fix: http to https
This commit is contained in:
@@ -3,7 +3,7 @@
|
||||
大规模推荐系统需要实时对用户行为做出海量预测,为了保证这种实时性,大规模的推荐系统通常严重依赖于预先计算好的产品索引。产品索引的功能为:给定种子产品返回排序后的候选相关产品列表。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2relations.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2relations.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
|
||||
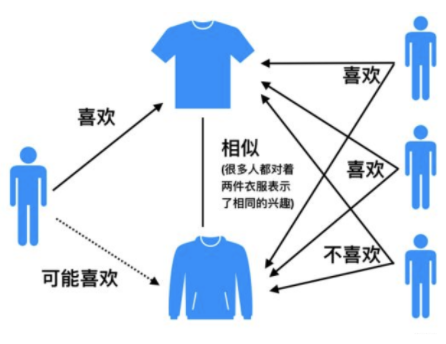
相关性产品索引主要包含两部分:替代性产品和互补性产品。例如图中的不同种类的衬衫构成了替代关系,而衬衫和风衣裤子等构成了互补关系。用户通常希望在完成购买行为之前尽可能看更多的衬衫,而用户购买过衬衫之后更希望看到与之搭配的单品而不是其他衬衫了。
|
||||
@@ -23,7 +23,7 @@ Swing 通过利用 User-Item-User 路径中所包含的信息,考虑 User-Item
|
||||
- 什么是内部子结构?
|
||||
以经典的啤酒尿布故事为例,张三同时购买了啤酒和尿布,这可能是一种巧合。但两个甚至多个顾客都同时购买了啤酒尿布,这就证明啤酒和尿布具有相关关系。这样共同购买啤酒和尿布的用户越多,啤酒和尿布的相关度就会越高。
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片example_of_swing.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片example_of_swing.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
图中的红色四边形就是一种Swing子结构,这种子结构可以作为给王五推荐尿布的依据。
|
||||
|
||||
@@ -256,7 +256,7 @@ Swing 通过利用 User-Item-User 路径中所包含的信息,考虑 User-Item
|
||||
由于类别直接的种类差异,每个类别的相关类数量存在差异,因此采用最大相对落点来作为划分阈值。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片max_drop.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片max_drop.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
|
||||
例如图(a)中T恤的相关类选择前八个,图(b)中手机的相关类选择前三个。
|
||||
|
||||
@@ -9,13 +9,13 @@
|
||||
|
||||
举例来说,如果用户 1 喜欢物品 A ,而物品 A 和 C 非常相似,则可以将物品 C 推荐给用户1。ItemCF算法并不利用物品的内容属性计算物品之间的相似度, 主要通过分析用户的行为记录计算物品之间的相似度, 该算法认为, 物品 A 和物品 C 具有很大的相似度是因为喜欢物品 A 的用户极可能喜欢物品 C。
|
||||
|
||||
|
||||

|
||||
|
||||
## 计算过程
|
||||
|
||||
基于物品的协同过滤算法和基于用户的协同过滤算法很像, 所以我们这里直接还是拿上面 Alice 的那个例子来看。
|
||||
|
||||
|
||||

|
||||
|
||||
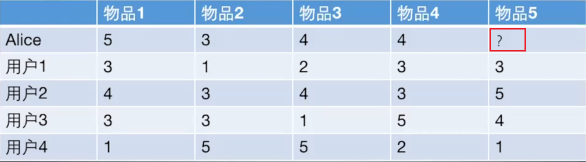
如果想知道 Alice 对物品5打多少分, 基于物品的协同过滤算法会这么做:
|
||||
|
||||
@@ -41,7 +41,7 @@
|
||||
|
||||
2. 基于 `sklearn` 计算物品之间的皮尔逊相关系数:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/JavaJOyFti58um61zPsa.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/JavaJOyFti58um61zPsa.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
|
||||
3. 根据皮尔逊相关系数, 可以找到与物品5最相似的2个物品是 item1 和 item4, 下面基于上面的公式计算最终得分:
|
||||
|
||||
@@ -196,7 +196,7 @@ $$
|
||||
|
||||
比如下面这个例子:
|
||||
|
||||
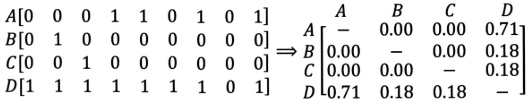
|
||||
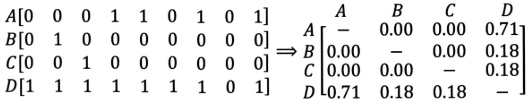
|
||||
|
||||
+ 左边矩阵中,$A, B, C, D$ 表示的是物品。
|
||||
+ 可以看出,$D $ 是一件热门物品,其与 $A、B、C$ 的相似度比较大。因此,推荐系统更可能将 $D$ 推荐给用过 $A、B、C$ 的用户。
|
||||
@@ -242,7 +242,7 @@ $$
|
||||
>
|
||||
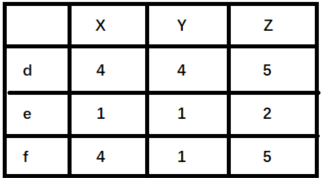
> 举例来说明,如下图(`X,Y,Z` 表示物品,`d,e,f`表示用户):
|
||||
>
|
||||
> 
|
||||
> 
|
||||
>
|
||||
> + 如果使用余弦相似度进行计算,用户 d 和 e 之间较为相似。但是实际上,用户 d 和 f 之间应该更加相似。只不过由于 d 倾向于打高分,e 倾向于打低分导致二者之间的余弦相似度更高。
|
||||
> + 这种情况下,可以考虑使用皮尔逊相关系数计算用户之间的相似性关系。
|
||||
|
||||
@@ -99,13 +99,13 @@
|
||||
+ 例如,我们要对用户 $A$ 进行物品推荐,可以先找到和他有相似兴趣的其他用户。
|
||||
+ 然后,将共同兴趣用户喜欢的,但用户 $A$ 未交互过的物品推荐给 $A$。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210629232540289.png" alt="image-20210629232540289" style="zoom: 80%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210629232540289.png" alt="image-20210629232540289" style="zoom: 80%;" />
|
||||
|
||||
## 计算过程
|
||||
|
||||
以下图为例,给用户推荐物品的过程可以形象化为一个猜测用户对物品进行打分的任务,表格里面是5个用户对于5件物品的一个打分情况,就可以理解为用户对物品的喜欢程度。
|
||||
|
||||

|
||||

|
||||
|
||||
UserCF算法的两个步骤:
|
||||
|
||||
@@ -164,7 +164,7 @@ UserCF算法的两个步骤:
|
||||
|
||||
+ 基于 sklearn 计算所有用户之间的皮尔逊相关系数。可以看出,与 Alice 相似度最高的用户为用户1和用户2。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/JavaWJkjP2fHH27Rajrj.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/JavaWJkjP2fHH27Rajrj.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
|
||||
2. **根据相似度用户计算 Alice对物品5的最终得分**
|
||||
用户1对物品5的评分是3, 用户2对物品5的打分是5, 那么根据上面的计算公式, 可以计算出 Alice 对物品5的最终得分是
|
||||
|
||||
@@ -16,11 +16,11 @@
|
||||
- 当用户在查看某一个房源时,接下来的有两种方式继续搜索:
|
||||
- 返回搜索结果页,继续查看其他搜索结果。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049527431-0b09af70-bda0-4a30-8082-6aa69548213a.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049527431-0b09af70-bda0-4a30-8082-6aa69548213a.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 在当前房源的详情页下,「相似房源」板块(你可能还喜欢)所推荐的房源。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049385995-7a775df1-a36f-4795-9e79-8e577bcf2097.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049385995-7a775df1-a36f-4795-9e79-8e577bcf2097.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- Airbnb 平台 99% 的房源预订来自于搜索排序和相似房源推荐。
|
||||
# Embedding 方法
|
||||
@@ -59,7 +59,7 @@ $$
|
||||
- Airbnb 将最终预定的房源,始终作为滑窗的上下文,即全局上下文。如下图:
|
||||
- 如图,对于当前滑动窗口的 central listing,实线箭头表示context listings,虚线(指向booked listing)表示 global context listing。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653053823336-0564b2da-c993-46aa-9b22-f5cbb784dae2.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653053823336-0564b2da-c993-46aa-9b22-f5cbb784dae2.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- booked listing 作为全局正样本,故优化的目标函数更新为:
|
||||
|
||||
@@ -103,12 +103,12 @@ $$
|
||||
- 理论上,同一区域的房源相似性应该更高,不同区域房源相似性更低。
|
||||
- Airbnb 利用 k-means 聚类,将加利福尼亚州的房源聚成100个集群,来验证类似位置的房源是否聚集在一起。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056809526-15401069-6fff-40d8-ac5e-35871d3f254a.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056809526-15401069-6fff-40d8-ac5e-35871d3f254a.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 评估不同类型、价格区间的房源之间的相似性。
|
||||
- 简而言之,我们希望类型相同、价格区间一致的房源它们之间的相似度更高。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056981037-18edee91-493a-4d5b-b066-57f0b200032d.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056981037-18edee91-493a-4d5b-b066-57f0b200032d.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 评估房源的隐式特征
|
||||
- Airbnb 在训练房源(listing)的 Embedding时,并没有用到房源的图像信息。
|
||||
@@ -117,7 +117,7 @@ $$
|
||||
- 大致原理就是,利用训练好的 Embedding 进行 K 近邻相似度检索。
|
||||
- 如下,与查询房源在 Embedding 相似性高的其他房源,它们之间的外观风格也很相似。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653057336798-fd8451cb-84b6-40fb-8733-1e3d08a39793.png" alt="img" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653057336798-fd8451cb-84b6-40fb-8733-1e3d08a39793.png" alt="img" />
|
||||
|
||||
## User-type & Listing-type Embedding
|
||||
|
||||
@@ -169,7 +169,7 @@ Airbnb 除了挖掘 Listing 的短期兴趣特征表示外,还对 User 和 Lis
|
||||
- 所有的属性,都基于一定的规则进行了分桶(buckets)。例如21岁,被分桶到 20-30 岁的区间。
|
||||
- 对于首次预定的用户,他的属性为 buckets 的前5行,因为预定之前没有历史预定相关的信息。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653125260611-7d33731b-9167-4fcc-b83b-0a2407ea89ca.png" alt="img" style="zoom: 67%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653125260611-7d33731b-9167-4fcc-b83b-0a2407ea89ca.png" alt="img" style="zoom: 67%;" />
|
||||
|
||||
看到过前面那个简单的例子后,现在可以看一个原文的 Listing-type 的例子:
|
||||
|
||||
@@ -233,7 +233,7 @@ Type Embedding 的学习同样是基于 Skip-Gram 模型,但是有两点需要
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653131985447-e033cb39-235b-4f46-9634-3b7faec284be.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653131985447-e033cb39-235b-4f46-9634-3b7faec284be.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
# 实验部分
|
||||
|
||||
@@ -276,13 +276,13 @@ Airbnb 的搜索排名的大致流程为:
|
||||
|
||||
- 表中的 Embedding Features 包含了8种类型,前6种类型的特征计算方式相同。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653139981920-a100085b-007b-4a9c-9edf-74297e9115ae.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653139981920-a100085b-007b-4a9c-9edf-74297e9115ae.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
**① 基于 Listing Embedding Features 的特征构建**
|
||||
|
||||
- Airbnb 保留了用户过去两周6种不同类型的历史行为,如下图:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653140202230-1f49e1dd-5c8c-4445-bd0b-9a17788a7b3f.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653140202230-1f49e1dd-5c8c-4445-bd0b-9a17788a7b3f.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 对于每个行为,还要将其按照 market (地域)进行划分。以 $ H_c $ 为例:
|
||||
|
||||
@@ -312,7 +312,7 @@ Airbnb 的搜索排名的大致流程为:
|
||||
|
||||
为了验证上述特征的构建是否有效,Airbnb 还做了特征重要性排序,如下表:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653142188111-1975bcc4-22a2-45cf-bff0-2783ecb00a0c.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653142188111-1975bcc4-22a2-45cf-bff0-2783ecb00a0c.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
**(3)模型**
|
||||
特征构建完成后,开始对模型进行训练。
|
||||
|
||||
@@ -56,7 +56,7 @@ one-hot向量的维度是词汇表的大小(如:500,000)
|
||||
如果我们可以使用某种方法为每个单词构建一个合适的dense vector,如下图,那么通过点积等数学计算就可以获得单词之间的某种联系
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1.png" />
|
||||
|
||||
|
||||
# Word2vec
|
||||
@@ -71,7 +71,7 @@ one-hot向量的维度是词汇表的大小(如:500,000)
|
||||
我们先引入上下文context的概念:当单词 w 出现在文本中时,其**上下文context**是出现在w附近的一组单词(在固定大小的窗口内),如下图
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2.png" />
|
||||
|
||||
|
||||
这些上下文单词context words决定了banking的意义
|
||||
@@ -97,13 +97,13 @@ Word2vec包含两个模型,**Skip-gram与CBOW**。下面,我们先讲**Skip-
|
||||
下图展示了以“into”为中心词,窗口大小为2的情况下它的上下文词。以及相对应的$P(o|c)$
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片3.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片3.png" />
|
||||
|
||||
|
||||
我们滑动窗口,再以banking为中心词
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片4.png"在这里插入图片描述" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片4.png"在这里插入图片描述" />
|
||||
|
||||
|
||||
那么,如果我们在整个语料库上不断地滑动窗口,我们可以得到所有位置的$P(o|c)$,我们希望在所有位置上**最大化单词o在单词c周围出现了这一事实**,由极大似然法,可得:
|
||||
@@ -115,13 +115,13 @@ $$
|
||||
此式还可以依图3写为:
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片5.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片5.png" />
|
||||
|
||||
|
||||
加log,加负号,缩放大小可得:
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片7.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片7.png" />
|
||||
|
||||
|
||||
上式即为**skip-gram的损失函数**,最小化损失函数,就可以得到合适的词向量
|
||||
@@ -141,7 +141,7 @@ $$
|
||||
又P(o|c)是一个概率,所以我们在整个语料库上使用**softmax**将点积的值映射到概率,如图6
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片6.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片6.png" />
|
||||
|
||||
|
||||
注:注意到上图,中心词词向量为$v_{c}$,而上下文词词向量为$u_{o}$。也就是说每个词会对应两个词向量,**在词w做中心词时,使用$v_{w}$作为词向量,而在它做上下文词时,使用$u_{w}$作为词向量**。这样做的原因是为了求导等操作时计算上的简便。当整个模型训练完成后,我们既可以使用$v_{w}$作为词w的词向量,也可以使用$u_{w}$作为词w的词向量,亦或是将二者平均。在下一部分的模型结构中,我们将更清楚地看到两个词向量究竟在模型的哪个位置。
|
||||
@@ -153,7 +153,7 @@ $$
|
||||
## Word2vec模型结构
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片8.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片8.png" />
|
||||
|
||||
|
||||
如图八所示,这是一个输入为1 X V维的one-hot向量(V为整个词汇表的长度,这个向量只有一个1值,其余为0值表示一个词),单隐藏层(**隐藏层的维度为N,这里是一个超参数,这个参数由我们定义,也就是词向量的维度**),输出为1 X V维的softmax层的模型。
|
||||
@@ -175,13 +175,13 @@ $W^{I}$为V X N的参数矩阵,$W^{O}$为N X V的参数矩阵。
|
||||
如上文所述,Skip-gram为给定中心词,预测周围的词,即求P(o|c),如下图所示:
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105817437.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105817437.png" />
|
||||
|
||||
|
||||
而CBOW为给定周围的词,预测中心词,即求P(c|o),如下图所示:
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片10.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片10.png" />
|
||||
|
||||
|
||||
|
||||
@@ -194,7 +194,7 @@ $W^{I}$为V X N的参数矩阵,$W^{O}$为N X V的参数矩阵。
|
||||
我们再看一眼,通过softmax得到的$P(o|c)$,如图:
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105958191.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105958191.png" />
|
||||
|
||||
|
||||
|
||||
@@ -209,7 +209,7 @@ $W^{I}$为V X N的参数矩阵,$W^{O}$为N X V的参数矩阵。
|
||||
我们首先给出负采样的损失函数:
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片12.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片12.png" />
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -33,7 +33,7 @@
|
||||
在介绍三个模型之前,我们首先需要构建好item-item图。由于基于CF的方法仅考虑物品之间的共现,忽略了行为的序列信息(即序列中相邻的物品之间的语义信息),因此item-item图的构建方式如下图所示。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328133138263.png" style="zoom:80%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328133138263.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
首先根据用户的session行为序列构建网络结构,即序列中相邻两个item之间在存在边,并且是有向带权图。物品图边上的权重为所有用户行为序列中两个 item 共现的次数,最终构造出来简单的有向有权图。
|
||||
@@ -53,7 +53,7 @@
|
||||
对于图嵌入模型,第一步先进行随机游走得到物品序列;第二部通过skip-gram为图上节点生成embedding。那么对于随机游走的思想:如何利用随机游走在图中生成的序列?不同于DeepWalk中的随机游走,本文的采样策略使用的是带权游走策略,不同权重的游走到的概率不同,(其本质上就是node2vec),传统的node2vec方法可以直接支持有向带权图。因此在给定图的邻接矩阵M后(表示节点之间的边权重),随机游走中每次转移的概率为:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144516898.png" style="zoom:80%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144516898.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中$M_{ij}$为边$e_{ij}$上的权重,$N_{+}(v_i)$表示节点$v_i$所有邻居节点集合,并且随机游走的转移概率的对每个节点所有邻接边权重的归一化结果。在随即游走之后,每个item得到一个序列,如下图所示:
|
||||
@@ -65,19 +65,19 @@
|
||||
然后类似于word2vec,为每个item学习embedding,于是优化目标如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144931957.png" style="zoom:77%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144931957.png" style="zoom:77%;"/>
|
||||
</div>
|
||||
|
||||
其中,w 为窗口大小。考虑独立性假设的话,上面的式子可以进一步化简:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145101109.png" style="zoom:77%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145101109.png" style="zoom:77%;"/>
|
||||
</div>
|
||||
|
||||
这样看起来就很直观了,在已知物品 i 时,最大化序列中(上下文)其他物品 j 的条件概率。为了近似计算,采样了Negative sampling,上面的优化目标可以化简得到如下式子:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145318718.png" style="zoom:80%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145318718.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中$N(v_i)'$表示负样本集合,负采样个数越多,结果越好。
|
||||
@@ -101,7 +101,7 @@
|
||||
针对上述问题,作者提出了weight pooling方法来聚合不同类型的 side information。具体地,EGES 与 GES 的区别在聚合不同类型 side information计算不同的权重,根据权重聚合 side information 得到商品的embedding,如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328154950289.png" style="zoom:80%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328154950289.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中 $a_i$ 表示每个side information 用于计算权重的参数向量,最终通过下面的公式得到商品的embedding:
|
||||
@@ -117,13 +117,13 @@
|
||||
以上就是这三个模型主要的区别,下面是EGES的伪代码。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155406291.png" style="zoom:80%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155406291.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中**WeightedSkipGram**函数为带权重的SkipGram算法。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155533704.png" style="zoom:80%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155533704.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
@@ -9,7 +9,7 @@
|
||||
**树结构**
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420213149324.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420213149324.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
</div>
|
||||
|
||||
如上图,树中的每一个叶子节点对应一个商品item,非叶子结点表示的是item的集合**(这里的树不限于二叉树)**。这种层次化结构体现了粒度从粗到细的item架构。
|
||||
@@ -17,7 +17,7 @@
|
||||
**整体结构**
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420200433442.png" alt="image-20210308142624189" style="zoom: 70%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420200433442.png" alt="image-20210308142624189" style="zoom: 70%;" />
|
||||
</div>
|
||||
|
||||
# 算法详解
|
||||
@@ -34,7 +34,7 @@
|
||||
2. 对兴趣进行建模
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420214040264.png" alt="image-20210308142624189" style="zoom: 50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420214040264.png" alt="image-20210308142624189" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
如上图,用户对叶子层item6感兴趣,可以认为它的兴趣是1,同层别的候选节点的兴趣为0,顺着着绿色线路上去的节点都标记为1,路线上的同层别的候选节点都标记为0。这样的操作就可以根据1和0构建用于每一层的正负样本。
|
||||
@@ -44,7 +44,7 @@
|
||||
3. 训练过程
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420220831318.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420220831318.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
</div>
|
||||
|
||||
整体联合训练的方式如下:
|
||||
|
||||
Reference in New Issue
Block a user