docs: fun-rec
This commit is contained in:
288
4.人工智能/ch02/ch2.1/ch2.1.1/Swing.md
Normal file
288
4.人工智能/ch02/ch2.1/ch2.1.1/Swing.md
Normal file
@@ -0,0 +1,288 @@
|
||||
# Swing(Graph-based)
|
||||
## 动机
|
||||
大规模推荐系统需要实时对用户行为做出海量预测,为了保证这种实时性,大规模的推荐系统通常严重依赖于预先计算好的产品索引。产品索引的功能为:给定种子产品返回排序后的候选相关产品列表。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2relations.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
|
||||
相关性产品索引主要包含两部分:替代性产品和互补性产品。例如图中的不同种类的衬衫构成了替代关系,而衬衫和风衣裤子等构成了互补关系。用户通常希望在完成购买行为之前尽可能看更多的衬衫,而用户购买过衬衫之后更希望看到与之搭配的单品而不是其他衬衫了。
|
||||
|
||||
## 之前方法局限性
|
||||
- 基于 Cosine, Jaccard, 皮尔逊相关性等相似度计算的协同过滤算法,在计算邻居关联强度的时候只关注于 Item-based (常用,因为item相比于用户变化的慢,且新Item特征比较容易获得),Item-based CF 只关注于 Item-User-Item 的路径,把所有的User-Item交互都平等得看待,从而忽视了 User-Item 交互中的大量噪声,推荐精度存在局限性。
|
||||
- 对互补性产品的建模不足,可能会导致用户购买过手机之后还继续推荐手机,但用户短时间内不会再继续购买手机,因此产生无效曝光。
|
||||
|
||||
## 贡献
|
||||
提出了高效建立产品索引图的技术。
|
||||
主要包括:
|
||||
- Swing 算法利用 user-item 二部图的子结构捕获产品间的替代关系。
|
||||
- Surprise 算法利用商品分类信息和用户共同购买图上的聚类技术来建模产品之间的组合关系。
|
||||
|
||||
## Swing算法
|
||||
Swing 通过利用 User-Item-User 路径中所包含的信息,考虑 User-Item 二部图中的鲁棒内部子结构计算相似性。
|
||||
- 什么是内部子结构?
|
||||
以经典的啤酒尿布故事为例,张三同时购买了啤酒和尿布,这可能是一种巧合。但两个甚至多个顾客都同时购买了啤酒尿布,这就证明啤酒和尿布具有相关关系。这样共同购买啤酒和尿布的用户越多,啤酒和尿布的相关度就会越高。
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片example_of_swing.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
图中的红色四边形就是一种Swing子结构,这种子结构可以作为给王五推荐尿布的依据。
|
||||
|
||||
- 通俗解释:若用户 $u$ 和用户 $v$ 之间除了购买过 $i$ 外,还购买过商品 $j$ ,则认为两件商品是具有某种程度上的相似的。也就是说,商品与商品之间的相似关系,是通过用户关系来传递的。为了衡量物品 $i$ 和 $j$ 的相似性,比较同时购买了物品 $i$ 和 $j$ 的用户 $u$ 和用户 $v$, 如果这两个用户共同购买的物品越少,即这两个用户原始兴趣不相似,但仍同时购买了两个相同的物品 $i$ 和 $j$, 则物品 $i$ 和 $j$ 的相似性越高。
|
||||
|
||||
- 计算公式
|
||||
|
||||
$$s(i,j)=\sum\limits_{u\in U_i\cap U_j} \sum\limits_{v \in U_i\cap U_j}w_u*w_v* \frac{1}{\alpha+|I_u \cap I_v|}$$
|
||||
|
||||
其中$U_i$ 是点击过商品i的用户集合,$I_u$ 是用户u点击过的商品集合,$\alpha$是平滑系数。
|
||||
|
||||
$w_u=\frac{1}{\sqrt{|I_u|}},w_v=\frac{1}{\sqrt{|I_v|}}$ 是用户权重参数,来降低活跃用户的影响。
|
||||
|
||||
- 代码实现
|
||||
- Python (建议自行debug方便理解)
|
||||
```python
|
||||
from itertools import combinations
|
||||
import pandas as pd
|
||||
alpha = 0.5
|
||||
top_k = 20
|
||||
def load_data(train_path):
|
||||
train_data = pd.read_csv(train_path, sep="\t", engine="python", names=["userid", "itemid", "rate"])#提取用户交互记录数据
|
||||
print(train_data.head(3))
|
||||
return train_data
|
||||
|
||||
def get_uitems_iusers(train):
|
||||
u_items = dict()
|
||||
i_users = dict()
|
||||
for index, row in train.iterrows():#处理用户交互记录
|
||||
u_items.setdefault(row["userid"], set())
|
||||
i_users.setdefault(row["itemid"], set())
|
||||
u_items[row["userid"]].add(row["itemid"])#得到user交互过的所有item
|
||||
i_users[row["itemid"]].add(row["userid"])#得到item交互过的所有user
|
||||
print("使用的用户个数为:{}".format(len(u_items)))
|
||||
print("使用的item个数为:{}".format(len(i_users)))
|
||||
return u_items, i_users
|
||||
|
||||
def swing_model(u_items, i_users):
|
||||
# print([i for i in i_users.values()][:5])
|
||||
# print([i for i in u_items.values()][:5])
|
||||
item_pairs = list(combinations(i_users.keys(), 2)) #全排列组合对
|
||||
print("item pairs length:{}".format(len(item_pairs)))
|
||||
item_sim_dict = dict()
|
||||
for (i, j) in item_pairs:
|
||||
user_pairs = list(combinations(i_users[i] & i_users[j], 2)) #item_i和item_j对应的user取交集后全排列 得到user对
|
||||
result = 0
|
||||
for (u, v) in user_pairs:
|
||||
result += 1 / (alpha + list(u_items[u] & u_items[v]).__len__()) #分数公式
|
||||
if result != 0 :
|
||||
item_sim_dict.setdefault(i, dict())
|
||||
item_sim_dict[i][j] = format(result, '.6f')
|
||||
return item_sim_dict
|
||||
|
||||
def save_item_sims(item_sim_dict, top_k, path):
|
||||
new_item_sim_dict = dict()
|
||||
try:
|
||||
writer = open(path, 'w', encoding='utf-8')
|
||||
for item, sim_items in item_sim_dict.items():
|
||||
new_item_sim_dict.setdefault(item, dict())
|
||||
new_item_sim_dict[item] = dict(sorted(sim_items.items(), key = lambda k:k[1], reverse=True)[:top_k])#排序取出 top_k个相似的item
|
||||
writer.write('item_id:%d\t%s\n' % (item, new_item_sim_dict[item]))
|
||||
print("SUCCESS: top_{} item saved".format(top_k))
|
||||
except Exception as e:
|
||||
print(e.args)
|
||||
|
||||
if __name__ == "__main__":
|
||||
train_data_path = "./ratings_final.txt"
|
||||
item_sim_save_path = "./item_sim_dict.txt"
|
||||
top_k = 10 #与item相似的前 k 个item
|
||||
train = load_data(train_data_path)
|
||||
u_items, i_users = get_uitems_iusers(train)
|
||||
item_sim_dict = swing_model(u_items, i_users)
|
||||
save_item_sims(item_sim_dict, top_k, item_sim_save_path)
|
||||
```
|
||||
|
||||
- Spark(仅为核心代码需要补全配置才能跑通)
|
||||
```scala
|
||||
object Swing {
|
||||
|
||||
def main(args: Array[String]): Unit = {
|
||||
val spark = SparkSession.builder()
|
||||
.appName("test")
|
||||
.master("local[2]")
|
||||
.getOrCreate()
|
||||
val alpha = 1 //分数计算参数
|
||||
val filter_n_items = 10000 //想要计算的item数量 测试的时候取少点
|
||||
val top_n_items = 500 //保存item的score排序前500个相似的item
|
||||
val model = new SwingModel(spark)
|
||||
.setAlpha(alpha.toDouble)
|
||||
.setFilter_N_Items(filter_n_items.toInt)
|
||||
.setTop_N_Items(top_n_items.toInt)
|
||||
val url = "file:///usr/local/var/scala/common/part-00022-e17c0014.snappy.parquet"
|
||||
val ratings = DataLoader.getRatingLog(spark, url)
|
||||
val df = model.fit(ratings).item2item()
|
||||
df.show(3,false)
|
||||
// df.write.mode("overwrite").parquet(dest_url)
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
```scala
|
||||
/**
|
||||
* swing
|
||||
* @param ratings 打分dataset
|
||||
* @return
|
||||
*/
|
||||
def fit(ratings: Dataset[Rating]): SwingModel = {
|
||||
|
||||
def interWithAlpha = udf(
|
||||
(array_1: Seq[GenericRowWithSchema],
|
||||
array_2: Seq[GenericRowWithSchema]) => {
|
||||
var score = 0.0
|
||||
val u_set_1 = array_1.toSet
|
||||
val u_set_2 = array_2.toSet
|
||||
val user_set = u_set_1.intersect(u_set_2).toArray //取交集得到两个item共同user
|
||||
|
||||
for (i <- user_set.indices; j <- i + 1 until user_set.length) {
|
||||
val user_1 = user_set(i)
|
||||
val user_2 = user_set(j)
|
||||
val item_set_1 = user_1.getAs[Seq[String]]("_2").toSet
|
||||
val item_set_2 = user_2.getAs[Seq[String]]("_2").toSet
|
||||
score = score + 1 / (item_set_1
|
||||
.intersect(item_set_2)
|
||||
.size
|
||||
.toDouble + alpha.get)
|
||||
}
|
||||
score
|
||||
}
|
||||
)
|
||||
val df = ratings.repartition(defaultParallelism).cache()
|
||||
|
||||
val groupUsers = df
|
||||
.groupBy("user_id")
|
||||
.agg(collect_set("item_id")) //聚合itme_id
|
||||
.toDF("user_id", "item_set")
|
||||
.repartition(defaultParallelism)
|
||||
println("groupUsers")
|
||||
groupUsers.show(3, false)//user_id|[item_id_set]: 422|[6117,611,6117]
|
||||
|
||||
val groupItems = df
|
||||
.join(groupUsers, "user_id")
|
||||
.rdd
|
||||
.map { x =>
|
||||
val item_id = x.getAs[String]("item_id")
|
||||
val user_id = x.getAs[String]("user_id")
|
||||
val item_set = x.getAs[Seq[String]]("item_set")
|
||||
(item_id, (user_id, item_set))
|
||||
}//i_[user(item_set)]
|
||||
.toDF("item_id", "user")
|
||||
.groupBy("item_id")
|
||||
.agg(collect_set("user"), count("item_id"))
|
||||
.toDF("item_id", "user_set", "count")
|
||||
.filter("size(user_set) > 1")//过滤掉没有交互的
|
||||
.sort($"count".desc) //根据count倒排item_id数量
|
||||
.limit(filter_n_items.get)//item可能百万级别但后面召回的需求量小所以只取前n个item进行计算
|
||||
.drop("count")
|
||||
.repartition(defaultParallelism)
|
||||
.cache()
|
||||
println("groupItems") //得到与itme_id有交互的user_id
|
||||
groupItems.show(3, false)//item_id|[[user_id,[item_set]],[user_id,[item_set]]]: 67|[[562,[66, 813, 61, 67]],[563,[67, 833, 62, 64]]]
|
||||
|
||||
val itemJoined = groupItems
|
||||
.join(broadcast(groupItems))//内连接两个item列表
|
||||
.toDF("item_id_1", "user_set_1", "item_id_2", "user_set_2")
|
||||
.filter("item_id_1 > item_id_2")//内连接 item两两配对
|
||||
.withColumn("score", interWithAlpha(col("user_set_1"), col("user_set_2")))//将上面得到的与item相关的user_set输入到函数interWithAlpha计算分数
|
||||
.select("item_id_1", "item_id_2", "score")
|
||||
.filter("score > 0")
|
||||
.repartition(defaultParallelism)
|
||||
.cache()
|
||||
println("itemJoined")
|
||||
itemJoined.show(5)//得到两两item之间的分数结果 item_id_1 item_id_2 score
|
||||
similarities = Option(itemJoined)
|
||||
this
|
||||
}
|
||||
|
||||
/**
|
||||
* 从fit结果,对item_id进行聚合并排序,每个item后截取n个item,并返回。
|
||||
* @param num 取n个item
|
||||
* @return
|
||||
*/
|
||||
def item2item(): DataFrame = {
|
||||
|
||||
case class itemWithScore(item_id: String, score: Double)
|
||||
val sim = similarities.get.select("item_id_1", "item_id_2", "score")
|
||||
val topN = sim
|
||||
.map { x =>
|
||||
val item_id_1 = x.getAs[String]("item_id_1")
|
||||
val item_id_2 = x.getAs[String]("item_id_2")
|
||||
val score = x.getAs[Double]("score")
|
||||
(item_id_1, (item_id_2, score))
|
||||
}
|
||||
.toDF("item_id", "itemWithScore")
|
||||
.groupBy("item_id")
|
||||
.agg(collect_set("itemWithScore"))
|
||||
.toDF("item_id", "item_set")//item_id |[[item_id1:score],[item_id2:score]]
|
||||
.rdd
|
||||
.map { x =>
|
||||
val item_id_1 = x.getAs[String]("item_id")
|
||||
val item_set = x //对itme_set中score进行排序操作
|
||||
.getAs[Seq[GenericRowWithSchema]]("item_set")
|
||||
.map { x =>
|
||||
val item_id_2 = x.getAs[String]("_1")
|
||||
val score = x.getAs[Double]("_2")
|
||||
(item_id_2, score)
|
||||
}
|
||||
.sortBy(-_._2)//根据score进行排序
|
||||
.take(top_n_items.get)//取top_n
|
||||
.map(x => x._1 + ":" + x._2.toString)
|
||||
(item_id_1, item_set)
|
||||
}
|
||||
.filter(_._2.nonEmpty)
|
||||
.toDF("id", "sorted_items")
|
||||
topN
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Surprise算法
|
||||
首先在行为相关性中引入连续时间衰减因子,然后引入基于交互数据的聚类方法解决数据稀疏的问题,旨在帮助用户找到互补商品。互补相关性主要从三个层面考虑,类别层面,商品层面和聚类层面。
|
||||
|
||||
- 类别层面
|
||||
首先通过商品和类别的映射关系,我们可以得到 user-category 矩阵。随后使用简单的相关性度量可以计算出类别 $i,j$ 的相关性。
|
||||
|
||||
$\theta_{i,j}=p(c_{i,j}|c_j)=\frac{N(c_{i,j})}{N(c_j)}$
|
||||
|
||||
即,$N(c_{i,j})$为在购买过i之后购买j类的数量,$N(c_{j})$为购买j类的数量。
|
||||
|
||||
由于类别直接的种类差异,每个类别的相关类数量存在差异,因此采用最大相对落点来作为划分阈值。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片max_drop.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
|
||||
例如图(a)中T恤的相关类选择前八个,图(b)中手机的相关类选择前三个。
|
||||
|
||||
- 商品层面
|
||||
商品层面的相关性挖掘主要有两个关键设计:
|
||||
- 商品的购买顺序是需要被考虑的,例如在用户购买手机后推荐充电宝是合理的,但在用户购买充电宝后推荐手机是不合理的。
|
||||
- 两个商品购买的时间间隔也是需要被考虑的,时间间隔越短越能证明两个商品的互补关系。
|
||||
|
||||
最终商品层面的互补相关性被定义为:
|
||||
|
||||
$s_{1}(i, j)=\frac{\sum_{u \in U_{i} \cap U_{j}} 1 /\left(1+\left|t_{u i}-t_{u j}\right|\right)}{\left\|U_{i}\right\| \times\left\|U_{j}\right\|}$,其中$j$属于$i$的相关类,且$j$ 的购买时间晚于$i$。
|
||||
|
||||
- 聚类层面
|
||||
- 如何聚类?
|
||||
传统的聚类算法(基于密度和 k-means )在数十亿产品规模下的淘宝场景中不可行,所以作者采用了标签传播算法。
|
||||
- 在哪里标签传播?
|
||||
Item-item 图,其中又 Swing 计算的排名靠前 item 为邻居,边的权重就是 Swing 分数。
|
||||
- 表现如何?
|
||||
快速而有效,15分钟即可对数十亿个项目进行聚类。
|
||||
最终聚类层面的相关度计算同上面商品层面的计算公式
|
||||
|
||||
- 线性组合:
|
||||
$s(i, j)=\omega * s_{1}(i, j)+(1-\omega) * s_{2}(i, j)$,其中$\omega=0.8$是作者设置的权重超参数。
|
||||
Surprise算法通过利用类别信息和标签传播技术解决了用户共同购买图上的稀疏性问题。
|
||||
|
||||
**参考资料**
|
||||
- [Large Scale Product Graph Construction for Recommendation in E-commerce](https://arxiv.org/pdf/2010.05525)
|
||||
- [推荐召回-Swing](https://zhuanlan.zhihu.com/p/383346471)
|
||||
269
4.人工智能/ch02/ch2.1/ch2.1.1/itemcf.md
Normal file
269
4.人工智能/ch02/ch2.1/ch2.1.1/itemcf.md
Normal file
@@ -0,0 +1,269 @@
|
||||
# 基于物品的协同过滤
|
||||
|
||||
## 基本思想
|
||||
|
||||
基于物品的协同过滤(ItemCF):
|
||||
|
||||
+ 预先根据所有用户的历史行为数据,计算物品之间的相似性。
|
||||
+ 然后,把与用户喜欢的物品相类似的物品推荐给用户。
|
||||
|
||||
举例来说,如果用户 1 喜欢物品 A ,而物品 A 和 C 非常相似,则可以将物品 C 推荐给用户1。ItemCF算法并不利用物品的内容属性计算物品之间的相似度, 主要通过分析用户的行为记录计算物品之间的相似度, 该算法认为, 物品 A 和物品 C 具有很大的相似度是因为喜欢物品 A 的用户极可能喜欢物品 C。
|
||||
|
||||
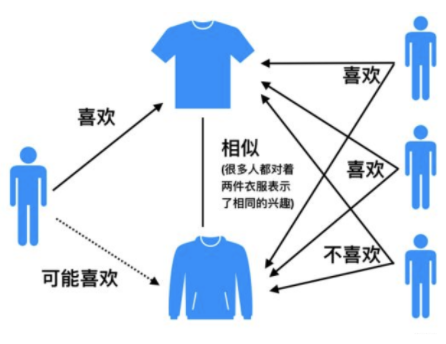
|
||||
|
||||
## 计算过程
|
||||
|
||||
基于物品的协同过滤算法和基于用户的协同过滤算法很像, 所以我们这里直接还是拿上面 Alice 的那个例子来看。
|
||||
|
||||
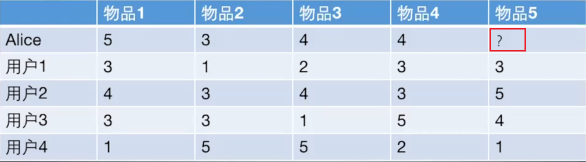
|
||||
|
||||
如果想知道 Alice 对物品5打多少分, 基于物品的协同过滤算法会这么做:
|
||||
|
||||
+ 首先计算一下物品5和物品1, 2, 3, 4之间的相似性。
|
||||
|
||||
+ 在Alice找出与物品 5 最相近的 n 个物品。
|
||||
|
||||
+ 根据 Alice 对最相近的 n 个物品的打分去计算对物品 5 的打分情况。
|
||||
|
||||
**手动计算:**
|
||||
|
||||
1. 手动计算物品之间的相似度
|
||||
|
||||
>物品向量: $物品 1(3,4,3,1) ,物品2(1,3,3,5) ,物品3(2,4,1,5) ,物品4(3,3,5,2) ,物品5(3,5,41)$
|
||||
>
|
||||
>+ 下面计算物品 5 和物品 1 之间的余弦相似性:
|
||||
> $$
|
||||
> \operatorname{sim}(\text { 物品1, 物品5 })=\operatorname{cosine}(\text { 物品1, 物品5 } )=\frac{9+20+12+1}{\operatorname{sqrt}(9+16+9+1)*\operatorname{sqrt}(9+25+16+1)}
|
||||
> $$
|
||||
>
|
||||
>+ 皮尔逊相关系数类似。
|
||||
>
|
||||
|
||||
2. 基于 `sklearn` 计算物品之间的皮尔逊相关系数:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/JavaJOyFti58um61zPsa.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
|
||||
3. 根据皮尔逊相关系数, 可以找到与物品5最相似的2个物品是 item1 和 item4, 下面基于上面的公式计算最终得分:
|
||||
|
||||
$$
|
||||
P_{Alice, 物品5}=\bar{R}_{物品5}+\frac{\sum_{k=1}^{2}\left(w_{物品5,物品 k}\left(R_{Alice, 物品k}-\bar{R}_{物品k}\right)\right)}{\sum_{k=1}^{2} w_{物品k, 物品5}} \\
|
||||
=\frac{13}{4}+\frac{0.97*(5-3.2)+0.58*(4-3.4)}{0.97+0.58}=4.6
|
||||
$$
|
||||
|
||||
## ItemCF编程实现
|
||||
|
||||
1. 构建物品-用户的评分矩阵
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
|
||||
def loadData():
|
||||
items = {'A': {'Alice': 5.0, 'user1': 3.0, 'user2': 4.0, 'user3': 3.0, 'user4': 1.0},
|
||||
'B': {'Alice': 3.0, 'user1': 1.0, 'user2': 3.0, 'user3': 3.0, 'user4': 5.0},
|
||||
'C': {'Alice': 4.0, 'user1': 2.0, 'user2': 4.0, 'user3': 1.0, 'user4': 5.0},
|
||||
'D': {'Alice': 4.0, 'user1': 3.0, 'user2': 3.0, 'user3': 5.0, 'user4': 2.0},
|
||||
'E': {'user1': 3.0, 'user2': 5.0, 'user3': 4.0, 'user4': 1.0}
|
||||
}
|
||||
return items
|
||||
```
|
||||
|
||||
2. 计算物品间的相似度矩阵
|
||||
|
||||
```python
|
||||
item_data = loadData()
|
||||
|
||||
similarity_matrix = pd.DataFrame(
|
||||
np.identity(len(item_data)),
|
||||
index=item_data.keys(),
|
||||
columns=item_data.keys(),
|
||||
)
|
||||
|
||||
# 遍历每条物品-用户评分数据
|
||||
for i1, users1 in item_data.items():
|
||||
for i2, users2 in item_data.items():
|
||||
if i1 == i2:
|
||||
continue
|
||||
vec1, vec2 = [], []
|
||||
for user, rating1 in users1.items():
|
||||
rating2 = users2.get(user, -1)
|
||||
if rating2 == -1:
|
||||
continue
|
||||
vec1.append(rating1)
|
||||
vec2.append(rating2)
|
||||
similarity_matrix[i1][i2] = np.corrcoef(vec1, vec2)[0][1]
|
||||
|
||||
print(similarity_matrix)
|
||||
```
|
||||
|
||||
```
|
||||
A B C D E
|
||||
A 1.000000 -0.476731 -0.123091 0.532181 0.969458
|
||||
B -0.476731 1.000000 0.645497 -0.310087 -0.478091
|
||||
C -0.123091 0.645497 1.000000 -0.720577 -0.427618
|
||||
D 0.532181 -0.310087 -0.720577 1.000000 0.581675
|
||||
E 0.969458 -0.478091 -0.427618 0.581675 1.000000
|
||||
```
|
||||
|
||||
3. 从 Alice 购买过的物品中,选出与物品 `E` 最相似的 `num` 件物品。
|
||||
|
||||
```python
|
||||
target_user = ' Alice '
|
||||
target_item = 'E'
|
||||
num = 2
|
||||
|
||||
sim_items = []
|
||||
sim_items_list = similarity_matrix[target_item].sort_values(ascending=False).index.tolist()
|
||||
for item in sim_items_list:
|
||||
# 如果target_user对物品item评分过
|
||||
if target_user in item_data[item]:
|
||||
sim_items.append(item)
|
||||
if len(sim_items) == num:
|
||||
break
|
||||
print(f'与物品{target_item}最相似的{num}个物品为:{sim_items}')
|
||||
```
|
||||
|
||||
```
|
||||
与物品E最相似的2个物品为:['A', 'D']
|
||||
```
|
||||
|
||||
4. 预测用户 Alice 对物品 `E` 的评分
|
||||
|
||||
```python
|
||||
target_user_mean_rating = np.mean(list(item_data[target_item].values()))
|
||||
weighted_scores = 0.
|
||||
corr_values_sum = 0.
|
||||
|
||||
target_item = 'E'
|
||||
for item in sim_items:
|
||||
corr_value = similarity_matrix[target_item][item]
|
||||
user_mean_rating = np.mean(list(item_data[item].values()))
|
||||
|
||||
weighted_scores += corr_value * (item_data[item][target_user] - user_mean_rating)
|
||||
corr_values_sum += corr_value
|
||||
|
||||
target_item_pred = target_user_mean_rating + weighted_scores / corr_values_sum
|
||||
print(f'用户{target_user}对物品{target_item}的预测评分为:{target_item_pred}')
|
||||
```
|
||||
|
||||
```
|
||||
用户 Alice 对物品E的预测评分为:4.6
|
||||
```
|
||||
|
||||
# 协同过滤算法的权重改进
|
||||
|
||||
* base 公式
|
||||
$$
|
||||
w_{i j}=\frac{|N(i) \bigcap N(j)|}{|N(i)|}
|
||||
$$
|
||||
|
||||
+ 该公式表示同时喜好物品 $i$ 和物品 $j$ 的用户数,占喜爱物品 $i$ 的比例。
|
||||
+ 缺点:若物品 $j$ 为热门物品,那么它与任何物品的相似度都很高。
|
||||
|
||||
* 对热门物品进行惩罚
|
||||
$$
|
||||
w_{i j}=\frac{|N(i) \cap N(j)|}{\sqrt{|N(i)||N(j)|}}
|
||||
$$
|
||||
|
||||
|
||||
* 根据 base 公式在的问题,对物品 $j$ 进行打压。打压的出发点很简单,就是在分母再除以一个物品 $j$ 被购买的数量。
|
||||
* 此时,若物品 $j$ 为热门物品,那么对应的 $N(j)$ 也会很大,受到的惩罚更多。
|
||||
|
||||
* 控制对热门物品的惩罚力度
|
||||
$$
|
||||
w_{i j}=\frac{|N(i) \cap N(j)|}{|N(i)|^{1-\alpha}|N(j)|^{\alpha}}
|
||||
$$
|
||||
|
||||
* 除了第二点提到的办法,在计算物品之间相似度时可以对热门物品进行惩罚外。
|
||||
* 可以在此基础上,进一步引入参数 $\alpha$ ,这样可以通过控制参数 $\alpha$来决定对热门物品的惩罚力度。
|
||||
|
||||
* 对活跃用户的惩罚
|
||||
|
||||
* 在计算物品之间的相似度时,可以进一步将用户的活跃度考虑进来。
|
||||
$$
|
||||
w_{i j}=\frac{\sum_{\operatorname{\text {u}\in N(i) \cap N(j)}} \frac{1}{\log 1+|N(u)|}}{|N(i)|^{1-\alpha}|N(j)|^{\alpha}}
|
||||
$$
|
||||
|
||||
+ 对于异常活跃的用户,在计算物品之间的相似度时,他的贡献应该小于非活跃用户。
|
||||
|
||||
# 协同过滤算法的问题分析
|
||||
|
||||
协同过滤算法存在的问题之一就是泛化能力弱:
|
||||
|
||||
+ 即协同过滤无法将两个物品相似的信息推广到其他物品的相似性上。
|
||||
+ 导致的问题是**热门物品具有很强的头部效应, 容易跟大量物品产生相似, 而尾部物品由于特征向量稀疏, 导致很少被推荐**。
|
||||
|
||||
比如下面这个例子:
|
||||
|
||||
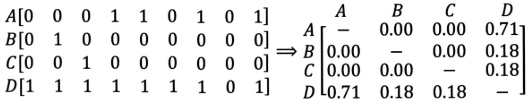
|
||||
|
||||
+ 左边矩阵中,$A, B, C, D$ 表示的是物品。
|
||||
+ 可以看出,$D $ 是一件热门物品,其与 $A、B、C$ 的相似度比较大。因此,推荐系统更可能将 $D$ 推荐给用过 $A、B、C$ 的用户。
|
||||
+ 但是,推荐系统无法找出 $A,B,C$ 之间相似性的原因是交互数据太稀疏, 缺乏相似性计算的直接数据。
|
||||
|
||||
所以这就是协同过滤的天然缺陷:**推荐系统头部效应明显, 处理稀疏向量的能力弱**。
|
||||
|
||||
为了解决这个问题, 同时增加模型的泛化能力。2006年,**矩阵分解技术(Matrix Factorization, MF**)被提出:
|
||||
|
||||
+ 该方法在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品, 挖掘用户和物品的隐含兴趣和隐含特征。
|
||||
+ 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
|
||||
|
||||
# 课后思考
|
||||
|
||||
1. **什么时候使用UserCF,什么时候使用ItemCF?为什么?**
|
||||
|
||||
> (1)UserCF
|
||||
>
|
||||
> + 由于是基于用户相似度进行推荐, 所以具备更强的社交特性, 这样的特点非常适于**用户少, 物品多, 时效性较强的场合**。
|
||||
>
|
||||
> + 比如新闻推荐场景, 因为新闻本身兴趣点分散, 相比用户对不同新闻的兴趣偏好, 新闻的及时性,热点性往往更加重要, 所以正好适用于发现热点,跟踪热点的趋势。
|
||||
> + 另外还具有推荐新信息的能力, 更有可能发现惊喜, 因为看的是人与人的相似性, 推出来的结果可能更有惊喜,可以发现用户潜在但自己尚未察觉的兴趣爱好。
|
||||
>
|
||||
> (2)ItemCF
|
||||
>
|
||||
> + 这个更适用于兴趣变化较为稳定的应用, 更接近于个性化的推荐, 适合**物品少,用户多,用户兴趣固定持久, 物品更新速度不是太快的场合**。
|
||||
> + 比如推荐艺术品, 音乐, 电影。
|
||||
|
||||
|
||||
|
||||
2.**协同过滤在计算上有什么缺点?有什么比较好的思路可以解决(缓解)?**
|
||||
|
||||
> 该问题答案参考上一小节的**协同过滤算法的问题分析**。
|
||||
|
||||
|
||||
|
||||
**3.上面介绍的相似度计算方法有什么优劣之处?**
|
||||
|
||||
> cosine相似度计算简单方便,一般较为常用。但是,当用户的评分数据存在 bias 时,效果往往不那么好。
|
||||
>
|
||||
> + 简而言之,就是不同用户评分的偏向不同。部分用户可能乐于给予好评,而部分用户习惯给予差评或者乱评分。
|
||||
> + 这个时候,根据cosine 相似度计算出来的推荐结果效果会打折扣。
|
||||
>
|
||||
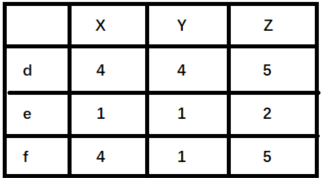
> 举例来说明,如下图(`X,Y,Z` 表示物品,`d,e,f`表示用户):
|
||||
>
|
||||
> 
|
||||
>
|
||||
> + 如果使用余弦相似度进行计算,用户 d 和 e 之间较为相似。但是实际上,用户 d 和 f 之间应该更加相似。只不过由于 d 倾向于打高分,e 倾向于打低分导致二者之间的余弦相似度更高。
|
||||
> + 这种情况下,可以考虑使用皮尔逊相关系数计算用户之间的相似性关系。
|
||||
|
||||
|
||||
|
||||
4.**协同过滤还存在其他什么缺陷?有什么比较好的思路可以解决(缓解)?**
|
||||
|
||||
> + 协同过滤的优点就是没有使用更多的用户或者物品属性信息,仅利用用户和物品之间的交互信息就能完成推荐,该算法简单高效。
|
||||
> + 但这也是协同过滤算法的一个弊端。由于未使用更丰富的用户和物品特征信息,这也导致协同过滤算法的模型表达能力有限。
|
||||
> + 对于该问题,逻辑回归模型(LR)可以更好地在推荐模型中引入更多特征信息,提高模型的表达能力。
|
||||
|
||||
|
||||
|
||||
# 参考资料
|
||||
|
||||
* [基于用户的协同过滤来构建推荐系统:https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw](https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw)
|
||||
* [协同过滤算法概述:https://chenk.tech/posts/8ad63d9d.html](https://chenk.tech/posts/8ad63d9d.html)
|
||||
* B站黑马推荐系统实战课程
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
370
4.人工智能/ch02/ch2.1/ch2.1.1/mf.md
Normal file
370
4.人工智能/ch02/ch2.1/ch2.1.1/mf.md
Normal file
@@ -0,0 +1,370 @@
|
||||
# 隐语义模型与矩阵分解
|
||||
|
||||
协同过滤算法的特点:
|
||||
|
||||
+ 协同过滤算法的特点就是完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息就可以实现推荐,是一个可解释性很强, 非常直观的模型。
|
||||
+ 但是也存在一些问题,处理稀疏矩阵的能力比较弱。
|
||||
|
||||
为了使得协同过滤更好处理稀疏矩阵问题, 增强泛化能力。从协同过滤中衍生出矩阵分解模型(Matrix Factorization, MF)或者叫隐语义模型:
|
||||
|
||||
+ 在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品。
|
||||
+ 通过挖掘用户和物品的隐含兴趣和隐含特征, 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
|
||||
|
||||
|
||||
|
||||
# 隐语义模型
|
||||
|
||||
隐语义模型最早在文本领域被提出,用于找到文本的隐含语义。在2006年, 被用于推荐中, 它的核心思想是通过隐含特征(latent factor)联系用户兴趣和物品(item), 基于用户的行为找出潜在的主题和分类, 然后对物品进行自动聚类,划分到不同类别/主题(用户的兴趣)。
|
||||
|
||||
以项亮老师《推荐系统实践》书中的内容为例:
|
||||
|
||||
>如果我们知道了用户A和用户B两个用户在豆瓣的读书列表, 从他们的阅读列表可以看出,用户A的兴趣涉及侦探小说、科普图书以及一些计算机技术书, 而用户B的兴趣比较集中在数学和机器学习方面。 那么如何给A和B推荐图书呢? 先说说协同过滤算法, 这样好对比不同:
|
||||
>* 对于UserCF,首先需要找到和他们看了同样书的其他用户(兴趣相似的用户),然后给他们推荐那些用户喜欢的其他书。
|
||||
>* 对于ItemCF,需要给他们推荐和他们已经看的书相似的书,比如作者B看了很多关于数据挖掘的书,可以给他推荐机器学习或者模式识别方面的书。
|
||||
>
|
||||
>而如果是隐语义模型的话, 它会先通过一些角度把用户兴趣和这些书归一下类, 当来了用户之后, 首先得到他的兴趣分类, 然后从这个分类中挑选他可能喜欢的书籍。
|
||||
|
||||
隐语义模型和协同过滤的不同主要体现在隐含特征上, 比如书籍的话它的内容, 作者, 年份, 主题等都可以算隐含特征。
|
||||
|
||||
以王喆老师《深度学习推荐系统》中的一个原理图为例,看看是如何通过隐含特征来划分开用户兴趣和物品的。
|
||||
|
||||
<img src="https://img-blog.csdnimg.cn/20200822212051499.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
|
||||
## 音乐评分实例
|
||||
|
||||
假设每个用户都有自己的听歌偏好, 比如用户 A 喜欢带有**小清新的**, **吉他伴奏的**, **王菲**的歌曲,如果一首歌正好**是王菲唱的, 并且是吉他伴奏的小清新**, 那么就可以将这首歌推荐给这个用户。 也就是说是**小清新, 吉他伴奏, 王菲**这些元素连接起了用户和歌曲。
|
||||
|
||||
当然每个用户对不同的元素偏好不同, 每首歌包含的元素也不一样, 所以我们就希望找到下面的两个矩阵:
|
||||
|
||||
1. 潜在因子—— 用户矩阵Q
|
||||
这个矩阵表示不同用户对于不同元素的偏好程度, 1代表很喜欢, 0代表不喜欢, 比如下面这样:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/2020082222025968.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
2. 潜在因子——音乐矩阵P
|
||||
表示每种音乐含有各种元素的成分, 比如下表中, 音乐A是一个偏小清新的音乐, 含有小清新的Latent Factor的成分是0.9, 重口味的成分是0.1, 优雅成分0.2...
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822220751394.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
**计算张三对音乐A的喜爱程度**
|
||||
|
||||
利用上面的这两个矩阵,将对应向量进行内积计算,我们就能得出张三对音乐A的喜欢程度:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822221627219.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
+ 张三对**小清新**的偏好 * 音乐A含有**小清新**的成分 + 张三对**重口味**的偏好 * 音乐A含有**重口味**的成分 + 张三对**优雅**的偏好 * 音乐A含有**优雅**的成分...
|
||||
|
||||
+ 根据隐向量其实就可以得到张三对音乐A的打分,即: $$0.6 * 0.9 + 0.8 * 0.1 + 0.1 * 0.2 + 0.1 * 0.4 + 0.7 * 0 = 0.68$$。
|
||||
|
||||
**计算所有用户对不同音乐的喜爱程度**
|
||||
|
||||
按照这个计算方式, 每个用户对每首歌其实都可以得到这样的分数, 最后就得到了我们的评分矩阵:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822222141231.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:60%;" />
|
||||
</div>
|
||||
+ 红色部分表示用户没有打分,可以通过隐向量计算得到的。
|
||||
|
||||
**小结**
|
||||
|
||||
+ 上面例子中的小清晰, 重口味, 优雅这些就可以看做是隐含特征, 而通过这个隐含特征就可以把用户的兴趣和音乐的进行一个分类, 其实就是找到了每个用户每个音乐的一个隐向量表达形式(与深度学习中的embedding等价)
|
||||
+ 这个隐向量就可以反映出用户的兴趣和物品的风格,并能将相似的物品推荐给相似的用户等。 **有没有感觉到是把协同过滤算法进行了一种延伸, 把用户的相似性和物品的相似性通过了一个叫做隐向量的方式进行表达**
|
||||
|
||||
+ 现实中,类似于上述的矩阵 $P,Q$ 一般很难获得。有的只是用户的评分矩阵,如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822223313349.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:60%;" />
|
||||
</div>
|
||||
|
||||
+ 这种矩阵非常的稀疏,如果直接基于用户相似性或者物品相似性去填充这个矩阵是不太容易的。
|
||||
+ 并且很容易出现长尾问题, 而矩阵分解就可以比较容易的解决这个问题。
|
||||
|
||||
+ 矩阵分解模型:
|
||||
|
||||
+ 基于评分矩阵,将其分解成Q和P两个矩阵乘积的形式,获取用户兴趣和物品的隐向量表达。
|
||||
+ 然后,基于两个分解矩阵去预测某个用户对某个物品的评分了。
|
||||
+ 最后,基于预测评分去进行物品推荐。
|
||||
|
||||
|
||||
|
||||
# 矩阵分解算法
|
||||
|
||||
## 算法原理
|
||||
|
||||
在矩阵分解的算法框架下, **可以通过分解协同过滤的共现矩阵(评分矩阵)来得到用户和物品的隐向量**,原理如下:。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200823101513233.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
+ 矩阵分解算法将 $m\times n$ 维的共享矩阵 $R$ ,分解成 $m \times k$ 维的用户矩阵 $U$ 和 $k \times n$ 维的物品矩阵 $V$ 相乘的形式。
|
||||
+ 其中,$m$ 是用户数量, $n$ 是物品数量, $k$ 是隐向量维度, 也就是隐含特征个数。
|
||||
+ 这里的隐含特征没有太好的可解释性,需要模型自己去学习。
|
||||
+ 一般而言, $k$ 越大隐向量能承载的信息内容越多,表达能力也会更强,但相应的学习难度也会增加。所以,我们需要根据训练集样本的数量去选择合适的数值,在保证信息学习相对完整的前提下,降低模型的学习难度。
|
||||
|
||||
## 评分预测
|
||||
|
||||
在分解得到用户矩阵和物品矩阵后,若要计算用户 $u$ 对物品 $i$ 的评分,公式如下:
|
||||
$$
|
||||
\operatorname{Preference}(u, i)=r_{u i}=p_{u}^{T} q_{i}=\sum_{k=1}^{K} p_{u, k} q_{i,k}
|
||||
$$
|
||||
+ 其中,向量 $p_u$ 表示用户 $u$ 的隐向量,向量 $q_i$ 表示物品 $i$ 的隐向量。
|
||||
+ 用户向量和物品向量的内积 $p_{u}^{T} q_{i}$ 可以表示为用户 $u$ 对物品 $i$ 的预测评分。
|
||||
+ $p_{u,k}$ 和 $q_{i,k}$ 是模型的参数, $p_{u,k}$ 度量的是用户 $u$ 的兴趣和第 $k$ 个隐类的关系,$q_{i,k}$ 度量了第 $k$ 个隐类和物品 $i$ 之间的关系。
|
||||
|
||||
## 矩阵分解求解
|
||||
|
||||
常用的矩阵分解方法有特征值分解(EVD)或者奇异值分解(SVD), 具体原理可参考:
|
||||
|
||||
> [奇异值分解svd原理详解及推导](https://blog.csdn.net/wuzhongqiang/article/details/108168238)
|
||||
|
||||
+ 对于 EVD, 它要求分解的矩阵是方阵, 绝大部分场景下用户-物品矩阵不满足这个要求。
|
||||
+ 传统的 SVD 分解, 会要求原始矩阵是稠密的。但现实中用户的评分矩阵是非常稀疏的。
|
||||
+ 如果想用奇异值分解, 就必须对缺失的元素进行填充(比如填 0 )。
|
||||
+ 填充不但会导致空间复杂度增高,且补全内容不一定准确。
|
||||
+ 另外,SVD 分解计算复杂度非常高,而用户-物品的评分矩阵较大,不具备普适性。
|
||||
|
||||
## FunkSVD
|
||||
|
||||
2006年的Netflix Prize之后, Simon Funk公布了一个矩阵分解算法叫做**Funk-SVD**, 后来被 Netflix Prize 的冠军Koren称为**Latent Factor Model(LFM)**。
|
||||
|
||||
Funk-SVD的思想很简单: **把求解上面两个矩阵的参数问题转换成一个最优化问题, 可以通过训练集里面的观察值利用最小化来学习用户矩阵和物品矩阵**。
|
||||
|
||||
**算法过程**
|
||||
|
||||
1. 根据前面提到的,在有用户矩阵和物品矩阵的前提下,若要计算用户 $u$ 对物品 $i$ 的评分, 可以根据公式:
|
||||
$$
|
||||
\operatorname{Preference}(u, i)=r_{u i}=p_{u}^{T} q_{i}=\sum_{k=1}^{K} p_{u, k} q_{i,k}
|
||||
$$
|
||||
|
||||
+ 其中,向量 $p_u$ 表示用户 $u$ 的隐向量,向量 $q_i$ 表示物品 $i$ 的隐向量。
|
||||
|
||||
2. 随机初始化一个用户矩阵 $U$ 和一个物品矩阵 $V$,获取每个用户和物品的初始隐语义向量。
|
||||
|
||||
3. 将用户和物品的向量内积 $p_{u}^{T} q_{i}$, 作为用户对物品的预测评分 $\hat{r}_{u i}$。
|
||||
|
||||
+ $\hat{r}_{u i}=p_{u}^{T} q_{i}$ 表示的是通过建模,求得的用户 $u$ 对物品的预测评分。
|
||||
+ 在用户对物品的评分矩阵中,矩阵中的元素 $r_{u i}$ 才是用户对物品的真实评分。
|
||||
|
||||
4. 对于评分矩阵中的每个元素,计算预测误差 $e_{u i}=r_{u i}-\hat{r}_{u i}$,对所有训练样本的平方误差进行累加:
|
||||
$$
|
||||
\operatorname{SSE}=\sum_{u, i} e_{u i}^{2}=\sum_{u, i}\left(r_{u i}-\sum_{k=1}^{K} p_{u,k} q_{i,k}\right)^{2}
|
||||
$$
|
||||
|
||||
+ 从上述公式可以看出,$SSE$ 建立起了训练数据和预测模型之间的关系。
|
||||
|
||||
+ 如果我们希望模型预测的越准确,那么在训练集(已有的评分矩阵)上的预测误差应该仅可能小。
|
||||
|
||||
+ 为方便后续求解,给 $SSE$ 增加系数 $1/2$ :
|
||||
$$
|
||||
\operatorname{SSE}=\frac{1}{2} \sum_{u, i} e_{u i}^{2}=\frac{1}{2} \sum_{u, i}\left(r_{u i}-\sum_{k=1}^{K} p_{u k} q_{i k}\right)^{2}
|
||||
$$
|
||||
|
||||
5. 前面提到,模型预测越准确等价于预测误差越小,那么优化的目标函数变为:
|
||||
$$
|
||||
\min _{\boldsymbol{q}^{*}, \boldsymbol{p}^{*}} \frac{1}{2} \sum_{(u, i) \in K}\left(\boldsymbol{r}_{\mathrm{ui}}-p_{u}^{T} q_{i}\right)^{2}
|
||||
$$
|
||||
|
||||
+ $K$ 表示所有用户评分样本的集合,**即评分矩阵中不为空的元素**,其他空缺值在测试时是要预测的。
|
||||
+ 该目标函数需要优化的目标是用户矩阵 $U$ 和一个物品矩阵 $V$。
|
||||
|
||||
6. 对于给定的目标函数,可以通过梯度下降法对参数进行优化。
|
||||
|
||||
+ 求解目标函数 $SSE$ 关于用户矩阵中参数 $p_{u,k}$ 的梯度:
|
||||
$$
|
||||
\frac{\partial}{\partial p_{u,k}} S S E=\frac{\partial}{\partial p_{u,k}}\left(\frac{1}{2}e_{u i}^{2}\right) =e_{u i} \frac{\partial}{\partial p_{u,k}} e_{u i}=e_{u i} \frac{\partial}{\partial p_{u,k}}\left(r_{u i}-\sum_{k=1}^{K} p_{u,k} q_{i,k}\right)=-e_{u i} q_{i,k}
|
||||
$$
|
||||
|
||||
+ 求解目标函数 $SSE$ 关于 $q_{i,k}$ 的梯度:
|
||||
$$
|
||||
\frac{\partial}{\partial q_{i,k}} S S E=\frac{\partial}{\partial q_{i,k}}\left(\frac{1}{2}e_{u i}^{2}\right) =e_{u i} \frac{\partial}{\partial q_{i,k}} e_{u i}=e_{u i} \frac{\partial}{\partial q_{i,k}}\left(r_{u i}-\sum_{k=1}^{K} p_{u,k} q_{i,k}\right)=-e_{u i} p_{u,k}
|
||||
$$
|
||||
|
||||
7. 参数梯度更新
|
||||
$$
|
||||
p_{u, k}=p_{u,k}-\eta (-e_{ui}q_{i, k})=p_{u,k}+\eta e_{ui}q_{i, k} \\
|
||||
q_{i, k}=q_{i,k}-\eta (-e_{ui}p_{u,k})=q_{i, k}+\eta e_{ui}p_{u, k}
|
||||
$$
|
||||
|
||||
+ 其中,$\eta$ 表示学习率, 用于控制步长。
|
||||
+ 但上面这个有个问题就是当参数很多的时候, 就是两个矩阵很大的时候, 往往容易陷入过拟合的困境, 这时候, 就需要在目标函数上面加上正则化的损失, 就变成了RSVD, 关于RSVD的详细内容, 可以参考下面给出的链接, 由于篇幅原因, 这里不再过多的赘述。
|
||||
|
||||
**加入正则项**
|
||||
|
||||
为了控制模型的复杂度。在原有模型的基础上,加入 $l2$ 正则项,来防止过拟合。
|
||||
|
||||
+ 当模型参数过大,而输入数据发生变化时,可能会造成输出的不稳定。
|
||||
|
||||
+ $l2$ 正则项等价于假设模型参数符合0均值的正态分布,从而使得模型的输出更加稳定。
|
||||
|
||||
$$
|
||||
\min _{\boldsymbol{q}^{*}, \boldsymbol{p}^{*}} \frac{1}{2} \sum_{(u, i) \in K}\left(\boldsymbol{r}_{\mathrm{ui}}-p_{u}^{T} q_{i}\right)^{2}
|
||||
+ \lambda\left(\left\|p_{u}\right\|^{2}+\left\|q_{i}\right\|^{2}\right)
|
||||
$$
|
||||
|
||||
## BiasSVD
|
||||
|
||||
在推荐系统中,评分预测除了与用户的兴趣偏好、物品的特征属性相关外,与其他的因素也相关。例如:
|
||||
|
||||
+ 例如,对于乐观的用户来说,它的评分行为普遍偏高,而对批判性用户来说,他的评分记录普遍偏低,即使他们对同一物品的评分相同,但是他们对该物品的喜好程度却并不一样。
|
||||
+ 对物品来说也是类似的。以电影为例,受大众欢迎的电影得到的评分普遍偏高,而一些烂片的评分普遍偏低,这些因素都是独立于用户或产品的因素,和用户对产品的的喜好无关。
|
||||
|
||||
因此, Netfix Prize中提出了另一种LFM, 在原来的基础上加了偏置项, 来消除用户和物品打分的偏差, 即预测公式如下:
|
||||
$$
|
||||
\hat{r}_{u i}=\mu+b_{u}+b_{i}+p_{u}^{T} \cdot q_{i}
|
||||
$$
|
||||
这个预测公式加入了3项偏置参数 $\mu,b_u,b_i$, 作用如下:
|
||||
|
||||
- $\mu$: 该参数反映的是推荐模型整体的平均评分,一般使用所有样本评分的均值。
|
||||
- $b_u$:用户偏差系数。可以使用用户 $u$ 给出的所有评分的均值, 也可以当做训练参数。
|
||||
- 这一项表示了用户的评分习惯中和物品没有关系的那种因素。 比如有些用户比较苛刻, 对什么东西要求很高, 那么他评分就会偏低, 而有些用户比较宽容, 对什么东西都觉得不错, 那么评分就偏高
|
||||
- $b_i$:物品偏差系数。可以使用物品 $i$ 收到的所有评分的均值, 也可以当做训练参数。
|
||||
- 这一项表示了物品接受的评分中和用户没有关系的因素。 比如有些物品本身质量就很高, 因此获得的评分相对比较高, 有的物品本身质量很差, 因此获得的评分相对较低。
|
||||
|
||||
加了用户和物品的打分偏差之后, 矩阵分解得到的隐向量更能反映不同用户对不同物品的“真实”态度差异, 也就更容易捕捉评价数据中有价值的信息, 从而避免推荐结果有偏。
|
||||
|
||||
**优化函数**
|
||||
|
||||
在加入正则项的FunkSVD的基础上,BiasSVD 的目标函数如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\min _{q^{*}, p^{*}} \frac{1}{2} \sum_{(u, i) \in K} &\left(r_{u i}-\left(\mu+b_{u}+b_{i}+q_{i}^{T} p_{u}\right)\right)^{2} \\
|
||||
&+\lambda\left(\left\|p_{u}\right\|^{2}+\left\|q_{i}\right\|^{2}+b_{u}^{2}+b_{i}^{2}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
可得偏置项的梯度更新公式如下:
|
||||
|
||||
+ $\frac{\partial}{\partial b_{i}} S S E=-e_{u i}+\lambda b_{i}$
|
||||
+ $ \frac{\partial}{\partial b_{u}} S S E=-e_{u i}+\lambda b_{u} \ $
|
||||
|
||||
# 编程实现
|
||||
|
||||
本小节,使用如下图表来预测Alice对物品5的评分:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200827150237921.png#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
</div>
|
||||
基于矩阵分解算法的流程如下:
|
||||
|
||||
1. 首先, 它会先初始化用户矩阵 $P$ 和物品矩阵 $Q$ , $P$ 的维度是`[users_num, K]`,$Q$ 的维度是`[items_num, K]`,
|
||||
|
||||
+ 其中,`F`表示隐向量的维度。 也就是把通过隐向量的方式把用户的兴趣和`F`的特点关联了起来。
|
||||
|
||||
+ 初始化这两个矩阵的方式很多, 但根据经验, 随机数需要和`1/sqrt(F)`成正比。
|
||||
|
||||
2. 根据预测评分和真实评分的偏差,利用梯度下降法进行参数更新。
|
||||
|
||||
+ 遍历用户及其交互过的物品,对已交互过的物品进行评分预测。
|
||||
+ 由于预测评分与真实评分存在偏差, 再根据第3节的梯度更新公式更新参数。
|
||||
|
||||
3. 训练完成后,利用用户向量与目标物品向量的内积进行评分预测。
|
||||
|
||||
**完整代码如下:**
|
||||
|
||||
```python
|
||||
import random
|
||||
import math
|
||||
|
||||
|
||||
class BiasSVD():
|
||||
def __init__(self, rating_data, F=5, alpha=0.1, lmbda=0.1, max_iter=100):
|
||||
self.F = F # 这个表示隐向量的维度
|
||||
self.P = dict() # 用户矩阵P 大小是[users_num, F]
|
||||
self.Q = dict() # 物品矩阵Q 大小是[item_nums, F]
|
||||
self.bu = dict() # 用户偏置系数
|
||||
self.bi = dict() # 物品偏置系数
|
||||
self.mu = 0 # 全局偏置系数
|
||||
self.alpha = alpha # 学习率
|
||||
self.lmbda = lmbda # 正则项系数
|
||||
self.max_iter = max_iter # 最大迭代次数
|
||||
self.rating_data = rating_data # 评分矩阵
|
||||
|
||||
for user, items in self.rating_data.items():
|
||||
# 初始化矩阵P和Q, 随机数需要和1/sqrt(F)成正比
|
||||
self.P[user] = [random.random() / math.sqrt(self.F) for x in range(0, F)]
|
||||
self.bu[user] = 0
|
||||
for item, rating in items.items():
|
||||
if item not in self.Q:
|
||||
self.Q[item] = [random.random() / math.sqrt(self.F) for x in range(0, F)]
|
||||
self.bi[item] = 0
|
||||
|
||||
# 采用随机梯度下降的方式训练模型参数
|
||||
def train(self):
|
||||
cnt, mu_sum = 0, 0
|
||||
for user, items in self.rating_data.items():
|
||||
for item, rui in items.items():
|
||||
mu_sum, cnt = mu_sum + rui, cnt + 1
|
||||
self.mu = mu_sum / cnt
|
||||
|
||||
for step in range(self.max_iter):
|
||||
# 遍历所有的用户及历史交互物品
|
||||
for user, items in self.rating_data.items():
|
||||
# 遍历历史交互物品
|
||||
for item, rui in items.items():
|
||||
rhat_ui = self.predict(user, item) # 评分预测
|
||||
e_ui = rui - rhat_ui # 评分预测偏差
|
||||
|
||||
# 参数更新
|
||||
self.bu[user] += self.alpha * (e_ui - self.lmbda * self.bu[user])
|
||||
self.bi[item] += self.alpha * (e_ui - self.lmbda * self.bi[item])
|
||||
for k in range(0, self.F):
|
||||
self.P[user][k] += self.alpha * (e_ui * self.Q[item][k] - self.lmbda * self.P[user][k])
|
||||
self.Q[item][k] += self.alpha * (e_ui * self.P[user][k] - self.lmbda * self.Q[item][k])
|
||||
# 逐步降低学习率
|
||||
self.alpha *= 0.1
|
||||
|
||||
|
||||
# 评分预测
|
||||
def predict(self, user, item):
|
||||
return sum(self.P[user][f] * self.Q[item][f] for f in range(0, self.F)) + self.bu[user] + self.bi[
|
||||
item] + self.mu
|
||||
|
||||
|
||||
# 通过字典初始化训练样本,分别表示不同用户(1-5)对不同物品(A-E)的真实评分
|
||||
def loadData():
|
||||
rating_data={1: {'A': 5, 'B': 3, 'C': 4, 'D': 4},
|
||||
2: {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},
|
||||
3: {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},
|
||||
4: {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},
|
||||
5: {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}
|
||||
}
|
||||
return rating_data
|
||||
|
||||
# 加载数据
|
||||
rating_data = loadData()
|
||||
# 建立模型
|
||||
basicsvd = BiasSVD(rating_data, F=10)
|
||||
# 参数训练
|
||||
basicsvd.train()
|
||||
# 预测用户1对物品E的评分
|
||||
for item in ['E']:
|
||||
print(item, basicsvd.predict(1, item))
|
||||
|
||||
# 预测结果:E 3.685084274454321
|
||||
```
|
||||
# 课后思考
|
||||
|
||||
1. 矩阵分解算法后续有哪些改进呢?针对这些改进,是为了解决什么的问题呢?请大家自行探索RSVD,消除用户和物品打分偏差等。
|
||||
|
||||
2. 矩阵分解的优缺点分析
|
||||
|
||||
* 优点:
|
||||
* 泛化能力强: 一定程度上解决了稀疏问题
|
||||
* 空间复杂度低: 由于用户和物品都用隐向量的形式存放, 少了用户和物品相似度矩阵, 空间复杂度由$n^2$降到了$(n+m)*f$
|
||||
* 更好的扩展性和灵活性:矩阵分解的最终产物是用户和物品隐向量, 这个深度学习的embedding思想不谋而合, 因此矩阵分解的结果非常便于与其他特征进行组合和拼接, 并可以与深度学习无缝结合。
|
||||
|
||||
+ 缺点:
|
||||
+ 矩阵分解算法依然是只用到了评分矩阵, 没有考虑到用户特征, 物品特征和上下文特征, 这使得矩阵分解丧失了利用很多有效信息的机会。
|
||||
+ 同时在缺乏用户历史行为的时候, 无法进行有效的推荐。
|
||||
+ 为了解决这个问题, **逻辑回归模型及后续的因子分解机模型**, 凭借其天然的融合不同特征的能力, 逐渐在推荐系统领域得到了更广泛的应用。
|
||||
|
||||
# 参考资料
|
||||
|
||||
* 王喆 - 《深度学习推荐系统》
|
||||
* 项亮 - 《推荐系统实战》
|
||||
* [奇异值分解(SVD)的原理详解及推导](https://blog.csdn.net/wuzhongqiang/article/details/108168238)
|
||||
* [Matrix factorization techniques for recommender systems论文](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=5197422&tag=1)
|
||||
* [隐语义模型(LFM)和矩阵分解(MF)](https://blog.csdn.net/wuzhongqiang/article/details/108173885)
|
||||
345
4.人工智能/ch02/ch2.1/ch2.1.1/usercf.md
Normal file
345
4.人工智能/ch02/ch2.1/ch2.1.1/usercf.md
Normal file
@@ -0,0 +1,345 @@
|
||||
# 协同过滤算法
|
||||
|
||||
## 基本思想
|
||||
|
||||
协同过滤(Collaborative Filtering)推荐算法是最经典、最常用的推荐算法。基本思想是:
|
||||
|
||||
+ 根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品。
|
||||
|
||||
+ 基于对用户历史行为数据的挖掘发现用户的喜好偏向, 并预测用户可能喜好的产品进行推荐。
|
||||
+ 一般是仅仅基于用户的行为数据(评价、购买、下载等), 而不依赖于项的任何附加信息(物品自身特征)或者用户的任何附加信息(年龄, 性别等)。
|
||||
+ 目前应用比较广泛的协同过滤算法是基于邻域的方法,主要有:
|
||||
+ 基于用户的协同过滤算法(UserCF):给用户推荐和他兴趣相似的其他用户喜欢的产品。
|
||||
+ 基于物品的协同过滤算法(ItemCF):给用户推荐和他之前喜欢的物品相似的物品。
|
||||
|
||||
不管是 UserCF 还是 ItemCF 算法, 重点是计算用户之间(或物品之间)的相似度。
|
||||
|
||||
## 相似性度量方法
|
||||
|
||||
1. **杰卡德(Jaccard)相似系数**
|
||||
|
||||
`Jaccard` 系数是衡量两个集合的相似度一种指标,计算公式如下:
|
||||
$$
|
||||
sim_{uv}=\frac{|N(u) \cap N(v)|}{|N(u)| \cup|N(v)|}
|
||||
$$
|
||||
|
||||
+ 其中 $N(u)$,$N(v)$ 分别表示用户 $u$ 和用户 $v$ 交互物品的集合。
|
||||
|
||||
+ 对于用户 $u$ 和 $v$ ,该公式反映了两个交互物品交集的数量占这两个用户交互物品并集的数量的比例。
|
||||
|
||||
由于杰卡德相似系数一般无法反映具体用户的评分喜好信息,所以常用来评估用户是否会对某物品进行打分, 而不是预估用户会对某物品打多少分。
|
||||
|
||||
2. **余弦相似度**
|
||||
余弦相似度衡量了两个向量的夹角,夹角越小越相似。余弦相似度的计算如下,其与杰卡德(Jaccard)相似系数只是在分母上存在差异:
|
||||
$$
|
||||
sim_{uv}=\frac{|N(u) \cap N(v)|}{\sqrt{|N(u)|\cdot|N(v)|}}
|
||||
$$
|
||||
从向量的角度进行描述,令矩阵 $A$ 为用户-物品交互矩阵,矩阵的行表示用户,列表示物品。
|
||||
|
||||
+ 设用户和物品数量分别为 $m,n$,交互矩阵$A$就是一个 $m$ 行 $n$ 列的矩阵。
|
||||
|
||||
+ 矩阵中的元素均为 $0/1$。若用户 $i$ 对物品 $j$ 存在交互,那么 $A_{i,j}=1$,否则为 $0$ 。
|
||||
|
||||
+ 那么,用户之间的相似度可以表示为:
|
||||
$$
|
||||
sim_{uv} = cos(u,v) =\frac{u\cdot v}{|u|\cdot |v|}
|
||||
$$
|
||||
|
||||
+ 向量 $u,v$ 在形式都是 one-hot 类型,$u\cdot v$ 表示向量点积。
|
||||
|
||||
上述用户-物品交互矩阵在现实中是十分稀疏的,为了节省内存,交互矩阵会采用字典进行存储。在 `sklearn` 中,余弦相似度的实现:
|
||||
|
||||
```python
|
||||
from sklearn.metrics.pairwise import cosine_similarity
|
||||
|
||||
i = [1, 0, 0, 0]
|
||||
j = [1, 0, 1, 0]
|
||||
cosine_similarity([i, j])
|
||||
```
|
||||
|
||||
3. **皮尔逊相关系数**
|
||||
|
||||
在用户之间的余弦相似度计算时,将用户向量的内积展开为各元素乘积和:
|
||||
$$
|
||||
sim_{uv} = \frac{\sum_i r_{ui}*r_{vi}}{\sqrt{\sum_i r_{ui}^2}\sqrt{\sum_i r_{vi}^2}}
|
||||
$$
|
||||
+ 其中,$r_{ui},r_{vi}$ 分别表示用户 $u$ 和用户 $v$ 对物品 $i$ 是否有交互(或具体评分值)。
|
||||
|
||||
皮尔逊相关系数与余弦相似度的计算公式非常的类似,如下:
|
||||
$$
|
||||
sim(u,v)=\frac{\sum_{i\in I}(r_{ui}-\bar r_u)(r_{vi}-\bar r_v)}{\sqrt{\sum_{i\in I }(r_{ui}-\bar r_u)^2}\sqrt{\sum_{i\in I }(r_{vi}-\bar r_v)^2}}
|
||||
$$
|
||||
+ 其中,$r_{ui},r_{vi}$ 分别表示用户 $u$ 和用户 $v$ 对物品 $i$ 是否有交互(或具体评分值);
|
||||
+ $\bar r_u, \bar r_v$ 分别表示用户 $u$ 和用户 $v$ 交互的所有物品交互数量或者评分的平均值;
|
||||
|
||||
相较于余弦相似度,皮尔逊相关系数通过使用用户的平均分对各独立评分进行修正,减小了用户评分偏置的影响。在`scipy`中,皮尔逊相关系数的实现:
|
||||
|
||||
```python
|
||||
from scipy.stats import pearsonr
|
||||
|
||||
i = [1, 0, 0, 0]
|
||||
j = [1, 0.5, 0.5, 0]
|
||||
pearsonr(i, j)
|
||||
```
|
||||
|
||||
**适用场景**
|
||||
|
||||
+ $Jaccard$ 相似度表示两个集合的交集元素个数在并集中所占的比例 ,所以适用于隐式反馈数据(0-1)。
|
||||
+ 余弦相似度在度量文本相似度、用户相似度、物品相似度的时候都较为常用。
|
||||
+ 皮尔逊相关度,实际上也是一种余弦相似度。不过先对向量做了中心化,范围在 $-1$ 到 $1$。
|
||||
+ 相关度量的是两个变量的变化趋势是否一致,两个随机变量是不是同增同减。
|
||||
+ 不适合用作计算布尔值向量(0-1)之间相关度。
|
||||
|
||||
# 基于用户的协同过滤
|
||||
|
||||
## 基本思想
|
||||
|
||||
基于用户的协同过滤(UserCF):
|
||||
|
||||
+ 例如,我们要对用户 $A$ 进行物品推荐,可以先找到和他有相似兴趣的其他用户。
|
||||
+ 然后,将共同兴趣用户喜欢的,但用户 $A$ 未交互过的物品推荐给 $A$。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210629232540289.png" alt="image-20210629232540289" style="zoom: 80%;" />
|
||||
|
||||
## 计算过程
|
||||
|
||||
以下图为例,给用户推荐物品的过程可以形象化为一个猜测用户对物品进行打分的任务,表格里面是5个用户对于5件物品的一个打分情况,就可以理解为用户对物品的喜欢程度。
|
||||
|
||||

|
||||
|
||||
UserCF算法的两个步骤:
|
||||
|
||||
+ 首先,根据前面的这些打分情况(或者说已有的用户向量)计算一下 Alice 和用户1, 2, 3, 4的相似程度, 找出与 Alice 最相似的 n 个用户。
|
||||
|
||||
+ 根据这 n 个用户对物品 5 的评分情况和与 Alice 的相似程度会猜测出 Alice 对物品5的评分。如果评分比较高的话, 就把物品5推荐给用户 Alice, 否则不推荐。
|
||||
|
||||
**具体过程:**
|
||||
|
||||
1. 计算用户之间的相似度
|
||||
|
||||
+ 根据 1.2 节的几种方法, 我们可以计算出各用户之间的相似程度。对于用户 Alice,选取出与其最相近的 $N$ 个用户。
|
||||
|
||||
2. 计算用户对新物品的评分预测
|
||||
|
||||
+ 常用的方式之一:利用目标用户与相似用户之间的相似度以及相似用户对物品的评分,来预测目标用户对候选物品的评分估计:
|
||||
$$
|
||||
R_{\mathrm{u}, \mathrm{p}}=\frac{\sum_{\mathrm{s} \in S}\left(w_{\mathrm{u}, \mathrm{s}} \cdot R_{\mathrm{s}, \mathrm{p}}\right)}{\sum_{\mathrm{s} \in S} w_{\mathrm{u}, \mathrm{s}}}
|
||||
$$
|
||||
|
||||
+ 其中,权重 $w_{u,s}$ 是用户 $u$ 和用户 $s$ 的相似度, $R_{s,p}$ 是用户 $s$ 对物品 $p$ 的评分。
|
||||
|
||||
+ 另一种方式:考虑到用户评分的偏置,即有的用户喜欢打高分, 有的用户喜欢打低分的情况。公式如下:
|
||||
$$
|
||||
R_{\mathrm{u}, \mathrm{p}}=\bar{R}_{u} + \frac{\sum_{\mathrm{s} \in S}\left(w_{\mathrm{u}, \mathrm{s}} \cdot \left(R_{s, p}-\bar{R}_{s}\right)\right)}{\sum_{\mathrm{s} \in S} w_{\mathrm{u}, \mathrm{s}}}
|
||||
$$
|
||||
|
||||
+ 其中,$\bar{R}_{s}$ 表示用户 $s$ 对物品的历史平均评分。
|
||||
|
||||
3. 对用户进行物品推荐
|
||||
|
||||
+ 在获得用户 $u$ 对不同物品的评价预测后, 最终的推荐列表根据预测评分进行排序得到。
|
||||
|
||||
**手动计算:**
|
||||
|
||||
根据上面的问题, 下面手动计算 Alice 对物品 5 的得分:
|
||||
|
||||
|
||||
1. 计算 Alice 与其他用户的相似度(基于皮尔逊相关系数)
|
||||
|
||||
+ 手动计算 Alice 与用户 1 之间的相似度:
|
||||
|
||||
>用户向量 $\text {Alice}:(5,3,4,4) , \text{user1}:(3,1,2,3) , \text {user2}:( 4,3,4,3) , \text {user3}:(3,3,1,5) , \text {user4}:(1,5,5,2) $
|
||||
>
|
||||
>+ 计算Alice与user1的余弦相似性:
|
||||
>$$
|
||||
>\operatorname{sim}(\text { Alice, user1 })=\cos (\text { Alice, user } 1)=\frac{15+3+8+12}{\operatorname{sqrt}(25+9+16+16) * \operatorname{sqrt}(9+1+4+9)}=0.975
|
||||
>$$
|
||||
>
|
||||
>+ 计算Alice与user1皮尔逊相关系数:
|
||||
> + $Alice\_ave =4 \quad user1\_ave =2.25 $
|
||||
> + 向量减去均值: $\text {Alice}:(1,-1, 0,0) \quad \text { user1 }:(0.75,-1.25,-0.25,0.75)$
|
||||
>
|
||||
>+ 计算这俩新向量的余弦相似度和上面计算过程一致, 结果是 0.852 。
|
||||
>
|
||||
|
||||
+ 基于 sklearn 计算所有用户之间的皮尔逊相关系数。可以看出,与 Alice 相似度最高的用户为用户1和用户2。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/JavaWJkjP2fHH27Rajrj.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
|
||||
2. **根据相似度用户计算 Alice对物品5的最终得分**
|
||||
用户1对物品5的评分是3, 用户2对物品5的打分是5, 那么根据上面的计算公式, 可以计算出 Alice 对物品5的最终得分是
|
||||
$$
|
||||
P_{Alice, 物品5}=\bar{R}_{Alice}+\frac{\sum_{k=1}^{2}\left(w_{Alice,user k}\left(R_{userk, 物品5}-\bar{R}_{userk}\right)\right)}{\sum_{k=1}^{2} w_{Alice, userk}}=4+\frac{0.85*(3-2.4)+0.7*(5-3.8)}{0.85+0.7}=4.87
|
||||
$$
|
||||
|
||||
+ 同样方式,可以计算用户 Alice 对其他物品的评分预测。
|
||||
|
||||
3. **根据用户评分对用户进行推荐**
|
||||
|
||||
+ 根据 Alice 的打分对物品排个序从大到小:$$物品1>物品5>物品3=物品4>物品2$$。
|
||||
+ 如果要向 Alice 推荐2款产品的话, 我们就可以推荐物品 1 和物品 5 给 Alice。
|
||||
|
||||
至此, 基于用户的协同过滤算法原理介绍完毕。
|
||||
|
||||
## UserCF编程实现
|
||||
|
||||
1. 建立实验使用的数据表:
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
|
||||
def loadData():
|
||||
users = {'Alice': {'A': 5, 'B': 3, 'C': 4, 'D': 4},
|
||||
'user1': {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},
|
||||
'user2': {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},
|
||||
'user3': {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},
|
||||
'user4': {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}
|
||||
}
|
||||
return users
|
||||
```
|
||||
|
||||
+ 这里使用字典来建立用户-物品的交互表。
|
||||
+ 字典`users`的键表示不同用户的名字,值为一个评分字典,评分字典的键值对表示某物品被当前用户的评分。
|
||||
+ 由于现实场景中,用户对物品的评分比较稀疏。如果直接使用矩阵进行存储,会存在大量空缺值,故此处使用了字典。
|
||||
|
||||
2. 计算用户相似性矩阵
|
||||
|
||||
+ 由于训练数据中共包含 5 个用户,所以这里的用户相似度矩阵的维度也为 $5 \times 5$。
|
||||
|
||||
```python
|
||||
user_data = loadData()
|
||||
similarity_matrix = pd.DataFrame(
|
||||
np.identity(len(user_data)),
|
||||
index=user_data.keys(),
|
||||
columns=user_data.keys(),
|
||||
)
|
||||
|
||||
# 遍历每条用户-物品评分数据
|
||||
for u1, items1 in user_data.items():
|
||||
for u2, items2 in user_data.items():
|
||||
if u1 == u2:
|
||||
continue
|
||||
vec1, vec2 = [], []
|
||||
for item, rating1 in items1.items():
|
||||
rating2 = items2.get(item, -1)
|
||||
if rating2 == -1:
|
||||
continue
|
||||
vec1.append(rating1)
|
||||
vec2.append(rating2)
|
||||
# 计算不同用户之间的皮尔逊相关系数
|
||||
similarity_matrix[u1][u2] = np.corrcoef(vec1, vec2)[0][1]
|
||||
|
||||
print(similarity_matrix)
|
||||
```
|
||||
|
||||
```
|
||||
1 2 3 4 5
|
||||
1 1.000000 0.852803 0.707107 0.000000 -0.792118
|
||||
2 0.852803 1.000000 0.467707 0.489956 -0.900149
|
||||
3 0.707107 0.467707 1.000000 -0.161165 -0.466569
|
||||
4 0.000000 0.489956 -0.161165 1.000000 -0.641503
|
||||
5 -0.792118 -0.900149 -0.466569 -0.641503 1.000000
|
||||
```
|
||||
|
||||
3. 计算与 Alice 最相似的 `num` 个用户
|
||||
|
||||
```python
|
||||
target_user = ' Alice '
|
||||
num = 2
|
||||
# 由于最相似的用户为自己,去除本身
|
||||
sim_users = similarity_matrix[target_user].sort_values(ascending=False)[1:num+1].index.tolist()
|
||||
print(f'与用户{target_user}最相似的{num}个用户为:{sim_users}')
|
||||
```
|
||||
|
||||
```
|
||||
与用户 Alice 最相似的2个用户为:['user1', 'user2']
|
||||
```
|
||||
|
||||
4. 预测用户 Alice 对物品 `E` 的评分
|
||||
|
||||
```python
|
||||
weighted_scores = 0.
|
||||
corr_values_sum = 0.
|
||||
|
||||
target_item = 'E'
|
||||
# 基于皮尔逊相关系数预测用户评分
|
||||
for user in sim_users:
|
||||
corr_value = similarity_matrix[target_user][user]
|
||||
user_mean_rating = np.mean(list(user_data[user].values()))
|
||||
|
||||
weighted_scores += corr_value * (user_data[user][target_item] - user_mean_rating)
|
||||
corr_values_sum += corr_value
|
||||
|
||||
target_user_mean_rating = np.mean(list(user_data[target_user].values()))
|
||||
target_item_pred = target_user_mean_rating + weighted_scores / corr_values_sum
|
||||
print(f'用户{target_user}对物品{target_item}的预测评分为:{target_item_pred}')
|
||||
```
|
||||
|
||||
```
|
||||
用户 Alice 对物品E的预测评分为:4.871979899370592
|
||||
```
|
||||
|
||||
## UserCF优缺点
|
||||
|
||||
User-based算法存在两个重大问题:
|
||||
|
||||
|
||||
1. 数据稀疏性
|
||||
+ 一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。
|
||||
+ 这导致UserCF不适用于那些正反馈获取较困难的应用场景(如酒店预订, 大件物品购买等低频应用)。
|
||||
|
||||
1. 算法扩展性
|
||||
+ 基于用户的协同过滤需要维护用户相似度矩阵以便快速的找出 $TopN$ 相似用户, 该矩阵的存储开销非常大,存储空间随着用户数量的增加而增加。
|
||||
+ 故不适合用户数据量大的情况使用。
|
||||
|
||||
由于UserCF技术上的两点缺陷, 导致很多电商平台并没有采用这种算法, 而是采用了ItemCF算法实现最初的推荐系统。
|
||||
|
||||
|
||||
|
||||
# 算法评估
|
||||
|
||||
由于UserCF和ItemCF结果评估部分是共性知识点, 所以在这里统一标识。
|
||||
|
||||
## 召回率
|
||||
|
||||
对用户 $u$ 推荐 $N$ 个物品记为 $R(u)$, 令用户 $u$ 在测试集上喜欢的物品集合为$T(u)$, 那么召回率定义为:
|
||||
$$
|
||||
\operatorname{Recall}=\frac{\sum_{u}|R(u) \cap T(u)|}{\sum_{u}|T(u)|}
|
||||
$$
|
||||
+ 含义:在模型召回预测的物品中,预测准确的物品占用户实际喜欢的物品的比例。
|
||||
|
||||
## 精确率
|
||||
精确率定义为:
|
||||
$$
|
||||
\operatorname{Precision}=\frac{\sum_{u} \mid R(u) \cap T(u)|}{\sum_{u}|R(u)|}
|
||||
$$
|
||||
+ 含义:推荐的物品中,对用户准确推荐的物品占总物品的比例。
|
||||
+ 如要确保召回率高,一般是推荐更多的物品,期望推荐的物品中会涵盖用户喜爱的物品。而实际中,推荐的物品中用户实际喜爱的物品占少数,推荐的精确率就会很低。故同时要确保高召回率和精确率往往是矛盾的,所以实际中需要在二者之间进行权衡。
|
||||
|
||||
## 覆盖率
|
||||
覆盖率反映了推荐算法发掘长尾的能力, 覆盖率越高, 说明推荐算法越能将长尾中的物品推荐给用户。
|
||||
$$
|
||||
\text { Coverage }=\frac{\left|\bigcup_{u \in U} R(u)\right|}{|I|}
|
||||
$$
|
||||
|
||||
+ 含义:推荐系统能够推荐出来的物品占总物品集合的比例。
|
||||
+ 其中 $|I|$ 表示所有物品的个数;
|
||||
+ 系统的用户集合为$U$;
|
||||
+ 推荐系统给每个用户推荐一个长度为 $N$ 的物品列表$R(u)$.
|
||||
|
||||
+ 覆盖率表示最终的推荐列表中包含多大比例的物品。如果所有物品都被给推荐给至少一个用户, 那么覆盖率是100%。
|
||||
|
||||
## 新颖度
|
||||
用推荐列表中物品的平均流行度度量推荐结果的新颖度。 如果推荐出的物品都很热门, 说明推荐的新颖度较低。 由于物品的流行度分布呈长尾分布, 所以为了流行度的平均值更加稳定, 在计算平均流行度时对每个物品的流行度取对数。
|
||||
|
||||
- O’scar Celma 在博士论文 "[Music Recommendation and Discovery in the Long Tail](http://mtg.upf.edu/static/media/PhD_ocelma.pdf) " 中研究了新颖度的评测。
|
||||
|
||||
|
||||
|
||||
# 参考资料
|
||||
|
||||
* [基于用户的协同过滤来构建推荐系统:https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw](https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw)
|
||||
* [协同过滤算法概述:https://chenk.tech/posts/8ad63d9d.html](https://chenk.tech/posts/8ad63d9d.html)
|
||||
* B站黑马推荐系统实战课程
|
||||
Reference in New Issue
Block a user