update
many chore
This commit is contained in:
@@ -1,4 +1,5 @@
|
||||
# 程序示例——maze 迷宫解搜索
|
||||
|
||||
::: warning 😋
|
||||
阅读程序中涉及搜索算法的部分,然后运行程序,享受机器自动帮你寻找路径的快乐!
|
||||
完成习题
|
||||
@@ -10,7 +11,7 @@
|
||||
|
||||
/4.人工智能/code/MAZE.zip
|
||||
|
||||
# Node
|
||||
## Node
|
||||
|
||||
```python
|
||||
# 节点类 Node
|
||||
@@ -21,7 +22,7 @@ class Node:
|
||||
self.action = action # 存储采取的行动
|
||||
```
|
||||
|
||||
## 节点复习:
|
||||
## 节点复习
|
||||
|
||||
- 节点是一种包含以下数据的数据结构:
|
||||
- 状态——state
|
||||
@@ -29,7 +30,7 @@ class Node:
|
||||
- 应用于父级状态以获取当前节点的操作——action
|
||||
- 从初始状态到该节点的路径成本——path cost
|
||||
|
||||
# 堆栈边域——DFS
|
||||
## 堆栈边域——DFS
|
||||
|
||||
```python
|
||||
class StackFrontier: # 堆栈边域
|
||||
@@ -50,11 +51,11 @@ class StackFrontier: # 堆栈边域
|
||||
return node
|
||||
```
|
||||
|
||||
## 深度优先搜索复习:
|
||||
## 深度优先搜索复习
|
||||
|
||||
- 深度优先搜索算法在尝试另一个方向之前耗尽每个方向。在这些情况下,边域作为堆栈数据结构进行管理。这里需要记住的流行语是“后进先出”。在将节点添加到边域后,第一个要删除和考虑的节点是最后一个要添加的节点。这导致了一种搜索算法,该算法在第一个方向上尽可能深入,直到尽头,同时将所有其他方向留到后面。“不撞南墙不回头”
|
||||
|
||||
# 队列边域——BFS
|
||||
## 队列边域——BFS
|
||||
|
||||
```python
|
||||
class QueueFrontier(StackFrontier): # 队列边域
|
||||
@@ -67,11 +68,11 @@ class QueueFrontier(StackFrontier): # 队列边域
|
||||
return node
|
||||
```
|
||||
|
||||
## 广度优先搜索复习:
|
||||
## 广度优先搜索复习
|
||||
|
||||
- 广度优先搜索算法将同时遵循多个方向,在每个可能的方向上迈出一步,然后在每个方向上迈出第二步。在这种情况下,边域作为队列数据结构进行管理。这里需要记住的流行语是“先进先出”。在这种情况下,所有新节点都会排成一行,并根据先添加的节点来考虑节点(先到先得!)。这导致搜索算法在任何一个方向上迈出第二步之前,在每个可能的方向上迈出一步。
|
||||
|
||||
# 迷宫解——Maze_solution
|
||||
## 迷宫解——Maze_solution
|
||||
|
||||
```python
|
||||
class Maze:
|
||||
@@ -111,7 +112,7 @@ class Maze:
|
||||
# 打印结果
|
||||
def print(self):
|
||||
...
|
||||
# 寻找邻结点,返回元组(动作,坐标(x,y))
|
||||
# 寻找邻结点,返回元组 (动作,坐标 (x,y))
|
||||
def neighbors(self, state):
|
||||
row, col = state
|
||||
candidates = [
|
||||
@@ -130,8 +131,8 @@ class Maze:
|
||||
self.num_explored = 0 # 已搜索的路径长度
|
||||
# 将边界初始化为起始位置
|
||||
start = Node(state=self.start, parent=None, action=None)
|
||||
frontier = StackFrontier() # 采用DFS
|
||||
# frontier = QueueFrontier() # 采用BFS
|
||||
frontier = StackFrontier() # 采用 DFS
|
||||
# frontier = QueueFrontier() # 采用 BFS
|
||||
frontier.add(start)
|
||||
# 初始化一个空的探索集
|
||||
self.explored = set() # 存储已搜索的结点
|
||||
@@ -166,7 +167,7 @@ class Maze:
|
||||
...
|
||||
```
|
||||
|
||||
# Quiz
|
||||
## Quiz
|
||||
|
||||
1. 在深度优先搜索(DFS)和广度优先搜索(BFS)之间,哪一个会在迷宫中找到更短的路径?
|
||||
1. DFS 将始终找到比 BFS 更短的路径
|
||||
@@ -190,11 +191,11 @@ class Maze:
|
||||
7. 可能是四种算法中的任何一种
|
||||
8. 不可能是四种算法中的任何一种
|
||||
3. 为什么有深度限制的极大极小算法有时比没有深度限制的极大极小更可取?
|
||||
1. 深度受限的极大极小算法可以更快地做出决定,因为它探索的状态更少
|
||||
2. 深度受限的极大极小算法将在没有深度限制的情况下实现与极大极小算法相同的输出,但有时会使用较少的内存
|
||||
3. 深度受限的极大极小算法可以通过不探索已知的次优状态来做出更优化的决策
|
||||
4. 深度限制的极小极大值永远不会比没有深度限制的极大极小值更可取
|
||||
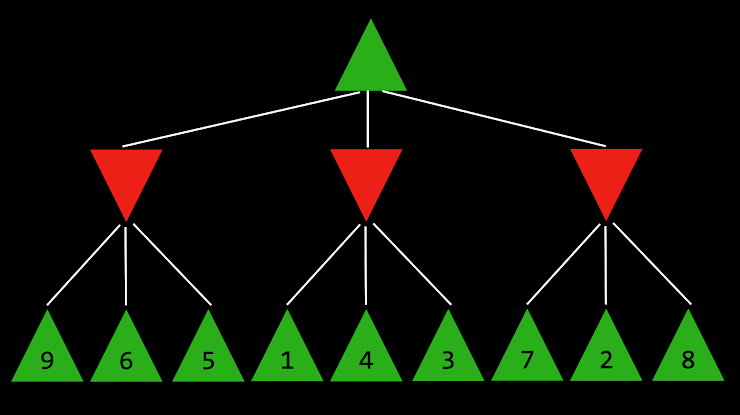
4. 下面的问题将询问您关于下面的 Minimax 树,其中绿色向上箭头表示 MAX 玩家,红色向下箭头表示 MIN 玩家。每个叶节点都标有其值。
|
||||
1. 深度受限的极大极小算法可以更快地做出决定,因为它探索的状态更少
|
||||
2. 深度受限的极大极小算法将在没有深度限制的情况下实现与极大极小算法相同的输出,但有时会使用较少的内存
|
||||
3. 深度受限的极大极小算法可以通过不探索已知的次优状态来做出更优化的决策
|
||||
4. 深度限制的极小极大值永远不会比没有深度限制的极大极小值更可取
|
||||
4. 下面的问题将询问您关于下面的 Minimax 树,其中绿色向上箭头表示 MAX 玩家,红色向下箭头表示 MIN 玩家。每个叶节点都标有其值。
|
||||
|
||||
|
||||
|
||||
|
||||
Reference in New Issue
Block a user