docs: fun-rec
This commit is contained in:
288
4.人工智能/ch02/ch2.1/ch2.1.1/Swing.md
Normal file
288
4.人工智能/ch02/ch2.1/ch2.1.1/Swing.md
Normal file
@@ -0,0 +1,288 @@
|
||||
# Swing(Graph-based)
|
||||
## 动机
|
||||
大规模推荐系统需要实时对用户行为做出海量预测,为了保证这种实时性,大规模的推荐系统通常严重依赖于预先计算好的产品索引。产品索引的功能为:给定种子产品返回排序后的候选相关产品列表。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2relations.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
|
||||
相关性产品索引主要包含两部分:替代性产品和互补性产品。例如图中的不同种类的衬衫构成了替代关系,而衬衫和风衣裤子等构成了互补关系。用户通常希望在完成购买行为之前尽可能看更多的衬衫,而用户购买过衬衫之后更希望看到与之搭配的单品而不是其他衬衫了。
|
||||
|
||||
## 之前方法局限性
|
||||
- 基于 Cosine, Jaccard, 皮尔逊相关性等相似度计算的协同过滤算法,在计算邻居关联强度的时候只关注于 Item-based (常用,因为item相比于用户变化的慢,且新Item特征比较容易获得),Item-based CF 只关注于 Item-User-Item 的路径,把所有的User-Item交互都平等得看待,从而忽视了 User-Item 交互中的大量噪声,推荐精度存在局限性。
|
||||
- 对互补性产品的建模不足,可能会导致用户购买过手机之后还继续推荐手机,但用户短时间内不会再继续购买手机,因此产生无效曝光。
|
||||
|
||||
## 贡献
|
||||
提出了高效建立产品索引图的技术。
|
||||
主要包括:
|
||||
- Swing 算法利用 user-item 二部图的子结构捕获产品间的替代关系。
|
||||
- Surprise 算法利用商品分类信息和用户共同购买图上的聚类技术来建模产品之间的组合关系。
|
||||
|
||||
## Swing算法
|
||||
Swing 通过利用 User-Item-User 路径中所包含的信息,考虑 User-Item 二部图中的鲁棒内部子结构计算相似性。
|
||||
- 什么是内部子结构?
|
||||
以经典的啤酒尿布故事为例,张三同时购买了啤酒和尿布,这可能是一种巧合。但两个甚至多个顾客都同时购买了啤酒尿布,这就证明啤酒和尿布具有相关关系。这样共同购买啤酒和尿布的用户越多,啤酒和尿布的相关度就会越高。
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片example_of_swing.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
图中的红色四边形就是一种Swing子结构,这种子结构可以作为给王五推荐尿布的依据。
|
||||
|
||||
- 通俗解释:若用户 $u$ 和用户 $v$ 之间除了购买过 $i$ 外,还购买过商品 $j$ ,则认为两件商品是具有某种程度上的相似的。也就是说,商品与商品之间的相似关系,是通过用户关系来传递的。为了衡量物品 $i$ 和 $j$ 的相似性,比较同时购买了物品 $i$ 和 $j$ 的用户 $u$ 和用户 $v$, 如果这两个用户共同购买的物品越少,即这两个用户原始兴趣不相似,但仍同时购买了两个相同的物品 $i$ 和 $j$, 则物品 $i$ 和 $j$ 的相似性越高。
|
||||
|
||||
- 计算公式
|
||||
|
||||
$$s(i,j)=\sum\limits_{u\in U_i\cap U_j} \sum\limits_{v \in U_i\cap U_j}w_u*w_v* \frac{1}{\alpha+|I_u \cap I_v|}$$
|
||||
|
||||
其中$U_i$ 是点击过商品i的用户集合,$I_u$ 是用户u点击过的商品集合,$\alpha$是平滑系数。
|
||||
|
||||
$w_u=\frac{1}{\sqrt{|I_u|}},w_v=\frac{1}{\sqrt{|I_v|}}$ 是用户权重参数,来降低活跃用户的影响。
|
||||
|
||||
- 代码实现
|
||||
- Python (建议自行debug方便理解)
|
||||
```python
|
||||
from itertools import combinations
|
||||
import pandas as pd
|
||||
alpha = 0.5
|
||||
top_k = 20
|
||||
def load_data(train_path):
|
||||
train_data = pd.read_csv(train_path, sep="\t", engine="python", names=["userid", "itemid", "rate"])#提取用户交互记录数据
|
||||
print(train_data.head(3))
|
||||
return train_data
|
||||
|
||||
def get_uitems_iusers(train):
|
||||
u_items = dict()
|
||||
i_users = dict()
|
||||
for index, row in train.iterrows():#处理用户交互记录
|
||||
u_items.setdefault(row["userid"], set())
|
||||
i_users.setdefault(row["itemid"], set())
|
||||
u_items[row["userid"]].add(row["itemid"])#得到user交互过的所有item
|
||||
i_users[row["itemid"]].add(row["userid"])#得到item交互过的所有user
|
||||
print("使用的用户个数为:{}".format(len(u_items)))
|
||||
print("使用的item个数为:{}".format(len(i_users)))
|
||||
return u_items, i_users
|
||||
|
||||
def swing_model(u_items, i_users):
|
||||
# print([i for i in i_users.values()][:5])
|
||||
# print([i for i in u_items.values()][:5])
|
||||
item_pairs = list(combinations(i_users.keys(), 2)) #全排列组合对
|
||||
print("item pairs length:{}".format(len(item_pairs)))
|
||||
item_sim_dict = dict()
|
||||
for (i, j) in item_pairs:
|
||||
user_pairs = list(combinations(i_users[i] & i_users[j], 2)) #item_i和item_j对应的user取交集后全排列 得到user对
|
||||
result = 0
|
||||
for (u, v) in user_pairs:
|
||||
result += 1 / (alpha + list(u_items[u] & u_items[v]).__len__()) #分数公式
|
||||
if result != 0 :
|
||||
item_sim_dict.setdefault(i, dict())
|
||||
item_sim_dict[i][j] = format(result, '.6f')
|
||||
return item_sim_dict
|
||||
|
||||
def save_item_sims(item_sim_dict, top_k, path):
|
||||
new_item_sim_dict = dict()
|
||||
try:
|
||||
writer = open(path, 'w', encoding='utf-8')
|
||||
for item, sim_items in item_sim_dict.items():
|
||||
new_item_sim_dict.setdefault(item, dict())
|
||||
new_item_sim_dict[item] = dict(sorted(sim_items.items(), key = lambda k:k[1], reverse=True)[:top_k])#排序取出 top_k个相似的item
|
||||
writer.write('item_id:%d\t%s\n' % (item, new_item_sim_dict[item]))
|
||||
print("SUCCESS: top_{} item saved".format(top_k))
|
||||
except Exception as e:
|
||||
print(e.args)
|
||||
|
||||
if __name__ == "__main__":
|
||||
train_data_path = "./ratings_final.txt"
|
||||
item_sim_save_path = "./item_sim_dict.txt"
|
||||
top_k = 10 #与item相似的前 k 个item
|
||||
train = load_data(train_data_path)
|
||||
u_items, i_users = get_uitems_iusers(train)
|
||||
item_sim_dict = swing_model(u_items, i_users)
|
||||
save_item_sims(item_sim_dict, top_k, item_sim_save_path)
|
||||
```
|
||||
|
||||
- Spark(仅为核心代码需要补全配置才能跑通)
|
||||
```scala
|
||||
object Swing {
|
||||
|
||||
def main(args: Array[String]): Unit = {
|
||||
val spark = SparkSession.builder()
|
||||
.appName("test")
|
||||
.master("local[2]")
|
||||
.getOrCreate()
|
||||
val alpha = 1 //分数计算参数
|
||||
val filter_n_items = 10000 //想要计算的item数量 测试的时候取少点
|
||||
val top_n_items = 500 //保存item的score排序前500个相似的item
|
||||
val model = new SwingModel(spark)
|
||||
.setAlpha(alpha.toDouble)
|
||||
.setFilter_N_Items(filter_n_items.toInt)
|
||||
.setTop_N_Items(top_n_items.toInt)
|
||||
val url = "file:///usr/local/var/scala/common/part-00022-e17c0014.snappy.parquet"
|
||||
val ratings = DataLoader.getRatingLog(spark, url)
|
||||
val df = model.fit(ratings).item2item()
|
||||
df.show(3,false)
|
||||
// df.write.mode("overwrite").parquet(dest_url)
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
```scala
|
||||
/**
|
||||
* swing
|
||||
* @param ratings 打分dataset
|
||||
* @return
|
||||
*/
|
||||
def fit(ratings: Dataset[Rating]): SwingModel = {
|
||||
|
||||
def interWithAlpha = udf(
|
||||
(array_1: Seq[GenericRowWithSchema],
|
||||
array_2: Seq[GenericRowWithSchema]) => {
|
||||
var score = 0.0
|
||||
val u_set_1 = array_1.toSet
|
||||
val u_set_2 = array_2.toSet
|
||||
val user_set = u_set_1.intersect(u_set_2).toArray //取交集得到两个item共同user
|
||||
|
||||
for (i <- user_set.indices; j <- i + 1 until user_set.length) {
|
||||
val user_1 = user_set(i)
|
||||
val user_2 = user_set(j)
|
||||
val item_set_1 = user_1.getAs[Seq[String]]("_2").toSet
|
||||
val item_set_2 = user_2.getAs[Seq[String]]("_2").toSet
|
||||
score = score + 1 / (item_set_1
|
||||
.intersect(item_set_2)
|
||||
.size
|
||||
.toDouble + alpha.get)
|
||||
}
|
||||
score
|
||||
}
|
||||
)
|
||||
val df = ratings.repartition(defaultParallelism).cache()
|
||||
|
||||
val groupUsers = df
|
||||
.groupBy("user_id")
|
||||
.agg(collect_set("item_id")) //聚合itme_id
|
||||
.toDF("user_id", "item_set")
|
||||
.repartition(defaultParallelism)
|
||||
println("groupUsers")
|
||||
groupUsers.show(3, false)//user_id|[item_id_set]: 422|[6117,611,6117]
|
||||
|
||||
val groupItems = df
|
||||
.join(groupUsers, "user_id")
|
||||
.rdd
|
||||
.map { x =>
|
||||
val item_id = x.getAs[String]("item_id")
|
||||
val user_id = x.getAs[String]("user_id")
|
||||
val item_set = x.getAs[Seq[String]]("item_set")
|
||||
(item_id, (user_id, item_set))
|
||||
}//i_[user(item_set)]
|
||||
.toDF("item_id", "user")
|
||||
.groupBy("item_id")
|
||||
.agg(collect_set("user"), count("item_id"))
|
||||
.toDF("item_id", "user_set", "count")
|
||||
.filter("size(user_set) > 1")//过滤掉没有交互的
|
||||
.sort($"count".desc) //根据count倒排item_id数量
|
||||
.limit(filter_n_items.get)//item可能百万级别但后面召回的需求量小所以只取前n个item进行计算
|
||||
.drop("count")
|
||||
.repartition(defaultParallelism)
|
||||
.cache()
|
||||
println("groupItems") //得到与itme_id有交互的user_id
|
||||
groupItems.show(3, false)//item_id|[[user_id,[item_set]],[user_id,[item_set]]]: 67|[[562,[66, 813, 61, 67]],[563,[67, 833, 62, 64]]]
|
||||
|
||||
val itemJoined = groupItems
|
||||
.join(broadcast(groupItems))//内连接两个item列表
|
||||
.toDF("item_id_1", "user_set_1", "item_id_2", "user_set_2")
|
||||
.filter("item_id_1 > item_id_2")//内连接 item两两配对
|
||||
.withColumn("score", interWithAlpha(col("user_set_1"), col("user_set_2")))//将上面得到的与item相关的user_set输入到函数interWithAlpha计算分数
|
||||
.select("item_id_1", "item_id_2", "score")
|
||||
.filter("score > 0")
|
||||
.repartition(defaultParallelism)
|
||||
.cache()
|
||||
println("itemJoined")
|
||||
itemJoined.show(5)//得到两两item之间的分数结果 item_id_1 item_id_2 score
|
||||
similarities = Option(itemJoined)
|
||||
this
|
||||
}
|
||||
|
||||
/**
|
||||
* 从fit结果,对item_id进行聚合并排序,每个item后截取n个item,并返回。
|
||||
* @param num 取n个item
|
||||
* @return
|
||||
*/
|
||||
def item2item(): DataFrame = {
|
||||
|
||||
case class itemWithScore(item_id: String, score: Double)
|
||||
val sim = similarities.get.select("item_id_1", "item_id_2", "score")
|
||||
val topN = sim
|
||||
.map { x =>
|
||||
val item_id_1 = x.getAs[String]("item_id_1")
|
||||
val item_id_2 = x.getAs[String]("item_id_2")
|
||||
val score = x.getAs[Double]("score")
|
||||
(item_id_1, (item_id_2, score))
|
||||
}
|
||||
.toDF("item_id", "itemWithScore")
|
||||
.groupBy("item_id")
|
||||
.agg(collect_set("itemWithScore"))
|
||||
.toDF("item_id", "item_set")//item_id |[[item_id1:score],[item_id2:score]]
|
||||
.rdd
|
||||
.map { x =>
|
||||
val item_id_1 = x.getAs[String]("item_id")
|
||||
val item_set = x //对itme_set中score进行排序操作
|
||||
.getAs[Seq[GenericRowWithSchema]]("item_set")
|
||||
.map { x =>
|
||||
val item_id_2 = x.getAs[String]("_1")
|
||||
val score = x.getAs[Double]("_2")
|
||||
(item_id_2, score)
|
||||
}
|
||||
.sortBy(-_._2)//根据score进行排序
|
||||
.take(top_n_items.get)//取top_n
|
||||
.map(x => x._1 + ":" + x._2.toString)
|
||||
(item_id_1, item_set)
|
||||
}
|
||||
.filter(_._2.nonEmpty)
|
||||
.toDF("id", "sorted_items")
|
||||
topN
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Surprise算法
|
||||
首先在行为相关性中引入连续时间衰减因子,然后引入基于交互数据的聚类方法解决数据稀疏的问题,旨在帮助用户找到互补商品。互补相关性主要从三个层面考虑,类别层面,商品层面和聚类层面。
|
||||
|
||||
- 类别层面
|
||||
首先通过商品和类别的映射关系,我们可以得到 user-category 矩阵。随后使用简单的相关性度量可以计算出类别 $i,j$ 的相关性。
|
||||
|
||||
$\theta_{i,j}=p(c_{i,j}|c_j)=\frac{N(c_{i,j})}{N(c_j)}$
|
||||
|
||||
即,$N(c_{i,j})$为在购买过i之后购买j类的数量,$N(c_{j})$为购买j类的数量。
|
||||
|
||||
由于类别直接的种类差异,每个类别的相关类数量存在差异,因此采用最大相对落点来作为划分阈值。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片max_drop.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
|
||||
例如图(a)中T恤的相关类选择前八个,图(b)中手机的相关类选择前三个。
|
||||
|
||||
- 商品层面
|
||||
商品层面的相关性挖掘主要有两个关键设计:
|
||||
- 商品的购买顺序是需要被考虑的,例如在用户购买手机后推荐充电宝是合理的,但在用户购买充电宝后推荐手机是不合理的。
|
||||
- 两个商品购买的时间间隔也是需要被考虑的,时间间隔越短越能证明两个商品的互补关系。
|
||||
|
||||
最终商品层面的互补相关性被定义为:
|
||||
|
||||
$s_{1}(i, j)=\frac{\sum_{u \in U_{i} \cap U_{j}} 1 /\left(1+\left|t_{u i}-t_{u j}\right|\right)}{\left\|U_{i}\right\| \times\left\|U_{j}\right\|}$,其中$j$属于$i$的相关类,且$j$ 的购买时间晚于$i$。
|
||||
|
||||
- 聚类层面
|
||||
- 如何聚类?
|
||||
传统的聚类算法(基于密度和 k-means )在数十亿产品规模下的淘宝场景中不可行,所以作者采用了标签传播算法。
|
||||
- 在哪里标签传播?
|
||||
Item-item 图,其中又 Swing 计算的排名靠前 item 为邻居,边的权重就是 Swing 分数。
|
||||
- 表现如何?
|
||||
快速而有效,15分钟即可对数十亿个项目进行聚类。
|
||||
最终聚类层面的相关度计算同上面商品层面的计算公式
|
||||
|
||||
- 线性组合:
|
||||
$s(i, j)=\omega * s_{1}(i, j)+(1-\omega) * s_{2}(i, j)$,其中$\omega=0.8$是作者设置的权重超参数。
|
||||
Surprise算法通过利用类别信息和标签传播技术解决了用户共同购买图上的稀疏性问题。
|
||||
|
||||
**参考资料**
|
||||
- [Large Scale Product Graph Construction for Recommendation in E-commerce](https://arxiv.org/pdf/2010.05525)
|
||||
- [推荐召回-Swing](https://zhuanlan.zhihu.com/p/383346471)
|
||||
269
4.人工智能/ch02/ch2.1/ch2.1.1/itemcf.md
Normal file
269
4.人工智能/ch02/ch2.1/ch2.1.1/itemcf.md
Normal file
@@ -0,0 +1,269 @@
|
||||
# 基于物品的协同过滤
|
||||
|
||||
## 基本思想
|
||||
|
||||
基于物品的协同过滤(ItemCF):
|
||||
|
||||
+ 预先根据所有用户的历史行为数据,计算物品之间的相似性。
|
||||
+ 然后,把与用户喜欢的物品相类似的物品推荐给用户。
|
||||
|
||||
举例来说,如果用户 1 喜欢物品 A ,而物品 A 和 C 非常相似,则可以将物品 C 推荐给用户1。ItemCF算法并不利用物品的内容属性计算物品之间的相似度, 主要通过分析用户的行为记录计算物品之间的相似度, 该算法认为, 物品 A 和物品 C 具有很大的相似度是因为喜欢物品 A 的用户极可能喜欢物品 C。
|
||||
|
||||
|
||||
|
||||
## 计算过程
|
||||
|
||||
基于物品的协同过滤算法和基于用户的协同过滤算法很像, 所以我们这里直接还是拿上面 Alice 的那个例子来看。
|
||||
|
||||
|
||||
|
||||
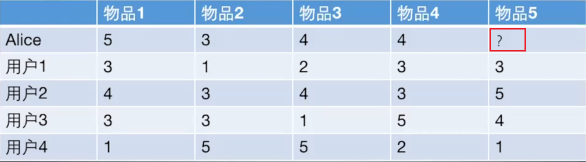
如果想知道 Alice 对物品5打多少分, 基于物品的协同过滤算法会这么做:
|
||||
|
||||
+ 首先计算一下物品5和物品1, 2, 3, 4之间的相似性。
|
||||
|
||||
+ 在Alice找出与物品 5 最相近的 n 个物品。
|
||||
|
||||
+ 根据 Alice 对最相近的 n 个物品的打分去计算对物品 5 的打分情况。
|
||||
|
||||
**手动计算:**
|
||||
|
||||
1. 手动计算物品之间的相似度
|
||||
|
||||
>物品向量: $物品 1(3,4,3,1) ,物品2(1,3,3,5) ,物品3(2,4,1,5) ,物品4(3,3,5,2) ,物品5(3,5,41)$
|
||||
>
|
||||
>+ 下面计算物品 5 和物品 1 之间的余弦相似性:
|
||||
> $$
|
||||
> \operatorname{sim}(\text { 物品1, 物品5 })=\operatorname{cosine}(\text { 物品1, 物品5 } )=\frac{9+20+12+1}{\operatorname{sqrt}(9+16+9+1)*\operatorname{sqrt}(9+25+16+1)}
|
||||
> $$
|
||||
>
|
||||
>+ 皮尔逊相关系数类似。
|
||||
>
|
||||
|
||||
2. 基于 `sklearn` 计算物品之间的皮尔逊相关系数:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/JavaJOyFti58um61zPsa.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
|
||||
3. 根据皮尔逊相关系数, 可以找到与物品5最相似的2个物品是 item1 和 item4, 下面基于上面的公式计算最终得分:
|
||||
|
||||
$$
|
||||
P_{Alice, 物品5}=\bar{R}_{物品5}+\frac{\sum_{k=1}^{2}\left(w_{物品5,物品 k}\left(R_{Alice, 物品k}-\bar{R}_{物品k}\right)\right)}{\sum_{k=1}^{2} w_{物品k, 物品5}} \\
|
||||
=\frac{13}{4}+\frac{0.97*(5-3.2)+0.58*(4-3.4)}{0.97+0.58}=4.6
|
||||
$$
|
||||
|
||||
## ItemCF编程实现
|
||||
|
||||
1. 构建物品-用户的评分矩阵
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
|
||||
def loadData():
|
||||
items = {'A': {'Alice': 5.0, 'user1': 3.0, 'user2': 4.0, 'user3': 3.0, 'user4': 1.0},
|
||||
'B': {'Alice': 3.0, 'user1': 1.0, 'user2': 3.0, 'user3': 3.0, 'user4': 5.0},
|
||||
'C': {'Alice': 4.0, 'user1': 2.0, 'user2': 4.0, 'user3': 1.0, 'user4': 5.0},
|
||||
'D': {'Alice': 4.0, 'user1': 3.0, 'user2': 3.0, 'user3': 5.0, 'user4': 2.0},
|
||||
'E': {'user1': 3.0, 'user2': 5.0, 'user3': 4.0, 'user4': 1.0}
|
||||
}
|
||||
return items
|
||||
```
|
||||
|
||||
2. 计算物品间的相似度矩阵
|
||||
|
||||
```python
|
||||
item_data = loadData()
|
||||
|
||||
similarity_matrix = pd.DataFrame(
|
||||
np.identity(len(item_data)),
|
||||
index=item_data.keys(),
|
||||
columns=item_data.keys(),
|
||||
)
|
||||
|
||||
# 遍历每条物品-用户评分数据
|
||||
for i1, users1 in item_data.items():
|
||||
for i2, users2 in item_data.items():
|
||||
if i1 == i2:
|
||||
continue
|
||||
vec1, vec2 = [], []
|
||||
for user, rating1 in users1.items():
|
||||
rating2 = users2.get(user, -1)
|
||||
if rating2 == -1:
|
||||
continue
|
||||
vec1.append(rating1)
|
||||
vec2.append(rating2)
|
||||
similarity_matrix[i1][i2] = np.corrcoef(vec1, vec2)[0][1]
|
||||
|
||||
print(similarity_matrix)
|
||||
```
|
||||
|
||||
```
|
||||
A B C D E
|
||||
A 1.000000 -0.476731 -0.123091 0.532181 0.969458
|
||||
B -0.476731 1.000000 0.645497 -0.310087 -0.478091
|
||||
C -0.123091 0.645497 1.000000 -0.720577 -0.427618
|
||||
D 0.532181 -0.310087 -0.720577 1.000000 0.581675
|
||||
E 0.969458 -0.478091 -0.427618 0.581675 1.000000
|
||||
```
|
||||
|
||||
3. 从 Alice 购买过的物品中,选出与物品 `E` 最相似的 `num` 件物品。
|
||||
|
||||
```python
|
||||
target_user = ' Alice '
|
||||
target_item = 'E'
|
||||
num = 2
|
||||
|
||||
sim_items = []
|
||||
sim_items_list = similarity_matrix[target_item].sort_values(ascending=False).index.tolist()
|
||||
for item in sim_items_list:
|
||||
# 如果target_user对物品item评分过
|
||||
if target_user in item_data[item]:
|
||||
sim_items.append(item)
|
||||
if len(sim_items) == num:
|
||||
break
|
||||
print(f'与物品{target_item}最相似的{num}个物品为:{sim_items}')
|
||||
```
|
||||
|
||||
```
|
||||
与物品E最相似的2个物品为:['A', 'D']
|
||||
```
|
||||
|
||||
4. 预测用户 Alice 对物品 `E` 的评分
|
||||
|
||||
```python
|
||||
target_user_mean_rating = np.mean(list(item_data[target_item].values()))
|
||||
weighted_scores = 0.
|
||||
corr_values_sum = 0.
|
||||
|
||||
target_item = 'E'
|
||||
for item in sim_items:
|
||||
corr_value = similarity_matrix[target_item][item]
|
||||
user_mean_rating = np.mean(list(item_data[item].values()))
|
||||
|
||||
weighted_scores += corr_value * (item_data[item][target_user] - user_mean_rating)
|
||||
corr_values_sum += corr_value
|
||||
|
||||
target_item_pred = target_user_mean_rating + weighted_scores / corr_values_sum
|
||||
print(f'用户{target_user}对物品{target_item}的预测评分为:{target_item_pred}')
|
||||
```
|
||||
|
||||
```
|
||||
用户 Alice 对物品E的预测评分为:4.6
|
||||
```
|
||||
|
||||
# 协同过滤算法的权重改进
|
||||
|
||||
* base 公式
|
||||
$$
|
||||
w_{i j}=\frac{|N(i) \bigcap N(j)|}{|N(i)|}
|
||||
$$
|
||||
|
||||
+ 该公式表示同时喜好物品 $i$ 和物品 $j$ 的用户数,占喜爱物品 $i$ 的比例。
|
||||
+ 缺点:若物品 $j$ 为热门物品,那么它与任何物品的相似度都很高。
|
||||
|
||||
* 对热门物品进行惩罚
|
||||
$$
|
||||
w_{i j}=\frac{|N(i) \cap N(j)|}{\sqrt{|N(i)||N(j)|}}
|
||||
$$
|
||||
|
||||
|
||||
* 根据 base 公式在的问题,对物品 $j$ 进行打压。打压的出发点很简单,就是在分母再除以一个物品 $j$ 被购买的数量。
|
||||
* 此时,若物品 $j$ 为热门物品,那么对应的 $N(j)$ 也会很大,受到的惩罚更多。
|
||||
|
||||
* 控制对热门物品的惩罚力度
|
||||
$$
|
||||
w_{i j}=\frac{|N(i) \cap N(j)|}{|N(i)|^{1-\alpha}|N(j)|^{\alpha}}
|
||||
$$
|
||||
|
||||
* 除了第二点提到的办法,在计算物品之间相似度时可以对热门物品进行惩罚外。
|
||||
* 可以在此基础上,进一步引入参数 $\alpha$ ,这样可以通过控制参数 $\alpha$来决定对热门物品的惩罚力度。
|
||||
|
||||
* 对活跃用户的惩罚
|
||||
|
||||
* 在计算物品之间的相似度时,可以进一步将用户的活跃度考虑进来。
|
||||
$$
|
||||
w_{i j}=\frac{\sum_{\operatorname{\text {u}\in N(i) \cap N(j)}} \frac{1}{\log 1+|N(u)|}}{|N(i)|^{1-\alpha}|N(j)|^{\alpha}}
|
||||
$$
|
||||
|
||||
+ 对于异常活跃的用户,在计算物品之间的相似度时,他的贡献应该小于非活跃用户。
|
||||
|
||||
# 协同过滤算法的问题分析
|
||||
|
||||
协同过滤算法存在的问题之一就是泛化能力弱:
|
||||
|
||||
+ 即协同过滤无法将两个物品相似的信息推广到其他物品的相似性上。
|
||||
+ 导致的问题是**热门物品具有很强的头部效应, 容易跟大量物品产生相似, 而尾部物品由于特征向量稀疏, 导致很少被推荐**。
|
||||
|
||||
比如下面这个例子:
|
||||
|
||||
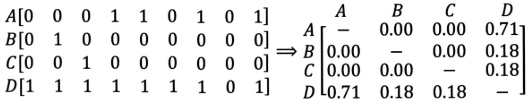
|
||||
|
||||
+ 左边矩阵中,$A, B, C, D$ 表示的是物品。
|
||||
+ 可以看出,$D $ 是一件热门物品,其与 $A、B、C$ 的相似度比较大。因此,推荐系统更可能将 $D$ 推荐给用过 $A、B、C$ 的用户。
|
||||
+ 但是,推荐系统无法找出 $A,B,C$ 之间相似性的原因是交互数据太稀疏, 缺乏相似性计算的直接数据。
|
||||
|
||||
所以这就是协同过滤的天然缺陷:**推荐系统头部效应明显, 处理稀疏向量的能力弱**。
|
||||
|
||||
为了解决这个问题, 同时增加模型的泛化能力。2006年,**矩阵分解技术(Matrix Factorization, MF**)被提出:
|
||||
|
||||
+ 该方法在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品, 挖掘用户和物品的隐含兴趣和隐含特征。
|
||||
+ 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
|
||||
|
||||
# 课后思考
|
||||
|
||||
1. **什么时候使用UserCF,什么时候使用ItemCF?为什么?**
|
||||
|
||||
> (1)UserCF
|
||||
>
|
||||
> + 由于是基于用户相似度进行推荐, 所以具备更强的社交特性, 这样的特点非常适于**用户少, 物品多, 时效性较强的场合**。
|
||||
>
|
||||
> + 比如新闻推荐场景, 因为新闻本身兴趣点分散, 相比用户对不同新闻的兴趣偏好, 新闻的及时性,热点性往往更加重要, 所以正好适用于发现热点,跟踪热点的趋势。
|
||||
> + 另外还具有推荐新信息的能力, 更有可能发现惊喜, 因为看的是人与人的相似性, 推出来的结果可能更有惊喜,可以发现用户潜在但自己尚未察觉的兴趣爱好。
|
||||
>
|
||||
> (2)ItemCF
|
||||
>
|
||||
> + 这个更适用于兴趣变化较为稳定的应用, 更接近于个性化的推荐, 适合**物品少,用户多,用户兴趣固定持久, 物品更新速度不是太快的场合**。
|
||||
> + 比如推荐艺术品, 音乐, 电影。
|
||||
|
||||
|
||||
|
||||
2.**协同过滤在计算上有什么缺点?有什么比较好的思路可以解决(缓解)?**
|
||||
|
||||
> 该问题答案参考上一小节的**协同过滤算法的问题分析**。
|
||||
|
||||
|
||||
|
||||
**3.上面介绍的相似度计算方法有什么优劣之处?**
|
||||
|
||||
> cosine相似度计算简单方便,一般较为常用。但是,当用户的评分数据存在 bias 时,效果往往不那么好。
|
||||
>
|
||||
> + 简而言之,就是不同用户评分的偏向不同。部分用户可能乐于给予好评,而部分用户习惯给予差评或者乱评分。
|
||||
> + 这个时候,根据cosine 相似度计算出来的推荐结果效果会打折扣。
|
||||
>
|
||||
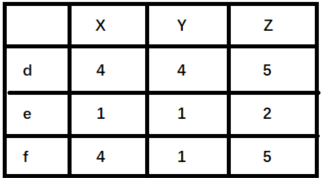
> 举例来说明,如下图(`X,Y,Z` 表示物品,`d,e,f`表示用户):
|
||||
>
|
||||
> 
|
||||
>
|
||||
> + 如果使用余弦相似度进行计算,用户 d 和 e 之间较为相似。但是实际上,用户 d 和 f 之间应该更加相似。只不过由于 d 倾向于打高分,e 倾向于打低分导致二者之间的余弦相似度更高。
|
||||
> + 这种情况下,可以考虑使用皮尔逊相关系数计算用户之间的相似性关系。
|
||||
|
||||
|
||||
|
||||
4.**协同过滤还存在其他什么缺陷?有什么比较好的思路可以解决(缓解)?**
|
||||
|
||||
> + 协同过滤的优点就是没有使用更多的用户或者物品属性信息,仅利用用户和物品之间的交互信息就能完成推荐,该算法简单高效。
|
||||
> + 但这也是协同过滤算法的一个弊端。由于未使用更丰富的用户和物品特征信息,这也导致协同过滤算法的模型表达能力有限。
|
||||
> + 对于该问题,逻辑回归模型(LR)可以更好地在推荐模型中引入更多特征信息,提高模型的表达能力。
|
||||
|
||||
|
||||
|
||||
# 参考资料
|
||||
|
||||
* [基于用户的协同过滤来构建推荐系统:https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw](https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw)
|
||||
* [协同过滤算法概述:https://chenk.tech/posts/8ad63d9d.html](https://chenk.tech/posts/8ad63d9d.html)
|
||||
* B站黑马推荐系统实战课程
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
370
4.人工智能/ch02/ch2.1/ch2.1.1/mf.md
Normal file
370
4.人工智能/ch02/ch2.1/ch2.1.1/mf.md
Normal file
@@ -0,0 +1,370 @@
|
||||
# 隐语义模型与矩阵分解
|
||||
|
||||
协同过滤算法的特点:
|
||||
|
||||
+ 协同过滤算法的特点就是完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息就可以实现推荐,是一个可解释性很强, 非常直观的模型。
|
||||
+ 但是也存在一些问题,处理稀疏矩阵的能力比较弱。
|
||||
|
||||
为了使得协同过滤更好处理稀疏矩阵问题, 增强泛化能力。从协同过滤中衍生出矩阵分解模型(Matrix Factorization, MF)或者叫隐语义模型:
|
||||
|
||||
+ 在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品。
|
||||
+ 通过挖掘用户和物品的隐含兴趣和隐含特征, 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
|
||||
|
||||
|
||||
|
||||
# 隐语义模型
|
||||
|
||||
隐语义模型最早在文本领域被提出,用于找到文本的隐含语义。在2006年, 被用于推荐中, 它的核心思想是通过隐含特征(latent factor)联系用户兴趣和物品(item), 基于用户的行为找出潜在的主题和分类, 然后对物品进行自动聚类,划分到不同类别/主题(用户的兴趣)。
|
||||
|
||||
以项亮老师《推荐系统实践》书中的内容为例:
|
||||
|
||||
>如果我们知道了用户A和用户B两个用户在豆瓣的读书列表, 从他们的阅读列表可以看出,用户A的兴趣涉及侦探小说、科普图书以及一些计算机技术书, 而用户B的兴趣比较集中在数学和机器学习方面。 那么如何给A和B推荐图书呢? 先说说协同过滤算法, 这样好对比不同:
|
||||
>* 对于UserCF,首先需要找到和他们看了同样书的其他用户(兴趣相似的用户),然后给他们推荐那些用户喜欢的其他书。
|
||||
>* 对于ItemCF,需要给他们推荐和他们已经看的书相似的书,比如作者B看了很多关于数据挖掘的书,可以给他推荐机器学习或者模式识别方面的书。
|
||||
>
|
||||
>而如果是隐语义模型的话, 它会先通过一些角度把用户兴趣和这些书归一下类, 当来了用户之后, 首先得到他的兴趣分类, 然后从这个分类中挑选他可能喜欢的书籍。
|
||||
|
||||
隐语义模型和协同过滤的不同主要体现在隐含特征上, 比如书籍的话它的内容, 作者, 年份, 主题等都可以算隐含特征。
|
||||
|
||||
以王喆老师《深度学习推荐系统》中的一个原理图为例,看看是如何通过隐含特征来划分开用户兴趣和物品的。
|
||||
|
||||
<img src="https://img-blog.csdnimg.cn/20200822212051499.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
|
||||
## 音乐评分实例
|
||||
|
||||
假设每个用户都有自己的听歌偏好, 比如用户 A 喜欢带有**小清新的**, **吉他伴奏的**, **王菲**的歌曲,如果一首歌正好**是王菲唱的, 并且是吉他伴奏的小清新**, 那么就可以将这首歌推荐给这个用户。 也就是说是**小清新, 吉他伴奏, 王菲**这些元素连接起了用户和歌曲。
|
||||
|
||||
当然每个用户对不同的元素偏好不同, 每首歌包含的元素也不一样, 所以我们就希望找到下面的两个矩阵:
|
||||
|
||||
1. 潜在因子—— 用户矩阵Q
|
||||
这个矩阵表示不同用户对于不同元素的偏好程度, 1代表很喜欢, 0代表不喜欢, 比如下面这样:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/2020082222025968.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
2. 潜在因子——音乐矩阵P
|
||||
表示每种音乐含有各种元素的成分, 比如下表中, 音乐A是一个偏小清新的音乐, 含有小清新的Latent Factor的成分是0.9, 重口味的成分是0.1, 优雅成分0.2...
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822220751394.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
**计算张三对音乐A的喜爱程度**
|
||||
|
||||
利用上面的这两个矩阵,将对应向量进行内积计算,我们就能得出张三对音乐A的喜欢程度:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822221627219.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
+ 张三对**小清新**的偏好 * 音乐A含有**小清新**的成分 + 张三对**重口味**的偏好 * 音乐A含有**重口味**的成分 + 张三对**优雅**的偏好 * 音乐A含有**优雅**的成分...
|
||||
|
||||
+ 根据隐向量其实就可以得到张三对音乐A的打分,即: $$0.6 * 0.9 + 0.8 * 0.1 + 0.1 * 0.2 + 0.1 * 0.4 + 0.7 * 0 = 0.68$$。
|
||||
|
||||
**计算所有用户对不同音乐的喜爱程度**
|
||||
|
||||
按照这个计算方式, 每个用户对每首歌其实都可以得到这样的分数, 最后就得到了我们的评分矩阵:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822222141231.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:60%;" />
|
||||
</div>
|
||||
+ 红色部分表示用户没有打分,可以通过隐向量计算得到的。
|
||||
|
||||
**小结**
|
||||
|
||||
+ 上面例子中的小清晰, 重口味, 优雅这些就可以看做是隐含特征, 而通过这个隐含特征就可以把用户的兴趣和音乐的进行一个分类, 其实就是找到了每个用户每个音乐的一个隐向量表达形式(与深度学习中的embedding等价)
|
||||
+ 这个隐向量就可以反映出用户的兴趣和物品的风格,并能将相似的物品推荐给相似的用户等。 **有没有感觉到是把协同过滤算法进行了一种延伸, 把用户的相似性和物品的相似性通过了一个叫做隐向量的方式进行表达**
|
||||
|
||||
+ 现实中,类似于上述的矩阵 $P,Q$ 一般很难获得。有的只是用户的评分矩阵,如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822223313349.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:60%;" />
|
||||
</div>
|
||||
|
||||
+ 这种矩阵非常的稀疏,如果直接基于用户相似性或者物品相似性去填充这个矩阵是不太容易的。
|
||||
+ 并且很容易出现长尾问题, 而矩阵分解就可以比较容易的解决这个问题。
|
||||
|
||||
+ 矩阵分解模型:
|
||||
|
||||
+ 基于评分矩阵,将其分解成Q和P两个矩阵乘积的形式,获取用户兴趣和物品的隐向量表达。
|
||||
+ 然后,基于两个分解矩阵去预测某个用户对某个物品的评分了。
|
||||
+ 最后,基于预测评分去进行物品推荐。
|
||||
|
||||
|
||||
|
||||
# 矩阵分解算法
|
||||
|
||||
## 算法原理
|
||||
|
||||
在矩阵分解的算法框架下, **可以通过分解协同过滤的共现矩阵(评分矩阵)来得到用户和物品的隐向量**,原理如下:。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200823101513233.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
+ 矩阵分解算法将 $m\times n$ 维的共享矩阵 $R$ ,分解成 $m \times k$ 维的用户矩阵 $U$ 和 $k \times n$ 维的物品矩阵 $V$ 相乘的形式。
|
||||
+ 其中,$m$ 是用户数量, $n$ 是物品数量, $k$ 是隐向量维度, 也就是隐含特征个数。
|
||||
+ 这里的隐含特征没有太好的可解释性,需要模型自己去学习。
|
||||
+ 一般而言, $k$ 越大隐向量能承载的信息内容越多,表达能力也会更强,但相应的学习难度也会增加。所以,我们需要根据训练集样本的数量去选择合适的数值,在保证信息学习相对完整的前提下,降低模型的学习难度。
|
||||
|
||||
## 评分预测
|
||||
|
||||
在分解得到用户矩阵和物品矩阵后,若要计算用户 $u$ 对物品 $i$ 的评分,公式如下:
|
||||
$$
|
||||
\operatorname{Preference}(u, i)=r_{u i}=p_{u}^{T} q_{i}=\sum_{k=1}^{K} p_{u, k} q_{i,k}
|
||||
$$
|
||||
+ 其中,向量 $p_u$ 表示用户 $u$ 的隐向量,向量 $q_i$ 表示物品 $i$ 的隐向量。
|
||||
+ 用户向量和物品向量的内积 $p_{u}^{T} q_{i}$ 可以表示为用户 $u$ 对物品 $i$ 的预测评分。
|
||||
+ $p_{u,k}$ 和 $q_{i,k}$ 是模型的参数, $p_{u,k}$ 度量的是用户 $u$ 的兴趣和第 $k$ 个隐类的关系,$q_{i,k}$ 度量了第 $k$ 个隐类和物品 $i$ 之间的关系。
|
||||
|
||||
## 矩阵分解求解
|
||||
|
||||
常用的矩阵分解方法有特征值分解(EVD)或者奇异值分解(SVD), 具体原理可参考:
|
||||
|
||||
> [奇异值分解svd原理详解及推导](https://blog.csdn.net/wuzhongqiang/article/details/108168238)
|
||||
|
||||
+ 对于 EVD, 它要求分解的矩阵是方阵, 绝大部分场景下用户-物品矩阵不满足这个要求。
|
||||
+ 传统的 SVD 分解, 会要求原始矩阵是稠密的。但现实中用户的评分矩阵是非常稀疏的。
|
||||
+ 如果想用奇异值分解, 就必须对缺失的元素进行填充(比如填 0 )。
|
||||
+ 填充不但会导致空间复杂度增高,且补全内容不一定准确。
|
||||
+ 另外,SVD 分解计算复杂度非常高,而用户-物品的评分矩阵较大,不具备普适性。
|
||||
|
||||
## FunkSVD
|
||||
|
||||
2006年的Netflix Prize之后, Simon Funk公布了一个矩阵分解算法叫做**Funk-SVD**, 后来被 Netflix Prize 的冠军Koren称为**Latent Factor Model(LFM)**。
|
||||
|
||||
Funk-SVD的思想很简单: **把求解上面两个矩阵的参数问题转换成一个最优化问题, 可以通过训练集里面的观察值利用最小化来学习用户矩阵和物品矩阵**。
|
||||
|
||||
**算法过程**
|
||||
|
||||
1. 根据前面提到的,在有用户矩阵和物品矩阵的前提下,若要计算用户 $u$ 对物品 $i$ 的评分, 可以根据公式:
|
||||
$$
|
||||
\operatorname{Preference}(u, i)=r_{u i}=p_{u}^{T} q_{i}=\sum_{k=1}^{K} p_{u, k} q_{i,k}
|
||||
$$
|
||||
|
||||
+ 其中,向量 $p_u$ 表示用户 $u$ 的隐向量,向量 $q_i$ 表示物品 $i$ 的隐向量。
|
||||
|
||||
2. 随机初始化一个用户矩阵 $U$ 和一个物品矩阵 $V$,获取每个用户和物品的初始隐语义向量。
|
||||
|
||||
3. 将用户和物品的向量内积 $p_{u}^{T} q_{i}$, 作为用户对物品的预测评分 $\hat{r}_{u i}$。
|
||||
|
||||
+ $\hat{r}_{u i}=p_{u}^{T} q_{i}$ 表示的是通过建模,求得的用户 $u$ 对物品的预测评分。
|
||||
+ 在用户对物品的评分矩阵中,矩阵中的元素 $r_{u i}$ 才是用户对物品的真实评分。
|
||||
|
||||
4. 对于评分矩阵中的每个元素,计算预测误差 $e_{u i}=r_{u i}-\hat{r}_{u i}$,对所有训练样本的平方误差进行累加:
|
||||
$$
|
||||
\operatorname{SSE}=\sum_{u, i} e_{u i}^{2}=\sum_{u, i}\left(r_{u i}-\sum_{k=1}^{K} p_{u,k} q_{i,k}\right)^{2}
|
||||
$$
|
||||
|
||||
+ 从上述公式可以看出,$SSE$ 建立起了训练数据和预测模型之间的关系。
|
||||
|
||||
+ 如果我们希望模型预测的越准确,那么在训练集(已有的评分矩阵)上的预测误差应该仅可能小。
|
||||
|
||||
+ 为方便后续求解,给 $SSE$ 增加系数 $1/2$ :
|
||||
$$
|
||||
\operatorname{SSE}=\frac{1}{2} \sum_{u, i} e_{u i}^{2}=\frac{1}{2} \sum_{u, i}\left(r_{u i}-\sum_{k=1}^{K} p_{u k} q_{i k}\right)^{2}
|
||||
$$
|
||||
|
||||
5. 前面提到,模型预测越准确等价于预测误差越小,那么优化的目标函数变为:
|
||||
$$
|
||||
\min _{\boldsymbol{q}^{*}, \boldsymbol{p}^{*}} \frac{1}{2} \sum_{(u, i) \in K}\left(\boldsymbol{r}_{\mathrm{ui}}-p_{u}^{T} q_{i}\right)^{2}
|
||||
$$
|
||||
|
||||
+ $K$ 表示所有用户评分样本的集合,**即评分矩阵中不为空的元素**,其他空缺值在测试时是要预测的。
|
||||
+ 该目标函数需要优化的目标是用户矩阵 $U$ 和一个物品矩阵 $V$。
|
||||
|
||||
6. 对于给定的目标函数,可以通过梯度下降法对参数进行优化。
|
||||
|
||||
+ 求解目标函数 $SSE$ 关于用户矩阵中参数 $p_{u,k}$ 的梯度:
|
||||
$$
|
||||
\frac{\partial}{\partial p_{u,k}} S S E=\frac{\partial}{\partial p_{u,k}}\left(\frac{1}{2}e_{u i}^{2}\right) =e_{u i} \frac{\partial}{\partial p_{u,k}} e_{u i}=e_{u i} \frac{\partial}{\partial p_{u,k}}\left(r_{u i}-\sum_{k=1}^{K} p_{u,k} q_{i,k}\right)=-e_{u i} q_{i,k}
|
||||
$$
|
||||
|
||||
+ 求解目标函数 $SSE$ 关于 $q_{i,k}$ 的梯度:
|
||||
$$
|
||||
\frac{\partial}{\partial q_{i,k}} S S E=\frac{\partial}{\partial q_{i,k}}\left(\frac{1}{2}e_{u i}^{2}\right) =e_{u i} \frac{\partial}{\partial q_{i,k}} e_{u i}=e_{u i} \frac{\partial}{\partial q_{i,k}}\left(r_{u i}-\sum_{k=1}^{K} p_{u,k} q_{i,k}\right)=-e_{u i} p_{u,k}
|
||||
$$
|
||||
|
||||
7. 参数梯度更新
|
||||
$$
|
||||
p_{u, k}=p_{u,k}-\eta (-e_{ui}q_{i, k})=p_{u,k}+\eta e_{ui}q_{i, k} \\
|
||||
q_{i, k}=q_{i,k}-\eta (-e_{ui}p_{u,k})=q_{i, k}+\eta e_{ui}p_{u, k}
|
||||
$$
|
||||
|
||||
+ 其中,$\eta$ 表示学习率, 用于控制步长。
|
||||
+ 但上面这个有个问题就是当参数很多的时候, 就是两个矩阵很大的时候, 往往容易陷入过拟合的困境, 这时候, 就需要在目标函数上面加上正则化的损失, 就变成了RSVD, 关于RSVD的详细内容, 可以参考下面给出的链接, 由于篇幅原因, 这里不再过多的赘述。
|
||||
|
||||
**加入正则项**
|
||||
|
||||
为了控制模型的复杂度。在原有模型的基础上,加入 $l2$ 正则项,来防止过拟合。
|
||||
|
||||
+ 当模型参数过大,而输入数据发生变化时,可能会造成输出的不稳定。
|
||||
|
||||
+ $l2$ 正则项等价于假设模型参数符合0均值的正态分布,从而使得模型的输出更加稳定。
|
||||
|
||||
$$
|
||||
\min _{\boldsymbol{q}^{*}, \boldsymbol{p}^{*}} \frac{1}{2} \sum_{(u, i) \in K}\left(\boldsymbol{r}_{\mathrm{ui}}-p_{u}^{T} q_{i}\right)^{2}
|
||||
+ \lambda\left(\left\|p_{u}\right\|^{2}+\left\|q_{i}\right\|^{2}\right)
|
||||
$$
|
||||
|
||||
## BiasSVD
|
||||
|
||||
在推荐系统中,评分预测除了与用户的兴趣偏好、物品的特征属性相关外,与其他的因素也相关。例如:
|
||||
|
||||
+ 例如,对于乐观的用户来说,它的评分行为普遍偏高,而对批判性用户来说,他的评分记录普遍偏低,即使他们对同一物品的评分相同,但是他们对该物品的喜好程度却并不一样。
|
||||
+ 对物品来说也是类似的。以电影为例,受大众欢迎的电影得到的评分普遍偏高,而一些烂片的评分普遍偏低,这些因素都是独立于用户或产品的因素,和用户对产品的的喜好无关。
|
||||
|
||||
因此, Netfix Prize中提出了另一种LFM, 在原来的基础上加了偏置项, 来消除用户和物品打分的偏差, 即预测公式如下:
|
||||
$$
|
||||
\hat{r}_{u i}=\mu+b_{u}+b_{i}+p_{u}^{T} \cdot q_{i}
|
||||
$$
|
||||
这个预测公式加入了3项偏置参数 $\mu,b_u,b_i$, 作用如下:
|
||||
|
||||
- $\mu$: 该参数反映的是推荐模型整体的平均评分,一般使用所有样本评分的均值。
|
||||
- $b_u$:用户偏差系数。可以使用用户 $u$ 给出的所有评分的均值, 也可以当做训练参数。
|
||||
- 这一项表示了用户的评分习惯中和物品没有关系的那种因素。 比如有些用户比较苛刻, 对什么东西要求很高, 那么他评分就会偏低, 而有些用户比较宽容, 对什么东西都觉得不错, 那么评分就偏高
|
||||
- $b_i$:物品偏差系数。可以使用物品 $i$ 收到的所有评分的均值, 也可以当做训练参数。
|
||||
- 这一项表示了物品接受的评分中和用户没有关系的因素。 比如有些物品本身质量就很高, 因此获得的评分相对比较高, 有的物品本身质量很差, 因此获得的评分相对较低。
|
||||
|
||||
加了用户和物品的打分偏差之后, 矩阵分解得到的隐向量更能反映不同用户对不同物品的“真实”态度差异, 也就更容易捕捉评价数据中有价值的信息, 从而避免推荐结果有偏。
|
||||
|
||||
**优化函数**
|
||||
|
||||
在加入正则项的FunkSVD的基础上,BiasSVD 的目标函数如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\min _{q^{*}, p^{*}} \frac{1}{2} \sum_{(u, i) \in K} &\left(r_{u i}-\left(\mu+b_{u}+b_{i}+q_{i}^{T} p_{u}\right)\right)^{2} \\
|
||||
&+\lambda\left(\left\|p_{u}\right\|^{2}+\left\|q_{i}\right\|^{2}+b_{u}^{2}+b_{i}^{2}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
可得偏置项的梯度更新公式如下:
|
||||
|
||||
+ $\frac{\partial}{\partial b_{i}} S S E=-e_{u i}+\lambda b_{i}$
|
||||
+ $ \frac{\partial}{\partial b_{u}} S S E=-e_{u i}+\lambda b_{u} \ $
|
||||
|
||||
# 编程实现
|
||||
|
||||
本小节,使用如下图表来预测Alice对物品5的评分:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200827150237921.png#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
</div>
|
||||
基于矩阵分解算法的流程如下:
|
||||
|
||||
1. 首先, 它会先初始化用户矩阵 $P$ 和物品矩阵 $Q$ , $P$ 的维度是`[users_num, K]`,$Q$ 的维度是`[items_num, K]`,
|
||||
|
||||
+ 其中,`F`表示隐向量的维度。 也就是把通过隐向量的方式把用户的兴趣和`F`的特点关联了起来。
|
||||
|
||||
+ 初始化这两个矩阵的方式很多, 但根据经验, 随机数需要和`1/sqrt(F)`成正比。
|
||||
|
||||
2. 根据预测评分和真实评分的偏差,利用梯度下降法进行参数更新。
|
||||
|
||||
+ 遍历用户及其交互过的物品,对已交互过的物品进行评分预测。
|
||||
+ 由于预测评分与真实评分存在偏差, 再根据第3节的梯度更新公式更新参数。
|
||||
|
||||
3. 训练完成后,利用用户向量与目标物品向量的内积进行评分预测。
|
||||
|
||||
**完整代码如下:**
|
||||
|
||||
```python
|
||||
import random
|
||||
import math
|
||||
|
||||
|
||||
class BiasSVD():
|
||||
def __init__(self, rating_data, F=5, alpha=0.1, lmbda=0.1, max_iter=100):
|
||||
self.F = F # 这个表示隐向量的维度
|
||||
self.P = dict() # 用户矩阵P 大小是[users_num, F]
|
||||
self.Q = dict() # 物品矩阵Q 大小是[item_nums, F]
|
||||
self.bu = dict() # 用户偏置系数
|
||||
self.bi = dict() # 物品偏置系数
|
||||
self.mu = 0 # 全局偏置系数
|
||||
self.alpha = alpha # 学习率
|
||||
self.lmbda = lmbda # 正则项系数
|
||||
self.max_iter = max_iter # 最大迭代次数
|
||||
self.rating_data = rating_data # 评分矩阵
|
||||
|
||||
for user, items in self.rating_data.items():
|
||||
# 初始化矩阵P和Q, 随机数需要和1/sqrt(F)成正比
|
||||
self.P[user] = [random.random() / math.sqrt(self.F) for x in range(0, F)]
|
||||
self.bu[user] = 0
|
||||
for item, rating in items.items():
|
||||
if item not in self.Q:
|
||||
self.Q[item] = [random.random() / math.sqrt(self.F) for x in range(0, F)]
|
||||
self.bi[item] = 0
|
||||
|
||||
# 采用随机梯度下降的方式训练模型参数
|
||||
def train(self):
|
||||
cnt, mu_sum = 0, 0
|
||||
for user, items in self.rating_data.items():
|
||||
for item, rui in items.items():
|
||||
mu_sum, cnt = mu_sum + rui, cnt + 1
|
||||
self.mu = mu_sum / cnt
|
||||
|
||||
for step in range(self.max_iter):
|
||||
# 遍历所有的用户及历史交互物品
|
||||
for user, items in self.rating_data.items():
|
||||
# 遍历历史交互物品
|
||||
for item, rui in items.items():
|
||||
rhat_ui = self.predict(user, item) # 评分预测
|
||||
e_ui = rui - rhat_ui # 评分预测偏差
|
||||
|
||||
# 参数更新
|
||||
self.bu[user] += self.alpha * (e_ui - self.lmbda * self.bu[user])
|
||||
self.bi[item] += self.alpha * (e_ui - self.lmbda * self.bi[item])
|
||||
for k in range(0, self.F):
|
||||
self.P[user][k] += self.alpha * (e_ui * self.Q[item][k] - self.lmbda * self.P[user][k])
|
||||
self.Q[item][k] += self.alpha * (e_ui * self.P[user][k] - self.lmbda * self.Q[item][k])
|
||||
# 逐步降低学习率
|
||||
self.alpha *= 0.1
|
||||
|
||||
|
||||
# 评分预测
|
||||
def predict(self, user, item):
|
||||
return sum(self.P[user][f] * self.Q[item][f] for f in range(0, self.F)) + self.bu[user] + self.bi[
|
||||
item] + self.mu
|
||||
|
||||
|
||||
# 通过字典初始化训练样本,分别表示不同用户(1-5)对不同物品(A-E)的真实评分
|
||||
def loadData():
|
||||
rating_data={1: {'A': 5, 'B': 3, 'C': 4, 'D': 4},
|
||||
2: {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},
|
||||
3: {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},
|
||||
4: {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},
|
||||
5: {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}
|
||||
}
|
||||
return rating_data
|
||||
|
||||
# 加载数据
|
||||
rating_data = loadData()
|
||||
# 建立模型
|
||||
basicsvd = BiasSVD(rating_data, F=10)
|
||||
# 参数训练
|
||||
basicsvd.train()
|
||||
# 预测用户1对物品E的评分
|
||||
for item in ['E']:
|
||||
print(item, basicsvd.predict(1, item))
|
||||
|
||||
# 预测结果:E 3.685084274454321
|
||||
```
|
||||
# 课后思考
|
||||
|
||||
1. 矩阵分解算法后续有哪些改进呢?针对这些改进,是为了解决什么的问题呢?请大家自行探索RSVD,消除用户和物品打分偏差等。
|
||||
|
||||
2. 矩阵分解的优缺点分析
|
||||
|
||||
* 优点:
|
||||
* 泛化能力强: 一定程度上解决了稀疏问题
|
||||
* 空间复杂度低: 由于用户和物品都用隐向量的形式存放, 少了用户和物品相似度矩阵, 空间复杂度由$n^2$降到了$(n+m)*f$
|
||||
* 更好的扩展性和灵活性:矩阵分解的最终产物是用户和物品隐向量, 这个深度学习的embedding思想不谋而合, 因此矩阵分解的结果非常便于与其他特征进行组合和拼接, 并可以与深度学习无缝结合。
|
||||
|
||||
+ 缺点:
|
||||
+ 矩阵分解算法依然是只用到了评分矩阵, 没有考虑到用户特征, 物品特征和上下文特征, 这使得矩阵分解丧失了利用很多有效信息的机会。
|
||||
+ 同时在缺乏用户历史行为的时候, 无法进行有效的推荐。
|
||||
+ 为了解决这个问题, **逻辑回归模型及后续的因子分解机模型**, 凭借其天然的融合不同特征的能力, 逐渐在推荐系统领域得到了更广泛的应用。
|
||||
|
||||
# 参考资料
|
||||
|
||||
* 王喆 - 《深度学习推荐系统》
|
||||
* 项亮 - 《推荐系统实战》
|
||||
* [奇异值分解(SVD)的原理详解及推导](https://blog.csdn.net/wuzhongqiang/article/details/108168238)
|
||||
* [Matrix factorization techniques for recommender systems论文](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=5197422&tag=1)
|
||||
* [隐语义模型(LFM)和矩阵分解(MF)](https://blog.csdn.net/wuzhongqiang/article/details/108173885)
|
||||
345
4.人工智能/ch02/ch2.1/ch2.1.1/usercf.md
Normal file
345
4.人工智能/ch02/ch2.1/ch2.1.1/usercf.md
Normal file
@@ -0,0 +1,345 @@
|
||||
# 协同过滤算法
|
||||
|
||||
## 基本思想
|
||||
|
||||
协同过滤(Collaborative Filtering)推荐算法是最经典、最常用的推荐算法。基本思想是:
|
||||
|
||||
+ 根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品。
|
||||
|
||||
+ 基于对用户历史行为数据的挖掘发现用户的喜好偏向, 并预测用户可能喜好的产品进行推荐。
|
||||
+ 一般是仅仅基于用户的行为数据(评价、购买、下载等), 而不依赖于项的任何附加信息(物品自身特征)或者用户的任何附加信息(年龄, 性别等)。
|
||||
+ 目前应用比较广泛的协同过滤算法是基于邻域的方法,主要有:
|
||||
+ 基于用户的协同过滤算法(UserCF):给用户推荐和他兴趣相似的其他用户喜欢的产品。
|
||||
+ 基于物品的协同过滤算法(ItemCF):给用户推荐和他之前喜欢的物品相似的物品。
|
||||
|
||||
不管是 UserCF 还是 ItemCF 算法, 重点是计算用户之间(或物品之间)的相似度。
|
||||
|
||||
## 相似性度量方法
|
||||
|
||||
1. **杰卡德(Jaccard)相似系数**
|
||||
|
||||
`Jaccard` 系数是衡量两个集合的相似度一种指标,计算公式如下:
|
||||
$$
|
||||
sim_{uv}=\frac{|N(u) \cap N(v)|}{|N(u)| \cup|N(v)|}
|
||||
$$
|
||||
|
||||
+ 其中 $N(u)$,$N(v)$ 分别表示用户 $u$ 和用户 $v$ 交互物品的集合。
|
||||
|
||||
+ 对于用户 $u$ 和 $v$ ,该公式反映了两个交互物品交集的数量占这两个用户交互物品并集的数量的比例。
|
||||
|
||||
由于杰卡德相似系数一般无法反映具体用户的评分喜好信息,所以常用来评估用户是否会对某物品进行打分, 而不是预估用户会对某物品打多少分。
|
||||
|
||||
2. **余弦相似度**
|
||||
余弦相似度衡量了两个向量的夹角,夹角越小越相似。余弦相似度的计算如下,其与杰卡德(Jaccard)相似系数只是在分母上存在差异:
|
||||
$$
|
||||
sim_{uv}=\frac{|N(u) \cap N(v)|}{\sqrt{|N(u)|\cdot|N(v)|}}
|
||||
$$
|
||||
从向量的角度进行描述,令矩阵 $A$ 为用户-物品交互矩阵,矩阵的行表示用户,列表示物品。
|
||||
|
||||
+ 设用户和物品数量分别为 $m,n$,交互矩阵$A$就是一个 $m$ 行 $n$ 列的矩阵。
|
||||
|
||||
+ 矩阵中的元素均为 $0/1$。若用户 $i$ 对物品 $j$ 存在交互,那么 $A_{i,j}=1$,否则为 $0$ 。
|
||||
|
||||
+ 那么,用户之间的相似度可以表示为:
|
||||
$$
|
||||
sim_{uv} = cos(u,v) =\frac{u\cdot v}{|u|\cdot |v|}
|
||||
$$
|
||||
|
||||
+ 向量 $u,v$ 在形式都是 one-hot 类型,$u\cdot v$ 表示向量点积。
|
||||
|
||||
上述用户-物品交互矩阵在现实中是十分稀疏的,为了节省内存,交互矩阵会采用字典进行存储。在 `sklearn` 中,余弦相似度的实现:
|
||||
|
||||
```python
|
||||
from sklearn.metrics.pairwise import cosine_similarity
|
||||
|
||||
i = [1, 0, 0, 0]
|
||||
j = [1, 0, 1, 0]
|
||||
cosine_similarity([i, j])
|
||||
```
|
||||
|
||||
3. **皮尔逊相关系数**
|
||||
|
||||
在用户之间的余弦相似度计算时,将用户向量的内积展开为各元素乘积和:
|
||||
$$
|
||||
sim_{uv} = \frac{\sum_i r_{ui}*r_{vi}}{\sqrt{\sum_i r_{ui}^2}\sqrt{\sum_i r_{vi}^2}}
|
||||
$$
|
||||
+ 其中,$r_{ui},r_{vi}$ 分别表示用户 $u$ 和用户 $v$ 对物品 $i$ 是否有交互(或具体评分值)。
|
||||
|
||||
皮尔逊相关系数与余弦相似度的计算公式非常的类似,如下:
|
||||
$$
|
||||
sim(u,v)=\frac{\sum_{i\in I}(r_{ui}-\bar r_u)(r_{vi}-\bar r_v)}{\sqrt{\sum_{i\in I }(r_{ui}-\bar r_u)^2}\sqrt{\sum_{i\in I }(r_{vi}-\bar r_v)^2}}
|
||||
$$
|
||||
+ 其中,$r_{ui},r_{vi}$ 分别表示用户 $u$ 和用户 $v$ 对物品 $i$ 是否有交互(或具体评分值);
|
||||
+ $\bar r_u, \bar r_v$ 分别表示用户 $u$ 和用户 $v$ 交互的所有物品交互数量或者评分的平均值;
|
||||
|
||||
相较于余弦相似度,皮尔逊相关系数通过使用用户的平均分对各独立评分进行修正,减小了用户评分偏置的影响。在`scipy`中,皮尔逊相关系数的实现:
|
||||
|
||||
```python
|
||||
from scipy.stats import pearsonr
|
||||
|
||||
i = [1, 0, 0, 0]
|
||||
j = [1, 0.5, 0.5, 0]
|
||||
pearsonr(i, j)
|
||||
```
|
||||
|
||||
**适用场景**
|
||||
|
||||
+ $Jaccard$ 相似度表示两个集合的交集元素个数在并集中所占的比例 ,所以适用于隐式反馈数据(0-1)。
|
||||
+ 余弦相似度在度量文本相似度、用户相似度、物品相似度的时候都较为常用。
|
||||
+ 皮尔逊相关度,实际上也是一种余弦相似度。不过先对向量做了中心化,范围在 $-1$ 到 $1$。
|
||||
+ 相关度量的是两个变量的变化趋势是否一致,两个随机变量是不是同增同减。
|
||||
+ 不适合用作计算布尔值向量(0-1)之间相关度。
|
||||
|
||||
# 基于用户的协同过滤
|
||||
|
||||
## 基本思想
|
||||
|
||||
基于用户的协同过滤(UserCF):
|
||||
|
||||
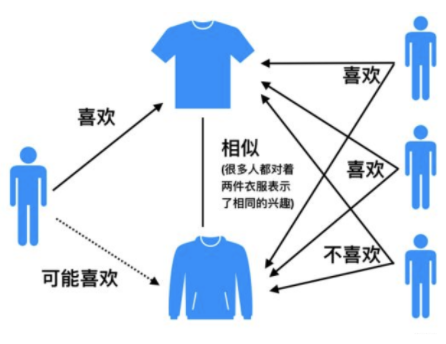
+ 例如,我们要对用户 $A$ 进行物品推荐,可以先找到和他有相似兴趣的其他用户。
|
||||
+ 然后,将共同兴趣用户喜欢的,但用户 $A$ 未交互过的物品推荐给 $A$。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210629232540289.png" alt="image-20210629232540289" style="zoom: 80%;" />
|
||||
|
||||
## 计算过程
|
||||
|
||||
以下图为例,给用户推荐物品的过程可以形象化为一个猜测用户对物品进行打分的任务,表格里面是5个用户对于5件物品的一个打分情况,就可以理解为用户对物品的喜欢程度。
|
||||
|
||||

|
||||
|
||||
UserCF算法的两个步骤:
|
||||
|
||||
+ 首先,根据前面的这些打分情况(或者说已有的用户向量)计算一下 Alice 和用户1, 2, 3, 4的相似程度, 找出与 Alice 最相似的 n 个用户。
|
||||
|
||||
+ 根据这 n 个用户对物品 5 的评分情况和与 Alice 的相似程度会猜测出 Alice 对物品5的评分。如果评分比较高的话, 就把物品5推荐给用户 Alice, 否则不推荐。
|
||||
|
||||
**具体过程:**
|
||||
|
||||
1. 计算用户之间的相似度
|
||||
|
||||
+ 根据 1.2 节的几种方法, 我们可以计算出各用户之间的相似程度。对于用户 Alice,选取出与其最相近的 $N$ 个用户。
|
||||
|
||||
2. 计算用户对新物品的评分预测
|
||||
|
||||
+ 常用的方式之一:利用目标用户与相似用户之间的相似度以及相似用户对物品的评分,来预测目标用户对候选物品的评分估计:
|
||||
$$
|
||||
R_{\mathrm{u}, \mathrm{p}}=\frac{\sum_{\mathrm{s} \in S}\left(w_{\mathrm{u}, \mathrm{s}} \cdot R_{\mathrm{s}, \mathrm{p}}\right)}{\sum_{\mathrm{s} \in S} w_{\mathrm{u}, \mathrm{s}}}
|
||||
$$
|
||||
|
||||
+ 其中,权重 $w_{u,s}$ 是用户 $u$ 和用户 $s$ 的相似度, $R_{s,p}$ 是用户 $s$ 对物品 $p$ 的评分。
|
||||
|
||||
+ 另一种方式:考虑到用户评分的偏置,即有的用户喜欢打高分, 有的用户喜欢打低分的情况。公式如下:
|
||||
$$
|
||||
R_{\mathrm{u}, \mathrm{p}}=\bar{R}_{u} + \frac{\sum_{\mathrm{s} \in S}\left(w_{\mathrm{u}, \mathrm{s}} \cdot \left(R_{s, p}-\bar{R}_{s}\right)\right)}{\sum_{\mathrm{s} \in S} w_{\mathrm{u}, \mathrm{s}}}
|
||||
$$
|
||||
|
||||
+ 其中,$\bar{R}_{s}$ 表示用户 $s$ 对物品的历史平均评分。
|
||||
|
||||
3. 对用户进行物品推荐
|
||||
|
||||
+ 在获得用户 $u$ 对不同物品的评价预测后, 最终的推荐列表根据预测评分进行排序得到。
|
||||
|
||||
**手动计算:**
|
||||
|
||||
根据上面的问题, 下面手动计算 Alice 对物品 5 的得分:
|
||||
|
||||
|
||||
1. 计算 Alice 与其他用户的相似度(基于皮尔逊相关系数)
|
||||
|
||||
+ 手动计算 Alice 与用户 1 之间的相似度:
|
||||
|
||||
>用户向量 $\text {Alice}:(5,3,4,4) , \text{user1}:(3,1,2,3) , \text {user2}:( 4,3,4,3) , \text {user3}:(3,3,1,5) , \text {user4}:(1,5,5,2) $
|
||||
>
|
||||
>+ 计算Alice与user1的余弦相似性:
|
||||
>$$
|
||||
>\operatorname{sim}(\text { Alice, user1 })=\cos (\text { Alice, user } 1)=\frac{15+3+8+12}{\operatorname{sqrt}(25+9+16+16) * \operatorname{sqrt}(9+1+4+9)}=0.975
|
||||
>$$
|
||||
>
|
||||
>+ 计算Alice与user1皮尔逊相关系数:
|
||||
> + $Alice\_ave =4 \quad user1\_ave =2.25 $
|
||||
> + 向量减去均值: $\text {Alice}:(1,-1, 0,0) \quad \text { user1 }:(0.75,-1.25,-0.25,0.75)$
|
||||
>
|
||||
>+ 计算这俩新向量的余弦相似度和上面计算过程一致, 结果是 0.852 。
|
||||
>
|
||||
|
||||
+ 基于 sklearn 计算所有用户之间的皮尔逊相关系数。可以看出,与 Alice 相似度最高的用户为用户1和用户2。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/JavaWJkjP2fHH27Rajrj.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
|
||||
2. **根据相似度用户计算 Alice对物品5的最终得分**
|
||||
用户1对物品5的评分是3, 用户2对物品5的打分是5, 那么根据上面的计算公式, 可以计算出 Alice 对物品5的最终得分是
|
||||
$$
|
||||
P_{Alice, 物品5}=\bar{R}_{Alice}+\frac{\sum_{k=1}^{2}\left(w_{Alice,user k}\left(R_{userk, 物品5}-\bar{R}_{userk}\right)\right)}{\sum_{k=1}^{2} w_{Alice, userk}}=4+\frac{0.85*(3-2.4)+0.7*(5-3.8)}{0.85+0.7}=4.87
|
||||
$$
|
||||
|
||||
+ 同样方式,可以计算用户 Alice 对其他物品的评分预测。
|
||||
|
||||
3. **根据用户评分对用户进行推荐**
|
||||
|
||||
+ 根据 Alice 的打分对物品排个序从大到小:$$物品1>物品5>物品3=物品4>物品2$$。
|
||||
+ 如果要向 Alice 推荐2款产品的话, 我们就可以推荐物品 1 和物品 5 给 Alice。
|
||||
|
||||
至此, 基于用户的协同过滤算法原理介绍完毕。
|
||||
|
||||
## UserCF编程实现
|
||||
|
||||
1. 建立实验使用的数据表:
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
|
||||
def loadData():
|
||||
users = {'Alice': {'A': 5, 'B': 3, 'C': 4, 'D': 4},
|
||||
'user1': {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},
|
||||
'user2': {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},
|
||||
'user3': {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},
|
||||
'user4': {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}
|
||||
}
|
||||
return users
|
||||
```
|
||||
|
||||
+ 这里使用字典来建立用户-物品的交互表。
|
||||
+ 字典`users`的键表示不同用户的名字,值为一个评分字典,评分字典的键值对表示某物品被当前用户的评分。
|
||||
+ 由于现实场景中,用户对物品的评分比较稀疏。如果直接使用矩阵进行存储,会存在大量空缺值,故此处使用了字典。
|
||||
|
||||
2. 计算用户相似性矩阵
|
||||
|
||||
+ 由于训练数据中共包含 5 个用户,所以这里的用户相似度矩阵的维度也为 $5 \times 5$。
|
||||
|
||||
```python
|
||||
user_data = loadData()
|
||||
similarity_matrix = pd.DataFrame(
|
||||
np.identity(len(user_data)),
|
||||
index=user_data.keys(),
|
||||
columns=user_data.keys(),
|
||||
)
|
||||
|
||||
# 遍历每条用户-物品评分数据
|
||||
for u1, items1 in user_data.items():
|
||||
for u2, items2 in user_data.items():
|
||||
if u1 == u2:
|
||||
continue
|
||||
vec1, vec2 = [], []
|
||||
for item, rating1 in items1.items():
|
||||
rating2 = items2.get(item, -1)
|
||||
if rating2 == -1:
|
||||
continue
|
||||
vec1.append(rating1)
|
||||
vec2.append(rating2)
|
||||
# 计算不同用户之间的皮尔逊相关系数
|
||||
similarity_matrix[u1][u2] = np.corrcoef(vec1, vec2)[0][1]
|
||||
|
||||
print(similarity_matrix)
|
||||
```
|
||||
|
||||
```
|
||||
1 2 3 4 5
|
||||
1 1.000000 0.852803 0.707107 0.000000 -0.792118
|
||||
2 0.852803 1.000000 0.467707 0.489956 -0.900149
|
||||
3 0.707107 0.467707 1.000000 -0.161165 -0.466569
|
||||
4 0.000000 0.489956 -0.161165 1.000000 -0.641503
|
||||
5 -0.792118 -0.900149 -0.466569 -0.641503 1.000000
|
||||
```
|
||||
|
||||
3. 计算与 Alice 最相似的 `num` 个用户
|
||||
|
||||
```python
|
||||
target_user = ' Alice '
|
||||
num = 2
|
||||
# 由于最相似的用户为自己,去除本身
|
||||
sim_users = similarity_matrix[target_user].sort_values(ascending=False)[1:num+1].index.tolist()
|
||||
print(f'与用户{target_user}最相似的{num}个用户为:{sim_users}')
|
||||
```
|
||||
|
||||
```
|
||||
与用户 Alice 最相似的2个用户为:['user1', 'user2']
|
||||
```
|
||||
|
||||
4. 预测用户 Alice 对物品 `E` 的评分
|
||||
|
||||
```python
|
||||
weighted_scores = 0.
|
||||
corr_values_sum = 0.
|
||||
|
||||
target_item = 'E'
|
||||
# 基于皮尔逊相关系数预测用户评分
|
||||
for user in sim_users:
|
||||
corr_value = similarity_matrix[target_user][user]
|
||||
user_mean_rating = np.mean(list(user_data[user].values()))
|
||||
|
||||
weighted_scores += corr_value * (user_data[user][target_item] - user_mean_rating)
|
||||
corr_values_sum += corr_value
|
||||
|
||||
target_user_mean_rating = np.mean(list(user_data[target_user].values()))
|
||||
target_item_pred = target_user_mean_rating + weighted_scores / corr_values_sum
|
||||
print(f'用户{target_user}对物品{target_item}的预测评分为:{target_item_pred}')
|
||||
```
|
||||
|
||||
```
|
||||
用户 Alice 对物品E的预测评分为:4.871979899370592
|
||||
```
|
||||
|
||||
## UserCF优缺点
|
||||
|
||||
User-based算法存在两个重大问题:
|
||||
|
||||
|
||||
1. 数据稀疏性
|
||||
+ 一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。
|
||||
+ 这导致UserCF不适用于那些正反馈获取较困难的应用场景(如酒店预订, 大件物品购买等低频应用)。
|
||||
|
||||
1. 算法扩展性
|
||||
+ 基于用户的协同过滤需要维护用户相似度矩阵以便快速的找出 $TopN$ 相似用户, 该矩阵的存储开销非常大,存储空间随着用户数量的增加而增加。
|
||||
+ 故不适合用户数据量大的情况使用。
|
||||
|
||||
由于UserCF技术上的两点缺陷, 导致很多电商平台并没有采用这种算法, 而是采用了ItemCF算法实现最初的推荐系统。
|
||||
|
||||
|
||||
|
||||
# 算法评估
|
||||
|
||||
由于UserCF和ItemCF结果评估部分是共性知识点, 所以在这里统一标识。
|
||||
|
||||
## 召回率
|
||||
|
||||
对用户 $u$ 推荐 $N$ 个物品记为 $R(u)$, 令用户 $u$ 在测试集上喜欢的物品集合为$T(u)$, 那么召回率定义为:
|
||||
$$
|
||||
\operatorname{Recall}=\frac{\sum_{u}|R(u) \cap T(u)|}{\sum_{u}|T(u)|}
|
||||
$$
|
||||
+ 含义:在模型召回预测的物品中,预测准确的物品占用户实际喜欢的物品的比例。
|
||||
|
||||
## 精确率
|
||||
精确率定义为:
|
||||
$$
|
||||
\operatorname{Precision}=\frac{\sum_{u} \mid R(u) \cap T(u)|}{\sum_{u}|R(u)|}
|
||||
$$
|
||||
+ 含义:推荐的物品中,对用户准确推荐的物品占总物品的比例。
|
||||
+ 如要确保召回率高,一般是推荐更多的物品,期望推荐的物品中会涵盖用户喜爱的物品。而实际中,推荐的物品中用户实际喜爱的物品占少数,推荐的精确率就会很低。故同时要确保高召回率和精确率往往是矛盾的,所以实际中需要在二者之间进行权衡。
|
||||
|
||||
## 覆盖率
|
||||
覆盖率反映了推荐算法发掘长尾的能力, 覆盖率越高, 说明推荐算法越能将长尾中的物品推荐给用户。
|
||||
$$
|
||||
\text { Coverage }=\frac{\left|\bigcup_{u \in U} R(u)\right|}{|I|}
|
||||
$$
|
||||
|
||||
+ 含义:推荐系统能够推荐出来的物品占总物品集合的比例。
|
||||
+ 其中 $|I|$ 表示所有物品的个数;
|
||||
+ 系统的用户集合为$U$;
|
||||
+ 推荐系统给每个用户推荐一个长度为 $N$ 的物品列表$R(u)$.
|
||||
|
||||
+ 覆盖率表示最终的推荐列表中包含多大比例的物品。如果所有物品都被给推荐给至少一个用户, 那么覆盖率是100%。
|
||||
|
||||
## 新颖度
|
||||
用推荐列表中物品的平均流行度度量推荐结果的新颖度。 如果推荐出的物品都很热门, 说明推荐的新颖度较低。 由于物品的流行度分布呈长尾分布, 所以为了流行度的平均值更加稳定, 在计算平均流行度时对每个物品的流行度取对数。
|
||||
|
||||
- O’scar Celma 在博士论文 "[Music Recommendation and Discovery in the Long Tail](http://mtg.upf.edu/static/media/PhD_ocelma.pdf) " 中研究了新颖度的评测。
|
||||
|
||||
|
||||
|
||||
# 参考资料
|
||||
|
||||
* [基于用户的协同过滤来构建推荐系统:https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw](https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw)
|
||||
* [协同过滤算法概述:https://chenk.tech/posts/8ad63d9d.html](https://chenk.tech/posts/8ad63d9d.html)
|
||||
* B站黑马推荐系统实战课程
|
||||
332
4.人工智能/ch02/ch2.1/ch2.1.2/Airbnb.md
Normal file
332
4.人工智能/ch02/ch2.1/ch2.1.2/Airbnb.md
Normal file
@@ -0,0 +1,332 @@
|
||||
# 前言
|
||||
这是 Airbnb 于2018年发表的一篇论文,主要介绍了 Airbnb 在 Embedding 技术上的应用,并获得了 KDD 2018 的 Best Paper。Airbnb 是全球最大的短租平台,包含了数百万种不同的房源。这篇论文介绍了 Airbnb 如何使用 Embedding 来实现相似房源推荐以及实时个性化搜索。在本文中,Airbnb 在用户和房源的 Embedding 上的生成都是基于谷歌的 Word2Vec 模型,<u>故阅读本文要求大家了解 Word2Vec 模型,特别是 Skip-Gram 模型**(重点*)**</u>。
|
||||
本文将从以下几个方面来介绍该论文:
|
||||
|
||||
- 了解 Airbnb 是如何利用 Word2Vec 技术生成房源和用户的Embedding,并做出了哪些改进。
|
||||
- 了解 Airbnb 是如何利用 Embedding 解决房源冷启动问题。
|
||||
- 了解 Airbnb 是如何衡量生成的 Embedding 的有效性。
|
||||
- 了解 Airbnb 是如何利用用户和房源 Embedding 做召回和搜索排序。
|
||||
|
||||
考虑到本文的目的是为了让大家快速了解 Airbnb 在 Embedding 技术上的应用,故不会完全翻译原论文。如需进一步了解,建议阅读原论文或文末的参考链接。原论文链接:https://dl.acm.org/doi/pdf/10.1145/3219819.3219885
|
||||
|
||||
# Airbnb 的业务背景
|
||||
在介绍 Airbnb 在 Embedding 技术上的方法前,先了解 Airbnb 的业务背景。
|
||||
|
||||
- Airbnb 平台包含数百万种不同的房源,用户可以通过**浏览搜索结果页面**来寻找想要的房源。Airbnb 技术团队通过复杂的机器学习模型,并使用上百种信号对搜索结果中的房源进行排序。
|
||||
- 当用户在查看某一个房源时,接下来的有两种方式继续搜索:
|
||||
- 返回搜索结果页,继续查看其他搜索结果。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049527431-0b09af70-bda0-4a30-8082-6aa69548213a.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 在当前房源的详情页下,「相似房源」板块(你可能还喜欢)所推荐的房源。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049385995-7a775df1-a36f-4795-9e79-8e577bcf2097.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- Airbnb 平台 99% 的房源预订来自于搜索排序和相似房源推荐。
|
||||
# Embedding 方法
|
||||
Airbnb 描述了两种 Embedding 的构建方法,分别为:
|
||||
|
||||
- 用于描述短期实时性的个性化特征 Embedding:**listing Embeddings**
|
||||
- **listing 表示房源的意思,<u>它将贯穿全文,请务必了解</u>。**
|
||||
- 用于描述长期的个性化特征 Embedding:**user-type & listing type Embeddings**
|
||||
## Listing Embeddings
|
||||
Listing Embeddings 是基于用户的点击 session 学习得到的,用于表示房源的短期实时性特征。给定数据集 $ \mathcal{S} $ ,其中包含了 $ N $ 个用户的 $ S $ 个点击 session(序列)。
|
||||
|
||||
- 每个 session $ s=\left(l_{1}, \ldots, l_{M}\right) \in \mathcal{S} $ ,包含了 $ M $ 个被用户点击过的 listing ids 。
|
||||
- 对于用户连续两次点击,若时间间隔超过了30分钟,则启动新的 session。
|
||||
|
||||
在拿到多个用户点击的 session 后,可以基于 Word2Vec 的 Skip-Gram 模型来学习不同 listing 的 Embedding 表示。最大化目标函数 $ \mathcal{L} $ :
|
||||
$$
|
||||
\mathcal{L}=\sum_{s \in \mathcal{S}} \sum_{l_{i} \in s}\left(\sum_{-m \geq j \leq m, i \neq 0} \log \mathbb{P}\left(l_{i+j} \mid l_{i}\right)\right)
|
||||
$$
|
||||
概率 $ \mathbb{P}\left(l_{i+j} \mid l_{i}\right) $ 是基于 soft-max 函数的表达式。表示在一个 session 中,已知中心 listing $ l_i $ 来预测上下文 listing $ l_{i+j} $ 的概率:
|
||||
$$
|
||||
\mathbb{P}\left(l_{i+j} \mid l_{i}\right)=\frac{\exp \left(\mathbf{v}_{l_{i}}^{\top} \mathbf{v}_{l_{i+j}}^{\prime}\right)}{\sum_{l=1}^{|\mathcal{V}|} \exp \left(\mathbf{v}_{l_{i}}^{\top} \mathbf{v}_{l}^{\prime}\right)}
|
||||
$$
|
||||
|
||||
- 其中, $ \mathbf{v}_{l_{i}} $ 表示 listing $ l_i $ 的 Embedding 向量, $ |\mathcal{V}| $ 表示全部的物料库的数量。
|
||||
|
||||
考虑到物料库 $ \mathcal{V} $ 过大,模型中参数更新的时间成本和 $ |\mathcal{V}| $ 成正比。为了降低计算复杂度,要进行负采样。负采样后,优化的目标函数如下:
|
||||
$$
|
||||
\underset{\theta}{\operatorname{argmax}} \sum_{(l, c) \in \mathcal{D}_{p}} \log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime^{\prime}} \mathbf{v}_{l}}}+\sum_{(l, c) \in \mathcal{D}_{n}} \log \frac{1}{1+e^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{l}}}
|
||||
$$
|
||||
至此,对 Skip-Gram 模型和 NEG 了解的同学肯定很熟悉,上述方法和 Word2Vec 思想基本一致。
|
||||
下面,将进一步介绍 Airbnb 是如何改进 Listing Embedding 的学习以及其他方面的应用。
|
||||
**(1)正负样本集构建的改进**
|
||||
|
||||
- 使用 booked listing 作为全局上下文
|
||||
- booked listing 表示用户在 session 中最终预定的房源,一般只会出现在结束的 session 中。
|
||||
- Airbnb 将最终预定的房源,始终作为滑窗的上下文,即全局上下文。如下图:
|
||||
- 如图,对于当前滑动窗口的 central listing,实线箭头表示context listings,虚线(指向booked listing)表示 global context listing。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653053823336-0564b2da-c993-46aa-9b22-f5cbb784dae2.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- booked listing 作为全局正样本,故优化的目标函数更新为:
|
||||
|
||||
$$
|
||||
\underset{\theta}{\operatorname{argmax}} \sum_{(l, c) \in \mathcal{D}_{p}} \log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime^{\prime}} \mathbf{v}_{l}}}+\sum_{(l, c) \in \mathcal{D}_{n}} \log \frac{1}{1+e^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{l}}} +
|
||||
\log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime} \mathbf{v}_{l_b}}}
|
||||
$$
|
||||
|
||||
- 优化负样本的选择
|
||||
- 用户通过在线网站预定房间时,通常只会在同一个 market (将要停留区域)内进行搜索。
|
||||
|
||||
- 对于用户点击过的样本集 $ \mathcal{D}_{p} $ (正样本集)而言,它们大概率位于同一片区域。考虑到负样本集 $ \mathcal{D}_{n} $ 是随机抽取的,大概率来源不同的区域。
|
||||
|
||||
- Airbnb 发现这种样本的不平衡,在学习同一片区域房源的 Embedding 时会得到次优解。
|
||||
|
||||
- 解决办法也很简单,对于每个滑窗中的中心 lisitng,其负样本的选择新增了与其位于同一个 market 的 listing。至此,优化函数更新如下:
|
||||
$$
|
||||
\underset{\theta}{\operatorname{argmax}} \sum_{(l, c) \in \mathcal{D}_{p}} \log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime^{\prime}} \mathbf{v}_{l}}}+\sum_{(l, c) \in \mathcal{D}_{n}} \log \frac{1}{1+e^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{l}}} +\log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime} \mathbf{v}_{l_b}}} +
|
||||
\sum_{(l, m_n ) \in \mathcal{D}_{m_n}} \log \frac{1}{1+e^{\mathbf{v}_{m_n}^{\prime} \mathbf{v}_{l}}}
|
||||
$$
|
||||
|
||||
+ $ \mathcal{D}_{m_n} $ 表示与滑窗中的中心 listing 位于同一区域的负样本集。
|
||||
|
||||
**(2)Listing Embedding 的冷启动**
|
||||
|
||||
- Airbnb 每天都有新的 listings 产生,而这些 listings 却没有 Embedding 向量表征。
|
||||
- Airbnb 建议利用其他 listing 的现有的 Embedding 来为新的 listing 创建 Embedding。
|
||||
- 在新的 listing 被创建后,房主需要提供如位置、价格、类型等在内的信息。
|
||||
- 然后利用房主提供的房源信息,为其查找3个相似的 listing,并将它们 Embedding 的均值作为新 listing 的 Embedding表示。
|
||||
- 这里的相似,包含了位置最近(10英里半径内),房源类型相似,价格区间相近。
|
||||
- 通过该手段,Airbnb 可以解决 98% 以上的新 listing 的 Embedding 冷启动问题。
|
||||
|
||||
**(3)Listing Embedding 的评估**
|
||||
经过上述的两点对 Embedding 的改进后,为了评估改进后 listing Embedding 的效果。
|
||||
|
||||
- Airbnb 使用了800万的点击 session,并将 Embedding 的维度设为32。
|
||||
|
||||
评估方法包括:
|
||||
|
||||
- 评估 Embedding 是否包含 listing 的地理位置相似性。
|
||||
- 理论上,同一区域的房源相似性应该更高,不同区域房源相似性更低。
|
||||
- Airbnb 利用 k-means 聚类,将加利福尼亚州的房源聚成100个集群,来验证类似位置的房源是否聚集在一起。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056809526-15401069-6fff-40d8-ac5e-35871d3f254a.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 评估不同类型、价格区间的房源之间的相似性。
|
||||
- 简而言之,我们希望类型相同、价格区间一致的房源它们之间的相似度更高。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056981037-18edee91-493a-4d5b-b066-57f0b200032d.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 评估房源的隐式特征
|
||||
- Airbnb 在训练房源(listing)的 Embedding时,并没有用到房源的图像信息。
|
||||
- 对于一些隐式信息,例如架构、风格、观感等是无法直接学习。
|
||||
- 为了验证基于 Word2Vec 学习到的 Embedding是否隐含了它们在外观等隐式信息上的相似性,Airbnb 内部开发了一款内部相似性探索工具。
|
||||
- 大致原理就是,利用训练好的 Embedding 进行 K 近邻相似度检索。
|
||||
- 如下,与查询房源在 Embedding 相似性高的其他房源,它们之间的外观风格也很相似。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653057336798-fd8451cb-84b6-40fb-8733-1e3d08a39793.png" alt="img" />
|
||||
|
||||
## User-type & Listing-type Embedding
|
||||
|
||||
前面提到的 Listing Embedding,它是基于用户的点击 sessions 学习得到的。
|
||||
|
||||
- 同一个 session 内的点击时间间隔低于30分钟,所以**它们更适合短期,session 内的个性化需求**。
|
||||
- 在用户搜索 session 期间,该方法有利于向用户展示与点击过的 listing 更相似的其他 listings 。
|
||||
|
||||
Airbnb 除了挖掘 Listing 的短期兴趣特征表示外,还对 User 和 Listing 的长期兴趣特征表示进行了探索。长期兴趣的探索是有利于 Airbnb 的业务发展。例如,用户当前在洛杉矶进行搜索,并且过去在纽约和伦敦预定过其他房源。那么,向用户推荐与之前预定过的 listing 相似的 listings 是更合适的。
|
||||
|
||||
- 长期兴趣的探索是基于 booking session(用户的历史预定序列)。
|
||||
- 与前面 Listing Embedding 的学习类似,Airbnb 希望借助了 Skip-Gram 模型学习不同房源的 Embedding 表示。
|
||||
|
||||
但是,面临着如下的挑战:
|
||||
|
||||
- booking sessions $ \mathcal{S}_{b} $ 数据量的大小远远小于 click sessions $ \mathcal{S} $ ,因为预定本身就是一件低频率事件。
|
||||
- 许多用户过去只预定了单个数量的房源,无法从长度为1的 session 中学习 Embedding
|
||||
- 对于任何实体,要基于 context 学习到有意义的 Embedding,该实体至少在数据中出现5-10次。
|
||||
- 但平台上大多数 listing_ids 被预定的次数低于5-10次。
|
||||
- 用户连续两次预定的时间间隔可能较长,在此期间用户的行为(如价格敏感点)偏好可能会发生改变(由于职业的变化)。
|
||||
|
||||
为了解决该问题,Airbnb 提出了基于 booking session 来学习用户和房源的 Type Embedding。给定一个 booking sessions 集合 $ \mathcal{S}_{b} $ ,其中包含了 $ M $ 个用户的 booking session:
|
||||
|
||||
- 每个 booking session 表示为: $ s_{b}=\left(l_{b 1}, \ldots, l_{b M}\right) $
|
||||
- 这里 $ l_{b1} $ 表示 listing_id,学习到 Embedding 记作 $ \mathbf{v}_{l_{i d}} $
|
||||
|
||||
**(1)什么是Type Embedding ?**
|
||||
在介绍 Type Embedding 之前,回顾一下 Listing Embedding:
|
||||
|
||||
- 在 Listing Embedding 的学习中,只学习房源的 Embedding 表示,未学习用户的 Embedding。
|
||||
- 对于 Listing Embedding,与相应的 Lisitng ID 是一一对应的, 每个 Listing 它们的 Embedding 表示是唯一的。
|
||||
|
||||
对于 Type Embedding ,有如下的区别:
|
||||
|
||||
- 对于不同的 Listing,它们的 Type Embedding **可能是相同的**(User 同样如此)。
|
||||
- Type Embedding 包含了 User-type Embedding 和 Listing-type Embedding。
|
||||
|
||||
为了更直接快速地了解什么是 Listing-type 和 User-type,举个简单的例子:
|
||||
|
||||
- 小王,是一名西藏人,性别男,今年21岁,就读于中国山东的蓝翔技校的挖掘机专业。
|
||||
- 通常,对于不同的用户(如小王),给定一个 ID 编码,然后学习相应的 User Embedding。
|
||||
- 但前面说了,用户数据过于稀疏,学习到的 User Embedding 特征表达能力不好。
|
||||
- 另一种方式:利用小王身上的用户标签,先组合出他的 User-type,然后学习 Embedding 表示。
|
||||
- 小王的 User-type:西藏人_男_学生_21岁_位置中国山东_南翔技校_挖掘机专业。
|
||||
- 组合得到的 User-type 本质上可视为一个 Category 特征,然后学习其对应的 Embedding 表示。
|
||||
|
||||
下表给出了原文中,Listing-type 和 User-type 包含的属性及属性的值:
|
||||
|
||||
- 所有的属性,都基于一定的规则进行了分桶(buckets)。例如21岁,被分桶到 20-30 岁的区间。
|
||||
- 对于首次预定的用户,他的属性为 buckets 的前5行,因为预定之前没有历史预定相关的信息。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653125260611-7d33731b-9167-4fcc-b83b-0a2407ea89ca.png" alt="img" style="zoom: 67%;" />
|
||||
|
||||
看到过前面那个简单的例子后,现在可以看一个原文的 Listing-type 的例子:
|
||||
|
||||
- 一个来自 US 的 Entire Home listing(lt1),它是一个二人间(c2),1 床(b1),一个卧室(bd2),1 个浴室(bt2),每晚平均价格为 60.8 美元(pn3),每晚每个客人的平均价格为 29.3 美元(pg3),5 个评价(r3),所有均 5 星好评(5s4),100% 的新客接受率(nu3)。
|
||||
- 因此该 listing 根据上表规则可以映射为:Listing-type = US_lt1_pn3_pg3_r3_5s4_c2_b1_bd2_bt2_nu3。
|
||||
|
||||
**(2)Type Embedding 的好处**
|
||||
前面在介绍 Type Embedding 和 Listing Embedding 的区别时,提到过不同 User 或 Listing 他们的 Type 可能相同。
|
||||
|
||||
- 故 User-type 和 Listing-type 在一定程度上可以缓解数据稀疏性的问题。
|
||||
- 对于 user 和 listing 而言,他们的属性可能会随着时间的推移而变化。
|
||||
- 故它们的 Embedding 在时间上也具备了动态变化属性。
|
||||
|
||||
**(3)Type Embedding 的训练过程**
|
||||
Type Embedding 的学习同样是基于 Skip-Gram 模型,但是有两点需要注意:
|
||||
|
||||
- 联合训练 User-type Embedding 和 Listing-type Embedding
|
||||
- 如下图(a),在 booking session 中,每个元素代表的是 (User-type, Listing-type)组合。
|
||||
- 为了学习在相同向量空间中的 User-type 和 Listing-type 的 Embeddings,Airbnb 的做法是将 User-type 插入到 booking sessions 中。
|
||||
- 形成一个(User-type, Listing-type)组成的元组序列,这样就可以让 User-type 和 Listing-type 的在 session 中的相对位置保持一致了。
|
||||
|
||||
- User-type 的目标函数:
|
||||
$$
|
||||
\underset{\theta}{\operatorname{argmax}} \sum_{\left(u_{t}, c\right) \in \mathcal{D}_{b o o k}} \log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime} \mathbf{v}_{u_{t}}}}+\sum_{\left(u_{t}, c\right) \in \mathcal{D}_{n e g}} \log \frac{1}{1+e^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{u_{t}}}}
|
||||
$$
|
||||
|
||||
+ $ \mathcal{D}_{\text {book }} $ 中的 $ u_t $ (中心词)表示 User-type, $ c $ (上下文)表示用户最近的预定过的 Listing-type。 $ \mathcal{D}_{\text {neg}} $ 中的 $ c $ 表示 negative Listing-type。
|
||||
+ $ u_t $ 表示 User-type 的 Embedding, $ \mathbf{v}_{c}^{\prime} $ 表示 Listing-type 的Embedding。
|
||||
|
||||
- Listing-type 的目标函数:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\underset{\theta}{\operatorname{argmax}} & \sum_{\left(l_{t}, c\right) \in \mathcal{D}_{b o o k}} \log \frac{1}{1+\exp ^{-\mathrm{v}_{c}^{\prime} \mathbf{v}_{l_{t}}}}+\sum_{\left(l_{t}, c\right) \in \mathcal{D}_{n e g}} \log \frac{1}{1+\exp ^{\mathrm{v}_{c}^{\prime} \mathbf{v}_{l_{t}}}} \\
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 同理,不过窗口中的中心词为 Listing-type, 上下文为 User-type。
|
||||
|
||||
- Explicit Negatives for Rejections
|
||||
- 用户预定房源以后,还要等待房源主人的确认,主人可能接受或者拒绝客人的预定。
|
||||
- 拒接的原因可能包括,客人星级评定不佳,资料不完整等。
|
||||
|
||||
- 前面学习到的 User-type Embedding 包含了客人的兴趣偏好,Listing-type Embedding 包含了房源的属性特征。
|
||||
- 但是,用户的 Embedding 未包含更容易被哪类房源主人拒绝的潜语义信息。
|
||||
- 房源的 Embedding 未包含主人对哪类客人的拒绝偏好。
|
||||
|
||||
- 为了提高用户预定房源以后,被主人接受的概率。同时,降低房源主人拒绝客人的概率。Airbnb 在训练 User-type 和 Listing-type 的 Embedding时,将用户预定后却被拒绝的样本加入负样本集中(如下图b)。
|
||||
- 更新后,Listing-type 的目标函数:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\underset{\theta}{\operatorname{argmax}} & \sum_{\left(u_{t}, c\right) \in \mathcal{D}_{b o o k}} \log \frac{1}{1+\exp ^{-\mathbf{v}_{c}^{\prime} \mathbf{v}_{u_{t}}}}+\sum_{\left(u_{t}, c\right) \in \mathcal{D}_{n e g}} \log \frac{1}{1+\exp ^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{u_{t}}}} \\
|
||||
&+\sum_{\left(u_{t}, l_{t}\right) \in \mathcal{D}_{\text {reject }}} \log \frac{1}{1+\exp ^{\mathrm{v}_{{l_{t}}}^{\prime} \mathrm{v}_{u_{t}}}}
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
- 更新后,User-type 的目标函数:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\underset{\theta}{\operatorname{argmax}} & \sum_{\left(l_{t}, c\right) \in \mathcal{D}_{b o o k}} \log \frac{1}{1+\exp ^{-\mathrm{v}_{c}^{\prime} \mathbf{v}_{l_{t}}}}+\sum_{\left(l_{t}, c\right) \in \mathcal{D}_{n e g}} \log \frac{1}{1+\exp ^{\mathrm{v}_{c}^{\prime} \mathbf{v}_{l_{t}}}} \\
|
||||
&+\sum_{\left(l_{t}, u_{t}\right) \in \mathcal{D}_{\text {reject }}} \log \frac{1}{1+\exp ^{\mathrm{v}^{\prime}_{u_{t}} \mathrm{v}_{l_{t}}}}
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653131985447-e033cb39-235b-4f46-9634-3b7faec284be.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
# 实验部分
|
||||
|
||||
前面介绍了两种 Embedding 的生成方法,分别为 Listing Embedding 和 User-type & Listing-type Embedding。本节的实验部分,将会介绍它们是如何被使用的。回顾 Airbnb 的业务背景,当用户查看一个房源时,他们有两种方式继续搜索:返回搜索结果页,或者查看房源详情页的「相似房源」。
|
||||
## 相似房源检索
|
||||
在给定学习到的 Listing Embedding,通过计算其向量 $ v_l $ 和来自同一区域的所有 Listing 的向量 $ v_j $ 之间的余弦相似度,可以找到给定房源 $ l $ 的相似房源。
|
||||
|
||||
- 这些相似房源可在同一日期被预定(如果入住-离开时间已确定)。
|
||||
- 相似度最高的 $ K $ 个房源被检索为相似房源。
|
||||
- 计算是在线执行的,并使用我们的分片架构并行进行,其中部分 Embedding 存储在每个搜索机器上。
|
||||
|
||||
A/B 测试显示,基于 Embedding 的解决方案使「相似房源」点击率增加了21%,最终通过「相似房源」产生的预订增加了 4.9%。
|
||||
|
||||
## 实时个性化搜索排名
|
||||
Airbnb 的搜索排名的大致流程为:
|
||||
|
||||
- 给定查询 $ q $ ,返回 $ K $ 条搜索结果。
|
||||
- 基于排序模型 GBDT,对预测结果进行排序。
|
||||
- 将排序后的结果展示给用户。
|
||||
|
||||
**(1)Query Embedding**
|
||||
原文中似乎并没有详细介绍 Airbnb 的搜索技术,在参考的博客中对他们的 Query Embedding 技术进行了描述。如下:
|
||||
|
||||
> Airbnb 对搜索的 Query 也进行了 Embedding,和普通搜索引擎的 Embedding 不太相同的是,这里的 Embedding 不是用自然语言中的语料库去训练的,而是用 Search Session 作为关系训练数据,训练方式更类似于 Item2Vec,Airbnb 中 Queue Embedding 的一个很重要的作用是捕获用户模糊查询与相关目的地的关联,这样做的好处是可以使搜索结果不再仅仅是简单地进行关键字匹配,而是通过更深层次的语义和关系来找到关联信息。比如下图所示的使用 Query Embedding 之前和之后的两个示例(Airbnb 非常人性化地在搜索栏的添加了自动补全,通过算法去 “猜想” 用户的真实目的,大大提高了用户的检索体验)
|
||||
|
||||
**(2)特征构建**
|
||||
对于各查询,给定的训练数据形式为: $ D_s = \left(\mathbf{x}_{i}, y_{i}\right), i=1 \ldots K $ ,其中 $ K $ 表示查询返回的房源数量。
|
||||
|
||||
- $ \mathbf{x}_{i} $ 表示第 $ i $ 个房源结果的 vector containing features:
|
||||
- 由 listing features,user features,query features 以及 cross-features 组成。
|
||||
- $ y_{i} \in\{0,0.01,0.25,1,-0.4\} $ 表示第 $ i $ 个结果的标签。
|
||||
- $ y_i=1 $ 表示用户预定了房源,..., $ y_i=-0.4 $ 表示房主拒绝了用户。
|
||||
|
||||
下面,介绍 Airbnb 是如何利用前面的两种种 Embedding 进行特征构建的。
|
||||
|
||||
- 如果用一句话来概括,这些基于 Embedding 的构建特征均为余弦相似度。
|
||||
- 新构建的特征均为样本 $ \mathbf{x}_{i} $ 特征的一部分。
|
||||
|
||||
构建的特征如下表所示:
|
||||
|
||||
- 表中的 Embedding Features 包含了8种类型,前6种类型的特征计算方式相同。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653139981920-a100085b-007b-4a9c-9edf-74297e9115ae.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
**① 基于 Listing Embedding Features 的特征构建**
|
||||
|
||||
- Airbnb 保留了用户过去两周6种不同类型的历史行为,如下图:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653140202230-1f49e1dd-5c8c-4445-bd0b-9a17788a7b3f.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 对于每个行为,还要将其按照 market (地域)进行划分。以 $ H_c $ 为例:
|
||||
|
||||
- 假如 $ H_c $ 包含了 New YorK 和 Los Angeles 两个 market 的点击记录,则划分为 $ H_c(NY) $ 和 $ H_c(LA) $ 。
|
||||
|
||||
- 计算候选房源和不同行为之间的相似度。
|
||||
- 上述6种行为对应的相似度特征计算方式是相同的,以 $ H_c $ 为例:
|
||||
$$
|
||||
\operatorname{EmbClickSim}\left(l_{i}, H_{c}\right)=\max _{m \in M} \cos \left(\mathbf{v}_{l_{i}}, \sum_{l_{h} \in m, l_{h} \in H_{c}} \mathbf{v}_{l_{h}}\right)
|
||||
$$
|
||||
|
||||
- 其中, $ M $ 表示 market 的集合。第二项实际上为 Centroid Embedding(Embedding 的均值)。
|
||||
|
||||
- 除此之外,Airbnb 还计算了候选房源的 Embedding 与 latest long click 的 Embedding 之间的余弦相似度。
|
||||
$$
|
||||
\operatorname{EmbLastLongClickSim }\left(l_{i}, H_{l c}\right)=\cos \left(\mathbf{v}_{l_{i}}, \mathbf{v}_{l_{\text {last }}}\right)
|
||||
$$
|
||||
|
||||
**② 基于 User-type & Listing-type Embedding Features 的特征构建**
|
||||
|
||||
- 对于候选房源 $ l_i $ ,先查到其对应的 Listing-type $ l_t $ ,再找到用户的 User-type $ u_t $ 。
|
||||
|
||||
- 最后,计算 $ u_t $ 与 $ l_t $ 对应的 Embedding 之间的余弦相似度:
|
||||
$$
|
||||
\text { UserTypeListingTypeSim }\left(u_{t}, l_{t}\right)=\cos \left(\mathbf{v}_{u_{t}}, \mathbf{v}_{l_{t}}\right)
|
||||
$$
|
||||
|
||||
为了验证上述特征的构建是否有效,Airbnb 还做了特征重要性排序,如下表:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653142188111-1975bcc4-22a2-45cf-bff0-2783ecb00a0c.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
**(3)模型**
|
||||
特征构建完成后,开始对模型进行训练。
|
||||
|
||||
- Airbnb 在搜索排名中使用的是 GBDT 模型,该模型是一个回归模型。
|
||||
- 模型的训练数据包括数据集 $ \mathcal{D} $ 和 search labels 。
|
||||
|
||||
最后,利用 GBDT 模型来预测线上各搜索房源的在线分数。得到预测分数后,将按照降序的方式展现给用户。
|
||||
# 参考链接
|
||||
|
||||
+ [Embedding 在大厂推荐场景中的工程化实践 - 卢明冬的博客 (lumingdong.cn)](https://lumingdong.cn/engineering-practice-of-embedding-in-recommendation-scenario.html#Airbnb)
|
||||
|
||||
+ [KDD'2018 Best Paper-Embedding技术在Airbnb实时搜索排序中的应用 (qq.com)](https://mp.weixin.qq.com/s/f9IshxX29sWg9NhSa7CaNg)
|
||||
|
||||
+ [再评Airbnb的经典Embedding论文 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/162163054)
|
||||
|
||||
+ [Airbnb爱彼迎房源排序中的嵌入(Embedding)技术 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/43295545)
|
||||
629
4.人工智能/ch02/ch2.1/ch2.1.2/DSSM.md
Normal file
629
4.人工智能/ch02/ch2.1/ch2.1.2/DSSM.md
Normal file
@@ -0,0 +1,629 @@
|
||||
# 双塔召回模型
|
||||
|
||||
---
|
||||
|
||||
双塔模型在推荐领域中是一个十分经典的模型,无论是在召回还是粗排阶段,都会是首选。这主要是得益于双塔模型结构,使得能够在线预估时满足低延时的要求。但也是因为其模型结构的问题,使得无法考虑到user和item特之间的特征交叉,使得影响模型最终效果,因此很多工作尝试调整经典双塔模型结构,在保持在线预估低延时的同时,保证双塔两侧之间有效的信息交叉。下面针对于经典双塔模型以及一些改进版本进行介绍。
|
||||
|
||||
|
||||
|
||||
## 经典双塔模型
|
||||
|
||||
DSSM(Deep Structured Semantic Model)是由微软研究院于CIKM在2013年提出的一篇工作,该模型主要用来解决NLP领域语义相似度任务 ,利用深度神经网络将文本表示为低维度的向量,用来提升搜索场景下文档和query匹配的问题。DSSM 模型的原理主要是:通过用户搜索行为中query 和 doc 的日志数据,通过深度学习网络将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之 间的余弦相似度,从而训练得到隐含语义模型,即 query 侧特征的 embedding 和 doc 侧特征的 embedding,进而可以获取语句的低维 语义向量表达 sentence embedding,可以预测两句话的语义相似度。模型结构如下所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/v2-7f75cc71f5e959d6efa95289d2f5ac13_r.jpg" style="zoom:45%;"/>
|
||||
</div>
|
||||
|
||||
|
||||
从上图可以看出,该网络结构比较简单,是一个由几层DNN组成网络,我们将要搜索文本(Query)和要匹配的文本(Document)的 embedding 输入到网络,网络输出为 128 维的向量,然后通过向量之间计算余弦相似度来计算向量之间距离,可以看作每一个 query 和 document 之间相似分数,然后在做 softmax。
|
||||
|
||||
|
||||
|
||||
而在推荐系统中,最为关键的问题是如何做好用户与item的匹配问题,因此对于推荐系统中DSSM模型的则是为 user 和 item 分别构建独立的子网络塔式结构,利用user和item的曝光或点击日期进行训练,最终得到user侧的embedding和item侧的embedding。因此在推荐系统中,常见的模型结构如下所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220522103456450.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
|
||||
从模型结构上来看,主要包括两个部分:user侧塔和item侧塔,对于每个塔分别是一个DNN结构。通过两侧的特征输入,通过DNN模块到user和item的embedding,然后计算两者之间的相似度(常用內积或者余弦值,下面会说这两种方式的联系和区别),因此对于user和item两侧最终得到的embedding维度需要保持一致,即最后一层全连接层隐藏单元个数相同。
|
||||
|
||||
|
||||
|
||||
在召回模型中,将这种检索行为视为多类分类问题,类似于YouTubeDNN模型。将物料库中所有的item视为一个类别,因此损失函数需要计算每个类的概率值:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220522110742879.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
|
||||
其中$s(x,y)$表示两个向量的相似度,$P(y|x;\theta)$表示预测类别的概率,$M$表示物料库所有的item。但是在实际场景中,由于物料库中的item数量巨大,在计算上式时会十分的耗时,因此会采样一定的数量的负样本来近似计算,后面针对负样本的采样做一些简单介绍。
|
||||
|
||||
|
||||
|
||||
以上就是推荐系统中经典的双塔模型,之所以在实际应用中非常常见,是因为**在海量的候选数据进行召回的场景下,速度很快,效果说不上极端好,但一般而言效果也够用了**。之所以双塔模型在服务时速度很快,是因为模型结构简单(两侧没有特征交叉),但这也带来了问题,双塔的结构无法考虑两侧特征之间的交互信息,**在一定程度上牺牲掉模型的部分精准性**。例如在精排模型中,来自user侧和item侧的特征会在第一层NLP层就可以做细粒度的特征交互,而对于双塔模型,user侧和item侧的特征只会在最后的內积计算时发生,这就导致很多有用的信息在经过DNN结构时就已经被其他特征所模糊了,因此双塔结构由于其结构问题先天就会存在这样的问题。下面针对这个问题来看看一下现有模型的解决思路。
|
||||
|
||||
|
||||
|
||||
## SENet双塔模型
|
||||
|
||||
SENet由Momenta在2017年提出,当时是一种应用于图像处理的新型网络结构。后来张俊林大佬将SENet引入了精排模型[FiBiNET](https%3A//arxiv.org/abs/1905.09433)中,其作用是为了将大量长尾的低频特征抛弃,弱化不靠谱低频特征embedding的负面影响,强化高频特征的重要作用。那SENet结构到底是怎么样的呢,为什么可以起到特征筛选的作用?
|
||||
|
||||
<div align=center>
|
||||
<img src="https://camo.githubusercontent.com/ccf54fc4fcac46667d451f22368e31cf86855bc8bfbff40b7675d524bc899ecf/68747470733a2f2f696d672d626c6f672e6373646e696d672e636e2f32303231303730333136313830373133392e706e673f782d6f73732d70726f636573733d696d6167652f77617465726d61726b2c747970655f5a6d46755a33706f5a57356e6147567064476b2c736861646f775f31302c746578745f6148523063484d364c7939696247396e4c6d4e7a5a473475626d56304c336431656d6876626d6478615746755a773d3d2c73697a655f312c636f6c6f725f4646464646462c745f3730237069635f63656e746572" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
从上图可以看出SENET主要分为三个步骤Squeeze, Excitation, Re-weight:
|
||||
|
||||
- Squeeze阶段:我们对每个特征的Embedding向量进行数据压缩与信息汇总,即在Embedding维度计算均值:
|
||||
|
||||
$$z_i = F_{sq}(e_i) = \frac{1}{k} \sum_{t=1}^k e_i^{(t)}$$
|
||||
|
||||
其中k表示Embedding的维度,Squeeze阶段是将每个特征的Squeeze转换成单一的数值。
|
||||
|
||||
- Excitation阶段:这阶段是根据上一阶段得到的向量进行缩放,即将上阶段的得到的 $1 \times f$ 的向量$Z$先压缩成 $1 \times \frac{f}{r}$ 长度,然后在放回到 $1 \times f$ 的维度,其中$r$表示压缩的程度。这个过程的具体操作就是经过两层DNN。
|
||||
|
||||
$$A = F_{ex}(Z) = \sigma_2(W_2\sigma_1(W_1Z)) $$
|
||||
|
||||
该过程可以理解为:对于当前所有输入的特征,通过相互发生关联,来动态地判断哪些特征重要,哪些特征不重要,而这体现在Excitation阶段的输出结果 $A$,其反应每个特征对应的重要性权重。
|
||||
|
||||
- Re-weight阶段:是将Excitation阶段得到的每个特征对应的权重 $A$ 再乘回到特征对应的Embedding里,就完成了对特征重要性的加权操作。
|
||||
|
||||
$$V=F_{ReWeight }(A,E)=[a_1 \cdot e_1,⋯,a_f \cdot e_f]=[v_1,⋯,v_f]$$
|
||||
|
||||
以上简单的介绍了一下SENet结构,可以发现这种结构可以通过对特征embedding先压缩,再交互,再选择,进而实现特征选择的效果。
|
||||
|
||||
|
||||
|
||||
此外张俊林大佬还将SENet应用于双塔模型中[(SENet双塔模型:在推荐领域召回粗排的应用及其它)](https://zhuanlan.zhihu.com/p/358779957),模型结构如下所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220522152508824.png" style="zoom:70%;"/>
|
||||
</div>
|
||||
|
||||
从上图可以发现,具体地是将双塔中的user塔和Item侧塔的特征输入部分加上一个SENet模块,通过SENet网络,动态地学习这些特征的重要性,通过小权重抑制噪音或者无效低频特征,通过大权重放大重要特征影响的目的。
|
||||
|
||||
|
||||
|
||||
之所以SENet双塔模型是有效的呢?张俊林老师的解释是:双塔模型的问题在于User侧特征和Item侧特征交互太晚,在高层交互,会造成细节信息,也就是具体特征信息的损失,影响两侧特征交叉的效果。而SENet模块在最底层就进行了特征的过滤,使得很多无效低频特征即使被过滤掉,这样更多有用的信息被保留到了双塔的最高层,使得两侧的交叉效果很好;同时由于SENet模块选择出更加重要的信息,使得User侧和Item侧特征之间的交互表达方面增强了DNN双塔的能力。
|
||||
|
||||
|
||||
|
||||
因此SENet双塔模型主要是从特征选择的角度,提高了两侧特征交叉的有效性,减少了噪音对有效信息的干扰,进而提高了双塔模型的效果。此外,除了这样的方式,还可以通过增加通道的方式来增强两侧的信息交互。即对于user和item两侧不仅仅使用一个DNN结构,而是可以通过不同结构(如FM,DCN等)来建模user和item的自身特征交叉,例如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/v2-9c2f7a30c6cadc47be23d6797f095b61_b.jpg" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
|
||||
这样对于user和item侧会得到多个embedding,类似于多兴趣的概念。通过得到的多个user和item的embedding,然后分别计算余弦值再相加(两侧的Embedding维度需要对齐),进而增加了双塔两侧的信息交互。而这种方法在腾讯进行过尝试,他们提出的“并联”双塔就是按照这样的思路,感兴趣的可以了解一下。
|
||||
|
||||
|
||||
|
||||
## 多目标的双塔模型
|
||||
|
||||
现如今多任务学习在实际的应用场景也十分的常见,主要是因为实际场景中业务复杂,往往有很多的衡量指标,例如点击,评论,收藏,关注,转发等。在多任务学习中,往往会针对不同的任务使用一个独有的tower,然后优化不同任务损失。那么针对双塔模型应该如何构建多任务学习框架呢?
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220523113206177.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
如上图所示,在user侧和item侧分别通过多个通道(DNN结构)为每个任务得到一个user embedding和item embedding,然后针对不同的目标分别计算user 和 item 的相似度,并计算各个目标的损失,最后的优化目标可以是多个任务损失之和,或者使用多任务学习中的动态损失权重。
|
||||
|
||||
|
||||
|
||||
这种模型结构,可以针对多目标进行联合建模,通过多任务学习的结构,一方面可以利用不同任务之间的信息共享,为一些稀疏特征提供其他任务中的迁移信息,另一方面可以在召回时,直接使用一个模型得到多个目标预测,解决了多个模型维护困难的问题。也就是说,在线上通过这一个模型就可以同时得到多个指标,例如视频场景,一个模型就可以直接得到点赞,品论,转发等目标的预测值,进而通过这些值计算分数获得最终的Top-K召回结果。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 双塔模型的细节
|
||||
|
||||
关于双塔模型,其模型结构相比排序模型来说很简单,没有过于复杂的结构。但除了结构,有一些细节部分容易被忽视,而这些细节部分往往比模型结构更加重要,因此下面主要介绍一下双塔模型中需要主要的一些细节问题。
|
||||
|
||||
|
||||
|
||||
### 归一化与温度系数
|
||||
|
||||
在[Google的双塔召回模型](https://dl.acm.org/doi/pdf/10.1145/3298689.3346996)中,重点介绍了两个trick,将user和item侧输出的embedding进行归一化以及对于內积值除以温度系数,实验证明这两种方式可以取得十分好的效果。那为什么这两种方法会使得模型的效果更好呢?
|
||||
|
||||
- 归一化:对user侧和item侧的输入embedding,进行L2归一化
|
||||
|
||||
$$u(x,\theta) \leftarrow = \frac{u(x,\theta)}{||u(x,\theta)||_2}$$
|
||||
|
||||
$$v(x,\theta) \leftarrow = \frac{v(x,\theta)}{||v(x,\theta)||_2}$$
|
||||
|
||||
- 温度系数:在归一化之后的向量计算內积之后,除以一个固定的超参 $r$ ,论文中命名为温度系数。
|
||||
|
||||
$$s(u,v) = \frac{<u(x,\theta), v(x,\theta)>}{r}$$
|
||||
|
||||
那为什么需要进行上述的两个操作呢?
|
||||
|
||||
- 归一化的操作主要原因是因为向量点积距离是非度量空间,不满足三角不等式,而归一化的操作使得点击行为转化成了欧式距离。
|
||||
|
||||
首先向量点积是向量对应位相乘并求和,即向量內积。而向量內积**不保序**,例如空间上三个点(A=(10,0),B=(0,10),C=(11,0)),利用向量点积计算的距离 dis(A,B) < dis(A,C),但是在欧式距离下这是错误的。而归一化的操作则会让向量点积转化为欧式距离,例如 $user_{emb}$ 表示归一化user的embedding, $item_{emb}$ 表示归一化 item 的embedding,那么两者之间的欧式距离 $||user_{emb} - item_{emb}||$ 如下, 可以看出归一化的向量点积已转化成了欧式距离。
|
||||
|
||||
$$||user_{emb} - item_{emb}||=\sqrt{||user_{emb}||^2+||item_{emb}||^2-2<user_{emb},item_{emb}>} = \sqrt{2-2<user_{emb},item_{emb}>}$$
|
||||
|
||||
|
||||
|
||||
那没啥非要转为欧式距离呢?这是因为ANN一般是通过计算欧式距离进行检索,这样转化成欧式空间,保证训练和检索一致。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 模型的应用
|
||||
|
||||
在实际的工业应用场景中,分为离线训练和在线服务两个环节。
|
||||
|
||||
- 在离线训练阶段,同过训练数据,训练好模型参数。然后将候选库中所有的item集合离线计算得到对应的embedding,并存储进ANN检索系统,比如faiss。为什么将离线计算item集合,主要是因为item的会相对稳定,不会频繁的变动,而对于用户而言,如果将用户行为作为user侧的输入,那么user的embedding会随着用户行为的发生而不断变化,因此对于user侧的embedding需要实时的计算。
|
||||
- 在线服务阶段,正是因为用户的行为变化需要被即使的反应在用户的embedding中,以更快的反应用户当前的兴趣,即可以实时地体现用户即时兴趣的变化。因此在线服务阶段需要实时的通过拼接用户特征,输入到user侧的DNN当中,进而得到user embedding,在通过user embedding去 faiss中进行ANN检索,召回最相似的K个item embedding。
|
||||
|
||||
可以看到双塔模型结构十分的适合实际的应用场景,在快速服务的同时,还可以更快的反应用户即时兴趣的变化。
|
||||
|
||||
|
||||
|
||||
### 负样本采样
|
||||
|
||||
相比于排序模型而言,召回阶段的模型除了在结构上的不同,在样本选择方面也存在着很大的差异,可以说样本的选择很大程度上会影响召回模型的效果。对于召回模型而言,其负样本并不能和排序模型一样只使用展现未点击样本,因为召回模型在线上面临的数据分布是全部的item,而不仅仅是展现未点击样本。因此在离线训练时,需要让其保证和线上分布尽可能一致,所以在负样本的选择样要尽可能的增加很多未被曝光的item。下面简单的介绍一些常见的采样方法:
|
||||
|
||||
#### 全局随机采样
|
||||
|
||||
全局随机采样指:从全局候选item里面随机抽取一定数量item做为召回模型的负样本。这样的方式实现简单,也可以让模型尽可能的和线上保持一致的分布,尽可能的多的让模型对于全局item有区分的能力。例如YoutubeDNN算法。
|
||||
|
||||
但这样的方式也会存在一定的问题,由于候选的item属于长尾数据,即“八二定律”,也就是说少数热门物料占据了绝大多数的曝光与点击。因此存随机的方式只能让模型在学到粗粒度上差异,对一些尾部item并不友好。
|
||||
|
||||
|
||||
|
||||
#### 全局随机采样 + 热门打压
|
||||
|
||||
针对于全局随机采样的不足,一个直观的方法是针对于item的热度item进行打压,即对于热门的item很多用户可能会点击,需要进行一定程度的欠采样,使得模型更加关注一些非热门的item。 此外在进行负样本采样时,应该对一些热门item进行适当的过采样,这可以尽可能的让模型对于负样本有更加细粒度的区分。例如在word2vec中,负采样方法是根据word的频率,对 negative words进行随机抽样,降 低 negative words 量级。
|
||||
|
||||
之所以热门item做负样本时,要适当过采样,增加负样本难度。因为对于全量的item,模型可以轻易的区分一些和用户兴趣差异性很大的item,难点在于很难区分一些和用户兴趣相似的item。因此在训练模型时,需要适当的增加一些难以区分的负样本来提升模型面对相似item的分区能力。
|
||||
|
||||
|
||||
|
||||
|
||||
#### Hard Negative增强样本
|
||||
|
||||
Hard Negative指的是选取一部分匹配度适中的item,能够增加模型在训练时的难度,提升模型能学习到item之间细粒度上的差异。至于 如何选取在工业界也有很多的解决方案。
|
||||
|
||||
例如Airbnb根据业务逻辑来采样一些hard negative (增加与正样本同城的房间作为负样本,增强了正负样本在地域上的相似性;增加与正样本同城的房间作为负样本,增强了正负样本在地域上的相似性,),详细内容可以查看[原文](https://www.kdd.org/kdd2018/accepted-papers/view/real-time-personalization-using-embeddings-for-search-ranking-at-airbnb)
|
||||
|
||||
例如百度和facebook依靠模型自己来挖掘Hard Negative,都是用上一版本的召回模型筛选出"没那么相似"的<user,item>对,作为额外负样本,用于训练下一版本召回模型。 详细可以查看[Mobius](http://research.baidu.com/Public/uploads/5d12eca098d40.pdf) 和 [EBR](https://arxiv.org/pdf/2006.11632.pdf)
|
||||
|
||||
|
||||
|
||||
#### Batch内随机选择负采样
|
||||
|
||||
基于batch的负采样方法是将batch内选择除了正样本之外的其它Item,做为负样本,其本质就是利用其他样本的正样本随机采样作为自己的负样本。这样的方法可以作为负样本的选择方式,特别是在如今分布式训练以及增量训练的场景中是一个非常值得一试的方法。但这种方法也存在他的问题,基于batch的负采样方法受batch的影响很大,当batch的分布与整体的分布差异很大时就会出现问题,同时batch内负采样也会受到热门item的影响,需要考虑打压热门item的问题。至于解决的办法,Google的双塔召回模型中给出了答案,想了解的同学可以去学习一下。
|
||||
|
||||
|
||||
|
||||
总的来说负样本的采样方法,不光是双塔模型应该重视的工作,而是所有召回模型都应该仔细考虑的方法。
|
||||
|
||||
|
||||
|
||||
## 代码实现
|
||||
|
||||
下面使用一点资讯提供的数据,实践一下DSSM召回模型。该模型的实现主要参考:DeepCtr和DeepMatch模块。
|
||||
|
||||
### 模型训练数据
|
||||
|
||||
1、数据预处理
|
||||
用户侧主要包含一些用户画像属性(用户性别,年龄,所在省市,使用设备及系统);新闻侧主要包括新闻的创建时间,题目,所属 一级、二级类别,题片个数以及关键词。下面主要是对着两部分数据的简单处理:
|
||||
|
||||
```python
|
||||
def proccess(file):
|
||||
if file=="user_info_data_5w.csv":
|
||||
data = pd.read_csv(file_path + file, sep="\t",index_col=0)
|
||||
data["age"] = data["age"].map(lambda x: get_pro_age(x))
|
||||
data["gender"] = data["gender"].map(lambda x: get_pro_age(x))
|
||||
|
||||
data["province"]=data["province"].fillna(method='ffill')
|
||||
data["city"]=data["city"].fillna(method='ffill')
|
||||
|
||||
data["device"] = data["device"].fillna(method='ffill')
|
||||
data["os"] = data["os"].fillna(method='ffill')
|
||||
return data
|
||||
|
||||
elif file=="doc_info.txt":
|
||||
data = pd.read_csv(file_path + file, sep="\t")
|
||||
data.columns = ["article_id", "title", "ctime", "img_num","cate","sub_cate", "key_words"]
|
||||
select_column = ["article_id", "title_len", "ctime", "img_num","cate","sub_cate", "key_words"]
|
||||
|
||||
# 去除时间为nan的新闻以及除脏数据
|
||||
data= data[(data["ctime"].notna()) & (data["ctime"] != 'Android')]
|
||||
data['ctime'] = data['ctime'].astype('str')
|
||||
data['ctime'] = data['ctime'].apply(lambda x: int(x[:10]))
|
||||
data['ctime'] = pd.to_datetime(data['ctime'], unit='s', errors='coerce')
|
||||
|
||||
|
||||
# 这里存在nan字符串和异常数据
|
||||
data["sub_cate"] = data["sub_cate"].astype(str)
|
||||
data["sub_cate"] = data["sub_cate"].apply(lambda x: pro_sub_cate(x))
|
||||
data["img_num"] = data["img_num"].astype(str)
|
||||
data["img_num"] = data["img_num"].apply(photoNums)
|
||||
data["title_len"] = data["title"].apply(lambda x: len(x) if isinstance(x, str) else 0)
|
||||
data["cate"] = data["cate"].fillna('其他')
|
||||
|
||||
return data[select_column]
|
||||
```
|
||||
|
||||
2、构造训练样本
|
||||
该部分主要是根据用户的交互日志中前6天的数据作为训练集,第7天的数据作为测试集,来构造模型的训练测试样本。
|
||||
|
||||
```python
|
||||
def dealsample(file, doc_data, user_data, s_data_str = "2021-06-24 00:00:00", e_data_str="2021-06-30 23:59:59", neg_num=5):
|
||||
# 先处理时间问题
|
||||
data = pd.read_csv(file_path + file, sep="\t",index_col=0)
|
||||
data['expo_time'] = data['expo_time'].astype('str')
|
||||
data['expo_time'] = data['expo_time'].apply(lambda x: int(x[:10]))
|
||||
data['expo_time'] = pd.to_datetime(data['expo_time'], unit='s', errors='coerce')
|
||||
|
||||
s_date = datetime.datetime.strptime(s_data_str,"%Y-%m-%d %H:%M:%S")
|
||||
e_date = datetime.datetime.strptime(e_data_str,"%Y-%m-%d %H:%M:%S") + datetime.timedelta(days=-1)
|
||||
t_date = datetime.datetime.strptime(e_data_str,"%Y-%m-%d %H:%M:%S")
|
||||
|
||||
# 选取训练和测试所需的数据
|
||||
all_data_tmp = data[(data["expo_time"]>=s_date) & (data["expo_time"]<=t_date)]
|
||||
|
||||
# 处理训练数据集 防止穿越样本
|
||||
# 1. merge 新闻信息,得到曝光时间和新闻创建时间; inner join 去除doc_data之外的新闻
|
||||
all_data_tmp = all_data_tmp.join(doc_data.set_index("article_id"),on="article_id",how='inner')
|
||||
|
||||
# 发现还存在 ctime大于expo_time的交互存在 去除这部分错误数据
|
||||
all_data_tmp = all_data_tmp[(all_data_tmp["ctime"]<=all_data_tmp["expo_time"])]
|
||||
|
||||
# 2. 去除与新闻的创建时间在测试数据时间内的交互 ()
|
||||
train_data = all_data_tmp[(all_data_tmp["expo_time"]>=s_date) & (all_data_tmp["expo_time"]<=e_date)]
|
||||
train_data = train_data[(train_data["ctime"]<=e_date)]
|
||||
|
||||
print("有效的样本数:",train_data["expo_time"].count())
|
||||
|
||||
# 负采样
|
||||
if os.path.exists(file_path + "neg_sample.pkl") and os.path.getsize(file_path + "neg_sample.pkl"):
|
||||
neg_samples = pd.read_pickle(file_path + "neg_sample.pkl")
|
||||
# train_neg_samples.insert(loc=2, column="click", value=[0] * train_neg_samples["user_id"].count())
|
||||
else:
|
||||
# 进行负采样的时候对于样本进行限制,只对一定时间范围之内的样本进行负采样
|
||||
doc_data_tmp = doc_data[(doc_data["ctime"]>=datetime.datetime.strptime("2021-06-01 00:00:00","%Y-%m-%d %H:%M:%S"))]
|
||||
neg_samples = negSample_like_word2vec(train_data, doc_data_tmp[["article_id"]].values, user_data[["user_id"]].values, neg_num=neg_num)
|
||||
neg_samples = pd.DataFrame(neg_samples, columns= ["user_id","article_id","click"])
|
||||
neg_samples.to_pickle(file_path + "neg_sample.pkl")
|
||||
|
||||
train_pos_samples = train_data[train_data["click"] == 1][["user_id","article_id", "expo_time", "click"]] # 取正样本
|
||||
|
||||
neg_samples_df = train_data[train_data["click"] == 0][["user_id","article_id", "click"]]
|
||||
train_neg_samples = pd.concat([neg_samples_df.sample(n=train_pos_samples["click"].count()) ,neg_samples],axis=0) # 取负样本
|
||||
|
||||
print("训练集正样本数:",train_pos_samples["click"].count())
|
||||
print("训练集负样本数:",train_neg_samples["click"].count())
|
||||
|
||||
train_data_df = pd.concat([train_neg_samples,train_pos_samples],axis=0)
|
||||
train_data_df = train_data_df.sample(frac=1) # shuffle
|
||||
|
||||
print("训练集总样本数:",train_data_df["click"].count())
|
||||
|
||||
test_data_df = all_data_tmp[(all_data_tmp["expo_time"]>e_date) & (all_data_tmp["expo_time"]<=t_date)][["user_id","article_id", "expo_time", "click"]]
|
||||
|
||||
print("测试集总样本数:",test_data_df["click"].count())
|
||||
print("测试集总样本数:",test_data_df["click"].count())
|
||||
|
||||
all_data_df = pd.concat([train_data_df, test_data_df],axis=0)
|
||||
|
||||
print("总样本数:",all_data_df["click"].count())
|
||||
|
||||
return all_data_df
|
||||
```
|
||||
|
||||
3、负样本采样
|
||||
该部分主要采用基于item的展现次数对全局item进行负采样。
|
||||
|
||||
```python
|
||||
def negSample_like_word2vec(train_data, all_items, all_users, neg_num=10):
|
||||
"""
|
||||
为所有item计算一个采样概率,根据概率为每个用户采样neg_num个负样本,返回所有负样本对
|
||||
1. 统计所有item在交互中的出现频次
|
||||
2. 根据频次进行排序,并计算item采样概率(频次出现越多,采样概率越低,打压热门item)
|
||||
3. 根据采样概率,利用多线程为每个用户采样 neg_num 个负样本
|
||||
"""
|
||||
pos_samples = train_data[train_data["click"] == 1][["user_id","article_id"]]
|
||||
|
||||
pos_samples_dic = {}
|
||||
for idx,u in enumerate(pos_samples["user_id"].unique().tolist()):
|
||||
pos_list = list(pos_samples[pos_samples["user_id"] == u]["article_id"].unique().tolist())
|
||||
if len(pos_list) >= 30: # 30是拍的 需要数据统计的支持确定
|
||||
pos_samples_dic[u] = pos_list[30:]
|
||||
else:
|
||||
pos_samples_dic[u] = pos_list
|
||||
|
||||
# 统计出现频次
|
||||
article_counts = train_data["article_id"].value_counts()
|
||||
df_article_counts = pd.DataFrame(article_counts)
|
||||
dic_article_counts = dict(zip(df_article_counts.index.values.tolist(),df_article_counts.article_id.tolist()))
|
||||
|
||||
for item in all_items:
|
||||
if item[0] not in dic_article_counts.keys():
|
||||
dic_article_counts[item[0]] = 0
|
||||
|
||||
# 根据频次排序, 并计算每个item的采样概率
|
||||
tmp = sorted(list(dic_article_counts.items()), key=lambda x:x[1], reverse=True) # 降序
|
||||
n_articles = len(tmp)
|
||||
article_prob = {}
|
||||
for idx, item in enumerate(tmp):
|
||||
article_prob[item[0]] = cal_pos(idx, n_articles)
|
||||
|
||||
# 为每个用户进行负采样
|
||||
article_id_list = [a[0] for a in article_prob.items()]
|
||||
article_pro_list = [a[1] for a in article_prob.items()]
|
||||
pos_sample_users = list(pos_samples_dic.keys())
|
||||
|
||||
all_users_list = [u[0] for u in all_users]
|
||||
|
||||
print("start negative sampling !!!!!!")
|
||||
pool = multiprocessing.Pool(core_size)
|
||||
res = pool.map(SampleOneProb((pos_sample_users,article_id_list,article_pro_list,pos_samples_dic,neg_num)), tqdm(all_users_list))
|
||||
pool.close()
|
||||
pool.join()
|
||||
|
||||
neg_sample_dic = {}
|
||||
for idx, u in tqdm(enumerate(all_users_list)):
|
||||
neg_sample_dic[u] = res[idx]
|
||||
|
||||
return [[k,i,0] for k,v in neg_sample_dic.items() for i in v]
|
||||
```
|
||||
|
||||
### DSSM 模型
|
||||
|
||||
1、模型构建
|
||||
|
||||
模型构建部分主要是将输入的user 特征以及 item 特征处理完之后分别送入两侧的DNN结构。
|
||||
|
||||
```python
|
||||
def DSSM(user_feature_columns, item_feature_columns, dnn_units=[64, 32],
|
||||
temp=10, task='binary'):
|
||||
# 构建所有特征的Input层和Embedding层
|
||||
feature_encode = FeatureEncoder(user_feature_columns + item_feature_columns)
|
||||
feature_input_layers_list = list(feature_encode.feature_input_layer_dict.values())
|
||||
|
||||
# 特征处理
|
||||
user_dnn_input, item_dnn_input = process_feature(user_feature_columns,\
|
||||
item_feature_columns, feature_encode)
|
||||
|
||||
# 构建模型的核心层
|
||||
if len(user_dnn_input) >= 2:
|
||||
user_dnn_input = Concatenate(axis=1)(user_dnn_input)
|
||||
else:
|
||||
user_dnn_input = user_dnn_input[0]
|
||||
if len(item_dnn_input) >= 2:
|
||||
item_dnn_input = Concatenate(axis=1)(item_dnn_input)
|
||||
else:
|
||||
item_dnn_input = item_dnn_input[0]
|
||||
user_dnn_input = Flatten()(user_dnn_input)
|
||||
item_dnn_input = Flatten()(item_dnn_input)
|
||||
user_dnn_out = DNN(dnn_units)(user_dnn_input)
|
||||
item_dnn_out = DNN(dnn_units)(item_dnn_input)
|
||||
|
||||
|
||||
# 计算相似度
|
||||
scores = CosinSimilarity(temp)([user_dnn_out, item_dnn_out]) # (B,1)
|
||||
# 确定拟合目标
|
||||
output = PredictLayer()(scores)
|
||||
# 根据输入输出构建模型
|
||||
model = Model(feature_input_layers_list, output)
|
||||
return model
|
||||
```
|
||||
|
||||
2、CosinSimilarity相似度计算
|
||||
|
||||
在余弦相似度计算,主要是注意使用归一化以及温度系数的技巧。
|
||||
|
||||
```python
|
||||
def call(self, inputs, **kwargs):
|
||||
"""inputs 是一个列表"""
|
||||
query, candidate = inputs
|
||||
# 计算两个向量的二范数
|
||||
query_norm = tf.norm(query, axis=self.axis) # (B, 1)
|
||||
candidate_norm = tf.norm(candidate, axis=self.axis)
|
||||
# 计算向量点击,即內积操作
|
||||
scores = tf.reduce_sum(tf.multiply(query, candidate), axis=-1)#(B,1)
|
||||
# 相似度除以二范数, 防止除零
|
||||
scores = tf.divide(scores, query_norm * candidate_norm + 1e-8)
|
||||
# 对score的范围限制到(-1, 1)之间
|
||||
scores = tf.clip_by_value(scores, -1, 1)
|
||||
# 乘以温度系数
|
||||
score = scores * self.temperature
|
||||
return score
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 模型训练
|
||||
|
||||
1、稀疏特征编码
|
||||
该部分主要是针对于用户侧和新闻侧的稀疏特征进行编码,并将训练样本join上两侧的特征。
|
||||
|
||||
```python
|
||||
# 数据和测试数据
|
||||
data, user_data, doc_data = get_all_data()
|
||||
|
||||
# 1.Label Encoding for sparse features,and process sequence features with `gen_date_set` and `gen_model_input`
|
||||
feature_max_idx = {}
|
||||
feature_encoder = {}
|
||||
|
||||
user_sparse_features = ["user_id", "device", "os", "province", "city", "age", "gender"]
|
||||
for feature in user_sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
user_data[feature] = lbe.fit_transform(user_data[feature]) + 1
|
||||
feature_max_idx[feature] = user_data[feature].max() + 1
|
||||
feature_encoder[feature] = lbe
|
||||
|
||||
|
||||
doc_sparse_features = ["article_id", "cate", "sub_cate"]
|
||||
doc_dense_features = ["title_len", "img_num"]
|
||||
|
||||
for feature in doc_sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
if feature in ["cate","sub_cate"]:
|
||||
# 这里面会出现一些float的数据,导致无法编码
|
||||
doc_data[feature] = lbe.fit_transform(doc_data[feature].astype(str)) + 1
|
||||
else:
|
||||
doc_data[feature] = lbe.fit_transform(doc_data[feature]) + 1
|
||||
feature_max_idx[feature] = doc_data[feature].max() + 1
|
||||
feature_encoder[feature] = lbe
|
||||
|
||||
data["article_id"] = feature_encoder["article_id"].transform(data["article_id"].tolist())
|
||||
data["user_id"] = feature_encoder["user_id"].transform(data["user_id"].tolist())
|
||||
|
||||
|
||||
# join 用户侧和新闻侧的特征
|
||||
data = data.join(user_data.set_index("user_id"), on="user_id", how="inner")
|
||||
data = data.join(doc_data.set_index("article_id"), on="article_id", how="inner")
|
||||
|
||||
sparse_features = user_sparse_features + doc_sparse_features
|
||||
dense_features = doc_dense_features
|
||||
|
||||
features = sparse_features + dense_features
|
||||
|
||||
mms = MinMaxScaler(feature_range=(0, 1))
|
||||
data[dense_features] = mms.fit_transform(data[dense_features])
|
||||
```
|
||||
|
||||
2、配置特征以及模型训练
|
||||
构建模型所需的输入特征,同时构建DSSM模型及训练。
|
||||
|
||||
```python
|
||||
embedding_dim = 8
|
||||
user_feature_columns = [SparseFeat('user_id', feature_max_idx['user_id'], embedding_dim),
|
||||
SparseFeat("gender", feature_max_idx['gender'], embedding_dim),
|
||||
SparseFeat("age", feature_max_idx['age'], embedding_dim),
|
||||
SparseFeat("device", feature_max_idx['device'], embedding_dim),
|
||||
SparseFeat("os", feature_max_idx['os'], embedding_dim),
|
||||
SparseFeat("province", feature_max_idx['province'], embedding_dim),
|
||||
SparseFeat("city", feature_max_idx['city'], embedding_dim), ]
|
||||
|
||||
item_feature_columns = [SparseFeat('article_id', feature_max_idx['article_id'], embedding_dim),
|
||||
DenseFeat('img_num', 1),
|
||||
DenseFeat('title_len', 1),
|
||||
SparseFeat('cate', feature_max_idx['cate'], embedding_dim),
|
||||
SparseFeat('sub_cate', feature_max_idx['sub_cate'], embedding_dim)]
|
||||
|
||||
model = DSSM(user_feature_columns, item_feature_columns,
|
||||
user_dnn_hidden_units=(32, 16, embedding_dim), item_dnn_hidden_units=(32, 16, embedding_dim)) # FM(user_feature_columns,item_feature_columns)
|
||||
|
||||
model.compile(optimizer="adagrad", loss = "binary_crossentropy", metrics=[tf.keras.metrics.Recall(), tf.keras.metrics.Precision()] ) #
|
||||
|
||||
history = model.fit(train_model_input, train_label, batch_size=256, epochs=4, verbose=1, validation_split=0.2, )
|
||||
```
|
||||
|
||||
3、生成embedding用于召回
|
||||
利用训练过的模型获取所有item的embeddings,同时获取所有测试集的user embedding,保存之后用于之后的召回工作。
|
||||
|
||||
```python
|
||||
all_item_model_input = {"article_id": item_profile['article_id'].values,
|
||||
"img_num": item_profile['img_num'].values,
|
||||
"title_len": item_profile['title_len'].values,
|
||||
"cate": item_profile['cate'].values,
|
||||
"sub_cate": item_profile['sub_cate'].values,}
|
||||
|
||||
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
|
||||
item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
|
||||
|
||||
user_embs = user_embedding_model.predict(test_user_model_input, batch_size=2 ** 12)
|
||||
item_embs = item_embedding_model.predict(all_item_model_input, batch_size=2 ** 12)
|
||||
|
||||
user_idx_2_rawid, doc_idx_2_rawid = {}, {}
|
||||
|
||||
for i in range(len(user_embs)):
|
||||
user_idx_2_rawid[i] = test_user_model_input["user_id"][i]
|
||||
|
||||
for i in range(len(item_embs)):
|
||||
doc_idx_2_rawid[i] = all_item_model_input["article_id"][i]
|
||||
|
||||
# 保存一份
|
||||
pickle.dump((user_embs, user_idx_2_rawid, feature_encoder["user_id"]), open(file_path + 'user_embs.pkl', 'wb'))
|
||||
pickle.dump((item_embs, doc_idx_2_rawid, feature_encoder["article_id"]), open(file_path + 'item_embs.pkl', 'wb'))
|
||||
```
|
||||
|
||||
|
||||
### ANN召回
|
||||
|
||||
1、为测试集用户召回
|
||||
通过annoy tree为所有的item构建索引,并通过测试集中所有的user embedding为每个用户召回一定数量的item。
|
||||
|
||||
```python
|
||||
def get_DSSM_recall_res(user_embs, doc_embs, user_idx_2_rawid, doc_idx_2_rawid, topk):
|
||||
"""近邻检索,这里用annoy tree"""
|
||||
# 把doc_embs构建成索引树
|
||||
f = user_embs.shape[1]
|
||||
t = AnnoyIndex(f, 'angular')
|
||||
for i, v in enumerate(doc_embs):
|
||||
t.add_item(i, v)
|
||||
t.build(10)
|
||||
|
||||
# 每个用户向量, 返回最近的TopK个item
|
||||
user_recall_items_dict = collections.defaultdict(dict)
|
||||
for i, u in enumerate(user_embs):
|
||||
recall_doc_scores = t.get_nns_by_vector(u, topk, include_distances=True)
|
||||
# recall_doc_scores是(([doc_idx], [scores])), 这里需要转成原始doc的id
|
||||
raw_doc_scores = list(recall_doc_scores)
|
||||
raw_doc_scores[0] = [doc_idx_2_rawid[i] for i in raw_doc_scores[0]]
|
||||
# 转换成实际用户id
|
||||
user_recall_items_dict[user_idx_2_rawid[i]] = dict(zip(*raw_doc_scores))
|
||||
|
||||
# 默认是分数从小到大排的序, 这里要从大到小
|
||||
user_recall_items_dict = {k: sorted(v.items(), key=lambda x: x[1], reverse=True) for k, v in user_recall_items_dict.items()}
|
||||
|
||||
pickle.dump(user_recall_items_dict, open(file_path + 'DSSM_u2i_dict.pkl', 'wb'))
|
||||
|
||||
return user_recall_items_dict
|
||||
```
|
||||
|
||||
2、测试召回结果
|
||||
为测试集用户的召回结果进行测试。
|
||||
|
||||
```python
|
||||
user_recall_items_dict = get_DSSM_recall_res(user_embs, item_embs, user_idx_2_rawid, doc_idx_2_rawid, topk=TOP_NUM)
|
||||
|
||||
test_true_items = {line[0]:line[1] for line in test_set}
|
||||
|
||||
s = []
|
||||
precision = []
|
||||
for i, uid in tqdm(enumerate(list(user_recall_items_dict.keys()))):
|
||||
# try:
|
||||
pred = [x for x, _ in user_recall_items_dict[uid]]
|
||||
filter_item = None
|
||||
recall_score = recall_N(test_true_items[uid], pred, N=TOP_NUM)
|
||||
s.append(recall_score)
|
||||
precision_score = precision_N(test_true_items[uid], pred, N=TOP_NUM)
|
||||
precision.append(precision_score)
|
||||
print("recall", np.mean(s))
|
||||
print("precision", np.mean(precision))
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 参考
|
||||
|
||||
- [负样本为王:评Facebook的向量化召回算法](https://zhuanlan.zhihu.com/p/165064102)
|
||||
|
||||
- [多目标DSSM召回实战](https://mp.weixin.qq.com/s/aorZ43WozKrD2AudR6AnOg)
|
||||
|
||||
- [召回模型中的负样本构造](https://zhuanlan.zhihu.com/p/358450850)
|
||||
|
||||
- [Youtube双塔模型](https://dl.acm.org/doi/10.1145/3298689.3346996)
|
||||
|
||||
- [张俊林:SENet双塔模型:在推荐领域召回粗排的应用及其它](https://zhuanlan.zhihu.com/p/358779957)
|
||||
|
||||
- [双塔召回模型的前世今生(上篇)](https://zhuanlan.zhihu.com/p/430503952)
|
||||
|
||||
- [双塔召回模型的前世今生(下篇)](https://zhuanlan.zhihu.com/p/441597009)
|
||||
|
||||
- [Learning Deep Structured Semantic Models for Web Search using Clickthrough Data](https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2013_DSSM_fullversion.pdf)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
124
4.人工智能/ch02/ch2.1/ch2.1.2/FM.md
Normal file
124
4.人工智能/ch02/ch2.1/ch2.1.2/FM.md
Normal file
@@ -0,0 +1,124 @@
|
||||
# FM 模型结构
|
||||
|
||||
FM 模型用于排序时,模型的公式定义如下:
|
||||
$$
|
||||
\hat{y}(\mathbf{x}):=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}
|
||||
$$
|
||||
+ 其中,$i$ 表示特征的序号,$n$ 表示特征的数量;$x_i \in \mathbb{R}$ 表示第 $i$ 个特征的值。
|
||||
+ $v_i,v_j \in \mathbb{R}^{k} $ 分别表示特征 $x_i,x_j$ 对应的隐语义向量(Embedding向量), $\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle:=\sum_{f=1}^{k} v_{i, f} \cdot v_{j, f}$ 。
|
||||
+ $w_0,w_i\in \mathbb{R}$ 均表示需要学习的参数。
|
||||
|
||||
**FM 的一阶特征交互**
|
||||
|
||||
在 FM 的表达式中,前两项为特征的一阶交互项。将其拆分为用户特征和物品特征的一阶特征交互项,如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
& w_{0}+\sum_{i=1}^{n} w_{i} x_{i} \\
|
||||
&= w_{0} + \sum_{t \in I}w_{t} x_{t} + \sum_{u\in U}w_{u} x_{u} \\
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 其中,$U$ 表示用户相关特征集合,$I$ 表示物品相关特征集合。
|
||||
|
||||
**FM 的二阶特征交互**
|
||||
|
||||
观察 FM 的二阶特征交互项,可知其计算复杂度为 $O\left(k n^{2}\right)$ 。为了降低计算复杂度,按照如下公式进行变换。
|
||||
$$
|
||||
\begin{aligned}
|
||||
& \sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j} \\
|
||||
=& \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}-\frac{1}{2} \sum_{i=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{i}\right\rangle x_{i} x_{i} \\
|
||||
=& \frac{1}{2}\left(\sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{j, f} x_{i} x_{j}-\sum_{i=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{i, f} x_{i} x_{i}\right) \\
|
||||
=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{}\left(\sum_{j=1}^{n} v_{j, f} x_{j}\right)-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \\
|
||||
=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
+ 公式变换后,计算复杂度由 $O\left(k n^{2}\right)$ 降到 $O\left(k n\right)$。
|
||||
|
||||
由于本文章需要将 FM 模型用在召回,故将二阶特征交互项拆分为用户和物品项。有:
|
||||
$$
|
||||
\begin{aligned}
|
||||
& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \\
|
||||
=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{u \in U} v_{u, f} x_{u} + \sum_{t \in I} v_{t, f} x_{t}\right)^{2}-\sum_{u \in U} v_{u, f}^{2} x_{u}^{2} - \sum_{t\in I} v_{t, f}^{2} x_{t}^{2}\right) \\
|
||||
=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{u \in U} v_{u, f} x_{u}\right)^{2} + \left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} + 2{\sum_{u \in U} v_{u, f} x_{u}}{\sum_{t \in I} v_{t, f} x_{t}} - \sum_{u \in U} v_{u, f}^{2} x_{u}^{2} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 其中,$U$ 表示用户相关特征集合,$I$ 表示物品相关特征集合。
|
||||
|
||||
|
||||
|
||||
# FM 用于召回
|
||||
|
||||
基于 FM 召回,我们可以将 $\hat{y}(\mathbf{x}):=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}$ 作为用户和物品之间的匹配分。
|
||||
|
||||
+ 在上一小节中,对于 FM 的一阶、二阶特征交互项,已将其拆分为用户项和物品项。
|
||||
+ 对于同一用户,即便其与不同物品进行交互,但用户特征内部之间的一阶、二阶交互项得分都是相同的。
|
||||
+ 这就意味着,在比较用户与不同物品之间的匹配分时,只需要比较:(1)物品内部之间的特征交互得分;(2)用户和物品之间的特征交互得分。
|
||||
|
||||
**FM 的一阶特征交互**
|
||||
|
||||
+ 将全局偏置和用户一阶特征交互项进行丢弃,有:
|
||||
$$
|
||||
FM_{一阶} = \sum_{t \in I} w_{t} x_{t}
|
||||
$$
|
||||
|
||||
**FM 的二阶特征交互**
|
||||
|
||||
+ 将用户特征内部的特征交互项进行丢弃,有:
|
||||
$$
|
||||
\begin{aligned}
|
||||
& FM_{二阶} = \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} + 2{\sum_{u \in U} v_{u, f} x_{u}}{\sum_{t \in I} v_{t, f} x_{t}} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right) \\
|
||||
&= \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right) + \sum_{f=1}^{k}\left( {\sum_{u \in U} v_{u, f} x_{u}}{\sum_{t \in I} v_{t, f} x_{t}} \right)
|
||||
|
||||
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
合并 FM 的一阶、二阶特征交互项,得到基于 FM 召回的匹配分计算公式:
|
||||
$$
|
||||
\text{MatchScore}_{FM} = \sum_{t \in I} w_{t} x_{t} + \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right) + \sum_{f=1}^{k}\left( {\sum_{u \in U} v_{u, f} x_{u}}{\sum_{t \in I} v_{t, f} x_{t}} \right)
|
||||
$$
|
||||
在基于向量的召回模型中,为了 ANN(近似最近邻算法) 或 Faiss 加速查找与用户兴趣度匹配的物品。基于向量的召回模型,一般最后都会得到用户和物品的特征向量表示,然后通过向量之间的内积或者余弦相似度表示用户对物品的兴趣程度。
|
||||
|
||||
基于 FM 模型的召回算法,也是向量召回算法的一种。所以下面,将 $\text{MatchScore}_{FM}$ 化简为用户向量和物品向量的内积形式,如下:
|
||||
$$
|
||||
\text{MatchScore}_{FM} = V_{item} V_{user}^T
|
||||
$$
|
||||
|
||||
+ 用户向量:
|
||||
$$
|
||||
V_{user} = [1; \quad {\sum_{u \in U} v_{u} x_{u}}]
|
||||
$$
|
||||
|
||||
+ 用户向量由两项表达式拼接得到。
|
||||
+ 第一项为常数 $1$,第二项是将用户相关的特征向量进行 sum pooling 。
|
||||
|
||||
+ 物品向量:
|
||||
$$
|
||||
V_{item} = [\sum_{t \in I} w_{t} x_{t} + \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right); \quad
|
||||
{\sum_{t \in I} v_{t} x_{t}} ]
|
||||
$$
|
||||
|
||||
+ 第一项表示物品相关特征向量的一阶、二阶特征交互。
|
||||
+ 第二项是将物品相关的特征向量进行 sum pooling 。
|
||||
|
||||
|
||||
|
||||
# 思考题
|
||||
|
||||
1. 为什么不直接将 FM 中学习到的 User Embedding: ${\sum_{u \in U} v_{u} x_{u}}$ 和 Item Embedding: $\sum_{t \in I} v_{t} x_{t}$ 的内积做召回呢?
|
||||
|
||||
答:这样做,也不是不行,但是效果不是特别好。**因为用户喜欢的,未必一定是与自身最匹配的,也包括一些自身性质极佳的item(e.g.,热门item)**,所以,**非常有必要将"所有Item特征一阶权重之和"和“所有Item特征隐向量两两点积之和”考虑进去**,但是也还必须写成点积的形式。
|
||||
|
||||
|
||||
|
||||
# 代码实战
|
||||
|
||||
正在完善...
|
||||
|
||||
|
||||
|
||||
# 参考链接
|
||||
|
||||
+ [paper.dvi (ntu.edu.tw)](https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf)
|
||||
+ [FM:推荐算法中的瑞士军刀 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/343174108)
|
||||
589
4.人工智能/ch02/ch2.1/ch2.1.2/YoutubeDNN.md
Normal file
589
4.人工智能/ch02/ch2.1/ch2.1.2/YoutubeDNN.md
Normal file
@@ -0,0 +1,589 @@
|
||||
## 写在前面
|
||||
YouTubeDNN模型是2016年的一篇文章,虽然离着现在有些久远, 但这篇文章无疑是工业界论文的典范, 完全是从工业界的角度去思考如何去做好一个推荐系统,并且处处是YouTube工程师留给我们的宝贵经验, 由于这两天用到了这个模型,今天也正好重温了下这篇文章,所以借着这个机会也整理出来吧, 王喆老师都称这篇文章是"神文", 可见其不一般处。
|
||||
|
||||
今天读完之后, 给我的最大感觉,首先是从工程的角度去剖析了整个推荐系统,讲到了推荐系统中最重要的两大模块: 召回和排序, 这篇论文对初学者非常友好,之前的论文模型是看不到这么全面的系统的,总有一种管中规豹的感觉,看不到全局,容易着相。 其次就是这篇文章给出了很多优化推荐系统中的工程性经验, 不管是召回还是排序上,都有很多的套路或者trick,比如召回方面的"example age", "负采样","非对称消费,防止泄露",排序方面的特征工程,加权逻辑回归等, 这些东西至今也都非常的实用,所以这也是这篇文章厉害的地方。
|
||||
|
||||
本篇文章依然是以paper为主线, 先剖析paper里面的每个细节,当然我这里也参考了其他大佬写的文章,王喆老师的几篇文章写的都很好,链接我也放在了下面,建议也看看。然后就是如何用YouTubeDNN模型,代码复现部分,由于时间比较短,自己先不复现了,调deepmatch的包跑起来,然后在新闻推荐数据集上进行了一些实验, 尝试了论文里面讲述的一些方法,这里主要是把deepmatch的YouTubeDNN模型怎么使用,以及我整个实验过程的所思所想给整理下, 因为这个模型结构本质上并不是很复杂(三四层的全连接网络),就不自己在实现一遍啦, 一些工程经验或者思想,我觉得才是这篇文章的精华部分。
|
||||
|
||||
|
||||
## 引言与推荐系统的漏斗范式
|
||||
### 引言部分
|
||||
本篇论文是工程性论文(之前的DIN也是偏工程实践的论文), 行文风格上以实际应用为主, 我们知道YouTube是全球性的视频网站, 所以这篇文章主要讲述了YouTube视频推荐系统的基本架构以及细节,以及各种处理tricks。
|
||||
|
||||
在Introduction部分, 作者首先说了在工业上的YouTube视频推荐系统主要面临的三大挑战:
|
||||
1. Scale(规模): 视频数量非常庞大,大规模数据下需要分布式学习算法以及高效的线上服务系统,文中体现这一点的是召回模型线下训练的时候,采用了负采样的思路,线上服务的时候,采用了hash映射,然后近邻检索的方式来满足实时性的需求, 这个之前我整理过faiss包和annoy包的使用, 感兴趣的可以看看。 其实,再拔高一层,我们推荐系统的整体架构呈漏斗范式,也是为了保证能从大规模情景下实时推荐。
|
||||
2. Freshness(新鲜度): YouTube上的视频是一个动态的, 用户实时上传,且实时访问, 那么这时候, 最新的视频往往就容易博得用户的眼球, 用户一般都比较喜欢看比较新的视频, 而不管是不是真和用户相关(这个感觉和新闻比较类似呀), 这时候,就需要模型有建模新上传内容以及用户最新发生的行为能力。 为了让模型学习到用户对新视频有偏好, 后面策略里面加了一个"example age"作为体现。我们说的"探索与利用"中的探索,其实也是对新鲜度的把握。
|
||||
3. Noise(噪声): 由于数据的稀疏和不可见的其他原因, 数据里面的噪声非常之多,这时候,就需要让这个推荐系统变得鲁棒,怎么鲁棒呢? 这个涉及到召回和排序两块,召回上需要考虑更多实际因素,比如非对称消费特性,高活用户因素,时间因素,序列因素等,并采取了相应的措施, 而排序上做更加细致的特征工程, 尽量的刻画出用户兴趣以及视频的特征 优化训练目标,使用加权的逻辑回归等。而召回和排序模型上,都采用了深度神经网络,通过特征的相互交叉,有了更强大的建模能力, 相比于之前用的MF(矩阵分解), 建模能力上有了很大的提升, 这些都有助于帮助减少噪声, 使得推荐结果更加准确。
|
||||
|
||||
所以从文章整体逻辑上看, 后面的各个细节,其实都是围绕着挑战展开的,找到当前推荐面临的问题,就得想办法解决问题,所以这篇文章的行文逻辑也是非常清晰的。
|
||||
|
||||
知道了挑战, 那么下面就看看YouTubeDNN的整体推荐系统架构。
|
||||
|
||||
### YouTubeDNN推荐系统架构
|
||||
整个推荐架构图如下, 这个算是比较原始的漏斗结构了:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/1c5dbd6d6c1646d09998b18d45f869e5.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
这篇文章之所以写的好, 是给了我们一个看推荐系统的宏观视角, 这个系统主要是两大部分组成: 召回和排序。召回的目的是根据用户部分特征,从海量物品库,快速找到小部分用户潜在感兴趣的物品交给精排,重点强调快,精排主要是融入更多特征,使用复杂模型,来做个性化推荐,强调准。
|
||||
|
||||
而对于这两块的具体描述, 论文里面也给出了解释, 我这里简单基于我目前的理解扩展下主流方法:
|
||||
1. 召回侧
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/5ebcd6f882934b7e9e2ffb9de2aee29d.png#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
召回侧模型的输入一般是用户的点击历史, 因为我们认为这些历史能更好的代表用户的兴趣, 另外还有一些人口统计学特征,比如性别,年龄,地域等, 都可以作为召回侧模型的输入。 而最终模型的输出,就是与该用户相关的一个候选视频集合, 量级的话一般是几百。
|
||||
<br>召回侧, 目前根据我的理解,大致上有两大类召回方式,一类是策略规则,一类是监督模型+embedding,其中策略规则,往往和真实场景有关,比如热度,历史重定向等等,不同的场景会有不同的召回方式,这种属于"特异性"知识。
|
||||
<br>后面的模型+embedding思路是一种"普适"方法,我上面图里面梳理出了目前给用户和物品打embedding的主流方法, 这些方法大致成几个系列,比如FM系列(FM,FFM等), 用户行为序列,基于图和知识图谱系列,经典双塔系列等,这些方法看似很多很复杂,其实本质上还是给用户或者是物品打embedding而已,只不过考虑的角度方式不同。 这里的YouTubeDNN召回模型,也是这里的一种方式而已。
|
||||
2. 精排侧
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/08953c0e8a00476f90bd9e206d4a02c6.png#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
召回那边对于每个用户, 给出了几百个比较相关的候选视频, 把几百万的规模降到了几百, 当然,召回那边利用的特征信息有限,并不能很好的刻画用户和视频特点,所以, 在精排侧,主要是想利用更多的用户,视频特征,刻画特点更加准确些,从这几百个里面选出几个或者十几个推荐给用户。 而涉及到准, 主要的发力点一般有三个:特征工程, 模型设计以及训练方法。 这三个发力点文章几乎都有所涉及, 除了模式设计有点审时度势之外,特征工程以及训练方法的处理上非常漂亮,具体的后面再整理。<br>
|
||||
精排侧,这一块的大致发展趋势,从ctr预估到多目标, 而模型演化上,从人工特征工程到特征工程自动化。主要是三大块, CTR预估主要分为了传统的LR,FM大家族,以及后面自动特征交叉的DNN家族,而多目标优化,目前是很多大公司的研究现状,更是未来的一大发展趋势,如何能让模型在各个目标上面的学习都能"游刃有余"是一件非常具有挑战的事情,毕竟不同的目标可能会互相冲突,互相影响,所以这里的研究热点又可以拆分成网络结构演化以及loss设计优化等, 而网络结构演化中,又可以再一次细分。 当然这每个模型或者技术几乎都有对应paper,我们依然可以通过读paper的方式,把这些关键技术学习到。
|
||||
|
||||
这两阶段的方法, 就能保证我们从大规模视频库中实时推荐, 又能保证个性化,吸引用户。 当然,随着时间的发展, 可能数据量非常非常大了, 此时召回结果规模精排依然无法处理,所以现在一般还会在召回和精排之间,加一个粗排进一步筛选作为过渡, 而随着场景越来越复杂, 精排产生的结果也不是直接给到用户,而是会再后面加一个重排后处理下,这篇paper里面其实也简单的提了下这种思想,在排序那块会整理到。 所以如今的漏斗, 也变得长了些。
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/aeae52971a1345a98b310890ea81be53.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
论文里面还提到了对模型的评估方面, 线下评估的时候,主要是采用一些常用的评估指标(精确率,召回率, 排序损失或者auc这种), 但是最终看算法和模型的有效性, 是通过A/B实验, 在A/B实验中会观察用户真实行为,比如点击率, 观看时长, 留存率这种, 这些才是我们终极目标, 而有时候, A/B实验的结果和线下我们用的这些指标并不总是相关, 这也是推荐系统这个场景的复杂性。 我们往往也会用一些策略,比如修改模型的优化目标,损失函数这种, 让线下的这个目标尽量的和A/B衡量的这种指标相关性大一些。 当然,这块又是属于业务场景问题了,不在整理范畴之中。 但2016年,竟然就提出了这种方式, 所以我觉得,作为小白的我们, 想了解工业上的推荐系统, 这篇paper是不二之选。
|
||||
|
||||
OK, 从宏观的大视角看完了漏斗型的推荐架构,我们就详细看看YouTube视频推荐架构里面召回和排序模块的模型到底长啥样子? 为啥要设计成这个样子? 为了应对实际中出现的挑战,又有哪些策略?
|
||||
|
||||
## YouTubeDNN的召回模型细节剖析
|
||||
上面说过, 召回模型的目的是在大量YouTube视频中检索出数百个和用户相关的视频来。
|
||||
|
||||
这个问题,我们可以看成一个多分类的问题,即用户在某一个时刻点击了某个视频, 可以建模成输入一个用户向量, 从海量视频中预测出被点击的那个视频的概率。
|
||||
|
||||
换成比较准确的数学语言描述, 在时刻$t$下, 用户$U$在背景$C$下对每个视频$i$的观看行为建模成下面的公式:
|
||||
$$
|
||||
P\left(w_{t}=i \mid U, C\right)=\frac{e^{v_{i} u}}{\sum_{j \in V} e^{v_{j} u}}
|
||||
$$
|
||||
这里的$u$表示用户向量, 这里的$v$表示视频向量, 两者的维度都是$N$, 召回模型的任务,就是通过用户的历史点击和山下文特征, 去学习最终的用户表示向量$u$以及视频$i$的表示向量$v_i$, 不过这俩还有个区别是$v_i$本身就是模型参数, 而$u$是神经网络的输出(函数输出),是输入与模型参数的计算结果。
|
||||
>解释下这个公式, 为啥要写成这个样子,其实是word2vec那边借鉴过来的,$e^{ (v_{i} u)}$表示的是当前用户向量$u$与当前视频$v_i$的相似程度,$e$只是放大这个相似程度而已, 不用管。 为啥这个就能表示相似程度呢? 因为两个向量的点积运算的含义就是可以衡量两个向量的相似程度, 两个向量越相似, 点积就会越大。 所以这个应该解释明白了。 再看分母$\sum_{j \in V} e^{v_{j} u}$, 这个显然是用户向量$u$与所有视频$v$的一个相似程度求和。 那么两者一除, 依然是代表了用户$u$与输出的视频$v_i$的相似程度,只不过归一化到了0-1之间, 毕竟我们知道概率是0-1之间的, 这就是为啥这个概率是右边形式的原因。 因为右边公式表示了用户$u$与输出的视频$v_i$的相似程度, 并且这个相似程度已经归一化到了0-1之间, 我们给定$u$希望输出$v_i$的概率越大,因为这样,当前的视频$v_i$和当前用户$u$更加相关,正好对应着点击行为不是吗?
|
||||
|
||||
那么,这个召回模型到底长啥样子呢?
|
||||
### 召回模型结构
|
||||
召回模型的结构如下:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/724ff38c1d6448399edb658b1b27e18e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这个模型结构呢,相比之前的模型, 比较简单,就是一个DNN。
|
||||
|
||||
它的输入主要是用户侧的特征,包括用户观看的历史video序列, 用户搜索的历史tokens, 然后就是用户的人文特征,比如地理位置, 性别,年龄这些。 这些特征处理上,和之前那些模型的也比较类似,
|
||||
* 用户历史序列,历史搜索tokens这种序列性的特征: 一般长这样`[item_id5, item_id2, item_id3, ...]`, 这种id特征是高维稀疏,首先会通过一个embedding层,转成低维稠密的embedding特征,即历史序列里面的每个id都会对应一个embedding向量, 这样历史序列就变成了多个embedding向量的形式, 这些向量一般会进行融合,常见的是average pooling,即每一维求平均得到一个最终向量来表示用户的历史兴趣或搜索兴趣。
|
||||
>这里值的一提的是这里的embedding向量得到的方式, 论文中作者这里说是通过word2vec方法计算的, 关于word2vec,这里就不过多解释,也就是每个item事先通过w2v方式算好了的embedding,直接作为了输入,然后进行pooling融合。<br><br>除了这种算好embedding方式之外,还可以过embedding层,跟上面的DNN一起训练,这些都是常规操作,之前整理的精排模型里面大都是用这种方式。
|
||||
|
||||
论文里面使用了用户最近的50次观看历史,用户最近50次搜索历史token, embedding维度是256维, 采用的average pooling。 当然,这里还可以把item的类别信息也隐射到embedding, 与前面的concat起来。
|
||||
* 用户人文特征, 这种特征处理方式就是离散型的依然是labelEncoder,然后embedding转成低维稠密, 而连续型特征,一般是先归一化操作,然后直接输入,当然有的也通过分桶,转成离散特征,这里不过多整理,特征工程做的事情了。 当然,这里还有一波操作值得注意,就是连续型特征除了用了$x$本身,还用了$x^2$,$logx$这种, 可以加入更多非线性,增加模型表达能力。<br>
|
||||
这些特征对新用户的推荐会比较有帮助,常见的用户的地理位置, 设备, 性别,年龄等。
|
||||
* 这里一个比较特色的特征是example age,这个特征后面需要单独整理。
|
||||
|
||||
这些特征处理好了之后,拼接起来,就成了一个非常长的向量,然后就是过DNN,这里用了一个三层的DNN, 得到了输出, 这个输出也是向量。
|
||||
|
||||
Ok,到这里平淡无奇, 前向传播也大致上快说完了, 还差最后一步。 最后这一步,就是做多分类问题,然后求损失,这就是training那边做的事情。 但是在详细说这个之前, 我想先简单回忆下word2vec里面的skip-gram Model, 这个模型,如果回忆起来,这里理解起来就非常的简单了。
|
||||
|
||||
这里只需要看一张图即可, 这个来自cs231N公开课PPT, 我之前整理w2v的时候用到的,详细内容可看我[这篇博客](https://zhongqiang.blog.csdn.net/article/details/106948860), 这里的思想其实也是从w2v那边过来的。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200624193409649.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
skip-gram的原理咱这里就不整理了, 这里就只看这张图,这其实就是w2v训练的一种方式,当然是最原始的。 word2vec的核心思想呢? 就是共现频率高的词相关性越大,所以skip-gram采用中心词预测上下文词的方式去训练词向量,模型的输入是中心词,做样本采用滑动窗口的形式,和这里序列其实差不多,窗口滑动一次就能得到一个序列[word1, word2, ...wordn], 而这个序列里面呢? 就会有中心词(比如中间那个), 两边向量的是上下文词。 如果我们输入中心词之后,模型能预测上下文词的概率大,那说明这个模型就能解决词相关性问题了。
|
||||
>一开始, 我们的中心单词$w_t$就是one-hot的表示形式,也就是在词典中的位置,这里的形状是$V \times1$, $V$表示词库里面有$V$个单词, 这里的$W$长上面那样, 是一个$d\times V$的矩阵, $d$表示的是词嵌入的维度, 那么用$W*w_t$(矩阵乘法)就会得到中心词的词向量表示$v_c$, 大小是$d\times1$。这个就是中心词的embedding向量。 其实就是中心词过了一个embedding层得到了它的embedding向量。
|
||||
><br>然后就是$v_c$和上下文矩阵$W'$相乘, 这里的$W'$是$V\times d$的一个矩阵, 每一行代表每个单词作为上下文的时候的词向量表示, 也就是$u_w$, 每一列是词嵌入的维度。 这样通过$W'*v_c$就会得到一个$V\times 1$的向量,这个表示的就是中心单词$w_t$与每个单词的相似程度。
|
||||
><br>最后,我们通过softmax操作把这个相似程度转成概率, 选择概率最大的index输出。
|
||||
|
||||
这就是这个模型的前向传播过程。
|
||||
|
||||
有了这个过程, 再理解YouTubeDNN顶部就非常容易了, 我单独截出来:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/98811e09226f42a2be981b0aa3449ab3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
只看这里的这个过程, 其实就是上面skip-gram过程, 不一样的是右边这个中心词向量$v_c$是直接过了一个embedding层得到的,而左边这个用户向量$u$是用户的各种特征先拼接成一个大的向量,然后过了一个DNN降维。 训练方式上,这两个也是一模一样的,无非就是左边的召回模型,多了几层全连接而已。
|
||||
> 这样,也就很容易的理解,模型训练好了之后,用户向量和item向量到底在哪里取了吧。
|
||||
> * 用户向量,其实就是全连接的DNN网络的输出向量,其实即使没有全连接,原始的用户各个特征拼接起来的那个长向量也能用,不过维度可能太大了,所以DNN在这里的作用一个是特征交叉,另一个还有降维的功效。
|
||||
> * item向量: 这个其实和skip-gram那个一样,每个item其实是用两个embedding向量的,比如skip-gram那里就有一个作为中心词时候的embedding矩阵$W$和作为上下文词时候的embedding矩阵$W'$, 一般取的时候会取前面那个$W$作为每个词的词向量。 这里其实一个道理,只不过这里最前面那个item向量矩阵,是通过了w2v的方式训练好了直接作为的输入,如果不事先计算好,对应的是embedding层得到的那个矩阵。 后面的item向量矩阵,就是这里得到用户向量之后,后面进行softmax之前的这个矩阵, **YouTubeDNN最终是从这个矩阵里面拿item向量**。
|
||||
|
||||
这就是知识串联的魅力,其实熟悉了word2vec, 这个召回模型理解非常简单。
|
||||
|
||||
这其实就是这个模型训练阶段最原始的剖析,实际训练的时候,依然是采用了优化方法, 这个和word2vec也是一样,采用了负采样的方式(当然实现细节上有区别),因为视频的数量太大,每次做多分类,最终那个概率分母上的加和就非常可怕了,所以就把多分类问题转成了多个二分类的问题。 也就是不用全部的视频,而是随机选择出了一些没点的视频, 标记为0, 点了的视频标记为1, 这样就成了二分类的问题。 关于负样本采样原理, 我之前也整理了[一篇博客](https://blog.csdn.net/wuzhongqiang/article/details/106979179?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164310239216780274177509%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=164310239216780274177509&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-106979179.nonecase&utm_term=word2vec&spm=1018.2226.3001.4450)
|
||||
>负类基于样本分布抽取而来。负采样是针对类别数很多情况下的常用方法。当然,负样本的选择也是有讲究的,详细的看[这篇文章](https://www.zhihu.com/question/334844408/answer/2299283878), 我后面实验主要用了下面两种
|
||||
>* 展示数据随机选择负例
|
||||
>* 随机负例与热门打压
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/6fe56d71de8a4d769a583f27a3ce9f40.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这样整个召回模型训练部分的"基本操作"就基本整理完了。关于细节部分,后面代码里面会描述下, 但是在训练召回模型过程中,还有一些经验性的知识也非常重要。 下面重点整理一下。
|
||||
|
||||
### 训练数据的选取和生成
|
||||
模型训练的时候, 为了计算更加高效,采用了负采样的方法, 但正负样本的选取,以及训练样本的来源, 还有一些注意事项。
|
||||
|
||||
首先,训练样本来源于全部的YouTube观看记录,而不仅仅是被推荐的观看记录
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/faf8a8abf7b54b779287acadc015b6a0.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
否则对于新视频会难以被曝光,会使最终推荐结果有偏;同时系统也会采集用户从其他渠道观看的视频,从而可以快速应用到协同过滤中;
|
||||
|
||||
其次, 是训练数据来源于用户的隐式数据, 且**用户看完了的视频作为正样本**, 注意这里是看完了, 有一定的时长限制, 而不是仅仅曝光点击,有可能有误点的。 而负样本,是从视频库里面随机选取,或者在曝光过的里面随机选取用户没看过的作为负样本。
|
||||
|
||||
==这里的一个经验==是**训练数据中对于每个用户选取相同的样本数, 保证用户在损失函数等权重**, 因为这样可以减少高度活跃用户对于loss的影响。可以改进线上A/B测试的效果。
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/35386af8fd064de3a87cb418b008e444.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这里的==另一个经验==是**避免让模型知道不该知道的信息**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/0765134e1ca445c693058aaaaf20ae74.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这里作者举了一个例子是如果模型知道用户最后的行为是搜索了"Taylor Swift", 那么模型可能会倾向于推荐搜索页面搜"Taylor Swift"时搜索的视频, 这个不是推荐模型期望的行为。 解法方法是**扔掉时序信息**, 历史搜索tokens随机打乱, 使用无序的搜索tokens来表示搜索queryies(average pooling)。
|
||||
>基于这个例子就把时序信息扔掉理由挺勉强的,解决这种特殊场景的信息泄露会有更针对性的方法,比如把搜索query与搜索结果行为绑定让它们不可分。 感觉时序信息还是挺重要的, 有专门针对时序信息建模的研究。
|
||||
|
||||
在生成样本的时候, 如果我们的用户比较少,行为比较少, 是不足以训练一个较好的召回模型,此时一个用户的历史观看序列,可以采用滑动窗口的形式生成多个训练样本, 比如一个用户的历史观看记录是"abcdef", 那么采用滑动窗口, 可以是abc预测d, bcd预测e, cde预测f,这样一个用户就能生成3条训练样本。 后面实验里面也是这么做的。 但这时候一定要注意一点,就是**信息泄露**,这个也是和word2vec的cbow不一样的地方。
|
||||
|
||||
论文中上面这种滑动制作样本的方式依据是用户的"asymmetric co-watch probabilities(非对称观看概率)",即一般情况下,用户开始浏览范围较广, 之后浏览范围逐渐变窄。
|
||||
|
||||
下图中的$w_{tN}$表示当前样本, 原来的做法是它前后的用户行为都可以用来产生特征行为输入(word2vec的CBOW做样本的方法)。 而作者担心这一点会导致信息泄露, 模型**不该知道的信息是未来的用户行为**, 所以作者的做法是只使用更早时间的用户行为来产生特征, 这个也是目前通用的做法。 两种方法的对比如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/049cbeb814f843fd97638ef02d6c5703.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_2,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
(a)是许多协同过滤会采取的方法,利用全局的观看信息作为输入(包括时间节点N前,N后的观看),这种方法忽略了观看序列的不对称性,而本文中采取(b)所示的方法,只把历史信息当作输入,用历史来预测未来
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/4ac0c81e5f4f4276a4ed0e4c6329f458.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
模型的测试集, 往往也是用户最近一次观看行为, 后面的实验中,把用户最后一次点击放到了测试集里面去。这样可以防止信息穿越。
|
||||
|
||||
数据集的细节和tricks基本上说完, 更细的东西,就得通过代码去解释了。 接下来, 再聊聊作者加入的非常有意思的一个特征,叫做example age。
|
||||
|
||||
### "Example Age"特征
|
||||
这个特征我想单独拿出来说,是因为这个是和场景比较相关的特征,也是作者的经验传授。 我们知道,视频有明显的生命周期,例如刚上传的视频比之后更受欢迎,也就是用户往往喜欢看最新的东西,而不管它是不是和用户相关,所以视频的流行度随着时间的分布是高度非稳态变化的(下面图中的绿色曲线)
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/15dfce743bd2490a8adb21fd3b2b294e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
但是我们模型训练的时候,是基于历史数据训练的(历史观看记录的平均),所以模型对播放某个视频预测值的期望会倾向于其在训练数据时间内的平均播放概率(平均热度), 上图中蓝色线。但如上面绿色线,实际上该视频在训练数据时间窗口内热度很可能不均匀, 用户本身就喜欢新上传的内容。 所以,为了让模型学习到用户这种对新颖内容的bias, 作者引入了"example age"这个特征来捕捉视频的生命周期。
|
||||
|
||||
"example age"定义为$t_{max}-t$, 其中$t_{max}$是训练数据中所有样本的时间最大值(有的文章说是当前时间,但我总觉得还是选取的训练数据所在时间段的右端点时间比较合适,就比如我用的数据集, 最晚时间是2021年7月的,总不能用现在的时间吧), 而$t$为当前样本的时间。**线上预测时, 直接把example age全部设为0或一个小的负值,这样就不依赖于各个视频的上传时间了**。
|
||||
>其实这个操作, 现在常用的是位置上的除偏, 比如商品推荐的时候, 用户往往喜欢点击最上面位置的商品或广告, 但这个bias模型依然是不知道, 为了让模型学习到这个东西, 也可以把商品或者广告的位置信息做成一个feature, 训练的时候告诉模型。 而线上推理的那些商品, 这个feature也都用一样的。 异曲同工的意思有没有。<br><br>那么这样的操作为啥会work呢? example age这个我理解,是有了这个特征, 就可以把某视频的热度分布信息传递给模型了, 比如某个example age时间段该视频播放较多, 而另外的时间段播放较少, 这样模型就能发现用户的这种新颖偏好, 消除热度偏见。<br><br>这个地方看了一些文章写说, 这样做有利于让模型推新热内容, 总感觉不是很通。 我这里理解是类似让模型消除位置偏见那样, 这里消除一种热度偏见。 <br><br>我理解是这样,假设没有这样一个example age特征表示视频新颖信息,或者一个位置特征表示商品的位置信息,那模型训练的样本,可能是用户点击了这个item,就是正样本, 但此时有可能是用户真的喜欢这个item, 也有可能是因为一些bias, 比如用户本身喜欢新颖, 用户本身喜欢点击上面位置的item等, 但模型推理的时候,都会误认为是用户真的喜欢这个item。 所以,为了让模型了解到可能是存在后面这种bias, 我们就把item的新颖信息, item的位置信息等做成特征, 在模型训练的时候就告诉模型,用户点了这个东西可能是它比较新或者位置比较靠上面等,这样模型在训练的时候, 就了解到了这些bias,等到模型在线推理的时候呢, 我们把这些bias特征都弄成一样的,这样每个样品在模型看来,就没有了新颖信息和位置信息bias(一视同仁了),只能靠着相关性去推理, 这样才能推到用户真正感兴趣的东西吧。<br><br>而有些文章记录的, 能够推荐更热门的视频啥的, 我很大一个疑问就是推理的时候,不是把example age用0表示吗? 模型应该不知道这些视频哪个新不新吧。 当然,这是我自己的看法,感兴趣的可以帮我解答下呀。
|
||||
|
||||
`example age`这个特征到这里还没完, 原来加入这种时间bias的传统方法是使用`video age`, 即一个video上传到样本生成的这段时间跨度, 这么说可能有些懵, 看个图吧, 原来这是两个东西:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/10475c194c0044a3a93b01a3193e294f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
王喆老师那篇文章里面也谈到了这两种理解, 对于某个视频的不同样本,其实这两种定义是等价的,因为他们的和是一个常数。
|
||||
$$
|
||||
t_{\text {video age }}+t_{\text {example age }}=\text { Const }
|
||||
$$
|
||||
详细证明可以看参考的第三篇文章。但`example age`的定义有下面两点好处:
|
||||
1. 线上预测时`example age`是常数值, 所有item可以设置成统一的, 但如果是`video age`的话,这个根每个视频的上传时间有关, 那这样在计算用户向量的时候,就依赖每个候选item了。 而统一的这个好处就是用户向量只需要计算一次。
|
||||
2. 对不同的视频,对应的`example age`所在范围一致, 只依赖训练数据选取的时间跨度,便于归一化操作。
|
||||
|
||||
### 实验结果
|
||||
这里就简单过下就好, 作者这里主要验证了下DNN的结构对推荐效果的影响,对于DNN的层级,作者尝试了0~4层, 实验结果是**层数越多越好, 但4层之后提升很有限, 层数越多训练越困难**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/fd1849a8881444fbb12490bad7598125.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
作者这里还启发了一个事情, 从"双塔"的角度再看YouTubeDNN召回模型, 这里的DNN个结构,其实就是一个用户塔, 输入用户的特征,最终通过DNN,编码出了用户的embedding向量。
|
||||
|
||||
而得到用户embedding向量到后面做softmax那块,不是说了会经过一个item embedding矩阵吗? 其实这个矩阵也可以用一个item塔来实现, 和用户embedding计算的方式类似, 首先各个item通过一个物品塔(输入是item 特征, 输出是item embedding),这样其实也能得到每个item的embedding,然后做多分类或者是二分类等。 所以**YouTubeDNN召回模型本质上还是双塔结构**, 只不过上面图里面值体现了用户塔。 我看deepmatch包里面实现的时候, 用户特征和item特征分开输入的, 感觉应该就是实现了个双塔。源码倒是没看, 等看了之后再确认。
|
||||
|
||||
### 线上服务
|
||||
线上服务的时候, YouTube采用了一种最近邻搜索的方法去完成topK推荐,这其实是工程与学术trade-off的结果, model serving过程中对几百万个候选集一一跑模型显然不现实, 所以通过召回模型得到用户和video的embedding之后, 用最近邻搜索的效率会快很多。
|
||||
|
||||
我们甚至不用把任何model inference的过程搬上服务器,只需要把user embedding和video embedding存到redis或者内存中就好了。like this:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/86751a834d224ad69220b5040e0e03c9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
在线上,可以根据用户兴趣Embedding,采用类似Faiss等高效Embedding检索工具,快速找出和用户兴趣匹配的物品, 高效embedding检索工具, 我目前接触到了两个,一个是Faiss, 一个是annoy, 关于这两个工具的使用, 我也整理了两篇文章:
|
||||
* [annoy(快速近邻向量搜索包)学习小记](https://blog.csdn.net/wuzhongqiang/article/details/122516942?spm=1001.2014.3001.5501)
|
||||
* [Faiss(Facebook开源的高效相似搜索库)学习小记](https://blog.csdn.net/wuzhongqiang/article/details/122516942?spm=1001.2014.3001.5501)
|
||||
|
||||
|
||||
之前写新闻推荐比赛的时候用过Faiss, 这次实验中使用的是annoy工具包。
|
||||
|
||||
另外多整理一点:
|
||||
>我们做线上召回的时候, 其实可以有两种:
|
||||
>1. item_2_item: 因为我们有了所有item的embedding了, 那么就可以进行物品与物品之间相似度计算,每个物品得到近似的K个, 这时候,就和协同过滤原理一样, 之间通过用户观看过的历史item,就能进行相似召回了, 工程实现上,一般会每个item建立一个相似度倒排表
|
||||
>2. user_2_item: 将item用faiss或者annoy组织成index,然后用user embedding去查相近item
|
||||
|
||||
## 基于Deepmatch包YouTubeDNN的使用方法
|
||||
由于时间原因, 我这里并没有自己写代码复现YouTubeDNN模型,这个结构也比较简单, 几层的DNN,自己再写一遍剖析架构也没有啥意思, 所以就采用浅梦大佬写的deepmatch包, 直接用到了自己的数据集上做了实验。 关于Deepmatch源码, 还是看[deepmatch项目](https://github.com/shenweichen/DeepMatch), 这里主要是整理下YouTubeDNN如何用。
|
||||
|
||||
项目里面其实给出了如何使用YouTubeDNN,采用的是movielens数据集, 见[这里](https://github.com/shenweichen/DeepMatch/blob/master/examples/run_youtubednn.py)
|
||||
|
||||
我这里就基于我做实验用的新闻推荐数据集, 把代码的主要逻辑过一遍。
|
||||
|
||||
### 数据集
|
||||
实验用的数据集是新闻推荐的一个数据集,是做func-rec项目时候一个伙伴分享的,来自于某个推荐比赛,因为这个数据集是来自工业上的真实数据,所以使用起来比之前用的movielens数据集可尝试的东西多一些,并且原数据有8个多G,总共3个文件: 用户画像,文章画像, 点击日志,用户数量100多万,6000多万次点击, 文章规模是几百,数据量也比较丰富,所以后面就打算采用这个统一的数据集, 重新做实验,对比目前GitHub上的各个模型。关于数据集每个文件详细描述,后面会更新到GitHub项目。
|
||||
|
||||
这里只整理我目前的使用过程, 由于有8个多G的数据,我这边没法直接跑,所以对数据进行了采样, 采样方法写成了一个jupyter文件。 主要包括:
|
||||
1. 分块读取数据, 无法一下子读入内存
|
||||
2. 对于每块数据,基于一些筛选规则进行记录的删除,比如只用了后7天的数据, 删除了一些文章不在物料池的数据, 删除不合法的点击记录(曝光时间大于文章上传时间), 删除没有历史点击的用户,删除观看时间低于3s的视频, 删除历史点击序列太短和太长的用户记录
|
||||
3. 删除完之后重新保存一份新数据集,大约3个G,然后再从这里面随机采样了20000用户进行了后面实验
|
||||
|
||||
通过上面的一波操作, 我的小本子就能跑起来了,当然可能数据比较少,最终训练的YouTubeDNN效果并不是很好。详细看后面GitHub的: `点击日志数据集初步处理与采样.ipynb`
|
||||
|
||||
### 简单数据预处理
|
||||
这个也是写成了一个笔记本, 主要是看了下采样后的数据,序列长度分布等,由于上面做了一些规整化,这里有毛病的数据不是太多,并没有太多处理, 但是用户数据里面的年龄,性别源数据是给出了多种可能, 每个可能有概率值,我这里选出了概率最大的那个,然后简单填充了缺失。
|
||||
|
||||
最后把能用到的用户画像和文章画像统一拼接到了点击日志数据,又保存了一份。 作为YouTubeDNN模型的使用数据, 其他模型我也打算使用这份数据了。
|
||||
|
||||
详见`EDA与数据预处理.ipynb`
|
||||
|
||||
### YouTubeDNN召回
|
||||
这里就需要解释下一些代码了, 首先拿到采样的数据集,我们先划分下训练集和测试集:
|
||||
* 测试集: 每个用户的最后一次点击记录
|
||||
* 训练集: 每个用户除最后一次点击的所有点击记录
|
||||
|
||||
这个具体代码就不在这里写了。
|
||||
|
||||
```python
|
||||
user_click_hist_df, user_click_last_df = get_hist_and_last_click(click_df)
|
||||
```
|
||||
|
||||
这么划分的依据,就是保证不能发生数据穿越,拿最后的测试,不能让模型看到。
|
||||
|
||||
接下来,就是YouTubeDNN模型的召回,从构造数据集 -> 训练模型 -> 产生召回结果,我写到了一个函数里面去。
|
||||
|
||||
```cpp
|
||||
def youtubednn_recall(data, topk=200, embedding_dim=8, his_seq_maxlen=50, negsample=0,
|
||||
batch_size=64, epochs=1, verbose=1, validation_split=0.0):
|
||||
"""通过YouTubeDNN模型,计算用户向量和文章向量
|
||||
param: data: 用户日志数据
|
||||
topk: 对于每个用户,召回多少篇文章
|
||||
"""
|
||||
user_id_raw = data[['user_id']].drop_duplicates('user_id')
|
||||
doc_id_raw = data[['article_id']].drop_duplicates('article_id')
|
||||
|
||||
# 类别数据编码
|
||||
base_features = ['user_id', 'article_id', 'city', 'age', 'gender']
|
||||
feature_max_idx = {}
|
||||
for f in base_features:
|
||||
lbe = LabelEncoder()
|
||||
data[f] = lbe.fit_transform(data[f])
|
||||
feature_max_idx[f] = data[f].max() + 1
|
||||
|
||||
# 构建用户id词典和doc的id词典,方便从用户idx找到原始的id
|
||||
user_id_enc = data[['user_id']].drop_duplicates('user_id')
|
||||
doc_id_enc = data[['article_id']].drop_duplicates('article_id')
|
||||
user_idx_2_rawid = dict(zip(user_id_enc['user_id'], user_id_raw['user_id']))
|
||||
doc_idx_2_rawid = dict(zip(doc_id_enc['article_id'], doc_id_raw['article_id']))
|
||||
|
||||
# 保存下每篇文章的被点击数量, 方便后面高热文章的打压
|
||||
doc_clicked_count_df = data.groupby('article_id')['click'].apply(lambda x: x.count()).reset_index()
|
||||
doc_clicked_count_dict = dict(zip(doc_clicked_count_df['article_id'], doc_clicked_count_df['click']))
|
||||
|
||||
train_set, test_set = gen_data_set(data, doc_clicked_count_dict, negsample, control_users=True)
|
||||
|
||||
# 构造youtubeDNN模型的输入
|
||||
train_model_input, train_label = gen_model_input(train_set, his_seq_maxlen)
|
||||
test_model_input, test_label = gen_model_input(test_set, his_seq_maxlen)
|
||||
|
||||
# 构建模型并完成训练
|
||||
model = train_youtube_model(train_model_input, train_label, embedding_dim, feature_max_idx, his_seq_maxlen, batch_size, epochs, verbose, validation_split)
|
||||
|
||||
# 获得用户embedding和doc的embedding, 并进行保存
|
||||
user_embs, doc_embs = get_embeddings(model, test_model_input, user_idx_2_rawid, doc_idx_2_rawid)
|
||||
|
||||
# 对每个用户,拿到召回结果并返回回来
|
||||
user_recall_doc_dict = get_youtube_recall_res(user_embs, doc_embs, user_idx_2_rawid, doc_idx_2_rawid, topk)
|
||||
|
||||
return user_recall_doc_dict
|
||||
```
|
||||
这里面说一下主要逻辑,主要是下面几步:
|
||||
1. 用户id和文章id我们要先建立索引-原始id的字典,因为我们模型里面是要把id转成embedding,模型的表示形式会是{索引: embedding}的形式, 如果我们想得到原始id,必须先建立起映射来
|
||||
2. 把类别特征进行label Encoder, 模型输入需要, embedding层需要,这是构建词典常规操作, 这里要记录下每个特征特征值的个数,建词典索引的时候用到,得知道词典大小
|
||||
3. 保存了下每篇文章被点击数量, 方便后面对高热文章实施打压
|
||||
4. 构建数据集
|
||||
|
||||
```python
|
||||
rain_set, test_set = gen_data_set(data, doc_clicked_count_dict, negsample, control_users=True)
|
||||
```
|
||||
这个需要解释下, 虽然我们上面有了一个训练集,但是这个东西是不能直接作为模型输入的, 第一个原因是正样本太少,样本数量不足,我们得需要滑动窗口,每个用户再滑动构造一些,第二个是不满足deepmatch实现的模型输入格式,所以gen_data_set这个函数,是用deepmatch YouTubeDNN的第一个范式,基本上得按照这个来,只不过我加了一些策略上的尝试:
|
||||
```python
|
||||
def gen_data_set(click_data, doc_clicked_count_dict, negsample, control_users=False):
|
||||
"""构造youtubeDNN的数据集"""
|
||||
# 按照曝光时间排序
|
||||
click_data.sort_values("expo_time", inplace=True)
|
||||
item_ids = click_data['article_id'].unique()
|
||||
|
||||
train_set, test_set = [], []
|
||||
for user_id, hist_click in tqdm(click_data.groupby('user_id')):
|
||||
# 这里按照expo_date分开,每一天用滑动窗口滑,可能相关性更高些,另外,这样序列不会太长,因为eda发现有点击1111个的
|
||||
#for expo_date, hist_click in hist_date_click.groupby('expo_date'):
|
||||
# 用户当天的点击历史id
|
||||
pos_list = hist_click['article_id'].tolist()
|
||||
user_control_flag = True
|
||||
|
||||
if control_users:
|
||||
user_samples_cou = 0
|
||||
|
||||
# 过长的序列截断
|
||||
if len(pos_list) > 50:
|
||||
pos_list = pos_list[-50:]
|
||||
|
||||
if negsample > 0:
|
||||
neg_list = gen_neg_sample_candiate(pos_list, item_ids, doc_clicked_count_dict, negsample, methods='multinomial')
|
||||
|
||||
# 只有1个的也截断 去掉,当然我之前做了处理,这里没有这种情况了
|
||||
if len(pos_list) < 2:
|
||||
continue
|
||||
else:
|
||||
# 序列至少是2
|
||||
for i in range(1, len(pos_list)):
|
||||
hist = pos_list[:i]
|
||||
# 这里采用打压热门item策略,降低高展item成为正样本的概率
|
||||
freq_i = doc_clicked_count_dict[pos_list[i]] / (np.sum(list(doc_clicked_count_dict.values())))
|
||||
p_posi = (np.sqrt(freq_i/0.001)+1)*(0.001/freq_i)
|
||||
|
||||
# p_posi=0.3 表示该item_i成为正样本的概率是0.3,
|
||||
if user_control_flag and i != len(pos_list) - 1:
|
||||
if random.random() > (1-p_posi):
|
||||
row = [user_id, hist[::-1], pos_list[i], hist_click.iloc[0]['city'], hist_click.iloc[0]['age'], hist_click.iloc[0]['gender'], hist_click.iloc[i]['example_age'], 1, len(hist[::-1])]
|
||||
train_set.append(row)
|
||||
|
||||
for negi in range(negsample):
|
||||
row = [user_id, hist[::-1], neg_list[i*negsample+negi], hist_click.iloc[0]['city'], hist_click.iloc[0]['age'], hist_click.iloc[0]['gender'], hist_click.iloc[i]['example_age'], 0, len(hist[::-1])]
|
||||
train_set.append(row)
|
||||
|
||||
if control_users:
|
||||
user_samples_cou += 1
|
||||
# 每个用户序列最长是50, 即每个用户正样本个数最多是50个, 如果每个用户训练样本数量到了30个,训练集不能加这个用户了
|
||||
if user_samples_cou > 30:
|
||||
user_samples_cou = False
|
||||
|
||||
# 整个序列加入到test_set, 注意,这里一定每个用户只有一个最长序列,相当于测试集数目等于用户个数
|
||||
elif i == len(pos_list) - 1:
|
||||
row = [user_id, hist[::-1], pos_list[i], hist_click.iloc[0]['city'], hist_click.iloc[0]['age'], hist_click.iloc[0]['gender'], 0, 0, len(hist[::-1])]
|
||||
test_set.append(row)
|
||||
|
||||
|
||||
random.shuffle(train_set)
|
||||
random.shuffle(test_set)
|
||||
|
||||
return train_set, test_set
|
||||
```
|
||||
关键代码逻辑是首先点击数据按照时间戳排序,然后按照用户分组,对于每个用户的历史点击, 采用滑动窗口的形式,边滑动边构造样本, 第一个注意的地方,是每滑动一次生成一条正样本的时候, 要加入一定比例的负样本进去, 第二个注意最后一整条序列要放到test_set里面。<br><br>我这里面加入的一些策略,负样本候选集生成我单独写成一个函数,因为尝试了随机采样和打压热门item采样两种方式, 可以通过methods参数选择。 另外一个就是正样本里面也按照热门实现了打压, 减少高热item成为正样本概率,增加高热item成为负样本概率。 还加了一个控制用户样本数量的参数,去保证每个用户生成一样多的样本数量,打压下高活用户。
|
||||
5. 构造模型输入
|
||||
这个也是调包的定式操作,必须按照这个写法来:
|
||||
|
||||
|
||||
```python
|
||||
def gen_model_input(train_set, his_seq_max_len):
|
||||
"""构造模型的输入"""
|
||||
# row: [user_id, hist_list, cur_doc_id, city, age, gender, label, hist_len]
|
||||
train_uid = np.array([row[0] for row in train_set])
|
||||
train_hist_seq = [row[1] for row in train_set]
|
||||
train_iid = np.array([row[2] for row in train_set])
|
||||
train_u_city = np.array([row[3] for row in train_set])
|
||||
train_u_age = np.array([row[4] for row in train_set])
|
||||
train_u_gender = np.array([row[5] for row in train_set])
|
||||
train_u_example_age = np.array([row[6] for row in train_set])
|
||||
train_label = np.array([row[7] for row in train_set])
|
||||
train_hist_len = np.array([row[8] for row in train_set])
|
||||
|
||||
train_seq_pad = pad_sequences(train_hist_seq, maxlen=his_seq_max_len, padding='post', truncating='post', value=0)
|
||||
train_model_input = {
|
||||
"user_id": train_uid,
|
||||
"click_doc_id": train_iid,
|
||||
"hist_doc_ids": train_seq_pad,
|
||||
"hist_len": train_hist_len,
|
||||
"u_city": train_u_city,
|
||||
"u_age": train_u_age,
|
||||
"u_gender": train_u_gender,
|
||||
"u_example_age":train_u_example_age
|
||||
}
|
||||
return train_model_input, train_label
|
||||
```
|
||||
上面构造数据集的时候,是把每个特征加入到了二维数组里面去, 这里得告诉模型,每一个维度是啥特征数据。如果相加特征,首先构造数据集的时候,得把数据加入到数组中, 然后在这个函数里面再指定新加入的特征是啥。 下面的那个词典, 是为了把数据输入和模型的Input层给对应起来,通过字典键进行标识。
|
||||
6. 训练YouTubeDNN
|
||||
这一块也是定式, 在建模型事情,要把特征封装起来,告诉模型哪些是离散特征,哪些是连续特征, 模型要为这些特征建立不同的Input层,处理方式是不一样的
|
||||
|
||||
```python
|
||||
def train_youtube_model(train_model_input, train_label, embedding_dim, feature_max_idx, his_seq_maxlen, batch_size, epochs, verbose, validation_split):
|
||||
"""构建youtubednn并完成训练"""
|
||||
# 特征封装
|
||||
user_feature_columns = [
|
||||
SparseFeat('user_id', feature_max_idx['user_id'], embedding_dim),
|
||||
VarLenSparseFeat(SparseFeat('hist_doc_ids', feature_max_idx['article_id'], embedding_dim,
|
||||
embedding_name="click_doc_id"), his_seq_maxlen, 'mean', 'hist_len'),
|
||||
|
||||
SparseFeat('u_city', feature_max_idx['city'], embedding_dim),
|
||||
SparseFeat('u_age', feature_max_idx['age'], embedding_dim),
|
||||
SparseFeat('u_gender', feature_max_idx['gender'], embedding_dim),
|
||||
DenseFeat('u_example_age', 1,)
|
||||
]
|
||||
doc_feature_columns = [
|
||||
SparseFeat('click_doc_id', feature_max_idx['article_id'], embedding_dim)
|
||||
# 这里后面也可以把文章的类别画像特征加入
|
||||
]
|
||||
|
||||
# 定义模型
|
||||
model = YoutubeDNN(user_feature_columns, doc_feature_columns, num_sampled=5, user_dnn_hidden_units=(64, embedding_dim))
|
||||
|
||||
# 模型编译
|
||||
model.compile(optimizer="adam", loss=sampledsoftmaxloss)
|
||||
|
||||
# 模型训练,这里可以定义验证集的比例,如果设置为0的话就是全量数据直接进行训练
|
||||
history = model.fit(train_model_input, train_label, batch_size=batch_size, epochs=epochs, verbose=verbose, validation_split=validation_split)
|
||||
|
||||
return model
|
||||
```
|
||||
然后就是建模型,编译训练即可。这块就非常简单了,当然模型方面有些参数,可以了解下,另外一个注意点,就是这里用户特征和item特征进行了分开, 这其实和双塔模式很像, 用户特征最后编码成用户向量, item特征最后编码成item向量。
|
||||
7. 获得用户向量和item向量
|
||||
模型训练完之后,就能从模型里面拿用户向量和item向量, 我这里单独写了一个函数:
|
||||
|
||||
```python
|
||||
获取用户embedding和文章embedding
|
||||
def get_embeddings(model, test_model_input, user_idx_2_rawid, doc_idx_2_rawid, save_path='embedding/'):
|
||||
doc_model_input = {'click_doc_id':np.array(list(doc_idx_2_rawid.keys()))}
|
||||
|
||||
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
|
||||
doc_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
|
||||
|
||||
# 保存当前的item_embedding 和 user_embedding 排序的时候可能能够用到,但是需要注意保存的时候需要和原始的id对应
|
||||
user_embs = user_embedding_model.predict(test_model_input, batch_size=2 ** 12)
|
||||
doc_embs = doc_embedding_model.predict(doc_model_input, batch_size=2 ** 12)
|
||||
# embedding保存之前归一化一下
|
||||
user_embs = user_embs / np.linalg.norm(user_embs, axis=1, keepdims=True)
|
||||
doc_embs = doc_embs / np.linalg.norm(doc_embs, axis=1, keepdims=True)
|
||||
|
||||
# 将Embedding转换成字典的形式方便查询
|
||||
raw_user_id_emb_dict = {user_idx_2_rawid[k]: \
|
||||
v for k, v in zip(user_idx_2_rawid.keys(), user_embs)}
|
||||
raw_doc_id_emb_dict = {doc_idx_2_rawid[k]: \
|
||||
v for k, v in zip(doc_idx_2_rawid.keys(), doc_embs)}
|
||||
# 将Embedding保存到本地
|
||||
pickle.dump(raw_user_id_emb_dict, open(save_path + 'user_youtube_emb.pkl', 'wb'))
|
||||
pickle.dump(raw_doc_id_emb_dict, open(save_path + 'doc_youtube_emb.pkl', 'wb'))
|
||||
|
||||
# 读取
|
||||
#user_embs_dict = pickle.load(open('embedding/user_youtube_emb.pkl', 'rb'))
|
||||
#doc_embs_dict = pickle.load(open('embedding/doc_youtube_emb.pkl', 'rb'))
|
||||
return user_embs, doc_embs
|
||||
```
|
||||
获取embedding的这两行代码是固定操作, 下面做了一些归一化操作,以及把索引转成了原始id的形式。
|
||||
8. 向量最近邻检索,为每个用户召回相似item
|
||||
|
||||
```python
|
||||
def get_youtube_recall_res(user_embs, doc_embs, user_idx_2_rawid, doc_idx_2_rawid, topk):
|
||||
"""近邻检索,这里用annoy tree"""
|
||||
# 把doc_embs构建成索引树
|
||||
f = user_embs.shape[1]
|
||||
t = AnnoyIndex(f, 'angular')
|
||||
for i, v in enumerate(doc_embs):
|
||||
t.add_item(i, v)
|
||||
t.build(10)
|
||||
# 可以保存该索引树 t.save('annoy.ann')
|
||||
|
||||
# 每个用户向量, 返回最近的TopK个item
|
||||
user_recall_items_dict = collections.defaultdict(dict)
|
||||
for i, u in enumerate(user_embs):
|
||||
recall_doc_scores = t.get_nns_by_vector(u, topk, include_distances=True)
|
||||
# recall_doc_scores是(([doc_idx], [scores])), 这里需要转成原始doc的id
|
||||
raw_doc_scores = list(recall_doc_scores)
|
||||
raw_doc_scores[0] = [doc_idx_2_rawid[i] for i in raw_doc_scores[0]]
|
||||
# 转换成实际用户id
|
||||
try:
|
||||
user_recall_items_dict[user_idx_2_rawid[i]] = dict(zip(*raw_doc_scores))
|
||||
except:
|
||||
continue
|
||||
|
||||
# 默认是分数从小到大排的序, 这里要从大到小
|
||||
user_recall_items_dict = {k: sorted(v.items(), key=lambda x: x[1], reverse=True) for k, v in user_recall_items_dict.items()}
|
||||
|
||||
# 保存一份
|
||||
pickle.dump(user_recall_items_dict, open('youtube_u2i_dict.pkl', 'wb'))
|
||||
|
||||
return user_recall_items_dict
|
||||
```
|
||||
用了用户embedding和item向量,就可以通过这个函数进行检索, 这块主要是annoy包做近邻检索的固定格式, 检索完毕,为用户生成最相似的200个候选item。
|
||||
|
||||
以上,就是使用YouTubeDNN做召回的整个流程。 效果如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/e904362d28fd4bdbacb5715ff2abaac2.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这个字典长这样:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/840e3abaf30845499f0926c61ba88635.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
接下来就是评估模型的效果,这里我采用了简单的HR@N计算的, 具体代码看GitHub吧, 结果如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/eb6ccadaa98e46bd87e594ee11e957a7.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
结果不怎么样啊,唉, 难道是数据量太少了? 总归是跑起来且能用了。
|
||||
|
||||
详细代码见尾部GitHub链接吧, 硬件设施到位的可以尝试多用一些数据试试看哈哈。
|
||||
|
||||
## YouTubeDNN新闻推荐数据集的实验记录
|
||||
这块就比较简单了,简单的整理下我用上面代码做个的实验,尝试了论文里面的几个点,记录下:
|
||||
1. 负采样方式上,尝试了随机负采样和打压高热item两种方式, 从我的实验结果上来看, 带打压的效果略好一点点
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/7cf27f1b849049f0b4bd98d0ebb7925f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
2. 特征上, 尝试原论文给出的example age的方式,做一个样本的年龄特征出来
|
||||
这个年龄样本,我是用的训练集的最大时间减去曝光的时间,然后转成小时间隔算的,而测试集里面的统一用0表示, 但效果好差。 看好多文章说这个时间单位是个坑,不知道是小时,分钟,另外这个特征我只做了简单归一化,感觉应该需要做归一化
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/1ea482f538c94b8bb07a69023b14ca9b.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
3. 尝试了控制用户数量,即每个用户的样本数量保持一样,效果比上面略差
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/8653b76d0b434d1088da196ce94bb954.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
4. 开始模型评估,我尝试用最后一天的,而不是最后一次点击的, 感觉效果不如最后一次点击作为测试集效果好
|
||||
|
||||
当然,上面实验并没有太大说服力,第一个是我采样的数据量太少,模型本身训练的不怎么样,第二个这些策略相差的并不是很大, 可能有偶然性。
|
||||
|
||||
并且我这边做一次实验,要花费好长时间,探索就先到这里吧, example age那个确实是个迷, 其他的感觉起来, 打压高活效果要比不打压要好。
|
||||
|
||||
另外要记录下学习小tricks:
|
||||
> 跑一次这样的实验,我这边一般会花费两个小时左右的时间, 而这个时间在做实验之前,一定要做规划才能好好的利用起来, 比如,我计划明天上午要开始尝试各种策略做实验, 今天晚上的todo里面,就要记录好, 我会尝试哪些策略,记录一个表, 调整策略,跑模型的时候,我这段空档要干什么事情, todo里面都要记录好,比如我这段空档就是解读这篇paper,写完这篇博客,基本上是所有实验做完,我这篇博客也差不多写完,正好,哈哈<br><br>这个空档利用,一定要提前在todo里面写好,而不是跑模型的时候再想,这个时候往往啥也干不下去,并且还会时不时的看模型跑,或者盯着进度条发呆,那这段时间就有些浪费了呀,即使这段时间不学习,看个久违的电视剧, 久违的书,或者keep下不香吗哈哈, 但得提前规划。<br><br>可能每个人习惯不一样,对于我,是这样哈,所以记录下 ;)
|
||||
|
||||
## 总结
|
||||
|
||||
由于这篇文章里面的工程经验太多啦,我前面介绍的时候,可能涉及到知识的一些扩展补充,把经验整理的比较凌乱,这里再统一整理下, 这些也都是工业界常用的一些经验了:
|
||||
|
||||
召回部分:
|
||||
1. 训练数据的样本来源应该是全部物料, 而不仅仅是被推荐的物料,否则对于新物料难以曝光
|
||||
2. 训练数据中对于每个用户选取相同的样本数, 保证用户在损失函数等权重, 这个虽然不一定非得这么做,但考虑打压高活用户或者是高活item的影响还是必须的
|
||||
3. 序列无序化: 用户的最近一次搜索与搜索之后的播放行为有很强关联,为了避免信息泄露,将搜索行为顺序打乱。
|
||||
4. 训练数据构造: 预测接下来播放而不是用传统cbow中的两侧预测中间的考虑是可以防止信息泄露,并且可以学习到用户的非对称视频消费模式
|
||||
5. 召回模型中,类似word2vec,video 有input embedding和output embedding两组embedding,并不是共享的, input embedding论文里面是用w2v事先训练好的, 其实也可以用embedding层联合训练
|
||||
6. 召回模型的用户embedding来自网络输出, 而video的embedding往往用后面output处的
|
||||
7. 使用 `example age` 特征处理 time bias,这样线上检索时可以预先计算好用户向量
|
||||
|
||||
|
||||
**参考资料**:
|
||||
* [重读Youtube深度学习推荐系统论文](https://zhuanlan.zhihu.com/p/52169807)
|
||||
* [YouTube深度学习推荐系统的十大工程问题](https://zhuanlan.zhihu.com/p/52169807)
|
||||
* [你真的读懂了Youtube DNN推荐论文吗](https://zhuanlan.zhihu.com/p/372238343)
|
||||
* [推荐系统经典论文(二)】YouTube DNN](https://zhuanlan.zhihu.com/p/128597084)
|
||||
* [张俊林-推荐技术发展趋势与召回模型](https://www.icode9.com/content-4-764359.html)
|
||||
* [揭开YouTube深度推荐系统模型Serving之谜](https://zhuanlan.zhihu.com/p/61827629)
|
||||
* [Deep Neural Networks for YouTube Recommendations YouTubeDNN推荐召回与排序](https://www.pianshen.com/article/82351182400/)
|
||||
308
4.人工智能/ch02/ch2.1/ch2.1.2/YoutubeTwoTower.md
Normal file
308
4.人工智能/ch02/ch2.1/ch2.1.2/YoutubeTwoTower.md
Normal file
@@ -0,0 +1,308 @@
|
||||
# 背景介绍
|
||||
|
||||
**文章核心思想**
|
||||
|
||||
+ 在大规模的推荐系统中,利用双塔模型对user-item对的交互关系进行建模,学习 $\{user,context\}$ 向量与 $\{item\}$ 向量.
|
||||
+ 针对大规模流数据,提出in-batch softmax损失函数与流数据频率估计方法(Streaming Frequency Estimation),可以更好的适应item的多种数据分布。
|
||||
|
||||
**文章主要贡献**
|
||||
|
||||
+ 提出了改进的流数据频率估计方法:针对流数据来估计item出现的频率,利用实验分析估计结果的偏差与方差,模拟实验证明该方法在数据动态变化时的功效
|
||||
|
||||
+ 提出了双塔模型架构:提供了一个针对大规模的检索推荐系统,包括了 in-batch softmax 损失函数与流数据频率估计方法,减少了负采样在每个batch中可能会出现的采样偏差问题。
|
||||
|
||||
# 算法原理
|
||||
|
||||
给定一个查询集 $Query: \left\{x_{i}\right\}_{i=1}^{N}$ 和一个物品集$Item:\left\{y_{j}\right\}_{j=1}^{M}$。
|
||||
|
||||
+ $x_{i} \in X,\quad y_{j} \in \mathcal{Y}$ 是由多种特征(例如:稀疏ID和 Dense 特征)组成的高维混合体。
|
||||
|
||||
+ 推荐的目标是对于给定一个 $query$,检索到一系列 $item$ 子集用于后续排序推荐任务。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/%E5%9B%BE%E7%89%87image-20220506202824884.png" alt="image-20220506202824884" style="zoom:50%;" />
|
||||
|
||||
## 模型目标
|
||||
|
||||
模型结构如上图所示,论文旨在对用户和物品建立两个不同的模型,将它们投影到相同维度的空间:
|
||||
$$
|
||||
u: X \times \mathbb{R}^{d} \rightarrow \mathbb{R}^{k}, v: y \times \mathbb{R}^{d} \rightarrow \mathbb{R}^{k}
|
||||
$$
|
||||
|
||||
模型的输出为用户与物品向量的内积:
|
||||
|
||||
$$
|
||||
s(x, y)=\langle u(x, \theta), v(y, \theta)\rangle
|
||||
$$
|
||||
|
||||
模型的目标是为了学习参数 $\theta$, 样本集被表示为如下格式 $\{query, item, reward \}$:
|
||||
|
||||
$$
|
||||
\mathcal{T}:=\left\{\left(x_{i}, y_{i}, r_{i}\right)\right\}_{i=1}^{T}
|
||||
$$
|
||||
|
||||
* 在推荐系统中,$r_i$ 可以扩展来捕获用户对不同候选物品的参与度。
|
||||
* 例如,在新闻推荐中 $r_i$ 可以是用户在某篇文章上花费的时间。
|
||||
|
||||
## 模型流程
|
||||
|
||||
1. 给定用户 $x$,基于 softmax 函数从物料库 $M$ 中选中候选物品 $y$ 的概率为:
|
||||
$$
|
||||
\mathcal{P}(y \mid x ; \theta)=\frac{e^{s(x, y)}}{\sum_{j \in[M]} e^{s\left(x, y_{j}\right)}}
|
||||
$$
|
||||
|
||||
* 考虑到相关奖励 $r_i$ ,加权对数似然函数的定义如下:
|
||||
|
||||
$$
|
||||
L_{T}(\theta):=-\frac{1}{T} \sum_{i \in[T]} r_{i} \cdot \log \left(\mathcal{P}\left(y_{i} \mid x_{i} ; \theta\right)\right)
|
||||
$$
|
||||
|
||||
2. 原表达式 $\mathcal{P}(y \mid x ; \theta)$ 中的分母需要遍历物料库中所有的物品,计算成本太高,故对分母中的物品要进行负采样。为了提高负采样的速度,一般是直接从训练样本所在 Batch 中进行负样本选择。于是有:
|
||||
$$
|
||||
\mathcal{P}_{B}\left(y_{i} \mid x_{i} ; \theta\right)=\frac{e^{s\left(x_{i}, y_{i}\right)}}{\sum_{j \in[B]} e^{s\left(x_{i}, y_{j}\right)}}
|
||||
$$
|
||||
|
||||
* 其中,$B$ 表示与样本 $\{x_i,y_j\}$ 同在一个 Batch 的物品集合。
|
||||
* 举例来说,对于用户1,Batch 内其他用户的正样本是用户1的负样本。
|
||||
|
||||
3. 一般而言,负采样分为 Easy Negative Sample 和 Hard Negative Sample。
|
||||
|
||||
+ 这里的 Easy Negative Sample 一般是直接从全局物料库中随机选取的负样本,由于每个用户感兴趣的物品有限,而物料库又往往很大,故即便从物料库中随机选取负样本,也大概率是用户不感兴趣的。
|
||||
|
||||
+ 在真实场景中,热门物品占据了绝大多数的购买点击。而这些热门物品往往只占据物料库物品的少部分,绝大部分物品是冷门物品。
|
||||
|
||||
+ 在物料库中随机选择负样本,往往被选中的是冷门物品。这就会造成马太效应,热门物品更热,冷门物品更冷。
|
||||
+ 一种解决方式时,在对训练样本进行负采样时,提高热门物品被选为负样本的概率,工业界的经验做法是物品被选为负样本的概率正比于物品点击次数的 0.75 次幂。
|
||||
|
||||
+ 前面提到 Batch 内进行负采样,热门物品出现在一个 Batch 的概率正比于它的点击次数。问题是,热门物品被选为负样本的概率过高了(一般正比于点击次数的 0.75 次幂),导致热门物品被过度打压。
|
||||
|
||||
+ 在本文中,为了避免对热门物品进行过度惩罚,进行了纠偏。公式如下:
|
||||
$$
|
||||
s^{c}\left(x_{i}, y_{j}\right)=s\left(x_{i}, y_{j}\right)-\log \left(p_{j}\right)
|
||||
$$
|
||||
|
||||
+ 在内积 $s(x_i,y_j)$ 的基础上,减去了物品 $j$ 的采样概率的对数。
|
||||
|
||||
4. 纠偏后,物品 $y$ 被选中的概率为:
|
||||
$$
|
||||
\mathcal{P}_{B}^{c}\left(y_{i} \mid x_{i} ; \theta\right)=\frac{e^{s^{c}\left(x_{i}, y_{i}\right)}}{e^{s^{c}\left(x_{i}, y_{i}\right)}+\sum_{j \in[B], j \neq i} e^{s^{c}\left(x_{i}, y_{j}\right)}}
|
||||
$$
|
||||
|
||||
+ 此时,batch loss function 的表示式如下:
|
||||
|
||||
$$
|
||||
L_{B}(\theta):=-\frac{1}{B} \sum_{i \in[B]} r_{i} \cdot \log \left(\mathcal{P}_{B}^{c}\left(y_{i} \mid x_{i} ; \theta\right)\right)
|
||||
$$
|
||||
+ 通过 SGD 和学习率,来优化模型参数 $\theta$ :
|
||||
|
||||
$$
|
||||
\theta \leftarrow \theta-\gamma \cdot \nabla L_{B}(\theta)
|
||||
$$
|
||||
|
||||
5. Normalization and Temperature
|
||||
|
||||
* 最后一层,得到用户和物品的特征 Embedding 表示后,再进行进行 $l2$ 归一化:
|
||||
$$
|
||||
\begin{aligned}
|
||||
u(x, \theta) \leftarrow u(x, \theta) /\|u(x, \theta)\|_{2}
|
||||
\\
|
||||
v(y, \theta) \leftarrow v(y, \theta) /\|v(y, \theta)\|_{2}
|
||||
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 本质上,其实就是将用户和物品的向量内积转换为了余弦相似度。
|
||||
|
||||
* 对于内积的结果,再除以温度参数 $\tau$:
|
||||
$$
|
||||
s(x, y)=\langle u(x, \theta), v(y, \theta)\rangle / \tau
|
||||
$$
|
||||
|
||||
+ 论文提到,这样有利于提高预测准确度。
|
||||
+ 从实验结果来看,温度参数 $\tau$ 一般小于 $1$,所以感觉就是放大了内积结果。
|
||||
|
||||
**上述模型训练过程可以归纳为:**
|
||||
|
||||
(1)从实时数据流中采样得到一个 batch 的训练样本。
|
||||
|
||||
(2)基于流频估计法,估算物品 $y_i$ 的采样概率 $p_i$ 。
|
||||
|
||||
(3)计算损失函数 $L_B$ ,再利用 SGD 方法更新参数。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/%E5%9B%BE%E7%89%87image-20220506211935092.png" alt="image-20220506211935092" style="zoom: 50%;" />
|
||||
|
||||
## 流频估计算法
|
||||
|
||||
考虑一个随机的数据 batch ,每个 batch 中包含一组物品。现在的问题是如何估计一个 batch 中物品 $y$ 的命中概率。具体方法如下:
|
||||
|
||||
+ 利用全局步长,将对物品采样频率 $p$ 转换为 对 $\delta$ 的估计,其中 $\delta$ 表示连续两次采样物品之间的平均步数。
|
||||
+ 例如,某物品平均 50 个步后会被采样到,那么采样频率 $p=1/\delta=0.02$ 。
|
||||
|
||||
**具体的实现方法为:**
|
||||
|
||||
1. 建立两个大小为 $H$ 的数组 $A,B$ 。
|
||||
|
||||
2. 通过哈希函数 $h(\cdot)$ 可以把每个物品映射为 $[H]$ 范围内的整数。
|
||||
|
||||
+ 映射的内容可以是 ID 或者其他的简单特征值。
|
||||
|
||||
+ 对于给定的物品 $y$,哈希后的整数记为 $h(y)$,本质上它表示物品 $y$ 在数组中的序号。
|
||||
|
||||
3. 数组 $A$ 中存放的 $A[h(y)]$ 表示物品 $y$ 上次被采样的时间, 数组 $B$ 中存放的 $B[h(y)]$ 表示物品 $y$ 的全局步长。
|
||||
|
||||
+ 假设在第 $t$ 步时采样到物品 $y$,则 $A[h(y)]$ 和 $B[h(y)]$ 的更新公式为:
|
||||
$$
|
||||
B[h(y)] \leftarrow(1-\alpha) \cdot B[h(y)]+\alpha \cdot(t-A[h(y)])
|
||||
$$
|
||||
|
||||
+ 在$B$ 被更新后,将 $t$ 赋值给 $A[h(y)]$ 。
|
||||
|
||||
4. 对整个batch数据采样后,取数组 $B$ 中 $B[h(y)]$ 的倒数,作为物品 $y$ 的采样频率,即:
|
||||
$$
|
||||
\hat{p}=1 / B[h(y)]
|
||||
$$
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/%E5%9B%BE%E7%89%87image-20220506220529932.png" alt="image-20220506220529932" style="zoom:50%;" />
|
||||
|
||||
**从数学理论上证明这种迭代更新的有效性:**
|
||||
|
||||
假设物品 $y$ 被采样到的时间间隔序列为 $\Delta=\left\{\Delta_{1}, \ldots, \Delta_{t}\right\}$ 满足独立同分布,这个随机变量的均值为$\delta=E[\Delta]$。对于每一次采样迭代:$\delta_{i}=(1-\alpha) \delta_{i-1}+\alpha \Delta_{i}$,可以证明时间间隔序列的均值和方差满足:
|
||||
|
||||
$$
|
||||
\begin{aligned}
|
||||
& E\left(\delta_{t}\right)-\delta=(1-\alpha)^{t} \delta_{0}-(1-\alpha)^{t-1} \delta
|
||||
\\ \\
|
||||
& E\left[\left(\delta_{t}-E\left[\delta_{t}\right]\right)^{2}\right] \leq(1-\alpha)^{2 t}\left(\delta_{0}-\delta\right)^{2}+\alpha E\left[\left(\Delta_{1}-\alpha\right)^{2}\right]
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
1. **对于均值的证明:**
|
||||
$$
|
||||
\begin{aligned}
|
||||
E\left[\delta_{t}\right] &=(1-\alpha) E\left[\delta_{t-1}\right]+\alpha \delta \\
|
||||
&=(1-\alpha)\left[(1-\alpha) E\left[\delta_{t-2}\right]+\alpha \delta\right]+\alpha \delta \\
|
||||
&=(1-\alpha)^{2} E\left[\delta_{t-2}\right]+\left[(1-\alpha)^{1}+(1-\alpha)^{0}\right] \alpha \delta \\
|
||||
&=(1-\alpha)^{3} E\left[\delta_{t-3}\right]+\left[(1-\alpha)^{2}+(1-\alpha)^{1}+(1-\alpha)^{0}\right] \alpha \delta \\
|
||||
&=\ldots \ldots \\
|
||||
&=(1-\alpha)^{t} \delta_{0}+\left[(1-\alpha)^{t-1}+\ldots+(1-\alpha)^{1}+(1-\alpha)^{0}\right] \alpha \delta \\
|
||||
&=(1-\alpha)^{t} \delta_{0}+\left[1-(1-\alpha)^{t-1}\right] \delta
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 根据均值公式可以看出:$t \rightarrow \infty \text { 时, }\left|E\left[\delta_{t}\right]-\delta\right| \rightarrow 0 $ 。
|
||||
+ 即当采样数据足够多的时候,数组 $B$ (每多少步采样一次)趋于真实采样频率。
|
||||
+ 因此递推式合理,且当初始值 $\delta_{0}=\delta /(1-\alpha)$,递推式为无偏估计。
|
||||
|
||||
2. **对于方差的证明:**
|
||||
$$
|
||||
\begin{aligned}
|
||||
E\left[\left(\delta_{t}-E\left[\delta_{t}\right]\right)^{2}\right] &=E\left[\left(\delta_{t}-\delta+\delta-E\left[\delta_{t}\right]\right)^{2}\right] \\
|
||||
&=E\left[\left(\delta_{t}-\delta\right)^{2}\right]+2 E\left[\left(\delta_{t}-\delta\right)\left(\delta-E\left[\delta_{t}\right]\right)\right]+\left(\delta-E\left[\delta_{t}\right]\right)^{2} \\
|
||||
&=E\left[\left(\delta_{t}-\delta\right)^{2}\right]-\left(E\left[\delta_{t}\right]-\delta\right)^{2} \\
|
||||
& \leq E\left[\left(\delta_{t}-\delta\right)^{2}\right]
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 对于 $E\left[\left(\delta_{i}-\delta\right)^{2}\right]$:
|
||||
$$
|
||||
\begin{aligned}
|
||||
E\left[\left(\delta_{i}-\delta\right)^{2}\right] &=E\left[\left((1-\alpha) \delta_{i-1}+\alpha \Delta_{i}-\delta\right)^{2}\right] \\
|
||||
&=E\left[\left((1-\alpha) \delta_{i-1}+\alpha \Delta_{i}-(1-\alpha+\alpha) \delta\right)^{2}\right] \\
|
||||
&=E\left[\left((1-\alpha)\left(\delta_{i-1}-\delta\right)+\alpha\left(\Delta_{i}-\delta\right)\right)^{2}\right] \\
|
||||
&=(1-\alpha)^{2} E\left[\left(\delta_{i-1}-\delta\right)^{2}\right]+\alpha^{2} E\left[\Delta_{i}-\delta\right]^{2}+2 \alpha(1-\alpha) E\left[\left(\delta_{i-1}-\delta\right)\left(\Delta_{i}-\delta\right)\right]
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 由于 $\delta_{i-1}$ 和 $\Delta_{i}$ 独立,所以上式最后一项为 0,因此:
|
||||
$$
|
||||
E\left[\left(\delta_{i}-\delta\right)^{2}\right]=(1-\alpha)^{2} E\left[\left(\delta_{i-1}-\delta\right)^{2}\right]+\alpha^{2} E\left[\Delta_{i}-\delta\right]^{2}
|
||||
$$
|
||||
|
||||
+ 与均值的推导类似,可得:
|
||||
$$
|
||||
\begin{aligned}
|
||||
E\left[\left(\delta_{t}-\delta\right)^{2}\right] &=(1-\alpha)^{2 t}\left(\delta_{0}-\delta\right)^{2}+\alpha^{2} \frac{1-(1-\alpha)^{2 t-2}}{1-(1-\alpha)^{2}} E\left[\left(\Delta_{1}-\delta\right)^{2}\right] \\
|
||||
& \leq(1-\alpha)^{2 t}\left(\delta_{0}-\delta\right)^{2}+\alpha E\left[\left(\Delta_{1}-\delta\right)^{2}\right]
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 由此可证明:
|
||||
$$
|
||||
E\left[\left(\delta_{t}-E\left[\delta_{t}\right]\right)^{2}\right] \leq(1-\alpha)^{2 t}\left(\delta_{0}-\delta\right)^{2}+\alpha E\left[\left(\Delta_{1}-\alpha\right)^{2}\right]
|
||||
$$
|
||||
|
||||
+ 对于方差,上式给了一个估计方差的上界。
|
||||
|
||||
## 多重哈希
|
||||
|
||||
上述流动采样频率估计算法存在的问题:
|
||||
|
||||
+ 对于不同的物品,经过哈希函数映射的整数可能相同,这就会导致哈希碰撞的问题。
|
||||
|
||||
+ 由于哈希碰撞,对导致对物品采样频率过高的估计。
|
||||
|
||||
**解决方法:**
|
||||
|
||||
* 使用 $m$ 个哈希函数,取 $m$ 个估计值中的最大值来表示物品连续两次被采样到之间的步长。
|
||||
|
||||
**具体的算法流程:**
|
||||
|
||||
1. 分别建立 $m$ 个大小为 $H$ 的数组 $\{A\}_{i=1}^{m}$,$\{B\}_{i=1}^{m}$,一组对应的独立哈希函数集合 $\{h\}_{i=1}^{m}$ 。
|
||||
|
||||
2. 通过哈希函数 $h(\cdot)$ 可以把每个物品映射为 $[H]$ 范围内的整数。对于给定的物品 $y$,哈希后的整数记为$h(y)$
|
||||
|
||||
3. 数组 $A_i$ 中存放的 $A_i[h(y)]$ 表示在第 $i$ 个哈希函数中物品 $y$ 上次被采样的时间。数组 $B_i$ 中存放的 $B_i[h(y)]$ 表示在第 $i$ 个哈希函数中物品 $y$ 的全局步长。
|
||||
|
||||
4. 假设在第 $t$ 步采样到物品 $y$,分别对 $m$ 个哈希函数对应的 $A[h(y)]$ 和 $B[h(y)]$ 进行更新:
|
||||
$$
|
||||
\begin{aligned}
|
||||
& B_i[h(y)] \leftarrow(1-\alpha) \cdot B_i[h(y)]+\alpha \cdot(t-A_i[h(y)])\\ \\
|
||||
& A_i[h(y)]\leftarrow t
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
5. 对整个 batch 数据采样后,取 $\{B\}_{i=1}^{m}$ 中最大的 $B[h(y)]$ 的倒数,作为物品 $y$ 的采样频率,即:
|
||||
|
||||
$$
|
||||
\hat{p}=1 / \max _{i}\left\{B_{i}[h(y)]\right\}
|
||||
$$
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/%E5%9B%BE%E7%89%87image-20220506223731749.png" alt="image-20220506223731749" style="zoom:50%;" />
|
||||
|
||||
|
||||
|
||||
# YouTube 神经召回模型
|
||||
|
||||
本文构建的 YouTube 神经检索模型由查询和候选网络组成。下图展示了整体的模型架构。
|
||||
|
||||
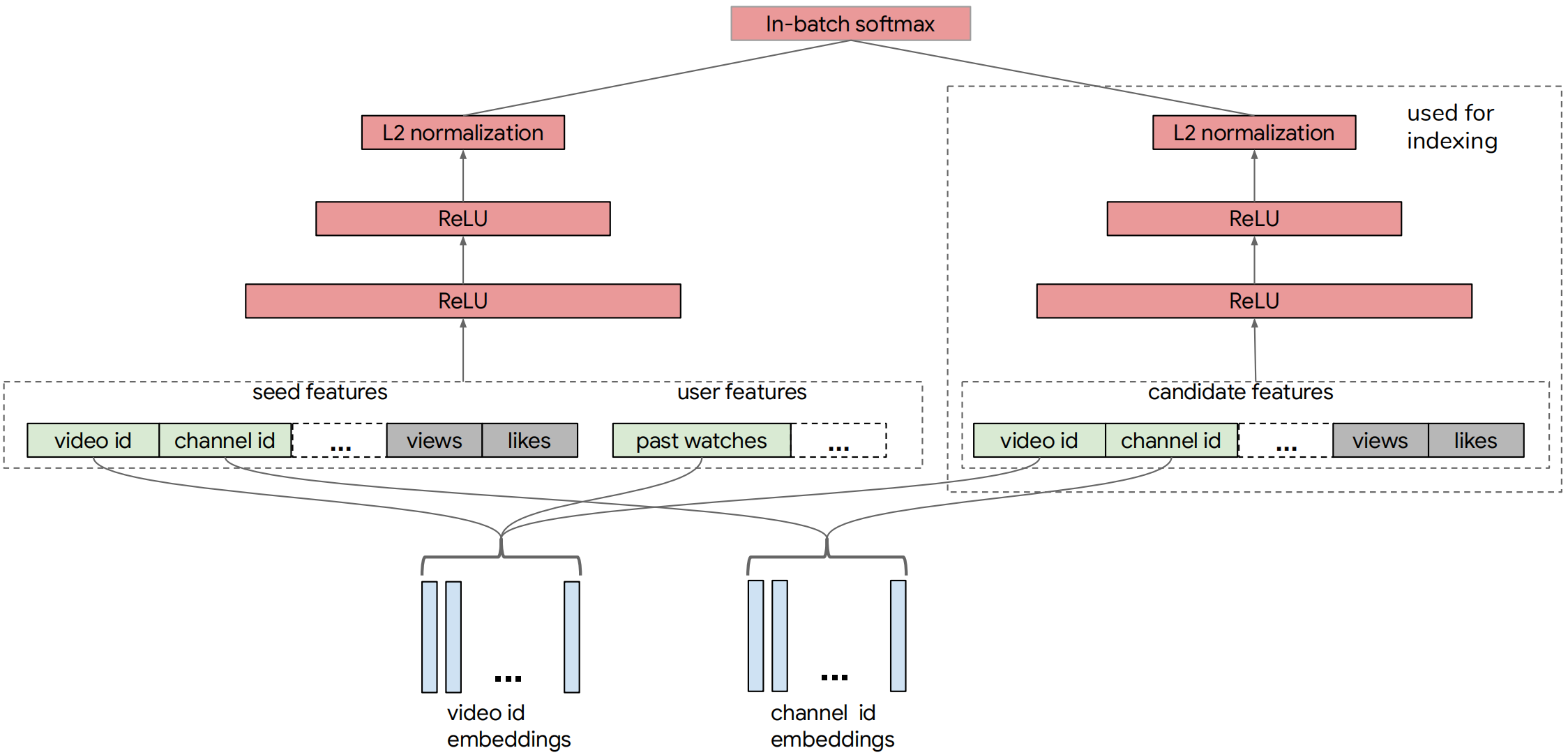
|
||||
|
||||
在任何时间点,用户正在观看的视频,即种子视频,都会提供有关用户当前兴趣的强烈信号。因此,本文利用了大量种子视频特征以及用户的观看历史记录。候选塔是为了从候选视频特征中学习而构建的。
|
||||
|
||||
* Training Label
|
||||
|
||||
* 视频点击被用作正面标签。对于每次点击,我们都会构建一个 rewards 来反映用户对视频的不同程度的参与。
|
||||
* $r_i$ = 0:观看时间短的点击视频;$r_i$ = 1:表示观看了整个视频。
|
||||
* Video Features
|
||||
|
||||
* YouTube 使用的视频特征包括 categorical 特征和 dense 特征。
|
||||
|
||||
* 例如 categorical 特征有 video id 和 channel id 。
|
||||
* 对于 categorical 特征,都会创建一个嵌入层以将每个分类特征映射到一个 Embedding 向量。
|
||||
* 通常 YouTube 要处理两种类别特征。从原文的意思来看,这两类应该是 one-hot 型和 multi-hot 型。
|
||||
* User Features
|
||||
|
||||
* 使用**用户观看历史记录**来捕捉 seed video 之外的兴趣。将用户最近观看的 k个视频视为一个词袋(BOW),然后将它们的 Embedding 平均。
|
||||
* 在查询塔中,最后将用户和历史 seed video 的特征进行融合,并送入输入前馈神经网络。
|
||||
* 类别特征的 Embedding 共享
|
||||
|
||||
* 原文:For the same type of IDs, embeddings are shared among the related features. For example, the same set of video id embeddings is used for seed, candidate and users past watches. We did experiment with non-shared embeddings, but did not observe significant model quality improvement.
|
||||
* 大致意思就是,对于相同 ID 的类别,他们之间的 Embedding 是共享的。例如对于 seed video,出现的地方包括用户历史观看,以及作为候选物品,故只要视频的 ID 相同,Embedding也是相同的。如果不共享,也没啥提升。
|
||||
|
||||
# 参考链接
|
||||
|
||||
+ [Sampling-bias-corrected neural modeling for large corpus item recommendations | Proceedings of the 13th ACM Conference on Recommender Systems](https://dl.acm.org/doi/abs/10.1145/3298689.3346996)
|
||||
|
||||
+ [【推荐系统经典论文(九)】谷歌双塔模型 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/137538147)
|
||||
|
||||
+ [借Youtube论文,谈谈双塔模型的八大精髓问题 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/369152684)
|
||||
114
4.人工智能/ch02/ch2.1/ch2.1.2/item2vec.md
Normal file
114
4.人工智能/ch02/ch2.1/ch2.1.2/item2vec.md
Normal file
@@ -0,0 +1,114 @@
|
||||
# 前言
|
||||
|
||||
在自然语言处理(NLP)领域,谷歌提出的 Word2Vec 模型是学习词向量表示的重要方法。其中,带有负采样(SGNS,Skip-gram with negative sampling)的 Skip-Gram 神经词向量模型在当时被证明是最先进的方法之一。各位读者需要自行了解 Word2Vec 中的 Skip-Gram 模型,本文只会做简单介绍。
|
||||
|
||||
在论文 Item2Vec:Neural Item Embedding for Collaborative Filtering 中,作者受到 SGNS 的启发,提出了名为 Item2Vec 的方法来生成物品的向量表示,然后将其用于基于物品的协同过滤。
|
||||
|
||||
# 基于负采样的 Skip-Gram 模型
|
||||
|
||||
Skip-Gram 模型的思想很简单:给定一个句子 $(w_i)^K_{i=1}$,然后基于中心词来预测它的上下文。目标函数如下:
|
||||
$$
|
||||
\frac{1}{K} \sum_{i=1}^{K} \sum_{-c \leq j \leq c, j \neq 0} \log p\left(w_{i+j} \mid w_{i}\right)
|
||||
$$
|
||||
|
||||
+ 其中,$c$ 表示上下文的窗口大小;$w_i$ 表示中心词;$w_{i+j}$ 表示上下文。
|
||||
|
||||
+ 表达式中的概率 $p\left(w_{j} \mid w_{i}\right)$ 的公式为:
|
||||
$$
|
||||
p\left(w_{j} \mid w_{i}\right)=\frac{\exp \left(u_{i}^{T} v_{j}\right)}{\sum_{k \in I_{W}} \exp \left(u_{i}^{T} v_{k}^{T}\right)}
|
||||
$$
|
||||
|
||||
+ $u_{i} \in U\left(\subset \mathbb{R}^{m}\right),v_{i} \in V\left(\subset \mathbb{R}^{m}\right)$,分别对应中心和上下文词的 Embedding 特征表示。
|
||||
+ 这里的意思是每个单词有2个特征表示,作为中心词 $u_i$ 和上下文 $v_i$ 时的特征表示不一样。
|
||||
+ $I_{W} \triangleq\{1, \ldots,|W|\}$ ,$|W|$ 表示语料库中词的数量。
|
||||
|
||||
简单来理解一下 Skip-Gram 模型的表达式:
|
||||
|
||||
+ 对于句子中的某个词 $w_i$,当其作为中心词时,希望尽可能准确预测它的上下文。
|
||||
+ 我们可以将其转换为多分类问题:
|
||||
+ 对于中心词 $w_i$ 预测的上下文 $w_j$,其 $label=1$ ;那么,模型对上下文的概率预测 $p\left(w_{j} \mid w_{i}\right)$ 越接近1越好。
|
||||
+ 若要 $p\left(w_{j} \mid w_{i}\right)$ 接近1,对于分母项中的 $k\ne j$,其 $\exp \left(u_{i}^{T} v_{k}^{T}\right)$ 越小越好(等价于将其视为了负样本)。
|
||||
|
||||
|
||||
注意到分母项,由于需要遍历语料库中所有的单词,从而导致计算成本过高。一种解决办法是基于负采样(NEG)的方式来降低计算复杂度:
|
||||
$$
|
||||
p\left(w_{j} \mid w_{i}\right)=\sigma\left(u_{i}^{T} v_{j}\right) \prod_{k=1}^{N} \sigma\left(-u_{i}^{T} v_{k}\right)
|
||||
$$
|
||||
|
||||
+ 其中,$\sigma(x)=1/1+exp(-x)$,$N$ 表示负样本的数量。
|
||||
|
||||
其它细节:
|
||||
|
||||
+ 单词 $w$ 作为负样本时,被采样到的概率:
|
||||
$$
|
||||
\frac{[\operatorname{counter}(w)]^{0.75}}{\sum_{u \in \mathcal{W}}[\operatorname{counter}(u)]^{0.75}}
|
||||
$$
|
||||
|
||||
+ 单词 $w$ 作为中心词时,被丢弃的概率:
|
||||
$$
|
||||
\operatorname{prob}(w)=1-\sqrt{\frac{t}{f(w)}}
|
||||
$$
|
||||
|
||||
|
||||
# Item2Vec模型
|
||||
|
||||
Item2Vec 的原理十分十分简单,它是基于 Skip-Gram 模型的物品向量训练方法。但又存在一些区别,如下:
|
||||
|
||||
+ 词向量的训练是基于句子序列(sequence),但是物品向量的训练是基于物品集合(set)。
|
||||
+ 因此,物品向量的训练丢弃了空间、时间信息。
|
||||
|
||||
Item2Vec 论文假设对于一个集合的物品,它们之间是相似的,与用户购买它们的顺序、时间无关。当然,该假设在其他场景下不一定使用,但是原论文只讨论了该场景下它们实验的有效性。由于忽略了空间信息,原文将共享同一集合的每对物品视为正样本。目标函数如下:
|
||||
$$
|
||||
\frac{1}{K} \sum_{i=1}^{K} \sum_{j \neq i}^{K} \log p\left(w_{j} \mid w_{i}\right)
|
||||
$$
|
||||
|
||||
+ 对于窗口大小 $K$,由设置的决定。
|
||||
|
||||
在 Skip-Gram 模型中,提到过每个单词 $w_i$ 有2个特征表示。在 Item2Vec 中同样如此,论文中是将物品的中心词向量 $u_i$ 作为物品的特征向量。作者还提到了其他两种方式来表示物品向量:
|
||||
|
||||
+ **add**:$u_i + v_i$
|
||||
+ **concat**:$\left[u_{i}^{T} v_{i}^{T}\right]^{T}$
|
||||
|
||||
原文还补充到,这两种方式有时候会有很好的表现。
|
||||
|
||||
# 总结
|
||||
|
||||
+ Item2Vec 的原理很简单,就是基于 Word2Vec 的 Skip-Gram 模型,并且还丢弃了时间、空间信息。
|
||||
+ 基于 Item2Vec 得到物品的向量表示后,物品之间的相似度可由二者之间的余弦相似度计算得到。
|
||||
+ 可以看出,Item2Vec 在计算物品之间相似度时,仍然依赖于不同物品之间的共现。因为,其无法解决物品的冷启动问题。
|
||||
+ 一种解决方法:取出与冷启物品类别相同的非冷启物品,将它们向量的均值作为冷启动物品的向量表示。
|
||||
|
||||
原论文链接:[[1603.04259\] Item2Vec: Neural Item Embedding for Collaborative Filtering (arxiv.org)](https://arxiv.org/abs/1603.04259)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
341
4.人工智能/ch02/ch2.1/ch2.1.2/word2vec.md
Normal file
341
4.人工智能/ch02/ch2.1/ch2.1.2/word2vec.md
Normal file
@@ -0,0 +1,341 @@
|
||||
# 背景和引入
|
||||
在所有的NLP任务中,首先面临的第一个问题是我们该如何表示单词。这种表示将作为inputs输入到特定任务的模型中,如机器翻译,文本分类等典型NLP任务。
|
||||
|
||||
## 同义词表达单词
|
||||
一个很容易想到的解决方案是使用同义词来表示一个单词的意义。
|
||||
比如***WordNet***,一个包含同义词(和有“is a”关系的词)的词库。
|
||||
|
||||
**导包**
|
||||
|
||||
```python
|
||||
!pip install --user -U nltk
|
||||
```
|
||||
|
||||
```python
|
||||
!python -m nltk.downloader popular
|
||||
```
|
||||
|
||||
**如获取"good"的同义词**
|
||||
|
||||
```python
|
||||
from nltk.corpus import wordnet as wn
|
||||
poses = { 'n':'noun', 'v':'verb', 's':'adj (s)', 'a':'adj', 'r':'adv'}
|
||||
for synset in wn.synsets("good"):
|
||||
print("{}: {}".format(poses[synset.pos()],", ".join([l.name() for l in synset.lemmas()])))
|
||||
```
|
||||
|
||||
**如获取与“pandas”有"is a"关系的词**
|
||||
|
||||
```python
|
||||
panda = wn.synset("panda.n.01")
|
||||
hyper = lambda s: s.hypernyms()
|
||||
list(panda.closure(hyper))
|
||||
```
|
||||
|
||||
***WordNet的问题***
|
||||
1. 单词与单词之间缺少些微差异的描述。比如“高效”只在某些语境下是"好"的同义词
|
||||
2. 丢失一些词的新含义。比如“芜湖”,“蚌埠”等词的新含义
|
||||
3. 相对主观
|
||||
4. 需要人手动创建和调整
|
||||
5. 无法准确计算单词的相似性
|
||||
|
||||
## one-hot编码
|
||||
在传统NLP中,人们使用one-hot向量(一个向量只有一个值为1,其余的值为0)来表示单词
|
||||
如:motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
|
||||
如:hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
|
||||
one-hot向量的维度是词汇表的大小(如:500,000)
|
||||
注:上面示例词向量的维度为方便展示所以比较小
|
||||
|
||||
|
||||
**one-hot向量表示单词的问题:**
|
||||
1. 这些词向量是***正交向量***,无法通过数学计算(如点积)计算相似性
|
||||
2. 依赖WordNet等同义词库建立相似性效果也不好
|
||||
|
||||
|
||||
## dense word vectors表达单词
|
||||
如果我们可以使用某种方法为每个单词构建一个合适的dense vector,如下图,那么通过点积等数学计算就可以获得单词之间的某种联系
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1.png" alt="在这里插入图片描述" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
# Word2vec
|
||||
|
||||
## 语言学基础
|
||||
首先,我们引入一个上世纪五十年代,一个语言学家的研究成果:**“一个单词的意义由它周围的单词决定”**
|
||||
|
||||
“You shall know a word by the company it keeps” (J. R. Firth 1957: 11)
|
||||
|
||||
这是现代NLP中一个最为成功的理念。
|
||||
|
||||
我们先引入上下文context的概念:当单词 w 出现在文本中时,其**上下文context**是出现在w附近的一组单词(在固定大小的窗口内),如下图
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2.png" alt="在这里插入图片描述" style="zoom:60%;" />
|
||||
</div>
|
||||
|
||||
这些上下文单词context words决定了banking的意义
|
||||
|
||||
## Word2vec概述
|
||||
|
||||
Word2vec(Mikolov et al. 2013)是一个用来学习dense word vector的算法:
|
||||
|
||||
1. 我们使用**大量的文本语料库**
|
||||
2. 词汇表中的每个单词都由一个**词向量dense word vector**表示
|
||||
3. 遍历文本中的每个位置 t,都有一个**中心词 c(center) 和上下文词 o(“outside”)**,如图1中的banking
|
||||
4. 在整个语料库上使用数学方法**最大化单词o在单词c周围出现了这一事实**,从而得到单词表中每一个单词的dense vector
|
||||
5. 不断调整词向量dense word vector以达到最好的效果
|
||||
|
||||
|
||||
## Skip-gram(SG)
|
||||
Word2vec包含两个模型,**Skip-gram与CBOW**。下面,我们先讲**Skip-gram**模型,用此模型详细讲解概述中所提到的内容。
|
||||
|
||||
概述中我们提到,我们希望**最大化单词o在单词c周围出现了这一事实**,而我们需要用数学语言表示“单词o在单词c周围出现了”这一事件,如此才能进行词向量的不断调整。
|
||||
|
||||
很自然地,我们需要**使用概率工具描述事件的发生**,我们想到用条件概率$P(o|c)$表示“给定中心词c,它的上下文词o在它周围出现了”
|
||||
|
||||
下图展示了以“into”为中心词,窗口大小为2的情况下它的上下文词。以及相对应的$P(o|c)$
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片3.png" alt="在这里插入图片描述" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
我们滑动窗口,再以banking为中心词
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片4.png"在这里插入图片描述" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
那么,如果我们在整个语料库上不断地滑动窗口,我们可以得到所有位置的$P(o|c)$,我们希望在所有位置上**最大化单词o在单词c周围出现了这一事实**,由极大似然法,可得:
|
||||
|
||||
$$
|
||||
max\prod_{c} \prod_{o}P(o|c)
|
||||
$$
|
||||
|
||||
此式还可以依图3写为:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片5.png" alt="在这里插入图片描述" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
加log,加负号,缩放大小可得:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片7.png" alt="在这里插入图片描述" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
上式即为**skip-gram的损失函数**,最小化损失函数,就可以得到合适的词向量
|
||||
|
||||
|
||||
得到式1后,产生了两个问题:
|
||||
|
||||
1. P(o|c)怎么表示?
|
||||
|
||||
2. 为何最小化损失函数能够得到良好表示的词向量dense word vector?
|
||||
|
||||
|
||||
回答1:我们使用**中心词c和上下文词o的相似性**来计算$P(o|c)$,更具体地,相似性由**词向量的点积**表示:$u_o \cdot v_c$。
|
||||
|
||||
使用词向量的点积表示P(o|c)的原因:1.计算简单 2.出现在一起的词向量意义相关,则希望它们相似
|
||||
|
||||
又P(o|c)是一个概率,所以我们在整个语料库上使用**softmax**将点积的值映射到概率,如图6
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片6.png" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
注:注意到上图,中心词词向量为$v_{c}$,而上下文词词向量为$u_{o}$。也就是说每个词会对应两个词向量,**在词w做中心词时,使用$v_{w}$作为词向量,而在它做上下文词时,使用$u_{w}$作为词向量**。这样做的原因是为了求导等操作时计算上的简便。当整个模型训练完成后,我们既可以使用$v_{w}$作为词w的词向量,也可以使用$u_{w}$作为词w的词向量,亦或是将二者平均。在下一部分的模型结构中,我们将更清楚地看到两个词向量究竟在模型的哪个位置。
|
||||
|
||||
|
||||
回答2:由上文所述,$P(o|c)=softmax(u_{o^T} \cdot v_c)$。所以损失函数是关于$u_{o}$和$v_c$的函数,我们通过梯度下降法调整$u_{o}$和$v_c$的值,最小化损失函数,即得到了良好表示的词向量。
|
||||
|
||||
|
||||
## Word2vec模型结构
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片8.png" alt="在这里插入图片描述" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
如图八所示,这是一个输入为1 X V维的one-hot向量(V为整个词汇表的长度,这个向量只有一个1值,其余为0值表示一个词),单隐藏层(**隐藏层的维度为N,这里是一个超参数,这个参数由我们定义,也就是词向量的维度**),输出为1 X V维的softmax层的模型。
|
||||
|
||||
$W^{I}$为V X N的参数矩阵,$W^{O}$为N X V的参数矩阵。
|
||||
|
||||
模型的输入为1 X V形状的one-hot向量(V为整个词汇表的长度,这个向量只有一个1值,其余为0值表示一个词)。隐藏层的维度为N,这里是一个超参数,这个参数由我们定义,也就是词向量的维度。$W^{I}$为V X N的参数矩阵。
|
||||
|
||||
我们这里,考虑Skip-gram算法,输入为中心词c的one-hot表示
|
||||
|
||||
由输入层到隐藏层,根据矩阵乘法规则,可知,**$W^{I}$的每一行即为词汇表中的每一个单词的词向量v**,1 X V 的 inputs 乘上 V X N 的$W^{I}$,隐藏层即为1 X N维的$v_{c}$。
|
||||
|
||||
而$W^{O}$中的每一列即为词汇表中的每一个单词的词向量u。根据乘法规则,1 X N 的隐藏层乘上N X V的$W^{O}$参数矩阵,得到的1 X V 的输出层的每一个值即为$u_{w^T} \cdot v_c$,加上softmax变化即为$P(w|c)$。
|
||||
|
||||
有V个w,其中的P(o|c)即实际样本中的上下文词的概率,为我们最为关注的值。
|
||||
|
||||
## CBOW
|
||||
|
||||
如上文所述,Skip-gram为给定中心词,预测周围的词,即求P(o|c),如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105817437.png" alt="在这里插入图片描述" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
而CBOW为给定周围的词,预测中心词,即求P(c|o),如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片10.png" alt="在这里插入图片描述" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
注意:在使用CBOW时,上文所给出的模型结构并没有变,在这里,我们输入多个上下文词o,在隐藏层,**将这多个上下文词经过第一个参数矩阵的计算得到的词向量相加作为隐藏单元的值**。其余均不变,$W^{O}$中的每一列依然为为词汇表中的每一个单词的词向量u。
|
||||
|
||||
# 负采样 Negative Sampling
|
||||
|
||||
## softmax函数带来的问题
|
||||
|
||||
我们再看一眼,通过softmax得到的$P(o|c)$,如图:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105958191.png" alt="在这里插入图片描述" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
可以看到,$P(o|c)$的分母需要在整个单词表上做乘积和exp运算,这无疑是非常消耗计算资源的,Word2vec的作者针对这个问题,做出了改进。
|
||||
|
||||
他提出了两种改进的方法:Hierarchical Softmax和Negative Sampling,因为Negative Sampling更加常见,所以我们下面只介绍Negative Sampling,感兴趣的朋友可以在文章下面的参考资料中学习Hierarchical Softmax。
|
||||
|
||||
## 负采样Negative Sampling
|
||||
|
||||
我们依然以Skip-gram为例(CBOW与之差别不大,感兴趣的朋友们依然可以参阅参考资料)
|
||||
|
||||
我们首先给出负采样的损失函数:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片12.png" alt="在这里插入图片描述" style="zoom:40%;" />
|
||||
</div>
|
||||
|
||||
|
||||
其中$\sigma$为sigmoid函数$1/(1+e^{-x})$, $u_{o}$为实际样本中的上下文词的词向量,而$u_{k}$为我们在单词表中随机选出(按一定的规则随机选出,具体可参阅参考资料)的K个单词。
|
||||
|
||||
由函数单调性易知,**$u_{o^T} \cdot v_c$越大,损失函数越小,而$u_{k^T} \cdot v_c$越小**,损失函数越大。这与原始的softmax损失函数优化目标一致,即$maxP(o|c)$,而且避免了在整个词汇表上的计算。
|
||||
|
||||
# 核心代码与核心推导
|
||||
|
||||
## Naive softmax 损失函数
|
||||
|
||||
损失函数关于$v_c$的导数:
|
||||
|
||||
$$
|
||||
\frac{\partial{J_{naive-softmax}(\boldsymbol v_c,o,\boldsymbol U)}}{\partial \boldsymbol v_c} \\=
|
||||
-\frac{\partial{log(P(O=o|C=c))}}{\partial \boldsymbol v_c} \\ =
|
||||
-\frac{\partial{log(exp( \boldsymbol u_o^T\boldsymbol v_c))}}{\partial \boldsymbol v_c} + \frac{\partial{log(\sum_{w=1}^{V}exp(\boldsymbol u_w^T\boldsymbol v_c))}}{\partial \boldsymbol v_c} \\=
|
||||
-\boldsymbol u_o + \sum_{w=1}^{V} \frac{exp(\boldsymbol u_w^T\boldsymbol v_c)}{\sum_{w=1}^{V}exp(\boldsymbol u_w^T\boldsymbol v_c)}\boldsymbol u_w \\=
|
||||
-\boldsymbol u_o+ \sum_{w=1}^{V}P(O=w|C=c)\boldsymbol u_w \\=
|
||||
\boldsymbol U^T(\hat{\boldsymbol y} - \boldsymbol y)
|
||||
$$
|
||||
|
||||
可以看到涉及整个U矩阵的计算,计算量很大,关于$u_w$的导数读者可自行推导
|
||||
|
||||
损失函数及其梯度的求解
|
||||
|
||||
来自:https://github.com/lrs1353281004/CS224n_winter2019_notes_and_assignments
|
||||
|
||||
```python
|
||||
def naiveSoftmaxLossAndGradient(
|
||||
centerWordVec,
|
||||
outsideWordIdx,
|
||||
outsideVectors,
|
||||
dataset
|
||||
):
|
||||
""" Naive Softmax loss & gradient function for word2vec models
|
||||
|
||||
Arguments:
|
||||
centerWordVec -- numpy ndarray, center word's embedding
|
||||
in shape (word vector length, )
|
||||
(v_c in the pdf handout)
|
||||
outsideWordIdx -- integer, the index of the outside word
|
||||
(o of u_o in the pdf handout)
|
||||
outsideVectors -- outside vectors is
|
||||
in shape (num words in vocab, word vector length)
|
||||
for all words in vocab (tranpose of U in the pdf handout)
|
||||
dataset -- needed for negative sampling, unused here.
|
||||
|
||||
Return:
|
||||
loss -- naive softmax loss
|
||||
gradCenterVec -- the gradient with respect to the center word vector
|
||||
in shape (word vector length, )
|
||||
(dJ / dv_c in the pdf handout)
|
||||
gradOutsideVecs -- the gradient with respect to all the outside word vectors
|
||||
in shape (num words in vocab, word vector length)
|
||||
(dJ / dU)
|
||||
"""
|
||||
|
||||
# centerWordVec: (embedding_dim,1)
|
||||
# outsideVectors: (vocab_size,embedding_dim)
|
||||
|
||||
scores = np.matmul(outsideVectors, centerWordVec) # size=(vocab_size, 1)
|
||||
probs = softmax(scores) # size=(vocab, 1)
|
||||
|
||||
loss = -np.log(probs[outsideWordIdx]) # scalar
|
||||
|
||||
dscores = probs.copy() # size=(vocab, 1)
|
||||
dscores[outsideWordIdx] = dscores[outsideWordIdx] - 1 # dscores=y_hat - y
|
||||
gradCenterVec = np.matmul(outsideVectors, dscores) # J关于vc的偏导数公式 size=(vocab_size, 1)
|
||||
gradOutsideVecs = np.outer(dscores, centerWordVec) # J关于u的偏导数公式 size=(vocab_size, embedding_dim)
|
||||
|
||||
return loss, gradCenterVec, gradOutsideVecs
|
||||
```
|
||||
|
||||
## 负采样损失函数
|
||||
|
||||
负采样损失函数关于$v_c$的导数:
|
||||
|
||||
$$
|
||||
\frac{\partial{J_{neg-sample}(\boldsymbol v_c,o,\boldsymbol U)}}{\partial\boldsymbol v_c} \\=
|
||||
\frac{\partial (-log(\sigma (\boldsymbol u_o^T\boldsymbol v_c))-\sum_{k=1}^{K} log(\sigma (-\boldsymbol u_k^T\boldsymbol v_c)))}{\partial \boldsymbol v_c} \\=
|
||||
-\frac{\sigma(\boldsymbol u_o^T\boldsymbol v_c)(1-\sigma(\boldsymbol u_o^T\boldsymbol v_c))}{\sigma(\boldsymbol u_o^T\boldsymbol v_c)}\frac{\partial \boldsymbol u_o^T\boldsymbol v_c}{\partial \boldsymbol v_c} -
|
||||
\sum_{k=1}^{K}\frac{\partial log(\sigma(-\boldsymbol u_k^T\boldsymbol v_c))}{\partial \boldsymbol v_c} \\=
|
||||
-(1-\sigma(\boldsymbol u_o^T\boldsymbol v_c))\boldsymbol u_o+\sum_{k=1}^{K}(1-\sigma(-\boldsymbol u_k^T\boldsymbol v_c))\boldsymbol u_k
|
||||
$$
|
||||
|
||||
可以看到其只与$u_k$和$u_o$有关,避免了在整个单词表上的计算
|
||||
|
||||
负采样方法的损失函数及其导数的求解
|
||||
|
||||
```python
|
||||
def negSamplingLossAndGradient(
|
||||
centerWordVec,
|
||||
outsideWordIdx,
|
||||
outsideVectors,
|
||||
dataset,
|
||||
K=10
|
||||
):
|
||||
|
||||
negSampleWordIndices = getNegativeSamples(outsideWordIdx, dataset, K)
|
||||
indices = [outsideWordIdx] + negSampleWordIndices
|
||||
|
||||
gradCenterVec =np.zeros(centerWordVec.shape) # (embedding_size,1)
|
||||
gradOutsideVecs = np.zeros(outsideVectors.shape) # (vocab_size, embedding_size)
|
||||
loss = 0.0
|
||||
|
||||
u_o = outsideVectors[outsideWordIdx] # size=(embedding_size,1)
|
||||
z = sigmoid(np.dot(u_o, centerWordVec)) # size=(1, )
|
||||
loss -= np.log(z) # 损失函数的第一部分
|
||||
gradCenterVec += u_o * (z - 1) # J关于vc的偏导数的第一部分
|
||||
gradOutsideVecs[outsideWordIdx] = centerWordVec * (z - 1) # J关于u_o的偏导数计算
|
||||
|
||||
for i in range(K):
|
||||
neg_id = indices[1 + i]
|
||||
u_k = outsideVectors[neg_id]
|
||||
z = sigmoid(-np.dot(u_k, centerWordVec))
|
||||
loss -= np.log(z)
|
||||
gradCenterVec += u_k * (1-z)
|
||||
gradOutsideVecs[neg_id] += centerWordVec * (1 - z)
|
||||
|
||||
|
||||
return loss, gradCenterVec, gradOutsideVecs
|
||||
```
|
||||
|
||||
**参考资料**
|
||||
- Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[J]. Advances in neural information processing systems, 2013, 26.
|
||||
- https://www.cnblogs.com/peghoty/p/3857839.html
|
||||
- http://web.stanford.edu/class/cs224n/
|
||||
|
||||
399
4.人工智能/ch02/ch2.1/ch2.1.3/EGES.md
Normal file
399
4.人工智能/ch02/ch2.1/ch2.1.3/EGES.md
Normal file
@@ -0,0 +1,399 @@
|
||||
# Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
|
||||
|
||||
这篇论文是阿里巴巴在18年发表于KDD的关于召回阶段的工作。该论文提出的方法是在基于图嵌入的方法上,通过引入side information来解决实际问题中的数据稀疏和冷启动问题。
|
||||
|
||||
## 动机
|
||||
|
||||
在电商领域,推荐已经是不可或缺的一部分,旨在为用户的喜好提供有趣的物品,并且成为淘宝和阿里巴巴收入的重要引擎。尽管学术界和产业界的各种推荐方法都取得了成功,如协同过滤、基于内容的方法和基于深度学习的方法,但由于用户和项目的数十亿规模,传统的方法已经不能满足于实际的需求,主要的问题体现在三个方面:
|
||||
|
||||
- 可扩展性:现有的推荐方法无法扩展到在拥有十亿的用户和二十亿商品的淘宝中。
|
||||
- 稀疏性:存在大量的物品与用户的交互行为稀疏。即用户的交互到多集中于以下部分商品,存在大量商品很少被用户交互。
|
||||
- 冷启动:在淘宝中,每分钟会上传很多新的商品,由于这些商品没有用户行为的信息(点击、购买等),无法进行很好的预测。
|
||||
|
||||
针对于这三个方面的问题, 本文设计了一个两阶段的推荐框架:**召回阶段和排序阶段**,这也是推荐领域最常见的模型架构。而本文提及的EGES模型主要是解决了匹配阶段的问题,通过用户行为计算商品间两两的相似性,然后根基相似性选出topK的商品输入到排序阶段。
|
||||
|
||||
为了学习更好的商品向量表示,本文通过用户的行为历史中构造一个item-item 图,然后应用随机游走方法在item-item 图为每个item获取到一个序列,然后通过Skip-Gram的方式为每个item学习embedding(这里的item序列类似于语句,其中每个item类比于句子中每个word),这种方式被称为图嵌入方法(Graph Embedding)。文中提出三个具体模型来学习更好的物品embedding,更好的服务于召回阶段。
|
||||
|
||||
## 思路
|
||||
|
||||
根据上述所面临的三个问题,本文针对性的提出了三个模型予以解决:Base Graph Embedding(BGE);Graph Embedding with Side Information(GES);Enhanced Graph Embedding with Side Information(EGES)。
|
||||
|
||||
考虑可扩展性的问题,图嵌入的随机游走方式可以在物品图上捕获**物品之间高阶相似性**,即Base Graph Embedding(BGE)方法。其不同于CF方法,除了考虑物品的共现,还考虑到了行为的序列信息。
|
||||
|
||||
考虑到稀疏性和冷启物品问题,在图嵌入的基础上,考虑了节点的属性信息。希望具有相似属性的物品可以在空间上相似,即希望通过头部物品,提高属性信息的泛化能力,进而帮助尾部和冷启物品获取更加准确的embedding,即Graph Embedding with Side Information(GES)方法。
|
||||
|
||||
考虑到不同属性信息对于学习embedding的贡献不同,因此在聚合不同的属性信息时,动态的学习不同属性对于学习节点的embedding所参与的重要性权重,即Enhanced Graph Embedding with Side Information(EGES)。
|
||||
|
||||
## 模型结构与原理
|
||||
|
||||
文中所提出的方法是基于经典的图嵌入模型DeepWalk进行改进,其目标是通过物品图G,学习一个映射函数$f:V -> R^d$ ,将图上节点映射成一个embedding。具体的步骤包括两步:1.通过随机游走为图上每个物品生成序列;2.通过Skip-Gram算法学习每个物品的embedding。因此对于该方法优化的目标是,在给定的上下文物品的前提下,最大化物品v的条件概率,即物品v对于一个序列里面的其他物品要尽可能的相似。接下来看一些每个模型具体内容。
|
||||
|
||||
### 构建物品图
|
||||
|
||||
在介绍三个模型之前,我们首先需要构建好item-item图。由于基于CF的方法仅考虑物品之间的共现,忽略了行为的序列信息(即序列中相邻的物品之间的语义信息),因此item-item图的构建方式如下图所示。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328133138263.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
首先根据用户的session行为序列构建网络结构,即序列中相邻两个item之间在存在边,并且是有向带权图。物品图边上的权重为所有用户行为序列中两个 item 共现的次数,最终构造出来简单的有向有权图。
|
||||
|
||||
值得注意的是,本文通过行为序列中物品的共现来表示其中的**语义信息**,并将这种语义信息理解为**物品之间的相似性**,并将共现频次作为相似性的一个度量值。其次基于用户的历史行为序列数据,一般不太可能取全量的历史序列数据,一方面行为数据量过大,一方面用户的兴趣会随时间发生演变,因此在处理行为序列时会设置了一个窗口来截断历史序列数据,切分出来的序列称为session。
|
||||
|
||||
由于实际中会存在一些现实因素,数据中会有一些噪音,需要特殊处理,主要分为三个方面:
|
||||
|
||||
- 从行为方面考虑,用户在点击后停留的时间少于1秒,可以认为是误点,需要移除。
|
||||
- 从用户方面考虑,淘宝场景中会有一些过度活跃用户。本文对活跃用户的定义是三月内购买商品数超过1000,或者点击数超过3500,就可以认为是一个无效用户,需要去除。
|
||||
- 从商品方面考虑,存在一些商品频繁的修改,即ID对应的商品频繁更新,这使得这个ID可能变成一个完全不同的商品,这就需要移除与这个ID相关的这个商品。
|
||||
|
||||
在构建完item-item图之后,接下来看看三个模型的具体内容。
|
||||
|
||||
### 图嵌入(BGE)
|
||||
|
||||
对于图嵌入模型,第一步先进行随机游走得到物品序列;第二部通过skip-gram为图上节点生成embedding。那么对于随机游走的思想:如何利用随机游走在图中生成的序列?不同于DeepWalk中的随机游走,本文的采样策略使用的是带权游走策略,不同权重的游走到的概率不同,(其本质上就是node2vec),传统的node2vec方法可以直接支持有向带权图。因此在给定图的邻接矩阵M后(表示节点之间的边权重),随机游走中每次转移的概率为:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144516898.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中$M_{ij}$为边$e_{ij}$上的权重,$N_{+}(v_i)$表示节点$v_i$所有邻居节点集合,并且随机游走的转移概率的对每个节点所有邻接边权重的归一化结果。在随即游走之后,每个item得到一个序列,如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220418142135912.png" style="zoom:47%;"/>
|
||||
</div>
|
||||
|
||||
然后类似于word2vec,为每个item学习embedding,于是优化目标如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144931957.png" style="zoom:77%;"/>
|
||||
</div>
|
||||
|
||||
其中,w 为窗口大小。考虑独立性假设的话,上面的式子可以进一步化简:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145101109.png" style="zoom:77%;"/>
|
||||
</div>
|
||||
|
||||
这样看起来就很直观了,在已知物品 i 时,最大化序列中(上下文)其他物品 j 的条件概率。为了近似计算,采样了Negative sampling,上面的优化目标可以化简得到如下式子:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145318718.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中$N(v_i)'$表示负样本集合,负采样个数越多,结果越好。
|
||||
|
||||
### 基于side information的图嵌入(GES)
|
||||
|
||||
尽管BGE将行为序列关系编码进物品的embedding中,从而从用户行为中捕捉高阶相似性。但是这里有个问题,对于新加入的商品,由于未和用户产生过交互,所以不会出现在item-item图上,进而模型无法学习到其embedding,即无法解决冷启动问题。
|
||||
|
||||
为了解决冷启问题,本文通过使用side information( 类别,店铺, 价格等)加入模型的训练过程中,使得模型最终的泛化能力体现在商品的side information上。这样通过**side information学习到的embedding来表示具体的商品**,使得相似side information的物品可以得到在空间上相近的表示,进而来增强 BGE。
|
||||
|
||||
那么对于每个商品如何通过side information的embedidng来表示呢?对于随机游走之后得到的商品序列,其中每个每个商品由其id和属性(品牌,价格等)组成。用公式表示,对于序列中的每一个物品可以得到$W^0_V,...W_V^n$,(n+1)个向量表示,$W^0_V$表示物品v,剩下是side information的embedding。然后将所有的side information聚合成一个整体来表示物品,聚合方式如下:
|
||||
|
||||
$$H_v = \frac{1}{n+1}\sum_{s=0}^n W^s_v$$
|
||||
|
||||
其中,$H_v$是商品 v 的聚合后的 embedding 向量。
|
||||
|
||||
### 增强型EGS(EGES)
|
||||
|
||||
尽管 GES 相比 BGE 在性能上有了提升,但是在聚合多个属性向量得到商品的embedding的过程中,不同 side information的聚合依然存在问题。在GES中采用 average-pooling 是在假设不同种类的 side information 对商品embedding的贡献是相等的,但实际中却并非如此。例如,购买 Iphone 的用户更可能倾向于 Macbook 或者 Ipad,相比于价格属性,品牌属性相对于苹果类商品具有更重要的影响。因此,根据实际现状,不同类型的 side information 对商品的表示是具有不同的贡献值的。
|
||||
|
||||
针对上述问题,作者提出了weight pooling方法来聚合不同类型的 side information。具体地,EGES 与 GES 的区别在聚合不同类型 side information计算不同的权重,根据权重聚合 side information 得到商品的embedding,如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328154950289.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中 $a_i$ 表示每个side information 用于计算权重的参数向量,最终通过下面的公式得到商品的embedding:
|
||||
|
||||
$$H_v = \frac{\sum_{j=0}^n e^{a_v^j} W_v^j}{\sum_{j=0}^n e^{a_v^j}}$$
|
||||
|
||||
这里对参数 $a_v^j$ 先做指数变换,目的是为了保证每个边界信息的贡献都能大于0,然后通过归一化为每个特征得到一个o-1之内的权重。最终物品的embedding通过权重进行加权聚合得到,进而优化损失函数:
|
||||
|
||||
$$L(v,u,y)=-[ylog( \sigma (H_v^TZ_u)) + (1-y)log(1 - \sigma(H_v^TZ_u))]$$
|
||||
|
||||
y是标签符号,等于1时表示正样本,等于0时表示负样本。$H_v$表示商品 v 的最终的隐层表示,$Z_u$表示训练数据中的上下文节点的embedding。
|
||||
|
||||
以上就是这三个模型主要的区别,下面是EGES的伪代码。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155406291.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中**WeightedSkipGram**函数为带权重的SkipGram算法。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155533704.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
## 代码实现
|
||||
|
||||
下面我们简单的来看一下模型代码的实现,参考的内容在[这里](https://github.com/wangzhegeek/EGES),其中实验使用的是jd 2019年比赛中提供的数据。
|
||||
|
||||
### 构建物品图
|
||||
|
||||
首先对用户的下单(type=2)行为序列进行session划分,其中30分钟没有产生下一个行为,划分为一个session。
|
||||
|
||||
```python
|
||||
def cnt_session(data, time_cut=30, cut_type=2):
|
||||
# 商品属性 id 被交互时间 商品种类
|
||||
sku_list = data['sku_id']
|
||||
time_list = data['action_time']
|
||||
type_list = data['type']
|
||||
session = []
|
||||
tmp_session = []
|
||||
for i, item in enumerate(sku_list):
|
||||
# 两个商品之间如果被交互的时间大于1小时,划分成不同的session
|
||||
if type_list[i] == cut_type or (i < len(sku_list)-1 and \
|
||||
(time_list[i+1] - time_list[i]).seconds/60 > time_cut) or i == len(sku_list)-1:
|
||||
tmp_session.append(item)
|
||||
session.append(tmp_session)
|
||||
tmp_session = []
|
||||
else:
|
||||
tmp_session.append(item)
|
||||
return session # 返回多个session list
|
||||
```
|
||||
|
||||
获取到所有session list之后(这里不区分具体用户),对于session长度不超过1的去除(没有意义)。
|
||||
|
||||
接下来就是构建图,主要是先计算所有session中,相邻的物品共现频次(通过字典计算)。然后通过入度节点、出度节点以及权重分别转化成list,通过network来构建有向图。
|
||||
|
||||
```python
|
||||
node_pair = dict()
|
||||
# 遍历所有session list
|
||||
for session in session_list_all:
|
||||
for i in range(1, len(session)):
|
||||
# 将session共现的item存到node_pair中,用于构建item-item图
|
||||
# 将共现次数所谓边的权重,即node_pair的key为边(src_node,dst_node),value为边的权重(共现次数)
|
||||
if (session[i - 1], session[i]) not in node_pair.keys():
|
||||
node_pair[(session[i - 1], session[i])] = 1
|
||||
else:
|
||||
node_pair[(session[i - 1], session[i])] += 1
|
||||
|
||||
in_node_list = list(map(lambda x: x[0], list(node_pair.keys())))
|
||||
out_node_list = list(map(lambda x: x[1], list(node_pair.keys())))
|
||||
weight_list = list(node_pair.values())
|
||||
graph_list = list([(i,o,w) for i,o,w in zip(in_node_list,out_node_list,weight_list)])
|
||||
# 通过 network 构建图结构
|
||||
G = nx.DiGraph().add_weighted_edges_from(graph_list)
|
||||
|
||||
```
|
||||
|
||||
### 随机游走
|
||||
|
||||
先是基于构建的图进行随机游走,其中p和q是参数,用于控制采样的偏向于DFS还是BFS,其实也就是node2vec。
|
||||
|
||||
```python
|
||||
walker = RandomWalker(G, p=args.p, q=args.q)
|
||||
print("Preprocess transition probs...")
|
||||
walker.preprocess_transition_probs()
|
||||
```
|
||||
|
||||
对于采样的具体过程,是根据边的归一化权重作为采样概率进行采样。其中关于如何通过AliasSampling来实现概率采样的可以[参考](https://blog.csdn.net/haolexiao/article/details/65157026),具体的是先通过计算create_alias_table,然后根据边上两个节点的alias计算边的alias。其中可以看到这里计算alias_table是根据边的归一化权重。
|
||||
|
||||
```python
|
||||
def preprocess_transition_probs(self):
|
||||
"""预处理随即游走的转移概率"""
|
||||
G = self.G
|
||||
alias_nodes = {}
|
||||
for node in G.nodes():
|
||||
# 获取每个节点与邻居节点边上的权重
|
||||
unnormalized_probs = [G[node][nbr].get('weight', 1.0)
|
||||
for nbr in G.neighbors(node)]
|
||||
norm_const = sum(unnormalized_probs)
|
||||
# 对每个节点的邻居权重进行归一化
|
||||
normalized_probs = [
|
||||
float(u_prob)/norm_const for u_prob in unnormalized_probs]
|
||||
# 根据权重创建alias表
|
||||
alias_nodes[node] = create_alias_table(normalized_probs)
|
||||
alias_edges = {}
|
||||
for edge in G.edges():
|
||||
# 获取边的alias
|
||||
alias_edges[edge] = self.get_alias_edge(edge[0], edge[1])
|
||||
self.alias_nodes = alias_nodes
|
||||
self.alias_edges = alias_edges
|
||||
return
|
||||
```
|
||||
|
||||
在构建好Alias之后,进行带权重的随机游走。
|
||||
|
||||
```python
|
||||
session_reproduce = walker.simulate_walks(num_walks=args.num_walks,
|
||||
walk_length=args.walk_length, workers=4,verbose=1)
|
||||
```
|
||||
|
||||
其中这里的随机游走是根据p和q的值,来选择是使用Deepwalk还是node2vec。
|
||||
|
||||
```python
|
||||
def _simulate_walks(self, nodes, num_walks, walk_length,):
|
||||
walks = []
|
||||
for _ in range(num_walks):
|
||||
# 打乱所有起始节点
|
||||
random.shuffle(nodes)
|
||||
for v in nodes:
|
||||
# 根据p和q选择随机游走或者带权游走
|
||||
if self.p == 1 and self.q == 1:
|
||||
walks.append(self.deepwalk_walk(
|
||||
walk_length=walk_length, start_node=v))
|
||||
else:
|
||||
walks.append(self.node2vec_walk(
|
||||
walk_length=walk_length, start_node=v))
|
||||
return walks
|
||||
|
||||
```
|
||||
|
||||
### 加载side information并构造训练正样本
|
||||
|
||||
主要是将目前所有的sku和其对应的side infromation进行left join,没有的特征用0补充。然后对所有的特征进行labelEncoder()
|
||||
|
||||
```python
|
||||
sku_side_info = pd.merge(all_skus, product_data, on='sku_id', how='left').fillna(0) # 为商品加载side information
|
||||
for feat in sku_side_info.columns:
|
||||
if feat != 'sku_id':
|
||||
lbe = LabelEncoder()
|
||||
# 对side information进行编码
|
||||
sku_side_info[feat] = lbe.fit_transform(sku_side_info[feat])
|
||||
else:
|
||||
sku_side_info[feat] = sku_lbe.transform(sku_side_info[feat])
|
||||
```
|
||||
|
||||
通过图中的公式可以知道优化目标是让在一个窗口内的物品尽可能相似,采样若干负样本使之与目标物品不相似。因此需要将一个窗口内的所有物品与目标物品组成pair作为训练正样本。这里不需要采样负样本,负样本是通过tf中的sample softmax方法自动进行采样。
|
||||
|
||||
```python
|
||||
def get_graph_context_all_pairs(walks, window_size):
|
||||
all_pairs = []
|
||||
for k in range(len(walks)):
|
||||
for i in range(len(walks[k])):
|
||||
# 通过窗口的方式采取正样本,具体的是,让随机游走序列的起始item与窗口内的每个item组成正样本对
|
||||
for j in range(i - window_size, i + window_size + 1):
|
||||
if i == j or j < 0 or j >= len(walks[k]):
|
||||
continue
|
||||
else:
|
||||
all_pairs.append([walks[k][i], walks[k][j]])
|
||||
return np.array(all_pairs, dtype=np.int32)
|
||||
|
||||
```
|
||||
|
||||
#### EGES模型
|
||||
|
||||
构造完数据之后,在funrec的基础上实现了EGES模型:
|
||||
|
||||
```python
|
||||
def EGES(side_information_columns, items_columns, merge_type = "weight", share_flag=True,
|
||||
l2_reg=0.0001, seed=1024):
|
||||
# side_information 所对应的特征
|
||||
feature_columns = list(set(side_information_columns))
|
||||
# 获取输入层,查字典
|
||||
feature_encode = FeatureEncoder(feature_columns, linear_sparse_feature=None)
|
||||
# 输入的值
|
||||
feature_inputs_list = list(feature_encode.feature_input_layer_dict.values())
|
||||
# item id 获取输入层的值
|
||||
items_Map = FeatureMap(items_columns)
|
||||
items_inputs_list = list(items_Map.feature_input_layer_dict.values())
|
||||
|
||||
# 正样本的id,在softmax中需要传入正样本的id
|
||||
label_columns = [DenseFeat('label_id', 1)]
|
||||
label_Map = FeatureMap(label_columns)
|
||||
label_inputs_list = list(label_Map.feature_input_layer_dict.values())
|
||||
|
||||
# 通过输入的值查side_information的embedding,返回所有side_information的embedding的list
|
||||
side_embedding_list = process_feature(side_information_columns, feature_encode)
|
||||
# 拼接 N x num_feature X Dim
|
||||
side_embeddings = Concatenate(axis=1)(side_embedding_list)
|
||||
|
||||
# items_inputs_list[0] 为了查找每个item 用于计算权重的 aplha 向量
|
||||
eges_inputs = [side_embeddings, items_inputs_list[0]]
|
||||
|
||||
merge_emb = EGESLayer(items_columns[0].vocabulary_size, merge_type=merge_type,
|
||||
l2_reg=l2_reg, seed=seed)(eges_inputs) # B * emb_dim
|
||||
|
||||
label_idx = label_Map.feature_input_layer_dict[label_columns[0].name]
|
||||
softmaxloss_inputs = [merge_emb,label_idx]
|
||||
|
||||
item_vocabulary_size = items_columns[0].vocabulary_size
|
||||
|
||||
all_items_idx = EmbeddingIndex(list(range(item_vocabulary_size)))
|
||||
all_items_embeddings = feature_encode.embedding_layers_dict[side_information_columns[0].name](all_items_idx)
|
||||
|
||||
if share_flag:
|
||||
softmaxloss_inputs.append(all_items_embeddings)
|
||||
|
||||
output = SampledSoftmaxLayer(num_items=item_vocabulary_size, share_flage=share_flag,
|
||||
emb_dim=side_information_columns[0].embedding_dim,num_sampled=10)(softmaxloss_inputs)
|
||||
|
||||
model = Model(feature_inputs_list + items_inputs_list + label_inputs_list, output)
|
||||
|
||||
model.__setattr__("feature_inputs_list", feature_inputs_list)
|
||||
model.__setattr__("label_inputs_list", label_inputs_list)
|
||||
model.__setattr__("merge_embedding", merge_emb)
|
||||
model.__setattr__("item_embedding", get_item_embedding(all_items_embeddings, items_Map.feature_input_layer_dict[items_columns[0].name]))
|
||||
return model
|
||||
|
||||
```
|
||||
|
||||
其中EGESLayer为聚合每个item的多个side information的方法,其中根据merge_type可以选择average-pooling或者weight-pooling
|
||||
|
||||
```python
|
||||
class EGESLayer(Layer):
|
||||
def __init__(self,item_nums, merge_type="weight",l2_reg=0.001,seed=1024, **kwargs):
|
||||
super(EGESLayer, self).__init__(**kwargs)
|
||||
self.item_nums = item_nums
|
||||
self.merge_type = merge_type #聚合方式
|
||||
self.l2_reg = l2_reg
|
||||
self.seed = seed
|
||||
|
||||
def build(self, input_shape):
|
||||
if not isinstance(input_shape, list) or len(input_shape) < 2:
|
||||
raise ValueError('`EGESLayer` layer should be called \
|
||||
on a list of at least 2 inputs')
|
||||
self.feat_nums = input_shape[0][1]
|
||||
|
||||
if self.merge_type == "weight":
|
||||
self.alpha_embeddings = self.add_weight(
|
||||
name='alpha_attention',
|
||||
shape=(self.item_nums, self.feat_nums),
|
||||
dtype=tf.float32,
|
||||
initializer=tf.keras.initializers.RandomUniform(minval=-1, maxval=1, seed=self.seed),
|
||||
regularizer=l2(self.l2_reg))
|
||||
|
||||
def call(self, inputs, **kwargs):
|
||||
if self.merge_type == "weight":
|
||||
stack_embedding = inputs[0] # (B * num_feate * embedding_size)
|
||||
item_input = inputs[1] # (B * 1)
|
||||
alpha_embedding = tf.nn.embedding_lookup(self.alpha_embeddings, item_input) #(B * 1 * num_feate)
|
||||
alpha_emb = tf.exp(alpha_embedding)
|
||||
alpha_i_sum = tf.reduce_sum(alpha_emb, axis=-1)
|
||||
merge_embedding = tf.squeeze(tf.matmul(alpha_emb, stack_embedding),axis=1) / alpha_i_sum
|
||||
else:
|
||||
stack_embedding = inputs[0] # (B * num_feate * embedding_size)
|
||||
merge_embedding = tf.squeeze(tf.reduce_mean(alpha_emb, axis=1),axis=1) # (B * embedding_size)
|
||||
|
||||
return merge_embedding
|
||||
|
||||
def compute_output_shape(self, input_shape):
|
||||
return input_shape
|
||||
|
||||
def get_config(self):
|
||||
config = {"merge_type": self.merge_type, "seed": self.seed}
|
||||
base_config = super(EGESLayer, self).get_config()
|
||||
base_config.update(config)
|
||||
return base_config
|
||||
|
||||
```
|
||||
|
||||
至此已经从原理到代码详细的介绍了关于EGES的内容。
|
||||
|
||||
|
||||
|
||||
## 参考
|
||||
|
||||
[Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba](https://arxiv.org/abs/1803.02349)
|
||||
|
||||
[深度学习中不得不学的Graph Embedding方法](https://zhuanlan.zhihu.com/p/64200072)
|
||||
|
||||
[【Embedding】EGES:阿里在图嵌入领域中的探索](https://blog.csdn.net/qq_27075943/article/details/106244434)
|
||||
|
||||
[推荐系统遇上深度学习(四十六)-阿里电商推荐中亿级商品的embedding策略](https://www.jianshu.com/p/229b686535f1)
|
||||
|
||||
579
4.人工智能/ch02/ch2.1/ch2.1.3/PinSage.md
Normal file
579
4.人工智能/ch02/ch2.1/ch2.1.3/PinSage.md
Normal file
@@ -0,0 +1,579 @@
|
||||
|
||||
|
||||
# Graph Convolutional Neural Networks for Web-Scale Recommender Systems
|
||||
|
||||
该论文是斯坦福大学和Pinterest公司与2018年联合发表与KDD上的一篇关于GCN成功应用于工业级推荐系统的工作。该论文提到的PinSage模型,是在GraphSAGE的理论基础进行了更改,以适用于实际的工业场景。下面将简单介绍一下GraphSAGE的原理,以及Pinsage的核心和细节。
|
||||
|
||||
## GraphSAGE原理
|
||||
|
||||
GraphSAGE提出的前提是因为基于直推式(transductive)学习的图卷积网络无法适应工业界的大多数业务场景。我们知道的是,基于直推式学习的图卷积网络是通过拉普拉斯矩阵直接为图上的每个节点学习embedding表示,每次学习是针对于当前图上所有的节点。然而在实际的工业场景中,图中的结构和节点都不可能是固定的,会随着时间的变化而发生改变。例如在Pinterest公司的场景下,每分钟都会上传新的照片素材,同时也会有新用户不断的注册,那么图上的节点会不断的变化。在这样的场景中,直推式学习的方法就需要不断的重新训练才能够为新加入的节点学习embedding,导致在实际场景中无法投入使用。
|
||||
|
||||
在这样的背景下,斯坦福大学提出了一种归纳(inductive)学习的GCN方法——GraphSAGE,即**通过聚合邻居信息的方式为给定的节点学习embedding**。不同于直推式(transductive)学习,GraphSAGE是通过学习聚合节点邻居生成节点Embedding的函数的方式,为任意节点学习embedding,进而将GCN扩展成归纳学习任务。
|
||||
|
||||
对于想直接应用GCN或者GraphSAGE的我们而言,不用非要去理解其背后晦涩难懂的数学原理,可以仅从公式的角度来理解GraphSAGE的具体操作。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220423094435223.png" style="zoom:90%;"/>
|
||||
</div>
|
||||
|
||||
上面这个公式可以非常直观的让我们理解GraphSAGE的原理。
|
||||
|
||||
- $h_v^0$表示图上节点的初始化表示,等同于节点自身的特征。
|
||||
- $h_v^k$表示第k层卷积后的节点表示,其来源于两个部分:
|
||||
- 第一部分来源于节点v的邻居节点集合$N(v)$,利用邻居节点的第k-1层卷积后的特征$h_u^{k-1}$进行 ( $\sum_{u \in N(v)} \frac{h_u^{k-1}}{|N(v)|}$ )后,在进行线性变换。这里**借助图上的边将邻居节点的信息通过边关系聚合到节点表示中(简称卷积操作)**。
|
||||
- 第二部分来源于节点v的第k-1成卷积后的特征$h_v^{k-1}$,进行线性变换。总的来说图卷积的思想是**在对自身做多次非线性变换时,同时利用边关系聚合邻居节点信息。**
|
||||
- 最后一次卷积结果作为节点的最终表示$Z_v$,以用于下游任务(节点分类,链路预测或节点召回)。
|
||||
|
||||
可以发现相比传统的方法(MLP,CNN,DeepWalk 或 EGES),GCN或GraphSAGE存在一些优势:
|
||||
|
||||
1. 相比于传统的深度学习方法(MLP,CNN),GCN在对自身节点进行非线性变换时,同时考虑了图中的邻接关系。从CNN的角度理解,GCN通过堆叠多层结构在图结构数据上拥有更大的**感受野**,利用更加广域内的信息。
|
||||
2. 相比于图嵌入学习方法(DeepWalk,EGES),GCN在学习节点表示的过程中,在利用节点自身的属性信息之外,更好的利用图结构上的边信息。相比于借助随机采样的方式来使用边信息,GCN的方式能从全局的角度利用的邻居信息。此外,类似于GraphSAGE这种归纳(inductive)学习的GCN方法,通过学习聚合节点邻居生成节点Embedding的函数的方式,更适用于图结构和节点会不断变化的工业场景。
|
||||
|
||||
在采样得到目标节点的邻居集之后,那么如何聚合邻居节点的信息来更新目标节点的嵌入表示呢?下面就来看看GraphSAGE中提及的四个聚合函数。
|
||||
|
||||
## GraphSAGE的采样和聚合
|
||||
|
||||
通过上面的公式可以知道,得到节点的表示主要依赖于两部分,其中一部分其邻居节点。因此对于GraphSAGE的关键主要分为两步:Sample采样和Aggregate聚合。其中Sample的作用是从庞大的邻居节点中选出用于聚合的邻居节点集合$N(v)$以达到降低迭代计算复杂度,而聚合操作就是如何利用邻居节点的表示来更新节点v的表示,已达到聚合作用。具体的过程如下伪代码所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220406135753358.png" style="zoom:90%;"/>
|
||||
</div>
|
||||
|
||||
GraphSAGE的minibatch算法的思路是针对Batch内的所有节点,通过采样和聚合节点,为每一个节点学习一个embedding。
|
||||
|
||||
#### 邻居采样
|
||||
|
||||
GraphSAGE的具体采样过程是,首先根据中心节点集合$B^k$,对集合中每个中心节点通过随机采样的方式对其邻居节点采样固定数量S个(如果邻居节点数量大于S,采用无放回抽样;如果小于S,则采用有放回抽样),形成的集合表示为$B^{k-1}$;以此类推每次都是为前一个得到的集合的每个节点随机采样S个邻居,最终得到第k层的所有需要参与计算的节点集合$B^{0}$。值得注意的有两点:**为什么需要采样并且固定采样数量S?** **为什么第k层所采样的节点集合表示为$B^0$?**
|
||||
|
||||
进行邻居采样并固定采样数量S主要是因为:1. 采样邻居节点避免了在全图的搜索以及使用全部邻居节点所导致计算复杂度高的问题;2. 可以通过采样使得部分节点更同质化,即两个相似的节点具有相同表达形式。3. 采样固定数量是保持每个batch的计算占用空间是固定的,方便进行批量训练。
|
||||
|
||||
第k层所采样的节点集合表示为$B^0$主要是因为:采样和聚合过程是相反的,即采样时我们是从中心节点组层进行采样,而聚合的过程是从中心节点的第k阶邻居逐层聚合得到前一层的节点表示。因此可以认为聚合阶段是:将k阶邻居的信息聚合到k-1阶邻居上,k-1阶邻居的信息聚合到k-2阶邻居上,....,1阶邻居的信息聚合到中心节点上的过程。
|
||||
|
||||
#### 聚合函数
|
||||
|
||||
如何对于采样到的节点集进行聚合,介绍的4种方式:Mean 聚合、Convolutional 聚合、LSTM聚合以及Pooling聚合。由于邻居节点是无序的,所以希望构造的聚合函数具有**对称性(即输出的结果不因输入排序的不同而改变)**,同时拥有**较强的表达能力**。
|
||||
|
||||
- Mean 聚合:首先会对邻居节点按照**element-wise**进行均值聚合,然后将当前节点k-1层得到特征$h_v^{k-1}$与邻居节点均值聚合后的特征 $MEAN(h_u^k | u\in N(v))$**分别**送入全连接网络后**相加**得到结果。
|
||||
- Convolutional 聚合:这是一种基于GCN聚合方式的变种,首先对邻居节点特征和自身节点特征求均值,得到的聚合特征送入到全连接网络中。与Mean不同的是,这里**只经过一个全连接层**。
|
||||
|
||||
- LSTM聚合:由于LSTM可以捕捉到序列信息,因此相比于Mean聚合,这种聚合方式的**表达能力更强**;但由于LSTM对于输入是有序的,因此该方法不具备**对称性**。作者对于无序的节点进行随机排列以调整LSTM所需的有序性。
|
||||
- Pooling聚合:对于邻居节点和中心节点进行一次非线性转化,将结果进行一次基于**element-wise**的**最大池化**操作。该种方式具有**较强的表达能力**的同时还具有**对称性**。
|
||||
|
||||
综上,可以发现GraphSAGE之所以可以用于大规模的工业场景,主要是因为模型主要是通过学习聚合函数,通过归纳式的学习方法为节点学习特征表示。接下来看看PinSAGE 的主要内容。
|
||||
|
||||
## PinSAGE
|
||||
|
||||
### 背景
|
||||
|
||||
PinSAGE 模型是Pinterest 在GraphSAGE 的基础上实现的可以应用于实际工业场景的召回算法。Pinterest 公司的主要业务是采用瀑布流的形式向用户展现图片,无需用户翻页,新的图片会自动加载。因此在Pinterest网站上,有大量的图片(被称为pins),而用户可以将喜欢的图片分类,即将pins钉在画板 boards上。可以发现基于这样的场景,pin相当于普通推荐场景中item,用户**钉**的行为可以认为是用于的交互行为。于是PinSAGE 模型主要应用的思路是,基于GraphSAGE 的原理学习到聚合方法,并为每个图片(pin)学习一个向量表示,然后基于pin的向量表示做**item2item的召回**。
|
||||
|
||||
可以知道的是,PinSAGE 是在GraphSAGE的基础上进行改进以适应实际的工业场景,因此除了改进卷积操作中的邻居采样策略以及聚合函数的同时还有一些工程技巧上的改进,使得在大数据场景下能更快更好的进行模型训练。因此在了解GraphSAGE的原理后,我们详细的了解一下本文的主要改进以及与GraphSAGE的区别。
|
||||
|
||||
### 重要性采样
|
||||
|
||||
在实际场景当中,一个item可能被数以百万,千万的用户交互过,所以不可能聚合所有邻居节点是不可行的,只可能是采样部分邻居进行信息聚合。但是如果采用GraphSAGE中随机采样的方法,由于采样的邻居有限(这里是相对于所有节点而言),会存在一定的偏差。因此PinSAGE 在采样中考虑了更加重要的邻居节点,即卷积时只注重部分重要的邻居节点信息,已达到高效计算的同时又可以消除偏置。
|
||||
|
||||
PinSAGE使用重要性采样方法,即需要为每个邻居节点计算一个重要性权重,根据权重选取top-t的邻居作为聚合时的邻居集合。其中计算重要性的过程是,以目标节点为起点,进行random-walk,采样结束之后计算所有节点访问数的L1-normalized作为重要性权重,同时这个权重也会在聚合过程中加以使用(**加权聚合**)。
|
||||
|
||||
这里对于**计算权重之后如何得到top-t的邻居节点,**原文并没有直接的叙述。这里可以有两种做法,第一种就是直接采用重要权重,这种方法言简意赅,比较直观。第二种做法就是对游走得到的所有邻居进行随机抽样,而计算出的权重可以用于聚合阶段。个人理解第二种做法的可行性出于两点原因,其一是这样方法可以避免存在一些item由于权重系数低永远不会被选中的问题;其二可能并不是将所有重要性的邻居进行聚合更合理,毕竟重要性权重是通过随机采样而得到的,具有一定的随机性。当然以上两种方法都是可行的方案,可以通过尝试看看具体哪种方法会更有效。
|
||||
|
||||
### 聚合函数
|
||||
|
||||
PinSAGE中提到的Convolve算法(单层图卷积操作)相当于GraphSAGE算法的聚合过程,在实际执行过程中通过对每一层执行一次图卷积操作以得到不同阶邻居的信息,具体过程如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220406202027832.png" style="zoom:110%;"/>
|
||||
</div>
|
||||
|
||||
上述的单层图卷积过程如下三步:
|
||||
|
||||
1. 聚合邻居: 先将所有的邻居节点经过一次非线性转化(一层DNN),再由聚合函数(Pooling聚合) $\gamma$(如元素平均,**加权和**等)将所有邻居信息聚合成目标节点的embedding。这里的加权聚合采用的是通过random-walk得到的重要性权重。
|
||||
2. 更新当前节点的embedding:将目标节点当前的向量 $z_u$ 与步骤1中聚合得到的邻居向量 $n_u$ 进行拼接,在通过一次非线性转化。
|
||||
3. 归一化操作:对目标节点向量 $z_u$ 归一化。
|
||||
|
||||
Convolve算法的聚合方法与GraphSAGE的Pooling聚合函数相同,主要区别在于对更新得到的向量 $z_u$ 进行归一化操作,**可以使训练更稳定,以及在近似查找最近邻的应用中更有效率。**
|
||||
|
||||
### 基于**mini-batch**堆叠多层图卷积
|
||||
|
||||
与GraphSAGE类似,采用的是基于mini-batch 的方式进行训练。之所以这么做的原因是因为什么呢?在实际的工业场景中,由于用户交互图非常庞大,无法对于所有的节点同时学习一个embedding,因此需要从原始图上寻找与 mini-batch 节点相关的子图。具体地是说,对于mini-batch内的所有节点,会通过采样的方式逐层的寻找相关邻居节点,再通过对每一层的节点做一次图卷积操作,以从k阶邻居节点聚合信息。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220406204431024.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
|
||||
如上图所示:对于batch内的所有节点(图上最顶层的6个节点),依次根据权重采样,得到batch内所有节点的一阶邻居(图上第二层的所有节点);然后对于所有一阶邻居再次进行采样,得到所有二阶邻居(图上的最后一层)。节点采样阶段完成之后,与采样的顺序相反进行聚合操作。首先对二阶邻居进行单次图卷积,将二阶节点信息聚合已更新一阶节点的向量表示(其中小方块表示的是一层非线性转化);其次对一阶节点再次进行图卷积操作,将一阶节点的信息聚合已更新batch内所有节点的向量表示。仅此对于一个batch内的所有的样本通过卷积操作学习到一个embedding,而每一个batch的学习过程中仅**利用与mini-batch内相关节点的子图结构。**
|
||||
|
||||
### **训练过程**
|
||||
|
||||
PinSage在训练时采用的是 Margin Hinge Loss 损失函数,主要的思想是最大化正例embedding之间的相关性,同时还要保证负例之间相关性相比正例之间的相关性小于某个阈值(Margin)。具体的公式如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220406210833675.png" style="zoom:100%;"/>
|
||||
</div>
|
||||
|
||||
其中$Z_p$是学习得到的目标节点embedding,$Z_i$是与目标节点相关item的embedding,$Z_{n_k}$是与目标节点不相关item的embedding,$\Delta$为margin值,具体大小需要调参。那么对于相关节点i,以及不相关节点nk,具体都是如何定义的,这对于召回模型的训练意义重大,让我们看看具体是如何定义的。
|
||||
|
||||
对于正样本而言,文中的定义是如果用户在点击的 item q之后立即点击了 item i,即认为 < q, i >构成正样本对。直观的我们很好理解这句话,不过在参考DGL中相关代码实现时,发现这部分的内容和原文中有一定的出入。具体地,代码中将所有的训练样本构造成用户-项目二部图,然后对batch内的每个 item q,根据item-user-item的元路径进行随机游走,得到被同一个用户交互过的 item i,因此组成<q,i>正样本对。对于负样本部分,相对来说更为重要,因此内容相对比较多,将在下面的负样本生成部分详细介绍。
|
||||
|
||||
这里还有一个比较重要的细节需要注意,由于模型是用于 item to item的召回,因此优化目标是与正样本之间的表示尽可能的相近,与负样本之间的表示尽可能的远。而图卷积操作会使得具有邻接关系的节点表示具有同质性,因此结合这两点,就需要在构建图结构的时,要将**训练样本之间可能存在的边在二部图上删除**,避免因为边的存在使得因卷积操作而导致的信息泄露。
|
||||
|
||||
### 工程技巧
|
||||
|
||||
由于PinSAGE是一篇工业界的论文,其中会涉及与实际工程相关的内容,这里在了解完算法思想之后,再从实际落地的角度看看PinSAGE给我们介绍的工程技巧。
|
||||
|
||||
**负样本的生成**
|
||||
|
||||
召回模型最主要的任务是从候选集合中选出用户可能感兴趣的item,直观的理解就是让模型将用户喜欢的和不喜欢的进行区分。然而由于候选集合的庞大数量,许多item之间十分相似,导致模型划分出来用户喜欢的item中会存在一些难以区分的item(即与用户非常喜欢item比较相似的那一部分)。因此对于召回模型不仅能区分用户喜欢和不喜欢的 item,同时还能区分与用户喜欢的 item 十分相似的那一部分item。那么如果做到呢?这主要是交给 easy negative examples 和 hard negative examples 两种负样本给模型学习。
|
||||
|
||||
- easy 负样本:这里对于mini-batch内的所有pair(训练样本对)会共享500负样本,这500个样本从batch之外的所有节点中随机采样得到。这么做可以减少在每个mini-batch中因计算所有节点的embedding所需的时间,文中指出这和为每个item采样一定数量负样本无差异。
|
||||
- hard 负样本:这里使用hard 负样本的原因是根据实际场景的问题出发,模型需要从20亿的物品item集合中识别出最相似的1000个,即模型需要从2百万 item 中识别出最相似的那一个 item。也就是说模型的区分能力不够细致,为了解决这个问题,加入了一些hard样本。对于hard 负样本,应该是与 q 相似 以及和 i 不相似的物品,具体地的生成方式是将图上的节点计算相对节点 q 的个性化PageRank分值,根据分值的排序随机从2000~5000的位置选取节点作为负样本。
|
||||
|
||||
负样本的构建是召回模型的中关键的内容,在各家公司的工作都予以体现,具体的大家可以参考 Facebook 发表的[《Embedding-based Retrieval in Facebook Search》]([https://arxiv.org/pdf/2006.11632v1.pdf](https://links.jianshu.com/go?to=https%3A%2F%2Farxiv.org%2Fpdf%2F2006.11632v1.pdf))
|
||||
|
||||
**渐进式训练(Curriculum training)**
|
||||
|
||||
由于hard 负样本的加入,模型的训练时间加长(由于与q过于相似,导致loss比较小,导致梯度更新的幅度比较小,训练起来比较慢),那么渐进式训练就是为了来解决这个问题。
|
||||
|
||||
如何渐进式:先在第一轮训练使用easy 负样本,帮助模型先快速收敛(先让模型有个最基本的分辨能力)到一定范围,然后在逐步分加入hard负样本(方式是在第n轮训练时给每个物品的负样本集合增加n-1个 hard 负样本),以调整模型细粒度的区分能力(让模型能够区分相似的item)。
|
||||
|
||||
**节点特征(side information)**
|
||||
|
||||
这里与EGES的不同,这里的边信息不是端到端训练得到,而是通过事前的预处理得到的。对于每个节点(即 pin),都会有一个图片和一点文本信息。因此对于每个节点使用图片的向量、文字的向量以及节点的度拼接得到。这里其实也解释了为什么在图卷积操作时,会先进行一个非线性转化,其实就是将不同空间的特征进行转化(融合)。
|
||||
|
||||
**构建 mini-batch**
|
||||
|
||||
不同于常规的构建方式,PinSAGE中构建mini-batch的方式是基于生产者消费者模式。什么意思的,就是将CPU和GPU分开工作,让CPU负责取特征,重建索引,邻接列表,负采样等工作,让GPU进行矩阵运算,即CPU负责生产每个batch所需的所有数据,GPU则根据CPU生产的数据进行消费(运算)。这样由于考虑GPU的利用率,无法将所有特征矩阵放在GPU,只能存在CPU中,然而每次查找会导致非常耗时,通过上面的方式使得图卷积操作过程中就没有GPU与CPU的通信需求。
|
||||
|
||||
**多GPU训练超大batch**
|
||||
|
||||
前向传播过程中,各个GPU等分minibatch,共享一套模型参数;反向传播时,将每个GPU中的参数梯度都聚合到一起,同步执行SGD。为了保证因海量数据而使用的超大batchsize的情况下模型快速收敛以及泛化精度,采用warmup过程,即在第一个epoch中将学习率线性提升到最高,后面的epoch中再逐步指数下降。
|
||||
|
||||
**使用MapReduce高效推断**
|
||||
|
||||
在模型训练结束之后,需要为所有节点计算一个embedding,如果按照训练过程中的前向传播过程来生成,会存在大量重复的计算。因为当计算一个节点的embedding的时候,其部分邻居节点已经计算过了,同时如果该节点作为其他节点邻居时,也会被再次计算。针对这个问题,本文采用MapReduce的方法进行推断。该过程主要分为两步,具体如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220407132111547.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
|
||||
1. 将item的embedding进行聚合,即利用item的图片、文字和度等信息的表示进行join(拼接),在通过一层dense后得到item的低维向量。
|
||||
2. 然后根据item来匹配其一阶邻居(join),然后根据item进行pooling(其实就是GroupBy pooling),得到一次图卷积操作。通过堆叠多次直接得到全量的embedding。
|
||||
|
||||
其实这块主要就是通过MapReduce的大数据处理能力,直接对全量节点进行一次运算得到其embedding,避免了分batch所导致的重复计算。
|
||||
|
||||
## 代码解析
|
||||
|
||||
了解完基本的原理之后,最关键的还是得解析源码,以证实上面讲的细节的准确性。下面基于DGL中实现的代码,看看模型中的一些细节。
|
||||
|
||||
### 数据处理
|
||||
|
||||
在弄清楚模型之前,最重要的就是知道送入模型的数据到底是什么养的,以及PinSAGE相对于GraphSAGE最大的区别就在于如何采样邻居,如何构建负样本等。
|
||||
|
||||
首先需要明确的是,无论是**邻居采样**还是**样本的构造**都发生在图结构上,因此最主要的是需要先构建一个user和item组成的二部图。
|
||||
|
||||
```python
|
||||
# ratings是所有的用户交互
|
||||
# 过滤掉为出现在交互中的用户和项目
|
||||
distinct_users_in_ratings = ratings['user_id'].unique()
|
||||
distinct_movies_in_ratings = ratings['movie_id'].unique()
|
||||
users = users[users['user_id'].isin(distinct_users_in_ratings)]
|
||||
movies = movies[movies['movie_id'].isin(distinct_movies_in_ratings)]
|
||||
|
||||
# 将电影特征分组 genres (a vector), year (a category), title (a string)
|
||||
genre_columns = movies.columns.drop(['movie_id', 'title', 'year'])
|
||||
movies[genre_columns] = movies[genre_columns].fillna(False).astype('bool')
|
||||
movies_categorical = movies.drop('title', axis=1)
|
||||
|
||||
## 构建图
|
||||
graph_builder = PandasGraphBuilder()
|
||||
graph_builder.add_entities(users, 'user_id', 'user') # 添加user类型节点
|
||||
graph_builder.add_entities(movies_categorical, 'movie_id', 'movie') # 添加movie类型节点
|
||||
|
||||
# 构建用户-电影的无向图
|
||||
graph_builder.add_binary_relations(ratings, 'user_id', 'movie_id', 'watched')
|
||||
graph_builder.add_binary_relations(ratings, 'movie_id', 'user_id', 'watched-by')
|
||||
|
||||
g = graph_builder.build()
|
||||
```
|
||||
|
||||
在构建完原图之后,需要将交互数据(ratings)分成训练集和测试集,然后根据测试集从原图中抽取出与训练集中相关节点的子图。
|
||||
|
||||
```python
|
||||
# train_test_split_by_time 根据时间划分训练集和测试集
|
||||
# 将用户的倒数第二次交互作为验证,最后一次交互用作测试
|
||||
# train_indices 为用于训练的用户与电影的交互
|
||||
train_indices, val_indices, test_indices = train_test_split_by_time(ratings, 'timestamp', 'user_id')
|
||||
|
||||
# 只使用训练交互来构建图形,测试集相关的节点不应该出现在训练过程中。
|
||||
# 从原图中提取与训练集相关节点的子图
|
||||
train_g = build_train_graph(g, train_indices, 'user', 'movie', 'watched', 'watched-by')
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 正负样本采样
|
||||
|
||||
在得到训练图结构之后,为了进行PinSAGE提出的item2item召回任务,需要构建相应的训练样本。对于训练样本主要是构建正样本对和负样本对,前面我们已经提到了正样本对是基于 item to user to item的随即游走得到的;对于负样本DGL的实现主要是随机采样,即只有easy sample,未实现hard sample。具体地,DGL中主要是通过sampler_module.ItemToItemBatchSampler方法进行采样,主要代码如下:
|
||||
|
||||
```python
|
||||
class ItemToItemBatchSampler(IterableDataset):
|
||||
def __init__(self, g, user_type, item_type, batch_size):
|
||||
self.g = g
|
||||
self.user_type = user_type
|
||||
self.item_type = item_type
|
||||
self.user_to_item_etype = list(g.metagraph()[user_type][item_type])[0]
|
||||
self.item_to_user_etype = list(g.metagraph()[item_type][user_type])[0]
|
||||
self.batch_size = batch_size
|
||||
|
||||
def __iter__(self):
|
||||
while True:
|
||||
# 随机采样batch_size个节点作为head 即论文中的q
|
||||
heads = torch.randint(0, self.g.number_of_nodes(self.item_type), (self.batch_size,))
|
||||
|
||||
# 本次元路径表示从item游走到user,再从user游走到item,总共二跳,取出二跳节点(电影节点)作为tails(即正样本)
|
||||
# 得到与heads被同一个用户消费过的其他item,做正样本
|
||||
# 这么做可能存在问题,
|
||||
# 1. 这种游走肯定会使正样本集中于少数热门item;
|
||||
# 2. 如果item只被一个用户消费过,二跳游走岂不是又回到起始item,这种case还是要处理的
|
||||
tails = dgl.sampling.random_walk(
|
||||
self.g,
|
||||
heads,
|
||||
metapath=[self.item_to_user_etype, self.user_to_item_etype])[0][:, 2]
|
||||
|
||||
# 随机采样做负样本, 没有hard negative
|
||||
# 这么做会存在被同一个用户交互过的movie也会作为负样本
|
||||
neg_tails = torch.randint(0, self.g.number_of_nodes(self.item_type), (self.batch_size,))
|
||||
|
||||
mask = (tails != -1)
|
||||
yield heads[mask], tails[mask], neg_tails[mask]
|
||||
```
|
||||
|
||||
上面的样本采样过程只是一个简单的示例,如果面对实际问题,需要自己来重新完成这部分的内容。
|
||||
|
||||
### 邻居节点采样
|
||||
|
||||
再得到训练样本之后,接下来主要是在训练图上,为heads节点采用其邻居节点。在DGL中主要是通过sampler_module.NeighborSampler来实现,具体地,通过**sample_blocks**方法回溯生成各层卷积需要的block,即所有的邻居集合。其中需要注意的几个地方,基于随机游走的重要邻居采样,DGL已经实现,具体参考**[dgl.sampling.PinSAGESampler](https://link.zhihu.com/?target=https%3A//docs.dgl.ai/generated/dgl.sampling.PinSAGESampler.html%3Fhighlight%3Dpinsagesampler)**,其次避免信息泄漏,代码中,先将head → tails,head → neg_tails从frontier中先删除,再生成block。
|
||||
|
||||
```python
|
||||
class NeighborSampler(object): # 图卷积的邻居采样
|
||||
def __init__(self, g, user_type, item_type, random_walk_length, random_walk_restart_prob,
|
||||
num_random_walks, num_neighbors, num_layers):
|
||||
self.g = g
|
||||
self.user_type = user_type
|
||||
self.item_type = item_type
|
||||
self.user_to_item_etype = list(g.metagraph()[user_type][item_type])[0]
|
||||
self.item_to_user_etype = list(g.metagraph()[item_type][user_type])[0]
|
||||
|
||||
# 每层都有一个采样器,根据随机游走来决定某节点邻居的重要性(主要的实现已封装在PinSAGESampler中)
|
||||
# 可以认为经过多次游走,落脚于某邻居节点的次数越多,则这个邻居越重要,就更应该优先作为邻居
|
||||
self.samplers = [
|
||||
dgl.sampling.PinSAGESampler(g, item_type, user_type, random_walk_length,
|
||||
random_walk_restart_prob, num_random_walks, num_neighbors)
|
||||
for _ in range(num_layers)]
|
||||
|
||||
def sample_blocks(self, seeds, heads=None, tails=None, neg_tails=None):
|
||||
"""根据随机游走得到的重要性权重,进行邻居采样"""
|
||||
blocks = []
|
||||
for sampler in self.samplers:
|
||||
frontier = sampler(seeds) # 通过随机游走进行重要性采样,生成中间状态
|
||||
if heads is not None:
|
||||
# 如果是在训练,需要将heads->tails 和 head->neg_tails这些待预测的边都去掉
|
||||
eids = frontier.edge_ids(torch.cat([heads, heads]), torch.cat([tails, neg_tails]), return_uv=True)
|
||||
|
||||
if len(eids) > 0:
|
||||
old_frontier = frontier
|
||||
frontier = dgl.remove_edges(old_frontier, eids)
|
||||
|
||||
# 只保留seeds这些节点,将frontier压缩成block
|
||||
# 并设置block的input/output nodes
|
||||
block = compact_and_copy(frontier, seeds)
|
||||
|
||||
# 本层的输入节点就是下一层的seeds
|
||||
seeds = block.srcdata[dgl.NID]
|
||||
blocks.insert(0, block)
|
||||
return blocks
|
||||
```
|
||||
|
||||
其次**sample_from_item_pairs**方法是通过上面得到的heads, tails, neg_tails分别构建基于正样本对以及基于负样本对的item-item图。由heads→tails生成的pos_graph,用于计算pairwise loss中的pos_score,由heads→neg_tails生成的neg_graph,用于计算pairwise loss中的neg_score。
|
||||
|
||||
```python
|
||||
class NeighborSampler(object): # 图卷积的邻居采样
|
||||
def __init__(self, g, user_type, item_type, random_walk_length, ....):
|
||||
pass
|
||||
|
||||
def sample_blocks(self, seeds, heads=None, tails=None, neg_tails=None):
|
||||
pass
|
||||
|
||||
def sample_from_item_pairs(self, heads, tails, neg_tails):
|
||||
# 由heads->tails构建positive graph, num_nodes设置成原图中所有item节点
|
||||
pos_graph = dgl.graph(
|
||||
(heads, tails),
|
||||
num_nodes=self.g.number_of_nodes(self.item_type))
|
||||
|
||||
# 由heads->neg_tails构建negative graph,num_nodes设置成原图中所有item节点
|
||||
neg_graph = dgl.graph(
|
||||
(heads, neg_tails),
|
||||
num_nodes=self.g.number_of_nodes(self.item_type))
|
||||
|
||||
# 去除heads, tails, neg_tails以外的节点,将大图压缩成小图,避免与本轮训练不相关节点的结构也传入模型,提升计算效率
|
||||
pos_graph, neg_graph = dgl.compact_graphs([pos_graph, neg_graph])
|
||||
|
||||
# 压缩后的图上的节点是原图中的编号
|
||||
# 注意这时pos_graph与neg_graph不是分开编号的两个图,它们来自于同一幅由heads, tails, neg_tails组成的大图
|
||||
# pos_graph和neg_graph中的节点相同,都是heads+tails+neg_tails,即这里的seeds,pos_graph和neg_graph只是边不同而已
|
||||
seeds = pos_graph.ndata[dgl.NID] # 字典 不同类型节点为一个tensor,为每个节点的id值
|
||||
|
||||
blocks = self.sample_blocks(seeds, heads, tails, neg_tails)
|
||||
return pos_graph, neg_graph, blocks
|
||||
```
|
||||
|
||||
|
||||
|
||||
### PinSAGE
|
||||
|
||||
在得到所有所需的数据之后,看看模型结构。其中主要分为三个部分:**节点特征映射**,**多层卷积模块 **和 **给边打分**。
|
||||
|
||||
```python
|
||||
class PinSAGEModel(nn.Module):
|
||||
def __init__(self, full_graph, ntype, textsets, hidden_dims, n_layers):
|
||||
super().__init__()
|
||||
# 负责将节点上的各种特征都映射成向量,并聚合在一起,形成这个节点的原始特征向量
|
||||
self.proj = layers.LinearProjector(full_graph, ntype, textsets, hidden_dims)
|
||||
# 负责多层图卷积,得到各节点最终的embedding
|
||||
self.sage = layers.SAGENet(hidden_dims, n_layers)
|
||||
# 负责根据首尾两端的节点的embedding,计算边上的得分
|
||||
self.scorer = layers.ItemToItemScorer(full_graph, ntype)
|
||||
|
||||
def forward(self, pos_graph, neg_graph, blocks):
|
||||
""" pos_graph, neg_graph, blocks 的最后一层都对应batch中 heads+tails+neg_tails 这些节点
|
||||
"""
|
||||
# 得到batch中heads+tails+neg_tails这些节点的最终embedding
|
||||
h_item = self.get_repr(blocks)
|
||||
# 得到heads->tails这些边上的得分
|
||||
pos_score = self.scorer(pos_graph, h_item)
|
||||
# 得到heads->neg_tails这些边上的得分
|
||||
neg_score = self.scorer(neg_graph, h_item)
|
||||
# pos_graph与neg_graph边数相等,因此neg_score与pos_score相减
|
||||
# 返回margin hinge loss,这里的margin是1
|
||||
return (neg_score - pos_score + 1).clamp(min=0)
|
||||
|
||||
def get_repr(self, blocks):
|
||||
"""
|
||||
通过self.sage,经过多层卷积,得到输出节点上的卷积结果,再加上这些输出节点上原始特征的映射结果
|
||||
得到输出节点上最终的向量表示
|
||||
"""
|
||||
h_item = self.proj(blocks[0].srcdata) # 将输入节点上的原始特征映射成hidden_dims长的向量
|
||||
h_item_dst = self.proj(blocks[-1].dstdata) # 将输出节点上的原始特征映射成hidden_dims长的向量
|
||||
return h_item_dst + self.sage(blocks, h_item)
|
||||
```
|
||||
|
||||
**节点特征映射:**由于节点使用到了多种类型(int,float array,text)的原始特征,这里使用了一个DNN层来融合成固定的长度。
|
||||
|
||||
```python
|
||||
class LinearProjector(nn.Module):
|
||||
def __init__(self, full_graph, ntype, textset, hidden_dims):
|
||||
super().__init__()
|
||||
self.ntype = ntype
|
||||
# 初始化参数,这里为全图中所有节点特征初始化
|
||||
# 如果特征类型是float,就定义一个nn.Linear线性变化为指定维度
|
||||
# 如果特征类型是int,就定义Embedding矩阵,将id型特征转化为向量
|
||||
self.inputs = _init_input_modules(full_graph, ntype, textset, hidden_dims)
|
||||
|
||||
def forward(self, ndata):
|
||||
projections = []
|
||||
for feature, data in ndata.items():
|
||||
# NID是计算子图中节点、边在原图中的编号,没必要用做特征
|
||||
if feature == dgl.NID:
|
||||
continue
|
||||
module = self.inputs[feature] # 根据特征名取出相应的特征转化器
|
||||
# 对文本属性进行处理
|
||||
if isinstance(module, (BagOfWords, BagOfWordsPretrained)):
|
||||
length = ndata[feature + '__len']
|
||||
result = module(data, length)
|
||||
else:
|
||||
result = module(data) # look_up
|
||||
projections.append(result)
|
||||
|
||||
# 将每个特征都映射后的hidden_dims长的向量,element-wise相加
|
||||
return torch.stack(projections, 1).sum(1) # [nodes, hidden_dims]
|
||||
```
|
||||
|
||||
**多层卷积模块:**根据采样得到的节点blocks,然后通过进行逐层卷积,得到各节点最终的embedding。
|
||||
|
||||
```python
|
||||
class SAGENet(nn.Module):
|
||||
def __init__(self, hidden_dims, n_layers):
|
||||
"""g : 二部图"""
|
||||
super().__init__()
|
||||
self.convs = nn.ModuleList()
|
||||
for _ in range(n_layers):
|
||||
self.convs.append(WeightedSAGEConv(hidden_dims, hidden_dims, hidden_dims))
|
||||
|
||||
def forward(self, blocks, h):
|
||||
# 这里根据邻居节点进逐层聚合
|
||||
for layer, block in zip(self.convs, blocks):
|
||||
h_dst = h[:block.number_of_nodes('DST/' + block.ntypes[0])] #前一次卷积的结果
|
||||
h = layer(block, (h, h_dst), block.edata['weights'])
|
||||
return h
|
||||
```
|
||||
|
||||
其中WeightedSAGEConv为根据邻居权重的聚合函数。
|
||||
|
||||
```python
|
||||
class WeightedSAGEConv(nn.Module):
|
||||
def __init__(self, input_dims, hidden_dims, output_dims, act=F.relu):
|
||||
super().__init__()
|
||||
self.act = act
|
||||
self.Q = nn.Linear(input_dims, hidden_dims)
|
||||
self.W = nn.Linear(input_dims + hidden_dims, output_dims)
|
||||
self.reset_parameters()
|
||||
self.dropout = nn.Dropout(0.5)
|
||||
|
||||
def reset_parameters(self):
|
||||
gain = nn.init.calculate_gain('relu')
|
||||
nn.init.xavier_uniform_(self.Q.weight, gain=gain)
|
||||
nn.init.xavier_uniform_(self.W.weight, gain=gain)
|
||||
nn.init.constant_(self.Q.bias, 0)
|
||||
nn.init.constant_(self.W.bias, 0)
|
||||
|
||||
def forward(self, g, h, weights):
|
||||
"""
|
||||
g : 基于batch的子图
|
||||
h : 节点特征
|
||||
weights : 边的权重
|
||||
"""
|
||||
h_src, h_dst = h # 邻居节点特征,自身节点特征
|
||||
with g.local_scope():
|
||||
# 将src节点上的原始特征映射成hidden_dims长,存储于'n'字段
|
||||
g.srcdata['n'] = self.act(self.Q(self.dropout(h_src)))
|
||||
g.edata['w'] = weights.float()
|
||||
|
||||
# src节点上的特征'n'乘以边上的权重,构成消息'm'
|
||||
# dst节点将所有接收到的消息'm',相加起来,存入dst节点的'n'字段
|
||||
g.update_all(fn.u_mul_e('n', 'w', 'm'), fn.sum('m', 'n'))
|
||||
|
||||
# 将边上的权重w拷贝成消息'm'
|
||||
# dst节点将所有接收到的消息'm',相加起来,存入dst节点的'ws'字段
|
||||
g.update_all(fn.copy_e('w', 'm'), fn.sum('m', 'ws'))
|
||||
|
||||
# 邻居节点的embedding的加权和
|
||||
n = g.dstdata['n']
|
||||
ws = g.dstdata['ws'].unsqueeze(1).clamp(min=1) # 边上权重之和
|
||||
|
||||
# 先将邻居节点的embedding,做加权平均
|
||||
# 再拼接上一轮卷积后,dst节点自身的embedding
|
||||
# 再经过线性变化与非线性激活,得到这一轮卷积后各dst节点的embedding
|
||||
z = self.act(self.W(self.dropout(torch.cat([n / ws, h_dst], 1))))
|
||||
|
||||
# 本轮卷积后,各dst节点的embedding除以模长,进行归一化
|
||||
z_norm = z.norm(2, 1, keepdim=True)
|
||||
z_norm = torch.where(z_norm == 0, torch.tensor(1.).to(z_norm), z_norm)
|
||||
z = z / z_norm
|
||||
return z
|
||||
```
|
||||
|
||||
**给边打分:** 经过SAGENet得到了batch内所有节点的embedding,这时需要根据学习到的embedding为pos_graph和neg_graph中的每个边打分,即计算正样本对和负样本的內积。具体逻辑是根据两端节点embedding的点积,然后加上两端节点的bias。
|
||||
|
||||
```python
|
||||
class ItemToItemScorer(nn.Module):
|
||||
def __init__(self, full_graph, ntype):
|
||||
super().__init__()
|
||||
n_nodes = full_graph.number_of_nodes(ntype)
|
||||
self.bias = nn.Parameter(torch.zeros(n_nodes, 1))
|
||||
|
||||
def _add_bias(self, edges):
|
||||
bias_src = self.bias[edges.src[dgl.NID]]
|
||||
bias_dst = self.bias[edges.dst[dgl.NID]]
|
||||
# 边上两顶点的embedding的点积,再加上两端节点的bias
|
||||
return {'s': edges.data['s'] + bias_src + bias_dst}
|
||||
|
||||
def forward(self, item_item_graph, h):
|
||||
"""
|
||||
item_item_graph : 每个边 为 pair 对
|
||||
h : 每个节点隐层状态
|
||||
"""
|
||||
with item_item_graph.local_scope():
|
||||
item_item_graph.ndata['h'] = h
|
||||
# 边两端节点的embedding做点积,保存到s
|
||||
item_item_graph.apply_edges(fn.u_dot_v('h', 'h', 's'))
|
||||
# 为每个边加上偏置,即加上两个顶点的偏置
|
||||
item_item_graph.apply_edges(self._add_bias)
|
||||
# 算出来的得分为 pair 的预测得分
|
||||
pair_score = item_item_graph.edata['s']
|
||||
return pair_score
|
||||
```
|
||||
|
||||
### 训练过程
|
||||
|
||||
介绍完“数据处理”和“PinSAGE模块”之后,接下来就是通过训练过程将上述两部分串起来,详细的见代码:
|
||||
|
||||
```python
|
||||
def train(dataset, args):
|
||||
#从dataset中加载数据和原图
|
||||
g = dataset['train-graph']
|
||||
...
|
||||
|
||||
device = torch.device(args.device)
|
||||
# 为节点随机初始化一个id,用于做embedding
|
||||
g.nodes[user_ntype].data['id'] = torch.arange(g.number_of_nodes(user_ntype))
|
||||
g.nodes[item_ntype].data['id'] = torch.arange(g.number_of_nodes(item_ntype))
|
||||
|
||||
|
||||
# 负责采样出batch_size大小的节点列表: heads, tails, neg_tails
|
||||
batch_sampler = sampler_module.ItemToItemBatchSampler(
|
||||
g, user_ntype, item_ntype, args.batch_size)
|
||||
|
||||
# 由一个batch中的heads,tails,neg_tails构建训练这个batch所需要的
|
||||
# pos_graph,neg_graph 和 blocks
|
||||
neighbor_sampler = sampler_module.NeighborSampler(
|
||||
g, user_ntype, item_ntype, args.random_walk_length,
|
||||
args.random_walk_restart_prob, args.num_random_walks, args.num_neighbors,
|
||||
args.num_layers)
|
||||
|
||||
# 每次next()返回: pos_graph,neg_graph和blocks,做训练之用
|
||||
collator = sampler_module.PinSAGECollator(neighbor_sampler, g, item_ntype, textset)
|
||||
dataloader = DataLoader(
|
||||
batch_sampler,
|
||||
collate_fn=collator.collate_train,
|
||||
num_workers=args.num_workers)
|
||||
|
||||
# 每次next()返回blocks,做训练中测试之用
|
||||
dataloader_test = DataLoader(
|
||||
torch.arange(g.number_of_nodes(item_ntype)),
|
||||
batch_size=args.batch_size,
|
||||
collate_fn=collator.collate_test,
|
||||
num_workers=args.num_workers)
|
||||
dataloader_it = iter(dataloader)
|
||||
|
||||
# 准备模型
|
||||
model = PinSAGEModel(g, item_ntype, textset, args.hidden_dims, args.num_layers).to(device)
|
||||
opt = torch.optim.Adam(model.parameters(), lr=args.lr)
|
||||
|
||||
# 训练过程
|
||||
for epoch_id in range(args.num_epochs):
|
||||
model.train()
|
||||
for batch_id in tqdm.trange(args.batches_per_epoch):
|
||||
pos_graph, neg_graph, blocks = next(dataloader_it)
|
||||
for i in range(len(blocks)):
|
||||
blocks[i] = blocks[i].to(device)
|
||||
pos_graph = pos_graph.to(device)
|
||||
neg_graph = neg_graph.to(device)
|
||||
|
||||
loss = model(pos_graph, neg_graph, blocks).mean()
|
||||
opt.zero_grad()
|
||||
loss.backward()
|
||||
opt.step()
|
||||
```
|
||||
|
||||
至此,DGL PinSAGE example的主要实现代码已经全部介绍完了,感兴趣的可以去官网对照源代码自行学习。
|
||||
|
||||
## 参考
|
||||
|
||||
[Graph Convolutional Neural Networks for Web-Scale Recommender Systems](https://arxiv.org/abs/1806.01973)
|
||||
|
||||
[PinSAGE 召回模型及源码分析(1): PinSAGE 简介](https://zhuanlan.zhihu.com/p/275942839)
|
||||
|
||||
[全面理解PinSage](https://zhuanlan.zhihu.com/p/133739758)
|
||||
|
||||
[[论文笔记]PinSAGE——Graph Convolutional Neural Networks for Web-Scale Recommender Systems](https://zhuanlan.zhihu.com/p/461720302)
|
||||
|
||||
415
4.人工智能/ch02/ch2.1/ch2.1.4/MIND.md
Normal file
415
4.人工智能/ch02/ch2.1/ch2.1.4/MIND.md
Normal file
@@ -0,0 +1,415 @@
|
||||
## 写在前面
|
||||
MIND模型(Multi-Interest Network with Dynamic Routing), 是阿里团队2019年在CIKM上发的一篇paper,该模型依然是用在召回阶段的一个模型,解决的痛点是之前在召回阶段的模型,比如双塔,YouTubeDNN召回模型等,在模拟用户兴趣的时候,总是基于用户的历史点击,最后通过pooling的方式得到一个兴趣向量,用该向量来表示用户的兴趣,但是该篇论文的作者认为,**用一个向量来表示用户的广泛兴趣未免有点太过于单一**,这是作者基于天猫的实际场景出发的发现,每个用户每天与数百种产品互动, 而互动的产品往往来自于很多个类别,这就说明用户的兴趣极其广泛,**用一个向量是无法表示这样广泛的兴趣的**,于是乎,就自然而然的引出一个问题,**有没有可能用多个向量来表示用户的多种兴趣呢?**
|
||||
|
||||
这篇paper的核心是胶囊网络,**该网络采用了动态路由算法能非常自然的将历史商品聚成多个集合,每个集合的历史行为进一步推断对应特定兴趣的用户表示向量。这样,对于一个特定的用户,MND输出了多个表示向量,它们代表了用户的不同兴趣。当用户再有新的交互时,通过胶囊网络,还能实时的改变用户的兴趣表示向量,做到在召回阶段的实时个性化**。那么,胶囊网络究竟是怎么做到的呢? 胶囊网络又是什么原理呢?
|
||||
|
||||
**主要内容**:
|
||||
* 背景与动机
|
||||
* 胶囊网络与动态路由机制
|
||||
* MIND模型的网络结构与细节剖析
|
||||
* MIND模型之简易代码复现
|
||||
* 总结
|
||||
|
||||
## 背景与动机
|
||||
本章是基于天猫APP的背景来探索十亿级别的用户个性化推荐。天猫的推荐的流程主要分为召回阶段和排序阶段。召回阶段负责检索数千个与用户兴趣相关的候选物品,之后,排序阶段预测用户与这些候选物品交互的精确概率。这篇文章做的是召回阶段的工作,来对满足用户兴趣的物品的有效检索。
|
||||
|
||||
作者这次的出发点是基于场景出发,在天猫的推荐场景中,作者发现**用户的兴趣存在多样性**。平均上,10亿用户访问天猫,每个用户每天与数百种产品互动。交互后的物品往往属于不同的类别,说明用户兴趣的多样性。 一张图片会更加简洁直观:
|
||||
|
||||

|
||||
因此如果能在**召回阶段建立用户多兴趣模型来模拟用户的这种广泛兴趣**,那么作者认为是非常有必要的,因为召回阶段的任务就是根据用户兴趣检索候选商品嘛。
|
||||
|
||||
那么,如何能基于用户的历史交互来学习用户的兴趣表示呢? 以往的解决方案如下:
|
||||
* 协同过滤的召回方法(itemcf和usercf)是通过历史交互过的物品或隐藏因子直接表示用户兴趣, 但会遇到**稀疏或计算问题**
|
||||
* 基于深度学习的方法用低维的embedding向量表示用户,比如YoutubeDNN召回模型,双塔模型等,都是把用户的基本信息,或者用户交互过的历史商品信息等,过一个全连接层,最后编码成一个向量,用这个向量来表示用户兴趣,但作者认为,**这是多兴趣表示的瓶颈**,因为需要压缩所有与用户多兴趣相关的信息到一个表示向量,所有用户多兴趣的信息进行了混合,导致这种多兴趣并无法体现,所以往往召回回来的商品并不是很准确,除非向量维度很大,但是大维度又会带来高计算。
|
||||
* DIN模型在Embedding的基础上加入了Attention机制,来选择的捕捉用户兴趣的多样性,但采用Attention机制,**对于每个目标物品,都需要重新计算用户表示**,这在召回阶段是行不通的(海量),所以DIN一般是用于排序。
|
||||
|
||||
所以,作者想在召回阶段去建模用户的多兴趣,但以往的方法都不好使,为了解决这个问题,就提出了动态路由的多兴趣网络MIND。为了推断出用户的多兴趣表示,提出了一个多兴趣提取层,该层使用动态路由机制自动的能将用户的历史行为聚类,然后每个类簇中产生一个表示向量,这个向量能代表用户某种特定的兴趣,而多个类簇的多个向量合起来,就能表示用户广泛的兴趣了。
|
||||
|
||||
这就是MIND的提出动机以及初步思路了,这里面的核心是Multi-interest extractor layer, 而这里面重点是动态路由与胶囊网络,所以接下来先补充这方面的相关知识。
|
||||
|
||||
## 胶囊网络与动态路由机制
|
||||
### 胶囊网络初识
|
||||
Hinton大佬在2011年的时候,就首次提出了"胶囊"的概念, "胶囊"可以看成是一组聚合起来输出整个向量的小神经元组合,这个向量的每个维度(每个小神经元),代表着某个实体的某个特征。
|
||||
|
||||
胶囊网络其实可以和神经网络对比着看可能更好理解,我们知道神经网络的每一层的神经元输出的是单个的标量值,接收的输入,也是多个标量值,所以这是一种value to value的形式,而胶囊网络每一层的胶囊输出的是一个向量值,接收的输入也是多个向量,所以它是vector to vector形式的。来个图对比下就清楚了:
|
||||
|
||||
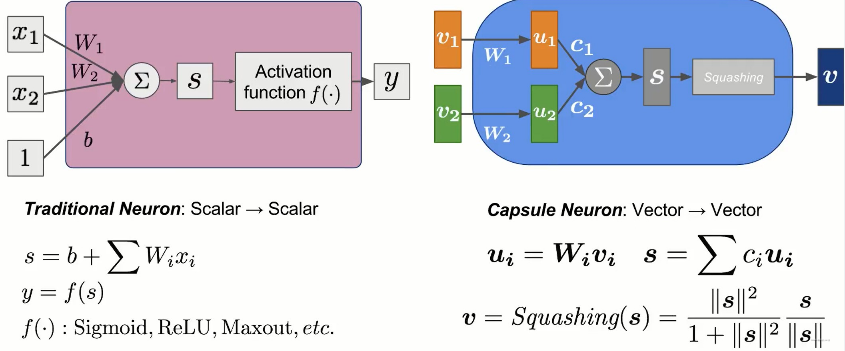
|
||||
左边的图是普通神经元的计算示意,而右边是一个胶囊内部的计算示意图。 神经元这里不过多解释,这里主要是剖析右边的这个胶囊计算原理。从上图可以看出, 输入是两个向量$v_1,v_2$,首先经过了一个线性映射,得到了两个新向量$u_1,u_2$,然后呢,经过了一个向量的加权汇总,这里的$c_1$,$c_2$可以先理解成权重,具体计算后面会解释。 得到汇总后的向量$s$,接下来进行了Squash操作,整体的计算公式如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
&u^{1}=W^{1} v^{1} \quad u^{2}=W^{2} v^{2} \\
|
||||
&s=c_{1} u^{1}+c_{2} u^{2} \\
|
||||
&v=\operatorname{Squash}(s) =\frac{\|s\|^{2}}{1+\|s\|^{2}} \frac{s}{\|s\|}
|
||||
\end{aligned}
|
||||
$$
|
||||
这里的Squash操作可以简单看下,主要包括两部分,右边的那部分其实就是向量归一化操作,把norm弄成1,而左边那部分算是一个非线性操作,如果$s$的norm很大,那么这个整体就接近1, 而如果这个norm很小,那么整体就会接近0, 和sigmoid很像有没有?
|
||||
|
||||
这样就完成了一个胶囊的计算,但有两点需要注意:
|
||||
1. 这里的$W^i$参数是可学习的,和神经网络一样, 通过BP算法更新
|
||||
2. 这里的$c_i$参数不是BP算法学习出来的,而是采用动态路由机制现场算出来的,这个非常类似于pooling层,我们知道pooling层的参数也不是学习的,而是根据前面的输入现场取最大或者平均计算得到的。
|
||||
|
||||
所以这里的问题,就是怎么通过动态路由机制得到$c_i$,下面是动态路由机制的过程。
|
||||
|
||||
### 动态路由机制原理
|
||||
我们先来一个胶囊结构:
|
||||
|
||||
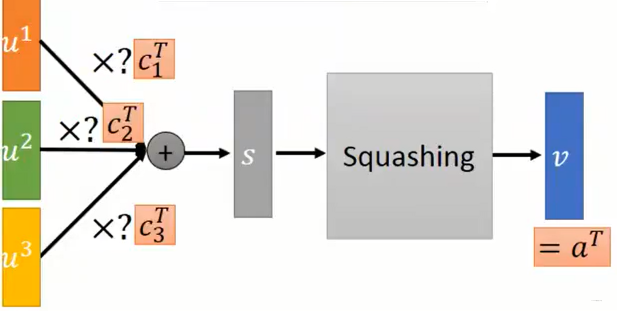
|
||||
这个$c_i$是通过动态路由机制计算得到,那么动态路由机制究竟是啥子意思? 其实就是通过迭代的方式去计算,没有啥神秘的,迭代计算的流程如下图:
|
||||
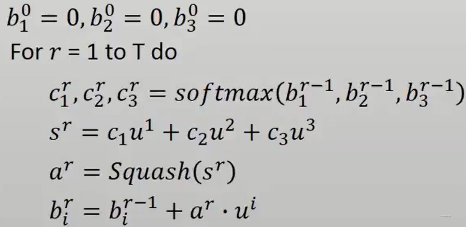
|
||||
首先我们先初始化$b_i$,与每一个输入胶囊$u_i$进行对应,这哥们有个名字叫做"routing logit", 表示的是输出的这个胶囊与输入胶囊的相关性,和注意力机制里面的score值非常像。由于一开始不知道这个哪个胶囊与输出的胶囊有关系,所以默认相关性分数都一样,然后进入迭代。
|
||||
|
||||
在每一次迭代中,首先把分数转成权重,然后加权求和得到$s$,这个很类似于注意力机制的步骤,得到$s$之后,通过归一化操作,得到$a$,接下来要通过$a$和输入胶囊的相关性以及上一轮的$b_i$来更新$b_i$。最后那个公式有必要说一下在干嘛:
|
||||
>如果当前的$a$与某一个输入胶囊$u_i$非常相关,即内积结果很大的话,那么相应的下一轮的该输入胶囊对应的$b_i$就会变大, 那么, 在计算下一轮的$a$的时候,与上一轮$a$相关的$u_i$就会占主导,相当于下一轮的$a$与上一轮中和他相关的那些$u_i$之间的路径权重会大一些,这样从空间点的角度观察,就相当于$a$点朝与它相关的那些$u$点更近了一点。
|
||||
|
||||
通过若干次迭代之后,得到最后的输出胶囊向量$a$会慢慢的走到与它更相关的那些$u$附近,而远离那些与它不相干的$u$。所以上面的这个迭代过程有点像**排除异常输入胶囊的感觉**。
|
||||
|
||||
|
||||
|
||||
而从另一个角度来考虑,这个过程其实像是聚类的过程,因为胶囊的输出向量$v$经过若干次迭代之后,会最终停留到与其非常相关的那些输入胶囊里面,而这些输入胶囊,其实就可以看成是某个类别了,因为既然都共同的和输出胶囊$v$比较相关,那么彼此之间的相关性也比较大,于是乎,经过这样一个动态路由机制之后,就不自觉的,把输入胶囊实现了聚类。把和与其他输入胶囊不同的那些胶囊给排除了出去。
|
||||
|
||||
所以,这个动态路由机制的计算设计的还是比较巧妙的, 下面是上述过程的展开计算过程, 这个和RNN的计算有点类似:
|
||||
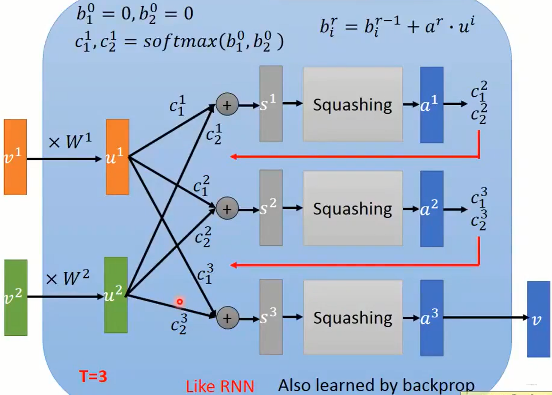
|
||||
这样就完成了一个胶囊内部的计算过程了。
|
||||
|
||||
Ok, 有了上面的这些铺垫,再来看MIND就会比较简单了。下面正式对MIND模型的网络架构剖析。
|
||||
|
||||
## MIND模型的网络结构与细节剖析
|
||||
### 网络整体结构
|
||||
MIND网络的架构如下:
|
||||

|
||||
初步先分析这个网络结构的运作: 首先接收的输入有三类特征,用户base属性,历史行为属性以及商品的属性,用户的历史行为序列属性过了一个多兴趣提取层得到了多个兴趣胶囊,接下来和用户base属性拼接过DNN,得到了交互之后的用户兴趣。然后在训练阶段,用户兴趣和当前商品向量过一个label-aware attention,然后求softmax损失。 在服务阶段,得到用户的向量之后,就可以直接进行近邻检索,找候选商品了。 这就是宏观过程,但是,多兴趣提取层以及这个label-aware attention是在做什么事情呢? 如果单独看这个图,感觉得到多个兴趣胶囊之后,直接把这些兴趣胶囊以及用户的base属性拼接过全连接,那最终不就成了一个用户向量,此时label-aware attention的意义不就没了? 所以这个图初步感觉画的有问题,和论文里面描述的不符。所以下面先以论文为主,正式开始描述具体细节。
|
||||
|
||||
### 任务目标
|
||||
召回任务的目标是对于每一个用户$u \in \mathcal{U}$从十亿规模的物品池$\mathcal{I}$检索出包含与用户兴趣相关的上千个物品集。
|
||||
#### 模型的输入
|
||||
对于模型,每个样本的输入可以表示为一个三元组:$\left(\mathcal{I}_{u}, \mathcal{P}_{u}, \mathcal{F}_{i}\right)$,其中$\mathcal{I}_{u}$代表与用户$u$交互过的物品集,即用户的历史行为;$\mathcal{P}_{u}$表示用户的属性,例如性别、年龄等;$\mathcal{F}_{i}$定义为目标物品$i$的一些特征,例如物品id和种类id等。
|
||||
#### 任务描述
|
||||
MIND的核心任务是学习一个从原生特征映射到**用户表示**的函数,用户表示定义为:
|
||||
$$
|
||||
\mathrm{V}_{u}=f_{u s e r}\left(\mathcal{I}_{u}, \mathcal{P}_{u}\right)
|
||||
$$
|
||||
其中,$\mathbf{V}_{u}=\left(\overrightarrow{\boldsymbol{v}}_{u}^{1}, \ldots, \overrightarrow{\boldsymbol{v}}_{u}^{K}\right) \in \mathbb{R}^{d \times k}$是用户$u$的表示向量,$d$是embedding的维度,$K$表示向量的个数,即兴趣的数量。如果$K=1$,那么MIND模型就退化成YouTubeDNN的向量表示方式了。
|
||||
|
||||
目标物品$i$的embedding函数为:
|
||||
$$
|
||||
\overrightarrow{\mathbf{e}}_{i}=f_{\text {item }}\left(\mathcal{F}_{i}\right)
|
||||
$$
|
||||
其中,$\overrightarrow{\mathbf{e}}_{i} \in \mathbb{R}^{d \times 1}, \quad f_{i t e m}(\cdot)$表示一个embedding&pooling层。
|
||||
#### 最终结果
|
||||
根据评分函数检索(根据**目标物品与用户表示向量的内积的最大值作为相似度依据**,DIN的Attention部分也是以这种方式来衡量两者的相似度),得到top N个候选项:
|
||||
|
||||
$$
|
||||
f_{\text {score }}\left(\mathbf{V}_{u}, \overrightarrow{\mathbf{e}}_{i}\right)=\max _{1 \leq k \leq K} \overrightarrow{\mathbf{e}}_{i}^{\mathrm{T}} \overrightarrow{\mathbf{V}}_{u}^{\mathrm{k}}
|
||||
$$
|
||||
|
||||
### Embedding & Pooling层
|
||||
Embedding层的输入由三部分组成,用户属性$\mathcal{P}_{u}$、用户行为$\mathcal{I}_{u}$和目标物品标签$\mathcal{F}_{i}$。每一部分都由多个id特征组成,则是一个高维的稀疏数据,因此需要Embedding技术将其映射为低维密集向量。具体来说,
|
||||
|
||||
* 对于$\mathcal{P}_{u}$的id特征(年龄、性别等)是将其Embedding的向量进行Concat,组成用户属性Embedding$\overrightarrow{\mathbf{p}}_{u}$;
|
||||
* 目标物品$\mathcal{F}_{i}$通常包含其他分类特征id(品牌id、店铺id等) ,这些特征有利于物品的冷启动问题,需要将所有的分类特征的Embedding向量进行平均池化,得到一个目标物品向量$\overrightarrow{\mathbf{e}}_{i}$;
|
||||
* 对于用户行为$\mathcal{I}_{u}$,由物品的Embedding向量组成用户行为Embedding列表$E_{u}=\overrightarrow{\mathbf{e}}_{j}, j \in \mathcal{I}_{u}$, 当然这里不仅只有物品embedding哈,也可能有类别,品牌等其他的embedding信息。
|
||||
|
||||
### Multi-Interest Extractor Layer(核心)
|
||||
作者认为,单一的向量不足以表达用户的多兴趣。所以作者采用**多个表示向量**来分别表示用户不同的兴趣。通过这个方式,在召回阶段,用户的多兴趣可以分别考虑,对于兴趣的每一个方面,能够更精确的进行物品检索。
|
||||
|
||||
为了学习多兴趣表示,作者利用胶囊网络表示学习的动态路由将用户的历史行为分组到多个簇中。来自一个簇的物品应该密切相关,并共同代表用户兴趣的一个特定方面。
|
||||
|
||||
由于多兴趣提取器层的设计灵感来自于胶囊网络表示学习的动态路由,所以这里作者回顾了动态路由机制。当然,如果之前对胶囊网络或动态路由不了解,这里读起来就会有点艰难,但由于我上面进行了铺垫,这里就直接拿过原文并解释即可。
|
||||
#### 动态路由
|
||||
动态路由是胶囊网络中的迭代学习算法,用于学习低水平胶囊和高水平胶囊之间的路由对数(logit)$b_{ij}$,来得到高水平胶囊的表示。
|
||||
|
||||
我们假设胶囊网络有两层,即低水平胶囊$\vec{c}_{i}^{l} \in \mathbb{R}^{N_{l} \times 1}, i \in\{1, \ldots, m\}$和高水平胶囊$\vec{c}_{j}^{h} \in \mathbb{R}^{N_{h} \times 1}, j \in\{1, \ldots, n\}$,其中$m,n$表示胶囊的个数, $N_l,N_h$表示胶囊的维度。 路由对数$b_{ij}$计算公式如下:
|
||||
$$
|
||||
b_{i j}=\left(\vec{c}_{j}^{h}\right)^{T} \mathrm{~S}_{i j} \vec{c}_{i}^{l}
|
||||
$$
|
||||
其中$\mathbf{S}_{i j} \in \mathbb{R}^{N_{h} \times N_{l}}$表示待学习的双线性映射矩阵【在胶囊网络的原文中称为转换矩阵】
|
||||
|
||||
通过计算路由对数,将高阶胶囊$j$的候选向量计算为所有低阶胶囊的加权和:
|
||||
$$
|
||||
\vec{z}_{j}^{h}=\sum_{i=1}^{m} w_{i j} S_{i j} \vec{c}_{i}^{l}
|
||||
$$
|
||||
其中$w_{ij}$定义为连接低阶胶囊$i$和高阶胶囊$j$的权重【称为耦合系数】,而且其通过对路由对数执行softmax来计算:
|
||||
$$
|
||||
w_{i j}=\frac{\exp b_{i j}}{\sum_{k=1}^{m} \exp b_{i k}}
|
||||
$$
|
||||
最后,应用一个非线性的“压缩”函数来获得一个高阶胶囊的向量【胶囊网络向量的模表示由胶囊所代表的实体存在的概率】
|
||||
$$
|
||||
\vec{c}_{j}^{h}=\operatorname{squash}\left(\vec{z}_{j}^{h}\right)=\frac{\left\|\vec{z}_{j}^{h}\right\|^{2}}{1+\left\|\vec{z}_{j}^{h}\right\|^{2}} \frac{\vec{z}_{j}^{h}}{\left\|\vec{z}_{j}^{h}\right\|}
|
||||
$$
|
||||
路由过程重复进行3次达到收敛。当路由结束,高阶胶囊值$\vec{c}_{j}^{h}$固定,作为下一层的输入。
|
||||
|
||||
Ok,下面我们开始解释,其实上面说的这些就是胶囊网络的计算过程,只不过和之前所用的符号不一样了。这里拿个图:
|
||||
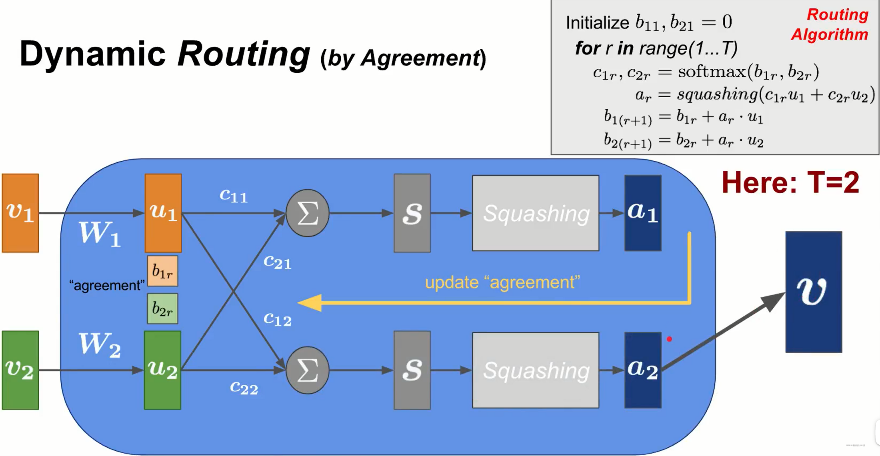
|
||||
首先,论文里面也是个两层的胶囊网络,低水平层->高水平层。 低水平层有$m$个胶囊,每个胶囊向量维度是$N_l$,用$\vec{c}_{i}^l$表示的,高水平层有$n$个胶囊,每个胶囊$N_h$维,用$\vec{c}_{j}^h$表示。
|
||||
|
||||
单独拿出每个$\vec{c}_{j}^h$,其计算过程如上图所示。首先,先随机初始化路由对数$b_{ij}=0$,然后开始迭代,对于每次迭代:
|
||||
$$
|
||||
w_{i j}=\frac{\exp b_{i j}}{\sum_{k=1}^{m} \exp b_{i k}} \\
|
||||
\vec{z}_{j}^{h}=\sum_{i=1}^{m} w_{i j} S_{i j} \vec{c}_{i}^{l} \\ \vec{c}_{j}^{h}=\operatorname{squash}\left(\vec{z}_{j}^{h}\right)=\frac{\left\|\vec{z}_{j}^{h}\right\|^{2}}{1+\left\|\vec{z}_{j}^{h}\right\|^{2}} \frac{\vec{z}_{j}^{h}}{\left\|\vec{z}_{j}^{h}\right\|} \\ b_{i j}=\left(\vec{c}_{j}^{h}\right)^{T} \mathrm{~S}_{i j} \vec{c}_{i}^{l}
|
||||
$$
|
||||
只不过这里的符合和上图中的不太一样,这里的$w_{ij}$对应的是每个输入胶囊的权重$c_{ij}$, 这里的$\vec{c}_{j}^h$对应上图中的$a$, 这里的$\vec{z}_{j}^h$对应的是输入胶囊的加权组合。这里的$\vec{c}_{i}^l$对应上图中的$v_i$,这里的$S_{ij}$对应的是上图的权重$W_{ij}$,只不过这个可以换成矩阵运算。 和上图中不同的是路由对数$b_{ij}$更新那里,没有了上一层的路由对数值,但感觉这样会有问题。
|
||||
|
||||
所以,这样解释完之后就会发现,其实上面的一顿操作就是说的传统的动态路由机制。
|
||||
|
||||
#### B2I动态路由
|
||||
作者设计的多兴趣提取层就是就是受到了上述胶囊网络的启发。
|
||||
|
||||
如果把用户的行为序列看成是行为胶囊, 把用户的多兴趣看成兴趣胶囊,那么多兴趣提取层就是利用动态路由机制学习行为胶囊`->`兴趣胶囊的映射关系。但是原始路由算法无法直接应用于处理用户行为数据。因此,提出了**行为(Behavior)到兴趣(Interest)(B2I)动态路由**来自适应地将用户的行为聚合到兴趣表示向量中,它与原始路由算法有三个不同之处:
|
||||
|
||||
1. **共享双向映射矩阵**。在初始动态路由中,使用固定的或者说共享的双线性映射矩阵$S$而不是单独的双线性映射矩阵, 在原始的动态路由中,对于每个输出胶囊$\vec{c}_{j}^h$,都会有对应的$S_{ij}$,而这里是每个输出胶囊,都共用一个$S$矩阵。 原因有两个:
|
||||
1. 一方面,用户行为是可变长度的,从几十个到几百个不等,因此使用共享的双线性映射矩阵是有利于泛化。
|
||||
2. 另一方面,希望兴趣胶囊在同一个向量空间中,但不同的双线性映射矩阵将兴趣胶囊映射到不同的向量空间中。因为映射矩阵的作用就是对用户的行为胶囊进行线性映射嘛, 由于用户的行为序列都是商品,所以希望经过映射之后,到统一的商品向量空间中去。路由对数计算如下:
|
||||
$$
|
||||
b_{i j}=\overrightarrow{\boldsymbol{u}}_{j}^{T} \mathrm{S\overrightarrow{e}}_{i}, \quad i \in \mathcal{I}_{u}, j \in\{1, \ldots, K\}
|
||||
$$
|
||||
其中,$\overrightarrow{\boldsymbol{e}}_{i} \in \mathbb{R}^{d}$是历史物品$i$的embedding,$\vec{u}_{j} \in \mathbb{R}^{d}$表示兴趣胶囊$j$的向量。$S \in \mathbb{R}^{d \times d}$是每一对行为胶囊(低价)到兴趣胶囊(高阶)之间 的共享映射矩阵。
|
||||
|
||||
|
||||
2. **随机初始化路由对数**。由于利用共享双向映射矩阵$S$,如果再初始化路由对数为0将导致相同的初始的兴趣胶囊。随后的迭代将陷入到一个不同兴趣胶囊在所有的时间保持相同的情景。因为每个输出胶囊的运算都一样了嘛(除非迭代的次数不同,但这样也会导致兴趣胶囊都很类似),为了减轻这种现象,作者通过高斯分布进行随机采样来初始化路由对数$b_{ij}$,让初始兴趣胶囊与其他每一个不同,其实就是希望在计算每个输出胶囊的时候,通过随机化的方式,希望这几个聚类中心离得远一点,这样才能表示出广泛的用户兴趣(我们已经了解这个机制就仿佛是聚类,而计算过程就是寻找聚类中心)。
|
||||
3. **动态的兴趣数量**,兴趣数量就是聚类中心的个数,由于不同用户的历史行为序列不同,那么相应的,其兴趣胶囊有可能也不一样多,所以这里使用了一种启发式方式自适应调整聚类中心的数量,即$K$值。
|
||||
$$
|
||||
K_{u}^{\prime}=\max \left(1, \min \left(K, \log _{2}\left(\left|\mathcal{I}_{u}\right|\right)\right)\right)
|
||||
$$
|
||||
这种调整兴趣胶囊数量的策略可以为兴趣较小的用户节省一些资源,包括计算和内存资源。这个公式不用多解释,与行为序列长度成正比。
|
||||
|
||||
最终的B2I动态路由算法如下:
|
||||

|
||||
应该很好理解了吧。
|
||||
|
||||
### Label-aware Attention Layer
|
||||
通过多兴趣提取器层,从用户的行为embedding中生成多个兴趣胶囊。不同的兴趣胶囊代表用户兴趣的不同方面,相应的兴趣胶囊用于评估用户对特定类别的偏好。所以,在训练的期间,最后需要设置一个Label-aware的注意力层,对于当前的商品,根据相关性选择最相关的兴趣胶囊。这里其实就是一个普通的注意力机制,和DIN里面的那个注意力层基本上是一模一样,计算公式如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\overrightarrow{\boldsymbol{v}}_{u} &=\operatorname{Attention}\left(\overrightarrow{\boldsymbol{e}}_{i}, \mathrm{~V}_{u}, \mathrm{~V}_{u}\right) \\
|
||||
&=\mathrm{V}_{u} \operatorname{softmax}\left(\operatorname{pow}\left(\mathrm{V}_{u}^{\mathrm{T}} \overrightarrow{\boldsymbol{e}}_{i}, p\right)\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
首先这里的$\overrightarrow{\boldsymbol{e}}_{i}$表示当前的商品向量,$V_u$表示用户的多兴趣向量组合,里面有$K$个向量,表示用户的$K$的兴趣。用户的各个兴趣向量与目标商品做内积,然后softmax转成权重,然后反乘到多个兴趣向量进行加权求和。 但是这里需要注意的一个小点,就是这里做内积求完相似性之后,先做了一个指数操作,**这个操作其实能放大或缩小相似程度**,至于放大或者缩小的程度,由$p$控制。 比如某个兴趣向量与当前商品非常相似,那么再进行指数操作之后,如果$p$也很大,那么显然这个兴趣向量就占了主导作用。$p$是一个可调节的参数来调整注意力分布。当$p$接近0,每一个兴趣胶囊都得到相同的关注。当$p$大于1时,随着$p$的增加,具有较大值的点积将获得越来越多的权重。考虑极限情况,当$p$趋近于无穷大时,注意机制就变成了一种硬注意,选关注最大的值而忽略其他值。在实验中,发现使用硬注意导致更快的收敛。
|
||||
>理解:$p$小意味着所有的相似程度都缩小了, 使得之间的差距会变小,所以相当于每个胶囊都会受到关注,而越大的话,使得各个相似性差距拉大,相似程度越大的会更大,就类似于贫富差距, 最终使得只关注于比较大的胶囊。
|
||||
|
||||
### 训练与服务
|
||||
得到用户向量$\overrightarrow{\boldsymbol{v}}_{u}$和标签物品embedding$\vec{e}_{i}$后,计算用户$u$与标签物品$i$交互的概率:
|
||||
$$
|
||||
\operatorname{Pr}(i \mid u)=\operatorname{Pr}\left(\vec{e}_{i} \mid \vec{v}_{u}\right)=\frac{\exp \left(\vec{v}_{u}^{\mathrm{T} \rightarrow}\right)}{\sum_{j \in I} \exp \left(\vec{v}_{u}^{\mathrm{T}} \vec{e}_{j}\right)}
|
||||
$$
|
||||
目标函数是:
|
||||
$$
|
||||
L=\sum_{(u, i) \in \mathcal{D}} \log \operatorname{Pr}(i \mid u)
|
||||
$$
|
||||
其中$\mathcal{D}$是训练数据包含用户物品交互的集合。因为物品的数量可伸缩到数十亿,所以不能直接算。因此。使用采样的softmax技术,并且选择Adam优化来训练MIND。
|
||||
|
||||
训练结束后,抛开label-aware注意力层,MIND网络得到一个用户表示映射函数$f_{user}$。在服务期间,用户的历史序列与自身属性喂入到$f_{user}$,每个用户得到多兴趣向量。然后这个表示向量通过一个近似邻近方法来检索top N物品。
|
||||
|
||||
这就是整个MIND模型的细节了。
|
||||
|
||||
## MIND模型之简易代码复现
|
||||
下面参考Deepctr,用简易的代码实现下MIND,并在新闻推荐的数据集上进行召回任务。
|
||||
|
||||
### 整个代码架构
|
||||
|
||||
整个MIND模型算是参考deepmatch修改的一个简易版本:
|
||||
|
||||
```python
|
||||
def MIND(user_feature_columns, item_feature_columns, num_sampled=5, k_max=2, p=1.0, dynamic_k=False, user_dnn_hidden_units=(64, 32),
|
||||
dnn_activation='relu', dnn_use_bn=False, l2_reg_dnn=0, l2_reg_embedding=1e-6, dnn_dropout=0, output_activation='linear', seed=1024):
|
||||
"""
|
||||
:param k_max: 用户兴趣胶囊的最大个数
|
||||
"""
|
||||
# 目前这里只支持item_feature_columns为1的情况,即只能转入item_id
|
||||
if len(item_feature_columns) > 1:
|
||||
raise ValueError("Now MIND only support 1 item feature like item_id")
|
||||
|
||||
# 获取item相关的配置参数
|
||||
item_feature_column = item_feature_columns[0]
|
||||
item_feature_name = item_feature_column.name
|
||||
item_vocabulary_size = item_feature_column.vocabulary_size
|
||||
item_embedding_dim = item_feature_column.embedding_dim
|
||||
|
||||
behavior_feature_list = [item_feature_name]
|
||||
|
||||
# 为用户特征创建Input层
|
||||
user_input_layer_dict = build_input_layers(user_feature_columns)
|
||||
item_input_layer_dict = build_input_layers(item_feature_columns)
|
||||
# 将Input层转化成列表的形式作为model的输入
|
||||
user_input_layers = list(user_input_layer_dict.values())
|
||||
item_input_layers = list(item_input_layer_dict.values())
|
||||
|
||||
# 筛选出特征中的sparse特征和dense特征,方便单独处理
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
varlen_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
|
||||
# 由于这个变长序列里面只有历史点击文章,没有类别啥的,所以这里直接可以用varlen_feature_columns
|
||||
# deepctr这里单独把点击文章这个放到了history_feature_columns
|
||||
seq_max_len = varlen_feature_columns[0].maxlen
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(user_feature_columns+item_feature_columns)
|
||||
|
||||
# 获取当前的行为特征(doc)的embedding,这里面可能又多个类别特征,所以需要pooling下
|
||||
query_embed_list = embedding_lookup(behavior_feature_list, item_input_layer_dict, embedding_layer_dict) # 长度为1
|
||||
# 获取行为序列(doc_id序列, hist_doc_id) 对应的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
keys_embed_list = embedding_lookup([varlen_feature_columns[0].name], user_input_layer_dict, embedding_layer_dict) # 长度为1
|
||||
|
||||
# 用户离散特征的输入层与embedding层拼接
|
||||
dnn_input_emb_list = embedding_lookup([col.name for col in sparse_feature_columns], user_input_layer_dict, embedding_layer_dict)
|
||||
|
||||
# 获取dense
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
if fc.name != 'hist_len': # 连续特征不要这个
|
||||
dnn_dense_input.append(user_input_layer_dict[fc.name])
|
||||
|
||||
# 把keys_emb_list和query_emb_listpooling操作, 这是因为可能每个商品不仅有id,还可能用类别,品牌等多个embedding向量,这种需要pooling成一个
|
||||
history_emb = PoolingLayer()(NoMask()(keys_embed_list)) # (None, 50, 8)
|
||||
target_emb = PoolingLayer()(NoMask()(query_embed_list)) # (None, 1, 8)
|
||||
|
||||
hist_len = user_input_layer_dict['hist_len']
|
||||
# 胶囊网络
|
||||
# (None, 2, 8) 得到了两个兴趣胶囊
|
||||
high_capsule = CapsuleLayer(input_units=item_embedding_dim, out_units=item_embedding_dim,
|
||||
max_len=seq_max_len, k_max=k_max)((history_emb, hist_len))
|
||||
|
||||
|
||||
# 把用户的其他特征拼接到胶囊网络上来
|
||||
if len(dnn_input_emb_list) > 0 or len(dnn_dense_input) > 0:
|
||||
user_other_feature = combined_dnn_input(dnn_input_emb_list, dnn_dense_input)
|
||||
# (None, 2, 32) 这里会发现其他的用户特征是每个胶囊复制了一份,然后拼接起来
|
||||
other_feature_tile = tf.keras.layers.Lambda(tile_user_otherfeat, arguments={'k_max': k_max})(user_other_feature)
|
||||
user_deep_input = Concatenate()([NoMask()(other_feature_tile), high_capsule]) # (None, 2, 40)
|
||||
else:
|
||||
user_deep_input = high_capsule
|
||||
|
||||
# 接下来过一个DNN层,获取最终的用户表示向量 如果是三维输入, 那么最后一个维度与w相乘,所以这里如果不自己写,可以用Dense层的列表也可以
|
||||
user_embeddings = DNN(user_dnn_hidden_units, dnn_activation, l2_reg_dnn,
|
||||
dnn_dropout, dnn_use_bn, output_activation=output_activation, seed=seed,
|
||||
name="user_embedding")(user_deep_input) # (None, 2, 8)
|
||||
|
||||
# 接下来,过Label-aware layer
|
||||
if dynamic_k:
|
||||
user_embedding_final = LabelAwareAttention(k_max=k_max, pow_p=p,)((user_embeddings, target_emb, hist_len))
|
||||
else:
|
||||
user_embedding_final = LabelAwareAttention(k_max=k_max, pow_p=p,)((user_embeddings, target_emb))
|
||||
|
||||
# 接下来
|
||||
item_embedding_matrix = embedding_layer_dict[item_feature_name] # 获取doc_id的embedding层
|
||||
item_index = EmbeddingIndex(list(range(item_vocabulary_size)))(item_input_layer_dict[item_feature_name]) # 所有doc_id的索引
|
||||
item_embedding_weight = NoMask()(item_embedding_matrix(item_index)) # 拿到所有item的embedding
|
||||
pooling_item_embedding_weight = PoolingLayer()([item_embedding_weight]) # 这里依然是当可能不止item_id,或许还有brand_id, cat_id等,需要池化
|
||||
|
||||
# 这里传入的是整个doc_id的embedding, user_embedding, 以及用户点击的doc_id,然后去进行负采样计算损失操作
|
||||
output = SampledSoftmaxLayer(num_sampled)([pooling_item_embedding_weight, user_embedding_final, item_input_layer_dict[item_feature_name]])
|
||||
|
||||
model = Model(inputs=user_input_layers+item_input_layers, outputs=output)
|
||||
|
||||
# 下面是等模型训练完了之后,获取用户和item的embedding
|
||||
model.__setattr__("user_input", user_input_layers)
|
||||
model.__setattr__("user_embedding", user_embeddings)
|
||||
model.__setattr__("item_input", item_input_layers)
|
||||
model.__setattr__("item_embedding", get_item_embedding(pooling_item_embedding_weight, item_input_layer_dict[item_feature_name]))
|
||||
|
||||
return model
|
||||
```
|
||||
简单说下流程, 函数式API搭建模型的方式,首先我们需要传入封装好的用户特征描述以及item特征描述,比如:
|
||||
|
||||
```python
|
||||
# 建立模型
|
||||
user_feature_columns = [
|
||||
SparseFeat('user_id', feature_max_idx['user_id'], embedding_dim),
|
||||
VarLenSparseFeat(SparseFeat('hist_doc_ids', feature_max_idx['article_id'], embedding_dim,
|
||||
embedding_name="click_doc_id"), his_seq_maxlen, 'mean', 'hist_len'),
|
||||
DenseFeat('hist_len', 1),
|
||||
SparseFeat('u_city', feature_max_idx['city'], embedding_dim),
|
||||
SparseFeat('u_age', feature_max_idx['age'], embedding_dim),
|
||||
SparseFeat('u_gender', feature_max_idx['gender'], embedding_dim),
|
||||
]
|
||||
doc_feature_columns = [
|
||||
SparseFeat('click_doc_id', feature_max_idx['article_id'], embedding_dim)
|
||||
# 这里后面也可以把文章的类别画像特征加入
|
||||
]
|
||||
```
|
||||
首先, 函数会对传入的这种特征建立模型的Input层,主要是`build_input_layers`函数。建立完了之后,获取到Input层列表,这个是为了最终定义模型用的,keras要求定义模型的时候是列表的形式。
|
||||
|
||||
接下来是选出sparse特征和Dense特征来,这个也是常规操作了,因为不同的特征后面处理方式不一样,对于sparse特征,后面要接embedding层,Dense特征的话,直接可以拼接起来。这就是筛选特征的3行代码。
|
||||
|
||||
接下来,是为所有的离散特征建立embedding层,通过函数`build_embedding_layers`。建立完了之后,把item相关的embedding层与对应的Input层接起来,作为query_embed_list, 而用户历史行为序列的embedding层与Input层接起来作为keys_embed_list,这两个有单独的用户。而Input层与embedding层拼接是通过`embedding_lookup`函数完成的。 这样完成了之后,就能通过Input层-embedding层拿到item的系列embedding,以及历史序列里面item系列embedding,之所以这里是系列embedding,是有可能不止item_id这一个特征,还可能有品牌id, 类别id等好几个,所以接下来把系列embedding通过pooling操作,得到最终表示item的向量。 就是这两行代码:
|
||||
|
||||
```python
|
||||
# 把keys_emb_list和query_emb_listpooling操作, 这是因为可能每个商品不仅有id,还可能用类别,品牌等多个embedding向量,这种需要pooling成一个
|
||||
history_emb = PoolingLayer()(NoMask()(keys_embed_list)) # (None, 50, 8)
|
||||
target_emb = PoolingLayer()(NoMask()(query_embed_list)) # (None, 1, 8)
|
||||
```
|
||||
而像其他的输入类别特征, 依然是Input层与embedding层拼起来,留着后面用,这个存到了dnn_input_emb_list中。 而dense特征, 不需要embedding层,直接通过Input层获取到,然后存到列表里面,留着后面用。
|
||||
|
||||
上面得到的history_emb,就是用户的历史行为序列,这个东西接下来要过兴趣提取层,去学习用户的多兴趣,当然这里还需要传入行为序列的真实长度。因为每个用户行为序列不一样长,通过mask让其等长了,但是真实在胶囊网络计算的时候,这些填充的序列是要被mask掉的。所以必须要知道真实长度。
|
||||
|
||||
```python
|
||||
# 胶囊网络
|
||||
# (None, 2, 8) 得到了两个兴趣胶囊
|
||||
high_capsule = CapsuleLayer(input_units=item_embedding_dim, out_units=item_embedding_dim,max_len=seq_max_len, k_max=k_max)((history_emb, hist_len))
|
||||
```
|
||||
通过这步操作,就得到了两个兴趣胶囊。 至于具体细节,下一节看。 然后把用户的其他特征拼接上来,这里有必要看下代码究竟是怎么拼接的:
|
||||
|
||||
```python
|
||||
# 把用户的其他特征拼接到胶囊网络上来
|
||||
if len(dnn_input_emb_list) > 0 or len(dnn_dense_input) > 0:
|
||||
user_other_feature = combined_dnn_input(dnn_input_emb_list, dnn_dense_input)
|
||||
# (None, 2, 32) 这里会发现其他的用户特征是每个胶囊复制了一份,然后拼接起来
|
||||
other_feature_tile = tf.keras.layers.Lambda(tile_user_otherfeat, arguments={'k_max': k_max})(user_other_feature)
|
||||
user_deep_input = Concatenate()([NoMask()(other_feature_tile), high_capsule]) # (None, 2, 40)
|
||||
else:
|
||||
user_deep_input = high_capsule
|
||||
```
|
||||
这里会发现,使用了一个Lambda层,这个东西的作用呢,其实是将用户的其他特征在胶囊个数的维度上复制了一份,再拼接,这就相当于在每个胶囊的后面都拼接上了用户的基础特征。这样得到的维度就成了(None, 2, 40),2是胶囊个数, 40是兴趣胶囊的维度+其他基础特征维度总和。这样拼完了之后,接下来过全连接层
|
||||
|
||||
```python
|
||||
# 接下来过一个DNN层,获取最终的用户表示向量 如果是三维输入, 那么最后一个维度与w相乘,所以这里如果不自己写,可以用Dense层的列表也可以
|
||||
user_embeddings = DNN(user_dnn_hidden_units, dnn_activation, l2_reg_dnn,
|
||||
dnn_dropout, dnn_use_bn, output_activation=output_activation, seed=seed,
|
||||
name="user_embedding")(user_deep_input) # (None, 2, 8)
|
||||
```
|
||||
最终得到的是(None, 2, 8)的向量,这样就解决了之前的那个疑问, 最终得到的兴趣向量个数并不是1个,而是多个兴趣向量了,因为上面用户特征拼接,是每个胶囊后面都拼接一份同样的特征。另外,就是原来DNN这里的输入还可以是3维的,这样进行运算的话,是最后一个维度与W进行运算,相当于只在第3个维度上进行了降维操作后者非线性操作,这样得到的兴趣个数是不变的。
|
||||
|
||||
这样,有了两个兴趣的输出之后,接下来,就是过LabelAwareAttention层了,对这两个兴趣向量与当前item的相关性加注意力权重,最后变成1个用户的最终向量。
|
||||
|
||||
```python
|
||||
user_embedding_final = LabelAwareAttention(k_max=k_max, pow_p=p,)((user_embeddings, target_emb))
|
||||
```
|
||||
这样,就得到了用户的最终表示向量,当然这个操作仅是训练的时候,服务的时候是拿的上面DNN的输出,即多个兴趣,这里注意一下。
|
||||
|
||||
拿到了最终的用户向量,如何计算损失呢? 这里用了负采样层进行操作。关于这个层具体的原理,后面我们可能会出一篇文章总结。
|
||||
|
||||
接下来有几行代码也需要注意:
|
||||
|
||||
```python
|
||||
# 下面是等模型训练完了之后,获取用户和item的embedding
|
||||
model.__setattr__("user_input", user_input_layers)
|
||||
model.__setattr__("user_embedding", user_embeddings)
|
||||
model.__setattr__("item_input", item_input_layers)
|
||||
model.__setattr__("item_embedding", get_item_embedding(pooling_item_embedding_weight, item_input_layer_dict[item_feature_name]))
|
||||
```
|
||||
这几行代码是为了模型训练完,我们给定输入之后,拿embedding用的,设置好了之后,通过:
|
||||
|
||||
```python
|
||||
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
|
||||
item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
|
||||
|
||||
user_embs = user_embedding_model.predict(test_user_model_input, batch_size=2 ** 12)
|
||||
# user_embs = user_embs[:, i, :] # i in [0,k_max) if MIND
|
||||
item_embs = item_embedding_model.predict(all_item_model_input, batch_size=2 ** 12)
|
||||
```
|
||||
这样就能拿到用户和item的embedding, 接下来近邻检索完成召回过程。 注意,MIND的话,这里是拿到的多个兴趣向量的。
|
||||
|
||||
## 总结
|
||||
今天这篇文章整理的MIND,这是一个多兴趣的召回模型,核心是兴趣提取层,该层通过动态路由机制能够自动的对用户的历史行为序列进行聚类,得到多个兴趣向量,这样能在召回阶段捕获到用户的广泛兴趣,从而召回更好的候选商品。
|
||||
|
||||
|
||||
**参考**:
|
||||
* Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
|
||||
* [ AI上推荐 之 MIND(动态路由与胶囊网络的奇光异彩)](https://blog.csdn.net/wuzhongqiang/article/details/123696462?spm=1001.2014.3001.5501)
|
||||
* [Dynamic Routing Between Capsule ](https://arxiv.org/pdf/1710.09829.pdf)
|
||||
* [CIKM2019|MIND---召回阶段的多兴趣模型](https://zhuanlan.zhihu.com/p/262638999)
|
||||
* [B站胶囊网络课程](https://www.bilibili.com/video/BV1eW411Q7CE?p=2)
|
||||
* [胶囊网络识别交通标志](https://blog.csdn.net/shebao3333/article/details/79008688)
|
||||
|
||||
|
||||
404
4.人工智能/ch02/ch2.1/ch2.1.4/SDM.md
Normal file
404
4.人工智能/ch02/ch2.1/ch2.1.4/SDM.md
Normal file
@@ -0,0 +1,404 @@
|
||||
## 写在前面
|
||||
SDM模型(Sequential Deep Matching Model),是阿里团队在2019年CIKM上的一篇paper。和MIND模型一样,是一种序列召回模型,研究的依然是如何通过用户的历史行为序列去学习到用户的丰富兴趣。 对于MIND,我们已经知道是基于胶囊网络的动态路由机制,设计了一个动态兴趣提取层,把用户的行为序列通过路由机制聚类,然后映射成了多个兴趣胶囊,以此来获取到用户的广泛兴趣。而SDM模型,是先把用户的历史序列根据交互的时间分成了短期和长期两类,然后从**短期会话**和**长期行为**中分别采取**相应的措施(短期的RNN+多头注意力, 长期的Att Net)** 去学习到用户的短期兴趣和长期行为偏好,并**巧妙的设计了一个门控网络==有选择==的将长短期兴趣进行融合**,以此得到用户的最终兴趣向量。 这篇paper中的一些亮点,比如长期偏好的行为表示,多头注意力机制学习多兴趣,长短期兴趣的融合机制等,又给了一些看待问题的新角度,同时,给出了我们一种利用历史行为序列去捕捉用户动态偏好的新思路。
|
||||
|
||||
这篇paper依然是从引言开始, 介绍SDM模型提出的动机以及目前方法存在的不足(why), 接下来就是SDM的网络模型架构(what), 这里面的关键是如何从短期会话和长期行为两个方面学习到用户的短期长期偏好(how),最后,依然是简易代码实现。
|
||||
|
||||
大纲如下:
|
||||
* 背景与动机
|
||||
* SDM的网络结构与细节
|
||||
* SDM模型代码复现
|
||||
|
||||
## 背景与动机
|
||||
这里要介绍该模型提出的动机,即why要有这样的一个模型?
|
||||
|
||||
一个好的推荐系统应该是能精确的捕捉用户兴趣偏好以及能对他们当前需求进行快速响应的,往往工业上的推荐系统,为了能快速响应, 一般会把整个推荐流程分成召回和排序两个阶段,先通过召回,从海量商品中得到一个小的候选集,然后再给到排序模型做精确的筛选操作。 这也是目前推荐系统的一个范式了。在这个过程中,召回模块所检索到的候选对象的质量在整个系统中起着至关重要的作用。
|
||||
|
||||
淘宝目前的召回模型是一些基于协同过滤的模型, 这些模型是通过用户与商品的历史交互建模,从而得到用户的物品的表示向量,但这个过程是**静态的**,而用户的行为或者兴趣是时刻变化的, 对于协同过滤的模型来说,并不能很好的捕捉到用户整个行为序列的动态变化。
|
||||
|
||||
那我们知道了学习用户历史行为序列很重要, 那么假设序列很长呢?这时候直接用模型学习长序列之间的演进可能不是很好,因为很长的序列里面可能用户的兴趣发生过很大的转变,很多商品压根就没有啥关系,这样硬学,反而会导致越学越乱,就别提这个演进了。所以这里是以会话为单位,对长序列进行切分。作者这里的依据就是用户在同一个Session下,其需求往往是很明确的, 这时候,交互的商品也往往都非常类似。 但是Session与Session之间,可能需求改变,那么商品类型可能骤变。 所以以Session为单位来学习商品之间的序列信息,感觉要比整个长序列学习来的靠谱。
|
||||
|
||||
作者首先是先把长序列分成了多个会话, 然后**把最近的一次会话,和之前的会话分别视为了用户短期行为和长期行为分别进行了建模,并采用不同的措施学习用户的短期兴趣和长期兴趣,然后通过一个门控机制融合得到用户最终的表示向量**。这就是SDM在做的事情,
|
||||
|
||||
|
||||
长短期行为序列联合建模,其实是在给我们提供一种新的学习用户兴趣的新思路, 那么究竟是怎么做的呢?以及为啥这么做呢?
|
||||
* 对于短期用户行为, 首先作者使用了LSTM来学习序列关系, 而接下来是用一个Multi-head attention机制,学习用户的多兴趣。
|
||||
|
||||
先分析分析作者为啥用多头注意力机制,作者这里依然是基于实际的场景出发,作者发现,**用户的兴趣点在一个会话里面其实也是多重的**。这个可能之前的很多模型也是没考虑到的,但在商品购买的场景中,这确实也是个事实, 顾客在买一个商品的时候,往往会进行多方比较, 考虑品牌,颜色,商店等各种因素。作者认为用普通的注意力机制是无法反映广泛的兴趣了,所以用多头注意力网络。
|
||||
|
||||
多头注意力机制从某个角度去看,也有类似聚类的功效,首先它接收了用户的行为序列,然后从多个角度学习到每个商品与其他商品的相关性,然后根据与其他商品的相关性加权融合,这样,相似的item向量大概率就融合到了一块组成一个向量,所谓用户的多兴趣,可能是因为这些行为商品之间,可以从多个空间或者角度去get彼此之间的相关性,这里面有着用户多兴趣的表达信息。
|
||||
|
||||
* 用户的长期行为也会影响当前的决策,作者在这里举了一个NBA粉丝的例子,说如果一个是某个NBA球星的粉丝,那么他可能在之前会买很多有关这个球星的商品,如果现在这个时刻想买鞋的时候,大概率会考虑和球星相关的。所以作者说**长期偏好和短期行为都非常关键**。但是长期偏好或者行为往往是复杂广泛的,就像刚才这个例子里面,可能长期行为里面,买的与这个球星相关商品只占一小部分,而就只有这一小部分对当前决策有用。
|
||||
这个也是之前的模型利用长期偏好方面存在的问题,那么如何选择出长期偏好里面对于当前决策有用的那部分呢? 作者这里设计了一个门控的方式融合短期和长期,这个想法还是很巧妙的,后面介绍这个东西的时候说下我的想法。
|
||||
|
||||
所以下面总结动机以及本篇论文的亮点:
|
||||
* 动机: 召回模型需要捕获用户的动态兴趣变化,这个过程中利用好用户的长期行为和短期偏好非常关键,而以往的模型有下面几点不足:
|
||||
* 协同过滤模型: 基于用户的交互进行静态建模,无法感知用户的兴趣变化过程,易召回同质性的商品
|
||||
* 早期的一些序列推荐模型: 要么是对整个长序列直接建模,但这样太暴力,没法很好的学习商品之间的序列信息,有些是把长序列分成会话,但忽视了一个会话中用户的多重兴趣
|
||||
* 有些方法在考虑用户的长期行为方面,只是简单的拼接或者加权求和,而实际上用户长期行为中只有很少一小部分对当前的预测有用,这样暴力融合反而会适得其反,起不到效果。另外还有一些多任务或者对抗方法, 在工业场景中不适用等。
|
||||
* 这些我只是通过我的理解简单总结,详细内容看原论文相关工作部分。
|
||||
* 亮点:
|
||||
* SDM模型, 考虑了用户的短期行为和长期兴趣,以会话的形式进行分割,并对这两方面分别建模
|
||||
* 短期会话由于对当前决策影响比较大,那么我们就学习的全面一点, 首先RNN学习序列关系,其次通过多头注意力机制捕捉多兴趣,然后通过一个Attention Net加权得到短期兴趣表示
|
||||
* 长期会话通过Attention Net融合,然后过DNN,得到用户的长期表示
|
||||
* 我们设计了一个门控机制,类似于LSTM的那种门控,能巧妙的融合这两种兴趣,得到用户最终的表示向量
|
||||
|
||||
这就是动机与背景总结啦。 那么接下来,SDM究竟是如何学习短期和长期表示,又是如何融合的? 为什么要这么玩?
|
||||
|
||||
## SDM的网络结构与细节剖析
|
||||
### 问题定义
|
||||
这里本来直接看模型结构,但感觉还是先过一下问题定义吧,毕竟这次涉及到了会话,还有几个小规则。
|
||||
|
||||
$\mathcal{U}$表示用户集合,$\mathcal{I}$表示item集合,模型考虑在时间$t$,是否用户$u$会对$i$产生交互。 对于$u$, 我们能够得到它的历史行为序列,那么先说一下如何进行会话的划分, 这里有三个规则:
|
||||
1. 相同会话ID的商品(后台能获取)算是一个会话
|
||||
2. 相邻的商品,时间间隔小于10分钟(业务自己调整)算一个会话
|
||||
3. 同一个会话中的商品不能超过50个,多出来的放入下一个会话
|
||||
|
||||
这样划分开会话之后, 对于用户$u$的短期行为定义是离目前最近的这次会话, 用$\mathcal{S}^{u}=\left[i_{1}^{u}, \ldots, i_{t}^{u}, \ldots, i_{m}^{u}\right]$表示,$m$是序列长度。 而长期的用户行为是过去一周内的会话,但不包括短期的这次会话, 这个用$\mathcal{L}^{u}$表示。网络推荐架构如下:
|
||||
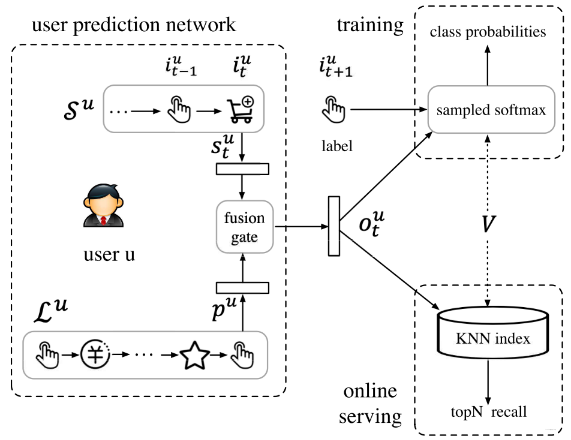
|
||||
这个感觉并不用过多解释。看过召回的应该都能懂, 接收了用户的短期行为和长期行为,然后分别通过两个盲盒得到表示向量,再通过门控融合就得到了最终的用户表示。
|
||||
|
||||
下面要开那三个盲盒操作,即短期行为学习,长期行为学习以及门控融合机制。但在这之前,得先说一个东西,就是输入层这里, 要带物品的side infomation,比如物品的item ID, 物品的品牌ID,商铺ID, 类别ID等等, 那你说,为啥要单独说呢? 之前的模型不也有, 但是这里在利用方式上有些不一样需要注意。
|
||||
|
||||
### Input Embedding with side Information
|
||||
在淘宝的推荐场景中,作者发现, 顾客与物品产生交互行为的时候,不仅考虑特定的商品本身,还考虑产品, 商铺,价格等,这个显然。所以,这里对于一个商品来说,不仅要用到Item ID,还用了更多的side info信息,包括`leat category, fist level category, brand,shop`。
|
||||
|
||||
所以,假设用户的短期行为是$\mathcal{S}^{u}=\left[i_{1}^{u}, \ldots, i_{t}^{u}, \ldots, i_{m}^{u}\right]$, 这里面的每个商品$i_t^u$其实有5个属性表示了,每个属性本质是ID,但转成embedding之后,就得到了5个embedding, 所以这里就涉及到了融合问题。 这里用$\boldsymbol{e}_{{i}^u_t} \in \mathbb{R}^{d \times 1}$来表示每个$i_t^u$,但这里不是embedding的pooling操作,而是Concat
|
||||
$$
|
||||
\boldsymbol{e}_{i_{t}^{u}}=\operatorname{concat}\left(\left\{\boldsymbol{e}_{i}^{f} \mid f \in \mathcal{F}\right\}\right)
|
||||
$$
|
||||
其中,$\boldsymbol{e}_{i}^{f}=\boldsymbol{W}^{f} \boldsymbol{x}_{i}^{f} \in \mathbb{R}^{d_{f} \times 1}$, 这个公式看着负责,其实就是每个side info的id过embedding layer得到各自的embedding。这里embedding的维度是$d_f$, 等拼接起来之后,就是$d$维了。这个点要注意。
|
||||
|
||||
另外就是用户的base表示向量了,这个很简单, 就是用户的基础画像,得到embedding,直接也是Concat,这个常规操作不解释:
|
||||
$$
|
||||
\boldsymbol{e}_{u}=\operatorname{concat}\left(\left\{\boldsymbol{e}_{u}^{p} \mid p \in \mathcal{P}\right\}\right)
|
||||
$$
|
||||
$e_u^p$是特征$p$的embedding。
|
||||
|
||||
Ok,输入这里说完了之后,就直接开盲盒, 不按照论文里面的顺序来了。想看更多细节的就去看原论文吧,感觉那里面说的有些啰嗦。不如直接上图解释来的明显:
|
||||
|
||||
|
||||
这里正好三个框把盒子框住了,下面剖析出每个来就行啦。
|
||||
### 短期用户行为建模
|
||||
这里短期用户行为是下面的那个框, 接收的输入,首先是用户最近的那次会话,里面各个商品加入了side info信息之后,有了最终的embedding表示$\left[\boldsymbol{e}_{i_{1}^{u}}, \ldots, \boldsymbol{e}_{i_{t}^{u}}\right]$。
|
||||
|
||||
这个东西,首先要过LSTM,学习序列信息,这个感觉不用多说,直接上公式:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\boldsymbol{i} \boldsymbol{n}_{t}^{u} &=\sigma\left(\boldsymbol{W}_{i n}^{1} \boldsymbol{e}_{i_{t}^{u}}+\boldsymbol{W}_{i n}^{2} \boldsymbol{h}_{t-1}^{u}+b_{i n}\right) \\
|
||||
f_{t}^{u} &=\sigma\left(\boldsymbol{W}_{f}^{1} \boldsymbol{e}_{i_{t}^{u}}+\boldsymbol{W}_{f}^{2} \boldsymbol{h}_{t-1}^{u}+b_{f}\right) \\
|
||||
\boldsymbol{o}_{t}^{u} &=\sigma\left(\boldsymbol{W}_{o}^{1} \boldsymbol{e}_{i}^{u}+\boldsymbol{W}_{o}^{2} \boldsymbol{h}_{t-1}^{u}+b_{o}\right) \\
|
||||
\boldsymbol{c}_{t}^{u} &=\boldsymbol{f}_{t} \boldsymbol{c}_{t-1}^{u}+\boldsymbol{i} \boldsymbol{n}_{t}^{u} \tanh \left(\boldsymbol{W}_{c}^{1} \boldsymbol{e}_{i_{t}^{u}}+\boldsymbol{W}_{c}^{2} \boldsymbol{h}_{t-1}^{u}+b_{c}\right) \\
|
||||
\boldsymbol{h}_{t}^{u} &=\boldsymbol{o}_{t}^{u} \tanh \left(\boldsymbol{c}_{t}^{u}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这里采用的是多输入多输出, 即每个时间步都会有一个隐藏状态$h_t^u$输出出来,那么经过LSTM之后,原始的序列就有了序列相关信息,得到了$\left[\boldsymbol{h}_{1}^{u}, \ldots, \boldsymbol{h}_{t}^{u}\right]$, 把这个记为$\boldsymbol{X}^{u}$。这里的$\boldsymbol{h}_{t}^{u} \in \mathbb{R}^{d \times 1}$表示时间$t$的序列偏好表示。
|
||||
|
||||
接下来, 这个东西要过Multi-head self-attention层,这个东西的原理我这里就不多讲了,这个东西可以学习到$h_i^u$系列之间的相关性,这个操作从某种角度看,也很像聚类, 因为我们这里是先用多头矩阵把$h_i^u$系列映射到多个空间,然后从各个空间中互求相关性
|
||||
$$
|
||||
\text { head }{ }_{i}^{u}=\operatorname{Attention}\left(\boldsymbol{W}_{i}^{Q} \boldsymbol{X}^{u}, \boldsymbol{W}_{i}^{K} \boldsymbol{X}^{u}, \boldsymbol{W}_{i}^{V} \boldsymbol{X}^{u}\right)
|
||||
$$
|
||||
得到权重后,对原始的向量加权融合。 让$Q_{i}^{u}=W_{i}^{Q} X^{u}$, $K_{i}^{u}=W_{i}^{K} \boldsymbol{X}^{u}$,$V_{i}^{u}=W_{i}^{V} X^{u}$, 背后计算是:
|
||||
$$
|
||||
\begin{aligned}
|
||||
&f\left(Q_{i}^{u}, K_{i}^{u}\right)=Q_{i}^{u T} K_{i}^{u} \\
|
||||
&A_{i}^{u}=\operatorname{softmax}\left(f\left(Q_{i}^{u}, K_{i}^{u}\right)\right)
|
||||
\end{aligned} \\ \operatorname{head}_{i}^{u}=V_{i}^{u} A_{i}^{u T}
|
||||
$$
|
||||
|
||||
这里如果有多头注意力基础的话非常好理解啊,不多解释,可以看我[这篇文章](https://blog.csdn.net/wuzhongqiang/article/details/104414239?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164872966516781683952272%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=164872966516781683952272&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-104414239.nonecase&utm_term=Attention+is+all&spm=1018.2226.3001.4450)补一下。
|
||||
|
||||
这是一个头的计算, 接下来每个头都这么算,假设有$h$个头,这里会通过上面的映射矩阵$W$系列,先把原始的$h_i^u$向量映射到$d_{k}=\frac{1}{h} d$维度,然后计算$head_i^u$也是$d_k$维,这样$h$个head进行拼接,正好是$d$维, 接下来过一个全连接或者线性映射得到MultiHead的输出。
|
||||
$$
|
||||
\hat{X}^{u}=\text { MultiHead }\left(X^{u}\right)=W^{O} \text { concat }\left(\text { head }_{1}^{u}, \ldots, \text { head }_{h}^{u}\right)
|
||||
$$
|
||||
|
||||
这样就相当于更相似的$h_i^u$融合到了一块,而这个更相似又是从多个角度得到的,于是乎, 作者认为,这样就能学习到用户的多兴趣。
|
||||
|
||||
得到这个东西之后,接下来再过一个User Attention, 因为作者发现,对于相似历史行为的不同用户,其兴趣偏好也不太一样。
|
||||
所以加入这个用户Attention层,想挖掘更细粒度的用户个性化信息。 当然,这个就是普通的embedding层了, 用户的base向量$e_u$作为query,与$\hat{X}^{u}$的每个向量做Attention,然后加权求和得最终向量:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\alpha_{k} &=\frac{\exp \left(\hat{\boldsymbol{h}}_{k}^{u T} \boldsymbol{e}_{u}\right)}{\sum_{k=1}^{t} \exp \left(\hat{\boldsymbol{h}}_{k}^{u T} \boldsymbol{e}_{u}\right)} \\
|
||||
\boldsymbol{s}_{t}^{u} &=\sum_{k=1}^{t} \alpha_{k} \hat{\boldsymbol{h}}_{k}^{u}
|
||||
\end{aligned}
|
||||
$$
|
||||
其中$s_{t}^{u} \in \mathbb{R}^{d \times 1}$,这样短期行为兴趣就修成了正果。
|
||||
|
||||
### 用户长期行为建模
|
||||
从长期的视角来看,用户在不同的维度上可能积累了广泛的兴趣,用户可能经常访问一组类似的商店,并反复购买属于同一类别的商品。 所以长期行为$\mathcal{L}^{u}$来自于不同的特征尺度。
|
||||
$$
|
||||
\mathcal{L}^{u}=\left\{\mathcal{L}_{f}^{u} \mid f \in \mathcal{F}\right\}
|
||||
$$
|
||||
这里面包含了各种side特征。这里就和短期行为那里不太一样了,长期行为这里,是从特征的维度进行聚合,也就是把用户的历史长序列分成了多个特征,比如用户历史点击过的商品,历史逛过的店铺,历史看过的商品的类别,品牌等,分成了多个特征子集,然后这每个特征子集里面有对应的id,比如商品有商品id, 店铺有店铺id等,对于每个子集,过user Attention layer,和用户的base向量求Attention, 相当于看看用户喜欢逛啥样的商店, 喜欢啥样的品牌,啥样的商品类别等等,得到每个子集最终的表示向量。每个子集的计算过程如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\alpha_{k} &=\frac{\exp \left(\boldsymbol{g}_{k}^{u T} \boldsymbol{e}_{u}\right)}{\sum_{k=1}^{\left|\mathcal{L}_{f}^{u}\right|} \exp \left(\boldsymbol{g}_{k}^{u T} \boldsymbol{e}_{u}\right)} \\
|
||||
z_{f}^{u} &=\sum_{k=1}^{\left|\mathcal{L}_{f}^{u}\right|} \alpha_{k} \boldsymbol{g}_{k}^{u}
|
||||
\end{aligned}
|
||||
$$
|
||||
每个子集都会得到一个加权的向量,把这个东西拼起来,然后过DNN。
|
||||
$$
|
||||
\begin{aligned}
|
||||
&z^{u}=\operatorname{concat}\left(\left\{z_{f}^{u} \mid f \in \mathcal{F}\right\}\right) \\
|
||||
&\boldsymbol{p}^{u}=\tanh \left(\boldsymbol{W}^{p} z^{u}+b\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这里的$\boldsymbol{p}^{u} \in \mathbb{R}^{d \times 1}$, 这样就得到了用户的长期兴趣表示。
|
||||
### 短长期兴趣融合
|
||||
长短期兴趣融合这里,作者发现之前模型往往喜欢直接拼接起来,或者加和,注意力加权等,但作者认为这样不能很好的将两类兴趣融合起来,因为长期序列里面,其实只有很少的一部分行为和当前有关。那么这样的话,直接无脑融合是有问题的。所以这里作者用了一种较为巧妙的方式,即门控机制:
|
||||
$$
|
||||
G_{t}^{u}=\operatorname{sigmoid}\left(\boldsymbol{W}^{1} \boldsymbol{e}_{u}+\boldsymbol{W}^{2} s_{t}^{u}+\boldsymbol{W}^{3} \boldsymbol{p}^{u}+b\right) \\
|
||||
o_{t}^{u}=\left(1-G_{t}^{u}\right) \odot p^{u}+G_{t}^{u} \odot s_{t}^{u}
|
||||
$$
|
||||
这个和LSTM的这种门控机制很像,首先门控接收的输入有用户画像$e_u$,用户短期兴趣$s_t^u$, 用户长期兴趣$p^u$,经过sigmoid函数得到了$G_{t}^{u} \in \mathbb{R}^{d \times 1}$,用来决定在$t$时刻短期和长期兴趣的贡献程度。然后根据这个贡献程度对短期和长期偏好加权进行融合。
|
||||
|
||||
为啥这东西就有用了呢? 实验中证明了这个东西有用,但这里给出我的理解哈,我们知道最终得到的短期或者长期兴趣都是$d$维的向量, 每一个维度可能代表着不同的兴趣偏好,比如第一维度代表品牌,第二个维度代表类别,第三个维度代表价格,第四个维度代表商店等等,当然假设哈,真实的向量不可解释。
|
||||
|
||||
那么如果我们是直接相加或者是加权相加,其实都意味着长短期兴趣这每个维度都有很高的保留, 但其实上,万一长期兴趣和短期兴趣维度冲突了呢? 比如短期兴趣里面可能用户喜欢这个品牌,长期用户里面用户喜欢那个品牌,那么听谁的? 你可能说短期兴趣这个占更大权重呗,那么普通加权可是所有向量都加的相同的权重,品牌这个维度听短期兴趣的,其他维度比如价格,商店也都听短期兴趣的?本身存在不合理性。那么反而直接相加或者加权效果会不好。
|
||||
|
||||
而门控机制的巧妙就在于,我会给每个维度都学习到一个权重,而这个权重非0即1(近似哈), 那么接下来融合的时候,我通过这个门控机制,取长期和短期兴趣向量每个维度上的其中一个。比如在品牌方面听谁的,类别方面听谁的,价格方面听谁的,只会听短期和长期兴趣的其中一个的。这样就不会有冲突发生,而至于具体听谁的,交给网络自己学习。这样就使得用户长期兴趣和短期兴趣融合的时候,每个维度上的信息保留变得**有选择**。使得兴趣的融合方式更加的灵活。
|
||||
|
||||
==这其实又给我们提供了一种两个向量融合的一种新思路,并不一定非得加权或者拼接或者相加了,还可以通过门控机制让网络自己学==
|
||||
|
||||
|
||||
## SDM模型的简易复现
|
||||
下面参考DeepMatch,用简易的代码实现下SDM,并在新闻推荐的数据集上进行召回任务。
|
||||
|
||||
首先,下面分析SDM的整体架构,从代码层面看运行流程, 然后就这里面几个关键的细节进行说明。
|
||||
|
||||
### 模型的输入
|
||||
对于SDM模型,由于它是将用户的行为序列分成了会话的形式,所以在构造SDM模型输入方面和前面的MIND以及YouTubeDNN有很大的不同了,所以这里需要先重点强调下输入。
|
||||
|
||||
在为SDM产生数据集的时候, 需要传入短期会话的长度以及长期会话的长度, 这样, 对于一个行为序列,构造数据集的时候要按照两个长度分成短期行为和长期行为两种,并且每一种都需要指明真实的序列长度。另外,由于这里用到了文章的side info信息,所以我这里在之前列的基础上加入了文章的两个类别特征分别是cat_1和cat_2,作为文章的side info。 这个产生数据集的代码如下:
|
||||
|
||||
```python
|
||||
"""构造sdm数据集"""
|
||||
def get_data_set(click_data, seq_short_len=5, seq_prefer_len=50):
|
||||
"""
|
||||
:param: seq_short_len: 短期会话的长度
|
||||
:param: seq_prefer_len: 会话的最长长度
|
||||
"""
|
||||
click_data.sort_values("expo_time", inplace=True)
|
||||
|
||||
train_set, test_set = [], []
|
||||
for user_id, hist_click in tqdm(click_data.groupby('user_id')):
|
||||
pos_list = hist_click['article_id'].tolist()
|
||||
cat1_list = hist_click['cat_1'].tolist()
|
||||
cat2_list = hist_click['cat_2'].tolist()
|
||||
|
||||
# 滑动窗口切分数据
|
||||
for i in range(1, len(pos_list)):
|
||||
hist = pos_list[:i]
|
||||
cat1_hist = cat1_list[:i]
|
||||
cat2_hist = cat2_list[:i]
|
||||
# 序列长度只够短期的
|
||||
if i <= seq_short_len and i != len(pos_list) - 1:
|
||||
train_set.append((
|
||||
# 用户id, 用户短期历史行为序列, 用户长期历史行为序列, 当前行为文章, label,
|
||||
user_id, hist[::-1], [0]*seq_prefer_len, pos_list[i], 1,
|
||||
# 用户短期历史序列长度, 用户长期历史序列长度,
|
||||
len(hist[::-1]), 0,
|
||||
# 用户短期历史序列对应类别1, 用户长期历史行为序列对应类别1
|
||||
cat1_hist[::-1], [0]*seq_prefer_len,
|
||||
# 历史短期历史序列对应类别2, 用户长期历史行为序列对应类别2
|
||||
cat2_hist[::-1], [0]*seq_prefer_len
|
||||
))
|
||||
# 序列长度够长期的
|
||||
elif i != len(pos_list) - 1:
|
||||
train_set.append((
|
||||
# 用户id, 用户短期历史行为序列,用户长期历史行为序列, 当前行为文章, label
|
||||
user_id, hist[::-1][:seq_short_len], hist[::-1][seq_short_len:], pos_list[i], 1,
|
||||
# 用户短期行为序列长度,用户长期行为序列长度,
|
||||
seq_short_len, len(hist[::-1])-seq_short_len,
|
||||
# 用户短期历史行为序列对应类别1, 用户长期历史行为序列对应类别1
|
||||
cat1_hist[::-1][:seq_short_len], cat1_hist[::-1][seq_short_len:],
|
||||
# 用户短期历史行为序列对应类别2, 用户长期历史行为序列对应类别2
|
||||
cat2_hist[::-1][:seq_short_len], cat2_hist[::-1][seq_short_len:]
|
||||
))
|
||||
# 测试集保留最长的那一条
|
||||
elif i <= seq_short_len and i == len(pos_list) - 1:
|
||||
test_set.append((
|
||||
user_id, hist[::-1], [0]*seq_prefer_len, pos_list[i], 1,
|
||||
len(hist[::-1]), 0,
|
||||
cat1_hist[::-1], [0]*seq_perfer_len,
|
||||
cat2_hist[::-1], [0]*seq_prefer_len
|
||||
))
|
||||
else:
|
||||
test_set.append((
|
||||
user_id, hist[::-1][:seq_short_len], hist[::-1][seq_short_len:], pos_list[i], 1,
|
||||
seq_short_len, len(hist[::-1])-seq_short_len,
|
||||
cat1_hist[::-1][:seq_short_len], cat1_hist[::-1][seq_short_len:],
|
||||
cat2_list[::-1][:seq_short_len], cat2_hist[::-1][seq_short_len:]
|
||||
))
|
||||
|
||||
random.shuffle(train_set)
|
||||
random.shuffle(test_set)
|
||||
|
||||
return train_set, test_set
|
||||
```
|
||||
思路和之前的是一样的,无非就是根据会话的长短,把之前的一个长行为序列划分成了短期和长期两个,然后加入两个新的side info特征。
|
||||
|
||||
### 模型的代码架构
|
||||
整个SDM模型算是参考deepmatch修改的一个简易版本:
|
||||
|
||||
```python
|
||||
def SDM(user_feature_columns, item_feature_columns, history_feature_list, num_sampled=5, units=32, rnn_layers=2,
|
||||
dropout_rate=0.2, rnn_num_res=1, num_head=4, l2_reg_embedding=1e-6, dnn_activation='tanh', seed=1024):
|
||||
"""
|
||||
:param rnn_num_res: rnn的残差层个数
|
||||
:param history_feature_list: short和long sequence field
|
||||
"""
|
||||
# item_feature目前只支持doc_id, 再加别的就不行了,其实这里可以改造下
|
||||
if (len(item_feature_columns)) > 1:
|
||||
raise ValueError("SDM only support 1 item feature like doc_id")
|
||||
|
||||
# 获取item_feature的一些属性
|
||||
item_feature_column = item_feature_columns[0]
|
||||
item_feature_name = item_feature_column.name
|
||||
item_vocabulary_size = item_feature_column.vocabulary_size
|
||||
|
||||
# 为用户特征创建Input层
|
||||
user_input_layer_dict = build_input_layers(user_feature_columns)
|
||||
item_input_layer_dict = build_input_layers(item_feature_columns)
|
||||
|
||||
# 将Input层转化成列表的形式作为model的输入
|
||||
user_input_layers = list(user_input_layer_dict.values())
|
||||
item_input_layers = list(item_input_layer_dict.values())
|
||||
|
||||
# 筛选出特征中的sparse特征和dense特征,方便单独处理
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
if len(dense_feature_columns) != 0:
|
||||
raise ValueError("SDM dont support dense feature") # 目前不支持Dense feature
|
||||
varlen_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(user_feature_columns+item_feature_columns)
|
||||
|
||||
# 拿到短期会话和长期会话列 之前的命名规则在这里起作用
|
||||
sparse_varlen_feature_columns = []
|
||||
prefer_history_columns = []
|
||||
short_history_columns = []
|
||||
|
||||
prefer_fc_names = list(map(lambda x: "prefer_" + x, history_feature_list))
|
||||
short_fc_names = list(map(lambda x: "short_" + x, history_feature_list))
|
||||
|
||||
for fc in varlen_feature_columns:
|
||||
if fc.name in prefer_fc_names:
|
||||
prefer_history_columns.append(fc)
|
||||
elif fc.name in short_fc_names:
|
||||
short_history_columns.append(fc)
|
||||
else:
|
||||
sparse_varlen_feature_columns.append(fc)
|
||||
|
||||
# 获取用户的长期行为序列列表 L^u
|
||||
# [<tf.Tensor 'emb_prefer_doc_id_2/Identity:0' shape=(None, 50, 32) dtype=float32>, <tf.Tensor 'emb_prefer_cat1_2/Identity:0' shape=(None, 50, 32) dtype=float32>, <tf.Tensor 'emb_prefer_cat2_2/Identity:0' shape=(None, 50, 32) dtype=float32>]
|
||||
prefer_emb_list = embedding_lookup(prefer_fc_names, user_input_layer_dict, embedding_layer_dict)
|
||||
# 获取用户的短期序列列表 S^u
|
||||
# [<tf.Tensor 'emb_short_doc_id_2/Identity:0' shape=(None, 5, 32) dtype=float32>, <tf.Tensor 'emb_short_cat1_2/Identity:0' shape=(None, 5, 32) dtype=float32>, <tf.Tensor 'emb_short_cat2_2/Identity:0' shape=(None, 5, 32) dtype=float32>]
|
||||
short_emb_list = embedding_lookup(short_fc_names, user_input_layer_dict, embedding_layer_dict)
|
||||
|
||||
# 用户离散特征的输入层与embedding层拼接 e^u
|
||||
user_emb_list = embedding_lookup([col.name for col in sparse_feature_columns], user_input_layer_dict, embedding_layer_dict)
|
||||
user_emb = concat_func(user_emb_list)
|
||||
user_emb_output = Dense(units, activation=dnn_activation, name='user_emb_output')(user_emb) # (None, 1, 32)
|
||||
|
||||
# 长期序列行为编码
|
||||
# 过AttentionSequencePoolingLayer --> Concat --> DNN
|
||||
prefer_sess_length = user_input_layer_dict['prefer_sess_length']
|
||||
prefer_att_outputs = []
|
||||
# 遍历长期行为序列
|
||||
for i, prefer_emb in enumerate(prefer_emb_list):
|
||||
prefer_attention_output = AttentionSequencePoolingLayer(dropout_rate=0)([user_emb_output, prefer_emb, prefer_sess_length])
|
||||
prefer_att_outputs.append(prefer_attention_output)
|
||||
prefer_att_concat = concat_func(prefer_att_outputs) # (None, 1, 64) <== Concat(item_embedding,cat1_embedding,cat2_embedding)
|
||||
prefer_output = Dense(units, activation=dnn_activation, name='prefer_output')(prefer_att_concat)
|
||||
# print(prefer_output.shape) # (None, 1, 32)
|
||||
|
||||
# 短期行为序列编码
|
||||
short_sess_length = user_input_layer_dict['short_sess_length']
|
||||
short_emb_concat = concat_func(short_emb_list) # (None, 5, 64) 这里注意下, 对于短期序列,描述item的side info信息进行了拼接
|
||||
short_emb_input = Dense(units, activation=dnn_activation, name='short_emb_input')(short_emb_concat) # (None, 5, 32)
|
||||
# 过rnn 这里的return_sequence=True, 每个时间步都需要输出h
|
||||
short_rnn_output = DynamicMultiRNN(num_units=units, return_sequence=True, num_layers=rnn_layers,
|
||||
num_residual_layers=rnn_num_res, # 这里竟然能用到残差
|
||||
dropout_rate=dropout_rate)([short_emb_input, short_sess_length])
|
||||
# print(short_rnn_output) # (None, 5, 32)
|
||||
# 过MultiHeadAttention # (None, 5, 32)
|
||||
short_att_output = MultiHeadAttention(num_units=units, head_num=num_head, dropout_rate=dropout_rate)([short_rnn_output, short_sess_length]) # (None, 5, 64)
|
||||
# user_attention # (None, 1, 32)
|
||||
short_output = UserAttention(num_units=units, activation=dnn_activation, use_res=True, dropout_rate=dropout_rate)([user_emb_output, short_att_output, short_sess_length])
|
||||
|
||||
# 门控融合
|
||||
gated_input = concat_func([prefer_output, short_output, user_emb_output])
|
||||
gate = Dense(units, activation='sigmoid')(gated_input) # (None, 1, 32)
|
||||
|
||||
# temp = tf.multiply(gate, short_output) + tf.multiply(1-gate, prefer_output) 感觉这俩一样?
|
||||
gated_output = Lambda(lambda x: tf.multiply(x[0], x[1]) + tf.multiply(1-x[0], x[2]))([gate, short_output, prefer_output]) # [None, 1,32]
|
||||
gated_output_reshape = Lambda(lambda x: tf.squeeze(x, 1))(gated_output) # (None, 32) 这个维度必须要和docembedding层的维度一样,否则后面没法sortmax_loss
|
||||
|
||||
# 接下来
|
||||
item_embedding_matrix = embedding_layer_dict[item_feature_name] # 获取doc_id的embedding层
|
||||
item_index = EmbeddingIndex(list(range(item_vocabulary_size)))(item_input_layer_dict[item_feature_name]) # 所有doc_id的索引
|
||||
item_embedding_weight = NoMask()(item_embedding_matrix(item_index)) # 拿到所有item的embedding
|
||||
pooling_item_embedding_weight = PoolingLayer()([item_embedding_weight]) # 这里依然是当可能不止item_id,或许还有brand_id, cat_id等,需要池化
|
||||
|
||||
# 这里传入的是整个doc_id的embedding, user_embedding, 以及用户点击的doc_id,然后去进行负采样计算损失操作
|
||||
output = SampledSoftmaxLayer(num_sampled)([pooling_item_embedding_weight, gated_output_reshape, item_input_layer_dict[item_feature_name]])
|
||||
|
||||
model = Model(inputs=user_input_layers+item_input_layers, outputs=output)
|
||||
|
||||
# 下面是等模型训练完了之后,获取用户和item的embedding
|
||||
model.__setattr__("user_input", user_input_layers)
|
||||
model.__setattr__("user_embedding", gated_output_reshape) # 用户embedding是取得门控融合的用户向量
|
||||
model.__setattr__("item_input", item_input_layers)
|
||||
# item_embedding取得pooling_item_embedding_weight, 这个会发现是负采样操作训练的那个embedding矩阵
|
||||
model.__setattr__("item_embedding", get_item_embedding(pooling_item_embedding_weight, item_input_layer_dict[item_feature_name]))
|
||||
return model
|
||||
```
|
||||
函数式API搭建模型的方式,首先我们需要传入封装好的用户特征描述以及item特征描述,比如:
|
||||
|
||||
```python
|
||||
# 建立模型
|
||||
user_feature_columns = [
|
||||
SparseFeat('user_id', feature_max_idx['user_id'], 16),
|
||||
SparseFeat('gender', feature_max_idx['gender'], 16),
|
||||
SparseFeat('age', feature_max_idx['age'], 16),
|
||||
SparseFeat('city', feature_max_idx['city'], 16),
|
||||
|
||||
VarLenSparseFeat(SparseFeat('short_doc_id', feature_max_idx['article_id'], embedding_dim, embedding_name="doc_id"), SEQ_LEN_short, 'mean', 'short_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('prefer_doc_id', feature_max_idx['article_id'], embedding_dim, embedding_name='doc_id'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('short_cat1', feature_max_idx['cat_1'], embedding_dim, embedding_name='cat_1'), SEQ_LEN_short, 'mean', 'short_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('prefer_cat1', feature_max_idx['cat_1'], embedding_dim, embedding_name='cat_1'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('short_cat2', feature_max_idx['cat_2'], embedding_dim, embedding_name='cat_2'), SEQ_LEN_short, 'mean', 'short_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('prefer_cat2', feature_max_idx['cat_2'], embedding_dim, embedding_name='cat_2'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
|
||||
]
|
||||
|
||||
item_feature_columns = [SparseFeat('doc_id', feature_max_idx['article_id'], embedding_dim)]
|
||||
```
|
||||
这里需要注意的一个点是短期和长期序列的名字,必须严格的`short_, prefer_`进行标识,因为在模型搭建的时候就是靠着这个去找到短期和长期序列特征的。
|
||||
|
||||
逻辑其实也比较清晰,首先是建立Input层,然后是embedding层, 接下来,根据命名选择出用户的base特征列, 短期行为序列和长期行为序列。长期序列的话是过`AttentionPoolingLayer`层进行编码,这里本质上注意力然后融合,但这里注意的一个点就是for循环,也就是长期序列行为里面的特征列,比如商品,cat_1, cat_2是for循环的形式求融合向量,再拼接起来过DNN,和论文图保持一致。
|
||||
|
||||
短期序列编码部分,是`item_embedding,cat_1embedding, cat_2embedding`拼接起来,过`DynamicMultiRNN`层学习序列信息, 过`MultiHeadAttention`学习多兴趣,最后过`UserAttentionLayer`进行向量融合。 接下来,长期兴趣向量和短期兴趣向量以及用户base向量,过门控融合机制,得到最终的`user_embedding`。
|
||||
|
||||
而后面的那块是为了模型训练完之后,拿用户embedding和item embedding用的, 这个在MIND那篇文章里作了解释。
|
||||
|
||||
## 总结
|
||||
今天整理的是SDM,这也是一个标准的序列推荐召回模型,主要还是研究用户的序列,不过这篇paper里面一个有意思的点就是把用户的行为训练以会话的形式进行切分,然后再根据时间,分成了短期会话和长期会话,然后分别采用不同的策略去学习用户的短期兴趣和长期兴趣。
|
||||
* 对于短期会话,可能和当前预测相关性较大,所以首先用RNN来学习序列信息,然后采用多头注意力机制得到用户的多兴趣, 隐隐约约感觉多头注意力机制还真有种能聚类的功效,接下来就是和用户的base向量进行注意力融合得到短期兴趣
|
||||
* 长期会话序列中,每个side info信息进行分开,然后分别进行注意力编码融合得到
|
||||
|
||||
为了使得长期会话中对当前预测有用的部分得以体现,在融合短期兴趣和长期兴趣的时候,采用了门控的方式,而不是普通的拼接或者加和等操作,使得兴趣保留信息变得**有选择**。
|
||||
|
||||
这其实就是这篇paper的故事了,借鉴的地方首先是多头注意力机制也能学习到用户的多兴趣, 这样对于多兴趣,就有了胶囊网络与多头注意力机制两种思路。 而对于两个向量融合,这里又给我们提供了一种门控融合机制。
|
||||
|
||||
|
||||
**参考**:
|
||||
|
||||
* SDM原论文
|
||||
* [AI上推荐 之 SDM模型(建模用户长短期兴趣的Match模型)](https://blog.csdn.net/wuzhongqiang/article/details/123856954?spm=1001.2014.3001.5501)
|
||||
* [一文读懂Attention机制](https://zhuanlan.zhihu.com/p/129316415)
|
||||
* [【推荐系统经典论文(十)】阿里SDM模型](https://zhuanlan.zhihu.com/p/137775247?from_voters_page=true)
|
||||
* [SDM-深度序列召回模型](https://zhuanlan.zhihu.com/p/395673080)
|
||||
* [推荐广告中的序列建模](https://blog.csdn.net/qq_41010971/article/details/123762312?spm=1001.2014.3001.5501)
|
||||
65
4.人工智能/ch02/ch2.1/ch2.1.5/TDM.md
Normal file
65
4.人工智能/ch02/ch2.1/ch2.1.5/TDM.md
Normal file
@@ -0,0 +1,65 @@
|
||||
# 背景和目的
|
||||
|
||||
召回早前经历的第一代协同过滤技术,让模型可以在数量级巨大的item集中找到用户潜在想要看到的商品。这种方式有很明显的缺点,一个是对于用户而言,只能通过他历史行为去构建候选集,并且会基于算力的局限做截断。所以推荐结果的多样性和新颖性比较局限,导致推荐的有可能都是用户看过的或者买过的商品。之后在Facebook开源了FASSI库之后,基于内积模型的向量检索方案得到了广泛应用,也就是第二代召回技术。这种技术通过将用户和物品用向量表示,然后用内积的大小度量兴趣,借助向量索引实现大规模的全量检索。这里虽然改善了第一代的无法全局检索的缺点,然而这种模式下存在索引构建和模型优化目标不一致的问题,索引优化是基于向量的近似误差,而召回问题的目标是最大化topK召回率。且这类方法也不方便在用户和物品之间做特征组合。
|
||||
|
||||
所以阿里开发了一种可以承载各种深度模型来检索用户潜在兴趣的推荐算法解决方案。这个TDM模型是基于树结构,利用树结构对全量商品进行检索,将复杂度由O(N)下降到O(logN)。
|
||||
|
||||
# 模型结构
|
||||
|
||||
**树结构**
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420213149324.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
</div>
|
||||
|
||||
如上图,树中的每一个叶子节点对应一个商品item,非叶子结点表示的是item的集合**(这里的树不限于二叉树)**。这种层次化结构体现了粒度从粗到细的item架构。
|
||||
|
||||
**整体结构**
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420200433442.png" alt="image-20210308142624189" style="zoom: 70%;" />
|
||||
</div>
|
||||
|
||||
# 算法详解
|
||||
|
||||
1. 基于树的高效检索
|
||||
|
||||
算法通常采用beam-search的方法,根据用户对每层节点挑选出topK,将挑选出来的这几个topK节点的子节点作为下一层的候选集,最终会落到叶子节点上。
|
||||
这么做的理论依据是当前层的最有优topK节点的父亲必然属于上次的父辈节点的最优topK:
|
||||
$$
|
||||
p^{(j)}(n|u) = {{max \atop{n_{c}\in{\{n's children nodes in level j+1\}}}}p^{(j+1)}(n_{c}|u) \over {\alpha^{j}}}
|
||||
$$
|
||||
其中$p^{(j)}(n|u)$表示用户u对j层节点n感兴趣的概率,$\alpha^{j}$表示归一化因子。
|
||||
|
||||
2. 对兴趣进行建模
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420214040264.png" alt="image-20210308142624189" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
如上图,用户对叶子层item6感兴趣,可以认为它的兴趣是1,同层别的候选节点的兴趣为0,顺着着绿色线路上去的节点都标记为1,路线上的同层别的候选节点都标记为0。这样的操作就可以根据1和0构建用于每一层的正负样本。
|
||||
|
||||
样本构建完成后,可以在模型结构左侧采用任意的深度学习模型来承担用户兴趣判别器的角色,输入就是当前层构造的正负样本,输出则是(用户,节点)对的兴趣度,这个将被用作检索过程中选取topK的评判指标。**在整体结构图中,我们可以看到节点特征方面,使用的是node embedding**,说明在进入模型前已经向量化了。
|
||||
|
||||
3. 训练过程
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420220831318.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
</div>
|
||||
|
||||
整体联合训练的方式如下:
|
||||
|
||||
1. 构造随机二叉树
|
||||
2. 基于树模型生成样本
|
||||
3. 训练DNN模型直到收敛
|
||||
4. 基于DNN模型得到样本的Embedding,重新构造聚类二叉树
|
||||
5. 循环上述2~4过程
|
||||
|
||||
具体的,在初始化树结构的时候,首先借助商品的类别信息进行排序,将相同类别的商品放到一起,然后递归的将同类别中的商品等量的分到两个子类中,直到集合中只包含一项,利用这种自顶向下的方式来初始化一棵树。基于该树采样生成深度模型训练所需的样本,然后进一步训练模型,训练结束之后可以得到每个树节点对应的Embedding向量,利用节点的Embedding向量,采用K-Means聚类方法来重新构建一颗树,最后基于这颗新生成的树,重新训练深层网络。
|
||||
|
||||
**参考资料**
|
||||
|
||||
- [阿里妈妈深度树检索技术(TDM) 及应用框架的探索实践](https://mp.weixin.qq.com/s/sw16_sUsyYuzpqqy39RsdQ)
|
||||
- [阿里TDM:Tree-based Deep Model](https://zhuanlan.zhihu.com/p/78941783)
|
||||
- [阿里妈妈TDM模型详解](https://zhuanlan.zhihu.com/p/93201318)
|
||||
- [Paddle TDM 模型实现](https://github.com/PaddlePaddle/PaddleRec/blob/master/models/treebased/README.md)
|
||||
Reference in New Issue
Block a user