chore: turn cos to cdn
This commit is contained in:
@@ -219,13 +219,13 @@ ICL(In-Context Learning,上下文学习)和 COT(Chain of Thought,思
|
||||
|
||||
虽然学界对此没有太大的共识,但其原理无非在于给予 LLMs 更翔实的上下文,让输出与输入有着更紧密的关联与惯性。(从某种意义上来说,也可以将其认为是一种图灵机式的编程)
|
||||
|
||||
> ICL:<br/>
|
||||
> ICL:<br/>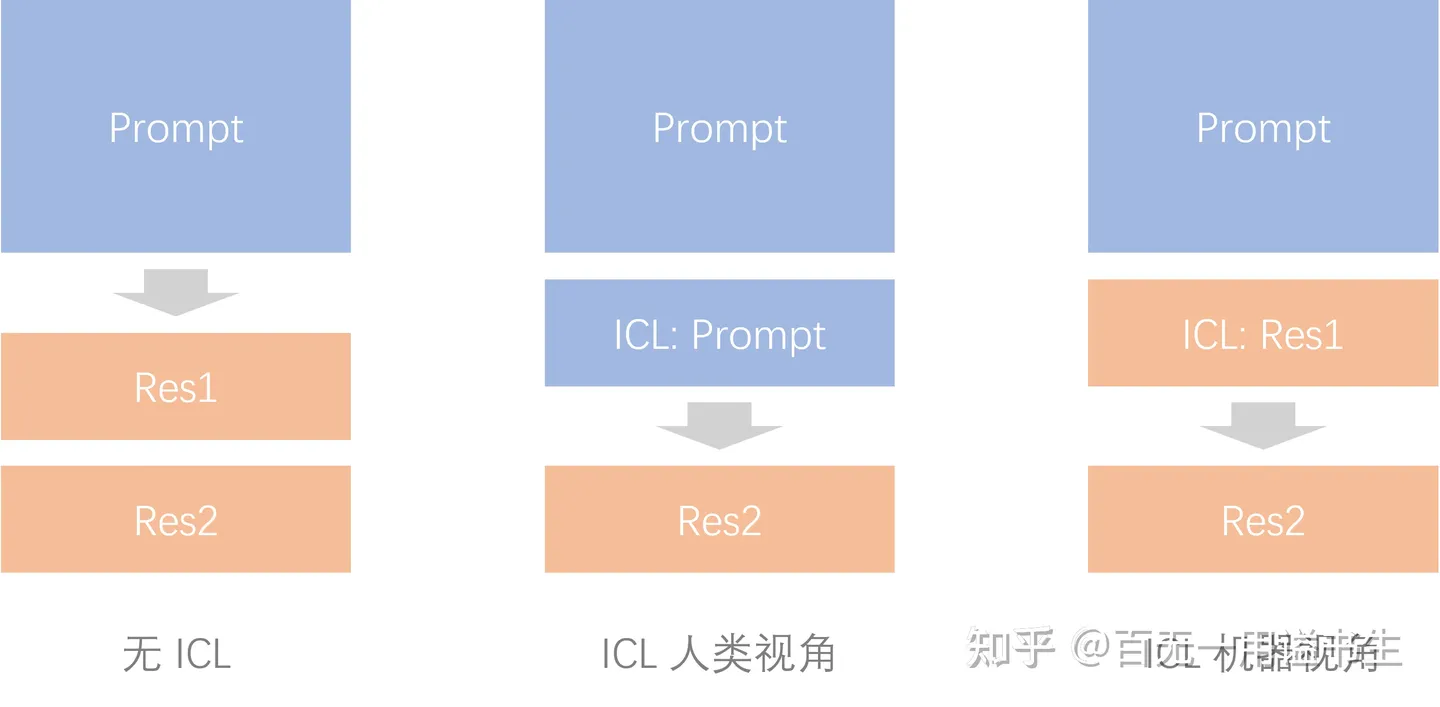
|
||||
|
||||
ICL 为输出增加惯性
|
||||
|
||||
> 可以简单认为,通过 ICL Prompt,能强化人类输入到机器输出的连贯性,借以提升输出的确定性。<br/>在经过“回答”的 finetune 之前,大模型的原始能力就是基于给定文本进行接龙,而 ICL 的引入则在“回答”这一前提条件下,降低了机器开始接龙这一步骤中的语义跨度,从而使得输出更加可控。<br/>
|
||||
|
||||
COT:<br/>
|
||||
COT:<br/>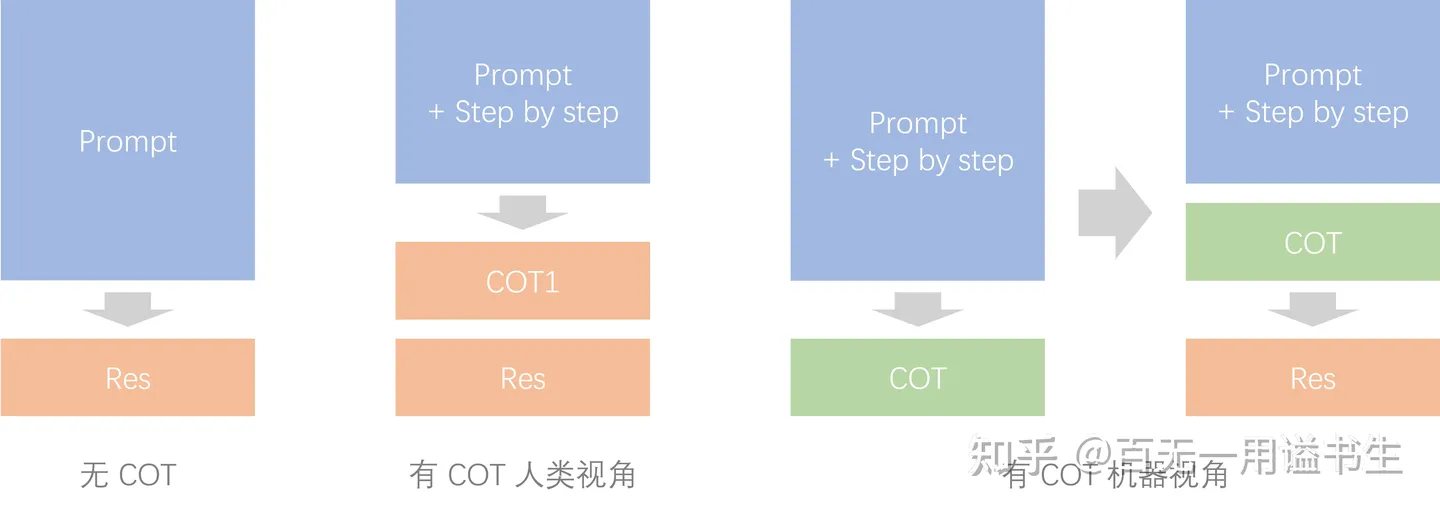
|
||||
|
||||
COT 为输出增加关联
|
||||
|
||||
@@ -240,7 +240,7 @@ COT 为输出增加关联
|
||||
|
||||
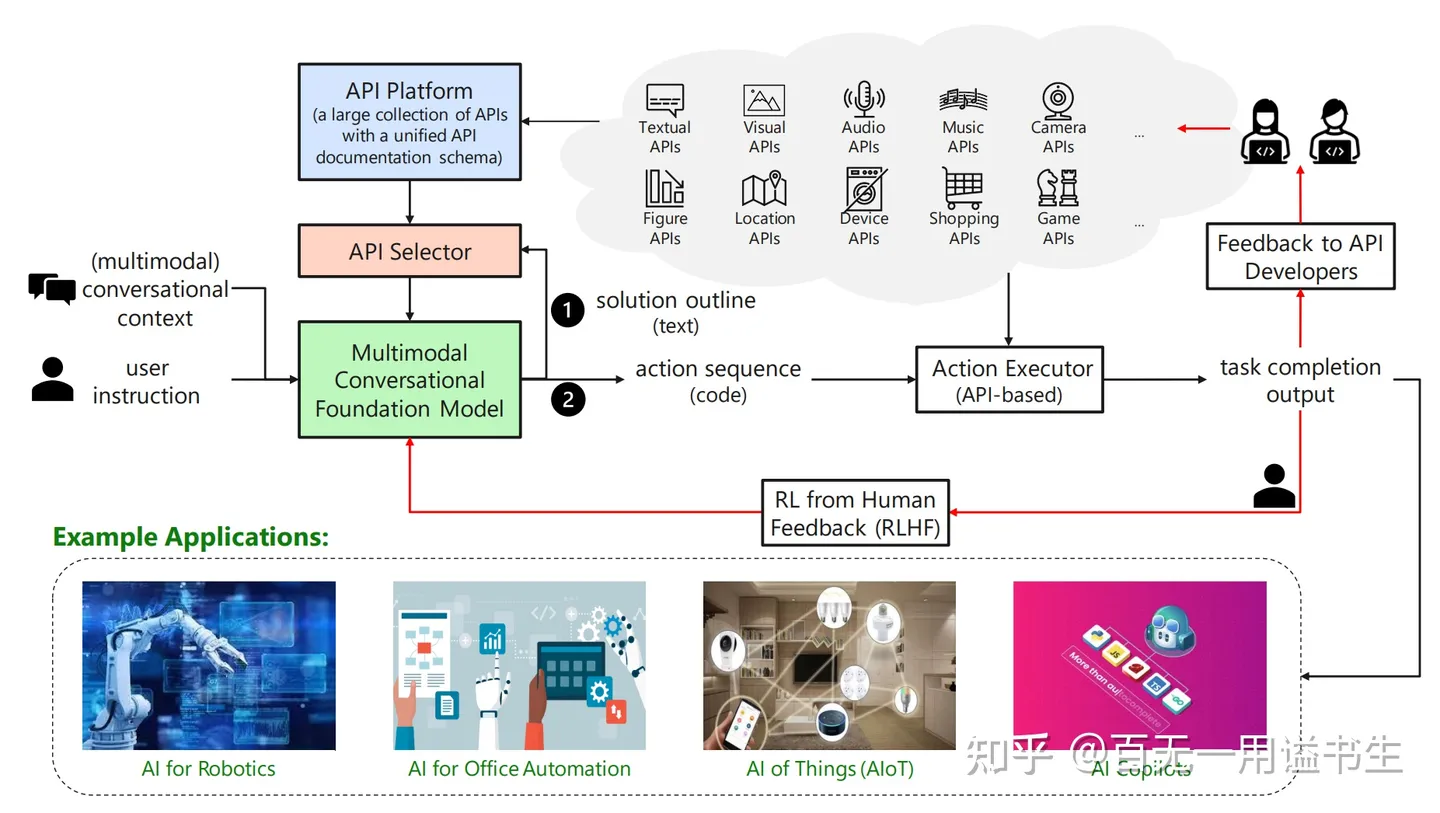
(需要注意的是,TaskMatrix.AI 更大程度上是一个愿景向的调研案例,尚未正式落地生态)
|
||||
|
||||

|
||||
|
||||
|
||||
TaskMatrix 的生态愿景
|
||||
|
||||
@@ -275,7 +275,7 @@ TaskMatrix 的生态愿景
|
||||
- Usage Example:API 的调用方法样例
|
||||
- Composition Instruction:API 的使用贴士,如应该与其它什么 API 组合使用,是否需要手动释放等
|
||||
|
||||
> 样例:打开文件 API<br/>
|
||||
> 样例:打开文件 API<br/>
|
||||
|
||||
基于此类文档内容和 ICL 的能力,LLMs 能从输入中习得调用 API 的方法,依此快速拓展了其横向能力
|
||||
|
||||
@@ -287,11 +287,11 @@ COT for TaskMatrix
|
||||
|
||||
在 TaskMatirx 中,通过该模式,让 MCFM 将任务转化为待办大纲,并最终围绕大纲检索并组合 API,完成整体工作
|
||||
|
||||
> 样例:写论文<br/>构建完成工作大纲<br/>
|
||||
> 样例:写论文<br/>构建完成工作大纲<br/>
|
||||
|
||||
TaskMatrix 自动围绕目标拆解任务
|
||||
|
||||
> 自动调用插件和组件<br/>
|
||||
> 自动调用插件和组件<br/>
|
||||
|
||||
TaskMatrix 自动为任务创建 API 调用链
|
||||
|
||||
@@ -313,7 +313,7 @@ TaskMatrix 自动为任务创建 API 调用链
|
||||
|
||||
Decomp 的核心思想为将复杂问题通过 Prompt 技巧,将一个复杂的问题由 LLMs 自主划分为多个子任务。随后,我们通过 LLMs 完成多个任务,并将过程信息最终组合并输出理想的效果
|
||||
|
||||

|
||||

|
||||
|
||||
几种 Prompt 方法图示
|
||||
|
||||
@@ -321,7 +321,7 @@ Decomp 的核心思想为将复杂问题通过 Prompt 技巧,将一个复杂
|
||||
|
||||
而对于 Decomp 过程,则又是由一个原始的 Decomp Prompt 驱动
|
||||
|
||||

|
||||

|
||||
|
||||
Decomp 方法执行样例
|
||||
|
||||
@@ -347,7 +347,7 @@ Decomp 的原始功能实际上并不值得太过关注,但我们急需考虑
|
||||
|
||||
通过问题的分解和通过“专用函数”的执行,我们可以轻易让 LLMs 实现自身无法做到的调用 API 工作,例如主动从外部检索获取回答问题所需要的知识。
|
||||
|
||||

|
||||

|
||||
|
||||
Decomp 方法调用外部接口样例
|
||||
|
||||
@@ -359,7 +359,7 @@ Decomp 方法调用外部接口样例
|
||||
|
||||
[HuggingGPT](https://arxiv.org/abs/2303.17580) 一文也许并未直接参考 Decomp 方法,而是用一些更规范的手法完成该任务,但其充分流水线化的 Prompt 工程无疑是 Decomp 方法在落地实践上的最佳注脚
|
||||
|
||||

|
||||

|
||||
|
||||
HuggingGPT
|
||||
|
||||
@@ -407,7 +407,7 @@ Generative Agents 构建了一套框架,让 NPC 可以感知被模块化的世
|
||||
|
||||
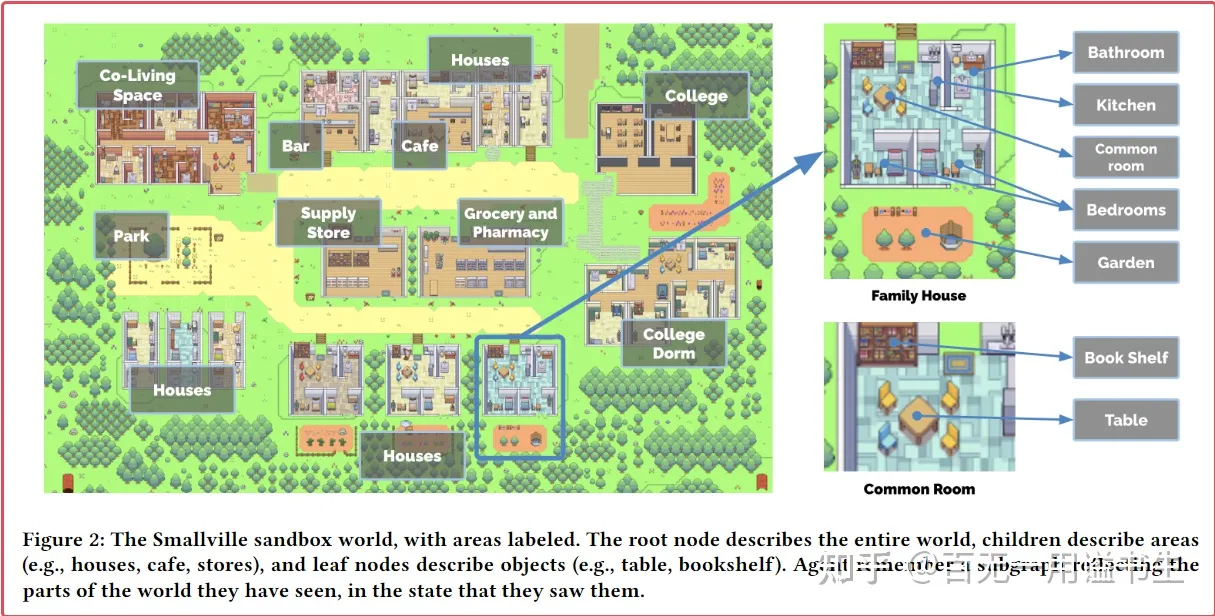
- 一方面,其包含场景中既有对象,包括建筑和摆件等的基础层级信息
|
||||
|
||||

|
||||
|
||||
|
||||
Generative Agents 的场景信息管理
|
||||
|
||||
@@ -635,7 +635,7 @@ AutoGPT 主要特性如下:
|
||||
|
||||
其提醒我们,就连我们的意识主体性,也只是陈述自我的一个表述器而已。我们是否应当反思对语言能力的过度迷信,从而相信我们能通过训练模型构建 All in One 的智能实体?
|
||||
|
||||

|
||||
|
||||
|
||||
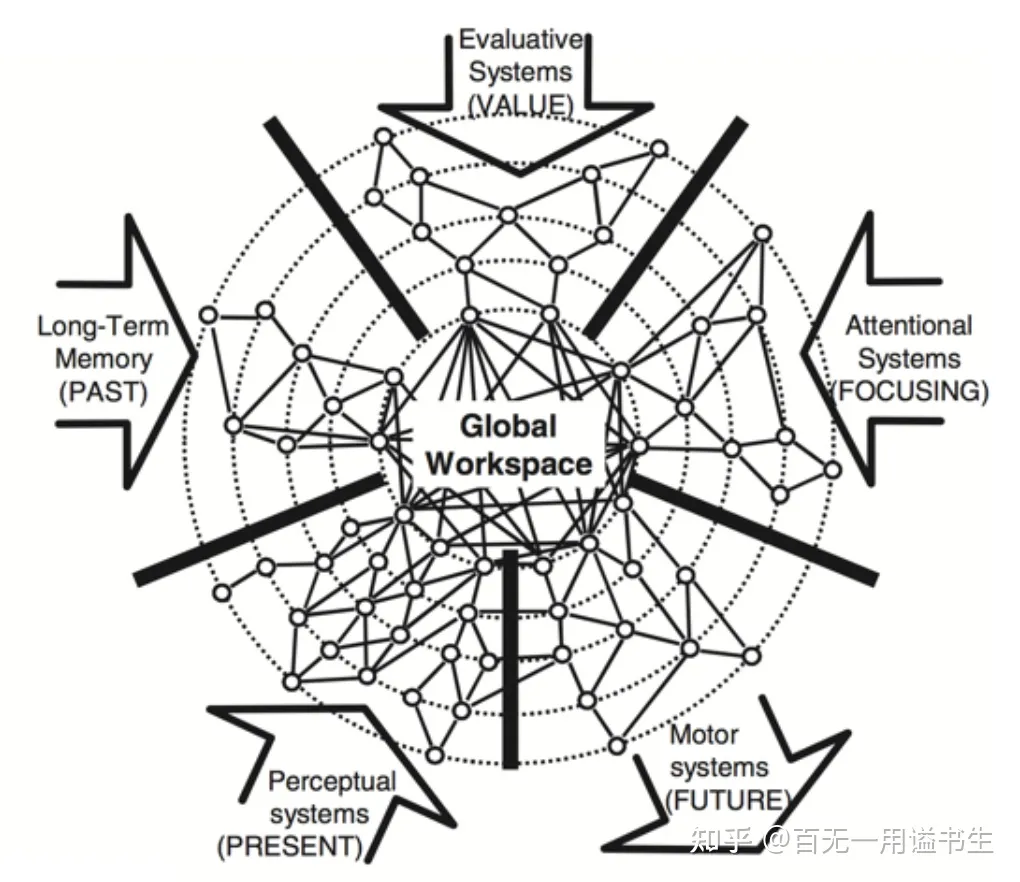
全局工作空间理论
|
||||
|
||||
@@ -905,7 +905,7 @@ AutoGPT 的核心记忆设计依赖于预包装的 Prompt 本体,这一包装
|
||||
|
||||
Generative Agent 通过自动化评估记忆的价值,并构建遗忘系统、关注系统等用于精准从自己繁杂的记忆中检索对于当前情景有用的信息。
|
||||
|
||||

|
||||
|
||||
|
||||
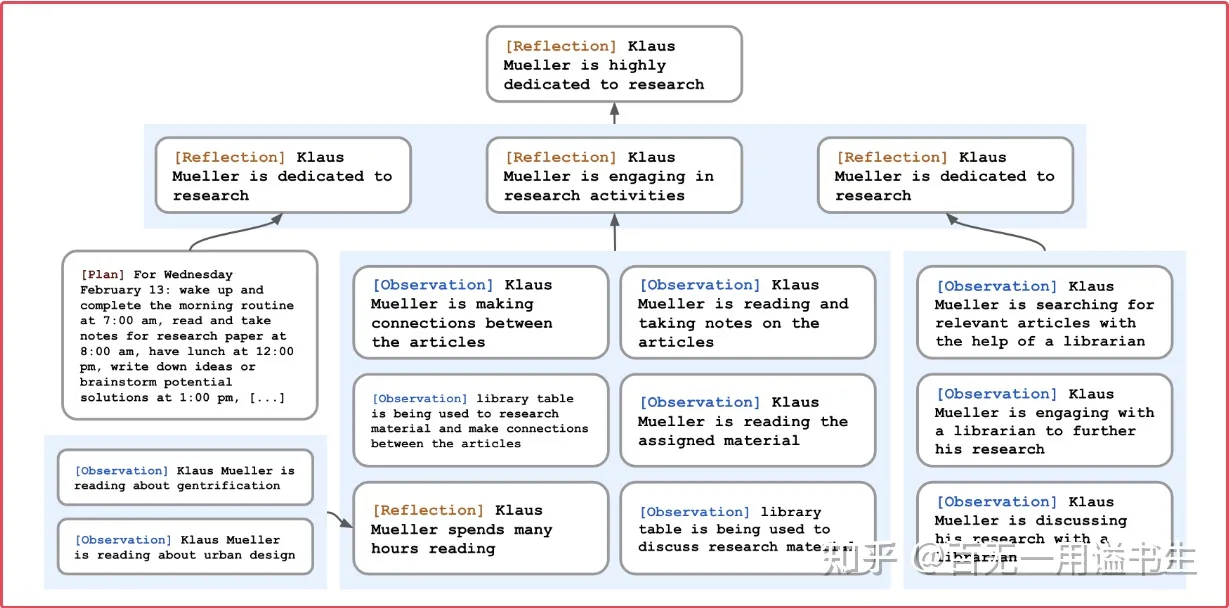
Generative Agents :基于 Reflection 构建记忆金字塔
|
||||
|
||||
|
||||
@@ -60,4 +60,4 @@ ZZM 曾经尝试过投入大量时间去钻研数学以及机器学习相关的
|
||||
|
||||
联系 ZZM,我努力改
|
||||
|
||||

|
||||

|
||||
|
||||
@@ -13,7 +13,7 @@
|
||||
|
||||
计算机视觉旨在<strong>用计算机模拟人类处理图片信息的能力</strong>,就比如这里有一张图片——手写数字 9
|
||||
|
||||

|
||||

|
||||
|
||||
对我们人类而言,能够很轻松地知道这张图片中包含的信息(数字 9),而对计算机来说这只是一堆像素。计算机视觉的任务就是让计算机能够从这堆像素中得到‘数字 9’这个信息。
|
||||
|
||||
@@ -21,15 +21,15 @@
|
||||
|
||||
<strong>图像分割</strong>是在图片中对物体分类,并且把它们所对应的位置标示出来。下图就是把人的五官,面部皮肤和头发分割出来,效(小)果(丑)图如下:
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
<strong>图像生成</strong>相信大家一定不陌生,NovalAI 在 2022 年火的一塌糊涂,我觉得不需要我过多赘述,对它(Diffusion model)的改进工作也是层出不穷,这里就放一张由可控姿势网络(ControlNet)生成的图片吧:
|
||||
|
||||

|
||||

|
||||
|
||||
<strong>三维重建</strong>也是很多研究者关注的方向,指的是传入对同一物体不同视角的照片,来生成 3D 建模的任务。这方面比图像处理更加前沿并且难度更大。具体见[4.6.5.4神经辐射场(NeRF)](4.6.5.4%E7%A5%9E%E7%BB%8F%E8%BE%90%E5%B0%84%E5%9C%BA(NeRF).md) 章节。
|
||||
|
||||
@@ -39,9 +39,9 @@
|
||||
|
||||
这就更好理解了,让计算机能够像人类一样,理解文本中的“真正含义”。在计算机眼中,文本就是单纯的字符串,NLP 的工作就是把字符转换为计算机可理解的数据。举个例子,ChatGPT(或者 New Bing)都是 NLP 的成果。在过去,NLP 领域被细分为了多个小任务,比如文本情感分析、关键段落提取等。而 ChatGPT 的出现可以说是集几乎所有小任务于大成,接下来 NLP 方向的工作会向 ChatGPT 的方向靠近。
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
## 多模态(跨越模态的处理)
|
||||
|
||||
@@ -53,7 +53,7 @@
|
||||
|
||||
具体的任务比如说<strong>图片问答</strong>,传入一张图片,问 AI 这张图片里面有几只猫猫,它们是什么颜色,它告诉我有一只猫猫,是橙色的:
|
||||
|
||||

|
||||

|
||||
|
||||
## 对比学习
|
||||
|
||||
|
||||
@@ -26,7 +26,7 @@
|
||||
|
||||
甚至深度学习,也只是机器学习的一部分,不过使用了更多技巧和方法,增大了计算能力罢了。
|
||||
|
||||

|
||||

|
||||
|
||||
# 两种机器学习算法
|
||||
|
||||
@@ -42,11 +42,11 @@
|
||||
|
||||
近三个月来,每当你的城市里有人卖了房子,你都记录了下面的细节——卧室数量、房屋大小、地段等等。但最重要的是,你写下了最终的成交价:
|
||||
|
||||

|
||||

|
||||
|
||||
然后你让新人根据着你的成交价来估计新的数量
|
||||
|
||||

|
||||

|
||||
|
||||
这就是监督学习,你有一个参照物可以帮你决策。
|
||||
|
||||
@@ -66,7 +66,7 @@
|
||||
|
||||
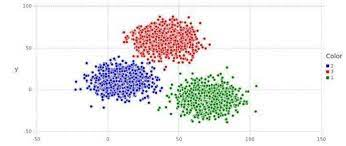
这其实就是一种经典的聚类算法
|
||||
|
||||

|
||||
|
||||
|
||||
可以把特征不一样的数据分开,有非常多的操作,你感兴趣可以选择性的去了解一下。
|
||||
|
||||
@@ -139,7 +139,7 @@ def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
|
||||
|
||||
第二步把每个数值都带入进行运算。
|
||||
|
||||

|
||||

|
||||
|
||||
比如说,如果第一套房产实际成交价为 25 万美元,你的函数估价为 17.8 万美元,这一套房产你就差了 7.2 万。
|
||||
|
||||
@@ -168,13 +168,13 @@ def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
|
||||
|
||||
为了避免这种情况,数学家们找到了很多种[聪明的办法](https://link.zhihu.com/?target=http%3A//en.wikipedia.org/wiki/Gradient_descent)来快速找到优秀的权重值。下面是一种:
|
||||
|
||||

|
||||

|
||||
|
||||
这就是被称为 loss 函数的东西。
|
||||
|
||||
这是个专业属于,你可以选择性忽略他,我们将它改写一下
|
||||
|
||||

|
||||

|
||||
|
||||
<em>θ 表示当前的权重值。 J(θ) 表示「当前权重的代价」。</em>
|
||||
|
||||
@@ -182,7 +182,7 @@ def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
|
||||
|
||||
如果我们为这个等式中所有卧室数和面积的可能权重值作图的话,我们会得到类似下图的图表:
|
||||
|
||||

|
||||

|
||||
|
||||
因此,我们需要做的只是调整我们的权重,使得我们在图上朝着最低点「走下坡路」。如果我们不断微调权重,一直向最低点移动,那么我们最终不用尝试太多权重就可以到达那里。
|
||||
|
||||
@@ -194,7 +194,7 @@ def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
|
||||
|
||||
当你使用一个机器学习算法库来解决实际问题时,这些都已经为你准备好了。但清楚背后的原理依然是有用的。
|
||||
|
||||

|
||||

|
||||
|
||||
枚举法
|
||||
|
||||
@@ -225,7 +225,7 @@ def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
|
||||
|
||||
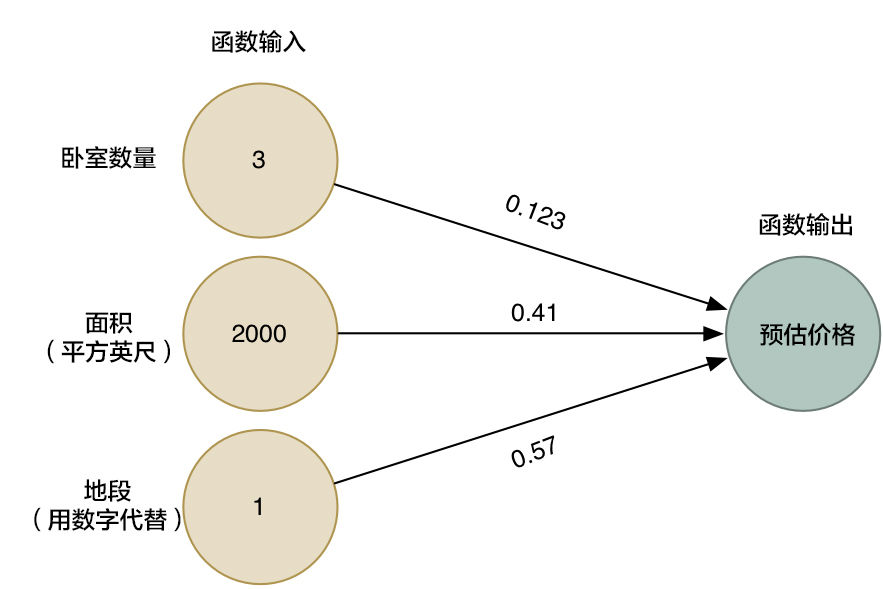
我们换一个好看的形式给他展示
|
||||
|
||||

|
||||
|
||||
|
||||
<em>箭头头表示了函数中的权重。</em>
|
||||
|
||||
@@ -233,17 +233,17 @@ def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
|
||||
|
||||
所以为了更加的智能化,我们可以利用不同的权重来多次运行这个算法,收集各种不同情况下的估价。
|
||||
|
||||

|
||||
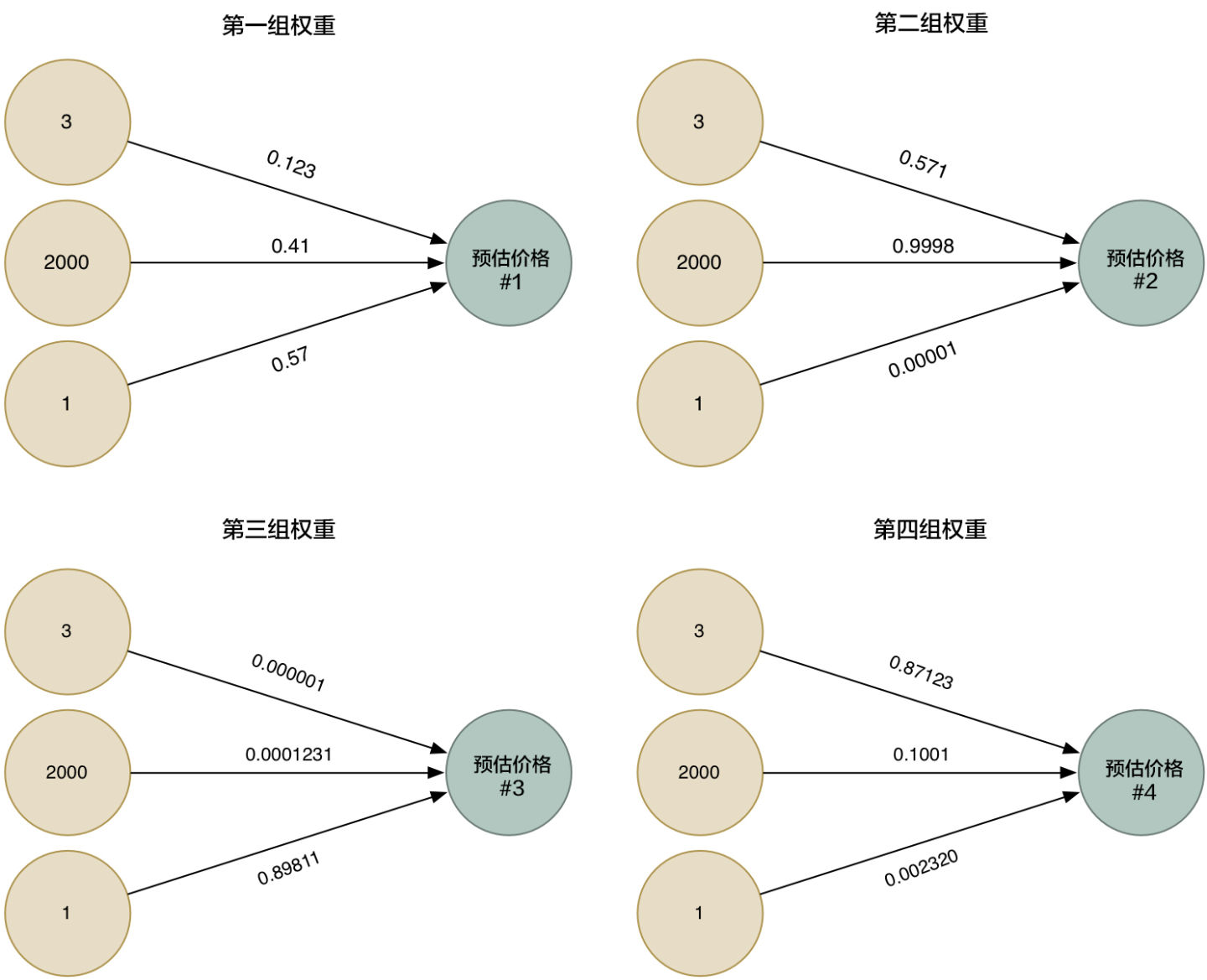
|
||||
|
||||
然后我们把四种整合到一起,就得到一个超级答案
|
||||
|
||||

|
||||

|
||||
|
||||
这样我们相当于得到了更为准确的答案
|
||||
|
||||
# 神经网络是什么
|
||||
|
||||

|
||||

|
||||
|
||||
我们把四个超级网络的结合图整体画出来,其实这就是个超级简单的神经网络,虽然我们省略了很多的内容,但是他仍然有了一定的拟合能力
|
||||
|
||||
@@ -318,17 +318,17 @@ print('y_pred=',y_test.data)
|
||||
|
||||
我们试着只识别一个数字 8
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
我们把一幅 18×18 像素的图片当成一串含有 324 个数字的数组,就可以把它输入到我们的神经网络里面了:
|
||||
|
||||

|
||||

|
||||
|
||||
为了更好地操控我们的输入数据,我们把神经网络的输入节点扩大到 324 个:
|
||||
|
||||

|
||||

|
||||
|
||||
请注意,我们的神经网络现在有了两个输出(而不仅仅是一个房子的价格)。第一个输出会预测图片是「8」的概率,而第二个则输出不是「8」的概率。概括地说,我们就可以依靠多种不同的输出,利用神经网络把要识别的物品进行分组。
|
||||
|
||||
@@ -349,7 +349,7 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
|
||||
|
||||
当数字并不是正好在图片中央的时候,我们的识别器就完全不工作了。一点点的位移我们的识别器就掀桌子不干了
|
||||
|
||||

|
||||

|
||||
|
||||
这是因为我们的网络只学习到了正中央的「8」。它并不知道那些偏离中心的「8」长什么样子。它仅仅知道中间是「8」的图片规律。
|
||||
|
||||
@@ -365,9 +365,9 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
|
||||
|
||||
当然,你同时也需要更强的拟合能力和更深的网络。
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||
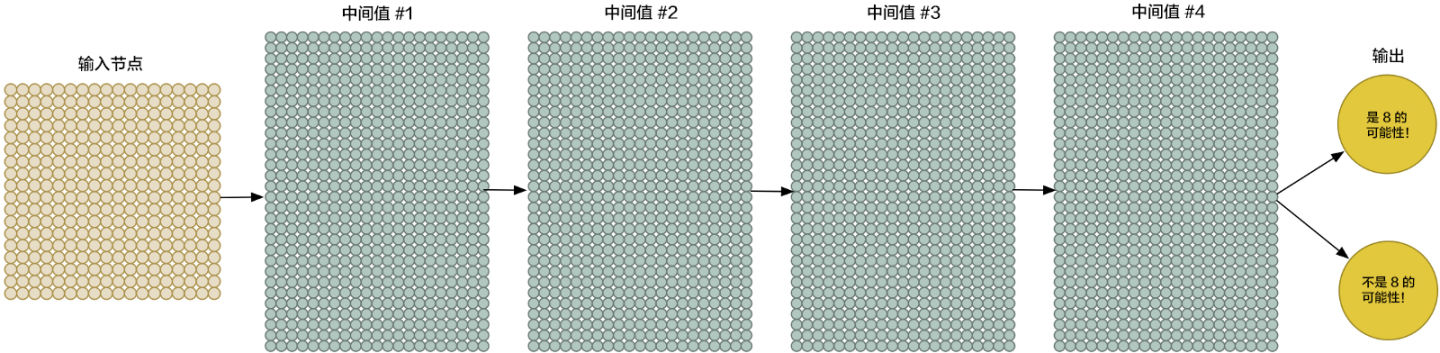
|
||||
|
||||
一层一层堆叠起来,这种方法很早就出现了。
|
||||
|
||||
@@ -377,7 +377,7 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
|
||||
|
||||
作为人类,你能够直观地感知到图片中存在某种层级(hierarchy)或者是概念结构(conceptual structure)。比如说,你在看
|
||||
|
||||

|
||||

|
||||
|
||||
你会快速的辨认出一匹马,一个人。
|
||||
|
||||
@@ -387,7 +387,7 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
|
||||
|
||||
有人对此做过研究,人的眼睛可能会逐步判断一个物体的信息,比如说你看到一张图片,你会先看颜色,然后看纹理然后再看整体,那么我们需要一种操作来模拟这个过程,我们管这种操作叫卷积操作。
|
||||
|
||||

|
||||

|
||||
|
||||
## 卷积是如何工作的
|
||||
|
||||
@@ -395,13 +395,13 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
|
||||
|
||||
当然也有最新研究说卷积不具备平移不变性,但是我这里使用这个概念是为了大伙更好的理解,举个例子:你将 8 无论放在左上角还是左下角都改变不了他是 8 的事实
|
||||
|
||||

|
||||

|
||||
|
||||
我们将一张图像分成这么多个小块,然后输入神经网络中的是一个小块。<em>每次判断一张小图块。</em>
|
||||
|
||||
然而,有一个非常重要的不同:对于每个小图块,我们会使用同样的神经网络权重。换一句话来说,我们平等对待每一个小图块。如果哪个小图块有任何异常出现,我们就认为这个图块是「异常」
|
||||
|
||||

|
||||
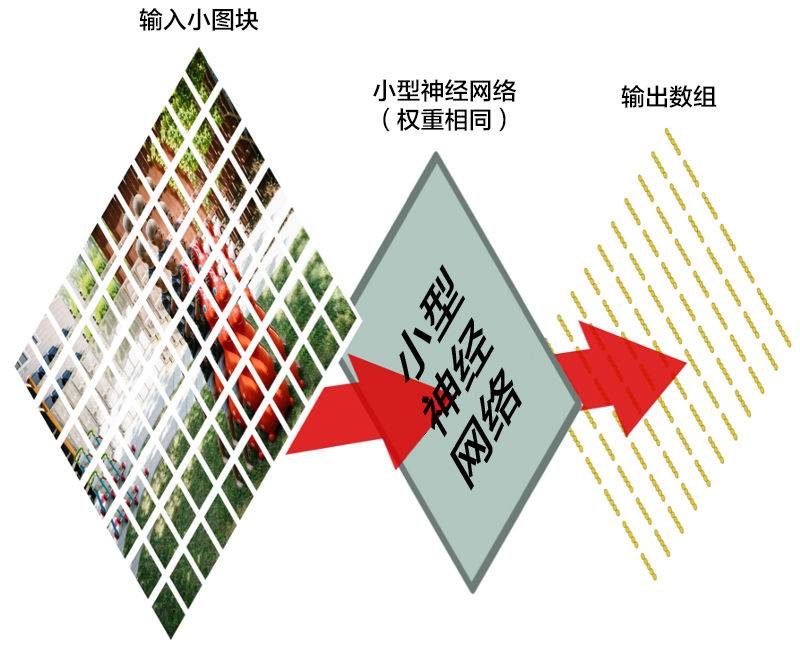
|
||||
|
||||
换一句话来说,我们从一整张图片开始,最后得到一个稍小一点的数组,里面存储着我们图片中的哪一部分有异常。
|
||||
|
||||
@@ -413,7 +413,7 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
|
||||
|
||||
让我们先来看每个 2×2 的方阵数组,并且留下最大的数:
|
||||
|
||||

|
||||

|
||||
|
||||
每一波我们只保留一个数,这样就大大减少了图片的计算量了。
|
||||
|
||||
@@ -435,7 +435,7 @@ model.add(Activation('relu'))# 激活函数,你可以理解为加上这个东
|
||||
|
||||
你猜怎么着?数组就是一串数字而已,所以我们我们可以把这个数组输入到另外一个神经网络里面去。最后的这个神经网络会决定这个图片是否匹配。为了区分它和卷积的不同,我们把它称作「全连接」网络
|
||||
|
||||

|
||||
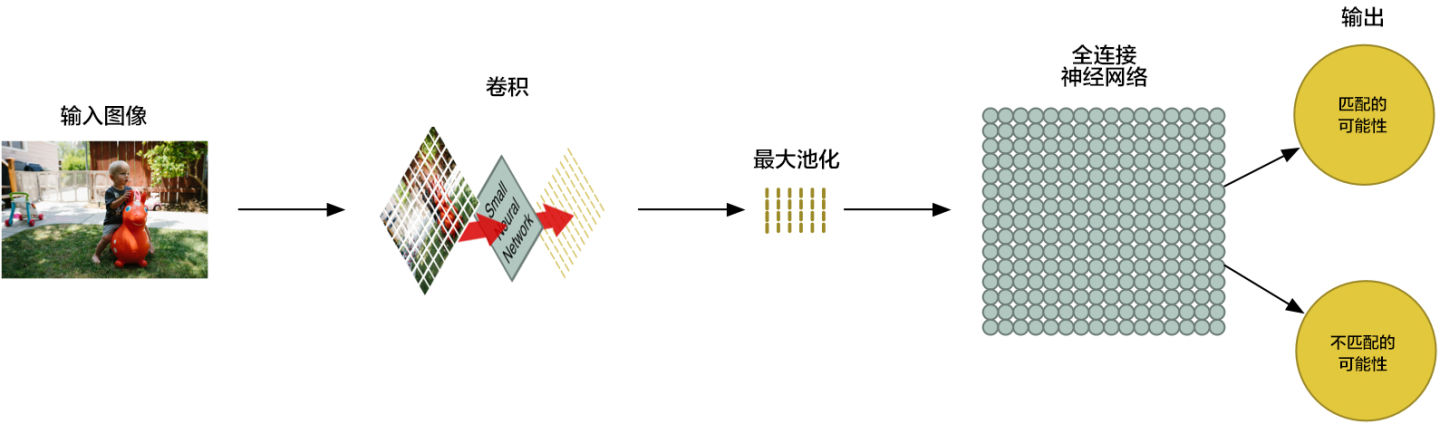
|
||||
|
||||
我们的图片处理管道是一系列的步骤:卷积、最大池化,还有最后的「全连接」网络。
|
||||
|
||||
|
||||
@@ -5,7 +5,7 @@
|
||||
:::
|
||||
|
||||
::: tip 📥
|
||||
本节附件下载 <Download url="https://pic-hdu-cs-wiki-1307923872.cos.ap-shanghai.myqcloud.com/code/1-Lecture.zip"/>
|
||||
本节附件下载 <Download url="https://cdn.xyxsw.site/code/1-Lecture.zip"/>
|
||||
:::
|
||||
|
||||
/4.人工智能/code/MAZE.zip
|
||||
@@ -176,7 +176,7 @@ class Maze:
|
||||
5. 两种算法总是能找到相同长度的路径
|
||||
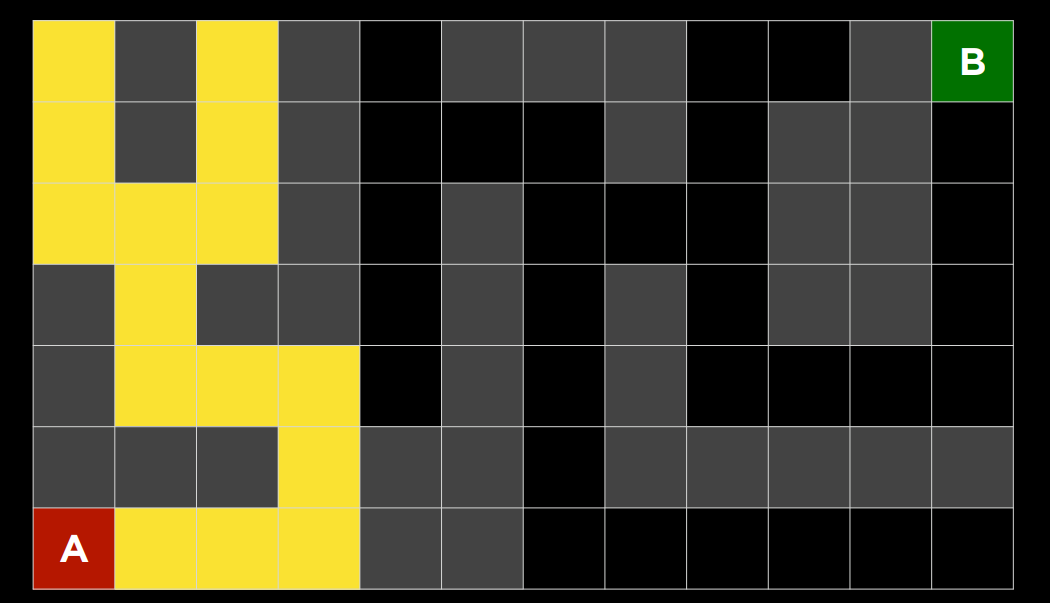
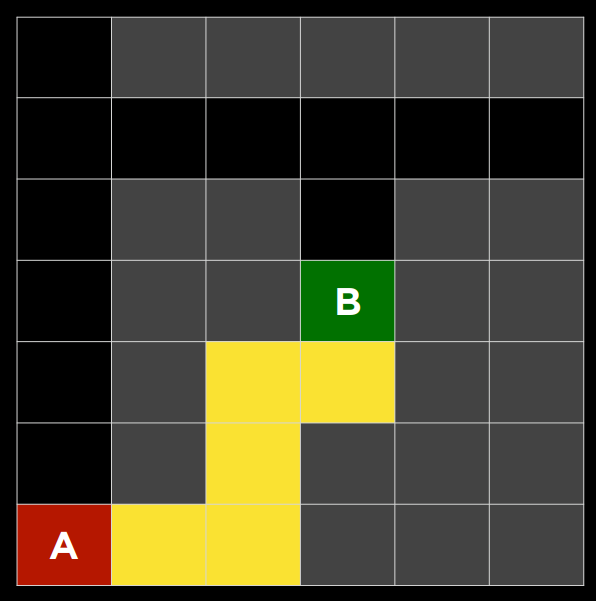
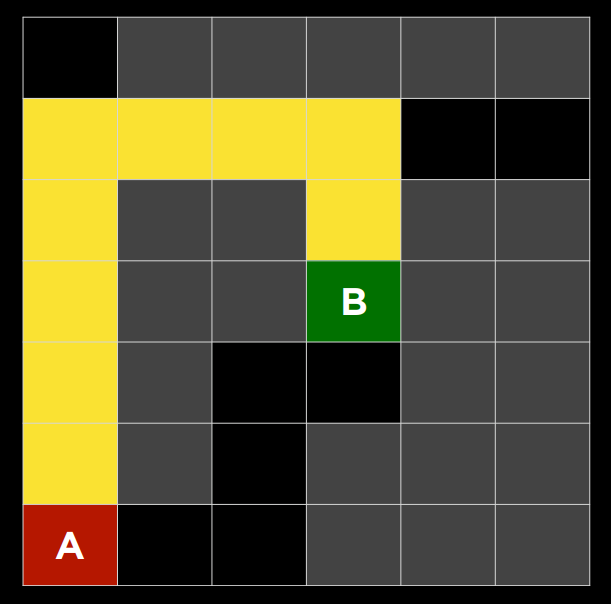
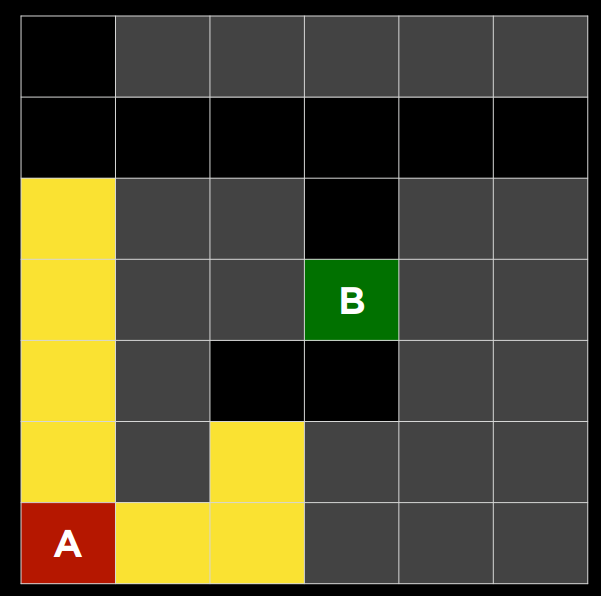
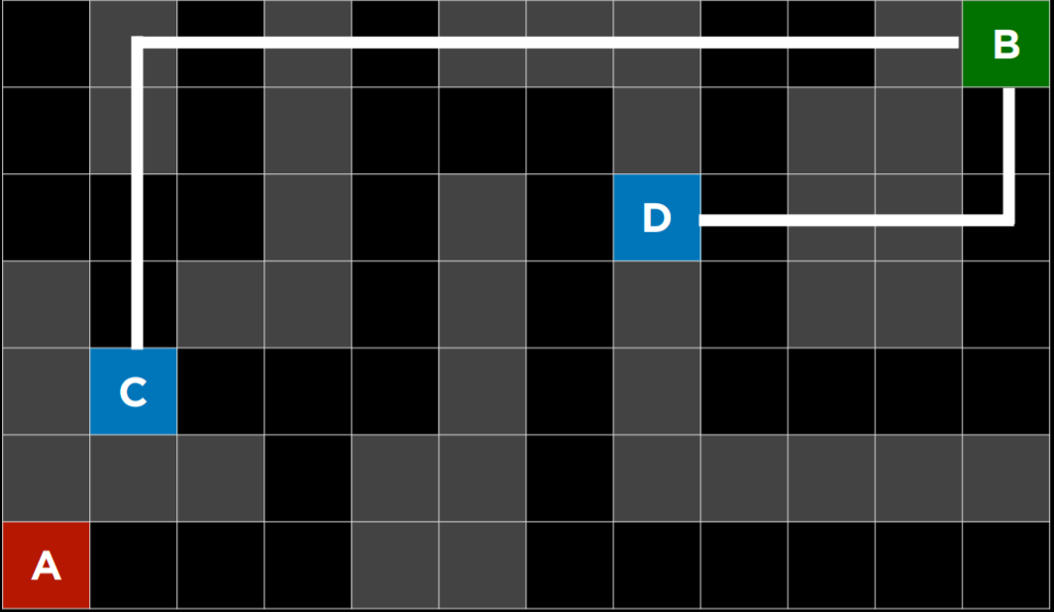
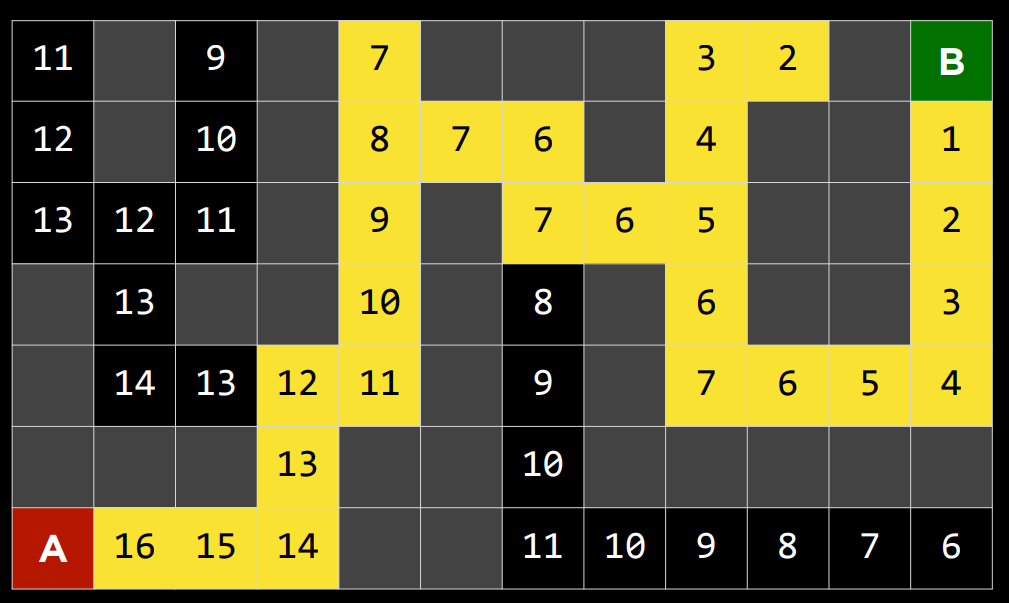
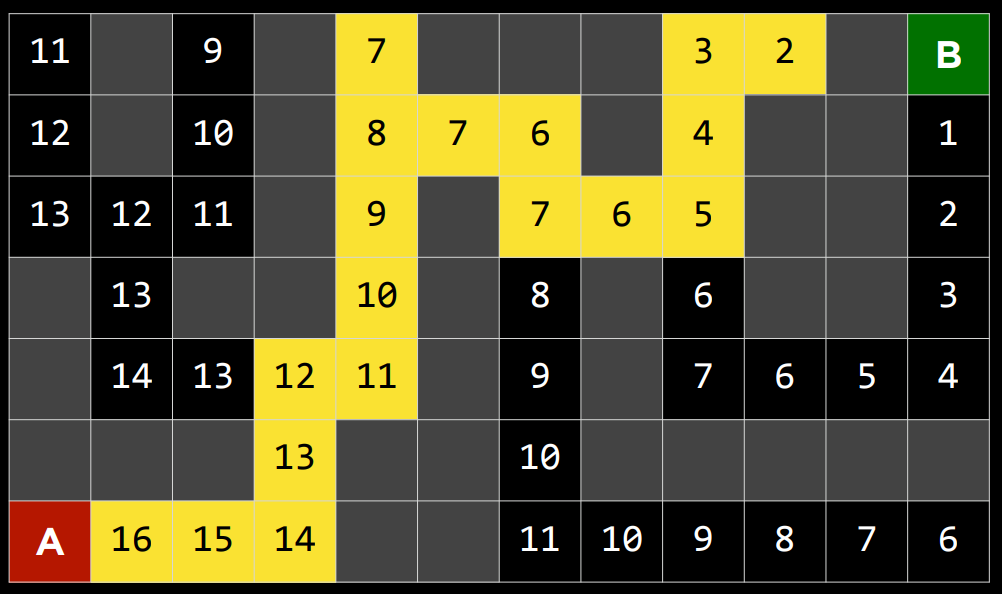
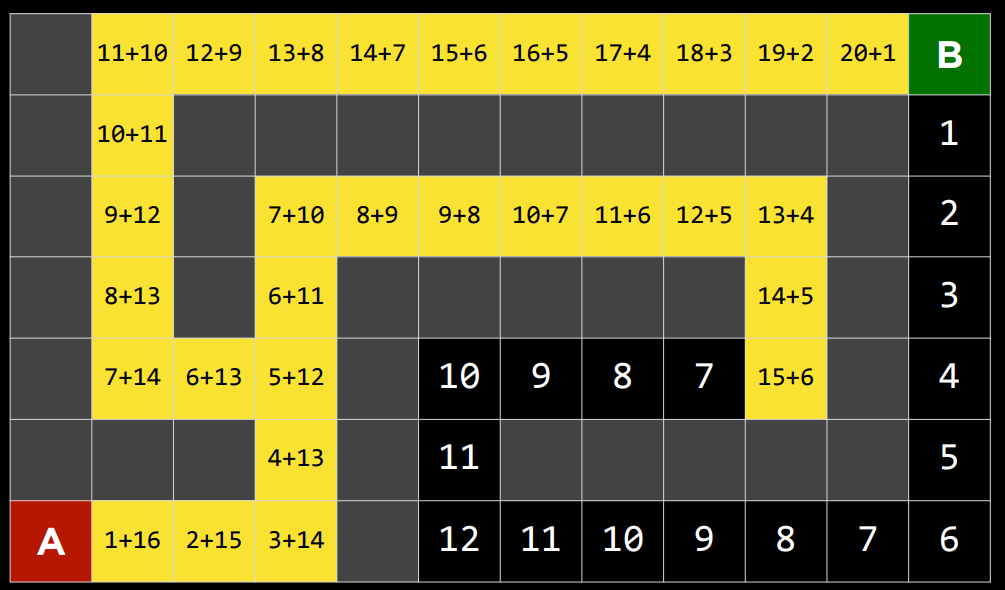
2. 下面的问题将问你关于下面迷宫的问题。灰色单元格表示墙壁。在这个迷宫上运行了一个搜索算法,找到了从 A 点到 B 点的黄色突出显示的路径。在这样做的过程中,红色突出显示的细胞是探索的状态,但并没有达到目标。
|
||||
|
||||

|
||||
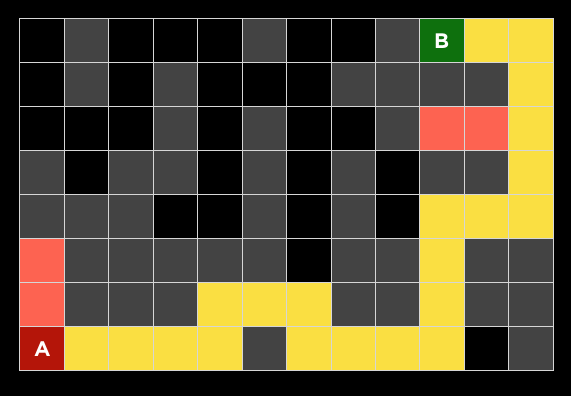
|
||||
|
||||
在讲座中讨论的四种搜索算法中——深度优先搜索、广度优先搜索、曼哈顿距离启发式贪婪最佳优先搜索和曼哈顿距离启发式$A^*$
|
||||
|
||||
@@ -196,7 +196,7 @@ class Maze:
|
||||
4. 深度限制的极小极大值永远不会比没有深度限制的极大极小值更可取
|
||||
4. 下面的问题将询问您关于下面的 Minimax 树,其中绿色向上箭头表示 MAX 玩家,红色向下箭头表示 MIN 玩家。每个叶节点都标有其值。
|
||||
|
||||

|
||||
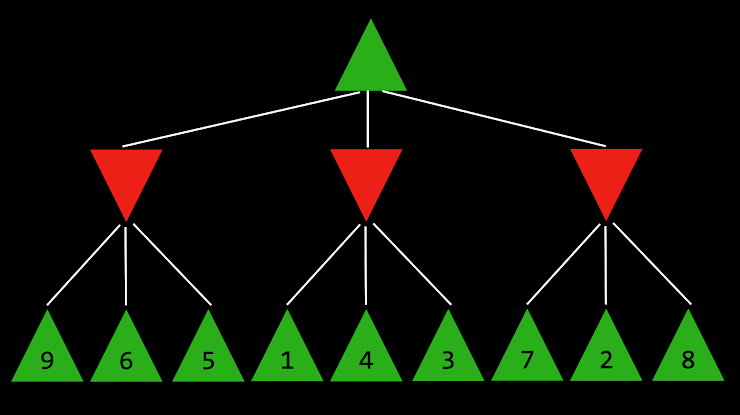
|
||||
|
||||
根节点的值是多少?
|
||||
|
||||
|
||||
@@ -5,7 +5,7 @@
|
||||
如果你卡住了,请记得回来阅读文档,或请求身边人的帮助。
|
||||
|
||||
::: tip 📥
|
||||
本节附件下载 <Download url="https://pic-hdu-cs-wiki-1307923872.cos.ap-shanghai.myqcloud.com/code/1-Projects.zip"/>
|
||||
本节附件下载 <Download url="https://cdn.xyxsw.site/code/1-Projects.zip"/>
|
||||
:::
|
||||
|
||||
`pip3 install -r requirements.txt`
|
||||
|
||||
@@ -18,13 +18,13 @@
|
||||
|
||||
导航是使用搜索算法的一个典型的搜索,它接收您的当前位置和目的地作为输入,并根据搜索算法返回建议的路径。
|
||||
|
||||

|
||||
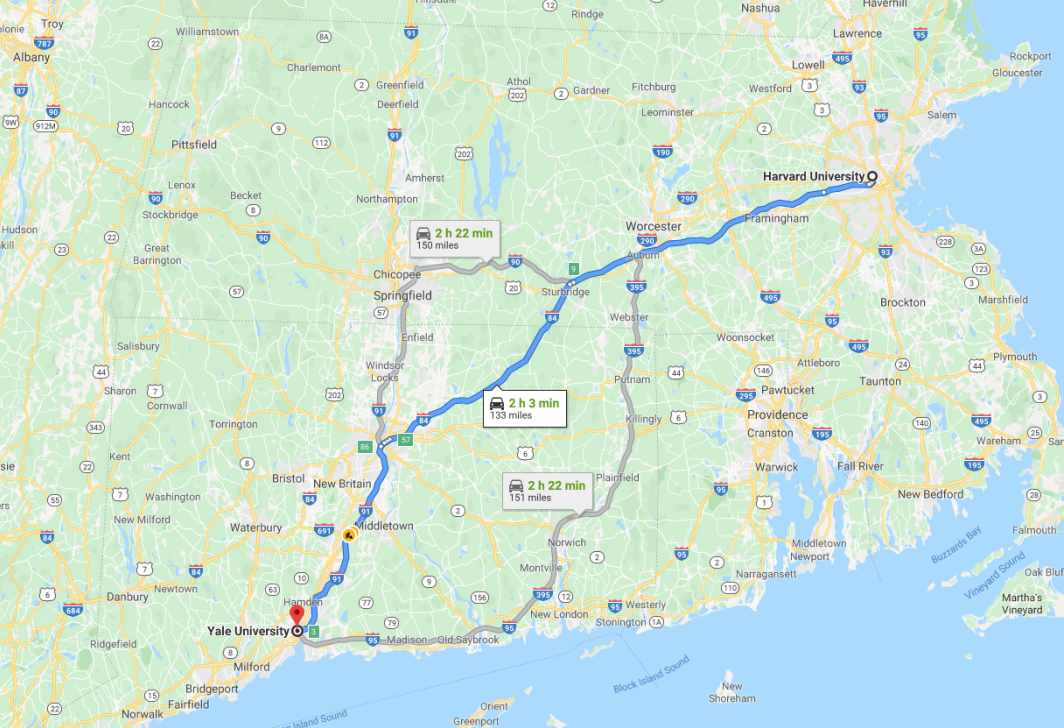
|
||||
|
||||
在计算机科学中,还有许多其他形式的搜索问题,比如谜题或迷宫。
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
# 举个例子
|
||||
|
||||
@@ -42,14 +42,14 @@
|
||||
|
||||
- 搜索算法开始的状态。在导航应用程序中,这将是当前位置。
|
||||
|
||||

|
||||
|
||||
|
||||
- 动作(Action)
|
||||
|
||||
- 一个状态可以做出的选择。更确切地说,动作可以定义为一个函数。当接收到状态$s$作为输入时,$Actions(s)$将返回可在状态$s$ 中执行的一组操作作为输出。
|
||||
- 例如,在一个数字华容道中,给定状态的操作是您可以在当前配置中滑动方块的方式。
|
||||
|
||||

|
||||
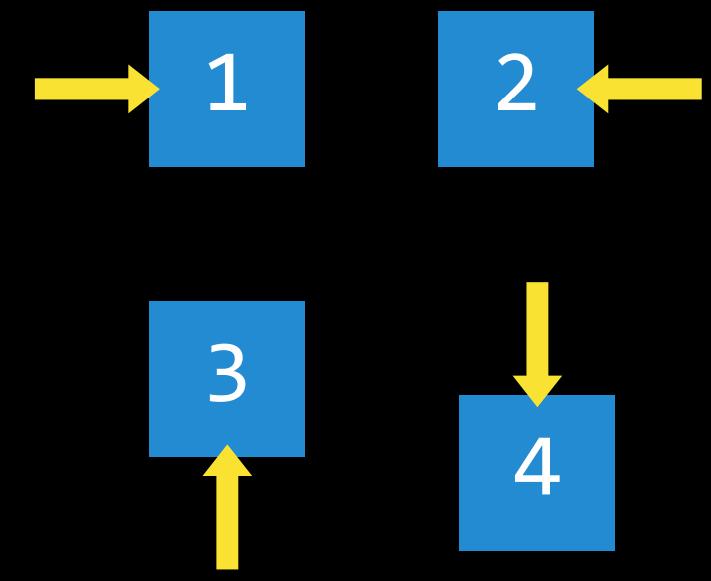
|
||||
|
||||
- 过渡模型(Transition Model)
|
||||
|
||||
@@ -58,14 +58,14 @@
|
||||
- 在接收到状态$s$和动作$a$作为输入时,$Results(s,a)$返回在状态$s$中执行动作$a$ 所产生的状态。
|
||||
- 例如,给定数字华容道的特定配置(状态$s$),在任何方向上移动正方形(动作$a$)将导致谜题的新配置(新状态)。
|
||||
|
||||

|
||||

|
||||
|
||||
- 状态空间(State Space)
|
||||
|
||||
- 通过一系列的操作目标从初始状态可达到的所有状态的集合。
|
||||
- 例如,在一个数字华容道谜题中,状态空间由所有$\frac{16!}{2}$种配置,可以从任何初始状态达到。状态空间可以可视化为有向图,其中状态表示为节点,动作表示为节点之间的箭头。
|
||||
|
||||

|
||||

|
||||
|
||||
- 目标测试(Goal Test)
|
||||
|
||||
@@ -112,9 +112,9 @@
|
||||
- 展开节点(找到可以从该节点到达的所有新节点),并将生成的节点添加到边域。
|
||||
- 将当前节点添加到探索集。
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||
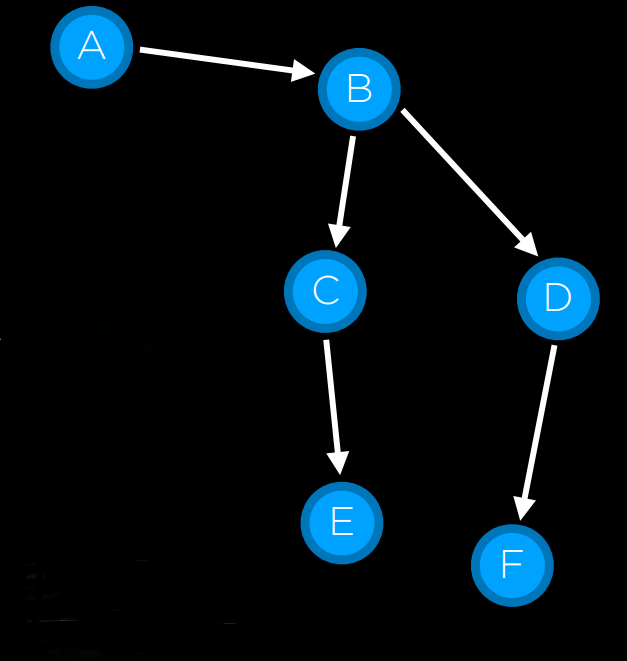
|
||||
|
||||
边域从节点 A 初始化开始
|
||||
|
||||
@@ -122,9 +122,9 @@ a. 取出边域中的节点 A,展开节点 A,将节点 B 添加到边域。
|
||||
b. 取出节点 B,展开,添加......
|
||||
c. 到达目标节点,停止,返回解决方案
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||
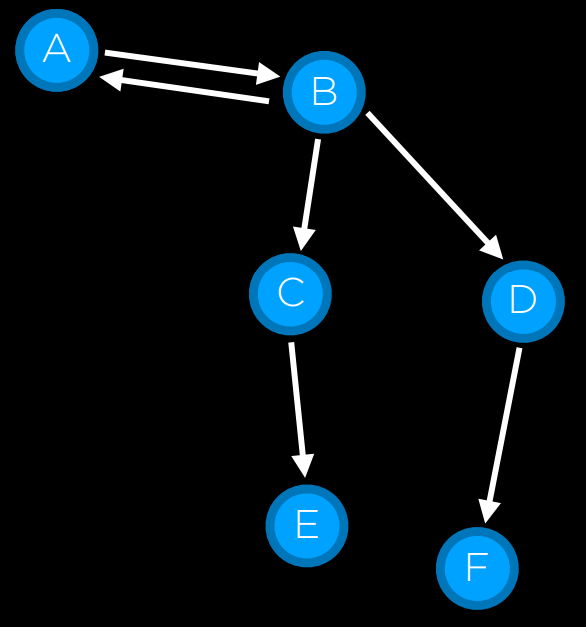
|
||||
|
||||
会出现什么问题?节点 A-> 节点 B-> 节点 A->......-> 节点 A。我们需要一个探索集,记录已搜索的节点!
|
||||
|
||||
@@ -143,13 +143,13 @@ c. 到达目标节点,停止,返回解决方案
|
||||
- 所找到的解决方案可能不是最优的。
|
||||
- 在最坏的情况下,该算法将在找到解决方案之前探索每一条可能的路径,从而在到达解决方案之前花费尽可能长的时间。
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
- 代码实现
|
||||
|
||||
@@ -175,13 +175,13 @@ def remove(self):
|
||||
- 几乎可以保证该算法的运行时间会比最短时间更长。
|
||||
- 在最坏的情况下,这种算法需要尽可能长的时间才能运行。
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
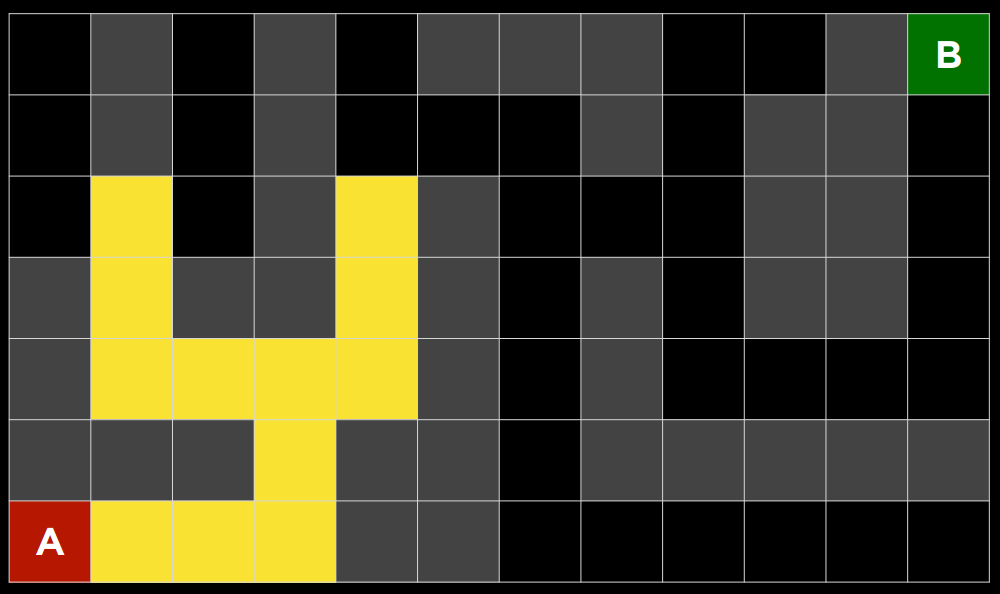
|
||||
|
||||

|
||||

|
||||
|
||||
- 代码实现
|
||||
|
||||
@@ -202,13 +202,13 @@ def remove(self):
|
||||
|
||||
- 贪婪最佳优先搜索扩展最接近目标的节点,如启发式函数$h(n)$所确定的。顾名思义,该函数估计下一个节点离目标有多近,但可能会出错。贪婪最佳优先算法的效率取决于启发式函数的好坏。例如,在迷宫中,算法可以使用启发式函数,该函数依赖于可能节点和迷宫末端之间的曼哈顿距离。曼哈顿距离忽略了墙壁,并计算了从一个位置到目标位置需要向上、向下或向两侧走多少步。这是一个简单的估计,可以基于当前位置和目标位置的$(x,y)$坐标导出。
|
||||
|
||||

|
||||
|
||||
|
||||
- 然而,重要的是要强调,与任何启发式算法一样,它可能会出错,并导致算法走上比其他情况下更慢的道路。不知情的搜索算法有可能更快地提供一个更好的解决方案,但它比知情算法更不可能这样。
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
- $A^*$搜索
|
||||
|
||||
@@ -220,9 +220,9 @@ def remove(self):
|
||||
|
||||
- 一致性,这意味着从新节点到目标的估计路径成本加上从先前节点转换到该新节点的成本应该大于或等于先前节点到目标的估计路径成本。用方程的形式表示,$h(n)$是一致的,如果对于每个节点n$和后续节点n'$,从n$到$n'$的步长为c$,满足$h(n)≤h(n')+c$。
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
# 对抗性搜索
|
||||
|
||||
@@ -232,41 +232,41 @@ def remove(self):
|
||||
|
||||
- 作为对抗性搜索中的一种算法,Minimax 将获胜条件表示为$(-1)$表示为一方,$(+1)$表示为另一方。进一步的行动将受到这些条件的驱动,最小化的一方试图获得最低分数,而最大化的一方则试图获得最高分数。
|
||||
|
||||

|
||||
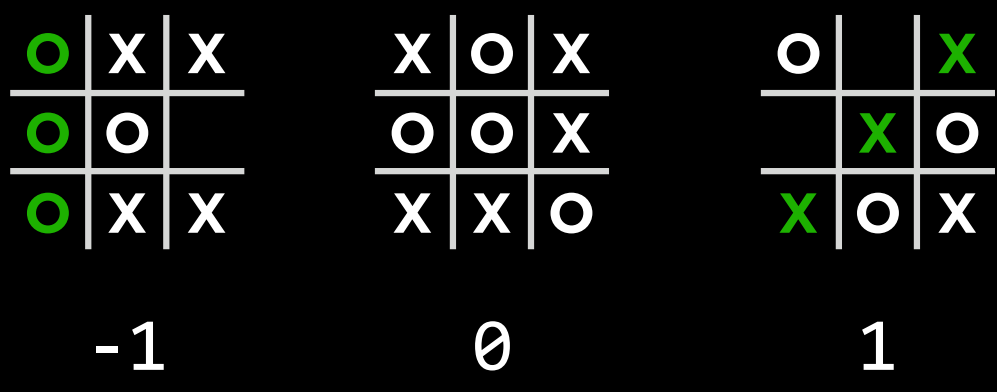
|
||||
|
||||
- 井字棋 AI 为例
|
||||
|
||||
- $s_0$: 初始状态(在我们的情况下,是一个空的3X3棋盘)
|
||||
|
||||

|
||||

|
||||
|
||||
- $Players(s)$: 一个函数,在给定状态$$s$$的情况下,返回轮到哪个玩家(X或O)。
|
||||
|
||||

|
||||
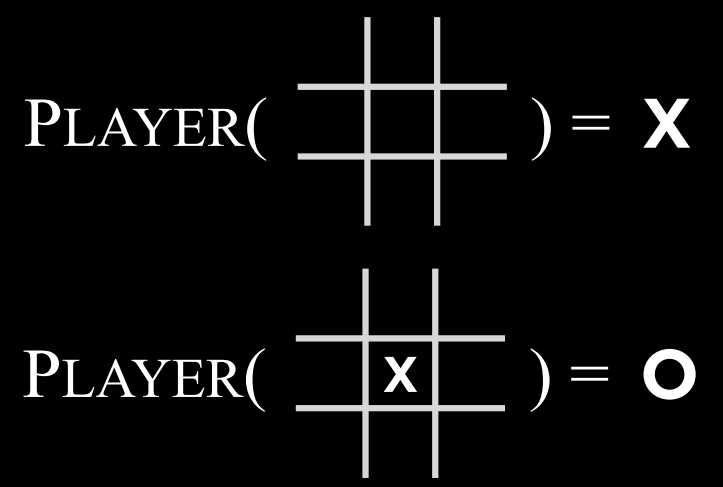
|
||||
|
||||
- $Actions(s)$: 一个函数,在给定状态$$s$$的情况下,返回该状态下的所有合法动作(棋盘上哪些位置是空的)。
|
||||
|
||||

|
||||
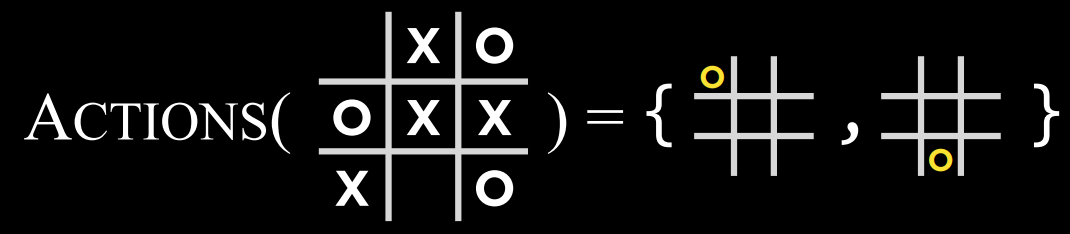
|
||||
|
||||
- $Result(s, a)$: 一个函数,在给定状态$$s$$和操作$$a$$的情况下,返回一个新状态。这是在状态$$s$$上执行动作$$a$$(在游戏中移动)所产生的棋盘。
|
||||
|
||||

|
||||
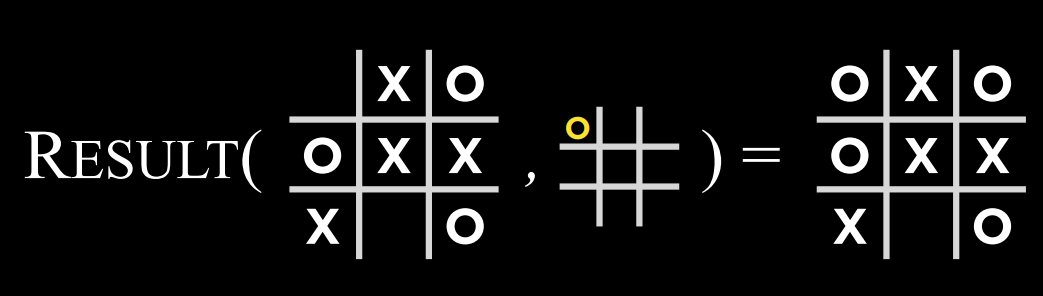
|
||||
|
||||
- $Terminal(s)$: 一个函数,在给定状态$$s$$的情况下,检查这是否是游戏的最后一步,即是否有人赢了或打成平手。如果游戏已结束,则返回True,否则返回False。
|
||||
|
||||

|
||||
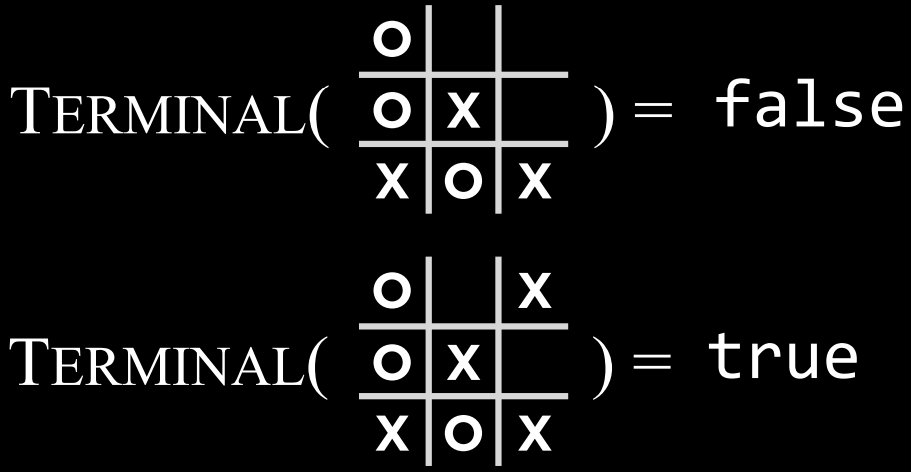
|
||||
|
||||
- $Utility(s)$: 一个函数,在给定终端状态s的情况下,返回状态的效用值:$$-1、0或1$$。
|
||||
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
- 算法的工作原理:
|
||||
|
||||
- 该算法递归地模拟从当前状态开始直到达到终端状态为止可能发生的所有游戏状态。每个终端状态的值为$(-1)$、$0$或$(+1)$。
|
||||
|
||||

|
||||

|
||||
|
||||
- 根据轮到谁的状态,算法可以知道当前玩家在最佳游戏时是否会选择导致状态值更低或更高的动作。
|
||||
|
||||
@@ -278,7 +278,7 @@ def remove(self):
|
||||
|
||||
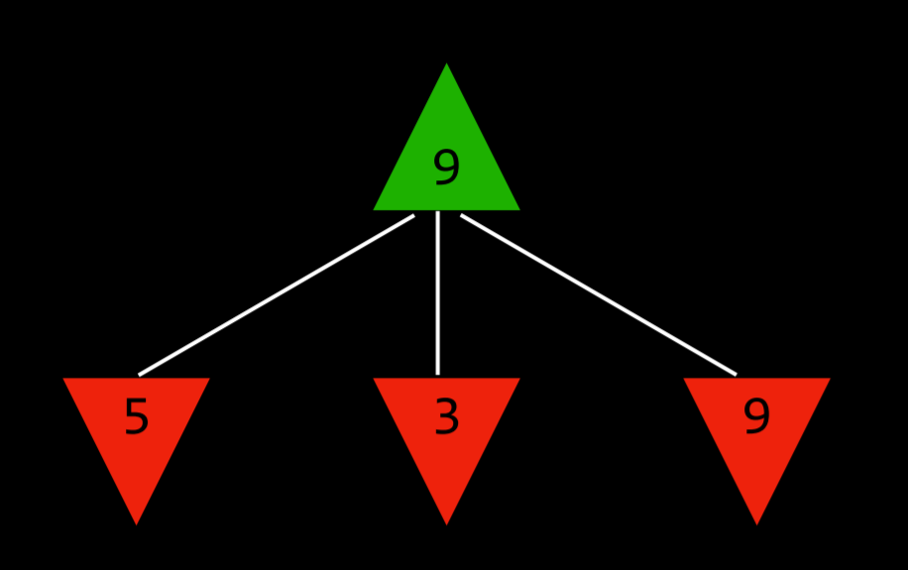
在得到这些值之后,最大化的玩家会选择最高的一个。
|
||||
|
||||

|
||||
|
||||
|
||||
- 具体算法:
|
||||
|
||||
@@ -310,7 +310,7 @@ def remove(self):
|
||||
|
||||
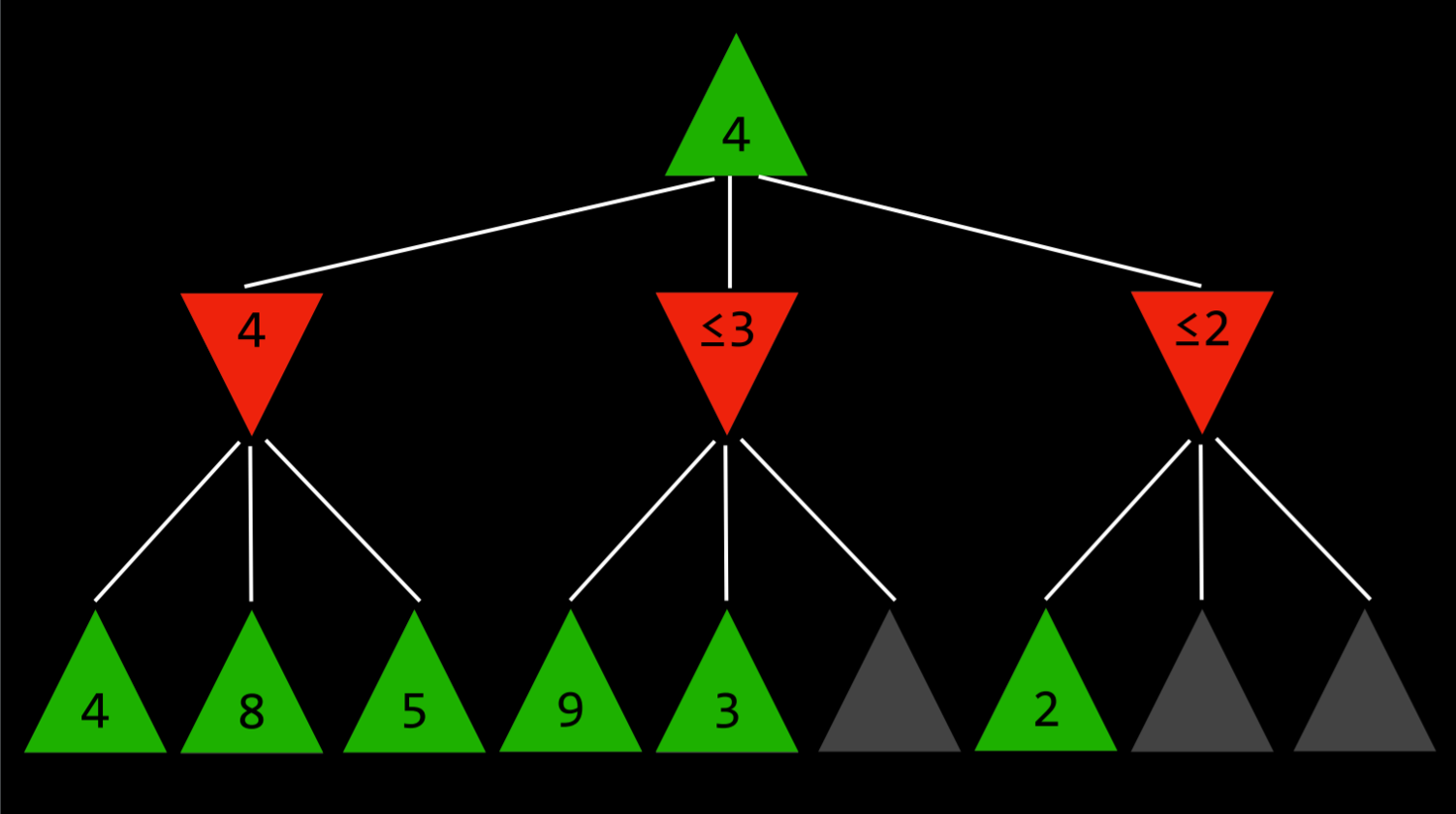
- 这一点最容易用一个例子来说明:最大化的玩家知道,在下一步,最小化的玩家将试图获得最低分数。假设最大化玩家有三个可能的动作,第一个动作的值为4。然后玩家开始为下一个动作生成值。要做到这一点,如果当前玩家做出这个动作,玩家会生成最小化者动作的值,并且知道最小化者会选择最低的一个。然而,在完成最小化器所有可能动作的计算之前,玩家会看到其中一个选项的值为3。这意味着没有理由继续探索最小化玩家的其他可能行动。尚未赋值的动作的值无关紧要,无论是10还是(-10)。如果该值为10,则最小化器将选择最低选项3,该选项已经比预先设定的4差。如果尚未估价的行动结果是(-10),那么最小化者将选择(-10)这一选项,这对最大化者来说更加不利。因此,在这一点上为最小化者计算额外的可能动作与最大化者无关,因为最大化玩家已经有了一个明确的更好的选择,其值为4。
|
||||
|
||||

|
||||
|
||||
|
||||
- 深度限制的极大极小算法(Depth-Limited Minimax)
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@
|
||||
:::
|
||||
|
||||
::: tip 📥
|
||||
本节附件下载 <Download url="https://pic-hdu-cs-wiki-1307923872.cos.ap-shanghai.myqcloud.com/code/2-Lecture.zip"/>
|
||||
本节附件下载 <Download url="https://cdn.xyxsw.site/code/2-Lecture.zip"/>
|
||||
:::
|
||||
# Sentence——父类
|
||||
|
||||
@@ -315,15 +315,15 @@ check_knowledge(knowledge)
|
||||
|
||||
在这个游戏中,玩家一按照一定的顺序排列颜色,然后玩家二必须猜测这个顺序。每一轮,玩家二进行猜测,玩家一返回一个数字,指示玩家二正确选择了多少颜色。让我们用四种颜色模拟一个游戏。假设玩家二猜测以下顺序:
|
||||
|
||||

|
||||

|
||||
|
||||
玩家一回答“二”。因此,我们知道其中一些两种颜色位于正确的位置,而另两种颜色则位于错误的位置。根据这些信息,玩家二试图切换两种颜色的位置。
|
||||
|
||||

|
||||

|
||||
|
||||
现在玩家一回答“零”。因此,玩家二知道切换后的颜色最初位于正确的位置,这意味着未被切换的两种颜色位于错误的位置。玩家二切换它们。
|
||||
|
||||

|
||||

|
||||
|
||||
在命题逻辑中表示这一点需要我们有(颜色的数量)$^2$个原子命题。所以,在四种颜色的情况下,我们会有命题 red0,red1,red2,red3,blue0…代表颜色和位置。下一步是用命题逻辑表示游戏规则(每个位置只有一种颜色,没有颜色重复),并将它们添加到知识库中。最后一步是将我们所拥有的所有线索添加到知识库中。在我们的案例中,我们会补充说,在第一次猜测中,两个位置是错误的,两个是正确的,而在第二次猜测中没有一个是对的。利用这些知识,模型检查算法可以为我们提供难题的解决方案。
|
||||
|
||||
|
||||
@@ -5,7 +5,7 @@
|
||||
如果你卡住了,请记得回来阅读文档,或请求身边人的帮助。
|
||||
|
||||
::: tip 📥
|
||||
本节附件下载 <Download url="https://pic-hdu-cs-wiki-1307923872.cos.ap-shanghai.myqcloud.com/code/2-Projects.zip"/>
|
||||
本节附件下载 <Download url="https://cdn.xyxsw.site/code/2-Projects.zip"/>
|
||||
:::
|
||||
|
||||
`pip3 install -r requirements.txt`
|
||||
@@ -75,7 +75,7 @@ C 说:“A 是骑士。”
|
||||
|
||||
写一个 AI 来玩扫雷游戏。
|
||||
|
||||

|
||||

|
||||
|
||||
## 背景
|
||||
|
||||
@@ -84,7 +84,7 @@ C 说:“A 是骑士。”
|
||||
- 扫雷器是一款益智游戏,由一个单元格网格组成,其中一些单元格包含隐藏的“地雷”。点击包含地雷的单元格会引爆地雷,导致用户输掉游戏。单击“安全”单元格(即不包含地雷的单元格)会显示一个数字,指示有多少相邻单元格包含地雷,其中相邻单元格是指从给定单元格向左、向右、向上、向下或对角线一个正方形的单元格。
|
||||
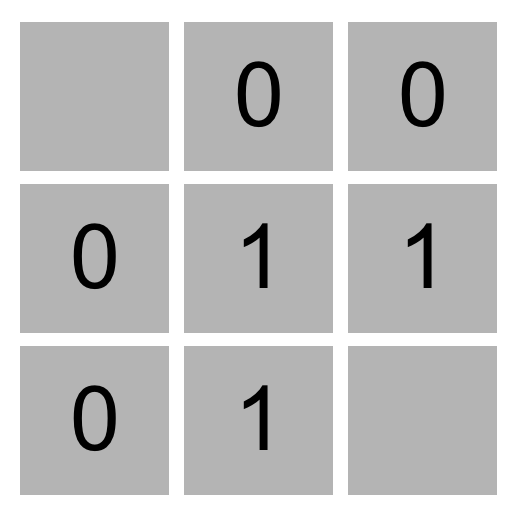
- 例如,在这个 3x3 扫雷游戏中,三个 1 值表示这些单元格中的每个单元格都有一个相邻的单元格,该单元格是地雷。四个 0 值表示这些单元中的每一个都没有相邻的地雷。
|
||||
|
||||

|
||||
|
||||
|
||||
- 给定这些信息,玩家根据逻辑可以得出结论,右下角单元格中一定有地雷,左上角单元格中没有地雷,因为只有在这种情况下,其他单元格上的数字标签才会准确。
|
||||
- 游戏的目标是标记(即识别)每个地雷。在游戏的许多实现中,包括本项目中的实现中,玩家可以通过右键单击单元格(或左键双击,具体取决于计算机)来标记地雷。
|
||||
@@ -94,7 +94,7 @@ C 说:“A 是骑士。”
|
||||
- 你在这个项目中的目标是建立一个可以玩扫雷游戏的人工智能。回想一下,基于知识的智能主体通过考虑他们的知识库来做出决策,并根据这些知识做出推断。
|
||||
- 我们可以表示人工智能关于扫雷游戏的知识的一种方法是,使每个单元格成为命题变量,如果单元格包含地雷,则为真,否则为假。
|
||||
|
||||

|
||||

|
||||
|
||||
- 我们现在掌握了什么信息?我们现在知道八个相邻的单元格中有一个是地雷。因此,我们可以写一个逻辑表达式,如下所示,表示其中一个相邻的单元格是地雷。
|
||||
- `Or(A,B,C,D,E,F,G,H)`
|
||||
@@ -128,12 +128,12 @@ Or(
|
||||
- 这种表示法中的每个逻辑命题都有两个部分:一个是网格中与提示数字有关的一组单元格 `cell`,另一个是数字计数 `count`,表示这些单元格中有多少是地雷。上面的逻辑命题说,在单元格 A、B、C、D、E、F、G 和 H 中,正好有 1 个是地雷。
|
||||
- 为什么这是一个有用的表示?在某种程度上,它很适合某些类型的推理。考虑下面的游戏。
|
||||
|
||||

|
||||

|
||||
|
||||
- 利用左下数的知识,我们可以构造命题 `{D,E,G}=0`,意思是在 D、E 和 G 单元中,正好有 0 个是地雷。凭直觉,我们可以从这句话中推断出所有的单元格都必须是安全的。通过推理,每当我们有一个 `count` 为 0 的命题时,我们就知道该命题的所有 `cell` 都必须是安全的。
|
||||
- 同样,考虑下面的游戏。
|
||||
|
||||

|
||||

|
||||
|
||||
- 我们的人工智能会构建命题 `{E,F,H}=3`。凭直觉,我们可以推断出所有的 E、F 和 H 都是地雷。更一般地说,任何时候 `cell` 的数量等于 `count`,我们都知道这个命题的所有单元格都必须是地雷。
|
||||
- 一般来说,我们只希望我们的命题是关于那些还不知道是安全的还是地雷的 `cell`。这意味着,一旦我们知道一个单元格是否是地雷,我们就可以更新我们的知识库来简化它们,并可能得出新的结论。
|
||||
@@ -141,7 +141,7 @@ Or(
|
||||
- 同样,如果我们的人工智能知道命题 `{A,B,C}=2`,并且我们被告知 C 是一颗地雷,我们可以从命题中删除 C,并减少计数的值(因为 C 是导致该计数的地雷),从而得到命题 `{A、B}=1`。这是合乎逻辑的:如果 A、B 和 C 中有两个是地雷,并且我们知道 C 是地雷,那么 A 和 B 中一定有一个是地雷。
|
||||
- 如果我们更聪明,我们可以做最后一种推理。
|
||||
|
||||

|
||||

|
||||
|
||||
- 考虑一下我们的人工智能根据中间顶部单元格和中间底部单元格会知道的两个命题。从中上角的单元格中,我们得到 `{A,B,C}=1`。从底部中间单元格中,我们得到 `{A,B,C,D,E}=2`。从逻辑上讲,我们可以推断出一个新的知识,即 `{D,E}=1`。毕竟,如果 A、B、C、D 和 E 中有两个是地雷,而 A、B 和 C 中只有一个是地雷的话,那么 D 和 E 必须是另一个地雷。
|
||||
- 更一般地说,任何时候我们有两个命题满足 `set1=count1` 和 `set2=count2`,其中 `set1` 是 `set2` 的子集,那么我们可以构造新的命题 `set2-set1=count2-count1`。考虑上面的例子,以确保你理解为什么这是真的。
|
||||
|
||||
@@ -112,7 +112,7 @@
|
||||
- $KB$: 如果今天是星期四并且不下雨,那我将出门跑步;今天是星期四;今天不下雨。$(P\land\lnot Q)\to R,P,\lnot Q$
|
||||
- 查询结论(query): $R$
|
||||
|
||||

|
||||
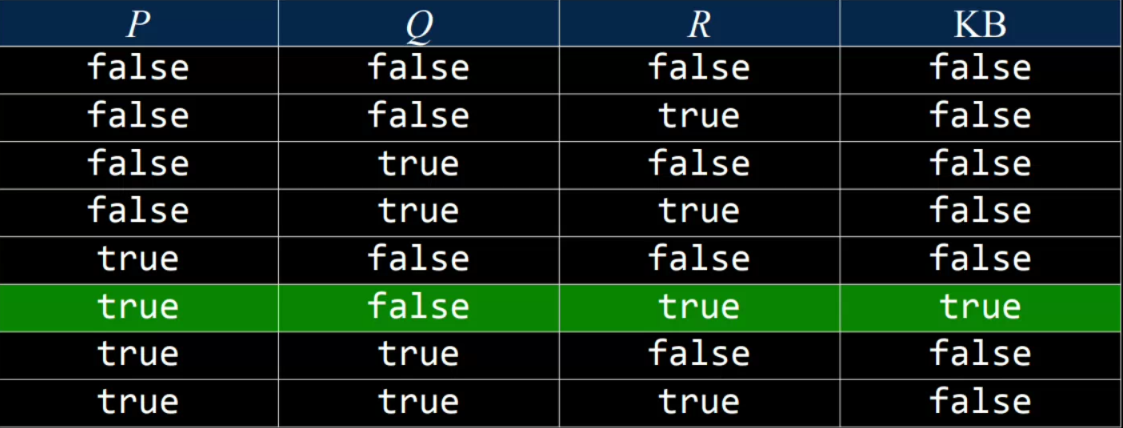
|
||||
|
||||
- 接下来,让我们看看如何将知识和逻辑表示为代码。
|
||||
|
||||
@@ -175,31 +175,31 @@ def check_all(knowledge, query, symbols, model):# 如果模型对每个符号都
|
||||
- 模型检查不是一种有效的算法,因为它必须在给出答案之前考虑每个可能的模型(提醒:如果在$KB$为真的所有模型(真值分配)下,查询结论$R$为真,则$R$ 也为真)。 推理规则允许我们根据现有知识生成新信息,而无需考虑所有可能的模型。
|
||||
- 推理规则通常使用将顶部部分(前提)与底部部分(结论)分开的水平条表示。 前提是我们有什么知识,结论是根据这个前提可以产生什么知识。
|
||||
|
||||

|
||||

|
||||
|
||||
- 肯定前件(Modus Ponens)
|
||||
|
||||
- 如果我们知道一个蕴涵及其前件为真,那么后件也为真。
|
||||
|
||||

|
||||
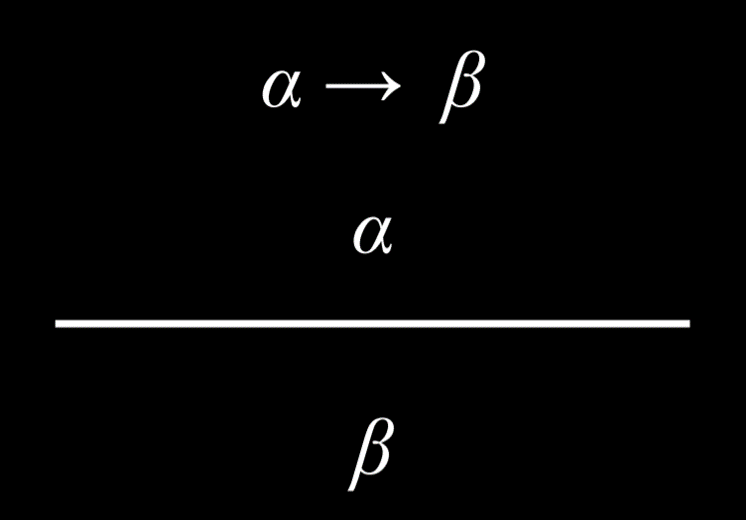
|
||||
|
||||
- 合取消除(And Elimination)
|
||||
|
||||
- 如果 And 命题为真,则其中的任何一个原子命题也为真。 例如,如果我们知道哈利与罗恩和赫敏是朋友,我们就可以得出结论,哈利与赫敏是朋友。
|
||||
|
||||

|
||||
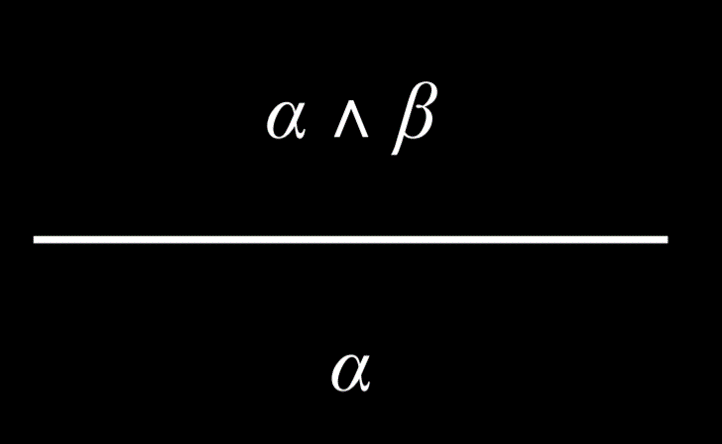
|
||||
|
||||
- 双重否定消除(Double Negation Elimination)
|
||||
|
||||
- 被两次否定的命题为真。 例如,考虑命题“哈利没有通过考试是不正确的”。 这两个否定相互抵消,将命题“哈利通过考试”标记为真。
|
||||
|
||||

|
||||
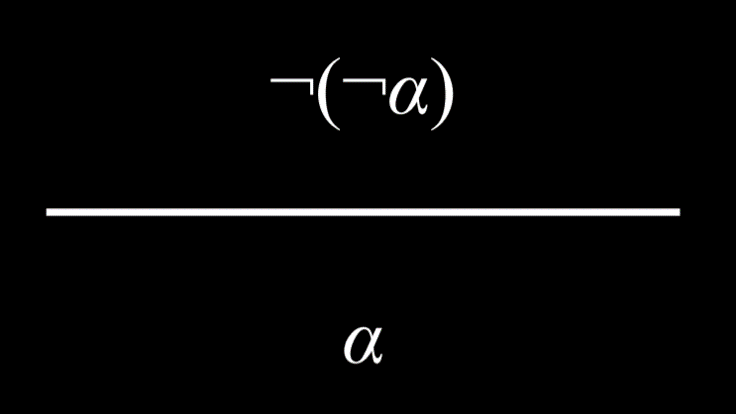
|
||||
|
||||
- 蕴含消除(Implication Elimination)
|
||||
|
||||
- 蕴涵等价于被否定的前件和后件之间的 Or 关系。 例如,命题“如果正在下雨,哈利在室内”等同于命题“(没有下雨)或(哈利在室内)”。
|
||||
|
||||

|
||||
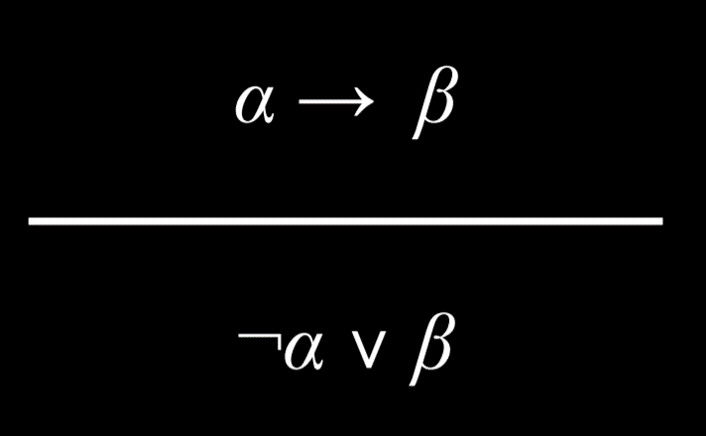
|
||||
|
||||
| $P$ | $Q$ | $P\to Q$ | $\lnot P\lor Q$ |
|
||||
| --- | --- | -------- | --------------- |
|
||||
@@ -212,25 +212,25 @@ def check_all(knowledge, query, symbols, model):# 如果模型对每个符号都
|
||||
|
||||
- 等值命题等价于蕴涵及其逆命题的 And 关系。 例如,“当且仅当 Harry 在室内时才下雨”等同于(“如果正在下雨,Harry 在室内”和“如果 Harry 在室内,则正在下雨”)。
|
||||
|
||||

|
||||
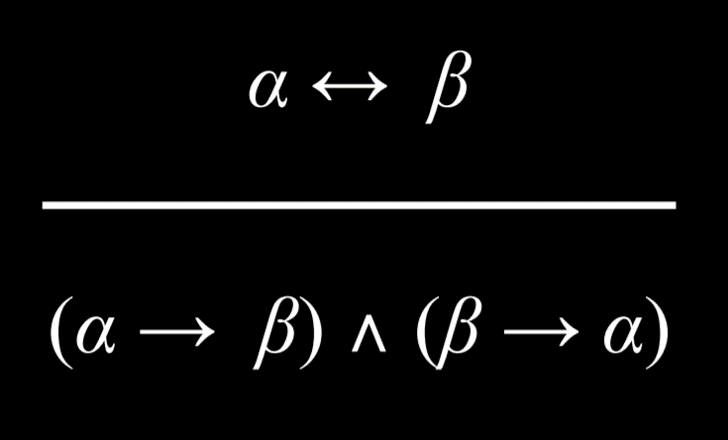
|
||||
|
||||
- 德摩根律(De Morgan’s Law)
|
||||
|
||||
- 可以将 And 连接词变成 Or 连接词。考虑以下命题:“哈利和罗恩都通过了考试是不正确的。” 由此,可以得出“哈利通过考试不是真的”或者“罗恩不是真的通过考试”的结论。 也就是说,要使前面的 And 命题为真,Or 命题中至少有一个命题必须为真。
|
||||
|
||||

|
||||
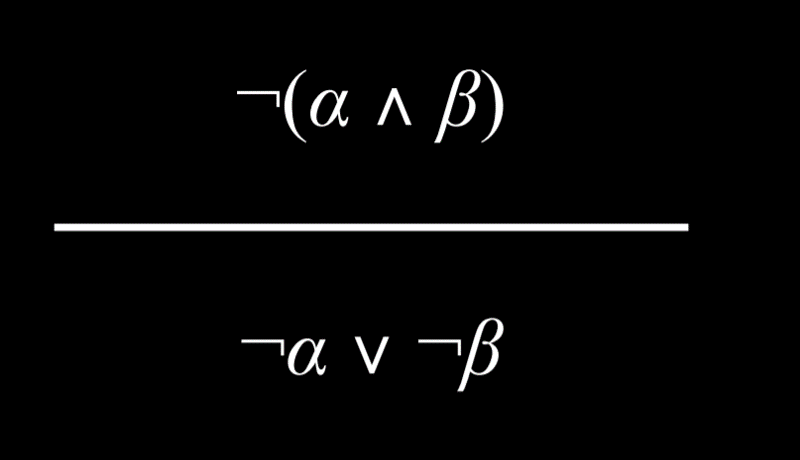
|
||||
|
||||
- 同样,可以得出相反的结论。考虑这个命题“哈利或罗恩通过考试是不正确的”。 这可以改写为“哈利没有通过考试”和“罗恩没有通过考试”。
|
||||
|
||||

|
||||
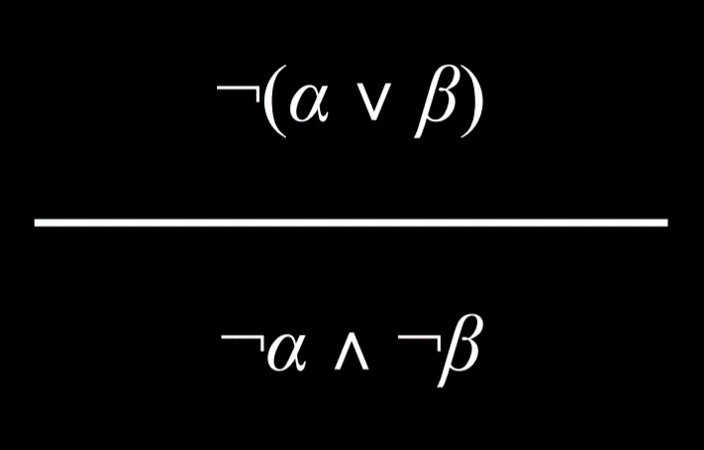
|
||||
|
||||
- 分配律(Distributive Property)
|
||||
|
||||
- 具有两个用 And 或 Or 连接词分组的命题可以分解为由 And 和 Or 组成的更小单元。
|
||||
|
||||

|
||||
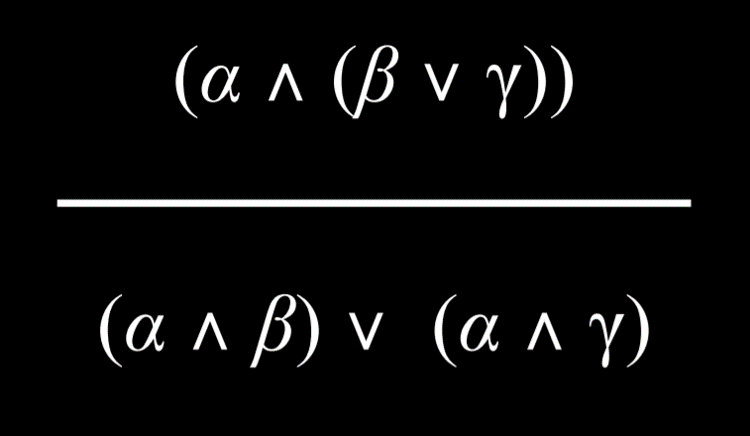
|
||||
|
||||

|
||||
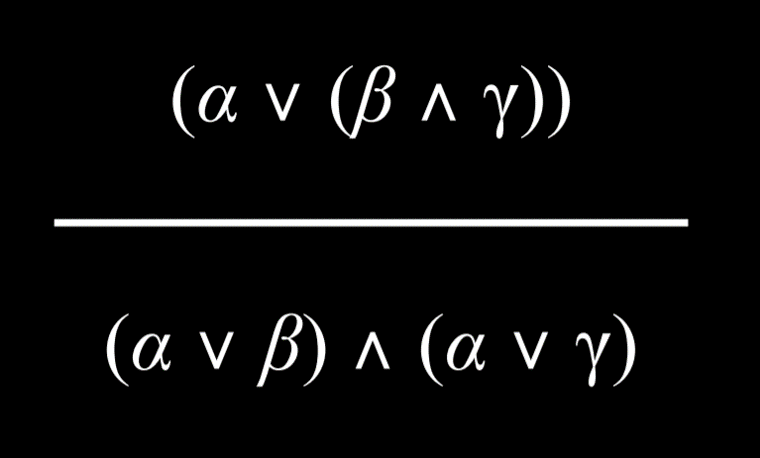
|
||||
|
||||
## 知识和搜索问题
|
||||
|
||||
@@ -247,16 +247,16 @@ def check_all(knowledge, query, symbols, model):# 如果模型对每个符号都
|
||||
|
||||
- 归结是一个强大的推理规则,它规定如果 Or 命题中的两个原子命题之一为假,则另一个必须为真。 例如,给定命题“Ron 在礼堂”或“Hermione 在图书馆”,除了命题“Ron 不在礼堂”之外,我们还可以得出“Hermione 在图书馆”的结论。 更正式地说,我们可以通过以下方式定义归结:
|
||||
|
||||

|
||||
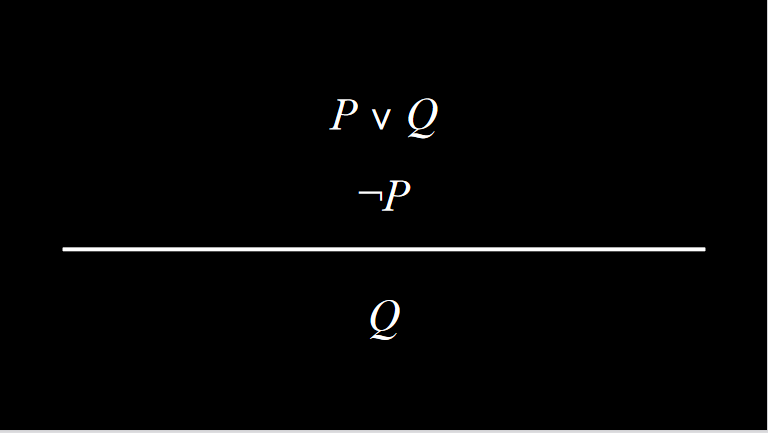
|
||||
|
||||

|
||||
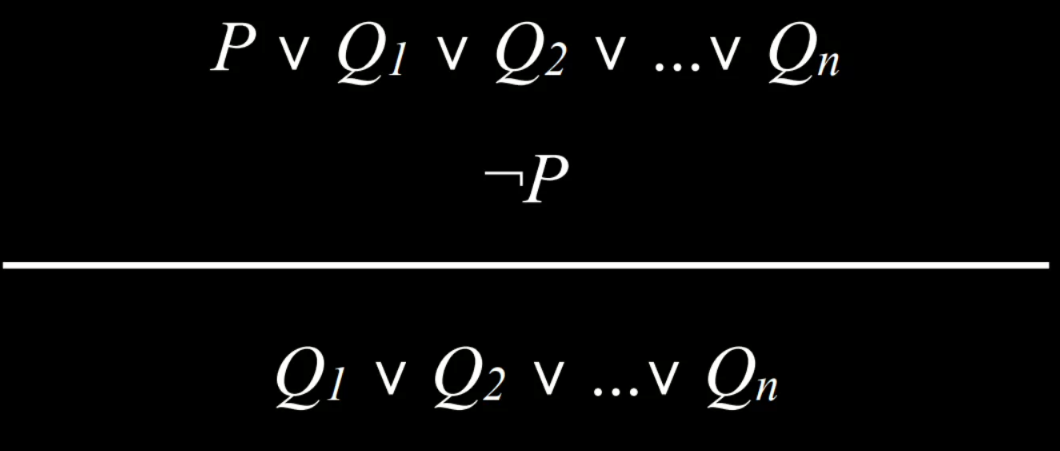
|
||||
|
||||
- 归结依赖于互补文字,两个相同的原子命题,其中一个被否定而另一个不被否定,例如$P$和$¬P$。
|
||||
- 归结可以进一步推广。 假设除了“Rom 在礼堂”或“Hermione 在图书馆”的命题外,我们还知道“Rom 不在礼堂”或“Harry 在睡觉”。 我们可以从中推断出“Hermione 在图书馆”或“Harry 在睡觉”。 正式地说:
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||
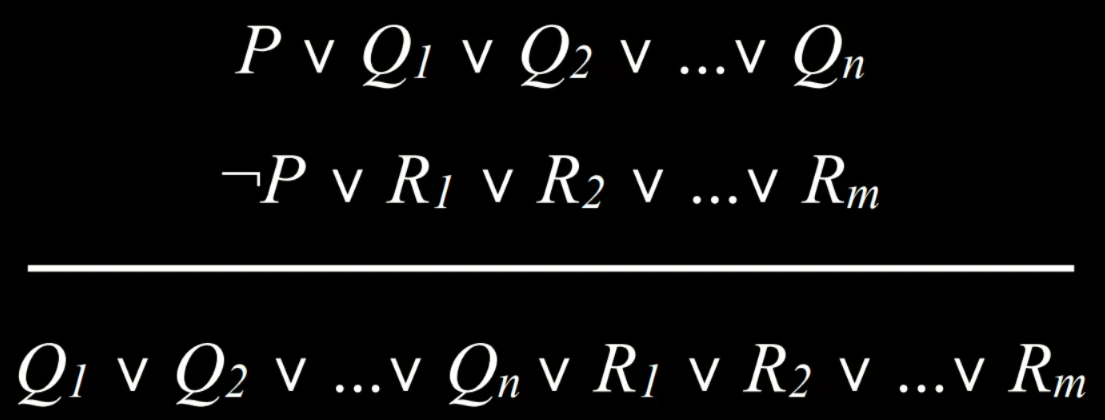
|
||||
|
||||
- 互补文字使我们能够通过解析推理生成新句子。 因此,推理算法定位互补文字以生成新知识。
|
||||
- 从句(Clause)是多个原子命题的析取式(命题符号或命题符号的否定,例如$P$, $¬P$)。 析取式由Or逻辑连接词 ($P ∨ Q ∨ R$) 相连的命题组成。 另一方面,连接词由And逻辑连接词 ($P ∧ Q ∧ R$) 相连的命题组成。 从句允许我们将任何逻辑语句转换为合取范式 (CNF),它是从句的合取,例如:$(A ∨ B ∨ C) ∧ (D ∨ ¬E) ∧ (F ∨ G)$。
|
||||
|
||||
@@ -7,7 +7,7 @@
|
||||
|
||||
|
||||
::: tip 📥
|
||||
本节附件下载 <Download url="https://pic-hdu-cs-wiki-1307923872.cos.ap-shanghai.myqcloud.com/code/3-Lecture.zip"/>
|
||||
本节附件下载 <Download url="https://cdn.xyxsw.site/code/3-Lecture.zip"/>
|
||||
:::
|
||||
|
||||
本节代码不做额外梳理,[不确定性问题](./4.3.3%E4%B8%8D%E7%A1%AE%E5%AE%9A%E6%80%A7%E9%97%AE%E9%A2%98.md) 中已有解释。
|
||||
@@ -35,7 +35,7 @@
|
||||
9. 1
|
||||
3. 回答关于贝叶斯网络的问题,问题如下:
|
||||
|
||||

|
||||

|
||||
|
||||
以下哪句话是真的?
|
||||
|
||||
|
||||
@@ -7,7 +7,7 @@
|
||||
:::
|
||||
|
||||
::: tip 📥
|
||||
本节附件下载 <Download url="https://pic-hdu-cs-wiki-1307923872.cos.ap-shanghai.myqcloud.com/code/3-Projects.zip"/>
|
||||
本节附件下载 <Download url="https://cdn.xyxsw.site/code/3-Projects.zip"/>
|
||||
:::
|
||||
|
||||
## 背景
|
||||
@@ -16,7 +16,7 @@
|
||||
- 每个孩子都会从他们的父母那里继承一个 GJB2 基因。如果父母有两个变异基因,那么他们会将变异基因传给孩子;如果父母没有变异基因,那么他们不会将变异基因传给孩子;如果父母有一个变异基因,那么该基因传给孩子的概率为 0.5。不过,在基因被传递后,它有一定的概率发生额外的突变:从导致听力障碍的基因版本转变为不导致听力障碍的版本,或者反过来。
|
||||
- 我们可以尝试通过对所有相关变量形成一个贝叶斯网络来模拟所有这些关系,就像下面这个网络一样,它考虑了一个由两个父母和一个孩子组成的家庭。
|
||||
|
||||

|
||||
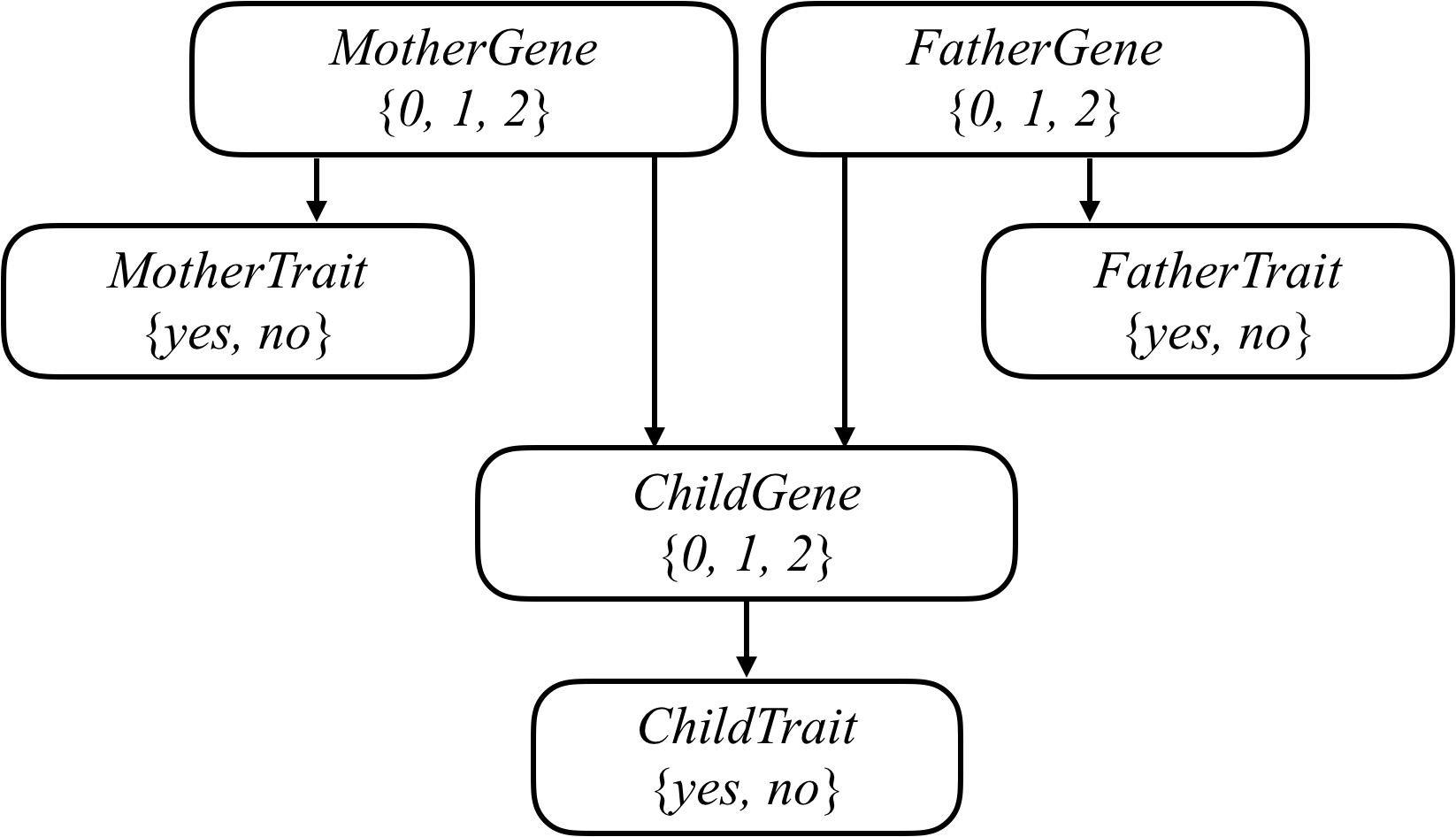
|
||||
|
||||
- 家庭中的每个人都有一个 `Gene` 随机变量,代表一个人有多少个特定基因(例如,GJB2 的听力障碍版本):一个 0、1 或 2 的值。家族中的每个人也有一个 `Trait` 随机变量,它是 `yes` 或 `no`,取决于该人是否表达基于该基因的性状(例如,听力障碍)。从每个人的 `Gene` 变量到他们的 `Trait` 变量之间有一个箭头,以编码一个人的基因影响他们具有特定性状的概率的想法。同时,也有一个箭头从母亲和父亲的 `Gene` 随机变量到他们孩子的 `Gene` 随机变量:孩子的基因取决于他们父母的基因。
|
||||
- 你在这个项目中的任务是使用这个模型对人群进行推断。给出人们的信息,他们的父母是谁,以及他们是否具有由特定基因引起的特定可观察特征(如听力损失),你的人工智能将推断出每个人的基因的概率分布,以及任何一个人是否会表现出有关特征的概率分布。
|
||||
|
||||
@@ -24,11 +24,11 @@ $
|
||||
|
||||
- 用标准骰子掷出数字 R 的概率可以表示为 $P(R)$ 。在我们的例子中,$P(R)=1/6$ ,因为有六个可能的世界(从 1 到 6 的任何数字),并且每个世界有相同的可能性发生。现在,考虑掷两个骰子的事件。现在,有 36 个可能的事件,同样有相同的可能性发生。
|
||||
|
||||

|
||||

|
||||
|
||||
- 然而,如果我们试图预测两个骰子的总和,会发生什么?在这种情况下,我们只有 11 个可能的值(总和必须在 2 到 12 之间),而且它们的出现频率并不相同。
|
||||
|
||||

|
||||

|
||||
|
||||
- 为了得到事件发生的概率,我们将事件发生的世界数量除以可能发生的世界总数。例如,当掷两个骰子时,有 36 个可能的世界。只有在其中一个世界中,当两个骰子都得到 6 时,我们才能得到 12 的总和。因此,$P(12)=\frac{1}{36}$,或者,换句话说,掷两个骰子并得到两个和为 12 的数字的概率是$\frac{1}{36}$。$P(7)$是多少?我们数了数,发现和 7 出现在 6 个世界中。因此,$P(7)=\frac{6}{36}=\frac{1}{6}$。
|
||||
|
||||
@@ -49,11 +49,11 @@ $P(a\land b)=P(a)P(b|a)$
|
||||
|
||||
- 例如,考虑$P(总和为12|在一个骰子上掷出6)$,或者掷两个骰子假设我们已经掷了一个骰子并获得了六,得到十二的概率。为了计算这一点,我们首先将我们的世界限制在第一个骰子的值为六的世界:
|
||||
|
||||

|
||||

|
||||
|
||||
- 现在我们问,在我们将问题限制在(除以$P(6)$,或第一个骰子产生 6 的概率)的世界中,事件 a(和为 12)发生了多少次?
|
||||
|
||||

|
||||

|
||||
|
||||
## 随机变量(Random Variables)
|
||||
|
||||
@@ -135,7 +135,7 @@ $P(Flight=取消)=0.1$
|
||||
- 每个节点 X 具有概率分布$P(X|Parents(X))$。
|
||||
- 让我们考虑一个贝叶斯网络的例子,该网络包含影响我们是否按时赴约的随机变量。
|
||||
|
||||

|
||||
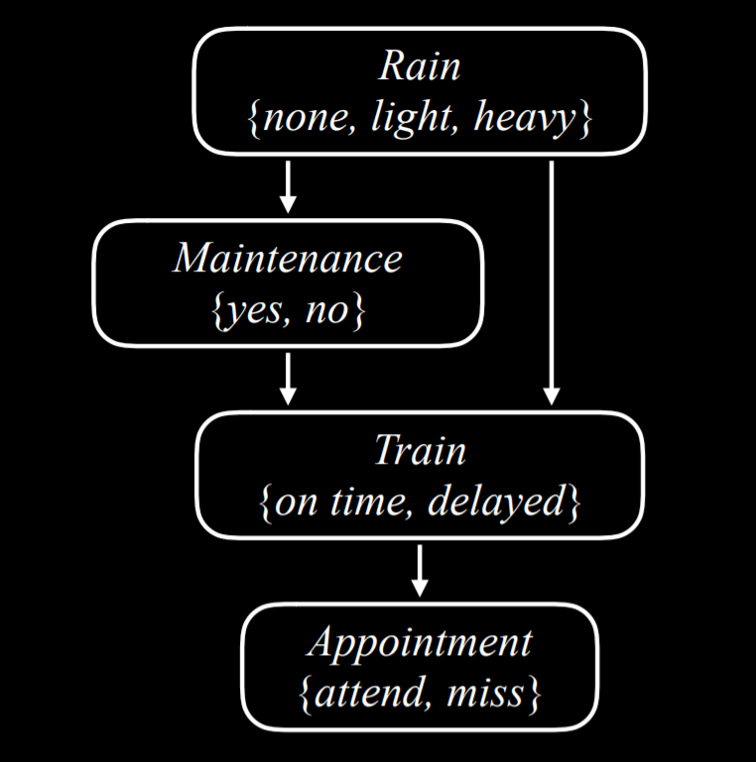
|
||||
|
||||
- 让我们从上到下描述这个贝叶斯网络:
|
||||
|
||||
@@ -279,21 +279,21 @@ for node, prediction in zip(model.states, predictions):
|
||||
|
||||
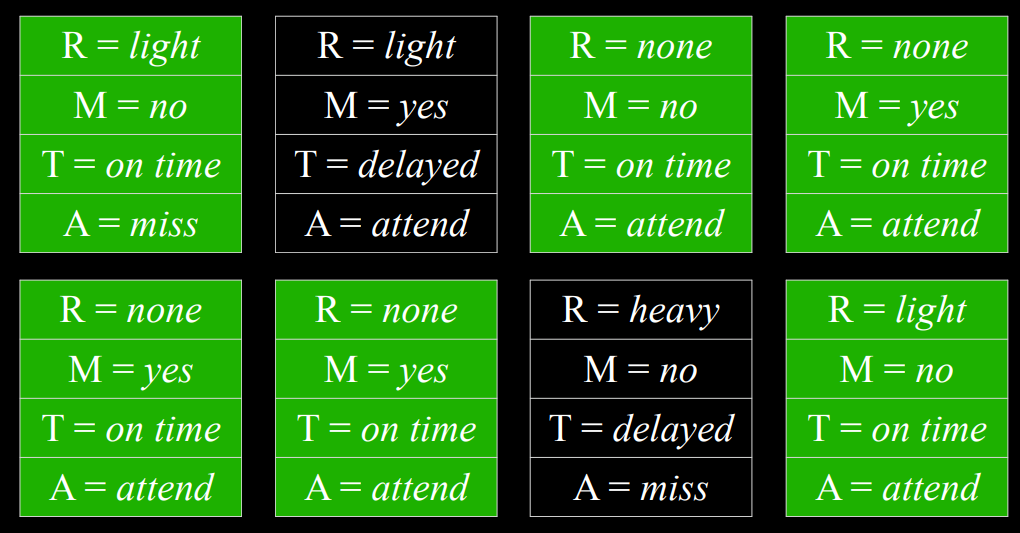
- 如果我们从对 Rain 变量进行采样开始,则生成的值 none 的概率为 0.7,生成的值 light 的概率为 0.2,而生成的值 heavy 的概率则为 0.1。假设我们的采样值为 none。当我们得到 Maintenance 变量时,我们也会对其进行采样,但只能从 Rain 等于 none 的概率分布中进行采样,因为这是一个已经采样的结果。我们将通过所有节点继续这样做。现在我们有一个样本,多次重复这个过程会生成一个分布。现在,如果我们想回答一个问题,比如什么是$P(Train=on\ time)$,我们可以计算变量 Train 具有准时值的样本数量,并将结果除以样本总数。通过这种方式,我们刚刚生成了$P(Train=on\ {time})$的近似概率。
|
||||
|
||||

|
||||
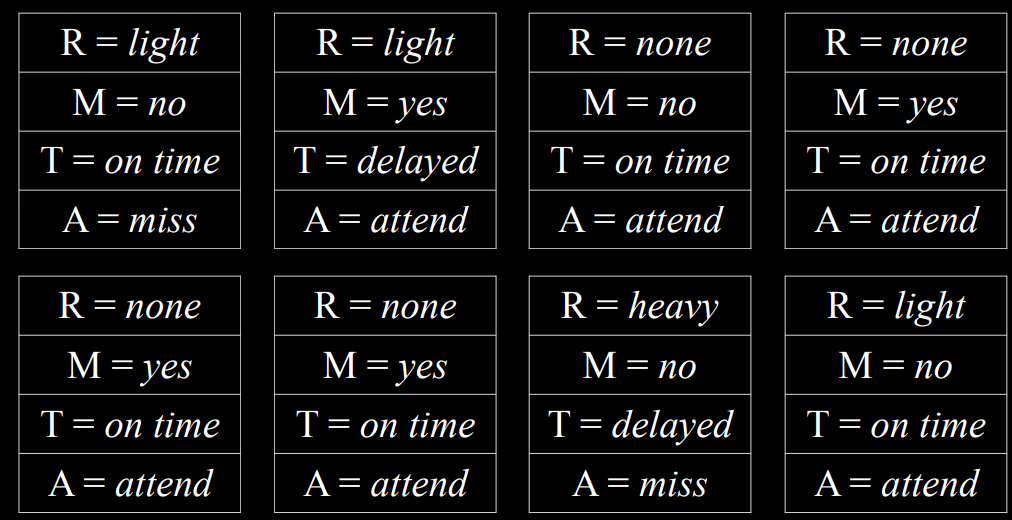
|
||||
|
||||

|
||||
|
||||
|
||||
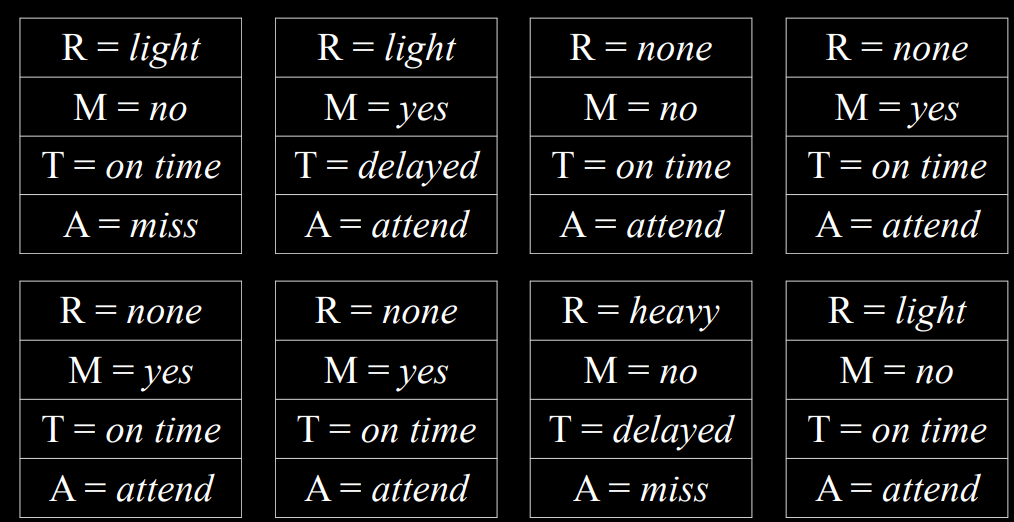
- 我们也可以回答涉及条件概率的问题,例如$P(rain=light|train=on\ {time})$。在这种情况下,我们忽略 Train 值为 delay 的所有样本,然后照常进行。我们计算在$Train=\text{on time}$的样本中有多少样本具有变量$Rain=light$,然后除以$Train=\text{on time}$的样本总数。
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
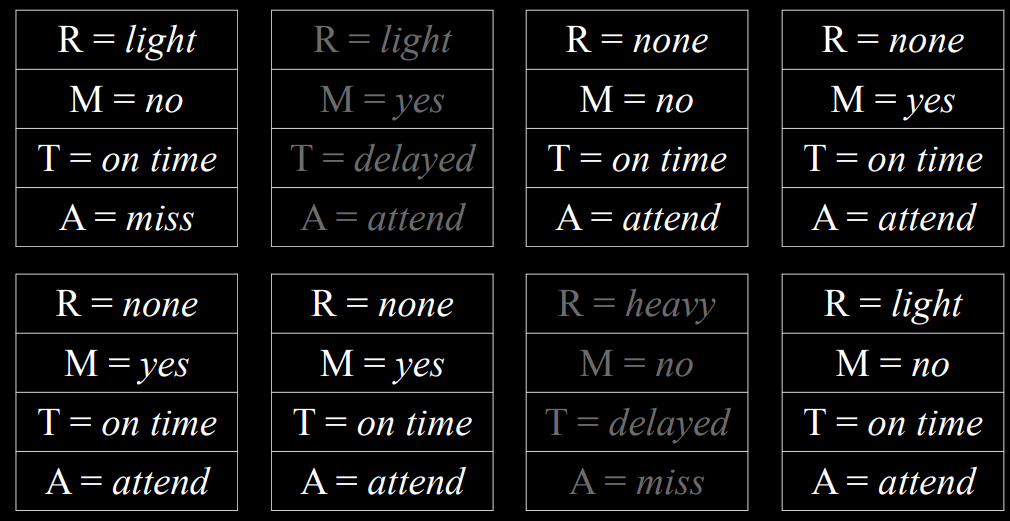
去除$T= on time$的样本
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
选择$R=light$的样本
|
||||
|
||||
@@ -357,11 +357,11 @@ print(Counter(data))
|
||||
- 马尔科夫链是一个随机变量的序列,每个变量的分布都遵循马尔科夫假设。也就是说,链中的每个事件的发生都是基于之前事件的概率。
|
||||
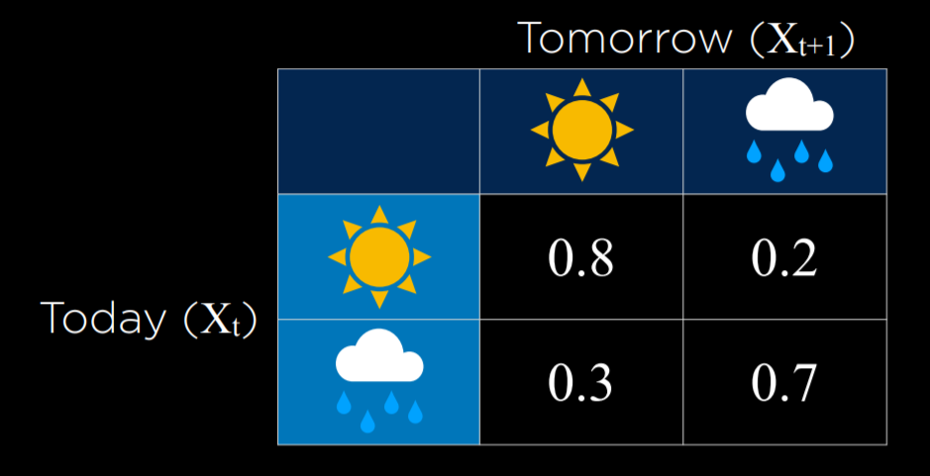
- 为了构建马尔可夫链,我们需要一个过渡模型,该模型将根据当前事件的可能值来指定下一个事件的概率分布。
|
||||
|
||||

|
||||
|
||||
|
||||
- 在这个例子中,基于今天是晴天,明天是晴天的概率是 0.8。这是合理的,因为晴天之后更可能是晴天。然而,如果今天是雨天,明天下雨的概率是 0.7,因为雨天更有可能相继出现。使用这个过渡模型,可以对马尔可夫链进行采样。从一天是雨天或晴天开始,然后根据今天的天气,对第二天的晴天或雨天的概率进行采样。然后,根据明天的情况对后天的概率进行采样,以此类推,形成马尔科夫链:
|
||||
|
||||

|
||||
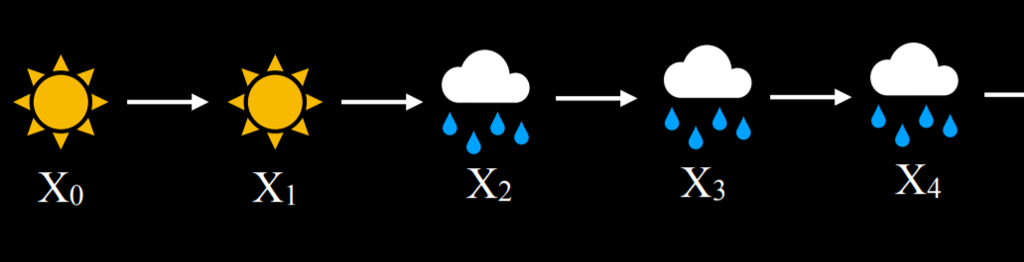
|
||||
|
||||
- 给定这个马尔可夫链,我们现在可以回答诸如“连续四个雨天的概率是多少?”这样的问题。下面是一个如何在代码中实现马尔可夫链的例子:
|
||||
|
||||
@@ -394,7 +394,7 @@ print(model.sample(50))
|
||||
- 在衡量网站的用户参与度时,隐藏的状态是用户的参与程度,而观察是网站或应用程序的分析。
|
||||
- 举个例子。我们的人工智能想要推断天气(隐藏状态),但它只能接触到一个室内摄像头,记录有多少人带了雨伞。这里是我们的传感器模型(sensor model),表示了这些概率:
|
||||
|
||||

|
||||

|
||||
|
||||
- 在这个模型中,如果是晴天,人们很可能不会带伞到大楼。如果是雨天,那么人们就很有可能带伞到大楼来。通过对人们是否带伞的观察,我们可以合理地预测外面的天气情况。
|
||||
|
||||
@@ -403,7 +403,7 @@ print(model.sample(50))
|
||||
- 假设证据变量只取决于相应的状态。例如,对于我们的模型,我们假设人们是否带雨伞去办公室只取决于天气。这不一定反映了完整的事实,因为,比如说,比较自觉的、不喜欢下雨的人可能即使在阳光明媚的时候也会到处带伞,如果我们知道每个人的个性,会给模型增加更多的数据。然而,传感器马尔科夫假设忽略了这些数据,假设只有隐藏状态会影响观察。
|
||||
- 隐马尔科夫模型可以用一个有两层的马尔科夫链来表示。上层,变量$X$,代表隐藏状态。底层,变量$E$,代表证据,即我们所拥有的观察。
|
||||
|
||||

|
||||
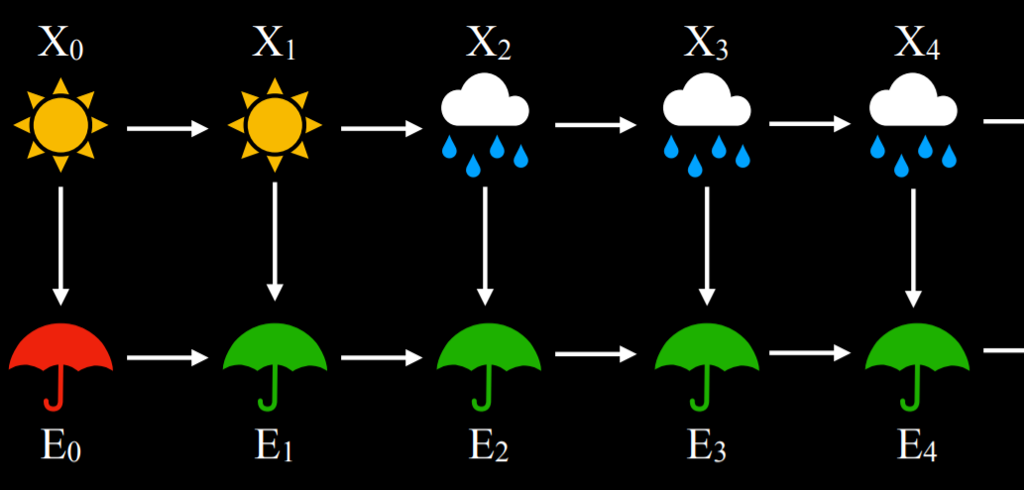
|
||||
|
||||
- 基于隐马尔科夫模型,可以实现多种任务:
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@
|
||||
|
||||
人工智能是一个宏大的愿景,目标是让机器像我们人类一样思考和行动,既包括增强我们人类脑力也包括增强我们体力的研究领域。而学习只是实现人工智能的手段之一,并且,只是增强我们人类脑力的方法之一。所以,人工智能包含机器学习。机器学习又包含了深度学习,他们三者之间的关系见下图。
|
||||
|
||||

|
||||

|
||||
|
||||
# 如何学习本节内容
|
||||
|
||||
|
||||
@@ -42,11 +42,11 @@
|
||||
|
||||
机器学习包括深度学习
|
||||
|
||||

|
||||
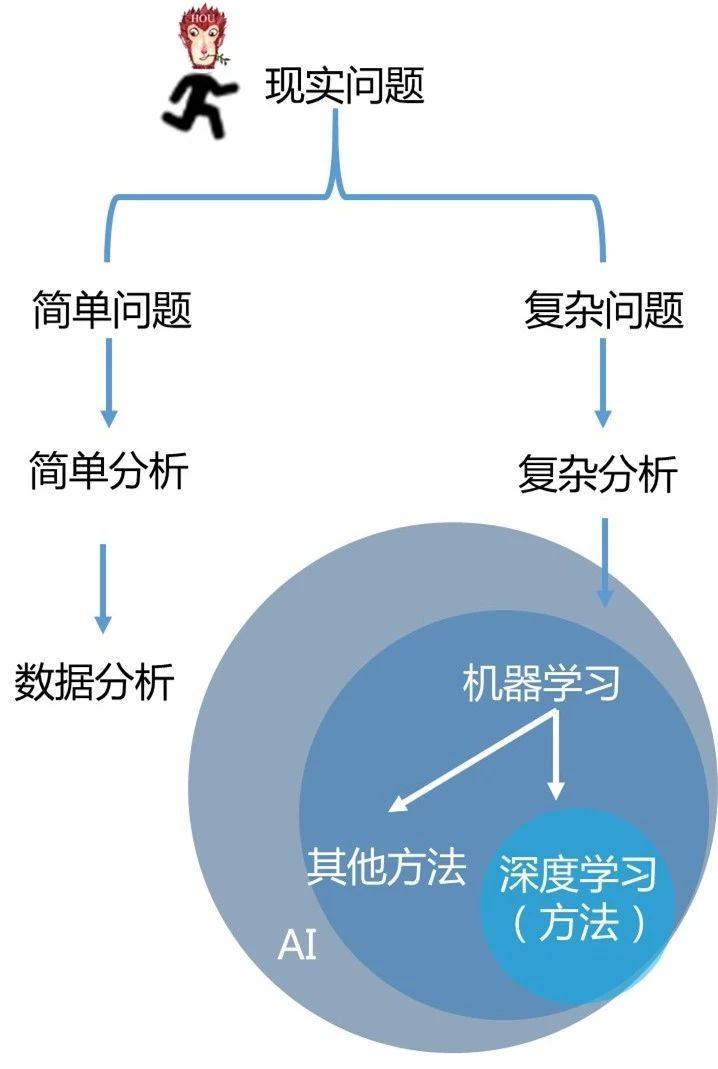
|
||||
|
||||
[同时向你推荐这个 Data Analytics,Data Analysis,数据挖掘,数据科学,机器学习,大数据的区别是什么?](https://www.quora.com/What-is-the-difference-between-Data-Analytics-Data-Analysis-Data-Mining-Data-Science-Machine-Learning-and-Big-Data-1)
|
||||
|
||||

|
||||

|
||||
|
||||
## 我没有任何相关概念
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@
|
||||
|
||||
## 深度学习框架
|
||||
|
||||

|
||||

|
||||
|
||||
### 1、深度学习框架是什么
|
||||
|
||||
@@ -113,9 +113,9 @@ PyTorch 完全基于 Python。
|
||||
|
||||
官网如下
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
选择 Conda 或者 Pip 安装皆可
|
||||
|
||||
@@ -140,7 +140,7 @@ conda config --set show_channel_urls yes
|
||||
|
||||
### TensorFlow
|
||||
|
||||

|
||||

|
||||
|
||||
#### 教程
|
||||
|
||||
@@ -167,17 +167,17 @@ cuda 版本需要额外配置,我们将这个任务留给聪明的你!!!
|
||||
同时按下键盘的 win+r 键,打开 cmd,键入 `dxdiag` 然后回车
|
||||
系统、显卡、声卡以及其他输入设备的信息都在这里了。(给出我的界面)
|
||||
|
||||

|
||||

|
||||
|
||||
cuda 版本查看
|
||||
|
||||
桌面空白位置摁下右键
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
#### linux
|
||||
|
||||
@@ -193,11 +193,11 @@ nvidia-smi
|
||||
|
||||
通常大家所指的 cuda 是位于/usr/local 下的 cuda
|
||||
|
||||

|
||||

|
||||
|
||||
当然可以看到 cuda 是 cuda-11.6 所指向的软链接(类似 windows 的快捷方式),所以我们如果要切换 cuda 版本只需要改变软链接的指向即可。
|
||||
|
||||

|
||||

|
||||
|
||||
cuda driver version 是 cuda 的驱动版本。
|
||||
|
||||
@@ -205,9 +205,9 @@ cuda runtimer version 是我们实际很多时候我们实际调用的版本。
|
||||
|
||||
二者的版本是可以不一致的。如下图所示:
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
一般来讲 cuda driver 是向下兼容的。所以 cuda driver version >= cuda runtime version 就不会太大问题。
|
||||
|
||||
@@ -217,13 +217,13 @@ cuda runtimer version 是我们实际很多时候我们实际调用的版本。
|
||||
|
||||
以 pytorch 为例,可以看到在安装过程中我们选择的 cuda 版本是 10.2
|
||||
|
||||

|
||||

|
||||
|
||||
那么这个 cudatookit10.2 和 nvidia-smi 的 11.7 以及 nvcc -V 的 11.4 三者有什么区别呢?
|
||||
|
||||
pytorch 实际只需要 cuda 的链接文件,即.so 文件,这些链接文件就都包含的 cudatookkit 里面。并不需要 cuda 的头文件等其他东西,如下所示
|
||||
|
||||

|
||||

|
||||
|
||||
所以我们如果想让使用 pytorch-cuda 版本,我们实际上不需要/usr/local/cuda。只需要在安装驱动的前提下,在 python 里面安装 cudatookit 即可。
|
||||
|
||||
@@ -233,8 +233,8 @@ pytorch 实际只需要 cuda 的链接文件,即.so 文件,这些链接文
|
||||
|
||||
Cudnn 是一些链接文件,你可以理解成是为了给 cuda 计算加速的东西。同样的我们也可以用以下命令查看/usr/local/cuda 的 cudnn:
|
||||
|
||||

|
||||

|
||||
|
||||
以及 pytorch 的 cuda 环境的 cudnn
|
||||
|
||||

|
||||

|
||||
|
||||
@@ -40,8 +40,8 @@
|
||||
|
||||
这是我用照片重建的独角兽<strong>稀疏</strong>点云,红色的不用管,是照相机视角(图不够多,巨糊)
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
先这些,后续想起来了可能会补充。
|
||||
|
||||
@@ -68,7 +68,7 @@ Crash course 的课程,可以基本了解pytorch的内容,但是当然有很
|
||||
|
||||
### 损失
|
||||
|
||||

|
||||

|
||||
|
||||
首先我们需要有一个损失函数$F(x),x=true-predict$
|
||||
|
||||
@@ -77,13 +77,13 @@ Crash course 的课程,可以基本了解pytorch的内容,但是当然有很
|
||||
|
||||
### 梯度下降
|
||||
|
||||

|
||||

|
||||
|
||||
假设损失函数为$y=x^2$,梯度下降的目的是快速找到导数为 0 的位置(附近)
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
以此类推,我们最后的 w 在 0 的附近反复横跳,最后最接近目标函数的权重 w 就是 0。
|
||||
|
||||
@@ -97,7 +97,7 @@ Crash course 的课程,可以基本了解pytorch的内容,但是当然有很
|
||||
|
||||
# 关于 MINIST
|
||||
|
||||

|
||||

|
||||
|
||||
这个数据集可以说是最最经典的数据集了,里面有 0-9 这 10 个数字的手写图片和标注,正确率最高已经到了 99.7%.
|
||||
|
||||
|
||||
@@ -4,7 +4,7 @@
|
||||
|
||||
进入官网后选择 Install,在下面表格中按照你的配置进行选择:
|
||||
|
||||

|
||||

|
||||
|
||||
其中 Package 部分选择安装的途径,这里主要介绍 Pip 和 Conda 两种途径。
|
||||
|
||||
@@ -56,8 +56,8 @@ conda config --show channels
|
||||
|
||||
同时按下 Win+R,运行 cmd,输入 `dxdiag` 并回车。系统、显卡、声卡以及其他设备信息都会显示。
|
||||
|
||||

|
||||

|
||||
|
||||
cuda 版本查看
|
||||
|
||||

|
||||

|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
### CV 领域的大任务
|
||||
|
||||

|
||||

|
||||
|
||||
#### (a)Image classification <strong>图像分类</strong>
|
||||
|
||||
@@ -18,7 +18,7 @@
|
||||
|
||||
- 这张图我们需要标注两个类别 `head(头)、helmet(头盔)`
|
||||
|
||||

|
||||

|
||||
|
||||
#### (c)Semantic segmentation <strong>语义分割</strong>
|
||||
|
||||
@@ -32,13 +32,13 @@
|
||||
|
||||
#### (e)Key Point 人体关键点检测
|
||||
|
||||

|
||||

|
||||
|
||||
通过人体关键节点的组合和追踪来识别人的运动和行为,对于描述人体姿态,预测人体行为至关重要。
|
||||
|
||||
#### (f)Scene Text Recognition(STR)场景文字识别
|
||||
|
||||

|
||||

|
||||
|
||||
很多照片中都有一些文字信息,这对理解图像有重要的作用。
|
||||
|
||||
@@ -48,7 +48,7 @@
|
||||
|
||||
利用两张图片或者其他信息生成一张新的图片
|
||||
|
||||

|
||||

|
||||
|
||||
利用左边两张小图生成右边的图片
|
||||
|
||||
@@ -56,6 +56,6 @@
|
||||
|
||||
将输入图片分辨率增加
|
||||
|
||||

|
||||

|
||||
|
||||
当然还有一些新兴领域我们没有写入~
|
||||
|
||||
@@ -117,7 +117,7 @@ Torchvision 库中的 torchvision.datasets 包中提供了丰富的图像数据
|
||||
|
||||
下表中列出了 torchvision.datasets 包所有支持的数据集。各个数据集的说明与接口,详见链接 [https://pytorch.org/vision/stable/datasets.html](https://pytorch.org/vision/stable/datasets.html)。
|
||||
|
||||

|
||||

|
||||
|
||||
注意,torchvision.datasets 这个包本身并不包含数据集的文件本身,它的工作方式是先从网络上把数据集下载到用户指定目录,然后再用它的加载器把数据集加载到内存中。最后,把这个加载后的数据集作为对象返回给用户。
|
||||
|
||||
@@ -129,11 +129,11 @@ MNIST 数据集是一个著名的手写数字数据集,因为上手简单,
|
||||
|
||||
MNIST 数据集是 NIST 数据集的一个子集,MNIST 数据集你可以通过[这里](http://yann.lecun.com/exdb/mnist/)下载。它包含了四个部分。
|
||||
|
||||

|
||||

|
||||
|
||||
MNIST 数据集是 ubyte 格式存储,我们先将“训练集图片”解析成图片格式,来直观地看一看数据集具体是什么样子的。具体怎么解析,我们在后面数据预览再展开。
|
||||
|
||||

|
||||

|
||||
|
||||
接下来,我们看一下如何使用 Torchvision 来读取 MNIST 数据集。
|
||||
|
||||
|
||||
@@ -12,21 +12,21 @@ AlexNet 有 6 千万个参数和 650,000 个神经元。
|
||||
|
||||
### <strong>网络框架图</strong>
|
||||
|
||||

|
||||

|
||||
|
||||
### <strong>使用 ReLU 激活函数代替 tanh</strong>
|
||||
|
||||
在当时,标准的神经元激活函数是 tanh()函数,这种饱和的非线性函数在梯度下降的时候要比非饱和的非线性函数慢得多,因此,在 AlexNet 中使用 ReLU 函数作为激活函数。
|
||||
|
||||

|
||||

|
||||
|
||||
### <strong>采用 Dropout 防止过拟合</strong>
|
||||
|
||||
dropout 方法会遍历网络的每一层,并设置消除神经网络中节点的概率。假设网络中的每一层,每个节点都以抛硬币的方式设置概率,每个节点得以保留和消除的概率都是 0.5,设置完节点概率,我们会消除一些节点,然后删除掉从该节点进出的连线,最后得到一个节点更少,规模更小的网络(如下图所示),然后再用反向传播方法进行训练。
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
###
|
||||
|
||||
|
||||
@@ -10,7 +10,7 @@
|
||||
|
||||
### 框架图
|
||||
|
||||

|
||||

|
||||
|
||||
### 同 CNN 的对比
|
||||
|
||||
@@ -26,7 +26,7 @@ FCN 对图像进行像素级的分类,从而解决了语义级别的图像分
|
||||
|
||||
这里图像的反卷积使用了这一种反卷积手段使得图像可以变大,FCN 作者使用的方法是这里所说反卷积的一种变体,这样就可以获得相应的像素值,图像可以实现 end to end。
|
||||
|
||||

|
||||

|
||||
|
||||
### 视频
|
||||
|
||||
|
||||
@@ -21,11 +21,11 @@
|
||||
|
||||
如图所示,随着层数越来越深,预测的效果反而越来越差(error 越大)
|
||||
:::
|
||||

|
||||

|
||||
|
||||
## 网络模型
|
||||
|
||||

|
||||

|
||||
|
||||
::: warning 😺
|
||||
我们可以看到,ResNet 的网络依旧非常深,这是因为研究团队不仅发现了退化现象,还采用出一个可以将网络继续加深的 trick:shortcut,亦即我们所说的 residual。
|
||||
@@ -35,7 +35,7 @@
|
||||
:::
|
||||
### residual 结构
|
||||
|
||||

|
||||

|
||||
|
||||
## 网络代码
|
||||
|
||||
|
||||
@@ -8,7 +8,7 @@
|
||||
|
||||
## 网络框架
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
::: warning 😺
|
||||
|
||||
@@ -6,11 +6,11 @@
|
||||
|
||||
- 你可以先行尝试一下怎么把在 MNIST 上训练的网络真正投入应用,比如识别一张你自己用黑笔写的数字~
|
||||
|
||||

|
||||

|
||||
|
||||
- 比如你可以尝试训练一个网络来实现人体五官分割(笔者之前就玩过这个)数据集采用 [helen 数据集](https://pages.cs.wisc.edu/~lizhang/projects/face-parsing/),关于数据集的架构你可以搜一搜,自己设计一个 Dataloader 和 YourModle 来实现前言中的五官分割效果(真的很有乐子 hhh)
|
||||
|
||||

|
||||

|
||||
|
||||
- 当然你也可以尝试一些自己感兴趣的小任务来锻炼工程能力~
|
||||
|
||||
|
||||
@@ -6,11 +6,11 @@ NeRF 想做这样一件事,不需要中间三维重建的过程,仅根据位
|
||||
|
||||
在生成建模前,我们需要对被建模物体进行密集的采样,如下图是一个示例的训练集,它含有 100 张图片以及保存了每一张图片相机参数(表示拍摄位置,拍摄角度,焦距的矩阵)的 json 文件。
|
||||
|
||||

|
||||

|
||||
|
||||
你可以看到,这 100 张图片是对一个乐高推土机的多角度拍摄结果。我们需要的是一个可<strong>以获取这个推土机在任意角度下拍摄的图片</strong>的模型。如图所示:
|
||||
|
||||

|
||||

|
||||
|
||||
现在来看 NeRF 网络:
|
||||
|
||||
@@ -40,7 +40,7 @@ NeRF 想做这样一件事,不需要中间三维重建的过程,仅根据位
|
||||
- 对应的小方块的 RGB 信息
|
||||
- 不透明度
|
||||
|
||||

|
||||

|
||||
|
||||
在这里,作者选择了最简单的 MLP,因此,<strong>这是一个输入为 5 维,输出为 4 维向量</strong>($R,G,B,\sigma$)的简单网络,值得注意的是,不透明度与观察角度无关,这里在网络中进行了特殊处理,让这个值与后两维无关。
|
||||
|
||||
@@ -58,15 +58,15 @@ NeRF 想做这样一件事,不需要中间三维重建的过程,仅根据位
|
||||
|
||||
这段要仔细看和推导,第一遍不容易直接懂。顺带一提,我们的<strong>小方块</strong>学名叫<strong>体素</strong>,<del>为了显得我们更专业一点以后就叫它体素罢</del>
|
||||
|
||||

|
||||

|
||||
|
||||
上面所说的公式具体如下:t 是我们的$\sigma$,$t_f,t_n$分别是离发射点最远的体素和最近的体素。这个公式求得是像素的颜色。
|
||||
|
||||

|
||||

|
||||
|
||||
思路总体如上,这里放一张找来的渲染过程示意图(<del>不知道为什么有点包浆</del>)
|
||||
|
||||

|
||||

|
||||
|
||||
# 算法细节部分
|
||||
|
||||
@@ -86,10 +86,10 @@ NeRF 想做这样一件事,不需要中间三维重建的过程,仅根据位
|
||||
|
||||
粗网络就是上述采样方法用的普通网络,而<strong>粗网络输出的不透明度值会被作为一个概率分布函数</strong>,精细网络根据这个概率分布在光线上进行采样,不透明度越大的点,它的邻域被采样的概率越大,也就实现了我们要求的在实体上多采样,空气中少采样。最后精细网络输出作为结果,因此粗网络可以只求不透明度,无视颜色信息。
|
||||
|
||||

|
||||

|
||||
|
||||
## 位置编码
|
||||
|
||||
学过 cv 的大家想必对这个东西耳熟能详了吧~,这里的位置编码是对输入的两个位置和一个方向进行的(体素位置,相机位置和方向),使用的是类似 transformer 的三角函数类编码如下。位置编码存在的意义是放大原本的 5 维输入对网络的影响程度,把原本的 5D 输入变为 90 维向量;并且加入了与其他体素的相对位置信息。
|
||||
|
||||

|
||||

|
||||
|
||||
@@ -12,19 +12,19 @@
|
||||
|
||||
<strong>Pixel-nerf</strong><strong> </strong>对输入图像使用卷积进行特征提取再执行 nerf,若有多个输入,对每个视角都执行 CNN,在计算光线时,取每一个已有视角下该坐标的特征,经过 mlp 后算平均。可以在少量视角下重建视图,需要进行预训练才能使用,有一定自动补全能力(有限)
|
||||
|
||||

|
||||

|
||||
|
||||
### 2.IBRnet
|
||||
|
||||
<strong>IBRnet</strong><strong> </strong>是 pixel-nerf 的改进版,取消了 CNN,并且在 mlp 后接入了 transformer 结构处理体密度(不透明度),对这条光线上所有的采样点进行一个 transformer。同时,在获取某个体素的颜色和密度时,作者用了本视角相邻的两个视角,获取对应体素在这两张图片中的像素,以图片像素颜色,视角,图片特征作为 mlp 的输入。
|
||||
|
||||

|
||||

|
||||
|
||||
### 3.MVSnerf
|
||||
|
||||
<strong>MVSnerf</strong><strong> </strong>它用 MVS 的方法构建代价体然后在后面接了一个 nerf,MVS 是使用<strong>多视角立体匹配</strong>构建一个代价体,用 3D 卷积网络进行优化,这里对代价体进行 nerf 采样,可以得到可泛化网络。它需要 15min 的微调才能在新数据上使用。<strong>多视角立体匹配是一种传统算法,通过光线,几何等信息计算图像中小块的相似度,得出两个相机视角之间的位置关系。这个算法也被广泛使用在得到我们自己采样的数据的相机变换矩阵上(我就是这么干的)</strong>
|
||||
|
||||

|
||||

|
||||
|
||||
此处涉及较多图形学,使用了平面扫描算法,其中有单应性变换这个角度变换算法,推导与讲解如下:
|
||||
|
||||
@@ -34,7 +34,7 @@
|
||||
|
||||
平面扫描就是把 A 视角中的某一像素点(如图中红色区域)的相邻的几个像素提取出来,用单应性变换转换到 B 视角中,这时候用的深度是假设的深度,遍历所有假设的深度,计算通过每一个假设深度经过单应性变换得到的像素小块和 B 视角中对应位置的差值(loss),取最小的 loss 处的深度作为该像素的深度。
|
||||
|
||||

|
||||

|
||||
|
||||
构建代价体:
|
||||
|
||||
@@ -55,7 +55,7 @@
|
||||
|
||||
展开说说:其实这也是神经网络发展的一个方向,以前的深层网络倾向于把所有东西用网络参数表示,这样推理速度就会慢,这里使用哈希表的快速查找能力存储一些数据信息,instant-ngp 就是把要表达的模型数据特征按照不同的精细度存在哈希表中,使用时通过哈希表调用或插值调用。
|
||||
|
||||

|
||||

|
||||
|
||||
# 3.可编辑(指比如人体运动等做修改工作的)
|
||||
|
||||
@@ -63,7 +63,7 @@
|
||||
|
||||
<strong>Human-nerf</strong><strong> </strong>生成可编辑的人体运动视频建模,输入是一段人随便动动的视频。输出的动作可以编辑修改,并且对衣物折叠等有一定优化。使用的模型并非全隐式的,并且对头发和衣物单独使用变换模型。使用了逆线性蒙皮模型提取人物骨骼(可学习的模型),上面那个蓝色的就是姿态矫正模块,这个模块赋予骨骼之间运动关系的权重(因为使用的是插值处理同一运动时不同骨骼的平移旋转矩阵,一块骨骼动会牵动其他骨骼)图中的 Ω 就是权重的集合,它通过 mlp 学习得到。然后得到显式表达的人物骨骼以及传入视频中得到的对应骨骼的 mesh,skeletal motion 就是做游戏人物动作用的编辑器这种,后面残差链接了一个 non-rigid-motion(非刚性动作),这个是专门处理衣物和毛发的,主要通过学习得到,然后粗暴的加起来就能得到模型,再经过传统的 nerf 渲染出图像。
|
||||
|
||||

|
||||

|
||||
|
||||
### 2.Neural Body
|
||||
|
||||
@@ -75,7 +75,7 @@
|
||||
|
||||
EasyMocap 是通过多视角视频生成骨架以及 SMPL 模型的一个工作,演示视频右下。
|
||||
|
||||

|
||||

|
||||
|
||||
这是 EasyMocap 的演示。
|
||||
|
||||
@@ -87,7 +87,7 @@ EasyMocap 是通过多视角视频生成骨架以及 SMPL 模型的一个工作
|
||||
|
||||
是个预训练模型,<strong>训练的模块就是这个 3D 卷积神经网络</strong>。
|
||||
|
||||

|
||||

|
||||
|
||||
### 3.wild-nerf
|
||||
|
||||
@@ -101,11 +101,11 @@ EasyMocap 是通过多视角视频生成骨架以及 SMPL 模型的一个工作
|
||||
|
||||
在此网络的单个输出上貌似是不监督的,因为没办法进行人为标注。这点我不是很确定,以后如果发现了会来修改的。
|
||||
|
||||

|
||||

|
||||
|
||||
渲染经过形变的物体时,光线其实是在 t=0 时刻进行渲染的,因为推土机的铲子放下去了,所以<strong>光线是弯曲的</strong>。
|
||||
|
||||

|
||||

|
||||
|
||||
# 4.用于辅助传统图像处理
|
||||
|
||||
@@ -123,23 +123,23 @@ EasyMocap 是通过多视角视频生成骨架以及 SMPL 模型的一个工作
|
||||
|
||||
<strong>GRAF</strong><strong> </strong>把 GAN 与 nerf 结合,增加了两个输入,分别是<strong>外观/形状编码 z</strong>和<strong>2D 采样编码 v</strong>,z 用来改变渲染出来东西的特征,比如把生成的车变色或者变牌子,suv 变老爷车之类的。v(s,u)用来改变下图 2 中训练时选择光线的标准。这里训练时不是拿 G 生成的整张图扔进 D 网络,而是根据 v 的参数选择一些光线组成的 batch 扔进 D 进行辨别
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
### 2.GIRAFFE
|
||||
|
||||
<strong>GIRAFFE</strong> 是 GRAF 的改进工作,可以把图片中的物品,背景一个个解耦出来单独进行改变或者移动和旋转,也可以增加新的物品或者减少物品,下图中蓝色是不可训练的模块,橙色可训练。以我的理解好像要设置你要解耦多少个(N)物品再训练,网络根据类似 k 近邻法的方法在特征空间上对物品进行分割解耦,然后分为 N 个渲染 mlp 进行训练,训练前加入外观/形状编码 z。最后还是要扔进 D 训练。
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
### 3.OSF
|
||||
|
||||
<strong>OSF</strong>Object-Centric Neural Scene Rendering,可以给移动的物体生成合理的阴影和光照效果。加入了新的坐标信息:光源位置,与相机坐标等一起输入。对每个小物件构建一个单独的小 nerf,计算这个小 nerf 的体素时要先经过光源照射处理(训练出来的)然后在每个小物件之间也要计算反射这样的光线影响,最后进行正常的渲染。<del>这篇文章没人写 review,有点冷门,这些都是我自己读完感觉的,不一定对。</del>
|
||||
|
||||

|
||||

|
||||
|
||||
### 4.Hyper-nerf-gan
|
||||
|
||||
@@ -153,7 +153,7 @@ EasyMocap 是通过多视角视频生成骨架以及 SMPL 模型的一个工作
|
||||
|
||||
左边是常规卷积网络生成图像,右边是用 INR 生成图像。
|
||||
|
||||

|
||||

|
||||
|
||||
这种方法存在两个问题:
|
||||
|
||||
@@ -165,8 +165,8 @@ EasyMocap 是通过多视角视频生成骨架以及 SMPL 模型的一个工作
|
||||
|
||||
FMM 主要是把要学习的矩阵转化为两个低秩矩阵,去先生成他们俩再相乘,减少网络计算量。
|
||||
|
||||

|
||||

|
||||
|
||||
现在开始讲 Hyper-nerf-gan 本身,它看上去其实就是 nerf 接在 gan 上。不过有一些变化,比如输入不再包含视角信息,我<strong>很怀疑它不能很好表达反光效果</strong>。而且抛弃了粗网络细网络的设计,只使用粗网络减少计算量。这里的 generator 完全就是 INR-Gan 的形状,生成权重,然后再经过 nerf 的 mlp 层生成,没啥别的了,就这样吧。
|
||||
|
||||

|
||||

|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
如何使用和怎么下载就不讲了,直接搜就有,它可以把多个拍摄同一物体的图片转换为它们对应视角的相机矩阵和拍摄角度,可以实现自制数据集做 nerf。它的流程(SFM 算法)可以概括如下:
|
||||
|
||||

|
||||

|
||||
|
||||
这里主要是记录一下它的原理:
|
||||
首先是一个经典关键点匹配技术:<strong>SIFT</strong>
|
||||
@@ -11,53 +11,53 @@
|
||||
|
||||
## DOG 金字塔
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
下面是原理方法:
|
||||
|
||||
首先是<strong>高斯金字塔</strong>,它是把原图先放大两倍,然后使用高斯滤波(高斯卷积)对图像进行模糊化数次,取出倒数第三层缩小一半继续进行这个过程,也就是说它是由一组一组的小金字塔组成的。
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
然后是基于高斯金字塔的 DOG 金字塔,也叫差分金字塔,它是把相邻的高斯金字塔层做减法得到的,因为经过高斯模糊,物体的轮廓(或者说不变特征)被模糊化,也就是被改变。通过相减可以得到这些被改变的点。
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
## 空间极值点检测
|
||||
|
||||
为了找到变化的最大的几个点来作为特征点,我们需要找到变化的极值点,因此需要进行比较,这里是在整个金字塔中进行对比,我们提取某个点周边 3*3*3 的像素点进行比较,找到最大或最小的局部极值点。
|
||||
|
||||

|
||||

|
||||
|
||||
同时我们也对关键点分配方向,也就是这个点在图片空间中的梯度方向
|
||||
|
||||
梯度为:
|
||||
|
||||

|
||||

|
||||
|
||||
梯度方向为:
|
||||
|
||||

|
||||

|
||||
|
||||
我们计算以关键点为中心的邻域内所有点的梯度方向,然后把这些 360 度范围内的方向分配到 36 个每个 10 度的方向中,并构建方向直方图,这里的示例使用了 8 个方向,几个随你其实:
|
||||
|
||||

|
||||

|
||||
|
||||
取其中最大的为主方向,若有一个方向超过主方向的 80%,那么把它作为辅方向。
|
||||
|
||||
操作可以优化为下图,先把关键点周围的像素分成 4 块,每块求一次上面的操作,以这个 4 个梯度直方图作为关键点的方向描述。也就是一个 2*2*8(方向数量)的矩阵作为这个点的方向特征。
|
||||
|
||||

|
||||

|
||||
|
||||
实验表明,使用 4*4*8=122 的描述更加可靠。
|
||||
|
||||

|
||||

|
||||
|
||||
特征点的匹配是通过计算两组特征点的 128 维的关键点的欧式距离实现的。欧式距离越小,则相似度越高,当欧式距离小于设定的阈值时,可以判定为匹配成功。
|
||||
|
||||
|
||||
@@ -8,10 +8,10 @@
|
||||
|
||||
该任务目前在学术上是检索出不同摄像头下的相同行人图片,同时数据集中只有人的全身照,如下图所示。
|
||||
|
||||

|
||||

|
||||
|
||||
但是实际上在实际应用中的时候会和检测结合,简单来说先框出目标后分类,如下图所示。
|
||||
|
||||

|
||||

|
||||
|
||||
这个方向做的比较的奇怪,该模块只做整体性介绍,同时希望学习该模块的你对经典网络有所了解。
|
||||
|
||||
@@ -4,25 +4,25 @@
|
||||
|
||||
<strong>分类 (text classification):</strong> 给一句话或者一段文本,判断一个标签。
|
||||
|
||||

|
||||

|
||||
|
||||
图 2:分类 (text classification)
|
||||
|
||||
<strong>蕴含 (textual entailment):</strong> 给一段话,和一个假设,看看前面这段话有没有蕴含后面的假设。
|
||||
|
||||

|
||||

|
||||
|
||||
图 3:蕴含 (textual entailment)
|
||||
|
||||
<strong>相似 (Similarity):</strong> 判断两段文字是否相似。
|
||||
|
||||

|
||||

|
||||
|
||||
图 4:相似 (Similarity)
|
||||
|
||||
<strong>多选题 (Multiple Choice):</strong> 给个问题,从 N 个答案中选出正确答案。
|
||||
|
||||

|
||||

|
||||
|
||||
图 5:多选题 (Multiple Choice)
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# 推荐系统的外围架构
|
||||
|
||||

|
||||

|
||||
|
||||
<center>推荐系统外围架构图</center>
|
||||
|
||||
@@ -22,7 +22,7 @@
|
||||
若是将推荐系统的任务细分,可以结合现实实际情况:将最新加入的物品推荐给用户;商业上需要宣传的物品推荐给用户;为用户推荐不同种类的物品。
|
||||
**复杂的特征和情况不同的任务**会让推荐系统变得非常复杂,所以推荐系统的架构为了方便考虑,采用多个不同的推荐引擎组成,每个推荐引擎专门负责某一类特征和一种任务,而推荐系统再将推荐引擎的结果按照一定的优先级合并,排序并返回给UI系统。
|
||||
|
||||

|
||||

|
||||
|
||||
<center>推荐系统的架构</center>
|
||||
如上图所示。
|
||||
@@ -38,7 +38,7 @@
|
||||
|
||||
- 推荐列表筛选、过滤、重排列部分
|
||||
|
||||

|
||||

|
||||
|
||||
以上为推荐引擎的架构图。
|
||||
|
||||
|
||||
@@ -179,7 +179,7 @@ $$Preference(u,i)=r_{ui}=p^T_uq_i=\sum^F_{f=1}{p_{u,k}q_{i,k}}$$
|
||||
|
||||
在研究图模型之前,需要用已有的数据生成一个图,设二元组 $(u,i)$ 表示用u对于物品 i 产生过行为。令 $G(V,E)$ 表示用户物品二分图,其中$V=V_U\cup V_I$ 由用户顶点集合和物品顶点集合组成,$E$ 是边的集合。对于数据集中的二元组 $(u,i)$ 图中都会有对应的边 $e(v_u,v_i)\in E$ 如下图所示。
|
||||
|
||||

|
||||

|
||||
|
||||
### 基于图的推荐算法
|
||||
|
||||
|
||||
@@ -10,5 +10,5 @@
|
||||
<br/><br/>
|
||||
而SRSs则是将用户和商品的交互建模为一个动态的序列并且利用序列的依赖性来活捉当前和最近用户的喜好。
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
@@ -4,7 +4,7 @@
|
||||
|
||||
如下图是阿里巴巴著名的“千人千面”推荐系统
|
||||
|
||||

|
||||

|
||||
|
||||
还有短视频应用用户数量的急剧增长,这背后,视频推荐引擎发挥着不可替代的作用
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@
|
||||
|
||||
## 模型详解
|
||||
|
||||

|
||||

|
||||
|
||||
### 模型主题结构
|
||||
|
||||
@@ -51,9 +51,9 @@
|
||||
|
||||
例如
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
其中该张图片的编码为[0.5,0.6,0.3,....]
|
||||
|
||||
|
||||
@@ -30,13 +30,13 @@ mlp 的重点和创新并非它的模型结构,而是它的训练方式,前
|
||||
|
||||
BERT 模型的输入就是上面三者的和,如图所示:
|
||||
|
||||

|
||||

|
||||
|
||||
## 模型结构
|
||||
|
||||
简单来说,BERT 是 transformer<strong>编码器</strong>的叠加,<strong>也就是下图左边部分</strong>。这算一个 block。
|
||||
|
||||

|
||||

|
||||
|
||||
说白了就是一个 多头自注意力=>layer-norm=> 接 feed forward(其实就是 mlp)=>layer-norm,没有什么创新点在这里。因为是一个 backbone 模型,它没有具体的分类头之类的东西。输出就是最后一层 block 的输出。
|
||||
|
||||
|
||||
@@ -28,7 +28,7 @@ cv 领域,其实预训练模型早已推广,一般是在 imagenet 上进行
|
||||
|
||||
在这里,作者为了加大任务的难度,扩大了被 mask 掉的比例,避免模型只学到双线性插值去修补缺的图像。作者把 75% 的 patch 进行 mask,然后放入模型训练。从下图可以看出,被 mask 的块是不进行编码的,这样也可以降低计算量,减少成本。
|
||||
|
||||

|
||||

|
||||
|
||||
在被保留的块通过编码器后,我们再在原先位置插入只包含位置信息的 mask 块,一起放入解码器。
|
||||
|
||||
@@ -38,7 +38,7 @@ cv 领域,其实预训练模型早已推广,一般是在 imagenet 上进行
|
||||
|
||||
下面是原论文给的训练结果,可以看到效果是很惊人的。(有些图我脑补都补不出来)
|
||||
|
||||

|
||||

|
||||
|
||||
# 相关资料
|
||||
|
||||
|
||||
@@ -24,7 +24,7 @@
|
||||
|
||||
直观来讲,我们把特征的向量进行一下归一化,它们就分布在一个超球面上。简单起见,我们先看 3 维向量
|
||||
|
||||

|
||||

|
||||
|
||||
我们通过<strong>正样本</strong>(跟拿到的特征<strong>应当相近</strong>的另一个特征)与<strong>负样本</strong>(反之)的对比,使得
|
||||
|
||||
|
||||
@@ -8,7 +8,7 @@
|
||||
|
||||
作者团队认为,让这些猎豹,雪豹的标签相互接近(指互相在判别时都排名靠前)的原因并不是它们有相似的标签,而是它们有相似的图像特征。
|
||||
|
||||

|
||||

|
||||
|
||||
## 个体判别任务
|
||||
|
||||
@@ -16,7 +16,7 @@
|
||||
|
||||
于是他们<strong>把每一个图片当作一个类别</strong>,去跟其他的图片做对比,具体模型如下
|
||||
|
||||

|
||||

|
||||
|
||||
先介绍一下模型结构:
|
||||
|
||||
@@ -48,11 +48,11 @@
|
||||
|
||||
A 是起始点,B 是第一次更新后的点,C 是第二次更新后的点
|
||||
|
||||

|
||||

|
||||
|
||||
而在我们刚刚提到的动量更新里,它的公式可以概括为:
|
||||
|
||||

|
||||

|
||||
|
||||
m 表示动量,k 是新的特征,q 是上一个特征,只要设置小的动量就可以使改变放缓。
|
||||
|
||||
|
||||
@@ -4,7 +4,7 @@
|
||||
|
||||
# 1.时序性定义(生成式模型)
|
||||
|
||||

|
||||

|
||||
|
||||
这是处理音频的一个例子,<strong>给模型 t 时刻以前的信息,让它抽取特征并对后文进行预测,真正的后文作为正样本,负样本当然是随便选取就好啦。</strong>
|
||||
|
||||
@@ -24,4 +24,4 @@
|
||||
|
||||
(这篇论文我准备开个新坑放着了,因为说实话不算对比学习,算多模态)
|
||||
|
||||

|
||||

|
||||
|
||||
@@ -24,7 +24,7 @@ NCE 把<strong>所有负样本都视作一样的</strong>,但实际上负样
|
||||
|
||||
右边就是 memory bank 啦
|
||||
|
||||

|
||||

|
||||
|
||||
# MoCo 做出的改进
|
||||
|
||||
@@ -38,7 +38,7 @@ NCE 把<strong>所有负样本都视作一样的</strong>,但实际上负样
|
||||
|
||||
动量编码器是独立于原编码器的一个编码器,它的参数是根据原编码器动量更新的,k 和 q 就是指代全部参数了
|
||||
|
||||

|
||||

|
||||
|
||||
这样的话就是解码器在缓慢更新,比对特征使用动量更新要更有连续性。
|
||||
|
||||
@@ -48,7 +48,7 @@ NCE 把<strong>所有负样本都视作一样的</strong>,但实际上负样
|
||||
|
||||
[(什么?你看到这了还不会交叉熵?戳这里)](https://zhuanlan.zhihu.com/p/149186719)
|
||||
|
||||

|
||||

|
||||
|
||||
q·k 其实就是各个特征(因为那时候用的都是 transformer 了,这里就是 trnasformer 里的 k 和 q)
|
||||
|
||||
@@ -56,9 +56,9 @@ q·k 其实就是各个特征(因为那时候用的都是 transformer 了,
|
||||
|
||||
T 越大,损失函数就越对所有负样本<strong>一视同仁</strong>,退化为二分类的 NCEloss;T 越小,损失函数就<strong>越关注一些难分类的特征</strong>,但有时候会出现两张其实都是猫猫的图片,你硬要让模型说猫猫跟猫猫不一样,这也不太好,这个参数要根据数据集情况适中调整。
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
上面那张是 T 较大的情况,下面是 T 较小的情况(x 轴是各个类别,y 轴是分类得分)
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@
|
||||
|
||||
x 是输入的图片,它经过两种不同的数据增强得到 xi 和 xj 两个正样本,而同一个 mini-batch 里的所有其他样本都作为负样本。<del>说白了还是个体判别任务</del>
|
||||
|
||||

|
||||

|
||||
|
||||
左右的<strong>f 都是编码器</strong>,并且是<strong>完全一致共享权重</strong>的,可以说是同一个。
|
||||
|
||||
@@ -18,7 +18,7 @@ x 是输入的图片,它经过两种不同的数据增强得到 xi 和 xj 两
|
||||
|
||||
下面这个是更加具体的流程图
|
||||
|
||||

|
||||

|
||||
|
||||
# 总结
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@
|
||||
|
||||
下图左边是常规的对比学习(比如 SimCLR)的结构,右图是 SWAV 的结构,不难看出多了一个叫 prototypes 的东西。这个东西其实是聚类中心向量所构成的矩阵。
|
||||
|
||||

|
||||

|
||||
|
||||
下面的内容可能有些理解上的难度(反正我第一次听讲解的时候就云里雾里的),我会尽可能直白地描述这个过程。
|
||||
|
||||
@@ -40,7 +40,7 @@
|
||||
|
||||
而我们的优化要采用 [K-means](https://zhuanlan.zhihu.com/p/78798251)(不懂可以看这里)的类似做法,先对聚类中心进行优化,再对特征进行优化。
|
||||
|
||||

|
||||

|
||||
|
||||
so,why?相信你现在肯定是一脸懵,不过别急,希望我能为你讲懂。
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@
|
||||
|
||||
<strong>predictor</strong>的模型结构就是跟 z 一样的<strong>mlp 层</strong>。它的任务是<strong>通过紫色的特征去预测粉色的特征</strong>。也就是说它的代理任务换成了<strong>生成式</strong>。
|
||||
|
||||

|
||||

|
||||
|
||||
而具体的损失只有预测特征和真实特征的损失,用的是<strong>MSEloss</strong>。
|
||||
|
||||
@@ -32,7 +32,7 @@
|
||||
|
||||
### 有篇博客在复现 BYOL 时,不小心没加这个 BN 层,导致模型直接摆烂。那么 BN 到底藏着什么呢?
|
||||
|
||||

|
||||

|
||||
|
||||
我们得先来回顾一下 BN 做了什么。
|
||||
|
||||
@@ -52,7 +52,7 @@ BN 根据批次的均值和方差进行归一化
|
||||
|
||||
这篇论文叫 BYOL works even without batch statistics,即在没有 BN 的时候 BYOL 照样能工作,详细的消融实验结果如下表所示 :
|
||||
|
||||

|
||||

|
||||
|
||||
<strong>BN 非常关键</strong>:只要是 `projector`(SimCLR 提出的 mlp)中没有 BN 的地方,SimCLR 性稍微下降;但是 BYOL 全都模型坍塌了。
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@ BYOL 之后,大家都发现对比学习是靠许许多多的小 trick 和技
|
||||
|
||||
虽然看起来只有左边预测右边,其实右边也有一个 predictor 去预测左边的特征,两边是对称的,左右的优化有先后顺序。
|
||||
|
||||

|
||||

|
||||
|
||||
结构其实没什么特殊的地方,主要讲讲思想。
|
||||
|
||||
@@ -44,7 +44,7 @@ BYOL 之后,大家都发现对比学习是靠许许多多的小 trick 和技
|
||||
|
||||
这是作者总结的所有”孪生网络“的模型结构,很精炼。
|
||||
|
||||

|
||||

|
||||
|
||||
下面是这些网络训练结果的对比,也列出了它们分别有哪些 trick(用的是分类任务)
|
||||
|
||||
@@ -52,8 +52,8 @@ BYOL 之后,大家都发现对比学习是靠许许多多的小 trick 和技
|
||||
负样本 动量编码器 训练轮数
|
||||
```
|
||||
|
||||

|
||||

|
||||
|
||||
具体结果还是图片比较直观(
|
||||
|
||||

|
||||

|
||||
|
||||
@@ -10,7 +10,7 @@ MoCo v3,它缝合了 MoCo 和 SimSiam,以及新的骨干网络 VIT。
|
||||
|
||||
可能因为和前面的工作太像了,作者就没有给模型总览图,我们借 MoCo 的总览图来讲
|
||||
|
||||

|
||||

|
||||
|
||||
总体架构其实没有太多变化,还是 memory bank 的结构,右边也还是动量编码器,不过加入了 SimCLR 提出的 projection head(就是额外的那层 mlp),并且在对比上用了 SimSiam 的预测头对称学习方式。具体也不展开了,都是老东西缝合在一起。
|
||||
|
||||
@@ -18,11 +18,11 @@ MoCo v3,它缝合了 MoCo 和 SimSiam,以及新的骨干网络 VIT。
|
||||
|
||||
作者在用 VIT 做骨干网络训练的时候,发现如下问题:
|
||||
|
||||

|
||||

|
||||
|
||||
在使用 VIT 训练的时候,batchsize 不算太大时训练很平滑,但是一旦 batchsize 变大,训练的图像就会出现如上图这样的<strong>波动</strong>。于是作者去查看了每一层的梯度,发现问题出在<strong>VIT 的第一层线性变换</strong>上。也就是下图中的粉色那个层,<strong>把图片打成 patch 后展平做的线性变换</strong>。
|
||||
|
||||

|
||||

|
||||
|
||||
在这一层中,梯度会出现波峰,而正确率则会突然下跌。
|
||||
|
||||
|
||||
@@ -4,13 +4,13 @@
|
||||
|
||||
## 强化学习的基本过程
|
||||
前面已经介绍过强化学习的核心过程,在于智能体与环境进行交互,通过给出的奖励反馈作为信号学习的过程。简单地用图片表示如下:
|
||||

|
||||

|
||||
正是在这个与环境的交互过程中,智能体不断得到反馈,目标就是尽可能地让环境反馈的奖励足够大。
|
||||
|
||||
## 强化学习过程的基本组成内容
|
||||
为了便于理解,我们引入任天堂经典游戏——[新超级马里奥兄弟U](https://www.nintendoswitch.com.cn/new_super_mario_bros_u_deluxe/pc/index.html),作为辅助理解的帮手。作为一个2D横向的闯关游戏,它的状态空间和动作空间无疑是简单的。
|
||||
|
||||

|
||||

|
||||
|
||||
1.智能体(Agent):它与环境交互,可以观察到环境并且做出决策,然后反馈给环境。在马里奥游戏中,能操控的这个马里奥本体就是智能体。
|
||||
|
||||
@@ -22,7 +22,7 @@
|
||||
|
||||
5.策略(Policy):智能体采取动作的规则,分为**确定性策略**与**随机性策略**。确定性策略代表在相同的状态下,智能体所输出的动作是唯一的。而随机性策略哪怕是在相同的状态下,输出的动作也有可能不一样。这么说有点过于抽象了,那么请思考这个问题:在下面这张图的环境中,如果执行确定性策略会发生什么?(提示:着重关注两个灰色的格子)
|
||||
|
||||

|
||||

|
||||
|
||||
因此,在强化学习中我们一般使用随机性策略。随机性策略通过引入一定的随机性,使环境能够被更好地探索。同时,如果策略固定——你的对手很容易能预测你的下一步动作并予以反击,这在博弈中是致命的。
|
||||
随机性策略$\pi$定义如下:
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
SRT 社团,全名 Student Research Trainning,旨在通过真正的科研活动培养本科生的科研能力。SRT 社团依托 [智能信息处理处理实验室](http://iipl.net.cn/index/list_team.aspx)(IIPL),主要研究方向围绕人工智能,具体来说,包括:计算机视觉,多模态,3D 视觉,Slam 等领域。有充足且优质的显卡资源,工位资源,以及学长学姐,老师的指导。
|
||||
|
||||

|
||||

|
||||
|
||||
社团每年都在全校范围为智能信息处理实验室招收,培养本科生。本科生进入实验室后跟随导师独立或合作进行科研项目,发表论文。我们届时会在自动化以及通信学院进行宣讲招新,新生在经过1-2学期的培养后,能够具备独立科研的能力。在正式进入实验室前,可以暂时使用社团的工位,进入实验室后可以拥有独立工位以及显卡资源。社团的实验室在科技馆五楼,欢迎大家常来 ~
|
||||
|
||||
@@ -12,4 +12,4 @@ SRT 社团,全名 Student Research Trainning,旨在通过真正的科研活
|
||||
|
||||
当然,在学习人工智能模块时遇到任何问题也都可以咨询我们,我们将在能力范围内尽力给各位解答!
|
||||
|
||||

|
||||

|
||||
|
||||
Reference in New Issue
Block a user