23 KiB
Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
这篇论文是阿里巴巴在18年发表于KDD的关于召回阶段的工作。该论文提出的方法是在基于图嵌入的方法上,通过引入side information来解决实际问题中的数据稀疏和冷启动问题。
动机
在电商领域,推荐已经是不可或缺的一部分,旨在为用户的喜好提供有趣的物品,并且成为淘宝和阿里巴巴收入的重要引擎。尽管学术界和产业界的各种推荐方法都取得了成功,如协同过滤、基于内容的方法和基于深度学习的方法,但由于用户和项目的数十亿规模,传统的方法已经不能满足于实际的需求,主要的问题体现在三个方面:
- 可扩展性:现有的推荐方法无法扩展到在拥有十亿的用户和二十亿商品的淘宝中。
- 稀疏性:存在大量的物品与用户的交互行为稀疏。即用户的交互到多集中于以下部分商品,存在大量商品很少被用户交互。
- 冷启动:在淘宝中,每分钟会上传很多新的商品,由于这些商品没有用户行为的信息(点击、购买等),无法进行很好的预测。
针对于这三个方面的问题, 本文设计了一个两阶段的推荐框架:召回阶段和排序阶段,这也是推荐领域最常见的模型架构。而本文提及的EGES模型主要是解决了匹配阶段的问题,通过用户行为计算商品间两两的相似性,然后根基相似性选出topK的商品输入到排序阶段。
为了学习更好的商品向量表示,本文通过用户的行为历史中构造一个item-item 图,然后应用随机游走方法在item-item 图为每个item获取到一个序列,然后通过Skip-Gram的方式为每个item学习embedding(这里的item序列类似于语句,其中每个item类比于句子中每个word),这种方式被称为图嵌入方法(Graph Embedding)。文中提出三个具体模型来学习更好的物品embedding,更好的服务于召回阶段。
思路
根据上述所面临的三个问题,本文针对性的提出了三个模型予以解决:Base Graph Embedding(BGE);Graph Embedding with Side Information(GES);Enhanced Graph Embedding with Side Information(EGES)。
考虑可扩展性的问题,图嵌入的随机游走方式可以在物品图上捕获物品之间高阶相似性,即Base Graph Embedding(BGE)方法。其不同于CF方法,除了考虑物品的共现,还考虑到了行为的序列信息。
考虑到稀疏性和冷启物品问题,在图嵌入的基础上,考虑了节点的属性信息。希望具有相似属性的物品可以在空间上相似,即希望通过头部物品,提高属性信息的泛化能力,进而帮助尾部和冷启物品获取更加准确的embedding,即Graph Embedding with Side Information(GES)方法。
考虑到不同属性信息对于学习embedding的贡献不同,因此在聚合不同的属性信息时,动态的学习不同属性对于学习节点的embedding所参与的重要性权重,即Enhanced Graph Embedding with Side Information(EGES)。
模型结构与原理
文中所提出的方法是基于经典的图嵌入模型DeepWalk进行改进,其目标是通过物品图G,学习一个映射函数f:V -> R^d ,将图上节点映射成一个embedding。具体的步骤包括两步:1.通过随机游走为图上每个物品生成序列;2.通过Skip-Gram算法学习每个物品的embedding。因此对于该方法优化的目标是,在给定的上下文物品的前提下,最大化物品v的条件概率,即物品v对于一个序列里面的其他物品要尽可能的相似。接下来看一些每个模型具体内容。
构建物品图
在介绍三个模型之前,我们首先需要构建好item-item图。由于基于CF的方法仅考虑物品之间的共现,忽略了行为的序列信息(即序列中相邻的物品之间的语义信息),因此item-item图的构建方式如下图所示。

首先根据用户的session行为序列构建网络结构,即序列中相邻两个item之间在存在边,并且是有向带权图。物品图边上的权重为所有用户行为序列中两个 item 共现的次数,最终构造出来简单的有向有权图。
值得注意的是,本文通过行为序列中物品的共现来表示其中的语义信息,并将这种语义信息理解为物品之间的相似性,并将共现频次作为相似性的一个度量值。其次基于用户的历史行为序列数据,一般不太可能取全量的历史序列数据,一方面行为数据量过大,一方面用户的兴趣会随时间发生演变,因此在处理行为序列时会设置了一个窗口来截断历史序列数据,切分出来的序列称为session。
由于实际中会存在一些现实因素,数据中会有一些噪音,需要特殊处理,主要分为三个方面:
- 从行为方面考虑,用户在点击后停留的时间少于1秒,可以认为是误点,需要移除。
- 从用户方面考虑,淘宝场景中会有一些过度活跃用户。本文对活跃用户的定义是三月内购买商品数超过1000,或者点击数超过3500,就可以认为是一个无效用户,需要去除。
- 从商品方面考虑,存在一些商品频繁的修改,即ID对应的商品频繁更新,这使得这个ID可能变成一个完全不同的商品,这就需要移除与这个ID相关的这个商品。
在构建完item-item图之后,接下来看看三个模型的具体内容。
图嵌入(BGE)
对于图嵌入模型,第一步先进行随机游走得到物品序列;第二部通过skip-gram为图上节点生成embedding。那么对于随机游走的思想:如何利用随机游走在图中生成的序列?不同于DeepWalk中的随机游走,本文的采样策略使用的是带权游走策略,不同权重的游走到的概率不同,(其本质上就是node2vec),传统的node2vec方法可以直接支持有向带权图。因此在给定图的邻接矩阵M后(表示节点之间的边权重),随机游走中每次转移的概率为:

其中$M_{ij}$为边$e_{ij}$上的权重,$N_{+}(v_i)$表示节点$v_i$所有邻居节点集合,并且随机游走的转移概率的对每个节点所有邻接边权重的归一化结果。在随即游走之后,每个item得到一个序列,如下图所示:
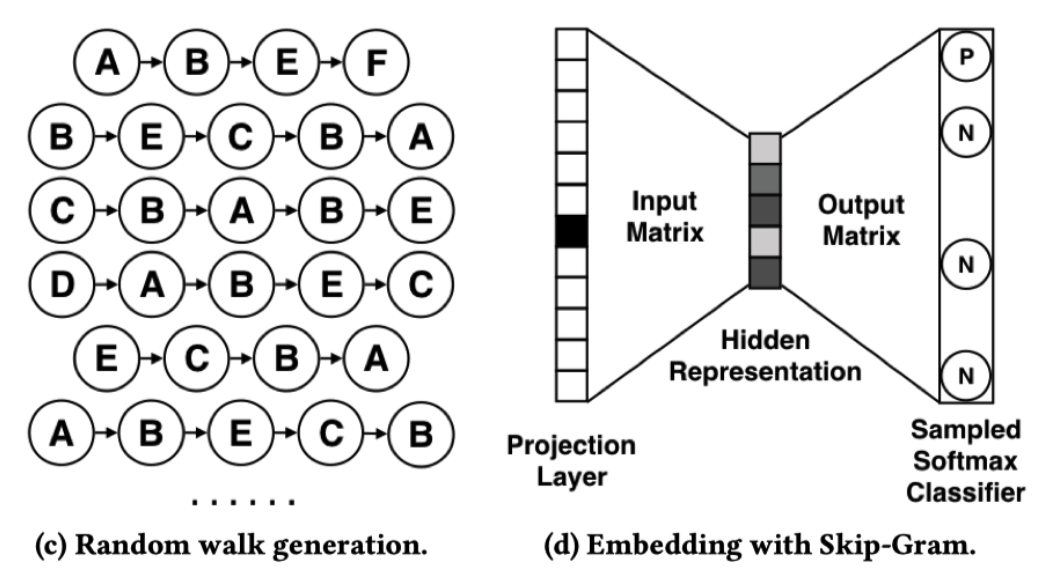
然后类似于word2vec,为每个item学习embedding,于是优化目标如下:

其中,w 为窗口大小。考虑独立性假设的话,上面的式子可以进一步化简:

这样看起来就很直观了,在已知物品 i 时,最大化序列中(上下文)其他物品 j 的条件概率。为了近似计算,采样了Negative sampling,上面的优化目标可以化简得到如下式子:

其中$N(v_i)'$表示负样本集合,负采样个数越多,结果越好。
基于side information的图嵌入(GES)
尽管BGE将行为序列关系编码进物品的embedding中,从而从用户行为中捕捉高阶相似性。但是这里有个问题,对于新加入的商品,由于未和用户产生过交互,所以不会出现在item-item图上,进而模型无法学习到其embedding,即无法解决冷启动问题。
为了解决冷启问题,本文通过使用side information( 类别,店铺, 价格等)加入模型的训练过程中,使得模型最终的泛化能力体现在商品的side information上。这样通过side information学习到的embedding来表示具体的商品,使得相似side information的物品可以得到在空间上相近的表示,进而来增强 BGE。
那么对于每个商品如何通过side information的embedidng来表示呢?对于随机游走之后得到的商品序列,其中每个每个商品由其id和属性(品牌,价格等)组成。用公式表示,对于序列中的每一个物品可以得到W^0_V,...W_V^n,(n+1)个向量表示,$W^0_V$表示物品v,剩下是side information的embedding。然后将所有的side information聚合成一个整体来表示物品,聚合方式如下:
H_v = \frac{1}{n+1}\sum_{s=0}^n W^s_v
其中,$H_v$是商品 v 的聚合后的 embedding 向量。
增强型EGS(EGES)
尽管 GES 相比 BGE 在性能上有了提升,但是在聚合多个属性向量得到商品的embedding的过程中,不同 side information的聚合依然存在问题。在GES中采用 average-pooling 是在假设不同种类的 side information 对商品embedding的贡献是相等的,但实际中却并非如此。例如,购买 Iphone 的用户更可能倾向于 Macbook 或者 Ipad,相比于价格属性,品牌属性相对于苹果类商品具有更重要的影响。因此,根据实际现状,不同类型的 side information 对商品的表示是具有不同的贡献值的。
针对上述问题,作者提出了weight pooling方法来聚合不同类型的 side information。具体地,EGES 与 GES 的区别在聚合不同类型 side information计算不同的权重,根据权重聚合 side information 得到商品的embedding,如下图所示:

其中 a_i 表示每个side information 用于计算权重的参数向量,最终通过下面的公式得到商品的embedding:
H_v = \frac{\sum_{j=0}^n e^{a_v^j} W_v^j}{\sum_{j=0}^n e^{a_v^j}}
这里对参数 a_v^j 先做指数变换,目的是为了保证每个边界信息的贡献都能大于0,然后通过归一化为每个特征得到一个o-1之内的权重。最终物品的embedding通过权重进行加权聚合得到,进而优化损失函数:
L(v,u,y)=-[ylog( \sigma (H_v^TZ_u)) + (1-y)log(1 - \sigma(H_v^TZ_u))]
y是标签符号,等于1时表示正样本,等于0时表示负样本。$H_v$表示商品 v 的最终的隐层表示,$Z_u$表示训练数据中的上下文节点的embedding。
以上就是这三个模型主要的区别,下面是EGES的伪代码。

其中WeightedSkipGram函数为带权重的SkipGram算法。

代码实现
下面我们简单的来看一下模型代码的实现,参考的内容在这里,其中实验使用的是jd 2019年比赛中提供的数据。
构建物品图
首先对用户的下单(type=2)行为序列进行session划分,其中30分钟没有产生下一个行为,划分为一个session。
def cnt_session(data, time_cut=30, cut_type=2):
# 商品属性 id 被交互时间 商品种类
sku_list = data['sku_id']
time_list = data['action_time']
type_list = data['type']
session = []
tmp_session = []
for i, item in enumerate(sku_list):
# 两个商品之间如果被交互的时间大于1小时,划分成不同的session
if type_list[i] == cut_type or (i < len(sku_list)-1 and \
(time_list[i+1] - time_list[i]).seconds/60 > time_cut) or i == len(sku_list)-1:
tmp_session.append(item)
session.append(tmp_session)
tmp_session = []
else:
tmp_session.append(item)
return session # 返回多个session list
获取到所有session list之后(这里不区分具体用户),对于session长度不超过1的去除(没有意义)。
接下来就是构建图,主要是先计算所有session中,相邻的物品共现频次(通过字典计算)。然后通过入度节点、出度节点以及权重分别转化成list,通过network来构建有向图。
node_pair = dict()
# 遍历所有session list
for session in session_list_all:
for i in range(1, len(session)):
# 将session共现的item存到node_pair中,用于构建item-item图
# 将共现次数所谓边的权重,即node_pair的key为边(src_node,dst_node),value为边的权重(共现次数)
if (session[i - 1], session[i]) not in node_pair.keys():
node_pair[(session[i - 1], session[i])] = 1
else:
node_pair[(session[i - 1], session[i])] += 1
in_node_list = list(map(lambda x: x[0], list(node_pair.keys())))
out_node_list = list(map(lambda x: x[1], list(node_pair.keys())))
weight_list = list(node_pair.values())
graph_list = list([(i,o,w) for i,o,w in zip(in_node_list,out_node_list,weight_list)])
# 通过 network 构建图结构
G = nx.DiGraph().add_weighted_edges_from(graph_list)
随机游走
先是基于构建的图进行随机游走,其中p和q是参数,用于控制采样的偏向于DFS还是BFS,其实也就是node2vec。
walker = RandomWalker(G, p=args.p, q=args.q)
print("Preprocess transition probs...")
walker.preprocess_transition_probs()
对于采样的具体过程,是根据边的归一化权重作为采样概率进行采样。其中关于如何通过AliasSampling来实现概率采样的可以参考,具体的是先通过计算create_alias_table,然后根据边上两个节点的alias计算边的alias。其中可以看到这里计算alias_table是根据边的归一化权重。
def preprocess_transition_probs(self):
"""预处理随即游走的转移概率"""
G = self.G
alias_nodes = {}
for node in G.nodes():
# 获取每个节点与邻居节点边上的权重
unnormalized_probs = [G[node][nbr].get('weight', 1.0)
for nbr in G.neighbors(node)]
norm_const = sum(unnormalized_probs)
# 对每个节点的邻居权重进行归一化
normalized_probs = [
float(u_prob)/norm_const for u_prob in unnormalized_probs]
# 根据权重创建alias表
alias_nodes[node] = create_alias_table(normalized_probs)
alias_edges = {}
for edge in G.edges():
# 获取边的alias
alias_edges[edge] = self.get_alias_edge(edge[0], edge[1])
self.alias_nodes = alias_nodes
self.alias_edges = alias_edges
return
在构建好Alias之后,进行带权重的随机游走。
session_reproduce = walker.simulate_walks(num_walks=args.num_walks,
walk_length=args.walk_length, workers=4,verbose=1)
其中这里的随机游走是根据p和q的值,来选择是使用Deepwalk还是node2vec。
def _simulate_walks(self, nodes, num_walks, walk_length,):
walks = []
for _ in range(num_walks):
# 打乱所有起始节点
random.shuffle(nodes)
for v in nodes:
# 根据p和q选择随机游走或者带权游走
if self.p == 1 and self.q == 1:
walks.append(self.deepwalk_walk(
walk_length=walk_length, start_node=v))
else:
walks.append(self.node2vec_walk(
walk_length=walk_length, start_node=v))
return walks
加载side information并构造训练正样本
主要是将目前所有的sku和其对应的side infromation进行left join,没有的特征用0补充。然后对所有的特征进行labelEncoder()
sku_side_info = pd.merge(all_skus, product_data, on='sku_id', how='left').fillna(0) # 为商品加载side information
for feat in sku_side_info.columns:
if feat != 'sku_id':
lbe = LabelEncoder()
# 对side information进行编码
sku_side_info[feat] = lbe.fit_transform(sku_side_info[feat])
else:
sku_side_info[feat] = sku_lbe.transform(sku_side_info[feat])
通过图中的公式可以知道优化目标是让在一个窗口内的物品尽可能相似,采样若干负样本使之与目标物品不相似。因此需要将一个窗口内的所有物品与目标物品组成pair作为训练正样本。这里不需要采样负样本,负样本是通过tf中的sample softmax方法自动进行采样。
def get_graph_context_all_pairs(walks, window_size):
all_pairs = []
for k in range(len(walks)):
for i in range(len(walks[k])):
# 通过窗口的方式采取正样本,具体的是,让随机游走序列的起始item与窗口内的每个item组成正样本对
for j in range(i - window_size, i + window_size + 1):
if i == j or j < 0 or j >= len(walks[k]):
continue
else:
all_pairs.append([walks[k][i], walks[k][j]])
return np.array(all_pairs, dtype=np.int32)
EGES模型
构造完数据之后,在funrec的基础上实现了EGES模型:
def EGES(side_information_columns, items_columns, merge_type = "weight", share_flag=True,
l2_reg=0.0001, seed=1024):
# side_information 所对应的特征
feature_columns = list(set(side_information_columns))
# 获取输入层,查字典
feature_encode = FeatureEncoder(feature_columns, linear_sparse_feature=None)
# 输入的值
feature_inputs_list = list(feature_encode.feature_input_layer_dict.values())
# item id 获取输入层的值
items_Map = FeatureMap(items_columns)
items_inputs_list = list(items_Map.feature_input_layer_dict.values())
# 正样本的id,在softmax中需要传入正样本的id
label_columns = [DenseFeat('label_id', 1)]
label_Map = FeatureMap(label_columns)
label_inputs_list = list(label_Map.feature_input_layer_dict.values())
# 通过输入的值查side_information的embedding,返回所有side_information的embedding的list
side_embedding_list = process_feature(side_information_columns, feature_encode)
# 拼接 N x num_feature X Dim
side_embeddings = Concatenate(axis=1)(side_embedding_list)
# items_inputs_list[0] 为了查找每个item 用于计算权重的 aplha 向量
eges_inputs = [side_embeddings, items_inputs_list[0]]
merge_emb = EGESLayer(items_columns[0].vocabulary_size, merge_type=merge_type,
l2_reg=l2_reg, seed=seed)(eges_inputs) # B * emb_dim
label_idx = label_Map.feature_input_layer_dict[label_columns[0].name]
softmaxloss_inputs = [merge_emb,label_idx]
item_vocabulary_size = items_columns[0].vocabulary_size
all_items_idx = EmbeddingIndex(list(range(item_vocabulary_size)))
all_items_embeddings = feature_encode.embedding_layers_dict[side_information_columns[0].name](all_items_idx)
if share_flag:
softmaxloss_inputs.append(all_items_embeddings)
output = SampledSoftmaxLayer(num_items=item_vocabulary_size, share_flage=share_flag,
emb_dim=side_information_columns[0].embedding_dim,num_sampled=10)(softmaxloss_inputs)
model = Model(feature_inputs_list + items_inputs_list + label_inputs_list, output)
model.__setattr__("feature_inputs_list", feature_inputs_list)
model.__setattr__("label_inputs_list", label_inputs_list)
model.__setattr__("merge_embedding", merge_emb)
model.__setattr__("item_embedding", get_item_embedding(all_items_embeddings, items_Map.feature_input_layer_dict[items_columns[0].name]))
return model
其中EGESLayer为聚合每个item的多个side information的方法,其中根据merge_type可以选择average-pooling或者weight-pooling
class EGESLayer(Layer):
def __init__(self,item_nums, merge_type="weight",l2_reg=0.001,seed=1024, **kwargs):
super(EGESLayer, self).__init__(**kwargs)
self.item_nums = item_nums
self.merge_type = merge_type #聚合方式
self.l2_reg = l2_reg
self.seed = seed
def build(self, input_shape):
if not isinstance(input_shape, list) or len(input_shape) < 2:
raise ValueError('`EGESLayer` layer should be called \
on a list of at least 2 inputs')
self.feat_nums = input_shape[0][1]
if self.merge_type == "weight":
self.alpha_embeddings = self.add_weight(
name='alpha_attention',
shape=(self.item_nums, self.feat_nums),
dtype=tf.float32,
initializer=tf.keras.initializers.RandomUniform(minval=-1, maxval=1, seed=self.seed),
regularizer=l2(self.l2_reg))
def call(self, inputs, **kwargs):
if self.merge_type == "weight":
stack_embedding = inputs[0] # (B * num_feate * embedding_size)
item_input = inputs[1] # (B * 1)
alpha_embedding = tf.nn.embedding_lookup(self.alpha_embeddings, item_input) #(B * 1 * num_feate)
alpha_emb = tf.exp(alpha_embedding)
alpha_i_sum = tf.reduce_sum(alpha_emb, axis=-1)
merge_embedding = tf.squeeze(tf.matmul(alpha_emb, stack_embedding),axis=1) / alpha_i_sum
else:
stack_embedding = inputs[0] # (B * num_feate * embedding_size)
merge_embedding = tf.squeeze(tf.reduce_mean(alpha_emb, axis=1),axis=1) # (B * embedding_size)
return merge_embedding
def compute_output_shape(self, input_shape):
return input_shape
def get_config(self):
config = {"merge_type": self.merge_type, "seed": self.seed}
base_config = super(EGESLayer, self).get_config()
base_config.update(config)
return base_config
至此已经从原理到代码详细的介绍了关于EGES的内容。
参考
Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba