Merge branch 'master' of https://github.com/E1PsyCongroo/hdu-cs-wiki
This commit is contained in:
@@ -105,7 +105,7 @@ const customElements = [
|
||||
export default withMermaid({
|
||||
lang: 'zh-CN',
|
||||
title: "HDU-CS-WIKI",
|
||||
description: "HDU计算机科学讲义",
|
||||
description: "HDU 计算机科学讲义",
|
||||
lastUpdated: true,
|
||||
head: [['script', { async: "async", src: 'https://umami.hdu-cs.wiki/script.js', "data-website-id": "3f11687a-faae-463a-b863-6127a8c28301", "data-domains": "wiki.xyxsw.site,hdu-cs.wiki" }]],
|
||||
themeConfig: {
|
||||
|
||||
@@ -24,6 +24,7 @@ export function main_sidebar() {
|
||||
{ text: '1.10如何读论文', link: '/1.杭电生存指南/1.10如何读论文' },
|
||||
{ text: '1.11陷入虚无主义?进来看看吧', link: '/1.杭电生存指南/1.11陷入虚无主义?进来看看吧' },
|
||||
{ text: '1.12选课原则与抢课技巧', link: '/1.杭电生存指南/1.12选课原则与抢课技巧' },
|
||||
{ text: '1.13数学学习篇', link: '/1.杭电生存指南/1.13数学学习篇'},
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -225,7 +226,14 @@ export function chapter3() {
|
||||
{ text: '3.6.4.6结语', link: '/3.编程思维体系构建/3.6.4.6结语' },
|
||||
]
|
||||
},
|
||||
{text: '3.6.5CS61A食用指南',link: '/3.编程思维体系构建/3.6.5CS61A食用指南'}
|
||||
{
|
||||
text: '3.6.5CS61A食用指南',
|
||||
collapsed: true,
|
||||
items: [
|
||||
{ text: '3.6.5CS61A食用指南', link: '/3.编程思维体系构建/3.6.5CS61A食用指南' },
|
||||
{ text: '3.6.5.1CS61A Sec1', link: '/3.编程思维体系构建/3.6.5.1CS61A Sec1' },
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{ text: '3.X 聊聊设计模式和程序设计', link: '/3.编程思维体系构建/3.X 聊聊设计模式和程序设计' },
|
||||
@@ -653,7 +661,12 @@ export function chapter9() {
|
||||
text: '9.计算机网络',
|
||||
collapsed: false,
|
||||
items: [
|
||||
{ text: '9.计算机网络', link: '/9.计算机网络/9.计算机网络' },
|
||||
{ text: '9 计算机网络', link: '/9.计算机网络/9.计算机网络' },
|
||||
{ text: '9.1 计网速通', link: '/9.计算机网络/9.1计网速通' },
|
||||
{ text: '9.2.1 物理层' },
|
||||
{ text: '9.2.2 链路层' },
|
||||
{ text: '9.2.3 网络层' , link: '/9.计算机网络/9.2.3网络层'},
|
||||
{ text: '9.2.3.1 IP 协议', link: '/9.计算机网络/9.2.3.1IP协议' },
|
||||
]
|
||||
}
|
||||
]
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
// https://vitepress.dev/guide/custom-theme
|
||||
import { h, watch } from 'vue'
|
||||
import { inject } from '@vercel/analytics';
|
||||
// import Theme from 'vitepress/theme'
|
||||
import DefaultTheme from 'vitepress/theme-without-fonts'
|
||||
import Download from '../../components/Download.vue'
|
||||
@@ -10,6 +11,7 @@ import './rainbow.css'
|
||||
|
||||
let homePageStyle = undefined
|
||||
|
||||
inject()
|
||||
|
||||
export default {
|
||||
...DefaultTheme,
|
||||
|
||||
263
1.杭电生存指南/1.13数学学习篇.md
Normal file
263
1.杭电生存指南/1.13数学学习篇.md
Normal file
@@ -0,0 +1,263 @@
|
||||
# 数学学习篇
|
||||
|
||||
> author:张晓鹏
|
||||
>
|
||||
> 本文章仅为导引
|
||||
|
||||
## 认知部分
|
||||
|
||||
其实之前这一部分写了一大堆,但感觉文字实在是太太太多了,又觉得这种认知篇应该在生存指南部分,因此重新修改了一个相对精简版,希望读者能理解我的意思,也容忍我的啰嗦。(实际上还是很多啊啊啊啊)
|
||||
|
||||
在开始正式这一篇章前,我们需要先闲聊几句,这几句无关你的学习,但又可能无时无刻与你的学习相关。
|
||||
|
||||
1. 互联网时代下,学习资源过分的多,但学习资源的**质量参差不齐**。
|
||||
|
||||
- 啰嗦一:国内的教培太过魔怔,各种速成课、考研课,这种总结式的,反刍式的学习资源,在前期学习是极其不推荐的,它很可能会限制你的思维。
|
||||
- 啰嗦二:很多课程不是为你电定制的,你电虽然不算特别好的学校,但也不算差的,按照我老师的说法,根据当年精英教育比例来看,我们虽然算垫底,但还是精英教育。互联网上有非常非常多的课程是为了二三本同学,播放量高也是如此,毕竟市场人数差很大啊!
|
||||
|
||||
2. 资源的**好坏定义取决于你自身的适配度**,适配度越高越好,并不是难度越高越好。
|
||||
|
||||
- 解释:他人认为的极好的书籍或课程,对他来说适配度 100%,对你来说却可能是 0%,因为你可能完全学不懂,或者对你而言,其学习过程完全没有兴趣。
|
||||
|
||||
3. 时间是极其稀贵的物品,不要浪费你的时间!
|
||||
|
||||
- 解释:对于大部分工科学生来说,**数学更多是工具**,需要的是数学应用,而不是像数学系同学一样,理解数学的理论。诚然,能深刻理解数学,是能更好的利用工具,甚至创造工具,但是时间成本太高,大部分情况下性价比过低。
|
||||
|
||||
- 有人会说:专业学到很深的时候,后面会涉及大量数学理论,因此他要前期打下极其扎实的数学基础。
|
||||
|
||||
- 笔者的回复是:你不是小说男主,你不需要一开始就选择逆天功法,踏踏实实的努力足以支撑你的小世界。如果为了后续极高的上限,而在前期花费过多时间,其一,你很可能在应用层面被同龄人甩远而承受打击;其二,你很可能学了一堆其他领域侧重的数学理论,这在你实际专业和工作中可能完全用不到;其三,数学学不完的,他不像高中有考纲,有穷尽。
|
||||
|
||||
4. 高效利用时间的前提就是**明确自我需求**,针对需求进行**合理取舍**,建议设计一个尽可能适合自己的学习计划,过程中可以询问学长学姐一些建议,但仅是建议,最终决定权在你!
|
||||
|
||||
- 解释:比如你未来的梦想工作是算法工程师,那么你在对应算法领域的数学要多尝试些,而其他部分可以省略些;如果你的未来工作和数学没有关系!那么别学了(开个玩笑,但是要求就变成了能过就行)!
|
||||
- 啰嗦:学长学姐仅比你早一些来到学校,与你也没有责任与义务,其所表达观点也不一定对的,甚至大部分情况下,很多人的观念就是很被动的,千万千万不要被限制了,请主动思考什么是合适你的,什么是你想要的!
|
||||
|
||||
5. 学习资源不代表视频资源,公共性课程视频资源很多,但随着专业深入,视频会越来越少,书籍和文献会成为主要学习路径,特别是外文文献。因此在能继续学习的前提下,**多尝试直接啃书**,而不是看视频。
|
||||
|
||||
- 啰嗦:国内的一些论文和书籍真的是依托答辩!原因没法告诉,这是不能碰的滑梯,但理工科文献尽可能就别看国内的了,说不定里面就有错误,然后影响你很久!(不代表国外就没错误,但是国内的这个整体问题比例太离谱了)
|
||||
|
||||
6. 相信国外热门的资源都会有本土化,但是本土化的水平可能参差不齐,当自己**过于难理解时**,**请看一下英文原著**,因为可能问题不在于你,而在于翻译。
|
||||
|
||||
- 啰嗦:有些书籍的翻译是依托答辩!甚至题目都会给你抄错!
|
||||
|
||||
7. **不要拒绝英文**,尝试拥抱,即便这看起来很困难,但慢慢会好起来的。(这与你的高考英语一点关系没有,别担心,你可以的!)
|
||||
|
||||
8. 国内和国外的教材区别比较大,有一个恰当又不恰当的比喻:**国内的多数教材就像讲义**,看似清清楚楚,实则云里雾里,需要老师来带才能理解;**国外的经典教材如同仙人指路**,带你拨开迷雾。
|
||||
|
||||
- 啰嗦:这里并不代表国外就好,国内就差,前提也是国外经典教材,其次国情不同,国内中学阶段都是阅读讲义,因此大学这样编写也是正常的,默认需要老师来讲。(即便笔者觉得这很不合适)
|
||||
|
||||
## 推荐学习线路篇
|
||||
|
||||
### 高等数学
|
||||
|
||||
#### 整体框架介绍
|
||||
|
||||
这里我对高等数学做一些简单的个人视角的介绍
|
||||
|
||||
其实高等数学/微积分,**全篇内容都在讲极限**,而这也是大学数学与高中数学最大的不同,高等数学的一切都**建立于无穷之上**,而极限是无穷的一种极好的表达方式。如果你在学习的过程中,全篇以极限的角度去审视这些内容,你就会发现,这里面所有的运算都是极限运算,包括导数、积分,甚至级数部分,前期可能感受不深,越到后面越发会感受到,一切的运算都是极限运算,那些所谓的性质和一些不能使用的特殊情况,往往也都来源于这个最本质的家伙,极限!就这样,是不是感觉讲了没讲,没错,还真是!因为数学太深了,再细节下去就不是一篇文章所讲的完了。还想知道更多吗?那就去看下面的**3Blue1Brown 的微积分本质**!
|
||||
|
||||
下面到这个文章没啥意思的推荐部分了。不过还是强调一句:**根据你的需求进行选择**!!!
|
||||
|
||||
#### 系统性的网课推荐
|
||||
|
||||
这里没有放速成课和考研课,因为笔者认为这两类课程的功利性过强,并且对知识的总结过多,不利于未来深入学习其他内容,因此不算传统学习路线,将速成课放在了最后应试技巧部分(考研课没推荐,因为笔者是数学系同学,这些不清楚,是一点也没看过)
|
||||
|
||||
个人推荐优先级(以难度和深度划分):上交大乐经良>国防科大版本>宋浩
|
||||
|
||||
风格上前两者更传统,内容也更系统深刻,个人更喜欢乐老师一些;第三个宋浩老师课堂相对更活跃些,会讲比较多的段子,难度也更低一些。
|
||||
|
||||
系统性的网课选其一能完整跟下来即可(跟不下来也正常,坚持挺难的)
|
||||
|
||||
如果你只是为了考试,选择宋浩版本就足够了;如果为了未来工作,工程应用方面会涉及比较多,请选择前两个更系统的课程。如果觉得这些不合适,那么可以自行搜索选择其他课程。
|
||||
|
||||
##### 《高等数学》上交大乐经良老师
|
||||
|
||||
- 链接:[【高等数学 - 上海交通大学 - 乐经良老师 高清修复 1080p(全集)】](https://www.bilibili.com/video/BV1aY4y137fr/?share_source=copy_web&vd_source=1958d03181be22cf265b18eeec1314ff)
|
||||
|
||||
<Bilibili bvid='BV1aY4y137fr'/>
|
||||
|
||||
##### 国防科大《高等数学》
|
||||
|
||||
- 链接:[【国防科大高等数学【全网最佳】](https://www.bilibili.com/video/BV1F7411B7ep/?p=291&share_source=copy_web&vd_source=1958d03181be22cf265b18eeec1314ff)
|
||||
|
||||
<Bilibili bvid='BV1F7411B7ep'/>
|
||||
|
||||
##### 宋浩《高等数学》
|
||||
|
||||
- 链接:[【《高等数学》同济版 全程教学视频(宋浩老师)】](https://www.bilibili.com/video/BV1Eb411u7Fw/?share_source=copy_web&vd_source=1958d03181be22cf265b18eeec1314ff)
|
||||
|
||||
<Bilibili bvid='BV1Eb411u7Fw'/>
|
||||
|
||||
##### 《微积分》苏德矿
|
||||
|
||||
这个版本比较特别,比较**偏向经管类**的同学,因此没有放在前面比较。
|
||||
|
||||
- 【[微积分(浙江大学 苏德矿/矿爷)】](https://www.bilibili.com/video/BV1Lt411r7NQ/?share_source=copy_web&vd_source=1958d03181be22cf265b18eeec1314ff)
|
||||
|
||||
<Bilibili bvid='BV1Lt411r7NQ'/>
|
||||
|
||||
- 如果苏德矿老师版本不太能接受的话,请看宋浩老师版本的微积分,但需要注意的是**宋浩老师版本与杭电考试范围有所不同**,可能需要缺失部分补齐一下。
|
||||
- 因为笔者对经管类数学了解远不如理工科数学,因此这里不做过多阐述,同学可以自行搜索了解。
|
||||
|
||||
#### 教材推荐
|
||||
|
||||
这一块相对简略一些,主要是几个点
|
||||
|
||||
1. 如果是自学,不推荐看同济版教材,和前面说的一样,那个像讲义,并且难度也不够,太浅了,需要老师来给你上课做额外注记。
|
||||
2. 图灵系列的书籍都是很不错的,并且套系的书很多,具体的可以先不着急买,可以先自行搜索电子书(前面章节应该有教的)
|
||||
3. 书单链接:[数学经典教材有什么? - 人民邮电出版社的回答 - 知乎](https://www.zhihu.com/question/22302252/answer/1733795665)
|
||||
4. 自行选择,能读完一个本就足够了,而且读不完正常,根据以往经验的不科学推断,大部分人最多看完网课,书本草草翻过。
|
||||
|
||||
#### 辅助工具推荐
|
||||
|
||||
这部分内容与传统的网课不同,更倾向于**知识体系的辅助构建和补充**,某种程度上你可以认为是精华内容。
|
||||
|
||||
##### 3Blue1Brown 的微积分本质
|
||||
|
||||
这个名字听起来就很不错,对吧!
|
||||
|
||||
1. 链接:[3Blue1Brown 的个人空间_哔哩哔哩_bilibili](https://space.bilibili.com/88461692/channel/seriesdetail?sid=1528931)
|
||||
2. 内容是英文的,但实际上不会怎么影响,若是过于难接受英文,可以自行搜索汉语翻译版。
|
||||
3. 这部分内容和传统的高数教学不同,从直观的**图形角度**,讲解各个微积分中的重要概念由来和应用。
|
||||
4. 学习时间:与传统网课无任何冲突,可以在**任何时间观看**,即传统网课的前、中、后三个阶段均可看,并且不同阶段看感受不同,**建议反复观看**。
|
||||
5. 学习难度:简单又不简单,简单在于讲解的方式非常通俗,图形化知识非常直观,不简单在于其本身内容是深刻的,彻底理解这些内容或许需要不断反复的看以及配合传统网课的学习,搭建完知识体系后顿悟。
|
||||
|
||||
##### Brilliant
|
||||
|
||||
1. 链接:[https://brilliant.org/](https://brilliant.org/)。
|
||||
2. 国外非常火的直观学习数学网站,国内本土化产物是马同学图解数学,个人不推荐购买马同学图解数学,因为据个人了解,里面错误似乎比较多,但可以看其知乎上的好文章。
|
||||
3. 这个网站不做过多介绍,自己打开玩一玩就明白了。
|
||||
4. 额外补充一:这是一个付费内容,前几天是免费的,如果你觉得他值得,可以进行购买,购买途径可以官网,但第三方价格会便宜些,比如淘宝、闲鱼、PDD。
|
||||
5. 额外补充二:一个好用的翻译浏览器插件:沉浸式翻译,可以更好的体验。
|
||||
|
||||
##### MIT-微积分重点
|
||||
|
||||
1. 链接:[【我在 B 站上大学!【完整版 - 麻省理工 - 微积分重点】全 18 讲!学数学不看的微积分课程,看完顺滑一整年。_人工智能数学基础/机器学习/微积分/麻省理工/高等数学】](https://www.bilibili.com/video/BV1rY4y1P7er/?p=2&share_source=copy_web&vd_source=1958d03181be22cf265b18eeec1314ff)
|
||||
<Bilibili bvid='BV1rY4y1P7er'/>
|
||||
2. 非常**优雅的入门课**,同前面 3Blue1Brown 的微积分本质一样的使用方法。
|
||||
3. 注意,这个是**入门课**,不算系统课程!
|
||||
4. **建议看完!**
|
||||
|
||||
### 线性代数
|
||||
|
||||
#### 整体框架介绍
|
||||
|
||||
下面又是我一点点个人理解,好吧,其实就一句话,别担心!线性代数是一个很特别的学科,刚开始很难,中间很混乱,最后很通透,因为全篇都在以不同的角度阐述相同又不同的内容,所以某种意义上,线性代数可以从任何一章节开始学习(当然,实际上要根据教材来,不然很怪啦)
|
||||
|
||||
而关于线性代数整体研究什么,我极力推荐下面辅助部分的丘维声先生高等代数第一节高等代数研究对象(就第一节哦!因为这是数学系课程,偏理论,非数同学看多了不合适)
|
||||
|
||||
#### 系统性的网课推荐
|
||||
|
||||
与高等数学模块相同,这里没有放速成课和考研课,因为笔者认为这两类课程的功利性过强,并且对知识的总结过多,不利于未来深入学习其他内容,因此不算传统学习路线,将速成课放在了最后应试技巧部分(考研课没推荐,因为笔者是数学系同学,这些不清楚,是一点也没看过)
|
||||
|
||||
这里只推荐两个网课,如果觉得自身不合适,可以自行去寻找其他更合适的。
|
||||
|
||||
##### MIT 版的线性代数
|
||||
|
||||
1. 链接:[【麻省理工学院 - MIT - 线性代数(我愿称之为线性代数教程天花板)】](https://www.bilibili.com/video/BV16Z4y1U7oU/?share_source=copy_web&vd_source=1958d03181be22cf265b18eeec1314ff)
|
||||
<Bilibili bvid='BV16Z4y1U7oU'/>
|
||||
2. 评价:神中神!未来做工程应用的学生很推荐看这个!
|
||||
|
||||
##### 宋浩线性代数
|
||||
|
||||
1. 链接:[【《线性代数》高清教学视频“惊叹号”系列 宋浩老师】](https://www.bilibili.com/video/BV1aW411Q7x1/?share_source=copy_web&vd_source=1958d03181be22cf265b18eeec1314ff)
|
||||
<Bilibili bvid='BV1aW411Q7x1'/>
|
||||
2. 评价:MIT 系列过于强大,宋浩版本显得有些暗淡无光,但实际上宋浩老师版本完全是可以应对考试,如果接受不了 MIT 的版本,还是可以考虑有趣的宋浩老师。
|
||||
|
||||
#### 教材推荐
|
||||
|
||||
与前面高等数学部分相同,这里只做几个点说明
|
||||
|
||||
1. 有一些线性代数的图解书籍或者讲几何意义的,可以看,但这里没做推荐,因为很多书不太严谨,可以自行搜索。
|
||||
2. 书单链接:[有没有讲线性代数比较好的教材? - 如何表达的回答 - 知乎](https://www.zhihu.com/question/586392502/answer/2913648674)
|
||||
3. 主推荐还是 MIT 网课老爷子的配套书籍,
|
||||
4. 尽可能看英文原版,不要害怕。
|
||||
5. 《线性代数及其应用》千万别看翻译版,有很大问题,要看只看原版!
|
||||
|
||||
#### 辅助部分
|
||||
|
||||
跟上面的高数部分一样,不过对于线性代数来说,可视化的理解会更有效果
|
||||
|
||||
##### 3Blue1Brown 的线性代数本质
|
||||
|
||||
1. 链接:[【官方双语/合集】线性代数的本质 - 系列合集】](https://www.bilibili.com/video/BV1ys411472E/?share_source=copy_web&vd_source=1958d03181be22cf265b18eeec1314ff)
|
||||
<Bilibili bvid='BV1ys411472E'/>
|
||||
2. 神中神!多看,反复看!不允许学线性代数的人不看这个视频!
|
||||
3. 其他不多说,和前面高数一样
|
||||
|
||||
##### Brilliant
|
||||
|
||||
1. 链接:[https://brilliant.org/](https://brilliant.org/)
|
||||
2. 和高数部分一样,不多说了
|
||||
|
||||
##### 丘维声《高等代数》第一节课--高等代数研究对象
|
||||
|
||||
这个课程是数学系同学学习的,也是笔者学习的课程,本来不该给非数学系的同学推荐,但是这里面的第一节讲的太好了,能让你很快的构建起一个**大概的框架**,并且能很好的避免传统无脑填鸭式的上来就给你讲行列式的课程体系(**点名批评线性代数紫皮书**,也就是杭电教材,同济大学版的线代)
|
||||
|
||||
1. 链接:[【北大丘维声教授清华高等代数课程 1080P 高清修复版 (全 151 集)】](https://www.bilibili.com/video/BV1jR4y1M78W/?share_source=copy_web&vd_source=1958d03181be22cf265b18eeec1314ff)
|
||||
<Bilibili bvid='BV1jR4y1M78W'/>
|
||||
2. 再强调一下嗷,就**只看第一节**,也就是 001 和 002 两个视频。因为后续整个内容偏理论,应用层太少,不适合传统工科,但这第一节,绝对能让你搭建一个大概的**框架**,助力后续学习不晕眩!
|
||||
|
||||
##### 线性代数可视化手册
|
||||
|
||||
- 一个非常好的笔记,总结的很不错,但刚开始看会看不明白(毕竟是总结),建议学完一遍再看
|
||||
|
||||
- 链接:[kenjihiranabe/The-Art-of-Linear-Algebra: Graphic notes on Gilbert Strang's "Linear Algebra for Everyone" (github.com)](https://github.com/kenjihiranabe/The-Art-of-Linear-Algebra)
|
||||
- 别告诉我不会在 GitHub 上下载文件哈(不会就去学下,利用 AI 工具
|
||||
|
||||
## 其他部分
|
||||
|
||||
### 新生先修课
|
||||
|
||||
【Warning】这里别的不能多说,只能简略提几点,希望你能懂。
|
||||
|
||||
1. 这是自愿内容,不是必须的。
|
||||
2. 合理利用机制,可以考虑替代期中成绩,为部分同学刷分需要(注!不是所有人都要刷分的!具体看 1.6 节正确解读 GPA)。
|
||||
3. 这份网课面向的是全体学子,其不一定适合你,或过于简单,或效率不高,但你应该尝试作为独立个体将其与其他课程进行对比,选择合适你自己的,为自己负责。
|
||||
4. 相信互联网资源的筛选法则。
|
||||
|
||||
### 未央学社数学答疑(应试部分)
|
||||
|
||||
是不是有点同学会觉得很奇怪,未央学社不是搞技术的吗,好像 java 后端很厉害,实际上这里打个小广告,未央学社除了技术部,还有讲师团和运营部,而讲师团专门负责给大家数学答疑和整理资料,我们构建了**HDU 数学营**,里面有很多资料,比如**往年卷**,比如我们专属出品**复习提纲**等,还有**非常多的同学互帮互助**,不说了,直接来看吧!
|
||||
|
||||
#### 未央学社 HDU 数学营
|
||||
|
||||
|
||||
|
||||
#### 钉钉答疑
|
||||
|
||||
我们还提供答疑服务,详细内容可以看下面的推文哈
|
||||
|
||||
[未央学社学业答疑服务来啦 | 助力解决学业问题](https://mp.weixin.qq.com/s/FmwT_V8j4we22KzJiHWmtQ)
|
||||
|
||||
#### 应试技巧
|
||||
|
||||
##### 往年卷
|
||||
|
||||
因为知识点不会变化,每年只是侧重有些区别,并且大部分题型还是一样的,因此往年卷有助于快速提分,做 3 份往年卷,你就会发现,欸,好像每年差不多。
|
||||
|
||||
##### 速成视频
|
||||
|
||||
个人不推荐猴博士,不适合杭电,看了容易挂科。
|
||||
|
||||
为了不挂科,速成方面,微信公众号:蜂考,相对合适一些,但仅用于速成!
|
||||
|
||||
关于视频资源:可以支持购买正版,也可以 PDD,TB 等地方获取。
|
||||
|
||||
##### 高分复习顺序(个人推荐版)
|
||||
|
||||
这部分内容仅为个人看法,不代表一定能高分,也不代表不这样做拿不到高分。
|
||||
|
||||
最完整的复习顺序:知识点→书本例题→课堂例题(一般有 PPT)→作业题→书本课后题→往年卷真题
|
||||
|
||||
考试题型来源:作业题和例题,因此当回顾作业题完成后,做往年卷会有特别感受。
|
||||
|
||||
随时间可不做的优先级(若时间来不及,先砍)
|
||||
|
||||
1. 书本课后题
|
||||
2. 作业题
|
||||
3. 知识点(这里值得是细看知识点,不是粗看,粗看都不看,直接跳转第 7 步)
|
||||
4. 课堂例题
|
||||
5. 书本例题
|
||||
6. 往年卷真题
|
||||
7. 如果平时没努力的话,这时候可以开始准备补考了
|
||||
@@ -60,7 +60,7 @@
|
||||
计算机信息安全竞赛在社会上的知名度并不高,但它和 ACM 一样是强技术竞赛,无任何 PPT 环节以及展示环节(除了一些少数比赛如国赛省赛有知识竞赛这一环节/赛道),技术就是唯一取胜的关键。CTF 是计算机安全竞赛的一种赛制,全称“Capture The Flag”,即夺旗赛,比赛选手需利用自己的计算机安全技术完成挑战,成功拿下题目后会获得一个使用`flag{}`包裹的字符串,这个字符串就是flag,提交到平台上就可以获得一定的分数。
|
||||
|
||||
杭电的 CTF 竞赛历史悠久,Vidar-Team 信息安全协会的主打比赛就是 CTF,据本文档编写之时算起已有 15 年的历史,大大小小国内国外获奖无数,本 wiki 的计算机安全部分也由信息安全协会编写。
|
||||

|
||||

|
||||
|
||||
### 优点
|
||||
|
||||
@@ -69,7 +69,7 @@
|
||||
CTF 在计算机安全类招聘,以及计算机安全类研究生招生中占有很大作用,安全类企业在招聘时更喜欢 CTF 选手,就好像算法岗更喜欢 ACM 选手一样(虽然现在两者的就业都没有以前好了)。
|
||||
|
||||
计算机安全也是一个挑战性很强的领域,在国外有很高的研究热情,如今在国内也受政府大力支持,比如强网杯由河南省政府主办,奖金高达 500 万元,西湖论剑由浙江省政府主办,奖金也很丰厚。除此之外,在计算机安全领域还有漏洞赏金这一说,大型企业都会有 SRC(Security Response Center,安全应急响应中心)这种平台,上交该企业的漏洞就可以获得赏金,比如微软 RDP 远程代码执行漏洞(通过一定手段使得另一台电脑执行任意代码)赏金高达 10 万刀。VMware 虚拟机逃逸(在虚拟机内通过一定的手段可以在主机上执行任意代码)20 万刀等,越有挑战性的领域赏金越高。国内的SRC平台:https://www.anquanke.com/src
|
||||

|
||||

|
||||
|
||||
### 缺点
|
||||
|
||||
|
||||
BIN
1.杭电生存指南/static/image-20230801062631288.png
Normal file
BIN
1.杭电生存指南/static/image-20230801062631288.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 31 KiB |
BIN
1.杭电生存指南/static/v2-704a5d77d767493bada1feccadcd6c4c_720w.webp
Normal file
BIN
1.杭电生存指南/static/v2-704a5d77d767493bada1feccadcd6c4c_720w.webp
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 54 KiB |
@@ -7,8 +7,8 @@
|
||||
本模块将以有趣的任务的形式替你检测是否你已经达到了基本掌握 C 语言语法和一些特性的目的
|
||||
|
||||
- 该任务模块旨在帮助巩固 C 语言基础知识,传递一些编程思维,入门学习请看 [3.4.4C 语言前置概念学习](3.4.4C%E8%AF%AD%E8%A8%80%E5%89%8D%E7%BD%AE%E6%A6%82%E5%BF%B5%E5%AD%A6%E4%B9%A0.md)
|
||||
- 你可以通过使用 git工具 `git clone https://github.com/E1PsyCongroo/HDU_C_Assignments.git` 获取任务
|
||||
- 或者访问 https://github.com/E1PsyCongroo/HDU_C_Assignments 学习
|
||||
- 你可以通过使用 git 工具 `git clone https://github.com/E1PsyCongroo/HDU_C_Assignments.git` 获取任务
|
||||
- 或者访问 [https://github.com/E1PsyCongroo/HDU_C_Assignments](https://github.com/E1PsyCongroo/HDU_C_Assignments) 学习
|
||||
|
||||
## 任务一做前必查
|
||||
|
||||
|
||||
@@ -144,7 +144,7 @@ words = set(shakespeare.read().decode().split())
|
||||
|
||||
这个调用表达式有子表达式:<em>操作符</em>是括号前的表达式,它包含了一个用逗号分隔的<em>操作数</em>列表。
|
||||
|
||||

|
||||

|
||||
|
||||
运算符指定了一个<em>函数</em>。当这个调用表达式被评估时,我们说对<em>参数</em>`7.5` 和 `9.5`<em>调用</em>函数 `max`,并<em>返回</em>一个 9.5 的<em>返回值</em>。
|
||||
|
||||
@@ -326,7 +326,7 @@ Python 定义了大量的函数,包括上一节中提到的运算符函数,
|
||||
|
||||
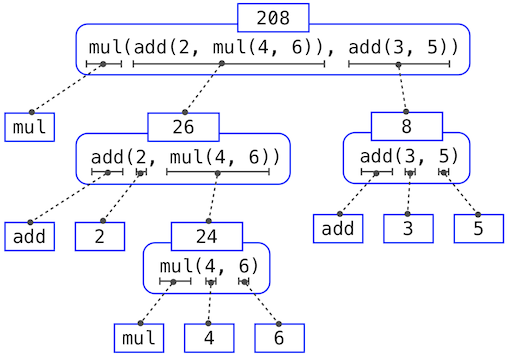
需要这个按照上述过程重复四次。如果我们画出每个被计算的表达式,我们就可以直观地看到这个过程的层次结构。
|
||||
|
||||

|
||||
|
||||
|
||||
这张插图被称为<em>表达式树</em>。在计算机科学中,树(Tree,一种数据结构,我们将在后续的章节中进行讨论)通常是自上而下生长的。树中每一点的对象被称为节点;在这张插图的情况下,节点是与值配对的表达式。
|
||||
|
||||
@@ -372,7 +372,7 @@ Python 定义了大量的函数,包括上一节中提到的运算符函数,
|
||||
```
|
||||
|
||||
可以被描述为一台接受输入并产生输出的小型机器。
|
||||

|
||||

|
||||
函数 `abs` 是*纯函数*。纯函数的特性是,调用它们除了返回一个值之外没有任何影响。此外,当用相同的参数调用两次时,一个纯函数必须总是返回相同的值。
|
||||
|
||||
**非纯函数**
|
||||
@@ -384,7 +384,7 @@ Python 定义了大量的函数,包括上一节中提到的运算符函数,
|
||||
```
|
||||
|
||||
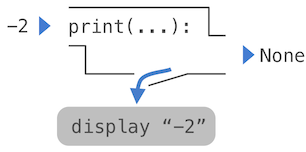
虽然`print`和`abs`在这些例子中可能看起来很相似,但它们的工作方式根本不同。打印返回的值总是`None`,这是一个特殊的 Python 值,不代表任何东西。交互式 Python 解释器不会自动打印值`None`。在`print`的情况下,函数本身是打印输出,也是被调用的副作用。
|
||||

|
||||
|
||||
|
||||
对`print`函数的嵌套调用突出了纯函数和非纯函数的区别
|
||||
|
||||
@@ -418,3 +418,9 @@ None
|
||||
## 课后作业
|
||||
|
||||
一个好的课程怎么能少得了精心准备的课后作业呢?🤗
|
||||
|
||||
如果被题目卡住了,那就再去看看食用指南吧!😋
|
||||
|
||||
::: tip 📥
|
||||
本小节课后作业下载 <Download url="https://cdn.xyxsw.site/code/HW 01.zip"/>
|
||||
:::
|
||||
|
||||
@@ -113,7 +113,7 @@ cs61a 绝对是一个挑战,但是我们都希望你学习并且成功,所
|
||||
|
||||
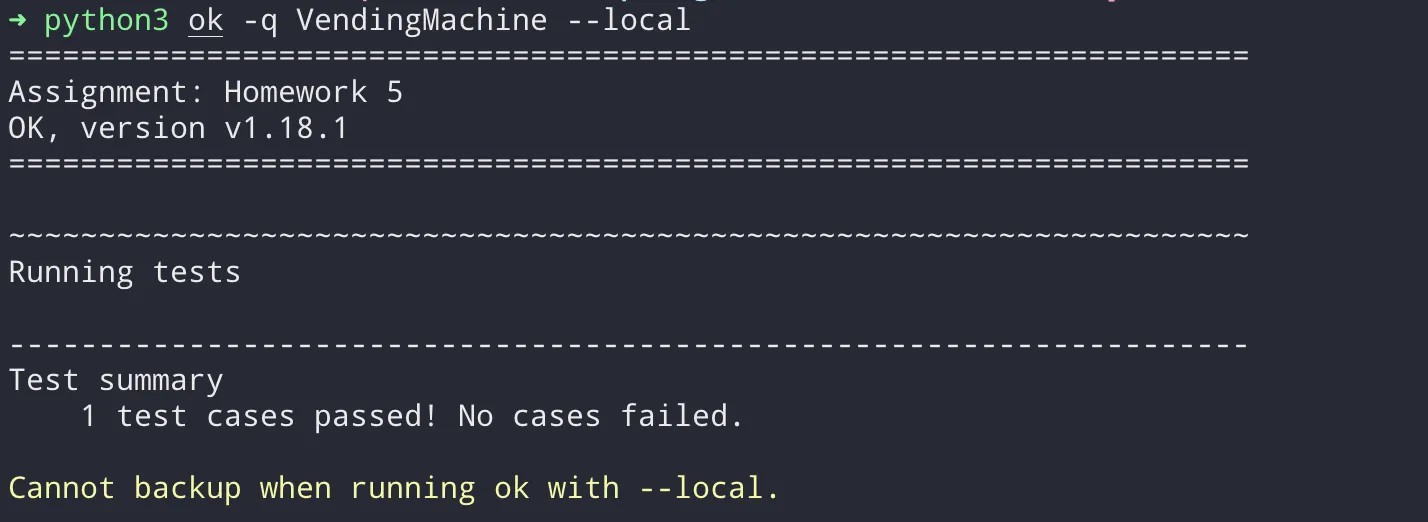
一般情况下,执行上述 ok 指令后,都会在终端里提示输入 Berkeley 账号进行提交,这时候输入 `Ctrl+C` 退出即可;不过我们可以在代码后面加上 `--local` 进行本地测试;所有的测试都可以本地完成,不需要联网
|
||||
|
||||

|
||||
|
||||
|
||||
关于使用 Ok 命令的更多信息,请在[此处](https://inst.eecs.berkeley.edu/~cs61a/fa22/articles/using-ok/)了解更多
|
||||
|
||||
@@ -121,9 +121,15 @@ cs61a 绝对是一个挑战,但是我们都希望你学习并且成功,所
|
||||
|
||||
1. 在 CS61A 的学习过程中,你可能会找不到 61A 的每一个 lab、hw、disc、proj 的答案,这是因为 61A 是不断更新并进行授课的,所以每过一个季度 61A 是会进行换季的,所以为了避免这个问题,请尽早将 61A 主页的每一个答案保存下来。如果你已经遇到了这种问题,那么向已经学习了这门课的学长学姐求助是个不错的选择。
|
||||
2. 如果出现以下情况,这说明你的并没有在测试对象的目录进行测试,最简单解决办法就是在你对应位置的目录进行鼠标右键点击“在终端中打开”进行输入测试。
|
||||

|
||||
|
||||

|
||||
3. 如果输入了命令后回车没有任何反应,请试试将测试代码的 python3 变为 python 或者 py 进行操作,如果还没有解决请仔细阅读 61A hw 部分的 Using ok,链接一般位于 HW 01 的开头。
|
||||
4. 如果在解决问题的过程中遇到了问题,那就多读几遍题目吧,题干中或许会给出 `Hint`,这可能很有用
|
||||
|
||||
1. 如果输入了命令后回车没有任何反应,请试试将测试代码的 python3 变为 python 或者 py 进行操作,如果还没有解决请仔细阅读 61A hw 部分的 Using ok,链接一般位于 HW 01 的开头。
|
||||
这是 cs61a 的官网[https://cs61a.org/](https://cs61a.org/)
|
||||
|
||||
如果你觉得全英教学对你来说比较困难,可以参考[2.5 以理工科的方式阅读英语](../2.高效学习/2.5以理工科的方式阅读英语.md)
|
||||
|
||||
也可以看看我们本地化之后的 cs61a 课程,我们尽可能准确和符合中文阅读习惯地翻译了 textbook,但我们保留了作业中的英语(绝对不是因为偷懒),来锻炼同学们的英语能力
|
||||
|
||||
英文学习的痛苦比不上接触国外优秀课程带来的快乐,请保持初心,砥砺前进,祝愿同学们都能有一个有趣的学习体验 🥰
|
||||
|
||||
BIN
3.编程思维体系构建/code/HW 01.zip
Normal file
BIN
3.编程思维体系构建/code/HW 01.zip
Normal file
Binary file not shown.
@@ -12,13 +12,13 @@
|
||||
|
||||
我分为两大块:先想清楚你干了什么,在训练好你表达的规范性
|
||||
|
||||
<font color=green>大白话 -》提取后的逻辑链条</font> -》<font color=red>科研写作 -》英文翻译</font>
|
||||
<font color=green>大白话 -> 提取后的逻辑链条</font> -> <font color=red>科研写作 -> 英文翻译</font>
|
||||
|
||||
<strong>干了什么:</strong>
|
||||
|
||||
1. 如果没有想清楚要做的是什么,要写什么,可以先用大白话,在草稿上写,有利于理清思路,抽丝剥茧
|
||||
|
||||
失败案例:一上来直接英文【】‘’写作,一会 we want ,一会 80 个词语的长难句,思路英语都不清晰
|
||||
失败案例:一上来直接英文[ ] ' '写作,一会 we want,一会 80 个词语的长难句,思路英语都不清晰
|
||||
|
||||
2. 先列出 Outline 每一个科研 section 你打算做什么,尝试去回答问题
|
||||
|
||||
@@ -33,9 +33,11 @@
|
||||
|
||||
1: How do we verify that we solved it:
|
||||
|
||||
1a) Experimental results1b)
|
||||
1a) Experimental results
|
||||
|
||||
TheoryExtra space? Future work!Extra points for havingFigure 1
|
||||
1b) Theory Extra space? Future work!
|
||||
|
||||
Extra points for having Figure 1
|
||||
|
||||
on the first page
|
||||
|
||||
@@ -51,7 +53,6 @@
|
||||
|
||||
2. 迭代式写作,尝试多次更改写作的内容,优秀的作品都是改出来的,在把一部分的意思表达清晰知识
|
||||
|
||||
|
||||
上述内容是写作的怎么去写,而下面则是内容层面,什么样的文章算是一篇好的文章
|
||||
|
||||
::: warning 📌
|
||||
@@ -59,6 +60,6 @@ C 会文章与 A 会文章的区别认知:
|
||||
|
||||
(1).C 是对于相关工作一个是罗列,A 是整理相关工作的脉络和方法类别,以及方法缺陷。
|
||||
|
||||
(2).对于设计的方法,C会只是说明我们比另外几个模型好,并不能从原理层面深入分析为什么比别人好,而A会则是能够说明每一部设计对模型的增量效果,以及为什么要做这一步。
|
||||
(2).对于设计的方法,C 会只是说明我们比另外几个模型好,并不能从原理层面深入分析为什么比别人好,而 A 会则是能够说明每一部设计对模型的增量效果,以及为什么要做这一步。
|
||||
|
||||
:::
|
||||
@@ -6,16 +6,16 @@ author:廖总
|
||||
|
||||
先声夺人:AI 时代最大的陷阱,就是盲目考察 AI 能为我们做什么,而不去考虑我们能为 AI 提供什么
|
||||
|
||||
### <em>免责声明</em>
|
||||
## <em>免责声明</em>
|
||||
|
||||
本文纯文本量达 16k(我也不知道字数统计的 28k 是怎么来的),在这 游离散乱的主线 和 支离破碎的文字 中挣扎,可能浪费您生命中宝贵的十数分钟。
|
||||
|
||||
但如果您坚持尝试阅读,可能看到如下内容(假设没在其中绕晕的话 ):
|
||||
但如果您坚持尝试阅读,可能看到如下内容(假设没在其中绕晕的话):
|
||||
|
||||
- 对大语言模型本质 以及 AI 时代人们生产创作本位 的讨论
|
||||
- 对大语言模型 上下文学习(In-Context Learning,ICL)和 思维链(Chain of Thought,COT)能力的几种通识性认知
|
||||
- 围绕 Prompt Decomposition 对使用大语言模型构建复杂应用的基础讨论
|
||||
- 对当前热门大模型 Agent 化框架(如 Generative Agents (即斯坦福 25 人小镇)、AutoGPT)其本质的讨论
|
||||
- 对当前热门大模型 Agent 化框架(如 Generative Agents(即斯坦福 25 人小镇)、AutoGPT)其本质的讨论
|
||||
- 对使用大语言模型构建智能系统(基于全局工作空间意识理论)的初步讨论
|
||||
- 对使用大语言模型构建符合当今生产需求的智能系统的方法论讨论
|
||||
|
||||
@@ -31,7 +31,7 @@ author:廖总
|
||||
- LLMs 能力考察:讨论了大语言模型涌现的一系列基本能力,并讨论基于这些基本能力和工程化,大模型能做到哪一步
|
||||
- Decomp 方法论:将大语言模型微分化使用的方法论,以此展开对大语言模型的新认知
|
||||
- AI 作为智能系统:结合 Generative Agents、AutoGPT 两项工作讨论大语言模型本身的局限性,围绕人类认知模型的启发,讨论通过构建复杂系统使得 LLMs Agent 化的可能性
|
||||
- 予智能以信息:讨论基于 LLMs 构建能够充分帮助我们提升生产力的 AI 剩余的一切痛点。借以回到主题 —— 在 AI 时代,我们要打造什么样的生产和信息管理新范式 (有一说,还是空口无凭)
|
||||
- 予智能以信息:讨论基于 LLMs 构建能够充分帮助我们提升生产力的 AI 剩余的一切痛点。借以回到主题 —— 在 AI 时代,我们要打造什么样的生产和信息管理新范式(有一说,还是空口无凭)
|
||||
|
||||
总体而言,本文包括对 LLM 领域近一个月的最新几项工作(TaskMatrix、HuggingGPT、Generative Agents、AutoGPT)的讨论,并基于此考察一个真正可用的 AI 会以什么样的形态出现在我们面前。
|
||||
|
||||
@@ -43,7 +43,7 @@ author:廖总
|
||||
|
||||
仅作展望。
|
||||
|
||||
# 引言
|
||||
## 引言
|
||||
|
||||
在开启正式讨论之前,我们希望从两个角度分别对 AI 进行讨论,从而夹逼出我们 从 AI 到 智能系统 的主题
|
||||
|
||||
@@ -56,7 +56,7 @@ author:廖总
|
||||
|
||||
以前只知前边两句,现在才知精髓全在后者
|
||||
|
||||
## 形而下者器:LLMs + DB 的使用样例
|
||||
### 形而下者器:LLMs + DB 的使用样例
|
||||
|
||||
(为了不让话题一开场就显得那么无聊,我们先来谈点有意思的例子)
|
||||
|
||||
@@ -77,7 +77,7 @@ author:廖总
|
||||
|
||||
(后面会给出更多关联的讨论,这里就先不赘叙了)
|
||||
|
||||
## 形而上者道:对 LLM 既有智能能力及其局限性的讨论
|
||||
### 形而上者道:对 LLM 既有智能能力及其局限性的讨论
|
||||
|
||||
这一节中,想讨论一下人工智能与人类智能的碰撞()
|
||||
|
||||
@@ -99,7 +99,7 @@ ChatGPT Plugins 在两篇论文两个角度的基础上,对 LLMs 的能力的
|
||||
- 为 AI 提供接口,为 AI 拓展能力
|
||||
- 建模自身问题,促进有效生成
|
||||
|
||||
### 从人工智能到人类智能
|
||||
#### 从人工智能到人类智能
|
||||
|
||||
在上面的论断中,我们看似已经能将绝大多数智能能力出让予 AI 了,但我还想从另一角度对 AI 与人类的能力进行展开讨论:
|
||||
|
||||
@@ -109,7 +109,7 @@ ChatGPT Plugins 在两篇论文两个角度的基础上,对 LLMs 的能力的
|
||||
- “人工”智能:辅佐 AI 实现的智能
|
||||
- 人类智能:于人类独一无二的东西
|
||||
|
||||
### AI 智能的形态
|
||||
#### AI 智能的形态
|
||||
|
||||
大语言模型的原始目的是制造一个“压缩器”,设计者们希望他能有效地学习世界上所有信息,并对其进行通用的压缩。
|
||||
|
||||
@@ -120,11 +120,11 @@ ChatGPT Plugins 在两篇论文两个角度的基础上,对 LLMs 的能力的
|
||||
> “人总是要死的,苏格拉底也是人,所以苏格拉底是要死的”<br/>这是一个经典苏格拉底式的三段论,其中蕴含着人类对于演绎推理能力的智慧。<br/>假设上面的样本是 LLM 既有学习的,而这时来了一个新的样本:<br/>“人不吃饭会被饿死,我是人,所以我也是要恰饭的嘛”<br/>那么对于一个理想的智能压缩器而言,其可能发现新句与旧句之间的关联,并有效学习到了句子的表征形式及其背后的逻辑
|
||||
|
||||
$$
|
||||
S1=<(人,苏格拉底,死),三段式推理>
|
||||
S1=<(人,苏格拉底,死),三段式推理>
|
||||
$$
|
||||
|
||||
$$
|
||||
S2=<(人,我,恰饭),三段式推理>
|
||||
S2=<(人,我,恰饭),三段式推理>
|
||||
$$
|
||||
|
||||
> 而随后,压缩器会倾向于储存三段式推理这一智能结构,并在一定程度上丢弃后来的(人,我,恰饭)这一实体关系组,仅简单建模其间联系,并在生成时按需调整预测权重。
|
||||
@@ -144,7 +144,7 @@ LLM 的实质上还是通过“语言结构”对“外显人类智能”进行
|
||||
|
||||
而也正是这些固有缺陷,为人类的自我定位和进一步利用 AI 找到了立足点。
|
||||
|
||||
### 赋能 AI 实现智能
|
||||
#### 赋能 AI 实现智能
|
||||
|
||||
作为上面一点的衍生,我们可以从大体两个角度去辅助 AI 智能的实现:
|
||||
|
||||
@@ -200,13 +200,13 @@ LLM 的实质上还是通过“语言结构”对“外显人类智能”进行
|
||||
|
||||
简而言之,我希望能追随着 AI 的发展,讨论是否能构建这样一个通用的 AI 框架,并将其引入工作生产的方方面面。希望能讨论及如何对生产信息进行有效的管理,也包括如何让我们更好调用 AI,如何让 AI 满足我们的生产需要。
|
||||
|
||||
# LLMs:生成原理及能力考察
|
||||
## LLMs:生成原理及能力考察
|
||||
|
||||
相信无论是否专业,各位对 LLMs 的生成原理都有着一定的认知
|
||||
|
||||
简单来说,这就是一个单字接龙游戏,通过自回归地预测“下一个字”。在这个过程的训练中,LLMs 学习到了知识结构,乃至一系列更复杂的底层关联,成为了一种人类无法理解的智能体。
|
||||
|
||||
## In-Context Learning / Chain of Thought
|
||||
### In-Context Learning / Chain of Thought
|
||||
|
||||
经过人们对模型背后能力的不懈考察,发现了一系列亮点,其中最瞩目的还是两点:
|
||||
|
||||
@@ -233,8 +233,7 @@ COT 为输出增加关联
|
||||
|
||||
进一步的,ICL 的发现,让 LLMs 能避免过多的传统 Finetune,轻易将能力运用在当前的情景中;COT 的发现,使得通过 LLMs 解决复杂问题成为可能。此二者的组合,为 LLMs 的通用能力打下了基础。
|
||||
|
||||
|
||||
## TaskMatrix.AI
|
||||
### TaskMatrix.AI
|
||||
|
||||
微软对 [TaskMatrix.AI](https://arxiv.org/abs/2303.16434) 这一项目的研究,很大程度上展示了 LLMs 基于 ICL 和 COT 所能展现的能力
|
||||
|
||||
@@ -261,7 +260,7 @@ TaskMatrix 的生态愿景
|
||||
|
||||
(当然,硬要说的话,对 ICL 和 COT 两种能力都有一个狭义与广义之争,但这不重要,因为我喜欢广义)
|
||||
|
||||
### ICL for TaskMatrix
|
||||
#### ICL for TaskMatrix
|
||||
|
||||
> 狭义的 ICL:从输入的既有样例中学习分布和规范<br/>广义的 ICL:有效的将输入内容有效运用到输出中
|
||||
|
||||
@@ -295,13 +294,13 @@ TaskMatrix 自动围绕目标拆解任务
|
||||
|
||||
TaskMatrix 自动为任务创建 API 调用链
|
||||
|
||||
## 初步考察
|
||||
### 初步考察
|
||||
|
||||
基于上述的简单介绍,我们已经初步认识了 AI 在实际情景中的高度可用性
|
||||
|
||||
而接下来,我们继续从工程的角度揭示这种可用性的根源 —— 其源自一项通用的 Prompt 技术
|
||||
|
||||
# Prompt Decomposition:方法论
|
||||
## Prompt Decomposition:方法论
|
||||
|
||||
我们可以认为,TaskMatirx 的能力极大程度上依托于 Prompt Decomposition 的方法
|
||||
|
||||
@@ -309,7 +308,7 @@ TaskMatrix 自动为任务创建 API 调用链
|
||||
|
||||
[[2210.02406] Decomposed Prompting: A Modular Approach for Solving Complex Tasks (](https://arxiv.org/abs/2210.02406)[arxiv.org](https://arxiv.org/abs/2210.02406)[)](https://arxiv.org/abs/2210.02406)
|
||||
|
||||
## 原始 Decomp
|
||||
### 原始 Decomp
|
||||
|
||||
Decomp 的核心思想为将复杂问题通过 Prompt 技巧,将一个复杂的问题由 LLMs 自主划分为多个子任务。随后,我们通过 LLMs 完成多个任务,并将过程信息最终组合并输出理想的效果
|
||||
|
||||
@@ -327,7 +326,7 @@ Decomp 方法执行样例
|
||||
|
||||
在实际运行中,Decomp 过程由一个任务分解器,和一组程序解析器组成
|
||||
|
||||
其中分解器作为语言中枢,需要被授予如何分解复杂任务 —— 其将根据一个问题 Q 构建一个完整的提示程序 P ,这个程序包含一系列简单的子问题 Q_i,以及用于处理该子问题的专用函数 f_i(可以通过特定小型 LLM 或专用程序,也可以以更小的提示程序 P_i 形式呈现)。
|
||||
其中分解器作为语言中枢,需要被授予如何分解复杂任务 —— 其将根据一个问题 Q 构建一个完整的提示程序 P,这个程序包含一系列简单的子问题 Q_i,以及用于处理该子问题的专用函数 f_i(可以通过特定小型 LLM 或专用程序,也可以以更小的提示程序 P_i 形式呈现)。
|
||||
|
||||
模型将通过递归运行完整的提示程序,来获得理想的答案。
|
||||
|
||||
@@ -335,15 +334,15 @@ Decomp 方法执行样例
|
||||
|
||||
我们也可以认为,在每个子任务中,我们通过 Prompt 将 LLMs 的能力进行了劣化,从而让其成为一个专职的功能零件。而这种对单个 LLMs 能力迷信的削减,正延伸出了后续的发展趋势。
|
||||
|
||||
## Decomp 衍生
|
||||
### Decomp 衍生
|
||||
|
||||
Decomp 的原始功能实际上并不值得太过关注,但我们急需考虑,该方法还能用于处理些什么问题。
|
||||
|
||||
### 递归调用
|
||||
#### 递归调用
|
||||
|
||||
我们可以构建规则,让 Decomp 方法中的分解器递归调用自身,从而使得一个可能困难的问题无限细分,并最终得以解决
|
||||
|
||||
### 外部调用
|
||||
#### 外部调用
|
||||
|
||||
通过问题的分解和通过“专用函数”的执行,我们可以轻易让 LLMs 实现自身无法做到的调用 API 工作,例如主动从外部检索获取回答问题所需要的知识。
|
||||
|
||||
@@ -355,7 +354,7 @@ Decomp 方法调用外部接口样例
|
||||
|
||||
基于此,我们还希望进一步研究基于这些机制能整出什么花活儿,并能讨论如何进一步利用 LLMs 的能力
|
||||
|
||||
## 回顾:HuggingGPT 对 Decomp 方法的使用
|
||||
### 回顾:HuggingGPT 对 Decomp 方法的使用
|
||||
|
||||
[HuggingGPT](https://arxiv.org/abs/2303.17580) 一文也许并未直接参考 Decomp 方法,而是用一些更规范的手法完成该任务,但其充分流水线化的 Prompt 工程无疑是 Decomp 方法在落地实践上的最佳注脚
|
||||
|
||||
@@ -373,7 +372,7 @@ HuggingGPT
|
||||
|
||||
接下来,我们会讨论一个很新的,在为 Agent 模拟任务构建框架上,把 Decomp 和 Prompting 技术用到登峰造极的样例。
|
||||
|
||||
# Generative Agents:社群模拟实验
|
||||
## Generative Agents:社群模拟实验
|
||||
|
||||
[[2304.03442] Generative Agents: Interactive Simulacra of Human Behavior (](https://arxiv.org/abs/2304.03442)[arxiv.org](https://arxiv.org/abs/2304.03442)[)](https://arxiv.org/abs/2304.03442)
|
||||
|
||||
@@ -383,7 +382,7 @@ Generative Agents 一文通过的自然语言框架 AI 构建出了一个模拟
|
||||
|
||||
因为,其本质是一个信息管理框架的实验。
|
||||
|
||||
## 简要介绍
|
||||
### 简要介绍
|
||||
|
||||
简单介绍该项目构建的框架:
|
||||
|
||||
@@ -399,7 +398,7 @@ Generative Agents 构建了一套框架,让 NPC 可以感知被模块化的世
|
||||
|
||||
根据 NPC 的决策,NPC 能反向更新自身所使用的记忆数据库,并提炼总结出高层记忆供后续使用。
|
||||
|
||||
## 世界沙盒的构建
|
||||
### 世界沙盒的构建
|
||||
|
||||
相比角色信息的构建是重头戏,世界沙盒的构建使用的方法要相对朴素一些
|
||||
|
||||
@@ -419,7 +418,7 @@ Generative Agents 的场景信息管理
|
||||
|
||||
同时,空间信息会被自动组成自然语言 Prompt,用于帮助 Agent 更好地理解外部信息。甚至当 Agent 希望获取空间信息时,其能主动递归调用世界信息,从而让 NPC 能准确找到其希望抵达的叶子节点。
|
||||
|
||||
## Agent 构建
|
||||
### Agent 构建
|
||||
|
||||
模型中的 Agent 由 数据库 + LLMs 构建
|
||||
|
||||
@@ -431,13 +430,13 @@ Generative Agents 的场景信息管理
|
||||
|
||||
而对于过去经验的输入,则是文章的一大亮点
|
||||
|
||||
## 记忆模式
|
||||
### 记忆模式
|
||||
|
||||
对于 Agent 的记忆,依托于一个储存信息流的数据库
|
||||
|
||||
数据库中核心储存三类关键记忆信息 memory, planning and reflection
|
||||
|
||||
### Memory
|
||||
#### Memory
|
||||
|
||||
对于 Agent 每个时间步观测到的事件,会被顺序标记时间戳储存进记忆数据库中
|
||||
|
||||
@@ -449,11 +448,11 @@ Generative Agents 的场景信息管理
|
||||
|
||||
对于对记忆数据库进行索引的情况,会实时评估上述三个指标,并组合权重,返回对记忆索引内容的排序
|
||||
|
||||
### Reflection
|
||||
#### Reflection
|
||||
|
||||
反思机制用于定期整理当前的 memory 数据库,让 npc 构建对世界和自身的高层认知
|
||||
|
||||
反思机制依靠一个自动的过程,反思-提问-解答
|
||||
反思机制依靠一个自动的过程,反思 - 提问 - 解答
|
||||
|
||||
在这个过程中,Agent 需要复盘自身所接受的记忆,并基于记忆对自己进行追问:
|
||||
|
||||
@@ -465,7 +464,7 @@ Generative Agents 的场景信息管理
|
||||
|
||||
进一步的,我们将这些洞察以相同的形式重新储存至记忆库中,由此模拟人类的记忆认知过程
|
||||
|
||||
### Planning
|
||||
#### Planning
|
||||
|
||||
Planning 的核心在于鼓励 Agent 为未来做出一定的规划,使得后续行动变得可信
|
||||
|
||||
@@ -475,13 +474,13 @@ Planning 的核心在于鼓励 Agent 为未来做出一定的规划,使得后
|
||||
|
||||
在此基础上,Agent 也需要对环境做出反应而调整自己的计划表(例如自身判断外界交互的优先级比当前计划更高。
|
||||
|
||||
## 交互构建
|
||||
### 交互构建
|
||||
|
||||
基于上述记忆框架,进一步实时让 Agent 自行感知并选择与其它 Agent 构建交互
|
||||
|
||||
并最终使得复杂的社群在交互中涌现
|
||||
|
||||
## 启发
|
||||
### 启发
|
||||
|
||||
Generative Agent 框架主要带来了一些启发,不止于 AI-NPC 的构建,其操作的诸多细节都是能进一步为我们在实际的工程中所延拓的。
|
||||
|
||||
@@ -497,7 +496,7 @@ Generative Agent 框架主要带来了一些启发,不止于 AI-NPC 的构建
|
||||
- AI x 信息自动化系统的构建:基于 AI + 软件系统而非基于人工对数据进行收集和管理
|
||||
- etc...
|
||||
|
||||
# AutoGPT:自动化的智能软件系统
|
||||
## AutoGPT:自动化的智能软件系统
|
||||
|
||||
[Torantulino/Auto-GPT: An experimental open-source attempt to make GPT-4 fully autonomous. (](https://github.com/Torantulino/Auto-GPT)[github.com](https://github.com/Torantulino/Auto-GPT)[)](https://github.com/Torantulino/Auto-GPT)[github.com/Torantulino/Auto-GPT](https://github.com/Torantulino/Auto-GPT)
|
||||
|
||||
@@ -530,7 +529,7 @@ AutoGPT 主要特性如下:
|
||||
|
||||
(如下是 AutoGPT 的基础 Prompt)
|
||||
|
||||
```
|
||||
```txt
|
||||
[
|
||||
{
|
||||
'content': 'You are Eliza, an AI designed to write code according to my requirements.\n'
|
||||
@@ -613,7 +612,7 @@ AutoGPT 主要特性如下:
|
||||
]
|
||||
```
|
||||
|
||||
# 回归正题:AI 作为智能系统
|
||||
## 回归正题:AI 作为智能系统
|
||||
|
||||
作为正题的回归,我们需要重新考虑什么是一个 AI,一个能帮助我们的 AI 应当处于什么样的现实形态?
|
||||
|
||||
@@ -625,7 +624,7 @@ AutoGPT 主要特性如下:
|
||||
|
||||
接下来,我们会围绕此进行展开
|
||||
|
||||
## 意识理论之于 AI:全局工作空间理论
|
||||
### 意识理论之于 AI:全局工作空间理论
|
||||
|
||||
全局工作空间理论(英语:Global workspace theory,GWT)是美国心理学家伯纳德·巴尔斯提出的[意识](https://zh.wikipedia.org/wiki/%E6%84%8F%E8%AF%86)模型。该理论假设意识与一个全局的“广播系统”相关联,这个系统会在整个大脑中广播资讯。大脑中专属的智能处理器会按照惯常的方式自动处理资讯,这个时候不会形成[意识](https://zh.wikipedia.org/wiki/%E6%84%8F%E8%AF%86)。当人面对新的或者是与习惯性刺激不同的事物时,各种专属智能处理器会透过合作或竞争的方式,在全局工作空间中对新事物进行分析以获得最佳结果,而意识正是在这个过程中得以产生。
|
||||
|
||||
@@ -649,7 +648,7 @@ AutoGPT 主要特性如下:
|
||||
- 知觉系统(现在)
|
||||
- 运动系统(未来)
|
||||
|
||||
### 例子:意识系统 For Generative Agent
|
||||
#### 例子:意识系统 For Generative Agent
|
||||
|
||||
单独解释的话,或许会比较麻烦,毕竟我对认知科学并不专业
|
||||
|
||||
@@ -671,9 +670,9 @@ AutoGPT 主要特性如下:
|
||||
|
||||
当然,我个人对该问题的认知与 GPT4 并非完全相同,包括注意系统与运动系统的部分。但其实我并不一定需要将所有东西全都呈现出来,因为在框架上它已然如此。
|
||||
|
||||
记忆、评估、反思这几块的设计通过 Prompt 把 LLMs 劣化成专用的智能处理器单元, 并系统性实现信息的整合与输出。从整体的观点上来看,Generative Agents 中的 Agent,其主体性并不在于 LLM,而是在于这个完整的系统。(相应的,LLMs 只是这个系统的运算工具和陈述工具)
|
||||
记忆、评估、反思这几块的设计通过 Prompt 把 LLMs 劣化成专用的智能处理器单元,并系统性实现信息的整合与输出。从整体的观点上来看,Generative Agents 中的 Agent,其主体性并不在于 LLM,而是在于这个完整的系统。(相应的,LLMs 只是这个系统的运算工具和陈述工具)
|
||||
|
||||
### 例子:AutoGPT 的考察
|
||||
#### 例子:AutoGPT 的考察
|
||||
|
||||
我们再从相同的角度考察 AutoGPT 这一项目:
|
||||
|
||||
@@ -690,7 +689,7 @@ AutoGPT 主要特性如下:
|
||||
|
||||
这也对应 AutoGPT 虽然看似有着极强的能力,但实际智能效果又不足为外人道也
|
||||
|
||||
## 构建一个什么样的智能系统
|
||||
### 构建一个什么样的智能系统
|
||||
|
||||
再次回归正题,Generative Agents 和 AutoGPT 这两个知名项目共同将 AI 研究从大模型能力研究导向了智能系统能力研究。而我们也不能驻足不前,我们应当更积极地考虑我们对于一个 AI 智能体有着什么样的需求,也对应我们需要构建、要怎么构建一个基于 LLMs 语言能力的可信可用的智能系统。
|
||||
|
||||
@@ -708,7 +707,7 @@ AutoGPT 主要特性如下:
|
||||
|
||||
这些问题都在指导、质问我们究竟需要一个怎样的智能系统。
|
||||
|
||||
# 予智能以信息:难题与展望
|
||||
## 予智能以信息:难题与展望
|
||||
|
||||
回到最开始的话题,我们构建一个可用智能系统的基底,依旧是信息系统
|
||||
|
||||
@@ -724,7 +723,7 @@ AutoGPT 主要特性如下:
|
||||
|
||||
而接下来,我们希望对其进行逐一评估,讨论他们各自将作用的形式,讨论他们需要做到哪一步,又能做到哪一步。
|
||||
|
||||
## 知觉系统:构建 AI 可读的结构化环境
|
||||
### 知觉系统:构建 AI 可读的结构化环境
|
||||
|
||||
知觉系统负责让智能体实现信息的感知,其中也包括对复杂输入信息的解析
|
||||
|
||||
@@ -752,7 +751,7 @@ AutoGPT 所使用的 Commands 接口中,就有很大一部分接口用于实
|
||||
- args: "file": `"<file>"`
|
||||
- 读取文件并解析文本数据
|
||||
|
||||
这些访问接口由程序集暴露给 GPT ,将知觉系统中实际使用的微观处理器隐藏在了系统框架之下
|
||||
这些访问接口由程序集暴露给 GPT,将知觉系统中实际使用的微观处理器隐藏在了系统框架之下
|
||||
|
||||
AutoGPT 所实际感知的信息为纯文本的格式,得益于以开放性 Web 为基础的网络世界环境,AutoGPT 能较方便地通过搜索(依赖于搜索引擎 API)和解析 html 文件(依赖于软件辅助,GPT 难以自行裁剪 html 中过于冗杂的格式信息),从而有效阅读绝大多数互联网信息。
|
||||
|
||||
@@ -804,7 +803,7 @@ Generative Agents 的知觉设计:关联性难题
|
||||
|
||||
仅就这方面而言,作为一个方向性的倡议,对知觉系统的开发可能分为以下步骤
|
||||
|
||||
### <em>数据处理/管理</em>
|
||||
#### <em>数据处理/管理</em>
|
||||
|
||||
- 对 办公文件/数据 构建通用读取接口
|
||||
- 以同类信息为单位,设计通用的字段(由人设计和管理,AI 能力尚不至此)
|
||||
@@ -828,7 +827,7 @@ Generative Agents 的知觉设计:关联性难题
|
||||
- 如储存进 mongoDB
|
||||
- (设计孪生数据的自动更新机制)
|
||||
|
||||
### <em>知觉系统驱动</em>
|
||||
#### <em>知觉系统驱动</em>
|
||||
|
||||
- 基于上述索引数据库,以视图为单位进行访问,并设计 视图 2 Prompt 的转化格式
|
||||
|
||||
@@ -847,7 +846,7 @@ Generative Agents 的知觉设计:关联性难题
|
||||
|
||||
- 对于 Agent 开启的指定任务线程(区分于主线程的感知模块),其起始 Prompt 可能呈这样的形式
|
||||
|
||||
> <br/>如上是你的目标,为了实现这个目标,你可能需要获取一系列的信息,为了帮助你获得信息,我会为你提供一系列的索引访问接口,请你通过如下格式输出语句让我为你返回信息。<br/>注:如果你请求错误,请你阅读返回的报错信息以自我纠正<br/>例:<br/>< 通过接口名称检索("接口名称")><br/>< 通过接口功能检索("访问网页")><br/>< 通过父级名称检索("父级名称")>
|
||||
> <br/>如上是你的目标,为了实现这个目标,你可能需要获取一系列的信息,为了帮助你获得信息,我会为你提供一系列的索引访问接口,请你通过如下格式输出语句让我为你返回信息。<br/>注:如果你请求错误,请你阅读返回的报错信息以自我纠正<br/>例:<br/>< 通过接口名称检索 ("接口名称")><br/>< 通过接口功能检索 ("访问网页")><br/>< 通过父级名称检索 ("父级名称")>
|
||||
|
||||
- 为 GPT 设计自动化指令解析与执行模块
|
||||
|
||||
@@ -861,7 +860,7 @@ Generative Agents 的知觉设计:关联性难题
|
||||
|
||||
> TBD:号被 OpenAI 噶了,我也很绝望啊
|
||||
|
||||
## 工作记忆:组织 AI 记忆系统
|
||||
### 工作记忆:组织 AI 记忆系统
|
||||
|
||||
记忆系统的构成其实相较知觉系统等更为抽象,它用于管理 AI 运行时作为背景的长期记忆,以及定义决定了 AI 当前任务及目标的短期记忆。
|
||||
|
||||
@@ -869,9 +868,9 @@ Generative Agents 的知觉设计:关联性难题
|
||||
|
||||
但我们依旧能从前人的工作中获得一定的参考。
|
||||
|
||||
### AutoGPT 的记忆设计:粗放但有效
|
||||
#### AutoGPT 的记忆设计:粗放但有效
|
||||
|
||||
在 长时记忆(过去)、评估系统(价值)、注意系统(关注) 这三个要素中,AutoGPT 做得比较好的无疑只有第一个。
|
||||
在 长时记忆(过去)、评估系统(价值)、注意系统(关注)这三个要素中,AutoGPT 做得比较好的无疑只有第一个。
|
||||
|
||||
AutoGPT 的核心记忆设计依赖于预包装的 Prompt 本体,这一包装包含如下部分:
|
||||
|
||||
@@ -899,7 +898,7 @@ AutoGPT 的核心记忆设计依赖于预包装的 Prompt 本体,这一包装
|
||||
|
||||
但从另一角度,其“自主将收集到的信息写入记忆”这一功能作为一个 以完成任务为目标 的 Agent 而言无疑是非常合适的架构设计。
|
||||
|
||||
### Generative Agents 的记忆设计:精心构建的金字塔
|
||||
#### Generative Agents 的记忆设计:精心构建的金字塔
|
||||
|
||||
区别于 AutoGPT 主动写入的记忆,Generative Agents 的记忆源自被动的无限感知和记录,因此显得更加没有目的性。也正因如此,其需要一种更妥善的管理形式。
|
||||
|
||||
@@ -907,7 +906,7 @@ Generative Agent 通过自动化评估记忆的价值,并构建遗忘系统、
|
||||
|
||||
|
||||
|
||||
Generative Agents :基于 Reflection 构建记忆金字塔
|
||||
Generative Agents:基于 Reflection 构建记忆金字塔
|
||||
|
||||
进一步的,其通过反思机制强化了记忆的价值,使得高层洞察从既有记忆的连结中涌现,这一机制通常被用于将 信息转化为知识,并构建出了有效记忆的金字塔。
|
||||
|
||||
@@ -915,7 +914,7 @@ Generative Agents :基于 Reflection 构建记忆金字塔
|
||||
|
||||
相关的更有效的记忆管理无疑很快就会被更新的项目学习。
|
||||
|
||||
### 记忆系统的构建讨论(放飞大脑)
|
||||
#### 记忆系统的构建讨论(放飞大脑)
|
||||
|
||||
但从某种意义上来说,对于一个我们希望其帮助我们工作的智能体而言,像 Generative Agent 这般的巨大数据库也许并未有充分的价值,何况我们所输入的内容原始层级就较高(这一层可能在前面的知觉系统中,就让一定程度上的高层洞见自主产生了),不易于进一步的堆叠。
|
||||
|
||||
@@ -933,7 +932,7 @@ Generative Agents :基于 Reflection 构建记忆金字塔
|
||||
|
||||
(可以遇见的,以 AutoGPT 的热度,半个月内就会有人为其设计相应的 mod)
|
||||
|
||||
## 运动系统:让 AI 可及一切
|
||||
### 运动系统:让 AI 可及一切
|
||||
|
||||
基于知觉系统和记忆系统,已经能构建一个使用语言解决问题的智能体了。但最为关键的改造世界部分则依旧缺席。
|
||||
|
||||
@@ -943,7 +942,7 @@ Generative Agents :基于 Reflection 构建记忆金字塔
|
||||
|
||||
- 我们大胆假设未来游戏中的 Agent 能通过 API 驱动自身在场景中无拘无束(拼装行为树
|
||||
- 再大胆假设他们能使用 API 实时把需求的内容转化为发布给玩家的任务(拼装任务节点
|
||||
- 继续大胆假设, AI 根据我的需求把今天要配的啥比表直接配完,当场下班(笑
|
||||
- 继续大胆假设,AI 根据我的需求把今天要配的啥比表直接配完,当场下班(笑
|
||||
|
||||
(而这一切,都是可能,且近在眼前的)
|
||||
|
||||
@@ -963,7 +962,7 @@ AI 能做的一切都基于我们的赋予,包括语言能力,包括思维
|
||||
- 我们不该将其当作独立的智能体看待,但能在其基础上通过构建系统创建智能 Agent
|
||||
- 为此,我们需要通过信息工程,让 AI 能够真正感知和改造世界,从而改变我们的生产进程
|
||||
|
||||
# 寄予厚望
|
||||
## 寄予厚望
|
||||
|
||||
感谢有人忍受了我阴间的行文和一路跑偏的思路,真能看到这里
|
||||
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# LLM Agent之结构化输出
|
||||
# LLM Agent 之结构化输出
|
||||
|
||||
author:Marlene
|
||||
|
||||
@@ -6,33 +6,33 @@ author:Marlene
|
||||
|
||||
## 引言
|
||||
|
||||
自去年年底以来,GPT的迅速发展诞生了一系列大模型。出现了更新、更大、更强的GPT-4。OpenAI不断推出GPT-4,ChatGPT Plugins,代码解释器,Function calling,图片处理等等。7月的WAIC上,笔者也有幸见到了国内一众企业相继展示自家的大模型。在这段时间里,LLM从最初的PE工程走向智能体交互。而笔者从最开始考虑LLM能不能多人协作,思考”一个专家完成所有任务好还是很多人分工完成好“,到各种论文层出不穷,到如今火热的LLM Agent开发模式。可以说,如果你从大学里随便问某个人都知道GPT,甚至大部分都用过。
|
||||
自去年年底以来,GPT 的迅速发展诞生了一系列大模型。出现了更新、更大、更强的 GPT-4。OpenAI 不断推出 GPT-4,ChatGPT Plugins,代码解释器,Function calling,图片处理等等。7 月的 WAIC 上,笔者也有幸见到了国内一众企业相继展示自家的大模型。在这段时间里,LLM 从最初的 PE 工程走向智能体交互。而笔者从最开始考虑 LLM 能不能多人协作,思考”一个专家完成所有任务好还是很多人分工完成好“,到各种论文层出不穷,到如今火热的 LLM Agent 开发模式。可以说,如果你从大学里随便问某个人都知道 GPT,甚至大部分都用过。
|
||||
|
||||
好了,前言少叙。进入正题。众所周知,Agent 基本= LLM(大型语言模型)+ 记忆 + 规划技能 + 工具使用。
|
||||
|
||||
想要使用工具,让GPT掌握如何使用工具,常见的方法是告知GPT工具(通常是一个可以调用的函数)的参数,让GPT生成这些参数即可。那么如何让GPT可靠的生成这些规定的参数呢?换一种说法,如何让GPT输出结构化的数据信息呢?
|
||||
想要使用工具,让 GPT 掌握如何使用工具,常见的方法是告知 GPT 工具(通常是一个可以调用的函数)的参数,让 GPT 生成这些参数即可。那么如何让 GPT 可靠的生成这些规定的参数呢?换一种说法,如何让 GPT 输出结构化的数据信息呢?
|
||||
|
||||
## 原理及相关框架
|
||||
|
||||
现如今大部分的结构化输出工具的原理都是:告诉GPT要输出一个怎么样的结构即可。没错~当然,为什么会出现这么多开发工具都用来解决这个问题,明明是一个简单的原理呢?
|
||||
现如今大部分的结构化输出工具的原理都是:告诉 GPT 要输出一个怎么样的结构即可。没错~当然,为什么会出现这么多开发工具都用来解决这个问题,明明是一个简单的原理呢?
|
||||
|
||||
```
|
||||
```txt
|
||||
1. 通过 prompt 告知 LLM 我们所需要的返回格式,并进行生成。
|
||||
2. 通过一些规则来检查返回结果,如果不符合格式,生成相关错误信息。
|
||||
3. 将上一次的生成内容和检查的错误信息告知 LLM,进行下一次的修正生成。
|
||||
4. 重复 2-3 步骤,直到生成的内容完全符合我们的要求。
|
||||
```
|
||||
|
||||
首先,关于怎样描述这样一个结构的prompt模板,众口难调。有些人认为结构就应该用自然语言描述,这样足够简单,上手难度足够低,方便快速迭代开发。有些人认为结构描述?JSON Schema不就够了?有些人觉得YAML也可以。有些人觉得上面这些对于我的需求还是够不着啊,于是自己造了一个伪代码描述。
|
||||
首先,关于怎样描述这样一个结构的 prompt 模板,众口难调。有些人认为结构就应该用自然语言描述,这样足够简单,上手难度足够低,方便快速迭代开发。有些人认为结构描述?JSON Schema 不就够了?有些人觉得 YAML 也可以。有些人觉得上面这些对于我的需求还是够不着啊,于是自己造了一个伪代码描述。
|
||||
其次,自动处理修正机制也可以做很多文章。还有许多对性能和开销的优化。
|
||||
下文就是关于一众框架的简单分析。希望会对选择困难症的你有所帮助。
|
||||
|
||||
### **guardrails**
|
||||
|
||||
guardrails这个项目,就是将上述的步骤做了进一步的抽象与封装,提供更加 high level 的配置与 API 来完成整个过程。
|
||||
guardrails 这个项目,就是将上述的步骤做了进一步的抽象与封装,提供更加 high level 的配置与 API 来完成整个过程。
|
||||
优点:
|
||||
|
||||
1. 定义了一套RAIL spec
|
||||
1. 定义了一套 RAIL spec
|
||||
2. 更聚焦于错误信息
|
||||
|
||||
```markdown
|
||||
@@ -78,7 +78,7 @@ Given the following doctor's notes about a patient, please extract a dictionary
|
||||
</rail>
|
||||
```
|
||||
|
||||
可以看到,guardrails定义了一套类似xml的语言用于结构化输出,又结合了自然语言的prompt。虽然比起常见的模板语言要更加“繁琐”,但可以包含的内容也可以更加完善。比如可以提供字段的描述信息,检查规范,一定程度上也能帮助 LLM 更好地理解需求,生成预期的结果。
|
||||
可以看到,guardrails 定义了一套类似 xml 的语言用于结构化输出,又结合了自然语言的 prompt。虽然比起常见的模板语言要更加“繁琐”,但可以包含的内容也可以更加完善。比如可以提供字段的描述信息,检查规范,一定程度上也能帮助 LLM 更好地理解需求,生成预期的结果。
|
||||
|
||||
```markdown
|
||||
I was given the following JSON response, which had problems due to incorrect values.
|
||||
@@ -127,11 +127,11 @@ define bot inform capabilities
|
||||
"I am an AI assistant which helps answer questions based on a given knowledge base. For this interaction, I can answer question based on the job report published by US Bureau of Labor Statistics."
|
||||
```
|
||||
|
||||
从代码可以看出其结合了python和自然语言,方便相似度检索。
|
||||
从代码可以看出其结合了 python 和自然语言,方便相似度检索。
|
||||
其整体的运作流程如下:
|
||||
|
||||
1. 根据用户输入识别用户意图。在这一步,系统会将用户的输入在 flow 定义的各种用户回复文本中做相似性查找,也就是上面文件中“What can you do?”这一连串内容。这些检索到的预设用户意图内容,结合其它信息如对话样例,最近聊天记录等,形成整体的 prompt,发给 LLM 来生成回复。最终再从回复中提取用户意图。
|
||||
2. 根据意图,判断下一步操作动作。这一步有两种做法,一是当前的状态能够匹配上预定义的 flow。例如用户就是提了一个 bot 能力的问题,那么就会匹配上面定义的user ask capabilities,下一步动作自然就是bot inform capabilities。如果没有匹配上,就要由 LLM 自己来决定下一步动作,这时候也会跟生成用户意图一样,对于 flow 定义做一个相似性查找,将相关信息发给 LLM 来做生成。
|
||||
2. 根据意图,判断下一步操作动作。这一步有两种做法,一是当前的状态能够匹配上预定义的 flow。例如用户就是提了一个 bot 能力的问题,那么就会匹配上面定义的 user ask capabilities,下一步动作自然就是 bot inform capabilities。如果没有匹配上,就要由 LLM 自己来决定下一步动作,这时候也会跟生成用户意图一样,对于 flow 定义做一个相似性查找,将相关信息发给 LLM 来做生成。
|
||||
3. 生成 bot 回复。如果上一步生成的 bot 回复意图已经有明确定义了(例如上面的 bot 能力的回复),那么就直接用预定义的回复内容来回复用户。如果没有,就跟生成用户意图一样,做意图的相似性查找,将相关信息给 LLM 来生成回复。注意到很多动态的问题例如 QA 场景,是很难预先定义好回复内容的,这里也支持对接知识库,同样是做 vector search 之后,将相关 context 信息发给 LLM 来生成具体回复。
|
||||
|
||||
### guidance
|
||||
@@ -174,7 +174,7 @@ program(description="A quick and nimble fighter.", valid_weapons=valid_weapons)
|
||||
1. 生成的 json 结构是保证合法且可控的,不会出现语法错误或者缺失/错误字段等。
|
||||
2. 通过 LLM 生成的 token 数量减少了,理论上可以提升生成速度。
|
||||
|
||||
除了prompt模板,它还提供了:
|
||||
除了 prompt 模板,它还提供了:
|
||||
|
||||
- 支持 hidden block,例如 LLM 的一些推理过程可能并不需要暴露给最终用户,就可以灵活利用这个特性来生成一些中间结果。
|
||||
- Generation caching,自动把已经生成过的结果缓存起来,提升速度。
|
||||
@@ -186,7 +186,7 @@ program(description="A quick and nimble fighter.", valid_weapons=valid_weapons)
|
||||
|
||||
### lmql
|
||||
|
||||
在 guidance 的基础上,lmql这个项目进一步把“prompt 模板”这个概念推进到了一种新的编程语言。从官网能看到给出的一系列示例。语法结构看起来有点像 SQL,但函数与缩进都是 Python 的风格。
|
||||
在 guidance 的基础上,lmql 这个项目进一步把“prompt 模板”这个概念推进到了一种新的编程语言。从官网能看到给出的一系列示例。语法结构看起来有点像 SQL,但函数与缩进都是 Python 的风格。
|
||||

|
||||
从支持的功能来看,相比 guidance 毫不逊色。例如各种限制条件,代码调用,各种 caching 加速,工具集成等基本都具备。这个框架的格式化输出是其次,其各种可控的输出及语言本身或许更值得关注。
|
||||
|
||||
@@ -194,17 +194,17 @@ program(description="A quick and nimble fighter.", valid_weapons=valid_weapons)
|
||||
|
||||
TypeChat 将 prompt 工程替换为 schema 工程:无需编写非结构化的自然语言 prompt 来描述所需输出的格式,而是编写 TS 类型定义。TypeChat 可以帮助 LLM 以 JSON 的形式响应,并且响应结果非常合理:例如用户要求将这句话「我可以要一份蓝莓松饼和一杯特级拿铁咖啡吗?」转化成 JSON 格式,TypeChat 响应结果如下:
|
||||

|
||||
其本质原理是把interface之类的ts代码作为prompt模板。因此它不仅可以对输出结果进行ts校验,甚至能够输入注释描述,不可谓非常方便js开发者。不过,近日typechat爆火,很多开发者企图尝试将typechat移植到python,笔者认为这是缘木求鱼,因为其校验本身依赖的是ts。笔者在开发过程中,将typechat融合到自己的库中,效果不错。但是它本身自带的prompt和笔者输入的prompt还是存在冲突,还是需要扣扣源码。
|
||||
其本质原理是把 interface 之类的 ts 代码作为 prompt 模板。因此它不仅可以对输出结果进行 ts 校验,甚至能够输入注释描述,不可谓非常方便 js 开发者。不过,近日 typechat 爆火,很多开发者企图尝试将 typechat 移植到 python,笔者认为这是缘木求鱼,因为其校验本身依赖的是 ts。笔者在开发过程中,将 typechat 融合到自己的库中,效果不错。但是它本身自带的 prompt 和笔者输入的 prompt 还是存在冲突,还是需要扣扣源码。
|
||||
|
||||
### Langchain
|
||||
|
||||
如果你关注了过去几个月中人工智能的爆炸式发展,那你大概率听说过 LangChain。简单来说,LangChain 是一个 Python 和 JavaScript 库,由 Harrison Chase 开发,用于连接 OpenAI 的 GPT API(后续已扩展到更多模型)以生成人工智能文本。
|
||||
|
||||
langchain具有特别多的结构化输出工具。例如使用yaml定义Schema,输出结构化JSON。使用zodSchema定义Schema,输出结构化JSON。使用FunctionParameters定义Schema,输出结构化JSON。
|
||||
langchain 具有特别多的结构化输出工具。例如使用 yaml 定义 Schema,输出结构化 JSON。使用 zodSchema 定义 Schema,输出结构化 JSON。使用 FunctionParameters 定义 Schema,输出结构化 JSON。
|
||||
|
||||
但是笔者这里不打算介绍langchain。究其原因,是笔者被langchain折磨不堪。明明可以几行代码写清楚的东西,langchain可以各种封装,花了好几十行才写出来。更何况,笔者是用ts开发,开发时甚至偷不了任何懒,甚至其文档丝毫不友好。这几天,《机器之心》发布文章表示放弃langchain。要想让 LangChain 做笔者想让它做的事,就必须花大力气破解它,这将造成大量的技术负担。因为使用人工智能本身就需要花费足够的脑力。LangChain 是为数不多的在大多数常用情况下都会增加开销的软件之一。所以笔者建议非必要,不使用langchain。
|
||||
但是笔者这里不打算介绍 langchain。究其原因,是笔者被 langchain 折磨不堪。明明可以几行代码写清楚的东西,langchain 可以各种封装,花了好几十行才写出来。更何况,笔者是用 ts 开发,开发时甚至偷不了任何懒,甚至其文档丝毫不友好。这几天,《机器之心》发布文章表示放弃 langchain。要想让 LangChain 做笔者想让它做的事,就必须花大力气破解它,这将造成大量的技术负担。因为使用人工智能本身就需要花费足够的脑力。LangChain 是为数不多的在大多数常用情况下都会增加开销的软件之一。所以笔者建议非必要,不使用 langchain。
|
||||
|
||||
## LLM对于结构化信息的理解
|
||||
## LLM 对于结构化信息的理解
|
||||
|
||||
LLM 的可控性、稳定性、事实性、安全性等问题是推进企业级应用中非常关键的问题,上面分享的这些项目都是在这方面做了很多探索,也有很多值得借鉴的地方。总体思路上来说,主要是:
|
||||
|
||||
@@ -216,24 +216,24 @@ LLM 的可控性、稳定性、事实性、安全性等问题是推进企业级
|
||||
|
||||
即使我们不直接使用上述的项目做开发,也可以从中学习到很多有用的思路。当然也非常期待这个领域出现更多有意思的想法与研究,以及 prompt 与编程语言结合能否碰撞出更多的火花。
|
||||
|
||||
同时笔者认为自动处理机制、自己设计的编程语言等等内容,随着时间发展,一定会层出不穷,不断迭代更新。笔者抛去这些时效性较弱的内容,从描述信息和位置信息两方面思考peompt模板该如何设计,当然只是浅浅的抛砖引玉一下。
|
||||
同时笔者认为自动处理机制、自己设计的编程语言等等内容,随着时间发展,一定会层出不穷,不断迭代更新。笔者抛去这些时效性较弱的内容,从描述信息和位置信息两方面思考 peompt 模板该如何设计,当然只是浅浅的抛砖引玉一下。
|
||||
|
||||
### 描述信息
|
||||
|
||||
到底哪种方式更容易于LLM去理解?我们不谈框架的设计,只考虑prompt的设计。上述框架关于这方面有一些参考,例如有些直接拿json作为prompt模板,有些拿xml作为prompt模板,有些拿自己设计的语言作为prompt,有些拿自然语言作为prompt模板。时至今日,选用哪种最适合LLM去理解格式化的信息,输出格式化的内容完全没有盖棺定论。甚至时至今日,格式化输出问题还是没有得到可靠稳定的解决,要不然笔者肯定不会介绍这么多框架实践了。
|
||||
到底哪种方式更容易于 LLM 去理解?我们不谈框架的设计,只考虑 prompt 的设计。上述框架关于这方面有一些参考,例如有些直接拿 json 作为 prompt 模板,有些拿 xml 作为 prompt 模板,有些拿自己设计的语言作为 prompt,有些拿自然语言作为 prompt 模板。时至今日,选用哪种最适合 LLM 去理解格式化的信息,输出格式化的内容完全没有盖棺定论。甚至时至今日,格式化输出问题还是没有得到可靠稳定的解决,要不然笔者肯定不会介绍这么多框架实践了。
|
||||
|
||||
笔者认为不管哪种方式,都可以从两个方面考量:更简单,更结构。如果想要在开发的时候更简单,或者在使用时更简单,选择md、yaml方式描述结构化信息更合适。如果想要更结构化的方式,选择json、xml、ts,输出都能更有结构,甚至之后做结构校验都更方便。
|
||||
笔者认为不管哪种方式,都可以从两个方面考量:更简单,更结构。如果想要在开发的时候更简单,或者在使用时更简单,选择 md、yaml 方式描述结构化信息更合适。如果想要更结构化的方式,选择 json、xml、ts,输出都能更有结构,甚至之后做结构校验都更方便。
|
||||
|
||||
想要LLM结构化输出更加稳定和理想,笔者认为选择prompt模板时必须考虑每个字段是否有足够的辅助信息。例如xml描述时,每个标签都有一个描述属性描述这个标签时什么意思。
|
||||
想要 LLM 结构化输出更加稳定和理想,笔者认为选择 prompt 模板时必须考虑每个字段是否有足够的辅助信息。例如 xml 描述时,每个标签都有一个描述属性描述这个标签时什么意思。
|
||||
|
||||
#### 额外引申
|
||||
|
||||
笔者之前在开发LLM应用时,也曾思考类似的问题。笔者需要将多模态的数据进行结构化的标注,方便LLM去理解。但是标注成什么样却是一个很大的难题。笔者选择的是JSON。但是,关于里面许多内容的标注。笔者在众多方案中徘徊。在细节处深挖,如何设计一种既简单,又能表示各种结构复杂关系,还能够节约token的方案及其的难。
|
||||
> 关于后续如何解决,请容笔者卖个关子sai~
|
||||
笔者之前在开发 LLM 应用时,也曾思考类似的问题。笔者需要将多模态的数据进行结构化的标注,方便 LLM 去理解。但是标注成什么样却是一个很大的难题。笔者选择的是 JSON。但是,关于里面许多内容的标注。笔者在众多方案中徘徊。在细节处深挖,如何设计一种既简单,又能表示各种结构复杂关系,还能够节约 token 的方案及其的难。
|
||||
> 关于后续如何解决,请容笔者卖个关子 sai~
|
||||
|
||||
### 位置信息
|
||||
|
||||
是否有人注意到llm对于关键信息在prompt中的位置会对结果产生影响呢?在设计 prompt 方面,人们通常建议为语言模型提供详尽的任务描述和背景信息。近期的一些语言模型有能力输入较长的上下文,但它究竟能多好地利用更长的上下文?这一点却相对少有人知。近日,有学者研究发现如果上下文太长,语言模型会更关注其中的前后部分,中间部分却几乎被略过不看,导致模型难以找到放在输入上下文中部的相关信息。下文部分是该论文一些核心内容:
|
||||
是否有人注意到 llm 对于关键信息在 prompt 中的位置会对结果产生影响呢?在设计 prompt 方面,人们通常建议为语言模型提供详尽的任务描述和背景信息。近期的一些语言模型有能力输入较长的上下文,但它究竟能多好地利用更长的上下文?这一点却相对少有人知。近日,有学者研究发现如果上下文太长,语言模型会更关注其中的前后部分,中间部分却几乎被略过不看,导致模型难以找到放在输入上下文中部的相关信息。下文部分是该论文一些核心内容:
|
||||

|
||||
这是由其本身训练和结构设计有关的,但却对于我们开发有着莫大的帮助和指导意义。
|
||||

|
||||
@@ -243,18 +243,19 @@ LLM 的可控性、稳定性、事实性、安全性等问题是推进企业级
|
||||
|
||||
## 题外话
|
||||
|
||||
之前,妙鸭相机突然爆火。其只需9.9即可生成同款数字分身,效果拔群。但是很多人发现,其生成的内容极其容易造成肖像权侵犯,这显然是有问题的。更有甚至的是,用户发现妙鸭相机的用户协议存在问题。根据该应用最初版本的用户服务协议,用户需授权妙鸭相机在全世界(包括元宇宙等虚拟空间)范围内享有永久的、不可撤销的、可转让的、可转授权的、免费的和非独家的许可,使得妙鸭相机可以任何形式、任何媒体或技术(无论现在已知或以后开发)使用用户的内容。对于上述内容,妙鸭相机称系“为了使我方能够提供、确保和改进本服务(包括但不限于使用AI生成内容作为再训练数据等)”。
|
||||
之前,妙鸭相机突然爆火。其只需 9.9 即可生成同款数字分身,效果拔群。但是很多人发现,其生成的内容极其容易造成肖像权侵犯,这显然是有问题的。更有甚至的是,用户发现妙鸭相机的用户协议存在问题。根据该应用最初版本的用户服务协议,用户需授权妙鸭相机在全世界(包括元宇宙等虚拟空间)范围内享有永久的、不可撤销的、可转让的、可转授权的、免费的和非独家的许可,使得妙鸭相机可以任何形式、任何媒体或技术(无论现在已知或以后开发)使用用户的内容。对于上述内容,妙鸭相机称系“为了使我方能够提供、确保和改进本服务(包括但不限于使用 AI 生成内容作为再训练数据等)”。
|
||||
|
||||
一句话理解,就是你的肖像它随便用,与你无关。
|
||||
|
||||
这不禁让我联想到一部非常发人深省的剧作:《黑镜》。它的第六季第一集讲述的同样是隐私的问题。该集中,主人公的生活隐私由于同意了用户协议,被无时无刻搜集。然后当天晚上就发现流媒体电视上居然出现了跟她同名的电视剧,内容与它当天的生活一模一样,台词甚至更加夸张。于是她的不方便公之于众的生活变得一塌涂地,但她甚至没有办法打官司,因为肯定会输。更令人深省的是,电视剧的主人公是AI生成的视频,其肖像确是根据现实存在的明星生成的。那位明星也无法对她的肖像有任何权利。这样一个荒诞的故事,但是仔细想想,却又非常可能发生。
|
||||
这不禁让我联想到一部非常发人深省的剧作:《黑镜》。它的第六季第一集讲述的同样是隐私的问题。该集中,主人公的生活隐私由于同意了用户协议,被无时无刻搜集。然后当天晚上就发现流媒体电视上居然出现了跟她同名的电视剧,内容与它当天的生活一模一样,台词甚至更加夸张。于是她的不方便公之于众的生活变得一塌涂地,但她甚至没有办法打官司,因为肯定会输。更令人深省的是,电视剧的主人公是 AI 生成的视频,其肖像确是根据现实存在的明星生成的。那位明星也无法对她的肖像有任何权利。这样一个荒诞的故事,但是仔细想想,却又非常可能发生。
|
||||
|
||||
如今的社会出现了各种大模型。大模型的发展必定需要大数据的支撑。企业为了盈利必定会想方设法的搜集数据,然后肆意使用,转卖。而很多用户对此不自知,更有甚至是非常乐意。例如抖音、B站,当你对其交互时,你希望它推荐更适合你的视频,它也在搜集你的数据,这是明知且主动的。
|
||||
如今的社会出现了各种大模型。大模型的发展必定需要大数据的支撑。企业为了盈利必定会想方设法的搜集数据,然后肆意使用,转卖。而很多用户对此不自知,更有甚至是非常乐意。例如抖音、B 站,当你对其交互时,你希望它推荐更适合你的视频,它也在搜集你的数据,这是明知且主动的。
|
||||
|
||||
隐私的掠夺是无声的。你认为你的一下点击是没啥价值的隐私数据,殊不知这正中了资本家的下怀。几年前,我也是这样的。高中的大门出现了闸机,可以刷脸进校园。我当时以为这需要像手机解锁一样需要扫描人脸ID。结果发现,我可以直接进去,闸机上甚至会出现我的照片。我仔细看了看,发现是我入学的证件照。原来一张照片就能刷脸进校园。原来就连学校也可以不经同学同意,将照片用作其他用途。那更何况其他的呢。
|
||||
隐私的掠夺是无声的。你认为你的一下点击是没啥价值的隐私数据,殊不知这正中了资本家的下怀。几年前,我也是这样的。高中的大门出现了闸机,可以刷脸进校园。我当时以为这需要像手机解锁一样需要扫描人脸 ID。结果发现,我可以直接进去,闸机上甚至会出现我的照片。我仔细看了看,发现是我入学的证件照。原来一张照片就能刷脸进校园。原来就连学校也可以不经同学同意,将照片用作其他用途。那更何况其他的呢。
|
||||
我想,未来,这样的隐私问题会越来越多。
|
||||
|
||||
## 参考
|
||||
|
||||
<https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650885029&idx=4&sn=ac01576a8957b41529dd3c877d262d5e&chksm=84e48fdbb39306cd8979a4fa7f7da14a9428dc28ccc47880d668ef6293b1a8b7b0964569ec36&mpshare=1&scene=23&srcid=0725w9FPsVnOOzkPGPB7lH8h&sharer_sharetime=1690303766527&sharer_shareid=d2396b329b12f49d34967e2b183540dd#rd>
|
||||
<https://mp.weixin.qq.com/s/BngY2WgCcpTOlvdyBNJxqA>
|
||||
<https://microsoft.github.io/TypeChat/>
|
||||
|
||||
@@ -12,7 +12,7 @@
|
||||
|
||||
无数伟大的科学家究其一生的研究和探索它,但是你发现本章内容少有相关内容,还是以深度学习为主?为什么?
|
||||
|
||||
## 原因一:时代的浪潮
|
||||
## 原因一:时代的浪潮
|
||||
|
||||
近乎全民深度学习的浪潮下,机器学习的知识被科研界一而再再而三的抛掷脑后,大家争先恐后的刷点,并使用深度学习的解决问题,因此深度学习领域的知识材料得到了井喷式的增长,而少有人愿意投入非常长的时间去研究机器学习的每一条数学公式的背后机理。
|
||||
|
||||
@@ -34,7 +34,7 @@ ZZM 曾经尝试过投入大量时间去钻研数学以及机器学习相关的
|
||||
|
||||
如果你阅览了本章节的数学相关知识和内容以及拓展感觉非常感兴趣并且毫无压力的话,我推荐你尝试去啃一啃大家公认的困难的书籍,比如说著名的花书,互联网上,社区内也有大量的辅助材料来帮助你更进一步的入门
|
||||
|
||||
# 科研导向明显
|
||||
## 科研导向明显
|
||||
|
||||
整篇教程大范围的在教怎么从科研角度去理解一些知识,感觉和工业上的逻有不符之处。
|
||||
|
||||
@@ -48,7 +48,7 @@ ZZM 曾经尝试过投入大量时间去钻研数学以及机器学习相关的
|
||||
|
||||
因此如果你对这方面感兴趣,可能你需要别的途径去获取更多的思考和资源了。
|
||||
|
||||
# 繁杂的知识内容
|
||||
## 繁杂的知识内容
|
||||
|
||||
这点非常抱歉,AI 领域的知识本身就是网状的,复杂的,甚至是互相引用的,这点会导致不可避免的内容变得冗长。
|
||||
|
||||
@@ -56,8 +56,11 @@ ZZM 曾经尝试过投入大量时间去钻研数学以及机器学习相关的
|
||||
|
||||
而不是别人强行灌输给你的
|
||||
|
||||
# 还有更多???
|
||||
## 还有更多???
|
||||
|
||||
联系 ZZM,我努力改
|
||||
::: tip 邮箱
|
||||
1264517821@qq.com
|
||||
:::
|
||||
|
||||

|
||||
<img src=https://cdn.xyxsw.site/boxcnfYSoVgoERduiWP0jWNWMxf.jpg width=200>
|
||||
|
||||
@@ -2,18 +2,16 @@
|
||||
|
||||
人工智能(Artificial Intelligence, AI)是机器,特别是计算机系统对人类智能过程的模拟。人工智能是一个愿景,目标就是让机器像我们人类一样思考与行动,能够代替我们人类去做各种各样的工作。人工智能研究的范围非常广,包括演绎、推理和解决问题、知识表示、学习、运动和控制、数据挖掘等众多领域。
|
||||
|
||||
# 人工智能、机器学习与深度学习关系
|
||||
## 人工智能、机器学习与深度学习关系
|
||||
|
||||
人工智能是一个宏大的愿景,目标是让机器像我们人类一样思考和行动,既包括增强我们人类脑力也包括增强我们体力的研究领域。而学习只是实现人工智能的手段之一,并且,只是增强我们人类脑力的方法之一。所以,人工智能包含机器学习。机器学习又包含了深度学习,他们三者之间的关系见下图。
|
||||
|
||||

|
||||
|
||||
# 如何学习本节内容
|
||||
## 如何学习本节内容
|
||||
|
||||
作者深知学习人工智能时面临许多繁碎数学知识,复杂数学公式的痛苦,因此,本节内容重在讲解核心概念和算法,略去了复杂的数学推导,尽可能以直觉的方式去理解,本文的数学知识,高中生足以掌握。阅读本节内容不需要人工智能基础,你可以直接从本节入门 AI。本节内容的算法、项目实现将使用 python 实现,需要掌握一定的 python 基础语法。当然如果你急于了解 AI,却又不会 python,没有关系,你可以选择跳过其中的编程部分,着眼于其中的概念、算法,程序语言是算法实现的工具,并非学习算法的必须品。
|
||||
|
||||
# 学习建议
|
||||
## 学习建议
|
||||
|
||||
本节内容是作者根据[哈佛的 CS50AI 导论](https://cs50.harvard.edu/ai/2020/)以及 [Andrew Ng 的机器学习专项课程](https://www.coursera.org/specializations/machine-learning-introduction)简化编写,当然你可以直接学习这两门课程。本节内容的总学习时间应该是二到三个月,如果你在某个知识点上卡住了,你也许需要反复阅读讲义,必要时向身边人求助。
|
||||
|
||||
# 目录
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
# FAQ:常见问题
|
||||
|
||||
## 我是非计算机专业的,感觉AI很火,可以看这篇内容吗
|
||||
## 我是非计算机专业的,感觉 AI 很火,可以看这篇内容吗
|
||||
|
||||
如果你不打算做相关研究的话,我觉得你最先应该考虑的是熟练掌握使用AI工具,本章内容更偏向于完善AI方面的知识体系架构
|
||||
如果你不打算做相关研究的话,我觉得你最先应该考虑的是熟练掌握使用 AI 工具,本章内容更偏向于完善 AI 方面的知识体系架构
|
||||
|
||||
## 我对AI/CV/NLP/blabla研究方向很感兴趣可以看这篇内容吗?
|
||||
|
||||
@@ -10,7 +10,7 @@
|
||||
|
||||
因此如果你想学某个知识体系,可以参考本章内容的路线,但是若你有足够强大的能力可以直接应对国外课程体系的困难,那么我非常推荐你去直接看英文内容
|
||||
|
||||
因为我们在降低门槛的时候也一定程度上让各位损失了一定的训练,在概括的过程中,信息量被稀释了,抽象地描述也许更能让你get到一些思想性的内容
|
||||
因为我们在降低门槛的时候也一定程度上让各位损失了一定的训练,在概括的过程中,信息量被稀释了,抽象地描述也许更能让你 get 到一些思想性的内容
|
||||
|
||||
## 我数学不好可以学吗
|
||||
|
||||
@@ -30,11 +30,9 @@
|
||||
|
||||
你应该更多地依赖自己而不是学校
|
||||
|
||||
## [如果不是相关领域可以找到这个领域工作吗](https://www.quora.com/How-do-I-get-a-job-in-Machine-Learning-as-a-software-programmer-who-self-studies-Machine-Learning-but-never-has-a-chance-to-use-it-at-work)
|
||||
|
||||
|
||||
# [如果不是相关领域可以找到这个领域工作吗](https://www.quora.com/How-do-I-get-a-job-in-Machine-Learning-as-a-software-programmer-who-self-studies-Machine-Learning-but-never-has-a-chance-to-use-it-at-work)
|
||||
|
||||
> “我正在为团队招聘专家,但你的 MOOC 并没有给你带来工作学习机会。我大部分机器学习方向的硕士也并不会得到机会,因为他们(与大多数工作)上过 MOOC 的人一样)并没有深入地去理解。他们都无法帮助我的团队解决问题。” Ross C. Taylor
|
||||
> “我正在为团队招聘专家,但你的 MOOC 并没有给你带来工作学习机会。我大部分机器学习方向的硕士也并不会得到机会,因为他们(与大多数工作)上过 MOOC 的人一样)并没有深入地去理解。他们都无法帮助我的团队解决问题。”Ross C. Taylor
|
||||
|
||||
## 人工智能,深度学习,机器学习,数据分析,我该如何区分
|
||||
|
||||
|
||||
@@ -81,7 +81,7 @@ $
|
||||
|
||||
## ChebNet 及其思考
|
||||
|
||||
ChebNet 的引入是当今神经网络大热门的开端,也是图卷积网络的基础。其思路为,使用切比雪夫多项式对卷积过程 K 阶拟合([参考](https://zhuanlan.zhihu.com/p/138420723))
|
||||
ChebNet 的引入是当今神经网络大热门的开端,也是图卷积网络的基础。其思路为,使用切比雪夫多项式对卷积过程 K 阶拟合 ([参考](https://zhuanlan.zhihu.com/p/138420723))
|
||||
|
||||
ChebNet 假设$g\theta$对$\Lambda$的滤波结果是原始特征值多项式函数,而网络的目的是抛弃原本通过矩阵相乘来对卷积结果进行求解,而通过参数学习来对结果进行表示,给出下式
|
||||
|
||||
@@ -114,9 +114,7 @@ $$
|
||||
\mathbf{U}^\mathsf{T}x
|
||||
\end{matrix}
|
||||
$$
|
||||
|
||||
,并对其中无关输入信号 $x$ 的部分进行改写
|
||||
|
||||
并对其中无关输入信号 $x$ 的部分进行改写
|
||||
|
||||
$$
|
||||
\mathbf{U}\begin{matrix}\sum_{k=0}^K
|
||||
@@ -163,7 +161,6 @@ x
|
||||
\end{matrix}
|
||||
$$
|
||||
|
||||
|
||||
作为 ChebNet 的卷积结构
|
||||
|
||||
其中值得注意的一点是,ChebNet 的 K 值限制了卷积核的多项式次数,但是这里的多项式次数描述了什么呢?其实就是卷积的“范围”,即单次卷积内最高可获得的 K 阶相邻节点信息。在 K=n 的时候,我们从理论上可以通过单次卷积,获取一张连通图上所有结点的信息,而这也是原方法难以计算的根本原因。
|
||||
|
||||
@@ -1,12 +1,14 @@
|
||||
# 数据科学
|
||||
|
||||
author:zzm
|
||||
# 本章内容会从一个小故事开始
|
||||
|
||||
## 本章内容会从一个小故事开始
|
||||
|
||||
讲讲某个人在大一的悲惨经历来为大家串起来一个精简的数据科学工作包括了哪些步骤,同时给各位介绍一些优质的教程
|
||||
|
||||
同时,这章内容将详细阐述[与人合作的生死疲劳](../1.杭电生存指南/1.5小组作业避雷指南.md)
|
||||
|
||||
# 悲惨世界
|
||||
## 悲惨世界
|
||||
|
||||
::: danger 若有雷同,纯属瞎编~~根据真实事件改编
|
||||
|
||||
@@ -15,35 +17,40 @@ author:zzm
|
||||
请欣赏小故事的同时,根据自己的需求选择自己想学的教程
|
||||
|
||||
:::
|
||||
## Day1
|
||||
|
||||
### Day1
|
||||
|
||||
你是一个可怜的大一学生,学校的短学期的第一天,你的心情非常好,因为要放寒假了,只要再坚持过这个短学期,你的快乐假期要来了!什么是短学期?不知道啊,也没听学长说过,好像是新研究出来的一个课程,去试试看吧。
|
||||
|
||||
当你快乐的走进教室,老师告诉你:“你们看看PPT上的任务,自由选择啊!”
|
||||
当你快乐的走进教室,老师告诉你:“你们看看 PPT 上的任务,自由选择啊!”
|
||||
|
||||
你看到PPT上赫然印着
|
||||
你看到 PPT 上赫然印着
|
||||
::: tip 任务目标
|
||||
基础系统:
|
||||
基础系统:
|
||||
|
||||
1. 淘宝客户价值分析系统,实现爬取数据,数据处理,数据分析。
|
||||
2. 二手房数据分析预测系统,实现爬取数据,数据分析,绘制图表。
|
||||
3. 智能停车场运营分析系统,实现爬取数据,数据分析,绘制图表。
|
||||
4. 影视作品分析系统,实现爬取数据,数据分析,绘制图表。
|
||||
升级系统:
|
||||
|
||||
升级系统:
|
||||
|
||||
1. 利用爬虫理论,实现 12306 抢票小助手系统。
|
||||
2. 利用数据分析方法,实现淘宝商品排行分析。
|
||||
3. 利用爬虫原理,爬 Google 搜索引擎分析。”
|
||||
要求实现三项以上的功能模块或三种以上的特征分析或提取。
|
||||
|
||||
:::
|
||||
|
||||
心中一惊,暗道不妙,这都什么玩意,怎么还有爬谷歌,淘宝和抢12306的票啊,这tm不是犯法的么!这我要能做出来我还上什么大一的学啊!🥺🥺🥺🥺
|
||||
心中一惊,暗道不妙,这都什么玩意,怎么还有爬谷歌,淘宝和抢 12306 的票啊,这 tm 不是犯法的么!这我要能做出来我还上什么大一的学啊!🥺🥺🥺🥺
|
||||
|
||||
老师紧接着补充“十个人一组啊!一周内做完,数据自己想办法,第三天就要检查你们的进度了!”
|
||||
|
||||
这是你倒是暗暗松了一口气,好像十个人一起干也没有那么复杂!😎(这时正是愚昧之峰,错误的认为工作总量就是工作量除以十)迅速的组好队之后,你问了问大伙的进度,what?大伙都没有python基础,只有我有?幸好学了hdu-wiki和datawhale的[聪明方法学python](https://github.com/datawhalechina/learn-python-the-smart-way)
|
||||
这是你倒是暗暗松了一口气,好像十个人一起干也没有那么复杂!😎(这时正是愚昧之峰,错误的认为工作总量就是工作量除以十)迅速的组好队之后,你问了问大伙的进度,what?大伙都没有 python 基础,只有我有?幸好学了 hdu-wiki 和 datawhale 的[聪明方法学 python](https://github.com/datawhalechina/learn-python-the-smart-way)
|
||||
|
||||
那就把教程分给大伙吧,我们选一个最简单的,二手房数据的分析系统好了!
|
||||
|
||||
第一天选好题了,又是大下午的,摆了摆了,你开心的打开电脑,打开了steam,开摆!
|
||||
第一天选好题了,又是大下午的,摆了摆了,你开心的打开电脑,打开了 steam,开摆!
|
||||
|
||||
day 1 End!🤣
|
||||
|
||||
@@ -51,9 +58,9 @@ day 1 End!🤣
|
||||
|
||||
昨天真是美滋滋的一天,玩了一晚上的你有点头昏脑涨,今天就开始干活好了,反正一周时间呢,比期末复习周可长太多了,就做这么个玩意我还能做不出来吗?
|
||||
|
||||
虽然你没有学过爬虫,但是你很幸运的找到了github上一个现成的爬虫代码,虽然费了一翻力气,但是仍然躲过了某房价网站的爬虫,他成功爬下来了,我们就把他存在哪里呢?~~(爬虫待补充)
|
||||
虽然你没有学过爬虫,但是你很幸运的找到了 github 上一个现成的爬虫代码,虽然费了一翻力气,但是仍然躲过了某房价网站的爬虫,他成功爬下来了,我们就把他存在哪里呢?~~(爬虫待补充)
|
||||
|
||||
先试试excel好了,毕竟这是大家最耳熟能详的存表格的方法,但是你貌似没有深入了解过他,打开了datawhale的[free-excel](https://github.com/datawhalechina/free-excel),你才惊讶的发现,wow,原来他有这么多牛逼的功能啊!它除了可以将房价统计,找到它的平均价格,算出他的最高价格之类以外,竟然也可以把他可视化!甚至它还可以对房价进行多元分析!根据房屋数量面积地段等等因素帮你预测房价,甚至可以自动帮你检索和去除重复数据,实在是太好用啦!
|
||||
先试试 excel 好了,毕竟这是大家最耳熟能详的存表格的方法,但是你貌似没有深入了解过他,打开了 datawhale 的[free-excel](https://github.com/datawhalechina/free-excel),你才惊讶的发现,wow,原来他有这么多牛逼的功能啊!它除了可以将房价统计,找到它的平均价格,算出他的最高价格之类以外,竟然也可以把他可视化!甚至它还可以对房价进行多元分析!根据房屋数量面积地段等等因素帮你预测房价,甚至可以自动帮你检索和去除重复数据,实在是太好用啦!
|
||||
|
||||
当然,这只是一个理想状态,残酷的现实很快给你当头一棒!当你试着多爬点不同城市数据的时候,他崩了!这么脆弱的吗?!干点活就喊累的吗?!😨
|
||||
|
||||
@@ -61,22 +68,22 @@ day 1 End!🤣
|
||||
|
||||
之前好像看到有一个教程叫做[wonderful-sql](https://github.com/datawhalechina/wonderful-sql?from=from_parent_mindnote)
|
||||
|
||||
他提到“随着社会的快速发展,各类企业数字化转型迫在眉睫,SQL 应用能力日趋重要。 在诸多领域中 SQL 应用广泛,数据分析、开发、测试、维护、产品经理等都有可能会用到SQL,而在学校里系统性讲授 SQL 的课程较少,但是面试及日常工作中却经常会涉及到 SQL。”
|
||||
他提到“随着社会的快速发展,各类企业数字化转型迫在眉睫,SQL 应用能力日趋重要。在诸多领域中 SQL 应用广泛,数据分析、开发、测试、维护、产品经理等都有可能会用到 SQL,而在学校里系统性讲授 SQL 的课程较少,但是面试及日常工作中却经常会涉及到 SQL。”
|
||||
|
||||
确实学校没有教过,但是幸好你有教程,折腾了一翻之后,你发现你对数据库有了更深的理解,他帮助了我们在容纳大量的多种不同的数据形式的时候不用专门去考虑怎么设计一个数据结构而是规划了一定的存储方法后全部塞给他,完全不用考虑具体的物理性的以及性能问题存储模式,并且他很多高级的功能可以帮助你便捷的把数据组织成一般情况下难以到达的形式,他的底层设计被严格的包装起来让你在进行数据增删改查的时候都又快又好。
|
||||
|
||||
并且它可以非常方便的存一些excel不好存的所谓的非结构化的数据,比如说图像等等,并且他不会动不动就喊累!处理几十万条也是一下子!
|
||||
并且它可以非常方便的存一些 excel 不好存的所谓的非结构化的数据,比如说图像等等,并且他不会动不动就喊累!处理几十万条也是一下子!
|
||||
|
||||
当然同时你也了解到,你所用的是关系型数据库,是老东西了,目前还有很多较为前沿的非关系型数据库,例如MongoDB(这玩意什么都能存,比如说地图),Neo4j(像一张蜘蛛网一样的结构,图)等等,他们不用固定的表来存储,可以用图存或者键值对进行存储,听起来好像非常的高级,不过你暂时用不到,数据搞都搞下来了,量也够了,是时候看看队友做到哪了?说不定后面你都不用做了,已经做的够多够累的了!
|
||||
当然同时你也了解到,你所用的是关系型数据库,是老东西了,目前还有很多较为前沿的非关系型数据库,例如 MongoDB(这玩意什么都能存,比如说地图),Neo4j(像一张蜘蛛网一样的结构,图)等等,他们不用固定的表来存储,可以用图存或者键值对进行存储,听起来好像非常的高级,不过你暂时用不到,数据搞都搞下来了,量也够了,是时候看看队友做到哪了?说不定后面你都不用做了,已经做的够多够累的了!
|
||||
|
||||
什么?!刚开始学python?!woc!完蛋,你逐渐来到了绝望之谷,唉!明天继续做吧!看来休息不了了。
|
||||
什么?!刚开始学 python?!woc! 完蛋,你逐渐来到了绝望之谷,唉!明天继续做吧!看来休息不了了。
|
||||
day 2 End 😔!
|
||||
|
||||
## Day 3
|
||||
|
||||
God!No!昨天已经够累的了,今天老师还要讲课,还要早起!你期待着老师可以降低要求,可是当老师托起长音,讲起了他知道了学生的累,所以今天决定开始讲课了!(现在讲有毛用啊,你明天就要验收我们的进度了!)
|
||||
God!No! 昨天已经够累的了,今天老师还要讲课,还要早起!你期待着老师可以降低要求,可是当老师托起长音,讲起了他知道了学生的累,所以今天决定开始讲课了!(现在讲有毛用啊,你明天就要验收我们的进度了!)
|
||||
|
||||
而他却慢悠悠的开始讲python的历史,把这点内容讲了足足两节课,你终于绷不住了,本来时间就不够,他竟然又浪费了你足足一早上的时间!这也太该死了!🤬
|
||||
而他却慢悠悠的开始讲 python 的历史,把这点内容讲了足足两节课,你终于绷不住了,本来时间就不够,他竟然又浪费了你足足一早上的时间!这也太该死了!🤬
|
||||
|
||||
你回到了寝室,准备今天争取数据分析完就直接交上去好了!
|
||||
|
||||
@@ -84,23 +91,25 @@ God!No!昨天已经够累的了,今天老师还要讲课,还要早起!你
|
||||
|
||||
这个野鸡房价网站每个城市的排版不一样,你爬虫爬取的完全是按照顺序标的,也就是说你爬取的所有房价信息处于混沌状态!完全就相当于给每个房子爬了一段句子的描述!
|
||||
|
||||
没有办法了,看来今天有的折腾了,你找到了一个叫pandas(熊猫?)的东西,找到了这个教程[Joyful-Pandas](https://github.com/datawhalechina/joyful-pandas),开始了一天的学习!
|
||||
没有办法了,看来今天有的折腾了,你找到了一个叫 pandas(熊猫?)的东西,找到了这个教程[Joyful-Pandas](https://github.com/datawhalechina/joyful-pandas),开始了一天的学习!
|
||||
|
||||
你了解到pandas是一个开源的Python数据处理库,提供了高性能、易用、灵活和丰富的数据结构,可以帮助用户轻松地完成数据处理、清洗、分析和建模等任务。你使用了DataFrame来装载二维表格对象。
|
||||
你了解到 pandas 是一个开源的 Python 数据处理库,提供了高性能、易用、灵活和丰富的数据结构,可以帮助用户轻松地完成数据处理、清洗、分析和建模等任务。你使用了 DataFrame 来装载二维表格对象。
|
||||
|
||||
用一些关键词来提取数据中隐藏的信息,例如提取“平米”前面的数字放到‘area'列,提取房价到'price’列,提取位置到'locate'里面,当然你也遇到了可怕的bug,提取所有“室”和“厅”前面的数字,他总是告诉你有bug,全部输出之后才发现你提取到了“地下室”结果他没法识别到数字所以炸了!
|
||||
用一些关键词来提取数据中隐藏的信息,例如提取“平米”前面的数字放到‘area'列,提取房价到'price’列,提取位置到'locate'里面,当然你也遇到了可怕的 bug,提取所有“室”和“厅”前面的数字,他总是告诉你有 bug,全部输出之后才发现你提取到了“地下室”结果他没法识别到数字所以炸了!
|
||||
|
||||
将数据勉强弄得有序之后,你提取了平均数填充到缺失数据的房屋里面,将一些处理不了的删掉。
|
||||
|
||||
当然,你也额外了解到pandas这只可爱的小熊猫还有非常多强大的功能,例如数据可视化,例如分类数据,甚至可以让房屋按照时序排列,但是你实在不想动了!
|
||||
当然,你也额外了解到 pandas 这只可爱的小熊猫还有非常多强大的功能,例如数据可视化,例如分类数据,甚至可以让房屋按照时序排列,但是你实在不想动了!
|
||||
|
||||
不论怎么说,你勉强有了一份看得过去的数据,你看了看表,已经晚上十一点半了,今天实在是身心俱疲!
|
||||
|
||||
问问队友吧,什么,他们怎么还是在python语法?!你就像进了米奇不妙屋~队友在想你说“嘿~你呀瞅什么呢~是我!你爹~”
|
||||
问问队友吧,什么,他们怎么还是在 python 语法?!你就像进了米奇不妙屋~队友在说
|
||||
|
||||
此时你像一头挨了锤的老驴,曾经的你有好多奢望,你想要GPA,想要老师的认同,甚至想要摸一摸水里忽明忽暗的🐟,可是一切都随着你的hadworking变成了泡影。
|
||||
~~“嘿~你呀瞅什么呢~是我!你爹~”~~
|
||||
|
||||
可是步步逼近的截止日期不允许你有太多的emo期,说好的七天时间,最后一天就剩下展示了!也就是说实际上只有6天的开发时间,也就是说你必须得挑起大梁了
|
||||
此时你像一头挨了锤的老驴,曾经的你有好多奢望,你想要 GPA,想要老师的认同,甚至想要摸一摸水里忽明忽暗的🐠,可是一切都随着你的 hardworking 变成了泡影。
|
||||
|
||||
可是步步逼近的截止日期不允许你有太多的 emo 时间,说好的七天时间,最后一天就剩下展示了!也就是说实际上只有 6 天的开发时间,也就是说你必须得挑起大梁了
|
||||
|
||||
> 世界上只有一种真正的英雄主义,那就是看清生活的真相之后,依然热爱生活
|
||||
|
||||
@@ -110,17 +119,17 @@ day 3 end!👿 👹 👺 🤡
|
||||
|
||||
## Day 4
|
||||
|
||||
老师在验收的时候认为你什么工作也没做,他认为一份数据实在是太单薄了,特别是被你疯狂结构优化后的数据已经没几个特征了,让你去做点看得到的东西,不然就要让你不及格了,你的心里很难过,你想到也许你需要一些更好看的东西。数据可视化你在昨天的pandas看到过,可是你并没有详细了解,你觉得pandas已经在昨天把你狠狠的暴捶一顿了,并且老师想要更好看的图。
|
||||
老师在验收的时候认为你什么工作也没做,他认为一份数据实在是太单薄了,特别是被你疯狂结构优化后的数据已经没几个特征了,让你去做点看得到的东西,不然就要让你不及格了,你的心里很难过,你想到也许你需要一些更好看的东西。数据可视化你在昨天的 pandas 看到过,可是你并没有详细了解,你觉得 pandas 已经在昨天把你狠狠的暴捶一顿了,并且老师想要更好看的图。
|
||||
|
||||
于是你考虑pandas配合Matplotlib画一些简单的图(Matplotlib的缺点是它的绘图语法比较繁琐,需要编写较多的代码才能得到漂亮的图形。)
|
||||
于是你考虑 pandas 配合 Matplotlib 画一些简单的图(Matplotlib 的缺点是它的绘图语法比较繁琐,需要编写较多的代码才能得到漂亮的图形。)
|
||||
|
||||
加上Plotly绘制一些复杂的图,让你的图有着更漂亮的交互效果,然后加上看起来很牛逼的英语描述
|
||||
加上 Plotly 绘制一些复杂的图,让你的图有着更漂亮的交互效果,然后加上看起来很牛逼的英语描述
|
||||
|
||||
你找到了下面的教程:
|
||||
|
||||
你找到了下面的教程
|
||||
[matplotlib奇遇记文字教程](https://github.com/datawhalechina/fantastic-matplotlib)
|
||||
[matplotlib 奇遇记文字教程](https://github.com/datawhalechina/fantastic-matplotlib)
|
||||
|
||||
[极好的Plotly文字教程:](https://github.com/datawhalechina/wow-plotly)
|
||||
[极好的 Plotly 文字教程:](https://github.com/datawhalechina/wow-plotly)
|
||||
[视频教程](https://www.bilibili.com/video/BV1Df4y1A7aR)
|
||||
|
||||
🤗
|
||||
@@ -148,13 +157,13 @@ day 4 end!~🤤
|
||||
|
||||
你对着他啃了半天,觉得很多东西你都能看懂了,你脑子里已经有了很多思路,你想按使用高级的机器学习的算法!
|
||||
|
||||
但是!时间还是太紧张了!你没有办法从头开始实现了!
|
||||
但是!时间还是太紧张了!你没有办法从头开始实现了!
|
||||
|
||||
你想尝试[pytorch文字教程](https://github.com/datawhalechina/thorough-pytorch),但是时间也不够让你去重整数据去训练了。你随便塞在线性层里的数据梯度直接爆炸,你这时候还不知道归一化的重要性,紧张之下把几万几十万的房价往里面塞,结果结果烂成💩了,并且你没有波如蝉翼的基础知识并不够让你去解决这些个bug,只能疯狂的瞎挑参数,可是结果往往不如人意~
|
||||
你想尝试[pytorch 文字教程](https://github.com/datawhalechina/thorough-pytorch),但是时间也不够让你去重整数据去训练了。你随便塞在线性层里的数据梯度直接爆炸,你这时候还不知道归一化的重要性,紧张之下把几万几十万的房价往里面塞,结果结果烂成💩了,并且你那薄如蝉翼的基础知识并不够让你去解决这些个 bug,只能疯狂的瞎调参数,可是结果往往不如人意~
|
||||
|
||||
时间来到了晚上八点,明天就要最后验收了,走投无路的你把目光看向了远在几十千米外已经入职了的大哥,晚上跟他打电话哭诉你最近的遭遇,你实在搞不懂,为什么十二生肖大伙都属虎,就你属驴。
|
||||
|
||||
大哥嘎嘎猛,连夜打车过来,我在因疫情封校的最后两个小时赶出了学校,和大哥一起租了个酒店,通宵奋战,他采取了更多更为优雅的特征工程和模型调参的方式,让模型优雅的收敛到了一定程度,再用春秋笔法进行汇总,在半夜两点半,终于将内容搞定了
|
||||
大哥嘎嘎猛,连夜打车过来,你在因疫情封校的最后两个小时跑出了学校,和大哥一起租了个酒店,通宵奋战,他采取了更多更为优雅的特征工程和模型调参的方式,让模型优雅的收敛到了一定程度,再用春秋笔法进行汇总,在半夜两点半,终于将内容搞定了😭
|
||||
|
||||
终于你可以睡个好觉了~
|
||||
|
||||
@@ -162,7 +171,7 @@ day 5 end!😍 🥰 😘
|
||||
|
||||
## Day 6
|
||||
|
||||
验收日,老师端坐在底下,宛如一尊大佛,提出了一系列无关紧要的问题,比如问我们能不能拿这个程序给老年人查资料???
|
||||
验收日,老师端坐在底下,宛如一尊大佛,提出了一系列无关紧要的问题,比如问“我们能不能拿这个程序给老年人查资料???”
|
||||
|
||||
等等问题和技术一点关系都没有!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
|
||||
|
||||
@@ -172,20 +181,19 @@ day 5 end!😍 🥰 😘
|
||||
|
||||
The End~~~~~~~~~~
|
||||
|
||||
# 事后总结
|
||||
## 事后总结
|
||||
|
||||
你在那个暑假详细了解和学习一下数据科学竞赛,发现他的含金量在职场领域有时候相当高,并且对提升自身的实力也有相当大的帮助!
|
||||
你在那个暑假详细了解和学习一下数据科学竞赛,发现他的含金量在职场领域有时候相当高,并且对提升自身的实力也有相当大的帮助!
|
||||
|
||||
[数据竞赛Baseline & Topline分享](https://github.com/datawhalechina/competition-baseline)
|
||||
[数据竞赛 Baseline & Topline 分享](https://github.com/datawhalechina/competition-baseline)
|
||||
|
||||
你还发现了之前从来没有注意到的kaggle平台以及一些很棒的综合实践项目!
|
||||
你还发现了之前从来没有注意到的 kaggle 平台以及一些很棒的综合实践项目!
|
||||
|
||||
例如[根据贷款申请人的数据信息预测其是否有违约的可能](https://github.com/datawhalechina/team-learning-data-mining/tree/master/FinancialRiskControl)
|
||||
|
||||
[根据汽车类型等信息预测二手汽车的交易价格](https://github.com/datawhalechina/team-learning-data-mining/tree/master/SecondHandCarPriceForecast)
|
||||
|
||||
例如:[使用公开的arXiv论文完成对应的数据分析操作](https://github.com/datawhalechina/team-learning-data-mining/tree/master/AcademicTrends)
|
||||
|
||||
例如:[使用公开的 arXiv 论文完成对应的数据分析操作](https://github.com/datawhalechina/team-learning-data-mining/tree/master/AcademicTrends)
|
||||
|
||||
想到如果你早做准备,没有荒废大一的时光,也许你不但能圆满的通过这次课程,也可以开辟更为广阔的新世界了吧~
|
||||
|
||||
@@ -195,14 +203,14 @@ The End~~~~~~~~~~
|
||||
|
||||
::: danger 再次警告,本章内容有很多瞎编的内容,不要全信
|
||||
|
||||
比如说一天学完pandas,一天学完sql之类的都是很不现实的!希望大家注意!
|
||||
比如说一天学完 pandas,一天学完 sql 之类的都是很不现实的!希望大家注意!
|
||||
|
||||
当然你也可以在需要用的时候再研究,也来得及,就是很累
|
||||
|
||||
不要打击到大家的自信心!
|
||||
:::
|
||||
|
||||
# 补充内容:下个定义
|
||||
## 补充内容:下个定义
|
||||
|
||||
数据分析是独立于开发和算法岗的另一个方向,它主要是通过<strong>应用</strong>机器学习和深度学习的<strong>已有算法</strong>来分析现实问题的一个方向
|
||||
|
||||
@@ -210,11 +218,9 @@ The End~~~~~~~~~~
|
||||
|
||||
数据这门科学就像中西医混合的一门医学,既要有西医的理论、分析模型以及实验,又需要有中医的望闻问切这些个人经验。
|
||||
|
||||
|
||||
> 这世界缺的真不是算法和技术,而是能用算法、技术解决实际问题的人
|
||||
|
||||
|
||||
# 什么是数据科学
|
||||
## 什么是数据科学
|
||||
|
||||
数据科学是当今计算机和互联网领域最热门的话题之一。直到今天,人们已经从应用程序和系统中收集了相当大量的数据,现在是分析它们的时候了。从数据中产生建议并创建对未来的预测。[在这个网站中](https://www.quora.com/Data-Science/What-is-data-science),您可以找到对于数据科学的更为精确的定义。
|
||||
|
||||
@@ -222,6 +228,6 @@ The End~~~~~~~~~~
|
||||
|
||||
<Bilibili bvid='BV1ZW4y1x7UU'/>
|
||||
|
||||
# Datawhale的生态体系
|
||||
## Datawhale 的生态体系
|
||||
|
||||
在与Datawhale开源委员会的负责人文睿进行一翻畅谈之后。zzm受震惊于其理念以及已经构建的较为完善的体系架构,毅然决然的删除了本章和其广泛的体系比起来相形见绌的内容。为了更大伙更好的阅读以及学习体验,我们决定在本章内容引入了[datawhale人工智能培养方案数据分析体系](https://datawhale.feishu.cn/docs/doccn0AOicI3LJ8RwhY0cuDPSOc#),希望各位站在巨人的肩膀上,争取更进一步的去完善它。
|
||||
在与 Datawhale 开源委员会的负责人文睿进行一翻畅谈之后。zzm 受震惊于其理念以及已经构建的较为完善的体系架构,毅然决然的删除了本章和其广泛的体系比起来相形见绌的内容。为了更大伙更好的阅读以及学习体验,我们决定在本章内容引入了[datawhale 人工智能培养方案数据分析体系](https://datawhale.feishu.cn/docs/doccn0AOicI3LJ8RwhY0cuDPSOc#),希望各位站在巨人的肩膀上,争取更进一步的去完善它。
|
||||
|
||||
@@ -1,16 +1,15 @@
|
||||
# 如何做研究
|
||||
|
||||
# 0. 讲在前面
|
||||
## 0. 讲在前面
|
||||
|
||||
Author: 任浩帆
|
||||
Author:任浩帆
|
||||
|
||||
Email: yqykrhf@163.com
|
||||
|
||||
术语介绍的补充:Spy
|
||||
|
||||
仅供参考,如有不足,不吝赐教。
|
||||
|
||||
# 术语的介绍
|
||||
## 术语的介绍
|
||||
|
||||
<strong>Benchmark:</strong>评测的基准。通常会是一些公开的数据集。
|
||||
|
||||
@@ -34,7 +33,7 @@ Email: yqykrhf@163.com
|
||||
|
||||
一般是描述这个工作非常扎实。
|
||||
|
||||
这个工作很 solid。 每一步都 make sense(合理)。没有特意为了刷 benchmark 上的指标,用一些 fancy trick(奇技淫巧)。
|
||||
这个工作很 solid。每一步都 make sense(合理)。没有特意为了刷 benchmark 上的指标,用一些 fancy trick(奇技淫巧)。
|
||||
|
||||
<strong>Robust</strong>
|
||||
|
||||
@@ -44,16 +43,16 @@ Email: yqykrhf@163.com
|
||||
|
||||
我们的系统的图片加入大量的噪声,已经旋转平移缩放以后,仍然能正确的分类,这表明了我们的工作具有一定的鲁棒性。
|
||||
|
||||
# 坐而论道
|
||||
## 坐而论道
|
||||
|
||||
## 2.1 研究是什么
|
||||
### 2.1 研究是什么
|
||||
|
||||
从实际的几个例子讲起:
|
||||
|
||||
1. 某学生,被老师分配了一个课题的名字:《语义分割》。之后开始看相关的论文,了解到有实时语义分割,视频语义分割,跨模态语义分割等等子任务或者交叉任务,然后跟导师开始汇报自己的一些感想,最后在老师的建议之下拟定了具体的课题,开始思考解决方案。
|
||||
2. 某学生,被老师分配了一个课题的名字:《存在遮挡情况下的单目人体重建》 。之后这个学生对这个问题提出了有效的解决方案。
|
||||
3. 某同学在 waymo(Google 自动驾驶子公司)实习,发现没有用神经网络来直接处理点云的工作。于是决定做一个神经网络能够直接输入点云,经过几番尝试以后,提出了《第一个能直接处理点云的网络》。
|
||||
4. 某高校的本科生在 lcw 下的指导下做科研的流程: 老师直接给给一个 basic idea,然后让本科做实验,在这个工程中非常有针对性的指导。
|
||||
4. 某高校的本科生在 lcw 下的指导下做科研的流程:老师直接给给一个 basic idea,然后让本科做实验,在这个工程中非常有针对性的指导。
|
||||
|
||||
例 1 是在给定一个大题目的基础下,去阅读论文寻找小题目。
|
||||
|
||||
@@ -73,55 +72,55 @@ Step 3. 验证解决方案的有效性。
|
||||
|
||||
有些问题是一直存在,但没有彻底解决的。这一类的问题通常,就不存在 Step 1。从事这一课题的研究者经常会在 2,3 之间来回反复。
|
||||
|
||||
## 2.2 如何做研究
|
||||
### 2.2 如何做研究
|
||||
|
||||
从上一小节的几个例子当中,其实不同的人做研究所需要完成的工作是完全不一样的。很多时候只需要做 step 3 即可,从功利的角度来讲这是性价比最高的。
|
||||
|
||||
如果我们是一个合格的博士或者我们致力于如此,那么首先的第一步要找到一个好的问题,这是一个非常重要的开始,<strong>一个好的问题往往意味着研究已经成功了一半。 </strong>什么是一个好的问题?它可能会有以下几个特点:
|
||||
|
||||
1. 理论上能实现某种意义上的统一,从而使得问题的描述变得非常优雅。比如 [DepthAwareCNN](https://arxiv.org/abs/1803.06791)
|
||||
2. 对于之后的工作非常具有启发的作用,甚至达到某种意义的纠偏作用。 比如 [OccuSeg](https://arxiv.org/abs/2003.06537)
|
||||
3. 本身足够 solid,可以作为 meta algorithm。 比如 Mask-RCNN
|
||||
4. 是一个大家没有引起足够重视,却非常棘手且非常迫切的问题。 比如相机快速运动下的重建,[MBA-VO](https://openaccess.thecvf.com/content/ICCV2021/papers/Liu_MBA-VO_Motion_Blur_Aware_Visual_Odometry_ICCV_2021_paper.pdf)
|
||||
2. 对于之后的工作非常具有启发的作用,甚至达到某种意义的纠偏作用。比如 [OccuSeg](https://arxiv.org/abs/2003.06537)
|
||||
3. 本身足够 solid,可以作为 meta algorithm。比如 Mask-RCNN
|
||||
4. 是一个大家没有引起足够重视,却非常棘手且非常迫切的问题。比如相机快速运动下的重建,[MBA-VO](https://openaccess.thecvf.com/content/ICCV2021/papers/Liu_MBA-VO_Motion_Blur_Aware_Visual_Odometry_ICCV_2021_paper.pdf)
|
||||
|
||||
### 2.2.1 如何去找一个好的问题
|
||||
#### 2.2.1 如何去找一个好的问题
|
||||
|
||||
如何确保自己选的问题是一个好的问题?这需要和指导老师及时的反馈。如果指导老师不给力,那么一些方法仅供参考。
|
||||
|
||||
1. 自己和工业界的一些人去交流与沟通,看看实际落地的痛点是什么?面对这些痛点,已有的研究方法能否解决,是否有一些现有的 benchmark 或者容易制作的 benchmark 来做为评价标准。
|
||||
2. 做加法。举个例子:图片可以做语义分割。 那么图片 + 深度图如何更好的做语义分割。 图片 + 文字描述的做语义分割。现在的语义分割的标注都是 0,1,2,3 这些数字,然后每一个数字对应一个实际的类别,这个对应表是认为规定的。如果我把 0,1 的对应关系换掉。重新训练以后就,网络的性能是否会影响?
|
||||
3. 做减法。对于点云的语义分割的标注,通过是非常费时费力的。 那么对于点云来说,少量的标注是否是可行的?比如只标注百分之 10 的点。
|
||||
2. 做加法。举个例子:图片可以做语义分割。那么图片 + 深度图如何更好的做语义分割。图片 + 文字描述的做语义分割。现在的语义分割的标注都是 0,1,2,3 这些数字,然后每一个数字对应一个实际的类别,这个对应表是认为规定的。如果我把 0,1 的对应关系换掉。重新训练以后就,网络的性能是否会影响?
|
||||
3. 做减法。对于点云的语义分割的标注,通过是非常费时费力的。那么对于点云来说,少量的标注是否是可行的?比如只标注百分之 10 的点。
|
||||
|
||||
以上是一些技巧,把输入调整一下,约束去掉一些,就会有很多新的问题。 这个过程通常被叫做<strong>“调研”</strong>
|
||||
以上是一些技巧,把输入调整一下,约束去掉一些,就会有很多新的问题。这个过程通常被叫做<strong>“调研”</strong>
|
||||
|
||||
这个过程在是一个相对比较痛苦的过程,因为调研的过程中你会发现很多问题,想到很多所谓创新的解决方法,但是实际上你会发现你的解决方法已经有很多人做过了。这一阶段调整心态很重要,切忌急于求成。
|
||||
|
||||
### 2.2.2 如果提出解决方法
|
||||
#### 2.2.2 如果提出解决方法
|
||||
|
||||
这个阶段需要百折不挠,小步快跑了。 一下是有一些可能有帮助的技巧:
|
||||
这个阶段需要百折不挠,小步快跑了。一下是有一些可能有帮助的技巧:
|
||||
|
||||
1. 多读本领域的论文。(说起来非常玄妙,会在如何读论文部分详细解释)
|
||||
2. 读一些基础,跨领域的论文。 把其他领域的方法搬过来直接用。直接用通常情况下会存在一些问题,那么需要针对性的做一些改进。
|
||||
2. 读一些基础,跨领域的论文。把其他领域的方法搬过来直接用。直接用通常情况下会存在一些问题,那么需要针对性的做一些改进。
|
||||
3. 从历史出发。将你面对的问题抽象成数学问题,这个数学问题可能过去很多人都遇到过,去看一看他们是如何解决的,从中获取一些灵感。
|
||||
|
||||
### 2.2.3 如果做实验
|
||||
#### 2.2.3 如果做实验
|
||||
|
||||
做实验的目的是为了快速的验证想法的正确性。 以下两个东西最好要有
|
||||
做实验的目的是为了快速的验证想法的正确性。以下两个东西最好要有
|
||||
|
||||
1. 版本控制
|
||||
2. 日志系统
|
||||
|
||||
剩下就是一些工程习惯的问题,比如出现错误用 `std::cerr` 而不是 `std::cout`。这是一个需要实践积累的部分,与做研究有些脱节,之后有时间会在其他小节做一些补充。
|
||||
|
||||
# 快速出成果的捷径与方法
|
||||
## 快速出成果的捷径与方法
|
||||
|
||||
如何快速的出成果,不管别人如何帮你,前提是你自己要足够的强。不能存在 <strong>“靠别人” </strong>的想法。
|
||||
|
||||
对于一个博士生来讲,出成果保毕业,那么可能要对学术的进展要敏感,比如 Nerf 八月份刚出来的时候,如果你非常敏锐的意识到这个工作的基础性和重要性。那么你稍微思考一两个月,总是能有一些创新的 ieda 产生的。 所以这个<strong>timing 和 senstive</strong>就非常重要,当然导师是不是审稿人可能更重要。
|
||||
对于一个博士生来讲,出成果保毕业,那么可能要对学术的进展要敏感,比如 Nerf 八月份刚出来的时候,如果你非常敏锐的意识到这个工作的基础性和重要性。那么你稍微思考一两个月,总是能有一些创新的 ieda 产生的。所以这个<strong>timing 和 senstive</strong>就非常重要,当然导师是不是审稿人可能更重要。
|
||||
|
||||
对于一个本科生来讲,当然是跟着指导老师的脚步去做。但是如果指导老师只是把你当成一个工具人,一直打杂货的话。你想发论文,一种所谓的捷径是 A+B。就是把一个方法直接拿过来用在另一个地方,大概率这样会有一些问题,那么你就可以针对性的改进,如何针对性的改进?不好的方式是 A+B 套娃,好一些的方式是分析这个不好的原因在哪里,现有的方法多大程度可以帮助解决这个问题,或者现有的方法解决不了这个问题,但是其中的一个模块是否是可以参考的。
|
||||
|
||||
## 3.2 学习别人是如何改进网络的(Beta)
|
||||
### 3.2 学习别人是如何改进网络的(Beta)
|
||||
|
||||
自 UNet 提出后就有许多的魔改版本,如 UNet++, U2Net, 而这些 UNet 的性能也十分优异。
|
||||
|
||||
@@ -132,13 +131,13 @@ Step 3. 验证解决方案的有效性。
|
||||
1. 你认为你提出的改进方法是有效的,但是实际是不 OK 的
|
||||
2. 你认为你提出的方法可能有效,实际上也确实有效。然而你不能以令人信服的方式说明这为什么有效。
|
||||
|
||||
举个例子 ResNet 为什么有效。“因为网络越深,可以拟合的函数空间就会复杂,但是越深网络效果反而变差。那么从一个角度来思考:网络至少某一层 i 开始到最后一层 k,如果学习到的函数是 f(x)=x 的恒等映射,那么网络变深以后至少输出是和 i-1 层的是一模一样的,从而网络变深可能不一定会变好,但是至少不会变差才对。” 看起来很有道理,然后 CVPR2021 分享会,ResNet 的作者之一,xiangyu zhang 说 “当时也完全不能使人很信服的解释为什么 ResNet 就一定效果好,感觉更像是基于一些灵感,得到了一个很棒的东西,更像是一个工程化的问题,而不是一个研究。但我们可以先告诉别人这个是非常有效的,至于为什么有效,可能需要其他人来解决。”
|
||||
举个例子 ResNet 为什么有效。“因为网络越深,可以拟合的函数空间就会复杂,但是越深网络效果反而变差。那么从一个角度来思考:网络至少某一层 i 开始到最后一层 k,如果学习到的函数是 f(x)=x 的恒等映射,那么网络变深以后至少输出是和 i-1 层的是一模一样的,从而网络变深可能不一定会变好,但是至少不会变差才对。”看起来很有道理,然后 CVPR2021 分享会,ResNet 的作者之一,xiangyu zhang 说“当时也完全不能使人很信服的解释为什么 ResNet 就一定效果好,感觉更像是基于一些灵感,得到了一个很棒的东西,更像是一个工程化的问题,而不是一个研究。但我们可以先告诉别人这个是非常有效的,至于为什么有效,可能需要其他人来解决。”
|
||||
|
||||
再举一个例子 BN(Batch normalization)为什么有效,你去看 BN 的原论文和之后关于 BN 为什么有效的研究,会发现原论文认为有效的原因是不太能让人信服的。 但这不妨碍 BN 有效,而且非常快的推广起来。
|
||||
再举一个例子 BN(Batch normalization) 为什么有效,你去看 BN 的原论文和之后关于 BN 为什么有效的研究,会发现原论文认为有效的原因是不太能让人信服的。但这不妨碍 BN 有效,而且非常快的推广起来。
|
||||
|
||||
其实这件事可以类比于中医,做研究就好比要提出一套理论,但是我不知怎得忽然发现有一个方子经过测试非常有效,但是我确实不能给出一个很好的理论解释说明这个房子为什么有效。但是我尽快把这个方子告诉大家,这同样是非常有意义的。
|
||||
|
||||
举这个两个例子是为了说明,类似 ResNet 这种拍一拍脑袋就想出的 idea,一天可能能想出十几个,但是最后做出来,并且真正 work 的非常少。这里面就存在一个大浪淘沙的过程,可能我们看到的经典的网络,比如 Unet 就是拍拍脑袋,迅速做实验出来的。 我认为这种思考方式仅仅值得参考,并不值得效仿。 现在早已经不是 5 年前那样,却设计各种 fancy 的网络结构去发论文的年代了。
|
||||
举这个两个例子是为了说明,类似 ResNet 这种拍一拍脑袋就想出的 idea,一天可能能想出十几个,但是最后做出来,并且真正 work 的非常少。这里面就存在一个大浪淘沙的过程,可能我们看到的经典的网络,比如 Unet 就是拍拍脑袋,迅速做实验出来的。我认为这种思考方式仅仅值得参考,并不值得效仿。现在早已经不是 5 年前那样,却设计各种 fancy 的网络结构去发论文的年代了。
|
||||
|
||||
那么我们应该如何对待神经网络?(之后再写)
|
||||
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
# 4.人工智能
|
||||
|
||||
## 开篇
|
||||
对于所谓AI的开篇该怎么写,我思考了很久,因为这实在是太过于宏大的话题了,从2012年开始这个行业迎来了所谓的技术爆炸阶段
|
||||
|
||||
对于所谓 AI 的开篇该怎么写,我思考了很久,因为这实在是太过于宏大的话题了,从 2012 年开始这个行业迎来了所谓的技术爆炸阶段
|
||||
|
||||
> 宇宙的时间尺度来看,一个文明的技术在科技发展的过程中,可能短时间内快速发展、科技发展速度不断增加的现象 --------《三体》
|
||||
|
||||
@@ -10,7 +12,7 @@
|
||||
|
||||
阅读本篇内容的群体,我想主要是自动化或计算机的大学生,更多的是没有基础的同学才会翻阅。
|
||||
|
||||
因此本篇不将技术,笔者将从自己的视角,笔者进入大学到现在对所谓AI发展的思想感受的变迁为明线,为将要开启人工智能学习的大伙勾勒出一个笔者眼中的,**人工智能**时代。
|
||||
因此本篇不将技术,笔者将从自己的视角,笔者进入大学到现在对所谓 AI 发展的思想感受的变迁为明线,为将要开启人工智能学习的大伙勾勒出一个笔者眼中的,**人工智能**时代。
|
||||
|
||||
同时,我也会在本篇内容中给你,你可以在本篇内容中获得什么。
|
||||
> 这是一个最好的时代,也是一个最坏的时代;
|
||||
@@ -27,13 +29,13 @@
|
||||
>
|
||||
> 人们正踏上天堂之路,人们正走向地狱之门。
|
||||
>
|
||||
> ——《双城记》 查尔斯·狄更斯
|
||||
> ——《双城记》查尔斯·狄更斯
|
||||
|
||||
## 看山是山
|
||||
|
||||
2020年,在一门杭电的程序设计实践课上,老师要求我们用C语言去实现一些算法,我本来是将目标定为去大厂赚更多的钱的,对所谓AI仅仅停留在概念上,对其内容一无所知。
|
||||
2020 年,在一门杭电的程序设计实践课上,老师要求我们用 C 语言去实现一些算法,我本来是将目标定为去大厂赚更多的钱的,对所谓 AI 仅仅停留在概念上,对其内容一无所知。
|
||||
|
||||
在实验的过程中,偶然和一位转专业学长偶然聊起到程设变态难得题目设计,要求用C语言实现KNN之类的算法,这TM对于我当时的水平简直是太难了!聊到他自己所在的某个实验室本科生的入组任务也不过是这个难度偏低一点点。
|
||||
在实验的过程中,偶然和一位转专业学长偶然聊起到程设变态难得题目设计,要求用 C 语言实现 KNN 之类的算法,这 TM 对于我当时的水平简直是太难了!聊到他自己所在的某个实验室本科生的入组任务也不过是这个难度偏低一点点。
|
||||
|
||||
带着投机主义的心态,想着能不能混到一些论文之类的成果更好就业,毅然决然上了船。
|
||||
|
||||
@@ -43,9 +45,9 @@
|
||||
|
||||
对所谓的科研,所谓的论文,所谓的项目的含金量都是一知半解,只不过是“看到感觉他很火,感觉他很好,具体怎么样我不知道”的心态。这也是在当时的市场上,很多人的心态,由此也是人工智能第一轮狂潮的热点所在,因为大家其实很多都不清楚这个新技术,究竟有什么样的上线,吹起了很大的泡泡。
|
||||
|
||||
就算是有点远见的本科生,也仅仅是看到了所谓的CV和NLP在学校和整个社会大规模宣传下的科普性的概念,也许也没有深入了解过,当时的我也一样。但是我也陷入了同样的狂热中,仅仅是因为他足够火热或有足够的前景,我就想着跟随着潮流走。
|
||||
就算是有点远见的本科生,也仅仅是看到了所谓的 CV 和 NLP 在学校和整个社会大规模宣传下的科普性的概念,也许也没有深入了解过,当时的我也一样。但是我也陷入了同样的狂热中,仅仅是因为他足够火热或有足够的前景,我就想着跟随着潮流走。
|
||||
|
||||
我看了一点非常基础的教程,老师便给我发了两篇非常刺激的CV论文,都是他专业下比较前沿的文章了,我对这到底意味着什么仍然是一无所知,我完全没有搭建起合理的知识框架,我眼里AI只有深度学习,只有用框架写的那几行短短的代码,于是开启了受难之旅。
|
||||
我看了一点非常基础的教程,老师便给我发了两篇非常刺激的 CV 论文,都是他专业下比较前沿的文章了,我对这到底意味着什么仍然是一无所知,我完全没有搭建起合理的知识框架,我眼里 AI 只有深度学习,只有用框架写的那几行短短的代码,于是开启了受难之旅。
|
||||
|
||||
老师并没有做错什么,他只是在这个人工智能大潮下的一朵浪花,他也尽其所能的做到了对本科学生的关注,错的是我,我没有仔细考究过,也没有站在足够高的角度去审视如果我加入了他的工作,我在这个行业中会处在什么样的位置。
|
||||
|
||||
@@ -71,46 +73,46 @@
|
||||
|
||||
**我厌恶他!我厌恶他破坏了科研的纯洁性!我厌恶他成为了急功近利者的帮凶!我厌恶他堆砌的沙堆是充斥着无产者的血和泪!我厌恶他让马太效应发挥到了极致!我厌恶他让所有人都贴上了他的面具,但可能对本质上的东西一无所知!我厌恶他只注重结果,完全不注重过程然后让写的故事变成了捏造!**
|
||||
|
||||
但是,现在我会说,也许当时的我真的错了。我并没有思考过所谓人类的智能和AI的智能的关系,也忽视了当某一个趋势或方向发展到极致之后,量变会引发什么样的质变。
|
||||
但是,现在我会说,也许当时的我真的错了。我并没有思考过所谓人类的智能和 AI 的智能的关系,也忽视了当某一个趋势或方向发展到极致之后,量变会引发什么样的质变。
|
||||
|
||||
[推荐大伙可以看看这个](https://www.bilibili.com/video/BV11c41157aU)
|
||||
|
||||
<Bilibili bvid='BV11c41157aU'/>
|
||||
|
||||
## 看山是山
|
||||
> 孟德尔出生于奥地利帝国(今天的捷克共和国)的西里西亚,是现代遗传学的创始人。尽管几千年来农民就知道动植物的杂交可以促进某些理想的性状,但孟德尔在1856年至1863年之间进行的豌豆植物实验建立了许多遗传规则,现称为孟德尔定律。
|
||||
## 看山还是山
|
||||
|
||||
> 孟德尔出生于奥地利帝国(今天的捷克共和国)的西里西亚,是现代遗传学的创始人。尽管几千年来农民就知道动植物的杂交可以促进某些理想的性状,但孟德尔在 1856 年至 1863 年之间进行的豌豆植物实验建立了许多遗传规则,现称为孟德尔定律。
|
||||
|
||||
在孟德尔那个时代,人们不知道基因,人们也看不到那么小的东西,他给基因取了个名字叫遗传因子。他没能掌握“真实的规律”,可是我们不得不承认的是,他是一个真正有科研精神的人的科研人。 -
|
||||
|
||||
我在不断地绝望之后,走向了极端,我放弃了跟进这个方面的学习,孟尝高洁,空余报国之情;阮籍猖狂,岂效穷途之哭!我失去了搞科研的热情,只想一心去做些别的。
|
||||
|
||||
我看到了南大的课程,我去看一生一芯,去看jyy老师的OS,我听到了蒋老师对未来AI的发展充满了信心,我虽然很崇拜他,但我仍对此嗤之以鼻,我不相信。
|
||||
我看到了南大的课程,我去看一生一芯,去看 jyy 老师的 OS,我听到了蒋老师对未来 AI 的发展充满了信心,我虽然很崇拜他,但我仍对此嗤之以鼻,我不相信。
|
||||
|
||||
一直到有一天,相先生在实验室玩一个叫chatGPT的东西,虽然之前懵懵懂懂的有了解过GPT3之类的东西,但是都对此行的发展没有什么了解,只是知道他又非常大的参数的语言模型,在好奇之下,我去亲自体验chat GPT,我受震惊于他能准确无误的理解我的意思,甚至能替我写代码,只要将问题拆解,他几乎可以就任何一个问题给出一个反而化之的答案。
|
||||
一直到有一天,相先生在实验室玩一个叫 chatGPT 的东西,虽然之前懵懵懂懂的有了解过 GPT3 之类的东西,但是都对此行的发展没有什么了解,只是知道他又非常大的参数的语言模型,在好奇之下,我去亲自体验 chat GPT,我受震惊于他能准确无误的理解我的意思,甚至能替我写代码,只要将问题拆解,他几乎可以就任何一个问题给出一个反而化之的答案。
|
||||
|
||||
随后没过多久,GPT4与new bing应运而生,可以理解用户的意图和情感,根据用户的偏好和反馈来调整输出,甚至利用网络搜索来增强其的知识和回答能力,他们还结合了CV的功能,可以让他们来进行图像的生成工作。作为科研人的最高追求,大一统,一通半通的解决所有问题的模型竟然真的可能在我的有生之年实现,不由得震惊至极。同时,大模型也进入了CV领域,出现了segmenting anything这样可以做到零样本迁移这样的神奇功能,auto GPT出现了在电脑主机上直接替人解决问题甚至是完成某一项工程任务的GPT,以及可以在手机上本地做的mini GPT,技术的爆炸以及变革似乎一瞬间到来了,但是当我回过头展望的时候,正是我最看不起的沙砾,堆叠成了如此强大石之巨人,并且随着资本的涌入,他还在不断强大!!!
|
||||
随后没过多久,GPT4 与 new bing 应运而生,可以理解用户的意图和情感,根据用户的偏好和反馈来调整输出,甚至利用网络搜索来增强其的知识和回答能力,他们还结合了 CV 的功能,可以让他们来进行图像的生成工作。作为科研人的最高追求,大一统,一通半通的解决所有问题的模型竟然真的可能在我的有生之年实现,不由得震惊至极。同时,大模型也进入了 CV 领域,出现了 segmenting anything 这样可以做到零样本迁移这样的神奇功能,auto GPT 出现了在电脑主机上直接替人解决问题甚至是完成某一项工程任务的 GPT,以及可以在手机上本地做的 mini GPT,技术的爆炸以及变革似乎一瞬间到来了,但是当我回过头展望的时候,正是我最看不起的沙砾,堆叠成了如此强大石之巨人,并且随着资本的涌入,他还在不断强大!!!
|
||||
|
||||
2012年,被我们认定为人工智能学习的开篇之作,Alex net诞生了,由Alex Krizhevsky和他的导师Geoffrey Hinton以及Ilya Sutskever设计,在2012年的ImageNet大规模视觉识别挑战赛中获得了冠军,展示了深度学习在图像分类方面的强大能力,并且正式启动了深度学习的革命,在当时他也引发了大量的争议,奉承这符号主义的大师们对着他指指点点,可是他们并不能阻碍时代的巨石碾过一切非议,并且在各个领域都爆发出极其强大的生命力。
|
||||
2012 年,被我们认定为人工智能学习的开篇之作,Alex net 诞生了,由 Alex Krizhevsky 和他的导师 Geoffrey Hinton 以及 Ilya Sutskever 设计,在 2012 年的 ImageNet 大规模视觉识别挑战赛中获得了冠军,展示了深度学习在图像分类方面的强大能力,并且正式启动了深度学习的革命,在当时他也引发了大量的争议,奉承这符号主义的大师们对着他指指点点,可是他们并不能阻碍时代的巨石碾过一切非议,并且在各个领域都爆发出极其强大的生命力。
|
||||
|
||||
想起在学操作系统的时候,linus在几十年前被大老师tanenbaum狂喷,说整了什么垃圾玩意儿。当时的minix基本上可以说是横扫江湖,linus却坚持说用户只考虑用户态是否好用而不在乎内核有多牛逼,当时的论战基本上把各类大神都炸出来,结果几十年后的如今我们发现原来遍布世界的居然是宏内核/混合内核。
|
||||
想起在学操作系统的时候,linus 在几十年前被大老师 tanenbaum 狂喷,说整了什么垃圾玩意儿。当时的 minix 基本上可以说是横扫江湖,linus 却坚持说用户只考虑用户态是否好用而不在乎内核有多牛逼,当时的论战基本上把各类大神都炸出来,结果几十年后的如今我们发现原来遍布世界的居然是宏内核/混合内核。
|
||||
|
||||
时代的发展连大佬都可以拍死在沙滩上!
|
||||
|
||||
从短期来看,也许未来 GPT 会接管小 AI 形成一套上下左右俱为一体的 AI 智能模型,在所谓自动驾驶,智能家居领域发挥极其卓越的作用。
|
||||
|
||||
从长远来看,不由得联想起 AI 在围棋方面 alpha zero 的论文里面提到过,当他们不适用人类的知识的时候,反而模型的效果好很多,有没有可能 AI 在短短的未来总结出一套人类自然语言的规则后,自发创造出一个全新的语言,最终就彻底脱离人类变成一种全新的生命形式,从而彻底颠覆人类以公理为基础的数学,创造一套全新的数学体系,数学体系重做,物理学是否也会迎来质变?
|
||||
|
||||
从短期来看,也许未来GPT会接管小AI形成一套上下左右俱为一体的AI智能模型,在所谓自动驾驶,智能家居领域发挥极其卓越的作用。
|
||||
AI 是一个复杂且多样化的研究领域,他能取得如此长远的发展,并非是仅仅一个两个人靠着所谓的理论研究就可以推动起来的,它伴随着底层的硬件设施配套的完善,算力的突破性增长等等,发展本身,也许就是兼容并蓄的,我们应该在这个发展的洪流前,找到自己的位置以更为谦卑谨慎的姿态,进行更为长远的思考和学习吧。
|
||||
|
||||
从长远来看,不由得联想起AI在围棋方面alpha zero的论文里面提到过,当他们不适用人类的知识的时候,反而模型的效果好很多,有没有可能AI在短短的未来总结出一套人类自然语言的规则后,自发创造出一个全新的语言,最终就彻底脱离人类变成一种全新的生命形式,从而彻底颠覆人类以公理为基础的数学,创造一套全新的数学体系,数学体系重做,物理学是否也会迎来质变?
|
||||
|
||||
AI是一个复杂且多样化的研究领域,他能取得如此长远的发展,并非是仅仅一个两个人靠着所谓的理论研究就可以推动起来的,它伴随着底层的硬件设施配套的完善,算力的突破性增长等等,发展本身,也许就是兼容并蓄的,我们应该在这个发展的洪流前,找到自己的位置以更为谦卑谨慎的姿态,进行更为长远的思考和学习吧。
|
||||
|
||||
> 三花聚顶本是幻,脚下腾云亦非真。大梦一场终须醒,无根无极本归尘。
|
||||
> 三花聚顶本是幻,脚下腾云亦非真。大梦一场终须醒,无根无极本归尘。
|
||||
|
||||
## 结语
|
||||
让我们回到最开始的那几句话
|
||||
这是一个最好的时代(AI技术正在改变人们的生活)
|
||||
|
||||
也是一个最坏的时代(AI也许取代大量人的饭碗)
|
||||
让我们回到最开始的那几句话
|
||||
这是一个最好的时代(AI 技术正在改变人们的生活)
|
||||
|
||||
也是一个最坏的时代(AI 也许取代大量人的饭碗)
|
||||
|
||||
这是一个智慧的年代(很多顶尖的科学家正在改变世界)
|
||||
|
||||
@@ -118,7 +120,7 @@ AI是一个复杂且多样化的研究领域,他能取得如此长远的发展
|
||||
|
||||
这是一个信任的时期(人们将更加信任这个社会会因此变好)
|
||||
|
||||
这是一个怀疑的时期(AI技术带来伦理,毁灭世界等方面的讨论)
|
||||
这是一个怀疑的时期(AI 技术带来伦理,毁灭世界等方面的讨论)
|
||||
|
||||
这是一个光明的季节(前沿科研或科技从来没有离普通的本科生这么近)
|
||||
|
||||
@@ -128,7 +130,7 @@ AI是一个复杂且多样化的研究领域,他能取得如此长远的发展
|
||||
|
||||
这是失望之冬(我国仍有很多需要发展的地方)
|
||||
|
||||
人们面前应有尽有(人们以后可能拥有了AI也就拥有了一切)
|
||||
人们面前应有尽有(人们以后可能拥有了 AI 也就拥有了一切)
|
||||
|
||||
人们面前一无所有(隐私,版权,安全等问题正在受到质疑)
|
||||
|
||||
@@ -146,7 +148,7 @@ AI是一个复杂且多样化的研究领域,他能取得如此长远的发展
|
||||
|
||||
而这些都不会使他停滞
|
||||
|
||||
**这是本讲义想做的第三件事,拥有学习新技术,跟上时代的能力**
|
||||
<strong>这是本讲义想做的第三件事,拥有学习新技术,跟上时代的能力**</strong>
|
||||
|
||||
而愿不愿意在这激荡翻腾的年份,贡献出你的力量,让世界变得更好/更坏,就取决于你的选择了!
|
||||
|
||||
|
||||
@@ -1,34 +1,35 @@
|
||||
# FunRec概述
|
||||
# FunRec 概述
|
||||
|
||||
# 序言
|
||||
## 序言
|
||||
|
||||
这是一篇datawhale的相当优秀的推荐系统教程,因此特别废了九牛二虎之力把FunRec的半套内容,较为完整的移植到了本wiki中。
|
||||
这是一篇 datawhale 的相当优秀的推荐系统教程,因此特别废了九牛二虎之力把 FunRec 的半套内容,较为完整的移植到了本 wiki 中。
|
||||
|
||||
## 为什么要专门移植这篇?
|
||||
### 为什么要专门移植这篇?
|
||||
|
||||
zzm个人以为推荐系统是一个非常有趣的横向和纵向都有很多应用的领域(放到外面是因为放到某一个模块下会因为次级链接太多把wiki撑爆了)
|
||||
zzm 个人以为推荐系统是一个非常有趣的横向和纵向都有很多应用的领域(放到外面是因为放到某一个模块下会因为次级链接太多把 wiki 撑爆了)
|
||||
|
||||
若你想尝试一个新领域,也许这是一个不错的切入点。更何况,如果你想足够完整的构建一个有实际价值的推荐系统,可能需要你去了解相当全面的知识。
|
||||
|
||||
在学习了基础内容之后,如果你想向着科研领域进发,也许对你而言最好的方式或许是选择一个大佬然后去follow他的进度。
|
||||
在学习了基础内容之后,如果你想向着科研领域进发,也许对你而言最好的方式或许是选择一个大佬然后去 follow 他的进度。
|
||||
|
||||
如果你想去找相关的工作,你可以自行去深入学习有关本教程内容的实践部分,甚至是阅读算法面经。
|
||||
|
||||
同时只放上半部的原因是毕竟本偏内容是人工智能大类下的内容,后续可能会涉及一些前后端以及一些更为深入的东西,如果你只是想大致了解一下,那么阅读放在本片的内容被也许是一个不错的选择。
|
||||
|
||||
再次感谢Datawhale的大伙做出了如此卓著的贡献
|
||||
再次感谢 Datawhale 的大伙做出了如此卓著的贡献
|
||||
|
||||
## 正文
|
||||
|
||||
# 正文
|
||||
本教程主要是针对具有机器学习基础并想找推荐算法岗位的同学。教程内容由推荐系统概述、推荐算法基础、推荐系统实战和推荐系统面经四个部分组成。本教程对于入门推荐算法的同学来说,可以从推荐算法的基础到实战再到面试,形成一个闭环。每个部分的详细内容如下:
|
||||
|
||||
- **推荐系统概述。** 这部分内容会从推荐系统的意义及应用,到架构及相关的技术栈做一个概述性的总结,目的是为了让初学者更加了解推荐系统。
|
||||
- **推荐系统算法基础。** 这部分会介绍推荐系统中对于算法工程师来说基础并且重要的相关算法,如经典的召回、排序算法。随着项目的迭代,后续还会不断的总结其他的关键算法和技术,如重排、冷启动等。
|
||||
- **推荐系统实战。** 这部分内容包含推荐系统竞赛实战和新闻推荐系统的实践。其中推荐系统竞赛实战是结合阿里天池上的新闻推荐入门赛做的相关内容。新闻推荐系统实践是实现一个具有前后端交互及整个推荐链路的项目,该项目是一个新闻推荐系统的demo没有实际的商业化价值。
|
||||
- **推荐系统实战。** 这部分内容包含推荐系统竞赛实战和新闻推荐系统的实践。其中推荐系统竞赛实战是结合阿里天池上的新闻推荐入门赛做的相关内容。新闻推荐系统实践是实现一个具有前后端交互及整个推荐链路的项目,该项目是一个新闻推荐系统的 demo 没有实际的商业化价值。
|
||||
- **推荐系统算法面经。** 这里会将推荐算法工程师面试过程中常考的一些基础知识、热门技术等面经进行整理,方便同学在有了一定推荐算法基础之后去面试,因为对于初学者来说只有在公司实习学到的东西才是最有价值的。
|
||||
|
||||
**特别说明**:项目内容是由一群热爱分享的同学一起花时间整理而成,**大家的水平都非常有限,内容难免存在一些错误和问题,如果学习者发现问题,也欢迎及时反馈,避免让后学者踩坑!** 如果对该项目有改进或者优化的建议,还希望通过下面的二维码找到项目负责人或者在交流社区中提出,我们会参考大家的意见进一步对该项目进行修改和调整!如果想对该项目做一些贡献,也可以通过上述同样的方法找到我们!
|
||||
|
||||
为了方便学习和交流,**我们建立了FunRec学习社区(微信群+知识星球)**,微信群方便大家平时日常交流和讨论,知识星球方便沉淀内容。由于我们的内容面向的人群主要是学生,所以**知识星球永久免费**,感兴趣的可以加入星球讨论(加入星球的同学先看置定的必读帖)!**FunRec学习社区内部会不定期分享(FunRec社区中爱分享的同学)技术总结、个人管理等内容,[跟技术相关的分享内容都放在了B站](https://space.bilibili.com/431850986/channel/collectiondetail?sid=339597)上面**。由于微信群的二维码只有7天内有效,所以直接加下面这个微信,备注:**Fun-Rec**,会被拉到Fun-Rec交流群,如果觉得微信群比较吵建议直接加知识星球!。
|
||||
为了方便学习和交流,**我们建立了 FunRec 学习社区(微信群 + 知识星球)**,微信群方便大家平时日常交流和讨论,知识星球方便沉淀内容。由于我们的内容面向的人群主要是学生,所以**知识星球永久免费**,感兴趣的可以加入星球讨论(加入星球的同学先看置定的必读帖)!**FunRec 学习社区内部会不定期分享 (FunRec 社区中爱分享的同学) 技术总结、个人管理等内容,[跟技术相关的分享内容都放在了 B 站](https://space.bilibili.com/431850986/channel/collectiondetail?sid=339597)上面**。由于微信群的二维码只有 7 天内有效,所以直接加下面这个微信,备注:**Fun-Rec**,会被拉到 Fun-Rec 交流群,如果觉得微信群比较吵建议直接加知识星球!。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220408193745249.png" />
|
||||
|
||||
@@ -28,7 +28,7 @@
|
||||
|
||||
本文写于 2023 年 4 月,2023 年以来,AI(ChatGPT、Copilot、MidJourney)正在颠覆每个领域。可能在不远的将来,大部分的前后端开发,都能通过 AI 自动生成 99% 的代码,然后人工审核、校对、修改剩下的 1%。
|
||||
|
||||
### <strong>步入正题 - 何为前后端-通俗认识</strong>
|
||||
### <strong>步入正题 - 何为前后端 - 通俗认识</strong>
|
||||
|
||||
<strong>前端</strong>
|
||||
|
||||
@@ -40,17 +40,17 @@
|
||||
|
||||
为什么有前端?因为光有后端是不行的哈哈哈。
|
||||
|
||||
举个例子,网上有很多软件都可以修改支付宝上的「余额」,如果只有 APP 表面,即前端,那不是人均黑客,人均首付?
|
||||
举个例子,网上有很多软件都可以修改支付宝上的「余额」,如果只有 APP 表面,即前端,那不是人均黑客,人均首富?
|
||||
|
||||
所以一个软件的关键数据,肯定不是存在用户侧(即前端)的。需要有这么一个东西,来存储数据(存储数据的地方叫数据库),来解析用户的请求,这就是后端。
|
||||
所以一个软件的关键数据,肯定不是在用户侧(即前端)的。需要有这么一个东西,来存储数据(存储数据的地方叫数据库),来解析用户的请求,这就是后端。
|
||||
|
||||
<strong>例子</strong>
|
||||
|
||||
举个详细的例子,购物软件上点了下单并支付,这时候前端就会发送一个网络请求,告诉后端:<em>用户某某某,买了什么东西,价格和数量是多少,收货地址是多少。。。</em>
|
||||
|
||||
后端收到了信息,先解析,然后修改数据库中存储的关键信息,比如新建一个订单信息,把商品的数量-1 等等,再把下单的结果告诉给前端。前端收到信息后,就会渲染页面,提示「下单成功」!
|
||||
后端收到了信息,先解析,然后修改数据库中存储的关键信息,比如新建一个订单信息,把商品的数量 -1 等等,再把下单的结果告诉给前端。前端收到信息后,就会渲染页面,提示「下单成功」!
|
||||
|
||||
### <strong>深入 - 何为前后端-技术剖析</strong>
|
||||
### <strong>深入 - 何为前后端 - 技术剖析</strong>
|
||||
|
||||
在了解了前后端的宏观概念后,我们继续来感受一下背后的技术细节吧!
|
||||
|
||||
@@ -59,9 +59,11 @@
|
||||
干讲技术细节实在太无趣了,我们直接上手实战吧!
|
||||
|
||||
不要怕,我「实战」,你「感谢」就行!
|
||||
|
||||
::: warning 📌
|
||||
假设我们要做一个「留言板」
|
||||
:::
|
||||
|
||||
#### 2.3.1 明确需求
|
||||
|
||||
开发程序前(无论是自己独立开发、还是以后工作),一定要先明确需求。
|
||||
@@ -83,7 +85,7 @@
|
||||
|
||||
比如控制留言的字体、大小、颜色,边框、动画、特效。
|
||||
|
||||
要在不同的软件载体上「作画」,需要不同的编程语言/技术,比如网页需要 htlm+css,安卓 APP 需要 Android(Java),IOS 软件是 Swift。
|
||||
要在不同的软件载体上「作画」,需要不同的编程语言/技术,比如网页需要 html+css,安卓 APP 需要 Android(Java),IOS 软件是 Swift。
|
||||
|
||||
<em>(拓展:还有一些技术能够做到跨平台,比如通过某种技术把浏览器包装成一个 APP,就能只出同时支持浏览器和 APP 的</em><em>前端</em><em>;比如创建新的第三方前端框架,能把程序员写的代码转换成原生的 IOS、安卓 APP)</em>
|
||||
|
||||
|
||||
@@ -1 +1,343 @@
|
||||
# 9.1计网速通
|
||||
|
||||
> Author: 柏喵樱
|
||||
>
|
||||
> copyright reserved
|
||||
|
||||
计算机网络是一个非常复杂的系统。在这一章节中,系统的底层实现将被隐去,只留下暴露给用户的内容。
|
||||
|
||||
这一章节为 Web 开发入门设计,用于速通 Web 开发和计网的交叉知识,故命名为 “计网速通”。
|
||||
|
||||
## IP 地址与端口
|
||||
|
||||
`1.1.1.1:80`
|
||||
|
||||
如你所见,上面一串字符表示一个 IP 和端口,他的格式是 `IP:端口`
|
||||
|
||||
IP 是一个由小数点分割成四段的序列,每段数字的取值为 $[0,255]$ , 在上面的示例中,IP是`1.1.1.1`
|
||||
|
||||
而端口是一个数字,取值范围是$[0,65535]$ , 在上面的示例中,端口是`80`
|
||||
|
||||
所有在互联网上的计算机都会被分配到一个IP,用于标识自己。
|
||||
|
||||
现在先抛开具体的实现方式不提,给你一个既定的事实: 互联网能够将数据从一个IP地址传递到另一个任意的IP地址。
|
||||
|
||||
现在你已经知道了怎样使用互联网传送数据,先不讨论怎么说,**理论上说只需要知道对方的IP,给他发数据就可以了**。
|
||||
|
||||
### 那么端口是干什么用的呢?
|
||||
|
||||
想象你的电脑上有很多的应用程序,他们都往互联网上同一个服务器发数据,互联网上的这个服务器也给他们回复数据。当接受到的所有的数据都到了操作系统手里,此时,操作系统如何知道,哪些个数据应该给哪些个应用程序?
|
||||
|
||||
解决方案也很简单,给发出的数据打一个“标记”,这个标记就是端口(Port)。
|
||||
|
||||
想象一个港口,里面有很多的码头,一个应用程序他可以接管一个码头,用于自己传输数据。
|
||||
|
||||
我们可以从一些数据从 IP 地址 1.1.1.1 的 54321 号码头发送数据到 IP 地址 2.2.2.2 的 12345 号码头,同时在发送的数据上做标记,标记他来自什么地方的几号码头。回复数据的时候自然知道往什么地方回复了。
|
||||
|
||||
上面的描述也就是
|
||||
|
||||
`1.1.1.1:54321 -> 2.2.2.2:12345`
|
||||
|
||||
即,将数据从1.1.1.1的54321端口发送到2.2.2.2的12345端口
|
||||
|
||||
可以说这个数据包有以下属性
|
||||
|
||||
- 源IP 1.1.1.1
|
||||
- 源端口 54321
|
||||
- 目的IP 2.2.2.2
|
||||
- 目的端口 12345
|
||||
|
||||
## TCP 与 UDP
|
||||
|
||||
TCP 和 UDP 两个协议的具体实现都是由操作系统提供的,应用程序发送TCP包和UDP包一般都是使用操作系统的API发送的,所以我们无需关系这两个协议的具体实现细节。
|
||||
|
||||
下面通过表格对比两个协议来告诉大家如何选择去使用哪一个协议。
|
||||
|
||||
||TCP|UDP|
|
||||
|---|---|---|
|
||||
|可靠性|有|无|
|
||||
|速度|慢|快|
|
||||
|
||||
表格很小,但是最本质的区别就是这些了。
|
||||
|
||||
TCP的最大特点就是**可靠交付**,他有一个ACK确认机制,简单来说就是对于发送的数据,如果没有收到对方的ACK确认收到,他会不断尝试重发,直到他认为无法送达。
|
||||
|
||||
UDP和TCP虽然经常一起被提起,也确实属于互联网的同一个层,但从他们的复杂度看,他们并不是两个对等的协议。比起TCP有一套非常复杂的算法实现可靠交付流量控制等协议,UDP真的就是单纯发了一个数据包过去,然后什么也不管。
|
||||
|
||||
不过不用担心,大家也没多少机会直接接触这两个协议,还是接触HTTP居多。如果真的需要做出选择,除非你知道你在做什么,选TCP。
|
||||
|
||||
现在,你应该知道,虽然你不知道具体怎么做,但是从理论上说,你可以选择其中一种协议发送数据到另一台联网的计算机的某个端口上。
|
||||
|
||||
如果此时这台计算机的某个应用程序在这个端口使用了正确的协议监听,这个程序他能够正确地获取到数据。两个程序之间的点对点(p2p)通信就这样建立了。
|
||||
|
||||
## DNS
|
||||
|
||||
DNS(Domain Name System) 域名系统
|
||||
|
||||
目前我们已经能够和服务器建立起可靠的连接了,但这与我们日常所见的并不一样。
|
||||
|
||||
对于日常使用,如果我要打开一个网页,我会选择使用比如`bilibili.com`这样的东西,这一串字符叫做**域名**
|
||||
|
||||
域名的最直观用途是代替你记忆 IP 地址,当你访问 `bilibili.com` 这个网址的时候,一般首先会调用操作系统API,操作系统会代替你发送域名解析请求到 DNS 服务器,最后DNS服务器会返回给你域名对应的IP地址。
|
||||
|
||||
其实你也可以拥有自己的域名这很简单。如果你要搭建你自己的网站,购买域名是逃不掉的,在国内的话还需要备案。
|
||||
|
||||
|
||||
|
||||
如上图所示,一个域名有很多不同的解析类型,但是目前你只需要知道 A 记录是什么。
|
||||
|
||||
A 记录是目前互联网上最主要的记录类型,他的记录值是一个 IPv4 地址(就是上述的IP,v4是版本号)。
|
||||
|
||||
举个例子,域名`aaa.bbb.cn`做 A 解析到 `1.1.1.1`,我们需要设置:
|
||||
|
||||
- 主机记录 aaa
|
||||
- 记录类型 A
|
||||
- 记录值 `1.1.1.1`
|
||||
- 其他默认
|
||||
|
||||
此时如果你如果将这个域名作为网址使用,浏览器就会通过域名解析拿到 `1.1.1.1`,向 `1.1.1.1` 发送 HTTP 请求获取数据
|
||||
|
||||
## HTTP
|
||||
|
||||
|
||||
HTTP 协议用于 WEB 服务器,一般多见于浏览器获取网页内容。浏览器会用 HTTP 协议发送 HTTP 请求到服务器,服务器处理 HTTP 请求并返回 HTTP 响应。很多的APP,小程序和电脑上的应用程序都在广泛地使用HTTP
|
||||
|
||||
HTTP 协议有不少版本,现在互联网上最流行的是 HTTP/1.1 版本,浏览器一般最高支持 HTTP/2.0,最新版本是 HTTP/3.0,下面只讨论 HTTP/1.1
|
||||
|
||||
HTTP 的底层是 TCP ,他基于此规定了一套文本格式,用于表达一些信息
|
||||
|
||||
单纯说说是说不明白的,HTTP 报文分请求和响应两种格式,下面给出实例
|
||||
|
||||
> 如果你有兴趣做 HTTP 抓包,推荐用 Yakit ,本人实习正在做这个产品,也欢迎反馈bug
|
||||
|
||||
### 请求
|
||||
|
||||
``` http
|
||||
POST /x/click-interface/web/heartbeat HTTP/1.1
|
||||
Host: api.bilibili.com
|
||||
Accept: application/json, text/plain, */*
|
||||
Accept-Encoding: gzip, deflate, br
|
||||
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
|
||||
Content-Length: 397
|
||||
Content-Type: application/x-www-form-urlencoded
|
||||
Cookie: balh_server_inner=__custom__;dy_spec_agreed=1; balh_is_closed=; PVID=1; i-wanna-go-back=-1; CURRENT_BLACKGAP=0; buvid_fp_plain=undefined; DedeUserID=74145050; DedeUserID__ckMd5=a31c4db0fb996454; blackside_state=0; b_nut=100;
|
||||
Origin: https://www.bilibili.com
|
||||
Referer: https://www.bilibili.com/video/BV1Kx4y1Z7xb/?vd_source=9ec246e4a5695e749fc2f84871669501
|
||||
Sec-Fetch-Dest: empty
|
||||
Sec-Fetch-Mode: cors
|
||||
Sec-Fetch-Site: same-site
|
||||
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.188
|
||||
sec-ch-ua: "Not/A)Brand";v="99", "Microsoft Edge";v="115", "Chromium";v="115"
|
||||
sec-ch-ua-mobile: ?0
|
||||
sec-ch-ua-platform: "Windows"
|
||||
|
||||
start_ts=1690809334&mid=74145050&aid=998480789&cid=1195467370&type=3&sub_type=0&dt=2&play_type=4&realtime=27&played_time=27&real_played_time=35&refer_url=https%3A%2F%2Fmember.bilibili.com%2F&quality=0&video_duration=186&last_play_progress_time=27&max_play_progress_time=27&spmid=333.788.0.0&from_spmid=&extra=%7B%22player_version%22%3A%224.2.4-rc.2132.0%22%7D
|
||||
```
|
||||
|
||||
所见即所得,除了部分敏感字段被隐去外,HTTP 报文在网络中传输时,就长这样
|
||||
|
||||
#### 请求方法
|
||||
|
||||
首先看到第一行
|
||||
|
||||
`POST /x/click-interface/web/heartbeat HTTP/1.1`
|
||||
|
||||
`POST`是请求方法,具体如何使用没有明确的规定,可以参考 Restful 风格,Restful 规定的请求方法有
|
||||
|
||||
- GET
|
||||
- POST
|
||||
- PUT
|
||||
- DELETE
|
||||
|
||||
分别对应查,增,改,删四个动作,这四个动作统称增删查改,英文 CRUD(Create Read Update Delete)
|
||||
|
||||
其中,一般来说 GET 和 DELETE 两个请求方法是不带负载(后面有讲什么是负载)的,但这也不是硬性规定。
|
||||
|
||||
如果你从浏览器地址栏打开一个网页,那么他首先会向对面服务器发送一个 GET 请求,而其他类型的请求往往是网页加载过程中js脚本向服务器获取数据所带来的的。
|
||||
|
||||
#### 请求路径 HTTP版本号
|
||||
|
||||
早期的 Web 服务器采用纯静态+文件目录结构,这其实相当于说暴露一个文件夹在互联网上,然后大家使用文件路径获取这个文件夹中的一个特定的文件。
|
||||
|
||||
这个格式一直以来都得到了沿用,现代的路径早已经失去了这个固定意义,成为了一种分类和标识。
|
||||
|
||||
请求路径可以带请求参数的,上面的例子没有展现出来,类似于
|
||||
|
||||
`/shell?cmd=ls&a=b`
|
||||
|
||||
这种写法只是一种所有人都遵循的格式,这样的路径带2个参数,第一个名字叫`cmd`,参数的值是`ls`,第二个名字叫`a`,参数的值是`b`。
|
||||
|
||||
如果出现字符冲突,比如你需要一个参数值为`&`的参数,可以使用URL编码,写成`%26`,这是`%+16进制ascii码`的格式。
|
||||
|
||||
这一行最后跟一个 HTTP 版本号
|
||||
|
||||
#### 请求头(header)
|
||||
|
||||
紧接着的是请求头,其固定格式为`Key: Value`
|
||||
|
||||
一行一个请求头,不同的请求头有不用的用途,广泛认可的请求头有
|
||||
|
||||
- Host 主机名,也就是域名,如果使用IP访问,这里会写成IP
|
||||
- Content-Type 表示 Payload 的内容格式
|
||||
- User-Agent 发 HTTP 包的人用的浏览器类型和版本号
|
||||
- Cookie 用于存储认证信息等,由服务器设置,浏览器每次请求都会携带
|
||||
|
||||
别的可以暂时不知道
|
||||
|
||||
请求头也可以自定义,如果你觉得有必要你可以添加你自己的请求头
|
||||
|
||||
#### 负载(payload)
|
||||
|
||||
上面的实例是一个 application/x-www-form-urlencoded 类型的 payload ,这由 Content-Type 规定。他的格式和请求参数是一致的。
|
||||
|
||||
负载还有很多种不同的格式,比如 json,xml,form-data Web开发那一块应该会讲,这里就不提了。
|
||||
|
||||
### 响应
|
||||
|
||||
``` http
|
||||
HTTP/1.1 200 OK
|
||||
Access-Control-Allow-Credentials: true
|
||||
Access-Control-Allow-Headers: Origin,No-Cache,X-Requested-With,If-Modified-Since,Pragma,Last-Modified,Cache-Control,Expires,Content-Type,Access-Control-Allow-Credentials,DNT,X-CustomHeader,Keep-Alive,User-Agent,X-Cache-Webcdn,x-bilibili-key-real-ip,x-backend-bili-real-ip,x-risk-header
|
||||
Access-Control-Allow-Origin: https://www.bilibili.com
|
||||
Access-Control-Expose-Headers: X-Bili-Gaia-Vvoucher
|
||||
Bili-Status-Code: 0
|
||||
Bili-Trace-Id: 014a52764364c7b4
|
||||
Connection: keep-alive
|
||||
Content-Type: application/json; charset=utf-8
|
||||
Cross-Origin-Resource-Policy: cross-origin
|
||||
Date: Mon, 31 Jul 2023 13:17:39 GMT
|
||||
X-Bili-Trace-Id: 369754a5d2179290014a52764364c7b4
|
||||
X-Cache-Webcdn: BYPASS from blzone03
|
||||
Content-Length: 51
|
||||
|
||||
{
|
||||
"code": 0,
|
||||
"message": "0",
|
||||
"ttl": 1
|
||||
}
|
||||
```
|
||||
|
||||
#### 协议版本 响应状态码
|
||||
|
||||
协议版本不提了
|
||||
|
||||
响应状态码有很多种
|
||||
|
||||
上面响应了 200 OK 这是最主要的一种对于请求成功的响应,其他常见的有
|
||||
|
||||
- 500 服务器内部错误
|
||||
- 404 服务器找不到资源
|
||||
- 403 没权限
|
||||
- 301 永久跳转
|
||||
- 302 暂时跳转
|
||||
- 200 成功返回
|
||||
|
||||
其中跳转类型会附带 Location 响应头,响应头的内容是要跳转到的地方
|
||||
|
||||
#### 响应头
|
||||
|
||||
格式和请求头保持一致
|
||||
|
||||
在实例的响应头中可以看到很多由 Bilibili 自定义的响应头
|
||||
|
||||
其他和请求头基本一致不做讲解
|
||||
|
||||
#### 负载(payload)
|
||||
|
||||
这是一个 json 格式的负载,具体参考 Web开发章节
|
||||
|
||||
## TLS
|
||||
|
||||
现在大多数的网址都会使用 HTTPS 协议而不是 HTTP,其区别在于,HTTP 是把上面提到的报文直接放在 TCP 里传输,此时如果有人抓包获取了你的报文,他是可以看到完整内容的。为了安全,TLS诞生了。
|
||||
|
||||
HTTPS 的本质就是在将 HTTP 报文通过 TLS 进行发送,而不是直接通过TCP发送。
|
||||
|
||||
TLS 建立在 TCP 的基础上,他会通过加密来确保传输过程中数据的安全。
|
||||
|
||||
具体如何加解密在这里不讨论,比较复杂,这里只能指条路:服务器想要处理 TLS 握手构建安全传输,服务器需要证书和秘钥。这两个东西是由证书签发机构签发的,免费的证书签发机构最出名的是 Let’s Encrypt,签发证书最方便的脚本是 acme.sh。
|
||||
|
||||
## 常用协议端口
|
||||
|
||||
我们在打开一个网页的时候,是不是从来没有考虑过端口的问题?
|
||||
|
||||
这是因为 HTTP/HTTPS 协议有个默认端口,分别是 80 和 443,不写就是默认端口
|
||||
|
||||
下面给一个常用端口列表,随便记一下差不多了
|
||||
|
||||
| 应用层协议 | 端口 | 传输层实现 |
|
||||
| ---------- | ---- | ---------- |
|
||||
| FTP | 21 | TCP |
|
||||
| SSH | 22 | TCP |
|
||||
| SMTP | 25 | TCP |
|
||||
| DNS | 53 | UDP |
|
||||
| HTTP | 80 | TCP |
|
||||
| POP3 | 110 | TCP |
|
||||
| HTTPS | 443 | TCP |
|
||||
| Mysql | 3306 | TCP |
|
||||
| RDP | 3389 | 默认UDP |
|
||||
| Redis | 6379 | TCP |
|
||||
|
||||
## 公网与内网 --- 真实环境分析
|
||||
|
||||
基本的内容介绍的差不多了,下面分析一个简单的网络案例,顺带介绍公网和内网的概念。
|
||||
|
||||
相信在看这篇文章的大家都正在使用互联网,如果你正在使用windows设备,你可以先按 `win`+`R` ,输入 `cmd`,在弹出的窗口输入 `ipconfig` 你可以看到里面有一串类似于下文的内容:
|
||||
|
||||
```
|
||||
无线局域网适配器 WLAN:
|
||||
|
||||
连接特定的 DNS 后缀 . . . . . . . :
|
||||
本地链接 IPv6 地址. . . . . . . . : fe80::4835:c258:e07d:acc3%24
|
||||
IPv4 地址 . . . . . . . . . . . . : 192.168.0.109
|
||||
子网掩码 . . . . . . . . . . . . : 255.255.255.0
|
||||
默认网关. . . . . . . . . . . . . : 192.168.0.1
|
||||
```
|
||||
|
||||
IPv4 地址一栏有一个形似 `192.168.XXX.XXX`的地址,这是一个典型的内网地址,类似的还有很多,比如说
|
||||
|
||||
- 192.168.0.0 - 192.168.255.255
|
||||
- 10.0.0.0 - 10.255.255.255
|
||||
- 172.16.0.0 - 172.31.255.255
|
||||
|
||||
看到以上任意一个都是非常合情合理的,虽然还有其他内网地址,但是那些都比较冷门,可能一辈子碰不到,不用记忆。
|
||||
|
||||
因此,除了上面列出的 IP 地址,请将他们一律视为公网地址,公网地址是独一无二的,绝对的,内网地址在不同的子网里可以重复使用,是相对的。
|
||||
|
||||
此外下面还有子网掩码和默认网关,掩码会在后续的内容中介绍,现在知道你只需要知道:
|
||||
|
||||
- 上面显示的 `IPv4 地址` 是你这台设备的 IP 地址
|
||||
- 家庭和寝室网络子网掩码默认 `255.255.255.0`
|
||||
- 默认网关是路由器在内网的 IP,你的设备需要路由器的帮助将数据包从内网转发到公网
|
||||
|
||||
此刻你可能会有一个疑问,作为一台联网的计算机设备,我可以把数据发送到公网的服务器上,因为我知道他的公网IP,而且这是独一无二的,只要我联网,互联网上的路由设备会尽力帮我把数据送到地方。
|
||||
|
||||
### 但是,返回的数据该怎么办?
|
||||
|
||||
显然,对面不可能把数据包发给一个内网地址,他只有发给一个公网地址,互联网上的路由设备才知道他要去哪,才能帮他将数据送到地方。
|
||||
|
||||
问题的答案很简单,我们的路由器,他通过 PPPoE 拨号的方式向运营商拿到了一个公网IP。他在把数据包转发到互联网上前,做了一个网络地址转换的操作,把数据包的源地址替换成了他的公网IP,再找了一个随机端口号,在那里将修改后的数据发送到公网,**这个转换的操作会被路由器记录**。
|
||||
|
||||
这样,公网上的服务器在收到数据包后也能知道,这个包来自于哪个公网IP的哪个端口,回复的时候就知道发到什么地方了。
|
||||
|
||||
路由器拿到公网上的服务器回复的数据包后,可以根据做网络地址转换时的记录,逆向推导出他应该将包发送到内网的哪台机器的哪个端口,就完成了数据的收发。
|
||||
|
||||
绝大多数的家庭或者寝室网络都遵循着这个规则。
|
||||
|
||||
### 那为什么要这么做呢?
|
||||
|
||||
对于一般家庭网络,有两个简单的理由
|
||||
|
||||
- 安全,只有你主动连接才能拿到回复,互联网上的设备无法主动访问你的设备
|
||||
- IPv4 不够用啦
|
||||
|
||||
### 其他特殊IP地址
|
||||
|
||||
- 127.0.0.1 本机,用于自己的设备给自己的设备另一个端口发送数据
|
||||
- 169.254.x.x 保留地址,向路由器获取内网地址前会临时使用这个地址,如果你发现你的电脑正在使用这个地址,路由器可能坏了
|
||||
- 198.18.x.x 保留地址,但是有些软件会使用这个地址来实现透明代理(tun)
|
||||
|
||||
好,我们的计网速通章节,到此结束,这些计算机网络知识应该足够你做简单的 Web 开发了
|
||||
|
||||
## 参考资料
|
||||
|
||||
- HTTP 教程 <https://www.runoob.com/http/http-tutorial.html>
|
||||
|
||||
185
9.计算机网络/9.2.3.1IP协议.md
Normal file
185
9.计算机网络/9.2.3.1IP协议.md
Normal file
@@ -0,0 +1,185 @@
|
||||
# IP协议
|
||||
|
||||
> Author: 柏喵樱
|
||||
>
|
||||
> copyright reserved
|
||||
|
||||
## IP 协议数据包结构
|
||||
|
||||
IP 协议是网络层最主要的协议,几乎所有的上层数据包都需要IP协议的承载,我们网络层的第一块内容将从 IP 协议讲起。
|
||||
|
||||
下图展示了 IP 协议的报文头部格式,这张图每行代表 32 个 bit,也就是 4 个字节(byte)。如果不计算 Options 这种可选项的话,IP 协议的报头长度为 20 个字节。
|
||||
|
||||
在头部的后面,会携带负载(payload),这个词可能略显晦涩,但实际上就是我们需要发送的数据。
|
||||
|
||||
<pre>
|
||||
0 1 2 3
|
||||
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
|
||||
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|
||||
|Version| IHL |Type of Service| Total Length |
|
||||
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|
||||
| Identification |Flags| Fragment Offset |
|
||||
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|
||||
| Time to Live | Protocol | Header Checksum |
|
||||
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|
||||
| Source Address |
|
||||
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|
||||
| Destination Address |
|
||||
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|
||||
| Options | Padding |
|
||||
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|
||||
Example Internet Datagram Header
|
||||
</pre>
|
||||
## 版本
|
||||
|
||||
第一个字段是IP协议版本号,用于标识IPv4和IPv6两个版本,这两个版本的报文格式是不同的。上图展示的是 IPv4 的报文格式
|
||||
|
||||
## IHL(Internet Header Length)
|
||||
|
||||
就是IP协议的头部部分的长度,单位是 4byte,由于 IP 头一般长度为 20byte,所以这个值一般为 5。如果存在Options字段,这个值会相应增加。
|
||||
|
||||
## Type of Service
|
||||
|
||||
服务类型,标记服务类型最初是为了对不同服务的数据包做不同的转发策略,比如说哪些数据包应该被优先转发,应该更注重转发延时还是更注重吞吐量一类的问题,除非到运营商层面一般接触不太到。
|
||||
|
||||
## 数据包总长度
|
||||
|
||||
Total Length 很好理解就是包括 IP 头在内的 IP 报文的总长度,报文长度上限就是 MTU。
|
||||
|
||||
## Identification & Flags & Fragment Offset
|
||||
|
||||
这三个字段放在一起讲,他们都是用于控制分片的。
|
||||
|
||||
我们的 MTU 他一般是 1500,去除 20 bytes 的头部他还能够携带 1480 bytes 的数据,但是现实中的负载很容易就能够超出这个大小,这时候就需要将内容切片分块发送。
|
||||
|
||||
切片时,会切出许多 1480 bytes 的切片,和剩下的不足 1480 bytes 的部分。对于以上的所有切片,都会给他们加一个自己的 IP 头。这些 IP 头有一个共同点,就是他们具有一个相同的 Identification 用于识别(identify)他们原先是一块的。
|
||||
|
||||
现在还存在两个问题,
|
||||
|
||||
1. 服务器接收到一个分片后,不知道要不要继续接收
|
||||
2. 分片很有可能乱序抵达,服务器不知道分片的顺序
|
||||
|
||||
对于第二个问题,引入了 Fragment Offset(分片偏移量),他的单位是 byte,用于标识这一个分片的数据,是从原来超长负载的哪个位置开始的。比如对于一个长度为 5000 bytes 的负载,他的几个分片的 Fragment Offset 依次为 0,1480,2960,4440。在收到数据后,服务器只需要按照这个字段重新组装即可。
|
||||
|
||||
对于第一个问题,引入了 Flags(标志位), Flags 里有三个 Flag,其中最后一位的意义是“后面还有更多分片“,这就相当于告诉服务器,你要继续等待接收其他分片。而当最后的分片抵达时,服务器在知道这是最后的分片的同时,他也能从这个分片的 Fragment Offset里得知前面应该有多少数据,如果缺失,服务器也能继续等待接收。
|
||||
|
||||
关于Flags的其他两位,最高位是目前保留不使用,永远为0。后面那位的意义是不要分片,这一般是不设置的,他这句话是对传输过程中的路由设备讲的,因为如果途径 MTU 低于当前包长度的链路可能会进行二次分片。如果设置了这个 Flag,转发时再碰到 MTU 低的链路这种包会被直接丢弃同时返回一个 ICMP 包告诉源IP地址的设备发生了什么。
|
||||
|
||||
## TTL(Time To Live)
|
||||
|
||||
TTL 是一个unsigned int,代表数据包的剩余生存时间,指的是数据包在互联网中还能转发多少时间,单位是秒。
|
||||
|
||||
虽然单位是秒,但是一般情况下转发耗时是远远低于一秒的,根据 IP 协议的规定,无论转发耗时多少,TTL 应当至少 -1,所以在实践中 TTL 往往指的是转发了几次。
|
||||
|
||||
一般发往互联网的数据包初始 TTL 为 64 或 128,你可以试试 ping 命令,他会显示一个TTL,这是对面服务器回复的包到自己的设备的时候的 TTL。
|
||||
|
||||
```powershell
|
||||
PS C:\Users\bs> ping baidu.com
|
||||
|
||||
正在 Ping baidu.com [39.156.66.10] 具有 32 字节的数据:
|
||||
来自 39.156.66.10 的回复: 字节=32 时间=43ms TTL=47
|
||||
来自 39.156.66.10 的回复: 字节=32 时间=144ms TTL=47
|
||||
来自 39.156.66.10 的回复: 字节=32 时间=43ms TTL=47
|
||||
来自 39.156.66.10 的回复: 字节=32 时间=42ms TTL=47
|
||||
|
||||
39.156.66.10 的 Ping 统计信息:
|
||||
数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失),
|
||||
往返行程的估计时间(以毫秒为单位):
|
||||
最短 = 42ms,最长 = 144ms,平均 = 68ms
|
||||
```
|
||||
|
||||
TTL 减少到 0 的时候,这个数据包会被丢弃,所以如果互联网中出现路由配置错误,以至于产生了一个环,TTL 能够帮助数据包及时停止转发,避免事故扩大最终导致网络设施瘫痪。
|
||||
|
||||
当路由设备由于 TTL 为 0,而丢弃这个数据包的时候,路由设备还会向源 IP 回复一个 `TTL超时`的 ICMP 报文
|
||||
|
||||
```powershell
|
||||
PS C:\Users\bs> ping baidu.com -i 2
|
||||
|
||||
正在 Ping baidu.com [39.156.66.10] 具有 32 字节的数据:
|
||||
来自 192.168.1.1 的回复: TTL 传输中过期。
|
||||
来自 192.168.1.1 的回复: TTL 传输中过期。
|
||||
来自 192.168.1.1 的回复: TTL 传输中过期。
|
||||
来自 192.168.1.1 的回复: TTL 传输中过期。
|
||||
|
||||
39.156.66.10 的 Ping 统计信息:
|
||||
数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失),
|
||||
```
|
||||
|
||||
traceroute 就是利用这个性质来实现的,通过从 0 开始遍历 TTL 的方式,可以拿到转发过程中的所有路由器的 ICMP 回复,从这些回复中可以读取到这些路由器的 IP。
|
||||
|
||||
当然 traceroute 不是万能的,真实互联网中广泛存在拦截,不响应 ,改写等等行为,会导致 traceroute 产生丢失或者藏跳等等比较迷惑的结果。
|
||||
|
||||
```powershell
|
||||
PS C:\Users\bs> TRACERT.EXE bilibili.com
|
||||
|
||||
通过最多 30 个跃点跟踪
|
||||
到 bilibili.com [8.134.50.24] 的路由:
|
||||
|
||||
1 8 ms 13 ms 2 ms 192.168.0.1 [192.168.0.1]
|
||||
2 1 ms 1 ms 2 ms 192.168.1.1 [192.168.1.1]
|
||||
3 8 ms 8 ms * 100.66.0.1
|
||||
4 * * * 请求超时。
|
||||
5 * * * 请求超时。
|
||||
6 * * * 请求超时。
|
||||
7 * * * 请求超时。
|
||||
8 * * 8 ms 61.139.121.77
|
||||
9 * * * 请求超时。
|
||||
10 78 ms * * 113.96.5.134
|
||||
11 * 83 ms 43 ms 121.14.50.241
|
||||
12 45 ms 42 ms 41 ms 121.14.24.82
|
||||
13 * * * 请求超时。
|
||||
14 * * * 请求超时。
|
||||
15 * * * 请求超时。
|
||||
16 * * * 请求超时。
|
||||
17 42 ms 50 ms 40 ms 8.134.50.24
|
||||
|
||||
跟踪完成。
|
||||
```
|
||||
|
||||
上面就是一个真实案例,有很多路由设备在丢弃数据包时并没有给出 ICMP 回复。
|
||||
|
||||
## 协议
|
||||
|
||||
协议(Protocol)指的是负载中的数据所使用的协议。这就很广泛了,比如
|
||||
|
||||
- TCP
|
||||
|
||||
- UDP
|
||||
|
||||
- ICMP
|
||||
|
||||
- Telnet
|
||||
|
||||
- OSPF
|
||||
|
||||
具体可以参考 [List of IP protocol numbers - Wikipedia](https://en.wikipedia.org/wiki/List_of_IP_protocol_numbers)
|
||||
|
||||
## 头部校验和
|
||||
|
||||
头部校验和(Header Checksum)用于检验传输的数据是否出错,一旦出错直接丢弃。
|
||||
|
||||
在计算头部的校验和的时候,头部校验和这个字段会被置零,再使用特定算法计算得到校验和,填写到这个位置。
|
||||
|
||||
这个校验和算法比较简单,就是头部以 16 bits 为单位,取补码再求和
|
||||
|
||||
注意,由于 TTL 在每次转发中都会改变,所以实际上,每次转发都会重新计算校验和。
|
||||
|
||||
|
||||
## IP地址
|
||||
|
||||
正如上图的 `Source Address` 和 `Destination Address` 字段所展示的一样,一个 IP 地址占用 4 byte 的存储空间。在书面的写法上,我们用 `.` 将每一个 byte 分割开,例如 `1.1.1.1` 这样更便于人类处理和分类。
|
||||
|
||||
有一些 IP 地址被用作特殊用途,除了这些 IP 地址外的地址都是公网 IP,一个公网 IP 在整个互联网范围内按照规范来说,只能由一台网络设备占有(也有例外,anycast)。但互联网是复杂的,也有人占用这些地址作为自己的内网地址(例如 tr069),这个由网络运维人员自行分析情景把握。
|
||||
|
||||
网络地址的分类需要更多的前置知识,我们后续再介绍。
|
||||
|
||||
## 可选项
|
||||
|
||||
可选参数(Options)比较繁琐,一般没啥用,有兴趣的可以看看下面参考资料中 RFC 791 对此的描述。
|
||||
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [RFC 791 - Internet Protocol (ietf.org)](https://datatracker.ietf.org/doc/html/rfc791)
|
||||
- [Reserved IP addresses - Wikipedia](https://en.wikipedia.org/wiki/Reserved_IP_addresses)
|
||||
- [List of IP protocol numbers - Wikipedia](https://en.wikipedia.org/wiki/List_of_IP_protocol_numbers)
|
||||
18
9.计算机网络/9.2.3网络层.md
Normal file
18
9.计算机网络/9.2.3网络层.md
Normal file
@@ -0,0 +1,18 @@
|
||||
# 9.2.3 网络层
|
||||
|
||||
> Author: 柏喵樱
|
||||
>
|
||||
> copyright reserved
|
||||
|
||||
本章节是网络层的开篇章节,我们先做两个约定:
|
||||
|
||||
- 没有提及IP协议版本,都是IPv4( IPv6 会单独介绍不详细展开)
|
||||
|
||||
- 路由表已经配置好了,给IP地址就能发到正确的地方(路由技术参照“路由与交换”章节)
|
||||
|
||||
以上两个约定适用于所有网络层章节。
|
||||
|
||||
在链路层我们已经实现了两个直接相连的设备之间的数据收发,也可以在总线类型的网络上完成数据手法,更成熟一点,可以借助交换机来构建一个具有一定规模的中心化网络。
|
||||
|
||||
但中心化是有极限的,这必然无法承载这个整个互联网,因此,我们需要再往上一层,定义一个新的概念,IP 地址,并完成实现数据包的转发操作,将互联网推向去中心化。
|
||||
|
||||
@@ -1 +0,0 @@
|
||||
# 9.2计网基础
|
||||
@@ -95,7 +95,7 @@
|
||||
链路层 ---> 数据帧/MAC/CRC
|
||||
链路层 ---> PPP
|
||||
链路层 ---> ARP
|
||||
网络层 ---> IP地址
|
||||
网络层 ---> IP 协议
|
||||
网络层 ---> 子网/掩码/CIDR
|
||||
网络层 ---> IPv6概述
|
||||
传输层 ---> 端口
|
||||
|
||||
BIN
9.计算机网络/static/dnspod-domain.png
Normal file
BIN
9.计算机网络/static/dnspod-domain.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 190 KiB |
@@ -18,6 +18,9 @@
|
||||
<a href="https://app.netlify.com/sites/hdu-cs-wiki/deploys">
|
||||
<img src="https://api.netlify.com/api/v1/badges/92121c47-e608-4736-bffa-c0958e570348/deploy-status">
|
||||
</a>
|
||||
<a href="https://vercel.com/camera-2018/hdu-cs-wiki/deployments">
|
||||
<img src="http://therealsujitk-vercel-badge.vercel.app/?app=hdu-cs-wiki&logo=true">
|
||||
</a>
|
||||
<a href="https://conventionalcommits.org">
|
||||
<img src="https://img.shields.io/badge/Conventional%20Commits-1.0.0-%23FE5196?logo=conventionalcommits&logoColor=white">
|
||||
</a>
|
||||
@@ -26,7 +29,7 @@
|
||||
<pre align="center">喜欢本项目可以点击右上角 star 收藏哦🎇</pre>
|
||||
<br/>
|
||||
<p align="center">
|
||||
<a href="https://hdu-cs.wiki/" target="_blank">📚在线阅读(美国、AWS节点)</a>
|
||||
<a href="https://hdu-cs.wiki/" target="_blank">📚在线阅读(美国加利福尼亚、Vercel节点)</a>
|
||||
<a href="https://cn.hdu-cs.wiki/" target="_blank">🎉【推荐】📚在线阅读(中国腾讯云CDN节点)</a>
|
||||
</p>
|
||||
|
||||
|
||||
41
index.md
41
index.md
@@ -26,6 +26,43 @@ features:
|
||||
details: 给你学习大学理应掌握的编程思维,构建合理的编程思维方式!当然,未完待续,很多内容仍在测试阶段。
|
||||
- title: 🤣what's more?
|
||||
details: 还有非常多的内容尚未更新完毕,我们期待着你的反馈和加入!
|
||||
---
|
||||
|
||||
<meta name="baidu-site-verification" content="codeva-GDehy1VQ6d" />
|
||||
head:
|
||||
- - meta
|
||||
- name: description
|
||||
content: HDU计算机科学讲义
|
||||
- - meta
|
||||
- property: 'og:url'
|
||||
content: https://hdu-cs.wiki/
|
||||
- - meta
|
||||
- property: 'og:type'
|
||||
content: wiki
|
||||
- - meta
|
||||
- property: 'og:title'
|
||||
content: HDU-CS-WIKI | HDU-CS-WIKI
|
||||
- - meta
|
||||
- property: 'og:description'
|
||||
content: HDU计算机科学讲义
|
||||
- - meta
|
||||
- property: 'og:image'
|
||||
content: https://cdn.xyxsw.site/og-img.png
|
||||
- - meta
|
||||
- name: twitter:card
|
||||
content: summary_large_image
|
||||
- - meta
|
||||
- property: 'twitter:domain'
|
||||
content: hdu-cs.wiki
|
||||
- - meta
|
||||
- property: 'twitter:url'
|
||||
content: https://hdu-cs.wiki/
|
||||
- - meta
|
||||
- name: twitter:title
|
||||
content: HDU-CS-WIKI | HDU-CS-WIKI
|
||||
- - meta
|
||||
- name: twitter:description
|
||||
content: HDU计算机科学讲义
|
||||
- - meta
|
||||
- name: twitter:image
|
||||
content: https://cdn.xyxsw.site/og-img.png
|
||||
|
||||
---
|
||||
|
||||
11
package-lock.json
generated
11
package-lock.json
generated
@@ -9,6 +9,7 @@
|
||||
"@codemirror/lang-sql": "^6.5.2",
|
||||
"@jupyterlab/mathjax2": "^3.6.5",
|
||||
"@jupyterlab/theme-light-extension": "^4.0.3",
|
||||
"@vercel/analytics": "^1.0.1",
|
||||
"@vueuse/core": "^10.3.0",
|
||||
"markdown-it": "^13.0.1",
|
||||
"markdown-it-pangu": "^1.0.2",
|
||||
@@ -1399,6 +1400,11 @@
|
||||
"resolved": "https://registry.npmmirror.com/@types/web-bluetooth/-/web-bluetooth-0.0.17.tgz",
|
||||
"integrity": "sha512-4p9vcSmxAayx72yn70joFoL44c9MO/0+iVEBIQXe3v2h2SiAsEIo/G5v6ObFWvNKRFjbrVadNf9LqEEZeQPzdA=="
|
||||
},
|
||||
"node_modules/@vercel/analytics": {
|
||||
"version": "1.0.1",
|
||||
"resolved": "https://registry.npmmirror.com/@vercel/analytics/-/analytics-1.0.1.tgz",
|
||||
"integrity": "sha512-Ux0c9qUfkcPqng3vrR0GTrlQdqNJ2JREn/2ydrVuKwM3RtMfF2mWX31Ijqo1opSjNAq6rK76PwtANw6kl6TAow=="
|
||||
},
|
||||
"node_modules/@vitejs/plugin-vue": {
|
||||
"version": "4.2.3",
|
||||
"resolved": "https://repo.huaweicloud.com/repository/npm/@vitejs/plugin-vue/-/plugin-vue-4.2.3.tgz",
|
||||
@@ -5260,6 +5266,11 @@
|
||||
"resolved": "https://registry.npmmirror.com/@types/web-bluetooth/-/web-bluetooth-0.0.17.tgz",
|
||||
"integrity": "sha512-4p9vcSmxAayx72yn70joFoL44c9MO/0+iVEBIQXe3v2h2SiAsEIo/G5v6ObFWvNKRFjbrVadNf9LqEEZeQPzdA=="
|
||||
},
|
||||
"@vercel/analytics": {
|
||||
"version": "1.0.1",
|
||||
"resolved": "https://registry.npmmirror.com/@vercel/analytics/-/analytics-1.0.1.tgz",
|
||||
"integrity": "sha512-Ux0c9qUfkcPqng3vrR0GTrlQdqNJ2JREn/2ydrVuKwM3RtMfF2mWX31Ijqo1opSjNAq6rK76PwtANw6kl6TAow=="
|
||||
},
|
||||
"@vitejs/plugin-vue": {
|
||||
"version": "4.2.3",
|
||||
"resolved": "https://repo.huaweicloud.com/repository/npm/@vitejs/plugin-vue/-/plugin-vue-4.2.3.tgz",
|
||||
|
||||
@@ -9,6 +9,7 @@
|
||||
"@codemirror/lang-sql": "^6.5.2",
|
||||
"@jupyterlab/mathjax2": "^3.6.5",
|
||||
"@jupyterlab/theme-light-extension": "^4.0.3",
|
||||
"@vercel/analytics": "^1.0.1",
|
||||
"@vueuse/core": "^10.3.0",
|
||||
"markdown-it": "^13.0.1",
|
||||
"markdown-it-pangu": "^1.0.2",
|
||||
|
||||
Reference in New Issue
Block a user