😅 在我们日常生活中,其实有非常多的地方使用了所谓的 AI 算法,只是我们通常没有察觉。
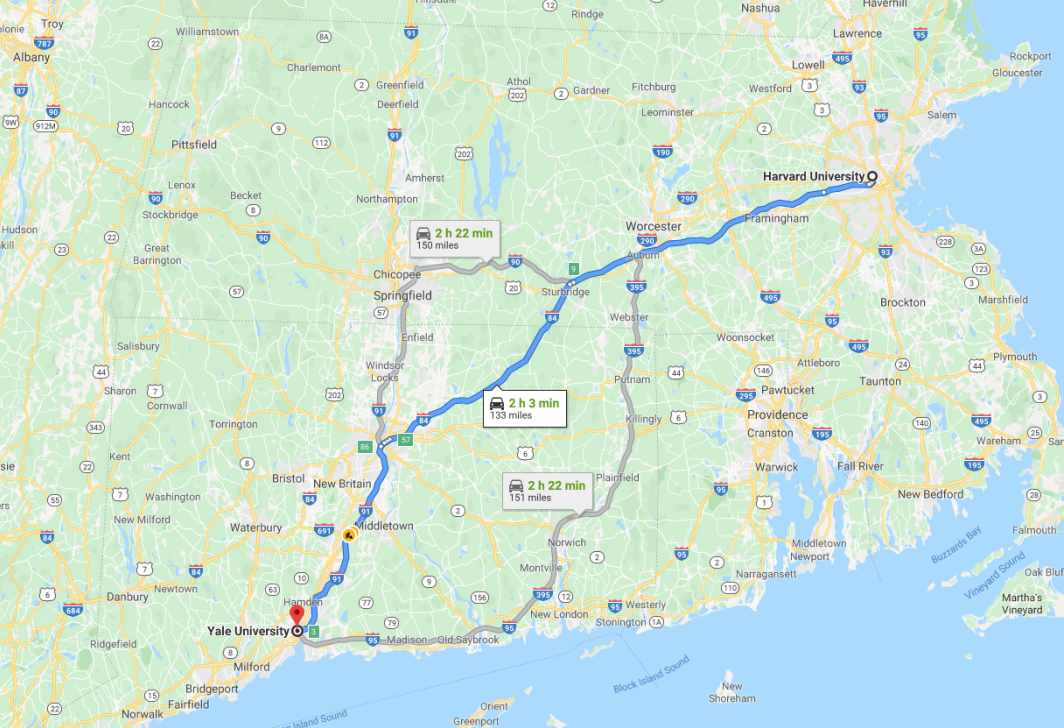
比如美团的外卖程序里面,可以看到外卖员到达你所在的位置的路线,它是如何规划出相关路线的呢?
在我们和电脑下围棋下五子棋的时候,他是如何“思考”的呢?希望你在阅读完本章内容之后,可以有一个最基本的理解。并且,我们还会给你留下一个井字棋的小任务,可以让你的电脑和你下井字棋,是不是很 cool
让我们现在开始吧!
🤔 也许第一次看会觉得云里雾里,没有必要全部记住所有的概念。可以先大致浏览一遍之后,再后续的代码中与概念进行结合,相信你会有更深入的理解
即检索存储在某个数据结构中的信息,或者在问题域的搜索空间中计算的信息。 --wiki
从本质上来说,你将搜索问题理解为一个函数,那么它的输入将会是你用计算机的数据结构或计算机数据所构成的初始状态以及你期望他达成的目标状态,搜索问题将尝试从中得到解决方案。
导航是使用搜索算法的一个典型的搜索,它接收您的当前位置和目的地作为输入,并根据搜索算法返回建议的路径。
在计算机科学中,还有许多其他形式的搜索问题,比如谜题或迷宫。
 |  |
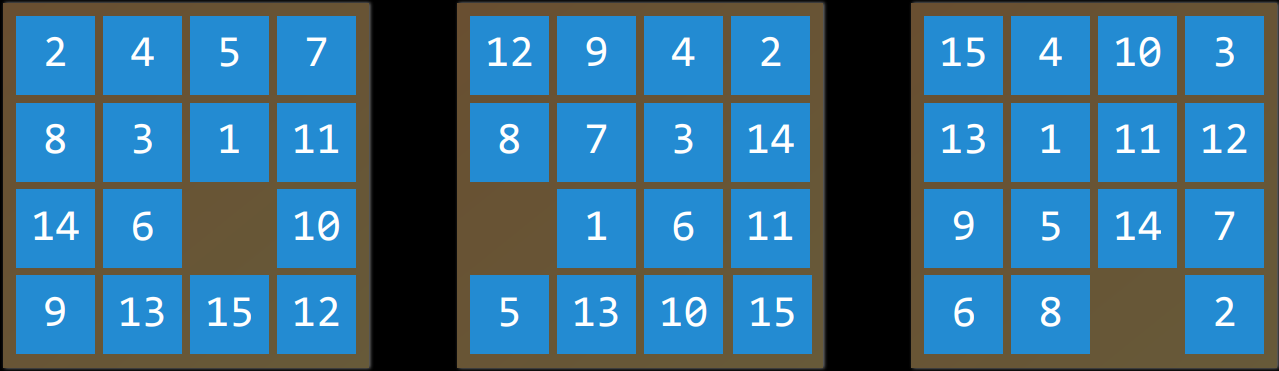
要找到一个数字华容道谜题的解决方案,需要使用搜索算法。
智能主体 (Agent)
感知其环境并对该环境采取行动的实体。
例如,在导航应用程序中,智能主体将是一辆汽车的代表,它需要决定采取哪些行动才能到达目的地。
状态 (State)
智能主体在其环境中的配置。
例如,在一个数字华容道谜题中,一个状态是所有数字排列在棋盘上的任何一种方式。
初始状态(Initial State)
搜索算法开始的状态。在导航应用程序中,这将是当前位置。
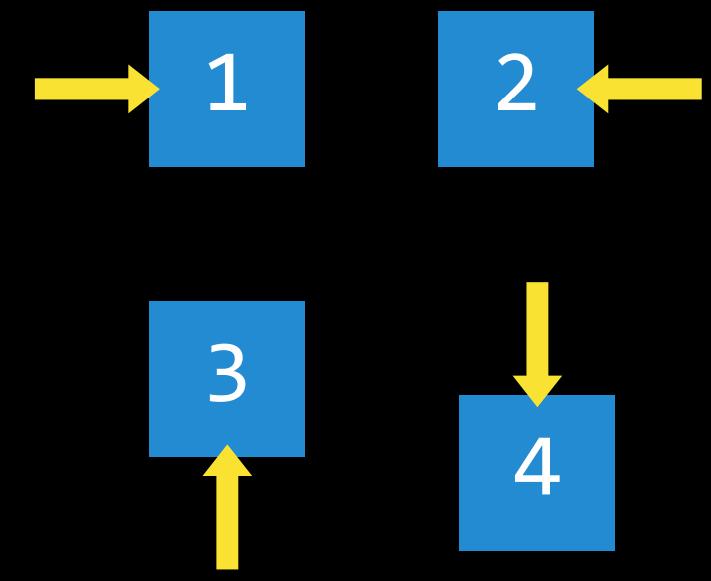
动作 (Action)
一个状态可以做出的选择。更确切地说,动作可以定义为一个函数。当接收到状态$s$作为输入时,$Actions(s)$将返回可在状态$s$ 中执行的一组操作作为输出。
例如,在一个数字华容道中,给定状态的操作是您可以在当前配置中滑动方块的方式。
过渡模型 (Transition Model)
对在任何状态下执行任何适用操作所产生的状态的描述。
更确切地说,过渡模型可以定义为一个函数。
在接收到状态$s$和动作$a$作为输入时,$Results(s,a)$返回在状态$s$中执行动作$a$ 所产生的状态。
例如,给定数字华容道的特定配置(状态$s$),在任何方向上移动正方形(动作$a$)将导致谜题的新配置(新状态)。

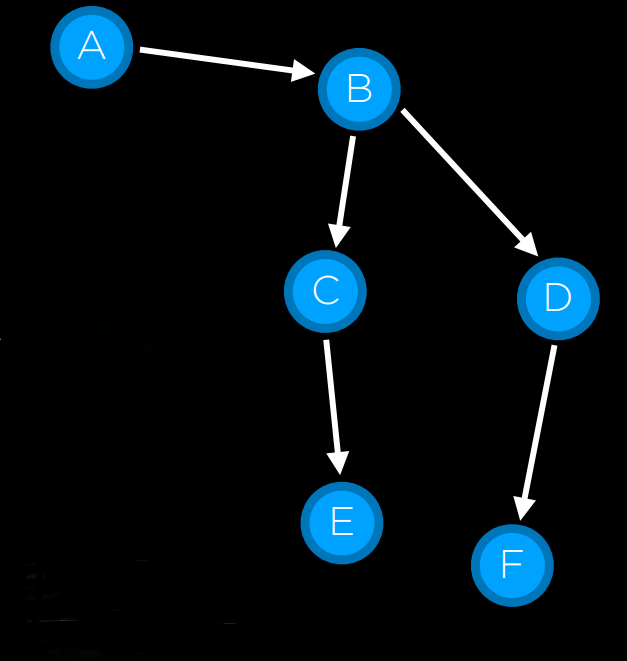
状态空间 (State Space)
通过一系列的操作目标从初始状态可达到的所有状态的集合。
例如,在一个数字华容道谜题中,状态空间由所有$\\frac{16!}{2}$种配置,可以从任何初始状态达到。状态空间可以可视化为有向图,其中状态表示为节点,动作表示为节点之间的箭头。

目标测试 (Goal Test)
确定给定状态是否为目标状态的条件。例如,在导航应用程序中,目标测试将是智能主体的当前位置是否在目的地。如果是,问题解决了。如果不是,我们将继续搜索。
路径成本 (Path Cost)
完成给定路径相关的代价。例如,导航应用程序并不是简单地让你达到目标;它这样做的同时最大限度地减少了路径成本,为您找到了达到目标状态的最快方法。
从初始状态到目标状态的一系列动作。
- 在所有解决方案中路径成本最低的解决方案。
在搜索过程中,数据通常存储在节点 (Node) 中,节点是一种包含以下数据的数据结构:
状态——state
其父节点,通过该父节点生成当前节点——parent node
应用于父级状态以获取当前节点的操作——action
从初始状态到该节点的路径成本——path cost
节点包含的信息使它们对于搜索算法非常有用。
它们包含一个状态,可以使用目标测试来检查该状态是否为最终状态。
如果是,则可以将节点的路径成本与其他节点的路径代价进行比较,从而可以选择最佳解决方案。
一旦选择了节点,通过存储父节点和从父节点到当前节点的动作,就可以追溯从初始状态到该节点的每一步,而这一系列动作就是解决方案。
然而,节点只是一个数据结构——它们不搜索,而是保存信息。为了实际搜索,我们使用了边域 (frontier),即“管理”节点的机制。边域首先包含一个初始状态和一组空的已探索项目(探索集),然后重复以下操作,直到找到解决方案:
重复:
 |  |
边域从节点 A 初始化开始
 | 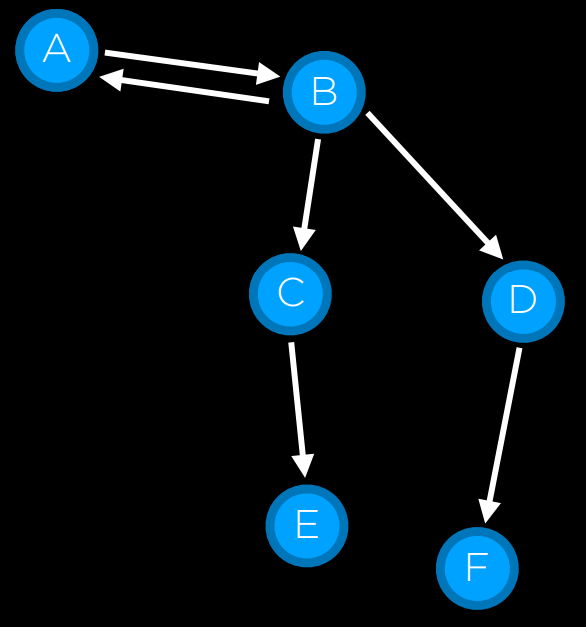 |
会出现什么问题?节点 A-> 节点 B-> 节点 A->......-> 节点 A。我们需要一个探索集,记录已搜索的节点!
在之前对边域的描述中,有一件事没有被提及。在上面伪代码的第 1 阶段,应该删除哪个节点?这种选择对解决方案的质量和实现速度有影响。关于应该首先考虑哪些节点的问题,有多种方法,其中两种可以用堆栈(深度优先搜索)和队列(广度优先搜索)的数据结构来表示。
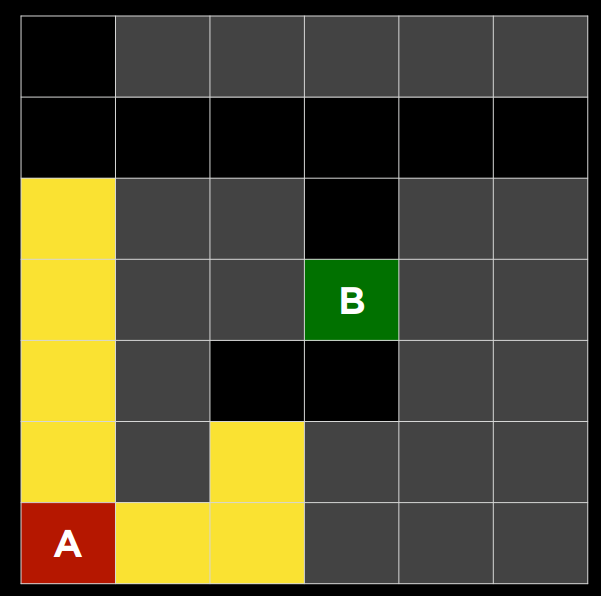
深度优先搜索算法在尝试另一个方向之前耗尽每个方向。在这些情况下,边域作为堆栈数据结构进行管理。这里需要记住的流行语是“后进先出”。在将节点添加到边域后,第一个要删除和考虑的节点是最后一个要添加的节点。这导致了一种搜索算法,该算法在第一个方向上尽可能深入,直到尽头,同时将所有其他方向留到后面。“不撞南墙不回头”
(一个例子:以你正在寻找钥匙的情况为例。在深度优先搜索方法中,如果你选择从裤子里搜索开始,你会先仔细检查每一个口袋,清空每个口袋,仔细检查里面的东西。只有当你完全筋疲力尽时,你才会停止在裤子里搜索,开始在其他地方搜索。)
 |  |
 |  |
def remove(self):
if self.empty():
raise Exception("empty frontier")
else:
node = self.frontier[-1]
self.frontier = self.frontier[:-1]
return node广度优先搜索算法将同时遵循多个方向,在每个可能的方向上迈出一步,然后在每个方向上迈出第二步。在这种情况下,边域作为队列数据结构进行管理。这里需要记住的流行语是“先进先出”。在这种情况下,所有新节点都会排成一行,并根据先添加的节点来考虑节点(先到先得!)。这导致搜索算法在任何一个方向上迈出第二步之前,在每个可能的方向上迈出一步。
(一个例子:假设你正在寻找钥匙。在这种情况下,如果你从裤子开始,你会看你的右口袋。之后,你会在一个抽屉里看一眼,而不是看你的左口袋。然后在桌子上。以此类推,在你能想到的每个地方。只有在你用完所有位置后,你才会回到你的裤子上,在下一个口袋里找。)
 |  |
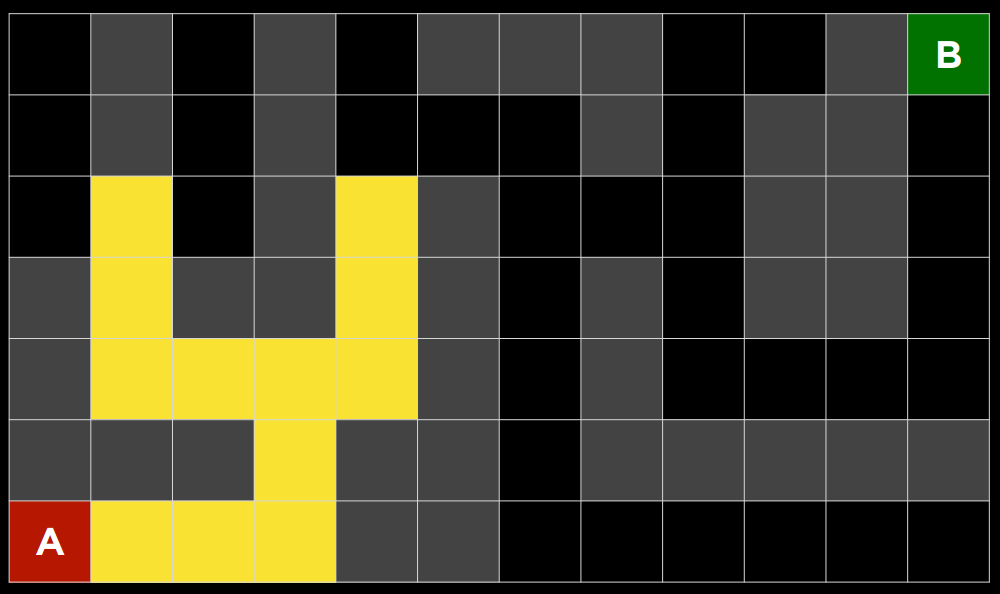 |  |
代码实现
def remove(self):
if self.empty():
raise Exception("empty frontier")
else:
node = self.frontier[0]
self.frontier = self.frontier[1:]
return node广度优先和深度优先都是不知情的搜索算法。也就是说,这些算法没有利用他们没有通过自己的探索获得的关于问题的任何知识。然而,大多数情况下,关于这个问题的一些知识实际上是可用的。例如,当人类进入一个路口时,人类可以看到哪条路沿着解决方案的大致方向前进,哪条路没有。人工智能也可以这样做。一种考虑额外知识以试图提高性能的算法被称为知情搜索算法。
贪婪最佳优先搜索扩展最接近目标的节点,如启发式函数$h(n)$所确定的。顾名思义,该函数估计下一个节点离目标有多近,但可能会出错。贪婪最佳优先算法的效率取决于启发式函数的好坏。例如,在迷宫中,算法可以使用启发式函数,该函数依赖于可能节点和迷宫末端之间的曼哈顿距离。曼哈顿距离忽略了墙壁,并计算了从一个位置到目标位置需要向上、向下或向两侧走多少步。这是一个简单的估计,可以基于当前位置和目标位置的$(x,y)$坐标导出。
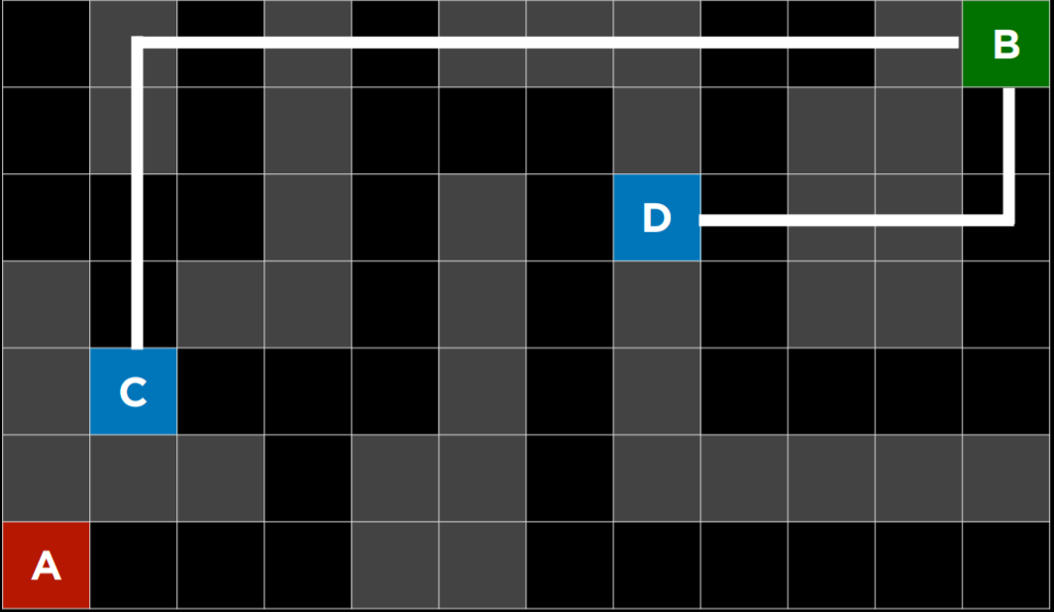
然而,重要的是要强调,与任何启发式算法一样,它可能会出错,并导致算法走上比其他情况下更慢的道路。不知情的搜索算法有可能更快地提供一个更好的解决方案,但它比知情算法更不可能这样。
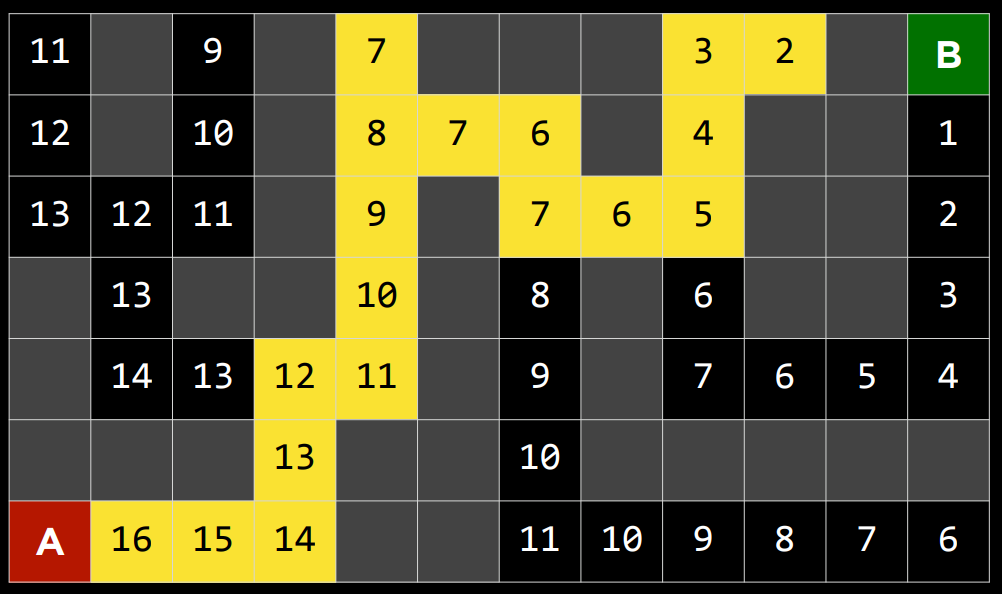 | 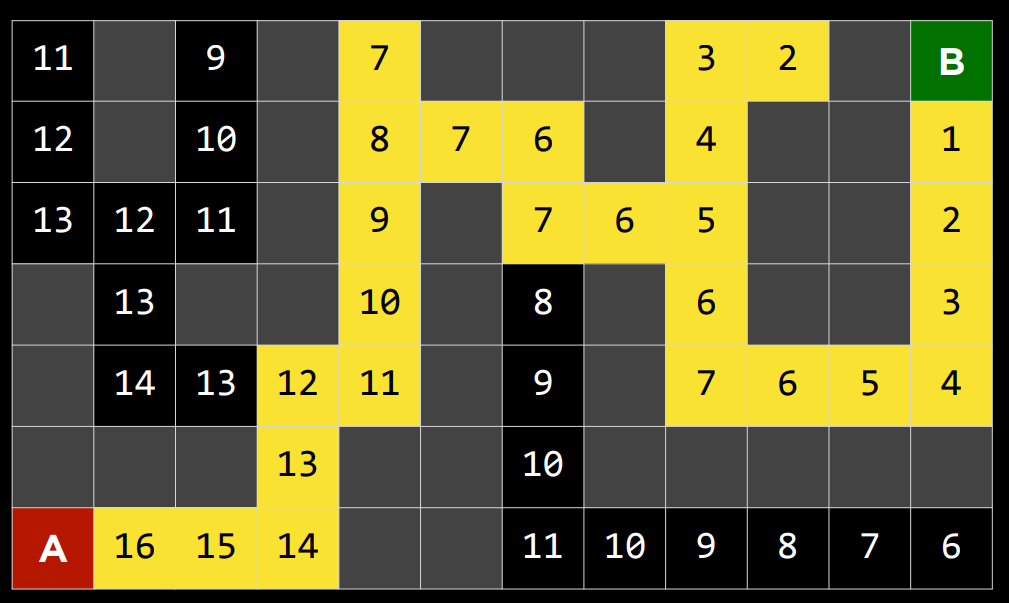 |
作为贪婪最佳优先算法的一种发展,$A^{*}$ 搜索不仅考虑了从当前位置到目标的估计成本 $h(n)$ ,还考虑了直到当前位置为止累积的成本 $g(n)$ 。通过组合这两个值,该算法可以更准确地确定解决方案的成本并在旅途中优化其选择。该算法跟踪(到目前为止的路径成本 + 到目标的估计成本, $g(n)+h(n)$ ),一旦它超过了之前某个选项的估计成本,该算法将放弃当前路径并返回到之前的选项,从而防止自己沿着 $h(n)$ 错误地标记为最佳的却长而低效的路径前进。
然而,由于这种算法也依赖于启发式,所以它依赖它所使用的启发式。在某些情况下,它可能比贪婪的最佳第一搜索甚至不知情的算法效率更低。对于最佳的$A^*$搜索,启发式函数$h(n)$应该:
 | 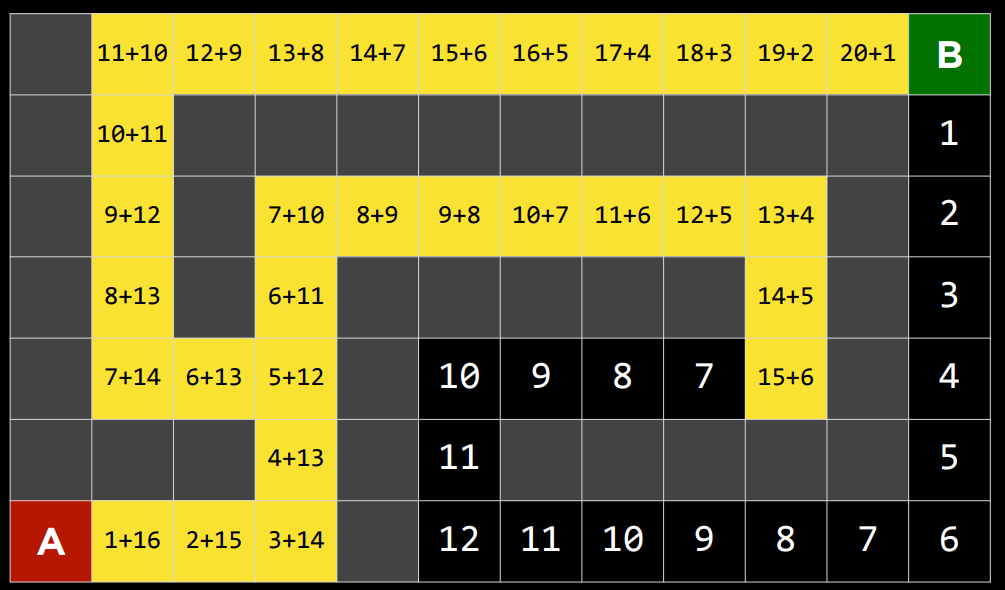 |
尽管之前我们讨论过需要找到问题答案的算法,但在对抗性搜索中,算法面对的是试图实现相反目标的对手。通常,在游戏中会遇到使用对抗性搜索的人工智能,比如井字游戏。
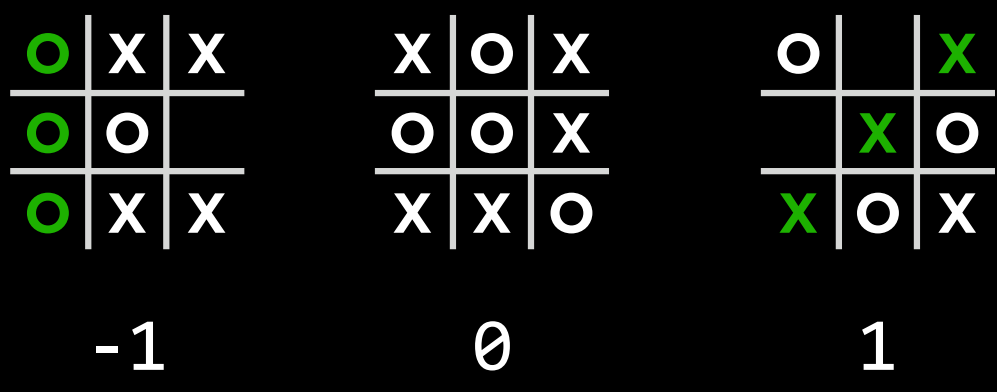
作为对抗性搜索中的一种算法,Minimax 将获胜条件表示为$(-1)$表示为一方,$(+1)$表示为另一方。进一步的行动将受到这些条件的驱动,最小化的一方试图获得最低分数,而最大化的一方则试图获得最高分数。
$s_0$: 初始状态(在我们的情况下,是一个空的 3X3 棋盘)

$Players(s)$: 一个函数,在给定状态$s$的情况下,返回轮到哪个玩家(X 或 O)。
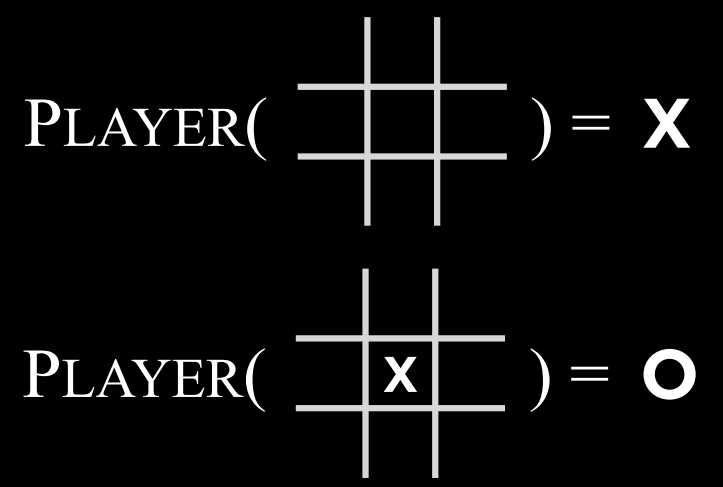
$Actions(s)$: 一个函数,在给定状态$s$的情况下,返回该状态下的所有合法动作(棋盘上哪些位置是空的)。
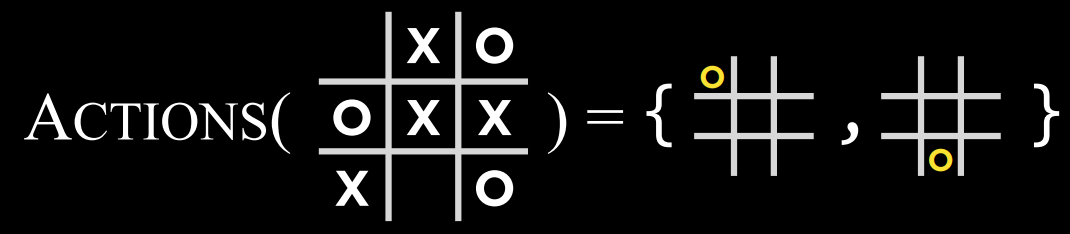
$Result(s, a)$: 一个函数,在给定状态$s$和操作$a$的情况下,返回一个新状态。这是在状态$s$上执行动作$a$(在游戏中移动)所产生的棋盘。
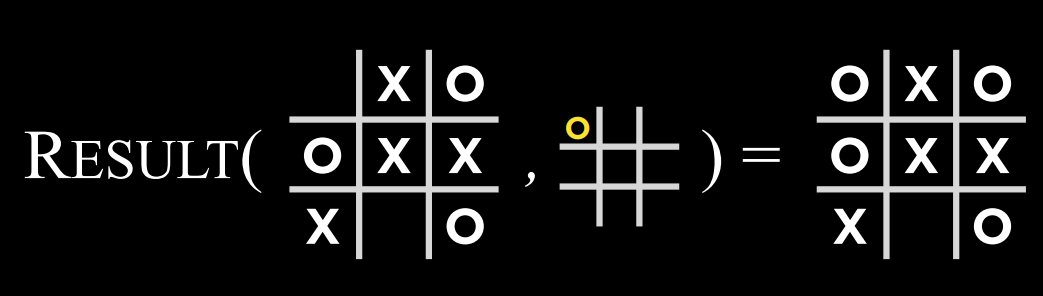
$Terminal(s)$: 一个函数,在给定状态$s$的情况下,检查这是否是游戏的最后一步,即是否有人赢了或打成平手。如果游戏已结束,则返回 True,否则返回 False。
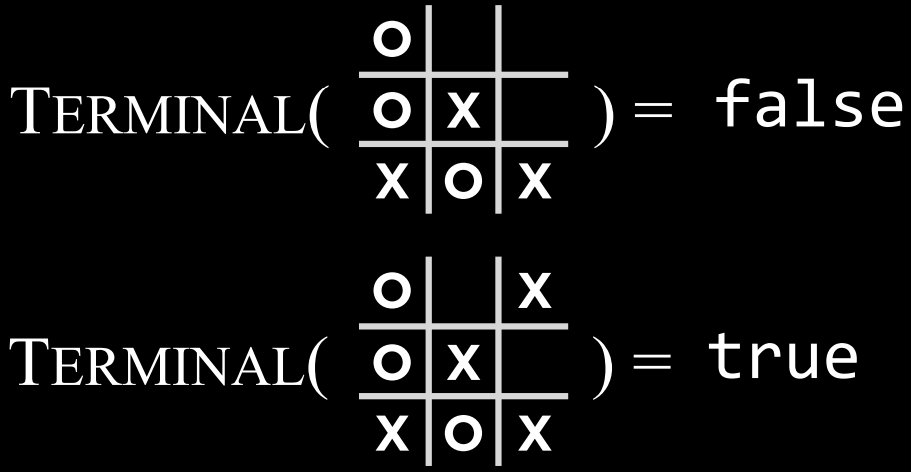
$Utility(s)$: 一个函数,在给定终端状态 s 的情况下,返回状态的效用值:$-1、0 或 1$。

算法的工作原理:
该算法递归地模拟从当前状态开始直到达到终端状态为止可能发生的所有游戏状态。每个终端状态的值为$(-1)$、$0$或$(+1)$。 
根据轮到谁的状态,算法可以知道当前玩家在最佳游戏时是否会选择导致状态值更低或更高的动作。
通过这种方式,在最小化和最大化之间交替,算法为每个可能的动作产生的状态创建值。举一个更具体的例子,我们可以想象,最大化的玩家在每一个回合都会问:“如果我采取这个行动,就会产生一个新的状态。如果最小化的玩家发挥得最好,那么该玩家可以采取什么行动来达到最低值?”
然而,为了回答这个问题,最大化玩家必须问:“要想知道最小化玩家会做什么,我需要在最小化者的脑海中模拟同样的过程:最小化玩家会试图问:‘如果我采取这个动作,最大化玩家可以采取什么动作来达到最高值?’”
这是一个递归过程,你可能很难理解它;看看下面的伪代码会有所帮助。最终,通过这个递归推理过程,最大化玩家为每个状态生成值,这些值可能是当前状态下所有可能的操作所产生的。
在得到这些值之后,最大化的玩家会选择最高的一个。
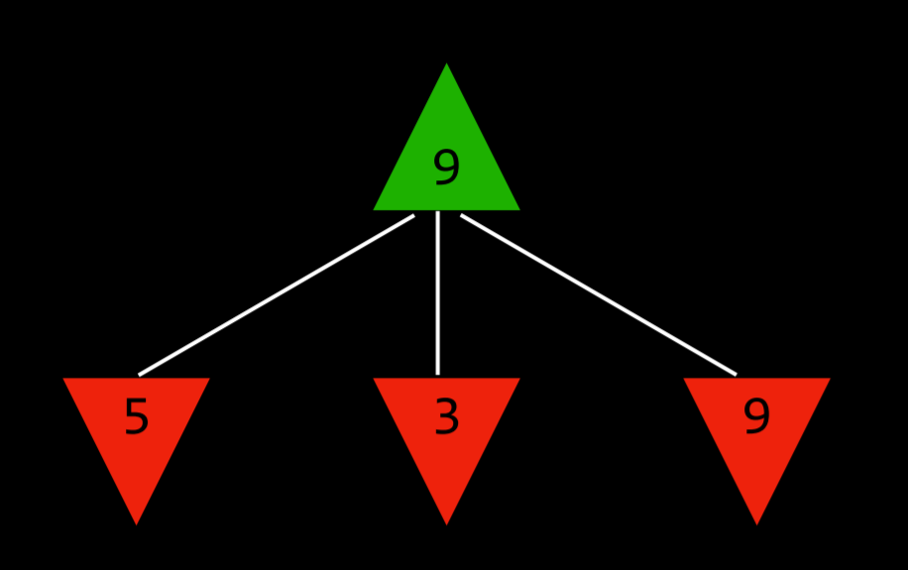
具体算法:
Function Max-Value(state):
v=-∞
if Terminal(state):
return Utility(state)
for action in Actions(state):
v = Max(v, Min-Value(Result(state, action)))
return v
Function Min-Value(state):
v=+∞
if Terminal(state):
return Utility(state)
for action in Actions(state):
v = Min(v, Max-Value(Result(state, action)))
return v不会理解递归?也许你需要看看这个:阶段二:递归操作
作为一种优化 Minimax 的方法,Alpha-Beta 剪枝跳过了一些明显不利的递归计算。在确定了一个动作的价值后,如果有初步证据表明接下来的动作可以让对手获得比已经确定的动作更好的分数,那么就没有必要进一步调查这个动作,因为它肯定比之前确定的动作不利。
这一点最容易用一个例子来说明:最大化的玩家知道,在下一步,最小化的玩家将试图获得最低分数。假设最大化玩家有三个可能的动作,第一个动作的值为 4。然后玩家开始为下一个动作生成值。要做到这一点,如果当前玩家做出这个动作,玩家会生成最小化者动作的值,并且知道最小化者会选择最低的一个。然而,在完成最小化器所有可能动作的计算之前,玩家会看到其中一个选项的值为 3。这意味着没有理由继续探索最小化玩家的其他可能行动。尚未赋值的动作的值无关紧要,无论是 10 还是(-10)。如果该值为 10,则最小化器将选择最低选项 3,该选项已经比预先设定的 4 差。如果尚未估价的行动结果是(-10),那么最小化者将选择(-10)这一选项,这对最大化者来说更加不利。因此,在这一点上为最小化者计算额外的可能动作与最大化者无关,因为最大化玩家已经有了一个明确的更好的选择,其值为 4。
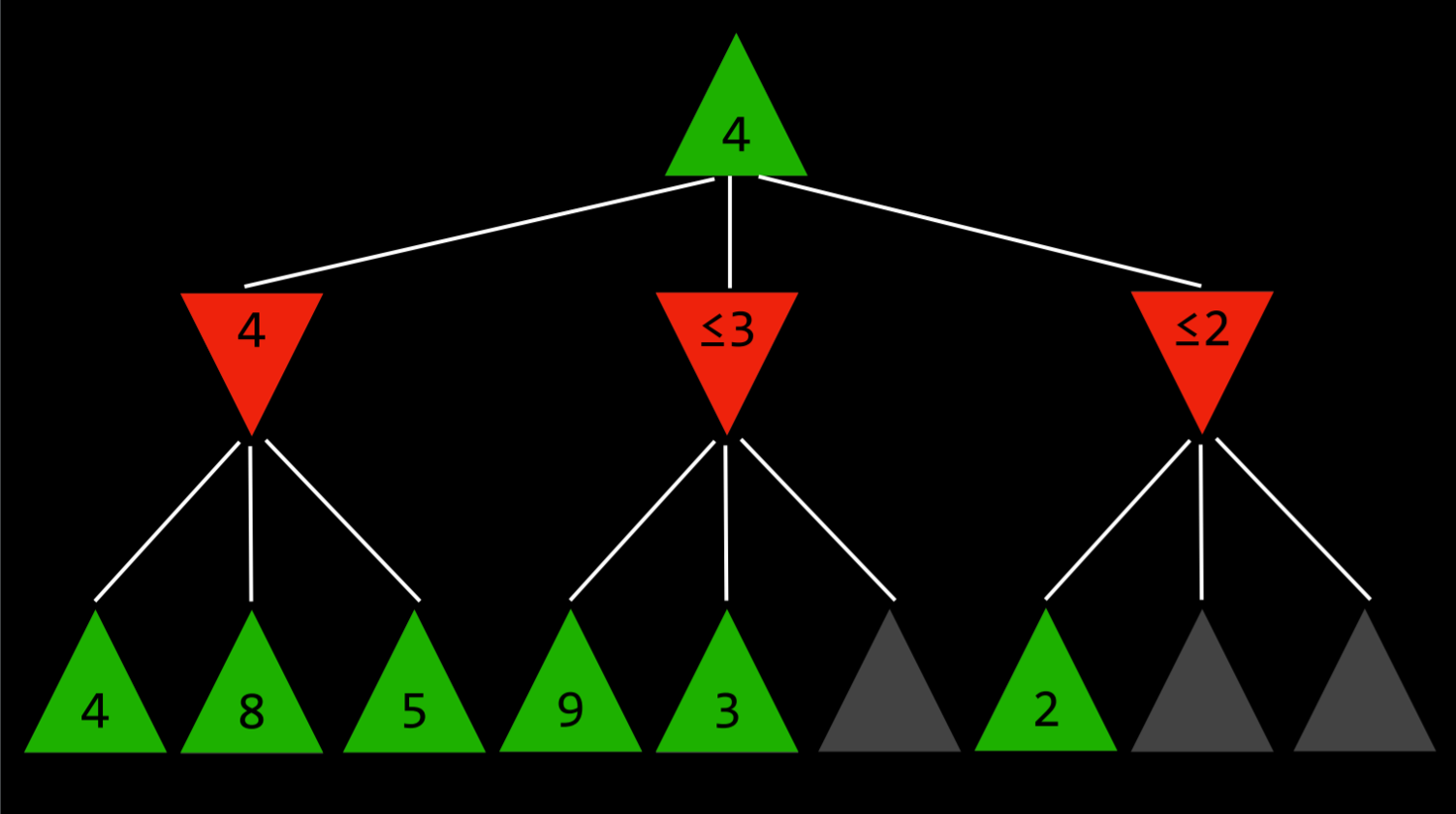
深度限制的 Minimax 算法在停止之前只考虑预先定义的移动次数,而从未达到终端状态。然而,这不允许获得每个动作的精确值,因为假设的游戏还没有结束。为了解决这个问题,深度限制 Minimax 依赖于一个评估函数,该函数从给定状态估计游戏的预期效用,或者换句话说,为状态赋值。例如,在国际象棋游戏中,效用函数会将棋盘的当前配置作为输入,尝试评估其预期效用(基于每个玩家拥有的棋子及其在棋盘上的位置),然后返回一个正值或负值,表示棋盘对一个玩家对另一个玩家的有利程度。这些值可以用来决定正确的操作,并且评估函数越好,依赖它的 Minimax 算法就越好。
`,93),l=[p];function e(h,r,d,c,o,k){return a(),i("div",null,l)}const x=s(n,[["render",e]]);export{u as __pageData,x as default};