diff --git a/.vitepress/config.ts b/.vitepress/config.js
similarity index 100%
rename from .vitepress/config.ts
rename to .vitepress/config.js
diff --git a/.vitepress/theme/index.ts b/.vitepress/theme/index.js
similarity index 100%
rename from .vitepress/theme/index.ts
rename to .vitepress/theme/index.js
diff --git a/1.杭电生存指南/1.2竞赛指北.md b/1.杭电生存指南/1.2竞赛指北.md
index b98dbbc..08b9534 100644
--- a/1.杭电生存指南/1.2竞赛指北.md
+++ b/1.杭电生存指南/1.2竞赛指北.md
@@ -77,6 +77,6 @@
由于笔者是创意组的,对其他组别不是很了解,就来介绍一下我们组别的情况。我们组别全称是智能车百度创意组,是由百度与鲸鱼机器人赞助的一个比较新的组别(目前是第三年,不过也开始卷起来了),该组别与传统组别的一个比较大的不同是对于硬件方面的要求并不高(但也是需要了解的,像 arduino,stm32 这些稍微都得玩的起来),侧重会偏向软件算法方向。百度创意组总体分为两个阶段,线上赛和线下赛,线上赛的任务有点像是 kaggle 打榜,不过是百度官方命题,并且在飞浆平台上进行测试的,本质考验的就是你对神经网络的理解和调参(炼丹),如下图所示,如果有兴趣可以玩玩常规赛,目前也是开放了的。而线下赛则是通过你搭的车模去完成官方设置的任务,完成相应任务会有相应分值,最终会有一个总分值,排名按照分值来排,分值越高,排名越高。如果同分的话就是按照完成任务的总时间来排序,时间越短,排名越高。总的来说,是一个能够比较好的把目前 AI 与硬件结合起来的一个组别(小车自动驾驶,目标检测算法,传感器通信协议)。欢迎大家多多了解,参与到我们这里来!!!
-
+
diff --git a/1.杭电生存指南/1.4小心项目陷阱.md b/1.杭电生存指南/1.4小心项目陷阱.md
index 1549385..a2ff123 100644
--- a/1.杭电生存指南/1.4小心项目陷阱.md
+++ b/1.杭电生存指南/1.4小心项目陷阱.md
@@ -1,6 +1,6 @@
# 小心项目陷阱
-
+
# 辨别项目质量
@@ -54,7 +54,7 @@
一般情况下,要么你技术特别强,要么.......
-
+
所以说,还是那句话,小心甄别。
diff --git a/1.杭电生存指南/1.7杭电出国自救指南.md b/1.杭电生存指南/1.7杭电出国自救指南.md
index bdb732c..8be69dc 100644
--- a/1.杭电生存指南/1.7杭电出国自救指南.md
+++ b/1.杭电生存指南/1.7杭电出国自救指南.md
@@ -6,13 +6,13 @@ author:晓宇
# 序言:一组数据看出国
-
+
点开图片可以看到左边是西交利物浦的出国数据,中间是杭电的数据,右边是成都电子科技大学的数据,可以看出西交利物浦每年去名校的数量大概是杭电一年的 20-40 倍,成电是杭电的一年的 10 倍左右,杭电出国数据实际上只有寥寥几个名校,剩下的则是一些英国院校。
这其中原因除了杭电高性价比的就业环境,双非院校选择出国深造的人数较低,我认为比较还有一点则是信息差。优秀的大学都有他们自己的飞跃手册,其中会介绍每个国家的优劣,以及申请的一些注意事项,详见下图。
-
+
优越的校友资源和前人留下的数据和方案,加下信息差的叠加,就像符合幂律分布的无标度网络一样,只会让我们的差距越来越大,在感叹其他学校飞跃手册的优越性的同时也发现了一些不可参考性,因为在其中也存在着很多问题,在这些学校中,可能名校读博就是老师写个推荐信就有了面试的机会,可能去港大/G5 就是大学四年均分 80 分的难度。有很多资料在不同的角度,我们很难参考,所以我不经会想问?那我们呢,我们考多少多少分能够去什么学校,我们想要直博应该怎么准备,所以我打算完成这份出国留学的手册,能够为学弟学妹们铺路,同样希望后面也能够有学弟学妹做完善和补充。
diff --git a/2.高效学习/2.1.2浮躁的心理状态.md b/2.高效学习/2.1.2浮躁的心理状态.md
index 8b8c7ee..d6a1fa6 100644
--- a/2.高效学习/2.1.2浮躁的心理状态.md
+++ b/2.高效学习/2.1.2浮躁的心理状态.md
@@ -26,4 +26,4 @@
如果实在不行,来找 ZZM 聊聊吧。
-
+
diff --git a/2.高效学习/2.1.3错误的提问姿态.md b/2.高效学习/2.1.3错误的提问姿态.md
index 8d760e9..5e772dd 100644
--- a/2.高效学习/2.1.3错误的提问姿态.md
+++ b/2.高效学习/2.1.3错误的提问姿态.md
@@ -28,7 +28,7 @@
问题还是没有解决,现在我该怎么做?
-
+
欢迎大家阅读
diff --git a/2.高效学习/2.1.4书籍的盲目崇拜.md b/2.高效学习/2.1.4书籍的盲目崇拜.md
index 1e9ba62..4027e6d 100644
--- a/2.高效学习/2.1.4书籍的盲目崇拜.md
+++ b/2.高效学习/2.1.4书籍的盲目崇拜.md
@@ -6,7 +6,7 @@
"我们要学 C 语言,我买一本大黑书看看!"
-
+
诚然,上面的各种书写的非常好,但是我们需要思考的是,阅读这些真的能达到我们想要的目标吗???
diff --git a/2.高效学习/2.1.5错误的学习配比.md b/2.高效学习/2.1.5错误的学习配比.md
index 09e1762..806812d 100644
--- a/2.高效学习/2.1.5错误的学习配比.md
+++ b/2.高效学习/2.1.5错误的学习配比.md
@@ -18,4 +18,4 @@
在你完成这份讲义的时候,希望你可以有选择的阅览一部分,然后带着问题去看某些课,效率也会高很多。
-
+
diff --git a/2.高效学习/2.1高效的前提:摆脱高中思维.md b/2.高效学习/2.1高效的前提:摆脱高中思维.md
index 92c651f..ad381b2 100644
--- a/2.高效学习/2.1高效的前提:摆脱高中思维.md
+++ b/2.高效学习/2.1高效的前提:摆脱高中思维.md
@@ -14,7 +14,7 @@
并且,全部依赖他人给你指明方向的人生已经结束了!
-
+
你无法依赖大学里的老师还是家里的父母来为你指明所谓的方向,你的人生只属于你自己,你的道路也只能由你自己来思考。
diff --git a/2.高效学习/2.2优雅的使用工具.md b/2.高效学习/2.2优雅的使用工具.md
index 92a320e..3fc51fe 100644
--- a/2.高效学习/2.2优雅的使用工具.md
+++ b/2.高效学习/2.2优雅的使用工具.md
@@ -10,7 +10,7 @@
- [MarkText](https://github.com/marktext/marktext) 免费的 平替 Typora (?)感觉不太好用 😤
- [思源笔记](https://b3log.org/siyuan/) 一个国产开源的笔记/知识库软件,优势是 本地化、双链、Markdown 语法,与 Obsidian 定位相似,但 Geek 成分和自定义空间相对更高
-
+
- [IDM 及百度云脚本](https://greasyfork.org/zh-CN/scripts/436446-%E7%BD%91%E7%9B%98%E7%9B%B4%E9%93%BE%E4%B8%8B%E8%BD%BD%E5%8A%A9%E6%89%8B) 帮助你将百度云提速(暂不可用)
- [知云文献翻译](https://www.zhiyunwenxian.cn/):可以有效帮助你翻译论文和文章甚至英文书籍
diff --git a/2.高效学习/2.6以理工科的方式阅读英语.md b/2.高效学习/2.6以理工科的方式阅读英语.md
index 4cec91e..a99f062 100644
--- a/2.高效学习/2.6以理工科的方式阅读英语.md
+++ b/2.高效学习/2.6以理工科的方式阅读英语.md
@@ -2,7 +2,7 @@
作为一名理工科学生,也许英语并不是你的强势,但往往学习又难以避开英语。
-
+
下面提供一些英语阅读的方法:
diff --git a/2.高效学习/2.高效学习.md b/2.高效学习/2.高效学习.md
index 46984d6..0005ea1 100644
--- a/2.高效学习/2.高效学习.md
+++ b/2.高效学习/2.高效学习.md
@@ -41,7 +41,7 @@ Search the "friendly" website
# 如果真的不知道怎么解决怎么办?
-
+
来细看看本章节的内容吧!
diff --git a/3.编程思维体系构建/3.2.2手把手教你学算法——如何使用OJ(Online Judge).md b/3.编程思维体系构建/3.2.2手把手教你学算法——如何使用OJ(Online Judge).md
index fabaa61..6758252 100644
--- a/3.编程思维体系构建/3.2.2手把手教你学算法——如何使用OJ(Online Judge).md
+++ b/3.编程思维体系构建/3.2.2手把手教你学算法——如何使用OJ(Online Judge).md
@@ -6,7 +6,7 @@
进入 [https://www.luogu.com.cn/](https://www.luogu.com.cn/)
-
+
## 社交模块
@@ -16,11 +16,11 @@
点开题库,我们看见以下界面
-
+
在上方我们可以筛选我们想要的题目,接下来我们点开 P1000 为例
-
+
右侧三个模块为折叠状态,下面介绍他们的作用
@@ -34,7 +34,7 @@
点击提交答案
-
+
左侧可以选择语言类型,C++ 用户建议选择 C++14。
@@ -44,7 +44,7 @@ O2 优化是一种优化(废话)假如您的代码复杂度正确但 TLE,
怎么知道自己代码的问题出在哪里呢?记录模块是帮助你的好工具。
-
+
AC:通过该数据点
@@ -64,7 +64,7 @@ OLE:输出超限 放心你见不到的
点开侧栏题单
-
+
建议新手从官方精选题单开始,由浅入深,由简到难。等到对算法形成概念,针对漏洞补习时可以尝试用户分享题单(到那个阶段已经有很多手段去找题了,刘教练的题单就够你做了)
@@ -76,7 +76,7 @@ OLE:输出超限 放心你见不到的
进入 [https://codeforces.com/?locale=en](https://codeforces.com/?locale=en)
-
+
比起 Luogu,这样的 UI 设计离 CN 互联网已经很远了(然而比起更硬核的一些做题网站,CF 的 UI 真是越看越顺眼)
@@ -100,7 +100,7 @@ OLE:输出超限 放心你见不到的
进入比赛页面
-
+
上方为将举办比赛,显示开始时间(UTC+8 也就是我们时区的时间)和持续时间大多都开始的比较晚,例如笔者就没有这么晚学习的习惯,所以一般赛后写题。比赛分为以下几种类型(例如写在括号里的 Div.2)
@@ -114,14 +114,14 @@ Div.1、Div.2、Div.3、Div.4 数字越小难度越大。
## VP
-
+
这是一场笔者之前赛后补过的 Div.2,画面右下角分别为赛后公告和题解,右侧便是开启 VP 的按钮。
-
+
VP模拟赛时的好处就是在虚拟参赛中获得真实比赛才能积累的经验,比如这里笔者发现通过前三题后,我应该先去看看 F 题,因为做出来的人更多,我有更大的可能性做出来,ACM 中题目并不是 100% 按难度排序。
-
+
进入 VP 后,我们可以发现比起正常赛后补题有了明显不同。
@@ -135,25 +135,25 @@ Div.1、Div.2、Div.3、Div.4 数字越小难度越大。
让我们点开 A 题,来看看如何提交答案
-
+
可以看见,右侧有一个 submit,与 luogu 不同的是,你需要上传源代码文件(如 cpp)然后选择 G++17 为语言,提交。
当然,你也可以点开上侧的 submit code
-
+
选择题目、语言,填写代码后提交,就和 Luogu 的方式一样了。
同样,在上侧 MY SUBMISSIONS 处可以查看已提交的代码和状态
-
+
## PROBLEMSET
同样,CF 也有题库
-
+
如果你只想做某道题而不是某场比赛,这里也许更适合你。
diff --git a/3.编程思维体系构建/3.3如何选择编程语言.md b/3.编程思维体系构建/3.3如何选择编程语言.md
index 7cf136d..c797b5a 100644
--- a/3.编程思维体系构建/3.3如何选择编程语言.md
+++ b/3.编程思维体系构建/3.3如何选择编程语言.md
@@ -10,7 +10,7 @@
首先附上一张经典老图
-
+
## C 语言/C++
@@ -56,6 +56,6 @@ Python 在图里是电锯,适合干比较“狂野”的任务,也是深度
频繁应用于Web 开发,安卓应用等等。
-
+
当然还有各种形形色色的编程语言等着同学们去探索。
diff --git a/3.编程思维体系构建/3.4.1FAQ:常见问题.md b/3.编程思维体系构建/3.4.1FAQ:常见问题.md
index c822ee0..9327da4 100644
--- a/3.编程思维体系构建/3.4.1FAQ:常见问题.md
+++ b/3.编程思维体系构建/3.4.1FAQ:常见问题.md
@@ -8,7 +8,7 @@
尝试借鉴他人的代码也未尝不可,但是要保证每一行都看懂哦
-
+
# 我感觉讲义写的不够细
@@ -67,6 +67,6 @@ NJU-ICS-PA 南京大学计算机系统基础
# 坚持了好久还是搞不定, 我想放弃了
-
+
也许是你坚持的姿势不对,来和 ZZM 聊聊吧
diff --git a/3.编程思维体系构建/3.4.2用什么写 C 语言.md b/3.编程思维体系构建/3.4.2用什么写 C 语言.md
index ad5d2b0..6232ff8 100644
--- a/3.编程思维体系构建/3.4.2用什么写 C 语言.md
+++ b/3.编程思维体系构建/3.4.2用什么写 C 语言.md
@@ -16,7 +16,7 @@ Visual Studio (以下简称 VS )是 Windows 下最完美的 C/C++ 等语言
选择社区版
-
+
社区版和专业版等的区别:社区版免费,功能上几乎无差别
@@ -24,7 +24,7 @@ Visual Studio (以下简称 VS )是 Windows 下最完美的 C/C++ 等语言
选择 C++ 桌面开发,其他不用选,有需要了再说。另外,Python 开发不好使,不要像我一样选 Python 开发。
-
+
安装完成后,一般来说 VS 不会自动创建桌面快捷方式,你需要到开始菜单中启动 VS。
@@ -38,19 +38,19 @@ VS 是项目制,你需要创建一个项目才能开始编写代码并运行
打开 VS,会打开如下界面(我使用深色主题),在此处单击“创建新项目”
-
+
在创建新项目页面中选择项目模板为控制台应用(空项目亦可,后续手动添加.c 源文件),并单击下一步
-
+
为你的项目起一个名字,以及选择项目的位置,一般默认即可,如果你有强迫症,C 盘一定不能放个人数据,请自行修改。完成后单击“创建”
-
+
自此就创建了一个项目了,你将会到达如下界面:
-
+
其中,左侧(如果在一开始没有选择 C++ 开发环境的话可能在右侧)为资源管理器,列出了本项目所用到的所有文件,包括代码(外部依赖项、源文件、头文件),以及将来开发图形化界面所需的资源文件;最中间占据面积最多的是代码编辑器窗口,你以后将会在这里编写你的 C 语言代码。最下面是输出窗口,源代码进行编译时,会在此处给出编译进度以及可能的代码中的错误。
@@ -66,7 +66,7 @@ C 语言是编译型语言,因此说“运行”代码其实并不是十分合
当你编写完自己的代码后,即可单击“本地 Windows 调试器”(或者使用快捷键 F5)进行“运行”。
-
+
你可能会发现在“本地 Windows 调试器”右侧还有一个绿色三角形,并且单击这个也可以“运行”,这两个的区别在于“本地 Windows 调试器”是调试运行,右侧那个是不调试直接运行。
@@ -74,17 +74,17 @@ C 语言是编译型语言,因此说“运行”代码其实并不是十分合
如果你的代码被 VS 提示“This function or variable may be unsafe. Consider using scanf_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.”
-
+
需要你在项目-xxx 属性(xxx 是你的项目名)-C/C++-代码生成-安全检查里将安全检查禁用
-
+
## 调试
IDE 相比于代码编辑器,最强大的一点莫过于成熟的调试系统。通过调试,可以快速定位代码中没有被编译器检查出来的逻辑错误。如果需要调试,则可以在这个位置单击,打下断点,并且运行程序,程序运行时,就会在此处暂停下来,暂停时就可以查看各个变量的值了。
-
+
## 深色主题
@@ -94,15 +94,15 @@ IDE 相比于代码编辑器,最强大的一点莫过于成熟的调试系统
### 仔细查看报错
-
+
如果程序代码中出现红色波浪线,则表示该处代码有“错误”,并且该处的错误会同步显示在下面的这个位置,单击即可看到错误详情。如果代码中出现绿色波浪线,则表示该处代码中有警告。警告和错误的区别是警告可以通过编译运行,但编译器认为你这里可能写错了;错误是完全不可以通过编译。
-
+
### 善用提示
-
+
当你打一些函数名或者关键字时,VS 会给出你语法提示,如果这个提示正确,按下 Tab 键即可将这个提示补全到你的代码里;或者你也可以跟着这个提示打一遍,防止打错关键字。
@@ -136,7 +136,7 @@ vscode 的项目和 VS 不同,vscode 的项目比较松散,并没有 VS 那
编写完代码后,保存文件,并点击运行-启动调试
-
+
此时会弹出如下选择框,我的电脑上同时安装有 VS 和 gcc 编译器,因此有两个,大部分的电脑上应该只有一个“C++ (Windows)”,选择你电脑上的编译器并运行即可。
@@ -162,25 +162,25 @@ CLion 是 jetbrains 家族的 C 语言 IDE
XCode 是 mac 官方的 IDE,能编写所有 mac 家族设备的软件。但缺点是没有中文。
-
+
打开以后选择 Create a new Xcode project,选择 macOS-Command Line Tool
-
+
-
+
两个空里第一个填项目名,第二个随便填就行
next 后选择项目保存的位置,之后即可到达以下界面:
-
+
点左上方小三角即可运行
在行号上点击并运行即可调试
-
+
# Linux
diff --git a/3.编程思维体系构建/3.4.3解决编程问题的普适性过程.md b/3.编程思维体系构建/3.4.3解决编程问题的普适性过程.md
index 19ceb16..aa47eed 100644
--- a/3.编程思维体系构建/3.4.3解决编程问题的普适性过程.md
+++ b/3.编程思维体系构建/3.4.3解决编程问题的普适性过程.md
@@ -3,7 +3,7 @@
- 本篇不需要任何前置知识,推荐在学习 C 语言和学完 C 语言后各看一遍。
- 我们鼓励你在解决问题的时候进行思考,锻炼解决问题的能力,而不只是成为一个做代码翻译工作的“码农”。
-
+
解决编程问题的常见误区:
@@ -13,7 +13,7 @@
如果你计划得足够好并且代码编写得正确,你的代码将在第一次工作。即便它第一次不起作用,那么你至少有一个对于代码如何调试的可靠计划。
-
+
## Work an Example Yourself
diff --git a/3.编程思维体系构建/3.4.4C语言前置概念学习.md b/3.编程思维体系构建/3.4.4C语言前置概念学习.md
index 116005e..49ca40d 100644
--- a/3.编程思维体系构建/3.4.4C语言前置概念学习.md
+++ b/3.编程思维体系构建/3.4.4C语言前置概念学习.md
@@ -34,6 +34,6 @@
计算机思维与计算机科学与编码能力
-
+
### CS education is more than just “learning how to code”!
diff --git a/3.编程思维体系构建/3.4.5.1C语言自测标准——链表.md b/3.编程思维体系构建/3.4.5.1C语言自测标准——链表.md
index 03be730..fa4e451 100644
--- a/3.编程思维体系构建/3.4.5.1C语言自测标准——链表.md
+++ b/3.编程思维体系构建/3.4.5.1C语言自测标准——链表.md
@@ -6,13 +6,13 @@
使用链表存储数据,不强制要求数据在内存中集中存储,各个元素可以分散存储在内存中。例如,使用链表存储 {1,2,3},各个元素在内存中的存储状态可能是:
-
+
可以看到,数据不仅没有集中存放,在内存中的存储次序也是混乱的。那么,链表是如何存储数据间逻辑关系的呢?
链表存储数据间逻辑关系的实现方案是:为每一个元素配置一个指针,每个元素的指针都指向自己的直接后继元素,如下图所示:
-
+
显然,我们只需要记住元素 1 的存储位置,通过它的指针就可以找到元素 2,通过元素 2 的指针就可以找到元素 3,以此类推,各个元素的先后次序一目了然。像图 2 这样,数据元素随机存储在内存中,通过指针维系数据之间“一对一”的逻辑关系,这样的存储结构就是链表。
@@ -20,13 +20,13 @@
在链表中,每个数据元素都配有一个指针,这意味着,链表上的每个“元素”都长下图这个样子:
-
+
数据域用来存储元素的值,指针域用来存放指针。数据结构中,通常将这样的整体称为结点。
也就是说,链表中实际存放的是一个一个的结点,数据元素存放在各个结点的数据域中。举个简单的例子,图 3 中 {1,2,3} 的存储状态用链表表示,如下图所示:
-
+
在 C 语言中,可以用结构体表示链表中的结点,例如:
@@ -66,7 +66,7 @@ typedef struct Node* Link;
例如,创建一个包含头结点的链表存储 {1,2,3},如下图所示:
-
+
## 链表的创建
@@ -104,7 +104,7 @@ while (Judgement)
}
```
-
+
### 创建结点——尾插法
@@ -121,7 +121,7 @@ while (Judgement) //for同理
}
```
-
+
## 链表的基本操作
@@ -176,7 +176,7 @@ int GetElem(Link *L, int i; int *e)
例如,在链表 `{1,2,3,4}` 的基础上分别实现在头部、中间、尾部插入新元素 5,其实现过程如图所示:
-
+
从图中可以看出,虽然新元素的插入位置不同,但实现插入操作的方法是一致的,都是先执行步骤 1 ,再执行步骤 2。实现代码如下:
@@ -207,7 +207,7 @@ int ListInsert(Link *L, int i, int e)
对于没有头结点的链表,在头部插入结点比较特殊,需要单独实现。
-
+
和 2)、3) 种情况相比,由于链表没有头结点,在头部插入新结点,此结点之前没有任何结点,实现的步骤如下:
@@ -253,7 +253,7 @@ temp->next=temp->next->next;
例如,从存有 `{1,2,3,4}` 的链表中删除存储元素 3 的结点,则此代码的执行效果如图 3 所示:
-
+
实现代码如下:
@@ -282,7 +282,7 @@ int ListDelete(Link *L, int i, int* e)
对于不带头结点的链表,需要单独考虑删除首元结点的情况,删除其它结点的方式和图 3 完全相同,如下图所示:
-
+
实现代码如下:
@@ -319,7 +319,7 @@ int ListDelete(Link *L, int i, int* e)
如图所示,假设此时圆周周围有 5 个人,要求从编号为 3 的人开始顺时针数数,数到 2 的那个人出列:
-
+
出列顺序依次为:
@@ -339,10 +339,10 @@ int ListDelete(Link *L, int i, int* e)
为了使空链表和非空链表处理一致,我们通常设一个头结点,当然,并不是说,循环链表一定要头结点,这需要注意。循环链表带有头结点的空链表如图所示:
-
+
对于非空的循环链表如图所示:
-
+
循环链表和单链表的主要差异就在于循环的判断条件上,原来是判断 p->next 是否为空,现在则是 p->next 不等于头结点,则循环未结束。
diff --git a/3.编程思维体系构建/3.4.6阶段二:文字冒险(cool).md b/3.编程思维体系构建/3.4.6阶段二:文字冒险(cool).md
index 0295202..1b45adc 100644
--- a/3.编程思维体系构建/3.4.6阶段二:文字冒险(cool).md
+++ b/3.编程思维体系构建/3.4.6阶段二:文字冒险(cool).md
@@ -20,7 +20,7 @@
当然,如果你选择跳过,也不会对 python 开发那里造成非常大的影响但是你会错失一个非常宝贵的学习机会。
-
+
在 1980 年代, [文字冒险](http://en.wikipedia.org/wiki/Text_adventure) 是一种受人尊敬的电脑游戏类型。但是时代已经变了,在 21 世纪,它们与 带有 3D 引擎的现代 [MMORPG 相比显得苍白无力。](http://en.wikipedia.org/wiki/Mmorpg)书籍在电影的兴起中幸存下来,而基于文本的游戏很快就输掉了与图形游戏的战斗。“互动小说”由一个活跃的社区保持活力,但它的商业价值早已不复存在。
diff --git a/3.编程思维体系构建/3.4.7.1.1调试理论.md b/3.编程思维体系构建/3.4.7.1.1调试理论.md
index e79e5df..51160b9 100644
--- a/3.编程思维体系构建/3.4.7.1.1调试理论.md
+++ b/3.编程思维体系构建/3.4.7.1.1调试理论.md
@@ -28,7 +28,7 @@
- 打印变量, 断点, 监视点, 函数调用栈...
-
+
# 调试理论
diff --git a/3.编程思维体系构建/3.4.7.1GDB初探索(编程可阅览).md b/3.编程思维体系构建/3.4.7.1GDB初探索(编程可阅览).md
index e7650b1..34e2c55 100644
--- a/3.编程思维体系构建/3.4.7.1GDB初探索(编程可阅览).md
+++ b/3.编程思维体系构建/3.4.7.1GDB初探索(编程可阅览).md
@@ -2,7 +2,7 @@
请在开始进行 C 语言编程之后查阅使用
-
+
# GDB 是什么?
diff --git a/3.编程思维体系构建/3.4.7.2C的历史问题:undefined behavior.md b/3.编程思维体系构建/3.4.7.2C的历史问题:undefined behavior.md
index 78e003e..e919267 100644
--- a/3.编程思维体系构建/3.4.7.2C的历史问题:undefined behavior.md
+++ b/3.编程思维体系构建/3.4.7.2C的历史问题:undefined behavior.md
@@ -1,6 +1,6 @@
# C 的历史问题:undefined behavior
-
+
简写为 UB
diff --git a/3.编程思维体系构建/3.4C语言.md b/3.编程思维体系构建/3.4C语言.md
index ef4bc94..92d378b 100644
--- a/3.编程思维体系构建/3.4C语言.md
+++ b/3.编程思维体系构建/3.4C语言.md
@@ -6,7 +6,7 @@
值得一提的是,我不会在本教程讲授过于基础的概念,但是会贴出你可能需要学习的内容。
-
+
同时我要说的是:C 语言为了适配多种多样的硬件以及各式各样的操作,他对非常多的 undefined 操作不做太多限制,也就是说你可能会出现各种各样的问题,甚至把你电脑炸了
diff --git a/3.编程思维体系构建/3.5git与github.md b/3.编程思维体系构建/3.5git与github.md
index c0ce108..a718995 100644
--- a/3.编程思维体系构建/3.5git与github.md
+++ b/3.编程思维体系构建/3.5git与github.md
@@ -204,7 +204,7 @@ git checkout -B 分支名
页面大概是这样:
-
+
### Git 和 Github
@@ -234,11 +234,11 @@ ssh-keygen -t rsa -C "youremail@example.com" # youremail为你注册用的电
登陆 `GitHub`,打开 `settings`
-
+
然后打开左侧栏 `SSH and GPG`` keys` 页面
-
+
然后,点 `New SSH Key`,填上任意 Title,在 Key 文本框里粘贴 `id_rsa.pub` 文件的内容即可
@@ -247,11 +247,11 @@ ssh-keygen -t rsa -C "youremail@example.com" # youremail为你注册用的电
绑定完 GitHub 然后你可以创建仓库了
首先在 GitHub 主页,找到 “New” 按钮,创建一个新的仓库
-
+
然后填上这个仓库的大名就可以创建了
-
+
根据之前学习的方法在本地创建完 git 仓库之后
@@ -282,7 +282,7 @@ git clone [url]
首先,代码的 url 在下图所示的位置
-
+
然后复制完代码后切换回我们的命令行
@@ -294,7 +294,7 @@ git clone https://github.com/camera-2018/git-example.git
一阵抽搐过后就下载好了
-
+
注意:用完之后别忘记给 camera-2018 点个 follow 呃呃 follow 没用 star 有用
@@ -304,7 +304,7 @@ git clone https://github.com/camera-2018/git-example.git
如图 我在仓库里新建了 `helloworld.c` 并且写了一些代码
-
+
接下来是提交操作
@@ -312,7 +312,7 @@ git clone https://github.com/camera-2018/git-example.git
git status #看一下文件暂存区
```
-
+
红色表示文件没有提交到暂存区 我们要提交
@@ -322,7 +322,7 @@ git status #看一下文件暂存区
git add . #将没有提交的所有文件加入暂存区
```
-
+
绿色表示所有文件已加入暂存
@@ -332,7 +332,7 @@ git commit -m "feat(helloworld): add helloworld file"
将刚才加入暂区的文件发起了一个提交 注释是 `feat(helloworld): add helloworld file`
-
+
1. 如果这是你自己的仓库有权限 你就可以直接使用
@@ -343,7 +343,7 @@ git push origin main # origin是第四步里remote add起的远程名字
上传本次提交
-
+
1. 如果你没有本仓库的主分支提交权限 可以提交 pr(pull requests)
@@ -351,7 +351,7 @@ git push origin main # origin是第四步里remote add起的远程名字
首先创建一个新分支 命名为 `yourname-dev`
-
+
然后按照上面的方法 `git clone` 并切换到你刚创建的分支
@@ -361,30 +361,30 @@ git switch camera-2018-dev
然后提交一个文件 这里使用 vscode 自带的 git 工具试试
-
+
点暂存所有更改 写好 comment 之后点提交
-
+
最后点同步更改上传
-
+
如果是你提交 在 github 上会显示这个 快捷创建 pr 的按钮
-
+
-
+
点它创建 pr
-
+
这样管理本仓库的人看到 pr 请求就可以 merge 合并辣
-
+
-
+
实际合作过程中可能会出现代码冲突无法 merge 的情况 😋 遇到了自己去 STFW 吧
diff --git a/3.编程思维体系构建/3.6.2环境配置.md b/3.编程思维体系构建/3.6.2环境配置.md
index 7c02805..abf536f 100644
--- a/3.编程思维体系构建/3.6.2环境配置.md
+++ b/3.编程思维体系构建/3.6.2环境配置.md
@@ -10,21 +10,21 @@
装下来之后具体操作可以看[安装教程](https://blog.csdn.net/in546/article/details/117400839),如果自动配置环境变量的选项是灰色的话,请按照下面的教程把下面的几个文件路径加入环境变量。
-
+
-
+
-
+
在里面添加并写入文件路径加入就好了~
-
+
然后打开 Pycharm,创建新项目,设置按照以下方式操作,记得挂梯子。
如果不挂梯子,请按照教程配置清华源。[我是教程](https://blog.csdn.net/jasneik/article/details/114227716)
-
+
然后一个新的环境就创建好辣~
diff --git a/3.编程思维体系构建/3.6.3安装python.md b/3.编程思维体系构建/3.6.3安装python.md
index 61ea5f9..ef45cc6 100644
--- a/3.编程思维体系构建/3.6.3安装python.md
+++ b/3.编程思维体系构建/3.6.3安装python.md
@@ -32,7 +32,7 @@
可以输入 `python3 --version` 检验是否成功。
-
+
# Jupyter Notebook
@@ -50,6 +50,6 @@ jupyter notebook
进行使用
-
+
[Pycharm](https://www.jetbrains.com/zh-cn/pycharm/):可能很多同学已经用上了,我在这里不做更多解释
diff --git a/3.编程思维体系构建/3.6.4.2阶段二:递归操作.md b/3.编程思维体系构建/3.6.4.2阶段二:递归操作.md
index 9cd9e10..532bbd5 100644
--- a/3.编程思维体系构建/3.6.4.2阶段二:递归操作.md
+++ b/3.编程思维体系构建/3.6.4.2阶段二:递归操作.md
@@ -2,7 +2,7 @@
什么是递归呢?
-
+
#
diff --git a/3.编程思维体系构建/3.6.4.3阶段三:数据抽象.md b/3.编程思维体系构建/3.6.4.3阶段三:数据抽象.md
index 14c50bd..625575e 100644
--- a/3.编程思维体系构建/3.6.4.3阶段三:数据抽象.md
+++ b/3.编程思维体系构建/3.6.4.3阶段三:数据抽象.md
@@ -184,7 +184,7 @@ P7:9*9 乘法表
可能现在对你来说,构建像下图这样的 99 乘法表已经是非常容易的一件事了,可是如果我要求你使用 python 的列表生成器,在两行以内完成呢?
-
+
P8:couple 情侣
diff --git a/3.编程思维体系构建/3.6.5.1lab00:让我们开始吧.md b/3.编程思维体系构建/3.6.5.1lab00:让我们开始吧.md
index 0191ef0..a6e032b 100644
--- a/3.编程思维体系构建/3.6.5.1lab00:让我们开始吧.md
+++ b/3.编程思维体系构建/3.6.5.1lab00:让我们开始吧.md
@@ -158,7 +158,7 @@ VS Code 的另一个不错的功能是它具有“嵌入式终端”。因此,
首先,打开一个终端窗口。
-
+
#### 主目录
@@ -174,11 +174,11 @@ VS Code 的另一个不错的功能是它具有“嵌入式终端”。因此,
PATH 就像一个地址:它告诉您和计算机到某个文件夹的完整路径(或路由)。请记住,您可以通过两种不同的方式访问计算机上的文件和目录(文件夹)。您可以使用终端(这是一个命令行界面或 CLI),也可以使用 Finder 。Finder 是图形用户界面(或 GUI)的一个 例子。导航技术不同,但文件相同。例如,这是我的 CS 61A 实验室文件夹在我的 GUI 中的样子:
-
+
这是完全相同的文件夹在终端中的外观:
-
+
请注意,在这两种情况下,黄色框都显示了 PATH,紫色椭圆显示了“labs”文件夹的内容。
@@ -186,7 +186,7 @@ PATH 就像一个地址:它告诉您和计算机到某个文件夹的完整路
让我们停下来思考一下终端和 Python 解释器之间的区别。
-
+
1. 哪个是终端?
2. 哪个是 Python 解释器?
@@ -197,7 +197,7 @@ A 和 D 都是我的终端。在这里您可以运行 bash 命令,例如 `cd`
B 是 Python 解释器。你可以从 >>> 提示中看出这意味着你已经启动了一个 Python 解释器。您还可以判断,因为启动它的命令是可见的:`python3`。该 `python3` 命令启动 Python 解释器。如果您在 Python 解释器中键入 bash 命令,您可能会遇到语法错误!这是一个例子:
-
+
C 是我的代码编辑器。这是我可以编写 Python 代码以通过我的终端执行的地方。
@@ -287,7 +287,7 @@ mkdir lab
现在,如果您列出目录的内容(使用 `ls`),您将看到两个文件夹,`projects` 和 `lab`.
-
+
### 更多目录更改
@@ -475,7 +475,7 @@ ______
实验室还将包括函数编写问题。在你的文本编辑器中打开 `lab00.py`。您可以 `open .` 在 MacOS 或 `start .` Windows 上键入以在 Finder/文件资源管理器中打开当前目录。然后双击或右键单击以在文本编辑器中打开文件。你应该看到这样的东西:
-
+
三引号中的行 `"""` 称为文档字符串(Docstring),它描述了函数应该做什么。在 61A 中编写代码时,您应该始终阅读文档字符串!
@@ -483,7 +483,7 @@ ______
在这里,我们圈出了文档字符串和文档测试,以便于查看:
-
+
在 `twenty_twenty_two`,
diff --git a/3.编程思维体系构建/3.Y.1VMware的安装与安装Ubuntu22.04系统.md b/3.编程思维体系构建/3.Y.1VMware的安装与安装Ubuntu22.04系统.md
index fc07b29..60f4533 100644
--- a/3.编程思维体系构建/3.Y.1VMware的安装与安装Ubuntu22.04系统.md
+++ b/3.编程思维体系构建/3.Y.1VMware的安装与安装Ubuntu22.04系统.md
@@ -14,13 +14,13 @@
一路下一步
-
+
-
+
这俩我推荐勾掉
-
+
安装过后点许可证 输上面的 key 激活
@@ -30,15 +30,15 @@
下好回到 VMware
-
+
创建新的虚拟机-典型(推荐)-下一步-安装程序 iso 选中你刚下的 iso 下一步
-
+
这里填你一会儿要登录 linux 的个人信息
-
+
这里建议把位置改到其他盘
@@ -46,21 +46,21 @@
启动后进入 Ubuntu 安装
-
+
键盘映射 直接 continue
接下来一路 continue install now
-
+
最后 restart
-
+
-
+
-
+
这个 skip
@@ -68,15 +68,15 @@
点右上角 settings
-
+
-
+
-
+
然后按指引 restart 系统
-
+
会提示你要不要重新命名这些用户下的文件夹
@@ -84,27 +84,27 @@
如果你的语言还没有变过来的话
-
+
点击这个他会安装语言
-
+
把汉语拖到英文之上 点应用到整个系统
-
+
右上角 logout 重新登陆 就是中文辣
最后在设置-电源把息屏改成从不
-
+
至此 恭喜安装完成!
之后就可以在桌面上右键
-
+
打开命令行
diff --git a/3.编程思维体系构建/3.Y.2WSL的安装.md b/3.编程思维体系构建/3.Y.2WSL的安装.md
index a122d0e..307cf97 100644
--- a/3.编程思维体系构建/3.Y.2WSL的安装.md
+++ b/3.编程思维体系构建/3.Y.2WSL的安装.md
@@ -15,10 +15,10 @@
(现在可能是只开 `适用于Linux的windows子系统`)
-
+
如果你的 windows 版本为家庭版 那么 hyperv 选项是没有的
你需要右键以管理员权限打开以下脚本来强行开启 hyperv
-
+
diff --git a/3.编程思维体系构建/3.编程思维体系构建.md b/3.编程思维体系构建/3.编程思维体系构建.md
index fc73d95..e7332fc 100644
--- a/3.编程思维体系构建/3.编程思维体系构建.md
+++ b/3.编程思维体系构建/3.编程思维体系构建.md
@@ -15,4 +15,4 @@
-
+
diff --git a/4.人工智能/4.10从 AI 到 智能系统 —— 从 LLMs 到 Agents.md b/4.人工智能/4.10从 AI 到 智能系统 —— 从 LLMs 到 Agents.md
index 8119327..8e6fee9 100644
--- a/4.人工智能/4.10从 AI 到 智能系统 —— 从 LLMs 到 Agents.md
+++ b/4.人工智能/4.10从 AI 到 智能系统 —— 从 LLMs 到 Agents.md
@@ -219,11 +219,11 @@ ICL(In-Context Learning,上下文学习)和 COT(Chain of Thought,思
虽然学界对此没有太大的共识,但其原理无非在于给予 LLMs 更翔实的上下文,让输出与输入有着更紧密的关联与惯性。(从某种意义上来说,也可以将其认为是一种图灵机式的编程)
-> ICL:

+> ICL:

ICL 为输出增加惯性
-> 可以简单认为,通过 ICL Prompt,能强化人类输入到机器输出的连贯性,借以提升输出的确定性。
在经过“回答”的 finetune 之前,大模型的原始能力就是基于给定文本进行接龙,而 ICL 的引入则在“回答”这一前提条件下,降低了机器开始接龙这一步骤中的语义跨度,从而使得输出更加可控。
COT:

+> 可以简单认为,通过 ICL Prompt,能强化人类输入到机器输出的连贯性,借以提升输出的确定性。
在经过“回答”的 finetune 之前,大模型的原始能力就是基于给定文本进行接龙,而 ICL 的引入则在“回答”这一前提条件下,降低了机器开始接龙这一步骤中的语义跨度,从而使得输出更加可控。
COT:

COT 为输出增加关联
@@ -239,7 +239,7 @@ COT 为输出增加关联
(需要注意的是,TaskMatrix.AI 更大程度上是一个愿景向的调研案例,尚未正式落地生态)
-
+
TaskMatrix 的生态愿景
@@ -274,7 +274,7 @@ TaskMatrix 的生态愿景
- Usage Example:API 的调用方法样例
- Composition Instruction:API 的使用贴士,如应该与其它什么 API 组合使用,是否需要手动释放等
-> 样例:打开文件 API

+> 样例:打开文件 API

基于此类文档内容和 ICL 的能力,LLMs 能从输入中习得调用 API 的方法,依此快速拓展了其横向能力
@@ -286,11 +286,11 @@ COT for TaskMatrix
在 TaskMatirx 中,通过该模式,让 MCFM 将任务转化为待办大纲,并最终围绕大纲检索并组合 API,完成整体工作
-> 样例:写论文
构建完成工作大纲

+> 样例:写论文
构建完成工作大纲

TaskMatrix 自动围绕目标拆解任务
-> 自动调用插件和组件

+> 自动调用插件和组件

TaskMatrix 自动为任务创建 API 调用链
@@ -312,7 +312,7 @@ TaskMatrix 自动为任务创建 API 调用链
Decomp 的核心思想为将复杂问题通过 Prompt 技巧,将一个复杂的问题由 LLMs 自主划分为多个子任务。随后,我们通过 LLMs 完成多个任务,并将过程信息最终组合并输出理想的效果
-
+
几种 Prompt 方法图示
@@ -320,7 +320,7 @@ Decomp 的核心思想为将复杂问题通过 Prompt 技巧,将一个复杂
而对于 Decomp 过程,则又是由一个原始的 Decomp Prompt 驱动
-
+
Decomp 方法执行样例
@@ -346,7 +346,7 @@ Decomp 的原始功能实际上并不值得太过关注,但我们急需考虑
通过问题的分解和通过“专用函数”的执行,我们可以轻易让 LLMs 实现自身无法做到的调用 API 工作,例如主动从外部检索获取回答问题所需要的知识。
-
+
Decomp 方法调用外部接口样例
@@ -358,7 +358,7 @@ Decomp 方法调用外部接口样例
[HuggingGPT](https://arxiv.org/abs/2303.17580) 一文也许并未直接参考 Decomp 方法,而是用一些更规范的手法完成该任务,但其充分流水线化的 Prompt 工程无疑是 Decomp 方法在落地实践上的最佳注脚
-
+
HuggingGPT
@@ -406,7 +406,7 @@ Generative Agents 构建了一套框架,让 NPC 可以感知被模块化的世
- 一方面,其包含场景中既有对象,包括建筑和摆件等的基础层级信息
-
+
Generative Agents 的场景信息管理
@@ -634,7 +634,7 @@ AutoGPT 主要特性如下:
其提醒我们,就连我们的意识主体性,也只是陈述自我的一个表述器而已。我们是否应当反思对语言能力的过度迷信,从而相信我们能通过训练模型构建 All in One 的智能实体?
-
+
全局工作空间理论
@@ -904,7 +904,7 @@ AutoGPT 的核心记忆设计依赖于预包装的 Prompt 本体,这一包装
Generative Agent 通过自动化评估记忆的价值,并构建遗忘系统、关注系统等用于精准从自己繁杂的记忆中检索对于当前情景有用的信息。
-
+
Generative Agents :基于 Reflection 构建记忆金字塔
diff --git a/4.人工智能/4.12本章节内容的局限性.md b/4.人工智能/4.12本章节内容的局限性.md
index 9ccb25e..a6591c5 100644
--- a/4.人工智能/4.12本章节内容的局限性.md
+++ b/4.人工智能/4.12本章节内容的局限性.md
@@ -56,4 +56,4 @@ ZZM 曾经尝试过投入大量时间去钻研数学以及机器学习相关的
联系 ZZM,我努力改
-
+
diff --git a/4.人工智能/4.1前言.md b/4.人工智能/4.1前言.md
index fc380b2..2845755 100644
--- a/4.人工智能/4.1前言.md
+++ b/4.人工智能/4.1前言.md
@@ -38,7 +38,7 @@
计算机视觉旨在用计算机模拟人类处理图片信息的能力,就比如这里有一张图片——手写数字 9(by:wy)
-
+
对我们人类而言,能够很轻松地知道这张图片中包含的信息(数字 9),而对计算机来说这只是一堆像素。计算机视觉的任务就是让计算机能够从这堆像素中得到‘数字 9’这个信息。
@@ -46,15 +46,15 @@
图像分割是在图片中对物体分类,并且把它们所对应的位置标示出来。下图就是把人的五官,面部皮肤和头发分割出来,效(小)果(丑)图如下:
-
+
-
+
-
+
图像生成相信大家一定不陌生,NovalAI 在 2022 年火的一塌糊涂,我觉得不需要我过多赘述,对它(Diffusion model)的改进工作也是层出不穷,这里就放一张由可控姿势网络(ControlNet)生成的图片吧:
-
+
三维重建也是很多研究者关注的方向,指的是传入对同一物体不同视角的照片,来生成 3D 建模的任务。这方面比图像处理更加前沿并且难度更大。具体见[4.6.5.4神经辐射场(NeRF)](4.6.5.4%E7%A5%9E%E7%BB%8F%E8%BE%90%E5%B0%84%E5%9C%BA(NeRF).md) 章节。
@@ -64,9 +64,9 @@
这就更好理解了,让计算机能够像人类一样,理解文本中的“真正含义”。在计算机眼中,文本就是单纯的字符串,NLP 的工作就是把字符转换为计算机可理解的数据。举个例子,ChatGPT(或者 New Bing)都是 NLP 的成果。在过去,NLP 领域被细分为了多个小任务,比如文本情感分析、关键段落提取等。而 ChatGPT 的出现可以说是集几乎所有小任务于大成,接下来 NLP 方向的工作会向 ChatGPT 的方向靠近。
-
+
-
+
## 多模态(跨越模态的处理)
@@ -78,7 +78,7 @@
具体的任务比如说图片问答,传入一张图片,问 AI 这张图片里面有几只猫猫,它们是什么颜色,它告诉我有一只猫猫,是橙色的:
-
+
## 对比学习
diff --git a/4.人工智能/4.2机器学习(AI)快速入门(quick start).md b/4.人工智能/4.2机器学习(AI)快速入门(quick start).md
index 213c34d..1a125bc 100644
--- a/4.人工智能/4.2机器学习(AI)快速入门(quick start).md
+++ b/4.人工智能/4.2机器学习(AI)快速入门(quick start).md
@@ -26,7 +26,7 @@
甚至深度学习,也只是机器学习的一部分,不过使用了更多技巧和方法,增大了计算能力罢了。
-
+
# 两种机器学习算法
@@ -42,11 +42,11 @@
近三个月来,每当你的城市里有人卖了房子,你都记录了下面的细节——卧室数量、房屋大小、地段等等。但最重要的是,你写下了最终的成交价:
-
+
然后你让新人根据着你的成交价来估计新的数量
-
+
这就是监督学习,你有一个参照物可以帮你决策。
@@ -66,7 +66,7 @@
这其实就是一种经典的聚类算法
-
+
可以把特征不一样的数据分开,有非常多的操作,你感兴趣可以选择性的去了解一下。
@@ -139,7 +139,7 @@ def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
第二步把每个数值都带入进行运算。
-
+
比如说,如果第一套房产实际成交价为 25 万美元,你的函数估价为 17.8 万美元,这一套房产你就差了 7.2 万。
@@ -168,13 +168,13 @@ def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
为了避免这种情况,数学家们找到了很多种[聪明的办法](https://link.zhihu.com/?target=http%3A//en.wikipedia.org/wiki/Gradient_descent)来快速找到优秀的权重值。下面是一种:
-
+
这就是被称为 loss 函数的东西。
这是个专业属于,你可以选择性忽略他,我们将它改写一下
-
+
θ 表示当前的权重值。 J(θ) 表示「当前权重的代价」。
@@ -182,7 +182,7 @@ def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
如果我们为这个等式中所有卧室数和面积的可能权重值作图的话,我们会得到类似下图的图表:
-
+
因此,我们需要做的只是调整我们的权重,使得我们在图上朝着最低点「走下坡路」。如果我们不断微调权重,一直向最低点移动,那么我们最终不用尝试太多权重就可以到达那里。
@@ -194,7 +194,7 @@ def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
当你使用一个机器学习算法库来解决实际问题时,这些都已经为你准备好了。但清楚背后的原理依然是有用的。
-
+
枚举法
@@ -225,7 +225,7 @@ def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
我们换一个好看的形式给他展示
-
+
箭头头表示了函数中的权重。
@@ -233,17 +233,17 @@ def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
所以为了更加的智能化,我们可以利用不同的权重来多次运行这个算法,收集各种不同情况下的估价。
-
+
然后我们把四种整合到一起,就得到一个超级答案
-
+
这样我们相当于得到了更为准确的答案
# 神经网络是什么
-
+
我们把四个超级网络的结合图整体画出来,其实这就是个超级简单的神经网络,虽然我们省略了很多的内容,但是他仍然有了一定的拟合能力
@@ -318,17 +318,17 @@ print('y_pred=',y_test.data)
我们试着只识别一个数字 8
-
+
-
+
我们把一幅 18×18 像素的图片当成一串含有 324 个数字的数组,就可以把它输入到我们的神经网络里面了:
-
+
为了更好地操控我们的输入数据,我们把神经网络的输入节点扩大到 324 个:
-
+
请注意,我们的神经网络现在有了两个输出(而不仅仅是一个房子的价格)。第一个输出会预测图片是「8」的概率,而第二个则输出不是「8」的概率。概括地说,我们就可以依靠多种不同的输出,利用神经网络把要识别的物品进行分组。
@@ -349,7 +349,7 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
当数字并不是正好在图片中央的时候,我们的识别器就完全不工作了。一点点的位移我们的识别器就掀桌子不干了
-
+
这是因为我们的网络只学习到了正中央的「8」。它并不知道那些偏离中心的「8」长什么样子。它仅仅知道中间是「8」的图片规律。
@@ -365,9 +365,9 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
当然,你同时也需要更强的拟合能力和更深的网络。
-
+
-
+
一层一层堆叠起来,这种方法很早就出现了。
@@ -377,7 +377,7 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
作为人类,你能够直观地感知到图片中存在某种层级(hierarchy)或者是概念结构(conceptual structure)。比如说,你在看
-
+
你会快速的辨认出一匹马,一个人。
@@ -387,7 +387,7 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
有人对此做过研究,人的眼睛可能会逐步判断一个物体的信息,比如说你看到一张图片,你会先看颜色,然后看纹理然后再看整体,那么我们需要一种操作来模拟这个过程,我们管这种操作叫卷积操作。
-
+
## 卷积是如何工作的
@@ -395,13 +395,13 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
当然也有最新研究说卷积不具备平移不变性,但是我这里使用这个概念是为了大伙更好的理解,举个例子:你将 8 无论放在左上角还是左下角都改变不了他是 8 的事实
-
+
我们将一张图像分成这么多个小块,然后输入神经网络中的是一个小块。每次判断一张小图块。
然而,有一个非常重要的不同:对于每个小图块,我们会使用同样的神经网络权重。换一句话来说,我们平等对待每一个小图块。如果哪个小图块有任何异常出现,我们就认为这个图块是「异常」
-
+
换一句话来说,我们从一整张图片开始,最后得到一个稍小一点的数组,里面存储着我们图片中的哪一部分有异常。
@@ -413,7 +413,7 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
让我们先来看每个 2×2 的方阵数组,并且留下最大的数:
-
+
每一波我们只保留一个数,这样就大大减少了图片的计算量了。
@@ -435,7 +435,7 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
你猜怎么着?数组就是一串数字而已,所以我们我们可以把这个数组输入到另外一个神经网络里面去。最后的这个神经网络会决定这个图片是否匹配。为了区分它和卷积的不同,我们把它称作「全连接」网络
-
+
我们的图片处理管道是一系列的步骤:卷积、最大池化,还有最后的「全连接」网络。
diff --git a/4.人工智能/4.3.1.1程序示例——maze迷宫解搜索.md b/4.人工智能/4.3.1.1程序示例——maze迷宫解搜索.md
index b5795a4..89a42d8 100644
--- a/4.人工智能/4.3.1.1程序示例——maze迷宫解搜索.md
+++ b/4.人工智能/4.3.1.1程序示例——maze迷宫解搜索.md
@@ -170,7 +170,7 @@ class Maze:
5. 两种算法总是能找到相同长度的路径
2. 下面的问题将问你关于下面迷宫的问题。灰色单元格表示墙壁。在这个迷宫上运行了一个搜索算法,找到了从 A 点到 B 点的黄色突出显示的路径。在这样做的过程中,红色突出显示的细胞是探索的状态,但并没有达到目标。
- 
+ 
在讲座中讨论的四种搜索算法中——深度优先搜索、广度优先搜索、曼哈顿距离启发式贪婪最佳优先搜索和曼哈顿距离启发式$A^*$
@@ -190,7 +190,7 @@ class Maze:
4. 深度限制的极小极大值永远不会比没有深度限制的极大极小值更可取
4. 下面的问题将询问您关于下面的 Minimax 树,其中绿色向上箭头表示 MAX 玩家,红色向下箭头表示 MIN 玩家。每个叶节点都标有其值。
-
+
根节点的值是多少?
diff --git a/4.人工智能/4.3.1搜索.md b/4.人工智能/4.3.1搜索.md
index 503e98a..588be5c 100644
--- a/4.人工智能/4.3.1搜索.md
+++ b/4.人工智能/4.3.1搜索.md
@@ -18,13 +18,13 @@
导航是使用搜索算法的一个典型的搜索,它接收您的当前位置和目的地作为输入,并根据搜索算法返回建议的路径。
-
+
在计算机科学中,还有许多其他形式的搜索问题,比如谜题或迷宫。
-
+
-
+
# 举个例子
@@ -42,14 +42,14 @@
- 搜索算法开始的状态。在导航应用程序中,这将是当前位置。
-
+
- 动作(Action)
- 一个状态可以做出的选择。更确切地说,动作可以定义为一个函数。当接收到状态$s$作为输入时,$Actions(s)$将返回可在状态$s$ 中执行的一组操作作为输出。
- 例如,在一个数字华容道中,给定状态的操作是您可以在当前配置中滑动方块的方式。
-
+
- 过渡模型(Transition Model)
@@ -58,14 +58,14 @@
- 在接收到状态$s$和动作$a$作为输入时,$Results(s,a)$返回在状态$s$中执行动作$a$ 所产生的状态。
- 例如,给定数字华容道的特定配置(状态$s$),在任何方向上移动正方形(动作$a$)将导致谜题的新配置(新状态)。
-
+
- 状态空间(State Space)
- 通过一系列的操作目标从初始状态可达到的所有状态的集合。
- 例如,在一个数字华容道谜题中,状态空间由所有$\frac{16!}{2}$种配置,可以从任何初始状态达到。状态空间可以可视化为有向图,其中状态表示为节点,动作表示为节点之间的箭头。
-
+
- 目标测试(Goal Test)
@@ -112,9 +112,9 @@
- 展开节点(找到可以从该节点到达的所有新节点),并将生成的节点添加到边域。
- 将当前节点添加到探索集。
-
+
-
+
边域从节点 A 初始化开始
@@ -122,9 +122,9 @@ a. 取出边域中的节点 A,展开节点 A,将节点 B 添加到边域。
b. 取出节点 B,展开,添加......
c. 到达目标节点,停止,返回解决方案
-
+
-
+
会出现什么问题?节点 A-> 节点 B-> 节点 A->......-> 节点 A。我们需要一个探索集,记录已搜索的节点!
@@ -143,13 +143,13 @@ c. 到达目标节点,停止,返回解决方案
- 所找到的解决方案可能不是最优的。
- 在最坏的情况下,该算法将在找到解决方案之前探索每一条可能的路径,从而在到达解决方案之前花费尽可能长的时间。
-
+
-
+
-
+
-
+
- 代码实现
@@ -175,13 +175,13 @@ def remove(self):
- 几乎可以保证该算法的运行时间会比最短时间更长。
- 在最坏的情况下,这种算法需要尽可能长的时间才能运行。
-
+
-
+
-
+
-
+
- 代码实现
@@ -202,13 +202,13 @@ def remove(self):
- 贪婪最佳优先搜索扩展最接近目标的节点,如启发式函数$h(n)$所确定的。顾名思义,该函数估计下一个节点离目标有多近,但可能会出错。贪婪最佳优先算法的效率取决于启发式函数的好坏。例如,在迷宫中,算法可以使用启发式函数,该函数依赖于可能节点和迷宫末端之间的曼哈顿距离。曼哈顿距离忽略了墙壁,并计算了从一个位置到目标位置需要向上、向下或向两侧走多少步。这是一个简单的估计,可以基于当前位置和目标位置的$(x,y)$坐标导出。
-
+
- 然而,重要的是要强调,与任何启发式算法一样,它可能会出错,并导致算法走上比其他情况下更慢的道路。不知情的搜索算法有可能更快地提供一个更好的解决方案,但它比知情算法更不可能这样。
-
+
-
+
- $A^*$搜索
@@ -220,9 +220,9 @@ def remove(self):
- 一致性,这意味着从新节点到目标的估计路径成本加上从先前节点转换到该新节点的成本应该大于或等于先前节点到目标的估计路径成本。用方程的形式表示,$h(n)$是一致的,如果对于每个节点n$和后续节点n'$,从n$到$n'$的步长为c$,满足$h(n)≤h(n')+c$。
-
+
-
+
# 对抗性搜索
@@ -232,41 +232,41 @@ def remove(self):
- 作为对抗性搜索中的一种算法,Minimax 将获胜条件表示为$(-1)$表示为一方,$(+1)$表示为另一方。进一步的行动将受到这些条件的驱动,最小化的一方试图获得最低分数,而最大化的一方则试图获得最高分数。
- 
+ 
- 井字棋 AI 为例
- $s_0$: 初始状态(在我们的情况下,是一个空的3X3棋盘)
- 
+ 
- $$Players(s)$$: 一个函数,在给定状态$$s$$的情况下,返回轮到哪个玩家(X或O)。
- 
+ 
- $Actions(s)$: 一个函数,在给定状态$$s$$的情况下,返回该状态下的所有合法动作(棋盘上哪些位置是空的)。
- 
+ 
- $Result(s, a)$: 一个函数,在给定状态$$s$$和操作$$a$$的情况下,返回一个新状态。这是在状态$$s$$上执行动作$$a$$(在游戏中移动)所产生的棋盘。
- 
+ 
- $Terminal(s)$: 一个函数,在给定状态$$s$$的情况下,检查这是否是游戏的最后一步,即是否有人赢了或打成平手。如果游戏已结束,则返回True,否则返回False。
- 
+ 
- $Utility(s)$: 一个函数,在给定终端状态s的情况下,返回状态的效用值:$$-1、0或1$$。
-
+
- 算法的工作原理:
- 该算法递归地模拟从当前状态开始直到达到终端状态为止可能发生的所有游戏状态。每个终端状态的值为$(-1)$、$0$或$(+1)$。
-
+
- 根据轮到谁的状态,算法可以知道当前玩家在最佳游戏时是否会选择导致状态值更低或更高的动作。
@@ -278,7 +278,7 @@ def remove(self):
在得到这些值之后,最大化的玩家会选择最高的一个。
-
+
- 具体算法:
@@ -309,7 +309,7 @@ def remove(self):
- 这一点最容易用一个例子来说明:最大化的玩家知道,在下一步,最小化的玩家将试图获得最低分数。假设最大化玩家有三个可能的动作,第一个动作的值为4。然后玩家开始为下一个动作生成值。要做到这一点,如果当前玩家做出这个动作,玩家会生成最小化者动作的值,并且知道最小化者会选择最低的一个。然而,在完成最小化器所有可能动作的计算之前,玩家会看到其中一个选项的值为3。这意味着没有理由继续探索最小化玩家的其他可能行动。尚未赋值的动作的值无关紧要,无论是10还是(-10)。如果该值为10,则最小化器将选择最低选项3,该选项已经比预先设定的4差。如果尚未估价的行动结果是(-10),那么最小化者将选择(-10)这一选项,这对最大化者来说更加不利。因此,在这一点上为最小化者计算额外的可能动作与最大化者无关,因为最大化玩家已经有了一个明确的更好的选择,其值为4。
$$
-
+
- 深度限制的极大极小算法(Depth-Limited Minimax)
diff --git a/4.人工智能/4.3.2.1程序示例——命题逻辑与模型检测.md b/4.人工智能/4.3.2.1程序示例——命题逻辑与模型检测.md
index 3e3025e..7a4513b 100644
--- a/4.人工智能/4.3.2.1程序示例——命题逻辑与模型检测.md
+++ b/4.人工智能/4.3.2.1程序示例——命题逻辑与模型检测.md
@@ -311,15 +311,15 @@ check_knowledge(knowledge)
在这个游戏中,玩家一按照一定的顺序排列颜色,然后玩家二必须猜测这个顺序。每一轮,玩家二进行猜测,玩家一返回一个数字,指示玩家二正确选择了多少颜色。让我们用四种颜色模拟一个游戏。假设玩家二猜测以下顺序:
-
+
玩家一回答“二”。因此,我们知道其中一些两种颜色位于正确的位置,而另两种颜色则位于错误的位置。根据这些信息,玩家二试图切换两种颜色的位置。
-
+
现在玩家一回答“零”。因此,玩家二知道切换后的颜色最初位于正确的位置,这意味着未被切换的两种颜色位于错误的位置。玩家二切换它们。
-
+
在命题逻辑中表示这一点需要我们有(颜色的数量)$^2$个原子命题。所以,在四种颜色的情况下,我们会有命题 red0,red1,red2,red3,blue0…代表颜色和位置。下一步是用命题逻辑表示游戏规则(每个位置只有一种颜色,没有颜色重复),并将它们添加到知识库中。最后一步是将我们所拥有的所有线索添加到知识库中。在我们的案例中,我们会补充说,在第一次猜测中,两个位置是错误的,两个是正确的,而在第二次猜测中没有一个是对的。利用这些知识,模型检查算法可以为我们提供难题的解决方案。
diff --git a/4.人工智能/4.3.2.2项目:扫雷,骑士与流氓问题.md b/4.人工智能/4.3.2.2项目:扫雷,骑士与流氓问题.md
index 6c9201c..7951b78 100644
--- a/4.人工智能/4.3.2.2项目:扫雷,骑士与流氓问题.md
+++ b/4.人工智能/4.3.2.2项目:扫雷,骑士与流氓问题.md
@@ -71,7 +71,7 @@ C 说:“A 是骑士。”
写一个 AI 来玩扫雷游戏。
-
+
## 背景
@@ -80,7 +80,7 @@ C 说:“A 是骑士。”
- 扫雷器是一款益智游戏,由一个单元格网格组成,其中一些单元格包含隐藏的“地雷”。点击包含地雷的单元格会引爆地雷,导致用户输掉游戏。单击“安全”单元格(即不包含地雷的单元格)会显示一个数字,指示有多少相邻单元格包含地雷,其中相邻单元格是指从给定单元格向左、向右、向上、向下或对角线一个正方形的单元格。
- 例如,在这个 3x3 扫雷游戏中,三个 1 值表示这些单元格中的每个单元格都有一个相邻的单元格,该单元格是地雷。四个 0 值表示这些单元中的每一个都没有相邻的地雷。
-
+
- 给定这些信息,玩家根据逻辑可以得出结论,右下角单元格中一定有地雷,左上角单元格中没有地雷,因为只有在这种情况下,其他单元格上的数字标签才会准确。
- 游戏的目标是标记(即识别)每个地雷。在游戏的许多实现中,包括本项目中的实现中,玩家可以通过右键单击单元格(或左键双击,具体取决于计算机)来标记地雷。
@@ -90,7 +90,7 @@ C 说:“A 是骑士。”
- 你在这个项目中的目标是建立一个可以玩扫雷游戏的人工智能。回想一下,基于知识的智能主体通过考虑他们的知识库来做出决策,并根据这些知识做出推断。
- 我们可以表示人工智能关于扫雷游戏的知识的一种方法是,使每个单元格成为命题变量,如果单元格包含地雷,则为真,否则为假。
-
+
- 我们现在掌握了什么信息?我们现在知道八个相邻的单元格中有一个是地雷。因此,我们可以写一个逻辑表达式,如下所示,表示其中一个相邻的单元格是地雷。
- `Or(A,B,C,D,E,F,G,H)`
@@ -124,12 +124,12 @@ Or(
- 这种表示法中的每个逻辑命题都有两个部分:一个是网格中与提示数字有关的一组单元格 `cell`,另一个是数字计数 `count`,表示这些单元格中有多少是地雷。上面的逻辑命题说,在单元格 A、B、C、D、E、F、G 和 H 中,正好有 1 个是地雷。
- 为什么这是一个有用的表示?在某种程度上,它很适合某些类型的推理。考虑下面的游戏。
-
+
- 利用左下数的知识,我们可以构造命题 `{D,E,G}=0`,意思是在 D、E 和 G 单元中,正好有 0 个是地雷。凭直觉,我们可以从这句话中推断出所有的单元格都必须是安全的。通过推理,每当我们有一个 `count` 为 0 的命题时,我们就知道该命题的所有 `cell` 都必须是安全的。
- 同样,考虑下面的游戏。
-
+
- 我们的人工智能会构建命题 `{E,F,H}=3`。凭直觉,我们可以推断出所有的 E、F 和 H 都是地雷。更一般地说,任何时候 `cell` 的数量等于 `count`,我们都知道这个命题的所有单元格都必须是地雷。
- 一般来说,我们只希望我们的命题是关于那些还不知道是安全的还是地雷的 `cell`。这意味着,一旦我们知道一个单元格是否是地雷,我们就可以更新我们的知识库来简化它们,并可能得出新的结论。
@@ -137,7 +137,7 @@ Or(
- 同样,如果我们的人工智能知道命题 `{A,B,C}=2`,并且我们被告知 C 是一颗地雷,我们可以从命题中删除 C,并减少计数的值(因为 C 是导致该计数的地雷),从而得到命题 `{A、B}=1`。这是合乎逻辑的:如果 A、B 和 C 中有两个是地雷,并且我们知道 C 是地雷,那么 A 和 B 中一定有一个是地雷。
- 如果我们更聪明,我们可以做最后一种推理。
-
+
- 考虑一下我们的人工智能根据中间顶部单元格和中间底部单元格会知道的两个命题。从中上角的单元格中,我们得到 `{A,B,C}=1`。从底部中间单元格中,我们得到 `{A,B,C,D,E}=2`。从逻辑上讲,我们可以推断出一个新的知识,即 `{D,E}=1`。毕竟,如果 A、B、C、D 和 E 中有两个是地雷,而 A、B 和 C 中只有一个是地雷的话,那么 D 和 E 必须是另一个地雷。
- 更一般地说,任何时候我们有两个命题满足 `set1=count1` 和 `set2=count2`,其中 `set1` 是 `set2` 的子集,那么我们可以构造新的命题 `set2-set1=count2-count1`。考虑上面的例子,以确保你理解为什么这是真的。
diff --git a/4.人工智能/4.3.2知识推理.md b/4.人工智能/4.3.2知识推理.md
index 0ff372a..7738ade 100644
--- a/4.人工智能/4.3.2知识推理.md
+++ b/4.人工智能/4.3.2知识推理.md
@@ -112,7 +112,7 @@
- $KB$: 如果今天是星期四并且不下雨,那我将出门跑步;今天是星期四;今天不下雨。$(P\land\lnot Q)\to R,P,\lnot Q$
- 查询结论(query): $R$
- 
+ 
- 接下来,让我们看看如何将知识和逻辑表示为代码。
@@ -175,31 +175,31 @@ def check_all(knowledge, query, symbols, model):# 如果模型对每个符号都
- 模型检查不是一种有效的算法,因为它必须在给出答案之前考虑每个可能的模型(提醒:如果在$KB$为真的所有模型(真值分配)下,查询结论$R$为真,则$R$ 也为真)。 推理规则允许我们根据现有知识生成新信息,而无需考虑所有可能的模型。
- 推理规则通常使用将顶部部分(前提)与底部部分(结论)分开的水平条表示。 前提是我们有什么知识,结论是根据这个前提可以产生什么知识。
- 
+ 
- 肯定前件(Modus Ponens)
- 如果我们知道一个蕴涵及其前件为真,那么后件也为真。
- 
+ 
- 合取消除(And Elimination)
- 如果 And 命题为真,则其中的任何一个原子命题也为真。 例如,如果我们知道哈利与罗恩和赫敏是朋友,我们就可以得出结论,哈利与赫敏是朋友。
- 
+ 
- 双重否定消除(Double Negation Elimination)
- 被两次否定的命题为真。 例如,考虑命题“哈利没有通过考试是不正确的”。 这两个否定相互抵消,将命题“哈利通过考试”标记为真。
- 
+ 
- 蕴含消除(Implication Elimination)
- 蕴涵等价于被否定的前件和后件之间的 Or 关系。 例如,命题“如果正在下雨,哈利在室内”等同于命题“(没有下雨)或(哈利在室内)”。
- 
+ 
| $P$ | $Q$ | $P\to Q$ | $\lnot P\lor Q$ |
| --- | --- | -------- | --------------- |
@@ -212,25 +212,25 @@ def check_all(knowledge, query, symbols, model):# 如果模型对每个符号都
- 等值命题等价于蕴涵及其逆命题的 And 关系。 例如,“当且仅当 Harry 在室内时才下雨”等同于(“如果正在下雨,Harry 在室内”和“如果 Harry 在室内,则正在下雨”)。
- 
+ 
- 德摩根律(De Morgan’s Law)
- 可以将 And 连接词变成 Or 连接词。考虑以下命题:“哈利和罗恩都通过了考试是不正确的。” 由此,可以得出“哈利通过考试不是真的”或者“罗恩不是真的通过考试”的结论。 也就是说,要使前面的 And 命题为真,Or 命题中至少有一个命题必须为真。
- 
+ 
- 同样,可以得出相反的结论。考虑这个命题“哈利或罗恩通过考试是不正确的”。 这可以改写为“哈利没有通过考试”和“罗恩没有通过考试”。
- 
+ 
- 分配律(Distributive Property)
- 具有两个用 And 或 Or 连接词分组的命题可以分解为由 And 和 Or 组成的更小单元。
- 
+ 
- 
+ 
## 知识和搜索问题
@@ -247,16 +247,16 @@ def check_all(knowledge, query, symbols, model):# 如果模型对每个符号都
- 归结是一个强大的推理规则,它规定如果 Or 命题中的两个原子命题之一为假,则另一个必须为真。 例如,给定命题“Ron 在礼堂”或“Hermione 在图书馆”,除了命题“Ron 不在礼堂”之外,我们还可以得出“Hermione 在图书馆”的结论。 更正式地说,我们可以通过以下方式定义归结:
- 
+ 
- 
+ 
- 归结依赖于互补文字,两个相同的原子命题,其中一个被否定而另一个不被否定,例如$P$和$¬P$。
- 归结可以进一步推广。 假设除了“Rom 在礼堂”或“Hermione 在图书馆”的命题外,我们还知道“Rom 不在礼堂”或“Harry 在睡觉”。 我们可以从中推断出“Hermione 在图书馆”或“Harry 在睡觉”。 正式地说:
- 
+ 
- 
+ 
- 互补文字使我们能够通过解析推理生成新句子。 因此,推理算法定位互补文字以生成新知识。
- 从句(Clause)是多个原子命题的析取式(命题符号或命题符号的否定,例如$P$, $¬P$)。 析取式由Or逻辑连接词 ($P ∨ Q ∨ R$) 相连的命题组成。 另一方面,连接词由And逻辑连接词 ($P ∧ Q ∧ R$) 相连的命题组成。 从句允许我们将任何逻辑语句转换为合取范式 (CNF),它是从句的合取,例如:$(A ∨ B ∨ C) ∧ (D ∨ ¬E) ∧ (F ∨ G)$。
diff --git a/4.人工智能/4.3人工智能导论及机器学习入门.md b/4.人工智能/4.3人工智能导论及机器学习入门.md
index 16596c8..c02a88b 100644
--- a/4.人工智能/4.3人工智能导论及机器学习入门.md
+++ b/4.人工智能/4.3人工智能导论及机器学习入门.md
@@ -6,7 +6,7 @@
人工智能是一个宏大的愿景,目标是让机器像我们人类一样思考和行动,既包括增强我们人类脑力也包括增强我们体力的研究领域。而学习只是实现人工智能的手段之一,并且,只是增强我们人类脑力的方法之一。所以,人工智能包含机器学习。机器学习又包含了深度学习,他们三者之间的关系见下图。
-
+
# 如何学习本节内容
diff --git a/4.人工智能/4.4FAQ:常见问题.md b/4.人工智能/4.4FAQ:常见问题.md
index 3e201c1..e65d99b 100644
--- a/4.人工智能/4.4FAQ:常见问题.md
+++ b/4.人工智能/4.4FAQ:常见问题.md
@@ -35,11 +35,11 @@
机器学习包括深度学习
-
+
[同时向你推荐这个 Data Analytics,Data Analysis,数据挖掘,数据科学,机器学习,大数据的区别是什么?](https://www.quora.com/What-is-the-difference-between-Data-Analytics-Data-Analysis-Data-Mining-Data-Science-Machine-Learning-and-Big-Data-1)
-
+
# 我没有任何相关概念
diff --git a/4.人工智能/4.6.1工欲善其事,必先利其器.md b/4.人工智能/4.6.1工欲善其事,必先利其器.md
index bd8708a..3e30ec4 100644
--- a/4.人工智能/4.6.1工欲善其事,必先利其器.md
+++ b/4.人工智能/4.6.1工欲善其事,必先利其器.md
@@ -6,7 +6,7 @@
## 深度学习框架
-
+
### 1、深度学习框架是什么
@@ -113,9 +113,9 @@ PyTorch 完全基于 Python。
官网如下
-
+
-
+
选择 Conda 或者 Pip 安装皆可
@@ -140,7 +140,7 @@ conda config --set show_channel_urls yes
### TensorFlow
-
+
#### 教程
@@ -161,17 +161,17 @@ cuda 版本需要额外配置,我们将这个任务留给聪明的你!!!
同时按下键盘的 win+r 键,打开 cmd,键入 `dxdiag` 然后回车
系统、显卡、声卡以及其他输入设备的信息都在这里了。(给出我的界面)
-
+
cuda 版本查看
桌面空白位置摁下右键
-
+
-
+
-
+
#### linux
@@ -187,11 +187,11 @@ nvidia-smi
通常大家所指的 cuda 是位于/usr/local 下的 cuda
-
+
当然可以看到 cuda 是 cuda-11.6 所指向的软链接(类似 windows 的快捷方式),所以我们如果要切换 cuda 版本只需要改变软链接的指向即可。
-
+
cuda driver version 是 cuda 的驱动版本。
@@ -199,9 +199,9 @@ cuda runtimer version 是我们实际很多时候我们实际调用的版本。
二者的版本是可以不一致的。如下图所示:
-
+
-
+
一般来讲 cuda driver 是向下兼容的。所以 cuda driver version >= cuda runtime version 就不会太大问题。
@@ -211,13 +211,13 @@ cuda runtimer version 是我们实际很多时候我们实际调用的版本。
以 pytorch 为例,可以看到在安装过程中我们选择的 cuda 版本是 10.2
-
+
那么这个 cudatookit10.2 和 nvidia-smi 的 11.7 以及 nvcc -V 的 11.4 三者有什么区别呢?
pytorch 实际只需要 cuda 的链接文件,即.so 文件,这些链接文件就都包含的 cudatookkit 里面。并不需要 cuda 的头文件等其他东西,如下所示
-
+
所以我们如果想让使用 pytorch-cuda 版本,我们实际上不需要/usr/local/cuda。只需要在安装驱动的前提下,在 python 里面安装 cudatookit 即可。
@@ -227,8 +227,8 @@ pytorch 实际只需要 cuda 的链接文件,即.so 文件,这些链接文
Cudnn 是一些链接文件,你可以理解成是为了给 cuda 计算加速的东西。同样的我们也可以用以下命令查看/usr/local/cuda 的 cudnn:
-
+
以及 pytorch 的 cuda 环境的 cudnn
-
+
diff --git a/4.人工智能/4.6.2你可能会需要的术语介绍.md b/4.人工智能/4.6.2你可能会需要的术语介绍.md
index fdfc74a..9e6ee71 100644
--- a/4.人工智能/4.6.2你可能会需要的术语介绍.md
+++ b/4.人工智能/4.6.2你可能会需要的术语介绍.md
@@ -40,8 +40,8 @@
这是我用照片重建的独角兽稀疏点云,红色的不用管,是照相机视角(图不够多,巨糊)
-
+
-
+
先这些,后续想起来了可能会补充。
diff --git a/4.人工智能/4.6.3深度学习快速入门.md b/4.人工智能/4.6.3深度学习快速入门.md
index 0689400..a0d0132 100644
--- a/4.人工智能/4.6.3深度学习快速入门.md
+++ b/4.人工智能/4.6.3深度学习快速入门.md
@@ -68,7 +68,7 @@ Crash course 的课程,适合速成性的了解 AI 的基本方向和内容
### 损失
-
+
首先我们需要有一个损失函数$F(x),x=true-predict$
@@ -77,13 +77,13 @@ Crash course 的课程,适合速成性的了解 AI 的基本方向和内容
### 梯度下降
-
+
假设损失函数为$y=x^2$,梯度下降的目的是快速找到导数为 0 的位置(附近)
-
+
-
+
以此类推,我们最后的 w 在 0 的附近反复横跳,最后最接近目标函数的权重 w 就是 0。
@@ -97,7 +97,7 @@ Crash course 的课程,适合速成性的了解 AI 的基本方向和内容
# 关于 MINIST
-
+
这个数据集可以说是最最经典的数据集了,里面有 0-9 这 10 个数字的手写图片和标注,正确率最高已经到了 99.7%.
diff --git a/4.人工智能/4.6.4Pytorch安装.md b/4.人工智能/4.6.4Pytorch安装.md
index d773556..c874237 100644
--- a/4.人工智能/4.6.4Pytorch安装.md
+++ b/4.人工智能/4.6.4Pytorch安装.md
@@ -4,7 +4,7 @@
进入官网后选择 Install,在下面表格中按照你的配置进行选择:
-
+
其中 Package 部分选择安装的途径,这里主要介绍 Pip 和 Conda 两种途径。
@@ -56,8 +56,8 @@ conda config --show channels
同时按下 Win+R,运行 cmd,输入 `dxdiag` 并回车。系统、显卡、声卡以及其他设备信息都会显示。
-
+
cuda 版本查看
-
+
diff --git a/4.人工智能/4.6.5.1CV领域任务(研究目标).md b/4.人工智能/4.6.5.1CV领域任务(研究目标).md
index d8cbb86..5b313cb 100644
--- a/4.人工智能/4.6.5.1CV领域任务(研究目标).md
+++ b/4.人工智能/4.6.5.1CV领域任务(研究目标).md
@@ -2,7 +2,7 @@
### CV 领域的大任务
-
+
#### (a)Image classification 图像分类
@@ -18,7 +18,7 @@
- 这张图我们需要标注两个类别 `head(头)、helmet(头盔)`
-
+
#### (c)Semantic segmentation 语义分割
@@ -32,13 +32,13 @@
#### (e)Key Point 人体关键点检测
-
+
通过人体关键节点的组合和追踪来识别人的运动和行为,对于描述人体姿态,预测人体行为至关重要。
#### (f)Scene Text Recognition(STR)场景文字识别
-
+
很多照片中都有一些文字信息,这对理解图像有重要的作用。
@@ -48,7 +48,7 @@
利用两张图片或者其他信息生成一张新的图片
-
+
利用左边两张小图生成右边的图片
@@ -56,6 +56,6 @@
将输入图片分辨率增加
-
+
当然还有一些新兴领域我们没有写入~
diff --git a/4.人工智能/4.6.5.2.1数据读取.md b/4.人工智能/4.6.5.2.1数据读取.md
index 8e9dc81..11673aa 100644
--- a/4.人工智能/4.6.5.2.1数据读取.md
+++ b/4.人工智能/4.6.5.2.1数据读取.md
@@ -117,7 +117,7 @@ Torchvision 库中的 torchvision.datasets 包中提供了丰富的图像数据
下表中列出了 torchvision.datasets 包所有支持的数据集。各个数据集的说明与接口,详见链接 [https://pytorch.org/vision/stable/datasets.html](https://pytorch.org/vision/stable/datasets.html)。
-
+
注意,torchvision.datasets 这个包本身并不包含数据集的文件本身,它的工作方式是先从网络上把数据集下载到用户指定目录,然后再用它的加载器把数据集加载到内存中。最后,把这个加载后的数据集作为对象返回给用户。
@@ -129,11 +129,11 @@ MNIST 数据集是一个著名的手写数字数据集,因为上手简单,
MNIST 数据集是 NIST 数据集的一个子集,MNIST 数据集你可以通过[这里](http://yann.lecun.com/exdb/mnist/)下载。它包含了四个部分。
-
+
MNIST 数据集是 ubyte 格式存储,我们先将“训练集图片”解析成图片格式,来直观地看一看数据集具体是什么样子的。具体怎么解析,我们在后面数据预览再展开。
-
+
接下来,我们看一下如何使用 Torchvision 来读取 MNIST 数据集。
diff --git a/4.人工智能/4.6.5.3.1AlexNet.md b/4.人工智能/4.6.5.3.1AlexNet.md
index 01fa66d..c52e06a 100644
--- a/4.人工智能/4.6.5.3.1AlexNet.md
+++ b/4.人工智能/4.6.5.3.1AlexNet.md
@@ -12,21 +12,21 @@ AlexNet 有 6 千万个参数和 650,000 个神经元。
### 网络框架图
-
+
### 使用 ReLU 激活函数代替 tanh
在当时,标准的神经元激活函数是 tanh()函数,这种饱和的非线性函数在梯度下降的时候要比非饱和的非线性函数慢得多,因此,在 AlexNet 中使用 ReLU 函数作为激活函数。
-
+
### 采用 Dropout 防止过拟合
dropout 方法会遍历网络的每一层,并设置消除神经网络中节点的概率。假设网络中的每一层,每个节点都以抛硬币的方式设置概率,每个节点得以保留和消除的概率都是 0.5,设置完节点概率,我们会消除一些节点,然后删除掉从该节点进出的连线,最后得到一个节点更少,规模更小的网络(如下图所示),然后再用反向传播方法进行训练。
-
+
-
+
###
diff --git a/4.人工智能/4.6.5.3.2FCN.md b/4.人工智能/4.6.5.3.2FCN.md
index 6eaf637..ba2c1b5 100644
--- a/4.人工智能/4.6.5.3.2FCN.md
+++ b/4.人工智能/4.6.5.3.2FCN.md
@@ -10,7 +10,7 @@
### 框架图
-
+
### 同 CNN 的对比
@@ -26,7 +26,7 @@ FCN 对图像进行像素级的分类,从而解决了语义级别的图像分
这里图像的反卷积使用了这一种反卷积手段使得图像可以变大,FCN 作者使用的方法是这里所说反卷积的一种变体,这样就可以获得相应的像素值,图像可以实现 end to end。
-
+
### 视频
diff --git a/4.人工智能/4.6.5.3.3ResNet.md b/4.人工智能/4.6.5.3.3ResNet.md
index d2eff34..22e5bf5 100644
--- a/4.人工智能/4.6.5.3.3ResNet.md
+++ b/4.人工智能/4.6.5.3.3ResNet.md
@@ -21,11 +21,11 @@
如图所示,随着层数越来越深,预测的效果反而越来越差(error 越大)
-
+
# 网络模型
-
+
我们可以看到,ResNet 的网络依旧非常深,这是因为研究团队不仅发现了退化现象,还采用出一个可以将网络继续加深的 trick:shortcut,亦即我们所说的 residual。
@@ -34,7 +34,7 @@
## residual 结构
-
+
# 网络代码
diff --git a/4.人工智能/4.6.5.3.4UNet.md b/4.人工智能/4.6.5.3.4UNet.md
index 7dbfd95..dc02f06 100644
--- a/4.人工智能/4.6.5.3.4UNet.md
+++ b/4.人工智能/4.6.5.3.4UNet.md
@@ -8,7 +8,7 @@
### 网络框架
-
+
2015 年,OlafRonneberger 等人提出了 U-net 网络结构,U-net 网络是基于 FCN 的一种语义分割网络,适用于做医学图像的分割
diff --git a/4.人工智能/4.6.5.3.7还要学更多?.md b/4.人工智能/4.6.5.3.7还要学更多?.md
index ea52576..ee633e0 100644
--- a/4.人工智能/4.6.5.3.7还要学更多?.md
+++ b/4.人工智能/4.6.5.3.7还要学更多?.md
@@ -6,11 +6,11 @@
- 你可以先行尝试一下怎么把在 MNIST 上训练的网络真正投入应用,比如识别一张你自己用黑笔写的数字~
-
+
- 比如你可以尝试训练一个网络来实现人体五官分割(笔者之前就玩过这个)数据集采用 [helen 数据集](https://pages.cs.wisc.edu/~lizhang/projects/face-parsing/),关于数据集的架构你可以搜一搜,自己设计一个 Dataloader 和 YourModle 来实现前言中的五官分割效果(真的很有乐子 hhh)
-
+
- 当然你也可以尝试一些自己感兴趣的小任务来锻炼工程能力~
diff --git a/4.人工智能/4.6.5.4.1NeRF.md b/4.人工智能/4.6.5.4.1NeRF.md
index bf77942..3a9ed3c 100644
--- a/4.人工智能/4.6.5.4.1NeRF.md
+++ b/4.人工智能/4.6.5.4.1NeRF.md
@@ -6,11 +6,11 @@ NeRF 想做这样一件事,不需要中间三维重建的过程,仅根据位
在生成建模前,我们需要对被建模物体进行密集的采样,如下图是一个示例的训练集,它含有 100 张图片以及保存了每一张图片相机参数(表示拍摄位置,拍摄角度,焦距的矩阵)的 json 文件。
-
+
你可以看到,这 100 张图片是对一个乐高推土机的多角度拍摄结果。我们需要的是一个可以获取这个推土机在任意角度下拍摄的图片的模型。如图所示:
-
+
现在来看 NeRF 网络:
@@ -43,7 +43,7 @@ NeRF 想做这样一件事,不需要中间三维重建的过程,仅根据位
- 对应的小方块的 RGB 信息
- 不透明度
-
+
在这里,作者选择了最简单的 MLP,因此,这是一个输入为 5 维,输出为 4 维向量(
$$
@@ -98,7 +98,7 @@ $$
这段要仔细看和推导,第一遍不容易直接懂。顺带一提,我们的小方块学名叫体素,为了显得我们更专业一点以后就叫它体素罢
-
+
上面所说的公式具体如下:t 是我们的
$$
@@ -112,11 +112,11 @@ $$
分别是离发射点最远的体素和最近的体素。这个公式求得是像素的颜色。
-
+
思路总体如上,这里放一张找来的渲染过程示意图(不知道为什么有点包浆)
-
+
# 算法细节部分
@@ -136,10 +136,10 @@ $$
粗网络就是上述采样方法用的普通网络,而粗网络输出的不透明度值会被作为一个概率分布函数,精细网络根据这个概率分布在光线上进行采样,不透明度越大的点,它的邻域被采样的概率越大,也就实现了我们要求的在实体上多采样,空气中少采样。最后精细网络输出作为结果,因此粗网络可以只求不透明度,无视颜色信息。
-
+
## 位置编码
学过 cv 的大家想必对这个东西耳熟能详了吧~,这里的位置编码是对输入的两个位置和一个方向进行的(体素位置,相机位置和方向),使用的是类似 transformer 的三角函数类编码如下。位置编码存在的意义是放大原本的 5 维输入对网络的影响程度,把原本的 5D 输入变为 90 维向量;并且加入了与其他体素的相对位置信息。
-
+
diff --git a/4.人工智能/4.6.5.4.2NeRF的改进方向.md b/4.人工智能/4.6.5.4.2NeRF的改进方向.md
index 19238aa..2d74469 100644
--- a/4.人工智能/4.6.5.4.2NeRF的改进方向.md
+++ b/4.人工智能/4.6.5.4.2NeRF的改进方向.md
@@ -12,19 +12,19 @@
Pixel-nerf 对输入图像使用卷积进行特征提取再执行 nerf,若有多个输入,对每个视角都执行 CNN,在计算光线时,取每一个已有视角下该坐标的特征,经过 mlp 后算平均。可以在少量视角下重建视图,需要进行预训练才能使用,有一定自动补全能力(有限)
-
+
### 2.IBRnet
IBRnet 是 pixel-nerf 的改进版,取消了 CNN,并且在 mlp 后接入了 transformer 结构处理体密度(不透明度),对这条光线上所有的采样点进行一个 transformer。同时,在获取某个体素的颜色和密度时,作者用了本视角相邻的两个视角,获取对应体素在这两张图片中的像素,以图片像素颜色,视角,图片特征作为 mlp 的输入。
-
+
### 3.MVSnerf
MVSnerf 它用 MVS 的方法构建代价体然后在后面接了一个 nerf,MVS 是使用多视角立体匹配构建一个代价体,用 3D 卷积网络进行优化,这里对代价体进行 nerf 采样,可以得到可泛化网络。它需要 15min 的微调才能在新数据上使用。多视角立体匹配是一种传统算法,通过光线,几何等信息计算图像中小块的相似度,得出两个相机视角之间的位置关系。这个算法也被广泛使用在得到我们自己采样的数据的相机变换矩阵上(我就是这么干的)
-
+
此处涉及较多图形学,使用了平面扫描算法,其中有单应性变换这个角度变换算法,推导与讲解如下:
@@ -34,7 +34,7 @@
平面扫描就是把 A 视角中的某一像素点(如图中红色区域)的相邻的几个像素提取出来,用单应性变换转换到 B 视角中,这时候用的深度是假设的深度,遍历所有假设的深度,计算通过每一个假设深度经过单应性变换得到的像素小块和 B 视角中对应位置的差值(loss),取最小的 loss 处的深度作为该像素的深度。
-
+
构建代价体:
@@ -55,7 +55,7 @@
展开说说:其实这也是神经网络发展的一个方向,以前的深层网络倾向于把所有东西用网络参数表示,这样推理速度就会慢,这里使用哈希表的快速查找能力存储一些数据信息,instant-ngp 就是把要表达的模型数据特征按照不同的精细度存在哈希表中,使用时通过哈希表调用或插值调用。
-
+
# 3.可编辑(指比如人体运动等做修改工作的)
@@ -63,7 +63,7 @@
Human-nerf 生成可编辑的人体运动视频建模,输入是一段人随便动动的视频。输出的动作可以编辑修改,并且对衣物折叠等有一定优化。使用的模型并非全隐式的,并且对头发和衣物单独使用变换模型。使用了逆线性蒙皮模型提取人物骨骼(可学习的模型),上面那个蓝色的就是姿态矫正模块,这个模块赋予骨骼之间运动关系的权重(因为使用的是插值处理同一运动时不同骨骼的平移旋转矩阵,一块骨骼动会牵动其他骨骼)图中的 Ω 就是权重的集合,它通过 mlp 学习得到。然后得到显式表达的人物骨骼以及传入视频中得到的对应骨骼的 mesh,skeletal motion 就是做游戏人物动作用的编辑器这种,后面残差链接了一个 non-rigid-motion(非刚性动作),这个是专门处理衣物和毛发的,主要通过学习得到,然后粗暴的加起来就能得到模型,再经过传统的 nerf 渲染出图像。
-
+
### 2.Neural Body
@@ -75,7 +75,7 @@
EasyMocap 是通过多视角视频生成骨架以及 SMPL 模型的一个工作,演示视频右下。
-
+
这是 EasyMocap 的演示。
@@ -87,7 +87,7 @@ EasyMocap 是通过多视角视频生成骨架以及 SMPL 模型的一个工作
是个预训练模型,训练的模块就是这个 3D 卷积神经网络。
-
+
### 3.wild-nerf
@@ -101,11 +101,11 @@ EasyMocap 是通过多视角视频生成骨架以及 SMPL 模型的一个工作
在此网络的单个输出上貌似是不监督的,因为没办法进行人为标注。这点我不是很确定,以后如果发现了会来修改的。
-
+
渲染经过形变的物体时,光线其实是在 t=0 时刻进行渲染的,因为推土机的铲子放下去了,所以光线是弯曲的。
-
+
# 4.用于辅助传统图像处理
@@ -123,23 +123,23 @@ EasyMocap 是通过多视角视频生成骨架以及 SMPL 模型的一个工作
GRAF 把 GAN 与 nerf 结合,增加了两个输入,分别是外观/形状编码 z和2D 采样编码 v,z 用来改变渲染出来东西的特征,比如把生成的车变色或者变牌子,suv 变老爷车之类的。v(s,u)用来改变下图 2 中训练时选择光线的标准。这里训练时不是拿 G 生成的整张图扔进 D 网络,而是根据 v 的参数选择一些光线组成的 batch 扔进 D 进行辨别
-
+
-
+
### 2.GIRAFFE
GIRAFFE 是 GRAF 的改进工作,可以把图片中的物品,背景一个个解耦出来单独进行改变或者移动和旋转,也可以增加新的物品或者减少物品,下图中蓝色是不可训练的模块,橙色可训练。以我的理解好像要设置你要解耦多少个(N)物品再训练,网络根据类似 k 近邻法的方法在特征空间上对物品进行分割解耦,然后分为 N 个渲染 mlp 进行训练,训练前加入外观/形状编码 z。最后还是要扔进 D 训练。
-
+
-
+
### 3.OSF
OSFObject-Centric Neural Scene Rendering,可以给移动的物体生成合理的阴影和光照效果。加入了新的坐标信息:光源位置,与相机坐标等一起输入。对每个小物件构建一个单独的小 nerf,计算这个小 nerf 的体素时要先经过光源照射处理(训练出来的)然后在每个小物件之间也要计算反射这样的光线影响,最后进行正常的渲染。这篇文章没人写 review,有点冷门,这些都是我自己读完感觉的,不一定对。
-
+
### 4.Hyper-nerf-gan
@@ -153,7 +153,7 @@ EasyMocap 是通过多视角视频生成骨架以及 SMPL 模型的一个工作
左边是常规卷积网络生成图像,右边是用 INR 生成图像。
-
+
这种方法存在两个问题:
@@ -165,8 +165,8 @@ EasyMocap 是通过多视角视频生成骨架以及 SMPL 模型的一个工作
FMM 主要是把要学习的矩阵转化为两个低秩矩阵,去先生成他们俩再相乘,减少网络计算量。
-
+
现在开始讲 Hyper-nerf-gan 本身,它看上去其实就是 nerf 接在 gan 上。不过有一些变化,比如输入不再包含视角信息,我很怀疑它不能很好表达反光效果。而且抛弃了粗网络细网络的设计,只使用粗网络减少计算量。这里的 generator 完全就是 INR-Gan 的形状,生成权重,然后再经过 nerf 的 mlp 层生成,没啥别的了,就这样吧。
-
+
diff --git a/4.人工智能/4.6.5.4.3自制数据集的工具COLMAP.md b/4.人工智能/4.6.5.4.3自制数据集的工具COLMAP.md
index bf2295f..0dd2147 100644
--- a/4.人工智能/4.6.5.4.3自制数据集的工具COLMAP.md
+++ b/4.人工智能/4.6.5.4.3自制数据集的工具COLMAP.md
@@ -2,7 +2,7 @@
如何使用和怎么下载就不讲了,直接搜就有,它可以把多个拍摄同一物体的图片转换为它们对应视角的相机矩阵和拍摄角度,可以实现自制数据集做 nerf。它的流程(SFM 算法)可以概括如下:
-
+
这里主要是记录一下它的原理:
首先是一个经典关键点匹配技术:SIFT
@@ -11,53 +11,53 @@
## DOG 金字塔
-
+
-
+
下面是原理方法:
首先是高斯金字塔,它是把原图先放大两倍,然后使用高斯滤波(高斯卷积)对图像进行模糊化数次,取出倒数第三层缩小一半继续进行这个过程,也就是说它是由一组一组的小金字塔组成的。
-
+
-
+
然后是基于高斯金字塔的 DOG 金字塔,也叫差分金字塔,它是把相邻的高斯金字塔层做减法得到的,因为经过高斯模糊,物体的轮廓(或者说不变特征)被模糊化,也就是被改变。通过相减可以得到这些被改变的点。
-
+
-
+
## 空间极值点检测
为了找到变化的最大的几个点来作为特征点,我们需要找到变化的极值点,因此需要进行比较,这里是在整个金字塔中进行对比,我们提取某个点周边 3*3*3 的像素点进行比较,找到最大或最小的局部极值点。
-
+
同时我们也对关键点分配方向,也就是这个点在图片空间中的梯度方向
梯度为:
-
+
梯度方向为:
-
+
我们计算以关键点为中心的邻域内所有点的梯度方向,然后把这些 360 度范围内的方向分配到 36 个每个 10 度的方向中,并构建方向直方图,这里的示例使用了 8 个方向,几个随你其实:
-
+
取其中最大的为主方向,若有一个方向超过主方向的 80%,那么把它作为辅方向。
操作可以优化为下图,先把关键点周围的像素分成 4 块,每块求一次上面的操作,以这个 4 个梯度直方图作为关键点的方向描述。也就是一个 2*2*8(方向数量)的矩阵作为这个点的方向特征。
-
+
实验表明,使用 4*4*8=122 的描述更加可靠。
-
+
特征点的匹配是通过计算两组特征点的 128 维的关键点的欧式距离实现的。欧式距离越小,则相似度越高,当欧式距离小于设定的阈值时,可以判定为匹配成功。
diff --git a/4.人工智能/4.6.6.1NLP领域任务(研究目标).md b/4.人工智能/4.6.6.1NLP领域任务(研究目标).md
index ca62ca2..28f933c 100644
--- a/4.人工智能/4.6.6.1NLP领域任务(研究目标).md
+++ b/4.人工智能/4.6.6.1NLP领域任务(研究目标).md
@@ -4,25 +4,25 @@
分类 (text classification): 给一句话或者一段文本,判断一个标签。
-
+
图 2:分类 (text classification)
蕴含 (textual entailment): 给一段话,和一个假设,看看前面这段话有没有蕴含后面的假设。
-
+
图 3:蕴含 (textual entailment)
相似 (Similarity): 判断两段文字是否相似。
-
+
图 4:相似 (Similarity)
多选题 (Multiple Choice): 给个问题,从 N 个答案中选出正确答案。
-
+
图 5:多选题 (Multiple Choice)
diff --git a/4.人工智能/4.6.6.2.3序列化推荐.md b/4.人工智能/4.6.6.2.3序列化推荐.md
index f4d9e95..312ee80 100644
--- a/4.人工智能/4.6.6.2.3序列化推荐.md
+++ b/4.人工智能/4.6.6.2.3序列化推荐.md
@@ -10,5 +10,5 @@
而SRSs则是将用户和商品的交互建模为一个动态的序列并且利用序列的依赖性来活捉当前和最近用户的喜好。
-
+
diff --git a/4.人工智能/4.6.6.2推荐系统.md b/4.人工智能/4.6.6.2推荐系统.md
index c3f28c8..b7d488b 100644
--- a/4.人工智能/4.6.6.2推荐系统.md
+++ b/4.人工智能/4.6.6.2推荐系统.md
@@ -4,7 +4,7 @@
如下图是阿里巴巴著名的“千人千面”推荐系统
-
+
还有短视频应用用户数量的急剧增长,这背后,视频推荐引擎发挥着不可替代的作用
diff --git a/4.人工智能/4.6.7.1VIT.md b/4.人工智能/4.6.7.1VIT.md
index 33ef80b..c4d1419 100644
--- a/4.人工智能/4.6.7.1VIT.md
+++ b/4.人工智能/4.6.7.1VIT.md
@@ -13,7 +13,7 @@
## 模型详解
-
+
### 模型主题结构
@@ -46,9 +46,9 @@
例如
-
+
-
+
其中该张图片的编码为[0.5,0.6,0.3,....]
diff --git a/4.人工智能/4.6.7.2BERT.md b/4.人工智能/4.6.7.2BERT.md
index 6fb482b..09fbc71 100644
--- a/4.人工智能/4.6.7.2BERT.md
+++ b/4.人工智能/4.6.7.2BERT.md
@@ -30,13 +30,13 @@ mlp 的重点和创新并非它的模型结构,而是它的训练方式,前
BERT 模型的输入就是上面三者的和,如图所示:
-
+
## 模型结构
简单来说,BERT 是 transformer编码器的叠加,也就是下图左边部分。这算一个 block。
-
+
说白了就是一个 多头自注意力=>layer-norm=> 接 feed forward(其实就是 mlp)=>layer-norm,没有什么创新点在这里。因为是一个 backbone 模型,它没有具体的分类头之类的东西。输出就是最后一层 block 的输出。
diff --git a/4.人工智能/4.6.7.3MAE.md b/4.人工智能/4.6.7.3MAE.md
index 331524c..3f34265 100644
--- a/4.人工智能/4.6.7.3MAE.md
+++ b/4.人工智能/4.6.7.3MAE.md
@@ -28,7 +28,7 @@ cv 领域,其实预训练模型早已推广,一般是在 imagenet 上进行
在这里,作者为了加大任务的难度,扩大了被 mask 掉的比例,避免模型只学到双线性插值去修补缺的图像。作者把 75% 的 patch 进行 mask,然后放入模型训练。从下图可以看出,被 mask 的块是不进行编码的,这样也可以降低计算量,减少成本。
-
+
在被保留的块通过编码器后,我们再在原先位置插入只包含位置信息的 mask 块,一起放入解码器。
@@ -38,7 +38,7 @@ cv 领域,其实预训练模型早已推广,一般是在 imagenet 上进行
下面是原论文给的训练结果,可以看到效果是很惊人的。(有些图我脑补都补不出来)
-
+
# 相关资料
diff --git a/4.人工智能/4.6.8.1前言.md b/4.人工智能/4.6.8.1前言.md
index 709fe6d..91210d0 100644
--- a/4.人工智能/4.6.8.1前言.md
+++ b/4.人工智能/4.6.8.1前言.md
@@ -24,7 +24,7 @@
直观来讲,我们把特征的向量进行一下归一化,它们就分布在一个超球面上。简单起见,我们先看 3 维向量
-
+
我们通过正样本(跟拿到的特征应当相近的另一个特征)与负样本(反之)的对比,使得
diff --git a/4.人工智能/4.6.8.2Inst Disc.md b/4.人工智能/4.6.8.2Inst Disc.md
index a10b25b..108f14f 100644
--- a/4.人工智能/4.6.8.2Inst Disc.md
+++ b/4.人工智能/4.6.8.2Inst Disc.md
@@ -8,7 +8,7 @@
作者团队认为,让这些猎豹,雪豹的标签相互接近(指互相在判别时都排名靠前)的原因并不是它们有相似的标签,而是它们有相似的图像特征。
-
+
## 个体判别任务
@@ -16,7 +16,7 @@
于是他们把每一个图片当作一个类别,去跟其他的图片做对比,具体模型如下
-
+
先介绍一下模型结构:
@@ -48,11 +48,11 @@
A 是起始点,B 是第一次更新后的点,C 是第二次更新后的点
-
+
而在我们刚刚提到的动量更新里,它的公式可以概括为:
-
+
m 表示动量,k 是新的特征,q 是上一个特征,只要设置小的动量就可以使改变放缓。
diff --git a/4.人工智能/4.6.8.3定义正负样本的方式.md b/4.人工智能/4.6.8.3定义正负样本的方式.md
index f78330e..11e65b6 100644
--- a/4.人工智能/4.6.8.3定义正负样本的方式.md
+++ b/4.人工智能/4.6.8.3定义正负样本的方式.md
@@ -4,7 +4,7 @@
# 1.时序性定义(生成式模型)
-
+
这是处理音频的一个例子,给模型 t 时刻以前的信息,让它抽取特征并对后文进行预测,真正的后文作为正样本,负样本当然是随便选取就好啦。
@@ -24,4 +24,4 @@
(这篇论文我准备开个新坑放着了,因为说实话不算对比学习,算多模态)
-
+
diff --git a/4.人工智能/4.6.8.4MoCo.md b/4.人工智能/4.6.8.4MoCo.md
index 0c8aead..3288838 100644
--- a/4.人工智能/4.6.8.4MoCo.md
+++ b/4.人工智能/4.6.8.4MoCo.md
@@ -24,7 +24,7 @@ NCE 把所有负样本都视作一样的,但实际上负样
右边就是 memory bank 啦
-
+
# MoCo 做出的改进
@@ -38,7 +38,7 @@ NCE 把所有负样本都视作一样的,但实际上负样
动量编码器是独立于原编码器的一个编码器,它的参数是根据原编码器动量更新的,k 和 q 就是指代全部参数了
-
+
这样的话就是解码器在缓慢更新,比对特征使用动量更新要更有连续性。
@@ -48,7 +48,7 @@ NCE 把所有负样本都视作一样的,但实际上负样
[(什么?你看到这了还不会交叉熵?戳这里)](https://zhuanlan.zhihu.com/p/149186719)
-
+
q·k 其实就是各个特征(因为那时候用的都是 transformer 了,这里就是 trnasformer 里的 k 和 q)
@@ -56,9 +56,9 @@ q·k 其实就是各个特征(因为那时候用的都是 transformer 了,
T 越大,损失函数就越对所有负样本一视同仁,退化为二分类的 NCEloss;T 越小,损失函数就越关注一些难分类的特征,但有时候会出现两张其实都是猫猫的图片,你硬要让模型说猫猫跟猫猫不一样,这也不太好,这个参数要根据数据集情况适中调整。
-
+
-
+
上面那张是 T 较大的情况,下面是 T 较小的情况(x 轴是各个类别,y 轴是分类得分)
diff --git a/4.人工智能/4.6.8.5SimCLR.md b/4.人工智能/4.6.8.5SimCLR.md
index c83f063..58696f0 100644
--- a/4.人工智能/4.6.8.5SimCLR.md
+++ b/4.人工智能/4.6.8.5SimCLR.md
@@ -6,7 +6,7 @@
x 是输入的图片,它经过两种不同的数据增强得到 xi 和 xj 两个正样本,而同一个 mini-batch 里的所有其他样本都作为负样本。说白了还是个体判别任务
-
+
左右的f 都是编码器,并且是完全一致共享权重的,可以说是同一个。
@@ -18,7 +18,7 @@ x 是输入的图片,它经过两种不同的数据增强得到 xi 和 xj 两
下面这个是更加具体的流程图
-
+
# 总结
diff --git a/4.人工智能/4.6.8.6SwAV.md b/4.人工智能/4.6.8.6SwAV.md
index dfe140c..53db0b4 100644
--- a/4.人工智能/4.6.8.6SwAV.md
+++ b/4.人工智能/4.6.8.6SwAV.md
@@ -20,7 +20,7 @@
下图左边是常规的对比学习(比如 SimCLR)的结构,右图是 SWAV 的结构,不难看出多了一个叫 prototypes 的东西。这个东西其实是聚类中心向量所构成的矩阵。
-
+
下面的内容可能有些理解上的难度(反正我第一次听讲解的时候就云里雾里的),我会尽可能直白地描述这个过程。
@@ -40,7 +40,7 @@
而我们的优化要采用 [K-means](https://zhuanlan.zhihu.com/p/78798251)(不懂可以看这里)的类似做法,先对聚类中心进行优化,再对特征进行优化。
-
+
so,why?相信你现在肯定是一脸懵,不过别急,希望我能为你讲懂。
diff --git a/4.人工智能/4.6.8.7BYOL.md b/4.人工智能/4.6.8.7BYOL.md
index 89d2bb2..1c4afd7 100644
--- a/4.人工智能/4.6.8.7BYOL.md
+++ b/4.人工智能/4.6.8.7BYOL.md
@@ -18,7 +18,7 @@
predictor的模型结构就是跟 z 一样的mlp 层。它的任务是通过紫色的特征去预测粉色的特征。也就是说它的代理任务换成了生成式。
-
+
而具体的损失只有预测特征和真实特征的损失,用的是MSEloss。
@@ -32,7 +32,7 @@
### 有篇博客在复现 BYOL 时,不小心没加这个 BN 层,导致模型直接摆烂。那么 BN 到底藏着什么呢?
-
+
我们得先来回顾一下 BN 做了什么。
@@ -52,7 +52,7 @@ BN 根据批次的均值和方差进行归一化
这篇论文叫 BYOL works even without batch statistics,即在没有 BN 的时候 BYOL 照样能工作,详细的消融实验结果如下表所示 :
-
+
BN 非常关键:只要是 `projector`(SimCLR 提出的 mlp)中没有 BN 的地方,SimCLR 性稍微下降;但是 BYOL 全都模型坍塌了。
diff --git a/4.人工智能/4.6.8.8SimSiam.md b/4.人工智能/4.6.8.8SimSiam.md
index f0467f9..88bc544 100644
--- a/4.人工智能/4.6.8.8SimSiam.md
+++ b/4.人工智能/4.6.8.8SimSiam.md
@@ -20,7 +20,7 @@ BYOL 之后,大家都发现对比学习是靠许许多多的小 trick 和技
虽然看起来只有左边预测右边,其实右边也有一个 predictor 去预测左边的特征,两边是对称的,左右的优化有先后顺序。
-
+
结构其实没什么特殊的地方,主要讲讲思想。
@@ -44,7 +44,7 @@ BYOL 之后,大家都发现对比学习是靠许许多多的小 trick 和技
这是作者总结的所有”孪生网络“的模型结构,很精炼。
-
+
下面是这些网络训练结果的对比,也列出了它们分别有哪些 trick(用的是分类任务)
@@ -52,8 +52,8 @@ BYOL 之后,大家都发现对比学习是靠许许多多的小 trick 和技
负样本 动量编码器 训练轮数
```
-
+
具体结果还是图片比较直观(
-
+
diff --git a/4.人工智能/4.6.8.9MoCo v3.md b/4.人工智能/4.6.8.9MoCo v3.md
index a0309cd..8613747 100644
--- a/4.人工智能/4.6.8.9MoCo v3.md
+++ b/4.人工智能/4.6.8.9MoCo v3.md
@@ -10,7 +10,7 @@ MoCo v3,它缝合了 MoCo 和 SimSiam,以及新的骨干网络 VIT。
可能因为和前面的工作太像了,作者就没有给模型总览图,我们借 MoCo 的总览图来讲
-
+
总体架构其实没有太多变化,还是 memory bank 的结构,右边也还是动量编码器,不过加入了 SimCLR 提出的 projection head(就是额外的那层 mlp),并且在对比上用了 SimSiam 的预测头对称学习方式。具体也不展开了,都是老东西缝合在一起。
@@ -18,11 +18,11 @@ MoCo v3,它缝合了 MoCo 和 SimSiam,以及新的骨干网络 VIT。
作者在用 VIT 做骨干网络训练的时候,发现如下问题:
-
+
在使用 VIT 训练的时候,batchsize 不算太大时训练很平滑,但是一旦 batchsize 变大,训练的图像就会出现如上图这样的波动。于是作者去查看了每一层的梯度,发现问题出在VIT 的第一层线性变换上。也就是下图中的粉色那个层,把图片打成 patch 后展平做的线性变换。
-
+
在这一层中,梯度会出现波峰,而正确率则会突然下跌。
diff --git a/4.人工智能/4.7数据分析.md b/4.人工智能/4.7数据分析.md
index a6c709a..1530782 100644
--- a/4.人工智能/4.7数据分析.md
+++ b/4.人工智能/4.7数据分析.md
@@ -33,11 +33,11 @@
# 挑战 1:泰坦尼克号数据分析
-
+
-
+
-
+
泰坦尼克号的沉没是历史上最臭名昭著的沉船事件之一。
@@ -55,7 +55,7 @@
# 挑战 2:豆瓣电影数据分析
-
+
豆瓣电影是非常好爬的网站,甚至 B 站某爬虫教程都以豆瓣电影来进行教学,你可以自行爬取豆瓣上的数据并进行相应的分析。
@@ -65,7 +65,7 @@
# 挑战 3 二手房数据分析
-
+
本课题拟收集整理城市近几年的二手房交易数据,挖掘数据信息并进行可视化分析与展示,从而帮助用户了解城市二手房的交易情况,为用户进一步决策提供帮助。
diff --git a/5.富有生命的嵌入式/5.1嵌入式是什么?可以吃吗?.md b/5.富有生命的嵌入式/5.1嵌入式是什么?可以吃吗?.md
index bb15cdb..8932e2c 100644
--- a/5.富有生命的嵌入式/5.1嵌入式是什么?可以吃吗?.md
+++ b/5.富有生命的嵌入式/5.1嵌入式是什么?可以吃吗?.md
@@ -8,7 +8,7 @@ Author:肖扬
这不是因为那些人没有完全入门嵌入式,而是因为在嵌入式的学习过程中你会发现,它的概念会越来越大,逐渐模糊了你的认知,就拿一张某乎上的照片而言:
-
+
可见嵌入式的概念之广。
@@ -20,7 +20,7 @@ Author:肖扬
这玩意儿大家估计不陌生,比如你去酒店里,也许会有一个可以坐电梯上下楼层来完成特定任务的机器人(说实话高二在某季酒店第一次见的时候还蛮新鲜)
-
+
而它也是一个嵌入式产品(或者说它们)。
diff --git a/5.富有生命的嵌入式/5.富有生命的嵌入式.md b/5.富有生命的嵌入式/5.富有生命的嵌入式.md
index 9928cb4..83497ee 100644
--- a/5.富有生命的嵌入式/5.富有生命的嵌入式.md
+++ b/5.富有生命的嵌入式/5.富有生命的嵌入式.md
@@ -16,6 +16,6 @@ Author:肖扬
> “点星星之火,燃燎原之势,热血芳华,理想当燃”
-
+
ps:若对此部分讲义有相关疑问或者建议,欢迎 QQ 联系-1213047454
diff --git a/6.计算机安全/6.1.1SQL 注入.md b/6.计算机安全/6.1.1SQL 注入.md
index a7631b5..149456d 100644
--- a/6.计算机安全/6.1.1SQL 注入.md
+++ b/6.计算机安全/6.1.1SQL 注入.md
@@ -34,7 +34,7 @@ def check_pass(username, password):
从 `users` 表中查出 `username` 对应的 `password` 的哈希值,将其与用户传入的密码哈希值进行比对,若相等则意味着用户传入的密码与数据库中储存的密码相吻合,于是返回准许登录
-
+
那么问题来了,在语句
@@ -144,7 +144,7 @@ mysql> select group_concat(id,username separator '_') from users;
现在我们传入 `Liki4'` 这个字符串
-
+
很遗憾,报错了,这个查询因为 SQL 语句存在语法错误而无法完成。
@@ -154,7 +154,7 @@ mysql> select group_concat(id,username separator '_') from users;
那如果我们传入 `Liki4';#` 这个字符串,那么在拼接后的查询又是什么结果呢
-
+
很显然,`#` 号将原本语句的 `';` 注释掉了
@@ -166,7 +166,7 @@ mysql> select group_concat(id,username separator '_') from users;
`raw_sql_danger' UNION SELECT password FROM users WHERE username = 'Liki5';#`
-
+
真是惊人的壮举!我完全不认识这个叫 Liki5 的家伙,但我居然知道了他的密码对应的哈希值!
@@ -273,7 +273,7 @@ if __name__ == "__main__":
接下来我们进行一次常规查询
-
+
可以看到我们成功从数据库中查出了 `username` 和 `password`,并显示在返回中
@@ -293,7 +293,7 @@ def query(username):
...
```
-
+
可以看到,实际执行的语句为
@@ -307,7 +307,7 @@ SELECT * FROM users WHERE username = '123' UNION SELECT 1, 2;#'
构造语句 `123' UNION SELECT DATABASE(), @@version;#`
-
+
我们就能看到返回中包含了当前数据库名与当前数据库版本
@@ -317,13 +317,13 @@ SELECT * FROM users WHERE username = '123' UNION SELECT 1, 2;#'
> `information_schema` 库是一个 MySQL 内置数据库,储存了数据库中的一些基本信息,比如数据库名,表名,列名等一系列关键数据,SQL 注入中可以查询该库来获取数据库中的敏感信息。
-
+
我们可以发现,当前数据库中还存在一张叫 `secret` 的表,让我们偷看一下里面存的是什么
构造语句 `123' UNION SELECT 1, secret_string FROM secret;#`
-
+
好像得到了什么不得了的秘密 :-)
@@ -363,7 +363,7 @@ if __name__ == "__main__":
这样一来我们就只能知道自己是否登录成功,并不能看到查询返回的结果了
-
+
那也就是说,我们无法直观地查看数据库中的数据了,即便查出了不该查的也看不到了 :-(
@@ -396,7 +396,7 @@ else:
> rlike 是 MySQL 中的一个关键字,是 regex 和 like 的结合体
-
+
这里实际执行的语句就变成了
@@ -404,13 +404,13 @@ else:
SELECT password FROM users WHERE username = 'Liki4' AND if(@@version rlike '^5',1,0);
```
-
+
```sql
SELECT password FROM users WHERE username = 'Liki4' AND if(@@version rlike '^8',1,0);
```
-
+
也就是说,当 if 语句中的条件为真时,这个查询才会将 password 查询出来
@@ -480,7 +480,7 @@ if __name__ == "__main__":
exp()
```
-
+
####
@@ -523,7 +523,7 @@ if __name__ == "__main__":
如果想要让布尔盲注不可用,我们可以做一个假设,假设我们并不知道账户的密码,也就无法通过登陆验证,这个时候就失去了布尔盲注最大的依赖,也就无法得知 if 表达式的真或假了。
-
+
但,真的没办法了吗?
@@ -600,7 +600,7 @@ if __name__ == "__main__":
exp()
```
-
+
### 基于报错的 SQL 注入 (TODO)
@@ -640,7 +640,7 @@ if __name__ == "__main__":
main()
```
-
+
这样一来如果 SQL 语句执行报错的话,错误信息就会被打印出来
@@ -671,9 +671,9 @@ MySQL 8.0 doc: [https://dev.mysql.com/doc/refman/8.0/en/](https://dev.mysql.com/
`Liki4';INSERT INTO users VALUES ('Liki3','01848f8e70090495a136698a41c5b37406968c648ab12133e0f256b2364b5bb5');#`
-
+
-
+
INSERT 语句也被成功执行了,向数据库中插入了 Liki3 的数据
@@ -776,7 +776,7 @@ INSERT 语句也被成功执行了,向数据库中插入了 Liki3 的数据
在 GB2312、GBK、GB18030、BIG5、Shift_JIS 等编码下来吃掉 ASCII 字符的方法,可以用来绕过 `addslashes()`
`id=0%df%27%20union%20select%201,2,database();`
-
+
### information_schema 被过滤
@@ -795,7 +795,7 @@ select table_name from mysql.innodb_index_stats where database_name=database
select table_name from mysql.innodb_table_stats where database_name=database();
```
-
+
##### MySQL 5.7 的新特性
@@ -812,7 +812,7 @@ select table_name from sys.schema_table_statistics_with_buffer where table_schem
select table_name from sys.x$schema_table_statistics_with_buffer where table_schema=database();
```
-
+
### 无列名注入
@@ -820,7 +820,7 @@ select table_name from sys.x$schema_table_statistics_with_buffer where table_sch
`select a,b from (select 1 as a, 2 as b union select * from users)x;`
-
+
## 超脱 MySQL 之外 (TODO)
diff --git a/6.计算机安全/6.2.2软件破解、软件加固.md b/6.计算机安全/6.2.2软件破解、软件加固.md
index e0077ad..9f6627e 100644
--- a/6.计算机安全/6.2.2软件破解、软件加固.md
+++ b/6.计算机安全/6.2.2软件破解、软件加固.md
@@ -45,7 +45,7 @@ ESP 定律的原理在于利用程序中堆栈平衡来快速找到 OEP.
还是上一篇的示例, 入口一句 `pushad`, 我们按下 F8 执行 `pushad` 保存寄存器状态, 我们可以在右边的寄存器窗口里发现 `ESP` 寄存器的值变为了红色, 也即值发生了改变.
-
+
我们鼠标右击 `ESP` 寄存器的值, 也就是图中的 `0019FF64`, 选择 `HW break[ESP]` 后, 按下 `F9` 运行程序, 程序会在触发断点时断下. 如图来到了 `0040D3B0` 的位置. 这里就是上一篇我们单步跟踪时到达的位置, 剩余的就不再赘述.
diff --git a/7.Web开发入门/7.1.1基础部分.md b/7.Web开发入门/7.1.1基础部分.md
index c1a76bc..c5766f2 100644
--- a/7.Web开发入门/7.1.1基础部分.md
+++ b/7.Web开发入门/7.1.1基础部分.md
@@ -45,13 +45,13 @@
设计稿如下:
-
+
#### 可能需要用到的图片资源
-
+
-
+
#### 基本要求
@@ -93,9 +93,9 @@
### 🎫TodoList
-
+
-
+
一些参考
@@ -121,7 +121,7 @@
- 实现不同设备屏幕尺寸的自适应
- 添加任务热力图(可以参考一下 GitHub 个人主页哦 🤔)
-
+
#### 可能涉及的知识点
diff --git a/7.Web开发入门/7.1.2进阶部分.md b/7.Web开发入门/7.1.2进阶部分.md
index b436e57..778e4ef 100644
--- a/7.Web开发入门/7.1.2进阶部分.md
+++ b/7.Web开发入门/7.1.2进阶部分.md
@@ -10,11 +10,11 @@
如果你曾经用过助手的小程序,你可能会在首页看到这样的天气卡片:
-
+
当然了,平时大家也会用到各种天气 APP
-
+
那么,让我们动手实现一个天气卡片吧~
@@ -63,9 +63,9 @@
## 🎶 音乐播放器
-
+
-
+
相信你平时或多或少都会听音乐,那么你是喜欢用网易云还是 QQ 音乐呢?或者是系统自带的音乐播放器?不过,其实你也可以自己做一个音乐播放器,来满足你对听音乐这件事的所有幻想,听起来是不是很酷呢 😎~那么,来试试看吧!
diff --git a/7.Web开发入门/7.Web开发入门.md b/7.Web开发入门/7.Web开发入门.md
index 2d9ba5e..7004859 100644
--- a/7.Web开发入门/7.Web开发入门.md
+++ b/7.Web开发入门/7.Web开发入门.md
@@ -107,7 +107,7 @@ A:理论上可以。但一般不会这么做(除了一些实时的网络聊
登登登,后端登场!
-
+
解释一下:
diff --git a/8.基础学科/8.2定积分.md b/8.基础学科/8.2定积分.md
index d66dd70..55aabf3 100644
--- a/8.基础学科/8.2定积分.md
+++ b/8.基础学科/8.2定积分.md
@@ -1,5 +1,5 @@
本文主要讲解定积分在计算时运用的各种化简技巧。
-
+
# 一:由不定积分计算定积分
@@ -14,7 +14,7 @@
## 2.1奇偶对称和周期性
-
+
命题1:设函数f在区间$[0,a]$可积,且关于区间中点$\frac{a}{2}$为奇函数,即对于$x\in[0,a]$,有$f(x)=-f(a-x)$,则成立
$\int_0^af(x)dx=0$。
命题2:设函数f在区间$[0,a]$可积,且关于区间中点$\frac{a}{2}$为偶函数,即对于$x\in[0,a]$,有$f(x)=f(a-x)$, 则成立
$\int_0^af(x)dx=2\int_0^{\frac{a}{2}}f(x)dx$。
命题3:若函数f为定义在$-\infty$\int_a^{a+T}f(x)dx=\int_0^Tf(x)dx$
**_Proof:_**
将积分区间拆成多段,带入上文对称公式,之后换元即可,证明的本质是统一了积分区间。
_**Example:**
$\int_0^{2\pi}\frac{dx}{sin^4x+cos^4x}$
@@ -30,7 +30,7 @@
## 3.1高阶三角函数
$I_0=\int_0^{\pi/2}dx=\pi/2$,$I_1=\int_0^{\pi/2}sinxdx=1$,$I_2=\int_0^{\pi/2}sin^2xdx=\pi/4$
思考:如果$I_n$为一数列$I_n=\int_0^{\pi/2}sin^nxdx$,请问
(1)$I_n$的递推表达式为?
(2)$I_n$的通项表达式为?
(3)$I_n(n\to\infty)$的极限为?
(4)求$\lim_{k\to\infty}\frac{I_{2k+1}}{I_{2k}}$?
答案:
(1),(2)
-
+
推论:由命题4得,对cosx做上述操作得到结果相同。
(3)$I_n(n\to\infty)$的极限为0,如图为$sin^n(x)在[0,1]$的函数图像,因为$sin^n(x)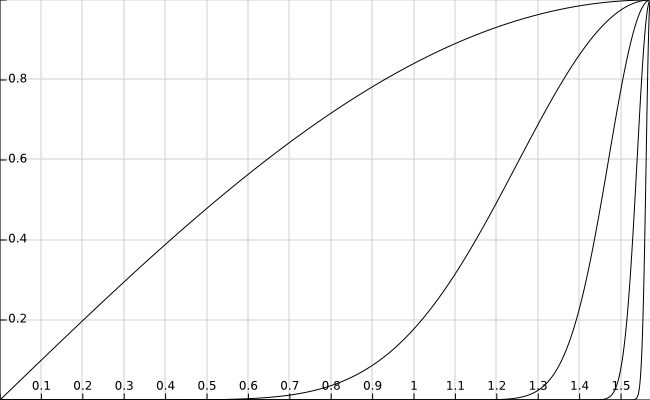
证明:
法一:积分的有界性
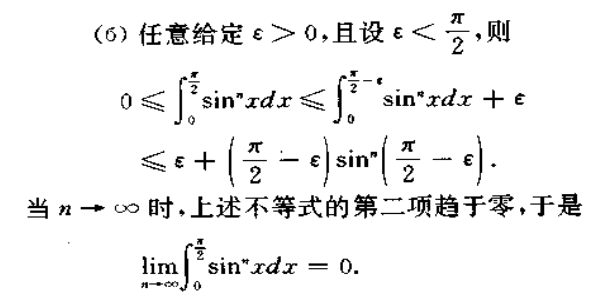
这里第二项趋于0是因为$sin^n(x)\to0$,从图中也可以观察出来。
法二:
$if\ n=2k$
$I_{2k}=\frac{(2k-1)!!}{(2k)!!}=\frac{(2k-1)\cdot(2k-3)\cdot\cdot\cdot5\cdot3\cdot1}{(2k)(2k-2)\cdot\cdot\cdot6\cdot4\cdot2}\cdot\frac{\pi}{2}$
$0$\therefore I_{2k}\to0$
$\therefore I_{2k+1}=\int_0^{\pi/2}sinx\cdot sin^{2k}xdx=sinx_0\cdot\int_0^{\pi/2}sin^{2k}xdx\to0$
$\therefore I_{n}\to0$
(4)

维基百科:[沃利斯乘积](https://zh.wikipedia.org/wiki/%E6%B2%83%E5%88%A9%E6%96%AF%E4%B9%98%E7%A7%AF)
3B1B:[沃利斯乘积的几何解释](https://www.bilibili.com/video/av22808876/)
diff --git a/README.md b/README.md
index 328220e..9422a78 100644
--- a/README.md
+++ b/README.md
@@ -12,7 +12,7 @@
 -
+
-
+
 diff --git a/contributors.md b/contributors.md
index e05c413..f4716a6 100644
--- a/contributors.md
+++ b/contributors.md
@@ -1,6 +1,6 @@
diff --git a/contributors.md b/contributors.md
index e05c413..f4716a6 100644
--- a/contributors.md
+++ b/contributors.md
@@ -1,6 +1,6 @@