Compare commits
6 Commits
38f1e5bcd4
...
main
| Author | SHA1 | Date | |
|---|---|---|---|
| 1e6825f654 | |||
| 999e3d7bed | |||
| 9ada60a7ce | |||
| 99417cea0a | |||
| 5c879a0f2b | |||
| bd752e71c2 |
11
.gitignore
vendored
11
.gitignore
vendored
@@ -1,7 +1,12 @@
|
||||
node_modules
|
||||
dist
|
||||
cache
|
||||
.temp
|
||||
.vitepress/dist
|
||||
dev-dist
|
||||
package-lock.json
|
||||
dist
|
||||
.vitepress/dist
|
||||
.vitest
|
||||
.vscode
|
||||
.env
|
||||
.env.local
|
||||
.env.development.local
|
||||
.env.test.local
|
||||
@@ -9,15 +9,36 @@ export default defineConfig({
|
||||
nav: [
|
||||
{ text: '首页', link: '/' },
|
||||
{ text: '章节', items: [
|
||||
{ text: '1. 前言', link: '/技术资源汇总(杭电支持版)/' },
|
||||
{ text: '2. 高效学习', link: '/技术资源汇总(杭电支持版)/2.高效学习/2.高效学习' },
|
||||
{ text: '3. 编程思维体系构建', link: '/技术资源汇总(杭电支持版)/3.编程思维体系构建/3.编程思维体系构建' },
|
||||
{ text: '4. 人工智能', link: '/技术资源汇总(杭电支持版)/4.人工智能/4.人工智能' },
|
||||
{ text: '5. 富有生命的嵌入式', link: '/技术资源汇总(杭电支持版)/5.富有生命的嵌入式/5.富有生命的嵌入式' },
|
||||
{ text: '6. 计算机安全', link: '/技术资源汇总(杭电支持版)/6.计算机安全/6.计算机安全' },
|
||||
{ text: '7. 网络应用开发', link: '/技术资源汇总(杭电支持版)/7.网络应用开发/7.网络应用开发' },
|
||||
{ text: '8. 基础学科', link: '/技术资源汇总(杭电支持版)/8.基础学科/8.基础学科' },
|
||||
{ text: '9. 计算机网络', link: '/技术资源汇总(杭电支持版)/9.计算机网络/9.计算机网络' },
|
||||
{
|
||||
text: '使用指南',
|
||||
link: '/使用指南'
|
||||
},
|
||||
{
|
||||
text: '福大生存指南',
|
||||
items: [
|
||||
{ text: '2.竞赛指北', link: '/福大生存指南/2.竞赛指北' },
|
||||
{ text: '3.正确解读GPA', link: '/福大生存指南/3.正确解读GPA' },
|
||||
{ text: '4.学生工作选择', link: '/福大生存指南/4.学生工作选择' },
|
||||
{ text: '5.Q&A', link: '/福大生存指南/5.Q&A' },
|
||||
{ text: '6.小组作业避雷指南', link: '/福大生存指南/6.小组作业避雷指南' },
|
||||
{ text: '7.选课原则与抢课技巧', link: '/福大生存指南/7.选课原则与抢课技巧' },
|
||||
{ text: '8.社团篇', link: '/福大生存指南/8.社团篇' },
|
||||
|
||||
]
|
||||
},
|
||||
{
|
||||
text: '技术资源汇总(杭电支持版)',
|
||||
items: [
|
||||
{ text: '2.高效学习', link: '/技术资源汇总(杭电支持版)/2.高效学习/2.高效学习' },
|
||||
{ text: '3.编程思维体系构建', link: '/技术资源汇总(杭电支持版)/3.编程思维体系构建/3.编程思维体系构建' },
|
||||
{ text: '4.人工智能', link: '/技术资源汇总(杭电支持版)/4.人工智能/4.人工智能' },
|
||||
{ text: '5.富有生命的嵌入式', link: '/技术资源汇总(杭电支持版)/5.富有生命的嵌入式/5.富有生命的嵌入式' },
|
||||
{ text: '6.计算机安全', link: '/技术资源汇总(杭电支持版)/6.计算机安全/6.计算机安全' },
|
||||
{ text: '7.网络应用开发', link: '/技术资源汇总(杭电支持版)/7.网络应用开发/7.网络应用开发入门' },
|
||||
{ text: '8.基础学科', link: '/技术资源汇总(杭电支持版)/8.基础学科/8.基础学科' },
|
||||
{ text: '9.计算机网络', link: '/技术资源汇总(杭电支持版)/9.计算机网络/9.计算机网络' },
|
||||
]
|
||||
}
|
||||
]}
|
||||
],
|
||||
|
||||
@@ -50,5 +71,10 @@ export default defineConfig({
|
||||
prev: '上一小节',
|
||||
next: '下一小节'
|
||||
},
|
||||
editLink: {
|
||||
pattern: 'https://gitea.xinxijishubu.asia/moyin/fzu-product/src/branch/main/:path',
|
||||
text: '在 Gitea 上修改此页'
|
||||
},
|
||||
externalLinkIcon: true,
|
||||
}
|
||||
})
|
||||
|
||||
@@ -4,32 +4,34 @@ import path from 'path';
|
||||
export function main_sidebar() {
|
||||
return [
|
||||
{
|
||||
text: '简介',
|
||||
text: '使用指南',
|
||||
link: '/使用指南'
|
||||
},
|
||||
{
|
||||
text: '福大生存指南',
|
||||
collapsed: true,
|
||||
items: [
|
||||
{ text: '简介', link: '/简介' },
|
||||
{ text: '使用指南', link: '/使用指南' },
|
||||
{ text: '技术资源汇总(杭电支持版)', link: '/技术资源汇总(杭电支持版)/内容索引' },
|
||||
{ text: '2.竞赛指北', link: '/福大生存指南/2.竞赛指北' },
|
||||
{ text: '3.正确解读GPA', link: '/福大生存指南/3.正确解读GPA' },
|
||||
{ text: '4.学生工作选择', link: '/福大生存指南/4.学生工作选择' },
|
||||
{ text: '5.Q&A', link: '/福大生存指南/5.Q&A' },
|
||||
{ text: '6.小组作业避雷指南', link: '/福大生存指南/6.小组作业避雷指南' },
|
||||
{ text: '7.选课原则与抢课技巧', link: '/福大生存指南/7.选课原则与抢课技巧' },
|
||||
{ text: '8.社团篇', link: '/福大生存指南/8.社团篇' },
|
||||
]
|
||||
},
|
||||
{
|
||||
text: '1.杭电生存指南(最重要模块)',
|
||||
text: '技术资源汇总(杭电支持版)',
|
||||
collapsed: true,
|
||||
items: [
|
||||
{ text: '1.1 人文社科的重要性(韩健夫老师寄语)', link: '/1.杭电生存指南/1.1人文社科的重要性(韩健夫老师寄语)' },
|
||||
{ text: '1.2 竞赛指北', link: '/1.杭电生存指南/1.2竞赛指北' },
|
||||
{ text: '1.3 导师选择', link: '/1.杭电生存指南/1.3导师选择' },
|
||||
{ text: '1.4 小心项目陷阱', link: '/1.杭电生存指南/1.4小心项目陷阱' },
|
||||
{ text: '1.5 小组作业避雷指南', link: '/1.杭电生存指南/1.5小组作业避雷指南' },
|
||||
{ text: '1.6 正确解读GPA', link: '/1.杭电生存指南/1.6正确解读GPA' },
|
||||
{ text: '1.7 杭电出国自救指南', link: '/1.杭电生存指南/1.7杭电出国自救指南' },
|
||||
{ text: '1.8 转专业二三事', link: '/1.杭电生存指南/1.8转专业二三事' },
|
||||
{ text: '1.9 问题专题:好想进入实验室', link: '/1.杭电生存指南/1.9问题专题:好想进入实验室' },
|
||||
{ text: '1.10 如何读论文', link: '/1.杭电生存指南/1.10如何读论文' },
|
||||
{ text: '1.11 陷入虚无主义?进来看看吧', link: '/1.杭电生存指南/1.11陷入虚无主义?进来看看吧' },
|
||||
{ text: '1.12 选课原则与抢课技巧', link: '/1.杭电生存指南/1.12选课原则与抢课技巧' },
|
||||
{ text: '1.13 数学学习篇', link: '/1.杭电生存指南/1.13数学学习篇' },
|
||||
{ text: '1.14 杭电“失败”指南', link: '/1.杭电生存指南/1.14 杭电失败指南' },
|
||||
{ text: '2.高效学习', link: '/技术资源汇总(杭电支持版)/2.高效学习/2.高效学习' },
|
||||
{ text: '3.编程思维体系构建', link: '/技术资源汇总(杭电支持版)/3.编程思维体系构建/3.编程思维体系构建' },
|
||||
{ text: '4.人工智能', link: '/技术资源汇总(杭电支持版)/4.人工智能/4.人工智能' },
|
||||
{ text: '5.富有生命的嵌入式', link: '/技术资源汇总(杭电支持版)/5.富有生命的嵌入式/5.富有生命的嵌入式' },
|
||||
{ text: '6.计算机安全', link: '/技术资源汇总(杭电支持版)/6.计算机安全/6.计算机安全' },
|
||||
{ text: '7.网络应用开发', link: '/技术资源汇总(杭电支持版)/7.网络应用开发/7.网络应用开发入门' },
|
||||
{ text: '8.基础学科', link: '/技术资源汇总(杭电支持版)/8.基础学科/8.基础学科' },
|
||||
{ text: '9.计算机网络', link: '/技术资源汇总(杭电支持版)/9.计算机网络/9.计算机网络' },
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -45,6 +47,7 @@ export function main_sidebar() {
|
||||
|
||||
export function main_sidebar_old() {
|
||||
return [
|
||||
{ text: '返回上一层', link: '/使用指南' },
|
||||
{
|
||||
text: "2.高效学习",
|
||||
collapsed: true,
|
||||
@@ -488,6 +491,30 @@ export function chapter9_old() {
|
||||
}
|
||||
]
|
||||
}
|
||||
export function chapter_survive() {
|
||||
return [
|
||||
{ text: '返回上一层', link: '/福大生存指南/生存指南' },
|
||||
{
|
||||
text: '福大生存指南',
|
||||
collapsed: false,
|
||||
items: [
|
||||
{ text: '9 计算机网络', link: '/技术资源汇总(杭电支持版)/9.计算机网络/9.计算机网络' },
|
||||
{ text: '9.1 计网速通', link: '/技术资源汇总(杭电支持版)/9.计算机网络/9.1计网速通' },
|
||||
{ text: '9.2.1 物理层(待完成)' },
|
||||
{ text: '9.2.2 链路层(待完成)' },
|
||||
{
|
||||
text: '9.2.3 网络层',
|
||||
collapsed: true,
|
||||
items: [
|
||||
{ text: '9.2.3 网络层', link: '/技术资源汇总(杭电支持版)/9.计算机网络/9.2.3网络层' },
|
||||
{ text: '9.2.3.1 IP 协议', link: '/技术资源汇总(杭电支持版)/9.计算机网络/9.2.3.1IP协议' },
|
||||
{ text: '9.2.3.2 子网与无类域间路由', link: '/技术资源汇总(杭电支持版)/9.计算机网络/9.2.3.2子网与无类域间路由' }
|
||||
]
|
||||
},
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
// Function to extract numeric prefix as an array of numbers
|
||||
function getNumericPrefix(fileName) {
|
||||
|
||||
@@ -311,7 +311,7 @@ npm run docs:preview #预览线上环境
|
||||
|
||||
## 如何使用 Git 和 Github
|
||||
|
||||
详见 [3.5 Git和Github](./2023旧版内容/3.编程思维体系构建/3.5git与github.md)
|
||||
详见 [3.5 Git和Github](./技术资源汇总(杭电支持版)/3.编程思维体系构建/3.5git与github.md)
|
||||
|
||||
## Commit Message 规范
|
||||
|
||||
|
||||
41
README.md
41
README.md
@@ -2,8 +2,10 @@
|
||||
<img src="https://cdn.xyxsw.site/hdu-cs-wiki%20full.svg" alt="logo" width="450rem" height="450rem"/>
|
||||
</div>
|
||||
<h1 align="center">FZU-WIKI</h1>
|
||||
<pre align="center">喜欢本项目可以点击右上角 star 收藏哦🎇</pre>
|
||||
<pre align="center">喜欢本项目可以点击右上角 “点赞” 收藏哦🎇</pre>
|
||||
|
||||
## 📖 项目介绍
|
||||
|
||||
FZU-WIKI 是福州大学星航电子工作室自发组织的一个开源项目,旨在为全校学生提供一个全面、系统、易用的小百科全书,方便新生以及在校同学快速了解学校方方面面,同时为同学提供学习和生活方面的帮助。
|
||||
|
||||
该项目将完全由校内全体学生共同维护,欢迎任何有想法且具备开源精神的伙伴加入到项目贡献中来,完成这项接力式项目的迭代与完善!
|
||||
@@ -11,12 +13,49 @@ FZU-WIKI 是福州大学星航电子工作室自发组织的一个开源项目
|
||||
项目完全开源,未来计划划分多个文档模块,交由各个学院代表同学负责维护,以最大限度保证项目文档的实时性和准确性。
|
||||
|
||||
## 🌟 项目特色
|
||||
|
||||
- **全面性**:涵盖学校各个方面的信息,目前主要涵盖学习和生活两大板块。
|
||||
- **易用性**:采用简洁明了的界面设计,同时支持全页面模糊查询,方便同学快速查找所需信息。
|
||||
- **开放性**:项目完全开源,欢迎任何有想法且具备开源精神的伙伴加入到项目贡献中来。
|
||||
- **持续更新**:项目将不断更新,确保信息的时效性和准确性。
|
||||
|
||||
## 🚀 项目支持
|
||||
|
||||
- 本项目基于hdu-cs-wiki项目进行二次开发,感谢hdu-cs-wiki团队的无私奉献!
|
||||
- 本项目q&a模块数据来自“福州大学新生群”(QQ群号:829337155)管理员“23 落枫F.M.”对群内问答的总结,感谢落枫大佬的无私奉献!
|
||||
- 本项目由星航电子工作室提供技术支持。
|
||||
|
||||
## 🤝 贡献者
|
||||
|
||||
感谢所有为本项目做出贡献的同学,你们的努力让本项目更加完善!
|
||||
|
||||
## 📝 许可证
|
||||
|
||||
本作品采用 `知识共享 署名-非商业性使用-相同方式共享 3.0 中国大陆` 许可协议进行许可。 要查看该许可协议, 可访问[这里](http://creativecommons.org/licenses/by-nc-sa/3.0/cn/), 或者写信到 Creative Commons, PO Box 1866, Mountain View, CA 94042, USA.
|
||||
|
||||
© 2022. 此文章采用 [**CC BY-NC-SA 3.0 CN**](http://creativecommons.org/licenses/by-nc-sa/3.0/cn/) 许可授权。
|
||||
|
||||
## 📣 部署方式
|
||||
|
||||
### 1. 克隆项目
|
||||
|
||||
```bash
|
||||
git clone https://gitea.xinxijishubu.asia/moyin/fzu-product.git
|
||||
```
|
||||
|
||||
### 2. 安装依赖
|
||||
|
||||
```bash
|
||||
cd FZU-WIKI
|
||||
yarn install
|
||||
```
|
||||
|
||||
### 3. 启动项目
|
||||
|
||||
```bash
|
||||
npm run docs:dev
|
||||
```
|
||||
|
||||
### 4. 访问项目
|
||||
|
||||
在浏览器中访问 `http://localhost:5173` 即可查看项目。
|
||||
|
||||
1
index.md
1
index.md
@@ -22,6 +22,7 @@ features:
|
||||
- title: 福大生存指南
|
||||
icon: <svg xmlns="http://www.w3.org/2000/svg" width="32" height="32" viewBox="0 0 32 32"><path fill="currentColor" d="M10 31H6a2.006 2.006 0 0 1-2-2v-7a2.006 2.006 0 0 1-2-2v-6a2.947 2.947 0 0 1 3-3h6a2.947 2.947 0 0 1 3 3v6a2.006 2.006 0 0 1-2 2v7a2.006 2.006 0 0 1-2 2M5 13a.945.945 0 0 0-1 1v6h2v9h4v-9h2v-6a.945.945 0 0 0-1-1zm3-3a4 4 0 1 1 4-4a4.005 4.005 0 0 1-4 4m0-6a2 2 0 1 0 2 2a2 2 0 0 0-2-2m20.766.256A4.21 4.21 0 0 0 23 4.032a4.21 4.21 0 0 0-5.766.224a4.32 4.32 0 0 0 0 6.044l5.764 5.84l.002-.002l.002.001l5.764-5.839a4.32 4.32 0 0 0 0-6.044m-1.424 4.639l-4.34 4.397L23 13.29l-.002.002l-4.34-4.397a2.31 2.31 0 0 1 0-3.234a2.264 2.264 0 0 1 3.156 0l1.181 1.207l.005-.005l.005.005l1.18-1.207a2.264 2.264 0 0 1 3.157 0a2.31 2.31 0 0 1 0 3.234"/></svg>
|
||||
details: 福大生存指南,为所有FZUer提供生存指南,包括生活、学习等各方面。
|
||||
link: /福大生存指南/生存指南
|
||||
- title: 技术资源汇总(杭电支持版)
|
||||
icon: <svg xmlns="http://www.w3.org/2000/svg" width="32" height="32" viewBox="0 0 32 32"><path fill="none" d="m16 7l1.912 3.667l4.088.506l-3 2.753l.6 4.074l-3.6-2.292L12.4 18l.6-4.074l-3-2.753l4.2-.506z"/><path fill="currentColor" d="M16 2A11.013 11.013 0 0 0 5 13a10.9 10.9 0 0 0 2.216 6.6s.3.395.349.452L16 30l8.439-9.953c.044-.053.345-.447.345-.447l.001-.003A10.9 10.9 0 0 0 27 13A11.013 11.013 0 0 0 16 2m3.6 16L16 15.709L12.4 18l.6-4.074l-3-2.753l4.2-.507L16 7l1.912 3.667l4.088.506l-3 2.753Z"/></svg>
|
||||
link: /技术资源汇总(杭电支持版)/内容索引
|
||||
|
||||
40
members.ts
40
members.ts
@@ -14,11 +14,43 @@ type Member = {
|
||||
|
||||
export const members: Member = [
|
||||
{
|
||||
avatar: 'https://avatars.hdu-cs.wiki/camera-2018',
|
||||
name: 'camera-2018',
|
||||
avatar: 'https://avatars.githubusercontent.com/u/177922725?s=400&u=b01cbf836e5e2885a16e892e08a58af92bdd23fa&v=4',
|
||||
name: 'xinghang',
|
||||
title: 'Maintainer',
|
||||
links: [
|
||||
{ icon: 'github', link: 'https://github.com/camera-2018' },
|
||||
{ icon: 'github', link: 'https://github.com/xinghang-ee' },
|
||||
]
|
||||
}
|
||||
},
|
||||
{
|
||||
avatar: 'https://gitea.xinxijishubu.asia/avatars/16c385a504c5ab7d1072949846e6a6258d89c5c7453964fb28806c824fa4a2b8?size=512',
|
||||
name: 'moyin',
|
||||
title: 'Maintainer',
|
||||
links: [
|
||||
{ icon: 'github', link: 'https://gitea.xinxijishubu.asia/moyin' },
|
||||
]
|
||||
},
|
||||
{
|
||||
avatar: 'https://avatars.hdu-cs.wiki/wjj1117',
|
||||
name: 'WJJ',
|
||||
title: 'Maintainer',
|
||||
links: [
|
||||
{ icon: 'github', link: 'https://github.com/wjj1117' },
|
||||
]
|
||||
},
|
||||
{
|
||||
avatar: 'https://gitea.xinxijishubu.asia/avatar/3344e9e767a6e8551d755367d190e6a3?size=512',
|
||||
name: 'kitor',
|
||||
title: 'Maintainer',
|
||||
links: [
|
||||
{ icon: 'github', link: 'https://gitea.xinxijishubu.asia/kitor' },
|
||||
]
|
||||
},
|
||||
{
|
||||
avatar: 'https://avatars.githubusercontent.com/u/141472712?v=4',
|
||||
name: 'Maple013',
|
||||
title: 'Contributer',
|
||||
links: [
|
||||
{ icon: 'github', link: 'https://github.com/Maple013' },
|
||||
]
|
||||
},
|
||||
]
|
||||
|
||||
10
使用指南.md
10
使用指南.md
@@ -46,12 +46,12 @@
|
||||
|
||||
- 请在提交问题时,尽量详细描述问题,以便我们更好地解决您的问题。
|
||||
|
||||
## 如何参与贡献?
|
||||
## 如何参与贡献(提交PR)?
|
||||
|
||||
- 点击页面右上角 `编辑本页` 按钮,即可编辑页面内容。
|
||||
- 点击页面末尾的`在Gitea上修改此页` 按钮,跳转到gitea对应编辑页位置。
|
||||
|
||||
- 请在编辑时,尽量遵循 `Markdown` 语法,以便其他用户更好地阅读。
|
||||
- 注意,只有fork(派生,也就是抓取)仓库的用户才能编辑。
|
||||
|
||||
- 如果您有其他建议,欢迎在 `讨论区` 提出。
|
||||
- 编辑完成后,点击页面右上角 `提交` 按钮,即可提交您的修改。
|
||||
|
||||
## 如何查看历史版本?
|
||||
- 请在提交修改时,尽量遵循 `Markdown` 语法,以便其他用户更好地阅读。
|
||||
@@ -119,7 +119,7 @@
|
||||
|
||||
## 选择大于努力
|
||||
|
||||
[正确解读 GPA](/1.杭电生存指南/1.6正确解读GPA) 这篇文档写得很好,和我的想法完全一致,但是被放得太后面了,我想把它提上来。
|
||||
正确解读 GPA这篇文档写得很好,和我的想法完全一致,但是被放得太后面了,我想把它提上来。
|
||||
|
||||
大学不是唯分数论的,起码编程不是这样。我的建议是,如果以后大概率考研,可以多抓一下绩点;如果以后大概率工作,就不必追求高绩点了(指把大部分时间都花在提高绩点上)。
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@ author:zzm
|
||||
|
||||
讲讲某个人在大一的悲惨经历来为大家串起来一个精简的数据科学工作包括了哪些步骤,同时给各位介绍一些优质的教程
|
||||
|
||||
同时,这章内容将详细阐述[与人合作的生死疲劳](/1.杭电生存指南/1.5小组作业避雷指南)
|
||||
同时,这章内容将详细阐述与人合作的生死疲劳
|
||||
|
||||
## 悲惨世界
|
||||
|
||||
|
||||
@@ -1,95 +0,0 @@
|
||||
# 推荐系统的意义
|
||||
|
||||
随着移动互联网的飞速发展,人们已经处于一个信息过载的时代。在这个时代中,信息的生产者很难将信息呈现在对它们感兴趣的信息消费者面前,而对于信息消费者也很难从海量的信息中找到自己感兴趣的信息。推荐系统就是一个将信息生产者和信息消费者连接起来的桥梁。平台往往会作为推荐系统的载体,实现信息生产者和消费者之间信息的匹配。上述提到的平台方、信息生产者和消费者可以分别用平台方(如:腾讯视频、淘宝、网易云音乐等)、物品(如:视频、商品、音乐等)和用户和来指代。下面分别从这三方需求出发,介绍推荐系统的存在的意义。
|
||||
|
||||
|
||||
## 平台方
|
||||
|
||||
平台方一般是为信息生产者提供物品展示的位置,然后通过不同的方式吸引用户来到平台上寻找他们感兴趣的物品。平台通过商家对物品的展示以及用户的浏览、观看或下单等行为,就产生了所谓的"流量"。
|
||||
|
||||
对平台方而言,流量的高效利用是推荐系统存在的重要原因。以典型的电商网站一般具有如图所示的树状拓扑结构,树状结构在连通性方面有着天然的劣势,阻碍这流量的高效流通。推荐系统的出现使得原本的树状结构变成网络拓扑结构,大大增强了整个网络的连通性。推荐模块不仅使用户在当前页面有了更好的选择路径,同时也给了每个商品增加入口和展示机会,进而提高了成交概率。而推荐质量的好坏,直接决定了用户选择这条路径的可能性,进而影响着流量的利用效率。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://typoraimg-1252051831.cos.ap-guangzhou.myqcloud.com/image-20220514232543182.png" alt="image-20220514232543182" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
推荐系统解决产品能够最大限度地吸引用户、留存用户、增加用户粘性、提高用户转化率的问题,从而达到平台商业目标增长的目的。不同平台的目标取决于其商业的盈利目的,例如对于YouTube,其商业目标是最大化视频被点击(点击率)以及用户观看的时长(完播率),同时也会最大化内置广告的点击率;对于淘宝等电商平台,除了最大化商品的点击率外,最关键的目标则是最大化用户的转化率,即由点击到完成商品购买的指标。推荐系统能够平台带来丰厚的商业价值 。
|
||||
|
||||
|
||||
## 信息生产者(物品)
|
||||
|
||||
因为在互联网大数据时代下,物品的长尾性和二八原则是非常严重的。具体来说,对于一个平台而言80%的销售额可能是那些最畅销20%的物品。但是那20%的物品其实只能满足一小部分人的需求,对于绝大多数的用户的需求需要从那80%的长尾物品中去满足。虽然长尾物品的总销售额占比不大,但是因为长尾物品的数量及其庞大,如果可以充分挖掘长尾物品,那这些长尾物品的销售额的总量有可能会超过热门商品。
|
||||
|
||||
物品只是信息生产者的产物,对于信息生产者而言,例如商家、视频创作者等,他们也更希望自己生产的内容可以得到更多的曝光,尤其是对于新来的商家或者视频创作者,这样可以激发他们创作的热情,进而创作出更多的商品或者视频,让更多的用户的需求得到满足。
|
||||
|
||||
对于一个平台而言,无论是否靠平台上的物品直接盈利,其将平台上的内容与用户进行匹配的能力都是衡量平台的重要标准之一,推荐系统的好坏很大程度上决定了平台匹配需求和供给的能力。推荐系统匹配需求和供给的能力决定了其最终的商业价值。
|
||||
|
||||
|
||||
## 信息消费者(用户)
|
||||
|
||||
推荐系统对于用户而言,除了将平台上的需求和供给进行匹配外,还需要尽可能地提高用户的体验,但是对于一个平台来说,影响用户体验的因素非常多(产品设计、广告数量等)。对于一个有明确需求的用户来说,用户在平台上可以直接通过搜索来快速满足自己的需求,但这也仅仅是一个平台最基础的用户体验(平台做的好是应该的,但是做的不好可能会被喷)。对于一个没有明确需求的用户来说,用户会通过浏览平台上的推荐页来获取一些额外的惊喜需求。因为用户没有明确的需求,也就对推荐页浏览的内容没有明确的预期,但是并不说明用户没有期待。我们每天都希望自己的一天中充满惊喜,这样生活才会感觉更加的多姿多彩。推荐系统可以像为用户准备生日礼物一样,让呈现的内容给用户带来惊喜,进而增强用户对平台的依赖。此外,在给用户带来惊喜的同时,也会提高平台的转化率(例如成交额)
|
||||
|
||||
|
||||
## 推荐和搜索的区别
|
||||
|
||||
搜索和推荐都是解决互联网大数据时代信息过载的手段,但是它们也存在着许多的不同:
|
||||
1. **用户意图**:搜索时的用户意图是非常明确的,用户通过查询的关键词主动发起搜索请求。对于推荐而言,用户的需求是不明确的,推荐系统在通过对用户历史兴趣的分析给用户推荐他们可能感兴趣的内容。
|
||||
2. **个性化程度**:对于搜索而言,由于限定的了搜索词,所以展示的内容对于用户来说是有标准答案的,所以搜索的个性化程度较低。而对于推荐来说,推荐的内容本身就是没有标准答案的,每个人都有不同的兴趣,所以每个人展示的内容,个性化程度比较强。
|
||||
3. **优化目标**:对于搜索系统而言,更希望可以快速地、准确地定位到标准答案,所以希望搜索结果中答案越靠前越好,通常评价指标有:归一化折损累计收益(NDCG)、精确率(Precision)和召回率(Recall)。对于推荐系统而言,因为没有标准的答案,所以优化目标可能会更宽泛。例如用户停留时长、点击、多样性,评分等。不同的优化目标又可以拆解成具体的不同的评价指标。
|
||||
4. **马太效应和长尾理论**:对于搜索系统来说,用户的点击基本都集中在排列靠前的内容上,对于排列靠后的很少会被关注,这就是马太效应。而对于推荐系统来说,热门物品被用户关注更多,冷门物品不怎么被关注的现象也是存在的,所以也存在马太效应。此外,在推荐系统中,冷门物品的数量远远高于热门物品的数量,所以物品的长尾性非常明显。
|
||||
|
||||
> 对于搜索、推荐、广告这三个领域的区别和联系可以参考王喆老师写的[排得更好VS估得更准VS搜的更全「推荐、广告、搜索」算法间到底有什么区别?](https://zhuanlan.zhihu.com/p/430431149)
|
||||
|
||||
## 推荐系统的应用
|
||||
个性化推荐系统通过分析用户的行为日志,得到用户当前的甚至未来可能的兴趣,给不同的用户展示不同的(个性化)的页面,来提高网站或者app的点击率、转化率、留存率等指标。推荐系统被广泛应用在广告、电商、影视、音乐、社交、饮食、阅读等领域。下面简单的通过不同的app的推荐页来感受一下推荐系统在各个内容平台的存在形式。
|
||||
|
||||
- **电商首页推荐(淘宝、京东、拼多多)**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421190313917.png" alt="image-20220421190313917" style="zoom: 15%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421191138469.png" alt="image-20220421191138469" style="zoom:53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421191441104.png" alt="image-20220421191441104" style="zoom:53%;" />
|
||||
</div>
|
||||
|
||||
- **视频推荐(抖音、快手、B站、爱奇艺)**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421190629410.png" alt="image-20220421190629410" style="zoom:55%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421191849577.png" alt="image-20220421191849577" style="zoom: 53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192047973.png" alt="image-20220421192047973" style="zoom:53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192209412.png" alt="image-20220421192209412" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
|
||||
- **饮食推荐(美团、饿了么、叮咚买菜)**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192623380.png" alt="image-20220421192623380" style="zoom:53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192717773.png" alt="image-20220421192717773" style="zoom:55%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192749794.png" alt="image-20220421192749794" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
|
||||
- **音乐电台(网易云音乐、QQ音乐、喜马拉雅)**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193139183.png" alt="image-20220421193139183" style="zoom: 57%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193447933.png" alt="image-20220421193447933" style="zoom:68%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193325921.png" alt="image-20220421193325921" style="zoom: 54%;" />
|
||||
</div>
|
||||
|
||||
|
||||
- **资讯、阅读(头条、知乎、豆瓣)**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193856262.png" alt="image-20220421193856262" style="zoom:53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193923283.png" alt="image-20220421193923283" style="zoom:55%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421194244083.png" alt="image-20220421194244083" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
|
||||
**参考资料:**
|
||||
|
||||
- 《推荐系统实践》
|
||||
- 《从零开始构建企业级推荐系统》
|
||||
- 《智能搜索和推荐系统》
|
||||
@@ -1,174 +0,0 @@
|
||||
# 推荐系统架构
|
||||
推荐和搜索系统核心的的任务是从海量物品中找到用户感兴趣的内容。在这个背景下,推荐系统包含的模块非常多,每个模块将会有很多专业研究的工程和研究工程师,作为刚入门的应届生或者实习生很难对每个模块都有很深的理解,实际上也大可不必,我们完全可以从学习好一个模块技术后,以点带面学习整个系统,虽然正式工作中我们放入门每个人将只会负责的也是整个系统的一部分。但是掌握推荐系统最重要的还是梳理清楚整个推荐系统的架构,知道每一个部分需要完成哪些任务,是如何做的,主要的技术栈是什么,有哪些局限和可以研究的问题,能够对我们学习推荐系统有一个提纲挈领的作用。
|
||||
|
||||
所以这篇文章将会从**系统架构**和**算法架构**两个角度出发解析推荐系统通用架构。系统架构设计思想是大数据背景下如何有效利用海量和实时数据,将推荐系统按照对数据利用情况和系统响应要求出发,将整个架构分为**离线层、近线层、在线层**三个模块。然后分析这三个模块分别承担推荐系统什么任务,有什么制约要求。这种角度不和召回、排序这种通俗我们理解算法架构,因为更多的是考虑推荐算法在工程技术实现上的问题,系统架构是如何权衡利弊,如何利用各种技术工具帮助我们达到想要的目的的,方便我们理解为什么推荐系统要这样设计。
|
||||
|
||||
而算法架构是从我们比较熟悉的**召回、粗排、排序、重排**等算法环节角度出发的,重要的是要去理解每个环节需要完成的任务,每个环节的评价体系,以及为什么要那么设计。还有一个重要问题是每个环节涉及到的技术栈和主流算法,这部分非常重要而且篇幅较大,所以我们放在下一个章节讲述。
|
||||
|
||||
架构设计是一个非常大的话题,设计的核心在于平衡和妥协。在推荐系统不同时期、不同的环境、不同的数据,架构都会面临不一样的问题。网飞官方博客有一段总结:
|
||||
|
||||
> We want the ability to use sophisticated machine learning algorithms that can grow to arbitrary complexity and can deal with huge amounts of data. We also want an architecture that allows for flexible and agile innovation where new approaches can be developed and plugged-in easily. Plus, we want our recommendation results to be fresh and respond quickly to new data and user actions. Finding the sweet spot between these desires is not trivial: it requires a thoughtful analysis of requirements, careful selection of technologies, and a strategic decomposition of recommendation algorithms to achieve the best outcomes for our members.
|
||||
> **“我们需要具备使用复杂机器学习算法的能力,这些算法要可以适应高度复杂性,可以处理大量数据。我们还要能够提供灵活、敏捷创新的架构,新的方法可以很容易在其基础上开发和插入。而且,我们需要我们的推荐结果足够新,能快速响应新的数据和用户行为。找到这些要求之间恰当的平衡并不容易,需要深思熟虑的需求分析,细心的技术选择,战略性的推荐算法分解,最终才能为客户达成最佳的结果。”**
|
||||
|
||||
所以在思考推荐系统架构考虑的第一个问题是确定边界:知道推荐系统要负责哪部分问题,这就是边界内的部分。在这个基础上,架构要分为哪几个部分,每一部分需要完成的子功能是什么,每一部分依赖外界的什么。了解推荐系统架构也和上文讲到的思路一样,我们需要知道的是推荐系统要负责的是怎么问题,每一个子模块分别承担了哪些功能,它们的主流技术栈是什么。从这个角度来阅读本文,将会有助于读者抓住重点。
|
||||
|
||||
## 系统架构
|
||||
|
||||
推荐系统架构,首先从数据驱动角度,对于数据,最简单的方法是存下来,留作后续离线处理,**离线层**就是我们用来管理离线作业的部分架构。**在线层**能更快地响应最近的事件和用户交互,但必须实时完成。这会限制使用算法的复杂性和处理的数据量。离线计算对于数据数量和算法复杂度限制更少,因为它以批量方式完成,没有很强的时间要求。不过,由于没有及时加入最新的数据,所以很容易过时。
|
||||
|
||||
个性化架构的关键问题,就是如何以无缝方式结合、管理在线和离线计算过程。**近线层**介于两种方法之间,可以执行类似于在线计算的方法,但又不必以实时方式完成。这种设计思想最经典的就是Netflix在2013年提出的架构,整个架构分为
|
||||
|
||||
1. 离线层:不用实时数据,不提供实时响应;
|
||||
2. 近线层:使用实时数据,不保证实时响应;
|
||||
3. 在线层:使用实时数据,保证实时在线服务;
|
||||
|
||||
### 设计思想
|
||||
网飞的这个架构提出的非常早,其中的技术也许不是现在常用的技术了,但是架构模型仍然被很多公司采用。
|
||||
|
||||
这个架构为什么要这么设计,本质上是因为推荐系统是由大量数据驱动的,大数据框架最经典的就是lambda架构和kappa架构。而推荐系统在不同环节所使用的数据、处理数据的量级、需要的读取速度都是不同的,目前的技术还是很难实现一套端到端的及时响应系统,所以这种架构的设计本质上还是一种权衡后的产物,所以有了下图这种模型:
|
||||
|
||||
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409205047285.png" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
上面是网飞的原图,我搬运了更加容易理解的线条梳理后的结构:
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409204658032.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
整个数据部分其实是一整个链路,主要是三块,分别是客户端及服务器实时数据处理、流处理平台准实时数据处理和大数据平台离线数据处理这三个部分。
|
||||
|
||||
看到这里,一个很直观的问题就是,为什么数据处理需要这么多步骤?这些步骤都是干嘛的,存在的意义是什么?
|
||||
|
||||
我们一个一个来说,首先是客户端和服务端的实时数据处理。这个很好理解,这个步骤的工作就是记录。将用户在平台上真实的行为记录下来,比如用户看到了哪些内容,和哪些内容发生了交互,和哪些没有发生了交互。如果再精细一点,还会记录用户停留的时间,用户使用的设备等等。除此之外还会记录行为发生的时间,行为发生的session等其他上下文信息。
|
||||
|
||||
这一部分主要是后端和客户端完成,行业术语叫做埋点。所谓的埋点其实就是记录点,因为数据这种东西需要工程师去主动记录,不记录就没有数据,记录了才有数据。既然我们要做推荐系统,要分析用户行为,还要训练模型,显然需要数据。需要数据,就需要记录。
|
||||
|
||||
第二个步骤是流处理平台准实时数据处理,这一步是干嘛的呢,其实也是记录数据,不过是记录一些准实时的数据。很多同学又会迷糊了,实时我理解,就是当下立即的意思,准实时是什么意思呢?准实时的意思也是实时,只不过没有那么即时,比如可能存在几分钟的误差。这样存在误差的即时数据,行业术语叫做准实时。那什么样的准实时数据需要记录呢?在推荐领域基本上只有一个类别,就是用户行为数据。也就是用户在观看这个内容之前还看过哪些内容,和哪些内容发生过交互。理想情况这部分数据也需要做成实时,但由于这部分数据量比较大,并且逻辑也相对复杂,所以很难做到非常实时,一般都是通过消息队列加在线缓存的方式做成准实时。
|
||||
|
||||
最后我们看第三个步骤,叫做离线数据处理,离线也就是线下处理,基本上就没有时限的要求了。
|
||||
|
||||
一般来说,离线处理才是数据处理的大头。所有“脏活累活”复杂的操作都是在离线完成的,比如说一些join操作。后端只是记录了用户交互的商品id,我们需要商品的详细信息怎么办?需要去和商品表关联查表。显然数据关联是一个非常耗时的操作,所以只能放到离线来做。
|
||||
|
||||
接下来详细介绍一下这三个模块。
|
||||
|
||||
### 离线层
|
||||
离线层是计算量最大的一个部分,它的特点是不依赖实时数据,也不需要实时提供服务。需要实现的主要功能模块是:
|
||||
|
||||
1. 数据处理、数据存储;
|
||||
2. 特征工程、离线特征计算;
|
||||
3. 离线模型的训练;
|
||||
|
||||
这里我们可以看出离线层的任务是最接近学校中我们处理数据、训练模型这种任务的,不同可能就是需要面临更大规模的数据。离线任务一般会按照天或者更久运行,比如每天晚上定期更新这一天的数据,然后重新训练模型,第二天上线新模型。
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409205904314.png" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
#### 离线层优势和不足
|
||||
离线层面临的数据量级是最大的,面临主要的问题是海量数据存储、大规模特征工程、多机分布式机器学习模型训练。目前主流的做法是HDFS,收集到我们所有的业务数据,通过HIVE等工具,从全量数据中抽取出我们需要的数据,进行相应的加工,离线阶段主流使用的分布式框架一般是Spark。所以离线层有如下的优势:
|
||||
1. 可以处理大量的数据,进行大规模特征工程;
|
||||
2. 可以进行批量处理和计算;
|
||||
3. 不用有响应时间要求;
|
||||
|
||||
但是同样的,如果我们只使用用户离线数据,最大的不足就是无法反应用户的实时兴趣变化,这就促使了近线层的产生。
|
||||
|
||||
### 近线层
|
||||
近线层的主要特点是准实时,它可以获得实时数据,然后快速计算提供服务,但是并不要求它和在线层一样达到几十毫秒这种延时要求。近线层的产生是同时想要弥补离线层和在线层的不足,折中的产物。
|
||||
|
||||
它适合处理一些对延时比较敏感的任务,比如:
|
||||
1. 特征的事实更新计算:例如统计用户对不同type的ctr,推荐系统一个老生常谈的问题就是特征分布不一致怎么办,如果使用离线算好的特征就容易出现这个问题。近线层能够获取实时数据,按照用户的实时兴趣计算就能很好避免这个问题。
|
||||
2. 实时训练数据的获取:比如在使用DIN、DSIN这行网络会依赖于用户的实时兴趣变化,用户几分钟前的点击就可以通过近线层获取特征输入模型。
|
||||
3. 模型实时训练:可以通过在线学习的方法更新模型,实时推送到线上;
|
||||
|
||||
近线层的发展得益于最近几年大数据技术的发展,很多流处理框架的提出大大促进了近线层的进步。如今Flink、Storm等工具一统天下。
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409205830027.png" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
### 在线层
|
||||
在线层,就是直接面向用户的的那一层了。最大的特点是对响应延时有要求,因为它是直接面对用户群体的,你可以想象你打开抖音淘宝等界面,几乎都是秒刷出来给你的推荐结果的,不会说还需要让你等待几秒钟时间。所有的用户请求都会发送到在线层,在线层需要快速返回结果,它主要承担的工作有:
|
||||
|
||||
1. 模型在线服务;包括了快速召回和排序;
|
||||
2. 在线特征快速处理拼接::根据传入的用户ID和场景,快速读取特征和处理;
|
||||
3. AB实验或者分流:根据不同用户采用不一样的模型,比如冷启动用户和正常服务模型;
|
||||
4. 运筹优化和业务干预:比如要对特殊商家流量扶持、对某些内容限流;
|
||||
|
||||
典型的在线服务是用过RESTful/RPC等提供服务,一般是公司后台服务部门调用我们的这个服务,返回给前端。具体部署应用比较多的方式就是使用Docker在K8S部署。而在线服务的数据源就是我们在离线层计算好的每个用户和商品特征,我们事先存放在数据库中,在线层只需要实时拼接,不进行复杂的特征运算,然后输入近线层或者离线层已经训练好的模型,根据推理结果进行排序,最后返回给后台服务器,后台服务器根据我们对每一个用户的打分,再返回给用户。
|
||||
|
||||
在线层最大的问题就是对实时性要求特别高,一般来说是几十毫秒,这就限制了我们能做的工作,很多任务往往无法及时完成,需要近线层协助我们做。
|
||||
## 算法架构
|
||||
|
||||
我们在入门学习推荐系统的时候,更加关注的是哪个模型AUC更高、topK效果好,哪个模型更加牛逼的问题,从基本的协同过滤到点击率预估算法,从深度学习到强化学习,学术界都始终走在最前列。一个推荐算法从出现到在业界得到广泛应用是一个长期的过程,因为在实际的生产系统中,首先需要保证的是稳定、实时地向用户提供推荐服务,在这个前提下才能追求推荐系统的效果。
|
||||
|
||||
算法架构的设计思想就是在实际的工业场景中,不管是用户维度、物品维度还是用户和物品的交互维度,数据都是极其丰富的,学术界对算法的使用方法不能照搬到工业界。当一个用户访问推荐模块时,系统不可能针对该用户对所有的物品进行排序,那么推荐系统是怎么解决的呢?对应的商品众多,如何决定将哪些商品展示给用户?对于排序好的商品,如何合理地展示给用户?
|
||||
|
||||
所以一个通用的算法架构,设计思想就是对数据层层建模,层层筛选,帮助用户从海量数据中找出其真正感兴趣的部分。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409211354342.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
- 召回
|
||||
|
||||
召回层的主要目标时从推荐池中选取几千上万的item,送给后续的排序模块。由于召回面对的候选集十分大,且一般需要在线输出,故召回模块必须轻量快速低延迟。由于后续还有排序模块作为保障,召回不需要十分准确,但不可遗漏(特别是搜索系统中的召回模块)。
|
||||
|
||||
如果没有召回层,每个User都能和每一个Item去在线排序阶段预测目标概率,理论上来说是效果最好,但是是不现实的,线上不延迟允许,所以召回和粗排阶段就要做一些候选集筛选的工作,保证在有限的能够给到排序层去做精排的候选集的时间里,效果最大化。另一个方面就是通过这种模型级联的方式,可以减少用排序阶段拟合多目标的压力,比如召回阶段我们现在主要是在保证Item质量的基础上注重覆盖率多样性,粗排阶段主要用简单的模型来解决不同路的召回和当前用户的相关性问题,最后截断到1k个以内的候选集,这个候选集符合一定的个性化相关性、视频质量和多样性的保证,然后做ranking去做复杂模型的predict。
|
||||
|
||||
目前基本上采用多路召回解决范式,分为非个性化召回和个性化召回。个性化召回又有content-based、behavior-based、feature-based等多种方式。
|
||||
|
||||
召回主要考虑的内容有:
|
||||
|
||||
1. **考虑用户层面**:用户兴趣的多元化,用户需求与场景的多元化:例如:新闻需求,重大要闻,相关内容沉浸阅读等等
|
||||
2. **考虑系统层面**:增强系统的鲁棒性;部分召回失效,其余召回队列兜底不会导致整个召回层失效;排序层失效,召回队列兜底不会导致整个推荐系统失效
|
||||
3. **系统多样性内容分发**:图文、视频、小视频;精准、试探、时效一定比例;召回目标的多元化,例如:相关性,沉浸时长,时效性,特色内容等等
|
||||
4. **可解释性推荐一部分召回是有明确推荐理由的**:很好的解决产品性数据的引入;
|
||||
|
||||
- 粗排
|
||||
|
||||
粗排的原因是有时候召回的结果还是太多,精排层速度还是跟不上,所以加入粗排。粗排可以理解为精排前的一轮过滤机制,减轻精排模块的压力。粗排介于召回和精排之间,要同时兼顾精准性和低延迟。目前粗排一般也都模型化了,其训练样本类似于精排,选取曝光点击为正样本,曝光未点击为负样本。但由于粗排一般面向上万的候选集,而精排只有几百上千,其解空间大很多。
|
||||
|
||||
粗排阶段的架构设计主要是考虑三个方面,一个是根据精排模型中的重要特征,来做候选集的截断,另一部分是有一些召回设计,比如热度或者语义相关的这些结果,仅考虑了item侧的特征,可以用粗排模型来排序跟当前User之间的相关性,据此来做截断,这样是比单独的按照item侧的倒排分数截断得到更加个性化的结果,最后是算法的选型要在在线服务的性能上有保证,因为这个阶段在pipeline中完成从召回到精排的截断工作,在延迟允许的范围内能处理更多的召回候选集理论上与精排效果正相关。
|
||||
|
||||
- 精排
|
||||
|
||||
精排层,也是我们学习推荐入门最常常接触的层,我们所熟悉的算法很大一部分都来自精排层。这一层的任务是获取粗排模块的结果,对候选集进行打分和排序。精排需要在最大时延允许的情况下,保证打分的精准性,是整个系统中至关重要的一个模块,也是最复杂,研究最多的一个模块。
|
||||
|
||||
精排是推荐系统各层级中最纯粹的一层,他的目标比较单一且集中,一门心思的实现目标的调优即可。最开始的时候精排模型的常见目标是ctr,后续逐渐发展了cvr等多类目标。精排和粗排层的基本目标是一致的,都是对商品集合进行排序,但是和粗排不同的是,精排只需要对少量的商品(即粗排输出的商品集合的topN)进行排序即可。因此,精排中可以使用比粗排更多的特征,更复杂的模型和更精细的策略(用户的特征和行为在该层的大量使用和参与也是基于这个原因)。
|
||||
|
||||
精排层模型是推荐系统中涵盖的研究方向最多,有非常多的子领域值得研究探索,这也是推荐系统中技术含量最高的部分,毕竟它是直接面对用户,产生的结果对用户影响最大的一层。目前精排层深度学习已经一统天下了,精排阶段采用的方案相对通用,首先一天的样本量是几十亿的级别,我们要解决的是样本规模的问题,尽量多的喂给模型去记忆,另一个方面时效性上,用户的反馈产生的时候,怎么尽快的把新的反馈给到模型里去,学到最新的知识。
|
||||
|
||||
- 重排
|
||||
|
||||
常见的有三种优化目标:Point Wise、Pair Wise 和 List Wise。重排序阶段对精排生成的Top-N个物品的序列进行重新排序,生成一个Top-K个物品的序列,作为排序系统最后的结果,直接展现给用户。重排序的原因是因为多个物品之间往往是相互影响的,而精排序是根据PointWise得分,容易造成推荐结果同质化严重,有很多冗余信息。而重排序面对的挑战就是海量状态空间如何求解的问题,一般在精排层我们使用AUC作为指标,但是在重排序更多关注NDCG等指标。
|
||||
|
||||
重排序在业务中,获取精排的排序结果,还会根据一些策略、运营规则参与排序,比如强制去重、间隔排序、流量扶持等、运营策略、多样性、context上下文等,重新进行一个微调。重排序更多的是List Wise作为优化目标的,它关注的是列表中商品顺序的问题来优化模型,但是一般List Wise因为状态空间大,存在训练速度慢的问题。
|
||||
|
||||
由于精排模型一般比较复杂,基于系统时延考虑,一般采用point-wise方式,并行对每个item进行打分。这就使得打分时缺少了上下文感知能力。用户最终是否会点击购买一个商品,除了和它自身有关外,和它周围其他的item也息息相关。重排一般比较轻量,可以加入上下文感知能力,提升推荐整体算法效率。比如三八节对美妆类目商品提权,类目打散、同图打散、同卖家打散等保证用户体验措施。重排中规则比较多,但目前也有不少基于模型来提升重排效果的方案。
|
||||
|
||||
- 混排
|
||||
|
||||
多个业务线都想在Feeds流中获取曝光,则需要对它们的结果进行混排。比如推荐流中插入广告、视频流中插入图文和banner等。可以基于规则策略(如广告定坑)和强化学习来实现。
|
||||
|
||||
## 总结
|
||||
|
||||
整篇文章从系统架构梳理了Netfliex的经典推荐系统架构,整个架构更多是偏向实时性能和效果之间tradeoff的结果。如果从另外的角度看推荐系统架构,比如从数据流向,或者说从推荐系统各个时序依赖来看,就是我们最熟悉的召回、粗排、精排、重排、混排等模块了。这种角度来看是把推荐系统从前往后串起来,其中每一个模块既有在离线层工作的,也有在在线层工作的。而从数据驱动角度看,更能够看到推荐系统的完整技术栈,推荐系统当前面临的局限和发展方向。
|
||||
|
||||
召回、排序这些里面单拿出任何一个模块都非常复杂。这也是为什么大家都说大厂拧螺丝的原因,因为很可能某个人只会负责其中很小的一个模块。许多人说起自己的模块来如数家珍,但对于全局缺乏认识,带来的结果是当你某天跳槽了或者是工作内容变化了,之前从工作当中的学习积累很难沉淀下来,这对于程序员的成长来说是很不利的。
|
||||
|
||||
所以希望这篇文章能够帮助大家在负责某一个模块,优化某一个功能的时候,除了能够有算法和数据,还能能够考虑对整个架构带来的影响,如何提升整体的一个性能,慢慢开阔自己的眼界,构建出一个更好的推荐系统。
|
||||
|
||||
|
||||
|
||||
**参考资料**
|
||||
- 《从零开始构建企业级推荐系统》
|
||||
- [Netflix](https://netflixtechblog.com/system-architectures-for-personalization-and-recommendation-e081aa94b5d8)
|
||||
- [回顾经典,Netflix的推荐系统架构](https://zhuanlan.zhihu.com/p/114590897)
|
||||
- [大数据处理中的Lambda架构和Kappa架构](https://www.cnblogs.com/xiaodf/p/11642555.html)
|
||||
- [张俊林:推荐系统技术演进趋势](https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247496363&idx=1&sn=0d2b2ac176e2a72eb2e760b7b591788f&chksm=fbd740c7cca0c9d16c76fdeb1a874a53f7408d8125b2e1bed3173ecb69d131167c1c9c35c71f&scene=21#wechat_redirect)
|
||||
- [推荐算法架构1:召回/等](https://blog.csdn.net/u013510838/article/details/123023259)
|
||||
- [微信"看一看"多模型内容策略与召回](https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247503484&idx=2&sn=e2a2cdd3a517ab09e903e69ccb1e9f94&chksm=fbd77c10cca0f50642dde47439ed919aa2e61b7ff57bc4cbaacc3acaac3c620a1ed6f92684ab&scene=21#wechat_redirect)
|
||||
- [阿里粗排技术体系](https://mp.weixin.qq.com/s/CN3a4Zb4yEjgi4mkm2lX6w)
|
||||
- [推荐系统架构与算法流程详解](https://mp.weixin.qq.com/s/tgZIdYENwQqDScjt7R28EQ)
|
||||
- [业内推荐系统架构介绍](https://mp.weixin.qq.com/s/waLW4aULeLoOB54_X-CzdQ)
|
||||
- [推荐系统笔记,一张图看懂系统架构](https://mp.weixin.qq.com/s/Zj4lCBe2bYNT6uT2-d-pNg)
|
||||
@@ -1,200 +0,0 @@
|
||||
## 推荐系统的技术栈
|
||||
|
||||
推荐系统是一个非常大的框架,有非常多的模块在里面,完整的一套推荐系统体系里,不仅会涉及到推荐算法工程师、后台开发工程师、数据挖掘/分析工程师、NLP/CV工程师还有前端、客户端甚至产品、运营等支持。我们作为算法工程师,需要掌握的技术栈主要就是在算法和工程两个区域了,所以这篇文章将会分别从算法和工程两个角度出发,结合两者分析当前主流的一些推荐算法技术栈。
|
||||
|
||||
## 算法
|
||||
|
||||
首先我们从推荐系统架构出发,一种分法是将整个推荐系统架构分为召回、粗排、精排、重排、混排等模块。它的分解方法是从一份数据如何从生产出来,到线上服务完整顺序的一个流程。因为在不同环节,我们一般会考虑不同的算法,所以这种角度出发我们来研究推荐系统主流的算法技术栈。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409211354342.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
为了帮助新手在后文方便理解,首先简单介绍这些模块的功能主要是:
|
||||
- 召回:从推荐池中选取几千上万的item,送给后续的排序模块。由于召回面对的候选集十分大,且一般需要在线输出,故召回模块必须轻量快速低延迟。由于后续还有排序模块作为保障,召回不需要十分准确,但不可遗漏(特别是搜索系统中的召回模块)。目前基本上采用多路召回解决范式,分为非个性化召回和个性化召回。个性化召回又有content-based、behavior-based、feature-based等多种方式。
|
||||
- 粗排:粗拍的原因是有时候召回的结果还是太多,精排层速度还是跟不上,所以加入粗排。粗排可以理解为精排前的一轮过滤机制,减轻精排模块的压力。粗排介于召回和精排之间,要同时兼顾精准性和低延迟。一般模型也不能过于复杂
|
||||
- 精排:获取粗排模块的结果,对候选集进行打分和排序。精排需要在最大时延允许的情况下,保证打分的精准性,是整个系统中至关重要的一个模块,也是最复杂,研究最多的一个模块。精排系统构建一般需要涉及样本、特征、模型三部分。
|
||||
- 重排:获取精排的排序结果,基于运营策略、多样性、context上下文等,重新进行一个微调。比如三八节对美妆类目商品提权,类目打散、同图打散、同卖家打散等保证用户体验措施。重排中规则比较多,但目前也有不少基于模型来提升重排效果的方案。
|
||||
- 混排:多个业务线都想在Feeds流中获取曝光,则需要对它们的结果进行混排。比如推荐流中插入广告、视频流中插入图文和banner等。可以基于规则策略(如广告定坑)和强化学习来实现。
|
||||
|
||||
### 画像层
|
||||
|
||||
首先是推荐系统的物料库,这部分内容里,算法主要体现在如何绘制一个用户画像和商品画像。这个环节是推荐系统架构的基础设施,一般可能新用户/商品进来,或者每周定期会重新一次整个物料库,计算其中信息,为用户打上标签,计算统计信息,为商品做内容理解等内容。其中用户画像是大家比较容易理解的,比如用户年龄、爱好通常APP会通过注册界面收集这些信息。而商品画像形式就非常多了,比如淘宝主要推荐商品,抖音主要是短视频,所以大家的物料形式比较多,内容、质量差异也比较大,所以内容画像各家的做法也不同,当前比较主流的都会涉及到一个多模态信息内容理解。下面我贴了一个微信看一看的内容画像框架,然后我们来介绍下在这一块主要使用的算法技术。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220410143333692.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
一般推荐系统会加入多模态的一个内容理解。我们用短视频形式举个例子,假设用户拍摄了一条短视频,上传到了平台,从推荐角度看,首先我们有的信息是这条短视频的作者、长度、作者为它选择的标签、时间戳这些信息。但是这对于推荐来说是远远不够的,首先作者打上的标签不一定准确反映作品,原因可能是我们模型的语义空间可能和作者/现实世界不一致。其次我们需要更多维度的特征,比如有些用户喜欢看小姐姐跳舞,那我希望能够判断一条视频中是否有小姐姐,这就涉及到封面图的基于CV的内容抽取或者整个视频的抽取;再比如作品的标题一般能够反映主题信息,除了很多平台常用的用“#”加上一个标签以外,我们也希望能够通过标题抽取出基于NLP的信息。还有更多的维度可以考虑:封面图多维度的多媒体特征体系,包括人脸识别,人脸embedding,标签,一二级分类,视频embedding表示,水印,OCR识别,清晰度,低俗色情,敏感信息等多种维度。
|
||||
|
||||
这里面涉及的任务主要是CV的目标检测、语义分割等任务,NLP中的情感分析、摘要抽取、自然语言理解等任务。但是这部分算法一般团队都会有专门负责的组,不需要推荐算法工程师来负责,他们会有多模态的语意标签输出,主要形式是各种粒度的Embedding。我们只需要在我们的推荐模型中引入这些预训练的Embedding。
|
||||
|
||||
#### 文本理解
|
||||
|
||||
这应该是用的最多的模态信息,包括item的标题、正文、OCR、评论等数据。这里面也可以产生不同粒度的信息,比如文本分类,把整个item做一个粗粒度的分类。
|
||||
|
||||
这里的典型算法有:RNN、TextCNN、FastText、Bert等;
|
||||
|
||||
#### 关键词标签
|
||||
|
||||
相比文本分类,关键词是更细粒度的信息,往往是一个mutil-hot的形式,它会对item在我们的标签库的选取最合适的关键词或者标签。
|
||||
|
||||
这里典型的算法有:TF-IDF、Bert、LSTM-CRF等。
|
||||
|
||||
#### 内容理解
|
||||
|
||||
在很多场景下,推荐的主题都是视频或者图片,远远多于仅推荐文本的情况,这里视频/图片item中的内容中除了文本的内容以外,更多的信息其实来源于视频/图片内容本身, 因此需要尝试从多种模态中抽取更丰富的信息。主要包括分类信息、封面图OCR的信息、视频标签信息等
|
||||
|
||||
这里典型的算法有:TSN、RetinaFace、PSENet等。
|
||||
|
||||
#### 知识图谱
|
||||
|
||||
知识图谱作为知识承载系统,用于对接内外部关键词信息与词关系信息;内容画像会将原关系信息整合,并构建可业务应用的关系知识体系,其次,依赖业务中积累用户行为产生的实体关系数据,本身用户需求的标签信息,一并用于构建业务知识的兴趣图谱,基于同构网络与异构网络表示学习等核心模型,输出知识表示与表达,抽象后的图谱用于文本识别,推荐语义理解,兴趣拓展推理等场景,直接用于兴趣推理的冷启场景已经验证有很不错的收益。
|
||||
|
||||
这方面的算法有:KGAT、RippleNet等。
|
||||
|
||||
### 召回/粗排
|
||||
|
||||
推荐系统的召回阶段可以理解为根据用户的历史行为数据,为用户在海量的信息中粗选一批待推荐的内容,挑选出一个小的候选集的过程。粗排用到的很多技术与召回重合,所以放在一起讲,粗排也不是必需的环节,它的功能对召回的结果进行个粗略的排序,在保证一定精准的前提下,进一步减少往后传送的物品数量,这就是粗排的作用。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220410000221817.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
召回模块面对几百上千万的推荐池物料规模,候选集十分庞大。由于后续有排序模块作为保障,故不需要十分准确,但必须保证不要遗漏和低延迟。目前主要通过多路召回来实现,一方面各路可以并行计算,另一方面取长补短。可以看到各类同类竞品的系统虽然细节上多少存在差异,但不约而同的采取了多路召回的架构,这类设计考虑如下几点问题:
|
||||
|
||||
1. **考虑用户层面**:用户兴趣的多元化,用户需求与场景的多元化:例如:新闻需求,重大要闻,相关内容沉浸阅读等等
|
||||
|
||||
2. **考虑系统层面**:增强系统的鲁棒性;部分召回失效,其余召回队列兜底不会导致整个召回层失效;排序层失效,召回队列兜底不会导致整个推荐系统失效
|
||||
|
||||
3. **系统多样性内容分发**:图文、视频、小视频;精准、试探、时效一定比例;召回目标的多元化,例如:相关性,沉浸时长,时效性,特色内容等等
|
||||
|
||||
4. **可解释性推荐一部分召回是有明确推荐理由的**:很好的解决产品性数据的引入;
|
||||
|
||||
介绍了召回任务的目的和场景后,接下来分析召回层面主要的技术栈,因为召回一般都是多路召回,从模型角度分析有很多召回算法,这种一般是在召回层占大部分比例点召回,除此之外,还会有探索类召回、策略运营类召回、社交类召回等。接下来我们着重介绍模型类召回。
|
||||
|
||||
#### 经典模型召回
|
||||
|
||||
随着技术发展,在Embedding基础上的模型化召回是一个技术发展潮流方向。这种召回的范式是通过某种算法,对user和item分别打上Embedding,然后user与item在线进行KNN计算实时查询最近领结果作为召回结果,快速找出匹配的物品。需要注意的是如果召回采用模型召回方法,优化目标最好和排序的优化目标一致,否则可能被过滤掉。
|
||||
|
||||
在这方面典型的算法有:FM、双塔DSSM、Multi-View DNN等。
|
||||
|
||||
#### 序列模型召回
|
||||
|
||||
推荐系统主要解决的是基于用户的隐式阅读行为来做个性化推荐的问题,序列模型一些基于神经网络模型学习得到Word2Vec模型,再后面的基于RNN的语言模型,最先用的最多的Bert,这些方法都可以应用到召回的学习中。
|
||||
|
||||
用户在使用 APP 或者网站的时候,一般会产生一些针对物品的行为,比如点击一些感兴趣的物品,收藏或者互动行为,或者是购买商品等。而一般用户之所以会对物品发生行为,往往意味着这些物品是符合用户兴趣的,而不同类型的行为,可能代表了不同程度的兴趣。比如购买就是比点击更能表征用户兴趣的行为。在召回阶段,如何根据用户行为序列打 embedding,可以采取有监督的模型,比如 Next Item Prediction 的预测方式即可;也可以采用无监督的方式,比如物品只要能打出 embedding,就能无监督集成用户行为序列内容,例如 Sum Pooling。
|
||||
|
||||
这方面典型的算法有:CBOW、Skip-Gram、GRU、Bert等。
|
||||
|
||||
#### 用户序列拆分
|
||||
|
||||
上文讲了利用用户行为物品序列,打出用户兴趣 Embedding 的做法。但是,另外一个现实是:用户往往是多兴趣的,比如可能同时对娱乐、体育、收藏感兴趣。这些不同的兴趣也能从用户行为序列的物品构成上看出来,比如行为序列中大部分是娱乐类,一部分体育类,少部分收藏类等。那么能否把用户行为序列物品中,这种不同类型的用户兴趣细分,而不是都笼统地打到一个用户兴趣 Embedding 里呢?用户多兴趣拆分就是解决这类更细致刻画用户兴趣的方向。
|
||||
|
||||
本质上,把用户行为序列打到多个 embedding 上,实际它是个类似聚类的过程,就是把不同的 Item,聚类到不同的兴趣类别里去。目前常用的拆分用户兴趣 embedding 的方法,主要是胶囊网络和 Memory Network,但是理论上,很多类似聚类的方法应该都是有效的,所以完全可以在这块替换成你自己的能产生聚类效果的方法来做。
|
||||
|
||||
这方面典型的算法有:Multi-Interest Network with Dynamic Routing for Recommendation at Tmall等。
|
||||
|
||||
#### 知识图谱
|
||||
|
||||
知识图谱有一个独有的优势和价值,那就是对于推荐结果的可解释性;比如推荐给用户某个物品,可以在知识图谱里通过物品的关键关联路径给出合理解释,这对于推荐结果的解释性来说是很好的,因为知识图谱说到底是人编码出来让自己容易理解的一套知识体系,所以人非常容易理解其间的关系。知识图谱的可解释性往往是和图路径方法关联在一起的,而 Path 类方法,很多实验证明了,在排序角度来看,是效果最差的一类方法,但是它在可解释性方面有很好的效果,所以往往可以利用知识图谱构建一条可解释性的召回通路。
|
||||
|
||||
这方面的算法有:KGAT、RippleNet等。
|
||||
|
||||
#### 图模型
|
||||
|
||||
推荐系统中User和Item相关的行为、需求、属性和社交信息具有天然的图结构,可以使用一张复杂的异构图来表示整个推荐系统。图神经网络模型推荐就是基于这个想法,把异构网络中包含的结构和语义信息编码到结点Embedding表示中,并使用得到向量进行个性化推荐。知识图谱其实是图神经网络的一个比较特殊的具体实例,但是,知识图谱因为编码的是静态知识,而不是用户比较直接的行为数据,和具体应用距离比较远,这可能是导致两者在推荐领域表现有差异的主要原因。
|
||||
|
||||
这方面典型的算法有:GraphSAGE、PinSage等。
|
||||
|
||||
### 精排
|
||||
|
||||
排序模型是推荐系统中涵盖的研究方向最多,有非常多的子领域值得研究探索,这也是推荐系统中技术含量最高的部分,毕竟它是直接面对用户,产生的结果对用户影响最大的一层。目前精排层深度学习已经一统天下了,这是王喆老师《深度学习推荐算法》书中的精排层模型演化线路。具体来看分为DNN、Wide&Deep两大块,实际深入还有序列建模,以及没有提到的多任务建模都是工业界非常常用的,所以我们接下来具体谈论其中每一块的技术栈。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220410234144149.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
#### 特征交叉模型
|
||||
|
||||
在深度学习推荐算法发展早期,很多论文聚焦于如何提升模型的特征组合和交叉的能力,这其中既包含隐式特征交叉Deep Crossing也有采用显式特征交叉的探究。本质上是希望模型能够摆脱人工先验的特征工程,实现端到端的一套模型。
|
||||
|
||||
在早期的推荐系统中,基本是由人工进行特征交叉的,往往凭借对业务的理解和经验,但是费时费力。于是有了很多的这方面的研究,从FM到GBDT+LR都是引入模型进行自动化的特征交叉。再往后就是深度模型,深度模型虽然有万能近似定理,但是真正想要发挥模型的潜力,显式的特征交叉还是必不可少的。
|
||||
|
||||
这方面的经典研究工作有:DCN、DeepFM、xDeepFM等;
|
||||
|
||||
#### 序列模型
|
||||
|
||||
在推荐系统中,历史行为序列是非常重要的特征。在序列建模中,主要任务目标是得到用户此刻的兴趣向量(user interest vector)。如何刻画用户兴趣的广泛性,是推荐系统比较大的一个难点,用户历史行为序列建模的研究经历了从Pooling、RNN到attention、capsule再到transformer的顺序。在序列模型中,又有很多细分的方向,比如根据用户行为长度有研究用户终身行为序列的,也有聚焦当下兴趣的,还有研究如何抽取序列特征的抽取器,比如研究attention还是胶囊网络。
|
||||
|
||||
这方面典型的研究工作有:DIN、DSIN、DIEN、SIM等;
|
||||
|
||||
#### 多模态信息融合
|
||||
|
||||
在上文我们提到算法团队往往会利用内容画像信息,既有基于CV也有基于NLP抽取出来的信息。这是非常合理的,我们在逛抖音、淘宝的时候关注的不仅仅item的价格、品牌,同样会关注封面小姐姐好不好看、标题够不够震惊等信息。除此之外,在冷启动场景下,我们能够利用等信息不够多,如果能够使用多模态信息,能很大程度上解决数据稀疏的问题。
|
||||
|
||||
传统做法在多模态信息融合就是希望把不同模态信息利用起来,通过Embedding技术融合进模型。在推荐领域,主流的做法还是一套非端到端的体系,由其他模型抽取出多模态信息,推荐只需要融合入这些信息就好了。同时也有其他工作是利用注意力机制等方法来学习不同模态之间的关联,来增强多模态的表示。
|
||||
|
||||
比较典型的工作有:Image Matters: Visually modeling user behaviors using Advanced Model Server、UMPR等。
|
||||
|
||||
#### 多任务学习
|
||||
|
||||
很多场景下我们模型优化的目标都是CTR,有一些场景只考虑CTR是不够的,点击率模型、时长模型和完播率模型是大部分信息流产品推荐算法团队都会尝试去做的模型。单独优化点击率模型容易推出来标题党,单独优化时长模型可能推出来的都是长视频或长文章,单独优化完播率模型可能短视频短图文就容易被推出来,所以多目标就应运而生。信息流推荐中,我们不仅希望用户点进我们的item,还希望能有一个不错的完播率,即希望用户能看完我们推荐的商品。或者电商场景希望用户不仅点进来,还希望他买下或者加入购物车了。这些概率实际上就是模型要学习的目标,多种目标综合起来,包括阅读、点赞、收藏、分享等等一系列的行为,归纳到一个模型里面进行学习,这就是推荐系统的多目标学习。
|
||||
|
||||
这方面比较典型的算法有:ESSM、MMoE、DUPN等。
|
||||
|
||||
#### 强化学习
|
||||
|
||||
强化学习与一般有监督的深度学习相比有一些很显著的优势,首先强化学习能够比较灵活的定义优化的业务目标,考虑推荐系统长短期的收益,比如用户留存,在深度模型下,我们很难设计这个指标的优化函数,而强化学习是可以对长期收益下来建模。第二是能够体现用户兴趣的动态变化,比如在新闻推荐下,用户兴趣变化很快,强化学习更容易通过用户行为动态产生推荐结果。最后是EE也就是利用探索机制,这种一种当前和长期收益的权衡,强化学习能够更好的调节这里的回报。
|
||||
|
||||
这方面比较典型的算法有:DQN、Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology;
|
||||
|
||||
#### 跨域推荐
|
||||
|
||||
一般一家公司业务线都是非常多的,比如腾讯既有腾讯视频,也有微信看一看、视频号,还有腾讯音乐,如果能够结合这几个场景的数据,同时进行推荐,一方面对于冷启动是非常有利的,另一方面也能补充更多数据,更好的进行精确推荐。
|
||||
|
||||
跨域推荐系统相比一般的推荐系统要更加复杂。在传统推荐系统中,我们只需要考虑建立当前领域内的一个推荐模型进行分析;而在跨域推荐中,我们更要关心在不同领域间要选择何种信息进行迁移,以及如何迁移这些信息,这是跨域推荐系统中非常关键的问题。
|
||||
|
||||
这方面典型的模型有:DTCDR、MV-DNN、EMCDR等;
|
||||
|
||||
### 重排序
|
||||
|
||||
我们知道常见的有三种优化目标:Point Wise、Pair Wise 和 List Wise。重排序阶段对精排生成的Top-N个物品的序列进行重新排序,生成一个Top-K个物品的序列,作为排序系统最后的结果,直接展现给用户。重排序的原因是因为多个物品之间往往是相互影响的,而精排序是根据PointWise得分,容易造成推荐结果同质化严重,有很多冗余信息。而重排序面对的挑战就是海量状态空间如何求解的问题,一般在精排层我们使用AUC作为指标,但是在重排序更多关注NDCG等指标。
|
||||
|
||||
重排序在业务中,还会根据一些策略、运营规则参与排序,比如强制去重、间隔排序、流量扶持等,但是总计趋势上看还是算法排序越来越占据主流趋势。重排序更多的是List Wise作为优化目标的,它关注的是列表中商品顺序的问题来优化模型,但是一般List Wise因为状态空间大,存在训练速度慢的问题。这方面典型的做法,基于RNN、Transformer、强化学习的都有,这方面因为不是推荐的一个核心,所以没有展开来讲,而且这一块比较依赖实际的业务场景。
|
||||
|
||||
这里的经典算法有:MRR、DPP、RNN等;
|
||||
|
||||
## 工程
|
||||
|
||||
推荐系统的实现需要依托工程,很多研究界Paper的idea满天飞,却忽视了工业界能否落地,进入工业界我们很难或者很少有组是做纯research的,所以我们同样有很多工程技术需要掌握。下面列举了在推荐中主要用到的工程技术:
|
||||
|
||||
- **编程语言**:Python、Java(scala)、C++、sql、shell;
|
||||
- **机器学习**:Tensorflow/Pytorch、GraphLab/GraphCHI、LGB/Xgboost、SKLearn;
|
||||
- **数据分析**:Pandas、Numpy、Seaborn、Spark;
|
||||
- 数据存储:mysql、redis、mangodb、hive、kafka、es、hbase;
|
||||
- 相似计算:annoy、faiss、kgraph
|
||||
- 流计算:Spark Streaming、Flink
|
||||
- 分布式:Hadoop、Spark
|
||||
|
||||
上面那么多技术,我内容最重要的就是加粗的三部分,第一是语言:必须掌握的是Python,C++和JAVA中根据不同的组使用的是不同的语言,这个如果没有时间可以等进组后慢慢学习。然后是机器学习框架:Tensorflow和Pytorch至少要掌握一个吧,前期不用纠结学哪个,这个迁移成本很低,基本能够达到触类旁通,而且面试官不会为难你只会这个不会那个。最后是数据分析工具:Pandas是我们处理单机规模数据的利器,但是进入工业界,Hadoop和Spark是需要会用的,不过不用学太深,会用即可。
|
||||
|
||||
## 总结
|
||||
|
||||
本文从算法和工程两个角度分析了推荐系统的一个技术栈,但是还有很多方向遗漏,也有很多方向受限于现在的技术水平深度不够和有错误的情况,后续会不断补充和更正。
|
||||
|
||||
所以技术栈我列出的是一个非常广度的技术,实际上每一个技术钻研下去都需要非常多时间,而且不一定是你实际工作中会遇到的,所以不要被那么多技术吓到,也要避免陷入技术细节的海洋中。
|
||||
|
||||
我和非常多的大厂面试官讨论过技术深度和广度的问题,得出来的结论是对于入门的推荐算法工程师而言,实际上深度和广度的要求取决于你要去的组,有些组有很深的推荐技术沉淀,有很强的工程师团队,这样的组就会希望候选者能够在某个方面有比较深入的研究,这个方面既包含工程方面也包含研究方面。但是如果是比较新的组、或者技术沉淀不深、推荐不是主要任务的组,对深度要求就不会很高。总而言之,我认为对于应届生/实习生来说,在推荐最重要的工程技术/研究方向,至少在召回和排序模块,需要选一个作为方向,是需要较深钻研。对于其他技术/研究方向需要有一定了解,比如可以没用过强化学习,但是要知道强化学习能够在推荐中解决什么问题,剩下的可以等到真实**遇到需要后再去学习**。
|
||||
|
||||
|
||||
|
||||
**参考资料**
|
||||
|
||||
- [万字入门推荐系统](https://mp.weixin.qq.com/s/aaOosZ57qJpIU6cma820Xw)
|
||||
- [张俊林:技术演进趋势:召回->排序->重排](https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247496363&idx=1&sn=0d2b2ac176e2a72eb2e760b7b591788f&chksm=fbd740c7cca0c9d16c76fdeb1a874a53f7408d8125b2e1bed3173ecb69d131167c1c9c35c71f&scene=21#wechat_redirect)
|
||||
- [微信"看一看"多模型内容策略与召回](https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247503484&idx=2&sn=e2a2cdd3a517ab09e903e69ccb1e9f94&chksm=fbd77c10cca0f50642dde47439ed919aa2e61b7ff57bc4cbaacc3acaac3c620a1ed6f92684ab&scene=21#wechat_redirect)
|
||||
- [多目标学习在推荐系统中的应用](https://mp.weixin.qq.com/s/u_5RdZ-BcIu_RoWNri76ig)
|
||||
- [强化学习在美团“猜你喜欢”的实践](https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749434&idx=2&sn=343e811408542dd1984582b8639240a6&chksm=bd12a5778a652c61ed4297f1a17582cad4ca6b8e8d4d66843f169e0eda9f6aede988bc675743&mpshare=1&scene=23&srcid=1115EcgbMw6GAhMnzV0URvgd#rd)
|
||||
- [推荐系统技术演进趋势:重排篇](https://mp.weixin.qq.com/s/YorzRyK0iplzqutnhEhrvw)
|
||||
- [阿里强化学习重排实践](https://mp.weixin.qq.com/s/ylavFA_MXLUhIBLCqxAjLQ)
|
||||
@@ -1,288 +0,0 @@
|
||||
# Swing(Graph-based)
|
||||
## 动机
|
||||
大规模推荐系统需要实时对用户行为做出海量预测,为了保证这种实时性,大规模的推荐系统通常严重依赖于预先计算好的产品索引。产品索引的功能为:给定种子产品返回排序后的候选相关产品列表。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2relations.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
|
||||
相关性产品索引主要包含两部分:替代性产品和互补性产品。例如图中的不同种类的衬衫构成了替代关系,而衬衫和风衣裤子等构成了互补关系。用户通常希望在完成购买行为之前尽可能看更多的衬衫,而用户购买过衬衫之后更希望看到与之搭配的单品而不是其他衬衫了。
|
||||
|
||||
## 之前方法局限性
|
||||
- 基于 Cosine, Jaccard, 皮尔逊相关性等相似度计算的协同过滤算法,在计算邻居关联强度的时候只关注于 Item-based (常用,因为item相比于用户变化的慢,且新Item特征比较容易获得),Item-based CF 只关注于 Item-User-Item 的路径,把所有的User-Item交互都平等得看待,从而忽视了 User-Item 交互中的大量噪声,推荐精度存在局限性。
|
||||
- 对互补性产品的建模不足,可能会导致用户购买过手机之后还继续推荐手机,但用户短时间内不会再继续购买手机,因此产生无效曝光。
|
||||
|
||||
## 贡献
|
||||
提出了高效建立产品索引图的技术。
|
||||
主要包括:
|
||||
- Swing 算法利用 user-item 二部图的子结构捕获产品间的替代关系。
|
||||
- Surprise 算法利用商品分类信息和用户共同购买图上的聚类技术来建模产品之间的组合关系。
|
||||
|
||||
## Swing算法
|
||||
Swing 通过利用 User-Item-User 路径中所包含的信息,考虑 User-Item 二部图中的鲁棒内部子结构计算相似性。
|
||||
- 什么是内部子结构?
|
||||
以经典的啤酒尿布故事为例,张三同时购买了啤酒和尿布,这可能是一种巧合。但两个甚至多个顾客都同时购买了啤酒尿布,这就证明啤酒和尿布具有相关关系。这样共同购买啤酒和尿布的用户越多,啤酒和尿布的相关度就会越高。
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片example_of_swing.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
图中的红色四边形就是一种Swing子结构,这种子结构可以作为给王五推荐尿布的依据。
|
||||
|
||||
- 通俗解释:若用户 $u$ 和用户 $v$ 之间除了购买过 $i$ 外,还购买过商品 $j$ ,则认为两件商品是具有某种程度上的相似的。也就是说,商品与商品之间的相似关系,是通过用户关系来传递的。为了衡量物品 $i$ 和 $j$ 的相似性,比较同时购买了物品 $i$ 和 $j$ 的用户 $u$ 和用户 $v$, 如果这两个用户共同购买的物品越少,即这两个用户原始兴趣不相似,但仍同时购买了两个相同的物品 $i$ 和 $j$, 则物品 $i$ 和 $j$ 的相似性越高。
|
||||
|
||||
- 计算公式
|
||||
|
||||
$$s(i,j)=\sum\limits_{u\in U_i\cap U_j} \sum\limits_{v \in U_i\cap U_j}w_u*w_v* \frac{1}{\alpha+|I_u \cap I_v|}$$
|
||||
|
||||
其中$U_i$ 是点击过商品i的用户集合,$I_u$ 是用户u点击过的商品集合,$\alpha$是平滑系数。
|
||||
|
||||
$w_u=\frac{1}{\sqrt{|I_u|}},w_v=\frac{1}{\sqrt{|I_v|}}$ 是用户权重参数,来降低活跃用户的影响。
|
||||
|
||||
- 代码实现
|
||||
- Python (建议自行debug方便理解)
|
||||
```python
|
||||
from itertools import combinations
|
||||
import pandas as pd
|
||||
alpha = 0.5
|
||||
top_k = 20
|
||||
def load_data(train_path):
|
||||
train_data = pd.read_csv(train_path, sep="\t", engine="python", names=["userid", "itemid", "rate"])#提取用户交互记录数据
|
||||
print(train_data.head(3))
|
||||
return train_data
|
||||
|
||||
def get_uitems_iusers(train):
|
||||
u_items = dict()
|
||||
i_users = dict()
|
||||
for index, row in train.iterrows():#处理用户交互记录
|
||||
u_items.setdefault(row["userid"], set())
|
||||
i_users.setdefault(row["itemid"], set())
|
||||
u_items[row["userid"]].add(row["itemid"])#得到user交互过的所有item
|
||||
i_users[row["itemid"]].add(row["userid"])#得到item交互过的所有user
|
||||
print("使用的用户个数为:{}".format(len(u_items)))
|
||||
print("使用的item个数为:{}".format(len(i_users)))
|
||||
return u_items, i_users
|
||||
|
||||
def swing_model(u_items, i_users):
|
||||
# print([i for i in i_users.values()][:5])
|
||||
# print([i for i in u_items.values()][:5])
|
||||
item_pairs = list(combinations(i_users.keys(), 2)) #全排列组合对
|
||||
print("item pairs length:{}".format(len(item_pairs)))
|
||||
item_sim_dict = dict()
|
||||
for (i, j) in item_pairs:
|
||||
user_pairs = list(combinations(i_users[i] & i_users[j], 2)) #item_i和item_j对应的user取交集后全排列 得到user对
|
||||
result = 0
|
||||
for (u, v) in user_pairs:
|
||||
result += 1 / (alpha + list(u_items[u] & u_items[v]).__len__()) #分数公式
|
||||
if result != 0 :
|
||||
item_sim_dict.setdefault(i, dict())
|
||||
item_sim_dict[i][j] = format(result, '.6f')
|
||||
return item_sim_dict
|
||||
|
||||
def save_item_sims(item_sim_dict, top_k, path):
|
||||
new_item_sim_dict = dict()
|
||||
try:
|
||||
writer = open(path, 'w', encoding='utf-8')
|
||||
for item, sim_items in item_sim_dict.items():
|
||||
new_item_sim_dict.setdefault(item, dict())
|
||||
new_item_sim_dict[item] = dict(sorted(sim_items.items(), key = lambda k:k[1], reverse=True)[:top_k])#排序取出 top_k个相似的item
|
||||
writer.write('item_id:%d\t%s\n' % (item, new_item_sim_dict[item]))
|
||||
print("SUCCESS: top_{} item saved".format(top_k))
|
||||
except Exception as e:
|
||||
print(e.args)
|
||||
|
||||
if __name__ == "__main__":
|
||||
train_data_path = "./ratings_final.txt"
|
||||
item_sim_save_path = "./item_sim_dict.txt"
|
||||
top_k = 10 #与item相似的前 k 个item
|
||||
train = load_data(train_data_path)
|
||||
u_items, i_users = get_uitems_iusers(train)
|
||||
item_sim_dict = swing_model(u_items, i_users)
|
||||
save_item_sims(item_sim_dict, top_k, item_sim_save_path)
|
||||
```
|
||||
|
||||
- Spark(仅为核心代码需要补全配置才能跑通)
|
||||
```scala
|
||||
object Swing {
|
||||
|
||||
def main(args: Array[String]): Unit = {
|
||||
val spark = SparkSession.builder()
|
||||
.appName("test")
|
||||
.master("local[2]")
|
||||
.getOrCreate()
|
||||
val alpha = 1 //分数计算参数
|
||||
val filter_n_items = 10000 //想要计算的item数量 测试的时候取少点
|
||||
val top_n_items = 500 //保存item的score排序前500个相似的item
|
||||
val model = new SwingModel(spark)
|
||||
.setAlpha(alpha.toDouble)
|
||||
.setFilter_N_Items(filter_n_items.toInt)
|
||||
.setTop_N_Items(top_n_items.toInt)
|
||||
val url = "file:///usr/local/var/scala/common/part-00022-e17c0014.snappy.parquet"
|
||||
val ratings = DataLoader.getRatingLog(spark, url)
|
||||
val df = model.fit(ratings).item2item()
|
||||
df.show(3,false)
|
||||
// df.write.mode("overwrite").parquet(dest_url)
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
```scala
|
||||
/**
|
||||
* swing
|
||||
* @param ratings 打分dataset
|
||||
* @return
|
||||
*/
|
||||
def fit(ratings: Dataset[Rating]): SwingModel = {
|
||||
|
||||
def interWithAlpha = udf(
|
||||
(array_1: Seq[GenericRowWithSchema],
|
||||
array_2: Seq[GenericRowWithSchema]) => {
|
||||
var score = 0.0
|
||||
val u_set_1 = array_1.toSet
|
||||
val u_set_2 = array_2.toSet
|
||||
val user_set = u_set_1.intersect(u_set_2).toArray //取交集得到两个item共同user
|
||||
|
||||
for (i <- user_set.indices; j <- i + 1 until user_set.length) {
|
||||
val user_1 = user_set(i)
|
||||
val user_2 = user_set(j)
|
||||
val item_set_1 = user_1.getAs[Seq[String]]("_2").toSet
|
||||
val item_set_2 = user_2.getAs[Seq[String]]("_2").toSet
|
||||
score = score + 1 / (item_set_1
|
||||
.intersect(item_set_2)
|
||||
.size
|
||||
.toDouble + alpha.get)
|
||||
}
|
||||
score
|
||||
}
|
||||
)
|
||||
val df = ratings.repartition(defaultParallelism).cache()
|
||||
|
||||
val groupUsers = df
|
||||
.groupBy("user_id")
|
||||
.agg(collect_set("item_id")) //聚合itme_id
|
||||
.toDF("user_id", "item_set")
|
||||
.repartition(defaultParallelism)
|
||||
println("groupUsers")
|
||||
groupUsers.show(3, false)//user_id|[item_id_set]: 422|[6117,611,6117]
|
||||
|
||||
val groupItems = df
|
||||
.join(groupUsers, "user_id")
|
||||
.rdd
|
||||
.map { x =>
|
||||
val item_id = x.getAs[String]("item_id")
|
||||
val user_id = x.getAs[String]("user_id")
|
||||
val item_set = x.getAs[Seq[String]]("item_set")
|
||||
(item_id, (user_id, item_set))
|
||||
}//i_[user(item_set)]
|
||||
.toDF("item_id", "user")
|
||||
.groupBy("item_id")
|
||||
.agg(collect_set("user"), count("item_id"))
|
||||
.toDF("item_id", "user_set", "count")
|
||||
.filter("size(user_set) > 1")//过滤掉没有交互的
|
||||
.sort($"count".desc) //根据count倒排item_id数量
|
||||
.limit(filter_n_items.get)//item可能百万级别但后面召回的需求量小所以只取前n个item进行计算
|
||||
.drop("count")
|
||||
.repartition(defaultParallelism)
|
||||
.cache()
|
||||
println("groupItems") //得到与itme_id有交互的user_id
|
||||
groupItems.show(3, false)//item_id|[[user_id,[item_set]],[user_id,[item_set]]]: 67|[[562,[66, 813, 61, 67]],[563,[67, 833, 62, 64]]]
|
||||
|
||||
val itemJoined = groupItems
|
||||
.join(broadcast(groupItems))//内连接两个item列表
|
||||
.toDF("item_id_1", "user_set_1", "item_id_2", "user_set_2")
|
||||
.filter("item_id_1 > item_id_2")//内连接 item两两配对
|
||||
.withColumn("score", interWithAlpha(col("user_set_1"), col("user_set_2")))//将上面得到的与item相关的user_set输入到函数interWithAlpha计算分数
|
||||
.select("item_id_1", "item_id_2", "score")
|
||||
.filter("score > 0")
|
||||
.repartition(defaultParallelism)
|
||||
.cache()
|
||||
println("itemJoined")
|
||||
itemJoined.show(5)//得到两两item之间的分数结果 item_id_1 item_id_2 score
|
||||
similarities = Option(itemJoined)
|
||||
this
|
||||
}
|
||||
|
||||
/**
|
||||
* 从fit结果,对item_id进行聚合并排序,每个item后截取n个item,并返回。
|
||||
* @param num 取n个item
|
||||
* @return
|
||||
*/
|
||||
def item2item(): DataFrame = {
|
||||
|
||||
case class itemWithScore(item_id: String, score: Double)
|
||||
val sim = similarities.get.select("item_id_1", "item_id_2", "score")
|
||||
val topN = sim
|
||||
.map { x =>
|
||||
val item_id_1 = x.getAs[String]("item_id_1")
|
||||
val item_id_2 = x.getAs[String]("item_id_2")
|
||||
val score = x.getAs[Double]("score")
|
||||
(item_id_1, (item_id_2, score))
|
||||
}
|
||||
.toDF("item_id", "itemWithScore")
|
||||
.groupBy("item_id")
|
||||
.agg(collect_set("itemWithScore"))
|
||||
.toDF("item_id", "item_set")//item_id |[[item_id1:score],[item_id2:score]]
|
||||
.rdd
|
||||
.map { x =>
|
||||
val item_id_1 = x.getAs[String]("item_id")
|
||||
val item_set = x //对itme_set中score进行排序操作
|
||||
.getAs[Seq[GenericRowWithSchema]]("item_set")
|
||||
.map { x =>
|
||||
val item_id_2 = x.getAs[String]("_1")
|
||||
val score = x.getAs[Double]("_2")
|
||||
(item_id_2, score)
|
||||
}
|
||||
.sortBy(-_._2)//根据score进行排序
|
||||
.take(top_n_items.get)//取top_n
|
||||
.map(x => x._1 + ":" + x._2.toString)
|
||||
(item_id_1, item_set)
|
||||
}
|
||||
.filter(_._2.nonEmpty)
|
||||
.toDF("id", "sorted_items")
|
||||
topN
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Surprise算法
|
||||
首先在行为相关性中引入连续时间衰减因子,然后引入基于交互数据的聚类方法解决数据稀疏的问题,旨在帮助用户找到互补商品。互补相关性主要从三个层面考虑,类别层面,商品层面和聚类层面。
|
||||
|
||||
- 类别层面
|
||||
首先通过商品和类别的映射关系,我们可以得到 user-category 矩阵。随后使用简单的相关性度量可以计算出类别 $i,j$ 的相关性。
|
||||
|
||||
$\theta_{i,j}=p(c_{i,j}|c_j)=\frac{N(c_{i,j})}{N(c_j)}$
|
||||
|
||||
即,$N(c_{i,j})$为在购买过i之后购买j类的数量,$N(c_{j})$为购买j类的数量。
|
||||
|
||||
由于类别直接的种类差异,每个类别的相关类数量存在差异,因此采用最大相对落点来作为划分阈值。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片max_drop.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
|
||||
例如图(a)中T恤的相关类选择前八个,图(b)中手机的相关类选择前三个。
|
||||
|
||||
- 商品层面
|
||||
商品层面的相关性挖掘主要有两个关键设计:
|
||||
- 商品的购买顺序是需要被考虑的,例如在用户购买手机后推荐充电宝是合理的,但在用户购买充电宝后推荐手机是不合理的。
|
||||
- 两个商品购买的时间间隔也是需要被考虑的,时间间隔越短越能证明两个商品的互补关系。
|
||||
|
||||
最终商品层面的互补相关性被定义为:
|
||||
|
||||
$s_{1}(i, j)=\frac{\sum_{u \in U_{i} \cap U_{j}} 1 /\left(1+\left|t_{u i}-t_{u j}\right|\right)}{\left\|U_{i}\right\| \times\left\|U_{j}\right\|}$,其中$j$属于$i$的相关类,且$j$ 的购买时间晚于$i$。
|
||||
|
||||
- 聚类层面
|
||||
- 如何聚类?
|
||||
传统的聚类算法(基于密度和 k-means )在数十亿产品规模下的淘宝场景中不可行,所以作者采用了标签传播算法。
|
||||
- 在哪里标签传播?
|
||||
Item-item 图,其中又 Swing 计算的排名靠前 item 为邻居,边的权重就是 Swing 分数。
|
||||
- 表现如何?
|
||||
快速而有效,15分钟即可对数十亿个项目进行聚类。
|
||||
最终聚类层面的相关度计算同上面商品层面的计算公式
|
||||
|
||||
- 线性组合:
|
||||
$s(i, j)=\omega * s_{1}(i, j)+(1-\omega) * s_{2}(i, j)$,其中$\omega=0.8$是作者设置的权重超参数。
|
||||
Surprise算法通过利用类别信息和标签传播技术解决了用户共同购买图上的稀疏性问题。
|
||||
|
||||
**参考资料**
|
||||
- [Large Scale Product Graph Construction for Recommendation in E-commerce](https://arxiv.org/pdf/2010.05525)
|
||||
- [推荐召回-Swing](https://zhuanlan.zhihu.com/p/383346471)
|
||||
@@ -1,263 +0,0 @@
|
||||
# 基于物品的协同过滤
|
||||
|
||||
## 基本思想
|
||||
|
||||
基于物品的协同过滤(ItemCF):
|
||||
|
||||
+ 预先根据所有用户的历史行为数据,计算物品之间的相似性。
|
||||
+ 然后,把与用户喜欢的物品相类似的物品推荐给用户。
|
||||
|
||||
举例来说,如果用户 1 喜欢物品 A ,而物品 A 和 C 非常相似,则可以将物品 C 推荐给用户1。ItemCF算法并不利用物品的内容属性计算物品之间的相似度, 主要通过分析用户的行为记录计算物品之间的相似度, 该算法认为, 物品 A 和物品 C 具有很大的相似度是因为喜欢物品 A 的用户极可能喜欢物品 C。
|
||||
|
||||
|
||||
|
||||
## 计算过程
|
||||
|
||||
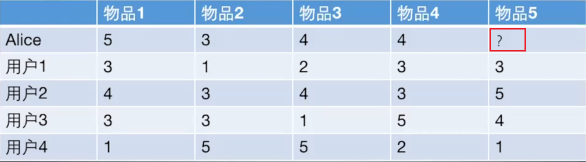
基于物品的协同过滤算法和基于用户的协同过滤算法很像, 所以我们这里直接还是拿上面 Alice 的那个例子来看。
|
||||
|
||||
|
||||
|
||||
如果想知道 Alice 对物品5打多少分, 基于物品的协同过滤算法会这么做:
|
||||
|
||||
+ 首先计算一下物品5和物品1, 2, 3, 4之间的相似性。
|
||||
|
||||
+ 在Alice找出与物品 5 最相近的 n 个物品。
|
||||
|
||||
+ 根据 Alice 对最相近的 n 个物品的打分去计算对物品 5 的打分情况。
|
||||
|
||||
**手动计算:**
|
||||
|
||||
1. 手动计算物品之间的相似度
|
||||
|
||||
>物品向量: $物品 1(3,4,3,1) ,物品2(1,3,3,5) ,物品3(2,4,1,5) ,物品4(3,3,5,2) ,物品5(3,5,41)$
|
||||
>
|
||||
>+ 下面计算物品 5 和物品 1 之间的余弦相似性:
|
||||
> $$
|
||||
> \operatorname{sim}(\text { 物品1, 物品5 })=\operatorname{cosine}(\text { 物品1, 物品5 } )=\frac{9+20+12+1}{\operatorname{sqrt}(9+16+9+1)*\operatorname{sqrt}(9+25+16+1)}
|
||||
> $$
|
||||
>
|
||||
>+ 皮尔逊相关系数类似。
|
||||
>
|
||||
|
||||
2. 基于 `sklearn` 计算物品之间的皮尔逊相关系数:
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/JavaJOyFti58um61zPsa.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
|
||||
3. 根据皮尔逊相关系数, 可以找到与物品5最相似的2个物品是 item1 和 item4, 下面基于上面的公式计算最终得分:
|
||||
|
||||
$$
|
||||
P_{Alice, 物品5}=\bar{R}_{物品5}+\frac{\sum_{k=1}^{2}\left(w_{物品5,物品 k}\left(R_{Alice, 物品k}-\bar{R}_{物品k}\right)\right)}{\sum_{k=1}^{2} w_{物品k, 物品5}} \\
|
||||
=\frac{13}{4}+\frac{0.97*(5-3.2)+0.58*(4-3.4)}{0.97+0.58}=4.6
|
||||
$$
|
||||
|
||||
## ItemCF编程实现
|
||||
|
||||
1. 构建物品-用户的评分矩阵
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
|
||||
def loadData():
|
||||
items = {'A': {'Alice': 5.0, 'user1': 3.0, 'user2': 4.0, 'user3': 3.0, 'user4': 1.0},
|
||||
'B': {'Alice': 3.0, 'user1': 1.0, 'user2': 3.0, 'user3': 3.0, 'user4': 5.0},
|
||||
'C': {'Alice': 4.0, 'user1': 2.0, 'user2': 4.0, 'user3': 1.0, 'user4': 5.0},
|
||||
'D': {'Alice': 4.0, 'user1': 3.0, 'user2': 3.0, 'user3': 5.0, 'user4': 2.0},
|
||||
'E': {'user1': 3.0, 'user2': 5.0, 'user3': 4.0, 'user4': 1.0}
|
||||
}
|
||||
return items
|
||||
```
|
||||
|
||||
2. 计算物品间的相似度矩阵
|
||||
|
||||
```python
|
||||
item_data = loadData()
|
||||
|
||||
similarity_matrix = pd.DataFrame(
|
||||
np.identity(len(item_data)),
|
||||
index=item_data.keys(),
|
||||
columns=item_data.keys(),
|
||||
)
|
||||
|
||||
# 遍历每条物品-用户评分数据
|
||||
for i1, users1 in item_data.items():
|
||||
for i2, users2 in item_data.items():
|
||||
if i1 == i2:
|
||||
continue
|
||||
vec1, vec2 = [], []
|
||||
for user, rating1 in users1.items():
|
||||
rating2 = users2.get(user, -1)
|
||||
if rating2 == -1:
|
||||
continue
|
||||
vec1.append(rating1)
|
||||
vec2.append(rating2)
|
||||
similarity_matrix[i1][i2] = np.corrcoef(vec1, vec2)[0][1]
|
||||
|
||||
print(similarity_matrix)
|
||||
```
|
||||
|
||||
```python
|
||||
A B C D E
|
||||
A 1.000000 -0.476731 -0.123091 0.532181 0.969458
|
||||
B -0.476731 1.000000 0.645497 -0.310087 -0.478091
|
||||
C -0.123091 0.645497 1.000000 -0.720577 -0.427618
|
||||
D 0.532181 -0.310087 -0.720577 1.000000 0.581675
|
||||
E 0.969458 -0.478091 -0.427618 0.581675 1.000000
|
||||
```
|
||||
|
||||
3. 从 Alice 购买过的物品中,选出与物品 `E` 最相似的 `num` 件物品。
|
||||
|
||||
```python
|
||||
target_user = ' Alice '
|
||||
target_item = 'E'
|
||||
num = 2
|
||||
|
||||
sim_items = []
|
||||
sim_items_list = similarity_matrix[target_item].sort_values(ascending=False).index.tolist()
|
||||
for item in sim_items_list:
|
||||
# 如果target_user对物品item评分过
|
||||
if target_user in item_data[item]:
|
||||
sim_items.append(item)
|
||||
if len(sim_items) == num:
|
||||
break
|
||||
print(f'与物品{target_item}最相似的{num}个物品为:{sim_items}')
|
||||
```
|
||||
|
||||
```python
|
||||
与物品E最相似的2个物品为:['A', 'D']
|
||||
```
|
||||
|
||||
4. 预测用户 Alice 对物品 `E` 的评分
|
||||
|
||||
```python
|
||||
target_user_mean_rating = np.mean(list(item_data[target_item].values()))
|
||||
weighted_scores = 0.
|
||||
corr_values_sum = 0.
|
||||
|
||||
target_item = 'E'
|
||||
for item in sim_items:
|
||||
corr_value = similarity_matrix[target_item][item]
|
||||
user_mean_rating = np.mean(list(item_data[item].values()))
|
||||
|
||||
weighted_scores += corr_value * (item_data[item][target_user] - user_mean_rating)
|
||||
corr_values_sum += corr_value
|
||||
|
||||
target_item_pred = target_user_mean_rating + weighted_scores / corr_values_sum
|
||||
print(f'用户{target_user}对物品{target_item}的预测评分为:{target_item_pred}')
|
||||
```
|
||||
|
||||
```python
|
||||
用户 Alice 对物品E的预测评分为:4.6
|
||||
```
|
||||
|
||||
# 协同过滤算法的权重改进
|
||||
|
||||
* base 公式
|
||||
$$
|
||||
w_{i j}=\frac{|N(i) \bigcap N(j)|}{|N(i)|}
|
||||
$$
|
||||
|
||||
+ 该公式表示同时喜好物品 $i$ 和物品 $j$ 的用户数,占喜爱物品 $i$ 的比例。
|
||||
+ 缺点:若物品 $j$ 为热门物品,那么它与任何物品的相似度都很高。
|
||||
|
||||
* 对热门物品进行惩罚
|
||||
$$
|
||||
w_{i j}=\frac{|N(i) \cap N(j)|}{\sqrt{|N(i)||N(j)|}}
|
||||
$$
|
||||
|
||||
|
||||
* 根据 base 公式在的问题,对物品 $j$ 进行打压。打压的出发点很简单,就是在分母再除以一个物品 $j$ 被购买的数量。
|
||||
* 此时,若物品 $j$ 为热门物品,那么对应的 $N(j)$ 也会很大,受到的惩罚更多。
|
||||
|
||||
* 控制对热门物品的惩罚力度
|
||||
$$
|
||||
w_{i j}=\frac{|N(i) \cap N(j)|}{|N(i)|^{1-\alpha}|N(j)|^{\alpha}}
|
||||
$$
|
||||
|
||||
* 除了第二点提到的办法,在计算物品之间相似度时可以对热门物品进行惩罚外。
|
||||
* 可以在此基础上,进一步引入参数 $\alpha$ ,这样可以通过控制参数 $\alpha$来决定对热门物品的惩罚力度。
|
||||
|
||||
* 对活跃用户的惩罚
|
||||
|
||||
* 在计算物品之间的相似度时,可以进一步将用户的活跃度考虑进来。
|
||||
$$
|
||||
w_{i j}=\frac{\sum_{\operatorname{\text {u}\in N(i) \cap N(j)}} \frac{1}{\log 1+|N(u)|}}{|N(i)|^{1-\alpha}|N(j)|^{\alpha}}
|
||||
$$
|
||||
|
||||
+ 对于异常活跃的用户,在计算物品之间的相似度时,他的贡献应该小于非活跃用户。
|
||||
|
||||
# 协同过滤算法的问题分析
|
||||
|
||||
协同过滤算法存在的问题之一就是泛化能力弱:
|
||||
|
||||
+ 即协同过滤无法将两个物品相似的信息推广到其他物品的相似性上。
|
||||
+ 导致的问题是**热门物品具有很强的头部效应, 容易跟大量物品产生相似, 而尾部物品由于特征向量稀疏, 导致很少被推荐**。
|
||||
|
||||
比如下面这个例子:
|
||||
|
||||
|
||||
|
||||
+ 左边矩阵中,$A, B, C, D$ 表示的是物品。
|
||||
+ 可以看出,$D $ 是一件热门物品,其与 $A、B、C$ 的相似度比较大。因此,推荐系统更可能将 $D$ 推荐给用过 $A、B、C$ 的用户。
|
||||
+ 但是,推荐系统无法找出 $A,B,C$ 之间相似性的原因是交互数据太稀疏, 缺乏相似性计算的直接数据。
|
||||
|
||||
所以这就是协同过滤的天然缺陷:**推荐系统头部效应明显, 处理稀疏向量的能力弱**。
|
||||
|
||||
为了解决这个问题, 同时增加模型的泛化能力。2006年,**矩阵分解技术(Matrix Factorization, MF**)被提出:
|
||||
|
||||
+ 该方法在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品, 挖掘用户和物品的隐含兴趣和隐含特征。
|
||||
+ 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
|
||||
|
||||
# 课后思考
|
||||
|
||||
1. **什么时候使用UserCF,什么时候使用ItemCF?为什么?**
|
||||
|
||||
> (1)UserCF
|
||||
>
|
||||
> + 由于是基于用户相似度进行推荐, 所以具备更强的社交特性, 这样的特点非常适于**用户少, 物品多, 时效性较强的场合**。
|
||||
>
|
||||
> + 比如新闻推荐场景, 因为新闻本身兴趣点分散, 相比用户对不同新闻的兴趣偏好, 新闻的及时性,热点性往往更加重要, 所以正好适用于发现热点,跟踪热点的趋势。
|
||||
> + 另外还具有推荐新信息的能力, 更有可能发现惊喜, 因为看的是人与人的相似性, 推出来的结果可能更有惊喜,可以发现用户潜在但自己尚未察觉的兴趣爱好。
|
||||
>
|
||||
> (2)ItemCF
|
||||
>
|
||||
> + 这个更适用于兴趣变化较为稳定的应用, 更接近于个性化的推荐, 适合**物品少,用户多,用户兴趣固定持久, 物品更新速度不是太快的场合**。
|
||||
> + 比如推荐艺术品, 音乐, 电影。
|
||||
|
||||
|
||||
|
||||
2.**协同过滤在计算上有什么缺点?有什么比较好的思路可以解决(缓解)?**
|
||||
|
||||
> 该问题答案参考上一小节的**协同过滤算法的问题分析**。
|
||||
|
||||
|
||||
|
||||
**3.上面介绍的相似度计算方法有什么优劣之处?**
|
||||
|
||||
> cosine相似度计算简单方便,一般较为常用。但是,当用户的评分数据存在 bias 时,效果往往不那么好。
|
||||
>
|
||||
> + 简而言之,就是不同用户评分的偏向不同。部分用户可能乐于给予好评,而部分用户习惯给予差评或者乱评分。
|
||||
> + 这个时候,根据cosine 相似度计算出来的推荐结果效果会打折扣。
|
||||
>
|
||||
> 举例来说明,如下图(`X,Y,Z` 表示物品,`d,e,f`表示用户):
|
||||
>
|
||||
> 
|
||||
>
|
||||
> + 如果使用余弦相似度进行计算,用户 d 和 e 之间较为相似。但是实际上,用户 d 和 f 之间应该更加相似。只不过由于 d 倾向于打高分,e 倾向于打低分导致二者之间的余弦相似度更高。
|
||||
> + 这种情况下,可以考虑使用皮尔逊相关系数计算用户之间的相似性关系。
|
||||
|
||||
|
||||
|
||||
4.**协同过滤还存在其他什么缺陷?有什么比较好的思路可以解决(缓解)?**
|
||||
|
||||
> + 协同过滤的优点就是没有使用更多的用户或者物品属性信息,仅利用用户和物品之间的交互信息就能完成推荐,该算法简单高效。
|
||||
> + 但这也是协同过滤算法的一个弊端。由于未使用更丰富的用户和物品特征信息,这也导致协同过滤算法的模型表达能力有限。
|
||||
> + 对于该问题,逻辑回归模型(LR)可以更好地在推荐模型中引入更多特征信息,提高模型的表达能力。
|
||||
|
||||
|
||||
|
||||
# 参考资料
|
||||
|
||||
* [基于用户的协同过滤来构建推荐系统:https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw](https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw)
|
||||
* B站黑马推荐系统实战课程
|
||||
@@ -1,370 +0,0 @@
|
||||
# 隐语义模型与矩阵分解
|
||||
|
||||
协同过滤算法的特点:
|
||||
|
||||
+ 协同过滤算法的特点就是完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息就可以实现推荐,是一个可解释性很强, 非常直观的模型。
|
||||
+ 但是也存在一些问题,处理稀疏矩阵的能力比较弱。
|
||||
|
||||
为了使得协同过滤更好处理稀疏矩阵问题, 增强泛化能力。从协同过滤中衍生出矩阵分解模型(Matrix Factorization, MF)或者叫隐语义模型:
|
||||
|
||||
+ 在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品。
|
||||
+ 通过挖掘用户和物品的隐含兴趣和隐含特征, 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
|
||||
|
||||
|
||||
|
||||
# 隐语义模型
|
||||
|
||||
隐语义模型最早在文本领域被提出,用于找到文本的隐含语义。在2006年, 被用于推荐中, 它的核心思想是通过隐含特征(latent factor)联系用户兴趣和物品(item), 基于用户的行为找出潜在的主题和分类, 然后对物品进行自动聚类,划分到不同类别/主题(用户的兴趣)。
|
||||
|
||||
以项亮老师《推荐系统实践》书中的内容为例:
|
||||
|
||||
>如果我们知道了用户A和用户B两个用户在豆瓣的读书列表, 从他们的阅读列表可以看出,用户A的兴趣涉及侦探小说、科普图书以及一些计算机技术书, 而用户B的兴趣比较集中在数学和机器学习方面。 那么如何给A和B推荐图书呢? 先说说协同过滤算法, 这样好对比不同:
|
||||
>* 对于UserCF,首先需要找到和他们看了同样书的其他用户(兴趣相似的用户),然后给他们推荐那些用户喜欢的其他书。
|
||||
>* 对于ItemCF,需要给他们推荐和他们已经看的书相似的书,比如作者B看了很多关于数据挖掘的书,可以给他推荐机器学习或者模式识别方面的书。
|
||||
>
|
||||
>而如果是隐语义模型的话, 它会先通过一些角度把用户兴趣和这些书归一下类, 当来了用户之后, 首先得到他的兴趣分类, 然后从这个分类中挑选他可能喜欢的书籍。
|
||||
|
||||
隐语义模型和协同过滤的不同主要体现在隐含特征上, 比如书籍的话它的内容, 作者, 年份, 主题等都可以算隐含特征。
|
||||
|
||||
以王喆老师《深度学习推荐系统》中的一个原理图为例,看看是如何通过隐含特征来划分开用户兴趣和物品的。
|
||||
|
||||
<img src="https://img-blog.csdnimg.cn/20200822212051499.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
|
||||
## 音乐评分实例
|
||||
|
||||
假设每个用户都有自己的听歌偏好, 比如用户 A 喜欢带有**小清新的**, **吉他伴奏的**, **王菲**的歌曲,如果一首歌正好**是王菲唱的, 并且是吉他伴奏的小清新**, 那么就可以将这首歌推荐给这个用户。 也就是说是**小清新, 吉他伴奏, 王菲**这些元素连接起了用户和歌曲。
|
||||
|
||||
当然每个用户对不同的元素偏好不同, 每首歌包含的元素也不一样, 所以我们就希望找到下面的两个矩阵:
|
||||
|
||||
1. 潜在因子—— 用户矩阵Q
|
||||
这个矩阵表示不同用户对于不同元素的偏好程度, 1代表很喜欢, 0代表不喜欢, 比如下面这样:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/2020082222025968.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
2. 潜在因子——音乐矩阵P
|
||||
表示每种音乐含有各种元素的成分, 比如下表中, 音乐A是一个偏小清新的音乐, 含有小清新的Latent Factor的成分是0.9, 重口味的成分是0.1, 优雅成分0.2...
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822220751394.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
**计算张三对音乐A的喜爱程度**
|
||||
|
||||
利用上面的这两个矩阵,将对应向量进行内积计算,我们就能得出张三对音乐A的喜欢程度:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822221627219.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
+ 张三对**小清新**的偏好 * 音乐A含有**小清新**的成分 + 张三对**重口味**的偏好 * 音乐A含有**重口味**的成分 + 张三对**优雅**的偏好 * 音乐A含有**优雅**的成分...
|
||||
|
||||
+ 根据隐向量其实就可以得到张三对音乐A的打分,即: $$0.6 * 0.9 + 0.8 * 0.1 + 0.1 * 0.2 + 0.1 * 0.4 + 0.7 * 0 = 0.68$$。
|
||||
|
||||
**计算所有用户对不同音乐的喜爱程度**
|
||||
|
||||
按照这个计算方式, 每个用户对每首歌其实都可以得到这样的分数, 最后就得到了我们的评分矩阵:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822222141231.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:60%;" />
|
||||
</div>
|
||||
+ 红色部分表示用户没有打分,可以通过隐向量计算得到的。
|
||||
|
||||
**小结**
|
||||
|
||||
+ 上面例子中的小清晰, 重口味, 优雅这些就可以看做是隐含特征, 而通过这个隐含特征就可以把用户的兴趣和音乐的进行一个分类, 其实就是找到了每个用户每个音乐的一个隐向量表达形式(与深度学习中的embedding等价)
|
||||
+ 这个隐向量就可以反映出用户的兴趣和物品的风格,并能将相似的物品推荐给相似的用户等。 **有没有感觉到是把协同过滤算法进行了一种延伸, 把用户的相似性和物品的相似性通过了一个叫做隐向量的方式进行表达**
|
||||
|
||||
+ 现实中,类似于上述的矩阵 $P,Q$ 一般很难获得。有的只是用户的评分矩阵,如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200822223313349.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:60%;" />
|
||||
</div>
|
||||
|
||||
+ 这种矩阵非常的稀疏,如果直接基于用户相似性或者物品相似性去填充这个矩阵是不太容易的。
|
||||
+ 并且很容易出现长尾问题, 而矩阵分解就可以比较容易的解决这个问题。
|
||||
|
||||
+ 矩阵分解模型:
|
||||
|
||||
+ 基于评分矩阵,将其分解成Q和P两个矩阵乘积的形式,获取用户兴趣和物品的隐向量表达。
|
||||
+ 然后,基于两个分解矩阵去预测某个用户对某个物品的评分了。
|
||||
+ 最后,基于预测评分去进行物品推荐。
|
||||
|
||||
|
||||
|
||||
# 矩阵分解算法
|
||||
|
||||
## 算法原理
|
||||
|
||||
在矩阵分解的算法框架下, **可以通过分解协同过滤的共现矩阵(评分矩阵)来得到用户和物品的隐向量**,原理如下:。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200823101513233.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
+ 矩阵分解算法将 $m\times n$ 维的共享矩阵 $R$ ,分解成 $m \times k$ 维的用户矩阵 $U$ 和 $k \times n$ 维的物品矩阵 $V$ 相乘的形式。
|
||||
+ 其中,$m$ 是用户数量, $n$ 是物品数量, $k$ 是隐向量维度, 也就是隐含特征个数。
|
||||
+ 这里的隐含特征没有太好的可解释性,需要模型自己去学习。
|
||||
+ 一般而言, $k$ 越大隐向量能承载的信息内容越多,表达能力也会更强,但相应的学习难度也会增加。所以,我们需要根据训练集样本的数量去选择合适的数值,在保证信息学习相对完整的前提下,降低模型的学习难度。
|
||||
|
||||
## 评分预测
|
||||
|
||||
在分解得到用户矩阵和物品矩阵后,若要计算用户 $u$ 对物品 $i$ 的评分,公式如下:
|
||||
$$
|
||||
\operatorname{Preference}(u, i)=r_{u i}=p_{u}^{T} q_{i}=\sum_{k=1}^{K} p_{u, k} q_{i,k}
|
||||
$$
|
||||
+ 其中,向量 $p_u$ 表示用户 $u$ 的隐向量,向量 $q_i$ 表示物品 $i$ 的隐向量。
|
||||
+ 用户向量和物品向量的内积 $p_{u}^{T} q_{i}$ 可以表示为用户 $u$ 对物品 $i$ 的预测评分。
|
||||
+ $p_{u,k}$ 和 $q_{i,k}$ 是模型的参数, $p_{u,k}$ 度量的是用户 $u$ 的兴趣和第 $k$ 个隐类的关系,$q_{i,k}$ 度量了第 $k$ 个隐类和物品 $i$ 之间的关系。
|
||||
|
||||
## 矩阵分解求解
|
||||
|
||||
常用的矩阵分解方法有特征值分解(EVD)或者奇异值分解(SVD), 具体原理可参考:
|
||||
|
||||
> [奇异值分解svd原理详解及推导](https://blog.csdn.net/wuzhongqiang/article/details/108168238)
|
||||
|
||||
+ 对于 EVD, 它要求分解的矩阵是方阵, 绝大部分场景下用户-物品矩阵不满足这个要求。
|
||||
+ 传统的 SVD 分解, 会要求原始矩阵是稠密的。但现实中用户的评分矩阵是非常稀疏的。
|
||||
+ 如果想用奇异值分解, 就必须对缺失的元素进行填充(比如填 0 )。
|
||||
+ 填充不但会导致空间复杂度增高,且补全内容不一定准确。
|
||||
+ 另外,SVD 分解计算复杂度非常高,而用户-物品的评分矩阵较大,不具备普适性。
|
||||
|
||||
## FunkSVD
|
||||
|
||||
2006年的Netflix Prize之后, Simon Funk公布了一个矩阵分解算法叫做**Funk-SVD**, 后来被 Netflix Prize 的冠军Koren称为**Latent Factor Model(LFM)**。
|
||||
|
||||
Funk-SVD的思想很简单: **把求解上面两个矩阵的参数问题转换成一个最优化问题, 可以通过训练集里面的观察值利用最小化来学习用户矩阵和物品矩阵**。
|
||||
|
||||
**算法过程**
|
||||
|
||||
1. 根据前面提到的,在有用户矩阵和物品矩阵的前提下,若要计算用户 $u$ 对物品 $i$ 的评分, 可以根据公式:
|
||||
$$
|
||||
\operatorname{Preference}(u, i)=r_{u i}=p_{u}^{T} q_{i}=\sum_{k=1}^{K} p_{u, k} q_{i,k}
|
||||
$$
|
||||
|
||||
+ 其中,向量 $p_u$ 表示用户 $u$ 的隐向量,向量 $q_i$ 表示物品 $i$ 的隐向量。
|
||||
|
||||
2. 随机初始化一个用户矩阵 $U$ 和一个物品矩阵 $V$,获取每个用户和物品的初始隐语义向量。
|
||||
|
||||
3. 将用户和物品的向量内积 $p_{u}^{T} q_{i}$, 作为用户对物品的预测评分 $\hat{r}_{u i}$。
|
||||
|
||||
+ $\hat{r}_{u i}=p_{u}^{T} q_{i}$ 表示的是通过建模,求得的用户 $u$ 对物品的预测评分。
|
||||
+ 在用户对物品的评分矩阵中,矩阵中的元素 $r_{u i}$ 才是用户对物品的真实评分。
|
||||
|
||||
4. 对于评分矩阵中的每个元素,计算预测误差 $e_{u i}=r_{u i}-\hat{r}_{u i}$,对所有训练样本的平方误差进行累加:
|
||||
$$
|
||||
\operatorname{SSE}=\sum_{u, i} e_{u i}^{2}=\sum_{u, i}\left(r_{u i}-\sum_{k=1}^{K} p_{u,k} q_{i,k}\right)^{2}
|
||||
$$
|
||||
|
||||
+ 从上述公式可以看出,$SSE$ 建立起了训练数据和预测模型之间的关系。
|
||||
|
||||
+ 如果我们希望模型预测的越准确,那么在训练集(已有的评分矩阵)上的预测误差应该仅可能小。
|
||||
|
||||
+ 为方便后续求解,给 $SSE$ 增加系数 $1/2$ :
|
||||
$$
|
||||
\operatorname{SSE}=\frac{1}{2} \sum_{u, i} e_{u i}^{2}=\frac{1}{2} \sum_{u, i}\left(r_{u i}-\sum_{k=1}^{K} p_{u k} q_{i k}\right)^{2}
|
||||
$$
|
||||
|
||||
5. 前面提到,模型预测越准确等价于预测误差越小,那么优化的目标函数变为:
|
||||
$$
|
||||
\min _{\boldsymbol{q}^{*}, \boldsymbol{p}^{*}} \frac{1}{2} \sum_{(u, i) \in K}\left(\boldsymbol{r}_{\mathrm{ui}}-p_{u}^{T} q_{i}\right)^{2}
|
||||
$$
|
||||
|
||||
+ $K$ 表示所有用户评分样本的集合,**即评分矩阵中不为空的元素**,其他空缺值在测试时是要预测的。
|
||||
+ 该目标函数需要优化的目标是用户矩阵 $U$ 和一个物品矩阵 $V$。
|
||||
|
||||
6. 对于给定的目标函数,可以通过梯度下降法对参数进行优化。
|
||||
|
||||
+ 求解目标函数 $SSE$ 关于用户矩阵中参数 $p_{u,k}$ 的梯度:
|
||||
$$
|
||||
\frac{\partial}{\partial p_{u,k}} S S E=\frac{\partial}{\partial p_{u,k}}\left(\frac{1}{2}e_{u i}^{2}\right) =e_{u i} \frac{\partial}{\partial p_{u,k}} e_{u i}=e_{u i} \frac{\partial}{\partial p_{u,k}}\left(r_{u i}-\sum_{k=1}^{K} p_{u,k} q_{i,k}\right)=-e_{u i} q_{i,k}
|
||||
$$
|
||||
|
||||
+ 求解目标函数 $SSE$ 关于 $q_{i,k}$ 的梯度:
|
||||
$$
|
||||
\frac{\partial}{\partial q_{i,k}} S S E=\frac{\partial}{\partial q_{i,k}}\left(\frac{1}{2}e_{u i}^{2}\right) =e_{u i} \frac{\partial}{\partial q_{i,k}} e_{u i}=e_{u i} \frac{\partial}{\partial q_{i,k}}\left(r_{u i}-\sum_{k=1}^{K} p_{u,k} q_{i,k}\right)=-e_{u i} p_{u,k}
|
||||
$$
|
||||
|
||||
7. 参数梯度更新
|
||||
$$
|
||||
p_{u, k}=p_{u,k}-\eta (-e_{ui}q_{i, k})=p_{u,k}+\eta e_{ui}q_{i, k} \\
|
||||
q_{i, k}=q_{i,k}-\eta (-e_{ui}p_{u,k})=q_{i, k}+\eta e_{ui}p_{u, k}
|
||||
$$
|
||||
|
||||
+ 其中,$\eta$ 表示学习率, 用于控制步长。
|
||||
+ 但上面这个有个问题就是当参数很多的时候, 就是两个矩阵很大的时候, 往往容易陷入过拟合的困境, 这时候, 就需要在目标函数上面加上正则化的损失, 就变成了RSVD, 关于RSVD的详细内容, 可以参考下面给出的链接, 由于篇幅原因, 这里不再过多的赘述。
|
||||
|
||||
**加入正则项**
|
||||
|
||||
为了控制模型的复杂度。在原有模型的基础上,加入 $l2$ 正则项,来防止过拟合。
|
||||
|
||||
+ 当模型参数过大,而输入数据发生变化时,可能会造成输出的不稳定。
|
||||
|
||||
+ $l2$ 正则项等价于假设模型参数符合0均值的正态分布,从而使得模型的输出更加稳定。
|
||||
|
||||
$$
|
||||
\min _{\boldsymbol{q}^{*}, \boldsymbol{p}^{*}} \frac{1}{2} \sum_{(u, i) \in K}\left(\boldsymbol{r}_{\mathrm{ui}}-p_{u}^{T} q_{i}\right)^{2}
|
||||
+ \lambda\left(\left\|p_{u}\right\|^{2}+\left\|q_{i}\right\|^{2}\right)
|
||||
$$
|
||||
|
||||
## BiasSVD
|
||||
|
||||
在推荐系统中,评分预测除了与用户的兴趣偏好、物品的特征属性相关外,与其他的因素也相关。例如:
|
||||
|
||||
+ 例如,对于乐观的用户来说,它的评分行为普遍偏高,而对批判性用户来说,他的评分记录普遍偏低,即使他们对同一物品的评分相同,但是他们对该物品的喜好程度却并不一样。
|
||||
+ 对物品来说也是类似的。以电影为例,受大众欢迎的电影得到的评分普遍偏高,而一些烂片的评分普遍偏低,这些因素都是独立于用户或产品的因素,和用户对产品的的喜好无关。
|
||||
|
||||
因此, Netfix Prize中提出了另一种LFM, 在原来的基础上加了偏置项, 来消除用户和物品打分的偏差, 即预测公式如下:
|
||||
$$
|
||||
\hat{r}_{u i}=\mu+b_{u}+b_{i}+p_{u}^{T} \cdot q_{i}
|
||||
$$
|
||||
这个预测公式加入了3项偏置参数 $\mu,b_u,b_i$, 作用如下:
|
||||
|
||||
- $\mu$: 该参数反映的是推荐模型整体的平均评分,一般使用所有样本评分的均值。
|
||||
- $b_u$:用户偏差系数。可以使用用户 $u$ 给出的所有评分的均值, 也可以当做训练参数。
|
||||
- 这一项表示了用户的评分习惯中和物品没有关系的那种因素。 比如有些用户比较苛刻, 对什么东西要求很高, 那么他评分就会偏低, 而有些用户比较宽容, 对什么东西都觉得不错, 那么评分就偏高
|
||||
- $b_i$:物品偏差系数。可以使用物品 $i$ 收到的所有评分的均值, 也可以当做训练参数。
|
||||
- 这一项表示了物品接受的评分中和用户没有关系的因素。 比如有些物品本身质量就很高, 因此获得的评分相对比较高, 有的物品本身质量很差, 因此获得的评分相对较低。
|
||||
|
||||
加了用户和物品的打分偏差之后, 矩阵分解得到的隐向量更能反映不同用户对不同物品的“真实”态度差异, 也就更容易捕捉评价数据中有价值的信息, 从而避免推荐结果有偏。
|
||||
|
||||
**优化函数**
|
||||
|
||||
在加入正则项的FunkSVD的基础上,BiasSVD 的目标函数如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\min _{q^{*}, p^{*}} \frac{1}{2} \sum_{(u, i) \in K} &\left(r_{u i}-\left(\mu+b_{u}+b_{i}+q_{i}^{T} p_{u}\right)\right)^{2} \\
|
||||
&+\lambda\left(\left\|p_{u}\right\|^{2}+\left\|q_{i}\right\|^{2}+b_{u}^{2}+b_{i}^{2}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
可得偏置项的梯度更新公式如下:
|
||||
|
||||
+ $\frac{\partial}{\partial b_{i}} S S E=-e_{u i}+\lambda b_{i}$
|
||||
+ $ \frac{\partial}{\partial b_{u}} S S E=-e_{u i}+\lambda b_{u} \ $
|
||||
|
||||
# 编程实现
|
||||
|
||||
本小节,使用如下图表来预测Alice对物品5的评分:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200827150237921.png#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
</div>
|
||||
基于矩阵分解算法的流程如下:
|
||||
|
||||
1. 首先, 它会先初始化用户矩阵 $P$ 和物品矩阵 $Q$ , $P$ 的维度是`[users_num, K]`,$Q$ 的维度是`[items_num, K]`,
|
||||
|
||||
+ 其中,`F`表示隐向量的维度。 也就是把通过隐向量的方式把用户的兴趣和`F`的特点关联了起来。
|
||||
|
||||
+ 初始化这两个矩阵的方式很多, 但根据经验, 随机数需要和`1/sqrt(F)`成正比。
|
||||
|
||||
2. 根据预测评分和真实评分的偏差,利用梯度下降法进行参数更新。
|
||||
|
||||
+ 遍历用户及其交互过的物品,对已交互过的物品进行评分预测。
|
||||
+ 由于预测评分与真实评分存在偏差, 再根据第3节的梯度更新公式更新参数。
|
||||
|
||||
3. 训练完成后,利用用户向量与目标物品向量的内积进行评分预测。
|
||||
|
||||
**完整代码如下:**
|
||||
|
||||
```python
|
||||
import random
|
||||
import math
|
||||
|
||||
|
||||
class BiasSVD():
|
||||
def __init__(self, rating_data, F=5, alpha=0.1, lmbda=0.1, max_iter=100):
|
||||
self.F = F # 这个表示隐向量的维度
|
||||
self.P = dict() # 用户矩阵P 大小是[users_num, F]
|
||||
self.Q = dict() # 物品矩阵Q 大小是[item_nums, F]
|
||||
self.bu = dict() # 用户偏置系数
|
||||
self.bi = dict() # 物品偏置系数
|
||||
self.mu = 0 # 全局偏置系数
|
||||
self.alpha = alpha # 学习率
|
||||
self.lmbda = lmbda # 正则项系数
|
||||
self.max_iter = max_iter # 最大迭代次数
|
||||
self.rating_data = rating_data # 评分矩阵
|
||||
|
||||
for user, items in self.rating_data.items():
|
||||
# 初始化矩阵P和Q, 随机数需要和1/sqrt(F)成正比
|
||||
self.P[user] = [random.random() / math.sqrt(self.F) for x in range(0, F)]
|
||||
self.bu[user] = 0
|
||||
for item, rating in items.items():
|
||||
if item not in self.Q:
|
||||
self.Q[item] = [random.random() / math.sqrt(self.F) for x in range(0, F)]
|
||||
self.bi[item] = 0
|
||||
|
||||
# 采用随机梯度下降的方式训练模型参数
|
||||
def train(self):
|
||||
cnt, mu_sum = 0, 0
|
||||
for user, items in self.rating_data.items():
|
||||
for item, rui in items.items():
|
||||
mu_sum, cnt = mu_sum + rui, cnt + 1
|
||||
self.mu = mu_sum / cnt
|
||||
|
||||
for step in range(self.max_iter):
|
||||
# 遍历所有的用户及历史交互物品
|
||||
for user, items in self.rating_data.items():
|
||||
# 遍历历史交互物品
|
||||
for item, rui in items.items():
|
||||
rhat_ui = self.predict(user, item) # 评分预测
|
||||
e_ui = rui - rhat_ui # 评分预测偏差
|
||||
|
||||
# 参数更新
|
||||
self.bu[user] += self.alpha * (e_ui - self.lmbda * self.bu[user])
|
||||
self.bi[item] += self.alpha * (e_ui - self.lmbda * self.bi[item])
|
||||
for k in range(0, self.F):
|
||||
self.P[user][k] += self.alpha * (e_ui * self.Q[item][k] - self.lmbda * self.P[user][k])
|
||||
self.Q[item][k] += self.alpha * (e_ui * self.P[user][k] - self.lmbda * self.Q[item][k])
|
||||
# 逐步降低学习率
|
||||
self.alpha *= 0.1
|
||||
|
||||
|
||||
# 评分预测
|
||||
def predict(self, user, item):
|
||||
return sum(self.P[user][f] * self.Q[item][f] for f in range(0, self.F)) + self.bu[user] + self.bi[
|
||||
item] + self.mu
|
||||
|
||||
|
||||
# 通过字典初始化训练样本,分别表示不同用户(1-5)对不同物品(A-E)的真实评分
|
||||
def loadData():
|
||||
rating_data={1: {'A': 5, 'B': 3, 'C': 4, 'D': 4},
|
||||
2: {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},
|
||||
3: {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},
|
||||
4: {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},
|
||||
5: {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}
|
||||
}
|
||||
return rating_data
|
||||
|
||||
# 加载数据
|
||||
rating_data = loadData()
|
||||
# 建立模型
|
||||
basicsvd = BiasSVD(rating_data, F=10)
|
||||
# 参数训练
|
||||
basicsvd.train()
|
||||
# 预测用户1对物品E的评分
|
||||
for item in ['E']:
|
||||
print(item, basicsvd.predict(1, item))
|
||||
|
||||
# 预测结果:E 3.685084274454321
|
||||
```
|
||||
# 课后思考
|
||||
|
||||
1. 矩阵分解算法后续有哪些改进呢?针对这些改进,是为了解决什么的问题呢?请大家自行探索RSVD,消除用户和物品打分偏差等。
|
||||
|
||||
2. 矩阵分解的优缺点分析
|
||||
|
||||
* 优点:
|
||||
* 泛化能力强: 一定程度上解决了稀疏问题
|
||||
* 空间复杂度低: 由于用户和物品都用隐向量的形式存放, 少了用户和物品相似度矩阵, 空间复杂度由$n^2$降到了$(n+m)*f$
|
||||
* 更好的扩展性和灵活性:矩阵分解的最终产物是用户和物品隐向量, 这个深度学习的embedding思想不谋而合, 因此矩阵分解的结果非常便于与其他特征进行组合和拼接, 并可以与深度学习无缝结合。
|
||||
|
||||
+ 缺点:
|
||||
+ 矩阵分解算法依然是只用到了评分矩阵, 没有考虑到用户特征, 物品特征和上下文特征, 这使得矩阵分解丧失了利用很多有效信息的机会。
|
||||
+ 同时在缺乏用户历史行为的时候, 无法进行有效的推荐。
|
||||
+ 为了解决这个问题, **逻辑回归模型及后续的因子分解机模型**, 凭借其天然的融合不同特征的能力, 逐渐在推荐系统领域得到了更广泛的应用。
|
||||
|
||||
# 参考资料
|
||||
|
||||
* 王喆 - 《深度学习推荐系统》
|
||||
* 项亮 - 《推荐系统实战》
|
||||
* [奇异值分解(SVD)的原理详解及推导](https://blog.csdn.net/wuzhongqiang/article/details/108168238)
|
||||
* [Matrix factorization techniques for recommender systems论文](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=5197422&tag=1)
|
||||
* [隐语义模型(LFM)和矩阵分解(MF)](https://blog.csdn.net/wuzhongqiang/article/details/108173885)
|
||||
@@ -1,344 +0,0 @@
|
||||
# 协同过滤算法
|
||||
|
||||
## 基本思想
|
||||
|
||||
协同过滤(Collaborative Filtering)推荐算法是最经典、最常用的推荐算法。基本思想是:
|
||||
|
||||
+ 根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品。
|
||||
|
||||
+ 基于对用户历史行为数据的挖掘发现用户的喜好偏向, 并预测用户可能喜好的产品进行推荐。
|
||||
+ 一般是仅仅基于用户的行为数据(评价、购买、下载等), 而不依赖于项的任何附加信息(物品自身特征)或者用户的任何附加信息(年龄, 性别等)。
|
||||
+ 目前应用比较广泛的协同过滤算法是基于邻域的方法,主要有:
|
||||
+ 基于用户的协同过滤算法(UserCF):给用户推荐和他兴趣相似的其他用户喜欢的产品。
|
||||
+ 基于物品的协同过滤算法(ItemCF):给用户推荐和他之前喜欢的物品相似的物品。
|
||||
|
||||
不管是 UserCF 还是 ItemCF 算法, 重点是计算用户之间(或物品之间)的相似度。
|
||||
|
||||
## 相似性度量方法
|
||||
|
||||
1. **杰卡德(Jaccard)相似系数**
|
||||
|
||||
`Jaccard` 系数是衡量两个集合的相似度一种指标,计算公式如下:
|
||||
$$
|
||||
sim_{uv}=\frac{|N(u) \cap N(v)|}{|N(u)| \cup|N(v)|}
|
||||
$$
|
||||
|
||||
+ 其中 $N(u)$,$N(v)$ 分别表示用户 $u$ 和用户 $v$ 交互物品的集合。
|
||||
|
||||
+ 对于用户 $u$ 和 $v$ ,该公式反映了两个交互物品交集的数量占这两个用户交互物品并集的数量的比例。
|
||||
|
||||
由于杰卡德相似系数一般无法反映具体用户的评分喜好信息,所以常用来评估用户是否会对某物品进行打分, 而不是预估用户会对某物品打多少分。
|
||||
|
||||
2. **余弦相似度**
|
||||
余弦相似度衡量了两个向量的夹角,夹角越小越相似。余弦相似度的计算如下,其与杰卡德(Jaccard)相似系数只是在分母上存在差异:
|
||||
$$
|
||||
sim_{uv}=\frac{|N(u) \cap N(v)|}{\sqrt{|N(u)|\cdot|N(v)|}}
|
||||
$$
|
||||
从向量的角度进行描述,令矩阵 $A$ 为用户-物品交互矩阵,矩阵的行表示用户,列表示物品。
|
||||
|
||||
+ 设用户和物品数量分别为 $m,n$,交互矩阵$A$就是一个 $m$ 行 $n$ 列的矩阵。
|
||||
|
||||
+ 矩阵中的元素均为 $0/1$。若用户 $i$ 对物品 $j$ 存在交互,那么 $A_{i,j}=1$,否则为 $0$ 。
|
||||
|
||||
+ 那么,用户之间的相似度可以表示为:
|
||||
$$
|
||||
sim_{uv} = cos(u,v) =\frac{u\cdot v}{|u|\cdot |v|}
|
||||
$$
|
||||
|
||||
+ 向量 $u,v$ 在形式都是 one-hot 类型,$u\cdot v$ 表示向量点积。
|
||||
|
||||
上述用户-物品交互矩阵在现实中是十分稀疏的,为了节省内存,交互矩阵会采用字典进行存储。在 `sklearn` 中,余弦相似度的实现:
|
||||
|
||||
```python
|
||||
from sklearn.metrics.pairwise import cosine_similarity
|
||||
|
||||
i = [1, 0, 0, 0]
|
||||
j = [1, 0, 1, 0]
|
||||
cosine_similarity([i, j])
|
||||
```
|
||||
|
||||
3. **皮尔逊相关系数**
|
||||
|
||||
在用户之间的余弦相似度计算时,将用户向量的内积展开为各元素乘积和:
|
||||
$$
|
||||
sim_{uv} = \frac{\sum_i r_{ui}*r_{vi}}{\sqrt{\sum_i r_{ui}^2}\sqrt{\sum_i r_{vi}^2}}
|
||||
$$
|
||||
+ 其中,$r_{ui},r_{vi}$ 分别表示用户 $u$ 和用户 $v$ 对物品 $i$ 是否有交互(或具体评分值)。
|
||||
|
||||
皮尔逊相关系数与余弦相似度的计算公式非常的类似,如下:
|
||||
$$
|
||||
sim(u,v)=\frac{\sum_{i\in I}(r_{ui}-\bar r_u)(r_{vi}-\bar r_v)}{\sqrt{\sum_{i\in I }(r_{ui}-\bar r_u)^2}\sqrt{\sum_{i\in I }(r_{vi}-\bar r_v)^2}}
|
||||
$$
|
||||
+ 其中,$r_{ui},r_{vi}$ 分别表示用户 $u$ 和用户 $v$ 对物品 $i$ 是否有交互(或具体评分值);
|
||||
+ $\bar r_u, \bar r_v$ 分别表示用户 $u$ 和用户 $v$ 交互的所有物品交互数量或者评分的平均值;
|
||||
|
||||
相较于余弦相似度,皮尔逊相关系数通过使用用户的平均分对各独立评分进行修正,减小了用户评分偏置的影响。在`scipy`中,皮尔逊相关系数的实现:
|
||||
|
||||
```python
|
||||
from scipy.stats import pearsonr
|
||||
|
||||
i = [1, 0, 0, 0]
|
||||
j = [1, 0.5, 0.5, 0]
|
||||
pearsonr(i, j)
|
||||
```
|
||||
|
||||
**适用场景**
|
||||
|
||||
+ $Jaccard$ 相似度表示两个集合的交集元素个数在并集中所占的比例 ,所以适用于隐式反馈数据(0-1)。
|
||||
+ 余弦相似度在度量文本相似度、用户相似度、物品相似度的时候都较为常用。
|
||||
+ 皮尔逊相关度,实际上也是一种余弦相似度。不过先对向量做了中心化,范围在 $-1$ 到 $1$。
|
||||
+ 相关度量的是两个变量的变化趋势是否一致,两个随机变量是不是同增同减。
|
||||
+ 不适合用作计算布尔值向量(0-1)之间相关度。
|
||||
|
||||
# 基于用户的协同过滤
|
||||
|
||||
## 基本思想
|
||||
|
||||
基于用户的协同过滤(UserCF):
|
||||
|
||||
+ 例如,我们要对用户 $A$ 进行物品推荐,可以先找到和他有相似兴趣的其他用户。
|
||||
+ 然后,将共同兴趣用户喜欢的,但用户 $A$ 未交互过的物品推荐给 $A$。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210629232540289.png" alt="image-20210629232540289" style="zoom: 80%;" />
|
||||
|
||||
## 计算过程
|
||||
|
||||
以下图为例,给用户推荐物品的过程可以形象化为一个猜测用户对物品进行打分的任务,表格里面是5个用户对于5件物品的一个打分情况,就可以理解为用户对物品的喜欢程度。
|
||||
|
||||

|
||||
|
||||
UserCF算法的两个步骤:
|
||||
|
||||
+ 首先,根据前面的这些打分情况(或者说已有的用户向量)计算一下 Alice 和用户1, 2, 3, 4的相似程度, 找出与 Alice 最相似的 n 个用户。
|
||||
|
||||
+ 根据这 n 个用户对物品 5 的评分情况和与 Alice 的相似程度会猜测出 Alice 对物品5的评分。如果评分比较高的话, 就把物品5推荐给用户 Alice, 否则不推荐。
|
||||
|
||||
**具体过程:**
|
||||
|
||||
1. 计算用户之间的相似度
|
||||
|
||||
+ 根据 1.2 节的几种方法, 我们可以计算出各用户之间的相似程度。对于用户 Alice,选取出与其最相近的 $N$ 个用户。
|
||||
|
||||
2. 计算用户对新物品的评分预测
|
||||
|
||||
+ 常用的方式之一:利用目标用户与相似用户之间的相似度以及相似用户对物品的评分,来预测目标用户对候选物品的评分估计:
|
||||
$$
|
||||
R_{\mathrm{u}, \mathrm{p}}=\frac{\sum_{\mathrm{s} \in S}\left(w_{\mathrm{u}, \mathrm{s}} \cdot R_{\mathrm{s}, \mathrm{p}}\right)}{\sum_{\mathrm{s} \in S} w_{\mathrm{u}, \mathrm{s}}}
|
||||
$$
|
||||
|
||||
+ 其中,权重 $w_{u,s}$ 是用户 $u$ 和用户 $s$ 的相似度, $R_{s,p}$ 是用户 $s$ 对物品 $p$ 的评分。
|
||||
|
||||
+ 另一种方式:考虑到用户评分的偏置,即有的用户喜欢打高分, 有的用户喜欢打低分的情况。公式如下:
|
||||
$$
|
||||
R_{\mathrm{u}, \mathrm{p}}=\bar{R}_{u} + \frac{\sum_{\mathrm{s} \in S}\left(w_{\mathrm{u}, \mathrm{s}} \cdot \left(R_{s, p}-\bar{R}_{s}\right)\right)}{\sum_{\mathrm{s} \in S} w_{\mathrm{u}, \mathrm{s}}}
|
||||
$$
|
||||
|
||||
+ 其中,$\bar{R}_{s}$ 表示用户 $s$ 对物品的历史平均评分。
|
||||
|
||||
3. 对用户进行物品推荐
|
||||
|
||||
+ 在获得用户 $u$ 对不同物品的评价预测后, 最终的推荐列表根据预测评分进行排序得到。
|
||||
|
||||
**手动计算:**
|
||||
|
||||
根据上面的问题, 下面手动计算 Alice 对物品 5 的得分:
|
||||
|
||||
|
||||
1. 计算 Alice 与其他用户的相似度(基于皮尔逊相关系数)
|
||||
|
||||
+ 手动计算 Alice 与用户 1 之间的相似度:
|
||||
|
||||
>用户向量 $\text {Alice}:(5,3,4,4) , \text{user1}:(3,1,2,3) , \text {user2}:( 4,3,4,3) , \text {user3}:(3,3,1,5) , \text {user4}:(1,5,5,2) $
|
||||
>
|
||||
>+ 计算Alice与user1的余弦相似性:
|
||||
>$$
|
||||
>\operatorname{sim}(\text { Alice, user1 })=\cos (\text { Alice, user } 1)=\frac{15+3+8+12}{\operatorname{sqrt}(25+9+16+16) * \operatorname{sqrt}(9+1+4+9)}=0.975
|
||||
>$$
|
||||
>
|
||||
>+ 计算Alice与user1皮尔逊相关系数:
|
||||
> + $Alice\_ave =4 \quad user1\_ave =2.25 $
|
||||
> + 向量减去均值: $\text {Alice}:(1,-1, 0,0) \quad \text { user1 }:(0.75,-1.25,-0.25,0.75)$
|
||||
>
|
||||
>+ 计算这俩新向量的余弦相似度和上面计算过程一致, 结果是 0.852 。
|
||||
>
|
||||
|
||||
+ 基于 sklearn 计算所有用户之间的皮尔逊相关系数。可以看出,与 Alice 相似度最高的用户为用户1和用户2。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/JavaWJkjP2fHH27Rajrj.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
|
||||
2. **根据相似度用户计算 Alice对物品5的最终得分**
|
||||
用户1对物品5的评分是3, 用户2对物品5的打分是5, 那么根据上面的计算公式, 可以计算出 Alice 对物品5的最终得分是
|
||||
$$
|
||||
P_{Alice, 物品5}=\bar{R}_{Alice}+\frac{\sum_{k=1}^{2}\left(w_{Alice,user k}\left(R_{userk, 物品5}-\bar{R}_{userk}\right)\right)}{\sum_{k=1}^{2} w_{Alice, userk}}=4+\frac{0.85*(3-2.4)+0.7*(5-3.8)}{0.85+0.7}=4.87
|
||||
$$
|
||||
|
||||
+ 同样方式,可以计算用户 Alice 对其他物品的评分预测。
|
||||
|
||||
3. **根据用户评分对用户进行推荐**
|
||||
|
||||
+ 根据 Alice 的打分对物品排个序从大到小:$$物品1>物品5>物品3=物品4>物品2$$。
|
||||
+ 如果要向 Alice 推荐2款产品的话, 我们就可以推荐物品 1 和物品 5 给 Alice。
|
||||
|
||||
至此, 基于用户的协同过滤算法原理介绍完毕。
|
||||
|
||||
## UserCF编程实现
|
||||
|
||||
1. 建立实验使用的数据表:
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
|
||||
def loadData():
|
||||
users = {'Alice': {'A': 5, 'B': 3, 'C': 4, 'D': 4},
|
||||
'user1': {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},
|
||||
'user2': {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},
|
||||
'user3': {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},
|
||||
'user4': {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}
|
||||
}
|
||||
return users
|
||||
```
|
||||
|
||||
+ 这里使用字典来建立用户-物品的交互表。
|
||||
+ 字典`users`的键表示不同用户的名字,值为一个评分字典,评分字典的键值对表示某物品被当前用户的评分。
|
||||
+ 由于现实场景中,用户对物品的评分比较稀疏。如果直接使用矩阵进行存储,会存在大量空缺值,故此处使用了字典。
|
||||
|
||||
2. 计算用户相似性矩阵
|
||||
|
||||
+ 由于训练数据中共包含 5 个用户,所以这里的用户相似度矩阵的维度也为 $5 \times 5$。
|
||||
|
||||
```python
|
||||
user_data = loadData()
|
||||
similarity_matrix = pd.DataFrame(
|
||||
np.identity(len(user_data)),
|
||||
index=user_data.keys(),
|
||||
columns=user_data.keys(),
|
||||
)
|
||||
|
||||
# 遍历每条用户-物品评分数据
|
||||
for u1, items1 in user_data.items():
|
||||
for u2, items2 in user_data.items():
|
||||
if u1 == u2:
|
||||
continue
|
||||
vec1, vec2 = [], []
|
||||
for item, rating1 in items1.items():
|
||||
rating2 = items2.get(item, -1)
|
||||
if rating2 == -1:
|
||||
continue
|
||||
vec1.append(rating1)
|
||||
vec2.append(rating2)
|
||||
# 计算不同用户之间的皮尔逊相关系数
|
||||
similarity_matrix[u1][u2] = np.corrcoef(vec1, vec2)[0][1]
|
||||
|
||||
print(similarity_matrix)
|
||||
```
|
||||
|
||||
```python
|
||||
1 2 3 4 5
|
||||
1 1.000000 0.852803 0.707107 0.000000 -0.792118
|
||||
2 0.852803 1.000000 0.467707 0.489956 -0.900149
|
||||
3 0.707107 0.467707 1.000000 -0.161165 -0.466569
|
||||
4 0.000000 0.489956 -0.161165 1.000000 -0.641503
|
||||
5 -0.792118 -0.900149 -0.466569 -0.641503 1.000000
|
||||
```
|
||||
|
||||
3. 计算与 Alice 最相似的 `num` 个用户
|
||||
|
||||
```python
|
||||
target_user = ' Alice '
|
||||
num = 2
|
||||
# 由于最相似的用户为自己,去除本身
|
||||
sim_users = similarity_matrix[target_user].sort_values(ascending=False)[1:num+1].index.tolist()
|
||||
print(f'与用户{target_user}最相似的{num}个用户为:{sim_users}')
|
||||
```
|
||||
|
||||
```python
|
||||
与用户 Alice 最相似的2个用户为:['user1', 'user2']
|
||||
```
|
||||
|
||||
4. 预测用户 Alice 对物品 `E` 的评分
|
||||
|
||||
```python
|
||||
weighted_scores = 0.
|
||||
corr_values_sum = 0.
|
||||
|
||||
target_item = 'E'
|
||||
# 基于皮尔逊相关系数预测用户评分
|
||||
for user in sim_users:
|
||||
corr_value = similarity_matrix[target_user][user]
|
||||
user_mean_rating = np.mean(list(user_data[user].values()))
|
||||
|
||||
weighted_scores += corr_value * (user_data[user][target_item] - user_mean_rating)
|
||||
corr_values_sum += corr_value
|
||||
|
||||
target_user_mean_rating = np.mean(list(user_data[target_user].values()))
|
||||
target_item_pred = target_user_mean_rating + weighted_scores / corr_values_sum
|
||||
print(f'用户{target_user}对物品{target_item}的预测评分为:{target_item_pred}')
|
||||
```
|
||||
|
||||
```python
|
||||
用户 Alice 对物品E的预测评分为:4.871979899370592
|
||||
```
|
||||
|
||||
## UserCF优缺点
|
||||
|
||||
User-based算法存在两个重大问题:
|
||||
|
||||
|
||||
1. 数据稀疏性
|
||||
+ 一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。
|
||||
+ 这导致UserCF不适用于那些正反馈获取较困难的应用场景(如酒店预订, 大件物品购买等低频应用)。
|
||||
|
||||
1. 算法扩展性
|
||||
+ 基于用户的协同过滤需要维护用户相似度矩阵以便快速的找出 $TopN$ 相似用户, 该矩阵的存储开销非常大,存储空间随着用户数量的增加而增加。
|
||||
+ 故不适合用户数据量大的情况使用。
|
||||
|
||||
由于UserCF技术上的两点缺陷, 导致很多电商平台并没有采用这种算法, 而是采用了ItemCF算法实现最初的推荐系统。
|
||||
|
||||
|
||||
|
||||
# 算法评估
|
||||
|
||||
由于UserCF和ItemCF结果评估部分是共性知识点, 所以在这里统一标识。
|
||||
|
||||
## 召回率
|
||||
|
||||
对用户 $u$ 推荐 $N$ 个物品记为 $R(u)$, 令用户 $u$ 在测试集上喜欢的物品集合为$T(u)$, 那么召回率定义为:
|
||||
$$
|
||||
\operatorname{Recall}=\frac{\sum_{u}|R(u) \cap T(u)|}{\sum_{u}|T(u)|}
|
||||
$$
|
||||
+ 含义:在模型召回预测的物品中,预测准确的物品占用户实际喜欢的物品的比例。
|
||||
|
||||
## 精确率
|
||||
精确率定义为:
|
||||
$$
|
||||
\operatorname{Precision}=\frac{\sum_{u} \mid R(u) \cap T(u)|}{\sum_{u}|R(u)|}
|
||||
$$
|
||||
+ 含义:推荐的物品中,对用户准确推荐的物品占总物品的比例。
|
||||
+ 如要确保召回率高,一般是推荐更多的物品,期望推荐的物品中会涵盖用户喜爱的物品。而实际中,推荐的物品中用户实际喜爱的物品占少数,推荐的精确率就会很低。故同时要确保高召回率和精确率往往是矛盾的,所以实际中需要在二者之间进行权衡。
|
||||
|
||||
## 覆盖率
|
||||
覆盖率反映了推荐算法发掘长尾的能力, 覆盖率越高, 说明推荐算法越能将长尾中的物品推荐给用户。
|
||||
$$
|
||||
\text { Coverage }=\frac{\left|\bigcup_{u \in U} R(u)\right|}{|I|}
|
||||
$$
|
||||
|
||||
+ 含义:推荐系统能够推荐出来的物品占总物品集合的比例。
|
||||
+ 其中 $|I|$ 表示所有物品的个数;
|
||||
+ 系统的用户集合为$U$;
|
||||
+ 推荐系统给每个用户推荐一个长度为 $N$ 的物品列表$R(u)$.
|
||||
|
||||
+ 覆盖率表示最终的推荐列表中包含多大比例的物品。如果所有物品都被给推荐给至少一个用户, 那么覆盖率是100%。
|
||||
|
||||
## 新颖度
|
||||
用推荐列表中物品的平均流行度度量推荐结果的新颖度。 如果推荐出的物品都很热门, 说明推荐的新颖度较低。 由于物品的流行度分布呈长尾分布, 所以为了流行度的平均值更加稳定, 在计算平均流行度时对每个物品的流行度取对数。
|
||||
|
||||
- O’scar Celma 在博士论文 "[Music Recommendation and Discovery in the Long Tail](http://mtg.upf.edu/static/media/PhD_ocelma.pdf) " 中研究了新颖度的评测。
|
||||
|
||||
|
||||
|
||||
# 参考资料
|
||||
|
||||
* [基于用户的协同过滤来构建推荐系统:https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw](https://mp.weixin.qq.com/s/ZtnaQrVIpVOPJpqMdLWOcw)
|
||||
* B站黑马推荐系统实战课程
|
||||
@@ -1,332 +0,0 @@
|
||||
# 前言
|
||||
这是 Airbnb 于2018年发表的一篇论文,主要介绍了 Airbnb 在 Embedding 技术上的应用,并获得了 KDD 2018 的 Best Paper。Airbnb 是全球最大的短租平台,包含了数百万种不同的房源。这篇论文介绍了 Airbnb 如何使用 Embedding 来实现相似房源推荐以及实时个性化搜索。在本文中,Airbnb 在用户和房源的 Embedding 上的生成都是基于谷歌的 Word2Vec 模型,<u>故阅读本文要求大家了解 Word2Vec 模型,特别是 Skip-Gram 模型**(重点*)**</u>。
|
||||
本文将从以下几个方面来介绍该论文:
|
||||
|
||||
- 了解 Airbnb 是如何利用 Word2Vec 技术生成房源和用户的Embedding,并做出了哪些改进。
|
||||
- 了解 Airbnb 是如何利用 Embedding 解决房源冷启动问题。
|
||||
- 了解 Airbnb 是如何衡量生成的 Embedding 的有效性。
|
||||
- 了解 Airbnb 是如何利用用户和房源 Embedding 做召回和搜索排序。
|
||||
|
||||
考虑到本文的目的是为了让大家快速了解 Airbnb 在 Embedding 技术上的应用,故不会完全翻译原论文。如需进一步了解,建议阅读原论文或文末的参考链接。原论文链接:https://dl.acm.org/doi/pdf/10.1145/3219819.3219885
|
||||
|
||||
# Airbnb 的业务背景
|
||||
在介绍 Airbnb 在 Embedding 技术上的方法前,先了解 Airbnb 的业务背景。
|
||||
|
||||
- Airbnb 平台包含数百万种不同的房源,用户可以通过**浏览搜索结果页面**来寻找想要的房源。Airbnb 技术团队通过复杂的机器学习模型,并使用上百种信号对搜索结果中的房源进行排序。
|
||||
- 当用户在查看某一个房源时,接下来的有两种方式继续搜索:
|
||||
- 返回搜索结果页,继续查看其他搜索结果。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049527431-0b09af70-bda0-4a30-8082-6aa69548213a.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 在当前房源的详情页下,「相似房源」板块(你可能还喜欢)所推荐的房源。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049385995-7a775df1-a36f-4795-9e79-8e577bcf2097.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- Airbnb 平台 99% 的房源预订来自于搜索排序和相似房源推荐。
|
||||
# Embedding 方法
|
||||
Airbnb 描述了两种 Embedding 的构建方法,分别为:
|
||||
|
||||
- 用于描述短期实时性的个性化特征 Embedding:**listing Embeddings**
|
||||
- **listing 表示房源的意思,<u>它将贯穿全文,请务必了解</u>。**
|
||||
- 用于描述长期的个性化特征 Embedding:**user-type & listing type Embeddings**
|
||||
## Listing Embeddings
|
||||
Listing Embeddings 是基于用户的点击 session 学习得到的,用于表示房源的短期实时性特征。给定数据集 $ \mathcal{S} $ ,其中包含了 $ N $ 个用户的 $ S $ 个点击 session(序列)。
|
||||
|
||||
- 每个 session $ s=\left(l_{1}, \ldots, l_{M}\right) \in \mathcal{S} $ ,包含了 $ M $ 个被用户点击过的 listing ids 。
|
||||
- 对于用户连续两次点击,若时间间隔超过了30分钟,则启动新的 session。
|
||||
|
||||
在拿到多个用户点击的 session 后,可以基于 Word2Vec 的 Skip-Gram 模型来学习不同 listing 的 Embedding 表示。最大化目标函数 $ \mathcal{L} $ :
|
||||
$$
|
||||
\mathcal{L}=\sum_{s \in \mathcal{S}} \sum_{l_{i} \in s}\left(\sum_{-m \geq j \leq m, i \neq 0} \log \mathbb{P}\left(l_{i+j} \mid l_{i}\right)\right)
|
||||
$$
|
||||
概率 $ \mathbb{P}\left(l_{i+j} \mid l_{i}\right) $ 是基于 soft-max 函数的表达式。表示在一个 session 中,已知中心 listing $ l_i $ 来预测上下文 listing $ l_{i+j} $ 的概率:
|
||||
$$
|
||||
\mathbb{P}\left(l_{i+j} \mid l_{i}\right)=\frac{\exp \left(\mathbf{v}_{l_{i}}^{\top} \mathbf{v}_{l_{i+j}}^{\prime}\right)}{\sum_{l=1}^{|\mathcal{V}|} \exp \left(\mathbf{v}_{l_{i}}^{\top} \mathbf{v}_{l}^{\prime}\right)}
|
||||
$$
|
||||
|
||||
- 其中, $ \mathbf{v}_{l_{i}} $ 表示 listing $ l_i $ 的 Embedding 向量, $ |\mathcal{V}| $ 表示全部的物料库的数量。
|
||||
|
||||
考虑到物料库 $ \mathcal{V} $ 过大,模型中参数更新的时间成本和 $ |\mathcal{V}| $ 成正比。为了降低计算复杂度,要进行负采样。负采样后,优化的目标函数如下:
|
||||
$$
|
||||
\underset{\theta}{\operatorname{argmax}} \sum_{(l, c) \in \mathcal{D}_{p}} \log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime^{\prime}} \mathbf{v}_{l}}}+\sum_{(l, c) \in \mathcal{D}_{n}} \log \frac{1}{1+e^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{l}}}
|
||||
$$
|
||||
至此,对 Skip-Gram 模型和 NEG 了解的同学肯定很熟悉,上述方法和 Word2Vec 思想基本一致。
|
||||
下面,将进一步介绍 Airbnb 是如何改进 Listing Embedding 的学习以及其他方面的应用。
|
||||
**(1)正负样本集构建的改进**
|
||||
|
||||
- 使用 booked listing 作为全局上下文
|
||||
- booked listing 表示用户在 session 中最终预定的房源,一般只会出现在结束的 session 中。
|
||||
- Airbnb 将最终预定的房源,始终作为滑窗的上下文,即全局上下文。如下图:
|
||||
- 如图,对于当前滑动窗口的 central listing,实线箭头表示context listings,虚线(指向booked listing)表示 global context listing。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653053823336-0564b2da-c993-46aa-9b22-f5cbb784dae2.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- booked listing 作为全局正样本,故优化的目标函数更新为:
|
||||
|
||||
$$
|
||||
\underset{\theta}{\operatorname{argmax}} \sum_{(l, c) \in \mathcal{D}_{p}} \log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime^{\prime}} \mathbf{v}_{l}}}+\sum_{(l, c) \in \mathcal{D}_{n}} \log \frac{1}{1+e^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{l}}} +
|
||||
\log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime} \mathbf{v}_{l_b}}}
|
||||
$$
|
||||
|
||||
- 优化负样本的选择
|
||||
- 用户通过在线网站预定房间时,通常只会在同一个 market (将要停留区域)内进行搜索。
|
||||
|
||||
- 对于用户点击过的样本集 $ \mathcal{D}_{p} $ (正样本集)而言,它们大概率位于同一片区域。考虑到负样本集 $ \mathcal{D}_{n} $ 是随机抽取的,大概率来源不同的区域。
|
||||
|
||||
- Airbnb 发现这种样本的不平衡,在学习同一片区域房源的 Embedding 时会得到次优解。
|
||||
|
||||
- 解决办法也很简单,对于每个滑窗中的中心 lisitng,其负样本的选择新增了与其位于同一个 market 的 listing。至此,优化函数更新如下:
|
||||
$$
|
||||
\underset{\theta}{\operatorname{argmax}} \sum_{(l, c) \in \mathcal{D}_{p}} \log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime^{\prime}} \mathbf{v}_{l}}}+\sum_{(l, c) \in \mathcal{D}_{n}} \log \frac{1}{1+e^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{l}}} +\log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime} \mathbf{v}_{l_b}}} +
|
||||
\sum_{(l, m_n ) \in \mathcal{D}_{m_n}} \log \frac{1}{1+e^{\mathbf{v}_{m_n}^{\prime} \mathbf{v}_{l}}}
|
||||
$$
|
||||
|
||||
+ $ \mathcal{D}_{m_n} $ 表示与滑窗中的中心 listing 位于同一区域的负样本集。
|
||||
|
||||
**(2)Listing Embedding 的冷启动**
|
||||
|
||||
- Airbnb 每天都有新的 listings 产生,而这些 listings 却没有 Embedding 向量表征。
|
||||
- Airbnb 建议利用其他 listing 的现有的 Embedding 来为新的 listing 创建 Embedding。
|
||||
- 在新的 listing 被创建后,房主需要提供如位置、价格、类型等在内的信息。
|
||||
- 然后利用房主提供的房源信息,为其查找3个相似的 listing,并将它们 Embedding 的均值作为新 listing 的 Embedding表示。
|
||||
- 这里的相似,包含了位置最近(10英里半径内),房源类型相似,价格区间相近。
|
||||
- 通过该手段,Airbnb 可以解决 98% 以上的新 listing 的 Embedding 冷启动问题。
|
||||
|
||||
**(3)Listing Embedding 的评估**
|
||||
经过上述的两点对 Embedding 的改进后,为了评估改进后 listing Embedding 的效果。
|
||||
|
||||
- Airbnb 使用了800万的点击 session,并将 Embedding 的维度设为32。
|
||||
|
||||
评估方法包括:
|
||||
|
||||
- 评估 Embedding 是否包含 listing 的地理位置相似性。
|
||||
- 理论上,同一区域的房源相似性应该更高,不同区域房源相似性更低。
|
||||
- Airbnb 利用 k-means 聚类,将加利福尼亚州的房源聚成100个集群,来验证类似位置的房源是否聚集在一起。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056809526-15401069-6fff-40d8-ac5e-35871d3f254a.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 评估不同类型、价格区间的房源之间的相似性。
|
||||
- 简而言之,我们希望类型相同、价格区间一致的房源它们之间的相似度更高。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056981037-18edee91-493a-4d5b-b066-57f0b200032d.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 评估房源的隐式特征
|
||||
- Airbnb 在训练房源(listing)的 Embedding时,并没有用到房源的图像信息。
|
||||
- 对于一些隐式信息,例如架构、风格、观感等是无法直接学习。
|
||||
- 为了验证基于 Word2Vec 学习到的 Embedding是否隐含了它们在外观等隐式信息上的相似性,Airbnb 内部开发了一款内部相似性探索工具。
|
||||
- 大致原理就是,利用训练好的 Embedding 进行 K 近邻相似度检索。
|
||||
- 如下,与查询房源在 Embedding 相似性高的其他房源,它们之间的外观风格也很相似。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653057336798-fd8451cb-84b6-40fb-8733-1e3d08a39793.png" alt="img" />
|
||||
|
||||
## User-type & Listing-type Embedding
|
||||
|
||||
前面提到的 Listing Embedding,它是基于用户的点击 sessions 学习得到的。
|
||||
|
||||
- 同一个 session 内的点击时间间隔低于30分钟,所以**它们更适合短期,session 内的个性化需求**。
|
||||
- 在用户搜索 session 期间,该方法有利于向用户展示与点击过的 listing 更相似的其他 listings 。
|
||||
|
||||
Airbnb 除了挖掘 Listing 的短期兴趣特征表示外,还对 User 和 Listing 的长期兴趣特征表示进行了探索。长期兴趣的探索是有利于 Airbnb 的业务发展。例如,用户当前在洛杉矶进行搜索,并且过去在纽约和伦敦预定过其他房源。那么,向用户推荐与之前预定过的 listing 相似的 listings 是更合适的。
|
||||
|
||||
- 长期兴趣的探索是基于 booking session(用户的历史预定序列)。
|
||||
- 与前面 Listing Embedding 的学习类似,Airbnb 希望借助了 Skip-Gram 模型学习不同房源的 Embedding 表示。
|
||||
|
||||
但是,面临着如下的挑战:
|
||||
|
||||
- booking sessions $ \mathcal{S}_{b} $ 数据量的大小远远小于 click sessions $ \mathcal{S} $ ,因为预定本身就是一件低频率事件。
|
||||
- 许多用户过去只预定了单个数量的房源,无法从长度为1的 session 中学习 Embedding
|
||||
- 对于任何实体,要基于 context 学习到有意义的 Embedding,该实体至少在数据中出现5-10次。
|
||||
- 但平台上大多数 listing_ids 被预定的次数低于5-10次。
|
||||
- 用户连续两次预定的时间间隔可能较长,在此期间用户的行为(如价格敏感点)偏好可能会发生改变(由于职业的变化)。
|
||||
|
||||
为了解决该问题,Airbnb 提出了基于 booking session 来学习用户和房源的 Type Embedding。给定一个 booking sessions 集合 $ \mathcal{S}_{b} $ ,其中包含了 $ M $ 个用户的 booking session:
|
||||
|
||||
- 每个 booking session 表示为: $ s_{b}=\left(l_{b 1}, \ldots, l_{b M}\right) $
|
||||
- 这里 $ l_{b1} $ 表示 listing_id,学习到 Embedding 记作 $ \mathbf{v}_{l_{i d}} $
|
||||
|
||||
**(1)什么是Type Embedding ?**
|
||||
在介绍 Type Embedding 之前,回顾一下 Listing Embedding:
|
||||
|
||||
- 在 Listing Embedding 的学习中,只学习房源的 Embedding 表示,未学习用户的 Embedding。
|
||||
- 对于 Listing Embedding,与相应的 Lisitng ID 是一一对应的, 每个 Listing 它们的 Embedding 表示是唯一的。
|
||||
|
||||
对于 Type Embedding ,有如下的区别:
|
||||
|
||||
- 对于不同的 Listing,它们的 Type Embedding **可能是相同的**(User 同样如此)。
|
||||
- Type Embedding 包含了 User-type Embedding 和 Listing-type Embedding。
|
||||
|
||||
为了更直接快速地了解什么是 Listing-type 和 User-type,举个简单的例子:
|
||||
|
||||
- 小王,是一名西藏人,性别男,今年21岁,就读于中国山东的蓝翔技校的挖掘机专业。
|
||||
- 通常,对于不同的用户(如小王),给定一个 ID 编码,然后学习相应的 User Embedding。
|
||||
- 但前面说了,用户数据过于稀疏,学习到的 User Embedding 特征表达能力不好。
|
||||
- 另一种方式:利用小王身上的用户标签,先组合出他的 User-type,然后学习 Embedding 表示。
|
||||
- 小王的 User-type:西藏人_男_学生_21岁_位置中国山东_南翔技校_挖掘机专业。
|
||||
- 组合得到的 User-type 本质上可视为一个 Category 特征,然后学习其对应的 Embedding 表示。
|
||||
|
||||
下表给出了原文中,Listing-type 和 User-type 包含的属性及属性的值:
|
||||
|
||||
- 所有的属性,都基于一定的规则进行了分桶(buckets)。例如21岁,被分桶到 20-30 岁的区间。
|
||||
- 对于首次预定的用户,他的属性为 buckets 的前5行,因为预定之前没有历史预定相关的信息。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653125260611-7d33731b-9167-4fcc-b83b-0a2407ea89ca.png" alt="img" style="zoom: 67%;" />
|
||||
|
||||
看到过前面那个简单的例子后,现在可以看一个原文的 Listing-type 的例子:
|
||||
|
||||
- 一个来自 US 的 Entire Home listing(lt1),它是一个二人间(c2),1 床(b1),一个卧室(bd2),1 个浴室(bt2),每晚平均价格为 60.8 美元(pn3),每晚每个客人的平均价格为 29.3 美元(pg3),5 个评价(r3),所有均 5 星好评(5s4),100% 的新客接受率(nu3)。
|
||||
- 因此该 listing 根据上表规则可以映射为:Listing-type = US_lt1_pn3_pg3_r3_5s4_c2_b1_bd2_bt2_nu3。
|
||||
|
||||
**(2)Type Embedding 的好处**
|
||||
前面在介绍 Type Embedding 和 Listing Embedding 的区别时,提到过不同 User 或 Listing 他们的 Type 可能相同。
|
||||
|
||||
- 故 User-type 和 Listing-type 在一定程度上可以缓解数据稀疏性的问题。
|
||||
- 对于 user 和 listing 而言,他们的属性可能会随着时间的推移而变化。
|
||||
- 故它们的 Embedding 在时间上也具备了动态变化属性。
|
||||
|
||||
**(3)Type Embedding 的训练过程**
|
||||
Type Embedding 的学习同样是基于 Skip-Gram 模型,但是有两点需要注意:
|
||||
|
||||
- 联合训练 User-type Embedding 和 Listing-type Embedding
|
||||
- 如下图(a),在 booking session 中,每个元素代表的是 (User-type, Listing-type)组合。
|
||||
- 为了学习在相同向量空间中的 User-type 和 Listing-type 的 Embeddings,Airbnb 的做法是将 User-type 插入到 booking sessions 中。
|
||||
- 形成一个(User-type, Listing-type)组成的元组序列,这样就可以让 User-type 和 Listing-type 的在 session 中的相对位置保持一致了。
|
||||
|
||||
- User-type 的目标函数:
|
||||
$$
|
||||
\underset{\theta}{\operatorname{argmax}} \sum_{\left(u_{t}, c\right) \in \mathcal{D}_{b o o k}} \log \frac{1}{1+e^{-\mathbf{v}_{c}^{\prime} \mathbf{v}_{u_{t}}}}+\sum_{\left(u_{t}, c\right) \in \mathcal{D}_{n e g}} \log \frac{1}{1+e^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{u_{t}}}}
|
||||
$$
|
||||
|
||||
+ $ \mathcal{D}_{\text {book }} $ 中的 $ u_t $ (中心词)表示 User-type, $ c $ (上下文)表示用户最近的预定过的 Listing-type。 $ \mathcal{D}_{\text {neg}} $ 中的 $ c $ 表示 negative Listing-type。
|
||||
+ $ u_t $ 表示 User-type 的 Embedding, $ \mathbf{v}_{c}^{\prime} $ 表示 Listing-type 的Embedding。
|
||||
|
||||
- Listing-type 的目标函数:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\underset{\theta}{\operatorname{argmax}} & \sum_{\left(l_{t}, c\right) \in \mathcal{D}_{b o o k}} \log \frac{1}{1+\exp ^{-\mathrm{v}_{c}^{\prime} \mathbf{v}_{l_{t}}}}+\sum_{\left(l_{t}, c\right) \in \mathcal{D}_{n e g}} \log \frac{1}{1+\exp ^{\mathrm{v}_{c}^{\prime} \mathbf{v}_{l_{t}}}} \\
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 同理,不过窗口中的中心词为 Listing-type, 上下文为 User-type。
|
||||
|
||||
- Explicit Negatives for Rejections
|
||||
- 用户预定房源以后,还要等待房源主人的确认,主人可能接受或者拒绝客人的预定。
|
||||
- 拒接的原因可能包括,客人星级评定不佳,资料不完整等。
|
||||
|
||||
- 前面学习到的 User-type Embedding 包含了客人的兴趣偏好,Listing-type Embedding 包含了房源的属性特征。
|
||||
- 但是,用户的 Embedding 未包含更容易被哪类房源主人拒绝的潜语义信息。
|
||||
- 房源的 Embedding 未包含主人对哪类客人的拒绝偏好。
|
||||
|
||||
- 为了提高用户预定房源以后,被主人接受的概率。同时,降低房源主人拒绝客人的概率。Airbnb 在训练 User-type 和 Listing-type 的 Embedding时,将用户预定后却被拒绝的样本加入负样本集中(如下图b)。
|
||||
- 更新后,Listing-type 的目标函数:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\underset{\theta}{\operatorname{argmax}} & \sum_{\left(u_{t}, c\right) \in \mathcal{D}_{b o o k}} \log \frac{1}{1+\exp ^{-\mathbf{v}_{c}^{\prime} \mathbf{v}_{u_{t}}}}+\sum_{\left(u_{t}, c\right) \in \mathcal{D}_{n e g}} \log \frac{1}{1+\exp ^{\mathbf{v}_{c}^{\prime} \mathbf{v}_{u_{t}}}} \\
|
||||
&+\sum_{\left(u_{t}, l_{t}\right) \in \mathcal{D}_{\text {reject }}} \log \frac{1}{1+\exp ^{\mathrm{v}_{{l_{t}}}^{\prime} \mathrm{v}_{u_{t}}}}
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
- 更新后,User-type 的目标函数:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\underset{\theta}{\operatorname{argmax}} & \sum_{\left(l_{t}, c\right) \in \mathcal{D}_{b o o k}} \log \frac{1}{1+\exp ^{-\mathrm{v}_{c}^{\prime} \mathbf{v}_{l_{t}}}}+\sum_{\left(l_{t}, c\right) \in \mathcal{D}_{n e g}} \log \frac{1}{1+\exp ^{\mathrm{v}_{c}^{\prime} \mathbf{v}_{l_{t}}}} \\
|
||||
&+\sum_{\left(l_{t}, u_{t}\right) \in \mathcal{D}_{\text {reject }}} \log \frac{1}{1+\exp ^{\mathrm{v}^{\prime}_{u_{t}} \mathrm{v}_{l_{t}}}}
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653131985447-e033cb39-235b-4f46-9634-3b7faec284be.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
# 实验部分
|
||||
|
||||
前面介绍了两种 Embedding 的生成方法,分别为 Listing Embedding 和 User-type & Listing-type Embedding。本节的实验部分,将会介绍它们是如何被使用的。回顾 Airbnb 的业务背景,当用户查看一个房源时,他们有两种方式继续搜索:返回搜索结果页,或者查看房源详情页的「相似房源」。
|
||||
## 相似房源检索
|
||||
在给定学习到的 Listing Embedding,通过计算其向量 $ v_l $ 和来自同一区域的所有 Listing 的向量 $ v_j $ 之间的余弦相似度,可以找到给定房源 $ l $ 的相似房源。
|
||||
|
||||
- 这些相似房源可在同一日期被预定(如果入住-离开时间已确定)。
|
||||
- 相似度最高的 $ K $ 个房源被检索为相似房源。
|
||||
- 计算是在线执行的,并使用我们的分片架构并行进行,其中部分 Embedding 存储在每个搜索机器上。
|
||||
|
||||
A/B 测试显示,基于 Embedding 的解决方案使「相似房源」点击率增加了21%,最终通过「相似房源」产生的预订增加了 4.9%。
|
||||
|
||||
## 实时个性化搜索排名
|
||||
Airbnb 的搜索排名的大致流程为:
|
||||
|
||||
- 给定查询 $ q $ ,返回 $ K $ 条搜索结果。
|
||||
- 基于排序模型 GBDT,对预测结果进行排序。
|
||||
- 将排序后的结果展示给用户。
|
||||
|
||||
**(1)Query Embedding**
|
||||
原文中似乎并没有详细介绍 Airbnb 的搜索技术,在参考的博客中对他们的 Query Embedding 技术进行了描述。如下:
|
||||
|
||||
> Airbnb 对搜索的 Query 也进行了 Embedding,和普通搜索引擎的 Embedding 不太相同的是,这里的 Embedding 不是用自然语言中的语料库去训练的,而是用 Search Session 作为关系训练数据,训练方式更类似于 Item2Vec,Airbnb 中 Queue Embedding 的一个很重要的作用是捕获用户模糊查询与相关目的地的关联,这样做的好处是可以使搜索结果不再仅仅是简单地进行关键字匹配,而是通过更深层次的语义和关系来找到关联信息。比如下图所示的使用 Query Embedding 之前和之后的两个示例(Airbnb 非常人性化地在搜索栏的添加了自动补全,通过算法去 “猜想” 用户的真实目的,大大提高了用户的检索体验)
|
||||
|
||||
**(2)特征构建**
|
||||
对于各查询,给定的训练数据形式为: $ D_s = \left(\mathbf{x}_{i}, y_{i}\right), i=1 \ldots K $ ,其中 $ K $ 表示查询返回的房源数量。
|
||||
|
||||
- $ \mathbf{x}_{i} $ 表示第 $ i $ 个房源结果的 vector containing features:
|
||||
- 由 listing features,user features,query features 以及 cross-features 组成。
|
||||
- $ y_{i} \in\{0,0.01,0.25,1,-0.4\} $ 表示第 $ i $ 个结果的标签。
|
||||
- $ y_i=1 $ 表示用户预定了房源,..., $ y_i=-0.4 $ 表示房主拒绝了用户。
|
||||
|
||||
下面,介绍 Airbnb 是如何利用前面的两种种 Embedding 进行特征构建的。
|
||||
|
||||
- 如果用一句话来概括,这些基于 Embedding 的构建特征均为余弦相似度。
|
||||
- 新构建的特征均为样本 $ \mathbf{x}_{i} $ 特征的一部分。
|
||||
|
||||
构建的特征如下表所示:
|
||||
|
||||
- 表中的 Embedding Features 包含了8种类型,前6种类型的特征计算方式相同。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653139981920-a100085b-007b-4a9c-9edf-74297e9115ae.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
**① 基于 Listing Embedding Features 的特征构建**
|
||||
|
||||
- Airbnb 保留了用户过去两周6种不同类型的历史行为,如下图:
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653140202230-1f49e1dd-5c8c-4445-bd0b-9a17788a7b3f.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 对于每个行为,还要将其按照 market (地域)进行划分。以 $ H_c $ 为例:
|
||||
|
||||
- 假如 $ H_c $ 包含了 New YorK 和 Los Angeles 两个 market 的点击记录,则划分为 $ H_c(NY) $ 和 $ H_c(LA) $ 。
|
||||
|
||||
- 计算候选房源和不同行为之间的相似度。
|
||||
- 上述6种行为对应的相似度特征计算方式是相同的,以 $ H_c $ 为例:
|
||||
$$
|
||||
\operatorname{EmbClickSim}\left(l_{i}, H_{c}\right)=\max _{m \in M} \cos \left(\mathbf{v}_{l_{i}}, \sum_{l_{h} \in m, l_{h} \in H_{c}} \mathbf{v}_{l_{h}}\right)
|
||||
$$
|
||||
|
||||
- 其中, $ M $ 表示 market 的集合。第二项实际上为 Centroid Embedding(Embedding 的均值)。
|
||||
|
||||
- 除此之外,Airbnb 还计算了候选房源的 Embedding 与 latest long click 的 Embedding 之间的余弦相似度。
|
||||
$$
|
||||
\operatorname{EmbLastLongClickSim }\left(l_{i}, H_{l c}\right)=\cos \left(\mathbf{v}_{l_{i}}, \mathbf{v}_{l_{\text {last }}}\right)
|
||||
$$
|
||||
|
||||
**② 基于 User-type & Listing-type Embedding Features 的特征构建**
|
||||
|
||||
- 对于候选房源 $ l_i $ ,先查到其对应的 Listing-type $ l_t $ ,再找到用户的 User-type $ u_t $ 。
|
||||
|
||||
- 最后,计算 $ u_t $ 与 $ l_t $ 对应的 Embedding 之间的余弦相似度:
|
||||
$$
|
||||
\text { UserTypeListingTypeSim }\left(u_{t}, l_{t}\right)=\cos \left(\mathbf{v}_{u_{t}}, \mathbf{v}_{l_{t}}\right)
|
||||
$$
|
||||
|
||||
为了验证上述特征的构建是否有效,Airbnb 还做了特征重要性排序,如下表:
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653142188111-1975bcc4-22a2-45cf-bff0-2783ecb00a0c.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
**(3)模型**
|
||||
特征构建完成后,开始对模型进行训练。
|
||||
|
||||
- Airbnb 在搜索排名中使用的是 GBDT 模型,该模型是一个回归模型。
|
||||
- 模型的训练数据包括数据集 $ \mathcal{D} $ 和 search labels 。
|
||||
|
||||
最后,利用 GBDT 模型来预测线上各搜索房源的在线分数。得到预测分数后,将按照降序的方式展现给用户。
|
||||
# 参考链接
|
||||
|
||||
+ [Embedding 在大厂推荐场景中的工程化实践 - 卢明冬的博客 (lumingdong.cn)](https://lumingdong.cn/engineering-practice-of-embedding-in-recommendation-scenario.html#Airbnb)
|
||||
|
||||
+ [KDD'2018 Best Paper-Embedding技术在Airbnb实时搜索排序中的应用 (qq.com)](https://mp.weixin.qq.com/s/f9IshxX29sWg9NhSa7CaNg)
|
||||
|
||||
+ [再评Airbnb的经典Embedding论文 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/162163054)
|
||||
|
||||
+ [Airbnb爱彼迎房源排序中的嵌入(Embedding)技术 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/43295545)
|
||||
@@ -1,629 +0,0 @@
|
||||
# 双塔召回模型
|
||||
|
||||
---
|
||||
|
||||
双塔模型在推荐领域中是一个十分经典的模型,无论是在召回还是粗排阶段,都会是首选。这主要是得益于双塔模型结构,使得能够在线预估时满足低延时的要求。但也是因为其模型结构的问题,使得无法考虑到user和item特之间的特征交叉,使得影响模型最终效果,因此很多工作尝试调整经典双塔模型结构,在保持在线预估低延时的同时,保证双塔两侧之间有效的信息交叉。下面针对于经典双塔模型以及一些改进版本进行介绍。
|
||||
|
||||
|
||||
|
||||
## 经典双塔模型
|
||||
|
||||
DSSM(Deep Structured Semantic Model)是由微软研究院于CIKM在2013年提出的一篇工作,该模型主要用来解决NLP领域语义相似度任务 ,利用深度神经网络将文本表示为低维度的向量,用来提升搜索场景下文档和query匹配的问题。DSSM 模型的原理主要是:通过用户搜索行为中query 和 doc 的日志数据,通过深度学习网络将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之 间的余弦相似度,从而训练得到隐含语义模型,即 query 侧特征的 embedding 和 doc 侧特征的 embedding,进而可以获取语句的低维 语义向量表达 sentence embedding,可以预测两句话的语义相似度。模型结构如下所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/v2-7f75cc71f5e959d6efa95289d2f5ac13_r.jpg" style="zoom:45%;"/>
|
||||
</div>
|
||||
|
||||
|
||||
从上图可以看出,该网络结构比较简单,是一个由几层DNN组成网络,我们将要搜索文本(Query)和要匹配的文本(Document)的 embedding 输入到网络,网络输出为 128 维的向量,然后通过向量之间计算余弦相似度来计算向量之间距离,可以看作每一个 query 和 document 之间相似分数,然后在做 softmax。
|
||||
|
||||
|
||||
|
||||
而在推荐系统中,最为关键的问题是如何做好用户与item的匹配问题,因此对于推荐系统中DSSM模型的则是为 user 和 item 分别构建独立的子网络塔式结构,利用user和item的曝光或点击日期进行训练,最终得到user侧的embedding和item侧的embedding。因此在推荐系统中,常见的模型结构如下所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220522103456450.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
|
||||
从模型结构上来看,主要包括两个部分:user侧塔和item侧塔,对于每个塔分别是一个DNN结构。通过两侧的特征输入,通过DNN模块到user和item的embedding,然后计算两者之间的相似度(常用內积或者余弦值,下面会说这两种方式的联系和区别),因此对于user和item两侧最终得到的embedding维度需要保持一致,即最后一层全连接层隐藏单元个数相同。
|
||||
|
||||
|
||||
|
||||
在召回模型中,将这种检索行为视为多类分类问题,类似于YouTubeDNN模型。将物料库中所有的item视为一个类别,因此损失函数需要计算每个类的概率值:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220522110742879.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
|
||||
其中$s(x,y)$表示两个向量的相似度,$P(y|x;\theta)$表示预测类别的概率,$M$表示物料库所有的item。但是在实际场景中,由于物料库中的item数量巨大,在计算上式时会十分的耗时,因此会采样一定的数量的负样本来近似计算,后面针对负样本的采样做一些简单介绍。
|
||||
|
||||
|
||||
|
||||
以上就是推荐系统中经典的双塔模型,之所以在实际应用中非常常见,是因为**在海量的候选数据进行召回的场景下,速度很快,效果说不上极端好,但一般而言效果也够用了**。之所以双塔模型在服务时速度很快,是因为模型结构简单(两侧没有特征交叉),但这也带来了问题,双塔的结构无法考虑两侧特征之间的交互信息,**在一定程度上牺牲掉模型的部分精准性**。例如在精排模型中,来自user侧和item侧的特征会在第一层NLP层就可以做细粒度的特征交互,而对于双塔模型,user侧和item侧的特征只会在最后的內积计算时发生,这就导致很多有用的信息在经过DNN结构时就已经被其他特征所模糊了,因此双塔结构由于其结构问题先天就会存在这样的问题。下面针对这个问题来看看一下现有模型的解决思路。
|
||||
|
||||
|
||||
|
||||
## SENet双塔模型
|
||||
|
||||
SENet由Momenta在2017年提出,当时是一种应用于图像处理的新型网络结构。后来张俊林大佬将SENet引入了精排模型[FiBiNET](https://arxiv.org/abs/1905.09433)中,其作用是为了将大量长尾的低频特征抛弃,弱化不靠谱低频特征embedding的负面影响,强化高频特征的重要作用。那SENet结构到底是怎么样的呢,为什么可以起到特征筛选的作用?
|
||||
|
||||
<div align=center>
|
||||
<img src="https://camo.githubusercontent.com/ccf54fc4fcac46667d451f22368e31cf86855bc8bfbff40b7675d524bc899ecf/68747470733a2f2f696d672d626c6f672e6373646e696d672e636e2f32303231303730333136313830373133392e706e673f782d6f73732d70726f636573733d696d6167652f77617465726d61726b2c747970655f5a6d46755a33706f5a57356e6147567064476b2c736861646f775f31302c746578745f6148523063484d364c7939696247396e4c6d4e7a5a473475626d56304c336431656d6876626d6478615746755a773d3d2c73697a655f312c636f6c6f725f4646464646462c745f3730237069635f63656e746572" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
从上图可以看出SENET主要分为三个步骤Squeeze, Excitation, Re-weight:
|
||||
|
||||
- Squeeze阶段:我们对每个特征的Embedding向量进行数据压缩与信息汇总,即在Embedding维度计算均值:
|
||||
|
||||
$$z_i = F_{sq}(e_i) = \frac{1}{k} \sum_{t=1}^k e_i^{(t)}$$
|
||||
|
||||
其中k表示Embedding的维度,Squeeze阶段是将每个特征的Squeeze转换成单一的数值。
|
||||
|
||||
- Excitation阶段:这阶段是根据上一阶段得到的向量进行缩放,即将上阶段的得到的 $1 \times f$ 的向量$Z$先压缩成 $1 \times \frac{f}{r}$ 长度,然后在放回到 $1 \times f$ 的维度,其中$r$表示压缩的程度。这个过程的具体操作就是经过两层DNN。
|
||||
|
||||
$$A = F_{ex}(Z) = \sigma_2(W_2\sigma_1(W_1Z)) $$
|
||||
|
||||
该过程可以理解为:对于当前所有输入的特征,通过相互发生关联,来动态地判断哪些特征重要,哪些特征不重要,而这体现在Excitation阶段的输出结果 $A$,其反应每个特征对应的重要性权重。
|
||||
|
||||
- Re-weight阶段:是将Excitation阶段得到的每个特征对应的权重 $A$ 再乘回到特征对应的Embedding里,就完成了对特征重要性的加权操作。
|
||||
|
||||
$$V=F_{ReWeight }(A,E)=[a_1 \cdot e_1,⋯,a_f \cdot e_f]=[v_1,⋯,v_f]$$
|
||||
|
||||
以上简单的介绍了一下SENet结构,可以发现这种结构可以通过对特征embedding先压缩,再交互,再选择,进而实现特征选择的效果。
|
||||
|
||||
|
||||
|
||||
此外张俊林大佬还将SENet应用于双塔模型中[(SENet双塔模型:在推荐领域召回粗排的应用及其它)](https://zhuanlan.zhihu.com/p/358779957),模型结构如下所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220522152508824.png" style="zoom:70%;"/>
|
||||
</div>
|
||||
|
||||
从上图可以发现,具体地是将双塔中的user塔和Item侧塔的特征输入部分加上一个SENet模块,通过SENet网络,动态地学习这些特征的重要性,通过小权重抑制噪音或者无效低频特征,通过大权重放大重要特征影响的目的。
|
||||
|
||||
|
||||
|
||||
之所以SENet双塔模型是有效的呢?张俊林老师的解释是:双塔模型的问题在于User侧特征和Item侧特征交互太晚,在高层交互,会造成细节信息,也就是具体特征信息的损失,影响两侧特征交叉的效果。而SENet模块在最底层就进行了特征的过滤,使得很多无效低频特征即使被过滤掉,这样更多有用的信息被保留到了双塔的最高层,使得两侧的交叉效果很好;同时由于SENet模块选择出更加重要的信息,使得User侧和Item侧特征之间的交互表达方面增强了DNN双塔的能力。
|
||||
|
||||
|
||||
|
||||
因此SENet双塔模型主要是从特征选择的角度,提高了两侧特征交叉的有效性,减少了噪音对有效信息的干扰,进而提高了双塔模型的效果。此外,除了这样的方式,还可以通过增加通道的方式来增强两侧的信息交互。即对于user和item两侧不仅仅使用一个DNN结构,而是可以通过不同结构(如FM,DCN等)来建模user和item的自身特征交叉,例如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/v2-9c2f7a30c6cadc47be23d6797f095b61_b.jpg" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
|
||||
这样对于user和item侧会得到多个embedding,类似于多兴趣的概念。通过得到的多个user和item的embedding,然后分别计算余弦值再相加(两侧的Embedding维度需要对齐),进而增加了双塔两侧的信息交互。而这种方法在腾讯进行过尝试,他们提出的“并联”双塔就是按照这样的思路,感兴趣的可以了解一下。
|
||||
|
||||
|
||||
|
||||
## 多目标的双塔模型
|
||||
|
||||
现如今多任务学习在实际的应用场景也十分的常见,主要是因为实际场景中业务复杂,往往有很多的衡量指标,例如点击,评论,收藏,关注,转发等。在多任务学习中,往往会针对不同的任务使用一个独有的tower,然后优化不同任务损失。那么针对双塔模型应该如何构建多任务学习框架呢?
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220523113206177.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
如上图所示,在user侧和item侧分别通过多个通道(DNN结构)为每个任务得到一个user embedding和item embedding,然后针对不同的目标分别计算user 和 item 的相似度,并计算各个目标的损失,最后的优化目标可以是多个任务损失之和,或者使用多任务学习中的动态损失权重。
|
||||
|
||||
|
||||
|
||||
这种模型结构,可以针对多目标进行联合建模,通过多任务学习的结构,一方面可以利用不同任务之间的信息共享,为一些稀疏特征提供其他任务中的迁移信息,另一方面可以在召回时,直接使用一个模型得到多个目标预测,解决了多个模型维护困难的问题。也就是说,在线上通过这一个模型就可以同时得到多个指标,例如视频场景,一个模型就可以直接得到点赞,品论,转发等目标的预测值,进而通过这些值计算分数获得最终的Top-K召回结果。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 双塔模型的细节
|
||||
|
||||
关于双塔模型,其模型结构相比排序模型来说很简单,没有过于复杂的结构。但除了结构,有一些细节部分容易被忽视,而这些细节部分往往比模型结构更加重要,因此下面主要介绍一下双塔模型中需要主要的一些细节问题。
|
||||
|
||||
|
||||
|
||||
### 归一化与温度系数
|
||||
|
||||
在[Google的双塔召回模型](https://dl.acm.org/doi/pdf/10.1145/3298689.3346996)中,重点介绍了两个trick,将user和item侧输出的embedding进行归一化以及对于內积值除以温度系数,实验证明这两种方式可以取得十分好的效果。那为什么这两种方法会使得模型的效果更好呢?
|
||||
|
||||
- 归一化:对user侧和item侧的输入embedding,进行L2归一化
|
||||
|
||||
$$u(x,\theta) \leftarrow = \frac{u(x,\theta)}{||u(x,\theta)||_2}$$
|
||||
|
||||
$$v(x,\theta) \leftarrow = \frac{v(x,\theta)}{||v(x,\theta)||_2}$$
|
||||
|
||||
- 温度系数:在归一化之后的向量计算內积之后,除以一个固定的超参 $r$ ,论文中命名为温度系数。
|
||||
|
||||
$$s(u,v) = \frac{<u(x,\theta), v(x,\theta)>}{r}$$
|
||||
|
||||
那为什么需要进行上述的两个操作呢?
|
||||
|
||||
- 归一化的操作主要原因是因为向量点积距离是非度量空间,不满足三角不等式,而归一化的操作使得点击行为转化成了欧式距离。
|
||||
|
||||
首先向量点积是向量对应位相乘并求和,即向量內积。而向量內积**不保序**,例如空间上三个点(A=(10,0),B=(0,10),C=(11,0)),利用向量点积计算的距离 dis(A,B) < dis(A,C),但是在欧式距离下这是错误的。而归一化的操作则会让向量点积转化为欧式距离,例如 $user_{emb}$ 表示归一化user的embedding, $item_{emb}$ 表示归一化 item 的embedding,那么两者之间的欧式距离 $||user_{emb} - item_{emb}||$ 如下, 可以看出归一化的向量点积已转化成了欧式距离。
|
||||
|
||||
$$||user_{emb} - item_{emb}||=\sqrt{||user_{emb}||^2+||item_{emb}||^2-2<user_{emb},item_{emb}>} = \sqrt{2-2<user_{emb},item_{emb}>}$$
|
||||
|
||||
|
||||
|
||||
那没啥非要转为欧式距离呢?这是因为ANN一般是通过计算欧式距离进行检索,这样转化成欧式空间,保证训练和检索一致。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 模型的应用
|
||||
|
||||
在实际的工业应用场景中,分为离线训练和在线服务两个环节。
|
||||
|
||||
- 在离线训练阶段,同过训练数据,训练好模型参数。然后将候选库中所有的item集合离线计算得到对应的embedding,并存储进ANN检索系统,比如faiss。为什么将离线计算item集合,主要是因为item的会相对稳定,不会频繁的变动,而对于用户而言,如果将用户行为作为user侧的输入,那么user的embedding会随着用户行为的发生而不断变化,因此对于user侧的embedding需要实时的计算。
|
||||
- 在线服务阶段,正是因为用户的行为变化需要被即使的反应在用户的embedding中,以更快的反应用户当前的兴趣,即可以实时地体现用户即时兴趣的变化。因此在线服务阶段需要实时的通过拼接用户特征,输入到user侧的DNN当中,进而得到user embedding,在通过user embedding去 faiss中进行ANN检索,召回最相似的K个item embedding。
|
||||
|
||||
可以看到双塔模型结构十分的适合实际的应用场景,在快速服务的同时,还可以更快的反应用户即时兴趣的变化。
|
||||
|
||||
|
||||
|
||||
### 负样本采样
|
||||
|
||||
相比于排序模型而言,召回阶段的模型除了在结构上的不同,在样本选择方面也存在着很大的差异,可以说样本的选择很大程度上会影响召回模型的效果。对于召回模型而言,其负样本并不能和排序模型一样只使用展现未点击样本,因为召回模型在线上面临的数据分布是全部的item,而不仅仅是展现未点击样本。因此在离线训练时,需要让其保证和线上分布尽可能一致,所以在负样本的选择样要尽可能的增加很多未被曝光的item。下面简单的介绍一些常见的采样方法:
|
||||
|
||||
#### 全局随机采样
|
||||
|
||||
全局随机采样指:从全局候选item里面随机抽取一定数量item做为召回模型的负样本。这样的方式实现简单,也可以让模型尽可能的和线上保持一致的分布,尽可能的多的让模型对于全局item有区分的能力。例如YoutubeDNN算法。
|
||||
|
||||
但这样的方式也会存在一定的问题,由于候选的item属于长尾数据,即“八二定律”,也就是说少数热门物料占据了绝大多数的曝光与点击。因此存随机的方式只能让模型在学到粗粒度上差异,对一些尾部item并不友好。
|
||||
|
||||
|
||||
|
||||
#### 全局随机采样 + 热门打压
|
||||
|
||||
针对于全局随机采样的不足,一个直观的方法是针对于item的热度item进行打压,即对于热门的item很多用户可能会点击,需要进行一定程度的欠采样,使得模型更加关注一些非热门的item。 此外在进行负样本采样时,应该对一些热门item进行适当的过采样,这可以尽可能的让模型对于负样本有更加细粒度的区分。例如在word2vec中,负采样方法是根据word的频率,对 negative words进行随机抽样,降 低 negative words 量级。
|
||||
|
||||
之所以热门item做负样本时,要适当过采样,增加负样本难度。因为对于全量的item,模型可以轻易的区分一些和用户兴趣差异性很大的item,难点在于很难区分一些和用户兴趣相似的item。因此在训练模型时,需要适当的增加一些难以区分的负样本来提升模型面对相似item的分区能力。
|
||||
|
||||
|
||||
|
||||
|
||||
#### Hard Negative增强样本
|
||||
|
||||
Hard Negative指的是选取一部分匹配度适中的item,能够增加模型在训练时的难度,提升模型能学习到item之间细粒度上的差异。至于 如何选取在工业界也有很多的解决方案。
|
||||
|
||||
例如Airbnb根据业务逻辑来采样一些hard negative (增加与正样本同城的房间作为负样本,增强了正负样本在地域上的相似性;增加与正样本同城的房间作为负样本,增强了正负样本在地域上的相似性,),详细内容可以查看[原文](https://www.kdd.org/kdd2018/accepted-papers/view/real-time-personalization-using-embeddings-for-search-ranking-at-airbnb)
|
||||
|
||||
例如百度和facebook依靠模型自己来挖掘Hard Negative,都是用上一版本的召回模型筛选出"没那么相似"的<user,item>对,作为额外负样本,用于训练下一版本召回模型。 详细可以查看[Mobius](http://research.baidu.com/Public/uploads/5d12eca098d40.pdf) 和 [EBR](https://arxiv.org/pdf/2006.11632.pdf)
|
||||
|
||||
|
||||
|
||||
#### Batch内随机选择负采样
|
||||
|
||||
基于batch的负采样方法是将batch内选择除了正样本之外的其它Item,做为负样本,其本质就是利用其他样本的正样本随机采样作为自己的负样本。这样的方法可以作为负样本的选择方式,特别是在如今分布式训练以及增量训练的场景中是一个非常值得一试的方法。但这种方法也存在他的问题,基于batch的负采样方法受batch的影响很大,当batch的分布与整体的分布差异很大时就会出现问题,同时batch内负采样也会受到热门item的影响,需要考虑打压热门item的问题。至于解决的办法,Google的双塔召回模型中给出了答案,想了解的同学可以去学习一下。
|
||||
|
||||
|
||||
|
||||
总的来说负样本的采样方法,不光是双塔模型应该重视的工作,而是所有召回模型都应该仔细考虑的方法。
|
||||
|
||||
|
||||
|
||||
## 代码实现
|
||||
|
||||
下面使用一点资讯提供的数据,实践一下DSSM召回模型。该模型的实现主要参考:DeepCtr和DeepMatch模块。
|
||||
|
||||
### 模型训练数据
|
||||
|
||||
1、数据预处理
|
||||
用户侧主要包含一些用户画像属性(用户性别,年龄,所在省市,使用设备及系统);新闻侧主要包括新闻的创建时间,题目,所属 一级、二级类别,题片个数以及关键词。下面主要是对着两部分数据的简单处理:
|
||||
|
||||
```python
|
||||
def proccess(file):
|
||||
if file=="user_info_data_5w.csv":
|
||||
data = pd.read_csv(file_path + file, sep="\t",index_col=0)
|
||||
data["age"] = data["age"].map(lambda x: get_pro_age(x))
|
||||
data["gender"] = data["gender"].map(lambda x: get_pro_age(x))
|
||||
|
||||
data["province"]=data["province"].fillna(method='ffill')
|
||||
data["city"]=data["city"].fillna(method='ffill')
|
||||
|
||||
data["device"] = data["device"].fillna(method='ffill')
|
||||
data["os"] = data["os"].fillna(method='ffill')
|
||||
return data
|
||||
|
||||
elif file=="doc_info.txt":
|
||||
data = pd.read_csv(file_path + file, sep="\t")
|
||||
data.columns = ["article_id", "title", "ctime", "img_num","cate","sub_cate", "key_words"]
|
||||
select_column = ["article_id", "title_len", "ctime", "img_num","cate","sub_cate", "key_words"]
|
||||
|
||||
# 去除时间为nan的新闻以及除脏数据
|
||||
data= data[(data["ctime"].notna()) & (data["ctime"] != 'Android')]
|
||||
data['ctime'] = data['ctime'].astype('str')
|
||||
data['ctime'] = data['ctime'].apply(lambda x: int(x[:10]))
|
||||
data['ctime'] = pd.to_datetime(data['ctime'], unit='s', errors='coerce')
|
||||
|
||||
|
||||
# 这里存在nan字符串和异常数据
|
||||
data["sub_cate"] = data["sub_cate"].astype(str)
|
||||
data["sub_cate"] = data["sub_cate"].apply(lambda x: pro_sub_cate(x))
|
||||
data["img_num"] = data["img_num"].astype(str)
|
||||
data["img_num"] = data["img_num"].apply(photoNums)
|
||||
data["title_len"] = data["title"].apply(lambda x: len(x) if isinstance(x, str) else 0)
|
||||
data["cate"] = data["cate"].fillna('其他')
|
||||
|
||||
return data[select_column]
|
||||
```
|
||||
|
||||
2、构造训练样本
|
||||
该部分主要是根据用户的交互日志中前6天的数据作为训练集,第7天的数据作为测试集,来构造模型的训练测试样本。
|
||||
|
||||
```python
|
||||
def dealsample(file, doc_data, user_data, s_data_str = "2021-06-24 00:00:00", e_data_str="2021-06-30 23:59:59", neg_num=5):
|
||||
# 先处理时间问题
|
||||
data = pd.read_csv(file_path + file, sep="\t",index_col=0)
|
||||
data['expo_time'] = data['expo_time'].astype('str')
|
||||
data['expo_time'] = data['expo_time'].apply(lambda x: int(x[:10]))
|
||||
data['expo_time'] = pd.to_datetime(data['expo_time'], unit='s', errors='coerce')
|
||||
|
||||
s_date = datetime.datetime.strptime(s_data_str,"%Y-%m-%d %H:%M:%S")
|
||||
e_date = datetime.datetime.strptime(e_data_str,"%Y-%m-%d %H:%M:%S") + datetime.timedelta(days=-1)
|
||||
t_date = datetime.datetime.strptime(e_data_str,"%Y-%m-%d %H:%M:%S")
|
||||
|
||||
# 选取训练和测试所需的数据
|
||||
all_data_tmp = data[(data["expo_time"]>=s_date) & (data["expo_time"]<=t_date)]
|
||||
|
||||
# 处理训练数据集 防止穿越样本
|
||||
# 1. merge 新闻信息,得到曝光时间和新闻创建时间; inner join 去除doc_data之外的新闻
|
||||
all_data_tmp = all_data_tmp.join(doc_data.set_index("article_id"),on="article_id",how='inner')
|
||||
|
||||
# 发现还存在 ctime大于expo_time的交互存在 去除这部分错误数据
|
||||
all_data_tmp = all_data_tmp[(all_data_tmp["ctime"]<=all_data_tmp["expo_time"])]
|
||||
|
||||
# 2. 去除与新闻的创建时间在测试数据时间内的交互 ()
|
||||
train_data = all_data_tmp[(all_data_tmp["expo_time"]>=s_date) & (all_data_tmp["expo_time"]<=e_date)]
|
||||
train_data = train_data[(train_data["ctime"]<=e_date)]
|
||||
|
||||
print("有效的样本数:",train_data["expo_time"].count())
|
||||
|
||||
# 负采样
|
||||
if os.path.exists(file_path + "neg_sample.pkl") and os.path.getsize(file_path + "neg_sample.pkl"):
|
||||
neg_samples = pd.read_pickle(file_path + "neg_sample.pkl")
|
||||
# train_neg_samples.insert(loc=2, column="click", value=[0] * train_neg_samples["user_id"].count())
|
||||
else:
|
||||
# 进行负采样的时候对于样本进行限制,只对一定时间范围之内的样本进行负采样
|
||||
doc_data_tmp = doc_data[(doc_data["ctime"]>=datetime.datetime.strptime("2021-06-01 00:00:00","%Y-%m-%d %H:%M:%S"))]
|
||||
neg_samples = negSample_like_word2vec(train_data, doc_data_tmp[["article_id"]].values, user_data[["user_id"]].values, neg_num=neg_num)
|
||||
neg_samples = pd.DataFrame(neg_samples, columns= ["user_id","article_id","click"])
|
||||
neg_samples.to_pickle(file_path + "neg_sample.pkl")
|
||||
|
||||
train_pos_samples = train_data[train_data["click"] == 1][["user_id","article_id", "expo_time", "click"]] # 取正样本
|
||||
|
||||
neg_samples_df = train_data[train_data["click"] == 0][["user_id","article_id", "click"]]
|
||||
train_neg_samples = pd.concat([neg_samples_df.sample(n=train_pos_samples["click"].count()) ,neg_samples],axis=0) # 取负样本
|
||||
|
||||
print("训练集正样本数:",train_pos_samples["click"].count())
|
||||
print("训练集负样本数:",train_neg_samples["click"].count())
|
||||
|
||||
train_data_df = pd.concat([train_neg_samples,train_pos_samples],axis=0)
|
||||
train_data_df = train_data_df.sample(frac=1) # shuffle
|
||||
|
||||
print("训练集总样本数:",train_data_df["click"].count())
|
||||
|
||||
test_data_df = all_data_tmp[(all_data_tmp["expo_time"]>e_date) & (all_data_tmp["expo_time"]<=t_date)][["user_id","article_id", "expo_time", "click"]]
|
||||
|
||||
print("测试集总样本数:",test_data_df["click"].count())
|
||||
print("测试集总样本数:",test_data_df["click"].count())
|
||||
|
||||
all_data_df = pd.concat([train_data_df, test_data_df],axis=0)
|
||||
|
||||
print("总样本数:",all_data_df["click"].count())
|
||||
|
||||
return all_data_df
|
||||
```
|
||||
|
||||
3、负样本采样
|
||||
该部分主要采用基于item的展现次数对全局item进行负采样。
|
||||
|
||||
```python
|
||||
def negSample_like_word2vec(train_data, all_items, all_users, neg_num=10):
|
||||
"""
|
||||
为所有item计算一个采样概率,根据概率为每个用户采样neg_num个负样本,返回所有负样本对
|
||||
1. 统计所有item在交互中的出现频次
|
||||
2. 根据频次进行排序,并计算item采样概率(频次出现越多,采样概率越低,打压热门item)
|
||||
3. 根据采样概率,利用多线程为每个用户采样 neg_num 个负样本
|
||||
"""
|
||||
pos_samples = train_data[train_data["click"] == 1][["user_id","article_id"]]
|
||||
|
||||
pos_samples_dic = {}
|
||||
for idx,u in enumerate(pos_samples["user_id"].unique().tolist()):
|
||||
pos_list = list(pos_samples[pos_samples["user_id"] == u]["article_id"].unique().tolist())
|
||||
if len(pos_list) >= 30: # 30是拍的 需要数据统计的支持确定
|
||||
pos_samples_dic[u] = pos_list[30:]
|
||||
else:
|
||||
pos_samples_dic[u] = pos_list
|
||||
|
||||
# 统计出现频次
|
||||
article_counts = train_data["article_id"].value_counts()
|
||||
df_article_counts = pd.DataFrame(article_counts)
|
||||
dic_article_counts = dict(zip(df_article_counts.index.values.tolist(),df_article_counts.article_id.tolist()))
|
||||
|
||||
for item in all_items:
|
||||
if item[0] not in dic_article_counts.keys():
|
||||
dic_article_counts[item[0]] = 0
|
||||
|
||||
# 根据频次排序, 并计算每个item的采样概率
|
||||
tmp = sorted(list(dic_article_counts.items()), key=lambda x:x[1], reverse=True) # 降序
|
||||
n_articles = len(tmp)
|
||||
article_prob = {}
|
||||
for idx, item in enumerate(tmp):
|
||||
article_prob[item[0]] = cal_pos(idx, n_articles)
|
||||
|
||||
# 为每个用户进行负采样
|
||||
article_id_list = [a[0] for a in article_prob.items()]
|
||||
article_pro_list = [a[1] for a in article_prob.items()]
|
||||
pos_sample_users = list(pos_samples_dic.keys())
|
||||
|
||||
all_users_list = [u[0] for u in all_users]
|
||||
|
||||
print("start negative sampling !!!!!!")
|
||||
pool = multiprocessing.Pool(core_size)
|
||||
res = pool.map(SampleOneProb((pos_sample_users,article_id_list,article_pro_list,pos_samples_dic,neg_num)), tqdm(all_users_list))
|
||||
pool.close()
|
||||
pool.join()
|
||||
|
||||
neg_sample_dic = {}
|
||||
for idx, u in tqdm(enumerate(all_users_list)):
|
||||
neg_sample_dic[u] = res[idx]
|
||||
|
||||
return [[k,i,0] for k,v in neg_sample_dic.items() for i in v]
|
||||
```
|
||||
|
||||
### DSSM 模型
|
||||
|
||||
1、模型构建
|
||||
|
||||
模型构建部分主要是将输入的user 特征以及 item 特征处理完之后分别送入两侧的DNN结构。
|
||||
|
||||
```python
|
||||
def DSSM(user_feature_columns, item_feature_columns, dnn_units=[64, 32],
|
||||
temp=10, task='binary'):
|
||||
# 构建所有特征的Input层和Embedding层
|
||||
feature_encode = FeatureEncoder(user_feature_columns + item_feature_columns)
|
||||
feature_input_layers_list = list(feature_encode.feature_input_layer_dict.values())
|
||||
|
||||
# 特征处理
|
||||
user_dnn_input, item_dnn_input = process_feature(user_feature_columns,\
|
||||
item_feature_columns, feature_encode)
|
||||
|
||||
# 构建模型的核心层
|
||||
if len(user_dnn_input) >= 2:
|
||||
user_dnn_input = Concatenate(axis=1)(user_dnn_input)
|
||||
else:
|
||||
user_dnn_input = user_dnn_input[0]
|
||||
if len(item_dnn_input) >= 2:
|
||||
item_dnn_input = Concatenate(axis=1)(item_dnn_input)
|
||||
else:
|
||||
item_dnn_input = item_dnn_input[0]
|
||||
user_dnn_input = Flatten()(user_dnn_input)
|
||||
item_dnn_input = Flatten()(item_dnn_input)
|
||||
user_dnn_out = DNN(dnn_units)(user_dnn_input)
|
||||
item_dnn_out = DNN(dnn_units)(item_dnn_input)
|
||||
|
||||
|
||||
# 计算相似度
|
||||
scores = CosinSimilarity(temp)([user_dnn_out, item_dnn_out]) # (B,1)
|
||||
# 确定拟合目标
|
||||
output = PredictLayer()(scores)
|
||||
# 根据输入输出构建模型
|
||||
model = Model(feature_input_layers_list, output)
|
||||
return model
|
||||
```
|
||||
|
||||
2、CosinSimilarity相似度计算
|
||||
|
||||
在余弦相似度计算,主要是注意使用归一化以及温度系数的技巧。
|
||||
|
||||
```python
|
||||
def call(self, inputs, **kwargs):
|
||||
"""inputs 是一个列表"""
|
||||
query, candidate = inputs
|
||||
# 计算两个向量的二范数
|
||||
query_norm = tf.norm(query, axis=self.axis) # (B, 1)
|
||||
candidate_norm = tf.norm(candidate, axis=self.axis)
|
||||
# 计算向量点击,即內积操作
|
||||
scores = tf.reduce_sum(tf.multiply(query, candidate), axis=-1)#(B,1)
|
||||
# 相似度除以二范数, 防止除零
|
||||
scores = tf.divide(scores, query_norm * candidate_norm + 1e-8)
|
||||
# 对score的范围限制到(-1, 1)之间
|
||||
scores = tf.clip_by_value(scores, -1, 1)
|
||||
# 乘以温度系数
|
||||
score = scores * self.temperature
|
||||
return score
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 模型训练
|
||||
|
||||
1、稀疏特征编码
|
||||
该部分主要是针对于用户侧和新闻侧的稀疏特征进行编码,并将训练样本join上两侧的特征。
|
||||
|
||||
```python
|
||||
# 数据和测试数据
|
||||
data, user_data, doc_data = get_all_data()
|
||||
|
||||
# 1.Label Encoding for sparse features,and process sequence features with `gen_date_set` and `gen_model_input`
|
||||
feature_max_idx = {}
|
||||
feature_encoder = {}
|
||||
|
||||
user_sparse_features = ["user_id", "device", "os", "province", "city", "age", "gender"]
|
||||
for feature in user_sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
user_data[feature] = lbe.fit_transform(user_data[feature]) + 1
|
||||
feature_max_idx[feature] = user_data[feature].max() + 1
|
||||
feature_encoder[feature] = lbe
|
||||
|
||||
|
||||
doc_sparse_features = ["article_id", "cate", "sub_cate"]
|
||||
doc_dense_features = ["title_len", "img_num"]
|
||||
|
||||
for feature in doc_sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
if feature in ["cate","sub_cate"]:
|
||||
# 这里面会出现一些float的数据,导致无法编码
|
||||
doc_data[feature] = lbe.fit_transform(doc_data[feature].astype(str)) + 1
|
||||
else:
|
||||
doc_data[feature] = lbe.fit_transform(doc_data[feature]) + 1
|
||||
feature_max_idx[feature] = doc_data[feature].max() + 1
|
||||
feature_encoder[feature] = lbe
|
||||
|
||||
data["article_id"] = feature_encoder["article_id"].transform(data["article_id"].tolist())
|
||||
data["user_id"] = feature_encoder["user_id"].transform(data["user_id"].tolist())
|
||||
|
||||
|
||||
# join 用户侧和新闻侧的特征
|
||||
data = data.join(user_data.set_index("user_id"), on="user_id", how="inner")
|
||||
data = data.join(doc_data.set_index("article_id"), on="article_id", how="inner")
|
||||
|
||||
sparse_features = user_sparse_features + doc_sparse_features
|
||||
dense_features = doc_dense_features
|
||||
|
||||
features = sparse_features + dense_features
|
||||
|
||||
mms = MinMaxScaler(feature_range=(0, 1))
|
||||
data[dense_features] = mms.fit_transform(data[dense_features])
|
||||
```
|
||||
|
||||
2、配置特征以及模型训练
|
||||
构建模型所需的输入特征,同时构建DSSM模型及训练。
|
||||
|
||||
```python
|
||||
embedding_dim = 8
|
||||
user_feature_columns = [SparseFeat('user_id', feature_max_idx['user_id'], embedding_dim),
|
||||
SparseFeat("gender", feature_max_idx['gender'], embedding_dim),
|
||||
SparseFeat("age", feature_max_idx['age'], embedding_dim),
|
||||
SparseFeat("device", feature_max_idx['device'], embedding_dim),
|
||||
SparseFeat("os", feature_max_idx['os'], embedding_dim),
|
||||
SparseFeat("province", feature_max_idx['province'], embedding_dim),
|
||||
SparseFeat("city", feature_max_idx['city'], embedding_dim), ]
|
||||
|
||||
item_feature_columns = [SparseFeat('article_id', feature_max_idx['article_id'], embedding_dim),
|
||||
DenseFeat('img_num', 1),
|
||||
DenseFeat('title_len', 1),
|
||||
SparseFeat('cate', feature_max_idx['cate'], embedding_dim),
|
||||
SparseFeat('sub_cate', feature_max_idx['sub_cate'], embedding_dim)]
|
||||
|
||||
model = DSSM(user_feature_columns, item_feature_columns,
|
||||
user_dnn_hidden_units=(32, 16, embedding_dim), item_dnn_hidden_units=(32, 16, embedding_dim)) # FM(user_feature_columns,item_feature_columns)
|
||||
|
||||
model.compile(optimizer="adagrad", loss = "binary_crossentropy", metrics=[tf.keras.metrics.Recall(), tf.keras.metrics.Precision()] ) #
|
||||
|
||||
history = model.fit(train_model_input, train_label, batch_size=256, epochs=4, verbose=1, validation_split=0.2, )
|
||||
```
|
||||
|
||||
3、生成embedding用于召回
|
||||
利用训练过的模型获取所有item的embeddings,同时获取所有测试集的user embedding,保存之后用于之后的召回工作。
|
||||
|
||||
```python
|
||||
all_item_model_input = {"article_id": item_profile['article_id'].values,
|
||||
"img_num": item_profile['img_num'].values,
|
||||
"title_len": item_profile['title_len'].values,
|
||||
"cate": item_profile['cate'].values,
|
||||
"sub_cate": item_profile['sub_cate'].values,}
|
||||
|
||||
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
|
||||
item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
|
||||
|
||||
user_embs = user_embedding_model.predict(test_user_model_input, batch_size=2 ** 12)
|
||||
item_embs = item_embedding_model.predict(all_item_model_input, batch_size=2 ** 12)
|
||||
|
||||
user_idx_2_rawid, doc_idx_2_rawid = {}, {}
|
||||
|
||||
for i in range(len(user_embs)):
|
||||
user_idx_2_rawid[i] = test_user_model_input["user_id"][i]
|
||||
|
||||
for i in range(len(item_embs)):
|
||||
doc_idx_2_rawid[i] = all_item_model_input["article_id"][i]
|
||||
|
||||
# 保存一份
|
||||
pickle.dump((user_embs, user_idx_2_rawid, feature_encoder["user_id"]), open(file_path + 'user_embs.pkl', 'wb'))
|
||||
pickle.dump((item_embs, doc_idx_2_rawid, feature_encoder["article_id"]), open(file_path + 'item_embs.pkl', 'wb'))
|
||||
```
|
||||
|
||||
|
||||
### ANN召回
|
||||
|
||||
1、为测试集用户召回
|
||||
通过annoy tree为所有的item构建索引,并通过测试集中所有的user embedding为每个用户召回一定数量的item。
|
||||
|
||||
```python
|
||||
def get_DSSM_recall_res(user_embs, doc_embs, user_idx_2_rawid, doc_idx_2_rawid, topk):
|
||||
"""近邻检索,这里用annoy tree"""
|
||||
# 把doc_embs构建成索引树
|
||||
f = user_embs.shape[1]
|
||||
t = AnnoyIndex(f, 'angular')
|
||||
for i, v in enumerate(doc_embs):
|
||||
t.add_item(i, v)
|
||||
t.build(10)
|
||||
|
||||
# 每个用户向量, 返回最近的TopK个item
|
||||
user_recall_items_dict = collections.defaultdict(dict)
|
||||
for i, u in enumerate(user_embs):
|
||||
recall_doc_scores = t.get_nns_by_vector(u, topk, include_distances=True)
|
||||
# recall_doc_scores是(([doc_idx], [scores])), 这里需要转成原始doc的id
|
||||
raw_doc_scores = list(recall_doc_scores)
|
||||
raw_doc_scores[0] = [doc_idx_2_rawid[i] for i in raw_doc_scores[0]]
|
||||
# 转换成实际用户id
|
||||
user_recall_items_dict[user_idx_2_rawid[i]] = dict(zip(*raw_doc_scores))
|
||||
|
||||
# 默认是分数从小到大排的序, 这里要从大到小
|
||||
user_recall_items_dict = {k: sorted(v.items(), key=lambda x: x[1], reverse=True) for k, v in user_recall_items_dict.items()}
|
||||
|
||||
pickle.dump(user_recall_items_dict, open(file_path + 'DSSM_u2i_dict.pkl', 'wb'))
|
||||
|
||||
return user_recall_items_dict
|
||||
```
|
||||
|
||||
2、测试召回结果
|
||||
为测试集用户的召回结果进行测试。
|
||||
|
||||
```python
|
||||
user_recall_items_dict = get_DSSM_recall_res(user_embs, item_embs, user_idx_2_rawid, doc_idx_2_rawid, topk=TOP_NUM)
|
||||
|
||||
test_true_items = {line[0]:line[1] for line in test_set}
|
||||
|
||||
s = []
|
||||
precision = []
|
||||
for i, uid in tqdm(enumerate(list(user_recall_items_dict.keys()))):
|
||||
# try:
|
||||
pred = [x for x, _ in user_recall_items_dict[uid]]
|
||||
filter_item = None
|
||||
recall_score = recall_N(test_true_items[uid], pred, N=TOP_NUM)
|
||||
s.append(recall_score)
|
||||
precision_score = precision_N(test_true_items[uid], pred, N=TOP_NUM)
|
||||
precision.append(precision_score)
|
||||
print("recall", np.mean(s))
|
||||
print("precision", np.mean(precision))
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 参考
|
||||
|
||||
- [负样本为王:评Facebook的向量化召回算法](https://zhuanlan.zhihu.com/p/165064102)
|
||||
|
||||
- [多目标DSSM召回实战](https://mp.weixin.qq.com/s/aorZ43WozKrD2AudR6AnOg)
|
||||
|
||||
- [召回模型中的负样本构造](https://zhuanlan.zhihu.com/p/358450850)
|
||||
|
||||
- [Youtube双塔模型](https://dl.acm.org/doi/10.1145/3298689.3346996)
|
||||
|
||||
- [张俊林:SENet双塔模型:在推荐领域召回粗排的应用及其它](https://zhuanlan.zhihu.com/p/358779957)
|
||||
|
||||
- [双塔召回模型的前世今生(上篇)](https://zhuanlan.zhihu.com/p/430503952)
|
||||
|
||||
- [双塔召回模型的前世今生(下篇)](https://zhuanlan.zhihu.com/p/441597009)
|
||||
|
||||
- [Learning Deep Structured Semantic Models for Web Search using Clickthrough Data](https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2013_DSSM_fullversion.pdf)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,124 +0,0 @@
|
||||
# FM 模型结构
|
||||
|
||||
FM 模型用于排序时,模型的公式定义如下:
|
||||
$$
|
||||
\hat{y}(\mathbf{x}):=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}
|
||||
$$
|
||||
+ 其中,$i$ 表示特征的序号,$n$ 表示特征的数量;$x_i \in \mathbb{R}$ 表示第 $i$ 个特征的值。
|
||||
+ $v_i,v_j \in \mathbb{R}^{k} $ 分别表示特征 $x_i,x_j$ 对应的隐语义向量(Embedding向量), $\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle:=\sum_{f=1}^{k} v_{i, f} \cdot v_{j, f}$ 。
|
||||
+ $w_0,w_i\in \mathbb{R}$ 均表示需要学习的参数。
|
||||
|
||||
**FM 的一阶特征交互**
|
||||
|
||||
在 FM 的表达式中,前两项为特征的一阶交互项。将其拆分为用户特征和物品特征的一阶特征交互项,如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
& w_{0}+\sum_{i=1}^{n} w_{i} x_{i} \\
|
||||
&= w_{0} + \sum_{t \in I}w_{t} x_{t} + \sum_{u\in U}w_{u} x_{u} \\
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 其中,$U$ 表示用户相关特征集合,$I$ 表示物品相关特征集合。
|
||||
|
||||
**FM 的二阶特征交互**
|
||||
|
||||
观察 FM 的二阶特征交互项,可知其计算复杂度为 $O\left(k n^{2}\right)$ 。为了降低计算复杂度,按照如下公式进行变换。
|
||||
$$
|
||||
\begin{aligned}
|
||||
& \sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j} \\
|
||||
=& \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}-\frac{1}{2} \sum_{i=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{i}\right\rangle x_{i} x_{i} \\
|
||||
=& \frac{1}{2}\left(\sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{j, f} x_{i} x_{j}-\sum_{i=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{i, f} x_{i} x_{i}\right) \\
|
||||
=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{}\left(\sum_{j=1}^{n} v_{j, f} x_{j}\right)-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \\
|
||||
=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
+ 公式变换后,计算复杂度由 $O\left(k n^{2}\right)$ 降到 $O\left(k n\right)$。
|
||||
|
||||
由于本文章需要将 FM 模型用在召回,故将二阶特征交互项拆分为用户和物品项。有:
|
||||
$$
|
||||
\begin{aligned}
|
||||
& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \\
|
||||
=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{u \in U} v_{u, f} x_{u} + \sum_{t \in I} v_{t, f} x_{t}\right)^{2}-\sum_{u \in U} v_{u, f}^{2} x_{u}^{2} - \sum_{t\in I} v_{t, f}^{2} x_{t}^{2}\right) \\
|
||||
=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{u \in U} v_{u, f} x_{u}\right)^{2} + \left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} + 2{\sum_{u \in U} v_{u, f} x_{u}}{\sum_{t \in I} v_{t, f} x_{t}} - \sum_{u \in U} v_{u, f}^{2} x_{u}^{2} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 其中,$U$ 表示用户相关特征集合,$I$ 表示物品相关特征集合。
|
||||
|
||||
|
||||
|
||||
# FM 用于召回
|
||||
|
||||
基于 FM 召回,我们可以将 $\hat{y}(\mathbf{x}):=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}$ 作为用户和物品之间的匹配分。
|
||||
|
||||
+ 在上一小节中,对于 FM 的一阶、二阶特征交互项,已将其拆分为用户项和物品项。
|
||||
+ 对于同一用户,即便其与不同物品进行交互,但用户特征内部之间的一阶、二阶交互项得分都是相同的。
|
||||
+ 这就意味着,在比较用户与不同物品之间的匹配分时,只需要比较:(1)物品内部之间的特征交互得分;(2)用户和物品之间的特征交互得分。
|
||||
|
||||
**FM 的一阶特征交互**
|
||||
|
||||
+ 将全局偏置和用户一阶特征交互项进行丢弃,有:
|
||||
$$
|
||||
FM_{一阶} = \sum_{t \in I} w_{t} x_{t}
|
||||
$$
|
||||
|
||||
**FM 的二阶特征交互**
|
||||
|
||||
+ 将用户特征内部的特征交互项进行丢弃,有:
|
||||
$$
|
||||
\begin{aligned}
|
||||
& FM_{二阶} = \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} + 2{\sum_{u \in U} v_{u, f} x_{u}}{\sum_{t \in I} v_{t, f} x_{t}} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right) \\
|
||||
&= \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right) + \sum_{f=1}^{k}\left( {\sum_{u \in U} v_{u, f} x_{u}}{\sum_{t \in I} v_{t, f} x_{t}} \right)
|
||||
|
||||
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
合并 FM 的一阶、二阶特征交互项,得到基于 FM 召回的匹配分计算公式:
|
||||
$$
|
||||
\text{MatchScore}_{FM} = \sum_{t \in I} w_{t} x_{t} + \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right) + \sum_{f=1}^{k}\left( {\sum_{u \in U} v_{u, f} x_{u}}{\sum_{t \in I} v_{t, f} x_{t}} \right)
|
||||
$$
|
||||
在基于向量的召回模型中,为了 ANN(近似最近邻算法) 或 Faiss 加速查找与用户兴趣度匹配的物品。基于向量的召回模型,一般最后都会得到用户和物品的特征向量表示,然后通过向量之间的内积或者余弦相似度表示用户对物品的兴趣程度。
|
||||
|
||||
基于 FM 模型的召回算法,也是向量召回算法的一种。所以下面,将 $\text{MatchScore}_{FM}$ 化简为用户向量和物品向量的内积形式,如下:
|
||||
$$
|
||||
\text{MatchScore}_{FM} = V_{item} V_{user}^T
|
||||
$$
|
||||
|
||||
+ 用户向量:
|
||||
$$
|
||||
V_{user} = [1; \quad {\sum_{u \in U} v_{u} x_{u}}]
|
||||
$$
|
||||
|
||||
+ 用户向量由两项表达式拼接得到。
|
||||
+ 第一项为常数 $1$,第二项是将用户相关的特征向量进行 sum pooling 。
|
||||
|
||||
+ 物品向量:
|
||||
$$
|
||||
V_{item} = [\sum_{t \in I} w_{t} x_{t} + \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{t \in I} v_{t, f} x_{t}\right)^{2} - \sum_{t \in I} v_{t, f}^{2} x_{t}^{2}\right); \quad
|
||||
{\sum_{t \in I} v_{t} x_{t}} ]
|
||||
$$
|
||||
|
||||
+ 第一项表示物品相关特征向量的一阶、二阶特征交互。
|
||||
+ 第二项是将物品相关的特征向量进行 sum pooling 。
|
||||
|
||||
|
||||
|
||||
# 思考题
|
||||
|
||||
1. 为什么不直接将 FM 中学习到的 User Embedding: ${\sum_{u \in U} v_{u} x_{u}}$ 和 Item Embedding: $\sum_{t \in I} v_{t} x_{t}$ 的内积做召回呢?
|
||||
|
||||
答:这样做,也不是不行,但是效果不是特别好。**因为用户喜欢的,未必一定是与自身最匹配的,也包括一些自身性质极佳的item(e.g.,热门item)**,所以,**非常有必要将"所有Item特征一阶权重之和"和“所有Item特征隐向量两两点积之和”考虑进去**,但是也还必须写成点积的形式。
|
||||
|
||||
|
||||
|
||||
# 代码实战
|
||||
|
||||
正在完善...
|
||||
|
||||
|
||||
|
||||
# 参考链接
|
||||
|
||||
+ [paper.dvi (ntu.edu.tw)](https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf)
|
||||
+ [FM:推荐算法中的瑞士军刀 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/343174108)
|
||||
@@ -1,589 +0,0 @@
|
||||
## 写在前面
|
||||
YouTubeDNN模型是2016年的一篇文章,虽然离着现在有些久远, 但这篇文章无疑是工业界论文的典范, 完全是从工业界的角度去思考如何去做好一个推荐系统,并且处处是YouTube工程师留给我们的宝贵经验, 由于这两天用到了这个模型,今天也正好重温了下这篇文章,所以借着这个机会也整理出来吧, 王喆老师都称这篇文章是"神文", 可见其不一般处。
|
||||
|
||||
今天读完之后, 给我的最大感觉,首先是从工程的角度去剖析了整个推荐系统,讲到了推荐系统中最重要的两大模块: 召回和排序, 这篇论文对初学者非常友好,之前的论文模型是看不到这么全面的系统的,总有一种管中规豹的感觉,看不到全局,容易着相。 其次就是这篇文章给出了很多优化推荐系统中的工程性经验, 不管是召回还是排序上,都有很多的套路或者trick,比如召回方面的"example age", "负采样","非对称消费,防止泄露",排序方面的特征工程,加权逻辑回归等, 这些东西至今也都非常的实用,所以这也是这篇文章厉害的地方。
|
||||
|
||||
本篇文章依然是以paper为主线, 先剖析paper里面的每个细节,当然我这里也参考了其他大佬写的文章,王喆老师的几篇文章写的都很好,链接我也放在了下面,建议也看看。然后就是如何用YouTubeDNN模型,代码复现部分,由于时间比较短,自己先不复现了,调deepmatch的包跑起来,然后在新闻推荐数据集上进行了一些实验, 尝试了论文里面讲述的一些方法,这里主要是把deepmatch的YouTubeDNN模型怎么使用,以及我整个实验过程的所思所想给整理下, 因为这个模型结构本质上并不是很复杂(三四层的全连接网络),就不自己在实现一遍啦, 一些工程经验或者思想,我觉得才是这篇文章的精华部分。
|
||||
|
||||
|
||||
## 引言与推荐系统的漏斗范式
|
||||
### 引言部分
|
||||
本篇论文是工程性论文(之前的DIN也是偏工程实践的论文), 行文风格上以实际应用为主, 我们知道YouTube是全球性的视频网站, 所以这篇文章主要讲述了YouTube视频推荐系统的基本架构以及细节,以及各种处理tricks。
|
||||
|
||||
在Introduction部分, 作者首先说了在工业上的YouTube视频推荐系统主要面临的三大挑战:
|
||||
1. Scale(规模): 视频数量非常庞大,大规模数据下需要分布式学习算法以及高效的线上服务系统,文中体现这一点的是召回模型线下训练的时候,采用了负采样的思路,线上服务的时候,采用了hash映射,然后近邻检索的方式来满足实时性的需求, 这个之前我整理过faiss包和annoy包的使用, 感兴趣的可以看看。 其实,再拔高一层,我们推荐系统的整体架构呈漏斗范式,也是为了保证能从大规模情景下实时推荐。
|
||||
2. Freshness(新鲜度): YouTube上的视频是一个动态的, 用户实时上传,且实时访问, 那么这时候, 最新的视频往往就容易博得用户的眼球, 用户一般都比较喜欢看比较新的视频, 而不管是不是真和用户相关(这个感觉和新闻比较类似呀), 这时候,就需要模型有建模新上传内容以及用户最新发生的行为能力。 为了让模型学习到用户对新视频有偏好, 后面策略里面加了一个"example age"作为体现。我们说的"探索与利用"中的探索,其实也是对新鲜度的把握。
|
||||
3. Noise(噪声): 由于数据的稀疏和不可见的其他原因, 数据里面的噪声非常之多,这时候,就需要让这个推荐系统变得鲁棒,怎么鲁棒呢? 这个涉及到召回和排序两块,召回上需要考虑更多实际因素,比如非对称消费特性,高活用户因素,时间因素,序列因素等,并采取了相应的措施, 而排序上做更加细致的特征工程, 尽量的刻画出用户兴趣以及视频的特征 优化训练目标,使用加权的逻辑回归等。而召回和排序模型上,都采用了深度神经网络,通过特征的相互交叉,有了更强大的建模能力, 相比于之前用的MF(矩阵分解), 建模能力上有了很大的提升, 这些都有助于帮助减少噪声, 使得推荐结果更加准确。
|
||||
|
||||
所以从文章整体逻辑上看, 后面的各个细节,其实都是围绕着挑战展开的,找到当前推荐面临的问题,就得想办法解决问题,所以这篇文章的行文逻辑也是非常清晰的。
|
||||
|
||||
知道了挑战, 那么下面就看看YouTubeDNN的整体推荐系统架构。
|
||||
|
||||
### YouTubeDNN推荐系统架构
|
||||
整个推荐架构图如下, 这个算是比较原始的漏斗结构了:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/1c5dbd6d6c1646d09998b18d45f869e5.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
这篇文章之所以写的好, 是给了我们一个看推荐系统的宏观视角, 这个系统主要是两大部分组成: 召回和排序。召回的目的是根据用户部分特征,从海量物品库,快速找到小部分用户潜在感兴趣的物品交给精排,重点强调快,精排主要是融入更多特征,使用复杂模型,来做个性化推荐,强调准。
|
||||
|
||||
而对于这两块的具体描述, 论文里面也给出了解释, 我这里简单基于我目前的理解扩展下主流方法:
|
||||
1. 召回侧
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/5ebcd6f882934b7e9e2ffb9de2aee29d.png#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
召回侧模型的输入一般是用户的点击历史, 因为我们认为这些历史能更好的代表用户的兴趣, 另外还有一些人口统计学特征,比如性别,年龄,地域等, 都可以作为召回侧模型的输入。 而最终模型的输出,就是与该用户相关的一个候选视频集合, 量级的话一般是几百。
|
||||
<br>召回侧, 目前根据我的理解,大致上有两大类召回方式,一类是策略规则,一类是监督模型+embedding,其中策略规则,往往和真实场景有关,比如热度,历史重定向等等,不同的场景会有不同的召回方式,这种属于"特异性"知识。
|
||||
<br>后面的模型+embedding思路是一种"普适"方法,我上面图里面梳理出了目前给用户和物品打embedding的主流方法, 这些方法大致成几个系列,比如FM系列(FM,FFM等), 用户行为序列,基于图和知识图谱系列,经典双塔系列等,这些方法看似很多很复杂,其实本质上还是给用户或者是物品打embedding而已,只不过考虑的角度方式不同。 这里的YouTubeDNN召回模型,也是这里的一种方式而已。
|
||||
2. 精排侧
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/08953c0e8a00476f90bd9e206d4a02c6.png#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
召回那边对于每个用户, 给出了几百个比较相关的候选视频, 把几百万的规模降到了几百, 当然,召回那边利用的特征信息有限,并不能很好的刻画用户和视频特点,所以, 在精排侧,主要是想利用更多的用户,视频特征,刻画特点更加准确些,从这几百个里面选出几个或者十几个推荐给用户。 而涉及到准, 主要的发力点一般有三个:特征工程, 模型设计以及训练方法。 这三个发力点文章几乎都有所涉及, 除了模式设计有点审时度势之外,特征工程以及训练方法的处理上非常漂亮,具体的后面再整理。<br>
|
||||
精排侧,这一块的大致发展趋势,从ctr预估到多目标, 而模型演化上,从人工特征工程到特征工程自动化。主要是三大块, CTR预估主要分为了传统的LR,FM大家族,以及后面自动特征交叉的DNN家族,而多目标优化,目前是很多大公司的研究现状,更是未来的一大发展趋势,如何能让模型在各个目标上面的学习都能"游刃有余"是一件非常具有挑战的事情,毕竟不同的目标可能会互相冲突,互相影响,所以这里的研究热点又可以拆分成网络结构演化以及loss设计优化等, 而网络结构演化中,又可以再一次细分。 当然这每个模型或者技术几乎都有对应paper,我们依然可以通过读paper的方式,把这些关键技术学习到。
|
||||
|
||||
这两阶段的方法, 就能保证我们从大规模视频库中实时推荐, 又能保证个性化,吸引用户。 当然,随着时间的发展, 可能数据量非常非常大了, 此时召回结果规模精排依然无法处理,所以现在一般还会在召回和精排之间,加一个粗排进一步筛选作为过渡, 而随着场景越来越复杂, 精排产生的结果也不是直接给到用户,而是会再后面加一个重排后处理下,这篇paper里面其实也简单的提了下这种思想,在排序那块会整理到。 所以如今的漏斗, 也变得长了些。
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/aeae52971a1345a98b310890ea81be53.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
论文里面还提到了对模型的评估方面, 线下评估的时候,主要是采用一些常用的评估指标(精确率,召回率, 排序损失或者auc这种), 但是最终看算法和模型的有效性, 是通过A/B实验, 在A/B实验中会观察用户真实行为,比如点击率, 观看时长, 留存率这种, 这些才是我们终极目标, 而有时候, A/B实验的结果和线下我们用的这些指标并不总是相关, 这也是推荐系统这个场景的复杂性。 我们往往也会用一些策略,比如修改模型的优化目标,损失函数这种, 让线下的这个目标尽量的和A/B衡量的这种指标相关性大一些。 当然,这块又是属于业务场景问题了,不在整理范畴之中。 但2016年,竟然就提出了这种方式, 所以我觉得,作为小白的我们, 想了解工业上的推荐系统, 这篇paper是不二之选。
|
||||
|
||||
OK, 从宏观的大视角看完了漏斗型的推荐架构,我们就详细看看YouTube视频推荐架构里面召回和排序模块的模型到底长啥样子? 为啥要设计成这个样子? 为了应对实际中出现的挑战,又有哪些策略?
|
||||
|
||||
## YouTubeDNN的召回模型细节剖析
|
||||
上面说过, 召回模型的目的是在大量YouTube视频中检索出数百个和用户相关的视频来。
|
||||
|
||||
这个问题,我们可以看成一个多分类的问题,即用户在某一个时刻点击了某个视频, 可以建模成输入一个用户向量, 从海量视频中预测出被点击的那个视频的概率。
|
||||
|
||||
换成比较准确的数学语言描述, 在时刻$t$下, 用户$U$在背景$C$下对每个视频$i$的观看行为建模成下面的公式:
|
||||
$$
|
||||
P\left(w_{t}=i \mid U, C\right)=\frac{e^{v_{i} u}}{\sum_{j \in V} e^{v_{j} u}}
|
||||
$$
|
||||
这里的$u$表示用户向量, 这里的$v$表示视频向量, 两者的维度都是$N$, 召回模型的任务,就是通过用户的历史点击和山下文特征, 去学习最终的用户表示向量$u$以及视频$i$的表示向量$v_i$, 不过这俩还有个区别是$v_i$本身就是模型参数, 而$u$是神经网络的输出(函数输出),是输入与模型参数的计算结果。
|
||||
>解释下这个公式, 为啥要写成这个样子,其实是word2vec那边借鉴过来的,$e^{ (v_{i} u)}$表示的是当前用户向量$u$与当前视频$v_i$的相似程度,$e$只是放大这个相似程度而已, 不用管。 为啥这个就能表示相似程度呢? 因为两个向量的点积运算的含义就是可以衡量两个向量的相似程度, 两个向量越相似, 点积就会越大。 所以这个应该解释明白了。 再看分母$\sum_{j \in V} e^{v_{j} u}$, 这个显然是用户向量$u$与所有视频$v$的一个相似程度求和。 那么两者一除, 依然是代表了用户$u$与输出的视频$v_i$的相似程度,只不过归一化到了0-1之间, 毕竟我们知道概率是0-1之间的, 这就是为啥这个概率是右边形式的原因。 因为右边公式表示了用户$u$与输出的视频$v_i$的相似程度, 并且这个相似程度已经归一化到了0-1之间, 我们给定$u$希望输出$v_i$的概率越大,因为这样,当前的视频$v_i$和当前用户$u$更加相关,正好对应着点击行为不是吗?
|
||||
|
||||
那么,这个召回模型到底长啥样子呢?
|
||||
### 召回模型结构
|
||||
召回模型的结构如下:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/724ff38c1d6448399edb658b1b27e18e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这个模型结构呢,相比之前的模型, 比较简单,就是一个DNN。
|
||||
|
||||
它的输入主要是用户侧的特征,包括用户观看的历史video序列, 用户搜索的历史tokens, 然后就是用户的人文特征,比如地理位置, 性别,年龄这些。 这些特征处理上,和之前那些模型的也比较类似,
|
||||
* 用户历史序列,历史搜索tokens这种序列性的特征: 一般长这样`[item_id5, item_id2, item_id3, ...]`, 这种id特征是高维稀疏,首先会通过一个embedding层,转成低维稠密的embedding特征,即历史序列里面的每个id都会对应一个embedding向量, 这样历史序列就变成了多个embedding向量的形式, 这些向量一般会进行融合,常见的是average pooling,即每一维求平均得到一个最终向量来表示用户的历史兴趣或搜索兴趣。
|
||||
>这里值的一提的是这里的embedding向量得到的方式, 论文中作者这里说是通过word2vec方法计算的, 关于word2vec,这里就不过多解释,也就是每个item事先通过w2v方式算好了的embedding,直接作为了输入,然后进行pooling融合。<br><br>除了这种算好embedding方式之外,还可以过embedding层,跟上面的DNN一起训练,这些都是常规操作,之前整理的精排模型里面大都是用这种方式。
|
||||
|
||||
论文里面使用了用户最近的50次观看历史,用户最近50次搜索历史token, embedding维度是256维, 采用的average pooling。 当然,这里还可以把item的类别信息也隐射到embedding, 与前面的concat起来。
|
||||
* 用户人文特征, 这种特征处理方式就是离散型的依然是labelEncoder,然后embedding转成低维稠密, 而连续型特征,一般是先归一化操作,然后直接输入,当然有的也通过分桶,转成离散特征,这里不过多整理,特征工程做的事情了。 当然,这里还有一波操作值得注意,就是连续型特征除了用了$x$本身,还用了$x^2$,$logx$这种, 可以加入更多非线性,增加模型表达能力。<br>
|
||||
这些特征对新用户的推荐会比较有帮助,常见的用户的地理位置, 设备, 性别,年龄等。
|
||||
* 这里一个比较特色的特征是example age,这个特征后面需要单独整理。
|
||||
|
||||
这些特征处理好了之后,拼接起来,就成了一个非常长的向量,然后就是过DNN,这里用了一个三层的DNN, 得到了输出, 这个输出也是向量。
|
||||
|
||||
Ok,到这里平淡无奇, 前向传播也大致上快说完了, 还差最后一步。 最后这一步,就是做多分类问题,然后求损失,这就是training那边做的事情。 但是在详细说这个之前, 我想先简单回忆下word2vec里面的skip-gram Model, 这个模型,如果回忆起来,这里理解起来就非常的简单了。
|
||||
|
||||
这里只需要看一张图即可, 这个来自cs231N公开课PPT, 我之前整理w2v的时候用到的,这里的思想其实也是从w2v那边过来的。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200624193409649.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
skip-gram的原理咱这里就不整理了, 这里就只看这张图,这其实就是w2v训练的一种方式,当然是最原始的。 word2vec的核心思想呢? 就是共现频率高的词相关性越大,所以skip-gram采用中心词预测上下文词的方式去训练词向量,模型的输入是中心词,做样本采用滑动窗口的形式,和这里序列其实差不多,窗口滑动一次就能得到一个序列[word1, word2, ...wordn], 而这个序列里面呢? 就会有中心词(比如中间那个), 两边向量的是上下文词。 如果我们输入中心词之后,模型能预测上下文词的概率大,那说明这个模型就能解决词相关性问题了。
|
||||
>一开始, 我们的中心单词$w_t$就是one-hot的表示形式,也就是在词典中的位置,这里的形状是$V \times1$, $V$表示词库里面有$V$个单词, 这里的$W$长上面那样, 是一个$d\times V$的矩阵, $d$表示的是词嵌入的维度, 那么用$W*w_t$(矩阵乘法)就会得到中心词的词向量表示$v_c$, 大小是$d\times1$。这个就是中心词的embedding向量。 其实就是中心词过了一个embedding层得到了它的embedding向量。
|
||||
><br>然后就是$v_c$和上下文矩阵$W'$相乘, 这里的$W'$是$V\times d$的一个矩阵, 每一行代表每个单词作为上下文的时候的词向量表示, 也就是$u_w$, 每一列是词嵌入的维度。 这样通过$W'*v_c$就会得到一个$V\times 1$的向量,这个表示的就是中心单词$w_t$与每个单词的相似程度。
|
||||
><br>最后,我们通过softmax操作把这个相似程度转成概率, 选择概率最大的index输出。
|
||||
|
||||
这就是这个模型的前向传播过程。
|
||||
|
||||
有了这个过程, 再理解YouTubeDNN顶部就非常容易了, 我单独截出来:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/98811e09226f42a2be981b0aa3449ab3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
只看这里的这个过程, 其实就是上面skip-gram过程, 不一样的是右边这个中心词向量$v_c$是直接过了一个embedding层得到的,而左边这个用户向量$u$是用户的各种特征先拼接成一个大的向量,然后过了一个DNN降维。 训练方式上,这两个也是一模一样的,无非就是左边的召回模型,多了几层全连接而已。
|
||||
> 这样,也就很容易的理解,模型训练好了之后,用户向量和item向量到底在哪里取了吧。
|
||||
> * 用户向量,其实就是全连接的DNN网络的输出向量,其实即使没有全连接,原始的用户各个特征拼接起来的那个长向量也能用,不过维度可能太大了,所以DNN在这里的作用一个是特征交叉,另一个还有降维的功效。
|
||||
> * item向量: 这个其实和skip-gram那个一样,每个item其实是用两个embedding向量的,比如skip-gram那里就有一个作为中心词时候的embedding矩阵$W$和作为上下文词时候的embedding矩阵$W'$, 一般取的时候会取前面那个$W$作为每个词的词向量。 这里其实一个道理,只不过这里最前面那个item向量矩阵,是通过了w2v的方式训练好了直接作为的输入,如果不事先计算好,对应的是embedding层得到的那个矩阵。 后面的item向量矩阵,就是这里得到用户向量之后,后面进行softmax之前的这个矩阵, **YouTubeDNN最终是从这个矩阵里面拿item向量**。
|
||||
|
||||
这就是知识串联的魅力,其实熟悉了word2vec, 这个召回模型理解非常简单。
|
||||
|
||||
这其实就是这个模型训练阶段最原始的剖析,实际训练的时候,依然是采用了优化方法, 这个和word2vec也是一样,采用了负采样的方式(当然实现细节上有区别),因为视频的数量太大,每次做多分类,最终那个概率分母上的加和就非常可怕了,所以就把多分类问题转成了多个二分类的问题。 也就是不用全部的视频,而是随机选择出了一些没点的视频, 标记为0, 点了的视频标记为1, 这样就成了二分类的问题。 关于负样本采样原理, 我之前也整理了[一篇博客](https://blog.csdn.net/wuzhongqiang/article/details/106979179?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164310239216780274177509%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=164310239216780274177509&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-106979179.nonecase&utm_term=word2vec&spm=1018.2226.3001.4450)
|
||||
>负类基于样本分布抽取而来。负采样是针对类别数很多情况下的常用方法。当然,负样本的选择也是有讲究的,详细的看[这篇文章](https://www.zhihu.com/question/334844408/answer/2299283878), 我后面实验主要用了下面两种
|
||||
>* 展示数据随机选择负例
|
||||
>* 随机负例与热门打压
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/6fe56d71de8a4d769a583f27a3ce9f40.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这样整个召回模型训练部分的"基本操作"就基本整理完了。关于细节部分,后面代码里面会描述下, 但是在训练召回模型过程中,还有一些经验性的知识也非常重要。 下面重点整理一下。
|
||||
|
||||
### 训练数据的选取和生成
|
||||
模型训练的时候, 为了计算更加高效,采用了负采样的方法, 但正负样本的选取,以及训练样本的来源, 还有一些注意事项。
|
||||
|
||||
首先,训练样本来源于全部的YouTube观看记录,而不仅仅是被推荐的观看记录
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/faf8a8abf7b54b779287acadc015b6a0.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
否则对于新视频会难以被曝光,会使最终推荐结果有偏;同时系统也会采集用户从其他渠道观看的视频,从而可以快速应用到协同过滤中;
|
||||
|
||||
其次, 是训练数据来源于用户的隐式数据, 且**用户看完了的视频作为正样本**, 注意这里是看完了, 有一定的时长限制, 而不是仅仅曝光点击,有可能有误点的。 而负样本,是从视频库里面随机选取,或者在曝光过的里面随机选取用户没看过的作为负样本。
|
||||
|
||||
==这里的一个经验==是**训练数据中对于每个用户选取相同的样本数, 保证用户在损失函数等权重**, 因为这样可以减少高度活跃用户对于loss的影响。可以改进线上A/B测试的效果。
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/35386af8fd064de3a87cb418b008e444.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这里的==另一个经验==是**避免让模型知道不该知道的信息**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/0765134e1ca445c693058aaaaf20ae74.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这里作者举了一个例子是如果模型知道用户最后的行为是搜索了"Taylor Swift", 那么模型可能会倾向于推荐搜索页面搜"Taylor Swift"时搜索的视频, 这个不是推荐模型期望的行为。 解法方法是**扔掉时序信息**, 历史搜索tokens随机打乱, 使用无序的搜索tokens来表示搜索queryies(average pooling)。
|
||||
>基于这个例子就把时序信息扔掉理由挺勉强的,解决这种特殊场景的信息泄露会有更针对性的方法,比如把搜索query与搜索结果行为绑定让它们不可分。 感觉时序信息还是挺重要的, 有专门针对时序信息建模的研究。
|
||||
|
||||
在生成样本的时候, 如果我们的用户比较少,行为比较少, 是不足以训练一个较好的召回模型,此时一个用户的历史观看序列,可以采用滑动窗口的形式生成多个训练样本, 比如一个用户的历史观看记录是"abcdef", 那么采用滑动窗口, 可以是abc预测d, bcd预测e, cde预测f,这样一个用户就能生成3条训练样本。 后面实验里面也是这么做的。 但这时候一定要注意一点,就是**信息泄露**,这个也是和word2vec的cbow不一样的地方。
|
||||
|
||||
论文中上面这种滑动制作样本的方式依据是用户的"asymmetric co-watch probabilities(非对称观看概率)",即一般情况下,用户开始浏览范围较广, 之后浏览范围逐渐变窄。
|
||||
|
||||
下图中的$w_{tN}$表示当前样本, 原来的做法是它前后的用户行为都可以用来产生特征行为输入(word2vec的CBOW做样本的方法)。 而作者担心这一点会导致信息泄露, 模型**不该知道的信息是未来的用户行为**, 所以作者的做法是只使用更早时间的用户行为来产生特征, 这个也是目前通用的做法。 两种方法的对比如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/049cbeb814f843fd97638ef02d6c5703.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_2,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
(a)是许多协同过滤会采取的方法,利用全局的观看信息作为输入(包括时间节点N前,N后的观看),这种方法忽略了观看序列的不对称性,而本文中采取(b)所示的方法,只把历史信息当作输入,用历史来预测未来
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/4ac0c81e5f4f4276a4ed0e4c6329f458.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
模型的测试集, 往往也是用户最近一次观看行为, 后面的实验中,把用户最后一次点击放到了测试集里面去。这样可以防止信息穿越。
|
||||
|
||||
数据集的细节和tricks基本上说完, 更细的东西,就得通过代码去解释了。 接下来, 再聊聊作者加入的非常有意思的一个特征,叫做example age。
|
||||
|
||||
### "Example Age"特征
|
||||
这个特征我想单独拿出来说,是因为这个是和场景比较相关的特征,也是作者的经验传授。 我们知道,视频有明显的生命周期,例如刚上传的视频比之后更受欢迎,也就是用户往往喜欢看最新的东西,而不管它是不是和用户相关,所以视频的流行度随着时间的分布是高度非稳态变化的(下面图中的绿色曲线)
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/15dfce743bd2490a8adb21fd3b2b294e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
但是我们模型训练的时候,是基于历史数据训练的(历史观看记录的平均),所以模型对播放某个视频预测值的期望会倾向于其在训练数据时间内的平均播放概率(平均热度), 上图中蓝色线。但如上面绿色线,实际上该视频在训练数据时间窗口内热度很可能不均匀, 用户本身就喜欢新上传的内容。 所以,为了让模型学习到用户这种对新颖内容的bias, 作者引入了"example age"这个特征来捕捉视频的生命周期。
|
||||
|
||||
"example age"定义为$t_{max}-t$, 其中$t_{max}$是训练数据中所有样本的时间最大值(有的文章说是当前时间,但我总觉得还是选取的训练数据所在时间段的右端点时间比较合适,就比如我用的数据集, 最晚时间是2021年7月的,总不能用现在的时间吧), 而$t$为当前样本的时间。**线上预测时, 直接把example age全部设为0或一个小的负值,这样就不依赖于各个视频的上传时间了**。
|
||||
>其实这个操作, 现在常用的是位置上的除偏, 比如商品推荐的时候, 用户往往喜欢点击最上面位置的商品或广告, 但这个bias模型依然是不知道, 为了让模型学习到这个东西, 也可以把商品或者广告的位置信息做成一个feature, 训练的时候告诉模型。 而线上推理的那些商品, 这个feature也都用一样的。 异曲同工的意思有没有。<br><br>那么这样的操作为啥会work呢? example age这个我理解,是有了这个特征, 就可以把某视频的热度分布信息传递给模型了, 比如某个example age时间段该视频播放较多, 而另外的时间段播放较少, 这样模型就能发现用户的这种新颖偏好, 消除热度偏见。<br><br>这个地方看了一些文章写说, 这样做有利于让模型推新热内容, 总感觉不是很通。 我这里理解是类似让模型消除位置偏见那样, 这里消除一种热度偏见。 <br><br>我理解是这样,假设没有这样一个example age特征表示视频新颖信息,或者一个位置特征表示商品的位置信息,那模型训练的样本,可能是用户点击了这个item,就是正样本, 但此时有可能是用户真的喜欢这个item, 也有可能是因为一些bias, 比如用户本身喜欢新颖, 用户本身喜欢点击上面位置的item等, 但模型推理的时候,都会误认为是用户真的喜欢这个item。 所以,为了让模型了解到可能是存在后面这种bias, 我们就把item的新颖信息, item的位置信息等做成特征, 在模型训练的时候就告诉模型,用户点了这个东西可能是它比较新或者位置比较靠上面等,这样模型在训练的时候, 就了解到了这些bias,等到模型在线推理的时候呢, 我们把这些bias特征都弄成一样的,这样每个样品在模型看来,就没有了新颖信息和位置信息bias(一视同仁了),只能靠着相关性去推理, 这样才能推到用户真正感兴趣的东西吧。<br><br>而有些文章记录的, 能够推荐更热门的视频啥的, 我很大一个疑问就是推理的时候,不是把example age用0表示吗? 模型应该不知道这些视频哪个新不新吧。 当然,这是我自己的看法,感兴趣的可以帮我解答下呀。
|
||||
|
||||
`example age`这个特征到这里还没完, 原来加入这种时间bias的传统方法是使用`video age`, 即一个video上传到样本生成的这段时间跨度, 这么说可能有些懵, 看个图吧, 原来这是两个东西:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/10475c194c0044a3a93b01a3193e294f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
王喆老师那篇文章里面也谈到了这两种理解, 对于某个视频的不同样本,其实这两种定义是等价的,因为他们的和是一个常数。
|
||||
$$
|
||||
t_{\text {video age }}+t_{\text {example age }}=\text { Const }
|
||||
$$
|
||||
详细证明可以看参考的第三篇文章。但`example age`的定义有下面两点好处:
|
||||
1. 线上预测时`example age`是常数值, 所有item可以设置成统一的, 但如果是`video age`的话,这个根每个视频的上传时间有关, 那这样在计算用户向量的时候,就依赖每个候选item了。 而统一的这个好处就是用户向量只需要计算一次。
|
||||
2. 对不同的视频,对应的`example age`所在范围一致, 只依赖训练数据选取的时间跨度,便于归一化操作。
|
||||
|
||||
### 实验结果
|
||||
这里就简单过下就好, 作者这里主要验证了下DNN的结构对推荐效果的影响,对于DNN的层级,作者尝试了0~4层, 实验结果是**层数越多越好, 但4层之后提升很有限, 层数越多训练越困难**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/fd1849a8881444fbb12490bad7598125.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
作者这里还启发了一个事情, 从"双塔"的角度再看YouTubeDNN召回模型, 这里的DNN个结构,其实就是一个用户塔, 输入用户的特征,最终通过DNN,编码出了用户的embedding向量。
|
||||
|
||||
而得到用户embedding向量到后面做softmax那块,不是说了会经过一个item embedding矩阵吗? 其实这个矩阵也可以用一个item塔来实现, 和用户embedding计算的方式类似, 首先各个item通过一个物品塔(输入是item 特征, 输出是item embedding),这样其实也能得到每个item的embedding,然后做多分类或者是二分类等。 所以**YouTubeDNN召回模型本质上还是双塔结构**, 只不过上面图里面值体现了用户塔。 我看deepmatch包里面实现的时候, 用户特征和item特征分开输入的, 感觉应该就是实现了个双塔。源码倒是没看, 等看了之后再确认。
|
||||
|
||||
### 线上服务
|
||||
线上服务的时候, YouTube采用了一种最近邻搜索的方法去完成topK推荐,这其实是工程与学术trade-off的结果, model serving过程中对几百万个候选集一一跑模型显然不现实, 所以通过召回模型得到用户和video的embedding之后, 用最近邻搜索的效率会快很多。
|
||||
|
||||
我们甚至不用把任何model inference的过程搬上服务器,只需要把user embedding和video embedding存到redis或者内存中就好了。like this:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/86751a834d224ad69220b5040e0e03c9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
在线上,可以根据用户兴趣Embedding,采用类似Faiss等高效Embedding检索工具,快速找出和用户兴趣匹配的物品, 高效embedding检索工具, 我目前接触到了两个,一个是Faiss, 一个是annoy, 关于这两个工具的使用, 我也整理了两篇文章:
|
||||
* [annoy(快速近邻向量搜索包)学习小记](https://blog.csdn.net/wuzhongqiang/article/details/122516942?spm=1001.2014.3001.5501)
|
||||
* [Faiss(Facebook开源的高效相似搜索库)学习小记](https://blog.csdn.net/wuzhongqiang/article/details/122516942?spm=1001.2014.3001.5501)
|
||||
|
||||
|
||||
之前写新闻推荐比赛的时候用过Faiss, 这次实验中使用的是annoy工具包。
|
||||
|
||||
另外多整理一点:
|
||||
>我们做线上召回的时候, 其实可以有两种:
|
||||
>1. item_2_item: 因为我们有了所有item的embedding了, 那么就可以进行物品与物品之间相似度计算,每个物品得到近似的K个, 这时候,就和协同过滤原理一样, 之间通过用户观看过的历史item,就能进行相似召回了, 工程实现上,一般会每个item建立一个相似度倒排表
|
||||
>2. user_2_item: 将item用faiss或者annoy组织成index,然后用user embedding去查相近item
|
||||
|
||||
## 基于Deepmatch包YouTubeDNN的使用方法
|
||||
由于时间原因, 我这里并没有自己写代码复现YouTubeDNN模型,这个结构也比较简单, 几层的DNN,自己再写一遍剖析架构也没有啥意思, 所以就采用浅梦大佬写的deepmatch包, 直接用到了自己的数据集上做了实验。 关于Deepmatch源码, 还是看[deepmatch项目](https://github.com/shenweichen/DeepMatch), 这里主要是整理下YouTubeDNN如何用。
|
||||
|
||||
项目里面其实给出了如何使用YouTubeDNN,采用的是movielens数据集, 见[这里](https://github.com/shenweichen/DeepMatch/blob/master/examples/run_youtubednn.py)
|
||||
|
||||
我这里就基于我做实验用的新闻推荐数据集, 把代码的主要逻辑过一遍。
|
||||
|
||||
### 数据集
|
||||
实验用的数据集是新闻推荐的一个数据集,是做func-rec项目时候一个伙伴分享的,来自于某个推荐比赛,因为这个数据集是来自工业上的真实数据,所以使用起来比之前用的movielens数据集可尝试的东西多一些,并且原数据有8个多G,总共3个文件: 用户画像,文章画像, 点击日志,用户数量100多万,6000多万次点击, 文章规模是几百,数据量也比较丰富,所以后面就打算采用这个统一的数据集, 重新做实验,对比目前GitHub上的各个模型。关于数据集每个文件详细描述,后面会更新到GitHub项目。
|
||||
|
||||
这里只整理我目前的使用过程, 由于有8个多G的数据,我这边没法直接跑,所以对数据进行了采样, 采样方法写成了一个jupyter文件。 主要包括:
|
||||
1. 分块读取数据, 无法一下子读入内存
|
||||
2. 对于每块数据,基于一些筛选规则进行记录的删除,比如只用了后7天的数据, 删除了一些文章不在物料池的数据, 删除不合法的点击记录(曝光时间大于文章上传时间), 删除没有历史点击的用户,删除观看时间低于3s的视频, 删除历史点击序列太短和太长的用户记录
|
||||
3. 删除完之后重新保存一份新数据集,大约3个G,然后再从这里面随机采样了20000用户进行了后面实验
|
||||
|
||||
通过上面的一波操作, 我的小本子就能跑起来了,当然可能数据比较少,最终训练的YouTubeDNN效果并不是很好。详细看后面GitHub的: `点击日志数据集初步处理与采样.ipynb`
|
||||
|
||||
### 简单数据预处理
|
||||
这个也是写成了一个笔记本, 主要是看了下采样后的数据,序列长度分布等,由于上面做了一些规整化,这里有毛病的数据不是太多,并没有太多处理, 但是用户数据里面的年龄,性别源数据是给出了多种可能, 每个可能有概率值,我这里选出了概率最大的那个,然后简单填充了缺失。
|
||||
|
||||
最后把能用到的用户画像和文章画像统一拼接到了点击日志数据,又保存了一份。 作为YouTubeDNN模型的使用数据, 其他模型我也打算使用这份数据了。
|
||||
|
||||
详见`EDA与数据预处理.ipynb`
|
||||
|
||||
### YouTubeDNN召回
|
||||
这里就需要解释下一些代码了, 首先拿到采样的数据集,我们先划分下训练集和测试集:
|
||||
* 测试集: 每个用户的最后一次点击记录
|
||||
* 训练集: 每个用户除最后一次点击的所有点击记录
|
||||
|
||||
这个具体代码就不在这里写了。
|
||||
|
||||
```python
|
||||
user_click_hist_df, user_click_last_df = get_hist_and_last_click(click_df)
|
||||
```
|
||||
|
||||
这么划分的依据,就是保证不能发生数据穿越,拿最后的测试,不能让模型看到。
|
||||
|
||||
接下来,就是YouTubeDNN模型的召回,从构造数据集 -> 训练模型 -> 产生召回结果,我写到了一个函数里面去。
|
||||
|
||||
```cpp
|
||||
def youtubednn_recall(data, topk=200, embedding_dim=8, his_seq_maxlen=50, negsample=0,
|
||||
batch_size=64, epochs=1, verbose=1, validation_split=0.0):
|
||||
"""通过YouTubeDNN模型,计算用户向量和文章向量
|
||||
param: data: 用户日志数据
|
||||
topk: 对于每个用户,召回多少篇文章
|
||||
"""
|
||||
user_id_raw = data[['user_id']].drop_duplicates('user_id')
|
||||
doc_id_raw = data[['article_id']].drop_duplicates('article_id')
|
||||
|
||||
# 类别数据编码
|
||||
base_features = ['user_id', 'article_id', 'city', 'age', 'gender']
|
||||
feature_max_idx = {}
|
||||
for f in base_features:
|
||||
lbe = LabelEncoder()
|
||||
data[f] = lbe.fit_transform(data[f])
|
||||
feature_max_idx[f] = data[f].max() + 1
|
||||
|
||||
# 构建用户id词典和doc的id词典,方便从用户idx找到原始的id
|
||||
user_id_enc = data[['user_id']].drop_duplicates('user_id')
|
||||
doc_id_enc = data[['article_id']].drop_duplicates('article_id')
|
||||
user_idx_2_rawid = dict(zip(user_id_enc['user_id'], user_id_raw['user_id']))
|
||||
doc_idx_2_rawid = dict(zip(doc_id_enc['article_id'], doc_id_raw['article_id']))
|
||||
|
||||
# 保存下每篇文章的被点击数量, 方便后面高热文章的打压
|
||||
doc_clicked_count_df = data.groupby('article_id')['click'].apply(lambda x: x.count()).reset_index()
|
||||
doc_clicked_count_dict = dict(zip(doc_clicked_count_df['article_id'], doc_clicked_count_df['click']))
|
||||
|
||||
train_set, test_set = gen_data_set(data, doc_clicked_count_dict, negsample, control_users=True)
|
||||
|
||||
# 构造youtubeDNN模型的输入
|
||||
train_model_input, train_label = gen_model_input(train_set, his_seq_maxlen)
|
||||
test_model_input, test_label = gen_model_input(test_set, his_seq_maxlen)
|
||||
|
||||
# 构建模型并完成训练
|
||||
model = train_youtube_model(train_model_input, train_label, embedding_dim, feature_max_idx, his_seq_maxlen, batch_size, epochs, verbose, validation_split)
|
||||
|
||||
# 获得用户embedding和doc的embedding, 并进行保存
|
||||
user_embs, doc_embs = get_embeddings(model, test_model_input, user_idx_2_rawid, doc_idx_2_rawid)
|
||||
|
||||
# 对每个用户,拿到召回结果并返回回来
|
||||
user_recall_doc_dict = get_youtube_recall_res(user_embs, doc_embs, user_idx_2_rawid, doc_idx_2_rawid, topk)
|
||||
|
||||
return user_recall_doc_dict
|
||||
```
|
||||
这里面说一下主要逻辑,主要是下面几步:
|
||||
1. 用户id和文章id我们要先建立索引-原始id的字典,因为我们模型里面是要把id转成embedding,模型的表示形式会是{索引: embedding}的形式, 如果我们想得到原始id,必须先建立起映射来
|
||||
2. 把类别特征进行label Encoder, 模型输入需要, embedding层需要,这是构建词典常规操作, 这里要记录下每个特征特征值的个数,建词典索引的时候用到,得知道词典大小
|
||||
3. 保存了下每篇文章被点击数量, 方便后面对高热文章实施打压
|
||||
4. 构建数据集
|
||||
|
||||
```python
|
||||
rain_set, test_set = gen_data_set(data, doc_clicked_count_dict, negsample, control_users=True)
|
||||
```
|
||||
这个需要解释下, 虽然我们上面有了一个训练集,但是这个东西是不能直接作为模型输入的, 第一个原因是正样本太少,样本数量不足,我们得需要滑动窗口,每个用户再滑动构造一些,第二个是不满足deepmatch实现的模型输入格式,所以gen_data_set这个函数,是用deepmatch YouTubeDNN的第一个范式,基本上得按照这个来,只不过我加了一些策略上的尝试:
|
||||
```python
|
||||
def gen_data_set(click_data, doc_clicked_count_dict, negsample, control_users=False):
|
||||
"""构造youtubeDNN的数据集"""
|
||||
# 按照曝光时间排序
|
||||
click_data.sort_values("expo_time", inplace=True)
|
||||
item_ids = click_data['article_id'].unique()
|
||||
|
||||
train_set, test_set = [], []
|
||||
for user_id, hist_click in tqdm(click_data.groupby('user_id')):
|
||||
# 这里按照expo_date分开,每一天用滑动窗口滑,可能相关性更高些,另外,这样序列不会太长,因为eda发现有点击1111个的
|
||||
#for expo_date, hist_click in hist_date_click.groupby('expo_date'):
|
||||
# 用户当天的点击历史id
|
||||
pos_list = hist_click['article_id'].tolist()
|
||||
user_control_flag = True
|
||||
|
||||
if control_users:
|
||||
user_samples_cou = 0
|
||||
|
||||
# 过长的序列截断
|
||||
if len(pos_list) > 50:
|
||||
pos_list = pos_list[-50:]
|
||||
|
||||
if negsample > 0:
|
||||
neg_list = gen_neg_sample_candiate(pos_list, item_ids, doc_clicked_count_dict, negsample, methods='multinomial')
|
||||
|
||||
# 只有1个的也截断 去掉,当然我之前做了处理,这里没有这种情况了
|
||||
if len(pos_list) < 2:
|
||||
continue
|
||||
else:
|
||||
# 序列至少是2
|
||||
for i in range(1, len(pos_list)):
|
||||
hist = pos_list[:i]
|
||||
# 这里采用打压热门item策略,降低高展item成为正样本的概率
|
||||
freq_i = doc_clicked_count_dict[pos_list[i]] / (np.sum(list(doc_clicked_count_dict.values())))
|
||||
p_posi = (np.sqrt(freq_i/0.001)+1)*(0.001/freq_i)
|
||||
|
||||
# p_posi=0.3 表示该item_i成为正样本的概率是0.3,
|
||||
if user_control_flag and i != len(pos_list) - 1:
|
||||
if random.random() > (1-p_posi):
|
||||
row = [user_id, hist[::-1], pos_list[i], hist_click.iloc[0]['city'], hist_click.iloc[0]['age'], hist_click.iloc[0]['gender'], hist_click.iloc[i]['example_age'], 1, len(hist[::-1])]
|
||||
train_set.append(row)
|
||||
|
||||
for negi in range(negsample):
|
||||
row = [user_id, hist[::-1], neg_list[i*negsample+negi], hist_click.iloc[0]['city'], hist_click.iloc[0]['age'], hist_click.iloc[0]['gender'], hist_click.iloc[i]['example_age'], 0, len(hist[::-1])]
|
||||
train_set.append(row)
|
||||
|
||||
if control_users:
|
||||
user_samples_cou += 1
|
||||
# 每个用户序列最长是50, 即每个用户正样本个数最多是50个, 如果每个用户训练样本数量到了30个,训练集不能加这个用户了
|
||||
if user_samples_cou > 30:
|
||||
user_samples_cou = False
|
||||
|
||||
# 整个序列加入到test_set, 注意,这里一定每个用户只有一个最长序列,相当于测试集数目等于用户个数
|
||||
elif i == len(pos_list) - 1:
|
||||
row = [user_id, hist[::-1], pos_list[i], hist_click.iloc[0]['city'], hist_click.iloc[0]['age'], hist_click.iloc[0]['gender'], 0, 0, len(hist[::-1])]
|
||||
test_set.append(row)
|
||||
|
||||
|
||||
random.shuffle(train_set)
|
||||
random.shuffle(test_set)
|
||||
|
||||
return train_set, test_set
|
||||
```
|
||||
关键代码逻辑是首先点击数据按照时间戳排序,然后按照用户分组,对于每个用户的历史点击, 采用滑动窗口的形式,边滑动边构造样本, 第一个注意的地方,是每滑动一次生成一条正样本的时候, 要加入一定比例的负样本进去, 第二个注意最后一整条序列要放到test_set里面。<br><br>我这里面加入的一些策略,负样本候选集生成我单独写成一个函数,因为尝试了随机采样和打压热门item采样两种方式, 可以通过methods参数选择。 另外一个就是正样本里面也按照热门实现了打压, 减少高热item成为正样本概率,增加高热item成为负样本概率。 还加了一个控制用户样本数量的参数,去保证每个用户生成一样多的样本数量,打压下高活用户。
|
||||
5. 构造模型输入
|
||||
这个也是调包的定式操作,必须按照这个写法来:
|
||||
|
||||
|
||||
```python
|
||||
def gen_model_input(train_set, his_seq_max_len):
|
||||
"""构造模型的输入"""
|
||||
# row: [user_id, hist_list, cur_doc_id, city, age, gender, label, hist_len]
|
||||
train_uid = np.array([row[0] for row in train_set])
|
||||
train_hist_seq = [row[1] for row in train_set]
|
||||
train_iid = np.array([row[2] for row in train_set])
|
||||
train_u_city = np.array([row[3] for row in train_set])
|
||||
train_u_age = np.array([row[4] for row in train_set])
|
||||
train_u_gender = np.array([row[5] for row in train_set])
|
||||
train_u_example_age = np.array([row[6] for row in train_set])
|
||||
train_label = np.array([row[7] for row in train_set])
|
||||
train_hist_len = np.array([row[8] for row in train_set])
|
||||
|
||||
train_seq_pad = pad_sequences(train_hist_seq, maxlen=his_seq_max_len, padding='post', truncating='post', value=0)
|
||||
train_model_input = {
|
||||
"user_id": train_uid,
|
||||
"click_doc_id": train_iid,
|
||||
"hist_doc_ids": train_seq_pad,
|
||||
"hist_len": train_hist_len,
|
||||
"u_city": train_u_city,
|
||||
"u_age": train_u_age,
|
||||
"u_gender": train_u_gender,
|
||||
"u_example_age":train_u_example_age
|
||||
}
|
||||
return train_model_input, train_label
|
||||
```
|
||||
上面构造数据集的时候,是把每个特征加入到了二维数组里面去, 这里得告诉模型,每一个维度是啥特征数据。如果相加特征,首先构造数据集的时候,得把数据加入到数组中, 然后在这个函数里面再指定新加入的特征是啥。 下面的那个词典, 是为了把数据输入和模型的Input层给对应起来,通过字典键进行标识。
|
||||
6. 训练YouTubeDNN
|
||||
这一块也是定式, 在建模型事情,要把特征封装起来,告诉模型哪些是离散特征,哪些是连续特征, 模型要为这些特征建立不同的Input层,处理方式是不一样的
|
||||
|
||||
```python
|
||||
def train_youtube_model(train_model_input, train_label, embedding_dim, feature_max_idx, his_seq_maxlen, batch_size, epochs, verbose, validation_split):
|
||||
"""构建youtubednn并完成训练"""
|
||||
# 特征封装
|
||||
user_feature_columns = [
|
||||
SparseFeat('user_id', feature_max_idx['user_id'], embedding_dim),
|
||||
VarLenSparseFeat(SparseFeat('hist_doc_ids', feature_max_idx['article_id'], embedding_dim,
|
||||
embedding_name="click_doc_id"), his_seq_maxlen, 'mean', 'hist_len'),
|
||||
|
||||
SparseFeat('u_city', feature_max_idx['city'], embedding_dim),
|
||||
SparseFeat('u_age', feature_max_idx['age'], embedding_dim),
|
||||
SparseFeat('u_gender', feature_max_idx['gender'], embedding_dim),
|
||||
DenseFeat('u_example_age', 1,)
|
||||
]
|
||||
doc_feature_columns = [
|
||||
SparseFeat('click_doc_id', feature_max_idx['article_id'], embedding_dim)
|
||||
# 这里后面也可以把文章的类别画像特征加入
|
||||
]
|
||||
|
||||
# 定义模型
|
||||
model = YoutubeDNN(user_feature_columns, doc_feature_columns, num_sampled=5, user_dnn_hidden_units=(64, embedding_dim))
|
||||
|
||||
# 模型编译
|
||||
model.compile(optimizer="adam", loss=sampledsoftmaxloss)
|
||||
|
||||
# 模型训练,这里可以定义验证集的比例,如果设置为0的话就是全量数据直接进行训练
|
||||
history = model.fit(train_model_input, train_label, batch_size=batch_size, epochs=epochs, verbose=verbose, validation_split=validation_split)
|
||||
|
||||
return model
|
||||
```
|
||||
然后就是建模型,编译训练即可。这块就非常简单了,当然模型方面有些参数,可以了解下,另外一个注意点,就是这里用户特征和item特征进行了分开, 这其实和双塔模式很像, 用户特征最后编码成用户向量, item特征最后编码成item向量。
|
||||
7. 获得用户向量和item向量
|
||||
模型训练完之后,就能从模型里面拿用户向量和item向量, 我这里单独写了一个函数:
|
||||
|
||||
```python
|
||||
获取用户embedding和文章embedding
|
||||
def get_embeddings(model, test_model_input, user_idx_2_rawid, doc_idx_2_rawid, save_path='embedding/'):
|
||||
doc_model_input = {'click_doc_id':np.array(list(doc_idx_2_rawid.keys()))}
|
||||
|
||||
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
|
||||
doc_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
|
||||
|
||||
# 保存当前的item_embedding 和 user_embedding 排序的时候可能能够用到,但是需要注意保存的时候需要和原始的id对应
|
||||
user_embs = user_embedding_model.predict(test_model_input, batch_size=2 ** 12)
|
||||
doc_embs = doc_embedding_model.predict(doc_model_input, batch_size=2 ** 12)
|
||||
# embedding保存之前归一化一下
|
||||
user_embs = user_embs / np.linalg.norm(user_embs, axis=1, keepdims=True)
|
||||
doc_embs = doc_embs / np.linalg.norm(doc_embs, axis=1, keepdims=True)
|
||||
|
||||
# 将Embedding转换成字典的形式方便查询
|
||||
raw_user_id_emb_dict = {user_idx_2_rawid[k]: \
|
||||
v for k, v in zip(user_idx_2_rawid.keys(), user_embs)}
|
||||
raw_doc_id_emb_dict = {doc_idx_2_rawid[k]: \
|
||||
v for k, v in zip(doc_idx_2_rawid.keys(), doc_embs)}
|
||||
# 将Embedding保存到本地
|
||||
pickle.dump(raw_user_id_emb_dict, open(save_path + 'user_youtube_emb.pkl', 'wb'))
|
||||
pickle.dump(raw_doc_id_emb_dict, open(save_path + 'doc_youtube_emb.pkl', 'wb'))
|
||||
|
||||
# 读取
|
||||
#user_embs_dict = pickle.load(open('embedding/user_youtube_emb.pkl', 'rb'))
|
||||
#doc_embs_dict = pickle.load(open('embedding/doc_youtube_emb.pkl', 'rb'))
|
||||
return user_embs, doc_embs
|
||||
```
|
||||
获取embedding的这两行代码是固定操作, 下面做了一些归一化操作,以及把索引转成了原始id的形式。
|
||||
8. 向量最近邻检索,为每个用户召回相似item
|
||||
|
||||
```python
|
||||
def get_youtube_recall_res(user_embs, doc_embs, user_idx_2_rawid, doc_idx_2_rawid, topk):
|
||||
"""近邻检索,这里用annoy tree"""
|
||||
# 把doc_embs构建成索引树
|
||||
f = user_embs.shape[1]
|
||||
t = AnnoyIndex(f, 'angular')
|
||||
for i, v in enumerate(doc_embs):
|
||||
t.add_item(i, v)
|
||||
t.build(10)
|
||||
# 可以保存该索引树 t.save('annoy.ann')
|
||||
|
||||
# 每个用户向量, 返回最近的TopK个item
|
||||
user_recall_items_dict = collections.defaultdict(dict)
|
||||
for i, u in enumerate(user_embs):
|
||||
recall_doc_scores = t.get_nns_by_vector(u, topk, include_distances=True)
|
||||
# recall_doc_scores是(([doc_idx], [scores])), 这里需要转成原始doc的id
|
||||
raw_doc_scores = list(recall_doc_scores)
|
||||
raw_doc_scores[0] = [doc_idx_2_rawid[i] for i in raw_doc_scores[0]]
|
||||
# 转换成实际用户id
|
||||
try:
|
||||
user_recall_items_dict[user_idx_2_rawid[i]] = dict(zip(*raw_doc_scores))
|
||||
except:
|
||||
continue
|
||||
|
||||
# 默认是分数从小到大排的序, 这里要从大到小
|
||||
user_recall_items_dict = {k: sorted(v.items(), key=lambda x: x[1], reverse=True) for k, v in user_recall_items_dict.items()}
|
||||
|
||||
# 保存一份
|
||||
pickle.dump(user_recall_items_dict, open('youtube_u2i_dict.pkl', 'wb'))
|
||||
|
||||
return user_recall_items_dict
|
||||
```
|
||||
用了用户embedding和item向量,就可以通过这个函数进行检索, 这块主要是annoy包做近邻检索的固定格式, 检索完毕,为用户生成最相似的200个候选item。
|
||||
|
||||
以上,就是使用YouTubeDNN做召回的整个流程。 效果如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/e904362d28fd4bdbacb5715ff2abaac2.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这个字典长这样:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/840e3abaf30845499f0926c61ba88635.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
接下来就是评估模型的效果,这里我采用了简单的HR@N计算的, 具体代码看GitHub吧, 结果如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/eb6ccadaa98e46bd87e594ee11e957a7.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
结果不怎么样啊,唉, 难道是数据量太少了? 总归是跑起来且能用了。
|
||||
|
||||
详细代码见尾部GitHub链接吧, 硬件设施到位的可以尝试多用一些数据试试看哈哈。
|
||||
|
||||
## YouTubeDNN新闻推荐数据集的实验记录
|
||||
这块就比较简单了,简单的整理下我用上面代码做个的实验,尝试了论文里面的几个点,记录下:
|
||||
1. 负采样方式上,尝试了随机负采样和打压高热item两种方式, 从我的实验结果上来看, 带打压的效果略好一点点
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/7cf27f1b849049f0b4bd98d0ebb7925f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
2. 特征上, 尝试原论文给出的example age的方式,做一个样本的年龄特征出来
|
||||
这个年龄样本,我是用的训练集的最大时间减去曝光的时间,然后转成小时间隔算的,而测试集里面的统一用0表示, 但效果好差。 看好多文章说这个时间单位是个坑,不知道是小时,分钟,另外这个特征我只做了简单归一化,感觉应该需要做归一化
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/1ea482f538c94b8bb07a69023b14ca9b.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
3. 尝试了控制用户数量,即每个用户的样本数量保持一样,效果比上面略差
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/8653b76d0b434d1088da196ce94bb954.png#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
4. 开始模型评估,我尝试用最后一天的,而不是最后一次点击的, 感觉效果不如最后一次点击作为测试集效果好
|
||||
|
||||
当然,上面实验并没有太大说服力,第一个是我采样的数据量太少,模型本身训练的不怎么样,第二个这些策略相差的并不是很大, 可能有偶然性。
|
||||
|
||||
并且我这边做一次实验,要花费好长时间,探索就先到这里吧, example age那个确实是个迷, 其他的感觉起来, 打压高活效果要比不打压要好。
|
||||
|
||||
另外要记录下学习小tricks:
|
||||
> 跑一次这样的实验,我这边一般会花费两个小时左右的时间, 而这个时间在做实验之前,一定要做规划才能好好的利用起来, 比如,我计划明天上午要开始尝试各种策略做实验, 今天晚上的todo里面,就要记录好, 我会尝试哪些策略,记录一个表, 调整策略,跑模型的时候,我这段空档要干什么事情, todo里面都要记录好,比如我这段空档就是解读这篇paper,写完这篇博客,基本上是所有实验做完,我这篇博客也差不多写完,正好,哈哈<br><br>这个空档利用,一定要提前在todo里面写好,而不是跑模型的时候再想,这个时候往往啥也干不下去,并且还会时不时的看模型跑,或者盯着进度条发呆,那这段时间就有些浪费了呀,即使这段时间不学习,看个久违的电视剧, 久违的书,或者keep下不香吗哈哈, 但得提前规划。<br><br>可能每个人习惯不一样,对于我,是这样哈,所以记录下 ;)
|
||||
|
||||
## 总结
|
||||
|
||||
由于这篇文章里面的工程经验太多啦,我前面介绍的时候,可能涉及到知识的一些扩展补充,把经验整理的比较凌乱,这里再统一整理下, 这些也都是工业界常用的一些经验了:
|
||||
|
||||
召回部分:
|
||||
1. 训练数据的样本来源应该是全部物料, 而不仅仅是被推荐的物料,否则对于新物料难以曝光
|
||||
2. 训练数据中对于每个用户选取相同的样本数, 保证用户在损失函数等权重, 这个虽然不一定非得这么做,但考虑打压高活用户或者是高活item的影响还是必须的
|
||||
3. 序列无序化: 用户的最近一次搜索与搜索之后的播放行为有很强关联,为了避免信息泄露,将搜索行为顺序打乱。
|
||||
4. 训练数据构造: 预测接下来播放而不是用传统cbow中的两侧预测中间的考虑是可以防止信息泄露,并且可以学习到用户的非对称视频消费模式
|
||||
5. 召回模型中,类似word2vec,video 有input embedding和output embedding两组embedding,并不是共享的, input embedding论文里面是用w2v事先训练好的, 其实也可以用embedding层联合训练
|
||||
6. 召回模型的用户embedding来自网络输出, 而video的embedding往往用后面output处的
|
||||
7. 使用 `example age` 特征处理 time bias,这样线上检索时可以预先计算好用户向量
|
||||
|
||||
|
||||
**参考资料**:
|
||||
* [重读Youtube深度学习推荐系统论文](https://zhuanlan.zhihu.com/p/52169807)
|
||||
* [YouTube深度学习推荐系统的十大工程问题](https://zhuanlan.zhihu.com/p/52169807)
|
||||
* [你真的读懂了Youtube DNN推荐论文吗](https://zhuanlan.zhihu.com/p/372238343)
|
||||
* [推荐系统经典论文(二)】YouTube DNN](https://zhuanlan.zhihu.com/p/128597084)
|
||||
* [张俊林-推荐技术发展趋势与召回模型](https://www.icode9.com/content-4-764359.html)
|
||||
* [揭开YouTube深度推荐系统模型Serving之谜](https://zhuanlan.zhihu.com/p/61827629)
|
||||
* [Deep Neural Networks for YouTube Recommendations YouTubeDNN推荐召回与排序](https://www.pianshen.com/article/82351182400/)
|
||||
@@ -1,308 +0,0 @@
|
||||
# 背景介绍
|
||||
|
||||
**文章核心思想**
|
||||
|
||||
+ 在大规模的推荐系统中,利用双塔模型对user-item对的交互关系进行建模,学习 $\{user,context\}$ 向量与 $\{item\}$ 向量.
|
||||
+ 针对大规模流数据,提出in-batch softmax损失函数与流数据频率估计方法(Streaming Frequency Estimation),可以更好的适应item的多种数据分布。
|
||||
|
||||
**文章主要贡献**
|
||||
|
||||
+ 提出了改进的流数据频率估计方法:针对流数据来估计item出现的频率,利用实验分析估计结果的偏差与方差,模拟实验证明该方法在数据动态变化时的功效
|
||||
|
||||
+ 提出了双塔模型架构:提供了一个针对大规模的检索推荐系统,包括了 in-batch softmax 损失函数与流数据频率估计方法,减少了负采样在每个batch中可能会出现的采样偏差问题。
|
||||
|
||||
# 算法原理
|
||||
|
||||
给定一个查询集 $Query: \left\{x_{i}\right\}_{i=1}^{N}$ 和一个物品集$Item:\left\{y_{j}\right\}_{j=1}^{M}$。
|
||||
|
||||
+ $x_{i} \in X,\quad y_{j} \in \mathcal{Y}$ 是由多种特征(例如:稀疏ID和 Dense 特征)组成的高维混合体。
|
||||
|
||||
+ 推荐的目标是对于给定一个 $query$,检索到一系列 $item$ 子集用于后续排序推荐任务。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/%E5%9B%BE%E7%89%87image-20220506202824884.png" alt="image-20220506202824884" style="zoom:50%;" />
|
||||
|
||||
## 模型目标
|
||||
|
||||
模型结构如上图所示,论文旨在对用户和物品建立两个不同的模型,将它们投影到相同维度的空间:
|
||||
$$
|
||||
u: X \times \mathbb{R}^{d} \rightarrow \mathbb{R}^{k}, v: y \times \mathbb{R}^{d} \rightarrow \mathbb{R}^{k}
|
||||
$$
|
||||
|
||||
模型的输出为用户与物品向量的内积:
|
||||
|
||||
$$
|
||||
s(x, y)=\langle u(x, \theta), v(y, \theta)\rangle
|
||||
$$
|
||||
|
||||
模型的目标是为了学习参数 $\theta$, 样本集被表示为如下格式 $\{query, item, reward \}$:
|
||||
|
||||
$$
|
||||
\mathcal{T}:=\left\{\left(x_{i}, y_{i}, r_{i}\right)\right\}_{i=1}^{T}
|
||||
$$
|
||||
|
||||
* 在推荐系统中,$r_i$ 可以扩展来捕获用户对不同候选物品的参与度。
|
||||
* 例如,在新闻推荐中 $r_i$ 可以是用户在某篇文章上花费的时间。
|
||||
|
||||
## 模型流程
|
||||
|
||||
1. 给定用户 $x$,基于 softmax 函数从物料库 $M$ 中选中候选物品 $y$ 的概率为:
|
||||
$$
|
||||
\mathcal{P}(y \mid x ; \theta)=\frac{e^{s(x, y)}}{\sum_{j \in[M]} e^{s\left(x, y_{j}\right)}}
|
||||
$$
|
||||
|
||||
* 考虑到相关奖励 $r_i$ ,加权对数似然函数的定义如下:
|
||||
|
||||
$$
|
||||
L_{T}(\theta):=-\frac{1}{T} \sum_{i \in[T]} r_{i} \cdot \log \left(\mathcal{P}\left(y_{i} \mid x_{i} ; \theta\right)\right)
|
||||
$$
|
||||
|
||||
2. 原表达式 $\mathcal{P}(y \mid x ; \theta)$ 中的分母需要遍历物料库中所有的物品,计算成本太高,故对分母中的物品要进行负采样。为了提高负采样的速度,一般是直接从训练样本所在 Batch 中进行负样本选择。于是有:
|
||||
$$
|
||||
\mathcal{P}_{B}\left(y_{i} \mid x_{i} ; \theta\right)=\frac{e^{s\left(x_{i}, y_{i}\right)}}{\sum_{j \in[B]} e^{s\left(x_{i}, y_{j}\right)}}
|
||||
$$
|
||||
|
||||
* 其中,$B$ 表示与样本 $\{x_i,y_j\}$ 同在一个 Batch 的物品集合。
|
||||
* 举例来说,对于用户1,Batch 内其他用户的正样本是用户1的负样本。
|
||||
|
||||
3. 一般而言,负采样分为 Easy Negative Sample 和 Hard Negative Sample。
|
||||
|
||||
+ 这里的 Easy Negative Sample 一般是直接从全局物料库中随机选取的负样本,由于每个用户感兴趣的物品有限,而物料库又往往很大,故即便从物料库中随机选取负样本,也大概率是用户不感兴趣的。
|
||||
|
||||
+ 在真实场景中,热门物品占据了绝大多数的购买点击。而这些热门物品往往只占据物料库物品的少部分,绝大部分物品是冷门物品。
|
||||
|
||||
+ 在物料库中随机选择负样本,往往被选中的是冷门物品。这就会造成马太效应,热门物品更热,冷门物品更冷。
|
||||
+ 一种解决方式时,在对训练样本进行负采样时,提高热门物品被选为负样本的概率,工业界的经验做法是物品被选为负样本的概率正比于物品点击次数的 0.75 次幂。
|
||||
|
||||
+ 前面提到 Batch 内进行负采样,热门物品出现在一个 Batch 的概率正比于它的点击次数。问题是,热门物品被选为负样本的概率过高了(一般正比于点击次数的 0.75 次幂),导致热门物品被过度打压。
|
||||
|
||||
+ 在本文中,为了避免对热门物品进行过度惩罚,进行了纠偏。公式如下:
|
||||
$$
|
||||
s^{c}\left(x_{i}, y_{j}\right)=s\left(x_{i}, y_{j}\right)-\log \left(p_{j}\right)
|
||||
$$
|
||||
|
||||
+ 在内积 $s(x_i,y_j)$ 的基础上,减去了物品 $j$ 的采样概率的对数。
|
||||
|
||||
4. 纠偏后,物品 $y$ 被选中的概率为:
|
||||
$$
|
||||
\mathcal{P}_{B}^{c}\left(y_{i} \mid x_{i} ; \theta\right)=\frac{e^{s^{c}\left(x_{i}, y_{i}\right)}}{e^{s^{c}\left(x_{i}, y_{i}\right)}+\sum_{j \in[B], j \neq i} e^{s^{c}\left(x_{i}, y_{j}\right)}}
|
||||
$$
|
||||
|
||||
+ 此时,batch loss function 的表示式如下:
|
||||
|
||||
$$
|
||||
L_{B}(\theta):=-\frac{1}{B} \sum_{i \in[B]} r_{i} \cdot \log \left(\mathcal{P}_{B}^{c}\left(y_{i} \mid x_{i} ; \theta\right)\right)
|
||||
$$
|
||||
+ 通过 SGD 和学习率,来优化模型参数 $\theta$ :
|
||||
|
||||
$$
|
||||
\theta \leftarrow \theta-\gamma \cdot \nabla L_{B}(\theta)
|
||||
$$
|
||||
|
||||
5. Normalization and Temperature
|
||||
|
||||
* 最后一层,得到用户和物品的特征 Embedding 表示后,再进行进行 $l2$ 归一化:
|
||||
$$
|
||||
\begin{aligned}
|
||||
u(x, \theta) \leftarrow u(x, \theta) /\|u(x, \theta)\|_{2}
|
||||
\\
|
||||
v(y, \theta) \leftarrow v(y, \theta) /\|v(y, \theta)\|_{2}
|
||||
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 本质上,其实就是将用户和物品的向量内积转换为了余弦相似度。
|
||||
|
||||
* 对于内积的结果,再除以温度参数 $\tau$:
|
||||
$$
|
||||
s(x, y)=\langle u(x, \theta), v(y, \theta)\rangle / \tau
|
||||
$$
|
||||
|
||||
+ 论文提到,这样有利于提高预测准确度。
|
||||
+ 从实验结果来看,温度参数 $\tau$ 一般小于 $1$,所以感觉就是放大了内积结果。
|
||||
|
||||
**上述模型训练过程可以归纳为:**
|
||||
|
||||
(1)从实时数据流中采样得到一个 batch 的训练样本。
|
||||
|
||||
(2)基于流频估计法,估算物品 $y_i$ 的采样概率 $p_i$ 。
|
||||
|
||||
(3)计算损失函数 $L_B$ ,再利用 SGD 方法更新参数。
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/%E5%9B%BE%E7%89%87image-20220506211935092.png" alt="image-20220506211935092" style="zoom: 50%;" />
|
||||
|
||||
## 流频估计算法
|
||||
|
||||
考虑一个随机的数据 batch ,每个 batch 中包含一组物品。现在的问题是如何估计一个 batch 中物品 $y$ 的命中概率。具体方法如下:
|
||||
|
||||
+ 利用全局步长,将对物品采样频率 $p$ 转换为 对 $\delta$ 的估计,其中 $\delta$ 表示连续两次采样物品之间的平均步数。
|
||||
+ 例如,某物品平均 50 个步后会被采样到,那么采样频率 $p=1/\delta=0.02$ 。
|
||||
|
||||
**具体的实现方法为:**
|
||||
|
||||
1. 建立两个大小为 $H$ 的数组 $A,B$ 。
|
||||
|
||||
2. 通过哈希函数 $h(\cdot)$ 可以把每个物品映射为 $[H]$ 范围内的整数。
|
||||
|
||||
+ 映射的内容可以是 ID 或者其他的简单特征值。
|
||||
|
||||
+ 对于给定的物品 $y$,哈希后的整数记为 $h(y)$,本质上它表示物品 $y$ 在数组中的序号。
|
||||
|
||||
3. 数组 $A$ 中存放的 $A[h(y)]$ 表示物品 $y$ 上次被采样的时间, 数组 $B$ 中存放的 $B[h(y)]$ 表示物品 $y$ 的全局步长。
|
||||
|
||||
+ 假设在第 $t$ 步时采样到物品 $y$,则 $A[h(y)]$ 和 $B[h(y)]$ 的更新公式为:
|
||||
$$
|
||||
B[h(y)] \leftarrow(1-\alpha) \cdot B[h(y)]+\alpha \cdot(t-A[h(y)])
|
||||
$$
|
||||
|
||||
+ 在$B$ 被更新后,将 $t$ 赋值给 $A[h(y)]$ 。
|
||||
|
||||
4. 对整个batch数据采样后,取数组 $B$ 中 $B[h(y)]$ 的倒数,作为物品 $y$ 的采样频率,即:
|
||||
$$
|
||||
\hat{p}=1 / B[h(y)]
|
||||
$$
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/%E5%9B%BE%E7%89%87image-20220506220529932.png" alt="image-20220506220529932" style="zoom:50%;" />
|
||||
|
||||
**从数学理论上证明这种迭代更新的有效性:**
|
||||
|
||||
假设物品 $y$ 被采样到的时间间隔序列为 $\Delta=\left\{\Delta_{1}, \ldots, \Delta_{t}\right\}$ 满足独立同分布,这个随机变量的均值为$\delta=E[\Delta]$。对于每一次采样迭代:$\delta_{i}=(1-\alpha) \delta_{i-1}+\alpha \Delta_{i}$,可以证明时间间隔序列的均值和方差满足:
|
||||
|
||||
$$
|
||||
\begin{aligned}
|
||||
& E\left(\delta_{t}\right)-\delta=(1-\alpha)^{t} \delta_{0}-(1-\alpha)^{t-1} \delta
|
||||
\\ \\
|
||||
& E\left[\left(\delta_{t}-E\left[\delta_{t}\right]\right)^{2}\right] \leq(1-\alpha)^{2 t}\left(\delta_{0}-\delta\right)^{2}+\alpha E\left[\left(\Delta_{1}-\alpha\right)^{2}\right]
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
1. **对于均值的证明:**
|
||||
$$
|
||||
\begin{aligned}
|
||||
E\left[\delta_{t}\right] &=(1-\alpha) E\left[\delta_{t-1}\right]+\alpha \delta \\
|
||||
&=(1-\alpha)\left[(1-\alpha) E\left[\delta_{t-2}\right]+\alpha \delta\right]+\alpha \delta \\
|
||||
&=(1-\alpha)^{2} E\left[\delta_{t-2}\right]+\left[(1-\alpha)^{1}+(1-\alpha)^{0}\right] \alpha \delta \\
|
||||
&=(1-\alpha)^{3} E\left[\delta_{t-3}\right]+\left[(1-\alpha)^{2}+(1-\alpha)^{1}+(1-\alpha)^{0}\right] \alpha \delta \\
|
||||
&=\ldots \ldots \\
|
||||
&=(1-\alpha)^{t} \delta_{0}+\left[(1-\alpha)^{t-1}+\ldots+(1-\alpha)^{1}+(1-\alpha)^{0}\right] \alpha \delta \\
|
||||
&=(1-\alpha)^{t} \delta_{0}+\left[1-(1-\alpha)^{t-1}\right] \delta
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 根据均值公式可以看出:$t \rightarrow \infty \text { 时, }\left|E\left[\delta_{t}\right]-\delta\right| \rightarrow 0 $ 。
|
||||
+ 即当采样数据足够多的时候,数组 $B$ (每多少步采样一次)趋于真实采样频率。
|
||||
+ 因此递推式合理,且当初始值 $\delta_{0}=\delta /(1-\alpha)$,递推式为无偏估计。
|
||||
|
||||
2. **对于方差的证明:**
|
||||
$$
|
||||
\begin{aligned}
|
||||
E\left[\left(\delta_{t}-E\left[\delta_{t}\right]\right)^{2}\right] &=E\left[\left(\delta_{t}-\delta+\delta-E\left[\delta_{t}\right]\right)^{2}\right] \\
|
||||
&=E\left[\left(\delta_{t}-\delta\right)^{2}\right]+2 E\left[\left(\delta_{t}-\delta\right)\left(\delta-E\left[\delta_{t}\right]\right)\right]+\left(\delta-E\left[\delta_{t}\right]\right)^{2} \\
|
||||
&=E\left[\left(\delta_{t}-\delta\right)^{2}\right]-\left(E\left[\delta_{t}\right]-\delta\right)^{2} \\
|
||||
& \leq E\left[\left(\delta_{t}-\delta\right)^{2}\right]
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 对于 $E\left[\left(\delta_{i}-\delta\right)^{2}\right]$:
|
||||
$$
|
||||
\begin{aligned}
|
||||
E\left[\left(\delta_{i}-\delta\right)^{2}\right] &=E\left[\left((1-\alpha) \delta_{i-1}+\alpha \Delta_{i}-\delta\right)^{2}\right] \\
|
||||
&=E\left[\left((1-\alpha) \delta_{i-1}+\alpha \Delta_{i}-(1-\alpha+\alpha) \delta\right)^{2}\right] \\
|
||||
&=E\left[\left((1-\alpha)\left(\delta_{i-1}-\delta\right)+\alpha\left(\Delta_{i}-\delta\right)\right)^{2}\right] \\
|
||||
&=(1-\alpha)^{2} E\left[\left(\delta_{i-1}-\delta\right)^{2}\right]+\alpha^{2} E\left[\Delta_{i}-\delta\right]^{2}+2 \alpha(1-\alpha) E\left[\left(\delta_{i-1}-\delta\right)\left(\Delta_{i}-\delta\right)\right]
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 由于 $\delta_{i-1}$ 和 $\Delta_{i}$ 独立,所以上式最后一项为 0,因此:
|
||||
$$
|
||||
E\left[\left(\delta_{i}-\delta\right)^{2}\right]=(1-\alpha)^{2} E\left[\left(\delta_{i-1}-\delta\right)^{2}\right]+\alpha^{2} E\left[\Delta_{i}-\delta\right]^{2}
|
||||
$$
|
||||
|
||||
+ 与均值的推导类似,可得:
|
||||
$$
|
||||
\begin{aligned}
|
||||
E\left[\left(\delta_{t}-\delta\right)^{2}\right] &=(1-\alpha)^{2 t}\left(\delta_{0}-\delta\right)^{2}+\alpha^{2} \frac{1-(1-\alpha)^{2 t-2}}{1-(1-\alpha)^{2}} E\left[\left(\Delta_{1}-\delta\right)^{2}\right] \\
|
||||
& \leq(1-\alpha)^{2 t}\left(\delta_{0}-\delta\right)^{2}+\alpha E\left[\left(\Delta_{1}-\delta\right)^{2}\right]
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
+ 由此可证明:
|
||||
$$
|
||||
E\left[\left(\delta_{t}-E\left[\delta_{t}\right]\right)^{2}\right] \leq(1-\alpha)^{2 t}\left(\delta_{0}-\delta\right)^{2}+\alpha E\left[\left(\Delta_{1}-\alpha\right)^{2}\right]
|
||||
$$
|
||||
|
||||
+ 对于方差,上式给了一个估计方差的上界。
|
||||
|
||||
## 多重哈希
|
||||
|
||||
上述流动采样频率估计算法存在的问题:
|
||||
|
||||
+ 对于不同的物品,经过哈希函数映射的整数可能相同,这就会导致哈希碰撞的问题。
|
||||
|
||||
+ 由于哈希碰撞,对导致对物品采样频率过高的估计。
|
||||
|
||||
**解决方法:**
|
||||
|
||||
* 使用 $m$ 个哈希函数,取 $m$ 个估计值中的最大值来表示物品连续两次被采样到之间的步长。
|
||||
|
||||
**具体的算法流程:**
|
||||
|
||||
1. 分别建立 $m$ 个大小为 $H$ 的数组 $\{A\}_{i=1}^{m}$,$\{B\}_{i=1}^{m}$,一组对应的独立哈希函数集合 $\{h\}_{i=1}^{m}$ 。
|
||||
|
||||
2. 通过哈希函数 $h(\cdot)$ 可以把每个物品映射为 $[H]$ 范围内的整数。对于给定的物品 $y$,哈希后的整数记为$h(y)$
|
||||
|
||||
3. 数组 $A_i$ 中存放的 $A_i[h(y)]$ 表示在第 $i$ 个哈希函数中物品 $y$ 上次被采样的时间。数组 $B_i$ 中存放的 $B_i[h(y)]$ 表示在第 $i$ 个哈希函数中物品 $y$ 的全局步长。
|
||||
|
||||
4. 假设在第 $t$ 步采样到物品 $y$,分别对 $m$ 个哈希函数对应的 $A[h(y)]$ 和 $B[h(y)]$ 进行更新:
|
||||
$$
|
||||
\begin{aligned}
|
||||
& B_i[h(y)] \leftarrow(1-\alpha) \cdot B_i[h(y)]+\alpha \cdot(t-A_i[h(y)])\\ \\
|
||||
& A_i[h(y)]\leftarrow t
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
5. 对整个 batch 数据采样后,取 $\{B\}_{i=1}^{m}$ 中最大的 $B[h(y)]$ 的倒数,作为物品 $y$ 的采样频率,即:
|
||||
|
||||
$$
|
||||
\hat{p}=1 / \max _{i}\left\{B_{i}[h(y)]\right\}
|
||||
$$
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/%E5%9B%BE%E7%89%87image-20220506223731749.png" alt="image-20220506223731749" style="zoom:50%;" />
|
||||
|
||||
|
||||
|
||||
# YouTube 神经召回模型
|
||||
|
||||
本文构建的 YouTube 神经检索模型由查询和候选网络组成。下图展示了整体的模型架构。
|
||||
|
||||
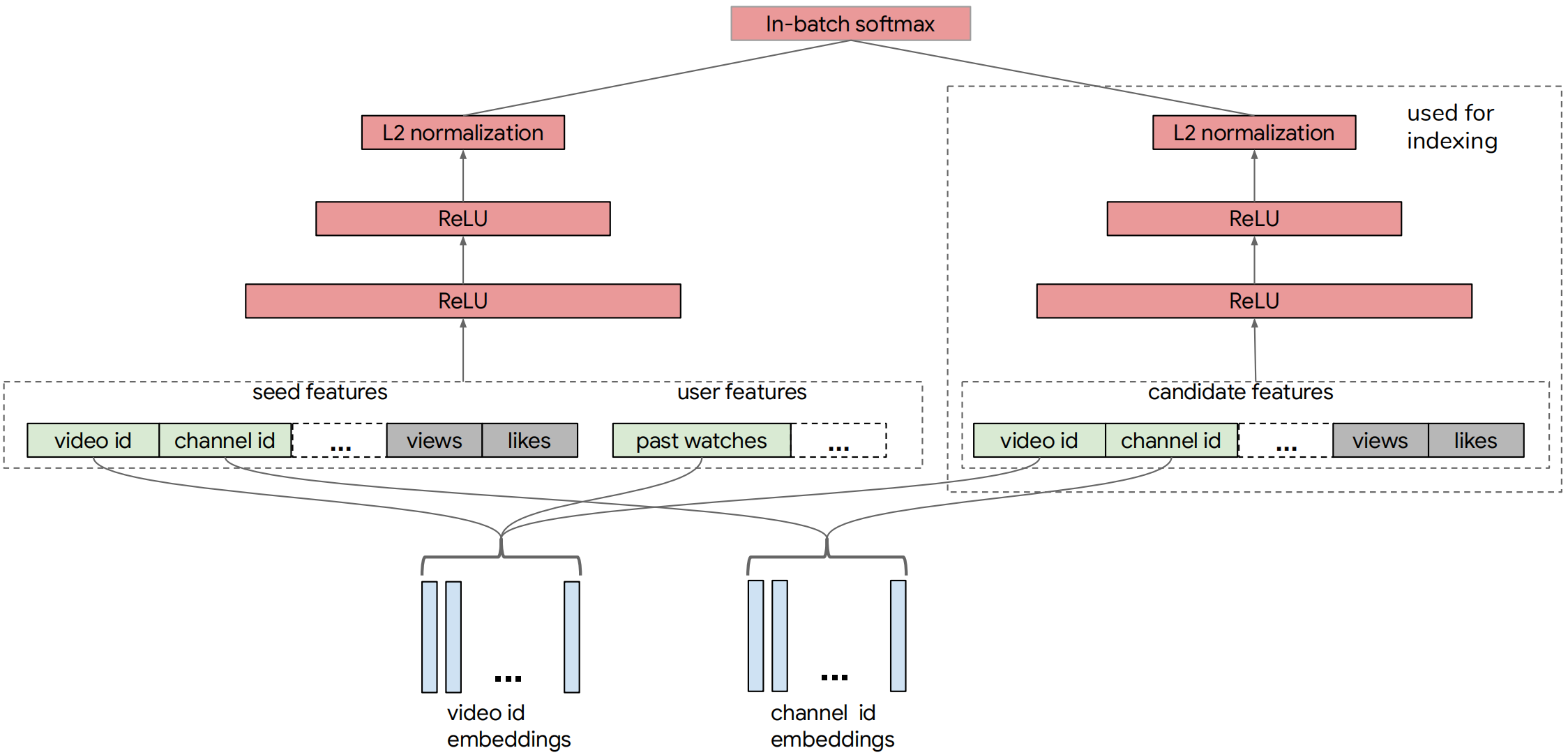
|
||||
|
||||
在任何时间点,用户正在观看的视频,即种子视频,都会提供有关用户当前兴趣的强烈信号。因此,本文利用了大量种子视频特征以及用户的观看历史记录。候选塔是为了从候选视频特征中学习而构建的。
|
||||
|
||||
* Training Label
|
||||
|
||||
* 视频点击被用作正面标签。对于每次点击,我们都会构建一个 rewards 来反映用户对视频的不同程度的参与。
|
||||
* $r_i$ = 0:观看时间短的点击视频;$r_i$ = 1:表示观看了整个视频。
|
||||
* Video Features
|
||||
|
||||
* YouTube 使用的视频特征包括 categorical 特征和 dense 特征。
|
||||
|
||||
* 例如 categorical 特征有 video id 和 channel id 。
|
||||
* 对于 categorical 特征,都会创建一个嵌入层以将每个分类特征映射到一个 Embedding 向量。
|
||||
* 通常 YouTube 要处理两种类别特征。从原文的意思来看,这两类应该是 one-hot 型和 multi-hot 型。
|
||||
* User Features
|
||||
|
||||
* 使用**用户观看历史记录**来捕捉 seed video 之外的兴趣。将用户最近观看的 k个视频视为一个词袋(BOW),然后将它们的 Embedding 平均。
|
||||
* 在查询塔中,最后将用户和历史 seed video 的特征进行融合,并送入输入前馈神经网络。
|
||||
* 类别特征的 Embedding 共享
|
||||
|
||||
* 原文:For the same type of IDs, embeddings are shared among the related features. For example, the same set of video id embeddings is used for seed, candidate and users past watches. We did experiment with non-shared embeddings, but did not observe significant model quality improvement.
|
||||
* 大致意思就是,对于相同 ID 的类别,他们之间的 Embedding 是共享的。例如对于 seed video,出现的地方包括用户历史观看,以及作为候选物品,故只要视频的 ID 相同,Embedding也是相同的。如果不共享,也没啥提升。
|
||||
|
||||
# 参考链接
|
||||
|
||||
+ [Sampling-bias-corrected neural modeling for large corpus item recommendations | Proceedings of the 13th ACM Conference on Recommender Systems](https://dl.acm.org/doi/abs/10.1145/3298689.3346996)
|
||||
|
||||
+ [【推荐系统经典论文(九)】谷歌双塔模型 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/137538147)
|
||||
|
||||
+ [借Youtube论文,谈谈双塔模型的八大精髓问题 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/369152684)
|
||||
@@ -1,114 +0,0 @@
|
||||
# 前言
|
||||
|
||||
在自然语言处理(NLP)领域,谷歌提出的 Word2Vec 模型是学习词向量表示的重要方法。其中,带有负采样(SGNS,Skip-gram with negative sampling)的 Skip-Gram 神经词向量模型在当时被证明是最先进的方法之一。各位读者需要自行了解 Word2Vec 中的 Skip-Gram 模型,本文只会做简单介绍。
|
||||
|
||||
在论文 Item2Vec:Neural Item Embedding for Collaborative Filtering 中,作者受到 SGNS 的启发,提出了名为 Item2Vec 的方法来生成物品的向量表示,然后将其用于基于物品的协同过滤。
|
||||
|
||||
# 基于负采样的 Skip-Gram 模型
|
||||
|
||||
Skip-Gram 模型的思想很简单:给定一个句子 $(w_i)^K_{i=1}$,然后基于中心词来预测它的上下文。目标函数如下:
|
||||
$$
|
||||
\frac{1}{K} \sum_{i=1}^{K} \sum_{-c \leq j \leq c, j \neq 0} \log p\left(w_{i+j} \mid w_{i}\right)
|
||||
$$
|
||||
|
||||
+ 其中,$c$ 表示上下文的窗口大小;$w_i$ 表示中心词;$w_{i+j}$ 表示上下文。
|
||||
|
||||
+ 表达式中的概率 $p\left(w_{j} \mid w_{i}\right)$ 的公式为:
|
||||
$$
|
||||
p\left(w_{j} \mid w_{i}\right)=\frac{\exp \left(u_{i}^{T} v_{j}\right)}{\sum_{k \in I_{W}} \exp \left(u_{i}^{T} v_{k}^{T}\right)}
|
||||
$$
|
||||
|
||||
+ $u_{i} \in U\left(\subset \mathbb{R}^{m}\right),v_{i} \in V\left(\subset \mathbb{R}^{m}\right)$,分别对应中心和上下文词的 Embedding 特征表示。
|
||||
+ 这里的意思是每个单词有2个特征表示,作为中心词 $u_i$ 和上下文 $v_i$ 时的特征表示不一样。
|
||||
+ $I_{W} \triangleq\{1, \ldots,|W|\}$ ,$|W|$ 表示语料库中词的数量。
|
||||
|
||||
简单来理解一下 Skip-Gram 模型的表达式:
|
||||
|
||||
+ 对于句子中的某个词 $w_i$,当其作为中心词时,希望尽可能准确预测它的上下文。
|
||||
+ 我们可以将其转换为多分类问题:
|
||||
+ 对于中心词 $w_i$ 预测的上下文 $w_j$,其 $label=1$ ;那么,模型对上下文的概率预测 $p\left(w_{j} \mid w_{i}\right)$ 越接近1越好。
|
||||
+ 若要 $p\left(w_{j} \mid w_{i}\right)$ 接近1,对于分母项中的 $k\ne j$,其 $\exp \left(u_{i}^{T} v_{k}^{T}\right)$ 越小越好(等价于将其视为了负样本)。
|
||||
|
||||
|
||||
注意到分母项,由于需要遍历语料库中所有的单词,从而导致计算成本过高。一种解决办法是基于负采样(NEG)的方式来降低计算复杂度:
|
||||
$$
|
||||
p\left(w_{j} \mid w_{i}\right)=\sigma\left(u_{i}^{T} v_{j}\right) \prod_{k=1}^{N} \sigma\left(-u_{i}^{T} v_{k}\right)
|
||||
$$
|
||||
|
||||
+ 其中,$\sigma(x)=1/1+exp(-x)$,$N$ 表示负样本的数量。
|
||||
|
||||
其它细节:
|
||||
|
||||
+ 单词 $w$ 作为负样本时,被采样到的概率:
|
||||
$$
|
||||
\frac{[\operatorname{counter}(w)]^{0.75}}{\sum_{u \in \mathcal{W}}[\operatorname{counter}(u)]^{0.75}}
|
||||
$$
|
||||
|
||||
+ 单词 $w$ 作为中心词时,被丢弃的概率:
|
||||
$$
|
||||
\operatorname{prob}(w)=1-\sqrt{\frac{t}{f(w)}}
|
||||
$$
|
||||
|
||||
|
||||
# Item2Vec模型
|
||||
|
||||
Item2Vec 的原理十分十分简单,它是基于 Skip-Gram 模型的物品向量训练方法。但又存在一些区别,如下:
|
||||
|
||||
+ 词向量的训练是基于句子序列(sequence),但是物品向量的训练是基于物品集合(set)。
|
||||
+ 因此,物品向量的训练丢弃了空间、时间信息。
|
||||
|
||||
Item2Vec 论文假设对于一个集合的物品,它们之间是相似的,与用户购买它们的顺序、时间无关。当然,该假设在其他场景下不一定使用,但是原论文只讨论了该场景下它们实验的有效性。由于忽略了空间信息,原文将共享同一集合的每对物品视为正样本。目标函数如下:
|
||||
$$
|
||||
\frac{1}{K} \sum_{i=1}^{K} \sum_{j \neq i}^{K} \log p\left(w_{j} \mid w_{i}\right)
|
||||
$$
|
||||
|
||||
+ 对于窗口大小 $K$,由设置的决定。
|
||||
|
||||
在 Skip-Gram 模型中,提到过每个单词 $w_i$ 有2个特征表示。在 Item2Vec 中同样如此,论文中是将物品的中心词向量 $u_i$ 作为物品的特征向量。作者还提到了其他两种方式来表示物品向量:
|
||||
|
||||
+ **add**:$u_i + v_i$
|
||||
+ **concat**:$\left[u_{i}^{T} v_{i}^{T}\right]^{T}$
|
||||
|
||||
原文还补充到,这两种方式有时候会有很好的表现。
|
||||
|
||||
# 总结
|
||||
|
||||
+ Item2Vec 的原理很简单,就是基于 Word2Vec 的 Skip-Gram 模型,并且还丢弃了时间、空间信息。
|
||||
+ 基于 Item2Vec 得到物品的向量表示后,物品之间的相似度可由二者之间的余弦相似度计算得到。
|
||||
+ 可以看出,Item2Vec 在计算物品之间相似度时,仍然依赖于不同物品之间的共现。因为,其无法解决物品的冷启动问题。
|
||||
+ 一种解决方法:取出与冷启物品类别相同的非冷启物品,将它们向量的均值作为冷启动物品的向量表示。
|
||||
|
||||
原论文链接:[[1603.04259\] Item2Vec: Neural Item Embedding for Collaborative Filtering (arxiv.org)](https://arxiv.org/abs/1603.04259)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,341 +0,0 @@
|
||||
# 背景和引入
|
||||
在所有的NLP任务中,首先面临的第一个问题是我们该如何表示单词。这种表示将作为inputs输入到特定任务的模型中,如机器翻译,文本分类等典型NLP任务。
|
||||
|
||||
## 同义词表达单词
|
||||
一个很容易想到的解决方案是使用同义词来表示一个单词的意义。
|
||||
比如***WordNet***,一个包含同义词(和有“is a”关系的词)的词库。
|
||||
|
||||
**导包**
|
||||
|
||||
```python
|
||||
!pip install --user -U nltk
|
||||
```
|
||||
|
||||
```python
|
||||
!python -m nltk.downloader popular
|
||||
```
|
||||
|
||||
**如获取"good"的同义词**
|
||||
|
||||
```python
|
||||
from nltk.corpus import wordnet as wn
|
||||
poses = { 'n':'noun', 'v':'verb', 's':'adj (s)', 'a':'adj', 'r':'adv'}
|
||||
for synset in wn.synsets("good"):
|
||||
print("{}: {}".format(poses[synset.pos()],", ".join([l.name() for l in synset.lemmas()])))
|
||||
```
|
||||
|
||||
**如获取与“pandas”有"is a"关系的词**
|
||||
|
||||
```python
|
||||
panda = wn.synset("panda.n.01")
|
||||
hyper = lambda s: s.hypernyms()
|
||||
list(panda.closure(hyper))
|
||||
```
|
||||
|
||||
***WordNet的问题***
|
||||
1. 单词与单词之间缺少些微差异的描述。比如“高效”只在某些语境下是"好"的同义词
|
||||
2. 丢失一些词的新含义。比如“芜湖”,“蚌埠”等词的新含义
|
||||
3. 相对主观
|
||||
4. 需要人手动创建和调整
|
||||
5. 无法准确计算单词的相似性
|
||||
|
||||
## one-hot编码
|
||||
在传统NLP中,人们使用one-hot向量(一个向量只有一个值为1,其余的值为0)来表示单词
|
||||
如:motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
|
||||
如:hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
|
||||
one-hot向量的维度是词汇表的大小(如:500,000)
|
||||
注:上面示例词向量的维度为方便展示所以比较小
|
||||
|
||||
|
||||
**one-hot向量表示单词的问题:**
|
||||
1. 这些词向量是***正交向量***,无法通过数学计算(如点积)计算相似性
|
||||
2. 依赖WordNet等同义词库建立相似性效果也不好
|
||||
|
||||
|
||||
## dense word vectors表达单词
|
||||
如果我们可以使用某种方法为每个单词构建一个合适的dense vector,如下图,那么通过点积等数学计算就可以获得单词之间的某种联系
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1.png" />
|
||||
|
||||
|
||||
# Word2vec
|
||||
|
||||
## 语言学基础
|
||||
首先,我们引入一个上世纪五十年代,一个语言学家的研究成果:**“一个单词的意义由它周围的单词决定”**
|
||||
|
||||
“You shall know a word by the company it keeps” (J. R. Firth 1957: 11)
|
||||
|
||||
这是现代NLP中一个最为成功的理念。
|
||||
|
||||
我们先引入上下文context的概念:当单词 w 出现在文本中时,其**上下文context**是出现在w附近的一组单词(在固定大小的窗口内),如下图
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2.png" />
|
||||
|
||||
|
||||
这些上下文单词context words决定了banking的意义
|
||||
|
||||
## Word2vec概述
|
||||
|
||||
Word2vec(Mikolov et al. 2013)是一个用来学习dense word vector的算法:
|
||||
|
||||
1. 我们使用**大量的文本语料库**
|
||||
2. 词汇表中的每个单词都由一个**词向量dense word vector**表示
|
||||
3. 遍历文本中的每个位置 t,都有一个**中心词 c(center) 和上下文词 o(“outside”)**,如图1中的banking
|
||||
4. 在整个语料库上使用数学方法**最大化单词o在单词c周围出现了这一事实**,从而得到单词表中每一个单词的dense vector
|
||||
5. 不断调整词向量dense word vector以达到最好的效果
|
||||
|
||||
|
||||
## Skip-gram(SG)
|
||||
Word2vec包含两个模型,**Skip-gram与CBOW**。下面,我们先讲**Skip-gram**模型,用此模型详细讲解概述中所提到的内容。
|
||||
|
||||
概述中我们提到,我们希望**最大化单词o在单词c周围出现了这一事实**,而我们需要用数学语言表示“单词o在单词c周围出现了”这一事件,如此才能进行词向量的不断调整。
|
||||
|
||||
很自然地,我们需要**使用概率工具描述事件的发生**,我们想到用条件概率$P(o|c)$表示“给定中心词c,它的上下文词o在它周围出现了”
|
||||
|
||||
下图展示了以“into”为中心词,窗口大小为2的情况下它的上下文词。以及相对应的$P(o|c)$
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片3.png" />
|
||||
|
||||
|
||||
我们滑动窗口,再以banking为中心词
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片4.png" />
|
||||
|
||||
|
||||
那么,如果我们在整个语料库上不断地滑动窗口,我们可以得到所有位置的$P(o|c)$,我们希望在所有位置上**最大化单词o在单词c周围出现了这一事实**,由极大似然法,可得:
|
||||
|
||||
$$
|
||||
max\prod_{c} \prod_{o}P(o|c)
|
||||
$$
|
||||
|
||||
此式还可以依图3写为:
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片5.png" />
|
||||
|
||||
|
||||
加log,加负号,缩放大小可得:
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片7.png" />
|
||||
|
||||
|
||||
上式即为**skip-gram的损失函数**,最小化损失函数,就可以得到合适的词向量
|
||||
|
||||
|
||||
得到式1后,产生了两个问题:
|
||||
|
||||
1. P(o|c)怎么表示?
|
||||
|
||||
2. 为何最小化损失函数能够得到良好表示的词向量dense word vector?
|
||||
|
||||
|
||||
回答1:我们使用**中心词c和上下文词o的相似性**来计算$P(o|c)$,更具体地,相似性由**词向量的点积**表示:$u_o \cdot v_c$。
|
||||
|
||||
使用词向量的点积表示P(o|c)的原因:1.计算简单 2.出现在一起的词向量意义相关,则希望它们相似
|
||||
|
||||
又P(o|c)是一个概率,所以我们在整个语料库上使用**softmax**将点积的值映射到概率,如图6
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片6.png" />
|
||||
|
||||
|
||||
注:注意到上图,中心词词向量为$v_{c}$,而上下文词词向量为$u_{o}$。也就是说每个词会对应两个词向量,**在词w做中心词时,使用$v_{w}$作为词向量,而在它做上下文词时,使用$u_{w}$作为词向量**。这样做的原因是为了求导等操作时计算上的简便。当整个模型训练完成后,我们既可以使用$v_{w}$作为词w的词向量,也可以使用$u_{w}$作为词w的词向量,亦或是将二者平均。在下一部分的模型结构中,我们将更清楚地看到两个词向量究竟在模型的哪个位置。
|
||||
|
||||
|
||||
回答2:由上文所述,$P(o|c)=softmax(u_{o^T} \cdot v_c)$。所以损失函数是关于$u_{o}$和$v_c$的函数,我们通过梯度下降法调整$u_{o}$和$v_c$的值,最小化损失函数,即得到了良好表示的词向量。
|
||||
|
||||
|
||||
## Word2vec模型结构
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片8.png" />
|
||||
|
||||
|
||||
如图八所示,这是一个输入为1 X V维的one-hot向量(V为整个词汇表的长度,这个向量只有一个1值,其余为0值表示一个词),单隐藏层(**隐藏层的维度为N,这里是一个超参数,这个参数由我们定义,也就是词向量的维度**),输出为1 X V维的softmax层的模型。
|
||||
|
||||
$W^{I}$为V X N的参数矩阵,$W^{O}$为N X V的参数矩阵。
|
||||
|
||||
模型的输入为1 X V形状的one-hot向量(V为整个词汇表的长度,这个向量只有一个1值,其余为0值表示一个词)。隐藏层的维度为N,这里是一个超参数,这个参数由我们定义,也就是词向量的维度。$W^{I}$为V X N的参数矩阵。
|
||||
|
||||
我们这里,考虑Skip-gram算法,输入为中心词c的one-hot表示
|
||||
|
||||
由输入层到隐藏层,根据矩阵乘法规则,可知,**$W^{I}$的每一行即为词汇表中的每一个单词的词向量v**,1 X V 的 inputs 乘上 V X N 的$W^{I}$,隐藏层即为1 X N维的$v_{c}$。
|
||||
|
||||
而$W^{O}$中的每一列即为词汇表中的每一个单词的词向量u。根据乘法规则,1 X N 的隐藏层乘上N X V的$W^{O}$参数矩阵,得到的1 X V 的输出层的每一个值即为$u_{w^T} \cdot v_c$,加上softmax变化即为$P(w|c)$。
|
||||
|
||||
有V个w,其中的P(o|c)即实际样本中的上下文词的概率,为我们最为关注的值。
|
||||
|
||||
## CBOW
|
||||
|
||||
如上文所述,Skip-gram为给定中心词,预测周围的词,即求P(o|c),如下图所示:
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105817437.png" />
|
||||
|
||||
|
||||
而CBOW为给定周围的词,预测中心词,即求P(c|o),如下图所示:
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片10.png" />
|
||||
|
||||
|
||||
|
||||
注意:在使用CBOW时,上文所给出的模型结构并没有变,在这里,我们输入多个上下文词o,在隐藏层,**将这多个上下文词经过第一个参数矩阵的计算得到的词向量相加作为隐藏单元的值**。其余均不变,$W^{O}$中的每一列依然为为词汇表中的每一个单词的词向量u。
|
||||
|
||||
# 负采样 Negative Sampling
|
||||
|
||||
## softmax函数带来的问题
|
||||
|
||||
我们再看一眼,通过softmax得到的$P(o|c)$,如图:
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105958191.png" />
|
||||
|
||||
|
||||
|
||||
可以看到,$P(o|c)$的分母需要在整个单词表上做乘积和exp运算,这无疑是非常消耗计算资源的,Word2vec的作者针对这个问题,做出了改进。
|
||||
|
||||
他提出了两种改进的方法:Hierarchical Softmax和Negative Sampling,因为Negative Sampling更加常见,所以我们下面只介绍Negative Sampling,感兴趣的朋友可以在文章下面的参考资料中学习Hierarchical Softmax。
|
||||
|
||||
## 负采样Negative Sampling
|
||||
|
||||
我们依然以Skip-gram为例(CBOW与之差别不大,感兴趣的朋友们依然可以参阅参考资料)
|
||||
|
||||
我们首先给出负采样的损失函数:
|
||||
|
||||
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片12.png" />
|
||||
|
||||
|
||||
|
||||
其中$\sigma$为sigmoid函数$1/(1+e^{-x})$, $u_{o}$为实际样本中的上下文词的词向量,而$u_{k}$为我们在单词表中随机选出(按一定的规则随机选出,具体可参阅参考资料)的K个单词。
|
||||
|
||||
由函数单调性易知,**$u_{o^T} \cdot v_c$越大,损失函数越小,而$u_{k^T} \cdot v_c$越小**,损失函数越大。这与原始的softmax损失函数优化目标一致,即$maxP(o|c)$,而且避免了在整个词汇表上的计算。
|
||||
|
||||
# 核心代码与核心推导
|
||||
|
||||
## Naive softmax 损失函数
|
||||
|
||||
损失函数关于$v_c$的导数:
|
||||
|
||||
$$
|
||||
\frac{\partial{J_{naive-softmax}(\boldsymbol v_c,o,\boldsymbol U)}}{\partial \boldsymbol v_c} \\=
|
||||
-\frac{\partial{log(P(O=o|C=c))}}{\partial \boldsymbol v_c} \\ =
|
||||
-\frac{\partial{log(exp( \boldsymbol u_o^T\boldsymbol v_c))}}{\partial \boldsymbol v_c} + \frac{\partial{log(\sum_{w=1}^{V}exp(\boldsymbol u_w^T\boldsymbol v_c))}}{\partial \boldsymbol v_c} \\=
|
||||
-\boldsymbol u_o + \sum_{w=1}^{V} \frac{exp(\boldsymbol u_w^T\boldsymbol v_c)}{\sum_{w=1}^{V}exp(\boldsymbol u_w^T\boldsymbol v_c)}\boldsymbol u_w \\=
|
||||
-\boldsymbol u_o+ \sum_{w=1}^{V}P(O=w|C=c)\boldsymbol u_w \\=
|
||||
\boldsymbol U^T(\hat{\boldsymbol y} - \boldsymbol y)
|
||||
$$
|
||||
|
||||
可以看到涉及整个U矩阵的计算,计算量很大,关于$u_w$的导数读者可自行推导
|
||||
|
||||
损失函数及其梯度的求解
|
||||
|
||||
来自:https://github.com/lrs1353281004/CS224n_winter2019_notes_and_assignments
|
||||
|
||||
```python
|
||||
def naiveSoftmaxLossAndGradient(
|
||||
centerWordVec,
|
||||
outsideWordIdx,
|
||||
outsideVectors,
|
||||
dataset
|
||||
):
|
||||
""" Naive Softmax loss & gradient function for word2vec models
|
||||
|
||||
Arguments:
|
||||
centerWordVec -- numpy ndarray, center word's embedding
|
||||
in shape (word vector length, )
|
||||
(v_c in the pdf handout)
|
||||
outsideWordIdx -- integer, the index of the outside word
|
||||
(o of u_o in the pdf handout)
|
||||
outsideVectors -- outside vectors is
|
||||
in shape (num words in vocab, word vector length)
|
||||
for all words in vocab (tranpose of U in the pdf handout)
|
||||
dataset -- needed for negative sampling, unused here.
|
||||
|
||||
Return:
|
||||
loss -- naive softmax loss
|
||||
gradCenterVec -- the gradient with respect to the center word vector
|
||||
in shape (word vector length, )
|
||||
(dJ / dv_c in the pdf handout)
|
||||
gradOutsideVecs -- the gradient with respect to all the outside word vectors
|
||||
in shape (num words in vocab, word vector length)
|
||||
(dJ / dU)
|
||||
"""
|
||||
|
||||
# centerWordVec: (embedding_dim,1)
|
||||
# outsideVectors: (vocab_size,embedding_dim)
|
||||
|
||||
scores = np.matmul(outsideVectors, centerWordVec) # size=(vocab_size, 1)
|
||||
probs = softmax(scores) # size=(vocab, 1)
|
||||
|
||||
loss = -np.log(probs[outsideWordIdx]) # scalar
|
||||
|
||||
dscores = probs.copy() # size=(vocab, 1)
|
||||
dscores[outsideWordIdx] = dscores[outsideWordIdx] - 1 # dscores=y_hat - y
|
||||
gradCenterVec = np.matmul(outsideVectors, dscores) # J关于vc的偏导数公式 size=(vocab_size, 1)
|
||||
gradOutsideVecs = np.outer(dscores, centerWordVec) # J关于u的偏导数公式 size=(vocab_size, embedding_dim)
|
||||
|
||||
return loss, gradCenterVec, gradOutsideVecs
|
||||
```
|
||||
|
||||
## 负采样损失函数
|
||||
|
||||
负采样损失函数关于$v_c$的导数:
|
||||
|
||||
$$
|
||||
\frac{\partial{J_{neg-sample}(\boldsymbol v_c,o,\boldsymbol U)}}{\partial\boldsymbol v_c} \\=
|
||||
\frac{\partial (-log(\sigma (\boldsymbol u_o^T\boldsymbol v_c))-\sum_{k=1}^{K} log(\sigma (-\boldsymbol u_k^T\boldsymbol v_c)))}{\partial \boldsymbol v_c} \\=
|
||||
-\frac{\sigma(\boldsymbol u_o^T\boldsymbol v_c)(1-\sigma(\boldsymbol u_o^T\boldsymbol v_c))}{\sigma(\boldsymbol u_o^T\boldsymbol v_c)}\frac{\partial \boldsymbol u_o^T\boldsymbol v_c}{\partial \boldsymbol v_c} -
|
||||
\sum_{k=1}^{K}\frac{\partial log(\sigma(-\boldsymbol u_k^T\boldsymbol v_c))}{\partial \boldsymbol v_c} \\=
|
||||
-(1-\sigma(\boldsymbol u_o^T\boldsymbol v_c))\boldsymbol u_o+\sum_{k=1}^{K}(1-\sigma(-\boldsymbol u_k^T\boldsymbol v_c))\boldsymbol u_k
|
||||
$$
|
||||
|
||||
可以看到其只与$u_k$和$u_o$有关,避免了在整个单词表上的计算
|
||||
|
||||
负采样方法的损失函数及其导数的求解
|
||||
|
||||
```python
|
||||
def negSamplingLossAndGradient(
|
||||
centerWordVec,
|
||||
outsideWordIdx,
|
||||
outsideVectors,
|
||||
dataset,
|
||||
K=10
|
||||
):
|
||||
|
||||
negSampleWordIndices = getNegativeSamples(outsideWordIdx, dataset, K)
|
||||
indices = [outsideWordIdx] + negSampleWordIndices
|
||||
|
||||
gradCenterVec =np.zeros(centerWordVec.shape) # (embedding_size,1)
|
||||
gradOutsideVecs = np.zeros(outsideVectors.shape) # (vocab_size, embedding_size)
|
||||
loss = 0.0
|
||||
|
||||
u_o = outsideVectors[outsideWordIdx] # size=(embedding_size,1)
|
||||
z = sigmoid(np.dot(u_o, centerWordVec)) # size=(1, )
|
||||
loss -= np.log(z) # 损失函数的第一部分
|
||||
gradCenterVec += u_o * (z - 1) # J关于vc的偏导数的第一部分
|
||||
gradOutsideVecs[outsideWordIdx] = centerWordVec * (z - 1) # J关于u_o的偏导数计算
|
||||
|
||||
for i in range(K):
|
||||
neg_id = indices[1 + i]
|
||||
u_k = outsideVectors[neg_id]
|
||||
z = sigmoid(-np.dot(u_k, centerWordVec))
|
||||
loss -= np.log(z)
|
||||
gradCenterVec += u_k * (1-z)
|
||||
gradOutsideVecs[neg_id] += centerWordVec * (1 - z)
|
||||
|
||||
|
||||
return loss, gradCenterVec, gradOutsideVecs
|
||||
```
|
||||
|
||||
**参考资料**
|
||||
- Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[J]. Advances in neural information processing systems, 2013, 26.
|
||||
- https://www.cnblogs.com/peghoty/p/3857839.html
|
||||
- http://web.stanford.edu/class/cs224n/
|
||||
|
||||
@@ -1,399 +0,0 @@
|
||||
# Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
|
||||
|
||||
这篇论文是阿里巴巴在18年发表于KDD的关于召回阶段的工作。该论文提出的方法是在基于图嵌入的方法上,通过引入side information来解决实际问题中的数据稀疏和冷启动问题。
|
||||
|
||||
## 动机
|
||||
|
||||
在电商领域,推荐已经是不可或缺的一部分,旨在为用户的喜好提供有趣的物品,并且成为淘宝和阿里巴巴收入的重要引擎。尽管学术界和产业界的各种推荐方法都取得了成功,如协同过滤、基于内容的方法和基于深度学习的方法,但由于用户和项目的数十亿规模,传统的方法已经不能满足于实际的需求,主要的问题体现在三个方面:
|
||||
|
||||
- 可扩展性:现有的推荐方法无法扩展到在拥有十亿的用户和二十亿商品的淘宝中。
|
||||
- 稀疏性:存在大量的物品与用户的交互行为稀疏。即用户的交互到多集中于以下部分商品,存在大量商品很少被用户交互。
|
||||
- 冷启动:在淘宝中,每分钟会上传很多新的商品,由于这些商品没有用户行为的信息(点击、购买等),无法进行很好的预测。
|
||||
|
||||
针对于这三个方面的问题, 本文设计了一个两阶段的推荐框架:**召回阶段和排序阶段**,这也是推荐领域最常见的模型架构。而本文提及的EGES模型主要是解决了匹配阶段的问题,通过用户行为计算商品间两两的相似性,然后根基相似性选出topK的商品输入到排序阶段。
|
||||
|
||||
为了学习更好的商品向量表示,本文通过用户的行为历史中构造一个item-item 图,然后应用随机游走方法在item-item 图为每个item获取到一个序列,然后通过Skip-Gram的方式为每个item学习embedding(这里的item序列类似于语句,其中每个item类比于句子中每个word),这种方式被称为图嵌入方法(Graph Embedding)。文中提出三个具体模型来学习更好的物品embedding,更好的服务于召回阶段。
|
||||
|
||||
## 思路
|
||||
|
||||
根据上述所面临的三个问题,本文针对性的提出了三个模型予以解决:Base Graph Embedding(BGE);Graph Embedding with Side Information(GES);Enhanced Graph Embedding with Side Information(EGES)。
|
||||
|
||||
考虑可扩展性的问题,图嵌入的随机游走方式可以在物品图上捕获**物品之间高阶相似性**,即Base Graph Embedding(BGE)方法。其不同于CF方法,除了考虑物品的共现,还考虑到了行为的序列信息。
|
||||
|
||||
考虑到稀疏性和冷启物品问题,在图嵌入的基础上,考虑了节点的属性信息。希望具有相似属性的物品可以在空间上相似,即希望通过头部物品,提高属性信息的泛化能力,进而帮助尾部和冷启物品获取更加准确的embedding,即Graph Embedding with Side Information(GES)方法。
|
||||
|
||||
考虑到不同属性信息对于学习embedding的贡献不同,因此在聚合不同的属性信息时,动态的学习不同属性对于学习节点的embedding所参与的重要性权重,即Enhanced Graph Embedding with Side Information(EGES)。
|
||||
|
||||
## 模型结构与原理
|
||||
|
||||
文中所提出的方法是基于经典的图嵌入模型DeepWalk进行改进,其目标是通过物品图G,学习一个映射函数$f:V -> R^d$ ,将图上节点映射成一个embedding。具体的步骤包括两步:1.通过随机游走为图上每个物品生成序列;2.通过Skip-Gram算法学习每个物品的embedding。因此对于该方法优化的目标是,在给定的上下文物品的前提下,最大化物品v的条件概率,即物品v对于一个序列里面的其他物品要尽可能的相似。接下来看一些每个模型具体内容。
|
||||
|
||||
### 构建物品图
|
||||
|
||||
在介绍三个模型之前,我们首先需要构建好item-item图。由于基于CF的方法仅考虑物品之间的共现,忽略了行为的序列信息(即序列中相邻的物品之间的语义信息),因此item-item图的构建方式如下图所示。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328133138263.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
首先根据用户的session行为序列构建网络结构,即序列中相邻两个item之间在存在边,并且是有向带权图。物品图边上的权重为所有用户行为序列中两个 item 共现的次数,最终构造出来简单的有向有权图。
|
||||
|
||||
值得注意的是,本文通过行为序列中物品的共现来表示其中的**语义信息**,并将这种语义信息理解为**物品之间的相似性**,并将共现频次作为相似性的一个度量值。其次基于用户的历史行为序列数据,一般不太可能取全量的历史序列数据,一方面行为数据量过大,一方面用户的兴趣会随时间发生演变,因此在处理行为序列时会设置了一个窗口来截断历史序列数据,切分出来的序列称为session。
|
||||
|
||||
由于实际中会存在一些现实因素,数据中会有一些噪音,需要特殊处理,主要分为三个方面:
|
||||
|
||||
- 从行为方面考虑,用户在点击后停留的时间少于1秒,可以认为是误点,需要移除。
|
||||
- 从用户方面考虑,淘宝场景中会有一些过度活跃用户。本文对活跃用户的定义是三月内购买商品数超过1000,或者点击数超过3500,就可以认为是一个无效用户,需要去除。
|
||||
- 从商品方面考虑,存在一些商品频繁的修改,即ID对应的商品频繁更新,这使得这个ID可能变成一个完全不同的商品,这就需要移除与这个ID相关的这个商品。
|
||||
|
||||
在构建完item-item图之后,接下来看看三个模型的具体内容。
|
||||
|
||||
### 图嵌入(BGE)
|
||||
|
||||
对于图嵌入模型,第一步先进行随机游走得到物品序列;第二部通过skip-gram为图上节点生成embedding。那么对于随机游走的思想:如何利用随机游走在图中生成的序列?不同于DeepWalk中的随机游走,本文的采样策略使用的是带权游走策略,不同权重的游走到的概率不同,(其本质上就是node2vec),传统的node2vec方法可以直接支持有向带权图。因此在给定图的邻接矩阵M后(表示节点之间的边权重),随机游走中每次转移的概率为:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144516898.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中$M_{ij}$为边$e_{ij}$上的权重,$N_{+}(v_i)$表示节点$v_i$所有邻居节点集合,并且随机游走的转移概率的对每个节点所有邻接边权重的归一化结果。在随即游走之后,每个item得到一个序列,如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220418142135912.png" style="zoom:47%;"/>
|
||||
</div>
|
||||
|
||||
然后类似于word2vec,为每个item学习embedding,于是优化目标如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144931957.png" style="zoom:77%;"/>
|
||||
</div>
|
||||
|
||||
其中,w 为窗口大小。考虑独立性假设的话,上面的式子可以进一步化简:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145101109.png" style="zoom:77%;"/>
|
||||
</div>
|
||||
|
||||
这样看起来就很直观了,在已知物品 i 时,最大化序列中(上下文)其他物品 j 的条件概率。为了近似计算,采样了Negative sampling,上面的优化目标可以化简得到如下式子:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145318718.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中$N(v_i)'$表示负样本集合,负采样个数越多,结果越好。
|
||||
|
||||
### 基于side information的图嵌入(GES)
|
||||
|
||||
尽管BGE将行为序列关系编码进物品的embedding中,从而从用户行为中捕捉高阶相似性。但是这里有个问题,对于新加入的商品,由于未和用户产生过交互,所以不会出现在item-item图上,进而模型无法学习到其embedding,即无法解决冷启动问题。
|
||||
|
||||
为了解决冷启问题,本文通过使用side information( 类别,店铺, 价格等)加入模型的训练过程中,使得模型最终的泛化能力体现在商品的side information上。这样通过**side information学习到的embedding来表示具体的商品**,使得相似side information的物品可以得到在空间上相近的表示,进而来增强 BGE。
|
||||
|
||||
那么对于每个商品如何通过side information的embedidng来表示呢?对于随机游走之后得到的商品序列,其中每个每个商品由其id和属性(品牌,价格等)组成。用公式表示,对于序列中的每一个物品可以得到$W^0_V,...W_V^n$,(n+1)个向量表示,$W^0_V$表示物品v,剩下是side information的embedding。然后将所有的side information聚合成一个整体来表示物品,聚合方式如下:
|
||||
|
||||
$$H_v = \frac{1}{n+1}\sum_{s=0}^n W^s_v$$
|
||||
|
||||
其中,$H_v$是商品 v 的聚合后的 embedding 向量。
|
||||
|
||||
### 增强型EGS(EGES)
|
||||
|
||||
尽管 GES 相比 BGE 在性能上有了提升,但是在聚合多个属性向量得到商品的embedding的过程中,不同 side information的聚合依然存在问题。在GES中采用 average-pooling 是在假设不同种类的 side information 对商品embedding的贡献是相等的,但实际中却并非如此。例如,购买 Iphone 的用户更可能倾向于 Macbook 或者 Ipad,相比于价格属性,品牌属性相对于苹果类商品具有更重要的影响。因此,根据实际现状,不同类型的 side information 对商品的表示是具有不同的贡献值的。
|
||||
|
||||
针对上述问题,作者提出了weight pooling方法来聚合不同类型的 side information。具体地,EGES 与 GES 的区别在聚合不同类型 side information计算不同的权重,根据权重聚合 side information 得到商品的embedding,如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328154950289.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中 $a_i$ 表示每个side information 用于计算权重的参数向量,最终通过下面的公式得到商品的embedding:
|
||||
|
||||
$$H_v = \frac{\sum_{j=0}^n e^{a_v^j} W_v^j}{\sum_{j=0}^n e^{a_v^j}}$$
|
||||
|
||||
这里对参数 $a_v^j$ 先做指数变换,目的是为了保证每个边界信息的贡献都能大于0,然后通过归一化为每个特征得到一个o-1之内的权重。最终物品的embedding通过权重进行加权聚合得到,进而优化损失函数:
|
||||
|
||||
$$L(v,u,y)=-[ylog( \sigma (H_v^TZ_u)) + (1-y)log(1 - \sigma(H_v^TZ_u))]$$
|
||||
|
||||
y是标签符号,等于1时表示正样本,等于0时表示负样本。$H_v$表示商品 v 的最终的隐层表示,$Z_u$表示训练数据中的上下文节点的embedding。
|
||||
|
||||
以上就是这三个模型主要的区别,下面是EGES的伪代码。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155406291.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中**WeightedSkipGram**函数为带权重的SkipGram算法。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155533704.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
## 代码实现
|
||||
|
||||
下面我们简单的来看一下模型代码的实现,参考的内容在[这里](https://github.com/wangzhegeek/EGES),其中实验使用的是jd 2019年比赛中提供的数据。
|
||||
|
||||
### 构建物品图
|
||||
|
||||
首先对用户的下单(type=2)行为序列进行session划分,其中30分钟没有产生下一个行为,划分为一个session。
|
||||
|
||||
```python
|
||||
def cnt_session(data, time_cut=30, cut_type=2):
|
||||
# 商品属性 id 被交互时间 商品种类
|
||||
sku_list = data['sku_id']
|
||||
time_list = data['action_time']
|
||||
type_list = data['type']
|
||||
session = []
|
||||
tmp_session = []
|
||||
for i, item in enumerate(sku_list):
|
||||
# 两个商品之间如果被交互的时间大于1小时,划分成不同的session
|
||||
if type_list[i] == cut_type or (i < len(sku_list)-1 and \
|
||||
(time_list[i+1] - time_list[i]).seconds/60 > time_cut) or i == len(sku_list)-1:
|
||||
tmp_session.append(item)
|
||||
session.append(tmp_session)
|
||||
tmp_session = []
|
||||
else:
|
||||
tmp_session.append(item)
|
||||
return session # 返回多个session list
|
||||
```
|
||||
|
||||
获取到所有session list之后(这里不区分具体用户),对于session长度不超过1的去除(没有意义)。
|
||||
|
||||
接下来就是构建图,主要是先计算所有session中,相邻的物品共现频次(通过字典计算)。然后通过入度节点、出度节点以及权重分别转化成list,通过network来构建有向图。
|
||||
|
||||
```python
|
||||
node_pair = dict()
|
||||
# 遍历所有session list
|
||||
for session in session_list_all:
|
||||
for i in range(1, len(session)):
|
||||
# 将session共现的item存到node_pair中,用于构建item-item图
|
||||
# 将共现次数所谓边的权重,即node_pair的key为边(src_node,dst_node),value为边的权重(共现次数)
|
||||
if (session[i - 1], session[i]) not in node_pair.keys():
|
||||
node_pair[(session[i - 1], session[i])] = 1
|
||||
else:
|
||||
node_pair[(session[i - 1], session[i])] += 1
|
||||
|
||||
in_node_list = list(map(lambda x: x[0], list(node_pair.keys())))
|
||||
out_node_list = list(map(lambda x: x[1], list(node_pair.keys())))
|
||||
weight_list = list(node_pair.values())
|
||||
graph_list = list([(i,o,w) for i,o,w in zip(in_node_list,out_node_list,weight_list)])
|
||||
# 通过 network 构建图结构
|
||||
G = nx.DiGraph().add_weighted_edges_from(graph_list)
|
||||
|
||||
```
|
||||
|
||||
### 随机游走
|
||||
|
||||
先是基于构建的图进行随机游走,其中p和q是参数,用于控制采样的偏向于DFS还是BFS,其实也就是node2vec。
|
||||
|
||||
```python
|
||||
walker = RandomWalker(G, p=args.p, q=args.q)
|
||||
print("Preprocess transition probs...")
|
||||
walker.preprocess_transition_probs()
|
||||
```
|
||||
|
||||
对于采样的具体过程,是根据边的归一化权重作为采样概率进行采样。其中关于如何通过AliasSampling来实现概率采样的可以[参考](https://blog.csdn.net/haolexiao/article/details/65157026),具体的是先通过计算create_alias_table,然后根据边上两个节点的alias计算边的alias。其中可以看到这里计算alias_table是根据边的归一化权重。
|
||||
|
||||
```python
|
||||
def preprocess_transition_probs(self):
|
||||
"""预处理随即游走的转移概率"""
|
||||
G = self.G
|
||||
alias_nodes = {}
|
||||
for node in G.nodes():
|
||||
# 获取每个节点与邻居节点边上的权重
|
||||
unnormalized_probs = [G[node][nbr].get('weight', 1.0)
|
||||
for nbr in G.neighbors(node)]
|
||||
norm_const = sum(unnormalized_probs)
|
||||
# 对每个节点的邻居权重进行归一化
|
||||
normalized_probs = [
|
||||
float(u_prob)/norm_const for u_prob in unnormalized_probs]
|
||||
# 根据权重创建alias表
|
||||
alias_nodes[node] = create_alias_table(normalized_probs)
|
||||
alias_edges = {}
|
||||
for edge in G.edges():
|
||||
# 获取边的alias
|
||||
alias_edges[edge] = self.get_alias_edge(edge[0], edge[1])
|
||||
self.alias_nodes = alias_nodes
|
||||
self.alias_edges = alias_edges
|
||||
return
|
||||
```
|
||||
|
||||
在构建好Alias之后,进行带权重的随机游走。
|
||||
|
||||
```python
|
||||
session_reproduce = walker.simulate_walks(num_walks=args.num_walks,
|
||||
walk_length=args.walk_length, workers=4,verbose=1)
|
||||
```
|
||||
|
||||
其中这里的随机游走是根据p和q的值,来选择是使用Deepwalk还是node2vec。
|
||||
|
||||
```python
|
||||
def _simulate_walks(self, nodes, num_walks, walk_length,):
|
||||
walks = []
|
||||
for _ in range(num_walks):
|
||||
# 打乱所有起始节点
|
||||
random.shuffle(nodes)
|
||||
for v in nodes:
|
||||
# 根据p和q选择随机游走或者带权游走
|
||||
if self.p == 1 and self.q == 1:
|
||||
walks.append(self.deepwalk_walk(
|
||||
walk_length=walk_length, start_node=v))
|
||||
else:
|
||||
walks.append(self.node2vec_walk(
|
||||
walk_length=walk_length, start_node=v))
|
||||
return walks
|
||||
|
||||
```
|
||||
|
||||
### 加载side information并构造训练正样本
|
||||
|
||||
主要是将目前所有的sku和其对应的side infromation进行left join,没有的特征用0补充。然后对所有的特征进行labelEncoder()
|
||||
|
||||
```python
|
||||
sku_side_info = pd.merge(all_skus, product_data, on='sku_id', how='left').fillna(0) # 为商品加载side information
|
||||
for feat in sku_side_info.columns:
|
||||
if feat != 'sku_id':
|
||||
lbe = LabelEncoder()
|
||||
# 对side information进行编码
|
||||
sku_side_info[feat] = lbe.fit_transform(sku_side_info[feat])
|
||||
else:
|
||||
sku_side_info[feat] = sku_lbe.transform(sku_side_info[feat])
|
||||
```
|
||||
|
||||
通过图中的公式可以知道优化目标是让在一个窗口内的物品尽可能相似,采样若干负样本使之与目标物品不相似。因此需要将一个窗口内的所有物品与目标物品组成pair作为训练正样本。这里不需要采样负样本,负样本是通过tf中的sample softmax方法自动进行采样。
|
||||
|
||||
```python
|
||||
def get_graph_context_all_pairs(walks, window_size):
|
||||
all_pairs = []
|
||||
for k in range(len(walks)):
|
||||
for i in range(len(walks[k])):
|
||||
# 通过窗口的方式采取正样本,具体的是,让随机游走序列的起始item与窗口内的每个item组成正样本对
|
||||
for j in range(i - window_size, i + window_size + 1):
|
||||
if i == j or j < 0 or j >= len(walks[k]):
|
||||
continue
|
||||
else:
|
||||
all_pairs.append([walks[k][i], walks[k][j]])
|
||||
return np.array(all_pairs, dtype=np.int32)
|
||||
|
||||
```
|
||||
|
||||
#### EGES模型
|
||||
|
||||
构造完数据之后,在funrec的基础上实现了EGES模型:
|
||||
|
||||
```python
|
||||
def EGES(side_information_columns, items_columns, merge_type = "weight", share_flag=True,
|
||||
l2_reg=0.0001, seed=1024):
|
||||
# side_information 所对应的特征
|
||||
feature_columns = list(set(side_information_columns))
|
||||
# 获取输入层,查字典
|
||||
feature_encode = FeatureEncoder(feature_columns, linear_sparse_feature=None)
|
||||
# 输入的值
|
||||
feature_inputs_list = list(feature_encode.feature_input_layer_dict.values())
|
||||
# item id 获取输入层的值
|
||||
items_Map = FeatureMap(items_columns)
|
||||
items_inputs_list = list(items_Map.feature_input_layer_dict.values())
|
||||
|
||||
# 正样本的id,在softmax中需要传入正样本的id
|
||||
label_columns = [DenseFeat('label_id', 1)]
|
||||
label_Map = FeatureMap(label_columns)
|
||||
label_inputs_list = list(label_Map.feature_input_layer_dict.values())
|
||||
|
||||
# 通过输入的值查side_information的embedding,返回所有side_information的embedding的list
|
||||
side_embedding_list = process_feature(side_information_columns, feature_encode)
|
||||
# 拼接 N x num_feature X Dim
|
||||
side_embeddings = Concatenate(axis=1)(side_embedding_list)
|
||||
|
||||
# items_inputs_list[0] 为了查找每个item 用于计算权重的 aplha 向量
|
||||
eges_inputs = [side_embeddings, items_inputs_list[0]]
|
||||
|
||||
merge_emb = EGESLayer(items_columns[0].vocabulary_size, merge_type=merge_type,
|
||||
l2_reg=l2_reg, seed=seed)(eges_inputs) # B * emb_dim
|
||||
|
||||
label_idx = label_Map.feature_input_layer_dict[label_columns[0].name]
|
||||
softmaxloss_inputs = [merge_emb,label_idx]
|
||||
|
||||
item_vocabulary_size = items_columns[0].vocabulary_size
|
||||
|
||||
all_items_idx = EmbeddingIndex(list(range(item_vocabulary_size)))
|
||||
all_items_embeddings = feature_encode.embedding_layers_dict[side_information_columns[0].name](all_items_idx)
|
||||
|
||||
if share_flag:
|
||||
softmaxloss_inputs.append(all_items_embeddings)
|
||||
|
||||
output = SampledSoftmaxLayer(num_items=item_vocabulary_size, share_flage=share_flag,
|
||||
emb_dim=side_information_columns[0].embedding_dim,num_sampled=10)(softmaxloss_inputs)
|
||||
|
||||
model = Model(feature_inputs_list + items_inputs_list + label_inputs_list, output)
|
||||
|
||||
model.__setattr__("feature_inputs_list", feature_inputs_list)
|
||||
model.__setattr__("label_inputs_list", label_inputs_list)
|
||||
model.__setattr__("merge_embedding", merge_emb)
|
||||
model.__setattr__("item_embedding", get_item_embedding(all_items_embeddings, items_Map.feature_input_layer_dict[items_columns[0].name]))
|
||||
return model
|
||||
|
||||
```
|
||||
|
||||
其中EGESLayer为聚合每个item的多个side information的方法,其中根据merge_type可以选择average-pooling或者weight-pooling
|
||||
|
||||
```python
|
||||
class EGESLayer(Layer):
|
||||
def __init__(self,item_nums, merge_type="weight",l2_reg=0.001,seed=1024, **kwargs):
|
||||
super(EGESLayer, self).__init__(**kwargs)
|
||||
self.item_nums = item_nums
|
||||
self.merge_type = merge_type #聚合方式
|
||||
self.l2_reg = l2_reg
|
||||
self.seed = seed
|
||||
|
||||
def build(self, input_shape):
|
||||
if not isinstance(input_shape, list) or len(input_shape) < 2:
|
||||
raise ValueError('`EGESLayer` layer should be called \
|
||||
on a list of at least 2 inputs')
|
||||
self.feat_nums = input_shape[0][1]
|
||||
|
||||
if self.merge_type == "weight":
|
||||
self.alpha_embeddings = self.add_weight(
|
||||
name='alpha_attention',
|
||||
shape=(self.item_nums, self.feat_nums),
|
||||
dtype=tf.float32,
|
||||
initializer=tf.keras.initializers.RandomUniform(minval=-1, maxval=1, seed=self.seed),
|
||||
regularizer=l2(self.l2_reg))
|
||||
|
||||
def call(self, inputs, **kwargs):
|
||||
if self.merge_type == "weight":
|
||||
stack_embedding = inputs[0] # (B * num_feate * embedding_size)
|
||||
item_input = inputs[1] # (B * 1)
|
||||
alpha_embedding = tf.nn.embedding_lookup(self.alpha_embeddings, item_input) #(B * 1 * num_feate)
|
||||
alpha_emb = tf.exp(alpha_embedding)
|
||||
alpha_i_sum = tf.reduce_sum(alpha_emb, axis=-1)
|
||||
merge_embedding = tf.squeeze(tf.matmul(alpha_emb, stack_embedding),axis=1) / alpha_i_sum
|
||||
else:
|
||||
stack_embedding = inputs[0] # (B * num_feate * embedding_size)
|
||||
merge_embedding = tf.squeeze(tf.reduce_mean(alpha_emb, axis=1),axis=1) # (B * embedding_size)
|
||||
|
||||
return merge_embedding
|
||||
|
||||
def compute_output_shape(self, input_shape):
|
||||
return input_shape
|
||||
|
||||
def get_config(self):
|
||||
config = {"merge_type": self.merge_type, "seed": self.seed}
|
||||
base_config = super(EGESLayer, self).get_config()
|
||||
base_config.update(config)
|
||||
return base_config
|
||||
|
||||
```
|
||||
|
||||
至此已经从原理到代码详细的介绍了关于EGES的内容。
|
||||
|
||||
|
||||
|
||||
## 参考
|
||||
|
||||
[Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba](https://arxiv.org/abs/1803.02349)
|
||||
|
||||
[深度学习中不得不学的Graph Embedding方法](https://zhuanlan.zhihu.com/p/64200072)
|
||||
|
||||
[【Embedding】EGES:阿里在图嵌入领域中的探索](https://blog.csdn.net/qq_27075943/article/details/106244434)
|
||||
|
||||
[推荐系统遇上深度学习(四十六)-阿里电商推荐中亿级商品的embedding策略](https://www.jianshu.com/p/229b686535f1)
|
||||
|
||||
@@ -1,577 +0,0 @@
|
||||
# Graph Convolutional Neural Networks for Web-Scale Recommender Systems
|
||||
|
||||
该论文是斯坦福大学和Pinterest公司与2018年联合发表与KDD上的一篇关于GCN成功应用于工业级推荐系统的工作。该论文提到的PinSage模型,是在GraphSAGE的理论基础进行了更改,以适用于实际的工业场景。下面将简单介绍一下GraphSAGE的原理,以及Pinsage的核心和细节。
|
||||
|
||||
## GraphSAGE原理
|
||||
|
||||
GraphSAGE提出的前提是因为基于直推式(transductive)学习的图卷积网络无法适应工业界的大多数业务场景。我们知道的是,基于直推式学习的图卷积网络是通过拉普拉斯矩阵直接为图上的每个节点学习embedding表示,每次学习是针对于当前图上所有的节点。然而在实际的工业场景中,图中的结构和节点都不可能是固定的,会随着时间的变化而发生改变。例如在Pinterest公司的场景下,每分钟都会上传新的照片素材,同时也会有新用户不断的注册,那么图上的节点会不断的变化。在这样的场景中,直推式学习的方法就需要不断的重新训练才能够为新加入的节点学习embedding,导致在实际场景中无法投入使用。
|
||||
|
||||
在这样的背景下,斯坦福大学提出了一种归纳(inductive)学习的GCN方法——GraphSAGE,即**通过聚合邻居信息的方式为给定的节点学习embedding**。不同于直推式(transductive)学习,GraphSAGE是通过学习聚合节点邻居生成节点Embedding的函数的方式,为任意节点学习embedding,进而将GCN扩展成归纳学习任务。
|
||||
|
||||
对于想直接应用GCN或者GraphSAGE的我们而言,不用非要去理解其背后晦涩难懂的数学原理,可以仅从公式的角度来理解GraphSAGE的具体操作。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220423094435223.png" style="zoom:90%;"/>
|
||||
</div>
|
||||
|
||||
上面这个公式可以非常直观的让我们理解GraphSAGE的原理。
|
||||
|
||||
- $h_v^0$表示图上节点的初始化表示,等同于节点自身的特征。
|
||||
- $h_v^k$表示第k层卷积后的节点表示,其来源于两个部分:
|
||||
- 第一部分来源于节点v的邻居节点集合$N(v)$,利用邻居节点的第k-1层卷积后的特征$h_u^{k-1}$进行 ( $\sum_{u \in N(v)} \frac{h_u^{k-1}}{|N(v)|}$ )后,在进行线性变换。这里**借助图上的边将邻居节点的信息通过边关系聚合到节点表示中(简称卷积操作)**。
|
||||
- 第二部分来源于节点v的第k-1成卷积后的特征$h_v^{k-1}$,进行线性变换。总的来说图卷积的思想是**在对自身做多次非线性变换时,同时利用边关系聚合邻居节点信息。**
|
||||
- 最后一次卷积结果作为节点的最终表示$Z_v$,以用于下游任务(节点分类,链路预测或节点召回)。
|
||||
|
||||
可以发现相比传统的方法(MLP,CNN,DeepWalk 或 EGES),GCN或GraphSAGE存在一些优势:
|
||||
|
||||
1. 相比于传统的深度学习方法(MLP,CNN),GCN在对自身节点进行非线性变换时,同时考虑了图中的邻接关系。从CNN的角度理解,GCN通过堆叠多层结构在图结构数据上拥有更大的**感受野**,利用更加广域内的信息。
|
||||
2. 相比于图嵌入学习方法(DeepWalk,EGES),GCN在学习节点表示的过程中,在利用节点自身的属性信息之外,更好的利用图结构上的边信息。相比于借助随机采样的方式来使用边信息,GCN的方式能从全局的角度利用的邻居信息。此外,类似于GraphSAGE这种归纳(inductive)学习的GCN方法,通过学习聚合节点邻居生成节点Embedding的函数的方式,更适用于图结构和节点会不断变化的工业场景。
|
||||
|
||||
在采样得到目标节点的邻居集之后,那么如何聚合邻居节点的信息来更新目标节点的嵌入表示呢?下面就来看看GraphSAGE中提及的四个聚合函数。
|
||||
|
||||
## GraphSAGE的采样和聚合
|
||||
|
||||
通过上面的公式可以知道,得到节点的表示主要依赖于两部分,其中一部分其邻居节点。因此对于GraphSAGE的关键主要分为两步:Sample采样和Aggregate聚合。其中Sample的作用是从庞大的邻居节点中选出用于聚合的邻居节点集合$N(v)$以达到降低迭代计算复杂度,而聚合操作就是如何利用邻居节点的表示来更新节点v的表示,已达到聚合作用。具体的过程如下伪代码所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220406135753358.png" style="zoom:90%;"/>
|
||||
</div>
|
||||
|
||||
GraphSAGE的minibatch算法的思路是针对Batch内的所有节点,通过采样和聚合节点,为每一个节点学习一个embedding。
|
||||
|
||||
#### 邻居采样
|
||||
|
||||
GraphSAGE的具体采样过程是,首先根据中心节点集合$B^k$,对集合中每个中心节点通过随机采样的方式对其邻居节点采样固定数量S个(如果邻居节点数量大于S,采用无放回抽样;如果小于S,则采用有放回抽样),形成的集合表示为$B^{k-1}$;以此类推每次都是为前一个得到的集合的每个节点随机采样S个邻居,最终得到第k层的所有需要参与计算的节点集合$B^{0}$。值得注意的有两点:**为什么需要采样并且固定采样数量S?** **为什么第k层所采样的节点集合表示为$B^0$?**
|
||||
|
||||
进行邻居采样并固定采样数量S主要是因为:1. 采样邻居节点避免了在全图的搜索以及使用全部邻居节点所导致计算复杂度高的问题;2. 可以通过采样使得部分节点更同质化,即两个相似的节点具有相同表达形式。3. 采样固定数量是保持每个batch的计算占用空间是固定的,方便进行批量训练。
|
||||
|
||||
第k层所采样的节点集合表示为$B^0$主要是因为:采样和聚合过程是相反的,即采样时我们是从中心节点组层进行采样,而聚合的过程是从中心节点的第k阶邻居逐层聚合得到前一层的节点表示。因此可以认为聚合阶段是:将k阶邻居的信息聚合到k-1阶邻居上,k-1阶邻居的信息聚合到k-2阶邻居上,....,1阶邻居的信息聚合到中心节点上的过程。
|
||||
|
||||
#### 聚合函数
|
||||
|
||||
如何对于采样到的节点集进行聚合,介绍的4种方式:Mean 聚合、Convolutional 聚合、LSTM聚合以及Pooling聚合。由于邻居节点是无序的,所以希望构造的聚合函数具有**对称性(即输出的结果不因输入排序的不同而改变)**,同时拥有**较强的表达能力**。
|
||||
|
||||
- Mean 聚合:首先会对邻居节点按照**element-wise**进行均值聚合,然后将当前节点k-1层得到特征$h_v^{k-1}$与邻居节点均值聚合后的特征 $MEAN(h_u^k | u\in N(v))$**分别**送入全连接网络后**相加**得到结果。
|
||||
- Convolutional 聚合:这是一种基于GCN聚合方式的变种,首先对邻居节点特征和自身节点特征求均值,得到的聚合特征送入到全连接网络中。与Mean不同的是,这里**只经过一个全连接层**。
|
||||
|
||||
- LSTM聚合:由于LSTM可以捕捉到序列信息,因此相比于Mean聚合,这种聚合方式的**表达能力更强**;但由于LSTM对于输入是有序的,因此该方法不具备**对称性**。作者对于无序的节点进行随机排列以调整LSTM所需的有序性。
|
||||
- Pooling聚合:对于邻居节点和中心节点进行一次非线性转化,将结果进行一次基于**element-wise**的**最大池化**操作。该种方式具有**较强的表达能力**的同时还具有**对称性**。
|
||||
|
||||
综上,可以发现GraphSAGE之所以可以用于大规模的工业场景,主要是因为模型主要是通过学习聚合函数,通过归纳式的学习方法为节点学习特征表示。接下来看看PinSAGE 的主要内容。
|
||||
|
||||
## PinSAGE
|
||||
|
||||
### 背景
|
||||
|
||||
PinSAGE 模型是Pinterest 在GraphSAGE 的基础上实现的可以应用于实际工业场景的召回算法。Pinterest 公司的主要业务是采用瀑布流的形式向用户展现图片,无需用户翻页,新的图片会自动加载。因此在Pinterest网站上,有大量的图片(被称为pins),而用户可以将喜欢的图片分类,即将pins钉在画板 boards上。可以发现基于这样的场景,pin相当于普通推荐场景中item,用户**钉**的行为可以认为是用于的交互行为。于是PinSAGE 模型主要应用的思路是,基于GraphSAGE 的原理学习到聚合方法,并为每个图片(pin)学习一个向量表示,然后基于pin的向量表示做**item2item的召回**。
|
||||
|
||||
可以知道的是,PinSAGE 是在GraphSAGE的基础上进行改进以适应实际的工业场景,因此除了改进卷积操作中的邻居采样策略以及聚合函数的同时还有一些工程技巧上的改进,使得在大数据场景下能更快更好的进行模型训练。因此在了解GraphSAGE的原理后,我们详细的了解一下本文的主要改进以及与GraphSAGE的区别。
|
||||
|
||||
### 重要性采样
|
||||
|
||||
在实际场景当中,一个item可能被数以百万,千万的用户交互过,所以不可能聚合所有邻居节点是不可行的,只可能是采样部分邻居进行信息聚合。但是如果采用GraphSAGE中随机采样的方法,由于采样的邻居有限(这里是相对于所有节点而言),会存在一定的偏差。因此PinSAGE 在采样中考虑了更加重要的邻居节点,即卷积时只注重部分重要的邻居节点信息,已达到高效计算的同时又可以消除偏置。
|
||||
|
||||
PinSAGE使用重要性采样方法,即需要为每个邻居节点计算一个重要性权重,根据权重选取top-t的邻居作为聚合时的邻居集合。其中计算重要性的过程是,以目标节点为起点,进行random-walk,采样结束之后计算所有节点访问数的L1-normalized作为重要性权重,同时这个权重也会在聚合过程中加以使用(**加权聚合**)。
|
||||
|
||||
这里对于**计算权重之后如何得到top-t的邻居节点,**原文并没有直接的叙述。这里可以有两种做法,第一种就是直接采用重要权重,这种方法言简意赅,比较直观。第二种做法就是对游走得到的所有邻居进行随机抽样,而计算出的权重可以用于聚合阶段。个人理解第二种做法的可行性出于两点原因,其一是这样方法可以避免存在一些item由于权重系数低永远不会被选中的问题;其二可能并不是将所有重要性的邻居进行聚合更合理,毕竟重要性权重是通过随机采样而得到的,具有一定的随机性。当然以上两种方法都是可行的方案,可以通过尝试看看具体哪种方法会更有效。
|
||||
|
||||
### 聚合函数
|
||||
|
||||
PinSAGE中提到的Convolve算法(单层图卷积操作)相当于GraphSAGE算法的聚合过程,在实际执行过程中通过对每一层执行一次图卷积操作以得到不同阶邻居的信息,具体过程如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220406202027832.png" style="zoom:110%;"/>
|
||||
</div>
|
||||
|
||||
上述的单层图卷积过程如下三步:
|
||||
|
||||
1. 聚合邻居: 先将所有的邻居节点经过一次非线性转化(一层DNN),再由聚合函数(Pooling聚合) $\gamma$(如元素平均,**加权和**等)将所有邻居信息聚合成目标节点的embedding。这里的加权聚合采用的是通过random-walk得到的重要性权重。
|
||||
2. 更新当前节点的embedding:将目标节点当前的向量 $z_u$ 与步骤1中聚合得到的邻居向量 $n_u$ 进行拼接,在通过一次非线性转化。
|
||||
3. 归一化操作:对目标节点向量 $z_u$ 归一化。
|
||||
|
||||
Convolve算法的聚合方法与GraphSAGE的Pooling聚合函数相同,主要区别在于对更新得到的向量 $z_u$ 进行归一化操作,**可以使训练更稳定,以及在近似查找最近邻的应用中更有效率。**
|
||||
|
||||
### 基于**mini-batch**堆叠多层图卷积
|
||||
|
||||
与GraphSAGE类似,采用的是基于mini-batch 的方式进行训练。之所以这么做的原因是因为什么呢?在实际的工业场景中,由于用户交互图非常庞大,无法对于所有的节点同时学习一个embedding,因此需要从原始图上寻找与 mini-batch 节点相关的子图。具体地是说,对于mini-batch内的所有节点,会通过采样的方式逐层的寻找相关邻居节点,再通过对每一层的节点做一次图卷积操作,以从k阶邻居节点聚合信息。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220406204431024.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
|
||||
如上图所示:对于batch内的所有节点(图上最顶层的6个节点),依次根据权重采样,得到batch内所有节点的一阶邻居(图上第二层的所有节点);然后对于所有一阶邻居再次进行采样,得到所有二阶邻居(图上的最后一层)。节点采样阶段完成之后,与采样的顺序相反进行聚合操作。首先对二阶邻居进行单次图卷积,将二阶节点信息聚合已更新一阶节点的向量表示(其中小方块表示的是一层非线性转化);其次对一阶节点再次进行图卷积操作,将一阶节点的信息聚合已更新batch内所有节点的向量表示。仅此对于一个batch内的所有的样本通过卷积操作学习到一个embedding,而每一个batch的学习过程中仅**利用与mini-batch内相关节点的子图结构。**
|
||||
|
||||
### **训练过程**
|
||||
|
||||
PinSage在训练时采用的是 Margin Hinge Loss 损失函数,主要的思想是最大化正例embedding之间的相关性,同时还要保证负例之间相关性相比正例之间的相关性小于某个阈值(Margin)。具体的公式如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220406210833675.png" style="zoom:100%;"/>
|
||||
</div>
|
||||
|
||||
其中$Z_p$是学习得到的目标节点embedding,$Z_i$是与目标节点相关item的embedding,$Z_{n_k}$是与目标节点不相关item的embedding,$\Delta$为margin值,具体大小需要调参。那么对于相关节点i,以及不相关节点nk,具体都是如何定义的,这对于召回模型的训练意义重大,让我们看看具体是如何定义的。
|
||||
|
||||
对于正样本而言,文中的定义是如果用户在点击的 item q之后立即点击了 item i,即认为 < q, i >构成正样本对。直观的我们很好理解这句话,不过在参考DGL中相关代码实现时,发现这部分的内容和原文中有一定的出入。具体地,代码中将所有的训练样本构造成用户-项目二部图,然后对batch内的每个 item q,根据item-user-item的元路径进行随机游走,得到被同一个用户交互过的 item i,因此组成<q,i>正样本对。对于负样本部分,相对来说更为重要,因此内容相对比较多,将在下面的负样本生成部分详细介绍。
|
||||
|
||||
这里还有一个比较重要的细节需要注意,由于模型是用于 item to item的召回,因此优化目标是与正样本之间的表示尽可能的相近,与负样本之间的表示尽可能的远。而图卷积操作会使得具有邻接关系的节点表示具有同质性,因此结合这两点,就需要在构建图结构的时,要将**训练样本之间可能存在的边在二部图上删除**,避免因为边的存在使得因卷积操作而导致的信息泄露。
|
||||
|
||||
### 工程技巧
|
||||
|
||||
由于PinSAGE是一篇工业界的论文,其中会涉及与实际工程相关的内容,这里在了解完算法思想之后,再从实际落地的角度看看PinSAGE给我们介绍的工程技巧。
|
||||
|
||||
**负样本的生成**
|
||||
|
||||
召回模型最主要的任务是从候选集合中选出用户可能感兴趣的item,直观的理解就是让模型将用户喜欢的和不喜欢的进行区分。然而由于候选集合的庞大数量,许多item之间十分相似,导致模型划分出来用户喜欢的item中会存在一些难以区分的item(即与用户非常喜欢item比较相似的那一部分)。因此对于召回模型不仅能区分用户喜欢和不喜欢的 item,同时还能区分与用户喜欢的 item 十分相似的那一部分item。那么如果做到呢?这主要是交给 easy negative examples 和 hard negative examples 两种负样本给模型学习。
|
||||
|
||||
- easy 负样本:这里对于mini-batch内的所有pair(训练样本对)会共享500负样本,这500个样本从batch之外的所有节点中随机采样得到。这么做可以减少在每个mini-batch中因计算所有节点的embedding所需的时间,文中指出这和为每个item采样一定数量负样本无差异。
|
||||
- hard 负样本:这里使用hard 负样本的原因是根据实际场景的问题出发,模型需要从20亿的物品item集合中识别出最相似的1000个,即模型需要从2百万 item 中识别出最相似的那一个 item。也就是说模型的区分能力不够细致,为了解决这个问题,加入了一些hard样本。对于hard 负样本,应该是与 q 相似 以及和 i 不相似的物品,具体地的生成方式是将图上的节点计算相对节点 q 的个性化PageRank分值,根据分值的排序随机从2000~5000的位置选取节点作为负样本。
|
||||
|
||||
负样本的构建是召回模型的中关键的内容,在各家公司的工作都予以体现,具体的大家可以参考 Facebook 发表的[《Embedding-based Retrieval in Facebook Search》](https://arxiv.org/pdf/2006.11632v1.pdf)
|
||||
|
||||
**渐进式训练(Curriculum training)**
|
||||
|
||||
由于hard 负样本的加入,模型的训练时间加长(由于与q过于相似,导致loss比较小,导致梯度更新的幅度比较小,训练起来比较慢),那么渐进式训练就是为了来解决这个问题。
|
||||
|
||||
如何渐进式:先在第一轮训练使用easy 负样本,帮助模型先快速收敛(先让模型有个最基本的分辨能力)到一定范围,然后在逐步分加入hard负样本(方式是在第n轮训练时给每个物品的负样本集合增加n-1个 hard 负样本),以调整模型细粒度的区分能力(让模型能够区分相似的item)。
|
||||
|
||||
**节点特征(side information)**
|
||||
|
||||
这里与EGES的不同,这里的边信息不是端到端训练得到,而是通过事前的预处理得到的。对于每个节点(即 pin),都会有一个图片和一点文本信息。因此对于每个节点使用图片的向量、文字的向量以及节点的度拼接得到。这里其实也解释了为什么在图卷积操作时,会先进行一个非线性转化,其实就是将不同空间的特征进行转化(融合)。
|
||||
|
||||
**构建 mini-batch**
|
||||
|
||||
不同于常规的构建方式,PinSAGE中构建mini-batch的方式是基于生产者消费者模式。什么意思的,就是将CPU和GPU分开工作,让CPU负责取特征,重建索引,邻接列表,负采样等工作,让GPU进行矩阵运算,即CPU负责生产每个batch所需的所有数据,GPU则根据CPU生产的数据进行消费(运算)。这样由于考虑GPU的利用率,无法将所有特征矩阵放在GPU,只能存在CPU中,然而每次查找会导致非常耗时,通过上面的方式使得图卷积操作过程中就没有GPU与CPU的通信需求。
|
||||
|
||||
**多GPU训练超大batch**
|
||||
|
||||
前向传播过程中,各个GPU等分minibatch,共享一套模型参数;反向传播时,将每个GPU中的参数梯度都聚合到一起,同步执行SGD。为了保证因海量数据而使用的超大batchsize的情况下模型快速收敛以及泛化精度,采用warmup过程,即在第一个epoch中将学习率线性提升到最高,后面的epoch中再逐步指数下降。
|
||||
|
||||
**使用MapReduce高效推断**
|
||||
|
||||
在模型训练结束之后,需要为所有节点计算一个embedding,如果按照训练过程中的前向传播过程来生成,会存在大量重复的计算。因为当计算一个节点的embedding的时候,其部分邻居节点已经计算过了,同时如果该节点作为其他节点邻居时,也会被再次计算。针对这个问题,本文采用MapReduce的方法进行推断。该过程主要分为两步,具体如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://cdn.jsdelivr.net/gh/swallown1/blogimages@main/images/image-20220407132111547.png" style="zoom:60%;"/>
|
||||
</div>
|
||||
|
||||
1. 将item的embedding进行聚合,即利用item的图片、文字和度等信息的表示进行join(拼接),在通过一层dense后得到item的低维向量。
|
||||
2. 然后根据item来匹配其一阶邻居(join),然后根据item进行pooling(其实就是GroupBy pooling),得到一次图卷积操作。通过堆叠多次直接得到全量的embedding。
|
||||
|
||||
其实这块主要就是通过MapReduce的大数据处理能力,直接对全量节点进行一次运算得到其embedding,避免了分batch所导致的重复计算。
|
||||
|
||||
## 代码解析
|
||||
|
||||
了解完基本的原理之后,最关键的还是得解析源码,以证实上面讲的细节的准确性。下面基于DGL中实现的代码,看看模型中的一些细节。
|
||||
|
||||
### 数据处理
|
||||
|
||||
在弄清楚模型之前,最重要的就是知道送入模型的数据到底是什么养的,以及PinSAGE相对于GraphSAGE最大的区别就在于如何采样邻居,如何构建负样本等。
|
||||
|
||||
首先需要明确的是,无论是**邻居采样**还是**样本的构造**都发生在图结构上,因此最主要的是需要先构建一个user和item组成的二部图。
|
||||
|
||||
```python
|
||||
# ratings是所有的用户交互
|
||||
# 过滤掉为出现在交互中的用户和项目
|
||||
distinct_users_in_ratings = ratings['user_id'].unique()
|
||||
distinct_movies_in_ratings = ratings['movie_id'].unique()
|
||||
users = users[users['user_id'].isin(distinct_users_in_ratings)]
|
||||
movies = movies[movies['movie_id'].isin(distinct_movies_in_ratings)]
|
||||
|
||||
# 将电影特征分组 genres (a vector), year (a category), title (a string)
|
||||
genre_columns = movies.columns.drop(['movie_id', 'title', 'year'])
|
||||
movies[genre_columns] = movies[genre_columns].fillna(False).astype('bool')
|
||||
movies_categorical = movies.drop('title', axis=1)
|
||||
|
||||
## 构建图
|
||||
graph_builder = PandasGraphBuilder()
|
||||
graph_builder.add_entities(users, 'user_id', 'user') # 添加user类型节点
|
||||
graph_builder.add_entities(movies_categorical, 'movie_id', 'movie') # 添加movie类型节点
|
||||
|
||||
# 构建用户-电影的无向图
|
||||
graph_builder.add_binary_relations(ratings, 'user_id', 'movie_id', 'watched')
|
||||
graph_builder.add_binary_relations(ratings, 'movie_id', 'user_id', 'watched-by')
|
||||
|
||||
g = graph_builder.build()
|
||||
```
|
||||
|
||||
在构建完原图之后,需要将交互数据(ratings)分成训练集和测试集,然后根据测试集从原图中抽取出与训练集中相关节点的子图。
|
||||
|
||||
```python
|
||||
# train_test_split_by_time 根据时间划分训练集和测试集
|
||||
# 将用户的倒数第二次交互作为验证,最后一次交互用作测试
|
||||
# train_indices 为用于训练的用户与电影的交互
|
||||
train_indices, val_indices, test_indices = train_test_split_by_time(ratings, 'timestamp', 'user_id')
|
||||
|
||||
# 只使用训练交互来构建图形,测试集相关的节点不应该出现在训练过程中。
|
||||
# 从原图中提取与训练集相关节点的子图
|
||||
train_g = build_train_graph(g, train_indices, 'user', 'movie', 'watched', 'watched-by')
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 正负样本采样
|
||||
|
||||
在得到训练图结构之后,为了进行PinSAGE提出的item2item召回任务,需要构建相应的训练样本。对于训练样本主要是构建正样本对和负样本对,前面我们已经提到了正样本对是基于 item to user to item的随即游走得到的;对于负样本DGL的实现主要是随机采样,即只有easy sample,未实现hard sample。具体地,DGL中主要是通过sampler_module.ItemToItemBatchSampler方法进行采样,主要代码如下:
|
||||
|
||||
```python
|
||||
class ItemToItemBatchSampler(IterableDataset):
|
||||
def __init__(self, g, user_type, item_type, batch_size):
|
||||
self.g = g
|
||||
self.user_type = user_type
|
||||
self.item_type = item_type
|
||||
self.user_to_item_etype = list(g.metagraph()[user_type][item_type])[0]
|
||||
self.item_to_user_etype = list(g.metagraph()[item_type][user_type])[0]
|
||||
self.batch_size = batch_size
|
||||
|
||||
def __iter__(self):
|
||||
while True:
|
||||
# 随机采样batch_size个节点作为head 即论文中的q
|
||||
heads = torch.randint(0, self.g.number_of_nodes(self.item_type), (self.batch_size,))
|
||||
|
||||
# 本次元路径表示从item游走到user,再从user游走到item,总共二跳,取出二跳节点(电影节点)作为tails(即正样本)
|
||||
# 得到与heads被同一个用户消费过的其他item,做正样本
|
||||
# 这么做可能存在问题,
|
||||
# 1. 这种游走肯定会使正样本集中于少数热门item;
|
||||
# 2. 如果item只被一个用户消费过,二跳游走岂不是又回到起始item,这种case还是要处理的
|
||||
tails = dgl.sampling.random_walk(
|
||||
self.g,
|
||||
heads,
|
||||
metapath=[self.item_to_user_etype, self.user_to_item_etype])[0][:, 2]
|
||||
|
||||
# 随机采样做负样本, 没有hard negative
|
||||
# 这么做会存在被同一个用户交互过的movie也会作为负样本
|
||||
neg_tails = torch.randint(0, self.g.number_of_nodes(self.item_type), (self.batch_size,))
|
||||
|
||||
mask = (tails != -1)
|
||||
yield heads[mask], tails[mask], neg_tails[mask]
|
||||
```
|
||||
|
||||
上面的样本采样过程只是一个简单的示例,如果面对实际问题,需要自己来重新完成这部分的内容。
|
||||
|
||||
### 邻居节点采样
|
||||
|
||||
再得到训练样本之后,接下来主要是在训练图上,为heads节点采用其邻居节点。在DGL中主要是通过sampler_module.NeighborSampler来实现,具体地,通过**sample_blocks**方法回溯生成各层卷积需要的block,即所有的邻居集合。其中需要注意的几个地方,基于随机游走的重要邻居采样,DGL已经实现,具体参考**[dgl.sampling.PinSAGESampler](https://docs.dgl.ai/generated/dgl.sampling.PinSAGESampler.html)**,其次避免信息泄漏,代码中,先将head → tails,head → neg_tails从frontier中先删除,再生成block。
|
||||
|
||||
```python
|
||||
class NeighborSampler(object): # 图卷积的邻居采样
|
||||
def __init__(self, g, user_type, item_type, random_walk_length, random_walk_restart_prob,
|
||||
num_random_walks, num_neighbors, num_layers):
|
||||
self.g = g
|
||||
self.user_type = user_type
|
||||
self.item_type = item_type
|
||||
self.user_to_item_etype = list(g.metagraph()[user_type][item_type])[0]
|
||||
self.item_to_user_etype = list(g.metagraph()[item_type][user_type])[0]
|
||||
|
||||
# 每层都有一个采样器,根据随机游走来决定某节点邻居的重要性(主要的实现已封装在PinSAGESampler中)
|
||||
# 可以认为经过多次游走,落脚于某邻居节点的次数越多,则这个邻居越重要,就更应该优先作为邻居
|
||||
self.samplers = [
|
||||
dgl.sampling.PinSAGESampler(g, item_type, user_type, random_walk_length,
|
||||
random_walk_restart_prob, num_random_walks, num_neighbors)
|
||||
for _ in range(num_layers)]
|
||||
|
||||
def sample_blocks(self, seeds, heads=None, tails=None, neg_tails=None):
|
||||
"""根据随机游走得到的重要性权重,进行邻居采样"""
|
||||
blocks = []
|
||||
for sampler in self.samplers:
|
||||
frontier = sampler(seeds) # 通过随机游走进行重要性采样,生成中间状态
|
||||
if heads is not None:
|
||||
# 如果是在训练,需要将heads->tails 和 head->neg_tails这些待预测的边都去掉
|
||||
eids = frontier.edge_ids(torch.cat([heads, heads]), torch.cat([tails, neg_tails]), return_uv=True)
|
||||
|
||||
if len(eids) > 0:
|
||||
old_frontier = frontier
|
||||
frontier = dgl.remove_edges(old_frontier, eids)
|
||||
|
||||
# 只保留seeds这些节点,将frontier压缩成block
|
||||
# 并设置block的input/output nodes
|
||||
block = compact_and_copy(frontier, seeds)
|
||||
|
||||
# 本层的输入节点就是下一层的seeds
|
||||
seeds = block.srcdata[dgl.NID]
|
||||
blocks.insert(0, block)
|
||||
return blocks
|
||||
```
|
||||
|
||||
其次**sample_from_item_pairs**方法是通过上面得到的heads, tails, neg_tails分别构建基于正样本对以及基于负样本对的item-item图。由heads→tails生成的pos_graph,用于计算pairwise loss中的pos_score,由heads→neg_tails生成的neg_graph,用于计算pairwise loss中的neg_score。
|
||||
|
||||
```python
|
||||
class NeighborSampler(object): # 图卷积的邻居采样
|
||||
def __init__(self, g, user_type, item_type, random_walk_length, ....):
|
||||
pass
|
||||
|
||||
def sample_blocks(self, seeds, heads=None, tails=None, neg_tails=None):
|
||||
pass
|
||||
|
||||
def sample_from_item_pairs(self, heads, tails, neg_tails):
|
||||
# 由heads->tails构建positive graph, num_nodes设置成原图中所有item节点
|
||||
pos_graph = dgl.graph(
|
||||
(heads, tails),
|
||||
num_nodes=self.g.number_of_nodes(self.item_type))
|
||||
|
||||
# 由heads->neg_tails构建negative graph,num_nodes设置成原图中所有item节点
|
||||
neg_graph = dgl.graph(
|
||||
(heads, neg_tails),
|
||||
num_nodes=self.g.number_of_nodes(self.item_type))
|
||||
|
||||
# 去除heads, tails, neg_tails以外的节点,将大图压缩成小图,避免与本轮训练不相关节点的结构也传入模型,提升计算效率
|
||||
pos_graph, neg_graph = dgl.compact_graphs([pos_graph, neg_graph])
|
||||
|
||||
# 压缩后的图上的节点是原图中的编号
|
||||
# 注意这时pos_graph与neg_graph不是分开编号的两个图,它们来自于同一幅由heads, tails, neg_tails组成的大图
|
||||
# pos_graph和neg_graph中的节点相同,都是heads+tails+neg_tails,即这里的seeds,pos_graph和neg_graph只是边不同而已
|
||||
seeds = pos_graph.ndata[dgl.NID] # 字典 不同类型节点为一个tensor,为每个节点的id值
|
||||
|
||||
blocks = self.sample_blocks(seeds, heads, tails, neg_tails)
|
||||
return pos_graph, neg_graph, blocks
|
||||
```
|
||||
|
||||
|
||||
|
||||
### PinSAGE
|
||||
|
||||
在得到所有所需的数据之后,看看模型结构。其中主要分为三个部分:**节点特征映射**,**多层卷积模块 **和 **给边打分**。
|
||||
|
||||
```python
|
||||
class PinSAGEModel(nn.Module):
|
||||
def __init__(self, full_graph, ntype, textsets, hidden_dims, n_layers):
|
||||
super().__init__()
|
||||
# 负责将节点上的各种特征都映射成向量,并聚合在一起,形成这个节点的原始特征向量
|
||||
self.proj = layers.LinearProjector(full_graph, ntype, textsets, hidden_dims)
|
||||
# 负责多层图卷积,得到各节点最终的embedding
|
||||
self.sage = layers.SAGENet(hidden_dims, n_layers)
|
||||
# 负责根据首尾两端的节点的embedding,计算边上的得分
|
||||
self.scorer = layers.ItemToItemScorer(full_graph, ntype)
|
||||
|
||||
def forward(self, pos_graph, neg_graph, blocks):
|
||||
""" pos_graph, neg_graph, blocks 的最后一层都对应batch中 heads+tails+neg_tails 这些节点
|
||||
"""
|
||||
# 得到batch中heads+tails+neg_tails这些节点的最终embedding
|
||||
h_item = self.get_repr(blocks)
|
||||
# 得到heads->tails这些边上的得分
|
||||
pos_score = self.scorer(pos_graph, h_item)
|
||||
# 得到heads->neg_tails这些边上的得分
|
||||
neg_score = self.scorer(neg_graph, h_item)
|
||||
# pos_graph与neg_graph边数相等,因此neg_score与pos_score相减
|
||||
# 返回margin hinge loss,这里的margin是1
|
||||
return (neg_score - pos_score + 1).clamp(min=0)
|
||||
|
||||
def get_repr(self, blocks):
|
||||
"""
|
||||
通过self.sage,经过多层卷积,得到输出节点上的卷积结果,再加上这些输出节点上原始特征的映射结果
|
||||
得到输出节点上最终的向量表示
|
||||
"""
|
||||
h_item = self.proj(blocks[0].srcdata) # 将输入节点上的原始特征映射成hidden_dims长的向量
|
||||
h_item_dst = self.proj(blocks[-1].dstdata) # 将输出节点上的原始特征映射成hidden_dims长的向量
|
||||
return h_item_dst + self.sage(blocks, h_item)
|
||||
```
|
||||
|
||||
**节点特征映射:**由于节点使用到了多种类型(int,float array,text)的原始特征,这里使用了一个DNN层来融合成固定的长度。
|
||||
|
||||
```python
|
||||
class LinearProjector(nn.Module):
|
||||
def __init__(self, full_graph, ntype, textset, hidden_dims):
|
||||
super().__init__()
|
||||
self.ntype = ntype
|
||||
# 初始化参数,这里为全图中所有节点特征初始化
|
||||
# 如果特征类型是float,就定义一个nn.Linear线性变化为指定维度
|
||||
# 如果特征类型是int,就定义Embedding矩阵,将id型特征转化为向量
|
||||
self.inputs = _init_input_modules(full_graph, ntype, textset, hidden_dims)
|
||||
|
||||
def forward(self, ndata):
|
||||
projections = []
|
||||
for feature, data in ndata.items():
|
||||
# NID是计算子图中节点、边在原图中的编号,没必要用做特征
|
||||
if feature == dgl.NID:
|
||||
continue
|
||||
module = self.inputs[feature] # 根据特征名取出相应的特征转化器
|
||||
# 对文本属性进行处理
|
||||
if isinstance(module, (BagOfWords, BagOfWordsPretrained)):
|
||||
length = ndata[feature + '__len']
|
||||
result = module(data, length)
|
||||
else:
|
||||
result = module(data) # look_up
|
||||
projections.append(result)
|
||||
|
||||
# 将每个特征都映射后的hidden_dims长的向量,element-wise相加
|
||||
return torch.stack(projections, 1).sum(1) # [nodes, hidden_dims]
|
||||
```
|
||||
|
||||
**多层卷积模块:**根据采样得到的节点blocks,然后通过进行逐层卷积,得到各节点最终的embedding。
|
||||
|
||||
```python
|
||||
class SAGENet(nn.Module):
|
||||
def __init__(self, hidden_dims, n_layers):
|
||||
"""g : 二部图"""
|
||||
super().__init__()
|
||||
self.convs = nn.ModuleList()
|
||||
for _ in range(n_layers):
|
||||
self.convs.append(WeightedSAGEConv(hidden_dims, hidden_dims, hidden_dims))
|
||||
|
||||
def forward(self, blocks, h):
|
||||
# 这里根据邻居节点进逐层聚合
|
||||
for layer, block in zip(self.convs, blocks):
|
||||
h_dst = h[:block.number_of_nodes('DST/' + block.ntypes[0])] #前一次卷积的结果
|
||||
h = layer(block, (h, h_dst), block.edata['weights'])
|
||||
return h
|
||||
```
|
||||
|
||||
其中WeightedSAGEConv为根据邻居权重的聚合函数。
|
||||
|
||||
```python
|
||||
class WeightedSAGEConv(nn.Module):
|
||||
def __init__(self, input_dims, hidden_dims, output_dims, act=F.relu):
|
||||
super().__init__()
|
||||
self.act = act
|
||||
self.Q = nn.Linear(input_dims, hidden_dims)
|
||||
self.W = nn.Linear(input_dims + hidden_dims, output_dims)
|
||||
self.reset_parameters()
|
||||
self.dropout = nn.Dropout(0.5)
|
||||
|
||||
def reset_parameters(self):
|
||||
gain = nn.init.calculate_gain('relu')
|
||||
nn.init.xavier_uniform_(self.Q.weight, gain=gain)
|
||||
nn.init.xavier_uniform_(self.W.weight, gain=gain)
|
||||
nn.init.constant_(self.Q.bias, 0)
|
||||
nn.init.constant_(self.W.bias, 0)
|
||||
|
||||
def forward(self, g, h, weights):
|
||||
"""
|
||||
g : 基于batch的子图
|
||||
h : 节点特征
|
||||
weights : 边的权重
|
||||
"""
|
||||
h_src, h_dst = h # 邻居节点特征,自身节点特征
|
||||
with g.local_scope():
|
||||
# 将src节点上的原始特征映射成hidden_dims长,存储于'n'字段
|
||||
g.srcdata['n'] = self.act(self.Q(self.dropout(h_src)))
|
||||
g.edata['w'] = weights.float()
|
||||
|
||||
# src节点上的特征'n'乘以边上的权重,构成消息'm'
|
||||
# dst节点将所有接收到的消息'm',相加起来,存入dst节点的'n'字段
|
||||
g.update_all(fn.u_mul_e('n', 'w', 'm'), fn.sum('m', 'n'))
|
||||
|
||||
# 将边上的权重w拷贝成消息'm'
|
||||
# dst节点将所有接收到的消息'm',相加起来,存入dst节点的'ws'字段
|
||||
g.update_all(fn.copy_e('w', 'm'), fn.sum('m', 'ws'))
|
||||
|
||||
# 邻居节点的embedding的加权和
|
||||
n = g.dstdata['n']
|
||||
ws = g.dstdata['ws'].unsqueeze(1).clamp(min=1) # 边上权重之和
|
||||
|
||||
# 先将邻居节点的embedding,做加权平均
|
||||
# 再拼接上一轮卷积后,dst节点自身的embedding
|
||||
# 再经过线性变化与非线性激活,得到这一轮卷积后各dst节点的embedding
|
||||
z = self.act(self.W(self.dropout(torch.cat([n / ws, h_dst], 1))))
|
||||
|
||||
# 本轮卷积后,各dst节点的embedding除以模长,进行归一化
|
||||
z_norm = z.norm(2, 1, keepdim=True)
|
||||
z_norm = torch.where(z_norm == 0, torch.tensor(1.).to(z_norm), z_norm)
|
||||
z = z / z_norm
|
||||
return z
|
||||
```
|
||||
|
||||
**给边打分:** 经过SAGENet得到了batch内所有节点的embedding,这时需要根据学习到的embedding为pos_graph和neg_graph中的每个边打分,即计算正样本对和负样本的內积。具体逻辑是根据两端节点embedding的点积,然后加上两端节点的bias。
|
||||
|
||||
```python
|
||||
class ItemToItemScorer(nn.Module):
|
||||
def __init__(self, full_graph, ntype):
|
||||
super().__init__()
|
||||
n_nodes = full_graph.number_of_nodes(ntype)
|
||||
self.bias = nn.Parameter(torch.zeros(n_nodes, 1))
|
||||
|
||||
def _add_bias(self, edges):
|
||||
bias_src = self.bias[edges.src[dgl.NID]]
|
||||
bias_dst = self.bias[edges.dst[dgl.NID]]
|
||||
# 边上两顶点的embedding的点积,再加上两端节点的bias
|
||||
return {'s': edges.data['s'] + bias_src + bias_dst}
|
||||
|
||||
def forward(self, item_item_graph, h):
|
||||
"""
|
||||
item_item_graph : 每个边 为 pair 对
|
||||
h : 每个节点隐层状态
|
||||
"""
|
||||
with item_item_graph.local_scope():
|
||||
item_item_graph.ndata['h'] = h
|
||||
# 边两端节点的embedding做点积,保存到s
|
||||
item_item_graph.apply_edges(fn.u_dot_v('h', 'h', 's'))
|
||||
# 为每个边加上偏置,即加上两个顶点的偏置
|
||||
item_item_graph.apply_edges(self._add_bias)
|
||||
# 算出来的得分为 pair 的预测得分
|
||||
pair_score = item_item_graph.edata['s']
|
||||
return pair_score
|
||||
```
|
||||
|
||||
### 训练过程
|
||||
|
||||
介绍完“数据处理”和“PinSAGE模块”之后,接下来就是通过训练过程将上述两部分串起来,详细的见代码:
|
||||
|
||||
```python
|
||||
def train(dataset, args):
|
||||
#从dataset中加载数据和原图
|
||||
g = dataset['train-graph']
|
||||
...
|
||||
|
||||
device = torch.device(args.device)
|
||||
# 为节点随机初始化一个id,用于做embedding
|
||||
g.nodes[user_ntype].data['id'] = torch.arange(g.number_of_nodes(user_ntype))
|
||||
g.nodes[item_ntype].data['id'] = torch.arange(g.number_of_nodes(item_ntype))
|
||||
|
||||
|
||||
# 负责采样出batch_size大小的节点列表: heads, tails, neg_tails
|
||||
batch_sampler = sampler_module.ItemToItemBatchSampler(
|
||||
g, user_ntype, item_ntype, args.batch_size)
|
||||
|
||||
# 由一个batch中的heads,tails,neg_tails构建训练这个batch所需要的
|
||||
# pos_graph,neg_graph 和 blocks
|
||||
neighbor_sampler = sampler_module.NeighborSampler(
|
||||
g, user_ntype, item_ntype, args.random_walk_length,
|
||||
args.random_walk_restart_prob, args.num_random_walks, args.num_neighbors,
|
||||
args.num_layers)
|
||||
|
||||
# 每次next()返回: pos_graph,neg_graph和blocks,做训练之用
|
||||
collator = sampler_module.PinSAGECollator(neighbor_sampler, g, item_ntype, textset)
|
||||
dataloader = DataLoader(
|
||||
batch_sampler,
|
||||
collate_fn=collator.collate_train,
|
||||
num_workers=args.num_workers)
|
||||
|
||||
# 每次next()返回blocks,做训练中测试之用
|
||||
dataloader_test = DataLoader(
|
||||
torch.arange(g.number_of_nodes(item_ntype)),
|
||||
batch_size=args.batch_size,
|
||||
collate_fn=collator.collate_test,
|
||||
num_workers=args.num_workers)
|
||||
dataloader_it = iter(dataloader)
|
||||
|
||||
# 准备模型
|
||||
model = PinSAGEModel(g, item_ntype, textset, args.hidden_dims, args.num_layers).to(device)
|
||||
opt = torch.optim.Adam(model.parameters(), lr=args.lr)
|
||||
|
||||
# 训练过程
|
||||
for epoch_id in range(args.num_epochs):
|
||||
model.train()
|
||||
for batch_id in tqdm.trange(args.batches_per_epoch):
|
||||
pos_graph, neg_graph, blocks = next(dataloader_it)
|
||||
for i in range(len(blocks)):
|
||||
blocks[i] = blocks[i].to(device)
|
||||
pos_graph = pos_graph.to(device)
|
||||
neg_graph = neg_graph.to(device)
|
||||
|
||||
loss = model(pos_graph, neg_graph, blocks).mean()
|
||||
opt.zero_grad()
|
||||
loss.backward()
|
||||
opt.step()
|
||||
```
|
||||
|
||||
至此,DGL PinSAGE example的主要实现代码已经全部介绍完了,感兴趣的可以去官网对照源代码自行学习。
|
||||
|
||||
## 参考
|
||||
|
||||
[Graph Convolutional Neural Networks for Web-Scale Recommender Systems](https://arxiv.org/abs/1806.01973)
|
||||
|
||||
[PinSAGE 召回模型及源码分析(1): PinSAGE 简介](https://zhuanlan.zhihu.com/p/275942839)
|
||||
|
||||
[全面理解PinSage](https://zhuanlan.zhihu.com/p/133739758)
|
||||
|
||||
[[论文笔记]PinSAGE——Graph Convolutional Neural Networks for Web-Scale Recommender Systems](https://zhuanlan.zhihu.com/p/461720302)
|
||||
|
||||
@@ -1,415 +0,0 @@
|
||||
## 写在前面
|
||||
MIND模型(Multi-Interest Network with Dynamic Routing), 是阿里团队2019年在CIKM上发的一篇paper,该模型依然是用在召回阶段的一个模型,解决的痛点是之前在召回阶段的模型,比如双塔,YouTubeDNN召回模型等,在模拟用户兴趣的时候,总是基于用户的历史点击,最后通过pooling的方式得到一个兴趣向量,用该向量来表示用户的兴趣,但是该篇论文的作者认为,**用一个向量来表示用户的广泛兴趣未免有点太过于单一**,这是作者基于天猫的实际场景出发的发现,每个用户每天与数百种产品互动, 而互动的产品往往来自于很多个类别,这就说明用户的兴趣极其广泛,**用一个向量是无法表示这样广泛的兴趣的**,于是乎,就自然而然的引出一个问题,**有没有可能用多个向量来表示用户的多种兴趣呢?**
|
||||
|
||||
这篇paper的核心是胶囊网络,**该网络采用了动态路由算法能非常自然的将历史商品聚成多个集合,每个集合的历史行为进一步推断对应特定兴趣的用户表示向量。这样,对于一个特定的用户,MND输出了多个表示向量,它们代表了用户的不同兴趣。当用户再有新的交互时,通过胶囊网络,还能实时的改变用户的兴趣表示向量,做到在召回阶段的实时个性化**。那么,胶囊网络究竟是怎么做到的呢? 胶囊网络又是什么原理呢?
|
||||
|
||||
**主要内容**:
|
||||
* 背景与动机
|
||||
* 胶囊网络与动态路由机制
|
||||
* MIND模型的网络结构与细节剖析
|
||||
* MIND模型之简易代码复现
|
||||
* 总结
|
||||
|
||||
## 背景与动机
|
||||
本章是基于天猫APP的背景来探索十亿级别的用户个性化推荐。天猫的推荐的流程主要分为召回阶段和排序阶段。召回阶段负责检索数千个与用户兴趣相关的候选物品,之后,排序阶段预测用户与这些候选物品交互的精确概率。这篇文章做的是召回阶段的工作,来对满足用户兴趣的物品的有效检索。
|
||||
|
||||
作者这次的出发点是基于场景出发,在天猫的推荐场景中,作者发现**用户的兴趣存在多样性**。平均上,10亿用户访问天猫,每个用户每天与数百种产品互动。交互后的物品往往属于不同的类别,说明用户兴趣的多样性。 一张图片会更加简洁直观:
|
||||
|
||||

|
||||
因此如果能在**召回阶段建立用户多兴趣模型来模拟用户的这种广泛兴趣**,那么作者认为是非常有必要的,因为召回阶段的任务就是根据用户兴趣检索候选商品嘛。
|
||||
|
||||
那么,如何能基于用户的历史交互来学习用户的兴趣表示呢? 以往的解决方案如下:
|
||||
* 协同过滤的召回方法(itemcf和usercf)是通过历史交互过的物品或隐藏因子直接表示用户兴趣, 但会遇到**稀疏或计算问题**
|
||||
* 基于深度学习的方法用低维的embedding向量表示用户,比如YoutubeDNN召回模型,双塔模型等,都是把用户的基本信息,或者用户交互过的历史商品信息等,过一个全连接层,最后编码成一个向量,用这个向量来表示用户兴趣,但作者认为,**这是多兴趣表示的瓶颈**,因为需要压缩所有与用户多兴趣相关的信息到一个表示向量,所有用户多兴趣的信息进行了混合,导致这种多兴趣并无法体现,所以往往召回回来的商品并不是很准确,除非向量维度很大,但是大维度又会带来高计算。
|
||||
* DIN模型在Embedding的基础上加入了Attention机制,来选择的捕捉用户兴趣的多样性,但采用Attention机制,**对于每个目标物品,都需要重新计算用户表示**,这在召回阶段是行不通的(海量),所以DIN一般是用于排序。
|
||||
|
||||
所以,作者想在召回阶段去建模用户的多兴趣,但以往的方法都不好使,为了解决这个问题,就提出了动态路由的多兴趣网络MIND。为了推断出用户的多兴趣表示,提出了一个多兴趣提取层,该层使用动态路由机制自动的能将用户的历史行为聚类,然后每个类簇中产生一个表示向量,这个向量能代表用户某种特定的兴趣,而多个类簇的多个向量合起来,就能表示用户广泛的兴趣了。
|
||||
|
||||
这就是MIND的提出动机以及初步思路了,这里面的核心是Multi-interest extractor layer, 而这里面重点是动态路由与胶囊网络,所以接下来先补充这方面的相关知识。
|
||||
|
||||
## 胶囊网络与动态路由机制
|
||||
### 胶囊网络初识
|
||||
Hinton大佬在2011年的时候,就首次提出了"胶囊"的概念, "胶囊"可以看成是一组聚合起来输出整个向量的小神经元组合,这个向量的每个维度(每个小神经元),代表着某个实体的某个特征。
|
||||
|
||||
胶囊网络其实可以和神经网络对比着看可能更好理解,我们知道神经网络的每一层的神经元输出的是单个的标量值,接收的输入,也是多个标量值,所以这是一种value to value的形式,而胶囊网络每一层的胶囊输出的是一个向量值,接收的输入也是多个向量,所以它是vector to vector形式的。来个图对比下就清楚了:
|
||||
|
||||
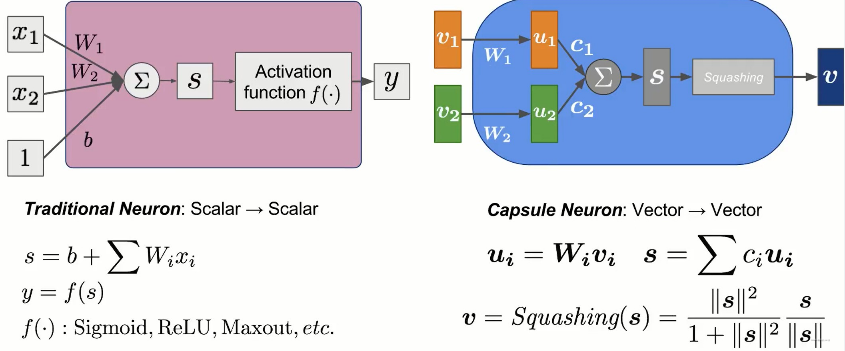
|
||||
左边的图是普通神经元的计算示意,而右边是一个胶囊内部的计算示意图。 神经元这里不过多解释,这里主要是剖析右边的这个胶囊计算原理。从上图可以看出, 输入是两个向量$v_1,v_2$,首先经过了一个线性映射,得到了两个新向量$u_1,u_2$,然后呢,经过了一个向量的加权汇总,这里的$c_1$,$c_2$可以先理解成权重,具体计算后面会解释。 得到汇总后的向量$s$,接下来进行了Squash操作,整体的计算公式如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
&u^{1}=W^{1} v^{1} \quad u^{2}=W^{2} v^{2} \\
|
||||
&s=c_{1} u^{1}+c_{2} u^{2} \\
|
||||
&v=\operatorname{Squash}(s) =\frac{\|s\|^{2}}{1+\|s\|^{2}} \frac{s}{\|s\|}
|
||||
\end{aligned}
|
||||
$$
|
||||
这里的Squash操作可以简单看下,主要包括两部分,右边的那部分其实就是向量归一化操作,把norm弄成1,而左边那部分算是一个非线性操作,如果$s$的norm很大,那么这个整体就接近1, 而如果这个norm很小,那么整体就会接近0, 和sigmoid很像有没有?
|
||||
|
||||
这样就完成了一个胶囊的计算,但有两点需要注意:
|
||||
1. 这里的$W^i$参数是可学习的,和神经网络一样, 通过BP算法更新
|
||||
2. 这里的$c_i$参数不是BP算法学习出来的,而是采用动态路由机制现场算出来的,这个非常类似于pooling层,我们知道pooling层的参数也不是学习的,而是根据前面的输入现场取最大或者平均计算得到的。
|
||||
|
||||
所以这里的问题,就是怎么通过动态路由机制得到$c_i$,下面是动态路由机制的过程。
|
||||
|
||||
### 动态路由机制原理
|
||||
我们先来一个胶囊结构:
|
||||
|
||||
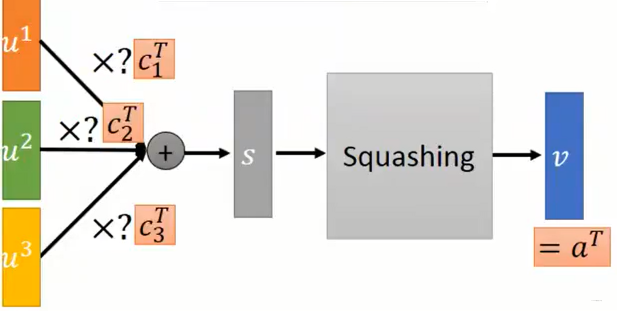
|
||||
这个$c_i$是通过动态路由机制计算得到,那么动态路由机制究竟是啥子意思? 其实就是通过迭代的方式去计算,没有啥神秘的,迭代计算的流程如下图:
|
||||
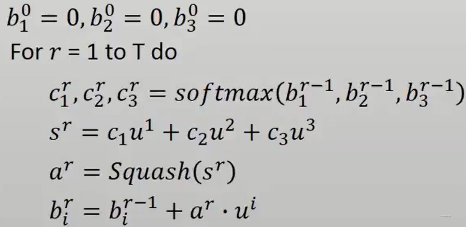
|
||||
首先我们先初始化$b_i$,与每一个输入胶囊$u_i$进行对应,这哥们有个名字叫做"routing logit", 表示的是输出的这个胶囊与输入胶囊的相关性,和注意力机制里面的score值非常像。由于一开始不知道这个哪个胶囊与输出的胶囊有关系,所以默认相关性分数都一样,然后进入迭代。
|
||||
|
||||
在每一次迭代中,首先把分数转成权重,然后加权求和得到$s$,这个很类似于注意力机制的步骤,得到$s$之后,通过归一化操作,得到$a$,接下来要通过$a$和输入胶囊的相关性以及上一轮的$b_i$来更新$b_i$。最后那个公式有必要说一下在干嘛:
|
||||
>如果当前的$a$与某一个输入胶囊$u_i$非常相关,即内积结果很大的话,那么相应的下一轮的该输入胶囊对应的$b_i$就会变大, 那么, 在计算下一轮的$a$的时候,与上一轮$a$相关的$u_i$就会占主导,相当于下一轮的$a$与上一轮中和他相关的那些$u_i$之间的路径权重会大一些,这样从空间点的角度观察,就相当于$a$点朝与它相关的那些$u$点更近了一点。
|
||||
|
||||
通过若干次迭代之后,得到最后的输出胶囊向量$a$会慢慢的走到与它更相关的那些$u$附近,而远离那些与它不相干的$u$。所以上面的这个迭代过程有点像**排除异常输入胶囊的感觉**。
|
||||
|
||||
|
||||
|
||||
而从另一个角度来考虑,这个过程其实像是聚类的过程,因为胶囊的输出向量$v$经过若干次迭代之后,会最终停留到与其非常相关的那些输入胶囊里面,而这些输入胶囊,其实就可以看成是某个类别了,因为既然都共同的和输出胶囊$v$比较相关,那么彼此之间的相关性也比较大,于是乎,经过这样一个动态路由机制之后,就不自觉的,把输入胶囊实现了聚类。把和与其他输入胶囊不同的那些胶囊给排除了出去。
|
||||
|
||||
所以,这个动态路由机制的计算设计的还是比较巧妙的, 下面是上述过程的展开计算过程, 这个和RNN的计算有点类似:
|
||||
|
||||
这样就完成了一个胶囊内部的计算过程了。
|
||||
|
||||
Ok, 有了上面的这些铺垫,再来看MIND就会比较简单了。下面正式对MIND模型的网络架构剖析。
|
||||
|
||||
## MIND模型的网络结构与细节剖析
|
||||
### 网络整体结构
|
||||
MIND网络的架构如下:
|
||||

|
||||
初步先分析这个网络结构的运作: 首先接收的输入有三类特征,用户base属性,历史行为属性以及商品的属性,用户的历史行为序列属性过了一个多兴趣提取层得到了多个兴趣胶囊,接下来和用户base属性拼接过DNN,得到了交互之后的用户兴趣。然后在训练阶段,用户兴趣和当前商品向量过一个label-aware attention,然后求softmax损失。 在服务阶段,得到用户的向量之后,就可以直接进行近邻检索,找候选商品了。 这就是宏观过程,但是,多兴趣提取层以及这个label-aware attention是在做什么事情呢? 如果单独看这个图,感觉得到多个兴趣胶囊之后,直接把这些兴趣胶囊以及用户的base属性拼接过全连接,那最终不就成了一个用户向量,此时label-aware attention的意义不就没了? 所以这个图初步感觉画的有问题,和论文里面描述的不符。所以下面先以论文为主,正式开始描述具体细节。
|
||||
|
||||
### 任务目标
|
||||
召回任务的目标是对于每一个用户$u \in \mathcal{U}$从十亿规模的物品池$\mathcal{I}$检索出包含与用户兴趣相关的上千个物品集。
|
||||
#### 模型的输入
|
||||
对于模型,每个样本的输入可以表示为一个三元组:$\left(\mathcal{I}_{u}, \mathcal{P}_{u}, \mathcal{F}_{i}\right)$,其中$\mathcal{I}_{u}$代表与用户$u$交互过的物品集,即用户的历史行为;$\mathcal{P}_{u}$表示用户的属性,例如性别、年龄等;$\mathcal{F}_{i}$定义为目标物品$i$的一些特征,例如物品id和种类id等。
|
||||
#### 任务描述
|
||||
MIND的核心任务是学习一个从原生特征映射到**用户表示**的函数,用户表示定义为:
|
||||
$$
|
||||
\mathrm{V}_{u}=f_{u s e r}\left(\mathcal{I}_{u}, \mathcal{P}_{u}\right)
|
||||
$$
|
||||
其中,$\mathbf{V}_{u}=\left(\overrightarrow{\boldsymbol{v}}_{u}^{1}, \ldots, \overrightarrow{\boldsymbol{v}}_{u}^{K}\right) \in \mathbb{R}^{d \times k}$是用户$u$的表示向量,$d$是embedding的维度,$K$表示向量的个数,即兴趣的数量。如果$K=1$,那么MIND模型就退化成YouTubeDNN的向量表示方式了。
|
||||
|
||||
目标物品$i$的embedding函数为:
|
||||
$$
|
||||
\overrightarrow{\mathbf{e}}_{i}=f_{\text {item }}\left(\mathcal{F}_{i}\right)
|
||||
$$
|
||||
其中,$\overrightarrow{\mathbf{e}}_{i} \in \mathbb{R}^{d \times 1}, \quad f_{i t e m}(\cdot)$表示一个embedding&pooling层。
|
||||
#### 最终结果
|
||||
根据评分函数检索(根据**目标物品与用户表示向量的内积的最大值作为相似度依据**,DIN的Attention部分也是以这种方式来衡量两者的相似度),得到top N个候选项:
|
||||
|
||||
$$
|
||||
f_{\text {score }}\left(\mathbf{V}_{u}, \overrightarrow{\mathbf{e}}_{i}\right)=\max _{1 \leq k \leq K} \overrightarrow{\mathbf{e}}_{i}^{\mathrm{T}} \overrightarrow{\mathbf{V}}_{u}^{\mathrm{k}}
|
||||
$$
|
||||
|
||||
### Embedding & Pooling层
|
||||
Embedding层的输入由三部分组成,用户属性$\mathcal{P}_{u}$、用户行为$\mathcal{I}_{u}$和目标物品标签$\mathcal{F}_{i}$。每一部分都由多个id特征组成,则是一个高维的稀疏数据,因此需要Embedding技术将其映射为低维密集向量。具体来说,
|
||||
|
||||
* 对于$\mathcal{P}_{u}$的id特征(年龄、性别等)是将其Embedding的向量进行Concat,组成用户属性Embedding$\overrightarrow{\mathbf{p}}_{u}$;
|
||||
* 目标物品$\mathcal{F}_{i}$通常包含其他分类特征id(品牌id、店铺id等) ,这些特征有利于物品的冷启动问题,需要将所有的分类特征的Embedding向量进行平均池化,得到一个目标物品向量$\overrightarrow{\mathbf{e}}_{i}$;
|
||||
* 对于用户行为$\mathcal{I}_{u}$,由物品的Embedding向量组成用户行为Embedding列表$E_{u}=\overrightarrow{\mathbf{e}}_{j}, j \in \mathcal{I}_{u}$, 当然这里不仅只有物品embedding哈,也可能有类别,品牌等其他的embedding信息。
|
||||
|
||||
### Multi-Interest Extractor Layer(核心)
|
||||
作者认为,单一的向量不足以表达用户的多兴趣。所以作者采用**多个表示向量**来分别表示用户不同的兴趣。通过这个方式,在召回阶段,用户的多兴趣可以分别考虑,对于兴趣的每一个方面,能够更精确的进行物品检索。
|
||||
|
||||
为了学习多兴趣表示,作者利用胶囊网络表示学习的动态路由将用户的历史行为分组到多个簇中。来自一个簇的物品应该密切相关,并共同代表用户兴趣的一个特定方面。
|
||||
|
||||
由于多兴趣提取器层的设计灵感来自于胶囊网络表示学习的动态路由,所以这里作者回顾了动态路由机制。当然,如果之前对胶囊网络或动态路由不了解,这里读起来就会有点艰难,但由于我上面进行了铺垫,这里就直接拿过原文并解释即可。
|
||||
#### 动态路由
|
||||
动态路由是胶囊网络中的迭代学习算法,用于学习低水平胶囊和高水平胶囊之间的路由对数(logit)$b_{ij}$,来得到高水平胶囊的表示。
|
||||
|
||||
我们假设胶囊网络有两层,即低水平胶囊$\vec{c}_{i}^{l} \in \mathbb{R}^{N_{l} \times 1}, i \in\{1, \ldots, m\}$和高水平胶囊$\vec{c}_{j}^{h} \in \mathbb{R}^{N_{h} \times 1}, j \in\{1, \ldots, n\}$,其中$m,n$表示胶囊的个数, $N_l,N_h$表示胶囊的维度。 路由对数$b_{ij}$计算公式如下:
|
||||
$$
|
||||
b_{i j}=\left(\vec{c}_{j}^{h}\right)^{T} \mathrm{~S}_{i j} \vec{c}_{i}^{l}
|
||||
$$
|
||||
其中$\mathbf{S}_{i j} \in \mathbb{R}^{N_{h} \times N_{l}}$表示待学习的双线性映射矩阵【在胶囊网络的原文中称为转换矩阵】
|
||||
|
||||
通过计算路由对数,将高阶胶囊$j$的候选向量计算为所有低阶胶囊的加权和:
|
||||
$$
|
||||
\vec{z}_{j}^{h}=\sum_{i=1}^{m} w_{i j} S_{i j} \vec{c}_{i}^{l}
|
||||
$$
|
||||
其中$w_{ij}$定义为连接低阶胶囊$i$和高阶胶囊$j$的权重【称为耦合系数】,而且其通过对路由对数执行softmax来计算:
|
||||
$$
|
||||
w_{i j}=\frac{\exp b_{i j}}{\sum_{k=1}^{m} \exp b_{i k}}
|
||||
$$
|
||||
最后,应用一个非线性的“压缩”函数来获得一个高阶胶囊的向量【胶囊网络向量的模表示由胶囊所代表的实体存在的概率】
|
||||
$$
|
||||
\vec{c}_{j}^{h}=\operatorname{squash}\left(\vec{z}_{j}^{h}\right)=\frac{\left\|\vec{z}_{j}^{h}\right\|^{2}}{1+\left\|\vec{z}_{j}^{h}\right\|^{2}} \frac{\vec{z}_{j}^{h}}{\left\|\vec{z}_{j}^{h}\right\|}
|
||||
$$
|
||||
路由过程重复进行3次达到收敛。当路由结束,高阶胶囊值$\vec{c}_{j}^{h}$固定,作为下一层的输入。
|
||||
|
||||
Ok,下面我们开始解释,其实上面说的这些就是胶囊网络的计算过程,只不过和之前所用的符号不一样了。这里拿个图:
|
||||
|
||||
首先,论文里面也是个两层的胶囊网络,低水平层->高水平层。 低水平层有$m$个胶囊,每个胶囊向量维度是$N_l$,用$\vec{c}_{i}^l$表示的,高水平层有$n$个胶囊,每个胶囊$N_h$维,用$\vec{c}_{j}^h$表示。
|
||||
|
||||
单独拿出每个$\vec{c}_{j}^h$,其计算过程如上图所示。首先,先随机初始化路由对数$b_{ij}=0$,然后开始迭代,对于每次迭代:
|
||||
$$
|
||||
w_{i j}=\frac{\exp b_{i j}}{\sum_{k=1}^{m} \exp b_{i k}} \\
|
||||
\vec{z}_{j}^{h}=\sum_{i=1}^{m} w_{i j} S_{i j} \vec{c}_{i}^{l} \\ \vec{c}_{j}^{h}=\operatorname{squash}\left(\vec{z}_{j}^{h}\right)=\frac{\left\|\vec{z}_{j}^{h}\right\|^{2}}{1+\left\|\vec{z}_{j}^{h}\right\|^{2}} \frac{\vec{z}_{j}^{h}}{\left\|\vec{z}_{j}^{h}\right\|} \\ b_{i j}=\left(\vec{c}_{j}^{h}\right)^{T} \mathrm{~S}_{i j} \vec{c}_{i}^{l}
|
||||
$$
|
||||
只不过这里的符合和上图中的不太一样,这里的$w_{ij}$对应的是每个输入胶囊的权重$c_{ij}$, 这里的$\vec{c}_{j}^h$对应上图中的$a$, 这里的$\vec{z}_{j}^h$对应的是输入胶囊的加权组合。这里的$\vec{c}_{i}^l$对应上图中的$v_i$,这里的$S_{ij}$对应的是上图的权重$W_{ij}$,只不过这个可以换成矩阵运算。 和上图中不同的是路由对数$b_{ij}$更新那里,没有了上一层的路由对数值,但感觉这样会有问题。
|
||||
|
||||
所以,这样解释完之后就会发现,其实上面的一顿操作就是说的传统的动态路由机制。
|
||||
|
||||
#### B2I动态路由
|
||||
作者设计的多兴趣提取层就是就是受到了上述胶囊网络的启发。
|
||||
|
||||
如果把用户的行为序列看成是行为胶囊, 把用户的多兴趣看成兴趣胶囊,那么多兴趣提取层就是利用动态路由机制学习行为胶囊`->`兴趣胶囊的映射关系。但是原始路由算法无法直接应用于处理用户行为数据。因此,提出了**行为(Behavior)到兴趣(Interest)(B2I)动态路由**来自适应地将用户的行为聚合到兴趣表示向量中,它与原始路由算法有三个不同之处:
|
||||
|
||||
1. **共享双向映射矩阵**。在初始动态路由中,使用固定的或者说共享的双线性映射矩阵$S$而不是单独的双线性映射矩阵, 在原始的动态路由中,对于每个输出胶囊$\vec{c}_{j}^h$,都会有对应的$S_{ij}$,而这里是每个输出胶囊,都共用一个$S$矩阵。 原因有两个:
|
||||
1. 一方面,用户行为是可变长度的,从几十个到几百个不等,因此使用共享的双线性映射矩阵是有利于泛化。
|
||||
2. 另一方面,希望兴趣胶囊在同一个向量空间中,但不同的双线性映射矩阵将兴趣胶囊映射到不同的向量空间中。因为映射矩阵的作用就是对用户的行为胶囊进行线性映射嘛, 由于用户的行为序列都是商品,所以希望经过映射之后,到统一的商品向量空间中去。路由对数计算如下:
|
||||
$$
|
||||
b_{i j}=\overrightarrow{\boldsymbol{u}}_{j}^{T} \mathrm{S\overrightarrow{e}}_{i}, \quad i \in \mathcal{I}_{u}, j \in\{1, \ldots, K\}
|
||||
$$
|
||||
其中,$\overrightarrow{\boldsymbol{e}}_{i} \in \mathbb{R}^{d}$是历史物品$i$的embedding,$\vec{u}_{j} \in \mathbb{R}^{d}$表示兴趣胶囊$j$的向量。$S \in \mathbb{R}^{d \times d}$是每一对行为胶囊(低价)到兴趣胶囊(高阶)之间 的共享映射矩阵。
|
||||
|
||||
|
||||
2. **随机初始化路由对数**。由于利用共享双向映射矩阵$S$,如果再初始化路由对数为0将导致相同的初始的兴趣胶囊。随后的迭代将陷入到一个不同兴趣胶囊在所有的时间保持相同的情景。因为每个输出胶囊的运算都一样了嘛(除非迭代的次数不同,但这样也会导致兴趣胶囊都很类似),为了减轻这种现象,作者通过高斯分布进行随机采样来初始化路由对数$b_{ij}$,让初始兴趣胶囊与其他每一个不同,其实就是希望在计算每个输出胶囊的时候,通过随机化的方式,希望这几个聚类中心离得远一点,这样才能表示出广泛的用户兴趣(我们已经了解这个机制就仿佛是聚类,而计算过程就是寻找聚类中心)。
|
||||
3. **动态的兴趣数量**,兴趣数量就是聚类中心的个数,由于不同用户的历史行为序列不同,那么相应的,其兴趣胶囊有可能也不一样多,所以这里使用了一种启发式方式自适应调整聚类中心的数量,即$K$值。
|
||||
$$
|
||||
K_{u}^{\prime}=\max \left(1, \min \left(K, \log _{2}\left(\left|\mathcal{I}_{u}\right|\right)\right)\right)
|
||||
$$
|
||||
这种调整兴趣胶囊数量的策略可以为兴趣较小的用户节省一些资源,包括计算和内存资源。这个公式不用多解释,与行为序列长度成正比。
|
||||
|
||||
最终的B2I动态路由算法如下:
|
||||

|
||||
应该很好理解了吧。
|
||||
|
||||
### Label-aware Attention Layer
|
||||
通过多兴趣提取器层,从用户的行为embedding中生成多个兴趣胶囊。不同的兴趣胶囊代表用户兴趣的不同方面,相应的兴趣胶囊用于评估用户对特定类别的偏好。所以,在训练的期间,最后需要设置一个Label-aware的注意力层,对于当前的商品,根据相关性选择最相关的兴趣胶囊。这里其实就是一个普通的注意力机制,和DIN里面的那个注意力层基本上是一模一样,计算公式如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\overrightarrow{\boldsymbol{v}}_{u} &=\operatorname{Attention}\left(\overrightarrow{\boldsymbol{e}}_{i}, \mathrm{~V}_{u}, \mathrm{~V}_{u}\right) \\
|
||||
&=\mathrm{V}_{u} \operatorname{softmax}\left(\operatorname{pow}\left(\mathrm{V}_{u}^{\mathrm{T}} \overrightarrow{\boldsymbol{e}}_{i}, p\right)\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
首先这里的$\overrightarrow{\boldsymbol{e}}_{i}$表示当前的商品向量,$V_u$表示用户的多兴趣向量组合,里面有$K$个向量,表示用户的$K$的兴趣。用户的各个兴趣向量与目标商品做内积,然后softmax转成权重,然后反乘到多个兴趣向量进行加权求和。 但是这里需要注意的一个小点,就是这里做内积求完相似性之后,先做了一个指数操作,**这个操作其实能放大或缩小相似程度**,至于放大或者缩小的程度,由$p$控制。 比如某个兴趣向量与当前商品非常相似,那么再进行指数操作之后,如果$p$也很大,那么显然这个兴趣向量就占了主导作用。$p$是一个可调节的参数来调整注意力分布。当$p$接近0,每一个兴趣胶囊都得到相同的关注。当$p$大于1时,随着$p$的增加,具有较大值的点积将获得越来越多的权重。考虑极限情况,当$p$趋近于无穷大时,注意机制就变成了一种硬注意,选关注最大的值而忽略其他值。在实验中,发现使用硬注意导致更快的收敛。
|
||||
>理解:$p$小意味着所有的相似程度都缩小了, 使得之间的差距会变小,所以相当于每个胶囊都会受到关注,而越大的话,使得各个相似性差距拉大,相似程度越大的会更大,就类似于贫富差距, 最终使得只关注于比较大的胶囊。
|
||||
|
||||
### 训练与服务
|
||||
得到用户向量$\overrightarrow{\boldsymbol{v}}_{u}$和标签物品embedding$\vec{e}_{i}$后,计算用户$u$与标签物品$i$交互的概率:
|
||||
$$
|
||||
\operatorname{Pr}(i \mid u)=\operatorname{Pr}\left(\vec{e}_{i} \mid \vec{v}_{u}\right)=\frac{\exp \left(\vec{v}_{u}^{\mathrm{T} \rightarrow}\right)}{\sum_{j \in I} \exp \left(\vec{v}_{u}^{\mathrm{T}} \vec{e}_{j}\right)}
|
||||
$$
|
||||
目标函数是:
|
||||
$$
|
||||
L=\sum_{(u, i) \in \mathcal{D}} \log \operatorname{Pr}(i \mid u)
|
||||
$$
|
||||
其中$\mathcal{D}$是训练数据包含用户物品交互的集合。因为物品的数量可伸缩到数十亿,所以不能直接算。因此。使用采样的softmax技术,并且选择Adam优化来训练MIND。
|
||||
|
||||
训练结束后,抛开label-aware注意力层,MIND网络得到一个用户表示映射函数$f_{user}$。在服务期间,用户的历史序列与自身属性喂入到$f_{user}$,每个用户得到多兴趣向量。然后这个表示向量通过一个近似邻近方法来检索top N物品。
|
||||
|
||||
这就是整个MIND模型的细节了。
|
||||
|
||||
## MIND模型之简易代码复现
|
||||
下面参考Deepctr,用简易的代码实现下MIND,并在新闻推荐的数据集上进行召回任务。
|
||||
|
||||
### 整个代码架构
|
||||
|
||||
整个MIND模型算是参考deepmatch修改的一个简易版本:
|
||||
|
||||
```python
|
||||
def MIND(user_feature_columns, item_feature_columns, num_sampled=5, k_max=2, p=1.0, dynamic_k=False, user_dnn_hidden_units=(64, 32),
|
||||
dnn_activation='relu', dnn_use_bn=False, l2_reg_dnn=0, l2_reg_embedding=1e-6, dnn_dropout=0, output_activation='linear', seed=1024):
|
||||
"""
|
||||
:param k_max: 用户兴趣胶囊的最大个数
|
||||
"""
|
||||
# 目前这里只支持item_feature_columns为1的情况,即只能转入item_id
|
||||
if len(item_feature_columns) > 1:
|
||||
raise ValueError("Now MIND only support 1 item feature like item_id")
|
||||
|
||||
# 获取item相关的配置参数
|
||||
item_feature_column = item_feature_columns[0]
|
||||
item_feature_name = item_feature_column.name
|
||||
item_vocabulary_size = item_feature_column.vocabulary_size
|
||||
item_embedding_dim = item_feature_column.embedding_dim
|
||||
|
||||
behavior_feature_list = [item_feature_name]
|
||||
|
||||
# 为用户特征创建Input层
|
||||
user_input_layer_dict = build_input_layers(user_feature_columns)
|
||||
item_input_layer_dict = build_input_layers(item_feature_columns)
|
||||
# 将Input层转化成列表的形式作为model的输入
|
||||
user_input_layers = list(user_input_layer_dict.values())
|
||||
item_input_layers = list(item_input_layer_dict.values())
|
||||
|
||||
# 筛选出特征中的sparse特征和dense特征,方便单独处理
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
varlen_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
|
||||
# 由于这个变长序列里面只有历史点击文章,没有类别啥的,所以这里直接可以用varlen_feature_columns
|
||||
# deepctr这里单独把点击文章这个放到了history_feature_columns
|
||||
seq_max_len = varlen_feature_columns[0].maxlen
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(user_feature_columns+item_feature_columns)
|
||||
|
||||
# 获取当前的行为特征(doc)的embedding,这里面可能又多个类别特征,所以需要pooling下
|
||||
query_embed_list = embedding_lookup(behavior_feature_list, item_input_layer_dict, embedding_layer_dict) # 长度为1
|
||||
# 获取行为序列(doc_id序列, hist_doc_id) 对应的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
keys_embed_list = embedding_lookup([varlen_feature_columns[0].name], user_input_layer_dict, embedding_layer_dict) # 长度为1
|
||||
|
||||
# 用户离散特征的输入层与embedding层拼接
|
||||
dnn_input_emb_list = embedding_lookup([col.name for col in sparse_feature_columns], user_input_layer_dict, embedding_layer_dict)
|
||||
|
||||
# 获取dense
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
if fc.name != 'hist_len': # 连续特征不要这个
|
||||
dnn_dense_input.append(user_input_layer_dict[fc.name])
|
||||
|
||||
# 把keys_emb_list和query_emb_listpooling操作, 这是因为可能每个商品不仅有id,还可能用类别,品牌等多个embedding向量,这种需要pooling成一个
|
||||
history_emb = PoolingLayer()(NoMask()(keys_embed_list)) # (None, 50, 8)
|
||||
target_emb = PoolingLayer()(NoMask()(query_embed_list)) # (None, 1, 8)
|
||||
|
||||
hist_len = user_input_layer_dict['hist_len']
|
||||
# 胶囊网络
|
||||
# (None, 2, 8) 得到了两个兴趣胶囊
|
||||
high_capsule = CapsuleLayer(input_units=item_embedding_dim, out_units=item_embedding_dim,
|
||||
max_len=seq_max_len, k_max=k_max)((history_emb, hist_len))
|
||||
|
||||
|
||||
# 把用户的其他特征拼接到胶囊网络上来
|
||||
if len(dnn_input_emb_list) > 0 or len(dnn_dense_input) > 0:
|
||||
user_other_feature = combined_dnn_input(dnn_input_emb_list, dnn_dense_input)
|
||||
# (None, 2, 32) 这里会发现其他的用户特征是每个胶囊复制了一份,然后拼接起来
|
||||
other_feature_tile = tf.keras.layers.Lambda(tile_user_otherfeat, arguments={'k_max': k_max})(user_other_feature)
|
||||
user_deep_input = Concatenate()([NoMask()(other_feature_tile), high_capsule]) # (None, 2, 40)
|
||||
else:
|
||||
user_deep_input = high_capsule
|
||||
|
||||
# 接下来过一个DNN层,获取最终的用户表示向量 如果是三维输入, 那么最后一个维度与w相乘,所以这里如果不自己写,可以用Dense层的列表也可以
|
||||
user_embeddings = DNN(user_dnn_hidden_units, dnn_activation, l2_reg_dnn,
|
||||
dnn_dropout, dnn_use_bn, output_activation=output_activation, seed=seed,
|
||||
name="user_embedding")(user_deep_input) # (None, 2, 8)
|
||||
|
||||
# 接下来,过Label-aware layer
|
||||
if dynamic_k:
|
||||
user_embedding_final = LabelAwareAttention(k_max=k_max, pow_p=p,)((user_embeddings, target_emb, hist_len))
|
||||
else:
|
||||
user_embedding_final = LabelAwareAttention(k_max=k_max, pow_p=p,)((user_embeddings, target_emb))
|
||||
|
||||
# 接下来
|
||||
item_embedding_matrix = embedding_layer_dict[item_feature_name] # 获取doc_id的embedding层
|
||||
item_index = EmbeddingIndex(list(range(item_vocabulary_size)))(item_input_layer_dict[item_feature_name]) # 所有doc_id的索引
|
||||
item_embedding_weight = NoMask()(item_embedding_matrix(item_index)) # 拿到所有item的embedding
|
||||
pooling_item_embedding_weight = PoolingLayer()([item_embedding_weight]) # 这里依然是当可能不止item_id,或许还有brand_id, cat_id等,需要池化
|
||||
|
||||
# 这里传入的是整个doc_id的embedding, user_embedding, 以及用户点击的doc_id,然后去进行负采样计算损失操作
|
||||
output = SampledSoftmaxLayer(num_sampled)([pooling_item_embedding_weight, user_embedding_final, item_input_layer_dict[item_feature_name]])
|
||||
|
||||
model = Model(inputs=user_input_layers+item_input_layers, outputs=output)
|
||||
|
||||
# 下面是等模型训练完了之后,获取用户和item的embedding
|
||||
model.__setattr__("user_input", user_input_layers)
|
||||
model.__setattr__("user_embedding", user_embeddings)
|
||||
model.__setattr__("item_input", item_input_layers)
|
||||
model.__setattr__("item_embedding", get_item_embedding(pooling_item_embedding_weight, item_input_layer_dict[item_feature_name]))
|
||||
|
||||
return model
|
||||
```
|
||||
简单说下流程, 函数式API搭建模型的方式,首先我们需要传入封装好的用户特征描述以及item特征描述,比如:
|
||||
|
||||
```python
|
||||
# 建立模型
|
||||
user_feature_columns = [
|
||||
SparseFeat('user_id', feature_max_idx['user_id'], embedding_dim),
|
||||
VarLenSparseFeat(SparseFeat('hist_doc_ids', feature_max_idx['article_id'], embedding_dim,
|
||||
embedding_name="click_doc_id"), his_seq_maxlen, 'mean', 'hist_len'),
|
||||
DenseFeat('hist_len', 1),
|
||||
SparseFeat('u_city', feature_max_idx['city'], embedding_dim),
|
||||
SparseFeat('u_age', feature_max_idx['age'], embedding_dim),
|
||||
SparseFeat('u_gender', feature_max_idx['gender'], embedding_dim),
|
||||
]
|
||||
doc_feature_columns = [
|
||||
SparseFeat('click_doc_id', feature_max_idx['article_id'], embedding_dim)
|
||||
# 这里后面也可以把文章的类别画像特征加入
|
||||
]
|
||||
```
|
||||
首先, 函数会对传入的这种特征建立模型的Input层,主要是`build_input_layers`函数。建立完了之后,获取到Input层列表,这个是为了最终定义模型用的,keras要求定义模型的时候是列表的形式。
|
||||
|
||||
接下来是选出sparse特征和Dense特征来,这个也是常规操作了,因为不同的特征后面处理方式不一样,对于sparse特征,后面要接embedding层,Dense特征的话,直接可以拼接起来。这就是筛选特征的3行代码。
|
||||
|
||||
接下来,是为所有的离散特征建立embedding层,通过函数`build_embedding_layers`。建立完了之后,把item相关的embedding层与对应的Input层接起来,作为query_embed_list, 而用户历史行为序列的embedding层与Input层接起来作为keys_embed_list,这两个有单独的用户。而Input层与embedding层拼接是通过`embedding_lookup`函数完成的。 这样完成了之后,就能通过Input层-embedding层拿到item的系列embedding,以及历史序列里面item系列embedding,之所以这里是系列embedding,是有可能不止item_id这一个特征,还可能有品牌id, 类别id等好几个,所以接下来把系列embedding通过pooling操作,得到最终表示item的向量。 就是这两行代码:
|
||||
|
||||
```python
|
||||
# 把keys_emb_list和query_emb_listpooling操作, 这是因为可能每个商品不仅有id,还可能用类别,品牌等多个embedding向量,这种需要pooling成一个
|
||||
history_emb = PoolingLayer()(NoMask()(keys_embed_list)) # (None, 50, 8)
|
||||
target_emb = PoolingLayer()(NoMask()(query_embed_list)) # (None, 1, 8)
|
||||
```
|
||||
而像其他的输入类别特征, 依然是Input层与embedding层拼起来,留着后面用,这个存到了dnn_input_emb_list中。 而dense特征, 不需要embedding层,直接通过Input层获取到,然后存到列表里面,留着后面用。
|
||||
|
||||
上面得到的history_emb,就是用户的历史行为序列,这个东西接下来要过兴趣提取层,去学习用户的多兴趣,当然这里还需要传入行为序列的真实长度。因为每个用户行为序列不一样长,通过mask让其等长了,但是真实在胶囊网络计算的时候,这些填充的序列是要被mask掉的。所以必须要知道真实长度。
|
||||
|
||||
```python
|
||||
# 胶囊网络
|
||||
# (None, 2, 8) 得到了两个兴趣胶囊
|
||||
high_capsule = CapsuleLayer(input_units=item_embedding_dim, out_units=item_embedding_dim,max_len=seq_max_len, k_max=k_max)((history_emb, hist_len))
|
||||
```
|
||||
通过这步操作,就得到了两个兴趣胶囊。 至于具体细节,下一节看。 然后把用户的其他特征拼接上来,这里有必要看下代码究竟是怎么拼接的:
|
||||
|
||||
```python
|
||||
# 把用户的其他特征拼接到胶囊网络上来
|
||||
if len(dnn_input_emb_list) > 0 or len(dnn_dense_input) > 0:
|
||||
user_other_feature = combined_dnn_input(dnn_input_emb_list, dnn_dense_input)
|
||||
# (None, 2, 32) 这里会发现其他的用户特征是每个胶囊复制了一份,然后拼接起来
|
||||
other_feature_tile = tf.keras.layers.Lambda(tile_user_otherfeat, arguments={'k_max': k_max})(user_other_feature)
|
||||
user_deep_input = Concatenate()([NoMask()(other_feature_tile), high_capsule]) # (None, 2, 40)
|
||||
else:
|
||||
user_deep_input = high_capsule
|
||||
```
|
||||
这里会发现,使用了一个Lambda层,这个东西的作用呢,其实是将用户的其他特征在胶囊个数的维度上复制了一份,再拼接,这就相当于在每个胶囊的后面都拼接上了用户的基础特征。这样得到的维度就成了(None, 2, 40),2是胶囊个数, 40是兴趣胶囊的维度+其他基础特征维度总和。这样拼完了之后,接下来过全连接层
|
||||
|
||||
```python
|
||||
# 接下来过一个DNN层,获取最终的用户表示向量 如果是三维输入, 那么最后一个维度与w相乘,所以这里如果不自己写,可以用Dense层的列表也可以
|
||||
user_embeddings = DNN(user_dnn_hidden_units, dnn_activation, l2_reg_dnn,
|
||||
dnn_dropout, dnn_use_bn, output_activation=output_activation, seed=seed,
|
||||
name="user_embedding")(user_deep_input) # (None, 2, 8)
|
||||
```
|
||||
最终得到的是(None, 2, 8)的向量,这样就解决了之前的那个疑问, 最终得到的兴趣向量个数并不是1个,而是多个兴趣向量了,因为上面用户特征拼接,是每个胶囊后面都拼接一份同样的特征。另外,就是原来DNN这里的输入还可以是3维的,这样进行运算的话,是最后一个维度与W进行运算,相当于只在第3个维度上进行了降维操作后者非线性操作,这样得到的兴趣个数是不变的。
|
||||
|
||||
这样,有了两个兴趣的输出之后,接下来,就是过LabelAwareAttention层了,对这两个兴趣向量与当前item的相关性加注意力权重,最后变成1个用户的最终向量。
|
||||
|
||||
```python
|
||||
user_embedding_final = LabelAwareAttention(k_max=k_max, pow_p=p,)((user_embeddings, target_emb))
|
||||
```
|
||||
这样,就得到了用户的最终表示向量,当然这个操作仅是训练的时候,服务的时候是拿的上面DNN的输出,即多个兴趣,这里注意一下。
|
||||
|
||||
拿到了最终的用户向量,如何计算损失呢? 这里用了负采样层进行操作。关于这个层具体的原理,后面我们可能会出一篇文章总结。
|
||||
|
||||
接下来有几行代码也需要注意:
|
||||
|
||||
```python
|
||||
# 下面是等模型训练完了之后,获取用户和item的embedding
|
||||
model.__setattr__("user_input", user_input_layers)
|
||||
model.__setattr__("user_embedding", user_embeddings)
|
||||
model.__setattr__("item_input", item_input_layers)
|
||||
model.__setattr__("item_embedding", get_item_embedding(pooling_item_embedding_weight, item_input_layer_dict[item_feature_name]))
|
||||
```
|
||||
这几行代码是为了模型训练完,我们给定输入之后,拿embedding用的,设置好了之后,通过:
|
||||
|
||||
```python
|
||||
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
|
||||
item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
|
||||
|
||||
user_embs = user_embedding_model.predict(test_user_model_input, batch_size=2 ** 12)
|
||||
# user_embs = user_embs[:, i, :] # i in [0,k_max) if MIND
|
||||
item_embs = item_embedding_model.predict(all_item_model_input, batch_size=2 ** 12)
|
||||
```
|
||||
这样就能拿到用户和item的embedding, 接下来近邻检索完成召回过程。 注意,MIND的话,这里是拿到的多个兴趣向量的。
|
||||
|
||||
## 总结
|
||||
今天这篇文章整理的MIND,这是一个多兴趣的召回模型,核心是兴趣提取层,该层通过动态路由机制能够自动的对用户的历史行为序列进行聚类,得到多个兴趣向量,这样能在召回阶段捕获到用户的广泛兴趣,从而召回更好的候选商品。
|
||||
|
||||
|
||||
**参考**:
|
||||
* Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
|
||||
* [ AI上推荐 之 MIND(动态路由与胶囊网络的奇光异彩)](https://blog.csdn.net/wuzhongqiang/article/details/123696462?spm=1001.2014.3001.5501)
|
||||
* [Dynamic Routing Between Capsule ](https://arxiv.org/pdf/1710.09829.pdf)
|
||||
* [CIKM2019|MIND---召回阶段的多兴趣模型](https://zhuanlan.zhihu.com/p/262638999)
|
||||
* [B站胶囊网络课程](https://www.bilibili.com/video/BV1eW411Q7CE?p=2)
|
||||
* [胶囊网络识别交通标志](https://blog.csdn.net/shebao3333/article/details/79008688)
|
||||
|
||||
|
||||
@@ -1,404 +0,0 @@
|
||||
## 写在前面
|
||||
SDM模型(Sequential Deep Matching Model),是阿里团队在2019年CIKM上的一篇paper。和MIND模型一样,是一种序列召回模型,研究的依然是如何通过用户的历史行为序列去学习到用户的丰富兴趣。 对于MIND,我们已经知道是基于胶囊网络的动态路由机制,设计了一个动态兴趣提取层,把用户的行为序列通过路由机制聚类,然后映射成了多个兴趣胶囊,以此来获取到用户的广泛兴趣。而SDM模型,是先把用户的历史序列根据交互的时间分成了短期和长期两类,然后从**短期会话**和**长期行为**中分别采取**相应的措施(短期的RNN+多头注意力, 长期的Att Net)** 去学习到用户的短期兴趣和长期行为偏好,并**巧妙的设计了一个门控网络==有选择==的将长短期兴趣进行融合**,以此得到用户的最终兴趣向量。 这篇paper中的一些亮点,比如长期偏好的行为表示,多头注意力机制学习多兴趣,长短期兴趣的融合机制等,又给了一些看待问题的新角度,同时,给出了我们一种利用历史行为序列去捕捉用户动态偏好的新思路。
|
||||
|
||||
这篇paper依然是从引言开始, 介绍SDM模型提出的动机以及目前方法存在的不足(why), 接下来就是SDM的网络模型架构(what), 这里面的关键是如何从短期会话和长期行为两个方面学习到用户的短期长期偏好(how),最后,依然是简易代码实现。
|
||||
|
||||
大纲如下:
|
||||
* 背景与动机
|
||||
* SDM的网络结构与细节
|
||||
* SDM模型代码复现
|
||||
|
||||
## 背景与动机
|
||||
这里要介绍该模型提出的动机,即why要有这样的一个模型?
|
||||
|
||||
一个好的推荐系统应该是能精确的捕捉用户兴趣偏好以及能对他们当前需求进行快速响应的,往往工业上的推荐系统,为了能快速响应, 一般会把整个推荐流程分成召回和排序两个阶段,先通过召回,从海量商品中得到一个小的候选集,然后再给到排序模型做精确的筛选操作。 这也是目前推荐系统的一个范式了。在这个过程中,召回模块所检索到的候选对象的质量在整个系统中起着至关重要的作用。
|
||||
|
||||
淘宝目前的召回模型是一些基于协同过滤的模型, 这些模型是通过用户与商品的历史交互建模,从而得到用户的物品的表示向量,但这个过程是**静态的**,而用户的行为或者兴趣是时刻变化的, 对于协同过滤的模型来说,并不能很好的捕捉到用户整个行为序列的动态变化。
|
||||
|
||||
那我们知道了学习用户历史行为序列很重要, 那么假设序列很长呢?这时候直接用模型学习长序列之间的演进可能不是很好,因为很长的序列里面可能用户的兴趣发生过很大的转变,很多商品压根就没有啥关系,这样硬学,反而会导致越学越乱,就别提这个演进了。所以这里是以会话为单位,对长序列进行切分。作者这里的依据就是用户在同一个Session下,其需求往往是很明确的, 这时候,交互的商品也往往都非常类似。 但是Session与Session之间,可能需求改变,那么商品类型可能骤变。 所以以Session为单位来学习商品之间的序列信息,感觉要比整个长序列学习来的靠谱。
|
||||
|
||||
作者首先是先把长序列分成了多个会话, 然后**把最近的一次会话,和之前的会话分别视为了用户短期行为和长期行为分别进行了建模,并采用不同的措施学习用户的短期兴趣和长期兴趣,然后通过一个门控机制融合得到用户最终的表示向量**。这就是SDM在做的事情,
|
||||
|
||||
|
||||
长短期行为序列联合建模,其实是在给我们提供一种新的学习用户兴趣的新思路, 那么究竟是怎么做的呢?以及为啥这么做呢?
|
||||
* 对于短期用户行为, 首先作者使用了LSTM来学习序列关系, 而接下来是用一个Multi-head attention机制,学习用户的多兴趣。
|
||||
|
||||
先分析分析作者为啥用多头注意力机制,作者这里依然是基于实际的场景出发,作者发现,**用户的兴趣点在一个会话里面其实也是多重的**。这个可能之前的很多模型也是没考虑到的,但在商品购买的场景中,这确实也是个事实, 顾客在买一个商品的时候,往往会进行多方比较, 考虑品牌,颜色,商店等各种因素。作者认为用普通的注意力机制是无法反映广泛的兴趣了,所以用多头注意力网络。
|
||||
|
||||
多头注意力机制从某个角度去看,也有类似聚类的功效,首先它接收了用户的行为序列,然后从多个角度学习到每个商品与其他商品的相关性,然后根据与其他商品的相关性加权融合,这样,相似的item向量大概率就融合到了一块组成一个向量,所谓用户的多兴趣,可能是因为这些行为商品之间,可以从多个空间或者角度去get彼此之间的相关性,这里面有着用户多兴趣的表达信息。
|
||||
|
||||
* 用户的长期行为也会影响当前的决策,作者在这里举了一个NBA粉丝的例子,说如果一个是某个NBA球星的粉丝,那么他可能在之前会买很多有关这个球星的商品,如果现在这个时刻想买鞋的时候,大概率会考虑和球星相关的。所以作者说**长期偏好和短期行为都非常关键**。但是长期偏好或者行为往往是复杂广泛的,就像刚才这个例子里面,可能长期行为里面,买的与这个球星相关商品只占一小部分,而就只有这一小部分对当前决策有用。
|
||||
这个也是之前的模型利用长期偏好方面存在的问题,那么如何选择出长期偏好里面对于当前决策有用的那部分呢? 作者这里设计了一个门控的方式融合短期和长期,这个想法还是很巧妙的,后面介绍这个东西的时候说下我的想法。
|
||||
|
||||
所以下面总结动机以及本篇论文的亮点:
|
||||
* 动机: 召回模型需要捕获用户的动态兴趣变化,这个过程中利用好用户的长期行为和短期偏好非常关键,而以往的模型有下面几点不足:
|
||||
* 协同过滤模型: 基于用户的交互进行静态建模,无法感知用户的兴趣变化过程,易召回同质性的商品
|
||||
* 早期的一些序列推荐模型: 要么是对整个长序列直接建模,但这样太暴力,没法很好的学习商品之间的序列信息,有些是把长序列分成会话,但忽视了一个会话中用户的多重兴趣
|
||||
* 有些方法在考虑用户的长期行为方面,只是简单的拼接或者加权求和,而实际上用户长期行为中只有很少一小部分对当前的预测有用,这样暴力融合反而会适得其反,起不到效果。另外还有一些多任务或者对抗方法, 在工业场景中不适用等。
|
||||
* 这些我只是通过我的理解简单总结,详细内容看原论文相关工作部分。
|
||||
* 亮点:
|
||||
* SDM模型, 考虑了用户的短期行为和长期兴趣,以会话的形式进行分割,并对这两方面分别建模
|
||||
* 短期会话由于对当前决策影响比较大,那么我们就学习的全面一点, 首先RNN学习序列关系,其次通过多头注意力机制捕捉多兴趣,然后通过一个Attention Net加权得到短期兴趣表示
|
||||
* 长期会话通过Attention Net融合,然后过DNN,得到用户的长期表示
|
||||
* 我们设计了一个门控机制,类似于LSTM的那种门控,能巧妙的融合这两种兴趣,得到用户最终的表示向量
|
||||
|
||||
这就是动机与背景总结啦。 那么接下来,SDM究竟是如何学习短期和长期表示,又是如何融合的? 为什么要这么玩?
|
||||
|
||||
## SDM的网络结构与细节剖析
|
||||
### 问题定义
|
||||
这里本来直接看模型结构,但感觉还是先过一下问题定义吧,毕竟这次涉及到了会话,还有几个小规则。
|
||||
|
||||
$\mathcal{U}$表示用户集合,$\mathcal{I}$表示item集合,模型考虑在时间$t$,是否用户$u$会对$i$产生交互。 对于$u$, 我们能够得到它的历史行为序列,那么先说一下如何进行会话的划分, 这里有三个规则:
|
||||
1. 相同会话ID的商品(后台能获取)算是一个会话
|
||||
2. 相邻的商品,时间间隔小于10分钟(业务自己调整)算一个会话
|
||||
3. 同一个会话中的商品不能超过50个,多出来的放入下一个会话
|
||||
|
||||
这样划分开会话之后, 对于用户$u$的短期行为定义是离目前最近的这次会话, 用$\mathcal{S}^{u}=\left[i_{1}^{u}, \ldots, i_{t}^{u}, \ldots, i_{m}^{u}\right]$表示,$m$是序列长度。 而长期的用户行为是过去一周内的会话,但不包括短期的这次会话, 这个用$\mathcal{L}^{u}$表示。网络推荐架构如下:
|
||||
|
||||
这个感觉并不用过多解释。看过召回的应该都能懂, 接收了用户的短期行为和长期行为,然后分别通过两个盲盒得到表示向量,再通过门控融合就得到了最终的用户表示。
|
||||
|
||||
下面要开那三个盲盒操作,即短期行为学习,长期行为学习以及门控融合机制。但在这之前,得先说一个东西,就是输入层这里, 要带物品的side infomation,比如物品的item ID, 物品的品牌ID,商铺ID, 类别ID等等, 那你说,为啥要单独说呢? 之前的模型不也有, 但是这里在利用方式上有些不一样需要注意。
|
||||
|
||||
### Input Embedding with side Information
|
||||
在淘宝的推荐场景中,作者发现, 顾客与物品产生交互行为的时候,不仅考虑特定的商品本身,还考虑产品, 商铺,价格等,这个显然。所以,这里对于一个商品来说,不仅要用到Item ID,还用了更多的side info信息,包括`leat category, fist level category, brand,shop`。
|
||||
|
||||
所以,假设用户的短期行为是$\mathcal{S}^{u}=\left[i_{1}^{u}, \ldots, i_{t}^{u}, \ldots, i_{m}^{u}\right]$, 这里面的每个商品$i_t^u$其实有5个属性表示了,每个属性本质是ID,但转成embedding之后,就得到了5个embedding, 所以这里就涉及到了融合问题。 这里用$\boldsymbol{e}_{{i}^u_t} \in \mathbb{R}^{d \times 1}$来表示每个$i_t^u$,但这里不是embedding的pooling操作,而是Concat
|
||||
$$
|
||||
\boldsymbol{e}_{i_{t}^{u}}=\operatorname{concat}\left(\left\{\boldsymbol{e}_{i}^{f} \mid f \in \mathcal{F}\right\}\right)
|
||||
$$
|
||||
其中,$\boldsymbol{e}_{i}^{f}=\boldsymbol{W}^{f} \boldsymbol{x}_{i}^{f} \in \mathbb{R}^{d_{f} \times 1}$, 这个公式看着负责,其实就是每个side info的id过embedding layer得到各自的embedding。这里embedding的维度是$d_f$, 等拼接起来之后,就是$d$维了。这个点要注意。
|
||||
|
||||
另外就是用户的base表示向量了,这个很简单, 就是用户的基础画像,得到embedding,直接也是Concat,这个常规操作不解释:
|
||||
$$
|
||||
\boldsymbol{e}_{u}=\operatorname{concat}\left(\left\{\boldsymbol{e}_{u}^{p} \mid p \in \mathcal{P}\right\}\right)
|
||||
$$
|
||||
$e_u^p$是特征$p$的embedding。
|
||||
|
||||
Ok,输入这里说完了之后,就直接开盲盒, 不按照论文里面的顺序来了。想看更多细节的就去看原论文吧,感觉那里面说的有些啰嗦。不如直接上图解释来的明显:
|
||||
|
||||
|
||||
这里正好三个框把盒子框住了,下面剖析出每个来就行啦。
|
||||
### 短期用户行为建模
|
||||
这里短期用户行为是下面的那个框, 接收的输入,首先是用户最近的那次会话,里面各个商品加入了side info信息之后,有了最终的embedding表示$\left[\boldsymbol{e}_{i_{1}^{u}}, \ldots, \boldsymbol{e}_{i_{t}^{u}}\right]$。
|
||||
|
||||
这个东西,首先要过LSTM,学习序列信息,这个感觉不用多说,直接上公式:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\boldsymbol{i} \boldsymbol{n}_{t}^{u} &=\sigma\left(\boldsymbol{W}_{i n}^{1} \boldsymbol{e}_{i_{t}^{u}}+\boldsymbol{W}_{i n}^{2} \boldsymbol{h}_{t-1}^{u}+b_{i n}\right) \\
|
||||
f_{t}^{u} &=\sigma\left(\boldsymbol{W}_{f}^{1} \boldsymbol{e}_{i_{t}^{u}}+\boldsymbol{W}_{f}^{2} \boldsymbol{h}_{t-1}^{u}+b_{f}\right) \\
|
||||
\boldsymbol{o}_{t}^{u} &=\sigma\left(\boldsymbol{W}_{o}^{1} \boldsymbol{e}_{i}^{u}+\boldsymbol{W}_{o}^{2} \boldsymbol{h}_{t-1}^{u}+b_{o}\right) \\
|
||||
\boldsymbol{c}_{t}^{u} &=\boldsymbol{f}_{t} \boldsymbol{c}_{t-1}^{u}+\boldsymbol{i} \boldsymbol{n}_{t}^{u} \tanh \left(\boldsymbol{W}_{c}^{1} \boldsymbol{e}_{i_{t}^{u}}+\boldsymbol{W}_{c}^{2} \boldsymbol{h}_{t-1}^{u}+b_{c}\right) \\
|
||||
\boldsymbol{h}_{t}^{u} &=\boldsymbol{o}_{t}^{u} \tanh \left(\boldsymbol{c}_{t}^{u}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这里采用的是多输入多输出, 即每个时间步都会有一个隐藏状态$h_t^u$输出出来,那么经过LSTM之后,原始的序列就有了序列相关信息,得到了$\left[\boldsymbol{h}_{1}^{u}, \ldots, \boldsymbol{h}_{t}^{u}\right]$, 把这个记为$\boldsymbol{X}^{u}$。这里的$\boldsymbol{h}_{t}^{u} \in \mathbb{R}^{d \times 1}$表示时间$t$的序列偏好表示。
|
||||
|
||||
接下来, 这个东西要过Multi-head self-attention层,这个东西的原理我这里就不多讲了,这个东西可以学习到$h_i^u$系列之间的相关性,这个操作从某种角度看,也很像聚类, 因为我们这里是先用多头矩阵把$h_i^u$系列映射到多个空间,然后从各个空间中互求相关性
|
||||
$$
|
||||
\text { head }{ }_{i}^{u}=\operatorname{Attention}\left(\boldsymbol{W}_{i}^{Q} \boldsymbol{X}^{u}, \boldsymbol{W}_{i}^{K} \boldsymbol{X}^{u}, \boldsymbol{W}_{i}^{V} \boldsymbol{X}^{u}\right)
|
||||
$$
|
||||
得到权重后,对原始的向量加权融合。 让$Q_{i}^{u}=W_{i}^{Q} X^{u}$, $K_{i}^{u}=W_{i}^{K} \boldsymbol{X}^{u}$,$V_{i}^{u}=W_{i}^{V} X^{u}$, 背后计算是:
|
||||
$$
|
||||
\begin{aligned}
|
||||
&f\left(Q_{i}^{u}, K_{i}^{u}\right)=Q_{i}^{u T} K_{i}^{u} \\
|
||||
&A_{i}^{u}=\operatorname{softmax}\left(f\left(Q_{i}^{u}, K_{i}^{u}\right)\right)
|
||||
\end{aligned} \\ \operatorname{head}_{i}^{u}=V_{i}^{u} A_{i}^{u T}
|
||||
$$
|
||||
|
||||
这里如果有多头注意力基础的话非常好理解啊,不多解释,可以看我[这篇文章](https://blog.csdn.net/wuzhongqiang/article/details/104414239?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164872966516781683952272%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=164872966516781683952272&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-104414239.nonecase&utm_term=Attention+is+all&spm=1018.2226.3001.4450)补一下。
|
||||
|
||||
这是一个头的计算, 接下来每个头都这么算,假设有$h$个头,这里会通过上面的映射矩阵$W$系列,先把原始的$h_i^u$向量映射到$d_{k}=\frac{1}{h} d$维度,然后计算$head_i^u$也是$d_k$维,这样$h$个head进行拼接,正好是$d$维, 接下来过一个全连接或者线性映射得到MultiHead的输出。
|
||||
$$
|
||||
\hat{X}^{u}=\text { MultiHead }\left(X^{u}\right)=W^{O} \text { concat }\left(\text { head }_{1}^{u}, \ldots, \text { head }_{h}^{u}\right)
|
||||
$$
|
||||
|
||||
这样就相当于更相似的$h_i^u$融合到了一块,而这个更相似又是从多个角度得到的,于是乎, 作者认为,这样就能学习到用户的多兴趣。
|
||||
|
||||
得到这个东西之后,接下来再过一个User Attention, 因为作者发现,对于相似历史行为的不同用户,其兴趣偏好也不太一样。
|
||||
所以加入这个用户Attention层,想挖掘更细粒度的用户个性化信息。 当然,这个就是普通的embedding层了, 用户的base向量$e_u$作为query,与$\hat{X}^{u}$的每个向量做Attention,然后加权求和得最终向量:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\alpha_{k} &=\frac{\exp \left(\hat{\boldsymbol{h}}_{k}^{u T} \boldsymbol{e}_{u}\right)}{\sum_{k=1}^{t} \exp \left(\hat{\boldsymbol{h}}_{k}^{u T} \boldsymbol{e}_{u}\right)} \\
|
||||
\boldsymbol{s}_{t}^{u} &=\sum_{k=1}^{t} \alpha_{k} \hat{\boldsymbol{h}}_{k}^{u}
|
||||
\end{aligned}
|
||||
$$
|
||||
其中$s_{t}^{u} \in \mathbb{R}^{d \times 1}$,这样短期行为兴趣就修成了正果。
|
||||
|
||||
### 用户长期行为建模
|
||||
从长期的视角来看,用户在不同的维度上可能积累了广泛的兴趣,用户可能经常访问一组类似的商店,并反复购买属于同一类别的商品。 所以长期行为$\mathcal{L}^{u}$来自于不同的特征尺度。
|
||||
$$
|
||||
\mathcal{L}^{u}=\left\{\mathcal{L}_{f}^{u} \mid f \in \mathcal{F}\right\}
|
||||
$$
|
||||
这里面包含了各种side特征。这里就和短期行为那里不太一样了,长期行为这里,是从特征的维度进行聚合,也就是把用户的历史长序列分成了多个特征,比如用户历史点击过的商品,历史逛过的店铺,历史看过的商品的类别,品牌等,分成了多个特征子集,然后这每个特征子集里面有对应的id,比如商品有商品id, 店铺有店铺id等,对于每个子集,过user Attention layer,和用户的base向量求Attention, 相当于看看用户喜欢逛啥样的商店, 喜欢啥样的品牌,啥样的商品类别等等,得到每个子集最终的表示向量。每个子集的计算过程如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\alpha_{k} &=\frac{\exp \left(\boldsymbol{g}_{k}^{u T} \boldsymbol{e}_{u}\right)}{\sum_{k=1}^{\left|\mathcal{L}_{f}^{u}\right|} \exp \left(\boldsymbol{g}_{k}^{u T} \boldsymbol{e}_{u}\right)} \\
|
||||
z_{f}^{u} &=\sum_{k=1}^{\left|\mathcal{L}_{f}^{u}\right|} \alpha_{k} \boldsymbol{g}_{k}^{u}
|
||||
\end{aligned}
|
||||
$$
|
||||
每个子集都会得到一个加权的向量,把这个东西拼起来,然后过DNN。
|
||||
$$
|
||||
\begin{aligned}
|
||||
&z^{u}=\operatorname{concat}\left(\left\{z_{f}^{u} \mid f \in \mathcal{F}\right\}\right) \\
|
||||
&\boldsymbol{p}^{u}=\tanh \left(\boldsymbol{W}^{p} z^{u}+b\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这里的$\boldsymbol{p}^{u} \in \mathbb{R}^{d \times 1}$, 这样就得到了用户的长期兴趣表示。
|
||||
### 短长期兴趣融合
|
||||
长短期兴趣融合这里,作者发现之前模型往往喜欢直接拼接起来,或者加和,注意力加权等,但作者认为这样不能很好的将两类兴趣融合起来,因为长期序列里面,其实只有很少的一部分行为和当前有关。那么这样的话,直接无脑融合是有问题的。所以这里作者用了一种较为巧妙的方式,即门控机制:
|
||||
$$
|
||||
G_{t}^{u}=\operatorname{sigmoid}\left(\boldsymbol{W}^{1} \boldsymbol{e}_{u}+\boldsymbol{W}^{2} s_{t}^{u}+\boldsymbol{W}^{3} \boldsymbol{p}^{u}+b\right) \\
|
||||
o_{t}^{u}=\left(1-G_{t}^{u}\right) \odot p^{u}+G_{t}^{u} \odot s_{t}^{u}
|
||||
$$
|
||||
这个和LSTM的这种门控机制很像,首先门控接收的输入有用户画像$e_u$,用户短期兴趣$s_t^u$, 用户长期兴趣$p^u$,经过sigmoid函数得到了$G_{t}^{u} \in \mathbb{R}^{d \times 1}$,用来决定在$t$时刻短期和长期兴趣的贡献程度。然后根据这个贡献程度对短期和长期偏好加权进行融合。
|
||||
|
||||
为啥这东西就有用了呢? 实验中证明了这个东西有用,但这里给出我的理解哈,我们知道最终得到的短期或者长期兴趣都是$d$维的向量, 每一个维度可能代表着不同的兴趣偏好,比如第一维度代表品牌,第二个维度代表类别,第三个维度代表价格,第四个维度代表商店等等,当然假设哈,真实的向量不可解释。
|
||||
|
||||
那么如果我们是直接相加或者是加权相加,其实都意味着长短期兴趣这每个维度都有很高的保留, 但其实上,万一长期兴趣和短期兴趣维度冲突了呢? 比如短期兴趣里面可能用户喜欢这个品牌,长期用户里面用户喜欢那个品牌,那么听谁的? 你可能说短期兴趣这个占更大权重呗,那么普通加权可是所有向量都加的相同的权重,品牌这个维度听短期兴趣的,其他维度比如价格,商店也都听短期兴趣的?本身存在不合理性。那么反而直接相加或者加权效果会不好。
|
||||
|
||||
而门控机制的巧妙就在于,我会给每个维度都学习到一个权重,而这个权重非0即1(近似哈), 那么接下来融合的时候,我通过这个门控机制,取长期和短期兴趣向量每个维度上的其中一个。比如在品牌方面听谁的,类别方面听谁的,价格方面听谁的,只会听短期和长期兴趣的其中一个的。这样就不会有冲突发生,而至于具体听谁的,交给网络自己学习。这样就使得用户长期兴趣和短期兴趣融合的时候,每个维度上的信息保留变得**有选择**。使得兴趣的融合方式更加的灵活。
|
||||
|
||||
==这其实又给我们提供了一种两个向量融合的一种新思路,并不一定非得加权或者拼接或者相加了,还可以通过门控机制让网络自己学==
|
||||
|
||||
|
||||
## SDM模型的简易复现
|
||||
下面参考DeepMatch,用简易的代码实现下SDM,并在新闻推荐的数据集上进行召回任务。
|
||||
|
||||
首先,下面分析SDM的整体架构,从代码层面看运行流程, 然后就这里面几个关键的细节进行说明。
|
||||
|
||||
### 模型的输入
|
||||
对于SDM模型,由于它是将用户的行为序列分成了会话的形式,所以在构造SDM模型输入方面和前面的MIND以及YouTubeDNN有很大的不同了,所以这里需要先重点强调下输入。
|
||||
|
||||
在为SDM产生数据集的时候, 需要传入短期会话的长度以及长期会话的长度, 这样, 对于一个行为序列,构造数据集的时候要按照两个长度分成短期行为和长期行为两种,并且每一种都需要指明真实的序列长度。另外,由于这里用到了文章的side info信息,所以我这里在之前列的基础上加入了文章的两个类别特征分别是cat_1和cat_2,作为文章的side info。 这个产生数据集的代码如下:
|
||||
|
||||
```python
|
||||
"""构造sdm数据集"""
|
||||
def get_data_set(click_data, seq_short_len=5, seq_prefer_len=50):
|
||||
"""
|
||||
:param: seq_short_len: 短期会话的长度
|
||||
:param: seq_prefer_len: 会话的最长长度
|
||||
"""
|
||||
click_data.sort_values("expo_time", inplace=True)
|
||||
|
||||
train_set, test_set = [], []
|
||||
for user_id, hist_click in tqdm(click_data.groupby('user_id')):
|
||||
pos_list = hist_click['article_id'].tolist()
|
||||
cat1_list = hist_click['cat_1'].tolist()
|
||||
cat2_list = hist_click['cat_2'].tolist()
|
||||
|
||||
# 滑动窗口切分数据
|
||||
for i in range(1, len(pos_list)):
|
||||
hist = pos_list[:i]
|
||||
cat1_hist = cat1_list[:i]
|
||||
cat2_hist = cat2_list[:i]
|
||||
# 序列长度只够短期的
|
||||
if i <= seq_short_len and i != len(pos_list) - 1:
|
||||
train_set.append((
|
||||
# 用户id, 用户短期历史行为序列, 用户长期历史行为序列, 当前行为文章, label,
|
||||
user_id, hist[::-1], [0]*seq_prefer_len, pos_list[i], 1,
|
||||
# 用户短期历史序列长度, 用户长期历史序列长度,
|
||||
len(hist[::-1]), 0,
|
||||
# 用户短期历史序列对应类别1, 用户长期历史行为序列对应类别1
|
||||
cat1_hist[::-1], [0]*seq_prefer_len,
|
||||
# 历史短期历史序列对应类别2, 用户长期历史行为序列对应类别2
|
||||
cat2_hist[::-1], [0]*seq_prefer_len
|
||||
))
|
||||
# 序列长度够长期的
|
||||
elif i != len(pos_list) - 1:
|
||||
train_set.append((
|
||||
# 用户id, 用户短期历史行为序列,用户长期历史行为序列, 当前行为文章, label
|
||||
user_id, hist[::-1][:seq_short_len], hist[::-1][seq_short_len:], pos_list[i], 1,
|
||||
# 用户短期行为序列长度,用户长期行为序列长度,
|
||||
seq_short_len, len(hist[::-1])-seq_short_len,
|
||||
# 用户短期历史行为序列对应类别1, 用户长期历史行为序列对应类别1
|
||||
cat1_hist[::-1][:seq_short_len], cat1_hist[::-1][seq_short_len:],
|
||||
# 用户短期历史行为序列对应类别2, 用户长期历史行为序列对应类别2
|
||||
cat2_hist[::-1][:seq_short_len], cat2_hist[::-1][seq_short_len:]
|
||||
))
|
||||
# 测试集保留最长的那一条
|
||||
elif i <= seq_short_len and i == len(pos_list) - 1:
|
||||
test_set.append((
|
||||
user_id, hist[::-1], [0]*seq_prefer_len, pos_list[i], 1,
|
||||
len(hist[::-1]), 0,
|
||||
cat1_hist[::-1], [0]*seq_perfer_len,
|
||||
cat2_hist[::-1], [0]*seq_prefer_len
|
||||
))
|
||||
else:
|
||||
test_set.append((
|
||||
user_id, hist[::-1][:seq_short_len], hist[::-1][seq_short_len:], pos_list[i], 1,
|
||||
seq_short_len, len(hist[::-1])-seq_short_len,
|
||||
cat1_hist[::-1][:seq_short_len], cat1_hist[::-1][seq_short_len:],
|
||||
cat2_list[::-1][:seq_short_len], cat2_hist[::-1][seq_short_len:]
|
||||
))
|
||||
|
||||
random.shuffle(train_set)
|
||||
random.shuffle(test_set)
|
||||
|
||||
return train_set, test_set
|
||||
```
|
||||
思路和之前的是一样的,无非就是根据会话的长短,把之前的一个长行为序列划分成了短期和长期两个,然后加入两个新的side info特征。
|
||||
|
||||
### 模型的代码架构
|
||||
整个SDM模型算是参考deepmatch修改的一个简易版本:
|
||||
|
||||
```python
|
||||
def SDM(user_feature_columns, item_feature_columns, history_feature_list, num_sampled=5, units=32, rnn_layers=2,
|
||||
dropout_rate=0.2, rnn_num_res=1, num_head=4, l2_reg_embedding=1e-6, dnn_activation='tanh', seed=1024):
|
||||
"""
|
||||
:param rnn_num_res: rnn的残差层个数
|
||||
:param history_feature_list: short和long sequence field
|
||||
"""
|
||||
# item_feature目前只支持doc_id, 再加别的就不行了,其实这里可以改造下
|
||||
if (len(item_feature_columns)) > 1:
|
||||
raise ValueError("SDM only support 1 item feature like doc_id")
|
||||
|
||||
# 获取item_feature的一些属性
|
||||
item_feature_column = item_feature_columns[0]
|
||||
item_feature_name = item_feature_column.name
|
||||
item_vocabulary_size = item_feature_column.vocabulary_size
|
||||
|
||||
# 为用户特征创建Input层
|
||||
user_input_layer_dict = build_input_layers(user_feature_columns)
|
||||
item_input_layer_dict = build_input_layers(item_feature_columns)
|
||||
|
||||
# 将Input层转化成列表的形式作为model的输入
|
||||
user_input_layers = list(user_input_layer_dict.values())
|
||||
item_input_layers = list(item_input_layer_dict.values())
|
||||
|
||||
# 筛选出特征中的sparse特征和dense特征,方便单独处理
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
if len(dense_feature_columns) != 0:
|
||||
raise ValueError("SDM dont support dense feature") # 目前不支持Dense feature
|
||||
varlen_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(user_feature_columns+item_feature_columns)
|
||||
|
||||
# 拿到短期会话和长期会话列 之前的命名规则在这里起作用
|
||||
sparse_varlen_feature_columns = []
|
||||
prefer_history_columns = []
|
||||
short_history_columns = []
|
||||
|
||||
prefer_fc_names = list(map(lambda x: "prefer_" + x, history_feature_list))
|
||||
short_fc_names = list(map(lambda x: "short_" + x, history_feature_list))
|
||||
|
||||
for fc in varlen_feature_columns:
|
||||
if fc.name in prefer_fc_names:
|
||||
prefer_history_columns.append(fc)
|
||||
elif fc.name in short_fc_names:
|
||||
short_history_columns.append(fc)
|
||||
else:
|
||||
sparse_varlen_feature_columns.append(fc)
|
||||
|
||||
# 获取用户的长期行为序列列表 L^u
|
||||
# [<tf.Tensor 'emb_prefer_doc_id_2/Identity:0' shape=(None, 50, 32) dtype=float32>, <tf.Tensor 'emb_prefer_cat1_2/Identity:0' shape=(None, 50, 32) dtype=float32>, <tf.Tensor 'emb_prefer_cat2_2/Identity:0' shape=(None, 50, 32) dtype=float32>]
|
||||
prefer_emb_list = embedding_lookup(prefer_fc_names, user_input_layer_dict, embedding_layer_dict)
|
||||
# 获取用户的短期序列列表 S^u
|
||||
# [<tf.Tensor 'emb_short_doc_id_2/Identity:0' shape=(None, 5, 32) dtype=float32>, <tf.Tensor 'emb_short_cat1_2/Identity:0' shape=(None, 5, 32) dtype=float32>, <tf.Tensor 'emb_short_cat2_2/Identity:0' shape=(None, 5, 32) dtype=float32>]
|
||||
short_emb_list = embedding_lookup(short_fc_names, user_input_layer_dict, embedding_layer_dict)
|
||||
|
||||
# 用户离散特征的输入层与embedding层拼接 e^u
|
||||
user_emb_list = embedding_lookup([col.name for col in sparse_feature_columns], user_input_layer_dict, embedding_layer_dict)
|
||||
user_emb = concat_func(user_emb_list)
|
||||
user_emb_output = Dense(units, activation=dnn_activation, name='user_emb_output')(user_emb) # (None, 1, 32)
|
||||
|
||||
# 长期序列行为编码
|
||||
# 过AttentionSequencePoolingLayer --> Concat --> DNN
|
||||
prefer_sess_length = user_input_layer_dict['prefer_sess_length']
|
||||
prefer_att_outputs = []
|
||||
# 遍历长期行为序列
|
||||
for i, prefer_emb in enumerate(prefer_emb_list):
|
||||
prefer_attention_output = AttentionSequencePoolingLayer(dropout_rate=0)([user_emb_output, prefer_emb, prefer_sess_length])
|
||||
prefer_att_outputs.append(prefer_attention_output)
|
||||
prefer_att_concat = concat_func(prefer_att_outputs) # (None, 1, 64) <== Concat(item_embedding,cat1_embedding,cat2_embedding)
|
||||
prefer_output = Dense(units, activation=dnn_activation, name='prefer_output')(prefer_att_concat)
|
||||
# print(prefer_output.shape) # (None, 1, 32)
|
||||
|
||||
# 短期行为序列编码
|
||||
short_sess_length = user_input_layer_dict['short_sess_length']
|
||||
short_emb_concat = concat_func(short_emb_list) # (None, 5, 64) 这里注意下, 对于短期序列,描述item的side info信息进行了拼接
|
||||
short_emb_input = Dense(units, activation=dnn_activation, name='short_emb_input')(short_emb_concat) # (None, 5, 32)
|
||||
# 过rnn 这里的return_sequence=True, 每个时间步都需要输出h
|
||||
short_rnn_output = DynamicMultiRNN(num_units=units, return_sequence=True, num_layers=rnn_layers,
|
||||
num_residual_layers=rnn_num_res, # 这里竟然能用到残差
|
||||
dropout_rate=dropout_rate)([short_emb_input, short_sess_length])
|
||||
# print(short_rnn_output) # (None, 5, 32)
|
||||
# 过MultiHeadAttention # (None, 5, 32)
|
||||
short_att_output = MultiHeadAttention(num_units=units, head_num=num_head, dropout_rate=dropout_rate)([short_rnn_output, short_sess_length]) # (None, 5, 64)
|
||||
# user_attention # (None, 1, 32)
|
||||
short_output = UserAttention(num_units=units, activation=dnn_activation, use_res=True, dropout_rate=dropout_rate)([user_emb_output, short_att_output, short_sess_length])
|
||||
|
||||
# 门控融合
|
||||
gated_input = concat_func([prefer_output, short_output, user_emb_output])
|
||||
gate = Dense(units, activation='sigmoid')(gated_input) # (None, 1, 32)
|
||||
|
||||
# temp = tf.multiply(gate, short_output) + tf.multiply(1-gate, prefer_output) 感觉这俩一样?
|
||||
gated_output = Lambda(lambda x: tf.multiply(x[0], x[1]) + tf.multiply(1-x[0], x[2]))([gate, short_output, prefer_output]) # [None, 1,32]
|
||||
gated_output_reshape = Lambda(lambda x: tf.squeeze(x, 1))(gated_output) # (None, 32) 这个维度必须要和docembedding层的维度一样,否则后面没法sortmax_loss
|
||||
|
||||
# 接下来
|
||||
item_embedding_matrix = embedding_layer_dict[item_feature_name] # 获取doc_id的embedding层
|
||||
item_index = EmbeddingIndex(list(range(item_vocabulary_size)))(item_input_layer_dict[item_feature_name]) # 所有doc_id的索引
|
||||
item_embedding_weight = NoMask()(item_embedding_matrix(item_index)) # 拿到所有item的embedding
|
||||
pooling_item_embedding_weight = PoolingLayer()([item_embedding_weight]) # 这里依然是当可能不止item_id,或许还有brand_id, cat_id等,需要池化
|
||||
|
||||
# 这里传入的是整个doc_id的embedding, user_embedding, 以及用户点击的doc_id,然后去进行负采样计算损失操作
|
||||
output = SampledSoftmaxLayer(num_sampled)([pooling_item_embedding_weight, gated_output_reshape, item_input_layer_dict[item_feature_name]])
|
||||
|
||||
model = Model(inputs=user_input_layers+item_input_layers, outputs=output)
|
||||
|
||||
# 下面是等模型训练完了之后,获取用户和item的embedding
|
||||
model.__setattr__("user_input", user_input_layers)
|
||||
model.__setattr__("user_embedding", gated_output_reshape) # 用户embedding是取得门控融合的用户向量
|
||||
model.__setattr__("item_input", item_input_layers)
|
||||
# item_embedding取得pooling_item_embedding_weight, 这个会发现是负采样操作训练的那个embedding矩阵
|
||||
model.__setattr__("item_embedding", get_item_embedding(pooling_item_embedding_weight, item_input_layer_dict[item_feature_name]))
|
||||
return model
|
||||
```
|
||||
函数式API搭建模型的方式,首先我们需要传入封装好的用户特征描述以及item特征描述,比如:
|
||||
|
||||
```python
|
||||
# 建立模型
|
||||
user_feature_columns = [
|
||||
SparseFeat('user_id', feature_max_idx['user_id'], 16),
|
||||
SparseFeat('gender', feature_max_idx['gender'], 16),
|
||||
SparseFeat('age', feature_max_idx['age'], 16),
|
||||
SparseFeat('city', feature_max_idx['city'], 16),
|
||||
|
||||
VarLenSparseFeat(SparseFeat('short_doc_id', feature_max_idx['article_id'], embedding_dim, embedding_name="doc_id"), SEQ_LEN_short, 'mean', 'short_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('prefer_doc_id', feature_max_idx['article_id'], embedding_dim, embedding_name='doc_id'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('short_cat1', feature_max_idx['cat_1'], embedding_dim, embedding_name='cat_1'), SEQ_LEN_short, 'mean', 'short_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('prefer_cat1', feature_max_idx['cat_1'], embedding_dim, embedding_name='cat_1'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('short_cat2', feature_max_idx['cat_2'], embedding_dim, embedding_name='cat_2'), SEQ_LEN_short, 'mean', 'short_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('prefer_cat2', feature_max_idx['cat_2'], embedding_dim, embedding_name='cat_2'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
|
||||
]
|
||||
|
||||
item_feature_columns = [SparseFeat('doc_id', feature_max_idx['article_id'], embedding_dim)]
|
||||
```
|
||||
这里需要注意的一个点是短期和长期序列的名字,必须严格的`short_, prefer_`进行标识,因为在模型搭建的时候就是靠着这个去找到短期和长期序列特征的。
|
||||
|
||||
逻辑其实也比较清晰,首先是建立Input层,然后是embedding层, 接下来,根据命名选择出用户的base特征列, 短期行为序列和长期行为序列。长期序列的话是过`AttentionPoolingLayer`层进行编码,这里本质上注意力然后融合,但这里注意的一个点就是for循环,也就是长期序列行为里面的特征列,比如商品,cat_1, cat_2是for循环的形式求融合向量,再拼接起来过DNN,和论文图保持一致。
|
||||
|
||||
短期序列编码部分,是`item_embedding,cat_1embedding, cat_2embedding`拼接起来,过`DynamicMultiRNN`层学习序列信息, 过`MultiHeadAttention`学习多兴趣,最后过`UserAttentionLayer`进行向量融合。 接下来,长期兴趣向量和短期兴趣向量以及用户base向量,过门控融合机制,得到最终的`user_embedding`。
|
||||
|
||||
而后面的那块是为了模型训练完之后,拿用户embedding和item embedding用的, 这个在MIND那篇文章里作了解释。
|
||||
|
||||
## 总结
|
||||
今天整理的是SDM,这也是一个标准的序列推荐召回模型,主要还是研究用户的序列,不过这篇paper里面一个有意思的点就是把用户的行为训练以会话的形式进行切分,然后再根据时间,分成了短期会话和长期会话,然后分别采用不同的策略去学习用户的短期兴趣和长期兴趣。
|
||||
* 对于短期会话,可能和当前预测相关性较大,所以首先用RNN来学习序列信息,然后采用多头注意力机制得到用户的多兴趣, 隐隐约约感觉多头注意力机制还真有种能聚类的功效,接下来就是和用户的base向量进行注意力融合得到短期兴趣
|
||||
* 长期会话序列中,每个side info信息进行分开,然后分别进行注意力编码融合得到
|
||||
|
||||
为了使得长期会话中对当前预测有用的部分得以体现,在融合短期兴趣和长期兴趣的时候,采用了门控的方式,而不是普通的拼接或者加和等操作,使得兴趣保留信息变得**有选择**。
|
||||
|
||||
这其实就是这篇paper的故事了,借鉴的地方首先是多头注意力机制也能学习到用户的多兴趣, 这样对于多兴趣,就有了胶囊网络与多头注意力机制两种思路。 而对于两个向量融合,这里又给我们提供了一种门控融合机制。
|
||||
|
||||
|
||||
**参考**:
|
||||
|
||||
* SDM原论文
|
||||
* [AI上推荐 之 SDM模型(建模用户长短期兴趣的Match模型)](https://blog.csdn.net/wuzhongqiang/article/details/123856954?spm=1001.2014.3001.5501)
|
||||
* [一文读懂Attention机制](https://zhuanlan.zhihu.com/p/129316415)
|
||||
* [【推荐系统经典论文(十)】阿里SDM模型](https://zhuanlan.zhihu.com/p/137775247?from_voters_page=true)
|
||||
* [SDM-深度序列召回模型](https://zhuanlan.zhihu.com/p/395673080)
|
||||
* [推荐广告中的序列建模](https://blog.csdn.net/qq_41010971/article/details/123762312?spm=1001.2014.3001.5501)
|
||||
@@ -1,65 +0,0 @@
|
||||
# 背景和目的
|
||||
|
||||
召回早前经历的第一代协同过滤技术,让模型可以在数量级巨大的item集中找到用户潜在想要看到的商品。这种方式有很明显的缺点,一个是对于用户而言,只能通过他历史行为去构建候选集,并且会基于算力的局限做截断。所以推荐结果的多样性和新颖性比较局限,导致推荐的有可能都是用户看过的或者买过的商品。之后在Facebook开源了FASSI库之后,基于内积模型的向量检索方案得到了广泛应用,也就是第二代召回技术。这种技术通过将用户和物品用向量表示,然后用内积的大小度量兴趣,借助向量索引实现大规模的全量检索。这里虽然改善了第一代的无法全局检索的缺点,然而这种模式下存在索引构建和模型优化目标不一致的问题,索引优化是基于向量的近似误差,而召回问题的目标是最大化topK召回率。且这类方法也不方便在用户和物品之间做特征组合。
|
||||
|
||||
所以阿里开发了一种可以承载各种深度模型来检索用户潜在兴趣的推荐算法解决方案。这个TDM模型是基于树结构,利用树结构对全量商品进行检索,将复杂度由O(N)下降到O(logN)。
|
||||
|
||||
# 模型结构
|
||||
|
||||
**树结构**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420213149324.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
</div>
|
||||
|
||||
如上图,树中的每一个叶子节点对应一个商品item,非叶子结点表示的是item的集合**(这里的树不限于二叉树)**。这种层次化结构体现了粒度从粗到细的item架构。
|
||||
|
||||
**整体结构**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420200433442.png" alt="image-20210308142624189" style="zoom: 70%;" />
|
||||
</div>
|
||||
|
||||
# 算法详解
|
||||
|
||||
1. 基于树的高效检索
|
||||
|
||||
算法通常采用beam-search的方法,根据用户对每层节点挑选出topK,将挑选出来的这几个topK节点的子节点作为下一层的候选集,最终会落到叶子节点上。
|
||||
这么做的理论依据是当前层的最有优topK节点的父亲必然属于上次的父辈节点的最优topK:
|
||||
$$
|
||||
p^{(j)}(n|u) = {{max \atop{n_{c}\in{\{n's children nodes in level j+1\}}}}p^{(j+1)}(n_{c}|u) \over {\alpha^{j}}}
|
||||
$$
|
||||
其中$p^{(j)}(n|u)$表示用户u对j层节点n感兴趣的概率,$\alpha^{j}$表示归一化因子。
|
||||
|
||||
2. 对兴趣进行建模
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420214040264.png" alt="image-20210308142624189" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
如上图,用户对叶子层item6感兴趣,可以认为它的兴趣是1,同层别的候选节点的兴趣为0,顺着着绿色线路上去的节点都标记为1,路线上的同层别的候选节点都标记为0。这样的操作就可以根据1和0构建用于每一层的正负样本。
|
||||
|
||||
样本构建完成后,可以在模型结构左侧采用任意的深度学习模型来承担用户兴趣判别器的角色,输入就是当前层构造的正负样本,输出则是(用户,节点)对的兴趣度,这个将被用作检索过程中选取topK的评判指标。**在整体结构图中,我们可以看到节点特征方面,使用的是node embedding**,说明在进入模型前已经向量化了。
|
||||
|
||||
3. 训练过程
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420220831318.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
</div>
|
||||
|
||||
整体联合训练的方式如下:
|
||||
|
||||
1. 构造随机二叉树
|
||||
2. 基于树模型生成样本
|
||||
3. 训练DNN模型直到收敛
|
||||
4. 基于DNN模型得到样本的Embedding,重新构造聚类二叉树
|
||||
5. 循环上述2~4过程
|
||||
|
||||
具体的,在初始化树结构的时候,首先借助商品的类别信息进行排序,将相同类别的商品放到一起,然后递归的将同类别中的商品等量的分到两个子类中,直到集合中只包含一项,利用这种自顶向下的方式来初始化一棵树。基于该树采样生成深度模型训练所需的样本,然后进一步训练模型,训练结束之后可以得到每个树节点对应的Embedding向量,利用节点的Embedding向量,采用K-Means聚类方法来重新构建一颗树,最后基于这颗新生成的树,重新训练深层网络。
|
||||
|
||||
**参考资料**
|
||||
|
||||
- [阿里妈妈深度树检索技术(TDM) 及应用框架的探索实践](https://mp.weixin.qq.com/s/sw16_sUsyYuzpqqy39RsdQ)
|
||||
- [阿里TDM:Tree-based Deep Model](https://zhuanlan.zhihu.com/p/78941783)
|
||||
- [阿里妈妈TDM模型详解](https://zhuanlan.zhihu.com/p/93201318)
|
||||
- [Paddle TDM 模型实现](https://github.com/PaddlePaddle/PaddleRec/blob/master/models/treebased/README.md)
|
||||
@@ -1,352 +0,0 @@
|
||||
### GBDT+LR简介
|
||||
|
||||
前面介绍的协同过滤和矩阵分解存在的劣势就是仅利用了用户与物品相互行为信息进行推荐, 忽视了用户自身特征, 物品自身特征以及上下文信息等,导致生成的结果往往会比较片面。 而这次介绍的这个模型是2014年由Facebook提出的GBDT+LR模型, 该模型利用GBDT自动进行特征筛选和组合, 进而生成新的离散特征向量, 再把该特征向量当做LR模型的输入, 来产生最后的预测结果, 该模型能够综合利用用户、物品和上下文等多种不同的特征, 生成较为全面的推荐结果, 在CTR点击率预估场景下使用较为广泛。
|
||||
|
||||
下面首先会介绍逻辑回归和GBDT模型各自的原理及优缺点, 然后介绍GBDT+LR模型的工作原理和细节。
|
||||
|
||||
### 逻辑回归模型
|
||||
|
||||
逻辑回归模型非常重要, 在推荐领域里面, 相比于传统的协同过滤, 逻辑回归模型能够综合利用用户、物品、上下文等多种不同的特征生成较为“全面”的推荐结果, 关于逻辑回归的更多细节, 可以参考下面给出的链接,这里只介绍比较重要的一些细节和在推荐中的应用。
|
||||
|
||||
逻辑回归是在线性回归的基础上加了一个 Sigmoid 函数(非线形)映射,使得逻辑回归成为了一个优秀的分类算法, 学习逻辑回归模型, 首先应该记住一句话:**逻辑回归假设数据服从伯努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数,来达到将数据二分类的目的。**
|
||||
|
||||
相比于协同过滤和矩阵分解利用用户的物品“相似度”进行推荐, 逻辑回归模型将问题看成了一个分类问题, 通过预测正样本的概率对物品进行排序。这里的正样本可以是用户“点击”了某个商品或者“观看”了某个视频, 均是推荐系统希望用户产生的“正反馈”行为, 因此**逻辑回归模型将推荐问题转化成了一个点击率预估问题**。而点击率预测就是一个典型的二分类, 正好适合逻辑回归进行处理, 那么逻辑回归是如何做推荐的呢? 过程如下:
|
||||
1. 将用户年龄、性别、物品属性、物品描述、当前时间、当前地点等特征转成数值型向量
|
||||
2. 确定逻辑回归的优化目标,比如把点击率预测转换成二分类问题, 这样就可以得到分类问题常用的损失作为目标, 训练模型
|
||||
3. 在预测的时候, 将特征向量输入模型产生预测, 得到用户“点击”物品的概率
|
||||
4. 利用点击概率对候选物品排序, 得到推荐列表
|
||||
|
||||
推断过程可以用下图来表示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200909215410263.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
这里的关键就是每个特征的权重参数$w$, 我们一般是使用梯度下降的方式, 首先会先随机初始化参数$w$, 然后将特征向量(也就是我们上面数值化出来的特征)输入到模型, 就会通过计算得到模型的预测概率, 然后通过对目标函数求导得到每个$w$的梯度, 然后进行更新$w$
|
||||
|
||||
这里的目标函数长下面这样:
|
||||
|
||||
$$
|
||||
J(w)=-\frac{1}{m}\left(\sum_{i=1}^{m}\left(y^{i} \log f_{w}\left(x^{i}\right)+\left(1-y^{i}\right) \log \left(1-f_{w}\left(x^{i}\right)\right)\right)\right.
|
||||
$$
|
||||
求导之后的方式长这样:
|
||||
$$
|
||||
w_{j} \leftarrow w_{j}-\gamma \frac{1}{m} \sum_{i=1}^{m}\left(f_{w}\left(x^{i}\right)-y^{i}\right) x_{j}^{i}
|
||||
$$
|
||||
这样通过若干次迭代, 就可以得到最终的$w$了, 关于这些公式的推导,可以参考下面给出的文章链接, 下面我们分析一下逻辑回归模型的优缺点。
|
||||
|
||||
**优点:**
|
||||
1. LR模型形式简单,可解释性好,从特征的权重可以看到不同的特征对最后结果的影响。
|
||||
2. 训练时便于并行化,在预测时只需要对特征进行线性加权,所以**性能比较好**,往往适合处理**海量id类特征**,用id类特征有一个很重要的好处,就是**防止信息损失**(相对于范化的 CTR 特征),对于头部资源会有更细致的描述
|
||||
3. 资源占用小,尤其是内存。在实际的工程应用中只需要存储权重比较大的特征及特征对应的权重。
|
||||
4. 方便输出结果调整。逻辑回归可以很方便的得到最后的分类结果,因为输出的是每个样本的概率分数,我们可以很容易的对这些概率分数进行cutoff,也就是划分阈值(大于某个阈值的是一类,小于某个阈值的是一类)
|
||||
|
||||
**当然, 逻辑回归模型也有一定的局限性**
|
||||
1. 表达能力不强, 无法进行特征交叉, 特征筛选等一系列“高级“操作(这些工作都得人工来干, 这样就需要一定的经验, 否则会走一些弯路), 因此可能造成信息的损失
|
||||
2. 准确率并不是很高。因为这毕竟是一个线性模型加了个sigmoid, 形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布
|
||||
3. 处理非线性数据较麻烦。逻辑回归在不引入其他方法的情况下,只能处理线性可分的数据, 如果想处理非线性, 首先对连续特征的处理需要先进行**离散化**(离散化的目的是为了引入非线性),如上文所说,人工分桶的方式会引入多种问题。
|
||||
4. LR 需要进行**人工特征组合**,这就需要开发者有非常丰富的领域经验,才能不走弯路。这样的模型迁移起来比较困难,换一个领域又需要重新进行大量的特征工程。
|
||||
|
||||
所以如何**自动发现有效的特征、特征组合,弥补人工经验不足,缩短LR特征实验周期**,是亟需解决的问题, 而GBDT模型, 正好可以**自动发现特征并进行有效组合**
|
||||
|
||||
### GBDT模型
|
||||
|
||||
GBDT全称梯度提升决策树,在传统机器学习算法里面是对真实分布拟合的最好的几种算法之一,在前几年深度学习还没有大行其道之前,gbdt在各种竞赛是大放异彩。原因大概有几个,一是效果确实挺不错。二是即可以用于分类也可以用于回归。三是可以筛选特征, 所以这个模型依然是一个非常重要的模型。
|
||||
|
||||
GBDT是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的误差来达到将数据分类或者回归的算法, 其训练过程如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200908202508786.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" style="zoom:65%;" />
|
||||
</div>
|
||||
gbdt通过多轮迭代, 每轮迭代会产生一个弱分类器, 每个分类器在上一轮分类器的残差基础上进行训练。 gbdt对弱分类器的要求一般是足够简单, 并且低方差高偏差。 因为训练的过程是通过降低偏差来不断提高最终分类器的精度。 由于上述高偏差和简单的要求,每个分类回归树的深度不会很深。最终的总分类器是将每轮训练得到的弱分类器加权求和得到的(也就是加法模型)。
|
||||
|
||||
关于GBDT的详细细节,依然是可以参考下面给出的链接。这里想分析一下GBDT如何来进行二分类的,因为我们要明确一点就是**gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练的**, 而这里的残差指的就是当前模型的负梯度值, 这个就要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的, 而**gbdt 无论用于分类还是回归一直都是使用的CART 回归树**, 那么既然是回归树, 是如何进行二分类问题的呢?
|
||||
|
||||
GBDT 来解决二分类问题和解决回归问题的本质是一样的,都是通过不断构建决策树的方式,使预测结果一步步的接近目标值, 但是二分类问题和回归问题的损失函数是不同的, 关于GBDT在回归问题上的树的生成过程, 损失函数和迭代原理可以参考给出的链接, 回归问题中一般使用的是平方损失, 而二分类问题中, GBDT和逻辑回归一样, 使用的下面这个:
|
||||
|
||||
$$
|
||||
L=\arg \min \left[\sum_{i}^{n}-\left(y_{i} \log \left(p_{i}\right)+\left(1-y_{i}\right) \log \left(1-p_{i}\right)\right)\right]
|
||||
$$
|
||||
其中, $y_i$是第$i$个样本的观测值, 取值要么是0要么是1, 而$p_i$是第$i$个样本的预测值, 取值是0-1之间的概率,由于我们知道GBDT拟合的残差是当前模型的负梯度, 那么我们就需要求出这个模型的导数, 即$\frac{dL}{dp_i}$, 对于某个特定的样本, 求导的话就可以只考虑它本身, 去掉加和号, 那么就变成了$\frac{dl}{dp_i}$, 其中$l$如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
l &=-y_{i} \log \left(p_{i}\right)-\left(1-y_{i}\right) \log \left(1-p_{i}\right) \\
|
||||
&=-y_{i} \log \left(p_{i}\right)-\log \left(1-p_{i}\right)+y_{i} \log \left(1-p_{i}\right) \\
|
||||
&=-y_{i}\left(\log \left(\frac{p_{i}}{1-p_{i}}\right)\right)-\log \left(1-p_{i}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
如果对逻辑回归非常熟悉的话, $\left(\log \left(\frac{p_{i}}{1-p_{i}}\right)\right)$一定不会陌生吧, 这就是对几率比取了个对数, 并且在逻辑回归里面这个式子会等于$\theta X$, 所以才推出了$p_i=\frac{1}{1+e^-{\theta X}}$的那个形式。 这里令$\eta_i=\frac{p_i}{1-p_i}$, 即$p_i=\frac{\eta_i}{1+\eta_i}$, 则上面这个式子变成了:
|
||||
|
||||
$$
|
||||
\begin{aligned}
|
||||
l &=-y_{i} \log \left(\eta_{i}\right)-\log \left(1-\frac{e^{\log \left(\eta_{i}\right)}}{1+e^{\log \left(\eta_{i}\right)}}\right) \\
|
||||
&=-y_{i} \log \left(\eta_{i}\right)-\log \left(\frac{1}{1+e^{\log \left(\eta_{i}\right)}}\right) \\
|
||||
&=-y_{i} \log \left(\eta_{i}\right)+\log \left(1+e^{\log \left(\eta_{i}\right)}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这时候,我们对$log(\eta_i)$求导, 得
|
||||
$$
|
||||
\frac{d l}{d \log (\eta_i)}=-y_{i}+\frac{e^{\log \left(\eta_{i}\right)}}{1+e^{\log \left(\eta_{i}\right)}}=-y_i+p_i
|
||||
$$
|
||||
这样, 我们就得到了某个训练样本在当前模型的梯度值了, 那么残差就是$y_i-p_i$。GBDT二分类的这个思想,其实和逻辑回归的思想一样,**逻辑回归是用一个线性模型去拟合$P(y=1|x)$这个事件的对数几率$log\frac{p}{1-p}=\theta^Tx$**, GBDT二分类也是如此, 用一系列的梯度提升树去拟合这个对数几率, 其分类模型可以表达为:
|
||||
$$
|
||||
P(Y=1 \mid x)=\frac{1}{1+e^{-F_{M}(x)}}
|
||||
$$
|
||||
|
||||
下面我们具体来看GBDT的生成过程, 构建分类GBDT的步骤有两个:
|
||||
1. 初始化GBDT
|
||||
和回归问题一样, 分类 GBDT 的初始状态也只有一个叶子节点,该节点为所有样本的初始预测值,如下:
|
||||
$$
|
||||
F_{0}(x)=\arg \min _{\gamma} \sum_{i=1}^{n} L(y, \gamma)
|
||||
$$
|
||||
上式里面, $F$代表GBDT模型, $F_0$是模型的初识状态, 该式子的意思是找到一个$\gamma$,使所有样本的 Loss 最小,在这里及下文中,$\gamma$都表示节点的输出,即叶子节点, 且它是一个 $log(\eta_i)$ 形式的值(回归值),在初始状态,$\gamma =F_0$。
|
||||
|
||||
下面看例子(该例子来自下面的第二个链接), 假设我们有下面3条样本:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200910095539432.png#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
</div>
|
||||
|
||||
我们希望构建 GBDT 分类树,它能通过「喜欢爆米花」、「年龄」和「颜色偏好」这 3 个特征来预测某一个样本是否喜欢看电影。我们把数据代入上面的公式中求Loss:
|
||||
$$
|
||||
\operatorname{Loss}=L(1, \gamma)+L(1, \gamma)+L(0, \gamma)
|
||||
$$
|
||||
为了令其最小, 我们求导, 且让导数为0, 则:
|
||||
$$
|
||||
\operatorname{Loss}=p-1 + p-1+p=0
|
||||
$$
|
||||
于是, 就得到了初始值$p=\frac{2}{3}=0.67, \gamma=log(\frac{p}{1-p})=0.69$, 模型的初识状态$F_0(x)=0.69$
|
||||
|
||||
2. 循环生成决策树
|
||||
这里回忆一下回归树的生成步骤, 其实有4小步, 第一就是计算负梯度值得到残差, 第二步是用回归树拟合残差, 第三步是计算叶子节点的输出值, 第四步是更新模型。 下面我们一一来看:
|
||||
|
||||
1. 计算负梯度得到残差
|
||||
$$
|
||||
r_{i m}=-\left[\frac{\partial L\left(y_{i}, F\left(x_{i}\right)\right)}{\partial F\left(x_{i}\right)}\right]_{F(x)=F_{m-1}(x)}
|
||||
$$
|
||||
此处使用$m-1$棵树的模型, 计算每个样本的残差$r_{im}$, 就是上面的$y_i-pi$, 于是例子中, 每个样本的残差:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200910101154282.png#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
</div>
|
||||
|
||||
2. 使用回归树来拟合$r_{im}$, 这里的$i$表示样本哈,回归树的建立过程可以参考下面的链接文章,简单的说就是遍历每个特征, 每个特征下遍历每个取值, 计算分裂后两组数据的平方损失, 找到最小的那个划分节点。 假如我们产生的第2棵决策树如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200910101558282.png#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
</div>
|
||||
|
||||
3. 对于每个叶子节点$j$, 计算最佳残差拟合值
|
||||
$$
|
||||
\gamma_{j m}=\arg \min _{\gamma} \sum_{x \in R_{i j}} L\left(y_{i}, F_{m-1}\left(x_{i}\right)+\gamma\right)
|
||||
$$
|
||||
意思是, 在刚构建的树$m$中, 找到每个节点$j$的输出$\gamma_{jm}$, 能使得该节点的loss最小。 那么我们看一下这个$\gamma$的求解方式, 这里非常的巧妙。 首先, 我们把损失函数写出来, 对于左边的第一个样本, 有
|
||||
$$
|
||||
L\left(y_{1}, F_{m-1}\left(x_{1}\right)+\gamma\right)=-y_{1}\left(F_{m-1}\left(x_{1}\right)+\gamma\right)+\log \left(1+e^{F_{m-1}\left(x_{1}\right)+\gamma}\right)
|
||||
$$
|
||||
这个式子就是上面推导的$l$, 因为我们要用回归树做分类, 所以这里把分类的预测概率转换成了对数几率回归的形式, 即$log(\eta_i)$, 这个就是模型的回归输出值。而如果求这个损失的最小值, 我们要求导, 解出令损失最小的$\gamma$。 但是上面这个式子求导会很麻烦, 所以这里介绍了一个技巧就是**使用二阶泰勒公式来近似表示该式, 再求导**, 还记得伟大的泰勒吗?
|
||||
$$
|
||||
f(x+\Delta x) \approx f(x)+\Delta x f^{\prime}(x)+\frac{1}{2} \Delta x^{2} f^{\prime \prime}(x)+O(\Delta x)
|
||||
$$
|
||||
这里就相当于把$L(y_1, F_{m-1}(x_1))$当做常量$f(x)$, $\gamma$作为变量$\Delta x$, 将$f(x)$二阶展开:
|
||||
$$
|
||||
L\left(y_{1}, F_{m-1}\left(x_{1}\right)+\gamma\right) \approx L\left(y_{1}, F_{m-1}\left(x_{1}\right)\right)+L^{\prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right) \gamma+\frac{1}{2} L^{\prime \prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right) \gamma^{2}
|
||||
$$
|
||||
这时候再求导就简单了
|
||||
$$
|
||||
\frac{d L}{d \gamma}=L^{\prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right)+L^{\prime \prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right) \gamma
|
||||
$$
|
||||
Loss最小的时候, 上面的式子等于0, 就可以得到$\gamma$:
|
||||
$$
|
||||
\gamma_{11}=\frac{-L^{\prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right)}{L^{\prime \prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right)}
|
||||
$$
|
||||
**因为分子就是残差(上述已经求到了), 分母可以通过对残差求导,得到原损失函数的二阶导:**
|
||||
$$
|
||||
\begin{aligned}
|
||||
L^{\prime \prime}\left(y_{1}, F(x)\right) &=\frac{d L^{\prime}}{d \log (\eta_1)} \\
|
||||
&=\frac{d}{d \log (\eta_1)}\left[-y_{i}+\frac{e^{\log (\eta_1)}}{1+e^{\log (\eta_1)}}\right] \\
|
||||
&=\frac{d}{d \log (\eta_1)}\left[e^{\log (\eta_1)}\left(1+e^{\log (\eta_1)}\right)^{-1}\right] \\
|
||||
&=e^{\log (\eta_1)}\left(1+e^{\log (\eta_1)}\right)^{-1}-e^{2 \log (\eta_1)}\left(1+e^{\log (\eta_1)}\right)^{-2} \\
|
||||
&=\frac{e^{\log (\eta_1)}}{\left(1+e^{\log (\eta_1)}\right)^{2}} \\
|
||||
&=\frac{\eta_1}{(1+\eta_1)}\frac{1}{(1+\eta_1)} \\
|
||||
&=p_1(1-p_1)
|
||||
\end{aligned}
|
||||
$$
|
||||
这时候, 就可以算出该节点的输出:
|
||||
$$
|
||||
\gamma_{11}=\frac{r_{11}}{p_{10}\left(1-p_{10}\right)}=\frac{0.33}{0.67 \times 0.33}=1.49
|
||||
$$
|
||||
这里的下面$\gamma_{jm}$表示第$m$棵树的第$j$个叶子节点。 接下来是右边节点的输出, 包含样本2和样本3, 同样使用二阶泰勒公式展开:
|
||||
$$
|
||||
\begin{array}{l}
|
||||
L\left(y_{2}, F_{m-1}\left(x_{2}\right)+\gamma\right)+L\left(y_{3}, F_{m-1}\left(x_{3}\right)+\gamma\right) \\
|
||||
\approx L\left(y_{2}, F_{m-1}\left(x_{2}\right)\right)+L^{\prime}\left(y_{2}, F_{m-1}\left(x_{2}\right)\right) \gamma+\frac{1}{2} L^{\prime \prime}\left(y_{2}, F_{m-1}\left(x_{2}\right)\right) \gamma^{2} \\
|
||||
+L\left(y_{3}, F_{m-1}\left(x_{3}\right)\right)+L^{\prime}\left(y_{3}, F_{m-1}\left(x_{3}\right)\right) \gamma+\frac{1}{2} L^{\prime \prime}\left(y_{3}, F_{m-1}\left(x_{3}\right)\right) \gamma^{2}
|
||||
\end{array}
|
||||
$$
|
||||
求导, 令其结果为0,就会得到, 第1棵树的第2个叶子节点的输出:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\gamma_{21} &=\frac{-L^{\prime}\left(y_{2}, F_{m-1}\left(x_{2}\right)\right)-L^{\prime}\left(y_{3}, F_{m-1}\left(x_{3}\right)\right)}{L^{\prime \prime}\left(y_{2}, F_{m-1}\left(x_{2}\right)\right)+L^{\prime \prime}\left(y_{3}, F_{m-1}\left(x_{3}\right)\right)} \\
|
||||
&=\frac{r_{21}+r_{31}}{p_{20}\left(1-p_{20}\right)+p_{30}\left(1-p_{30}\right)} \\
|
||||
&=\frac{0.33-0.67}{0.67 \times 0.33+0.67 \times 0.33} \\
|
||||
&=-0.77
|
||||
\end{aligned}
|
||||
$$
|
||||
可以看出, 对于任意叶子节点, 我们可以直接计算其输出值:
|
||||
$$
|
||||
\gamma_{j m}=\frac{\sum_{i=1}^{R_{i j}} r_{i m}}{\sum_{i=1}^{R_{i j}} p_{i, m-1}\left(1-p_{i, m-1}\right)}
|
||||
$$
|
||||
|
||||
4. 更新模型$F_m(x)$
|
||||
$$
|
||||
F_{m}(x)=F_{m-1}(x)+\nu \sum_{j=1}^{J_{m}} \gamma_{m}
|
||||
$$
|
||||
|
||||
这样, 通过多次循环迭代, 就可以得到一个比较强的学习器$F_m(x)$
|
||||
|
||||
<br>
|
||||
|
||||
**下面分析一下GBDT的优缺点:**
|
||||
|
||||
我们可以把树的生成过程理解成**自动进行多维度的特征组合**的过程,从根结点到叶子节点上的整个路径(多个特征值判断),才能最终决定一棵树的预测值, 另外,对于**连续型特征**的处理,GBDT 可以拆分出一个临界阈值,比如大于 0.027 走左子树,小于等于 0.027(或者 default 值)走右子树,这样很好的规避了人工离散化的问题。这样就非常轻松的解决了逻辑回归那里**自动发现特征并进行有效组合**的问题, 这也是GBDT的优势所在。
|
||||
|
||||
但是GBDT也会有一些局限性, 对于**海量的 id 类特征**,GBDT 由于树的深度和棵树限制(防止过拟合),不能有效的存储;另外海量特征在也会存在性能瓶颈,当 GBDT 的 one hot 特征大于 10 万维时,就必须做分布式的训练才能保证不爆内存。所以 GBDT 通常配合少量的反馈 CTR 特征来表达,这样虽然具有一定的范化能力,但是同时会有**信息损失**,对于头部资源不能有效的表达。
|
||||
|
||||
所以, 我们发现其实**GBDT和LR的优缺点可以进行互补**。
|
||||
|
||||
### GBDT+LR模型
|
||||
2014年, Facebook提出了一种利用GBDT自动进行特征筛选和组合, 进而生成新的离散特征向量, 再把该特征向量当做LR模型的输入, 来产生最后的预测结果, 这就是著名的GBDT+LR模型了。GBDT+LR 使用最广泛的场景是CTR点击率预估,即预测当给用户推送的广告会不会被用户点击。
|
||||
|
||||
有了上面的铺垫, 这个模型解释起来就比较容易了, 模型的总体结构长下面这样:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200910161923481.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:67%;" />
|
||||
</div>
|
||||
**训练时**,GBDT 建树的过程相当于自动进行的特征组合和离散化,然后从根结点到叶子节点的这条路径就可以看成是不同特征进行的特征组合,用叶子节点可以唯一的表示这条路径,并作为一个离散特征传入 LR 进行**二次训练**。
|
||||
|
||||
比如上图中, 有两棵树,x为一条输入样本,遍历两棵树后,x样本分别落到两颗树的叶子节点上,每个叶子节点对应LR一维特征,那么通过遍历树,就得到了该样本对应的所有LR特征。构造的新特征向量是取值0/1的。 比如左树有三个叶子节点,右树有两个叶子节点,最终的特征即为五维的向量。对于输入x,假设他落在左树第二个节点,编码[0,1,0],落在右树第二个节点则编码[0,1],所以整体的编码为[0,1,0,0,1],这类编码作为特征,输入到线性分类模型(LR or FM)中进行分类。
|
||||
|
||||
**预测时**,会先走 GBDT 的每棵树,得到某个叶子节点对应的一个离散特征(即一组特征组合),然后把该特征以 one-hot 形式传入 LR 进行线性加权预测。
|
||||
|
||||
这个方案应该比较简单了, 下面有几个关键的点我们需要了解:
|
||||
1. **通过GBDT进行特征组合之后得到的离散向量是和训练数据的原特征一块作为逻辑回归的输入, 而不仅仅全是这种离散特征**
|
||||
2. 建树的时候用ensemble建树的原因就是一棵树的表达能力很弱,不足以表达多个有区分性的特征组合,多棵树的表达能力更强一些。GBDT每棵树都在学习前面棵树尚存的不足,迭代多少次就会生成多少棵树。
|
||||
3. RF也是多棵树,但从效果上有实践证明不如GBDT。且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
|
||||
4. 在CRT预估中, GBDT一般会建立两类树(非ID特征建一类, ID类特征建一类), AD,ID类特征在CTR预估中是非常重要的特征,直接将AD,ID作为feature进行建树不可行,故考虑为每个AD,ID建GBDT树。
|
||||
1. 非ID类树:不以细粒度的ID建树,此类树作为base,即便曝光少的广告、广告主,仍可以通过此类树得到有区分性的特征、特征组合
|
||||
2. ID类树:以细粒度 的ID建一类树,用于发现曝光充分的ID对应有区分性的特征、特征组合
|
||||
|
||||
### 编程实践
|
||||
|
||||
下面我们通过kaggle上的一个ctr预测的比赛来看一下GBDT+LR模型部分的编程实践, [数据来源](https://github.com/zhongqiangwu960812/AI-RecommenderSystem/tree/master/Rank/GBDT%2BLR/data)
|
||||
|
||||
我们回顾一下上面的模型架构, 首先是要训练GBDT模型, GBDT的实现一般可以使用xgboost, 或者lightgbm。训练完了GBDT模型之后, 我们需要预测出每个样本落在了哪棵树上的哪个节点上, 然后通过one-hot就会得到一些新的离散特征, 这和原来的特征进行合并组成新的数据集, 然后作为逻辑回归的输入,最后通过逻辑回归模型得到结果。
|
||||
|
||||
根据上面的步骤, 我们看看代码如何实现:
|
||||
|
||||
假设我们已经有了处理好的数据x_train, y_train。
|
||||
|
||||
1. **训练GBDT模型**
|
||||
|
||||
GBDT模型的搭建我们可以通过XGBOOST, lightgbm等进行构建。比如:
|
||||
|
||||
```python
|
||||
gbm = lgb.LGBMRegressor(objective='binary',
|
||||
subsample= 0.8,
|
||||
min_child_weight= 0.5,
|
||||
colsample_bytree= 0.7,
|
||||
num_leaves=100,
|
||||
max_depth = 12,
|
||||
learning_rate=0.05,
|
||||
n_estimators=10,
|
||||
)
|
||||
|
||||
gbm.fit(x_train, y_train,
|
||||
eval_set = [(x_train, y_train), (x_val, y_val)],
|
||||
eval_names = ['train', 'val'],
|
||||
eval_metric = 'binary_logloss',
|
||||
# early_stopping_rounds = 100,
|
||||
)
|
||||
```
|
||||
|
||||
2. **特征转换并构建新的数据集**
|
||||
|
||||
通过上面我们建立好了一个gbdt模型, 我们接下来要用它来预测出样本会落在每棵树的哪个叶子节点上, 为后面的离散特征构建做准备, 由于不是用gbdt预测结果而是预测训练数据在每棵树上的具体位置, 就需要用到下面的语句:
|
||||
|
||||
```python
|
||||
model = gbm.booster_ # 获取到建立的树
|
||||
|
||||
# 每个样本落在每个树的位置 , 下面两个是矩阵 (样本个数, 树的棵树) , 每一个数字代表某个样本落在了某个数的哪个叶子节点
|
||||
gbdt_feats_train = model.predict(train, pred_leaf = True)
|
||||
gbdt_feats_test = model.predict(test, pred_leaf = True)
|
||||
|
||||
# 把上面的矩阵转成新的样本-特征的形式, 与原有的数据集合并
|
||||
gbdt_feats_name = ['gbdt_leaf_' + str(i) for i in range(gbdt_feats_train.shape[1])]
|
||||
df_train_gbdt_feats = pd.DataFrame(gbdt_feats_train, columns = gbdt_feats_name)
|
||||
df_test_gbdt_feats = pd.DataFrame(gbdt_feats_test, columns = gbdt_feats_name)
|
||||
|
||||
# 构造新数据集
|
||||
train = pd.concat([train, df_train_gbdt_feats], axis = 1)
|
||||
test = pd.concat([test, df_test_gbdt_feats], axis = 1)
|
||||
train_len = train.shape[0]
|
||||
data = pd.concat([train, test])
|
||||
```
|
||||
|
||||
3. **离散特征的独热编码,并划分数据集**
|
||||
|
||||
```python
|
||||
# 新数据的新特征进行读入编码
|
||||
for col in gbdt_feats_name:
|
||||
onehot_feats = pd.get_dummies(data[col], prefix = col)
|
||||
data.drop([col], axis = 1, inplace = True)
|
||||
data = pd.concat([data, onehot_feats], axis = 1)
|
||||
|
||||
# 划分数据集
|
||||
train = data[: train_len]
|
||||
test = data[train_len:]
|
||||
|
||||
x_train, x_val, y_train, y_val = train_test_split(train, target, test_size = 0.3, random_state = 2018)
|
||||
```
|
||||
|
||||
4. **训练逻辑回归模型作最后的预测**
|
||||
|
||||
```python
|
||||
# 训练逻辑回归模型
|
||||
lr = LogisticRegression()
|
||||
lr.fit(x_train, y_train)
|
||||
tr_logloss = log_loss(y_train, lr.predict_proba(x_train)[:, 1])
|
||||
print('tr-logloss: ', tr_logloss)
|
||||
val_logloss = log_loss(y_val, lr.predict_proba(x_val)[:, 1])
|
||||
print('val-logloss: ', val_logloss)
|
||||
|
||||
# 预测
|
||||
y_pred = lr.predict_proba(test)[:, 1]
|
||||
```
|
||||
|
||||
上面我们就完成了GBDT+LR模型的基本训练步骤, 具体详细的代码可以参考链接。
|
||||
|
||||
### 思考
|
||||
1. **为什么使用集成的决策树? 为什么使用GBDT构建决策树而不是随机森林?**
|
||||
2. **面对高维稀疏类特征的时候(比如ID类特征), 逻辑回归一般要比GBDT这种非线性模型好, 为什么?**
|
||||
|
||||
|
||||
**参考资料**
|
||||
|
||||
* 王喆 - 《深度学习推荐系统》
|
||||
* [决策树之 GBDT 算法 - 分类部分](https://www.jianshu.com/p/f5e5db6b29f2)
|
||||
* [深入理解GBDT二分类算法](https://zhuanlan.zhihu.com/p/89549390?utm_source=zhihu)
|
||||
* [逻辑回归、优化算法和正则化的幕后细节补充](https://blog.csdn.net/wuzhongqiang/article/details/108456051)
|
||||
* [梯度提升树GBDT的理论学习与细节补充](https://blog.csdn.net/wuzhongqiang/article/details/108471107)
|
||||
* [推荐系统遇上深度学习(十)--GBDT+LR融合方案实战](https://zhuanlan.zhihu.com/p/37522339)
|
||||
* [CTR预估中GBDT与LR融合方案](https://blog.csdn.net/lilyth_lilyth/article/details/48032119)
|
||||
* [GBDT+LR算法解析及Python实现](https://www.cnblogs.com/wkang/p/9657032.html)
|
||||
* [常见计算广告点击率预估算法总结](https://zhuanlan.zhihu.com/p/29053940)
|
||||
* [GBDT--分类篇](https://blog.csdn.net/On_theway10/article/details/83576715?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.channel_param)
|
||||
|
||||
**论文**
|
||||
|
||||
* [http://quinonero.net/Publications/predicting-clicks-facebook.pdf 原论文](http://quinonero.net/Publications/predicting-clicks-facebook.pdf)
|
||||
* [Predicting Clicks: Estimating the Click-Through Rate for New Ads](https://www.microsoft.com/en-us/research/publication/predicting-clicks-estimating-the-click-through-rate-for-new-ads/)\
|
||||
* [Greedy Fun tion Approximation : A Gradient Boosting](https://www.semanticscholar.org/paper/Greedy-Fun-tion-Approximation-%3A-A-Gradient-Boosting-Friedman/0d97ee4888506beb30a3f3b6552d88a9b0ca11f0?p2df)
|
||||
|
||||
@@ -1,277 +0,0 @@
|
||||
## 写在前面
|
||||
AutoInt(Automatic Feature Interaction),这是2019年发表在CIKM上的文章,这里面提出的模型,重点也是在特征交互上,而所用到的结构,就是大名鼎鼎的transformer结构了,也就是通过多头的自注意力机制来显示的构造高阶特征,有效的提升了模型的效果。所以这个模型的提出动机比较简单,和xdeepFM这种其实是一样的,就是针对目前很多浅层模型无法学习高阶的交互, 而DNN模型能学习高阶交互,但确是隐性学习,缺乏可解释性,并不知道好不好使。而transformer的话,我们知道, 有着天然的全局意识,在NLP里面的话,各个词通过多头的自注意力机制,就能够使得各个词从不同的子空间中学习到与其它各个词的相关性,汇聚其它各个词的信息。 而放到推荐系统领域,同样也是这个道理,无非是把词换成了这里的离散特征而已, 而如果通过多个这样的交叉块堆积,就能学习到任意高阶的交互啦。这其实就是本篇文章的思想核心。
|
||||
|
||||
## AutoInt模型的理论及论文细节
|
||||
### 动机和原理
|
||||
这篇文章的前言部分依然是说目前模型的不足,以引出模型的动机所在, 简单的来讲,就是两句话:
|
||||
1. 浅层的模型会受到交叉阶数的限制,没法完成高阶交叉
|
||||
2. 深层模型的DNN在学习高阶隐性交叉的效果并不是很好, 且不具有可解释性
|
||||
|
||||
于是乎:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/60f5f213f34d4e2b9bdb800e6f029b34.png#pic_center" alt="image-20210308142624189" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
那么是如何做到的呢? 引入了transformer, 做成了一个特征交互层, 原理如下:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/d05a80906b484ab7a026e52ed2d8f9d4.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="image-20210308142624189" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
### AutoInt模型的前向过程梳理
|
||||
下面看下AutoInt模型的结构了,并不是很复杂
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/1aeabdd3cee74cbf814d7eed3147be4e.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_1#pic_center" alt="image-20210308142624189" style="zoom: 85%;" />
|
||||
</div>
|
||||
|
||||
#### Input Layer
|
||||
输入层这里, 用到的特征主要是离散型特征和连续性特征, 这里不管是哪一类特征,都会过embedding层转成低维稠密的向量,是的, **连续性特征,这里并没有经过分桶离散化,而是直接走embedding**。这个是怎么做到的呢?就是就是类似于预训练时候的思路,先通过item_id把连续型特征与类别特征关联起来,最简单的,就是把item_id拿过来,过完embedding层取出对应的embedding之后,再乘上连续值即可, 所以这个连续值事先一定要是归一化的。 当然,这个玩法,我也是第一次见。 学习到了, 所以模型整体的输入如下:
|
||||
|
||||
$$
|
||||
\mathbf{x}=\left[\mathbf{x}_{1} ; \mathbf{x}_{2} ; \ldots ; \mathbf{x}_{\mathbf{M}}\right]
|
||||
$$
|
||||
这里的$M$表示特征的个数, $X_1, X_2$这是离散型特征, one-hot的形式, 而$X_M$在这里是连续性特征。过embedding层的细节应该是我上面说的那样。
|
||||
#### Embedding Layer
|
||||
embedding层的作用是把高维稀疏的特征转成低维稠密, 离散型的特征一般是取出对应的embedding向量即可, 具体计算是这样:
|
||||
$$
|
||||
\mathbf{e}_{\mathbf{i}}=\mathbf{V}_{\mathbf{i}} \mathbf{x}_{\mathbf{i}}
|
||||
$$
|
||||
对于第$i$个离散特征,直接第$i$个嵌入矩阵$V_i$乘one-hot向量就取出了对应位置的embedding。 当然,如果输入的时候不是个one-hot, 而是个multi-hot的形式,那么对应的embedding输出是各个embedding求平均得到的。
|
||||
|
||||
$$
|
||||
\mathbf{e}_{\mathbf{i}}=\frac{1}{q} \mathbf{V}_{\mathbf{i}} \mathbf{x}_{\mathbf{i}}
|
||||
$$
|
||||
比如, 推荐里面用户的历史行为item。过去点击了多个item,最终的输出就是这多个item的embedding求平均。
|
||||
而对于连续特征, 我上面说的那样, 也是过一个embedding矩阵取相应的embedding, 不过,最后要乘一个连续值
|
||||
$$
|
||||
\mathbf{e}_{\mathbf{m}}=\mathbf{v}_{\mathbf{m}} x_{m}
|
||||
$$
|
||||
这样,不管是连续特征,离散特征还是变长的离散特征,经过embedding之后,都能得到等长的embedding向量。 我们把这个向量拼接到一块,就得到了交互层的输入。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/089b846a7f5c4125bc99a5a60e03d1ff.png#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
#### Interacting Layer
|
||||
这个是本篇论文的核心了,其实这里说的就是transformer块的前向传播过程,所以这里我就直接用比较白话的语言简述过程了,不按照论文中的顺序展开了。
|
||||
|
||||
通过embedding层, 我们会得到M个向量$e_1, ...e_M$,假设向量的维度是$d$维, 那么这个就是一个$d\times M$的矩阵, 我们定一个符号$X$。 接下来我们基于这个矩阵$X$,做三次变换,也就是分别乘以三个矩阵$W_k^{(h)}, W_q^{(h)},W_v^{(h)}$, 这三个矩阵的维度是$d'\times d$的话, 那么我们就会得到三个结果:
|
||||
$$Q^{(h)}=W_q^{(h)}\times X \\ K^{(h)} = W_k^{(h)} \times X \\ V^{(h)} = W_v^{(h)} \times X$$
|
||||
这三个矩阵都是$d'\times M$的。这其实就完成了一个Head的操作。所谓的自注意力, 就是$X$通过三次变换得到的结果之间,通过交互得到相关性,并通过相关性进行加权汇总,全是$X$自发的。 那么是怎么做到的呢?首先, 先进行这样的操作:
|
||||
$$Score(Q^h,K^h)=Q^h \times {K^h}^T$$
|
||||
这个结果得到的是一个$d'\times d'$的矩阵, 那么这个操作到底是做了一个什么事情呢?
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200220195022623.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 90%;" />
|
||||
</div>
|
||||
|
||||
假设这里的$c_1..c_6$是我们的6个特征, 而每一行代表每个特征的embedding向量,这样两个矩阵相乘,相当于得到了当前特征与其它特征两两之间的內积值, 而內积可以表示两个向量之间的相似程度。所以得到的结果每一行,就代表当前这个特征与其它特征的相似性程度。
|
||||
|
||||
接下来,我们对$Score(Q^h,K^h)$, 在最后一个维度上进行softmax,就根据相似性得到了权重信息,这其实就是把相似性分数归一化到了0-1之间
|
||||
|
||||
$$Attention(Q^h,K^h)=Softmax(Score(Q^h,K^h))$$
|
||||
接下来, 我们再进行这样的一步操作
|
||||
$$E^{(h)}=Attention(Q^h,K^h) \times V$$
|
||||
这样就得到了$d'\times M$的矩阵$E$, 这步操作,其实就是一个加权汇总的过程, 对于每个特征, 先求与其它特征的相似度,然后得到一个权重,再回乘到各自的特征向量再求和。 只不过这里的特征是经过了一次线性变化的过程,降维到了$d'$。
|
||||
|
||||
上面是我从矩阵的角度又过了一遍, 这个是直接针对所有的特征向量一部到位。 论文里面的从单个特征的角度去描述的,只说了一个矩阵向量过多头注意力的操作。
|
||||
$$
|
||||
\begin{array}{c}
|
||||
\alpha_{\mathbf{m}, \mathbf{k}}^{(\mathbf{h})}=\frac{\exp \left(\psi^{(h)}\left(\mathbf{e}_{\mathbf{m}}, \mathbf{e}_{\mathbf{k}}\right)\right)}{\sum_{l=1}^{M} \exp \left(\psi^{(h)}\left(\mathbf{e}_{\mathbf{m}}, \mathbf{e}_{1}\right)\right)} \\
|
||||
\psi^{(h)}\left(\mathbf{e}_{\mathbf{m}}, \mathbf{e}_{\mathbf{k}}\right)=\left\langle\mathbf{W}_{\text {Query }}^{(\mathbf{h})} \mathbf{e}_{\mathbf{m}}, \mathbf{W}_{\text {Key }}^{(\mathbf{h})} \mathbf{e}_{\mathbf{k}}\right\rangle
|
||||
\end{array} \\
|
||||
\widetilde{\mathbf{e}}_{\mathrm{m}}^{(\mathbf{h})}=\sum_{k=1}^{M} \alpha_{\mathbf{m}, \mathbf{k}}^{(\mathbf{h})}\left(\mathbf{W}_{\text {Value }}^{(\mathbf{h})} \mathbf{e}_{\mathbf{k}}\right)
|
||||
$$
|
||||
|
||||
这里会更好懂一些, 就是相当于上面矩阵的每一行操作拆开了, 首先,整个拼接起来的embedding矩阵还是过三个参数矩阵得到$Q,K,V$, 然后是每一行单独操作的方式,对于某个特征向量$e_k$,与其它的特征两两內积得到权重,然后在softmax,回乘到对应向量,然后进行求和就得到了融合其它特征信息的新向量。 具体过程如图:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/700bf353ce2f4c229839761e7815515d.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBATWlyYWNsZTgwNzA=,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="image-20210308142624189" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
上面的过程是用了一个头,理解的话就类似于从一个角度去看特征之间的相关关系,用论文里面的话讲,这是从一个子空间去看, 如果是想从多个角度看,这里可以用多个头,即换不同的矩阵$W_q,W_k,W_v$得到不同的$Q,K,V$然后得到不同的$e_m$, 每个$e_m$是$d'\times 1$的。
|
||||
|
||||
然后,多个头的结果concat起来
|
||||
$$
|
||||
\widetilde{\mathbf{e}}_{\mathrm{m}}=\widetilde{\mathbf{e}}_{\mathrm{m}}^{(1)} \oplus \widetilde{\mathbf{e}}_{\mathrm{m}}^{(2)} \oplus \cdots \oplus \widetilde{\mathbf{e}}_{\mathbf{m}}^{(\mathbf{H})}
|
||||
$$
|
||||
这是一个$d'\times H$的向量, 假设有$H$个头。
|
||||
|
||||
接下来, 过一个残差网络层,这是为了保留原始的特征信息
|
||||
$$
|
||||
\mathbf{e}_{\mathbf{m}}^{\mathrm{Res}}=\operatorname{ReL} U\left(\widetilde{\mathbf{e}}_{\mathbf{m}}+\mathbf{W}_{\text {Res }} \mathbf{e}_{\mathbf{m}}\right)
|
||||
$$
|
||||
这里的$e_m$是$d\times 1$的向量, $W_{Res}$是$d'H\times d$的矩阵, 最后得到的$e_m^{Res}$是$d'H\times 1$的向量, 这是其中的一个特征,如果是$M$个特征堆叠的话,最终就是$d'HM\times 1$的矩阵, 这个就是Interacting Layer的结果输出。
|
||||
#### Output Layer
|
||||
输出层就非常简单了,加一层全连接映射出输出值即可:
|
||||
$$
|
||||
\hat{y}=\sigma\left(\mathbf{w}^{\mathrm{T}}\left(\mathbf{e}_{1}^{\mathbf{R e s}} \oplus \mathbf{e}_{2}^{\mathbf{R e s}} \oplus \cdots \oplus \mathbf{e}_{\mathbf{M}}^{\text {Res }}\right)+b\right)
|
||||
$$
|
||||
这里的$W$是$d'HM\times 1$的, 这样最终得到的是一个概率值了, 接下来交叉熵损失更新模型参数即可。
|
||||
|
||||
AutoInt的前向传播过程梳理完毕。
|
||||
|
||||
### AutoInt的分析
|
||||
这里论文里面分析了为啥AutoInt能建模任意的高阶交互以及时间复杂度和空间复杂度的分析。我们一一来看。
|
||||
|
||||
关于建模任意的高阶交互, 我们这里拿一个transformer块看下, 对于一个transformer块, 我们发现特征之间完成了一个2阶的交互过程,得到的输出里面我们还保留着1阶的原始特征。
|
||||
|
||||
那么再经过一个transformer块呢? 这里面就会有2阶和1阶的交互了, 也就是会得到3阶的交互信息。而此时的输出,会保留着第一个transformer的输出信息特征。再过一个transformer块的话,就会用4阶的信息交互信息, 其实就相当于, 第$n$个transformer里面会建模出$n+1$阶交互来, 这个与CrossNet其实有异曲同工之妙的,无法是中间交互时的方式不一样。 前者是bit-wise级别的交互,而后者是vector-wise的交互。
|
||||
|
||||
所以, AutoInt是可以建模任意高阶特征的交互的,并且这种交互还是显性。
|
||||
|
||||
关于时间复杂度和空间复杂度,空间复杂度是$O(Ldd'H)$级别的, 这个也很好理解,看参数量即可, 3个W矩阵, H个head,再假设L个transformer块的话,参数量就达到这了。 时间复杂度的话是$O(MHd'(M+d))$的,论文说如果d和d'很小的话,其实这个模型不算复杂。
|
||||
### 3.4 更多细节
|
||||
这里整理下实验部分的细节,主要是对于一些超参的实验设置,在实验里面,作者首先指出了logloss下降多少算是有效呢?
|
||||
>It is noticeable that a slightly higher AUC or lower Logloss at 0.001-level is regarded significant for CTR prediction task, which has also been pointed out in existing works
|
||||
|
||||
这个和在fibinet中auc说的意思差不多。
|
||||
|
||||
在这一块,作者还写到了几个观点:
|
||||
1. NFM use the deep neural network as a core component to learning high-order feature interactions, they do not guarantee improvement over FM and AFM.
|
||||
2. AFM准确的说是二阶显性交互基础上加了交互重要性选择的操作, 这里应该是没有在上面加全连接
|
||||
3. xdeepFM这种CIN网络,在实际场景中非常难部署,不实用
|
||||
4. AutoInt的交互层2-3层差不多, embedding维度16-24
|
||||
5. 在AutoInt上面加2-3层的全连接会有点提升,但是提升效果并不是很大
|
||||
|
||||
所以感觉AutoInt这篇paper更大的价值,在于给了我们一种特征高阶显性交叉与特征选择性的思路,就是transformer在这里起的功效。所以后面用的时候, 更多的应该考虑如何用这种思路或者这个交互模块,而不是直接搬模型。
|
||||
|
||||
## AutoInt模型的简单复现及结构解释
|
||||
经过上面的分析, AutoInt模型的核心其实还是Transformer,所以代码部分呢? 主要还是Transformer的实现过程, 这个之前在整理DSIN的时候也整理过,由于Transformer特别重要,所以这里再重新复习一遍, 依然是基于Deepctr,写成一个简版的形式。
|
||||
|
||||
```python
|
||||
def AutoInt(linear_feature_columns, dnn_feature_columns, att_layer_num=3, att_embedding_size=8, att_head_num=2, att_res=True):
|
||||
"""
|
||||
:param att_layer_num: transformer块的数量,一个transformer块里面是自注意力计算 + 残差计算
|
||||
:param att_embedding_size: 文章里面的d', 自注意力时候的att的维度
|
||||
:param att_head_num: 头的数量或者自注意力子空间的数量
|
||||
:param att_res: 是否使用残差网络
|
||||
"""
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns+dnn_feature_columns)
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入预Input层对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 线性部分的计算逻辑 -- linear
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
# 线性层和dnn层统一的embedding层
|
||||
embedding_layer_dict = build_embedding_layers(linear_feature_columns+dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 构造self-att的输入
|
||||
att_sparse_kd_embed = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=False)
|
||||
att_input = Concatenate(axis=1)(att_sparse_kd_embed) # (None, field_num, embed_num)
|
||||
|
||||
# 下面的循环,就是transformer的前向传播,多个transformer块的计算逻辑
|
||||
for _ in range(att_layer_num):
|
||||
att_input = InteractingLayer(att_embedding_size, att_head_num, att_res)(att_input)
|
||||
att_output = Flatten()(att_input)
|
||||
att_logits = Dense(1)(att_output)
|
||||
|
||||
# DNN侧的计算逻辑 -- Deep
|
||||
# 将dnn_feature_columns里面的连续特征筛选出来,并把相应的Input层拼接到一块
|
||||
dnn_dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), dnn_feature_columns)) if dnn_feature_columns else []
|
||||
dnn_dense_feature_columns = [fc.name for fc in dnn_dense_feature_columns]
|
||||
dnn_concat_dense_inputs = Concatenate(axis=1)([dense_input_dict[col] for col in dnn_dense_feature_columns])
|
||||
|
||||
# 将dnn_feature_columns里面的离散特征筛选出来,相应的embedding层拼接到一块
|
||||
dnn_sparse_kd_embed = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
|
||||
dnn_concat_sparse_kd_embed = Concatenate(axis=1)(dnn_sparse_kd_embed)
|
||||
|
||||
# DNN层的输入和输出
|
||||
dnn_input = Concatenate(axis=1)([dnn_concat_dense_inputs, dnn_concat_sparse_kd_embed, att_output])
|
||||
dnn_out = get_dnn_output(dnn_input)
|
||||
dnn_logits = Dense(1)(dnn_out)
|
||||
|
||||
# 三边的结果stack
|
||||
stack_output = Add()([linear_logits, dnn_logits])
|
||||
|
||||
# 输出层
|
||||
output_layer = Dense(1, activation='sigmoid')(stack_output)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
|
||||
return model
|
||||
```
|
||||
这里由于大部分都是之前见过的模块,唯一改变的地方,就是加了一个`InteractingLayer`, 这个是一个transformer块,在这里面实现特征交互。而这个的结果输出,最终和DNN的输出结合到一起了。 而这个层,主要就是一个transformer块的前向传播过程。这应该算是最简单的一个版本了:
|
||||
|
||||
```python
|
||||
class InteractingLayer(Layer):
|
||||
"""A layer user in AutoInt that model the correction between different feature fields by multi-head self-att mechanism
|
||||
input: 3维张量, (none, field_num, embedding_size)
|
||||
output: 3维张量, (none, field_num, att_embedding_size * head_num)
|
||||
"""
|
||||
def __init__(self, att_embedding_size=8, head_num=2, use_res=True, seed=2021):
|
||||
super(InteractingLayer, self).__init__()
|
||||
self.att_embedding_size = att_embedding_size
|
||||
self.head_num = head_num
|
||||
self.use_res = use_res
|
||||
self.seed = seed
|
||||
|
||||
|
||||
def build(self, input_shape):
|
||||
embedding_size = int(input_shape[-1])
|
||||
|
||||
# 定义三个矩阵Wq, Wk, Wv
|
||||
self.W_query = self.add_weight(name="query", shape=[embedding_size, self.att_embedding_size * self.head_num],
|
||||
dtype=tf.float32, initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed))
|
||||
self.W_key = self.add_weight(name="key", shape=[embedding_size, self.att_embedding_size * self.head_num],
|
||||
dtype=tf.float32, initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed+1))
|
||||
self.W_value = self.add_weight(name="value", shape=[embedding_size, self.att_embedding_size * self.head_num],
|
||||
dtype=tf.float32, initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed+2))
|
||||
|
||||
if self.use_res:
|
||||
self.W_res = self.add_weight(name="res", shape=[embedding_size, self.att_embedding_size * self.head_num],
|
||||
dtype=tf.float32, initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed+3))
|
||||
|
||||
super(InteractingLayer, self).build(input_shape)
|
||||
|
||||
def call(self, inputs):
|
||||
# inputs (none, field_nums, embed_num)
|
||||
|
||||
querys = tf.tensordot(inputs, self.W_query, axes=(-1, 0)) # (None, field_nums, att_emb_size*head_num)
|
||||
keys = tf.tensordot(inputs, self.W_key, axes=(-1, 0))
|
||||
values = tf.tensordot(inputs, self.W_value, axes=(-1, 0))
|
||||
|
||||
# 多头注意力计算 按照头分开 (head_num, None, field_nums, att_embed_size)
|
||||
querys = tf.stack(tf.split(querys, self.head_num, axis=2))
|
||||
keys = tf.stack(tf.split(keys, self.head_num, axis=2))
|
||||
values = tf.stack(tf.split(values, self.head_num, axis=2))
|
||||
|
||||
# Q * K, key的后两维转置,然后再矩阵乘法
|
||||
inner_product = tf.matmul(querys, keys, transpose_b=True) # (head_num, None, field_nums, field_nums)
|
||||
normal_att_scores = tf.nn.softmax(inner_product, axis=-1)
|
||||
|
||||
result = tf.matmul(normal_att_scores, values) # (head_num, None, field_nums, att_embed_size)
|
||||
result = tf.concat(tf.split(result, self.head_num, ), axis=-1) # (1, None, field_nums, att_emb_size*head_num)
|
||||
result = tf.squeeze(result, axis=0) # (None, field_num, att_emb_size*head_num)
|
||||
|
||||
if self.use_res:
|
||||
result += tf.tensordot(inputs, self.W_res, axes=(-1, 0))
|
||||
|
||||
result = tf.nn.relu(result)
|
||||
|
||||
return result
|
||||
```
|
||||
这就是一个Transformer块做的事情,这里只说两个小细节:
|
||||
* 第一个是参数初始化那个地方, 后面的seed一定要指明出参数来,我第一次写的时候, 没有用seed=,结果导致训练有问题。
|
||||
* 第二个就是这里自注意力机制计算的时候,这里的多头计算处理方式, **把多个头分开,采用堆叠的方式进行计算(堆叠到第一个维度上去了)**。只有这样才能使得每个头与每个头之间的自注意力运算是独立不影响的。如果不这么做的话,最后得到的结果会含有当前单词在这个头和另一个单词在另一个头上的关联,这是不合理的。
|
||||
|
||||
OK, 这就是AutoInt比较核心的部分了,当然,上面自注意部分的输出结果与DNN或者Wide部分结合也不一定非得这么一种形式,也可以灵活多变,具体得结合着场景来。详细代码依然是看后面的GitHub啦。
|
||||
|
||||
## 总结
|
||||
这篇文章整理了AutoInt模型,这个模型的重点是引入了transformer来实现特征之间的高阶显性交互, 而transformer的魅力就是多头的注意力机制,相当于在多个子空间中, 根据不同的相关性策略去让特征交互然后融合,在这个交互过程中,特征之间计算相关性得到权重,并加权汇总,使得最终每个特征上都有了其它特征的信息,且其它特征的信息重要性还有了权重标识。 这个过程的自注意力计算以及汇总是一个自动的过程,这是很powerful的。
|
||||
|
||||
所以这篇文章的重要意义是又给我们传授了一个特征交互时候的新思路,就是transformer的多头注意力机制。
|
||||
|
||||
在整理transformer交互层的时候, 这里忽然想起了和一个同学的讨论, 顺便记在这里吧,就是:
|
||||
> 自注意力里面的Q,K能用一个吗? 也就是类似于只用Q, 算注意力的时候,直接$QQ^T$, 得到的矩阵维度和原来的是一样的,并且在参数量上,由于去掉了$w_k$矩阵, 也会有所减少。
|
||||
|
||||
关于这个问题, 我目前没有尝试用同一个的效果,但总感觉是违背了当时设计自注意力的初衷,最直接的一个结论,就是这里如果直接$QQ^T$,那么得到的注意力矩阵是一个对称的矩阵, 这在汇总信息的时候可能会出现问题。 因为这基于了一个假设就是A特征对于B特征的重要性,和B特征对于A的重要性是一致的, 这个显然是不太符合常规的。 比如"学历"这个特征和"职业"这个特征, 对于计算机行业,高中生和研究生或许都可以做, 但是对于金融类的行业, 对学历就有着很高的要求。 这就说明对于职业这个特征, 学历特征对其影响很大。 而如果是看学历的话,研究生学历或许可以入计算机,也可以入金融, 可能职业特征对学历的影响就不是那么明显。 也就是学历对于职业的重要性可能会比职业对于学历的重要性要大。 所以我感觉直接用同一个矩阵,在表达能力上会受到限制。当然,是自己的看法哈, 这个问题也欢迎一块讨论呀!
|
||||
|
||||
|
||||
**参考资料**:
|
||||
* [AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks](https://arxiv.org/abs/1810.11921)
|
||||
* [AutoInt:基于Multi-Head Self-Attention构造高阶特征](https://zhuanlan.zhihu.com/p/60185134)
|
||||
@@ -1,155 +0,0 @@
|
||||
# DCN
|
||||
## 动机
|
||||
Wide&Deep模型的提出不仅综合了“记忆能力”和“泛化能力”, 而且开启了不同网络结构融合的新思路。 所以后面就有各式各样的模型改进Wide部分或者Deep部分, 而Deep&Cross模型(DCN)就是其中比较典型的一个,这是2017年斯坦福大学和谷歌的研究人员在ADKDD会议上提出的, 该模型针对W&D的wide部分进行了改进, 因为Wide部分有一个不足就是需要人工进行特征的组合筛选, 过程繁琐且需要经验, 而2阶的FM模型在线性的时间复杂度中自动进行特征交互,但是这些特征交互的表现能力并不够,并且随着阶数的上升,模型复杂度会大幅度提高。于是乎,作者用一个Cross Network替换掉了Wide部分,来自动进行特征之间的交叉,并且网络的时间和空间复杂度都是线性的。 通过与Deep部分相结合,构成了深度交叉网络(Deep & Cross Network),简称DCN。
|
||||
|
||||
## 模型结构及原理
|
||||
|
||||
这个模型的结构是这个样子的:
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片dcn.png" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
这个模型的结构也是比较简洁的, 从下到上依次为:Embedding和Stacking层, Cross网络层与Deep网络层并列, 以及最后的输出层。下面也是一一为大家剖析。
|
||||
|
||||
### Embedding和Stacking 层
|
||||
|
||||
Embedding层我们已经非常的熟悉了吧, 这里的作用依然是把稀疏离散的类别型特征变成低维密集型。
|
||||
$$
|
||||
\mathbf{x}_{\text {embed, } i}=W_{\text {embed, } i} \mathbf{x}_{i}
|
||||
$$
|
||||
其中对于某一类稀疏分类特征(如id),$X_{embed, i}$是第个$i$分类值(id序号)的embedding向量。$W_{embed,i}$是embedding矩阵, $n_e\times n_v$维度, $n_e$是embedding维度, $n_v$是该类特征的唯一取值个数。$x_i$属于该特征的二元稀疏向量(one-hot)编码的。 【实质上就是在训练得到的Embedding参数矩阵中找到属于当前样本对应的Embedding向量】。其实绝大多数基于深度学习的推荐模型都需要Embedding操作,参数学习是通过神经网络进行训练。
|
||||
|
||||
最后,该层需要将所有的密集型特征与通过embedding转换后的特征进行联合(Stacking):
|
||||
$$
|
||||
\mathbf{x}_{0}=\left[\mathbf{x}_{\text {embed, } 1}^{T}, \ldots, \mathbf{x}_{\text {embed, }, k}^{T}, \mathbf{x}_{\text {dense }}^{T}\right]
|
||||
$$
|
||||
一共$k$个类别特征, dense是数值型特征, 两者在特征维度拼在一块。 上面的这两个操作如果是看了前面的模型的话,应该非常容易理解了。
|
||||
|
||||
### Cross Network
|
||||
|
||||
这个就是本模型最大的亮点了【Cross网络】, 这个思路感觉非常Nice。设计该网络的目的是增加特征之间的交互力度。交叉网络由多个交叉层组成, 假设第$l$层的输出向量$x_l$, 那么对于第$l+1$层的输出向量$x_{l+1}$表示为:
|
||||
|
||||
$$
|
||||
\mathbf{x}_{l+1}=\mathbf{x}_{0} \mathbf{x}_{l}^{T} \mathbf{w}_{l}+\mathbf{b}_{l}+\mathbf{x}_{l}=f\left(\mathbf{x}_{l}, \mathbf{w}_{l}, \mathbf{b}_{l}\right)+\mathbf{x}_{l}
|
||||
$$
|
||||
可以看到, 交叉层的二阶部分非常类似PNN提到的外积操作, 在此基础上增加了外积操作的权重向量$w_l$, 以及原输入向量$x_l$和偏置向量$b_l$。 交叉层的可视化如下:
|
||||
|
||||
<div align=center> <img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片cross.png" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
可以看到, 每一层增加了一个$n$维的权重向量$w_l$(n表示输入向量维度), 并且在每一层均保留了输入向量, 因此输入和输出之间的变化不会特别明显。关于这一层, 原论文里面有个具体的证明推导Cross Network为啥有效, 不过比较复杂,这里我拿一个式子简单的解释下上面这个公式的伟大之处:
|
||||
|
||||
> **我们根据上面这个公式, 尝试的写前面几层看看:**
|
||||
>
|
||||
> $l=0:\mathbf{x}_{1} =\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}$
|
||||
>
|
||||
> $l=1:\mathbf{x}_{2} =\mathbf{x}_{0} \mathbf{x}_{1}^{T} \mathbf{w}_{1}+ \mathbf{b}_{1}+\mathbf{x}_{1}=\mathbf{x}_{0} [\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}]^{T}\mathbf{w}_{1}+\mathbf{b}_{1}+\mathbf{x}_{1}$
|
||||
>
|
||||
> $l=2:\mathbf{x}_{3} =\mathbf{x}_{0} \mathbf{x}_{2}^{T} \mathbf{w}_{2}+ \mathbf{b}_{2}+\mathbf{x}_{2}=\mathbf{x}_{0} [\mathbf{x}_{0} [\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}]^{T}\mathbf{w}_{1}+\mathbf{b}_{1}+\mathbf{x}_{1}]^{T}\mathbf{w}_{2}+\mathbf{b}_{2}+\mathbf{x}_{2}$
|
||||
|
||||
我们暂且写到第3层的计算, 我们会发现什么结论呢? 给大家总结一下:
|
||||
|
||||
1. $\mathrm{x}_1$中包含了所有的$\mathrm{x}_0$的1,2阶特征的交互, $\mathrm{x}_2$包含了所有的$\mathrm{x}_1, \mathrm{x}_0$的1、2、3阶特征的交互,$\mathrm{x}_3$中包含了所有的$\mathrm{x}_2$, $\mathrm{x}_1$与$\mathrm{x}_0$的交互,$\mathrm{x}_0$的1、2、3、4阶特征交互。 因此, 交叉网络层的叉乘阶数是有限的。 **第$l$层特征对应的最高的叉乘阶数$l+1$**
|
||||
|
||||
2. Cross网络的参数是共享的, 每一层的这个权重特征之间共享, 这个可以使得模型泛化到看不见的特征交互作用, 并且对噪声更具有鲁棒性。 例如两个稀疏的特征$x_i,x_j$, 它们在数据中几乎不发生交互, 那么学习$x_i,x_j$的权重对于预测没有任何的意义。
|
||||
|
||||
3. 计算交叉网络的参数数量。 假设交叉层的数量是$L_c$, 特征$x$的维度是$n$, 那么总共的参数是:
|
||||
|
||||
$$
|
||||
n\times L_c \times 2
|
||||
$$
|
||||
这个就是每一层会有$w$和$b$。且$w$维度和$x$的维度是一致的。
|
||||
|
||||
4. 交叉网络的时间和空间复杂度是线性的。这是因为, 每一层都只有$w$和$b$, 没有激活函数的存在,相对于深度学习网络, 交叉网络的复杂性可以忽略不计。
|
||||
|
||||
5. Cross网络是FM的泛化形式, 在FM模型中, 特征$x_i$的权重$v_i$, 那么交叉项$x_i,x_j$的权重为$<x_i,x_j>$。在DCN中, $x_i$的权重为${W_K^{(i)}}_{k=1}^l$, 交叉项$x_i,x_j$的权重是参数${W_K^{(i)}}_{k=1}^l$和${W_K^{(j)}}_{k=1}^l$的乘积,这个看上面那个例子展开感受下。因此两个模型都各自学习了独立于其他特征的一些参数,并且交叉项的权重是相应参数的某种组合。FM只局限于2阶的特征交叉(一般),而DCN可以构建更高阶的特征交互, 阶数由网络深度决定,并且交叉网络的参数只依据输入的维度线性增长。
|
||||
|
||||
6. 还有一点我们也要了解,对于每一层的计算中, 都会跟着$\mathrm{x}_0$, 这个是咱们的原始输入, 之所以会乘以一个这个,是为了保证后面不管怎么交叉,都不能偏离我们的原始输入太远,别最后交叉交叉都跑偏了。
|
||||
|
||||
7. $\mathbf{x}_{l+1}=f\left(\mathbf{x}_{l}, \mathbf{w}_{l}, \mathbf{b}_{l}\right)+\mathbf{x}_{l}$, 这个东西其实有点跳远连接的意思,也就是和ResNet也有点相似,无形之中还能有效的缓解梯度消失现象。
|
||||
|
||||
好了, 关于本模型的交叉网络的细节就介绍到这里了。这应该也是本模型的精华之处了,后面就简单了。
|
||||
|
||||
### Deep Network
|
||||
|
||||
这个就和上面的D&W的全连接层原理一样。这里不再过多的赘述。
|
||||
$$
|
||||
\mathbf{h}_{l+1}=f\left(W_{l} \mathbf{h}_{l}+\mathbf{b}_{l}\right)
|
||||
$$
|
||||
具体的可以参考W&D模型。
|
||||
|
||||
### 组合输出层
|
||||
|
||||
这个层负责将两个网络的输出进行拼接, 并且通过简单的Logistics回归完成最后的预测:
|
||||
$$
|
||||
p=\sigma\left(\left[\mathbf{x}_{L_{1}}^{T}, \mathbf{h}_{L_{2}}^{T}\right] \mathbf{w}_{\text {logits }}\right)
|
||||
$$
|
||||
其中$\mathbf{x}_{L_{1}}^{T}$和$\mathbf{h}_{L_{2}}^{T}$分别表示交叉网络和深度网络的输出。
|
||||
最后二分类的损失函数依然是交叉熵损失:
|
||||
$$
|
||||
\text { loss }=-\frac{1}{N} \sum_{i=1}^{N} y_{i} \log \left(p_{i}\right)+\left(1-y_{i}\right) \log \left(1-p_{i}\right)+\lambda \sum_{l}\left\|\mathbf{w}_{i}\right\|^{2}
|
||||
$$
|
||||
|
||||
Cross&Deep模型的原理就是这些了,其核心部分就是Cross Network, 这个可以进行特征的自动交叉, 避免了更多基于业务理解的人工特征组合。 该模型相比于W&D,Cross部分表达能力更强, 使得模型具备了更强的非线性学习能力。
|
||||
|
||||
## 代码实现
|
||||
|
||||
下面我们看下DCN的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。
|
||||
|
||||
从上面的结构图我们也可以看出, DCN的模型搭建,其实主要分为几大模块, 首先就是建立输入层,用到的函数式`build_input_layers`,有了输入层之后, 我们接下来是embedding层的搭建,用到的函数是`build_embedding_layers`, 这个层的作用是接收离散特征,变成低维稠密。 接下来就是把连续特征和embedding之后的离散特征进行拼接,分别进入wide端和deep端。 wide端就是交叉网络,而deep端是DNN网络, 这里分别是`CrossNet()`和`get_dnn_output()`, 接下来就是把这两块的输出拼接得到最后的输出了。所以整体代码如下:
|
||||
|
||||
```python
|
||||
def DCN(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layer_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
concat_dense_inputs = Concatenate(axis=1)(list(dense_input_dict.values()))
|
||||
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns)) if linear_feature_columns else []
|
||||
|
||||
sparse_kd_embed = concat_embedding_list(sparse_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
|
||||
|
||||
concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed)
|
||||
|
||||
dnn_input = Concatenate(axis=1)([concat_dense_inputs, concat_sparse_kd_embed])
|
||||
|
||||
dnn_output = get_dnn_output(dnn_input)
|
||||
|
||||
cross_output = CrossNet()(dnn_input)
|
||||
|
||||
# stack layer
|
||||
stack_output = Concatenate(axis=1)([dnn_output, cross_output])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layer = Dense(1, activation='sigmoid')(stack_output)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
```
|
||||
|
||||
这个模型的实现过程和DeepFM比较类似,这里不画草图了,如果想看的可以去参考DeepFM草图及代码之间的对应关系。
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center> <img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片DCN.png" alt="image-20210308143101261" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
|
||||
1. 请计算Cross Network的复杂度,需要的变量请自己定义。
|
||||
2. 在实现矩阵计算$x_0*x_l^Tw$的过程中,有人说要先算前两个,有人说要先算后两个,请问那种方式更好?为什么?
|
||||
|
||||
**参考资料**
|
||||
* 《深度学习推荐系统》 --- 王喆
|
||||
* [Deep&Cross模型原论文](https://arxiv.org/abs/1708.05123)
|
||||
* AI上推荐 之 Wide&Deep与Deep&Cross模型(记忆与泛化并存的华丽转身)
|
||||
* [Wide&Deep模型的进阶---Cross&Deep模型](https://mp.weixin.qq.com/s/DkoaMaXhlgQv1NhZHF-7og)
|
||||
|
||||
@@ -1,147 +0,0 @@
|
||||
### FM模型的引入
|
||||
|
||||
#### 逻辑回归模型及其缺点
|
||||
|
||||
FM模型其实是一种思路,具体的应用稍少。一般来说做推荐CTR预估时最简单的思路就是将特征做线性组合(逻辑回归LR),传入sigmoid中得到一个概率值,本质上这就是一个线性模型,因为sigmoid是单调增函数不会改变里面的线性模型的CTR预测顺序,因此逻辑回归模型效果会比较差。也就是LR的缺点有:
|
||||
|
||||
* 是一个线性模型
|
||||
* 每个特征对最终输出结果独立,需要手动特征交叉($x_i*x_j$),比较麻烦
|
||||
|
||||
<br>
|
||||
|
||||
#### 二阶交叉项的考虑及改进
|
||||
|
||||
由于LR模型的上述缺陷(主要是手动做特征交叉比较麻烦),干脆就考虑所有的二阶交叉项,也就是将目标函数由原来的
|
||||
|
||||
$$
|
||||
y = w_0+\sum_{i=1}^nw_ix_i
|
||||
$$
|
||||
变为
|
||||
|
||||
$$
|
||||
y = w_0+\sum_{i=1}^nw_ix_i+\sum_{i=1}^{n-1}\sum_{i+1}^nw_{ij}x_ix_j
|
||||
$$
|
||||
但这个式子有一个问题,**只有当$x_i$与$x_j$均不为0时这个二阶交叉项才会生效**,后面这个特征交叉项本质是和多项式核SVM等价的,为了解决这个问题,我们的FM登场了!
|
||||
|
||||
FM模型使用了如下的优化函数:
|
||||
|
||||
$$
|
||||
y = w_0+\sum_{i=1}^nw_ix_i+\sum_{i=1}^{n}\sum_{i+1}^n\lt v_i,v_j\gt x_ix_j
|
||||
$$
|
||||
事实上做的唯一改动就是把$w_{ij}$替换成了$\lt v_i,v_j\gt$,大家应该就看出来了,这实际上就有深度学习的意味在里面了,实质上就是给每个$x_i$计算一个embedding,然后将两个向量之间的embedding做内积得到之前所谓的$w_{ij}$好处就是这个模型泛化能力强 ,即使两个特征之前从未在训练集中**同时**出现,我们也不至于像之前一样训练不出$w_{ij}$,事实上只需要$x_i$和其他的$x_k$同时出现过就可以计算出$x_i$的embedding!
|
||||
|
||||
<br>
|
||||
|
||||
### FM公式的理解
|
||||
|
||||
从公式来看,模型前半部分就是普通的LR线性组合,后半部分的交叉项:特征组合。首先,单从模型表达能力上来看,FM是要强于LR的,至少它不会比LR弱,当交叉项参数$w_{ij}$全为0的时候,整个模型就退化为普通的LR模型。对于有$n$个特征的模型,特征组合的参数数量共有$1+2+3+\cdots + n-1=\frac{n(n-1)}{2}$个,并且任意两个参数之间是独立的。所以说特征数量比较多的时候,特征组合之后,维度自然而然就高了。
|
||||
|
||||
> 定理:任意一个实对称矩阵(正定矩阵)$W$都存在一个矩阵$V$,使得 $W=V.V^{T}$成立。
|
||||
|
||||
类似地,所有二次项参数$\omega_{ij}$可以组成一个对称阵$W$(为了方便说明FM的由来,对角元素可以设置为正实数),那么这个矩阵就可以分解为$W=V^TV$,$V$ 的第$j$列($v_{j}$)便是第$j$维特征($x_{j}$)的隐向量。
|
||||
|
||||
$$
|
||||
\hat{y}(X) = \omega_{0}+\sum_{i=1}^{n}{\omega_{i}x_{i}}+\sum_{i=1}^{n-1}{\sum_{j=i+1}^{n} \color{red}{<v_{i},v_{j}>x_{i}x_{j}}}
|
||||
$$
|
||||
|
||||
需要估计的参数有$\omega_{0}∈ R$,$\omega_{i}∈ R$,$V∈ R$,$< \cdot, \cdot>$是长度为$k$的两个向量的点乘,公式如下:
|
||||
|
||||
$$
|
||||
<v_{i},v_{j}> = \sum_{f=1}^{k}{v_{i,f}\cdot v_{j,f}}
|
||||
$$
|
||||
|
||||
上面的公式中:
|
||||
|
||||
- $\omega_{0}$为全局偏置;
|
||||
- $\omega_{i}$是模型第$i$个变量的权重;
|
||||
- $\omega_{ij} = < v_{i}, v_{j}>$特征$i$和$j$的交叉权重;
|
||||
- $v_{i} $是第$i$维特征的隐向量;
|
||||
- $<\cdot, \cdot>$代表向量点积;
|
||||
- $k(k<<n)$为隐向量的长度,包含 $k$ 个描述特征的因子。
|
||||
|
||||
FM模型中二次项的参数数量减少为 $kn $个,远少于多项式模型的参数数量。另外,参数因子化使得 $x_{h}x_{i}$ 的参数和 $x_{i}x_{j}$ 的参数不再是相互独立的,因此我们可以在样本稀疏的情况下相对合理地估计FM的二次项参数。具体来说,$x_{h}x_{i}$ 和 $x_{i}x_{j}$的系数分别为 $\lt v_{h},v_{i}\gt$ 和 $\lt v_{i},v_{j}\gt$ ,它们之间有共同项 $v_{i}$ 。也就是说,所有包含“ $x_{i}$ 的非零组合特征”(存在某个 $j \ne i$ ,使得 $x_{i}x_{j}\neq 0$ )的样本都可以用来学习隐向量$v_{i}$,这很大程度上避免了数据稀疏性造成的影响。而在多项式模型中,$w_{hi}$ 和 $w_{ij}$ 是相互独立的。
|
||||
|
||||
显而易见,FM的公式是一个通用的拟合方程,可以采用不同的损失函数用于解决regression、classification等问题,比如可以采用MSE(Mean Square Error)loss function来求解回归问题,也可以采用Hinge/Cross-Entropy loss来求解分类问题。当然,在进行二元分类时,FM的输出需要使用sigmoid函数进行变换,该原理与LR是一样的。直观上看,FM的复杂度是 $O(kn^2)$ 。但是FM的二次项可以化简,其复杂度可以优化到 $O(kn)$ 。由此可见,FM可以在线性时间对新样本作出预测。
|
||||
|
||||
**证明**:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\sum_{i=1}^{n-1}{\sum_{j=i+1}^{n}{<v_i,v_j>x_ix_j}}
|
||||
&= \frac{1}{2}\sum_{i=1}^{n}{\sum_{j=1}^{n}{<v_i,v_j>x_ix_j}} - \frac{1}{2} {\sum_{i=1}^{n}{<v_i,v_i>x_ix_i}} \\
|
||||
&= \frac{1}{2} \left( \sum_{i=1}^{n}{\sum_{j=1}^{n}{\sum_{f=1}^{k}{v_{i,f}v_{j,f}x_ix_j}}} - \sum_{i=1}^{n}{\sum_{f=1}^{k}{v_{i,f}v_{i,f}x_ix_i}} \right) \\
|
||||
&= \frac{1}{2}\sum_{f=1}^{k}{\left[ \left( \sum_{i=1}^{n}{v_{i,f}x_i} \right) \cdot \left( \sum_{j=1}^{n}{v_{j,f}x_j} \right) - \sum_{i=1}^{n}{v_{i,f}^2 x_i^2} \right]} \\
|
||||
&= \frac{1}{2}\sum_{f=1}^{k}{\left[ \left( \sum_{i=1}^{n}{v_{i,f}x_i} \right)^2 - \sum_{i=1}^{n}{v_{i,f}^2 x_i^2} \right]}
|
||||
\end{aligned}
|
||||
$$
|
||||
**解释**:
|
||||
|
||||
- $v_{i,f}$ 是一个具体的值;
|
||||
- 第1个等号:对称矩阵 $W$ 对角线上半部分;
|
||||
- 第2个等号:把向量内积 $v_{i}$,$v_{j}$ 展开成累加和的形式;
|
||||
- 第3个等号:提出公共部分;
|
||||
- 第4个等号: $i$ 和 $j$ 相当于是一样的,表示成平方过程。
|
||||
|
||||
<br>
|
||||
|
||||
### FM优缺点
|
||||
|
||||
**优点**
|
||||
1. 通过向量内积作为交叉特征的权重,可以在数据非常稀疏的情况下还能有效的训练处交叉特征的权重(因为不需要两个特征同时不为零)
|
||||
2. 可以通过公式上的优化,得到O(nk)的计算复杂度,k一般比较小,所以基本上和n是正相关的,计算效率非常高
|
||||
3. 尽管推荐场景下的总体特征空间非常大,但是FM的训练和预测只需要处理样本中的非零特征,这也提升了模型训练和线上预测的速度
|
||||
4. 由于模型的计算效率高,并且在稀疏场景下可以自动挖掘长尾低频物料。所以在召回、粗排和精排三个阶段都可以使用。应用在不同阶段时,样本构造、拟合目标及线上服务都有所不同(注意FM用于召回时对于user和item相似度的优化)
|
||||
5. 其他优点及工程经验参考石塔西的文章
|
||||
|
||||
**缺点**
|
||||
1. 只能显示的做特征的二阶交叉,对于更高阶的交叉无能为力。对于此类问题,后续就提出了各类显示、隐式交叉的模型,来充分挖掘特征之间的关系
|
||||
|
||||
### 代码实现
|
||||
|
||||
```python
|
||||
class FM(Layer):
|
||||
"""显示特征交叉,直接按照优化后的公式实现即可
|
||||
注意:
|
||||
1. 传入进来的参数看起来是一个Embedding权重,没有像公式中出现的特征,那是因
|
||||
为,输入的id特征本质上都是onehot编码,取出对应的embedding就等价于特征乘以
|
||||
权重。所以后续的操作直接就是对特征进行操作
|
||||
2. 在实现过程中,对于公式中的平方的和与和的平方两部分,需要留意是在哪个维度
|
||||
上计算,这样就可以轻松实现FM特征交叉模块
|
||||
"""
|
||||
def __init__(self, **kwargs):
|
||||
super(FM, self).__init__(**kwargs)
|
||||
|
||||
def build(self, input_shape):
|
||||
if not isinstance(input_shape, list) or len(input_shape) < 2:
|
||||
raise ValueError('`FM` layer should be called \
|
||||
on a list of at least 2 inputs')
|
||||
super(FM, self).build(input_shape) # Be sure to call this somewhere!
|
||||
|
||||
def call(self, inputs, **kwargs):
|
||||
"""
|
||||
inputs: 是一个列表,列表中每个元素的维度为:(None, 1, emb_dim), 列表长度
|
||||
为field_num
|
||||
"""
|
||||
concated_embeds_value = Concatenate(axis=1)(inputs) #(None,field_num,emb_dim)
|
||||
# 根据最终优化的公式计算即可,需要注意的是计算过程中是沿着哪个维度计算的,将代码和公式结合起来看会更清晰
|
||||
square_of_sum = tf.square(tf.reduce_sum(
|
||||
concated_embeds_value, axis=1, keepdims=True)) # (None, 1, emb_dim)
|
||||
sum_of_square = tf.reduce_sum(
|
||||
concated_embeds_value * concated_embeds_value,
|
||||
axis=1, keepdims=True) # (None, 1, emb_dim)
|
||||
cross_term = square_of_sum - sum_of_square
|
||||
cross_term = 0.5 * tf.reduce_sum(cross_term, axis=2, keepdims=False)#(None,1)
|
||||
return cross_term
|
||||
|
||||
def compute_output_shape(self, input_shape):
|
||||
return (None, 1)
|
||||
|
||||
def get_config(self):
|
||||
return super().get_config()
|
||||
```
|
||||
|
||||
|
||||
**参考资料**
|
||||
* [FM:推荐算法中的瑞士军刀](https://zhuanlan.zhihu.com/p/343174108)
|
||||
* [FM算法解析](https://zhuanlan.zhihu.com/p/37963267)
|
||||
* [FM论文原文](https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf)
|
||||
* [AI上推荐 之 FM和FFM](https://blog.csdn.net/wuzhongqiang/article/details/108719417)
|
||||
@@ -1,451 +0,0 @@
|
||||
## 写在前面
|
||||
FiBiNET(Feature Importance and Bilinear feature Interaction)是2019年发表在RecSys的一个模型,来自新浪微博张俊林老师的团队。这个模型如果从模型演化的角度来看, 主要是在特征重要性以及特征之间交互上做出了探索。所以,如果想掌握FiBiNet的话,需要掌握两大核心模块:
|
||||
* 模型的特征重要性选择 --- SENET网络
|
||||
* 特征之间的交互 --- 双线性交叉层(组合了内积和哈达玛积)
|
||||
|
||||
|
||||
## FiBiNet? 我们先需要先了解这些
|
||||
|
||||
FiBiNet的提出动机是因为在特征交互这一方面, 目前的ctr模型要么是简单的两两embedding内积(这里针对离散特征), 比如FM,FFM。 或者是两两embedding进行哈达玛积(NFM这种), 作者认为这两种交互方式还是过于简单, 另外像NFM这种,FM这种,也忽视了特征之间的重要性程度。
|
||||
|
||||
对于特征重要性,作者在论文中举得例子非常形象
|
||||
>the feature occupation is more important than the feature hobby when we predict a person’s income
|
||||
|
||||
所以要想让模型学习到更多的信息, 从作者的角度来看,首先是离散特征之间的交互必不可少,且需要更细粒度。第二个就是需要考虑不同特征对于预测目标的重要性程度,给不同的特征根据重要性程度进行加权。 写到这里, 如果看过之前的文章的话,这个是不是和某些模型有些像呀, 没错,AFM其实考虑了这一点, 不过那里是用了一个Attention网络对特征进行的加权, 这里采用了另一种思路而已,即SENET, 所以这里我们如果是考虑特征重要性程度的话, 就有了两种思路:
|
||||
* Attention
|
||||
* SENET
|
||||
|
||||
而考虑特征交互的话, 思路应该会更多:
|
||||
* PNN里面的内积和外积
|
||||
* NFM里面的哈达玛积
|
||||
* 这里的双线性函数交互(内积和哈达玛积的组合)
|
||||
|
||||
所以,读论文, 这些思路感觉要比模型本身重要,而读论文还有一个有意思的事情,那就是我们既能了解思路,也能想一下,为啥这些方法会有效果呢? 我们自己能不能提出新的方法来呢? 如果读一篇paper,再顺便把后面的这些问题想通了, 那么这篇paper对于我们来说就发挥效用了, 后面就可以用拉马努金式方法训练自己的思维。
|
||||
|
||||
在前面的准备工作中,作者依然是带着我们梳理了整个推荐模型的演化过程, 我们也简单梳理下,就当回忆:
|
||||
* FNN: 下面是经过FM预训练的embedding层, 也就是先把FM训练好,得到各个特征的embedding,用这个embedding初始化FNN下面的embedding层, 上面是DNN。 这个模型用的不是很多,缺点是只能搞隐性高阶交互,并且下面的embedding和高层的DNN配合不是很好。
|
||||
* WDL: 这是一个经典的W&D架构, w逻辑回归维持记忆, DNN保持高阶特征交互。问题是W端依然需要手动特征工程,也就是低阶交互需要手动来搞,需要一定的经验。一般工业上也不用了。
|
||||
* DeepFM:对WDL的逻辑回归进行升级, 把逻辑回归换成FM, 这样能保证低阶特征的自动交互, 兼顾记忆和泛化性能,低阶和高阶交互。 目前这个模型在工业上非常常用,效果往往还不错,SOTA模型。
|
||||
* DCN: 认为DeepFM的W端的FM的交互还不是很彻底,只能到二阶交互。所以就提出了一种交叉性网络,可以在W端完成高阶交互。
|
||||
* xDeepFM: DCN的再次升级,认为DCN的wide端交叉网络这种element-wise的交互方式不行,且不是显性的高阶交互,所以提出了一个专门用户高阶显性交互的CIN网络, vector-wise层次上的特征交互。
|
||||
* NFM: 下层是FM, 中间一个交叉池化层进行两两交互,然后上面接DNN, 工业上用的不多。
|
||||
* AFM: 从NFM的基础上,考虑了交互完毕之后的特征重要性程度, 从NFM的基础上加了一个Attention网络,所以如果用的话,也应该用AFM。
|
||||
|
||||
综上, 这几个网络里面最常用的还是属DeepFM了, 当然对于交互来讲,在我的任务上试过AFM和xDeepFM, 结果是AFM和DeepFM差不多持平, 而xDeepFM要比这俩好一些,但并不多,而考虑完了复杂性, 还是DeepFM或者AFM。
|
||||
|
||||
对于上面模型的问题,作者说了两点,第一个是大部分模型没有考虑特征重要性,也就是交互完事之后,没考虑对于预测目标来讲谁更重要,一视同仁。 第二个是目前的两两特征交互,大部分依然是内积或者哈达玛积, 作者认为还不是细粒度(fine-grained way)交互。
|
||||
|
||||
那么,作者是怎么针对这两个问题进行改进的呢? 为什么这么改进呢?
|
||||
|
||||
## FiBiNet模型的理论以及论文细节
|
||||
这里我们直接分析模型架构即可, 因为这个模型不是很复杂,也非常好理解前向传播的过程:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210703160140322.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
从模型架构上来看,如果把我框出来的两部分去掉, 这个基本上就退化成了最简单的推荐深度模型DeepCrossing,甚至还比不上那个(那个还用了残差网络)。不过,加上了两个框,效果可就不一样了。所以下面重点是剖析下这两个框的结构,其他的简单一过即可。
|
||||
>梳理细节之前, 先说下前向传播的过程。 <br>
|
||||
>首先,我们输入的特征有离散和连续,对于连续的特征,输入完了之后,先不用管,等待后面拼起来进DNN即可,这里也没有刻意处理连续特征。
|
||||
><br>对于离散特征,过embedding转成低维稠密,一般模型的话,这样完了之后,就去考虑embedding之间交互了。 而这个模型不是, 在得到离散特征的embedding之后,分成了两路
|
||||
>* 一路保持原样, 继续往后做两两之间embedding交互,不过这里的交互方式,不是简单的内积或者哈达玛积,而是采用了非线性函数,这个后面会提到。
|
||||
>* 另一路,过一个SENET Layer, 过完了之后得到的输出是和原来embedding有着相同维度的,这个SENET的理解方式和Attention网络差不多,也是根据embedding的重要性不同出来个权重乘到了上面。 这样得到了SENET-like Embedding,就是加权之后的embedding。 这时候再往上两两双线性交互。
|
||||
>
|
||||
>两路embedding都两两交互完事, Flatten展平,和连续特征拼在一块过DNN输出。
|
||||
|
||||
|
||||
### Embedding Layer
|
||||
这个不多讲, 整理这个是为了后面统一符号。
|
||||
|
||||
假设我们有$f$个离散特征,经过embedding层之后,会得到$E=\left[e_{1}, e_{2}, \cdots, e_{i}, \cdots, e_{f}\right]$, 其中$e_{i} \in R^{k}$,表示第$i$个离散特征对应的embedding向量,$k$维。
|
||||
|
||||
### SENET Layer
|
||||
这是第一个重点,首先这个网络接收的输入是上面的$E=\left[e_{1}, e_{2}, \cdots, e_{i}, \cdots, e_{f}\right]$, 网络的输出也是个同样大小的张量`(None, f, k)`矩阵。 结构如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210703162008862.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
SENet由自动驾驶公司Momenta在2017年提出,在当时,是一种应用于图像处理的新型网络结构。它基于CNN结构,**通过对特征通道间的相关性进行建模,对重要特征进行强化来提升模型准确率,本质上就是针对CNN中间层卷积核特征的Attention操作**。ENet仍然是效果最好的图像处理网络结构之一。
|
||||
>SENet能否用到推荐系统?--- 张俊林老师的知乎(链接在文末)<br>
|
||||
>推荐领域里面的特征有个特点,就是海量稀疏,意思是大量长尾特征是低频的,而这些低频特征,去学一个靠谱的Embedding是基本没希望的,但是你又不能把低频的特征全抛掉,因为有一些又是有效的。既然这样,**如果我们把SENet用在特征Embedding上,类似于做了个对特征的Attention,弱化那些不靠谱低频特征Embedding的负面影响,强化靠谱低频特征以及重要中高频特征的作用,从道理上是讲得通的**
|
||||
|
||||
所以拿来用了再说, 把SENet放在Embedding层之上,通过SENet网络,动态地学习这些特征的重要性。**对于每个特征学会一个特征权重,然后再把学习到的权重乘到对应特征的Embedding里,这样就可以动态学习特征权重,通过小权重抑制噪音或者无效低频特征,通过大权重放大重要特征影响的目的**。在推荐系统里面, 结构长这个样子:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210703161807139.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
下面看下这个网络里面的具体计算过程, SENET主要分为三个步骤Squeeze, Excitation, Re-weight。
|
||||
|
||||
* **在Squeeze阶段**,我们对每个特征的Embedding向量进行数据压缩与信息汇总,如下:
|
||||
|
||||
$$
|
||||
z_{i}=F_{s q}\left(e_{i}\right)=\frac{1}{k} \sum_{t=1}^{k} e_{i}^{(t)}
|
||||
$$
|
||||
|
||||
假设某个特征$v_i$是$k$维大小的$Embedding$,那么我们对$Embedding$里包含的$k$维数字求均值,得到能够代表这个特征汇总信息的数值 $z_i$,也就是说,把第$i$个特征的$Embedding$里的信息压缩到一个数值。原始版本的SENet,在这一步是对CNN的二维卷积核进行$Max$操作的,这里等于对某个特征Embedding元素求均值。我们试过,在推荐领域均值效果比$Max$效果好,这也很好理解,因为**图像领域对卷积核元素求$Max$,等于找到最强的那个特征,而推荐领域的特征$Embedding$,每一位的数字都是有意义的,所以求均值能更好地保留和融合信息**。通过Squeeze阶段,对于每个特征$v_i$ ,都压缩成了单个数值$z_i$,假设特征Embedding层有$f$个特征,就形成Squeeze向量$Z$,向量大小$f$。
|
||||
|
||||
* **Excitation阶段**,这个阶段引入了中间层比较窄的两层MLP网络,作用在Squeeze阶段的输出向量$Z$上,如下:
|
||||
|
||||
$$
|
||||
A=F_{e x}(Z)=\sigma_{2}\left(W_{2} \sigma_{1}\left(W_{1} Z\right)\right)
|
||||
$$
|
||||
|
||||
$\sigma$非线性激活函数,一般$relu$。本质上,这是在做特征的交叉,也就是说,每个特征以一个$Bit$来表征,通过MLP来进行交互,通过交互,得出这么个结果:对于当前所有输入的特征,通过相互发生关联,来动态地判断哪些特征重要,哪些特征不重要。
|
||||
|
||||
其中,第一个MLP的作用是做特征交叉,第二个MLP的作用是为了保持输出的大小维度。因为假设Embedding层有$f$个特征,那么我们需要保证输出$f$个权重值,而第二个MLP就是起到将大小映射到$f$个数值大小的作用。<br><br>这样,经过两层MLP映射,就会产生$f$个权重数值,第$i$个数值对应第$i$个特征Embedding的权重$a_i$ 。<br><br>这个东西有没有感觉和自动编码器很像,虽然不是一样的作用, 但网络结构是一样的。这就是知识串联的功效哈哈。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/2021070316343673.png#pic_center" alt="image-20210308142624189" style="zoom: 70%;" />
|
||||
</div>
|
||||
|
||||
瞬间是不是就把SENet这里的网络结构记住了哈哈。下面再分析下维度, SENet的输入是$E$,这个是`(None, f, k)`的维度, 通过Squeeze阶段,得到了`(None, f)`的矩阵,这个也就相当于Layer L1的输入(当然这里没有下面的偏置哈),接下来过MLP1, 这里的$W_{1} \in R^{f \times \frac{f}{r}}, W_{2} \in R^{\frac{f}{r} \times f}$, 这里的$r$叫做reduction
|
||||
ratio, $\frac{f}{r}$这个就是中间层神经元的个数, $r$表示了压缩的程度。
|
||||
|
||||
* Re-Weight
|
||||
我们把Excitation阶段得到的每个特征对应的权重$a_i$,再乘回到特征对应的Embedding里,就完成了对特征重要性的加权操作。
|
||||
$$V=F_{\text {ReWeight }}(A, E)=\left[a_{1} \cdot e_{1}, \cdots, a_{f} \cdot e_{f}\right]=\left[v_{1}, \cdots, v_{f}\right]$$
|
||||
$a_{i} \in R, e_{i} \in R^{k}$, and $v_{i} \in R^{k}$。$a_i$数值大,说明SENet判断这个特征在当前输入组合里比较重要, $a_i$数值小,说明SENet判断这个特征在当前输入组合里没啥用。如果非线性函数用Relu,会发现大量特征的权重会被Relu搞成0,也就是说,其实很多特征是没啥用的。
|
||||
|
||||
|
||||
这样,就可以将SENet引入推荐系统,用来对特征重要性进行动态判断。注意,**所谓动态,指的是比如对于某个特征,在某个输入组合里可能是没用的,但是换一个输入组合,很可能是重要特征。它重要不重要,不是静态的,而是要根据当前输入,动态变化的**。
|
||||
|
||||
这里正确的理解,算是一种特征重要性选择的思路, SENET和AFM的Attention网络是起着同样功效的一个网络。只不过那个是在特征交互之后进行特征交互重要性的选择,而这里是从embedding这里先压缩,再交互,再选择,去掉不太重要的特征。 **考虑特征重要性上的两种考虑思路,难以说孰好孰坏,具体看应用场景**。 不过如果分析下这个东西为啥会有效果, 就像张俊林老师提到的那样, 在Excitation阶段, 各个特征过了一个MLP进行了特征组合, 这样就真有可能过滤掉对于当前的交互不太重要的特征。 至于是不是, 那神经网络这东西就玄学了,让网络自己去学吧。
|
||||
|
||||
### Bilinear-Interaction Layer
|
||||
特征重要性选择完事, 接下来就是研究特征交互, 这里作者直接就列出了目前的两种常用交互以及双线性交互:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210703165031369.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 70%;" />
|
||||
</div>
|
||||
|
||||
这个图其实非常了然了。以往模型用的交互, 内积的方式(FM,FFM)这种或者哈达玛积的方式(NFM,AFM)这种。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210703165221794.png#pic_center" alt="image-20210308142624189" style="zoom: 70%;" >
|
||||
</div>
|
||||
|
||||
所谓的双线性,其实就是组合了内积和哈达玛积的操作,看上面的右图。就是在$v_i$和$v_j$之间先加一个$W$矩阵, 这个$W$矩阵的维度是$(f,f)$, $v_i, v_j$是$(1,f)$的向量。 先让$v_i$与$W$内积,得到$(1,f)$的向量,这时候先仔细体会下这个**新向量的每个元素,相当于是原来向量$v_i$在每个维度上的线性组合了**。这时候再与$v_j$进行哈达玛积得到结果。
|
||||
|
||||
这里我不由自主的考虑了下双线性的功效,也就是为啥作者会说双线性是细粒度,下面是我自己的看法哈。
|
||||
* 如果我们单独先看内积操作,特征交互如果是两个向量直接内积,这时候, 结果大的,说明两个向量相似或者特征相似, 但向量内积,其实是相当于向量的各个维度先对应位置元素相乘再相加求和。 这个过程中认为的是向量的各个维度信息的重要性是一致的。类似于$v_1+v_2+..v_k$, 但真的一致吗? --- **内积操作没有考虑向量各个维度的重要性**
|
||||
* 如果我们单独看哈达玛积操作, 特征交互如果是两个向量哈达玛积,这时候,是各个维度对应位置元素相乘得到一个向量, 而这个向量往往后面会进行线性或者非线性交叉的操作, 最后可能也会得到具体某个数值,但是这里经过了线性或者非线性交叉操作之后, 有没有感觉把向量各个维度信息的重要性考虑了进来? 就类似于$w_1v_{i1j1}+w_2k_{v2j2},...w_kv_{vkjk}$。 如果模型认为重要性相同,那么哈达玛积还有希望退化成内积,所以哈达玛积感觉考虑的比内积就多了一些。 --- **哈达玛积操作自身也没有考虑各个维度重要性,但通过后面的线性或者非线性操作,有一定的维度重要性在里面**
|
||||
* 再看看这个双线性, 是先内积再哈达玛积。这个内积操作不是直接$v_i$和$v_j$内积,而是中间引入了个$W$矩阵,参数可学习。 那么$v_i$和$W$做内积之后,虽然得到了同样大小的向量,但是这个向量是$v_i$各个维度元素的线性组合,相当于$v_i$变成了$[w_{11}v_{i1}+...w_{1k}v_{ik}, w_{21}v_{i1}+..w_{2k}v_{ik}, ...., w_{k1}v_{i1}+...w_{kk}v_{ik}]$, 这时候再与$v_j$哈达玛积的功效,就变成了$[(w_{11}v_{i1}+...w_{1k}v_{ik})v_{j1}, (w_{21}v_{i1}+..w_{2k}v_{ik})v_{j2}, ...., (w_{k1}v_{i1}+...w_{kk}v_{ik})v_{j_k}]$, 这时候,就可以看到,如果这里的$W$是个对角矩阵,那么这里就退化成了哈达玛积。 所以双线性感觉考虑的又比哈达玛积多了一些。如果后面再走一个非线性操作的话,就会发现这里同时考虑了两个交互向量各个维度上的重要性。---**双线性操作同时可以考虑交互的向量各自的各个维度上的重要性信息, 这应该是作者所说的细粒度,各个维度上的重要性**
|
||||
|
||||
**当然思路是思路,双线性并不一定见得一定比哈达玛积有效, SENET也不一定就会比原始embedding要好,一定要辩证看问题**
|
||||
|
||||
这里还有个厉害的地方在于这里的W有三种选择方式,也就是三种类型的双线性交互方式。
|
||||
1. Field-All Type
|
||||
$$
|
||||
p_{i j}=v_{i} \cdot W \odot v_{j}
|
||||
$$
|
||||
也就是所有的特征embedding共用一个$W$矩阵,这也是Field-All的名字来源。$W \in R^{k \times k}, \text { and } v_{i}, v_{j} \in R^{k}$。这种方式最简单
|
||||
2. Field-Each Type
|
||||
$$
|
||||
p_{i j}=v_{i} \cdot W_{i} \odot v_{j}
|
||||
$$
|
||||
每个特征embedding共用一个$W$矩阵, 那么如果有$f$个特征的话,这里的$W_i$需要$f$个。所以这里的参数个数$f-1\times k\times k$, 这里的$f-1$是因为两两组合之后,比如`[0,1,2]`, 两两组合`[0,1], [0,2], [1,2]`。 这里用到的域是0和1。
|
||||
3. Field-Interaction Type
|
||||
$$
|
||||
p_{i j}=v_{i} \cdot W_{i j} \odot v_{j}
|
||||
$$
|
||||
每组特征交互的时候,用一个$W$矩阵, 那么这里如果有$f$个特征的话,需要$W_{ij}$是$\frac{f(f-1)}{2}$个。参数个数$\frac{f(f-1)}{2}\times k\times k$个。
|
||||
|
||||
不知道看到这里,这种操作有没有种似曾相识的感觉, 有没有想起FM和FFM, 反正我是不自觉的想起了哈哈,不知道为啥。总感觉FM的风格和上面的Field-All很像, 而FFM和下面的Field-Interaction很像。
|
||||
|
||||
我们的原始embedding和SKNET-like embedding都需要过这个层,那么得到的就是一个双线性两两组合的矩阵, 维度是$(\frac{f(f-1)}{2}, k)$的矩阵。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210703173830995.png#pic_center" alt="image-20210308142624189" style="zoom: 70%;" >
|
||||
</div>
|
||||
|
||||
### Combination Layer
|
||||
这个层的作用就是把目前得到的特征拼起来
|
||||
$$
|
||||
c=F_{\text {concat }}(p, q)=\left[p_{1}, \cdots, p_{n}, q_{1}, \cdots, q_{n}\right]=\left[c_{1}, \cdots, c_{2 n}\right]
|
||||
$$
|
||||
这里他直拼了上面得到的两个离散特征通过各种交互之后的形式,如果是还有连续特征的话,也可以在这里拼起来,然后过DNN,不过这里其实还省略了一步操作就是Flatten,先展平再拼接。
|
||||
|
||||
### DNN和输出层
|
||||
这里就不多说了, DNN的话普通的全连接网络, 再捕捉一波高阶的隐性交互。
|
||||
$$
|
||||
a^{(l)}=\sigma\left(W^{(l)} a^{(l-1)}+b^{(l)}\right)
|
||||
$$
|
||||
而输出层
|
||||
$$
|
||||
\hat{y}=\sigma\left(w_{0}+\sum_{i=0}^{m} w_{i} x_{i}+y_{d}\right)
|
||||
$$
|
||||
分类问题损失函数:
|
||||
$$
|
||||
\operatorname{loss}=-\frac{1}{N} \sum_{i=1}^{N}\left(y_{i} \log \left(\hat{y}_{i}\right)+\left(1-y_{i}\right) * \log \left(1-\hat{y}_{i}\right)\right)
|
||||
$$
|
||||
这里就不解释了。
|
||||
|
||||
### 其他重要细节
|
||||
实验部分,这里作者也是做了大量的实验来证明提出的模型比其他模型要好,这个就不说了。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/2021070317512940.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 70%;" >
|
||||
</div>
|
||||
|
||||
竟然比xDeepFM都要好。
|
||||
|
||||
在模型评估指标上,用了AUC和Logloss,这个也是常用的指标,Logloss就是交叉熵损失, 反映了样本的平均偏差,经常作为模型的损失函数来做优化,可是,当训练数据正负样本不平衡时,比如我们经常会遇到正样本很少,负样本很多的情况,此时LogLoss会倾向于偏向负样本一方。 而AUC评估不会受很大影响,具体和AUC的计算原理有关。这个在这里就不解释了。
|
||||
|
||||
其次了解到的一个事情:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210703175052617.png#pic_center" alt="image-20210308142624189" style="zoom: 70%;" >
|
||||
</div>
|
||||
|
||||
接下来,得整理下双线性与哈达玛积的组合类型,因为我们这个地方其实有两路embedding的, 一路是原始embedding, 一路是SKNet侧的embedding。而面临的组合方式,有双线性和哈达玛积两种。那么怎么组合会比较好呢? 作者做了实验。结论是,作者建议:
|
||||
>深度学习模型中,原始那边依然哈达玛,SE那边双线性, 可能更有效, 不过后面的代码实现里面,都用了双线性。
|
||||
|
||||
|
||||
而具体,在双线性里面,那种W的原则有效呢? 这个视具体的数据集而定。
|
||||
|
||||
超参数选择,主要是embedding维度以及DNN层数, embedding维度这个10-50, 不同的数据集可能表现不一样, 但尽量不要超过50了。否则在DNN之前的特征维度会很大。
|
||||
|
||||
DNN层数,作者这里建议3层,而每一层神经单元个数,也是没有定数了。
|
||||
|
||||
这里竟然没有说$r$的确定范围。 Deepctr里面默认是3。
|
||||
|
||||
对于实际应用的一些经验:
|
||||
1. SE-FM 在实验数据效果略高于 FFM,优于FM,对于模型处于低阶的团队,升级FM、SE-FM成本比较低
|
||||
|
||||
2. deepSE-FM 效果优于DCN、XDeepFM 这类模型,相当于**XDeepFM这种难上线的模型**来说,很值得尝试,不过大概率怀疑是**增加特征交叉的效果,特征改进比模型改进work起来更稳**
|
||||
3. 实验中增加embeding 长度费力不讨好,效果增加不明显,如果只是增加长度不改变玩法边际效应递减,**不增加长度增加emmbedding 交叉方式类似模型的ensemble更容易有效果**
|
||||
|
||||
|
||||
## FiBiNet模型的代码复现及重要结构解释
|
||||
这里的话,参考deepctr修改的简化版本。
|
||||
### 全貌
|
||||
|
||||
对于输入,就不详细的说了,在xDeepFM那里已经解释了, 首先网络的整体全貌:
|
||||
|
||||
```python
|
||||
def fibinet(linear_feature_columns, dnn_feature_columns, bilinear_type='interaction', reduction_ratio=3, hidden_units=[128, 128]):
|
||||
"""
|
||||
:param linear_feature_columns, dnn_feature_columns: 封装好的wide端和deep端的特征
|
||||
:param bilinear_type: 双线性交互类型, 有'all', 'each', 'interaction'三种
|
||||
:param reduction_ratio: senet里面reduction ratio
|
||||
:param hidden_units: DNN隐藏单元个数
|
||||
"""
|
||||
|
||||
# 构建输出层, 即所有特征对应的Input()层, 用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入预Input层对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 线性部分的计算逻辑 -- linear
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
# 线性层和dnn层统一的embedding层
|
||||
embedding_layer_dict = build_embedding_layers(linear_feature_columns+dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# DNN侧的计算逻辑 -- Deep
|
||||
# 将dnn_feature_columns里面的连续特征筛选出来,并把相应的Input层拼接到一块
|
||||
dnn_dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), dnn_feature_columns)) if dnn_feature_columns else []
|
||||
dnn_dense_feature_columns = [fc.name for fc in dnn_dense_feature_columns]
|
||||
dnn_concat_dense_inputs = Concatenate(axis=1)([dense_input_dict[col] for col in dnn_dense_feature_columns])
|
||||
|
||||
# 将dnn_feature_columns里面的离散特征筛选出来,相应的embedding层拼接到一块,然后过SENet_layer
|
||||
dnn_sparse_kd_embed = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=False)
|
||||
sparse_embedding_list = Concatenate(axis=1)(dnn_sparse_kd_embed)
|
||||
|
||||
# SENet layer
|
||||
senet_embedding_list = SENETLayer(reduction_ratio)(sparse_embedding_list)
|
||||
|
||||
# 双线性交互层
|
||||
senet_bilinear_out = BilinearInteraction(bilinear_type=bilinear_type)(senet_embedding_list)
|
||||
raw_bilinear_out = BilinearInteraction(bilinear_type=bilinear_type)(sparse_embedding_list)
|
||||
|
||||
bilinear_out = Flatten()(Concatenate(axis=1)([senet_bilinear_out, raw_bilinear_out]))
|
||||
|
||||
# DNN层的输入和输出
|
||||
dnn_input = Concatenate(axis=1)([bilinear_out, dnn_concat_dense_inputs])
|
||||
dnn_out = get_dnn_output(dnn_input, hidden_units=hidden_units)
|
||||
dnn_logits = Dense(1)(dnn_out)
|
||||
|
||||
# 最后的输出
|
||||
final_logits = Add()([linear_logits, dnn_logits])
|
||||
|
||||
# 输出层
|
||||
output_layer = Dense(1, activation='sigmoid')(final_logits)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
|
||||
return model
|
||||
```
|
||||
这里依然是是采用了线性层计算与DNN相结合的方式。 前向传播这里也不详细描述了。这里面重点是SENETLayer和BilinearInteraction层,其他的和之前网络模块基本上一样。
|
||||
|
||||
### SENETLayer
|
||||
这里的输入是`[None, field_num embed_dim]`的维度,也就是离散特征的embedding, 拿到这个输入之后,三个步骤,得到的是一个`[None, feild_num, embed_dim]`的同样维度的矩阵,只不过这里是SKNET-like embedding了。
|
||||
|
||||
```python
|
||||
class SENETLayer(Layer):
|
||||
def __init__(self, reduction_ratio, seed=2021):
|
||||
super(SENETLayer, self).__init__()
|
||||
self.reduction_ratio = reduction_ratio
|
||||
self.seed = seed
|
||||
|
||||
def build(self, input_shape):
|
||||
# input_shape [None, field_nums, embedding_dim]
|
||||
self.field_size = input_shape[1]
|
||||
self.embedding_size = input_shape[-1]
|
||||
|
||||
# 中间层的神经单元个数 f/r
|
||||
reduction_size = max(1, self.field_size // self.reduction_ratio)
|
||||
|
||||
# FC layer1和layer2的参数
|
||||
self.W_1 = self.add_weight(shape=(
|
||||
self.field_size, reduction_size), initializer=glorot_normal(seed=self.seed), name="W_1")
|
||||
self.W_2 = self.add_weight(shape=(
|
||||
reduction_size, self.field_size), initializer=glorot_normal(seed=self.seed), name="W_2")
|
||||
|
||||
self.tensordot = tf.keras.layers.Lambda(
|
||||
lambda x: tf.tensordot(x[0], x[1], axes=(-1, 0)))
|
||||
|
||||
# Be sure to call this somewhere!
|
||||
super(SENETLayer, self).build(input_shape)
|
||||
|
||||
def call(self, inputs):
|
||||
# inputs [None, field_num, embed_dim]
|
||||
|
||||
# Squeeze -> [None, field_num]
|
||||
Z = tf.reduce_mean(inputs, axis=-1)
|
||||
|
||||
# Excitation
|
||||
A_1 = tf.nn.relu(self.tensordot([Z, self.W_1])) # [None, reduction_size]
|
||||
A_2 = tf.nn.relu(self.tensordot([A_1, self.W_2])) # [None, field_num]
|
||||
|
||||
# Re-Weight
|
||||
V = tf.multiply(inputs, tf.expand_dims(A_2, axis=2)) # [None, field_num, embedding_dim]
|
||||
|
||||
return V
|
||||
```
|
||||
三个步骤还是比较好理解的, 这里这种自定义层权重的方式需要学习下。
|
||||
|
||||
### 4.3 BilinearInteraction Layer
|
||||
这里接收的输入同样是`[None, field_num embed_dim]`的维度离散特征的embedding。 输出是来两两交互完毕的矩阵$[None, \frac{f(f-1)}{2}, embed\_dim]$
|
||||
|
||||
这里的双线性交互有三种形式,具体实现的话可以参考下面的代码,我加了注释, 后面两种用到了组合的方式, 感觉人家这种实现方式还是非常巧妙的。
|
||||
```python
|
||||
class BilinearInteraction(Layer):
|
||||
"""BilinearInteraction Layer used in FiBiNET.
|
||||
Input shape
|
||||
- 3D tensor with shape: ``(batch_size,field_size,embedding_size)``.
|
||||
Output shape
|
||||
- 3D tensor with shape: ``(batch_size,filed_size*(filed_size-1)/2,embedding_size)``.
|
||||
"""
|
||||
def __init__(self, bilinear_type="interaction", seed=2021, **kwargs):
|
||||
super(BilinearInteraction, self).__init__(**kwargs)
|
||||
self.bilinear_type = bilinear_type
|
||||
self.seed = seed
|
||||
|
||||
def build(self, input_shape):
|
||||
# input_shape: [None, field_num, embed_num]
|
||||
self.field_size = input_shape[1]
|
||||
self.embedding_size = input_shape[-1]
|
||||
|
||||
if self.bilinear_type == "all": # 所有embedding矩阵共用一个矩阵W
|
||||
self.W = self.add_weight(shape=(self.embedding_size, self.embedding_size), initializer=glorot_normal(
|
||||
seed=self.seed), name="bilinear_weight")
|
||||
elif self.bilinear_type == "each": # 每个field共用一个矩阵W
|
||||
self.W_list = [self.add_weight(shape=(self.embedding_size, self.embedding_size), initializer=glorot_normal(
|
||||
seed=self.seed), name="bilinear_weight" + str(i)) for i in range(self.field_size-1)]
|
||||
elif self.bilinear_type == "interaction": # 每个交互用一个矩阵W
|
||||
self.W_list = [self.add_weight(shape=(self.embedding_size, self.embedding_size), initializer=glorot_normal(
|
||||
seed=self.seed), name="bilinear_weight" + str(i) + '_' + str(j)) for i, j in
|
||||
itertools.combinations(range(self.field_size), 2)]
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
super(BilinearInteraction, self).build(input_shape) # Be sure to call this somewhere!
|
||||
|
||||
def call(self, inputs):
|
||||
# inputs: [None, field_nums, embed_dims]
|
||||
# 这里把inputs从field_nums处split, 划分成field_nums个embed_dims长向量的列表
|
||||
inputs = tf.split(inputs, self.field_size, axis=1) # [(None, embed_dims), (None, embed_dims), ..]
|
||||
n = len(inputs) # field_nums个
|
||||
|
||||
if self.bilinear_type == "all":
|
||||
# inputs[i] (none, embed_dims) self.W (embed_dims, embed_dims) -> (None, embed_dims)
|
||||
vidots = [tf.tensordot(inputs[i], self.W, axes=(-1, 0)) for i in range(n)] # 点积
|
||||
p = [tf.multiply(vidots[i], inputs[j]) for i, j in itertools.combinations(range(n), 2)] # 哈达玛积
|
||||
elif self.bilinear_type == "each":
|
||||
vidots = [tf.tensordot(inputs[i], self.W_list[i], axes=(-1, 0)) for i in range(n - 1)]
|
||||
# 假设3个域, 则两两组合[(0,1), (0,2), (1,2)] 这里的vidots是第一个维度, inputs是第二个维度 哈达玛积运算
|
||||
p = [tf.multiply(vidots[i], inputs[j]) for i, j in itertools.combinations(range(n), 2)]
|
||||
elif self.bilinear_type == "interaction":
|
||||
# combinations(inputs, 2) 这个得到的是两两向量交互的结果列表
|
||||
# 比如 combinations([[1,2], [3,4], [5,6]], 2)
|
||||
# 得到 [([1, 2], [3, 4]), ([1, 2], [5, 6]), ([3, 4], [5, 6])] (v[0], v[1]) 先v[0]与W点积,然后再和v[1]哈达玛积
|
||||
p = [tf.multiply(tf.tensordot(v[0], w, axes=(-1, 0)), v[1])
|
||||
for v, w in zip(itertools.combinations(inputs, 2), self.W_list)]
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
output = Concatenate(axis=1)(p)
|
||||
return output
|
||||
```
|
||||
这里第一个是需要学习组合交互的具体实现方式, 人家的代码方式非常巧妙,第二个会是理解下。
|
||||
|
||||
关于FiBiNet网络的代码细节就到这里了,具体代码放到了我的GitHub链接上了。
|
||||
|
||||
## 总结
|
||||
这篇文章主要是整理了一个新模型, 这个模型是在特征重要性选择以及特征交互上做出了新的探索,给了我们两个新思路。 这里面还有两个重要的地方,感觉是作者对于SENET在推荐系统上的使用思考,也就是为啥能把这个东西迁过来,以及为啥双线性会更加细粒度,这种双线性函数的优势在哪儿?我们通常所说的知其然,意思是针对特征交互, 针对特征选择,我又有了两种考虑思路双线性和SENet, 而知其所以然,应该考虑为啥双线性或者SENET会有效呢? 当然在文章中给出了自己的看法,当然这个可能不对哈,是自己对于问题的一种思考, 欢迎伙伴们一块讨论。
|
||||
|
||||
我现在读论文,一般读完了之后,会刻意逼着自己想这么几个问题:
|
||||
>本篇论文核心是讲了个啥东西? 是为啥会提出这么个东西? 为啥这个新东西会有效? 与这个新东西类似的东西还有啥? 在工业上通常会怎么用?
|
||||
|
||||
一般经过这样的灵魂5问就能把整篇论文拎起来了,而读完了这篇文章,你能根据这5问给出相应的答案吗? 欢迎在下方留言呀。
|
||||
|
||||
还有一种读论文的厉害姿势,和张俊林老师学的,就是拉马努金式思维,就是读论文之前,看完题目之后, 不要看正文,先猜测作者在尝试解决什么样的问题,比如
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210703183445412.png#pic_center" alt="image-20210308142624189" style="zoom: 70%;" >
|
||||
</div>
|
||||
|
||||
看到特征重要性和双线性特征交互, 就大体上能猜测到这篇推荐论文讲的应该是和特征选择和特征交互相关的知识。 那么如果是我解决这两方面的话应该怎么解决呢?
|
||||
* 特征选择 --- 联想到Attention
|
||||
* 特征交互 --- 联想到哈达玛积或者内积
|
||||
|
||||
这时候, 就可以读论文了,读完之后, 对比下人家提出的想法和自己的想法的区别,考虑下为啥会有这样的区别? 然后再就是上面的灵魂5问, 通过这样的方式读论文, 能够理解的更加深刻,就不会再有读完很多论文,依然很虚的感觉,啥也没记住了。 如果再能花点时间总结输出下, 和之前的论文做一个对比串联,再花点时间看看代码,复现下,用到自己的任务上。 那么这样, 就算是真正把握住模型背后的思想了,而不是仅仅会个模型而已, 并且这种读论文方式,只要习惯了之后, 读论文会很快,因为我隐约发现,万变不离其宗, 论文里面抛去实验部分,抛去前言部分, 剩下的精华其实没有几页的。当然整理会花费时间, 但也有相应的价值在里面。 我以后整理,也是以经典思路模型为主, 对于一般的,我会放到论文总结的专栏里面,一下子两三篇的那种整理,只整理大体思路就即可啦。
|
||||
|
||||
下面只整理来自工业大佬的使用经验和反思, 具体参考下面的第二篇参考:
|
||||
* 适用的数据集
|
||||
虽然模型是针对点击率预测的场景提出的,但可以尝试的数据场景也不少,比较适合包含大量categorical feature且这些feature cardinality本身很高,或者因为encode method导致的某些feature维度很高且稀疏的情况。推荐系统的场景因为大量的user/item属性都是符合这些要求的,所以效果格外好,但我们也可以举一反三把它推广到其他相似场景。另外,文字描述类的特征(比如人工标注的主观评价,名字,地址信息……)可以用tokenizer处理成int sequence/matrix作为embedding feature喂进模型,丰富的interaction方法可以很好的学习到这些样本中这些特征的相似之处并挖掘出一些潜在的关系。
|
||||
|
||||
* 回归和分类问题都可以做,无非改一下DNN最后一层的activation函数和objective,没有太大的差别。
|
||||
* 如果dense feature比较多而且是分布存在很多异常值的numeric feature,尽量就不要用FiBiNET了,相比大部分NN没有优势不说,SENET那里的一个最大池化极其容易把特征权重带偏,如果一定要上,可能需要修改一下池化的方法。
|
||||
|
||||
* DeepCTR的实现还把指定的linear feature作为类似于WDL中的wide部分直接输入到DNN的最后一层,以及DNN部分也吸收了一部分指定的dnn feature中的dense feature直接作为输入。毫无疑问,DeepCTR作者在尽可能的保留更多的特征作为输入防止信息的丢失。
|
||||
|
||||
|
||||
* 使用Field-Each方式能够达到最好的预测准确率,而且相比默认的Field-Interaction,参数也减少了不少,训练效率更高。当然,三种方式在准确率方面差异不是非常巨大。
|
||||
* reduce ratio设置到8效果最好,这方面我的经验和不少人达成了共识,SENET用于其他学习任务也可以得到相似的结论。 -- 这个试了下,确实有效果
|
||||
* 使用dropout方法扔掉hidden layer里的部分unit效果会更好,系数大约在0.3时最好,原文用的是0.5,请根据具体使用的网络结构和数据集特点自己调整。-- 这个有效果
|
||||
|
||||
* 在双线性部分引入Layer Norm效果可能会更好些
|
||||
|
||||
* 尝试在DNN部分使用残差防止DNN效果过差
|
||||
* 直接取出Bilinear的输出结果然后上XGBoost,也就是说不用它来训练而是作为一种特征embedding操作去使用, 这个方法可能发生leak
|
||||
* 在WDL上的调优经验: 适当调整DNN hideen layer之间的unit数量的减小比例,防止梯度爆炸/消失。
|
||||
|
||||
后记:
|
||||
>fibinet在我自己的任务上也试了下,确实会效果, 采用默认参数的话, 能和xdeepfm跑到同样的水平,而如果再稍微调调参, 就比xdeepfm要好些了。
|
||||
|
||||
**参考**:
|
||||
* [论文原文](https://arxiv.org/pdf/1905.09433.pdf)
|
||||
* [FiBiNET: paper reading + 实践调优经验](https://zhuanlan.zhihu.com/p/79659557)
|
||||
* [FiBiNET:结合特征重要性和双线性特征交互进行CTR预估](https://zhuanlan.zhihu.com/p/72931811)
|
||||
* [FiBiNET(新浪)](https://zhuanlan.zhihu.com/p/92130353)
|
||||
* [FiBiNet 网络介绍与源码浅析](https://zhuanlan.zhihu.com/p/343572144)
|
||||
* [SENET双塔模型及应用](https://mp.weixin.qq.com/s/Y3A8chyJ6ssh4WLJ8HNQqw)
|
||||
|
||||
|
||||
@@ -1,244 +0,0 @@
|
||||
# PNN
|
||||
## 动机
|
||||
在特征交叉的相关模型中FM, FFM都证明了特征交叉的重要性,FNN将神经网络的高阶隐式交叉加到了FM的二阶特征交叉上,一定程度上说明了DNN做特征交叉的有效性。但是对于DNN这种“add”操作的特征交叉并不能充分挖掘类别特征的交叉效果。PNN虽然也用了DNN来对特征进行交叉组合,但是并不是直接将低阶特征放入DNN中,而是设计了Product层先对低阶特征进行充分的交叉组合之后再送入到DNN中去。
|
||||
|
||||
PNN模型其实是对IPNN和OPNN的总称,两者分别对应的是不同的Product实现方法,前者采用的是inner product,后者采用的是outer product。在PNN的算法方面,比较重要的部分就是Product Layer的简化实现方法,需要在数学和代码上都能够比较深入的理解。
|
||||
|
||||
## 模型的结构及原理
|
||||
|
||||
> 在学习PNN模型之前,应当对于DNN结构具有一定的了解,同时已经学习过了前面的章节。
|
||||
|
||||
PNN模型的整体架构如下图所示:
|
||||
|
||||
<div align=center> <img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210308142624189.png" alt="image-20210308142624189" style="zoom: 50%;" /> </div>
|
||||
|
||||
一共分为五层,其中除了Product Layer别的layer都是比较常规的处理方法,均可以从前面的章节进一步了解。模型中最重要的部分就是通过Product层对embedding特征进行交叉组合,也就是上图中红框所显示的部分。
|
||||
|
||||
Product层主要有线性部分和非线性部分组成,分别用$l_z$和$l_p$来表示,
|
||||
|
||||
<div align=center> <img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210308143101261.png" alt="image-20210308143101261" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
1. 线性模块,一阶特征(未经过显示特征交叉处理),对应论文中的$l_z=(l_z^1,l_z^2, ..., l_z^{D_1})$
|
||||
2. 非线性模块,高阶特征(经过显示特征交叉处理),对应论文中的$l_p=(l_p^1,l_p^2, ..., l_p^{D_1})$
|
||||
|
||||
**线性部分**
|
||||
|
||||
先来解释一下$l_z$是如何计算得到的,在介绍计算$l_z$之前先介绍一下矩阵内积计算, 如下公式所示,用一句话来描述就是两个矩阵对应元素相称,然后将相乘之后的所有元素相加
|
||||
$$
|
||||
A \odot{B} = \sum_{i,j}A_{i,j}B_{i,j}
|
||||
$$
|
||||
$l_z^n$的计算就是矩阵内积,而$l_z$是有$D_1$个$l_z^n$组成,所以需要$D1$个矩阵求得,但是在代码实现的时候不一定是定义$D_1$个矩阵,可以将这些矩阵Flatten,具体的细节可以参考给出的代码。
|
||||
$$
|
||||
l_z=(l_z^1,l_z^2, ..., l_z^{D_1})\\
|
||||
l_z^n = W_z^n \odot{z} \\
|
||||
z = (z_1, z_2, ..., z_N)
|
||||
$$
|
||||
总之这一波操作就是将所有的embedding向量中的所有元素都乘以一个矩阵的对应元素,最后相加即可,这一部分比较简单(N表示的是特征的数量,M表示的是所有特征转化为embedding之后维度,也就是N*emb_dim)
|
||||
$$
|
||||
l_z^n = W_z^n \odot{z} = \sum_{i=1}^N \sum_{j=1}^M (W_z^n)_{i,j}z_{i,j}
|
||||
$$
|
||||
|
||||
### Product Layer
|
||||
**非线性部分**
|
||||
|
||||
上面介绍了线性部分$l_p$的计算,非线性部分的计算相比线性部分要复杂很多,先从整体上看$l_p$的计算
|
||||
$$
|
||||
l_p=(l_p^1,l_p^2, ..., l_p^{D_1}) \\
|
||||
l_p^n = W_p^n \odot{p} \\
|
||||
p = \{p_{i,j}\}, i=1,2,...,N,j=1,2,...,N
|
||||
$$
|
||||
从上述公式中可以发现,$l_p^n$和$l_z^n$类似需要$D_1$个$W_p^n$矩阵计算内积得到,重点就是如何求这个$p$,这里作者提出了两种方式,一种是使用内积计算,另一种是使用外积计算。
|
||||
|
||||
#### IPNN
|
||||
|
||||
使用内积实现特征交叉就和FM是类似的(两两向量计算内积),下面将向量内积操作表示如下表达式
|
||||
$$
|
||||
g(f_i,f_j) = <f_i, f_j>
|
||||
$$
|
||||
将内积的表达式带入$l_p^n$的计算表达式中有:
|
||||
$$
|
||||
\begin{aligned}
|
||||
|
||||
l_p^n &= W_p^n \odot{p} \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N (W_p^n)_{i,j}p_{i,j} \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N (W_p^n)_{i,j}<f_i, f_j>
|
||||
|
||||
\end{aligned}
|
||||
$$
|
||||
上面就提到了这里使用的内积是计算两两特征之间的内积,然而向量a和向量b的内积与向量b和向量a的内积是相同的,其实是没必要计算的,看一下下面FM的计算公式:
|
||||
$$
|
||||
\hat{y}(X) = \omega_{0}+\sum_{i=1}^{n}{\omega_{i}x_{i}}+\sum_{i=1}^{n}{\sum_{j=i+1}^{n} <v_{i},v_{j}>x_{i}x_{j}}
|
||||
$$
|
||||
也就是说计算的内积矩阵$p$是对称的,那么与其对应元素做矩阵内积的矩阵$W_p^n$也是对称的,对于可学习的权重来说如果是对称的是不是可以只使用其中的一半就行了呢,所以基于这个思考,对Inner Product的权重定义及内积计算进行优化,首先将权重矩阵分解$W_p^n=\theta^n \theta^{nT}$,此时$\theta^n \in R^N$(参数从原来的$N^2$变成了$N$),将分解后的$W_p^n$带入$l_p^n$的计算公式有:
|
||||
$$
|
||||
\begin{aligned}
|
||||
|
||||
l_p^n &= W_p^n \odot{p} \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N (W_p^n)_{i,j}p_{i,j} \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N \theta^n \theta^n <f_i, f_j> \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N <\theta^n f_i, \theta^n f_j> \\
|
||||
&= <\sum_{i=1}^N \theta^n f_i, \sum_{j=1}^N \theta^n f_j> \\
|
||||
&= ||\sum_{i=1}^N \theta^n f_i||^2
|
||||
\end{aligned}
|
||||
$$
|
||||
所以优化后的$l_p$的计算公式为:
|
||||
$$
|
||||
l_p = (||\sum_{i=1}^N \theta^1 f_i||^2, ||\sum_{i=1}^N \theta^2 f_i||^2, ..., ||\sum_{i=1}^N \theta^{D_1} f_i||^2)
|
||||
$$
|
||||
这里为了好理解不做过多的解释,其实这里对于矩阵分解省略了一些细节,感兴趣的可以去看原文,最后模型实现的时候就是基于上面的这个公式计算的(给出的代码也是基于优化之后的实现)。
|
||||
|
||||
#### OPNN
|
||||
|
||||
使用外积实现相比于使用内积实现,唯一的区别就是使用向量的外积来计算矩阵$p$,首先定义向量的外积计算
|
||||
$$
|
||||
g(i,j) = f_i f_j^T
|
||||
$$
|
||||
从外积公式可以发现两个向量的外积得到的是一个矩阵,与上面介绍的内积计算不太相同,内积得到的是一个数值。内积实现的Product层是将计算得到的内积矩阵,乘以一个与其大小一样的权重矩阵,然后求和,按照这个思路的话,通过外积得到的$p$计算$W_p^n \odot{p}$相当于之前的内积值乘以权重矩阵对应位置的值求和就变成了,外积矩阵乘以权重矩阵中对应位置的子矩阵然后将整个相乘得到的大矩阵对应元素相加,用公式表示如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
l_p^n &= W_p^n \odot{p} \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N (W_p^n)_{i,j}p_{i,j} \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N (W_p^n)_{i,j} f_i f_j^T
|
||||
\end{aligned}
|
||||
$$
|
||||
需要注意的是此时的$(W_p^n)_{i,j}$表示的是一个矩阵,而不是一个值,此时计算$l_p$的复杂度是$O(D_1*N^2*M^2)$, 其中$N^2$表示的是特征的组合数量,$M^2$表示的是计算外积的复杂度。这样的复杂度肯定是无法接受的,所以为了优化复杂度,PNN的作者重新定义了$p$的计算方式:
|
||||
$$
|
||||
p=\sum_{i=1}^{N} \sum_{j=1}^{N} f_{i} f_{j}^{T}=f_{\Sigma}\left(f_{\Sigma}\right)^{T} \\
|
||||
f_{\Sigma}=\sum_{i=1}^{N} f_{i}
|
||||
$$
|
||||
需要注意,这里新定义的外积计算与传统的外积计算时不等价的,这里是为了优化计算效率重新定义的计算方式,从公式中可以看出,相当于先将原来的embedding向量在特征维度上先求和,变成一个向量之后再计算外积。加入原embedding向量表示为$E \in R^{N\times M}$,其中$N$表示特征的数量,M表示的是所有特征的总维度,即$N*emb\_dim$, 在特征维度上进行求和就是将$E \in R^{N\times M}$矩阵压缩成了$E \in R^M$, 然后两个$M$维的向量计算外积得到最终所有特征的外积交叉结果$p\in R^{M\times M}$,最终的$l_p^n$可以表示为:
|
||||
$$
|
||||
l_p^n = W_p^n \odot{p} = \sum_{i=1}^N \sum_{j=1}^N (W_p^n)_{i,j}p_{i,j} \\
|
||||
$$
|
||||
最终的计算方式和$l_z$的计算方式看起来差不多,但是需要注意外积优化后的$W_p^n$的维度是$R^{M \times M}$的,$M$表示的是特征矩阵的维度,即$N*emb\_dim$。
|
||||
|
||||
> 虽然叠加概念的引入可以降低计算开销,但是中间的精度损失也是很大的,性能与精度之间的tradeoff
|
||||
|
||||
## 代码实现
|
||||
|
||||
代码实现的整体逻辑比较简单,就是对类别特征进行embedding编码,然后通过embedding特征计算$l_z,l_p$, 接着将$l_z, l_p$的输出concat到一起输入到DNN中得到最终的预测结果
|
||||
|
||||
```python
|
||||
def PNN(dnn_feature_columns, inner=True, outer=True):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
_, sparse_input_dict = build_input_layers(dnn_feature_columns)
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(sparse_input_dict.values())
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layer_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
sparse_embed_list = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=False)
|
||||
|
||||
dnn_inputs = ProductLayer(units=32, use_inner=True, use_outer=True)(sparse_embed_list)
|
||||
|
||||
# 输入到dnn中,需要提前定义需要几个残差块
|
||||
output_layer = get_dnn_logits(dnn_inputs)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
```
|
||||
|
||||
PNN的难点就是Product层的实现,下面是Product 层实现的代码,代码中是使用优化之后$l_p$的计算方式编写的, 代码中有详细的注释,但是要完全理解代码还需要去理解上述说过的优化思路。
|
||||
|
||||
```python
|
||||
class ProductLayer(Layer):
|
||||
def __init__(self, units, use_inner=True, use_outer=False):
|
||||
super(ProductLayer, self).__init__()
|
||||
self.use_inner = use_inner
|
||||
self.use_outer = use_outer
|
||||
self.units = units # 指的是原文中D1的大小
|
||||
|
||||
def build(self, input_shape):
|
||||
# 需要注意input_shape也是一个列表,并且里面的每一个元素都是TensorShape类型,
|
||||
# 需要将其转换成list然后才能参与数值计算,不然类型容易错
|
||||
# input_shape[0] : feat_nums x embed_dims
|
||||
self.feat_nums = len(input_shape)
|
||||
self.embed_dims = input_shape[0].as_list()[-1]
|
||||
flatten_dims = self.feat_nums * self.embed_dims
|
||||
|
||||
# Linear signals weight, 这部分是用于产生Z的权重,因为这里需要计算的是两个元素对应元素乘积然后再相加
|
||||
# 等价于先把矩阵拉成一维,然后相乘再相加
|
||||
self.linear_w = self.add_weight(name='linear_w', shape=(flatten_dims, self.units), initializer='glorot_normal')
|
||||
|
||||
# inner product weight
|
||||
if self.use_inner:
|
||||
# 优化之后的内积权重是未优化时的一个分解矩阵,未优化时的矩阵大小为:D x N x N
|
||||
# 优化后的内积权重大小为:D x N
|
||||
self.inner_w = self.add_weight(name='inner_w', shape=(self.units, self.feat_nums), initializer='glorot_normal')
|
||||
|
||||
if self.use_outer:
|
||||
# 优化之后的外积权重大小为:D x embed_dim x embed_dim, 因为计算外积的时候在特征维度通过求和的方式进行了压缩
|
||||
self.outer_w = self.add_weight(name='outer_w', shape=(self.units, self.embed_dims, self.embed_dims), initializer='glorot_normal')
|
||||
|
||||
|
||||
def call(self, inputs):
|
||||
# inputs是一个列表
|
||||
# 先将所有的embedding拼接起来计算线性信号部分的输出
|
||||
concat_embed = Concatenate(axis=1)(inputs) # B x feat_nums x embed_dims
|
||||
# 将两个矩阵都拉成二维的,然后通过矩阵相乘得到最终的结果
|
||||
concat_embed_ = tf.reshape(concat_embed, shape=[-1, self.feat_nums * self.embed_dims])
|
||||
lz = tf.matmul(concat_embed_, self.linear_w) # B x units
|
||||
|
||||
# inner
|
||||
lp_list = []
|
||||
if self.use_inner:
|
||||
for i in range(self.units):
|
||||
# 相当于给每一个特征向量都乘以一个权重
|
||||
# self.inner_w[i] : (embed_dims, ) 添加一个维度变成 (embed_dims, 1)
|
||||
# concat_embed: B x feat_nums x embed_dims; delta = B x feat_nums x embed_dims
|
||||
delta = tf.multiply(concat_embed, tf.expand_dims(self.inner_w[i], axis=1))
|
||||
# 在特征之间的维度上求和
|
||||
delta = tf.reduce_sum(delta, axis=1) # B x embed_dims
|
||||
# 最终在特征embedding维度上求二范数得到p
|
||||
lp_list.append(tf.reduce_sum(tf.square(delta), axis=1, keepdims=True)) # B x 1
|
||||
|
||||
# outer
|
||||
if self.use_outer:
|
||||
# 外积的优化是将embedding矩阵,在特征间的维度上通过求和进行压缩
|
||||
feat_sum = tf.reduce_sum(concat_embed, axis=1) # B x embed_dims
|
||||
|
||||
# 为了方便计算外积,将维度进行扩展
|
||||
f1 = tf.expand_dims(feat_sum, axis=2) # B x embed_dims x 1
|
||||
f2 = tf.expand_dims(feat_sum, axis=1) # B x 1 x embed_dims
|
||||
|
||||
# 求外积, a * a^T
|
||||
product = tf.matmul(f1, f2) # B x embed_dims x embed_dims
|
||||
|
||||
# 将product与外积权重矩阵对应元素相乘再相加
|
||||
for i in range(self.units):
|
||||
lpi = tf.multiply(product, self.outer_w[i]) # B x embed_dims x embed_dims
|
||||
# 将后面两个维度进行求和,需要注意的是,每使用一次reduce_sum就会减少一个维度
|
||||
lpi = tf.reduce_sum(lpi, axis=[1, 2]) # B
|
||||
# 添加一个维度便于特征拼接
|
||||
lpi = tf.expand_dims(lpi, axis=1) # B x 1
|
||||
lp_list.append(lpi)
|
||||
|
||||
# 将所有交叉特征拼接到一起
|
||||
lp = Concatenate(axis=1)(lp_list)
|
||||
|
||||
# 将lz和lp拼接到一起
|
||||
product_out = Concatenate(axis=1)([lz, lp])
|
||||
|
||||
return product_out
|
||||
```
|
||||
|
||||
因为这个模型的整体实现框架比较简单,就不画实现的草图了,直接看模型搭建的函数即可,对于PNN重点需要理解Product的两种类型及不同的优化方式。
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center> <img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片PNN.png" alt="image-20210308143101261" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
## 思考题
|
||||
|
||||
1. 降低复杂度的具体策略与具体的product函数选择有关,IPNN其实通过矩阵分解,“跳过”了显式的product层,而OPNN则是直接在product层入手进行优化。看原文去理解优化的动机及细节。
|
||||
|
||||
|
||||
**参考文献**
|
||||
- [PNN原文论文](https://arxiv.org/pdf/1611.00144.pdf)
|
||||
- [推荐系统系列(四):PNN理论与实践](https://zhuanlan.zhihu.com/p/89850560)
|
||||
- [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
@@ -1,127 +0,0 @@
|
||||
# AFM
|
||||
## AFM提出的动机
|
||||
|
||||
AFM的全称是Attentional Factorization Machines, 从模型的名称上来看是在FM的基础上加上了注意力机制,FM是通过特征隐向量的内积来对交叉特征进行建模,从公式中可以看出所有的交叉特征都具有相同的权重也就是1,没有考虑到不同的交叉特征的重要性程度:
|
||||
$$
|
||||
y_{fm} = w_0+\sum_{i=1}^nw_ix_i+\sum_{i=1}^{n}\sum_{i+1}^n\lt v_i,v_j\gt x_ix_j
|
||||
$$
|
||||
如何让不同的交叉特征具有不同的重要性就是AFM核心的贡献,在谈论AFM交叉特征注意力之前,对于FM交叉特征部分的改进还有FFM,其是考虑到了对于不同的其他特征,某个指定特征的隐向量应该是不同的(相比于FM对于所有的特征只有一个隐向量,FFM对于一个特征有多个不同的隐向量)。
|
||||
|
||||
## AFM模型原理
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210131092744905.png" alt="image-20210131092744905" style="zoom: 50%;" />
|
||||
</div>
|
||||
上图表示的就是AFM交叉特征部分的模型结构(非交叉部分与FM是一样的,图中并没有给出)。AFM最核心的两个点分别是Pair-wise Interaction Layer和Attention-based Pooling。前者将输入的非零特征的隐向量两两计算element-wise product(哈达玛积,两个向量对应元素相乘,得到的还是一个向量),假如输入的特征中的非零向量的数量为m,那么经过Pair-wise Interaction Layer之后输出的就是$\frac{m(m-1)}{2}$个向量,再将前面得到的交叉特征向量组输入到Attention-based Pooling,该pooling层会先计算出每个特征组合的自适应权重(通过Attention Net进行计算),通过加权求和的方式将向量组压缩成一个向量,由于最终需要输出的是一个数值,所以还需要将前一步得到的向量通过另外一个向量将其映射成一个值,得到最终的基于注意力加权的二阶交叉特征的输出。(对于这部分如果不是很清楚,可以先看下面对两个核心层的介绍)
|
||||
|
||||
### Pair-wise Interaction Layer
|
||||
|
||||
FM二阶交叉项:所有非零特征对应的隐向量两两点积再求和,输出的是一个数值
|
||||
$$
|
||||
\sum_{i=1}^{n}\sum_{i+1}^n\lt v_i,v_j\gt x_ix_j
|
||||
$$
|
||||
AFM二阶交叉项(无attention):所有非零特征对应的隐向量两两对应元素乘积,然后再向量求和,输出的还是一个向量。
|
||||
$$
|
||||
\sum_{i=1}^{n}\sum_{i+1}^n (v_i \odot v_j) x_ix_j
|
||||
$$
|
||||
上述写法是为了更好的与FM进行对比,下面将公式变形方便与原论文中保持一致。首先是特征的隐向量。从上图中可以看出,作者对数值特征也对应了一个隐向量,不同的数值乘以对应的隐向量就可以得到不同的隐向量,相对于onehot编码的特征乘以1还是其本身(并没有什么变化),其实就是为了将公式进行统一。虽然论文中给出了对数值特征定义隐向量,但是在作者的代码中并没有发现有对数值特征进行embedding的过程([原论文代码链接](https://github.com/hexiangnan/attentional_factorization_machine/blob/master/code/AFM.py))具体原因不详。
|
||||
|
||||
按照论文的意思,特征的embedding可以表示为:$\varepsilon = {v_ix_i}$,经过Pair-wise Interaction Layer输出可得:
|
||||
$$
|
||||
f_{PI}(\varepsilon)=\{(v_i \odot v_j) x_ix_j\}_{i,j \in R_x}
|
||||
$$
|
||||
$R_x$表示的是有效特征集合。此时的$f_{PI}(\varepsilon)$表示的是一个向量集合,所以需要先将这些向量集合聚合成一个向量,然后在转换成一个数值:
|
||||
$$
|
||||
\hat{y} = p^T \sum_{(i,j)\in R_x}(v_i \odot v_j) x_ix_j + b
|
||||
$$
|
||||
上式中的求和部分就是将向量集合聚合成一个维度与隐向量维度相同的向量,通过向量$p$再将其转换成一个数值,b表示的是偏置。
|
||||
|
||||
从开始介绍Pair-wise Interaction Layer到现在解决的一个问题是,如何将使用哈达玛积得到的交叉特征转换成一个最终输出需要的数值,到目前为止交叉特征之间的注意力权重还没有出现。在没有详细介绍注意力之前先感性的认识一下如果现在已经有了每个交叉特征的注意力权重,那么交叉特征的输出可以表示为:
|
||||
$$
|
||||
\hat{y} = p^T \sum_{(i,j)\in R_x}\alpha_{ij}(v_i \odot v_j) x_ix_j + b
|
||||
$$
|
||||
就是在交叉特征得到的新向量前面乘以一个注意力权重$\alpha_{ij}$, 那么这个注意力权重如何计算得到呢?
|
||||
|
||||
### Attention-based Pooling
|
||||
|
||||
对于神经网络注意力相关的基础知识大家可以去看一下邱锡鹏老师的《神经网络与深度学习》第8章注意力机制与外部记忆。这里简单的叙述一下使用MLP实现注意力机制的计算。假设现在有n个交叉特征(假如维度是k),将nxk的数据输入到一个kx1的全连接网络中,输出的张量维度为nx1,使用softmax函数将nx1的向量的每个维度进行归一化,得到一个新的nx1的向量,这个向量所有维度加起来的和为1,每个维度上的值就可以表示原nxk数据每一行(即1xk的数据)的权重。用公式表示为:
|
||||
$$
|
||||
\alpha_{ij}' = h^T ReLU(W(v_i \odot v_j)x_ix_j + b)
|
||||
$$
|
||||
使用softmax归一化可得:
|
||||
$$
|
||||
\alpha_{ij} = \frac{exp(\alpha_{ij}')}{\sum_{(i,j)\in R_x}exp(\alpha_{ij}')}
|
||||
$$
|
||||
这样就得到了AFM二阶交叉部分的注意力权重,如果将AFM的一阶项写在一起,AFM模型用公式表示为:
|
||||
$$
|
||||
\hat{y}_{afm}(x) = w_0+\sum_{i=1}^nw_ix_i+p^T \sum_{(i,j)\in R_x}\alpha_{ij}(v_i \odot v_j) x_ix_j + b
|
||||
$$
|
||||
### AFM模型训练
|
||||
|
||||
AFM从最终的模型公式可以看出与FM的模型公式是非常相似的,所以也可以和FM一样应用于不同的任务,例如分类、回归及排序(不同的任务的损失函数是不一样的),AFM也有对防止过拟合进行处理:
|
||||
|
||||
1. 在Pair-wise Interaction Layer层的输出结果上使用dropout防止过拟合,因为并不是所有的特征组合对预测结果都有用,所以随机的去除一些交叉特征,让剩下的特征去自适应的学习可以更好的防止过拟合。
|
||||
2. 对Attention-based Pooling层中的权重矩阵$W$使用L2正则,作者没有在这一层使用dropout的原因是发现同时在特征交叉层和注意力层加dropout会使得模型训练不稳定,并且性能还会下降。
|
||||
|
||||
加上正则参数之后的回归任务的损失函数表示为:
|
||||
$$
|
||||
L = \sum_{x\in T} (\hat{y}_{afm}(x) - y(x))^2 + \lambda ||W||^2
|
||||
$$
|
||||
## AFM代码实现
|
||||
|
||||
1. linear part: 这部分是有关于线性计算,也就是FM的前半部分$w1x1+w2x2...wnxn+b$的计算。对于这一块的计算,我们用了一个get_linear_logits函数实现,后面再说,总之通过这个函数,我们就可以实现上面这个公式的计算过程,得到linear的输出
|
||||
2. dnn part: 这部分是后面交叉特征的那部分计算,这一部分需要使用注意力机制来将所有类别特征的embedding计算注意力权重,然后通过加权求和的方式将所有交叉之后的特征池化成一个向量,最终通过一个映射矩阵$p$将向量转化成一个logits值
|
||||
3. 最终将linear部分与dnn部分相加之后,通过sigmoid激活得到最终的输出
|
||||
|
||||
```python
|
||||
def AFM(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
|
||||
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
# embedding层用户构建FM交叉部分和DNN的输入部分
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 将输入到dnn中的sparse特征筛选出来
|
||||
att_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
|
||||
att_logits = get_attention_logits(sparse_input_dict, att_sparse_feature_columns, embedding_layers) # B x (n(n-1)/2)
|
||||
|
||||
# 将linear,dnn的logits相加作为最终的logits
|
||||
output_logits = Add()([linear_logits, att_logits])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layers = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(input_layers, output_layers)
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210307200304199.png" alt="image-20210307200304199" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片AFM.png" alt="image-20210307200304199" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
1. AFM与NFM优缺点对比。
|
||||
|
||||
|
||||
**参考资料**
|
||||
[原论文](https://www.ijcai.org/Proceedings/2017/0435.pdf)
|
||||
[deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
@@ -1,156 +0,0 @@
|
||||
# DeepFM
|
||||
## 动机
|
||||
对于CTR问题,被证明的最有效的提升任务表现的策略是特征组合(Feature Interaction), 在CTR问题的探究历史上来看就是如何更好地学习特征组合,进而更加精确地描述数据的特点。可以说这是基础推荐模型到深度学习推荐模型遵循的一个主要的思想。而组合特征大牛们研究过组合二阶特征,三阶甚至更高阶,但是面临一个问题就是随着阶数的提升,复杂度就成几何倍的升高。这样即使模型的表现更好了,但是推荐系统在实时性的要求也不能满足了。所以很多模型的出现都是为了解决另外一个更加深入的问题:如何更高效的学习特征组合?
|
||||
|
||||
为了解决上述问题,出现了FM和FFM来优化LR的特征组合较差这一个问题。并且在这个时候科学家们已经发现了DNN在特征组合方面的优势,所以又出现了FNN和PNN等使用深度网络的模型。但是DNN也存在局限性。
|
||||
|
||||
- **DNN局限**
|
||||
当我们使用DNN网络解决推荐问题的时候存在网络参数过于庞大的问题,这是因为在进行特征处理的时候我们需要使用one-hot编码来处理离散特征,这会导致输入的维度猛增。这里借用AI大会的一张图片:
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-15.png" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
这样庞大的参数量也是不实际的。为了解决DNN参数量过大的局限性,可以采用非常经典的Field思想,将OneHot特征转换为Dense Vector
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-40.png" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
此时通过增加全连接层就可以实现高阶的特征组合,如下图所示:
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-59.png" style="zoom:67%;" />
|
||||
</div>
|
||||
但是仍然缺少低阶的特征组合,于是增加FM来表示低阶的特征组合。
|
||||
|
||||
- **FNN和PNN**
|
||||
结合FM和DNN其实有两种方式,可以并行结合也可以串行结合。这两种方式各有几种代表模型。在DeepFM之前有FNN,虽然在影响力上可能并不如DeepFM,但是了解FNN的思想对我们理解DeepFM的特点和优点是很有帮助的。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-12-19.png" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
FNN是使用预训练好的FM模块,得到隐向量,然后把隐向量作为DNN的输入,但是经过实验进一步发现,在Embedding layer和hidden layer1之间增加一个product层(如上图所示)可以提高模型的表现,所以提出了PNN,使用product layer替换FM预训练层。
|
||||
|
||||
- **Wide&Deep**
|
||||
FNN和PNN模型仍然有一个比较明显的尚未解决的缺点:对于低阶组合特征学习到的比较少,这一点主要是由于FM和DNN的串行方式导致的,也就是虽然FM学到了低阶特征组合,但是DNN的全连接结构导致低阶特征并不能在DNN的输出端较好的表现。看来我们已经找到问题了,将串行方式改进为并行方式能比较好的解决这个问题。于是Google提出了Wide&Deep模型(将前几章),但是如果深入探究Wide&Deep的构成方式,虽然将整个模型的结构调整为了并行结构,在实际的使用中Wide Module中的部分需要较为精巧的特征工程,换句话说人工处理对于模型的效果具有比较大的影响(这一点可以在Wide&Deep模型部分得到验证)。
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/Javaimage-20200910214310877.png" alt="image-20200910214310877" style="zoom:65%;" />
|
||||
</div>
|
||||
如上图所示,该模型仍然存在问题:**在output Units阶段直接将低阶和高阶特征进行组合,很容易让模型最终偏向学习到低阶或者高阶的特征,而不能做到很好的结合。**
|
||||
|
||||
综上所示,DeepFM模型横空出世。
|
||||
|
||||
## 模型的结构与原理
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225180556628.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
前面的Field和Embedding处理是和前面的方法是相同的,如上图中的绿色部分;DeepFM将Wide部分替换为了FM layer如上图中的蓝色部分
|
||||
|
||||
这幅图其实有很多的点需要注意,很多人都一眼略过了,这里我个人认为在DeepFM模型中有三点需要注意:
|
||||
|
||||
- **Deep模型部分**
|
||||
- **FM模型部分**
|
||||
- **Sparse Feature中黄色和灰色节点代表什么意思**
|
||||
|
||||
### FM
|
||||
详细内容参考FM模型部分的内容,下图是FM的一个结构图,从图中大致可以看出FM Layer是由一阶特征和二阶特征Concatenate到一起在经过一个Sigmoid得到logits(结合FM的公式一起看),所以在实现的时候需要单独考虑linear部分和FM交叉特征部分。
|
||||
$$
|
||||
\hat{y}_{FM}(x) = w_0+\sum_{i=1}^N w_ix_i + \sum_{i=1}^N \sum_{j=i+1}^N v_i^T v_j x_ix_j
|
||||
$$
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225181340313.png" alt="image-20210225181340313" style="zoom: 67%;" />
|
||||
</div>
|
||||
### Deep
|
||||
Deep架构图
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225181010107.png" alt="image-20210225181010107" style="zoom:50%;" />
|
||||
</div>
|
||||
Deep Module是为了学习高阶的特征组合,在上图中使用用全连接的方式将Dense Embedding输入到Hidden Layer,这里面Dense Embeddings就是为了解决DNN中的参数爆炸问题,这也是推荐模型中常用的处理方法。
|
||||
|
||||
Embedding层的输出是将所有id类特征对应的embedding向量concat到到一起输入到DNN中。其中$v_i$表示第i个field的embedding,m是field的数量。
|
||||
$$
|
||||
z_1=[v_1, v_2, ..., v_m]
|
||||
$$
|
||||
上一层的输出作为下一层的输入,我们得到:
|
||||
$$
|
||||
z_L=\sigma(W_{L-1} z_{L-1}+b_{L-1})
|
||||
$$
|
||||
其中$\sigma$表示激活函数,$z, W, b $分别表示该层的输入、权重和偏置。
|
||||
|
||||
最后进入DNN部分输出使用sigmod激活函数进行激活:
|
||||
$$
|
||||
y_{DNN}=\sigma(W^{L}a^L+b^L)
|
||||
$$
|
||||
|
||||
|
||||
## 代码实现
|
||||
DeepFM在模型的结构图中显示,模型大致由两部分组成,一部分是FM,还有一部分就是DNN, 而FM又由一阶特征部分与二阶特征交叉部分组成,所以可以将整个模型拆成三部分,分别是一阶特征处理linear部分,二阶特征交叉FM以及DNN的高阶特征交叉。在下面的代码中也能够清晰的看到这个结构。此外每一部分可能由是由不同的特征组成,所以在构建模型的时候需要分别对这三部分输入的特征进行选择。
|
||||
|
||||
- linear_logits: 这部分是有关于线性计算,也就是FM的前半部分$w1x1+w2x2...wnxn+b$的计算。对于这一块的计算,我们用了一个get_linear_logits函数实现,后面再说,总之通过这个函数,我们就可以实现上面这个公式的计算过程,得到linear的输出, 这部分特征由数值特征和类别特征的onehot编码组成的一维向量组成,实际应用中根据自己的业务放置不同的一阶特征(这里的dense特征并不是必须的,有可能会将数值特征进行分桶,然后在当做类别特征来处理)
|
||||
- fm_logits: 这一块主要是针对离散的特征,首先过embedding,然后使用FM特征交叉的方式,两两特征进行交叉,得到新的特征向量,最后计算交叉特征的logits
|
||||
- dnn_logits: 这一块主要是针对离散的特征,首先过embedding,然后将得到的embedding拼接成一个向量(具体的可以看代码,也可以看一下下面的模型结构图),通过dnn学习类别特征之间的隐式特征交叉并输出logits值
|
||||
|
||||
```python
|
||||
def DeepFM(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
|
||||
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
# embedding层用户构建FM交叉部分和DNN的输入部分
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 将输入到dnn中的所有sparse特征筛选出来
|
||||
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
|
||||
fm_logits = get_fm_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers) # 只考虑二阶项
|
||||
|
||||
# 将所有的Embedding都拼起来,一起输入到dnn中
|
||||
dnn_logits = get_dnn_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
|
||||
|
||||
# 将linear,FM,dnn的logits相加作为最终的logits
|
||||
output_logits = Add()([linear_logits, fm_logits, dnn_logits])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layers = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(input_layers, output_layers)
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210228161135777.png" alt="image-20210228161135777" />
|
||||
</div>
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片DeepFM.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
1. 如果对于FM采用随机梯度下降SGD训练模型参数,请写出模型各个参数的梯度和FM参数训练的复杂度
|
||||
2. 对于下图所示,根据你的理解Sparse Feature中的不同颜色节点分别表示什么意思
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225180556628.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
**参考资料**
|
||||
- [论文原文](https://arxiv.org/pdf/1703.04247.pdf)
|
||||
- [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
- [FM](https://github.com/datawhalechina/fun-rec/blob/master/docs/ch02/ch2.1/ch2.1.2/FM.md)
|
||||
- [推荐系统遇上深度学习(三)--DeepFM模型理论和实践](https://www.jianshu.com/p/6f1c2643d31b)
|
||||
- [FM算法公式推导](https://blog.csdn.net/qq_32486393/article/details/103498519)
|
||||
@@ -1,146 +0,0 @@
|
||||
# NFM
|
||||
## 动机
|
||||
|
||||
NFM(Neural Factorization Machines)是2017年由新加坡国立大学的何向南教授等人在SIGIR会议上提出的一个模型,传统的FM模型仅局限于线性表达和二阶交互, 无法胜任生活中各种具有复杂结构和规律性的真实数据, 针对FM的这点不足, 作者提出了一种将FM融合进DNN的策略,通过引进了一个特征交叉池化层的结构,使得FM与DNN进行了完美衔接,这样就组合了FM的建模低阶特征交互能力和DNN学习高阶特征交互和非线性的能力,形成了深度学习时代的神经FM模型(NFM)。
|
||||
|
||||
那么NFM具体是怎么做的呢? 首先看一下NFM的公式:
|
||||
$$
|
||||
\hat{y}_{N F M}(\mathbf{x})=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+f(\mathbf{x})
|
||||
$$
|
||||
我们对比FM, 就会发现变化的是第三项,前两项还是原来的, 因为我们说FM的一个问题,就是只能到二阶交叉, 且是线性模型, 这是他本身的一个局限性, 而如果想突破这个局限性, 就需要从他的公式本身下点功夫, 于是乎,作者在这里改进的思路就是**用一个表达能力更强的函数来替代原FM中二阶隐向量内积的部分**。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1.png" style="zoom:70%;" />
|
||||
</div>
|
||||
而这个表达能力更强的函数呢, 我们很容易就可以想到神经网络来充当,因为神经网络理论上可以拟合任何复杂能力的函数, 所以作者真的就把这个$f(x)$换成了一个神经网络,当然不是一个简单的DNN, 而是依然底层考虑了交叉,然后高层使用的DNN网络, 这个也就是我们最终的NFM网络了:
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2.png" style="zoom:80%;" />
|
||||
</div>
|
||||
这个结构,如果前面看过了PNN的伙伴会发现,这个结构和PNN非常像,只不过那里是一个product_layer, 而这里换成了Bi-Interaction Pooling了, 这个也是NFM的核心结构了。这里注意, 这个结构中,忽略了一阶部分,只可视化出来了$f(x)$, 我们还是下面从底层一点点的对这个网络进行剖析。
|
||||
|
||||
## 模型结构与原理
|
||||
### Input 和Embedding层
|
||||
输入层的特征, 文章指定了稀疏离散特征居多, 这种特征我们也知道一般是先one-hot, 然后会通过embedding,处理成稠密低维的。 所以这两层还是和之前一样,假设$\mathbf{v}_{\mathbf{i}} \in \mathbb{R}^{k}$为第$i$个特征的embedding向量, 那么$\mathcal{V}_{x}=\left\{x_{1} \mathbf{v}_{1}, \ldots, x_{n} \mathbf{v}_{n}\right\}$表示的下一层的输入特征。这里带上了$x_i$是因为很多$x_i$转成了One-hot之后,出现很多为0的, 这里的$\{x_iv_i\}$是$x_i$不等于0的那些特征向量。
|
||||
|
||||
### Bi-Interaction Pooling layer
|
||||
在Embedding层和神经网络之间加入了特征交叉池化层是本网络的核心创新了,正是因为这个结构,实现了FM与DNN的无缝连接, 组成了一个大的网络,且能够正常的反向传播。假设$\mathcal{V}_{x}$是所有特征embedding的集合, 那么在特征交叉池化层的操作:
|
||||
$$
|
||||
f_{B I}\left(\mathcal{V}_{x}\right)=\sum_{i=1}^{n} \sum_{j=i+1}^{n} x_{i} \mathbf{v}_{i} \odot x_{j} \mathbf{v}_{j}
|
||||
$$
|
||||
|
||||
$\odot$表示两个向量的元素积操作,即两个向量对应维度相乘得到的元素积向量(可不是点乘呀),其中第$k$维的操作:
|
||||
$$
|
||||
\left(v_{i} \odot v_{j}\right)_{k}=\boldsymbol{v}_{i k} \boldsymbol{v}_{j k}
|
||||
$$
|
||||
|
||||
这便定义了在embedding空间特征的二阶交互,这个不仔细看会和感觉FM的最后一项很像,但是不一样,一定要注意这个地方不是两个隐向量的内积,而是元素积,也就是这一个交叉完了之后k个维度不求和,最后会得到一个$k$维向量,而FM那里内积的话最后得到一个数, 在进行两两Embedding元素积之后,对交叉特征向量取和, 得到该层的输出向量, 很显然, 输出是一个$k$维的向量。
|
||||
|
||||
注意, 之前的FM到这里其实就完事了, 上面就是输出了,而这里很大的一点改进就是加入特征池化层之后, 把二阶交互的信息合并, 且上面接了一个DNN网络, 这样就能够增强FM的表达能力了, 因为FM只能到二阶, 而这里的DNN可以进行多阶且非线性,只要FM把二阶的学习好了, DNN这块学习来会更加容易, 作者在论文中也说明了这一点,且通过后面的实验证实了这个观点。
|
||||
|
||||
如果不加DNN, NFM就退化成了FM,所以改进的关键就在于加了一个这样的层,组合了一下二阶交叉的信息,然后又给了DNN进行高阶交叉的学习,成了一种“加强版”的FM。
|
||||
|
||||
Bi-Interaction层不需要额外的模型学习参数,更重要的是它在一个线性的时间内完成计算,和FM一致的,即时间复杂度为$O\left(k N_{x}\right)$,$N_x$为embedding向量的数量。参考FM,可以将上式转化为:
|
||||
$$
|
||||
f_{B I}\left(\mathcal{V}_{x}\right)=\frac{1}{2}\left[\left(\sum_{i=1}^{n} x_{i} \mathbf{v}_{i}\right)^{2}-\sum_{i=1}^{n}\left(x_{i} \mathbf{v}_{i}\right)^{2}\right]
|
||||
$$
|
||||
后面代码复现NFM就是用的这个公式直接计算,比较简便且清晰。
|
||||
|
||||
### 隐藏层
|
||||
这一层就是全连接的神经网络, DNN在进行特征的高层非线性交互上有着天然的学习优势,公式如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\mathbf{z}_{1}=&\sigma_{1}\left(\mathbf{W}_{1} f_{B I}
|
||||
\left(\mathcal{V}_{x}\right)+\mathbf{b}_{1}\right) \\
|
||||
\mathbf{z}_{2}=& \sigma_{2}\left(\mathbf{W}_{2} \mathbf{z}_{1}+\mathbf{b}_{2}\right) \\
|
||||
\ldots \ldots \\
|
||||
\mathbf{z}_{L}=& \sigma_{L}\left(\mathbf{W}_{L} \mathbf{z}_{L-1}+\mathbf{b}_{L}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这里的$\sigma_i$是第$i$层的激活函数,可不要理解成sigmoid激活函数。
|
||||
|
||||
### 预测层
|
||||
这个就是最后一层的结果直接过一个隐藏层,但注意由于这里是回归问题,没有加sigmoid激活:
|
||||
$$
|
||||
f(\mathbf{x})=\mathbf{h}^{T} \mathbf{z}_{L}
|
||||
$$
|
||||
|
||||
所以, NFM模型的前向传播过程总结如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\hat{y}_{N F M}(\mathbf{x}) &=w_{0}+\sum_{i=1}^{n} w_{i} x_{i} \\
|
||||
&+\mathbf{h}^{T} \sigma_{L}\left(\mathbf{W}_{L}\left(\ldots \sigma_{1}\left(\mathbf{W}_{1} f_{B I}\left(\mathcal{V}_{x}\right)+\mathbf{b}_{1}\right) \ldots\right)+\mathbf{b}_{L}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这就是NFM模型的全貌, NFM相比较于其他模型的核心创新点是特征交叉池化层,基于它,实现了FM和DNN的无缝连接,使得DNN可以在底层就学习到包含更多信息的组合特征,这时候,就会减少DNN的很多负担,只需要很少的隐藏层就可以学习到高阶特征信息。NFM相比之前的DNN, 模型结构更浅,更简单,但是性能更好,训练和调参更容易。集合FM二阶交叉线性和DNN高阶交叉非线性的优势,非常适合处理稀疏数据的场景任务。在对NFM的真实训练过程中,也会用到像Dropout和BatchNormalization这样的技术来缓解过拟合和在过大的改变数据分布。
|
||||
|
||||
下面通过代码看下NFM的具体实现过程, 学习一些细节。
|
||||
|
||||
## 代码实现
|
||||
下面我们看下NFM的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。下面开始:
|
||||
|
||||
这里主要说一下NFM模型的总体运行逻辑, 这样可以让大家从宏观的层面去把握模型的设计过程, 该模型所使用的数据集是criteo数据集,具体介绍参考后面的GitHub。 数据集的特征会分为dense特征(连续)和sparse特征(离散), 所以模型的输入层接收这两种输入。但是我们这里把输入分成了linear input和dnn input两种情况,而每种情况都有可能包含上面这两种输入。因为我们后面的模型逻辑会分这两部分走,这里有个细节要注意,就是光看上面那个NFM模型的话,是没有看到它线性特征处理的那部分的,也就是FM的前半部分公式那里图里面是没有的。但是这里我们要加上。
|
||||
$$
|
||||
\hat{y}_{N F M}(\mathbf{x})=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+f(\mathbf{x})
|
||||
$$
|
||||
所以模型的逻辑我们分成了两大部分,这里我分别给大家解释下每一块做了什么事情:
|
||||
|
||||
1. linear part: 这部分是有关于线性计算,也就是FM的前半部分$w1x1+w2x2...wnxn+b$的计算。对于这一块的计算,我们用了一个get_linear_logits函数实现,后面再说,总之通过这个函数,我们就可以实现上面这个公式的计算过程,得到linear的输出
|
||||
2. dnn part: 这部分是后面交叉特征的那部分计算,FM的最后那部分公式f(x)。 这一块主要是针对离散的特征,首先过embedding, 然后过特征交叉池化层,这个计算我们用了get_bi_interaction_pooling_output函数实现, 得到输出之后又过了DNN网络,最后得到dnn的输出
|
||||
|
||||
模型的最后输出结果,就是把这两个部分的输出结果加和(当然也可以加权),再过一个sigmoid得到。所以NFM的模型定义就出来了:
|
||||
|
||||
```python
|
||||
def NFM(linear_feature_columns, dnn_feature_columns):
|
||||
"""
|
||||
搭建NFM模型,上面已经把所有组块都写好了,这里拼起来就好
|
||||
:param linear_feature_columns: A list. 里面的每个元素是namedtuple(元组的一种扩展类型,同时支持序号和属性名访问组件)类型,表示的是linear数据的特征封装版
|
||||
:param dnn_feature_columns: A list. 里面的每个元素是namedtuple(元组的一种扩展类型,同时支持序号和属性名访问组件)类型,表示的是DNN数据的特征封装版
|
||||
"""
|
||||
# 构建输入层,即所有特征对应的Input()层, 这里使用字典的形式返回, 方便后续构建模型
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns+dnn_feature_columns)
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 线性部分的计算 w1x1 + w2x2 + ..wnxn + b部分,dense特征和sparse两部分的计算结果组成,具体看上面细节
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_feature_columns)
|
||||
|
||||
# DNN部分的计算
|
||||
# 首先,在这里构建DNN部分的embedding层,之所以写在这里,是为了灵活的迁移到其他网络上,这里用字典的形式返回
|
||||
# embedding层用于构建FM交叉部分以及DNN的输入部分
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 过特征交叉池化层
|
||||
pooling_output = get_bi_interaction_pooling_output(sparse_input_dict, dnn_feature_columns, embedding_layers)
|
||||
|
||||
# 加个BatchNormalization
|
||||
pooling_output = BatchNormalization()(pooling_output)
|
||||
|
||||
# dnn部分的计算
|
||||
dnn_logits = get_dnn_logits(pooling_output)
|
||||
|
||||
# 线性部分和dnn部分的结果相加,最后再过个sigmoid
|
||||
output_logits = Add()([linear_logits, dnn_logits])
|
||||
output_layers = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(inputs=input_layers, outputs=output_layers)
|
||||
|
||||
return model
|
||||
```
|
||||
|
||||
有了上面的解释,这个模型的宏观层面相信就很容易理解了。关于这每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片NFM_aaaa.png" alt="NFM_aaaa" style="zoom: 50%;" />
|
||||
</div>
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片nfm.png" alt="NFM_aaaa" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
## 思考题
|
||||
1. NFM中的特征交叉与FM中的特征交叉有何异同,分别从原理和代码实现上进行对比分析
|
||||
|
||||
**参考资料**
|
||||
- [论文原文](https://arxiv.org/pdf/1708.05027.pdf)
|
||||
- [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
- [AI上推荐 之 FNN、DeepFM与NFM(FM在深度学习中的身影重现)](https://blog.csdn.net/wuzhongqiang/article/details/109532267?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161442951716780255224635%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=161442951716780255224635&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v1~rank_blog_v1-1-109532267.pc_v1_rank_blog_v1&utm_term=NFM)
|
||||
@@ -1,117 +0,0 @@
|
||||
# Wide & Deep
|
||||
## 动机
|
||||
|
||||
在CTR预估任务中利用手工构造的交叉组合特征来使线性模型具有“记忆性”,使模型记住共现频率较高的特征组合,往往也能达到一个不错的baseline,且可解释性强。但这种方式有着较为明显的缺点:
|
||||
|
||||
1. 特征工程需要耗费太多精力。
|
||||
2. 模型是强行记住这些组合特征的,对于未曾出现过的特征组合,权重系数为0,无法进行泛化。
|
||||
|
||||
为了加强模型的泛化能力,研究者引入了DNN结构,将高维稀疏特征编码为低维稠密的Embedding vector,这种基于Embedding的方式能够有效提高模型的泛化能力。但是,基于Embedding的方式可能因为数据长尾分布,导致长尾的一些特征值无法被充分学习,其对应的Embedding vector是不准确的,这便会造成模型泛化过度。
|
||||
|
||||
Wide&Deep模型就是围绕记忆性和泛化性进行讨论的,模型能够从历史数据中学习到高频共现的特征组合的能力,称为是模型的Memorization。能够利用特征之间的传递性去探索历史数据中从未出现过的特征组合,称为是模型的Generalization。Wide&Deep兼顾Memorization与Generalization并在Google Play store的场景中成功落地。
|
||||
|
||||
## 模型结构及原理
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/Javaimage-20200910214310877.png" alt="image-20200910214310877" style="zoom:65%;" />
|
||||
</div>
|
||||
|
||||
其实wide&deep模型本身的结构是非常简单的,对于有点机器学习基础和深度学习基础的人来说都非常的容易看懂,但是如何根据自己的场景去选择那些特征放在Wide部分,哪些特征放在Deep部分就需要理解这篇论文提出者当时对于设计该模型不同结构时的意图了,所以这也是用好这个模型的一个前提。
|
||||
|
||||
**如何理解Wide部分有利于增强模型的“记忆能力”,Deep部分有利于增强模型的“泛化能力”?**
|
||||
|
||||
- wide部分是一个广义的线性模型,输入的特征主要有两部分组成,一部分是原始的部分特征,另一部分是原始特征的交叉特征(cross-product transformation),对于交互特征可以定义为:
|
||||
$$
|
||||
\phi_{k}(x)=\prod_{i=1}^d x_i^{c_{ki}}, c_{ki}\in \{0,1\}
|
||||
$$
|
||||
$c_{ki}$是一个布尔变量,当第i个特征属于第k个特征组合时,$c_{ki}$的值为1,否则为0,$x_i$是第i个特征的值,大体意思就是两个特征都同时为1这个新的特征才能为1,否则就是0,说白了就是一个特征组合。用原论文的例子举例:
|
||||
|
||||
> AND(user_installed_app=QQ, impression_app=WeChat),当特征user_installed_app=QQ,和特征impression_app=WeChat取值都为1的时候,组合特征AND(user_installed_app=QQ, impression_app=WeChat)的取值才为1,否则为0。
|
||||
|
||||
对于wide部分训练时候使用的优化器是带$L_1$正则的FTRL算法(Follow-the-regularized-leader),而L1 FTLR是非常注重模型稀疏性质的,也就是说W&D模型采用L1 FTRL是想让Wide部分变得更加的稀疏,即Wide部分的大部分参数都为0,这就大大压缩了模型权重及特征向量的维度。**Wide部分模型训练完之后留下来的特征都是非常重要的,那么模型的“记忆能力”就可以理解为发现"直接的",“暴力的”,“显然的”关联规则的能力。**例如Google W&D期望wide部分发现这样的规则:**用户安装了应用A,此时曝光应用B,用户安装应用B的概率大。**
|
||||
|
||||
- Deep部分是一个DNN模型,输入的特征主要分为两大类,一类是数值特征(可直接输入DNN),一类是类别特征(需要经过Embedding之后才能输入到DNN中),Deep部分的数学形式如下:
|
||||
$$
|
||||
a^{(l+1)} = f(W^{l}a^{(l)} + b^{l})
|
||||
$$
|
||||
**我们知道DNN模型随着层数的增加,中间的特征就越抽象,也就提高了模型的泛化能力。**对于Deep部分的DNN模型作者使用了深度学习常用的优化器AdaGrad,这也是为了使得模型可以得到更精确的解。
|
||||
|
||||
**Wide部分与Deep部分的结合**
|
||||
|
||||
W&D模型是将两部分输出的结果结合起来联合训练,将deep和wide部分的输出重新使用一个逻辑回归模型做最终的预测,输出概率值。联合训练的数学形式如下:需要注意的是,因为Wide侧的数据是高维稀疏的,所以作者使用了FTRL算法优化,而Deep侧使用的是 Adagrad。
|
||||
$$
|
||||
P(Y=1|x)=\delta(w_{wide}^T[x,\phi(x)] + w_{deep}^T a^{(lf)} + b)
|
||||
$$
|
||||
|
||||
## 代码实现
|
||||
|
||||
Wide侧记住的是历史数据中那些**常见、高频**的模式,是推荐系统中的“**红海**”。实际上,Wide侧没有发现新的模式,只是学习到这些模式之间的权重,做一些模式的筛选。正因为Wide侧不能发现新模式,因此我们需要**根据人工经验、业务背景,将我们认为有价值的、显而易见的特征及特征组合,喂入Wide侧**
|
||||
|
||||
Deep侧就是DNN,通过embedding的方式将categorical/id特征映射成稠密向量,让DNN学习到这些特征之间的**深层交叉**,以增强扩展能力。
|
||||
|
||||
模型的实现与模型结构类似由deep和wide两部分组成,这两部分结构所需要的特征在上面已经说过了,针对当前数据集实现,我们在wide部分加入了所有可能的一阶特征,包括数值特征和类别特征的onehot都加进去了,其实也可以加入一些与wide&deep原论文中类似交叉特征。只要能够发现高频、常见模式的特征都可以放在wide侧,对于Deep部分,在本数据中放入了数值特征和类别特征的embedding特征,实际应用也需要根据需求进行选择。
|
||||
|
||||
```python
|
||||
# Wide&Deep 模型的wide部分及Deep部分的特征选择,应该根据实际的业务场景去确定哪些特征应该放在Wide部分,哪些特征应该放在Deep部分
|
||||
def WideNDeep(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
|
||||
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# Wide&Deep模型论文中Wide部分使用的特征比较简单,并且得到的特征非常的稀疏,所以使用了FTRL优化Wide部分(这里没有实现FTRL)
|
||||
# 但是是根据他们业务进行选择的,我们这里将所有可能用到的特征都输入到Wide部分,具体的细节可以根据需求进行修改
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
|
||||
# 在Wide&Deep模型中,deep部分的输入是将dense特征和embedding特征拼在一起输入到dnn中
|
||||
dnn_logits = get_dnn_logits(dense_input_dict, sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
|
||||
|
||||
# 将linear,dnn的logits相加作为最终的logits
|
||||
output_logits = Add()([linear_logits, dnn_logits])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layer = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210228160557072.png" alt="image-20210228160557072" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片Wide&Deep.png" alt="image-20210228160557072" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
1. 在你的应用场景中,哪些特征适合放在Wide侧,哪些特征适合放在Deep侧,为什么呢?
|
||||
2. 为什么Wide部分要用L1 FTRL训练?
|
||||
3. 为什么Deep部分不特别考虑稀疏性的问题?
|
||||
|
||||
思考题可以参考[见微知著,你真的搞懂Google的Wide&Deep模型了吗?](https://zhuanlan.zhihu.com/p/142958834)
|
||||
|
||||
|
||||
**参考资料**
|
||||
- [论文原文](https://arxiv.org/pdf/1606.07792.pdf)
|
||||
- [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
- [看Google如何实现Wide & Deep模型(1)](https://zhuanlan.zhihu.com/p/47293765)
|
||||
- [推荐系统系列(六):Wide&Deep理论与实践](https://zhuanlan.zhihu.com/p/92279796?utm_source=wechat_session&utm_medium=social&utm_oi=753565305866829824&utm_campaign=shareopn)
|
||||
- [见微知著,你真的搞懂Google的Wide&Deep模型了吗?](https://zhuanlan.zhihu.com/p/142958834)
|
||||
- [用NumPy手工打造 Wide & Deep](https://zhuanlan.zhihu.com/p/53110408)
|
||||
- [tensorflow官网的WideDeepModel](https://www.tensorflow.org/versions/r1.15/api_docs/python/tf/keras/experimental/WideDeepModel)
|
||||
- [详解 Wide & Deep 结构背后的动机](https://zhuanlan.zhihu.com/p/53361519)
|
||||
|
||||
@@ -1,565 +0,0 @@
|
||||
## 写在前面
|
||||
xDeepFM(eXtreme DeepFM),这是2018年中科大联合微软在KDD上提出的一个模型,在DeepFM的前面加了一个eXtreme,看这个名字,貌似是DeepFM的加强版,但当我仔细的读完原文之后才发现,如果论血缘关系,这个模型应该离着DCN更近一些,这个模型的改进出发点依然是如何更好的学习特征之间的高阶交互作用,从而挖掘更多的交互信息。而基于这样的动机,作者提出了又一个更powerful的网络来完成特征间的高阶显性交互(DCN的话是一个交叉网络), 这个网络叫做CIN(Compressed Interaction Network),这个网络也是xDeepFM的亮点或者核心创新点了(牛x的地方), 有了这个网络才使得这里的"Deep"变得名副其实。而xDeepFM的模型架构依然是w&D结构,更好的理解方式就是用这个CIN网络代替了DCN里面的Cross Network, 这样使得该网络同时能够显性和隐性的学习特征的高阶交互(显性由CIN完成,隐性由DNN完成)。 那么为啥需要同时学习特征的显性和隐性高阶交互呢? 为啥会用CIN代替Cross Network呢? CIN到底有什么更加强大之处呢? xDeepFM与之前的DeepFM以及FM的关系是怎样的呢? 这些问题都会在后面一一揭晓。
|
||||
|
||||
这篇文章的逻辑和前面一样,首先依然是介绍xDeepFM的理论部分和论文里面的细节,我觉得这篇文章的创新思路还是非常厉害的,也就是CIN的结构,在里面是会看到RNN和CNN的身影的,又会看到Cross Network的身影。所以这个结构我这次也是花了一些时间去理解,花了一些时间找解读文章看, 但讲真,解读文章真没有论文里面讲的清晰,所以我这次整理也是完全基于原论文加上我自己的理解进行解读。 当然,我水平有限,难免有理解不到位的地方,如果发现有错,也麻烦各位大佬帮我指出来呀。这样优秀的一个模型,不管是工业上还是面试里面,也是非常喜欢用或者考的内容,所以后面依然参考deepctr的代码,进行简化版的复现,重点看看CIN结构的实现过程。最后就是简单介绍和小总。
|
||||
|
||||
这篇文章依然比较长,首先是CIN结构本身可能比较难理解,前面需要一定的铺垫任务,比如一些概念(显隐性交叉,bit-wise和vector-wise等), 一些基础模型(FM,FNN,PNN,DNN等),DCN的Cross Network,有了这些铺垫后再理解CIN以及操作会简单些,而CIN本身运算也可能比较复杂,再加上里面时间复杂度和空间复杂度那块的分析,还有后面实验的各个小细节以最后论文还帮助我们串联了各种模型,我想在这篇文章中都整理一下。 再加上模型的复现内容,所以篇幅上还是会很长,各取所需吧还是哈哈。当然这篇文章的重点还是在CIN,这个也是面试里面非常喜欢问的点。
|
||||
|
||||
## xDeepFM? 我们需要先了解这些
|
||||
### 简介与进化动机
|
||||
再具体介绍xDeepFM之前,想先整理点铺垫的知识,也是以前的一些内容,是基于原论文的Introduction部分摘抄了一些,算是对前面内容的一些回顾吧,因为这段时间一直忙着找实习,也已经好久没有写这个系列的相关文章了。所以多少还是有点风格和知识上的遗忘哈哈。
|
||||
|
||||
首先是在推荐系统里面, 一般原始的特征很难让模型学习到隐藏在数据背后的规律,因为推荐系统中的原始特征往往非常稀疏,且维度非常高。所以如果想得到一个好的推荐系统,我们必须尽可能的制作更多的特征出来,而特征组合往往是比较好的方式,毕竟特征一般都不是独立存在的,那么特征究竟怎么组合呢? 这是一个比较值得研究的难题,并且好多学者在这上面也下足了工夫。 如果你说,特征组合是啥来? 不太清楚了呀,那么文章中这个例子正好能解决你的疑问
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210504201748649.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
起初的时候,是人工特征组合,这个往往在作比赛的时候会遇到,就是特征工程里面自己进行某些特征的交叉与组合来生成新的特征。 这样的方式会有几个问题,作者在论文里面总结了:
|
||||
1. 一般需要一些经验和时间才会得到比较好的特征组合,也就是找这样的组合对于人来说有着非常高的要求,无脑组合不可取 --- 需要一定的经验,耗费大量的时间
|
||||
2. 由于推荐系统中数据的维度规模太大了,如果人工进行组合,根本就不太可能实现 --- 特征过多,无法全面顾及特征的组合
|
||||
3. 手工制作的特征也没有一定的泛化能力,而恰巧推荐系统中的数据往往又非常稀疏 --- 手工组合无泛化能力
|
||||
|
||||
所以,让**模型自动的进行特征交叉组合**探索成了推荐模型里面的比较重要的一个任务,还记得吗? 这个也是模型进化的方向之一,之所以从前面进行引出,是因为本质上这篇的主角xDeepFM也是从这个方向上进行的探索, 那么既然又探索,那也说明了前面模型在这方面还有一定的问题,那么我们就来再综合理一理。
|
||||
|
||||
1. FM模型: 这个模型能够自动学习特征之间的两两交叉,并且比较厉害的地方就是用特征的隐向量内积去表示两两交叉后特征的重要程度,这使得模型在学习交互信息的同时,也让模型有了一定的泛化能力。 But,这个模型也有缺点,首先一般是只能应付特征的两两交叉,再高阶一点的交叉虽然行,但计算复杂,并且作者在论文中提到了高阶交叉的FM模型是不管有用还是无用的交叉都建模,这往往会带来一定的噪声。
|
||||
2. DNN模型: 这个非常熟悉了,深度学习到来之后,推荐模型的演化都朝着DNN的时代去了,原因之一就是因为DNN的多层神经网络可以比较出色的完成特征之间的高阶交互,只需要增加网络的层数,就可以轻松的学习交互,这是DNN的优势所在。 比较有代表的模型PNN,DeepCrossing模型等。 But, DNN并不是非常可靠,有下面几个问题。
|
||||
1. 首先,DNN的这种特征交互是隐性的,后面会具体说显隐性交互区别,但直观上理解,这种隐性交互我们是无法看到到底特征之间是怎么交互的,具体交互到了几阶,这些都是带有一定的不可解释性。
|
||||
2. 其次,DNN是bit-wise层级的交叉,关于bit-wise,后面会说,这种方式论文里面说一个embedding向量里面的各个元素也会相互影响, 这样我觉得在这里带来的一个问题就是可能会发生过拟合。 因为我们知道embedding向量的表示方法就是想从不同的角度去看待某个商品(比如颜色,价格,质地等),当然embedding各个维度是无可解释性的,但我们还是希望这各个维度更加独立一点好,也就是相关性不那么大为妙,这样的话往往能更加表示出各个商品的区别来。 但如果这各个维度上的元素也互相影响了(神经网络会把这个也学习进去), 那过拟合的风险会变大。当然,上面这个是我自己的感觉, 原作者只是给了这样一段:<br>
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/2021050420491452.png#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
也就是**DNN是否能够真正的有效学习特征之间的高阶交互是个谜!**
|
||||
3. DNN还存在的问题就是学习高阶交互或许是可能,但没法再兼顾低阶交互,也就是记忆能力,所以后面w&D架构在成为了主流架构。
|
||||
3. Wide&Deep, DeepFM模型: 这两个模型是既有DNN的深度,也有FM或者传统模型的广度,兼顾记忆能力和泛化能力,也是后面的主流模型。但依然有不足之处,wide&Deep的话不用多讲,首先逻辑回归(宽度部分)仍然需要人工特征交叉,而深度部分的高阶交叉又是一个谜。 DeepFM的话是FM和DNN的组合,用FM替代了逻辑回归,这样至少是模型的自动交叉特征,结合了FM的二阶以及DNN的高阶交叉能力。 但如果DNN这块高度交叉是个谜的话,就有点玄乎了。
|
||||
4. DCN网络: 这个模型也是w&D架构,不过宽度那部分使用了一个Cross Network,这个网络的奇妙之处,就是扩展了FM这种只能显性交叉的二阶的模型, 通过交叉网络能真正的显性的进行特征间的高阶交叉。 具体结构后面还会在复习,毕竟这次的xdeepFM主要是在Cross Network的基础上进行的再升级,这也是为啥说论血缘关系,xdeepFM离DCN更近一些的原因。那么Cross network有啥问题呢? 这个想放在后面的2.4去说了,这样能更好的引出本篇主角来。
|
||||
|
||||
通过上面的一个梳理,首先是回忆起了前面这几个模型的发展脉络, 其次差不多也能明白xDeepFM到底再干个什么事情了,或者要解决啥问题了,xDeepFM其实简单的说,依然是研究如何自动的进行特征之间的交叉组合,以让模型学习的更好。 从上面这段梳理中,我们至少要得到3个重要信息:
|
||||
|
||||
1. 推荐模型如何有效的学习特征的交叉组合信息是非常重要的, 而原始的人工特征交叉组合不可取,如何让模型自动的学习交叉组合信息就变得非常关键
|
||||
2. 有的模型(FM)可以显性的交叉特征, 但往往没法高阶,只能到二阶
|
||||
3. 有的模型(DNN)可以进行高阶的特征交互,但往往是以一种无法解释的方式(隐性高阶交互),并且是bit-wise的形式,能不能真正的学习到高阶交互其实是个谜。
|
||||
4. 有的模型(DCN)探索了显性的高阶交叉特征,但仍然存在一些问题。
|
||||
|
||||
所以xDeepFM的改进动机来了: 更有效的高阶显性交叉特征(CIN),更高的泛化能力(vector-wise), 显性和隐性高阶特征的组合(CIN+DNN), 这就是xDeepFM了, 而这里面的关键,就是CIN网络了。在这之前,还是先把准备工作做足。
|
||||
|
||||
### Embedding Layer
|
||||
这个是为了回顾一下,简单一说,我们拿到的数据往往会有连续型数据和离散型或者叫类别型数据之分。 如果是连续型数据,那个不用多说,一般会归一化或者标准化处理,当然还可能进行一定的非线性化操作,就算处理完了。 而类别型数据,一般需要先LabelEncoder,转成类别型编码,然后再one-hot转成0或者1的编码格式。 比如论文里面的这个例子:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210504212842660.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
这样的数据往往是高维稀疏的,不利于模型的学习,所以往往在这样数据之后,加一个embedding层,把数据转成低维稠密的向量表示。 关于embedding的原理这里不说了,但这里要注意一个细节,就是如果某个特征每个样本只有一种取值,也就是one-hot里面只有一个地方是1,比如前面3个field。这时候,可以直接拿1所在位置的embedding当做此时类别特征的embedding向量。 但是如果某个特征域每个样本好多种取值,比如interests这个,有好几个1的这种,那么就拿到1所在位置的embedding向量之后**求和**来代表该类别特征的embedding。这样,经过embedding层之后,我们得到的数据成下面这样了:
|
||||
$$
|
||||
\mathbf{e}=\left[\mathbf{e}_{1}, \mathbf{e}_{2}, \ldots, \mathbf{e}_{m}\right]
|
||||
$$
|
||||
这个应该比较好理解,$e_i$表示的一个向量,一般是$D$维的(隐向量的维度), 那么假设$m$表示特征域的个数,那么此时的$\mathbf{e}$是$m\times D$的矩阵。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210504213606429.png#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
### bit-wise VS vector-wise
|
||||
这是特征交互的两种方式,需要了解下,因为论文里面的CIN结构是在vector-wise上完成特征交互的, 这里拿从网上找到的一个例子来解释概念。
|
||||
|
||||
假设隐向量的维度是3维, 如果两个特征对应的向量分别是$(a_1, b_1, c_1)$和$(a_2,b_2, c_2)$
|
||||
|
||||
1. bit-wise = element-wise
|
||||
在进行交互时,交互的形式类似于$f(w_1a_1a_2, w_2b_1b_2,w_3c_1c_2)$,此时我们认为特征交互发生在元素级别上,bit-wise的交互是以bit为最小单元的,也就是向量的每一位上交互,且学习一个$w_i$
|
||||
2. vector-wise
|
||||
如果特征交互形式类似于$f(w(a_1a_2,b_1b_2,c_1c_2))$, 我们认为特征交互发生在向量级别上,vector-wise交互是以整个向量为最小单元的,向量层级的交互,为交互完的向量学习一个统一的$w$
|
||||
|
||||
这个一直没弄明白后者为什么会比前者好,我也在讨论群里问过这个问题,下面是得到的一个伙伴的想法:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210504214822820.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
对于这个问题有想法的伙伴,也欢迎在下面评论,我自己的想法是bit-wise看上面的定义,仿佛是在元素的级别交叉,然后学习权重, 而vector-wise是在向量的级别交叉,然后学习统一权重,bit-wise具体到了元素级别上,虽然可能学习的更加细致,但这样应该会增加过拟合的风险,失去一定的泛化能力,再联想作者在论文里面解释的bit-wise:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210504215106707.png#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
更觉得这个想法会有一定的合理性,就想我在DNN那里解释这个一样,把细节学的太细,就看不到整体了,佛曰:着相了哈哈。如果再联想下FM的设计初衷,FM是一个vector-wise的模型,它进行了显性的二阶特征交叉,却是embedding级别的交互,这样的好处是有一定的泛化能力到看不见的特征交互。 emmm, 我在后面整理Cross Network问题的时候,突然悟了一下, bit-wise最大的问题其实在于**违背了特征交互的初衷**, 我们本意上其实是让模型学习特征之间的交互,放到embedding的角度,也理应是embedding与embedding的相关作用交互, 但bit-wise已经没有了embedding的概念,以bit为最细粒度进行学习, 这里面既有不同embedding的bit交互,也有同一embedding的bit交互,已经**意识不到Field vector的概念**。 具体可以看Cross Network那里的解释,分析了Cross Network之后,可能会更好理解些。
|
||||
|
||||
这个问题最好是先这样理解或者自己思考下,因为xDeepFM的一个挺大的亮点就是保留了FM的这种vector-wise的特征交互模式,也是作者一直强调的,vector-wise应该是要比bit-wise要好的,否则作者就不会强调Cross Network的弊端之一就是bit-wise,而改进的方法就是设计了CIN,用的是vector-wise。
|
||||
|
||||
### 高阶隐性特征交互(DNN) VS 高阶显性特征交互(Cross Network)
|
||||
#### DNN的隐性高阶交互
|
||||
DNN非常擅长学习特征之间的高阶交互信息,但是隐性的,这个比较好理解了,前面也提到过:
|
||||
$$
|
||||
\begin{array}{c}
|
||||
\mathbf{x}^{1}=\sigma\left(\mathbf{W}^{(1)} \mathbf{e}+\mathbf{b}^{1}\right) \\
|
||||
\mathbf{x}^{k}=\sigma\left(\mathbf{W}^{(k)} \mathbf{x}^{(k-1)}+\mathbf{b}^{k}\right)
|
||||
\end{array}
|
||||
$$
|
||||
但是问题的话,前面也剖析过了, 简单总结:
|
||||
1. DNN 是一种隐性的方式学习特征交互, 但这种交互是不可解释性的, 没法看出究竟是学习了几阶的特征交互
|
||||
2. DNN是在bit-wise层级上学习的特征交互, 这个不同于传统的FM的vector-wise
|
||||
3. DNN是否能有效的学习高阶特征交互是个迷,其实不知道学习了多少重要的高阶交互,哪些高阶交互会有作用,高阶到了几阶等, 如果用的话,只能靠玄学二字来解释
|
||||
|
||||
#### Cross Network的显性高阶交互
|
||||
谈到显性高阶交互,这里就必须先分析一下我们大名鼎鼎的DCN网络的Cross Network了, 关于这个模型,我在[AI上推荐 之 Wide&Deep与Deep&Cross模型](https://blog.csdn.net/wuzhongqiang/article/details/109254498)文章中进行了一些剖析,这里再复习的话我又参考了一个大佬的文章,因为再把我之前的拿过来感觉没有啥意思,重新再阅读别人的文章很可能会再get新的点,于是乎还真的学习到了新东西,具体链接放到了下面。 这里我们重温下Cross Network,看看到底啥子叫显性高阶交互。再根据论文看看这样子的交互有啥问题。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210505200049781.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
这里的输入$x_0$需要提醒下,首先对于离散的特征,需要进行embedding, 对于multi-hot的离散变量, 需要embedding之后再做一个简单的average pooling, 而dense特征,归一化, **然后和embedding的特征拼接到一块作为Cross层和Deep层的输入,也就是Dense特征会在这里进行拼接**。 下面回顾Cross Layer。
|
||||
|
||||
Cross的目的是一一种显性、可控且高效的方式,**自动**构造**有限高阶**交叉特征。 具体的公式如下:
|
||||
$$
|
||||
\boldsymbol{x}_{l+1}=\boldsymbol{x}_{0} \boldsymbol{x}_{l}^{T} \boldsymbol{w}_{l}+\boldsymbol{b}_{l}+\boldsymbol{x}_{l}=f\left(\boldsymbol{x}_{l}, \boldsymbol{w}_{l}, \boldsymbol{b}_{l}\right)+\boldsymbol{x}_{l}
|
||||
$$
|
||||
其中$\boldsymbol{x}_{l+1}, \boldsymbol{x}_{l}, \boldsymbol{x}_{0} \in \mathbb{R}^{d}$。有图有真相:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20201026200320611.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
Cross Layer的巧妙之处全部体现在上面的公式,下面放张图是为了更好的理解,这里我们回顾一些细节。
|
||||
1. 每层的神经元个数相同,都等于输入$\boldsymbol{x}_0$的维度$d$, 即每层的输入和输出维度是相等的(这个之前没有整理,没注意到)
|
||||
2. 残差网络的结构启发,每层的函数$\boldsymbol{f}$拟合的是$\boldsymbol{x}_{l+1}-\boldsymbol{x}_l$的残差,残差网络有很多优点,其中一个是处理梯度消失的问题,可以使得网络更“深”
|
||||
|
||||
那么显性交叉到底体会到哪里呢? 还是拿我之前举的那个例子:假设$\boldsymbol{x}_{0}=\left[\begin{array}{l}x_{0,1} \\ x_{0,2}\end{array}\right]$, 为了讨论各层,先令$\boldsymbol{b}_i=0$, 则
|
||||
|
||||
$$
|
||||
\boldsymbol{x}_{1}=\boldsymbol{x}_{0} \boldsymbol{x}_{0}^{T} \boldsymbol{w}_{0}+\boldsymbol{x}_{0}=\left[\begin{array}{l}
|
||||
x_{0,1} \\
|
||||
x_{0,2}
|
||||
\end{array}\right]\left[x_{0,1}, x_{0,2}\right]\left[\begin{array}{c}
|
||||
w_{0,1} \\
|
||||
w_{0,2}
|
||||
\end{array}\right]+\left[\begin{array}{l}
|
||||
x_{0,1} \\
|
||||
x_{0,2}
|
||||
\end{array}\right]=\left[\begin{array}{l}
|
||||
w_{0,1} x_{0,1}^{2}+w_{0,2} x_{0,1} x_{0,2}+x_{0,1} \\
|
||||
w_{0,1} x_{0,2} x_{0,1}+w_{0,2} x_{0,2}^{2}+x_{0,2}
|
||||
\end{array}\right] \\
|
||||
\begin{aligned}
|
||||
\boldsymbol{x}_{2}=& \boldsymbol{x}_{0} \boldsymbol{x}_{1}^{T} \boldsymbol{w}_{1}+\boldsymbol{x}_{1} \\
|
||||
=&\left[\begin{array}{l}
|
||||
w_{1,1} x_{0,1} x_{1,1}+w_{1,2} x_{0,1} x_{1,2}+x_{1,1} \\
|
||||
\left.w_{1,1} x_{0,2} x_{1,1}+w_{1,2} x_{0,2} x_{1,2}+x_{1,2}\right]
|
||||
\end{array}\right. \\
|
||||
&=\left[\begin{array}{l}
|
||||
\left.w_{0,1} w_{1,1} x_{0,1}^{3}+\left(w_{0,2} w_{1,1}+w_{0,1} w_{1,2}\right) x_{0,1}^{2} x_{0,2}+w_{0,2} w_{1,2} x_{0,1} x_{0,2}^{2}+\left(w_{0,1}+w_{1,1}\right) x_{0,1}^{2}+\left(w_{0,2}+w_{1,2}\right) x_{0,1} x_{0,2}+x_{0,1}\right] \\
|
||||
\ldots \ldots \ldots .
|
||||
\end{array}\right.
|
||||
\end{aligned}
|
||||
$$
|
||||
最后得到$y_{\text {cross }}=\boldsymbol{x}_{2}^{T} * \boldsymbol{w}_{\text {cross }} \in \mathbb{R}$参与到最后的loss计算。 可以看到$\boldsymbol{x}_1$包含了原始特征$x_{0,1},x_{0,2}$从一阶导二阶所有可能叉乘组合, 而$\boldsymbol{x}_2$包含了从一阶导三阶素有可能的叉乘组合, 而**显性特征组合的意思,就是最终的结果可以经过一系列转换,得到类似$W_{i,j}x_ix_j$的形式**, 上面这个可以说是非常明显了吧。
|
||||
1. **有限高阶**: 叉乘**阶数由网络深度决定**, 深度$L_c$对应最高$L_c+1$阶的叉乘
|
||||
2. **自动叉乘**:Cross输出包含了原始从一阶(本身)到$L_c+1$阶的**所有叉乘组合**, 而模型参数量仅仅随着输入维度**线性增长**:$2\times d\times L_c$
|
||||
3. **参数共享**: 不同叉乘项对应的权重不同,但并非每个叉乘组合对应独立的权重,通过参数共享,Cross有效**降低了参数数量**。 并且,使得模型有更强的**泛化性**和**鲁棒性**。例如,如果独立训练权重,当训练集中$x_{i} \neq 0 \wedge x_{j} \neq 0$这个叉乘特征没有出现,对应权重肯定是0,而参数共享不会,类似的,数据集中的一些噪声可以由大部分样本来纠正权重参数的学习
|
||||
|
||||
这里有一点很值得留意,前面介绍过,文中将dense特征和embedding特征拼接后作为Cross层和Deep层的共同输入。这对于Deep层是合理的,但我们知道人工交叉特征基本是对原始sparse特征进行叉乘,那为何不直接用原始sparse特征作为Cross的输入呢?联系这里介绍的Cross设计,每层layer的节点数都与Cross的输入维度一致的,**直接使用大规模高维的sparse特征作为输入,会导致极大地增加Cross的参数量**。当然,可以畅想一下,其实直接拿原始sparse特征喂给Cross层,才是论文真正宣称的“省去人工叉乘”的更完美实现,但是现实条件不太允许。所以将高维sparse特征转化为低维的embedding,再喂给Cross,实则是一种**trade-off**的可行选择。
|
||||
|
||||
看下DNN与Cross Network的参数量对比: <br><br>初始输入$x_0$维度是$d$, Deep和Cross层数分别为$L_{cross}$和$L_{deep}$, 为便于分析,设Deep每层神经元个数为$m$则两部分参数量:
|
||||
$$
|
||||
\text { Cross: } d * L_{\text {cross }} * 2 \quad V S \quad \text { Deep: }(d * m+m)+\left(m^{2}+m\right) *\left(L_{\text {deep }}-1\right)
|
||||
$$
|
||||
可以看到Cross的参数量随$d$增大仅呈“线性增长”!相比于Deep部分,对整体模型的复杂度影响不大,这得益于Cross的特殊网络设计,对于模型在业界落地并实际上线来说,这是一个相当诱人的特点。Deep那部分参数计算其实是第一层单算$m(d+1)$, 接下来的$L-1$层,每层都是$m$, 再加上$b$个个数,所以$m(m+1)$。
|
||||
|
||||
好了, Cross的好处啥的都分析完了, 下面得分析点不好的地方了,否则就没法引出这次的主角了。作者直接说:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210505195118178.png#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
每一层学习到的是$\boldsymbol{x}_0$的标量倍,这是啥意思。 这里有一个理论:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/202105051955220.png#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
这里作者用数学归纳法进行了证明。
|
||||
|
||||
当$k=1$的时候
|
||||
$$
|
||||
\begin{aligned}
|
||||
\mathbf{x}_{1} &=\mathbf{x}_{0}\left(\mathbf{x}_{0}^{T} \mathbf{w}_{1}\right)+\mathbf{x}_{0} \\
|
||||
&=\mathbf{x}_{0}\left(\mathbf{x}_{0}^{T} \mathbf{w}_{1}+1\right) \\
|
||||
&=\alpha^{1} \mathbf{x}_{0}
|
||||
\end{aligned}
|
||||
$$
|
||||
这里的$\alpha^{1}=\mathbf{x}_{0}^{T} \mathbf{w}_{1}+1$是$x_0$的一个线性回归, $x_1$是$x_0$的标量倍成立。 假设当$k=i$的时候也成立,那么$k=i+1$的时候:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\mathbf{x}_{i+1} &=\mathbf{x}_{0} \mathbf{x}_{i}^{T} \mathbf{w}_{i+1}+\mathbf{x}_{i} \\
|
||||
&=\mathbf{x}_{0}\left(\left(\alpha^{i} \mathbf{x}_{0}\right)^{T} \mathbf{w}_{i+1}\right)+\alpha^{i} \mathbf{x}_{0} \\
|
||||
&=\alpha^{i+1} \mathbf{x}_{0}
|
||||
\end{aligned}
|
||||
$$
|
||||
其中$\alpha^{i+1}=\alpha^{i}\left(\mathbf{x}_{0}^{T} \mathbf{w}_{i+1}+1\right)$, 即$x_{i+1}$依然是$x_0$的标量倍。
|
||||
|
||||
所以作者认为Cross Network有两个缺点:
|
||||
1. 由于每个隐藏层是$x_0$的标量倍,所以CrossNet的输出受到了特定形式的限制
|
||||
2. CrossNet的特征交互是bit-wise的方式(这个经过上面举例子应该是显然了),这种方式embedding向量的各个元素也会互相影响,这样在泛化能力上可能受到限制,并且也**意识不到Field Vector的概念**, **这其实违背了我们特征之间相互交叉的初衷**。因为我们想让模型学习的是特征与特征之间的交互或者是相关性,从embedding的角度,,那么自然的特征与特征之间的交互信息应该是embedding与embedding的交互信息。 但是**bit-wise的交互上,已经意识不到embedding的概念了**。由于最细粒度是bit(embedding的具体元素),所以这样的交互既包括了不同embedding不同元素之间的交互,也包括了同一embedding不同元素的交互。本质上其实发生了改变。 **这也是作者为啥强调CIN网络是vector-wise的原因**。而FM,恰好是以向量为最细粒度学习相关性。
|
||||
|
||||
好了, 如果真正理解了Cross Network,以及上面存在的两个问题,理解xDeepFM的动机就不难了,**xDeepFM的动机,正是将FM的vector-wise的思想引入到了Cross部分**。
|
||||
|
||||
下面主角登场了:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210505201840211.png#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
## xDeepFM模型的理论以及论文细节
|
||||
了解了xDeepFM的动机,再强调下xDeepFM的核心,就是提出的一个新的Cross Network(CIN),这个是基于DCN的Cross Network,但是有上面那几点好处。下面的逻辑打算是这样,首先先整体看下xDeepFM的模型架构,由于我们已经知道了这里其实就是用一个CIN网络代替了DCN的Cross Network,那么这里面除了这个网络,其他的我们都熟悉。 然后我们再重点看看CIN网络到底在干个什么样的事情,然后再看看CIN与FM等有啥关系,最后分析下这个新网络的时间复杂度等问题。
|
||||
### xDeepFM的架构剖析
|
||||
首先,我们先看下xDeepFM的架构
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/2021050520373226.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
这个网络结构名副其实,依然是采用了W&D架构,DNN负责Deep端,学习特征之间的隐性高阶交互, 而CIN网络负责wide端,学习特征之间的显性高阶交互,这样显隐性高阶交互就在这个模型里面体现的淋漓尽致了。不过这里的线性层单拿出来了。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210505204057446.png#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
最终的计算公式如下:
|
||||
$$
|
||||
\hat{y}=\sigma\left(\mathbf{w}_{\text {linear }}^{T} \mathbf{a}+\mathbf{w}_{d n n}^{T} \mathbf{x}_{d n n}^{k}+\mathbf{w}_{\text {cin }}^{T} \mathbf{p}^{+}+b\right)
|
||||
$$
|
||||
这里的$\mathbf{a}$表示原始的特征,$\mathbf{a}_{dnn}^k$表示的是DNN的输出, $\mathbf{p}^+$表示的是CIN的输出。最终的损失依然是交叉熵损失,这里也是做一个点击率预测的问题:
|
||||
$$
|
||||
\mathcal{L}=-\frac{1}{N} \sum_{i=1}^{N} y_{i} \log \hat{y}_{i}+\left(1-y_{i}\right) \log \left(1-\hat{y}_{i}\right)
|
||||
$$
|
||||
最终的目标函数加了正则化:
|
||||
$$
|
||||
\mathcal{J}=\mathcal{L}+\lambda_{*}\|\Theta\|
|
||||
$$
|
||||
|
||||
### CIN网络的细节(重头戏)
|
||||
这里尝试剖析下本篇论文的主角CIN网络,全称Compressed Interaction Network。这个东西说白了其实也是一个网络,并不是什么高大上的东西,和Cross Network一样,也是一层一层,每一层都是基于一个固定的公式进行的计算,那个公式长这样:
|
||||
$$
|
||||
\mathbf{X}_{h, *}^{k}=\sum_{i=1}^{H_{k-1}} \sum_{j=1}^{m} \mathbf{W}_{i j}^{k, h}\left(\mathbf{X}_{i, *}^{k-1} \circ \mathbf{X}_{j, *}^{0}\right)
|
||||
$$
|
||||
这个公式第一眼看过来,肯定更是懵逼,这是写的个啥玩意?如果我再把CIN的三个核心图放上来:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/2021050520530391.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
上面其实就是CIN网络的精髓了,也是它具体的运算过程,只不过直接上图的话,会有些抽象,难以理解,也不符合我整理论文的习惯。下面,我们就一一进行剖析, 先从上面这个公式开始。但在这之前,需要先约定一些符号。要不然不知道代表啥意思。
|
||||
1. $\mathbf{X}^{0} \in \mathbb{R}^{m \times D}$: 这个就是我们的输入,也就是embedding层的输出,可以理解为各个embedding的堆叠而成的矩阵,假设有$m$个特征,embedding的维度是$D$维,那么这样就得到了这样的矩阵, $m$行$D$列。$\mathbf{X}_{i, *}^{0}=\mathbf{e}_{i}$, 这个表示的是第$i$个特征的embedding向量$e_i$。所以上标在这里表示的是网络的层数,输入可以看做第0层,而下标表示的第几行的embedding向量,这个清楚了。
|
||||
2. $\mathbf{X}^{k} \in \mathbb{R}^{H_{k} \times D}$: 这个表示的是CIN网络第$k$层的输出,和上面这个一样,也是一个矩阵,每一行是一个embedding向量,每一列代表一个embedding维度。这里的$H_k$表示的是第$k$层特征的数量,也可以理解为神经元个数。那么显然,这个$\mathbf{X}^{k}$就是$H_k$个$D$为向量堆叠而成的矩阵,维度也显然了。$\mathbf{X}_{h, *}^{k}$代表的就是第$k$层第$h$个特征向量了。
|
||||
|
||||
所以上面的那个公式:
|
||||
$$
|
||||
\mathbf{X}_{h, *}^{k}=\sum_{i=1}^{H_{k-1}} \sum_{j=1}^{m} \mathbf{W}_{i j}^{k, h}\left(\mathbf{X}_{i, *}^{k-1} \circ \mathbf{X}_{j, *}^{0}\right)
|
||||
$$
|
||||
其实就是计算第$k$层第$h$个特征向量, 这里的$1 \leq h \leq H_{k}, \mathbf{W}^{k, h} \in \mathbb{R}^{H_{k-1} \times m}$是第$h$个特征向量的参数矩阵。 $\circ$表示的哈达玛积,也就是向量之间对应维度元素相乘(不相加了)。$\left\langle a_{1}, a_{2}, a_{3}\right\rangle \circ\left\langle b_{1}, b_{2}, b_{3}\right\rangle=\left\langle a_{1} b_{1}, a_{2} b_{2}, a_{3} b_{3}\right\rangle$。通过这个公式也能看到$\mathbf{X}^k$是通过$\mathbf{X}^{k-1}$和$\mathbf{X}^0$计算得来的,也就是说特征的显性交互阶数会虽然网络层数的加深而增加。
|
||||
|
||||
那么这个公式到底表示的啥意思呢? 是具体怎么计算的呢?我们往前计算一层就知道了,这里令$k=1$,也就是尝试计算第一层里面的第$h$个向量, 那么上面公式就变成了:
|
||||
|
||||
$$
|
||||
\mathbf{X}_{h, *}^{1}=\sum_{i=1}^{H_{0}} \sum_{j=1}^{m} \mathbf{W}_{i j}^{1, h}\left(\mathbf{X}_{i, *}^{0} \circ \mathbf{X}_{j, *}^{0}\right)
|
||||
$$
|
||||
这里的$\mathbf{W}^{1, h} \in \mathbb{R}^{H_{0} \times m}$。这个能看懂吗? 首先这个$\mathbf{W}$矩阵是$H_0$行$m$列, 而前面那两个累加正好也是$H_0$行$m$列的参数。$m$代表的是输入特征的个数, $H_0$代表的是第0层($k-1$层)的神经元的个数, 这个也是$m$。这个应该好理解,输入层就是第0层。所以这其实就是一个$m\times m$的矩阵。那么后面这个运算到底是怎么算的呢? 首先对于第$i$个特征向量, 要依次和其他的$m$个特征向量做哈达玛积操作,当然也乘以对应位置的权重,求和。对于每个$i$特征向量,都重复这样的操作,最终求和得到一个$D$维的向量,这个就是$\mathbf{X}_{h, *}^{1}$。好吧,这么说。我觉得应该也没有啥感觉,画一下就了然了,现在可以先不用管论文里面是怎么说的,先跟着这个思路走,只要理解了这个公式是怎么计算的,论文里面的那三个图就会非常清晰了。灵魂画手:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210505215026537.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
这就是上面那个公式的具体过程了,图实在是太难看了, 但应该能说明这个详细的过程了。这样只要给定一个$\mathbf{W}^{1,h}$之后,就能算出一个相应的$\mathbf{X}^1_{h,*}$来,这样第一层的$H_1$个神经元按照这样的步骤就能够都计算出来了。 后面的计算过程其实是同理,无非就是输入是前一层的输出以及$\mathbf{X}_0$罢了,而这时候,第一个矩阵特征数就不一定是$m$了,而是一个$H_{k-1}$行$D$列的矩阵了。这里的$\mathbf{W}^{k,h}$就是上面写的$H_{k-1}$行$m$列了。
|
||||
|
||||
这个过程明白了之后,再看论文后面的内容就相对容易了,首先
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210505215629371.png#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
CIN里面能看到RNN的身影,也就是当前层的隐藏单元的计算要依赖于上一层以及当前的输入层,只不过这里的当前输入每个时间步都是$\mathbf{X}_0$。 同时这里也能看到,CIN的计算是vector-wise级别的,也就是向量之间的哈达玛积的操作,并没有涉及到具体向量里面的位交叉。
|
||||
|
||||
下面我们再从CNN的角度去看这个计算过程。其实还是和上面一样的计算过程,只不过是换了个角度看而已,所以上面那个只要能理解,下面CNN也容易理解了。首先,这里引入了一个tensor张量$\mathbf{Z}^{k+1}$表示的是$\mathbf{X}^k$和$\mathbf{X}^0$的外积,那么这个东西是啥呢? 上面加权求和前的那个矩阵,是一个三维的张量。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210505221222945.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
这个可以看成是一个三维的图片,$H_{k-1}$高,$m$宽,$D$个通道。而$\mathbf{W}^{k,h}$的大小是$H_{k-1}\times m$的, 这个就相当于一个过滤器,用这个过滤器对输入的图片如果**逐通道进行卷积**,就会最终得到一个$D$维的向量,而这个其实就是$\mathbf{X}^{k}_{h,*}$,也就是一张特征图(每个通道过滤器是共享的)。 第$k$层其实有$H_k$个这样的过滤器,所以最后得到的是一个$H_k\times D$的矩阵。这样,在第$k$个隐藏层,就把了$H_{k-1}\times m\times D$的三维张量通过逐通道卷积的方式,压缩成了一个$H_k\times D$的矩阵($H_k$张特征图), 这就是第$k$层的输出$\mathbf{X}^k$。 而这也就是“compressed"的由来。这时候再看这两个图就非常舒服了:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210505222742858.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
通过这样的一个CIN网络,就很容易的实现了特征的显性高阶交互,并且是vector-wise级别的,那么最终的输出层是啥呢? 通过上面的分析,首先我们了解了对于第$k$层输出的某个特征向量,其实是综合了输入里面各个embedding向量显性高阶交互的信息(第$k$层其实学习的输入embedding$k+1$阶交互信息),这个看第一层那个输出就能看出来。第$k$层的每个特征向量其实都能学习到这样的信息,那么如果把这些向量在从$D$维度上进行加和,也就是$\mathbf{X}^k$,这是个$H_k\times D$的,我们沿着D这个维度加和,又会得到一个$H_k$的向量,公式如下:
|
||||
$$
|
||||
p_{i}^{k}=\sum_{j=1}^{D} \mathbf{X}_{i, j}^{k}
|
||||
$$
|
||||
每一层,都会得到一个这样的向量,那么把所有的向量拼接到一块,其实就是CIN网络的输出了。之所以,这里要把中间结果都与输出层相连,就是因为CIN与Cross不同的一点是,在第$k$层,CIN只包含$k+1$阶的组合特征,而Cross是能包含从1阶-$k+1$阶的组合特征的,所以为了让模型学习到从1阶到所有阶的组合特征,CIN这里需要把中间层的结果与输出层建立连接。
|
||||
|
||||
这也就是第三个图表示的含义:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210505223705748.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
这样, 就得到了最终CIN的输出$\mathbf{p}^+$了:
|
||||
|
||||
$$
|
||||
\mathbf{p}^{+}=\left[\mathbf{p}^{1}, \mathbf{p}^{2}, \ldots, \mathbf{p}^{T}\right] \in \mathbb{R} \sum_{i=1}^{T} H_{i}
|
||||
$$
|
||||
后面那个维度的意思,就是说每一层是的向量维度是$H_i$维, 最后是所有时间步的维度之和。 CIN网络的计算过程的细节就是这些了。
|
||||
|
||||
### CIN网络的其他角度分析
|
||||
#### 设计意图分析
|
||||
CIN和DCN层的设计动机是相似的,Cross层的input也是前一层与输入层,这么做的原因就是可以实现: **有限高阶交互,自动叉乘和参数共享**。
|
||||
|
||||
但是CIN与Cross的有些地方是不一样的:
|
||||
1. Cross是bit-wise级别的, 而CIN是vector-wise级别的
|
||||
2. 在第$l$层,Cross包含从1阶-$l+1$阶的所有组合特征, 而CIN只包含$l+1$阶的组合特征。 相应的,Cross在输出层输出全部结果, 而CIN在每层都输出中间结果。 而之所以会造成这两者的不同, 就是因为Cross层计算公式中除了与CIN一样包含"上一层与输入层的×乘"外,会再额外加了个"+输入层"。**这是两种涵盖所有阶特征交互的不同策略,CIN和Cross也可以使用对方的策略**。
|
||||
|
||||
#### 时间和空间复杂度分析
|
||||
1. 空间复杂度
|
||||
假设CIN和DNN每层神经元个数是$H$,网络深度为$T$。 那么CIN的参数空间复杂度$O(mTH^2)$。 这个我们先捋捋是怎么算的哈, 首先对于CIN,第$k$层的每个神经元都会对应着一个$H_{k-1}\times m$的参数矩阵$\mathbf{W}^{k,h}$, 那么第$k$层$H$个神经元的话,那就是$H \times H_{k-1} \times m$个参数,这里假设的是每层都有$H$个神经元,那么就是$O(H^2\times m)$,这是一层。 而网络深度一共$T$层的话,那就是$H \times H_{k-1} \times m\times T$的规模。 但别忘了,输出层还有参数, 由于输出层的参数会和输出向量的维度相对应,而输出向量的维度又和每一层神经单元个数相对应, 所以CIN的网络参数一共是$\sum_{k=1}^{T} H_{k} \times\left(1+H_{k-1} \times m\right)$, 而换成大O表示的话,其实就是上面那个了。当然,CIN还可以对$\mathbf{W}$进行$L$阶矩阵分解,使得空间复杂度再降低。 <br><br>再看DNN,第一层是$m\times D\times H_1$, 中间层$H_k\times H_{k-1}$,T-1层,这是一个$O(mDH+TH^2)$的空间复杂度,并且参数量会随着$D$的增加而增加。 <br><br>所以空间上来说,CIN会有优势。
|
||||
2. 时间复杂度
|
||||
对于CIN, 我们计算某一层的某个特征向量的时候,需要前面的$H_{k-1}$个向量与输入的$m$个向量两两哈达玛积的操作,这个过程花费的时间$O(Hm)$, 而哈达玛积完事之后,有需要拿个过滤器在D维度上逐通道卷积,这时候得到了$\mathbf{Z}^{k+1}$,花费时间$O(HmD)$。 这只是某个特征向量, $k$层一共$H$个向量, 那么花费时间$O(H^2mD)$, 而一共$T$层,所以最终时间为$O(mH^2TD)$<br><br>对于普通的DNN,花费时间$O(mHD+H^2T)$<br><br>**所以时间复杂度会是CIN的一大痛点**。
|
||||
|
||||
#### 多项式逼近
|
||||
这地方没怎么看懂,大体写写吧, 通过对问题进行简化,即假设CIN中不同层的feature map的数量全部一致,均为fields的数量$m$,并且用`[m]`表示小于等于m的正整数。CIN中的第一层的第$h$个feature map表示为$x_h^1 \in \mathbb{R}^D$,即
|
||||
$$
|
||||
\boldsymbol{x}_{\boldsymbol{h}}^{1}=\sum_{i \in[m], j \in[m]} \boldsymbol{W}_{i, j}^{1, h}\left(x_{i}^{0} \circ x_{j}^{0}\right)
|
||||
$$
|
||||
因此, 在第一层中通过$O(m^2)$个参数来建模成对的特征交互关系,相似的,第二层的第$h$个特征图表示为:
|
||||
$$
|
||||
\begin{array}{c}
|
||||
\boldsymbol{x}_{h}^{2}=\sum_{i \in[m], j \in[m]} \boldsymbol{W}_{i, j}^{2, h}\left(x_{i}^{1} \circ x_{j}^{0}\right) \\
|
||||
=\sum_{i \in[m], j \in[m]] \in[m], k \in[m]} \boldsymbol{W}_{i, j}^{2, h} \boldsymbol{W}_{l, k}^{1, h}\left(x_{j}^{0} \circ x_{k}^{0} \circ x_{l}^{0}\right)
|
||||
\end{array}
|
||||
$$
|
||||
由于第二个$\mathbf{W}$矩阵在前面一层计算好了,所以第二层的feature map也是只用了$O(m^2)$个参数就建模出了3阶特征交互关系。
|
||||
|
||||
我们知道一个经典的$k$阶多项式一般是需要$O(m^k)$个参数的,而我们展示了CIN在一系列feature map中只需要$O(k m^2)$个参数就可以近似此类多项式。而且paper使用了归纳假设的方法证明了一下,也就是后面那两个公式。具体的没咋看懂证明,不整理了。但得知道两个结论:
|
||||
1. 对于CIN来讲, 第$k$层只包含$k+1$阶特征间的显性特征交互
|
||||
2. CIN的一系列特征图只需要$O(km^2)$个参数就可以近似此类多项式
|
||||
|
||||
#### xDeepFM与其他模型的关系
|
||||
1. 对于xDeepFM,将CIN模块的层数设置为1,feature map数量也为1时,其实就是DeepFM的结构,因此DeepFM是xDeepFM的特殊形式,而xDeepFM是DeepFM的一般形式;
|
||||
2. 在1中的基础上,当我们再将xDeepFM中的DNN去除,并对feature map使用一个常数1形式的 `sum filter`,那么xDeepFM就退化成了FM形式了。
|
||||
|
||||
一般这种模型的改进,是基于之前模型进行的,也就是简化之后,会得到原来的模型,这样最差的结果,模型效果还是原来的,而不应该会比原来模型的表现差,这样的改进才更有说服力。
|
||||
|
||||
所以,既然提到了FM,再考虑下面两个问题理解下CIN设计的合理性。
|
||||
1. 每层通过sum pooling对vector的元素加和输出,这么做的意义或者合理性? 这个就是为了退化成FM做准备,如果CIN只有1层, 只有$m$个vector,即 $H_1=m$ ,且加和的权重矩阵恒等于1,即$W^1=1$ ,那么sum pooling的输出结果,就是一系列的两两向量内积之和,即标准的FM(不考虑一阶与偏置)。
|
||||
2. 除了第一层,中间层的基于Vector高阶组合有什么物理意义? 回顾FM,虽然是二阶的,但可以扩展到多阶,例如考虑三阶FM,是对三个嵌入向量做哈达玛积乘再对得到的vector做sum, CIN基于vector-wise的高阶组合再sum pooling与之类似,这也是模型名字"eXtreme Deep Factorization Machine(xDeepFM)"的由来。
|
||||
### 论文的其他重要细节
|
||||
#### 实验部分
|
||||
这一块就是后面实验了,这里作者依然是抛出了三个问题,并通过实验进行了解答。
|
||||
1. CIN如何学习高阶特征交互
|
||||
通过提出的交叉网络,这里单独证明了这个结构要比CrossNet,DNN模块和FM模块要好
|
||||
2. 推荐系统中,是否需要显性和隐性的高阶特征交互都存在?
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/2021050609553410.png#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
3. 超参对于xDeepFM的影响
|
||||
1. 网络的深度: 不用太深, CIN网络层数大于3,就不太好了,容易过拟合
|
||||
2. 每一层神经网络的单元数: 100是比较合适的一个数值
|
||||
3. 激活函数: CIN这里不用加任何的非线性激活函数,用恒等函数$f(x)=x$效果最好
|
||||
|
||||
|
||||
这里用了三个数据集
|
||||
1. 公开数据集 Criteo 与 微软数据集 BingNews
|
||||
2. DianPing 从大众点评网整理的相关数据,收集6个月的user check-in 餐厅poi的记录,从check-in餐厅周围3km内,按照poi受欢迎度抽取餐厅poi作为负例。根据user属性、poi属性,以及user之前3家check-in的poi,预测用户check-in一家给定poi的概率。
|
||||
|
||||
评估指标用了两个AUC和Logloss, 这两个是从不同的角度去评估模型。
|
||||
1. AUC: AUC度量一个正的实例比一个随机选择的负的实例排名更高的概率。它只考虑预测实例的顺序,对类的不平衡问题不敏感.
|
||||
2. LogLoss(交叉熵损失): 真实分数与预测分数的距离
|
||||
|
||||
作者说:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/2021050609492960.png#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
#### 相关工作部分
|
||||
这里作者又梳理了之前的模型,这里就再梳理一遍了
|
||||
|
||||
1. 经典推荐系统
|
||||
1. 非因子分解模型: 主要介绍了两类,一类是常见的线性模型,例如LR with FTRL,这一块很多工作是在交互特征的特征工程方面;另一类是提升决策树模型的研究(GBDT+LR)
|
||||
2. 因子分解模型: MF模型, FM模型,以及在FM模型基础上的贝叶斯模型
|
||||
|
||||
2. 深度学习模型
|
||||
1. 学习高阶交互特征: 论文中提到的DeepCross, FNN,PNN,DCN, NFM, W&D, DeepFM,
|
||||
2. 学习精心的表征学习:这块常见的深度学习模型不是focus在学习高阶特征交互关系。比如NCF,ACF,DIN等。
|
||||
|
||||
推荐系统数据特点: 稀疏,类别连续特征混合,高维。
|
||||
|
||||
关于未来两个方向:
|
||||
1. CIN的sum pooling这里, 后面可以考虑DIN的那种思路,根据当前候选商品与embedding的关联进行注意力权重的添加
|
||||
2. CIN的时间复杂度还是比较高的,后面在GPU集群上使用分布式的方式来训练模型。
|
||||
|
||||
|
||||
## xDeepFM模型的代码复现及重要结构解释
|
||||
### xDeepFM的整体代码逻辑
|
||||
下面看下xDeepFM模型的具体实现, 这样可以从更细节的角度去了解这个模型, 这里我依然是参考的deepctr的代码风格,这种函数式模型编程更清晰一些,当然由于时间原因,我这里目前只完成了一个tf2版本的(pytorch版本的后面有时间会补上)。 这里先看下xDeepFM的全貌:
|
||||
|
||||
```python
|
||||
def xDeepFM(linear_feature_columns, dnn_feature_columns, cin_size=[128, 128]):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns+dnn_feature_columns)
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入预Input层对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 线性部分的计算逻辑 -- linear
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
# 线性层和dnn层统一的embedding层
|
||||
embedding_layer_dict = build_embedding_layers(linear_feature_columns+dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# DNN侧的计算逻辑 -- Deep
|
||||
# 将dnn_feature_columns里面的连续特征筛选出来,并把相应的Input层拼接到一块
|
||||
dnn_dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), dnn_feature_columns)) if dnn_feature_columns else []
|
||||
dnn_dense_feature_columns = [fc.name for fc in dnn_dense_feature_columns]
|
||||
dnn_concat_dense_inputs = Concatenate(axis=1)([dense_input_dict[col] for col in dnn_dense_feature_columns])
|
||||
|
||||
# 将dnn_feature_columns里面的离散特征筛选出来,相应的embedding层拼接到一块
|
||||
dnn_sparse_kd_embed = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
|
||||
dnn_concat_sparse_kd_embed = Concatenate(axis=1)(dnn_sparse_kd_embed)
|
||||
|
||||
# DNN层的输入和输出
|
||||
dnn_input = Concatenate(axis=1)([dnn_concat_dense_inputs, dnn_concat_sparse_kd_embed])
|
||||
dnn_out = get_dnn_output(dnn_input)
|
||||
dnn_logits = Dense(1)(dnn_out)
|
||||
|
||||
# CIN侧的计算逻辑, 这里使用的DNN feature里面的sparse部分,这里不要flatten
|
||||
exFM_sparse_kd_embed = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=False)
|
||||
exFM_input = Concatenate(axis=1)(exFM_sparse_kd_embed)
|
||||
exFM_out = CIN(cin_size=cin_size)(exFM_input)
|
||||
exFM_logits = Dense(1)(exFM_out)
|
||||
|
||||
# 三边的结果stack
|
||||
stack_output = Add()([linear_logits, dnn_logits, exFM_logits])
|
||||
|
||||
# 输出层
|
||||
output_layer = Dense(1, activation='sigmoid')(stack_output)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
|
||||
return model
|
||||
```
|
||||
这种风格最好的一点,就是很容易从宏观上把握模型的整体逻辑。 首先,接收的输入是linear_feature_columns和dnn_feature_columns, 这两个是深度和宽度两侧的特征,具体选取要结合着场景来。 接下来,就是为这些特征建立相应的Input层,这里要分成连续特征和离散的特征,因为后面的处理方式不同, 连续特征的话可以直接拼了, 而离散特征的话,需要过一个embedding层转成低维稠密,这就是第一行代码干的事情了。
|
||||
|
||||
接下来, 计算线性部分,从上面xDeepFM的结构里面可以看出, 是分三路走的,线性,CIN和DNN路, 所以`get_linear_logits`就是线性这部分的计算结果,完成的是$w_1x_1+w_2x_2..w_kx_k+b$, 这里面依然是连续和离散的不太一样,对于连续特征,直接过一个全连接就实现了这个操作,而离散特征,这里依然过一个embedding,不过这个维度是1,目的是转成了一个连续数值(这个相当于离散特征对应的w值),这样后面进行总的加和操作即可。
|
||||
|
||||
接下来是另外两路,DNN这路也比较简单, dnn_feature_columns里面的离散特征过embedding,和连续特征拼接起来,然后过DNN即可。 CIN这路使用的是dnn_feature_columns里面的离散embedding特征,进行显性高阶交叉,这里的输入是`[None, field_num, embedding_dim]`的维度。这个也好理解,每个特征embedding之后,拼起来即可,注意`flatten=False`了。 这个输入,过CIN网络得到输出。
|
||||
|
||||
这样三路输出都得到,然后进行了一个加和,再连接一个Dense映射到最终输出。这就是整体的逻辑了,关于每个部分的具体细节,可以看代码。 下面主要是看看CIN这个网络是怎么实现的,因为其他的在之前的模型里面也基本是类似的操作,比如前面DIEN,DSIN版本,并且我后面项目里面补充了DCN的deepctr风格版,这个和那个超级像,唯一不同的就是把CrossNet换成了CIN,所以这个如果感觉看不大懂,可以先看那个网络代码。下面说CIN。
|
||||
### CIN网络的代码实现细节
|
||||
再具体代码实现, 我们先简单捋一下CIN网络的实现过程,这里的输入是`[None, field_num embed_dim]`的维度,在CIN里面,我们知道接下来的话,就是每一层会有$H_k$个神经元, 而每个神经元的计算要根据上面的那个计算公式,也就是$X_0$要和前面一层的输出两两embedding,加权求和再求和的方式。 而从CNN的角度来看,这个过程可以是这样,对于每一层的计算,先$X_0$和$X_k$进行外积运算(相当于两两embedding),然后采用$H_k$个过滤器对前面的结果逐通道卷积就能得到每一层的$X_k$了。 最后的输出是每一层的$X_k$拼接起来,然后在embedding维度上的求和。 所以依据这个思路,就能得到下面的实现代码:
|
||||
|
||||
```python
|
||||
class CIN(Layer):
|
||||
def __init__(self, cin_size, l2_reg=1e-4):
|
||||
"""
|
||||
:param: cin_size: A list. [H_1, H_2, ....H_T], a list of number of layers
|
||||
"""
|
||||
super(CIN, self).__init__()
|
||||
self.cin_size = cin_size
|
||||
self.l2_reg = l2_reg
|
||||
|
||||
def build(self, input_shape):
|
||||
# input_shape [None, field_nums, embedding_dim]
|
||||
self.field_nums = input_shape[1]
|
||||
|
||||
# CIN 的每一层大小,这里加入第0层,也就是输入层H_0
|
||||
self.field_nums = [self.field_nums] + self.cin_size
|
||||
|
||||
# 过滤器
|
||||
self.cin_W = {
|
||||
'CIN_W_' + str(i): self.add_weight(
|
||||
name='CIN_W_' + str(i),
|
||||
shape = (1, self.field_nums[0] * self.field_nums[i], self.field_nums[i+1]), # 这个大小要理解
|
||||
initializer='random_uniform',
|
||||
regularizer=l2(self.l2_reg),
|
||||
trainable=True
|
||||
)
|
||||
for i in range(len(self.field_nums)-1)
|
||||
}
|
||||
|
||||
super(CIN, self).build(input_shape)
|
||||
|
||||
def call(self, inputs):
|
||||
# inputs [None, field_num, embed_dim]
|
||||
embed_dim = inputs.shape[-1]
|
||||
hidden_layers_results = [inputs]
|
||||
|
||||
# 从embedding的维度把张量一个个的切开,这个为了后面逐通道进行卷积,算起来好算
|
||||
# 这个结果是个list, list长度是embed_dim, 每个元素维度是[None, field_nums[0], 1] field_nums[0]即输入的特征个数
|
||||
# 即把输入的[None, field_num, embed_dim],切成了embed_dim个[None, field_nums[0], 1]的张量
|
||||
split_X_0 = tf.split(hidden_layers_results[0], embed_dim, 2)
|
||||
|
||||
for idx, size in enumerate(self.cin_size):
|
||||
# 这个操作和上面是同理的,也是为了逐通道卷积的时候更加方便,分割的是当一层的输入Xk-1
|
||||
split_X_K = tf.split(hidden_layers_results[-1], embed_dim, 2) # embed_dim个[None, field_nums[i], 1] feild_nums[i] 当前隐藏层单元数量
|
||||
|
||||
# 外积的运算
|
||||
out_product_res_m = tf.matmul(split_X_0, split_X_K, transpose_b=True) # [embed_dim, None, field_nums[0], field_nums[i]]
|
||||
out_product_res_o = tf.reshape(out_product_res_m, shape=[embed_dim, -1, self.field_nums[0]*self.field_nums[idx]]) # 后两维合并起来
|
||||
out_product_res = tf.transpose(out_product_res_o, perm=[1, 0, 2]) # [None, dim, field_nums[0]*field_nums[i]]
|
||||
|
||||
# 卷积运算
|
||||
# 这个理解的时候每个样本相当于1张通道为1的照片 dim为宽度, field_nums[0]*field_nums[i]为长度
|
||||
# 这时候的卷积核大小是field_nums[0]*field_nums[i]的, 这样一个卷积核的卷积操作相当于在dim上进行滑动,每一次滑动会得到一个数
|
||||
# 这样一个卷积核之后,会得到dim个数,即得到了[None, dim, 1]的张量, 这个即当前层某个神经元的输出
|
||||
# 当前层一共有field_nums[i+1]个神经元, 也就是field_nums[i+1]个卷积核,最终的这个输出维度[None, dim, field_nums[i+1]]
|
||||
cur_layer_out = tf.nn.conv1d(input=out_product_res, filters=self.cin_W['CIN_W_'+str(idx)], stride=1, padding='VALID')
|
||||
|
||||
cur_layer_out = tf.transpose(cur_layer_out, perm=[0, 2, 1]) # [None, field_num[i+1], dim]
|
||||
|
||||
hidden_layers_results.append(cur_layer_out)
|
||||
|
||||
# 最后CIN的结果,要取每个中间层的输出,这里不要第0层的了
|
||||
final_result = hidden_layers_results[1:] # 这个的维度T个[None, field_num[i], dim] T 是CIN的网络层数
|
||||
|
||||
# 接下来在第一维度上拼起来
|
||||
result = tf.concat(final_result, axis=1) # [None, H1+H2+...HT, dim]
|
||||
# 接下来, dim维度上加和,并把第三个维度1干掉
|
||||
result = tf.reduce_sum(result, axis=-1, keepdims=False) # [None, H1+H2+..HT]
|
||||
|
||||
return result
|
||||
```
|
||||
这里主要是解释四点:
|
||||
1. 每一层的W的维度,是一个`[1, self.field_nums[0]*self.field_nums[i], self.field_nums[i+1]`的,首先,得明白这个`self.field_nums`存储的是每一层的神经单元个数,这里包括了输入层,也就是第0层。那么每一层的每个神经元计算都会有一个$W^{k,h}$, 这个的大小是$[H_{k-1},m]$维的,而第$K$层一共$H_k$个神经元,所以总的维度就是$[H_{k-1},m,H_k]$, 这和上面这个是一个意思,只不过前面扩展了维度1而已。
|
||||
2. 具体实现的时候,这里为了更方便计算,采用了切片的思路,也就是从embedding的维度把张量切开,这样外积的计算就会变得更加的简单。
|
||||
3. 具体卷积运算的时候,这里采用的是Conv1d,1维卷积对应的是一张张高度为1的图片(理解的时候可这么理解),输入维度是`[None, in_width, in_channels]`的形式,而对应这里的数据是`[None, dim, field_nums[0]*field_nums[i]]`, 而这里的过滤器大小是`[1, field_nums[0]*field_nums[i], field_nums[i+1]`, 这样进行卷积的话,最后一个维度是卷积核的数量。是沿着dim这个维度卷积,得到的是`[None, dim, field_nums[i+1]]`的张量,这个就是第$i+1$层的输出了。和我画的
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210505221222945.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="image-20210308142624189" style="zoom: 60%;" />
|
||||
</div>
|
||||
|
||||
这个不同的是它把前面这个矩形Flatten了,得到了一个$[D,H_{k-1}\times m]$的二维矩阵,然后用$[1,H_{k-1}\times m]$的卷积核沿着D这个维度进行Conv1D, 这样就直接得到了一个D维向量, 而$H_k$个卷积核,就得到了$H_k\times D$的矩阵了。
|
||||
4. 每一层的输出$X_k$先加入到列表里面,然后在$H_i$的维度上拼接,再从$D$这个维度上求和,这样就得到了CIN的最终输出。
|
||||
|
||||
关于CIN的代码细节解释到这里啦,剩下的可以看后面链接里面的代码了。
|
||||
|
||||
## 总结
|
||||
这篇文章主要是介绍了又一个新的模型xDeepFM, 这个模型的改进焦点依然是特征之间的交互信息,xDeepFM的核心就是提出了一个新的CIN结构(这个是重点,面试的时候也喜欢问),将基于Field的vecotr-wise思想引入到了Cross Network中,并保留了Cross高阶交互,自动叉乘,参数共享等优势,模型结构上保留了DeepFM的广深结构。主要有三大优势:
|
||||
1. CIN可以学习高效的学习有界的高阶特征;
|
||||
2. xDeepFM模型可以同时显示和隐式的学习高阶交互特征;
|
||||
3. 以vector-wise方式而不是bit-wise方式学习特征交互关系。
|
||||
|
||||
如果说DeepFM只是“Deep & FM”,那么xDeepFm就真正做到了”Deep” Factorization Machine。当然,xDeepFM的时间复杂度比较高,会是工业落地的主要瓶颈,后面需要进行一些优化操作。
|
||||
|
||||
这篇论文整体上还是非常清晰的,实验做的也非常丰富,语言描述上也非常地道,建议读读原文呀。
|
||||
|
||||
**参考**:
|
||||
* [xDeepFM原论文-建议读一下,这个真的超级不错](https://arxiv.org/abs/1803.05170)
|
||||
* [xDeepFM:名副其实的 ”Deep” Factorization Machine](https://zhuanlan.zhihu.com/p/57162373)
|
||||
* [深度CTR之xDeepFM:融合了显式和隐式特征交互关系的深度模型推荐系统](https://blog.csdn.net/oppo62258801/article/details/104236828)
|
||||
* [揭秘 Deep & Cross : 如何自动构造高阶交叉特征](https://zhuanlan.zhihu.com/p/55234968)
|
||||
* [一文读懂xDeepFM](https://zhuanlan.zhihu.com/p/110076629)
|
||||
* [推荐系统 - xDeepFM架构详解](https://blog.csdn.net/maqunfi/article/details/99664119)
|
||||
|
||||
@@ -1,177 +0,0 @@
|
||||
# DIEN
|
||||
## DIEN提出的动机
|
||||
在推荐场景,用户无需输入搜索关键词来表达意图,这种情况下捕捉用户兴趣并考虑兴趣的动态变化将是提升模型效果的关键。以Wide&Deep为代表的深度模型更多的是考虑不同field特征之间的相互作用,未关注用户兴趣。
|
||||
|
||||
DIN模型考虑了用户兴趣,并且强调用户兴趣是多样的,该模型使用注意力机制来捕捉和**target item**的相关的兴趣,这样以来用户的兴趣就会随着目标商品自适应的改变。但是大多该类模型包括DIN在内,直接将用户的行为当做用户的兴趣(因为DIN模型只是在行为序列上做了简单的特征处理),但是用户潜在兴趣一般很难直接通过用户的行为直接表示,大多模型都没有挖掘用户行为背后真实的兴趣,捕捉用户兴趣的动态变化对用户兴趣的表示非常重要。DIEN相比于之前的模型,即对用户的兴趣进行建模,又对建模出来的用户兴趣继续建模得到用户的兴趣变化过程。
|
||||
|
||||
## DIEN模型原理
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218155901144.png" alt="image-20210218155901144" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
模型的输入可以分成两大部分,一部分是用户的行为序列(这部分会通过兴趣提取层及兴趣演化层转换成与用户当前兴趣相关的embedding),另一部分就是除了用户行为以外的其他所有特征,如Target id, Coontext Feature, UserProfile Feature,这些特征都转化成embedding的类型然后concat在一起(形成一个大的embedding)作为非行为相关的特征(这里可能也会存在一些非id类特征,应该可以直接进行concat)。最后DNN输入的部分由行为序列embedding和非行为特征embedding(多个特征concat到一起之后形成的一个大的向量)组成,将两者concat之后输入到DNN中。
|
||||
|
||||
所以DIEN模型的重点就是如何将用户的行为序列转换成与用户兴趣相关的向量,在DIN中是直接通过与target item计算序列中每个元素的注意力分数,然后加权求和得到最终的兴趣表示向量。在DIEN中使用了两层结构来建模用户兴趣相关的向量。
|
||||
|
||||
### Interest Exterator Layer
|
||||
|
||||
兴趣抽取层的输入原本是一个id序列(按照点击时间的先后顺序形成的一个序列),通过Embedding层将其转化成一个embedding序列。然后使用GRU模块对兴趣进行抽取,GRU的输入是embedding层之后得到的embedding序列。对于GRU模块不是很了解的可以看一下[动手学深度学习中GRU相关的内容](https://zh.d2l.ai/chapter_recurrent-neural-networks/gru.html)
|
||||
|
||||
作者并没有直接完全使用原始的GRU来提取用户的兴趣,而是引入了一个辅助函数来指导用户兴趣的提取。作者认为如果直接使用GRU提取用户的兴趣,只能得到用户行为之间的依赖关系,不能有效的表示用户的兴趣。因为是用户的兴趣导致了用户的点击,用户的最后一次点击与用户点击之前的兴趣相关性就很强,但是直接使用行为序列训练GRU的话,只有用户最后一次点击的物品(也就是label,在这里可以认为是Target Ad), 那么最多就是能够捕捉到用户最后一次点击时的兴趣,而最后一次的兴趣又和前面点击过的物品在兴趣上是相关的,而前面点击的物品中并没有target item进行监督。**所以作者提出的辅助损失就是为了让行为序列中的每一个时刻都有一个target item进行监督训练,也就是使用下一个行为来监督兴趣状态的学习**
|
||||
|
||||
**辅助损失**
|
||||
首先需要明确的就是辅助损失是计算哪两个量的损失。计算的是用户每个时刻的兴趣表示(GRU每个时刻输出的隐藏状态形成的序列)与用户当前时刻实际点击的物品表示(输入的embedding序列)之间的损失,相当于是行为序列中的第t+1个物品与用户第t时刻的兴趣表示之间的损失**(为什么这里用户第t时刻的兴趣与第t+1时刻的真实点击做损失呢?我的理解是,只有知道了用户第t+1真实点击的商品,才能更好的确定用户第t时刻的兴趣)。**
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218163742638.png" alt="image-20210218163742638" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
当然,如果只计算用户点击物品与其点击前一次的兴趣之间的损失,只能认为是正样本之间的损失,那么用户第t时刻的兴趣其实还有很多其他的未点击的商品,这些未点击的商品就是负样本,负样本一般通过从用户点击序列中采样得到,这样一来辅助损失中就包含了用户某个时刻下的兴趣及与该时刻兴趣相关的正负物品。所以最终的损失函数表示如下。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218162447125.png" alt="image-20210218162447125" style="zoom: 25%;" />
|
||||
</div>
|
||||
其中$h_t^i$表示的是用户$i$第$t$时刻的隐藏状态,可以表示用户第$t$时刻的兴趣向量,$e_b^i,\hat{e_b^i}$分别表示的是正负样本,$e_b^i[t+1]$表示的是用户$i$第$t+1$时刻点击的物品向量。
|
||||
|
||||
辅助损失会加到最终的目标损失(ctr损失)中一起进行优化,并且通过$\alpha$参数来平衡点击率和兴趣的关系
|
||||
$$
|
||||
L = L_{target} + \alpha L_{aux}
|
||||
$$
|
||||
|
||||
**引入辅助函数的函数有:**
|
||||
|
||||
- 辅助loss可以帮助GRU的隐状态更好地表示用户兴趣。
|
||||
|
||||
- RNN在长序列建模场景下梯度传播可能并不能很好的影响到序列开始部分,如果在序列的每个部分都引入一个辅助的监督信号,则可一定程度降低优化难度。
|
||||
|
||||
- 辅助loss可以给embedding层的学习带来更多语义信息,学习到item对应的更好的embedding。
|
||||
|
||||
### Interest Evolving Layer
|
||||
将用户的行为序列通过GRU+辅助损失建模之后,对用户行为序列中的兴趣进行了提取并表达成了向量的形式(GRU每个时刻输出的隐藏状态)。而用户的兴趣会因为外部环境或内部认知随着时间变化,特点如下:
|
||||
|
||||
- **兴趣是多样化的,可能发生漂移**。兴趣漂移对行为的影响是用户可能在一段时间内对各种书籍感兴趣,而在另一段时间却需要衣服
|
||||
|
||||
- 虽然兴趣可能会相互影响,但是**每一种兴趣都有自己的发展过程**,例如书和衣服的发展过程几乎是独立的。**而我们只关注与target item相关的演进过程。**
|
||||
|
||||
由于用户的兴趣是多样的,但是用户的每一种兴趣都有自己的发展过程,即使兴趣发生漂移我们可以只考虑用户与target item(广告或者商品)相关的兴趣演化过程,这样就不用考虑用户多样化的兴趣的问题了,而如何只获取与target item相关的信息,作者使用了与DIN模型中提取与target item相同的方法,来计算用户历史兴趣与target item之间的相似度,即这里也使用了DIN中介绍的局部激活单元(就是下图中的Attention模块)。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218180755462.png" alt="image-20210218180755462" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
当得到了用户历史兴趣序列及兴趣序列与target item之间的相关性(注意力分数)之后,就需要再次对注意力序列进行建模得到用户注意力的演化过程,进一步表示用户最终的兴趣向量。此时的序列数据等同于有了一个序列及序列中每个向量的注意力权重,下面就是考虑如何使用这个注意力权重来一起优化序列建模的结果了。作者提出了三种注意力结合的GRU模型快:
|
||||
|
||||
1. **AIGRU:** 将注意力分数直接与输入的序列进行相乘,也就是权重越大的向量对应的值也越大, 其中$i_t^{'}, h_t, a_t$分别表示用户$i$在兴趣演化过程使用的GRU的第t时刻的输入,$h_t$表示的是兴趣抽取层第t时刻的输出,$a_t$表示的是$h_t$的注意力分数,这种方式的弊端是即使是零输入也会改变GRU的隐藏状态,所以相对较少的兴趣值也会影响兴趣的学习进化(根据GRU门的更新公式就可以知道,下一个隐藏状态的计算会用到上一个隐藏状态的信息,所以即使当前输入为0,最终隐藏状态也不会直接等于0,所以即使兴趣较少,也会影响到最终兴趣的演化)。
|
||||
$$
|
||||
i_t^{'} = h_t * a_t
|
||||
$$
|
||||
|
||||
2. **AGRU:** 将注意力分数直接作为GRU模块中,更新门的值,则重置门对应的值表示为$1-a_t$, 所以最终隐藏状态的更新公式表示为:其中$\hat{h_t^{'}}$表示的是候选隐藏状态。但是这种方式的弊端是弱化了兴趣之间的相关性,因为最终兴趣的更新前后是没关系的,只取决于输入的注意力分数
|
||||
$$
|
||||
h_t^{'} = (1-a_t)h_{t-1}^{'} + a_t * \tilde{h_t^{'}}
|
||||
$$
|
||||
|
||||
3. **AUGRU:** 将注意力分数作为更新门的权重,这样既兼顾了注意力分数很低时的状态更新值,也利用了兴趣之间的相关性,最终的表达式如下:
|
||||
$$
|
||||
\begin{align}
|
||||
& \tilde{u_t^{'}} = a_t * u_t \\
|
||||
& h_t^{'} = (1-\tilde{u_t^{'}})h_{t-1}^{'} + \tilde{u_t^{'}} * \tilde{h_t^{'}}
|
||||
\end{align}
|
||||
$$
|
||||
|
||||
**建模兴趣演化过程的好处:**
|
||||
- 追踪用户的interest可以使我们学习final interest的表达时包含更多的历史信息
|
||||
- 可以根据interest的变化趋势更好地进行CTR预测
|
||||
|
||||
## 代码实现
|
||||
下面我们看下DIN的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。下面开始:
|
||||
|
||||
这里主要和大家说一下DIN模型的总体运行逻辑,这样可以让大家从宏观的层面去把握模型的编写过程。该模型所使用的数据集是movielens数据集, 具体介绍可以参考后面的GitHub。 因为上面反复强调了DIN的应用场景,需要基于用户的历史行为数据, 所以在这个数据集中会有用户过去对电影评分的一系列行为。这在之前的数据集中往往是看不到的。 大家可以导入数据之后自行查看这种行为特征(hist_behavior)。另外还有一点需要说明的是这种历史行为是序列性质的特征, 并且**不同的用户这种历史行为特征长度会不一样**, 但是我们的神经网络是要求序列等长的,所以这种情况我们一般会按照最长的序列进行padding的操作(不够长的填0), 而到具体层上进行运算的时候,会用mask掩码的方式标记出这些填充的位置,好保证计算的准确性。 在我们给出的代码中,大家会在AttentionPoolingLayer层的前向传播中看到这种操作。下面开始说编写逻辑:
|
||||
|
||||
首先, DIN模型的输入特征大致上分为了三类: Dense(连续型), Sparse(离散型), VarlenSparse(变长离散型),也就是指的上面的历史行为数据。而不同的类型特征也就决定了后面处理的方式会不同:
|
||||
|
||||
* Dense型特征:由于是数值型了,这里为每个这样的特征建立Input层接收这种输入, 然后拼接起来先放着,等离散的那边处理好之后,和离散的拼接起来进DNN
|
||||
* Sparse型特征,为离散型特征建立Input层接收输入,然后需要先通过embedding层转成低维稠密向量,然后拼接起来放着,等变长离散那边处理好之后, 一块拼起来进DNN, 但是这里面要注意有个特征的embedding向量还得拿出来用,就是候选商品的embedding向量,这个还得和后面的计算相关性,对历史行为序列加权。
|
||||
* VarlenSparse型特征:这个一般指的用户的历史行为特征,变长数据, 首先会进行padding操作成等长, 然后建立Input层接收输入,然后通过embedding层得到各自历史行为的embedding向量, 拿着这些向量与上面的候选商品embedding向量进入AttentionPoolingLayer去对这些历史行为特征加权合并,最后得到输出。
|
||||
|
||||
通过上面的三种处理, 就得到了处理好的连续特征,离散特征和变长离散特征, 接下来把这三种特征拼接,进DNN网络,得到最后的输出结果即可。所以有了这个解释, 就可以放DIN模型的代码全貌了,大家可以感受下我上面解释的:
|
||||
|
||||
```python
|
||||
def DIEN(feature_columns, behavior_feature_list, behavior_seq_feature_list, neg_seq_feature_list, use_neg_sample=False, alpha=1.0):
|
||||
# 构建输入层
|
||||
input_layer_dict = build_input_layers(feature_columns)
|
||||
|
||||
# 将Input层转化为列表的形式作为model的输入
|
||||
input_layers = list(input_layer_dict.values()) # 各个输入层
|
||||
user_behavior_length = input_layer_dict["hist_len"]
|
||||
|
||||
# 筛选出特征中的sparse_fea, dense_fea, varlen_fea
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns)) if feature_columns else []
|
||||
varlen_sparse_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
# 获取dense
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
dnn_dense_input.append(input_layer_dict[fc.name])
|
||||
|
||||
# 将所有的dense特征拼接
|
||||
dnn_dense_input = concat_input_list(dnn_dense_input)
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)
|
||||
|
||||
# 因为这里最终需要将embedding拼接后直接输入到全连接层(Dense)中, 所以需要Flatten
|
||||
dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)
|
||||
# 将所有sparse特征的embedding进行拼接
|
||||
dnn_sparse_input = concat_input_list(dnn_sparse_embed_input)
|
||||
|
||||
# 获取当前的行为特征(movie)的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
query_embed_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
# 获取行为序列(movie_id序列, hist_movie_id) 对应的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
keys_embed_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
# 把q,k的embedding拼在一块
|
||||
query_emb, keys_emb = concat_input_list(query_embed_list), concat_input_list(keys_embed_list)
|
||||
|
||||
# 采样的负行为
|
||||
neg_uiseq_embed_list = embedding_lookup(neg_seq_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
neg_concat_behavior = concat_input_list(neg_uiseq_embed_list)
|
||||
|
||||
# 兴趣进化层的计算过程
|
||||
dnn_seq_input, aux_loss = interest_evolution(keys_emb, query_emb, user_behavior_length, neg_concat_behavior, gru_type="AUGRU")
|
||||
|
||||
# 后面的全连接层
|
||||
deep_input_embed = Concatenate()([dnn_dense_input, dnn_sparse_input, dnn_seq_input])
|
||||
|
||||
# 获取最终dnn的logits
|
||||
dnn_logits = get_dnn_logits(deep_input_embed, activation='prelu')
|
||||
model = Model(input_layers, dnn_logits)
|
||||
|
||||
# 加兴趣提取层的损失 这个比例可调
|
||||
if use_neg_sample:
|
||||
model.add_loss(alpha * aux_loss)
|
||||
|
||||
# 所有变量需要初始化
|
||||
tf.compat.v1.keras.backend.get_session().run(tf.compat.v1.global_variables_initializer())
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中(看不清的话可以自己用代码生成之后使用其他的软件打开看)。
|
||||
|
||||
> 下面这个图失效了
|
||||
<div align=center>
|
||||
此处无图
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
1. 对于知乎上大佬们对DIEN的探讨,你有什么看法呢?[也评Deep Interest Evolution Network](https://zhuanlan.zhihu.com/p/54838663)
|
||||
|
||||
|
||||
**参考资料**
|
||||
- [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
- [原论文](https://arxiv.org/pdf/1809.03672.pdf)
|
||||
- [论文阅读-阿里DIEN深度兴趣进化网络之总体解读](https://mp.weixin.qq.com/s/IlVZCVtDco3hWuvnsUmekg)
|
||||
- [也评Deep Interest Evolution Network](https://zhuanlan.zhihu.com/p/54838663)
|
||||
|
||||
@@ -1,177 +0,0 @@
|
||||
# DIN
|
||||
## 动机
|
||||
Deep Interest Network(DIIN)是2018年阿里巴巴提出来的模型, 该模型基于业务的观察,从实际应用的角度进行改进,相比于之前很多“学术风”的深度模型, 该模型更加具有业务气息。该模型的应用场景是阿里巴巴的电商广告推荐业务, 这样的场景下一般**会有大量的用户历史行为信息**, 这个其实是很关键的,因为DIN模型的创新点或者解决的问题就是使用了注意力机制来对用户的兴趣动态模拟, 而这个模拟过程存在的前提就是用户之前有大量的历史行为了,这样我们在预测某个商品广告用户是否点击的时候,就可以参考他之前购买过或者查看过的商品,这样就能猜测出用户的大致兴趣来,这样我们的推荐才能做的更加到位,所以这个模型的使用场景是**非常注重用户的历史行为特征(历史购买过的商品或者类别信息)**,也希望通过这一点,能够和前面的一些深度学习模型对比一下。
|
||||
|
||||
在个性化的电商广告推荐业务场景中,也正式由于用户留下了大量的历史交互行为,才更加看出了之前的深度学习模型(作者统称Embeding&MLP模型)的不足之处。如果学习了前面的各种深度学习模型,就会发现Embeding&MLP模型对于这种推荐任务一般有着差不多的固定处理套路,就是大量稀疏特征先经过embedding层, 转成低维稠密的,然后进行拼接,最后喂入到多层神经网络中去。
|
||||
|
||||
这些模型在这种个性化广告点击预测任务中存在的问题就是**无法表达用户广泛的兴趣**,因为这些模型在得到各个特征的embedding之后,就蛮力拼接了,然后就各种交叉等。这时候根本没有考虑之前用户历史行为商品具体是什么,究竟用户历史行为中的哪个会对当前的点击预测带来积极的作用。 而实际上,对于用户点不点击当前的商品广告,很大程度上是依赖于他的历史行为的,王喆老师举了个例子
|
||||
|
||||
>假设广告中的商品是键盘, 如果用户历史点击的商品中有化妆品, 包包,衣服, 洗面奶等商品, 那么大概率上该用户可能是对键盘不感兴趣的, 而如果用户历史行为中的商品有鼠标, 电脑,iPad,手机等, 那么大概率该用户对键盘是感兴趣的, 而如果用户历史商品中有鼠标, 化妆品, T-shirt和洗面奶, 鼠标这个商品embedding对预测“键盘”广告的点击率的重要程度应该大于后面的那三个。
|
||||
|
||||
这里也就是说如果是之前的那些深度学习模型,是没法很好的去表达出用户这广泛多样的兴趣的,如果想表达的准确些, 那么就得加大隐向量的维度,让每个特征的信息更加丰富, 那这样带来的问题就是计算量上去了,毕竟真实情景尤其是电商广告推荐的场景,特征维度的规模是非常大的。 并且根据上面的例子, 也**并不是用户所有的历史行为特征都会对某个商品广告点击预测起到作用**。所以对于当前某个商品广告的点击预测任务,没必要考虑之前所有的用户历史行为。
|
||||
|
||||
这样, DIN的动机就出来了,在业务的角度,我们应该自适应的去捕捉用户的兴趣变化,这样才能较为准确的实施广告推荐;而放到模型的角度, 我们应该**考虑到用户的历史行为商品与当前商品广告的一个关联性**,如果用户历史商品中很多与当前商品关联,那么说明该商品可能符合用户的品味,就把该广告推荐给他。而一谈到关联性的话, 我们就容易想到“注意力”的思想了, 所以为了更好的从用户的历史行为中学习到与当前商品广告的关联性,学习到用户的兴趣变化, 作者把注意力引入到了模型,设计了一个"local activation unit"结构,利用候选商品和历史问题商品之间的相关性计算出权重,这个就代表了对于当前商品广告的预测,用户历史行为的各个商品的重要程度大小, 而加入了注意力权重的深度学习网络,就是这次的主角DIN, 下面具体来看下该模型。
|
||||
|
||||
## DIN模型结构及原理
|
||||
在具体分析DIN模型之前, 我们还得先介绍两块小内容,一个是DIN模型的数据集和特征表示, 一个是上面提到的之前深度学习模型的基线模型, 有了这两个, 再看DIN模型,就感觉是水到渠成了。
|
||||
|
||||
### 特征表示
|
||||
工业上的CTR预测数据集一般都是`multi-group categorial form`的形式,就是类别型特征最为常见,这种数据集一般长这样:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210118190044920.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" style="zoom: 67%;" />
|
||||
</div>
|
||||
|
||||
这里的亮点就是框出来的那个特征,这个包含着丰富的用户兴趣信息。
|
||||
|
||||
对于特征编码,作者这里举了个例子:`[weekday=Friday, gender=Female, visited_cate_ids={Bag,Book}, ad_cate_id=Book]`, 这种情况我们知道一般是通过one-hot的形式对其编码, 转成系数的二值特征的形式。但是这里我们会发现一个`visted_cate_ids`, 也就是用户的历史商品列表, 对于某个用户来讲,这个值是个多值型的特征, 而且还要知道这个特征的长度不一样长,也就是用户购买的历史商品个数不一样多,这个显然。这个特征的话,我们一般是用到multi-hot编码,也就是可能不止1个1了,有哪个商品,对应位置就是1, 所以经过编码后的数据长下面这个样子:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210118185933510.png" style="zoom:67%;" />
|
||||
</div>
|
||||
这个就是喂入模型的数据格式了,这里还要注意一点 就是上面的特征里面没有任何的交互组合,也就是没有做特征交叉。这个交互信息交给后面的神经网络去学习。
|
||||
|
||||
### 基线模型
|
||||
|
||||
这里的base 模型,就是上面提到过的Embedding&MLP的形式, 这个之所以要介绍,就是因为DIN网络的基准也是他,只不过在这个的基础上添加了一个新结构(注意力网络)来学习当前候选广告与用户历史行为特征的相关性,从而动态捕捉用户的兴趣。
|
||||
|
||||
基准模型的结构相对比较简单,我们前面也一直用这个基准, 分为三大模块:Embedding layer,Pooling & Concat layer和MLP, 结构如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210118191224464.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" style="zoom:80%;" />
|
||||
</div>
|
||||
|
||||
前面的大部分深度模型结构也是遵循着这个范式套路, 简介一下各个模块。
|
||||
|
||||
1. **Embedding layer**:这个层的作用是把高维稀疏的输入转成低维稠密向量, 每个离散特征下面都会对应着一个embedding词典, 维度是$D\times K$, 这里的$D$表示的是隐向量的维度, 而$K$表示的是当前离散特征的唯一取值个数, 这里为了好理解,这里举个例子说明,就比如上面的weekday特征:
|
||||
|
||||
> 假设某个用户的weekday特征就是周五,化成one-hot编码的时候,就是[0,0,0,0,1,0,0]表示,这里如果再假设隐向量维度是D, 那么这个特征对应的embedding词典是一个$D\times7$的一个矩阵(每一列代表一个embedding,7列正好7个embedding向量,对应周一到周日),那么该用户这个one-hot向量经过embedding层之后会得到一个$D\times1$的向量,也就是周五对应的那个embedding,怎么算的,其实就是$embedding矩阵* [0,0,0,0,1,0,0]^T$ 。其实也就是直接把embedding矩阵中one-hot向量为1的那个位置的embedding向量拿出来。 这样就得到了稀疏特征的稠密向量了。其他离散特征也是同理,只不过上面那个multi-hot编码的那个,会得到一个embedding向量的列表,因为他开始的那个multi-hot向量不止有一个是1,这样乘以embedding矩阵,就会得到一个列表了。通过这个层,上面的输入特征都可以拿到相应的稠密embedding向量了。
|
||||
|
||||
2. **pooling layer and Concat layer**: pooling层的作用是将用户的历史行为embedding这个最终变成一个定长的向量,因为每个用户历史购买的商品数是不一样的, 也就是每个用户multi-hot中1的个数不一致,这样经过embedding层,得到的用户历史行为embedding的个数不一样多,也就是上面的embedding列表$t_i$不一样长, 那么这样的话,每个用户的历史行为特征拼起来就不一样长了。 而后面如果加全连接网络的话,我们知道,他需要定长的特征输入。 所以往往用一个pooling layer先把用户历史行为embedding变成固定长度(统一长度),所以有了这个公式:
|
||||
$$
|
||||
e_i=pooling(e_{i1}, e_{i2}, ...e_{ik})
|
||||
$$
|
||||
这里的$e_{ij}$是用户历史行为的那些embedding。$e_i$就变成了定长的向量, 这里的$i$表示第$i$个历史特征组(是历史行为,比如历史的商品id,历史的商品类别id等), 这里的$k$表示对应历史特种组里面用户购买过的商品数量,也就是历史embedding的数量,看上面图里面的user behaviors系列,就是那个过程了。 Concat layer层的作用就是拼接了,就是把这所有的特征embedding向量,如果再有连续特征的话也算上,从特征维度拼接整合,作为MLP的输入。
|
||||
|
||||
3. **MLP**:这个就是普通的全连接,用了学习特征之间的各种交互。
|
||||
|
||||
4. **Loss**: 由于这里是点击率预测任务, 二分类的问题,所以这里的损失函数用的负的log对数似然:
|
||||
$$
|
||||
L=-\frac{1}{N} \sum_{(\boldsymbol{x}, y) \in \mathcal{S}}(y \log p(\boldsymbol{x})+(1-y) \log (1-p(\boldsymbol{x})))
|
||||
$$
|
||||
|
||||
这就是base 模型的全貌, 这里应该能看出这种模型的问题, 通过上面的图也能看出来, 用户的历史行为特征和当前的候选广告特征在全都拼起来给神经网络之前,是一点交互的过程都没有, 而拼起来之后给神经网络,虽然是有了交互了,但是原来的一些信息,比如,每个历史商品的信息会丢失了一部分,因为这个与当前候选广告商品交互的是池化后的历史特征embedding, 这个embedding是综合了所有的历史商品信息, 这个通过我们前面的分析,对于预测当前广告点击率,并不是所有历史商品都有用,综合所有的商品信息反而会增加一些噪声性的信息,可以联想上面举得那个键盘鼠标的例子,如果加上了各种洗面奶,衣服啥的反而会起到反作用。其次就是这样综合起来,已经没法再看出到底用户历史行为中的哪个商品与当前商品比较相关,也就是丢失了历史行为中各个商品对当前预测的重要性程度。最后一点就是如果所有用户浏览过的历史行为商品,最后都通过embedding和pooling转换成了固定长度的embedding,这样会限制模型学习用户的多样化兴趣。
|
||||
|
||||
那么改进这个问题的思路有哪些呢? 第一个就是加大embedding的维度,增加之前各个商品的表达能力,这样即使综合起来,embedding的表达能力也会加强, 能够蕴涵用户的兴趣信息,但是这个在大规模的真实推荐场景计算量超级大,不可取。 另外一个思路就是**在当前候选广告和用户的历史行为之间引入注意力的机制**,这样在预测当前广告是否点击的时候,让模型更关注于与当前广告相关的那些用户历史产品,也就是说**与当前商品更加相关的历史行为更能促进用户的点击行为**。 作者这里又举了之前的一个例子:
|
||||
> 想象一下,当一个年轻母亲访问电子商务网站时,她发现展示的新手袋很可爱,就点击它。让我们来分析一下点击行为的驱动力。<br><br>展示的广告通过软搜索这位年轻母亲的历史行为,发现她最近曾浏览过类似的商品,如大手提袋和皮包,从而击中了她的相关兴趣
|
||||
|
||||
第二个思路就是DIN的改进之处了。DIN通过给定一个候选广告,然后去注意与该广告相关的局部兴趣的表示来模拟此过程。 DIN不会通过使用同一向量来表达所有用户的不同兴趣,而是通过考虑历史行为的相关性来自适应地计算用户兴趣的表示向量(对于给的广告)。 该表示向量随不同广告而变化。下面看一下DIN模型。
|
||||
|
||||
### DIN模型架构
|
||||
|
||||
上面分析完了base模型的不足和改进思路之后,DIN模型的结构就呼之欲出了,首先,它依然是采用了基模型的结构,只不过是在这个的基础上加了一个注意力机制来学习用户兴趣与当前候选广告间的关联程度, 用论文里面的话是,引入了一个新的`local activation unit`, 这个东西用在了用户历史行为特征上面, **能够根据用户历史行为特征和当前广告的相关性给用户历史行为特征embedding进行加权**。我们先看一下它的结构,然后看一下这个加权公式。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210118220015871.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
这里改进的地方已经框出来了,这里会发现相比于base model, 这里加了一个local activation unit, 这里面是一个前馈神经网络,输入是用户历史行为商品和当前的候选商品, 输出是它俩之间的相关性, 这个相关性相当于每个历史商品的权重,把这个权重与原来的历史行为embedding相乘求和就得到了用户的兴趣表示$\boldsymbol{v}_{U}(A)$, 这个东西的计算公式如下:
|
||||
$$
|
||||
\boldsymbol{v}_{U}(A)=f\left(\boldsymbol{v}_{A}, \boldsymbol{e}_{1}, \boldsymbol{e}_{2}, \ldots, \boldsymbol{e}_{H}\right)=\sum_{j=1}^{H} a\left(\boldsymbol{e}_{j}, \boldsymbol{v}_{A}\right) \boldsymbol{e}_{j}=\sum_{j=1}^{H} \boldsymbol{w}_{j} \boldsymbol{e}_{j}
|
||||
$$
|
||||
这里的$\{\boldsymbol{v}_{A}, \boldsymbol{e}_{1}, \boldsymbol{e}_{2}, \ldots, \boldsymbol{e}_{H}\}$是用户$U$的历史行为特征embedding, $v_{A}$表示的是候选广告$A$的embedding向量, $a(e_j, v_A)=w_j$表示的权重或者历史行为商品与当前广告$A$的相关性程度。$a(\cdot)$表示的上面那个前馈神经网络,也就是那个所谓的注意力机制, 当然,看图里的话,输入除了历史行为向量和候选广告向量外,还加了一个它俩的外积操作,作者说这里是有利于模型相关性建模的显性知识。
|
||||
|
||||
这里有一点需要特别注意,就是这里的权重加和不是1, 准确的说这里不是权重, 而是直接算的相关性的那种分数作为了权重,也就是平时的那种scores(softmax之前的那个值),这个是为了保留用户的兴趣强度。
|
||||
|
||||
## DIN实现
|
||||
|
||||
下面我们看下DIN的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。下面开始:
|
||||
|
||||
这里主要和大家说一下DIN模型的总体运行逻辑,这样可以让大家从宏观的层面去把握模型的编写过程。该模型所使用的数据集是movielens数据集, 具体介绍可以参考后面的GitHub。 因为上面反复强调了DIN的应用场景,需要基于用户的历史行为数据, 所以在这个数据集中会有用户过去对电影评分的一系列行为。这在之前的数据集中往往是看不到的。 大家可以导入数据之后自行查看这种行为特征(hist_behavior)。另外还有一点需要说明的是这种历史行为是序列性质的特征, 并且**不同的用户这种历史行为特征长度会不一样**, 但是我们的神经网络是要求序列等长的,所以这种情况我们一般会按照最长的序列进行padding的操作(不够长的填0), 而到具体层上进行运算的时候,会用mask掩码的方式标记出这些填充的位置,好保证计算的准确性。 在我们给出的代码中,大家会在AttentionPoolingLayer层的前向传播中看到这种操作。下面开始说编写逻辑:
|
||||
|
||||
首先, DIN模型的输入特征大致上分为了三类: Dense(连续型), Sparse(离散型), VarlenSparse(变长离散型),也就是指的上面的历史行为数据。而不同的类型特征也就决定了后面处理的方式会不同:
|
||||
|
||||
* Dense型特征:由于是数值型了,这里为每个这样的特征建立Input层接收这种输入, 然后拼接起来先放着,等离散的那边处理好之后,和离散的拼接起来进DNN
|
||||
* Sparse型特征,为离散型特征建立Input层接收输入,然后需要先通过embedding层转成低维稠密向量,然后拼接起来放着,等变长离散那边处理好之后, 一块拼起来进DNN, 但是这里面要注意有个特征的embedding向量还得拿出来用,就是候选商品的embedding向量,这个还得和后面的计算相关性,对历史行为序列加权。
|
||||
* VarlenSparse型特征:这个一般指的用户的历史行为特征,变长数据, 首先会进行padding操作成等长, 然后建立Input层接收输入,然后通过embedding层得到各自历史行为的embedding向量, 拿着这些向量与上面的候选商品embedding向量进入AttentionPoolingLayer去对这些历史行为特征加权合并,最后得到输出。
|
||||
|
||||
通过上面的三种处理, 就得到了处理好的连续特征,离散特征和变长离散特征, 接下来把这三种特征拼接,进DNN网络,得到最后的输出结果即可。所以有了这个解释, 就可以放DIN模型的代码全貌了,大家可以感受下我上面解释的:
|
||||
|
||||
```python
|
||||
# DIN网络搭建
|
||||
def DIN(feature_columns, behavior_feature_list, behavior_seq_feature_list):
|
||||
"""
|
||||
这里搭建DIN网络,有了上面的各个模块,这里直接拼起来
|
||||
:param feature_columns: A list. 里面的每个元素是namedtuple(元组的一种扩展类型,同时支持序号和属性名访问组件)类型,表示的是数据的特征封装版
|
||||
:param behavior_feature_list: A list. 用户的候选行为列表
|
||||
:param behavior_seq_feature_list: A list. 用户的历史行为列表
|
||||
"""
|
||||
# 构建Input层并将Input层转成列表作为模型的输入
|
||||
input_layer_dict = build_input_layers(feature_columns)
|
||||
input_layers = list(input_layer_dict.values())
|
||||
|
||||
# 筛选出特征中的sparse和Dense特征, 后面要单独处理
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns))
|
||||
|
||||
# 获取Dense Input
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
dnn_dense_input.append(input_layer_dict[fc.name])
|
||||
|
||||
# 将所有的dense特征拼接
|
||||
dnn_dense_input = concat_input_list(dnn_dense_input) # (None, dense_fea_nums)
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)
|
||||
|
||||
# 离散的这些特特征embedding之后,然后拼接,然后直接作为全连接层Dense的输入,所以需要进行Flatten
|
||||
dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)
|
||||
|
||||
# 将所有的sparse特征embedding特征拼接
|
||||
dnn_sparse_input = concat_input_list(dnn_sparse_embed_input) # (None, sparse_fea_nums*embed_dim)
|
||||
|
||||
# 获取当前行为特征的embedding, 这里有可能有多个行为产生了行为列表,所以需要列表将其放在一起
|
||||
query_embed_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
|
||||
# 获取历史行为的embedding, 这里有可能有多个行为产生了行为列表,所以需要列表将其放在一起
|
||||
keys_embed_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
# 使用注意力机制将历史行为的序列池化,得到用户的兴趣
|
||||
dnn_seq_input_list = []
|
||||
for i in range(len(keys_embed_list)):
|
||||
seq_embed = AttentionPoolingLayer()([query_embed_list[i], keys_embed_list[i]]) # (None, embed_dim)
|
||||
dnn_seq_input_list.append(seq_embed)
|
||||
|
||||
# 将多个行为序列的embedding进行拼接
|
||||
dnn_seq_input = concat_input_list(dnn_seq_input_list) # (None, hist_len*embed_dim)
|
||||
|
||||
# 将dense特征,sparse特征, 即通过注意力机制加权的序列特征拼接起来
|
||||
dnn_input = Concatenate(axis=1)([dnn_dense_input, dnn_sparse_input, dnn_seq_input]) # (None, dense_fea_num+sparse_fea_nums*embed_dim+hist_len*embed_dim)
|
||||
|
||||
# 获取最终的DNN的预测值
|
||||
dnn_logits = get_dnn_logits(dnn_input, activation='prelu')
|
||||
|
||||
model = Model(inputs=input_layers, outputs=dnn_logits)
|
||||
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片DIN_aaaa.png" alt="DIN_aaaa" style="zoom: 70%;" />
|
||||
</div>
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片din.png" alt="DIN_aaaa" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
DIN模型在工业上的应用还是比较广泛的, 大家可以自由去通过查资料看一下具体实践当中这个模型是怎么用的? 有什么问题?比如行为序列的制作是否合理, 如果时间间隔比较长的话应不应该分一下段? 再比如注意力机制那里能不能改成别的计算注意力的方式会好点?(我们也知道注意力机制的方式可不仅DNN这一种), 再比如注意力权重那里该不该加softmax? 这些其实都是可以值的思考探索的一些问题,根据实际的业务场景,大家也可以总结一些更加有意思的工业上应用该模型的技巧和tricks,欢迎一块讨论和分享。
|
||||
|
||||
**参考资料**
|
||||
* [DIN原论文](https://arxiv.org/pdf/1706.06978.pdf)
|
||||
* [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
* [AI上推荐 之 AFM与DIN模型(当推荐系统遇上了注意力机制)](https://blog.csdn.net/wuzhongqiang/article/details/109532346)
|
||||
* 王喆 - 《深度学习推荐系统》
|
||||
@@ -1,731 +0,0 @@
|
||||
## 写在前面
|
||||
DSIN全称是Deep Session Interest Network(深度会话兴趣网络), 重点在这个Session上,这个是在DIEN的基础上又进行的一次演化,这个模型的改进出发点依然是如何通过用户的历史点击行为,从里面更好的提取用户的兴趣以及兴趣的演化过程,这个模型就是从user历史行为信息挖掘方向上进行演化的。而提出的动机呢? 就是作者发现用户的行为序列的组成单位,其实应该是会话(按照用户的点击时间划分开的一段行为),每个会话里面的点击行为呢? 会高度相似,而会话与会话之间的行为,就不是那么相似了,但是像DIN,DIEN这两个模型,DIN的话,是直接忽略了行为之间的序列关系,使得对用户的兴趣建模或者演化不是很充分,而DIEN的话改进了DIN的序列关系的忽略缺点,但是忽视了行为序列的本质组成结构。所以阿里提出的DSIN模型就是从行为序列的组成结构会话的角度去进行用户兴趣的提取和演化过程的学习,在这个过程中用到了一些新的结构,比如Transformer中的多头注意力,比如双向LSTM结构,再比如前面的局部Attention结构。
|
||||
|
||||
|
||||
## DSIN模型的理论以及论文细节
|
||||
### DSIN的简介与进化动机
|
||||
DSIN模型全称叫做Deep Session Interest Network, 这个是阿里在2019年继DIEN之后的一个新模型, 这个模型依然是研究如何更好的从用户的历史行为中捕捉到用户的动态兴趣演化规律。而这个模型的改进动机呢? 就是作者认为之前的序列模型,比如DIEN等,忽视了序列的本质结构其实是由会话组成的:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210310143019924.png#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
这是个啥意思呢? 其实举个例子就非常容易明白DIEN存在的问题了(DIN这里就不说了,这个存在的问题在DIEN那里说的挺详细了,这里看看DIEN有啥问题),上一篇文章中我们说DIEN为了能够更好的利用用户的历史行为信息,把序列模型引进了推荐系统,用来学习用户历史行为之间的关系, 用兴趣提取层来学习各个历史行为之间的关系,而为了更有针对性的模拟与目标广告相关的兴趣进化路径,又在兴趣提取层后面加了注意力机制和兴趣进化层网络。这样理论上就感觉挺完美的了啊。这里依然是把DIEN拿过来,也方便和后面的DSIN对比:<br>
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210221165854948.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
但这个模型存在个啥问题呢? **就是只关注了如何去改进网络,而忽略了用户历史行为序列本身的特点**, 其实我们仔细想想的话,用户过去可能有很多历史点击行为,比如`[item3, item45, item69, item21, .....]`, 这个按照用户的点击时间排好序了,既然我们说用户的兴趣是非常广泛且多变的,那么这一大串序列的商品中,往往出现的一个规律就是**在比较短的时间间隔内的商品往往会很相似,时间间隔长了之后,商品之间就会出现很大的差别**,这个是很容易理解的,一个用户在半个小时之内的浏览点击的几个商品的相似度和一个用户上午点击和晚上点击的商品的相似度很可能是不一样的。这其实就是作者说的`homogeneous`和`heterogeneous`。而DIEN模型呢? 它并没有考虑这个问题,而是会直接把这一大串行为序列放入GRU让它自己去学(当然我们其实可以人工考虑这个问题,然后如果发现序列很长的话我们也可以分成多个样本哈,当然这里不考虑这个问题),如果一大串序列一块让GRU学习的话,往往用户的行为快速改变和突然终止的序列会有很多噪声点,不利于模型的学习。
|
||||
|
||||
所以,作者这里就是从序列本身的特点出发, 把一个用户的行为序列分成了多个会话,所谓会话,其实就是按照时间间隔把序列分段,每一段的商品列表就是一个会话,那这时候,会话里面每个商品之间的相似度就比较大了,而会话与会话之间商品相似度就可能比较小。作者这里给了个例子:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210310144926564.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
这是某个用户过去的历史点击行为,然后按照30分钟的时间间隔进行的分段,分成了3段。这里就一下子看出上面说的那些是啥意思了吧。就像这个女生,前30分钟在看裤子,再过30分钟又停留在了化妆品,又过30分钟,又看衣服。这种现象是非常普遍的啊,反映了一个用户通常在某个会话里面会有非常单一的兴趣但是当过一段时间之后,兴趣就会突然的改变。这个时候如果再统一的考虑所有行为就不合理了呀。**这其实也是DSIN改进的动机了**, DSIN,这次的关键就是在S上。
|
||||
|
||||
那它要怎么改呢? 如果是我们的话应该怎么改呢? 那一定会说,这个简单啊,不是说DIEN没考虑序列本身的特点吗? 既然我们发现了上面用户点击行为的这种会话规律,那么我们把序列进行分段,然后再用DIEN不就完事了? 哈哈, 那当然可以呀, 如果想用DIEN的话确实可以这么玩, 但那样就没有新模型了啊,那不还是DIEN? 这样的改进思路是没法发顶会的哟哈哈。 下面分析下人家是怎么改进的。
|
||||
|
||||
简单的说是用了四步,这个也是DSIN模型的整体逻辑:
|
||||
|
||||
1. 首先, 分段这个是必须的了吧,也就是在用户行为序列输入到模型之前,要按照固定的时间间隔(比如30分钟)给他分开段,每一段里面的商品序列称为一个会话Session。 这个叫做**会话划分层**
|
||||
|
||||
2. 然后呢,就是学习商品时间的依赖关系或者序列关系,由于上面把一个整的行为序列划分成了多段,那么在这里就是每一段的商品时间的序列关系要进行学习,当然我们说可以用GRU, 不过这里作者用了**多头的注意力机制**,这个东西是在**多个角度研究一个会话里面各个商品的关联关系**, 相比GRU来讲,没有啥梯度消失,并且可以并行计算,比GRU可强大多了。这个叫做**会话兴趣提取层**
|
||||
3. 上面研究了会话内各个商品之间的关联关系,接下来就是研究会话与会话之间的关系了,虽然我们说各个会话之间的关联性貌似不太大,但是可别忘了会话可是能够表示一段时间内用户兴趣的, 所以研究会话与会话的关系其实就是在学习用户兴趣的演化规律,这里用了**双向的LSTM**,不仅看从现在到未来的兴趣演化,还能学习未来到现在的变化规律, 这个叫做**会话交互层**。
|
||||
4. 既然会话内各个商品之间的关系学到了,会话与会话之间的关系学到了,然后呢? 当然也是针对性的模拟与目标广告相关的兴趣进化路径了, 所以后面是**会话兴趣局部激活层**, 这个就是注意力机制, 每次关注与当前商品更相关的兴趣。
|
||||
|
||||
所以,我们细品一下,其实DSIN和思路和DIEN的思路是差不多的,无非就是用了一些新的结构,这样,我们就从宏观上感受了一波这个模型。接下来,研究架构细节了。 看看上面那几块到底是怎么玩的。
|
||||
|
||||
### DSIN的架构剖析
|
||||
这里在说DSIN之前,作者也是又复习了一下base model模型架构,这里我就不整理了,其实是和DIEN那里一模一样的,具体的可以参考我上一篇文章。直接看DSIN的架构:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210310151619214.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
这个模型第一印象又是挺吓人的。核心的就是上面剖析的那四块,这里也分别用不同颜色表示出来了。也及时右边的那几块,左边的那两块还是我们之前的套路,用户特征和商品特征的串联。这里主要研究右边那四块,作者在这里又强调了下DSIN的两个目的,而这两个目的就对应着本模型最核心的两个层(会话兴趣提取层和会话交互层):
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210310151921213.png#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
#### Session Division Layer
|
||||
这一层是将用户的行为序列进行切分,首先将用户的点击行为按照时间排序,判断两个行为之间的时间间隔,如果前后间隔大于30min,就进行切分(划一刀), 当然30min不是定死的,具体跟着自己的业务场景来。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210310152906432.png#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
划分完了之后,我们就把一个行为序列$\mathbf{S}$转成了Sessions $\mathbf{Q}$,比如上面这个分成了4个会话,会分别用$\mathbf{Q_1}, \mathbf{Q_2}, \mathbf{Q_3}, \mathbf{Q_4}$表示。 第$k$个会话$\mathbf{Q_k}$中,又包含了$T$个行为,即
|
||||
$$
|
||||
\mathbf{Q}_{k}=\left[\mathbf{b}_{1} ; \ldots ; \mathbf{b}_{i} ; \ldots ; \mathbf{b}_{T}\right] \in \mathbb{R}^{T \times d_{\text {model }}}
|
||||
$$
|
||||
$\mathbf{b}_{i}$表示的是第$k$个会话里面的第$i$个点击行为(具体的item),这个东西是一个$d_{model}$维的embedding向量。所以$\mathbf{Q}_{k}$是一个$T \times d_{\text {model }}$维的。 而整个大$\mathbf{Q}$, 就是一个$K\times T \times d_{\text {model }}$维的矩阵。 这里的$K$指的是session的个数。 这样,就把这个给捋明白了。但要注意,这个层是在embedding层之后呀,也就是各个商品转成了embedding向量之后,我们再进行切割。
|
||||
|
||||
#### Session Interest Extractor Layer
|
||||
这个层是学习每个会话中各个行为之间的关系,之前也分析过,在同一个会话中的各个商品的相关性是非常大的。此外,作者这里还提到,用户的随意的那种点击行为会偏离用户当前会话兴趣的表达,所以**为了捕获同一会话中行为之间的内在关系,同时降低这些不相关行为的影响**,这里采用了multi-head self-attention。关于这个东西, 这里不会详细整理,可以参考我之前的文章。这里只给出两个最核心关键的图,有了这两个图,这里的知识就非常容易理解了哈哈。
|
||||
|
||||
第一个,就是Transformer的编码器的一小块:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210310154530852.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
拿过来是为了更好的对比,看DSIN的结构的第二层,其实就是这个东西。 而这个东西的整体的计算过程,我在之前的文章中剖析好了:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200220195348122.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_16,color_FFFFFF,t_70" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
有了上面这两张图,在解释这里就非常好说了。
|
||||
|
||||
这一块其实是分两步的,第一步叫做位置编码,而第二步就是self-attention计算关联。 同样,DSIN中也是这两步,只不过第一步里面的位置编码,作者在这里做了点改进,称为**Bias Encoding**。先看看这个是怎么做的。
|
||||
>这里先解释下为啥要进行位置编码或者Bias Encoding, 这是因为我们说self-attention机制是要去学习会话里面各个商品之间的关系的, 而商品我们知道是一个按照时间排好的小序列,由于后面的self-attention并没有循环神经网络的迭代运算,所以我们必须提供每个字的位置信息给后面的self-attention,这样后面self-attention的输出结果才能蕴含商品之间的顺序信息。
|
||||
|
||||
在Transformer中,对输入的序列会进行Positional Encoding。Positional Encoding对序列中每个物品,以及每个物品对应的Embedding的每个位置,进行了处理,如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210310155625208.png#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
上式中$pos$指的是某个会话里面item位于第几个位置位置, 取值范围是$[0, max\_len]$, $i$指的是词向量的某个维度, 取值范围是$[0, embed \_ dim]$, 上面有$sin$和$cos$一组公式, 也就是对应着$embed \_ dim$维度的一组奇数和偶数的序号的维度, 例如$0, 1$一组, $2, 3$一组, 分别用上面的$sin$和$cos$函数做处理, 从而产生不同的周期性变化, 而位置嵌入在$embed \_ dim$维度上随着维度序号增大, 周期变化会越来越慢, 而产生一种包含位置信息的纹理, 位置嵌入函数的周期从$2 \pi$到$10000 * 2 \pi$变化, 而每一个位置在$embed \_ dim$维度上都会得到不同周期的$sin$和$cos$函数的取值组合, 从而产生独一的纹理位置信息, 模型从而学到位置之间的依赖关系和自然语言的时序特性。这个在这里说可能有些迷糊,具体可以去另一篇文章看细节,**总结起来,就是通过这个公式,可以让每个item在每个embedding维度上都有独特的位置信息。但注意,位置编码的矩阵和输入的维度是一样的,这样两者加起来之后就相当于原来的序列加上了位置信息** 。
|
||||
|
||||
而这里,作者并不是用的这种方式,这是因为在这里还需要考虑各个会话之间的位置信息,毕竟这里是多个会话,并且各个会话之间也是有位置顺序的呀,所以还需要对每个会话添加一个Positional Encoding, 在DSIN中,这种对位置的处理,称为Bias Encoding。
|
||||
|
||||
于是乎作者在这里提出了个$\mathbf{B E} \in \mathbb{R}^{K \times T \times d_{\text {model }}}$,会发现这个东西的维度和会话分割层得到的$\mathbf{Q}$的维度也是一样的啊,其实这个东西就是这里使用的位置编码。那么这个东西咋计算呢?
|
||||
$$
|
||||
\mathbf{B} \mathbf{E}_{(k, t, c)}=\mathbf{w}_{k}^{K}+\mathbf{w}_{t}^{T}+\mathbf{w}_{c}^{C}
|
||||
$$
|
||||
$\mathbf{B} \mathbf{E}_{(k, t, c)}$表示的是第$k$个会话中,第$t$个物品在第$c$维度这个位置上的偏置项(是一个数), 其中$\mathbf{w}^{K} \in \mathbb{R}^{K}$表示的会话层次上的偏置项(位置信息)。如果有$n$个样本的话,这个应该是$[n, K, 1, 1]$的矩阵, 后面两个维度表示的$T$和$emb \_dim$。$\mathbf{w}^{T} \in \mathbb{R}^{T}$这个是在会话里面时间位置层次上的偏置项(位置信息),这个应该是$[n, 1, T, 1]$的矩阵。$\mathbf{w}^{C} \in \mathbb{R}^{d_{\text {model }}}$这个是embedding维度层次上的偏置(位置信息), 这个应该是$[n, 1, 1, d_{model}]$的矩阵。 而上面的$\mathbf{w}_{k}^{K},\mathbf{w}_{t}^{T},\mathbf{w}_{c}^{C}$都是表示某个维度上的具体的数字,所以$\mathbf{B} \mathbf{E}_{(k, t, c)}$也是一个数。
|
||||
|
||||
所以$\mathbf{B} \mathbf{E}$就是一个$[n,K, T, d_{model}]$的矩阵(这里其实是借助了广播机制的),蕴含了每个会话,每个物品,每个embedding位置的位置信息,所以经过Bias编码之后,得到的结果如下:
|
||||
$$
|
||||
\mathbf{Q}=\mathbf{Q}+\mathbf{B} \mathbf{E}
|
||||
$$
|
||||
这个$\mathbf{Q}$的维度$[n,K, T, d_{model}]$, 当然这里我们先不考虑样本个数,所以是$[K, T, d_{model}]$。相比上面的transformer,这里会多出一个会话的维度来。
|
||||
|
||||
接下来,就是每个会话的序列都通过Transformer进行处理:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210310163256416.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
一定要注意,这里说的是每个会话,这里我特意把下面的$Q_1$框出来了,就是每个$Q_i$都会走这个自注意力机制,因为我们算的是某个会话当中各个物品之间的关系。这里的计算和Transformer的block的计算是一模一样的了, 我这里就拿一个会话来解释。
|
||||
|
||||
首先$Q_1$这是一个$T\times embed \_dim$的一个矩阵,这个就和上面transformer的那个是一模一样的了,细节的计算过程其实是一样的。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200220194509277.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_16,color_FFFFFF,t_70" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
这里在拿过更细的个图来解释,首先这个$Q_1$会过一个多头的注意力机制,这个东西干啥用呢? 原理这里不说,我们只要知道,这里的头其实是从某个角度去看各个物品之间的关系,而多头的意思就是从不同的角度去计算各个物品之间的关系, 比如各个物品在价格上啊,重量上啊,颜色上啊,时尚程度上啊等等这些不同方面的关系。然后就是看这个运算图,我们会发现self-attention的输出维度和输入维度也是一样的,但经过这个多头注意力的东西之后,**就能够得到当前的商品与其他商品在多个角度上的相关性**。怎么得到呢?
|
||||
>拿一个head来举例子:<br>
|
||||
>我们看看这个$QK^T$在表示啥意思:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200220195022623.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
>假设当前会话有6个物品,embedding的维度是3的话,那么会看到这里一成,得到的结果中的每一行其实表示的是当前商品与其他商品之间的一个相似性大小(embedding内积的形式算的相似)。而沿着最后一个维度softmax归一化之后,得到的是个权重值。这是不是又想起我们的注意力机制来的啊,这个就叫做注意力矩阵,我们看看乘以V会是个啥
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200220195243968.png#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
>这时候,我们从注意力矩阵取出一行(和为1),然后依次点乘V的列,因为矩阵V的每一行代表着每一个字向量的数学表达,这样操作,**得到的正是注意力权重进行数学表达的加权线性组合,从而使每个物品向量都含有当前序列的所有物品向量的信息**。而多头,不过是含有多个角度的信息罢了,这就是Self-attention的魔力了。
|
||||
|
||||
|
||||
好了, 下面再看论文里面的描述就非常舒服了,如果令$\mathbf{Q}_{k}=\left[\mathbf{Q}_{k 1} ; \ldots ; \mathbf{Q}_{k h} ; \ldots ; \mathbf{Q}_{k H}\right]$, 这里面的$\mathbf{Q}_{k h} \in \mathbb{R}^{T \times d_{h}}$代表的就是多头里面的某一个头了,由于这多个头合起来的维度$d_{model}$维度,那么一个头就是$d_{h}=\frac{1}{h} d_{\text {model }}$, 这里必须要保证能整除才行。这里用了$h$个头。某个头$h$的计算为:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\text { head }_{h} &=\text { Attention }\left(\mathbf{Q}_{k h} \mathbf{W}^{Q}, \mathbf{Q}_{k h} \mathbf{W}^{K}, \mathbf{Q}_{k h} \mathbf{W}^{V}\right) \\
|
||||
&=\operatorname{softmax}\left(\frac{\mathbf{Q}_{k h} \mathbf{W}^{Q} \mathbf{W}^{K^{T}} \mathbf{Q}_{k h}^{T}}{\sqrt{d_{m o d e l}}}\right) \mathbf{Q}_{k h} \mathbf{W}^{V}
|
||||
\end{aligned}
|
||||
$$
|
||||
这里是某一个头的计算过程, 这里的$\mathbf{W}^{Q}, \mathbf{W}^{K}, \mathbf{W}^{Q}$是要学习的参数,由于是一个头,维度应该是$\frac{1}{h} d_{\text {model }}\times \frac{1}{h} d_{\text {model }}$, 这样的话softmax那块算出来的是$T \times T$的矩阵, 而后面是一个$T \times \frac{1}{h} d_{\text {model }}$的矩阵,这时候得到的$head_h$是一个$T \times \frac{1}{h} d_{\text {model }}$的矩阵。 而$h$个头的话,正好是$T \times d_{\text {model }}$的维度,也就是我们最后的输出了。即下面这个计算:
|
||||
$$
|
||||
\mathbf{I}_{k}^{Q}=\operatorname{FFN}\left(\text { Concat }\left(\text { head }_{1}, \ldots, \text { head }_{H}\right) \mathbf{W}^{O}\right)
|
||||
$$
|
||||
这个是self-attention 的输出再过一个全连接网络得到的。如果是用残差网络的话,最后的结果依然是个$T \times d_{\text {model }}$的,也就是$\mathbf{I}_{k}^{Q}$的维度。这时候我们在$T$的维度上进行一个avg pooling的操作,就能够把每个session兴趣转成一个$embedding$维的向量了,即
|
||||
$$
|
||||
\mathbf{I}_{k}=\operatorname{Avg}\left(\mathbf{I}_{k}^{Q}\right)
|
||||
$$
|
||||
即这个$\mathbf{I}_{k}$是一个embedding维度的向量, 表示当前用户在第$k$会话的兴趣。这就是一个会话里面兴趣提取的全过程了,如果用我之前的神图总结的话就是:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200220204538414.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
不同点就是这里用了两个transformer块,开始用的是bias编码。
|
||||
|
||||
接下来就是不同的会话都走这样的一个Transformer网络,就会得到一个$K \times embed \_dim$的矩阵,代表的是某个用户在$K$个会话里面的兴趣信息, 这个就是会话兴趣提取层的结果了。 两个注意点:
|
||||
1. 这$K$个会话是走同一个Transformer网络的,也就是在自注意力机制中不同的会话之间权重共享
|
||||
2. 最后得到的这个矩阵,$K$这个维度上是有时间先后关系的,这为后面用LSTM学习这各个会话之间的兴趣向量奠定了基础。
|
||||
|
||||
#### Session Interest Interacting Layer
|
||||
感觉这篇文章最难的地方在上面这块,所以我用了些篇幅,而下面这些就好说了,因为和之前的东西对上了又。 首先这个会话兴趣交互层
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210310172547359.png#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
作者这里就是想通过一个双向的LSTM来学习下会话兴趣之间的关系, 从而增加用户兴趣的丰富度,或许还能学习到演化规律。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/img_convert/8aa8363c1efa5101e578658515df7eba.png#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
双向的LSTM这个,这里就不介绍了,关于LSTM之前我也总结过了,无非双向的话,就是先从头到尾计算,在从尾到头回来。所以这里每个时刻隐藏状态的输出计算公式为:
|
||||
$$
|
||||
\mathbf{H}_{t}=\overrightarrow{\mathbf{h}_{f t}} \oplus \overleftarrow{\mathbf{h}_{b t}}
|
||||
$$
|
||||
这是一个$[1,\#hidden\_units]$的维度。相加的两项分别是前向传播和反向传播对应的t时刻的hidden state,这里得到的隐藏层状态$H_t$, 我们可以认为是混合了上下文信息的会话兴趣。
|
||||
#### Session Interest Activating Layer
|
||||
用户的会话兴趣与目标物品越相近,那么应该赋予更大的权重,这里依然使用注意力机制来刻画这种相关性,根据结构图也能看出,这里是用了两波注意力计算:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210310173413453.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
由于这里的这种局部Attention机制,DIN和DIEN里都见识过了, 这里就不详细解释了, 简单看下公式就可以啦。
|
||||
1. 会话兴趣提取层
|
||||
$$
|
||||
\begin{aligned}
|
||||
a_{k}^{I} &=\frac{\left.\exp \left(\mathbf{I}_{k} \mathbf{W}^{I} \mathbf{X}^{I}\right)\right)}{\sum_{k}^{K} \exp \left(\mathbf{I}_{k} \mathbf{W}^{I} \mathbf{X}^{I}\right)} \\
|
||||
\mathbf{U}^{I} &=\sum_{k}^{K} a_{k}^{I} \mathbf{I}_{k}
|
||||
\end{aligned}
|
||||
$$
|
||||
这里$X^I$是候选商品的embedding向量, 是$[embed \_dim,1]$的维度, $I_k$是$[1, embed \_dim]$的,而$W^I$是一个$[embed \_dim, embed \_dim]$, 所以这样能算出个分数,表示当前会话兴趣与候选商品之间的相似性程度。 而最终的$U^I$是各个会话兴趣向量的加权线性组合, 维度是$[1, embed \_dim]$。
|
||||
2. 会话兴趣交互层
|
||||
同样,混合了上下文信息的会话兴趣,也进行同样的处理:
|
||||
$$
|
||||
\begin{aligned}
|
||||
a_{k}^{H} &=\frac{\left.\exp \left(\mathbf{H}_{k} \mathbf{W}^{H} \mathbf{X}^{I}\right)\right)}{\sum_{k}^{K} \exp \left(\mathbf{H}_{k} \mathbf{W}^{H} \mathbf{X}^{I}\right)} \\
|
||||
\mathbf{U}^{H} &=\sum_{k}^{K} a_{k}^{H} \mathbf{H}_{k}
|
||||
\end{aligned}
|
||||
$$
|
||||
这里$X^I$是候选商品的embedding向量, 是$[embed \_dim,1]$的维度, $H_k$是$[1, \# hidden \_units]$的,而$W^I$是一个$[ \# hidden \_units, embed \_dim]$, 所以这样能算出个分数,当然实际实现,这里都是过神经网络的,表示混合了上下文信息的当前会话兴趣与候选商品之间的相似性程度。 而最终的$U^H$是各个混合了上下文信息的会话兴趣向量的加权线性组合, 维度是$[1, \# hidden \_units]$。
|
||||
|
||||
|
||||
#### Output Layer
|
||||
这个就很简单了,上面的用户行为特征, 物品行为特征以及求出的会话兴趣特征进行拼接,然后过一个DNN网络,就可以得到输出了。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210310174905503.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
损失这里依然用的交叉熵损失:
|
||||
$$
|
||||
L=-\frac{1}{N} \sum_{(x, y) \in \mathbb{D}}(y \log p(x)+(1-y) \log (1-p(x)))
|
||||
$$
|
||||
这里的$x$表示的是$\left[\mathbf{X}^{U}, \mathbf{X}^{I}, \mathbf{S}\right]$,分布表示用户特征,物品特征和会话兴趣特征。
|
||||
|
||||
到这里DSIN模型就解释完毕了。
|
||||
|
||||
### 论文的其他细节
|
||||
这里的其他细节,后面就是实验部分了,用的数据集是一个广告数据集一个推荐数据集, 对比了几个比较经典的模型Youtubetnet, W&D, DIN, DIEN, 用了RNN的DIN等。并做了一波消融实验,验证了偏置编码的有效性, 会话兴趣抽取层和会话交互兴趣抽取层的有效性。 最后可视化的self-attention和Action Unit的图比较有意思:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210310175643572.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
好了,下面就是DSIN的代码细节了。
|
||||
## DSIN的代码复现细节
|
||||
下面就是DSIN的代码部分,这里我依然是借鉴了Deepctr进行的简化版本的复现, 这次复现代码会非常多,因为想借着这个机会学习一波Transformer,具体的还是参考我后面的GitHub。 下面开始:
|
||||
|
||||
### 数据处理
|
||||
首先, 这里使用的数据集还是movielens数据集,延续的DIEN那里的,没来得及尝试其他,这里说下数据处理部分和DIEN不一样的地方。最大的区别就是这里的用户历史行为上的处理, 之前的是一个历史行为序列列表,这里得需要把这个列表分解成几个会话的形式, 由于每个用户的会话还不一定一样长,所以这里还需要进行填充。具体的数据格式如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210312161159945.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
就是把之前的hist_id序列改成了5个session。其他的特征那里没有变化。 而特征封装那里,需要把这5个会话封装起来,同时还得记录**每个用户的有效会话个数以及每个会话里面商品的有效个数, 这个在后面计算里面是有用的,因为目前是padding成了一样长,后面要根据这个个数进行mask, 所以这里有两波mask要做**
|
||||
|
||||
```python
|
||||
feature_columns = [SparseFeat('user_id', max(samples_data["user_id"])+1, embedding_dim=8),
|
||||
SparseFeat('gender', max(samples_data["gender"])+1, embedding_dim=8),
|
||||
SparseFeat('age', max(samples_data["age"])+1, embedding_dim=8),
|
||||
SparseFeat('movie_id', max(samples_data["movie_id"])+1, embedding_dim=8),
|
||||
SparseFeat('movie_type_id', max(samples_data["movie_type_id"])+1, embedding_dim=8),
|
||||
DenseFeat('hist_len', 1)]
|
||||
|
||||
feature_columns += [VarLenSparseFeat('sess1', vocabulary_size=max(samples_data["movie_id"])+1, embedding_dim=8, maxlen=10, length_name='seq_length1'),
|
||||
VarLenSparseFeat('sess2', vocabulary_size=max(samples_data["movie_id"])+1, embedding_dim=8, maxlen=10, length_name='seq_length2'),
|
||||
VarLenSparseFeat('sess3', vocabulary_size=max(samples_data["movie_id"])+1, embedding_dim=8, maxlen=10, length_name='seq_length3'),
|
||||
VarLenSparseFeat('sess4', vocabulary_size=max(samples_data["movie_id"])+1, embedding_dim=8, maxlen=10, length_name='seq_length4'),
|
||||
VarLenSparseFeat('sess5', vocabulary_size=max(samples_data["movie_id"])+1, embedding_dim=8, maxlen=10, length_name='seq_length5'),
|
||||
]
|
||||
feature_columns += ['sess_length']
|
||||
```
|
||||
封装代码变成了上面这个样子, 之所以放这里, 我是想说明一个问题,也是我这次才刚刚发觉的,就是这块封装特征的代码是用于建立模型用的, 也就是不用管有没有数据集,只要基于这个feature_columns就能把模型建立出来。 而这里面有几个重要的细节要梳理下:
|
||||
1. 上面的那一块特征是常规的离散和连续特征,封装起来即可,这个会对应的建立Input层接收后面的数据输入
|
||||
2. 第二块的变长离散特征, 注意后面的`seq_length`,这个东西的作用是标记每个用户在每个会话里面有效商品的真实长度,所以这5个会话建Input层的时候,不仅给前面的sess建立Input,还会给length_name建立Input层来接收每个用户每个会话里面商品的真实长度信息, 这样在后面创建mask的时候才有效。也就是**没有具体数据之前网络就能创建mask信息才行**。这个我是遇到了坑的,之前又忽略了这个`seq_length`, 想着直接用上面的真实数据算出长度来给网络不就行? 其实不行,因为我们算出来的长度mask给网络的时候,那个样本数已经确定了,这时候会出bug的到后面。 因为真实训练的时候,batch_size是我们自己指定。并且这个思路的话是网络依赖于数据才能建立出来,显然是不合理的。所以一定要切记,**先用`seq_length`在这里占坑,作为一个Input层, 然后过embedding,后面基于传进的序列长度和填充的最大长度用 `tf.sequence_mask`就能建立了**。
|
||||
3. 最后的`sess_length`, 这个标记每个用户的有效会话个数,后面在会话兴趣与当前候选商品算注意力的时候,也得进行mask操作,所以这里和上面这个原理是一样的,**必须先用sess_length在这里占坑,创建一个Input层**。
|
||||
4. 对应关系, 既然我们这里封装的时候是这样封装的,这样就会根据上面的建立出不同的Input层,这时候我们具体用X训练的时候,**一定要注意数据对应,也就是特征必须够且能对应起来,这里是通过名字对应的**, 看下面的X:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210312163227832.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
真实数据要和Input层接收进行对应好。
|
||||
|
||||
好了,关于数据处理就说这几个细节,感觉mask的那个处理非常需要注意。具体的看代码就可以啦。下面重头戏,剖析模型。
|
||||
|
||||
### DSIN模型全貌
|
||||
有了Deepctr的这种代码风格,使得建立模型会从宏观上看起来非常清晰,简单说下逻辑, 先建立输入层,由于输入的特征有三大类(离散,连续和变长离散),所以分别建立Input层,然后离散特征还得建立embedding层。下面三大类特征就有了不同的走向:
|
||||
1. 连续特征: 这类特征拼先拼接到一块,然后等待最后往DNN里面输入
|
||||
2. 普通离散特征: 这块从输入 -> embedding -> 拼接到一块,等待DNN里面输入
|
||||
3. 用户的会话特征: 这块从输入 -> embedding -> 会话兴趣分割层(`sess_interest_division`) -> 会话兴趣提取层(`sess_interest_extractor`) -> 会话兴趣交互层(`BiLSTM`) -> 会话兴趣激活层( `AttentionPoolingLayer`) -> 得到两个兴趣性特征
|
||||
|
||||
把上面的连续特征,离散特征和兴趣特征拼接起来,然后过DNN得到输出即可。就是这么个逻辑了,具体代码如下:
|
||||
|
||||
```python
|
||||
def DSIN(feature_columns, sess_feature_list, sess_max_count=5, bias_encoding=True, singlehead_emb_size=1,
|
||||
att_head_nums=8, dnn_hidden_units=(200, 80)):
|
||||
"""
|
||||
建立DSIN网络
|
||||
:param feature_columns: A list, 每个特征的封装 nametuple形式
|
||||
:param behavior_feature_list: A list, 行为特征名称
|
||||
:param sess_max_count: 会话的个数
|
||||
:param bias_encoding: 是否偏置编码
|
||||
:singlehead_emb_size: 每个头的注意力的维度,注意这个和头数的乘积必须等于输入的embedding的维度
|
||||
:att_head_nums: 头的个数
|
||||
:dnn_hidden_units: 这个是全连接网络的神经元个数
|
||||
"""
|
||||
|
||||
# 检查下embedding设置的是否合法,因为这里有了多头注意力机制之后,我们要保证我们的embedding维度 = att_head_nums * att_embedding_size
|
||||
hist_emb_size = sum(
|
||||
map(lambda fc: fc.embedding_dim, filter(lambda fc: fc.name in sess_feature_list, [feature for feature in feature_columns if not isinstance(feature, str)]))
|
||||
)
|
||||
if singlehead_emb_size * att_head_nums != hist_emb_size:
|
||||
raise ValueError(
|
||||
"hist_emb_size must equal to singlehead_emb_size * att_head_nums ,got %d != %d *%d" % (
|
||||
hist_emb_size, singlehead_emb_size, att_head_nums))
|
||||
|
||||
# 建立输入层
|
||||
input_layer_dict = build_input_layers(feature_columns)
|
||||
# 将Input层转化为列表的形式作为model的输入
|
||||
input_layers = list(input_layer_dict.values()) # 各个输入层
|
||||
input_keys = list(input_layer_dict.keys()) # 各个列名
|
||||
user_sess_seq_len = [input_layer_dict['seq_length'+str(i+1)] for i in range(sess_max_count)]
|
||||
user_sess_len = input_layer_dict['sess_length']
|
||||
|
||||
# 筛选出特征中的sparse_fra, dense_fea, varlen_fea
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns)) if feature_columns else []
|
||||
varlen_sparse_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
# 获取dense
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
dnn_dense_input.append(input_layer_dict[fc.name])
|
||||
# 将所有的dense特征拼接
|
||||
dnn_dense_input = concat_input_list(dnn_dense_input)
|
||||
|
||||
# 构建embedding词典
|
||||
embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)
|
||||
|
||||
# 因为这里最终需要将embedding拼接后直接输入到全连接层(Dense)中, 所以需要Flatten
|
||||
dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)
|
||||
# 将所有sparse特征的embedding进行拼接
|
||||
dnn_sparse_input = concat_input_list(dnn_sparse_embed_input)
|
||||
# dnn_dense_input和dnn_sparse_input这样就不用管了,等待后面的拼接就完事, 下面主要是会话行为兴趣的提取
|
||||
|
||||
|
||||
# 首先获取当前的行为特征(movie)的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
# 这个东西最后求局域Attention的时候使用,也就是选择与当前候选物品最相关的会话兴趣
|
||||
query_embed_list = embedding_lookup(sess_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
query_emb = concat_input_list(query_embed_list)
|
||||
|
||||
# 下面就是开始会话行为的处理了,四个层来: 会话分割层,会话兴趣提取层,会话兴趣交互层和局部Attention层,下面一一来做
|
||||
|
||||
# 首先这里是找到会话行为中的特征列的输入层, 其实用input_layer_dict也行
|
||||
user_behavior_input_dict = {}
|
||||
for idx in range(sess_max_count):
|
||||
sess_input = OrderedDict()
|
||||
for i, feat in enumerate(sess_feature_list): # 我这里只有一个movie_id
|
||||
sess_input[feat] = input_layer_dict["sess" + str(idx+1)]
|
||||
|
||||
user_behavior_input_dict['sess'+str(idx+1)] = sess_input # 这里其实是获取那五个会话的输入层
|
||||
|
||||
# 会话兴趣分割层: 拿到每个会话里面各个商品的embedding,并且进行偏置编码,得到transformer的输入
|
||||
transformer_input = sess_interest_division(embedding_layer_dict, user_behavior_input_dict,
|
||||
sparse_feature_columns, sess_feature_list,
|
||||
sess_max_count, bias_encoding=bias_encoding)
|
||||
# 这个transformer_input是个列表,里面的每个元素代表一个会话,维度是(None, max_seq_len, embed_dim)
|
||||
|
||||
# 会话兴趣提取层: 每个会话过transformer,从多个角度得到里面各个商品之间的相关性(交互)
|
||||
self_attention = Transformer(singlehead_emb_size, att_head_nums, dropout_rate=0, use_layer_norm=True,
|
||||
use_positional_encoding=(not bias_encoding), blinding=False)
|
||||
sess_fea = sess_interest_extractor(transformer_input, sess_max_count, self_attention, user_sess_seq_len)
|
||||
# 这里的输出sess_fea是个矩阵,维度(None, sess_max_cout, embed_dim), 这个东西后期要和当前的候选商品求Attention进行sess维度上的加权
|
||||
|
||||
# 会话兴趣交互层 上面的transformer结果,过双向的LSTM
|
||||
lstm_output = BiLSTM(hist_emb_size, layers=2, res_layers=0, dropout_rate=0.2)(sess_fea)
|
||||
# 这个lstm_output是个矩阵,维度是(None, sess_max_count, hidden_units_num)
|
||||
|
||||
# 会话兴趣激活层 这里就是计算两波注意力
|
||||
interest_attention = AttentionPoolingLayer(user_sess_len)([query_emb, sess_fea])
|
||||
lstm_attention = AttentionPoolingLayer(user_sess_len)([query_emb, lstm_output])
|
||||
# 上面这两个的维度分别是(None, embed_size), (None, hidden_units_num) 这里embed_size=hidden_units_num
|
||||
|
||||
# 下面就是把dnn_sense_input, dnn_sparse_input, interest_attention, lstm_attention拼接起来
|
||||
deep_input = Concatenate(axis=-1)([dnn_dense_input, dnn_sparse_input, interest_attention, lstm_attention])
|
||||
|
||||
# 全连接接网络, 获取最终的dnn_logits
|
||||
dnn_logits = get_dnn_logits(deep_input, activation='prelu')
|
||||
|
||||
model = Model(input_layers, dnn_logits)
|
||||
|
||||
# 所有变量需要初始化
|
||||
tf.compat.v1.keras.backend.get_session().run(tf.compat.v1.global_variables_initializer())
|
||||
|
||||
return model
|
||||
```
|
||||
下面开始解释每块的细节实现。
|
||||
|
||||
### 会话兴趣分割层(sess_interest_division)
|
||||
这里面接收的输入是一个每个用户的会话列表, 比如上面那5个会话的时候,每个会话里面是有若干个商品的,当然还不仅仅是有商品id,还有可能有类别id这种。 而这个函数干的事情就是遍历这5个会话,然后对于每个会话,要根据商品id拿到每个会话的商品embedding(有类别id的话也会拿到类别id然后拼起来), 所以每个会话会得到一个`(None, seq_len, embed_dim)`的一个矩阵,而最后的输出就是5个会话的矩阵放到一个列表里返回来。也就是上面的`transformer_input`, 作为transformer的输入。 这里面的一个细节,就是偏置编码。 如果需要偏置编码的话,要在这里面进行。偏置编码的过程
|
||||
|
||||
```python
|
||||
class BiasEncoding(Layer):
|
||||
"""位置编码"""
|
||||
def __init__(self, sess_max_count, seed=1024):
|
||||
super(BiasEncoding, self).__init__()
|
||||
self.sess_max_count = sess_max_count
|
||||
self.seed = seed
|
||||
|
||||
def build(self, input_shape):
|
||||
# 在该层创建一个可训练的权重 input_shape [None, sess_max_count, max_seq_len, embed_dim]
|
||||
if self.sess_max_count == 1:
|
||||
embed_size = input_shape[2]
|
||||
seq_len_max = input_shape[1]
|
||||
else:
|
||||
embed_size = input_shape[0][2]
|
||||
seq_len_max = input_shape[0][1]
|
||||
# 声明那三个位置偏置编码矩阵
|
||||
self.sess_bias_embedding = self.add_weight('sess_bias_encoding', shape=(self.sess_max_count, 1, 1),
|
||||
initializer=tf.keras.initializers.TruncatedNormal(mean=0.0, stddev=0.0001, seed=self.seed)) # 截断产生正太随机数
|
||||
self.seq_bias_embedding = self.add_weight('seq_bias_encoding', shape=(1, seq_len_max, 1),
|
||||
initializer=tf.keras.initializers.TruncatedNormal(mean=0.0, stddev=0.0001, seed=self.seed))
|
||||
self.embed_bias_embedding = self.add_weight('embed_beas_encoding', shape=(1, 1, embed_size),
|
||||
initializer=tf.keras.initializers.TruncatedNormal(mean=0.0, stddev=0.0001, seed=self.seed))
|
||||
super(BiasEncoding, self).build(input_shape)
|
||||
|
||||
def call(self, inputs, mask=None):
|
||||
"""
|
||||
:param inputs: A list 长度是会话数量,每个元素表示一个会话矩阵,维度是[None, max_seq_len, embed_dim]
|
||||
"""
|
||||
bias_encoding_out = []
|
||||
for i in range(self.sess_max_count):
|
||||
bias_encoding_out.append(
|
||||
inputs[i] + self.embed_bias_embedding + self.seq_bias_embedding + self.sess_bias_embedding[i] # 这里会广播
|
||||
)
|
||||
return bias_encoding_out
|
||||
```
|
||||
这里的核心就是build里面的那三个偏置矩阵,对应论文里面的$\mathbf{w}_{k}^{K},\mathbf{w}_{t}^{T},\mathbf{w}_{c}^{C}$, 这里之所以放到build里面建立,是为了让这些参数可学习, 而前向传播里面就是论文里面的公式加就完事,这里面会用到广播机制。
|
||||
|
||||
### 会话兴趣提取层(sess_interest_extractor)
|
||||
这里面就是复现了大名鼎鼎的Transformer了, 这也是我第一次看transformer的代码,果真与之前的理论分析还是有很多不一样的点,下面得一一梳理一下,Transformer是非常重要的。
|
||||
|
||||
首先是位置编码, 代码如下:
|
||||
|
||||
```python
|
||||
def positional_encoding(inputs, pos_embedding_trainable=True,scale=True):
|
||||
"""
|
||||
inputs: (None, max_seq_len, embed_dim)
|
||||
"""
|
||||
_, T, num_units = inputs.get_shape().as_list() # [None, max_seq_len, embed_dim]
|
||||
|
||||
position_ind = tf.expand_dims(tf.range(T), 0) # [1, max_seq_len]
|
||||
|
||||
# First part of the PE function: sin and cos argument
|
||||
position_enc = np.array([
|
||||
[pos / np.power(1000, 2. * i / num_units) for i in range(num_units)] for pos in range(T)
|
||||
])
|
||||
|
||||
# Second part, apply the cosine to even columns and sin to odds. # 这个操作秀
|
||||
position_enc[:, 0::2] = np.sin(position_enc[:, 0::2]) # dim 2i
|
||||
position_enc[:, 1::2] = np.cos(position_enc[:, 1::2]) # dim 2i+1
|
||||
|
||||
# 转成张量
|
||||
if pos_embedding_trainable:
|
||||
lookup_table = K.variable(position_enc, dtype=tf.float32)
|
||||
|
||||
outputs = tf.nn.embedding_lookup(lookup_table, position_ind)
|
||||
if scale:
|
||||
outputs = outputs * num_units ** 0.5
|
||||
return outputs + inputs
|
||||
```
|
||||
这一块的话没有啥好说的东西感觉,这个就是在按照论文里面的公式sin, cos变换, 这里面比较秀的操作感觉就是dim2i和dim 2i+1的赋值了。
|
||||
|
||||
接下来,LayerNormalization, 这个也是按照论文里面的公式实现的代码,求均值和方差的维度都是embedding:
|
||||
|
||||
```python
|
||||
class LayerNormalization(Layer):
|
||||
def __init__(self, axis=-1, eps=1e-9, center=True, scale=True):
|
||||
super(LayerNormalization, self).__init__()
|
||||
self.axis = axis
|
||||
self.eps = eps
|
||||
self.center = center
|
||||
self.scale = scale
|
||||
def build(self, input_shape):
|
||||
"""
|
||||
input_shape: [None, max_seq_len, singlehead_emb_dim*head_num]
|
||||
"""
|
||||
self.gamma = self.add_weight(name='gamma', shape=input_shape[-1:], # [1, max_seq_len, singlehead_emb_dim*head_num]
|
||||
initializer=tf.keras.initializers.Ones(), trainable=True)
|
||||
self.beta = self.add_weight(name='beta', shape=input_shape[-1:],
|
||||
initializer=tf.keras.initializers.Zeros(), trainable=True) # [1, max_seq_len, singlehead_emb_dim*head_num]
|
||||
super(LayerNormalization, self).build(input_shape)
|
||||
|
||||
def call(self, inputs):
|
||||
"""
|
||||
[None, max_seq_len, singlehead_emb_dim*head_num]
|
||||
"""
|
||||
mean = K.mean(inputs, axis=self.axis, keepdims=True) # embed_dim维度上求均值
|
||||
variance = K.mean(K.square(inputs-mean), axis=-1, keepdims=True) # embed_dim维度求方差
|
||||
std = K.sqrt(variance + self.eps)
|
||||
outputs = (inputs - mean) / std
|
||||
|
||||
if self.scale:
|
||||
outputs *= self.gamma
|
||||
if self.center:
|
||||
outputs += self.beta
|
||||
return outputs
|
||||
```
|
||||
下面就是伟大的Transformer网络,下面我先把整体代码放上来,然后解释一些和我之前见到过的一样的地方,也是通过看具体代码学习到的点:
|
||||
|
||||
```python
|
||||
class Transformer(Layer):
|
||||
"""Transformer网络"""
|
||||
def __init__(self, singlehead_emb_size=1, att_head_nums=8, dropout_rate=0.0, use_positional_encoding=False,use_res=True,
|
||||
use_feed_forword=True, use_layer_norm=False, blinding=False, seed=1024):
|
||||
super(Transformer, self).__init__()
|
||||
self.singlehead_emb_size = singlehead_emb_size
|
||||
self.att_head_nums = att_head_nums
|
||||
self.num_units = self.singlehead_emb_size * self.att_head_nums
|
||||
self.use_res = use_res
|
||||
self.use_feed_forword = use_feed_forword
|
||||
self.dropout_rate = dropout_rate
|
||||
self.use_positional_encoding = use_positional_encoding
|
||||
self.use_layer_norm = use_layer_norm
|
||||
self.blinding = blinding # 如果为True的话表明进行attention的时候未来的units都被屏蔽, 解码器的时候用
|
||||
self.seed = seed
|
||||
|
||||
# 这里需要为该层自定义可训练的参数矩阵 WQ, WK, WV
|
||||
def build(self, input_shape):
|
||||
# input_shape: [None, max_seq_len, embed_dim]
|
||||
embedding_size= int(input_shape[0][-1])
|
||||
# 检查合法性
|
||||
if self.num_units != embedding_size:
|
||||
raise ValueError(
|
||||
"att_embedding_size * head_num must equal the last dimension size of inputs,got %d * %d != %d" % (
|
||||
self.singlehead_emb_size, att_head_nums, embedding_size))
|
||||
self.seq_len_max = int(input_shape[0][-2])
|
||||
# 定义三个矩阵
|
||||
self.W_Query = self.add_weight(name='query', shape=[embedding_size, self.singlehead_emb_size*self.att_head_nums],
|
||||
dtype=tf.float32,initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed))
|
||||
self.W_Key = self.add_weight(name='key', shape=[embedding_size, self.singlehead_emb_size*self.att_head_nums],
|
||||
dtype=tf.float32,initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed+1))
|
||||
self.W_Value = self.add_weight(name='value', shape=[embedding_size, self.singlehead_emb_size*self.att_head_nums],
|
||||
dtype=tf.float32,initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed+2))
|
||||
# 用神经网络的话,加两层训练参数
|
||||
if self.use_feed_forword:
|
||||
self.fw1 = self.add_weight('fw1', shape=[self.num_units, 4 * self.num_units], dtype=tf.float32,
|
||||
initializer=tf.keras.initializers.glorot_uniform(seed=self.seed))
|
||||
self.fw2 = self.add_weight('fw2', shape=[4 * self.num_units, self.num_units], dtype=tf.float32,
|
||||
initializer=tf.keras.initializers.glorot_uniform(seed=self.seed+1))
|
||||
self.dropout = tf.keras.layers.Dropout(self.dropout_rate)
|
||||
self.ln = LayerNormalization()
|
||||
super(Transformer, self).build(input_shape)
|
||||
|
||||
def call(self, inputs, mask=None, training=None):
|
||||
"""
|
||||
:param inputs: [当前会话sessi, 当前会话sessi] 维度 (None, max_seq_len, embed_dim)
|
||||
:param mask: 当前会话mask 这是个1维数组, 维度是(None, ), 表示每个样本在当前会话里面的行为序列长度
|
||||
"""
|
||||
# q和k其实是一样的矩阵
|
||||
queries, keys = inputs
|
||||
query_masks, key_masks = mask, mask
|
||||
|
||||
# 这里需要对Q和K进行mask操作,
|
||||
# key masking目的是让key值的unit为0的key对应的attention score极小,这样加权计算value时相当于对结果不产生影响
|
||||
# Query Masking 要屏蔽的是被0所填充的内容。
|
||||
query_masks = tf.sequence_mask(query_masks, self.seq_len_max, dtype=tf.float32) # (None, 1, seq_len_max)
|
||||
key_masks = tf.sequence_mask(key_masks, self.seq_len_max, dtype=tf.float32) # (None, 1, seq_len_max), 注意key_masks开始是(None,1)
|
||||
key_masks = key_masks[:, 0, :] # 所以上面会多出个1维度来, 这里去掉才行,(None, seq_len_max)
|
||||
query_masks = query_masks[:, 0, :] # 这个同理
|
||||
|
||||
# 是否位置编码
|
||||
if self.use_positional_encoding:
|
||||
queries = positional_encoding(queries)
|
||||
keys = positional_encoding(queries)
|
||||
|
||||
# tensordot 是矩阵乘,好处是当两个矩阵维度不同的时候,只要指定axes也可以乘
|
||||
# 这里表示的是queries的-1维度与W_Query的0维度相乘
|
||||
# (None, max_seq_len, embedding_size) * [embedding_size, singlehead_emb_size*head_num]
|
||||
querys = tf.tensordot(queries, self.W_Query, axes=(-1, 0)) # [None, max_seq_len_q, singlehead_emb_size*head_num]
|
||||
|
||||
keys = tf.tensordot(keys, self.W_Key, axes=(-1, 0)) # [None, max_seq_len_k, singlehead_emb_size*head_num]
|
||||
values = tf.tensordot(keys, self.W_Value, axes=(-1, 0)) # [None, max_seq_len_k, singlehead_emb_size*head_num]
|
||||
|
||||
# tf.split切分张量 这里从头那里切分成head_num个张量, 然后从0维拼接
|
||||
querys = tf.concat(tf.split(querys, self.att_head_nums, axis=2), axis=0) # [head_num*None, max_seq_len_q, singlehead_emb_size]
|
||||
keys = tf.concat(tf.split(keys, self.att_head_nums, axis=2), axis=0) # [head_num*None, max_seq_len_k, singlehead_emb_size]
|
||||
values = tf.concat(tf.split(values, self.att_head_nums, axis=2), axis=0) # [head_num*None, max_seq_len_k, singlehead_emb_size]
|
||||
|
||||
# Q*K keys后两维转置然后再乘 [head_num*None, max_seq_len_q, max_seq_len_k]
|
||||
outputs = tf.matmul(querys, keys, transpose_b=True)
|
||||
outputs = outputs / (keys.get_shape().as_list()[-1] ** 0.5)
|
||||
|
||||
# 从0维度上复制head_num次
|
||||
key_masks = tf.tile(key_masks, [self.att_head_nums, 1]) # [head_num*None, max_seq_len_k]
|
||||
key_masks = tf.tile(tf.expand_dims(key_masks, 1), [1, tf.shape(queries)[1], 1]) # [head_num*None, max_seq_len_q,max_seq_len_k]
|
||||
paddings = tf.ones_like(outputs) * (-2**32+1)
|
||||
|
||||
outputs = tf.where(tf.equal(key_masks, 1), outputs, paddings) # 被填充的部分赋予极小的权重
|
||||
|
||||
# 标识是否屏蔽未来序列的信息(解码器self attention的时候不能看到自己之后的哪些信息)
|
||||
# 这里通过下三角矩阵的方式进行,依此表示预测第一个词,第二个词,第三个词...
|
||||
if self.blinding:
|
||||
diag_vals = tf.ones_like(outputs[0, :, :]) # (T_q, T_k)
|
||||
tril = tf.linalg.LinearOperatorLowerTriangular(diag_vals).to_dense() # (T_q, T_k) 这是个下三角矩阵
|
||||
masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(outputs)[0], 1, 1]) # (h*N, T_q, T_k)
|
||||
|
||||
paddings = tf.ones_like(masks) * (-2 ** 32 + 1)
|
||||
outputs = tf.where(tf.equal(masks, 0), paddings, outputs) # (h*N, T_q, T_k)
|
||||
|
||||
outputs -= tf.reduce_max(outputs, axis=-1, keepdims=True)
|
||||
outputs = tf.nn.softmax(outputs, axis=-1) # 最后一个维度求softmax,换成权重
|
||||
|
||||
query_masks = tf.tile(query_masks, [self.att_head_nums, 1]) # [head_num*None, max_seq_len_q]
|
||||
query_masks = tf.tile(tf.expand_dims(query_masks, -1), [1, 1, tf.shape(keys)[1]]) # [head_num*None, max_seq_len_q, max_seq_len_k]
|
||||
|
||||
outputs *= query_masks
|
||||
|
||||
# 权重矩阵过下dropout [head_num*None, max_seq_len_q, max_seq_len_k]
|
||||
outputs = self.dropout(outputs, training=training)
|
||||
|
||||
# weighted sum [head_num*None, max_seq_len_q, max_seq_len_k] * # [head_num*None, max_seq_len_k, singlehead_emb_size]
|
||||
result = tf.matmul(outputs, values) # [head_num*None, max_seq_len_q, singlehead_emb_size]
|
||||
# 换回去了
|
||||
result = tf.concat(tf.split(result, self.att_head_nums, axis=0), axis=2) # [None, max_seq_len_q, head_num*singlehead_emb_size]
|
||||
|
||||
if self.use_res: # 残差连接
|
||||
result += queries
|
||||
if self.use_layer_norm:
|
||||
result = self.ln(result)
|
||||
if self.use_feed_forword: # [None, max_seq_len_q, head_num*singlehead_emb_size] 与 [num_units, self.num_units]
|
||||
fw1 = tf.nn.relu(tf.tensordot(result, self.fw1, axes=[-1, 0])) # [None, max_seq_len_q, 4*num_units]
|
||||
fw1 = self.dropout(fw1, training=training)
|
||||
fw2 = tf.tensordot(fw1, self.fw2, axes=[-1, 0]) # [None, max_seq_len_q, num_units] 这个num_units其实就等于head_num*singlehead_emb_size
|
||||
|
||||
if self.use_res:
|
||||
result += fw2
|
||||
if self.use_layer_norm:
|
||||
result = self.ln(result)
|
||||
|
||||
return tf.reduce_mean(result, axis=1, keepdims=True) # [None, 1, head_num*singleh]
|
||||
```
|
||||
这里面的整体逻辑, 首先在build里面会构建3个矩阵`WQ, WK, WV`,在这里定义依然是为了这些参数可训练, 而出乎我意料的是残差网络的参数w也是这里定义, 之前还以为这个是单独写出来,后面看了前向传播的逻辑时候明白了。
|
||||
|
||||
前向传播的逻辑和我之前画的图上差不多,不一样的细节是这里的具体实现上, 就是这里的**把多个头分开,采用堆叠的方式进行计算(堆叠到第一个维度上去了)**。这个是我之前忽略的一个问题, 只有这样才能使得每个头与每个头之间的自注意力运算是独立不影响的。如果不这么做的话,最后得到的结果会含有当前单词在这个头和另一个单词在另一个头上的关联,这是不合理的。**这是看了源码之后才发现的细节**。
|
||||
|
||||
另外就是mask操作这里,Q和K都需要进行mask操作,因为我们接受的输入序列是经过填充的,这里必须通过指明长度在具体计算的时候进行遮盖,否则softmax那里算的时候会有影响,因为e的0次方是1,所以这里需要找到序列里面填充的那些地方,给他一个超级大的负数,这样e的负无穷接近0,才能没有影响。但之前不知道这里的细节,这次看发现是Q和K都进行mask操作,且目的还不一样。
|
||||
|
||||
第三个细节,就是对未来序列的屏蔽,这个在这里是用不到的,这个是Transformer的解码器用的一个操作,就是在解码的时候,我们不能让当前的序列看到自己之后的信息。这里也需要进行mask遮盖住后面的。而具体实现,竟然使用了一个下三角矩阵, 这个东西的感觉是这样:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210312171321963.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
解码的时候,只能看到自己及以前的相关性,然后加权,这个学到了哈哈。
|
||||
|
||||
transformer这里接收的是会话兴趣分割层传下来的兴趣列表,返回的是个矩阵,维度是`(None, sess_nums, embed_dim)`, 因为这里每个会话都要过Transformer, 输入的维度是(None, seq_len, embed_dim), 而经过transformer之后,本来输出的维度也是这个,但是最后返回的时候在seq_len的维度上求了个平均。所以每个会话得到的输出是(None, 1, embed_dim), 相当于兴趣综合了下。而5个会话,就会得到5个这样的结果,然后再会话维度上拼接,就是上面的这个矩阵结果了,这个东西作为双向LSTM的输入。
|
||||
|
||||
### 会话兴趣交互层(BiLSTM)
|
||||
这里主要是值得记录下多层双向LSTM的实现过程, 用下面的这种方式非常的灵活:
|
||||
|
||||
```python
|
||||
class BiLSTM(Layer):
|
||||
def __init__(self, units, layers=2, res_layers=0, dropout_rate=0.2, merge_mode='ave'):
|
||||
super(BiLSTM, self).__init__()
|
||||
self.units = units
|
||||
self.layers = layers
|
||||
self.res_layers = res_layers
|
||||
self.dropout_rate = dropout_rate
|
||||
self.merge_mode = merge_mode
|
||||
|
||||
# 这里要构建正向的LSTM和反向的LSTM, 因为我们是要两者的计算结果最后加和,所以这里需要分别计算
|
||||
def build(self, input_shape):
|
||||
"""
|
||||
input_shape: (None, sess_max_count, embed_dim)
|
||||
"""
|
||||
self.fw_lstm = []
|
||||
self.bw_lstm = []
|
||||
for _ in range(self.layers):
|
||||
self.fw_lstm.append(
|
||||
LSTM(self.units, dropout=self.dropout_rate, bias_initializer='ones', return_sequences=True, unroll=True)
|
||||
)
|
||||
# go_backwards 如果为真,则反向处理输入序列并返回相反的序列
|
||||
# unroll 布尔(默认错误)。如果为真,则网络将展开,否则使用符号循环。展开可以提高RNN的速度,尽管它往往会占用更多的内存。展开只适用于较短的序列。
|
||||
self.bw_lstm.append(
|
||||
LSTM(self.units, dropout=self.dropout_rate, bias_initializer='ones', return_sequences=True, go_backwards=True, unroll=True)
|
||||
)
|
||||
super(BiLSTM, self).build(input_shape)
|
||||
|
||||
def call(self, inputs):
|
||||
|
||||
input_fw = inputs
|
||||
input_bw = inputs
|
||||
for i in range(self.layers):
|
||||
output_fw = self.fw_lstm[i](input_fw)
|
||||
output_bw = self.bw_lstm[i](input_bw)
|
||||
output_bw = Lambda(lambda x: K.reverse(x, 1), mask=lambda inputs, mask:mask)(output_bw)
|
||||
|
||||
if i >= self.layers - self.res_layers:
|
||||
output_fw += input_fw
|
||||
output_bw += input_bw
|
||||
|
||||
input_fw = output_fw
|
||||
input_bw = output_bw
|
||||
|
||||
if self.merge_mode == "fw":
|
||||
output = output_fw
|
||||
elif self.merge_mode == "bw":
|
||||
output = output_bw
|
||||
elif self.merge_mode == 'concat':
|
||||
output = K.concatenate([output_fw, output_bw])
|
||||
elif self.merge_mode == 'sum':
|
||||
output = output_fw + output_bw
|
||||
elif self.merge_mode == 'ave':
|
||||
output = (output_fw + output_bw) / 2
|
||||
elif self.merge_mode == 'mul':
|
||||
output = output_fw * output_bw
|
||||
elif self.merge_mode is None:
|
||||
output = [output_fw, output_bw]
|
||||
|
||||
return output
|
||||
```
|
||||
这里这个操作是比较骚的,以后建立双向LSTM就用这个模板了,具体也不用解释,并且这里之所以说灵活,是因为最后前向LSTM的结果和反向LSTM的结果都能单独的拿到,且可以任意的两者运算。 我记得Keras里面应该是也有直接的函数实现双向LSTM的,但依然感觉不如这种灵活。 这个层数自己定,单元自己定看,最后结果形式自己定,太帅了简直。 关于LSTM,可以看[官方文档](https://tensorflow.google.cn/versions/r2.0/api_docs/python/tf/keras/layers/LSTM)
|
||||
|
||||
这个的输入是`(None, sess_nums, embed_dim)`, 输出是`(None, sess_nums, hidden_units_num)`。
|
||||
|
||||
### 会话兴趣局部激活
|
||||
这里就是局部Attention的操作了,这个在这里就不解释了,和之前的DIEN,DIN的操作就一样了, 代码也不放在这里了,剩下的代码都看后面的GitHub链接吧, 这里我只记录下我觉得后面做别的项目会有用的代码哈哈。
|
||||
|
||||
## 总结
|
||||
DSIN的核心创新点就是把用户的历史行为按照时间间隔进行切分,以会话为单位进行学习, 而学习的方式首先是会话之内的行为自学习,然后是会话之间的交互学习,最后是与当前候选商品相关的兴趣演进,总体上还是挺清晰的。
|
||||
|
||||
具体的实际使用场景依然是有丰富的用户历史行为序列才可以,而会话之间的划分间隔,也得依据具体业务场景。 具体的使用可以调deepctr的包。
|
||||
|
||||
**参考资料**:
|
||||
* [DSIN原论文](https://arxiv.org/abs/1905.06482)
|
||||
* [自然语言处理之Attention大详解(Attention is all you need)](https://blog.csdn.net/wuzhongqiang/article/details/104414239?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161512240816780357259240%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=161512240816780357259240&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v1~rank_blog_v1-1-104414239.pc_v1_rank_blog_v1&utm_term=Attention+is+all)
|
||||
* [推荐系统遇上深度学习(四十五)-探秘阿里之深度会话兴趣网络](https://www.jianshu.com/p/82ccb10f9ede)
|
||||
* [深度兴趣网络模型探索——DIN+DIEN+DSIN](https://blog.csdn.net/baymax_007/article/details/91130374)
|
||||
* [Transformer解读](https://www.cnblogs.com/flightless/p/12005895.html)
|
||||
* [Welcome to DeepCTR’s documentation!](https://deepctr-doc.readthedocs.io/en/latest/)
|
||||
@@ -1,129 +0,0 @@
|
||||
## 背景与动机
|
||||
|
||||
在推荐系统的精排模块,多任务学习的模型结构已成业界的主流,获得了广阔的应用。多任务学习(multi-task learning),本质上是希望使用一个模型完成多个任务的建模。在推荐系统中,多任务学习一般即指多目标学习(multi-label learning),不同目标输入相同的feature进行联合训练,是迁移学习的一种。他们之间的关系如图:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-130d040474f34095ec6d8c81133da538_1440w.jpg" style="zoom:60%;" />
|
||||
</div>
|
||||
|
||||
下面我们先讨论三个问题
|
||||
|
||||
**一、为什么要用多任务学习?**
|
||||
|
||||
(1)很多业界推荐的业务,天然就是一个多目标的建模场景,需要多目标共同优化。以微信视频号推荐为例,打开一个视频,如图,首页上除了由于视频自动播放带来的“播放时长”、“完播率”(用户播放时长占视频长度的比例)目标之外,还有大量的互动标签,例如“点击好友头像”、“进入主页”、“关注”、“收藏”、“分享”、“点赞”、“评论”等。究竟哪一个标签最符合推荐系统的建模目标呢?
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/80/v2-c18fc1ec65e308ee2e1477d7868007db_1440w.jpg" style="zoom:30%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
如果要用一个词来概括所有各式各样的推荐系统的终极目标,那就是“用户满意度”,但我们无法找到一个显示的指标量化用户满意度。业界一般使用“DAU”、“用户日均使用时长”、“留存率”来作为客观的间接的“用户满意度”(或者说算法工程师绩效)评价指标。而这些指标都是难以通过单一目标建模的,以使用时长为例,长视频播放长度天然大于短视频。所幸的是,虽然没有显式的用户满意度评价指标,但是现在的app都存在类似上述视频号推荐场景的丰富具体的隐式反馈。但这些独立的隐式反馈也存在一些挑战:
|
||||
|
||||
- 目标偏差:点赞、分享表达的满意度可能比播放要高
|
||||
- 物品偏差:不同视频的播放时长体现的满意度不一样,有的视频可能哄骗用户看到尾部(类似新闻推荐中的标题党)
|
||||
- 用户偏差:有的用户表达满意喜欢用点赞,有的用户可能喜欢用收藏
|
||||
|
||||
因此我们需要使用多任务学习模型针对多个目标进行预测,并在线上融合多目标的预测结果进行排序。多任务学习也不能直接表达用户满意度,但是可以最大限度利用能得到的用户反馈信息进行充分的表征学习,并且可建模业务之间的关系,从而高效协同学习具体任务。
|
||||
|
||||
(2)工程便利,不用针对不同的任务训练不同的模型。一般推荐系统中排序模块延时需求在40ms左右,如果分别对每个任务单独训练一个模型,难以满足需求。出于控制成本的目的,需要将部分模型进行合并。合并之后,能更高效的利用训练资源和进行模型的迭代升级。
|
||||
|
||||
**二、为什么多任务学习有效?**
|
||||
|
||||
当把业务独立建模变成多任务联合建模之后,有可能带来四种结果:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-44927ccdd6caf9685d3d9d5367af98dc_1440w.jpg" style="zoom:60%;" />
|
||||
</div>
|
||||
|
||||
多任务学习的优势在于通过部分参数共享,联合训练,能在保证“还不错”的前提下,实现多目标共同提升。原因有以下几种:
|
||||
|
||||
- 任务互助:对于某个任务难学到的特征,可通过其他任务学习
|
||||
- 隐式数据增强:不同任务有不同的噪声,一起学习可抵消部分噪声
|
||||
- 学到通用表达,提高泛化能力:模型学到的是对所有任务都偏好的权重,有助于推广到未来的新任务
|
||||
- 正则化:对于一个任务而言,其他任务的学习对该任务有正则化效果
|
||||
|
||||
**三、多任务学习都在研究什么问题**?
|
||||
|
||||
如上所述,多任务的核心优势在于通过不同任务的网络参数共享,实现1+1>2的提升,因此多任务学习的一大主流研究方向便是如何设计有效的网络结构。多个label的引入自然带来了多个loss,那么如何在联合训练中共同优化多个loss则是关键问题。
|
||||
|
||||
- 网络结构设计:主要研究哪些参数共享、在什么位置共享、如何共享。这一方向我们认为可以分为两大类,第一类是在设计网络结构时,考虑目标间的显式关系(例如淘宝中,点击之后才有购买行为发生),以阿里提出的ESMM为代表;另一类是目标间没有显示关系(例如短视频中的收藏与分享),在设计模型时不考虑label之间的量化关系,以谷歌提出的MMOE为代表。
|
||||
- 多loss的优化策略:主要解决loss数值有大有小、学习速度有快有慢、更新方向时而相反的问题。最经典的两个工作有UWL(Uncertainty Weight):通过自动学习任务的uncertainty,给uncertainty大的任务小权重,uncertainty小的任务大权重;GradNorm:结合任务梯度的二范数和loss下降梯度,引入带权重的损失函数Gradient Loss,并通过梯度下降更新该权重。
|
||||
|
||||
## loss加权融合
|
||||
|
||||
一种最简单的实现多任务学习的方式是对不同任务的loss进行加权。例如谷歌的Youtube DNN论文中提到的一种加权交叉熵:
|
||||
$$
|
||||
\text { Weighted CE Loss }=-\sum_{i}\left[T_{i} y_{i} \log p_{i}+\left(1-y_{i}\right) \log \left(1-p_{i}\right)\right]
|
||||
$$
|
||||
其中![[公式]](https://www.zhihu.com/equation?tex=T_i) 为观看时长。在原始训练数据中,正样本是视频展示后用户点击了该视频,负样本则是展示后未点击,这个一个标准的CTR预估问题。该loss通过改变训练样本的权重,让所有负样本的权重都为 1,而正样本的权重为点击后的视频观看时长 ![[公式]](https://www.zhihu.com/equation?tex=T_i) 。作者认为按点击率排序会倾向于把诱惑用户点击(用户未必真感兴趣)的视频排前面,而观看时长能更好地反映出用户对视频的兴趣,通过重新设计loss使得该模型在保证主目标点击的同时,将视频观看时长转化为样本的权重,达到优化平均观看时长的效果。
|
||||
|
||||
另一种更为简单粗暴的加权方式是人工手动调整权重,例如 0.3\*L(点击)+0.7*L\*(视频完播)
|
||||
|
||||
这种loss加权的方式优点如下:
|
||||
|
||||
- 模型简单,仅在训练时通过梯度乘以样本权重实现对其它目标的加权
|
||||
- 模型上线简单,和base完全相同,不需要额外开销
|
||||
|
||||
缺点:
|
||||
|
||||
- 本质上并不是多目标建模,而是将不同的目标转化为同一个目标。样本的加权权重需要根据AB测试才能确定。
|
||||
|
||||
## Shared-Bottom
|
||||
|
||||
最早的多任务学习模型是底层共享结构(Shared-Bottom),如图所示。
|
||||
|
||||
通过共享底层模块,学习任务间通用的特征表征,再往上针对每一个任务设置一个Tower网络,每个Tower网络的参数由自身对应的任务目标进行学习。Shared Bottom可以根据自身数据特点,使用MLP、DeepFM、DCN、DIN等,Tower网络一般使用简单的MLP。
|
||||
|
||||
代码如下,共享特征embedding,共享底层DNN网络,任务输出层独立,loss直接使用多个任务的loss值之和。
|
||||
|
||||
```python
|
||||
def Shared_Bottom(dnn_feature_columns, num_tasks=None, task_types=None, task_names=None,
|
||||
bottom_dnn_units=[128, 128], tower_dnn_units_lists=[[64,32], [64,32]],
|
||||
l2_reg_embedding=0.00001, l2_reg_dnn=0, seed=1024,dnn_dropout=0,
|
||||
dnn_activation='relu', dnn_use_bn=False):
|
||||
|
||||
features = build_input_features(dnn_feature_columns)
|
||||
inputs_list = list(features.values())
|
||||
|
||||
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns, l2_reg_embedding,seed)
|
||||
#共享输入特征
|
||||
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
|
||||
#共享底层网络
|
||||
shared_bottom_output = DNN(bottom_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
|
||||
#任务输出层
|
||||
tasks_output = []
|
||||
for task_type, task_name, tower_dnn in zip(task_types, task_names, tower_dnn_units_lists):
|
||||
tower_output = DNN(tower_dnn, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_'+task_name)(shared_bottom_output)
|
||||
|
||||
logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
|
||||
output = PredictionLayer(task_type, name=task_name)(logit)
|
||||
tasks_output.append(output)
|
||||
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=tasks_output)
|
||||
return model
|
||||
```
|
||||
|
||||
优点:
|
||||
|
||||
- 浅层参数共享,互相补充学习,任务相关性越高,模型loss优化效果越明显,也可以加速训练。
|
||||
|
||||
缺点:
|
||||
|
||||
- 任务不相关甚至优化目标相反时(例如新闻的点击与阅读时长),可能会带来负收益,多个任务性能一起下降。
|
||||
|
||||
一般把Shared-Bottom的结构称作“参数硬共享”,多任务学习网络结构设计的发展方向便是如何设计更灵活的共享机制,从而实现“参数软共享”。
|
||||
|
||||
|
||||
|
||||
参考资料:
|
||||
|
||||
[https://developer.aliyun.com/article/793252](https://developer.aliyun.com/article/793252)
|
||||
|
||||
https://zhuanlan.zhihu.com/p/291406172
|
||||
|
||||
Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks (ICML'2018)
|
||||
|
||||
UWL: Multi-task learning using uncertainty to weigh losses for scene geometry and semantics (CVPR'2018)
|
||||
|
||||
YoutubeDNN: Deep neural networks for youtube recommendations (RecSys'2016)
|
||||
@@ -1,162 +0,0 @@
|
||||
# ESMM
|
||||
|
||||
不同的目标由于业务逻辑,有显式的依赖关系,例如**曝光→点击→转化**。用户必然是在商品曝光界面中,先点击了商品,才有可能购买转化。阿里提出了ESMM(Entire Space Multi-Task Model)网络,显式建模具有依赖关系的任务联合训练。该模型虽然为多任务学习模型,但本质上是以CVR为主任务,引入CTR和CTCVR作为辅助任务,解决CVR预估的挑战。
|
||||
|
||||
## 背景与动机
|
||||
|
||||
传统的CVR预估问题存在着两个主要的问题:**样本选择偏差**和**稀疏数据**。下图的白色背景是曝光数据,灰色背景是点击行为数据,黑色背景是购买行为数据。传统CVR预估使用的训练样本仅为灰色和黑色的数据。
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/80/v2-2f0df0f6933dd8405c478fcce91f7b6f_1440w.jpg" alt="img" style="zoom:33%;" />
|
||||
</div>
|
||||
|
||||
这会导致两个问题:
|
||||
- 样本选择偏差(sample selection bias,SSB):如图所示,CVR模型的正负样本集合={点击后未转化的负样本+点击后转化的正样本},但是线上预测的时候是样本一旦曝光,就需要预测出CVR和CTR以排序,样本集合={曝光的样本}。构建的训练样本集相当于是从一个与真实分布不一致的分布中采样得到的,这一定程度上违背了机器学习中训练数据和测试数据独立同分布的假设。
|
||||
- 训练数据稀疏(data sparsity,DS):点击样本只占整个曝光样本的很小一部分,而转化样本又只占点击样本的很小一部分。如果只用点击后的数据训练CVR模型,可用的样本将极其稀疏。
|
||||
|
||||
## 解决方案
|
||||
|
||||
阿里妈妈团队提出ESMM,借鉴多任务学习的思路,引入两个辅助任务CTR、CTCVR(已点击然后转化),同时消除以上两个问题。
|
||||
|
||||
三个预测任务如下:
|
||||
|
||||
- **pCTR**:p(click=1 | impression);
|
||||
- **pCVR**: p(conversion=1 | click=1,impression);
|
||||
- **pCTCVR**: p(conversion=1, click=1 | impression) = p(click=1 | impression) * p(conversion=1 | click=1, impression);
|
||||
|
||||
> 注意:其中只有CTR和CVR的label都同时为1时,CTCVR的label才是正样本1。如果出现CTR=0,CVR=1的样本,则为不合法样本,需删除。
|
||||
> pCTCVR是指,当用户已经点击的前提下,用户会购买的概率;pCVR是指如果用户点击了,会购买的概率。
|
||||
|
||||
三个任务之间的关系为:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-7bbeb8767db5d6a157852c8cd4221548_1440w.jpg" alt="img" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
其中x表示曝光,y表示点击,z表示转化。针对这三个任务,设计了如图所示的模型结构:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-6d8189bfe378dc4bf6f0db2ba0255eac_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
如图,主任务和辅助任务共享特征,不同任务输出层使用不同的网络,将cvr的预测值*ctr的预测值作为ctcvr任务的预测值,利用ctcvr和ctr的label构造损失函数:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic3.zhimg.com/80/v2-0098ab4556a8c67a1c12322ea3f89606_1440w.jpg" alt="img" style="zoom: 33%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
该架构具有两大特点,分别给出上述两个问题的解决方案:
|
||||
|
||||
- 帮助CVR模型在完整样本空间建模(即曝光空间X)。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-0b0c6dc7d4c38fa422a2876b7c4cc638_1440w.jpg" alt="img" style="zoom:33%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
从公式中可以看出,pCVR 可以由pCTR 和pCTCVR推导出。从原理上来说,相当于分别单独训练两个模型拟合出pCTR 和pCTCVR,再通过pCTCVR 除以pCTR 得到最终的拟合目标pCVR 。在训练过程中,模型只需要预测pCTCVR和pCTR,利用两种相加组成的联合loss更新参数。pCVR 只是一个中间变量。而pCTCVR和pCTR的数据是在完整样本空间中提取的,从而相当于pCVR也是在整个曝光样本空间中建模。
|
||||
|
||||
- 提供特征表达的迁移学习(embedding层共享)。CVR和CTR任务的两个子网络共享embedding层,网络的embedding层把大规模稀疏的输入数据映射到低维的表示向量,该层的参数占了整个网络参数的绝大部分,需要大量的训练样本才能充分学习得到。由于CTR任务的训练样本量要大大超过CVR任务的训练样本量,ESMM模型中特征表示共享的机制能够使得CVR子任务也能够从只有展现没有点击的样本中学习,从而能够极大地有利于缓解训练数据稀疏性问题。
|
||||
|
||||
模型训练完成后,可以同时预测cvr、ctr、ctcvr三个指标,线上根据实际需求进行融合或者只采用此模型得到的cvr预估值。
|
||||
|
||||
## 总结与拓展
|
||||
|
||||
可以思考以下几个问题
|
||||
|
||||
1. 能不能将乘法换成除法?
|
||||
即分别训练CTR和CTCVR模型,两者相除得到pCVR。论文提供了消融实验的结果,表中的DIVISION模型,比起BASE模型直接建模CTCVRR和CVR,有显著提高,但低于ESMM。原因是pCTR 通常很小,除以一个很小的浮点数容易引起数值不稳定问题。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic3.zhimg.com/80/v2-c0b2c860bd63a680d27c911c2e1ba8a2_1440w.jpg" alt="img" style="zoom:53%;" />
|
||||
</div>
|
||||
|
||||
2. 网络结构优化,Tower模型更换?两个塔不一致?
|
||||
原论文中的子任务独立的Tower网络是纯MLP模型,事实上业界在使用过程中一般会采用更为先进的模型(例如DeepFM、DIN等),两个塔也完全可以根据自身特点设置不一样的模型。这也是ESMM框架的优势,子网络可以任意替换,非常容易与其他学习模型集成。
|
||||
|
||||
3. 比loss直接相加更好的方式?
|
||||
原论文是将两个loss直接相加,还可以引入动态加权的学习机制。
|
||||
|
||||
4. 更长的序列依赖建模?
|
||||
有些业务的依赖关系不止有曝光-点击-转化三层,后续的改进模型提出了更深层次的任务依赖关系建模。
|
||||
|
||||
阿里的ESMM2: 在点击到购买之前,用户还有可能产生加入购物车(Cart)、加入心愿单(Wish)等行为。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-4f9f5508412086315f85d1b7fda733e9_1440w.jpg" alt="img" style="zoom:53%;" />
|
||||
</div>
|
||||
|
||||
相较于直接学习 click->buy (稀疏度约2.6%),可以通过Action路径将目标分解,以Cart为例:click->cart (稀疏 度为10%),cart->buy(稀疏度为12%),通过分解路径,建立多任务学习模型来分步求解CVR模型,缓解稀疏问题,该模型同样也引入了特征共享机制。
|
||||
|
||||
美团的[AITM](https://zhuanlan.zhihu.com/p/508876139/[https://cloud.tencent.com/developer/article/1868117](https://cloud.tencent.com/developer/article/1868117)):信用卡业务中,用户转化通常是一个**曝光->点击->申请->核卡->激活**的过程,具有5层的链路。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/80/v2-0ecf42e999795511f40ac6cd7b85eccf_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
美团提出了一种自适应信息迁移多任务(**Adaptive Information Transfer Multi-task,AITM**)框架,该框架通过自适应信息迁移(AIT)模块对用户多步转化之间的序列依赖进行建模。AIT模块可以自适应地学习在不同的转化阶段需要迁移什么和迁移多少信息。
|
||||
|
||||
总结:
|
||||
|
||||
ESMM首创了利用用户行为序列数据在完整样本空间建模,并提出利用学习CTR和CTCVR的辅助任务,迂回学习CVR,避免了传统CVR模型经常遭遇的样本选择偏差和训练数据稀疏的问题,取得了显著的效果。
|
||||
|
||||
## 代码实践
|
||||
|
||||
与Shared-Bottom同样的共享底层机制,之后两个独立的Tower网络,分别输出CVR和CTR,计算loss时只利用CTR与CTCVR的loss。CVR Tower完成自身网络更新,CTR Tower同时完成自身网络和Embedding参数更新。在评估模型性能时,重点是评估主任务CVR的auc。
|
||||
|
||||
```python
|
||||
def ESSM(dnn_feature_columns, task_type='binary', task_names=['ctr', 'ctcvr'],
|
||||
tower_dnn_units_lists=[[128, 128],[128, 128]], l2_reg_embedding=0.00001, l2_reg_dnn=0,
|
||||
seed=1024, dnn_dropout=0,dnn_activation='relu', dnn_use_bn=False):
|
||||
|
||||
features = build_input_features(dnn_feature_columns)
|
||||
inputs_list = list(features.values())
|
||||
|
||||
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns, l2_reg_embedding,seed)
|
||||
|
||||
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
|
||||
|
||||
ctr_output = DNN(tower_dnn_units_lists[0], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
|
||||
cvr_output = DNN(tower_dnn_units_lists[1], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
|
||||
|
||||
ctr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(ctr_output)
|
||||
cvr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(cvr_output)
|
||||
|
||||
ctr_pred = PredictionLayer(task_type, name=task_names[0])(ctr_logit)
|
||||
cvr_pred = PredictionLayer(task_type)(cvr_logit)
|
||||
|
||||
ctcvr_pred = tf.keras.layers.Multiply(name=task_names[1])([ctr_pred, cvr_pred])#CTCVR = CTR * CVR
|
||||
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=[ctr_pred, cvr_pred, ctcvr_pred])
|
||||
return model
|
||||
```
|
||||
|
||||
测试数据集:
|
||||
|
||||
adult:[https://archive.ics.uci.edu/ml/datasets/census+income](https://archive.ics.uci.edu/dataset/20/census+income)
|
||||
|
||||
将里面两个特征转为label,完成两个任务的预测:
|
||||
|
||||
- 任务1预测该用户收入是否大于50K,
|
||||
- 任务2预测该用户的婚姻是否未婚。
|
||||
|
||||
以上两个任务均为二分类任务,使用交叉熵作为损失函数。在ESMM框架下,我们把任务1作为CTR任务,任务2作为CVR任务,两者label相乘得到CTCVR任务的标签。
|
||||
|
||||
除ESSM之外,之后的MMOE、PLE模型都使用本数据集做测试。
|
||||
|
||||
> 注意上述代码,并未实现论文模型图中提到的field element-wise +模块。该模块实现较为简单,即分别把用户、商品相关特征的embedding求和再拼接,然后输入Tower网络。我们使用数据不具有该属性,暂未区分。
|
||||
|
||||
参考资料:
|
||||
|
||||
https://www.zhihu.com/question/475787809
|
||||
|
||||
https://zhuanlan.zhihu.com/p/37562283
|
||||
|
||||
美团:[https://cloud.tencent.com/developer/article/1868117](https://cloud.tencent.com/developer/article/1868117)
|
||||
|
||||
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate (SIGIR'2018)
|
||||
@@ -1,178 +0,0 @@
|
||||
# MMOE
|
||||
|
||||
## 写在前面
|
||||
|
||||
MMOE是2018年谷歌提出的,全称是Multi-gate Mixture-of-Experts, 对于多个优化任务,引入了多个专家进行不同的决策和组合,最终完成多目标的预测。解决的是硬共享里面如果多个任务相似性不是很强,底层的embedding学习反而相互影响,最终都学不好的痛点。
|
||||
|
||||
本篇文章首先是先了解下Hard-parameter sharing以及存在的问题,然后引出MMOE,对理论部分进行整理,最后是参考deepctr简单复现。
|
||||
|
||||
## 背景与动机
|
||||
|
||||
推荐系统中,即使同一个场景,常常也不只有一个业务目标。 在Youtube的视频推荐中,推荐排序任务不仅需要考虑到用户点击率,完播率,也需要考虑到一些满意度指标,例如,对视频是否喜欢,用户观看后对视频的评分;在淘宝的信息流商品推荐中,需要考虑到点击率,也需要考虑转化率;而在一些内容场景中,需要考虑到点击和互动、关注、停留时长等指标。
|
||||
|
||||
模型中,如果采用一个网络同时完成多个任务,就可以把这样的网络模型称为多任务模型, 这种模型能在不同任务之间学习共性以及差异性,能够提高建模的质量以及效率。 常见的多任务模型的设计范式大致可以分为三大类:
|
||||
* hard parameter sharing 方法: 这是非常经典的一种方式,底层是共享的隐藏层,学习各个任务的共同模式,上层用一些特定的全连接层学习特定任务模式。
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/ed10df1df313413daf2a6a6174ef4f8c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA57-75rua55qE5bCPQOW8ug==,size_1,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
这种方法目前用的也有,比如美团的猜你喜欢,知乎推荐的Ranking等, 这种方法最大的优势是Task越多, 单任务更加不可能过拟合,即可以减少任务之间过拟合的风险。 但是劣势也非常明显,就是底层强制的shared layers难以学习到适用于所有任务的有效表达。 **尤其是任务之间存在冲突的时候**。MMOE中给出了实验结论,当两个任务相关性没那么好(比如排序中的点击率与互动,点击与停留时长),此时这种结果会遭受训练困境,毕竟所有任务底层用的是同一组参数。
|
||||
* soft parameter sharing: 硬的不行,那就来软的,这个范式对应的结果从`MOE->MMOE->PLE`等。 即底层不是使用共享的一个shared bottom,而是有多个tower, 称为多个专家,然后往往再有一个gating networks在多任务学习时,给不同的tower分配不同的权重,那么这样对于不同的任务,可以允许使用底层不同的专家组合去进行预测,相较于上面所有任务共享底层,这个方式显得更加灵活
|
||||
* 任务序列依赖关系建模:这种适合于不同任务之间有一定的序列依赖关系。比如电商场景里面的ctr和cvr,其中cvr这个行为只有在点击之后才会发生。所以这种依赖关系如果能加以利用,可以解决任务预估中的样本选择偏差(SSB)和数据稀疏性(DS)问题
|
||||
* 样本选择偏差: 后一阶段的模型基于上一阶段采样后的样本子集训练,但最终在全样本空间进行推理,带来严重泛化性问题
|
||||
* 样本稀疏: 后一阶段的模型训练样本远小于前一阶段任务
|
||||
|
||||
<br>ESSM是一种较为通用的任务序列依赖关系建模的方法,除此之外,阿里的DBMTL,ESSM2等工作都属于这一个范式。 这个范式可能后面会进行整理,本篇文章不过多赘述。
|
||||
|
||||
通过上面的描述,能大体上对多任务模型方面的几种常用建模范式有了解,然后也知道了hard parameter sharing存在的一些问题,即不能很好的权衡特定任务的目标与任务之间的冲突关系。而这也就是MMOE模型提出的一个动机所在了, 那么下面的关键就是MMOE模型是怎么建模任务之间的关系的,又是怎么能使得特定任务与任务关系保持平衡的?
|
||||
|
||||
带着这两个问题,下面看下MMOE的细节。
|
||||
|
||||
## MMOE模型的理论及论文细节
|
||||
MMOE模型结构图如下。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/29c5624f2c8a46c097f097af7dbf4b45.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA57-75rua55qE5bCPQOW8ug==,size_2,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
这其实是一个演进的过程,首先hard parameter sharing这个就不用过多描述了, 下面主要是看MOE模型以及MMOE模型。
|
||||
|
||||
### 混合专家模型
|
||||
我们知道共享的这种模型结构,会遭受任务之间冲突而导致可能无法很好的收敛,从而无法学习到任务之间的共同模式。这个结构也可以看成是多个任务共用了一个专家。
|
||||
|
||||
先抛开任务关系, 我们发现一个专家在多任务学习上的表达能力很有限,于是乎,尝试引入多个专家,这就慢慢的演化出了混合专家模型。 公式表达如下:
|
||||
$$
|
||||
y=\sum_{i=1}^{n} g(x)_{i} f_{i}(x)
|
||||
$$
|
||||
这里的$y$表示的是多个专家的汇总输出,接下来这个东西要过特定的任务塔去得到特定任务的输出。 这里还加了一个门控网络机制,就是一个注意力网络, 来学习各个专家的重要性权重$\sum_{i=1}^{n} g(x)_{i}=1$。$f_i(x)$就是每个专家的输出, 而$g(x)_i$就是每个专家对应的权重。 虽然感觉这个东西,无非就是在单个专家的基础上多引入了几个全连接网络,然后又给这几个全连接网络加权,但是在我看来,这里面至少蕴含了好几个厉害的思路:
|
||||
1. 模型集成思想: 这个东西很像bagging的思路,即训练多个模型进行决策,这个决策的有效性显然要比单独一个模型来的靠谱一点,不管是从泛化能力,表达能力,学习能力上,应该都强于一个模型
|
||||
2. 注意力思想: 为了增加灵活性, 为不同的模型还学习了重要性权重,这可能考虑到了在学习任务的共性模式上, 不同的模型学习的模式不同,那么聚合的时候,显然不能按照相同的重要度聚合,所以为各个专家学习权重,默认了不同专家的决策地位不一样。这个思想目前不过也非常普遍了。
|
||||
3. multi-head机制: 从另一个角度看, 多个专家其实代表了多个不同head, 而不同的head代表了不同的非线性空间,之所以说表达能力增强了,是因为把输入特征映射到了不同的空间中去学习任务之间的共性模式。可以理解成从多个角度去捕捉任务之间的共性特征模式。
|
||||
|
||||
MOE使用了多个混合专家增加了各种表达能力,但是, 一个门控并不是很灵活,因为这所有的任务,最终只能选定一组专家组合,即这个专家组合是在多个任务上综合衡量的结果,并没有针对性了。 如果这些任务都比较相似,那就相当于用这一组专家组合确实可以应对这多个任务,学习到多个相似任务的共性。 但如果任务之间差的很大,这种单门控控制的方式就不行了,因为此时底层的多个专家学习到的特征模式相差可能会很大,毕竟任务不同,而单门控机制选择专家组合的时候,肯定是选择出那些有利于大多数任务的专家, 而对于某些特殊任务,可能学习的一塌糊涂。
|
||||
|
||||
所以,这种方式的缺口很明显,这样,也更能理解为啥提出多门控控制的专家混合模型了。
|
||||
|
||||
### MMOE结构
|
||||
Multi-gate Mixture-of-Experts(MMOE)的魅力就在于在OMOE的基础上,对于每个任务都会涉及一个门控网络,这样,对于每个特定的任务,都能有一组对应的专家组合去进行预测。更关键的时候,参数量还不会增加太多。公式如下:
|
||||
|
||||
$$
|
||||
y_{k}=h^{k}\left(f^{k}(x)\right),
|
||||
$$
|
||||
where $f^{k}(x)=\sum_{i=1}^{n} g^{k}(x)_{i} f_{i}(x)$. 这里的$k$表示任务的个数。 每个门控网络是一个注意力网络:
|
||||
$$
|
||||
g^{k}(x)=\operatorname{softmax}\left(W_{g k} x\right)
|
||||
$$
|
||||
$W_{g k} \in \mathbb{R}^{n \times d}$表示权重矩阵, $n$是专家的个数, $d$是特征的维度。
|
||||
|
||||
上面的公式这里不用过多解释。
|
||||
|
||||
这个改造看似很简单,只是在OMOE上额外多加了几个门控网络,但是却起到了杠杆般的效果,我这里分享下我的理解。
|
||||
* 首先,就刚才分析的OMOE的问题,在专家组合选取上单门控会产生限制,此时如果多个任务产生了冲突,这种结构就无法进行很好的权衡。 而MMOE就不一样了。MMOE是针对每个任务都单独有个门控选择专家组合,那么即使任务冲突了,也能根据不同的门控进行调整,选择出对当前任务有帮助的专家组合。所以,我觉得单门控做到了**针对所有任务在专家选择上的解耦**,而多门控做到了**针对各个任务在专家组合选择上的解耦**。
|
||||
* 多门控机制能够建模任务之间的关系了。如果各个任务都冲突, 那么此时有多门控的帮助, 此时让每个任务独享一个专家,如果任务之间能聚成几个相似的类,那么这几类之间应该对应的不同的专家组合,那么门控机制也可以选择出来。如果所有任务都相似,那这几个门控网络学习到的权重也会相似,所以这种机制把任务的无关,部分相关和全相关进行了一种统一。
|
||||
* 灵活的参数共享, 这个我们可以和hard模式或者是针对每个任务单独建模的模型对比,对于hard模式,所有任务共享底层参数,而每个任务单独建模,是所有任务单独有一套参数,算是共享和不共享的两个极端,对于都共享的极端,害怕任务冲突,而对于一点都不共享的极端,无法利用迁移学习的优势,模型之间没法互享信息,互为补充,容易遭受过拟合的困境,另外还会增加计算量和参数量。 而MMOE处于两者的中间,既兼顾了如果有相似任务,那就参数共享,模式共享,互为补充,如果没有相似任务,那就独立学习,互不影响。 又把这两种极端给进行了统一。
|
||||
* 训练时能快速收敛,这是因为相似的任务对于特定的专家组合训练都会产生贡献,这样进行一轮epoch,相当于单独任务训练时的多轮epoch。
|
||||
|
||||
OK, 到这里就把MMOE的故事整理完了,模型结构本身并不是很复杂,非常符合"大道至简"原理,简单且实用。
|
||||
|
||||
|
||||
那么, 为什么多任务学习为什么是有效的呢? 这里整理一个看到比较不错的答案:
|
||||
>多任务学习有效的原因是引入了归纳偏置,两个效果:
|
||||
> - 互相促进: 可以把多任务模型之间的关系看作是互相 先验知识,也称为归纳迁移,有了对模型的先验假设,可以更好提升模型的效果。解决数据稀疏性其实本身也是迁移学习的一个特性,多任务学习中也同样会体现
|
||||
> - 泛化作用:不同模型学到的表征不同,可能A模型学到的是B模型所没有学好的,B模型也有其自身的特点,而这一点很可能A学不好,这样一来模型健壮性更强
|
||||
|
||||
## MMOE模型的简单复现之多任务预测
|
||||
### 模型概貌
|
||||
这里是MMOE模型的简单复现,参考的deepctr。
|
||||
|
||||
由于MMOE模型不是很复杂,所以这里就可以直接上代码,然后简单解释:
|
||||
|
||||
```python
|
||||
def MMOE(dnn_feature_columns, num_experts=3, expert_dnn_hidden_units=(256, 128), tower_dnn_hidden_units=(64,),
|
||||
gate_dnn_hidden_units=(), l2_reg_embedding=0.00001, l2_reg_dnn=0, dnn_dropout=0, dnn_activation='relu',
|
||||
dnn_use_bn=False, task_types=('binary', 'binary'), task_names=('ctr', 'ctcvr')):
|
||||
|
||||
num_tasks = len(task_names)
|
||||
|
||||
# 构建Input层并将Input层转成列表作为模型的输入
|
||||
input_layer_dict = build_input_layers(dnn_feature_columns)
|
||||
input_layers = list(input_layer_dict.values())
|
||||
|
||||
# 筛选出特征中的sparse和Dense特征, 后面要单独处理
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), dnn_feature_columns))
|
||||
|
||||
# 获取Dense Input
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
dnn_dense_input.append(input_layer_dict[fc.name])
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(dnn_feature_columns)
|
||||
# 离散的这些特特征embedding之后,然后拼接,然后直接作为全连接层Dense的输入,所以需要进行Flatten
|
||||
dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=False)
|
||||
|
||||
# 把连续特征和离散特征合并起来
|
||||
dnn_input = combined_dnn_input(dnn_sparse_embed_input, dnn_dense_input)
|
||||
|
||||
# 建立专家层
|
||||
expert_outputs = []
|
||||
for i in range(num_experts):
|
||||
expert_network = DNN(expert_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=2022, name='expert_'+str(i))(dnn_input)
|
||||
expert_outputs.append(expert_network)
|
||||
|
||||
expert_concat = Lambda(lambda x: tf.stack(x, axis=1))(expert_outputs)
|
||||
|
||||
# 建立多门控机制层
|
||||
mmoe_outputs = []
|
||||
for i in range(num_tasks): # num_tasks=num_gates
|
||||
# 建立门控层
|
||||
gate_input = DNN(gate_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=2022, name='gate_'+task_names[i])(dnn_input)
|
||||
gate_out = Dense(num_experts, use_bias=False, activation='softmax', name='gate_softmax_'+task_names[i])(gate_input)
|
||||
gate_out = Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
|
||||
|
||||
# gate multiply the expert
|
||||
gate_mul_expert = Lambda(lambda x: reduce_sum(x[0] * x[1], axis=1, keep_dims=False), name='gate_mul_expert_'+task_names[i])([expert_concat, gate_out])
|
||||
|
||||
mmoe_outputs.append(gate_mul_expert)
|
||||
|
||||
# 每个任务独立的tower
|
||||
task_outputs = []
|
||||
for task_type, task_name, mmoe_out in zip(task_types, task_names, mmoe_outputs):
|
||||
# 建立tower
|
||||
tower_output = DNN(tower_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=2022, name='tower_'+task_name)(mmoe_out)
|
||||
logit = Dense(1, use_bias=False, activation=None)(tower_output)
|
||||
output = PredictionLayer(task_type, name=task_name)(logit)
|
||||
task_outputs.append(output)
|
||||
|
||||
model = Model(inputs=input_layers, outputs=task_outputs)
|
||||
return model
|
||||
```
|
||||
这个其实比较简单, 首先是传入封装好的dnn_features_columns, 这个是
|
||||
|
||||
```python
|
||||
dnn_features_columns = [SparseFeat(feat, feature_max_idx[feat], embedding_dim=4) for feat in sparse_features] \
|
||||
+ [DenseFeat(feat, 1) for feat in dense_features]
|
||||
```
|
||||
就是数据集先根据特征类别分成离散型特征和连续型特征,然后通过sparseFeat或者DenseFeat进行封装起来,组成的一个列表。
|
||||
|
||||
传入之后, 首先为这所有的特征列建立Input层,然后选择出离散特征和连续特征来,连续特征直接拼接即可, 而离散特征需要过embedding层得到连续型输入。把这个输入与连续特征拼接起来,就得到了送入专家的输入。
|
||||
|
||||
接下来,建立MMOE的多个专家, 这里的专家直接就是DNN,当然这个可以替换,比如MOSE里面就用了LSTM,这样的搭建模型方式非常灵活,替换起来非常简单。 把输入过多个专家得到的专家的输出,这里放到了列表里面。
|
||||
|
||||
接下来,建立多个门控网络,由于MMOE里面是每个任务会有一个单独的门控进行控制,所以这里的门控网络个数和任务数相同,门控网络也是DNN,接收输入,得到专家个输出作为每个专家的权重,把每个专家的输出加权组合得到门控网络最终的输出,放到列表中,这里的列表长度和task_num对应。
|
||||
|
||||
接下来, 为每个任务建立tower,学习特定的feature信息。同样也是DNN,接收的输入是上面列表的输出,每个任务的门控输出输入到各自的tower里面,得到最终的输出即可。 最终的输出也是个列表,对应的每个任务最终的网络输出值。
|
||||
|
||||
这就是整个MMOE网络的搭建逻辑。
|
||||
|
||||
|
||||
**参考资料**:
|
||||
* [MMOE论文](https://dl.acm.org/doi/pdf/10.1145/3219819.3220007)
|
||||
* [Recommending What Video to Watch Next: A Multitask
|
||||
Ranking System](https://dl.acm.org/doi/pdf/10.1145/3298689.3346997)
|
||||
* [Multitask Mixture of Sequential Experts for User Activity Streams](https://research.google/pubs/pub49274/)
|
||||
* [推荐系统中的多目标学习](https://zhuanlan.zhihu.com/p/183760759)
|
||||
* [推荐精排模型之多目标](https://zhuanlan.zhihu.com/p/221738556)
|
||||
* [Youtube视频推荐中应用MMOE模型](http://t.zoukankan.com/Lee-yl-p-13274642.html)
|
||||
* [多任务学习论文导读:Recommending What Video to Watch Next-A Multitask Ranking System](https://blog.csdn.net/fanzitao/article/details/104525843/)
|
||||
* [多任务模型之MoSE](https://zhuanlan.zhihu.com/p/161628342)
|
||||
@@ -1,389 +0,0 @@
|
||||
# PLE
|
||||
|
||||
**PLE**(Progressive Layered Extraction)模型由腾讯PCG团队在2020年提出,主要为了解决跷跷板问题,该论文获得了RecSys'2020的最佳长论文(Best Lone Paper Award)。
|
||||
|
||||
## 背景与动机
|
||||
|
||||
文章首先提出多任务学习中不可避免的两个缺点:
|
||||
|
||||
- 负迁移(Negative Transfer):针对相关性较差的任务,使用shared-bottom这种硬参数共享的机制会出现负迁移现象,不同任务之间存在冲突时,会导致模型无法有效进行参数的学习,不如对多个任务单独训练。
|
||||
- 跷跷板现象(Seesaw Phenomenon):针对相关性较为复杂的场景,通常不可避免出现跷跷板现象。多任务学习模式下,往往能够提升一部分任务的效果,但同时需要牺牲其他任务的效果。即使通过MMOE这种方式减轻负迁移现象,跷跷板问题仍然广泛存在。
|
||||
|
||||
在腾讯视频推荐场景下,有两个核心建模任务:
|
||||
|
||||
- VCR(View Completion Ratio):播放完成率,播放时间占视频时长的比例,回归任务
|
||||
- VTR(View Through Rate) :有效播放率,播放时间是否超过某个阈值,分类任务
|
||||
|
||||
这两个任务之间的关系是复杂的,在应用以往的多任务模型中发现,要想提升VTR准确率,则VCR准确率会下降,反之亦然。
|
||||
|
||||
上一小节提到的MMOE网络存在如下几个缺点
|
||||
|
||||
- MMOE中所有的Expert是被所有任务所共享,这可能无法捕捉到任务之间更复杂的关系,从而给部分任务带来一定的噪声。
|
||||
- 在复杂任务机制下,MMOE不同专家在不同任务的权重学的差不多
|
||||
- 不同的Expert之间没有交互,联合优化的效果有所折扣
|
||||
|
||||
## 解决方案
|
||||
|
||||
为了解决跷跷板现象,以及优化MMOE模型,PLE在网络结构设计上提出两大改进:
|
||||
|
||||
**一、CGC**(Customized Gate Control) 定制门控
|
||||
|
||||
PLE将共享的部分和每个任务特定的部分**显式的分开**,强化任务自身独立特性。把MMOE中提出的Expert分成两种,任务特定task-specific和任务共享task-shared。保证expert“各有所得”,更好的降低了弱相关性任务之间参数共享带来的问题。
|
||||
|
||||
网络结构如图所示,同样的特征输入分别送往三类不同的专家模型(任务A专家、任务B专家、任务共享专家),再通过门控机制加权聚合之后输入各自的Tower网络。门控网络,把原始数据和expert网络输出共同作为输入,通过单层全连接网络+softmax激活函数,得到分配给expert的加权权重,与attention机制类型。
|
||||
|
||||
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic3.zhimg.com/80/v2-c92975f7c21cc568a13cd9447adc757a_1440w.jpg" style="zoom:40%;" />
|
||||
</div>
|
||||
|
||||
任务A有 ![[公式]](https://www.zhihu.com/equation?tex=m_A) 个expert,任务B有 ![[公式]](https://www.zhihu.com/equation?tex=m_B) 个expert,另外还有 ![[公式]](https://www.zhihu.com/equation?tex=m_S) 个任务A、B共享的Expert。这样对Expert做一个显式的分割,可以让task-specific expert只受自己任务梯度的影响,不会受到其他任务的干扰(每个任务保底有一个独立的网络模型),而只有task-shared expert才受多个任务的混合梯度影响。
|
||||
|
||||
MMOE则是将所有Expert一视同仁,都加权输入到每一个任务的Tower,其中任务之间的关系完全交由gate自身进行学习。虽然MMOE提出的门控机制理论上可以捕捉到任务之间的关系,比如任务A可能与任务B确实无关,则MMOE中gate可以学到,让个别专家对于任务A的权重趋近于0,近似得到PLE中提出的task-specific expert。如果说MMOE是希望让expert网络可以对不同的任务各有所得,则PLE是保证让expert网络各有所得。
|
||||
|
||||
二、**PLE** (progressive layered extraction) 分层萃取
|
||||
|
||||
PLE就是上述CGC网络的多层纵向叠加,以获得更加丰富的表征能力。在分层的机制下,Gate设计成两种类型,使得不同类型Expert信息融合交互。task-share gate融合所有Expert信息,task-specific gate只融合specific expert和share expert。模型结构如图:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-ff3b4aff3511e6e56a3b509f244c5ab1_1440w.jpg" style="zoom:40%;" />
|
||||
</div>
|
||||
|
||||
将任务A、任务B和shared expert的输出输入到下一层,下一层的gate是以这三个上一层输出的结果作为门控的输入,而不是用原始input特征作为输入。这使得gate同时融合task-shares expert和task-specific expert的信息,论文实验中证明这种不同类型expert信息的交叉,可以带来更好的效果。
|
||||
|
||||
三、多任务loss联合优化
|
||||
|
||||
该论文专门讨论了loss设计的问题。在传统的多任务学习模型中,多任务的loss一般为
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/80/v2-ec1a0ae2a4001fea296662a9a5a1942b_1440w.jpg" style="zoom:33%;" />
|
||||
</div>
|
||||
|
||||
其中K是指任务数, ![[公式]](https://www.zhihu.com/equation?tex=w_k) 是每个任务各自对应的权重。这种loss存在两个关键问题:
|
||||
|
||||
- 不同任务之间的样本空间不一致:在视频推荐场景中,目标之间的依赖关系如图,曝光→播放→点击→(分享、评论),不同任务有不同的样本空间。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic3.zhimg.com/80/v2-bdf39ef6fcaf000924294cb010642fce_1440w.jpg" style="zoom:63%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
PLE将训练样本空间作为全部任务样本空间的并集,在分别针对每个任务算loss时,只考虑该任务的样本的空 间,一般需对这种数据集会附带一个样本空间标签。loss公式如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-8defd1e5d1ba896bb2d18bdb1db4e3cd_1440w.jpg" style="zoom:40%;" />
|
||||
</div>
|
||||
|
||||
|
||||
其中, ![[公式]](https://www.zhihu.com/equation?tex=%5Cdelta_%7Bk%7D%5E%7Bi%7D+%5Cin%5C%7B0%2C1%5C%7D%2C+%5Cdelta_%7Bk%7D%5E%7Bi%7D+) 表示样本i是否处于任务k的样本空间。
|
||||
|
||||
- 不同任务各自独立的权重设定:PLE提出了一种加权的规则,它的思想是随着迭代次数的增加,任务的权重应当不断衰减。它为每个任务设定一个初始权重 ![[公式]](https://www.zhihu.com/equation?tex=w_%7Bk%2C0%7D) ,再按该公式进行更新:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-2fbd23599bd2cd62222607e76cb975ec_1440w.jpg" style="zoom:40%;" />
|
||||
</div>
|
||||
|
||||
## 实验
|
||||
|
||||
该论文的一大特点是提供了极其丰富的实验,首先是在自身大规模数据集上的离线实验。
|
||||
|
||||
第一组实验是两个关系复杂的任务VTR(回归)与VCR(分类),如表1,实验结果证明PLE可以实现多任务共赢,而其他的硬共享或者软共享机制,则会导致部分任务受损。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-4a190a8a3bcd810fbe1e810171ddc25c_1440w.jpg" alt="img" style="zoom: 33%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
第二组实验是两个关系简单清晰的任务,CTR与VCR,都是分类任务,且CTR→VCR存在任务依赖关系,如表2,这种多任务下,基本上所有参数共享的模型都能得到性能的提升,而PLE的提升效果最为明显。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/80/v2-29baaf461d29a4eff32e7ea324ef7f77_1440w.jpg" alt="img" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
第三组实验则是线上的A/B Test,上面两组离线实验中,其实PLE相比于其他baseline模型,无论是回归任务的mse,还是分类任务的auc,提升都不是特别显著。在推荐场景中,评估模型性能的最佳利器还是线上的A/B Test。作者在pcg视频推荐的场景中,将部分用户随机划分到不同的实验组中,用PLE模型预估VTR和VCR,进行四周的实验。如表3所示,线上评估指标(总播放完成视频数量和总播放时间)均得到了较为显著的提升,而硬参数共享模型则带对两个指标都带来显著的下降。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic3.zhimg.com/80/v2-d6daf1d58fa5edd9fa96aefd254f71ee_1440w.jpg" alt="img" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
第四组实验中,作者引入了更多的任务,验证PLE分层结构的必要性。如表4,随着任务数量的增加,PLE对比CGC的优势更加显著。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/80/v2-0b13558bc7e95f601c60a26deaff9acf_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
文中也设计实验,单独对MMOE和CGC的专家利用率进行对比分析,为了实现方便和公平,每个expert都是一个一层网络,每个expert module都只有一个expert,每一层只有3个expert。如图所示,柱子的高度和竖直短线分别表示expert权重的均值和方差。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/80/v2-557473be41f7f6fa5efc1ff17e21bab7_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
可以看到,无论是 MMoE 还是 ML-MMoE,不同任务在三个 Expert 上的权重都是接近的,但对于 CGC & PLE 来说,不同任务在共享 Expert 上的权重是有较大差异的。PLE针对不同的任务,能够有效利用共享 Expert 和独有 Expert 的信息,解释了为什么其能够达到比 MMoE 更好的训练结果。CGC理论上是MMOE的子集,该实验表明,现实中MMOE很难收敛成这个CGC的样子,所以PLE模型就显式的规定了CGC这样的结构。
|
||||
|
||||
## 总结与拓展
|
||||
|
||||
总结:
|
||||
|
||||
CGC在结构上设计的分化,实现了专家功能的分化,而PLE则是通过分层叠加,使得不同专家的信息进行融合。整个结构的设计,是为了让多任务学习模型,不仅可以学习到各自任务独有的表征,还能学习不同任务共享的表征。
|
||||
|
||||
论文中也对大多数的MTL模型进行了抽象,总结如下图:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-d607cd8e14d4a0fadb4dbef06dc2ffa9_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
不同的MTL模型即不同的参数共享机制,CGC的结构最为灵活。
|
||||
|
||||
可以思考下以下几个问题:
|
||||
|
||||
1. 多任务模型线上如何打分融合?
|
||||
在论文中,作者分享了腾讯视频的一种线上打分机制
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-9a412b82d45877287df2429fc89afac5_1440w.jpg" alt="img" style="zoom:33%;" />
|
||||
</div>
|
||||
|
||||
每个目标的预估值有一个固定的权重,通过乘法进行融合,并在最后未来排除视频自身时长的影响,使用 $ f(videolen)$对视频时长进行了非线性变化。其实在业界的案例中,也基本是依赖乘法或者加法进行融合,爱奇艺曾经公开分享过他们使用过的打分方法:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-661030ad194ae2059eace0804ef0f774_1440w.jpg" alt="img" style="zoom: 67%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
在业务目标较少时,通过加法方式融合新增目标可以短期内快速获得收益。但是随着目标增多,加法融合会 逐步弱化各字母表的重要性影响,而乘法融合则具有一定的模板独立性,乘法机制更加灵活,效益更好。融 合的权重超参一般在线上通过A/B test调试。
|
||||
|
||||
2. 专家的参数如何设置?
|
||||
PLE模型存在的超参数较多,其中专家和门控网络都有两种类型。一般来说,task-specific expert每个任务1-2个,shared expert个数在任务个数的1倍以上。原论文中的gate网络即单层FC,可以适当增加,调试。
|
||||
|
||||
3. ESMM、MMOE、PLE模型如何选择?
|
||||
|
||||
- 个人经验,无论任务之间是否有依赖关系,皆可以优先尝试CGC。而多层CGC(即PLE)未必比CGC效果好,且在相同参数规模小,CGC普遍好于MMOE。对于相关性特别差的多任务,CGC相对MMOE而言有多个专有expert兜底。
|
||||
|
||||
- 对于典型的label存在路径依赖的多任务,例如CTR与CVR,可尝试ESMM。
|
||||
|
||||
- 而在业界的实践案例中,更多的是两种范式的模型进行融合。例如美团在其搜索多业务排序场景上提出的模型:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-af16e969a0149aef9c2a1291de5c65d5_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
总框架是ESMM的架构,以建模下单(CVR)为主任务,CTR和CTCVR为辅助任务。在底层的模块中,则使用了CGC模块,提取多任务模式下的特征表达信息。
|
||||
|
||||
4. 不同Tower能否输入不同的特征?不同的expert使用不同的特征?不同的门控使用不同的特征?
|
||||
MMOE、PLE原论文中介绍的模型均是使用同样的原始特征输入各个不同的expert,也输入给第一层的gate。最顶层的Tower网络中则均是由一个gate融合所有expert输出作为输入。在实践中,可以根据业务需求进行调整。
|
||||
|
||||
- 例如上图中美团提出的模型,在CTR的tower下,设置了五个子塔:闪购子网络、买菜子网络、外卖子网络、优选子网络和团好货子网络,并且对不同的子塔有额外输入不同的特征。
|
||||
对于底层输入给expert的特征,美团提出通过增加一个自适应的特征选择门,使得选出的特征对不同的业务权重不同。例如“配送时间”这个特征对闪购业务比较重要,但对于团好货影响不是很大。模型结构如图:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-2e2370794bbd69ded636a248d8c36255_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
特征选择门与控制expert信息融合的gate类似,由一层FC和softmax组成,输出是特征维度的权重。对于每一个特征通过该门都得到一个权重向量,权重向量点乘原始特征的embedding作为expert的输入。
|
||||
|
||||
5. 多任务loss更高效的融合机制
|
||||
|
||||
推荐首先尝试两种简单实用的方法,GrandNorm和UWL,具体实现细节查看下文所附的参考资料。
|
||||
|
||||
- UWL(Uncertainty Weight):通过自动学习任务的uncertainty,给uncertainty大的任务小权重,uncertainty小的任务大权重;
|
||||
- GradNorm:结合任务梯度的二范数和loss下降梯度,引入带权重的损失函数Gradient Loss,并通过梯度下降更新该权重。
|
||||
|
||||
## 代码实践
|
||||
|
||||
主要是分两个层级,在PLE的层级下,由于PLE是分层,上一层是输出是下一层的输入,代码逻辑为:
|
||||
|
||||
```python
|
||||
# build Progressive Layered Extraction
|
||||
ple_inputs = [dnn_input] * (num_tasks + 1) # [task1, task2, ... taskn, shared task]
|
||||
ple_outputs = []
|
||||
for i in range(num_levels):
|
||||
if i == num_levels - 1: # the last level
|
||||
ple_outputs = cgc_net(inputs=ple_inputs, level_name='level_' + str(i) + '_', is_last=True)
|
||||
else:
|
||||
ple_outputs = cgc_net(inputs=ple_inputs, level_name='level_' + str(i) + '_', is_last=False)
|
||||
ple_inputs = ple_outputs
|
||||
```
|
||||
|
||||
其中cgc_net函数则对应论文中提出的CGC模块,我们把expert分成两类,task-specific和task-shared,为了方便索引,expert list中expert的排列顺序为[task1-expert1, task1-expert2,...task2-expert1, task2-expert2,...shared expert 1... ],则可以通过双重循环创建专家网络:
|
||||
|
||||
```python
|
||||
for i in range(num_tasks): #任务个数
|
||||
for j in range(specific_expert_num): #每个任务对应的task-specific专家个数
|
||||
pass
|
||||
```
|
||||
|
||||
注意门控网络也分为两种类型,task-specific gate的输入是每个任务对应的expert的输出和共享expert的输出,我们同样把共享expert的输出放在最后,方便索引
|
||||
|
||||
```python
|
||||
for i in range(num_tasks):
|
||||
# concat task-specific expert and task-shared expert
|
||||
cur_expert_num = specific_expert_num + shared_expert_num
|
||||
# task_specific + task_shared
|
||||
cur_experts = specific_expert_outputs[
|
||||
i * specific_expert_num:(i + 1) * specific_expert_num] + shared_expert_outputs
|
||||
```
|
||||
|
||||
在最后一层中,由于CGC模块的输出需要分别输入给不同任务各自的Tower模块,所以不需要创建task-shared gate。完整代码如下
|
||||
|
||||
```python
|
||||
def PLE(dnn_feature_columns, shared_expert_num=1, specific_expert_num=1, num_levels=2,
|
||||
expert_dnn_hidden_units=(256,), tower_dnn_hidden_units=(64,), gate_dnn_hidden_units=(),
|
||||
l2_reg_embedding=0.00001,
|
||||
l2_reg_dnn=0, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False,
|
||||
task_types=('binary', 'binary'), task_names=('ctr', 'ctcvr')):
|
||||
"""Instantiates the multi level of Customized Gate Control of Progressive Layered Extraction architecture.
|
||||
:param dnn_feature_columns: An iterable containing all the features used by deep part of the model.
|
||||
:param shared_expert_num: integer, number of task-shared experts.
|
||||
:param specific_expert_num: integer, number of task-specific experts.
|
||||
:param num_levels: integer, number of CGC levels.
|
||||
:param expert_dnn_hidden_units: list,list of positive integer or empty list, the layer number and units in each layer of expert DNN.
|
||||
:param tower_dnn_hidden_units: list,list of positive integer or empty list, the layer number and units in each layer of task-specific DNN.
|
||||
:param gate_dnn_hidden_units: list,list of positive integer or empty list, the layer number and units in each layer of gate DNN.
|
||||
:param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector.
|
||||
:param l2_reg_dnn: float. L2 regularizer strength applied to DNN.
|
||||
:param seed: integer ,to use as random seed.
|
||||
:param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
|
||||
:param dnn_activation: Activation function to use in DNN.
|
||||
:param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN.
|
||||
:param task_types: list of str, indicating the loss of each tasks, ``"binary"`` for binary logloss, ``"regression"`` for regression loss. e.g. ['binary', 'regression']
|
||||
:param task_names: list of str, indicating the predict target of each tasks
|
||||
:return: a Keras model instance.
|
||||
"""
|
||||
num_tasks = len(task_names)
|
||||
if num_tasks <= 1:
|
||||
raise ValueError("num_tasks must be greater than 1")
|
||||
|
||||
if len(task_types) != num_tasks:
|
||||
raise ValueError("num_tasks must be equal to the length of task_types")
|
||||
|
||||
for task_type in task_types:
|
||||
if task_type not in ['binary', 'regression']:
|
||||
raise ValueError("task must be binary or regression, {} is illegal".format(task_type))
|
||||
|
||||
features = build_input_features(dnn_feature_columns)
|
||||
|
||||
inputs_list = list(features.values())
|
||||
|
||||
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns,
|
||||
l2_reg_embedding, seed)
|
||||
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
|
||||
|
||||
# single Extraction Layer
|
||||
def cgc_net(inputs, level_name, is_last=False):
|
||||
# inputs: [task1, task2, ... taskn, shared task]
|
||||
specific_expert_outputs = []
|
||||
# build task-specific expert layer
|
||||
for i in range(num_tasks):
|
||||
for j in range(specific_expert_num):
|
||||
expert_network = DNN(expert_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn,
|
||||
seed=seed,
|
||||
name=level_name + 'task_' + task_names[i] + '_expert_specific_' + str(j))(
|
||||
inputs[i])
|
||||
specific_expert_outputs.append(expert_network)
|
||||
|
||||
# build task-shared expert layer
|
||||
shared_expert_outputs = []
|
||||
for k in range(shared_expert_num):
|
||||
expert_network = DNN(expert_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn,
|
||||
seed=seed,
|
||||
name=level_name + 'expert_shared_' + str(k))(inputs[-1])
|
||||
shared_expert_outputs.append(expert_network)
|
||||
|
||||
# task_specific gate (count = num_tasks)
|
||||
cgc_outs = []
|
||||
for i in range(num_tasks):
|
||||
# concat task-specific expert and task-shared expert
|
||||
cur_expert_num = specific_expert_num + shared_expert_num
|
||||
# task_specific + task_shared
|
||||
cur_experts = specific_expert_outputs[
|
||||
i * specific_expert_num:(i + 1) * specific_expert_num] + shared_expert_outputs
|
||||
|
||||
expert_concat = tf.keras.layers.Lambda(lambda x: tf.stack(x, axis=1))(cur_experts)
|
||||
|
||||
# build gate layers
|
||||
gate_input = DNN(gate_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn,
|
||||
seed=seed,
|
||||
name=level_name + 'gate_specific_' + task_names[i])(
|
||||
inputs[i]) # gate[i] for task input[i]
|
||||
gate_out = tf.keras.layers.Dense(cur_expert_num, use_bias=False, activation='softmax',
|
||||
name=level_name + 'gate_softmax_specific_' + task_names[i])(gate_input)
|
||||
gate_out = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
|
||||
|
||||
# gate multiply the expert
|
||||
gate_mul_expert = tf.keras.layers.Lambda(lambda x: reduce_sum(x[0] * x[1], axis=1, keep_dims=False),
|
||||
name=level_name + 'gate_mul_expert_specific_' + task_names[i])(
|
||||
[expert_concat, gate_out])
|
||||
cgc_outs.append(gate_mul_expert)
|
||||
|
||||
# task_shared gate, if the level not in last, add one shared gate
|
||||
if not is_last:
|
||||
cur_expert_num = num_tasks * specific_expert_num + shared_expert_num
|
||||
cur_experts = specific_expert_outputs + shared_expert_outputs # all the expert include task-specific expert and task-shared expert
|
||||
|
||||
expert_concat = tf.keras.layers.Lambda(lambda x: tf.stack(x, axis=1))(cur_experts)
|
||||
|
||||
# build gate layers
|
||||
gate_input = DNN(gate_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn,
|
||||
seed=seed,
|
||||
name=level_name + 'gate_shared')(inputs[-1]) # gate for shared task input
|
||||
|
||||
gate_out = tf.keras.layers.Dense(cur_expert_num, use_bias=False, activation='softmax',
|
||||
name=level_name + 'gate_softmax_shared')(gate_input)
|
||||
gate_out = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
|
||||
|
||||
# gate multiply the expert
|
||||
gate_mul_expert = tf.keras.layers.Lambda(lambda x: reduce_sum(x[0] * x[1], axis=1, keep_dims=False),
|
||||
name=level_name + 'gate_mul_expert_shared')(
|
||||
[expert_concat, gate_out])
|
||||
|
||||
cgc_outs.append(gate_mul_expert)
|
||||
return cgc_outs
|
||||
|
||||
# build Progressive Layered Extraction
|
||||
ple_inputs = [dnn_input] * (num_tasks + 1) # [task1, task2, ... taskn, shared task]
|
||||
ple_outputs = []
|
||||
for i in range(num_levels):
|
||||
if i == num_levels - 1: # the last level
|
||||
ple_outputs = cgc_net(inputs=ple_inputs, level_name='level_' + str(i) + '_', is_last=True)
|
||||
else:
|
||||
ple_outputs = cgc_net(inputs=ple_inputs, level_name='level_' + str(i) + '_', is_last=False)
|
||||
ple_inputs = ple_outputs
|
||||
|
||||
task_outs = []
|
||||
for task_type, task_name, ple_out in zip(task_types, task_names, ple_outputs):
|
||||
# build tower layer
|
||||
tower_output = DNN(tower_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed,
|
||||
name='tower_' + task_name)(ple_out)
|
||||
logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
|
||||
output = PredictionLayer(task_type, name=task_name)(logit)
|
||||
task_outs.append(output)
|
||||
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=task_outs)
|
||||
return model
|
||||
```
|
||||
|
||||
参考资料
|
||||
|
||||
Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations (RecSys'2020)
|
||||
|
||||
https://zhuanlan.zhihu.com/p/291406172
|
||||
|
||||
爱奇艺:[https://www.6aiq.com/article/1624916831286](https://www.6aiq.com/article/1624916831286)
|
||||
|
||||
美团:[https://mp.weixin.qq.com/s/WBwvfqOTDKCwGgoaGoSs6Q](https://mp.weixin.qq.com/s/WBwvfqOTDKCwGgoaGoSs6Q)
|
||||
|
||||
多任务loss优化:[https://blog.csdn.net/wuzhongqi](https://blog.csdn.net/wuzhongqi)
|
||||
@@ -51,6 +51,3 @@
|
||||
**但我更希望你是真正地对嵌入式感兴趣,热爱创造它的时光,热爱披荆斩棘后成功的欣喜,热爱它的生命,热爱它赋予你的意义...在这段学习历程中,竞赛会是你成长的一部分,但不是全部,也不能是全部。作为一个伪理想主义者(我认为完全的理想主义者不会痛苦,只有现实的理想主义者才会痛不欲生),生命中总会有更重要的东西,比如爱,无论是喜爱还是热爱,比如人,无论是亲朋还是蒹葭。**
|
||||
|
||||
科技的最终意义是提高生产力,但科技带来的意义也远不止于此,我希望你们在接下来学习嵌入式的过程中,能不忘本心,钦佩自己的永远独立,钦佩自己的永远自由,不被世界的功利化所迷惑,感受嵌入式那独特而又真实的生命力!
|
||||
|
||||
Ps:可以去看看韩健夫老师写的一篇文章,相信你会有更多的感悟[人文社科的重要性(韩健夫老师寄语)](/1.杭电生存指南/1.1人文社科的重要性(韩健夫老师寄语))
|
||||
最后,欢迎来到嵌入式王国:)
|
||||
|
||||
65
福大生存指南/2.竞赛指北.md
Normal file
65
福大生存指南/2.竞赛指北.md
Normal file
@@ -0,0 +1,65 @@
|
||||
# 竞赛指北
|
||||
|
||||
## 前言
|
||||
|
||||
|
||||
之所以要有这篇文章,就是要告诉各位同学,竞赛并不一定能帮助你提升自己的能力,也不一定能帮你丰富自己的简历,甚至对某些老师来说,发表了 “错误” 论文或是在某些项目里学会了一本正经胡说八道的同学还会是一个减分项,所以各位同学有必要对自身情况和比赛情况有一个清醒的认知。
|
||||
|
||||
|
||||
|
||||
## 竞赛可以真的可以锻炼我的技术吗?
|
||||
|
||||
首先我需要声明的点是,除了某些特殊的“黑客松”比赛以外,大多数所谓竞赛其实是带着镣铐跳舞,在竞赛中取得优异的成绩并不意味着你可以游刃有余的应对实际的开发场景。例如我们大家喜闻乐见的算法比赛。我首先必须承认的是这些比赛的选手往往有更强的编程能力和算法能力,但这并不意味着ACM选手就可以非常轻松的直接进入开发场景,包括电子类专业学生需要同硬件协同调试,实际上参加比赛也是获取经验,至于在未来的开发场景能利用的有多少,实际还是未知的。
|
||||
|
||||
|
||||
真正能从竞赛中获得乐趣并且锻炼非常优秀技术的人,往往原因并不是他打了竞赛,而是因为他有好奇心,他对技术本身有强烈的兴趣。如果你只是抱着我打个竞赛我能力就能上升,那我很抱歉你要失望了,更多情况是你在竞赛见了一堆童子功或者天才然后被嘎嘎乱杀,反而是对很多人是一种负反馈,对你来讲并不意味着是一件好事(除非你能从技术本身获得乐趣或者有某些特殊癖好)。
|
||||
|
||||
|
||||
除去这些非常硬核的比赛,我们谈及一些大学生创新创业类比赛,每年都会有一大堆人趋之若鹜,踊跃报名,这类比赛就算能锻炼能力,也并不一定是技术,更大程度上是你在应对答辩的技巧,做美观PPT的方法以及面对失败的时候沉稳的心态,并且这些项目本身的应用场景你未必有机会能接触到,更大程度上你会从“前人的智慧”中得到一些认知。
|
||||
|
||||
|
||||
很多含文本元素的比赛并不注重具体落地,只要文本写的够好就能入围。这种情况下
|
||||
|
||||
|
||||
1. 有可能组内成员提出一些工作量相当大的需求(例如一个人全栈)或者以现阶段能力完全做不了的需求,来圆上之前画的饼。
|
||||
2. 当发现 “只要糊弄一下套个空壳也可以” ,你可能就不想把项目落地了。这会极大地挫伤一个人独立开发完整项目的积极性。
|
||||
|
||||
## 哪个比赛更有含金量?
|
||||
|
||||
|
||||
|
||||
当你考虑这个问题的时候,那说明你更想功利性的从比赛中获得一些收益,例如写在简历上更好看,让HR有更大的几率要你,例如获得学校政策加成拿奖学金等等。
|
||||
|
||||
|
||||
- 如果你想要加绩点 / 德育分 / 创新创业学分
|
||||
|
||||
|
||||
最后我会放上fzu大学生学科竞赛项目级别文件,大家可以进行参照。具体的竞赛认定级别大家可以参照里面,值得一提的是,目前还有三个比赛能够获得保研资格的排名要求降低,分别是中国国际大学生创新大赛(原为互联网+)、“挑战杯”全国大学生课外学术科技作品竞赛、“挑战杯”中国大学生创业计划竞赛。但是这些比赛要求是十分高的,基本上只有一些学生干部有机会能够得到院里的支持获得参赛项目,但实际上,这些项目都是比较完善的成品,过去无非是打工做ppt,一遍遍地完善自己的演讲稿等等。
|
||||
|
||||
首先我认为,作为电子类专业的学生,全国大学生电子设计竞赛的含金量是极高的,在fzu物信学院中也是主推的比赛,可以看到很多公司的招聘要求中加分项都有电子设计竞赛获奖者优先,奇数年国赛偶数年省赛。当然这个比赛需要一定的基础沉淀与引路人,对此有志的大家建议加入物信学院的电子爱好者学社可以获得更多的资源。
|
||||
|
||||
当然,很多的同学也会选择去参加一些机器人大赛和数学建模比赛,对于机器人大赛而言,获得国奖的机会会比较多一点,推荐大家加入机器人爱好者协会,毕竟一台机器人的成本也是十分大的。而数学建模比赛,也是很多人会去涉猎的一个比赛,含金量还是有的,不过对于电子类专业,往往推荐大家参加和自身专业能力更相关的电赛。
|
||||
|
||||
还有其他很多作品赛,这里就大家自己去看了,个人认为对于大一新生而言,从院科技节的作品制作赛开始是一个不错的选择。
|
||||
|
||||
|
||||
大多数比赛校赛即可加德育分(这玩意是用来评奖学金的,也就是说如果你不想要奖学金就无所谓)。具体请以学院认定规则为准。
|
||||
|
||||
|
||||
认定的比赛是可以申请创新创业学分的(这玩意是学分,还是比较重要的),一般会在一个时间点统一开放表格让大家填写。
|
||||
|
||||
|
||||
总体来说,加分还是很容易的,只不过很多情况下没必要。
|
||||
|
||||
|
||||
- 硬核类比赛的含金量怎么样(如ACM和CTF)
|
||||
|
||||
|
||||
像 ACM、CTF 等纯技术类比赛,只要你能拿奖,他确实有用,而且含金量并不低。但是从投入产出比的角度来说未必划算(算法仙人或者童子功除外),很多零基础的同学如果就奔着这个含金量去的通常要付出多几十倍的努力,得到的收益很难回馈你的努力,如果你用这个时间做项目,可能正反馈多一些。当然我这些还是基于功利角度,如果你真的喜欢那打打也蛮好的。
|
||||
|
||||
对我们专业而言,电赛能获奖含金量不低(特别是省一以及国奖),这意味着选手在四天三夜的时间里面能够制定出一个比较不多的解决问题方案并运用到实际,这个能力也是工作需要的。但是不容易实现短时间内就能得到这个含金量,个人认为是需要时间沉淀的。
|
||||
|
||||
“如果你接受过一点理论计算机科学的训练,就会发现竞赛作为一种 “竞技体育”,其实是性价比极低的。”
|
||||
|
||||
|
||||
|
||||
100
福大生存指南/3.正确解读GPA.md
Normal file
100
福大生存指南/3.正确解读GPA.md
Normal file
@@ -0,0 +1,100 @@
|
||||
# 正确解读 GPA
|
||||
|
||||
正确认知绩点
|
||||
|
||||
## 序言
|
||||
|
||||
GPA,一个酷似成绩的东西,
|
||||
|
||||
高中生带着高中成绩的惯性会把 GPA 和高中班级成绩联系到一起,
|
||||
|
||||
毕竟在高中,一份理想的成绩意味着一个光明的未来。
|
||||
|
||||
但是我想说,**在大学,请摆脱高中的绩点惯性**。
|
||||
|
||||
在大学,绩点其实只是一个获得资源的工具,高的绩点并不代表光明的未来,也不能够代表高超的学习能力和扎实的专业知识。同时我们要明白,与高中截然不同的是,大学是一个多目标优化问题,绩点只是优化问题的一个维度,而非所有。
|
||||
|
||||
> **author:晓宇,WJJ**
|
||||
|
||||
所以本文会讲述 GPA 能够带来什么,什么是一个合理的对待 GPA 的态度,如果需要,如何获得一个较高的 GPA 。
|
||||
|
||||
## 首先,GPA 能带来什么?
|
||||
|
||||
从实质上来说,GPA 是评选奖学金(如校奖学金,一等奖学金),评选学校一些优秀称号(如十佳大学生,五四评优等),是出国的桥梁(90 的均分意味着 QS50 院校的入场券,80-85 的均分意味着 QS100 的入场券),是读博的门槛要求(很多国外直博的院校是卡均分 80,原因是尽管 GPA 是一个无关紧要的东西,但是如果连一个无关紧要的东西都处理不好的人,他们确实不想要,但是这只是一个默认的规定,并非所有院校如此),是全额奖学金 CSC 公费读博的是否占优的一个维度,是保研的重要评定维度,是转专业的评定指标。
|
||||
|
||||
另开一段讲讲fzu的保研,毕竟现在很多的人都在追求保研,在fzu,除去一些必要的要求外,最后的保研名额排名由综合测评成绩组成,1.学业综合成绩占90%,也就是GPA 2.学术沦文占3% 3.专利占2% 4.学科竞赛占2% 5.其他占(德育×85%+学生参军入伍服兵役5分+参加志愿服务5分+到国际组织实习5分)3%,由此看来,GPA是保研路上最重要的东西,有志于此的同学必然是要追求更高的GPA,但是这个东西一向是很卷的,绩点高的同学实际上也不一定是学的好的同学,更有可能是更懂应试的同学。但是又说回来,很高的绩点就意味着能去到更好的学校吗,我觉得不是的,GPA只是入场券,当你进入大门之后,衡量的指标就更多样了,对于保研夏令营来说,好的985可能只会让211绩点在前3名内的同学入营,甚至而言标准会更高,但是当你入营之后,如果发现自己向面试老师能展示的只有GPA,那应该怎么办呢?事实上据说,很多获得夏令营优营的同学,手上都是有论文的,所以有志好学校的同学也不光要关注自己的GPA,科研和竞赛等也是有一定重要性的。
|
||||
|
||||
## 那么,GPA 不能带来什么?
|
||||
|
||||
GPA 不能够带来一个扎实的专业技术能力,优越的项目能力,以及不能够帮助你找到一个理想的工作,或者说让个人的学术水平得到提高。
|
||||
|
||||
## 踩坑案例讲解
|
||||
|
||||
A. 花了大学百分之 80 的时间取得了优异的绩点( 90 分),但是却并没有准备任何的专业技能,最后找工作的时候,别的人凭借大厂实习入职了大厂,自己却发现自己除了绩点一无所有,所有的专业知识技能和面试都需要重新准备。
|
||||
|
||||
B. 大一进来从来不太在意 GPA,大部分经历在研究 Github 项目,大二下找到第一份工作实习,积累大量应用技术,在找工的季节斩获 N 个大厂 offer(这时候做题家 A 会表示非常不服气,但这是存在的事实),但是这也有问题,这种自认聪明的最优化路径,会导致未来如果如果想要深造的时候,路径狭隘,例如,想去外国做技术员,可能不足的均分很难申请到很好的院校,或者是想要出去读博,可能就把这条道路封死了。不过大部分时候也不存在有这样的需求,只是在此处点出有这样的雷存在。
|
||||
|
||||
## 问题
|
||||
|
||||
绩点会带来很多东西,但是同样会带走你的时间,让你无暇去优化其他的事物,如 探索大学生活,谈个恋爱,找找自己喜欢做的,做支教,做志愿者,做自媒体云云。
|
||||
|
||||
## 合理态度
|
||||
|
||||
把绩点当成一个玩具,玩具在于一种掌控感,毫无畏惧感。
|
||||
|
||||
首先是明确绩点对你有没有用,如奖学金,如评优的 title ,如有没有可能出国,有没有可能读博,如果说都没有的话,可以平常心对待,注意,我这里并没有说摆烂,因为你无法预测自己的未来,我从风险角度建议,凡事能够给自己留一条后路,当然也有激进流派成功的案例,所以仅仅出于保守的个人观点。
|
||||
|
||||
所谓平常心,意味着你要学习,要去学习专业知识,但要判断这个知识是真的假的,要能够拜托无意义内卷,如(老师要求 3000 字 我写个 90000 字炫个技, 老师要求完成学生信息管理系统,我完成一个淘宝 APP ,老师要求只有百分之 3 的人拿 A,我拼死要干掉其他人,哪怕付出很多努力),在这里,我说的是平常心,注意绩点对你不是极端的重要,不值得你为了他浪费任何你的美丽心灵。没错我说的是美丽心灵,因为我认为无意义内卷对一个人心神消耗是极大的。那么还有一种是绩点极端重要的人,那么这种人来说,主要集中在保研和出国的两种人,对于这种情况,我是提倡高效内卷,依然不提倡把绩点作为大学生活的全部。
|
||||
|
||||
综上总结一下:无善无恶心之体,有善有恶意之动,绩点本无好坏,在于明确自己要什么,摆脱高中的思维惯性,能明白。学知识和绩点是两回事,好坏由你个人来看待。
|
||||
|
||||
## 高效内卷
|
||||
|
||||
其实真的对我来说很难讲,因为这是一个系统性问题,我能说的是,大学和高中不一样,
|
||||
|
||||
这里讲讲我的流派,仅为一家之言。
|
||||
|
||||
我是认为知识的学习和绩点的提升要同步进行,日常生活中主要来学习知识,学期末来卷绩点。
|
||||
|
||||
为什么要将这两点分开来阐述呢?
|
||||
|
||||
核心原因是:大学教育下知识和成绩的不完全相关性,成绩可能意味着你的平时表现很好,每次作业都能通过抄答案对答案或者自己硬实力的情况拿到一个较高的分数,上课能够积极回答问题,能够让老师记住你,而掌握相关的知识则是意味着,当探讨到这个专业的问题的时候,能够灵活的使用。
|
||||
|
||||
上文提到了学知识和搞绩点的不同,这里补充下,造成这种情况的系统性原因:
|
||||
|
||||
**第一点**,跟随并不备课且基础不扎实的老师上课是对时间和知识的浪费,因为在大学的评级体系里,所有的评优指标中并没有对于培育优秀的学生有定量和定性的规定,反而对于科研论文有着明确的规定,在非升即走的科研压力下,甚至是没有压力在躺平的老师,认真设计教学和培育学生本质上是一件奢侈的事情。
|
||||
|
||||
**第二点**,大学教育的课程设计往往要考虑的是中等偏下水平的学生能力,并以此为基础上,在统计意义上的教育资源匮乏的大课堂制度,在授课体验上造成不理想的概率较大。
|
||||
|
||||
**第三点**,是对于不同学科的学习方法问题,例如计算机如 C 语言,CPP、JAVA 等编程语言实践类科目,如果以错误的纯讲授的形式,则学习效率则会相对较低,然而学院的数据结构等等课程,实际上都以偏讲授的形式,纵有实验,但大多同学也只是问问大模型或者抄抄其他同学的,学下来可能也是只理解了概念等,更别说在日后的开发情景中去运用它了。而对于我们电子类专业的学生而言,实际上需要不低的动手能力,举个例子,例如单片机课设,我们不光要解决硬件问题,更要进行软件编程,纵使你单片机课程考了高分,但也未必能够呈现一个相对不错的作品,开发过程不可能是一帆风顺,过程中出现问题才更贴合实际,才是我们需要重点学习并解决的,“纸上得来终觉浅,绝知此事要躬行”,实践才能更好地帮助我们理解知识。
|
||||
|
||||
虽然现在学校也正在改革,尝试解决上述问题,学院也有非常多优秀的老师精心设计课程,增加学生动手机会,开设小班化课程,实行翻转课堂,增强校企合作,但我想说,因为你不能保证你就是学校改革的受益者,所以应当做好比烂的准备。
|
||||
|
||||
那么,讲一下,我是怎么学知识的,
|
||||
|
||||
第一,研究的课程设置的有效性,这门课设置的是否合理(待写,也可能不写)
|
||||
|
||||
第二,是跳出课堂,从一个未来的角度,从很久之后这门课对你的影响来看,那么课程即为知识,成绩其实并不重要,
|
||||
|
||||
我一般学到一门新课,都不会抛开这门课程本身的书本知识,去看一些其他自学资料,例如我学习计算机组成原理,编译原理的时候,则是在看极客时间的一些技术员写的对于计算机的理解,编译语言的实现原理,日常的课堂,学大学物理的时候,则是在看量子力学的公开课,在学习电子电路原理的时候,则是在看 MIT 一门讲解电路的公开课,看他从物理到电路到计算机讲述整个计算机体系的神妙。这些可能都和考试无关,都是这也属于这门学科。我总是在想既然学了这门课,我总要留下一些东西,在这里我反对功利的学习观,例如,"什么我是学计算机的,以后纯纯码农,什么人文,什么物理,什么电路和我有什么关系"。
|
||||
|
||||
然后说说我是怎么备考的,对于备考,在考前,我一般是 check 的把上课老师的讲过题目(PPT 上的题目),以及作业上的题目,老师复习课上点到知识点,PPT里面的知识点,以及历年的考试试卷,一个一个做完,平常上课关注下老师问的问题,能答则答,如果对绩点有较高的要求的同学,可能会主动报名一些选做的题目。
|
||||
|
||||
|
||||
**关键词:**
|
||||
|
||||
及格:基础知识点,特别是老师发的PPT,重点更是PPT上面老师红字蓝字部分。
|
||||
|
||||
提高:历年卷子,考前知识点点题,日常作业。
|
||||
|
||||
高上加高:选做任务,课堂参与,有一些课程的老师实际上是根据上课活跃情况来计算平时分的,特别是对于马克思原理、毛概、思政这类课程。
|
||||
|
||||
## 结语与 GPA 之禅:
|
||||
|
||||
当你已经成为大学生的时候,GPA(成绩)不是和一个人的优秀的呈正相关的,这不过是一个通往一些资源的途径,同样的,也有很多资源可以不用 GPA,可以靠个人硬实力去争取,例如实习,例如科研助理云云。只是说,如果你不知道干啥,先认真学好专业课知识,是一个保有收益的事情,但当有其他选择的时候可以权衡,但也不可走另外一个极端,则完全不在乎 GPA,在职业规划并不清晰的时候不要自废道路。
|
||||
|
||||
最后想说的是,一个获得资源的玩具罢了,不值得让你**常沉苦海,永失真道**。
|
||||
|
||||
## GPA 补充内容:
|
||||
|
||||
GPA 是一件有着很强边际效应的事情,我并不是说不建议提高 GPA ,而是算好边际效用搞绩点,例如花 10 小时你可以考 85,花 2 小时可以 60,花 100 小时你可以 95,那或许权衡考个 85,而不是躺着搞个 60 对于大部分人来说,是一个比较好的选项。例如这门课未来还需要用到,我本着学知识的角度先把知识搞明白,而不是自负的认为,以后我打工又用不到这个,干嘛要学,看我摆一手。
|
||||
31
福大生存指南/4.学生工作选择.md
Normal file
31
福大生存指南/4.学生工作选择.md
Normal file
@@ -0,0 +1,31 @@
|
||||
# 学生工作选择
|
||||
|
||||
正确认识学生工作带来的资源
|
||||
|
||||
## 序言
|
||||
|
||||
为什么要有这篇文章,很多同学对学生工作有狂热的追求,但是我觉得需要考虑自己需不需要,首先我认为大学的学生工作和高中的十分不一样,高中的干部在一个班有一个班主任的情况下实际上事情不多同时也具有一个领导人物,而大学的班长、团支书等往往就是一个班级的核心人物,需要组织筹划的东西就多了。
|
||||
|
||||
## 学生工作能够锻炼我的能力吗
|
||||
|
||||
首先我认为这个问题的答案是肯定的,这个能力可能是组织协调能力、沟通能力以及时间管理能力等等,一次工作组织的实践可以让人提高领导力。
|
||||
|
||||
## 学生工作能够让我获得什么
|
||||
|
||||
实质上来说,各种奖学金的评比(宝钢、国家奖学金等等)、入党推优、各种荣誉(五四评优、十佳大学生等)都需要有一定的学生工作,哪怕是考公对学生工作也是有要求的。但如果你志不在此,不在乎荣誉,有自己明确的成长路线,这些东西,其实荣誉这个东西也就那样,而对于学生工作,我的观点是够用就行,在未来没有进体制内想法的时候,并不需要盲目的追求学院或者学校的学生会主席以及各个中心的主任,核心实际上是明确自己想要什么,大多数情况下,班级的班长团支书其实是够用了的。
|
||||
|
||||
而有些人会为了保研而追求学生工作,这实际上是有道理的,因为前面的竞赛指北说过,学校对创新创业类比赛是有一些政策性保研的,而这些比赛的项目往往是学院某些老师的比较成熟的项目,那么实际上只有院学生干部,比如主席、主任或者各个部门的部长才有机会接触到,于此进行学生工作的人也无可厚非,值得一提的是,部门的任务数量并不是均等的,有些部门甚至已经濒临解散,但实际上部长加的德育是一样的,显然这并不具备一定的性价比,所以留部的时候大家可以问问学长学姐,我认为这个原则还是,学生工作够用就行,当然大一的同学进入部门往往作为部员,更多的时候不会承担很大的责任,但是留部的时候往往有些学长学姐会称部门事情不多来让你留部,这个自行辨别。
|
||||
|
||||
当然做学生工作除了上述来说,你会获得和辅导员等更多的接触机会,能够更优先掌握一些消息,同时也可以交朋友等。
|
||||
|
||||
## 做学生工作我会失去什么
|
||||
|
||||
首先,我认为最重要的是时间,学生工作可能会占用大量的时间,导致学习时间被压缩。比如,在期末复习阶段,仍有学生工作需要处理,影响了复习进度。因为学生工作而极大地影响学习,我认为是不提倡的,过多地投入学生工作可能会分散在学业上的精力,导致成绩下滑。特别是对于一些专业性较强、课程难度较大的学科。
|
||||
|
||||
当然,工作中的责任和期望可能带来较大的心理压力。如活动效果不佳,可能会受到领导的批评和质疑,从而产生焦虑情绪。也有可能由于观点和工作方式的不同,可能会引发人际冲突,影响工作氛围和个人心情。
|
||||
|
||||
## 结言
|
||||
|
||||
当你成为大学生时,就该意识到,学生工作更多时候在于给领导干活,质量等都会被看在眼里,所以根据自己的需求选择合适的学生工作,而不是选择了一个活多的职位,而因为自己想要学习将工作草草了事,这倒不如交给更需要这个职位的人,我认为,学生工作、GPA以及竞赛这三者,大部分人是不能够兼得的,还望选择适合自己的成长路线。
|
||||
|
||||
|
||||
128
福大生存指南/5.Q&A.md
Normal file
128
福大生存指南/5.Q&A.md
Normal file
@@ -0,0 +1,128 @@
|
||||
# Q&A
|
||||
|
||||
## 专业篇
|
||||
|
||||
### 1非汉语言文学的语言类专业定性
|
||||
|
||||
非汉语言文学的语言类专业属于外国语学院而非人文学院。
|
||||
### 2什么专业上什么课
|
||||
看学校下发的培养计划,在专业培养手册里会有详细的解释。
|
||||
|
||||
|
||||
### 生活篇
|
||||
|
||||
### 学校地图
|
||||
|
||||
#### 旗山校区
|
||||
<!-- <img src="./static/旗山校区手绘地图.png" alt="旗山校区手绘地图" width="600" > -->
|
||||
|
||||

|
||||
#### 铜盘校区
|
||||
<!-- <img src="./static/铜盘校区手绘地图.png" alt="铜盘校区手绘地图" width="600" > -->
|
||||

|
||||
|
||||
|
||||
### 新生宿舍分配
|
||||
|
||||
大一新生大部分专业都会分配到铜盘校区,铜盘校区的宿舍都是四人间,配备空调,洗衣机(需要扫码,按次收费),饮水机(每栋宿舍的某几个楼层过道),一开始的宿舍分配是按学号进行宿舍分配,后面和舍友相处不来还可以申请换宿舍.
|
||||
|
||||
下面是铜盘校区床位图:
|
||||
<!-- <img src="./static/铜盘校区床位.jpg" alt="铜盘校区床位" width="600" > -->
|
||||

|
||||
|
||||
### 宿舍里可以用什么电器
|
||||
|
||||
宿舍可以用风扇,还有吹风机(需要用完后及时断电),电脑的话,有些学院会说大一新生不让带(但实际上并不会管).
|
||||
在宿舍使用任何形式烹饪的电器都是违规的!!!
|
||||
|
||||
### 勤工俭学
|
||||
|
||||
### 家教
|
||||
|
||||
### 校园卡,校园网
|
||||
|
||||
### 学校发的建行卡
|
||||
在录取通知书里,会有一张建行卡,大家可以就近找一家建行激活即可,后续学校扣学费,发放奖学金大多会用到这张卡
|
||||
##铜盘校区健身房
|
||||
在铜盘校区的食堂三楼,有一间免费健身房,有台球桌,乒乓球桌,跑步机等健身设施
|
||||
|
||||
### 外卖篇
|
||||
在旗山校区,很多食堂档口都提供外卖服务,大家点外卖的的时候要注意看,福大食堂的都可以送到宿舍楼下,外校的外卖有些能送到宿舍楼下(注意看商家的标注),有些就只能送到学校门口。
|
||||
在铜盘校区,校内食堂也有外卖服务,大家要是不想挤食堂的话,可以提前下单,校外的外卖都会放到校门口,去拿外卖都需要经过长长的绝望坡!
|
||||
|
||||
|
||||
|
||||
|
||||
## 课程相关
|
||||
|
||||
### 游泳课
|
||||
|
||||
|
||||
## 新生注意
|
||||
|
||||
### 防推销
|
||||
|
||||
|
||||
## 群聊问题汇总
|
||||
|
||||
1. **专业所属学院**:非汉语言文学的语言类专业属于外国语学院。
|
||||
2. **了解课程安排**:查看学校下发的培养计划以了解自己专业上的课程。
|
||||
3. **校内兼职工作**:可通过辅导员了解勤工俭学机会,如送外卖或超市零时工。
|
||||
4. **宿舍性别限制**:不允许男生进入女生宿舍,反之亦然。
|
||||
5. **经济困难帮助**:可申请助学贷款和入学后申请补助,可能获得学费减免和生活补助。
|
||||
6. **健身房位置**:铜盘食堂三楼设有健身房及自习室。
|
||||
7. **点外卖注意事项**:
|
||||
旗山校区:确认店家能否送到福大宿舍楼下;
|
||||
铜盘校区(铜盘校区校外外卖只能送到校门口,拿外卖需要爬绝望坡)。
|
||||
|
||||
8. **菜鸟驿站包裹存放**:包裹能放很长时间,但可能找起来较麻烦。建议还是尽早拿。
|
||||
9. **校园墙**:学校无官方校园墙,现有均为校友自运营。
|
||||
10. **身份认证问题**:若显示用户不存在,可能是系统未完全录入,建议等待。
|
||||
11. **宿舍熄灯与电器使用**:晚上22:30熄灯,可带允许的小型电器,晚上有查寝。
|
||||
12. **洗衣机**:建议自购洗衣机,因为学校提供的需付费且可能不清洁。
|
||||
13. **宿舍床位分配**:床位是预先分好的,不是先到先得。
|
||||
14. **教科书获取**:课本自选,可购买新书、二手书或电子版。
|
||||
15. **选课与老师选择**:大一一般不选课,老师好坏可咨询直系学长学姐。
|
||||
16. **图书馆与游泳馆**:铜盘校区设有图书馆,但没有游泳馆。
|
||||
17. **查寝方式**:查寝人员通过趴门缝看是否熄灯,若灯亮着可尝试拧开高亮台灯蒙混。
|
||||
18. **校园内动物**:校园里有猫猫狗狗。
|
||||
19. **车载冰箱使用**:冰箱需要特殊申请,如保鲜中药。
|
||||
20. **小型电器使用**:小型榨汁机和电热毯可能需查看具体规定。
|
||||
21. **大一带电脑报备**:非计算机系携带电脑需要报备,否则可能有处罚。
|
||||
22. **贫困补助申请**:需填报表格,导员会提醒,注意卡内金额以免被扣除。
|
||||
23. **学费迟交处理**:学校会进行第二轮收取,保证卡里有钱即可。
|
||||
24. **宿舍条件**:条件相当不错,但人文关怀可能较缺失。
|
||||
25. **教室空调使用**:上课时间自动开,晚上十点自动关,但可重新打开。
|
||||
26. **中午自习地点**:推荐晋江楼或16号楼下自习室,需预约。
|
||||
27. **宿舍自习可行性**:取决于个人自律能力,可能受舍友活动干扰。
|
||||
28. **晚自习时间**:根据学院要求,一般在19-21点或至21:30,大二一般无晚自习。
|
||||
29. **宿舍观看视频**:观看B站或油管一般无问题,但观看不当内容可能被抓。
|
||||
30. **大一年级忙碌程度**:取决于个人志向,加入社团或学生会可能较忙。
|
||||
31. **开学体测**:存在体测,但一般较为简单。
|
||||
32. **体育课选修推荐**:推荐桥牌和武术,具体看老师和个人兴趣。
|
||||
33. **大一课程内容**:包括水课、高数、大英等,课程相对较少。
|
||||
34. **学生会加入方式**:开学后有宣传,需经过无领导小组讨论。
|
||||
35. **摄影爱好社团**:学生会宣传部有摄影任务和专业相机。
|
||||
36. **校内超市被褥销售**:不卖被褥,需自带、网购或去小商品市场。
|
||||
37. **推销活动警惕**:以学长学姐名义推销的可能为诈骗。
|
||||
38. **考驾照与学分**:考驾照不增加学分。
|
||||
39. **快递收货地址**:写学校名称和宿舍即可。
|
||||
40. **宿舍抢选**:可能需先组队,在导员给定范围内挑选。
|
||||
41. **宿舍挑选依据**:低楼层宿舍较好,号数大的靠近门。
|
||||
42. **宿舍电梯情况**:宿舍没有电梯。
|
||||
43. **军训服装发放**:统一发放军训服装和鞋子。
|
||||
44. **研究生军训**:研究生同样需要参加军训。
|
||||
45. **校历查看方式**:可通过福大教务处官网或西二在线工作室开发的app查看。
|
||||
46. **新生开学活动**:新生需适应环境,可能有讲座和增进关系的活动。
|
||||
47. **学校支付方式**:使用支付码或手机支付,无饭卡。
|
||||
48. **宿舍分配消息发布时间**:通常在报道前一两天。
|
||||
49. **开学家长进校**:在无疫情封控下,家长应可进校。
|
||||
50. **新生交学费周期**:交纳一年费用,非整个学制。
|
||||
|
||||
|
||||
|
||||
|
||||
## 毕业相关
|
||||
### 毕业证补办
|
||||
|
||||
福州大学的毕业/学位证书是可以补办的,详细方法移步教务处文件:[福州大学补办毕业/学位证明书](https://jwch.fzu.edu.cn/info/1058/4132.htm)
|
||||
48
福大生存指南/6.小组作业避雷指南.md
Normal file
48
福大生存指南/6.小组作业避雷指南.md
Normal file
@@ -0,0 +1,48 @@
|
||||
# 小组作业避雷指南
|
||||
|
||||
小组作业,想避雷?
|
||||
|
||||
那么请你遵循以下几个要点,虽然可以不说绝对,但是也可以大幅度避免你受毒打的可能性。
|
||||
|
||||
## 不要和认识但不熟的人组队
|
||||
|
||||
如果你不清楚他到底靠不靠谱请假定他不靠谱,不然会出现各种各样的状况。
|
||||
|
||||
::: warning 🤣
|
||||
[与人合作中的 “生死疲劳” 哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1494y1o7jp)
|
||||
|
||||
<Bilibili bvid='BV1494y1o7jp'/>
|
||||
|
||||
**一定要看看这个**
|
||||
|
||||
:::
|
||||
|
||||
## 认清自身实力选择合适的题目
|
||||
|
||||
不要上来就为了最高分选最难的,可能会做不完适得其反。
|
||||
|
||||
## 认清自己的需求
|
||||
|
||||
追求高GPA的同学,自然是要多干活,建议便寻找比较随性的队友了,这样最后分功劳的时候,你多做多拿大家自然也不会说什么,毕竟大家也不追求这个自然没人和你争。若是和同样追求的同学一个队伍,有时候还是会引发争端的,这个其实也不好解决。
|
||||
|
||||
## 合理安排组员
|
||||
|
||||
如果你是队长,你需要整合各个组员的能力并且不断督促以及保证你能督促得到。
|
||||
|
||||
同时,要保证核心技术都是你在把握。即,假设组员们都摆烂了,你依然可以迅速找到替代,比如说去网上找别人做之类的。
|
||||
|
||||
## 御人先御己
|
||||
|
||||
在安排他人的时候,你需要也对自己严格要求,保证让他人对你很信服。光说不练,总是在要求他人,自身却倦于行动。如果你不确定自己属于哪类,请扪心自问:如果同样的要求标准,换你被别人管,你有没有信心自己不挨骂?
|
||||
|
||||
并且要有责任心,保证稳步地推进。
|
||||
|
||||
## 控制项目进度
|
||||
|
||||
展示非常重要,可能你的项目一般,但是你可以采用精妙的技巧将你的项目非常完整的优雅的展示给老师,那老师也会很高兴的。
|
||||
|
||||
也不要一次性展示一大堆,不合适不合理。
|
||||
|
||||
## 混脸熟
|
||||
|
||||
多和老师聊天沟通,可能加强你的印象分。
|
||||
60
福大生存指南/7.选课原则与抢课技巧.md
Normal file
60
福大生存指南/7.选课原则与抢课技巧.md
Normal file
@@ -0,0 +1,60 @@
|
||||
# 选课原则与抢课技巧
|
||||
|
||||
> author: WJJ
|
||||
>
|
||||
> 本文编写自 2024.08.10,也许当你观看时有些内容已经过时,请选择性参考。
|
||||
|
||||
## 选课原则
|
||||
|
||||
### 要选哪些课
|
||||
|
||||
在FZU,学生必须修读完培养计划上所有需要的学费,因此选课遵循的唯一纲要便是培养计划,一切以培养计划上的要求为准,总的来说分为必修与选修,必修则分为通识必修、学科必修、专业必修,选修分为专业选修、通识选修、创新创业实践选修、跨学科选修、本硕博贯通课等,一切以培养计划为主,各个课程的开课学期培养计划上面是有写的,需要十分注意的是,选修是可以根据自身决定修与不修,但建议跟随大部队进行选择,因为培养计划上部分选修课程实际上有可能已经不开课了,这个建议问一下直系学长学姐。
|
||||
|
||||
对于分流分方向的专业(由于作者是电子信息工程专业,便拿这个举例子),电子信息类分方向后会分成电子信息工程与通信工程,而电子信息工程与通信工程又都会分成两个小方向,电子信息工程为信号与信息处理还有嵌入式系统,故培养计划也对专业必修的课程分了两个小方向,那如果嵌入式系统的同学修了信号与信息处理方向同学的专业必修课,实际上这个学分会算在嵌入式系统同学的专业选修类的学分上面。还是说一下尽量避免挂科,期末挂科后开学还有得补考,补考挂了那就要重修了,重修1学分可要交121元的费用,不值当啊不值当,但是校选课挂科是没有事情的。
|
||||
|
||||
### 为什么要选课
|
||||
|
||||
选课其实是选老师,而选择的选课老师的背后则是课程考核方式、给分高低、成绩占比、课堂签到情况等等。选择正确的老师能够使课堂更加符合你的预期,不论是教学质量还是教学方式亦或期末分数上。
|
||||
|
||||
在讨论之前,必须声明一些学校课程的基本要求,例如学校要求老师采取易班点名的方式,所以除了某些老师以外大多数老师都会采取不定次数的课堂点名以及点教室人头的方式作为考核考勤情况的方式。
|
||||
|
||||
|
||||
### 选什么课好
|
||||
|
||||
在班级群、部门群或者与认识的室友、同学、学长学姐等等交流开展某课程的某老师教学情况,打听情报以选择合适的老师。此处的情报通常指老师的教学方式如何,采取怎样的签到方式等等。如果曾经上过某老师开展的 a 课程,那么通常对于他开展的 b 课程,签到情况和给分情况都仍然能够适用,但是教学情况则未必。
|
||||
|
||||
### 常见问题 Q&A
|
||||
|
||||
Q1:我该如何安排我这一学期的课程?
|
||||
|
||||
A1:尽可能按照培养计划给出的每学期修读建议修读,或者跟随大部队进行修读基本上是没错的,也可以问问直系学长学姐,建议大家本着早修完早结束去选课,反正迟早也是要修的。
|
||||
|
||||
Q2:大一上如何选课?
|
||||
|
||||
A2:大一上通常不需要选课,唯一的就是校选课,第一轮为线下授课,第二轮为网课(挂着刷课bushi)。
|
||||
|
||||
## 抢课技巧
|
||||
|
||||
### 选课背景
|
||||
|
||||
在FZU的选课中,通常使用教务处<https://jwch.fzu.edu.cn/>,福uu也可以,但是教务处晚上24点很多时候会崩溃加载不进去,教务处进不去福uu自然也是不行的 。
|
||||
|
||||
## 具体技巧
|
||||
|
||||
### 系统开放前
|
||||
|
||||
通常系统开放前可以查询开课情况,那么可以根据开课情况自己提前规划安排想上的课程,然后询问学长学姐选哪个老师。
|
||||
|
||||
### 系统开放时
|
||||
|
||||
#### 第一轮选课、第二轮选课开放系统时
|
||||
|
||||
FZU的选课采用投积分的形式,投积分多的人优先获得,相对而言,专业人数越多那么抢课则越激烈,基本上会出现每门课都需要投积分,这就要看个人的选课策略了,第一轮没有中选的同学第二轮还是继续投积分。
|
||||
|
||||
#### 第三轮选课开放系统时
|
||||
|
||||
事实上到了第三轮选课,未选到课程的同学以及不多了,更多的应该是体育课比较多的同学两轮过后了都还没选到,所以大家就需要24点准时进系统抢了,没错,第三轮选课是用抢的!点到了就算抢到了。
|
||||
|
||||
#### 开学前二至三周
|
||||
|
||||
这时候会有同学因为突然不想修这门课而在教务处上面进行退选,这时候就可以没事上系统看看去捡漏了。
|
||||
21
福大生存指南/8.社团篇.md
Normal file
21
福大生存指南/8.社团篇.md
Normal file
@@ -0,0 +1,21 @@
|
||||
# 社团篇
|
||||
|
||||
## 前言
|
||||
|
||||
发现很多的同学会对大学里面的社团有所向往,作为FZU物信的学子,就身处的专业谈一谈社团选择。
|
||||
|
||||
## 我应该选择什么样的社团
|
||||
|
||||
从FZU社团部给的社团名单(下面将给出)来看,社团可谓是丰富多彩了,实际上也有一些不在社团名单里面的社团,这个要靠大家自己挖掘了。关于选择什么样的社团,我觉得更多的取决于你想要什么,你感兴趣什么,举个例子,如果你想提升专业技能,那么与专业相关的学术社团就是不错的方向。不知道如何选择的话,实际上可以等百团大战的时候,实地体验一下社团的特色活动,这是了解社团的好机会。但是也要注意,不要同时加入过多的社团,以免精力分散,一切都看自己如何选择,加入社团并不是一个硬性要求。
|
||||
|
||||
## 热门社团介绍
|
||||
|
||||
作为FZU的物信人,这里就物信同学加入的较多的社团进行介绍。首先是电子社,专注与电子设计竞赛,物信将其作为部门使用,纳新时会从零开始培训新生,预计在新生开学以及百团大战进行纳新,是电子类专业学生一个不错的选择。其次是机协也就是机器人爱好者协会,里面比较主要的比赛算是中国机器人大赛,做机器人的花销比较大,有后台支撑还是十分有必要的,预计在每年上半年进行纳新。此外还有创客等等。顺便说一下,在大二上的时候,电气学院还有一个智能车队,专注于打智能车竞赛,也是不错的。当然加入这些社团或出于功利或出于兴趣,其实能学到东西那就是不错了。
|
||||
|
||||
至于其他社团,乒乓球之类的,想必就要凭借大家真正的兴趣了。
|
||||
|
||||
## 结言
|
||||
|
||||
大学社团生活也算得上是大学里不可分割的一部分,希望大家都能找到想去的地方。
|
||||
|
||||
.png)
|
||||
BIN
福大生存指南/static/【社团部】2024-2025福州大学学生社团名录(2024年4月).png
Normal file
BIN
福大生存指南/static/【社团部】2024-2025福州大学学生社团名录(2024年4月).png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 773 KiB |
BIN
福大生存指南/static/旗山校区手绘地图.png
Normal file
BIN
福大生存指南/static/旗山校区手绘地图.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 1.9 MiB |
BIN
福大生存指南/static/铜盘校区床位.jpg
Normal file
BIN
福大生存指南/static/铜盘校区床位.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 129 KiB |
BIN
福大生存指南/static/铜盘校区手绘地图.png
Normal file
BIN
福大生存指南/static/铜盘校区手绘地图.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 949 KiB |
1
福大生存指南/生存指南.md
Normal file
1
福大生存指南/生存指南.md
Normal file
@@ -0,0 +1 @@
|
||||
# 生存指南
|
||||
Reference in New Issue
Block a user