没有用神经网络来直接处理点云的工作。于是决定做一个神经网络能够直接输入点云,经过几番尝试以后,提出了《第一个能直接处理点云的网络》。
|
||||
4. 某高校的本科生在 lcw 下的指导下做科研的流程: 老师直接给给一个 basic idea,然后让本科做实验,在这个工程中非常有针对性的指导。
|
||||
|
||||
例 1 是在给定一个大题目的基础下,去阅读论文寻找小题目。
|
||||
|
||||
例 2 是在给定一个具体细致的题目基础下,直接去想如何解决。
|
||||
|
||||
例 3 是在实际工作的情况下发现了一个非常有意义的问题,然后思考如何解决。
|
||||
|
||||
例 4 是直接给定一个 idea,去实现,研究者所需要完成的几乎是工程实践。
|
||||
|
||||
理想情况下,研究流程应该包含:
|
||||
|
||||
Step 1. 提出问题
|
||||
|
||||
Step 2. 提出解决方案
|
||||
|
||||
Step 3. 验证解决方案的有效性。
|
||||
|
||||
有些问题是一直存在,但没有彻底解决的。这一类的问题通常,就不存在 Step 1。从事这一课题的研究者经常会在 2,3 之间来回反复。
|
||||
|
||||
## 2.2 如何做研究
|
||||
|
||||
从上一小节的几个例子当中,其实不同的人做研究所需要完成的工作是完全不一样的。很多时候只需要做 step 3 即可,从功利的角度来讲这是性价比最高的。
|
||||
|
||||
如果我们是一个合格的博士或者我们致力于如此,那么首先的第一步要找到一个好的问题,这是一个非常重要的开始,<strong>一个好的问题往往意味着研究已经成功了一半。 </strong>什么是一个好的问题?它可能会有以下几个特点:
|
||||
|
||||
1. 理论上能实现某种意义上的统一,从而使得问题的描述变得非常优雅。比如 [DepthAwareCNN](https://arxiv.org/abs/1803.06791)
|
||||
2. 对于之后的工作非常具有启发的作用,甚至达到某种意义的纠偏作用。 比如 [OccuSeg](https://arxiv.org/abs/2003.06537)
|
||||
3. 本身足够 solid,可以作为 meta algorithm。 比如 Mask-RCNN
|
||||
4. 是一个大家没有引起足够重视,却非常棘手且非常迫切的问题。 比如相机快速运动下的重建,[MBA-VO](https://openaccess.thecvf.com/content/ICCV2021/papers/Liu_MBA-VO_Motion_Blur_Aware_Visual_Odometry_ICCV_2021_paper.pdf)
|
||||
|
||||
### 2.2.1 如何去找一个好的问题
|
||||
|
||||
如何确保自己选的问题是一个好的问题?这需要和指导老师及时的反馈。如果指导老师不给力,那么一些方法仅供参考。
|
||||
|
||||
1. 自己和工业界的一些人去交流与沟通,看看实际落地的痛点是什么?面对这些痛点,已有的研究方法能否解决,是否有一些现有的 benchmark 或者容易制作的 benchmark 来做为评价标准。
|
||||
2. 做加法。举个例子:图片可以做语义分割。 那么图片 + 深度图如何更好的做语义分割。 图片 + 文字描述的做语义分割。现在的语义分割的标注都是 0,1,2,3 这些数字,然后每一个数字对应一个实际的类别,这个对应表是认为规定的。如果我把 0,1 的对应关系换掉。重新训练以后就,网络的性能是否会影响?
|
||||
3. 做减法。对于点云的语义分割的标注,通过是非常费时费力的。 那么对于点云来说,少量的标注是否是可行的?比如只标注百分之 10 的点。
|
||||
|
||||
以上是一些技巧,把输入调整一下,约束去掉一些,就会有很多新的问题。 这个过程通常被叫做<strong>“调研”</strong>
|
||||
|
||||
这个过程在是一个相对比较痛苦的过程,因为调研的过程中你会发现很多问题,想到很多所谓创新的解决方法,但是实际上你会发现你的解决方法已经有很多人做过了。这一阶段调整心态很重要,切忌急于求成。
|
||||
|
||||
### 2.2.2 如果提出解决方法
|
||||
|
||||
这个阶段需要百折不挠,小步快跑了。 一下是有一些可能有帮助的技巧:
|
||||
|
||||
1. 多读本领域的论文。(说起来非常玄妙,会在如何读论文部分详细解释)
|
||||
2. 读一些基础,跨领域的论文。 把其他领域的方法搬过来直接用。直接用通常情况下会存在一些问题,那么需要针对性的做一些改进。
|
||||
3. 从历史出发。将你面对的问题抽象成数学问题,这个数学问题可能过去很多人都遇到过,去看一看他们是如何解决的,从中获取一些灵感。
|
||||
|
||||
### 2.2.3 如果做实验
|
||||
|
||||
做实验的目的是为了快速的验证想法的正确性。 以下两个东西最好要有
|
||||
|
||||
1. 版本控制
|
||||
2. 日志系统
|
||||
|
||||
剩下就是一些工程习惯的问题,比如出现错误用 `std::cerr` 而不是 `std::cout`。这是一个需要实践积累的部分,与做研究有些脱节,之后有时间会在其他小节做一些补充。
|
||||
|
||||
# 快速出成果的捷径与方法
|
||||
|
||||
如何快速的出成果,不管别人如何帮你,前提是你自己要足够的强。不能存在 <strong>“靠别人” </strong>的想法。
|
||||
|
||||
对于一个博士生来讲,出成果保毕业,那么可能要对学术的进展要敏感,比如 Nerf 八月份刚出来的时候,如果你非常敏锐的意识到这个工作的基础性和重要性。那么你稍微思考一两个月,总是能有一些创新的 ieda 产生的。 所以这个<strong>timing 和 senstive</strong>就非常重要,当然导师是不是审稿人可能更重要。
|
||||
|
||||
对于一个本科生来讲,当然是跟着指导老师的脚步去做。但是如果指导老师只是把你当成一个工具人,一直打杂货的话。你想发论文,一种所谓的捷径是 A+B。就是把一个方法直接拿过来用在另一个地方,大概率这样会有一些问题,那么你就可以针对性的改进,如何针对性的改进?不好的方式是 A+B 套娃,好一些的方式是分析这个不好的原因在哪里,现有的方法多大程度可以帮助解决这个问题,或者现有的方法解决不了这个问题,但是其中的一个模块是否是可以参考的。
|
||||
|
||||
## 3.2 学习别人是如何改进网络的(Beta)
|
||||
|
||||
自 UNet 提出后就有许多的魔改版本,如 UNet++, U2Net, 而这些 UNet 的性能也十分优异。
|
||||
|
||||
可以参考 UNet 的发展历程,去学习如何在前人的工作上加以改进和提升。
|
||||
|
||||
注:通过历史的演变来学习是非常有必要的,但是你需要注意一点的是,深度学习很多时候会出现一些情况:
|
||||
|
||||
1. 你认为你提出的改进方法是有效的,但是实际是不 OK 的
|
||||
2. 你认为你提出的方法可能有效,实际上也确实有效。然而你不能以令人信服的方式说明这为什么有效。
|
||||
|
||||
举个例子 ResNet 为什么有效。“因为网络越深,可以拟合的函数空间就会复杂,但是越深网络效果反而变差。那么从一个角度来思考:网络至少某一层 i 开始到最后一层 k,如果学习到的函数是 f(x)=x 的恒等映射,那么网络变深以后至少输出是和 i-1 层的是一模一样的,从而网络变深可能不一定会变好,但是至少不会变差才对。” 看起来很有道理,然后 CVPR2021 分享会,ResNet 的作者之一,xiangyu zhang 说 “当时也完全不能使人很信服的解释为什么 ResNet 就一定效果好,感觉更像是基于一些灵感,得到了一个很棒的东西,更像是一个工程化的问题,而不是一个研究。但我们可以先告诉别人这个是非常有效的,至于为什么有效,可能需要其他人来解决。”
|
||||
|
||||
再举一个例子 BN(Batch normalization)为什么有效,你去看 BN 的原论文和之后关于 BN 为什么有效的研究,会发现原论文认为有效的原因是不太能让人信服的。 但这不妨碍 BN 有效,而且非常快的推广起来。
|
||||
|
||||
其实这件事可以类比于中医,做研究就好比要提出一套理论,但是我不知怎得忽然发现有一个方子经过测试非常有效,但是我确实不能给出一个很好的理论解释说明这个房子为什么有效。但是我尽快把这个方子告诉大家,这同样是非常有意义的。
|
||||
|
||||
举这个两个例子是为了说明,类似 ResNet 这种拍一拍脑袋就想出的 idea,一天可能能想出十几个,但是最后做出来,并且真正 work 的非常少。这里面就存在一个大浪淘沙的过程,可能我们看到的经典的网络,比如 Unet 就是拍拍脑袋,迅速做实验出来的。 我认为这种思考方式仅仅值得参考,并不值得效仿。 现在早已经不是 5 年前那样,却设计各种 fancy 的网络结构去发论文的年代了。
|
||||
|
||||
那么我们应该如何对待神经网络?(之后再写)
|
||||
|
||||
但我想 Charles qi 的思考方式是值得借鉴的。论文的顺序是
|
||||
|
||||
PointNet------>PointNet++------>PointFrustum-------->VoteNet
|
||||
|
||||
有对应的中文 Talk。但我建议先去读论文,之后再看 talk。
|
||||
|
||||
我们不应该无脑的认为我们给什么数据,网络就会得到好的结果。说什么高层,底层特征云云。
|
||||
|
||||
思考问题可以先从类似哲学的 high level 层面开始,但是具体操作一定要 make sense,不然只是一个空想家。
|
||||
153
4.人工智能/4.人工智能.md
153
4.人工智能/4.人工智能.md
@@ -1,153 +0,0 @@
|
||||
# 4.人工智能
|
||||
## 开篇
|
||||
对于所谓AI的开篇该怎么写,我思考了很久,因为这实在是太过于宏大的话题了,从2012年开始这个行业迎来了所谓的技术爆炸阶段
|
||||
|
||||
> 宇宙的时间尺度来看,一个文明的技术在科技发展的过程中,可能短时间内快速发展、科技发展速度不断增加的现象 --------《三体》
|
||||
|
||||
无论是工业界还是科研界似乎都在这轮发展中进入了一场狂欢,但是狂欢之下,时代的滚滚洪流,也引起了不少人的焦虑和恐慌。
|
||||
|
||||
我们人类在如此宏大的课题面前,我们将得到什么?又将会失去什么呢?也许只有时间可以告诉我们答案。
|
||||
|
||||
阅读本篇内容的群体,我想主要是自动化或计算机的大学生,更多的是没有基础的同学才会翻阅。
|
||||
|
||||
因此本篇不将技术,笔者将从自己的视角,笔者进入大学到现在对所谓AI发展的思想感受的变迁为明线,为将要开启人工智能学习的大伙勾勒出一个笔者眼中的,**人工智能**时代。
|
||||
|
||||
同时,我也会在本篇内容中给你,你可以在本篇内容中获得什么。
|
||||
> 这是一个最好的时代,也是一个最坏的时代;
|
||||
>
|
||||
> 这是一个智慧的年代,这是一个愚蠢的年代;
|
||||
>
|
||||
> 这是一个信任的时期,这是一个怀疑的时期。
|
||||
>
|
||||
> 这是一个光明的季节,这是一个黑暗的季节;
|
||||
>
|
||||
> 这是希望之春,这是失望之冬;
|
||||
>
|
||||
> 人们面前应有尽有,人们面前一无所有;
|
||||
>
|
||||
> 人们正踏上天堂之路,人们正走向地狱之门。
|
||||
>
|
||||
> ——《双城记》 查尔斯·狄更斯
|
||||
|
||||
## 看山是山
|
||||
|
||||
2020年,在一门杭电的程序设计实践课上,老师要求我们用C语言去实现一些算法,我本来是将目标定为去大厂赚更多的钱的,对所谓AI仅仅停留在概念上,对其内容一无所知。
|
||||
|
||||
在实验的过程中,偶然和一位转专业学长偶然聊起到程设变态难得题目设计,要求用C语言实现KNN之类的算法,这TM对于我当时的水平简直是太难了!聊到他自己所在的某个实验室本科生的入组任务也不过是这个难度偏低一点点。
|
||||
|
||||
带着投机主义的心态,想着能不能混到一些论文之类的成果更好就业,毅然决然上了船。
|
||||
|
||||
当然,这也是大伙可能愿意去看这篇文章或抱着本科生科研的心态去学习本篇讲义或学习人工智能的主要心态。
|
||||
|
||||
可能还有一些人想的是我学一下这个相关技术可以更好的打比赛或者做项目,都是在我“看山是山"的阶段有过的。
|
||||
|
||||
对所谓的科研,所谓的论文,所谓的项目的含金量都是一知半解,只不过是“看到感觉他很火,感觉他很好,具体怎么样我不知道”的心态。这也是在当时的市场上,很多人的心态,由此也是人工智能第一轮狂潮的热点所在,因为大家其实很多都不清楚这个新技术,究竟有什么样的上线,吹起了很大的泡泡。
|
||||
|
||||
就算是有点远见的本科生,也仅仅是看到了所谓的CV和NLP在学校和整个社会大规模宣传下的科普性的概念,也许也没有深入了解过,当时的我也一样。但是我也陷入了同样的狂热中,仅仅是因为他足够火热或有足够的前景,我就想着跟随着潮流走。
|
||||
|
||||
我看了一点非常基础的教程,老师便给我发了两篇非常刺激的CV论文,都是他专业下比较前沿的文章了,我对这到底意味着什么仍然是一无所知,我完全没有搭建起合理的知识框架,我眼里AI只有深度学习,只有用框架写的那几行短短的代码,于是开启了受难之旅。
|
||||
|
||||
老师并没有做错什么,他只是在这个人工智能大潮下的一朵浪花,他也尽其所能的做到了对本科学生的关注,错的是我,我没有仔细考究过,也没有站在足够高的角度去审视如果我加入了他的工作,我在这个行业中会处在什么样的位置。
|
||||
|
||||
**这也是本篇讲义想要做到的第一件事,让你可以从比较高的角度去搭建起对这个领域的知识框架,而不是贸然的进入某个领域然后发现自己不喜欢或者说自己“被坑了”。**
|
||||
|
||||
## 看山不是山
|
||||
|
||||
学习过程非常恐怖的一件事就是完全没有正反馈,我在阅读论文的时候面对的是我对他无数前置工作一无所知的情况,并且我完全不知道怎么入手去读一个纯英文论文,我也不知道做科研到底意味着什么?
|
||||
|
||||
**这也是本篇讲义想要做到的第二件事,让你可以阅读一些文章之后就有一个大致的方法论而不至于完全手足无措。在本章的如何做研究和如何科研论文写作的篇章里面。**
|
||||
|
||||
短短的两篇文章我足足啃了一个假期,去读了很多东西,看了很多文章,但是自己究竟学会了什么其实也是答不上来,唯一能带给我的欣喜就是我复现了那篇文章,我让他在自己想要的数据集上跑起来了,但是也没有什么太大的成就感,因为唯一可以看到的仅仅只是跳动的数字和分割出来效果极其糟糕的几张图片。
|
||||
|
||||
紧接着我阅读了更多的论文,带给我的只有更多的负反馈,我不清楚将前两个论文串起来为什么就变成了一个创新点,我不清楚为什么论文写的代码里没有,我也不清楚代码为什么那样写,创新方案为什么要做成那样?我最大的疑惑其实是我们在不断堆积数据和算力,这样也能叫科研吗?而他们却又真真切切的发表在了那些顶刊上?这合理吗?
|
||||
|
||||
我刚刚对科研建立起的美好神圣的幻想,被一篇又一篇近乎重复的论文打的粉碎,让我不禁身心俱疲。我根本不相信靠眼前这些,被当时的我定义为“学术垃圾”的论文能掀起什么风浪。可我也不知道到底什么样才是真正的科研,不知道我该怎么做。
|
||||
|
||||
当时唯一支撑我的是某位老师的观点,她认为科技的进步和学术的发展正是建立在无意义的沙堆上的。正是这高耸的沙堆,才让人们可以清晰的看见沙堆上蚌中的珍珠散发着耀眼的光。尽管很多看起来现在无用,也许几年后,他被挖掘出来,就会发挥新的作用,我对此完全不理解,只是觉得深度学习目前这个研究方向,为什么大方向这么不可理喻。
|
||||
|
||||
当时的我还看到了,因为他的爆火,带来了非常优秀的工具链,极大程度的降低了门槛。科研界将电子斗蛐蛐奉为圭臬,比赛和项目只是劳动力和资源的无限叠加堆砌出来结果亦或是单纯的硬扯,工业界不知道在搞些什么名堂,好像仅仅只知道跟着国外的脚步走。(甚至你在现在的讲义中仍然能发现一些我当时的看法)
|
||||
|
||||
很多本科生诚然发了优秀的论文,可他也不过是一颗坚挺的或者优秀的螺丝钉,在正确的时间,正确的位置,做了不知道正确还是错误的事,让他取得了不属于他目前能力的成就。无论是老师还是学生都被迫进入了这一场狂欢然后做了也许不那么正义的事情。
|
||||
|
||||
**我厌恶他!我厌恶他破坏了科研的纯洁性!我厌恶他成为了急功近利者的帮凶!我厌恶他堆砌的沙堆是充斥着无产者的血和泪!我厌恶他让马太效应发挥到了极致!我厌恶他让所有人都贴上了他的面具,但可能对本质上的东西一无所知!我厌恶他只注重结果,完全不注重过程然后让写的故事变成了捏造!**
|
||||
|
||||
但是,现在我会说,也许当时的我真的错了。我并没有思考过所谓人类的智能和AI的智能的关系,也忽视了当某一个趋势或方向发展到极致之后,量变会引发什么样的质变。
|
||||
|
||||
[推荐大伙可以看看这个](https://www.bilibili.com/video/BV11c41157aU)
|
||||
|
||||
<Bilibili bvid='BV11c41157aU'/>
|
||||
|
||||
## 看山是山
|
||||
> 孟德尔出生于奥地利帝国(今天的捷克共和国)的西里西亚,是现代遗传学的创始人。尽管几千年来农民就知道动植物的杂交可以促进某些理想的性状,但孟德尔在1856年至1863年之间进行的豌豆植物实验建立了许多遗传规则,现称为孟德尔定律。
|
||||
|
||||
在孟德尔那个时代,人们不知道基因,人们也看不到那么小的东西,他给基因取了个名字叫遗传因子。他没能掌握“真实的规律”,可是我们不得不承认的是,他是一个真正有科研精神的人的科研人。 -
|
||||
|
||||
我在不断地绝望之后,走向了极端,我放弃了跟进这个方面的学习,孟尝高洁,空余报国之情;阮籍猖狂,岂效穷途之哭!我失去了搞科研的热情,只想一心去做些别的。
|
||||
|
||||
我看到了南大的课程,我去看一生一芯,去看jyy老师的OS,我听到了蒋老师对未来AI的发展充满了信心,我虽然很崇拜他,但我仍对此嗤之以鼻,我不相信。
|
||||
|
||||
一直到有一天,相先生在实验室玩一个叫chatGPT的东西,虽然之前懵懵懂懂的有了解过GPT3之类的东西,但是都对此行的发展没有什么了解,只是知道他又非常大的参数的语言模型,在好奇之下,我去亲自体验chat GPT,我受震惊于他能准确无误的理解我的意思,甚至能替我写代码,只要将问题拆解,他几乎可以就任何一个问题给出一个反而化之的答案。
|
||||
|
||||
随后没过多久,GPT4与new bing应运而生,可以理解用户的意图和情感,根据用户的偏好和反馈来调整输出,甚至利用网络搜索来增强其的知识和回答能力,他们还结合了CV的功能,可以让他们来进行图像的生成工作。作为科研人的最高追求,大一统,一通半通的解决所有问题的模型竟然真的可能在我的有生之年实现,不由得震惊至极。同时,大模型也进入了CV领域,出现了segmenting anything这样可以做到零样本迁移这样的神奇功能,auto GPT出现了在电脑主机上直接替人解决问题甚至是完成某一项工程任务的GPT,以及可以在手机上本地做的mini GPT,技术的爆炸以及变革似乎一瞬间到来了,但是当我回过头展望的时候,正是我最看不起的沙砾,堆叠成了如此强大石之巨人,并且随着资本的涌入,他还在不断强大!!!
|
||||
|
||||
2012年,被我们认定为人工智能学习的开篇之作,Alex net诞生了,由Alex Krizhevsky和他的导师Geoffrey Hinton以及Ilya Sutskever设计,在2012年的ImageNet大规模视觉识别挑战赛中获得了冠军,展示了深度学习在图像分类方面的强大能力,并且正式启动了深度学习的革命,在当时他也引发了大量的争议,奉承这符号主义的大师们对着他指指点点,可是他们并不能阻碍时代的巨石碾过一切非议,并且在各个领域都爆发出极其强大的生命力。
|
||||
|
||||
想起在学操作系统的时候,linus在几十年前被大老师tanenbaum狂喷,说整了什么垃圾玩意儿。当时的minix基本上可以说是横扫江湖,linus却坚持说用户只考虑用户态是否好用而不在乎内核有多牛逼,当时的论战基本上把各类大神都炸出来,结果几十年后的如今我们发现原来遍布世界的居然是宏内核/混合内核。
|
||||
|
||||
时代的发展连大佬都可以拍死在沙滩上!
|
||||
|
||||
|
||||
|
||||
从短期来看,也许未来GPT会接管小AI形成一套上下左右俱为一体的AI智能模型,在所谓自动驾驶,智能家居领域发挥极其卓越的作用。
|
||||
|
||||
从长远来看,不由得联想起AI在围棋方面alpha zero的论文里面提到过,当他们不适用人类的知识的时候,反而模型的效果好很多,有没有可能AI在短短的未来总结出一套人类自然语言的规则后,自发创造出一个全新的语言,最终就彻底脱离人类变成一种全新的生命形式,从而彻底颠覆人类以公理为基础的数学,创造一套全新的数学体系,数学体系重做,物理学是否也会迎来质变?
|
||||
|
||||
AI是一个复杂且多样化的研究领域,他能取得如此长远的发展,并非是仅仅一个两个人靠着所谓的理论研究就可以推动起来的,它伴随着底层的硬件设施配套的完善,算力的突破性增长等等,发展本身,也许就是兼容并蓄的,我们应该在这个发展的洪流前,找到自己的位置以更为谦卑谨慎的姿态,进行更为长远的思考和学习吧。
|
||||
|
||||
> 三花聚顶本是幻,脚下腾云亦非真。大梦一场终须醒,无根无极本归尘。
|
||||
|
||||
## 结语
|
||||
让我们回到最开始的那几句话
|
||||
这是一个最好的时代(AI技术正在改变人们的生活)
|
||||
|
||||
也是一个最坏的时代(AI也许取代大量人的饭碗)
|
||||
|
||||
这是一个智慧的年代(很多顶尖的科学家正在改变世界)
|
||||
|
||||
这是一个愚蠢的年代(很多高校止步于电子斗蛐蛐,很多企业只想着追赶外国不想着自己创新)
|
||||
|
||||
这是一个信任的时期(人们将更加信任这个社会会因此变好)
|
||||
|
||||
这是一个怀疑的时期(AI技术带来伦理,毁灭世界等方面的讨论)
|
||||
|
||||
这是一个光明的季节(前沿科研或科技从来没有离普通的本科生这么近)
|
||||
|
||||
这是一个黑暗的季节(太近了导致很多人急功近利)
|
||||
|
||||
这是希望之春(我们迎来了技术爆炸)
|
||||
|
||||
这是失望之冬(我国仍有很多需要发展的地方)
|
||||
|
||||
人们面前应有尽有(人们以后可能拥有了AI也就拥有了一切)
|
||||
|
||||
人们面前一无所有(隐私,版权,安全等问题正在受到质疑)
|
||||
|
||||
人们正踏上天堂之路(也许未来人类不用干任何工作实现真正的共产主义)
|
||||
|
||||
人们正走向地狱之门(也许人类将被取代将被奴役,无数人会被取代)
|
||||
|
||||
技术的发展往往就伴随着激烈的争议和讨论
|
||||
|
||||
火车出现的年代人们责怪他破坏风水
|
||||
|
||||
蒸汽机出现的时代人指责他不安全
|
||||
|
||||
纺织机出现的时代女工辱骂他抢了自己工作
|
||||
|
||||
而这些都不会使他停滞
|
||||
|
||||
**这是本讲义想做的第三件事,拥有学习新技术,跟上时代的能力**
|
||||
|
||||
而愿不愿意在这激荡翻腾的年份,贡献出你的力量,让世界变得更好/更坏,就取决于你的选择了!
|
||||
|
||||
## 欢迎来到新世界!同学们!
|
||||
@@ -1,35 +0,0 @@
|
||||
# FunRec概述
|
||||
|
||||
# 序言
|
||||
|
||||
这是一篇datawhale的相当优秀的推荐系统教程,因此特别废了九牛二虎之力把FunRec的半套内容,较为完整的移植到了本wiki中。
|
||||
|
||||
## 为什么要专门移植这篇?
|
||||
|
||||
zzm个人以为推荐系统是一个非常有趣的横向和纵向都有很多应用的领域(放到外面是因为放到某一个模块下会因为次级链接太多把wiki撑爆了)
|
||||
|
||||
若你想尝试一个新领域,也许这是一个不错的切入点。更何况,如果你想足够完整的构建一个有实际价值的推荐系统,可能需要你去了解相当全面的知识。
|
||||
|
||||
在学习了基础内容之后,如果你想向着科研领域进发,也许对你而言最好的方式或许是选择一个大佬然后去follow他的进度。
|
||||
|
||||
如果你想去找相关的工作,你可以自行去深入学习有关本教程内容的实践部分,甚至是阅读算法面经。
|
||||
|
||||
同时只放上半部的原因是毕竟本偏内容是人工智能大类下的内容,后续可能会涉及一些前后端以及一些更为深入的东西,如果你只是想大致了解一下,那么阅读放在本片的内容被也许是一个不错的选择。
|
||||
|
||||
再次感谢Datawhale的大伙做出了如此卓著的贡献
|
||||
|
||||
# 正文
|
||||
本教程主要是针对具有机器学习基础并想找推荐算法岗位的同学。教程内容由推荐系统概述、推荐算法基础、推荐系统实战和推荐系统面经四个部分组成。本教程对于入门推荐算法的同学来说,可以从推荐算法的基础到实战再到面试,形成一个闭环。每个部分的详细内容如下:
|
||||
|
||||
- **推荐系统概述。** 这部分内容会从推荐系统的意义及应用,到架构及相关的技术栈做一个概述性的总结,目的是为了让初学者更加了解推荐系统。
|
||||
- **推荐系统算法基础。** 这部分会介绍推荐系统中对于算法工程师来说基础并且重要的相关算法,如经典的召回、排序算法。随着项目的迭代,后续还会不断的总结其他的关键算法和技术,如重排、冷启动等。
|
||||
- **推荐系统实战。** 这部分内容包含推荐系统竞赛实战和新闻推荐系统的实践。其中推荐系统竞赛实战是结合阿里天池上的新闻推荐入门赛做的相关内容。新闻推荐系统实践是实现一个具有前后端交互及整个推荐链路的项目,该项目是一个新闻推荐系统的demo没有实际的商业化价值。
|
||||
- **推荐系统算法面经。** 这里会将推荐算法工程师面试过程中常考的一些基础知识、热门技术等面经进行整理,方便同学在有了一定推荐算法基础之后去面试,因为对于初学者来说只有在公司实习学到的东西才是最有价值的。
|
||||
|
||||
**特别说明**:项目内容是由一群热爱分享的同学一起花时间整理而成,**大家的水平都非常有限,内容难免存在一些错误和问题,如果学习者发现问题,也欢迎及时反馈,避免让后学者踩坑!** 如果对该项目有改进或者优化的建议,还希望通过下面的二维码找到项目负责人或者在交流社区中提出,我们会参考大家的意见进一步对该项目进行修改和调整!如果想对该项目做一些贡献,也可以通过上述同样的方法找到我们!
|
||||
|
||||
为了方便学习和交流,**我们建立了FunRec学习社区(微信群+知识星球)**,微信群方便大家平时日常交流和讨论,知识星球方便沉淀内容。由于我们的内容面向的人群主要是学生,所以**知识星球永久免费**,感兴趣的可以加入星球讨论(加入星球的同学先看置定的必读帖)!**FunRec学习社区内部会不定期分享(FunRec社区中爱分享的同学)技术总结、个人管理等内容,[跟技术相关的分享内容都放在了B站](https://space.bilibili.com/431850986/channel/collectiondetail?sid=339597)上面**。由于微信群的二维码只有7天内有效,所以直接加下面这个微信,备注:**Fun-Rec**,会被拉到Fun-Rec交流群,如果觉得微信群比较吵建议直接加知识星球!。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220408193745249.png" />
|
||||
</div>
|
||||
@@ -1,15 +0,0 @@
|
||||
# SRT社团介绍
|
||||
|
||||
SRT 社团,全名 Student Research Trainning,旨在通过真正的科研活动培养本科生的科研能力。SRT 社团依托 [智能信息处理处理实验室](http://iipl.net.cn/index/list_team.aspx)(IIPL),主要研究方向围绕人工智能,具体来说,包括:计算机视觉,多模态,3D 视觉,Slam 等领域。有充足且优质的显卡资源,工位资源,以及学长学姐,老师的指导。
|
||||
|
||||

|
||||
|
||||
社团每年都在全校范围为智能信息处理实验室招收,培养本科生。本科生进入实验室后跟随导师独立或合作进行科研项目,发表论文。我们届时会在自动化以及通信学院进行宣讲招新,新生在经过1-2学期的培养后,能够具备独立科研的能力。在正式进入实验室前,可以暂时使用社团的工位,进入实验室后可以拥有独立工位以及显卡资源。社团的实验室在科技馆五楼,欢迎大家常来 ~
|
||||
|
||||
对于每一位新生,我们将教授包括但不限于:PyTorch,深度学习基础,卷积神经网络,Transformer 的知识和使用它们的能力。届时将会有定期随讲授内容发布的任务,完成任务,掌握相应技术且通过考核的同学在与导师交流后可以正式进入实验室。
|
||||
|
||||
同时,实验室推荐社团的本科生到杭电丽水研究院实习。
|
||||
|
||||
当然,在学习人工智能模块时遇到任何问题也都可以咨询我们,我们将在能力范围内尽力给各位解答!
|
||||
|
||||

|
||||
@@ -1,95 +0,0 @@
|
||||
# 推荐系统的意义
|
||||
|
||||
随着移动互联网的飞速发展,人们已经处于一个信息过载的时代。在这个时代中,信息的生产者很难将信息呈现在对它们感兴趣的信息消费者面前,而对于信息消费者也很难从海量的信息中找到自己感兴趣的信息。推荐系统就是一个将信息生产者和信息消费者连接起来的桥梁。平台往往会作为推荐系统的载体,实现信息生产者和消费者之间信息的匹配。上述提到的平台方、信息生产者和消费者可以分别用平台方(如:腾讯视频、淘宝、网易云音乐等)、物品(如:视频、商品、音乐等)和用户和来指代。下面分别从这三方需求出发,介绍推荐系统的存在的意义。
|
||||
|
||||
|
||||
## 平台方
|
||||
|
||||
平台方一般是为信息生产者提供物品展示的位置,然后通过不同的方式吸引用户来到平台上寻找他们感兴趣的物品。平台通过商家对物品的展示以及用户的浏览、观看或下单等行为,就产生了所谓的"流量"。
|
||||
|
||||
对平台方而言,流量的高效利用是推荐系统存在的重要原因。以典型的电商网站一般具有如图所示的树状拓扑结构,树状结构在连通性方面有着天然的劣势,阻碍这流量的高效流通。推荐系统的出现使得原本的树状结构变成网络拓扑结构,大大增强了整个网络的连通性。推荐模块不仅使用户在当前页面有了更好的选择路径,同时也给了每个商品增加入口和展示机会,进而提高了成交概率。而推荐质量的好坏,直接决定了用户选择这条路径的可能性,进而影响着流量的利用效率。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://typoraimg-1252051831.cos.ap-guangzhou.myqcloud.com/image-20220514232543182.png" alt="image-20220514232543182" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
推荐系统解决产品能够最大限度地吸引用户、留存用户、增加用户粘性、提高用户转化率的问题,从而达到平台商业目标增长的目的。不同平台的目标取决于其商业的盈利目的,例如对于YouTube,其商业目标是最大化视频被点击(点击率)以及用户观看的时长(完播率),同时也会最大化内置广告的点击率;对于淘宝等电商平台,除了最大化商品的点击率外,最关键的目标则是最大化用户的转化率,即由点击到完成商品购买的指标。推荐系统能够平台带来丰厚的商业价值 。
|
||||
|
||||
|
||||
## 信息生产者(物品)
|
||||
|
||||
因为在互联网大数据时代下,物品的长尾性和二八原则是非常严重的。具体来说,对于一个平台而言80%的销售额可能是那些最畅销20%的物品。但是那20%的物品其实只能满足一小部分人的需求,对于绝大多数的用户的需求需要从那80%的长尾物品中去满足。虽然长尾物品的总销售额占比不大,但是因为长尾物品的数量及其庞大,如果可以充分挖掘长尾物品,那这些长尾物品的销售额的总量有可能会超过热门商品。
|
||||
|
||||
物品只是信息生产者的产物,对于信息生产者而言,例如商家、视频创作者等,他们也更希望自己生产的内容可以得到更多的曝光,尤其是对于新来的商家或者视频创作者,这样可以激发他们创作的热情,进而创作出更多的商品或者视频,让更多的用户的需求得到满足。
|
||||
|
||||
对于一个平台而言,无论是否靠平台上的物品直接盈利,其将平台上的内容与用户进行匹配的能力都是衡量平台的重要标准之一,推荐系统的好坏很大程度上决定了平台匹配需求和供给的能力。推荐系统匹配需求和供给的能力决定了其最终的商业价值。
|
||||
|
||||
|
||||
## 信息消费者(用户)
|
||||
|
||||
推荐系统对于用户而言,除了将平台上的需求和供给进行匹配外,还需要尽可能地提高用户的体验,但是对于一个平台来说,影响用户体验的因素非常多(产品设计、广告数量等)。对于一个有明确需求的用户来说,用户在平台上可以直接通过搜索来快速满足自己的需求,但这也仅仅是一个平台最基础的用户体验(平台做的好是应该的,但是做的不好可能会被喷)。对于一个没有明确需求的用户来说,用户会通过浏览平台上的推荐页来获取一些额外的惊喜需求。因为用户没有明确的需求,也就对推荐页浏览的内容没有明确的预期,但是并不说明用户没有期待。我们每天都希望自己的一天中充满惊喜,这样生活才会感觉更加的多姿多彩。推荐系统可以像为用户准备生日礼物一样,让呈现的内容给用户带来惊喜,进而增强用户对平台的依赖。此外,在给用户带来惊喜的同时,也会提高平台的转化率(例如成交额)
|
||||
|
||||
|
||||
## 推荐和搜索的区别
|
||||
|
||||
搜索和推荐都是解决互联网大数据时代信息过载的手段,但是它们也存在着许多的不同:
|
||||
1. **用户意图**:搜索时的用户意图是非常明确的,用户通过查询的关键词主动发起搜索请求。对于推荐而言,用户的需求是不明确的,推荐系统在通过对用户历史兴趣的分析给用户推荐他们可能感兴趣的内容。
|
||||
2. **个性化程度**:对于搜索而言,由于限定的了搜索词,所以展示的内容对于用户来说是有标准答案的,所以搜索的个性化程度较低。而对于推荐来说,推荐的内容本身就是没有标准答案的,每个人都有不同的兴趣,所以每个人展示的内容,个性化程度比较强。
|
||||
3. **优化目标**:对于搜索系统而言,更希望可以快速地、准确地定位到标准答案,所以希望搜索结果中答案越靠前越好,通常评价指标有:归一化折损累计收益(NDCG)、精确率(Precision)和召回率(Recall)。对于推荐系统而言,因为没有标准的答案,所以优化目标可能会更宽泛。例如用户停留时长、点击、多样性,评分等。不同的优化目标又可以拆解成具体的不同的评价指标。
|
||||
4. **马太效应和长尾理论**:对于搜索系统来说,用户的点击基本都集中在排列靠前的内容上,对于排列靠后的很少会被关注,这就是马太效应。而对于推荐系统来说,热门物品被用户关注更多,冷门物品不怎么被关注的现象也是存在的,所以也存在马太效应。此外,在推荐系统中,冷门物品的数量远远高于热门物品的数量,所以物品的长尾性非常明显。
|
||||
|
||||
> 对于搜索、推荐、广告这三个领域的区别和联系可以参考王喆老师写的[排得更好VS估得更准VS搜的更全「推荐、广告、搜索」算法间到底有什么区别?](https://zhuanlan.zhihu.com/p/430431149)
|
||||
|
||||
## 推荐系统的应用
|
||||
个性化推荐系统通过分析用户的行为日志,得到用户当前的甚至未来可能的兴趣,给不同的用户展示不同的(个性化)的页面,来提高网站或者app的点击率、转化率、留存率等指标。推荐系统被广泛应用在广告、电商、影视、音乐、社交、饮食、阅读等领域。下面简单的通过不同的app的推荐页来感受一下推荐系统在各个内容平台的存在形式。
|
||||
|
||||
- **电商首页推荐(淘宝、京东、拼多多)**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421190313917.png" alt="image-20220421190313917" style="zoom: 15%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421191138469.png" alt="image-20220421191138469" style="zoom:53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421191441104.png" alt="image-20220421191441104" style="zoom:53%;" />
|
||||
</div>
|
||||
|
||||
- **视频推荐(抖音、快手、B站、爱奇艺)**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421190629410.png" alt="image-20220421190629410" style="zoom:55%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421191849577.png" alt="image-20220421191849577" style="zoom: 53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192047973.png" alt="image-20220421192047973" style="zoom:53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192209412.png" alt="image-20220421192209412" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
|
||||
- **饮食推荐(美团、饿了么、叮咚买菜)**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192623380.png" alt="image-20220421192623380" style="zoom:53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192717773.png" alt="image-20220421192717773" style="zoom:55%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192749794.png" alt="image-20220421192749794" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
|
||||
- **音乐电台(网易云音乐、QQ音乐、喜马拉雅)**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193139183.png" alt="image-20220421193139183" style="zoom: 57%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193447933.png" alt="image-20220421193447933" style="zoom:68%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193325921.png" alt="image-20220421193325921" style="zoom: 54%;" />
|
||||
</div>
|
||||
|
||||
|
||||
- **资讯、阅读(头条、知乎、豆瓣)**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193856262.png" alt="image-20220421193856262" style="zoom:53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193923283.png" alt="image-20220421193923283" style="zoom:55%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421194244083.png" alt="image-20220421194244083" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
|
||||
**参考资料:**
|
||||
|
||||
- 《推荐系统实践》
|
||||
- 《从零开始构建企业级推荐系统》
|
||||
- 《智能搜索和推荐系统》
|
||||
@@ -1,174 +0,0 @@
|
||||
# 推荐系统架构
|
||||
推荐和搜索系统核心的的任务是从海量物品中找到用户感兴趣的内容。在这个背景下,推荐系统包含的模块非常多,每个模块将会有很多专业研究的工程和研究工程师,作为刚入门的应届生或者实习生很难对每个模块都有很深的理解,实际上也大可不必,我们完全可以从学习好一个模块技术后,以点带面学习整个系统,虽然正式工作中我们放入门每个人将只会负责的也是整个系统的一部分。但是掌握推荐系统最重要的还是梳理清楚整个推荐系统的架构,知道每一个部分需要完成哪些任务,是如何做的,主要的技术栈是什么,有哪些局限和可以研究的问题,能够对我们学习推荐系统有一个提纲挈领的作用。
|
||||
|
||||
所以这篇文章将会从**系统架构**和**算法架构**两个角度出发解析推荐系统通用架构。系统架构设计思想是大数据背景下如何有效利用海量和实时数据,将推荐系统按照对数据利用情况和系统响应要求出发,将整个架构分为**离线层、近线层、在线层**三个模块。然后分析这三个模块分别承担推荐系统什么任务,有什么制约要求。这种角度不和召回、排序这种通俗我们理解算法架构,因为更多的是考虑推荐算法在工程技术实现上的问题,系统架构是如何权衡利弊,如何利用各种技术工具帮助我们达到想要的目的的,方便我们理解为什么推荐系统要这样设计。
|
||||
|
||||
而算法架构是从我们比较熟悉的**召回、粗排、排序、重排**等算法环节角度出发的,重要的是要去理解每个环节需要完成的任务,每个环节的评价体系,以及为什么要那么设计。还有一个重要问题是每个环节涉及到的技术栈和主流算法,这部分非常重要而且篇幅较大,所以我们放在下一个章节讲述。
|
||||
|
||||
架构设计是一个非常大的话题,设计的核心在于平衡和妥协。在推荐系统不同时期、不同的环境、不同的数据,架构都会面临不一样的问题。网飞官方博客有一段总结:
|
||||
|
||||
> We want the ability to use sophisticated machine learning algorithms that can grow to arbitrary complexity and can deal with huge amounts of data. We also want an architecture that allows for flexible and agile innovation where new approaches can be developed and plugged-in easily. Plus, we want our recommendation results to be fresh and respond quickly to new data and user actions. Finding the sweet spot between these desires is not trivial: it requires a thoughtful analysis of requirements, careful selection of technologies, and a strategic decomposition of recommendation algorithms to achieve the best outcomes for our members.
|
||||
> **“我们需要具备使用复杂机器学习算法的能力,这些算法要可以适应高度复杂性,可以处理大量数据。我们还要能够提供灵活、敏捷创新的架构,新的方法可以很容易在其基础上开发和插入。而且,我们需要我们的推荐结果足够新,能快速响应新的数据和用户行为。找到这些要求之间恰当的平衡并不容易,需要深思熟虑的需求分析,细心的技术选择,战略性的推荐算法分解,最终才能为客户达成最佳的结果。”**
|
||||
|
||||
所以在思考推荐系统架构考虑的第一个问题是确定边界:知道推荐系统要负责哪部分问题,这就是边界内的部分。在这个基础上,架构要分为哪几个部分,每一部分需要完成的子功能是什么,每一部分依赖外界的什么。了解推荐系统架构也和上文讲到的思路一样,我们需要知道的是推荐系统要负责的是怎么问题,每一个子模块分别承担了哪些功能,它们的主流技术栈是什么。从这个角度来阅读本文,将会有助于读者抓住重点。
|
||||
|
||||
## 系统架构
|
||||
|
||||
推荐系统架构,首先从数据驱动角度,对于数据,最简单的方法是存下来,留作后续离线处理,**离线层**就是我们用来管理离线作业的部分架构。**在线层**能更快地响应最近的事件和用户交互,但必须实时完成。这会限制使用算法的复杂性和处理的数据量。离线计算对于数据数量和算法复杂度限制更少,因为它以批量方式完成,没有很强的时间要求。不过,由于没有及时加入最新的数据,所以很容易过时。
|
||||
|
||||
个性化架构的关键问题,就是如何以无缝方式结合、管理在线和离线计算过程。**近线层**介于两种方法之间,可以执行类似于在线计算的方法,但又不必以实时方式完成。这种设计思想最经典的就是Netflix在2013年提出的架构,整个架构分为
|
||||
|
||||
1. 离线层:不用实时数据,不提供实时响应;
|
||||
2. 近线层:使用实时数据,不保证实时响应;
|
||||
3. 在线层:使用实时数据,保证实时在线服务;
|
||||
|
||||
### 设计思想
|
||||
网飞的这个架构提出的非常早,其中的技术也许不是现在常用的技术了,但是架构模型仍然被很多公司采用。
|
||||
|
||||
这个架构为什么要这么设计,本质上是因为推荐系统是由大量数据驱动的,大数据框架最经典的就是lambda架构和kappa架构。而推荐系统在不同环节所使用的数据、处理数据的量级、需要的读取速度都是不同的,目前的技术还是很难实现一套端到端的及时响应系统,所以这种架构的设计本质上还是一种权衡后的产物,所以有了下图这种模型:
|
||||
|
||||
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409205047285.png" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
上面是网飞的原图,我搬运了更加容易理解的线条梳理后的结构:
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409204658032.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
整个数据部分其实是一整个链路,主要是三块,分别是客户端及服务器实时数据处理、流处理平台准实时数据处理和大数据平台离线数据处理这三个部分。
|
||||
|
||||
看到这里,一个很直观的问题就是,为什么数据处理需要这么多步骤?这些步骤都是干嘛的,存在的意义是什么?
|
||||
|
||||
我们一个一个来说,首先是客户端和服务端的实时数据处理。这个很好理解,这个步骤的工作就是记录。将用户在平台上真实的行为记录下来,比如用户看到了哪些内容,和哪些内容发生了交互,和哪些没有发生了交互。如果再精细一点,还会记录用户停留的时间,用户使用的设备等等。除此之外还会记录行为发生的时间,行为发生的session等其他上下文信息。
|
||||
|
||||
这一部分主要是后端和客户端完成,行业术语叫做埋点。所谓的埋点其实就是记录点,因为数据这种东西需要工程师去主动记录,不记录就没有数据,记录了才有数据。既然我们要做推荐系统,要分析用户行为,还要训练模型,显然需要数据。需要数据,就需要记录。
|
||||
|
||||
第二个步骤是流处理平台准实时数据处理,这一步是干嘛的呢,其实也是记录数据,不过是记录一些准实时的数据。很多同学又会迷糊了,实时我理解,就是当下立即的意思,准实时是什么意思呢?准实时的意思也是实时,只不过没有那么即时,比如可能存在几分钟的误差。这样存在误差的即时数据,行业术语叫做准实时。那什么样的准实时数据需要记录呢?在推荐领域基本上只有一个类别,就是用户行为数据。也就是用户在观看这个内容之前还看过哪些内容,和哪些内容发生过交互。理想情况这部分数据也需要做成实时,但由于这部分数据量比较大,并且逻辑也相对复杂,所以很难做到非常实时,一般都是通过消息队列加在线缓存的方式做成准实时。
|
||||
|
||||
最后我们看第三个步骤,叫做离线数据处理,离线也就是线下处理,基本上就没有时限的要求了。
|
||||
|
||||
一般来说,离线处理才是数据处理的大头。所有“脏活累活”复杂的操作都是在离线完成的,比如说一些join操作。后端只是记录了用户交互的商品id,我们需要商品的详细信息怎么办?需要去和商品表关联查表。显然数据关联是一个非常耗时的操作,所以只能放到离线来做。
|
||||
|
||||
接下来详细介绍一下这三个模块。
|
||||
|
||||
### 离线层
|
||||
离线层是计算量最大的一个部分,它的特点是不依赖实时数据,也不需要实时提供服务。需要实现的主要功能模块是:
|
||||
|
||||
1. 数据处理、数据存储;
|
||||
2. 特征工程、离线特征计算;
|
||||
3. 离线模型的训练;
|
||||
|
||||
这里我们可以看出离线层的任务是最接近学校中我们处理数据、训练模型这种任务的,不同可能就是需要面临更大规模的数据。离线任务一般会按照天或者更久运行,比如每天晚上定期更新这一天的数据,然后重新训练模型,第二天上线新模型。
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409205904314.png" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
#### 离线层优势和不足
|
||||
离线层面临的数据量级是最大的,面临主要的问题是海量数据存储、大规模特征工程、多机分布式机器学习模型训练。目前主流的做法是HDFS,收集到我们所有的业务数据,通过HIVE等工具,从全量数据中抽取出我们需要的数据,进行相应的加工,离线阶段主流使用的分布式框架一般是Spark。所以离线层有如下的优势:
|
||||
1. 可以处理大量的数据,进行大规模特征工程;
|
||||
2. 可以进行批量处理和计算;
|
||||
3. 不用有响应时间要求;
|
||||
|
||||
但是同样的,如果我们只使用用户离线数据,最大的不足就是无法反应用户的实时兴趣变化,这就促使了近线层的产生。
|
||||
|
||||
### 近线层
|
||||
近线层的主要特点是准实时,它可以获得实时数据,然后快速计算提供服务,但是并不要求它和在线层一样达到几十毫秒这种延时要求。近线层的产生是同时想要弥补离线层和在线层的不足,折中的产物。
|
||||
|
||||
它适合处理一些对延时比较敏感的任务,比如:
|
||||
1. 特征的事实更新计算:例如统计用户对不同type的ctr,推荐系统一个老生常谈的问题就是特征分布不一致怎么办,如果使用离线算好的特征就容易出现这个问题。近线层能够获取实时数据,按照用户的实时兴趣计算就能很好避免这个问题。
|
||||
2. 实时训练数据的获取:比如在使用DIN、DSIN这行网络会依赖于用户的实时兴趣变化,用户几分钟前的点击就可以通过近线层获取特征输入模型。
|
||||
3. 模型实时训练:可以通过在线学习的方法更新模型,实时推送到线上;
|
||||
|
||||
近线层的发展得益于最近几年大数据技术的发展,很多流处理框架的提出大大促进了近线层的进步。如今Flink、Storm等工具一统天下。
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409205830027.png" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
### 在线层
|
||||
在线层,就是直接面向用户的的那一层了。最大的特点是对响应延时有要求,因为它是直接面对用户群体的,你可以想象你打开抖音淘宝等界面,几乎都是秒刷出来给你的推荐结果的,不会说还需要让你等待几秒钟时间。所有的用户请求都会发送到在线层,在线层需要快速返回结果,它主要承担的工作有:
|
||||
|
||||
1. 模型在线服务;包括了快速召回和排序;
|
||||
2. 在线特征快速处理拼接::根据传入的用户ID和场景,快速读取特征和处理;
|
||||
3. AB实验或者分流:根据不同用户采用不一样的模型,比如冷启动用户和正常服务模型;
|
||||
4. 运筹优化和业务干预:比如要对特殊商家流量扶持、对某些内容限流;
|
||||
|
||||
典型的在线服务是用过RESTful/RPC等提供服务,一般是公司后台服务部门调用我们的这个服务,返回给前端。具体部署应用比较多的方式就是使用Docker在K8S部署。而在线服务的数据源就是我们在离线层计算好的每个用户和商品特征,我们事先存放在数据库中,在线层只需要实时拼接,不进行复杂的特征运算,然后输入近线层或者离线层已经训练好的模型,根据推理结果进行排序,最后返回给后台服务器,后台服务器根据我们对每一个用户的打分,再返回给用户。
|
||||
|
||||
在线层最大的问题就是对实时性要求特别高,一般来说是几十毫秒,这就限制了我们能做的工作,很多任务往往无法及时完成,需要近线层协助我们做。
|
||||
## 算法架构
|
||||
|
||||
我们在入门学习推荐系统的时候,更加关注的是哪个模型AUC更高、topK效果好,哪个模型更加牛逼的问题,从基本的协同过滤到点击率预估算法,从深度学习到强化学习,学术界都始终走在最前列。一个推荐算法从出现到在业界得到广泛应用是一个长期的过程,因为在实际的生产系统中,首先需要保证的是稳定、实时地向用户提供推荐服务,在这个前提下才能追求推荐系统的效果。
|
||||
|
||||
算法架构的设计思想就是在实际的工业场景中,不管是用户维度、物品维度还是用户和物品的交互维度,数据都是极其丰富的,学术界对算法的使用方法不能照搬到工业界。当一个用户访问推荐模块时,系统不可能针对该用户对所有的物品进行排序,那么推荐系统是怎么解决的呢?对应的商品众多,如何决定将哪些商品展示给用户?对于排序好的商品,如何合理地展示给用户?
|
||||
|
||||
所以一个通用的算法架构,设计思想就是对数据层层建模,层层筛选,帮助用户从海量数据中找出其真正感兴趣的部分。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409211354342.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
- 召回
|
||||
|
||||
召回层的主要目标时从推荐池中选取几千上万的item,送给后续的排序模块。由于召回面对的候选集十分大,且一般需要在线输出,故召回模块必须轻量快速低延迟。由于后续还有排序模块作为保障,召回不需要十分准确,但不可遗漏(特别是搜索系统中的召回模块)。
|
||||
|
||||
如果没有召回层,每个User都能和每一个Item去在线排序阶段预测目标概率,理论上来说是效果最好,但是是不现实的,线上不延迟允许,所以召回和粗排阶段就要做一些候选集筛选的工作,保证在有限的能够给到排序层去做精排的候选集的时间里,效果最大化。另一个方面就是通过这种模型级联的方式,可以减少用排序阶段拟合多目标的压力,比如召回阶段我们现在主要是在保证Item质量的基础上注重覆盖率多样性,粗排阶段主要用简单的模型来解决不同路的召回和当前用户的相关性问题,最后截断到1k个以内的候选集,这个候选集符合一定的个性化相关性、视频质量和多样性的保证,然后做ranking去做复杂模型的predict。
|
||||
|
||||
目前基本上采用多路召回解决范式,分为非个性化召回和个性化召回。个性化召回又有content-based、behavior-based、feature-based等多种方式。
|
||||
|
||||
召回主要考虑的内容有:
|
||||
|
||||
1. **考虑用户层面**:用户兴趣的多元化,用户需求与场景的多元化:例如:新闻需求,重大要闻,相关内容沉浸阅读等等
|
||||
2. **考虑系统层面**:增强系统的鲁棒性;部分召回失效,其余召回队列兜底不会导致整个召回层失效;排序层失效,召回队列兜底不会导致整个推荐系统失效
|
||||
3. **系统多样性内容分发**:图文、视频、小视频;精准、试探、时效一定比例;召回目标的多元化,例如:相关性,沉浸时长,时效性,特色内容等等
|
||||
4. **可解释性推荐一部分召回是有明确推荐理由的**:很好的解决产品性数据的引入;
|
||||
|
||||
- 粗排
|
||||
|
||||
粗排的原因是有时候召回的结果还是太多,精排层速度还是跟不上,所以加入粗排。粗排可以理解为精排前的一轮过滤机制,减轻精排模块的压力。粗排介于召回和精排之间,要同时兼顾精准性和低延迟。目前粗排一般也都模型化了,其训练样本类似于精排,选取曝光点击为正样本,曝光未点击为负样本。但由于粗排一般面向上万的候选集,而精排只有几百上千,其解空间大很多。
|
||||
|
||||
粗排阶段的架构设计主要是考虑三个方面,一个是根据精排模型中的重要特征,来做候选集的截断,另一部分是有一些召回设计,比如热度或者语义相关的这些结果,仅考虑了item侧的特征,可以用粗排模型来排序跟当前User之间的相关性,据此来做截断,这样是比单独的按照item侧的倒排分数截断得到更加个性化的结果,最后是算法的选型要在在线服务的性能上有保证,因为这个阶段在pipeline中完成从召回到精排的截断工作,在延迟允许的范围内能处理更多的召回候选集理论上与精排效果正相关。
|
||||
|
||||
- 精排
|
||||
|
||||
精排层,也是我们学习推荐入门最常常接触的层,我们所熟悉的算法很大一部分都来自精排层。这一层的任务是获取粗排模块的结果,对候选集进行打分和排序。精排需要在最大时延允许的情况下,保证打分的精准性,是整个系统中至关重要的一个模块,也是最复杂,研究最多的一个模块。
|
||||
|
||||
精排是推荐系统各层级中最纯粹的一层,他的目标比较单一且集中,一门心思的实现目标的调优即可。最开始的时候精排模型的常见目标是ctr,后续逐渐发展了cvr等多类目标。精排和粗排层的基本目标是一致的,都是对商品集合进行排序,但是和粗排不同的是,精排只需要对少量的商品(即粗排输出的商品集合的topN)进行排序即可。因此,精排中可以使用比粗排更多的特征,更复杂的模型和更精细的策略(用户的特征和行为在该层的大量使用和参与也是基于这个原因)。
|
||||
|
||||
精排层模型是推荐系统中涵盖的研究方向最多,有非常多的子领域值得研究探索,这也是推荐系统中技术含量最高的部分,毕竟它是直接面对用户,产生的结果对用户影响最大的一层。目前精排层深度学习已经一统天下了,精排阶段采用的方案相对通用,首先一天的样本量是几十亿的级别,我们要解决的是样本规模的问题,尽量多的喂给模型去记忆,另一个方面时效性上,用户的反馈产生的时候,怎么尽快的把新的反馈给到模型里去,学到最新的知识。
|
||||
|
||||
- 重排
|
||||
|
||||
常见的有三种优化目标:Point Wise、Pair Wise 和 List Wise。重排序阶段对精排生成的Top-N个物品的序列进行重新排序,生成一个Top-K个物品的序列,作为排序系统最后的结果,直接展现给用户。重排序的原因是因为多个物品之间往往是相互影响的,而精排序是根据PointWise得分,容易造成推荐结果同质化严重,有很多冗余信息。而重排序面对的挑战就是海量状态空间如何求解的问题,一般在精排层我们使用AUC作为指标,但是在重排序更多关注NDCG等指标。
|
||||
|
||||
重排序在业务中,获取精排的排序结果,还会根据一些策略、运营规则参与排序,比如强制去重、间隔排序、流量扶持等、运营策略、多样性、context上下文等,重新进行一个微调。重排序更多的是List Wise作为优化目标的,它关注的是列表中商品顺序的问题来优化模型,但是一般List Wise因为状态空间大,存在训练速度慢的问题。
|
||||
|
||||
由于精排模型一般比较复杂,基于系统时延考虑,一般采用point-wise方式,并行对每个item进行打分。这就使得打分时缺少了上下文感知能力。用户最终是否会点击购买一个商品,除了和它自身有关外,和它周围其他的item也息息相关。重排一般比较轻量,可以加入上下文感知能力,提升推荐整体算法效率。比如三八节对美妆类目商品提权,类目打散、同图打散、同卖家打散等保证用户体验措施。重排中规则比较多,但目前也有不少基于模型来提升重排效果的方案。
|
||||
|
||||
- 混排
|
||||
|
||||
多个业务线都想在Feeds流中获取曝光,则需要对它们的结果进行混排。比如推荐流中插入广告、视频流中插入图文和banner等。可以基于规则策略(如广告定坑)和强化学习来实现。
|
||||
|
||||
## 总结
|
||||
|
||||
整篇文章从系统架构梳理了Netfliex的经典推荐系统架构,整个架构更多是偏向实时性能和效果之间tradeoff的结果。如果从另外的角度看推荐系统架构,比如从数据流向,或者说从推荐系统各个时序依赖来看,就是我们最熟悉的召回、粗排、精排、重排、混排等模块了。这种角度来看是把推荐系统从前往后串起来,其中每一个模块既有在离线层工作的,也有在在线层工作的。而从数据驱动角度看,更能够看到推荐系统的完整技术栈,推荐系统当前面临的局限和发展方向。
|
||||
|
||||
召回、排序这些里面单拿出任何一个模块都非常复杂。这也是为什么大家都说大厂拧螺丝的原因,因为很可能某个人只会负责其中很小的一个模块。许多人说起自己的模块来如数家珍,但对于全局缺乏认识,带来的结果是当你某天跳槽了或者是工作内容变化了,之前从工作当中的学习积累很难沉淀下来,这对于程序员的成长来说是很不利的。
|
||||
|
||||
所以希望这篇文章能够帮助大家在负责某一个模块,优化某一个功能的时候,除了能够有算法和数据,还能能够考虑对整个架构带来的影响,如何提升整体的一个性能,慢慢开阔自己的眼界,构建出一个更好的推荐系统。
|
||||
|
||||
|
||||
|
||||
**参考资料**
|
||||
- 《从零开始构建企业级推荐系统》
|
||||
- [Netflix](https://netflixtechblog.com/system-architectures-for-personalization-and-recommendation-e081aa94b5d8)
|
||||
- [回顾经典,Netflix的推荐系统架构](https://zhuanlan.zhihu.com/p/114590897)
|
||||
- [大数据处理中的Lambda架构和Kappa架构](https://www.cnblogs.com/xiaodf/p/11642555.html)
|
||||
- [张俊林:推荐系统技术演进趋势](https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247496363&idx=1&sn=0d2b2ac176e2a72eb2e760b7b591788f&chksm=fbd740c7cca0c9d16c76fdeb1a874a53f7408d8125b2e1bed3173ecb69d131167c1c9c35c71f&scene=21#wechat_redirect)
|
||||
- [推荐算法架构1:召回/等](https://blog.csdn.net/u013510838/article/details/123023259)
|
||||
- [微信"看一看"多模型内容策略与召回](https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247503484&idx=2&sn=e2a2cdd3a517ab09e903e69ccb1e9f94&chksm=fbd77c10cca0f50642dde47439ed919aa2e61b7ff57bc4cbaacc3acaac3c620a1ed6f92684ab&scene=21#wechat_redirect)
|
||||
- [阿里粗排技术体系](https://mp.weixin.qq.com/s/CN3a4Zb4yEjgi4mkm2lX6w)
|
||||
- [推荐系统架构与算法流程详解](https://mp.weixin.qq.com/s/tgZIdYENwQqDScjt7R28EQ)
|
||||
- [业内推荐系统架构介绍](https://mp.weixin.qq.com/s/waLW4aULeLoOB54_X-CzdQ)
|
||||
- [推荐系统笔记,一张图看懂系统架构](https://mp.weixin.qq.com/s/Zj4lCBe2bYNT6uT2-d-pNg)
|
||||
@@ -1,200 +0,0 @@
|
||||
## 推荐系统的技术栈
|
||||
|
||||
推荐系统是一个非常大的框架,有非常多的模块在里面,完整的一套推荐系统体系里,不仅会涉及到推荐算法工程师、后台开发工程师、数据挖掘/分析工程师、NLP/CV工程师还有前端、客户端甚至产品、运营等支持。我们作为算法工程师,需要掌握的技术栈主要就是在算法和工程两个区域了,所以这篇文章将会分别从算法和工程两个角度出发,结合两者分析当前主流的一些推荐算法技术栈。
|
||||
|
||||
## 算法
|
||||
|
||||
首先我们从推荐系统架构出发,一种分法是将整个推荐系统架构分为召回、粗排、精排、重排、混排等模块。它的分解方法是从一份数据如何从生产出来,到线上服务完整顺序的一个流程。因为在不同环节,我们一般会考虑不同的算法,所以这种角度出发我们来研究推荐系统主流的算法技术栈。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409211354342.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
为了帮助新手在后文方便理解,首先简单介绍这些模块的功能主要是:
|
||||
- 召回:从推荐池中选取几千上万的item,送给后续的排序模块。由于召回面对的候选集十分大,且一般需要在线输出,故召回模块必须轻量快速低延迟。由于后续还有排序模块作为保障,召回不需要十分准确,但不可遗漏(特别是搜索系统中的召回模块)。目前基本上采用多路召回解决范式,分为非个性化召回和个性化召回。个性化召回又有content-based、behavior-based、feature-based等多种方式。
|
||||
- 粗排:粗拍的原因是有时候召回的结果还是太多,精排层速度还是跟不上,所以加入粗排。粗排可以理解为精排前的一轮过滤机制,减轻精排模块的压力。粗排介于召回和精排之间,要同时兼顾精准性和低延迟。一般模型也不能过于复杂
|
||||
- 精排:获取粗排模块的结果,对候选集进行打分和排序。精排需要在最大时延允许的情况下,保证打分的精准性,是整个系统中至关重要的一个模块,也是最复杂,研究最多的一个模块。精排系统构建一般需要涉及样本、特征、模型三部分。
|
||||
- 重排:获取精排的排序结果,基于运营策略、多样性、context上下文等,重新进行一个微调。比如三八节对美妆类目商品提权,类目打散、同图打散、同卖家打散等保证用户体验措施。重排中规则比较多,但目前也有不少基于模型来提升重排效果的方案。
|
||||
- 混排:多个业务线都想在Feeds流中获取曝光,则需要对它们的结果进行混排。比如推荐流中插入广告、视频流中插入图文和banner等。可以基于规则策略(如广告定坑)和强化学习来实现。
|
||||
|
||||
### 画像层
|
||||
|
||||
首先是推荐系统的物料库,这部分内容里,算法主要体现在如何绘制一个用户画像和商品画像。这个环节是推荐系统架构的基础设施,一般可能新用户/商品进来,或者每周定期会重新一次整个物料库,计算其中信息,为用户打上标签,计算统计信息,为商品做内容理解等内容。其中用户画像是大家比较容易理解的,比如用户年龄、爱好通常APP会通过注册界面收集这些信息。而商品画像形式就非常多了,比如淘宝主要推荐商品,抖音主要是短视频,所以大家的物料形式比较多,内容、质量差异也比较大,所以内容画像各家的做法也不同,当前比较主流的都会涉及到一个多模态信息内容理解。下面我贴了一个微信看一看的内容画像框架,然后我们来介绍下在这一块主要使用的算法技术。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220410143333692.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
一般推荐系统会加入多模态的一个内容理解。我们用短视频形式举个例子,假设用户拍摄了一条短视频,上传到了平台,从推荐角度看,首先我们有的信息是这条短视频的作者、长度、作者为它选择的标签、时间戳这些信息。但是这对于推荐来说是远远不够的,首先作者打上的标签不一定准确反映作品,原因可能是我们模型的语义空间可能和作者/现实世界不一致。其次我们需要更多维度的特征,比如有些用户喜欢看小姐姐跳舞,那我希望能够判断一条视频中是否有小姐姐,这就涉及到封面图的基于CV的内容抽取或者整个视频的抽取;再比如作品的标题一般能够反映主题信息,除了很多平台常用的用“#”加上一个标签以外,我们也希望能够通过标题抽取出基于NLP的信息。还有更多的维度可以考虑:封面图多维度的多媒体特征体系,包括人脸识别,人脸embedding,标签,一二级分类,视频embedding表示,水印,OCR识别,清晰度,低俗色情,敏感信息等多种维度。
|
||||
|
||||
这里面涉及的任务主要是CV的目标检测、语义分割等任务,NLP中的情感分析、摘要抽取、自然语言理解等任务。但是这部分算法一般团队都会有专门负责的组,不需要推荐算法工程师来负责,他们会有多模态的语意标签输出,主要形式是各种粒度的Embedding。我们只需要在我们的推荐模型中引入这些预训练的Embedding。
|
||||
|
||||
#### 文本理解
|
||||
|
||||
这应该是用的最多的模态信息,包括item的标题、正文、OCR、评论等数据。这里面也可以产生不同粒度的信息,比如文本分类,把整个item做一个粗粒度的分类。
|
||||
|
||||
这里的典型算法有:RNN、TextCNN、FastText、Bert等;
|
||||
|
||||
#### 关键词标签
|
||||
|
||||
相比文本分类,关键词是更细粒度的信息,往往是一个mutil-hot的形式,它会对item在我们的标签库的选取最合适的关键词或者标签。
|
||||
|
||||
这里典型的算法有:TF-IDF、Bert、LSTM-CRF等。
|
||||
|
||||
#### 内容理解
|
||||
|
||||
在很多场景下,推荐的主题都是视频或者图片,远远多于仅推荐文本的情况,这里视频/图片item中的内容中除了文本的内容以外,更多的信息其实来源于视频/图片内容本身, 因此需要尝试从多种模态中抽取更丰富的信息。主要包括分类信息、封面图OCR的信息、视频标签信息等
|
||||
|
||||
这里典型的算法有:TSN、RetinaFace、PSENet等。
|
||||
|
||||
#### 知识图谱
|
||||
|
||||
知识图谱作为知识承载系统,用于对接内外部关键词信息与词关系信息;内容画像会将原关系信息整合,并构建可业务应用的关系知识体系,其次,依赖业务中积累用户行为产生的实体关系数据,本身用户需求的标签信息,一并用于构建业务知识的兴趣图谱,基于同构网络与异构网络表示学习等核心模型,输出知识表示与表达,抽象后的图谱用于文本识别,推荐语义理解,兴趣拓展推理等场景,直接用于兴趣推理的冷启场景已经验证有很不错的收益。
|
||||
|
||||
这方面的算法有:KGAT、RippleNet等。
|
||||
|
||||
### 召回/粗排
|
||||
|
||||
推荐系统的召回阶段可以理解为根据用户的历史行为数据,为用户在海量的信息中粗选一批待推荐的内容,挑选出一个小的候选集的过程。粗排用到的很多技术与召回重合,所以放在一起讲,粗排也不是必需的环节,它的功能对召回的结果进行个粗略的排序,在保证一定精准的前提下,进一步减少往后传送的物品数量,这就是粗排的作用。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220410000221817.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
召回模块面对几百上千万的推荐池物料规模,候选集十分庞大。由于后续有排序模块作为保障,故不需要十分准确,但必须保证不要遗漏和低延迟。目前主要通过多路召回来实现,一方面各路可以并行计算,另一方面取长补短。可以看到各类同类竞品的系统虽然细节上多少存在差异,但不约而同的采取了多路召回的架构,这类设计考虑如下几点问题:
|
||||
|
||||
1. **考虑用户层面**:用户兴趣的多元化,用户需求与场景的多元化:例如:新闻需求,重大要闻,相关内容沉浸阅读等等
|
||||
|
||||
2. **考虑系统层面**:增强系统的鲁棒性;部分召回失效,其余召回队列兜底不会导致整个召回层失效;排序层失效,召回队列兜底不会导致整个推荐系统失效
|
||||
|
||||
3. **系统多样性内容分发**:图文、视频、小视频;精准、试探、时效一定比例;召回目标的多元化,例如:相关性,沉浸时长,时效性,特色内容等等
|
||||
|
||||
4. **可解释性推荐一部分召回是有明确推荐理由的**:很好的解决产品性数据的引入;
|
||||
|
||||
介绍了召回任务的目的和场景后,接下来分析召回层面主要的技术栈,因为召回一般都是多路召回,从模型角度分析有很多召回算法,这种一般是在召回层占大部分比例点召回,除此之外,还会有探索类召回、策略运营类召回、社交类召回等。接下来我们着重介绍模型类召回。
|
||||
|
||||
#### 经典模型召回
|
||||
|
||||
随着技术发展,在Embedding基础上的模型化召回是一个技术发展潮流方向。这种召回的范式是通过某种算法,对user和item分别打上Embedding,然后user与item在线进行KNN计算实时查询最近领结果作为召回结果,快速找出匹配的物品。需要注意的是如果召回采用模型召回方法,优化目标最好和排序的优化目标一致,否则可能被过滤掉。
|
||||
|
||||
在这方面典型的算法有:FM、双塔DSSM、Multi-View DNN等。
|
||||
|
||||
#### 序列模型召回
|
||||
|
||||
推荐系统主要解决的是基于用户的隐式阅读行为来做个性化推荐的问题,序列模型一些基于神经网络模型学习得到Word2Vec模型,再后面的基于RNN的语言模型,最先用的最多的Bert,这些方法都可以应用到召回的学习中。
|
||||
|
||||
用户在使用 APP 或者网站的时候,一般会产生一些针对物品的行为,比如点击一些感兴趣的物品,收藏或者互动行为,或者是购买商品等。而一般用户之所以会对物品发生行为,往往意味着这些物品是符合用户兴趣的,而不同类型的行为,可能代表了不同程度的兴趣。比如购买就是比点击更能表征用户兴趣的行为。在召回阶段,如何根据用户行为序列打 embedding,可以采取有监督的模型,比如 Next Item Prediction 的预测方式即可;也可以采用无监督的方式,比如物品只要能打出 embedding,就能无监督集成用户行为序列内容,例如 Sum Pooling。
|
||||
|
||||
这方面典型的算法有:CBOW、Skip-Gram、GRU、Bert等。
|
||||
|
||||
#### 用户序列拆分
|
||||
|
||||
上文讲了利用用户行为物品序列,打出用户兴趣 Embedding 的做法。但是,另外一个现实是:用户往往是多兴趣的,比如可能同时对娱乐、体育、收藏感兴趣。这些不同的兴趣也能从用户行为序列的物品构成上看出来,比如行为序列中大部分是娱乐类,一部分体育类,少部分收藏类等。那么能否把用户行为序列物品中,这种不同类型的用户兴趣细分,而不是都笼统地打到一个用户兴趣 Embedding 里呢?用户多兴趣拆分就是解决这类更细致刻画用户兴趣的方向。
|
||||
|
||||
本质上,把用户行为序列打到多个 embedding 上,实际它是个类似聚类的过程,就是把不同的 Item,聚类到不同的兴趣类别里去。目前常用的拆分用户兴趣 embedding 的方法,主要是胶囊网络和 Memory Network,但是理论上,很多类似聚类的方法应该都是有效的,所以完全可以在这块替换成你自己的能产生聚类效果的方法来做。
|
||||
|
||||
这方面典型的算法有:Multi-Interest Network with Dynamic Routing for Recommendation at Tmall等。
|
||||
|
||||
#### 知识图谱
|
||||
|
||||
知识图谱有一个独有的优势和价值,那就是对于推荐结果的可解释性;比如推荐给用户某个物品,可以在知识图谱里通过物品的关键关联路径给出合理解释,这对于推荐结果的解释性来说是很好的,因为知识图谱说到底是人编码出来让自己容易理解的一套知识体系,所以人非常容易理解其间的关系。知识图谱的可解释性往往是和图路径方法关联在一起的,而 Path 类方法,很多实验证明了,在排序角度来看,是效果最差的一类方法,但是它在可解释性方面有很好的效果,所以往往可以利用知识图谱构建一条可解释性的召回通路。
|
||||
|
||||
这方面的算法有:KGAT、RippleNet等。
|
||||
|
||||
#### 图模型
|
||||
|
||||
推荐系统中User和Item相关的行为、需求、属性和社交信息具有天然的图结构,可以使用一张复杂的异构图来表示整个推荐系统。图神经网络模型推荐就是基于这个想法,把异构网络中包含的结构和语义信息编码到结点Embedding表示中,并使用得到向量进行个性化推荐。知识图谱其实是图神经网络的一个比较特殊的具体实例,但是,知识图谱因为编码的是静态知识,而不是用户比较直接的行为数据,和具体应用距离比较远,这可能是导致两者在推荐领域表现有差异的主要原因。
|
||||
|
||||
这方面典型的算法有:GraphSAGE、PinSage等。
|
||||
|
||||
### 精排
|
||||
|
||||
排序模型是推荐系统中涵盖的研究方向最多,有非常多的子领域值得研究探索,这也是推荐系统中技术含量最高的部分,毕竟它是直接面对用户,产生的结果对用户影响最大的一层。目前精排层深度学习已经一统天下了,这是王喆老师《深度学习推荐算法》书中的精排层模型演化线路。具体来看分为DNN、Wide&Deep两大块,实际深入还有序列建模,以及没有提到的多任务建模都是工业界非常常用的,所以我们接下来具体谈论其中每一块的技术栈。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220410234144149.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
#### 特征交叉模型
|
||||
|
||||
在深度学习推荐算法发展早期,很多论文聚焦于如何提升模型的特征组合和交叉的能力,这其中既包含隐式特征交叉Deep Crossing也有采用显式特征交叉的探究。本质上是希望模型能够摆脱人工先验的特征工程,实现端到端的一套模型。
|
||||
|
||||
在早期的推荐系统中,基本是由人工进行特征交叉的,往往凭借对业务的理解和经验,但是费时费力。于是有了很多的这方面的研究,从FM到GBDT+LR都是引入模型进行自动化的特征交叉。再往后就是深度模型,深度模型虽然有万能近似定理,但是真正想要发挥模型的潜力,显式的特征交叉还是必不可少的。
|
||||
|
||||
这方面的经典研究工作有:DCN、DeepFM、xDeepFM等;
|
||||
|
||||
#### 序列模型
|
||||
|
||||
在推荐系统中,历史行为序列是非常重要的特征。在序列建模中,主要任务目标是得到用户此刻的兴趣向量(user interest vector)。如何刻画用户兴趣的广泛性,是推荐系统比较大的一个难点,用户历史行为序列建模的研究经历了从Pooling、RNN到attention、capsule再到transformer的顺序。在序列模型中,又有很多细分的方向,比如根据用户行为长度有研究用户终身行为序列的,也有聚焦当下兴趣的,还有研究如何抽取序列特征的抽取器,比如研究attention还是胶囊网络。
|
||||
|
||||
这方面典型的研究工作有:DIN、DSIN、DIEN、SIM等;
|
||||
|
||||
#### 多模态信息融合
|
||||
|
||||
在上文我们提到算法团队往往会利用内容画像信息,既有基于CV也有基于NLP抽取出来的信息。这是非常合理的,我们在逛抖音、淘宝的时候关注的不仅仅item的价格、品牌,同样会关注封面小姐姐好不好看、标题够不够震惊等信息。除此之外,在冷启动场景下,我们能够利用等信息不够多,如果能够使用多模态信息,能很大程度上解决数据稀疏的问题。
|
||||
|
||||
传统做法在多模态信息融合就是希望把不同模态信息利用起来,通过Embedding技术融合进模型。在推荐领域,主流的做法还是一套非端到端的体系,由其他模型抽取出多模态信息,推荐只需要融合入这些信息就好了。同时也有其他工作是利用注意力机制等方法来学习不同模态之间的关联,来增强多模态的表示。
|
||||
|
||||
比较典型的工作有:Image Matters: Visually modeling user behaviors using Advanced Model Server、UMPR等。
|
||||
|
||||
#### 多任务学习
|
||||
|
||||
很多场景下我们模型优化的目标都是CTR,有一些场景只考虑CTR是不够的,点击率模型、时长模型和完播率模型是大部分信息流产品推荐算法团队都会尝试去做的模型。单独优化点击率模型容易推出来标题党,单独优化时长模型可能推出来的都是长视频或长文章,单独优化完播率模型可能短视频短图文就容易被推出来,所以多目标就应运而生。信息流推荐中,我们不仅希望用户点进我们的item,还希望能有一个不错的完播率,即希望用户能看完我们推荐的商品。或者电商场景希望用户不仅点进来,还希望他买下或者加入购物车了。这些概率实际上就是模型要学习的目标,多种目标综合起来,包括阅读、点赞、收藏、分享等等一系列的行为,归纳到一个模型里面进行学习,这就是推荐系统的多目标学习。
|
||||
|
||||
这方面比较典型的算法有:ESSM、MMoE、DUPN等。
|
||||
|
||||
#### 强化学习
|
||||
|
||||
强化学习与一般有监督的深度学习相比有一些很显著的优势,首先强化学习能够比较灵活的定义优化的业务目标,考虑推荐系统长短期的收益,比如用户留存,在深度模型下,我们很难设计这个指标的优化函数,而强化学习是可以对长期收益下来建模。第二是能够体现用户兴趣的动态变化,比如在新闻推荐下,用户兴趣变化很快,强化学习更容易通过用户行为动态产生推荐结果。最后是EE也就是利用探索机制,这种一种当前和长期收益的权衡,强化学习能够更好的调节这里的回报。
|
||||
|
||||
这方面比较典型的算法有:DQN、Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology;
|
||||
|
||||
#### 跨域推荐
|
||||
|
||||
一般一家公司业务线都是非常多的,比如腾讯既有腾讯视频,也有微信看一看、视频号,还有腾讯音乐,如果能够结合这几个场景的数据,同时进行推荐,一方面对于冷启动是非常有利的,另一方面也能补充更多数据,更好的进行精确推荐。
|
||||
|
||||
跨域推荐系统相比一般的推荐系统要更加复杂。在传统推荐系统中,我们只需要考虑建立当前领域内的一个推荐模型进行分析;而在跨域推荐中,我们更要关心在不同领域间要选择何种信息进行迁移,以及如何迁移这些信息,这是跨域推荐系统中非常关键的问题。
|
||||
|
||||
这方面典型的模型有:DTCDR、MV-DNN、EMCDR等;
|
||||
|
||||
### 重排序
|
||||
|
||||
我们知道常见的有三种优化目标:Point Wise、Pair Wise 和 List Wise。重排序阶段对精排生成的Top-N个物品的序列进行重新排序,生成一个Top-K个物品的序列,作为排序系统最后的结果,直接展现给用户。重排序的原因是因为多个物品之间往往是相互影响的,而精排序是根据PointWise得分,容易造成推荐结果同质化严重,有很多冗余信息。而重排序面对的挑战就是海量状态空间如何求解的问题,一般在精排层我们使用AUC作为指标,但是在重排序更多关注NDCG等指标。
|
||||
|
||||
重排序在业务中,还会根据一些策略、运营规则参与排序,比如强制去重、间隔排序、流量扶持等,但是总计趋势上看还是算法排序越来越占据主流趋势。重排序更多的是List Wise作为优化目标的,它关注的是列表中商品顺序的问题来优化模型,但是一般List Wise因为状态空间大,存在训练速度慢的问题。这方面典型的做法,基于RNN、Transformer、强化学习的都有,这方面因为不是推荐的一个核心,所以没有展开来讲,而且这一块比较依赖实际的业务场景。
|
||||
|
||||
这里的经典算法有:MRR、DPP、RNN等;
|
||||
|
||||
## 工程
|
||||
|
||||
推荐系统的实现需要依托工程,很多研究界Paper的idea满天飞,却忽视了工业界能否落地,进入工业界我们很难或者很少有组是做纯research的,所以我们同样有很多工程技术需要掌握。下面列举了在推荐中主要用到的工程技术:
|
||||
|
||||
- **编程语言**:Python、Java(scala)、C++、sql、shell;
|
||||
- **机器学习**:Tensorflow/Pytorch、GraphLab/GraphCHI、LGB/Xgboost、SKLearn;
|
||||
- **数据分析**:Pandas、Numpy、Seaborn、Spark;
|
||||
- 数据存储:mysql、redis、mangodb、hive、kafka、es、hbase;
|
||||
- 相似计算:annoy、faiss、kgraph
|
||||
- 流计算:Spark Streaming、Flink
|
||||
- 分布式:Hadoop、Spark
|
||||
|
||||
上面那么多技术,我内容最重要的就是加粗的三部分,第一是语言:必须掌握的是Python,C++和JAVA中根据不同的组使用的是不同的语言,这个如果没有时间可以等进组后慢慢学习。然后是机器学习框架:Tensorflow和Pytorch至少要掌握一个吧,前期不用纠结学哪个,这个迁移成本很低,基本能够达到触类旁通,而且面试官不会为难你只会这个不会那个。最后是数据分析工具:Pandas是我们处理单机规模数据的利器,但是进入工业界,Hadoop和Spark是需要会用的,不过不用学太深,会用即可。
|
||||
|
||||
## 总结
|
||||
|
||||
本文从算法和工程两个角度分析了推荐系统的一个技术栈,但是还有很多方向遗漏,也有很多方向受限于现在的技术水平深度不够和有错误的情况,后续会不断补充和更正。
|
||||
|
||||
所以技术栈我列出的是一个非常广度的技术,实际上每一个技术钻研下去都需要非常多时间,而且不一定是你实际工作中会遇到的,所以不要被那么多技术吓到,也要避免陷入技术细节的海洋中。
|
||||
|
||||
我和非常多的大厂面试官讨论过技术深度和广度的问题,得出来的结论是对于入门的推荐算法工程师而言,实际上深度和广度的要求取决于你要去的组,有些组有很深的推荐技术沉淀,有很强的工程师团队,这样的组就会希望候选者能够在某个方面有比较深入的研究,这个方面既包含工程方面也包含研究方面。但是如果是比较新的组、或者技术沉淀不深、推荐不是主要任务的组,对深度要求就不会很高。总而言之,我认为对于应届生/实习生来说,在推荐最重要的工程技术/研究方向,至少在召回和排序模块,需要选一个作为方向,是需要较深钻研。对于其他技术/研究方向需要有一定了解,比如可以没用过强化学习,但是要知道强化学习能够在推荐中解决什么问题,剩下的可以等到真实**遇到需要后再去学习**。
|
||||
|
||||
|
||||
|
||||
**参考资料**
|
||||
|
||||
- [万字入门推荐系统](https://mp.weixin.qq.com/s/aaOosZ57qJpIU6cma820Xw)
|
||||
- [张俊林:技术演进趋势:召回->排序->重排](https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247496363&idx=1&sn=0d2b2ac176e2a72eb2e760b7b591788f&chksm=fbd740c7cca0c9d16c76fdeb1a874a53f7408d8125b2e1bed3173ecb69d131167c1c9c35c71f&scene=21#wechat_redirect)
|
||||
- [微信"看一看"多模型内容策略与召回](https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247503484&idx=2&sn=e2a2cdd3a517ab09e903e69ccb1e9f94&chksm=fbd77c10cca0f50642dde47439ed919aa2e61b7ff57bc4cbaacc3acaac3c620a1ed6f92684ab&scene=21#wechat_redirect)
|
||||
- [多目标学习在推荐系统中的应用](https://mp.weixin.qq.com/s/u_5RdZ-BcIu_RoWNri76ig)
|
||||
- [强化学习在美团“猜你喜欢”的实践](https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749434&idx=2&sn=343e811408542dd1984582b8639240a6&chksm=bd12a5778a652c61ed4297f1a17582cad4ca6b8e8d4d66843f169e0eda9f6aede988bc675743&mpshare=1&scene=23&srcid=1115EcgbMw6GAhMnzV0URvgd#rd)
|
||||
- [推荐系统技术演进趋势:重排篇](https://mp.weixin.qq.com/s/YorzRyK0iplzqutnhEhrvw)
|
||||
- [阿里强化学习重排实践](https://mp.weixin.qq.com/s/ylavFA_MXLUhIBLCqxAjLQ)
|
||||
@@ -1,288 +0,0 @@
|
||||
# Swing(Graph-based)
|
||||
## 动机
|
||||
大规模推荐系统需要实时对用户行为做出海量预测,为了保证这种实时性,大规模的推荐系统通常严重依赖于预先计算好的产品索引。产品索引的功能为:给定种子产品返回排序后的候选相关产品列表。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2relations.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
|
||||
相关性产品索引主要包含两部分:替代性产品和互补性产品。例如图中的不同种类的衬衫构成了替代关系,而衬衫和风衣裤子等构成了互补关系。用户通常希望在完成购买行为之前尽可能看更多的衬衫,而用户购买过衬衫之后更希望看到与之搭配的单品而不是其他衬衫了。
|
||||
|
||||
## 之前方法局限性
|
||||
- 基于 Cosine, Jaccard, 皮尔逊相关性等相似度计算的协同过滤算法,在计算邻居关联强度的时候只关注于 Item-based (常用,因为item相比于用户变化的慢,且新Item特征比较容易获得),Item-based CF 只关注于 Item-User-Item 的路径,把所有的User-Item交互都平等得看待,从而忽视了 User-Item 交互中的大量噪声,推荐精度存在局限性。
|
||||
- 对互补性产品的建模不足,可能会导致用户购买过手机之后还继续推荐手机,但用户短时间内不会再继续购买手机,因此产生无效曝光。
|
||||
|
||||
## 贡献
|
||||
提出了高效建立产品索引图的技术。
|
||||
主要包括:
|
||||
- Swing 算法利用 user-item 二部图的子结构捕获产品间的替代关系。
|
||||
- Surprise 算法利用商品分类信息和用户共同购买图上的聚类技术来建模产品之间的组合关系。
|
||||
|
||||
## Swing算法
|
||||
Swing 通过利用 User-Item-User 路径中所包含的信息,考虑 User-Item 二部图中的鲁棒内部子结构计算相似性。
|
||||
- 什么是内部子结构?
|
||||
以经典的啤酒尿布故事为例,张三同时购买了啤酒和尿布,这可能是一种巧合。但两个甚至多个顾客都同时购买了啤酒尿布,这就证明啤酒和尿布具有相关关系。这样共同购买啤酒和尿布的用户越多,啤酒和尿布的相关度就会越高。
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片example_of_swing.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
图中的红色四边形就是一种Swing子结构,这种子结构可以作为给王五推荐尿布的依据。
|
||||
|
||||
- 通俗解释:若用户 $u$ 和用户 $v$ 之间除了购买过 $i$ 外,还购买过商品 $j$ ,则认为两件商品是具有某种程度上的相似的。也就是说,商品与商品之间的相似关系,是通过用户关系来传递的。为了衡量物品 $i$ 和 $j$ 的相似性,比较同时购买了物品 $i$ 和 $j$ 的用户 $u$ 和用户 $v$, 如果这两个用户共同购买的物品越少,即这两个用户原始兴趣不相似,但仍同时购买了两个相同的物品 $i$ 和 $j$, 则物品 $i$ 和 $j$ 的相似性越高。
|
||||
|
||||
- 计算公式
|
||||
|
||||
$$s(i,j)=\sum\limits_{u\in U_i\cap U_j} \sum\limits_{v \in U_i\cap U_j}w_u*w_v* \frac{1}{\alpha+|I_u \cap I_v|}$$
|
||||
|
||||
其中$U_i$ 是点击过商品i的用户集合,$I_u$ 是用户u点击过的商品集合,$\alpha$是平滑系数。
|
||||
|
||||
$w_u=\frac{1}{\sqrt{|I_u|}},w_v=\frac{1}{\sqrt{|I_v|}}$ 是用户权重参数,来降低活跃用户的影响。
|
||||
|
||||
- 代码实现
|
||||
- Python (建议自行debug方便理解)
|
||||
```python
|
||||
from itertools import combinations
|
||||
import pandas as pd
|
||||
alpha = 0.5
|
||||
top_k = 20
|
||||
def load_data(train_path):
|
||||
train_data = pd.read_csv(train_path, sep="\t", engine="python", names=["userid", "itemid", "rate"])#提取用户交互记录数据
|
||||
print(train_data.head(3))
|
||||
return train_data
|
||||
|
||||
def get_uitems_iusers(train):
|
||||
u_items = dict()
|
||||
i_users = dict()
|
||||
for index, row in train.iterrows():#处理用户交互记录
|
||||
u_items.setdefault(row["userid"], set())
|
||||
i_users.setdefault(row["itemid"], set())
|
||||
u_items[row["userid"]].add(row["itemid"])#得到user交互过的所有item
|
||||
i_users[row["itemid"]].add(row["userid"])#得到item交互过的所有user
|
||||
print("使用的用户个数为:{}".format(len(u_items)))
|
||||
print("使用的item个数为:{}".format(len(i_users)))
|
||||
return u_items, i_users
|
||||
|
||||
def swing_model(u_items, i_users):
|
||||
# print([i for i in i_users.values()][:5])
|
||||
# print([i for i in u_items.values()][:5])
|
||||
item_pairs = list(combinations(i_users.keys(), 2)) #全排列组合对
|
||||
print("item pairs length:{}".format(len(item_pairs)))
|
||||
item_sim_dict = dict()
|
||||
for (i, j) in item_pairs:
|
||||
user_pairs = list(combinations(i_users[i] & i_users[j], 2)) #item_i和item_j对应的user取交集后全排列 得到user对
|
||||
result = 0
|
||||
for (u, v) in user_pairs:
|
||||
result += 1 / (alpha + list(u_items[u] & u_items[v]).__len__()) #分数公式
|
||||
if result != 0 :
|
||||
item_sim_dict.setdefault(i, dict())
|
||||
item_sim_dict[i][j] = format(result, '.6f')
|
||||
return item_sim_dict
|
||||
|
||||
def save_item_sims(item_sim_dict, top_k, path):
|
||||
new_item_sim_dict = dict()
|
||||
try:
|
||||
writer = open(path, 'w', encoding='utf-8')
|
||||
for item, sim_items in item_sim_dict.items():
|
||||
new_item_sim_dict.setdefault(item, dict())
|
||||
new_item_sim_dict[item] = dict(sorted(sim_items.items(), key = lambda k:k[1], reverse=True)[:top_k])#排序取出 top_k个相似的item
|
||||
writer.write('item_id:%d\t%s\n' % (item, new_item_sim_dict[item]))
|
||||
print("SUCCESS: top_{} item saved".format(top_k))
|
||||
except Exception as e:
|
||||
print(e.args)
|
||||
|
||||
if __name__ == "__main__":
|
||||
train_data_path = "./ratings_final.txt"
|
||||
item_sim_save_path = "./item_sim_dict.txt"
|
||||
top_k = 10 #与item相似的前 k 个item
|
||||
train = load_data(train_data_path)
|
||||
u_items, i_users = get_uitems_iusers(train)
|
||||
item_sim_dict = swing_model(u_items, i_users)
|
||||
save_item_sims(item_sim_dict, top_k, item_sim_save_path)
|
||||
```
|
||||
|
||||
- Spark(仅为核心代码需要补全配置才能跑通)
|
||||
```scala
|
||||
object Swing {
|
||||
|
||||
def main(args: Array[String]): Unit = {
|
||||
val spark = SparkSession.builder()
|
||||
.appName("test")
|
||||
.master("local[2]")
|
||||
.getOrCreate()
|
||||
val alpha = 1 //分数计算参数
|
||||
val filter_n_items = 10000 //想要计算的item数量 测试的时候取少点
|
||||
val top_n_items = 500 //保存item的score排序前500个相似的item
|
||||
val model = new SwingModel(spark)
|
||||
.setAlpha(alpha.toDouble)
|
||||
.setFilter_N_Items(filter_n_items.toInt)
|
||||
.setTop_N_Items(top_n_items.toInt)
|
||||
val url = "file:///usr/local/var/scala/common/part-00022-e17c0014.snappy.parquet"
|
||||
val ratings = DataLoader.getRatingLog(spark, url)
|
||||
val df = model.fit(ratings).item2item()
|
||||
df.show(3,false)
|
||||
// df.write.mode("overwrite").parquet(dest_url)
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
```scala
|
||||
/**
|
||||
* swing
|
||||
* @param ratings 打分dataset
|
||||
* @return
|
||||
*/
|
||||
def fit(ratings: Dataset[Rating]): SwingModel = {
|
||||
|
||||
def interWithAlpha = udf(
|
||||
(array_1: Seq[GenericRowWithSchema],
|
||||
array_2: Seq[GenericRowWithSchema]) => {
|
||||
var score = 0.0
|
||||
val u_set_1 = array_1.toSet
|
||||
val u_set_2 = array_2.toSet
|
||||
val user_set = u_set_1.intersect(u_set_2).toArray //取交集得到两个item共同user
|
||||
|
||||
for (i <- user_set.indices; j <- i + 1 until user_set.length) {
|
||||
val user_1 = user_set(i)
|
||||
val user_2 = user_set(j)
|
||||
val item_set_1 = user_1.getAs[Seq[String]]("_2").toSet
|
||||
val item_set_2 = user_2.getAs[Seq[String]]("_2").toSet
|
||||
score = score + 1 / (item_set_1
|
||||
.intersect(item_set_2)
|
||||
.size
|
||||
.toDouble + alpha.get)
|
||||
}
|
||||
score
|
||||
}
|
||||
)
|
||||
val df = ratings.repartition(defaultParallelism).cache()
|
||||
|
||||
val groupUsers = df
|
||||
.groupBy("user_id")
|
||||
.agg(collect_set("item_id")) //聚合itme_id
|
||||
.toDF("user_id", "item_set")
|
||||
.repartition(defaultParallelism)
|
||||
println("groupUsers")
|
||||
groupUsers.show(3, false)//user_id|[item_id_set]: 422|[6117,611,6117]
|
||||
|
||||
val groupItems = df
|
||||
.join(groupUsers, "user_id")
|
||||
.rdd
|
||||
.map { x =>
|
||||
val item_id = x.getAs[String]("item_id")
|
||||
val user_id = x.getAs[String]("user_id")
|
||||
val item_set = x.getAs[Seq[String]]("item_set")
|
||||
(item_id, (user_id, item_set))
|
||||
}//i_[user(item_set)]
|
||||
.toDF("item_id", "user")
|
||||
.groupBy("item_id")
|
||||
.agg(collect_set("user"), count("item_id"))
|
||||
.toDF("item_id", "user_set", "count")
|
||||
.filter("size(user_set) > 1")//过滤掉没有交互的
|
||||
.sort($"count".desc) //根据count倒排item_id数量
|
||||
.limit(filter_n_items.get)//item可能百万级别但后面召回的需求量小所以只取前n个item进行计算
|
||||
.drop("count")
|
||||
.repartition(defaultParallelism)
|
||||
.cache()
|
||||
println("groupItems") //得到与itme_id有交互的user_id
|
||||
groupItems.show(3, false)//item_id|[[user_id,[item_set]],[user_id,[item_set]]]: 67|[[562,[66, 813, 61, 67]],[563,[67, 833, 62, 64]]]
|
||||
|
||||
val itemJoined = groupItems
|
||||
.join(broadcast(groupItems))//内连接两个item列表
|
||||
.toDF("item_id_1", "user_set_1", "item_id_2", "user_set_2")
|
||||
.filter("item_id_1 > item_id_2")//内连接 item两两配对
|
||||
.withColumn("score", interWithAlpha(col("user_set_1"), col("user_set_2")))//将上面得到的与item相关的user_set输入到函数interWithAlpha计算分数
|
||||
.select("item_id_1", "item_id_2", "score")
|
||||
.filter("score > 0")
|
||||
.repartition(defaultParallelism)
|
||||
.cache()
|
||||
println("itemJoined")
|
||||
itemJoined.show(5)//得到两两item之间的分数结果 item_id_1 item_id_2 score
|
||||
similarities = Option(itemJoined)
|
||||
this
|
||||
}
|
||||
|
||||
/**
|
||||
* 从fit结果,对item_id进行聚合并排序,每个item后截取n个item,并返回。
|
||||
* @param num 取n个item
|
||||
* @return
|
||||
*/
|
||||
def item2item(): DataFrame = {
|
||||
|
||||
case class itemWithScore(item_id: String, score: Double)
|
||||
val sim = similarities.get.select("item_id_1", "item_id_2", "score")
|
||||
val topN = sim
|
||||
.map { x =>
|
||||
val item_id_1 = x.getAs[String]("item_id_1")
|
||||
val item_id_2 = x.getAs[String]("item_id_2")
|
||||
val score = x.getAs[Double]("score")
|
||||
(item_id_1, (item_id_2, score))
|
||||
}
|
||||
.toDF("item_id", "itemWithScore")
|
||||
.groupBy("item_id")
|
||||
.agg(collect_set("itemWithScore"))
|
||||
.toDF("item_id", "item_set")//item_id |[[item_id1:score],[item_id2:score]]
|
||||
.rdd
|
||||
.map { x =>
|
||||
val item_id_1 = x.getAs[String]("item_id")
|
||||
val item_set = x //对itme_set中score进行排序操作
|
||||
.getAs[Seq[GenericRowWithSchema]]("item_set")
|
||||
.map { x =>
|
||||
val item_id_2 = x.getAs[String]("_1")
|
||||
val score = x.getAs[Double]("_2")
|
||||
(item_id_2, score)
|
||||
}
|
||||
.sortBy(-_._2)//根据score进行排序
|
||||
.take(top_n_items.get)//取top_n
|
||||
.map(x => x._1 + ":" + x._2.toString)
|
||||
(item_id_1, item_set)
|
||||
}
|
||||
.filter(_._2.nonEmpty)
|
||||
.toDF("id", "sorted_items")
|
||||
topN
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Surprise算法
|
||||
首先在行为相关性中引入连续时间衰减因子,然后引入基于交互数据的聚类方法解决数据稀疏的问题,旨在帮助用户找到互补商品。互补相关性主要从三个层面考虑,类别层面,商品层面和聚类层面。
|
||||
|
||||
- 类别层面
|
||||
首先通过商品和类别的映射关系,我们可以得到 user-category 矩阵。随后使用简单的相关性度量可以计算出类别 $i,j$ 的相关性。
|
||||
|
||||
$\theta_{i,j}=p(c_{i,j}|c_j)=\frac{N(c_{i,j})}{N(c_j)}$
|
||||
|
||||
即,$N(c_{i,j})$为在购买过i之后购买j类的数量,$N(c_{j})$为购买j类的数量。
|
||||
|
||||
由于类别直接的种类差异,每个类别的相关类数量存在差异,因此采用最大相对落点来作为划分阈值。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片max_drop.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
|
||||
例如图(a)中T恤的相关类选择前八个,图(b)中手机的相关类选择前三个。
|
||||
|
||||
- 商品层面
|
||||
商品层面的相关性挖掘主要有两个关键设计:
|
||||
- 商品的购买顺序是需要被考虑的,例如在用户购买手机后推荐充电宝是合理的,但在用户购买充电宝后推荐手机是不合理的。
|
||||
- 两个商品购买的时间间隔也是需要被考虑的,时间间隔越短越能证明两个商品的互补关系。
|
||||
|
||||
最终商品层面的互补相关性被定义为:
|
||||
|
||||
$s_{1}(i, j)=\frac{\sum_{u \in U_{i} \cap U_{j}} 1 /\left(1+\left|t_{u i}-t_{u j}\right|\right)}{\left\|U_{i}\right\| \times\left\|U_{j}\right\|}$,其中$j$属于$i$的相关类,且$j$ 的购买时间晚于$i$。
|
||||
|
||||
- 聚类层面
|
||||
- 如何聚类?
|
||||
传统的聚类算法(基于密度和 k-means )在数十亿产品规模下的淘宝场景中不可行,所以作者采用了标签传播算法。
|
||||
- 在哪里标签传播?
|
||||
Item-item 图,其中又 Swing 计算的排名靠前 item 为邻居,边的权重就是 Swing 分数。
|
||||
- 表现如何?
|
||||
快速而有效,15分钟即可对数十亿个项目进行聚类。
|
||||
最终聚类层面的相关度计算同上面商品层面的计算公式
|
||||
|
||||
- 线性组合:
|
||||
$s(i, j)=\omega * s_{1}(i, j)+(1-\omega) * s_{2}(i, j)$,其中$\omega=0.8$是作者设置的权重超参数。
|
||||
Surprise算法通过利用类别信息和标签传播技术解决了用户共同购买图上的稀疏性问题。
|
||||
|
||||
**参考资料**
|
||||
- [Large Scale Product Graph Construction for Recommendation in E-commerce](https://arxiv.org/pdf/2010.05525)
|
||||
- [推荐召回-Swing](https://zhuanlan.zhihu.com/p/383346471)
|
||||
@@ -1,263 +0,0 @@
|
||||
# 基于物品的协同过滤
|
||||
|
||||
## 基本思想
|
||||
|
||||
基于物品的协同过滤(ItemCF):
|
||||
|
||||
+ 预先根据所有用户的历史行为数据,计算物品之间的相似性。
|
||||
+ 然后,把与用户喜欢的物品相类似的物品推荐给用户。
|
||||
|
||||
举例来说,如果用户 1 喜欢物品 A ,而物品 A 和 C 非常相似,则可以将物品 C 推荐给用户1。ItemCF算法并不利用物品的内容属性计算物品之间的相似度, 主要通过分析用户的行为记录计算物品之间的相似度, 该算法认为, 物品 A 和物品 C 具有很大的相似度是因为喜欢物品 A 的用户极可能喜欢物品 C。
|
||||
|
||||
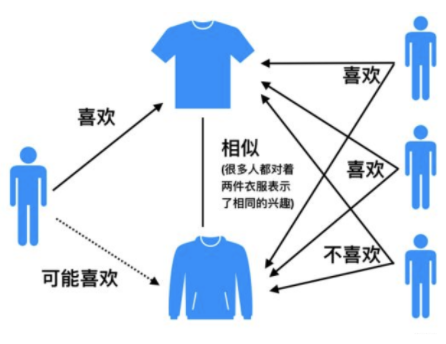
|
||||
|
||||
## 计算过程
|
||||
|
||||
基于物品的协同过滤算法和基于用户的协同过滤算法很像, 所以我们这里直接还是拿上面 Alice 的那个例子来看。
|
||||
|
||||
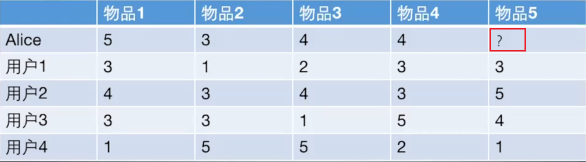
|
||||
|
||||
如果想知道 Alice 对物品5打多少分, 基于物品的协同过滤算法会这么做:
|
||||
|
||||
+ 首先计算一下物品5和物品1, 2, 3, 4之间的相似性。
|
||||
|
||||
+ 在Alice找出与物品 5 最相近的 n 个物品。
|
||||
|
||||
+ 根据 Alice 对最相近的 n 个物品的打分去计算对物品 5 的打分情况。
|
||||
|
||||
**手动计算:**
|
||||
|
||||
1. 手动计算物品之间的相似度
|
||||
|
||||
>物品向量: $物品 1(3,4,3,1) ,物品2(1,3,3,5) ,物品3(2,4,1,5) ,物品4(3,3,5,2) ,物品5(3,5,41)$
|
||||
>
|
||||
>+ 下面计算物品 5 和物品 1 之间的余弦相似性:
|
||||
> $$
|
||||
> \operatorname{sim}(\text { 物品1, 物品5 })=\operatorname{cosine}(\text { 物品1, 物品5 } )=\frac{9+20+12+1}{\operatorname{sqrt}(9+16+9+1)*\operatorname{sqrt}(9+25+16+1)}
|
||||
> $$
|
||||
>
|
||||
>+ 皮尔逊相关系数类似。
|
||||
>
|
||||
|
||||
2. 基于 `sklearn` 计算物品之间的皮尔逊相关系数:
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/JavaJOyFti58um61zPsa.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
|
||||
3. 根据皮尔逊相关系数, 可以找到与物品5最相似的2个物品是 item1 和 item4, 下面基于上面的公式计算最终得分:
|
||||
|
||||
$$
|
||||
P_{Alice, 物品5}=\bar{R}_{物品5}+\frac{\sum_{k=1}^{2}\left(w_{物品5,物品 k}\left(R_{Alice, 物品k}-\bar{R}_{物品k}\right)\right)}{\sum_{k=1}^{2} w_{物品k, 物品5}} \\
|
||||
=\frac{13}{4}+\frac{0.97*(5-3.2)+0.58*(4-3.4)}{0.97+0.58}=4.6
|
||||
$$
|
||||
|
||||
## ItemCF编程实现
|
||||
|
||||
1. 构建物品-用户的评分矩阵
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
|
||||
def loadData():
|
||||
items = {'A': {'Alice': 5.0, 'user1': 3.0, 'user2': 4.0, 'user3': 3.0, 'user4': 1.0},
|
||||
'B': {'Alice': 3.0, 'user1': 1.0, 'user2': 3.0, 'user3': 3.0, 'user4': 5.0},
|
||||
'C': {'Alice': 4.0, 'user1': 2.0, 'user2': 4.0, 'user3': 1.0, 'user4': 5.0},
|
||||
'D': {'Alice': 4.0, 'user1': 3.0, 'user2': 3.0, 'user3': 5.0, 'user4': 2.0},
|
||||
'E': {'user1': 3.0, 'user2': 5.0, 'user3': 4.0, 'user4': 1.0}
|
||||
}
|
||||
return items
|
||||
```
|
||||
|
||||
2. 计算物品间的相似度矩阵
|
||||
|
||||
```python
|
||||
item_data = loadData()
|
||||
|
||||
similarity_matrix = pd.DataFrame(
|
||||
np.identity(len(item_data)),
|
||||
index=item_data.keys(),
|
||||
columns=item_data.keys(),
|
||||
)
|
||||
|
||||
# 遍历每条物品-用户评分数据
|
||||
for i1, users1 in item_data.items():
|
||||
for i2, users2 in item_data.items():
|
||||
if i1 == i2:
|
||||
continue
|
||||
vec1, vec2 = [], []
|
||||
for user, rating1 in users1.items():
|
||||
rating2 = users2.get(user, -1)
|
||||
if rating2 == -1:
|
||||
continue
|
||||
vec1.append(rating1)
|
||||
vec2.append(rating2)
|
||||
similarity_matrix[i1][i2] = np.corrcoef(vec1, vec2)[0][1]
|
||||
|
||||
print(similarity_matrix)
|
||||
```
|
||||
|
||||
```
|
||||
A B C D E
|
||||
A 1.000000 -0.476731 -0.123091 0.532181 0.969458
|
||||
B -0.476731 1.000000 0.645497 -0.310087 -0.478091
|
||||
C -0.123091 0.645497 1.000000 -0.720577 -0.427618
|
||||
D 0.532181 -0.310087 -0.720577 1.000000 0.581675
|
||||
E 0.969458 -0.478091 -0.427618 0.581675 1.000000
|
||||
```
|
||||
|
||||
3. 从 Alice 购买过的物品中,选出与物品 `E` 最相似的 `num` 件物品。
|
||||
|
||||
```python
|
||||
target_user = ' Alice '
|
||||
target_item = 'E'
|
||||
num = 2
|
||||
|
||||
sim_items = []
|
||||
sim_items_list = similarity_matrix[target_item].sort_values(ascending=False).index.tolist()
|
||||
for item in sim_items_list:
|
||||
# 如果target_user对物品item评分过
|
||||
if target_user in item_data[item]:
|
||||
sim_items.append(item)
|
||||
if len(sim_items) == num:
|
||||
break
|
||||
print(f'与物品{target_item}最相似的{num}个物品为:{sim_items}')
|
||||
```
|
||||
|
||||
```
|
||||
与物品E最相似的2个物品为:['A', 'D']
|
||||
```
|
||||
|
||||
4. 预测用户 Alice 对物品 `E` 的评分
|
||||
|
||||
```python
|
||||
target_user_mean_rating = np.mean(list(item_data[target_item].values()))
|
||||
weighted_scores = 0.
|
||||
corr_values_sum = 0.
|
||||
|
||||
target_item = 'E'
|
||||
for item in sim_items:
|
||||
corr_value = similarity_matrix[target_item][item]
|
||||
user_mean_rating = np.mean(list(item_data[item].values()))
|
||||
|
||||
weighted_scores += corr_value * (item_data[item][target_user] - user_mean_rating)
|
||||
corr_values_sum += corr_value
|
||||
|
||||
target_item_pred = target_user_mean_rating + weighted_scores / corr_values_sum
|
||||
print(f'用户{target_user}对物品{target_item}的预测评分为:{target_item_pred}')
|
||||
```
|
||||
|
||||
```
|
||||
用户 Alice 对物品E的预测评分为:4.6
|
||||
```
|
||||
|
||||
# 协同过滤算法的权重改进
|
||||
|
||||
* base 公式
|
||||
$$
|
||||
w_{i j}=\frac{|N(i) \bigcap N(j)|}{|N(i)|}
|
||||
$$
|
||||
|
||||
+ 该公式表示同时喜好物品 $i$ 和物品 $j$ 的用户数,占喜爱物品 $i$ 的比例。
|
||||
+ 缺点:若物品 $j$ 为热门物品,那么它与任何物品的相似度都很高。
|
||||
|
||||
* 对热门物品进行惩罚
|
||||
$$
|
||||
w_{i j}=\frac{|N(i) \cap N(j)|}{\sqrt{|N(i)||N(j)|}}
|
||||
$$
|
||||
|
||||
|
||||
* 根据 base 公式在的问题,对物品 $j$ 进行打压。打压的出发点很简单,就是在分母再除以一个物品 $j$ 被购买的数量。
|
||||
* 此时,若物品 $j$ 为热门物品,那么对应的 $N(j)$ 也会很大,受到的惩罚更多。
|
||||
|
||||
* 控制对热门物品的惩罚力度
|
||||
$$
|
||||
w_{i j}=\frac{|N(i) \cap N(j)|}{|N(i)|^{1-\alpha}|N(j)|^{\alpha}}
|
||||
$$
|
||||
|
||||
* 除了第二点提到的办法,在计算物品之间相似度时可以对热门物品进行惩罚外。
|
||||
* 可以在此基础上,进一步引入参数 $\alpha$ ,这样可以通过控制参数 $\alpha$来决定对热门物品的惩罚力度。
|
||||
|
||||
* 对活跃用户的惩罚
|
||||
|
||||
* 在计算物品之间的相似度时,可以进一步将用户的活跃度考虑进来。
|
||||
$$
|
||||
w_{i j}=\frac{\sum_{\operatorname{\text {u}\in N(i) \cap N(j)}} \frac{1}{\log 1+|N(u)|}}{|N(i)|^{1-\alpha}|N(j)|^{\alpha}}
|
||||
$$
|
||||
|
||||
+ 对于异常活跃的用户,在计算物品之间的相似度时,他的贡献应该小于非活跃用户。
|
||||
|
||||
# 协同过滤算法的问题分析
|
||||
|
||||
协同过滤算法存在的问题之一就是泛化能力弱:
|
||||
|
||||
+ 即协同过滤无法将两个物品相似的信息推广到其他物品的相似性上。
|
||||
+ 导致的问题是**热门物品具有很强的头部效应, 容易跟大量物品产生相似, 而尾部物品由于特征向量稀疏, 导致很少被推荐**。
|
||||
|
||||
比如下面这个例子:
|
||||
|
||||
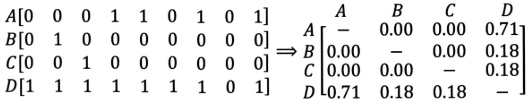
|
||||
|
||||
+ 左边矩阵中,$A, B, C, D$ 表示的是物品。
|
||||
+ 可以看出,$D $ 是一件热门物品,其与 $A、B、C$ 的相似度比较大。因此,推荐系统更可能将 $D$ 推荐给用过 $A、B、C$ 的用户。
|
||||
+ 但是,推荐系统无法找出 $A,B,C$ 之间相似性的原因是交互数据太稀疏, 缺乏相似性计算的直接数据。
|
||||
|
||||
所以这就是协同过滤的天然缺陷:**推荐系统头部效应明显, 处理稀疏向量的能力弱**。
|
||||
|
||||
为了解决这个问题, 同时增加模型的泛化能力。2006年,**矩阵分解技术(Matrix Factorization, MF**)被提出:
|
||||
|
||||
+ 该方法在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品, 挖掘用户和物品的隐含兴趣和隐含特征。
|
||||
+ 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
|
||||
|
||||
# 课后思考
|
||||
|
||||
1. **什么时候使用UserCF,什么时候使用ItemCF?为什么?**
|
||||
|
||||
> (1)UserCF
|
||||
>
|
||||
> + 由于是基于用户相似度进行推荐, 所以具备更强的社交特性, 这样的特点非常适于**用户少, 物品多, 时效性较强的场合**。
|
||||
>
|
||||
> + 比如新闻推荐场景, 因为新闻本身兴趣点分散, 相比用户对不同新闻的兴趣偏好, 新闻的及时性,热点性往往更加重要, 所以正好适用于发现热点,跟踪热点的趋势。
|
||||
> + 另外还具有推荐新信息的能力, 更有可能发现惊喜, 因为看的是人与人的相似性, 推出来的结果可能更有惊喜,可以发现用户潜在但自己尚未察觉的兴趣爱好。
|
||||
>
|
||||
> (2)ItemCF
|
||||
>
|
||||
> + 这个更适用于兴趣变化较为稳定的应用, 更接近于个性化的推荐, 适合**物品少,用户多,用户兴趣固定持久, 物品更新速度不是太快的场合**。
|
||||
> + 比如推荐艺术品, 音乐, 电影。
|
||||
|
||||
|
||||
|
||||
2.**协同过滤在计算上有什么缺点?有什么比较好的思路可以解决(缓解)?**
|
||||
|
||||
> 该问题答案参考上一小节的**协同过滤算法的问题分析**。
|
||||
|
||||
|
||||
|
||||
**3.上面介绍的相似度计算方法有什么优劣之处?**
|
||||
|
||||
> cosine相似度计算简单方便,一般较为常用。但是,当用户的评分数据存在 bias 时,效果往往不那么好。
|
||||
>
|
||||
> + 简而言之,就是不同用户评分的偏向不同。部分用户可能乐于给予好评,而部分用户习惯给予差评或者乱评分。
|
||||
> + 这个时候,根据cosine 相似度计算出来的推荐结果效果会打折扣。
|
||||
>
|
||||
> 举例来说明,如下图(`X,Y,Z` 表示物品,`d,e,f`表示用户):
|
||||
>
|
||||
> 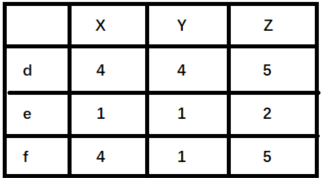
|
||||
>
|
||||
> + 如果使用余弦相似度进行计算,用户 d 和 e 之间较为相似。但是实际上,用户 d 和 f 之间应该更加相似。只不过由于 d 倾向于打高分,e 倾向于打低分导致二者之间的余弦相似度更高。
|
||||
> + 这种情况下,可以考虑使用皮尔逊相关系数计算用户之间的相似性关系。
|
||||
|
||||
|
||||
|
||||
4.**协同过滤还存在其他什么缺陷?有什么比较好的思路可以解决(缓解)?**
|
||||
|
||||
> + 协同过滤的优点就是没有使用更多的用户或者物品属性信息,仅利用用户和物品之间的交互信息就能完成推荐,该算法简单高效。
|
||||
> + 但这也是协同过滤算法的一个弊端。由于未使用更丰富的用户和物品特征信息,这也导致协同过滤算法的模型表达能力有限。
|
||||
> + 对于该问题,逻辑回归模型(LR)可以更好地在推荐模型中引入更多特征信息,提高模型的表达能力。
|
||||
|
||||
|
||||
|
||||
# 参考资料
|
||||
|
||||
* [基于用户的协同过滤来构建推荐系统:https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw](https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw)
|
||||
* B站黑马推荐系统实战课程
|
||||
@@ -1,370 +0,0 @@
|
||||
# 隐语义模型与矩阵分解
|
||||
|
||||
协同过滤算法的特点:
|
||||
|
||||
+ 协同过滤算法的特点就是完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息就可以实现推荐,是一个可解释性很强, 非常直观的模型。
|
||||
+ 但是也存在一些问题,处理稀疏矩阵的能力比较弱。
|
||||
|
||||
为了使得协同过滤更好处理稀疏矩阵问题, 增强泛化能力。从协同过滤中衍生出矩阵分解模型(Matrix Factorization, MF)或者叫隐语义模型:
|
||||
|
||||
+ 在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品。
|
||||
+ 通过挖掘用户和物品的隐含兴趣和隐含特征, 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
|
||||
|
||||
|
||||
|
||||
# 隐语义模型
|
||||
|
||||
隐语义模型最早在文本领域被提出,用于找到文本的隐含语义。在2006年, 被用于推荐中, 它的核心思想是通过隐含特征(latent factor)联系用户兴趣和物品(item), 基于用户的行为找出潜在的主题和分类, 然后对物品进行自动聚类,划分到不同类别/主题(用户的兴趣)。
|
||||
|
||||
以项亮老师《推荐系统实践》书中的内容为例:
|
||||
|
||||
>如果我们知道了用户A和用户B两个用户在豆瓣的读书列表, 从他们的阅读列表可以看出,用户A的兴趣涉及侦探小说、科普图书以及一些计算机技术书, 而用户B的兴趣比较集中在数学和机器学习方面。 那么如何给A和B推荐图书呢? 先说说协同过滤算法, 这样好对比不同:
|
||||
>* 对于UserCF,首先需要找到和他们看了同样书的其他用户(兴趣相似的用户),然后给他们推荐那些用户喜欢的其他书。
|
||||
>* 对于ItemCF,需要给他们推荐和他们已经看的书相似的书,比如作者B看了很多关于数据挖掘的书,可以给他推荐机器学习或者模式识别方面的书。
|
||||
>
|
||||
>而如果是隐语义模型的话, 它会先通过一些角度把用户兴趣和这些书归一下类, 当来了用户之后, 首先得到他的兴趣分类, 然后从这个分类中挑选他可能喜欢的书籍。
|
||||
|
||||
隐语义模型和协同过滤的不同主要体现在隐含特征上, 比如书籍的话它的内容, 作者, 年份, 主题等都可以算隐含特征。
|
||||
|
||||
以王喆老师《深度学习推荐系统》中的一个原理图为例,看看是如何通过隐含特征来划分开用户兴趣和物品的。
|
||||
|
||||
<img src="https://img-blog.csdnimg.cn/20200822212051499.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
|
||||
## 音乐评分实例
|
||||
|
||||
假设每个用户都有自己的听歌偏好, 比如用户 A 喜欢带有**小清新的**, **吉他伴奏的**, **王菲**的歌曲,如果一首歌正好**是王菲唱的, 并且是吉他伴奏的小清新**, 那么就可以将这首歌推荐给这个用户。 也就是说是**小清新, 吉他伴奏, 王菲**这些元素连接起了用户和歌曲。
|
||||
|
||||
当然每个用户对不同的元素偏好不同, 每首歌包含的元素也不一样, 所以我们就希望找到下面的两个矩阵:
|
||||
|
||||
1. 潜在因子—— 用户矩阵Q
|
||||
这个矩阵表示不同用户对于不同元素的偏好程度, 1代表很喜欢, 0代表不喜欢, 比如下面这样:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/2020082222025968.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
2. 潜在因子——音乐矩阵P
|
||||
表示每种音乐含有各种元素的成分, 比如下表中, 音乐A是一个偏小清新的音乐, 含有小清新的Latent Factor的成分是0.9, 重口味的成分是0.1, 优雅成分0.2...
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822220751394.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
**计算张三对音乐A的喜爱程度**
|
||||
|
||||
利用上面的这两个矩阵,将对应向量进行内积计算,我们就能得出张三对音乐A的喜欢程度:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822221627219.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
+ 张三对**小清新**的偏好 * 音乐A含有**小清新**的成分 + 张三对**重口味**的偏好 * 音乐A含有**重口味**的成分 + 张三对**优雅**的偏好 * 音乐A含有**优雅**的成分...
|
||||
|
||||
+ 根据隐向量其实就可以得到张三对音乐A的打分,即: $$0.6 * 0.9 + 0.8 * 0.1 + 0.1 * 0.2 + 0.1 * 0.4 + 0.7 * 0 = 0.68$$。
|
||||
|
||||
**计算所有用户对不同音乐的喜爱程度**
|
||||
|
||||
按照这个计算方式, 每个用户对每首歌其实都可以得到这样的分数, 最后就得到了我们的评分矩阵:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822222141231.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:60%;" />
|
||||
</div>
|
||||
+ 红色部分表示用户没有打分,可以通过隐向量计算得到的。
|
||||
|
||||
**小结**
|
||||
|
||||
+ 上面例子中的小清晰, 重口味, 优雅这些就可以看做是隐含特征, 而通过这个隐含特征就可以把用户的兴趣和音乐的进行一个分类, 其实就是找到了每个用户每个音乐的一个隐向量表达形式(与深度学习中的embedding等价)
|
||||
+ 这个隐向量就可以反映出用户的兴趣和物品的风格,并能将相似的物品推荐给相似的用户等。 **有没有感觉到是把协同过滤算法进行了一种延伸, 把用户的相似性和物品的相似性通过了一个叫做隐向量的方式进行表达**
|
||||
|
||||
+ 现实中,类似于上述的矩阵 $P,Q$ 一般很难获得。有的只是用户的评分矩阵,如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822223313349.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:60%;" />
|
||||
</div>
|
||||
|
||||
+ 这种矩阵非常的稀疏,如果直接基于用户相似性或者物品相似性去填充这个矩阵是不太容易的。
|
||||
+ 并且很容易出现长尾问题, 而矩阵分解就可以比较容易的解决这个问题。
|
||||
|
||||
+ 矩阵分解模型:
|
||||
|
||||
+ 基于评分矩阵,将其分解成Q和P两个矩阵乘积的形式,获取用户兴趣和物品的隐向量表达。
|
||||
+ 然后,基于两个分解矩阵去预测某个用户对某个物品的评分了。
|
||||
+ 最后,基于预测评分去进行物品推荐。
|
||||
|
||||
|
||||
|
||||
# 矩阵分解算法
|
||||
|
||||
## 算法原理
|
||||
|
||||
在矩阵分解的算法框架下, **可以通过分解协同过滤的共现矩阵(评分矩阵)来得到用户和物品的隐向量**,原理如下:。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200823101513233.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
+ 矩阵分解算法将 $m\times n$ 维的共享矩阵 $R$ ,分解成 $m \times k$ 维的用户矩阵 $U$ 和 $k \times n$ 维的物品矩阵 $V$ 相乘的形式。
|
||||
+ 其中,$m$ 是用户数量, $n$ 是物品数量, $k$ 是隐向量维度, 也就是隐含特征个数。
|
||||
+ 这里的隐含特征没有太好的可解释性,需要模型自己去学习。
|
||||
+ 一般而言, $k$ 越大隐向量能承载的信息内容越多,表达能力也会更强,但相应的学习难度也会增加。所以,我们需要根据训练集样本的数量去选择合适的数值,在保证信息学习相对完整的前提下,降低模型的学习难度。
|
||||
|
||||
## 评分预测
|
||||
|
||||
在分解得到用户矩阵和物品矩阵后,若要计算用户 $u$ 对物品 $i$ 的评分,公式如下:
|
||||
$$
|
||||
\operatorname{Preference}(u, i)=r_{u i}=p_{u}^{T} q_{i}=\sum_{k=1}^{K} p_{u, k} q_{i,k}
|
||||
$$
|
||||
+ 其中,向量 $p_u$ 表示用户 $u$ 的隐向量,向量 $q_i$ 表示物品 $i$ 的隐向量。
|
||||
+ 用户向量和物品向量的内积 $p_{u}^{T} q_{i}$ 可以表示为用户 $u$ 对物品 $i$ 的预测评分。
|
||||
+ $p_{u,k}$ 和 $q_{i,k}$ 是模型的参数, $p_{u,k}$ 度量的是用户 $u$ 的兴趣和第 $k$ 个隐类的关系,$q_{i,k}$ 度量了第 $k$ 个隐类和物品 $i$ 之间的关系。
|
||||
|
||||
## 矩阵分解求解
|
||||
|
||||
常用的矩阵分解方法有特征值分解(EVD)或者奇异值分解(SVD), 具体原理可参考:
|
||||
|
||||
> [奇异值分解svd原理详解及推导](https://blog.csdn.net/wuzhongqiang/article/details/108168238)
|
||||
|
||||
+ 对于 EVD, 它要求分解的矩阵是方阵, 绝大部分场景下用户-物品矩阵不满足这个要求。
|
||||
+ 传统的 SVD 分解, 会要求原始矩阵是稠密的。但现实中用户的评分矩阵是非常稀疏的。
|
||||
+ 如果想用奇异值分解, 就必须对缺失的元素进行填充(比如填 0 )。
|
||||
+ 填充不但会导致空间复杂度增高,且补全内容不一定准确。
|
||||
+ 另外,SVD 分解计算复杂度非常高,而用户-物品的评分矩阵较大,不具备普适性。
|
||||
|
||||
## FunkSVD
|
||||
|
||||
2006年的Netflix Prize之后, Simon Funk公布了一个矩阵分解算法叫做**Funk-SVD**, 后来被 Netflix Prize 的冠军Koren称为**Latent Factor Model(LFM)**。
|
||||
|
||||
Funk-SVD的思想很简单: **把求解上面两个矩阵的参数问题转换成一个最优化问题, 可以通过训练集里面的观察值利用最小化来学习用户矩阵和物品矩阵**。
|
||||
|
||||
**算法过程**
|
||||
|
||||
1. 根据前面提到的,在有用户矩阵和物品矩阵的前提下,若要计算用户 $u$ 对物品 $i$ 的评分, 可以根据公式:
|
||||
$$
|
||||
\operatorname{Preference}(u, i)=r_{u i}=p_{u}^{T} q_{i}=\sum_{k=1}^{K} p_{u, k} q_{i,k}
|
||||
$$
|
||||
|
||||
+ 其中,向量 $p_u$ 表示用户 $u$ 的隐向量,向量 $q_i$ 表示物品 $i$ 的隐向量。
|
||||
|
||||
2. 随机初始化一个用户矩阵 $U$ 和一个物品矩阵 $V$,获取每个用户和物品的初始隐语义向量。
|
||||
|
||||
3. 将用户和物品的向量内积 $p_{u}^{T} q_{i}$, 作为用户对物品的预测评分 $\hat{r}_{u i}$。
|
||||
|
||||
+ $\hat{r}_{u i}=p_{u}^{T} q_{i}$ 表示的是通过建模,求得的用户 $u$ 对物品的预测评分。
|
||||
+ 在用户对物品的评分矩阵中,矩阵中的元素 $r_{u i}$ 才是用户对物品的真实评分。
|
||||
|
||||
4. 对于评分矩阵中的每个元素,计算预测误差 $e_{u i}=r_{u i}-\hat{r}_{u i}$,对所有训练样本的平方误差进行累加:
|
||||
$$
|
||||
\operatorname{SSE}=\sum_{u, i} e_{u i}^{2}=\sum_{u, i}\left(r_{u i}-\sum_{k=1}^{K} p_{u,k} q_{i,k}\right)^{2}
|
||||
$$
|
||||
|
||||
+ 从上述公式可以看出,$SSE$ 建立起了训练数据和预测模型之间的关系。
|
||||
|
||||
+ 如果我们希望模型预测的越准确,那么在训练集(已有的评分矩阵)上的预测误差应该仅可能小。
|
||||
|
||||
+ 为方便后续求解,给 $SSE$ 增加系数 $1/2$ :
|
||||
$$
|
||||
\operatorname{SSE}=\frac{1}{2} \sum_{u, i} e_{u i}^{2}=\frac{1}{2} \sum_{u, i}\left(r_{u i}-\sum_{k=1}^{K} p_{u k} q_{i k}\right)^{2}
|
||||
$$
|
||||
|
||||
5. 前面提到,模型预测越准确等价于预测误差越小,那么优化的目标函数变为:
|
||||
$$
|
||||
\min _{\boldsymbol{q}^{*}, \boldsymbol{p}^{*}} \frac{1}{2} \sum_{(u, i) \in K}\left(\boldsymbol{r}_{\mathrm{ui}}-p_{u}^{T} q_{i}\right)^{2}
|
||||
$$
|
||||
|
||||
+ $K$ 表示所有用户评分样本的集合,**即评分矩阵中不为空的元素**,其他空缺值在测试时是要预测的。
|
||||
+ 该目标函数需要优化的目标是用户矩阵 $U$ 和一个物品矩阵 $V$。
|
||||
|
||||
6. 对于给定的目标函数,可以通过梯度下降法对参数进行优化。
|
||||
|
||||
+ 求解目标函数 $SSE$ 关于用户矩阵中参数 $p_{u,k}$ 的梯度:
|
||||
$$
|
||||
\frac{\partial}{\partial p_{u,k}} S S E=\frac{\partial}{\partial p_{u,k}}\left(\frac{1}{2}e_{u i}^{2}\right) =e_{u i} \frac{\partial}{\partial p_{u,k}} e_{u i}=e_{u i} \frac{\partial}{\partial p_{u,k}}\left(r_{u i}-\sum_{k=1}^{K} p_{u,k} q_{i,k}\right)=-e_{u i} q_{i,k}
|
||||
$$
|
||||
|
||||
+ 求解目标函数 $SSE$ 关于 $q_{i,k}$ 的梯度:
|
||||
$$
|
||||
\frac{\partial}{\partial q_{i,k}} S S E=\frac{\partial}{\partial q_{i,k}}\left(\frac{1}{2}e_{u i}^{2}\right) =e_{u i} \frac{\partial}{\partial q_{i,k}} e_{u i}=e_{u i} \frac{\partial}{\partial q_{i,k}}\left(r_{u i}-\sum_{k=1}^{K} p_{u,k} q_{i,k}\right)=-e_{u i} p_{u,k}
|
||||
$$
|
||||
|
||||
7. 参数梯度更新
|
||||
$$
|
||||
p_{u, k}=p_{u,k}-\eta (-e_{ui}q_{i, k})=p_{u,k}+\eta e_{ui}q_{i, k} \\
|
||||
q_{i, k}=q_{i,k}-\eta (-e_{ui}p_{u,k})=q_{i, k}+\eta e_{ui}p_{u, k}
|
||||
$$
|
||||
|
||||
+ 其中,$\eta$ 表示学习率, 用于控制步长。
|
||||
+ 但上面这个有个问题就是当参数很多的时候, 就是两个矩阵很大的时候, 往往容易陷入过拟合的困境, 这时候, 就需要在目标函数上面加上正则化的损失, 就变成了RSVD, 关于RSVD的详细内容, 可以参考下面给出的链接, 由于篇幅原因, 这里不再过多的赘述。
|
||||
|
||||
**加入正则项**
|
||||
|
||||
为了控制模型的复杂度。在原有模型的基础上,加入 $l2$ 正则项,来防止过拟合。
|
||||
|
||||
+ 当模型参数过大,而输入数据发生变化时,可能会造成输出的不稳定。
|
||||
|
||||
+ $l2$ 正则项等价于假设模型参数符合0均值的正态分布,从而使得模型的输出更加稳定。
|
||||
|
||||
$$
|
||||
\min _{\boldsymbol{q}^{*}, \boldsymbol{p}^{*}} \frac{1}{2} \sum_{(u, i) \in K}\left(\boldsymbol{r}_{\mathrm{ui}}-p_{u}^{T} q_{i}\right)^{2}
|
||||
+ \lambda\left(\left\|p_{u}\right\|^{2}+\left\|q_{i}\right\|^{2}\right)
|
||||
$$
|
||||
|
||||
## BiasSVD
|
||||
|
||||
在推荐系统中,评分预测除了与用户的兴趣偏好、物品的特征属性相关外,与其他的因素也相关。例如:
|
||||
|
||||
+ 例如,对于乐观的用户来说,它的评分行为普遍偏高,而对批判性用户来说,他的评分记录普遍偏低,即使他们对同一物品的评分相同,但是他们对该物品的喜好程度却并不一样。
|
||||
+ 对物品来说也是类似的。以电影为例,受大众欢迎的电影得到的评分普遍偏高,而一些烂片的评分普遍偏低,这些因素都是独立于用户或产品的因素,和用户对产品的的喜好无关。
|
||||
|
||||
因此, Netfix Prize中提出了另一种LFM, 在原来的基础上加了偏置项, 来消除用户和物品打分的偏差, 即预测公式如下:
|
||||
$$
|
||||
\hat{r}_{u i}=\mu+b_{u}+b_{i}+p_{u}^{T} \cdot q_{i}
|
||||
$$
|
||||
这个预测公式加入了3项偏置参数 $\mu,b_u,b_i$, 作用如下:
|
||||
|
||||
- $\mu$: 该参数反映的是推荐模型整体的平均评分,一般使用所有样本评分的均值。
|
||||
- $b_u$:用户偏差系数。可以使用用户 $u$ 给出的所有评分的均值, 也可以当做训练参数。
|
||||
- 这一项表示了用户的评分习惯中和物品没有关系的那种因素。 比如有些用户比较苛刻, 对什么东西要求很高, 那么他评分就会偏低, 而有些用户比较宽容, 对什么东西都觉得不错, 那么评分就偏高
|
||||
- $b_i$:物品偏差系数。可以使用物品 $i$ 收到的所有评分的均值, 也可以当做训练参数。
|
||||
- 这一项表示了物品接受的评分中和用户没有关系的因素。 比如有些物品本身质量就很高, 因此获得的评分相对比较高, 有的物品本身质量很差, 因此获得的评分相对较低。
|
||||
|
||||
加了用户和物品的打分偏差之后, 矩阵分解得到的隐向量更能反映不同用户对不同物品的“真实”态度差异, 也就更容易捕捉评价数据中有价值的信息, 从而避免推荐结果有偏。
|
||||
|
||||
**优化函数**
|
||||
|
||||
在加入正则项的FunkSVD的基础上,BiasSVD 的目标函数如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\min _{q^{*}, p^{*}} \frac{1}{2} \sum_{(u, i) \in K} &\left(r_{u i}-\left(\mu+b_{u}+b_{i}+q_{i}^{T} p_{u}\right)\right)^{2} \\
|
||||
&+\lambda\left(\left\|p_{u}\right\|^{2}+\left\|q_{i}\right\|^{2}+b_{u}^{2}+b_{i}^{2}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
可得偏置项的梯度更新公式如下:
|
||||
|
||||
+ $\frac{\partial}{\partial b_{i}} S S E=-e_{u i}+\lambda b_{i}$
|
||||
+ $ \frac{\partial}{\partial b_{u}} S S E=-e_{u i}+\lambda b_{u} \ $
|
||||
|
||||
# 编程实现
|
||||
|
||||
本小节,使用如下图表来预测Alice对物品5的评分:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200827150237921.png#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
</div>
|
||||
基于矩阵分解算法的流程如下:
|
||||
|
||||
1. 首先, 它会先初始化用户矩阵 $P$ 和物品矩阵 $Q$ , $P$ 的维度是`[users_num, K]`,$Q$ 的维度是`[items_num, K]`,
|
||||
|
||||
+ 其中,`F`表示隐向量的维度。 也就是把通过隐向量的方式把用户的兴趣和`F`的特点关联了起来。
|
||||
|
||||
+ 初始化这两个矩阵的方式很多, 但根据经验, 随机数需要和`1/sqrt(F)`成正比。
|
||||
|
||||
2. 根据预测评分和真实评分的偏差,利用梯度下降法进行参数更新。
|
||||
|
||||
+ 遍历用户及其交互过的物品,对已交互过的物品进行评分预测。
|
||||
+ 由于预测评分与真实评分存在偏差, 再根据第3节的梯度更新公式更新参数。
|
||||
|
||||
3. 训练完成后,利用用户向量与目标物品向量的内积进行评分预测。
|
||||
|
||||
**完整代码如下:**
|
||||
|
||||
```python
|
||||
import random
|
||||
import math
|
||||
|
||||
|
||||
class BiasSVD():
|
||||
def __init__(self, rating_data, F=5, alpha=0.1, lmbda=0.1, max_iter=100):
|
||||
self.F = F # 这个表示隐向量的维度
|
||||
self.P = dict() # 用户矩阵P 大小是[users_num, F]
|
||||
self.Q = dict() # 物品矩阵Q 大小是[item_nums, F]
|
||||
self.bu = dict() # 用户偏置系数
|
||||
self.bi = dict() # 物品偏置系数
|
||||
self.mu = 0 # 全局偏置系数
|
||||
self.alpha = alpha # 学习率
|
||||
self.lmbda = lmbda # 正则项系数
|
||||
self.max_iter = max_iter # 最大迭代次数
|
||||
self.rating_data = rating_data # 评分矩阵
|
||||
|
||||
for user, items in self.rating_data.items():
|
||||
# 初始化矩阵P和Q, 随机数需要和1/sqrt(F)成正比
|
||||
self.P[user] = [random.random() / math.sqrt(self.F) for x in range(0, F)]
|
||||
self.bu[user] = 0
|
||||
for item, rating in items.items():
|
||||
if item not in self.Q:
|
||||
self.Q[item] = [random.random() / math.sqrt(self.F) for x in range(0, F)]
|
||||
self.bi[item] = 0
|
||||
|
||||
# 采用随机梯度下降的方式训练模型参数
|
||||
def train(self):
|
||||
cnt, mu_sum = 0, 0
|
||||
for user, items in self.rating_data.items():
|
||||
for item, rui in items.items():
|
||||
mu_sum, cnt = mu_sum + rui, cnt + 1
|
||||
self.mu = mu_sum / cnt
|
||||
|
||||
for step in range(self.max_iter):
|
||||
# 遍历所有的用户及历史交互物品
|
||||
for user, items in self.rating_data.items():
|
||||
# 遍历历史交互物品
|
||||
for item, rui in items.items():
|
||||
rhat_ui = self.predict(user, item) # 评分预测
|
||||
e_ui = rui - rhat_ui # 评分预测偏差
|
||||
|
||||
# 参数更新
|
||||
self.bu[user] += self.alpha * (e_ui - self.lmbda * self.bu[user])
|
||||
self.bi[item] += self.alpha * (e_ui - self.lmbda * self.bi[item])
|
||||
for k in range(0, self.F):
|
||||
self.P[user][k] += self.alpha * (e_ui * self.Q[item][k] - self.lmbda * self.P[user][k])
|
||||
self.Q[item][k] += self.alpha * (e_ui * self.P[user][k] - self.lmbda * self.Q[item][k])
|
||||
# 逐步降低学习率
|
||||
self.alpha *= 0.1
|
||||
|
||||
|
||||
# 评分预测
|
||||
def predict(self, user, item):
|
||||
return sum(self.P[user][f] * self.Q[item][f] for f in range(0, self.F)) + self.bu[user] + self.bi[
|
||||
item] + self.mu
|
||||
|
||||
|
||||
# 通过字典初始化训练样本,分别表示不同用户(1-5)对不同物品(A-E)的真实评分
|
||||
def loadData():
|
||||
rating_data={1: {'A': 5, 'B': 3, 'C': 4, 'D': 4},
|
||||
2: {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},
|
||||
3: {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},
|
||||
4: {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},
|
||||
5: {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}
|
||||
}
|
||||
return rating_data
|
||||
|
||||
# 加载数据
|
||||
rating_data = loadData()
|
||||
# 建立模型
|
||||
basicsvd = BiasSVD(rating_data, F=10)
|
||||
# 参数训练
|
||||
basicsvd.train()
|
||||
# 预测用户1对物品E的评分
|
||||
for item in ['E']:
|
||||
print(item, basicsvd.predict(1, item))
|
||||
|
||||
# 预测结果:E 3.685084274454321
|
||||
```
|
||||
# 课后思考
|
||||
|
||||
1. 矩阵分解算法后续有哪些改进呢?针对这些改进,是为了解决什么的问题呢?请大家自行探索RSVD,消除用户和物品打分偏差等。
|
||||
|
||||
2. 矩阵分解的优缺点分析
|
||||
|
||||
* 优点:
|
||||
* 泛化能力强: 一定程度上解决了稀疏问题
|
||||
* 空间复杂度低: 由于用户和物品都用隐向量的形式存放, 少了用户和物品相似度矩阵, 空间复杂度由$n^2$降到了$(n+m)*f$
|
||||
* 更好的扩展性和灵活性:矩阵分解的最终产物是用户和物品隐向量, 这个深度学习的embedding思想不谋而合, 因此矩阵分解的结果非常便于与其他特征进行组合和拼接, 并可以与深度学习无缝结合。
|
||||
|
||||
+ 缺点:
|
||||
+ 矩阵分解算法依然是只用到了评分矩阵, 没有考虑到用户特征, 物品特征和上下文特征, 这使得矩阵分解丧失了利用很多有效信息的机会。
|
||||
+ 同时在缺乏用户历史行为的时候, 无法进行有效的推荐。
|
||||
+ 为了解决这个问题, **逻辑回归模型及后续的因子分解机模型**, 凭借其天然的融合不同特征的能力, 逐渐在推荐系统领域得到了更广泛的应用。
|
||||
|
||||
# 参考资料
|
||||
|
||||
* 王喆 - 《深度学习推荐系统》
|
||||
* 项亮 - 《推荐系统实战》
|
||||
* [奇异值分解(SVD)的原理详解及推导](https://blog.csdn.net/wuzhongqiang/article/details/108168238)
|
||||
* [Matrix factorization techniques for recommender systems论文](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=5197422&tag=1)
|
||||
* [隐语义模型(LFM)和矩阵分解(MF)](https://blog.csdn.net/wuzhongqiang/article/details/108173885)
|
||||
@@ -1,344 +0,0 @@
|
||||
# 协同过滤算法
|
||||
|
||||
## 基本思想
|
||||
|
||||
协同过滤(Collaborative Filtering)推荐算法是最经典、最常用的推荐算法。基本思想是:
|
||||
|
||||
+ 根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品。
|
||||
|
||||
+ 基于对用户历史行为数据的挖掘发现用户的喜好偏向, 并预测用户可能喜好的产品进行推荐。
|
||||
+ 一般是仅仅基于用户的行为数据(评价、购买、下载等), 而不依赖于项的任何附加信息(物品自身特征)或者用户的任何附加信息(年龄, 性别等)。
|
||||
+ 目前应用比较广泛的协同过滤算法是基于邻域的方法,主要有:
|
||||
+ 基于用户的协同过滤算法(UserCF):给用户推荐和他兴趣相似的其他用户喜欢的产品。
|
||||
+ 基于物品的协同过滤算法(ItemCF):给用户推荐和他之前喜欢的物品相似的物品。
|
||||
|
||||
不管是 UserCF 还是 ItemCF 算法, 重点是计算用户之间(或物品之间)的相似度。
|
||||
|
||||
## 相似性度量方法
|
||||
|
||||
1. **杰卡德(Jaccard)相似系数**
|
||||
|
||||
`Jaccard` 系数是衡量两个集合的相似度一种指标,计算公式如下:
|
||||
$$
|
||||
sim_{uv}=\frac{|N(u) \cap N(v)|}{|N(u)| \cup|N(v)|}
|
||||
$$
|
||||
|
||||
+ 其中 $N(u)$,$N(v)$ 分别表示用户 $u$ 和用户 $v$ 交互物品的集合。
|
||||
|
||||
+ 对于用户 $u$ 和 $v$ ,该公式反映了两个交互物品交集的数量占这两个用户交互物品并集的数量的比例。
|
||||
|
||||
由于杰卡德相似系数一般无法反映具体用户的评分喜好信息,所以常用来评估用户是否会对某物品进行打分, 而不是预估用户会对某物品打多少分。
|
||||
|
||||
2. **余弦相似度**
|
||||
余弦相似度衡量了两个向量的夹角,夹角越小越相似。余弦相似度的计算如下,其与杰卡德(Jaccard)相似系数只是在分母上存在差异:
|
||||
$$
|
||||
sim_{uv}=\frac{|N(u) \cap N(v)|}{\sqrt{|N(u)|\cdot|N(v)|}}
|
||||
$$
|
||||
从向量的角度进行描述,令矩阵 $A$ 为用户-物品交互矩阵,矩阵的行表示用户,列表示物品。
|
||||
|
||||
+ 设用户和物品数量分别为 $m,n$,交互矩阵$A$就是一个 $m$ 行 $n$ 列的矩阵。
|
||||
|
||||
+ 矩阵中的元素均为 $0/1$。若用户 $i$ 对物品 $j$ 存在交互,那么 $A_{i,j}=1$,否则为 $0$ 。
|
||||
|
||||
+ 那么,用户之间的相似度可以表示为:
|
||||
$$
|
||||
sim_{uv} = cos(u,v) =\frac{u\cdot v}{|u|\cdot |v|}
|
||||
$$
|
||||
|
||||
+ 向量 $u,v$ 在形式都是 one-hot 类型,$u\cdot v$ 表示向量点积。
|
||||
|
||||
上述用户-物品交互矩阵在现实中是十分稀疏的,为了节省内存,交互矩阵会采用字典进行存储。在 `sklearn` 中,余弦相似度的实现:
|
||||
|
||||
```python
|
||||
from sklearn.metrics.pairwise import cosine_similarity
|
||||
|
||||
i = [1, 0, 0, 0]
|
||||
j = [1, 0, 1, 0]
|
||||
cosine_similarity([i, j])
|
||||
```
|
||||
|
||||
3. **皮尔逊相关系数**
|
||||
|
||||
在用户之间的余弦相似度计算时,将用户向量的内积展开为各元素乘积和:
|
||||
$$
|
||||
sim_{uv} = \frac{\sum_i r_{ui}*r_{vi}}{\sqrt{\sum_i r_{ui}^2}\sqrt{\sum_i r_{vi}^2}}
|
||||
$$
|
||||
+ 其中,$r_{ui},r_{vi}$ 分别表示用户 $u$ 和用户 $v$ 对物品 $i$ 是否有交互(或具体评分值)。
|
||||
|
||||
皮尔逊相关系数与余弦相似度的计算公式非常的类似,如下:
|
||||
$$
|
||||
sim(u,v)=\frac{\sum_{i\in I}(r_{ui}-\bar r_u)(r_{vi}-\bar r_v)}{\sqrt{\sum_{i\in I }(r_{ui}-\bar r_u)^2}\sqrt{\sum_{i\in I }(r_{vi}-\bar r_v)^2}}
|
||||
$$
|
||||
+ 其中,$r_{ui},r_{vi}$ 分别表示用户 $u$ 和用户 $v$ 对物品 $i$ 是否有交互(或具体评分值);
|
||||
+ $\bar r_u, \bar r_v$ 分别表示用户 $u$ 和用户 $v$ 交互的所有物品交互数量或者评分的平均值;
|
||||
|
||||
相较于余弦相似度,皮尔逊相关系数通过使用用户的平均分对各独立评分进行修正,减小了用户评分偏置的影响。在`scipy`中,皮尔逊相关系数的实现:
|
||||
|
||||
```python
|
||||
from scipy.stats import pearsonr
|
||||
|
||||
i = [1, 0, 0, 0]
|
||||
j = [1, 0.5, 0.5, 0]
|
||||
pearsonr(i, j)
|
||||
```
|
||||
|
||||
**适用场景**
|
||||
|
||||
+ $Jaccard$ 相似度表示两个集合的交集元素个数在并集中所占的比例 ,所以适用于隐式反馈数据(0-1)。
|
||||
+ 余弦相似度在度量文本相似度、用户相似度、物品相似度的时候都较为常用。
|
||||
+ 皮尔逊相关度,实际上也是一种余弦相似度。不过先对向量做了中心化,范围在 $-1$ 到 $1$。
|
||||
+ 相关度量的是两个变量的变化趋势是否一致,两个随机变量是不是同增同减。
|
||||
+ 不适合用作计算布尔值向量(0-1)之间相关度。
|
||||
|
||||
# 基于用户的协同过滤
|
||||
|
||||
## 基本思想
|
||||
|
||||
基于用户的协同过滤(UserCF):
|
||||
|
||||
+ 例如,我们要对用户 $A$ 进行物品推荐,可以先找到和他有相似兴趣的其他用户。
|
||||
+ 然后,将共同兴趣用户喜欢的,但用户 $A$ 未交互过的物品推荐给 $A$。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210629232540289.png" alt="image-20210629232540289" style="zoom: 80%;" />
|
||||
|
||||
## 计算过程
|
||||
|
||||
以下图为例,给用户推荐物品的过程可以形象化为一个猜测用户对物品进行打分的任务,表格里面是5个用户对于5件物品的一个打分情况,就可以理解为用户对物品的喜欢程度。
|
||||
|
||||

|
||||
|
||||
UserCF算法的两个步骤:
|
||||
|
||||
+ 首先,根据前面的这些打分情况(或者说已有的用户向量)计算一下 Alice 和用户1, 2, 3, 4的相似程度, 找出与 Alice 最相似的 n 个用户。
|
||||
|
||||
+ 根据这 n 个用户对物品 5 的评分情况和与 Alice 的相似程度会猜测出 Alice 对物品5的评分。如果评分比较高的话, 就把物品5推荐给用户 Alice, 否则不推荐。
|
||||
|
||||
**具体过程:**
|
||||
|
||||
1. 计算用户之间的相似度
|
||||
|
||||
+ 根据 1.2 节的几种方法, 我们可以计算出各用户之间的相似程度。对于用户 Alice,选取出与其最相近的 $N$ 个用户。
|
||||
|
||||
2. 计算用户对新物品的评分预测
|
||||
|
||||
+ 常用的方式之一:利用目标用户与相似用户之间的相似度以及相似用户对物品的评分,来预测目标用户对候选物品的评分估计:
|
||||
$$
|
||||
R_{\mathrm{u}, \mathrm{p}}=\frac{\sum_{\mathrm{s} \in S}\left(w_{\mathrm{u}, \mathrm{s}} \cdot R_{\mathrm{s}, \mathrm{p}}\right)}{\sum_{\mathrm{s} \in S} w_{\mathrm{u}, \mathrm{s}}}
|
||||
$$
|
||||
|
||||
+ 其中,权重 $w_{u,s}$ 是用户 $u$ 和用户 $s$ 的相似度, $R_{s,p}$ 是用户 $s$ 对物品 $p$ 的评分。
|
||||
|
||||
+ 另一种方式:考虑到用户评分的偏置,即有的用户喜欢打高分, 有的用户喜欢打低分的情况。公式如下:
|
||||
$$
|
||||
R_{\mathrm{u}, \mathrm{p}}=\bar{R}_{u} + \frac{\sum_{\mathrm{s} \in S}\left(w_{\mathrm{u}, \mathrm{s}} \cdot \left(R_{s, p}-\bar{R}_{s}\right)\right)}{\sum_{\mathrm{s} \in S} w_{\mathrm{u}, \mathrm{s}}}
|
||||
$$
|
||||
|
||||
+ 其中,$\bar{R}_{s}$ 表示用户 $s$ 对物品的历史平均评分。
|
||||
|
||||
3. 对用户进行物品推荐
|
||||
|
||||
+ 在获得用户 $u$ 对不同物品的评价预测后, 最终的推荐列表根据预测评分进行排序得到。
|
||||
|
||||
**手动计算:**
|
||||
|
||||
根据上面的问题, 下面手动计算 Alice 对物品 5 的得分:
|
||||
|
||||
|
||||
1. 计算 Alice 与其他用户的相似度(基于皮尔逊相关系数)
|
||||
|
||||
+ 手动计算 Alice 与用户 1 之间的相似度:
|
||||
|
||||
>用户向量 $\text {Alice}:(5,3,4,4) , \text{user1}:(3,1,2,3) , \text {user2}:( 4,3,4,3) , \text {user3}:(3,3,1,5) , \text {user4}:(1,5,5,2) $
|
||||
>
|
||||
>+ 计算Alice与user1的余弦相似性:
|
||||
>$$
|
||||
>\operatorname{sim}(\text { Alice, user1 })=\cos (\text { Alice, user } 1)=\frac{15+3+8+12}{\operatorname{sqrt}(25+9+16+16) * \operatorname{sqrt}(9+1+4+9)}=0.975
|
||||
>$$
|
||||
>
|
||||
>+ 计算Alice与user1皮尔逊相关系数:
|
||||
> + $Alice\_ave =4 \quad user1\_ave =2.25 $
|
||||
> + 向量减去均值: $\text {Alice}:(1,-1, 0,0) \quad \text { user1 }:(0.75,-1.25,-0.25,0.75)$
|
||||
>
|
||||
>+ 计算这俩新向量的余弦相似度和上面计算过程一致, 结果是 0.852 。
|
||||
>
|
||||
|
||||
+ 基于 sklearn 计算所有用户之间的皮尔逊相关系数。可以看出,与 Alice 相似度最高的用户为用户1和用户2。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/JavaWJkjP2fHH27Rajrj.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
|
||||
2. **根据相似度用户计算 Alice对物品5的最终得分**
|
||||
用户1对物品5的评分是3, 用户2对物品5的打分是5, 那么根据上面的计算公式, 可以计算出 Alice 对物品5的最终得分是
|
||||
$$
|
||||
P_{Alice, 物品5}=\bar{R}_{Alice}+\frac{\sum_{k=1}^{2}\left(w_{Alice,user k}\left(R_{userk, 物品5}-\bar{R}_{userk}\right)\right)}{\sum_{k=1}^{2} w_{Alice, userk}}=4+\frac{0.85*(3-2.4)+0.7*(5-3.8)}{0.85+0.7}=4.87
|
||||
$$
|
||||
|
||||
+ 同样方式,可以计算用户 Alice 对其他物品的评分预测。
|
||||
|
||||
3. **根据用户评分对用户进行推荐**
|
||||
|
||||
+ 根据 Alice 的打分对物品排个序从大到小:$$物品1>物品5>物品3=物品4>物品2$$。
|
||||
+ 如果要向 Alice 推荐2款产品的话, 我们就可以推荐物品 1 和物品 5 给 Alice。
|
||||
|
||||
至此, 基于用户的协同过滤算法原理介绍完毕。
|
||||
|
||||
## UserCF编程实现
|
||||
|
||||
1. 建立实验使用的数据表:
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
|
||||
def loadData():
|
||||
users = {'Alice': {'A': 5, 'B': 3, 'C': 4, 'D': 4},
|
||||
'user1': {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},
|
||||
'user2': {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},
|
||||
'user3': {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},
|
||||
'user4': {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}
|
||||
}
|
||||
return users
|
||||
```
|
||||
|
||||
+ 这里使用字典来建立用户-物品的交互表。
|
||||
+ 字典`users`的键表示不同用户的名字,值为一个评分字典,评分字典的键值对表示某物品被当前用户的评分。
|
||||
+ 由于现实场景中,用户对物品的评分比较稀疏。如果直接使用矩阵进行存储,会存在大量空缺值,故此处使用了字典。
|
||||
|
||||
2. 计算用户相似性矩阵
|
||||
|
||||
+ 由于训练数据中共包含 5 个用户,所以这里的用户相似度矩阵的维度也为 $5 \times 5$。
|
||||
|
||||
```python
|
||||
user_data = loadData()
|
||||
similarity_matrix = pd.DataFrame(
|
||||
np.identity(len(user_data)),
|
||||
index=user_data.keys(),
|
||||
columns=user_data.keys(),
|
||||
)
|
||||
|
||||
# 遍历每条用户-物品评分数据
|
||||
for u1, items1 in user_data.items():
|
||||
for u2, items2 in user_data.items():
|
||||
if u1 == u2:
|
||||
continue
|
||||
vec1, vec2 = [], []
|
||||
for item, rating1 in items1.items():
|
||||
rating2 = items2.get(item, -1)
|
||||
if rating2 == -1:
|
||||
continue
|
||||
vec1.append(rating1)
|
||||
vec2.append(rating2)
|
||||
# 计算不同用户之间的皮尔逊相关系数
|
||||
similarity_matrix[u1][u2] = np.corrcoef(vec1, vec2)[0][1]
|
||||
|
||||
print(similarity_matrix)
|
||||
```
|
||||
|
||||
```
|
||||
1 2 3 4 5
|
||||
1 1.000000 0.852803 0.707107 0.000000 -0.792118
|
||||
2 0.852803 1.000000 0.467707 0.489956 -0.900149
|
||||
3 0.707107 0.467707 1.000000 -0.161165 -0.466569
|
||||
4 0.000000 0.489956 -0.161165 1.000000 -0.641503
|
||||
5 -0.792118 -0.900149 -0.466569 -0.641503 1.000000
|
||||
```
|
||||
|
||||
3. 计算与 Alice 最相似的 `num` 个用户
|
||||
|
||||
```python
|
||||
target_user = ' Alice '
|
||||
num = 2
|
||||
# 由于最相似的用户为自己,去除本身
|
||||
sim_users = similarity_matrix[target_user].sort_values(ascending=False)[1:num+1].index.tolist()
|
||||
print(f'与用户{target_user}最相似的{num}个用户为:{sim_users}')
|
||||
```
|
||||
|
||||
```
|
||||
与用户 Alice 最相似的2个用户为:['user1', 'user2']
|
||||
```
|
||||
|
||||
4. 预测用户 Alice 对物品 `E` 的评分
|
||||
|
||||
```python
|
||||
weighted_scores = 0.
|
||||
corr_values_sum = 0.
|
||||
|
||||
target_item = 'E'
|
||||
# 基于皮尔逊相关系数预测用户评分
|
||||
for user in sim_users:
|
||||
corr_value = similarity_matrix[target_user][user]
|
||||
user_mean_rating = np.mean(list(user_data[user].values()))
|
||||
|
||||
weighted_scores += corr_value * (user_data[user][target_item] - user_mean_rating)
|
||||
corr_values_sum += corr_value
|
||||
|
||||
target_user_mean_rating = np.mean(list(user_data[target_user].values()))
|
||||
target_item_pred = target_user_mean_rating + weighted_scores / corr_values_sum
|
||||
print(f'用户{target_user}对物品{target_item}的预测评分为:{target_item_pred}')
|
||||
```
|
||||
|
||||
```
|
||||
用户 Alice 对物品E的预测评分为:4.871979899370592
|
||||
```
|
||||
|
||||
## UserCF优缺点
|
||||
|
||||
User-based算法存在两个重大问题:
|
||||
|
||||
|
||||
1. 数据稀疏性
|
||||
+ 一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。
|
||||
+ 这导致UserCF不适用于那些正反馈获取较困难的应用场景(如酒店预订, 大件物品购买等低频应用)。
|
||||
|
||||
1. 算法扩展性
|
||||
+ 基于用户的协同过滤需要维护用户相似度矩阵以便快速的找出 $TopN$ 相似用户, 该矩阵的存储开销非常大,存储空间随着用户数量的增加而增加。
|
||||
+ 故不适合用户数据量大的情况使用。
|
||||
|
||||
由于UserCF技术上的两点缺陷, 导致很多电商平台并没有采用这种算法, 而是采用了ItemCF算法实现最初的推荐系统。
|
||||
|
||||
|
||||
|
||||
# 算法评估
|
||||
|
||||
由于UserCF和ItemCF结果评估部分是共性知识点, 所以在这里统一标识。
|
||||
|
||||
## 召回率
|
||||
|
||||
对用户 $u$ 推荐 $N$ 个物品记为 $R(u)$, 令用户 $u$ 在测试集上喜欢的物品集合为$T(u)$, 那么召回率定义为:
|
||||
$$
|
||||
\operatorname{Recall}=\frac{\sum_{u}|R(u) \cap T(u)|}{\sum_{u}|T(u)|}
|
||||
$$
|
||||
+ 含义:在模型召回预测的物品中,预测准确的物品占用户实际喜欢的物品的比例。
|
||||
|
||||
## 精确率
|
||||
精确率定义为:
|
||||
$$
|
||||
\operatorname{Precision}=\frac{\sum_{u} \mid R(u) \cap T(u)|}{\sum_{u}|R(u)|}
|
||||
$$
|
||||
+ 含义:推荐的物品中,对用户准确推荐的物品占总物品的比例。
|
||||
+ 如要确保召回率高,一般是推荐更多的物品,期望推荐的物品中会涵盖用户喜爱的物品。而实际中,推荐的物品中用户实际喜爱的物品占少数,推荐的精确率就会很低。故同时要确保高召回率和精确率往往是矛盾的,所以实际中需要在二者之间进行权衡。
|
||||
|
||||
## 覆盖率
|
||||
覆盖率反映了推荐算法发掘长尾的能力, 覆盖率越高, 说明推荐算法越能将长尾中的物品推荐给用户。
|
||||
$$
|
||||
\text { Coverage }=\frac{\left|\bigcup_{u \in U} R(u)\right|}{|I|}
|
||||
$$
|
||||
|
||||
+ 含义:推荐系统能够推荐出来的物品占总物品集合的比例。
|
||||
+ 其中 $|I|$ 表示所有物品的个数;
|
||||
+ 系统的用户集合为$U$;
|
||||
+ 推荐系统给每个用户推荐一个长度为 $N$ 的物品列表$R(u)$.
|
||||
|
||||
+ 覆盖率表示最终的推荐列表中包含多大比例的物品。如果所有物品都被给推荐给至少一个用户, 那么覆盖率是100%。
|
||||
|
||||
## 新颖度
|
||||
用推荐列表中物品的平均流行度度量推荐结果的新颖度。 如果推荐出的物品都很热门, 说明推荐的新颖度较低。 由于物品的流行度分布呈长尾分布, 所以为了流行度的平均值更加稳定, 在计算平均流行度时对每个物品的流行度取对数。
|
||||
|
||||
- O’scar Celma 在博士论文 "[Music Recommendation and Discovery in the Long Tail](http://mtg.upf.edu/static/media/PhD_ocelma.pdf) " 中研究了新颖度的评测。
|
||||
|
||||
|
||||
|
||||
# 参考资料
|
||||
|
||||
* [基于用户的协同过滤来构建推荐系统:https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw](https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw)
|
||||
* B站黑马推荐系统实战课程
|
||||
@@ -1,332 +0,0 @@
|
||||
# 前言
|
||||
这是 Airbnb 于2018年发表的一篇论文,主要介绍了 Airbnb 在 Embedding 技术上的应用,并获得了 KDD 2018 的 Best Paper。Airbnb 是全球最大的短租平台,包含了数百万种不同的房源。这篇论文介绍了 Airbnb 如何使用 Embedding 来实现相似房源推荐以及实时个性化搜索。在本文中,Airbnb 在用户和房源的 Embedding 上的生成都是基于谷歌的 Word2Vec 模型,<u>故阅读本文要求大家了解 Word2Vec 模型,特别是 Skip-Gram 模型**(重点*)**</u>。
|
||||
本文将从以下几个方面来介绍该论文:
|
||||
|
||||
- 了解 Airbnb 是如何利用 Word2Vec 技术生成房源和用户的Embedding,并做出了哪些改进。
|
||||
- 了解 Airbnb 是如何利用 Embedding 解决房源冷启动问题。
|
||||
- 了解 Airbnb 是如何衡量生成的 Embedding 的有效性。
|
||||
- 了解 Airbnb 是如何利用用户和房源 Embedding 做召回和搜索排序。
|
||||
|
||||
考虑到本文的目的是为了让大家快速了解 Airbnb 在 Embedding 技术上的应用,故不会完全翻译原论文。如需进一步了解,建议阅读原论文或文末的参考链接。原论文链接:https://dl.acm.org/doi/pdf/10.1145/3219819.3219885
|
||||
|
||||
# Airbnb 的业务背景
|
||||
在介绍 Airbnb 在 Embedding 技术上的方法前,先了解 Airbnb 的业务背景。
|
||||
|
||||
- Airbnb 平台包含数百万种不同的房源,用户可以通过**浏览搜索结果页面**来寻找想要的房源。Airbnb 技术团队通过复杂的机器学习模型,并使用上百种信号对搜索结果中的房源进行排序。
|
||||
- 当用户在查看某一个房源时,接下来的有两种方式继续搜索:
|
||||
- 返回搜索结果页,继续查看其他搜索结果。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049527431-0b09af70-bda0-4a30-8082-6aa69548213a.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 在当前房源的详情页下,「相似房源」板块(你可能还喜欢)所推荐的房源。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049385995-7a775df1-a36f-4795-9e79-8e577bcf2097.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- Airbnb 平台 99% 的房源预订来自于搜索排序和相似房源推荐。
|
||||
# Embedding 方法
|
||||
Airbnb 描述了两种 Embedding 的构建方法,分别为:
|
||||
|
||||
- 用于描述短期实时性的个性化特征 Embedding:**listing Embeddings**
|
||||
- **listing 表示房源的意思,<u>它将贯穿全文,请务必了解</u>。**
|
||||
- 用于描述长期的个性化特征 Embedding:**user-type & listing type Embeddings**
|
||||
## Listing Embeddings
|
||||
Listing Embeddings 是基于用户的点击 session 学习得到的,用于表示房源的短期实时性特征。给定数据集 $ \mathcal{S} $ ,其中包含了 $ N $ 个用户的 $ S $ 个点击 session(序列)。
|
||||
|
||||
- 每个 session $ s=\left(l_{1}, \ldots, l_{M}\right) \in \mathcal{S} $ ,包含了 $ M $ 个被用户点击过的 listing ids 。
|
||||
- 对于用户连续两次点击,若时间间隔超过了30分钟,则启动新的 session。
|
||||
|
||||
在拿到多个用户点击的 session 后,可以基于 Word2Vec 的 Skip-Gram 模型来学习不同 listing 的 Embedding 表示。最大化目标函数 $ \mathcal{L} $ :
|
||||
$$
|
||||
\mathcal{L}=\sum_{s \in \mathcal{S}} \sum_{l_{i} \in s}\left(\sum_{-m \geq j \leq m, i \neq 0} \log \mathbb{P}\left(l_{i+j} \mid l_{i}\right)\right)
|
||||
$$
|
||||
概率 $ \mathbb{P}\left(l_{i+j} \mid l_{i}\right) $ 是基于 soft-max 函数的表达式。表示在一个 session 中,已知中心 listing $ l_i $ 来预测上下文 listing $ l_{i+j} $ 的概率:
|
||||
$$
|
||||
\mathbb{P}\left(l_{i+j} \mid l_{i}\right)=\frac{\exp \left(\mathbf{v}_{l_{i}}^{\top} \mathbf{v}_{l_{i+j}}^{\prime}\right)}{\sum_{l=1}^{|\mathcal{V}|} \exp \left(\mathbf{v}_{l_{i}}^{\top} \mathbf{v}_{l}^{\prime}\right)}
|
||||
$$
|
||||
|
||||
- 其中, $ \mathbf{v}_{l_{i}} $ 表示 listing $ l_i $ 的 Embedding 向量, $ |\mathcal{V}| $ 表示全部的物料库的数量。
|
||||
|
||||
考虑到物料库 $ \mathcal{V} $ 过大,模型中参数更新的时间成本和 $ |\mathcal{V}| $ 成正比。为了降低计算复杂度,要进行负采样。负采样后,优化的目标函数如下:
|
||||
$$
|
||||
\underset{\theta}{\operatorname{argmax}} \sum_{(l, c) \in \mathcal{D}_{p}} \log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime^{\prime}} \mathbf{v}_{l}}}+\sum_{(l, c) \in \mathcal{D}_{n}} \log \frac{1}{1+e^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{l}}}
|
||||
$$
|
||||
至此,对 Skip-Gram 模型和 NEG 了解的同学肯定很熟悉,上述方法和 Word2Vec 思想基本一致。
|
||||
下面,将进一步介绍 Airbnb 是如何改进 Listing Embedding 的学习以及其他方面的应用。
|
||||
**(1)正负样本集构建的改进**
|
||||
|
||||
- 使用 booked listing 作为全局上下文
|
||||
- booked listing 表示用户在 session 中最终预定的房源,一般只会出现在结束的 session 中。
|
||||
- Airbnb 将最终预定的房源,始终作为滑窗的上下文,即全局上下文。如下图:
|
||||
- 如图,对于当前滑动窗口的 central listing,实线箭头表示context listings,虚线(指向booked listing)表示 global context listing。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653053823336-0564b2da-c993-46aa-9b22-f5cbb784dae2.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- booked listing 作为全局正样本,故优化的目标函数更新为:
|
||||
|
||||
$$
|
||||
\underset{\theta}{\operatorname{argmax}} \sum_{(l, c) \in \mathcal{D}_{p}} \log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime^{\prime}} \mathbf{v}_{l}}}+\sum_{(l, c) \in \mathcal{D}_{n}} \log \frac{1}{1+e^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{l}}} +
|
||||
\log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime} \mathbf{v}_{l_b}}}
|
||||
$$
|
||||
|
||||
- 优化负样本的选择
|
||||
- 用户通过在线网站预定房间时,通常只会在同一个 market (将要停留区域)内进行搜索。
|
||||
|
||||
- 对于用户点击过的样本集 $ \mathcal{D}_{p} $ (正样本集)而言,它们大概率位于同一片区域。考虑到负样本集 $ \mathcal{D}_{n} $ 是随机抽取的,大概率来源不同的区域。
|
||||
|
||||
- Airbnb 发现这种样本的不平衡,在学习同一片区域房源的 Embedding 时会得到次优解。
|
||||
|
||||
- 解决办法也很简单,对于每个滑窗中的中心 lisitng,其负样本的选择新增了与其位于同一个 market 的 listing。至此,优化函数更新如下:
|
||||
$$
|
||||
\underset{\theta}{\operatorname{argmax}} \sum_{(l, c) \in \mathcal{D}_{p}} \log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime^{\prime}} \mathbf{v}_{l}}}+\sum_{(l, c) \in \mathcal{D}_{n}} \log \frac{1}{1+e^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{l}}} +\log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime} \mathbf{v}_{l_b}}} +
|
||||
\sum_{(l, m_n ) \in \mathcal{D}_{m_n}} \log \frac{1}{1+e^{\mathbf{v}_{m_n}^{\prime} \mathbf{v}_{l}}}
|
||||
$$
|
||||
|
||||
+ $ \mathcal{D}_{m_n} $ 表示与滑窗中的中心 listing 位于同一区域的负样本集。
|
||||
|
||||
**(2)Listing Embedding 的冷启动**
|
||||
|
||||
- Airbnb 每天都有新的 listings 产生,而这些 listings 却没有 Embedding 向量表征。
|
||||
- Airbnb 建议利用其他 listing 的现有的 Embedding 来为新的 listing 创建 Embedding。
|
||||
- 在新的 listing 被创建后,房主需要提供如位置、价格、类型等在内的信息。
|
||||
- 然后利用房主提供的房源信息,为其查找3个相似的 listing,并将它们 Embedding 的均值作为新 listing 的 Embedding表示。
|
||||
- 这里的相似,包含了位置最近(10英里半径内),房源类型相似,价格区间相近。
|
||||
- 通过该手段,Airbnb 可以解决 98% 以上的新 listing 的 Embedding 冷启动问题。
|
||||
|
||||
**(3)Listing Embedding 的评估**
|
||||
经过上述的两点对 Embedding 的改进后,为了评估改进后 listing Embedding 的效果。
|
||||
|
||||
- Airbnb 使用了800万的点击 session,并将 Embedding 的维度设为32。
|
||||
|
||||
评估方法包括:
|
||||
|
||||
- 评估 Embedding 是否包含 listing 的地理位置相似性。
|
||||
- 理论上,同一区域的房源相似性应该更高,不同区域房源相似性更低。
|
||||
- Airbnb 利用 k-means 聚类,将加利福尼亚州的房源聚成100个集群,来验证类似位置的房源是否聚集在一起。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056809526-15401069-6fff-40d8-ac5e-35871d3f254a.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 评估不同类型、价格区间的房源之间的相似性。
|
||||
- 简而言之,我们希望类型相同、价格区间一致的房源它们之间的相似度更高。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056981037-18edee91-493a-4d5b-b066-57f0b200032d.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 评估房源的隐式特征
|
||||
- Airbnb 在训练房源(listing)的 Embedding时,并没有用到房源的图像信息。
|
||||
- 对于一些隐式信息,例如架构、风格、观感等是无法直接学习。
|
||||
- 为了验证基于 Word2Vec 学习到的 Embedding是否隐含了它们在外观等隐式信息上的相似性,Airbnb 内部开发了一款内部相似性探索工具。
|
||||
- 大致原理就是,利用训练好的 Embedding 进行 K 近邻相似度检索。
|
||||
- 如下,与查询房源在 Embedding 相似性高的其他房源,它们之间的外观风格也很相似。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653057336798-fd8451cb-84b6-40fb-8733-1e3d08a39793.png" alt="img" />
|
||||
|
||||
## User-type & Listing-type Embedding
|
||||
|
||||
前面提到的 Listing Embedding,它是基于用户的点击 sessions 学习得到的。
|
||||
|
||||
- 同一个 session 内的点击时间间隔低于30分钟,所以**它们更适合短期,session 内的个性化需求**。
|
||||
- 在用户搜索 session 期间,该方法有利于向用户展示与点击过的 listing 更相似的其他 listings 。
|
||||
|
||||
Airbnb 除了挖掘 Listing 的短期兴趣特征表示外,还对 User 和 Listing 的长期兴趣特征表示进行了探索。长期兴趣的探索是有利于 Airbnb 的业务发展。例如,用户当前在洛杉矶进行搜索,并且过去在纽约和伦敦预定过其他房源。那么,向用户推荐与之前预定过的 listing 相似的 listings 是更合适的。
|
||||
|
||||
- 长期兴趣的探索是基于 booking session(用户的历史预定序列)。
|
||||
- 与前面 Listing Embedding 的学习类似,Airbnb 希望借助了 Skip-Gram 模型学习不同房源的 Embedding 表示。
|
||||
|
||||
但是,面临着如下的挑战:
|
||||
|
||||
- booking sessions $ \mathcal{S}_{b} $ 数据量的大小远远小于 click sessions $ \mathcal{S} $ ,因为预定本身就是一件低频率事件。
|
||||
- 许多用户过去只预定了单个数量的房源,无法从长度为1的 session 中学习 Embedding
|
||||
- 对于任何实体,要基于 context 学习到有意义的 Embedding,该实体至少在数据中出现5-10次。
|
||||
- 但平台上大多数 listing_ids 被预定的次数低于5-10次。
|
||||
- 用户连续两次预定的时间间隔可能较长,在此期间用户的行为(如价格敏感点)偏好可能会发生改变(由于职业的变化)。
|
||||
|
||||
为了解决该问题,Airbnb 提出了基于 booking session 来学习用户和房源的 Type Embedding。给定一个 booking sessions 集合 $ \mathcal{S}_{b} $ ,其中包含了 $ M $ 个用户的 booking session:
|
||||
|
||||
- 每个 booking session 表示为: $ s_{b}=\left(l_{b 1}, \ldots, l_{b M}\right) $
|
||||
- 这里 $ l_{b1} $ 表示 listing_id,学习到 Embedding 记作 $ \mathbf{v}_{l_{i d}} $
|
||||
|
||||
**(1)什么是Type Embedding ?**
|
||||
在介绍 Type Embedding 之前,回顾一下 Listing Embedding:
|
||||
|
||||
- 在 Listing Embedding 的学习中,只学习房源的 Embedding 表示,未学习用户的 Embedding。
|
||||
- 对于 Listing Embedding,与相应的 Lisitng ID 是一一对应的, 每个 Listing 它们的 Embedding 表示是唯一的。
|
||||
|
||||
对于 Type Embedding ,有如下的区别:
|
||||
|
||||
- 对于不同的 Listing,它们的 Type Embedding **可能是相同的**(User 同样如此)。
|
||||
- Type Embedding 包含了 User-type Embedding 和 Listing-type Embedding。
|
||||
|
||||
为了更直接快速地了解什么是 Listing-type 和 User-type,举个简单的例子:
|
||||
|
||||
- 小王,是一名西藏人,性别男,今年21岁,就读于中国山东的蓝翔技校的挖掘机专业。
|
||||
- 通常,对于不同的用户(如小王),给定一个 ID 编码,然后学习相应的 User Embedding。
|
||||
- 但前面说了,用户数据过于稀疏,学习到的 User Embedding 特征表达能力不好。
|
||||
- 另一种方式:利用小王身上的用户标签,先组合出他的 User-type,然后学习 Embedding 表示。
|
||||
- 小王的 User-type:西藏人_男_学生_21岁_位置中国山东_南翔技校_挖掘机专业。
|
||||
- 组合得到的 User-type 本质上可视为一个 Category 特征,然后学习其对应的 Embedding 表示。
|
||||
|
||||
下表给出了原文中,Listing-type 和 User-type 包含的属性及属性的值:
|
||||
|
||||
- 所有的属性,都基于一定的规则进行了分桶(buckets)。例如21岁,被分桶到 20-30 岁的区间。
|
||||
- 对于首次预定的用户,他的属性为 buckets 的前5行,因为预定之前没有历史预定相关的信息。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653125260611-7d33731b-9167-4fcc-b83b-0a2407ea89ca.png" alt="img" style="zoom: 67%;" />
|
||||
|
||||
看到过前面那个简单的例子后,现在可以看一个原文的 Listing-type 的例子:
|
||||
|
||||
- 一个来自 US 的 Entire Home listing(lt1),它是一个二人间(c2),1 床(b1),一个卧室(bd2),1 个浴室(bt2),每晚平均价格为 60.8 美元(pn3),每晚每个客人的平均价格为 29.3 美元(pg3),5 个评价(r3),所有均 5 星好评(5s4),100% 的新客接受率(nu3)。
|
||||
- 因此该 listing 根据上表规则可以映射为:Listing-type = US_lt1_pn3_pg3_r3_5s4_c2_b1_bd2_bt2_nu3。
|
||||
|
||||
**(2)Type Embedding 的好处**
|
||||
前面在介绍 Type Embedding 和 Listing Embedding 的区别时,提到过不同 User 或 Listing 他们的 Type 可能相同。
|
||||
|
||||
- 故 User-type 和 Listing-type 在一定程度上可以缓解数据稀疏性的问题。
|
||||
- 对于 user 和 listing 而言,他们的属性可能会随着时间的推移而变化。
|
||||
- 故它们的 Embedding 在时间上也具备了动态变化属性。
|
||||
|
||||
**(3)Type Embedding 的训练过程**
|
||||
Type Embedding 的学习同样是基于 Skip-Gram 模型,但是有两点需要注意:
|
||||
|
||||
- 联合训练 User-type Embedding 和 Listing-type Embedding
|
||||
- 如下图(a),在 booking session 中,每个元素代表的是 (User-type, Listing-type)组合。
|
||||
- 为了学习在相同向量空间中的 User-type 和 Listing-type 的 Embeddings,Airbnb 的做法是将 User-type 插入到 booking sessions 中。
|
||||
- 形成一个(User-type, Listing-type)组成的元组序列,这样就可以让 User-type 和 Listing-type 的在 session 中的相对位置保持一致了。
|
||||
|
||||
- User-type 的目标函数:
|
||||
$$
|
||||
\underset{\theta}{\operatorname{argmax}} \sum_{\left(u_{t}, c\right) \in \mathcal{D}_{b o o k}} \log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime} \mathbf{v}_{u_{t}}}}+\sum_{\left(u_{t}, c\right) \in \mathcal{D}_{n e g}} \log \frac{1}{1+e^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{u_{t}}}}
|
||||
$$
|
||||
|
||||
+ $ \mathcal{D}_{\text {book }} $ 中的 $ u_t $ (中心词)表示 User-type, $ c $ (上下文)表示用户最近的预定过的 Listing-type。 $ \mathcal{D}_{\text {neg}} $ 中的 $ c $ 表示 negative Listing-type。
|
||||
+ $ u_t $ 表示 User-type 的 Embedding, $ \mathbf{v}_{c}^{\prime} $ 表示 Listing-type 的Embedding。
|
||||
|
||||
- Listing-type 的目标函数:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\underset{\theta}{\operatorname{argmax}} & \sum_{\left(l_{t}, c\right) \in \mathcal{D}_{b o o k}} \log \frac{1}{1+\exp ^{-\mathrm{v}_{c}^{\prime} \mathbf{v}_{l_{t}}}}+\sum_{\left(l_{t}, c\right) \in \mathcal{D}_{n e g}} \log \frac{1}{1+\exp ^{\mathrm{v}_{c}^{\prime} \mathbf{v}_{l_{t}}}} \\
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 同理,不过窗口中的中心词为 Listing-type, 上下文为 User-type。
|
||||
|
||||
- Explicit Negatives for Rejections
|
||||
- 用户预定房源以后,还要等待房源主人的确认,主人可能接受或者拒绝客人的预定。
|
||||
- 拒接的原因可能包括,客人星级评定不佳,资料不完整等。
|
||||
|
||||
- 前面学习到的 User-type Embedding 包含了客人的兴趣偏好,Listing-type Embedding 包含了房源的属性特征。
|
||||
- 但是,用户的 Embedding 未包含更容易被哪类房源主人拒绝的潜语义信息。
|
||||
- 房源的 Embedding 未包含主人对哪类客人的拒绝偏好。
|
||||
|
||||
- 为了提高用户预定房源以后,被主人接受的概率。同时,降低房源主人拒绝客人的概率。Airbnb 在训练 User-type 和 Listing-type 的 Embedding时,将用户预定后却被拒绝的样本加入负样本集中(如下图b)。
|
||||
- 更新后,Listing-type 的目标函数:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\underset{\theta}{\operatorname{argmax}} & \sum_{\left(u_{t}, c\right) \in \mathcal{D}_{b o o k}} \log \frac{1}{1+\exp ^{-\mathbf{v}_{c}^{\prime} \mathbf{v}_{u_{t}}}}+\sum_{\left(u_{t}, c\right) \in \mathcal{D}_{n e g}} \log \frac{1}{1+\exp ^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{u_{t}}}} \\
|
||||
&+\sum_{\left(u_{t}, l_{t}\right) \in \mathcal{D}_{\text {reject }}} \log \frac{1}{1+\exp ^{\mathrm{v}_{{l_{t}}}^{\prime} \mathrm{v}_{u_{t}}}}
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
- 更新后,User-type 的目标函数:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\underset{\theta}{\operatorname{argmax}} & \sum_{\left(l_{t}, c\right) \in \mathcal{D}_{b o o k}} \log \frac{1}{1+\exp ^{-\mathrm{v}_{c}^{\prime} \mathbf{v}_{l_{t}}}}+\sum_{\left(l_{t}, c\right) \in \mathcal{D}_{n e g}} \log \frac{1}{1+\exp ^{\mathrm{v}_{c}^{\prime} \mathbf{v}_{l_{t}}}} \\
|
||||
&+\sum_{\left(l_{t}, u_{t}\right) \in \mathcal{D}_{\text {reject }}} \log \frac{1}{1+\exp ^{\mathrm{v}^{\prime}_{u_{t}} \mathrm{v}_{l_{t}}}}
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653131985447-e033cb39-235b-4f46-9634-3b7faec284be.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
# 实验部分
|
||||
|
||||
前面介绍了两种 Embedding 的生成方法,分别为 Listing Embedding 和 User-type & Listing-type Embedding。本节的实验部分,将会介绍它们是如何被使用的。回顾 Airbnb 的业务背景,当用户查看一个房源时,他们有两种方式继续搜索:返回搜索结果页,或者查看房源详情页的「相似房源」。
|
||||
## 相似房源检索
|
||||
在给定学习到的 Listing Embedding,通过计算其向量 $ v_l $ 和来自同一区域的所有 Listing 的向量 $ v_j $ 之间的余弦相似度,可以找到给定房源 $ l $ 的相似房源。
|
||||
|
||||
- 这些相似房源可在同一日期被预定(如果入住-离开时间已确定)。
|
||||
- 相似度最高的 $ K $ 个房源被检索为相似房源。
|
||||
- 计算是在线执行的,并使用我们的分片架构并行进行,其中部分 Embedding 存储在每个搜索机器上。
|
||||
|
||||
A/B 测试显示,基于 Embedding 的解决方案使「相似房源」点击率增加了21%,最终通过「相似房源」产生的预订增加了 4.9%。
|
||||
|
||||
## 实时个性化搜索排名
|
||||
Airbnb 的搜索排名的大致流程为:
|
||||
|
||||
- 给定查询 $ q $ ,返回 $ K $ 条搜索结果。
|
||||
- 基于排序模型 GBDT,对预测结果进行排序。
|
||||
- 将排序后的结果展示给用户。
|
||||
|
||||
**(1)Query Embedding**
|
||||
原文中似乎并没有详细介绍 Airbnb 的搜索技术,在参考的博客中对他们的 Query Embedding 技术进行了描述。如下:
|
||||
|
||||
> Airbnb 对搜索的 Query 也进行了 Embedding,和普通搜索引擎的 Embedding 不太相同的是,这里的 Embedding 不是用自然语言中的语料库去训练的,而是用 Search Session 作为关系训练数据,训练方式更类似于 Item2Vec,Airbnb 中 Queue Embedding 的一个很重要的作用是捕获用户模糊查询与相关目的地的关联,这样做的好处是可以使搜索结果不再仅仅是简单地进行关键字匹配,而是通过更深层次的语义和关系来找到关联信息。比如下图所示的使用 Query Embedding 之前和之后的两个示例(Airbnb 非常人性化地在搜索栏的添加了自动补全,通过算法去 “猜想” 用户的真实目的,大大提高了用户的检索体验)
|
||||
|
||||
**(2)特征构建**
|
||||
对于各查询,给定的训练数据形式为: $ D_s = \left(\mathbf{x}_{i}, y_{i}\right), i=1 \ldots K $ ,其中 $ K $ 表示查询返回的房源数量。
|
||||
|
||||
- $ \mathbf{x}_{i} $ 表示第 $ i $ 个房源结果的 vector containing features:
|
||||
- 由 listing features,user features,query features 以及 cross-features 组成。
|
||||
- $ y_{i} \in\{0,0.01,0.25,1,-0.4\} $ 表示第 $ i $ 个结果的标签。
|
||||
- $ y_i=1 $ 表示用户预定了房源,..., $ y_i=-0.4 $ 表示房主拒绝了用户。
|
||||
|
||||
下面,介绍 Airbnb 是如何利用前面的两种种 Embedding 进行特征构建的。
|
||||
|
||||
- 如果用一句话来概括,这些基于 Embedding 的构建特征均为余弦相似度。
|
||||
- 新构建的特征均为样本 $ \mathbf{x}_{i} $ 特征的一部分。
|
||||
|
||||
构建的特征如下表所示:
|
||||
|
||||
- 表中的 Embedding Features 包含了8种类型,前6种类型的特征计算方式相同。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653139981920-a100085b-007b-4a9c-9edf-74297e9115ae.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
**① 基于 Listing Embedding Features 的特征构建**
|
||||
|
||||
- Airbnb 保留了用户过去两周6种不同类型的历史行为,如下图:
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653140202230-1f49e1dd-5c8c-4445-bd0b-9a17788a7b3f.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 对于每个行为,还要将其按照 market (地域)进行划分。以 $ H_c $ 为例:
|
||||
|
||||
- 假如 $ H_c $ 包含了 New YorK 和 Los Angeles 两个 market 的点击记录,则划分为 $ H_c(NY) $ 和 $ H_c(LA) $ 。
|
||||
|
||||
- 计算候选房源和不同行为之间的相似度。
|
||||
- 上述6种行为对应的相似度特征计算方式是相同的,以 $ H_c $ 为例:
|
||||
$$
|
||||
\operatorname{EmbClickSim}\left(l_{i}, H_{c}\right)=\max _{m \in M} \cos \left(\mathbf{v}_{l_{i}}, \sum_{l_{h} \in m, l_{h} \in H_{c}} \mathbf{v}_{l_{h}}\right)
|
||||
$$
|
||||
|
||||
- 其中, $ M $ 表示 market 的集合。第二项实际上为 Centroid Embedding(Embedding 的均值)。
|
||||
|
||||
- 除此之外,Airbnb 还计算了候选房源的 Embedding 与 latest long click 的 Embedding 之间的余弦相似度。
|
||||
$$
|
||||
\operatorname{EmbLastLongClickSim }\left(l_{i}, H_{l c}\right)=\cos \left(\mathbf{v}_{l_{i}}, \mathbf{v}_{l_{\text {last }}}\right)
|
||||
$$
|
||||
|
||||
**② 基于 User-type & Listing-type Embedding Features 的特征构建**
|
||||
|
||||
- 对于候选房源 $ l_i $ ,先查到其对应的 Listing-type $ l_t $ ,再找到用户的 User-type $ u_t $ 。
|
||||
|
||||
- 最后,计算 $ u_t $ 与 $ l_t $ 对应的 Embedding 之间的余弦相似度:
|
||||
$$
|
||||
\text { UserTypeListingTypeSim }\left(u_{t}, l_{t}\right)=\cos \left(\mathbf{v}_{u_{t}}, \mathbf{v}_{l_{t}}\right)
|
||||
$$
|
||||
|
||||
为了验证上述特征的构建是否有效,Airbnb 还做了特征重要性排序,如下表:
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653142188111-1975bcc4-22a2-45cf-bff0-2783ecb00a0c.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
**(3)模型**
|
||||
特征构建完成后,开始对模型进行训练。
|
||||
|
||||
- Airbnb 在搜索排名中使用的是 GBDT 模型,该模型是一个回归模型。
|
||||
- 模型的训练数据包括数据集 $ \mathcal{D} $ 和 search labels 。
|
||||
|
||||
最后,利用 GBDT 模型来预测线上各搜索房源的在线分数。得到预测分数后,将按照降序的方式展现给用户。
|
||||
# 参考链接
|
||||
|
||||
+ [Embedding 在大厂推荐场景中的工程化实践 - 卢明冬的博客 (lumingdong.cn)](https://lumingdong.cn/engineering-practice-of-embedding-in-recommendation-scenario.html#Airbnb)
|
||||
|
||||
+ [KDD'2018 Best Paper-Embedding技术在Airbnb实时搜索排序中的应用 (qq.com)](https://mp.weixin.qq.com/s/f9IshxX29sWg9NhSa7CaNg)
|
||||
|
||||
+ [再评Airbnb的经典Embedding论文 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/162163054)
|
||||
|
||||
+ [Airbnb爱彼迎房源排序中的嵌入(Embedding)技术 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/43295545)
|
||||
@@ -1,629 +0,0 @@
|
||||
# 双塔召回模型
|
||||
|
||||
---
|
||||
|
||||
双塔模型在推荐领域中是一个十分经典的模型,无论是在召回还是粗排阶段,都会是首选。这主要是得益于双塔模型结构,使得能够在线预估时满足低延时的要求。但也是因为其模型结构的问题,使得无法考虑到user和item特之间的特征交叉,使得影响模型最终效果,因此很多工作尝试调整经典双塔模型结构,在保持在线预估低延时的同时,保证双塔两侧之间有效的信息交叉。下面针对于经典双塔模型以及一些改进版本进行介绍。
|
||||
|
||||
|
||||
|
||||
## 经典双塔模型
|
||||
|
||||
DSSM(Deep Structured Semantic Model)是由微软研究院于CIKM在2013年提出的一篇工作,该模型主要用来解决NLP领域语义相似度任务 ,利用深度神经网络将文本表示为低维度的向量,用来提升搜索场景下文档和query匹配的问题。DSSM 模型的原理主要是:通过用户搜索行为中query 和 doc 的日志数据,通过深度学习网络将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之 间的余弦相似度,从而训练得到隐含语义模型,即 query 侧特征的 embedding 和 doc 侧特征的 embedding,进而可以获取语句的低维 语义向量表达 sentence embedding,可以预测两句话的语义相似度。模型结构如下所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/v2-7f75cc71f5e959d6efa95289d2f5ac13_r.jpg" style="zoom:45%;"/>
|
||||
</div>
|
||||
|
||||
|
||||
从上图可以看出,该网络结构比较简单,是一个由几层DNN组成网络,我们将要搜索文本(Query)和要匹配的文本(Document)的 embedding 输入到网络,网络输出为 128 维的向量,然后通过向量之间计算余弦相似度来计算向量之间距离,可以看作每一个 query 和 document 之间相似分数,然后在做 softmax。
|
||||
|
||||
|
||||
|
||||
而在推荐系统中,最为关键的问题是如何做好用户与item的匹配问题,因此对于推荐系统中DSSM模型的则是为 user 和 item 分别构建独立的子网络塔式结构,利用user和item的曝光或点击日期进行训练,最终得到user侧的embedding和item侧的embedding。因此在推荐系统中,常见的模型结构如下所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220522103456450.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
|
||||
从模型结构上来看,主要包括两个部分:user侧塔和item侧塔,对于每个塔分别是一个DNN结构。通过两侧的特征输入,通过DNN模块到user和item的embedding,然后计算两者之间的相似度(常用內积或者余弦值,下面会说这两种方式的联系和区别),因此对于user和item两侧最终得到的embedding维度需要保持一致,即最后一层全连接层隐藏单元个数相同。
|
||||
|
||||
|
||||
|
||||
在召回模型中,将这种检索行为视为多类分类问题,类似于YouTubeDNN模型。将物料库中所有的item视为一个类别,因此损失函数需要计算每个类的概率值:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220522110742879.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
|
||||
其中$s(x,y)$表示两个向量的相似度,$P(y|x;\theta)$表示预测类别的概率,$M$表示物料库所有的item。但是在实际场景中,由于物料库中的item数量巨大,在计算上式时会十分的耗时,因此会采样一定的数量的负样本来近似计算,后面针对负样本的采样做一些简单介绍。
|
||||
|
||||
|
||||
|
||||
以上就是推荐系统中经典的双塔模型,之所以在实际应用中非常常见,是因为**在海量的候选数据进行召回的场景下,速度很快,效果说不上极端好,但一般而言效果也够用了**。之所以双塔模型在服务时速度很快,是因为模型结构简单(两侧没有特征交叉),但这也带来了问题,双塔的结构无法考虑两侧特征之间的交互信息,**在一定程度上牺牲掉模型的部分精准性**。例如在精排模型中,来自user侧和item侧的特征会在第一层NLP层就可以做细粒度的特征交互,而对于双塔模型,user侧和item侧的特征只会在最后的內积计算时发生,这就导致很多有用的信息在经过DNN结构时就已经被其他特征所模糊了,因此双塔结构由于其结构问题先天就会存在这样的问题。下面针对这个问题来看看一下现有模型的解决思路。
|
||||
|
||||
|
||||
|
||||
## SENet双塔模型
|
||||
|
||||
SENet由Momenta在2017年提出,当时是一种应用于图像处理的新型网络结构。后来张俊林大佬将SENet引入了精排模型[FiBiNET](https%3A//arxiv.org/abs/1905.09433)中,其作用是为了将大量长尾的低频特征抛弃,弱化不靠谱低频特征embedding的负面影响,强化高频特征的重要作用。那SENet结构到底是怎么样的呢,为什么可以起到特征筛选的作用?
|
||||
|
||||
<div align=center>
|
||||
<img src="https://camo.githubusercontent.com/ccf54fc4fcac46667d451f22368e31cf86855bc8bfbff40b7675d524bc899ecf/68747470733a2f2f696d672d626c6f672e6373646e696d672e636e2f32303231303730333136313830373133392e706e673f782d6f73732d70726f636573733d696d6167652f77617465726d61726b2c747970655f5a6d46755a33706f5a57356e6147567064476b2c736861646f775f31302c746578745f6148523063484d364c7939696247396e4c6d4e7a5a473475626d56304c336431656d6876626d6478615746755a773d3d2c73697a655f312c636f6c6f725f4646464646462c745f3730237069635f63656e746572" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
从上图可以看出SENET主要分为三个步骤Squeeze, Excitation, Re-weight:
|
||||
|
||||
- Squeeze阶段:我们对每个特征的Embedding向量进行数据压缩与信息汇总,即在Embedding维度计算均值:
|
||||
|
||||
$$z_i = F_{sq}(e_i) = \frac{1}{k} \sum_{t=1}^k e_i^{(t)}$$
|
||||
|
||||
其中k表示Embedding的维度,Squeeze阶段是将每个特征的Squeeze转换成单一的数值。
|
||||
|
||||
- Excitation阶段:这阶段是根据上一阶段得到的向量进行缩放,即将上阶段的得到的 $1 \times f$ 的向量$Z$先压缩成 $1 \times \frac{f}{r}$ 长度,然后在放回到 $1 \times f$ 的维度,其中$r$表示压缩的程度。这个过程的具体操作就是经过两层DNN。
|
||||
|
||||
$$A = F_{ex}(Z) = \sigma_2(W_2\sigma_1(W_1Z)) $$
|
||||
|
||||
该过程可以理解为:对于当前所有输入的特征,通过相互发生关联,来动态地判断哪些特征重要,哪些特征不重要,而这体现在Excitation阶段的输出结果 $A$,其反应每个特征对应的重要性权重。
|
||||
|
||||
- Re-weight阶段:是将Excitation阶段得到的每个特征对应的权重 $A$ 再乘回到特征对应的Embedding里,就完成了对特征重要性的加权操作。
|
||||
|
||||
$$V=F_{ReWeight }(A,E)=[a_1 \cdot e_1,⋯,a_f \cdot e_f]=[v_1,⋯,v_f]$$
|
||||
|
||||
以上简单的介绍了一下SENet结构,可以发现这种结构可以通过对特征embedding先压缩,再交互,再选择,进而实现特征选择的效果。
|
||||
|
||||
|
||||
|
||||
此外张俊林大佬还将SENet应用于双塔模型中[(SENet双塔模型:在推荐领域召回粗排的应用及其它)](https://zhuanlan.zhihu.com/p/358779957),模型结构如下所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220522152508824.png" style="zoom:70%;"/>
|
||||
</div>
|
||||
|
||||
从上图可以发现,具体地是将双塔中的user塔和Item侧塔的特征输入部分加上一个SENet模块,通过SENet网络,动态地学习这些特征的重要性,通过小权重抑制噪音或者无效低频特征,通过大权重放大重要特征影响的目的。
|
||||
|
||||
|
||||
|
||||
之所以SENet双塔模型是有效的呢?张俊林老师的解释是:双塔模型的问题在于User侧特征和Item侧特征交互太晚,在高层交互,会造成细节信息,也就是具体特征信息的损失,影响两侧特征交叉的效果。而SENet模块在最底层就进行了特征的过滤,使得很多无效低频特征即使被过滤掉,这样更多有用的信息被保留到了双塔的最高层,使得两侧的交叉效果很好;同时由于SENet模块选择出更加重要的信息,使得User侧和Item侧特征之间的交互表达方面增强了DNN双塔的能力。
|
||||
|
||||
|
||||
|
||||
因此SENet双塔模型主要是从特征选择的角度,提高了两侧特征交叉的有效性,减少了噪音对有效信息的干扰,进而提高了双塔模型的效果。此外,除了这样的方式,还可以通过增加通道的方式来增强两侧的信息交互。即对于user和item两侧不仅仅使用一个DNN结构,而是可以通过不同结构(如FM,DCN等)来建模user和item的自身特征交叉,例如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/v2-9c2f7a30c6cadc47be23d6797f095b61_b.jpg" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
|
||||
这样对于user和item侧会得到多个embedding,类似于多兴趣的概念。通过得到的多个user和item的embedding,然后分别计算余弦值再相加(两侧的Embedding维度需要对齐),进而增加了双塔两侧的信息交互。而这种方法在腾讯进行过尝试,他们提出的“并联”双塔就是按照这样的思路,感兴趣的可以了解一下。
|
||||
|
||||
|
||||
|
||||
## 多目标的双塔模型
|
||||
|
||||
现如今多任务学习在实际的应用场景也十分的常见,主要是因为实际场景中业务复杂,往往有很多的衡量指标,例如点击,评论,收藏,关注,转发等。在多任务学习中,往往会针对不同的任务使用一个独有的tower,然后优化不同任务损失。那么针对双塔模型应该如何构建多任务学习框架呢?
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220523113206177.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
如上图所示,在user侧和item侧分别通过多个通道(DNN结构)为每个任务得到一个user embedding和item embedding,然后针对不同的目标分别计算user 和 item 的相似度,并计算各个目标的损失,最后的优化目标可以是多个任务损失之和,或者使用多任务学习中的动态损失权重。
|
||||
|
||||
|
||||
|
||||
这种模型结构,可以针对多目标进行联合建模,通过多任务学习的结构,一方面可以利用不同任务之间的信息共享,为一些稀疏特征提供其他任务中的迁移信息,另一方面可以在召回时,直接使用一个模型得到多个目标预测,解决了多个模型维护困难的问题。也就是说,在线上通过这一个模型就可以同时得到多个指标,例如视频场景,一个模型就可以直接得到点赞,品论,转发等目标的预测值,进而通过这些值计算分数获得最终的Top-K召回结果。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 双塔模型的细节
|
||||
|
||||
关于双塔模型,其模型结构相比排序模型来说很简单,没有过于复杂的结构。但除了结构,有一些细节部分容易被忽视,而这些细节部分往往比模型结构更加重要,因此下面主要介绍一下双塔模型中需要主要的一些细节问题。
|
||||
|
||||
|
||||
|
||||
### 归一化与温度系数
|
||||
|
||||
在[Google的双塔召回模型](https://dl.acm.org/doi/pdf/10.1145/3298689.3346996)中,重点介绍了两个trick,将user和item侧输出的embedding进行归一化以及对于內积值除以温度系数,实验证明这两种方式可以取得十分好的效果。那为什么这两种方法会使得模型的效果更好呢?
|
||||
|
||||
- 归一化:对user侧和item侧的输入embedding,进行L2归一化
|
||||
|
||||
$$u(x,\theta) \leftarrow = \frac{u(x,\theta)}{||u(x,\theta)||_2}$$
|
||||
|
||||
$$v(x,\theta) \leftarrow = \frac{v(x,\theta)}{||v(x,\theta)||_2}$$
|
||||
|
||||
- 温度系数:在归一化之后的向量计算內积之后,除以一个固定的超参 $r$ ,论文中命名为温度系数。
|
||||
|
||||
$$s(u,v) = \frac{<u(x,\theta), v(x,\theta)>}{r}$$
|
||||
|
||||
那为什么需要进行上述的两个操作呢?
|
||||
|
||||
- 归一化的操作主要原因是因为向量点积距离是非度量空间,不满足三角不等式,而归一化的操作使得点击行为转化成了欧式距离。
|
||||
|
||||
首先向量点积是向量对应位相乘并求和,即向量內积。而向量內积**不保序**,例如空间上三个点(A=(10,0),B=(0,10),C=(11,0)),利用向量点积计算的距离 dis(A,B) < dis(A,C),但是在欧式距离下这是错误的。而归一化的操作则会让向量点积转化为欧式距离,例如 $user_{emb}$ 表示归一化user的embedding, $item_{emb}$ 表示归一化 item 的embedding,那么两者之间的欧式距离 $||user_{emb} - item_{emb}||$ 如下, 可以看出归一化的向量点积已转化成了欧式距离。
|
||||
|
||||
$$||user_{emb} - item_{emb}||=\sqrt{||user_{emb}||^2+||item_{emb}||^2-2<user_{emb},item_{emb}>} = \sqrt{2-2<user_{emb},item_{emb}>}$$
|
||||
|
||||
|
||||
|
||||
那没啥非要转为欧式距离呢?这是因为ANN一般是通过计算欧式距离进行检索,这样转化成欧式空间,保证训练和检索一致。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 模型的应用
|
||||
|
||||
在实际的工业应用场景中,分为离线训练和在线服务两个环节。
|
||||
|
||||
- 在离线训练阶段,同过训练数据,训练好模型参数。然后将候选库中所有的item集合离线计算得到对应的embedding,并存储进ANN检索系统,比如faiss。为什么将离线计算item集合,主要是因为item的会相对稳定,不会频繁的变动,而对于用户而言,如果将用户行为作为user侧的输入,那么user的embedding会随着用户行为的发生而不断变化,因此对于user侧的embedding需要实时的计算。
|
||||
- 在线服务阶段,正是因为用户的行为变化需要被即使的反应在用户的embedding中,以更快的反应用户当前的兴趣,即可以实时地体现用户即时兴趣的变化。因此在线服务阶段需要实时的通过拼接用户特征,输入到user侧的DNN当中,进而得到user embedding,在通过user embedding去 faiss中进行ANN检索,召回最相似的K个item embedding。
|
||||
|
||||
可以看到双塔模型结构十分的适合实际的应用场景,在快速服务的同时,还可以更快的反应用户即时兴趣的变化。
|
||||
|
||||
|
||||
|
||||
### 负样本采样
|
||||
|
||||
相比于排序模型而言,召回阶段的模型除了在结构上的不同,在样本选择方面也存在着很大的差异,可以说样本的选择很大程度上会影响召回模型的效果。对于召回模型而言,其负样本并不能和排序模型一样只使用展现未点击样本,因为召回模型在线上面临的数据分布是全部的item,而不仅仅是展现未点击样本。因此在离线训练时,需要让其保证和线上分布尽可能一致,所以在负样本的选择样要尽可能的增加很多未被曝光的item。下面简单的介绍一些常见的采样方法:
|
||||
|
||||
#### 全局随机采样
|
||||
|
||||
全局随机采样指:从全局候选item里面随机抽取一定数量item做为召回模型的负样本。这样的方式实现简单,也可以让模型尽可能的和线上保持一致的分布,尽可能的多的让模型对于全局item有区分的能力。例如YoutubeDNN算法。
|
||||
|
||||
但这样的方式也会存在一定的问题,由于候选的item属于长尾数据,即“八二定律”,也就是说少数热门物料占据了绝大多数的曝光与点击。因此存随机的方式只能让模型在学到粗粒度上差异,对一些尾部item并不友好。
|
||||
|
||||
|
||||
|
||||
#### 全局随机采样 + 热门打压
|
||||
|
||||
针对于全局随机采样的不足,一个直观的方法是针对于item的热度item进行打压,即对于热门的item很多用户可能会点击,需要进行一定程度的欠采样,使得模型更加关注一些非热门的item。 此外在进行负样本采样时,应该对一些热门item进行适当的过采样,这可以尽可能的让模型对于负样本有更加细粒度的区分。例如在word2vec中,负采样方法是根据word的频率,对 negative words进行随机抽样,降 低 negative words 量级。
|
||||
|
||||
之所以热门item做负样本时,要适当过采样,增加负样本难度。因为对于全量的item,模型可以轻易的区分一些和用户兴趣差异性很大的item,难点在于很难区分一些和用户兴趣相似的item。因此在训练模型时,需要适当的增加一些难以区分的负样本来提升模型面对相似item的分区能力。
|
||||
|
||||
|
||||
|
||||
|
||||
#### Hard Negative增强样本
|
||||
|
||||
Hard Negative指的是选取一部分匹配度适中的item,能够增加模型在训练时的难度,提升模型能学习到item之间细粒度上的差异。至于 如何选取在工业界也有很多的解决方案。
|
||||
|
||||
例如Airbnb根据业务逻辑来采样一些hard negative (增加与正样本同城的房间作为负样本,增强了正负样本在地域上的相似性;增加与正样本同城的房间作为负样本,增强了正负样本在地域上的相似性,),详细内容可以查看[原文](https://www.kdd.org/kdd2018/accepted-papers/view/real-time-personalization-using-embeddings-for-search-ranking-at-airbnb)
|
||||
|
||||
例如百度和facebook依靠模型自己来挖掘Hard Negative,都是用上一版本的召回模型筛选出"没那么相似"的<user,item>对,作为额外负样本,用于训练下一版本召回模型。 详细可以查看[Mobius](http://research.baidu.com/Public/uploads/5d12eca098d40.pdf) 和 [EBR](https://arxiv.org/pdf/2006.11632.pdf)
|
||||
|
||||
|
||||
|
||||
#### Batch内随机选择负采样
|
||||
|
||||
基于batch的负采样方法是将batch内选择除了正样本之外的其它Item,做为负样本,其本质就是利用其他样本的正样本随机采样作为自己的负样本。这样的方法可以作为负样本的选择方式,特别是在如今分布式训练以及增量训练的场景中是一个非常值得一试的方法。但这种方法也存在他的问题,基于batch的负采样方法受batch的影响很大,当batch的分布与整体的分布差异很大时就会出现问题,同时batch内负采样也会受到热门item的影响,需要考虑打压热门item的问题。至于解决的办法,Google的双塔召回模型中给出了答案,想了解的同学可以去学习一下。
|
||||
|
||||
|
||||
|
||||
总的来说负样本的采样方法,不光是双塔模型应该重视的工作,而是所有召回模型都应该仔细考虑的方法。
|
||||
|
||||
|
||||
|
||||
## 代码实现
|
||||
|
||||
下面使用一点资讯提供的数据,实践一下DSSM召回模型。该模型的实现主要参考:DeepCtr和DeepMatch模块。
|
||||
|
||||
### 模型训练数据
|
||||
|
||||
1、数据预处理
|
||||
用户侧主要包含一些用户画像属性(用户性别,年龄,所在省市,使用设备及系统);新闻侧主要包括新闻的创建时间,题目,所属 一级、二级类别,题片个数以及关键词。下面主要是对着两部分数据的简单处理:
|
||||
|
||||
```python
|
||||
def proccess(file):
|
||||
if file=="user_info_data_5w.csv":
|
||||
data = pd.read_csv(file_path + file, sep="\t",index_col=0)
|
||||
data["age"] = data["age"].map(lambda x: get_pro_age(x))
|
||||
data["gender"] = data["gender"].map(lambda x: get_pro_age(x))
|
||||
|
||||
data["province"]=data["province"].fillna(method='ffill')
|
||||
data["city"]=data["city"].fillna(method='ffill')
|
||||
|
||||
data["device"] = data["device"].fillna(method='ffill')
|
||||
data["os"] = data["os"].fillna(method='ffill')
|
||||
return data
|
||||
|
||||
elif file=="doc_info.txt":
|
||||
data = pd.read_csv(file_path + file, sep="\t")
|
||||
data.columns = ["article_id", "title", "ctime", "img_num","cate","sub_cate", "key_words"]
|
||||
select_column = ["article_id", "title_len", "ctime", "img_num","cate","sub_cate", "key_words"]
|
||||
|
||||
# 去除时间为nan的新闻以及除脏数据
|
||||
data= data[(data["ctime"].notna()) & (data["ctime"] != 'Android')]
|
||||
data['ctime'] = data['ctime'].astype('str')
|
||||
data['ctime'] = data['ctime'].apply(lambda x: int(x[:10]))
|
||||
data['ctime'] = pd.to_datetime(data['ctime'], unit='s', errors='coerce')
|
||||
|
||||
|
||||
# 这里存在nan字符串和异常数据
|
||||
data["sub_cate"] = data["sub_cate"].astype(str)
|
||||
data["sub_cate"] = data["sub_cate"].apply(lambda x: pro_sub_cate(x))
|
||||
data["img_num"] = data["img_num"].astype(str)
|
||||
data["img_num"] = data["img_num"].apply(photoNums)
|
||||
data["title_len"] = data["title"].apply(lambda x: len(x) if isinstance(x, str) else 0)
|
||||
data["cate"] = data["cate"].fillna('其他')
|
||||
|
||||
return data[select_column]
|
||||
```
|
||||
|
||||
2、构造训练样本
|
||||
该部分主要是根据用户的交互日志中前6天的数据作为训练集,第7天的数据作为测试集,来构造模型的训练测试样本。
|
||||
|
||||
```python
|
||||
def dealsample(file, doc_data, user_data, s_data_str = "2021-06-24 00:00:00", e_data_str="2021-06-30 23:59:59", neg_num=5):
|
||||
# 先处理时间问题
|
||||
data = pd.read_csv(file_path + file, sep="\t",index_col=0)
|
||||
data['expo_time'] = data['expo_time'].astype('str')
|
||||
data['expo_time'] = data['expo_time'].apply(lambda x: int(x[:10]))
|
||||
data['expo_time'] = pd.to_datetime(data['expo_time'], unit='s', errors='coerce')
|
||||
|
||||
s_date = datetime.datetime.strptime(s_data_str,"%Y-%m-%d %H:%M:%S")
|
||||
e_date = datetime.datetime.strptime(e_data_str,"%Y-%m-%d %H:%M:%S") + datetime.timedelta(days=-1)
|
||||
t_date = datetime.datetime.strptime(e_data_str,"%Y-%m-%d %H:%M:%S")
|
||||
|
||||
# 选取训练和测试所需的数据
|
||||
all_data_tmp = data[(data["expo_time"]>=s_date) & (data["expo_time"]<=t_date)]
|
||||
|
||||
# 处理训练数据集 防止穿越样本
|
||||
# 1. merge 新闻信息,得到曝光时间和新闻创建时间; inner join 去除doc_data之外的新闻
|
||||
all_data_tmp = all_data_tmp.join(doc_data.set_index("article_id"),on="article_id",how='inner')
|
||||
|
||||
# 发现还存在 ctime大于expo_time的交互存在 去除这部分错误数据
|
||||
all_data_tmp = all_data_tmp[(all_data_tmp["ctime"]<=all_data_tmp["expo_time"])]
|
||||
|
||||
# 2. 去除与新闻的创建时间在测试数据时间内的交互 ()
|
||||
train_data = all_data_tmp[(all_data_tmp["expo_time"]>=s_date) & (all_data_tmp["expo_time"]<=e_date)]
|
||||
train_data = train_data[(train_data["ctime"]<=e_date)]
|
||||
|
||||
print("有效的样本数:",train_data["expo_time"].count())
|
||||
|
||||
# 负采样
|
||||
if os.path.exists(file_path + "neg_sample.pkl") and os.path.getsize(file_path + "neg_sample.pkl"):
|
||||
neg_samples = pd.read_pickle(file_path + "neg_sample.pkl")
|
||||
# train_neg_samples.insert(loc=2, column="click", value=[0] * train_neg_samples["user_id"].count())
|
||||
else:
|
||||
# 进行负采样的时候对于样本进行限制,只对一定时间范围之内的样本进行负采样
|
||||
doc_data_tmp = doc_data[(doc_data["ctime"]>=datetime.datetime.strptime("2021-06-01 00:00:00","%Y-%m-%d %H:%M:%S"))]
|
||||
neg_samples = negSample_like_word2vec(train_data, doc_data_tmp[["article_id"]].values, user_data[["user_id"]].values, neg_num=neg_num)
|
||||
neg_samples = pd.DataFrame(neg_samples, columns= ["user_id","article_id","click"])
|
||||
neg_samples.to_pickle(file_path + "neg_sample.pkl")
|
||||
|
||||
train_pos_samples = train_data[train_data["click"] == 1][["user_id","article_id", "expo_time", "click"]] # 取正样本
|
||||
|
||||
neg_samples_df = train_data[train_data["click"] == 0][["user_id","article_id", "click"]]
|
||||
train_neg_samples = pd.concat([neg_samples_df.sample(n=train_pos_samples["click"].count()) ,neg_samples],axis=0) # 取负样本
|
||||
|
||||
print("训练集正样本数:",train_pos_samples["click"].count())
|
||||
print("训练集负样本数:",train_neg_samples["click"].count())
|
||||
|
||||
train_data_df = pd.concat([train_neg_samples,train_pos_samples],axis=0)
|
||||
train_data_df = train_data_df.sample(frac=1) # shuffle
|
||||
|
||||
print("训练集总样本数:",train_data_df["click"].count())
|
||||
|
||||
test_data_df = all_data_tmp[(all_data_tmp["expo_time"]>e_date) & (all_data_tmp["expo_time"]<=t_date)][["user_id","article_id", "expo_time", "click"]]
|
||||
|
||||
print("测试集总样本数:",test_data_df["click"].count())
|
||||
print("测试集总样本数:",test_data_df["click"].count())
|
||||
|
||||
all_data_df = pd.concat([train_data_df, test_data_df],axis=0)
|
||||
|
||||
print("总样本数:",all_data_df["click"].count())
|
||||
|
||||
return all_data_df
|
||||
```
|
||||
|
||||
3、负样本采样
|
||||
该部分主要采用基于item的展现次数对全局item进行负采样。
|
||||
|
||||
```python
|
||||
def negSample_like_word2vec(train_data, all_items, all_users, neg_num=10):
|
||||
"""
|
||||
为所有item计算一个采样概率,根据概率为每个用户采样neg_num个负样本,返回所有负样本对
|
||||
1. 统计所有item在交互中的出现频次
|
||||
2. 根据频次进行排序,并计算item采样概率(频次出现越多,采样概率越低,打压热门item)
|
||||
3. 根据采样概率,利用多线程为每个用户采样 neg_num 个负样本
|
||||
"""
|
||||
pos_samples = train_data[train_data["click"] == 1][["user_id","article_id"]]
|
||||
|
||||
pos_samples_dic = {}
|
||||
for idx,u in enumerate(pos_samples["user_id"].unique().tolist()):
|
||||
pos_list = list(pos_samples[pos_samples["user_id"] == u]["article_id"].unique().tolist())
|
||||
if len(pos_list) >= 30: # 30是拍的 需要数据统计的支持确定
|
||||
pos_samples_dic[u] = pos_list[30:]
|
||||
else:
|
||||
pos_samples_dic[u] = pos_list
|
||||
|
||||
# 统计出现频次
|
||||
article_counts = train_data["article_id"].value_counts()
|
||||
df_article_counts = pd.DataFrame(article_counts)
|
||||
dic_article_counts = dict(zip(df_article_counts.index.values.tolist(),df_article_counts.article_id.tolist()))
|
||||
|
||||
for item in all_items:
|
||||
if item[0] not in dic_article_counts.keys():
|
||||
dic_article_counts[item[0]] = 0
|
||||
|
||||
# 根据频次排序, 并计算每个item的采样概率
|
||||
tmp = sorted(list(dic_article_counts.items()), key=lambda x:x[1], reverse=True) # 降序
|
||||
n_articles = len(tmp)
|
||||
article_prob = {}
|
||||
for idx, item in enumerate(tmp):
|
||||
article_prob[item[0]] = cal_pos(idx, n_articles)
|
||||
|
||||
# 为每个用户进行负采样
|
||||
article_id_list = [a[0] for a in article_prob.items()]
|
||||
article_pro_list = [a[1] for a in article_prob.items()]
|
||||
pos_sample_users = list(pos_samples_dic.keys())
|
||||
|
||||
all_users_list = [u[0] for u in all_users]
|
||||
|
||||
print("start negative sampling !!!!!!")
|
||||
pool = multiprocessing.Pool(core_size)
|
||||
res = pool.map(SampleOneProb((pos_sample_users,article_id_list,article_pro_list,pos_samples_dic,neg_num)), tqdm(all_users_list))
|
||||
pool.close()
|
||||
pool.join()
|
||||
|
||||
neg_sample_dic = {}
|
||||
for idx, u in tqdm(enumerate(all_users_list)):
|
||||
neg_sample_dic[u] = res[idx]
|
||||
|
||||
return [[k,i,0] for k,v in neg_sample_dic.items() for i in v]
|
||||
```
|
||||
|
||||
### DSSM 模型
|
||||
|
||||
1、模型构建
|
||||
|
||||
模型构建部分主要是将输入的user 特征以及 item 特征处理完之后分别送入两侧的DNN结构。
|
||||
|
||||
```python
|
||||
def DSSM(user_feature_columns, item_feature_columns, dnn_units=[64, 32],
|
||||
temp=10, task='binary'):
|
||||
# 构建所有特征的Input层和Embedding层
|
||||
feature_encode = FeatureEncoder(user_feature_columns + item_feature_columns)
|
||||
feature_input_layers_list = list(feature_encode.feature_input_layer_dict.values())
|
||||
|
||||
# 特征处理
|
||||
user_dnn_input, item_dnn_input = process_feature(user_feature_columns,\
|
||||
item_feature_columns, feature_encode)
|
||||
|
||||
# 构建模型的核心层
|
||||
if len(user_dnn_input) >= 2:
|
||||
user_dnn_input = Concatenate(axis=1)(user_dnn_input)
|
||||
else:
|
||||
user_dnn_input = user_dnn_input[0]
|
||||
if len(item_dnn_input) >= 2:
|
||||
item_dnn_input = Concatenate(axis=1)(item_dnn_input)
|
||||
else:
|
||||
item_dnn_input = item_dnn_input[0]
|
||||
user_dnn_input = Flatten()(user_dnn_input)
|
||||
item_dnn_input = Flatten()(item_dnn_input)
|
||||
user_dnn_out = DNN(dnn_units)(user_dnn_input)
|
||||
item_dnn_out = DNN(dnn_units)(item_dnn_input)
|
||||
|
||||
|
||||
# 计算相似度
|
||||
scores = CosinSimilarity(temp)([user_dnn_out, item_dnn_out]) # (B,1)
|
||||
# 确定拟合目标
|
||||
output = PredictLayer()(scores)
|
||||
# 根据输入输出构建模型
|
||||
model = Model(feature_input_layers_list, output)
|
||||
return model
|
||||
```
|
||||
|
||||
2、CosinSimilarity相似度计算
|
||||
|
||||
在余弦相似度计算,主要是注意使用归一化以及温度系数的技巧。
|
||||
|
||||
```python
|
||||
def call(self, inputs, **kwargs):
|
||||
"""inputs 是一个列表"""
|
||||
query, candidate = inputs
|
||||
# 计算两个向量的二范数
|
||||
query_norm = tf.norm(query, axis=self.axis) # (B, 1)
|
||||
candidate_norm = tf.norm(candidate, axis=self.axis)
|
||||
# 计算向量点击,即內积操作
|
||||
scores = tf.reduce_sum(tf.multiply(query, candidate), axis=-1)#(B,1)
|
||||
# 相似度除以二范数, 防止除零
|
||||
scores = tf.divide(scores, query_norm * candidate_norm + 1e-8)
|
||||
# 对score的范围限制到(-1, 1)之间
|
||||
scores = tf.clip_by_value(scores, -1, 1)
|
||||
# 乘以温度系数
|
||||
score = scores * self.temperature
|
||||
return score
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 模型训练
|
||||
|
||||
1、稀疏特征编码
|
||||
该部分主要是针对于用户侧和新闻侧的稀疏特征进行编码,并将训练样本join上两侧的特征。
|
||||
|
||||
```python
|
||||
# 数据和测试数据
|
||||
data, user_data, doc_data = get_all_data()
|
||||
|
||||
# 1.Label Encoding for sparse features,and process sequence features with `gen_date_set` and `gen_model_input`
|
||||
feature_max_idx = {}
|
||||
feature_encoder = {}
|
||||
|
||||
user_sparse_features = ["user_id", "device", "os", "province", "city", "age", "gender"]
|
||||
for feature in user_sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
user_data[feature] = lbe.fit_transform(user_data[feature]) + 1
|
||||
feature_max_idx[feature] = user_data[feature].max() + 1
|
||||
feature_encoder[feature] = lbe
|
||||
|
||||
|
||||
doc_sparse_features = ["article_id", "cate", "sub_cate"]
|
||||
doc_dense_features = ["title_len", "img_num"]
|
||||
|
||||
for feature in doc_sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
if feature in ["cate","sub_cate"]:
|
||||
# 这里面会出现一些float的数据,导致无法编码
|
||||
doc_data[feature] = lbe.fit_transform(doc_data[feature].astype(str)) + 1
|
||||
else:
|
||||
doc_data[feature] = lbe.fit_transform(doc_data[feature]) + 1
|
||||
feature_max_idx[feature] = doc_data[feature].max() + 1
|
||||
feature_encoder[feature] = lbe
|
||||
|
||||
data["article_id"] = feature_encoder["article_id"].transform(data["article_id"].tolist())
|
||||
data["user_id"] = feature_encoder["user_id"].transform(data["user_id"].tolist())
|
||||
|
||||
|
||||
# join 用户侧和新闻侧的特征
|
||||
data = data.join(user_data.set_index("user_id"), on="user_id", how="inner")
|
||||
data = data.join(doc_data.set_index("article_id"), on="article_id", how="inner")
|
||||
|
||||
sparse_features = user_sparse_features + doc_sparse_features
|
||||
dense_features = doc_dense_features
|
||||
|
||||
features = sparse_features + dense_features
|
||||
|
||||
mms = MinMaxScaler(feature_range=(0, 1))
|
||||
data[dense_features] = mms.fit_transform(data[dense_features])
|
||||
```
|
||||
|
||||
2、配置特征以及模型训练
|
||||
构建模型所需的输入特征,同时构建DSSM模型及训练。
|
||||
|
||||
```python
|
||||
embedding_dim = 8
|
||||
user_feature_columns = [SparseFeat('user_id', feature_max_idx['user_id'], embedding_dim),
|
||||
SparseFeat("gender", feature_max_idx['gender'], embedding_dim),
|
||||
SparseFeat("age", feature_max_idx['age'], embedding_dim),
|
||||
SparseFeat("device", feature_max_idx['device'], embedding_dim),
|
||||
SparseFeat("os", feature_max_idx['os'], embedding_dim),
|
||||
SparseFeat("province", feature_max_idx['province'], embedding_dim),
|
||||
SparseFeat("city", feature_max_idx['city'], embedding_dim), ]
|
||||
|
||||
item_feature_columns = [SparseFeat('article_id', feature_max_idx['article_id'], embedding_dim),
|
||||
DenseFeat('img_num', 1),
|
||||
DenseFeat('title_len', 1),
|
||||
SparseFeat('cate', feature_max_idx['cate'], embedding_dim),
|
||||
SparseFeat('sub_cate', feature_max_idx['sub_cate'], embedding_dim)]
|
||||
|
||||
model = DSSM(user_feature_columns, item_feature_columns,
|
||||
user_dnn_hidden_units=(32, 16, embedding_dim), item_dnn_hidden_units=(32, 16, embedding_dim)) # FM(user_feature_columns,item_feature_columns)
|
||||
|
||||
model.compile(optimizer="adagrad", loss = "binary_crossentropy", metrics=[tf.keras.metrics.Recall(), tf.keras.metrics.Precision()] ) #
|
||||
|
||||
history = model.fit(train_model_input, train_label, batch_size=256, epochs=4, verbose=1, validation_split=0.2, )
|
||||
```
|
||||
|
||||
3、生成embedding用于召回
|
||||
利用训练过的模型获取所有item的embeddings,同时获取所有测试集的user embedding,保存之后用于之后的召回工作。
|
||||
|
||||
```python
|
||||
all_item_model_input = {"article_id": item_profile['article_id'].values,
|
||||
"img_num": item_profile['img_num'].values,
|
||||
"title_len": item_profile['title_len'].values,
|
||||
"cate": item_profile['cate'].values,
|
||||
"sub_cate": item_profile['sub_cate'].values,}
|
||||
|
||||
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
|
||||
item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
|
||||
|
||||
user_embs = user_embedding_model.predict(test_user_model_input, batch_size=2 ** 12)
|
||||
item_embs = item_embedding_model.predict(all_item_model_input, batch_size=2 ** 12)
|
||||
|
||||
user_idx_2_rawid, doc_idx_2_rawid = {}, {}
|
||||
|
||||
for i in range(len(user_embs)):
|
||||
user_idx_2_rawid[i] = test_user_model_input["user_id"][i]
|
||||
|
||||
for i in range(len(item_embs)):
|
||||
doc_idx_2_rawid[i] = all_item_model_input["article_id"][i]
|
||||
|
||||
# 保存一份
|
||||
pickle.dump((user_embs, user_idx_2_rawid, feature_encoder["user_id"]), open(file_path + 'user_embs.pkl', 'wb'))
|
||||
pickle.dump((item_embs, doc_idx_2_rawid, feature_encoder["article_id"]), open(file_path + 'item_embs.pkl', 'wb'))
|
||||
```
|
||||
|
||||
|
||||
### ANN召回
|
||||
|
||||
1、为测试集用户召回
|
||||
通过annoy tree为所有的item构建索引,并通过测试集中所有的user embedding为每个用户召回一定数量的item。
|
||||
|
||||
```python
|
||||
def get_DSSM_recall_res(user_embs, doc_embs, user_idx_2_rawid, doc_idx_2_rawid, topk):
|
||||
"""近邻检索,这里用annoy tree"""
|
||||
# 把doc_embs构建成索引树
|
||||
f = user_embs.shape[1]
|
||||
t = AnnoyIndex(f, 'angular')
|
||||
for i, v in enumerate(doc_embs):
|
||||
t.add_item(i, v)
|
||||
t.build(10)
|
||||
|
||||
# 每个用户向量, 返回最近的TopK个item
|
||||
user_recall_items_dict = collections.defaultdict(dict)
|
||||
for i, u in enumerate(user_embs):
|
||||
recall_doc_scores = t.get_nns_by_vector(u, topk, include_distances=True)
|
||||
# recall_doc_scores是(([doc_idx], [scores])), 这里需要转成原始doc的id
|
||||
raw_doc_scores = list(recall_doc_scores)
|
||||
raw_doc_scores[0] = [doc_idx_2_rawid[i] for i in raw_doc_scores[0]]
|
||||
# 转换成实际用户id
|
||||
user_recall_items_dict[user_idx_2_rawid[i]] = dict(zip(*raw_doc_scores))
|
||||
|
||||
# 默认是分数从小到大排的序, 这里要从大到小
|
||||
user_recall_items_dict = {k: sorted(v.items(), key=lambda x: x[1], reverse=True) for k, v in user_recall_items_dict.items()}
|
||||
|
||||
pickle.dump(user_recall_items_dict, open(file_path + 'DSSM_u2i_dict.pkl', 'wb'))
|
||||
|
||||
return user_recall_items_dict
|
||||
```
|
||||
|
||||
2、测试召回结果
|
||||
为测试集用户的召回结果进行测试。
|
||||
|
||||
```python
|
||||
user_recall_items_dict = get_DSSM_recall_res(user_embs, item_embs, user_idx_2_rawid, doc_idx_2_rawid, topk=TOP_NUM)
|
||||
|
||||
test_true_items = {line[0]:line[1] for line in test_set}
|
||||
|
||||
s = []
|
||||
precision = []
|
||||
for i, uid in tqdm(enumerate(list(user_recall_items_dict.keys()))):
|
||||
# try:
|
||||
pred = [x for x, _ in user_recall_items_dict[uid]]
|
||||
filter_item = None
|
||||
recall_score = recall_N(test_true_items[uid], pred, N=TOP_NUM)
|
||||
s.append(recall_score)
|
||||
precision_score = precision_N(test_true_items[uid], pred, N=TOP_NUM)
|
||||
precision.append(precision_score)
|
||||
print("recall", np.mean(s))
|
||||
print("precision", np.mean(precision))
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 参考
|
||||
|
||||
- [负样本为王:评Facebook的向量化召回算法](https://zhuanlan.zhihu.com/p/165064102)
|
||||
|
||||
- [多目标DSSM召回实战](https://mp.weixin.qq.com/s/aorZ43WozKrD2AudR6AnOg)
|
||||
|
||||
- [召回模型中的负样本构造](https://zhuanlan.zhihu.com/p/358450850)
|
||||
|
||||
- [Youtube双塔模型](https://dl.acm.org/doi/10.1145/3298689.3346996)
|
||||
|
||||
- [张俊林:SENet双塔模型:在推荐领域召回粗排的应用及其它](https://zhuanlan.zhihu.com/p/358779957)
|
||||
|
||||
- [双塔召回模型的前世今生(上篇)](https://zhuanlan.zhihu.com/p/430503952)
|
||||
|
||||
- [双塔召回模型的前世今生(下篇)](https://zhuanlan.zhihu.com/p/441597009)
|
||||
|
||||
- [Learning Deep Structured Semantic Models for Web Search using Clickthrough Data](https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2013_DSSM_fullversion.pdf)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,124 +0,0 @@
|
||||
# FM 模型结构
|
||||
|
||||
FM 模型用于排序时,模型的公式定义如下:
|
||||
$$
|
||||
\hat{y}(\mathbf{x}):=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}
|
||||
$$
|
||||
+ 其中,$i$ 表示特征的序号,$n$ 表示特征的数量;$x_i \in \mathbb{R}$ 表示第 $i$ 个特征的值。
|
||||
+ $v_i,v_j \in \mathbb{R}^{k} $ 分别表示特征 $x_i,x_j$ 对应的隐语义向量(Embedding向量), $\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle:=\sum_{f=1}^{k} v_{i, f} \cdot v_{j, f}$ 。
|
||||
+ $w_0,w_i\in \mathbb{R}$ 均表示需要学习的参数。
|
||||
|
||||
**FM 的一阶特征交互**
|
||||
|
||||
在 FM 的表达式中,前两项为特征的一阶交互项。将其拆分为用户特征和物品特征的一阶特征交互项,如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
& w_{0}+\sum_{i=1}^{n} w_{i} x_{i} \\
|
||||
&= w_{0} + \sum_{t \in I}w_{t} x_{t} + \sum_{u\in U}w_{u} x_{u} \\
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 其中,$U$ 表示用户相关特征集合,$I$ 表示物品相关特征集合。
|
||||
|
||||
**FM 的二阶特征交互**
|
||||
|
||||
观察 FM 的二阶特征交互项,可知其计算复杂度为 $O\left(k n^{2}\right)$ 。为了降低计算复杂度,按照如下公式进行变换。
|
||||
$$
|
||||
\begin{aligned}
|
||||
& \sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j} \\
|
||||
=& \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}-\frac{1}{2} \sum_{i=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{i}\right\rangle x_{i} x_{i} \\
|
||||
=& \frac{1}{2}\left(\sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{j, f} x_{i} x_{j}-\sum_{i=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{i, f} x_{i} x_{i}\right) \\
|
||||
=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{}\left(\sum_{j=1}^{n} v_{j, f} x_{j}\right)-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \\
|
||||
=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
+ 公式变换后,计算复杂度由 $O\left(k n^{2}\right)$ 降到 $O\left(k n\right)$。
|
||||
|
||||
由于本文章需要将 FM 模型用在召回,故将二阶特征交互项拆分为用户和物品项。有:
|
||||
$$
|
||||
\begin{aligned}
|
||||
& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \\
|
||||
=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{u \in U} v_{u, f} x_{u} + \sum_{t \in I} v_{t, f} x_{t}\right)^{2}-\sum_{u \in U} v_{u, f}^{2} x_{u}^{2} - \sum_{t\in I} v_{t, f}^{2} x_{t}^{2}\right) \\
|
||||
=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{u \in U} v_{u, f} x_{u}\right)^{2} + \left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} + 2{\sum_{u \in U} v_{u, f} x_{u}}{\sum_{t \in I} v_{t, f} x_{t}} - \sum_{u \in U} v_{u, f}^{2} x_{u}^{2} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 其中,$U$ 表示用户相关特征集合,$I$ 表示物品相关特征集合。
|
||||
|
||||
|
||||
|
||||
# FM 用于召回
|
||||
|
||||
基于 FM 召回,我们可以将 $\hat{y}(\mathbf{x}):=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}$ 作为用户和物品之间的匹配分。
|
||||
|
||||
+ 在上一小节中,对于 FM 的一阶、二阶特征交互项,已将其拆分为用户项和物品项。
|
||||
+ 对于同一用户,即便其与不同物品进行交互,但用户特征内部之间的一阶、二阶交互项得分都是相同的。
|
||||
+ 这就意味着,在比较用户与不同物品之间的匹配分时,只需要比较:(1)物品内部之间的特征交互得分;(2)用户和物品之间的特征交互得分。
|
||||
|
||||
**FM 的一阶特征交互**
|
||||
|
||||
+ 将全局偏置和用户一阶特征交互项进行丢弃,有:
|
||||
$$
|
||||
FM_{一阶} = \sum_{t \in I} w_{t} x_{t}
|
||||
$$
|
||||
|
||||
**FM 的二阶特征交互**
|
||||
|
||||
+ 将用户特征内部的特征交互项进行丢弃,有:
|
||||
$$
|
||||
\begin{aligned}
|
||||
& FM_{二阶} = \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} + 2{\sum_{u \in U} v_{u, f} x_{u}}{\sum_{t \in I} v_{t, f} x_{t}} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right) \\
|
||||
&= \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right) + \sum_{f=1}^{k}\left( {\sum_{u \in U} v_{u, f} x_{u}}{\sum_{t \in I} v_{t, f} x_{t}} \right)
|
||||
|
||||
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
合并 FM 的一阶、二阶特征交互项,得到基于 FM 召回的匹配分计算公式:
|
||||
$$
|
||||
\text{MatchScore}_{FM} = \sum_{t \in I} w_{t} x_{t} + \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right) + \sum_{f=1}^{k}\left( {\sum_{u \in U} v_{u, f} x_{u}}{\sum_{t \in I} v_{t, f} x_{t}} \right)
|
||||
$$
|
||||
在基于向量的召回模型中,为了 ANN(近似最近邻算法) 或 Faiss 加速查找与用户兴趣度匹配的物品。基于向量的召回模型,一般最后都会得到用户和物品的特征向量表示,然后通过向量之间的内积或者余弦相似度表示用户对物品的兴趣程度。
|
||||
|
||||
基于 FM 模型的召回算法,也是向量召回算法的一种。所以下面,将 $\text{MatchScore}_{FM}$ 化简为用户向量和物品向量的内积形式,如下:
|
||||
$$
|
||||
\text{MatchScore}_{FM} = V_{item} V_{user}^T
|
||||
$$
|
||||
|
||||
+ 用户向量:
|
||||
$$
|
||||
V_{user} = [1; \quad {\sum_{u \in U} v_{u} x_{u}}]
|
||||
$$
|
||||
|
||||
+ 用户向量由两项表达式拼接得到。
|
||||
+ 第一项为常数 $1$,第二项是将用户相关的特征向量进行 sum pooling 。
|
||||
|
||||
+ 物品向量:
|
||||
$$
|
||||
V_{item} = [\sum_{t \in I} w_{t} x_{t} + \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right); \quad
|
||||
{\sum_{t \in I} v_{t} x_{t}} ]
|
||||
$$
|
||||
|
||||
+ 第一项表示物品相关特征向量的一阶、二阶特征交互。
|
||||
+ 第二项是将物品相关的特征向量进行 sum pooling 。
|
||||
|
||||
|
||||
|
||||
# 思考题
|
||||
|
||||
1. 为什么不直接将 FM 中学习到的 User Embedding: ${\sum_{u \in U} v_{u} x_{u}}$ 和 Item Embedding: $\sum_{t \in I} v_{t} x_{t}$ 的内积做召回呢?
|
||||
|
||||
答:这样做,也不是不行,但是效果不是特别好。**因为用户喜欢的,未必一定是与自身最匹配的,也包括一些自身性质极佳的item(e.g.,热门item)**,所以,**非常有必要将"所有Item特征一阶权重之和"和“所有Item特征隐向量两两点积之和”考虑进去**,但是也还必须写成点积的形式。
|
||||
|
||||
|
||||
|
||||
# 代码实战
|
||||
|
||||
正在完善...
|
||||
|
||||
|
||||
|
||||
# 参考链接
|
||||
|
||||
+ [paper.dvi (ntu.edu.tw)](https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf)
|
||||
+ [FM:推荐算法中的瑞士军刀 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/343174108)
|
||||
@@ -1,589 +0,0 @@
|
||||
## 写在前面
|
||||
YouTubeDNN模型是2016年的一篇文章,虽然离着现在有些久远, 但这篇文章无疑是工业界论文的典范, 完全是从工业界的角度去思考如何去做好一个推荐系统,并且处处是YouTube工程师留给我们的宝贵经验, 由于这两天用到了这个模型,今天也正好重温了下这篇文章,所以借着这个机会也整理出来吧, 王喆老师都称这篇文章是"神文", 可见其不一般处。
|
||||
|
||||
今天读完之后, 给我的最大感觉,首先是从工程的角度去剖析了整个推荐系统,讲到了推荐系统中最重要的两大模块: 召回和排序, 这篇论文对初学者非常友好,之前的论文模型是看不到这么全面的系统的,总有一种管中规豹的感觉,看不到全局,容易着相。 其次就是这篇文章给出了很多优化推荐系统中的工程性经验, 不管是召回还是排序上,都有很多的套路或者trick,比如召回方面的"example age", "负采样","非对称消费,防止泄露",排序方面的特征工程,加权逻辑回归等, 这些东西至今也都非常的实用,所以这也是这篇文章厉害的地方。
|
||||
|
||||
本篇文章依然是以paper为主线, 先剖析paper里面的每个细节,当然我这里也参考了其他大佬写的文章,王喆老师的几篇文章写的都很好,链接我也放在了下面,建议也看看。然后就是如何用YouTubeDNN模型,代码复现部分,由于时间比较短,自己先不复现了,调deepmatch的包跑起来,然后在新闻推荐数据集上进行了一些实验, 尝试了论文里面讲述的一些方法,这里主要是把deepmatch的YouTubeDNN模型怎么使用,以及我整个实验过程的所思所想给整理下, 因为这个模型结构本质上并不是很复杂(三四层的全连接网络),就不自己在实现一遍啦, 一些工程经验或者思想,我觉得才是这篇文章的精华部分。
|
||||
|
||||
|
||||
## 引言与推荐系统的漏斗范式
|
||||
### 引言部分
|
||||
本篇论文是工程性论文(之前的DIN也是偏工程实践的论文), 行文风格上以实际应用为主, 我们知道YouTube是全球性的视频网站, 所以这篇文章主要讲述了YouTube视频推荐系统的基本架构以及细节,以及各种处理tricks。
|
||||
|
||||
在Introduction部分, 作者首先说了在工业上的YouTube视频推荐系统主要面临的三大挑战:
|
||||
1. Scale(规模): 视频数量非常庞大,大规模数据下需要分布式学习算法以及高效的线上服务系统,文中体现这一点的是召回模型线下训练的时候,采用了负采样的思路,线上服务的时候,采用了hash映射,然后近邻检索的方式来满足实时性的需求, 这个之前我整理过faiss包和annoy包的使用, 感兴趣的可以看看。 其实,再拔高一层,我们推荐系统的整体架构呈漏斗范式,也是为了保证能从大规模情景下实时推荐。
|
||||
2. Freshness(新鲜度): YouTube上的视频是一个动态的, 用户实时上传,且实时访问, 那么这时候, 最新的视频往往就容易博得用户的眼球, 用户一般都比较喜欢看比较新的视频, 而不管是不是真和用户相关(这个感觉和新闻比较类似呀), 这时候,就需要模型有建模新上传内容以及用户最新发生的行为能力。 为了让模型学习到用户对新视频有偏好, 后面策略里面加了一个"example age"作为体现。我们说的"探索与利用"中的探索,其实也是对新鲜度的把握。
|
||||
3. Noise(噪声): 由于数据的稀疏和不可见的其他原因, 数据里面的噪声非常之多,这时候,就需要让这个推荐系统变得鲁棒,怎么鲁棒呢? 这个涉及到召回和排序两块,召回上需要考虑更多实际因素,比如非对称消费特性,高活用户因素,时间因素,序列因素等,并采取了相应的措施, 而排序上做更加细致的特征工程, 尽量的刻画出用户兴趣以及视频的特征 优化训练目标,使用加权的逻辑回归等。而召回和排序模型上,都采用了深度神经网络,通过特征的相互交叉,有了更强大的建模能力, 相比于之前用的MF(矩阵分解), 建模能力上有了很大的提升, 这些都有助于帮助减少噪声, 使得推荐结果更加准确。
|
||||
|
||||
所以从文章整体逻辑上看, 后面的各个细节,其实都是围绕着挑战展开的,找到当前推荐面临的问题,就得想办法解决问题,所以这篇文章的行文逻辑也是非常清晰的。
|
||||
|
||||
知道了挑战, 那么下面就看看YouTubeDNN的整体推荐系统架构。
|
||||
|
||||
### YouTubeDNN推荐系统架构
|
||||
整个推荐架构图如下, 这个算是比较原始的漏斗结构了:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/1c5dbd6d6c1646d09998b18d45f869e5.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
这篇文章之所以写的好, 是给了我们一个看推荐系统的宏观视角, 这个系统主要是两大部分组成: 召回和排序。召回的目的是根据用户部分特征,从海量物品库,快速找到小部分用户潜在感兴趣的物品交给精排,重点强调快,精排主要是融入更多特征,使用复杂模型,来做个性化推荐,强调准。
|
||||
|
||||
而对于这两块的具体描述, 论文里面也给出了解释, 我这里简单基于我目前的理解扩展下主流方法:
|
||||
1. 召回侧
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/5ebcd6f882934b7e9e2ffb9de2aee29d.png#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
召回侧模型的输入一般是用户的点击历史, 因为我们认为这些历史能更好的代表用户的兴趣, 另外还有一些人口统计学特征,比如性别,年龄,地域等, 都可以作为召回侧模型的输入。 而最终模型的输出,就是与该用户相关的一个候选视频集合, 量级的话一般是几百。
|
||||
<br>召回侧, 目前根据我的理解,大致上有两大类召回方式,一类是策略规则,一类是监督模型+embedding,其中策略规则,往往和真实场景有关,比如热度,历史重定向等等,不同的场景会有不同的召回方式,这种属于"特异性"知识。
|
||||
<br>后面的模型+embedding思路是一种"普适"方法,我上面图里面梳理出了目前给用户和物品打embedding的主流方法, 这些方法大致成几个系列,比如FM系列(FM,FFM等), 用户行为序列,基于图和知识图谱系列,经典双塔系列等,这些方法看似很多很复杂,其实本质上还是给用户或者是物品打embedding而已,只不过考虑的角度方式不同。 这里的YouTubeDNN召回模型,也是这里的一种方式而已。
|
||||
2. 精排侧
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/08953c0e8a00476f90bd9e206d4a02c6.png#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
召回那边对于每个用户, 给出了几百个比较相关的候选视频, 把几百万的规模降到了几百, 当然,召回那边利用的特征信息有限,并不能很好的刻画用户和视频特点,所以, 在精排侧,主要是想利用更多的用户,视频特征,刻画特点更加准确些,从这几百个里面选出几个或者十几个推荐给用户。 而涉及到准, 主要的发力点一般有三个:特征工程, 模型设计以及训练方法。 这三个发力点文章几乎都有所涉及, 除了模式设计有点审时度势之外,特征工程以及训练方法的处理上非常漂亮,具体的后面再整理。<br>
|
||||
精排侧,这一块的大致发展趋势,从ctr预估到多目标, 而模型演化上,从人工特征工程到特征工程自动化。主要是三大块, CTR预估主要分为了传统的LR,FM大家族,以及后面自动特征交叉的DNN家族,而多目标优化,目前是很多大公司的研究现状,更是未来的一大发展趋势,如何能让模型在各个目标上面的学习都能"游刃有余"是一件非常具有挑战的事情,毕竟不同的目标可能会互相冲突,互相影响,所以这里的研究热点又可以拆分成网络结构演化以及loss设计优化等, 而网络结构演化中,又可以再一次细分。 当然这每个模型或者技术几乎都有对应paper,我们依然可以通过读paper的方式,把这些关键技术学习到。
|
||||
|
||||
这两阶段的方法, 就能保证我们从大规模视频库中实时推荐, 又能保证个性化,吸引用户。 当然,随着时间的发展, 可能数据量非常非常大了, 此时召回结果规模精排依然无法处理,所以现在一般还会在召回和精排之间,加一个粗排进一步筛选作为过渡, 而随着场景越来越复杂, 精排产生的结果也不是直接给到用户,而是会再后面加一个重排后处理下,这篇paper里面其实也简单的提了下这种思想,在排序那块会整理到。 所以如今的漏斗, 也变得长了些。
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/aeae52971a1345a98b310890ea81be53.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
论文里面还提到了对模型的评估方面, 线下评估的时候,主要是采用一些常用的评估指标(精确率,召回率, 排序损失或者auc这种), 但是最终看算法和模型的有效性, 是通过A/B实验, 在A/B实验中会观察用户真实行为,比如点击率, 观看时长, 留存率这种, 这些才是我们终极目标, 而有时候, A/B实验的结果和线下我们用的这些指标并不总是相关, 这也是推荐系统这个场景的复杂性。 我们往往也会用一些策略,比如修改模型的优化目标,损失函数这种, 让线下的这个目标尽量的和A/B衡量的这种指标相关性大一些。 当然,这块又是属于业务场景问题了,不在整理范畴之中。 但2016年,竟然就提出了这种方式, 所以我觉得,作为小白的我们, 想了解工业上的推荐系统, 这篇paper是不二之选。
|
||||
|
||||
OK, 从宏观的大视角看完了漏斗型的推荐架构,我们就详细看看YouTube视频推荐架构里面召回和排序模块的模型到底长啥样子? 为啥要设计成这个样子? 为了应对实际中出现的挑战,又有哪些策略?
|
||||
|
||||
## YouTubeDNN的召回模型细节剖析
|
||||
上面说过, 召回模型的目的是在大量YouTube视频中检索出数百个和用户相关的视频来。
|
||||
|
||||
这个问题,我们可以看成一个多分类的问题,即用户在某一个时刻点击了某个视频, 可以建模成输入一个用户向量, 从海量视频中预测出被点击的那个视频的概率。
|
||||
|
||||
换成比较准确的数学语言描述, 在时刻$t$下, 用户$U$在背景$C$下对每个视频$i$的观看行为建模成下面的公式:
|
||||
$$
|
||||
P\left(w_{t}=i \mid U, C\right)=\frac{e^{v_{i} u}}{\sum_{j \in V} e^{v_{j} u}}
|
||||
$$
|
||||
这里的$u$表示用户向量, 这里的$v$表示视频向量, 两者的维度都是$N$, 召回模型的任务,就是通过用户的历史点击和山下文特征, 去学习最终的用户表示向量$u$以及视频$i$的表示向量$v_i$, 不过这俩还有个区别是$v_i$本身就是模型参数, 而$u$是神经网络的输出(函数输出),是输入与模型参数的计算结果。
|
||||
>解释下这个公式, 为啥要写成这个样子,其实是word2vec那边借鉴过来的,$e^{ (v_{i} u)}$表示的是当前用户向量$u$与当前视频$v_i$的相似程度,$e$只是放大这个相似程度而已, 不用管。 为啥这个就能表示相似程度呢? 因为两个向量的点积运算的含义就是可以衡量两个向量的相似程度, 两个向量越相似, 点积就会越大。 所以这个应该解释明白了。 再看分母$\sum_{j \in V} e^{v_{j} u}$, 这个显然是用户向量$u$与所有视频$v$的一个相似程度求和。 那么两者一除, 依然是代表了用户$u$与输出的视频$v_i$的相似程度,只不过归一化到了0-1之间, 毕竟我们知道概率是0-1之间的, 这就是为啥这个概率是右边形式的原因。 因为右边公式表示了用户$u$与输出的视频$v_i$的相似程度, 并且这个相似程度已经归一化到了0-1之间, 我们给定$u$希望输出$v_i$的概率越大,因为这样,当前的视频$v_i$和当前用户$u$更加相关,正好对应着点击行为不是吗?
|
||||
|
||||
那么,这个召回模型到底长啥样子呢?
|
||||
### 召回模型结构
|
||||
召回模型的结构如下:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/724ff38c1d6448399edb658b1b27e18e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这个模型结构呢,相比之前的模型, 比较简单,就是一个DNN。
|
||||
|
||||
它的输入主要是用户侧的特征,包括用户观看的历史video序列, 用户搜索的历史tokens, 然后就是用户的人文特征,比如地理位置, 性别,年龄这些。 这些特征处理上,和之前那些模型的也比较类似,
|
||||
* 用户历史序列,历史搜索tokens这种序列性的特征: 一般长这样`[item_id5, item_id2, item_id3, ...]`, 这种id特征是高维稀疏,首先会通过一个embedding层,转成低维稠密的embedding特征,即历史序列里面的每个id都会对应一个embedding向量, 这样历史序列就变成了多个embedding向量的形式, 这些向量一般会进行融合,常见的是average pooling,即每一维求平均得到一个最终向量来表示用户的历史兴趣或搜索兴趣。
|
||||
>这里值的一提的是这里的embedding向量得到的方式, 论文中作者这里说是通过word2vec方法计算的, 关于word2vec,这里就不过多解释,也就是每个item事先通过w2v方式算好了的embedding,直接作为了输入,然后进行pooling融合。<br><br>除了这种算好embedding方式之外,还可以过embedding层,跟上面的DNN一起训练,这些都是常规操作,之前整理的精排模型里面大都是用这种方式。
|
||||
|
||||
论文里面使用了用户最近的50次观看历史,用户最近50次搜索历史token, embedding维度是256维, 采用的average pooling。 当然,这里还可以把item的类别信息也隐射到embedding, 与前面的concat起来。
|
||||
* 用户人文特征, 这种特征处理方式就是离散型的依然是labelEncoder,然后embedding转成低维稠密, 而连续型特征,一般是先归一化操作,然后直接输入,当然有的也通过分桶,转成离散特征,这里不过多整理,特征工程做的事情了。 当然,这里还有一波操作值得注意,就是连续型特征除了用了$x$本身,还用了$x^2$,$logx$这种, 可以加入更多非线性,增加模型表达能力。<br>
|
||||
这些特征对新用户的推荐会比较有帮助,常见的用户的地理位置, 设备, 性别,年龄等。
|
||||
* 这里一个比较特色的特征是example age,这个特征后面需要单独整理。
|
||||
|
||||
这些特征处理好了之后,拼接起来,就成了一个非常长的向量,然后就是过DNN,这里用了一个三层的DNN, 得到了输出, 这个输出也是向量。
|
||||
|
||||
Ok,到这里平淡无奇, 前向传播也大致上快说完了, 还差最后一步。 最后这一步,就是做多分类问题,然后求损失,这就是training那边做的事情。 但是在详细说这个之前, 我想先简单回忆下word2vec里面的skip-gram Model, 这个模型,如果回忆起来,这里理解起来就非常的简单了。
|
||||
|
||||
这里只需要看一张图即可, 这个来自cs231N公开课PPT, 我之前整理w2v的时候用到的,这里的思想其实也是从w2v那边过来的。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200624193409649.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
skip-gram的原理咱这里就不整理了, 这里就只看这张图,这其实就是w2v训练的一种方式,当然是最原始的。 word2vec的核心思想呢? 就是共现频率高的词相关性越大,所以skip-gram采用中心词预测上下文词的方式去训练词向量,模型的输入是中心词,做样本采用滑动窗口的形式,和这里序列其实差不多,窗口滑动一次就能得到一个序列[word1, word2, ...wordn], 而这个序列里面呢? 就会有中心词(比如中间那个), 两边向量的是上下文词。 如果我们输入中心词之后,模型能预测上下文词的概率大,那说明这个模型就能解决词相关性问题了。
|
||||
>一开始, 我们的中心单词$w_t$就是one-hot的表示形式,也就是在词典中的位置,这里的形状是$V \times1$, $V$表示词库里面有$V$个单词, 这里的$W$长上面那样, 是一个$d\times V$的矩阵, $d$表示的是词嵌入的维度, 那么用$W*w_t$(矩阵乘法)就会得到中心词的词向量表示$v_c$, 大小是$d\times1$。这个就是中心词的embedding向量。 其实就是中心词过了一个embedding层得到了它的embedding向量。
|
||||
><br>然后就是$v_c$和上下文矩阵$W'$相乘, 这里的$W'$是$V\times d$的一个矩阵, 每一行代表每个单词作为上下文的时候的词向量表示, 也就是$u_w$, 每一列是词嵌入的维度。 这样通过$W'*v_c$就会得到一个$V\times 1$的向量,这个表示的就是中心单词$w_t$与每个单词的相似程度。
|
||||
><br>最后,我们通过softmax操作把这个相似程度转成概率, 选择概率最大的index输出。
|
||||
|
||||
这就是这个模型的前向传播过程。
|
||||
|
||||
有了这个过程, 再理解YouTubeDNN顶部就非常容易了, 我单独截出来:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/98811e09226f42a2be981b0aa3449ab3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
只看这里的这个过程, 其实就是上面skip-gram过程, 不一样的是右边这个中心词向量$v_c$是直接过了一个embedding层得到的,而左边这个用户向量$u$是用户的各种特征先拼接成一个大的向量,然后过了一个DNN降维。 训练方式上,这两个也是一模一样的,无非就是左边的召回模型,多了几层全连接而已。
|
||||
> 这样,也就很容易的理解,模型训练好了之后,用户向量和item向量到底在哪里取了吧。
|
||||
> * 用户向量,其实就是全连接的DNN网络的输出向量,其实即使没有全连接,原始的用户各个特征拼接起来的那个长向量也能用,不过维度可能太大了,所以DNN在这里的作用一个是特征交叉,另一个还有降维的功效。
|
||||
> * item向量: 这个其实和skip-gram那个一样,每个item其实是用两个embedding向量的,比如skip-gram那里就有一个作为中心词时候的embedding矩阵$W$和作为上下文词时候的embedding矩阵$W'$, 一般取的时候会取前面那个$W$作为每个词的词向量。 这里其实一个道理,只不过这里最前面那个item向量矩阵,是通过了w2v的方式训练好了直接作为的输入,如果不事先计算好,对应的是embedding层得到的那个矩阵。 后面的item向量矩阵,就是这里得到用户向量之后,后面进行softmax之前的这个矩阵, **YouTubeDNN最终是从这个矩阵里面拿item向量**。
|
||||
|
||||
这就是知识串联的魅力,其实熟悉了word2vec, 这个召回模型理解非常简单。
|
||||
|
||||
这其实就是这个模型训练阶段最原始的剖析,实际训练的时候,依然是采用了优化方法, 这个和word2vec也是一样,采用了负采样的方式(当然实现细节上有区别),因为视频的数量太大,每次做多分类,最终那个概率分母上的加和就非常可怕了,所以就把多分类问题转成了多个二分类的问题。 也就是不用全部的视频,而是随机选择出了一些没点的视频, 标记为0, 点了的视频标记为1, 这样就成了二分类的问题。 关于负样本采样原理, 我之前也整理了[一篇博客](https://blog.csdn.net/wuzhongqiang/article/details/106979179?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164310239216780274177509%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=164310239216780274177509&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-106979179.nonecase&utm_term=word2vec&spm=1018.2226.3001.4450)
|
||||
>负类基于样本分布抽取而来。负采样是针对类别数很多情况下的常用方法。当然,负样本的选择也是有讲究的,详细的看[这篇文章](https://www.zhihu.com/question/334844408/answer/2299283878), 我后面实验主要用了下面两种
|
||||
>* 展示数据随机选择负例
|
||||
>* 随机负例与热门打压
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/6fe56d71de8a4d769a583f27a3ce9f40.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这样整个召回模型训练部分的"基本操作"就基本整理完了。关于细节部分,后面代码里面会描述下, 但是在训练召回模型过程中,还有一些经验性的知识也非常重要。 下面重点整理一下。
|
||||
|
||||
### 训练数据的选取和生成
|
||||
模型训练的时候, 为了计算更加高效,采用了负采样的方法, 但正负样本的选取,以及训练样本的来源, 还有一些注意事项。
|
||||
|
||||
首先,训练样本来源于全部的YouTube观看记录,而不仅仅是被推荐的观看记录
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/faf8a8abf7b54b779287acadc015b6a0.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
否则对于新视频会难以被曝光,会使最终推荐结果有偏;同时系统也会采集用户从其他渠道观看的视频,从而可以快速应用到协同过滤中;
|
||||
|
||||
其次, 是训练数据来源于用户的隐式数据, 且**用户看完了的视频作为正样本**, 注意这里是看完了, 有一定的时长限制, 而不是仅仅曝光点击,有可能有误点的。 而负样本,是从视频库里面随机选取,或者在曝光过的里面随机选取用户没看过的作为负样本。
|
||||
|
||||
==这里的一个经验==是**训练数据中对于每个用户选取相同的样本数, 保证用户在损失函数等权重**, 因为这样可以减少高度活跃用户对于loss的影响。可以改进线上A/B测试的效果。
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/35386af8fd064de3a87cb418b008e444.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这里的==另一个经验==是**避免让模型知道不该知道的信息**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/0765134e1ca445c693058aaaaf20ae74.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这里作者举了一个例子是如果模型知道用户最后的行为是搜索了"Taylor Swift", 那么模型可能会倾向于推荐搜索页面搜"Taylor Swift"时搜索的视频, 这个不是推荐模型期望的行为。 解法方法是**扔掉时序信息**, 历史搜索tokens随机打乱, 使用无序的搜索tokens来表示搜索queryies(average pooling)。
|
||||
>基于这个例子就把时序信息扔掉理由挺勉强的,解决这种特殊场景的信息泄露会有更针对性的方法,比如把搜索query与搜索结果行为绑定让它们不可分。 感觉时序信息还是挺重要的, 有专门针对时序信息建模的研究。
|
||||
|
||||
在生成样本的时候, 如果我们的用户比较少,行为比较少, 是不足以训练一个较好的召回模型,此时一个用户的历史观看序列,可以采用滑动窗口的形式生成多个训练样本, 比如一个用户的历史观看记录是"abcdef", 那么采用滑动窗口, 可以是abc预测d, bcd预测e, cde预测f,这样一个用户就能生成3条训练样本。 后面实验里面也是这么做的。 但这时候一定要注意一点,就是**信息泄露**,这个也是和word2vec的cbow不一样的地方。
|
||||
|
||||
论文中上面这种滑动制作样本的方式依据是用户的"asymmetric co-watch probabilities(非对称观看概率)",即一般情况下,用户开始浏览范围较广, 之后浏览范围逐渐变窄。
|
||||
|
||||
下图中的$w_{tN}$表示当前样本, 原来的做法是它前后的用户行为都可以用来产生特征行为输入(word2vec的CBOW做样本的方法)。 而作者担心这一点会导致信息泄露, 模型**不该知道的信息是未来的用户行为**, 所以作者的做法是只使用更早时间的用户行为来产生特征, 这个也是目前通用的做法。 两种方法的对比如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/049cbeb814f843fd97638ef02d6c5703.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_2,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
(a)是许多协同过滤会采取的方法,利用全局的观看信息作为输入(包括时间节点N前,N后的观看),这种方法忽略了观看序列的不对称性,而本文中采取(b)所示的方法,只把历史信息当作输入,用历史来预测未来
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/4ac0c81e5f4f4276a4ed0e4c6329f458.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
模型的测试集, 往往也是用户最近一次观看行为, 后面的实验中,把用户最后一次点击放到了测试集里面去。这样可以防止信息穿越。
|
||||
|
||||
数据集的细节和tricks基本上说完, 更细的东西,就得通过代码去解释了。 接下来, 再聊聊作者加入的非常有意思的一个特征,叫做example age。
|
||||
|
||||
### "Example Age"特征
|
||||
这个特征我想单独拿出来说,是因为这个是和场景比较相关的特征,也是作者的经验传授。 我们知道,视频有明显的生命周期,例如刚上传的视频比之后更受欢迎,也就是用户往往喜欢看最新的东西,而不管它是不是和用户相关,所以视频的流行度随着时间的分布是高度非稳态变化的(下面图中的绿色曲线)
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/15dfce743bd2490a8adb21fd3b2b294e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
但是我们模型训练的时候,是基于历史数据训练的(历史观看记录的平均),所以模型对播放某个视频预测值的期望会倾向于其在训练数据时间内的平均播放概率(平均热度), 上图中蓝色线。但如上面绿色线,实际上该视频在训练数据时间窗口内热度很可能不均匀, 用户本身就喜欢新上传的内容。 所以,为了让模型学习到用户这种对新颖内容的bias, 作者引入了"example age"这个特征来捕捉视频的生命周期。
|
||||
|
||||
"example age"定义为$t_{max}-t$, 其中$t_{max}$是训练数据中所有样本的时间最大值(有的文章说是当前时间,但我总觉得还是选取的训练数据所在时间段的右端点时间比较合适,就比如我用的数据集, 最晚时间是2021年7月的,总不能用现在的时间吧), 而$t$为当前样本的时间。**线上预测时, 直接把example age全部设为0或一个小的负值,这样就不依赖于各个视频的上传时间了**。
|
||||
>其实这个操作, 现在常用的是位置上的除偏, 比如商品推荐的时候, 用户往往喜欢点击最上面位置的商品或广告, 但这个bias模型依然是不知道, 为了让模型学习到这个东西, 也可以把商品或者广告的位置信息做成一个feature, 训练的时候告诉模型。 而线上推理的那些商品, 这个feature也都用一样的。 异曲同工的意思有没有。<br><br>那么这样的操作为啥会work呢? example age这个我理解,是有了这个特征, 就可以把某视频的热度分布信息传递给模型了, 比如某个example age时间段该视频播放较多, 而另外的时间段播放较少, 这样模型就能发现用户的这种新颖偏好, 消除热度偏见。<br><br>这个地方看了一些文章写说, 这样做有利于让模型推新热内容, 总感觉不是很通。 我这里理解是类似让模型消除位置偏见那样, 这里消除一种热度偏见。 <br><br>我理解是这样,假设没有这样一个example age特征表示视频新颖信息,或者一个位置特征表示商品的位置信息,那模型训练的样本,可能是用户点击了这个item,就是正样本, 但此时有可能是用户真的喜欢这个item, 也有可能是因为一些bias, 比如用户本身喜欢新颖, 用户本身喜欢点击上面位置的item等, 但模型推理的时候,都会误认为是用户真的喜欢这个item。 所以,为了让模型了解到可能是存在后面这种bias, 我们就把item的新颖信息, item的位置信息等做成特征, 在模型训练的时候就告诉模型,用户点了这个东西可能是它比较新或者位置比较靠上面等,这样模型在训练的时候, 就了解到了这些bias,等到模型在线推理的时候呢, 我们把这些bias特征都弄成一样的,这样每个样品在模型看来,就没有了新颖信息和位置信息bias(一视同仁了),只能靠着相关性去推理, 这样才能推到用户真正感兴趣的东西吧。<br><br>而有些文章记录的, 能够推荐更热门的视频啥的, 我很大一个疑问就是推理的时候,不是把example age用0表示吗? 模型应该不知道这些视频哪个新不新吧。 当然,这是我自己的看法,感兴趣的可以帮我解答下呀。
|
||||
|
||||
`example age`这个特征到这里还没完, 原来加入这种时间bias的传统方法是使用`video age`, 即一个video上传到样本生成的这段时间跨度, 这么说可能有些懵, 看个图吧, 原来这是两个东西:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/10475c194c0044a3a93b01a3193e294f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
王喆老师那篇文章里面也谈到了这两种理解, 对于某个视频的不同样本,其实这两种定义是等价的,因为他们的和是一个常数。
|
||||
$$
|
||||
t_{\text {video age }}+t_{\text {example age }}=\text { Const }
|
||||
$$
|
||||
详细证明可以看参考的第三篇文章。但`example age`的定义有下面两点好处:
|
||||
1. 线上预测时`example age`是常数值, 所有item可以设置成统一的, 但如果是`video age`的话,这个根每个视频的上传时间有关, 那这样在计算用户向量的时候,就依赖每个候选item了。 而统一的这个好处就是用户向量只需要计算一次。
|
||||
2. 对不同的视频,对应的`example age`所在范围一致, 只依赖训练数据选取的时间跨度,便于归一化操作。
|
||||
|
||||
### 实验结果
|
||||
这里就简单过下就好, 作者这里主要验证了下DNN的结构对推荐效果的影响,对于DNN的层级,作者尝试了0~4层, 实验结果是**层数越多越好, 但4层之后提升很有限, 层数越多训练越困难**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/fd1849a8881444fbb12490bad7598125.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
作者这里还启发了一个事情, 从"双塔"的角度再看YouTubeDNN召回模型, 这里的DNN个结构,其实就是一个用户塔, 输入用户的特征,最终通过DNN,编码出了用户的embedding向量。
|
||||
|
||||
而得到用户embedding向量到后面做softmax那块,不是说了会经过一个item embedding矩阵吗? 其实这个矩阵也可以用一个item塔来实现, 和用户embedding计算的方式类似, 首先各个item通过一个物品塔(输入是item 特征, 输出是item embedding),这样其实也能得到每个item的embedding,然后做多分类或者是二分类等。 所以**YouTubeDNN召回模型本质上还是双塔结构**, 只不过上面图里面值体现了用户塔。 我看deepmatch包里面实现的时候, 用户特征和item特征分开输入的, 感觉应该就是实现了个双塔。源码倒是没看, 等看了之后再确认。
|
||||
|
||||
### 线上服务
|
||||
线上服务的时候, YouTube采用了一种最近邻搜索的方法去完成topK推荐,这其实是工程与学术trade-off的结果, model serving过程中对几百万个候选集一一跑模型显然不现实, 所以通过召回模型得到用户和video的embedding之后, 用最近邻搜索的效率会快很多。
|
||||
|
||||
我们甚至不用把任何model inference的过程搬上服务器,只需要把user embedding和video embedding存到redis或者内存中就好了。like this:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/86751a834d224ad69220b5040e0e03c9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
在线上,可以根据用户兴趣Embedding,采用类似Faiss等高效Embedding检索工具,快速找出和用户兴趣匹配的物品, 高效embedding检索工具, 我目前接触到了两个,一个是Faiss, 一个是annoy, 关于这两个工具的使用, 我也整理了两篇文章:
|
||||
* [annoy(快速近邻向量搜索包)学习小记](https://blog.csdn.net/wuzhongqiang/article/details/122516942?spm=1001.2014.3001.5501)
|
||||
* [Faiss(Facebook开源的高效相似搜索库)学习小记](https://blog.csdn.net/wuzhongqiang/article/details/122516942?spm=1001.2014.3001.5501)
|
||||
|
||||
|
||||
之前写新闻推荐比赛的时候用过Faiss, 这次实验中使用的是annoy工具包。
|
||||
|
||||
另外多整理一点:
|
||||
>我们做线上召回的时候, 其实可以有两种:
|
||||
>1. item_2_item: 因为我们有了所有item的embedding了, 那么就可以进行物品与物品之间相似度计算,每个物品得到近似的K个, 这时候,就和协同过滤原理一样, 之间通过用户观看过的历史item,就能进行相似召回了, 工程实现上,一般会每个item建立一个相似度倒排表
|
||||
>2. user_2_item: 将item用faiss或者annoy组织成index,然后用user embedding去查相近item
|
||||
|
||||
## 基于Deepmatch包YouTubeDNN的使用方法
|
||||
由于时间原因, 我这里并没有自己写代码复现YouTubeDNN模型,这个结构也比较简单, 几层的DNN,自己再写一遍剖析架构也没有啥意思, 所以就采用浅梦大佬写的deepmatch包, 直接用到了自己的数据集上做了实验。 关于Deepmatch源码, 还是看[deepmatch项目](https://github.com/shenweichen/DeepMatch), 这里主要是整理下YouTubeDNN如何用。
|
||||
|
||||
项目里面其实给出了如何使用YouTubeDNN,采用的是movielens数据集, 见[这里](https://github.com/shenweichen/DeepMatch/blob/master/examples/run_youtubednn.py)
|
||||
|
||||
我这里就基于我做实验用的新闻推荐数据集, 把代码的主要逻辑过一遍。
|
||||
|
||||
### 数据集
|
||||
实验用的数据集是新闻推荐的一个数据集,是做func-rec项目时候一个伙伴分享的,来自于某个推荐比赛,因为这个数据集是来自工业上的真实数据,所以使用起来比之前用的movielens数据集可尝试的东西多一些,并且原数据有8个多G,总共3个文件: 用户画像,文章画像, 点击日志,用户数量100多万,6000多万次点击, 文章规模是几百,数据量也比较丰富,所以后面就打算采用这个统一的数据集, 重新做实验,对比目前GitHub上的各个模型。关于数据集每个文件详细描述,后面会更新到GitHub项目。
|
||||
|
||||
这里只整理我目前的使用过程, 由于有8个多G的数据,我这边没法直接跑,所以对数据进行了采样, 采样方法写成了一个jupyter文件。 主要包括:
|
||||
1. 分块读取数据, 无法一下子读入内存
|
||||
2. 对于每块数据,基于一些筛选规则进行记录的删除,比如只用了后7天的数据, 删除了一些文章不在物料池的数据, 删除不合法的点击记录(曝光时间大于文章上传时间), 删除没有历史点击的用户,删除观看时间低于3s的视频, 删除历史点击序列太短和太长的用户记录
|
||||
3. 删除完之后重新保存一份新数据集,大约3个G,然后再从这里面随机采样了20000用户进行了后面实验
|
||||
|
||||
通过上面的一波操作, 我的小本子就能跑起来了,当然可能数据比较少,最终训练的YouTubeDNN效果并不是很好。详细看后面GitHub的: `点击日志数据集初步处理与采样.ipynb`
|
||||
|
||||
### 简单数据预处理
|
||||
这个也是写成了一个笔记本, 主要是看了下采样后的数据,序列长度分布等,由于上面做了一些规整化,这里有毛病的数据不是太多,并没有太多处理, 但是用户数据里面的年龄,性别源数据是给出了多种可能, 每个可能有概率值,我这里选出了概率最大的那个,然后简单填充了缺失。
|
||||
|
||||
最后把能用到的用户画像和文章画像统一拼接到了点击日志数据,又保存了一份。 作为YouTubeDNN模型的使用数据, 其他模型我也打算使用这份数据了。
|
||||
|
||||
详见`EDA与数据预处理.ipynb`
|
||||
|
||||
### YouTubeDNN召回
|
||||
这里就需要解释下一些代码了, 首先拿到采样的数据集,我们先划分下训练集和测试集:
|
||||
* 测试集: 每个用户的最后一次点击记录
|
||||
* 训练集: 每个用户除最后一次点击的所有点击记录
|
||||
|
||||
这个具体代码就不在这里写了。
|
||||
|
||||
```python
|
||||
user_click_hist_df, user_click_last_df = get_hist_and_last_click(click_df)
|
||||
```
|
||||
|
||||
这么划分的依据,就是保证不能发生数据穿越,拿最后的测试,不能让模型看到。
|
||||
|
||||
接下来,就是YouTubeDNN模型的召回,从构造数据集 -> 训练模型 -> 产生召回结果,我写到了一个函数里面去。
|
||||
|
||||
```cpp
|
||||
def youtubednn_recall(data, topk=200, embedding_dim=8, his_seq_maxlen=50, negsample=0,
|
||||
batch_size=64, epochs=1, verbose=1, validation_split=0.0):
|
||||
"""通过YouTubeDNN模型,计算用户向量和文章向量
|
||||
param: data: 用户日志数据
|
||||
topk: 对于每个用户,召回多少篇文章
|
||||
"""
|
||||
user_id_raw = data[['user_id']].drop_duplicates('user_id')
|
||||
doc_id_raw = data[['article_id']].drop_duplicates('article_id')
|
||||
|
||||
# 类别数据编码
|
||||
base_features = ['user_id', 'article_id', 'city', 'age', 'gender']
|
||||
feature_max_idx = {}
|
||||
for f in base_features:
|
||||
lbe = LabelEncoder()
|
||||
data[f] = lbe.fit_transform(data[f])
|
||||
feature_max_idx[f] = data[f].max() + 1
|
||||
|
||||
# 构建用户id词典和doc的id词典,方便从用户idx找到原始的id
|
||||
user_id_enc = data[['user_id']].drop_duplicates('user_id')
|
||||
doc_id_enc = data[['article_id']].drop_duplicates('article_id')
|
||||
user_idx_2_rawid = dict(zip(user_id_enc['user_id'], user_id_raw['user_id']))
|
||||
doc_idx_2_rawid = dict(zip(doc_id_enc['article_id'], doc_id_raw['article_id']))
|
||||
|
||||
# 保存下每篇文章的被点击数量, 方便后面高热文章的打压
|
||||
doc_clicked_count_df = data.groupby('article_id')['click'].apply(lambda x: x.count()).reset_index()
|
||||
doc_clicked_count_dict = dict(zip(doc_clicked_count_df['article_id'], doc_clicked_count_df['click']))
|
||||
|
||||
train_set, test_set = gen_data_set(data, doc_clicked_count_dict, negsample, control_users=True)
|
||||
|
||||
# 构造youtubeDNN模型的输入
|
||||
train_model_input, train_label = gen_model_input(train_set, his_seq_maxlen)
|
||||
test_model_input, test_label = gen_model_input(test_set, his_seq_maxlen)
|
||||
|
||||
# 构建模型并完成训练
|
||||
model = train_youtube_model(train_model_input, train_label, embedding_dim, feature_max_idx, his_seq_maxlen, batch_size, epochs, verbose, validation_split)
|
||||
|
||||
# 获得用户embedding和doc的embedding, 并进行保存
|
||||
user_embs, doc_embs = get_embeddings(model, test_model_input, user_idx_2_rawid, doc_idx_2_rawid)
|
||||
|
||||
# 对每个用户,拿到召回结果并返回回来
|
||||
user_recall_doc_dict = get_youtube_recall_res(user_embs, doc_embs, user_idx_2_rawid, doc_idx_2_rawid, topk)
|
||||
|
||||
return user_recall_doc_dict
|
||||
```
|
||||
这里面说一下主要逻辑,主要是下面几步:
|
||||
1. 用户id和文章id我们要先建立索引-原始id的字典,因为我们模型里面是要把id转成embedding,模型的表示形式会是{索引: embedding}的形式, 如果我们想得到原始id,必须先建立起映射来
|
||||
2. 把类别特征进行label Encoder, 模型输入需要, embedding层需要,这是构建词典常规操作, 这里要记录下每个特征特征值的个数,建词典索引的时候用到,得知道词典大小
|
||||
3. 保存了下每篇文章被点击数量, 方便后面对高热文章实施打压
|
||||
4. 构建数据集
|
||||
|
||||
```python
|
||||
rain_set, test_set = gen_data_set(data, doc_clicked_count_dict, negsample, control_users=True)
|
||||
```
|
||||
这个需要解释下, 虽然我们上面有了一个训练集,但是这个东西是不能直接作为模型输入的, 第一个原因是正样本太少,样本数量不足,我们得需要滑动窗口,每个用户再滑动构造一些,第二个是不满足deepmatch实现的模型输入格式,所以gen_data_set这个函数,是用deepmatch YouTubeDNN的第一个范式,基本上得按照这个来,只不过我加了一些策略上的尝试:
|
||||
```python
|
||||
def gen_data_set(click_data, doc_clicked_count_dict, negsample, control_users=False):
|
||||
"""构造youtubeDNN的数据集"""
|
||||
# 按照曝光时间排序
|
||||
click_data.sort_values("expo_time", inplace=True)
|
||||
item_ids = click_data['article_id'].unique()
|
||||
|
||||
train_set, test_set = [], []
|
||||
for user_id, hist_click in tqdm(click_data.groupby('user_id')):
|
||||
# 这里按照expo_date分开,每一天用滑动窗口滑,可能相关性更高些,另外,这样序列不会太长,因为eda发现有点击1111个的
|
||||
#for expo_date, hist_click in hist_date_click.groupby('expo_date'):
|
||||
# 用户当天的点击历史id
|
||||
pos_list = hist_click['article_id'].tolist()
|
||||
user_control_flag = True
|
||||
|
||||
if control_users:
|
||||
user_samples_cou = 0
|
||||
|
||||
# 过长的序列截断
|
||||
if len(pos_list) > 50:
|
||||
pos_list = pos_list[-50:]
|
||||
|
||||
if negsample > 0:
|
||||
neg_list = gen_neg_sample_candiate(pos_list, item_ids, doc_clicked_count_dict, negsample, methods='multinomial')
|
||||
|
||||
# 只有1个的也截断 去掉,当然我之前做了处理,这里没有这种情况了
|
||||
if len(pos_list) < 2:
|
||||
continue
|
||||
else:
|
||||
# 序列至少是2
|
||||
for i in range(1, len(pos_list)):
|
||||
hist = pos_list[:i]
|
||||
# 这里采用打压热门item策略,降低高展item成为正样本的概率
|
||||
freq_i = doc_clicked_count_dict[pos_list[i]] / (np.sum(list(doc_clicked_count_dict.values())))
|
||||
p_posi = (np.sqrt(freq_i/0.001)+1)*(0.001/freq_i)
|
||||
|
||||
# p_posi=0.3 表示该item_i成为正样本的概率是0.3,
|
||||
if user_control_flag and i != len(pos_list) - 1:
|
||||
if random.random() > (1-p_posi):
|
||||
row = [user_id, hist[::-1], pos_list[i], hist_click.iloc[0]['city'], hist_click.iloc[0]['age'], hist_click.iloc[0]['gender'], hist_click.iloc[i]['example_age'], 1, len(hist[::-1])]
|
||||
train_set.append(row)
|
||||
|
||||
for negi in range(negsample):
|
||||
row = [user_id, hist[::-1], neg_list[i*negsample+negi], hist_click.iloc[0]['city'], hist_click.iloc[0]['age'], hist_click.iloc[0]['gender'], hist_click.iloc[i]['example_age'], 0, len(hist[::-1])]
|
||||
train_set.append(row)
|
||||
|
||||
if control_users:
|
||||
user_samples_cou += 1
|
||||
# 每个用户序列最长是50, 即每个用户正样本个数最多是50个, 如果每个用户训练样本数量到了30个,训练集不能加这个用户了
|
||||
if user_samples_cou > 30:
|
||||
user_samples_cou = False
|
||||
|
||||
# 整个序列加入到test_set, 注意,这里一定每个用户只有一个最长序列,相当于测试集数目等于用户个数
|
||||
elif i == len(pos_list) - 1:
|
||||
row = [user_id, hist[::-1], pos_list[i], hist_click.iloc[0]['city'], hist_click.iloc[0]['age'], hist_click.iloc[0]['gender'], 0, 0, len(hist[::-1])]
|
||||
test_set.append(row)
|
||||
|
||||
|
||||
random.shuffle(train_set)
|
||||
random.shuffle(test_set)
|
||||
|
||||
return train_set, test_set
|
||||
```
|
||||
关键代码逻辑是首先点击数据按照时间戳排序,然后按照用户分组,对于每个用户的历史点击, 采用滑动窗口的形式,边滑动边构造样本, 第一个注意的地方,是每滑动一次生成一条正样本的时候, 要加入一定比例的负样本进去, 第二个注意最后一整条序列要放到test_set里面。<br><br>我这里面加入的一些策略,负样本候选集生成我单独写成一个函数,因为尝试了随机采样和打压热门item采样两种方式, 可以通过methods参数选择。 另外一个就是正样本里面也按照热门实现了打压, 减少高热item成为正样本概率,增加高热item成为负样本概率。 还加了一个控制用户样本数量的参数,去保证每个用户生成一样多的样本数量,打压下高活用户。
|
||||
5. 构造模型输入
|
||||
这个也是调包的定式操作,必须按照这个写法来:
|
||||
|
||||
|
||||
```python
|
||||
def gen_model_input(train_set, his_seq_max_len):
|
||||
"""构造模型的输入"""
|
||||
# row: [user_id, hist_list, cur_doc_id, city, age, gender, label, hist_len]
|
||||
train_uid = np.array([row[0] for row in train_set])
|
||||
train_hist_seq = [row[1] for row in train_set]
|
||||
train_iid = np.array([row[2] for row in train_set])
|
||||
train_u_city = np.array([row[3] for row in train_set])
|
||||
train_u_age = np.array([row[4] for row in train_set])
|
||||
train_u_gender = np.array([row[5] for row in train_set])
|
||||
train_u_example_age = np.array([row[6] for row in train_set])
|
||||
train_label = np.array([row[7] for row in train_set])
|
||||
train_hist_len = np.array([row[8] for row in train_set])
|
||||
|
||||
train_seq_pad = pad_sequences(train_hist_seq, maxlen=his_seq_max_len, padding='post', truncating='post', value=0)
|
||||
train_model_input = {
|
||||
"user_id": train_uid,
|
||||
"click_doc_id": train_iid,
|
||||
"hist_doc_ids": train_seq_pad,
|
||||
"hist_len": train_hist_len,
|
||||
"u_city": train_u_city,
|
||||
"u_age": train_u_age,
|
||||
"u_gender": train_u_gender,
|
||||
"u_example_age":train_u_example_age
|
||||
}
|
||||
return train_model_input, train_label
|
||||
```
|
||||
上面构造数据集的时候,是把每个特征加入到了二维数组里面去, 这里得告诉模型,每一个维度是啥特征数据。如果相加特征,首先构造数据集的时候,得把数据加入到数组中, 然后在这个函数里面再指定新加入的特征是啥。 下面的那个词典, 是为了把数据输入和模型的Input层给对应起来,通过字典键进行标识。
|
||||
6. 训练YouTubeDNN
|
||||
这一块也是定式, 在建模型事情,要把特征封装起来,告诉模型哪些是离散特征,哪些是连续特征, 模型要为这些特征建立不同的Input层,处理方式是不一样的
|
||||
|
||||
```python
|
||||
def train_youtube_model(train_model_input, train_label, embedding_dim, feature_max_idx, his_seq_maxlen, batch_size, epochs, verbose, validation_split):
|
||||
"""构建youtubednn并完成训练"""
|
||||
# 特征封装
|
||||
user_feature_columns = [
|
||||
SparseFeat('user_id', feature_max_idx['user_id'], embedding_dim),
|
||||
VarLenSparseFeat(SparseFeat('hist_doc_ids', feature_max_idx['article_id'], embedding_dim,
|
||||
embedding_name="click_doc_id"), his_seq_maxlen, 'mean', 'hist_len'),
|
||||
|
||||
SparseFeat('u_city', feature_max_idx['city'], embedding_dim),
|
||||
SparseFeat('u_age', feature_max_idx['age'], embedding_dim),
|
||||
SparseFeat('u_gender', feature_max_idx['gender'], embedding_dim),
|
||||
DenseFeat('u_example_age', 1,)
|
||||
]
|
||||
doc_feature_columns = [
|
||||
SparseFeat('click_doc_id', feature_max_idx['article_id'], embedding_dim)
|
||||
# 这里后面也可以把文章的类别画像特征加入
|
||||
]
|
||||
|
||||
# 定义模型
|
||||
model = YoutubeDNN(user_feature_columns, doc_feature_columns, num_sampled=5, user_dnn_hidden_units=(64, embedding_dim))
|
||||
|
||||
# 模型编译
|
||||
model.compile(optimizer="adam", loss=sampledsoftmaxloss)
|
||||
|
||||
# 模型训练,这里可以定义验证集的比例,如果设置为0的话就是全量数据直接进行训练
|
||||
history = model.fit(train_model_input, train_label, batch_size=batch_size, epochs=epochs, verbose=verbose, validation_split=validation_split)
|
||||
|
||||
return model
|
||||
```
|
||||
然后就是建模型,编译训练即可。这块就非常简单了,当然模型方面有些参数,可以了解下,另外一个注意点,就是这里用户特征和item特征进行了分开, 这其实和双塔模式很像, 用户特征最后编码成用户向量, item特征最后编码成item向量。
|
||||
7. 获得用户向量和item向量
|
||||
模型训练完之后,就能从模型里面拿用户向量和item向量, 我这里单独写了一个函数:
|
||||
|
||||
```python
|
||||
获取用户embedding和文章embedding
|
||||
def get_embeddings(model, test_model_input, user_idx_2_rawid, doc_idx_2_rawid, save_path='embedding/'):
|
||||
doc_model_input = {'click_doc_id':np.array(list(doc_idx_2_rawid.keys()))}
|
||||
|
||||
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
|
||||
doc_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
|
||||
|
||||
# 保存当前的item_embedding 和 user_embedding 排序的时候可能能够用到,但是需要注意保存的时候需要和原始的id对应
|
||||
user_embs = user_embedding_model.predict(test_model_input, batch_size=2 ** 12)
|
||||
doc_embs = doc_embedding_model.predict(doc_model_input, batch_size=2 ** 12)
|
||||
# embedding保存之前归一化一下
|
||||
user_embs = user_embs / np.linalg.norm(user_embs, axis=1, keepdims=True)
|
||||
doc_embs = doc_embs / np.linalg.norm(doc_embs, axis=1, keepdims=True)
|
||||
|
||||
# 将Embedding转换成字典的形式方便查询
|
||||
raw_user_id_emb_dict = {user_idx_2_rawid[k]: \
|
||||
v for k, v in zip(user_idx_2_rawid.keys(), user_embs)}
|
||||
raw_doc_id_emb_dict = {doc_idx_2_rawid[k]: \
|
||||
v for k, v in zip(doc_idx_2_rawid.keys(), doc_embs)}
|
||||
# 将Embedding保存到本地
|
||||
pickle.dump(raw_user_id_emb_dict, open(save_path + 'user_youtube_emb.pkl', 'wb'))
|
||||
pickle.dump(raw_doc_id_emb_dict, open(save_path + 'doc_youtube_emb.pkl', 'wb'))
|
||||
|
||||
# 读取
|
||||
#user_embs_dict = pickle.load(open('embedding/user_youtube_emb.pkl', 'rb'))
|
||||
#doc_embs_dict = pickle.load(open('embedding/doc_youtube_emb.pkl', 'rb'))
|
||||
return user_embs, doc_embs
|
||||
```
|
||||
获取embedding的这两行代码是固定操作, 下面做了一些归一化操作,以及把索引转成了原始id的形式。
|
||||
8. 向量最近邻检索,为每个用户召回相似item
|
||||
|
||||
```python
|
||||
def get_youtube_recall_res(user_embs, doc_embs, user_idx_2_rawid, doc_idx_2_rawid, topk):
|
||||
"""近邻检索,这里用annoy tree"""
|
||||
# 把doc_embs构建成索引树
|
||||
f = user_embs.shape[1]
|
||||
t = AnnoyIndex(f, 'angular')
|
||||
for i, v in enumerate(doc_embs):
|
||||
t.add_item(i, v)
|
||||
t.build(10)
|
||||
# 可以保存该索引树 t.save('annoy.ann')
|
||||
|
||||
# 每个用户向量, 返回最近的TopK个item
|
||||
user_recall_items_dict = collections.defaultdict(dict)
|
||||
for i, u in enumerate(user_embs):
|
||||
recall_doc_scores = t.get_nns_by_vector(u, topk, include_distances=True)
|
||||
# recall_doc_scores是(([doc_idx], [scores])), 这里需要转成原始doc的id
|
||||
raw_doc_scores = list(recall_doc_scores)
|
||||
raw_doc_scores[0] = [doc_idx_2_rawid[i] for i in raw_doc_scores[0]]
|
||||
# 转换成实际用户id
|
||||
try:
|
||||
user_recall_items_dict[user_idx_2_rawid[i]] = dict(zip(*raw_doc_scores))
|
||||
except:
|
||||
continue
|
||||
|
||||
# 默认是分数从小到大排的序, 这里要从大到小
|
||||
user_recall_items_dict = {k: sorted(v.items(), key=lambda x: x[1], reverse=True) for k, v in user_recall_items_dict.items()}
|
||||
|
||||
# 保存一份
|
||||
pickle.dump(user_recall_items_dict, open('youtube_u2i_dict.pkl', 'wb'))
|
||||
|
||||
return user_recall_items_dict
|
||||
```
|
||||
用了用户embedding和item向量,就可以通过这个函数进行检索, 这块主要是annoy包做近邻检索的固定格式, 检索完毕,为用户生成最相似的200个候选item。
|
||||
|
||||
以上,就是使用YouTubeDNN做召回的整个流程。 效果如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/e904362d28fd4bdbacb5715ff2abaac2.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这个字典长这样:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/840e3abaf30845499f0926c61ba88635.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
接下来就是评估模型的效果,这里我采用了简单的HR@N计算的, 具体代码看GitHub吧, 结果如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/eb6ccadaa98e46bd87e594ee11e957a7.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
结果不怎么样啊,唉, 难道是数据量太少了? 总归是跑起来且能用了。
|
||||
|
||||
详细代码见尾部GitHub链接吧, 硬件设施到位的可以尝试多用一些数据试试看哈哈。
|
||||
|
||||
## YouTubeDNN新闻推荐数据集的实验记录
|
||||
这块就比较简单了,简单的整理下我用上面代码做个的实验,尝试了论文里面的几个点,记录下:
|
||||
1. 负采样方式上,尝试了随机负采样和打压高热item两种方式, 从我的实验结果上来看, 带打压的效果略好一点点
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/7cf27f1b849049f0b4bd98d0ebb7925f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
2. 特征上, 尝试原论文给出的example age的方式,做一个样本的年龄特征出来
|
||||
这个年龄样本,我是用的训练集的最大时间减去曝光的时间,然后转成小时间隔算的,而测试集里面的统一用0表示, 但效果好差。 看好多文章说这个时间单位是个坑,不知道是小时,分钟,另外这个特征我只做了简单归一化,感觉应该需要做归一化
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/1ea482f538c94b8bb07a69023b14ca9b.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
3. 尝试了控制用户数量,即每个用户的样本数量保持一样,效果比上面略差
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/8653b76d0b434d1088da196ce94bb954.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
4. 开始模型评估,我尝试用最后一天的,而不是最后一次点击的, 感觉效果不如最后一次点击作为测试集效果好
|
||||
|
||||
当然,上面实验并没有太大说服力,第一个是我采样的数据量太少,模型本身训练的不怎么样,第二个这些策略相差的并不是很大, 可能有偶然性。
|
||||
|
||||
并且我这边做一次实验,要花费好长时间,探索就先到这里吧, example age那个确实是个迷, 其他的感觉起来, 打压高活效果要比不打压要好。
|
||||
|
||||
另外要记录下学习小tricks:
|
||||
> 跑一次这样的实验,我这边一般会花费两个小时左右的时间, 而这个时间在做实验之前,一定要做规划才能好好的利用起来, 比如,我计划明天上午要开始尝试各种策略做实验, 今天晚上的todo里面,就要记录好, 我会尝试哪些策略,记录一个表, 调整策略,跑模型的时候,我这段空档要干什么事情, todo里面都要记录好,比如我这段空档就是解读这篇paper,写完这篇博客,基本上是所有实验做完,我这篇博客也差不多写完,正好,哈哈<br><br>这个空档利用,一定要提前在todo里面写好,而不是跑模型的时候再想,这个时候往往啥也干不下去,并且还会时不时的看模型跑,或者盯着进度条发呆,那这段时间就有些浪费了呀,即使这段时间不学习,看个久违的电视剧, 久违的书,或者keep下不香吗哈哈, 但得提前规划。<br><br>可能每个人习惯不一样,对于我,是这样哈,所以记录下 ;)
|
||||
|
||||
## 总结
|
||||
|
||||
由于这篇文章里面的工程经验太多啦,我前面介绍的时候,可能涉及到知识的一些扩展补充,把经验整理的比较凌乱,这里再统一整理下, 这些也都是工业界常用的一些经验了:
|
||||
|
||||
召回部分:
|
||||
1. 训练数据的样本来源应该是全部物料, 而不仅仅是被推荐的物料,否则对于新物料难以曝光
|
||||
2. 训练数据中对于每个用户选取相同的样本数, 保证用户在损失函数等权重, 这个虽然不一定非得这么做,但考虑打压高活用户或者是高活item的影响还是必须的
|
||||
3. 序列无序化: 用户的最近一次搜索与搜索之后的播放行为有很强关联,为了避免信息泄露,将搜索行为顺序打乱。
|
||||
4. 训练数据构造: 预测接下来播放而不是用传统cbow中的两侧预测中间的考虑是可以防止信息泄露,并且可以学习到用户的非对称视频消费模式
|
||||
5. 召回模型中,类似word2vec,video 有input embedding和output embedding两组embedding,并不是共享的, input embedding论文里面是用w2v事先训练好的, 其实也可以用embedding层联合训练
|
||||
6. 召回模型的用户embedding来自网络输出, 而video的embedding往往用后面output处的
|
||||
7. 使用 `example age` 特征处理 time bias,这样线上检索时可以预先计算好用户向量
|
||||
|
||||
|
||||
**参考资料**:
|
||||
* [重读Youtube深度学习推荐系统论文](https://zhuanlan.zhihu.com/p/52169807)
|
||||
* [YouTube深度学习推荐系统的十大工程问题](https://zhuanlan.zhihu.com/p/52169807)
|
||||
* [你真的读懂了Youtube DNN推荐论文吗](https://zhuanlan.zhihu.com/p/372238343)
|
||||
* [推荐系统经典论文(二)】YouTube DNN](https://zhuanlan.zhihu.com/p/128597084)
|
||||
* [张俊林-推荐技术发展趋势与召回模型](https://www.icode9.com/content-4-764359.html)
|
||||
* [揭开YouTube深度推荐系统模型Serving之谜](https://zhuanlan.zhihu.com/p/61827629)
|
||||
* [Deep Neural Networks for YouTube Recommendations YouTubeDNN推荐召回与排序](https://www.pianshen.com/article/82351182400/)
|
||||
@@ -1,308 +0,0 @@
|
||||
# 背景介绍
|
||||
|
||||
**文章核心思想**
|
||||
|
||||
+ 在大规模的推荐系统中,利用双塔模型对user-item对的交互关系进行建模,学习 $\{user,context\}$ 向量与 $\{item\}$ 向量.
|
||||
+ 针对大规模流数据,提出in-batch softmax损失函数与流数据频率估计方法(Streaming Frequency Estimation),可以更好的适应item的多种数据分布。
|
||||
|
||||
**文章主要贡献**
|
||||
|
||||
+ 提出了改进的流数据频率估计方法:针对流数据来估计item出现的频率,利用实验分析估计结果的偏差与方差,模拟实验证明该方法在数据动态变化时的功效
|
||||
|
||||
+ 提出了双塔模型架构:提供了一个针对大规模的检索推荐系统,包括了 in-batch softmax 损失函数与流数据频率估计方法,减少了负采样在每个batch中可能会出现的采样偏差问题。
|
||||
|
||||
# 算法原理
|
||||
|
||||
给定一个查询集 $Query: \left\{x_{i}\right\}_{i=1}^{N}$ 和一个物品集$Item:\left\{y_{j}\right\}_{j=1}^{M}$。
|
||||
|
||||
+ $x_{i} \in X,\quad y_{j} \in \mathcal{Y}$ 是由多种特征(例如:稀疏ID和 Dense 特征)组成的高维混合体。
|
||||
|
||||
+ 推荐的目标是对于给定一个 $query$,检索到一系列 $item$ 子集用于后续排序推荐任务。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/%E5%9B%BE%E7%89%87image-20220506202824884.png" alt="image-20220506202824884" style="zoom:50%;" />
|
||||
|
||||
## 模型目标
|
||||
|
||||
模型结构如上图所示,论文旨在对用户和物品建立两个不同的模型,将它们投影到相同维度的空间:
|
||||
$$
|
||||
u: X \times \mathbb{R}^{d} \rightarrow \mathbb{R}^{k}, v: y \times \mathbb{R}^{d} \rightarrow \mathbb{R}^{k}
|
||||
$$
|
||||
|
||||
模型的输出为用户与物品向量的内积:
|
||||
|
||||
$$
|
||||
s(x, y)=\langle u(x, \theta), v(y, \theta)\rangle
|
||||
$$
|
||||
|
||||
模型的目标是为了学习参数 $\theta$, 样本集被表示为如下格式 $\{query, item, reward \}$:
|
||||
|
||||
$$
|
||||
\mathcal{T}:=\left\{\left(x_{i}, y_{i}, r_{i}\right)\right\}_{i=1}^{T}
|
||||
$$
|
||||
|
||||
* 在推荐系统中,$r_i$ 可以扩展来捕获用户对不同候选物品的参与度。
|
||||
* 例如,在新闻推荐中 $r_i$ 可以是用户在某篇文章上花费的时间。
|
||||
|
||||
## 模型流程
|
||||
|
||||
1. 给定用户 $x$,基于 softmax 函数从物料库 $M$ 中选中候选物品 $y$ 的概率为:
|
||||
$$
|
||||
\mathcal{P}(y \mid x ; \theta)=\frac{e^{s(x, y)}}{\sum_{j \in[M]} e^{s\left(x, y_{j}\right)}}
|
||||
$$
|
||||
|
||||
* 考虑到相关奖励 $r_i$ ,加权对数似然函数的定义如下:
|
||||
|
||||
$$
|
||||
L_{T}(\theta):=-\frac{1}{T} \sum_{i \in[T]} r_{i} \cdot \log \left(\mathcal{P}\left(y_{i} \mid x_{i} ; \theta\right)\right)
|
||||
$$
|
||||
|
||||
2. 原表达式 $\mathcal{P}(y \mid x ; \theta)$ 中的分母需要遍历物料库中所有的物品,计算成本太高,故对分母中的物品要进行负采样。为了提高负采样的速度,一般是直接从训练样本所在 Batch 中进行负样本选择。于是有:
|
||||
$$
|
||||
\mathcal{P}_{B}\left(y_{i} \mid x_{i} ; \theta\right)=\frac{e^{s\left(x_{i}, y_{i}\right)}}{\sum_{j \in[B]} e^{s\left(x_{i}, y_{j}\right)}}
|
||||
$$
|
||||
|
||||
* 其中,$B$ 表示与样本 $\{x_i,y_j\}$ 同在一个 Batch 的物品集合。
|
||||
* 举例来说,对于用户1,Batch 内其他用户的正样本是用户1的负样本。
|
||||
|
||||
3. 一般而言,负采样分为 Easy Negative Sample 和 Hard Negative Sample。
|
||||
|
||||
+ 这里的 Easy Negative Sample 一般是直接从全局物料库中随机选取的负样本,由于每个用户感兴趣的物品有限,而物料库又往往很大,故即便从物料库中随机选取负样本,也大概率是用户不感兴趣的。
|
||||
|
||||
+ 在真实场景中,热门物品占据了绝大多数的购买点击。而这些热门物品往往只占据物料库物品的少部分,绝大部分物品是冷门物品。
|
||||
|
||||
+ 在物料库中随机选择负样本,往往被选中的是冷门物品。这就会造成马太效应,热门物品更热,冷门物品更冷。
|
||||
+ 一种解决方式时,在对训练样本进行负采样时,提高热门物品被选为负样本的概率,工业界的经验做法是物品被选为负样本的概率正比于物品点击次数的 0.75 次幂。
|
||||
|
||||
+ 前面提到 Batch 内进行负采样,热门物品出现在一个 Batch 的概率正比于它的点击次数。问题是,热门物品被选为负样本的概率过高了(一般正比于点击次数的 0.75 次幂),导致热门物品被过度打压。
|
||||
|
||||
+ 在本文中,为了避免对热门物品进行过度惩罚,进行了纠偏。公式如下:
|
||||
$$
|
||||
s^{c}\left(x_{i}, y_{j}\right)=s\left(x_{i}, y_{j}\right)-\log \left(p_{j}\right)
|
||||
$$
|
||||
|
||||
+ 在内积 $s(x_i,y_j)$ 的基础上,减去了物品 $j$ 的采样概率的对数。
|
||||
|
||||
4. 纠偏后,物品 $y$ 被选中的概率为:
|
||||
$$
|
||||
\mathcal{P}_{B}^{c}\left(y_{i} \mid x_{i} ; \theta\right)=\frac{e^{s^{c}\left(x_{i}, y_{i}\right)}}{e^{s^{c}\left(x_{i}, y_{i}\right)}+\sum_{j \in[B], j \neq i} e^{s^{c}\left(x_{i}, y_{j}\right)}}
|
||||
$$
|
||||
|
||||
+ 此时,batch loss function 的表示式如下:
|
||||
|
||||
$$
|
||||
L_{B}(\theta):=-\frac{1}{B} \sum_{i \in[B]} r_{i} \cdot \log \left(\mathcal{P}_{B}^{c}\left(y_{i} \mid x_{i} ; \theta\right)\right)
|
||||
$$
|
||||
+ 通过 SGD 和学习率,来优化模型参数 $\theta$ :
|
||||
|
||||
$$
|
||||
\theta \leftarrow \theta-\gamma \cdot \nabla L_{B}(\theta)
|
||||
$$
|
||||
|
||||
5. Normalization and Temperature
|
||||
|
||||
* 最后一层,得到用户和物品的特征 Embedding 表示后,再进行进行 $l2$ 归一化:
|
||||
$$
|
||||
\begin{aligned}
|
||||
u(x, \theta) \leftarrow u(x, \theta) /\|u(x, \theta)\|_{2}
|
||||
\\
|
||||
v(y, \theta) \leftarrow v(y, \theta) /\|v(y, \theta)\|_{2}
|
||||
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 本质上,其实就是将用户和物品的向量内积转换为了余弦相似度。
|
||||
|
||||
* 对于内积的结果,再除以温度参数 $\tau$:
|
||||
$$
|
||||
s(x, y)=\langle u(x, \theta), v(y, \theta)\rangle / \tau
|
||||
$$
|
||||
|
||||
+ 论文提到,这样有利于提高预测准确度。
|
||||
+ 从实验结果来看,温度参数 $\tau$ 一般小于 $1$,所以感觉就是放大了内积结果。
|
||||
|
||||
**上述模型训练过程可以归纳为:**
|
||||
|
||||
(1)从实时数据流中采样得到一个 batch 的训练样本。
|
||||
|
||||
(2)基于流频估计法,估算物品 $y_i$ 的采样概率 $p_i$ 。
|
||||
|
||||
(3)计算损失函数 $L_B$ ,再利用 SGD 方法更新参数。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/%E5%9B%BE%E7%89%87image-20220506211935092.png" alt="image-20220506211935092" style="zoom: 50%;" />
|
||||
|
||||
## 流频估计算法
|
||||
|
||||
考虑一个随机的数据 batch ,每个 batch 中包含一组物品。现在的问题是如何估计一个 batch 中物品 $y$ 的命中概率。具体方法如下:
|
||||
|
||||
+ 利用全局步长,将对物品采样频率 $p$ 转换为 对 $\delta$ 的估计,其中 $\delta$ 表示连续两次采样物品之间的平均步数。
|
||||
+ 例如,某物品平均 50 个步后会被采样到,那么采样频率 $p=1/\delta=0.02$ 。
|
||||
|
||||
**具体的实现方法为:**
|
||||
|
||||
1. 建立两个大小为 $H$ 的数组 $A,B$ 。
|
||||
|
||||
2. 通过哈希函数 $h(\cdot)$ 可以把每个物品映射为 $[H]$ 范围内的整数。
|
||||
|
||||
+ 映射的内容可以是 ID 或者其他的简单特征值。
|
||||
|
||||
+ 对于给定的物品 $y$,哈希后的整数记为 $h(y)$,本质上它表示物品 $y$ 在数组中的序号。
|
||||
|
||||
3. 数组 $A$ 中存放的 $A[h(y)]$ 表示物品 $y$ 上次被采样的时间, 数组 $B$ 中存放的 $B[h(y)]$ 表示物品 $y$ 的全局步长。
|
||||
|
||||
+ 假设在第 $t$ 步时采样到物品 $y$,则 $A[h(y)]$ 和 $B[h(y)]$ 的更新公式为:
|
||||
$$
|
||||
B[h(y)] \leftarrow(1-\alpha) \cdot B[h(y)]+\alpha \cdot(t-A[h(y)])
|
||||
$$
|
||||
|
||||
+ 在$B$ 被更新后,将 $t$ 赋值给 $A[h(y)]$ 。
|
||||
|
||||
4. 对整个batch数据采样后,取数组 $B$ 中 $B[h(y)]$ 的倒数,作为物品 $y$ 的采样频率,即:
|
||||
$$
|
||||
\hat{p}=1 / B[h(y)]
|
||||
$$
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/%E5%9B%BE%E7%89%87image-20220506220529932.png" alt="image-20220506220529932" style="zoom:50%;" />
|
||||
|
||||
**从数学理论上证明这种迭代更新的有效性:**
|
||||
|
||||
假设物品 $y$ 被采样到的时间间隔序列为 $\Delta=\left\{\Delta_{1}, \ldots, \Delta_{t}\right\}$ 满足独立同分布,这个随机变量的均值为$\delta=E[\Delta]$。对于每一次采样迭代:$\delta_{i}=(1-\alpha) \delta_{i-1}+\alpha \Delta_{i}$,可以证明时间间隔序列的均值和方差满足:
|
||||
|
||||
$$
|
||||
\begin{aligned}
|
||||
& E\left(\delta_{t}\right)-\delta=(1-\alpha)^{t} \delta_{0}-(1-\alpha)^{t-1} \delta
|
||||
\\ \\
|
||||
& E\left[\left(\delta_{t}-E\left[\delta_{t}\right]\right)^{2}\right] \leq(1-\alpha)^{2 t}\left(\delta_{0}-\delta\right)^{2}+\alpha E\left[\left(\Delta_{1}-\alpha\right)^{2}\right]
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
1. **对于均值的证明:**
|
||||
$$
|
||||
\begin{aligned}
|
||||
E\left[\delta_{t}\right] &=(1-\alpha) E\left[\delta_{t-1}\right]+\alpha \delta \\
|
||||
&=(1-\alpha)\left[(1-\alpha) E\left[\delta_{t-2}\right]+\alpha \delta\right]+\alpha \delta \\
|
||||
&=(1-\alpha)^{2} E\left[\delta_{t-2}\right]+\left[(1-\alpha)^{1}+(1-\alpha)^{0}\right] \alpha \delta \\
|
||||
&=(1-\alpha)^{3} E\left[\delta_{t-3}\right]+\left[(1-\alpha)^{2}+(1-\alpha)^{1}+(1-\alpha)^{0}\right] \alpha \delta \\
|
||||
&=\ldots \ldots \\
|
||||
&=(1-\alpha)^{t} \delta_{0}+\left[(1-\alpha)^{t-1}+\ldots+(1-\alpha)^{1}+(1-\alpha)^{0}\right] \alpha \delta \\
|
||||
&=(1-\alpha)^{t} \delta_{0}+\left[1-(1-\alpha)^{t-1}\right] \delta
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 根据均值公式可以看出:$t \rightarrow \infty \text { 时, }\left|E\left[\delta_{t}\right]-\delta\right| \rightarrow 0 $ 。
|
||||
+ 即当采样数据足够多的时候,数组 $B$ (每多少步采样一次)趋于真实采样频率。
|
||||
+ 因此递推式合理,且当初始值 $\delta_{0}=\delta /(1-\alpha)$,递推式为无偏估计。
|
||||
|
||||
2. **对于方差的证明:**
|
||||
$$
|
||||
\begin{aligned}
|
||||
E\left[\left(\delta_{t}-E\left[\delta_{t}\right]\right)^{2}\right] &=E\left[\left(\delta_{t}-\delta+\delta-E\left[\delta_{t}\right]\right)^{2}\right] \\
|
||||
&=E\left[\left(\delta_{t}-\delta\right)^{2}\right]+2 E\left[\left(\delta_{t}-\delta\right)\left(\delta-E\left[\delta_{t}\right]\right)\right]+\left(\delta-E\left[\delta_{t}\right]\right)^{2} \\
|
||||
&=E\left[\left(\delta_{t}-\delta\right)^{2}\right]-\left(E\left[\delta_{t}\right]-\delta\right)^{2} \\
|
||||
& \leq E\left[\left(\delta_{t}-\delta\right)^{2}\right]
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 对于 $E\left[\left(\delta_{i}-\delta\right)^{2}\right]$:
|
||||
$$
|
||||
\begin{aligned}
|
||||
E\left[\left(\delta_{i}-\delta\right)^{2}\right] &=E\left[\left((1-\alpha) \delta_{i-1}+\alpha \Delta_{i}-\delta\right)^{2}\right] \\
|
||||
&=E\left[\left((1-\alpha) \delta_{i-1}+\alpha \Delta_{i}-(1-\alpha+\alpha) \delta\right)^{2}\right] \\
|
||||
&=E\left[\left((1-\alpha)\left(\delta_{i-1}-\delta\right)+\alpha\left(\Delta_{i}-\delta\right)\right)^{2}\right] \\
|
||||
&=(1-\alpha)^{2} E\left[\left(\delta_{i-1}-\delta\right)^{2}\right]+\alpha^{2} E\left[\Delta_{i}-\delta\right]^{2}+2 \alpha(1-\alpha) E\left[\left(\delta_{i-1}-\delta\right)\left(\Delta_{i}-\delta\right)\right]
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 由于 $\delta_{i-1}$ 和 $\Delta_{i}$ 独立,所以上式最后一项为 0,因此:
|
||||
$$
|
||||
E\left[\left(\delta_{i}-\delta\right)^{2}\right]=(1-\alpha)^{2} E\left[\left(\delta_{i-1}-\delta\right)^{2}\right]+\alpha^{2} E\left[\Delta_{i}-\delta\right]^{2}
|
||||
$$
|
||||
|
||||
+ 与均值的推导类似,可得:
|
||||
$$
|
||||
\begin{aligned}
|
||||
E\left[\left(\delta_{t}-\delta\right)^{2}\right] &=(1-\alpha)^{2 t}\left(\delta_{0}-\delta\right)^{2}+\alpha^{2} \frac{1-(1-\alpha)^{2 t-2}}{1-(1-\alpha)^{2}} E\left[\left(\Delta_{1}-\delta\right)^{2}\right] \\
|
||||
& \leq(1-\alpha)^{2 t}\left(\delta_{0}-\delta\right)^{2}+\alpha E\left[\left(\Delta_{1}-\delta\right)^{2}\right]
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 由此可证明:
|
||||
$$
|
||||
E\left[\left(\delta_{t}-E\left[\delta_{t}\right]\right)^{2}\right] \leq(1-\alpha)^{2 t}\left(\delta_{0}-\delta\right)^{2}+\alpha E\left[\left(\Delta_{1}-\alpha\right)^{2}\right]
|
||||
$$
|
||||
|
||||
+ 对于方差,上式给了一个估计方差的上界。
|
||||
|
||||
## 多重哈希
|
||||
|
||||
上述流动采样频率估计算法存在的问题:
|
||||
|
||||
+ 对于不同的物品,经过哈希函数映射的整数可能相同,这就会导致哈希碰撞的问题。
|
||||
|
||||
+ 由于哈希碰撞,对导致对物品采样频率过高的估计。
|
||||
|
||||
**解决方法:**
|
||||
|
||||
* 使用 $m$ 个哈希函数,取 $m$ 个估计值中的最大值来表示物品连续两次被采样到之间的步长。
|
||||
|
||||
**具体的算法流程:**
|
||||
|
||||
1. 分别建立 $m$ 个大小为 $H$ 的数组 $\{A\}_{i=1}^{m}$,$\{B\}_{i=1}^{m}$,一组对应的独立哈希函数集合 $\{h\}_{i=1}^{m}$ 。
|
||||
|
||||
2. 通过哈希函数 $h(\cdot)$ 可以把每个物品映射为 $[H]$ 范围内的整数。对于给定的物品 $y$,哈希后的整数记为$h(y)$
|
||||
|
||||
3. 数组 $A_i$ 中存放的 $A_i[h(y)]$ 表示在第 $i$ 个哈希函数中物品 $y$ 上次被采样的时间。数组 $B_i$ 中存放的 $B_i[h(y)]$ 表示在第 $i$ 个哈希函数中物品 $y$ 的全局步长。
|
||||
|
||||
4. 假设在第 $t$ 步采样到物品 $y$,分别对 $m$ 个哈希函数对应的 $A[h(y)]$ 和 $B[h(y)]$ 进行更新:
|
||||
$$
|
||||
\begin{aligned}
|
||||
& B_i[h(y)] \leftarrow(1-\alpha) \cdot B_i[h(y)]+\alpha \cdot(t-A_i[h(y)])\\ \\
|
||||
& A_i[h(y)]\leftarrow t
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
5. 对整个 batch 数据采样后,取 $\{B\}_{i=1}^{m}$ 中最大的 $B[h(y)]$ 的倒数,作为物品 $y$ 的采样频率,即:
|
||||
|
||||
$$
|
||||
\hat{p}=1 / \max _{i}\left\{B_{i}[h(y)]\right\}
|
||||
$$
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/%E5%9B%BE%E7%89%87image-20220506223731749.png" alt="image-20220506223731749" style="zoom:50%;" />
|
||||
|
||||
|
||||
|
||||
# YouTube 神经召回模型
|
||||
|
||||
本文构建的 YouTube 神经检索模型由查询和候选网络组成。下图展示了整体的模型架构。
|
||||
|
||||
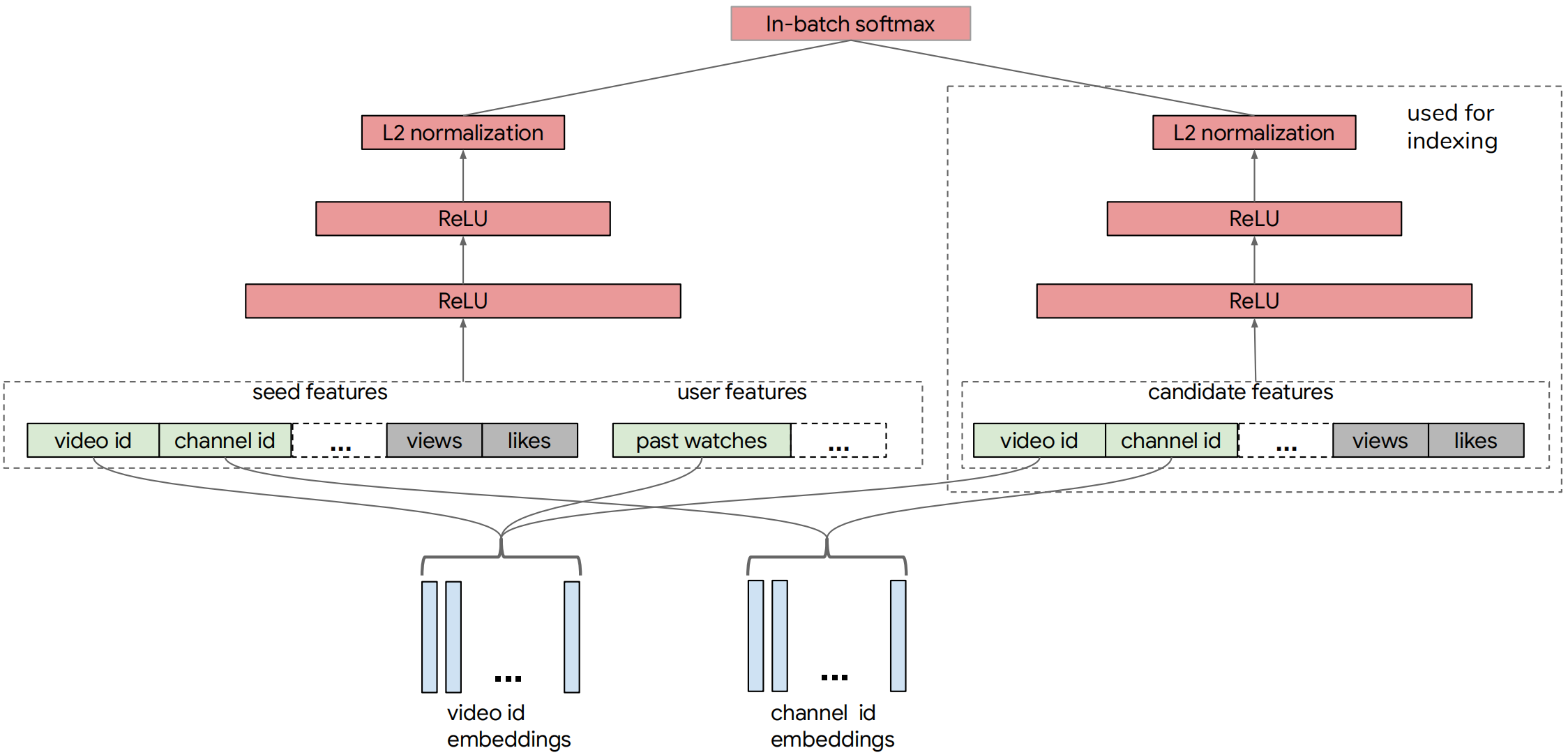
|
||||
|
||||
在任何时间点,用户正在观看的视频,即种子视频,都会提供有关用户当前兴趣的强烈信号。因此,本文利用了大量种子视频特征以及用户的观看历史记录。候选塔是为了从候选视频特征中学习而构建的。
|
||||
|
||||
* Training Label
|
||||
|
||||
* 视频点击被用作正面标签。对于每次点击,我们都会构建一个 rewards 来反映用户对视频的不同程度的参与。
|
||||
* $r_i$ = 0:观看时间短的点击视频;$r_i$ = 1:表示观看了整个视频。
|
||||
* Video Features
|
||||
|
||||
* YouTube 使用的视频特征包括 categorical 特征和 dense 特征。
|
||||
|
||||
* 例如 categorical 特征有 video id 和 channel id 。
|
||||
* 对于 categorical 特征,都会创建一个嵌入层以将每个分类特征映射到一个 Embedding 向量。
|
||||
* 通常 YouTube 要处理两种类别特征。从原文的意思来看,这两类应该是 one-hot 型和 multi-hot 型。
|
||||
* User Features
|
||||
|
||||
* 使用**用户观看历史记录**来捕捉 seed video 之外的兴趣。将用户最近观看的 k个视频视为一个词袋(BOW),然后将它们的 Embedding 平均。
|
||||
* 在查询塔中,最后将用户和历史 seed video 的特征进行融合,并送入输入前馈神经网络。
|
||||
* 类别特征的 Embedding 共享
|
||||
|
||||
* 原文:For the same type of IDs, embeddings are shared among the related features. For example, the same set of video id embeddings is used for seed, candidate and users past watches. We did experiment with non-shared embeddings, but did not observe significant model quality improvement.
|
||||
* 大致意思就是,对于相同 ID 的类别,他们之间的 Embedding 是共享的。例如对于 seed video,出现的地方包括用户历史观看,以及作为候选物品,故只要视频的 ID 相同,Embedding也是相同的。如果不共享,也没啥提升。
|
||||
|
||||
# 参考链接
|
||||
|
||||
+ [Sampling-bias-corrected neural modeling for large corpus item recommendations | Proceedings of the 13th ACM Conference on Recommender Systems](https://dl.acm.org/doi/abs/10.1145/3298689.3346996)
|
||||
|
||||
+ [【推荐系统经典论文(九)】谷歌双塔模型 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/137538147)
|
||||
|
||||
+ [借Youtube论文,谈谈双塔模型的八大精髓问题 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/369152684)
|
||||
@@ -1,114 +0,0 @@
|
||||
# 前言
|
||||
|
||||
在自然语言处理(NLP)领域,谷歌提出的 Word2Vec 模型是学习词向量表示的重要方法。其中,带有负采样(SGNS,Skip-gram with negative sampling)的 Skip-Gram 神经词向量模型在当时被证明是最先进的方法之一。各位读者需要自行了解 Word2Vec 中的 Skip-Gram 模型,本文只会做简单介绍。
|
||||
|
||||
在论文 Item2Vec:Neural Item Embedding for Collaborative Filtering 中,作者受到 SGNS 的启发,提出了名为 Item2Vec 的方法来生成物品的向量表示,然后将其用于基于物品的协同过滤。
|
||||
|
||||
# 基于负采样的 Skip-Gram 模型
|
||||
|
||||
Skip-Gram 模型的思想很简单:给定一个句子 $(w_i)^K_{i=1}$,然后基于中心词来预测它的上下文。目标函数如下:
|
||||
$$
|
||||
\frac{1}{K} \sum_{i=1}^{K} \sum_{-c \leq j \leq c, j \neq 0} \log p\left(w_{i+j} \mid w_{i}\right)
|
||||
$$
|
||||
|
||||
+ 其中,$c$ 表示上下文的窗口大小;$w_i$ 表示中心词;$w_{i+j}$ 表示上下文。
|
||||
|
||||
+ 表达式中的概率 $p\left(w_{j} \mid w_{i}\right)$ 的公式为:
|
||||
$$
|
||||
p\left(w_{j} \mid w_{i}\right)=\frac{\exp \left(u_{i}^{T} v_{j}\right)}{\sum_{k \in I_{W}} \exp \left(u_{i}^{T} v_{k}^{T}\right)}
|
||||
$$
|
||||
|
||||
+ $u_{i} \in U\left(\subset \mathbb{R}^{m}\right),v_{i} \in V\left(\subset \mathbb{R}^{m}\right)$,分别对应中心和上下文词的 Embedding 特征表示。
|
||||
+ 这里的意思是每个单词有2个特征表示,作为中心词 $u_i$ 和上下文 $v_i$ 时的特征表示不一样。
|
||||
+ $I_{W} \triangleq\{1, \ldots,|W|\}$ ,$|W|$ 表示语料库中词的数量。
|
||||
|
||||
简单来理解一下 Skip-Gram 模型的表达式:
|
||||
|
||||
+ 对于句子中的某个词 $w_i$,当其作为中心词时,希望尽可能准确预测它的上下文。
|
||||
+ 我们可以将其转换为多分类问题:
|
||||
+ 对于中心词 $w_i$ 预测的上下文 $w_j$,其 $label=1$ ;那么,模型对上下文的概率预测 $p\left(w_{j} \mid w_{i}\right)$ 越接近1越好。
|
||||
+ 若要 $p\left(w_{j} \mid w_{i}\right)$ 接近1,对于分母项中的 $k\ne j$,其 $\exp \left(u_{i}^{T} v_{k}^{T}\right)$ 越小越好(等价于将其视为了负样本)。
|
||||
|
||||
|
||||
注意到分母项,由于需要遍历语料库中所有的单词,从而导致计算成本过高。一种解决办法是基于负采样(NEG)的方式来降低计算复杂度:
|
||||
$$
|
||||
p\left(w_{j} \mid w_{i}\right)=\sigma\left(u_{i}^{T} v_{j}\right) \prod_{k=1}^{N} \sigma\left(-u_{i}^{T} v_{k}\right)
|
||||
$$
|
||||
|
||||
+ 其中,$\sigma(x)=1/1+exp(-x)$,$N$ 表示负样本的数量。
|
||||
|
||||
其它细节:
|
||||
|
||||
+ 单词 $w$ 作为负样本时,被采样到的概率:
|
||||
$$
|
||||
\frac{[\operatorname{counter}(w)]^{0.75}}{\sum_{u \in \mathcal{W}}[\operatorname{counter}(u)]^{0.75}}
|
||||
$$
|
||||
|
||||
+ 单词 $w$ 作为中心词时,被丢弃的概率:
|
||||
$$
|
||||
\operatorname{prob}(w)=1-\sqrt{\frac{t}{f(w)}}
|
||||
$$
|
||||
|
||||
|
||||
# Item2Vec模型
|
||||
|
||||
Item2Vec 的原理十分十分简单,它是基于 Skip-Gram 模型的物品向量训练方法。但又存在一些区别,如下:
|
||||
|
||||
+ 词向量的训练是基于句子序列(sequence),但是物品向量的训练是基于物品集合(set)。
|
||||
+ 因此,物品向量的训练丢弃了空间、时间信息。
|
||||
|
||||
Item2Vec 论文假设对于一个集合的物品,它们之间是相似的,与用户购买它们的顺序、时间无关。当然,该假设在其他场景下不一定使用,但是原论文只讨论了该场景下它们实验的有效性。由于忽略了空间信息,原文将共享同一集合的每对物品视为正样本。目标函数如下:
|
||||
$$
|
||||
\frac{1}{K} \sum_{i=1}^{K} \sum_{j \neq i}^{K} \log p\left(w_{j} \mid w_{i}\right)
|
||||
$$
|
||||
|
||||
+ 对于窗口大小 $K$,由设置的决定。
|
||||
|
||||
在 Skip-Gram 模型中,提到过每个单词 $w_i$ 有2个特征表示。在 Item2Vec 中同样如此,论文中是将物品的中心词向量 $u_i$ 作为物品的特征向量。作者还提到了其他两种方式来表示物品向量:
|
||||
|
||||
+ **add**:$u_i + v_i$
|
||||
+ **concat**:$\left[u_{i}^{T} v_{i}^{T}\right]^{T}$
|
||||
|
||||
原文还补充到,这两种方式有时候会有很好的表现。
|
||||
|
||||
# 总结
|
||||
|
||||
+ Item2Vec 的原理很简单,就是基于 Word2Vec 的 Skip-Gram 模型,并且还丢弃了时间、空间信息。
|
||||
+ 基于 Item2Vec 得到物品的向量表示后,物品之间的相似度可由二者之间的余弦相似度计算得到。
|
||||
+ 可以看出,Item2Vec 在计算物品之间相似度时,仍然依赖于不同物品之间的共现。因为,其无法解决物品的冷启动问题。
|
||||
+ 一种解决方法:取出与冷启物品类别相同的非冷启物品,将它们向量的均值作为冷启动物品的向量表示。
|
||||
|
||||
原论文链接:[[1603.04259\] Item2Vec: Neural Item Embedding for Collaborative Filtering (arxiv.org)](https://arxiv.org/abs/1603.04259)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,341 +0,0 @@
|
||||
# 背景和引入
|
||||
在所有的NLP任务中,首先面临的第一个问题是我们该如何表示单词。这种表示将作为inputs输入到特定任务的模型中,如机器翻译,文本分类等典型NLP任务。
|
||||
|
||||
## 同义词表达单词
|
||||
一个很容易想到的解决方案是使用同义词来表示一个单词的意义。
|
||||
比如***WordNet***,一个包含同义词(和有“is a”关系的词)的词库。
|
||||
|
||||
**导包**
|
||||
|
||||
```python
|
||||
!pip install --user -U nltk
|
||||
```
|
||||
|
||||
```python
|
||||
!python -m nltk.downloader popular
|
||||
```
|
||||
|
||||
**如获取"good"的同义词**
|
||||
|
||||
```python
|
||||
from nltk.corpus import wordnet as wn
|
||||
poses = { 'n':'noun', 'v':'verb', 's':'adj (s)', 'a':'adj', 'r':'adv'}
|
||||
for synset in wn.synsets("good"):
|
||||
print("{}: {}".format(poses[synset.pos()],", ".join([l.name() for l in synset.lemmas()])))
|
||||
```
|
||||
|
||||
**如获取与“pandas”有"is a"关系的词**
|
||||
|
||||
```python
|
||||
panda = wn.synset("panda.n.01")
|
||||
hyper = lambda s: s.hypernyms()
|
||||
list(panda.closure(hyper))
|
||||
```
|
||||
|
||||
***WordNet的问题***
|
||||
1. 单词与单词之间缺少些微差异的描述。比如“高效”只在某些语境下是"好"的同义词
|
||||
2. 丢失一些词的新含义。比如“芜湖”,“蚌埠”等词的新含义
|
||||
3. 相对主观
|
||||
4. 需要人手动创建和调整
|
||||
5. 无法准确计算单词的相似性
|
||||
|
||||
## one-hot编码
|
||||
在传统NLP中,人们使用one-hot向量(一个向量只有一个值为1,其余的值为0)来表示单词
|
||||
如:motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
|
||||
如:hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
|
||||
one-hot向量的维度是词汇表的大小(如:500,000)
|
||||
注:上面示例词向量的维度为方便展示所以比较小
|
||||
|
||||
|
||||
**one-hot向量表示单词的问题:**
|
||||
1. 这些词向量是***正交向量***,无法通过数学计算(如点积)计算相似性
|
||||
2. 依赖WordNet等同义词库建立相似性效果也不好
|
||||
|
||||
|
||||
## dense word vectors表达单词
|
||||
如果我们可以使用某种方法为每个单词构建一个合适的dense vector,如下图,那么通过点积等数学计算就可以获得单词之间的某种联系
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1.png" />
|
||||
|
||||
|
||||
# Word2vec
|
||||
|
||||
## 语言学基础
|
||||
首先,我们引入一个上世纪五十年代,一个语言学家的研究成果:**“一个单词的意义由它周围的单词决定”**
|
||||
|
||||
“You shall know a word by the company it keeps” (J. R. Firth 1957: 11)
|
||||
|
||||
这是现代NLP中一个最为成功的理念。
|
||||
|
||||
我们先引入上下文context的概念:当单词 w 出现在文本中时,其**上下文context**是出现在w附近的一组单词(在固定大小的窗口内),如下图
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2.png" />
|
||||
|
||||
|
||||
这些上下文单词context words决定了banking的意义
|
||||
|
||||
## Word2vec概述
|
||||
|
||||
Word2vec(Mikolov et al. 2013)是一个用来学习dense word vector的算法:
|
||||
|
||||
1. 我们使用**大量的文本语料库**
|
||||
2. 词汇表中的每个单词都由一个**词向量dense word vector**表示
|
||||
3. 遍历文本中的每个位置 t,都有一个**中心词 c(center) 和上下文词 o(“outside”)**,如图1中的banking
|
||||
4. 在整个语料库上使用数学方法**最大化单词o在单词c周围出现了这一事实**,从而得到单词表中每一个单词的dense vector
|
||||
5. 不断调整词向量dense word vector以达到最好的效果
|
||||
|
||||
|
||||
## Skip-gram(SG)
|
||||
Word2vec包含两个模型,**Skip-gram与CBOW**。下面,我们先讲**Skip-gram**模型,用此模型详细讲解概述中所提到的内容。
|
||||
|
||||
概述中我们提到,我们希望**最大化单词o在单词c周围出现了这一事实**,而我们需要用数学语言表示“单词o在单词c周围出现了”这一事件,如此才能进行词向量的不断调整。
|
||||
|
||||
很自然地,我们需要**使用概率工具描述事件的发生**,我们想到用条件概率$P(o|c)$表示“给定中心词c,它的上下文词o在它周围出现了”
|
||||
|
||||
下图展示了以“into”为中心词,窗口大小为2的情况下它的上下文词。以及相对应的$P(o|c)$
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片3.png" />
|
||||
|
||||
|
||||
我们滑动窗口,再以banking为中心词
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片4.png" />
|
||||
|
||||
|
||||
那么,如果我们在整个语料库上不断地滑动窗口,我们可以得到所有位置的$P(o|c)$,我们希望在所有位置上**最大化单词o在单词c周围出现了这一事实**,由极大似然法,可得:
|
||||
|
||||
$$
|
||||
max\prod_{c} \prod_{o}P(o|c)
|
||||
$$
|
||||
|
||||
此式还可以依图3写为:
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片5.png" />
|
||||
|
||||
|
||||
加log,加负号,缩放大小可得:
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片7.png" />
|
||||
|
||||
|
||||
上式即为**skip-gram的损失函数**,最小化损失函数,就可以得到合适的词向量
|
||||
|
||||
|
||||
得到式1后,产生了两个问题:
|
||||
|
||||
1. P(o|c)怎么表示?
|
||||
|
||||
2. 为何最小化损失函数能够得到良好表示的词向量dense word vector?
|
||||
|
||||
|
||||
回答1:我们使用**中心词c和上下文词o的相似性**来计算$P(o|c)$,更具体地,相似性由**词向量的点积**表示:$u_o \cdot v_c$。
|
||||
|
||||
使用词向量的点积表示P(o|c)的原因:1.计算简单 2.出现在一起的词向量意义相关,则希望它们相似
|
||||
|
||||
又P(o|c)是一个概率,所以我们在整个语料库上使用**softmax**将点积的值映射到概率,如图6
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片6.png" />
|
||||
|
||||
|
||||
注:注意到上图,中心词词向量为$v_{c}$,而上下文词词向量为$u_{o}$。也就是说每个词会对应两个词向量,**在词w做中心词时,使用$v_{w}$作为词向量,而在它做上下文词时,使用$u_{w}$作为词向量**。这样做的原因是为了求导等操作时计算上的简便。当整个模型训练完成后,我们既可以使用$v_{w}$作为词w的词向量,也可以使用$u_{w}$作为词w的词向量,亦或是将二者平均。在下一部分的模型结构中,我们将更清楚地看到两个词向量究竟在模型的哪个位置。
|
||||
|
||||
|
||||
回答2:由上文所述,$P(o|c)=softmax(u_{o^T} \cdot v_c)$。所以损失函数是关于$u_{o}$和$v_c$的函数,我们通过梯度下降法调整$u_{o}$和$v_c$的值,最小化损失函数,即得到了良好表示的词向量。
|
||||
|
||||
|
||||
## Word2vec模型结构
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片8.png" />
|
||||
|
||||
|
||||
如图八所示,这是一个输入为1 X V维的one-hot向量(V为整个词汇表的长度,这个向量只有一个1值,其余为0值表示一个词),单隐藏层(**隐藏层的维度为N,这里是一个超参数,这个参数由我们定义,也就是词向量的维度**),输出为1 X V维的softmax层的模型。
|
||||
|
||||
$W^{I}$为V X N的参数矩阵,$W^{O}$为N X V的参数矩阵。
|
||||
|
||||
模型的输入为1 X V形状的one-hot向量(V为整个词汇表的长度,这个向量只有一个1值,其余为0值表示一个词)。隐藏层的维度为N,这里是一个超参数,这个参数由我们定义,也就是词向量的维度。$W^{I}$为V X N的参数矩阵。
|
||||
|
||||
我们这里,考虑Skip-gram算法,输入为中心词c的one-hot表示
|
||||
|
||||
由输入层到隐藏层,根据矩阵乘法规则,可知,**$W^{I}$的每一行即为词汇表中的每一个单词的词向量v**,1 X V 的 inputs 乘上 V X N 的$W^{I}$,隐藏层即为1 X N维的$v_{c}$。
|
||||
|
||||
而$W^{O}$中的每一列即为词汇表中的每一个单词的词向量u。根据乘法规则,1 X N 的隐藏层乘上N X V的$W^{O}$参数矩阵,得到的1 X V 的输出层的每一个值即为$u_{w^T} \cdot v_c$,加上softmax变化即为$P(w|c)$。
|
||||
|
||||
有V个w,其中的P(o|c)即实际样本中的上下文词的概率,为我们最为关注的值。
|
||||
|
||||
## CBOW
|
||||
|
||||
如上文所述,Skip-gram为给定中心词,预测周围的词,即求P(o|c),如下图所示:
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105817437.png" />
|
||||
|
||||
|
||||
而CBOW为给定周围的词,预测中心词,即求P(c|o),如下图所示:
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片10.png" />
|
||||
|
||||
|
||||
|
||||
注意:在使用CBOW时,上文所给出的模型结构并没有变,在这里,我们输入多个上下文词o,在隐藏层,**将这多个上下文词经过第一个参数矩阵的计算得到的词向量相加作为隐藏单元的值**。其余均不变,$W^{O}$中的每一列依然为为词汇表中的每一个单词的词向量u。
|
||||
|
||||
# 负采样 Negative Sampling
|
||||
|
||||
## softmax函数带来的问题
|
||||
|
||||
我们再看一眼,通过softmax得到的$P(o|c)$,如图:
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105958191.png" />
|
||||
|
||||
|
||||
|
||||
可以看到,$P(o|c)$的分母需要在整个单词表上做乘积和exp运算,这无疑是非常消耗计算资源的,Word2vec的作者针对这个问题,做出了改进。
|
||||
|
||||
他提出了两种改进的方法:Hierarchical Softmax和Negative Sampling,因为Negative Sampling更加常见,所以我们下面只介绍Negative Sampling,感兴趣的朋友可以在文章下面的参考资料中学习Hierarchical Softmax。
|
||||
|
||||
## 负采样Negative Sampling
|
||||
|
||||
我们依然以Skip-gram为例(CBOW与之差别不大,感兴趣的朋友们依然可以参阅参考资料)
|
||||
|
||||
我们首先给出负采样的损失函数:
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片12.png" />
|
||||
|
||||
|
||||
|
||||
其中$\sigma$为sigmoid函数$1/(1+e^{-x})$, $u_{o}$为实际样本中的上下文词的词向量,而$u_{k}$为我们在单词表中随机选出(按一定的规则随机选出,具体可参阅参考资料)的K个单词。
|
||||
|
||||
由函数单调性易知,**$u_{o^T} \cdot v_c$越大,损失函数越小,而$u_{k^T} \cdot v_c$越小**,损失函数越大。这与原始的softmax损失函数优化目标一致,即$maxP(o|c)$,而且避免了在整个词汇表上的计算。
|
||||
|
||||
# 核心代码与核心推导
|
||||
|
||||
## Naive softmax 损失函数
|
||||
|
||||
损失函数关于$v_c$的导数:
|
||||
|
||||
$$
|
||||
\frac{\partial{J_{naive-softmax}(\boldsymbol v_c,o,\boldsymbol U)}}{\partial \boldsymbol v_c} \\=
|
||||
-\frac{\partial{log(P(O=o|C=c))}}{\partial \boldsymbol v_c} \\ =
|
||||
-\frac{\partial{log(exp( \boldsymbol u_o^T\boldsymbol v_c))}}{\partial \boldsymbol v_c} + \frac{\partial{log(\sum_{w=1}^{V}exp(\boldsymbol u_w^T\boldsymbol v_c))}}{\partial \boldsymbol v_c} \\=
|
||||
-\boldsymbol u_o + \sum_{w=1}^{V} \frac{exp(\boldsymbol u_w^T\boldsymbol v_c)}{\sum_{w=1}^{V}exp(\boldsymbol u_w^T\boldsymbol v_c)}\boldsymbol u_w \\=
|
||||
-\boldsymbol u_o+ \sum_{w=1}^{V}P(O=w|C=c)\boldsymbol u_w \\=
|
||||
\boldsymbol U^T(\hat{\boldsymbol y} - \boldsymbol y)
|
||||
$$
|
||||
|
||||
可以看到涉及整个U矩阵的计算,计算量很大,关于$u_w$的导数读者可自行推导
|
||||
|
||||
损失函数及其梯度的求解
|
||||
|
||||
来自:https://github.com/lrs1353281004/CS224n_winter2019_notes_and_assignments
|
||||
|
||||
```python
|
||||
def naiveSoftmaxLossAndGradient(
|
||||
centerWordVec,
|
||||
outsideWordIdx,
|
||||
outsideVectors,
|
||||
dataset
|
||||
):
|
||||
""" Naive Softmax loss & gradient function for word2vec models
|
||||
|
||||
Arguments:
|
||||
centerWordVec -- numpy ndarray, center word's embedding
|
||||
in shape (word vector length, )
|
||||
(v_c in the pdf handout)
|
||||
outsideWordIdx -- integer, the index of the outside word
|
||||
(o of u_o in the pdf handout)
|
||||
outsideVectors -- outside vectors is
|
||||
in shape (num words in vocab, word vector length)
|
||||
for all words in vocab (tranpose of U in the pdf handout)
|
||||
dataset -- needed for negative sampling, unused here.
|
||||
|
||||
Return:
|
||||
loss -- naive softmax loss
|
||||
gradCenterVec -- the gradient with respect to the center word vector
|
||||
in shape (word vector length, )
|
||||
(dJ / dv_c in the pdf handout)
|
||||
gradOutsideVecs -- the gradient with respect to all the outside word vectors
|
||||
in shape (num words in vocab, word vector length)
|
||||
(dJ / dU)
|
||||
"""
|
||||
|
||||
# centerWordVec: (embedding_dim,1)
|
||||
# outsideVectors: (vocab_size,embedding_dim)
|
||||
|
||||
scores = np.matmul(outsideVectors, centerWordVec) # size=(vocab_size, 1)
|
||||
probs = softmax(scores) # size=(vocab, 1)
|
||||
|
||||
loss = -np.log(probs[outsideWordIdx]) # scalar
|
||||
|
||||
dscores = probs.copy() # size=(vocab, 1)
|
||||
dscores[outsideWordIdx] = dscores[outsideWordIdx] - 1 # dscores=y_hat - y
|
||||
gradCenterVec = np.matmul(outsideVectors, dscores) # J关于vc的偏导数公式 size=(vocab_size, 1)
|
||||
gradOutsideVecs = np.outer(dscores, centerWordVec) # J关于u的偏导数公式 size=(vocab_size, embedding_dim)
|
||||
|
||||
return loss, gradCenterVec, gradOutsideVecs
|
||||
```
|
||||
|
||||
## 负采样损失函数
|
||||
|
||||
负采样损失函数关于$v_c$的导数:
|
||||
|
||||
$$
|
||||
\frac{\partial{J_{neg-sample}(\boldsymbol v_c,o,\boldsymbol U)}}{\partial\boldsymbol v_c} \\=
|
||||
\frac{\partial (-log(\sigma (\boldsymbol u_o^T\boldsymbol v_c))-\sum_{k=1}^{K} log(\sigma (-\boldsymbol u_k^T\boldsymbol v_c)))}{\partial \boldsymbol v_c} \\=
|
||||
-\frac{\sigma(\boldsymbol u_o^T\boldsymbol v_c)(1-\sigma(\boldsymbol u_o^T\boldsymbol v_c))}{\sigma(\boldsymbol u_o^T\boldsymbol v_c)}\frac{\partial \boldsymbol u_o^T\boldsymbol v_c}{\partial \boldsymbol v_c} -
|
||||
\sum_{k=1}^{K}\frac{\partial log(\sigma(-\boldsymbol u_k^T\boldsymbol v_c))}{\partial \boldsymbol v_c} \\=
|
||||
-(1-\sigma(\boldsymbol u_o^T\boldsymbol v_c))\boldsymbol u_o+\sum_{k=1}^{K}(1-\sigma(-\boldsymbol u_k^T\boldsymbol v_c))\boldsymbol u_k
|
||||
$$
|
||||
|
||||
可以看到其只与$u_k$和$u_o$有关,避免了在整个单词表上的计算
|
||||
|
||||
负采样方法的损失函数及其导数的求解
|
||||
|
||||
```python
|
||||
def negSamplingLossAndGradient(
|
||||
centerWordVec,
|
||||
outsideWordIdx,
|
||||
outsideVectors,
|
||||
dataset,
|
||||
K=10
|
||||
):
|
||||
|
||||
negSampleWordIndices = getNegativeSamples(outsideWordIdx, dataset, K)
|
||||
indices = [outsideWordIdx] + negSampleWordIndices
|
||||
|
||||
gradCenterVec =np.zeros(centerWordVec.shape) # (embedding_size,1)
|
||||
gradOutsideVecs = np.zeros(outsideVectors.shape) # (vocab_size, embedding_size)
|
||||
loss = 0.0
|
||||
|
||||
u_o = outsideVectors[outsideWordIdx] # size=(embedding_size,1)
|
||||
z = sigmoid(np.dot(u_o, centerWordVec)) # size=(1, )
|
||||
loss -= np.log(z) # 损失函数的第一部分
|
||||
gradCenterVec += u_o * (z - 1) # J关于vc的偏导数的第一部分
|
||||
gradOutsideVecs[outsideWordIdx] = centerWordVec * (z - 1) # J关于u_o的偏导数计算
|
||||
|
||||
for i in range(K):
|
||||
neg_id = indices[1 + i]
|
||||
u_k = outsideVectors[neg_id]
|
||||
z = sigmoid(-np.dot(u_k, centerWordVec))
|
||||
loss -= np.log(z)
|
||||
gradCenterVec += u_k * (1-z)
|
||||
gradOutsideVecs[neg_id] += centerWordVec * (1 - z)
|
||||
|
||||
|
||||
return loss, gradCenterVec, gradOutsideVecs
|
||||
```
|
||||
|
||||
**参考资料**
|
||||
- Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[J]. Advances in neural information processing systems, 2013, 26.
|
||||
- https://www.cnblogs.com/peghoty/p/3857839.html
|
||||
- http://web.stanford.edu/class/cs224n/
|
||||
|
||||
@@ -1,399 +0,0 @@
|
||||
# Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
|
||||
|
||||
这篇论文是阿里巴巴在18年发表于KDD的关于召回阶段的工作。该论文提出的方法是在基于图嵌入的方法上,通过引入side information来解决实际问题中的数据稀疏和冷启动问题。
|
||||
|
||||
## 动机
|
||||
|
||||
在电商领域,推荐已经是不可或缺的一部分,旨在为用户的喜好提供有趣的物品,并且成为淘宝和阿里巴巴收入的重要引擎。尽管学术界和产业界的各种推荐方法都取得了成功,如协同过滤、基于内容的方法和基于深度学习的方法,但由于用户和项目的数十亿规模,传统的方法已经不能满足于实际的需求,主要的问题体现在三个方面:
|
||||
|
||||
- 可扩展性:现有的推荐方法无法扩展到在拥有十亿的用户和二十亿商品的淘宝中。
|
||||
- 稀疏性:存在大量的物品与用户的交互行为稀疏。即用户的交互到多集中于以下部分商品,存在大量商品很少被用户交互。
|
||||
- 冷启动:在淘宝中,每分钟会上传很多新的商品,由于这些商品没有用户行为的信息(点击、购买等),无法进行很好的预测。
|
||||
|
||||
针对于这三个方面的问题, 本文设计了一个两阶段的推荐框架:**召回阶段和排序阶段**,这也是推荐领域最常见的模型架构。而本文提及的EGES模型主要是解决了匹配阶段的问题,通过用户行为计算商品间两两的相似性,然后根基相似性选出topK的商品输入到排序阶段。
|
||||
|
||||
为了学习更好的商品向量表示,本文通过用户的行为历史中构造一个item-item 图,然后应用随机游走方法在item-item 图为每个item获取到一个序列,然后通过Skip-Gram的方式为每个item学习embedding(这里的item序列类似于语句,其中每个item类比于句子中每个word),这种方式被称为图嵌入方法(Graph Embedding)。文中提出三个具体模型来学习更好的物品embedding,更好的服务于召回阶段。
|
||||
|
||||
## 思路
|
||||
|
||||
根据上述所面临的三个问题,本文针对性的提出了三个模型予以解决:Base Graph Embedding(BGE);Graph Embedding with Side Information(GES);Enhanced Graph Embedding with Side Information(EGES)。
|
||||
|
||||
考虑可扩展性的问题,图嵌入的随机游走方式可以在物品图上捕获**物品之间高阶相似性**,即Base Graph Embedding(BGE)方法。其不同于CF方法,除了考虑物品的共现,还考虑到了行为的序列信息。
|
||||
|
||||
考虑到稀疏性和冷启物品问题,在图嵌入的基础上,考虑了节点的属性信息。希望具有相似属性的物品可以在空间上相似,即希望通过头部物品,提高属性信息的泛化能力,进而帮助尾部和冷启物品获取更加准确的embedding,即Graph Embedding with Side Information(GES)方法。
|
||||
|
||||
考虑到不同属性信息对于学习embedding的贡献不同,因此在聚合不同的属性信息时,动态的学习不同属性对于学习节点的embedding所参与的重要性权重,即Enhanced Graph Embedding with Side Information(EGES)。
|
||||
|
||||
## 模型结构与原理
|
||||
|
||||
文中所提出的方法是基于经典的图嵌入模型DeepWalk进行改进,其目标是通过物品图G,学习一个映射函数$f:V -> R^d$ ,将图上节点映射成一个embedding。具体的步骤包括两步:1.通过随机游走为图上每个物品生成序列;2.通过Skip-Gram算法学习每个物品的embedding。因此对于该方法优化的目标是,在给定的上下文物品的前提下,最大化物品v的条件概率,即物品v对于一个序列里面的其他物品要尽可能的相似。接下来看一些每个模型具体内容。
|
||||
|
||||
### 构建物品图
|
||||
|
||||
在介绍三个模型之前,我们首先需要构建好item-item图。由于基于CF的方法仅考虑物品之间的共现,忽略了行为的序列信息(即序列中相邻的物品之间的语义信息),因此item-item图的构建方式如下图所示。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328133138263.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
首先根据用户的session行为序列构建网络结构,即序列中相邻两个item之间在存在边,并且是有向带权图。物品图边上的权重为所有用户行为序列中两个 item 共现的次数,最终构造出来简单的有向有权图。
|
||||
|
||||
值得注意的是,本文通过行为序列中物品的共现来表示其中的**语义信息**,并将这种语义信息理解为**物品之间的相似性**,并将共现频次作为相似性的一个度量值。其次基于用户的历史行为序列数据,一般不太可能取全量的历史序列数据,一方面行为数据量过大,一方面用户的兴趣会随时间发生演变,因此在处理行为序列时会设置了一个窗口来截断历史序列数据,切分出来的序列称为session。
|
||||
|
||||
由于实际中会存在一些现实因素,数据中会有一些噪音,需要特殊处理,主要分为三个方面:
|
||||
|
||||
- 从行为方面考虑,用户在点击后停留的时间少于1秒,可以认为是误点,需要移除。
|
||||
- 从用户方面考虑,淘宝场景中会有一些过度活跃用户。本文对活跃用户的定义是三月内购买商品数超过1000,或者点击数超过3500,就可以认为是一个无效用户,需要去除。
|
||||
- 从商品方面考虑,存在一些商品频繁的修改,即ID对应的商品频繁更新,这使得这个ID可能变成一个完全不同的商品,这就需要移除与这个ID相关的这个商品。
|
||||
|
||||
在构建完item-item图之后,接下来看看三个模型的具体内容。
|
||||
|
||||
### 图嵌入(BGE)
|
||||
|
||||
对于图嵌入模型,第一步先进行随机游走得到物品序列;第二部通过skip-gram为图上节点生成embedding。那么对于随机游走的思想:如何利用随机游走在图中生成的序列?不同于DeepWalk中的随机游走,本文的采样策略使用的是带权游走策略,不同权重的游走到的概率不同,(其本质上就是node2vec),传统的node2vec方法可以直接支持有向带权图。因此在给定图的邻接矩阵M后(表示节点之间的边权重),随机游走中每次转移的概率为:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144516898.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中$M_{ij}$为边$e_{ij}$上的权重,$N_{+}(v_i)$表示节点$v_i$所有邻居节点集合,并且随机游走的转移概率的对每个节点所有邻接边权重的归一化结果。在随即游走之后,每个item得到一个序列,如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220418142135912.png" style="zoom:47%;"/>
|
||||
</div>
|
||||
|
||||
然后类似于word2vec,为每个item学习embedding,于是优化目标如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144931957.png" style="zoom:77%;"/>
|
||||
</div>
|
||||
|
||||
其中,w 为窗口大小。考虑独立性假设的话,上面的式子可以进一步化简:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145101109.png" style="zoom:77%;"/>
|
||||
</div>
|
||||
|
||||
这样看起来就很直观了,在已知物品 i 时,最大化序列中(上下文)其他物品 j 的条件概率。为了近似计算,采样了Negative sampling,上面的优化目标可以化简得到如下式子:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145318718.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中$N(v_i)'$表示负样本集合,负采样个数越多,结果越好。
|
||||
|
||||
### 基于side information的图嵌入(GES)
|
||||
|
||||
尽管BGE将行为序列关系编码进物品的embedding中,从而从用户行为中捕捉高阶相似性。但是这里有个问题,对于新加入的商品,由于未和用户产生过交互,所以不会出现在item-item图上,进而模型无法学习到其embedding,即无法解决冷启动问题。
|
||||
|
||||
为了解决冷启问题,本文通过使用side information( 类别,店铺, 价格等)加入模型的训练过程中,使得模型最终的泛化能力体现在商品的side information上。这样通过**side information学习到的embedding来表示具体的商品**,使得相似side information的物品可以得到在空间上相近的表示,进而来增强 BGE。
|
||||
|
||||
那么对于每个商品如何通过side information的embedidng来表示呢?对于随机游走之后得到的商品序列,其中每个每个商品由其id和属性(品牌,价格等)组成。用公式表示,对于序列中的每一个物品可以得到$W^0_V,...W_V^n$,(n+1)个向量表示,$W^0_V$表示物品v,剩下是side information的embedding。然后将所有的side information聚合成一个整体来表示物品,聚合方式如下:
|
||||
|
||||
$$H_v = \frac{1}{n+1}\sum_{s=0}^n W^s_v$$
|
||||
|
||||
其中,$H_v$是商品 v 的聚合后的 embedding 向量。
|
||||
|
||||
### 增强型EGS(EGES)
|
||||
|
||||
尽管 GES 相比 BGE 在性能上有了提升,但是在聚合多个属性向量得到商品的embedding的过程中,不同 side information的聚合依然存在问题。在GES中采用 average-pooling 是在假设不同种类的 side information 对商品embedding的贡献是相等的,但实际中却并非如此。例如,购买 Iphone 的用户更可能倾向于 Macbook 或者 Ipad,相比于价格属性,品牌属性相对于苹果类商品具有更重要的影响。因此,根据实际现状,不同类型的 side information 对商品的表示是具有不同的贡献值的。
|
||||
|
||||
针对上述问题,作者提出了weight pooling方法来聚合不同类型的 side information。具体地,EGES 与 GES 的区别在聚合不同类型 side information计算不同的权重,根据权重聚合 side information 得到商品的embedding,如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328154950289.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中 $a_i$ 表示每个side information 用于计算权重的参数向量,最终通过下面的公式得到商品的embedding:
|
||||
|
||||
$$H_v = \frac{\sum_{j=0}^n e^{a_v^j} W_v^j}{\sum_{j=0}^n e^{a_v^j}}$$
|
||||
|
||||
这里对参数 $a_v^j$ 先做指数变换,目的是为了保证每个边界信息的贡献都能大于0,然后通过归一化为每个特征得到一个o-1之内的权重。最终物品的embedding通过权重进行加权聚合得到,进而优化损失函数:
|
||||
|
||||
$$L(v,u,y)=-[ylog( \sigma (H_v^TZ_u)) + (1-y)log(1 - \sigma(H_v^TZ_u))]$$
|
||||
|
||||
y是标签符号,等于1时表示正样本,等于0时表示负样本。$H_v$表示商品 v 的最终的隐层表示,$Z_u$表示训练数据中的上下文节点的embedding。
|
||||
|
||||
以上就是这三个模型主要的区别,下面是EGES的伪代码。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155406291.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中**WeightedSkipGram**函数为带权重的SkipGram算法。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155533704.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
## 代码实现
|
||||
|
||||
下面我们简单的来看一下模型代码的实现,参考的内容在[这里](https://github.com/wangzhegeek/EGES),其中实验使用的是jd 2019年比赛中提供的数据。
|
||||
|
||||
### 构建物品图
|
||||
|
||||
首先对用户的下单(type=2)行为序列进行session划分,其中30分钟没有产生下一个行为,划分为一个session。
|
||||
|
||||
```python
|
||||
def cnt_session(data, time_cut=30, cut_type=2):
|
||||
# 商品属性 id 被交互时间 商品种类
|
||||
sku_list = data['sku_id']
|
||||
time_list = data['action_time']
|
||||
type_list = data['type']
|
||||
session = []
|
||||
tmp_session = []
|
||||
for i, item in enumerate(sku_list):
|
||||
# 两个商品之间如果被交互的时间大于1小时,划分成不同的session
|
||||
if type_list[i] == cut_type or (i < len(sku_list)-1 and \
|
||||
(time_list[i+1] - time_list[i]).seconds/60 > time_cut) or i == len(sku_list)-1:
|
||||
tmp_session.append(item)
|
||||
session.append(tmp_session)
|
||||
tmp_session = []
|
||||
else:
|
||||
tmp_session.append(item)
|
||||
return session # 返回多个session list
|
||||
```
|
||||
|
||||
获取到所有session list之后(这里不区分具体用户),对于session长度不超过1的去除(没有意义)。
|
||||
|
||||
接下来就是构建图,主要是先计算所有session中,相邻的物品共现频次(通过字典计算)。然后通过入度节点、出度节点以及权重分别转化成list,通过network来构建有向图。
|
||||
|
||||
```python
|
||||
node_pair = dict()
|
||||
# 遍历所有session list
|
||||
for session in session_list_all:
|
||||
for i in range(1, len(session)):
|
||||
# 将session共现的item存到node_pair中,用于构建item-item图
|
||||
# 将共现次数所谓边的权重,即node_pair的key为边(src_node,dst_node),value为边的权重(共现次数)
|
||||
if (session[i - 1], session[i]) not in node_pair.keys():
|
||||
node_pair[(session[i - 1], session[i])] = 1
|
||||
else:
|
||||
node_pair[(session[i - 1], session[i])] += 1
|
||||
|
||||
in_node_list = list(map(lambda x: x[0], list(node_pair.keys())))
|
||||
out_node_list = list(map(lambda x: x[1], list(node_pair.keys())))
|
||||
weight_list = list(node_pair.values())
|
||||
graph_list = list([(i,o,w) for i,o,w in zip(in_node_list,out_node_list,weight_list)])
|
||||
# 通过 network 构建图结构
|
||||
G = nx.DiGraph().add_weighted_edges_from(graph_list)
|
||||
|
||||
```
|
||||
|
||||
### 随机游走
|
||||
|
||||
先是基于构建的图进行随机游走,其中p和q是参数,用于控制采样的偏向于DFS还是BFS,其实也就是node2vec。
|
||||
|
||||
```python
|
||||
walker = RandomWalker(G, p=args.p, q=args.q)
|
||||
print("Preprocess transition probs...")
|
||||
walker.preprocess_transition_probs()
|
||||
```
|
||||
|
||||
对于采样的具体过程,是根据边的归一化权重作为采样概率进行采样。其中关于如何通过AliasSampling来实现概率采样的可以[参考](https://blog.csdn.net/haolexiao/article/details/65157026),具体的是先通过计算create_alias_table,然后根据边上两个节点的alias计算边的alias。其中可以看到这里计算alias_table是根据边的归一化权重。
|
||||
|
||||
```python
|
||||
def preprocess_transition_probs(self):
|
||||
"""预处理随即游走的转移概率"""
|
||||
G = self.G
|
||||
alias_nodes = {}
|
||||
for node in G.nodes():
|
||||
# 获取每个节点与邻居节点边上的权重
|
||||
unnormalized_probs = [G[node][nbr].get('weight', 1.0)
|
||||
for nbr in G.neighbors(node)]
|
||||
norm_const = sum(unnormalized_probs)
|
||||
# 对每个节点的邻居权重进行归一化
|
||||
normalized_probs = [
|
||||
float(u_prob)/norm_const for u_prob in unnormalized_probs]
|
||||
# 根据权重创建alias表
|
||||
alias_nodes[node] = create_alias_table(normalized_probs)
|
||||
alias_edges = {}
|
||||
for edge in G.edges():
|
||||
# 获取边的alias
|
||||
alias_edges[edge] = self.get_alias_edge(edge[0], edge[1])
|
||||
self.alias_nodes = alias_nodes
|
||||
self.alias_edges = alias_edges
|
||||
return
|
||||
```
|
||||
|
||||
在构建好Alias之后,进行带权重的随机游走。
|
||||
|
||||
```python
|
||||
session_reproduce = walker.simulate_walks(num_walks=args.num_walks,
|
||||
walk_length=args.walk_length, workers=4,verbose=1)
|
||||
```
|
||||
|
||||
其中这里的随机游走是根据p和q的值,来选择是使用Deepwalk还是node2vec。
|
||||
|
||||
```python
|
||||
def _simulate_walks(self, nodes, num_walks, walk_length,):
|
||||
walks = []
|
||||
for _ in range(num_walks):
|
||||
# 打乱所有起始节点
|
||||
random.shuffle(nodes)
|
||||
for v in nodes:
|
||||
# 根据p和q选择随机游走或者带权游走
|
||||
if self.p == 1 and self.q == 1:
|
||||
walks.append(self.deepwalk_walk(
|
||||
walk_length=walk_length, start_node=v))
|
||||
else:
|
||||
walks.append(self.node2vec_walk(
|
||||
walk_length=walk_length, start_node=v))
|
||||
return walks
|
||||
|
||||
```
|
||||
|
||||
### 加载side information并构造训练正样本
|
||||
|
||||
主要是将目前所有的sku和其对应的side infromation进行left join,没有的特征用0补充。然后对所有的特征进行labelEncoder()
|
||||
|
||||
```python
|
||||
sku_side_info = pd.merge(all_skus, product_data, on='sku_id', how='left').fillna(0) # 为商品加载side information
|
||||
for feat in sku_side_info.columns:
|
||||
if feat != 'sku_id':
|
||||
lbe = LabelEncoder()
|
||||
# 对side information进行编码
|
||||
sku_side_info[feat] = lbe.fit_transform(sku_side_info[feat])
|
||||
else:
|
||||
sku_side_info[feat] = sku_lbe.transform(sku_side_info[feat])
|
||||
```
|
||||
|
||||
通过图中的公式可以知道优化目标是让在一个窗口内的物品尽可能相似,采样若干负样本使之与目标物品不相似。因此需要将一个窗口内的所有物品与目标物品组成pair作为训练正样本。这里不需要采样负样本,负样本是通过tf中的sample softmax方法自动进行采样。
|
||||
|
||||
```python
|
||||
def get_graph_context_all_pairs(walks, window_size):
|
||||
all_pairs = []
|
||||
for k in range(len(walks)):
|
||||
for i in range(len(walks[k])):
|
||||
# 通过窗口的方式采取正样本,具体的是,让随机游走序列的起始item与窗口内的每个item组成正样本对
|
||||
for j in range(i - window_size, i + window_size + 1):
|
||||
if i == j or j < 0 or j >= len(walks[k]):
|
||||
continue
|
||||
else:
|
||||
all_pairs.append([walks[k][i], walks[k][j]])
|
||||
return np.array(all_pairs, dtype=np.int32)
|
||||
|
||||
```
|
||||
|
||||
#### EGES模型
|
||||
|
||||
构造完数据之后,在funrec的基础上实现了EGES模型:
|
||||
|
||||
```python
|
||||
def EGES(side_information_columns, items_columns, merge_type = "weight", share_flag=True,
|
||||
l2_reg=0.0001, seed=1024):
|
||||
# side_information 所对应的特征
|
||||
feature_columns = list(set(side_information_columns))
|
||||
# 获取输入层,查字典
|
||||
feature_encode = FeatureEncoder(feature_columns, linear_sparse_feature=None)
|
||||
# 输入的值
|
||||
feature_inputs_list = list(feature_encode.feature_input_layer_dict.values())
|
||||
# item id 获取输入层的值
|
||||
items_Map = FeatureMap(items_columns)
|
||||
items_inputs_list = list(items_Map.feature_input_layer_dict.values())
|
||||
|
||||
# 正样本的id,在softmax中需要传入正样本的id
|
||||
label_columns = [DenseFeat('label_id', 1)]
|
||||
label_Map = FeatureMap(label_columns)
|
||||
label_inputs_list = list(label_Map.feature_input_layer_dict.values())
|
||||
|
||||
# 通过输入的值查side_information的embedding,返回所有side_information的embedding的list
|
||||
side_embedding_list = process_feature(side_information_columns, feature_encode)
|
||||
# 拼接 N x num_feature X Dim
|
||||
side_embeddings = Concatenate(axis=1)(side_embedding_list)
|
||||
|
||||
# items_inputs_list[0] 为了查找每个item 用于计算权重的 aplha 向量
|
||||
eges_inputs = [side_embeddings, items_inputs_list[0]]
|
||||
|
||||
merge_emb = EGESLayer(items_columns[0].vocabulary_size, merge_type=merge_type,
|
||||
l2_reg=l2_reg, seed=seed)(eges_inputs) # B * emb_dim
|
||||
|
||||
label_idx = label_Map.feature_input_layer_dict[label_columns[0].name]
|
||||
softmaxloss_inputs = [merge_emb,label_idx]
|
||||
|
||||
item_vocabulary_size = items_columns[0].vocabulary_size
|
||||
|
||||
all_items_idx = EmbeddingIndex(list(range(item_vocabulary_size)))
|
||||
all_items_embeddings = feature_encode.embedding_layers_dict[side_information_columns[0].name](all_items_idx)
|
||||
|
||||
if share_flag:
|
||||
softmaxloss_inputs.append(all_items_embeddings)
|
||||
|
||||
output = SampledSoftmaxLayer(num_items=item_vocabulary_size, share_flage=share_flag,
|
||||
emb_dim=side_information_columns[0].embedding_dim,num_sampled=10)(softmaxloss_inputs)
|
||||
|
||||
model = Model(feature_inputs_list + items_inputs_list + label_inputs_list, output)
|
||||
|
||||
model.__setattr__("feature_inputs_list", feature_inputs_list)
|
||||
model.__setattr__("label_inputs_list", label_inputs_list)
|
||||
model.__setattr__("merge_embedding", merge_emb)
|
||||
model.__setattr__("item_embedding", get_item_embedding(all_items_embeddings, items_Map.feature_input_layer_dict[items_columns[0].name]))
|
||||
return model
|
||||
|
||||
```
|
||||
|
||||
其中EGESLayer为聚合每个item的多个side information的方法,其中根据merge_type可以选择average-pooling或者weight-pooling
|
||||
|
||||
```python
|
||||
class EGESLayer(Layer):
|
||||
def __init__(self,item_nums, merge_type="weight",l2_reg=0.001,seed=1024, **kwargs):
|
||||
super(EGESLayer, self).__init__(**kwargs)
|
||||
self.item_nums = item_nums
|
||||
self.merge_type = merge_type #聚合方式
|
||||
self.l2_reg = l2_reg
|
||||
self.seed = seed
|
||||
|
||||
def build(self, input_shape):
|
||||
if not isinstance(input_shape, list) or len(input_shape) < 2:
|
||||
raise ValueError('`EGESLayer` layer should be called \
|
||||
on a list of at least 2 inputs')
|
||||
self.feat_nums = input_shape[0][1]
|
||||
|
||||
if self.merge_type == "weight":
|
||||
self.alpha_embeddings = self.add_weight(
|
||||
name='alpha_attention',
|
||||
shape=(self.item_nums, self.feat_nums),
|
||||
dtype=tf.float32,
|
||||
initializer=tf.keras.initializers.RandomUniform(minval=-1, maxval=1, seed=self.seed),
|
||||
regularizer=l2(self.l2_reg))
|
||||
|
||||
def call(self, inputs, **kwargs):
|
||||
if self.merge_type == "weight":
|
||||
stack_embedding = inputs[0] # (B * num_feate * embedding_size)
|
||||
item_input = inputs[1] # (B * 1)
|
||||
alpha_embedding = tf.nn.embedding_lookup(self.alpha_embeddings, item_input) #(B * 1 * num_feate)
|
||||
alpha_emb = tf.exp(alpha_embedding)
|
||||
alpha_i_sum = tf.reduce_sum(alpha_emb, axis=-1)
|
||||
merge_embedding = tf.squeeze(tf.matmul(alpha_emb, stack_embedding),axis=1) / alpha_i_sum
|
||||
else:
|
||||
stack_embedding = inputs[0] # (B * num_feate * embedding_size)
|
||||
merge_embedding = tf.squeeze(tf.reduce_mean(alpha_emb, axis=1),axis=1) # (B * embedding_size)
|
||||
|
||||
return merge_embedding
|
||||
|
||||
def compute_output_shape(self, input_shape):
|
||||
return input_shape
|
||||
|
||||
def get_config(self):
|
||||
config = {"merge_type": self.merge_type, "seed": self.seed}
|
||||
base_config = super(EGESLayer, self).get_config()
|
||||
base_config.update(config)
|
||||
return base_config
|
||||
|
||||
```
|
||||
|
||||
至此已经从原理到代码详细的介绍了关于EGES的内容。
|
||||
|
||||
|
||||
|
||||
## 参考
|
||||
|
||||
[Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba](https://arxiv.org/abs/1803.02349)
|
||||
|
||||
[深度学习中不得不学的Graph Embedding方法](https://zhuanlan.zhihu.com/p/64200072)
|
||||
|
||||
[【Embedding】EGES:阿里在图嵌入领域中的探索](https://blog.csdn.net/qq_27075943/article/details/106244434)
|
||||
|
||||
[推荐系统遇上深度学习(四十六)-阿里电商推荐中亿级商品的embedding策略](https://www.jianshu.com/p/229b686535f1)
|
||||
|
||||
@@ -1,577 +0,0 @@
|
||||
# Graph Convolutional Neural Networks for Web-Scale Recommender Systems
|
||||
|
||||
该论文是斯坦福大学和Pinterest公司与2018年联合发表与KDD上的一篇关于GCN成功应用于工业级推荐系统的工作。该论文提到的PinSage模型,是在GraphSAGE的理论基础进行了更改,以适用于实际的工业场景。下面将简单介绍一下GraphSAGE的原理,以及Pinsage的核心和细节。
|
||||
|
||||
## GraphSAGE原理
|
||||
|
||||
GraphSAGE提出的前提是因为基于直推式(transductive)学习的图卷积网络无法适应工业界的大多数业务场景。我们知道的是,基于直推式学习的图卷积网络是通过拉普拉斯矩阵直接为图上的每个节点学习embedding表示,每次学习是针对于当前图上所有的节点。然而在实际的工业场景中,图中的结构和节点都不可能是固定的,会随着时间的变化而发生改变。例如在Pinterest公司的场景下,每分钟都会上传新的照片素材,同时也会有新用户不断的注册,那么图上的节点会不断的变化。在这样的场景中,直推式学习的方法就需要不断的重新训练才能够为新加入的节点学习embedding,导致在实际场景中无法投入使用。
|
||||
|
||||
在这样的背景下,斯坦福大学提出了一种归纳(inductive)学习的GCN方法——GraphSAGE,即**通过聚合邻居信息的方式为给定的节点学习embedding**。不同于直推式(transductive)学习,GraphSAGE是通过学习聚合节点邻居生成节点Embedding的函数的方式,为任意节点学习embedding,进而将GCN扩展成归纳学习任务。
|
||||
|
||||
对于想直接应用GCN或者GraphSAGE的我们而言,不用非要去理解其背后晦涩难懂的数学原理,可以仅从公式的角度来理解GraphSAGE的具体操作。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220423094435223.png" style="zoom:90%;"/>
|
||||
</div>
|
||||
|
||||
上面这个公式可以非常直观的让我们理解GraphSAGE的原理。
|
||||
|
||||
- $h_v^0$表示图上节点的初始化表示,等同于节点自身的特征。
|
||||
- $h_v^k$表示第k层卷积后的节点表示,其来源于两个部分:
|
||||
- 第一部分来源于节点v的邻居节点集合$N(v)$,利用邻居节点的第k-1层卷积后的特征$h_u^{k-1}$进行 ( $\sum_{u \in N(v)} \frac{h_u^{k-1}}{|N(v)|}$ )后,在进行线性变换。这里**借助图上的边将邻居节点的信息通过边关系聚合到节点表示中(简称卷积操作)**。
|
||||
- 第二部分来源于节点v的第k-1成卷积后的特征$h_v^{k-1}$,进行线性变换。总的来说图卷积的思想是**在对自身做多次非线性变换时,同时利用边关系聚合邻居节点信息。**
|
||||
- 最后一次卷积结果作为节点的最终表示$Z_v$,以用于下游任务(节点分类,链路预测或节点召回)。
|
||||
|
||||
可以发现相比传统的方法(MLP,CNN,DeepWalk 或 EGES),GCN或GraphSAGE存在一些优势:
|
||||
|
||||
1. 相比于传统的深度学习方法(MLP,CNN),GCN在对自身节点进行非线性变换时,同时考虑了图中的邻接关系。从CNN的角度理解,GCN通过堆叠多层结构在图结构数据上拥有更大的**感受野**,利用更加广域内的信息。
|
||||
2. 相比于图嵌入学习方法(DeepWalk,EGES),GCN在学习节点表示的过程中,在利用节点自身的属性信息之外,更好的利用图结构上的边信息。相比于借助随机采样的方式来使用边信息,GCN的方式能从全局的角度利用的邻居信息。此外,类似于GraphSAGE这种归纳(inductive)学习的GCN方法,通过学习聚合节点邻居生成节点Embedding的函数的方式,更适用于图结构和节点会不断变化的工业场景。
|
||||
|
||||
在采样得到目标节点的邻居集之后,那么如何聚合邻居节点的信息来更新目标节点的嵌入表示呢?下面就来看看GraphSAGE中提及的四个聚合函数。
|
||||
|
||||
## GraphSAGE的采样和聚合
|
||||
|
||||
通过上面的公式可以知道,得到节点的表示主要依赖于两部分,其中一部分其邻居节点。因此对于GraphSAGE的关键主要分为两步:Sample采样和Aggregate聚合。其中Sample的作用是从庞大的邻居节点中选出用于聚合的邻居节点集合$N(v)$以达到降低迭代计算复杂度,而聚合操作就是如何利用邻居节点的表示来更新节点v的表示,已达到聚合作用。具体的过程如下伪代码所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220406135753358.png" style="zoom:90%;"/>
|
||||
</div>
|
||||
|
||||
GraphSAGE的minibatch算法的思路是针对Batch内的所有节点,通过采样和聚合节点,为每一个节点学习一个embedding。
|
||||
|
||||
#### 邻居采样
|
||||
|
||||
GraphSAGE的具体采样过程是,首先根据中心节点集合$B^k$,对集合中每个中心节点通过随机采样的方式对其邻居节点采样固定数量S个(如果邻居节点数量大于S,采用无放回抽样;如果小于S,则采用有放回抽样),形成的集合表示为$B^{k-1}$;以此类推每次都是为前一个得到的集合的每个节点随机采样S个邻居,最终得到第k层的所有需要参与计算的节点集合$B^{0}$。值得注意的有两点:**为什么需要采样并且固定采样数量S?** **为什么第k层所采样的节点集合表示为$B^0$?**
|
||||
|
||||
进行邻居采样并固定采样数量S主要是因为:1. 采样邻居节点避免了在全图的搜索以及使用全部邻居节点所导致计算复杂度高的问题;2. 可以通过采样使得部分节点更同质化,即两个相似的节点具有相同表达形式。3. 采样固定数量是保持每个batch的计算占用空间是固定的,方便进行批量训练。
|
||||
|
||||
第k层所采样的节点集合表示为$B^0$主要是因为:采样和聚合过程是相反的,即采样时我们是从中心节点组层进行采样,而聚合的过程是从中心节点的第k阶邻居逐层聚合得到前一层的节点表示。因此可以认为聚合阶段是:将k阶邻居的信息聚合到k-1阶邻居上,k-1阶邻居的信息聚合到k-2阶邻居上,....,1阶邻居的信息聚合到中心节点上的过程。
|
||||
|
||||
#### 聚合函数
|
||||
|
||||
如何对于采样到的节点集进行聚合,介绍的4种方式:Mean 聚合、Convolutional 聚合、LSTM聚合以及Pooling聚合。由于邻居节点是无序的,所以希望构造的聚合函数具有**对称性(即输出的结果不因输入排序的不同而改变)**,同时拥有**较强的表达能力**。
|
||||
|
||||
- Mean 聚合:首先会对邻居节点按照**element-wise**进行均值聚合,然后将当前节点k-1层得到特征$h_v^{k-1}$与邻居节点均值聚合后的特征 $MEAN(h_u^k | u\in N(v))$**分别**送入全连接网络后**相加**得到结果。
|
||||
- Convolutional 聚合:这是一种基于GCN聚合方式的变种,首先对邻居节点特征和自身节点特征求均值,得到的聚合特征送入到全连接网络中。与Mean不同的是,这里**只经过一个全连接层**。
|
||||
|
||||
- LSTM聚合:由于LSTM可以捕捉到序列信息,因此相比于Mean聚合,这种聚合方式的**表达能力更强**;但由于LSTM对于输入是有序的,因此该方法不具备**对称性**。作者对于无序的节点进行随机排列以调整LSTM所需的有序性。
|
||||
- Pooling聚合:对于邻居节点和中心节点进行一次非线性转化,将结果进行一次基于**element-wise**的**最大池化**操作。该种方式具有**较强的表达能力**的同时还具有**对称性**。
|
||||
|
||||
综上,可以发现GraphSAGE之所以可以用于大规模的工业场景,主要是因为模型主要是通过学习聚合函数,通过归纳式的学习方法为节点学习特征表示。接下来看看PinSAGE 的主要内容。
|
||||
|
||||
## PinSAGE
|
||||
|
||||
### 背景
|
||||
|
||||
PinSAGE 模型是Pinterest 在GraphSAGE 的基础上实现的可以应用于实际工业场景的召回算法。Pinterest 公司的主要业务是采用瀑布流的形式向用户展现图片,无需用户翻页,新的图片会自动加载。因此在Pinterest网站上,有大量的图片(被称为pins),而用户可以将喜欢的图片分类,即将pins钉在画板 boards上。可以发现基于这样的场景,pin相当于普通推荐场景中item,用户**钉**的行为可以认为是用于的交互行为。于是PinSAGE 模型主要应用的思路是,基于GraphSAGE 的原理学习到聚合方法,并为每个图片(pin)学习一个向量表示,然后基于pin的向量表示做**item2item的召回**。
|
||||
|
||||
可以知道的是,PinSAGE 是在GraphSAGE的基础上进行改进以适应实际的工业场景,因此除了改进卷积操作中的邻居采样策略以及聚合函数的同时还有一些工程技巧上的改进,使得在大数据场景下能更快更好的进行模型训练。因此在了解GraphSAGE的原理后,我们详细的了解一下本文的主要改进以及与GraphSAGE的区别。
|
||||
|
||||
### 重要性采样
|
||||
|
||||
在实际场景当中,一个item可能被数以百万,千万的用户交互过,所以不可能聚合所有邻居节点是不可行的,只可能是采样部分邻居进行信息聚合。但是如果采用GraphSAGE中随机采样的方法,由于采样的邻居有限(这里是相对于所有节点而言),会存在一定的偏差。因此PinSAGE 在采样中考虑了更加重要的邻居节点,即卷积时只注重部分重要的邻居节点信息,已达到高效计算的同时又可以消除偏置。
|
||||
|
||||
PinSAGE使用重要性采样方法,即需要为每个邻居节点计算一个重要性权重,根据权重选取top-t的邻居作为聚合时的邻居集合。其中计算重要性的过程是,以目标节点为起点,进行random-walk,采样结束之后计算所有节点访问数的L1-normalized作为重要性权重,同时这个权重也会在聚合过程中加以使用(**加权聚合**)。
|
||||
|
||||
这里对于**计算权重之后如何得到top-t的邻居节点,**原文并没有直接的叙述。这里可以有两种做法,第一种就是直接采用重要权重,这种方法言简意赅,比较直观。第二种做法就是对游走得到的所有邻居进行随机抽样,而计算出的权重可以用于聚合阶段。个人理解第二种做法的可行性出于两点原因,其一是这样方法可以避免存在一些item由于权重系数低永远不会被选中的问题;其二可能并不是将所有重要性的邻居进行聚合更合理,毕竟重要性权重是通过随机采样而得到的,具有一定的随机性。当然以上两种方法都是可行的方案,可以通过尝试看看具体哪种方法会更有效。
|
||||
|
||||
### 聚合函数
|
||||
|
||||
PinSAGE中提到的Convolve算法(单层图卷积操作)相当于GraphSAGE算法的聚合过程,在实际执行过程中通过对每一层执行一次图卷积操作以得到不同阶邻居的信息,具体过程如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220406202027832.png" style="zoom:110%;"/>
|
||||
</div>
|
||||
|
||||
上述的单层图卷积过程如下三步:
|
||||
|
||||
1. 聚合邻居: 先将所有的邻居节点经过一次非线性转化(一层DNN),再由聚合函数(Pooling聚合) $\gamma$(如元素平均,**加权和**等)将所有邻居信息聚合成目标节点的embedding。这里的加权聚合采用的是通过random-walk得到的重要性权重。
|
||||
2. 更新当前节点的embedding:将目标节点当前的向量 $z_u$ 与步骤1中聚合得到的邻居向量 $n_u$ 进行拼接,在通过一次非线性转化。
|
||||
3. 归一化操作:对目标节点向量 $z_u$ 归一化。
|
||||
|
||||
Convolve算法的聚合方法与GraphSAGE的Pooling聚合函数相同,主要区别在于对更新得到的向量 $z_u$ 进行归一化操作,**可以使训练更稳定,以及在近似查找最近邻的应用中更有效率。**
|
||||
|
||||
### 基于**mini-batch**堆叠多层图卷积
|
||||
|
||||
与GraphSAGE类似,采用的是基于mini-batch 的方式进行训练。之所以这么做的原因是因为什么呢?在实际的工业场景中,由于用户交互图非常庞大,无法对于所有的节点同时学习一个embedding,因此需要从原始图上寻找与 mini-batch 节点相关的子图。具体地是说,对于mini-batch内的所有节点,会通过采样的方式逐层的寻找相关邻居节点,再通过对每一层的节点做一次图卷积操作,以从k阶邻居节点聚合信息。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220406204431024.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
|
||||
如上图所示:对于batch内的所有节点(图上最顶层的6个节点),依次根据权重采样,得到batch内所有节点的一阶邻居(图上第二层的所有节点);然后对于所有一阶邻居再次进行采样,得到所有二阶邻居(图上的最后一层)。节点采样阶段完成之后,与采样的顺序相反进行聚合操作。首先对二阶邻居进行单次图卷积,将二阶节点信息聚合已更新一阶节点的向量表示(其中小方块表示的是一层非线性转化);其次对一阶节点再次进行图卷积操作,将一阶节点的信息聚合已更新batch内所有节点的向量表示。仅此对于一个batch内的所有的样本通过卷积操作学习到一个embedding,而每一个batch的学习过程中仅**利用与mini-batch内相关节点的子图结构。**
|
||||
|
||||
### **训练过程**
|
||||
|
||||
PinSage在训练时采用的是 Margin Hinge Loss 损失函数,主要的思想是最大化正例embedding之间的相关性,同时还要保证负例之间相关性相比正例之间的相关性小于某个阈值(Margin)。具体的公式如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220406210833675.png" style="zoom:100%;"/>
|
||||
</div>
|
||||
|
||||
其中$Z_p$是学习得到的目标节点embedding,$Z_i$是与目标节点相关item的embedding,$Z_{n_k}$是与目标节点不相关item的embedding,$\Delta$为margin值,具体大小需要调参。那么对于相关节点i,以及不相关节点nk,具体都是如何定义的,这对于召回模型的训练意义重大,让我们看看具体是如何定义的。
|
||||
|
||||
对于正样本而言,文中的定义是如果用户在点击的 item q之后立即点击了 item i,即认为 < q, i >构成正样本对。直观的我们很好理解这句话,不过在参考DGL中相关代码实现时,发现这部分的内容和原文中有一定的出入。具体地,代码中将所有的训练样本构造成用户-项目二部图,然后对batch内的每个 item q,根据item-user-item的元路径进行随机游走,得到被同一个用户交互过的 item i,因此组成<q,i>正样本对。对于负样本部分,相对来说更为重要,因此内容相对比较多,将在下面的负样本生成部分详细介绍。
|
||||
|
||||
这里还有一个比较重要的细节需要注意,由于模型是用于 item to item的召回,因此优化目标是与正样本之间的表示尽可能的相近,与负样本之间的表示尽可能的远。而图卷积操作会使得具有邻接关系的节点表示具有同质性,因此结合这两点,就需要在构建图结构的时,要将**训练样本之间可能存在的边在二部图上删除**,避免因为边的存在使得因卷积操作而导致的信息泄露。
|
||||
|
||||
### 工程技巧
|
||||
|
||||
由于PinSAGE是一篇工业界的论文,其中会涉及与实际工程相关的内容,这里在了解完算法思想之后,再从实际落地的角度看看PinSAGE给我们介绍的工程技巧。
|
||||
|
||||
**负样本的生成**
|
||||
|
||||
召回模型最主要的任务是从候选集合中选出用户可能感兴趣的item,直观的理解就是让模型将用户喜欢的和不喜欢的进行区分。然而由于候选集合的庞大数量,许多item之间十分相似,导致模型划分出来用户喜欢的item中会存在一些难以区分的item(即与用户非常喜欢item比较相似的那一部分)。因此对于召回模型不仅能区分用户喜欢和不喜欢的 item,同时还能区分与用户喜欢的 item 十分相似的那一部分item。那么如果做到呢?这主要是交给 easy negative examples 和 hard negative examples 两种负样本给模型学习。
|
||||
|
||||
- easy 负样本:这里对于mini-batch内的所有pair(训练样本对)会共享500负样本,这500个样本从batch之外的所有节点中随机采样得到。这么做可以减少在每个mini-batch中因计算所有节点的embedding所需的时间,文中指出这和为每个item采样一定数量负样本无差异。
|
||||
- hard 负样本:这里使用hard 负样本的原因是根据实际场景的问题出发,模型需要从20亿的物品item集合中识别出最相似的1000个,即模型需要从2百万 item 中识别出最相似的那一个 item。也就是说模型的区分能力不够细致,为了解决这个问题,加入了一些hard样本。对于hard 负样本,应该是与 q 相似 以及和 i 不相似的物品,具体地的生成方式是将图上的节点计算相对节点 q 的个性化PageRank分值,根据分值的排序随机从2000~5000的位置选取节点作为负样本。
|
||||
|
||||
负样本的构建是召回模型的中关键的内容,在各家公司的工作都予以体现,具体的大家可以参考 Facebook 发表的[《Embedding-based Retrieval in Facebook Search》](https://arxiv.org/pdf/2006.11632v1.pdf)
|
||||
|
||||
**渐进式训练(Curriculum training)**
|
||||
|
||||
由于hard 负样本的加入,模型的训练时间加长(由于与q过于相似,导致loss比较小,导致梯度更新的幅度比较小,训练起来比较慢),那么渐进式训练就是为了来解决这个问题。
|
||||
|
||||
如何渐进式:先在第一轮训练使用easy 负样本,帮助模型先快速收敛(先让模型有个最基本的分辨能力)到一定范围,然后在逐步分加入hard负样本(方式是在第n轮训练时给每个物品的负样本集合增加n-1个 hard 负样本),以调整模型细粒度的区分能力(让模型能够区分相似的item)。
|
||||
|
||||
**节点特征(side information)**
|
||||
|
||||
这里与EGES的不同,这里的边信息不是端到端训练得到,而是通过事前的预处理得到的。对于每个节点(即 pin),都会有一个图片和一点文本信息。因此对于每个节点使用图片的向量、文字的向量以及节点的度拼接得到。这里其实也解释了为什么在图卷积操作时,会先进行一个非线性转化,其实就是将不同空间的特征进行转化(融合)。
|
||||
|
||||
**构建 mini-batch**
|
||||
|
||||
不同于常规的构建方式,PinSAGE中构建mini-batch的方式是基于生产者消费者模式。什么意思的,就是将CPU和GPU分开工作,让CPU负责取特征,重建索引,邻接列表,负采样等工作,让GPU进行矩阵运算,即CPU负责生产每个batch所需的所有数据,GPU则根据CPU生产的数据进行消费(运算)。这样由于考虑GPU的利用率,无法将所有特征矩阵放在GPU,只能存在CPU中,然而每次查找会导致非常耗时,通过上面的方式使得图卷积操作过程中就没有GPU与CPU的通信需求。
|
||||
|
||||
**多GPU训练超大batch**
|
||||
|
||||
前向传播过程中,各个GPU等分minibatch,共享一套模型参数;反向传播时,将每个GPU中的参数梯度都聚合到一起,同步执行SGD。为了保证因海量数据而使用的超大batchsize的情况下模型快速收敛以及泛化精度,采用warmup过程,即在第一个epoch中将学习率线性提升到最高,后面的epoch中再逐步指数下降。
|
||||
|
||||
**使用MapReduce高效推断**
|
||||
|
||||
在模型训练结束之后,需要为所有节点计算一个embedding,如果按照训练过程中的前向传播过程来生成,会存在大量重复的计算。因为当计算一个节点的embedding的时候,其部分邻居节点已经计算过了,同时如果该节点作为其他节点邻居时,也会被再次计算。针对这个问题,本文采用MapReduce的方法进行推断。该过程主要分为两步,具体如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220407132111547.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
|
||||
1. 将item的embedding进行聚合,即利用item的图片、文字和度等信息的表示进行join(拼接),在通过一层dense后得到item的低维向量。
|
||||
2. 然后根据item来匹配其一阶邻居(join),然后根据item进行pooling(其实就是GroupBy pooling),得到一次图卷积操作。通过堆叠多次直接得到全量的embedding。
|
||||
|
||||
其实这块主要就是通过MapReduce的大数据处理能力,直接对全量节点进行一次运算得到其embedding,避免了分batch所导致的重复计算。
|
||||
|
||||
## 代码解析
|
||||
|
||||
了解完基本的原理之后,最关键的还是得解析源码,以证实上面讲的细节的准确性。下面基于DGL中实现的代码,看看模型中的一些细节。
|
||||
|
||||
### 数据处理
|
||||
|
||||
在弄清楚模型之前,最重要的就是知道送入模型的数据到底是什么养的,以及PinSAGE相对于GraphSAGE最大的区别就在于如何采样邻居,如何构建负样本等。
|
||||
|
||||
首先需要明确的是,无论是**邻居采样**还是**样本的构造**都发生在图结构上,因此最主要的是需要先构建一个user和item组成的二部图。
|
||||
|
||||
```python
|
||||
# ratings是所有的用户交互
|
||||
# 过滤掉为出现在交互中的用户和项目
|
||||
distinct_users_in_ratings = ratings['user_id'].unique()
|
||||
distinct_movies_in_ratings = ratings['movie_id'].unique()
|
||||
users = users[users['user_id'].isin(distinct_users_in_ratings)]
|
||||
movies = movies[movies['movie_id'].isin(distinct_movies_in_ratings)]
|
||||
|
||||
# 将电影特征分组 genres (a vector), year (a category), title (a string)
|
||||
genre_columns = movies.columns.drop(['movie_id', 'title', 'year'])
|
||||
movies[genre_columns] = movies[genre_columns].fillna(False).astype('bool')
|
||||
movies_categorical = movies.drop('title', axis=1)
|
||||
|
||||
## 构建图
|
||||
graph_builder = PandasGraphBuilder()
|
||||
graph_builder.add_entities(users, 'user_id', 'user') # 添加user类型节点
|
||||
graph_builder.add_entities(movies_categorical, 'movie_id', 'movie') # 添加movie类型节点
|
||||
|
||||
# 构建用户-电影的无向图
|
||||
graph_builder.add_binary_relations(ratings, 'user_id', 'movie_id', 'watched')
|
||||
graph_builder.add_binary_relations(ratings, 'movie_id', 'user_id', 'watched-by')
|
||||
|
||||
g = graph_builder.build()
|
||||
```
|
||||
|
||||
在构建完原图之后,需要将交互数据(ratings)分成训练集和测试集,然后根据测试集从原图中抽取出与训练集中相关节点的子图。
|
||||
|
||||
```python
|
||||
# train_test_split_by_time 根据时间划分训练集和测试集
|
||||
# 将用户的倒数第二次交互作为验证,最后一次交互用作测试
|
||||
# train_indices 为用于训练的用户与电影的交互
|
||||
train_indices, val_indices, test_indices = train_test_split_by_time(ratings, 'timestamp', 'user_id')
|
||||
|
||||
# 只使用训练交互来构建图形,测试集相关的节点不应该出现在训练过程中。
|
||||
# 从原图中提取与训练集相关节点的子图
|
||||
train_g = build_train_graph(g, train_indices, 'user', 'movie', 'watched', 'watched-by')
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 正负样本采样
|
||||
|
||||
在得到训练图结构之后,为了进行PinSAGE提出的item2item召回任务,需要构建相应的训练样本。对于训练样本主要是构建正样本对和负样本对,前面我们已经提到了正样本对是基于 item to user to item的随即游走得到的;对于负样本DGL的实现主要是随机采样,即只有easy sample,未实现hard sample。具体地,DGL中主要是通过sampler_module.ItemToItemBatchSampler方法进行采样,主要代码如下:
|
||||
|
||||
```python
|
||||
class ItemToItemBatchSampler(IterableDataset):
|
||||
def __init__(self, g, user_type, item_type, batch_size):
|
||||
self.g = g
|
||||
self.user_type = user_type
|
||||
self.item_type = item_type
|
||||
self.user_to_item_etype = list(g.metagraph()[user_type][item_type])[0]
|
||||
self.item_to_user_etype = list(g.metagraph()[item_type][user_type])[0]
|
||||
self.batch_size = batch_size
|
||||
|
||||
def __iter__(self):
|
||||
while True:
|
||||
# 随机采样batch_size个节点作为head 即论文中的q
|
||||
heads = torch.randint(0, self.g.number_of_nodes(self.item_type), (self.batch_size,))
|
||||
|
||||
# 本次元路径表示从item游走到user,再从user游走到item,总共二跳,取出二跳节点(电影节点)作为tails(即正样本)
|
||||
# 得到与heads被同一个用户消费过的其他item,做正样本
|
||||
# 这么做可能存在问题,
|
||||
# 1. 这种游走肯定会使正样本集中于少数热门item;
|
||||
# 2. 如果item只被一个用户消费过,二跳游走岂不是又回到起始item,这种case还是要处理的
|
||||
tails = dgl.sampling.random_walk(
|
||||
self.g,
|
||||
heads,
|
||||
metapath=[self.item_to_user_etype, self.user_to_item_etype])[0][:, 2]
|
||||
|
||||
# 随机采样做负样本, 没有hard negative
|
||||
# 这么做会存在被同一个用户交互过的movie也会作为负样本
|
||||
neg_tails = torch.randint(0, self.g.number_of_nodes(self.item_type), (self.batch_size,))
|
||||
|
||||
mask = (tails != -1)
|
||||
yield heads[mask], tails[mask], neg_tails[mask]
|
||||
```
|
||||
|
||||
上面的样本采样过程只是一个简单的示例,如果面对实际问题,需要自己来重新完成这部分的内容。
|
||||
|
||||
### 邻居节点采样
|
||||
|
||||
再得到训练样本之后,接下来主要是在训练图上,为heads节点采用其邻居节点。在DGL中主要是通过sampler_module.NeighborSampler来实现,具体地,通过**sample_blocks**方法回溯生成各层卷积需要的block,即所有的邻居集合。其中需要注意的几个地方,基于随机游走的重要邻居采样,DGL已经实现,具体参考**[dgl.sampling.PinSAGESampler](https://link.zhihu.com/?target=https%3A//docs.dgl.ai/generated/dgl.sampling.PinSAGESampler.html%3Fhighlight%3Dpinsagesampler)**,其次避免信息泄漏,代码中,先将head → tails,head → neg_tails从frontier中先删除,再生成block。
|
||||
|
||||
```python
|
||||
class NeighborSampler(object): # 图卷积的邻居采样
|
||||
def __init__(self, g, user_type, item_type, random_walk_length, random_walk_restart_prob,
|
||||
num_random_walks, num_neighbors, num_layers):
|
||||
self.g = g
|
||||
self.user_type = user_type
|
||||
self.item_type = item_type
|
||||
self.user_to_item_etype = list(g.metagraph()[user_type][item_type])[0]
|
||||
self.item_to_user_etype = list(g.metagraph()[item_type][user_type])[0]
|
||||
|
||||
# 每层都有一个采样器,根据随机游走来决定某节点邻居的重要性(主要的实现已封装在PinSAGESampler中)
|
||||
# 可以认为经过多次游走,落脚于某邻居节点的次数越多,则这个邻居越重要,就更应该优先作为邻居
|
||||
self.samplers = [
|
||||
dgl.sampling.PinSAGESampler(g, item_type, user_type, random_walk_length,
|
||||
random_walk_restart_prob, num_random_walks, num_neighbors)
|
||||
for _ in range(num_layers)]
|
||||
|
||||
def sample_blocks(self, seeds, heads=None, tails=None, neg_tails=None):
|
||||
"""根据随机游走得到的重要性权重,进行邻居采样"""
|
||||
blocks = []
|
||||
for sampler in self.samplers:
|
||||
frontier = sampler(seeds) # 通过随机游走进行重要性采样,生成中间状态
|
||||
if heads is not None:
|
||||
# 如果是在训练,需要将heads->tails 和 head->neg_tails这些待预测的边都去掉
|
||||
eids = frontier.edge_ids(torch.cat([heads, heads]), torch.cat([tails, neg_tails]), return_uv=True)
|
||||
|
||||
if len(eids) > 0:
|
||||
old_frontier = frontier
|
||||
frontier = dgl.remove_edges(old_frontier, eids)
|
||||
|
||||
# 只保留seeds这些节点,将frontier压缩成block
|
||||
# 并设置block的input/output nodes
|
||||
block = compact_and_copy(frontier, seeds)
|
||||
|
||||
# 本层的输入节点就是下一层的seeds
|
||||
seeds = block.srcdata[dgl.NID]
|
||||
blocks.insert(0, block)
|
||||
return blocks
|
||||
```
|
||||
|
||||
其次**sample_from_item_pairs**方法是通过上面得到的heads, tails, neg_tails分别构建基于正样本对以及基于负样本对的item-item图。由heads→tails生成的pos_graph,用于计算pairwise loss中的pos_score,由heads→neg_tails生成的neg_graph,用于计算pairwise loss中的neg_score。
|
||||
|
||||
```python
|
||||
class NeighborSampler(object): # 图卷积的邻居采样
|
||||
def __init__(self, g, user_type, item_type, random_walk_length, ....):
|
||||
pass
|
||||
|
||||
def sample_blocks(self, seeds, heads=None, tails=None, neg_tails=None):
|
||||
pass
|
||||
|
||||
def sample_from_item_pairs(self, heads, tails, neg_tails):
|
||||
# 由heads->tails构建positive graph, num_nodes设置成原图中所有item节点
|
||||
pos_graph = dgl.graph(
|
||||
(heads, tails),
|
||||
num_nodes=self.g.number_of_nodes(self.item_type))
|
||||
|
||||
# 由heads->neg_tails构建negative graph,num_nodes设置成原图中所有item节点
|
||||
neg_graph = dgl.graph(
|
||||
(heads, neg_tails),
|
||||
num_nodes=self.g.number_of_nodes(self.item_type))
|
||||
|
||||
# 去除heads, tails, neg_tails以外的节点,将大图压缩成小图,避免与本轮训练不相关节点的结构也传入模型,提升计算效率
|
||||
pos_graph, neg_graph = dgl.compact_graphs([pos_graph, neg_graph])
|
||||
|
||||
# 压缩后的图上的节点是原图中的编号
|
||||
# 注意这时pos_graph与neg_graph不是分开编号的两个图,它们来自于同一幅由heads, tails, neg_tails组成的大图
|
||||
# pos_graph和neg_graph中的节点相同,都是heads+tails+neg_tails,即这里的seeds,pos_graph和neg_graph只是边不同而已
|
||||
seeds = pos_graph.ndata[dgl.NID] # 字典 不同类型节点为一个tensor,为每个节点的id值
|
||||
|
||||
blocks = self.sample_blocks(seeds, heads, tails, neg_tails)
|
||||
return pos_graph, neg_graph, blocks
|
||||
```
|
||||
|
||||
|
||||
|
||||
### PinSAGE
|
||||
|
||||
在得到所有所需的数据之后,看看模型结构。其中主要分为三个部分:**节点特征映射**,**多层卷积模块 **和 **给边打分**。
|
||||
|
||||
```python
|
||||
class PinSAGEModel(nn.Module):
|
||||
def __init__(self, full_graph, ntype, textsets, hidden_dims, n_layers):
|
||||
super().__init__()
|
||||
# 负责将节点上的各种特征都映射成向量,并聚合在一起,形成这个节点的原始特征向量
|
||||
self.proj = layers.LinearProjector(full_graph, ntype, textsets, hidden_dims)
|
||||
# 负责多层图卷积,得到各节点最终的embedding
|
||||
self.sage = layers.SAGENet(hidden_dims, n_layers)
|
||||
# 负责根据首尾两端的节点的embedding,计算边上的得分
|
||||
self.scorer = layers.ItemToItemScorer(full_graph, ntype)
|
||||
|
||||
def forward(self, pos_graph, neg_graph, blocks):
|
||||
""" pos_graph, neg_graph, blocks 的最后一层都对应batch中 heads+tails+neg_tails 这些节点
|
||||
"""
|
||||
# 得到batch中heads+tails+neg_tails这些节点的最终embedding
|
||||
h_item = self.get_repr(blocks)
|
||||
# 得到heads->tails这些边上的得分
|
||||
pos_score = self.scorer(pos_graph, h_item)
|
||||
# 得到heads->neg_tails这些边上的得分
|
||||
neg_score = self.scorer(neg_graph, h_item)
|
||||
# pos_graph与neg_graph边数相等,因此neg_score与pos_score相减
|
||||
# 返回margin hinge loss,这里的margin是1
|
||||
return (neg_score - pos_score + 1).clamp(min=0)
|
||||
|
||||
def get_repr(self, blocks):
|
||||
"""
|
||||
通过self.sage,经过多层卷积,得到输出节点上的卷积结果,再加上这些输出节点上原始特征的映射结果
|
||||
得到输出节点上最终的向量表示
|
||||
"""
|
||||
h_item = self.proj(blocks[0].srcdata) # 将输入节点上的原始特征映射成hidden_dims长的向量
|
||||
h_item_dst = self.proj(blocks[-1].dstdata) # 将输出节点上的原始特征映射成hidden_dims长的向量
|
||||
return h_item_dst + self.sage(blocks, h_item)
|
||||
```
|
||||
|
||||
**节点特征映射:**由于节点使用到了多种类型(int,float array,text)的原始特征,这里使用了一个DNN层来融合成固定的长度。
|
||||
|
||||
```python
|
||||
class LinearProjector(nn.Module):
|
||||
def __init__(self, full_graph, ntype, textset, hidden_dims):
|
||||
super().__init__()
|
||||
self.ntype = ntype
|
||||
# 初始化参数,这里为全图中所有节点特征初始化
|
||||
# 如果特征类型是float,就定义一个nn.Linear线性变化为指定维度
|
||||
# 如果特征类型是int,就定义Embedding矩阵,将id型特征转化为向量
|
||||
self.inputs = _init_input_modules(full_graph, ntype, textset, hidden_dims)
|
||||
|
||||
def forward(self, ndata):
|
||||
projections = []
|
||||
for feature, data in ndata.items():
|
||||
# NID是计算子图中节点、边在原图中的编号,没必要用做特征
|
||||
if feature == dgl.NID:
|
||||
continue
|
||||
module = self.inputs[feature] # 根据特征名取出相应的特征转化器
|
||||
# 对文本属性进行处理
|
||||
if isinstance(module, (BagOfWords, BagOfWordsPretrained)):
|
||||
length = ndata[feature + '__len']
|
||||
result = module(data, length)
|
||||
else:
|
||||
result = module(data) # look_up
|
||||
projections.append(result)
|
||||
|
||||
# 将每个特征都映射后的hidden_dims长的向量,element-wise相加
|
||||
return torch.stack(projections, 1).sum(1) # [nodes, hidden_dims]
|
||||
```
|
||||
|
||||
**多层卷积模块:**根据采样得到的节点blocks,然后通过进行逐层卷积,得到各节点最终的embedding。
|
||||
|
||||
```python
|
||||
class SAGENet(nn.Module):
|
||||
def __init__(self, hidden_dims, n_layers):
|
||||
"""g : 二部图"""
|
||||
super().__init__()
|
||||
self.convs = nn.ModuleList()
|
||||
for _ in range(n_layers):
|
||||
self.convs.append(WeightedSAGEConv(hidden_dims, hidden_dims, hidden_dims))
|
||||
|
||||
def forward(self, blocks, h):
|
||||
# 这里根据邻居节点进逐层聚合
|
||||
for layer, block in zip(self.convs, blocks):
|
||||
h_dst = h[:block.number_of_nodes('DST/' + block.ntypes[0])] #前一次卷积的结果
|
||||
h = layer(block, (h, h_dst), block.edata['weights'])
|
||||
return h
|
||||
```
|
||||
|
||||
其中WeightedSAGEConv为根据邻居权重的聚合函数。
|
||||
|
||||
```python
|
||||
class WeightedSAGEConv(nn.Module):
|
||||
def __init__(self, input_dims, hidden_dims, output_dims, act=F.relu):
|
||||
super().__init__()
|
||||
self.act = act
|
||||
self.Q = nn.Linear(input_dims, hidden_dims)
|
||||
self.W = nn.Linear(input_dims + hidden_dims, output_dims)
|
||||
self.reset_parameters()
|
||||
self.dropout = nn.Dropout(0.5)
|
||||
|
||||
def reset_parameters(self):
|
||||
gain = nn.init.calculate_gain('relu')
|
||||
nn.init.xavier_uniform_(self.Q.weight, gain=gain)
|
||||
nn.init.xavier_uniform_(self.W.weight, gain=gain)
|
||||
nn.init.constant_(self.Q.bias, 0)
|
||||
nn.init.constant_(self.W.bias, 0)
|
||||
|
||||
def forward(self, g, h, weights):
|
||||
"""
|
||||
g : 基于batch的子图
|
||||
h : 节点特征
|
||||
weights : 边的权重
|
||||
"""
|
||||
h_src, h_dst = h # 邻居节点特征,自身节点特征
|
||||
with g.local_scope():
|
||||
# 将src节点上的原始特征映射成hidden_dims长,存储于'n'字段
|
||||
g.srcdata['n'] = self.act(self.Q(self.dropout(h_src)))
|
||||
g.edata['w'] = weights.float()
|
||||
|
||||
# src节点上的特征'n'乘以边上的权重,构成消息'm'
|
||||
# dst节点将所有接收到的消息'm',相加起来,存入dst节点的'n'字段
|
||||
g.update_all(fn.u_mul_e('n', 'w', 'm'), fn.sum('m', 'n'))
|
||||
|
||||
# 将边上的权重w拷贝成消息'm'
|
||||
# dst节点将所有接收到的消息'm',相加起来,存入dst节点的'ws'字段
|
||||
g.update_all(fn.copy_e('w', 'm'), fn.sum('m', 'ws'))
|
||||
|
||||
# 邻居节点的embedding的加权和
|
||||
n = g.dstdata['n']
|
||||
ws = g.dstdata['ws'].unsqueeze(1).clamp(min=1) # 边上权重之和
|
||||
|
||||
# 先将邻居节点的embedding,做加权平均
|
||||
# 再拼接上一轮卷积后,dst节点自身的embedding
|
||||
# 再经过线性变化与非线性激活,得到这一轮卷积后各dst节点的embedding
|
||||
z = self.act(self.W(self.dropout(torch.cat([n / ws, h_dst], 1))))
|
||||
|
||||
# 本轮卷积后,各dst节点的embedding除以模长,进行归一化
|
||||
z_norm = z.norm(2, 1, keepdim=True)
|
||||
z_norm = torch.where(z_norm == 0, torch.tensor(1.).to(z_norm), z_norm)
|
||||
z = z / z_norm
|
||||
return z
|
||||
```
|
||||
|
||||
**给边打分:** 经过SAGENet得到了batch内所有节点的embedding,这时需要根据学习到的embedding为pos_graph和neg_graph中的每个边打分,即计算正样本对和负样本的內积。具体逻辑是根据两端节点embedding的点积,然后加上两端节点的bias。
|
||||
|
||||
```python
|
||||
class ItemToItemScorer(nn.Module):
|
||||
def __init__(self, full_graph, ntype):
|
||||
super().__init__()
|
||||
n_nodes = full_graph.number_of_nodes(ntype)
|
||||
self.bias = nn.Parameter(torch.zeros(n_nodes, 1))
|
||||
|
||||
def _add_bias(self, edges):
|
||||
bias_src = self.bias[edges.src[dgl.NID]]
|
||||
bias_dst = self.bias[edges.dst[dgl.NID]]
|
||||
# 边上两顶点的embedding的点积,再加上两端节点的bias
|
||||
return {'s': edges.data['s'] + bias_src + bias_dst}
|
||||
|
||||
def forward(self, item_item_graph, h):
|
||||
"""
|
||||
item_item_graph : 每个边 为 pair 对
|
||||
h : 每个节点隐层状态
|
||||
"""
|
||||
with item_item_graph.local_scope():
|
||||
item_item_graph.ndata['h'] = h
|
||||
# 边两端节点的embedding做点积,保存到s
|
||||
item_item_graph.apply_edges(fn.u_dot_v('h', 'h', 's'))
|
||||
# 为每个边加上偏置,即加上两个顶点的偏置
|
||||
item_item_graph.apply_edges(self._add_bias)
|
||||
# 算出来的得分为 pair 的预测得分
|
||||
pair_score = item_item_graph.edata['s']
|
||||
return pair_score
|
||||
```
|
||||
|
||||
### 训练过程
|
||||
|
||||
介绍完“数据处理”和“PinSAGE模块”之后,接下来就是通过训练过程将上述两部分串起来,详细的见代码:
|
||||
|
||||
```python
|
||||
def train(dataset, args):
|
||||
#从dataset中加载数据和原图
|
||||
g = dataset['train-graph']
|
||||
...
|
||||
|
||||
device = torch.device(args.device)
|
||||
# 为节点随机初始化一个id,用于做embedding
|
||||
g.nodes[user_ntype].data['id'] = torch.arange(g.number_of_nodes(user_ntype))
|
||||
g.nodes[item_ntype].data['id'] = torch.arange(g.number_of_nodes(item_ntype))
|
||||
|
||||
|
||||
# 负责采样出batch_size大小的节点列表: heads, tails, neg_tails
|
||||
batch_sampler = sampler_module.ItemToItemBatchSampler(
|
||||
g, user_ntype, item_ntype, args.batch_size)
|
||||
|
||||
# 由一个batch中的heads,tails,neg_tails构建训练这个batch所需要的
|
||||
# pos_graph,neg_graph 和 blocks
|
||||
neighbor_sampler = sampler_module.NeighborSampler(
|
||||
g, user_ntype, item_ntype, args.random_walk_length,
|
||||
args.random_walk_restart_prob, args.num_random_walks, args.num_neighbors,
|
||||
args.num_layers)
|
||||
|
||||
# 每次next()返回: pos_graph,neg_graph和blocks,做训练之用
|
||||
collator = sampler_module.PinSAGECollator(neighbor_sampler, g, item_ntype, textset)
|
||||
dataloader = DataLoader(
|
||||
batch_sampler,
|
||||
collate_fn=collator.collate_train,
|
||||
num_workers=args.num_workers)
|
||||
|
||||
# 每次next()返回blocks,做训练中测试之用
|
||||
dataloader_test = DataLoader(
|
||||
torch.arange(g.number_of_nodes(item_ntype)),
|
||||
batch_size=args.batch_size,
|
||||
collate_fn=collator.collate_test,
|
||||
num_workers=args.num_workers)
|
||||
dataloader_it = iter(dataloader)
|
||||
|
||||
# 准备模型
|
||||
model = PinSAGEModel(g, item_ntype, textset, args.hidden_dims, args.num_layers).to(device)
|
||||
opt = torch.optim.Adam(model.parameters(), lr=args.lr)
|
||||
|
||||
# 训练过程
|
||||
for epoch_id in range(args.num_epochs):
|
||||
model.train()
|
||||
for batch_id in tqdm.trange(args.batches_per_epoch):
|
||||
pos_graph, neg_graph, blocks = next(dataloader_it)
|
||||
for i in range(len(blocks)):
|
||||
blocks[i] = blocks[i].to(device)
|
||||
pos_graph = pos_graph.to(device)
|
||||
neg_graph = neg_graph.to(device)
|
||||
|
||||
loss = model(pos_graph, neg_graph, blocks).mean()
|
||||
opt.zero_grad()
|
||||
loss.backward()
|
||||
opt.step()
|
||||
```
|
||||
|
||||
至此,DGL PinSAGE example的主要实现代码已经全部介绍完了,感兴趣的可以去官网对照源代码自行学习。
|
||||
|
||||
## 参考
|
||||
|
||||
[Graph Convolutional Neural Networks for Web-Scale Recommender Systems](https://arxiv.org/abs/1806.01973)
|
||||
|
||||
[PinSAGE 召回模型及源码分析(1): PinSAGE 简介](https://zhuanlan.zhihu.com/p/275942839)
|
||||
|
||||
[全面理解PinSage](https://zhuanlan.zhihu.com/p/133739758)
|
||||
|
||||
[[论文笔记]PinSAGE——Graph Convolutional Neural Networks for Web-Scale Recommender Systems](https://zhuanlan.zhihu.com/p/461720302)
|
||||
|
||||
@@ -1,415 +0,0 @@
|
||||
## 写在前面
|
||||
MIND模型(Multi-Interest Network with Dynamic Routing), 是阿里团队2019年在CIKM上发的一篇paper,该模型依然是用在召回阶段的一个模型,解决的痛点是之前在召回阶段的模型,比如双塔,YouTubeDNN召回模型等,在模拟用户兴趣的时候,总是基于用户的历史点击,最后通过pooling的方式得到一个兴趣向量,用该向量来表示用户的兴趣,但是该篇论文的作者认为,**用一个向量来表示用户的广泛兴趣未免有点太过于单一**,这是作者基于天猫的实际场景出发的发现,每个用户每天与数百种产品互动, 而互动的产品往往来自于很多个类别,这就说明用户的兴趣极其广泛,**用一个向量是无法表示这样广泛的兴趣的**,于是乎,就自然而然的引出一个问题,**有没有可能用多个向量来表示用户的多种兴趣呢?**
|
||||
|
||||
这篇paper的核心是胶囊网络,**该网络采用了动态路由算法能非常自然的将历史商品聚成多个集合,每个集合的历史行为进一步推断对应特定兴趣的用户表示向量。这样,对于一个特定的用户,MND输出了多个表示向量,它们代表了用户的不同兴趣。当用户再有新的交互时,通过胶囊网络,还能实时的改变用户的兴趣表示向量,做到在召回阶段的实时个性化**。那么,胶囊网络究竟是怎么做到的呢? 胶囊网络又是什么原理呢?
|
||||
|
||||
**主要内容**:
|
||||
* 背景与动机
|
||||
* 胶囊网络与动态路由机制
|
||||
* MIND模型的网络结构与细节剖析
|
||||
* MIND模型之简易代码复现
|
||||
* 总结
|
||||
|
||||
## 背景与动机
|
||||
本章是基于天猫APP的背景来探索十亿级别的用户个性化推荐。天猫的推荐的流程主要分为召回阶段和排序阶段。召回阶段负责检索数千个与用户兴趣相关的候选物品,之后,排序阶段预测用户与这些候选物品交互的精确概率。这篇文章做的是召回阶段的工作,来对满足用户兴趣的物品的有效检索。
|
||||
|
||||
作者这次的出发点是基于场景出发,在天猫的推荐场景中,作者发现**用户的兴趣存在多样性**。平均上,10亿用户访问天猫,每个用户每天与数百种产品互动。交互后的物品往往属于不同的类别,说明用户兴趣的多样性。 一张图片会更加简洁直观:
|
||||
|
||||

|
||||
因此如果能在**召回阶段建立用户多兴趣模型来模拟用户的这种广泛兴趣**,那么作者认为是非常有必要的,因为召回阶段的任务就是根据用户兴趣检索候选商品嘛。
|
||||
|
||||
那么,如何能基于用户的历史交互来学习用户的兴趣表示呢? 以往的解决方案如下:
|
||||
* 协同过滤的召回方法(itemcf和usercf)是通过历史交互过的物品或隐藏因子直接表示用户兴趣, 但会遇到**稀疏或计算问题**
|
||||
* 基于深度学习的方法用低维的embedding向量表示用户,比如YoutubeDNN召回模型,双塔模型等,都是把用户的基本信息,或者用户交互过的历史商品信息等,过一个全连接层,最后编码成一个向量,用这个向量来表示用户兴趣,但作者认为,**这是多兴趣表示的瓶颈**,因为需要压缩所有与用户多兴趣相关的信息到一个表示向量,所有用户多兴趣的信息进行了混合,导致这种多兴趣并无法体现,所以往往召回回来的商品并不是很准确,除非向量维度很大,但是大维度又会带来高计算。
|
||||
* DIN模型在Embedding的基础上加入了Attention机制,来选择的捕捉用户兴趣的多样性,但采用Attention机制,**对于每个目标物品,都需要重新计算用户表示**,这在召回阶段是行不通的(海量),所以DIN一般是用于排序。
|
||||
|
||||
所以,作者想在召回阶段去建模用户的多兴趣,但以往的方法都不好使,为了解决这个问题,就提出了动态路由的多兴趣网络MIND。为了推断出用户的多兴趣表示,提出了一个多兴趣提取层,该层使用动态路由机制自动的能将用户的历史行为聚类,然后每个类簇中产生一个表示向量,这个向量能代表用户某种特定的兴趣,而多个类簇的多个向量合起来,就能表示用户广泛的兴趣了。
|
||||
|
||||
这就是MIND的提出动机以及初步思路了,这里面的核心是Multi-interest extractor layer, 而这里面重点是动态路由与胶囊网络,所以接下来先补充这方面的相关知识。
|
||||
|
||||
## 胶囊网络与动态路由机制
|
||||
### 胶囊网络初识
|
||||
Hinton大佬在2011年的时候,就首次提出了"胶囊"的概念, "胶囊"可以看成是一组聚合起来输出整个向量的小神经元组合,这个向量的每个维度(每个小神经元),代表着某个实体的某个特征。
|
||||
|
||||
胶囊网络其实可以和神经网络对比着看可能更好理解,我们知道神经网络的每一层的神经元输出的是单个的标量值,接收的输入,也是多个标量值,所以这是一种value to value的形式,而胶囊网络每一层的胶囊输出的是一个向量值,接收的输入也是多个向量,所以它是vector to vector形式的。来个图对比下就清楚了:
|
||||
|
||||
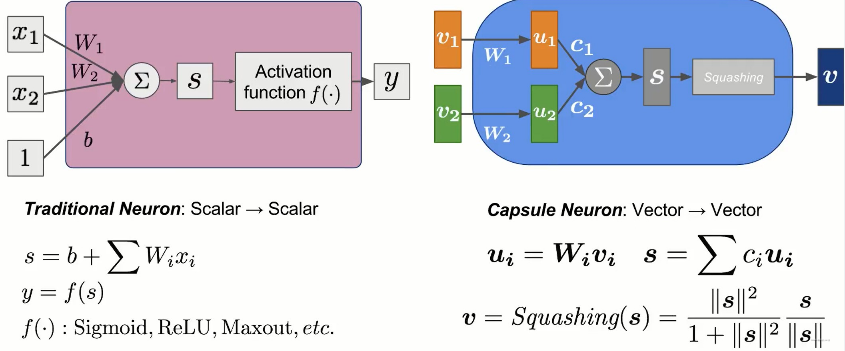
|
||||
左边的图是普通神经元的计算示意,而右边是一个胶囊内部的计算示意图。 神经元这里不过多解释,这里主要是剖析右边的这个胶囊计算原理。从上图可以看出, 输入是两个向量$v_1,v_2$,首先经过了一个线性映射,得到了两个新向量$u_1,u_2$,然后呢,经过了一个向量的加权汇总,这里的$c_1$,$c_2$可以先理解成权重,具体计算后面会解释。 得到汇总后的向量$s$,接下来进行了Squash操作,整体的计算公式如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
&u^{1}=W^{1} v^{1} \quad u^{2}=W^{2} v^{2} \\
|
||||
&s=c_{1} u^{1}+c_{2} u^{2} \\
|
||||
&v=\operatorname{Squash}(s) =\frac{\|s\|^{2}}{1+\|s\|^{2}} \frac{s}{\|s\|}
|
||||
\end{aligned}
|
||||
$$
|
||||
这里的Squash操作可以简单看下,主要包括两部分,右边的那部分其实就是向量归一化操作,把norm弄成1,而左边那部分算是一个非线性操作,如果$s$的norm很大,那么这个整体就接近1, 而如果这个norm很小,那么整体就会接近0, 和sigmoid很像有没有?
|
||||
|
||||
这样就完成了一个胶囊的计算,但有两点需要注意:
|
||||
1. 这里的$W^i$参数是可学习的,和神经网络一样, 通过BP算法更新
|
||||
2. 这里的$c_i$参数不是BP算法学习出来的,而是采用动态路由机制现场算出来的,这个非常类似于pooling层,我们知道pooling层的参数也不是学习的,而是根据前面的输入现场取最大或者平均计算得到的。
|
||||
|
||||
所以这里的问题,就是怎么通过动态路由机制得到$c_i$,下面是动态路由机制的过程。
|
||||
|
||||
### 动态路由机制原理
|
||||
我们先来一个胶囊结构:
|
||||
|
||||
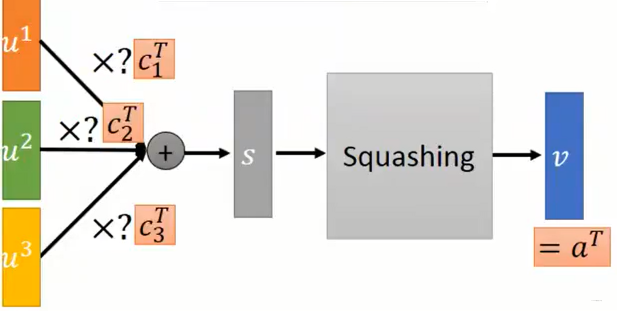
|
||||
这个$c_i$是通过动态路由机制计算得到,那么动态路由机制究竟是啥子意思? 其实就是通过迭代的方式去计算,没有啥神秘的,迭代计算的流程如下图:
|
||||
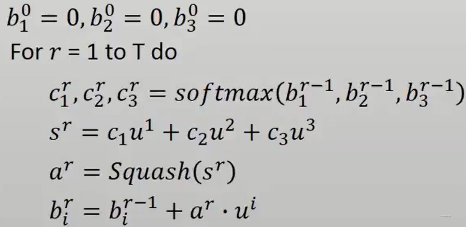
|
||||
首先我们先初始化$b_i$,与每一个输入胶囊$u_i$进行对应,这哥们有个名字叫做"routing logit", 表示的是输出的这个胶囊与输入胶囊的相关性,和注意力机制里面的score值非常像。由于一开始不知道这个哪个胶囊与输出的胶囊有关系,所以默认相关性分数都一样,然后进入迭代。
|
||||
|
||||
在每一次迭代中,首先把分数转成权重,然后加权求和得到$s$,这个很类似于注意力机制的步骤,得到$s$之后,通过归一化操作,得到$a$,接下来要通过$a$和输入胶囊的相关性以及上一轮的$b_i$来更新$b_i$。最后那个公式有必要说一下在干嘛:
|
||||
>如果当前的$a$与某一个输入胶囊$u_i$非常相关,即内积结果很大的话,那么相应的下一轮的该输入胶囊对应的$b_i$就会变大, 那么, 在计算下一轮的$a$的时候,与上一轮$a$相关的$u_i$就会占主导,相当于下一轮的$a$与上一轮中和他相关的那些$u_i$之间的路径权重会大一些,这样从空间点的角度观察,就相当于$a$点朝与它相关的那些$u$点更近了一点。
|
||||
|
||||
通过若干次迭代之后,得到最后的输出胶囊向量$a$会慢慢的走到与它更相关的那些$u$附近,而远离那些与它不相干的$u$。所以上面的这个迭代过程有点像**排除异常输入胶囊的感觉**。
|
||||
|
||||
|
||||
|
||||
而从另一个角度来考虑,这个过程其实像是聚类的过程,因为胶囊的输出向量$v$经过若干次迭代之后,会最终停留到与其非常相关的那些输入胶囊里面,而这些输入胶囊,其实就可以看成是某个类别了,因为既然都共同的和输出胶囊$v$比较相关,那么彼此之间的相关性也比较大,于是乎,经过这样一个动态路由机制之后,就不自觉的,把输入胶囊实现了聚类。把和与其他输入胶囊不同的那些胶囊给排除了出去。
|
||||
|
||||
所以,这个动态路由机制的计算设计的还是比较巧妙的, 下面是上述过程的展开计算过程, 这个和RNN的计算有点类似:
|
||||
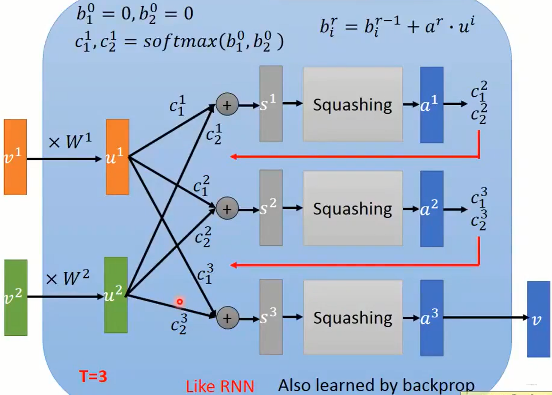
|
||||
这样就完成了一个胶囊内部的计算过程了。
|
||||
|
||||
Ok, 有了上面的这些铺垫,再来看MIND就会比较简单了。下面正式对MIND模型的网络架构剖析。
|
||||
|
||||
## MIND模型的网络结构与细节剖析
|
||||
### 网络整体结构
|
||||
MIND网络的架构如下:
|
||||

|
||||
初步先分析这个网络结构的运作: 首先接收的输入有三类特征,用户base属性,历史行为属性以及商品的属性,用户的历史行为序列属性过了一个多兴趣提取层得到了多个兴趣胶囊,接下来和用户base属性拼接过DNN,得到了交互之后的用户兴趣。然后在训练阶段,用户兴趣和当前商品向量过一个label-aware attention,然后求softmax损失。 在服务阶段,得到用户的向量之后,就可以直接进行近邻检索,找候选商品了。 这就是宏观过程,但是,多兴趣提取层以及这个label-aware attention是在做什么事情呢? 如果单独看这个图,感觉得到多个兴趣胶囊之后,直接把这些兴趣胶囊以及用户的base属性拼接过全连接,那最终不就成了一个用户向量,此时label-aware attention的意义不就没了? 所以这个图初步感觉画的有问题,和论文里面描述的不符。所以下面先以论文为主,正式开始描述具体细节。
|
||||
|
||||
### 任务目标
|
||||
召回任务的目标是对于每一个用户$u \in \mathcal{U}$从十亿规模的物品池$\mathcal{I}$检索出包含与用户兴趣相关的上千个物品集。
|
||||
#### 模型的输入
|
||||
对于模型,每个样本的输入可以表示为一个三元组:$\left(\mathcal{I}_{u}, \mathcal{P}_{u}, \mathcal{F}_{i}\right)$,其中$\mathcal{I}_{u}$代表与用户$u$交互过的物品集,即用户的历史行为;$\mathcal{P}_{u}$表示用户的属性,例如性别、年龄等;$\mathcal{F}_{i}$定义为目标物品$i$的一些特征,例如物品id和种类id等。
|
||||
#### 任务描述
|
||||
MIND的核心任务是学习一个从原生特征映射到**用户表示**的函数,用户表示定义为:
|
||||
$$
|
||||
\mathrm{V}_{u}=f_{u s e r}\left(\mathcal{I}_{u}, \mathcal{P}_{u}\right)
|
||||
$$
|
||||
其中,$\mathbf{V}_{u}=\left(\overrightarrow{\boldsymbol{v}}_{u}^{1}, \ldots, \overrightarrow{\boldsymbol{v}}_{u}^{K}\right) \in \mathbb{R}^{d \times k}$是用户$u$的表示向量,$d$是embedding的维度,$K$表示向量的个数,即兴趣的数量。如果$K=1$,那么MIND模型就退化成YouTubeDNN的向量表示方式了。
|
||||
|
||||
目标物品$i$的embedding函数为:
|
||||
$$
|
||||
\overrightarrow{\mathbf{e}}_{i}=f_{\text {item }}\left(\mathcal{F}_{i}\right)
|
||||
$$
|
||||
其中,$\overrightarrow{\mathbf{e}}_{i} \in \mathbb{R}^{d \times 1}, \quad f_{i t e m}(\cdot)$表示一个embedding&pooling层。
|
||||
#### 最终结果
|
||||
根据评分函数检索(根据**目标物品与用户表示向量的内积的最大值作为相似度依据**,DIN的Attention部分也是以这种方式来衡量两者的相似度),得到top N个候选项:
|
||||
|
||||
$$
|
||||
f_{\text {score }}\left(\mathbf{V}_{u}, \overrightarrow{\mathbf{e}}_{i}\right)=\max _{1 \leq k \leq K} \overrightarrow{\mathbf{e}}_{i}^{\mathrm{T}} \overrightarrow{\mathbf{V}}_{u}^{\mathrm{k}}
|
||||
$$
|
||||
|
||||
### Embedding & Pooling层
|
||||
Embedding层的输入由三部分组成,用户属性$\mathcal{P}_{u}$、用户行为$\mathcal{I}_{u}$和目标物品标签$\mathcal{F}_{i}$。每一部分都由多个id特征组成,则是一个高维的稀疏数据,因此需要Embedding技术将其映射为低维密集向量。具体来说,
|
||||
|
||||
* 对于$\mathcal{P}_{u}$的id特征(年龄、性别等)是将其Embedding的向量进行Concat,组成用户属性Embedding$\overrightarrow{\mathbf{p}}_{u}$;
|
||||
* 目标物品$\mathcal{F}_{i}$通常包含其他分类特征id(品牌id、店铺id等) ,这些特征有利于物品的冷启动问题,需要将所有的分类特征的Embedding向量进行平均池化,得到一个目标物品向量$\overrightarrow{\mathbf{e}}_{i}$;
|
||||
* 对于用户行为$\mathcal{I}_{u}$,由物品的Embedding向量组成用户行为Embedding列表$E_{u}=\overrightarrow{\mathbf{e}}_{j}, j \in \mathcal{I}_{u}$, 当然这里不仅只有物品embedding哈,也可能有类别,品牌等其他的embedding信息。
|
||||
|
||||
### Multi-Interest Extractor Layer(核心)
|
||||
作者认为,单一的向量不足以表达用户的多兴趣。所以作者采用**多个表示向量**来分别表示用户不同的兴趣。通过这个方式,在召回阶段,用户的多兴趣可以分别考虑,对于兴趣的每一个方面,能够更精确的进行物品检索。
|
||||
|
||||
为了学习多兴趣表示,作者利用胶囊网络表示学习的动态路由将用户的历史行为分组到多个簇中。来自一个簇的物品应该密切相关,并共同代表用户兴趣的一个特定方面。
|
||||
|
||||
由于多兴趣提取器层的设计灵感来自于胶囊网络表示学习的动态路由,所以这里作者回顾了动态路由机制。当然,如果之前对胶囊网络或动态路由不了解,这里读起来就会有点艰难,但由于我上面进行了铺垫,这里就直接拿过原文并解释即可。
|
||||
#### 动态路由
|
||||
动态路由是胶囊网络中的迭代学习算法,用于学习低水平胶囊和高水平胶囊之间的路由对数(logit)$b_{ij}$,来得到高水平胶囊的表示。
|
||||
|
||||
我们假设胶囊网络有两层,即低水平胶囊$\vec{c}_{i}^{l} \in \mathbb{R}^{N_{l} \times 1}, i \in\{1, \ldots, m\}$和高水平胶囊$\vec{c}_{j}^{h} \in \mathbb{R}^{N_{h} \times 1}, j \in\{1, \ldots, n\}$,其中$m,n$表示胶囊的个数, $N_l,N_h$表示胶囊的维度。 路由对数$b_{ij}$计算公式如下:
|
||||
$$
|
||||
b_{i j}=\left(\vec{c}_{j}^{h}\right)^{T} \mathrm{~S}_{i j} \vec{c}_{i}^{l}
|
||||
$$
|
||||
其中$\mathbf{S}_{i j} \in \mathbb{R}^{N_{h} \times N_{l}}$表示待学习的双线性映射矩阵【在胶囊网络的原文中称为转换矩阵】
|
||||
|
||||
通过计算路由对数,将高阶胶囊$j$的候选向量计算为所有低阶胶囊的加权和:
|
||||
$$
|
||||
\vec{z}_{j}^{h}=\sum_{i=1}^{m} w_{i j} S_{i j} \vec{c}_{i}^{l}
|
||||
$$
|
||||
其中$w_{ij}$定义为连接低阶胶囊$i$和高阶胶囊$j$的权重【称为耦合系数】,而且其通过对路由对数执行softmax来计算:
|
||||
$$
|
||||
w_{i j}=\frac{\exp b_{i j}}{\sum_{k=1}^{m} \exp b_{i k}}
|
||||
$$
|
||||
最后,应用一个非线性的“压缩”函数来获得一个高阶胶囊的向量【胶囊网络向量的模表示由胶囊所代表的实体存在的概率】
|
||||
$$
|
||||
\vec{c}_{j}^{h}=\operatorname{squash}\left(\vec{z}_{j}^{h}\right)=\frac{\left\|\vec{z}_{j}^{h}\right\|^{2}}{1+\left\|\vec{z}_{j}^{h}\right\|^{2}} \frac{\vec{z}_{j}^{h}}{\left\|\vec{z}_{j}^{h}\right\|}
|
||||
$$
|
||||
路由过程重复进行3次达到收敛。当路由结束,高阶胶囊值$\vec{c}_{j}^{h}$固定,作为下一层的输入。
|
||||
|
||||
Ok,下面我们开始解释,其实上面说的这些就是胶囊网络的计算过程,只不过和之前所用的符号不一样了。这里拿个图:
|
||||
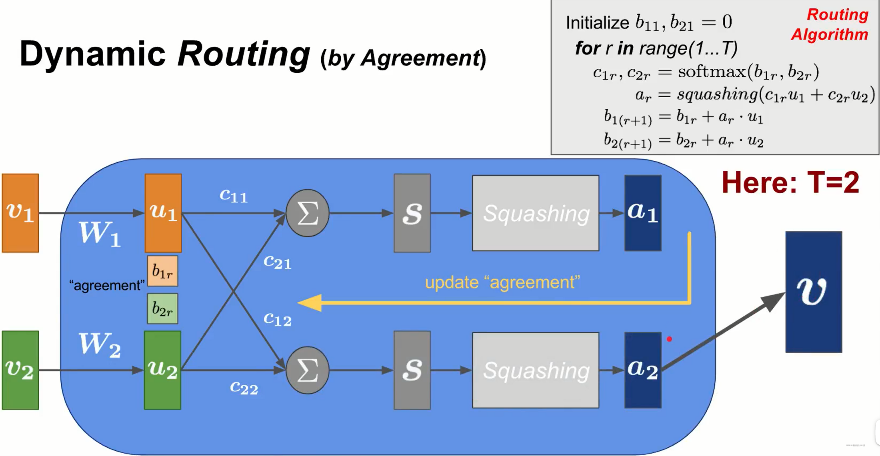
|
||||
首先,论文里面也是个两层的胶囊网络,低水平层->高水平层。 低水平层有$m$个胶囊,每个胶囊向量维度是$N_l$,用$\vec{c}_{i}^l$表示的,高水平层有$n$个胶囊,每个胶囊$N_h$维,用$\vec{c}_{j}^h$表示。
|
||||
|
||||
单独拿出每个$\vec{c}_{j}^h$,其计算过程如上图所示。首先,先随机初始化路由对数$b_{ij}=0$,然后开始迭代,对于每次迭代:
|
||||
$$
|
||||
w_{i j}=\frac{\exp b_{i j}}{\sum_{k=1}^{m} \exp b_{i k}} \\
|
||||
\vec{z}_{j}^{h}=\sum_{i=1}^{m} w_{i j} S_{i j} \vec{c}_{i}^{l} \\ \vec{c}_{j}^{h}=\operatorname{squash}\left(\vec{z}_{j}^{h}\right)=\frac{\left\|\vec{z}_{j}^{h}\right\|^{2}}{1+\left\|\vec{z}_{j}^{h}\right\|^{2}} \frac{\vec{z}_{j}^{h}}{\left\|\vec{z}_{j}^{h}\right\|} \\ b_{i j}=\left(\vec{c}_{j}^{h}\right)^{T} \mathrm{~S}_{i j} \vec{c}_{i}^{l}
|
||||
$$
|
||||
只不过这里的符合和上图中的不太一样,这里的$w_{ij}$对应的是每个输入胶囊的权重$c_{ij}$, 这里的$\vec{c}_{j}^h$对应上图中的$a$, 这里的$\vec{z}_{j}^h$对应的是输入胶囊的加权组合。这里的$\vec{c}_{i}^l$对应上图中的$v_i$,这里的$S_{ij}$对应的是上图的权重$W_{ij}$,只不过这个可以换成矩阵运算。 和上图中不同的是路由对数$b_{ij}$更新那里,没有了上一层的路由对数值,但感觉这样会有问题。
|
||||
|
||||
所以,这样解释完之后就会发现,其实上面的一顿操作就是说的传统的动态路由机制。
|
||||
|
||||
#### B2I动态路由
|
||||
作者设计的多兴趣提取层就是就是受到了上述胶囊网络的启发。
|
||||
|
||||
如果把用户的行为序列看成是行为胶囊, 把用户的多兴趣看成兴趣胶囊,那么多兴趣提取层就是利用动态路由机制学习行为胶囊`->`兴趣胶囊的映射关系。但是原始路由算法无法直接应用于处理用户行为数据。因此,提出了**行为(Behavior)到兴趣(Interest)(B2I)动态路由**来自适应地将用户的行为聚合到兴趣表示向量中,它与原始路由算法有三个不同之处:
|
||||
|
||||
1. **共享双向映射矩阵**。在初始动态路由中,使用固定的或者说共享的双线性映射矩阵$S$而不是单独的双线性映射矩阵, 在原始的动态路由中,对于每个输出胶囊$\vec{c}_{j}^h$,都会有对应的$S_{ij}$,而这里是每个输出胶囊,都共用一个$S$矩阵。 原因有两个:
|
||||
1. 一方面,用户行为是可变长度的,从几十个到几百个不等,因此使用共享的双线性映射矩阵是有利于泛化。
|
||||
2. 另一方面,希望兴趣胶囊在同一个向量空间中,但不同的双线性映射矩阵将兴趣胶囊映射到不同的向量空间中。因为映射矩阵的作用就是对用户的行为胶囊进行线性映射嘛, 由于用户的行为序列都是商品,所以希望经过映射之后,到统一的商品向量空间中去。路由对数计算如下:
|
||||
$$
|
||||
b_{i j}=\overrightarrow{\boldsymbol{u}}_{j}^{T} \mathrm{S\overrightarrow{e}}_{i}, \quad i \in \mathcal{I}_{u}, j \in\{1, \ldots, K\}
|
||||
$$
|
||||
其中,$\overrightarrow{\boldsymbol{e}}_{i} \in \mathbb{R}^{d}$是历史物品$i$的embedding,$\vec{u}_{j} \in \mathbb{R}^{d}$表示兴趣胶囊$j$的向量。$S \in \mathbb{R}^{d \times d}$是每一对行为胶囊(低价)到兴趣胶囊(高阶)之间 的共享映射矩阵。
|
||||
|
||||
|
||||
2. **随机初始化路由对数**。由于利用共享双向映射矩阵$S$,如果再初始化路由对数为0将导致相同的初始的兴趣胶囊。随后的迭代将陷入到一个不同兴趣胶囊在所有的时间保持相同的情景。因为每个输出胶囊的运算都一样了嘛(除非迭代的次数不同,但这样也会导致兴趣胶囊都很类似),为了减轻这种现象,作者通过高斯分布进行随机采样来初始化路由对数$b_{ij}$,让初始兴趣胶囊与其他每一个不同,其实就是希望在计算每个输出胶囊的时候,通过随机化的方式,希望这几个聚类中心离得远一点,这样才能表示出广泛的用户兴趣(我们已经了解这个机制就仿佛是聚类,而计算过程就是寻找聚类中心)。
|
||||
3. **动态的兴趣数量**,兴趣数量就是聚类中心的个数,由于不同用户的历史行为序列不同,那么相应的,其兴趣胶囊有可能也不一样多,所以这里使用了一种启发式方式自适应调整聚类中心的数量,即$K$值。
|
||||
$$
|
||||
K_{u}^{\prime}=\max \left(1, \min \left(K, \log _{2}\left(\left|\mathcal{I}_{u}\right|\right)\right)\right)
|
||||
$$
|
||||
这种调整兴趣胶囊数量的策略可以为兴趣较小的用户节省一些资源,包括计算和内存资源。这个公式不用多解释,与行为序列长度成正比。
|
||||
|
||||
最终的B2I动态路由算法如下:
|
||||

|
||||
应该很好理解了吧。
|
||||
|
||||
### Label-aware Attention Layer
|
||||
通过多兴趣提取器层,从用户的行为embedding中生成多个兴趣胶囊。不同的兴趣胶囊代表用户兴趣的不同方面,相应的兴趣胶囊用于评估用户对特定类别的偏好。所以,在训练的期间,最后需要设置一个Label-aware的注意力层,对于当前的商品,根据相关性选择最相关的兴趣胶囊。这里其实就是一个普通的注意力机制,和DIN里面的那个注意力层基本上是一模一样,计算公式如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\overrightarrow{\boldsymbol{v}}_{u} &=\operatorname{Attention}\left(\overrightarrow{\boldsymbol{e}}_{i}, \mathrm{~V}_{u}, \mathrm{~V}_{u}\right) \\
|
||||
&=\mathrm{V}_{u} \operatorname{softmax}\left(\operatorname{pow}\left(\mathrm{V}_{u}^{\mathrm{T}} \overrightarrow{\boldsymbol{e}}_{i}, p\right)\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
首先这里的$\overrightarrow{\boldsymbol{e}}_{i}$表示当前的商品向量,$V_u$表示用户的多兴趣向量组合,里面有$K$个向量,表示用户的$K$的兴趣。用户的各个兴趣向量与目标商品做内积,然后softmax转成权重,然后反乘到多个兴趣向量进行加权求和。 但是这里需要注意的一个小点,就是这里做内积求完相似性之后,先做了一个指数操作,**这个操作其实能放大或缩小相似程度**,至于放大或者缩小的程度,由$p$控制。 比如某个兴趣向量与当前商品非常相似,那么再进行指数操作之后,如果$p$也很大,那么显然这个兴趣向量就占了主导作用。$p$是一个可调节的参数来调整注意力分布。当$p$接近0,每一个兴趣胶囊都得到相同的关注。当$p$大于1时,随着$p$的增加,具有较大值的点积将获得越来越多的权重。考虑极限情况,当$p$趋近于无穷大时,注意机制就变成了一种硬注意,选关注最大的值而忽略其他值。在实验中,发现使用硬注意导致更快的收敛。
|
||||
>理解:$p$小意味着所有的相似程度都缩小了, 使得之间的差距会变小,所以相当于每个胶囊都会受到关注,而越大的话,使得各个相似性差距拉大,相似程度越大的会更大,就类似于贫富差距, 最终使得只关注于比较大的胶囊。
|
||||
|
||||
### 训练与服务
|
||||
得到用户向量$\overrightarrow{\boldsymbol{v}}_{u}$和标签物品embedding$\vec{e}_{i}$后,计算用户$u$与标签物品$i$交互的概率:
|
||||
$$
|
||||
\operatorname{Pr}(i \mid u)=\operatorname{Pr}\left(\vec{e}_{i} \mid \vec{v}_{u}\right)=\frac{\exp \left(\vec{v}_{u}^{\mathrm{T} \rightarrow}\right)}{\sum_{j \in I} \exp \left(\vec{v}_{u}^{\mathrm{T}} \vec{e}_{j}\right)}
|
||||
$$
|
||||
目标函数是:
|
||||
$$
|
||||
L=\sum_{(u, i) \in \mathcal{D}} \log \operatorname{Pr}(i \mid u)
|
||||
$$
|
||||
其中$\mathcal{D}$是训练数据包含用户物品交互的集合。因为物品的数量可伸缩到数十亿,所以不能直接算。因此。使用采样的softmax技术,并且选择Adam优化来训练MIND。
|
||||
|
||||
训练结束后,抛开label-aware注意力层,MIND网络得到一个用户表示映射函数$f_{user}$。在服务期间,用户的历史序列与自身属性喂入到$f_{user}$,每个用户得到多兴趣向量。然后这个表示向量通过一个近似邻近方法来检索top N物品。
|
||||
|
||||
这就是整个MIND模型的细节了。
|
||||
|
||||
## MIND模型之简易代码复现
|
||||
下面参考Deepctr,用简易的代码实现下MIND,并在新闻推荐的数据集上进行召回任务。
|
||||
|
||||
### 整个代码架构
|
||||
|
||||
整个MIND模型算是参考deepmatch修改的一个简易版本:
|
||||
|
||||
```python
|
||||
def MIND(user_feature_columns, item_feature_columns, num_sampled=5, k_max=2, p=1.0, dynamic_k=False, user_dnn_hidden_units=(64, 32),
|
||||
dnn_activation='relu', dnn_use_bn=False, l2_reg_dnn=0, l2_reg_embedding=1e-6, dnn_dropout=0, output_activation='linear', seed=1024):
|
||||
"""
|
||||
:param k_max: 用户兴趣胶囊的最大个数
|
||||
"""
|
||||
# 目前这里只支持item_feature_columns为1的情况,即只能转入item_id
|
||||
if len(item_feature_columns) > 1:
|
||||
raise ValueError("Now MIND only support 1 item feature like item_id")
|
||||
|
||||
# 获取item相关的配置参数
|
||||
item_feature_column = item_feature_columns[0]
|
||||
item_feature_name = item_feature_column.name
|
||||
item_vocabulary_size = item_feature_column.vocabulary_size
|
||||
item_embedding_dim = item_feature_column.embedding_dim
|
||||
|
||||
behavior_feature_list = [item_feature_name]
|
||||
|
||||
# 为用户特征创建Input层
|
||||
user_input_layer_dict = build_input_layers(user_feature_columns)
|
||||
item_input_layer_dict = build_input_layers(item_feature_columns)
|
||||
# 将Input层转化成列表的形式作为model的输入
|
||||
user_input_layers = list(user_input_layer_dict.values())
|
||||
item_input_layers = list(item_input_layer_dict.values())
|
||||
|
||||
# 筛选出特征中的sparse特征和dense特征,方便单独处理
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
varlen_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
|
||||
# 由于这个变长序列里面只有历史点击文章,没有类别啥的,所以这里直接可以用varlen_feature_columns
|
||||
# deepctr这里单独把点击文章这个放到了history_feature_columns
|
||||
seq_max_len = varlen_feature_columns[0].maxlen
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(user_feature_columns+item_feature_columns)
|
||||
|
||||
# 获取当前的行为特征(doc)的embedding,这里面可能又多个类别特征,所以需要pooling下
|
||||
query_embed_list = embedding_lookup(behavior_feature_list, item_input_layer_dict, embedding_layer_dict) # 长度为1
|
||||
# 获取行为序列(doc_id序列, hist_doc_id) 对应的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
keys_embed_list = embedding_lookup([varlen_feature_columns[0].name], user_input_layer_dict, embedding_layer_dict) # 长度为1
|
||||
|
||||
# 用户离散特征的输入层与embedding层拼接
|
||||
dnn_input_emb_list = embedding_lookup([col.name for col in sparse_feature_columns], user_input_layer_dict, embedding_layer_dict)
|
||||
|
||||
# 获取dense
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
if fc.name != 'hist_len': # 连续特征不要这个
|
||||
dnn_dense_input.append(user_input_layer_dict[fc.name])
|
||||
|
||||
# 把keys_emb_list和query_emb_listpooling操作, 这是因为可能每个商品不仅有id,还可能用类别,品牌等多个embedding向量,这种需要pooling成一个
|
||||
history_emb = PoolingLayer()(NoMask()(keys_embed_list)) # (None, 50, 8)
|
||||
target_emb = PoolingLayer()(NoMask()(query_embed_list)) # (None, 1, 8)
|
||||
|
||||
hist_len = user_input_layer_dict['hist_len']
|
||||
# 胶囊网络
|
||||
# (None, 2, 8) 得到了两个兴趣胶囊
|
||||
high_capsule = CapsuleLayer(input_units=item_embedding_dim, out_units=item_embedding_dim,
|
||||
max_len=seq_max_len, k_max=k_max)((history_emb, hist_len))
|
||||
|
||||
|
||||
# 把用户的其他特征拼接到胶囊网络上来
|
||||
if len(dnn_input_emb_list) > 0 or len(dnn_dense_input) > 0:
|
||||
user_other_feature = combined_dnn_input(dnn_input_emb_list, dnn_dense_input)
|
||||
# (None, 2, 32) 这里会发现其他的用户特征是每个胶囊复制了一份,然后拼接起来
|
||||
other_feature_tile = tf.keras.layers.Lambda(tile_user_otherfeat, arguments={'k_max': k_max})(user_other_feature)
|
||||
user_deep_input = Concatenate()([NoMask()(other_feature_tile), high_capsule]) # (None, 2, 40)
|
||||
else:
|
||||
user_deep_input = high_capsule
|
||||
|
||||
# 接下来过一个DNN层,获取最终的用户表示向量 如果是三维输入, 那么最后一个维度与w相乘,所以这里如果不自己写,可以用Dense层的列表也可以
|
||||
user_embeddings = DNN(user_dnn_hidden_units, dnn_activation, l2_reg_dnn,
|
||||
dnn_dropout, dnn_use_bn, output_activation=output_activation, seed=seed,
|
||||
name="user_embedding")(user_deep_input) # (None, 2, 8)
|
||||
|
||||
# 接下来,过Label-aware layer
|
||||
if dynamic_k:
|
||||
user_embedding_final = LabelAwareAttention(k_max=k_max, pow_p=p,)((user_embeddings, target_emb, hist_len))
|
||||
else:
|
||||
user_embedding_final = LabelAwareAttention(k_max=k_max, pow_p=p,)((user_embeddings, target_emb))
|
||||
|
||||
# 接下来
|
||||
item_embedding_matrix = embedding_layer_dict[item_feature_name] # 获取doc_id的embedding层
|
||||
item_index = EmbeddingIndex(list(range(item_vocabulary_size)))(item_input_layer_dict[item_feature_name]) # 所有doc_id的索引
|
||||
item_embedding_weight = NoMask()(item_embedding_matrix(item_index)) # 拿到所有item的embedding
|
||||
pooling_item_embedding_weight = PoolingLayer()([item_embedding_weight]) # 这里依然是当可能不止item_id,或许还有brand_id, cat_id等,需要池化
|
||||
|
||||
# 这里传入的是整个doc_id的embedding, user_embedding, 以及用户点击的doc_id,然后去进行负采样计算损失操作
|
||||
output = SampledSoftmaxLayer(num_sampled)([pooling_item_embedding_weight, user_embedding_final, item_input_layer_dict[item_feature_name]])
|
||||
|
||||
model = Model(inputs=user_input_layers+item_input_layers, outputs=output)
|
||||
|
||||
# 下面是等模型训练完了之后,获取用户和item的embedding
|
||||
model.__setattr__("user_input", user_input_layers)
|
||||
model.__setattr__("user_embedding", user_embeddings)
|
||||
model.__setattr__("item_input", item_input_layers)
|
||||
model.__setattr__("item_embedding", get_item_embedding(pooling_item_embedding_weight, item_input_layer_dict[item_feature_name]))
|
||||
|
||||
return model
|
||||
```
|
||||
简单说下流程, 函数式API搭建模型的方式,首先我们需要传入封装好的用户特征描述以及item特征描述,比如:
|
||||
|
||||
```python
|
||||
# 建立模型
|
||||
user_feature_columns = [
|
||||
SparseFeat('user_id', feature_max_idx['user_id'], embedding_dim),
|
||||
VarLenSparseFeat(SparseFeat('hist_doc_ids', feature_max_idx['article_id'], embedding_dim,
|
||||
embedding_name="click_doc_id"), his_seq_maxlen, 'mean', 'hist_len'),
|
||||
DenseFeat('hist_len', 1),
|
||||
SparseFeat('u_city', feature_max_idx['city'], embedding_dim),
|
||||
SparseFeat('u_age', feature_max_idx['age'], embedding_dim),
|
||||
SparseFeat('u_gender', feature_max_idx['gender'], embedding_dim),
|
||||
]
|
||||
doc_feature_columns = [
|
||||
SparseFeat('click_doc_id', feature_max_idx['article_id'], embedding_dim)
|
||||
# 这里后面也可以把文章的类别画像特征加入
|
||||
]
|
||||
```
|
||||
首先, 函数会对传入的这种特征建立模型的Input层,主要是`build_input_layers`函数。建立完了之后,获取到Input层列表,这个是为了最终定义模型用的,keras要求定义模型的时候是列表的形式。
|
||||
|
||||
接下来是选出sparse特征和Dense特征来,这个也是常规操作了,因为不同的特征后面处理方式不一样,对于sparse特征,后面要接embedding层,Dense特征的话,直接可以拼接起来。这就是筛选特征的3行代码。
|
||||
|
||||
接下来,是为所有的离散特征建立embedding层,通过函数`build_embedding_layers`。建立完了之后,把item相关的embedding层与对应的Input层接起来,作为query_embed_list, 而用户历史行为序列的embedding层与Input层接起来作为keys_embed_list,这两个有单独的用户。而Input层与embedding层拼接是通过`embedding_lookup`函数完成的。 这样完成了之后,就能通过Input层-embedding层拿到item的系列embedding,以及历史序列里面item系列embedding,之所以这里是系列embedding,是有可能不止item_id这一个特征,还可能有品牌id, 类别id等好几个,所以接下来把系列embedding通过pooling操作,得到最终表示item的向量。 就是这两行代码:
|
||||
|
||||
```python
|
||||
# 把keys_emb_list和query_emb_listpooling操作, 这是因为可能每个商品不仅有id,还可能用类别,品牌等多个embedding向量,这种需要pooling成一个
|
||||
history_emb = PoolingLayer()(NoMask()(keys_embed_list)) # (None, 50, 8)
|
||||
target_emb = PoolingLayer()(NoMask()(query_embed_list)) # (None, 1, 8)
|
||||
```
|
||||
而像其他的输入类别特征, 依然是Input层与embedding层拼起来,留着后面用,这个存到了dnn_input_emb_list中。 而dense特征, 不需要embedding层,直接通过Input层获取到,然后存到列表里面,留着后面用。
|
||||
|
||||
上面得到的history_emb,就是用户的历史行为序列,这个东西接下来要过兴趣提取层,去学习用户的多兴趣,当然这里还需要传入行为序列的真实长度。因为每个用户行为序列不一样长,通过mask让其等长了,但是真实在胶囊网络计算的时候,这些填充的序列是要被mask掉的。所以必须要知道真实长度。
|
||||
|
||||
```python
|
||||
# 胶囊网络
|
||||
# (None, 2, 8) 得到了两个兴趣胶囊
|
||||
high_capsule = CapsuleLayer(input_units=item_embedding_dim, out_units=item_embedding_dim,max_len=seq_max_len, k_max=k_max)((history_emb, hist_len))
|
||||
```
|
||||
通过这步操作,就得到了两个兴趣胶囊。 至于具体细节,下一节看。 然后把用户的其他特征拼接上来,这里有必要看下代码究竟是怎么拼接的:
|
||||
|
||||
```python
|
||||
# 把用户的其他特征拼接到胶囊网络上来
|
||||
if len(dnn_input_emb_list) > 0 or len(dnn_dense_input) > 0:
|
||||
user_other_feature = combined_dnn_input(dnn_input_emb_list, dnn_dense_input)
|
||||
# (None, 2, 32) 这里会发现其他的用户特征是每个胶囊复制了一份,然后拼接起来
|
||||
other_feature_tile = tf.keras.layers.Lambda(tile_user_otherfeat, arguments={'k_max': k_max})(user_other_feature)
|
||||
user_deep_input = Concatenate()([NoMask()(other_feature_tile), high_capsule]) # (None, 2, 40)
|
||||
else:
|
||||
user_deep_input = high_capsule
|
||||
```
|
||||
这里会发现,使用了一个Lambda层,这个东西的作用呢,其实是将用户的其他特征在胶囊个数的维度上复制了一份,再拼接,这就相当于在每个胶囊的后面都拼接上了用户的基础特征。这样得到的维度就成了(None, 2, 40),2是胶囊个数, 40是兴趣胶囊的维度+其他基础特征维度总和。这样拼完了之后,接下来过全连接层
|
||||
|
||||
```python
|
||||
# 接下来过一个DNN层,获取最终的用户表示向量 如果是三维输入, 那么最后一个维度与w相乘,所以这里如果不自己写,可以用Dense层的列表也可以
|
||||
user_embeddings = DNN(user_dnn_hidden_units, dnn_activation, l2_reg_dnn,
|
||||
dnn_dropout, dnn_use_bn, output_activation=output_activation, seed=seed,
|
||||
name="user_embedding")(user_deep_input) # (None, 2, 8)
|
||||
```
|
||||
最终得到的是(None, 2, 8)的向量,这样就解决了之前的那个疑问, 最终得到的兴趣向量个数并不是1个,而是多个兴趣向量了,因为上面用户特征拼接,是每个胶囊后面都拼接一份同样的特征。另外,就是原来DNN这里的输入还可以是3维的,这样进行运算的话,是最后一个维度与W进行运算,相当于只在第3个维度上进行了降维操作后者非线性操作,这样得到的兴趣个数是不变的。
|
||||
|
||||
这样,有了两个兴趣的输出之后,接下来,就是过LabelAwareAttention层了,对这两个兴趣向量与当前item的相关性加注意力权重,最后变成1个用户的最终向量。
|
||||
|
||||
```python
|
||||
user_embedding_final = LabelAwareAttention(k_max=k_max, pow_p=p,)((user_embeddings, target_emb))
|
||||
```
|
||||
这样,就得到了用户的最终表示向量,当然这个操作仅是训练的时候,服务的时候是拿的上面DNN的输出,即多个兴趣,这里注意一下。
|
||||
|
||||
拿到了最终的用户向量,如何计算损失呢? 这里用了负采样层进行操作。关于这个层具体的原理,后面我们可能会出一篇文章总结。
|
||||
|
||||
接下来有几行代码也需要注意:
|
||||
|
||||
```python
|
||||
# 下面是等模型训练完了之后,获取用户和item的embedding
|
||||
model.__setattr__("user_input", user_input_layers)
|
||||
model.__setattr__("user_embedding", user_embeddings)
|
||||
model.__setattr__("item_input", item_input_layers)
|
||||
model.__setattr__("item_embedding", get_item_embedding(pooling_item_embedding_weight, item_input_layer_dict[item_feature_name]))
|
||||
```
|
||||
这几行代码是为了模型训练完,我们给定输入之后,拿embedding用的,设置好了之后,通过:
|
||||
|
||||
```python
|
||||
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
|
||||
item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
|
||||
|
||||
user_embs = user_embedding_model.predict(test_user_model_input, batch_size=2 ** 12)
|
||||
# user_embs = user_embs[:, i, :] # i in [0,k_max) if MIND
|
||||
item_embs = item_embedding_model.predict(all_item_model_input, batch_size=2 ** 12)
|
||||
```
|
||||
这样就能拿到用户和item的embedding, 接下来近邻检索完成召回过程。 注意,MIND的话,这里是拿到的多个兴趣向量的。
|
||||
|
||||
## 总结
|
||||
今天这篇文章整理的MIND,这是一个多兴趣的召回模型,核心是兴趣提取层,该层通过动态路由机制能够自动的对用户的历史行为序列进行聚类,得到多个兴趣向量,这样能在召回阶段捕获到用户的广泛兴趣,从而召回更好的候选商品。
|
||||
|
||||
|
||||
**参考**:
|
||||
* Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
|
||||
* [ AI上推荐 之 MIND(动态路由与胶囊网络的奇光异彩)](https://blog.csdn.net/wuzhongqiang/article/details/123696462?spm=1001.2014.3001.5501)
|
||||
* [Dynamic Routing Between Capsule ](https://arxiv.org/pdf/1710.09829.pdf)
|
||||
* [CIKM2019|MIND---召回阶段的多兴趣模型](https://zhuanlan.zhihu.com/p/262638999)
|
||||
* [B站胶囊网络课程](https://www.bilibili.com/video/BV1eW411Q7CE?p=2)
|
||||
* [胶囊网络识别交通标志](https://blog.csdn.net/shebao3333/article/details/79008688)
|
||||
|
||||
|
||||
@@ -1,404 +0,0 @@
|
||||
## 写在前面
|
||||
SDM模型(Sequential Deep Matching Model),是阿里团队在2019年CIKM上的一篇paper。和MIND模型一样,是一种序列召回模型,研究的依然是如何通过用户的历史行为序列去学习到用户的丰富兴趣。 对于MIND,我们已经知道是基于胶囊网络的动态路由机制,设计了一个动态兴趣提取层,把用户的行为序列通过路由机制聚类,然后映射成了多个兴趣胶囊,以此来获取到用户的广泛兴趣。而SDM模型,是先把用户的历史序列根据交互的时间分成了短期和长期两类,然后从**短期会话**和**长期行为**中分别采取**相应的措施(短期的RNN+多头注意力, 长期的Att Net)** 去学习到用户的短期兴趣和长期行为偏好,并**巧妙的设计了一个门控网络==有选择==的将长短期兴趣进行融合**,以此得到用户的最终兴趣向量。 这篇paper中的一些亮点,比如长期偏好的行为表示,多头注意力机制学习多兴趣,长短期兴趣的融合机制等,又给了一些看待问题的新角度,同时,给出了我们一种利用历史行为序列去捕捉用户动态偏好的新思路。
|
||||
|
||||
这篇paper依然是从引言开始, 介绍SDM模型提出的动机以及目前方法存在的不足(why), 接下来就是SDM的网络模型架构(what), 这里面的关键是如何从短期会话和长期行为两个方面学习到用户的短期长期偏好(how),最后,依然是简易代码实现。
|
||||
|
||||
大纲如下:
|
||||
* 背景与动机
|
||||
* SDM的网络结构与细节
|
||||
* SDM模型代码复现
|
||||
|
||||
## 背景与动机
|
||||
这里要介绍该模型提出的动机,即why要有这样的一个模型?
|
||||
|
||||
一个好的推荐系统应该是能精确的捕捉用户兴趣偏好以及能对他们当前需求进行快速响应的,往往工业上的推荐系统,为了能快速响应, 一般会把整个推荐流程分成召回和排序两个阶段,先通过召回,从海量商品中得到一个小的候选集,然后再给到排序模型做精确的筛选操作。 这也是目前推荐系统的一个范式了。在这个过程中,召回模块所检索到的候选对象的质量在整个系统中起着至关重要的作用。
|
||||
|
||||
淘宝目前的召回模型是一些基于协同过滤的模型, 这些模型是通过用户与商品的历史交互建模,从而得到用户的物品的表示向量,但这个过程是**静态的**,而用户的行为或者兴趣是时刻变化的, 对于协同过滤的模型来说,并不能很好的捕捉到用户整个行为序列的动态变化。
|
||||
|
||||
那我们知道了学习用户历史行为序列很重要, 那么假设序列很长呢?这时候直接用模型学习长序列之间的演进可能不是很好,因为很长的序列里面可能用户的兴趣发生过很大的转变,很多商品压根就没有啥关系,这样硬学,反而会导致越学越乱,就别提这个演进了。所以这里是以会话为单位,对长序列进行切分。作者这里的依据就是用户在同一个Session下,其需求往往是很明确的, 这时候,交互的商品也往往都非常类似。 但是Session与Session之间,可能需求改变,那么商品类型可能骤变。 所以以Session为单位来学习商品之间的序列信息,感觉要比整个长序列学习来的靠谱。
|
||||
|
||||
作者首先是先把长序列分成了多个会话, 然后**把最近的一次会话,和之前的会话分别视为了用户短期行为和长期行为分别进行了建模,并采用不同的措施学习用户的短期兴趣和长期兴趣,然后通过一个门控机制融合得到用户最终的表示向量**。这就是SDM在做的事情,
|
||||
|
||||
|
||||
长短期行为序列联合建模,其实是在给我们提供一种新的学习用户兴趣的新思路, 那么究竟是怎么做的呢?以及为啥这么做呢?
|
||||
* 对于短期用户行为, 首先作者使用了LSTM来学习序列关系, 而接下来是用一个Multi-head attention机制,学习用户的多兴趣。
|
||||
|
||||
先分析分析作者为啥用多头注意力机制,作者这里依然是基于实际的场景出发,作者发现,**用户的兴趣点在一个会话里面其实也是多重的**。这个可能之前的很多模型也是没考虑到的,但在商品购买的场景中,这确实也是个事实, 顾客在买一个商品的时候,往往会进行多方比较, 考虑品牌,颜色,商店等各种因素。作者认为用普通的注意力机制是无法反映广泛的兴趣了,所以用多头注意力网络。
|
||||
|
||||
多头注意力机制从某个角度去看,也有类似聚类的功效,首先它接收了用户的行为序列,然后从多个角度学习到每个商品与其他商品的相关性,然后根据与其他商品的相关性加权融合,这样,相似的item向量大概率就融合到了一块组成一个向量,所谓用户的多兴趣,可能是因为这些行为商品之间,可以从多个空间或者角度去get彼此之间的相关性,这里面有着用户多兴趣的表达信息。
|
||||
|
||||
* 用户的长期行为也会影响当前的决策,作者在这里举了一个NBA粉丝的例子,说如果一个是某个NBA球星的粉丝,那么他可能在之前会买很多有关这个球星的商品,如果现在这个时刻想买鞋的时候,大概率会考虑和球星相关的。所以作者说**长期偏好和短期行为都非常关键**。但是长期偏好或者行为往往是复杂广泛的,就像刚才这个例子里面,可能长期行为里面,买的与这个球星相关商品只占一小部分,而就只有这一小部分对当前决策有用。
|
||||
这个也是之前的模型利用长期偏好方面存在的问题,那么如何选择出长期偏好里面对于当前决策有用的那部分呢? 作者这里设计了一个门控的方式融合短期和长期,这个想法还是很巧妙的,后面介绍这个东西的时候说下我的想法。
|
||||
|
||||
所以下面总结动机以及本篇论文的亮点:
|
||||
* 动机: 召回模型需要捕获用户的动态兴趣变化,这个过程中利用好用户的长期行为和短期偏好非常关键,而以往的模型有下面几点不足:
|
||||
* 协同过滤模型: 基于用户的交互进行静态建模,无法感知用户的兴趣变化过程,易召回同质性的商品
|
||||
* 早期的一些序列推荐模型: 要么是对整个长序列直接建模,但这样太暴力,没法很好的学习商品之间的序列信息,有些是把长序列分成会话,但忽视了一个会话中用户的多重兴趣
|
||||
* 有些方法在考虑用户的长期行为方面,只是简单的拼接或者加权求和,而实际上用户长期行为中只有很少一小部分对当前的预测有用,这样暴力融合反而会适得其反,起不到效果。另外还有一些多任务或者对抗方法, 在工业场景中不适用等。
|
||||
* 这些我只是通过我的理解简单总结,详细内容看原论文相关工作部分。
|
||||
* 亮点:
|
||||
* SDM模型, 考虑了用户的短期行为和长期兴趣,以会话的形式进行分割,并对这两方面分别建模
|
||||
* 短期会话由于对当前决策影响比较大,那么我们就学习的全面一点, 首先RNN学习序列关系,其次通过多头注意力机制捕捉多兴趣,然后通过一个Attention Net加权得到短期兴趣表示
|
||||
* 长期会话通过Attention Net融合,然后过DNN,得到用户的长期表示
|
||||
* 我们设计了一个门控机制,类似于LSTM的那种门控,能巧妙的融合这两种兴趣,得到用户最终的表示向量
|
||||
|
||||
这就是动机与背景总结啦。 那么接下来,SDM究竟是如何学习短期和长期表示,又是如何融合的? 为什么要这么玩?
|
||||
|
||||
## SDM的网络结构与细节剖析
|
||||
### 问题定义
|
||||
这里本来直接看模型结构,但感觉还是先过一下问题定义吧,毕竟这次涉及到了会话,还有几个小规则。
|
||||
|
||||
$\mathcal{U}$表示用户集合,$\mathcal{I}$表示item集合,模型考虑在时间$t$,是否用户$u$会对$i$产生交互。 对于$u$, 我们能够得到它的历史行为序列,那么先说一下如何进行会话的划分, 这里有三个规则:
|
||||
1. 相同会话ID的商品(后台能获取)算是一个会话
|
||||
2. 相邻的商品,时间间隔小于10分钟(业务自己调整)算一个会话
|
||||
3. 同一个会话中的商品不能超过50个,多出来的放入下一个会话
|
||||
|
||||
这样划分开会话之后, 对于用户$u$的短期行为定义是离目前最近的这次会话, 用$\mathcal{S}^{u}=\left[i_{1}^{u}, \ldots, i_{t}^{u}, \ldots, i_{m}^{u}\right]$表示,$m$是序列长度。 而长期的用户行为是过去一周内的会话,但不包括短期的这次会话, 这个用$\mathcal{L}^{u}$表示。网络推荐架构如下:
|
||||
|
||||
这个感觉并不用过多解释。看过召回的应该都能懂, 接收了用户的短期行为和长期行为,然后分别通过两个盲盒得到表示向量,再通过门控融合就得到了最终的用户表示。
|
||||
|
||||
下面要开那三个盲盒操作,即短期行为学习,长期行为学习以及门控融合机制。但在这之前,得先说一个东西,就是输入层这里, 要带物品的side infomation,比如物品的item ID, 物品的品牌ID,商铺ID, 类别ID等等, 那你说,为啥要单独说呢? 之前的模型不也有, 但是这里在利用方式上有些不一样需要注意。
|
||||
|
||||
### Input Embedding with side Information
|
||||
在淘宝的推荐场景中,作者发现, 顾客与物品产生交互行为的时候,不仅考虑特定的商品本身,还考虑产品, 商铺,价格等,这个显然。所以,这里对于一个商品来说,不仅要用到Item ID,还用了更多的side info信息,包括`leat category, fist level category, brand,shop`。
|
||||
|
||||
所以,假设用户的短期行为是$\mathcal{S}^{u}=\left[i_{1}^{u}, \ldots, i_{t}^{u}, \ldots, i_{m}^{u}\right]$, 这里面的每个商品$i_t^u$其实有5个属性表示了,每个属性本质是ID,但转成embedding之后,就得到了5个embedding, 所以这里就涉及到了融合问题。 这里用$\boldsymbol{e}_{{i}^u_t} \in \mathbb{R}^{d \times 1}$来表示每个$i_t^u$,但这里不是embedding的pooling操作,而是Concat
|
||||
$$
|
||||
\boldsymbol{e}_{i_{t}^{u}}=\operatorname{concat}\left(\left\{\boldsymbol{e}_{i}^{f} \mid f \in \mathcal{F}\right\}\right)
|
||||
$$
|
||||
其中,$\boldsymbol{e}_{i}^{f}=\boldsymbol{W}^{f} \boldsymbol{x}_{i}^{f} \in \mathbb{R}^{d_{f} \times 1}$, 这个公式看着负责,其实就是每个side info的id过embedding layer得到各自的embedding。这里embedding的维度是$d_f$, 等拼接起来之后,就是$d$维了。这个点要注意。
|
||||
|
||||
另外就是用户的base表示向量了,这个很简单, 就是用户的基础画像,得到embedding,直接也是Concat,这个常规操作不解释:
|
||||
$$
|
||||
\boldsymbol{e}_{u}=\operatorname{concat}\left(\left\{\boldsymbol{e}_{u}^{p} \mid p \in \mathcal{P}\right\}\right)
|
||||
$$
|
||||
$e_u^p$是特征$p$的embedding。
|
||||
|
||||
Ok,输入这里说完了之后,就直接开盲盒, 不按照论文里面的顺序来了。想看更多细节的就去看原论文吧,感觉那里面说的有些啰嗦。不如直接上图解释来的明显:
|
||||
|
||||
|
||||
这里正好三个框把盒子框住了,下面剖析出每个来就行啦。
|
||||
### 短期用户行为建模
|
||||
这里短期用户行为是下面的那个框, 接收的输入,首先是用户最近的那次会话,里面各个商品加入了side info信息之后,有了最终的embedding表示$\left[\boldsymbol{e}_{i_{1}^{u}}, \ldots, \boldsymbol{e}_{i_{t}^{u}}\right]$。
|
||||
|
||||
这个东西,首先要过LSTM,学习序列信息,这个感觉不用多说,直接上公式:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\boldsymbol{i} \boldsymbol{n}_{t}^{u} &=\sigma\left(\boldsymbol{W}_{i n}^{1} \boldsymbol{e}_{i_{t}^{u}}+\boldsymbol{W}_{i n}^{2} \boldsymbol{h}_{t-1}^{u}+b_{i n}\right) \\
|
||||
f_{t}^{u} &=\sigma\left(\boldsymbol{W}_{f}^{1} \boldsymbol{e}_{i_{t}^{u}}+\boldsymbol{W}_{f}^{2} \boldsymbol{h}_{t-1}^{u}+b_{f}\right) \\
|
||||
\boldsymbol{o}_{t}^{u} &=\sigma\left(\boldsymbol{W}_{o}^{1} \boldsymbol{e}_{i}^{u}+\boldsymbol{W}_{o}^{2} \boldsymbol{h}_{t-1}^{u}+b_{o}\right) \\
|
||||
\boldsymbol{c}_{t}^{u} &=\boldsymbol{f}_{t} \boldsymbol{c}_{t-1}^{u}+\boldsymbol{i} \boldsymbol{n}_{t}^{u} \tanh \left(\boldsymbol{W}_{c}^{1} \boldsymbol{e}_{i_{t}^{u}}+\boldsymbol{W}_{c}^{2} \boldsymbol{h}_{t-1}^{u}+b_{c}\right) \\
|
||||
\boldsymbol{h}_{t}^{u} &=\boldsymbol{o}_{t}^{u} \tanh \left(\boldsymbol{c}_{t}^{u}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这里采用的是多输入多输出, 即每个时间步都会有一个隐藏状态$h_t^u$输出出来,那么经过LSTM之后,原始的序列就有了序列相关信息,得到了$\left[\boldsymbol{h}_{1}^{u}, \ldots, \boldsymbol{h}_{t}^{u}\right]$, 把这个记为$\boldsymbol{X}^{u}$。这里的$\boldsymbol{h}_{t}^{u} \in \mathbb{R}^{d \times 1}$表示时间$t$的序列偏好表示。
|
||||
|
||||
接下来, 这个东西要过Multi-head self-attention层,这个东西的原理我这里就不多讲了,这个东西可以学习到$h_i^u$系列之间的相关性,这个操作从某种角度看,也很像聚类, 因为我们这里是先用多头矩阵把$h_i^u$系列映射到多个空间,然后从各个空间中互求相关性
|
||||
$$
|
||||
\text { head }{ }_{i}^{u}=\operatorname{Attention}\left(\boldsymbol{W}_{i}^{Q} \boldsymbol{X}^{u}, \boldsymbol{W}_{i}^{K} \boldsymbol{X}^{u}, \boldsymbol{W}_{i}^{V} \boldsymbol{X}^{u}\right)
|
||||
$$
|
||||
得到权重后,对原始的向量加权融合。 让$Q_{i}^{u}=W_{i}^{Q} X^{u}$, $K_{i}^{u}=W_{i}^{K} \boldsymbol{X}^{u}$,$V_{i}^{u}=W_{i}^{V} X^{u}$, 背后计算是:
|
||||
$$
|
||||
\begin{aligned}
|
||||
&f\left(Q_{i}^{u}, K_{i}^{u}\right)=Q_{i}^{u T} K_{i}^{u} \\
|
||||
&A_{i}^{u}=\operatorname{softmax}\left(f\left(Q_{i}^{u}, K_{i}^{u}\right)\right)
|
||||
\end{aligned} \\ \operatorname{head}_{i}^{u}=V_{i}^{u} A_{i}^{u T}
|
||||
$$
|
||||
|
||||
这里如果有多头注意力基础的话非常好理解啊,不多解释,可以看我[这篇文章](https://blog.csdn.net/wuzhongqiang/article/details/104414239?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164872966516781683952272%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=164872966516781683952272&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-104414239.nonecase&utm_term=Attention+is+all&spm=1018.2226.3001.4450)补一下。
|
||||
|
||||
这是一个头的计算, 接下来每个头都这么算,假设有$h$个头,这里会通过上面的映射矩阵$W$系列,先把原始的$h_i^u$向量映射到$d_{k}=\frac{1}{h} d$维度,然后计算$head_i^u$也是$d_k$维,这样$h$个head进行拼接,正好是$d$维, 接下来过一个全连接或者线性映射得到MultiHead的输出。
|
||||
$$
|
||||
\hat{X}^{u}=\text { MultiHead }\left(X^{u}\right)=W^{O} \text { concat }\left(\text { head }_{1}^{u}, \ldots, \text { head }_{h}^{u}\right)
|
||||
$$
|
||||
|
||||
这样就相当于更相似的$h_i^u$融合到了一块,而这个更相似又是从多个角度得到的,于是乎, 作者认为,这样就能学习到用户的多兴趣。
|
||||
|
||||
得到这个东西之后,接下来再过一个User Attention, 因为作者发现,对于相似历史行为的不同用户,其兴趣偏好也不太一样。
|
||||
所以加入这个用户Attention层,想挖掘更细粒度的用户个性化信息。 当然,这个就是普通的embedding层了, 用户的base向量$e_u$作为query,与$\hat{X}^{u}$的每个向量做Attention,然后加权求和得最终向量:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\alpha_{k} &=\frac{\exp \left(\hat{\boldsymbol{h}}_{k}^{u T} \boldsymbol{e}_{u}\right)}{\sum_{k=1}^{t} \exp \left(\hat{\boldsymbol{h}}_{k}^{u T} \boldsymbol{e}_{u}\right)} \\
|
||||
\boldsymbol{s}_{t}^{u} &=\sum_{k=1}^{t} \alpha_{k} \hat{\boldsymbol{h}}_{k}^{u}
|
||||
\end{aligned}
|
||||
$$
|
||||
其中$s_{t}^{u} \in \mathbb{R}^{d \times 1}$,这样短期行为兴趣就修成了正果。
|
||||
|
||||
### 用户长期行为建模
|
||||
从长期的视角来看,用户在不同的维度上可能积累了广泛的兴趣,用户可能经常访问一组类似的商店,并反复购买属于同一类别的商品。 所以长期行为$\mathcal{L}^{u}$来自于不同的特征尺度。
|
||||
$$
|
||||
\mathcal{L}^{u}=\left\{\mathcal{L}_{f}^{u} \mid f \in \mathcal{F}\right\}
|
||||
$$
|
||||
这里面包含了各种side特征。这里就和短期行为那里不太一样了,长期行为这里,是从特征的维度进行聚合,也就是把用户的历史长序列分成了多个特征,比如用户历史点击过的商品,历史逛过的店铺,历史看过的商品的类别,品牌等,分成了多个特征子集,然后这每个特征子集里面有对应的id,比如商品有商品id, 店铺有店铺id等,对于每个子集,过user Attention layer,和用户的base向量求Attention, 相当于看看用户喜欢逛啥样的商店, 喜欢啥样的品牌,啥样的商品类别等等,得到每个子集最终的表示向量。每个子集的计算过程如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\alpha_{k} &=\frac{\exp \left(\boldsymbol{g}_{k}^{u T} \boldsymbol{e}_{u}\right)}{\sum_{k=1}^{\left|\mathcal{L}_{f}^{u}\right|} \exp \left(\boldsymbol{g}_{k}^{u T} \boldsymbol{e}_{u}\right)} \\
|
||||
z_{f}^{u} &=\sum_{k=1}^{\left|\mathcal{L}_{f}^{u}\right|} \alpha_{k} \boldsymbol{g}_{k}^{u}
|
||||
\end{aligned}
|
||||
$$
|
||||
每个子集都会得到一个加权的向量,把这个东西拼起来,然后过DNN。
|
||||
$$
|
||||
\begin{aligned}
|
||||
&z^{u}=\operatorname{concat}\left(\left\{z_{f}^{u} \mid f \in \mathcal{F}\right\}\right) \\
|
||||
&\boldsymbol{p}^{u}=\tanh \left(\boldsymbol{W}^{p} z^{u}+b\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这里的$\boldsymbol{p}^{u} \in \mathbb{R}^{d \times 1}$, 这样就得到了用户的长期兴趣表示。
|
||||
### 短长期兴趣融合
|
||||
长短期兴趣融合这里,作者发现之前模型往往喜欢直接拼接起来,或者加和,注意力加权等,但作者认为这样不能很好的将两类兴趣融合起来,因为长期序列里面,其实只有很少的一部分行为和当前有关。那么这样的话,直接无脑融合是有问题的。所以这里作者用了一种较为巧妙的方式,即门控机制:
|
||||
$$
|
||||
G_{t}^{u}=\operatorname{sigmoid}\left(\boldsymbol{W}^{1} \boldsymbol{e}_{u}+\boldsymbol{W}^{2} s_{t}^{u}+\boldsymbol{W}^{3} \boldsymbol{p}^{u}+b\right) \\
|
||||
o_{t}^{u}=\left(1-G_{t}^{u}\right) \odot p^{u}+G_{t}^{u} \odot s_{t}^{u}
|
||||
$$
|
||||
这个和LSTM的这种门控机制很像,首先门控接收的输入有用户画像$e_u$,用户短期兴趣$s_t^u$, 用户长期兴趣$p^u$,经过sigmoid函数得到了$G_{t}^{u} \in \mathbb{R}^{d \times 1}$,用来决定在$t$时刻短期和长期兴趣的贡献程度。然后根据这个贡献程度对短期和长期偏好加权进行融合。
|
||||
|
||||
为啥这东西就有用了呢? 实验中证明了这个东西有用,但这里给出我的理解哈,我们知道最终得到的短期或者长期兴趣都是$d$维的向量, 每一个维度可能代表着不同的兴趣偏好,比如第一维度代表品牌,第二个维度代表类别,第三个维度代表价格,第四个维度代表商店等等,当然假设哈,真实的向量不可解释。
|
||||
|
||||
那么如果我们是直接相加或者是加权相加,其实都意味着长短期兴趣这每个维度都有很高的保留, 但其实上,万一长期兴趣和短期兴趣维度冲突了呢? 比如短期兴趣里面可能用户喜欢这个品牌,长期用户里面用户喜欢那个品牌,那么听谁的? 你可能说短期兴趣这个占更大权重呗,那么普通加权可是所有向量都加的相同的权重,品牌这个维度听短期兴趣的,其他维度比如价格,商店也都听短期兴趣的?本身存在不合理性。那么反而直接相加或者加权效果会不好。
|
||||
|
||||
而门控机制的巧妙就在于,我会给每个维度都学习到一个权重,而这个权重非0即1(近似哈), 那么接下来融合的时候,我通过这个门控机制,取长期和短期兴趣向量每个维度上的其中一个。比如在品牌方面听谁的,类别方面听谁的,价格方面听谁的,只会听短期和长期兴趣的其中一个的。这样就不会有冲突发生,而至于具体听谁的,交给网络自己学习。这样就使得用户长期兴趣和短期兴趣融合的时候,每个维度上的信息保留变得**有选择**。使得兴趣的融合方式更加的灵活。
|
||||
|
||||
==这其实又给我们提供了一种两个向量融合的一种新思路,并不一定非得加权或者拼接或者相加了,还可以通过门控机制让网络自己学==
|
||||
|
||||
|
||||
## SDM模型的简易复现
|
||||
下面参考DeepMatch,用简易的代码实现下SDM,并在新闻推荐的数据集上进行召回任务。
|
||||
|
||||
首先,下面分析SDM的整体架构,从代码层面看运行流程, 然后就这里面几个关键的细节进行说明。
|
||||
|
||||
### 模型的输入
|
||||
对于SDM模型,由于它是将用户的行为序列分成了会话的形式,所以在构造SDM模型输入方面和前面的MIND以及YouTubeDNN有很大的不同了,所以这里需要先重点强调下输入。
|
||||
|
||||
在为SDM产生数据集的时候, 需要传入短期会话的长度以及长期会话的长度, 这样, 对于一个行为序列,构造数据集的时候要按照两个长度分成短期行为和长期行为两种,并且每一种都需要指明真实的序列长度。另外,由于这里用到了文章的side info信息,所以我这里在之前列的基础上加入了文章的两个类别特征分别是cat_1和cat_2,作为文章的side info。 这个产生数据集的代码如下:
|
||||
|
||||
```python
|
||||
"""构造sdm数据集"""
|
||||
def get_data_set(click_data, seq_short_len=5, seq_prefer_len=50):
|
||||
"""
|
||||
:param: seq_short_len: 短期会话的长度
|
||||
:param: seq_prefer_len: 会话的最长长度
|
||||
"""
|
||||
click_data.sort_values("expo_time", inplace=True)
|
||||
|
||||
train_set, test_set = [], []
|
||||
for user_id, hist_click in tqdm(click_data.groupby('user_id')):
|
||||
pos_list = hist_click['article_id'].tolist()
|
||||
cat1_list = hist_click['cat_1'].tolist()
|
||||
cat2_list = hist_click['cat_2'].tolist()
|
||||
|
||||
# 滑动窗口切分数据
|
||||
for i in range(1, len(pos_list)):
|
||||
hist = pos_list[:i]
|
||||
cat1_hist = cat1_list[:i]
|
||||
cat2_hist = cat2_list[:i]
|
||||
# 序列长度只够短期的
|
||||
if i <= seq_short_len and i != len(pos_list) - 1:
|
||||
train_set.append((
|
||||
# 用户id, 用户短期历史行为序列, 用户长期历史行为序列, 当前行为文章, label,
|
||||
user_id, hist[::-1], [0]*seq_prefer_len, pos_list[i], 1,
|
||||
# 用户短期历史序列长度, 用户长期历史序列长度,
|
||||
len(hist[::-1]), 0,
|
||||
# 用户短期历史序列对应类别1, 用户长期历史行为序列对应类别1
|
||||
cat1_hist[::-1], [0]*seq_prefer_len,
|
||||
# 历史短期历史序列对应类别2, 用户长期历史行为序列对应类别2
|
||||
cat2_hist[::-1], [0]*seq_prefer_len
|
||||
))
|
||||
# 序列长度够长期的
|
||||
elif i != len(pos_list) - 1:
|
||||
train_set.append((
|
||||
# 用户id, 用户短期历史行为序列,用户长期历史行为序列, 当前行为文章, label
|
||||
user_id, hist[::-1][:seq_short_len], hist[::-1][seq_short_len:], pos_list[i], 1,
|
||||
# 用户短期行为序列长度,用户长期行为序列长度,
|
||||
seq_short_len, len(hist[::-1])-seq_short_len,
|
||||
# 用户短期历史行为序列对应类别1, 用户长期历史行为序列对应类别1
|
||||
cat1_hist[::-1][:seq_short_len], cat1_hist[::-1][seq_short_len:],
|
||||
# 用户短期历史行为序列对应类别2, 用户长期历史行为序列对应类别2
|
||||
cat2_hist[::-1][:seq_short_len], cat2_hist[::-1][seq_short_len:]
|
||||
))
|
||||
# 测试集保留最长的那一条
|
||||
elif i <= seq_short_len and i == len(pos_list) - 1:
|
||||
test_set.append((
|
||||
user_id, hist[::-1], [0]*seq_prefer_len, pos_list[i], 1,
|
||||
len(hist[::-1]), 0,
|
||||
cat1_hist[::-1], [0]*seq_perfer_len,
|
||||
cat2_hist[::-1], [0]*seq_prefer_len
|
||||
))
|
||||
else:
|
||||
test_set.append((
|
||||
user_id, hist[::-1][:seq_short_len], hist[::-1][seq_short_len:], pos_list[i], 1,
|
||||
seq_short_len, len(hist[::-1])-seq_short_len,
|
||||
cat1_hist[::-1][:seq_short_len], cat1_hist[::-1][seq_short_len:],
|
||||
cat2_list[::-1][:seq_short_len], cat2_hist[::-1][seq_short_len:]
|
||||
))
|
||||
|
||||
random.shuffle(train_set)
|
||||
random.shuffle(test_set)
|
||||
|
||||
return train_set, test_set
|
||||
```
|
||||
思路和之前的是一样的,无非就是根据会话的长短,把之前的一个长行为序列划分成了短期和长期两个,然后加入两个新的side info特征。
|
||||
|
||||
### 模型的代码架构
|
||||
整个SDM模型算是参考deepmatch修改的一个简易版本:
|
||||
|
||||
```python
|
||||
def SDM(user_feature_columns, item_feature_columns, history_feature_list, num_sampled=5, units=32, rnn_layers=2,
|
||||
dropout_rate=0.2, rnn_num_res=1, num_head=4, l2_reg_embedding=1e-6, dnn_activation='tanh', seed=1024):
|
||||
"""
|
||||
:param rnn_num_res: rnn的残差层个数
|
||||
:param history_feature_list: short和long sequence field
|
||||
"""
|
||||
# item_feature目前只支持doc_id, 再加别的就不行了,其实这里可以改造下
|
||||
if (len(item_feature_columns)) > 1:
|
||||
raise ValueError("SDM only support 1 item feature like doc_id")
|
||||
|
||||
# 获取item_feature的一些属性
|
||||
item_feature_column = item_feature_columns[0]
|
||||
item_feature_name = item_feature_column.name
|
||||
item_vocabulary_size = item_feature_column.vocabulary_size
|
||||
|
||||
# 为用户特征创建Input层
|
||||
user_input_layer_dict = build_input_layers(user_feature_columns)
|
||||
item_input_layer_dict = build_input_layers(item_feature_columns)
|
||||
|
||||
# 将Input层转化成列表的形式作为model的输入
|
||||
user_input_layers = list(user_input_layer_dict.values())
|
||||
item_input_layers = list(item_input_layer_dict.values())
|
||||
|
||||
# 筛选出特征中的sparse特征和dense特征,方便单独处理
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
if len(dense_feature_columns) != 0:
|
||||
raise ValueError("SDM dont support dense feature") # 目前不支持Dense feature
|
||||
varlen_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(user_feature_columns+item_feature_columns)
|
||||
|
||||
# 拿到短期会话和长期会话列 之前的命名规则在这里起作用
|
||||
sparse_varlen_feature_columns = []
|
||||
prefer_history_columns = []
|
||||
short_history_columns = []
|
||||
|
||||
prefer_fc_names = list(map(lambda x: "prefer_" + x, history_feature_list))
|
||||
short_fc_names = list(map(lambda x: "short_" + x, history_feature_list))
|
||||
|
||||
for fc in varlen_feature_columns:
|
||||
if fc.name in prefer_fc_names:
|
||||
prefer_history_columns.append(fc)
|
||||
elif fc.name in short_fc_names:
|
||||
short_history_columns.append(fc)
|
||||
else:
|
||||
sparse_varlen_feature_columns.append(fc)
|
||||
|
||||
# 获取用户的长期行为序列列表 L^u
|
||||
# [<tf.Tensor 'emb_prefer_doc_id_2/Identity:0' shape=(None, 50, 32) dtype=float32>, <tf.Tensor 'emb_prefer_cat1_2/Identity:0' shape=(None, 50, 32) dtype=float32>, <tf.Tensor 'emb_prefer_cat2_2/Identity:0' shape=(None, 50, 32) dtype=float32>]
|
||||
prefer_emb_list = embedding_lookup(prefer_fc_names, user_input_layer_dict, embedding_layer_dict)
|
||||
# 获取用户的短期序列列表 S^u
|
||||
# [<tf.Tensor 'emb_short_doc_id_2/Identity:0' shape=(None, 5, 32) dtype=float32>, <tf.Tensor 'emb_short_cat1_2/Identity:0' shape=(None, 5, 32) dtype=float32>, <tf.Tensor 'emb_short_cat2_2/Identity:0' shape=(None, 5, 32) dtype=float32>]
|
||||
short_emb_list = embedding_lookup(short_fc_names, user_input_layer_dict, embedding_layer_dict)
|
||||
|
||||
# 用户离散特征的输入层与embedding层拼接 e^u
|
||||
user_emb_list = embedding_lookup([col.name for col in sparse_feature_columns], user_input_layer_dict, embedding_layer_dict)
|
||||
user_emb = concat_func(user_emb_list)
|
||||
user_emb_output = Dense(units, activation=dnn_activation, name='user_emb_output')(user_emb) # (None, 1, 32)
|
||||
|
||||
# 长期序列行为编码
|
||||
# 过AttentionSequencePoolingLayer --> Concat --> DNN
|
||||
prefer_sess_length = user_input_layer_dict['prefer_sess_length']
|
||||
prefer_att_outputs = []
|
||||
# 遍历长期行为序列
|
||||
for i, prefer_emb in enumerate(prefer_emb_list):
|
||||
prefer_attention_output = AttentionSequencePoolingLayer(dropout_rate=0)([user_emb_output, prefer_emb, prefer_sess_length])
|
||||
prefer_att_outputs.append(prefer_attention_output)
|
||||
prefer_att_concat = concat_func(prefer_att_outputs) # (None, 1, 64) <== Concat(item_embedding,cat1_embedding,cat2_embedding)
|
||||
prefer_output = Dense(units, activation=dnn_activation, name='prefer_output')(prefer_att_concat)
|
||||
# print(prefer_output.shape) # (None, 1, 32)
|
||||
|
||||
# 短期行为序列编码
|
||||
short_sess_length = user_input_layer_dict['short_sess_length']
|
||||
short_emb_concat = concat_func(short_emb_list) # (None, 5, 64) 这里注意下, 对于短期序列,描述item的side info信息进行了拼接
|
||||
short_emb_input = Dense(units, activation=dnn_activation, name='short_emb_input')(short_emb_concat) # (None, 5, 32)
|
||||
# 过rnn 这里的return_sequence=True, 每个时间步都需要输出h
|
||||
short_rnn_output = DynamicMultiRNN(num_units=units, return_sequence=True, num_layers=rnn_layers,
|
||||
num_residual_layers=rnn_num_res, # 这里竟然能用到残差
|
||||
dropout_rate=dropout_rate)([short_emb_input, short_sess_length])
|
||||
# print(short_rnn_output) # (None, 5, 32)
|
||||
# 过MultiHeadAttention # (None, 5, 32)
|
||||
short_att_output = MultiHeadAttention(num_units=units, head_num=num_head, dropout_rate=dropout_rate)([short_rnn_output, short_sess_length]) # (None, 5, 64)
|
||||
# user_attention # (None, 1, 32)
|
||||
short_output = UserAttention(num_units=units, activation=dnn_activation, use_res=True, dropout_rate=dropout_rate)([user_emb_output, short_att_output, short_sess_length])
|
||||
|
||||
# 门控融合
|
||||
gated_input = concat_func([prefer_output, short_output, user_emb_output])
|
||||
gate = Dense(units, activation='sigmoid')(gated_input) # (None, 1, 32)
|
||||
|
||||
# temp = tf.multiply(gate, short_output) + tf.multiply(1-gate, prefer_output) 感觉这俩一样?
|
||||
gated_output = Lambda(lambda x: tf.multiply(x[0], x[1]) + tf.multiply(1-x[0], x[2]))([gate, short_output, prefer_output]) # [None, 1,32]
|
||||
gated_output_reshape = Lambda(lambda x: tf.squeeze(x, 1))(gated_output) # (None, 32) 这个维度必须要和docembedding层的维度一样,否则后面没法sortmax_loss
|
||||
|
||||
# 接下来
|
||||
item_embedding_matrix = embedding_layer_dict[item_feature_name] # 获取doc_id的embedding层
|
||||
item_index = EmbeddingIndex(list(range(item_vocabulary_size)))(item_input_layer_dict[item_feature_name]) # 所有doc_id的索引
|
||||
item_embedding_weight = NoMask()(item_embedding_matrix(item_index)) # 拿到所有item的embedding
|
||||
pooling_item_embedding_weight = PoolingLayer()([item_embedding_weight]) # 这里依然是当可能不止item_id,或许还有brand_id, cat_id等,需要池化
|
||||
|
||||
# 这里传入的是整个doc_id的embedding, user_embedding, 以及用户点击的doc_id,然后去进行负采样计算损失操作
|
||||
output = SampledSoftmaxLayer(num_sampled)([pooling_item_embedding_weight, gated_output_reshape, item_input_layer_dict[item_feature_name]])
|
||||
|
||||
model = Model(inputs=user_input_layers+item_input_layers, outputs=output)
|
||||
|
||||
# 下面是等模型训练完了之后,获取用户和item的embedding
|
||||
model.__setattr__("user_input", user_input_layers)
|
||||
model.__setattr__("user_embedding", gated_output_reshape) # 用户embedding是取得门控融合的用户向量
|
||||
model.__setattr__("item_input", item_input_layers)
|
||||
# item_embedding取得pooling_item_embedding_weight, 这个会发现是负采样操作训练的那个embedding矩阵
|
||||
model.__setattr__("item_embedding", get_item_embedding(pooling_item_embedding_weight, item_input_layer_dict[item_feature_name]))
|
||||
return model
|
||||
```
|
||||
函数式API搭建模型的方式,首先我们需要传入封装好的用户特征描述以及item特征描述,比如:
|
||||
|
||||
```python
|
||||
# 建立模型
|
||||
user_feature_columns = [
|
||||
SparseFeat('user_id', feature_max_idx['user_id'], 16),
|
||||
SparseFeat('gender', feature_max_idx['gender'], 16),
|
||||
SparseFeat('age', feature_max_idx['age'], 16),
|
||||
SparseFeat('city', feature_max_idx['city'], 16),
|
||||
|
||||
VarLenSparseFeat(SparseFeat('short_doc_id', feature_max_idx['article_id'], embedding_dim, embedding_name="doc_id"), SEQ_LEN_short, 'mean', 'short_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('prefer_doc_id', feature_max_idx['article_id'], embedding_dim, embedding_name='doc_id'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('short_cat1', feature_max_idx['cat_1'], embedding_dim, embedding_name='cat_1'), SEQ_LEN_short, 'mean', 'short_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('prefer_cat1', feature_max_idx['cat_1'], embedding_dim, embedding_name='cat_1'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('short_cat2', feature_max_idx['cat_2'], embedding_dim, embedding_name='cat_2'), SEQ_LEN_short, 'mean', 'short_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('prefer_cat2', feature_max_idx['cat_2'], embedding_dim, embedding_name='cat_2'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
|
||||
]
|
||||
|
||||
item_feature_columns = [SparseFeat('doc_id', feature_max_idx['article_id'], embedding_dim)]
|
||||
```
|
||||
这里需要注意的一个点是短期和长期序列的名字,必须严格的`short_, prefer_`进行标识,因为在模型搭建的时候就是靠着这个去找到短期和长期序列特征的。
|
||||
|
||||
逻辑其实也比较清晰,首先是建立Input层,然后是embedding层, 接下来,根据命名选择出用户的base特征列, 短期行为序列和长期行为序列。长期序列的话是过`AttentionPoolingLayer`层进行编码,这里本质上注意力然后融合,但这里注意的一个点就是for循环,也就是长期序列行为里面的特征列,比如商品,cat_1, cat_2是for循环的形式求融合向量,再拼接起来过DNN,和论文图保持一致。
|
||||
|
||||
短期序列编码部分,是`item_embedding,cat_1embedding, cat_2embedding`拼接起来,过`DynamicMultiRNN`层学习序列信息, 过`MultiHeadAttention`学习多兴趣,最后过`UserAttentionLayer`进行向量融合。 接下来,长期兴趣向量和短期兴趣向量以及用户base向量,过门控融合机制,得到最终的`user_embedding`。
|
||||
|
||||
而后面的那块是为了模型训练完之后,拿用户embedding和item embedding用的, 这个在MIND那篇文章里作了解释。
|
||||
|
||||
## 总结
|
||||
今天整理的是SDM,这也是一个标准的序列推荐召回模型,主要还是研究用户的序列,不过这篇paper里面一个有意思的点就是把用户的行为训练以会话的形式进行切分,然后再根据时间,分成了短期会话和长期会话,然后分别采用不同的策略去学习用户的短期兴趣和长期兴趣。
|
||||
* 对于短期会话,可能和当前预测相关性较大,所以首先用RNN来学习序列信息,然后采用多头注意力机制得到用户的多兴趣, 隐隐约约感觉多头注意力机制还真有种能聚类的功效,接下来就是和用户的base向量进行注意力融合得到短期兴趣
|
||||
* 长期会话序列中,每个side info信息进行分开,然后分别进行注意力编码融合得到
|
||||
|
||||
为了使得长期会话中对当前预测有用的部分得以体现,在融合短期兴趣和长期兴趣的时候,采用了门控的方式,而不是普通的拼接或者加和等操作,使得兴趣保留信息变得**有选择**。
|
||||
|
||||
这其实就是这篇paper的故事了,借鉴的地方首先是多头注意力机制也能学习到用户的多兴趣, 这样对于多兴趣,就有了胶囊网络与多头注意力机制两种思路。 而对于两个向量融合,这里又给我们提供了一种门控融合机制。
|
||||
|
||||
|
||||
**参考**:
|
||||
|
||||
* SDM原论文
|
||||
* [AI上推荐 之 SDM模型(建模用户长短期兴趣的Match模型)](https://blog.csdn.net/wuzhongqiang/article/details/123856954?spm=1001.2014.3001.5501)
|
||||
* [一文读懂Attention机制](https://zhuanlan.zhihu.com/p/129316415)
|
||||
* [【推荐系统经典论文(十)】阿里SDM模型](https://zhuanlan.zhihu.com/p/137775247?from_voters_page=true)
|
||||
* [SDM-深度序列召回模型](https://zhuanlan.zhihu.com/p/395673080)
|
||||
* [推荐广告中的序列建模](https://blog.csdn.net/qq_41010971/article/details/123762312?spm=1001.2014.3001.5501)
|
||||
@@ -1,65 +0,0 @@
|
||||
# 背景和目的
|
||||
|
||||
召回早前经历的第一代协同过滤技术,让模型可以在数量级巨大的item集中找到用户潜在想要看到的商品。这种方式有很明显的缺点,一个是对于用户而言,只能通过他历史行为去构建候选集,并且会基于算力的局限做截断。所以推荐结果的多样性和新颖性比较局限,导致推荐的有可能都是用户看过的或者买过的商品。之后在Facebook开源了FASSI库之后,基于内积模型的向量检索方案得到了广泛应用,也就是第二代召回技术。这种技术通过将用户和物品用向量表示,然后用内积的大小度量兴趣,借助向量索引实现大规模的全量检索。这里虽然改善了第一代的无法全局检索的缺点,然而这种模式下存在索引构建和模型优化目标不一致的问题,索引优化是基于向量的近似误差,而召回问题的目标是最大化topK召回率。且这类方法也不方便在用户和物品之间做特征组合。
|
||||
|
||||
所以阿里开发了一种可以承载各种深度模型来检索用户潜在兴趣的推荐算法解决方案。这个TDM模型是基于树结构,利用树结构对全量商品进行检索,将复杂度由O(N)下降到O(logN)。
|
||||
|
||||
# 模型结构
|
||||
|
||||
**树结构**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420213149324.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
</div>
|
||||
|
||||
如上图,树中的每一个叶子节点对应一个商品item,非叶子结点表示的是item的集合**(这里的树不限于二叉树)**。这种层次化结构体现了粒度从粗到细的item架构。
|
||||
|
||||
**整体结构**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420200433442.png" alt="image-20210308142624189" style="zoom: 70%;" />
|
||||
</div>
|
||||
|
||||
# 算法详解
|
||||
|
||||
1. 基于树的高效检索
|
||||
|
||||
算法通常采用beam-search的方法,根据用户对每层节点挑选出topK,将挑选出来的这几个topK节点的子节点作为下一层的候选集,最终会落到叶子节点上。
|
||||
这么做的理论依据是当前层的最有优topK节点的父亲必然属于上次的父辈节点的最优topK:
|
||||
$$
|
||||
p^{(j)}(n|u) = {{max \atop{n_{c}\in{\{n's children nodes in level j+1\}}}}p^{(j+1)}(n_{c}|u) \over {\alpha^{j}}}
|
||||
$$
|
||||
其中$p^{(j)}(n|u)$表示用户u对j层节点n感兴趣的概率,$\alpha^{j}$表示归一化因子。
|
||||
|
||||
2. 对兴趣进行建模
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420214040264.png" alt="image-20210308142624189" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
如上图,用户对叶子层item6感兴趣,可以认为它的兴趣是1,同层别的候选节点的兴趣为0,顺着着绿色线路上去的节点都标记为1,路线上的同层别的候选节点都标记为0。这样的操作就可以根据1和0构建用于每一层的正负样本。
|
||||
|
||||
样本构建完成后,可以在模型结构左侧采用任意的深度学习模型来承担用户兴趣判别器的角色,输入就是当前层构造的正负样本,输出则是(用户,节点)对的兴趣度,这个将被用作检索过程中选取topK的评判指标。**在整体结构图中,我们可以看到节点特征方面,使用的是node embedding**,说明在进入模型前已经向量化了。
|
||||
|
||||
3. 训练过程
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420220831318.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
</div>
|
||||
|
||||
整体联合训练的方式如下:
|
||||
|
||||
1. 构造随机二叉树
|
||||
2. 基于树模型生成样本
|
||||
3. 训练DNN模型直到收敛
|
||||
4. 基于DNN模型得到样本的Embedding,重新构造聚类二叉树
|
||||
5. 循环上述2~4过程
|
||||
|
||||
具体的,在初始化树结构的时候,首先借助商品的类别信息进行排序,将相同类别的商品放到一起,然后递归的将同类别中的商品等量的分到两个子类中,直到集合中只包含一项,利用这种自顶向下的方式来初始化一棵树。基于该树采样生成深度模型训练所需的样本,然后进一步训练模型,训练结束之后可以得到每个树节点对应的Embedding向量,利用节点的Embedding向量,采用K-Means聚类方法来重新构建一颗树,最后基于这颗新生成的树,重新训练深层网络。
|
||||
|
||||
**参考资料**
|
||||
|
||||
- [阿里妈妈深度树检索技术(TDM) 及应用框架的探索实践](https://mp.weixin.qq.com/s/sw16_sUsyYuzpqqy39RsdQ)
|
||||
- [阿里TDM:Tree-based Deep Model](https://zhuanlan.zhihu.com/p/78941783)
|
||||
- [阿里妈妈TDM模型详解](https://zhuanlan.zhihu.com/p/93201318)
|
||||
- [Paddle TDM 模型实现](https://github.com/PaddlePaddle/PaddleRec/blob/master/models/treebased/README.md)
|
||||
@@ -1,352 +0,0 @@
|
||||
### GBDT+LR简介
|
||||
|
||||
前面介绍的协同过滤和矩阵分解存在的劣势就是仅利用了用户与物品相互行为信息进行推荐, 忽视了用户自身特征, 物品自身特征以及上下文信息等,导致生成的结果往往会比较片面。 而这次介绍的这个模型是2014年由Facebook提出的GBDT+LR模型, 该模型利用GBDT自动进行特征筛选和组合, 进而生成新的离散特征向量, 再把该特征向量当做LR模型的输入, 来产生最后的预测结果, 该模型能够综合利用用户、物品和上下文等多种不同的特征, 生成较为全面的推荐结果, 在CTR点击率预估场景下使用较为广泛。
|
||||
|
||||
下面首先会介绍逻辑回归和GBDT模型各自的原理及优缺点, 然后介绍GBDT+LR模型的工作原理和细节。
|
||||
|
||||
### 逻辑回归模型
|
||||
|
||||
逻辑回归模型非常重要, 在推荐领域里面, 相比于传统的协同过滤, 逻辑回归模型能够综合利用用户、物品、上下文等多种不同的特征生成较为“全面”的推荐结果, 关于逻辑回归的更多细节, 可以参考下面给出的链接,这里只介绍比较重要的一些细节和在推荐中的应用。
|
||||
|
||||
逻辑回归是在线性回归的基础上加了一个 Sigmoid 函数(非线形)映射,使得逻辑回归成为了一个优秀的分类算法, 学习逻辑回归模型, 首先应该记住一句话:**逻辑回归假设数据服从伯努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数,来达到将数据二分类的目的。**
|
||||
|
||||
相比于协同过滤和矩阵分解利用用户的物品“相似度”进行推荐, 逻辑回归模型将问题看成了一个分类问题, 通过预测正样本的概率对物品进行排序。这里的正样本可以是用户“点击”了某个商品或者“观看”了某个视频, 均是推荐系统希望用户产生的“正反馈”行为, 因此**逻辑回归模型将推荐问题转化成了一个点击率预估问题**。而点击率预测就是一个典型的二分类, 正好适合逻辑回归进行处理, 那么逻辑回归是如何做推荐的呢? 过程如下:
|
||||
1. 将用户年龄、性别、物品属性、物品描述、当前时间、当前地点等特征转成数值型向量
|
||||
2. 确定逻辑回归的优化目标,比如把点击率预测转换成二分类问题, 这样就可以得到分类问题常用的损失作为目标, 训练模型
|
||||
3. 在预测的时候, 将特征向量输入模型产生预测, 得到用户“点击”物品的概率
|
||||
4. 利用点击概率对候选物品排序, 得到推荐列表
|
||||
|
||||
推断过程可以用下图来表示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200909215410263.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
这里的关键就是每个特征的权重参数$w$, 我们一般是使用梯度下降的方式, 首先会先随机初始化参数$w$, 然后将特征向量(也就是我们上面数值化出来的特征)输入到模型, 就会通过计算得到模型的预测概率, 然后通过对目标函数求导得到每个$w$的梯度, 然后进行更新$w$
|
||||
|
||||
这里的目标函数长下面这样:
|
||||
|
||||
$$
|
||||
J(w)=-\frac{1}{m}\left(\sum_{i=1}^{m}\left(y^{i} \log f_{w}\left(x^{i}\right)+\left(1-y^{i}\right) \log \left(1-f_{w}\left(x^{i}\right)\right)\right)\right.
|
||||
$$
|
||||
求导之后的方式长这样:
|
||||
$$
|
||||
w_{j} \leftarrow w_{j}-\gamma \frac{1}{m} \sum_{i=1}^{m}\left(f_{w}\left(x^{i}\right)-y^{i}\right) x_{j}^{i}
|
||||
$$
|
||||
这样通过若干次迭代, 就可以得到最终的$w$了, 关于这些公式的推导,可以参考下面给出的文章链接, 下面我们分析一下逻辑回归模型的优缺点。
|
||||
|
||||
**优点:**
|
||||
1. LR模型形式简单,可解释性好,从特征的权重可以看到不同的特征对最后结果的影响。
|
||||
2. 训练时便于并行化,在预测时只需要对特征进行线性加权,所以**性能比较好**,往往适合处理**海量id类特征**,用id类特征有一个很重要的好处,就是**防止信息损失**(相对于范化的 CTR 特征),对于头部资源会有更细致的描述
|
||||
3. 资源占用小,尤其是内存。在实际的工程应用中只需要存储权重比较大的特征及特征对应的权重。
|
||||
4. 方便输出结果调整。逻辑回归可以很方便的得到最后的分类结果,因为输出的是每个样本的概率分数,我们可以很容易的对这些概率分数进行cutoff,也就是划分阈值(大于某个阈值的是一类,小于某个阈值的是一类)
|
||||
|
||||
**当然, 逻辑回归模型也有一定的局限性**
|
||||
1. 表达能力不强, 无法进行特征交叉, 特征筛选等一系列“高级“操作(这些工作都得人工来干, 这样就需要一定的经验, 否则会走一些弯路), 因此可能造成信息的损失
|
||||
2. 准确率并不是很高。因为这毕竟是一个线性模型加了个sigmoid, 形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布
|
||||
3. 处理非线性数据较麻烦。逻辑回归在不引入其他方法的情况下,只能处理线性可分的数据, 如果想处理非线性, 首先对连续特征的处理需要先进行**离散化**(离散化的目的是为了引入非线性),如上文所说,人工分桶的方式会引入多种问题。
|
||||
4. LR 需要进行**人工特征组合**,这就需要开发者有非常丰富的领域经验,才能不走弯路。这样的模型迁移起来比较困难,换一个领域又需要重新进行大量的特征工程。
|
||||
|
||||
所以如何**自动发现有效的特征、特征组合,弥补人工经验不足,缩短LR特征实验周期**,是亟需解决的问题, 而GBDT模型, 正好可以**自动发现特征并进行有效组合**
|
||||
|
||||
### GBDT模型
|
||||
|
||||
GBDT全称梯度提升决策树,在传统机器学习算法里面是对真实分布拟合的最好的几种算法之一,在前几年深度学习还没有大行其道之前,gbdt在各种竞赛是大放异彩。原因大概有几个,一是效果确实挺不错。二是即可以用于分类也可以用于回归。三是可以筛选特征, 所以这个模型依然是一个非常重要的模型。
|
||||
|
||||
GBDT是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的误差来达到将数据分类或者回归的算法, 其训练过程如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200908202508786.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" style="zoom:65%;" />
|
||||
</div>
|
||||
gbdt通过多轮迭代, 每轮迭代会产生一个弱分类器, 每个分类器在上一轮分类器的残差基础上进行训练。 gbdt对弱分类器的要求一般是足够简单, 并且低方差高偏差。 因为训练的过程是通过降低偏差来不断提高最终分类器的精度。 由于上述高偏差和简单的要求,每个分类回归树的深度不会很深。最终的总分类器是将每轮训练得到的弱分类器加权求和得到的(也就是加法模型)。
|
||||
|
||||
关于GBDT的详细细节,依然是可以参考下面给出的链接。这里想分析一下GBDT如何来进行二分类的,因为我们要明确一点就是**gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练的**, 而这里的残差指的就是当前模型的负梯度值, 这个就要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的, 而**gbdt 无论用于分类还是回归一直都是使用的CART 回归树**, 那么既然是回归树, 是如何进行二分类问题的呢?
|
||||
|
||||
GBDT 来解决二分类问题和解决回归问题的本质是一样的,都是通过不断构建决策树的方式,使预测结果一步步的接近目标值, 但是二分类问题和回归问题的损失函数是不同的, 关于GBDT在回归问题上的树的生成过程, 损失函数和迭代原理可以参考给出的链接, 回归问题中一般使用的是平方损失, 而二分类问题中, GBDT和逻辑回归一样, 使用的下面这个:
|
||||
|
||||
$$
|
||||
L=\arg \min \left[\sum_{i}^{n}-\left(y_{i} \log \left(p_{i}\right)+\left(1-y_{i}\right) \log \left(1-p_{i}\right)\right)\right]
|
||||
$$
|
||||
其中, $y_i$是第$i$个样本的观测值, 取值要么是0要么是1, 而$p_i$是第$i$个样本的预测值, 取值是0-1之间的概率,由于我们知道GBDT拟合的残差是当前模型的负梯度, 那么我们就需要求出这个模型的导数, 即$\frac{dL}{dp_i}$, 对于某个特定的样本, 求导的话就可以只考虑它本身, 去掉加和号, 那么就变成了$\frac{dl}{dp_i}$, 其中$l$如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
l &=-y_{i} \log \left(p_{i}\right)-\left(1-y_{i}\right) \log \left(1-p_{i}\right) \\
|
||||
&=-y_{i} \log \left(p_{i}\right)-\log \left(1-p_{i}\right)+y_{i} \log \left(1-p_{i}\right) \\
|
||||
&=-y_{i}\left(\log \left(\frac{p_{i}}{1-p_{i}}\right)\right)-\log \left(1-p_{i}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
如果对逻辑回归非常熟悉的话, $\left(\log \left(\frac{p_{i}}{1-p_{i}}\right)\right)$一定不会陌生吧, 这就是对几率比取了个对数, 并且在逻辑回归里面这个式子会等于$\theta X$, 所以才推出了$p_i=\frac{1}{1+e^-{\theta X}}$的那个形式。 这里令$\eta_i=\frac{p_i}{1-p_i}$, 即$p_i=\frac{\eta_i}{1+\eta_i}$, 则上面这个式子变成了:
|
||||
|
||||
$$
|
||||
\begin{aligned}
|
||||
l &=-y_{i} \log \left(\eta_{i}\right)-\log \left(1-\frac{e^{\log \left(\eta_{i}\right)}}{1+e^{\log \left(\eta_{i}\right)}}\right) \\
|
||||
&=-y_{i} \log \left(\eta_{i}\right)-\log \left(\frac{1}{1+e^{\log \left(\eta_{i}\right)}}\right) \\
|
||||
&=-y_{i} \log \left(\eta_{i}\right)+\log \left(1+e^{\log \left(\eta_{i}\right)}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这时候,我们对$log(\eta_i)$求导, 得
|
||||
$$
|
||||
\frac{d l}{d \log (\eta_i)}=-y_{i}+\frac{e^{\log \left(\eta_{i}\right)}}{1+e^{\log \left(\eta_{i}\right)}}=-y_i+p_i
|
||||
$$
|
||||
这样, 我们就得到了某个训练样本在当前模型的梯度值了, 那么残差就是$y_i-p_i$。GBDT二分类的这个思想,其实和逻辑回归的思想一样,**逻辑回归是用一个线性模型去拟合$P(y=1|x)$这个事件的对数几率$log\frac{p}{1-p}=\theta^Tx$**, GBDT二分类也是如此, 用一系列的梯度提升树去拟合这个对数几率, 其分类模型可以表达为:
|
||||
$$
|
||||
P(Y=1 \mid x)=\frac{1}{1+e^{-F_{M}(x)}}
|
||||
$$
|
||||
|
||||
下面我们具体来看GBDT的生成过程, 构建分类GBDT的步骤有两个:
|
||||
1. 初始化GBDT
|
||||
和回归问题一样, 分类 GBDT 的初始状态也只有一个叶子节点,该节点为所有样本的初始预测值,如下:
|
||||
$$
|
||||
F_{0}(x)=\arg \min _{\gamma} \sum_{i=1}^{n} L(y, \gamma)
|
||||
$$
|
||||
上式里面, $F$代表GBDT模型, $F_0$是模型的初识状态, 该式子的意思是找到一个$\gamma$,使所有样本的 Loss 最小,在这里及下文中,$\gamma$都表示节点的输出,即叶子节点, 且它是一个 $log(\eta_i)$ 形式的值(回归值),在初始状态,$\gamma =F_0$。
|
||||
|
||||
下面看例子(该例子来自下面的第二个链接), 假设我们有下面3条样本:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200910095539432.png#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
</div>
|
||||
|
||||
我们希望构建 GBDT 分类树,它能通过「喜欢爆米花」、「年龄」和「颜色偏好」这 3 个特征来预测某一个样本是否喜欢看电影。我们把数据代入上面的公式中求Loss:
|
||||
$$
|
||||
\operatorname{Loss}=L(1, \gamma)+L(1, \gamma)+L(0, \gamma)
|
||||
$$
|
||||
为了令其最小, 我们求导, 且让导数为0, 则:
|
||||
$$
|
||||
\operatorname{Loss}=p-1 + p-1+p=0
|
||||
$$
|
||||
于是, 就得到了初始值$p=\frac{2}{3}=0.67, \gamma=log(\frac{p}{1-p})=0.69$, 模型的初识状态$F_0(x)=0.69$
|
||||
|
||||
2. 循环生成决策树
|
||||
这里回忆一下回归树的生成步骤, 其实有4小步, 第一就是计算负梯度值得到残差, 第二步是用回归树拟合残差, 第三步是计算叶子节点的输出值, 第四步是更新模型。 下面我们一一来看:
|
||||
|
||||
1. 计算负梯度得到残差
|
||||
$$
|
||||
r_{i m}=-\left[\frac{\partial L\left(y_{i}, F\left(x_{i}\right)\right)}{\partial F\left(x_{i}\right)}\right]_{F(x)=F_{m-1}(x)}
|
||||
$$
|
||||
此处使用$m-1$棵树的模型, 计算每个样本的残差$r_{im}$, 就是上面的$y_i-pi$, 于是例子中, 每个样本的残差:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200910101154282.png#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
</div>
|
||||
|
||||
2. 使用回归树来拟合$r_{im}$, 这里的$i$表示样本哈,回归树的建立过程可以参考下面的链接文章,简单的说就是遍历每个特征, 每个特征下遍历每个取值, 计算分裂后两组数据的平方损失, 找到最小的那个划分节点。 假如我们产生的第2棵决策树如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200910101558282.png#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
</div>
|
||||
|
||||
3. 对于每个叶子节点$j$, 计算最佳残差拟合值
|
||||
$$
|
||||
\gamma_{j m}=\arg \min _{\gamma} \sum_{x \in R_{i j}} L\left(y_{i}, F_{m-1}\left(x_{i}\right)+\gamma\right)
|
||||
$$
|
||||
意思是, 在刚构建的树$m$中, 找到每个节点$j$的输出$\gamma_{jm}$, 能使得该节点的loss最小。 那么我们看一下这个$\gamma$的求解方式, 这里非常的巧妙。 首先, 我们把损失函数写出来, 对于左边的第一个样本, 有
|
||||
$$
|
||||
L\left(y_{1}, F_{m-1}\left(x_{1}\right)+\gamma\right)=-y_{1}\left(F_{m-1}\left(x_{1}\right)+\gamma\right)+\log \left(1+e^{F_{m-1}\left(x_{1}\right)+\gamma}\right)
|
||||
$$
|
||||
这个式子就是上面推导的$l$, 因为我们要用回归树做分类, 所以这里把分类的预测概率转换成了对数几率回归的形式, 即$log(\eta_i)$, 这个就是模型的回归输出值。而如果求这个损失的最小值, 我们要求导, 解出令损失最小的$\gamma$。 但是上面这个式子求导会很麻烦, 所以这里介绍了一个技巧就是**使用二阶泰勒公式来近似表示该式, 再求导**, 还记得伟大的泰勒吗?
|
||||
$$
|
||||
f(x+\Delta x) \approx f(x)+\Delta x f^{\prime}(x)+\frac{1}{2} \Delta x^{2} f^{\prime \prime}(x)+O(\Delta x)
|
||||
$$
|
||||
这里就相当于把$L(y_1, F_{m-1}(x_1))$当做常量$f(x)$, $\gamma$作为变量$\Delta x$, 将$f(x)$二阶展开:
|
||||
$$
|
||||
L\left(y_{1}, F_{m-1}\left(x_{1}\right)+\gamma\right) \approx L\left(y_{1}, F_{m-1}\left(x_{1}\right)\right)+L^{\prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right) \gamma+\frac{1}{2} L^{\prime \prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right) \gamma^{2}
|
||||
$$
|
||||
这时候再求导就简单了
|
||||
$$
|
||||
\frac{d L}{d \gamma}=L^{\prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right)+L^{\prime \prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right) \gamma
|
||||
$$
|
||||
Loss最小的时候, 上面的式子等于0, 就可以得到$\gamma$:
|
||||
$$
|
||||
\gamma_{11}=\frac{-L^{\prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right)}{L^{\prime \prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right)}
|
||||
$$
|
||||
**因为分子就是残差(上述已经求到了), 分母可以通过对残差求导,得到原损失函数的二阶导:**
|
||||
$$
|
||||
\begin{aligned}
|
||||
L^{\prime \prime}\left(y_{1}, F(x)\right) &=\frac{d L^{\prime}}{d \log (\eta_1)} \\
|
||||
&=\frac{d}{d \log (\eta_1)}\left[-y_{i}+\frac{e^{\log (\eta_1)}}{1+e^{\log (\eta_1)}}\right] \\
|
||||
&=\frac{d}{d \log (\eta_1)}\left[e^{\log (\eta_1)}\left(1+e^{\log (\eta_1)}\right)^{-1}\right] \\
|
||||
&=e^{\log (\eta_1)}\left(1+e^{\log (\eta_1)}\right)^{-1}-e^{2 \log (\eta_1)}\left(1+e^{\log (\eta_1)}\right)^{-2} \\
|
||||
&=\frac{e^{\log (\eta_1)}}{\left(1+e^{\log (\eta_1)}\right)^{2}} \\
|
||||
&=\frac{\eta_1}{(1+\eta_1)}\frac{1}{(1+\eta_1)} \\
|
||||
&=p_1(1-p_1)
|
||||
\end{aligned}
|
||||
$$
|
||||
这时候, 就可以算出该节点的输出:
|
||||
$$
|
||||
\gamma_{11}=\frac{r_{11}}{p_{10}\left(1-p_{10}\right)}=\frac{0.33}{0.67 \times 0.33}=1.49
|
||||
$$
|
||||
这里的下面$\gamma_{jm}$表示第$m$棵树的第$j$个叶子节点。 接下来是右边节点的输出, 包含样本2和样本3, 同样使用二阶泰勒公式展开:
|
||||
$$
|
||||
\begin{array}{l}
|
||||
L\left(y_{2}, F_{m-1}\left(x_{2}\right)+\gamma\right)+L\left(y_{3}, F_{m-1}\left(x_{3}\right)+\gamma\right) \\
|
||||
\approx L\left(y_{2}, F_{m-1}\left(x_{2}\right)\right)+L^{\prime}\left(y_{2}, F_{m-1}\left(x_{2}\right)\right) \gamma+\frac{1}{2} L^{\prime \prime}\left(y_{2}, F_{m-1}\left(x_{2}\right)\right) \gamma^{2} \\
|
||||
+L\left(y_{3}, F_{m-1}\left(x_{3}\right)\right)+L^{\prime}\left(y_{3}, F_{m-1}\left(x_{3}\right)\right) \gamma+\frac{1}{2} L^{\prime \prime}\left(y_{3}, F_{m-1}\left(x_{3}\right)\right) \gamma^{2}
|
||||
\end{array}
|
||||
$$
|
||||
求导, 令其结果为0,就会得到, 第1棵树的第2个叶子节点的输出:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\gamma_{21} &=\frac{-L^{\prime}\left(y_{2}, F_{m-1}\left(x_{2}\right)\right)-L^{\prime}\left(y_{3}, F_{m-1}\left(x_{3}\right)\right)}{L^{\prime \prime}\left(y_{2}, F_{m-1}\left(x_{2}\right)\right)+L^{\prime \prime}\left(y_{3}, F_{m-1}\left(x_{3}\right)\right)} \\
|
||||
&=\frac{r_{21}+r_{31}}{p_{20}\left(1-p_{20}\right)+p_{30}\left(1-p_{30}\right)} \\
|
||||
&=\frac{0.33-0.67}{0.67 \times 0.33+0.67 \times 0.33} \\
|
||||
&=-0.77
|
||||
\end{aligned}
|
||||
$$
|
||||
可以看出, 对于任意叶子节点, 我们可以直接计算其输出值:
|
||||
$$
|
||||
\gamma_{j m}=\frac{\sum_{i=1}^{R_{i j}} r_{i m}}{\sum_{i=1}^{R_{i j}} p_{i, m-1}\left(1-p_{i, m-1}\right)}
|
||||
$$
|
||||
|
||||
4. 更新模型$F_m(x)$
|
||||
$$
|
||||
F_{m}(x)=F_{m-1}(x)+\nu \sum_{j=1}^{J_{m}} \gamma_{m}
|
||||
$$
|
||||
|
||||
这样, 通过多次循环迭代, 就可以得到一个比较强的学习器$F_m(x)$
|
||||
|
||||
<br>
|
||||
|
||||
**下面分析一下GBDT的优缺点:**
|
||||
|
||||
我们可以把树的生成过程理解成**自动进行多维度的特征组合**的过程,从根结点到叶子节点上的整个路径(多个特征值判断),才能最终决定一棵树的预测值, 另外,对于**连续型特征**的处理,GBDT 可以拆分出一个临界阈值,比如大于 0.027 走左子树,小于等于 0.027(或者 default 值)走右子树,这样很好的规避了人工离散化的问题。这样就非常轻松的解决了逻辑回归那里**自动发现特征并进行有效组合**的问题, 这也是GBDT的优势所在。
|
||||
|
||||
但是GBDT也会有一些局限性, 对于**海量的 id 类特征**,GBDT 由于树的深度和棵树限制(防止过拟合),不能有效的存储;另外海量特征在也会存在性能瓶颈,当 GBDT 的 one hot 特征大于 10 万维时,就必须做分布式的训练才能保证不爆内存。所以 GBDT 通常配合少量的反馈 CTR 特征来表达,这样虽然具有一定的范化能力,但是同时会有**信息损失**,对于头部资源不能有效的表达。
|
||||
|
||||
所以, 我们发现其实**GBDT和LR的优缺点可以进行互补**。
|
||||
|
||||
### GBDT+LR模型
|
||||
2014年, Facebook提出了一种利用GBDT自动进行特征筛选和组合, 进而生成新的离散特征向量, 再把该特征向量当做LR模型的输入, 来产生最后的预测结果, 这就是著名的GBDT+LR模型了。GBDT+LR 使用最广泛的场景是CTR点击率预估,即预测当给用户推送的广告会不会被用户点击。
|
||||
|
||||
有了上面的铺垫, 这个模型解释起来就比较容易了, 模型的总体结构长下面这样:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200910161923481.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:67%;" />
|
||||
</div>
|
||||
**训练时**,GBDT 建树的过程相当于自动进行的特征组合和离散化,然后从根结点到叶子节点的这条路径就可以看成是不同特征进行的特征组合,用叶子节点可以唯一的表示这条路径,并作为一个离散特征传入 LR 进行**二次训练**。
|
||||
|
||||
比如上图中, 有两棵树,x为一条输入样本,遍历两棵树后,x样本分别落到两颗树的叶子节点上,每个叶子节点对应LR一维特征,那么通过遍历树,就得到了该样本对应的所有LR特征。构造的新特征向量是取值0/1的。 比如左树有三个叶子节点,右树有两个叶子节点,最终的特征即为五维的向量。对于输入x,假设他落在左树第二个节点,编码[0,1,0],落在右树第二个节点则编码[0,1],所以整体的编码为[0,1,0,0,1],这类编码作为特征,输入到线性分类模型(LR or FM)中进行分类。
|
||||
|
||||
**预测时**,会先走 GBDT 的每棵树,得到某个叶子节点对应的一个离散特征(即一组特征组合),然后把该特征以 one-hot 形式传入 LR 进行线性加权预测。
|
||||
|
||||
这个方案应该比较简单了, 下面有几个关键的点我们需要了解:
|
||||
1. **通过GBDT进行特征组合之后得到的离散向量是和训练数据的原特征一块作为逻辑回归的输入, 而不仅仅全是这种离散特征**
|
||||
2. 建树的时候用ensemble建树的原因就是一棵树的表达能力很弱,不足以表达多个有区分性的特征组合,多棵树的表达能力更强一些。GBDT每棵树都在学习前面棵树尚存的不足,迭代多少次就会生成多少棵树。
|
||||
3. RF也是多棵树,但从效果上有实践证明不如GBDT。且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
|
||||
4. 在CRT预估中, GBDT一般会建立两类树(非ID特征建一类, ID类特征建一类), AD,ID类特征在CTR预估中是非常重要的特征,直接将AD,ID作为feature进行建树不可行,故考虑为每个AD,ID建GBDT树。
|
||||
1. 非ID类树:不以细粒度的ID建树,此类树作为base,即便曝光少的广告、广告主,仍可以通过此类树得到有区分性的特征、特征组合
|
||||
2. ID类树:以细粒度 的ID建一类树,用于发现曝光充分的ID对应有区分性的特征、特征组合
|
||||
|
||||
### 编程实践
|
||||
|
||||
下面我们通过kaggle上的一个ctr预测的比赛来看一下GBDT+LR模型部分的编程实践, [数据来源](https://github.com/zhongqiangwu960812/AI-RecommenderSystem/tree/master/Rank/GBDT%2BLR/data)
|
||||
|
||||
我们回顾一下上面的模型架构, 首先是要训练GBDT模型, GBDT的实现一般可以使用xgboost, 或者lightgbm。训练完了GBDT模型之后, 我们需要预测出每个样本落在了哪棵树上的哪个节点上, 然后通过one-hot就会得到一些新的离散特征, 这和原来的特征进行合并组成新的数据集, 然后作为逻辑回归的输入,最后通过逻辑回归模型得到结果。
|
||||
|
||||
根据上面的步骤, 我们看看代码如何实现:
|
||||
|
||||
假设我们已经有了处理好的数据x_train, y_train。
|
||||
|
||||
1. **训练GBDT模型**
|
||||
|
||||
GBDT模型的搭建我们可以通过XGBOOST, lightgbm等进行构建。比如:
|
||||
|
||||
```python
|
||||
gbm = lgb.LGBMRegressor(objective='binary',
|
||||
subsample= 0.8,
|
||||
min_child_weight= 0.5,
|
||||
colsample_bytree= 0.7,
|
||||
num_leaves=100,
|
||||
max_depth = 12,
|
||||
learning_rate=0.05,
|
||||
n_estimators=10,
|
||||
)
|
||||
|
||||
gbm.fit(x_train, y_train,
|
||||
eval_set = [(x_train, y_train), (x_val, y_val)],
|
||||
eval_names = ['train', 'val'],
|
||||
eval_metric = 'binary_logloss',
|
||||
# early_stopping_rounds = 100,
|
||||
)
|
||||
```
|
||||
|
||||
2. **特征转换并构建新的数据集**
|
||||
|
||||
通过上面我们建立好了一个gbdt模型, 我们接下来要用它来预测出样本会落在每棵树的哪个叶子节点上, 为后面的离散特征构建做准备, 由于不是用gbdt预测结果而是预测训练数据在每棵树上的具体位置, 就需要用到下面的语句:
|
||||
|
||||
```python
|
||||
model = gbm.booster_ # 获取到建立的树
|
||||
|
||||
# 每个样本落在每个树的位置 , 下面两个是矩阵 (样本个数, 树的棵树) , 每一个数字代表某个样本落在了某个数的哪个叶子节点
|
||||
gbdt_feats_train = model.predict(train, pred_leaf = True)
|
||||
gbdt_feats_test = model.predict(test, pred_leaf = True)
|
||||
|
||||
# 把上面的矩阵转成新的样本-特征的形式, 与原有的数据集合并
|
||||
gbdt_feats_name = ['gbdt_leaf_' + str(i) for i in range(gbdt_feats_train.shape[1])]
|
||||
df_train_gbdt_feats = pd.DataFrame(gbdt_feats_train, columns = gbdt_feats_name)
|
||||
df_test_gbdt_feats = pd.DataFrame(gbdt_feats_test, columns = gbdt_feats_name)
|
||||
|
||||
# 构造新数据集
|
||||
train = pd.concat([train, df_train_gbdt_feats], axis = 1)
|
||||
test = pd.concat([test, df_test_gbdt_feats], axis = 1)
|
||||
train_len = train.shape[0]
|
||||
data = pd.concat([train, test])
|
||||
```
|
||||
|
||||
3. **离散特征的独热编码,并划分数据集**
|
||||
|
||||
```python
|
||||
# 新数据的新特征进行读入编码
|
||||
for col in gbdt_feats_name:
|
||||
onehot_feats = pd.get_dummies(data[col], prefix = col)
|
||||
data.drop([col], axis = 1, inplace = True)
|
||||
data = pd.concat([data, onehot_feats], axis = 1)
|
||||
|
||||
# 划分数据集
|
||||
train = data[: train_len]
|
||||
test = data[train_len:]
|
||||
|
||||
x_train, x_val, y_train, y_val = train_test_split(train, target, test_size = 0.3, random_state = 2018)
|
||||
```
|
||||
|
||||
4. **训练逻辑回归模型作最后的预测**
|
||||
|
||||
```python
|
||||
# 训练逻辑回归模型
|
||||
lr = LogisticRegression()
|
||||
lr.fit(x_train, y_train)
|
||||
tr_logloss = log_loss(y_train, lr.predict_proba(x_train)[:, 1])
|
||||
print('tr-logloss: ', tr_logloss)
|
||||
val_logloss = log_loss(y_val, lr.predict_proba(x_val)[:, 1])
|
||||
print('val-logloss: ', val_logloss)
|
||||
|
||||
# 预测
|
||||
y_pred = lr.predict_proba(test)[:, 1]
|
||||
```
|
||||
|
||||
上面我们就完成了GBDT+LR模型的基本训练步骤, 具体详细的代码可以参考链接。
|
||||
|
||||
### 思考
|
||||
1. **为什么使用集成的决策树? 为什么使用GBDT构建决策树而不是随机森林?**
|
||||
2. **面对高维稀疏类特征的时候(比如ID类特征), 逻辑回归一般要比GBDT这种非线性模型好, 为什么?**
|
||||
|
||||
|
||||
**参考资料**
|
||||
|
||||
* 王喆 - 《深度学习推荐系统》
|
||||
* [决策树之 GBDT 算法 - 分类部分](https://www.jianshu.com/p/f5e5db6b29f2)
|
||||
* [深入理解GBDT二分类算法](https://zhuanlan.zhihu.com/p/89549390?utm_source=zhihu)
|
||||
* [逻辑回归、优化算法和正则化的幕后细节补充](https://blog.csdn.net/wuzhongqiang/article/details/108456051)
|
||||
* [梯度提升树GBDT的理论学习与细节补充](https://blog.csdn.net/wuzhongqiang/article/details/108471107)
|
||||
* [推荐系统遇上深度学习(十)--GBDT+LR融合方案实战](https://zhuanlan.zhihu.com/p/37522339)
|
||||
* [CTR预估中GBDT与LR融合方案](https://blog.csdn.net/lilyth_lilyth/article/details/48032119)
|
||||
* [GBDT+LR算法解析及Python实现](https://www.cnblogs.com/wkang/p/9657032.html)
|
||||
* [常见计算广告点击率预估算法总结](https://zhuanlan.zhihu.com/p/29053940)
|
||||
* [GBDT--分类篇](https://blog.csdn.net/On_theway10/article/details/83576715?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.channel_param)
|
||||
|
||||
**论文**
|
||||
|
||||
* [http://quinonero.net/Publications/predicting-clicks-facebook.pdf 原论文](http://quinonero.net/Publications/predicting-clicks-facebook.pdf)
|
||||
* [Predicting Clicks: Estimating the Click-Through Rate for New Ads](https://www.microsoft.com/en-us/research/publication/predicting-clicks-estimating-the-click-through-rate-for-new-ads/)\
|
||||
* [Greedy Fun tion Approximation : A Gradient Boosting](https://www.semanticscholar.org/paper/Greedy-Fun-tion-Approximation-%3A-A-Gradient-Boosting-Friedman/0d97ee4888506beb30a3f3b6552d88a9b0ca11f0?p2df)
|
||||
|
||||
@@ -1,277 +0,0 @@
|
||||
## 写在前面
|
||||
AutoInt(Automatic Feature Interaction),这是2019年发表在CIKM上的文章,这里面提出的模型,重点也是在特征交互上,而所用到的结构,就是大名鼎鼎的transformer结构了,也就是通过多头的自注意力机制来显示的构造高阶特征,有效的提升了模型的效果。所以这个模型的提出动机比较简单,和xdeepFM这种其实是一样的,就是针对目前很多浅层模型无法学习高阶的交互, 而DNN模型能学习高阶交互,但确是隐性学习,缺乏可解释性,并不知道好不好使。而transformer的话,我们知道, 有着天然的全局意识,在NLP里面的话,各个词通过多头的自注意力机制,就能够使得各个词从不同的子空间中学习到与其它各个词的相关性,汇聚其它各个词的信息。 而放到推荐系统领域,同样也是这个道理,无非是把词换成了这里的离散特征而已, 而如果通过多个这样的交叉块堆积,就能学习到任意高阶的交互啦。这其实就是本篇文章的思想核心。
|
||||
|
||||
## AutoInt模型的理论及论文细节
|
||||
### 动机和原理
|
||||
这篇文章的前言部分依然是说目前模型的不足,以引出模型的动机所在, 简单的来讲,就是两句话:
|
||||
1. 浅层的模型会受到交叉阶数的限制,没法完成高阶交叉
|
||||
2. 深层模型的DNN在学习高阶隐性交叉的效果并不是很好, 且不具有可解释性
|
||||
|
||||
于是乎:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/60f5f213f34d4e2b9bdb800e6f029b34.png#pic_center" alt="image-20210308142624189" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
那么是如何做到的呢? 引入了transformer, 做成了一个特征交互层, 原理如下:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/d05a80906b484ab7a026e52ed2d8f9d4.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="image-20210308142624189" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
### AutoInt模型的前向过程梳理
|
||||
下面看下AutoInt模型的结构了,并不是很复杂
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/1aeabdd3cee74cbf814d7eed3147be4e.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_1#pic_center" alt="image-20210308142624189" style="zoom: 85%;" />
|
||||
</div>
|
||||
|
||||
#### Input Layer
|
||||
输入层这里, 用到的特征主要是离散型特征和连续性特征, 这里不管是哪一类特征,都会过embedding层转成低维稠密的向量,是的, **连续性特征,这里并没有经过分桶离散化,而是直接走embedding**。这个是怎么做到的呢?就是就是类似于预训练时候的思路,先通过item_id把连续型特征与类别特征关联起来,最简单的,就是把item_id拿过来,过完embedding层取出对应的embedding之后,再乘上连续值即可, 所以这个连续值事先一定要是归一化的。 当然,这个玩法,我也是第一次见。 学习到了, 所以模型整体的输入如下:
|
||||
|
||||
$$
|
||||
\mathbf{x}=\left[\mathbf{x}_{1} ; \mathbf{x}_{2} ; \ldots ; \mathbf{x}_{\mathbf{M}}\right]
|
||||
$$
|
||||
这里的$M$表示特征的个数, $X_1, X_2$这是离散型特征, one-hot的形式, 而$X_M$在这里是连续性特征。过embedding层的细节应该是我上面说的那样。
|
||||
#### Embedding Layer
|
||||
embedding层的作用是把高维稀疏的特征转成低维稠密, 离散型的特征一般是取出对应的embedding向量即可, 具体计算是这样:
|
||||
$$
|
||||
\mathbf{e}_{\mathbf{i}}=\mathbf{V}_{\mathbf{i}} \mathbf{x}_{\mathbf{i}}
|
||||
$$
|
||||
对于第$i$个离散特征,直接第$i$个嵌入矩阵$V_i$乘one-hot向量就取出了对应位置的embedding。 当然,如果输入的时候不是个one-hot, 而是个multi-hot的形式,那么对应的embedding输出是各个embedding求平均得到的。
|
||||
|
||||
$$
|
||||
\mathbf{e}_{\mathbf{i}}=\frac{1}{q} \mathbf{V}_{\mathbf{i}} \mathbf{x}_{\mathbf{i}}
|
||||
$$
|
||||
比如, 推荐里面用户的历史行为item。过去点击了多个item,最终的输出就是这多个item的embedding求平均。
|
||||
而对于连续特征, 我上面说的那样, 也是过一个embedding矩阵取相应的embedding, 不过,最后要乘一个连续值
|
||||
$$
|
||||
\mathbf{e}_{\mathbf{m}}=\mathbf{v}_{\mathbf{m}} x_{m}
|
||||
$$
|
||||
这样,不管是连续特征,离散特征还是变长的离散特征,经过embedding之后,都能得到等长的embedding向量。 我们把这个向量拼接到一块,就得到了交互层的输入。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/089b846a7f5c4125bc99a5a60e03d1ff.png#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
#### Interacting Layer
|
||||
这个是本篇论文的核心了,其实这里说的就是transformer块的前向传播过程,所以这里我就直接用比较白话的语言简述过程了,不按照论文中的顺序展开了。
|
||||
|
||||
通过embedding层, 我们会得到M个向量$e_1, ...e_M$,假设向量的维度是$d$维, 那么这个就是一个$d\times M$的矩阵, 我们定一个符号$X$。 接下来我们基于这个矩阵$X$,做三次变换,也就是分别乘以三个矩阵$W_k^{(h)}, W_q^{(h)},W_v^{(h)}$, 这三个矩阵的维度是$d'\times d$的话, 那么我们就会得到三个结果:
|
||||
$$Q^{(h)}=W_q^{(h)}\times X \\ K^{(h)} = W_k^{(h)} \times X \\ V^{(h)} = W_v^{(h)} \times X$$
|
||||
这三个矩阵都是$d'\times M$的。这其实就完成了一个Head的操作。所谓的自注意力, 就是$X$通过三次变换得到的结果之间,通过交互得到相关性,并通过相关性进行加权汇总,全是$X$自发的。 那么是怎么做到的呢?首先, 先进行这样的操作:
|
||||
$$Score(Q^h,K^h)=Q^h \times {K^h}^T$$
|
||||
这个结果得到的是一个$d'\times d'$的矩阵, 那么这个操作到底是做了一个什么事情呢?
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200220195022623.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 90%;" />
|
||||
</div>
|
||||
|
||||
假设这里的$c_1..c_6$是我们的6个特征, 而每一行代表每个特征的embedding向量,这样两个矩阵相乘,相当于得到了当前特征与其它特征两两之间的內积值, 而內积可以表示两个向量之间的相似程度。所以得到的结果每一行,就代表当前这个特征与其它特征的相似性程度。
|
||||
|
||||
接下来,我们对$Score(Q^h,K^h)$, 在最后一个维度上进行softmax,就根据相似性得到了权重信息,这其实就是把相似性分数归一化到了0-1之间
|
||||
|
||||
$$Attention(Q^h,K^h)=Softmax(Score(Q^h,K^h))$$
|
||||
接下来, 我们再进行这样的一步操作
|
||||
$$E^{(h)}=Attention(Q^h,K^h) \times V$$
|
||||
这样就得到了$d'\times M$的矩阵$E$, 这步操作,其实就是一个加权汇总的过程, 对于每个特征, 先求与其它特征的相似度,然后得到一个权重,再回乘到各自的特征向量再求和。 只不过这里的特征是经过了一次线性变化的过程,降维到了$d'$。
|
||||
|
||||
上面是我从矩阵的角度又过了一遍, 这个是直接针对所有的特征向量一部到位。 论文里面的从单个特征的角度去描述的,只说了一个矩阵向量过多头注意力的操作。
|
||||
$$
|
||||
\begin{array}{c}
|
||||
\alpha_{\mathbf{m}, \mathbf{k}}^{(\mathbf{h})}=\frac{\exp \left(\psi^{(h)}\left(\mathbf{e}_{\mathbf{m}}, \mathbf{e}_{\mathbf{k}}\right)\right)}{\sum_{l=1}^{M} \exp \left(\psi^{(h)}\left(\mathbf{e}_{\mathbf{m}}, \mathbf{e}_{1}\right)\right)} \\
|
||||
\psi^{(h)}\left(\mathbf{e}_{\mathbf{m}}, \mathbf{e}_{\mathbf{k}}\right)=\left\langle\mathbf{W}_{\text {Query }}^{(\mathbf{h})} \mathbf{e}_{\mathbf{m}}, \mathbf{W}_{\text {Key }}^{(\mathbf{h})} \mathbf{e}_{\mathbf{k}}\right\rangle
|
||||
\end{array} \\
|
||||
\widetilde{\mathbf{e}}_{\mathrm{m}}^{(\mathbf{h})}=\sum_{k=1}^{M} \alpha_{\mathbf{m}, \mathbf{k}}^{(\mathbf{h})}\left(\mathbf{W}_{\text {Value }}^{(\mathbf{h})} \mathbf{e}_{\mathbf{k}}\right)
|
||||
$$
|
||||
|
||||
这里会更好懂一些, 就是相当于上面矩阵的每一行操作拆开了, 首先,整个拼接起来的embedding矩阵还是过三个参数矩阵得到$Q,K,V$, 然后是每一行单独操作的方式,对于某个特征向量$e_k$,与其它的特征两两內积得到权重,然后在softmax,回乘到对应向量,然后进行求和就得到了融合其它特征信息的新向量。 具体过程如图:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/700bf353ce2f4c229839761e7815515d.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="image-20210308142624189" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
上面的过程是用了一个头,理解的话就类似于从一个角度去看特征之间的相关关系,用论文里面的话讲,这是从一个子空间去看, 如果是想从多个角度看,这里可以用多个头,即换不同的矩阵$W_q,W_k,W_v$得到不同的$Q,K,V$然后得到不同的$e_m$, 每个$e_m$是$d'\times 1$的。
|
||||
|
||||
然后,多个头的结果concat起来
|
||||
$$
|
||||
\widetilde{\mathbf{e}}_{\mathrm{m}}=\widetilde{\mathbf{e}}_{\mathrm{m}}^{(1)} \oplus \widetilde{\mathbf{e}}_{\mathrm{m}}^{(2)} \oplus \cdots \oplus \widetilde{\mathbf{e}}_{\mathbf{m}}^{(\mathbf{H})}
|
||||
$$
|
||||
这是一个$d'\times H$的向量, 假设有$H$个头。
|
||||
|
||||
接下来, 过一个残差网络层,这是为了保留原始的特征信息
|
||||
$$
|
||||
\mathbf{e}_{\mathbf{m}}^{\mathrm{Res}}=\operatorname{ReL} U\left(\widetilde{\mathbf{e}}_{\mathbf{m}}+\mathbf{W}_{\text {Res }} \mathbf{e}_{\mathbf{m}}\right)
|
||||
$$
|
||||
这里的$e_m$是$d\times 1$的向量, $W_{Res}$是$d'H\times d$的矩阵, 最后得到的$e_m^{Res}$是$d'H\times 1$的向量, 这是其中的一个特征,如果是$M$个特征堆叠的话,最终就是$d'HM\times 1$的矩阵, 这个就是Interacting Layer的结果输出。
|
||||
#### Output Layer
|
||||
输出层就非常简单了,加一层全连接映射出输出值即可:
|
||||
$$
|
||||
\hat{y}=\sigma\left(\mathbf{w}^{\mathrm{T}}\left(\mathbf{e}_{1}^{\mathbf{R e s}} \oplus \mathbf{e}_{2}^{\mathbf{R e s}} \oplus \cdots \oplus \mathbf{e}_{\mathbf{M}}^{\text {Res }}\right)+b\right)
|
||||
$$
|
||||
这里的$W$是$d'HM\times 1$的, 这样最终得到的是一个概率值了, 接下来交叉熵损失更新模型参数即可。
|
||||
|
||||
AutoInt的前向传播过程梳理完毕。
|
||||
|
||||
### AutoInt的分析
|
||||
这里论文里面分析了为啥AutoInt能建模任意的高阶交互以及时间复杂度和空间复杂度的分析。我们一一来看。
|
||||
|
||||
关于建模任意的高阶交互, 我们这里拿一个transformer块看下, 对于一个transformer块, 我们发现特征之间完成了一个2阶的交互过程,得到的输出里面我们还保留着1阶的原始特征。
|
||||
|
||||
那么再经过一个transformer块呢? 这里面就会有2阶和1阶的交互了, 也就是会得到3阶的交互信息。而此时的输出,会保留着第一个transformer的输出信息特征。再过一个transformer块的话,就会用4阶的信息交互信息, 其实就相当于, 第$n$个transformer里面会建模出$n+1$阶交互来, 这个与CrossNet其实有异曲同工之妙的,无法是中间交互时的方式不一样。 前者是bit-wise级别的交互,而后者是vector-wise的交互。
|
||||
|
||||
所以, AutoInt是可以建模任意高阶特征的交互的,并且这种交互还是显性。
|
||||
|
||||
关于时间复杂度和空间复杂度,空间复杂度是$O(Ldd'H)$级别的, 这个也很好理解,看参数量即可, 3个W矩阵, H个head,再假设L个transformer块的话,参数量就达到这了。 时间复杂度的话是$O(MHd'(M+d))$的,论文说如果d和d'很小的话,其实这个模型不算复杂。
|
||||
### 3.4 更多细节
|
||||
这里整理下实验部分的细节,主要是对于一些超参的实验设置,在实验里面,作者首先指出了logloss下降多少算是有效呢?
|
||||
>It is noticeable that a slightly higher AUC or lower Logloss at 0.001-level is regarded significant for CTR prediction task, which has also been pointed out in existing works
|
||||
|
||||
这个和在fibinet中auc说的意思差不多。
|
||||
|
||||
在这一块,作者还写到了几个观点:
|
||||
1. NFM use the deep neural network as a core component to learning high-order feature interactions, they do not guarantee improvement over FM and AFM.
|
||||
2. AFM准确的说是二阶显性交互基础上加了交互重要性选择的操作, 这里应该是没有在上面加全连接
|
||||
3. xdeepFM这种CIN网络,在实际场景中非常难部署,不实用
|
||||
4. AutoInt的交互层2-3层差不多, embedding维度16-24
|
||||
5. 在AutoInt上面加2-3层的全连接会有点提升,但是提升效果并不是很大
|
||||
|
||||
所以感觉AutoInt这篇paper更大的价值,在于给了我们一种特征高阶显性交叉与特征选择性的思路,就是transformer在这里起的功效。所以后面用的时候, 更多的应该考虑如何用这种思路或者这个交互模块,而不是直接搬模型。
|
||||
|
||||
## AutoInt模型的简单复现及结构解释
|
||||
经过上面的分析, AutoInt模型的核心其实还是Transformer,所以代码部分呢? 主要还是Transformer的实现过程, 这个之前在整理DSIN的时候也整理过,由于Transformer特别重要,所以这里再重新复习一遍, 依然是基于Deepctr,写成一个简版的形式。
|
||||
|
||||
```python
|
||||
def AutoInt(linear_feature_columns, dnn_feature_columns, att_layer_num=3, att_embedding_size=8, att_head_num=2, att_res=True):
|
||||
"""
|
||||
:param att_layer_num: transformer块的数量,一个transformer块里面是自注意力计算 + 残差计算
|
||||
:param att_embedding_size: 文章里面的d', 自注意力时候的att的维度
|
||||
:param att_head_num: 头的数量或者自注意力子空间的数量
|
||||
:param att_res: 是否使用残差网络
|
||||
"""
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns+dnn_feature_columns)
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入预Input层对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 线性部分的计算逻辑 -- linear
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
# 线性层和dnn层统一的embedding层
|
||||
embedding_layer_dict = build_embedding_layers(linear_feature_columns+dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 构造self-att的输入
|
||||
att_sparse_kd_embed = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=False)
|
||||
att_input = Concatenate(axis=1)(att_sparse_kd_embed) # (None, field_num, embed_num)
|
||||
|
||||
# 下面的循环,就是transformer的前向传播,多个transformer块的计算逻辑
|
||||
for _ in range(att_layer_num):
|
||||
att_input = InteractingLayer(att_embedding_size, att_head_num, att_res)(att_input)
|
||||
att_output = Flatten()(att_input)
|
||||
att_logits = Dense(1)(att_output)
|
||||
|
||||
# DNN侧的计算逻辑 -- Deep
|
||||
# 将dnn_feature_columns里面的连续特征筛选出来,并把相应的Input层拼接到一块
|
||||
dnn_dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), dnn_feature_columns)) if dnn_feature_columns else []
|
||||
dnn_dense_feature_columns = [fc.name for fc in dnn_dense_feature_columns]
|
||||
dnn_concat_dense_inputs = Concatenate(axis=1)([dense_input_dict[col] for col in dnn_dense_feature_columns])
|
||||
|
||||
# 将dnn_feature_columns里面的离散特征筛选出来,相应的embedding层拼接到一块
|
||||
dnn_sparse_kd_embed = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
|
||||
dnn_concat_sparse_kd_embed = Concatenate(axis=1)(dnn_sparse_kd_embed)
|
||||
|
||||
# DNN层的输入和输出
|
||||
dnn_input = Concatenate(axis=1)([dnn_concat_dense_inputs, dnn_concat_sparse_kd_embed, att_output])
|
||||
dnn_out = get_dnn_output(dnn_input)
|
||||
dnn_logits = Dense(1)(dnn_out)
|
||||
|
||||
# 三边的结果stack
|
||||
stack_output = Add()([linear_logits, dnn_logits])
|
||||
|
||||
# 输出层
|
||||
output_layer = Dense(1, activation='sigmoid')(stack_output)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
|
||||
return model
|
||||
```
|
||||
这里由于大部分都是之前见过的模块,唯一改变的地方,就是加了一个`InteractingLayer`, 这个是一个transformer块,在这里面实现特征交互。而这个的结果输出,最终和DNN的输出结合到一起了。 而这个层,主要就是一个transformer块的前向传播过程。这应该算是最简单的一个版本了:
|
||||
|
||||
```python
|
||||
class InteractingLayer(Layer):
|
||||
"""A layer user in AutoInt that model the correction between different feature fields by multi-head self-att mechanism
|
||||
input: 3维张量, (none, field_num, embedding_size)
|
||||
output: 3维张量, (none, field_num, att_embedding_size * head_num)
|
||||
"""
|
||||
def __init__(self, att_embedding_size=8, head_num=2, use_res=True, seed=2021):
|
||||
super(InteractingLayer, self).__init__()
|
||||
self.att_embedding_size = att_embedding_size
|
||||
self.head_num = head_num
|
||||
self.use_res = use_res
|
||||
self.seed = seed
|
||||
|
||||
|
||||
def build(self, input_shape):
|
||||
embedding_size = int(input_shape[-1])
|
||||
|
||||
# 定义三个矩阵Wq, Wk, Wv
|
||||
self.W_query = self.add_weight(name="query", shape=[embedding_size, self.att_embedding_size * self.head_num],
|
||||
dtype=tf.float32, initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed))
|
||||
self.W_key = self.add_weight(name="key", shape=[embedding_size, self.att_embedding_size * self.head_num],
|
||||
dtype=tf.float32, initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed+1))
|
||||
self.W_value = self.add_weight(name="value", shape=[embedding_size, self.att_embedding_size * self.head_num],
|
||||
dtype=tf.float32, initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed+2))
|
||||
|
||||
if self.use_res:
|
||||
self.W_res = self.add_weight(name="res", shape=[embedding_size, self.att_embedding_size * self.head_num],
|
||||
dtype=tf.float32, initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed+3))
|
||||
|
||||
super(InteractingLayer, self).build(input_shape)
|
||||
|
||||
def call(self, inputs):
|
||||
# inputs (none, field_nums, embed_num)
|
||||
|
||||
querys = tf.tensordot(inputs, self.W_query, axes=(-1, 0)) # (None, field_nums, att_emb_size*head_num)
|
||||
keys = tf.tensordot(inputs, self.W_key, axes=(-1, 0))
|
||||
values = tf.tensordot(inputs, self.W_value, axes=(-1, 0))
|
||||
|
||||
# 多头注意力计算 按照头分开 (head_num, None, field_nums, att_embed_size)
|
||||
querys = tf.stack(tf.split(querys, self.head_num, axis=2))
|
||||
keys = tf.stack(tf.split(keys, self.head_num, axis=2))
|
||||
values = tf.stack(tf.split(values, self.head_num, axis=2))
|
||||
|
||||
# Q * K, key的后两维转置,然后再矩阵乘法
|
||||
inner_product = tf.matmul(querys, keys, transpose_b=True) # (head_num, None, field_nums, field_nums)
|
||||
normal_att_scores = tf.nn.softmax(inner_product, axis=-1)
|
||||
|
||||
result = tf.matmul(normal_att_scores, values) # (head_num, None, field_nums, att_embed_size)
|
||||
result = tf.concat(tf.split(result, self.head_num, ), axis=-1) # (1, None, field_nums, att_emb_size*head_num)
|
||||
result = tf.squeeze(result, axis=0) # (None, field_num, att_emb_size*head_num)
|
||||
|
||||
if self.use_res:
|
||||
result += tf.tensordot(inputs, self.W_res, axes=(-1, 0))
|
||||
|
||||
result = tf.nn.relu(result)
|
||||
|
||||
return result
|
||||
```
|
||||
这就是一个Transformer块做的事情,这里只说两个小细节:
|
||||
* 第一个是参数初始化那个地方, 后面的seed一定要指明出参数来,我第一次写的时候, 没有用seed=,结果导致训练有问题。
|
||||
* 第二个就是这里自注意力机制计算的时候,这里的多头计算处理方式, **把多个头分开,采用堆叠的方式进行计算(堆叠到第一个维度上去了)**。只有这样才能使得每个头与每个头之间的自注意力运算是独立不影响的。如果不这么做的话,最后得到的结果会含有当前单词在这个头和另一个单词在另一个头上的关联,这是不合理的。
|
||||
|
||||
OK, 这就是AutoInt比较核心的部分了,当然,上面自注意部分的输出结果与DNN或者Wide部分结合也不一定非得这么一种形式,也可以灵活多变,具体得结合着场景来。详细代码依然是看后面的GitHub啦。
|
||||
|
||||
## 总结
|
||||
这篇文章整理了AutoInt模型,这个模型的重点是引入了transformer来实现特征之间的高阶显性交互, 而transformer的魅力就是多头的注意力机制,相当于在多个子空间中, 根据不同的相关性策略去让特征交互然后融合,在这个交互过程中,特征之间计算相关性得到权重,并加权汇总,使得最终每个特征上都有了其它特征的信息,且其它特征的信息重要性还有了权重标识。 这个过程的自注意力计算以及汇总是一个自动的过程,这是很powerful的。
|
||||
|
||||
所以这篇文章的重要意义是又给我们传授了一个特征交互时候的新思路,就是transformer的多头注意力机制。
|
||||
|
||||
在整理transformer交互层的时候, 这里忽然想起了和一个同学的讨论, 顺便记在这里吧,就是:
|
||||
> 自注意力里面的Q,K能用一个吗? 也就是类似于只用Q, 算注意力的时候,直接$QQ^T$, 得到的矩阵维度和原来的是一样的,并且在参数量上,由于去掉了$w_k$矩阵, 也会有所减少。
|
||||
|
||||
关于这个问题, 我目前没有尝试用同一个的效果,但总感觉是违背了当时设计自注意力的初衷,最直接的一个结论,就是这里如果直接$QQ^T$,那么得到的注意力矩阵是一个对称的矩阵, 这在汇总信息的时候可能会出现问题。 因为这基于了一个假设就是A特征对于B特征的重要性,和B特征对于A的重要性是一致的, 这个显然是不太符合常规的。 比如"学历"这个特征和"职业"这个特征, 对于计算机行业,高中生和研究生或许都可以做, 但是对于金融类的行业, 对学历就有着很高的要求。 这就说明对于职业这个特征, 学历特征对其影响很大。 而如果是看学历的话,研究生学历或许可以入计算机,也可以入金融, 可能职业特征对学历的影响就不是那么明显。 也就是学历对于职业的重要性可能会比职业对于学历的重要性要大。 所以我感觉直接用同一个矩阵,在表达能力上会受到限制。当然,是自己的看法哈, 这个问题也欢迎一块讨论呀!
|
||||
|
||||
|
||||
**参考资料**:
|
||||
* [AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1810.11921)
|
||||
* [AutoInt:基于Multi-Head Self-Attention构造高阶特征](https://zhuanlan.zhihu.com/p/60185134)
|
||||
@@ -1,155 +0,0 @@
|
||||
# DCN
|
||||
## 动机
|
||||
Wide&Deep模型的提出不仅综合了“记忆能力”和“泛化能力”, 而且开启了不同网络结构融合的新思路。 所以后面就有各式各样的模型改进Wide部分或者Deep部分, 而Deep&Cross模型(DCN)就是其中比较典型的一个,这是2017年斯坦福大学和谷歌的研究人员在ADKDD会议上提出的, 该模型针对W&D的wide部分进行了改进, 因为Wide部分有一个不足就是需要人工进行特征的组合筛选, 过程繁琐且需要经验, 而2阶的FM模型在线性的时间复杂度中自动进行特征交互,但是这些特征交互的表现能力并不够,并且随着阶数的上升,模型复杂度会大幅度提高。于是乎,作者用一个Cross Network替换掉了Wide部分,来自动进行特征之间的交叉,并且网络的时间和空间复杂度都是线性的。 通过与Deep部分相结合,构成了深度交叉网络(Deep & Cross Network),简称DCN。
|
||||
|
||||
## 模型结构及原理
|
||||
|
||||
这个模型的结构是这个样子的:
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片dcn.png" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
这个模型的结构也是比较简洁的, 从下到上依次为:Embedding和Stacking层, Cross网络层与Deep网络层并列, 以及最后的输出层。下面也是一一为大家剖析。
|
||||
|
||||
### Embedding和Stacking 层
|
||||
|
||||
Embedding层我们已经非常的熟悉了吧, 这里的作用依然是把稀疏离散的类别型特征变成低维密集型。
|
||||
$$
|
||||
\mathbf{x}_{\text {embed, } i}=W_{\text {embed, } i} \mathbf{x}_{i}
|
||||
$$
|
||||
其中对于某一类稀疏分类特征(如id),$X_{embed, i}$是第个$i$分类值(id序号)的embedding向量。$W_{embed,i}$是embedding矩阵, $n_e\times n_v$维度, $n_e$是embedding维度, $n_v$是该类特征的唯一取值个数。$x_i$属于该特征的二元稀疏向量(one-hot)编码的。 【实质上就是在训练得到的Embedding参数矩阵中找到属于当前样本对应的Embedding向量】。其实绝大多数基于深度学习的推荐模型都需要Embedding操作,参数学习是通过神经网络进行训练。
|
||||
|
||||
最后,该层需要将所有的密集型特征与通过embedding转换后的特征进行联合(Stacking):
|
||||
$$
|
||||
\mathbf{x}_{0}=\left[\mathbf{x}_{\text {embed, } 1}^{T}, \ldots, \mathbf{x}_{\text {embed, }, k}^{T}, \mathbf{x}_{\text {dense }}^{T}\right]
|
||||
$$
|
||||
一共$k$个类别特征, dense是数值型特征, 两者在特征维度拼在一块。 上面的这两个操作如果是看了前面的模型的话,应该非常容易理解了。
|
||||
|
||||
### Cross Network
|
||||
|
||||
这个就是本模型最大的亮点了【Cross网络】, 这个思路感觉非常Nice。设计该网络的目的是增加特征之间的交互力度。交叉网络由多个交叉层组成, 假设第$l$层的输出向量$x_l$, 那么对于第$l+1$层的输出向量$x_{l+1}$表示为:
|
||||
|
||||
$$
|
||||
\mathbf{x}_{l+1}=\mathbf{x}_{0} \mathbf{x}_{l}^{T} \mathbf{w}_{l}+\mathbf{b}_{l}+\mathbf{x}_{l}=f\left(\mathbf{x}_{l}, \mathbf{w}_{l}, \mathbf{b}_{l}\right)+\mathbf{x}_{l}
|
||||
$$
|
||||
可以看到, 交叉层的二阶部分非常类似PNN提到的外积操作, 在此基础上增加了外积操作的权重向量$w_l$, 以及原输入向量$x_l$和偏置向量$b_l$。 交叉层的可视化如下:
|
||||
|
||||
<div align=center> <img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片cross.png" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
可以看到, 每一层增加了一个$n$维的权重向量$w_l$(n表示输入向量维度), 并且在每一层均保留了输入向量, 因此输入和输出之间的变化不会特别明显。关于这一层, 原论文里面有个具体的证明推导Cross Network为啥有效, 不过比较复杂,这里我拿一个式子简单的解释下上面这个公式的伟大之处:
|
||||
|
||||
> **我们根据上面这个公式, 尝试的写前面几层看看:**
|
||||
>
|
||||
> $l=0:\mathbf{x}_{1} =\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}$
|
||||
>
|
||||
> $l=1:\mathbf{x}_{2} =\mathbf{x}_{0} \mathbf{x}_{1}^{T} \mathbf{w}_{1}+ \mathbf{b}_{1}+\mathbf{x}_{1}=\mathbf{x}_{0} [\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}]^{T}\mathbf{w}_{1}+\mathbf{b}_{1}+\mathbf{x}_{1}$
|
||||
>
|
||||
> $l=2:\mathbf{x}_{3} =\mathbf{x}_{0} \mathbf{x}_{2}^{T} \mathbf{w}_{2}+ \mathbf{b}_{2}+\mathbf{x}_{2}=\mathbf{x}_{0} [\mathbf{x}_{0} [\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}]^{T}\mathbf{w}_{1}+\mathbf{b}_{1}+\mathbf{x}_{1}]^{T}\mathbf{w}_{2}+\mathbf{b}_{2}+\mathbf{x}_{2}$
|
||||
|
||||
我们暂且写到第3层的计算, 我们会发现什么结论呢? 给大家总结一下:
|
||||
|
||||
1. $\mathrm{x}_1$中包含了所有的$\mathrm{x}_0$的1,2阶特征的交互, $\mathrm{x}_2$包含了所有的$\mathrm{x}_1, \mathrm{x}_0$的1、2、3阶特征的交互,$\mathrm{x}_3$中包含了所有的$\mathrm{x}_2$, $\mathrm{x}_1$与$\mathrm{x}_0$的交互,$\mathrm{x}_0$的1、2、3、4阶特征交互。 因此, 交叉网络层的叉乘阶数是有限的。 **第$l$层特征对应的最高的叉乘阶数$l+1$**
|
||||
|
||||
2. Cross网络的参数是共享的, 每一层的这个权重特征之间共享, 这个可以使得模型泛化到看不见的特征交互作用, 并且对噪声更具有鲁棒性。 例如两个稀疏的特征$x_i,x_j$, 它们在数据中几乎不发生交互, 那么学习$x_i,x_j$的权重对于预测没有任何的意义。
|
||||
|
||||
3. 计算交叉网络的参数数量。 假设交叉层的数量是$L_c$, 特征$x$的维度是$n$, 那么总共的参数是:
|
||||
|
||||
$$
|
||||
n\times L_c \times 2
|
||||
$$
|
||||
这个就是每一层会有$w$和$b$。且$w$维度和$x$的维度是一致的。
|
||||
|
||||
4. 交叉网络的时间和空间复杂度是线性的。这是因为, 每一层都只有$w$和$b$, 没有激活函数的存在,相对于深度学习网络, 交叉网络的复杂性可以忽略不计。
|
||||
|
||||
5. Cross网络是FM的泛化形式, 在FM模型中, 特征$x_i$的权重$v_i$, 那么交叉项$x_i,x_j$的权重为$<x_i,x_j>$。在DCN中, $x_i$的权重为${W_K^{(i)}}_{k=1}^l$, 交叉项$x_i,x_j$的权重是参数${W_K^{(i)}}_{k=1}^l$和${W_K^{(j)}}_{k=1}^l$的乘积,这个看上面那个例子展开感受下。因此两个模型都各自学习了独立于其他特征的一些参数,并且交叉项的权重是相应参数的某种组合。FM只局限于2阶的特征交叉(一般),而DCN可以构建更高阶的特征交互, 阶数由网络深度决定,并且交叉网络的参数只依据输入的维度线性增长。
|
||||
|
||||
6. 还有一点我们也要了解,对于每一层的计算中, 都会跟着$\mathrm{x}_0$, 这个是咱们的原始输入, 之所以会乘以一个这个,是为了保证后面不管怎么交叉,都不能偏离我们的原始输入太远,别最后交叉交叉都跑偏了。
|
||||
|
||||
7. $\mathbf{x}_{l+1}=f\left(\mathbf{x}_{l}, \mathbf{w}_{l}, \mathbf{b}_{l}\right)+\mathbf{x}_{l}$, 这个东西其实有点跳远连接的意思,也就是和ResNet也有点相似,无形之中还能有效的缓解梯度消失现象。
|
||||
|
||||
好了, 关于本模型的交叉网络的细节就介绍到这里了。这应该也是本模型的精华之处了,后面就简单了。
|
||||
|
||||
### Deep Network
|
||||
|
||||
这个就和上面的D&W的全连接层原理一样。这里不再过多的赘述。
|
||||
$$
|
||||
\mathbf{h}_{l+1}=f\left(W_{l} \mathbf{h}_{l}+\mathbf{b}_{l}\right)
|
||||
$$
|
||||
具体的可以参考W&D模型。
|
||||
|
||||
### 组合输出层
|
||||
|
||||
这个层负责将两个网络的输出进行拼接, 并且通过简单的Logistics回归完成最后的预测:
|
||||
$$
|
||||
p=\sigma\left(\left[\mathbf{x}_{L_{1}}^{T}, \mathbf{h}_{L_{2}}^{T}\right] \mathbf{w}_{\text {logits }}\right)
|
||||
$$
|
||||
其中$\mathbf{x}_{L_{1}}^{T}$和$\mathbf{h}_{L_{2}}^{T}$分别表示交叉网络和深度网络的输出。
|
||||
最后二分类的损失函数依然是交叉熵损失:
|
||||
$$
|
||||
\text { loss }=-\frac{1}{N} \sum_{i=1}^{N} y_{i} \log \left(p_{i}\right)+\left(1-y_{i}\right) \log \left(1-p_{i}\right)+\lambda \sum_{l}\left\|\mathbf{w}_{i}\right\|^{2}
|
||||
$$
|
||||
|
||||
Cross&Deep模型的原理就是这些了,其核心部分就是Cross Network, 这个可以进行特征的自动交叉, 避免了更多基于业务理解的人工特征组合。 该模型相比于W&D,Cross部分表达能力更强, 使得模型具备了更强的非线性学习能力。
|
||||
|
||||
## 代码实现
|
||||
|
||||
下面我们看下DCN的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。
|
||||
|
||||
从上面的结构图我们也可以看出, DCN的模型搭建,其实主要分为几大模块, 首先就是建立输入层,用到的函数式`build_input_layers`,有了输入层之后, 我们接下来是embedding层的搭建,用到的函数是`build_embedding_layers`, 这个层的作用是接收离散特征,变成低维稠密。 接下来就是把连续特征和embedding之后的离散特征进行拼接,分别进入wide端和deep端。 wide端就是交叉网络,而deep端是DNN网络, 这里分别是`CrossNet()`和`get_dnn_output()`, 接下来就是把这两块的输出拼接得到最后的输出了。所以整体代码如下:
|
||||
|
||||
```python
|
||||
def DCN(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layer_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
concat_dense_inputs = Concatenate(axis=1)(list(dense_input_dict.values()))
|
||||
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns)) if linear_feature_columns else []
|
||||
|
||||
sparse_kd_embed = concat_embedding_list(sparse_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
|
||||
|
||||
concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed)
|
||||
|
||||
dnn_input = Concatenate(axis=1)([concat_dense_inputs, concat_sparse_kd_embed])
|
||||
|
||||
dnn_output = get_dnn_output(dnn_input)
|
||||
|
||||
cross_output = CrossNet()(dnn_input)
|
||||
|
||||
# stack layer
|
||||
stack_output = Concatenate(axis=1)([dnn_output, cross_output])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layer = Dense(1, activation='sigmoid')(stack_output)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
```
|
||||
|
||||
这个模型的实现过程和DeepFM比较类似,这里不画草图了,如果想看的可以去参考DeepFM草图及代码之间的对应关系。
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center> <img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片DCN.png" alt="image-20210308143101261" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
|
||||
1. 请计算Cross Network的复杂度,需要的变量请自己定义。
|
||||
2. 在实现矩阵计算$x_0*x_l^Tw$的过程中,有人说要先算前两个,有人说要先算后两个,请问那种方式更好?为什么?
|
||||
|
||||
**参考资料**
|
||||
* 《深度学习推荐系统》 --- 王喆
|
||||
* [Deep&Cross模型原论文](https://arxiv.org/abs/1708.05123)
|
||||
* AI上推荐 之 Wide&Deep与Deep&Cross模型(记忆与泛化并存的华丽转身)
|
||||
* [Wide&Deep模型的进阶---Cross&Deep模型](https://mp.weixin.qq.com/s/DkoaMaXhlgQv1NhZHF-7og)
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user