diff --git a/1.杭电生存指南/1.1人文社科的重要性(韩健夫老师寄语).md b/1.杭电生存指南/1.1人文社科的重要性(韩健夫老师寄语).md
index 76ccdbe..4f10c06 100644
--- a/1.杭电生存指南/1.1人文社科的重要性(韩健夫老师寄语).md
+++ b/1.杭电生存指南/1.1人文社科的重要性(韩健夫老师寄语).md
@@ -4,20 +4,20 @@
大学的真意是综合而全面的培养一个人。为什么大学有这样的职责?因为这是人最后的受教育阶段(研究生、博士生也是在大学里接受教育)。从接受教育开始到走向社会为止,这期间是人,变成一个人最为宝贵的阶段。
-大学是唯一可以与来自五湖四海、不同学科背景的人共处一个校园的时期,这里就应该是开放而需要激烈思想碰撞的地方。大学是专业的,但同时更是广博的,我们在黄金的年龄来到这里,就不要轻易的错过这样疯狂吸纳不同看法的机会。同样,大学是未来所有可能性的孵化器,请保持一颗尝试新事物的心,索取大学所能给予的任何一切,并让它成为提升自我的工具。
+**大学是唯一可以与来自五湖四海、不同学科背景的人共处一个校园的时期,这里就应该是开放而需要激烈思想碰撞的地方**。大学是专业的,但同时更是广博的,我们在黄金的年龄来到这里,就不要轻易的错过这样疯狂吸纳不同看法的机会。同样,大学是未来所有可能性的孵化器,请保持一颗尝试新事物的心,索取大学所能给予的任何一切,并让它成为提升自我的工具。
工具,我并不避讳这个词。只不过我并不想将这个词与人画等号。人非工具,而是使用工具的。我们的祖先经过数百万年的努力和尝试,才学会使用并创造工具,目的就是不再沦为工具,我们站在 21 世纪也不应该心甘情愿的将自己锻造成一个工具,这是返祖与退化的表现。
21 世纪是人类对高科技和超级想象力、创造力最渴求的百年。一个想法和主意胜过千万个重复的机械化劳动,虽然后者也能带来一定程度的好处,但这并不我们的目标。大学是否能迸发出惊人的创造力,在于学生和教师的思想与行为。而不同的学科交叉和碰撞会让创造力和科技的创新更大概率出现。
-听说乔布斯有对禅宗修习的经历,而他的工作可能并不与禅宗搭边。但他的成功却不能不说与他广泛的涉猎有关。工具是没有办法创造工具的,只有人才能创造。我们大学生应该去思考在大学四年如何想办法把自己锻造成真正的人。
+听说乔布斯有对禅宗修习的经历,而他的工作可能并不与禅宗搭边。但他的成功却不能不说与他广泛的涉猎有关。工具是没有办法创造工具的,只有人才能创造。**我们大学生应该去思考在大学四年如何想办法把自己锻造成真正的人。**
-这个人不是做题的机器,不是刷题的工具,不是眼中只有考高分的单一生物,当然更不可能是成天浑浑噩噩、行尸走肉的颓丧者、躺平者。说到这里,可能会讲,难道不躺平去卷吗?并不是,我反对 “卷”,因为 “卷” 的含义是无意义的恶性竞争和没有实际突破的简单重复劳动,边际效益递减的不划算却无奈的选择。“卷” 不等于 “勤奋” 、 “创造” 和 “想要变得更强” ,将之画等号我认为是当前观念中一个很大的误区。我们需要大学生有自己的思考和创造力,需要大学生是一个综合全面发展的人。只有这样大学才有活力、希望,社会才有动力,国家才有未来。
+这个人不是做题的机器,不是刷题的工具,不是眼中只有考高分的单一生物,当然更不可能是成天浑浑噩噩、行尸走肉的颓丧者、躺平者。说到这里,可能会讲,难道不躺平去卷吗?并不是,我反对 “卷”,**因为 “卷” 的含义是无意义的恶性竞争和没有实际突破的简单重复劳动,边际效益递减的不划算却无奈的选择。**“卷” 不等于 “勤奋” 、 “创造” 和 “想要变得更强” ,将之画等号我认为是当前观念中一个很大的误区。**我们需要大学生有自己的思考和创造力,需要大学生是一个综合全面发展的人。**只有这样大学才有活力、希望,社会才有动力,国家才有未来。
我知道大学可能并不如你们想象的那般美好,有不负责的、划水上课的老师以及你看不惯的、瞧不起的种种行为,但这并不是自己选择放弃和抱怨的理由。因为,我相信大学还有认真负责的老师、有思想的学者以及有想法的同学,我们需要和自己钦佩、三观相符的人多接触,让自己成为你佩服的人的样子,而非因为种种不好的现象而选择全盘的否定、甚至自暴自弃。
- 要有自己的目标,年轻是实现自己目标最好的资本。为了这个目标,在大学里徜徉、像海绵一样吸纳如水般的知识和见识。博采众长而非简单功利。可能你今天听了不重要的课(相对于专业课),但只要是值得听的老师讲的有涵养的课,你就不算枉费时光。因为这样的经历并不会让你浪费时间,而会在未来的某刻显示出它的价值。
+** 要有自己的目标,年轻是实现自己目标最好的资本。**为了这个目标,在大学里徜徉、像海绵一样吸纳如水般的知识和见识。博采众长而非简单功利。可能你今天听了不重要的课(相对于专业课),但只要是值得听的老师讲的有涵养的课,你就不算枉费时光。因为这样的经历并不会让你浪费时间,而会在未来的某刻显示出它的价值。
-不要让自己的大脑空空,刷抖音、看游戏直播或者看无聊的视频或许是娱乐的方式,但这些是你可以在余生每天都可做的最没有技术含量的事,而且这些并不会让你大脑填入真正有价值的东西。去做只有大学时光才能做的事吧!丰富自己、创造自己、提升自己。多看一页经典的著作,这是人类上百年乃至上千年思想的精华。多认真的听一节有价值的课吧,这是老师积几十年的学识认真准备的盛宴。
+不要让自己的大脑空空,刷抖音、看游戏直播或者看无聊的视频或许是娱乐的方式,但这些是你可以在余生每天都可做的最没有技术含量的事,而且这些并不会让你大脑填入真正有价值的东西。**去做只有大学时光才能做的事吧!**丰富自己、创造自己、提升自己。多看一页经典的著作,这是人类上百年乃至上千年思想的精华。多认真的听一节有价值的课吧,这是老师积几十年的学识认真准备的盛宴。
可能你会说,大学没有好的课程,老师都在划水。如果你有这样的看法,我想说,可能是你了解的太少所致,多去了解一下一定有让你满意的老师。另外,为什么大学会出现这样不好的课程呢?因为老师不愿意好好上课。为什么老师不愿意好好教学呢?因为在功利化的指挥棒下,好好上课是性价比最低的行为。如此,你就知道大学只知道功利化、工具化的接受教育,而不培养人文素养的恶果了吧!
diff --git a/1.杭电生存指南/1.2竞赛指北.md b/1.杭电生存指南/1.2竞赛指北.md
index 331f5d4..64e6cb0 100644
--- a/1.杭电生存指南/1.2竞赛指北.md
+++ b/1.杭电生存指南/1.2竞赛指北.md
@@ -43,7 +43,7 @@
好处是本身就是落地项目,在论证项目可行性时具有很强的说服力,这类项目也相对来说会容易获奖。对于想要做实际落地项目的技术人员来说是不错的锻炼机会。
-坏处是甲方可能提出大量需求,技术人员需付出大量精力跟进,然而因为项目本身参与比赛而无法收取原定的外包费用,技术人员成为白菜大学生被白嫖(当然这个潜在可能性带来的坏处也因人而异,如果不在乎频繁改动需求 / 愿意做没有外包费用的无偿奉献,只想锻炼自己,那就无所谓)。
+坏处是甲方**可能**提出大量需求,技术人员需付出大量精力跟进,然而因为项目本身参与比赛而无法收取原定的外包费用,技术人员成为白菜大学生被白嫖(当然这个潜在可能性带来的坏处也因人而异,如果不在乎频繁改动需求 / 愿意做没有外包费用的无偿奉献,只想锻炼自己,那就无所谓)。
- 自立初创项目
diff --git a/1.杭电生存指南/1.6正确解读GPA.md b/1.杭电生存指南/1.6正确解读GPA.md
index 9df0525..770bfb5 100644
--- a/1.杭电生存指南/1.6正确解读GPA.md
+++ b/1.杭电生存指南/1.6正确解读GPA.md
@@ -10,11 +10,11 @@ GPA,一个酷似成绩的东西,
毕竟在高中,一份理想的成绩意味着一个光明的未来。
-但是我想说,在大学,请摆脱高中的绩点惯性。
+但是我想说,**在大学,请摆脱高中的绩点惯性**。
在大学,绩点其实只是一个获得资源的工具,高的绩点并不代表光明的未来,也不能够代表高超的学习能力和扎实的专业知识。同时我们要明白,与高中截然不同的是,大学是一个多目标优化问题,绩点只是优化问题的一个维度,而非所有。
-> author:晓宇
+> **author:晓宇**
所以本文会讲述 GPA 能够带来什么,什么是一个合理的对待 GPA 的态度,如果需要,如何获得一个较高的 GPA 。
@@ -90,7 +90,7 @@ B. 大一进来从来不太在意 GPA,大部分经历在研究 Github 项目
当你已经成为大学生的时候,GPA(成绩)不是和一个人的优秀的呈正相关的,这不过是一个通往一些资源的途径,同样的,也有很多资源可以不用 GPA,可以靠个人硬实力去争取,例如实习,例如科研助理云云。只是说,如果你不知道干啥,先认真学好专业课知识,是一个保有收益的事情,但当有其他选择的时候可以权衡,但也不可走另外一个极端,则完全不在乎 GPA,在职业规划并不清晰的时候不要自废道路。
-最后想说的是,一个获得资源的玩具罢了,不值得让你常沉苦海,永失真道。
+最后想说的是,一个获得资源的玩具罢了,不值得让你**常沉苦海,永失真道**。
## GPA 补充内容:
diff --git a/1.杭电生存指南/1.8转专业二三事.md b/1.杭电生存指南/1.8转专业二三事.md
index 32bd68c..ed6b3a4 100644
--- a/1.杭电生存指南/1.8转专业二三事.md
+++ b/1.杭电生存指南/1.8转专业二三事.md
@@ -4,11 +4,11 @@
相信转专业的人里,不少是慕 HDU 的强势理工科热门专业来的。但是在转专业之前,你需要先确认以下几点。
-1. 你是跟风听你家七大姑八大姨说这个专业好,才想转来这个专业的吗?
-2. 你确定你所向往的和这个专业所学的相关吗?有没有比这个专业更贴切的选择?
-3. 你确定你能良好适应(至少不反感)这个专业所学的专业课吗?
+1. 你是**跟风**听你家七大姑八大姨说这个专业好,才想转来这个专业的吗?
+2. 你确定你**所向往的**和这个专业所学的**相关**吗?有没有比这个专业更贴切的选择?
+3. 你确定你能良好适应(**至少不反感**)这个专业所学的专业课吗?
-以上的问题,如果有觉得不确定的,也没关系,你至少有一学期在学校里探索。可以是问该学院的学长学姐的感受,可以是进研究相关专业知识的社团学习,也可以是自己研究。总之,不能转专业转得迷迷糊糊,因为虽然 HDU 转专业机制比较友好,但转专业机会只有一次,如果你转进去之后发现自己完全不适应,那也只能自认倒霉。
+以上的问题,如果有觉得不确定的,也没关系,你至少有一学期在学校里探索。可以是问该学院的学长学姐的感受,可以是进研究相关专业知识的社团学习,也可以是自己研究。总之,不能转专业转得迷迷糊糊,因为虽然 HDU 转专业机制比较友好,**但转专业机会只有一次**,如果你转进去之后发现自己完全不适应,那也只能自认倒霉。
像笔者本人最初其实想做游戏开发,本身也热爱绘画之类的艺术。当年只觉得游戏开发和计算机有关,一门心思转计算机,后来转成功之后才发现其实数媒的培养计划更贴合笔者想学的,而现在所在的计科学得更多的是计算机理论方面的知识,也跟游戏开发不搭边。
@@ -29,16 +29,16 @@
:::
-转专业填报截止时间一般是在期末考试结束前后,届时最多填两个意向专业。
+转专业填报截止时间一般是在期末考试结束前后,届时**最多填两个**意向专业。
-转专业公示时间一般在开学前后。在转专业结果公示一周内,可以申请放弃转专业,此时视作已用过一次转专业机会,不可再次转专业。所以如果是非某个专业不去,建议只填报一个意向专业,以防被第二个专业录取,失去转专业资格。
+转专业公示时间一般在开学前后。在转专业结果公示一周内,**可以申请放弃转专业**,此时视作已用过一次转专业机会,**不可再次转专业**。所以如果是非某个专业不去,建议只填报一个意向专业,以防被第二个专业录取,失去转专业资格。
## 转专业后的选课
在转专业公示结束后,转专业才正式生效。在公示期期间,如果想提前选课,需要走特殊退改选;也可以等转专业生效后再正常选课。
-需要注意的是,你必须退掉原专业所有的课程。如果在选课结束后,你仍有未退的原专业课程,你必须含泪又交学费又上课,说不好还要考这个课的试。其中要特别注意原专业的短学期实践课,这个课程比较容易被忽视。
+需要注意的是,**你必须退掉原专业所有的课程**。如果在选课结束后,你仍有未退的原专业课程,你必须含泪又交学费又上课,说不好还要考这个课的试。其中要特别注意原专业的短学期实践课,这个课程比较容易被忽视。
-在排课时,请找到你转入专业的培养计划,根据培养计划的课程号进行选课(而不是课程名)。HDU 有些课程同名不同号,如果选择了同名不同号的课程,只能寻求课程替代(而且有概率不成功)。这种情况常见于你发现你原来专业的课程和转入专业的某课程名字一样,你懒得换了,殊不知这两个课程完全不是一个课程号,喜变纯纯冤种。
+在排课时,请找到你转入专业的培养计划,根据培养计划的**课程号**进行选课(而不是课程名)。HDU 有些课程同名不同号,如果选择了同名不同号的课程,只能寻求课程替代(而且有概率不成功)。这种情况常见于你发现你原来专业的课程和转入专业的某课程名字一样,你懒得换了,殊不知这两个课程完全不是一个课程号,喜变纯纯冤种。
另外,建议根据开课班级排课。有些课程虽然课程号相同,但可能开给不同学院。比如计算机学院的课程经常和卓越或计算机二专业的一些课程同号,如果你选了其他专业的开课班级的班,期末考试可能会不一样(如计科和卓越的电路与电子学课程号同号,但在 20 级是分开期末考试的)。建议看清开课班级再选课。
diff --git a/1.杭电生存指南/1.9问题专题:好想进入实验室.md b/1.杭电生存指南/1.9问题专题:好想进入实验室.md
index 08a6c3d..fec7ab0 100644
--- a/1.杭电生存指南/1.9问题专题:好想进入实验室.md
+++ b/1.杭电生存指南/1.9问题专题:好想进入实验室.md
@@ -10,15 +10,15 @@
概括一下:摒弃伸手,被动思维,能够主动争取各种机会,带着一个能够独当一面的能力进入实验室,与老师能够形成合作关系。
-能力上:目前计算机上的科研主要在两大方向,第一大方向是 AI(关于这件事情是不是畸形要后期在讨论)第二大方向是系统数据库,
+**能力上:**目前计算机上的科研主要在两大方向,第一大方向是 AI(关于这件事情是不是畸形要后期在讨论)第二大方向是系统数据库,
对于数据库与系统,我目前还没有涉及
-领域的基础能力:这里要我力推我们的课题教程,有较好的 AI 路线图,尽管 AI 有非常多子方向,如 NLP,CV,多模态,CV 下面又有检测 语义分割,NLP 又有推荐系统等云云,但是无论如何他们的源头都是 MLP,MLP 的源头都是多维线性回归,都是基于统计学习理论体系下,都是使用 Pytorch,都要学习数学理论体系,所以是可以要有一套类似的培养体系的。视觉被推荐 cs231n NLP 被推荐 CS224n。
+**领域的基础能力:**这里要我力推我们的课题教程,有较好的 AI 路线图,尽管 AI 有非常多子方向,如 NLP,CV,多模态,CV 下面又有检测 语义分割,NLP 又有推荐系统等云云,但是无论如何他们的源头都是 MLP,MLP 的源头都是多维线性回归,都是基于统计学习理论体系下,都是使用 Pytorch,都要学习数学理论体系,所以是可以要有一套类似的培养体系的。视觉被推荐 cs231n NLP 被推荐 CS224n。
论文的阅读能力:在了解一个领域的时候,最开始会发现什么词都不懂,一篇文章无论是从语言上还是英文上都无法阅读,所以能否具备快速阅读并读懂一篇文章的能力也是非常重要的。
-如何寻找老师上:
+**如何寻找老师上:**
学校内和学校外都可以寻求合作,在学校内,
diff --git a/2.高效学习/2.1.3错误的提问姿态.md b/2.高效学习/2.1.3错误的提问姿态.md
index b6b1bbf..672bf95 100644
--- a/2.高效学习/2.1.3错误的提问姿态.md
+++ b/2.高效学习/2.1.3错误的提问姿态.md
@@ -56,7 +56,7 @@ ps:QQ 有长截图的功能,妈妈再也不用担心我不会滚动捕捉了

-这并不需要一个找到懂得如何解决问题的人 (或者甚至是一个人 —— 这种做法通常被称为橡皮鸭,因为你可以把一只橡皮鸭当作你的练习对象) ,因为主要目标是让你弄清楚你自己的想法,弄清楚你的理解和代码到底在哪里卡住了。这样你可以知道应该专注于哪一部分,以便更好地理解。
+**这并不需要一个找到懂得如何解决问题的人 (或者甚至是一个人 —— 这种做法通常被称为橡皮鸭,因为你可以把一只橡皮鸭当作你的练习对象) ,因为主要目标是让你弄清楚你自己的想法,弄清楚你的理解和代码到底在哪里卡住了。这样你可以知道应该专注于哪一部分,以便更好地理解。**
### 欢迎大家阅读
diff --git a/3.编程思维体系构建/3.0 编程入门之道.md b/3.编程思维体系构建/3.0 编程入门之道.md
index e84e8a2..145fe72 100644
--- a/3.编程思维体系构建/3.0 编程入门之道.md
+++ b/3.编程思维体系构建/3.0 编程入门之道.md
@@ -13,7 +13,7 @@
### 这篇讲义讲什么
- 首先,如上文所述,如何轻松地利用本章乃至整个讲义
-- 在第一点的基础上,引申出我自己归纳的编程入门之“道”
+- 在第一点的基础上,引申出我自己归纳的**编程入门之“道”**
### 请随意喷这篇讲义
@@ -28,7 +28,7 @@
1. 这里的文章的最大的作用是帮你打开信息壁垒,告诉你编程的世界有哪些东西,可以去学什么。
2. 把讲义当成字典来用。很多文章并不是完全对新人友好的,你现在不需要看懂,甚至可能不需要看。你只要大概记下有这么个概念和工具,当下次要用到的时候,再查阅、再仔细学习就好。
-简单来说就是,抱着平和的心态,随便看看,知道这一章都讲了哪些东西,看完有个印象就好,然后常回家看看。
+简单来说就是,**抱着平和的心态,随便看看**,知道这一章都讲了哪些东西,看完有个印象就好,然后常回家看看。
技术细节本身永远都不是最重要的,重要的是思想和方法,如何快速掌握一门技术。
@@ -38,7 +38,7 @@
这是我的第一个也是最重要的建议。
-无论是学一门语言,还是学一个工具:尽可能地先用最短的时间搞懂这个东西是做什么的,然后以最快的方式把它“run”起来。
+无论是学一门语言,还是学一个工具:**尽可能地先用最短的时间搞懂这个东西是做什么的,然后以最快的方式把它“run”起来。**
当你已经能跑起一个语言、一个工具的最简单的示例的时候,再去花时间慢慢了解背后的复杂的内容,再去拓展即可。先用起来,跑起来,带着问题去翻资料。
@@ -58,7 +58,7 @@
那么该怎么学呢?
-先简单地会一样东西的最核心的部分,再去找一个实际的编程场景、编程任务、项目。你会在完成这个项目中遇到各种各样的问题,无论是遗漏了知识点还是压根没思路,这时候不断地用搜索引擎来学习。( [2.3 高效的信息检索](../2.%E9%AB%98%E6%95%88%E5%AD%A6%E4%B9%A0/2.3%E9%AB%98%E6%95%88%E7%9A%84%E4%BF%A1%E6%81%AF%E6%A3%80%E7%B4%A2.md))
+**先简单地会一样东西的最核心的部分,再去找一个实际的编程场景、编程任务、项目。你会在完成这个项目中遇到各种各样的问题,无论是遗漏了知识点还是压根没思路,这时候不断地用搜索引擎来学习。( **[2.3 高效的信息检索](../2.%E9%AB%98%E6%95%88%E5%AD%A6%E4%B9%A0/2.3%E9%AB%98%E6%95%88%E7%9A%84%E4%BF%A1%E6%81%AF%E6%A3%80%E7%B4%A2.md)**)**
举个例子:你想做一个小程序,来检测某电影院的电影预售。程序大概要做到不断刷新网页,一检测到这个电影预售了,就马上发短信给自己手机(或者直接帮你抢)
@@ -85,7 +85,7 @@
刚开始你可能什么都不会,什么地方都被阻塞,但当你把坑踩遍了。就发现,哎嘿,不好意思,这玩意我怎么又会!
-所以让我们基于这个“任务驱动”,再看看本章的内容。这些内容大多看了就忘,因为细节非常多,而且并不一定能解决你手头上的问题。但这些文档,带你领进了新的领域的大门,让你的工具箱里多了一个可以解决问题的工具,以后用到了可以想起他们。并且,这些文章多是通俗的,且作者多是讲述了 ta 所认为的该语言/工具的最核心、最精华的部分,或者说第一次入门最需要学习的部分。
+**所以让我们基于这个“任务驱动”,再看看本章的内容。这些内容大多看了就忘,因为细节非常多,而且并不一定能解决你手头上的问题。但这些文档,带你领进了新的领域的大门,让你的工具箱里多了一个可以解决问题的工具,以后用到了可以想起他们。并且,这些文章多是通俗的,且作者多是讲述了 ta 所认为的该语言/工具的最核心、最精华的部分,或者说第一次入门最需要学习的部分。**
## 圈子
diff --git a/3.编程思维体系构建/3.1该使用哪个编辑器???.md b/3.编程思维体系构建/3.1该使用哪个编辑器???.md
index cc02447..5897c8a 100644
--- a/3.编程思维体系构建/3.1该使用哪个编辑器???.md
+++ b/3.编程思维体系构建/3.1该使用哪个编辑器???.md
@@ -20,9 +20,9 @@
当然在这里我们主要讲的是代码编辑器,一个好的编辑器可以节省开发时间,提高工作效率,它们都能提供非常方便易用的开发环境。你可以用它们来编写代码,查看源文件和文档等,简化你的工作。以下是一些常用的代码编辑器,每个不同的编辑器都有不尽相同的目标用户群体。
-- Visual Studio Code : 微软 VS 系列的新作品,适用于多平台的代码编辑器,其很好服从了轻量化 + 拓展的 Unix 思想,在整体快捷方便的同时具有极强的功能拓展空间,是值得首要推荐的编辑器。
-- Vim : Vim 是从 vi 发展出来的一个文本编辑器,在程序员中被广泛使用,运行在 Linux 环境下。
-- GNU Emacs : Emacs 是一个轻便、可扩展、免费的编辑器,它比其它的编辑器要更强大,是一个整合环境,或可称它为集成开发环境。它可以处理文字,图像,高亮语法,将代码更直观地展现给开发者。
+- *Visual Studio Code* : 微软 VS 系列的新作品,适用于多平台的代码编辑器,其很好服从了轻量化 + 拓展的 Unix 思想,在整体快捷方便的同时具有极强的功能拓展空间,是值得首要推荐的编辑器。
+- *Vim*: Vim 是从 vi 发展出来的一个文本编辑器,在程序员中被广泛使用,运行在 Linux 环境下。
+- *GNU Emacs* : Emacs 是一个轻便、可扩展、免费的编辑器,它比其它的编辑器要更强大,是一个整合环境,或可称它为集成开发环境。它可以处理文字,图像,高亮语法,将代码更直观地展现给开发者。
### 什么是编译器
diff --git a/3.编程思维体系构建/3.2.1为什么要选择ACM——谈谈我与ACM.md b/3.编程思维体系构建/3.2.1为什么要选择ACM——谈谈我与ACM.md
index 71047ad..cd02091 100644
--- a/3.编程思维体系构建/3.2.1为什么要选择ACM——谈谈我与ACM.md
+++ b/3.编程思维体系构建/3.2.1为什么要选择ACM——谈谈我与ACM.md
@@ -12,7 +12,7 @@ author:wenjing
## ACM 能为我带来什么?
-显然,做为一名计算机专业的学生,编程是一项必须掌握的技能。再次引用 Niklaus Emil Wirth 的一句话:程序=算法 + 数据结构。例如在大一开设的程序设计基础中,我们需要重点学习链表这一数据结构,熟悉运用分支与循环结构(勉强也算算法吧)。然而,在 ACM 中,这是基础到不值一提的事物,宛如空气与水一般基础。你们是否想过,花了大量课时学习的这些知识,其实小学生也可以学会(看看远处的小学编程补习班吧,家人们)那做为大学生去学习这些知识,是否应当得到一些不止于考试内容的知识呢?
+显然,做为一名计算机专业的学生,编程是一项必须掌握的技能。再次引用 Niklaus Emil Wirth 的一句话:**程序=算法 + 数据结构。**例如在大一开设的程序设计基础中,我们需要重点学习链表这一数据结构,熟悉运用分支与循环结构(勉强也算算法吧)。然而,在 ACM 中,这是基础到不值一提的事物,宛如空气与水一般基础。你们是否想过,花了大量课时学习的这些知识,其实小学生也可以学会(看看远处的小学编程补习班吧,家人们)那做为大学生去学习这些知识,是否应当得到一些不止于考试内容的知识呢?
我认为有两个方向,一是我们去学习一些更底层的逻辑与原理,此外就是学习如何更好的利用链表,实现一些别的数据结构做不到的事情,我认为 ACM 可以极大的提升我们对后者的理解。
diff --git a/3.编程思维体系构建/3.2.2手把手教你学算法——如何使用OJ(Online Judge).md b/3.编程思维体系构建/3.2.2手把手教你学算法——如何使用OJ(Online Judge).md
index 57306b1..6c48141 100644
--- a/3.编程思维体系构建/3.2.2手把手教你学算法——如何使用OJ(Online Judge).md
+++ b/3.编程思维体系构建/3.2.2手把手教你学算法——如何使用OJ(Online Judge).md
@@ -119,7 +119,7 @@ Div.1、Div.2、Div.3、Div.4 数字越小难度越大。
这是一场笔者之前赛后补过的 Div.2,画面右下角分别为赛后公告和题解,右侧便是开启 VP 的按钮。
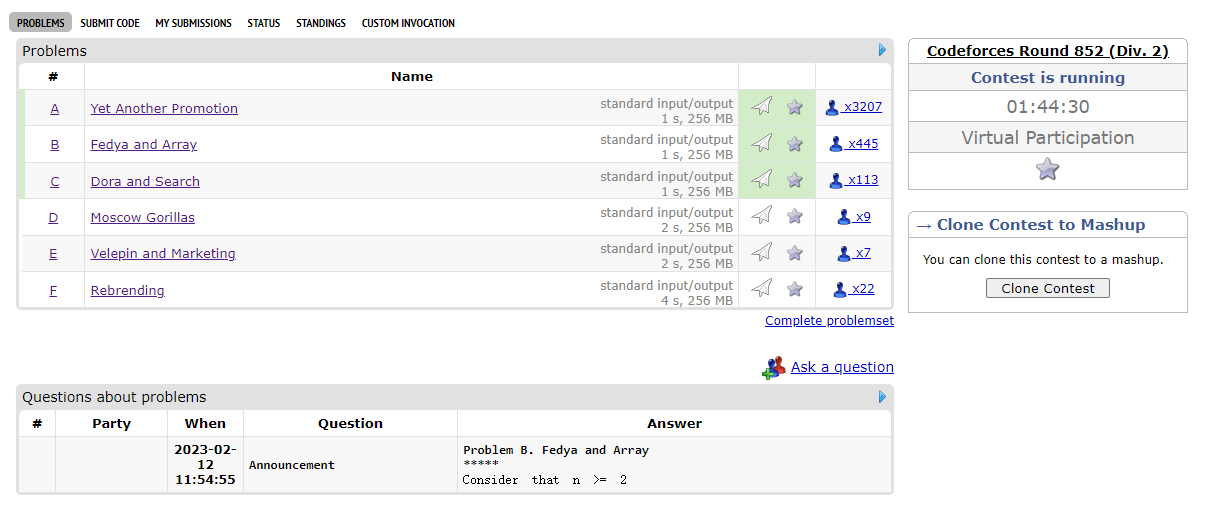
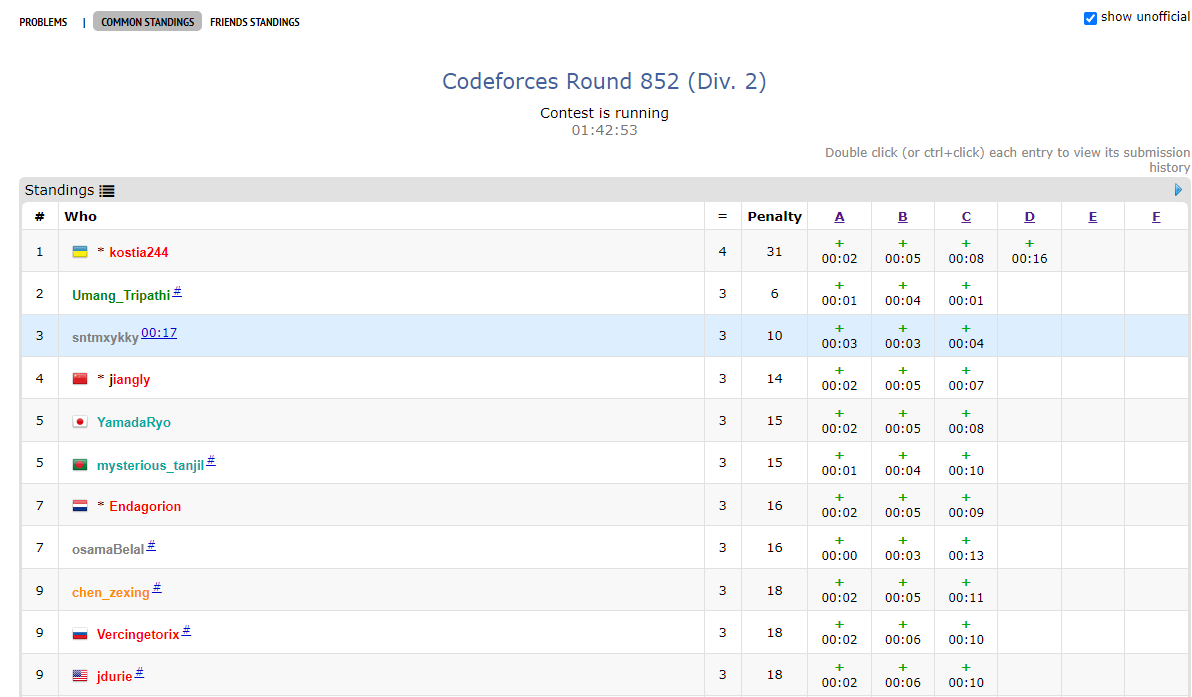
-VP模拟赛时的好处就是在虚拟参赛中获得真实比赛才能积累的经验,比如这里笔者发现通过前三题后,我应该先去看看 F 题,因为做出来的人更多,我有更大的可能性做出来,ACM 中题目并不是 100% 按难度排序。
+*VP模拟赛时的好处就是在虚拟参赛中获得真实比赛才能积累的经验,比如这里笔者发现通过前三题后,我应该先去看看 F 题,因为做出来的人更多,我有更大的可能性做出来,ACM 中题目并不是 100% 按难度排序。*
diff --git a/3.编程思维体系构建/3.2算法杂谈.md b/3.编程思维体系构建/3.2算法杂谈.md
index 9157afa..bc9d23e 100644
--- a/3.编程思维体系构建/3.2算法杂谈.md
+++ b/3.编程思维体系构建/3.2算法杂谈.md
@@ -12,7 +12,7 @@
## 学了算法就相当于学好了计算机吗?
-学好了算法当然不等于学好了计算机科学。计算机科学是一个非常庞大的知识体系,包括更为底层的计算机组成原理、编译原理等,更为表层的 AI,开发等,是一门综合性学科。总的来说,算法是计算机科学中较为重要的一部分,但远远不是全部。
+学好了算法当然不等于学好了计算机科学。计算机科学是一个非常庞大的知识体系,包括更为底层的计算机组成原理、编译原理等,更为表层的 AI,开发等,是一门综合性学科。总的来说,算法是计算机科学中较为重要的一部分,但**远远**不是全部。
## 学算法就要用《算法导论》一类的书吗?
@@ -32,6 +32,6 @@ ACM 是美国计算机协会(Association for Computing Machinery)的缩写
在我校,参加 ACM 社团(姑且叫做社团)并不代表能够参加有含金量的团体赛(ICPC、CCPC 等)。你需要先参加由我校教练刘春英老师组织的各种比赛,有资格进入集训队后,才有机会代表学校参加比赛(当然不限名额的个人赛想参加就参加)。
-进入集训队后采取末位淘汰制度(最后留下来的人在 20 人左右),最后留下来的人才有机会参加比赛。因此个人并不推荐 0 基础的同学对于 ACM 过于执着,有 0 基础的同学最后进入校队的例子,不过这通常意味着你一天至少得刷一道算法题。如果还是想尝试的同学,可以去洛谷 ([www.luogu.com.cn](http://www.luogu.com.cn))、Codeforces([www.codeforces.com](http://www.codeforces.com))、Atcoder([atcoder.jp](https://atcoder.jp/)) 等平台上注册账号,练习题目,参加这些网站定期组织的一些比赛。
+进入集训队后采取末位淘汰制度(最后留下来的人在 20 人左右),最后留下来的人才有机会参加比赛。**因此个人并不推荐 0 基础的同学对于 ACM 过于执着**,有 0 基础的同学最后进入校队的例子,不过这通常意味着你一天至少得刷一道算法题。如果还是想尝试的同学,可以去洛谷 ([www.luogu.com.cn](http://www.luogu.com.cn))、Codeforces([www.codeforces.com](http://www.codeforces.com))、Atcoder([atcoder.jp](https://atcoder.jp/)) 等平台上注册账号,练习题目,参加这些网站定期组织的一些比赛。
如果经过一段时间的练习能够在 Codefoces([www.codeforces.com](http://www.codeforces.com))上达到 1400 以上的 Rating,那么可以再观望观望参与 ACM。
diff --git a/3.编程思维体系构建/3.3如何选择编程语言.md b/3.编程思维体系构建/3.3如何选择编程语言.md
index afe19df..a8f949d 100644
--- a/3.编程思维体系构建/3.3如何选择编程语言.md
+++ b/3.编程思维体系构建/3.3如何选择编程语言.md
@@ -22,9 +22,9 @@ C 语言其实是一门优秀的承上启下的语言,既具有高级语言的
但是其功能毕竟受限,有时候用起来会苦恼其操作受限以及各种奇奇怪怪的 bug 问题。
-如果为了增强自身的编程能力和计算机素养,培养解决问题的能力,C 语言的你的不二选择。在这里强烈推荐 jyy 老师的各类课程。([http://jyywiki.cn/](http://jyywiki.cn/))
+**如果为了增强自身的编程能力和计算机素养,培养解决问题的能力,C 语言的你的不二选择。在这里强烈推荐 jyy 老师的各类课程。([http://jyywiki.cn/](http://jyywiki.cn/))**
-我们的任务一部分会使用 C 语言,一方面培养大家编程能力,一方面辅助大家期末考试。
+**我们的任务一部分会使用 C 语言,一方面培养大家编程能力,一方面辅助大家期末考试。**
### C++
@@ -34,7 +34,7 @@ C 语言其实是一门优秀的承上启下的语言,既具有高级语言的
- 更高级的语言特征,可自定义数据类型
- 标准库
-C++ 既有 C 面向过程的特点,又拥有面向对象的特性,是一门系统级的语言。
+**C++ 既有 C 面向过程的特点,又拥有面向对象的特性,是一门系统级的语言。**
编译器、操作系统的开发,高性能服务器的开发,游戏引擎的开发,硬件编程,深度学习框架的开发......只要是和底层系统或者是与性能相关的事情,通常都会有 C++ 的一席之地。
@@ -46,7 +46,7 @@ Python 在图里是电锯,适合干比较“狂野”的任务,也是深度
使用缩进控制语句是此语言的特点。
-作为深度学习的主要使用语言,我们将以Python 为主。
+**作为深度学习的主要使用语言,我们将以****P****ython 为主。**
## JAVA
@@ -54,7 +54,7 @@ Python 在图里是电锯,适合干比较“狂野”的任务,也是深度
他太老了,虽然不少框架都依托于 Java,但是不得不说,一些地方略有落后。
-频繁应用于Web 开发,安卓应用等等。
+**频繁应用于****W****eb 开发,安卓应用等等。**

diff --git a/3.编程思维体系构建/3.4.1FAQ:常见问题.md b/3.编程思维体系构建/3.4.1FAQ:常见问题.md
index 03b00ff..1872180 100644
--- a/3.编程思维体系构建/3.4.1FAQ:常见问题.md
+++ b/3.编程思维体系构建/3.4.1FAQ:常见问题.md
@@ -22,7 +22,7 @@
更严重的是,他可能会透支学校的信誉。
-同时,先学好 C 语言对你有以下帮助:
+**同时,先学好 C 语言对你有以下帮助:**
1. 掌握计算机底层知识:C 语言是一种高效的系统级语言,它的语法和数据结构设计直接映射到底层计算机硬件,通过学习 C 语言可以更深入地了解计算机底层运作原理,为理解更高级的编程语言和开发工具奠定基础。
2. 提高编程能力:C 语言的语法相对较为简单,但是它要求程序员手动管理内存,这需要编程者深入了解内存结构和指针的使用。通过学习 C 语言,可以锻炼编程能力,提高代码质量和效率。
@@ -65,7 +65,7 @@ NJU-ICS-PA 南京大学计算机系统基础
有且仅有大学有这样好的资源帮助你了
-## 坚持了好久还是搞不定,我想放弃了
+## **坚持了好久还是搞不定,我想放弃了**

diff --git a/3.编程思维体系构建/3.4.2用什么写 C 语言.md b/3.编程思维体系构建/3.4.2用什么写 C 语言.md
index 0b145db..21ea037 100644
--- a/3.编程思维体系构建/3.4.2用什么写 C 语言.md
+++ b/3.编程思维体系构建/3.4.2用什么写 C 语言.md
@@ -12,7 +12,7 @@ Visual Studio(以下简称 VS)是 Windows 下最完美的 C/C++ 等语言的
什么是 IDE,什么是代码编辑器,什么是编译器等等细碎问题参考文档 [3.1 该使用哪个编辑器???](3.1%E8%AF%A5%E4%BD%BF%E7%94%A8%E5%93%AA%E4%B8%AA%E7%BC%96%E8%BE%91%E5%99%A8%EF%BC%9F%EF%BC%9F%EF%BC%9F.md) 看不懂的话直接无脑装
-### 下载
+### **下载**
[https://visualstudio.microsoft.com/zh-hans/downloads/](https://visualstudio.microsoft.com/zh-hans/downloads/)
@@ -60,7 +60,7 @@ VS 是项目制,你需要创建一个项目才能开始编写代码并运行
阅读完以后,就可以将代码全部删去,编写自己的代码了。
-注意控制台项目初始源文件后缀为.cpp 为 C++ 文件,如果编写 C 语言建议将后缀改为.c。.cpp 存在隐患:如果不小心使用了 C++ 的语法而非 C 存在的语法,编译器并不会报错,且 C 与 C++ 在某些特性存在区别。
+注意控制台项目初始源文件后缀为.cpp 为 C++ 文件,如果编写 C 语言**建议将后缀改为.c**。.cpp 存在隐患:如果不小心使用了 C++ 的语法而非 C 存在的语法,编译器并不会报错,且 C 与 C++ 在某些特性存在区别。
### “运行”你的 C 语言代码
@@ -88,7 +88,7 @@ IDE 相比于代码编辑器,最强大的一点莫过于成熟的调试系统

-### 深色主题
+### **深色主题**
需要深色主题请在工具 - 主题里更改为深色
diff --git a/3.编程思维体系构建/3.4.3解决编程问题的普适性过程.md b/3.编程思维体系构建/3.4.3解决编程问题的普适性过程.md
index cf3bd42..c2cc8d3 100644
--- a/3.编程思维体系构建/3.4.3解决编程问题的普适性过程.md
+++ b/3.编程思维体系构建/3.4.3解决编程问题的普适性过程.md
@@ -17,7 +17,7 @@
## Work an Example Yourself
-尝试设计算法的第一步是自己(手动)处理至少一个问题实例,为每个参数选择特定值。往往需要确定一个正确的示例,以及错误的示例。
+尝试设计算法的第一步是**自己(手动)处理至少一个问题实例,为每个参数选择特定值。**往往需要确定**一个正确的示例,以及错误的示例。**
如果你在这一步陷入困境,这通常意味着两件事中的一件。第一种情况是问题不明确,不清楚你应该做什么。在这种情况下,你必须在继续之前解决问题。如果你正在解决自己创造的问题,你可能需要更仔细地思考正确的答案应该是什么,并完善你对问题的定义。
@@ -25,15 +25,15 @@
## Write Down What You Just Did
-这一步中,必须思考解决问题所做的工作,并写下解决该特定实例的步骤。思考这一步骤的另一种方式是,写下一组清晰的指示,其他人可以按照这些指示来重现刚刚解决的特定问题实例的答案。如果在步骤 1 中执行了多个实例,那么也将重复步骤 2 多次,对步骤 1 中的每个实例重复一次。如果一条指令有点复杂,那没关系,只要指令稍后有明确的含义,我们将把这些复杂的步骤转化为它们自己的编程问题,这些问题将单独解决。
+这一步中,必须思考解决问题所做的工作,并写下**解决该特定实例的步骤。**思考这一步骤的另一种方式是,写下一组清晰的指示,**其他人可以按照这些指示来重现刚刚解决的特定问题实例的答案**。如果在步骤 1 中执行了多个实例,那么也将重复步骤 2 多次,对步骤 1 中的每个实例重复一次。如果一条指令有点复杂,那没关系,只要指令稍后有明确的含义,我们将把这些复杂的步骤转化为它们自己的编程问题,这些问题将单独解决。
## Generalize Your Steps
-将步骤 2 得到的具体步骤,抽象为一般性的结论。有时可能很难概括步骤。发生这种情况时,返回步骤 1 和 2 可能会有所帮助。做更多的问题实例将提供更多的信息供参考,更能帮助深入算法。这个过程通常被称为编写“伪代码”,以编程方式设计算法,而不使用特定的目标语言。几乎所有的程序员在编写任何实际代码之前都会使用这种方法来确保他们的算法是正确的。
+**将步骤 2 得到的具体步骤,抽象为一般性的结论。**有时可能很难概括步骤。发生这种情况时,返回步骤 1 和 2 可能会有所帮助。做更多的问题实例将提供更多的信息供参考,更能帮助深入算法。这个过程通常被称为编写“伪代码”,以编程方式设计算法,而不使用特定的目标语言。几乎所有的程序员在编写任何实际代码之前都会使用这种方法来确保他们的算法是正确的。
## Test Your Algorithm
-在步骤 3 之后,我们有了一个我们认为正确的算法。然而,我们完全有可能在这一路上搞砸了。步骤 4 的主要目的是确保我们的步骤在继续之前是正确的。为了实现这一点,我们使用不同于设计算法时使用的参数值来测试我们的算法。我们手动执行算法,并将其获得的答案与正确的答案进行比较。如果它们不同,那么我们知道我们的算法是错误的。我们使用的测试用例(参数值)越多,我们就越能确信我们的算法是正确的。不幸的是,通过测试无法确保我们的算法是正确的。要完全确定你的算法是正确的,唯一的方法就是正式证明它的正确性(使用数学证明),这超出了这个专门化的范围。
+在步骤 3 之后,我们有了一个我们认为正确的算法。然而,我们完全有可能在这一路上搞砸了。步骤 4 的主要目的是确保我们的步骤在继续之前是正确的。为了实现这一点,我们使用**不同于设计算法时使用的参数值**来测试我们的算法。我们手动执行算法,并将其获得的答案与正确的答案进行比较。如果它们不同,那么我们知道我们的算法是错误的。我们使用的测试用例(参数值)越多,我们就越能确信我们的算法是正确的。不幸的是,通过测试无法确保我们的算法是正确的。要完全确定你的算法是正确的,唯一的方法就是正式证明它的正确性(使用数学证明),这超出了这个专门化的范围。
确定好的测试用例是一项重要的技能,可以随着实践而提高。对于步骤 4 中的测试,您需要使用至少产生几个不同答案的情况进行测试(例如,如果您的算法有“是”或“否”答案,则应使用同时产生“是”和“否”的参数进行测试)。您还应该测试任何角落情况,其中行为可能与更一般的情况不同。每当您有条件决定(包括计算位置的限制)时,您应该在这些条件的边界附近测试潜在的角点情况。
@@ -47,7 +47,7 @@
在黑盒测试中,测试人员只考虑功能的预期行为,而不考虑设计测试用例的任何实现细节。缺乏对实现细节的访问是这种测试方法的由来——函数的实现被视为测试人员无法查看的“黑盒子”。
-事实上我们无需执行步骤 1-5 就能够为假设问题设想好的测试用例。实际上,在开始解决问题之前,您可以针对问题提出一组黑盒测试。一些程序员提倡测试优先的开发方法。一个优点是,如果您在开始之前编写了一个全面的测试套件,那么在实现代码之后就不太可能在测试上有所疏漏。另一个优点是,通过提前考虑你的情况,你在开发和实现算法时能够降低错误率。
+事实上我们无需执行步骤 1-5 就能够为假设问题设想好的测试用例。实际上,在开始解决问题之前,您可以针对问题提出一组黑盒测试。一些程序员提倡**测试优先**的开发方法。一个优点是,如果您在开始之前编写了一个全面的测试套件,那么在实现代码之后就不太可能在测试上有所疏漏。另一个优点是,通过提前考虑你的情况,你在开发和实现算法时能够降低错误率。
- 选择测试用例的一些建议
diff --git a/3.编程思维体系构建/3.4.4C语言前置概念学习.md b/3.编程思维体系构建/3.4.4C语言前置概念学习.md
index 735839f..90f0c33 100644
--- a/3.编程思维体系构建/3.4.4C语言前置概念学习.md
+++ b/3.编程思维体系构建/3.4.4C语言前置概念学习.md
@@ -1,6 +1,6 @@
# C 语言前置概念学习
-如何学习 C 语言?第一步:Throw away the textbook。也许你可以通过以下途径:
+如何学习 C 语言?**第一步:Throw away the textbook。**也许你可以通过以下途径:
以下方式难度由易到难,但并不意味着收获由小到大:
@@ -14,9 +14,9 @@
4.Web:[CNote](https://github.com/coderit666/CNote)(例子密集,学习曲线平滑,覆盖面广且具有深度)
-5.Book:教材替换用书——《C Primer Plus》!(基础且深入的恰到好处,有一定拓展,可能后面的章节有点难懂,是一本不可多得的好书,不要忽视课本习题及 Projects)
+5.Book:**教材替换用书——《C Primer Plus》!**(基础且深入的恰到好处,有一定拓展,可能后面的章节有点难懂,是一本不可多得的好书,不要忽视课本习题及 Projects)
-6.MOOC:[Introductory C Programming 专项课程](https://www.coursera.org/specializations/c-programming)(全英文,好处是涉及到计算机思维,包含许多常用 tools 的教学例如 git、make、emacs、gdb,视频讲解结合文档阅读,对于 C 的重要核心知识讲解透彻,难度颇高,建议用作提升)
+6.MOOC:[Introductory C Programming 专项课程](https://www.coursera.org/specializations/c-programming)(**全英文**,好处是涉及到计算机思维,包含许多常用 tools 的教学例如 git、make、emacs、gdb,视频讲解结合文档阅读,对于 C 的重要核心知识讲解透彻,难度颇高,建议用作提升)
7.Web:[LinuxC 一站式编程](https://akaedu.github.io/book/)(难度大,枯燥硬核,收获多,基于 linux)
@@ -38,4 +38,4 @@

-### CS education is more than just “learning how to code”!
+### **CS education is more than just “learning how to code”!**
diff --git a/3.编程思维体系构建/3.4.5.1C语言自测标准——链表.md b/3.编程思维体系构建/3.4.5.1C语言自测标准——链表.md
index 17ef4c0..91dffb7 100644
--- a/3.编程思维体系构建/3.4.5.1C语言自测标准——链表.md
+++ b/3.编程思维体系构建/3.4.5.1C语言自测标准——链表.md
@@ -54,9 +54,9 @@ typedef struct Node* Link;
例如,若链表无头结点,则对于在链表中第一个数据结点之前插入一个新结点,或者对链表中第一个数据结点做删除操作,都必须要当做特殊情况,进行特殊考虑;而若链表中设有头结点,以上两种特殊情况都可被视为普通情况,不需要特殊考虑,降低了问题实现的难度。
-链表有头结点,也不一定都是有利的。例如解决约瑟夫环问题,若链表有头结点,在一定程度上会阻碍算法的实现。
+**链表有头结点,也不一定都是有利的。例如解决约瑟夫环问题,若链表有头结点,在一定程度上会阻碍算法的实现。**
-所以,对于一个链表来说,设置头指针是必要且必须的,但有没有头结点,则需要根据实际问题特殊分析。
+**所以,对于一个链表来说,设置头指针是必要且必须的,但有没有头结点,则需要根据实际问题特殊分析。**
首元结点:指的是链表开头第一个存有数据的结点。
@@ -329,7 +329,7 @@ int ListDelete(Link *L, int i, int* e)
- 3 出列后,从 5 开始数 1,2 数 2,所以 2 出列;
- 最后只剩下 5 自己,所以 5 胜出。
-那么,究竟要如何用链表实现约瑟夫环呢?如何让一个含 5 个元素的约瑟夫环,能从第 5 个元素出发,访问到第 2 个元素呢?上面所讲的链表操作显然是难以做到的,解决这个问题就需要用到循环链表。
+那么,究竟要如何用链表实现约瑟夫环呢?如何让一个含 5 个元素的约瑟夫环,能从第 5 个元素出发,访问到第 2 个元素呢?上面所讲的链表操作显然是难以做到的,解决这个问题就需要用到**循环链表**。
## 循环链表
diff --git a/3.编程思维体系构建/3.4.6.1.开始冒险.md b/3.编程思维体系构建/3.4.6.1.开始冒险.md
index a4f7828..96323ed 100644
--- a/3.编程思维体系构建/3.4.6.1.开始冒险.md
+++ b/3.编程思维体系构建/3.4.6.1.开始冒险.md
@@ -21,7 +21,7 @@ It is very dark in here.
Bye!
-尽管可能微不足道,但该程序确实展示 了任何文本冒险中最重要的方面:描述性文本。一个好的故事是制作一款好的冒险游戏的要素之一。
+尽管可能微不足道,但该程序确实展示 *了*任何文本冒险中最重要的方面:描述性文本。一个好的故事是制作一款好的冒险游戏的要素之一。
## 为什么要用英文?
diff --git a/3.编程思维体系构建/3.4.6.10.增添属性.md b/3.编程思维体系构建/3.4.6.10.增添属性.md
index 05e01da..beb9afc 100644
--- a/3.编程思维体系构建/3.4.6.10.增添属性.md
+++ b/3.编程思维体系构建/3.4.6.10.增添属性.md
@@ -12,7 +12,7 @@
举个例子,一条林道可能隐藏着陷阱。虽然通道似乎从位置 A 通向位置 B,但实际上终点是位置 C,即掉进坑了。
-假设我们的洞口被警卫挡住了。玩家就过不去,我们可以简单地将通道的目的地更改为终点位置(或 NULL),但这会导致对诸如 go cave 和 look cave 这样的命令做出不正确的回应:“你在这里看不到任何洞穴。我们需要一个将通道的实际终点和虚假终点分开的单独属性。为此,我们将引入一个属性 prospect 来表示后者。
+假设我们的洞口被警卫挡住了。玩家就过不去,我们可以简单地将通道的*目的地*更改为终点位置(或 *NULL*),但这会导致对*诸如 go cave 和 look cave* 这样的命令做出不正确的回应:“你在这里看不到任何洞穴。我们需要一个将通道的实际终点和虚假终点分开的单独属性。为此,我们将引入一个属性 prospect 来表示后者。
1. 在许多冒险中,玩家以及游戏中的 NPC 在携带量方面受到限制。给每件物品一个重量,角色库存中所有物品的总重量不应超过该角色所能承载的最大重量。当然,我们也可以给一个物体一个非常高的重量,使它不可移动(一棵树,一座房子,一座山)。
2. RPG 式的冒险游戏需要角色的整个属性范围 ( 玩家与非玩家 ),例如 HP。HP 为零的对象要么死了,要么根本不是角色。
@@ -120,7 +120,7 @@ extern OBJECT objs[];
::: warning 🤔 思考题:你能否自行实现上述伪代码?
:::
-现在,我们已经可以使用新属性 (如果你完成了上面的思考题),details 用于新识别的命令外观`,textGo 在我们的命令 go 实现中替换固定文本“OK”。
+现在,我们已经可以使用新属性 (如果你完成了上面的思考题),**details** 用于新识别的命令*外观`