fix: http to https
This commit is contained in:
@@ -12,5 +12,5 @@
|
||||
为了方便学习和交流,**我们建立了FunRec学习社区(微信群+知识星球)**,微信群方便大家平时日常交流和讨论,知识星球方便沉淀内容。由于我们的内容面向的人群主要是学生,所以**知识星球永久免费**,感兴趣的可以加入星球讨论(加入星球的同学先看置定的必读帖)!**FunRec学习社区内部会不定期分享(FunRec社区中爱分享的同学)技术总结、个人管理等内容,[跟技术相关的分享内容都放在了B站](https://space.bilibili.com/431850986/channel/collectiondetail?sid=339597)上面**。由于微信群的二维码只有7天内有效,所以直接加下面这个微信,备注:**Fun-Rec**,会被拉到Fun-Rec交流群,如果觉得微信群比较吵建议直接加知识星球!。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220408193745249.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220408193745249.png" />
|
||||
</div>
|
||||
|
||||
@@ -46,45 +46,45 @@
|
||||
- **电商首页推荐(淘宝、京东、拼多多)**
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421190313917.png" alt="image-20220421190313917" style="zoom: 15%;" />
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421191138469.png" alt="image-20220421191138469" style="zoom:53%;" />
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421191441104.png" alt="image-20220421191441104" style="zoom:53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421190313917.png" alt="image-20220421190313917" style="zoom: 15%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421191138469.png" alt="image-20220421191138469" style="zoom:53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421191441104.png" alt="image-20220421191441104" style="zoom:53%;" />
|
||||
</div>
|
||||
|
||||
- **视频推荐(抖音、快手、B站、爱奇艺)**
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421190629410.png" alt="image-20220421190629410" style="zoom:55%;" />
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421191849577.png" alt="image-20220421191849577" style="zoom: 53%;" />
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192047973.png" alt="image-20220421192047973" style="zoom:53%;" />
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192209412.png" alt="image-20220421192209412" style="zoom:55%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421190629410.png" alt="image-20220421190629410" style="zoom:55%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421191849577.png" alt="image-20220421191849577" style="zoom: 53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192047973.png" alt="image-20220421192047973" style="zoom:53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192209412.png" alt="image-20220421192209412" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
|
||||
- **饮食推荐(美团、饿了么、叮咚买菜)**
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192623380.png" alt="image-20220421192623380" style="zoom:53%;" />
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192717773.png" alt="image-20220421192717773" style="zoom:55%;" />
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192749794.png" alt="image-20220421192749794" style="zoom:55%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192623380.png" alt="image-20220421192623380" style="zoom:53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192717773.png" alt="image-20220421192717773" style="zoom:55%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421192749794.png" alt="image-20220421192749794" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
|
||||
- **音乐电台(网易云音乐、QQ音乐、喜马拉雅)**
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193139183.png" alt="image-20220421193139183" style="zoom: 57%;" />
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193447933.png" alt="image-20220421193447933" style="zoom:68%;" />
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193325921.png" alt="image-20220421193325921" style="zoom: 54%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193139183.png" alt="image-20220421193139183" style="zoom: 57%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193447933.png" alt="image-20220421193447933" style="zoom:68%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193325921.png" alt="image-20220421193325921" style="zoom: 54%;" />
|
||||
</div>
|
||||
|
||||
|
||||
- **资讯、阅读(头条、知乎、豆瓣)**
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193856262.png" alt="image-20220421193856262" style="zoom:53%;" />
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193923283.png" alt="image-20220421193923283" style="zoom:55%;" />
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421194244083.png" alt="image-20220421194244083" style="zoom:55%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193856262.png" alt="image-20220421193856262" style="zoom:53%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421193923283.png" alt="image-20220421193923283" style="zoom:55%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220421194244083.png" alt="image-20220421194244083" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
@@ -30,12 +30,12 @@
|
||||
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409205047285.png" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409205047285.png" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
上面是网飞的原图,我搬运了更加容易理解的线条梳理后的结构:
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409204658032.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409204658032.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
整个数据部分其实是一整个链路,主要是三块,分别是客户端及服务器实时数据处理、流处理平台准实时数据处理和大数据平台离线数据处理这三个部分。
|
||||
|
||||
@@ -62,7 +62,7 @@
|
||||
|
||||
这里我们可以看出离线层的任务是最接近学校中我们处理数据、训练模型这种任务的,不同可能就是需要面临更大规模的数据。离线任务一般会按照天或者更久运行,比如每天晚上定期更新这一天的数据,然后重新训练模型,第二天上线新模型。
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409205904314.png" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409205904314.png" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
#### 离线层优势和不足
|
||||
@@ -83,7 +83,7 @@
|
||||
|
||||
近线层的发展得益于最近几年大数据技术的发展,很多流处理框架的提出大大促进了近线层的进步。如今Flink、Storm等工具一统天下。
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409205830027.png" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409205830027.png" alt="在这里插入图片描述" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
### 在线层
|
||||
@@ -106,7 +106,7 @@
|
||||
所以一个通用的算法架构,设计思想就是对数据层层建模,层层筛选,帮助用户从海量数据中找出其真正感兴趣的部分。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409211354342.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409211354342.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
- 召回
|
||||
|
||||
@@ -7,7 +7,7 @@
|
||||
首先我们从推荐系统架构出发,一种分法是将整个推荐系统架构分为召回、粗排、精排、重排、混排等模块。它的分解方法是从一份数据如何从生产出来,到线上服务完整顺序的一个流程。因为在不同环节,我们一般会考虑不同的算法,所以这种角度出发我们来研究推荐系统主流的算法技术栈。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409211354342.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220409211354342.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
为了帮助新手在后文方便理解,首先简单介绍这些模块的功能主要是:
|
||||
@@ -22,7 +22,7 @@
|
||||
首先是推荐系统的物料库,这部分内容里,算法主要体现在如何绘制一个用户画像和商品画像。这个环节是推荐系统架构的基础设施,一般可能新用户/商品进来,或者每周定期会重新一次整个物料库,计算其中信息,为用户打上标签,计算统计信息,为商品做内容理解等内容。其中用户画像是大家比较容易理解的,比如用户年龄、爱好通常APP会通过注册界面收集这些信息。而商品画像形式就非常多了,比如淘宝主要推荐商品,抖音主要是短视频,所以大家的物料形式比较多,内容、质量差异也比较大,所以内容画像各家的做法也不同,当前比较主流的都会涉及到一个多模态信息内容理解。下面我贴了一个微信看一看的内容画像框架,然后我们来介绍下在这一块主要使用的算法技术。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220410143333692.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220410143333692.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
一般推荐系统会加入多模态的一个内容理解。我们用短视频形式举个例子,假设用户拍摄了一条短视频,上传到了平台,从推荐角度看,首先我们有的信息是这条短视频的作者、长度、作者为它选择的标签、时间戳这些信息。但是这对于推荐来说是远远不够的,首先作者打上的标签不一定准确反映作品,原因可能是我们模型的语义空间可能和作者/现实世界不一致。其次我们需要更多维度的特征,比如有些用户喜欢看小姐姐跳舞,那我希望能够判断一条视频中是否有小姐姐,这就涉及到封面图的基于CV的内容抽取或者整个视频的抽取;再比如作品的标题一般能够反映主题信息,除了很多平台常用的用“#”加上一个标签以外,我们也希望能够通过标题抽取出基于NLP的信息。还有更多的维度可以考虑:封面图多维度的多媒体特征体系,包括人脸识别,人脸embedding,标签,一二级分类,视频embedding表示,水印,OCR识别,清晰度,低俗色情,敏感信息等多种维度。
|
||||
@@ -58,7 +58,7 @@
|
||||
推荐系统的召回阶段可以理解为根据用户的历史行为数据,为用户在海量的信息中粗选一批待推荐的内容,挑选出一个小的候选集的过程。粗排用到的很多技术与召回重合,所以放在一起讲,粗排也不是必需的环节,它的功能对召回的结果进行个粗略的排序,在保证一定精准的前提下,进一步减少往后传送的物品数量,这就是粗排的作用。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220410000221817.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220410000221817.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
召回模块面对几百上千万的推荐池物料规模,候选集十分庞大。由于后续有排序模块作为保障,故不需要十分准确,但必须保证不要遗漏和低延迟。目前主要通过多路召回来实现,一方面各路可以并行计算,另一方面取长补短。可以看到各类同类竞品的系统虽然细节上多少存在差异,但不约而同的采取了多路召回的架构,这类设计考虑如下几点问题:
|
||||
@@ -112,7 +112,7 @@
|
||||
排序模型是推荐系统中涵盖的研究方向最多,有非常多的子领域值得研究探索,这也是推荐系统中技术含量最高的部分,毕竟它是直接面对用户,产生的结果对用户影响最大的一层。目前精排层深度学习已经一统天下了,这是王喆老师《深度学习推荐算法》书中的精排层模型演化线路。具体来看分为DNN、Wide&Deep两大块,实际深入还有序列建模,以及没有提到的多任务建模都是工业界非常常用的,所以我们接下来具体谈论其中每一块的技术栈。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220410234144149.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220410234144149.png" alt="在这里插入图片描述" style="zoom:90%;" />
|
||||
</div>
|
||||
|
||||
#### 特征交叉模型
|
||||
|
||||
@@ -3,7 +3,7 @@
|
||||
大规模推荐系统需要实时对用户行为做出海量预测,为了保证这种实时性,大规模的推荐系统通常严重依赖于预先计算好的产品索引。产品索引的功能为:给定种子产品返回排序后的候选相关产品列表。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2relations.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2relations.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
|
||||
相关性产品索引主要包含两部分:替代性产品和互补性产品。例如图中的不同种类的衬衫构成了替代关系,而衬衫和风衣裤子等构成了互补关系。用户通常希望在完成购买行为之前尽可能看更多的衬衫,而用户购买过衬衫之后更希望看到与之搭配的单品而不是其他衬衫了。
|
||||
@@ -23,7 +23,7 @@ Swing 通过利用 User-Item-User 路径中所包含的信息,考虑 User-Item
|
||||
- 什么是内部子结构?
|
||||
以经典的啤酒尿布故事为例,张三同时购买了啤酒和尿布,这可能是一种巧合。但两个甚至多个顾客都同时购买了啤酒尿布,这就证明啤酒和尿布具有相关关系。这样共同购买啤酒和尿布的用户越多,啤酒和尿布的相关度就会越高。
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片example_of_swing.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片example_of_swing.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
图中的红色四边形就是一种Swing子结构,这种子结构可以作为给王五推荐尿布的依据。
|
||||
|
||||
@@ -256,7 +256,7 @@ Swing 通过利用 User-Item-User 路径中所包含的信息,考虑 User-Item
|
||||
由于类别直接的种类差异,每个类别的相关类数量存在差异,因此采用最大相对落点来作为划分阈值。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片max_drop.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片max_drop.png" alt="在这里插入图片描述" style="zoom:30%;" />
|
||||
</div>
|
||||
|
||||
例如图(a)中T恤的相关类选择前八个,图(b)中手机的相关类选择前三个。
|
||||
|
||||
@@ -9,13 +9,13 @@
|
||||
|
||||
举例来说,如果用户 1 喜欢物品 A ,而物品 A 和 C 非常相似,则可以将物品 C 推荐给用户1。ItemCF算法并不利用物品的内容属性计算物品之间的相似度, 主要通过分析用户的行为记录计算物品之间的相似度, 该算法认为, 物品 A 和物品 C 具有很大的相似度是因为喜欢物品 A 的用户极可能喜欢物品 C。
|
||||
|
||||
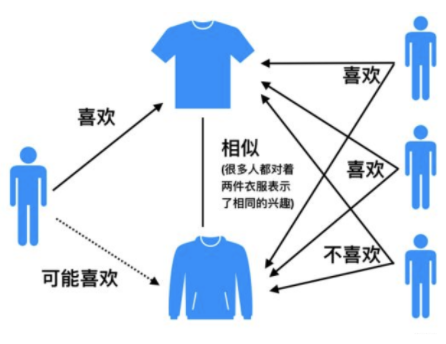
|
||||

|
||||
|
||||
## 计算过程
|
||||
|
||||
基于物品的协同过滤算法和基于用户的协同过滤算法很像, 所以我们这里直接还是拿上面 Alice 的那个例子来看。
|
||||
|
||||
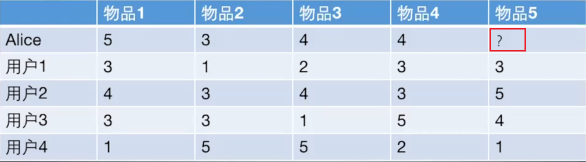
|
||||

|
||||
|
||||
如果想知道 Alice 对物品5打多少分, 基于物品的协同过滤算法会这么做:
|
||||
|
||||
@@ -41,7 +41,7 @@
|
||||
|
||||
2. 基于 `sklearn` 计算物品之间的皮尔逊相关系数:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/JavaJOyFti58um61zPsa.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/JavaJOyFti58um61zPsa.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
|
||||
3. 根据皮尔逊相关系数, 可以找到与物品5最相似的2个物品是 item1 和 item4, 下面基于上面的公式计算最终得分:
|
||||
|
||||
@@ -196,7 +196,7 @@ $$
|
||||
|
||||
比如下面这个例子:
|
||||
|
||||
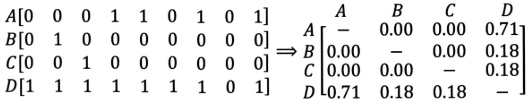
|
||||
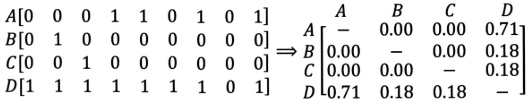
|
||||
|
||||
+ 左边矩阵中,$A, B, C, D$ 表示的是物品。
|
||||
+ 可以看出,$D $ 是一件热门物品,其与 $A、B、C$ 的相似度比较大。因此,推荐系统更可能将 $D$ 推荐给用过 $A、B、C$ 的用户。
|
||||
@@ -242,7 +242,7 @@ $$
|
||||
>
|
||||
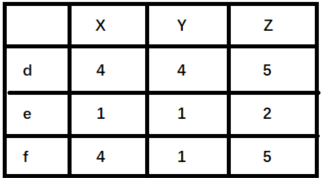
> 举例来说明,如下图(`X,Y,Z` 表示物品,`d,e,f`表示用户):
|
||||
>
|
||||
> 
|
||||
> 
|
||||
>
|
||||
> + 如果使用余弦相似度进行计算,用户 d 和 e 之间较为相似。但是实际上,用户 d 和 f 之间应该更加相似。只不过由于 d 倾向于打高分,e 倾向于打低分导致二者之间的余弦相似度更高。
|
||||
> + 这种情况下,可以考虑使用皮尔逊相关系数计算用户之间的相似性关系。
|
||||
|
||||
@@ -99,13 +99,13 @@
|
||||
+ 例如,我们要对用户 $A$ 进行物品推荐,可以先找到和他有相似兴趣的其他用户。
|
||||
+ 然后,将共同兴趣用户喜欢的,但用户 $A$ 未交互过的物品推荐给 $A$。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210629232540289.png" alt="image-20210629232540289" style="zoom: 80%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210629232540289.png" alt="image-20210629232540289" style="zoom: 80%;" />
|
||||
|
||||
## 计算过程
|
||||
|
||||
以下图为例,给用户推荐物品的过程可以形象化为一个猜测用户对物品进行打分的任务,表格里面是5个用户对于5件物品的一个打分情况,就可以理解为用户对物品的喜欢程度。
|
||||
|
||||

|
||||

|
||||
|
||||
UserCF算法的两个步骤:
|
||||
|
||||
@@ -164,7 +164,7 @@ UserCF算法的两个步骤:
|
||||
|
||||
+ 基于 sklearn 计算所有用户之间的皮尔逊相关系数。可以看出,与 Alice 相似度最高的用户为用户1和用户2。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/JavaWJkjP2fHH27Rajrj.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/JavaWJkjP2fHH27Rajrj.png!thumbnail" alt="图片" style="zoom:80%;" />
|
||||
|
||||
2. **根据相似度用户计算 Alice对物品5的最终得分**
|
||||
用户1对物品5的评分是3, 用户2对物品5的打分是5, 那么根据上面的计算公式, 可以计算出 Alice 对物品5的最终得分是
|
||||
|
||||
@@ -16,11 +16,11 @@
|
||||
- 当用户在查看某一个房源时,接下来的有两种方式继续搜索:
|
||||
- 返回搜索结果页,继续查看其他搜索结果。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049527431-0b09af70-bda0-4a30-8082-6aa69548213a.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049527431-0b09af70-bda0-4a30-8082-6aa69548213a.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 在当前房源的详情页下,「相似房源」板块(你可能还喜欢)所推荐的房源。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049385995-7a775df1-a36f-4795-9e79-8e577bcf2097.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653049385995-7a775df1-a36f-4795-9e79-8e577bcf2097.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- Airbnb 平台 99% 的房源预订来自于搜索排序和相似房源推荐。
|
||||
# Embedding 方法
|
||||
@@ -59,7 +59,7 @@ $$
|
||||
- Airbnb 将最终预定的房源,始终作为滑窗的上下文,即全局上下文。如下图:
|
||||
- 如图,对于当前滑动窗口的 central listing,实线箭头表示context listings,虚线(指向booked listing)表示 global context listing。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653053823336-0564b2da-c993-46aa-9b22-f5cbb784dae2.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653053823336-0564b2da-c993-46aa-9b22-f5cbb784dae2.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- booked listing 作为全局正样本,故优化的目标函数更新为:
|
||||
|
||||
@@ -103,12 +103,12 @@ $$
|
||||
- 理论上,同一区域的房源相似性应该更高,不同区域房源相似性更低。
|
||||
- Airbnb 利用 k-means 聚类,将加利福尼亚州的房源聚成100个集群,来验证类似位置的房源是否聚集在一起。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056809526-15401069-6fff-40d8-ac5e-35871d3f254a.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056809526-15401069-6fff-40d8-ac5e-35871d3f254a.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 评估不同类型、价格区间的房源之间的相似性。
|
||||
- 简而言之,我们希望类型相同、价格区间一致的房源它们之间的相似度更高。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056981037-18edee91-493a-4d5b-b066-57f0b200032d.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653056981037-18edee91-493a-4d5b-b066-57f0b200032d.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 评估房源的隐式特征
|
||||
- Airbnb 在训练房源(listing)的 Embedding时,并没有用到房源的图像信息。
|
||||
@@ -117,7 +117,7 @@ $$
|
||||
- 大致原理就是,利用训练好的 Embedding 进行 K 近邻相似度检索。
|
||||
- 如下,与查询房源在 Embedding 相似性高的其他房源,它们之间的外观风格也很相似。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653057336798-fd8451cb-84b6-40fb-8733-1e3d08a39793.png" alt="img" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653057336798-fd8451cb-84b6-40fb-8733-1e3d08a39793.png" alt="img" />
|
||||
|
||||
## User-type & Listing-type Embedding
|
||||
|
||||
@@ -169,7 +169,7 @@ Airbnb 除了挖掘 Listing 的短期兴趣特征表示外,还对 User 和 Lis
|
||||
- 所有的属性,都基于一定的规则进行了分桶(buckets)。例如21岁,被分桶到 20-30 岁的区间。
|
||||
- 对于首次预定的用户,他的属性为 buckets 的前5行,因为预定之前没有历史预定相关的信息。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653125260611-7d33731b-9167-4fcc-b83b-0a2407ea89ca.png" alt="img" style="zoom: 67%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653125260611-7d33731b-9167-4fcc-b83b-0a2407ea89ca.png" alt="img" style="zoom: 67%;" />
|
||||
|
||||
看到过前面那个简单的例子后,现在可以看一个原文的 Listing-type 的例子:
|
||||
|
||||
@@ -233,7 +233,7 @@ Type Embedding 的学习同样是基于 Skip-Gram 模型,但是有两点需要
|
||||
\end{aligned}
|
||||
$$
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653131985447-e033cb39-235b-4f46-9634-3b7faec284be.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653131985447-e033cb39-235b-4f46-9634-3b7faec284be.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
# 实验部分
|
||||
|
||||
@@ -276,13 +276,13 @@ Airbnb 的搜索排名的大致流程为:
|
||||
|
||||
- 表中的 Embedding Features 包含了8种类型,前6种类型的特征计算方式相同。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653139981920-a100085b-007b-4a9c-9edf-74297e9115ae.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653139981920-a100085b-007b-4a9c-9edf-74297e9115ae.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
**① 基于 Listing Embedding Features 的特征构建**
|
||||
|
||||
- Airbnb 保留了用户过去两周6种不同类型的历史行为,如下图:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653140202230-1f49e1dd-5c8c-4445-bd0b-9a17788a7b3f.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653140202230-1f49e1dd-5c8c-4445-bd0b-9a17788a7b3f.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
- 对于每个行为,还要将其按照 market (地域)进行划分。以 $ H_c $ 为例:
|
||||
|
||||
@@ -312,7 +312,7 @@ Airbnb 的搜索排名的大致流程为:
|
||||
|
||||
为了验证上述特征的构建是否有效,Airbnb 还做了特征重要性排序,如下表:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653142188111-1975bcc4-22a2-45cf-bff0-2783ecb00a0c.png" alt="img" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1653142188111-1975bcc4-22a2-45cf-bff0-2783ecb00a0c.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
**(3)模型**
|
||||
特征构建完成后,开始对模型进行训练。
|
||||
|
||||
@@ -56,7 +56,7 @@ one-hot向量的维度是词汇表的大小(如:500,000)
|
||||
如果我们可以使用某种方法为每个单词构建一个合适的dense vector,如下图,那么通过点积等数学计算就可以获得单词之间的某种联系
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1.png" />
|
||||
|
||||
|
||||
# Word2vec
|
||||
@@ -71,7 +71,7 @@ one-hot向量的维度是词汇表的大小(如:500,000)
|
||||
我们先引入上下文context的概念:当单词 w 出现在文本中时,其**上下文context**是出现在w附近的一组单词(在固定大小的窗口内),如下图
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2.png" />
|
||||
|
||||
|
||||
这些上下文单词context words决定了banking的意义
|
||||
@@ -97,13 +97,13 @@ Word2vec包含两个模型,**Skip-gram与CBOW**。下面,我们先讲**Skip-
|
||||
下图展示了以“into”为中心词,窗口大小为2的情况下它的上下文词。以及相对应的$P(o|c)$
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片3.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片3.png" />
|
||||
|
||||
|
||||
我们滑动窗口,再以banking为中心词
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片4.png"在这里插入图片描述" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片4.png"在这里插入图片描述" />
|
||||
|
||||
|
||||
那么,如果我们在整个语料库上不断地滑动窗口,我们可以得到所有位置的$P(o|c)$,我们希望在所有位置上**最大化单词o在单词c周围出现了这一事实**,由极大似然法,可得:
|
||||
@@ -115,13 +115,13 @@ $$
|
||||
此式还可以依图3写为:
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片5.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片5.png" />
|
||||
|
||||
|
||||
加log,加负号,缩放大小可得:
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片7.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片7.png" />
|
||||
|
||||
|
||||
上式即为**skip-gram的损失函数**,最小化损失函数,就可以得到合适的词向量
|
||||
@@ -141,7 +141,7 @@ $$
|
||||
又P(o|c)是一个概率,所以我们在整个语料库上使用**softmax**将点积的值映射到概率,如图6
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片6.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片6.png" />
|
||||
|
||||
|
||||
注:注意到上图,中心词词向量为$v_{c}$,而上下文词词向量为$u_{o}$。也就是说每个词会对应两个词向量,**在词w做中心词时,使用$v_{w}$作为词向量,而在它做上下文词时,使用$u_{w}$作为词向量**。这样做的原因是为了求导等操作时计算上的简便。当整个模型训练完成后,我们既可以使用$v_{w}$作为词w的词向量,也可以使用$u_{w}$作为词w的词向量,亦或是将二者平均。在下一部分的模型结构中,我们将更清楚地看到两个词向量究竟在模型的哪个位置。
|
||||
@@ -153,7 +153,7 @@ $$
|
||||
## Word2vec模型结构
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片8.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片8.png" />
|
||||
|
||||
|
||||
如图八所示,这是一个输入为1 X V维的one-hot向量(V为整个词汇表的长度,这个向量只有一个1值,其余为0值表示一个词),单隐藏层(**隐藏层的维度为N,这里是一个超参数,这个参数由我们定义,也就是词向量的维度**),输出为1 X V维的softmax层的模型。
|
||||
@@ -175,13 +175,13 @@ $W^{I}$为V X N的参数矩阵,$W^{O}$为N X V的参数矩阵。
|
||||
如上文所述,Skip-gram为给定中心词,预测周围的词,即求P(o|c),如下图所示:
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105817437.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105817437.png" />
|
||||
|
||||
|
||||
而CBOW为给定周围的词,预测中心词,即求P(c|o),如下图所示:
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片10.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片10.png" />
|
||||
|
||||
|
||||
|
||||
@@ -194,7 +194,7 @@ $W^{I}$为V X N的参数矩阵,$W^{O}$为N X V的参数矩阵。
|
||||
我们再看一眼,通过softmax得到的$P(o|c)$,如图:
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105958191.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220424105958191.png" />
|
||||
|
||||
|
||||
|
||||
@@ -209,7 +209,7 @@ $W^{I}$为V X N的参数矩阵,$W^{O}$为N X V的参数矩阵。
|
||||
我们首先给出负采样的损失函数:
|
||||
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片12.png" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片12.png" />
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -33,7 +33,7 @@
|
||||
在介绍三个模型之前,我们首先需要构建好item-item图。由于基于CF的方法仅考虑物品之间的共现,忽略了行为的序列信息(即序列中相邻的物品之间的语义信息),因此item-item图的构建方式如下图所示。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328133138263.png" style="zoom:80%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328133138263.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
首先根据用户的session行为序列构建网络结构,即序列中相邻两个item之间在存在边,并且是有向带权图。物品图边上的权重为所有用户行为序列中两个 item 共现的次数,最终构造出来简单的有向有权图。
|
||||
@@ -53,7 +53,7 @@
|
||||
对于图嵌入模型,第一步先进行随机游走得到物品序列;第二部通过skip-gram为图上节点生成embedding。那么对于随机游走的思想:如何利用随机游走在图中生成的序列?不同于DeepWalk中的随机游走,本文的采样策略使用的是带权游走策略,不同权重的游走到的概率不同,(其本质上就是node2vec),传统的node2vec方法可以直接支持有向带权图。因此在给定图的邻接矩阵M后(表示节点之间的边权重),随机游走中每次转移的概率为:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144516898.png" style="zoom:80%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144516898.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中$M_{ij}$为边$e_{ij}$上的权重,$N_{+}(v_i)$表示节点$v_i$所有邻居节点集合,并且随机游走的转移概率的对每个节点所有邻接边权重的归一化结果。在随即游走之后,每个item得到一个序列,如下图所示:
|
||||
@@ -65,19 +65,19 @@
|
||||
然后类似于word2vec,为每个item学习embedding,于是优化目标如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144931957.png" style="zoom:77%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328144931957.png" style="zoom:77%;"/>
|
||||
</div>
|
||||
|
||||
其中,w 为窗口大小。考虑独立性假设的话,上面的式子可以进一步化简:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145101109.png" style="zoom:77%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145101109.png" style="zoom:77%;"/>
|
||||
</div>
|
||||
|
||||
这样看起来就很直观了,在已知物品 i 时,最大化序列中(上下文)其他物品 j 的条件概率。为了近似计算,采样了Negative sampling,上面的优化目标可以化简得到如下式子:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145318718.png" style="zoom:80%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328145318718.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中$N(v_i)'$表示负样本集合,负采样个数越多,结果越好。
|
||||
@@ -101,7 +101,7 @@
|
||||
针对上述问题,作者提出了weight pooling方法来聚合不同类型的 side information。具体地,EGES 与 GES 的区别在聚合不同类型 side information计算不同的权重,根据权重聚合 side information 得到商品的embedding,如下图所示:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328154950289.png" style="zoom:80%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328154950289.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中 $a_i$ 表示每个side information 用于计算权重的参数向量,最终通过下面的公式得到商品的embedding:
|
||||
@@ -117,13 +117,13 @@
|
||||
以上就是这三个模型主要的区别,下面是EGES的伪代码。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155406291.png" style="zoom:80%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155406291.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
其中**WeightedSkipGram**函数为带权重的SkipGram算法。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155533704.png" style="zoom:80%;"/>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220328155533704.png" style="zoom:80%;"/>
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
@@ -9,7 +9,7 @@
|
||||
**树结构**
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420213149324.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420213149324.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
</div>
|
||||
|
||||
如上图,树中的每一个叶子节点对应一个商品item,非叶子结点表示的是item的集合**(这里的树不限于二叉树)**。这种层次化结构体现了粒度从粗到细的item架构。
|
||||
@@ -17,7 +17,7 @@
|
||||
**整体结构**
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420200433442.png" alt="image-20210308142624189" style="zoom: 70%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420200433442.png" alt="image-20210308142624189" style="zoom: 70%;" />
|
||||
</div>
|
||||
|
||||
# 算法详解
|
||||
@@ -34,7 +34,7 @@
|
||||
2. 对兴趣进行建模
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420214040264.png" alt="image-20210308142624189" style="zoom: 50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420214040264.png" alt="image-20210308142624189" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
如上图,用户对叶子层item6感兴趣,可以认为它的兴趣是1,同层别的候选节点的兴趣为0,顺着着绿色线路上去的节点都标记为1,路线上的同层别的候选节点都标记为0。这样的操作就可以根据1和0构建用于每一层的正负样本。
|
||||
@@ -44,7 +44,7 @@
|
||||
3. 训练过程
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420220831318.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220420220831318.png" alt="image-20210308142624189" style="zoom: 15%;" />
|
||||
</div>
|
||||
|
||||
整体联合训练的方式如下:
|
||||
|
||||
@@ -6,7 +6,7 @@ Wide&Deep模型的提出不仅综合了“记忆能力”和“泛化能力”
|
||||
|
||||
这个模型的结构是这个样子的:
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片dcn.png" style="zoom:67%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片dcn.png" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
这个模型的结构也是比较简洁的, 从下到上依次为:Embedding和Stacking层, Cross网络层与Deep网络层并列, 以及最后的输出层。下面也是一一为大家剖析。
|
||||
@@ -34,7 +34,7 @@ $$
|
||||
$$
|
||||
可以看到, 交叉层的二阶部分非常类似PNN提到的外积操作, 在此基础上增加了外积操作的权重向量$w_l$, 以及原输入向量$x_l$和偏置向量$b_l$。 交叉层的可视化如下:
|
||||
|
||||
<div align=center> <img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片cross.png" style="zoom:67%;" />
|
||||
<div align=center> <img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片cross.png" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
可以看到, 每一层增加了一个$n$维的权重向量$w_l$(n表示输入向量维度), 并且在每一层均保留了输入向量, 因此输入和输出之间的变化不会特别明显。关于这一层, 原论文里面有个具体的证明推导Cross Network为啥有效, 不过比较复杂,这里我拿一个式子简单的解释下上面这个公式的伟大之处:
|
||||
@@ -139,7 +139,7 @@ def DCN(linear_feature_columns, dnn_feature_columns):
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center> <img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片DCN.png" alt="image-20210308143101261" style="zoom: 50%;" />
|
||||
<div align=center> <img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片DCN.png" alt="image-20210308143101261" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
|
||||
@@ -10,13 +10,13 @@ PNN模型其实是对IPNN和OPNN的总称,两者分别对应的是不同的Pro
|
||||
|
||||
PNN模型的整体架构如下图所示:
|
||||
|
||||
<div align=center> <img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210308142624189.png" alt="image-20210308142624189" style="zoom: 50%;" /> </div>
|
||||
<div align=center> <img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210308142624189.png" alt="image-20210308142624189" style="zoom: 50%;" /> </div>
|
||||
|
||||
一共分为五层,其中除了Product Layer别的layer都是比较常规的处理方法,均可以从前面的章节进一步了解。模型中最重要的部分就是通过Product层对embedding特征进行交叉组合,也就是上图中红框所显示的部分。
|
||||
|
||||
Product层主要有线性部分和非线性部分组成,分别用$l_z$和$l_p$来表示,
|
||||
|
||||
<div align=center> <img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210308143101261.png" alt="image-20210308143101261" style="zoom: 50%;" />
|
||||
<div align=center> <img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210308143101261.png" alt="image-20210308143101261" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
1. 线性模块,一阶特征(未经过显示特征交叉处理),对应论文中的$l_z=(l_z^1,l_z^2, ..., l_z^{D_1})$
|
||||
@@ -230,7 +230,7 @@ class ProductLayer(Layer):
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center> <img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片PNN.png" alt="image-20210308143101261" style="zoom: 50%;" />
|
||||
<div align=center> <img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片PNN.png" alt="image-20210308143101261" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
## 思考题
|
||||
|
||||
@@ -9,7 +9,7 @@ $$
|
||||
|
||||
## AFM模型原理
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210131092744905.png" alt="image-20210131092744905" style="zoom: 50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210131092744905.png" alt="image-20210131092744905" style="zoom: 50%;" />
|
||||
</div>
|
||||
上图表示的就是AFM交叉特征部分的模型结构(非交叉部分与FM是一样的,图中并没有给出)。AFM最核心的两个点分别是Pair-wise Interaction Layer和Attention-based Pooling。前者将输入的非零特征的隐向量两两计算element-wise product(哈达玛积,两个向量对应元素相乘,得到的还是一个向量),假如输入的特征中的非零向量的数量为m,那么经过Pair-wise Interaction Layer之后输出的就是$\frac{m(m-1)}{2}$个向量,再将前面得到的交叉特征向量组输入到Attention-based Pooling,该pooling层会先计算出每个特征组合的自适应权重(通过Attention Net进行计算),通过加权求和的方式将向量组压缩成一个向量,由于最终需要输出的是一个数值,所以还需要将前一步得到的向量通过另外一个向量将其映射成一个值,得到最终的基于注意力加权的二阶交叉特征的输出。(对于这部分如果不是很清楚,可以先看下面对两个核心层的介绍)
|
||||
|
||||
@@ -109,13 +109,13 @@ def AFM(linear_feature_columns, dnn_feature_columns):
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210307200304199.png" alt="image-20210307200304199" style="zoom:67%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210307200304199.png" alt="image-20210307200304199" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片AFM.png" alt="image-20210307200304199" style="zoom:67%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片AFM.png" alt="image-20210307200304199" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
|
||||
@@ -7,17 +7,17 @@
|
||||
- **DNN局限**
|
||||
当我们使用DNN网络解决推荐问题的时候存在网络参数过于庞大的问题,这是因为在进行特征处理的时候我们需要使用one-hot编码来处理离散特征,这会导致输入的维度猛增。这里借用AI大会的一张图片:
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-15.png" style="zoom: 50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-15.png" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
这样庞大的参数量也是不实际的。为了解决DNN参数量过大的局限性,可以采用非常经典的Field思想,将OneHot特征转换为Dense Vector
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-40.png" style="zoom: 50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-40.png" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
此时通过增加全连接层就可以实现高阶的特征组合,如下图所示:
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-59.png" style="zoom:67%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-59.png" style="zoom:67%;" />
|
||||
</div>
|
||||
但是仍然缺少低阶的特征组合,于是增加FM来表示低阶的特征组合。
|
||||
|
||||
@@ -25,7 +25,7 @@
|
||||
结合FM和DNN其实有两种方式,可以并行结合也可以串行结合。这两种方式各有几种代表模型。在DeepFM之前有FNN,虽然在影响力上可能并不如DeepFM,但是了解FNN的思想对我们理解DeepFM的特点和优点是很有帮助的。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-12-19.png" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-12-19.png" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
FNN是使用预训练好的FM模块,得到隐向量,然后把隐向量作为DNN的输入,但是经过实验进一步发现,在Embedding layer和hidden layer1之间增加一个product层(如上图所示)可以提高模型的表现,所以提出了PNN,使用product layer替换FM预训练层。
|
||||
@@ -33,7 +33,7 @@ FNN是使用预训练好的FM模块,得到隐向量,然后把隐向量作为
|
||||
- **Wide&Deep**
|
||||
FNN和PNN模型仍然有一个比较明显的尚未解决的缺点:对于低阶组合特征学习到的比较少,这一点主要是由于FM和DNN的串行方式导致的,也就是虽然FM学到了低阶特征组合,但是DNN的全连接结构导致低阶特征并不能在DNN的输出端较好的表现。看来我们已经找到问题了,将串行方式改进为并行方式能比较好的解决这个问题。于是Google提出了Wide&Deep模型(将前几章),但是如果深入探究Wide&Deep的构成方式,虽然将整个模型的结构调整为了并行结构,在实际的使用中Wide Module中的部分需要较为精巧的特征工程,换句话说人工处理对于模型的效果具有比较大的影响(这一点可以在Wide&Deep模型部分得到验证)。
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/Javaimage-20200910214310877.png" alt="image-20200910214310877" style="zoom:65%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/Javaimage-20200910214310877.png" alt="image-20200910214310877" style="zoom:65%;" />
|
||||
</div>
|
||||
如上图所示,该模型仍然存在问题:**在output Units阶段直接将低阶和高阶特征进行组合,很容易让模型最终偏向学习到低阶或者高阶的特征,而不能做到很好的结合。**
|
||||
|
||||
@@ -41,7 +41,7 @@ FNN和PNN模型仍然有一个比较明显的尚未解决的缺点:对于低
|
||||
|
||||
## 模型的结构与原理
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225180556628.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225180556628.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
前面的Field和Embedding处理是和前面的方法是相同的,如上图中的绿色部分;DeepFM将Wide部分替换为了FM layer如上图中的蓝色部分
|
||||
@@ -58,12 +58,12 @@ $$
|
||||
\hat{y}_{FM}(x) = w_0+\sum_{i=1}^N w_ix_i + \sum_{i=1}^N \sum_{j=i+1}^N v_i^T v_j x_ix_j
|
||||
$$
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225181340313.png" alt="image-20210225181340313" style="zoom: 67%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225181340313.png" alt="image-20210225181340313" style="zoom: 67%;" />
|
||||
</div>
|
||||
### Deep
|
||||
Deep架构图
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225181010107.png" alt="image-20210225181010107" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225181010107.png" alt="image-20210225181010107" style="zoom:50%;" />
|
||||
</div>
|
||||
Deep Module是为了学习高阶的特征组合,在上图中使用用全连接的方式将Dense Embedding输入到Hidden Layer,这里面Dense Embeddings就是为了解决DNN中的参数爆炸问题,这也是推荐模型中常用的处理方法。
|
||||
|
||||
@@ -130,13 +130,13 @@ def DeepFM(linear_feature_columns, dnn_feature_columns):
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210228161135777.png" alt="image-20210228161135777" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210228161135777.png" alt="image-20210228161135777" />
|
||||
</div>
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片DeepFM.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片DeepFM.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
@@ -144,7 +144,7 @@ def DeepFM(linear_feature_columns, dnn_feature_columns):
|
||||
2. 对于下图所示,根据你的理解Sparse Feature中的不同颜色节点分别表示什么意思
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225180556628.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225180556628.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
@@ -10,11 +10,11 @@ $$
|
||||
我们对比FM, 就会发现变化的是第三项,前两项还是原来的, 因为我们说FM的一个问题,就是只能到二阶交叉, 且是线性模型, 这是他本身的一个局限性, 而如果想突破这个局限性, 就需要从他的公式本身下点功夫, 于是乎,作者在这里改进的思路就是**用一个表达能力更强的函数来替代原FM中二阶隐向量内积的部分**。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1.png" style="zoom:70%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片1.png" style="zoom:70%;" />
|
||||
</div>
|
||||
而这个表达能力更强的函数呢, 我们很容易就可以想到神经网络来充当,因为神经网络理论上可以拟合任何复杂能力的函数, 所以作者真的就把这个$f(x)$换成了一个神经网络,当然不是一个简单的DNN, 而是依然底层考虑了交叉,然后高层使用的DNN网络, 这个也就是我们最终的NFM网络了:
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2.png" style="zoom:80%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片2.png" style="zoom:80%;" />
|
||||
</div>
|
||||
这个结构,如果前面看过了PNN的伙伴会发现,这个结构和PNN非常像,只不过那里是一个product_layer, 而这里换成了Bi-Interaction Pooling了, 这个也是NFM的核心结构了。这里注意, 这个结构中,忽略了一阶部分,只可视化出来了$f(x)$, 我们还是下面从底层一点点的对这个网络进行剖析。
|
||||
|
||||
@@ -130,11 +130,11 @@ def NFM(linear_feature_columns, dnn_feature_columns):
|
||||
|
||||
有了上面的解释,这个模型的宏观层面相信就很容易理解了。关于这每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片NFM_aaaa.png" alt="NFM_aaaa" style="zoom: 50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片NFM_aaaa.png" alt="NFM_aaaa" style="zoom: 50%;" />
|
||||
</div>
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片nfm.png" alt="NFM_aaaa" style="zoom: 50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片nfm.png" alt="NFM_aaaa" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
## 思考题
|
||||
|
||||
@@ -12,7 +12,7 @@ Wide&Deep模型就是围绕记忆性和泛化性进行讨论的,模型能够
|
||||
|
||||
## 模型结构及原理
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/Javaimage-20200910214310877.png" alt="image-20200910214310877" style="zoom:65%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/Javaimage-20200910214310877.png" alt="image-20200910214310877" style="zoom:65%;" />
|
||||
</div>
|
||||
|
||||
其实wide&deep模型本身的结构是非常简单的,对于有点机器学习基础和深度学习基础的人来说都非常的容易看懂,但是如何根据自己的场景去选择那些特征放在Wide部分,哪些特征放在Deep部分就需要理解这篇论文提出者当时对于设计该模型不同结构时的意图了,所以这也是用好这个模型的一个前提。
|
||||
@@ -88,13 +88,13 @@ def WideNDeep(linear_feature_columns, dnn_feature_columns):
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210228160557072.png" alt="image-20210228160557072" style="zoom:67%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210228160557072.png" alt="image-20210228160557072" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片Wide&Deep.png" alt="image-20210228160557072" style="zoom:67%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片Wide&Deep.png" alt="image-20210228160557072" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
|
||||
@@ -6,7 +6,7 @@ DIN模型考虑了用户兴趣,并且强调用户兴趣是多样的,该模
|
||||
|
||||
## DIEN模型原理
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218155901144.png" alt="image-20210218155901144" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218155901144.png" alt="image-20210218155901144" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
模型的输入可以分成两大部分,一部分是用户的行为序列(这部分会通过兴趣提取层及兴趣演化层转换成与用户当前兴趣相关的embedding),另一部分就是除了用户行为以外的其他所有特征,如Target id, Coontext Feature, UserProfile Feature,这些特征都转化成embedding的类型然后concat在一起(形成一个大的embedding)作为非行为相关的特征(这里可能也会存在一些非id类特征,应该可以直接进行concat)。最后DNN输入的部分由行为序列embedding和非行为特征embedding(多个特征concat到一起之后形成的一个大的向量)组成,将两者concat之后输入到DNN中。
|
||||
@@ -23,13 +23,13 @@ DIN模型考虑了用户兴趣,并且强调用户兴趣是多样的,该模
|
||||
首先需要明确的就是辅助损失是计算哪两个量的损失。计算的是用户每个时刻的兴趣表示(GRU每个时刻输出的隐藏状态形成的序列)与用户当前时刻实际点击的物品表示(输入的embedding序列)之间的损失,相当于是行为序列中的第t+1个物品与用户第t时刻的兴趣表示之间的损失**(为什么这里用户第t时刻的兴趣与第t+1时刻的真实点击做损失呢?我的理解是,只有知道了用户第t+1真实点击的商品,才能更好的确定用户第t时刻的兴趣)。**
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218163742638.png" alt="image-20210218163742638" style="zoom:50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218163742638.png" alt="image-20210218163742638" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
当然,如果只计算用户点击物品与其点击前一次的兴趣之间的损失,只能认为是正样本之间的损失,那么用户第t时刻的兴趣其实还有很多其他的未点击的商品,这些未点击的商品就是负样本,负样本一般通过从用户点击序列中采样得到,这样一来辅助损失中就包含了用户某个时刻下的兴趣及与该时刻兴趣相关的正负物品。所以最终的损失函数表示如下。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218162447125.png" alt="image-20210218162447125" style="zoom: 25%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218162447125.png" alt="image-20210218162447125" style="zoom: 25%;" />
|
||||
</div>
|
||||
其中$h_t^i$表示的是用户$i$第$t$时刻的隐藏状态,可以表示用户第$t$时刻的兴趣向量,$e_b^i,\hat{e_b^i}$分别表示的是正负样本,$e_b^i[t+1]$表示的是用户$i$第$t+1$时刻点击的物品向量。
|
||||
|
||||
@@ -56,7 +56,7 @@ $$
|
||||
由于用户的兴趣是多样的,但是用户的每一种兴趣都有自己的发展过程,即使兴趣发生漂移我们可以只考虑用户与target item(广告或者商品)相关的兴趣演化过程,这样就不用考虑用户多样化的兴趣的问题了,而如何只获取与target item相关的信息,作者使用了与DIN模型中提取与target item相同的方法,来计算用户历史兴趣与target item之间的相似度,即这里也使用了DIN中介绍的局部激活单元(就是下图中的Attention模块)。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218180755462.png" alt="image-20210218180755462" style="zoom:70%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218180755462.png" alt="image-20210218180755462" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
当得到了用户历史兴趣序列及兴趣序列与target item之间的相关性(注意力分数)之后,就需要再次对注意力序列进行建模得到用户注意力的演化过程,进一步表示用户最终的兴趣向量。此时的序列数据等同于有了一个序列及序列中每个向量的注意力权重,下面就是考虑如何使用这个注意力权重来一起优化序列建模的结果了。作者提出了三种注意力结合的GRU模型快:
|
||||
|
||||
@@ -158,13 +158,13 @@ def DIN(feature_columns, behavior_feature_list, behavior_seq_feature_list):
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片DIN_aaaa.png" alt="DIN_aaaa" style="zoom: 70%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片DIN_aaaa.png" alt="DIN_aaaa" style="zoom: 70%;" />
|
||||
</div>
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片din.png" alt="DIN_aaaa" style="zoom: 50%;" />
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片din.png" alt="DIN_aaaa" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
|
||||
Reference in New Issue
Block a user