# FCN
图像分割领域的开山之作。
首次将End-to-End的思想应用在了 CV 领域。
[知乎](https://zhuanlan.zhihu.com/p/30195134)
[论文](https://arxiv.org/pdf/1411.4038.pdf)
### 框架图
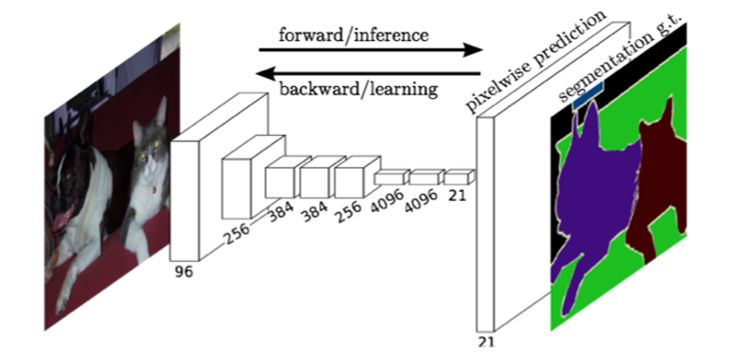
### 同 CNN 的对比
通常 CNN 网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。以 AlexNet 为代表的经典 CNN 结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的一个数值描述,比如 AlexNet 的 ImageNet 模型输出一个 1000 维的向量表示输入图像属于每一类的概率。
FCN 对图像进行像素级的分类,从而解决了语义级别的图像分割问题。与经典的 CNN 在卷积层之后使用全连接层得到固定长度的特征向量进行分类不同,FCN 可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的 feature map 进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
简单的来说,FCN 与 CNN 的区域在把于 CNN 最后的全连接层换成卷积层,输出的是一张已经 Label 好的图片。
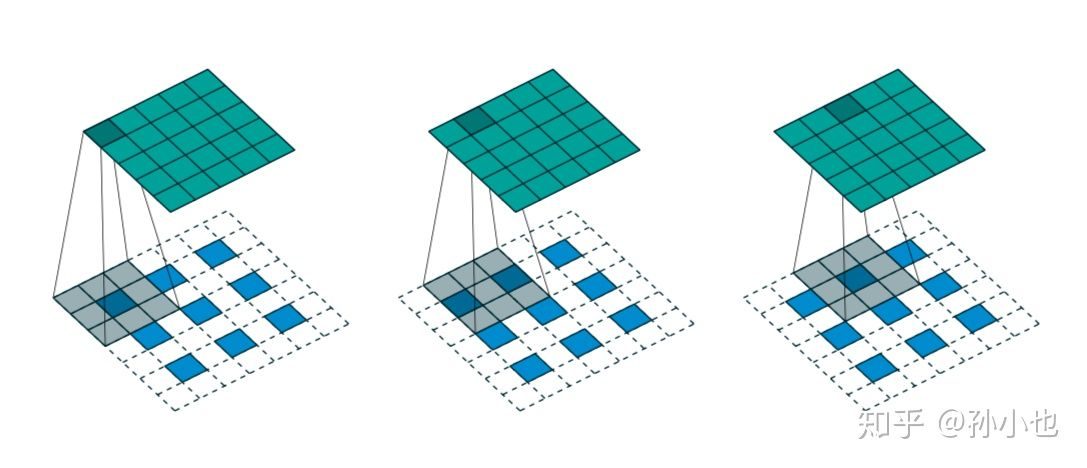
### 反卷积
这里提到的反卷积,FCN 作者称为 backwards convolution,有人称 Deconvolution layer is a very unfortunate name and should rather be called a transposed convolutional layer. 我们可以知道,在 CNN 中有 con layer 与 pool layer,con layer 进行对图像卷积提取特征,pool layer 对图像缩小一半筛选重要特征,对于经典的图像识别 CNN 网络,如 IMAGENET,最后输出结果是 1X1X1000,1000 是类别种类,1x1 得到的是。FCN 作者,或者后来对 end to end 研究的人员,就是对最终 1x1 的结果使用反卷积(事实上 FCN 作者最后的输出不是 1X1,是图片大小的 32 分之一,但不影响反卷积的使用)。
这里图像的反卷积使用了这一种反卷积手段使得图像可以变大,FCN 作者使用的方法是这里所说反卷积的一种变体,这样就可以获得相应的像素值,图像可以实现 end to end。
### 视频
# 思考
## 思考 1
什么是端到端(End-to-End)?
端到端的网络有什么优点?
## 思考 2
关于反卷积,你理解了吗?
## 思考 3
FCN 的任务和上一篇论文 AlexNet 有什么区别,从对图像的最终预测延伸到数学上是哪两种模型?
## 思考 4
在该文中提到的语义分割是什么意思呢?语义又代表什么?