38 KiB
写在前面
FiBiNET(Feature Importance and Bilinear feature Interaction)是2019年发表在RecSys的一个模型,来自新浪微博张俊林老师的团队。这个模型如果从模型演化的角度来看, 主要是在特征重要性以及特征之间交互上做出了探索。所以,如果想掌握FiBiNet的话,需要掌握两大核心模块:
- 模型的特征重要性选择 --- SENET网络
- 特征之间的交互 --- 双线性交叉层(组合了内积和哈达玛积)
FiBiNet? 我们先需要先了解这些
FiBiNet的提出动机是因为在特征交互这一方面, 目前的ctr模型要么是简单的两两embedding内积(这里针对离散特征), 比如FM,FFM。 或者是两两embedding进行哈达玛积(NFM这种), 作者认为这两种交互方式还是过于简单, 另外像NFM这种,FM这种,也忽视了特征之间的重要性程度。
对于特征重要性,作者在论文中举得例子非常形象
the feature occupation is more important than the feature hobby when we predict a person’s income
所以要想让模型学习到更多的信息, 从作者的角度来看,首先是离散特征之间的交互必不可少,且需要更细粒度。第二个就是需要考虑不同特征对于预测目标的重要性程度,给不同的特征根据重要性程度进行加权。 写到这里, 如果看过之前的文章的话,这个是不是和某些模型有些像呀, 没错,AFM其实考虑了这一点, 不过那里是用了一个Attention网络对特征进行的加权, 这里采用了另一种思路而已,即SENET, 所以这里我们如果是考虑特征重要性程度的话, 就有了两种思路:
- Attention
- SENET
而考虑特征交互的话, 思路应该会更多:
- PNN里面的内积和外积
- NFM里面的哈达玛积
- 这里的双线性函数交互(内积和哈达玛积的组合)
所以,读论文, 这些思路感觉要比模型本身重要,而读论文还有一个有意思的事情,那就是我们既能了解思路,也能想一下,为啥这些方法会有效果呢? 我们自己能不能提出新的方法来呢? 如果读一篇paper,再顺便把后面的这些问题想通了, 那么这篇paper对于我们来说就发挥效用了, 后面就可以用拉马努金式方法训练自己的思维。
在前面的准备工作中,作者依然是带着我们梳理了整个推荐模型的演化过程, 我们也简单梳理下,就当回忆:
- FNN: 下面是经过FM预训练的embedding层, 也就是先把FM训练好,得到各个特征的embedding,用这个embedding初始化FNN下面的embedding层, 上面是DNN。 这个模型用的不是很多,缺点是只能搞隐性高阶交互,并且下面的embedding和高层的DNN配合不是很好。
- WDL: 这是一个经典的W&D架构, w逻辑回归维持记忆, DNN保持高阶特征交互。问题是W端依然需要手动特征工程,也就是低阶交互需要手动来搞,需要一定的经验。一般工业上也不用了。
- DeepFM:对WDL的逻辑回归进行升级, 把逻辑回归换成FM, 这样能保证低阶特征的自动交互, 兼顾记忆和泛化性能,低阶和高阶交互。 目前这个模型在工业上非常常用,效果往往还不错,SOTA模型。
- DCN: 认为DeepFM的W端的FM的交互还不是很彻底,只能到二阶交互。所以就提出了一种交叉性网络,可以在W端完成高阶交互。
- xDeepFM: DCN的再次升级,认为DCN的wide端交叉网络这种element-wise的交互方式不行,且不是显性的高阶交互,所以提出了一个专门用户高阶显性交互的CIN网络, vector-wise层次上的特征交互。
- NFM: 下层是FM, 中间一个交叉池化层进行两两交互,然后上面接DNN, 工业上用的不多。
- AFM: 从NFM的基础上,考虑了交互完毕之后的特征重要性程度, 从NFM的基础上加了一个Attention网络,所以如果用的话,也应该用AFM。
综上, 这几个网络里面最常用的还是属DeepFM了, 当然对于交互来讲,在我的任务上试过AFM和xDeepFM, 结果是AFM和DeepFM差不多持平, 而xDeepFM要比这俩好一些,但并不多,而考虑完了复杂性, 还是DeepFM或者AFM。
对于上面模型的问题,作者说了两点,第一个是大部分模型没有考虑特征重要性,也就是交互完事之后,没考虑对于预测目标来讲谁更重要,一视同仁。 第二个是目前的两两特征交互,大部分依然是内积或者哈达玛积, 作者认为还不是细粒度(fine-grained way)交互。
那么,作者是怎么针对这两个问题进行改进的呢? 为什么这么改进呢?
FiBiNet模型的理论以及论文细节
这里我们直接分析模型架构即可, 因为这个模型不是很复杂,也非常好理解前向传播的过程:
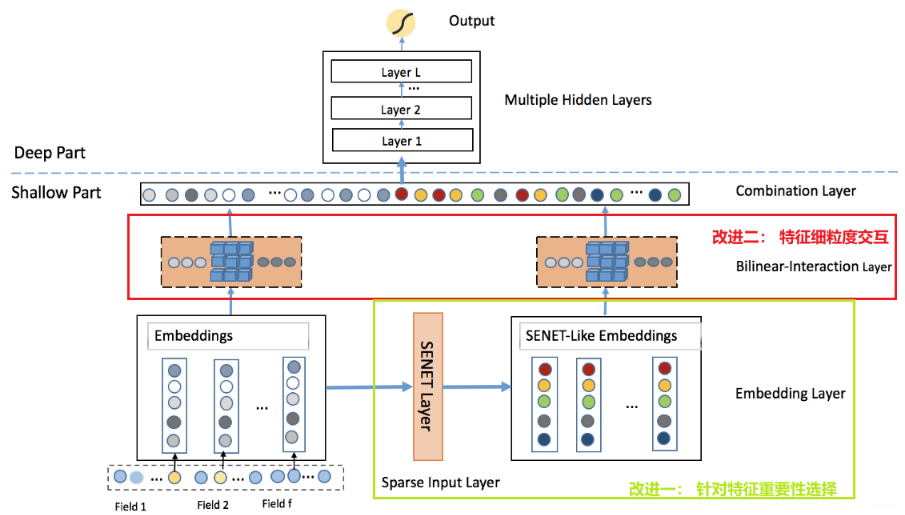
从模型架构上来看,如果把我框出来的两部分去掉, 这个基本上就退化成了最简单的推荐深度模型DeepCrossing,甚至还比不上那个(那个还用了残差网络)。不过,加上了两个框,效果可就不一样了。所以下面重点是剖析下这两个框的结构,其他的简单一过即可。
梳理细节之前, 先说下前向传播的过程。
首先,我们输入的特征有离散和连续,对于连续的特征,输入完了之后,先不用管,等待后面拼起来进DNN即可,这里也没有刻意处理连续特征。
对于离散特征,过embedding转成低维稠密,一般模型的话,这样完了之后,就去考虑embedding之间交互了。 而这个模型不是, 在得到离散特征的embedding之后,分成了两路
- 一路保持原样, 继续往后做两两之间embedding交互,不过这里的交互方式,不是简单的内积或者哈达玛积,而是采用了非线性函数,这个后面会提到。
- 另一路,过一个SENET Layer, 过完了之后得到的输出是和原来embedding有着相同维度的,这个SENET的理解方式和Attention网络差不多,也是根据embedding的重要性不同出来个权重乘到了上面。 这样得到了SENET-like Embedding,就是加权之后的embedding。 这时候再往上两两双线性交互。
两路embedding都两两交互完事, Flatten展平,和连续特征拼在一块过DNN输出。
Embedding Layer
这个不多讲, 整理这个是为了后面统一符号。
假设我们有$f$个离散特征,经过embedding层之后,会得到$E=\left[e_{1}, e_{2}, \cdots, e_{i}, \cdots, e_{f}\right]$, 其中$e_{i} \in R^{k}$,表示第$i$个离散特征对应的embedding向量,$k$维。
SENET Layer
这是第一个重点,首先这个网络接收的输入是上面的$E=\left[e_{1}, e_{2}, \cdots, e_{i}, \cdots, e_{f}\right]$, 网络的输出也是个同样大小的张量(None, f, k)矩阵。 结构如下: